







Línguas
Páginas
Legal



Explorando o Splunk
LINGUAGEM DE PROCESSAMENTO DE BUSCA (SPL) GUIA PRÁTICO
Por David Carasso, Chief-Mind do Splunk

Ressalva
Este livro foi feito somente como um texto ou livro de referências. O real uso do
software Splunk deve estar de acordo com sua licença de software e não com nada do
que está escrito neste livro. A documentação dada pelos produtos do software Splunk, e
não este livro, são a fonte de informação definitiva de como usar tais produtos.
Apesar de um grande cuidado ter sido tomado para garantir a precisão e atemporalidade
das informações neste livro, a Splunk não oferece nenhuma garantia da precisão ou
atemporalidade das informações e o Splunk não se responsabiliza quanto aos resultados
do uso das informações contidas neste livro. O leitor deve checar em docs.splunk.com
para as descrições definitivas das funções e conteúdos do Splunk.

Sumário
Prefácio .................................................................................. i
Sobre Este Livro ...................................................................... ii
O que está neste Livro? ......................................................... iii
Convenções ........................................................................... iv
Avisos..................................................................................... v
PARTE I EXPLORANDO SPLUNK ........................................ 1
1 A Historia do Splunk ............................................................ 1
Splunk ao resgate do Data Center ........................................ 1
Splunk ao resgate do departamento de marketing ................ 2
Se aproximando do Splunk.................................................... 2
Splunk: A companhia e o Conceito ....................................... 5
Como o Splunk aperfeiçoou os dados de maquina no data
Center .................................................................................... 6
Inteligência Operacional ........................................................ 7
Inteligência operacional no trabalho ...................................... 8
2 Integrando os Dados ......................................................... 10
O básico dos dados de maquina ......................................... 10
Tipos de dados que o Splunk consegue ler ........................ 12
Fontes de dados do Splunk ................................................. 12
Baixando, Instalando e Iniciando o Splunk .......................... 12
Baixando o Splunk ............................................................... 13
Instalando o Splunk ............................................................. 13
Starting Splunk .................................................................... 13
Trazendo os dados para serem Indexados ......................... 14
Entendendo como o Splunk Indexa os dados ..................... 15
3 Buscando com o Splunk .................................................... 17
A Dashboard de Busca ........................................................ 19
SPL™: Linguagem de Processamento de Busca ............... 22
Pipes .................................................................................... 23

AND Implícito ....................................................................... 23
top user ................................................................................ 23
Campos – Porcentagem ...................................................... 24
O comando de busca ........................................................... 24
Dicas para o uso do comando de busca ............................. 25
Subpesquisas ...................................................................... 26
4 SPL: Linguagem de Processamento de Busca .................. 27
Organizando Resultados ..................................................... 27
sort ....................................................................................... 27
Filtrando Resultados ............................................................ 29
where ................................................................................... 29
dedup ................................................................................... 30
head ..................................................................................... 32
Agrupando Resultados ........................................................ 33
transaction ........................................................................... 33
Reportando Resultados ....................................................... 36
top ........................................................................................ 36
stats ..................................................................................... 37
chart ..................................................................................... 40
timechart .............................................................................. 41
Filtrando, Modificando e Adicionando Campos ................... 43
fields .................................................................................... 43
replace ................................................................................. 44
eval ...................................................................................... 45
rex ........................................................................................ 46
lookup .................................................................................. 47
5 Enriquecendo seus dados ................................................. 50
Usando o Splunk para entender os dados .......................... 50
Identificando campos: Olhando entre as peças do quebra-
cabeça ................................................................................. 50
Explorando os dados para entender o escopo .................... 52

Preparando para reportagem e agregação ......................... 55
Visualizando os Dados ........................................................ 59
Criando Visualizações ......................................................... 60
Criando Dashboards ............................................................ 61
Criando Alertas .................................................................... 63
Criando Alertas através do Instrutor .................................... 63
Afinando Alertas Usando o Gerenciador ............................. 66
Customizando as Ações para um Alerta ............................. 68
O Gerenciador de Alertas .................................................... 69
PARTE II RECEITAS ........................................................... 70
6 Receitas para monitoramentos e alertas ........................... 70
Receitas de monitoramento ................................................. 70
Monitorando usuários concorrentes .................................... 70
Monitorando hospedeiros inativos ....................................... 71
Reportando dados categorizados ........................................ 72
Comparando o principais valores com os do último mês .... 73
Encontrando medidas que caíram em 10% na última hora. 75
Tabelando os resultados de semana a semana .................. 76
Identificando oscilações em seus dados ............................. 77
Compactando uma tabulação baseada em tempo .............. 79
Reportando em campos dentro do XML ou JSON .............. 79
Extraindo campos de um evento ......................................... 80
Receitas de Alerta ............................................................... 81
Alertar por e-mail quando o servidor atinge uma carga
determinada ......................................................................... 81
Alertando quando a performance de um servidor está lenta
............................................................................................. 82
Desligar instancias de EC2 desnecessárias ....................... 82
Convertendo um monitoramento em um alerta ................... 83
7 Agrupando Eventos ........................................................... 85
Introdução ............................................................................ 85
Receitas ............................................................................... 86

Unificando os nomes dos campos ....................................... 86
Encontrando Transações Incompletas ................................ 87
Calculando o tempo dentro de transações .......................... 88
Encontrando os últimos eventos ......................................... 90
Encontrando eventos repetidos ........................................... 90
Tempo entre transações ...................................................... 92
Encontrando transações especificas ................................... 94
Encontrando eventos perto de outros eventos .................... 97
Encontrando eventos depois de eventos ............................ 98
Agrupando grupos ............................................................... 99
8 Tabelas de Lookup .......................................................... 102
Introdução .......................................................................... 102
lookup ................................................................................ 102
inputlookup ........................................................................ 102
outputlookup ...................................................................... 102
Leitura Posterior ................................................................ 102
Receitas ............................................................................. 103
Colocando os Valores Padrões de Lookup ....................... 103
Usando Lookups reversos ................................................. 103
Usando um lookup de duas camadas ............................... 104
Usando lookups de múltiplos passos ................................ 105
Criando uma tabela de lookup usando os resultados de uma
busca ................................................................................. 106
Anexando resultados a tabelas de lookup ......................... 106
Usando tabelas gigantes de lookup .................................. 107
Comparando resultados com valores de lookup ............... 108
Controlando os encaixes da tabela de lookup ................... 110
Encaixando IPs .................................................................. 111
Encaixando Coringas ......................................................... 112
Apêndice A: Básico dos Dados de Maquina ....................... 113
Logs de Aplicação ............................................................. 114

Logs de Acesso Web ......................................................... 114
Logs de Proxy Web ........................................................... 114
Registros de Detalhes de Chamadas ................................ 115
Dados de Clickstream ........................................................ 115
Enfileiramento de Mensagem ............................................ 115
Pacotes de Dados ............................................................. 116
Arquivos de Configuração ................................................. 116
Logs de Auditoria de Bancos de Dados e Tabelas ........... 116
Logs de Auditoria do Sistema de Arquivos ........................ 116
Gerenciamento e APIs de Log .......................................... 116
Medidas de OS, Estado e Comandos de Diagnostico ...... 117
Fontes de Dados de Outras Maquinas .............................. 117
Apêndice B: Sensibilidade a Maiúsculas ............................ 118
Apêndice C: Comandos Comuns ....................................... 119
Apêndice D: Recursos mais usados ................................... 121
Apêndice E: Guia de Referencia Rápida do Splunk ............ 122
CONCEITOS ..................................................................... 122
COMANDOS COMUNS DE BUSCA ................................. 127
Otimizando Buscas ............................................................ 128
EXEMPLOS DE BUSCA .................................................... 128
FUNÇÔES EVAL ............................................................... 132
FUNÇÕES COMUNS DO STATS ..................................... 137
EXPRESSÕES REGULARES ........................................... 138
FUNÇÕES COMUNS DO STRPTIME DO SPLUNK ......... 139

i
Prefácio
A Empresa de Software Splunk (“Splunk”) é provavelmente a ferramenta mais
poderosa na assistência de busca e exploração de dados que você vai encontrar. Nós
escrevemos este livro para fornecer uma introdução ao Splunk e tudo o que ele pode
fazer. Este livro também seve como um ponto de partida de como ficar criativo com o
Splunk
O Splunk é geralmente usado por administradores de sistemas, administradores de redes
e gurus da segurança, mas o seu uso não é restrito a estas audiências. Existe um grande
valor de negócios escondido em dados corporativos que o Splunk pode liberar. Este
livro foi feito para alcançar alem do típico entusiasta de tecnologia para os grupos de
marketing e qualquer pessoa interessada em tópicos de Big Data e Inteligência
Operacional.

ii
Sobre Este Livro
O objetivo central deste livro é ajudar-lo a entender rapidamente o que o Splunk é e
como ele pode te ajudar. Ele cumpre isto lhe ensinando sobre as partes mais importantes
da Linguagem de Processamento de Busca do Splunk (SPL)™. O Splunk pode ajudar
tecnólogos e empresários de diversas formas. Não espere aprender sobre o Splunk de
uma vez. O Splunk não é como um canivete suíço, uma ferramenta simples que pode
fazer várias coisas incríveis.
Agora a questão é: Como este livro pode me ajudar? A resposta curta é que dando
rapidamente um senso de o que você pode fazer com o Splunk e aponte para onde você
pode aprender mais.
Mas já não existe um monte de documentação sobre o Splunk? Sim:
• Se você checar http://docs.splunk.com, você vai encontrar vários manuais com
explicações detalhada do maquinário do Splunk.
• Se você checar http://splunkbase.com, você vai encontrar uma base de dados
pesquisável com perguntas e respostas. Este tipo de conteúdo é valioso quanto você
sabe um pouco sobre o Splunk e está tentando resolver um problema comum.
Este livro cai entre estes dois níveis de documentação. Ele oferece um entendimento
básico das partes mais importantes do Splunk e combina isso com soluções para
problemas do mundo real.

iii
O que está neste Livro?
O capitulo 1 fala sobre o Splunk e como ele pode te ajudar.
O capitulo 2 discute como baixar o Splunk e os primeiros passos para usar-lo.
O capitulo 3 discute a interface de usuário para busca e como buscar usando o Splunk.
O capitulo 4 cobre as partes mais usadas da SPL.
O capitulo 5 explica como visualizar e enriquecer os seus dados com conhecimento.
O capitulo 6 cobre as soluções e monitoramento e alertas mais comuns.
O capitulo 7 cobre soluções para problemas que podem ser resolvidos através do
grupamento de eventos.
O capitulo 8 cobre muitas das formas que você pode usar as tabelas de lookup para
resolver problemas comuns.
Se você pensa que a Parte I (capítulos de 1 a 5) como um curso intensivo em Splunk, a
Parte II (capítulos de 6 a 8) mostra como você fazer manobras mais avançadas
combinando tudo isso, usando o Splunk para resolver alguns dos problemas mais
comuns e interessantes. Revisando estas receitas - e experimentando algumas - irá lhe
dar alguma idéia de como você usar o Splunk para responder a todos os mistérios do
universo (ou pelo menos do data center).
Os apêndices contornam o livro com algumas informações que podem ajudar. O
apêndice A dispõe um resumo do básico dos dados de maquina para abrir seus olhos
para as possibilidades e variedades de Big Datas. O apêndice B proporciona uma tabela
sobre o que é e não é sensível a letras maiúsculas nas buscas do Splunk. O apêndice C
proporciona uma olhada nas buscas mais comuns feitas com o Splunk (nós descobrimos
isto usando o Splunk, só pra avisar). O apêndice E aponta para algumas das maiores
fontes de aprendizagem relacionadas ao Splunk. O apêndice E é uma versão
especialmente projetada do cartão de referências do Splunk, que á o documento
educacional mais popular que nós temos.
iv
Convenções
Enquanto você for lendo este livro, você irá perceber que nós usamos varias fontes para
apontar certos elementos:
• Elementos da UI aparecem em negrito.
• Comandos e nomes de campo estão largura constante.
Se você for dito para selecionar a opção Y do menu X, ela estará escrita concisamente
como “selecione X » Y.”

v
Avisos
Este livro não seria possível se não fosse pela ajuda de inúmeras pessoas que
emprestaram seu tempo e talentos. Para revisões cuidadosas dos rascunhos do
manuscrito fazendo melhoramento valiosos, nós gostarias de agradecer especialmente
Ledion Bitincka, Gene Hartsell, Gerald Kanapathy, Vishal Patelm, Alex Raitz, Stephen
Sorkin, Sophy Ting e ao Steve Zhang, PhD; por me fornecer parte de seu tempo para
uma entrevista: Maverick Garner; pela ajuda adicional: Jessica Law, Tera Mendonca,
Rachel Perkins e Michael Wilde.

1
PARTE I EXPLORANDO SPLUNK
1 A Historia do Splunk
O Splunk é uma poderosa plataforma para análise de dados de maquina, dados que as
maquinas emitem em grandes volumes mas que são raramente usados efetivamente. Os
dados de maquina já são importantes para o mundo da tecnologia e estão se tornando
cada vez mais importantes no mundo dos negócios. (Para aprender mais sobre dados de
maquina, veja o Apêndice A.)
A forma mais rápida de entender o poder e versatilidade do Splunk é considerar duas
situações: uma no data Center e outra no departamento de marketing.
Splunk ao resgate do Data Center
São 2 da manha na quarta. O telefone toca. Seu chefe está ligando; o site está fora do
ar. Por que ele falhou? Foi por culpa dos servidores, das aplicações dos servidores de
dados, algum disco cheio ou algum balanceador de carga que fritou? Ele está gritando
com você para que conserte isto agora. Está chovendo. Você está perdendo a cabeça.
Relaxa. Você instalou Splunk no dia anterior.
Você liga o Splunk. Em um único lugar, você pode procurar os arquivos de log de todos
os seus servidores web, bancos de dados, firewalls, roteadores e balanceadores de
carga, assim como buscar dentro de arquivos de configuração e dados de todos os
outros dispositivos, sistemas operacionais ou aplicativos de interesse. (Isto é verdade,
não importa em quantos Data Centers ou provedores de nuvem eles possam estar
espalhados.)
Você olha no gráfico de tráfego do servidor para ver quando o problema ocorreu. As
17:03, erros no servidor web tiveram um pico repentino. Você então olha para as 10
paginas com mais erros, a home page estava bem. A página de busca estava bem. A,
mas o carrinho de comprar é o problema. Começando as 17:03, cada pedido na pagina
estava produzindo um erro. Isto está custando dinheiro - impedindo vendas e afastando
clientes - e isto tem que ser corrigido. Você sabe que o carrinho de comprar conta com
um servidor de e-commerce conectado ao banco de dados. Uma olhada nos logs mostra
que o banco de dados está online. Bom.
Vamos checar os logs do servidor de e-commerce. As 17:03m o servidor de e-commerce
começa a dizer que ele não consegue se conectar ao servidor de banco de dados. Você
então busca por mudanças na configuração dos arquivos e vê que alguém mudou uma
das configurações de rede. Você olha mais de perto; ela foi feita incorretamente. Você
contata a pessoas que fez a mudanças, que faz o rollback, e o sistema começa a
funcionar novamente.

2
Tudo isso pode levar menos de 5 minutos porque o Splunk já juntou todas as
informações relevantes em um índice central que você pode pesquisar rapidamente.
Splunk ao resgate do departamento de marketing
Você trabalha no departamento de promoções de um grande varejista. Você afina a
otimização e promoção do mecanismo de busca dos seus produtos para otimizar a
carga de trafego que vem dele. Na ultima semana, os caras do data Center instalaram
uma nova dashboard do Splunk que mostra (pelo ultima hora, dia e semana) todas os
termos de pesquisa usados para encontrar o site.
Olhando no gráfico pelas ultimas horas, você vê um pico de 20 minutos atrás. Buscas
pelo nome de sua companhia e o seu ultimo produto estão bem altos; Você chega o
relatório ao topo referenciando URLs na ultima hora e o Splunk mostra que uma
celebridade publicou um tweet sobre o produto e com o link para sua home page.
Você olha para outro gráfico que mostra a performance da maioria das páginas mais
frequentadas. A página de busca está sobre carregada e está ficando mais lenta. Uma
multidão de pessoas estão vindo ao seu site mas não podem achar chave do produto
que eles estão procurando, então eles estão todos usando a busca.
Você loga no sistema gerenciador de conteúdo do seu site e coloca uma propaganda
promocional para o novo produto ao centro da home page. Você então volta e olha as
paginas mais visitadas. O trafego de busca começa a diminuir, e o trafego na página do
novo produto começa a subir, da mesma forma, o trafego da página do carrinho de
compras. Você olha para a lista dos 10 produtos mais adicionados ao carrinho e os 10
produtos mais comprados; o novo produto se encontra no topo das listas. Você envia
um recado para do departamento de RP para acompanhar o processo. O trafego que
está chegando está sendo convertido em dinheiro ao invés de frustração, exatamente o
que você quer que aconteça. Sua habilidade de fazer o máximo com uma oportunidade
imprevista se tornou possível graças ao Splunk. Seu próximo passo é ter certeza de que
você tem o suficiente deste produto em estoque, pois isto é um problema grave.
Estes dois exemplos servem para mostrar como o Splunk pode providenciar uma janela
detalhada do que está acontecendo com o dados da sua maquina. O Splunk também
pode revelar padrões históricos, correlacionar múltiplas fontes de informação e ajudar
em milhares de outras forma.
Se aproximando do Splunk
Enquanto você usa o Splunk para responder certas questões, você vai descobrir que
você pode dividir a tarefa em três fases.
• Primeiro, identificar os dados que podem responder a sua questão.
• Segundo, transformar os dados em resultados que podem responder a sua questão.

3
• Terceiro, mostrar a resposta em forma de um relatório, tabela interativa ou gráfico
para tornar-la legível para uma audiência mais ampla.
Comece com a questão que você quer responder: Por que este sistema falhou? Por que
ele está tão lento ultimamente? Aonde as pessoas estão tendo problemas com o nosso
site?
Enquanto você fica melhor com o Splunk, fica mais obvio que tipos de dados e
pesquisas ajudam a responder estas questões. Este livro vai acelerar o progresso da sua
perícia.
A questão então se torna: Os dados podem oferecer a resposta? Muitas vezes, quando
iniciamos uma análise, não sabemos o que os dados podem nos dizer. Mas o Splunk
também é uma poderosa ferramenta para a exploração e entendimento dos dados.
Você pode descobrir a maioria dos valores mais comuns ou mais estranhos. Você pode
sumarizar os dados com estatísticas ou agrupar eventos em transações, de forma que
todos os eventos que fazem parte de uma reserva online em um hotel através de
sistemas de registro. Você pode criar fluxos que começam com data set inteiro, então é
filtrado dos eventos irrelevantes, analisando que sobrou. Então, talvez, adicionar
algumas informações de uma fonte externa até então, depois em um número de passos
simples, você tem somente os dados necessário para responder a sua questão. A figura
1-1 mostra o processo básico de análise do Splunk.
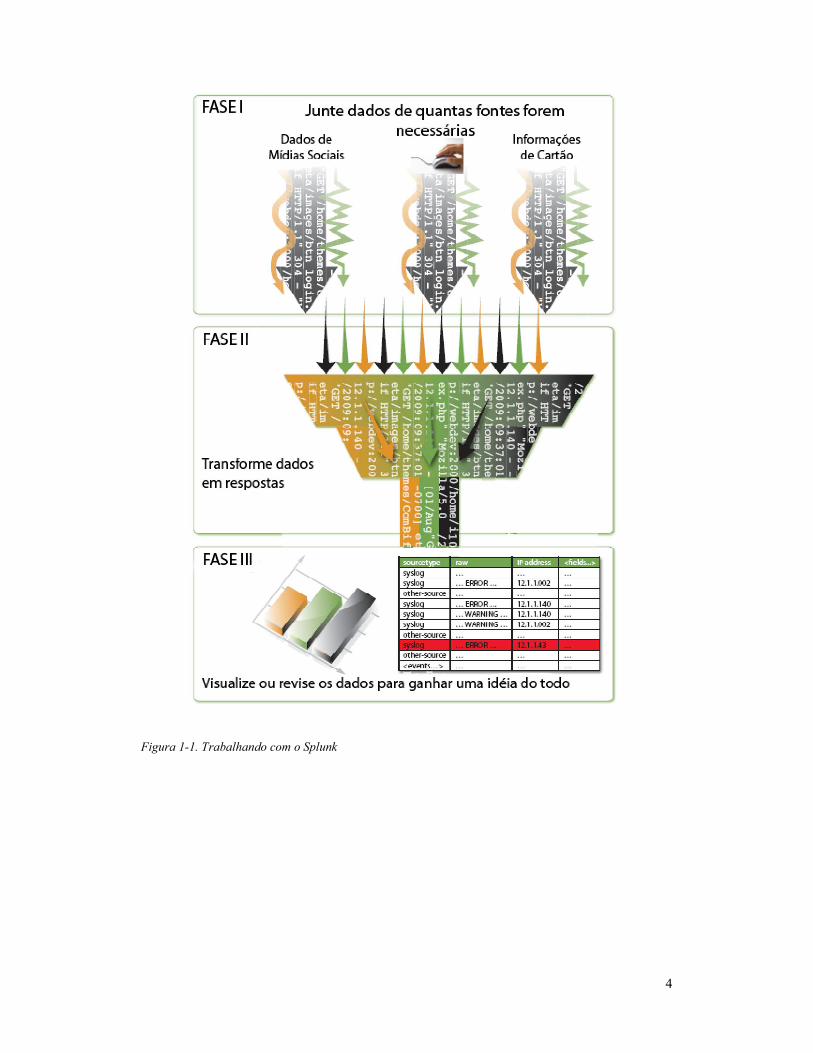
Figura 1-1. Trabalhando com o Splunk
1. Trabalhando com o Splunk
4

5
Splunk: A companhia e o Conceito
A verdadeira razão pela qual as pessoas estão excitadas com o Splunk é porque ele
ajuda a resolver problemas que os clientes sempre tiveram. A historia do Splunk
começou em 2002, quando os co fundadores Erik Swan e Rob Das começaram a
procurar pelo próximo desafio. Erik e Rob já haviam feito alguns projetos juntos e
estavam procurando por uma nova aventura, então eles começaram a falar sobre as
companhias e seus problemas.
Erik e Rob perguntaram a possíveis clientes “Como vocês resolvem os seus problemas
na sua infra estrutura?” continuamente, e ouviram sobre as experiências dos praticantes
tentando resolver os problemas de TI e recuperar os dados na forma tradicional. Os
dados estavam muito espalhados; eram difíceis de juntar e conseguir tirar algum sentido
de tudo aquilo. Todo mundo estava tentando resolver os problemas verificando
manualmente arquivos de log, algumas vezes escrevendo scripts para ajudar ao longo
do processo. Os scripts caseiros eram fracos e as pessoas que faziam eles geralmente
acabavam saindo das empresas depois de um tempo, levando com elas o conhecimento
de como eles funcionavam, e com cada nova tentativa de explorar o problema iria
acabar causando discussões, apontar culpados e a necessidade de refazer o script do
zero, com vários plantões do departamento de TI para suprir a emergência. Estes
praticantes disseram aos fundadores do Splunk que resolver problemas de infra
estrutura era como rastejar lentamente para fora de um buraco (seus datacenters) com
picaretas, iluminação ruim e navegação limitada (velhos scripts e tecnologia de
gerenciamento de logs). Resumindo, era como minerar uma caverna desconhecida, e
pensando na palavra Splunk (desbravador de cavernas) que eles escolheram dar o nome
do sistema de Splunk.
Entendendo a dificuldade da mineração digital, a única alternativa disponível para estas
pessoas era procurar na internet para ver se outras companhias tinham problemas
similares e haviam postado suas soluções online. Os fundadores estavam abismados que
as pessoas estavam gastando dinheiro nestes problemas de conhecimento comum, e
mesmo assim ninguém havia tentado construir uma solução. Erik e Rob perguntaram a
si mesmos, “Por que pesquisar dados de TI não pode ser tão fácil e intuitivo quanto uma
pesquisa no Google?™”
A primeira visão do Splunk estava direcionada em fazer um união e análise de dados
mais fácil de ser feita e resolver os problemas de um data Center ou grandes redes ou
ambientes computacionais. A missão do Splunk foi combinar a facilidade do uso das
pesquisas web com o poder dos trabalhosos métodos caseiros que os profissionais de
TI estavam usando para resolver os seus problemas.
Erik e Rob juntaram os fundos e a primeira versão do Splunk foi estreada na
LinuxWorld® 2005. O produto foi um grande sucesso e imediatamente virou um viral,
espalhado por sua disponibilidade como um download gratuito. Uma vez baixado, o
Splunk começou a resolver os problemas de uma diversa gama de problemas
impensados pelos clientes e acabou se espalhando de departamento em departamento e
de companhia em companhia. Quando usuários perguntaram a gerência para comprar

6
ele, eles já poderiam apontar para uma lista de problemas que já haviam sido resolvidos
com o Splunk.
Originalmente pensado como uma forma de ajudar os gerentes de TI e datacenters a
resolver problemas técnicos, o Splunk cresceu para se tornar uma plataforma
extremamente útil para todos os tipos de empresas porque ele permite que eles
pesquisem, coletem e organizem os dados de uma forma bem mais fácil de
compreender e seja uma forma que consuma menos recursos que os bancos de dados
tradicionais. O resultado é que temos novos pontos de vista e inteligência operacional
que as organizações nunca tiveram antes.
Como o Splunk aperfeiçoou os dados de maquina no data
Center
O primeiro lugar que o Splunk tomou, naturalmente, foi o data Center, que está
submerso em dados de maquina. O Splunk se tornou popular com administradores de
sistema, engenheiros de rede e desenvolvedores de aplicações como um mecanismo
para rapidamente entender (e aumentar a utilidade dos) dados de maquina. Mas por que
eles gostam tanto dele? Um exemplo que ajuda não somente a explicar a popularidade
precoce do Splunk mas também ajuda-nos a entender a natureza dos dados de maquina,
que é central para o valor que o Splunk agrega ao mundo dos negócios.
Na maioria dos ambientes computacionais, muitos sistemas diferentes dependem um do
outro. Sistemas de monitoramento enviam alertas depois de que algo deu errado.
Por exemplo, a página principal de um site pode depender de servidores web, servidores
de aplicação, servidores de dados, sistemas de arquivos, balanceadores de cargas,
roteadores, aceleradores de aplicação, sistema de cache, etc. Quando algo da errado em
algum destes sistemas, por exemplo o banco de dados, alarmes podem começar a apitar
em todos o níveis. Quando isto acontece, um administrador de sistema ou especialista
de aplicação deve encontrar a raiz do problema e consertar o que está causando ele. O
problema é que os arquivos de log estão espalhados através de múltiplas maquinas, as
vezes em múltiplas zonas de tempo e podem conter milhões de entradas que não tem
nada a ver com o problema. Em adição, os registros relevantes - aqueles que indicam
alguma falha do sistema - tendem a aparecer todos de uma vez. O desvio então é
encontrar o problema que começou tudo isso. Vamos dar uma olhada em como o
Splunk faz isso.
• O Splunk começa indexando, que significa juntar todos os dados de diversos locais e
combinar eles em índices centralizados. Antes do Splunk, administradores de sistema
teriam de criar um acesso a várias maquinas diferentes para alcançar toda a informação,
ainda usando ferramentas muito menos poderosas.
• Usando os índices, o Splunk pode rapidamente procurar logs de todos os servidores e
vasculhar por dentro onde o problema ocorreu. Com a sua velocidade, escala e
usabilidade, o Splunk faz a determinação de quando o problema ocorreu muito mais
rápida.

7
• O Splunk pode se aprofundar no tempo em que o problema originalmente ocorreu e
determinar a causa. Alertas podem ser criados para lidar com o problema no futuro.
Através da indexação e agregação de arquivos de log de várias fontes para fazer elas
pesquisáveis de forma centralizada, o Splunk se tornou popular entre os administradores
de sistema e outras pessoas que comandam operações técnicas para empresas ao redor
do mundo. Analistas de segurança usam o Splunk para farejar vulnerabilidades de
segurança e ataques. Analistas de sistemas usam o splunk para descobrir ineficiências e
gargalos em aplicações complexas. Analistas de rede usam o Splunk para encontrar as
causas de deficiências de rede e gargalos de bandwidth.
Esta discussão traz vários pontos chave sobre o Splunk:
• A criação de um repositório central é vital: Uma das maiores vitórias do Splunk é a
forma que diversos tipos de dados de diferente fontes são centralizados para a pesquisa.
• O Splunk converte dados em respostas: O Splunk te ajuda a encontrar os aspectos
escondidos nos dados.
• O Splunk ajuda a entender a estrutura e o significado dos dados: Quanto mais
você entender seus dados, mais você vai ter aproveitamento deles. O Splunk também
ajuda você a capturar o que você aprende e fazer futuras investigações mais fáceis e a
compartilhar o que você aprendeu com o outros.
• A visualização fecha o loop: Toda essa indexação e pesquisa dão frutos
eventualmente quando você vê uma tabela ou relatório que faz a respostas simples e
obvia. Ser capaz de visualizar dados de formas diferentes acelera o entendimento e
ajuda a compartilhar o seu entendimento com os outros.
Inteligência Operacional
Porque quase tudo que a gente faz é suportado de alguma forma por tecnologia, a
informação coletada sobre cada um de nós cresceu drasticamente. Muitos dos eventos
recordados pelos servidores na verdade representam o comportamento de clientes ou
parceiros. Os clientes do Splunk perceberam bem cedo que os logs de acesso web
poderiam ser usados não somente para diagnósticos de sistema mas também para
melhor entender o comportamento das pessoas navegando um site.
O Splunk tem sido a vanguarda em levantar a atenção sobre a inteligência operacional,
uma nova categoria de métodos e tecnologias para o uso de dados de maquina para
ganhar visibilidade dentro dos negócios de TI e o resto da empresa. A inteligência
operacional não é um subproduto da inteligência de negócios (BI), mas uma nova
aproximação baseada em fontes de informação não tipicamente dentro do escopo das
soluções de BI. Os dados operacionais não são somente inacreditavelmente valiosos
para o melhoramento das operações de TI, mas também fornece idéias para outras
partes dos negócios.

8
A inteligência operacional permite que organizações:
• Usando dados de maquina para ganhar um entendimento mais profundo dos seus
clientes: Por exemplo, se você observar as transações em um site, você o que as pessoas
compraram. Mas olhando com atenção nos logs servidor web você pode ver todas as
paginas que eles passaram antes de comprar, e, talvez elas sejam ainda mais importantes
para os lucros, as paginas que as pessoas que não compraram passaram. (Lembram-se
de nosso exemplo de busca para um novo produto no começo?)
• Revelar padrões importantes e dados analíticos derivados da correlação de várias
fontes: Quando você pode rastrear os indicadores do comportamento de um consumidor
de sites, chamar por detalhes dos registros, mídia social e informações de transações
armazenadas, uma imagem bem mais completa do consumidor começa a surgir. E
quanto mais e mais a interação com o cliente aparece nos dados de maquina, mais pode
ser aprendido.
• Reduzir o tempo entre um evento importante e a sua detecção:
Dados de maquina podem ser monitorados e co relatados em tempo real.
• Alavanque os feeds ao vivo e os dados históricos para fazer que está acontecendo
agora fazer sentido, encontrar tendências e anomalias e tomar uma decisão mais
informada baseada nesta informação: Por exemplo, o trafego criado pro uma
promoção na internet pode ser medido em tempo real e comparado com promoções
anteriores.
• Implementar uma solução rapidamente e entregar ela com a flexibilidade
necessária para as organizações de hoje em dia e no futuro - quer dizer, a
habilidade de entregar relatórios ad hoc, responder perguntas e adicionar novas
fontes de dados: Os dados do Splunk podem ser apresentados em dashboards
tradicionais que permitem aos usuários que eles explorem os eventos que continuem
fazendo novas questões.
Inteligência operacional no trabalho
O Splunk faz algo que nenhum outro produto pode: capturar de forma eficiente e
analisar enormes quantidade de dados de maquina não estruturados em series de tempo.
Apesar dos departamentos de TI geralmente começarem usando o Splunk para resolver
problemas tecnicamente esotéricos, eles rapidamente ganharão um entendimento
valioso para todos os outros setores dos negócio.
Usando dados de maquina no Splunk ajuda a resolver problemas irritantes de trabalho.
Aqui estão alguns exemplos:
• Um time de operações implementou uma aplicação de atendimento ao cliente através
da nuvem e usou o Splunk para fazer o diagnóstico. Eles logo perceberam que eles

9
poderiam acompanhar as estatísticas dos usuários e planejar melhor a capacidade - uma
medida com profundas implicações nos negócios.
• Logs de trafego de um servidor web podem ser usados para acompanhar quantos
carrinhos de compra estão sendo preenchidos e abandonados em tempo real. O
departamento de marketing pode usar esta informação para determinar aonde os
consumidores estão tendo problemas e que tipos de compras estão sendo abandonadas
para que qualquer problema possa ser corrigido na hora e promoções possam se focar
em itens que estão sendo abandonados.
• Organizações usando o Splunk para monitorar aplicações direcionadas a resolução de
problemas acabaram percebendo que elas podem facilmente providenciar visões para os
seus times de suporte de primeira linha para cuidas das chamadas dos clientes
diretamente, ao invés de acumular estas ligações em custosos recursos de engenharia.
• Uma das principais companhias de utilidades foi capaz de eliminar as custosas taxas
manutenção de software substituindo seis outras ferramentas de monitoramento e
diagnóstico pelo Splunk.
• Uma das principais organizações de mídia publica reduziu o tempo que levava para
capturar dados analíticos de extrema importância de meses para horas. Eles eram
também capazes de acompanhar o seus componentes digitais com confiabilidade e
precisão que eles não teriam de outra forma, resultando em uma melhor divisão de
lucros e marketing de conteúdo.
• Um restaurante fast-food que vende taco conectou seus pontos de vendas (POS) ao
Splunk, e dentro de uma hora, os analistas de negócios foram capazes de começar a
responder perguntas como “Quantas pessoas estão comprando tacos da meia noite as
duas da manha, neste local, nesta época do ano?”
Finalmente, a inteligência operacional permite as organizações que elas façam as
perguntas certa, levando a respostas que podem oferecer um entendimento melhor de
negócio, usando combinações de tempo real e dados históricos, mostrados de forma
fácil de digerir em dashboards e ferramentas gráficas.
Existe um motivo de por que temos a tendência de chamar dados de maquina de “big
data”. Ela é grande, é bagunçada e está lá, enterrada em algum lugar, ela é a chave para
o futuro do seu negócio. Agora vamos em frente para o capítulo 2, onde você irá
aprender como conseguir os dados no Splunk e começar a encontrar o ouro enterrado
em meio aos seus dados.

10
2 Integrando os Dados
O capitulo 1 ofereceu uma introdução ao Splunk e descreveu como ele pode te ajudar.
Agora vamos tomar o próximo passo em sua jornada: entrando os dados no Splunk.
Este capítulo cobre a instalação do Splunk, a importação dos dados e um pouco sobre
como os dados estão organizados para facilitar a busca.
O básico dos dados de maquina
A missão do Splunk é fazer com que os dados de maquina sejam úteis para as pessoas.
Para te dar um pouco de contexto, vale a pane resumir alguns dos aspectos básicos
sobre dados de maquina e como o Splunk percebe eles.
A pessoa que cria sistemas (como servidores web ou balance adores de carga ou vídeo
games ou plataformas de mídia social) também especifica a informação que estes
sistemas geram em arquivos logs quando estão rodando. Esta informação (os dados de
maquina em seus arquivos de log) é o que as pessoas que estão usando os sistemas
podem usar para entender o que estes sistemas estão fazendo enquanto rodam (ou
falham). Por exemplo, o arquivo de log que sai de uma aplicação de relógio hipotética
pode parecer com isso:
Action: ticked s:57, m:05, h:10, d:23, mo:03, y:2011
Action: ticked s:58, m:05, h:10, d:23, mo:03, y:2011
Action: ticked s:59, m:05, h:10, d:23, mo:03, y:2011
Action: ticked s:00, m:06, h:10, d:23, mo:03, y:2011
Toda vez que o relógio conta, ele cria um log para a ação e o tempo que ela ocorreu. Se
você estivesse realmente acompanhando o relógio, em adição do fato de que ele contou,
o log também pode incluir outras informações úteis: O nível de bateria, quando o
alarma está marcado para tocar, se ele está ligado ou não ou se tocou alguma vez - tudo
que poderia te dar uma noção de como o relógio está funcionando. Cada linha do dado
de maquina mostrado acima pode ser considerado um evento separado, mesmo que seja
comum para outros dados de maquina terem eventos que se espalhem por múltiplas, até
centenas de linhas.
O Splunk divide dado de maquina cru em discretas peças de informação conhecidas
como eventos. Quando você faz uma simples busca, o Splunk recolhe os eventos que
se encaixam nos termos da busca. Cada evento consiste de uma ou mais peças
discretas de dados conhecidas como campos (fields). Nos dados do relógio, os campos
podem incluir segundo, minuto, hora, dia, mês e ano. Se você pensar em grupos de
eventos organizados em um banco de dados ou tabelas, os eventos são as linhas e o
campos são as colunas, assim como a figura 2-1 mostra.
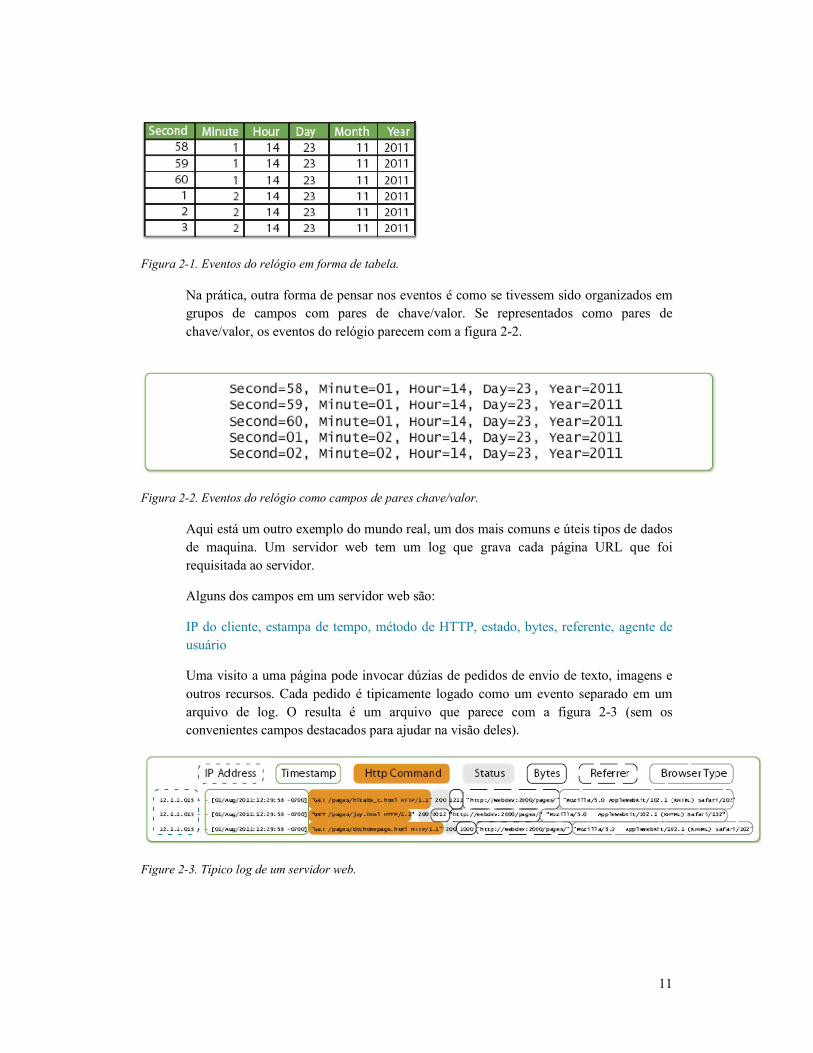
Figura 2-1. Eventos do relógio em forma de tabela.
Na prática, outra forma de pensar nos eventos
grupos de campos com pares de chave/valor. Se representados como pares de
chave/valor, os eventos do relógio parecem com a figura 2
Figura 2-2. Eventos do relógio como campos de pares chave/valor.
Aqui está um outro exemplo do mundo real, um dos mais comuns e úteis tipos de dados
de maquina. Um servidor web tem um log que grava cada página URL que foi
requisitada ao servidor.
Alguns dos campos em um servidor web são:
IP do cliente, estampa de tempo,
usuário
Uma visito a uma página pode invocar dúzias de pedidos de envio de texto, imagens e
outros recursos. Cada pedido é tipicamente logado como um evento separado em um
arquivo de log. O resulta é um arquivo que
convenientes campos destacados para ajudar na visão deles).
Figure 2-3. Típico log de um servidor web.
1. Eventos do relógio em forma de tabela.
Na prática, outra forma de pensar nos eventos é como se tivessem sido organizados em
grupos de campos com pares de chave/valor. Se representados como pares de
chave/valor, os eventos do relógio parecem com a figura 2-2.
2. Eventos do relógio como campos de pares chave/valor.
outro exemplo do mundo real, um dos mais comuns e úteis tipos de dados
de maquina. Um servidor web tem um log que grava cada página URL que foi
Alguns dos campos em um servidor web são:
IP do cliente, estampa de tempo, método de HTTP, estado, bytes, referente, agente de
Uma visito a uma página pode invocar dúzias de pedidos de envio de texto, imagens e
outros recursos. Cada pedido é tipicamente logado como um evento separado em um
arquivo de log. O resulta é um arquivo que parece com a figura 2-
convenientes campos destacados para ajudar na visão deles).
3. Típico log de um servidor web.
11
é como se tivessem sido organizados em
grupos de campos com pares de chave/valor. Se representados como pares de
outro exemplo do mundo real, um dos mais comuns e úteis tipos de dados
de maquina. Um servidor web tem um log que grava cada página URL que foi
, estado, bytes, referente, agente de
Uma visito a uma página pode invocar dúzias de pedidos de envio de texto, imagens e
outros recursos. Cada pedido é tipicamente logado como um evento separado em um
-3 (sem os

12
Tipos de dados que o Splunk consegue ler
Uma das características comuns dos dados de maquina é que quase sempre ele contem
alguma indicação de quando o dados foi criado ou quando o evento criado pelo dado
ocorreu. Tendo em conta esta característica, os índices do Splunk são otimizados para
recuperar eventos em ordem de uma série de tempo. Se os dados puros não possuem
uma estampa de tempo explicita, o Splunk da a ela o tempo em que o dado foi indexado
por ele para os eventos nos dados ou usa outras aproximações, como o tempo em que o
arquivo foi modificado pela ultima vez ou a estampa de tempo de um evento anterior.
O único outro requerimento é que este dado de maquina tem que ser textual, e não
binário. Arquivos de som e imagem são exemplos comuns de dados binários. Alguns
tipos de dados binários, como o despejo de núcleo produzido quando um programa
trava, podem ser convertidos em informação textual, como um stack trace. O Splunk
pode invocar os seus scripts para fazer esta conversão antes de indexar os dados.
Finalmente, apesar disso, os dados do Splunk tem que ter uma representação textual
para ser indexado e procurado.
Fontes de dados do Splunk
Durante a indexação, o Splunk pode ler os dados de maquina de qualquer número de
fonte. O tipos mais comuns de fontes de entrada são:
• Arquivos: O Splunk pode monitorar arquivos e diretórios específicos. Se dados são
adicionados ao arquivo ou arquivos ao diretório monitorado, o Splunk é capaz de ler os
dados.
• A rede: O Splunk pode escutar as portas TCP e UDP, lendo quaisquer dados
enviados.
• Entrada scriptadas: O Splunk pode ler os dados de maquina que saem de programas
ou scripts, como um comando Unix® ou um script customizado que monitora sensores.
Já basta de explicações: vamos começar a trabalhar com o Splunk.
Baixando, Instalando e Iniciando o Splunk
Nós recomendamos que você instale o Splunk e adiciona alguns dados de maquina para
te ajudar a trabalhar com os tópicos discutidos no livro. Tudo que iremos cobrir pode
ser feito usando o Splunk gratuito (veja abaixo).
Esta sessão descreve como fazer para o Splunk rodar.

Baixando o Splunk
Você pode baixar um Splu
suporte de uso moderado do Splunk. Na home page do splunk.com, você verá este
botão:
Clique nele para começar a baixar e instalar o Splunk em computadores rodando
Windows®, Mac™, Linux
Instalando o Splunk
Instalar o Splunk é fácil, então vamos assumir que você vai conseguir fazer isso
sozinho. Se você tiver alguma questão, refira
(http://splunk.com/goto/book#tutorial
Starting Splunk
Para iniciar o Splunk no Windows, lance a aplicação pelo menu Iniciar. Olhe para a tela
do Windows, mostrada na figura 2
Para iniciar o Splunk no Mac OS X ou no Unix, abra a janela do terminal. Vá para o
diretório onde você instalou o Splu
comando, digite:
./splunk start
A última linha de informação que você vê quando o Splunk inicia é:
The Splunk web interface is at http://your
Siga o link para a tela de login. Se você ainda
credenciais padrão são admin e changeme. Depois de logar, a tela de boas
aparecera.
Você pode baixar um Splunk completamente funcionar de graça, para aprendizado ou
suporte de uso moderado do Splunk. Na home page do splunk.com, você verá este
Clique nele para começar a baixar e instalar o Splunk em computadores rodando
, Mac™, Linux® e Unix.
Instalar o Splunk é fácil, então vamos assumir que você vai conseguir fazer isso
sozinho. Se você tiver alguma questão, refira-se ao Tutorial Splunk
http://splunk.com/goto/book#tutorial), que cobre tudo em detalhe.
iniciar o Splunk no Windows, lance a aplicação pelo menu Iniciar. Olhe para a tela
do Windows, mostrada na figura 2-4, e continue lendo.
Para iniciar o Splunk no Mac OS X ou no Unix, abra a janela do terminal. Vá para o
diretório onde você instalou o Splunk, vá para o subdiretório Bin e no prompt de
A última linha de informação que você vê quando o Splunk inicia é:
The Splunk web interface is at http://your-machinename:8000
Siga o link para a tela de login. Se você ainda não tem um usuário e senha, as
credenciais padrão são admin e changeme. Depois de logar, a tela de boas
13
nk completamente funcionar de graça, para aprendizado ou
suporte de uso moderado do Splunk. Na home page do splunk.com, você verá este
Clique nele para começar a baixar e instalar o Splunk em computadores rodando
Instalar o Splunk é fácil, então vamos assumir que você vai conseguir fazer isso
se ao Tutorial Splunk
iniciar o Splunk no Windows, lance a aplicação pelo menu Iniciar. Olhe para a tela
Para iniciar o Splunk no Mac OS X ou no Unix, abra a janela do terminal. Vá para o
e no prompt de
não tem um usuário e senha, as
credenciais padrão são admin e changeme. Depois de logar, a tela de boas-vindas
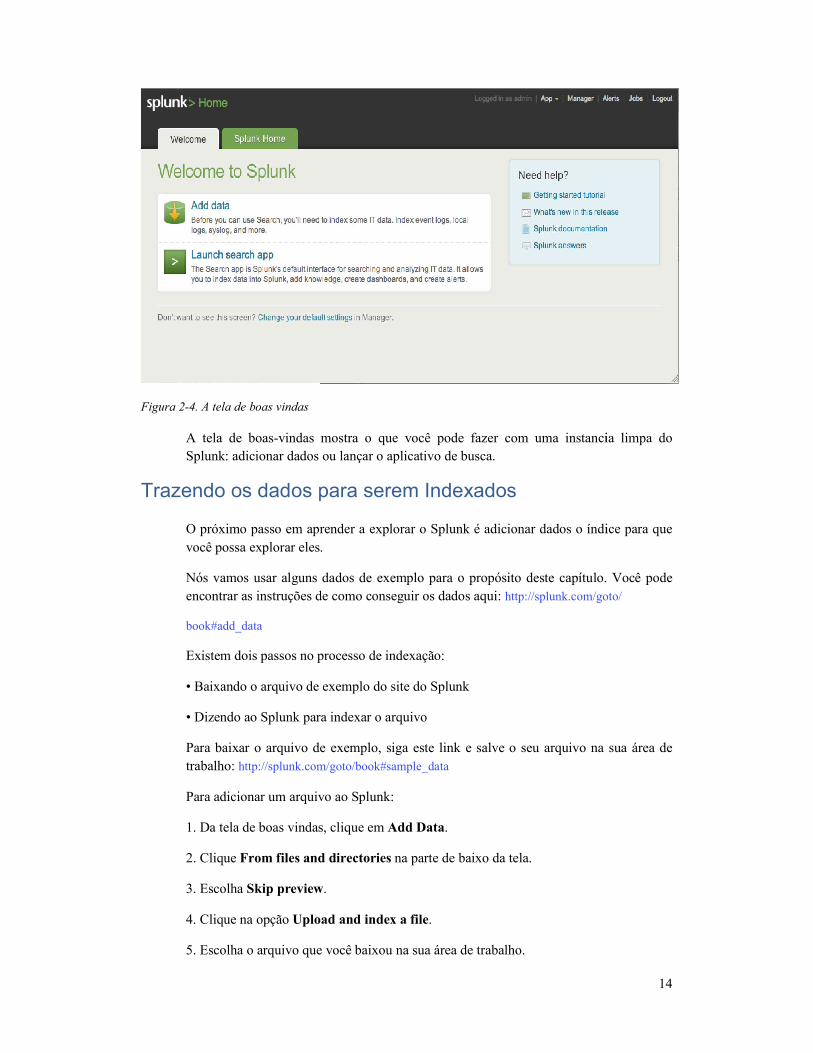
Figura 2-4. A tela de boas vindas
A tela de boas-vindas mostra o que você pode fazer com uma instancia limpa do
Splunk: adicionar dados ou lançar o aplicativo de busca.
Trazendo os dados para serem Indexados
O próximo passo em aprender a explorar o Splunk é adicionar dados o índice para que
você possa explorar eles.
Nós vamos usar alguns dados de exemplo para o propósito deste capítulo. Você pode
encontrar as instruções de como conseguir os dados aqui:
book#add_data
Existem dois passos no processo de indexação:
• Baixando o arquivo de exemplo d
• Dizendo ao Splunk para indexar o arquivo
Para baixar o arquivo de exemplo, siga este link e salve o seu arquivo na sua área de
trabalho: http://splunk.com/goto/book#sample_data
Para adicionar um arquivo ao Splunk:
1. Da tela de boas vindas, clique em
2. Clique From files and directories
3. Escolha Skip preview
4. Clique na opção Upload and index a file
5. Escolha o arquivo que você baixou na sua área de trabalho.
vindas mostra o que você pode fazer com uma instancia limpa do
dados ou lançar o aplicativo de busca.
Trazendo os dados para serem Indexados
O próximo passo em aprender a explorar o Splunk é adicionar dados o índice para que
você possa explorar eles.
Nós vamos usar alguns dados de exemplo para o propósito deste capítulo. Você pode
encontrar as instruções de como conseguir os dados aqui: http://splunk.com/goto/
Existem dois passos no processo de indexação:
• Baixando o arquivo de exemplo do site do Splunk
• Dizendo ao Splunk para indexar o arquivo
Para baixar o arquivo de exemplo, siga este link e salve o seu arquivo na sua área de
http://splunk.com/goto/book#sample_data
Para adicionar um arquivo ao Splunk:
as, clique em Add Data.
From files and directories na parte de baixo da tela.
Skip preview.
Upload and index a file.
5. Escolha o arquivo que você baixou na sua área de trabalho.
14
vindas mostra o que você pode fazer com uma instancia limpa do
O próximo passo em aprender a explorar o Splunk é adicionar dados o índice para que
Nós vamos usar alguns dados de exemplo para o propósito deste capítulo. Você pode
http://splunk.com/goto/
Para baixar o arquivo de exemplo, siga este link e salve o seu arquivo na sua área de

6. Clique Save.
Você terminou de adicionar dados. Vamos falar sobre o que o Splunk está fazendo por
traz das cenas.
Entendendo como o Splunk Indexa os dados
O valor central do Splunk para muitas das organizações é a sua habilidade única de
indexar os dados de maquina para que eles possam
reportados e alertados. Os dados que você começa são chamados de dados crus. O
Splunk indexa os dados crus através da criação de um mapa baseado em tempo das
palavras contidas nos dados sem modificar os dados em si.
Antes do Splunk poder procurar enormes quantidade de dados, ele primeiro deve
indexar os dados. O índice do Splunk é similar aos índices de livros, que apontam para
as páginas com palavras chave específicas. No Splunk, as “páginas” são chamadas de
eventos.
Figura 2-5. As características únicas dos índices do Splunk
O Splunk divide uma corrente de dados de maquina em eventos individuais. Lembre
um evento no dados de maquina pode ser tão simples quanto uma linha em um arquivo
de log ou até tão complicado como u
Cada evento no Splunk tem pelo menos os 4 campos mostrados na tabela 2
adicionar dados. Vamos falar sobre o que o Splunk está fazendo por
Entendendo como o Splunk Indexa os dados
O valor central do Splunk para muitas das organizações é a sua habilidade única de
indexar os dados de maquina para que eles possam ser rapidamente analisados,
reportados e alertados. Os dados que você começa são chamados de dados crus. O
Splunk indexa os dados crus através da criação de um mapa baseado em tempo das
palavras contidas nos dados sem modificar os dados em si.
plunk poder procurar enormes quantidade de dados, ele primeiro deve
indexar os dados. O índice do Splunk é similar aos índices de livros, que apontam para
as páginas com palavras chave específicas. No Splunk, as “páginas” são chamadas de
5. As características únicas dos índices do Splunk
O Splunk divide uma corrente de dados de maquina em eventos individuais. Lembre
um evento no dados de maquina pode ser tão simples quanto uma linha em um arquivo
de log ou até tão complicado como um stack trace contendo várias centenas de linhas.
Cada evento no Splunk tem pelo menos os 4 campos mostrados na tabela 2-1.
15
adicionar dados. Vamos falar sobre o que o Splunk está fazendo por
O valor central do Splunk para muitas das organizações é a sua habilidade única de
ser rapidamente analisados,
reportados e alertados. Os dados que você começa são chamados de dados crus. O
Splunk indexa os dados crus através da criação de um mapa baseado em tempo das
plunk poder procurar enormes quantidade de dados, ele primeiro deve
indexar os dados. O índice do Splunk é similar aos índices de livros, que apontam para
as páginas com palavras chave específicas. No Splunk, as “páginas” são chamadas de
O Splunk divide uma corrente de dados de maquina em eventos individuais. Lembre-se,
um evento no dados de maquina pode ser tão simples quanto uma linha em um arquivo
m stack trace contendo várias centenas de linhas.
1.

Tabela 2-1. Campos que o Splunk sempre Indexa
Estes campos padrões são indexados junto dos dados crus. O campo estampa de tempo
(_time) é especial porque os indexadores Splunk usam ele para ordenar os eventos,
permitindo que o Splunk possa recuperar efetivamente dentro de uma janela de tempo.
O capitulo 3 nos traz para o lugar onde a maioria da ação acontece: A interface de busca
do Splunk.
1. Campos que o Splunk sempre Indexa
Estes campos padrões são indexados junto dos dados crus. O campo estampa de tempo
) é especial porque os indexadores Splunk usam ele para ordenar os eventos,
permitindo que o Splunk possa recuperar efetivamente dentro de uma janela de tempo.
O capitulo 3 nos traz para o lugar onde a maioria da ação acontece: A interface de busca
16
Estes campos padrões são indexados junto dos dados crus. O campo estampa de tempo
) é especial porque os indexadores Splunk usam ele para ordenar os eventos,
permitindo que o Splunk possa recuperar efetivamente dentro de uma janela de tempo.
O capitulo 3 nos traz para o lugar onde a maioria da ação acontece: A interface de busca
3 Buscando com o Splunk
Agora que você ganhou um entendimento de como os índices de dados do Splunk
funcionam (no Capítulo 2), vai ser mais fácil de entender o que está acontecendo que
acontece uma pesquisa com o Splunk.
É claro, o objetivo de uma pesquisa é te ajudar a encontrar exatamente o que você
precisa. Isto pode significar filtrar, sumarizar e visualizar uma grande quantidade de
dados, para responder a sua questão sobre os dados. Outras vezes, você pode precisar
grandes quantidades de dados regularmente. Muitas vezes, você simplesmente quer
encontrar a agulha no palheiro, aquele evento enterrado que tirou tudo dos trilhos. O
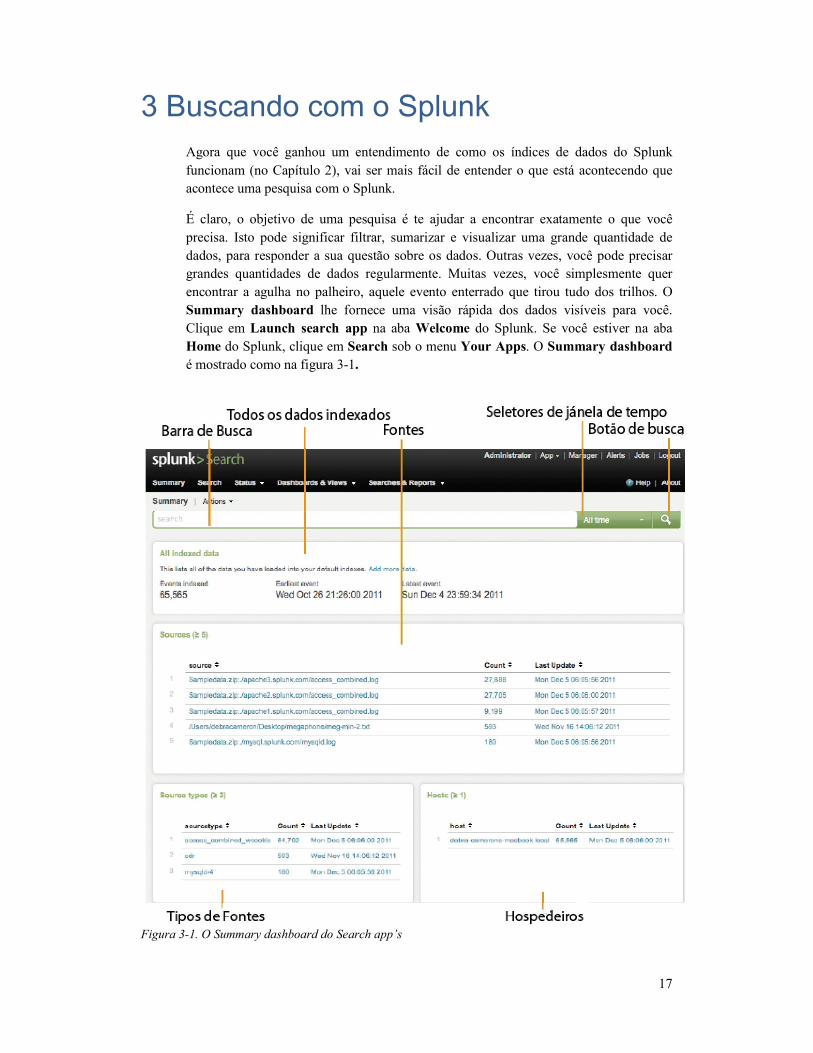
Summary dashboard lhe fornece uma visão rápida dos dados visíveis para você.
Clique em Launch search app
Home do Splunk, clique em
é mostrado como na figura 3
Figura 3-1. O Summary dashboard do Search app’s
Buscando com o Splunk
Agora que você ganhou um entendimento de como os índices de dados do Splunk
funcionam (no Capítulo 2), vai ser mais fácil de entender o que está acontecendo que
acontece uma pesquisa com o Splunk.
É claro, o objetivo de uma pesquisa é te ajudar a encontrar exatamente o que você
precisa. Isto pode significar filtrar, sumarizar e visualizar uma grande quantidade de
dados, para responder a sua questão sobre os dados. Outras vezes, você pode precisar
andes quantidades de dados regularmente. Muitas vezes, você simplesmente quer
encontrar a agulha no palheiro, aquele evento enterrado que tirou tudo dos trilhos. O
lhe fornece uma visão rápida dos dados visíveis para você.
h search app na aba Welcome do Splunk. Se você estiver na aba
do Splunk, clique em Search sob o menu Your Apps. O Summary dashboard
é mostrado como na figura 3-1.
1. O Summary dashboard do Search app’s
17
Agora que você ganhou um entendimento de como os índices de dados do Splunk
funcionam (no Capítulo 2), vai ser mais fácil de entender o que está acontecendo que
É claro, o objetivo de uma pesquisa é te ajudar a encontrar exatamente o que você
precisa. Isto pode significar filtrar, sumarizar e visualizar uma grande quantidade de
dados, para responder a sua questão sobre os dados. Outras vezes, você pode precisar
andes quantidades de dados regularmente. Muitas vezes, você simplesmente quer
encontrar a agulha no palheiro, aquele evento enterrado que tirou tudo dos trilhos. O
lhe fornece uma visão rápida dos dados visíveis para você.
do Splunk. Se você estiver na aba
Summary dashboard

Perceba algumas coisas sobre esta
• A search bar (barra de busca
pesquisa.
• O time range picker (
ajuste do alcance de tempo. Você pode ver eventos dos últimos 15 minuto
exemplo, ou qualquer intervalo de tempo desejado. Para transporte de dados em tempo
real, você pode selecionar um intervalo para a visão, indo de 30 segundos a uma hora.
• O painel de All indexed data
dos dados indexados.
Os próximos 3 painéis mostram o valores mais recentes ou comuns que foram
indexados a cada categoria:
• O painel Sources (Fontes
vem.
• O painel de Source types
• O painel de Hosts (Hospedeiros
Agora vamos dar uma olhada nos menus de negação de busca perto do topo da página:
Figura 3-2. Menus de navegação de bus
• Summary (Sumario) é onde nós estamos.
• Search (Busca) leva para a interface principal de busca, a
(Dashboard de Busca).
• Status (Estado) lista as dashboards no estado da sua instancia do Splunk.
• Dashboards & Views
• Searches & Reports
relatórios.
A próxima seção introduz para você a
Perceba algumas coisas sobre esta dashboard:
barra de busca) no topo está vazia, pronta para você digitar a
(seletor de janela de tempo) a direita da search bar
de tempo. Você pode ver eventos dos últimos 15 minuto
exemplo, ou qualquer intervalo de tempo desejado. Para transporte de dados em tempo
real, você pode selecionar um intervalo para a visão, indo de 30 segundos a uma hora.
All indexed data (Todos os dados indexados) mostra um total
Os próximos 3 painéis mostram o valores mais recentes ou comuns que foram
indexados a cada categoria:
Fontes) mostra de quais arquivos (ou outras fontes) seus dados
Source types (Tipos de Fontes) mostra os tipos de fontes nos seus dados.
Hospedeiros) mostra de quais hospedeiros os seus dados vieram.
Agora vamos dar uma olhada nos menus de negação de busca perto do topo da página:
2. Menus de navegação de busca
é onde nós estamos.
leva para a interface principal de busca, a Search dashboard
lista as dashboards no estado da sua instancia do Splunk.
• Dashboards & Views (Dashboards & Visões) lista as dashboards e as visões.
• Searches & Reports (Buscas & Relatórios) lista as suas buscas salvas e os seus
A próxima seção introduz para você a Search dashboard.
18
) no topo está vazia, pronta para você digitar a
search bar permite o
de tempo. Você pode ver eventos dos últimos 15 minutos, por
exemplo, ou qualquer intervalo de tempo desejado. Para transporte de dados em tempo
real, você pode selecionar um intervalo para a visão, indo de 30 segundos a uma hora.
total corrente
Os próximos 3 painéis mostram o valores mais recentes ou comuns que foram
) mostra de quais arquivos (ou outras fontes) seus dados
) mostra os tipos de fontes nos seus dados.
) mostra de quais hospedeiros os seus dados vieram.
Agora vamos dar uma olhada nos menus de negação de busca perto do topo da página:
Search dashboard
) lista as dashboards e as visões.
lista as suas buscas salvas e os seus
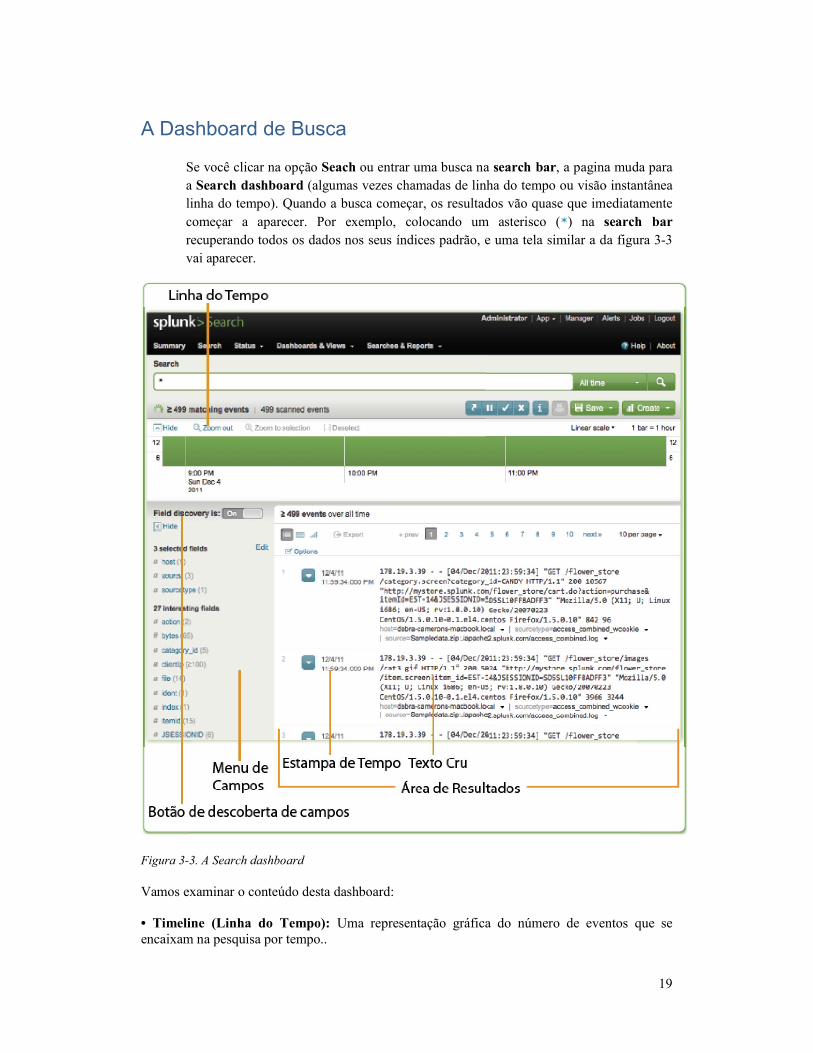
A Dashboard de Busca
Se você clicar na opção
a Search dashboard (algumas vezes chamadas de linha do tempo ou visão instantânea
linha do tempo). Quando a busca começar, os resultados vão quase que imediatamente
começar a aparecer. Por exemplo, col
recuperando todos os dados nos seus índices padrão, e uma tela similar a da figura 3
vai aparecer.
Figura 3-3. A Search dashboard Vamos examinar o conteúdo desta dashboard: • Timeline (Linha do Tempo): encaixam na pesquisa por tempo..
A Dashboard de Busca
Se você clicar na opção Seach ou entrar uma busca na search bar, a pagina muda para
(algumas vezes chamadas de linha do tempo ou visão instantânea
linha do tempo). Quando a busca começar, os resultados vão quase que imediatamente
começar a aparecer. Por exemplo, colocando um asterisco (*) na search bar
recuperando todos os dados nos seus índices padrão, e uma tela similar a da figura 3
desta dashboard:
• Timeline (Linha do Tempo): Uma representação gráfica do número de eventos que se encaixam na pesquisa por tempo..
19
, a pagina muda para
(algumas vezes chamadas de linha do tempo ou visão instantânea
linha do tempo). Quando a busca começar, os resultados vão quase que imediatamente
search bar
recuperando todos os dados nos seus índices padrão, e uma tela similar a da figura 3-3
representação gráfica do número de eventos que se
• Fields sidebar (Barra lateral de campos):
contagens de eventos. Este menu também permite que você adicione campos aos
resultados.
• Field discovery switch (Botão de descoberta de campos):
descoberta de campos ligada ou desligada. Quando o Splunk executa uma busca e a
descoberta de campos esta ligada, o Splunk tenta identificar campos automaticamente
com a busca atual.
• Results area (Área de resultados):
ordenados pelas Timestamps
evento. Sob o Raw Text
selecionados da Fields sidebar
Quando você começar a digitar na search bar, informação sensível ao contexto irá
começar a aparecer sob a barra, com as pesquisas que se encaixam a esquerda e a
ajuda a direita:
Figura 3-4. Informação útil aparece quando você coloca texto na search bar
Abaixo do time range picker, você vai v
• Fields sidebar (Barra lateral de campos): Mostra campos relevantes junto da
contagens de eventos. Este menu também permite que você adicione campos aos
d discovery switch (Botão de descoberta de campos): Torna automaticamente a
descoberta de campos ligada ou desligada. Quando o Splunk executa uma busca e a
descoberta de campos esta ligada, o Splunk tenta identificar campos automaticamente
• Results area (Área de resultados): Mostra os eventos de sua busca. Eventos são
Timestamps (Estampas de Tempo), que aparecem a esquerda de cada
Raw Text (Texto Cru) de cada evento estão quaisquer campos foram
Fields sidebar para que o eventos possua valores correspondentes.
Quando você começar a digitar na search bar, informação sensível ao contexto irá
começar a aparecer sob a barra, com as pesquisas que se encaixam a esquerda e a
4. Informação útil aparece quando você coloca texto na search bar
, você vai ver uma linha de icones:
20
Mostra campos relevantes junto da
contagens de eventos. Este menu também permite que você adicione campos aos
Torna automaticamente a
descoberta de campos ligada ou desligada. Quando o Splunk executa uma busca e a
descoberta de campos esta ligada, o Splunk tenta identificar campos automaticamente
Mostra os eventos de sua busca. Eventos são
), que aparecem a esquerda de cada
) de cada evento estão quaisquer campos foram
para que o eventos possua valores correspondentes.
Quando você começar a digitar na search bar, informação sensível ao contexto irá
começar a aparecer sob a barra, com as pesquisas que se encaixam a esquerda e a

Figura 3-5. Ícones de Busca
Os controles de busca
começou uma busca, ou se ela já tiver acabado, eles se tornarão inativos e acinzentados.
Mas se você estiver fazendo uma busca e ela demorar demais para completar, você pode
usar estes ícones para controlar o progresso da dela.
• Enviando uma busca para o segundo plano deixa que ela continue rodando no servidor
até que esteja completa enquanto você pode fazer outras buscas ou até fechar a janela e
deslogar. Quando você clicar em
plano), a search bar fica limpa e você pode continuar com outras tarefas. Quando ela
completar, uma notificação irá aparecer na sua tela se você ainda estiver logado; caso
contrario, o Splunk te manda um e
Se você quer checar o progresso no meio tempo, eu depois, clique em
pagina.
• Pausando uma busca temporariamente para ela e deixa que você explore os resultado
até este ponto. Enquanto a busca está pausada, o ícone
clicar no botão, a busca continua de onde você parou.
• Finalizar uma busca para ela antes que ela complete, mas
este ponto para que você possa ver e explorar ela no search
• Em contraste, cancelar uma busca para ela, descarta os resultados e limpa eles da tela.
O ícone do Job inspector
que mostra os detalhes da sua busca, como os custos de execução da busca, as
mensagens de debug e as p
Use o menu de Save (Salvar
os resultados. Se você salvar a busca, você pode encontrar
Reports (Buscas & Relatórios
no menu Jobs no canto superior direito da tela.
só são ativados quando a busca está acontecendo. Se você não
começou uma busca, ou se ela já tiver acabado, eles se tornarão inativos e acinzentados.
Mas se você estiver fazendo uma busca e ela demorar demais para completar, você pode
ra controlar o progresso da dela.
• Enviando uma busca para o segundo plano deixa que ela continue rodando no servidor
até que esteja completa enquanto você pode fazer outras buscas ou até fechar a janela e
. Quando você clicar em Send to background (Enviar para o segundo
fica limpa e você pode continuar com outras tarefas. Quando ela
completar, uma notificação irá aparecer na sua tela se você ainda estiver logado; caso
contrario, o Splunk te manda um e-mail (se você especificou um endereço de e
Se você quer checar o progresso no meio tempo, eu depois, clique em Jobs
• Pausando uma busca temporariamente para ela e deixa que você explore os resultado
até este ponto. Enquanto a busca está pausada, o ícone muda para um botão de play. Ao
clicar no botão, a busca continua de onde você parou.
• Finalizar uma busca para ela antes que ela complete, mas mantém os resultados até
este ponto para que você possa ver e explorar ela no search Views.
elar uma busca para ela, descarta os resultados e limpa eles da tela.
Job inspector (Inspetor de trabalhos) te leva a página do Job inspector
que mostra os detalhes da sua busca, como os custos de execução da busca, as
mensagens de debug e as propriedades de funcionamento da busca.
Salvar) para salvar a busca, os resultados ou salvar e compartilhar
os resultados. Se você salvar a busca, você pode encontrar-la no menu Searcher &
Buscas & Relatórios). Se você salvar os resultados, você pode visualizar
no canto superior direito da tela.
21
só são ativados quando a busca está acontecendo. Se você não
começou uma busca, ou se ela já tiver acabado, eles se tornarão inativos e acinzentados.
Mas se você estiver fazendo uma busca e ela demorar demais para completar, você pode
• Enviando uma busca para o segundo plano deixa que ela continue rodando no servidor
até que esteja completa enquanto você pode fazer outras buscas ou até fechar a janela e
Enviar para o segundo
fica limpa e você pode continuar com outras tarefas. Quando ela
completar, uma notificação irá aparecer na sua tela se você ainda estiver logado; caso
um endereço de e-mail).
Jobs no topo da
• Pausando uma busca temporariamente para ela e deixa que você explore os resultado
muda para um botão de play. Ao
os resultados até
elar uma busca para ela, descarta os resultados e limpa eles da tela.
Job inspector,
que mostra os detalhes da sua busca, como os custos de execução da busca, as
) para salvar a busca, os resultados ou salvar e compartilhar
Searcher &
). Se você salvar os resultados, você pode visualizar-los

Use o menu Create (Criar
agendar buscas. Nós iremos explicar eles em detalhe no capítulo 5.
superior esquerdo da área de resultados, você pode ver os seguintes ícones.
Figura 3-6. Ícones da área de resultados
Por padrão, o Splunk mostra os eventos em forma de lista, dos mais recentes aos mais
antigos, mas você pode clicar n
de tabela, ou clicar no ícone Chart (Gráfico) para ver eles como um gráfico. O botão
exportar exporta os resultados da pesquisa em vários formatos: CSV, eventos crus,
XML ou JSON.
Eventos? Resultados? Qual é a diferença?
Tecnicamente falando, eventos recuperados de alguns de seus índices são chamados de
“eventos”. Se este eventos estão transformados ou sumarizados de forma que eles não
fique mais na forma de mapeamentos de um
chamados de “resultados”.
comando de search é um evento, mas a URL mais visitada hoje é um resultado. Com
isso, nós não iremos ser tão chatos, e vamos usar ambas as formas como sinônimos
SPL™: Linguagem de Processamento de Busca
O Splunk ajuda a resumir os dados de uma infinidade de eventos indexados de uma
forma que ela seja útil para responder questões do mundo real.
A figura 3-7 ilustra um padrão comum de busca: Recupere eventos e g
Está busca retorna os valoras mais presentes nos erros do syslog.
Criar) para dashboards, alertas, relatórios, tipos de eventos e
agendar buscas. Nós iremos explicar eles em detalhe no capítulo 5. Indo para o canto
superior esquerdo da área de resultados, você pode ver os seguintes ícones.
6. Ícones da área de resultados
Por padrão, o Splunk mostra os eventos em forma de lista, dos mais recentes aos mais
antigos, mas você pode clicar no ícone Table (Tabela) para ver os resultados em forma
de tabela, ou clicar no ícone Chart (Gráfico) para ver eles como um gráfico. O botão
exportar exporta os resultados da pesquisa em vários formatos: CSV, eventos crus,
Qual é a diferença?
Tecnicamente falando, eventos recuperados de alguns de seus índices são chamados de
Se este eventos estão transformados ou sumarizados de forma que eles não
fique mais na forma de mapeamentos de um-para-um com os eventos em disco, eles são
chamados de “resultados”. Por exemplo, um evento de acesso web recuperado com o
comando de search é um evento, mas a URL mais visitada hoje é um resultado. Com
isso, nós não iremos ser tão chatos, e vamos usar ambas as formas como sinônimos
SPL™: Linguagem de Processamento de Busca
O Splunk ajuda a resumir os dados de uma infinidade de eventos indexados de uma
forma que ela seja útil para responder questões do mundo real.
7 ilustra um padrão comum de busca: Recupere eventos e gere um relatório.
Está busca retorna os valoras mais presentes nos erros do syslog.
22
) para dashboards, alertas, relatórios, tipos de eventos e
Indo para o canto
Por padrão, o Splunk mostra os eventos em forma de lista, dos mais recentes aos mais
o ícone Table (Tabela) para ver os resultados em forma
de tabela, ou clicar no ícone Chart (Gráfico) para ver eles como um gráfico. O botão
exportar exporta os resultados da pesquisa em vários formatos: CSV, eventos crus,
Tecnicamente falando, eventos recuperados de alguns de seus índices são chamados de
Se este eventos estão transformados ou sumarizados de forma que eles não
disco, eles são
Por exemplo, um evento de acesso web recuperado com o
comando de search é um evento, mas a URL mais visitada hoje é um resultado. Com
isso, nós não iremos ser tão chatos, e vamos usar ambas as formas como sinônimos.
O Splunk ajuda a resumir os dados de uma infinidade de eventos indexados de uma
ere um relatório.

Figura 3-7. Como uma simples busca no Splunk é processada
A String inteira
sourcetype=syslog ERROR | top user | fields
é chamada de busca, e o caractere de
fazem parte da busca.
Pipes
A primeira palavra chave depois da barra é o nome do comando de busca. Neste caso os
comandos são top e fields
existe um comando implícito
comece com uma barra. Então, realmente, estes são os 3 comandos de busca na
pesquisa acima: search,
Os resultados de cada comando são passados como entrada para o próximo coma
você alguma vez usou o shell do Linux como um bash, este conceito provavelmente lhe
é familiar.
AND Implícito
O sourcetype=syslog ERROR
eventos que tem o sourcetype
top user
O próximo comando, top
padrão, o top retorna os 10 valores mais comuns para o campo especificado, em ordem
decrescente. Neste caso, o campo
que mais aparecem nos eventos do syslog que contenham o termo
top é uma tabela com 3 colunas (
7. Como uma simples busca no Splunk é processada
sourcetype=syslog ERROR | top user | fields - percent
é chamada de busca, e o caractere de barra (|) separa os comandos individuais que
A primeira palavra chave depois da barra é o nome do comando de busca. Neste caso os
fields. Que comando está recuperando os eventos do índice? Bem,
implícito chamado search, no começo de qualquer busca que não
comece com uma barra. Então, realmente, estes são os 3 comandos de busca na
, top, e fields.
Os resultados de cada comando são passados como entrada para o próximo coma
você alguma vez usou o shell do Linux como um bash, este conceito provavelmente lhe
sourcetype=syslog ERROR diz ao comando search para recuperar somente os
sourcetype igual a syslog AND (&) contenham o termo ERROR
top, retorna os valores mais comuns do campo especificado. Por
retorna os 10 valores mais comuns para o campo especificado, em ordem
decrescente. Neste caso, o campo especificado é user, então o top retorna os usuários
que mais aparecem nos eventos do syslog que contenham o termo ERROR. A saída do
é uma tabela com 3 colunas (user, count e percent), com 10 linha de valores.
23
barra (|) separa os comandos individuais que
A primeira palavra chave depois da barra é o nome do comando de busca. Neste caso os
. Que comando está recuperando os eventos do índice? Bem,
, no começo de qualquer busca que não
comece com uma barra. Então, realmente, estes são os 3 comandos de busca na
Os resultados de cada comando são passados como entrada para o próximo comando, se
você alguma vez usou o shell do Linux como um bash, este conceito provavelmente lhe
para recuperar somente os
ERROR.
, retorna os valores mais comuns do campo especificado. Por
retorna os 10 valores mais comuns para o campo especificado, em ordem
retorna os usuários
. A saída do
), com 10 linha de valores.

24
Também é importante entender que a saída do comando top se torna na entrada do
próximo comando depois da barra. Neste sentido, o top transformou os resultados em
um conjunto menor de valores, que são ainda mais refinados pelo próximo comando.
Campos – Porcentagem
O segundo comando, fields, com um argumento de – percent, diz ao Splunk para
remover a coluna percent da saída do comando top.
Análise Exploratória de Dados: Escavando com o Splunk
E se você não souber nada sobre os dados? Seja criativo e explore. Você pode fazer
uma busca por “*” para recuperar todos os eventos e então aprender sobre eles: olhe
para alguns eventos, extraia alguns campos interessantes, extraia um top deste campo,
veja como os eventos estão divididos, talvez derive alguns campos novos baseados em
outros campos, organize os seus resultados, veja como um campo vária em relação a
outros campos, etc. (Para mais dicas sobre o aprendizado do que se encontra naquela
fonte que você não tem idéia, siga para http://splunk.com/goto/book#mining_tips.)
Antes de mergulharmos nos comandos de busca no Capitulo 4, vamos cobrir o comando
search em si: um comando bastante especial e crítico para o uso do Splunk.
O comando de busca
O comando search é o burro de carga do Splunk. É um dos mais simples e poderosos
comandos. É um comando tão básico que você precisa escrever-lo em lugar algum antes
da primeira barra, por que ele é invocado implicitamente no começa da pesquisa,
recuperando eventos dos índices no disco.
Nem todas as buscas recuperam dados dos índices do Splunk. Por exemplo, o comando
inputcsv lê os dados de um arquivo CSV. Para colocar comandos deste tipo como o
primeiro comando, coloque uma barra antes deles. Por exemplo | inputcsv
myfile.csv
Quando ele não é o primeiro comando na busca, o comando search pode filtrar um
grupo de resultados da busca anterior. Para fazer isso, use o comando search como
qualquer outro comando - com a barra seguida pelo nome de um comando explicito.
Por exemplo, o comando error | top url | search count>=2 busca por eventos no
disco que possuam a palavra error, encontrar as URLs que mais aparecem, e filtrem
qualquer URL que só apareça uma vez. Em outras palavras, dos 10 eventos de erro que
o top retornar, me mostre somente aqueles que tem de duas a mais instancias da mesma
URL.
A tabela 3-1 mostra alguns exemplos de chamadas implícitas para o comando search e
seus resultados.

Tabela 3-1. Comandos de busca implícitos
Dicas para o uso do comando de busca
Aqui estão algumas dicas para o uso do comando
outros comandos também.
Sensibilidade a maiúsculas
Argumentos de palavras chave para o comando
mas os nomes do campos são. (Veja o apêndice B para mais detalhes sobre a
sensibilidade a maiúsculas.)
Usando aspas em uma pesquisa
Você precisa de aspas em volta de frases ou valores de campos que contenham
caracteres de separação como espaço, virgulas, barras, chaves, colchetes,
sinais de igual, etc. Então,
por exemplo, você vai precisar colocar aspas em volta do valor, como em
host=”webserver
#9”. Em adição, para procurar por palavras reservadas (AND, OR, NOT,
aspas.
A busca por aspas usa barras invertidas para escapar do efeito padrão das aspas.
Para encontrar a frase —
por: “Splunk changed \”life itself
Lógica Booleana
Argumentos —palavras chave e campos
implicitamente.
Você pode especificar que qualquer um dos dois ou mais argumentos precisariam ser
verdadeiros, usando a palavra ch
1. Comandos de busca implícitos
Dicas para o uso do comando de busca
ão algumas dicas para o uso do comando search. Elas se aplicam a vários
outros comandos também.
Sensibilidade a maiúsculas
Argumentos de palavras chave para o comando search não são sensíveis a maiúsculas,
mas os nomes do campos são. (Veja o apêndice B para mais detalhes sobre a
sensibilidade a maiúsculas.)
Usando aspas em uma pesquisa
Você precisa de aspas em volta de frases ou valores de campos que contenham
separação como espaço, virgulas, barras, chaves, colchetes,
sinais de igual, etc. Então, host=web09 está bom, mas se o valor do host tem espaços,
por exemplo, você vai precisar colocar aspas em volta do valor, como em
ição, para procurar por palavras reservadas (AND, OR, NOT,
A busca por aspas usa barras invertidas para escapar do efeito padrão das aspas.
—Splunk changed “life itself” for me— você teria de procurar
”life itself\” for me”
palavras chave e campos— para o comando search são dados
Você pode especificar que qualquer um dos dois ou mais argumentos precisariam ser
verdadeiros, usando a palavra chave OR, em letras maiúsculas. O OR tem precedência
25
Elas se aplicam a vários
não são sensíveis a maiúsculas,
mas os nomes do campos são. (Veja o apêndice B para mais detalhes sobre a
Você precisa de aspas em volta de frases ou valores de campos que contenham
separação como espaço, virgulas, barras, chaves, colchetes, parênteses,
está bom, mas se o valor do host tem espaços,
por exemplo, você vai precisar colocar aspas em volta do valor, como em
ição, para procurar por palavras reservadas (AND, OR, NOT, etc.), use
A busca por aspas usa barras invertidas para escapar do efeito padrão das aspas.
você teria de procurar
ados juntos,
Você pode especificar que qualquer um dos dois ou mais argumentos precisariam ser
ave OR, em letras maiúsculas. O OR tem precedência

26
maior que o AND, então você pode em argumentos que usam OR como tendo
parênteses em volta deles.
Para filtrar os eventos que contem uma palavra em particular, use a palavra chave NOT.
Finalmente, você pode usar parênteses explicitamente para tornar as coisas mais claras
se você quiser. Por exemplo, a busca por x y OR z NOT w é a mesma coisa que AND (y
OR z) AND NOT w.
Subpesquisas
O comando search, como todos os comandos, podem ser usados como um subpesquisa
— uma busca cujo os resultados serão usados como argumentos para outro comando de
busca.
Subpesquisas são fechadas em colchetes. Por exemplo, para encontrar todos os
eventos do syslog do usuário tiveram um erro de login, use o seguinte comando:
sourcetype=syslog [search login error | return user]
Aqui, a busca por eventos tendo os termos login e error são executados, retornando o
primeiro valor de user encontrado, diga-se bob, seguido por uma pesquisa para o
sourcetype=syslog user=bob.
Se você está pronto para continuar a sua aventura de aprendizado no Splunk, o Capitulo
4 introduz para você mais comandos que você pode considerar imediatamente úteis.

4 SPL: Linguagem de Processamento
de Busca
No capítulo 3, nós cobrimos a maioria dos comandos básicos
Este capitulo descreve alguns dos outros comandos SPL que você vai querer saber.
Este capitulo usa um aproximação mais crua, ensinando os comandos SPL através de
exemplos. Para a documentação de referencia completa, veja
com.
A tabela 4-1 sumariza os comandos SPL cobertos neste capitulo, por categoria.
Tabela 4-1. Comandos comuns de SPL
Organizando Resultados
Organizar comandos é o trabalho do comando
sort
O comando sort organiza os resultados das
mostra alguns dos exemplos.
4 SPL: Linguagem de Processamento
No capítulo 3, nós cobrimos a maioria dos comandos básicos do Splunk na busca SPL.
Este capitulo descreve alguns dos outros comandos SPL que você vai querer saber.
Este capitulo usa um aproximação mais crua, ensinando os comandos SPL através de
exemplos. Para a documentação de referencia completa, veja http://docs.splunk.
1 sumariza os comandos SPL cobertos neste capitulo, por categoria.
1. Comandos comuns de SPL
Organizando Resultados
Organizar comandos é o trabalho do comando sort.
organiza os resultados das busca por campos específicos. A tabela 4
mostra alguns dos exemplos.
27
4 SPL: Linguagem de Processamento
do Splunk na busca SPL.
Este capitulo descreve alguns dos outros comandos SPL que você vai querer saber.
Este capitulo usa um aproximação mais crua, ensinando os comandos SPL através de
.splunk.
1 sumariza os comandos SPL cobertos neste capitulo, por categoria.
busca por campos específicos. A tabela 4-2

Resumindo partes da busca Se nós simplesmente mostrarmos partes de uma série de comandos (como nós fizemos na tabela 4-2), você vai ver: Isto significa que alguma busca veio antes do comando, mas nós estamos nos focando no que vem depois.
Tabela 4-2. Exemplos de Comando sort
Dica: A ordem crescente é o resultado padrão das buscas. Para reverter a ordem dos resultados, use o sinal de menos na frente do campos escolhido para organizar os resultados.
A figura 4-1 ilustra o segundo exemplo. Nós vamos organizar por preços crescentes e
notas decrescentes. O primeiro resultado vai ser o item mais barato e mais be
Se nós simplesmente mostrarmos partes de uma série de comandos (como nós fizemos 2), você vai ver: ... |
Isto significa que alguma busca veio antes do comando, mas nós estamos nos focando
sort
: A ordem crescente é o resultado padrão das buscas. Para reverter a ordem dos resultados, use o sinal de menos na frente do campos escolhido para organizar os
1 ilustra o segundo exemplo. Nós vamos organizar por preços crescentes e
notas decrescentes. O primeiro resultado vai ser o item mais barato e mais be
28
Se nós simplesmente mostrarmos partes de uma série de comandos (como nós fizemos
Isto significa que alguma busca veio antes do comando, mas nós estamos nos focando
: A ordem crescente é o resultado padrão das buscas. Para reverter a ordem dos resultados, use o sinal de menos na frente do campos escolhido para organizar os
1 ilustra o segundo exemplo. Nós vamos organizar por preços crescentes e
notas decrescentes. O primeiro resultado vai ser o item mais barato e mais bem votado.
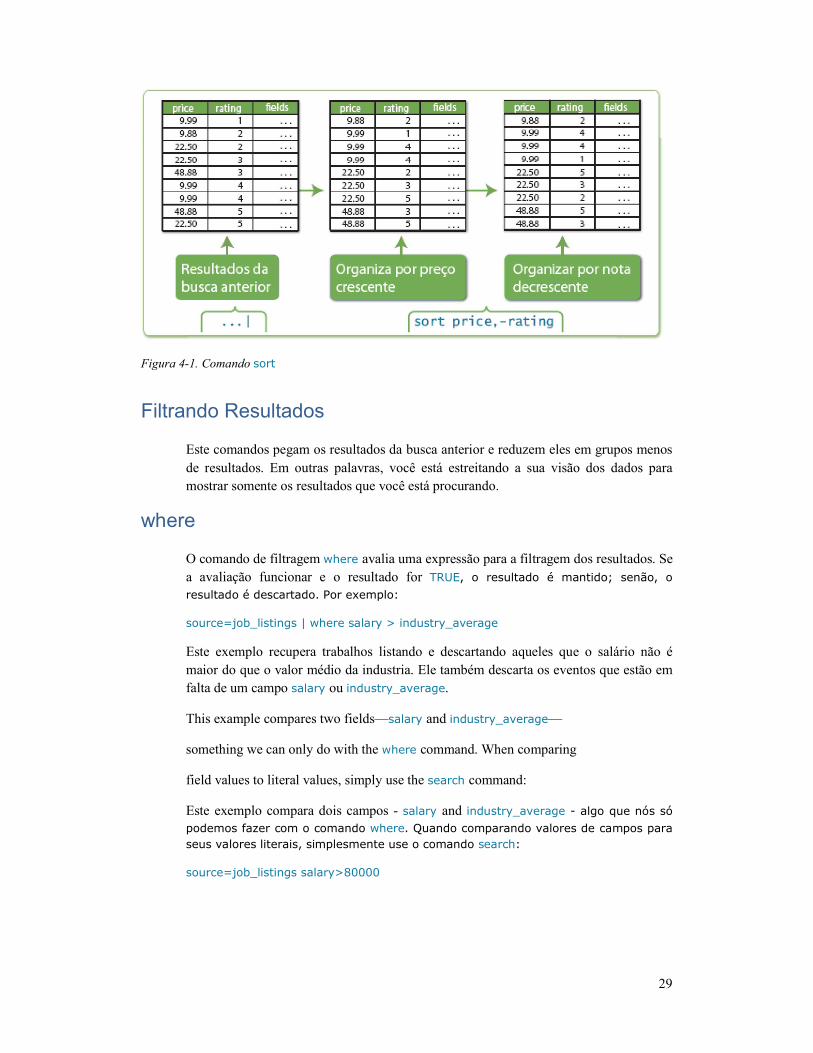
Figura 4-1. Comando sort
Filtrando Resultados
Este comandos pegam os resultados da busca anterior e reduzem eles em grupos menos
de resultados. Em outras palavras, você está estreitando a sua visão dos dados para
mostrar somente os resultad
where
O comando de filtragem
a avaliação funcionar e o resultado for
resultado é descartado. Por exemplo:
source=job_listings | where salary > industry_average
Este exemplo recupera trabalhos listando e descartando aqueles que o salário não é
maior do que o valor médio da industria. Ele também descarta os eventos que estão em
falta de um campo salary
This example compares two fields
something we can only do with the
field values to literal values, simply use the
Este exemplo compara dois campos podemos fazer com o comando
seus valores literais, simplesmente use o comando
source=job_listings salary>80000
Filtrando Resultados
Este comandos pegam os resultados da busca anterior e reduzem eles em grupos menos
de resultados. Em outras palavras, você está estreitando a sua visão dos dados para
mostrar somente os resultados que você está procurando.
O comando de filtragem where avalia uma expressão para a filtragem dos resultados. Se
a avaliação funcionar e o resultado for TRUE, o resultado é mantido; senão, o
resultado é descartado. Por exemplo:
| where salary > industry_average
Este exemplo recupera trabalhos listando e descartando aqueles que o salário não é
maior do que o valor médio da industria. Ele também descarta os eventos que estão em
salary ou industry_average.
example compares two fields—salary and industry_average—
something we can only do with the where command. When comparing
field values to literal values, simply use the search command:
Este exemplo compara dois campos - salary and industry_average - algo que nós só
podemos fazer com o comando where. Quando comparando valores de campos para
seus valores literais, simplesmente use o comando search:
source=job_listings salary>80000
29
Este comandos pegam os resultados da busca anterior e reduzem eles em grupos menos
de resultados. Em outras palavras, você está estreitando a sua visão dos dados para
avalia uma expressão para a filtragem dos resultados. Se
, o resultado é mantido; senão, o
Este exemplo recupera trabalhos listando e descartando aqueles que o salário não é
maior do que o valor médio da industria. Ele também descarta os eventos que estão em
algo que nós só
. Quando comparando valores de campos para

Tabela 4-3. Exemplos do comando where
A figura 4-2 ilustra o coman
Figure 4-2. Exemplo do comando where
Dicas para usar o where
Como o comando eval, o comando
de avaliação de expressões (veja o apêndice E para uma lista completa).
dedup
Removendo os dados redundantes é a razão comando de filtragem
comando remove resultados subsequentes que se encaixam em um critério.
comando só pode manter
valores dos campos especificados. Se o
pra 1 e retorna o primeiro valor encontrado (que é normalmente o mais recente).
where
2 ilustra o comando where distance/time > 100.
where
Dicas para usar o where
, o comando where funciona com um grande grupo de funções
de avaliação de expressões (veja o apêndice E para uma lista completa).
Removendo os dados redundantes é a razão comando de filtragem dedup
comando remove resultados subsequentes que se encaixam em um critério.
manter o primeiro resultado do count para cada combinação dos
specificados. Se o count não for especificado, por padrão ele vai
pra 1 e retorna o primeiro valor encontrado (que é normalmente o mais recente).
30
funciona com um grande grupo de funções
dedup. Este
comando remove resultados subsequentes que se encaixam em um critério. Este é, este
para cada combinação dos
não for especificado, por padrão ele vai
pra 1 e retorna o primeiro valor encontrado (que é normalmente o mais recente).
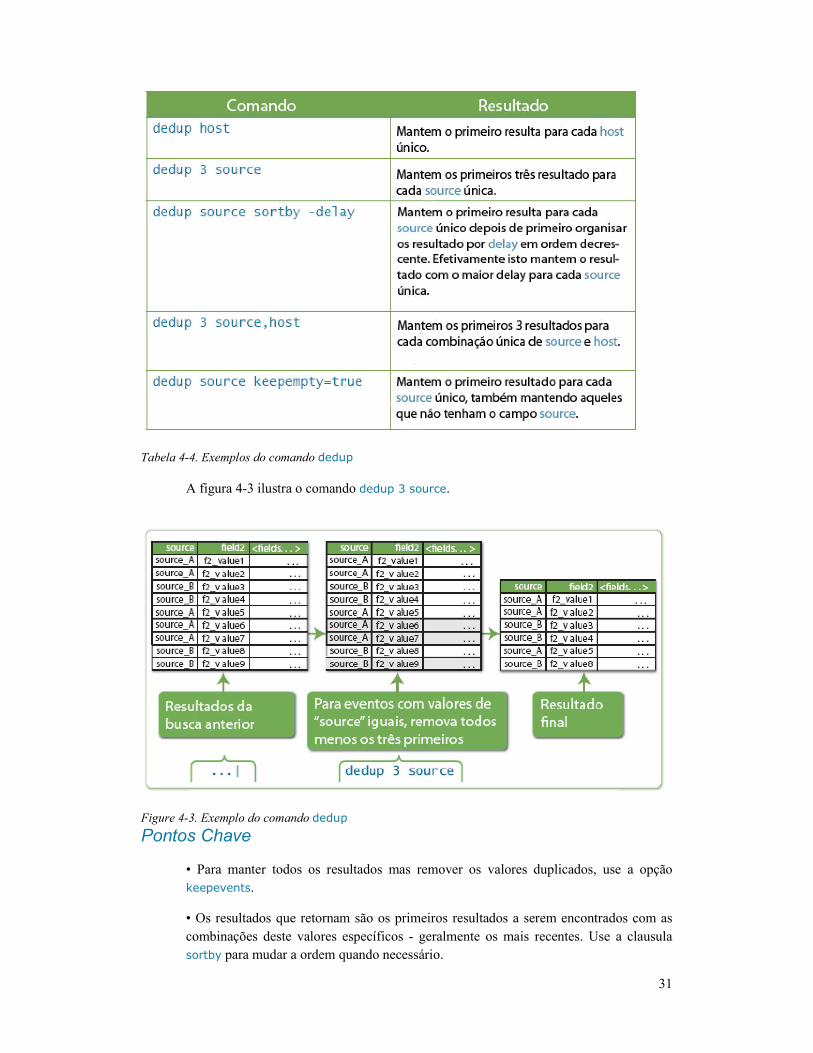
Tabela 4-4. Exemplos do comando dedup
A figura 4-3 ilustra o comando
Figure 4-3. Exemplo do comando dedup
Pontos Chave
• Para manter todos os resultados mas remover os valores duplicados, use a opção
keepevents.
• Os resultados que retornam são os primeiros resultados a serem encontrados com as
combinações deste valores es
sortby para mudar a ordem quando necessário.
dedup
3 ilustra o comando dedup 3 source.
dedup
• Para manter todos os resultados mas remover os valores duplicados, use a opção
• Os resultados que retornam são os primeiros resultados a serem encontrados com as
combinações deste valores específicos - geralmente os mais recentes. Use a clausula
para mudar a ordem quando necessário.
31
• Para manter todos os resultados mas remover os valores duplicados, use a opção
• Os resultados que retornam são os primeiros resultados a serem encontrados com as
geralmente os mais recentes. Use a clausula

• Campos onde o campo especificado não existe são mantidos por padrão. Use a opção
keepnull=<true/false> para substituir o comportamento padrão, se
head
O comando de filtragem
permite que uma busca pare de recuperar eventos do disco quando ele encontrar o
número desejado de resultados.
Da frente ou de traz? O oposto do comando é o primeiro. Os resultados são retornados em ordem reversa, começando pelo fim dos resultados. Lembre-se que este primeiro é relativo a ordem de entrada dos eventos, que normalmente desce confor 10 retorna os últimos 10 eventos.
Tabela 4-5. Exemplos do comando head
Figura 4-4. Exemplo do comando head
• Campos onde o campo especificado não existe são mantidos por padrão. Use a opção
para substituir o comportamento padrão, se desejar.
O comando de filtragem head retorna os primeiros resultados do count. Usar o
permite que uma busca pare de recuperar eventos do disco quando ele encontrar o
número desejado de resultados.
O oposto do comando é o head comando tail, que retorna o último resultado, em vez do primeiro. Os resultados são retornados em ordem reversa, começando pelo fim dos
se que este primeiro é relativo a ordem de entrada dos eventos, que normalmente desce conforme a ordem do tempo, significando que, por exemplo,
10 eventos.
head
head
32
• Campos onde o campo especificado não existe são mantidos por padrão. Use a opção
retorna os primeiros resultados do count. Usar o head
permite que uma busca pare de recuperar eventos do disco quando ele encontrar o
, que retorna o último resultado, em vez do primeiro. Os resultados são retornados em ordem reversa, começando pelo fim dos
se que este primeiro é relativo a ordem de entrada dos eventos, que me a ordem do tempo, significando que, por exemplo, head

33
Agrupando Resultados
O comando transaction agrupa eventos relacionados.
transaction
O comando transaction agrupa eventos que se encontram em várias restrições em
transações - coleções de eventos, possivelmente de múltiplas fontes. Os eventos são
agrupados se todas as definições de restrições da transação são alcançadas. Transações
são compostas de texto cru (o campo _raw) de cada evento membro, a estampa de
tempo (o campo _time) do membro mais antigo, a união de todos os outros campos de
cada membro, e alguns campos adicionais que descrevem a transação como duration e
eventcount.
Table 4-6. Exemplos do comando transactiontransaction
34

O segundo exemplo na tabela 4-6, transaction clientip maxspan=30s
maxpause=5s, é ilustrado na figura 4
Figura 4-5. Exemplo do comando transaction
Pontos chave
Todos argumentos do comando
de ser especificadas para definir como os eventos serão agrupado em transações.
O Splunk não necessariamente interpreta a transação definida por
como uma conjunção (field1 AND field2
field2 OR field3) destes campos. Se existe uma relação transitiva entre os campos no
<fields list>, o comando
Por exemplo, se você procura
eventos agrupados em uma única transação:
event=1 host=a
event=2 host=a cookie=b
event=3 cookie=b
Os primeiros dois eventos estão junto pois eles tem o
está com eles pois ele divide o
O comando transação produz dois campos:
• duration: a diferença entre as estampas de tempo para o primeiro e último evento na
transação.
transaction clientip maxspan=30s , é ilustrado na figura 4-5.
transaction
Todos argumentos do comando transaction são opcionais, mas algumas restrições tem
de ser especificadas para definir como os eventos serão agrupado em transações.
O Splunk não necessariamente interpreta a transação definida por múltiplos
field1 AND field2 AND field3) ou uma disjunção (
) destes campos. Se existe uma relação transitiva entre os campos no
, o comando transaction a usa.
Por exemplo, se você procura-se por transaction host cookie, você pode ver os seguintes
eventos agrupados em uma única transação:
event=2 host=a cookie=b
Os primeiros dois eventos estão junto pois eles tem o host=a em comum e o terceiro
está com eles pois ele divide o cookie=b com o segundo evento.
ransação produz dois campos:
: a diferença entre as estampas de tempo para o primeiro e último evento na
35
são opcionais, mas algumas restrições tem
de ser especificadas para definir como os eventos serão agrupado em transações.
múltiplos campos
) ou uma disjunção (field1 OR
) destes campos. Se existe uma relação transitiva entre os campos no
, você pode ver os seguintes
em comum e o terceiro
: a diferença entre as estampas de tempo para o primeiro e último evento na

• eventcount: número de eventos na transação.
depois nesta seção) e o comando
existe uma importante distinção:
• stats calcula valores estatísticos nos eventos agrupados pelos valores dos campos(e
então os eventos descartados).
• transaction agrupa evento, e suporta mais opções em como eles podem s
mantém o texto cru e os valores dos outros campos dos eventos originais.
Reportando Resultados
Os comandos de reportagem cobertos nesta seção incluem
top
Tendo uma lista de campos, o comando
valores de campos, junto de suas contagens e porcentagens. Se você especificar por
clausula os campos adicionais opcionais, o valores mais
distinto de valores dos campos por clausula que f
O oposto do comum é raro O oposto do comando top
os valores menos comuns de um campo (em vez dos mais comuns). O comando exatamente isso.
Tabela 4-7. Exemplos do comando top
O segundo exemplo da tabela 4
: número de eventos na transação. Mesmo que o comando stats
comando transaction ambos permitem que você agrupe eventos,
existe uma importante distinção:
calcula valores estatísticos nos eventos agrupados pelos valores dos campos(e
então os eventos descartados).
agrupa evento, e suporta mais opções em como eles podem ser agrupados e
o texto cru e os valores dos outros campos dos eventos originais.
Reportando Resultados
Os comandos de reportagem cobertos nesta seção incluem top, stats, chart,e
Tendo uma lista de campos, o comando top retorna os grupos mais freqüentes
valores de campos, junto de suas contagens e porcentagens. Se você especificar por
clausula os campos adicionais opcionais, o valores mais freqüentes para cada grupo
distinto de valores dos campos por clausula que foram retornados.
top é o comando rare. Algumas vezes você que saber quais são os valores menos comuns de um campo (em vez dos mais comuns). O comando
top
O segundo exemplo da tabela 4-7, top 2 user by host, é ilustrado na figura 4
36
stats (coberto
permitem que você agrupe eventos,
calcula valores estatísticos nos eventos agrupados pelos valores dos campos(e
er agrupados e
,e timechart.
freqüentes deste
valores de campos, junto de suas contagens e porcentagens. Se você especificar por
para cada grupo
. Algumas vezes você que saber quais são os valores menos comuns de um campo (em vez dos mais comuns). O comando rare faz
, é ilustrado na figura 4-6.

Figura 4-6. Exemplo do comando top
stats
O comando stats calcula as estatísticas agregadas sobre um dataset, similar a uma
agregação em SQL. A tabulação resultante pode conter uma linha, que representa a
agregação de todo o grupo de resultados, ou uma linha para cada valor distinto
especificado por clausula.
Existe mais de um comando para cálculos estatísticos. Os comandos
chart e timechart fazem os mesmos cálculos estatísticos nos seus dados, mas retornam
grupos de resultados diferentes para permitir que você possa conseguir os resultados
necessários mais facilmente.
• O comando stats retorna uma tabela de resultados onde cada linha representa uma
combinação única dos valores dos campos agrupados.
• O comando chart retorna a mesma tabela de resultados, com as linhas como os
campos arbitrários.
• O comando timechart retorna os mesmos resultados tabulados, mas a linha é colocada
como um campo interno,
tempo..
O que “as” significa Nota: O uso da palavra chave “as” em alguns dos comandos na tabe usado para renome ar um campo. Por exemplo, ele tem que adicionar todos os campos “Revenue.”
top
calcula as estatísticas agregadas sobre um dataset, similar a uma
agregação em SQL. A tabulação resultante pode conter uma linha, que representa a
agregação de todo o grupo de resultados, ou uma linha para cada valor distinto
especificado por clausula.
xiste mais de um comando para cálculos estatísticos. Os comandos stats,
fazem os mesmos cálculos estatísticos nos seus dados, mas retornam
grupos de resultados diferentes para permitir que você possa conseguir os resultados
is facilmente.
retorna uma tabela de resultados onde cada linha representa uma
combinação única dos valores dos campos agrupados.
retorna a mesma tabela de resultados, com as linhas como os
retorna os mesmos resultados tabulados, mas a linha é colocada
como um campo interno, _time, que te permite organizar o seu gráfico por períodos de
O uso da palavra chave “as” em alguns dos comandos na tabela 4um campo. Por exemplo, sum(price) as “Revenue” significa que
ele tem que adicionar todos os campos price e nomear a coluna resultante como
37
calcula as estatísticas agregadas sobre um dataset, similar a uma
agregação em SQL. A tabulação resultante pode conter uma linha, que representa a
agregação de todo o grupo de resultados, ou uma linha para cada valor distinto
fazem os mesmos cálculos estatísticos nos seus dados, mas retornam
grupos de resultados diferentes para permitir que você possa conseguir os resultados
retorna uma tabela de resultados onde cada linha representa uma
retorna a mesma tabela de resultados, com as linhas como os
retorna os mesmos resultados tabulados, mas a linha é colocada
, que te permite organizar o seu gráfico por períodos de
la 4-14. O as é significa que
e nomear a coluna resultante como

A tabela 4-8 mostra exemplos do uso do comando
Tabela 4-8. Exemplos do comando stats
O terceiro exemplo na tabela 4
por host, é ilustrado na figura 4
Figura 4-7. Exemplo de comando stats
A tabela 4-9 lista funções estatísticas que você pode usa
funções também podem ser usadas com os comandos
discutir depois)
8 mostra exemplos do uso do comando stats.
stats
O terceiro exemplo na tabela 4-8, recuperando o número de pedidos de GET e POST
por host, é ilustrado na figura 4-7.
stats
9 lista funções estatísticas que você pode usar com o comando stats
funções também podem ser usadas com os comandos chart e timechart,que nós vamos
38
8, recuperando o número de pedidos de GET e POST
stats. (Estas
,que nós vamos
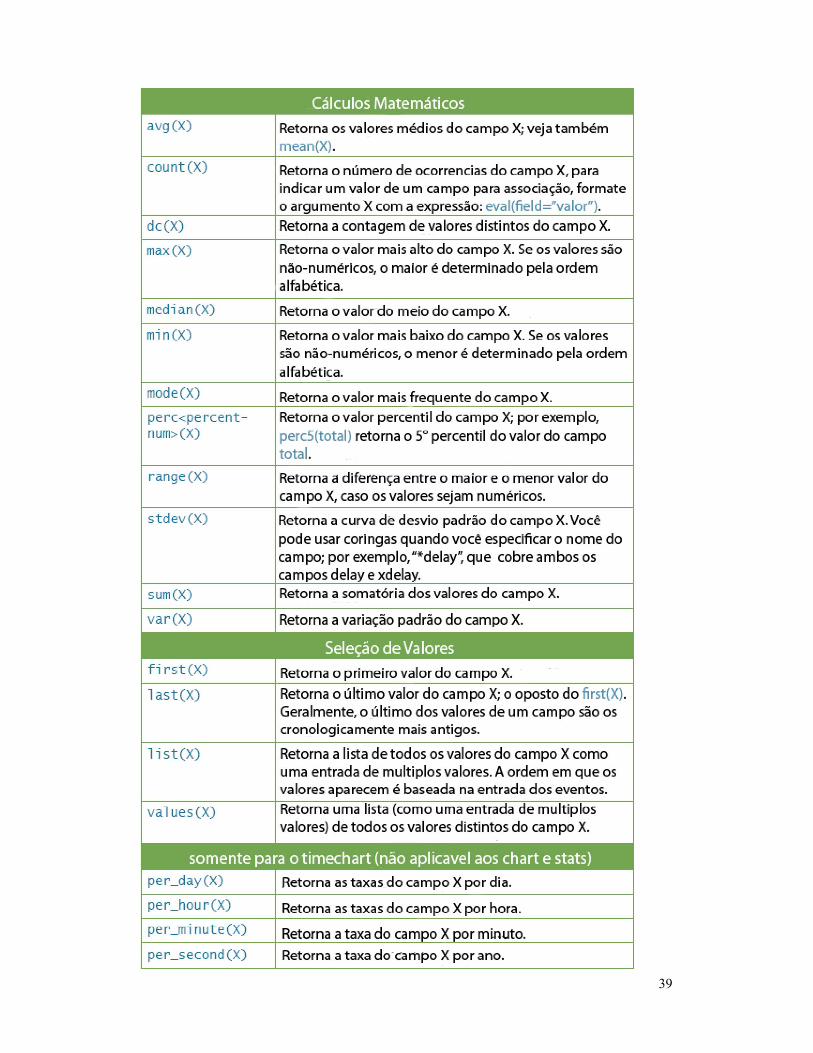
39

Tabela 4-9. Funções estatísticas do
Nota: Todas as funções exceto aquelas que são exclusivas do timechart são aplicáveis aos comandos
chart
O comando chart cria uma saída tabular de dados específica para gráficos. Você pode
especificar a variável do eixo x usando o
A tabela 4-10 mostra alguns exemplos de uso do comando
realistas, veja o capítulo 6.
Tabela 4-10. Exemplos do comando
As figuras 4-8 (resultados tabelados) e 4
ilustram os resultados do último exemplo da Tabela 4
9. Funções estatísticas do stats
Nota: Todas as funções exceto aquelas que são exclusivas do timechart são veis aos comandos chart, stats e timechart.
cria uma saída tabular de dados específica para gráficos. Você pode
especificar a variável do eixo x usando o over ou o by.
10 mostra alguns exemplos de uso do comando chart; para cenários mais
realistas, veja o capítulo 6.
10. Exemplos do comando chart
8 (resultados tabelados) e 4-9 (gráfico de barras em escala logarítmica)
ilustram os resultados do último exemplo da Tabela 4-10:
40
Nota: Todas as funções exceto aquelas que são exclusivas do timechart são
cria uma saída tabular de dados específica para gráficos. Você pode
ara cenários mais
9 (gráfico de barras em escala logarítmica)
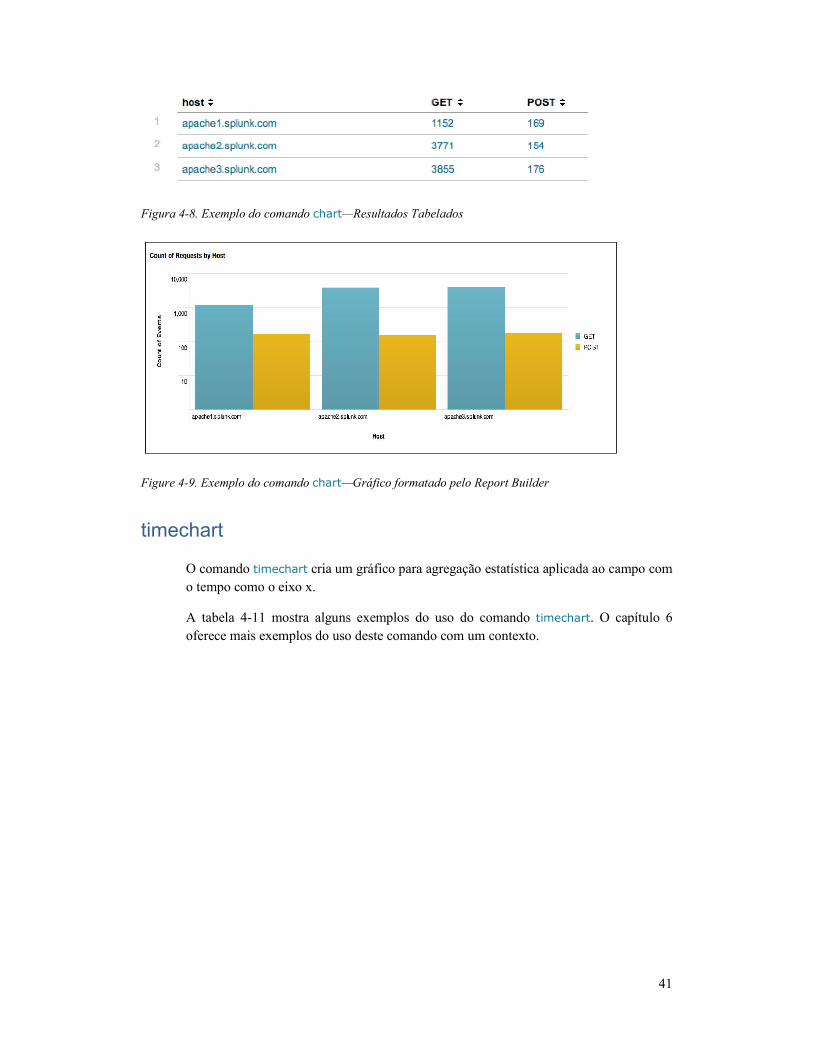
Figura 4-8. Exemplo do comando chart
Figure 4-9. Exemplo do comando chart
timechart
O comando timechart cria um gráfico para agregação estatística aplicada ao campo com
o tempo como o eixo x.
A tabela 4-11 mostra alguns exemplos do uso do comando
oferece mais exemplos do uso deste comando com um contexto.
chart—Resultados Tabelados
chart—Gráfico formatado pelo Report Builder
cria um gráfico para agregação estatística aplicada ao campo com
11 mostra alguns exemplos do uso do comando timechart. O capítulo 6
oferece mais exemplos do uso deste comando com um contexto.
41
cria um gráfico para agregação estatística aplicada ao campo com
. O capítulo 6
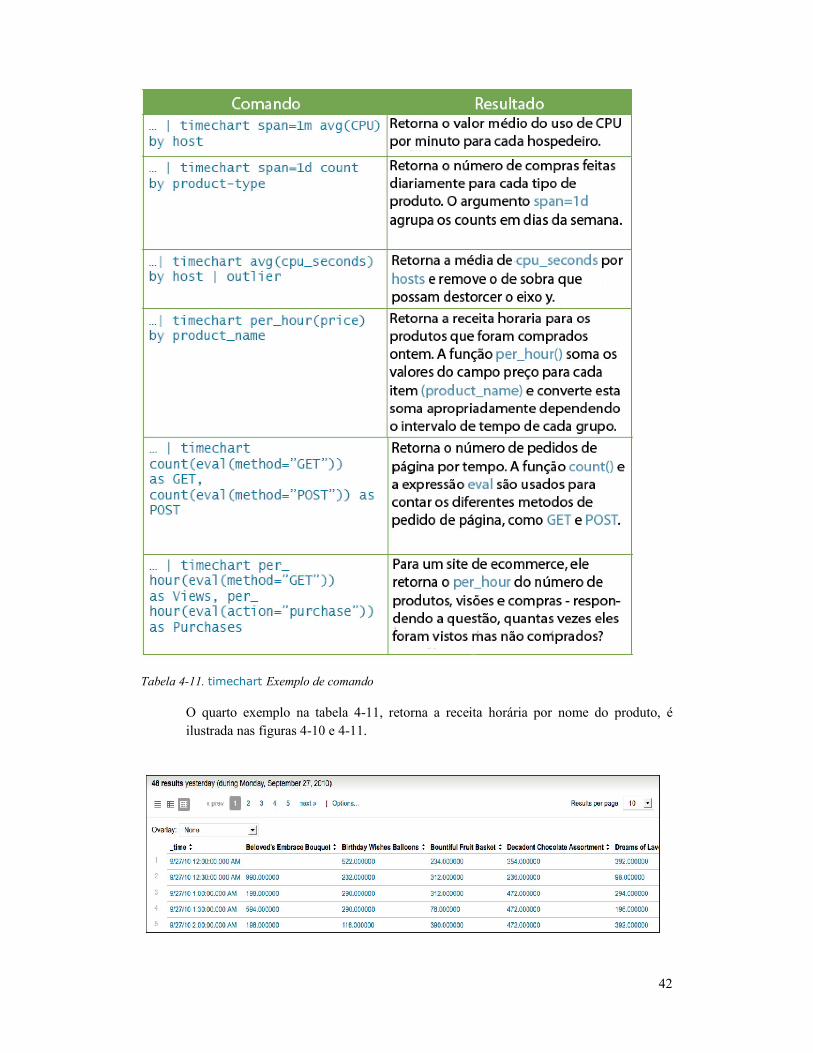
Tabela 4-11. timechart Exemplo de comando
O quarto exemplo na tabela 4
ilustrada nas figuras 4-10 e 4
Exemplo de comando
O quarto exemplo na tabela 4-11, retorna a receita horária por nome do produto, é
10 e 4-11.
42
o produto, é

Figure 4-10. Exemplo do comando timechart
Figure 4-11. Exemplo do comando timechart
Filtrando, Modificando e Adicionando Campos
Estes comandos irão te ajudar a obter somente os campos desejados em sua busca. Você
pode querer simplificar os seus resultados usando o comando
campos. Você pode querer que os valores dos seus campos fiquem mais fáceis de ler
usando o comando replace
Ou você precise adicionar novos campos com a ajuda de comandos como
lookup:
• O comando eval calcula o valor de um novo campo baseado nos outros campos, seja
numericamente, por concatenação ou através de lógica booleana.
• O comando rex pode ser usado para criar novos campos através do uso de expressões
regulares para a extração de padrões de dados em outros campos.
• O comando lookup adiciona campos baseados na busca de um valor em um evento,
referir ele para uma tabela
linha da tabela de lookup no evento. Estes comandos podem ser usados para criar novos
campos ou eles podem ser usados para substituir os valores de campos existentes. Isso
fica a sua escolha.
fields
O comando fields remove os campos de uma busca. Comandos típicos são mostrados na
tabela 4-12.
timechart—Resultados Tabelados
timechart—Gráfico formatado pelo Report Builder
Filtrando, Modificando e Adicionando Campos
Estes comandos irão te ajudar a obter somente os campos desejados em sua busca. Você
pode querer simplificar os seus resultados usando o comando fields para remover alguns
campos. Você pode querer que os valores dos seus campos fiquem mais fáceis de ler
replace.
Ou você precise adicionar novos campos com a ajuda de comandos como
calcula o valor de um novo campo baseado nos outros campos, seja
numericamente, por concatenação ou através de lógica booleana.
pode ser usado para criar novos campos através do uso de expressões
regulares para a extração de padrões de dados em outros campos.
adiciona campos baseados na busca de um valor em um evento,
referir ele para uma tabela de lookup, e adicionando os campos que se encaixam da
linha da tabela de lookup no evento. Estes comandos podem ser usados para criar novos
campos ou eles podem ser usados para substituir os valores de campos existentes. Isso
remove os campos de uma busca. Comandos típicos são mostrados na
43
Estes comandos irão te ajudar a obter somente os campos desejados em sua busca. Você
para remover alguns
campos. Você pode querer que os valores dos seus campos fiquem mais fáceis de ler
Ou você precise adicionar novos campos com a ajuda de comandos como eval, rex e
calcula o valor de um novo campo baseado nos outros campos, seja
pode ser usado para criar novos campos através do uso de expressões
adiciona campos baseados na busca de um valor em um evento,
de lookup, e adicionando os campos que se encaixam da
linha da tabela de lookup no evento. Estes comandos podem ser usados para criar novos
campos ou eles podem ser usados para substituir os valores de campos existentes. Isso
remove os campos de uma busca. Comandos típicos são mostrados na

Tabela 4-12. Exemplos do comando
O primeiro exemplo da tabela 4
Figura 4-12. Exemplo do comando fields
Pontos Chave
Campos internos, ou seja, campos cujo o nome começa com um underscore, não são
afetados pelo comando fields
replace
O comando replace executa
campo por outro valor substituto.
O valor em uma localização e substituição é sensível a maiúsculas.
12. Exemplos do comando fields
O primeiro exemplo da tabela 4-12, fields – field1, field2, é ilustrado na figura 4
fields
Campos internos, ou seja, campos cujo o nome começa com um underscore, não são
fields, a não ser que especificado.
executa uma localização e substituição de um valor especifico de
campo por outro valor substituto.
O valor em uma localização e substituição é sensível a maiúsculas.
44
, é ilustrado na figura 4-12.
Campos internos, ou seja, campos cujo o nome começa com um underscore, não são
uma localização e substituição de um valor especifico de

Tabela 4-13. Exemplos do comando
O segundo exemplo na tabela 4
msg_level, é ilustrado na figura 4
Figura 4-13. Exemplo do comando replace
eval
O comando eval calcula uma expressão e coloca o valor resultante em um novo campo.
Os comandos eval e where
todas as funções disponíveis.
13. Exemplos do comando replace
O segundo exemplo na tabela 4-13, muda de 0 para Critical e 1 para Error no
msg_level, é ilustrado na figura 4-13.
replace
calcula uma expressão e coloca o valor resultante em um novo campo.
where usam a mesma sintaxe de expressão; O Apêndice E lista
todas as funções disponíveis.
45
para Error no
calcula uma expressão e coloca o valor resultante em um novo campo.
expressão; O Apêndice E lista

Tabela 4-14. Exemplos do comando
A figura 4-14 ilustra o primeiro exemplo na tabela 4
Figura 4-14. Exemplo do comando eval
Os resultados do comando
chamado velocity já existe, o comando
substitui somente um campo por vez.
rex
O comando rex extrai campos que possuem um valor que se encaixa em uma
Regular Compatível de Perl (PCRE) especificado. (
expressão regular (Regular Ex
O que são expressões regulares? Pense nas expressões regulares como “coringas ao extremo”. Você provavelmente já procurou em arquivos com expressões como *.doc ou *.xls. Expressões regulares permitem que você leve isto para um novo patamar de poder e flexibilidade. Se você já está familiar com as expressões regulares, você provavelmente não está lendo esta caixa. Para aprender mais, veja site no tópico.
14. Exemplos do comando eval
14 ilustra o primeiro exemplo na tabela 4-14, eval velocity=distance/time
eval
Os resultados do comando eval criam um novo campo chamado velocity. (Se um campo
já existe, o comando eval atualiza o seu valor.) O comando
substitui somente um campo por vez.
extrai campos que possuem um valor que se encaixa em uma
Regular Compatível de Perl (PCRE) especificado. (rex é uma abreviação pa
expressão regular (Regular Expression).)
O que são expressões regulares?
Pense nas expressões regulares como “coringas ao extremo”. Você provavelmente já quivos com expressões como *.doc ou *.xls. Expressões regulares
permitem que você leve isto para um novo patamar de poder e flexibilidade. Se você já está familiar com as expressões regulares, você provavelmente não está lendo esta
mais, veja http://www.regular-expressions.info —facilmente o melhor
46
velocity=distance/time.
. (Se um campo
atualiza o seu valor.) O comando eval cria e
extrai campos que possuem um valor que se encaixa em uma Expressão
é uma abreviação para
Pense nas expressões regulares como “coringas ao extremo”. Você provavelmente já quivos com expressões como *.doc ou *.xls. Expressões regulares
permitem que você leve isto para um novo patamar de poder e flexibilidade. Se você já está familiar com as expressões regulares, você provavelmente não está lendo esta
facilmente o melhor

Tabela 4-15. Exemplos do comando
A figura 4-15 ilustra o primeiro exemplo na tabela 4
Figura 4-15. Exemplo do comando rex
lookup
O comando de lookup manualmente invoca campos de lookup de uma tabela de lookup,
permitindo que você adicione campos e valores de fontes externas. Por exemplo, se
você tem CEPs, você pode fazer um lookup no nome da rua.
Exemplos do comando rex
15 ilustra o primeiro exemplo na tabela 4-15, extraindo os campos
rex
manualmente invoca campos de lookup de uma tabela de lookup,
permitindo que você adicione campos e valores de fontes externas. Por exemplo, se
você tem CEPs, você pode fazer um lookup no nome da rua.
47
15, extraindo os campos from e to.
manualmente invoca campos de lookup de uma tabela de lookup,
permitindo que você adicione campos e valores de fontes externas. Por exemplo, se

48
Tabela 4-16. Exemplos do comando lookup
A figura 4-16 ilustra o primeiro exemplo da tabela 4-16, lookup usertogroup user as
local_user OUTPUT group as user_group.
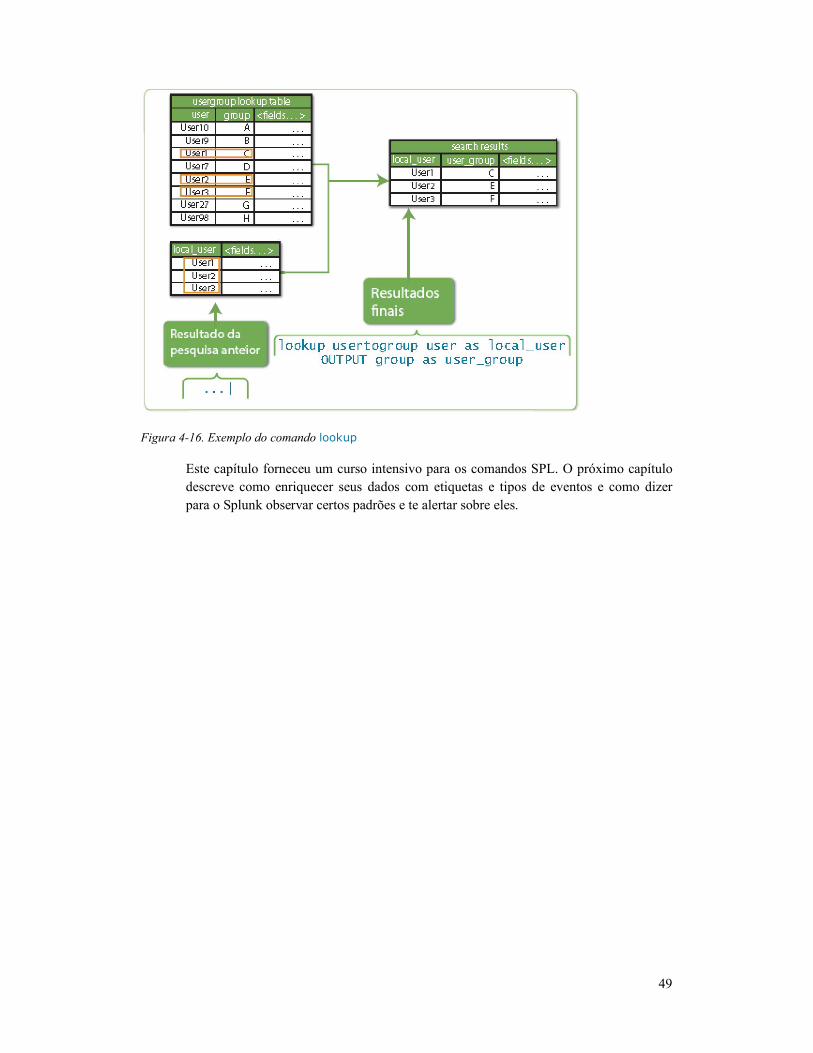
49
Figura 4-16. Exemplo do comando lookup
Este capítulo forneceu um curso intensivo para os comandos SPL. O próximo capítulo
descreve como enriquecer seus dados com etiquetas e tipos de eventos e como dizer
para o Splunk observar certos padrões e te alertar sobre eles.

50
5 Enriquecendo seus dados
Para fazer os seus dados mais úteis, adiciones conhecimento a eles. O que a gente quer
dizer com isso? Quando você diz ao Splunk como extrair os campos dos seus dados,
você pode começar a discutir sobre estes campos e dar ao Splunk o conhecimento para
classificar os seus dados para análises mais profundas. Quando você salva reportagens e
dashboards, seus dados se tornam mais fáceis de entender, tanto para você quanto para
os outros. E quando você cria alertas, o Splunk proativamente revela potenciais
problemas para que você não tenha que procurar manualmente depois do ocorrido.
Este capítulo cobre 3 áreas:
• Usando o Splunk para entender os seus dados mostra como explorar, categorizar e
se tornar mais familiar com os seus dados.
• Mostrando os dados mostra o básico da visualização de dados.
• Criando alertas para potenciais problemas mostra como localizar e mandar alertas
quando os dados alcançam uma marca.
Usando o Splunk para entender os dados
Quando você encontrar pela primeira vez uma nova fonte de dados de maquina, ele
pode parecer como uma massa sem sentido de números e texto crípticos. Quanto mais
você sabe sobre o sistema que está bombeando os dados, mais os dados irão fazer
sentido para você. Mas mesmo que você saiba o conjunto de dados bem, uma
exploração mais profunda pode lhe trazer novas perspectivas.
O primeiro passo em conhecer os dados é usar o Splunk para identificar os campos nos
seus dados. Você pode pensar que isto é como procurar entre todas as peças do quebra-
cabeça, primeiro notando seus formatos. O próximo passo é categorizar os dados como
uma proposta para agregação e reportagem. Isto é como organizar as peças do quebra-
cabeça em peças de borda e peças do meio. Quando mais você for capaz de entender os
dados e montar o quebra-cabeça, mais claro a imagem vai ficando.
E por último, a imagem está completa (mostrando os dados) e você pode compartilhar
ela com os outros.
Identificando campos: Olhando entre as peças do quebra-
cabeça
O Splunk reconhece muitos dos tipos mais comuns de dados, referidos como tipos de
fonte. Se você colocar o tipo de fonte correto, o Splunk pode usar ambientações pré-
configuradas para tentar identificar os campos. Este é o caso para muitos dos logs de
servidores web, por exemplo.

51
Mas ainda é comum existirem atributos escondidos nos dados de maquina. Por
exemplo, a categoria de um produto pode fazer parte de uma URL. Examinando os
eventos que possuem certas categorias de produtos nas suas URLs, você pode
determinar os tempos de resposta e taxas de erro para diferentes seções do site ou
informações sobre quais tipos de produtos são os mais procurados.
Descoberta de campo automática
Quando você faz uma busca, o Splunk automaticamente extrai os campos através da
identificação de padrões comuns nos dados, como a presença de um sinal igual entre a
chave e o valor. Por exemplo, se um evento contem “… id=11 lname=smith … ” o
Splunk automaticamente cria os campos id e lname com os valores de exemplo. E,
como foi mencionado no capítulo 2, alguns campos (como source, sourcetype, host,
_time e linecount) serão sempre identificados.
Não consegue achar o que você está procurando? Comece a procurar por isso. O
Splunk mostra somente um certo número de campos na tela por padrão. Centenas ou
mais podem ter sido extraídos perfeitamente. Procurar por eles faz com que eles
apareçam no topo.
O botão de Descoberta de Campos (Field Discovery) na barra lateral de Campos
(Fields) ta tela pode ligar ou desligar este comportamento. Você pode usar alguns
destes campos selecionados (campos que o Splunk selecionou por padrão ou que você
tenha escolhido), seguidos de campos que o Splunk achou pois eles aparecem em
múltiplos eventos. Se você clicar em Editar (Edit), o Splunk lista mais campos que
você pode adicionar ao grupo de campos selecionados. Criando em qualquer campo
mostra pra você os valores mais comuns extraídos dos resultados da sua busca.
Para mais informações sobre a extração automática de campos, veja
http://splunk.com/goto/book#auto_fields.
Configurando a Extração de Campos
A configuração da extração de campos pode ser feita de duas formas. Você pode deixar
o Splunk automatizar a configuração para você utilizando o Extrator de Campos
Interativo (Interactive Field Extrator), ou você pode manualmente especificar a
configuração você mesmo.
O Extrator de Campos Interativo
De qualquer evento no resultado de sua busca, você pode iniciar o Interactive Field
Extractor (IFX) selecionando a opção Extract Fields do menu Event option,
que você pode alcançar clicando na seta para baixo a esquerda de um evento na lista de
eventos (veja a figura 5-1).

Figure 5-1. Escolhendo o Extract Fields Extractor
O IFX aparecerá em outra aba ou janela no seu navegador. Colocando
que você deseja encontrar (como o IP do cliente nos endereços dentro dos logs de web),
o Splunk gera uma expressão regular que extrai valores similares (isto é especialmente
útil para aqueles que tem dificuldades com REX entre nós). Você
(para ter certeza que ela está encontrando o campo que você estava procurando) e salvar
ela com o nome do campo que deseja.
Para aprender mais sobre o IFX, veja
Configurando manualmente a extração dos
Do menu Manager » Fields » Field extractions
expressão regular para extrair o campo, que é um método mais flexível e avançado de
fazer a extração.
Para aprender mais sobre a extração manual de campos, veja
http://splunk.com/goto/book#config_fields
Extração de Linguagem de Busca
Outra forma de extrair campos é o uso de comandos de busca. O comando mais comum
para a extração de dados é o comando
expressão regular e extrai os campos que se encaixam na
Alguma vezes o comando que você usa depende do tipo de dado do qual você está
extraindo os campos. Para extrair os campos de eventos tabulares
como a saída de uma linha de comando), use o
JSON, use o spath ou xmlkv
Para aprender mais sobre comandos que extraem campos, veja
http://splunk.com/goto/book#search_fields
Explorando os dados pa
Depois que os campos são extraídos, você pode começar a explorar os dados para ver o
que ele te diz. Retornando a nossa analogia do quebra
Extract Fields do menu do Event Options você inicia o Interactive Field
O IFX aparecerá em outra aba ou janela no seu navegador. Colocando os tipos de valor
que você deseja encontrar (como o IP do cliente nos endereços dentro dos logs de web),
o Splunk gera uma expressão regular que extrai valores similares (isto é especialmente
útil para aqueles que tem dificuldades com REX entre nós). Você pode testar a extração
(para ter certeza que ela está encontrando o campo que você estava procurando) e salvar
ela com o nome do campo que deseja.
Para aprender mais sobre o IFX, veja http://splunk.com/goto/book#ifx.
Configurando manualmente a extração dos campos
Manager » Fields » Field extractions, você pode especificar manualmente a
expressão regular para extrair o campo, que é um método mais flexível e avançado de
Para aprender mais sobre a extração manual de campos, veja
//splunk.com/goto/book#config_fields.
Extração de Linguagem de Busca
Outra forma de extrair campos é o uso de comandos de busca. O comando mais comum
para a extração de dados é o comando rex, descrito no último capítulo. Ele toma uma
expressão regular e extrai os campos que se encaixam na expressão.
Alguma vezes o comando que você usa depende do tipo de dado do qual você está
extraindo os campos. Para extrair os campos de eventos tabulares multi linha
como a saída de uma linha de comando), use o multikv e para extrair de dados XML e
xmlkv.
Para aprender mais sobre comandos que extraem campos, veja
http://splunk.com/goto/book#search_fields.
Explorando os dados para entender o escopo
Depois que os campos são extraídos, você pode começar a explorar os dados para ver o
que ele te diz. Retornando a nossa analogia do quebra-cabeça, você começa procurando
52
Interactive Field
os tipos de valor
que você deseja encontrar (como o IP do cliente nos endereços dentro dos logs de web),
o Splunk gera uma expressão regular que extrai valores similares (isto é especialmente
pode testar a extração
(para ter certeza que ela está encontrando o campo que você estava procurando) e salvar
, você pode especificar manualmente a
expressão regular para extrair o campo, que é um método mais flexível e avançado de
Para aprender mais sobre a extração manual de campos, veja
Outra forma de extrair campos é o uso de comandos de busca. O comando mais comum
, descrito no último capítulo. Ele toma uma
Alguma vezes o comando que você usa depende do tipo de dado do qual você está
lti linha (Tal qual
e para extrair de dados XML e
Para aprender mais sobre comandos que extraem campos, veja
Depois que os campos são extraídos, você pode começar a explorar os dados para ver o
cabeça, você começa procurando
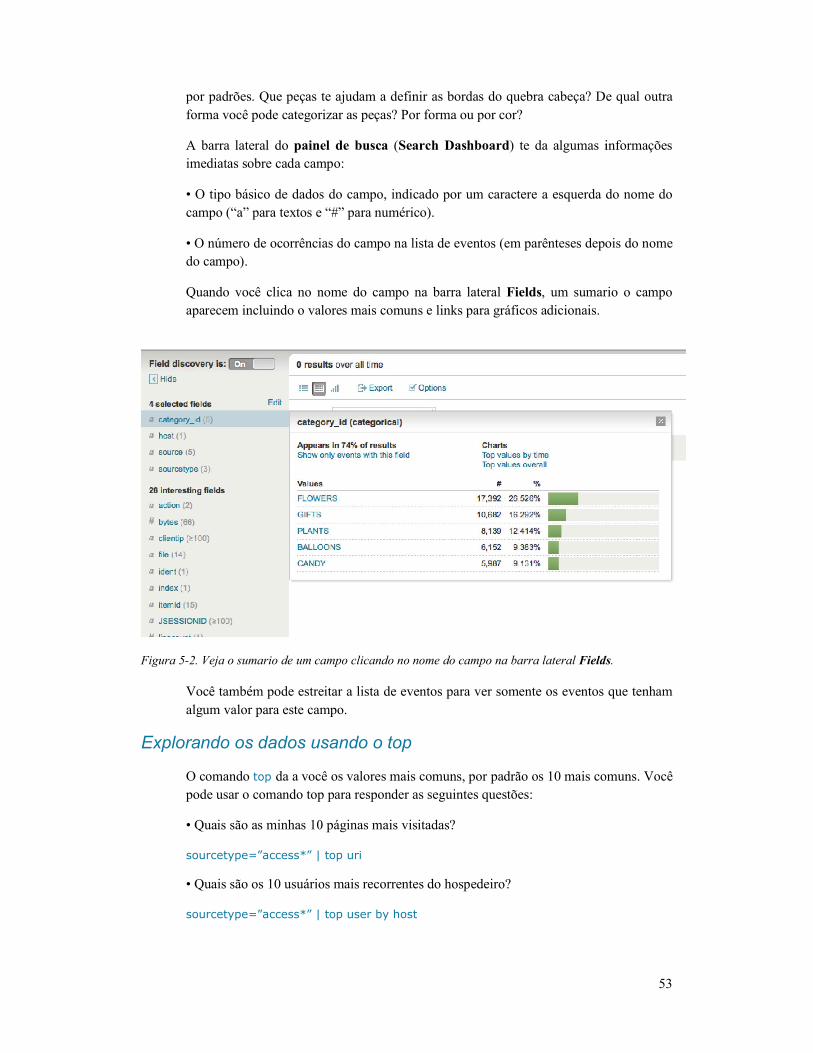
por padrões. Que peças te ajudam a definir as bordas do quebra c
forma você pode categorizar as peças? Por forma ou por cor?
A barra lateral do painel de busca
imediatas sobre cada campo:
• O tipo básico de dados do campo, indicado por um caractere a esquerda do nome do
campo (“a” para textos e “#” para
• O número de ocorrências do campo na lista de eventos (em
do campo).
Quando você clica no nome do cam
aparecem incluindo o valores mais comuns e links para gráficos adicionais.
Figura 5-2. Veja o sumario de um campo clicando no nome do campo na barra lateral
Você também pode estreitar a lista de
algum valor para este campo.
Explorando os dados usando o top
O comando top da a você os valores mais comuns, por padrão os 10 mais comuns. Você
pode usar o comando top para responder as seguintes questões:
• Quais são as minhas 10 páginas mais visitadas?
sourcetype=”access*” | top uri
• Quais são os 10 usuários mais recorrentes do hospedeiro?
sourcetype=”access*” | top user by host
por padrões. Que peças te ajudam a definir as bordas do quebra cabeça? De qual outra
forma você pode categorizar as peças? Por forma ou por cor?
painel de busca (Search Dashboard) te da algumas informações
imediatas sobre cada campo:
• O tipo básico de dados do campo, indicado por um caractere a esquerda do nome do
campo (“a” para textos e “#” para numérico).
• O número de ocorrências do campo na lista de eventos (em parênteses depois do nome
no nome do campo na barra lateral Fields, um sumario o campo
aparecem incluindo o valores mais comuns e links para gráficos adicionais.
2. Veja o sumario de um campo clicando no nome do campo na barra lateral Fields
Você também pode estreitar a lista de eventos para ver somente os eventos que tenham
algum valor para este campo.
Explorando os dados usando o top
da a você os valores mais comuns, por padrão os 10 mais comuns. Você
pode usar o comando top para responder as seguintes questões:
Quais são as minhas 10 páginas mais visitadas?
sourcetype=”access*” | top uri
• Quais são os 10 usuários mais recorrentes do hospedeiro?
sourcetype=”access*” | top user by host
53
abeça? De qual outra
) te da algumas informações
• O tipo básico de dados do campo, indicado por um caractere a esquerda do nome do
depois do nome
, um sumario o campo
Fields.
eventos para ver somente os eventos que tenham
da a você os valores mais comuns, por padrão os 10 mais comuns. Você

54
• Quais são os 50 pares de IP para fonte e destino?
…| top limit=50 src_ip, dest_ip
Explorando os dados usando o stats
O comando stats proporciona uma grande quantidade de informação estatística sobre os
seus dados.
Aqui estão algumas formas simples de como usar-lo:
• Quantas respostas de erro 503 eu tive?
sourcetype=”access*” status=503 | stats count
• Qual é a média de kilobytes por segundo do hospedeiro?
sourcetype=”access*” | stats avg(kbps) by host
• Quantas pessoas compraram flores ontem? Use o stats dc (contagem de distintos) para
ter certeza de que os endereços de IP repetidos serão contados apenas uma vez.
sourcetype=”access*” action=purchase category_id=flowers | stats dc(clientip)
• Quanto é 95% do tempo que os sites estão demorando para responder?
sourcetype=”access*” | stats perc95(spent)
Adicionando Sparklines a mistura
Desde o Splunk 4.3, você pode adicionar gráficos simples de linha, conhecidos como
Sparkline,
para os seus resultados tabulares. Os Sparklines te permitem a visualização de um
padrão de dados sem ter de criar um gráfico de linha separado.
Por exemplo, esta busca usa sparklines para mostrar o número de eventos por tempo
para cada hospedeiro?
* | stats sparkline count by host
A figura 5-3 mostra uma sparklines na tabela.

Figura 5-3. A Sparklines mostra os padrões nos dados dentro da tabela de even
Aqui estão alguns comandos a mais que demonstram formas de uso para as Sparklines:
• Qual é o número de eventos para cada combinação de status e categoria, por tempo?
sourcetype=”access*” | stats sparkline count by status,
• Qual é o tempo médio de resposta para cada categoria de produto,
por tempo?
sourcetype=”access*” | stats sparkline(avg(spent)) by category_
• Usando um grupo de dados diferente (dados de magnitude de terremotos), veja como a
magnitude de um terremoto vária de região pa
horas, com as regiões mais recorrentes primeiro.
source=eqs7day-M2.5.csv | stats sparkline(avg(Magnitude),6h)
count, avg(Magnitude) by Region | sort
Preparando para reportagem e agregação
Depois de já ter identificado os campos e explorado os dados, o próximo passo é
começar a entender o que está acontecendo. Agrupando os seus dados em categorias,
você pode buscar, reportar e alertar para estas categorias.
As categorias das quais estamos fa
dados, e você sabe o que você quer tirar deles. Usando o Splunk, você pode categorizar
seus dados de quantas formas você quiser.
Existem duas formas primárias de que o Splunk pode te ajudar com a categor
dados: etiquetas e tipos de eventos.
Etiquetagem (Tagging)
3. A Sparklines mostra os padrões nos dados dentro da tabela de eventos
Aqui estão alguns comandos a mais que demonstram formas de uso para as Sparklines:
• Qual é o número de eventos para cada combinação de status e categoria, por tempo?
=”access*” | stats sparkline count by status,category_id
médio de resposta para cada categoria de produto,
sourcetype=”access*” | stats sparkline(avg(spent)) by category_id
• Usando um grupo de dados diferente (dados de magnitude de terremotos), veja como a
magnitude de um terremoto vária de região para região em intervalos de tempo de 6
horas, com as regiões mais recorrentes primeiro.
M2.5.csv | stats sparkline(avg(Magnitude),6h) as magnitude_trend,
count, avg(Magnitude) by Region | sort count
Preparando para reportagem e agregação
Depois de já ter identificado os campos e explorado os dados, o próximo passo é
começar a entender o que está acontecendo. Agrupando os seus dados em categorias,
você pode buscar, reportar e alertar para estas categorias.
As categorias das quais estamos falando são definidas pelo usuário. Você sabe dos seus
dados, e você sabe o que você quer tirar deles. Usando o Splunk, você pode categorizar
seus dados de quantas formas você quiser.
Existem duas formas primárias de que o Splunk pode te ajudar com a categor
dados: etiquetas e tipos de eventos.
55
Aqui estão alguns comandos a mais que demonstram formas de uso para as Sparklines:
• Qual é o número de eventos para cada combinação de status e categoria, por tempo?
• Usando um grupo de dados diferente (dados de magnitude de terremotos), veja como a
ra região em intervalos de tempo de 6
as magnitude_trend,
Depois de já ter identificado os campos e explorado os dados, o próximo passo é
começar a entender o que está acontecendo. Agrupando os seus dados em categorias,
lando são definidas pelo usuário. Você sabe dos seus
dados, e você sabe o que você quer tirar deles. Usando o Splunk, você pode categorizar
Existem duas formas primárias de que o Splunk pode te ajudar com a categorização dos

Tags são uma forma fácil de etiquetar qualquer valor de um campo. Se o nome do
hospedeiro é bdgpu-login
autenticação authentication_server
valor interessante na interface e quer ser capaz de investigar ele futuramente para
conseguir mais contexto, você pode colocar a
Para etiquetar o valor de um campo na lista de eventos, clique na
esquerda do valor do campo que você quer etiquetar (veja a figura 5
Figura 5-4. Etiquetando os hospedeiros
Você pode gerenciar todas as suas etiquetas indo para
Suponhamos que você etiquetou vários dos seus valores de hospedeiro com etiquetas
como webserver, database_server
customizadas para ver os seus dados da maneira que você quer ao invés de como a eles
aparecem normalmente.
Por exemplo, para comparar como vários tipos de hospedeiros se dão com o tempo,
rode uma busca como:
… | timechart avg(delay) by tag::host
Reportando e a alegria da busca ne Do momento em que você começa a procurar os dados, você deveria estar pensando sobre reportar. O que você gostaria de saber sobre os dados? O que você está procurando? Que “barulho” você gostaria de remover dos seus dados para que fique mais fácil de achar o que procura? O último ponto possui um explicação mais profunda como um exemplo de algo que o Splunk faz muito bem e que outros softwares de análise de dados podem: Busca Negativa. É muitas vezes dito que você não pode provar uma negação. Você não olhar para um todo e dizer que o que você procura não está aqui. Com o Splunk, você pode fazer uma busca negativa e de fato deveria. A ra
Tags são uma forma fácil de etiquetar qualquer valor de um campo. Se o nome do
login-01 ele não é intuitivo, coloque uma tag, como servidor de
cation_server, para que ele faça mais sentido. Se você ver um
valor interessante na interface e quer ser capaz de investigar ele futuramente para
conseguir mais contexto, você pode colocar a tag follow_up nele.
Para etiquetar o valor de um campo na lista de eventos, clique na seta para baixo a
esquerda do valor do campo que você quer etiquetar (veja a figura 5-4).
4. Etiquetando os hospedeiros
Você pode gerenciar todas as suas etiquetas indo para Manager » Tags.
Suponhamos que você etiquetou vários dos seus valores de hospedeiro com etiquetas
database_server, etc. Você pode reportar estas etiquetas
customizadas para ver os seus dados da maneira que você quer ao invés de como a eles
arecem normalmente. De novo, você decide como você quer olhar para os seus dados.
Por exemplo, para comparar como vários tipos de hospedeiros se dão com o tempo,
… | timechart avg(delay) by tag::host
Reportando e a alegria da busca negativa
Do momento em que você começa a procurar os dados, você deveria estar pensando sobre reportar. O que você gostaria de saber sobre os dados? O que você está procurando? Que “barulho” você gostaria de remover dos seus dados para que fique
fácil de achar o que procura?
O último ponto possui um explicação mais profunda como um exemplo de algo que o Splunk faz muito bem e que outros softwares de análise de dados podem: Busca
É muitas vezes dito que você não pode provar uma negação. Você não olhar para um todo e dizer que o que você procura não está aqui. Com o Splunk, você pode fazer uma busca negativa e de fato deveria. A razão pela qual é difícil de ver o que está
56
Tags são uma forma fácil de etiquetar qualquer valor de um campo. Se o nome do
não é intuitivo, coloque uma tag, como servidor de
, para que ele faça mais sentido. Se você ver um
valor interessante na interface e quer ser capaz de investigar ele futuramente para
para baixo a
Suponhamos que você etiquetou vários dos seus valores de hospedeiro com etiquetas
, etc. Você pode reportar estas etiquetas
customizadas para ver os seus dados da maneira que você quer ao invés de como a eles
, você decide como você quer olhar para os seus dados.
Por exemplo, para comparar como vários tipos de hospedeiros se dão com o tempo,
Do momento em que você começa a procurar os dados, você deveria estar pensando sobre reportar. O que você gostaria de saber sobre os dados? O que você está procurando? Que “barulho” você gostaria de remover dos seus dados para que fique
O último ponto possui um explicação mais profunda como um exemplo de algo que o Splunk faz muito bem e que outros softwares de análise de dados podem: Busca
É muitas vezes dito que você não pode provar uma negação. Você não olhar para um todo e dizer que o que você procura não está aqui. Com o Splunk, você pode fazer uma
ão pela qual é difícil de ver o que está

57
acontecendo com os arquivos de log, a muitos outros tipo de dados, é que eles tem muito do mesmo, coisas que são lugar comum para dados de maquina. Com o Splunk você pode categorizar estes dados desinteressantes e dizer ao Splunk para mostrar para você somente o que é incomum e diferente. Mostre me o que eu não havia visto antes. Alguns especialistas de segurança usam o Splunk desta forma única para identificar eventos anômalos que poderiam indicar uma intrusão, por exemplo. Se eles já viram isto antes, eles deram uma etiqueta e excluíram da busca. Depois que você faz isso por um tempo, e algo estranho acontece, você vai perceber na hora.
Tipos de Eventos
Quando você faz uma busca no Splunk, você começa a recuperar eventos. Você
implicitamente procura por uma espécie particular de evento fazendo uma busca por
ele. Você pode dizer que você estava procurando um evento de certo tipo. É assim que
os “event types” são usados: eles lhes permitem categorizar eventos.
Tipos de eventos (event types) facilitam a categorização de eventos usando o poder total
do comando search,o que significa que você pode usa expressões booleanas, coringas,
valores de campos, frases, etc. Desta maneira, event types são ainda mais poderosos que
as tags, que são limitadas aos valores dos campos. Mas, como as tags, como os dados
serão categorizados está nas suas mãos.
Você pode criar um event type para categorizar eventos como um em que o cliente fez
uma compra, o sistema travou, ou alguma condição de erro ocorreu.
Tudo isso tem a ver com o que você precisa saber dos eventos.
Aqui estão algumas regras básicas para uma busca que define um event type.
• Sem barras. Você não pode colocar barras na busca usada para criar um event type
(ela não pode ter comandos de busca alem do comando search implícito).
• No sub pesquisas. No fim do do capítulo 3, nós cobrimos rapidamente a roda
engrenagem dentro de uma engrenagem que é a sub pesquisa; por agora, lembre-se que
você não pode usar elas para criar event types.
Aqui está um exemplo simples. Na nossa busca contínua de melhorar o seu site, nós
vamos criar quatro tipos de eventos baseados no campo status:
• status=”2*” é definido como sucess(sucesso).
• status=”3*” é definido como redirect(redirecionamento).
• status=”4*” é definido como client_error(erro_do_cliente).
• status=”5*” é definido como server_error(erro_do_servidor).
Para criar um event type success como nós definimos, você teria que fazer uma busca
assim:
sourcetype=”access*” status=”2*
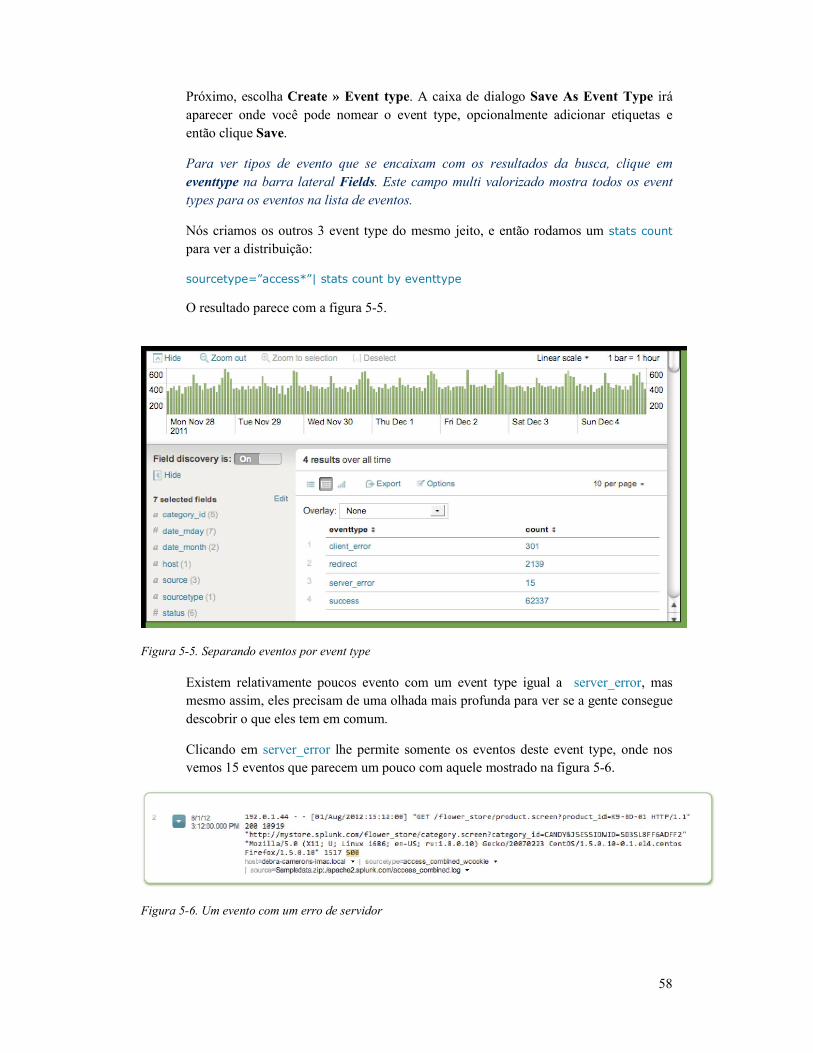
Próximo, escolha Create » Event type
aparecer onde você pode nomear o event type, opcionalmente adicionar etiquetas e
então clique Save.
Para ver tipos de evento que se encaixam com os resultados da busca, clique em
eventtype na barra lateral
types para os eventos na lista de eventos.
Nós criamos os outros 3 event type do mesmo jeito, e então rodamos um
para ver a distribuição:
sourcetype=”access*”| stats count
O resultado parece com a figura 5
Figura 5-5. Separando eventos por event type
Existem relativamente poucos evento com um event type igual a
mesmo assim, eles precisam de uma olhada mais profunda para ver se a gente
descobrir o que eles tem em comum.
Clicando em server_error
vemos 15 eventos que parecem um pouco com aquele mostrado na figura 5
Figura 5-6. Um evento com um erro de servidor
Create » Event type. A caixa de dialogo Save As Event Type
aparecer onde você pode nomear o event type, opcionalmente adicionar etiquetas e
Para ver tipos de evento que se encaixam com os resultados da busca, clique em
barra lateral Fields. Este campo multi valorizado mostra todos os event
types para os eventos na lista de eventos.
Nós criamos os outros 3 event type do mesmo jeito, e então rodamos um
sourcetype=”access*”| stats count by eventtype
O resultado parece com a figura 5-5.
5. Separando eventos por event type
Existem relativamente poucos evento com um event type igual a server_error
mesmo assim, eles precisam de uma olhada mais profunda para ver se a gente
descobrir o que eles tem em comum.
server_error lhe permite somente os eventos deste event type, onde nos
vemos 15 eventos que parecem um pouco com aquele mostrado na figura 5-6.
6. Um evento com um erro de servidor
58
Save As Event Type irá
aparecer onde você pode nomear o event type, opcionalmente adicionar etiquetas e
Para ver tipos de evento que se encaixam com os resultados da busca, clique em
mostra todos os event
Nós criamos os outros 3 event type do mesmo jeito, e então rodamos um stats count
server_error, mas
mesmo assim, eles precisam de uma olhada mais profunda para ver se a gente consegue
lhe permite somente os eventos deste event type, onde nos
6.

59
Os eventos de server_error tem uma coisa perturbadora em comum: pessoas estão
tentando comprar algo quando o status de servidor indisponível acontece. Em outras
palavras, isto está nos custando dinheiro! É hora de ir falar com a pessoa que administra
este servidor e descobrir o que há de errado.
Aninhando Event Types Você pode construir event types sobre os event types mais genéricos. Nós podemos definir um novo event type web_error com outros event types como tijolos: eventtype=client_error OR eventtype=server_error É claro, você deveria usar isto racionalmente, porque você não quer arriscar perder o foco e inadvertidamente criar definições circulares.
Etiquetando Event Types
Event types podem ter tags (assim como qualquer valor de um campo). Por exemplo,
você pode etiquetar todos os event types relacionados a erro sob a tag error. Você pode
adicionar tags mais descritivas sobre os tipos de erros dentro deste event type. Talvez
possa até haver 3 tipos de erros: um tipo que avisa com antecedência dos possíveis
problemas, outro que defina deficiências que podem afetar o usuário e outro que indica
uma falha catastrófica. Você pode adicionar outra tag aos event types de erros que seja
ainda mais descritiva, como early_
warning, user_impact ou red_alert, e reportar-las separadamente.
Juntos, event types e tags lhe permitem construir um modelo de alto nível dos eventos
detalhados nos dados de maquina em questão. Normalmente, isto é um processo
interativo. Você começa etiquetando alguns campos úteis, usando eles para monitorar e
alertar. Dali a pouco tempo, você vai começar a criar alguns event types para fazer uma
categorização mais complexa. Talvez colocar um event type de mais alto nível
referenciando event types de baixo nível. Talvez então você adicione tags aos seus
event types para unificar várias categorizações. O tempo todo, você vai estar
adicionando conhecimento ao Splunk de como ele pode organizar e rotular seus dados
da forma que você precisa.
Mais cedo, nós mencionamos a busca negativa. Se você etiquetar todos os event types
que você não quer ver como normal, você pode então procurar por eventos que não são
normais. Isto puxa as anomalias de volta para a superfície
NOT tag::eventtype=normal
Visualizando os Dados
Até agora nós lhe mostramos algumas forma de como conseguir a visualização dos seus
dados:
• Clicando no nome do campo na barra lateral Fields para ver alguns gráficos
simplificados sobre os valores do campo.
• Usando os comandos de busca top e stats.
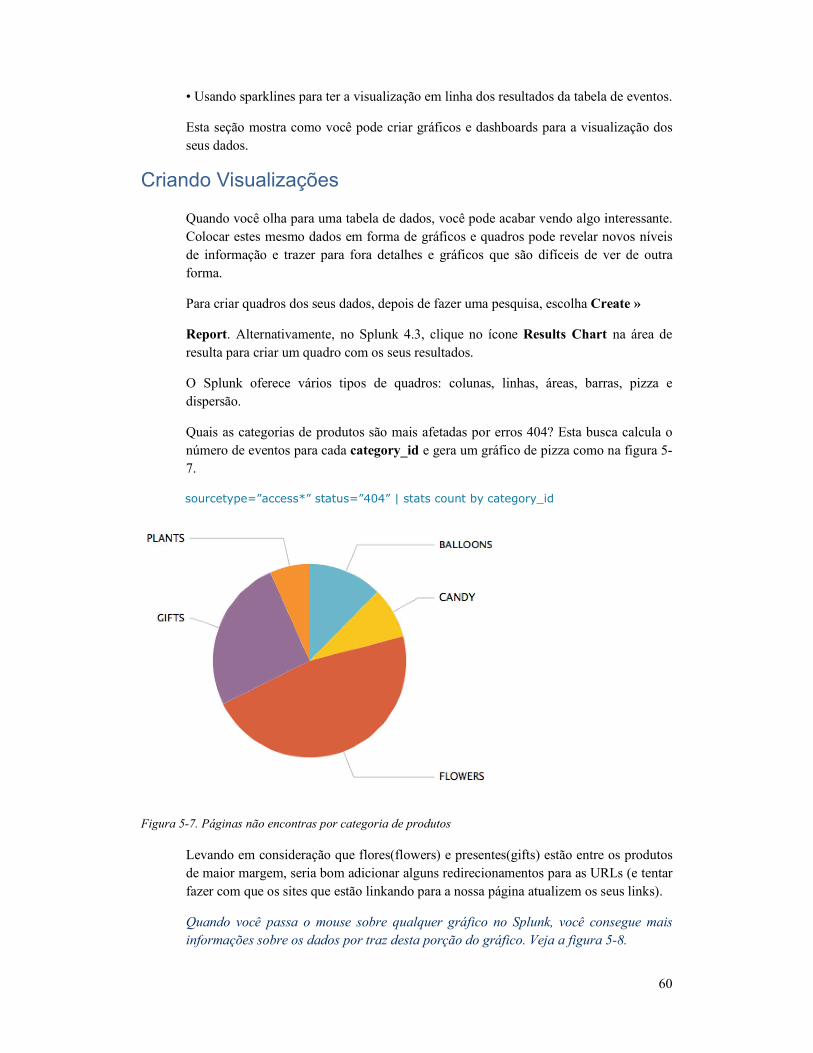
• Usando sparklines para ter a visualização em linha dos resultados da tabela de eventos.
Esta seção mostra como você pode criar gráficos e dashboards para a visualização dos
seus dados.
Criando Visualizações
Quando você olha para uma tabela de dados, você pode acabar vendo algo interessante.
Colocar estes mesmo dados em forma de gráficos e quadros pode
de informação e trazer para fora detalhes e gráficos que são difíceis de ver de outra
forma.
Para criar quadros dos seus dados, depois de fazer uma pesquisa, escolha
Report. Alternativamente, no Splunk 4.3, clique no ícone
resulta para criar um quadro com os seus resultados.
O Splunk oferece vários tipos de quadros: colunas, linhas, áreas, barras, pizza e
dispersão.
Quais as categorias de produtos são mais afetadas por erros 404? Esta busca calcula o
número de eventos para cada
7.
sourcetype=”access*” status=”404” | stats count by category_id
Figura 5-7. Páginas não encontras por categoria de produtos
Levando em consideração que
de maior margem, seria bom adicionar alguns redirecionamentos para as URLs (e tentar
fazer com que os sites que estão linkando para a nossa página atualizem os seus links).
Quando você passa o mous
informações sobre os dados por traz desta porção do gráfico. Veja a figura 5
• Usando sparklines para ter a visualização em linha dos resultados da tabela de eventos.
mostra como você pode criar gráficos e dashboards para a visualização dos
Criando Visualizações
Quando você olha para uma tabela de dados, você pode acabar vendo algo interessante.
Colocar estes mesmo dados em forma de gráficos e quadros pode revelar novos níveis
de informação e trazer para fora detalhes e gráficos que são difíceis de ver de outra
Para criar quadros dos seus dados, depois de fazer uma pesquisa, escolha Create »
. Alternativamente, no Splunk 4.3, clique no ícone Results Chart
resulta para criar um quadro com os seus resultados.
O Splunk oferece vários tipos de quadros: colunas, linhas, áreas, barras, pizza e
Quais as categorias de produtos são mais afetadas por erros 404? Esta busca calcula o
úmero de eventos para cada category_id e gera um gráfico de pizza como na figura 5
sourcetype=”access*” status=”404” | stats count by category_id
7. Páginas não encontras por categoria de produtos
Levando em consideração que flores(flowers) e presentes(gifts) estão entre os produtos
de maior margem, seria bom adicionar alguns redirecionamentos para as URLs (e tentar
fazer com que os sites que estão linkando para a nossa página atualizem os seus links).
Quando você passa o mouse sobre qualquer gráfico no Splunk, você consegue mais
informações sobre os dados por traz desta porção do gráfico. Veja a figura 5
60
• Usando sparklines para ter a visualização em linha dos resultados da tabela de eventos.
mostra como você pode criar gráficos e dashboards para a visualização dos
Quando você olha para uma tabela de dados, você pode acabar vendo algo interessante.
revelar novos níveis
de informação e trazer para fora detalhes e gráficos que são difíceis de ver de outra
Create »
sults Chart na área de
O Splunk oferece vários tipos de quadros: colunas, linhas, áreas, barras, pizza e
Quais as categorias de produtos são mais afetadas por erros 404? Esta busca calcula o
e gera um gráfico de pizza como na figura 5-
flores(flowers) e presentes(gifts) estão entre os produtos
de maior margem, seria bom adicionar alguns redirecionamentos para as URLs (e tentar
fazer com que os sites que estão linkando para a nossa página atualizem os seus links).
e sobre qualquer gráfico no Splunk, você consegue mais
informações sobre os dados por traz desta porção do gráfico. Veja a figura 5-8.
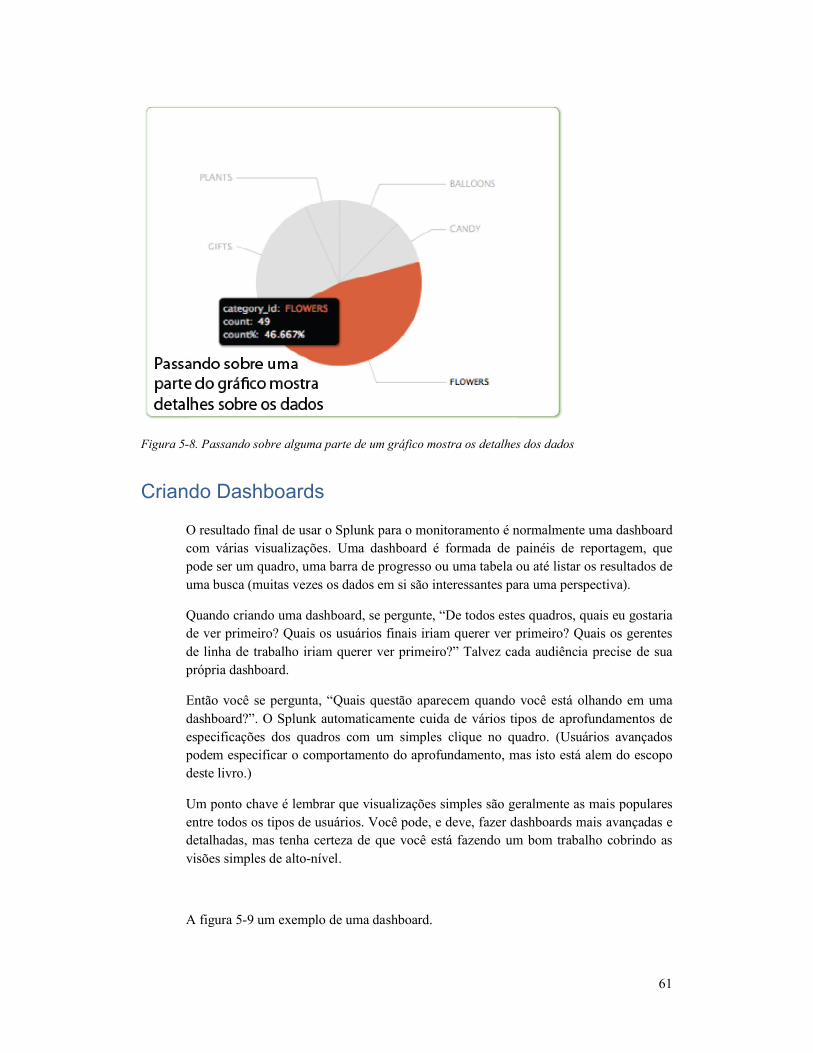
Figura 5-8. Passando sobre alguma parte de um gráfico mostra os detalhes dos dados
Criando Dashboards
O resultado final de usar o Splunk para o monitoramento é normalmente uma dashboard
com várias visualizações. Uma dashboard é formada de painéis de reportagem, que
pode ser um quadro, uma barra de progresso ou uma tabela ou até listar os resultados de
uma busca (muitas vezes os dados em si são interessantes para uma
Quando criando uma dashboard, se pergunte, “De todos estes quadros, quais eu gostaria
de ver primeiro? Quais os usuários finais iriam querer ver primeiro? Quais os gerentes
de linha de trabalho iriam querer ver primeiro?” Talvez cada audiência precise de sua
própria dashboard.
Então você se pergunta, “Quais questão aparecem quando você está olhando em uma
dashboard?”. O Splunk automaticamente cuida de vários tipos de aprofundamentos
especificações dos quadros com um simples clique no quadro.
podem especificar o comportamento do aprofundamento, mas isto está alem do escopo
deste livro.)
Um ponto chave é lembrar que visualizações simples são geralmente as mais po
entre todos os tipos de usuários. Você pode, e deve, fazer dashboards mais avançadas e
detalhadas, mas tenha certeza de que você está fazendo um bom trabalho cobrindo as
visões simples de alto-nível.
A figura 5-9 um exemplo de uma dashboard.
8. Passando sobre alguma parte de um gráfico mostra os detalhes dos dados
Criando Dashboards
O resultado final de usar o Splunk para o monitoramento é normalmente uma dashboard
com várias visualizações. Uma dashboard é formada de painéis de reportagem, que
pode ser um quadro, uma barra de progresso ou uma tabela ou até listar os resultados de
busca (muitas vezes os dados em si são interessantes para uma perspectiva
Quando criando uma dashboard, se pergunte, “De todos estes quadros, quais eu gostaria
de ver primeiro? Quais os usuários finais iriam querer ver primeiro? Quais os gerentes
a de trabalho iriam querer ver primeiro?” Talvez cada audiência precise de sua
Então você se pergunta, “Quais questão aparecem quando você está olhando em uma
O Splunk automaticamente cuida de vários tipos de aprofundamentos
especificações dos quadros com um simples clique no quadro. (Usuários avançados
podem especificar o comportamento do aprofundamento, mas isto está alem do escopo
Um ponto chave é lembrar que visualizações simples são geralmente as mais po
entre todos os tipos de usuários. Você pode, e deve, fazer dashboards mais avançadas e
detalhadas, mas tenha certeza de que você está fazendo um bom trabalho cobrindo as
nível.
9 um exemplo de uma dashboard.
61
O resultado final de usar o Splunk para o monitoramento é normalmente uma dashboard
com várias visualizações. Uma dashboard é formada de painéis de reportagem, que
pode ser um quadro, uma barra de progresso ou uma tabela ou até listar os resultados de
perspectiva).
Quando criando uma dashboard, se pergunte, “De todos estes quadros, quais eu gostaria
de ver primeiro? Quais os usuários finais iriam querer ver primeiro? Quais os gerentes
a de trabalho iriam querer ver primeiro?” Talvez cada audiência precise de sua
Então você se pergunta, “Quais questão aparecem quando você está olhando em uma
O Splunk automaticamente cuida de vários tipos de aprofundamentos de
(Usuários avançados
podem especificar o comportamento do aprofundamento, mas isto está alem do escopo
Um ponto chave é lembrar que visualizações simples são geralmente as mais populares
entre todos os tipos de usuários. Você pode, e deve, fazer dashboards mais avançadas e
detalhadas, mas tenha certeza de que você está fazendo um bom trabalho cobrindo as

Figura 5-9. Uma dashboard
A melhor forma de construir uma dashboard não é de cima para baixo, mas de baixo
para cima, com cada painel. Comece usando as habilidades de enquadramento do
Splunk para mostrar os sinais vitais de várias formas. Quando você tem v
individuais mostrando diferentes partes da saúde do sistema, coloque eles em uma
dashboard.
Criando uma Dashboard
No Splunk 4.3, para criar uma dashboard e adicionar um relatório, quadro ou resultados
de uma busca a ela:
1. Faça uma busca que gere o relatório para uma dashboard.
2. Escolha o painel Create » Dashboard
3. De um nome a sua busca, então clique em
4. Decida se você quer que este relatório irá para um nova dashboard alguma existente.
Se você for criar uma nova dashboard, d
5. Especifique o título da sua dashboard e a sua visualização (tabela, barra,
de progresso, etc.), e quando você quer que o relatório rode
chamada ou em uma rotina fixa).
6. Clique Next seguido pelo link
Vendo uma Dashboard
A qualquer hora você pode uma dashboard selecionando ela do menu
Views no topo da página.
A melhor forma de construir uma dashboard não é de cima para baixo, mas de baixo
para cima, com cada painel. Comece usando as habilidades de enquadramento do
Splunk para mostrar os sinais vitais de várias formas. Quando você tem vários gráficos
individuais mostrando diferentes partes da saúde do sistema, coloque eles em uma
Criando uma Dashboard
No Splunk 4.3, para criar uma dashboard e adicionar um relatório, quadro ou resultados
que gere o relatório para uma dashboard.
Create » Dashboard.
3. De um nome a sua busca, então clique em Next.
4. Decida se você quer que este relatório irá para um nova dashboard alguma existente.
Se você for criar uma nova dashboard, de a ela um nome. Clique Next.
5. Especifique o título da sua dashboard e a sua visualização (tabela, barra,
de progresso, etc.), e quando você quer que o relatório rode (sempre que a dashboard é
chamada ou em uma rotina fixa).
seguido pelo link View dashboard ou OK.
Vendo uma Dashboard
A qualquer hora você pode uma dashboard selecionando ela do menu Dashboards
no topo da página.
62
A melhor forma de construir uma dashboard não é de cima para baixo, mas de baixo
para cima, com cada painel. Comece usando as habilidades de enquadramento do
ários gráficos
individuais mostrando diferentes partes da saúde do sistema, coloque eles em uma
No Splunk 4.3, para criar uma dashboard e adicionar um relatório, quadro ou resultados
4. Decida se você quer que este relatório irá para um nova dashboard alguma existente.
pizza, barra
(sempre que a dashboard é
Dashboards &

63
Editando uma Dashboard
Enquanto você vê uma dashboard, você pode editar-la clicando On no selector de modo
Edit e então clicando no menu Edit de qualquer painel que você quer. Dai, você pode
editar a busca que é gera o relatório ou como ela é visualizada, ou deletar o painel.
Criando Alertas
O que é um alerta? Você pode pensar em um alerta como uma declaração de “se então”
que avaliado em uma rotina:
Se isso acontecer, então faça isso em resposta.
O “se” neste caso é a busca. O “então” é a ação que você quer que seja feita em resposta
ao “se” sendo realizado.
Mais formalmente, um alerta é uma busca que ocorre periodicamente com uma
condição avaliada nos resultados da busca. Quando a condição se encaixa, algumas
ações são executadas.
Criando Alertas através do Instrutor
Para ser iniciado na criação de alertas, o primeiro passo é fazer uma busca para que
possua os dados dos quais você quer ser alertado. O Splunk pega qualquer busca que
estiver na search bar na hora que você cria um alerta e usa ela como uma busca salva,
que se torna a base para o seu alerta (o “se” para o seu “se então”).
Com a busca que você quer na search bar, escolha Create » Alert. Ele inicia um
instrutor que torna o processo de criação mais fácil.
Agendando um Alerta
Na tela de Schedule(Agendamento) da caixa de dialogo Create Alerts, você coloca o
nome dele e como você quer que o Splunk execute ele.
Você pode escolher se o Splunk deve monitorar pela condição rodando uma busca em
tempo real, rodando a busca em uma rotina periódica ou monitoramento em tempo real
sobre uma janela deslizante.
Aqui estão casos de uso para as três opções:
• Monitorar em tempo real no caso de você querer ser avisado quando a condição for
satisfeita.
• Monitorar em uma rotina para situações menos urgentes que você mesmo assim quer
saber.
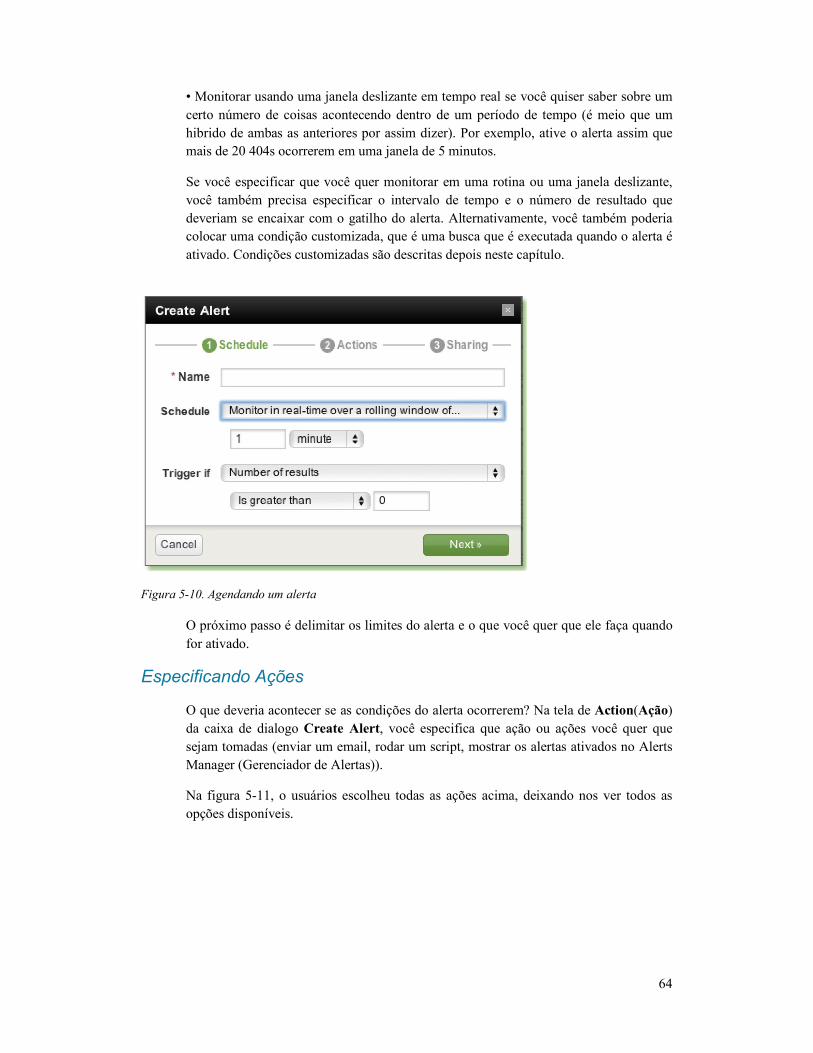
• Monitorar usando uma janela
certo número de coisas acontecendo dentro de um período de tempo (é meio que um
hibrido de ambas as anteriores por assim dizer). Por exemplo, ative o alerta assim que
mais de 20 404s ocorrerem em uma janela de 5
Se você especificar que você quer monitorar em uma rotina ou uma janela
você também precisa especificar o intervalo de tempo e o número de resultado que
deveriam se encaixar com o gatilho do alerta. Alternativamente, você também poder
colocar uma condição customizada, que é uma busca que é executada quando o alerta é
ativado. Condições customizadas são descritas depois neste capítulo.
Figura 5-10. Agendando um alerta
O próximo passo é delimitar os limites do alerta e o que você
for ativado.
Especificando Ações
O que deveria acontecer se as condições do alerta ocorrerem? Na tela de
da caixa de dialogo Create Alert
sejam tomadas (enviar um
Manager (Gerenciador de Alertas)).
Na figura 5-11, o usuários escolheu todas as ações acima, deixando nos ver todos as
opções disponíveis.
• Monitorar usando uma janela deslizante em tempo real se você quiser saber sobre um
certo número de coisas acontecendo dentro de um período de tempo (é meio que um
hibrido de ambas as anteriores por assim dizer). Por exemplo, ative o alerta assim que
mais de 20 404s ocorrerem em uma janela de 5 minutos.
Se você especificar que você quer monitorar em uma rotina ou uma janela
você também precisa especificar o intervalo de tempo e o número de resultado que
deveriam se encaixar com o gatilho do alerta. Alternativamente, você também poder
colocar uma condição customizada, que é uma busca que é executada quando o alerta é
ativado. Condições customizadas são descritas depois neste capítulo.
O próximo passo é delimitar os limites do alerta e o que você quer que ele faça quando
O que deveria acontecer se as condições do alerta ocorrerem? Na tela de Action
Create Alert, você especifica que ação ou ações você quer que
sejam tomadas (enviar um email, rodar um script, mostrar os alertas ativados no Alerts
Manager (Gerenciador de Alertas)).
11, o usuários escolheu todas as ações acima, deixando nos ver todos as
64
em tempo real se você quiser saber sobre um
certo número de coisas acontecendo dentro de um período de tempo (é meio que um
hibrido de ambas as anteriores por assim dizer). Por exemplo, ative o alerta assim que
Se você especificar que você quer monitorar em uma rotina ou uma janela deslizante,
você também precisa especificar o intervalo de tempo e o número de resultado que
deveriam se encaixar com o gatilho do alerta. Alternativamente, você também poderia
colocar uma condição customizada, que é uma busca que é executada quando o alerta é
quer que ele faça quando
Action(Ação)
, você especifica que ação ou ações você quer que
email, rodar um script, mostrar os alertas ativados no Alerts
11, o usuários escolheu todas as ações acima, deixando nos ver todos as
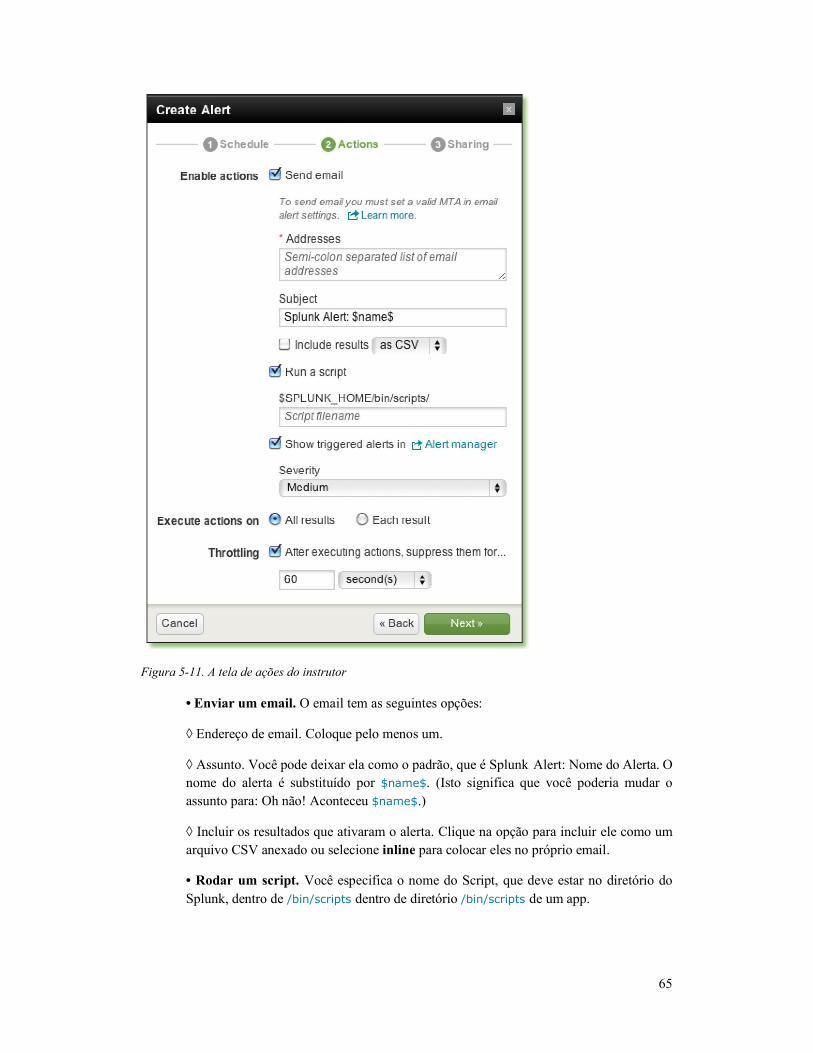
Figura 5-11. A tela de ações do instrutor
• Enviar um email. O email tem as seguintes opções:
◊ Endereço de email. Coloque pelo menos um.
◊ Assunto. Você pode deixar ela como o padrão, que é Splunk
nome do alerta é substituído por
assunto para: Oh não! Aconteceu
◊ Incluir os resultados que ativaram o alerta. Clique na opção para incluir ele como um
arquivo CSV anexado ou selecione
• Rodar um script. Você especifica o nome do Script,
Splunk, dentro de /bin/scripts
11. A tela de ações do instrutor
O email tem as seguintes opções:
Endereço de email. Coloque pelo menos um.
Assunto. Você pode deixar ela como o padrão, que é Splunk Alert: Nome do Alerta. O
nome do alerta é substituído por $name$. (Isto significa que você poderia mudar o
ssunto para: Oh não! Aconteceu $name$.)
Incluir os resultados que ativaram o alerta. Clique na opção para incluir ele como um
arquivo CSV anexado ou selecione inline para colocar eles no próprio email.
Você especifica o nome do Script, que deve estar no diretório do
/bin/scripts dentro de diretório /bin/scripts de um app.
65
Alert: Nome do Alerta. O
. (Isto significa que você poderia mudar o
Incluir os resultados que ativaram o alerta. Clique na opção para incluir ele como um
para colocar eles no próprio email.
que deve estar no diretório do

66
• Mostrar os alertas ativados no Alert manager, que pode ser alcançado clicando em
Alerts no canto superior esquerdo da interface.
Depois de escolher uma ação (ou duas, ou três), você pode preencher algumas opções:
• A seriedade. A seriedade é metadata para você referenciar quando organizando os
alertas. Os níveis são info, low, medium, high, and critical. A seriedade é mostrada no
Alert manager.
• Executar ações em todos os resultados ou em cada. Isto determina se o Splunk deve
tomar uma ação (como mandar um email) para o grupo inteiro de resultados que se
encaixam com o alerta ou para cada resultado individual. “All results” é o padrão.
• Afogar (Throttling). Alertas só são efetivos se eles te dizem o que você precisa saber
quando você precisa saber. Alertas demais e você vai começar a ignorar-los. Muito
poucos e você não vai ter como saber o que está acontecendo. Esta questão especifica o
quanto o Splunk deve esperar para refazer uma ação relacionada a um alerta, depois de
que ele foi ativado a primeira vez. Se você especificar uma janela deslizante, o instrutor
coloca a afogamento padrão para o tamanho da janela. Mais opções de afogamento são
descritas depois neste capítulo.
Depois de clicar em Next, o paço final é especificar se o alerta é privado ou é
compartilhado com acesso somente leitura para os usuários do app atual. Clique Finish
para finalizar o alerta.
Afinando Alertas Usando o Gerenciador
Colocando os limites corretos para os alertas normalmente requer tentativa e erro. isto
pode tomar alguns ajustes para prevenir que muitos alertas irrelevantes ou poucos
relevantes. Os limites devem ser afinados apara que, por exemplo, um pico em um sinal
vital isolado não ative um alerta, mas 10 sinais vitais ficando perto de 10% dos seus
limites sim.
É fácil de criar alertas rapidamente usando o instrutor, mas ainda mais opções para o
afinamento de alertas estão disponíveis no gerenciador.
Lembre-se que buscas salvas sustentam os alertas. Como um resultado, você pode editar
eles como você edita uma busca salva. Para editar o seu alerta, escolha Manager e
então Searches and Reports.
Escolha a busca salva da lista para mostrar os seus parâmetros.
Colocando Condições de Alerta
Pensando em um alerta como um declaração Se Então, você tem mais flexibilidade no
lado se editando ele pelo gerenciador. O alerta pode ser colocar para ativar:
• Sempre
• Dependendo do número de eventos, hospedeiros ou fontes

67
• Condição customizada
Apesar do instrutor oferecer alertar pelo número de eventos, aqui você pode ter opções
para alertar pelo número de hospedeiros ou fontes. Considere hospedeiros. É uma coisa
se você quer começar a ver o estado “servidor indisponível” em um servidor web em
um bolo, mas é uma coisa completamente diferente se você de repente ver ele em mais
de um de seus servidores. Claramente existe um pico e os servidores não estão
agüentando o trafego.
Esta tela oferece mais flexibilidade para a definição do escopo para um alerta:
• é maior que
•é menor que
• é igual a
• não é igual a
• sobe por
• cai por
As primeiras quatro opções foram expostas pelo instrutor, mas aqui a gente adiciona a
habilidade de alertar se os número sobem ou caem por uma certa margem ou
porcentagem (como 50%). “sobe por” e “cai por” permite que você coloque
efetivamente as condições dos alertas que são relativos (que não é o número absoluto
mas sim se ele duplicar ou triplicar que você quer saber). “sobe por” e “cai por” não são
suportados por condições que usam buscas em tempo real.
Aplicando Condições Customizadas
Apesar de a interface oferecer flexibilidade para a configuração dos tipos mais comuns
de alertas, algumas vezes você precisa de ainda mais flexibilidade na forma de
condições customizadas.
Uma condição customizada é uma busca contra os resultados da busca principal de um
alerta. Se ela retornar algum resultado, a condição é verdadeira, e o alerta é ativado. Por
exemplo, você pode querer ser alerta toda vez que um hospedeiro cair, mas excluir os
que estiverem sofrendo uma manutenção agendada. Para fazer isso, você faria uma
busca principal para localizar todos os servidores que estão fora do ar e uma condição
customizada para filtrar os “falsos positivos” - hospedeiros que estão em um calendário
para a manutenção agendada. Desta forma, você pode ser alertado somente dos
servidores que caírem inesperadamente.
Afogando Alertas
O Splunk lhe permite afinar os alertas para que eles de digam algo significativo. Uma
mensagem que te diz algo importante é útil. Cem mensagens, por outro lado,
justificadas ou não, não são úteis. São barulho.

O Splunk lhe permite afogar os alertas para que quando ele forem ativados, eles só ajam
uma vez. Em outras palavras, se o primeiro alerta é
estourar na panela, você não quer ser avisado de todos estes milhos estourando, que são
realmente relacionados ao primeiro alerta. (Se a pipoca tiver um segundo alerta, ele
deveria apitar somente depois de todos os milhos
Isto é o que o throttling faz. Você pode dizer ao Splunk para alertar a você mas não
continuar alertando.
In the middle of the Manager’s screen for editing alerts is an option called
No meio da tela do gerenciador para a edição de alertas existe uma opção chamada
Alert mode(Modo de Alerta
Figura 5-12. Modo de Alerta
Você pode ser alertado uma vez por busca, quer dizer, para todos os resultados, ou você
pode ser alertado uma vez para cada resultado. Alertas por resultados pode ser ainda
mais afogados por campos. Por exemplo, você pode querer ser alertado toda a vez que
uma condição for alcançada, mas só uma vez por hospedeiro. Digamos que o espaço em
disco está ficando baixo em um servidor e você quer ser alertado de que ele está com
menos de 30% de espaço livre disponível. Se você especificar o campo de host no
result throttling fields, você só seria notificado uma vez para cada servidor dentro
deste período de tempo especificado. Se você estivesse lidando com falhas de login dos
usuários, você vai querer colocar o username como o campo de afogamento por
resultado.
Customizando as Ações para um Alerta
Escrevendo ou modificando scripts, você pode colocar açõ
alertas.
Por exemplo, você pode querer que o alerta:
• Envie um SMS para as pessoas que possam te ajudar com o problema.
• Criar um tíquete para um helpdesk outro tíquete de resolução de problemas.
• Reiniciar o servidor.
O Splunk lhe permite afogar os alertas para que quando ele forem ativados, eles só ajam
uma vez. Em outras palavras, se o primeiro alerta é como o primeiro milho de pipoca a
estourar na panela, você não quer ser avisado de todos estes milhos estourando, que são
realmente relacionados ao primeiro alerta. (Se a pipoca tiver um segundo alerta, ele
deveria apitar somente depois de todos os milhos terem estourado e antes dela queimar.)
Isto é o que o throttling faz. Você pode dizer ao Splunk para alertar a você mas não
In the middle of the Manager’s screen for editing alerts is an option called
No meio da tela do gerenciador para a edição de alertas existe uma opção chamada
Modo de Alerta) (veja a figura 5-12).
Você pode ser alertado uma vez por busca, quer dizer, para todos os resultados, ou você
er alertado uma vez para cada resultado. Alertas por resultados pode ser ainda
mais afogados por campos. Por exemplo, você pode querer ser alertado toda a vez que
uma condição for alcançada, mas só uma vez por hospedeiro. Digamos que o espaço em
ficando baixo em um servidor e você quer ser alertado de que ele está com
menos de 30% de espaço livre disponível. Se você especificar o campo de host no
s, você só seria notificado uma vez para cada servidor dentro
o de tempo especificado. Se você estivesse lidando com falhas de login dos
usuários, você vai querer colocar o username como o campo de afogamento por
Customizando as Ações para um Alerta
Escrevendo ou modificando scripts, você pode colocar ações customizadas para os seus
Por exemplo, você pode querer que o alerta:
• Envie um SMS para as pessoas que possam te ajudar com o problema.
• Criar um tíquete para um helpdesk outro tíquete de resolução de problemas.
68
O Splunk lhe permite afogar os alertas para que quando ele forem ativados, eles só ajam
como o primeiro milho de pipoca a
estourar na panela, você não quer ser avisado de todos estes milhos estourando, que são
realmente relacionados ao primeiro alerta. (Se a pipoca tiver um segundo alerta, ele
terem estourado e antes dela queimar.)
Isto é o que o throttling faz. Você pode dizer ao Splunk para alertar a você mas não
No meio da tela do gerenciador para a edição de alertas existe uma opção chamada
Você pode ser alertado uma vez por busca, quer dizer, para todos os resultados, ou você
er alertado uma vez para cada resultado. Alertas por resultados pode ser ainda
mais afogados por campos. Por exemplo, você pode querer ser alertado toda a vez que
uma condição for alcançada, mas só uma vez por hospedeiro. Digamos que o espaço em
ficando baixo em um servidor e você quer ser alertado de que ele está com
menos de 30% de espaço livre disponível. Se você especificar o campo de host no Per
s, você só seria notificado uma vez para cada servidor dentro
o de tempo especificado. Se você estivesse lidando com falhas de login dos
usuários, você vai querer colocar o username como o campo de afogamento por
es customizadas para os seus
• Criar um tíquete para um helpdesk outro tíquete de resolução de problemas.
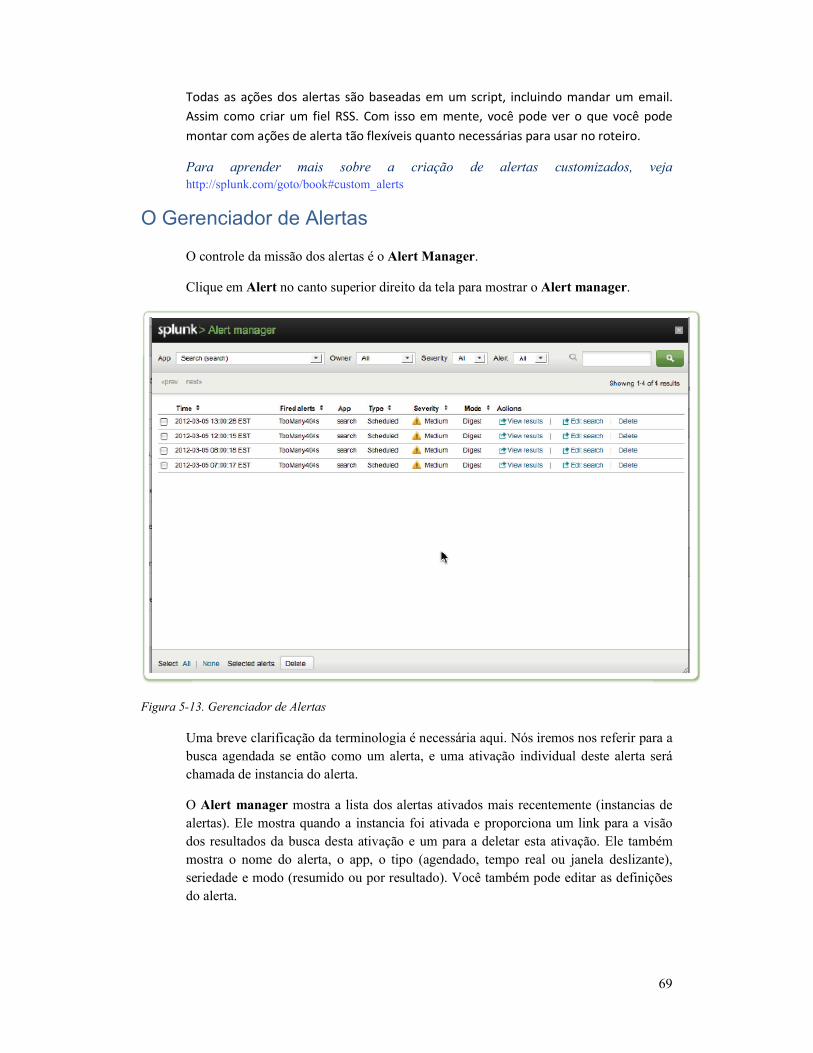
Todas as ações dos alertas são baseadas em um script, incluindo mandar um email.
Assim como criar um fiel
montar com ações de alerta tão flexíveis quanto necessárias para usar no roteiro.
Para aprender mais http://splunk.com/goto/book#custom_alerts
O Gerenciador de Alertas
O controle da missão dos alertas é o
Clique em Alert no canto superior direito da tela para mostrar o
Figura 5-13. Gerenciador de Alertas
Uma breve clarificação da terminologia é necessária aqui. Nós iremos nos referir para a
busca agendada se então
chamada de instancia do alerta.
O Alert manager mostra
alertas). Ele mostra quando a instancia foi ativada e proporciona um link para a visão
dos resultados da busca desta ativação e um para a deletar esta ativação. Ele também
mostra o nome do alerta, o app, o tipo (agendado, tempo real ou janela deslizante),
seriedade e modo (resumido ou por resultado). Você também pode editar as definições
do alerta.
as ações dos alertas são baseadas em um script, incluindo mandar um email.
fiel RSS. Com isso em mente, você pode ver o que você pode
montar com ações de alerta tão flexíveis quanto necessárias para usar no roteiro.
Para aprender mais sobre a criação de alertas customizados, veja http://splunk.com/goto/book#custom_alerts
O Gerenciador de Alertas
O controle da missão dos alertas é o Alert Manager.
no canto superior direito da tela para mostrar o Alert manager
13. Gerenciador de Alertas
Uma breve clarificação da terminologia é necessária aqui. Nós iremos nos referir para a
se então como um alerta, e uma ativação individual deste alerta será
chamada de instancia do alerta.
mostra a lista dos alertas ativados mais recentemente (instancias de
alertas). Ele mostra quando a instancia foi ativada e proporciona um link para a visão
dos resultados da busca desta ativação e um para a deletar esta ativação. Ele também
ta, o app, o tipo (agendado, tempo real ou janela deslizante),
seriedade e modo (resumido ou por resultado). Você também pode editar as definições
69
as ações dos alertas são baseadas em um script, incluindo mandar um email.
RSS. Com isso em mente, você pode ver o que você pode
montar com ações de alerta tão flexíveis quanto necessárias para usar no roteiro.
sobre a criação de alertas customizados, veja
Alert manager.
Uma breve clarificação da terminologia é necessária aqui. Nós iremos nos referir para a
como um alerta, e uma ativação individual deste alerta será
a lista dos alertas ativados mais recentemente (instancias de
alertas). Ele mostra quando a instancia foi ativada e proporciona um link para a visão
dos resultados da busca desta ativação e um para a deletar esta ativação. Ele também
ta, o app, o tipo (agendado, tempo real ou janela deslizante),
seriedade e modo (resumido ou por resultado). Você também pode editar as definições

70
PARTE II RECEITAS
6 Receitas para monitoramentos e
alertas
Os primeiros cinco capítulo deste livro lhe prepararam para usar o Splunk para resolver
problemas, responder questões e explorar os seus dados de formas interessantes.
Neste capítulo, nós vamos te apresentar algumas receitas de monitoramentos e alertas.
Monitoramento refere-se a relatórios que você pode monitorar visualmente e alerta
refere-se a condições monitoradas pelo Splunk, que podem ativar ações automáticas.
Estas receitas são pensadas como breves soluções para problemas comuns de alerta e
monitoramento. Cada receita inclui um enunciado de um problema seguido por uma
descrição de qual seria a solução do problema utilizando o Splunk. Alguns do exemplos
mais complexos sugerem variações na receita para que você possa explorar.
Para fazer mais perguntas e encontrar mais respostas, visite http://splunkbase.com.
Receitas de monitoramento
O monitoramento pode te ajudar a ver o que está acontecendo com os seus dados.
Quantos usuários concorrentes estão conectados atualmente? Como tendências
importantes estão mudando com o tempo?
Em adição as receitas de monitoramento de várias condições, esta seção dispõe receitas
que descrevem como usar os comandos de busca para extrair os campos de dados semi
ou completamente estruturados.
Monitorando usuários concorrentes
Problema
Você precisa determinar quantos usuários concorrentes você tem em qualquer horário
especifico. Isto pode te ajudar detectar se certos servidores estão sobre carregados e
causar uma melhor provisão de recursos para picos da demanda.
Solução
Primeiro, faça uma busca para encontrar eventos relevantes. Em seguida, use o
comando concurrency encontrar o número de usuários que se sobrepõem. Finalmente,
use o comando de reportagem timechart para mostrar um quadro do número de
usuários concorrentes em uma base de tempo.

71
Digamos que você tenha os seguintes eventos, que especificam data, tempo, duração de
pedido e nome de usuário:
5/10/10 1:00:01 ReqTime=3 User=jsmith
5/10/10 1:00:01 ReqTime=2 User=rtyler
5/10/10 1:00:01 ReqTime=50 User=hjones
5/10/10 1:00:11 ReqTime=2 User=rwilliams
5/10/10 1:00:12 ReqTime=3 User=apond
Você pode ver que, as 1:00:01, existem três eventos concorrentes (jsmith, rtyler,
hjones); as 1:00:11, existem dois (hjones, rwilliams); e as 1:00:12, existem três (hjones,
rwilliams, apond).
Use esta busca para mostrar o máximo de usuários concorrentes em qualquer hora:
<your search here> sourcetype=login_data
| concurrency duration=ReqTime
| timechart max(concurrency)
Para aprender mais sobre o comando concurrency, veja http://splunk.com/goto/book#concurrency
Monitorando hospedeiros inativos
Problema
Você precisa determinar quais hospedeiros pararam de enviar dados. Um hospedeiro
pode ter parado de anotar eventos se o servidor ou aplicações que produzam logs,
tenham travado ou tenham sido desligados. Isto normalmente indica um problema sério.
Se um hospedeiro para de anotar eventos, você vai querer saber sobre isso.
Solução
Use o comando metadata, que relata informações sobre os hospedeiros, fontes e tipos
de fontes nos índices do Splunk. É isto que é usado para fazer uma Dashboard de
Sumário. Note a barra que se encontra no início da busca, porque nós não estamos
recuperando eventos dos índices do Splunk, ao invés, nós estamos chamando um
comando de geração de eventos (metadata).
Use a seguinte busca para pegar as informações dos hospedeiros, organizar ela para que
os hospedeiros menos referenciados recentemente estejam em primeiro, e mostrar o
tempo em uma forma legível:
| metadata type=hosts
| sort recentTime
| convert ctime(recentTime) as Latest_Time

72
Você vai rapidamente ver que hospedeiros não tem anotado nada recentemente.
Para aprender mais sobre o comando metadata, veja http://splunk.com/goto/book#metadata
Reportando dados categorizados
Problema
Você precisar reportar segmentos dos seus dados que não estão bem definidos.
Solução
Para procurar por partes especificas dos seus dados, classifique os seus eventos com
tags ou event types. Tags são mais simples mas event types são mais poderosos (tags e
event types são discutidos no capítulo 5).
Você pode se perguntar como esta categorização de dos dados pode ser colocada sobre
monitoramento. Isto se da porque quando você categoriza os dados usando tags ou
event types, você não só categoriza os dados que você tem hoje, mas você ensina ao
Splunk que ele deve categorizar dados deste tipo todas as vezes que eles aparecerem.
Você está ensinando ao Splunk que ele deve ficar atento a certas características. Pense
em tags e event types como colocar um aviso geral nos seus dados.
Usando Tags
Você pode classificar simples pares de campo=valor usando tags. Por exemplo,
classificar eventos que tenham o host=db09 como hospedeiro database aplicando uma
tag ao valor do campo. Isto cria um campo tag::host tendo como valor database, em
eventos com host=db09. Você pode usar isto para criar uma classificação customizada
para a geração de relatórios. Aqui estão alguns exemplos do uso de tags:
Mostre os 10 tipos de hospedeiros mais comuns (ótimo para gráficos em barra ou
pizza):
... | top 10 tag::host
Compare como vários tipos de hospedeiro estão se desempenhando com o tempo:
... | timechart avg(delay) by tag::host
Usando Event Types
Quando você usa event types, em vês de tags, para classificar eventos, você não vai
estar limitado a um simples par de campo=valor. Você pode usar o poder completo do
comando search, incluindo operações booleanas, comparação de frases e até coringas.
Você poderia criar um tipo de evento chamado de database_host com a definição de
“host=db* OR host=orcl*”, e outro tipo de evento chamado de web_host. Repita as
mesmas buscas que você fez para as tags, mas substitua tag::host com o eventtype. Por
exemplo, para mostrar os 10 eventtypes mais comuns:

73
... | top 10 eventtype
Porque os tipos de eventos não específicos para uma dimensão, como hospedeiros, tipos
de usuários ou códigos de erro, eles estão todos em um mesmo espaço nominal,
amontoados.
Procurar por top eventtypes pode retornar database_host e web_error, que
provavelmente não é o que você quer pois isto seria como comparar maças com
laranjas. Por sorte você pode filtrar os tipos e eventos que você está reportando, usando
o comando eval, se você usa uma convenção de nomes para os seus eventtypes.
Como um exemplo, usando tipos de eventos, compare vários tipos de hospedeiros
(mostrados como uma timechart), usando somente eventtypes que terminam em _host:
…| eval host_types = mvfilter(match(eventtype, “_host$”))
| timechart avg(delay) by host_types
Comparando o principais valores com os do último mês
Problema
Você precisa saber os N valores mais comuns de hoje e como eles se comparam com os
valores do mês passado. Isto pode responder questões como, que produtos, ou erros de
base de dados estão espontaneamente ficando mais comuns do que eles costumavam
ser.
Solução
Para esta solução, nós vamos utilizar como exemplo dados de musica para mostrar quais
os artistas mais populares de hoje e a posição média dele no resto do mês. Assuma que
os eventos tenham um campo artist e um campo vendas sales que te diz quantas vendas
foram feitas neste específico período de tempo. Nó vamos usar a soma de sales como a
nossa medida — sum(sales) — mas nós poderíamos usar qualquer outra medida..
A pesquisa completa parece maçante no inicio, mas você pode dividir-la em simples
passos:
1. Pegue os rankings mensais por artista.
2. Peque os resultados diários e os combine com o resultados anteriores.
3. Use stats para unir os resultados diários e mensais por artista.
4. Use sort e eval para formatar os resultados..
Consiga os rankings mensais.
Use esta busca para encontrar os 10 resultados mais comuns:
sourcetype=music_sales earliest=-30d@d
| stats sum(sales) as month_sales by artist

74
| sort 10 - month_sales
| streamstats count as MonthRank
O earliest=-30d@d diz ao Splunk para recuperar eventos começando 30 dias atrás (em
outras palavras, eventos do mês passado). O stats calcula as vendas de cada artista
como o campo month_sales. Agora você tem uma fileira para cada artista, com duas
colunas: month_sales e artist. O sort 10 – month_sales mantem somente as fileiras
com os maiores valores de month_sales, organizados do maior para o menor. O
comando streamstats adiciona uma ou mais estatísticas para cada evento, baseado
no valor atualmente agregado a ele quando o eventos é recuperado (não nos resultados
como um todo, como o comando stats faz). Efetivamente, streamstats count as
MonthRank assinala o primeiro para o MonthRank=1, o segundo para MonthRank=2, e
assim vai.
Consiga os rankings de ontem
Faça três pequenas mudanças na busca de ranking mensais para conseguir os rankings
de ontem:
• Mude os valores do earliest de -30d@d para -1d@d para conseguir os rankings de
ontem.
• Mude cada instancia de “month” na busca para “day”.
• Envelope a busca com o comando append para que os resultados sejam unidos com os
resultados da primeira busca:
append [
search sourcetype=music_sales earliest=-1d@d
| stats sum(sales) as day_sales by artist
| sort 10 - day_sales
| streamstats count as DayRank
]
Use o stats para juntar os rankings diários e mensais por artistas.
Use o comando stats para unir os resultados por artista, colocando o primeiro resultado
mensal e diário no mesmo conjunto.
stats first(MonthRank) as MonthRank first(DayRank) as
DayRank by artist
Formatando o resultado
Finalmente, nós iremos calcular as diferenças no ranking diário e mensal, organizar os
seus resultados por ranking diário, e mostrar os resultados em ordem de billboard (rank,
artista, mudança no ranking, ranking antigo):

75
eval diff=MonthRank-DayRank
| sort DayRank
| table DayRank, artist, diff, MonthRank
Sumario
Juntando tudo a busca fica assim:
sourcetype=music_sales earliest=-30d@d
| stats sum(sales) as month_sales by artist
| sort 10 - month_sales | streamstats count as MonthRank
| append [
search sourcetype=music_sales earliest=-1d@d
| stats sum(sales) as day_sales by artist
| sort 10 - day_sales | streamstats count as DayRank
]
| stats first(MonthRank) as MonthRank first(DayRank) as
DayRank by artist
| eval diff=MonthRank-DayRank
| sort DayRank
| table DayRank, artist, diff, MonthRank
Variações
Aqui, nós usamos o sum como nossa medida — sum(sales) — mas poderíamos usar
qualquer medida, como o min(sales), ou mudar o timerange para comparar a última
semana com esta.
Para aprender mais sobre o comando streamstats, veja http://splunk.com/goto/book#streamstats
Encontrando medidas que caíram em 10% na última hora.
Problema
Você quer saber sobre medidas que caíram em 10% na última hora. Isto pode ser menos
clientes, menos visitas a página, menos pacotes de dados, etc.
Solução

76
Para ver uma queda na última hora, nós iremos precisar dar uma olhada nos resultados
para pelo menos as últimas 2 horas. Nó iremos olhar nos eventos de duas horas, calcular
uma medida separada para cada hora, e então, determinar como as medidas mudaram
entre estas duas horas. A medida que estamos procurando é a contagem do número de
eventos entre duas horas atrás e na hora passada.
Esta busca compara a contagem por hospedeiro da hora anterior com a hora atual e
filtra aqueles cuja a contagem caiu mais de 10%:
earliest=-2h@h latest=@h
| stats count by date_hour,host
| stats first(count) as previous, last(count) as current by
host
| where current/previous < 0.9
A primeira condição (earliest=-2h@h latest=@h) recupera duas horas de dados,
ignorando o intervalo entre horas (ele irá procurar 14-16 horas, e não 14:01-16:01).
Então nós conseguimos uma contagem do número de eventos por hora e hospedeiro.
Pelo fato de só haver duas horas (duas horas atrás e uma hora atrás), stats first(count)
retorna os resultados de duas horas atrás e last(count) de uma hora. A clausula where
retorna somente os eventos cuja a contagem atual é menor que 90% da contagem da
hora anterior 90% (que mostra que a porcentagem caiu em 10%).
Como um exercício para você, pense que pode dar errado quando o tempo passar da
meia noite. Você vê como corrigir isto adicionando first(_time) para o primeiro
comando stats e organizando pelo novo valor?
Variações
Em vez do número de eventos, use uma medida diferente, como uma média de atraso ou
bytes mínimos por segundo e considere diferentes janelas de tempo, como dia a dia.
Tabelando os resultados de semana a semana
Problema
Você precisa determinar como os resultados desta semana se comparam com os
resultados da semana passada.
Solução
Primeiro faça uma busca sobre todos os eventos marque se eles pertencem a esta
semana ou semana passada. Em seguida, ajuste o valor de tempo dos eventos da semana
passada para parecer com os dos eventos desta semana (para que eles se designem na
mesma janela de tempo). Finalmente crie um gráfico.
Vamos pegar os resultados das últimas duas semanas, marcados no começo da
semana:

77
earliest=-2w@w latest=@w
Marque os eventos como sendo desta semana ou da semana anterior:
eval marker = if (_time < relative_time(now(), “-1w@w”),
“last week”, “this week”)
Ajuste os eventos desta semana para parecer que são desta:
eval _time = if (marker==”last week”,
_time + 7*24*60*60, _time)
Tabele a medida desejada, usando o marcador de semana que a gente criou, como o
timechart da média de download em bytes da última semana:
timechart avg(bytes) by marker
Isto produz uma timechart com duas series etiquetadas: “last week” e “this week”.
Juntando tudo:
earliest=-2w@w latest=@w
| eval marker = if (_time < relative_time(now(), “-1w@w”),
“last week”, “this week”)
| eval _time = if (marker==”last week”,
_time + 7*24*60*60, _time)
| timechart avg(bytes) by marker
Se você usar este padrão comumente, você irá querer salvar isto com um macro para
poder reutilizar ele mais tarde.
Variações
Explore períodos de tempo diferentes, como na base de dia a dia, com diferentes tipos
de tabelas. Tente tipos de tabelas diferentes de avg(bytes). Alternativamente, remova a
marcação dos limites da semana colocando as configurações como earliest=-2w e não
colocando um valor para latest (isto deixa como padrão “now” que é agora), e mudando
o argumento relative_time() para –1w.
Identificando oscilações em seus dados
Problema
Você quer identificar as oscilações em seus dados. As oscilações podem te mostrar onde
você tem picos (ou depressões) que podem indicar que algumas de suas medidas estão
caindo ou subindo drasticamente. As oscilações de trafego, vendas, número de

78
respostas, carga do banco de dados - qualquer tipo de oscilação que você possa estar
interessado, você quer poder observar e talvez tomar alguma ação para cuidar destas
oscilações.
Solução
Use uma janela de tendências deslizante para te ajudar nesta situação. Faça uma busca
seguida pelo comando trendline usando o campo quer você quer usar para criar a janela
de tendências.
Por exemplo, no acesso de dados da web, nós podemos tabelar uma com o campo
bytes:
sourcetype=access* | timechart avg(bytes) as avg_bytes
Para adicionar outra série de linhas/barras a tabela com uma simples média variante dos
últimos 5 valores de bytes, use este comando:
trendline sma5(avg_bytes) as moving_avg_bytes
Se você quiser identificar os picos de forma clara, você pode adicionar uma série extra
para oscilações - quando o valor atual é mais que o dobro que a média variante.
eval spike=if(avg_bytes > 2 * moving_avg_bytes, 10000, 0)
O 10000 aqui é arbitrário e você deveria escolher uma valor relevante aos seus dados,
que faça a oscilação noticiável. Mudando a formatação do eixo Y na escala do Log
também ajuda.
Juntando tudo isso a nossa busca é:
sourcetype=access*
| timechart avg(bytes) as avg_bytes
| trendline sma5(avg_bytes) as moving_avg_bytes
| eval spike=if(avg_bytes > 2 * moving_avg_bytes, 10000, 0)
Variações
Nós utilizamos uma média variante para os últimos 5 resultados (sma5). Considerando
um número diferente de valores (por exemplo, sma20), e outros tipos de médias
variantes, como uma média variante exponencial (ema) e uma média variante pesada
(wma).
Alternativamente, você pode ultrapassar a tabulação por completo e substituir eval ali
em cima por uma clausula where para filtrar os resultados.
... | where avg_bytes > 2 * moving_avg_bytes

79
E olhando pela visão da tabela ou como um alerta, você só vera os tempos que o
avg_bytes oscilou.
Para aprender mais sobre o comando de busca trendline, veja http://splunk.com/goto/book#trendline
Compactando uma tabulação baseada em tempo
Problema
Você gostaria de ser capaz de visualizar múltiplas tendências em seus dados em um
pequeno espaço. Esta é a idéia por traz das sparklines - pequenas tabelas baseadas em
tempo mostradas dentro das células da sua tabela de resultados. Sparklines foram
inventadas por Edward Tufte e incorporadas no Splunk 4.3.
Solução
Para produzir estas sparklines em suas tabelas, simplesmente encapsule as suas funções
stats ou chart dentro da função sparkline().
Aqui, nós iremos usar como exemplo os logs de acesso web. Nós iremos criar um
gráfico mostrando o quanto demorou para cada página responder (assumindo que o
campo spent é no tempo de espera na página). Nós temos várias páginas, então nós
iremos organizar-las para descobrir quais as páginas mais acessadas (em outras
palavras, aquelas com o maior valor de count). O 5m diz ao Splunk que ele dever
mostrar os detalhes com uma escala de 5 minutos nas sparklines.
sourcetype=access*
| stats sparkline(avg(spent),5m), count by file
| sort - count
Faça esta busca na última hora. O resultado é uma série de mini gráficos mostrando
quanto tempo levou para cada página carregar em uma média de tempo.
Variações
Tente usar funções diferentes de avg. Tente usar valores diferentes de 5m para a escala.
Se você remover a escala 5m completamente, o Splunk automaticamente escolhe o
melhor valor para este intervalo de tempo.
Reportando em campos dentro do XML ou JSON
Problema
Você precisa formatar em dados formatados em XML ou JSON.
Solução

80
Use o comando spath, introduzido no Splunk 4.3, para extrair informações de dados
formatados em XML- ou JSON-. Neste exemplo, nós iremos assumir que um tipo de
fonte de dados sobre livros está formatada em XML ou JSON. Nós iremos rodar uma
pesquisar que retorna XML ou JSON como texto de evento, e usar o comando spath
para extrair o nome do autor:
sourcetype=books
| spath output=author path=catalog.book.author
Quando chamado se um argumento de path, spath extrair todos os campos nos
primeiros 5000 caracteres, o que é configurável, criando campos para caminhos dos
elementos. Caminhos tem a forma foo.bar.baz. Cada nível tem uma série de índices
opcionais, indicado por chaves (como foo{1}.bar). Todas as séries podem ser
representadas com chaves vazias (como foo{}). O nível final para filas em XML
também inclui o nome do atributo, também fechado entre chaves (como
foo.bar{@title}) e precedido por uma @.
Depois de ter extraído o campo, você pode reportar ele:
... | top author
Variações
Um comando de busca antigo chamado xmlkv extraia valores chaves simples de pares
em XML. Por exemplo, chamando ... | xmlkv em eventos que possuem um valor de
<foo>bar</foo> cria o campo foo com uma barra de valor. Outro comando antigo para
extrair eventos do XML é o xpath.
Extraindo campos de um evento
Problema
Você quer fazer uma busca por um padrão e extrair esta informação dos seus eventos.
Solução
Usando comandos para extrair os campos convenientes para rapidamente extrair
campos que são necessários temporariamente ou para aplicar eles a busca especificas e
não são tão comuns quanto o resto dos campos.
Expressões Regulares
O comando rex facilita a extração de campos usando expressões regulares. Por
exemplo, nos dados do e-mail, a seguinte busca extrai os campos “de” e “para” do e-
mail usando o comando rex:
sourcetype=sendmail_syslog
| rex “From: (?<from>.*) To: (?<to>.*)”

81
Delimitadores
Se você estiver trabalhando com múltiplos campos possuem delimitadores entre eles,
use o comando extract extrair eles.
Digamos que os seus eventos sejam assim:
|height:72|age:43|name:matt smith|
Extraia os campos event sem usar delimitadores usando:
... | extract pairdelim=”|” kvdelim=”:”
O resultado é o que você pode esperar:
height=72, age=43, and name=matt smith.
Variações
Tente usar multikv, spath ou xmlkv.
Receitas de Alerta
Lembre-se do capítulo 5 que um alerta é feito de duas partes:
• Uma condição: Uma coisa interessante que você gostaria de ficar sabendo.
• Uma ação: O que fazer quando esta coisa interessante acontece.
Adicionalmente, você pode usar afogamento para prevenir o excesso de alertas do
mesmo tipo.
Por exemplo:
• Eu quero receber um e-mail sempre que o meu servidor estivar com a carga acima da
média.
• Eu quero receber um e-mail sempre que o meu servidor estivar com a carga acima de
uma certa porcentagem, mas não faça spam na minha caixa de entrada, então afogue os
alertas para cada 24 horas.
Alertar por e-mail quando o servidor atinge uma carga
determinada
Problema
Você quer ser notificado por e-mail quando um servidor exceder 80% de sua
capacidade.
Solução

82
A seguinte busca recupera eventos que possuem uma carga acida de 80% da capacidade
e calcula o valor máximo para cada hospedeiro. O sourcetype “top” vem com o app do
Splunk Unix app (disponível na splunkbase.com), e é alimentado com dados do
comando de Unix top a cada 5 segundos:
sourcetype=top load_avg>80
| stats max(load_avg) by host
Monte um alerta da seguinte maneira, usando as instruções do capítulo 5:
• Condição de alerta: se a busca retornar pelo menos um resultado.
• Ação do Alerta: enviar um e-mail e colocar o assunto como: Carga do servidor acima
dos 80%.
• Suprimir: 1 hora.
Variações
Mude as condições de alerta e supressão.
Alertando quando a performance de um servidor está lenta
Problema
Você quer ser notificado por e-mail sempre que 95% do tempo de resposta de seu
servidor web está maior que um certo número de milissegundos.
Solução
A seguinte busca recupera eventos de logs de web, calcula se mais de 95% dos tempos
de resposta para cada endereço único de internet (uri_path) ultrapassa a amostra de 200
milissegundos para o par sourcetype=weblog.
| stats perc95(response_time) AS resp_time_95 by uri_path
| where resp_time_95>200
Monte o alerta da seguinte maneira:
• Condição de Alerta: alertar se a busca retornar X resultados (o número de respostas
lentas que você acha que é o mínimo necessário para ser alertado).
• Ações do Alerta: enviar e-mail com o assunto: “Servidores WEB ficando lentos.”
Se você estiver na nuvem (por exemplo Amazon EC2™), começar novas instancias de
servidor web.
• Suprimir: 1 hora.
Desligar instancias de EC2 desnecessárias

83
Problema
Você quer desligar instanciar de EC2 que não estão sendo utilizadas.
Solução
A seguinte busca recupera os eventos de logs de web e retorna uma tabela de
hospedeiros que possuem menos de 10000 pedidos (dentro da janela de tempo que a
busca cobre):
sourcetype=weblog
| stats count by host
| where count<10000
Monte o alerta da seguinte maneira:
• Condição de Alerta: alertar se a busca retornar X eventos (o número de eventos
máximos que você acredita ser necessário para tomar alguma atitude).
• Ações do Alerta: ativar um script que remova o servidor do balanceador de carga e
desligue o mesmo..
• Suprimir: 10 minutos.
Convertendo um monitoramento em um alerta
As receitas de monitoramento neste capítulo produzem reportagens úteis e valiosas.
Mas, se você der uma segunda olhada, muitas delas também podem ser usadas como
base para montar alertas, permitindo que o Splunk monitore a situação para você.
Aqui nós vamos discutir brevemente como converter algumas das receitas de
monitoramento em alertas.
Monitorando usuários concorrentes
Esta receita pode ser transformada em um alerta criando uma condição customizada
onde “where max(concurrency) > 20”. Isto servirá para te alertar se existem usuários
demais conectados simultaneamente.
Variações: Considere calcular a média de concorrência e alertar se o máximo é o dobro
da média.
Monitorando hospedeiros inativos
Uma condição de alerta customizado onde where now() - recentTime > 60*60 alerta
se algum dos hospedeiros não foi citado em mais de uma hora.
Comparando os maiores valores deste mês com o do mês passado

84
Uma condição de alerta customizado onde where diff < -10 alerta se um artista dispara
para o número um hoje e não estava na lista dos top 10 do último mês.
Variações: Use a mesma receita do monitorador de estado dos códigos HTTP e reporte
e o código de estado de um erro (como 404) se torne mais ou menos comuns do que ele
era no último mês.
Encontre medidas que caíram em 10% na última hora
Esta receita já está montada convenientemente para um alerta. Dispare o alerta quando
qualquer evento é notado.
Variação: Dispare somente quando N declínios são notados em seguida.
Mostrar uma linha de tendência deslizante e identificando oscilações
A variação para esta receita está convenientemente montada na própria receita.
Dispare um alerta para quando qualquer evento é notado.
Variações: Disparar somente quando mais de N oscilações são notadas em um período
de tempo (como 5 minutos).
Você pode pensar nisto como um exercício útil tentar adicionar alertas para o resto das
receitas de monitoramento.

85
7 Agrupando Eventos
Estas receitas oferecem soluções rápidas para alguns dos problemas do mundo real que
nós vemos por ai e que podem ser resolvidos com o agrupamento de eventos.
Introdução
Existem vários grupos de eventos. A aproximação mais comum usa ambos os comandos
transaction e stats. Mas quando você deveria usar transaction e quando você deveria
usar stats?
A regra de ouro: Se você pode usar stats, use stats. É mais rápido que o transaction,
especialmente em ambientes distribuídos. Com essa velocidade, como sempre, vem
algumas limitações. Você só pode agrupar eventos com o stats se eles tem pelo menos
um valor de campo em comum e se você não pedir nenhuma outra restrição.
Tipicamente, o texto cru do evento é descartado.
Como o stats, o comando transaction pode agrupar os eventos por valores de campos
comuns, mas ele também pode usar restrições mais complexas como o tempo total da
transação, atraso dentro da transação e eventos de inicio e fim requisitados. Diferente
do stats, transaction retém os textos crus dos eventos e os valores dos campo dos
eventos originais, mas não pode executar nenhuma estatística sobre os eventos
agrupados, alem da duração duration (o delta do campo _time entre o evento mais
velho e mais novo da transação) e o eventcount (o número de eventos na transação).
O comando transaction é o mais útil em dois casos:
• Quando valores únicos de campos (também conhecidos como identificadores) não são
o suficiente para discriminar entre transações discretas. Este é o caso onde o
identificador pode ser reutilizado, por exemplo em seções web que são identificados por
cookie/IP do cliente. Neste caso, intervalos ou pausas podem ser usados para
segmentar dados em transações. Em outros casos, quando o identificador é reusado,
por exemplo em logs DHCP, uma mensagem em particular pode identificar o inicio e o
fim de uma transação.
• Quando você quer ver o texto puro dos eventos em vez de uma simples análise dos
valores do campos.
De novo, quando nenhum destes casos é aplicável, é uma idéia melhor usar o stats, já
que a performance na busca com o stats é geralmente melhor que com o transaction.
Muitas vezes pode existir um identificadores único e o stats pode ser usado.
Por exemplo, para computar a duração das trocas identificadas pelo identificador único
trade_id, as seguintes buscas possuem a resposta:
… | transaction trade_id
| chart count by duration

86
… | stats range(_time) as duration by trade_id
| chart count by duration
A segunda busca é mais eficiente.
Apesar disto, se os valores do trade_id são reusados mas o último evento de cada
troca são identificados por “END”, a única solução viável é:
… | transaction trade_id endswith=END
| chart count by duration
Se, ao invés de uma condição de finalização, trade_id os valores não forem reusados
em pelo menos 10 minutos, a solução mais viável é:
… | transaction trade_id maxpause=10m
| chart count by duration
Finalmente, uma palavrinha sobre performance. Não importa quais comando de busca
você usar, é imperativo que você deixe a busca básica o mais específica o possível.
Considere esta busca:
sourcetype=x | transaction field=ip maxpause=15s | search
ip=1.2.3.4
Aqui nós estamos recuperando todos os eventos do sourcetype=x, construindo
transações e então se desfazendo de todas aquelas que não possuam o ip=1.2.3.4. Se
todos os seus eventos tem o mesmo valor de ip, a pesquisa deveria ser:
sourcetype=x ip=1.2.3.4 | transaction field=ip maxpause=15s
Esta busca recupera somente os eventos que ela precisa e é muito mais eficiente.
Mais obre isto em “Encontrando Transações Especificas” posteriormente neste capítulo.
Receitas
Unificando os nomes dos campos
Problema
Você precisa construir uma transação com múltiplas fontes de dados que usando nomes
diferentes para os campos com os mesmos identificadores
Solução
Tipicamente, você pode juntar campos comuns em transações usando:
… | transaction username

87
Mas quando o identificador username é chamado de diferentes nomes (login, name,
user, owner, e assim vai) em fontes de dados diferentes, você vai precisar normalizar os
nomes dos campos.
Se o sourcetype A só contem o campo field_A e o sourcetype B só contem o campo
field_B, crie um novo campo chamado de field_Z que pode ser tanto field_A ou field_B,
dependendo de que evento está sendo apresentado. Você pode construir a transação
baseando-se no campo field_Z.
sourcetype=A OR sourcetype=B
| eval field_Z = coalesce(field_A, field_B)
| transaction field_Z
Variações
Acima nós invocamos coalesce para usar qualquer campo que estivesse presente no
evento, mas as vezes você vai precisar usar alguma lógica para especificar quais campos
dos eventos tem de ser unificados. As funções if ou case do eval podem vir a calhar.
Encontrando Transações Incompletas
Problema
Você precisa reportas as transações incompletas, como as em que o usuário logou mas
não deslogou.
Solução
Suponha que nós estamos procurando por sessões de usuário que começam com login e
terminam com logout:
… | transaction userid startswith=”login”
endswith=”logout”
Você gostaria de construir uma reportagem que mostra-se as transações incompletas -
usuários que logaram não deslogaram. Como você pode conseguir isto?
O comando transaction cria um campo booleano interno chamado closed_txn para
indicar se uma certa transação foi fechada ou não. Normalmente transações incompletas
não possuem um retorno, mas você pode pedir por estas transações parciais
“desalojadas” especificando o parâmetro keepevicted=true.
Transações desalojadas são conjuntos de eventos que não se encaixam em todos os
parâmetros de transação. Por exemplo, os requerimentos de tempo não são encontram
em uma transação desalojada. Transações que cumprem todos os requerimentos são
marcadas como completas tendo os seus campos closed_txn colocados como 1 (ao
invés de 0 para transações inacabadas). Então o padrão para encontrar transações
incompletas seria geralmente:

88
… | transaction <conditions> keepevicted=true
| search closed_txn=0
No seu caso, apesar de tudo, existe um problema. Uma condição endswith não se
encaixa e não vai ativar o closed_txn=0 por que os eventos são colocados dos mais
novos para os mais velhos. Tecnicamente, a condição endswith começa a transação, em
termos de processamento. Para contornar isto, nós precisamos filtrar as transações
baseando-se no campo closed_txn, e também ter certeza que nossas transações não
possuem tanto um login quanto um logout:
… | transaction userid startswith=”login”
endswith=”logout”
keepevicted=true
| search closed_txn=0 NOT (login logout)
Variações
Uma variação para esta solução é utilizar o stats, se a transação não possui uma
condição startswith/endswith ou restrições de tempo, e você não se importa em
conservar o transaction. Neste exemplo, você só quer o userid dos usuários que não
deslogaram.
Primeiro, nós podemos procurar especificamente por eventos com login e logout:
action=”login” OR action=”logout”
Em seguida, para cada userid, nós usaremos stats para termos uma noção do número de
action por userid. Por eventos estarem em ordem decrescente de tempo, a primeira ação
é a mais recente.
… | stats first(action) as last_action by userid
Finalmente, nós mantemos os eventos cuja ação mais recente foi login::
… | search last_action=”login”
Neste ponto, nós temos uma lista de todos os valores userid onde a última ação foi
logar.
Calculando o tempo dentro de transações
Problema
Você precisa saber o tempo decorrido entre os eventos dentro de uma transação.
Solução
A aproximação básica é usar o comando eval para marcar os pontos no tempo
necessários para marcar os diferentes intervalos entre os eventos, então calcular o tempo
entre estes eventos aplicando estes pontos ao eval depois de um comando transaction.

89
Nota: Neste capítulo, eventos de amostra dentro de uma transação são numerados para
que nós possamos nos referir a eles como evento1, evento2, etc.
Por exemplo, suponha que nós temos uma transação composta de quatro eventos,
unificados por um campo id em comum e você quer medir a duração entre a fase 1 e 2:
[1] Tue Jul 6 09:16:00 id=1234 start of event.
[2] Tue Jul 6 09:16:10 id=1234 phase1: do some work.
[3] Tue Jul 6 09:16:40 id=1234 phase2: do some more.
[4] Tue Jul 6 09:17:00 id=1234 end of event.
Por padrão, as estampas de tempo destes eventos baseados em uma transação serão do
primeiro evento (evento1), e a duração será a diferença entre o evento1 e o evento4.
Para conseguir a fase de duração, nós teremos de marcas as estampas de tempo dos
evento2
e evento3. A função searchmatch do eval funciona bem para este exemplo, mas você
ainda tem todo o leque possibilidades da função eval disponível para situações mais
complexas.
…| eval p1start = if(searchmatch(“phase1”), _time, null())
| eval p2start = if(searchmatch(“phase2”), _time, null())
Agora nós faremos a transação em si:
… | transaction id startswith=”start of event”
endswith=“end of event”
Finalmente, nós calculamos o tempo de cada transaction, usando os valores calculados
acima.
…| eval p1_duration = p2start - p1start
| eval p2_duration = (_time + duration) - p2start
Neste exemplo, nós calculamos o tempo do último evento adicionado pelo campo _time
(o tempo do primeiro evento) e adicionando uma duração a ele. Assim que soubermos o
tempo do último, nós calculamos o p2_duration como a diferença entre o último evento
e o primeiro da fase nova.
Variações
Por padrão, o comando transaction faz campos de múltiplos valores dos valores dos
campos presentes dentro de um evento de uma transação composta, mas estes valores
são de forma desordenada, em bolsas de valores de duplicados.
Por exemplo, se uma transação é feita de 4 eventos, e estes eventos tem um campo
name assim - name=Matt, name=Amy, name=Rory, name=Amy - então a transação

90
composta por estes eventos terá um campo name de múltiplos valores com o valores
“Amy”, “matt” e “Rory”. Note que perdemos a ordem em que os eventos chegaram e
também perdemos um dos “Amy”! Para manter a lista inteira de valores, em ordem, use
a opção mvlist.
Aqui, nós estaremos construindo uma transação e criando uma lista de tempo para os
campos:
… | eval times=_time | transaction id mvlist=”times”
Daqui nós podemos adicionar comandos de eval para calcular as diferenças. Nós
podemos calcular a diferença entre o primeiro e o segundo evento da transação da
seguinte maneira:
… | eval diff_1_2 = mvindex(times,1) - mvindex(times,0)
Encontrando os últimos eventos
Problema
Você precisa encontrar o último evento de cada valor único de campo. Por exemplo,
quando foi a última vez que alguém logou?
Solução
De inicio, você pode estar tentado a usar os comandos transaction ou stats. Por
exemplo, esta busca retorna, para cada userid único, o primeiro valor em cada campo:
… | stats first(*) by userid
Note que esta busca retorna o primeiro valor para cada campo visto em eventos que
tenham o mesmo userid. ele dispõe uma união de todos os eventos que tenham ID de
usuário, o que não é o que a gente quer. O que a gente quer é o primeiro evento com um
userid único. A maneira correta de fazer isto é como o comando dedup:
… | dedup userid
Variações
Se você quiser obter o mais velho (não o mais novo) evento com um userid único,
use a clausula sortby do comando dedup:
… | dedup userid sortby + _time
Encontrando eventos repetidos
Problema
Você quer agrupar todos os eventos com ocorrências repedidas de valores em ordem
para remover o barulho das reportagem e dos alertas.

91
Solução
Suponha que nós tenhamos os seguintes eventos:
2012-07-22 11:45:23 code=239
2012-07-22 11:45:25 code=773
2012-07-22 11:45:26 code=-1
2012-07-22 11:45:27 code=-1
2012-07-22 11:45:28 code=-1
2012-07-22 11:45:29 code=292
2012-07-22 11:45:30 code=292
2012-07-22 11:45:32 code=-1
2012-07-22 11:45:33 code=444
2012-07-22 11:45:35 code=-1
2012-07-22 11:45:36 code=-1
O seu objetivo é pegar 7 eventos, um de cada valor de código em uma linha: 239, 773,
-1, 292, -1, 444, -1. Você pode se sentir tentado a usar o comando transaction da
seguinte maneira:
… | transaction code
Usando o transaction aqui é um caso de usar a ferramenta errada para o trabalho.
As long as we don’t really care about the number of repeated runs of
duplicates, the more straightforward approach is to use dedup, which
removes duplicates. By default, dedup will remove all duplicate events
(where an event is a duplicate if it has the same values for the specified
fields). But that’s not what we want; we want to remove duplicates that
appear in a cluster. To do this, dedup has a consecutive=true option that
tells it to remove only duplicates that are consecutive.
Enquanto a gente não precisar se preocupar com o número de ocorrências duplicadas, a
forma mais rápida é usar o dedup, que remove duplicatas. Por padrão, o dedup irá
remover todos os eventos duplicados (onde um evento duplicado conta como um evento
com o mesmo valor para o campo especificado). Mas isto não é o que a gente quer; nós
queremos remover as duplicatas que aparecem no bolo. Para fazer isto, o dedup tem
uma opção chamada consecutive=true diz para remover somente as duplicatas
seguidas.

92
… | dedup code consecutive=true
Tempo entre transações
Problema
Você quer determinar o tempo entre transações, como quanto tempo faz entre as visitas
ao seu site.
Solução
Suponha que tenhamos uma busca básica de transaction que agrupa todos os eventos
por um certo usuário (par de clientip-cookie), mas dividir a transação quando o usuário
ficar inativo por mais de 10 minutos:
… | transaction clientip, cookie maxpause=10m
No final, o nosso objetivo é calcular, para cada par de clientip-cookie, a diferença de
tempo entre o fim de uma transação e o inicio de tempo de uma nova transação (em
outras palavras, anterior em caso de eventos retornados).
A diferença de tempo é o espaço entre as transações. Por exemplo, suponha que a
gente tenha duas pseudo transações, retornadas na ordem de mais recente para
menos recente:
T1: start=10:30 end=10:40 clientip=a cookie=x
T2: start=10:10 end=10:20 clientip=a cookie=x
O espaço entre estas duas transações é a diferença entre o tempo de inicio de T1 (10:30)
e o tempo fim do tempo de T2 (10:20), ou seja, 10 minutos.
O resto desta receita explica como calcular estes valores.
Primeiro, nós precisamos calcular o tempo final de cada transação, mantendo em mente
que a timestamp da transação é o tempo em que o primeiro evento ocorreu e a duração é
o numero de segundos passados entre o primeiro e o último evento da transação:
… | eval end_time = _time + duration
Em seguida, nós precisamos adicionar o tempo de inicio da transação anterior (mais
recente) de cada transação. Isto irá nos permitir calcular a diferença entre o tempo de
inicio da transação anterior e a transação calculada.
end_time.
Para fazer isto nós podemos usar o streamstats o último valor do tempo de início
(_time) visto em uma janela deslizando de uma única transação - global=false and
window=1 - e para ignorar o evento atualmente na janela - current=false. Em efeito,
nós instruímos streamstats para olhar somente nos valores do evento anterior.
Finalmente, note que nós estamos especificando esta janela somente a um usuário (par
de clientip-cookie):

93
… | streamstats first(_time) as prev_starttime
global=false window=1 current=false
by clientip, cookie
Deste ponto em diante, os campos relevantes vão parecer com isto:
T1: _time=10:00:06, duration=4, end_time=10:00:10
T2: _time=10:00:01, duration=2, end_time=10:00:03
prev_starttime=10:00:06
T3: _time=10:00:00, duration=0, end_time=10:00:01
prev_starttime=10:00:01
Agora, nós finalmente poderemos calcular a diferencia de tempo entre o inicio da
transação anterior (prev_starttime) e o calculado end_time. Esta diferença é o espaço
entre as transações, a quantidade de tempo (em segundos) passado entre duas transações
consecutivas do mesmo usuário (par de clientip-cookie).
… | eval gap_time = prev_starttime – end_time
Juntando tudo isso, a busca se torna:
… | transaction clientip, cookie maxpause=10m
| eval end_time = _time + duration
| streamstats first(_time) as prev_starttime
global=false window=1 current=false
by clientip, cookie
| eval gap_time = prev_starttime - end_time
Neste ponto, você pode reportar nos valores de gap_time. Por exemplo, qual é a maior e
a média de espaço entre transações de cada usuário?
… | stats max(gap_time) as max,
avg(gap_time) as avg
by clientip, cookie
Variações
Tendo uma série de requerimentos mais simples, nós podemos calcular os espaços de
uma forma bem mais simples. Se as únicas restrições para transações são o startswith e
o endswith - significando que não existem restrições de tempo (como maxpause=10m)
ou campo (exemplo clientip, cookie) - significando que nós podemos calcular o espaço
de tempo entre as transações simplesmente trocando os valores de startswith e
endswith.

94
Por exemplo, tendo estes eventos:
10:00:01 login
10:00:02 logout
10:00:08 login
10:00:10 logout
10:00:15 login
10:00:16 logout
Em vez de fazer:
… | transaction startswith=”login” endswith=”logout”
Nós podemos fazer os espaços entre as transações padrão (login então logout) serem a
transação em si (logout então login):
… | transaction endswith=”login” startswith=”logout”
Daqui, as transações são os espaços entre os resultados, então subseqüentemente nós
podemos calcular as estatísticas usando a função duration:
… | stats max(duration) as max, avg(duration) as avg
Outra variação em encontrar o tempo entre eventos é se você estiver interessado em
encontrar o tempo entre um evento especifico (evento A) e o seu evento seguinte
(evento B). Usando streamstats, você pode terminar o alcance de tempo entre os dois
últimos eventos, que é a diferença entre o evento atual e o evento anterior:
… | streamstats range(_time) as duration window=2
Encontrando transações especificas
Problema
Você precisa encontrar transações com valores de campo específicos.
Solução
Uma busca geral por todas as transações pode parecer com algo assim:
sourcetype=email_logs | transaction userid
Suponha, apesar de tudo, que nós queiramos identificar só aquelas transações aonde
existem um evento com os pares de campo/valor to=root e from=msmith.
Você poderia usar esta busca:
sourcetype=email_logs
| transaction userid

95
| search to=root from=msmith
O problema aqui é que você está recuperando todos os eventos deste tipo de fonte
(potencialmente bilhões), construindo todas as transações, a então jogando 99% dos
dados direto no bit bucket. Não só isto é lento, mas também é dolorosamente
ineficiente.
Você pode estar tentado em reduzir os dados entrando da seguinte maneira:
sourcetype=email_logs (to=root OR from=msmith)
| transaction userid
| search to=root from=msmith
Apesar de você não estar ineficiente mente recuperando todos os eventos de um tipo de
fonte especifico, existem ainda dois problemas adicionais. O primeiro problema é fatal:
você só está conseguindo uma fração dos eventos necessários para resolver o problema.
Especificamente, você está somente recuperando eventos que tem o campo to ou from.
Usando esta sintaxe, você está perdendo todos os outros eventos que poderiam fazer
parte da transação. Por exemplo, suponha que isto é o que toda a transação deveria
parecer:
[1] 10/15/2012 10:11:12 userid=123 to=root
[2] 10/15/2012 10:11:13 userid=123 from=msmith
[3] 10/15/2012 10:11:14 userid=123 subject=”serious error”
[4] 10/15/2012 10:11:15 userid=123 server=mailserver
[5] 10/15/2012 10:11:16 userid=123 priority=high
A pesquisa acima não vai conseguir recuperar o evento3,que tem o subject, ou o
evento4, que tem o server, e não vai ser possível para o Splunk retornar a transação
completa.
O segundo problema com esta busca é que o to=root pode ser bem comum e você
estaria recuperando eventos demais, assim construindo transações demais.
Então qual é a solução? Existem dois métodos: usando sub pesquisas e usando o
comando searchtxn.
Usando Subpesquisas
O seu objetivo é conseguir todos o valores de userid para eventos que tenham to=root,
ou from=msmith. Escolhe a condição mais rara como candidato para os valores de
userid serem conseguidos o mais rápido o possível. Vamos assumir que é o
from=msmith o mais raro:
sourcetype=email_logs from=msmith
| dedup userid

96
| fields userid
Agora que você tem os valores relevantes de userid, você pode pesquisar somente pelos
eventos que possuem estes valores e de forma mais eficiente construir as transações:
… | transaction userid
Finalmente, filtre as transações para ter certeza que elas tenham o to=root e o
from=msmith (é possível que um valor de userid seja usado para outros valores de to e
from):
… | search to=root AND from=msmith
Juntando tudo isso, com a primeira busca e a subpesquisa passando o userid para o
busca final:
[
search sourcetype=email_logs from=msmith
| dedup userid
| fields userid
]
| transaction userid
| search to=root from=msmith
Usando searchtxn
O comando searchtxn (“buscar transação”) faz o trabalho chato da subpesquisa para
você. Ele busca só os eventos necessários para construir uma transaction.
Especificamente, o searchtxn faz uma observação transitiva para localizar os campos
necessários para a transaction, fazendo as pesquisas necessárias para recuperar os
eventos necessários para a transação, então rodando a busca do transaction e finalmente
filtrando para seguir as restrições especificadas. Se nós estivesses-mos unificando
transações por mais de um campo do evento, a solução da subpesquisa ficaria
problemática. O searchtxn também determina qual a condição raiz mais rara para
conseguir os resultamos mais rapidamente. Então, a sua pesquisa por transações de e-
mail com to=root e from=msmith, simplesmente se torna:
| searchtxn email_txn to=root from=msmith
Mas o que é este email_txn no meio da busca? Isto se refere a uma definição de tipo de
transação que tem de ser criada dentro de um arquivo de configuração do Splunk -
transactiontype.conf. Neste caso, transactiontype.conf pode parecer com isso:
[email_txn]
fields=userid

97
search = sourcetype=email_logs
Rodando a busca com searchtxn vai automaticamente rodar esta busca:
sourcetype=email_logs from=msmith | dedup userid
O resultado desta busca da ao searchtxn a lista dos userids que ele pode usar para
pesquisar. Ele também roda outra pesquisa para:
sourcetype=email_logs (userid=123 OR userid=369 OR userid=
576 ...)
| transaction name=email_txn
| search to=root from=msmith
Esta busca retorna a transações “agulha no palheiro” que foram obtidas dos resultado da
busca com searchtxn.
Nota: se a lista de campos do comando transaction tivesse mais de um campo,
searchtxn iria automaticamente rodar múltiplas busca para conseguir uma observação
transitiva de todos os valores necessários.
Variações
Explore usando múltiplos campos com o comando searchtxn. Se você estiver
interessado em obter somente os eventos relevantes e não quiser que o searchtxn
construa transações com eles, use o eventsonly=true.
Encontrando eventos perto de outros eventos
Problema
Você precisa encontrar eventos antes e depois de outro evento. Suponha que você
queira procurar por logins pelo root e então fazer uma busca retroativa por logins ao
root que não tiveram sucesso assim como procurar a frente um minuto para ver se
houve alguma mudança de password.
Solução
Uma solução é usar subspesquisas e procurar a última instância deste cenário. Faça uma
subpesquisa por logins no root e retorne starttimeu e endtimeu, que então guia a busca
pai para estes limites de tempo a serem procurado por failed_login ou
password_changed do mesmo src_ip:
[
search sourcetype=login_data action=login user=root
| eval starttimeu=_time - 60
| eval endtimeu=_time + 60

98
| return starttimeu, endtimeu, src_ip
]
action=failed_login OR action=password_changed
O lado negativo desta aproximação é que ela só encontra a última instancia do login e
possivelmente falsos positivos, já que ele não distingue entre failed_logins depois ou
antes de um password_changed.
No lugar disto, o problema pode ser resolvido filtrando os eventos para somente aquele
que a gente se importa:
sourcetype=login_data ( action=login OR action=failed_login
OR action=password_changed )
A transação deveria consistir de eventos com o mesmo src_ip que começam com um
failed login failed_login e terminam com um password_changed. Ainda mais, a
transação deveria passar de 2 minutes do inicio ao fim:
… | transaction src_ip maxspan=2m
startswith=(action=failed_login)
endswith=(action=password_changed)
Finalmente, você precisa filtrar somente as transações que tem user=root.
Desde um evento de failed_login geralmente não tenha user=root (o usuário não
logou), é necessário filtrar depois da transação:
… | search user=root
Conversivamente, se fosse certeza de que todos os eventos relevantes tivessem
user=root,
isto deveria ser adicionado a clausula da busca, pulando a filtragem final (search
user=root).
Encontrando eventos depois de eventos
Problema
Você precisa pegar os três primeiros eventos logo em seguida de um evento particular
(por exemplo, um evento de login) mas não existe um evento final bem definido.
Solução
Tendo a seguinte transação ideal que começa com uma ação de login:
[1] 10:11:12 src_ip=10.0.0.5 user=root action=login
[2] 10:11:13 src_ip=10.0.0.5 user=root action=”cd /”

99
[3] 10:11:14 src_ip=10.0.0.5 user=root action=”rm -rf *”
[4] 10:11:15 src_ip=10.0.0.5 user=root server=”echo lol”
A escolha obvia para uma busca é usar um transaction que tenha como startswith a
ação de dar login:
... | transaction src_ip, user startswith=”(action=login)”
maxevents=4
O problema é que você também vai pegar transações que não tem action=login.
Por que? A opção startswith não diz ao transaction para retornar somente as transações
que realmente comecem com o valor que você instanciou. Em vez disso, ele diz ao
transaction que quando ele encontrar uma linha que se encaixe com a diretiva do
startswith, este é o início da transação. De qualquer maneira, transações também serão
compostas por diferentes valores de src_ip, não importando a condição do startswith.
Para evitar isto, basta adicionar um comando de filtragem para a busca do transaction
acima:
… | search action=login
As transações retornadas irão começar com o action=login e incluir os próximos 3
eventos com src_ip e user.
Nota: Se houverem 3 eventos ou menos entre os logins, a transação irá ser menor que 4
eventos. O comando transaction adiciona um campo de eventcount a cada transação,
que você pode usar para filtrar ainda mais suas ações.
Agrupando grupos
Problema
Você precisa construir uma transação com múltiplos campos que podem mudar de valor
com cada transação.
Solução
Suppose you want to build a transaction from these four events, unified
by the host and cookie fields:
Suponha que você queira construir uma transação destes 4 eventos, unificados pelos
campos host e cookie:
[1] host=a
[2] host=a cookie=b
[3] host=b
[4] host=b cookie=b

100
Por causa do valor de host mudar durante a transação, um simples comando transaction
lamentavelmente irá criar duas transações:
… | transaction host, cookie
Quando ele ver o evento1 e o evento2, ele irá construir uma transação com o host=a,
mas quando ele chegar ao evento3, que tem um valor diferente de hospedeiro (host=b),
ele irá colocar o evento3 e o evento4 em uma transação diferente que tenha o host=b. O
resultado é que este dois eventos são transformados em duas transações, ao em vez de
duas transações com um valor comum de cookie:
Transação1:
[1] host=a
[2] host=a cookie=b
Transação2:
[3] host=b
[4] host=b cookie=b
Você pode estar tentado a remover o campo host do comando transaction
e unificar as transações baseando-se no valor do cookie. O problema é que isto iria criar
uma transação com o evento2 e o evento4 ignorando o evento1 e o evento3 por que eles
não tem um valor de cookie.
A solução para este problema está em construir uma transação sobre outra transação:
… | transaction host, cookie | transaction cookie
O segundo comando transaction vai pegar as duas transações acima e unificar elas
usando o campo cookie.
Note que se você se importa com os campos calculados duration e eventcount, eles
agora estão incorretos. A duration depois do segundo comando transaction vai ser
diferença entre as transações que ele unifica em vez de os eventos que as compõe.
Similarmente, o eventcount vai ser o número de transações unificadas, em vez do
número correto de eventos.
Para conseguir o eventcount correto depois do primeiro comando transaction, crie um
campo chamado mycount para guardar todos os valore de eventcount, então, depois do
segundo comando transaction some todos os valores de mycount para calcular o
verdadeiro real_eventcount. Similarmente, depois do primeiro comando transaction,
recorde o tempo de início e fim de cada transação e então no segundo comando
transaction pegue o tempo de início mínimo e o tempo de fim máximo e calcule para
conseguir o real_duration:
… | transaction host, cookie
| eval mycount=eventcount

101
| eval mystart=_time
| eval myend=duration + _time
| transaction cookie mvlist=”mycount”
| eval first = min(mystart)
| eval last=max(myend)
| eval real_duration=last-first
| eval real_eventcount = sum(mycount)

102
8 Tabelas de Lookup
Estas receitas de tabelas de lookup mostrarão rapidamente soluções avançadas para os
problemas comuns do mundo real. O recurso de lookup do Splunk lhe permite
referenciar campos em um arquivo de CSV externo por campos que se encaixam em
seus dados. Usando este dados encaixados, você pode enriquecer os seus dados de
eventos com campos adicionais. Note que nós não cobrimos os lookups scriptados
externamente ou baseados em tempo.
Introdução
Estas receitas usam extensivamente três comandos de busca: lookup, inputlookup e
outputlookup.
lookup
Para cada eventos, este comando encontra as linhas que se encaixam em uma tabela de
CSV externa e retorna os valores da outras colunas, assim enriquecendo os eventos. Por
exemplo, em um evento com um valor do campo host e uma tabela que tenha os
campos host e machine_type na mesma linha, especificando …| lookup mylookup host
adiciona o valor de machine_type correspondente ao valor de host de cada evento. Por
padrão, os encaixes são sensíveis a maiúscula e não suportam coringas, mas você pode
configurar estas opções. Usando o comando lookup você encaixa valores de uma tabela
externa explicitamente. Lookups automáticos, que são montados usando o Gerenciador
do Splunk (Splunk Manager), encaixa os valores implicitamente. Para aprender mais
sobre a configuração de lookups automáticos, veja
http://splunk.com/goto/book#autolookup.
inputlookup
Este comando retorna toda a tabela de lookup como resultados de uma busca. Por
exemplo, … | inputlookup mylookup retorna como resultado de uma busca para todas as
linhas da tabela mylookup, que tem dois valores de campos: host e machine_type.
outputlookup
Você pode estar se perguntando, como eu faço para criar uma tabela de lookup. Este
comando gera uma tabela no disco com os resultados da busca atual. Por exemplo, … |
outputlookup mytable.csv salva todos os resultados em mytable.csv.
Leitura Posterior http://splunk.com/goto/book#lookuptutorial http://splunk.com/goto/book#externallookups
103
Receitas
Colocando os Valores Padrões de Lookup
Problema
Você precisa de um valor padrão de campo se um valor de evento não estiver na sua
tabela de lookup.
Solução
Existem várias soluções:
Usando um lookup explicito, Você pode simplesmente usar a função eval coalesce:
… | lookup mylookup ip | eval domain=coalesce(domain,”unknown”)
Usando lookups automáticos, existe uma configuração para isso. Vá para Manager >>
Lookups >> Lookup Definition >> mylookup, assinale a caixa do Advanced options,
e mude o seguinte:
Coloque o Minimum matches como: 1
Coloque o Default matches como: unknown
Salve as mudanças.
Usando Lookups reversos
Problema
Você precisa fazer uma busca por eventos baseados na saída de uma tabela de lookup.
Solução
O Splunk permite que você use buscas de lookups reversas, significando que você pode
procurar pelos valores das saídas de um lookup automático e o Splunk traduz isto em
uma busca pelos campos de entrada correspondentes.
Por exemplo, suponha que você uma tabela de lookup que possua uma ligação de
machine_name para owner:
machine_name, owner
webserver1,erik
dbserver7,stephen
dbserver8,amrit

104
…
Se os seus eventos tem um campo machine_name e você quer procurar por um owner
em particular, o erik, você pode usar uma busca custosa, como esta:
… | lookup mylookup machine_name | search owner=erik
Esta busca é custosa porque você está recuperando todos os eventos e filtrando qualquer
um que não tenha como owner o erik.
Alternativamente, você pode considerar uma busca mais eficiente, mas mais
complicada:
… [ inputlookup mylookup | search owner=erik | fields machine_
name]
Esta busca recupera todas as linhas na tabela de lookup e filtra quaisquer linhas que não
tenham o erik como o owner e retorna uma grande expressão de OR de machine_names
para o Splunk poder fazer a busca.
Mas nenhum destes é necessário. Se você criou uma tabela automática de lookups, você
pode simplesmente pedir ao Splunk que busque por owner=erik.
É isso. Efetivamente, o Splunk faz a solução das subpesquisas por traz dos panos,
gerando a busca por clausulas OR por você.
Nota: O Splunk também faz lookups invertidos para extração de campos definidos, tags
e eventtypes - você pode começar a buscar pelo valor que seria extraído, etiquetado ou
tipado e o Splunk recupera os eventos corretos.
Variações
Usando lookups automáticos e os lookups reversos incluso, você pode recriar o sistema
de etiquetas do Splunk. Por exemplo, faça um mapeamento por host para o campo
chamado host_tag. Agora você pode buscar por eventos baseados no seu host_tag e
não somente nos valores de host. Muitas pessoas acham mais fácil manter tabelas de
lookups do que usar múltiplas etiquetas do Splunk.
Usando um lookup de duas camadas
Problema
Você precisa de um lookup de duas camadas. Por exemplo, procure um endereço de IP
uma das tabelas de um hospedeiro bem conhecido e se falhar para um certo evento, só
então usar a segunda tabela, mais completa de DNS.
Solução
Depois de termos recuperado os eventos, nós fazemos nossa comparação inicial com o
local_dns.csv, um arquivo de lookup local:

105
... | lookup local_dns ip OUTPUT hostname
Se ele não encaixar, o campo hostname é nulo para este evento.
Agora nós montamos uma segunda, mais custosa comparação de lookups em eventos
que tenham o hostname nulo. Usando o OUTPUTNEW em vez do OUTPUT, o lookup só
vai busca por hostname com valor nulo.
... | lookup dnslookup ip OUTPUTNEW hostname
Juntando tudo isso:
... | lookup local_dns ip OUTPUT hostname
| lookup dnslookup ip OUTPUTNEW hostname
Usando lookups de múltiplos passos
Problema
Você precisa procurar um valor em um campo de lookup e usar o valor do campo
retorna do primeiro lookup para fazer um segundo lookup usando um arquivo de lookup
diferente.
Solução
Você pode fazer isto manualmente rodando comandos de lookup seqüenciais. Por
exemplo, se a primeira tabela de lookup pega o valor do campo A e retorna o valor do
campo B uma segunda tabela de lookup pega o valor do campo B e retorna o valor do
campo C:
… | lookup my_first_lookup A | lookup my_second_lookup B
De forma mais interessante, isto pode ser feito usando tabelas de lookup automáticas,
onde o encadeamento acontece sozinho. É imperativo, apesar de tudo, que os lookups
sejam rolados na ordem correta, usando a procedência alfanumérica para o nomes dos
campos..
Vá ao Manager >> Lookups >> Automatic lookups, e crie dois lookups automáticos,
se certificando que aquele que vai funcionar depois tem um nome com um valor mais
alto que o nome do lookup anterior. Por exemplo:
0_first_lookup = my_first_lookup A OUTPUT B
1_second_lookup = my_second_lookup B OUTPUT C
Nota: Usando o encadeamento de lookups como foi mostrado nesta receita, reverter
lookups como visto na receita “Usando lookups reversos” não vai funcionar por que o
Splunk atualmente não é capaz de reverter múltiplos passos de um lookup automático
(automaticamente convertendo o valer de campo C=baz na entrada para a busca do
valor de campo A=foo).

106
Criando uma tabela de lookup usando os resultados de
uma busca
Problema
Você quer criar uma tabela de lookup dos resultados de uma busca.
Solução
Se nós simplesmente fizéssemos: <some search> | outputlookup mylookupfile.csv
você poderia encontrar dois problemas. Primeiro, eventos que tenham muitos campos,
incluindo campos internos como _raw e _time, que você não quer que apareçam em sua
tabela de lookup. Segundo, dos campos que a gente se importa, muito provavelmente
haveriam valores duplicados entre os recuperados. Para lidar com o primeiro problema,
nós não iremos usar o comando fields porque ele é inconveniente para remover campos
internos. Em vez disso, nós iremos usar o comando table para melhor limitar os campos
que nós queremos utilizar. Para resolver o segundo problema, use o comando dedup.
Juntando tudo:
… | table field1, field2
| dedup field1
| outputlookup mylookupfile.csv
Anexando resultados a tabelas de lookup
Problema
Você precisa anexar os resultados a um lookup existente. Por exemplo, você quer criar
uma única tabela de lookup baseada nos resultados múltiplas iterações da mesma busca.
Especificamente, suponha que você quer acompanhar o último IP que cada usuário usou
para se conectar. Você por querer rodar um trabalho a cada 15 minutos para procurar
por isso e atualizar a tabela de lookup com novos usuários.
Solução
O procedimento padrão é conseguir o conjunto de resultados que você quer anexar a
tabela de lookup, usar inputlookup para anexar eles ao conteúdo atual da tabela de
lookup e usar o outputlookup para escrever o lookup. O comando parece com isso:
your_search_to_retrieve_values_needed
| fields the_interesting_fields
| inputlookup mylookup append=true
| dedup the_interesting_fields
| outputlookup mylookup

107
Primeiro, nós dissemos ao Splunk para recuperar os novos dados e manter somente os
campos necessários para a tabela de lookup. Em seguida, nós usamos o inputlookup
para anexar as fileiras existentes ao mylookup usando a opção append=true. Em
seguida nós removemos as duplicadas com o dedup. Finalmente, nós usamos o
outputlookup para aplicar todos estes resultados ao mylookup.
Variações
Suponha que você queira que a sua tabela de lookup tenha somente os valos dos últimos
30 dias. Você pode montar uma tabela local para ser atualizada diariamente usando uma
busca agendada. Quando você montar a sua busca agendada para gerar a tabela de
lookup e antes do comando outputlookup, adicionar a condição para filtrar somente até
30 dias: ... | where _time >= now() - (60*60*24*30) onde 60*60*60*24*30 é o
número de segundos em 30 dias.
Usando o exemplo anterior como base, a sua busca se torna:
your_search_to_retrieve_values_needed
| fields just_the_interesting_fields
| inputlookup mylookup append=true
| where _time >= now() - (60*60*24*30)
| outputlookup mylookup
Obviamente, você vai precisar manter o _time como um dos campos em sua tabela de
lookup.
Usando tabelas gigantes de lookup
Problema
Você tem uma tabela gigante de lookup mas quer que a performance seja mais rápida.
Solução
Quando você tem uma tabela de lookup bem grande e começa a notar que a
performance está sendo afetada, existem diversas soluções.
Primeiro, considere se você pode fazer ela ficar menor, com tabelas mais específicas.
Por exemplo, se algumas de suas busca só precisam de um pequeno conjunto de linhas e
colunas, considere montar uma tabela mais concisa para ser usada nestas buscas. A
seguinte busca reduziu o tamanho da tabela mylookup reduzindo as linhas para somente
aquelas que seriam afetadas pela busca, removendo duplicatas, removendo todas as
colunas menos as necessárias e finalmente enviando os resultados para a tabela
mylookup2.
| inputlookup mylookup
| search somecondition

108
| dedup someinputfield
| table someinputfield, someoutputfield
| outputlookup mylookup2
Se você não pode reduzir o tamanho da tabela de lookup, existem outras soluções.
Se a sua instalação do Splunk possui vários indexadores, estes indexadores
automaticamente replicarão a sua tabela de lookups. Mas se sua tabela de lookup for
muito grande (como 100MB), isto pode demorar demais.
Uma solução é se os seus pacotes são atualizados constantemente, desabilitar a
replicação de pacotes e utilizar o NFS para tornar os pacotes disponíveis para todas as
entradas.
Veja: http://splunk.com/goto/book#mount
Outra solução, se a sua tabela não muda constantemente e você não pode contar com
drives compartilhados ou montados, é usar os lookups locais.
• Para evitar que o lookup seja replicado ou distribuído, adiciona a tabela de lookup
para o replicationBlacklist no distsearch.conf.
(Veja http://splunk.com/goto/book#distributed)
• Copie o arquivo CSV da tabela de lookup para cada um dos seus índices em
$SPLUNK_HOME/etc/system/lookup
• Quando você fizer uma busca, adicione a opção local=true no comando de busca
lookup.
Nota: Definições de lookup definidas para rodar implicitamente via o props.conf por
natureza não são locais e tem de ser distribuídas aos indexadores.
Finalmente, considere evitar arquivos CSV grandes e também considere usar lookups
externos (normalmente se baseando em um script que enfileira as bases de dados).
Nota: Quando uma tabela de lookup .csv alcança um certo tamanho (10 MB por
padrão), o Splunk indexa ele para conseguir um acesso mais rápido. Por indexar o
arquivo .csv, o Splunk pode buscar ao em vez de escanear a na tabela. Para editar o
tamanho antes de ser indexado, edite a instancia do lookup no limits.conf e mude o
valor do max_memtable_bytes.
Comparando resultados com valores de lookup
Problema
Você quer comparar os valores em uma lista de lookup com aqueles em seus eventos.
Por exemplo, você tem uma tabela de lookup com o endereço de IP e quer saber que
endereços de IP ocorrem em seus dados.
Solução

109
Se eventos com um valor de campos particular são só uma pequena parcela dos seus
eventos, você pode eficientemente usar subpesquisas para achar estes eventos
relevantes. Use o inputlookup para gerar uma grande busca em OR de todos os valores
vistos em sua tabela de lookup. O tamanho de uma lista retornada de uma pesquisa pode
ter até 10,000 itens de tamanho (modificável no limits.conf).
yoursearch [ inputlookup mylookup | fields ip ]
A busca resultante parece com:
yoursearch AND ( ip=1.2.3.4 OR ip=1.2.3.5 OR ... )
Você pode testar o que a subpesquisa retorna rodando a busca que está dentro da
subpesquisa e anexando o comando format:
| inputlookup mylookup | fields ip | format
Veja: http://splunk.com/goto/book#subsearch
Variação I
Similarmente, para recuperar eventos com valores que NÃO estão em sua tabela de
lookup, use um padrão assim:
yoursearch NOT [ inputlookup mylookup | fields ip ]
que resulta em uma busca assim:
yoursearch AND NOT ( ip=1.2.3.4 OR ip=1.2.3.5 OR ... )
Variação II
Alternativamente, se você quer os valores em sua tabela de lookup que não se encaixam
com os seus dados, use:
| inputlookup mylookup
| fields ip
| search NOT [ search yoursearch | dedup ip | fields ip ]
Que pega todos os valores no lookup filtra para fora aqueles que se encaixam nos seus
dados.
Variação III
Para listas gigantes, aqui está um padrão de busca eficiente e complicado para encontrar
todos os valores em seus eventos que também esteja na sua tabela de lookup: recupere
os seus eventos e então anexe a tabela de lookup inteira aos seus eventos. Aplicando um
campo (como o marker), nós podemos detectar se um resultado (pense nisso como uma

110
‘linha’) é um evento ou uma linha na tabela de lookup. Nós podemos usar o stats para
conseguir a lista de endereços de IP que estão em ambas as listas (count>1):
yoursearch
| eval marker=data
| append [ inputlookup mylookup | eval marker=lookup ]
| stats dc(marker) as list_count by ip
| where list_count > 1
Nota: Apesar do comando append parecer estar executando uma subpesquisa, ele não
está. Não existe limite no número de resultados que podem ser anexados,
diferentemente de uma subpesquisa, que tem como padrão o limite de 10 mil resultados.
Se você tiver que usar esta técnica por um longo período de tempo, é mais eficiente usar
uma outra tabela de lookup para manter um estado de longo termo. Resumindo, agende
uma busca para uma pequena janela de tempo - como um dia - que calcule a última vez
que o IP tinha sido visto. Então, use uma combinação de inputlookup, dedup e
outputlookup para atualizar incremental mente esta tabela de lookup por um grande
período. Isto lhe da um recurso bem rápido para olhar para o estado mais recente. Veja a
receita “Anexando resultados a tabela de lookup” para algo mais específico.
Controlando os encaixes da tabela de lookup
Problema
Você tem múltiplas entradas em sua tabela de lookup para uma certa combinação de
campos de entrada e quer que o só o primeiro valor seja encaixado. Por exemplo,a sua
tabela de lookup mapeia os nomes dos hospedeiros para vários apelos de hospedeiros e
você quer só o primeiro apelido.
Solução
Por padrão, o Splunk retorna até 100 encaixes para lookups que não envolvam um
elemento de tempo. Você pode atualizar isto para que ele retorne somente um.
Usando a interface, vá para o Manager >> Lookups >> Lookup definitions e edite ou
crie a sua definição de lookup. Selecione a caixa Advanced options e coloque 1 no
Maximum matches.
Alternativamente, você pode editar o transforms.conf relacionado. Adicione max_
matches=1 na sua instancia de lookup.
Veja: http://splunk.com/goto/book#field_lookup
Variações

111
Se a sua tabela de lookups tem duplicatas e você quer remover elas, você pode limpar-la
com uma busca parecida com esta:
| inputlookup mylookup | dedup host | outputlookup mylookup
Isto elimina todos menos a primeira ocorrência distinta de cada hospedeiro no arquivo.
Encaixando IPs
Problema
Você tem uma tabela de lookup com conjuntos de endereços de IP que você quer
encaixar.
Solução
Suponha que os seus eventos tenham endereços de IP neles e você tem um tabela de
conjuntos de IPs e ISPs:
network_range, isp
220.165.96.0/19, isp_name1
220.64.192.0/19, isp_name2
...
Você pode especificar um match_type para o seu lookup. Por desventura, esta
funcionalidade não está disponível na interface mas você pode colocar no
transforms.conf.
Coloque o match_type como CIDR para o seu network_range.
Em transforms.conf:
[mylookup]
match_type = CIDR(network_range)
Veja: http://splunk.com/goto/book#transform
Variações
Os valores disponíveis do match_type são WILDCARD, CIDR e EXACT. EXACT é o
padrão e não precisa ser especificado.
Também no transforms.conf, você pode especificar se os encaixes de lookups são
sensíveis a maiúsculas (por padrão) ou não. Para que elas não fiquem sensíveis:
case_sensitive_match = False

112
Encaixando Coringas
Problema
Você precisa que a sua tabela de lookup possa se encaixar com coringas.
Solução
Suponha que você tenha uma tabela de lookups com URLs que você gostaria de
encaixar:
url, allowed
*.google.com/*, True
www.blacklist.org*, False
*/img/*jpg, False
Incluindo um caractere coringa (*) nos valores de sua tabela de lookup, você pode
direcionar ao Splunk que ele procure com os coringas.
Como em “Encaixando IPs”, você pode especificar um match_type para um lookup no
transforms.conf:
[mylookup]
match_type = WILDCARD(url)
Nota: Por padrão, o número máximo de encaixes em uma tabela de lookup é 100, então
se você tiver múltiplos valores que se encaixam, os campos de saída terão múltiplos
valores. Por exemplo, uma URL como “www.google.com/img/pix.jpg” poderia se
encaixar com a primeira e terceira linha da tabela acima, o que permitiria que o
campos se tornasse um campo de múltiplos valores com os valore de True e False.
Normalmente não é isto que você quer. Colocando a configuração do Maximum
matches como 1, o primeiro valor a se encaixar é que vai estar válido, e você pode usar
a ordem da tabela para definir a prioridade. Você pode encontrar esta configuração no
Manager >> Lookups >> Lookup definitions >> mylookup, depois selecione a caixa
Advanced options.
Variações
A primeira receita deste capítulo lidava com os valores padrão quando um lookup
falhava em se encaixar. Outra forma de lidar com isso seria com o uso de coringas. Faça
com que o último item de sua lista seja um valor de *, e coloque os encaixes mínimos e
máximos da tabela de lookup com 1.

113
Apêndice A: Básico dos Dados de
Maquina
Dados gerados por maquina a tempos vem sendo usados em centros de dados por
profissionais de TI mas só recentemente tem sido reconhecida como uma nova fonte de
ajuda para os outros departamentos. Algumas vezes chamados de dados de TI ou dados
operacionais, dados de maquina são todos os dados gerados por aplicações, servidores,
mecanismos de redes, mecanismos de segurança e outros sistemas dentro do seu grupo
de trabalho.
O universo coberto pelos dados de maquina cobre muito mais do que logs - ele inclui
dados da configuração, clickstreams, mudanças em eventos, diagnósticos, APIs, filas de
mensagens e aplicações customizadas. Estes dados são rigidamente monitorados,
baseados em uma série de tempo e em grande quantidade. Eles são gerados por quase
todos os componentes de TI e os seus formatos e fontes variam muito. Milhares de
formatos de log, muitas aplicações customizadas, que são críticos para diagnosticar
problemas de serviço, detectar perigos a segurança e demonstrar conformidade. E com a
explosão dos dispositivos conectados, a quantidade de informação sendo criada por
maquinas de todos os tipos - aparelhos GPS, etiquetas de RFID, telefones moveis,
utilitários, etc - está expandindo mais rápido do que a gente pode processar.
O valor dos dados de maquina não é novo para os profissionais de TI; eles já vem
usando isto a anos. De forma crescente, usuários do Splunk descobrem que isto também
pode ajudar a dar luz aos problemas de trabalho. Dados de maquina são na maioria das
vezes guardados em arquivos enormes e antes do Splunk, ele ficaria dormente até que
algum problema surgisse e estes arquivos teriam de ser inspecionados manualmente.
Com o Splunk, estes arquivos são indexados e usáveis.
Usuários de negócio estão acostumados a lidar com dados gerados por pessoas
participantes no processo do negócio. Geralmente, estes dados transacionais, como são
chamados, estão guardados de duas formas.
Bases de Dados Relacionais são largamente usadas para armazenar dados
transacionais. Eles guardam dados empresariais de forma estruturada, como os registros
financeiros, os registros de funcionários, manufatura, informação logística,etc. Por
design, bancos de dados relacionais são estruturados com esquemas rígidos, ou
montados a partir de formulas que descrevem a estrutura do banco de dados. Mudanças
nestes esquemas podem estragar a funcionalidade, Introduzindo uma série de atrasos e
problemas que podem trazer riscos. Para construir uma busca em uma base de dados
relacional, praticantes devem se aproveitar de um esquema alternativo.
Bases de Dados Multidimensionais são projetadas para organizar enormes grupos de
registros. O termo OLAP (Processo Analítico On-Line) se tornou quase um sinônimo de
“base de dados multidimensional”. Ferramentas de OLAP permitem ao usuário analisar
diferentes dimensões de dados multidimensionais. Bases de dados multidimensionais
são ótimas para a mineração de registros mensais, mas não para eventos em tempo real.

114
Dados de maquina estão em um nível de detalhe muito menor do que o dos dados
transacionais.
Dados transacionais podem guardar todos os dados de produto, transporte e pagamento
associados com a compra online. Os dados de maquina associados com esta compra
poderiam incluir milhares de registros, ou eventos, que acompanham cada clique do
usuário, cada pagina e imagem carregada, cada pedido de propaganda, e por ai vai.
Dados de maquina não são só sobre o resultado final, ou o destino, mas sobre toda a
jornada.
Por ser tão detalhado, os dados de maquina podem ser usados para uma grande
variedade de propósitos, No mundo da TI, dados de maquina podem, por exemplo,
ajudar a encontrar problemas e também mostrar se os sistemas estão operando dento dos
padrões. No mundo dos negócios, dados de maquina podem detectar o comportamento
de consumo e ajudar a segmentar consumidores para a criação de vários públicos alvo.
Para ajudar a você a ter uma melhor idéia da natureza dos dados de maquina, este
apêndice vai descrever superficialmente alguns dos diferentes tipos que você pode
encontrar.
Logs de Aplicação
A maioria das aplicações caseira ou em pacotes escrevem arquivos de log, muitas vezes
adicionando serviços como intermediários - WebLogic, WebSphere®, JBoss™, .NET™,
PHP, e outros. Os arquivos de log são críticos para o debuggind diário de aplicações de
produção por desenvolvedores e para o suporte de aplicação. Eles também são a melhor
maneira de reportar as atividades de negócios e usuários e em detectar fraudes porque
eles também tem todos os detalhes das transações. Quando desenvolvedores colocam a
informação de tempo em seus logs de evento, os arquivos de log também podem ser
usados para monitorar e reportar a performance da aplicação.
Logs de Acesso Web
Logs de acesso web reportam todos os pedidos processados por um servidor web - qual
é o endereço de IP do cliente de onde o pedido veio, qual foi a URL requisitada, o que a
URL referente era e os dados sobre o sucesso ou a falha do pedido. Eles são mais
comumente processados para produzir relatórios de análise de web para o marketing -
contagens diárias de visitantes, páginas mais requisitadas, etc.
Eles também são valiosos como um ponto de partida para a investigação de problemas
reportados pelos usuários porque o log de um pedido que falhou pode estabelecer o
tempo exato do erro. Logs web são bem padrões e bem estruturados. O desafio principal
é lidar com eles em seu enorme volume, como sites bem ativos tipicamente recebem
bilhões de entradas por dia como norma.
Logs de Proxy Web
Quase todas as empresas, servidoras de serviços, instituições e organizações do governo
que proporcionem aos funcionários, consumidores ou convidados com acesso a rede

115
usam algum tipo de Proxy web para controlar e monitorar o acesso. Proxies Web
registram todos os pedidos de rede que foram feitos pelo usuário através do Proxy. Eles
podem incluir nomes de usuários corporativos e URLs, Estes logs são críticos para o
monitoramento e investigação dos abusos dos “termos de serviço” ou da política de uso
de acesso web e também são componentes vitais para o monitoramento efetivo do
vazamento de dados.
Registros de Detalhes de Chamadas
Registros de Detalhes de Chamadas (CDRs), Registros de Dados de Carga e Registros
de Dados de Eventos são alguns dos nomes dados aos eventos logados por telecons e
manipuladores de rede. Os CDRs contem dados úteis sobre chamadas e serviços
passados pelo manipulador, como o número fazendo a chamada, o número recebendo a
chamada, o tempo da chamada, a duração da chamada e o tipo de chamada. Enquanto os
serviços de comunicação se movem para serviços baseados em protocolos de internet,
estes dados são também referenciados como IPDRs, contendo detalhes como o endereço
de IP, número da porta, etc. As especificações, formatos e estruturas destes arquivos
variam monstruosamente; manter o passo com todas as transmutações da forma
tradicional tem sido um desafio. Ainda assim os dados que eles contem são de extrema
importância para as contas, certificação de renda, certificação de consumidores,
firmação de parcerias, inteligência de marketing e muito mais. O Splunk rapidamente
indexa os dados e combina eles com outros dados de negócios que permitem aos
usuários a entrega de novas visões desta informações ricas em utilidade.
Dados de Clickstream
O uso de uma página web em um site é capturada em dados de clickstream. Isto dispõe
uma visão de o que o usuário está fazendo e é útil para analisar a usabilidade, o
marketing e a em pesquisas gerais. Formatos para estes dados são fora do padrão, e
ações podem ser logadas em múltiplos lugares, como no servidor web, roteadores,
servidores proxy e servidores de propaganda. Ferramentas de monitoramento
geralmente tem visões parciais dos dados de uma fonte especifica. Estatísticas de web e
depósitos de dados produzem amostras de dados, assim, perdendo completamente a
visão do comportamento e não oferecendo a possibilidade de análise em tempo real.
Enfileiramento de Mensagem
Tecnologias de enfileiramento de mensagens como TIBCO®, JMS e AquaLogic™ são
usadas para passar dados e tarefas entre os serviços e os componentes de aplicações em
uma base de publicação/inscrição. Se inscrever nestas fileiras de mensagens é uma boa
maneira de fazer debug nos problemas de aplicações complexas - você pode ver
exatamente o que o próximo componente na cadeia recebei do componente anterior.
Separadamente, fileiras de mensagens estão se tornando cada vez mais usadas como a
coluna das arquiteturas de log para aplicações.

116
Pacotes de Dados
Dados gerados por redes são processados usando ferramentas como tcpdumpe tcpflow,
que geram dados pcaps ou outras informações úteis a nível de pacote e sessão. Estas
informações são necessárias para lidar com degradação de performance, perdas por
atraso, gargalos ou atividades suspeitas que podem indicar que a rede pode estar sendo
comprometida por um ataque remoto.
Arquivos de Configuração
Não existe substituto para uma verdadeira configuração de sistema ativa em entender
como a infra-estrutura foi montada. Configurações passadas são necessárias para
debugar falhas passadas que possam ocorrer novamente. Quando as configurações
mudam, é importante sabe o que foi mudado e quando, e se a mudança foi autorizada, e
se um ofensor teve sucesso em comprometer o sistema através de backdoors, bombas
relógio ou ameaças latentes.
Logs de Auditoria de Bancos de Dados e Tabelas
Bancos de dados contem alguns dos dados mais sensíveis de uma corporação - registros
de consumidores, dados financiais, registros de pacientes, etc. Registros de auditoria de
todas as filas do banco de dados são vitais para o entendimento de quem acessou ou
mudou os dados e quando. Logs de auditoria de banco de dados são úteis para entender
como uma aplicação está usando bancos de dados para otimizar fileiras. Alguns logs de
auditoria de banco de dado são salvos em arquivos, enquanto outros são mantidos em
tabelas acessíveis com o SQL.
Logs de Auditoria do Sistema de Arquivos
Dados sensíveis que não estão nos bancos de dados estão no sistema de arquivos,
muitas vezes compartilhado. Em algumas industrias como saúde, os maiores
vazamentos de dados arriscam os registros do consumidor mantidos no sistema de
arquivos. Diferentes sistemas operacionais, ferramentas de terceiros e tecnologias de
armazenamento disponibilizam diferentes opções para acesso da auditoria para ler
dados sensíveis no nível do sistema de arquivos. Estes dados de auditoria são uma
fonte vital para o monitoramento e investigação do acesso a informações sensíveis.
Gerenciamento e APIs de Log
Cada vez mais vendedores estão expondo dados de gerenciamento crítico e logs de
eventos em APIs padronizadas e proprietárias, em vez de logar eles em arquivos. O
Checkpoint® protege os logs usando o API de Exportação de Logs do OPSEC (OPSEC
LEA). Vendedores de virtualização, incluindo VMware® e Citrix®, expõem
configurações, logs e estado do sistema com seus próprios APIs.

117
Medidas de OS, Estado e Comandos de Diagnostico
Sistemas operacionais expõem medidas críticas, como o uso de CPU e memória e as
informações de estado usando utilidades de linha de comando como o ps e o iostat no
Unix e no Linux e o perfmon no Windows. Estes dados são normalmente agregados por
ferramentas de monitoramento de servidor mas eles são raramente persistentes, mesmo
que sejam indispensáveis para a resolução de problemas, analisando tendências e
problemas latentes e investigando problemas de segurança.
Fontes de Dados de Outras Maquinas
Existem incontáveis fontes alternativas de dados de maquina importantes que nós não
temos como descrever todas, incluindo os logs de repositórios de códigos fonte, logs de
segurança física, etc. Você ainda vai precisar de um firewall e logs de IDS para reportar
as conexões de rede e os ataque. Os logs OS, incluindo o syslog do Unix e Linux e os
event logs do Windows, registram quem logou em seus servidores, que ações
administrativas eles tomaram, quando o serviço começou e acabou e quando o os
pânicos de núcleo acontecem. Os logs do DNS, DHCP e outros serviços de rede
registram quem foi associado qual endereço de IP e como os domínios foram
resolvidos. Os Syslogs dos seus roteadores, alternadores e mecanismos de rede
recordam o estado das conexões de rede as falhas de componentes críticos da rede. Os
dados de máquina são mais do que somente logs e uma gama enorme de logs alem das
soluções suportadas pelo gerenciamento de logs tradicional.

Apêndice B: Sensibilidade a
Maiúsculas
Algumas coisas no Splunk são sensíveis a maiúsculas, enquanto outras não, como é
sumarizado na tabela B-1.
Tabela B-1. Sensibilidade a Maiúscula
Apêndice B: Sensibilidade a
Algumas coisas no Splunk são sensíveis a maiúsculas, enquanto outras não, como é
1.
1. Sensibilidade a Maiúscula
118
Apêndice B: Sensibilidade a
Algumas coisas no Splunk são sensíveis a maiúsculas, enquanto outras não, como é
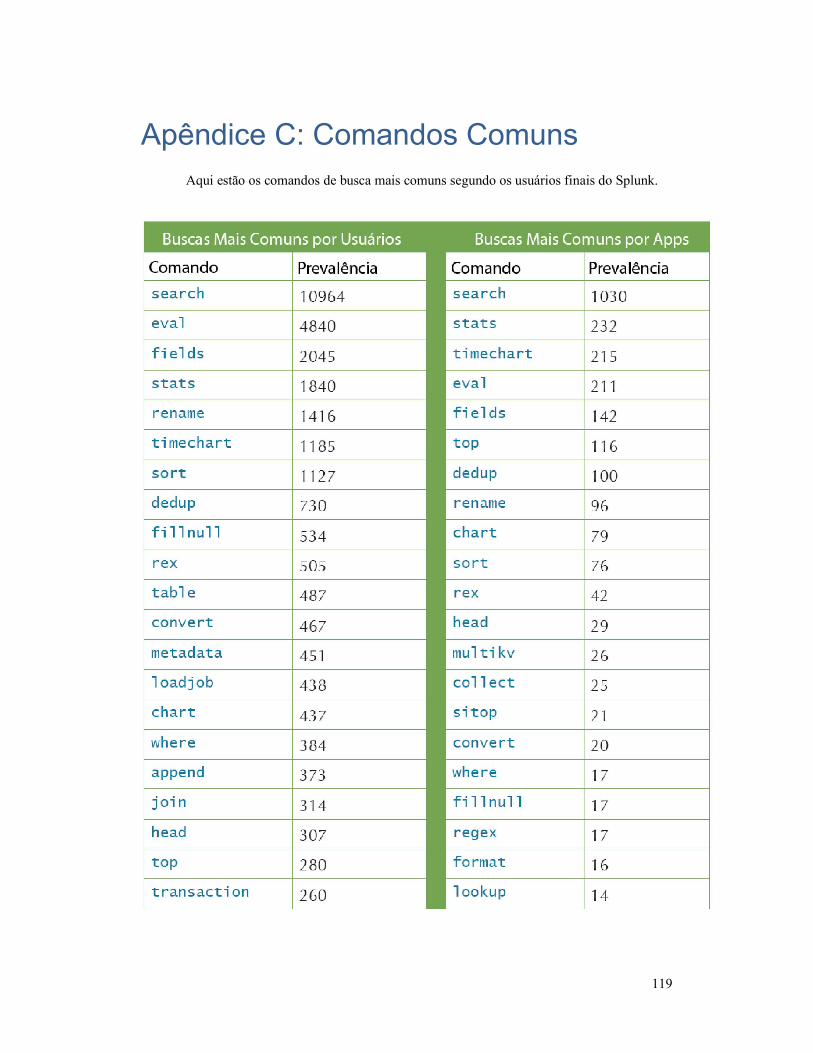
Apêndice C: Comandos Comuns
Aqui estão os comandos de busca mais comuns segundo os usuários finais do Splunk.
Apêndice C: Comandos Comuns
Aqui estão os comandos de busca mais comuns segundo os usuários finais do Splunk.
119
Aqui estão os comandos de busca mais comuns segundo os usuários finais do Splunk.
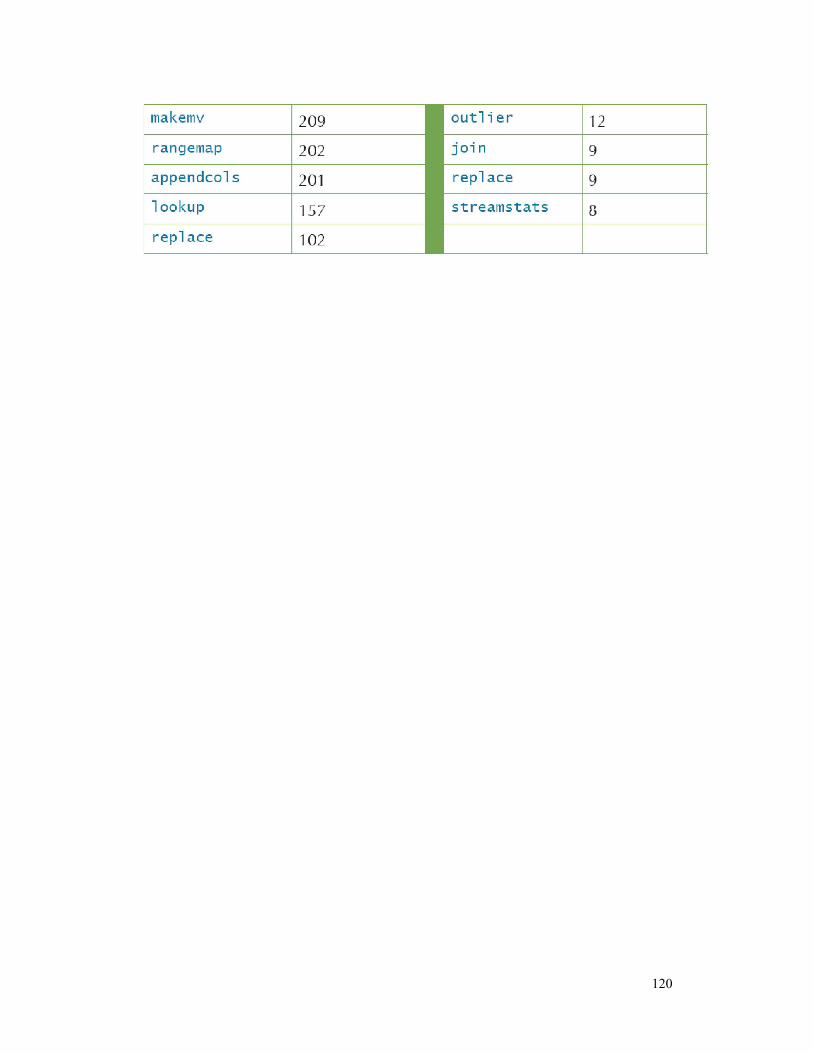
120

121
Apêndice D: Recursos mais usados
Nós percebemos que este livro não pode te oferecer tudo o que você precisa saber sobre
o Splunk. Aqui estão uma lista de sites para continuar os seus estudos. Estes links
também estão listados em http://splunk.com/goto/book#links.
Página de Download do Splunk
http://splunk.com/download
Documentação do Splunk http://docs.splunk.com
Comunidade do Splunk http://splunkbase.com
Documentos Criados pela Comunidade
http://innovato.com
Vídeos de Treinamento http://splunk.com/view/SP-CAAAGB6
Vídeos do Splunk http://splunk.com/videos
Blog do Splunk http://blogs.splunk.com
Splunk TV http://splunk.tv

122
Apêndice E: Guia de Referencia
Rápida do Splunk
CONCEITOS
Visão Geral
Processamento em Índice de Tempo: O Splunk lê os dados de uma fonte (source),
como um arquivo ou uma porta, em um hospedeiro (host) (“minha máquina”), classifica
esta fonte como uma sourcetype (como o syslog, o access_combined ou o apache
error), então extrai as estampas de tempos, dividindo a fonte em eventos individuais
(como logos de eventos, alertas, etc) que podem consistir de uma ou mais linhas, e
escreve cada evento um índice (index) no disco, para depois ser recuperado com uma
busca.
Processamento de Busca por Tempo: Quando uma busca começa, eventos indexados
que se encaixam são recuperados, campos (como code=404 ou user=david,...) são
extraídos do texto do evento, e o evento é classificado por como ele se encaixa nas
definições do eventtype (como error ou login). Os eventos retornados de uma busca
podem ser fortemente modificados usando o SPL para gerar relatórios que aparecem
nas dashboards.
Eventos
Um evento é uma linha de dados. Aqui está um evento de um log de web ativo:
173.26.34.223 - - [01/Jul/2009:12:05:27 -0700] “GET /trade/
app?action=logout HTTP/1.1” 200 2953
Mais especificamente, um evento é um conjunto de valos associados com uma estampa
de tempo. Enquanto muitos eventos são curtos e só tomam uma linha ou duas, outros
podem ser longos, como um documento de texto inteiro, um arquivo de configuração,
ou uma pilha de despejo em JAVA. o Splunk usa regras de quebra de linha para
determinar como ele deve dividir estes eventos para deixar a mostra nos resultados da
busca.
Fontes e Tipos de Fonte
Uma fonte é o nome do arquivo, stream, ou outro tipo de entrada de onde são tirados os
eventos - por exemplo, /var/log/messages ou UDP:514. Fontes são classificadas em
tipos de fontes, que podem ser bem conhecidas, como access_combined (servidores de
log web) ou podem ser criados na hora quando o Splunk vê uma nova fonte de dados e a
está formatando. Eventos com o mesmo tipo de fonte pode vir com diferentes fontes -

123
eventos do arquivo /var/log/messages e da entrada de syslog udp:514 podem ser
colocados no sourcetype=linux_syslog.
Hospedeiros
Um hospedeiro é o nome do dispositivo físico ou virtual de onde vem um evento.
Hospedeiros proporcionam uma forma fácil de juntar todos os eventos vindos de uma
única maquina.
Índices
Quando você adiciona dados ao Splunk, o Splunk processa ele, quebrando os dados em
eventos individuais, adiciona estampas de tempo as eventos, e armazena eles em um
índice para que os dados possam ser buscados e analisados posteriormente. Por padrão,
dados que você der ao Splunk são armazenados no índice main, mas você pode criar e
especificar outros índices para o Splunk usar para diferentes entradas de dados.
Campos
Campos são pares procuráveis de nome/valor dentro dos dados do evento. Enquanto o
Splunk processa os eventos na hora de indexar e na hora de buscar, ele automaticamente
extrai os campos. Na hora de indexar, o Splunk extrai um pequeno conjunto de campos
padrão para cada evento, incluindo o host, source e o sourcetype. Na hora da busca, o
Splunk extrai uma grande gama de campos dos dados do evento, incluindo padrões
definidos pelo usuário em pares de nome/valor óbvios como userid=jdoe.
Etiquetas
Etiquetas são apelidos para os valores dos campos. Por exemplo, se dois nomes de
hospedeiro se referirem ao mesmo computador, você pode dar a ambos os valores a
mesma etiqueta (por exemplo hal9000). Quando você buscar por tag=hal9000, o
Splunk retorna os eventos envolvendo ambos os valores de hospedeiro.
Tipos de Eventos
Tipos de eventos são etiquetas dinâmicas associadas a um evento, se ele se encaixar nos
requisitas da busca do tipo de evento. Por exemplo, se você definir um tipo de evento
chamado problem com a definição da busca como error OR warn OR fatal OR fail,
sempre que o resultado de uma busca error, warn, fatal ou fail, o evento tem um par de
campo/valor eventtype com eventtype=problem. Se você estiver procurando por login,
os logins com problemas serão anotados como eventtype=problem. Tipos de eventos
são uma forma de busca por referencias cruzadas em eventos na hora de buscar.
Reportagens e Quadros
Resultados de uma busca com informação de formatação (como uma tabela ou quadro)
são informalmente referidos como reportagens e múltiplas reportagens podem ser
colocadas em uma página em comum, chamada quadro.

124
Apps
Apps são uma coleção de configurações do Splunk, objetos e códigos. Os Apps
permitem que você construa diferentes ambientes que se baseiam no Splunk. Você pode
ter um app para lidar com problemas em um servidor de e-mail, um outro app para
análise web, etc.
Permissões/Usuários/Funções
Objetos salvos no Splunk, como as savedsearches, os eventtypes, as reports e as tags,
enriquecem os seus dados, fazendo eles mais fáceis de buscar e entender. Estes objetos
tem permissões e podem ser mantidos privados ou compartilhados com outros usuários
a partir de suas funções (como administrador, reforço ou usuário). Uma função é um
conjunto de capacidades que você define, como se uma função em particular pode
adicionar dados ou editar um relatório. O Splunk com licença livre não suporta
autenticação de usuários..
Transações
Uma transação é um grupo de eventos considerados como um para facilitar a análise.
Por exemplo, por um usuário de um sistema de compras online gerar múltiplos eventos
de acesso web com o mesmo ID de sessão, por ser conveniente agrupar todos estes
eventos em uma transação. Com um eventos de transação, é mais fácil gerar estatísticas
como por quanto tempo o cliente ficou fazendo as compras, quantos itens ele comprou,
que compradores compraram itens e devolveram, etc.
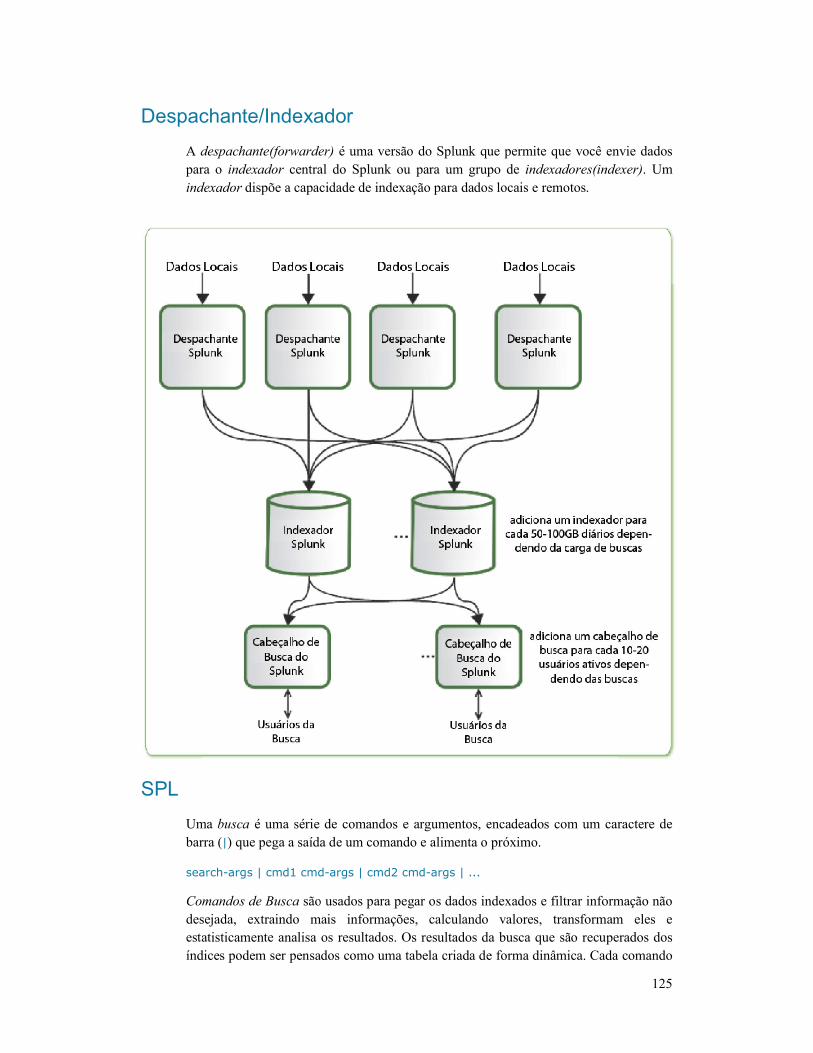
Despachante/Indexador
A despachante(forwarder)
para o indexador central do Splunk ou para um grupo de
indexador dispõe a capacidade de indexação para dados locais e remotos.
SPL
Uma busca é uma série de comandos e argumentos, encadeados com um caractere de
barra (|) que pega a saída de um comando e alimenta o próximo.
search-args | cmd1 cmd
Comandos de Busca são usados para pegar os dados indexados e filtrar informação não
desejada, extraindo mais informações, calculando valores, transformam
estatisticamente analisa os resultados. Os resultados da busca que são recuperados dos
índices podem ser pensados como uma tabela criada de forma dinâmica. Cada comando
Despachante/Indexador
despachante(forwarder) é uma versão do Splunk que permite que você envie d
central do Splunk ou para um grupo de indexadores(indexer)
dispõe a capacidade de indexação para dados locais e remotos.
é uma série de comandos e argumentos, encadeados com um caractere de
que pega a saída de um comando e alimenta o próximo.
args | cmd1 cmd-args | cmd2 cmd-args | ...
são usados para pegar os dados indexados e filtrar informação não
desejada, extraindo mais informações, calculando valores, transformam
estatisticamente analisa os resultados. Os resultados da busca que são recuperados dos
índices podem ser pensados como uma tabela criada de forma dinâmica. Cada comando
125
é uma versão do Splunk que permite que você envie dados
indexadores(indexer). Um
é uma série de comandos e argumentos, encadeados com um caractere de
são usados para pegar os dados indexados e filtrar informação não
desejada, extraindo mais informações, calculando valores, transformam eles e
estatisticamente analisa os resultados. Os resultados da busca que são recuperados dos
índices podem ser pensados como uma tabela criada de forma dinâmica. Cada comando

126
de busca redefine a forma da tabela. Cada evento indexado é uma linha, com colunas
para cada valor. Colunas podem incluir informações básicas sobre os dados extraídos
dinamicamente na hora da busca.
No cabeçalho de cada busca está um comando de busca-por-eventos-no-índice
implícito, que poderia ser usado para buscar por palavras chave (como error),
expressões booleanas (como (error OR failure) NOT success), frases (como “database
error”), coringas (como fail* que se encaixa com fail, fails e failure), valores de campos
(como code=404), diferenças (como code!=404 ou code>200), um campo tendo
qualquer valor ou valor nenhum (como code=* ou NOT code=*). Por exemplo, esta
busca:
sourcetype=”access_combined” error | top 10 uri
recupera os eventos indexados no access_combined do disco que contenham a palavra
error (os AND está implícito na busca), e então para estes eventos, reportar os 10 valore
de URI mais comuns.
Sub-pesquisas
Uma sub-pesquisa é um argumento para um comando que faz a sua própria busca,
retornando estes resultados para o comando pai como valores de um argumento. Sub-
pesquisas são encapsuladas em colchetes. Por exemplo, este comando encontra todos os
eventos do syslog do usuário com que teve o último erro de login:
sourcetype=syslog [search login error | return user]
Note que a sub-pesquisa retorna só um valor de usuário pois por padrão o comando
return retorna somente um valor, apesar de que existem opções para ele retornar mais
valores (como | return 5 user).
Modificadores de Tempo Relativos
Apesar de usar janelas de tempo customizadas na interface de usuário, você pode
especificar em suas buscas a janela de tempo dos eventos recuperados com os
modificadores de busca latest e earliest. Os tempos relativos são especificados com um
conjunto de caracteres que indicam a janela de tempo (inteiros e unidades) e,
opcionalmente, uma unidade tempo arredondada:
[+|-]<time_integer><time_unit>@<snap_time_unit>
Por exemplo, error earliest=-1d@d latest=-1h@h recupera eventos contendo o error
que de ontem (cortado a meia noite) até a última hora (certado pela hora).
Unidades de Tempo: Especificado como segundo (s), minuto (m), hora (h), dia (d),
semana (w), mês (mon), quarto (q) ou ano (y). O valor precedente é por padrão 1 (como
o m é o mesmo que 1m).
Corte: Indica a aproximação do a qual o tempo que você pode usar para o
arredondamento. O corte arredonda para o tempo mais recente que não seja depois do
tempo especificado. Por exemplo, se agora for 11:59:00 e você quer ”cortar” por horas
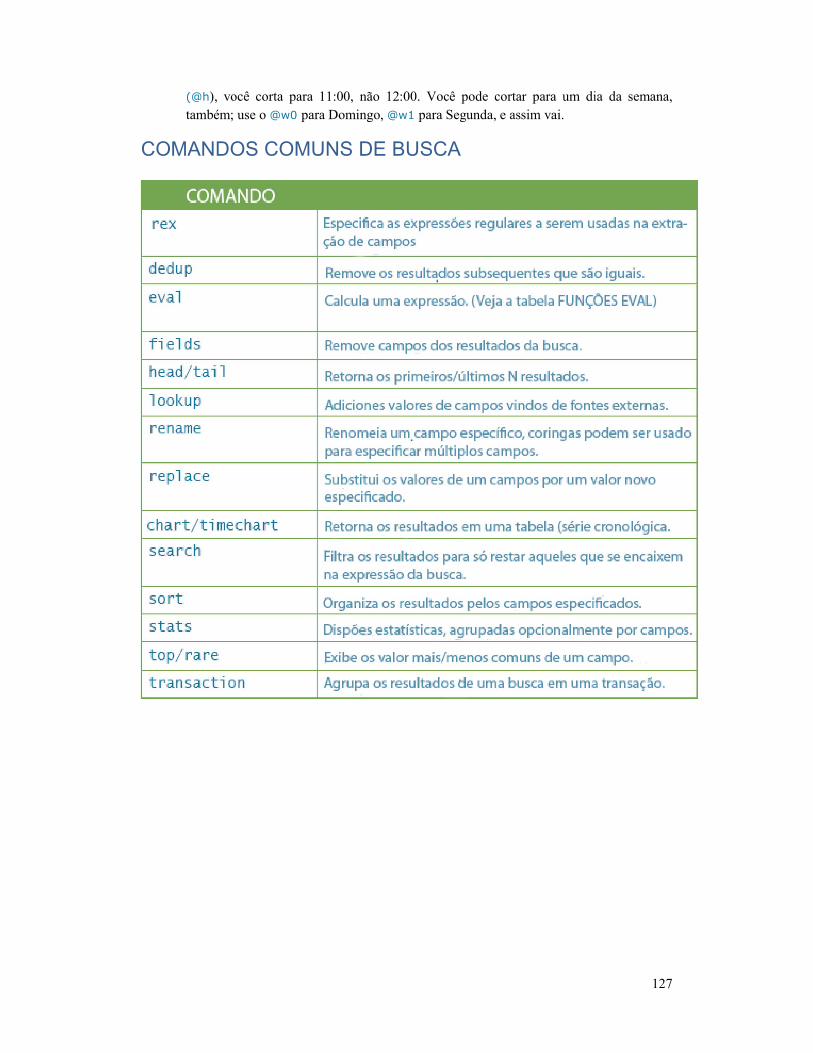
(@h), você corta para 11:00, não 12:00. Você pode cortar para um dia da semana,
também; use o @w0 para Domingo,
COMANDOS COMUNS DE BUSCA
), você corta para 11:00, não 12:00. Você pode cortar para um dia da semana,
para Domingo, @w1 para Segunda, e assim vai.
COMANDOS COMUNS DE BUSCA
127
), você corta para 11:00, não 12:00. Você pode cortar para um dia da semana,

Otimizando Buscas
A chave para uma busca mais rápida é limitar os dados que são lidos no disco para o
mínimo possível e então filtrar os dados o mais cedo o
processar a menor quantidade de dados.
Particione os dados em índices se você raramente faz buscas através de múltiplos tipos
de dados. Por exemplo, coloque os dados da web em um índice e os dados do firewall
em outro.
Mais dicas:
• Procure especificamente o que você quer (
• Limite a janela de tempo da busca (como
• Filtre os campos desnecessários o mais cedo o possível..
• Filtre os resultados o mais cedo o possível antes de fazer os
• Para busca que geram reportagens, use a visão de
Avançado), e não a visão de
• Desligue o botão de
necessário.
• Use os índices do sumário para
• Certifique-se de que o I/O do seu disco é o mais rápido que você tem disponível.
EXEMPLOS DE BUSCA
A chave para uma busca mais rápida é limitar os dados que são lidos no disco para o
mínimo possível e então filtrar os dados o mais cedo o possível para conseguir
processar a menor quantidade de dados.
Particione os dados em índices se você raramente faz buscas através de múltiplos tipos
de dados. Por exemplo, coloque os dados da web em um índice e os dados do firewall
Procure especificamente o que você quer (fatal_error, não *error*).
• Limite a janela de tempo da busca (como -1h e não -1w).
• Filtre os campos desnecessários o mais cedo o possível..
• Filtre os resultados o mais cedo o possível antes de fazer os cálculos.
• Para busca que geram reportagens, use a visão de Advanced Charting(Gráfico
, e não a visão de Timeline(Linha do Tempo), que calcula linhas do tempo.
• Desligue o botão de Field Discovery(Descoberta de Campos) quando não for
• Use os índices do sumário para pré calcular os valores mais comumente usados.
se de que o I/O do seu disco é o mais rápido que você tem disponível.
EXEMPLOS DE BUSCA
128
A chave para uma busca mais rápida é limitar os dados que são lidos no disco para o
possível para conseguir
Particione os dados em índices se você raramente faz buscas através de múltiplos tipos
de dados. Por exemplo, coloque os dados da web em um índice e os dados do firewall
Advanced Charting(Gráfico
, que calcula linhas do tempo.
quando não for
os valores mais comumente usados.
se de que o I/O do seu disco é o mais rápido que você tem disponível.

129

130
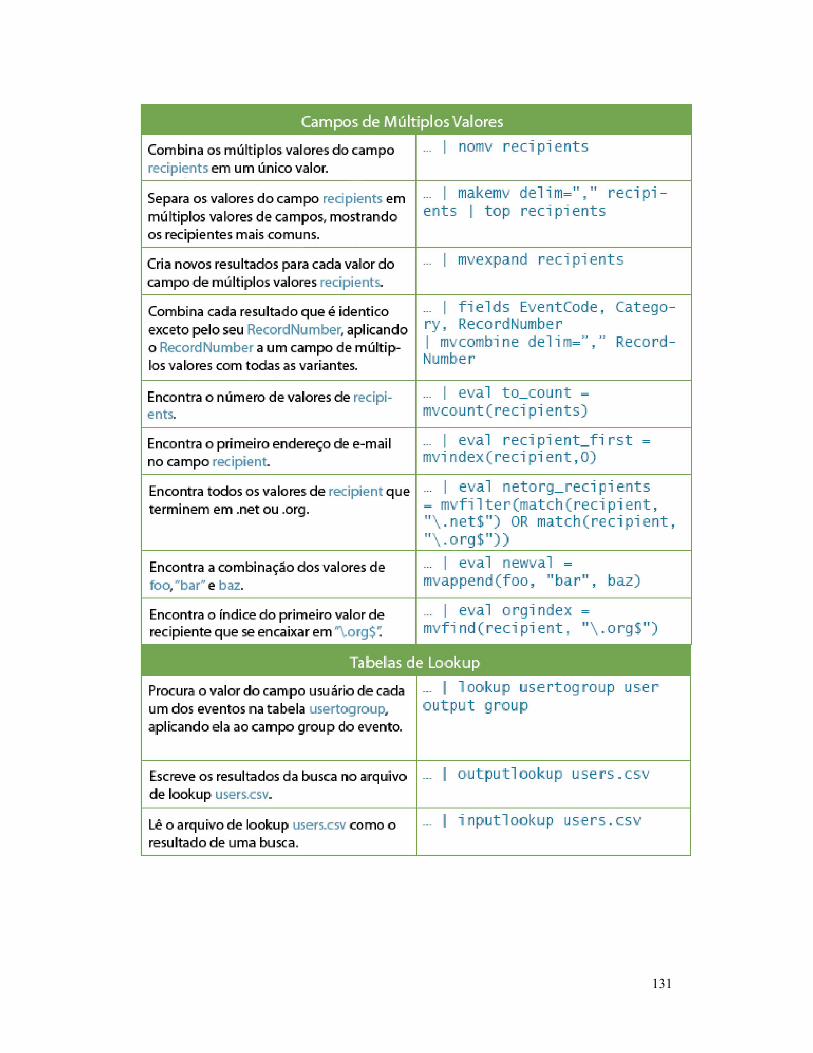
131

FUNÇÔES EVAL
O comando eval calcula uma expressão o coloca o resultado em um campo (com
eval force = mass * acceleration”
entende, em adição dos operadores
strings (como ‘...| eval
NOT XOR < > <= >= != = == LIKE).
Tabela de Funções do EVAL
calcula uma expressão o coloca o resultado em um campo (com
eval force = mass * acceleration”). A seguinte tabela lista as funções que o
entende, em adição dos operadores aritméticos básicos (+ - * / %), concatenação de
name = last . “, “ . last’) e operações booleanas (AND OR
XOR < > <= >= != = == LIKE).
132
calcula uma expressão o coloca o resultado em um campo (com “...|
). A seguinte tabela lista as funções que o eval
* / %), concatenação de
) e operações booleanas (AND OR
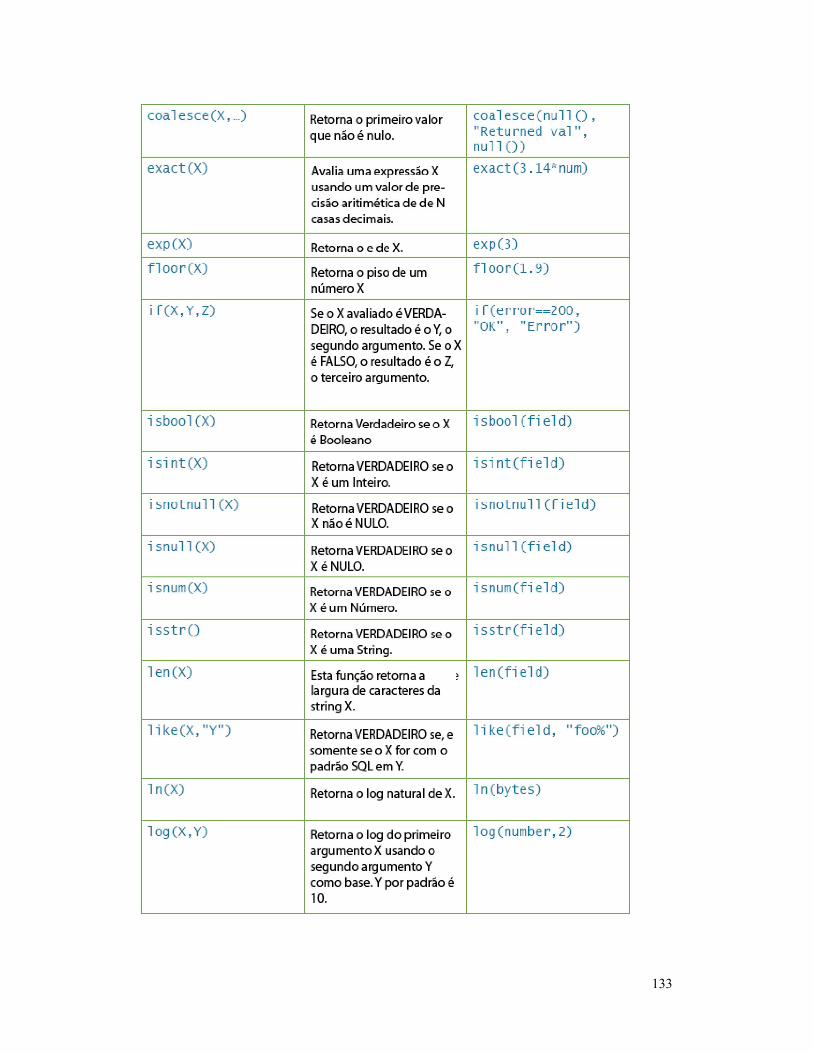
133
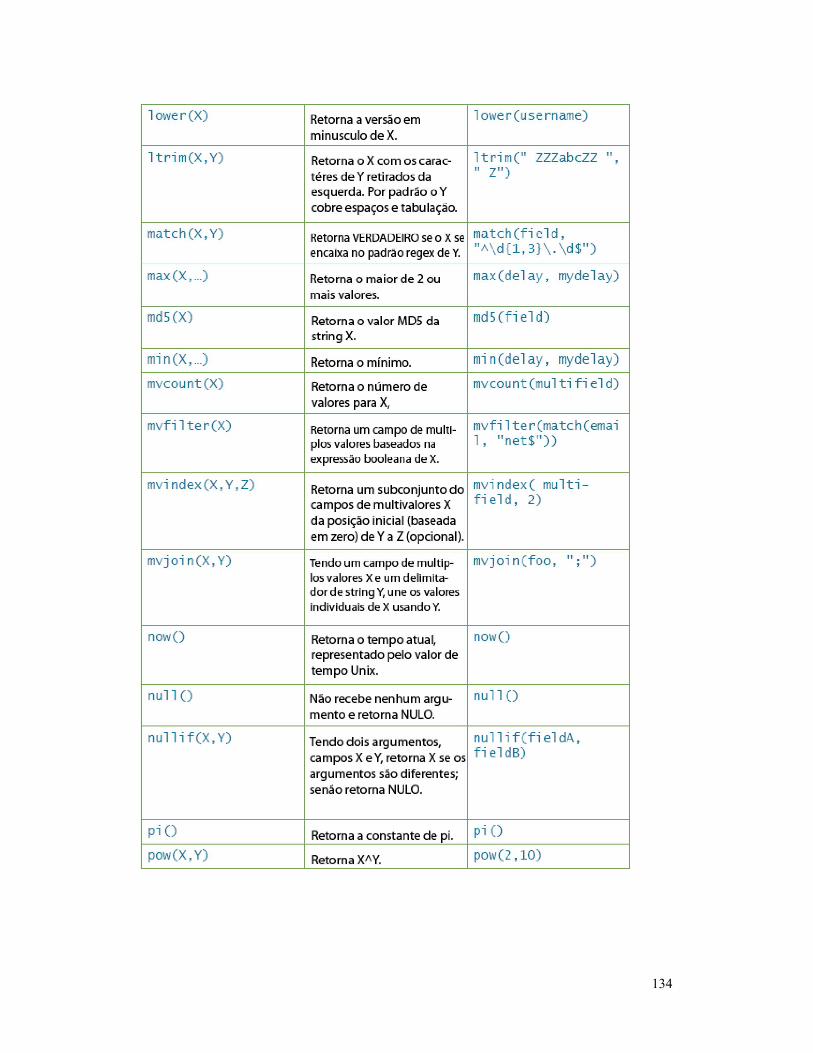
134
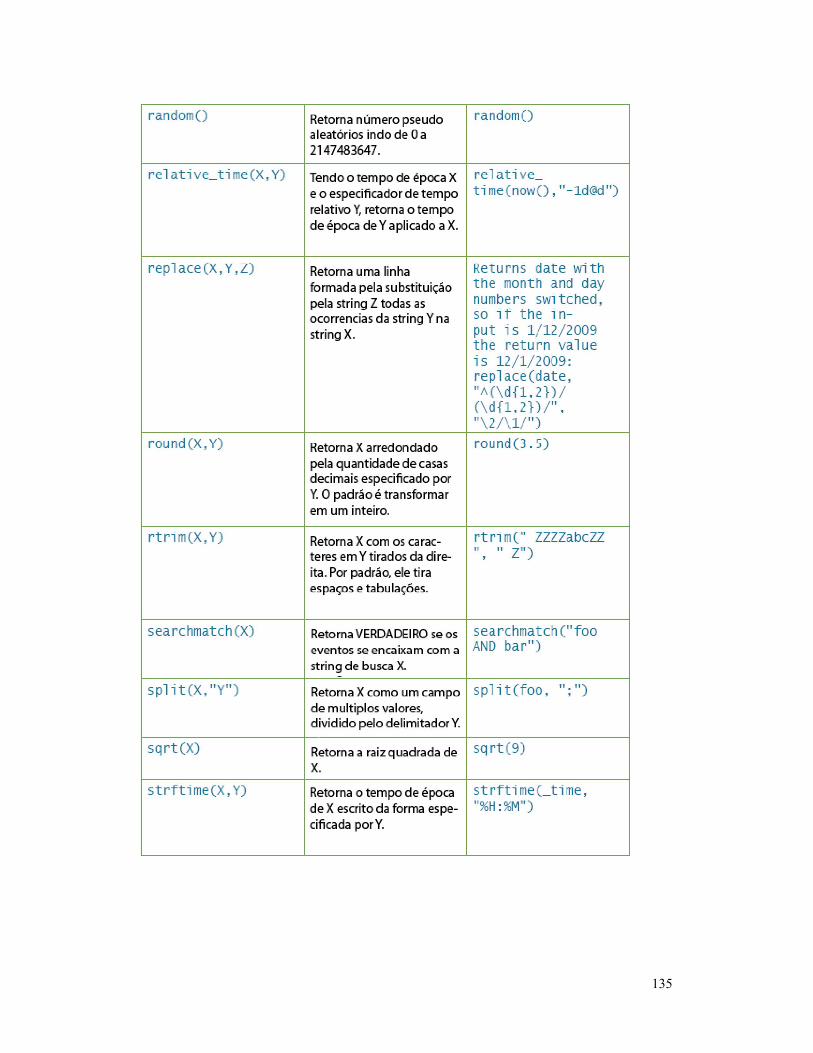
135

136
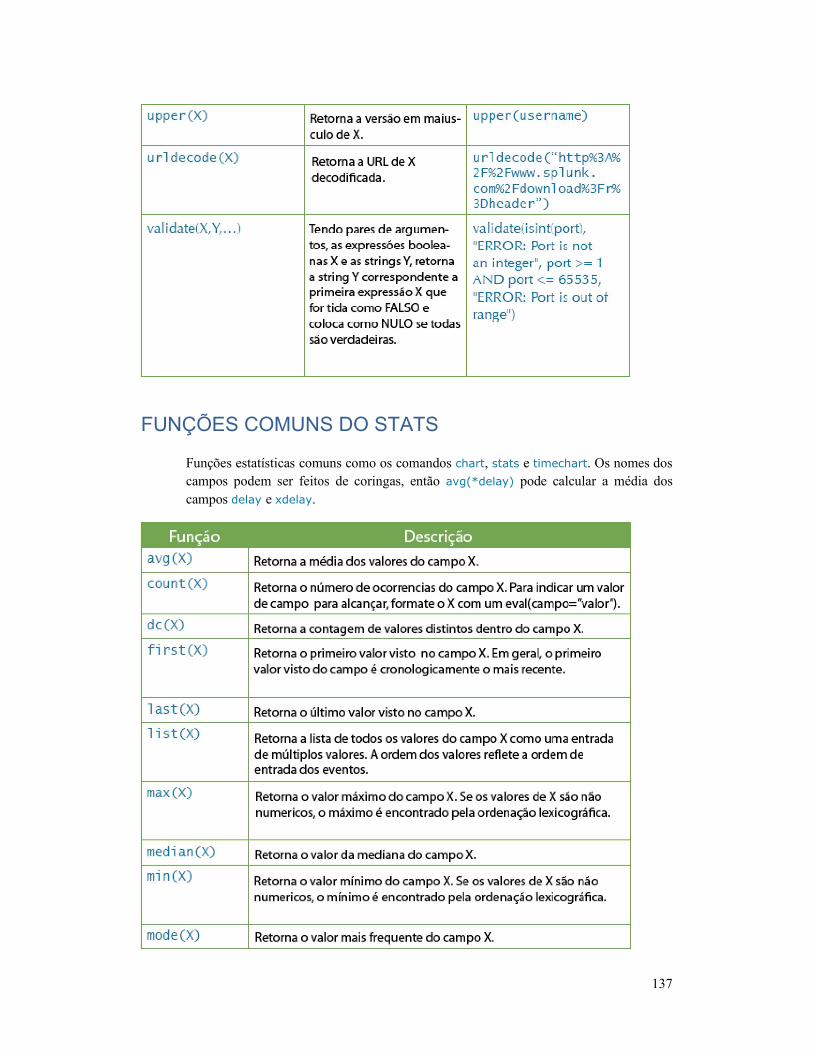
FUNÇÕES COMUNS DO STATS
Funções estatísticas comuns como
campos podem ser feitos de coringas
campos delay e xdelay.
FUNÇÕES COMUNS DO STATS
Funções estatísticas comuns como os comandos chart, stats e timechart. Os nomes
campos podem ser feitos de coringas, então avg(*delay) pode calcular a média dos
137
Os nomes dos
pode calcular a média dos
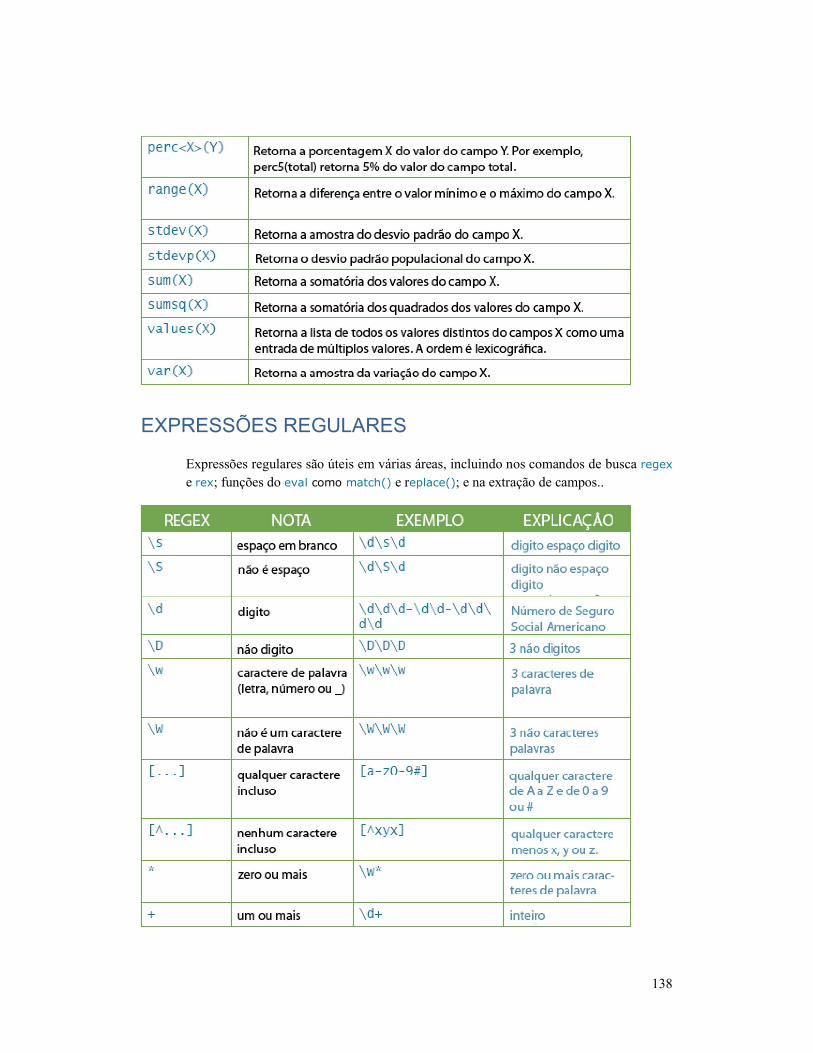
EXPRESSÕES REGULARES
Expressões regulares são úteis em várias áreas, incluindo nos comandos de busca
e rex; funções do eval como
EXPRESSÕES REGULARES
Expressões regulares são úteis em várias áreas, incluindo nos comandos de busca
como match() e replace(); e na extração de campos..
138
Expressões regulares são úteis em várias áreas, incluindo nos comandos de busca regex
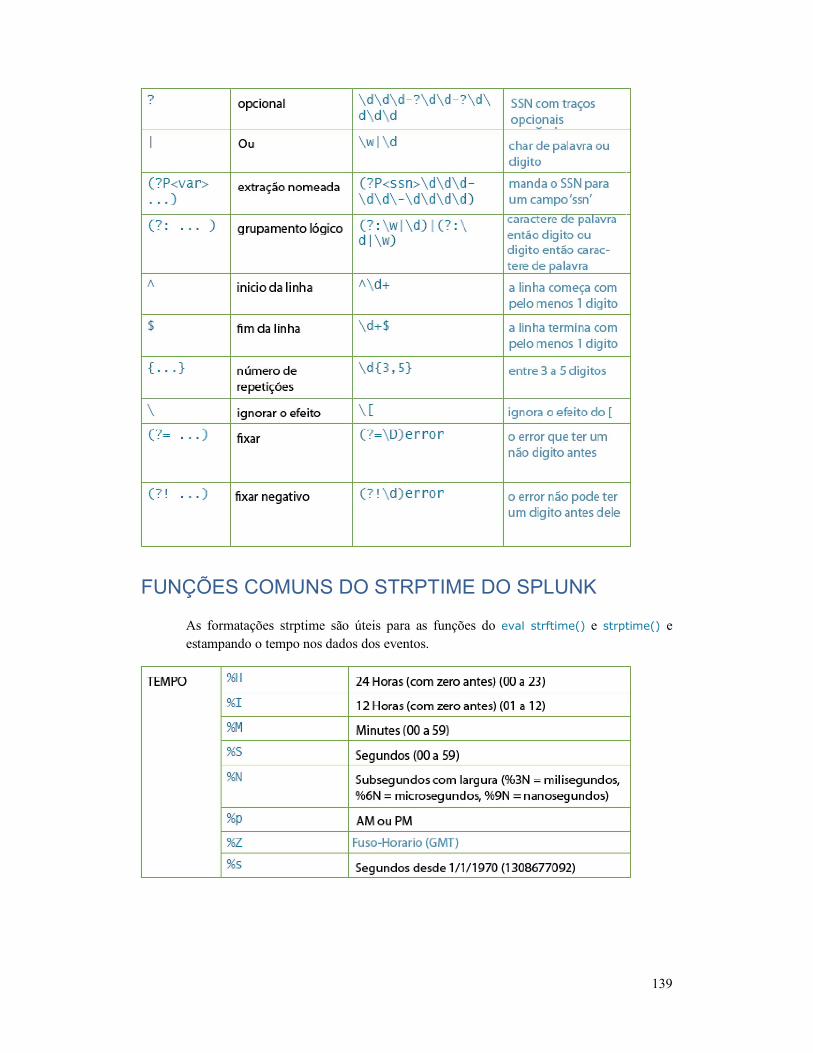
FUNÇÕES COMUNS DO STRPTIME DO SPLUNK
As formatações strptime são
estampando o tempo nos dados dos eventos.
FUNÇÕES COMUNS DO STRPTIME DO SPLUNK
As formatações strptime são úteis para as funções do eval strftime() e strptime()
estampando o tempo nos dados dos eventos.
139
strptime() e
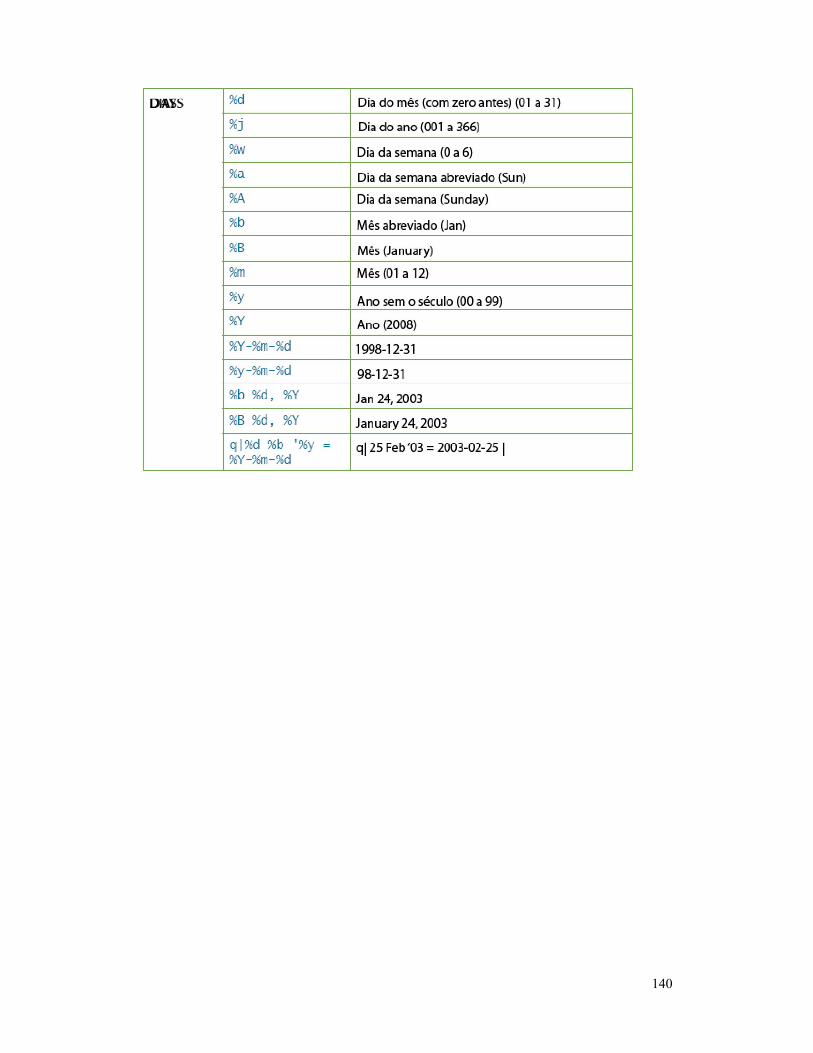
140