
UMA NOVA CLASSE DE ESTIMADORES DO INDICE DE...
38
UMA NOVA CLASSE DE ESTIMADORES DO ´ INDICE DE CAUDA Frederico Caeiro Dep. de Matem´ atica and C.M.A., F.C.T. - U.N.L.
-
Upload
trinhthien -
Category
Documents
-
view
214 -
download
0
Transcript of UMA NOVA CLASSE DE ESTIMADORES DO INDICE DE...

UMA NOVA CLASSE DE
ESTIMADORES DO INDICE DE
CAUDA
Frederico Caeiro
Dep. de Matematica and C.M.A., F.C.T. - U.N.L.

1 Resultados classicos em Teoria de
Valores Extremos
Sejam X1, X2, . . . Xn v.a.’s i.i.d. com f.d. F e
X1:n ≤ X2:n ≤ . . . ≤ Xn:n as respectivas estatısticas ordinais.
A distribuicao exacta de estatısticas ordinais e bastante simples
de obter. No entanto, salvo algumas excepcoes, estas expressoes
acabam por ser difıceis de calcular mesmo quando a dimensao
da amostra e pequena.
Ha assim o interesse em estudar o comportamento distribucional
para amostras de grande dimensao (distribuicao limite).
1

Definicao 1.1 Diz-se que uma f.d. F pertence ao domınio de
atraccao para maximos de uma f.d. G (nao degenerada) se
existirem sucessoes an > 0 e bn de constantes normalizadoras
tais que:
P
(
Xn:n − bnan
≤ x
)
= Fn(anx+ bn) −→n→∞
G(x),
em todos os pontos de continuidade de G(x) e escreve-se
F ∈ D(G).
2

Sabe-se que a f.d. do maximo e de um dos tres tipos - Gnedenko
(1943):
Φα(x) = exp(−x−α), x > 0, α > 0 Frechet
ψα(x) = exp(−(−xα)), x < 0, α > 0 Weibull
Λ(x) = exp(−e−x), x ∈ R Gumbel
3

Os tres tipos de f.d. podem ser escritos de forma unificada
atraves da f.d. de valores extremos (distribuicao GEV):
Gγ(x) =
exp[−(1 + γx)−1γ ], 1 + γx > 0 se γ 6= 0
exp(−e−x), x ∈ R se γ = 0
(1.1)
onde γ e o parametro de forma da distribuicao tambem
designado por ındice de cauda. Este parametro esta
directamente relacionado com o peso da cauda do modelo F , ou
seja, quanto maior o valor de γ mais pesada e a cauda 1 − F .
4

Definicao 1.2 Diz-se que f : R+ → R
+ e uma funcao de
variacao regular (em ∞) de ındice α e representa-se por
f ∈ RVα se:
limt→∞
f(tx)
f(t)= xα, ∀ x > 0.
Se α = 0 diz-se que f e de variacao lenta.
Uma funcao de variacao regular pode sempre ser decomposta
num produto de duas funcoes, ou seja, se f ∈ RVα entao
f(x) = xαl(x), onde l e uma funcao de variacao lenta, isto e:
limt→∞
l(tx)
l(t)= 1, ∀ x > 0.
5

As distribuicoes F para as quais γ > 0 designam-se por
distribuicoes tipo Pareto (ou de cauda pesada). Neste caso
1 − F (x) = x−1/γ lF , onde lF e uma funcao de variacao lenta.
A classe de funcoes de distribuicao no domınio de atraccao da
distribuicao Gumbel (γ = 0) e bastante vasta sendo
essencialmente caracterizada por caudas exponenciais
(decrescentes).
As distribuicoes no domınio de atraccao da Weibull (γ < 0)
caracterizam-se pela existencia de um limite superior do
suporte, x+, e verificam: 1 − F (x+ − 1/x) = x1/γ l∗F (x), onde l∗Fe uma funcao de variacao lenta.
6

2 Estimacao de γ > 0
No que se segue apenas se vai considerar modelos de cauda
pesada.
Observacao:
F ∈ D(Gγ), γ > 0 ⇔ 1 − F ∈ RV−1/γ ⇔ U ∈ RVγ
onde U(t) := F←(1 − 1/t), t ≥ 1 e f← e a inversa generalizada
de f , isto e, f←(t) = inf{x : f(x) ≥ t}.
7

2.1 Alguns estimadores de γ:
Estimador de Hill (1975):
γH
n (k) :=1
k
k∑
i=1
(lnXn−i+1:n − lnXn−k:n)
Estimador de Pickands (1975):
γP
n (k) := (ln 2)−1
lnXn−[k/4]:n −Xn−[k/2]:n
Xn−[k/2]:n −Xn−k:n
onde [x] e a parte inteira de x.
8

Estimador dos momentos, Dekkers, Einmahl e de Haan
(1989):
γM
n (k) := M (1)
n (k) + 1 − 1
2
[
1 − (M (1)n (k))
2
M (2)n (k)
]−1
,
onde M (α)n (k) := 1
k
k∑
i=1
(lnXn−i+1:n − lnXn−k:n)α, α > 0.
9

Principal problema: A escolha de k, o numero de
estatısticas de topo:
Dada uma amostra de dimensao n de um modelo F
desconhecido, verifica-se que a estimativa de γ varia bastante
consoante o valor de k. A escolha do nıvel optimo (nıvel que
minimize o EQM) nao e facil porque, se por um lado a
variancia assintotica diminui a medida que k aumenta, por
outro, o quadrado do vies aumenta.
10
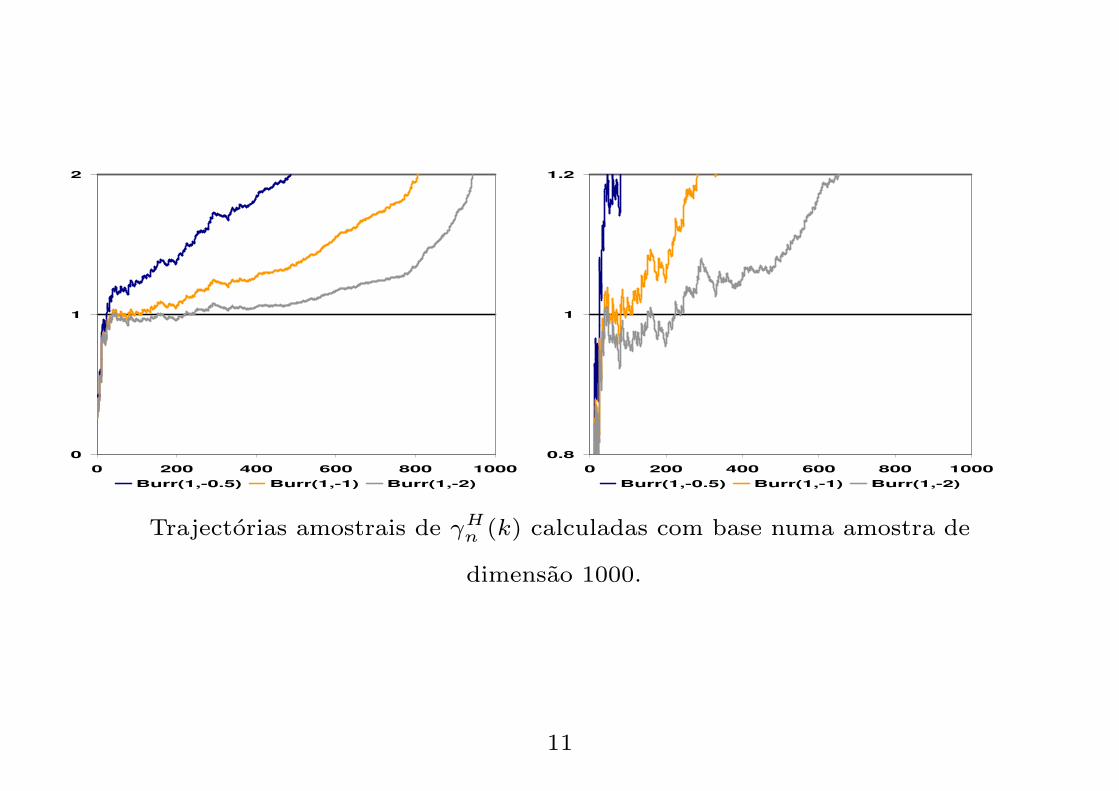
0
1
2
0 200 400 600 800 1000Burr(1,-0.5) Burr(1,-1) Burr(1,-2)
0.8
1
1.2
0 200 400 600 800 1000Burr(1,-0.5) Burr(1,-1) Burr(1,-2)
Trajectorias amostrais de γHn (k) calculadas com base numa amostra de
dimensao 1000.
11

2.2 Propriedades assintoticas do estimador de
Hill
Se se acrescentar uma condicao adicional (uma condicao de
variacao regular de segunda ordem) que mede a velocidade de
convergencia de U(tx)/U(t) para xγ , entao γHn (k) tem
distribuicao assintoticamente normal, com vies assintotico
eventualmente nao nulo. A condicao acrescentada e a seguinte:
Existe uma funcao A(·) tal que:
limt→∞
U(tx)U(t) − xγ
A(t)= xγ x
ρ − 1
ρ, x > 0,
12

ou seja
U(tx)
U(t)= xγ
(
1 +xρ − 1
ρA(t)
)
, x > 0, t −→ ∞,
onde ρ ≤ 0 e o parametro de segunda ordem e |A(.)| ∈ RVρ
(Geluk e de Haan (1987)).
13

Tabela 2.1: A condicao de segunda ordem para alguns modelos
Modelo U(tx)U(t)
Frechet xγ[
1 +(
x−1−1
−1
)
γ
2t
]
+ o(t−1)
Burr xγ[
1 +(
xρ−1ρ
)
γtρ]
+ o(tρ)
Log Logıstico xγ[
1 +(
x−1−1
−1
)
γ
t−1
]
+ o(t−1)
GP, γ > 0 xγ[
1 +(
x−γ−1
−γ
)
γ
tγ−1
]
Cauchy x[
1 +(
x−2−1
−2
)
23
π2
t2
]
+ o(t−2)
GEV, 0 < γ < 1 xγ[
1 +(
x−γ−1
−γ
)
γ
tγ
]
+ o(t−γ)
GEV, γ = 1 xγ[
1 +(
x−1−1
−1
)
32t
]
+ o(t−1)
GEV, γ > 1 xγ[
1 +(
x−1−1
−1
)
γ
2t
]
+ o(t−1)
14

Observacao:
γH
n (k) =1
k
k∑
i=1
lnXn−i+1:n
Xn−k:n
d=
1
k
k∑
i=1
lnUX
(
Yn−i+1:n
Yn−k:nYn−k:n
)
UX (Yn−k:n),
onde Y1, Y2, . . . Yn v.a.’s i.i.d. com distribuicao Pa(1)
(FY (x) = 1 − 1/x, x ≥ 1)
Admitindo validas as condicoes de variacao regular de primeira
e de segunda ordem para o modelo F e que k = k(n) e uma
sucessao intermedia,
γH
n (k)d= γ +
γ√kZ(1)
n +1
1 − ρA(n/k)(1 + op(1)),
onde Z(1)n e uma variavel assintoticamente normal reduzida.
15

2.3 Nova classe de estimadores
A classe de estimadores semiparametricos de γ > 0 aqui
introduzida e:
γ(θ,α)n (k) =
Γ(α)
M (α−1)n (k)
×(
M (θα)n (k)
Γ(θα+ 1)
)1θ
α ≥ 1, θ > 0.
parametrizada atraves de α e θ, onde M (0)n (k) ≡ 1.
Nota: Apenas serao usadas as subclasses que se obtem
substituindo θ pelos valores 1.5, 2 e 3, ou seja, os estimadores:
γ(1.5,α)n (k), γ(2,α)
n (k), e γ(3,α)n (k)
16

Trajectorias amostrais de γ(θ,α)n (k) para o modelo Burr com
(γ, ρ) = (1,−0.5)
0
1
2
0 1000 2000 3000 4000 5000k
Hill θ=2 ; α=1 θ=2 ; α=3 θ=2 ; α=5θ=2 ; α=2.374 θ=1.5 ; α=3.031 θ=3 ; α=1.877
17

Trajectorias amostrais de γ(θ,α)n (k) para o modelo Burr com
(γ, ρ) = (1,−1)
0
1
2
0 1000 2000 3000 4000 5000k
Hill θ=2 ; α=1 θ=2 ; α=3 θ=2 ; α=5θ=2 ; α=1.9 θ=1.5 ; α=2.355 θ=3 ; α=1.557
18

2.4 Propriedades assintoticas
Proposicao 2.1 Admitindo validas as condicoes de variacao
regular de primeira e de segunda ordem para o modelo F e que
k = k(n) e uma sucessao intermedia,
γ(θ,α)n (k)
d= γ+
γσθ,α√kZ(θ,α)
n +bθ(α)A(n/k)+op(A(n/k))+op(1/√k)
onde:
Z(θ,α)n =
1
σθ,α
(
Z(θα)n
θΓ(θα + 1)−
Z(α−1)n
Γ(α)
)
∼ N(0, 1),
σ2θ,α =
1
θ2
[
2Γ(2θα)
θαΓ2(θα)+
θ2Γ(2α− 1)
Γ2(α)−
2Γ((θ + 1)α)
αΓ(θα)Γ(α)− (θ − 1)
2
]
,
bθ(α) =
1θρ
[
(1− ρ)−θα − θ(1− ρ)1−α + (θ − 1)]
se ρ < 0
1 se ρ = 0
19

Proposicao 2.2 considere-se as condicoes da proposicaoanterior. Para ρ < 0 e para os valores θ = 1.5, 2, 3 existe sempreum valor α0 tal que bθ(α0) = 0, ou seja, existe um valor que
anula a componente dominante do vies de γ(θ,α)n (k):
α(1.5)0 (ρ) = −
2 ln
(1− ρ)
12 + cos
arctan
(
2√
(1−ρ)3−1
(1−ρ)3−2
)
+4π
3
ln(1− ρ)
α(2)0 (ρ) = −
ln[
1− ρ−√
(1− ρ)2 − 1]
ln(1− ρ)
α(3)0 (ρ) = −
ln
[
2√
1− ρ cos
(
arctan(
−√
(1−ρ)3−1)
+4π
3
)]
ln(1− ρ)
20
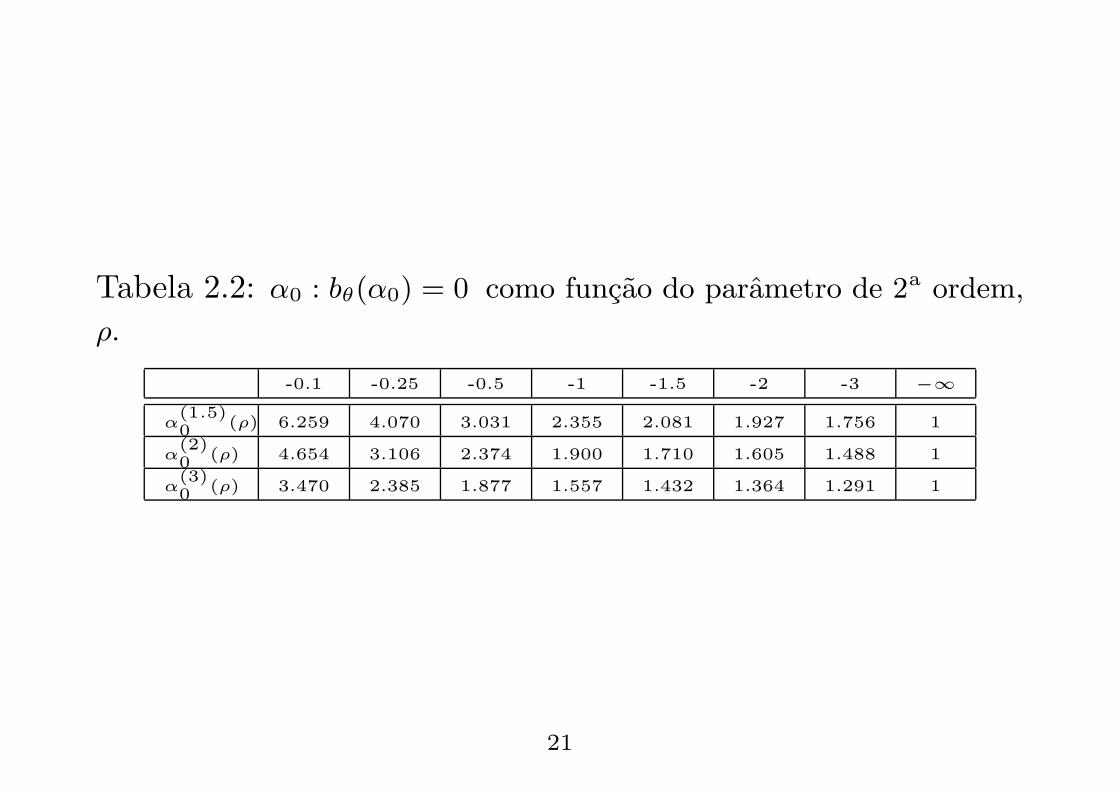
Tabela 2.2: α0 : bθ(α0) = 0 como funcao do parametro de 2a ordem,
ρ.
-0.1 -0.25 -0.5 -1 -1.5 -2 -3 −∞
α(1.5)0 (ρ) 6.259 4.070 3.031 2.355 2.081 1.927 1.756 1
α(2)0 (ρ) 4.654 3.106 2.374 1.900 1.710 1.605 1.488 1
α(3)0 (ρ) 3.470 2.385 1.877 1.557 1.432 1.364 1.291 1
21
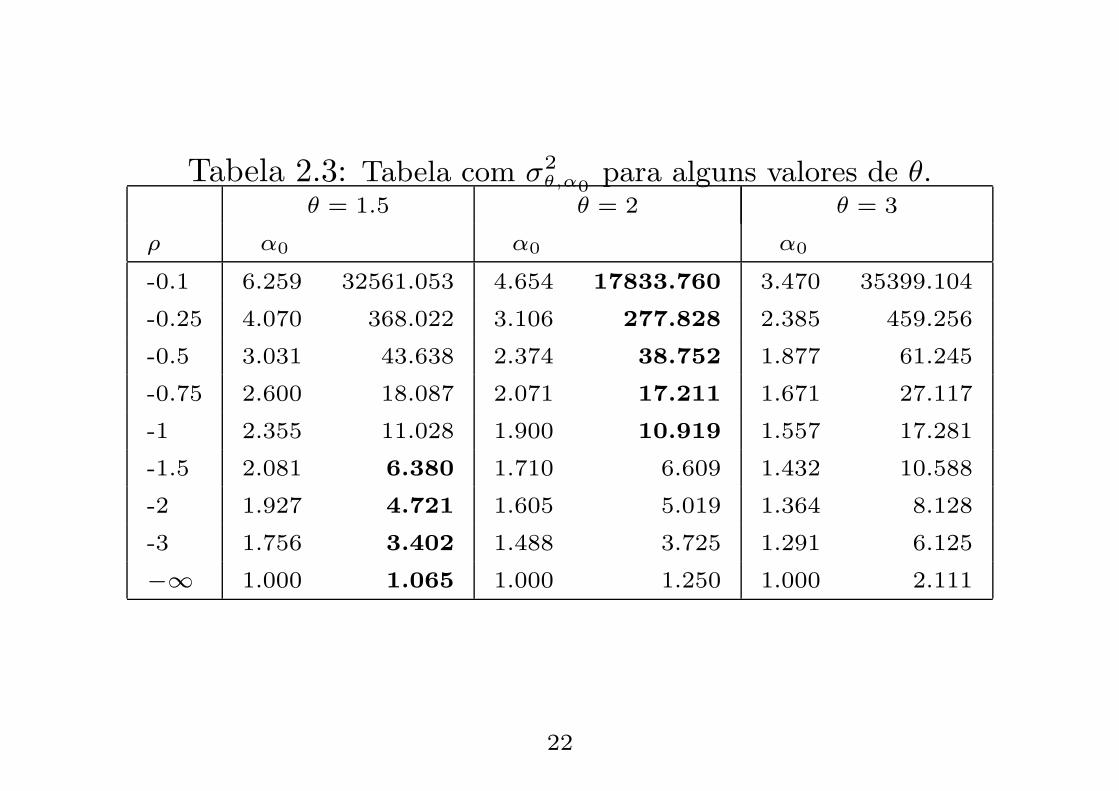
Tabela 2.3: Tabela com σ2θ,α0
para alguns valores de θ.θ = 1.5 θ = 2 θ = 3
ρ α0 α0 α0
-0.1 6.259 32561.053 4.654 17833.760 3.470 35399.104
-0.25 4.070 368.022 3.106 277.828 2.385 459.256
-0.5 3.031 43.638 2.374 38.752 1.877 61.245
-0.75 2.600 18.087 2.071 17.211 1.671 27.117
-1 2.355 11.028 1.900 10.919 1.557 17.281
-1.5 2.081 6.380 1.710 6.609 1.432 10.588
-2 1.927 4.721 1.605 5.019 1.364 8.128
-3 1.756 3.402 1.488 3.725 1.291 6.125
−∞ 1.000 1.065 1.000 1.250 1.000 2.111
22

2.5 Propriedades da nova classe de
estimadores para amostras de dimensao
finita
Os resultados que se seguem resultaram de simulacoes de
10 × 1000 amostras de dimensao n. Com as simulacoes
pretendeu-se obter as estimativas para: valor medio, erro medio
quadratico, nıvel optimo e eficiencia relativamente ao estimador
de Hill.
23

2.6 Modelo Frechet (γ = 1 , ρ = −1)
F (x) = exp(−x−1/γ), x > 0, γ > 0
U(t) =
(
ln
(
t
t− 1
))−γ
, t > 1
U(tx)
U(t)=xγ
[
1 +
(
x−1 − 1
−1
)
γ
2t
]
+ o(t−1)
24
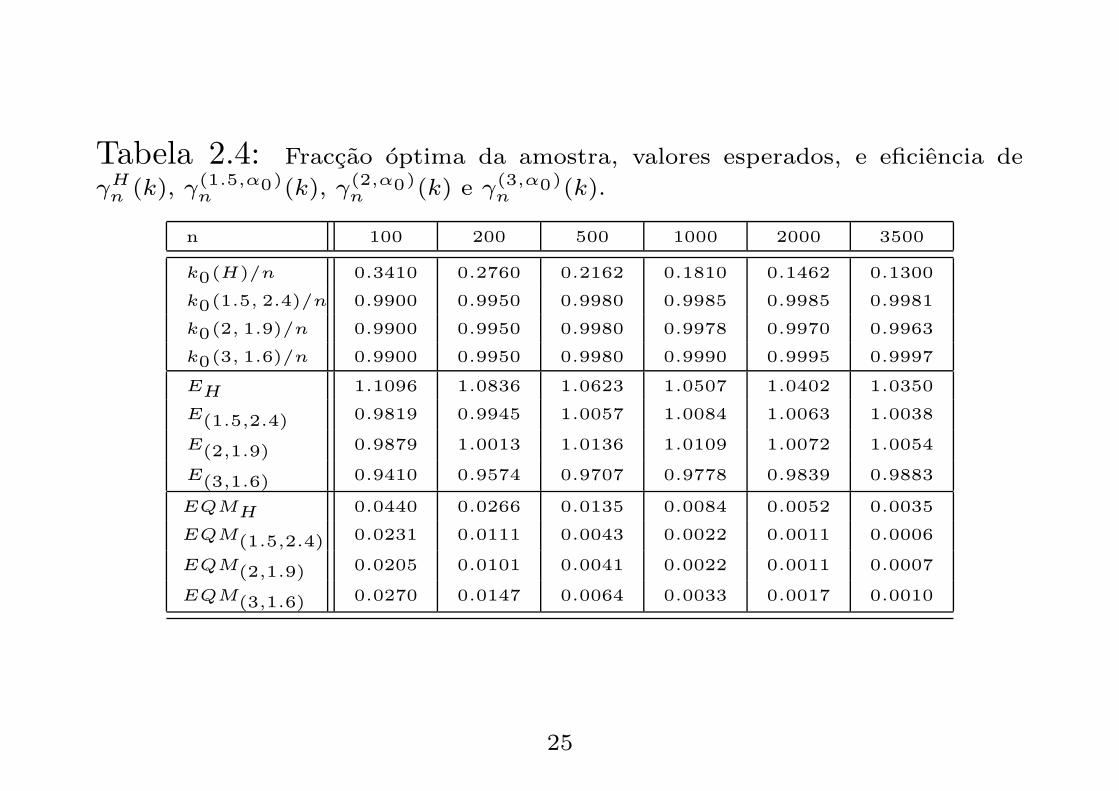
Tabela 2.4: Fraccao optima da amostra, valores esperados, e eficiencia de
γHn (k), γ(1.5,α0)
n (k), γ(2,α0)n (k) e γ(3,α0)
n (k).
n 100 200 500 1000 2000 3500
k0(H)/n 0.3410 0.2760 0.2162 0.1810 0.1462 0.1300
k0(1.5, 2.4)/n 0.9900 0.9950 0.9980 0.9985 0.9985 0.9981
k0(2, 1.9)/n 0.9900 0.9950 0.9980 0.9978 0.9970 0.9963
k0(3, 1.6)/n 0.9900 0.9950 0.9980 0.9990 0.9995 0.9997
EH 1.1096 1.0836 1.0623 1.0507 1.0402 1.0350
E(1.5,2.4) 0.9819 0.9945 1.0057 1.0084 1.0063 1.0038
E(2,1.9) 0.9879 1.0013 1.0136 1.0109 1.0072 1.0054
E(3,1.6) 0.9410 0.9574 0.9707 0.9778 0.9839 0.9883
EQMH 0.0440 0.0266 0.0135 0.0084 0.0052 0.0035
EQM(1.5,2.4) 0.0231 0.0111 0.0043 0.0022 0.0011 0.0006
EQM(2,1.9) 0.0205 0.0101 0.0041 0.0022 0.0011 0.0007
EQM(3,1.6) 0.0270 0.0147 0.0064 0.0033 0.0017 0.0010
25

0
1
2
0 500 1000
[ ])( kE Hnγ�
[ ])()9.1 , 2( kE nγ� [ ])()4.2 , 5.1( kE nγ�
[ ])()6.1 , 3( kE nγ�
0
0.005
0.01
0.015
0.02
0.025
0 500 1000
[ ])( kE Q M Hnγ�
[ ])()9.1 , 2( kE Q M nγ�
[ ])()4.2, 5.1( kE Q M nγ�
[ ])()6.1 , 3( kE Q M nγ�
Valor esperado (esquerda) e EQM (direita) simulados para o
Modelo Frechet com γ = 1 (ρ = −1)
26

2.7 Modelo Burr (γ = 1)
F (x) =(
1 + x−ρ/γ)1/ρ
, x > 0, γ > 0, ρ < 0
U(t) =(
t−ρ − 1)−γ/ρ
, t > 1
U(tx)
U(t)=xγ
[
1 +
(
xρ − 1
ρ
)
γtρ]
+ o(tρ)
27

Tabela 2.5: Fraccao optima da amostra de γHn (k), γ
(1.5,α0)n (k),
γ(2,α0)n (k) e respectivas eficiencias relativas, para o modelo Burr com
γ = 1 e ρ = −0.5,−1,−2.
α \ n 100 200 500 1000
Burr: γ = 1, ρ = −0.5
k0(H)/n 0.0980 ± .0094 0.0780 ± .0061 0.0486 ± .0029 0.0386 ± .0042
k0(1.5, 3.0)/n 0.7550 ± .0091 0.7155 ± .0049 0.6530 ± .0036 0.6013 ± .0060
k0(2, 2.4)/n 0.7590 ± .0071 0.7150 ± .0056 0.6528 ± .0036 0.6013 ± .0061
Ef(1.5,3.0),H 2.2609 ± .0643 2.1509 ± .0491 2.0806 ± .0343 2.0426 ± .0463
Ef(2,2.4),H 2.3863 ± .0616 2.2840 ± .0473 2.2217 ± .0336 2.1829 ± .0475
Ef(3,1.9),H 2.5296 ± .0650 2.3859 ± .0548 2.2796 ± .0360 2.2075 ± .0538
28

Burr: γ = 1, ρ = −1
k0(H)/n 0.2240 ± .0159 0.1785 ± .0103 0.1386 ± .0055 0.1182 ± .0083
k0(1.5, 2.4)/n 0.8670 ± .0083 0.8385 ± .0056 0.7896 ± .0044 0.7513 ± .0036
k0(2, 1.9)/n 0.8430 ± .0035 0.8185 ± .0059 0.7648 ± .0053 0.7189 ± .0038
Ef(1.5,2.4),H 1.5485 ± .0457 1.4963 ± .0400 1.4787 ± .0187 1.4983 ± .0225
Ef(2,1.9),H 1.5476 ± .0417 1.4813 ± .0382 1.4484 ± .0177 1.4543 ± .0233
Burr: γ = 1, ρ = −2
k0(H)/n 0.4240 ± .0203 0.3715 ± .0133 0.3134 ± .0079 0.2818 ± .0097
k0(1.5, 1.9)/n 0.9130 ± .0035 0.8935 ± .0041 0.8542 ± .0037 0.8180 ± .0029
k0(2, 1.6)/n 0.9180 ± .0045 0.9025 ± .0019 0.8696 ± .0046 0.8372 ± .0031
Ef(1.5,1.9),H 1.1272 ± .0149 1.0953 ± .0178 1.0764 ± .0124 1.0700 ± .0112
Ef(2,1.6),H 1.1363 ± .0157 1.0993 ± .0191 1.0749 ± .0133 1.0682 ± .0124
29

0
1
2
0 200 400 600 800 1000
[ ])(kE Hnγ�
0
0.05
0.1
0.15
0.2
0 200 400 600 800 1000
[ ])(kEQM Hnγ�
Valor esperado (esquerda) e EQM (direita) simulados para o
Modelo Burr com γ = 1 e ρ = −0.5
30

0
1
2
0 500 1000
[ ])( kE Hnγ�
[ ])()9.1 , 2( kE nγ�
[ ])()4.2 , 5.1( kE nγ�
0
0.005
0.01
0.015
0.02
0.025
0 500 1000
[ ])( kE Q M Hnγ�
[ ])()9.1 , 2( kE Q M nγ�
[ ])()4.2, 5.1( kE Q M nγ�
Valor esperado (esquerda) e EQM (direita) simulados para o
Modelo Burr com γ = 1 e ρ = −1
31

0
1
2
0 500 1000
[ ])(kE Hnγ
[ ])()9.1 , 2( kE nγ
[ ])()4.2 , 5.1( kE nγ
0
0.005
0.01
0.015
0.02
0.025
0 500 1000
[ ])( kE Q M Hnγ
[ ])()9.1 , 2( kE Q M nγ�
[ ])()4.2, 5.1( kE Q M nγ
Valor esperado (esquerda) e EQM (direita) simulados para o
Modelo Burr com γ = 1 ρ = −2
32

3 Estimacao de α e γ baseada num
criterio de estabilidade
Se se escolher alguns valores de α e se desenhar as γ(θ,α)n (k),
1 ≤ k ≤ n− 1, verifica-se que existe estabilidade nas trajectorias
amostrais. A estabilidade e mais elevada para valores α
proximos de α0. Pode-se assim sugerir um metodo heurıstico,
baseado num criterio do tipo mınimos quadrados, para estimar
α e γ.
33

Sejam:
m(α, k1, k2) := χ1/2(γ(α)n (k), k1 ≤ k ≤ k2)
s(α, k1, k2) :=
k2∑
k=k1
(
γ(α)n (k) −m(α, k1, k2)
)2
onde χ1/2(xk, k1 ≤ k ≤ k2) e a mediana da amostra xk,
k1 ≤ k ≤ k2. Deve-se assegurar que k1 e k2 nao sejam valores
muito proximos pois caso contrario o metodo nao funciona.
34

Entao sejam:
α0 := arg min s(α, k1, k2) γ0 := m(α0, k1, k2)
as estimativas de α e γ.
Pode-se tambem utilizar a estimativa de α para obter uma
estimativa de ρ. Seja ρ0 a estimativa ρ que pode agora ser
estimado, por exemplo no caso θ = 2 atraves da resolucao da
equacao:
(1 − ρ)−2α0 − 2(1 − ρ)1−α0 + 1 = 0
35

4 Conclusoes
• Os resultados de γ(1.5,α0)n (k) e γ
(2,α0)n (k) foram muito
semelhantes.
• Qualquer dos novos estimadores apresenta, no nıvel optimo,
eficiencias superiores a 1.
• Para o modelo Frechet (ρ = −1), e necessario para estimar γ ir
praticamente ate ao mınimo da amostra. Os graficos
apresentados para este modelo sugerem que os estimadores em
estudo praticamente nao tem vies.
• No modelo Burr, para valores de ρ pequenos, como por exemplo
ρ = −2, o desempenho dos novos estimadores, em termos de
EQM , nao e significativamente melhor que o desempenho do
estimador de γHn (k).
36

Referencias
[1] Caeiro, F. e M. I. Gomes (2001). A class of asymptotically unbiased
semi-parametric estimators of the tail index. Notas e Comunicacoes
8/01, CEAUL. Aceite em Test.
[2] Geluk, J. e L. de Haan (1987). Regular Variation, Extensions and
Tauberian Theorems. Tech. Report CWI Tract 40, Centre for
Mathematics and Computer Science, Amsterdam, Netherlands.
[3] Gomes, M. I., e M. J. Martins (2001). Generalizations of the Hill
estimator - asymptotic versus finite sample behaviour. Journal of
Statistical Planning and Inference 93, 161-180.
[4] Haan, L. de e L. Peng (1998). Comparison of Tail Index Estimators.
Statistica Neerlandica 52, 60-70.
[5] Hill, B. M. (1975). A Simple General Approach to Inference About the
Tail of a Distribution. Ann. Statist. 3, no. 5, 1163-1174.
37


















