
AMOSTRAGEM PREFERENCIAL EM PROCESSOS ESPACIAIS DISCRETOS: CASOS BERNOULLI … · 2015-12-01 ·...
75
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO INSTITUTO DE MATEM ´ ATICA DEPARTAMENTO DE M ´ ETODOS ESTAT ´ ISTICOS AMOSTRAGEM PREFERENCIAL EM PROCESSOS ESPACIAIS DISCRETOS: CASOS BERNOULLI E POISSON Disserta¸c˜ ao de mestrado por Ingrid Christyne Luquett de Oliveira 2015
Transcript of AMOSTRAGEM PREFERENCIAL EM PROCESSOS ESPACIAIS DISCRETOS: CASOS BERNOULLI … · 2015-12-01 ·...

UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
INSTITUTO DE MATEMATICA
DEPARTAMENTO DE METODOS ESTATISTICOS
AMOSTRAGEM PREFERENCIAL EM PROCESSOS
ESPACIAIS DISCRETOS: CASOS BERNOULLI E POISSON
Dissertacao de mestrado
por
Ingrid Christyne Luquett de Oliveira
2015

Amostragem Preferencial em Processos EspaciaisDiscretos: casos Bernoulli e Poisson
Ingrid Christyne L. de Oliveira
Dissertacao de Mestrado submetida ao Programa de Pos-Graduacao em Estatıstica do Ins-
tituto de Matematica da Universidade Federal do Rio de Janeiro - UFRJ, como parte dos
requisitos necessarios a obtencao do tıtulo de Mestre em Estatıstica.
Aprovada por:
Profa. Alexandra Mello Schmidt
Ph.D. - IM - UFRJ - Presidente
Prof. Gustavo da Silva Ferreira
D.Sc. - ENCE - IBGE
Prof. Helio dos Santos Migon
Ph.D. - IM - UFRJ
Rio de Janeiro, RJ - Brasil
2015
ii

Oliveira, Ingrid Christyne Luquett de
O48i Amostragem Preferencial em Processos Espaciais Discretos:
casos Bernoulli e Poisson / Ingrid Christyne Luquett de
Oliveira. - - Rio de Janeiro, 2015.
64f.
Orientadora: Alexandra Mello Schmidt.
Dissertacao (mestrado) - Universidade Federal do
Rio de Janeiro, Instituto de Matematica, Programa de
Pos-Graduacao em Estatıstica, 2015.
1. Estatıstica Espacial. 2. Amostragem Preferencial
3. Processos Espaciais Discretos. I. Schmidt, Alexandra
Mello, orient. II. Tıtulo.
iii

Agradecimentos
Sempre me encanto com uma frase que diz “Deseje ter asas, mas tambem raızes”. E sua
traducao mostra-se clara em minha vida: ainda que eu va, sempre retornarei ao meu porto
seguro, que e a minha famılia. Agradeco a eles por todo amor a mim dedicado e em nenhum lugar
me sentirei tao querida quanto em casa. Sou imensamente grata pela dedicacao, inspiracao,
educacao e todos os valores que me foram passados. Se hoje estou aqui, defendendo minha
dissertacao de mestrado, com toda certeza devo grande parte a eles. Agradeco aos meus pais,
Jorge e Valeria, pelo incentivo e por me fazerem acreditar que sempre posso dar um passo
adiante. Sei que minha mae, onde estiver, sorri pelo meu sucesso. Agradeco ao meu irmao,
Douglas, pelas incontaveis discussoes e por me motivar a ter um olhar mais crıtico sobre o
mundo. Ao meus avos, tios e primos agradeco por sempre se fazerem presentes e serem parte
tao fundamental de mim. Aos mais distantes agradeco por integrarem essa linda famılia.
Aos meus amigos gostaria de gritar ”obrigada”. Obrigada pela paciencia, pela parceria, por
me ouvirem e me consolarem quando precisei, por me incentivarem e por tantas outras atitudes
que me fazem sentir especial por ter pessoas maravilhosas ao meu lado. Aos que dividiram
muitas aulas de Estatıstica e agora dividem minha vida, obrigada! Aos que compartilhavam
somente momentos de lazer e sem os quais hoje nao vivo, obrigada! Aos amigos de infancia, com
os quais partilhei todas as fases, obrigada! Aos que mesmo a quilometros de distancia se fazem
presentes, obrigada! Agradeco a todos que, a sua maneira, torcem pela minha felicidade. Em
especial, agradeco a elas que acompanharam de perto esses anos de mestrado: Anyta, Evelyn,
Haydda, Isabel, Juliana F., Juliana G., Marcela, Sabrina e Sarah.
Aos queridıssimos Carlos, Mariana e Rafael agradeco pelas horas de estudo, por me moti-
varem, por compartilharem seu conhecimento, por dividirem comigo boa parte dos dias nesses
ultimos dois anos, pelas risadas e, principalmente, por me inspirarem. Ficarei feliz por cada
conquista de voces porque conheco o empenho e comprometimento devotados. Obrigada por
tornarem essa longa caminhada tao mais leve!
A minha orientadora Alexandra M. Schmidt dedico imensa gratidao. Obrigada pela opor-
tunidade de entrar nesse projeto, pela paciencia, pelos conselhos profissionais e pessoais, pela
disposicao em ajudar, pela calma em momentos em que o estresse me imobilizava e por ser uma
grande inspiracao.
Agradeco aos professores do DME/UFRJ pelo compromisso com o conhecimento e pelo
esforco em manter um programa de pos graduacao de excelencia. Agradeco tambem aos alunos
do programa que, de alguma maneira, contribuıram para que essa dissertacao tomasse forma.
iv

Resumo
Nos ultimos anos, grande destaque tem sido dado ao estudo de eventos georeferenciados.
Como consequencia, percebe-se uma rapida expansao das metodologias aplicadas a Estatıstica
Espacial. Em particular, problemas geoestatısticos, que consideram fixas as estacoes de coleta
de dados, ganham notoriedade em diferentes areas do conhecimento como, por exemplo, na
analise do nıvel de poluentes na atmosfera e em estudos climaticos.
A escolha dos locais de observacao do processo espacial de interesse e comumente norteada
por questoes praticas, nem sempre obedecendo a criterios rıgidos de amostragem. Por essa
razao, modelos que nao considerem informacoes sobre a selecao da amostra podem conduzir a
conclusoes erroneas na inferencia e na previsao do processo espacial. Nesse contexto, Diggle
et al. (2010) propoem uma classe de modelos que admite a possibilidade de dependencia
estocastica entre o processo espacial que determina as estacoes de monitoramento e o processo
espacial em estudo.
Em virtude da diversidade dos problemas encontrados, a presente dissertacao se propoe a
estender a metodologia abordada em Diggle et al. (2010) para situacoes onde as observacoes
sao de natureza discreta. Em especial, serao explorados cenarios para os quais as distribuicoes
de probabilidade Poisson e Bernoulli parecem descrever bem os dados. A analise dos modelos
propostos sera conduzida atraves de dados artificiais, verificando as consequencias da omissao
de informacoes sobre a amostragem das estacoes de monitoramento.
Palavras-Chave: Amostragem Preferencial; Processos Espaciais Discretos; Processo Pon-
tual; Geoestatıstica;
v

Abstract
In recent years, great emphasis has been given to the study of georeferenced events. As a
result, a rapid expansion of the methodologies applied to Spatial Statistics became notorious.
In particular, geostatistical problems, those that consider fixed stations to data collection, gain
notoriety in different knowledge areas such as in the climate analysis or in researches about the
level of pollutants into the atmosphere.
The choice of observation spots to the spatial process is commonly guided by practical
issues, not always according to strict sampling criteria. Due to this reason, models that do not
consider information about the sample selection can lead to erroneous conclusions over inference
and prediction of the spatial process. In this context, Diggle et al. (2010) proposed a class of
models that admits the possibility of stochastic dependence between the spatial process that
establishes the monitoring stations and the spatial process under investigation.
Due to the diversity of problems encountered, this dissertation proposes to extend the
methodology discussed in Diggle et al. (2010) for situations where the observations are discrete.
In particular, will be explored scenarios in which Poisson and Bernoulli probability distributions
seems to describe the data properly. The analysis of the proposed models will be conducted
through artificial data by checking the consequences of omitting information about the sampling
process of monitoring stations.
Keywords: Preferential Sampling; Discrete Spatial Processes; Point Process; Geoestatistics;
vi

Sumario
1 Introducao 1
1.1 Inferencia Bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Estimacao Pontual . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.2 Estimacao Intervalar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.3 Previsao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 Inferencia via simulacao estocastica . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.3 Metodos de Monte Carlo via Cadeias de Markov . . . . . . . . . . . . . . . . . . 5
1.3.1 Amostrador de Gibbs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.2 Algoritmo de Metropolis-Hastings . . . . . . . . . . . . . . . . . . . . . . 7
1.4 Modelos Lineares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.4.1 Modelos Lineares Generalizados . . . . . . . . . . . . . . . . . . . . . . . . 9
1.5 Organizacao da dissertacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 Processos Espaciais 11
2.1 Geoestatıstica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.1.1 Inferencia Bayesiana em Geoestatıstica . . . . . . . . . . . . . . . . . . . . 14
2.2 Processos Pontuais Espaciais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Modelos para Processos Pontuais Espaciais . . . . . . . . . . . . . . . . . 19
2.2.2 Inferencia via discretizacao espacial . . . . . . . . . . . . . . . . . . . . . . 22
3 Amostragem Preferencial 24
3.1 Estudo de Simulacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4 Amostragem Preferencial em Processos Espaciais Discretos 33
4.1 Modelos Lineares Espaciais Generalizados . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Modelo Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.2.1 Estudo de Simulacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.3 Modelo Bernoulli . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3.1 Estudo de simulacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5 Discussao e conclusoes 60
vii

Referencias Bibliograficas 63
viii

Lista de Tabelas
3.1 Estimativas de θ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1 Funcoes de ligacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.2 Estimativas de θ - Modelo Poisson (cenario 1) . . . . . . . . . . . . . . . . . . . . 41
4.3 Estimativas de θ - Modelo Poisson (cenario 2) . . . . . . . . . . . . . . . . . . . . 44
4.4 Estimativas de θ - Modelo Poisson (cenario 3) . . . . . . . . . . . . . . . . . . . . 47
4.5 Erro de previsao global - Modelo Poisson (cenario 3) . . . . . . . . . . . . . . . . 47
4.6 Estimativas de θ - Modelo Bernoulli (cenario 2) . . . . . . . . . . . . . . . . . . . 55
4.7 Estimativas de θ - Modelo Bernoulli (cenario 3) . . . . . . . . . . . . . . . . . . . 58
4.8 Erro de previsao global - Modelo Bernoulli (cenario 3) . . . . . . . . . . . . . . . 58
ix

Lista de Figuras
2.1 Exemplos de arranjos pontuais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.1 Histograma a posteriori de µ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2 Histogramas a posteriori de σ2, τ2 e φ . . . . . . . . . . . . . . . . . . . . . . . . 29
3.3 Histogramas a posteriori de α e β . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.4 Previsao de S em D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1 Histogramas a posteriori de µ, σ2 e φ - Modelo Poisson (cenario 1). As linhas ver-
ticais tracejadas correspondem aos respectivos valores verdadeiros dos parametros. 40
4.2 Previsao de S em D - Modelo Poisson (cenario 1) . . . . . . . . . . . . . . . . . . 41
4.3 Histogramas a posteriori de µ, σ2 e φ - Modelo Poisson (cenario 2). As linhas ver-
ticais tracejadas correspondem aos respectivos valores verdadeiros dos parametros. 43
4.4 Histogramas a posteriori de α e β - Modelo Poisson (cenario 2) . . . . . . . . . . 43
4.5 Previsao de S em D - Modelo Poisson (cenario 2) . . . . . . . . . . . . . . . . . . 45
4.6 Intervalos de 95% de credibilidade de θ para o modelo sob amostragem preferen-
cial com M = 400 sub-regioes (modelo 1) e com M = 225 sub-regioes (modelo
2). As linhas tracejadas correspondem aos respectivos valores verdadeiros dos
parametros. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.7 Histogramas a posteriori para o modelo sem considerar a amostragem preferencial
(modelo ) - Modelo Poisson (cenario 3) . . . . . . . . . . . . . . . . . . . . . . . . 46
4.8 Previsao de S em D - Modelo Poisson (cenario 3) . . . . . . . . . . . . . . . . . . 48
4.9 Histogramas a posteriori de µ, σ2 e φ - Modelo Bernoulli (cenario 1) . . . . . . . 53
4.10 Histogramas a posteriori de α e β - Modelo Bernoulli (cenario 1) . . . . . . . . . 53
4.11 Previsao de S em D - Modelo Bernoulli (cenario 1) . . . . . . . . . . . . . . . . . 54
4.12 Histogramas a posteriori para o modelo com 400 sub-regioes - Modelo Bernoulli
(cenario 3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.13 Histogramas a posteriori para o modelo com 225 sub-regioes - Modelo Bernoulli
(cenario 3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.14 Histogramas a posteriori para o modelo sem considerar a amostragem preferencial
- Modelo Bernoulli (cenario 3) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.15 Previsao de S em D para os modelos I e II - Modelo Bernoulli (cenario 3) . . . . 58
x

4.16 Previsao de S em D - Modelo Bernoulli (cenario 3) . . . . . . . . . . . . . . . . . 59
xi

Capıtulo 1
Introducao
A analise de eventos espacialmente referenciados ganhou bastante destaque nos ultimos
anos. A area da Estatıstica que abrange o estudo desses eventos e conhecida como Estatıstica
Espacial e engloba diversos metodos quantitativos para inferencia e previsao de processos cuja
localizacao de observacao dos dados e relevante.
Em particular, a Geoestatıstica e uma sub-area da Estatıstica Espacial na qual os dados sao
obtidos pela observacao do processo espacial contınuo S = S(x) : x ∈ Rd em um conjunto
de localizacoes x = (x1, . . . , xn) finito e fixo numa regiao de interesse D ⊂ Rd. Em geral, os
principais objetivos da Geoestatıstica sao inferir sobre processos contınuos em D e prever tais
processos para uma nova localizacao x0 ∈ D, baseados na amostra x.
A escolha de x e comumente guiada por questoes de ordem pratica como, por exemplo,
em estudos de poluentes atmosfericos onde pode haver a necessidade de alocar estacoes de
monitoramento proximas a provaveis fontes de poluicao e/ou em areas de maior densidade
populacional. Desta forma, alocar x de maneira a capturar valores altos (ou baixos) de S pode
levar a estimativas e previsoes viesadas.
Em grande parte da literatura em Geoestatıstica, os modelos para S tratam as localizacoes
xi como fixas de acordo com um desenho amostral ou assumem que o processo pontual X
que determina x e estocasticamente independente de S. Assim, modelos geoestatısticos assu-
mem, implicitamente, que a escolha das localizacoes xi ocorre de maneira nao preferencial, nao
havendo beneficiamento de nenhuma sub-regiao em D.
Recentemente, muita atencao tem sido dada ao tema. Diggle et al. (2010) admitem de-
pendencia entre o processo pontual X e o processo espacial S, que esta sendo modelado. Mais
especificamente, assume-se que X, condicional a S, e um processo de Poisson nao homogeneo
com funcao de intensidade λ(x) = expα + βS(x). A dependencia estocastica entre X e S
define o conceito de amostragem preferencial.
Motivados por contextos em que a variavel de interesse Y nao segue distribuicao de proba-
bilidade normal, mesmo sob tranformacoes, nosso estudo se propoe a estender a metodologia
apresentada em Diggle et al. (2010) para cenarios onde Y tem natureza discreta e seu valor
esperado E[Y ] esta associado a S por uma funcao de ligacao g. Abordaremos os casos onde
1

Y tem distribuicao de probabilidade Poisson e em que Y e binaria, apresentando estudos com
dados artificiais para as duas situacoes.
Neste capıtulo introdutorio sera apresentada uma breve revisao dos conceitos necessarios a
compreensao da presente dissertacao. As secoes nele contidas estao organizadas da seguinte ma-
neira: na Secao 1.1 encontra-se descrito o procedimento de inferencia sob o enfoque bayesiano;
a Secao 1.2 aborda metodos computacionais aplicados a inferencia Bayesiana; em particular
apresentaremos os Metodos de Monte Carlo via Cadeias de Markov ao longo da Secao 1.3;
na Secao 1.4 estao descritos os conceitos fundamentais sobre modelos lineares generalizados;
finalmente, a Secao 1.5 descreve a organizacao dos capıtulos da dissertacao.
1.1 Inferencia Bayesiana
Nesta secao serao apresentados os principais conceitos relacionados ao procedimento de
inferencia Bayesiana.
Considere Y uma variavel aleatoria (ou vetor aleatorio) cuja funcao de probabilidade e
denotada por p(Y | θ), onde θ e um parametro (ou um vetor de parametros) que caracteriza
a distribuicao de probabilidade de Y . O valor de θ nao e conhecido e, em geral, desejamos
estima-lo. Sob o enfoque bayesiano, podemos atribuir nossa incerteza acerca de θ associando a
ele uma distribuicao de probabilidade p(θ), chamada distribuicao a priori.
Uma vez obtida uma amostra de Y , denotada por y = (y1, . . . , yn), podemos combinar,
via teorema de Bayes, a informacao da funcao de verossimilhanca p(y | θ) com a distribuicao
a priori de θ, obtendo a distribuicao a posteriori de θ, p(θ | y). Pelo teorema de Bayes, a
atualizacao da informacao sobre θ e obtida pela expressao
p(θ | y) =p(y | θ)p(θ)
p(y), (1.1)
com
p(y) =
∫Θp(y, θ)dθ =
∫Θp(y | θ)p(θ)dθ,
onde Θ e o conjunto de todos os possıveis valores para θ.
Como p(y) nao depende de θ, podemos reescrever (1.1) como
p(θ | y) ∝ p(y | θ)p(θ). (1.2)
A influencia dos componentes p(y | θ) e p(θ) sobre a distribuicao a posteriori p(θ | y)
depende do peso dado a distribuicao a priori bem como do tamanho da amostra. Em resumo,
quanto maior o valor de n mais peso e dado a p(y | θ) e, em contrapartida, quanto mais
informativa for a distribuicao a priori mais peso sera dado a p(θ) na distribuicao a posteriori
de θ.
A inferencia sobre o parametro θ e baseada fundamentalmente nas informacoes contidas na
distribuicao a posteriori, distribuicao esta que contem toda a informacao probabilıstica acerca
2

de θ. Entretanto, existem situacoes em que deseja-se resumir a informacao contida em p(θ | y), o
que pode ser feito atraves de medidas resumo como mediana e variancia ou atraves de intervalos
de probabilidade. Nas Subsecoes 1.1.1 e 1.1.2 estao descritos os procedimentos de estimacao
pontual e intervalar, respectivamente.
1.1.1 Estimacao Pontual
A estimacao pontual e o caso mais simples e e utilizado quando se deseja sintetizar toda a
informacao contida na distribuicao a posteriori em um unico valor.
Podemos entao pensar na estimacao pontual como um problema de decisao, onde os ele-
mentos que compoem esse problema sao:
• espaco de parametros Θ;
• espaco de possıveis resultados do experimento Ω;
• espaco das possıveis acoes A;
Uma regra de decisao δ e uma funcao definida em Ω que assume valores em A, ou seja,
δ : Ω→ A. Para cada regra de decisao δ(y), y ∈ Ω, e para cada θ ∈ Θ associamos uma funcao
perda, L(δ, θ), que pode ser interpretada como uma medida de punicao ao tomarmos a decisao
δ(y), quando o verdadeiro valor do parametro e θ.
O risco associado a δ corresponde ao valor esperado da perda com respeito a distribuicao a
posteriori, e e dado por
R(δ) = Eθ|y[L(δ, θ)].
Um estimador pontual otimo de θ e aquele que minimiza, segundo uma funcao perda L(δ, θ),
o risco esperado de δ. Em particular, temos a seguir algumas funcoes perda que sao largamente
utilizadas:
• Perda absoluta: L(δ(y), θ) =| θ − δ(y) |
• Perda quadratica: L(δ(y), θ) = (θ − δ(y))T (θ − δ(y))
• Perda 0-1: L(δ(y), θ) =
1, se || θ − δ(y) ||≥ ε0, se || θ − δ(y) ||< ε
, para ε > 0 arbitrario.
3

Os estimadores otimos obtidos com a minimizacao de R(δ) para cada funcao de perda dada
anteriormente sao:
• Perda absoluta: θ tal que∫ θ−∞ p(θ | y)dθ = 0.5 (mediana a posteriori)
• Perda quadratica: θ = E(θ | y) (media a posteriori)
• Perda 0-1: θ tal que p(θ | y) = supθ∈Θp(θ | y) (moda a posteriori)
O valor obtido para θ apos a observacao da amostra y e chamado de estimativa de θ.
1.1.2 Estimacao Intervalar
Uma desvantagem inerente ao processo de estimacao pontual encontra-se no fato dele resu-
mir toda a informacao disponıvel na distribuicao a posteriori em um unico valor. Desta forma
nao e possıvel mensurar o quao precisa e a estimativa pontual. Uma alternativa e associar
alguma medida de incerteza a essa estimativa. Podemos, por exemplo, associar a variancia
amostral ao estimador dado pela media amostral.
Nesta subsecao sera apresentada uma outra abordagem, que consiste em encontrar um
intervalo de valores extraıdos da distribuicao a posteriori que mantenha um equilıbrio entre a
amplitude do intervalo e a probabilidade a ele associada. A esse intervalo chamamos intervalo
de credibilidade. Migon et al. (2014) definem um intervalo de credibilidade da seguinte maneira:
Seja θ uma quantidade desconhecida definida em Θ. A regiao C ⊂ Θ consiste em uma
regiao de 100(1 − α)% de credibilidade para θ se a probabilidade P (θ ∈ C | y) ≥ 1 − α. Nesse
caso, 1− α e dito o nıvel de credibilidade ou confianca.
A amplitude do intervalo nos informa sobre a dispersao dos valores de θ. Desta forma,
deseja-se que α e C sejam pequenos. Quanto menor C mais concentrada e a distribuicao a
posteriori. Em alguns casos, a desigualdade P (θ ∈ C | y) ≥ 1 − α pode ser substituıda pela
igualdade, o que implica que a regiao C sera a menor possıvel.
Cabe a ressalva que os intevalos de credibilidade sao invariantes a transformacoes um a
um. Assim, se C e um intervalo de 100(1 − α)% de credibilidade para θ e φ = g(θ) e uma
tranformacao biunıvoca, entao g(C) e um intervalo de 100(1− α)% de credibilidade para φ.
1.1.3 Previsao
Sob a otica Bayesiana, o processo de previsao de observacoes futuras e conduzido atraves
da obtencao da distribuicao preditiva.
Suponha que desejamos prever uma nova observacao y0 condicionalmente ao vetor de ob-
4

servacoes y. A distribuicao preditiva de y0 e dada por
p(y0 | y) =
∫Θp(y0, θ | y)dθ (1.3a)
=
∫Θp(y0 | θ,y)p(θ | y)dθ (1.3b)
=
∫Θp(y0 | θ)p(θ | y)dθ, (1.3c)
com a ultima igualdade valida somente se y0 e y forem independentes condicionais a θ.
Note que a equacao (1.3c) corresponde a esperanca de p(y0 | θ) com respeito a distribuicao
a posteriori. Desta forma, podemos reescrever a distribuicao preditiva avaliada em y0 como
p(y0 | y) = Eθ|y[p(y0 | θ)].
1.2 Inferencia via simulacao estocastica
Todo o procedimento de inferencia sob a abordagem Bayesiana e conduzido com base na
distribuicao a posteriori. Existem, porem, situacoes onde p(θ | y) pode ser complexa a ponto
de nao ser possıvel obte-la analiticamente. Entretanto, esse problema pode ser contornado
obtendo-se amostras da distribuicao a posteriori atraves de metodos de simulacao estocastica.
Entre os metodos de simulacao mais utilizados em inferencia Bayesiana encontram-se os
metodos de Monte Carlo via cadeias de Markov (MCMC). Enquanto a Secao 1.3 consiste em
uma breve introducao ao metodos MCMC, as Subsecoes 1.3.1 e 1.3.2 apresentam o algoritmo
de Gibbs e o algoritmo de Metropolis-Hastings, respectivamente. Ambos sao casos particulares
destes metodos e sao amplamente empregados em inferencia Bayesiana.
1.3 Metodos de Monte Carlo via Cadeias de Markov
Um metodo de Monte Carlo via Cadeias de Markov para simulacao de uma distribuicao
p e definido como qualquer metodo que produza uma cadeia de Markov ergodica (θt) cuja
distribuicao estacionaria seja p (Robert e Casella, 2004).
Uma cadeia de Markov (θt) e uma sequencia de variaveis aleatorias θ0,θ1, ...,θt, ... tal que
a distribuicao de θk+1 dados todos os valores anteriores θ0, . . . ,θk depende apenas de θk.
Matematicamente escreve-se
P (θk+1 ∈ A|θ0,θ1, ...,θk) = P (θk+1 ∈ A|θk),
para qualquer k. Cadeias de Markov sao ditas ergodicas se sao aperiodicas e recorrentes posi-
tivas. Resumidamente, uma cadeia de Markov e
5

• aperiodica: se, com probabilidade 1, nenhum dos seus estados e visitado apos d passos,
para qualquer d > 0 inteiro;
• recorrente positiva: quando o numero medio de passos para que uma cadeia retorne a
qualquer estado e finito;
Considere θ = (θ1, . . . , θp) o vetor de parametros do modelo em estudo, com funcao de
densidade conjunta p(θ) = p(θ1, . . . , θp). Considere, ainda, que q(θ,θ∗) define a distribuicao
condicional das transicoes entre os estados θ e θ∗. Alem da condicao de ergodicidade, a cadeia de
Markov deve ter probabilidades de transicao invariantes no tempo (condicao de homogeneidade)
e probabilidade positiva de transicao de um estado para qualquer outro estado em um numero
finito de iteracoes (condicao de irredutibilidade).
Satisfeitas todas as condicoes explicitadas acima, garantimos a existencia da distribuicao
estacionaria p e, apos um numero finito de iteracoes, podemos tomar os estados como uma
amostra aproximada de p. Em especial, em inferencia Bayesiana a distribuicao estacionaria da
qual desejamos amostrar e a distribuicao a posteriori de um vetor parametrico de interesse θ.
Nas subsecoes que seguem estao descritos os dois metodos MCMC mais utilizados: Amos-
trador de Gibbs e Algoritmo de Metropolis Hastings.
1.3.1 Amostrador de Gibbs
O amostrador de Gibbs foi originalmente proposto por Geman e Geman (1984) e, poste-
riormente, popularizado por Gelfand e Smith (1990). Trata-se de um esquema iterativo de
amostragem de uma cadeia de Markov cujas probabilidades de transicao sao formadas pelas
distribuicoes marginais condicionais dos elementos θi do vetor parametrico θ.
Denote por p(θi | θ−i) a funcao de densidade condicional de θi, onde θ−i = (θ1, θ2, . . . , θi−1,
θi+1, . . . , θp). A ela chamamos densidade condicional completa de θi, sendo obtida a partir da
funcao de densidade conjunta p(θ).
Podemos, entao, descrever o algoritmo da seguinte forma:
1. Inicialize o contador de iteracoes em j = 1 e atribua valores iniciais
θ(0) = (θ(0)1 , ..., θ(0)
p );
6

2. Obtenha um novo valor θ(j) a partir de θ(j−1) sucessivamente usando
θ(j)1 ∼ p(θ1 | θ(j−1)
2 , . . . , θ(j−1)p )
θ(j)2 ∼ p(θ2 | θ(j)
1 , θ(j−1)3 , . . . , θ(j−1)
p )
θ(j)3 ∼ p(θ3 | θ(j)
1 , θ(j)2 , θ
(j−1)4 , . . . , θ(j−1)
p )
...
θ(j)p ∼ p(θp | θ(j)
1 , θ(j)2 , . . . , θ
(j)p−1);
3. Mude o contador de j para j + 1 e retorne ao passo 2. Repita os passos 2 e 3 ate obter a
convergencia da cadeia.
Este algoritmo destaca-se quando as distribuicoes condicionais completas sao distribuicoes
de probabilidade conhecidas e assume-se que e possıvel amostrar dessas distribuicoes facilmente.
1.3.2 Algoritmo de Metropolis-Hastings
Outro metodo de Monte Carlo via Cadeias de Markov bastante utilizado e o algoritmo
de Metropolis-Hastings (proposto em Metropolis et al. (1953) e Hastings (1970)), usualmente
aplicado a situacoes onde nao conhecemos a distribuicao condicional completa p(θi | θ−i). Este
algoritmo e baseado no uso de uma distribuicao auxiliar, conhecida como distribuicao proposta,
da qual e mais facil obter uma amostra. Em linhas gerais, o procedimento consiste em amostrar
um valor da distribuicao proposta e aceita-lo ou nao de acordo com uma probabilidade α.
Considere uma densidade p(·) da qual desejamos simular e uma densidade proposta q(·). O
algoritmo de Metropolis - Hastings produz uma cadeia de Markov (θt) atraves dos seguintes
passos:
1. Inicialize o contador de iteracoes em j = 1 e atribua valores iniciais
θ(0) = (θ(0)1 , ..., θ(0)
p );
2. Sorteie um valor proposto θprop da densidade proposta q(θprop | θ(j−1));
3. Tome
θ(j) =
θprop, com probabilidade α
θ(j−1), com probabilidade 1− α,
onde
α = min
1,p(θprop)q(θ(j−1) | θprop)p(θ(j−1))q(θprop | θ(j−1))
;
7

4. Mude o contador de j para j + 1 e retorne ao passo 2. Repita sucessivamente ate obter a
convergencia da cadeia.
Nao ha unanimidade quanto a taxa de aceitacao otima para o algoritmo de Metropolis-
Hastings. A sintonizacao da variancia da distribuicao proposta q sera baseada no metodo
apresentado em Roberts e Rosenthal (2009), procurando manter a taxa de aceitacao em torno
de 44%.
Uma caracterıstica interessante do algoritmo de Metropolis-Hastings e que a distribuicao
da qual desejamos amostrar so precisa ser conhecida a menos de uma constante de proporci-
onalidade, uma vez que componentes constantes da funcao de densidade serao canceladas emp(θprop)q(θ(j−1)|θprop)
p(θ(j−1))q(θprop|θ(j−1)).
Dizemos que a convergencia da cadeia de Markov foi atingida quando a partir de determi-
nada iteracao K a cadeia aproxima-se de um estado de estacionariedade. Existem diferentes
formas disponıveis na literatura para avaliacao da convergencia das cadeias. Uma delas e ba-
seada na inspecao visual da amostra, onde analisamos se a trajetoria da cadeia de Markov
torna-se homogenea a partir de determinada iteracao. Neste estudo, a convergencia das cadeias
sera avaliada somente via inspecao visual.
Passadas as K primeiras iteracoes, denominado perıodo de aquecimento, podemos tomar
as iteracoes restantes como uma amostra da funcao de densidade p(·). Por se tratar de uma
cadeia de Markov, nossa amostra e aleatoria mas nao independente. Em alguns casos onde a
autocorrelacao das cadeias e alta, e possivel retirar uma subamostra sistematica para compor
uma nova amostra e lidar com o problema de autocorrelacao.
Metodos MCMC sao, portanto, uma ferramenta de grande importancia para amostragem
de distribuicoes de probabilidade complexas, permitindo a inferencia acerca dos parametros.
1.4 Modelos Lineares
Em diversos contextos estamos interessados em estudar se o comportamento de uma deter-
minada variavel e influenciado por outra variavel ou mesmo por um conjunto de variaveis. A
estrutura desta relacao pode assumir diferentes formas e, em alguns casos, apresenta compor-
tamento linear. Os modelos que assumem estrutura linear entre variavel resposta e variaveis
explicativas sao chamados modelos de regressao ou modelos lineares e sao descritos por
Yi = Ziβ + εi,
onde i ∈ 1, . . . , n, Yi e a variavel resposta, εi o erro do modelo, Z a matriz de dimentsao
n× (p+ 1) cujas colunas Zi correspondem as p variaveis explicativas, incluindo uma coluna de
uns associada ao intercepto do modelo, e β e o vetor com os coeficientes de regressao.
Usualmente assume-se que εi ∼ N(0, τ2). Deste modo, condicionado aos coeficientes de
8

regressao temos que
Yi ∼ N(Ziβ, τ2).
O problema em assumir que a variavel resposta Yi segue uma distribuicao de probabilidade
normal e que dificilmente em situacoes reais encontramos dados que sigam de fato esta dis-
tribuicao. Existem ainda problemas em que a variavel resposta assume valores discretos ou
esta definida somente para um subconjunto de R e, portanto, a distribuicao normal nao corres-
pondera a distribuicao dos dados. Para casos em que a distribuicao de probabilidade normal
nao pode ser assumida para descrever o comportamento de Yi utilizamos modelos mais gerais,
que admitem que Yi assuma outra distribuicao de probabilidade, aos quais chamamos modelos
lineares generalizados (MLG).
1.4.1 Modelos Lineares Generalizados
Modelos lineares generalizados sao uma classe de modelos estatısticos que compreendem
modelos lineares e nao lineares com a distribuicao de Yi pertencente a famılia exponencial.
Nessa secao daremos uma introducao a esses modelos, todavia maior aprofundamento sobre o
tema pode ser encontrado em McCullagh e Nelder (1989).
Uma famılia de distribuicoes com funcao de densidade p(y | θ) pertence a famılia exponencial
com r parametros se p(y | θ) puder ser escrito como
p(y | θ) = a(y) exp
r∑j=1
Uj(y)ψj(θ) + b(θ)
, y ∈W ⊂ R,
onde W nao depende de θ.
A famılia exponencial engloba diversas distribuicoes conhecidas, como, por exemplo, a Bi-
nomial, Normal, Poisson, Exponencial entre outras e e de grande importancia.
Os modelos lineares generalizados sao estruturados em tres componentes:
• Componente aleatoria: especifica a distribuicao de probabilidade de Yi condicional aos
valores das variaveis explicativas Xji, com E(Yi) = µi. A distribuicao de probabilidade
de Yi deve pertencer a famılia exponencial.
• Componente sistematica: consiste numa funcao linear das variaveis explicativas da
forma
νi = Ziβ,
sendo νi conhecida como preditor linear.
• Funcao de ligacao: funcao monotona e derivavel g que transforma a esperanca E(Yi)
em um preditor linear:
9

g(µi) = νi = Ziβ.
Como g e monotona e derivavel, existe a funcao inversa g−1 dada por
µi = g−1(νi) = g−1(Ziβ).
Deste modo, os MLGs podem ser pensados como um modelo linear para uma transformacao
de E(Yi) = µi ou como uma regressao nao linear da variavel resposta.
1.5 Organizacao da dissertacao
Este texto e composto por mais 4 capıtulos. O Capıtulo 2 apresenta uma revisao de Es-
tatıstica Espacial, em particular, Processos Pontuais e Geoestatıstica. Nele sao descritos os
conceitos fundamentais para a compreensao do tema central desta dissertacao que e a amos-
tragem preferencial, abordada no Capıtulo 3. Estudos simulados com dados de contagem sob
efeito de amostragem preferencial encontram-se no capıtulo 4. Por fim, o Capıtulo 5 apresenta
as conclusoes e aponta possıveis caminhos para extensao deste estudo.
10

Capıtulo 2
Processos Espaciais
Diferentes areas do conhecimento, como arqueologia, meio-ambiente, geografia, entre outras,
estudam processos que sao observados em localizacoes fixas de uma regiao de interesse. Estudos
dessa natureza visam compreender os processos espacias que governam as variaveis de interesse,
buscando padroes significativos na regiao estudada. Tambem e de grande interesse a previsao
desses processos em localizacoes nao observadas. Com o grande crescimento da literatura de
modelos estatısticos para analise de processos espaciais nos ultimos anos, nos tornamos capazes
de lidar com problemas cada vez mais complexos.
Um processo estocastico e definido por um conjunto Wkk∈K de variaveis aleatorias, in-
dexado por K. Processos espaciais sao processos estocasticos onde K e uma regiao no espaco
Rd.Considere D ⊂ Rd uma regiao de interesse e xi ∈ D certa localizacao onde um processo
espacial Y (x) : x ∈ D sera observado. Na maioria das aplicacoes a regiao D e bidimensional,
porem encontramos tambem aplicacoes na reta e, com o avanco tecnologico, e possıvel obter
observacoes em que d = 3.
Como abordado em Cressie (1993) , os processos espaciais podem ser classificados em tres
tipos:
• Dados de area: a regiao de interesse D ∈ Rd e fixa, mas particionada em um numero
finito de areas com fronteiras bem definidas. Neste caso, xi corresponde a uma sub-
regiao de D e Y (xi) e a variavel aleatoria a ela associada. Com este tipo de observacao e
possıvel investigar a relacao entre as diversas particoes de D. Exemplos: dados economicos
agregados por municıpios, numero de casos de uma doenca por estados.
• Geoestatıstica: Y (xi) e a variavel aleatoria de interesse observavel na localizacao xi ∈D. Nesse contexto, o conjunto de localizacoes x = (x1, . . . , xn) e fixo e discreto. E comum
assumir que o vetor Y = (Y (x1), . . . , Y (xn))T tem distribuicao de probabilidade normal,
sendo esses modelos amplamente utilizados em virtude das propriedades da distribuicao
gaussiana. Exemplos: medicoes de temperatura e medicoes do nıvel de dioxido de carbono
(CO2) em estacoes de monitoramento.
11

• Processos Pontuais: processos onde a localizacao da ocorrencia do evento e aleatoria,
ou seja, o conjunto de pontos x e aleatorio. Estamos interssados, com esse tipo de
observacao, em estudar se o processo espacial tende a formar regioes no espaco onde haja
aglomeracao de ocorrencias ou se ele se comporta homogeneamente ao longo de D. Na
pratica, e possıvel encontrar contextos onde uma variavel Y (xi) seja observada em xi,
i = 1, . . . , n. Exemplos: localizacoes de ocorrencia de crimes, localizacoes de foco de
incendio.
Concentraremos nosso estudo em modelos geoestatısticos e modelos para processos pontuais.
2.1 Geoestatıstica
Seja S(x) um processo espacial de interesse. A colecao de variaveis aleatorias S(x) :
x ∈ D ⊂ Rd consiste em um processo estocastico indexado por x. Como exemplo de dados
geoestatısticos para d = 2, suponha que S(xi) e a pressao atmosferica medida em uma estacao
de monitoramento xi = (x1i, x2i), onde x1i e a latitude e x2i e a longitude.
Observaremos S(x) em um conjunto finito de localizacoes x = x1, ..., xn, ou seja, os
dados serao uma realizacao parcial do processo espacial S(x) em x. Baseados nessa realizacao,
podemos inferir sobre esse processo alem preve-lo em um ponto arbitrario x0 ∈ D.
Assuma que a media do processo aleatorio S(x) existe para todo x ∈ D e denote-a por
E[S(x)] = µ(x). Suponha que a variancia de S(x), V ar[S(x)], tambem existe para todo x ∈ D.
Um processo estocastico S(x) : x ∈ D ⊂ Rd e dito gaussiano se para todo conjunto finito
de pontos x = (x1, . . . , xn), x ∈ D, e qualquer n = 1, 2, . . . , o vetor (S(x1), . . . , S(xn)) tem
distribuicao normal multivariada. O processo gaussiano S(x) e completamente especificado
por sua media µ(x) e por sua funcao de covariancia Cov(S(xi), S(xj)), para todo xi, xj ∈ x.
Denotamos por S(x) ∼ PG µ(x),Σ, o processo gaussiano com vetor de medias µ(x) e matriz
de covariancias Σ com entrada (i, j) dada por Cov(S(xi), S(xj)).
Duas suposicoes usualmente atribuıdas aos processos espaciais sao estacionariedade e iso-
tropia. Um processo e dito estritamente estacionario se suas distribuicoes finito-dimensionais
sao invariantes a translacoes. Matematicamente, estacionariedade significa que
[S(x1), . . . , S(xn)] = [S(x1 + h), . . . , S(xn + h)] ,
para quaisquer xi e xi + h ∈ D, i = 1, . . . , n e [·] representando uma distribuicao de probabi-
lidade. Quando essa suposicao e verificada, tem-se media e variancia constantes para todas as
distribuicoes unidimensionais, ou seja, µ(x) = µ e V ar[S(x)] = σ2, ∀x ∈ D.
Alem disso, um processo e dito intrinsicamente estacionario se
E[S(x+ h)] = E[S(x)]
12

V ar[S(x+ h)− S(x)] = 2γ(h),∀x, x+ h ∈ D,
onde γ(h) e uma funcao condicionalmente negativa definida chamada de semivariograma.
Menos restritiva, a estacionariedade de segunda ordem ou estacionariedade fraca pressupoe
que a media do processo e constante para todo x ∈ D, ou seja,
µ(x) = µ, x ∈ D,
e a covariancia entre dois pontos xi e xj ∈ D quaisquer, condicionada ao vetor parametrico ψ,
e dada por
Cov(S(xi), S(xj);ψ) = C(| xi − xj |;ψ),
somente dependendo da diferenca entre as duas localizacoes. No contexto de processos gaussi-
anos, a estacionariedade de segunda ordem implica em estacionariedade estrita visto que esses
processos estao completamente especificados por seu primeiro e segundo momentos.
Se a funcao de correlacao entre dois pontos xi e xj em D nao depender da direcao de
| xi − xj |, ou seja, for invariante a rotacoes no espaco, dizemos que o processo e isotropico.
Desta forma, podemos escrever a funcao de correlacao C(xi, xj ;ψ) em funcao do comprimento
do vetor de diferenca entre os pontos xi e xj , denotado por ‖ xi − xj ‖. Caso contrario, o
processo e dito anisotropico.
Quando um processo e intrinsicamente estacionario e isotropico, diz-se que o processo e
homogeneo (Smith, 1996). Por outro lado, se pelo menos uma dessas suposicoes nao e satisfeita
o processo e dito heterogeneo. Processos homogeneos tem funcao de covariancia entre S(xi) e
S(xj), xi, xj ∈ D dada por
Cov(S(xi), S(xj)) = C(‖ xi − xj ‖;ψ),
e, portanto, a variancia do processo e constante ao longo de D. Deste modo, podemos escrever
a funcao de covariancia de S(x) como
C(xi, xj ;ψ) = σ2ρ(‖ xi − xj ‖;ψ),
onde V ar[S(x)] = σ2 e ρ(·;ψ) e uma funcao de correlacao valida.
Dizemos que uma funcao de correlacao e valida se for positiva definida, o que significa que
devemos ter
ΣiΣjcicjρ(si, sj ;ψ) ≥ 0
para quaisquer ci, cj ∈ R.
Nota-se a conveniencia de processos homogeneos, uma vez que a estrutura de covariancia
de S(x) apenas necessita dos parametros σ2 e ψ para ser modelada.
Verificar a validade de uma funcao de correlacao nao e uma tarefa facil e, por essa razao, e
13

comum a opcao por aquelas ja conhecidas. Existem diversas famılias de funcoes de correlacao
na literatura, sendo alguns dos principais modelos parametricos de funcoes de correlacao apre-
sentados em Diggle e Ribeiro (2007). Exemplos de funcoes de correlacao largamente usadas
encontram-se a seguir.
(a) Famılia Matern:
ρ(dij ;ψ) =1
2λ−1Γ(λ)
(2√λdijφ
)κλ
(2√λdijφ
),
onde ψ = (φ, λ), φ > 0 e o parametro de escala, λ > 0 e o parametro de forma e
dij =‖ xi−xj ‖ e a distancia euclidiana entre xi e xj . A funcao κλ e a funcao modificada
de Bessel do terceiro tipo de ordem λ e Γ(·) e a funcao gama. Casos particulares da funcao
Matern ocorrem para λ = 0.5, quando encontramos a funcao de correlacao exponencial,
e para λ→∞ para o qual temos a funcao de correlacao gaussiana.
(b) Famılia Exponencial Potencia:
ρ(dij ;ψ) = exp
(−dκijφ
),
onde ψ = (φ, κ) com φ > 0 e κ ∈ (0, 2], dij e a distancia euclidiana entre os pontos xi e
xj . Quando k = 1 temos o caso particular da funcao de correlacao exponencial enquanto
para k = 2 temos a funcao de correlacao exponencial potencia quadratica ou gaussiana.
O grau de suavidade de um processo espacial e um aspecto importante, sendo matema-
ticamente descrito pelo grau de diferenciabilidade do processo. Em processos gaussianos, a
especificacao da famılia de funcao de correlacao deve ser cautelosa, pois nesse contexto a suavi-
dade do processo esta diretamente relacionada a diferenciabilidade da estrutura de covariancia.
Processos espaciais com funcao de correlacao gaussiana sao extremamente suaves uma vez que
ρ(·;φ, κ) e infinitamente diferenciavel para κ = 2. Para a famılia Matern, o parametro λ controla
a suavidade do processo.
Em particular, em nosso estudo utilizaremos a funcao de correlacao exponencial definida
por
ρ(dij ;φ) = exp
−dijφ
,
onde dij =‖ xi − xj ‖.
2.1.1 Inferencia Bayesiana em Geoestatıstica
Suponha que um processo espacial Y (x) : x ∈ D e observado em um conjunto de loca-
lizacoes x = (x1, . . . , xn) fixadas emD, resultando em uma amostra aleatoria y = (y(x1), . . . , y(xn))T .
Seja o modelo para Y (x) escrito como
14

Y = 1µ+ S(x) + ε, (2.1)
onde Y = (Y (x1), . . . , Y (xn))T e a realizacao de do processo Y em x, 1 = (1, . . . , 1)T de di-
mensao n×1 e µ uma media global para o processo Y (x). O componente ε = (ε(x1), . . . , ε(xn))T
e uma realizacao do processo espacial ε(x) : x ∈ D, independente de S, e cuja variancia e
usualmente chamada efeito pepita. O processo S consiste em um efeito aleatorio, fornecendo
ajuste local para a media e e interpretado como o componente que captura a estrutura espacial
em D, enquanto ε pode ser interpretado como um erro de medicao ou erro de microescala, com
E[ε(xi)] = 0 e V ar[ε(xi)] = τ2. Podemos interpretar Y como uma versao de S(x) com ruıdo.
Para simplicar a notacao, denotaremos Y (xi) por Yi.
E comum encontrarmos problemas geoestatısticos que associem S(x) e ε a processos gaussi-
anos ou a uma mistura de processos gaussianos devido as facilidades e a ampla literatura sobre
eles. Em nosso estudo assumiremos que S(x) ∼ Nn
0, σ2Rn
e ε ∼ Nn
0, τ2In
, onde os
elementos da matriz de correlacoes de S(x) sao dados por Rn(i, j) = ρ(dij ; θ), dij e a distancia
euclidiana entre xi e xj , In e a matriz identidade de dimensao n × n e 0 = (0, . . . , 0)T uma
matriz de zeros com dimensao n× 1.
Sob o enfoque Bayesiano, traduzimos nossa incerteza acerca dos parametros especificando a
distribuicao a priori para o vetor parametrico θ = (µ, φ, σ2, τ2), nos tornando capazes de inferir
sobre o mesmo. Combinamos, entao, a informacao contida na funcao de verossimilhanca com
a distribuicao a priori p(θ) atraves do teorema de Bayes e obtemos a funcao de densidade a
posteriori p(θ | y). Assumiremos que p(θ) = p(µ)p(φ)p(σ2)p(τ2).
Usualmente, atribui-se distribuicao Gama para o parametro de alcance φ, a variancia de S
σ−2 e ao efeito pepita τ−2 enquanto para µ a distribuicao Normal e assumida. E interessante
dar pouco peso as distribuicoes a priori e, por essa razao, especificam-se distribuicoes pouco
informativas para θ.
O modelo e completamente especificado por
Y | S(x), µ, τ2 ∼ N(1µ+ S(x), τ2In
)S(x) | σ2, φ ∼ N
(0, σ2Rn
)φ ∼ Gama (aφ, bφ)
σ−2 ∼ Gama (aσ, bσ)
τ−2 ∼ Gama (aτ , bτ )
µ ∼ N(0, σ2
µ
),
onde Rn(i, j) = ρ(dij ;φ). Ocasionalmente sera usada a notacao Σn = σ2Rn.
15

A funcao de verossimilhanca para esse modelo e dada por
l(y;θ, S(x)) = p(y | S(x), µ, τ2)
= (2π)−n2 | τ2In |
12 exp
−1
2(y − 1µ− S(x))T (τ2In)−1 (y − 1µ− S(x))
∝ (τ2)−
n2 exp
− 1
2τ2(y − 1µ− S(x))T (y − 1µ− S(x))
.
Pelo teorema de Bayes, combinando l(y; θ, S(x)) com p(θ) obtemos a densidade a posteriori
para o modelo na equacao (2.1) como
p(θ | y) ∝ l(y;θ, S(x)) p(S(x) | σ2, φ) p(θ)
(τ2)−n2 exp
− 1
2τ2(y − 1µ− S(x))T (y − 1µ− S(x))
(σ2)−
n2 | Rn |−
12 exp
− 1
2σ2S(x)TR−1
n S(x)
φaφ−1 exp −bφφ (σ2)−aσ+1 exp
− bσσ2
(τ2)−aτ+1 exp
− bττ2
exp
−µ
2
σ2µ
,
da qual simularemos atraves de Metodos de Monte Carlo via Cadeias de Markov.
Usando distribuicoes Gama para τ−2 e σ−2 temos distribuicoes a posteriori conjugadas, ou
seja, temos que as distribuicoes condicionais completas desses parametros tambem sao distri-
buicoes Gama. O mesmo ocorre para µ ao atribuirmos uma distribuicao normal para p(µ).
Deste modo, temos as seguintes distribuicoes condicionais completas:
[σ−2 | y, S(x)] ∼ Gama
(n
2+ aσ,
S(x)TR−1n S(x)
2+ bσ
)
[τ−2 | y, µ, S(x)] ∼ Gama
(n
2+ aτ ,
(y − 1µ− S(x))T (y − 1µ− S(x))
2+ bτ
)
[µ | y, τ2, S(x)] ∼ N
σ2µ
n∑i=1
yi − S(xi)
nσ2µ + τ2
,σ2µτ
2
nσ2µ + τ2
.
Como S e normalmente distribuıdo, temos que a condicional completa de S conjuga com
sua distribuicao a priori, sendo normalmente distribuıda com matriz de covariancias
ΣS|· =
(τ2In)−1 + (σ2Rn)−1−1
16

e vetor de media
(τ2In)−1(yT − µ)ΣS|·.
Amostras das condicionais completas de τ−2, σ−2, µ e S podem ser obtidas via Amostrador
de Gibbs. A distribuicao a posteriori de φ, entretanto, nao possui forma analıtica fechada e
para amostrar φ a posteriori precisaremos do algoritmo de Metropolis-Hastings. A condicional
completa de φ e dada por
p(φ | y, S(x), σ2) ∝| Rn |−12 φaφ−1 exp
−S(x)TR−1
n S(x)
2σ2− bφφ
,
onde Rn(i, j) = exp−dij
φ
e dij =‖ xi − xj ‖.
O algoritmo de Metropolis-Hastings exige a especificacao de uma funcao de densidade pro-
posta. Seguindo Ferreira e Gamerman (2015), adotaremos a seguinte densidade proposta
φprop | φ ∼ Lognormal ( log(φ) + δ/2, δ ),
onde δ representa o quao distante o valor proposto pode estar do valor corrente de φ. Devemos
escolher δ de forma a obtermos uma taxa de aceitacao razoavel para φ.
Suponha que, alem de inferir sobre S, estamos interessados na previsao desse processo em um
conjunto de pontos x∗ = (x∗1, . . . , x∗N ) nao observados em D. Denotaremos por S∗ a realizacao
de S em x∗, ou seja, S∗ = (S(x∗1), . . . , S(x∗N )). Devemos obter a distribuicao preditiva de
p(S∗ | y), que e dada por
p(S∗ | y) =
∫Θ
∫Sp(S∗, S,θ | y) dS dθ
=
∫Θ
∫Sp(S∗ | S,y,θ) p(S | θ) p(θ | y) dS dθ
=
∫Θ
∫Sp(S∗ | S,θ) p(S | θ) p(θ | y) dS dθ.
(2.2)
Podemos escrever p(S∗ | S,θ,y) = p(S∗ | S,θ), pois S∗ e independente de Y para S e θ dados.
Note que, por se tratar de uma realizacao do processo Gaussiano S, a distribuicao de S∗
tambem e normal multivariada com media 0 e matriz de covariancia ΣN = σ2RN . Assim, temos
que (S∗
S
∣∣∣∣∣ θ)
= N
(0
0
),
[ΣN ΣN,n
Σn,N Σn
],
onde ΣN,n e a matriz de covariancias entre os pontos de x e x∗ cujos elementos sao dados por
17

ΣN,n(i, j) = ρ(x∗i , xj ;φ), para i = 1, . . . , N e j = 1, . . . , n.
Por propriedades da distribuicao normal multivariada e por contas provenientes da algebra
linear, temos que [S∗ | y] segue uma distribuicao normal multivariada com vetor de medias e
matriz de covariancias dados, respectivamente, por
E[S∗ | y] = ΣN,n(τ2In + Σn)−1(y − 1µ) (2.3)
e
V ar[S∗ | y] = ΣN − ΣN,n(τ2 + Σn)−1Σn,N . (2.4)
Apesar da integral em (2.2) nao possuir solucao analıtica, podemos aproxima-la usando
metodos de Monte Carlo. Uma vez obtida uma amostra da posteriori de θ usando as distri-
buicoes condicionais completas descritas anteriormente, podemos calcular p(S∗ | y) como
p(S∗ | y) ≈K∑k=1
p(S∗ | Sk,θk),
onde k corresponde a k-esima iteracao do MCMC.
2.2 Processos Pontuais Espaciais
Um processo pontual espacial X e um mecanismo estocastico que governa o conjunto de
localizacoes de ocorrencia de um fenomeno em determinada regiao D do espaco. Uma realizacao
desse processo x = (x1, x2, ..., xn) e chamado arranjo pontual ou padrao de pontos e cada
localizacao xi e dita um evento.
Usualmente lidamos com processos espaciais que satisfazem as suposicoes de estacionarie-
dade e isotropia. Processos isotropicos e estacionarios consistem em processos que sao, respecti-
vamente, invariantes sob rotacao e translacao. Na pratica, essas suposicoes sao menos rigorosas
pois nem sempre sao realistas.
Os conceitos de media e covariancia de processos pontuais espaciais sao definidos em funcao
dos efeitos de primeira e segunda ordens. As propriedades de primeira ordem sao descritas pela
funcao intensidade λ(x) e estao relacionadas ao numero esperado de eventos por unidade de
area no ponto x. A funcao intensidade e definida por
λ(x) = lim|dx|→0
E[N(x)]
| dx |
, (2.5)
onde | dx | e a area de uma regiao infinitesimal dx em torno de x e E[N(dx)] denota o valor
esperado de N(dx), o numero de eventos em dx. Para processos estacionarios temos que λ(x) =
λ.
Similarmente, a funcao de intensidade de segunda ordem mensura os efeitos de segunda
ordem e e definida por
18

λ2(xi, xj) = lim|dxi|,|dxj |→0
E[N(dxi)N(dxj)]
| dxi || dxj |
.
A funcao λ2(xi, xj) pode ser interpretada como uma medida de dependencia entre localizacoes.
No contexto de processos estacionarios e isotropicos, a funcao de intensidade de segunda
ordem se resume a λ2(xi, xj) = λ2(‖xi − xj‖), onde ‖xi − xj‖ e a distancia euclidiana entre as
localizacoes xi e xj .
Em Diggle (2003), os padroes de pontos sao divididos em basicamente tres categorias: re-
gulares, agregados ou aleatorios, ilustrados na Figura 2.1.
No padrao aleatorio, tambem conhecido como aleatoriedade espacial completa, nao ha ne-
nhuma associacao entre os eventos, sendo uma realizacao aleatoria do processo espacial na regiao
de estudo D. Na Figura 2.1(a) observa-se a ausencia de estrutura espacial das localizacoes.
A Figura 2.1(b) exemplifica o padrao regular de pontos. Neste arranjo, existe uma distancia
entre os pontos que sugere a presenca de um mecanismo onde a ocorrencia de um evento xi em
determinada regiao repele a ocorrencia de eventos proximos.
Um arranjo agregado caracteriza-se pela presenca de agrupamentos de eventos no espaco.
Observa-se que a ocorrencia de um evento em uma localizacao xi torna mais provavel a ob-
servacao de outros eventos na vizinhanca de xi. Este comportamento de agregacao esta claro
na Figura 2.1(c).
(a) Aleatorio
(b) Regular
(c) Agregado
Figura 2.1: Exemplos de arranjos pontuais
Desejamos, portanto, compreender o mecanismo estocastico gerador dos arranjos pontu-
ais em estudo. Um caminho e atraves de modelos parametricos. Os principais modelos sao
apresentados na Subsecao 2.2.1.
2.2.1 Modelos para Processos Pontuais Espaciais
O processo de Poisson homogeneo representa o mecanismo estocastico mais simples para a
geracao de arranjos pontuais espaciais e trata-se da base da construcao da teoria de processos
19

pontuais espaciais. Esta secao descreve o processo de Poisson homogeneo e os processos pontuais
espaciais que sao originados diretamente neste processo, com enfase nos processos de Cox log
gaussiano que constituem parte fundamental na metodologia de amostragem preferencial.
Processo de Poisson homogeneo
O processo de Poisson caracteriza-se por possuir uma funcao de intensidade constante no
espaco e por nao haver interacao espacial entre eventos. Este processo e definido pelas seguintes
propriedades (Diggle, 2003):
• Para algum λ > 0 e uma regiao D ⊂ Rd, a variavel aleatoria N(D), correspondente ao
numero de eventos na regiao D, segue uma distribuicao Poisson com media λ | D |.
• Dado N(D) = n, os n eventos em D formam uma amostra aleatoria independente de uma
distribuicao uniforme em D.
• Para quaisquer duas regioes disjuntas D e D∗ ⊂ Rd, as variaveis aleatorias N(D) e N(D∗)
sao independentes.
O parametro λ correponde a intensidade do Processo de Poisson. Como nao existe associacao
espacial entre eventos, a funcao de intensidade de segunda ordem torna-se
λ2(xi, xj) = λ2.
Pelas propriedades do modelo, a funcao de verossimilhanca nao depende da localizacao dos
eventos x = (x1, x2, . . . , xn) em D resumindo-se a
p(x | λ) ∝ exp −λ |D| (λ |D|)n .
Em grande parte das aplicacoes o processo de Poisson se mostra pouco realıstico. Ainda que
os eventos nao possuam associacao espacial, o pressuposto de homogeneidade em D raramente
e satisfeito. Podemos permitir que a intensidade do processo varie deterministicamente no
espaco, caracterizando o chamado processo de Poisson nao homogeneo, que e descrito a seguir.
Processo de Poisson Nao Homogeneo
Um processo de Poisson nao homogeneo e um processo nao estacionario obtido pela subs-
tituicao da intensidade constante λ do processo de Poisson homogeneo por uma funcao de
intensidade que varia ao longo do espaco, denotada por λ(x). Definimos esse processo pelas
propriedades:
• A variavel aleatoria N(D) segue uma distribuicao Poisson com media∫D λ(x)dx.
20

• Dado N(D) = n, o numero de eventos n em A formam uma amostra aleatoria indepen-
dente de uma distribuicao em D com funcao de densidade de probabilidade proporcional
a λ(x).
Como no processo de Poisson homogeneo, regioes disjuntas possuem contagens independen-
tes.
A funcao de verossimilhanca associada ao processo de Poisson nao homogeneo, baseada em
um conjunto de n eventos x = (x1, x2, . . . , xn) e dada por
p(x) ∝ exp
−∫Dλ(x)dx
n∏i=1
λ(xi).
A aglomeracao de eventos pode ocorrer devido a interacao espacial entre eventos, carac-
terizando a existencia de efeitos de segunda ordem, mas tambem devido a heterogeneidade
da regiao em estudo. Do ponto de vista estatıstico, a distincao entre agrupamento segundo
um mecanismo de atracao/repulsao de evento e heterogeneidade somente pode ser sustentada
se houver informacao adicional disponıvel, por exemplo, na forma de covariaveis. Pela forma
como sao definidos, os processos de Poisson nao homogeneos com funcao de intensidade λ(x)
produzem grupos de eventos em regioes com intensidade relativamente alta.
Um metodo para simular uma realizacao de um Processo de Poisson com intensidade λ(x)
em uma regiao D foi apresentado em Lewis e Shedler (1979), onde os autores sugerem um
algoritmo baseado em amostragem por rejeicao. Em sua forma mais simples, este algoritmo
consiste em gerar um processo de Poisson em A com intensidade λ0 = maxx∈Dλ(x) e reter
um evento xi com probabilidade λ(xi)/λ0.
Processos pontuais espaciais podem apresentar intensidades que sejam estocasticas por na-
tureza. Um processo definido dessa forma e chamado processo de Cox e sera apresentado a
seguir.
Processo de Cox
Processos de Cox pertencem a classe de processos “duplamente estocasticos” formada por
processos de Poisson nao homogeneos com funcao de intensidade λ(x) aleatoria.
Considere Λ = Λ(x) : x ∈ D ⊂ Rd um processo estocastico nao-negativo. Formalmente,
dizemos que X e um processo de Cox se para Λ(x) = λ(x) : x ∈ Rd, X e um processo de
Poisson nao homogeneo com funcao de intensidade λ(x).
O processo pontual sera estacionario se, e somente se, o processo de intensidade Λ for
estacionario. O mesmo ocorre em relacao a isotropia.
As propriedades de primeira e segunda ordens sao obtidas das propriedades dos processos
de Poisson nao homogeneos tomando-se a esperanca com respeito a Λ(x). No caso estacionario
a intensidade de primeira ordem e dada por
21

λ(x) = E [Λ(x)]
enquanto a intensidade de segunda ordem e
λ2(xi, xj) = E [Λ(Xi)Λ(Xj)] .
Em especial, dizemos que X e um processo de Cox log-gaussiano (Moller at al., 1998) ao
assumirmos que a funcao de intensidade de X e dada por
Λ(x) = expW (x),
onde W (x) : x ∈ D ⊂ Rd e um processo Gaussiano.
As propriedades de segunda ordem desses processos seguem das propriedades das distri-
buicoes log-gaussianas.
Neste caso, a funcao de verossimilhanca do processo de Cox log-gaussiano segue diretamente
da funcao de verossimilhanca do processo de Poisson nao homogeneo, e e dada por
p(x |W ) ∝ exp
−∫D
expW (x)dx n∏i=1
exp(W (xi)), (2.6)
onde x = (x1, . . . , xn).
Note que a integral em (2.6) nao e tratavel analiticamente, pois depende de um numero
infinito de variaveis aleatorias W (x) : x ∈ D em todo D. Uma solucao para esse problema
de intratabilidade e discretizar a regiao D. Abordaremos esse assunto na Subsecao 2.2.2.
Em princıpio, qualquer processo de Cox pode ser simulado primeiro gerando Λ(x) e depois
usando o algoritmo de amostragem por rejeicao para processos de Poisson nao homogeneos
descrito anteriormente.
2.2.2 Inferencia via discretizacao espacial
Processos espaciais estao definidos, usualmente, em espacos contınuos. Por esse motivo,
a inferencia baseada na funcao de verossimilhanca e complicada devido a integral presente na
equacao (2.6). Na pratica, entretanto, podemos aproximar W segmentando D por uma particao
ζ = ζ1, . . . , ζM onde cada sub-regiao ζj tem centroide cj , j = 1, . . . ,M .
A particao ζ pode ser obtida de diferentes formas. Uma maneira, adotada em Møller et al.
(1998) e Benes et al. (2002), consiste em sobrepor uma grade regular a regiao de estudo e,
entao, considerar o numero de pontos observados, Nj , em cada sub-regiao ζj . Por definicao do
processo de Cox log-gaussiano, Nj pode ser considerado uma variavel aleatoria com distribuicao
Poisson(λj). A regiao discretizada sera a intersecao da regiao D com a grade regular. As sub-
regioes que contem as bordas de D possuem areas menores, o que deve ser incorporado na
modelagem.
22

Apesar do uso de particoes regulares de D ser amplamente utilizado, encontramos na li-
teratura outras formas de discretizacao. Um exemplo aparece em Heikkinen e Arjas (1999),
onde os autores usam uma particao denominada tesselagem de Voronoi. Em linhas gerais, essa
tesselagem origina-se na construcao de um polıgono ao redor do ponto observado xi que consiste
da regiao de D mais proxima a xi do que a qualquer outro ponto, para i = 1, . . . , n. Particionar
o espaco usando essa tesselagem e interessante quando os arranjos pontuais sao agregados, pois
ao usar a discretizacao regular muitas subregioes nao contem nenhum evento.
Waagepetersen (2004) demonstra que as posterioris aproximadas dos processos de Cox log-
gaussianos convergem para as posterioris exatas quando o tamanho das sub-regioes que parti-
cionam o espaco tendem a zero.
23

Capıtulo 3
Amostragem Preferencial
Grande parte dos modelos geoestatısticos tratam as localizacoes xi, onde os dados sao obser-
vados, como fixadas de acordo com um desenho amostral ou estocasticamente independentes do
processo espacial S = S(x) : x ∈ D (para maior aprofundamento ver, por exemplo, Banerjee
et al. (2004)). Nota-se, porem, que em algumas situacoes a disposicao dessas localizacoes e
feita de maneira a favorecer regioes em D ⊂ Rd que sejam mais informativas. A preferencia
por certas regioes surge em decorrencia de inumeros fatores, podendo ser citados os empecilhos
economicos e polıticos, os interesses particulares do estudo, entre outros. Nesses casos, o uso
do modelo geoestatıstico usual apresentado na Secao 2.1 nao parece adequado por nao levar
em consideracao que o conjunto de localizacoes observadas x = (x1, x2, . . . , xn) foi escolhido
preferencialmente.
Nesse contexto, Diggle et al. (2010) caracterizaram o efeito da escolha preferencial por certas
sub-regioes de D atraves da adocao de um modelo para o processo pontual X que determina as
localizacoes x. O artigo apresenta um modelo conjunto para X e S, utilizando o mesmo processo
gaussiano tanto na intensidade do processo pontual X, λ(x), quanto na media da distribuicao
de Y , processo espacial de interesse. Posteriormente, Pati et al. (2011) generalizaram essa
abordagem sob a perspectiva Bayesiana, introduzindo covariaveis em λ(x) e na media de Y .
O modelo por eles proposto assume processos gaussianos distintos para a intensidade de X
e para a media de Y . Assumindo uma abordagem diferente, Gelfand et al. (2012) procuram
corrigir o vies introduzido pela preferencialidade admitindo conhecimento substancial sobre os
mecanismos que geram o processo espacial Y . Zidek et al. (2014) apresentam uma metodologia
para a correcao desse vies em estudos de monitoramento ambiental. Mais recentemente, Ferreira
e Gamerman (2015) exploraram a alocacao otima de uma nova estacao de monitoriamento
levando em consideracao a amostragem preferencial.
Ao admitirmos a possibilidade de dependencia estocastica entre X e S, devemos especificar a
distribuicao conjunta [Y, S,X]. Como descrito em Diggle et al. (2010), dizemos que uma amos-
tragem e nao-preferencial quando os processos S e X sao independentes e, como consequencia,
a distribuicao conjunta e dada por [Y, S,X] = [S][X][Y | S(X)].
No modelo em (2.1), X e tratado como determinıstico e [Y, S,X] = [Y, S] = [Y | S(x)][S].
24

No caso em que associamos a S um processo Gaussiano, a distribuicao [Y | S(x)] na equacao
(2.1) e normal multivariada com media 1µ+ S(x) e matriz de covariancias τ2In.
Em contrapartida, definimos como amostragem preferencial aquela onde [S,X] 6= [S][X].
Deste modo, o modelo sob amostragem preferencial assume a existencia de um processo pontual
X que governa as localizacoes onde o processo S sera observado com ruıdo, sendo a distribuicao
de X dependente de S. O interesse principal continua sendo compreender as propriedades de S,
com base nos dados (X,Y ), e nao diretamente em [S,X]. Entretanto, desejamos nos precaver
contra incorrecoes na inferencia de S ao nao considerarmos a dependencia estocastica entre S
e X.
Diggle et al. (2010) especificam uma classes de modelos adicionando as seguintes suposicoes
ao modelo geoestatıstico apresentado na equacao (2.1):
1. Condicional a S, X e um processo de Poisson nao homogeneo com intensidade
λ(x) = exp (α+ βS(x)) .
2. Condicional a S e X, Y e um conjunto de variaveis normais mutuamente independentes
com Yi ∼(µ+ S(xi), τ
2).
Segue da suposicao 1 e do fato de S ser um processo Gaussiano que, incondicional a S, X
e um processo de Cox log-gaussiano.
A funcao de verossimilhanca do modelo proposto por Diggle et al. (2010) pode ser escrita
como
L(y,x;θ, S) = p(y,x | θ, S) = p(y | S, µ, τ2) p(x | S, α, β),
onde θ = (µ, τ2, σ2, α, β) representa o vetor de parametros do modelo, y = (y(x1), . . . , y(xn)) o
vetor de valores observados e x = (x1, . . . , xn) o conjunto de localizacoes onde Y e observado.
A obtencao da densidade p(x | S, α, β) requer que S esteja disponıvel para todo x ∈ D.
Sendo impossıvel observar S continuamente em D, aproximaremos a regiao D utilizando uma
discretizacao fina. Deste modo, D sera particionada em M sub-regioes com centroides cj ,
j = 1, . . . ,M . Diggle et al. (2010) adotam uma particao de D onde as sub-regioes contem no
maximo um ponto observado, aproximando L(y,x;θ, S) a partir da particao S = (S0, S1), onde
S0 denota os valores de S em cada um dos pontos observados xi ∈ x e S1 denota os valores
de S nos M − n centroides restantes. Generalizando essa abordagem, Ferreira e Gamerman
(2015) permitem que as sub-regioes contenham mais de um ponto observado. Em nosso estudo,
adotaremos a segunda abordagem.
Assumindo que a intensidade e constante dentro das sub-regioes, temos um processo de
Poisson homogeneo dentro de cada sub-regiao com intensidade em funcao do valor de S(cj),
realizacao de S no centroide da j-esima sub-regiao. O procedimento de inferencia sera imple-
mentado a partir dessa particao de D.
25

Substituiremos as localizacoes exatas x pelo centroide mais proximo, ou seja, pelo centroide
da sub-regiao que contem a localizacao xi. Assim, Sy e o vetor que contem os valores de S
referentes as sub-regioes onde observa-se algum ponto xi e SM denota a realizacao de S em
todos os M centroides. Portanto, o modelo completo e escrito como
[Y | Sy, µ, τ2] ∼ N(1µ+ Sy, τ2In)
p(n | SM , α, β) ∝M∏j=1
exp(α+ βSM (cj)nj exp
−M∑j=1
∆jexp(α+ βSM (cj))
(3.1)
SM | φ, σ2 ∼ N(0, σ2RM ),
onde ∆j denota o comprimento, area ou volume da sub-regiao j, de acordo com a dimensao de
D, nT = (n1, n2, . . . , nM ) com nj representando o numero de pontos observados contidos na
sub-regiao j eM∑j=1
nj = n. Supondo que a particao de D seja regular, temos que ∆j = ∆. Os
elementos da i-esima linha e da j-esima coluna de RM sao dados por RM (i, j) = ρ(xi, xj ;φ).
Simplificando a expressao de p(n | S, α, β), encontramos
p(n | S, α, β) ∝ exp(nα+ βnTS) exp
−eαM∑j=1
∆j exp(βSM (cj))
.
Sob o enfoque Bayesiano, devemos arbitrar uma densidade de probabilidade para θ que
represente nossa incerteza sobre os parametros do modelo. Combinada a funcao de verossimi-
lhanca L(y,x;θ, S) obtemos, via teorema de Bayes, a densidade a posteriori
p(SM ,θ | y,x) ∝ L(y,x;θ, SM ) p(θ, SM )
∝ p(y | SM , µ, τ2) p(x | SM , α, β) p(SM | φ, σ2) p(θ).
Assumindo independencia a priori entre os parametros em θ, temos que as distribuicoes a
priori sao
µ ∼ N(0, σ2µ)
τ2 ∼ InversaGama(aτ , bτ )
σ2 ∼ InversaGama(aσ, bσ)
α ∼ N(0, σ2α)
β ∼ N(0, σ2β)
26

φ ∼ Gama(aφ, bφ).
Os hiperparametros escolhido foram: σ2µ = 100, aσ = bσ = 2, σ2
α = σ2β = 200, aφ = 2 e
bφ = 0.05.
As distribuicoes condicionais completas para µ, τ2, σ2 sao dadas pelas mesmas expressoes
obtidas para o modelo geoestatıstico e estao descritas na Secao 2.1.1. Como essas distribuicoes
possuem forma analıtica fechada e sao conhecidas, a simulacao desses parametros sera feita via
Amostrador de Gibbs. O mesmo ocorre com a distribuicao condicional completa de φ e sua
expressao tambem esta descrita na Secao 2.1.1. Porem, como p(φ | ·) nao possui forma fechada,
o algoritmo de Metropolis-Hastings sera empregado para obter amostras de φ a posteriori.
Por outro lado, a distribuicao condicional completa de S se altera devido a presenca do
processo pontual X, que depende de S, sendo dada por
p(SM | µ, σ2, τ2, φ, α, β,y,x) ∝ exp
− 1
2τ2
[(y − 1µ− Sy)T (y − 1µ− Sy)
]
exp
βnTS −∆ eαM∑j=1
exp (βSM (cj))
exp
− 1
2σ2STMR
−1M SM
.
Alem disso, devemos obter as distribuicoes condicionais completas para os parametros α e
β do processo pontual X. Essas distribuicoes tambem nao possuem forma analıtica fechada e
podem ser escritas como
p(α | SM , β,x,y) ∝ exp
nα−∆eαM∑j=1
exp (βSM (cj))−α2
2σ2α
e
p(β | SM , α,x,y) ∝ exp
βSTn−∆eαM∑j=1
exp (βSM (cj))−β2
2σ2β
.
O algoritmo de Metropolis-Hastings tambem sera empregado para simular valores das dis-
tribuicoes condicionais completas de S, α e β.
Uma vez obtida uma amostra a posteriori para θ atraves de metodos de Monte Carlo via
cadeias de Markov, podemos resumir a informacao nela contida com o emprego de medidas
resumo. Sob funcao perda quadratica, por exemplo, temos que a estimativa de θ que minimiza
o risco esperado e
27

θ =1
T
T∑t=1
θ(t),
onde t e a t-esima iteracao do MCMC, ja eliminadas as iteracoes de “aquecimento ”e dado o
espacamento entre iteracoes.
Na proxima secao apresentaremos um estudo com dados artificiais buscando avaliar se ha di-
ferencas significativas ao usarmos um modelo sem considerar a amostragem preferencial quando,
de fato, estamos em um contexto onde a amostra foi preferencialmente escolhida.
3.1 Estudo de Simulacao
Nessa secao conduziremos um estudo simulado com o objetivo de analisar o comportamento
do modelo sob amostragem preferencial e compara-lo com o modelo sem usar amostragem
preferencial, o qual chamaremos ao longo do texto de modelo nao preferencial. A regiao em
estudo e bidimensional e compreende o quadrado D = [0, 100]2. Os parametros do modelo
foram escolhidos de maneira que a intensidade do processo pontual X nao fosse muito alta,
resultando em uma amostra pequena. O vetor parametrico arbitrado foi
(µ, σ2, τ2, φ, α, β) = (5, 0.8, 0.1, 20, −6.5, 1.5).
Na Figura 3.4(a) temos uma realizacao do processo gaussiano S juntamente com os pontos
observados. A simulacao da amostra (y,x) se deu em quatro etapas:
1. Particao da regiao D em sub-regioes usando uma grade regular de tamanho M = 225;
2. Seja cj o centroide da j-esima regiao. Obtenha a matriz de covariancias de S nesses
centroides dada por ΣM (i, j) = σ2 exp−‖ci−cj‖φ
;
3. Simule SM ∼ N (0,ΣM );
4. Para cada sub-regiao j, simule um processo de Poisson homogeneo com intensidade
λ(cj) = expα+ βSM (cj). O conjunto de localizacoes decorrentes desse passo formam a
amostra x = (x1, x2, . . . , xn);
5. Amostre de Y | x, S, µ, τ2 ∼ N(1µ+ Sy(x), τ2In), obtendo a amostra y = (y1, . . . , yn);
Como esperado, os pontos observados concentram-se em regioes de D onde o processo gaus-
siano S atinge valores maiores. Isso se deve ao fato de S governar a log-intensidade do processo
de Poisson nao homogeneo em D e a escolha de β > 0.
As amostras a posteriori para SM e θ foram obtidas via MCMC, sendo computacionalmente
custosa a amostragem em virtude da discretizacao de D. A simulacao estocastica foi feita em
500 mil iteracoes, sendo retiradas as 300 mil primeiras iteracoes e dado um espacamento de 50
28

iteracoes entre elementos da amostra a posteriori. Esse processo resultou em uma amostra com
4 mil observacoes. As Figuras 3.1-3.3 mostram os histogramas das amostras a posteriori para
cada um dos parametros em θ, tanto para amostras do modelo sob amostragem preferencial
quanto para o modelo nao preferencial.
Comecando pela amostra a posteriori de µ, temos na Figura 3.1 os histogramas correspon-
dentes ao modelo sob amostragem preferencial (3.1(a)) e ao modelo sem considerar a amostra-
gem preferencial (3.1(b)). As linhas verticais tracejadas correspondem ao µ verdadeiro, a saber
µ = 5. Observa-se que a amostra a posteriori para o modelo preferencial esta centrada no valor
verdadeiro de µ enquanto o modelo nao preferencial parece superestimar esse parametro.
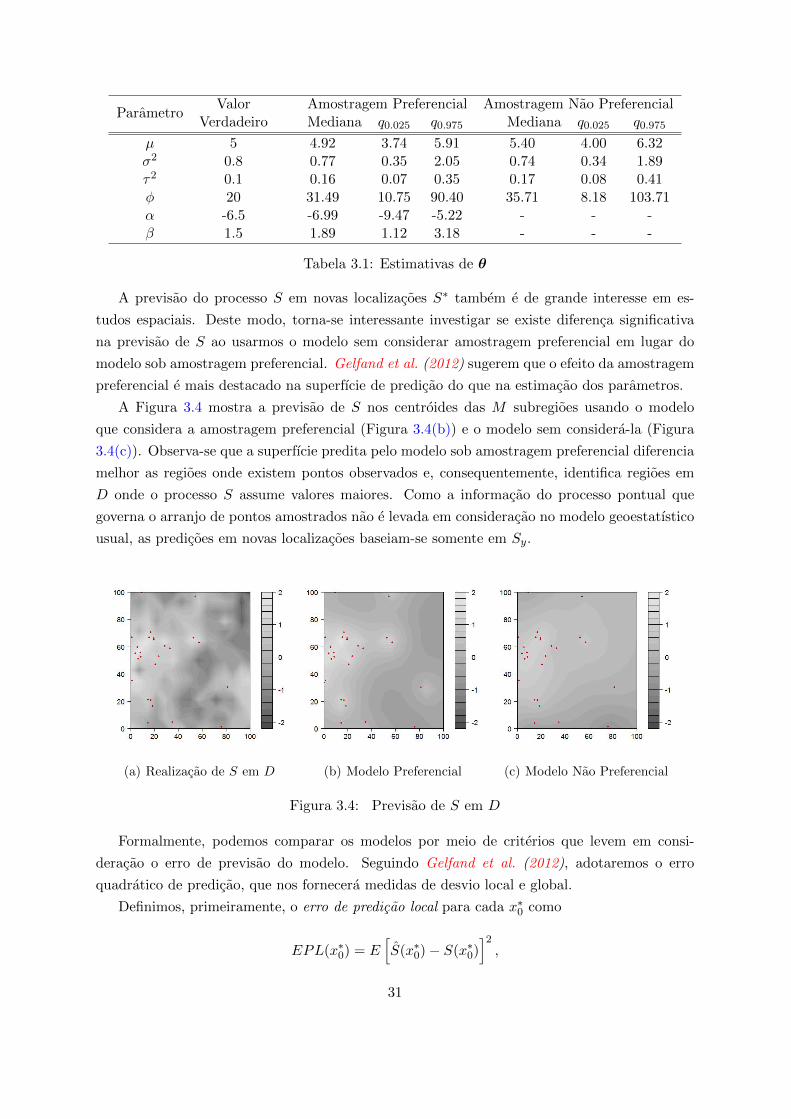
(a) µpref (b) µ
Figura 3.1: Histograma a posteriori de µ
(a) σ2pref (b) τ2pref (c) φpref
(d) σ2 (e) τ2 (f) φ
Figura 3.2: Histogramas a posteriori de σ2, τ2 e φ
29

Na Figura 3.2 apresentamos o comportamento das amostras a posteriori de (σ2, τ2, φ). Aqui,
a linha superior (3.2(a), 3.2(b), 3.2(c)) corresponde aos histogramas da posteriori para o mo-
delo considerando amostragem preferencial enquanto os graficos inferiores (3.2(d), 3.2(e), 3.2(f))
ilustram os resultados para o modelo nao preferencial. A linha tracejada representa o respec-
tivo valor verdadeiro do parametro, ou seja, σ2 = 0.8, τ2 = 0.1 e φ = 20. Comparando os
resultados para σ2, verificamos a similaridade entre as amostras da posteriori para o modelo
sob amostragem preferencial (Figura 3.2(a)) e para o modelo nao preferencial (Figura 3.2(d)),
sendo ambas centradas no valor real de σ2. Conclusoes semelhantes ocorrem ao analisarmos
τ2 e φ, os que nos leva a crer que nao houve ganho significativo com respeito a inferencia ao
introduzirmos um processo pontual X para explicar a disposicao de x para o presente estudo
simulado.
Para o modelo sob amostragem preferencial temos ainda os histogramas das distribuicoes a
posteriori de α (Figura 3.3(a)) e de β (Figura 3.3(b)). Note que o modelo parece subestimar
ligeiramente o valor de α. Por outro lado, β e superestimado pelo modelo preferencial, ainda
que o vies pareca pequeno. O fato do histograma a posteriori de β nao apresentar valores
muito proximos a zero sugere que a probabilidade a posteriori de β assumir valor zero e nula,
indicando preferencialidade na amostragem das localizacoes x.
(a) α (b) β
Figura 3.3: Histogramas a posteriori de α e β
Na Tabela 3.1 constam as estimativas dos parametros tanto sob amostragem preferencial
quanto sem considera-la. Sob funcao perda absoluta, as estimativas sao dadas pela mediana
a posteriori para cada um dos parametros. Tambem sao fornecidos os intervalos de 95% de
credibilidade para θ, sendo q0.025 e q0.975 os respectivos quantis 2.5% e 97.5% das amostras a
posteriori. Podemos notar que as estimativas fornecidas para os parametros sao ligeiramente
divergentes entre os modelos. Alem disso, os intervalos de credibilidade para o modelo nao
preferencial possuem amplitude um pouco maior do que para o modelo sob amostragem prefe-
rencial para a maioria dos parametros, indicando que o modelo nao preferencial e mais incerto.
Cabe destacar que o intervalo de 95% de credibilidade para β nao inclui o valor zero, nos
levando a concluir que ha presenca de preferencia na escolha da amostra x e nao leva-la em
consideracao pode nos conduzir a conclusoes erroneas.
30
ParametroValor Amostragem Preferencial Amostragem Nao Preferencial
Verdadeiro Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ 5 4.92 3.74 5.91 5.40 4.00 6.32σ2 0.8 0.77 0.35 2.05 0.74 0.34 1.89τ2 0.1 0.16 0.07 0.35 0.17 0.08 0.41φ 20 31.49 10.75 90.40 35.71 8.18 103.71α -6.5 -6.99 -9.47 -5.22 - - -β 1.5 1.89 1.12 3.18 - - -
Tabela 3.1: Estimativas de θ
A previsao do processo S em novas localizacoes S∗ tambem e de grande interesse em es-
tudos espaciais. Deste modo, torna-se interessante investigar se existe diferenca significativa
na previsao de S ao usarmos o modelo sem considerar amostragem preferencial em lugar do
modelo sob amostragem preferencial. Gelfand et al. (2012) sugerem que o efeito da amostragem
preferencial e mais destacado na superfıcie de predicao do que na estimacao dos parametros.
A Figura 3.4 mostra a previsao de S nos centroides das M subregioes usando o modelo
que considera a amostragem preferencial (Figura 3.4(b)) e o modelo sem considera-la (Figura
3.4(c)). Observa-se que a superfıcie predita pelo modelo sob amostragem preferencial diferencia
melhor as regioes onde existem pontos observados e, consequentemente, identifica regioes em
D onde o processo S assume valores maiores. Como a informacao do processo pontual que
governa o arranjo de pontos amostrados nao e levada em consideracao no modelo geoestatıstico
usual, as predicoes em novas localizacoes baseiam-se somente em Sy.
(a) Realizacao de S em D (b) Modelo Preferencial (c) Modelo Nao Preferencial
Figura 3.4: Previsao de S em D
Formalmente, podemos comparar os modelos por meio de criterios que levem em consi-
deracao o erro de previsao do modelo. Seguindo Gelfand et al. (2012), adotaremos o erro
quadratico de predicao, que nos fornecera medidas de desvio local e global.
Definimos, primeiramente, o erro de predicao local para cada x∗0 como
EPL(x∗0) = E[S(x∗0)− S(x∗0)
]2,
31

onde S(x∗0) e o preditor de S em x∗0.
O segundo passo e calcular uma medida global de erro baseada nos erros locais de predicao.
Essa medida e chamada erro de predicao global e tem forma
EPG =1
|D|
∫DEPL(x)dx,
com |D| correspondendo a area de D = [0, 100]2.
Para a previsao de S nos centroides c = (c1, . . . , cM ), o EPG e calculado como
EPG =1
M
M∑j=1
(S(cj)− S(cj))2.
O modelo sob amostragem preferencial apresentou erro de predicao global igual a 0.31
enquanto para o modelo sem considerar amostragem preferencial encontramos EPG igual a
0.60. Deste modo, parece haver vantagem do modelo sob amostragem preferencial em relacao
ao modelo geoestatıstico usual com respeito a previsao de S.
A comparacao entre o modelo sob amostragem preferencial e o modelo que nao considera esse
efeito, realizada nessa secao, nos fornece embasamento para concluir que e importante assumir
dependencia estocastica entre os processos S e X quando os dados sugerirem que a amostra foi
escolhida preferencialmente. O fato de β ter sido significativo nos sugere que devemos considerar
um processo gerador das localizacoes observadas. Alem disso, o modelo que considera que a
amostra e preferencial fornece previsoes que acompanham melhor o verdadeiro processo S,
identificando regioes em D onde S assume valores altos.
32

Capıtulo 4
Amostragem Preferencial em
Processos Espaciais Discretos
A suposicao de que a variavel aleatoria Y tem distribuicao gaussiana nao e sempre realista.
Na pratica, encontramos, por exemplo, observacoes que sao contagens de eventos, variaveis di-
cotomicas ou dados que tenham natureza contınua porem que sejam extremamente assimetricos.
Para esses cenarios, assumir que a distribuicao de probabilidade normal e a que melhor carac-
teriza Y nao parece razoavel.
Na Secao 4.1 apresentaremos as formulacoes gerais sobre modelos lineares espaciais gene-
ralizados (MLEG). Em particular, as Secoes 4.2 e 4.3 descrevem o procedimento de inferencia
Bayesiana para os modelos lineares espaciais generalizados para variaveis aleatorias com dis-
tribuicao Poisson e Bernoulli, respectivamente. Ainda nessas secoes, estendemos o modelo sob
amostragem preferencial proposto por Diggle et al. (2010) para ambos os contextos e apresen-
tamos estudos com dados artificiais objetivando validar tais modelos. Finalmente, na secao
?? discutimos os resultados obtidos para os estudos simulados e apresentamos as conclusoes
relacionadas a metodologia proposta.
4.1 Modelos Lineares Espaciais Generalizados
A Secao 1.4 apresentou os conceitos associados aos modelos lineares generalizados (MLG).
Na presente secao estenderemos esses modelos para o caso onde a variavel de interesse Y varia
ao longo de uma regiao D ⊂ Rd. Tais modelos sao referidos como modelos lineares espaciais
generalizados (MLEG).
Denotaremos a variavel aleatoria Y em dada localizacao xi ∈ D como Yi, por simplicidade,
e seu valor esperado por E[Yi]. O MLEG possui estrutura semelhante ao MLG, entretanto
no primeiro caso introduzimos um processo espacial S na expressao de E[Yi]. O processo
S = S(x) : x ∈ D determina a relacao espacial do vetor Y = (Y1, . . . , Yn), o qual sera
observado em um conjunto de localizacoes x = (x1, . . . , xn).
33

A funcao de ligacao g estabelece a forma como E[Yi] se relaciona a um preditor linear
com estrutura espacial. Exige-se que essa funcao seja monotona e derivavel, acarretando na
existencia da funcao inversa g−1 tal que E[Yi] = g−1(νi). Cabe a ressalva que devemos ter Yi
com distribuicao de probabilidade pertencente a famılia exponencial, para todo i = 1, . . . , n.
Assumiremos que E[Yi] e da forma
E[Yi] = µ+ S(xi),
onde µ e um nıvel comum a todas as localizacoes xi e S(xi) consiste na realizacao de S em
xi. E pratica comum adotar um processo gaussiano para S. Em particular, em nosso estudo
consideraremos S ∼ PG0,ΣS, com ΣS(i, j) = σ2ρ (‖ xi − xj ‖;φ), ‖ xi − xj ‖ a distancia
euclidiana entre xi e xj e ρ(·) e uma funcao de correlacao valida.
Os modelos lineares generalizados mais comumente encontrados na literatura sao aqueles
onde a variavel aleatoria Yi segue distribuicao Poisson, Bernoulli ou Binomial. A Tabela 4.1
expoe as funcoes de ligacao canonicas g correspondentes a essas distribuicoes de probabilidade.
Distribuicao Suporte da distribuicao Funcao de ligacao
Bernoulli 0, 1log(
µi1−µi
)Binomial NPoisson ln(µi)
Tabela 4.1: Funcoes de ligacao
Formalmente, o modelo linear espacial generalizado para Yi e escrito como
Yi ∼ p(Yi |µi), i = 1, . . . , n
µi = g−1(νi), onde νi = µ+ S(xi) (4.1)
S | σ2, φ ∼ Nn(0,ΣS),
com ΣS(i, j) = σ2ρ(dij ;φ) e dij =‖ xi − xj ‖.Sob o ponto de vista da construcao de modelos, ainda verificamos um numero reduzido
de trabalhos que levem em consideracao o efeito de amostragem preferencial na modelagem
de dados com estrutura espacial. Nosso estudo se propoe a explorar essa abordagem em con-
textos para dados que fogem a natureza gaussiana. Em particular, desejamos compreender o
comportamento de processos espaciais com distribuicao de probabilidade discreta.
A especificacao do modelo preferencial deve, portanto, levar em consideracao a densidade
do processo de Cox log-gaussiano X. Acrescentando essa densidade p(x) na Equacao (4.1)
obtemos
34

Yi ∼ p(Yi | µi),
µi = g−1(νi), onde νi = µ+ S(xi) (4.2)
p(x | α, β, S) ∝n∏i=1
exp (α+ βS(xi)) exp
−∫D
exp (α+ βS(x))
S | σ2, φ ∼ PG(0,ΣS),
onde ΣS(i, j) = σ2ρ (‖ xi − xj ‖;φ).
Note que na Equacao (4.2) a integral presente na densidade do processo pontual X precisa
ser avaliada para todo x ∈ D. Como nao e possıvel obter x para D contınuo, particionaremos
essa regiao em grade regular com M celulas de centroides cj , j = 1, . . . ,M .
Denotaremos por SM a realizacao de S nos M centroides, sendo o conjunto de todos os
centroides dado por c = (c1, . . . , cM ). Nao utilizaremos S nas localizacoes xi diretamente,
ao inves disso, construiremos um vetor Sy cujo i-esimo elemento representa a realizacao de S
no centroide da sub-regiao que contem xi. Por exemplo, se xi pertencer a sub-regiao j entao
Sy(xi) equivale a SM (cj). Note que, permitindo que mais de um ponto observado caia em cada
sub-regiao, Sy podera conter valores repetidos.
Adotando essa notacao e aproximando p(x | α, β, S) como descrito acima, reescrevemos o
modelo em (4.2) como
Yi ∼ p(Yi | µi)
µi = g−1(νi), onde νi = µ+ Sy(xi) (4.3)
p(n | α, β, SM ) ∝M∏j=1
exp (α+ βSM (cj))nj exp
−M∑j=1
∆j exp (α+ βSM (cj))
SM | σ2, φ ∼ N(0,ΣSM ),
onde ∆j e a area da j-esima sub-regiao (se d = 2), nj corresponde ao numero de localizacoes
em x que pertencem a sub-regiao j e ΣSM (i, j) = σ2ρ (‖ ci − cj ‖;φ).
O contexto Bayesiano exige que arbitremos distribuicoes de probabilidade para os parametros
35

do modelo que reflitam nossas informacoes a priori sobre eles. Manteremos as distribuicoes es-
colhidas para θ = (µ, σ2, φ, α, β) como nos capıtulos anteriores.
Note que o modelo apresentado em (4.3) e essencialmente o mesmo apresentado em (3.1),
porem a relacao entre Yi e µi nao e linear como anteriormente. A generalizacao do modelo
em (3.1), permitindo que Yi nao seja normalmente distribuıdo, implica no aumento do custo
computacional relacionado a simulacao da distribuicao a posteriori. Para os modelos lineares
espaciais generalizados nao teremos distribuicao conhecida para a condicional completa de µ.
Nas secoes que seguem sao descritos os procedimentos de inferencia em MLEG para variaveis
com distribuicao Poisson e Bernoulli. Apresentaremos tambem estudos simulados que validem
os metodos de simulacao estocastica implementados e discutiremos os resultados obtidos para
diferentes cenarios.
4.2 Modelo Poisson
O modelo linear espacial generalizado com variavel resposta Poisson, citado eventualmente
como MLEG Poisson ao longo do texto, aplica-se a situacoes onde o processo espacial de inte-
resse Y (x) : x ∈ D ⊂ Rd tem natureza discreta e consiste em contagens de eventos. E comum
obtermos essas contagens ao longo de uma regiao, caracterizando o que chamamos na Secao
2.1 de dados de area. Problemas como numero de casos de dengue em municıpios no estado
do Rio de Janeiro ou o numero de roubos de carro em bairros de Sao Paulo sao exemplos de
observacoes dessa natureza. Entretanto, problemas geoestatısticos tambem englobam variaveis
que possuam distribuicao Poisson, como e o caso do estudo conduzido em Rongelap, nas ilhas
Marshall, onde foram examinados os nıveis de 137Cs in situ atraves da contagem de raios γ em
157 localizacoes ao longo da ilha.
O modelo para dados dessa natureza esta descrito na equacao (4.3) assumindo que o pro-
cesso Y na localizacao xi, denotado por Yi, tem distribuicao Poisson com intensidade µi. Sob
amostragem preferencial, o MLEG Poisson e dado por
Yi | µi ∼ Poisson(µi)
log(µi) = µ+ Sy(xi)
p(n | α, β, SM ) ∝M∏j=1
exp (α+ βSM (cj))nj exp
−M∑j=1
∆i exp (α+ βSM (cj))
SM | σ2, φ ∼ NM (0,ΣSM ),
com a entrada (i, j) da matriz de covariancias ΣSM dada por σ2ρ(dij ;φ), para dij a distancia
36

euclidiana entre ci e cj e ρ uma funcao de correlacao valida. A localizacao cj corresponde ao
centroide da j-esima sub-regiao usada na aproximacao de p(x).
Seja x = (x1, x2, . . . , xn) o vetor de localizacoes e y = (y1, y2, . . . , yn) o vetor com os valores
observados de Y . Sendo g inversıvel, obtemos µi = exp(µ+Sy(xi)). A funcao de verossimilhanca
para o MLEG Poisson e dada por
l (y,n; θ, SM ) =
n∏i=1
e−µiµyiiyi!
p(c | α, β, S)
∝n∏i=1
e− exp(µ+Sy(xi)) exp(µ+ Sy(xi))yi p(c | α, β, S)
∝n∏i=1
e− exp(µ+Sy(xi)) exp(µ+ Sy(xi))yi
M∏j=1
exp (α+ βSM (cj))nj exp
−M∑j=1
∆i exp (α+ βSM (xj))
.
O procedimento computacional sera realizado como funcao do logaritmo natural, deno-
tado por log, para reduzir o risco de valores extremamente altos que possam conduzir a er-
ros numericos. Deste modo, para todas as contas usaremos a log-verossimilhanca dada por
L (y,n; θ, SM ) = log(l (y,n; θ, SM )) e escrita como
L (y,n; θ, SM ) ∝−n∑i=1
exp µ+ Sy(xi)+n∑i=1
yi(µ+ Sy(xi))
+
M∑j=1
nj(α+ βSM (cj))−M∑j=1
∆j exp(α+ βSM (cj)).
A inferencia bayesiana para esses modelos segue as mesmas etapas descritas ao longo dos
capıtulos anteriores. Devemos arbitrar prioris para o vetor parametrico θ = (µ, σ2, φ, α, β)
para, em conjunto com a funcao de verossimilhanca, obtermos a distribuicao a posteriori de θ,
que nos permitira inferir sobre os parametros. Manteremos a distribuicao a priori para θ usada
ate agora, portanto
µ ∼ N(0, σ2µ)
σ2 ∼ InversaGama(aσ, bσ)
α ∼ N(0, σ2α)
β ∼ N(0, σ2β)
φ ∼ Gama(aφ, bφ).
37

Os hiperparametros escolhido foram: σ2µ = 100, aσ = bσ = 2, σ2
α = σ2β = 200, aφ = 2 e
bφ = 0.05.
As distribuicoes condicionais completas de σ2, φ, α e β permancem as mesmas ja calculadas
no Capıtulo 3, uma vez que esses parametros nao aparecem na distribuicao de Yi. A distribuicao
condicional completa de µ nao possui forma analıtica fechada, em contraste ao modelo cuja
variavel resposta tem distribuicao gaussiana, sendo dada por
p(µ | SM ,y,x) ∝ µn∑i=1
yi −n∑i=1
exp(µ+ Sy(xi))−µ2
2σ2µ
.
A amostra a posteriori de µ na iteracao k sera obtida via algoritmo de Metropolis-Hastings,
com funcao de densidade proposta µk ∼ N(µk−1, γ), com γ a variancia do passeio aleatorio
para µ, fixada de modo que a taxa de aceitacao fique em torno de 44%.
A distribuicao condicional completa de SM tambem sofre alteracao no contexto de variaveis
Poisson, visto que SM compoe a funcao de verossimilhanca. Analogamente ao modelo prefe-
rencial apresentado no Capıtulo 3, temos que
p(SM | σ2, φ) ∝n∑i=1
Sy(xi)yi −n∑i=1
exp(µ+ Sy(xi))
M∑j=1
βnjSM (cj)−M∑j=1
exp(α+ βSM (cj))
−STMΣ−1
SMSM
2.
Para simular de p(SM | σ2, φ) utilizaremos uma reparametrizacao de SM , apresentada em
Papaspiliopoulos et al. (2007). Em linhas gerais, escrevemos SM = Σ1/2SMS∗M e sorteamos S∗M
ao inves de sortearmos diretamente SM , onde Σ1/2SM
e a decomposicao de Cholesky da matriz de
covariancias ΣSM . Esse procedimento gerou cadeias mais estaveis que a simulacao sem utilizar
a reparametrizacao, indicando convergencia da cadeia em um numero menor de iteracoes.
Elucidado o procedimento de inferencia, podemos avancar para o estudo desses modelos
com base em dados artificiais. Na Subsecao 4.2.1 serao apresentados diferentes cenarios a fim
de compreender o comportamento dos MLEGs com resposta Poisson para algumas combinacoes
de parametros e configuracoes da particao de D.
4.2.1 Estudo de Simulacao
Nessa secao serao apresentados estudos simulados com o objetivo de compreender o compor-
tamento do modelo sob amostragem preferencial com resposta Poisson. Diferentes configuracoes
para o vetor parametrico θ = (µ, σ2, φ, α, β) serao testadas a fim de explorar se existem mu-
dancas significativas ao considerar a amostragem preferencial em comparacao com o modelo
38

condicionado a localizacoes fixas.
A simulacao dos dados artificiais envolve, em todos os cenarios considerados, as seguintes
etapas:
1. Particao da regiao D em sub-regioes usando uma grade regular de tamanho M ;
2. Seja cj o centroide da j-esima sub-regiao. Obtenha a matriz de covariancia de SM nesses
centroides dada por ΣSM (i, j) = σ2 exp−‖ci−cj‖φ
;
3. Simule SM ∼ N (0,ΣSM );
4. Para cada sub-regiao j, simule um processo de Poisson homogeneo com intensidade
λ(cj) = expα+ βSM (ck). O conjunto de localizacoes decorrentes desse passo formam a
amostra x = (x1, x2, . . . , xn);
5. Amostre de Yi | x, SM , µ ∼ Poisson(µi), com µi = expµ + S(xi), obtendo a amostra
y = (y1, . . . , yn);
De posse da amostra (y,x) podemos inferir sobre o vetor parametrico θ a partir da distri-
buicao a posteriori. A amostra de θ foi obtida atraves da distribuicao a posteriori via MCMC
com 500 mil iteracoes, das quais retiramos as 100 mil ultimas com espacamento de 50 iteracoes,
originando uma amostra com 2 mil observacoes. Cabe a ressalva que, apesar de nao terem sido
apresentadas, todas as cadeias apresentaram um comportamento que sugere convergencia.
Para cada configuracao utilizaremos o modelo sob amostragem preferencial bem como o
modelo que nao considera o efeito da amostragem preferencial e faremos consideracoes acerca
da estimacao dos parametros e da previsao da superfıcie S.
Cenario 1:
Para o primeiro cenario, os parametros do modelo foram escolhidos de forma que a amostra
contivesse um grande numero de observacoes iguais a zero. O vetor parametrico escolhido foi
(µ, σ2, φ, α, β) = (−2, 0.7, 20, −8, 2).
A amostra contem n=17 localizacoes dentre as quais 11 possuem valor observado Yi = 0.
Como β > 0 espera-se que as regioes onde a realizacao de S assume valores mais altos sejam
regioes preferenciais para alocacao de estacoes de monitoramento. De fato, a Figura 4.2(a)
corrobora essa crenca. Nela temos uma realizacao do processo S em [0, 100]2 juntamente aos
pontos observados, notando-se que as regioes mais claras do grafico (regioes onde S tem os mai-
ores valores) possuem maior concentracao de pontos observados. Em face da preferencialidade
da amostra x por determinadas regioes, gostarıamos de comprovar que o uso de um modelo
39

(a) µpref (b) σ2pref (c) φpref
(d) µ (e) σ2 (f) φ
Figura 4.1: Histogramas a posteriori de µ, σ2 e φ - Modelo Poisson (cenario 1). As linhasverticais tracejadas correspondem aos respectivos valores verdadeiros dos parametros.
que considere esse efeito e superior no sentido de estimacao e previsao do que um modelo que
nao leva em consideracao a amostragem preferencial.
Os histogramas da Figura 4.1 ilustram amostras da distribuicao a posteriori para os parametros
µ, σ2 e φ tanto considerando a amostragem preferencial (4.1(a), 4.1(b) e 4.1(c)) quanto para o
modelo que considera as localizacoes fixas (4.1(d), 4.1(e) e 4.1(f)).
Analisando os histogramas percebemos que as amostras a posteriori para o modelo que
nao considera a amostragem preferencial sugerem certo vies em relacao ao valor verdadeiro dos
parametros. Ainda que os intervalos de 95% de credibilidade contenham seus respectivos valores
reais, as amostras a posteriori de µ e φ para o modelo nao preferencial concentram-se em valores
mais distantes dos verdadeiros se comparado ao modelo sob amostragem preferencial. Para esse
segundo modelo notamos que grande parte dos valores da amostra a posteriori encontram-se
proximos aos valores reais dos parametros, indicando que a inferencia forneceu boas estimativas
no sentido de estimativas pouco viesadas.
A Tabela 4.2 contem as estimativas dos parametros usando funcao perda absoluta, sendo
dadas pela mediana da respectiva amostra a posteriori para cada parametro. Alem disso, nessa
tabela encontramos os limites do intervalo de 95% de credibilidade para θ, onde qε corresponde
ao quantil 100ε% da amostra a posteriori do mesmo.
A estimativa de µ para o modelo sob amostragem preferencial e mais proxima do valor real
do que para o modelo nao preferencial bem como seu respectivo intervalo de 95% de credibili-
40

dade possui menor amplitude. O vies para a estimativa de σ2 tambem e menor para o modelo
sob amostragem preferencial. Sendo as amplitudes dos intervalos de 95% de credibilidade simi-
lares para ambos os modelos, concluımos que o modelo que considera a amostragem preferencial
possui ligeira vantagem contra o modelo que nao a considera. Para φ, o comportamento das
estimativas pontuais e intervalares tambem se mostra bastante semelhante nos dois modelos.
Como esperado, o verdadeiro valor de α esta incluıdo no intervalo de 95% de credibilidade asso-
ciado. Finalmente, a estimativa de β encontra-se bem proxima ao seu valor real e o respectivo
intervalo de 95% de credibilidade nao contem o zero, sugerindo que a amostra e preferencial e
nao considerar essa particularidade pode conduzir a conclusoes incorretas sobre o modelo.
ParametroValor Amostragem Preferencial Amostragem Nao Preferencial
verdadeiro Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ -2 -2.31 -4.15 -1.03 -1.16 -2.85 0.14σ2 0.7 0.78 0.31 3.04 1.00 0.35 3.90φ 20 25.24 6.90 86.81 15.01 0.63 78.95α -8 -8.18 -11.40 -6.07 - - -β 2 2.39 1.08 4.85 - - -
Tabela 4.2: Estimativas de θ - Modelo Poisson (cenario 1)
As analises ate esse momento consideraram somente as divergencias entre os modelos sob
o ponto de vista da inferencia dos parametros. Grande interesse esta voltado a previsao do
processo S, uma vez que ele explica a relacao espacial da variavel Y . As superfıcies preditas de
S nos M centroides das sub-regioes que particionam D encontram-se na Figura 4.2.
(a) Realizacao de S em D (b) Preferencial (c) Nao Preferencial
Figura 4.2: Previsao de S em D - Modelo Poisson (cenario 1)
Analogo as conclusoes do estudo simulado para o modelo sob amostragem preferencial com
resposta gaussiana apresentado na Secao 3.1, verificamos que as previsoes do modelo sob amos-
tragem preferencial aproximam-se da superfıcie S verdadeira em regioes onde ha pontos obser-
vados. Em regioes onde nao ha eventos ambos os modelos tem dificuldade em prever S, o que
era esperado uma vez que nao ha ganho de informacao atraves da amostra nessas regioes.
41

No cenario 1, ainda que a amostra y contenha muitos zeros, o modelo que considera a amos-
tragem preferencial se mostrou superior ao modelo que nao considera esse efeito de preferencia.
O modelo preferencial se destaca, principalmente, na previsao da superficie S, sendo capaz de
detectar melhor regioes onde S e alto uma vez que considera na previsao o vetor observado
(x,y) enquanto o modelo nao preferencial baseia-se somente em y, visto que x e suposto fixo.
Como medida formal de comparacao entre as previsoes dos dois modelos usamos, novamente,
o erro de previsao global (EPG). O modelo sob amostragem preferencial apresentou EPG igual
a 0.39 enquanto o EPG para o modelo sem considerar o efeito da amostragem preferencial foi
igual a 0.61, ratificando a conclusao de que e interessante introduzir um processo pontual X na
modelagem de Y em contextos onde existe suspeita de preferencia por certas regioes de D na
alocacao da amostra.
Cenario 2:
Neste segundo estudo simulado, desejamos explorar as mudancas ocorridas na estimacao dos
parametros e na previsao de S numa grade regular quando a variancia do processo gaussiano
S, a saber σ2, e aumentada em comparacao ao cenario anterior. O vetor parametrico escolhido
mantem os parametros φ, α e β inalterados, somente apresentando modificacoes em µ e σ2,
sendo dado por (µ, σ2, φ, α, β) = (1.2, 1.5, 20, −8, 2).
A escolha de µ foi feita para que a amostra de Y nao contivesse uma proporcao alta de
valores iguais a zero. A simulacao dos dados seguiu os passos apresentados no inıcio dessa
secao, produzindo uma amostra y com 26 elementos.
Nas Figuras 4.3 e 4.4 observamos os histogramas das amostras a posteriori dos parametros,
obtidas atraves de metodos de Monte Carlo via Cadeia de Markov. As linhas tracejadas repre-
sentam o valor arbitrado de cada parametro.
Na linha superior da Figura 4.3 estao dispostos os histogramas da amostra a posteriori de µ
(4.3(a)), σ2 (4.3(b)) e φ (4.3(c)) considerando o efeito da amostragem preferencial na modelagem
de Y , enquanto a linha inferior (Figuras 4.3(d), 4.3(e) e 4.3(f)) apresenta os histogramas a
posteriori para o modelo geoestatıstico com resposta Poisson. O modelo preferencial parece
subestimar µ enquanto o modelo nao preferencial parece superestima-lo, entretanto a estimativa
para o primeiro modelo aproxima-se mais do valor verdadeiro do parametro. A amostra a
posteriori de σ2 para o modelo preferencial encontra-se centrada no valor verdadeiro, enquanto
o modelo nao preferencial subestima esse parametro. Nesse aspecto, a modelagem que considera
o processo pontual ganha destaque quando comparada ao modelo que nao o considera. O
parametro φ apresenta comportamento similar para ambos os modelos. Por fim, na Figura 4.4
estao os histogramas a posteriori para α e β, tambem centrados nos valores corretos.
A Tabela 4.3 contem as estimativas dos parametros dos dois modelos em analise. Nela
encontramos, ainda, o valor real do parametro e os quantis 2.5% (q0.025) e 97.5% (q0.975) da
distribuicao a posteriori, que formam um intervalo de 95% de credibilidade de θ. Como obser-
vado na analise dos histogramas, com respeito a estimacao de µ o modelo que nao considera a
42

(a) µpref (b) σ2pref (c) φpref
(d) µ (e) σ2 (f) φ
Figura 4.3: Histogramas a posteriori de µ, σ2 e φ - Modelo Poisson (cenario 2). As linhasverticais tracejadas correspondem aos respectivos valores verdadeiros dos parametros.
(a) α (b) β
Figura 4.4: Histogramas a posteriori de α e β - Modelo Poisson (cenario 2)
amostragem preferencial apresenta desempenho pior que o modelo sob amostragem preferencial,
superestimando o parametro. Ambos os modelos apresentam desempenho ruim na estimacao
tanto de µ quanto de σ2, porem as estimativas pontuais para o modelo sob amostragem pre-
ferencial sao as que mais se aproximam do valor real do respectivo parametro, nos levando a
considerar ligeira vantagem para o modelo que considera o processo pontual X na modelagem
de Y . A estimativa de φ foi mais proxima ao real valor para o modelo sem considerar amos-
tragem preferencial, no entanto, o intervalo de 95% de credibilidade e mais amplo para esse
modelo indicando maior incerteza acerca dessa estimativa. Os parametros α e β foram bem
43
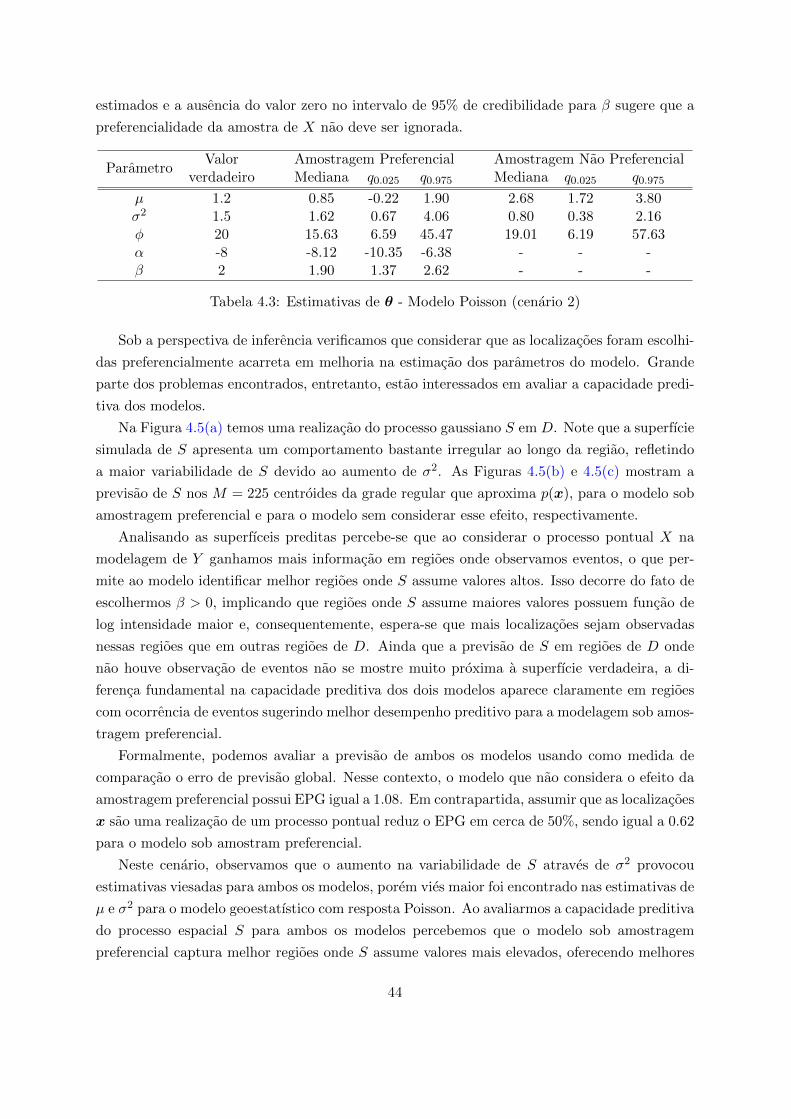
estimados e a ausencia do valor zero no intervalo de 95% de credibilidade para β sugere que a
preferencialidade da amostra de X nao deve ser ignorada.
ParametroValor Amostragem Preferencial Amostragem Nao Preferencial
verdadeiro Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ 1.2 0.85 -0.22 1.90 2.68 1.72 3.80σ2 1.5 1.62 0.67 4.06 0.80 0.38 2.16φ 20 15.63 6.59 45.47 19.01 6.19 57.63α -8 -8.12 -10.35 -6.38 - - -β 2 1.90 1.37 2.62 - - -
Tabela 4.3: Estimativas de θ - Modelo Poisson (cenario 2)
Sob a perspectiva de inferencia verificamos que considerar que as localizacoes foram escolhi-
das preferencialmente acarreta em melhoria na estimacao dos parametros do modelo. Grande
parte dos problemas encontrados, entretanto, estao interessados em avaliar a capacidade predi-
tiva dos modelos.
Na Figura 4.5(a) temos uma realizacao do processo gaussiano S em D. Note que a superfıcie
simulada de S apresenta um comportamento bastante irregular ao longo da regiao, refletindo
a maior variabilidade de S devido ao aumento de σ2. As Figuras 4.5(b) e 4.5(c) mostram a
previsao de S nos M = 225 centroides da grade regular que aproxima p(x), para o modelo sob
amostragem preferencial e para o modelo sem considerar esse efeito, respectivamente.
Analisando as superfıceis preditas percebe-se que ao considerar o processo pontual X na
modelagem de Y ganhamos mais informacao em regioes onde observamos eventos, o que per-
mite ao modelo identificar melhor regioes onde S assume valores altos. Isso decorre do fato de
escolhermos β > 0, implicando que regioes onde S assume maiores valores possuem funcao de
log intensidade maior e, consequentemente, espera-se que mais localizacoes sejam observadas
nessas regioes que em outras regioes de D. Ainda que a previsao de S em regioes de D onde
nao houve observacao de eventos nao se mostre muito proxima a superfıcie verdadeira, a di-
ferenca fundamental na capacidade preditiva dos dois modelos aparece claramente em regioes
com ocorrencia de eventos sugerindo melhor desempenho preditivo para a modelagem sob amos-
tragem preferencial.
Formalmente, podemos avaliar a previsao de ambos os modelos usando como medida de
comparacao o erro de previsao global. Nesse contexto, o modelo que nao considera o efeito da
amostragem preferencial possui EPG igual a 1.08. Em contrapartida, assumir que as localizacoes
x sao uma realizacao de um processo pontual reduz o EPG em cerca de 50%, sendo igual a 0.62
para o modelo sob amostram preferencial.
Neste cenario, observamos que o aumento na variabilidade de S atraves de σ2 provocou
estimativas viesadas para ambos os modelos, porem vies maior foi encontrado nas estimativas de
µ e σ2 para o modelo geoestatıstico com resposta Poisson. Ao avaliarmos a capacidade preditiva
do processo espacial S para ambos os modelos percebemos que o modelo sob amostragem
preferencial captura melhor regioes onde S assume valores mais elevados, oferecendo melhores
44

(a) Realizacao de S em D (b) Preferencial (c) Nao Preferencial
Figura 4.5: Previsao de S em D - Modelo Poisson (cenario 2)
previsoes nessas regioes. Em vista dessas comparacoes, concluımos que assumir a presenca
de um processo pontual nao homogeneo para modelar a disposicao dos eventos em D e de
grande valia quando x sugere preferencialidade, uma vez que melhora o desempenho inferencial
e preditivo do modelo geoestatıstico.
Cenario 3:
No cenario 3 desejamos avaliar se o aumento do numero de sub-regioes usadas na apro-
ximacao da densidade do processo pontual X, presente no modelo sob amostragem preferencial,
influencia significativamente a estimacao dos parametros e a previsao de S. Analisaremos duas
grades regulares em [0, 100]2, uma com 400 sub-regioes com areas iguais a 25 unidades metricas
ao quadrado e outra grade com 225 sub-regioes cada uma com area igual a 44.44 unidades
metricas ao quadrado. Analisaremos tambem o desempenho do modelo que nao considera a
amostragem preferencial.
O vetor parametrico e dado por (µ, σ2, φ, α, β) = (1.2, 0.7, 20, −6, 1.5). A amostra,
composta por 41 observacoes, foi novamente simulada a partir no algoritmo descrito no inıcio
dessa secao, para M = 400 e M = 225.
Na Figura 4.6 temos intervalos de 95% de credibilidade da amostra a posteriori de θ para o
modelo cuja particao de D usada na aproximacao de p(x) contem 225 sub-regioes (Modelo 1)
e para aquele que considera somente 400 celulas na divisao da regiao de interesse (Modelo 2).
Analisando os intervalos percebemos similaridade entre as amostras a posteriori de ambos
os modelos, com o modelo 1 mais incerto para σ2 enquanto para o restante dos parametros
o modelo 2 exibiu maior incerteza. Ainda que tenhamos identificado diferencas na amplitude
dos intervalos, tal discrepancia nao e de grande magnitude. Parece, entao, nao haver ganhos
substanciais em aumentar M de 225 para 400. Nesse sentido, optamos pela particao de D
em 225 sub-regioes devido ao custo computacional associado a estimacao dos parametros via
MCMC.
45

(a) µ (b) σ2 (c) φ (d) α (e) β
Figura 4.6: Intervalos de 95% de credibilidade de θ para o modelo sob amostragem preferencialcom M = 400 sub-regioes (modelo 1) e com M = 225 sub-regioes (modelo 2). As linhastracejadas correspondem aos respectivos valores verdadeiros dos parametros.
Os histogramas da amostra a posteriori para o modelo que nao considera o efeito da amos-
tragem preferencial (modelo 3) estao na Figura 4.7. A amosta a posteriori de σ2, apesar de
nao estar centrada no valor verdadeiro, apresenta vies relativamente pequeno em relacao ao
parametro real. Para o parametro φ obtivemos uma amostra a posteriori bem concentrada
ao redor do verdadeiro valor do parametro. O parametro µ e o unico para o qual a amostra
a posteriori parece se distanciar do valor correto, sendo esse modelo ligeiramente inferior ao
modelo sob amostragem preferencial no que se refere a estimacao dos parametros.
(a) µ (b) σ2 (c) φ
Figura 4.7: Histogramas a posteriori para o modelo sem considerar a amostragem preferencial(modelo ) - Modelo Poisson (cenario 3)
A Tabela 4.4 traz as estimativas dos parametros para os tres modelos explorados no presente
cenario e seus respectivos intervalos de 95% de credibilidade. Observe que o aumento do numero
de sub-regioes usadas para aproximar a densidade do processo pontual X nao melhora, necessa-
riamente, a inferencia sobre os parametros. Com excecao de φ, para todos os outros parametros
obtivemos estimativas similares tanto ao considerarmos 400 sub-regioes quanto com a particao
de D em 225 sub-regioes. Para o parametro φ, a estimativa encontrada via MCMC para o
modelo 1 e mais proxima ao verdadeiro valor de φ e seu intervalo de 95% de credibilidade tem
amplitude menor que o encontrado utilizando o modelo 2. As estimativas pontuais apresentadas
na Tabela 4.4 reiteram a conclusao de que o refinamento da particao de D nao acarreta em
grandes vantagens quando comparado a grade regular com 225 sub-regioes.
46

Comparando as estimativas do vetor parametrico para o modelo 1 com as estimativas para
o modelo 3, observa-se que aquelas para o modelo 1 se aproximam mais dos valores verdadeiros.
Ja os intervalos de 95% de credibilidade incluem os valores verdadeiros e possuem amplitude
semelhante entre os modelos para todo θ, indicando nao haver grandes discrepancias nas esti-
mativas intervalares dos parametros.
Amostragem Preferencial Amostragem Preferencial AmostragemValor Real (400 sub-regioes) (225 sub-regioes) Nao Preferencial
Mediana q0.025 q0.975 Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ = 1.2 1.27 0.21 2.21 1.24 0.42 2.04 1.90 0.91 2.76σ2 = 0.7 0.64 0.3 1.60 0.71 0.34 1.72 0.56 0.27 1.32φ = 20 32.24 8.93 84.62 24.85 6.48 80.09 30.93 7.67 89.10α = −6 -6.27 -8.14 -4.64 -6.25 -8.01 -5.01 - - -β = 1.5 1.74 0.97 2.91 1.73 0.97 2.70 - - -
Tabela 4.4: Estimativas de θ - Modelo Poisson (cenario 3)
Desejamos modelos que tenham boa capacidade tanto de inferencia quanto de previsao.
Como medida de qualidade da previsao do processo S nos centroides de uma grade regular
com 400 sub-regioes para os tres modelos abordados nesse cenario, apresentamos na Tabela 4.5
o erro de previsao global, ou EPG, de cada modelo. Como pode ser observado, a capacidade
preditiva do modelo sob amostragem preferencial e semelhante para M = 400 e M = 225
particoes. Note, tambem, que a capacidade preditiva dos modelos sob amostragem preferencial
e ligeiramente maior que para o modelo 3, sugerindo que a presenca do processo pontual X na
modelagem dos dados resulta em pequena melhora na previsao de S.
Amostragem Preferencial Amostragem Preferencial Amostragem(400 sub-regioes) (225 sub-regioes) Nao Preferencial
EPG 0.4048 0.4020 0.5608
Tabela 4.5: Erro de previsao global - Modelo Poisson (cenario 3)
Em vista dos resultados mostrados na Tabela 4.5, parece nao haver vantagens significativas
em particionar D em 400 sub-regioes ao inves de 225 sub-regioes que justifiquem o elevado custo
computacional envolvido na obtencao da amostra a posteriori para essa primeira particao.
Assim, na Figura 4.8 nao apresentaremos a previsao de S para o modelo sob amostragem
preferencial com 400 particoes de D.
A Figura 4.8(a) ilustra uma realizacao de S nos centroides de uma grade regular com 400
celulas, enquanto as Figuras 4.8(b) e 4.8(c) mostram a previsao de S nessa grade regular tanto
para o modelo 1 e 3, respectivamente. Em conformidade com a conclusao feita pela analise
dos erros de previsao globais, observamos que a previsao de S pelo modelo sob amostragem
preferencial detecta melhor as nuances de S ao longo de D. Em regioes onde nao ha eventos
ambos os modelos se mostram ineficazes na previsao de S, porem em regioes com pelo menos
um evento observado notamos que o modelo sob amostragem preferencial capta melhor valores
47

elevados de S se aproximando do valor verdadeiro nesse ponto.
(a) Realizacao de S em D (b) Preferencial (c) Nao Preferencial
Figura 4.8: Previsao de S em D - Modelo Poisson (cenario 3)
Os resultados observados para o cenario 3 nos levam a conclusao que o modelo 1 apresentou
equilıbrio entre capacidade preditiva, custo computacional e estimacao de θ, sugerindo ser
importante a suposicao do processo pontual X.
4.3 Modelo Bernoulli
Encontramos situacoes praticas onde a variavel Y (x), em estudo, somente assume valores
no conjunto 0, 1, sendo observada em uma colecao de localizacoes x = (x1, . . . , xn). Suponha,
por exemplo, que desejamos compreender o comportamento pluviometrico no estado do Parana,
entretanto as informacoes disponıveis somente informam se choveu ou nao em uma determinada
estacao de monitoramento. Variaveis como esta sao caracterizadas como sucesso ou falha. Por
exemplo, a presenca de determinada caracterıstica em xi pode ser interpretada como sucesso,
implicando em Y (xi) = 1. Ainda, quaisquer dados de natureza contınua podem ser separados
em duas classes, com uma classe representando falha e a outra sucesso.
A distribuicao de probabilidade Bernoulli representa bem o comportamento de Y (xi). As-
sumindo que em cada localizacao xi temos Y (xi) ∼ Bernoulli(pi), com pi a probabilidade de
sucesso, escrevemos o modelo espacial para Y (xi), com funcao de ligacao canonica, como
Y (xi) | pi ∼ Bernoulli(pi)
log
(pi
1− pi
)= µ+ Sn(xi) (4.4)
Sn | σ2, φ ∼ Nn(0,ΣSn),
48

com a entrada (i, j) da matriz de covariancias ΣSn dada por σ2ρ(dij ;φ), para dij a distancia
euclidiana entre xi e xj e ρ uma funcao de correlacao valida. Note que
pi =expµ+ Sn(xi)
1 + expµ+ Sn(xi).
Por simplicidade denotaremos Y (xi) = Yi, cujo valor observado sera representado por y(xi) =
yi.
Sob amostragem preferencial devemos considerar o efeito do processo pontual X que governa
a disposicao das localizacoes em D. Precisamos, entao, incluir a densidade de X no modelo
em (4.4). Como apontado na secao 2.2.2, nao e possivel tratar p(x) analiticamente devido
a natureza contınua de D. Uma solucao e particionar D em M sub-regioes com centroides
c = (c1, . . . , cM ) e avaliar p(c) ao inves de p(X). Em consequencia dessa particao, nao mais
teremos Sn. Ao longo dessa secao denotaremos por SM a realizacao de S em c enquanto Sy
e construıdo de forma que Sy(xi) corresponde a realizacao de S no centroide da sub-regiao a
qual xi pertence. Logo, o vetor Sy compreende a realizacao de S nos centroides das sub-regioes
que contem pelo menos um ponto observado. Portanto, sob amostragem preferencial, quando
Yi ∼ Bernoulli(pi), a especificacao completa do modelo e dada por
Yi | pi ∼ Bernoulli(pi)
log
(pi
1− pi
)= µ+ Sy(xi) (4.5)
p(n | α, β, SM ) ∝M∏j=1
exp (α+ βSM (cj))nj exp
M∑j=1
∆i exp (α+ βSM (cj))
SM | σ2, φ ∼ NM (0,ΣSM ),
onde a matriz de covariancias de SM tem elementos ΣSM (i, j) = σ2ρ (‖ ci − cj ‖;φ).
Em posse de uma amostra de X em D, denotada por x = (x1, . . . , xn), observaremos Yi
para cada localizacao xi ∈ x para, finalmente, obtermos uma amostra y = (y1, . . . , yn). Deste
modo, a funcao de verossimilhanca para o modelo da equacao (4.5) sera dada por
49

l (y,n; θ, SM ) ∝n∏i=1
[exp(µ+ Sy(xi))]yi
1 + exp(µ+ Sy(xi))×
M∏j=1
exp (α+ βSM (cj))nj exp
M∑j=1
∆i exp (α+ βSM (cj))
.
Assumiremos uma particao regular de D, de forma a todas as sub-regioes possuırem area
∆i = ∆.
A inferencia sob abordagem bayesiana demanda a especificacao de distribuicoes de probabi-
lidade a priori para o vetor de parametros, a saber θ = (µ, σ2, φ, α, β) para o modelo em (4.5).
Atribuiremos a θ as mesmas distribuicoes a priori descritas no capıtulo 3.
As distribuicoes condicionais completas de σ2, φ, α e β permanecem as mesmas encontradas
para os modelos sob amostragem preferencial para dados com distribuicao Normal e Poisson.
Para simular da condicional completa de µ e SM , porem, devemos calcular novamente as
respectivas distribuicoes condicionais completas uma vez que a funcao de verossimilhanca e
diferente para os modelos Normal, Poisson e Bernoulli. O algoritmo MCMC, neste caso, consiste
em simular das seguintes distribuicoes:
p(µ | SM ,y) ∝
exp
µ
n∑i1
yi
n∏i=1
1 + exp [µ+ Sy(xi)]
exp
− µ2
2σ2µ
e
p(SM | σ2, φ,y) ∝
exp
n∑i1
yiSy(xi)
n∏i=1
1 + exp [µ+ Sy(xi)]
×
expβnTSM
exp
−∆M∑j=1
exp (α+ βSM (cj))
×exp
−STMΣ−1
SMSM
2
,
onde nT = (n1, . . . , nM ) cujo elemento nj representa o numero de eventos observados na j-esima
sub-regiao.
Uma vez esclarecido o procedimento de inferencia aplicado aos modelos que consideram o
efeito da amostragem preferencial para variaveis aleatorias com distribuicao Bernoulli usando a
50

funcao de ligacao canonica, nos dedicaremos na Subsecao 4.3.1 a investigacao do comportamento
desses modelos com o auxılio de dados artificiais.
4.3.1 Estudo de simulacao
Ao longo da presente secao nos concentraremos na analise comparativa entre modelos que
ignoram a presenca de um processo pontual X que governa a disposicao de x em D e modelos
que consideram o efeito da amostragem preferencial, no ambito de variaveis aleatorias com
distribuicao Bernoulli. O primeiros modelos serao, ocasionalmente, referidos ao longo do texto
como modelos nao preferenciais enquanto os ultimos serao ditos modelos preferenciais.
Exibiremos algumas possibilidades para a escolha do vetor parametrico θ e estudaremos o
desempenho dos modelos acima citados, averiguando se diferencas significativas na estimacao
ou previsao surgem ao optarmos pelo modelo preferencial ao inves do modelo nao preferencial.
Analogamente aos estudos simulados apresentados anteriormente, com excecao do cenario
2, a simulacao dos dados envolvera os seguintes passos:
1. Particao da regiao D = [0, 100]2 em sub-regioes usando uma grade regular com M sub-
regioes;
2. Seja cj o centroide da j-esima regiao. Obtenha a matriz de covariancia de SM nesses
centroides dada por ΣSM (i, j) = σ2 exp−dij
φ
, dij =‖ ci − cj ‖;
3. Simule SM ∼ N (0,ΣSM );
4. Para cada sub-regiao j, simule um processo de Poisson homogeneo com intensidade
λ(cj) = expα+ βSM (cj). O conjunto de localizacoes decorrentes desse passo formam a
amostra x = (x1, x2, . . . , xn);
Observe que esse passo se deve ao fato da particao de D em M celulas resultar em um
processo de Poisson homogeneo em cada sub-regiao.
5. Para i = 1, 2, . . . , n, amostre de Yi | x, Sy, µ ∼ Bernoulli(pi), com log(
pi1−pi
)= µ+Sy(xi),
obtendo a amostra y = (y1, . . . , yn);
Obtida a amostra (y,x) seremos capazes de inferir sobre θ pela simulacao de p(θ | y,x).
Para cada cenario analisaremos o modelo preferencial e o modelo nao preferencial sob a luz da
estimacao e da previsao, fazendo consideracoes acerca do desempenho de cada modelo.
Para todos os estudos simulados que seguem serao usadas 500 mil iteracoes para o MCMC,
das quais somente as ultimas 100 mil serao utilizadas na amostra. Ainda, optou-se por retirar
uma amostra sistematica dessas 100 mil iteracoes com espacamento de 50 iteracoes, resultando
em uma amostra da posteriori com 2 mil elementos.
A comparacao da capacidade preditiva sera conduzida analisando-se a previsao de cada
modelo para os centroides das M sub-regioes que dividem D, tendo como medida comparativa
o erro de previsao global (EPG) apresentado na Secao 3.1.
51

Cenario 1:
Desejamos estudar o efeito da amostragem preferencial em dados com natureza discreta, em
particular que so assuma valores em 0, 1. Inicialmente, particionaremos a regiao [0, 100]2 em
225 sub-regioes e simularemos nossos dados segundo o esquema descrito no inıcio da presente
secao com vetor de parametros
(µ, σ2, φ, α, β) = (−1.5, 1.5, 20, −8, 2),
resultando em uma amostra com 31 observacoes.
Na Figura 4.9 sao exibidos os histogramas das amostras a posteriori de µ, σ2 e φ para ambos
os modelos em analise. O comportamento a posteriori de µ para os modelos sob amostragem
preferencial (modelo 1) e sem considera-la (modelo 2) sao apresentados nas Figuras 4.9(a)
e 4.9(d), respectivamente. Note que, apesar de nenhuma das duas amostras a posteriori se
concentrar ao redor do valor verdadeiro de µ, a amostra de µ para o modelo 2 esta centrada
em um valor mais distante de 2 se comparado ao primeiro modelo. Alem disso, o fato de
µ = 2 estar na cauda da distribuicao a posteriori de µ para o modelo 2 indica que a densidade
de probabilidade a posteriori e baixa para esse valor. Os modelos nao parecem, entretanto,
capturar bem esse parametro uma vez que os intervalos de credibilidade de 95% contem o valor
zero para os dois modelos.
Para o paramatro σ2 sao apresentados os histogramas a posteriori para os modelos 1 e
2 respectivamente nas Figuras 4.9(b) e 4.9(e). Observa-se que ambas as amostras parecem
centradas no valor verdadeiro de σ2, entretanto, o modelo 2 se mostra muito mais incerto que
o modelo 1 tendo como base a variabilidade da amostra a posteriori.
O parametro φ tem seus histogramas a posteriori retratados nas Figuras 4.9(c) e 4.9(f),
com o primeiro representando o modelo 1 e o segundo o modelo 2. Novamente, a amostra a
posteriori para o modelo 1 tem maior concentracao de valores proximos ao verdadeiro valor de
φ do que a amostra a posteriori para o modelo 2. Todavia, pontualmente nenhum dos dois
modelos forneceu boas estimativas para φ. O intervalo de credibilidade, por sua vez, parece
semelhante em ambos os modelos e reproduz a grande incerteza acerca de φ.
Por fim, os histogramas das amostras a posteriori de α e β estao ilustrados nas Figuras
4.10(a) e 4.10(b), respectivamente. A amostra a posteriori de α encontra-se bem centrada no
valor verdadeiro do parametro, porem apresenta grande variabilidade. Para β a correspondente
amostra a posteriori tambem se concentra aproximadamente ao redor do valor real, apresen-
tando poucos valores muito distantes de 2. A exclusao de 0 pelo intervalode 95% de credibilidade
para β indica que o efeito do processo pontual X nao deve ser desprezado na modelagem dos
dados.
Para os parametros do processo pontual X, observamos estimativas pontuais proximas aos
correspondentes valores verdadeiros. Olharemos agora para o desempenho preditivo dos mode-
los. A Figura 4.11(a) traz uma realizacao de S em D = [0, 100]2, que sera considerada como a
52

(a) µpref (b) σ2pref (c) φpref
(d) µ (e) σ2 (f) φ
Figura 4.9: Histogramas a posteriori de µ, σ2 e φ - Modelo Bernoulli (cenario 1)
(a) α (b) β
Figura 4.10: Histogramas a posteriori de α e β - Modelo Bernoulli (cenario 1)
superfıcie verdadeira de S. Como β > 0, os pontos observados encontram-se, em sua maioria,
reunidos em uma pequena regiao de D onde S assume valores maiores. Na Figura 4.11(b) temos
a previsao do modelo sob amostragem preferencial para os centroides das 225 sub-regioes que
dividem D. Em regioes onde nao ha nenhuma localizacao xi o modelo tem dificuldade de prever
corretamente, porem em regioes com pontos observados vemos uma melhora no desempenho
preditivo do modelo, como esperado. O mesmo acontece para a previsao do modelo que nao
considera a amostragem preferencial, como pode ser visto na Figura 4.11(c). Entretanto mesmo
em regioes com presenca de observacoes esse modelo nao consegue capturar bem valores mais
elevados de S. Comparando as superfıcies preditas, podemos perceber ganhos significativos na
53
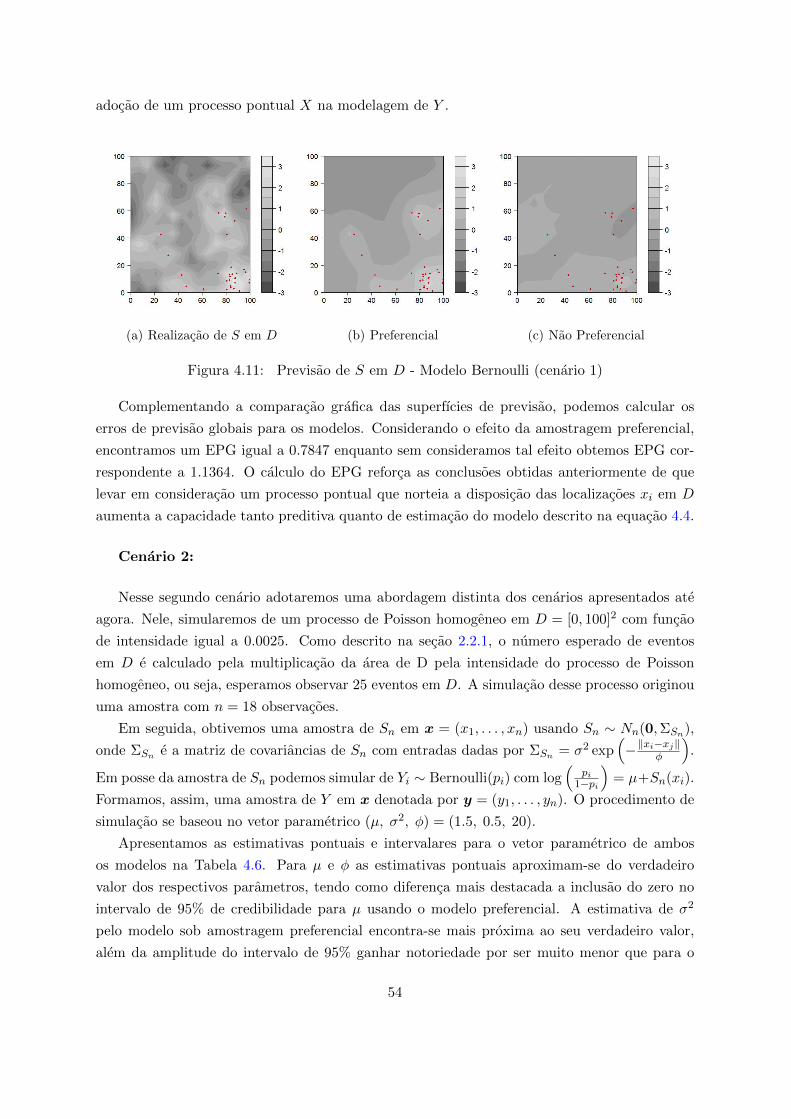
adocao de um processo pontual X na modelagem de Y .
(a) Realizacao de S em D (b) Preferencial (c) Nao Preferencial
Figura 4.11: Previsao de S em D - Modelo Bernoulli (cenario 1)
Complementando a comparacao grafica das superfıcies de previsao, podemos calcular os
erros de previsao globais para os modelos. Considerando o efeito da amostragem preferencial,
encontramos um EPG igual a 0.7847 enquanto sem consideramos tal efeito obtemos EPG cor-
respondente a 1.1364. O calculo do EPG reforca as conclusoes obtidas anteriormente de que
levar em consideracao um processo pontual que norteia a disposicao das localizacoes xi em D
aumenta a capacidade tanto preditiva quanto de estimacao do modelo descrito na equacao 4.4.
Cenario 2:
Nesse segundo cenario adotaremos uma abordagem distinta dos cenarios apresentados ate
agora. Nele, simularemos de um processo de Poisson homogeneo em D = [0, 100]2 com funcao
de intensidade igual a 0.0025. Como descrito na secao 2.2.1, o numero esperado de eventos
em D e calculado pela multiplicacao da area de D pela intensidade do processo de Poisson
homogeneo, ou seja, esperamos observar 25 eventos em D. A simulacao desse processo originou
uma amostra com n = 18 observacoes.
Em seguida, obtivemos uma amostra de Sn em x = (x1, . . . , xn) usando Sn ∼ Nn(0,ΣSn),
onde ΣSn e a matriz de covariancias de Sn com entradas dadas por ΣSn = σ2 exp(−‖xi−xj‖φ
).
Em posse da amostra de Sn podemos simular de Yi ∼ Bernoulli(pi) com log(
pi1−pi
)= µ+Sn(xi).
Formamos, assim, uma amostra de Y em x denotada por y = (y1, . . . , yn). O procedimento de
simulacao se baseou no vetor parametrico (µ, σ2, φ) = (1.5, 0.5, 20).
Apresentamos as estimativas pontuais e intervalares para o vetor parametrico de ambos
os modelos na Tabela 4.6. Para µ e φ as estimativas pontuais aproximam-se do verdadeiro
valor dos respectivos parametros, tendo como diferenca mais destacada a inclusao do zero no
intervalo de 95% de credibilidade para µ usando o modelo preferencial. A estimativa de σ2
pelo modelo sob amostragem preferencial encontra-se mais proxima ao seu verdadeiro valor,
alem da amplitude do intervalo de 95% ganhar notoriedade por ser muito menor que para o
54

modelo nao preferencial. Constatamos que o intervalo de 95% de credibilidade para β inclui o
valor zero, sugerindo que β nao fornece mudancas significativas no modelo. Essa conclusao era
esperada pela construcao do estudo simulado, uma vez que o processo pontual X e homogeneo
ao longo de D. Note que se tomarmos a funcao exponencial na amostra a posteriori de α e
obtivermos os limites do intervalo de 95% de credibilidade para essa transformacao, encontramos
o intervalo de 95% de credibilidade para a funcao de intensidade de X. Esse intervalo e dado
por [0.00062, 0.00321], contendo o verdadeiro valor da funcao de intensidade que e 0.0025.
ParametroValor Amostragem Preferencial Amostragem Nao Preferencial
Verdadeiro Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ 1.5 1.46 -0.19 3.20 1.64 0.07 3.98σ2 0.5 0.79 0.30 3.22 1.31 0.38 13.17φ 20 17.73 0.41 83.81 12.72 0.52 65.68α - -6.43 -7.38 -5.74 - - -β - 0.15 -1.61 1.69 - - -
Tabela 4.6: Estimativas de θ - Modelo Bernoulli (cenario 2)
A analise da capacidade preditiva dos dois modelos foi feita comparando-se a previsao de
S nas localizacoes x. O erro de previsao global para o modelo sob amostragem preferencial
foi de 0.2926, enquanto para o modelo que nao considera o efeito da amostragem preferencial
obtivemos EPG igual a 0.3037. Como pode ser observado, ambos os modelos apresentam
capacidades de previsao similares.
Cenario 3:
Como para o modelo Poisson, nesse cenario realizaremos uma analise do impacto do aumento
do numero de sub-regioes que particionam D. Desejamos verificar se particionar D em 400 sub-
regioes melhora significativamente o desempenho do modelo Bernoulli no que tange a inferencia
de θ e a previsao de S em D.
Para esse cenario, simulamos os dados segundo o algoritmo apresentado no inıcio dessa secao
com M = 400, M = 225 e vetor de parametros (µ, σ2, φ, α, β) = (−1.5, 1.5, 20, −7, 1.5). A
amostra resultante contem 32 observacoes.
As amostras a posteriori para θ via MCMC para o modelo sob amostragem preferencial
com resposta Bernoulli com 400 sub-regioes particionando D esta ilustrado pelos histogramas
na Figura 4.12. As amostras a posteriori de φ e α concentram-se proximas aos seus respec-
tivos valores verdadeiros, sugerindo que o modelo e capaz de estimar razoavelmente bem tais
parametros. Para µ, a amostra apresenta pequeno vies em relacao ao valor verdadeiro. O
histograma de µ sugere que o modelo o superestima. O mesmo ocorre para o parametro β,
componente da intensidade do processo de Cox log-gaussiano X. Na Figura 4.12(e) observa-se
que a amostra a posteriori de β esta concentrada em valores proximos a 3, quando o verdadeiro
valor de β e 1.5. Por fim, na direcao oposta, o modelo parece subestimar o valor de σ2. Note que
55

o histograma da amostra a posteriori para σ2 apresenta um vies em relacao ao valor verdadeiro
desse parametro, concentrando-se ao redor de 1. De maneira geral, o modelo sob amostragem
preferencial Bernoulli apresenta estimativas pontuais para θ relativamente proximas aos valores
corretos quando usamos 400 sub-regioes na divisao de D, ainda que para alguns parametros
observemos a presenca de vies.
(a) µ (b) σ2 (c) φ (d) α (e) β
Figura 4.12: Histogramas a posteriori para o modelo com 400 sub-regioes - Modelo Bernoulli(cenario 3)
Com o intuito de analisar o impacto da escolha do numero de sub-regioes, M , em D so-
bre a inferencia dos parametros, reduzimos M de 400 para 225 sub-regioes. Na Figura 4.13
encontram-se os histogramas da amostra a posteriori para cada um dos parametros em θ. Para
todos os parametros, os histogramas concentram-se ao redor do valor verdadeiro, indicando que
o modelo possui boa capacidade de inferencia sobre θ. Nao intuitivamente, o modelo sob amos-
tragem preferencial com 225 sub-regioes parece apresentar desempenho melhor na estimacao
dos parametros. Uma justificativa pode estar na estimacao de SM , pois o aumento do numero
de sub-regioes tambem aumenta a complexidade do modelo visto que o vetor SM , realizacao
de S nos centroides cj das M sub-regioes, passara a ter mais elementos enquanto o numero de
pontos observados permanece o mesmo. Em situacoes com grande quantidade de localizacoes
observadas e presumıvel que o desempenho de ambos os modelos se mostre semelhante.
(a) µ (b) σ2 (c) φ (d) α (e) β
Figura 4.13: Histogramas a posteriori para o modelo com 225 sub-regioes - Modelo Bernoulli(cenario 3)
Analisamos a presente configuracao, inclusive, para o modelo sem considerar a amostragem
preferencial. A Figura 4.14 mostra os histogramas a posteriori para o modelo apresentado
na equacao (4.4). Na Figura 4.14(a) percebe-se que a maior parte da amostra possui valores
56

distantes de −1.5, valor verdadeiro de µ, indicando que a distribuicao a posteriori para µ
atribui baixa probabilidade para valores num intervalo pequeno ao redor de −1.5. O modelo
em questao parece superestimar o parametro µ. Para φ e σ2 as amostras a posteriori concentram
seus valores relativamente proximos ao valor verdadeiro dos respectivos parametros.
(a) µ (b) σ2 (c) φ
Figura 4.14: Histogramas a posteriori para o modelo sem considerar a amostragem preferencial- Modelo Bernoulli (cenario 3)
Na Tabela 4.7 estao expostos os valores das estimativas pontuais assumindo funcao perda
absoluta para os modelos sob amostragem preferencial usando 400 sub-regioes de D (modelo
I), bem como 225 sub-regioes (modelo II) e para o modelo que nao considera a presenca do
processo pontual X na modelagem dos dados (modelo III). Tambem sao apresentados os quantis
2.5% (q0.025) e 97.5% (q0.975) como os limites do intervalo de 95% de credibilidade para os tres
modelos em analise. Examinando as estimativas para µ, observa-se que o modelo que mais se
aproximou do real valor foi o modelo II. Entretanto, para todos os modelos, os intervalos de 95%
de credibilidade contem o valor zero, indicando que eles nao foram capazes de capturar o efeito
comum a todas as localizacoes, µ, presente em pi, i = 1, . . . , n. Para σ2, a estimativa pontual
para o modelo III foi a mais proxima ao valor real. Porem, comparativamente ao segundo
modelo, o modelo III apresenta maior incerteza acerca dessa estimativa. Os intervalos de 95%
de credibilidade para φ sao bastante amplos em todos os modelos, sendo a estimativa pontual
muito incerta nos tres casos. Essa incerteza pode surgir devido a dificuldade de estimacao
dos parametros da funcao de correlacao em modelos espaciais. Pontualmente, o modelo III
apresenta a estimativa mais proxima ao valor verdadeiro φ = 20, alem de possuir o intervalo de
95% de credibilidade de menor amplitude.
Para os parametros do processo pontual X, temos que os resultados para ambos α e β
foram melhores para o modelo II. As estimativas pontuais desses parametros encontram-se
mais proximas ao reais valores para ambos os modelos, bem como os intervalos de 95% de
credibilidade sao mais estreitos para o modelo II do que para o modelo I. Em concordancia
com as conclusoes obtidas pela analise dos histogramas a posteriori, a estimacao de θ forneceu
melhores resultados para o modelo II do que para o modelo I.
Analisando a previsao S nos centroides das M = 400 sub-regioes da grade regular que
57

Amostragem Preferencial Amostragem Preferencial AmostragemValor Real (400 sub-regioes) (225 sub-regioes) Nao Preferencial
Mediana q0.025 q0.975 Mediana q0.025 q0.975 Mediana q0.025 q0.975
µ = −1.5 -0.89 -2.77 0.28 -1.18 -3.09 0.26 0.23 -1.44 1.70σ2 = 1.5 0.68 0.28 2.73 1.26 0.44 4.51 1.30 0.37 6.38φ = 20 30.63 10.75 95.55 24.93 8.96 81.51 16.70 0.65 71.05α = −7 -7.78 -12.19 -5.51 -7.08 -10.30 -5.45 - - -β = 1.5 2.99 1.14 5.60 1.52 0.67 3.54 - - -
Tabela 4.7: Estimativas de θ - Modelo Bernoulli (cenario 3)
particiona D, obtemos os erros de previsao globais apresentados na Tabela 4.8. Pela tabela
percebemos que os modelos I e II apresentam desempenho preditivo similares, com o modelo I
se mostrando um pouco superior. Ambos os modelos foram superiores ao modelo III, levando
em consideracao o EPG como medida de comparacao. Em virtude da diferenca entre os EPGs
dos modelos I e II ser pequena, concluımos que o modelo II e preferıvel devido a reducao do
custo computacional ao optarmos por 225 ao inves de 400 sub-regioes em D.
Amostragem Preferencial Amostragem Preferencial Amostragem(400 sub-regioes) (225 sub-regioes) Nao Preferencial
EPG 0.9050 0.9512 1.3461
Tabela 4.8: Erro de previsao global - Modelo Bernoulli (cenario 3)
Apoiando essa decisao, apresentamos na Figura 4.15 as previsoes para os modelos I e II.
Note que as superfıcies preditas sao bastante parecidas. As previsoes para algumas sub-regioes
de D diferem entre modelos, porem, de maneira geral os modelos conseguem captar regioes
onde S assume valores mais elevados, que sao aquelas onde sao observados eventos xi.
(a) M = 400 (b) M = 225
Figura 4.15: Previsao de S em D para os modelos I e II - Modelo Bernoulli (cenario 3)
Apresentamos em 4.16(a) uma realizacao de S nos centroides cj , j = 1, . . . , 400, da particao
deD, superfıcie que sera considerada como verdadeira em nosso estudo. Apresentamos, tambem,
58

a realizacao do processo pontual X, que sao os pontos observados xi. Escolhido o modelo II
para representar a modelagem sob amostragem preferencial, temos na Figura 4.16(b) a pre-
visao do processo espacial S nesses centroides considerando o efeito do processo pontual X na
modelagem de Y . Ja a Figura 4.16(c) corresponde a superfıcie de S predita para o modelo III.
(a) Realizacao de S em D (b) Preferencial (c) Nao Preferencial
Figura 4.16: Previsao de S em D - Modelo Bernoulli (cenario 3)
Em decorrencia da escolha de σ2 = 1.5, percebe-se grande variabilidade da superfıcie verda-
deira. Ainda, como esperado devido a β > 0, observamos eventos em regioes onde S apresenta
maiores valores em D. Pelo modo como o modelo preferencial e formulado, os pontos observa-
dos tendem a concentrar-se em algumas sub-regioes de D. Ao analisarmos as Figuras 4.16(b) e
4.16(c) percebemos a clara ineficiencia na previsao de S para os modelos II e III onde nao ha
pontos observados. Em contrapartida, em regioes com presenca de eventos, o modelo II conse-
gue adaptar melhor as variacoes de S, ou seja, a consideracao do processo pontual X aprimora
a previsao de S nessas regioes. Nesse sentido, o modelo sob amostragem preferencial se mostra
superior que o modelo que nao leva em conta o processo X na modelagem dos dados.
59

Capıtulo 5
Discussao e conclusoes
A presente dissertacao se dispos a discutir os efeitos da amostragem preferencial em variaveis
cuja distribuicao de probabilidade pertence a famılia exponencial. Nesse sentido, estendemos a
classe de modelos proposta por Diggle et al. (2010) para os casos onde, condicionado a S, θ e
X, Yi ∼ Poisson(λi) ou Yi ∼ Bernoulli(pi).
No capıtulo 3 encontra-se descrita a metodologia apresentada em Diggle et al. (2010), englo-
bando somente variaveis gaussianas. Em seguida, avaliamos as discrepancias entre os modelos
preferencial e nao preferencial, com respeito a inferencia dos parametros e a previsao, atraves
da simulacao de um conjunto de localizacoes escolhidas preferencialmente. Apesar das amos-
tras a posteriori de ambos os modelos se mostrarem semelhantes, os valores obtidos para o
intervalo de credibilidade de β nos fornecem evidencias de favoritismo na escolha da amostra,
como esperado. Alem disso, a previsao baseada no modelo que considera o processo X capta
melhor as nuances de S, principalmente em regioes proximas as estacoes de monitoramento.
Com o intuito de abranger uma variedade maior de problemas praticos, no Capıtulo 4
propusemos uma extensao do modelo em Diggle et al. (2010) para processos espaciais discretos.
Nele apresentamos os modelos sob amostragem preferencial para variaveis bem caracterizadas
pelas distribuicoes de probabilidade Poisson e Bernoulli.
Estudos com dados artificiais foram conduzidos para uma gama de possıveis cenarios, permi-
tindo uma melhor compreensao do procedimento de inferencia e previsao do modelo proposto.
Na Secao 4.2 exploramos tres situacoes distintas: na primeira o vetor y continha grande quan-
tidade de observacoes iguais a zero; na segunda analisamos o comportamento do modelo em
contextos de maior variabilidade de S, ocasionada pelo aumento no valor de σ2; e na ultima
avaliamos as diferencas decorrentes de mudancas no numero de sub-regioes da particao de D
empregada na aproximacao de p(x). Para processos com distribuicao Bernoulli, cujo modelo
preferencial foi exposto na Secao 4.3, tambem foram estudados tres contextos: no cenario 1
apresentamos um exemplo generico; o segundo cenario seguiu uma direcao distinta das demais,
com a geracao de um processo de Poisson homogeneo em D; finalmente, o cenario 3 verificou
a influencia da escolha da particao de D nos resultados do modelo preferencial. Em todos os
casos foram implementados os dois modelos, sob amostragem preferencial e sem considera-la,
60

levantando questoes acerca do vies introduzido pela omissao do processo pontual X.
Os resultados obtidos foram consistentes com os encontrados na Secao 3.1. O modelo
preferencial foi capaz de recuperar satisfatoriamente os valores verdadeiros dos parametros,
apresentando estimativas mais proximas ao valor correto do que aquelas encontradas para o
modelo geoestatıstico. Ainda, o modelo proposto resultou em intervalos de credibilidade de me-
nor amplitude, sugerindo reducao da incerteza na estimacao de θ. Portanto, a consideracao de
X, processo que governa a disposicao das localizacoes onde os dados serao coletados, melhorou
a inferencia dos parametros para a maioria dos estudos abordados.
A maior influencia da amostragem preferencial, entretanto, surge na previsao do processo
espacial S, como pontuado em Gelfand et al. (2012). Previsoes que consideram o processo pon-
tual X, quando a disposicao de x sugere influencia de S, parecem mais corretas, apresentando
menores desvios que as previsoes sem considera-lo.
Ainda a respeito da previsao de S, destacam-se as diferencas entre as abordagens frequentista
e bayesiana. Sob o enfoque frequentista, a previsao de S em Diggle et al. (2010) se da por meio
da avaliacao da distribuicao preditiva p(S | y), imputando as estimativas de θ nas expressoes
da media e da variancia de krigagem. Note que p(S | y), para esse contexto, nao considera a
informacao contida na amostra das localizacoes, x. Em contrapartida, adotando a abordagem
Bayesiana para o modelo sob amostragem preferencial, apresentada nos Capıtulos 3 e 4, a
distribuicao preditiva e de fato p(S | y,x), a correta distribuicao preditiva para S assumindo
que a amostra e informativa.
A metodologia proposta foi aplicada a dados de contagens de pragas coletados na fazenda
Bjetorp, no sudoeste da Suecia. A regiao consiste em um campo de trigo de 30 hectares e os
dados constituem o numero de ervas daninhas em janelas de 0.5 x 0.7 metros, com a informacao
de cada janela resumida em uma unica localizacao, num total de 100 localizacoes. Embora os
estudos com dados artificiais comportem-se de maneira adequada, a aplicacao a dados reais
levanta questoes acerca da convergencia do algoritmo de MCMC. Em face da forte correlacao
entre µ e S o algoritmo encontra dificuldade em convergir, apresentando cadeias que se movem
lentamente pelo espaco parametrico alem de autocorrelacao elevada. Metodos alternativos
foram experimentados, como o proposto em Gamerman (1997), entretanto sem sucesso. Como
etapa futura, desejamos estudar algoritmos que explorem o espaco parametrico de forma mais
eficiente, resultando na convergencia das cadeias e consequente estimacao dos parametros e
previsao de Y .
Apesar dos resultados obtidos indicarem que a suposicao de um processo pontual X, deter-
minante do conjunto de localizacoes, melhora a estimacao dos parametros e a previsao de S em
situacoes onde o arranjo de x sugere preferencia por determinadas regioes de D, nao devemos
empregar o modelo sob amostragem preferencial sem crıticas iniciais. Alguns pesquisadores
argumentam que a preferencialidade poderia ser explicada por covariaveis comuns a X e S ou
mesmo inserida atraves de prioris informativas e que o uso de um processo estocatico para carac-
terizar a disposicao de x nao parece intuitivo. Nesse sentido, Diggle et al. (2010) argumentam
61

que a metodologia apresentada mostra-se util como um teste da preferencialidade da amostra
e tambem para uma melhor compreensao das consequencias quando ela nao e adequada, mas
concordam que a insercao de informacoes sobre a escolha da amostra deve ser considerada.
Outra discussao sobre a metodologia abordada em Diggle et al. (2010) esta relacionada a
aproximacao da densidade do processo pontual X, p(x). Os autores optam pela discretizacao
de D em uma grade regular, todavia, outras particoes podem ser investigadas, como a tessela-
gem de Voronoi. Reis (2008) descreve alguns metodos de discretizacao espacial, apresentando
suas caracterısticas e vantagens especıficas. Alternativamente, Omiros Papaspiliopoulos e Paul
Fearnhead propoem que a verossimilhanca da classe de modelos em Diggle et al. (2010) seja
aproximada por um algoritmo baseado em metodos de Monte Carlo para estimacao de verossi-
milhancas para difusoes (Beskos et al. (2006), Fearnhead et al. (2008)).
Por fim, cabe destacar que, apesar dos resultados satisfatorios, os estudos aqui apresentados
reproduzem somente parte da sorte de cenarios plausıveis na pratica. Devemos, portanto, ser
cautelosos na aplicacao da metodologia uma vez que situacoes muito discrepantes do discutido
em nosso estudo podem apresentar resultados nao consistentes.
62

Referencias Bibliograficas
Banerjee, S., Carlin, B. e Gelfand, A. (2004) Hierarchical Modeling and Analysis for Spatial
Data. Chapman & Hall - CRC.
Benes, V., Bodlak, K., Møller, J. e Waagepetersen, R. (2002) Bayesian analysis of log Gaus-
sian processes for disease mapping. Relatorio tecnico, Centre for Mathematical Physics and
Statistics, University of Aarhus.
Beskos, A., Papaspiliopoulos, O., Roberts, G. O. e Fearnhead, P. (2006) Exact and computa-
tionally efficient likelihood-based estimation for discretely observed diffusion processes (with
discussion). J. R. Statistical Society: Series B (Statistical Methodology), 68, 333–382.
Cressie, N. (1993) Statistics for Spatial Data. Wiley Series, New York.
Diggle, P. e Ribeiro, P. J. (2007) Model-based geostatistics. Springer Science & Business Media.
Diggle, P. J. (2003) Statistical analysis of spatial point patterns. Edward Arnold.
Diggle, P. J., Menezes, R. e Su, T.-l. (2010) Geostatistical inference under preferential sampling.
J. R. Statistical Society: Series C (Applied Statistics), 59, 191–232.
Fearnhead, P., Papaspiliopoulos, O. e Roberts, G. O. (2008) Particle filters for partially observed
diffusions. J. R. Statistical Society: Series B (Statistical Methodology), 70, 755–777.
Ferreira, G. e Gamerman, D. (2015) Optimal design in geostatistics under preferential sampling.
Bayesian Analysis, 10, 711–735.
Gamerman, D. (1997) Sampling from the posterior distribution in generalized linear mixed
models. Statistics and Computing, 7, 57–68.
Gelfand, A. E., Sahu, S. K. e Holland, D. M. (2012) On the effect of preferential sampling in
spatial prediction. Environmetrics, 23, 565–578.
Gelfand, A. E. e Smith, A. F. (1990) Sampling-based approaches to calculating marginal den-
sities. Journal of the American Statistical Association, 85, 398–409.
63

Geman, S. e Geman, D. (1984) Stochastic relaxation, Gibbs distributions, and the Bayesian
restoration of images. Pattern Analysis and Machine Intelligence, IEEE Transactions on,
721–741.
Hastings, W. K. (1970) Monte carlo sampling methods using Markov chains and their applica-
tions. Biometrika, 57, 97–109.
Heikkinen, J. e Arjas, E. (1999) Modeling a Poisson forest in variable elevations: a nonparame-
tric Bayesian approach. Biometrics, 55, 738–745.
Lewis, P. A. e Shedler, G. S. (1979) Simulation of nonhomogeneous Poisson processes by thin-
ning. Naval Research Logistics Quarterly, 26, 403–413.
McCullagh, P. e Nelder, J. A. (1989) Generalized linear models, vol. 2. Chapman and Hall
London.
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H. e Teller, E. (1953) Equation
of state calculations by fast computing machines. The Journal of Chemical Physics, 21, 1087–
1092.
Migon, H. S., Gamerman, D. e Louzada, F. (2014) Statistical inference: an integrated approach.
CRC press.
Møller, J., Syversveen, A. R. e Waagepetersen, R. P. (1998) Log Gaussian Cox Processes.
Scandinavian Journal of Statistics, 25, 451–482.
Papaspiliopoulos, O., Roberts, G. O. e Skold, M. (2007) A general framework for the parame-
trization of hierarchical models. Statistical Science, 59–73.
Pati, D., Reich, B. J. e Dunson, D. B. (2011) Bayesian geostatistical modelling with informative
sampling locations. Biometrika, 98, 35–48.
Reis, E. A. (2008) Modelos Dinamicos Bayesianos para Processos Pontuais Espaco-Temporais.
Tese de Doutorado, Departamento de Metodos Estatısticos - IM/UFRJ.
Robert, C. e Casella, G. (2004) Monte Carlo statistical methods. Springer Texts in Statistics.
Roberts, G. O. e Rosenthal, J. S. (2009) Examples of adaptive MCMC. Journal of Computati-
onal and Graphical Statistics, 18, 349–367.
Waagepetersen, R. (2004) Convergence of posteriors for discretized log Gaussian Cox processes.
Statistics & Probability Letters, 66, 229–235.
Zidek, J. V., Shaddick, G., Taylor, C. G. et al. (2014) Reducing estimation bias in adapti-
vely changing monitoring networks with preferential site selection. The Annals of Applied
Statistics, 8, 1640–1670.
64


















