
Capítulo 4 Propriedades dos Estimadores de Mínimos Quadrados · 4.1 Os Estimadores de Mínimos...
29
Capítulo 4 Propriedades dos Estimadores de Mínimos Quadrados
Transcript of Capítulo 4 Propriedades dos Estimadores de Mínimos Quadrados · 4.1 Os Estimadores de Mínimos...

Capítulo 4
Propriedades dos Estimadores de Mínimos Quadrados
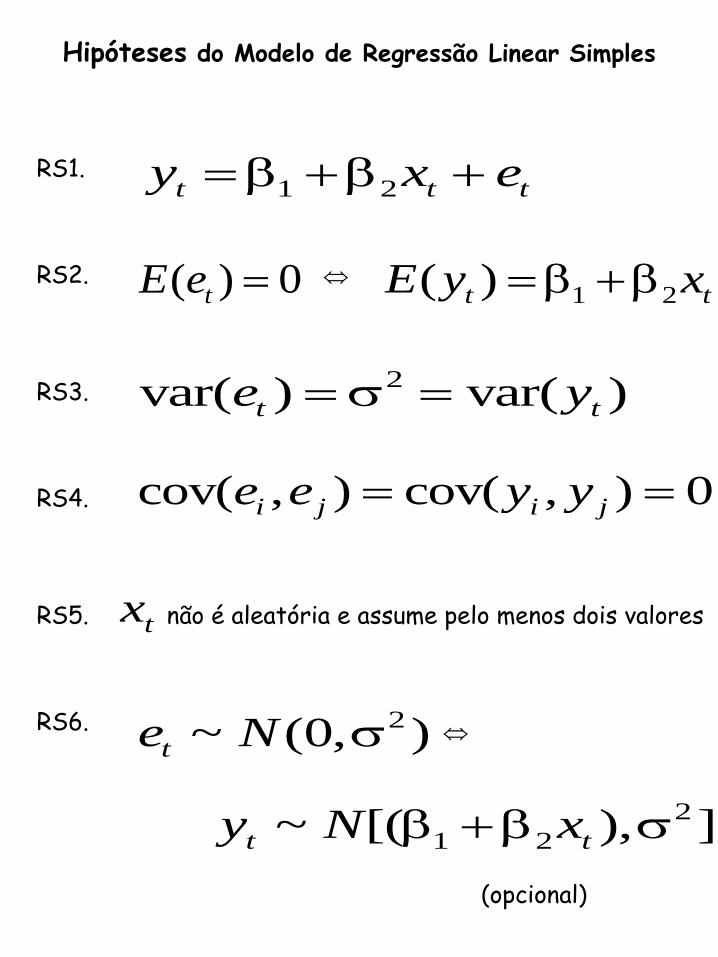
Hipóteses do Modelo de Regressão Linear Simples
1 2t t ty x e RS1.
RS2. ( ) 0tE e 1 2( )t tE y x
2var( ) var( )t te y RS3.
cov( , ) cov( , ) 0i j i je e y y RS4.
RS5.
RS6.
tx não é aleatória e assume pelo menos dois valores
2~ (0, )te N
2
1 2~ [( ), ]t ty N x
(opcional)

4.1 Os Estimadores de Mínimos Quadrados como Variáveis Aleatórias
• O estimador de mínimos quadrados b2 do parâmetro de inclinação 2, baseado em uma amostra de T observações, é
2 22
t t t t
t t
T x y x yb
T x x
• O estimador de mínimos quadrados b1 do parâmetro intercepto 1 é
1 2b y b x
/ e /t ty y T x x T
(3.3.8a)
(3.3.8b)
• Quando as fórmulas de b1 e b2, são tomadas para serem utilizadas como regras, qualquer que seja a amostra de dados extraída, então b1 e b2 são variáveis aleatórias. Nesse contexto, nós chamamos b1 e b2 de estimadores de mínimos quadrados.
• Quando os valores reais da amostra, números, são substituídos nas fórmulas, nós obtemos números que são valores das variáveis aleatórias. Nesse contexto, nós chamamos b1 e b2 de estimativas de mínimos quadrados.

4.2 As Propriedades Amostrais dos Estimadores de Mínimos Quadrados
4.2.1 Os Valores Esperados de b1 e b2
• Nós começamos reescrevendo a fórmula da equação 3.3.8a na seguinte fórmula que é mais conveniente para propósitos teóricos,
2 2 t tb w e
onde wt é um constate (não aleatória) dada por
2( )
tt
t
x xw
x x
O valor esperado de uma soma é a soma dos valores esperados (ver Seção 2.5.1):
2 2
2
2 2
( )
( ) ( )
( ) [como ( ) 0]
t t
t t
t t t
E b E w e
E E w e
w E e E e
(4.2.1)
(4.2.2)
(4.2.3)
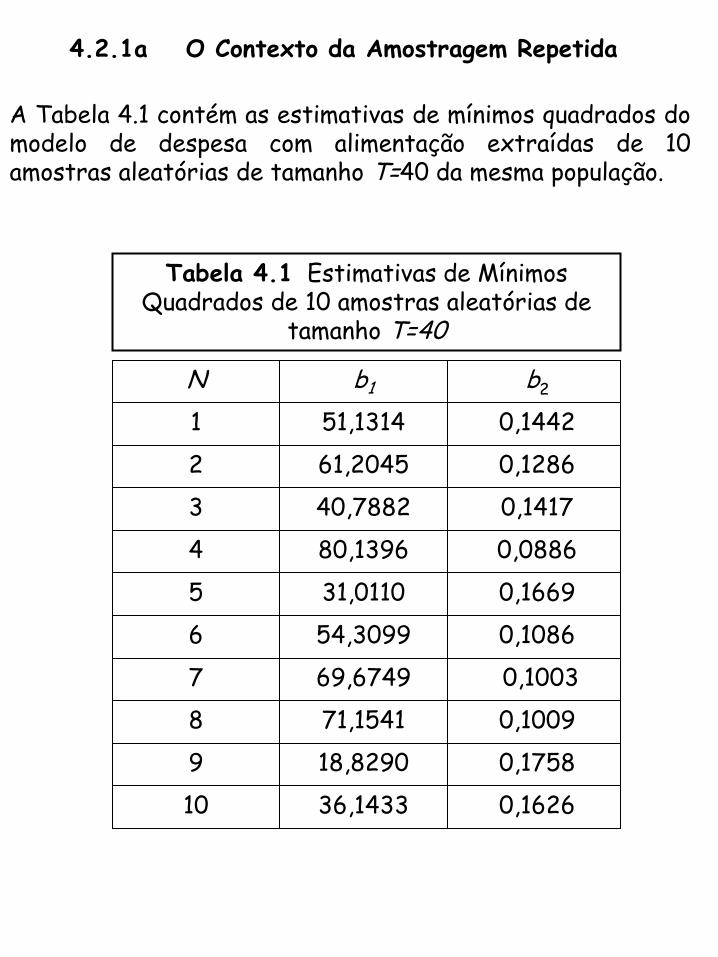
4.2.1a O Contexto da Amostragem Repetida
A Tabela 4.1 contém as estimativas de mínimos quadrados do modelo de despesa com alimentação extraídas de 10 amostras aleatórias de tamanho T=40 da mesma população.
Tabela 4.1 Estimativas de Mínimos Quadrados de 10 amostras aleatórias de
tamanho T=40
N
1
2
3
4
5
6
7
8
9
10
b1
51,1314
61,2045
40,7882
80,1396
31,0110
54,3099
69,6749
71,1541
18,8290
36,1433
b2
0,1442
0,1286
0,1417
0,0886
0,1669
0,1086
0,1003
0,1009
0,1758
0,1626

4.2.1b Dedução da Equação 4.2.1
2
2 2
2 2
2 2 2 2 2
( )
2
12
2
t
t t
t t
t t
x x
x x x T x
x x T x T xT
x T x T x x T x
2 2 2 2
2
2
( )t t t t
t
t
x x x T x x x x
xx
T
Para a obtenção desse resultado, nós levamos em consideração que
/tx x T então tx T x
( )( )t t
t t t t t t
x yx x y y x y Tx y x y
T
(4.2.4a)
(4.2.4b)
(4.2.5)

b2, na forma de desvios em relação à média, é:
2 2
( )( )
( )
t t
t
x x y yb
x x
• Lembre-se que ( ) 0tx x
• Então, a fórmula para b2 se torna
2 2 2
2 2
( )( ) ( ) ( )
( ) ( )
( ) ( )
( ) ( )
t t t t t
t t
t ttt t t
t t
x x y y x x y y x xb
x x x x
x x y x xy w y
x x x x
(4.2.6)
(4.2.7)
(4.2.8)
onde wt é a constante dada na equação 4.2.2.

Para obter a equação 4.2.1, substitua yt por e simplifique:
1 2t t ty x e
2 1 2
1 2
( )t t t t t
t t t t t
b w y w x e
w w x w e
0tw , isso elimina o termo 1 tw
1t tw x então 2 2t tw x
e (4.2.9a) se torna a equação 4.2.1.
2 2 t tb w e
(4.2.9a)
(4.2.9b)

O termo , porque 0tw
Para mostrar que 1t tw x nós novamente utilizamos
( ) 0tx x . Outra expressão para
2( )tx x é
2( ) ( )( )
( ) ( ) ( )
t t t
t t t t t
x x x x x x
x x x x x x x x x
Conseqüentemente,
2
( ) ( )1
( ) ( )
t t t t
t t
t t t
x x x x x xw x
x x x x x
2
2
( )
( )
1( ) 0
( )
usando ( ) 0
tt
t
t
t
t
x xw
x x
x xx x
x x

4.2.2 A Variância e Covariância de b1 e b2
2
2 2 2var( ) [ ( )]b E b E b
Se as hipóteses do modelo de regressão RS1-RS5 são corretas (RS6 não é necessária), então as variâncias e covariância de b1 e b2 são:
2
2
1 2
2
2 2
2
1 2 2
var( )( )
var( )( )
cov( , )( )
t
t
t
t
xb
T x x
bx x
xb b
x x
(4.2.10)
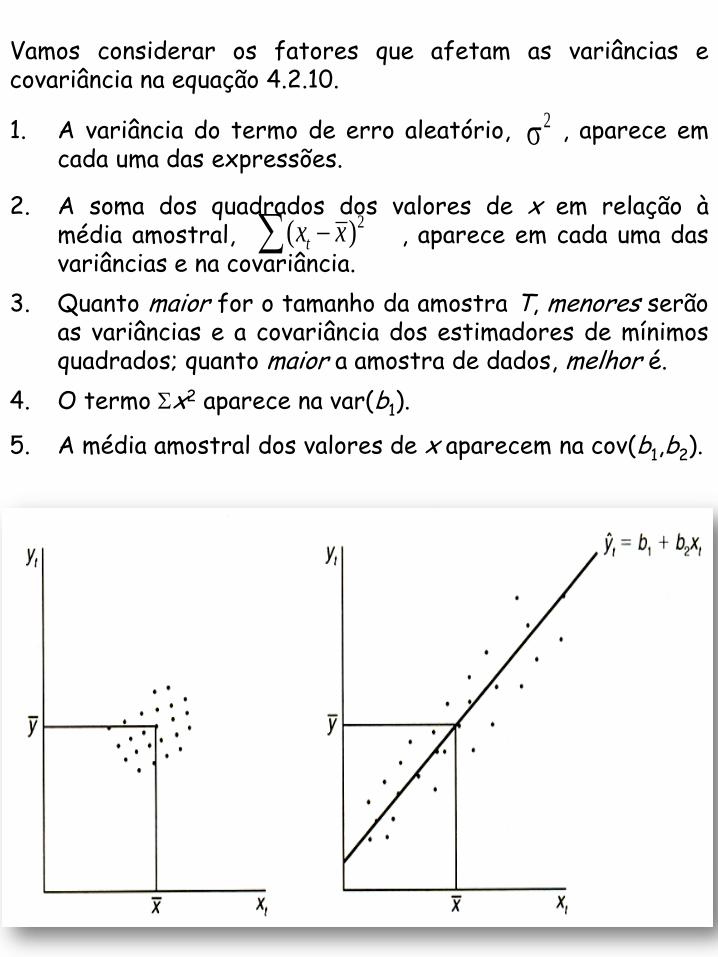
Vamos considerar os fatores que afetam as variâncias e covariância na equação 4.2.10.
1. A variância do termo de erro aleatório, , aparece em cada uma das expressões.
2
2. A soma dos quadrados dos valores de x em relação à média amostral, , aparece em cada uma das variâncias e na covariância.
2( )tx x
3. Quanto maior for o tamanho da amostra T, menores serão as variâncias e a covariância dos estimadores de mínimos quadrados; quanto maior a amostra de dados, melhor é.
4. O termo x2 aparece na var(b1).
5. A média amostral dos valores de x aparecem na cov(b1,b2).

Dedução da variância de b2: O ponto de partida é a equação 4.2.1.
2 2
2
2 2
2
2
var( ) var var
= var( )
=
( )
t t t t
t t
t
t
b w e w e
w e
w
x x
(4.2.11)
O último passo se baseia no fato de que
22
2 22
( ) 1
( )( )
tt
tt
x xw
x xx x
(4.2.12)
2[como é uma constante]
[usando cov( , ) 0]i je e
2[usando var( ) ]te

4.2.3 Estimadores Lineares
• O estimador de mínimos quadrados b2 é uma soma ponderada das observações de yt,
2 t tb w y
• Estimadores como b2 são chamados de estimadores lineares por serem combinações lineares de uma variável aleatória observável.
4.3 O Teorema de Gauss-Markov
O Teorema de Gauss-Markov: Satisfazendo as hipóteses RS1-RS5 do modelo de regressão linear, os estimadores b1 e b2 têm a menor variância de todos os estimadores lineares e não tendenciosos de 1 e 2. Eles são os melhores estimadores lineares não tendenciosos (the Best Linear Unbiased Estimators – BLUE) de 1 e 2

1. Os estimadores b1 e b2 são “melhores” quando comparados com estimadores similares, aqueles que são lineares e não tendenciosos. O Teorema não diz que b1 e b2 são os melhores de todos possíveis estimadores
2. Os estimadores b1 e b2 são os melhores dentro de sua classe porque eles possuem a menor variância.
3. Para o Teorema de Gauss-Markov ser válido, as hipóteses (RS1-RS5) devem ser satisfeitas. Se qualquer uma das hipóteses de 1-5 não forem satisfeitas, então b1 e b2 não são os melhores estimadores lineares não tendenciosos de 1 e 2.
4. O Teorema de Gauss-Markov não depende da hipótese de normalidade
5. No modelo de regressão linear simples, se nós queremos utilizar um estimador linear e não tendencioso, então nós não precisamos efetuar novas procuras.
6. O Teorema de Gauss-Markov é aplicado aos estimadores de mínimos quadrados. Ele não se aplica às estimativas extraídas de uma amostra individual.

4.4 Distribuição de Probabilidade dos Estimadores de Mínimos Quadrados
• Se nós assumirmos a hipótese de normalidade, hipótese RS6 sobre o termo de erro, então os estimadores de mínimos quadrados são normalmente distribuídos.
2 2
1 1 2
2
2 2 2
~ ,( )
~ ,( )
t
t
t
xb N
T x x
b Nx x
(4.4.1)
• Se as hipóteses RS1-RS5 forem mantidas e se o tamanho da amostra T for suficientemente grande, então os estimadores de mínimos quadrados têm uma distribuição que se aproxima das distribuições normais mostradas na equação 4.4.1

4.5 Estimação da Variância do Termo de Erro
A variância da variável aleatória et é
2 2 2var( ) [ ( )] ( )t t t te E e E e E e (4.5.1)
se a hipótese E(et) = 0 for correta.
Como a “esperança” é um valor médio, nós podemos estimar 2 pela média dos erros ao quadrado,
2
2ˆ te
T
(4.5.2)
• Lembre-se que os erros aleatórios são
1 2t t te y x

• Os resíduos de mínimos quadrados são obtidos pela substituição dos parâmetros desconhecidos pelos seus estimadores de mínimos quadrados,
1 2t t te y b b x
2
2ˆ
ˆ te
T
(4.5.3)
• Existe uma modificação simples que produz um estimador não tendencioso:
2
2ˆ
ˆ2
te
T
(4.5.4)
2 2ˆ( )E (4.5.5)

4.5.1 Estimação das Variâncias e Covariâncias dos Estimadores de Mínimos Quadrados
• Substitua a variância do erro desconhecida na equação 4.2.10 pelo seu estimador. Obtêm-se:
2
2
1 1 12
2
2 2 22
2
1 2 2
ˆ ˆˆvar( ) , ep( ) var( )( )
ˆˆ ˆvar( ) , ep( ) var( )
( )
ˆ ˆcov( , )( )
t
t
t
t
xb b b
T x x
b b bx x
xb b
x x
(4.6.6)
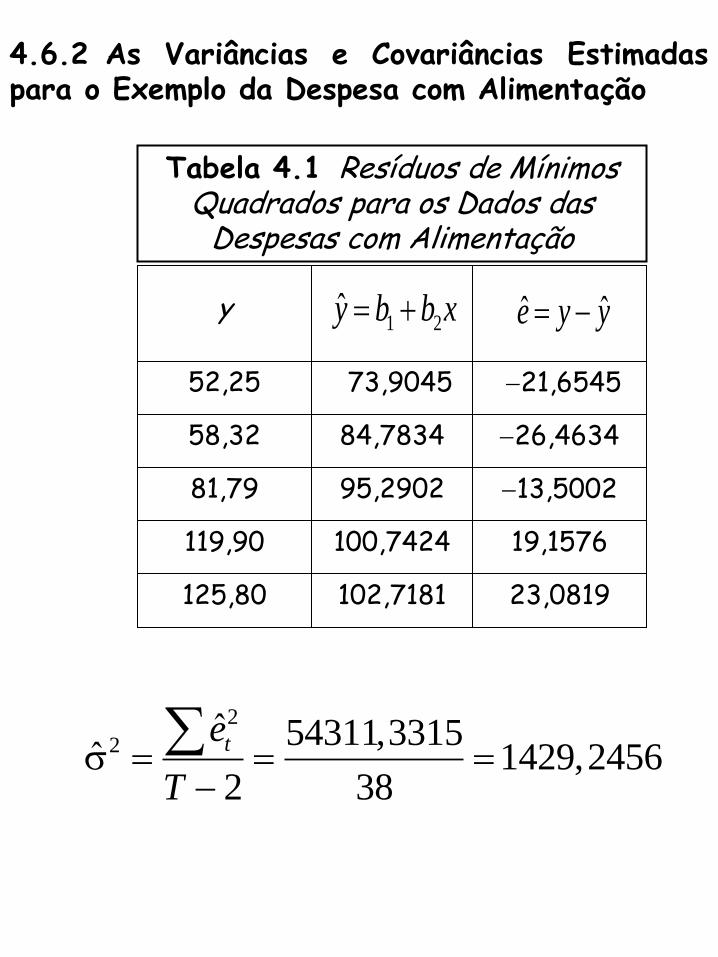
4.6.2 As Variâncias e Covariâncias Estimadas para o Exemplo da Despesa com Alimentação
Tabela 4.1 Resíduos de Mínimos Quadrados para os Dados das
Despesas com Alimentação
52,25
58,32
81,79
119,90
125,80 23,0819
19,1576
13,5002
26,4634
21,6545
84,7834
95,2902
100,7424
102,7181
y 1 2y b b x ˆ ˆe y y
73,9045
2
2ˆ 54311,3315
ˆ 1429,24562 38
te
T

2
2
1 2
1 1
2
2 2
2 2
1
ˆ ˆvar( )( )
210206231429,2456 490,1200
40(1532463)
ˆ ep( ) var( ) 490,1200 22,1387
ˆ 1429,2456ˆvar( ) 0,0009326
( ) 1532463
ˆep( ) var( ) 0,0009326 0,0305
ˆcov( ,
t
t
t
xb
T x x
b b
bx x
b b
b b
2
2 2ˆ)
( )
6981429,2456 0,6510
1532463
t
x
x x
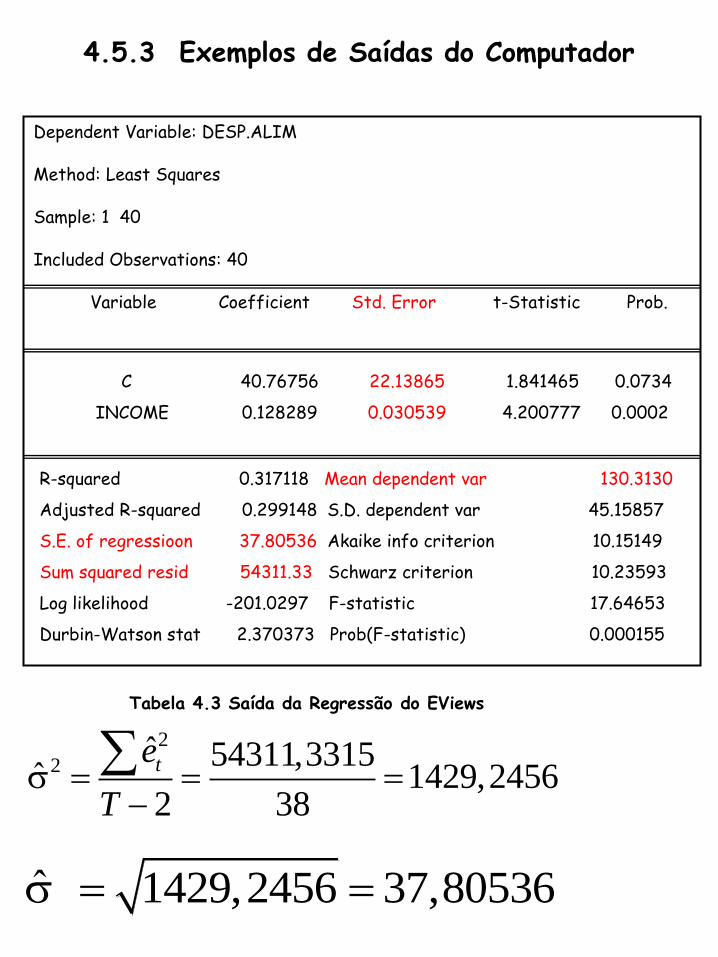
4.5.3 Exemplos de Saídas do Computador
Dependent Variable: DESP.ALIM
Method: Least Squares
Sample: 1 40
Included Observations: 40
Variable Coefficient Std. Error t-Statistic Prob.
C 40.76756 22.13865 1.841465 0.0734
INCOME 0.128289 0.030539 4.200777 0.0002
R-squared 0.317118 Mean dependent var 130.3130
Adjusted R-squared 0.299148 S.D. dependent var 45.15857
S.E. of regressioon 37.80536 Akaike info criterion 10.15149
Sum squared resid 54311.33 Schwarz criterion 10.23593
Log likelihood -201.0297 F-statistic 17.64653
Durbin-Watson stat 2.370373 Prob(F-statistic) 0.000155
Tabela 4.3 Saída da Regressão do EViews
2
2ˆ 54311,3315
ˆ 1429,24562 38
te
T
ˆ 1429,2456 37,80536

4.7 O Previsor de Mínimos Quadrados
Nós queremos prever o valor da variável dependente y0, dado um valor da variável explanatória x0, o qual é dado por
0 1 2 0 0y x e (4.7.1)
onde e0 é um erro aleatório. Esse erro aleatório tem média E(e0)=0 e variância var(e0)= . Nós também assumimos que cov(e0, et)=0.
2
O previsor de mínimos quadrados de y0 é
0 1 2 0y b b x (4.7.2)

o erro de previsão é
0 0 1 2 0 1 2 0 0
1 1 2 2 0 0
ˆ ( )
( ) ( )
f y y b b x x e
b b x e
(4.7.3)
O valor esperado de f é:
0 0 1 1 2 2 0 0ˆ( ) ( ) ( ) ( ) ( )
0 0 0 0
E f E y y E b E b x E e
Pode ser demonstrado que
22 0
0 0 2
1 ( )ˆvar( ) var( ) 1
( )t
x xf y y
T x x
(4.7.4)
(4.7.5)
A variância do erro de previsão é estimada pela substituição de pelo seu estimador ,
2 2
22 0
2
1 ( )ˆ ˆvar( ) 1
( )t
x xf
T x x
(4.7.6)
A raiz quadrada da variância estimada é o erro padrão da previsão,
ˆvarep f f (4.7.7)

4.7.1 Previsão no Modelo da Despesa com Alimentação
A despesa semanal prevista com alimentação para um domicílio com renda semanal de x0 = $750 é
0 1 2 0ˆ 40,7676 0,1283(750) 136,98y b b x
A variância estimada do erro de previsão é
22 0
2
2
( )1ˆ ˆvar( ) 1
( )
1 (750 698)1429,2456 1 1467,4986
40 1532463
t
x xf
T x x
O erro padrão de previsão é então
ˆep( ) var( ) 1467,4986 38,3079f f























