





Línguas
Páginas
Legal


DETECÇÃO DA RESPOSTA AUDITIVA EM REGIME
PERMANENTE A SONS VOCÁLICOS NATURAIS COM
ANALISADOR DE FOURIER
Wagner dos Santos
Projeto de Graduação apresentado ao Curso de
Engenharia Eletrônica e de Computação da Escola
Politécnica, Universidade Federal do Rio de
Janeiro, como parte dos requisitos necessários à
obtenção do título de Engenheiro.
Orientador: Carlos Julio Tierra Criollo
Coorientador: Pablo Fernando Cevallos Larrea
Rio de Janeiro
Agosto de 2018



iv
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
Escola Politécnica – Departamento de Eletrônica e de Computação
Centro de Tecnologia, bloco H, sala H-217, Cidade Universitária
Rio de Janeiro – RJ CEP 21949-900
Este exemplar é de propriedade da Universidade Federal do Rio de Janeiro, que
poderá incluí-lo em base de dados, armazenar em computador, microfilmar ou adotar
qualquer forma de arquivamento.
É permitida a menção, reprodução parcial ou integral e a transmissão entre
bibliotecas deste trabalho, sem modificação de seu texto, em qualquer meio que esteja
ou venha a ser fixado, para pesquisa acadêmica, comentários e citações, desde que sem
finalidade comercial e que seja feita a referência bibliográfica completa.
Os conceitos expressos neste trabalho são de responsabilidade do(s) autor(es).

v
AGRADECIMENTOS
Agradeço, primeiramente, à minha família pelo apoio incondicional.
À minha namorada, porque tornou ilógica qualquer meta de minha vida que não
envolva sua presença.
Ao meu orientador Prof. Carlos Julio Tierra Criollo e ao meu coorientador Pablo
Fernando Cevallos Larrea por toda a orientação, amizade, confiança e por terem me
permitido participar deste projeto, que ficará marcado como uma experiência valiosa.
Aos meu amigos da UFRJ, pelo companheirismo, por estarem sempre presentes e
pelos momentos de descontração. Com vocês, minha jornada nesta universidade tornou-
se mais amena, proveitosa e alegre.
Aos voluntários que participaram dos experimentos e, dessa forma, contribuíram
para o desenvolvimento desta monografia.
Aos professores do DEL (Departamento de Eletrônica), pela excelência
acadêmica e por terem me permitido realizar uma graduação de qualidade.
À Banca Examinadora pelo convite aceito e pela avaliação desta monografia.

vi
RESUMO
A análise da Resposta Auditiva em Regime Permanente (ASSR) a sons
vocálicos naturais possui ampla relevância no contexto de diagnóstico audiológico.
Pode ser considerada uma alternativa aos diagnósticos subjetivos comumente utilizados
na prática médica, beneficiando tanto os pacientes quanto os profissionais da saúde
auditiva.
Foram realizadas coletas de sinais de EEG de 10 voluntários normo-ouvintes,
estimulados pelos fonemas /a/, /i/ e /u/ nas intensidades de 55 dBSPL e 70 dBSPL. Foi
utilizado o Analisador de Fourier para avaliar a amplitude da resposta na frequência
fundamental e nos 5 harmônicos seguintes. Respostas significativas foram encontradas
para todos os fonemas, principalmente para os primeiros harmônicos. Estes resultados
confirmam a utilização do Analisador de Fourier como técnica para a avaliação das
ASSR a sons vocálicos naturais.
Palavras-Chave: ASSR, Analisador de Fourier, Sons Vocálicos Naturais, Potencial
Evocado Auditivo.

vi
i
ABSTRACT
ASSR (Auditory Steady State Response) analysis of natural vowel sounds has
wide relevance in the context of audiological diagnosis: it can be considered an
alternative to the subjective diagnoses commonly used in medical practice, benefiting
both patients and hearing health professionals.
EEG signals were collected from 10 normal-hearing volunteers, stimulated by
phonemes /a/, /i/ and /u/ at the intensities of 55 dBSPL and 70 dBSPL. The Fourier
Analyzer was used to evaluate the amplitude of the fundamental frequency response and
the following 5 harmonics. Significant responses were found for all phonemes,
especially for the first harmonics. These findings support the use of the Fourier
Analyzer as an ideal technique for ASSR evaluation of natural vowel sounds.
Key-words: ASSR, Fourier Analyzer, Natural Vowel Sounds, Auditory Evoked
Potential.

vi
ii
SIGLAS
AMFR - Amplitude Modulation Following Response.
AMFV – Amplitde Média das Frequências Vizinhas.
AR – Amplitude de Referência.
ASSR - Resposta Auditiva em Regime Permanente, do inglês Auditory Steady State
Response.
DFT - Transformada Discreta de Fourier, do inglês Discrete Fourier Transform.
EFR - Envelope-Following-Response.
EEG - Eletroencefalografia.
fm - Frequência de Modulação.
ORD : Detecção Objetiva de Resposta, do inglês Objective Response Detection.
PEA - Potencial Evocado Auditivo
RMS – Raiz do Valor Quadrático Médio, do inglês Root Mean Square.
SNR - Signal-to-Noise Ratio.
TFE – Teste F Espectral
TH – Transformada de Hilbert.

ix
Sumário
1 Introdução 1
1.1 Tema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Delimitação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Justificativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.4 Objetivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Fundamentação Teórica 4
2.1 Fisiologia do Sistema Auditivo . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Considerações Relevantes Sobre a Fonação . . . . . . . . . . . . . . . . . . . 4
2.3 Resposta Auditiva em Regime Permanente – ASSR . . . . . . . . . . . . . . . 6
2.3.1 Análise da ASSR a Sons Vocálicos Naturais . . . . . . . . . . . . . . . . . 8
2.4 Transformada de Hilbert . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5 Analisador de Fourier. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.6 Técnicas de Detecção Objetiva de Resposta . . . . . . . . . . . . . . . . . . . 15
2.6.1 Teste F Espectral Local (TFE Local) . . . . . . . . . . . . . . . . . . . . . 15
3 Materiais e Métodos 17
3.1 Sistema de Estimulação e Detecção de ASSR . . . . . . . . . . . . . . . . . 17
3.2 Voluntários . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Estímulos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.4 Formantes do Trato Vocal . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.5 Protocolo Experimental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.6 Análise da ASSR a Sons Vocálicos Naturais . . . . . . . . . . . . . . . . . . 27
4 Resultados e Discussão 32
4.1 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2 Discussão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5 Conclusão 45
6 Bibliografia 46

x
Lista de Figuras
2.1 – Modelo Fonte Filtro 6
2.2 - Posição recomendada dos eletrodos para registro da ASSR 8
2.3 - Espectrograma do sinal Chirp. Fs = 1 Khz. 0-250Hz. t = 10 s 14
2.4 - DFT do sinal Chirp. Fs = 1 Khz. F = 0-250Hz. t = 10 s 14
3.1 - Estrutura funcional do sistema de aquisição e análise de ASSR. 18
3.2 - Fonema /a/ filtrado em passa banda FIR (10 - 4000 Hz) 21
3.3 - Fonema /i/ filtrado em passa banda FIR (10 - 4000 Hz) 21
3.4 - Fonema /u/ filtrado em passa banda FIR (10 - 4000 Hz) 22
3.5 - Orelha artificial 4153 e o analisador de frequências 2250 22
3.6 - Curvas de ponderação espectral sonora A,C e Z. 23
3.7 - Calibração para fonemas /a/, /i/ e /u/ para 70 dBSPL 24
3.8 - Modelo Espectro vocal (Picos: Formantes para Fonema /a/). 25
3.9 - Modelo Espectro vocal (Picos: Formantes para Fonema /i/). 25
3.10 - Modelo Espectro vocal (Picos: Formantes para Fonema /u/). 25
3.11 - Envelope do fonema /a/. Abaixo, DFT do envelope. 28
3.12 - Envelope do fonema /i/. Abaixo, DFT do envelope. 29
3.13 - Envelope do fonema /u/. Abaixo, DFT do envelope. 29
3.14 - Frequência instantânea do envelope filtrado do fonema /a/ 30
3.15 - Frequência instantânea do envelope filtrado do fonema /i/, 30
3.16 - Frequência instantânea do envelope filtrado do fonema /u 31
4.1 - AR e AMFV. Fonema /a/;Intensidade 70 dBSPL. 33
4.2 - AR e AMFV. Fonema /a/;Intensidade 55 dBSPL 34
4.3 - AR e AMFV. Fonema /i/;Intensidade 70 dBSPL. 35
4.4 - AR e AMFV. Fonema /i/;Intensidade 55 dBSPL. 36
4.5 - AR e AMFV. Fonema /u/;Intensidade 70 dBSPL. 37
4.6 - AR e AMFV. Fonema /u/;Intensidade 55 dBSPL. 38
4.7 - AR e AMFV. Fonema /a/ (não audível);Intensidade 70 dBSPL. 39
4.8 - AR e AMFV. Fonema /i/ (não audível);Intensidade 70 dBSPL. 40
4.9 - AR e AMFV. Fonema /u/ (não audível);Intensidade 70 dBSPL. 41

xi
Lista de Tabelas
3.1 - Calibração dos fonemas 24
4.1 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 34
TFE local. Fonema /a/; Intensidade 70 dBSPL.
4.2 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 34
TFE local. Fonema /a/; Intensidade 55 dBSPL.
4.3 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 35
TFE local. Fonema /i/; Intensidade 70 dBSPL.
4.4 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 36
TFE local. Fonema /i/; Intensidade 55 dBSPL.
4.5 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 37
TFE local. Fonema /u/; Intensidade 70 dBSPL.
4.6 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 38
TFE local. Fonema /u/; Intensidade 55 dBSPL.
4.7 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 39
TFE local. Fonema /a/ (não audível); Intensidade 70 dBSPL.
4.8 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 40
TFE local. Fonema /i/ (não audível); Intensidade 70 dBSPL.
4.9 - Desvio padrão de “AR” e “AMFV”. Percentual de detecção com 41
TFE local. Fonema /u/ (não audível); Intensidade 70 dBSPL.

1
1 Introdução
1.1 Tema
O tema deste trabalho é a análise da Resposta Auditiva em Regime Permanente
(do inglês, ASSR – Auditory Steady State Response) durante a aplicação de estímulos
auditivos de vogais. A ASSR perante estímulos vocálicos tem capacidade para apoiar o
diagnóstico objetivo da audição, podendo se tornar uma alternativa aos diagnósticos
subjetivos comumente utilizados na prática médica. Os resultados deste estudo podem
contribuir ao conhecimento e aperfeiçoamento desta nova técnica como ferramenta de
diagnóstico audiológico, podendo beneficiar tanto os profissionais da saúde auditiva
quanto os pacientes.
1.2 Delimitação
O estudo consistiu no registro de sinais de eletroencefalografia (EEG) de
sujeitos adultos com limiares auditivos normais durante a estimulação controlada de
sons vocálicos. As respostas eletrofisiológicas evocadas por esses estímulos foram
adquiridas por um equipamento de registro de sinais biológicos e detectadas por um
modelo computacional (detecção objetiva).
1.3 Justificativa
Atualemnte, 466 milhões de pessoas são afetadas por perdas auditivas, das
quais 34 milhões são crianças (WHO, 2018). Estas são particularmente prejudicadas no
desenvolvimento da linguagem, fator que diminui sua qualidade de vida (ASHA,2018).
O diagnóstico da perda auditiva e a intervenção antecipada permitem o
desenvolvimento apropriado da função auditiva, enquanto o tratamento tardio pode
comprometer o sistema auditivo de forma irreversível (JCIH, 2007).

2
Um método utilizado na prática clínica para dar suporte ao diagnóstico da
audição retrococlear é a Resposta Auditiva em Regime Permanente (ASSR). Essa
resposta provém da ativação de diversos núcleos neuronais da via auditiva decorrentes
da ação do estímulo sonoro contínuo. Os núcleos geradores da ASSR estão localizados
desde a estrutura coclear, onde as células ciliadas iniciam um processo de ativação
neural, até o córtex auditivo. A atividade destes núcleos cria um campo eletromagnético
no cérebro (fontes cerebrais), sendo que o campo elétrico pode ser estudado por meio da
eletroencefalografia (EEG).
As técnicas de detecção objetiva da ASSR baseiam-se na frequência do envelope
que modula o som aplicado em um indivíduo, identificando-o quantitativamente para
inferir seu potencia evocado auditivo. Para estímulos de sons vocálicos, essa resposta é
conhecida como EFR (Envelope-Following-Response).
Na prática clínica, a ASSR é utilizada para estimar os limiares auditivos de seres
humanos e, especialmente, de sujeitos que não respondem a testes comportamentais, por
exemplo no caso de recém-nascidos. Além disso, os resultados de um teste ASSR
podem ser utilizados para o ajuste de aparelhos de amplificação auditiva, aferidos de
acordo com os limiares diagnosticados.
As características do estímulo utilizado para evocar uma ASSR determinam
quais estruturas nervosas são ativadas para gerar a resposta, bem como os requisitos
para sua detecção. Diversos estudos têm analisado a ASSR para estimulação por tons
modulados em amplitude (JOHN et al., 2002), frequência e ruído (JOHN et al., 2003) e
tone chirp (HEKIMOGLU et al., 2001). Esses estímulos, contudo, possuem
características acústicas projetadas apenas para avaliar limiares auditivos de frequência
específica.
O uso de estímulos vocálicos tem sido o tema de muitas pesquisas científicas
recentes, uma vez que a composição complexa destes estímulos (sua estrutura
harmônica, por exemplo) permite avaliar a complexa resposta de diversas estruturas do
processamento auditivo tanto no nível periférico quanto nos níveis de processamento
auditivo superior. Uma aplicação relevante, por exemplo, é a análise das respostas
eletrofisiológicas a estímulos auditivos vocálicos, utilizada no estudo da codificação de
som no tronco encefálico em crianças com problemas de aprendizado (CUNNINGHAM
et al., 2001; KING et al.,2002) e crianças com problemas no processamento auditivo
(JOHNSON et al., 2007). O uso de sons vocálicos naturais é preferível para um

3
teste direcionado a aferir a transmissão da informação do som vocálico ao tronco
encefálico para fins de concepção e ajuste de aparelhos auditivos. Afinal, muitos desses
aparelhos são designados para amplificar especificamente sons de fala e atenuar sons
que não são de fala (SCOLLIE e SEEWALD, 2002).
Em virtude do que foi mencionado, a ASSR para estímulos vocálicos pode ser
considerada uma técnica de amplo potencial para avaliar o processo de codificação
periférica de sons de vogais, a qual está nos seus primórdios. Portanto, foi escolhida
como tema de estudo e avaliação deste projeto de graduação.
1.4 Objetivo
O objetivo deste projeto de graduação é avaliar a capacidade da ASSR por
estímulos auditivos vocálicos utilizando o Analisador de Fourier.

4
2 Fundamentação Teórica
2.1 Fisiologia do Sistema Auditivo
Os impulsos nervosos resultantes da percepção da variação de pressão das ondas
sonoras são reconhecidos no cérebro como sons. O sistema auditivo humano reconhece
esses sons na faixa de 20 a 20 kHz (BEAR et al., 2007).
O reconhecimento da onda sonora como som pelo cérebro pode ser entendido
pela seguinte dinâmica : A orelha externa capta a onda sonora no pavilhão auricular e o
meato acústico externo encaminha-a até a membrana timpânica, que se encontra no
começo da orelha média. Finalmente, as ondas sonoras atingem a membrana timpânica
e vibram-na, movimentando os ossículos (martelo, bigorna e estribo) e, por conseguinte,
a janela oval na orelha interna, onde a energia mecânica é transformada em informação
nervosa (SILVERTHORN e HILL, 2010).
Na orelha interna, a estrutura coclear recebe as vibrações provocadas pelos
ossículos através dos fluidos cocleares, vibrando a membrana basilar do órgão de Corti.
A movimentação da membrana provoca deslocamento dos estereocílios das células
ciliadas, levando à despolarização ou hiperpolarização das células, que encaminham,
pelas sinapses, os impulsos elétricos até as fibras do gânglio espiral. Assim, padrões de
vibração na orelha interna desencadeiam padrões de potenciais de ação na via auditiva
nervosa (SILVERTHORN e HILL, 2010).
Mapeamento de Frequência e Intensidade
Na membrana basilar, as frequências sonoras provocam padrões de vibração em
diferentes regiões. As frequências altas vibram a base da membrana, enquanto que as
frequências baixas vibram o ápice. (BEAR et al., 2007).
O mapeamento de frequência ocorre desde a cóclea até o córtex. Isto é, os
neurônios responsáveis pela condução dos impulsos nervosos também são mais ou
menos responsivos em determinadas frequências. O sincronismo de fase atua no
máximo até 2000 Hz (faixa na qual atuam conjuntamente a sincronia de fase e o
mapeamento de frequências) (BEAR et al., 2007).

5
Sons mais intensos provocam uma maior taxa de potencias de ação nas fibras
ganglionares, bem como um maior número de neurônios recrutados. (BEAR et al.,
2007).
2.2 Considerações Relevantes sobre a Fonação
Nos sons vocálicos, um sinal periódico é gerado pelas cordas vocais. Seus
harmônicos são continuamente modificados em intensidade, na medida que os
articuladores primários (língua, mandíbula, lábios) alteram as características de
ressonância do trato vocal. Outro fator que altera a estrutura do som vocálico é a
variação da frequência fundamental acarretada pela entonação utilizada pelo falante
(AIKEN e PICTON, 2006).
A geração do som vocálico possui como modelo a teoria fonte-filtro de
produção da fala desenvolvida por Gunnar Fant na década de 1960, segundo a qual a
energia irradiada é o produto da energia da fonte (laringe) e do ressonador (trato vocal) ,
de acordo com a equação (ZEMLIN, 2000, p. 313, apud SANTOS, 2010, p. 26):
P(f) = |U(f)| . |H(f)| . |R(f)|
A interpretação desta expressão para sons vocálicos é (Figura 2.4):
P(f) : Espectro da pressão sonora a pequena distância dos lábios.
U(f) : Espectro do som produzido pela vibração das cordas vocais, determinado pela
frequência dos ciclos glóticos na laringe.
H(f) : Espectro característico da propagação pelo trato vocal (boca, faringe e nariz)
R(f) : Espectro característico da propagação através dos lábios.
Os pulsos gerados na fonação são filtrados pelas cavidades acústicas do trato
vocal, e propagam-se pelo ar.

6
U(f) H(f) R(f) P(f)
Figura 2.1 (modificado de VIEIRA(2004), domínio público) : Modelo Fonte-Filtro. A fonte é
representada por uma série harmônica, o filtro por formantes (F1, F2, etc : picos no espectro do
trato vocal), e a irradiação pela sua característica passa-altas.
2.3 Resposta Auditiva em Regime Permanente - ASSR
A Resposta Auditiva em Regime Permanente (ASSR) é a denominação da
resposta eletrofisiológica provocada no sistema auditivo e evocada por sons
(normalmente entre 500 e 4000 Hz) modulados em amplitude (em 80, 90 Hz,
geralmente) ou uma sucessão de estímulos acústicos aplicados a uma taxa rápida o
bastante para provocar a sobreposição de respostas. (JOHN et al., 1998).
O campo elétrico gerado pela ASSR pode ser registrado por meio da aquisição
de sinais de EEG.
A ASSR possui várias designações ou aplicações: Resposta que segue a
modulação de amplitude (AMFR - amplitude modulation following response) (LEVI et
al., 1993), potencial evocado em regime permanente ou potencial evocado em estado
estável (SSEP - steady state evoked potential) (RANCE et al., 1998), ou resposta
seguindo o envelope (EFR – envelope following response) (PURCELL et al., 2004).
Geradores da ASSR
Na membrana basilar, o som modulado acarreta ativação das células ciliadas nas
regiões correspondentes à frequência do estímulo (conforme mapeamento de
frequências, estudado no capítulo 2.1). Os potenciais de ação gerados nas células

7
ciliares internas, que possuem saturação para grandes amplitudes, são encaminhados
para as células ganglionares do nervo auditivo. Nestas, esses potenciais são retificados,
uma vez que os disparos neuronais conduzem o impulso nervoso num sentido único.
(BEAR et al.,2007).
Finalmente, a ASSR é gerada em determinadas regiões de acordo com
frequência de modulação (fm) utilizada no estímulo sonoro. Sugere-se que, para fm em
torno de 20-40 Hz, tanto o tronco encefálico quanto as regiões corticais podem ser
consideradas como responsáveis pela geração da ASSR. Para fm entre 70 e 100 Hz,
considera-se o tronco encefálico como gerador principal (MAUER e DÖRING,1999).
Estimulação
Os estímulos normalmente utilizados para evocar a ASSR são : Aplicação
repetida de tons curtos (clique, burst ou chirp) numa taxa que permita sobreposição de
respostas, tons modulados em amplitude e sons vocálicos, sendo os tons modulados os
mais utilizados.
O estímulo por tons modulados, normalmente, é dado pela modulação em
amplitude de uma senóide, de frequência audível e é comumente utilizado em
avaliações clínicas (entre 500 e 4000 Hz; portadora) por um sinal de frequência menor
(modulante). Assim, a frequência da portadora estabelece a região da membrana basilar
que será estimulada, e a frequência de modulação é utilizada como um “identificador”
que, posteriormente, será detectado pela análise dos sinais de EEG.
Os sons vocálicos, foco deste estudo, possuem uma aplicação mais complexa do
que a estimulação por tons modulados em amplitude ou a aplicação repetida de tons
curtos, devido a sua variabilidade espectral e temporal. Apesar disso, ele se assemelham
aos tons modulados, uma vez que seus harmônicos são naturalmente modulados em
amplitude na frequência fundamental de abertura e fechamento da glote (AIKEN e
PICTON, 2006). Além disso, a frequência de portadora utilizada para tons modulados
(500 – 4000 Hz) está dentro da faixa dos harmônicos do som vocálico, assim como a
frequência de modulação utilizada para tons modulados (em torno dos 80 Hz) está
próxima à frequência fundamental do envelope do sinal vocálico. Assim, de forma
análoga ao estímulo por tom modulado, as frequências do envelope do som vocálico são
utilizadas como “identificador”, posteriormente detectado através da análise dos sinais
de EEG.

8
Registro multicanal ASSR
A escolha do local no couro cabeludo para gravação da ASSR influenciará na
detecção da resposta, uma vez que derivações com maior SNR (Razão Sinal Ruído)
estão associadas com melhor desempenho das técnicas estatísticas de detecção e com
uma redução do tempo necessário para detecção da ASSR (VAN DER REIJDEN,
2005).
Para o registro da ASSR, as derivações normalmente recomendadas, usando
como referência o Sistema Internacional 10-20 (Figura 2.7), para registro dos sinais de
EEG são o Mastoide Esquerdo (M1), Mastoide Direito (M2) e Inion (Oz), com eletrodo
de referência posicionado no vertex (Cz) e o eletrodo de terra normalmente posicionado
na região fronto-central (Fpz). (LINS e PICTON, 1995)
Figura 2.2 : Posição recomendada dos eletrodos para registro da ASSR. Modificado de
(RESEARCH GATE, 2014)(Domínio público).
2.3.1 Análise da ASSR a sons vocálicos naturais
Uma diferença fundamental entre as modulações tradicionalmente utilizadas
para ASSR e modulações baseadas no som de fala é que o envelope desta varia
continuamente na frequência. ASSR’s são, normalmente, transformadas no domínio da
frequência pela aplicação da Transformada Discreta de Fourier (DFT), na qual a energia
da resposta na frequência modulada (estacionária) pode ser estimada (PICTON et al.,
2003). Entretanto, a frequência fundamental e os harmônicos do som vocálico, bem

9
como as frequências de seu envelope, podem variar até 50 Hz/s (AIKEN e PICTON,
2008).
Uma forma de eliminar o problema é usar sons vocálicos sintéticos, onde a
frequência fundamental pode ser mantida constante, permitindo a aplicação da DFT sem
prejuízos (KRISHNAM, 2002). Apesar dos benefícios associados ao uso de vogais
sintéticas, o uso de sons vocálicos naturais são preferíveis para um teste direcionado a
aferir a transmissão da informação do som vocálico ao tronco encefálico para fins de
concepção e ajuste de aparelhos auditivos, uma vez que muitos desses aparelhos são
designados para amplificar especificamente sons de fala e atenuar sons que não são de
fala (SCOLLIE e SEEWALD, 2002). Além disso, o sistema auditivo não é linear e pode
responder de forma diferente para sons sintéticos do que para sons de fala naturais
(GALBRAITH et al., 2004).
Estudos focados especificamente nas amplitudes do PEA (Potencial Evocado
Auditivo) normalmente evitam o uso da DFT para análise da ASSR a estímulos
vocálicos. Se a trajetória da frequência da resposta pode ser predita antecipadamente
(e.g. se a resposta seguir o envelope do som vocálico), como ocorre com os sons
vocálicos, uma melhor alternativa é fazer o uso do Analisador de Fourier (REGAN,
1989).
Ao contrário da DFT, que analisa o sinal sob um espectro de frequências
estacionárias, o FA relaciona a resposta gravada a uma frequência de referência que
não precisa necessariamente ser estacionária. O FA pode, então, seguir as variações de
frequência que ocorrem dentro de uma janela de análise. Se a resposta segue a uma
frequência de referência, a relação entre a resposta e a referência não se altera, portanto
a amplitude da resposta não é afetada pela variação de frequência. Assim, esta técnica
proporciona uma forma de identificar respostas não estacionárias (AIKEN e PICTON,
2006).
2.4 Transformada de Hilbert
O Analisador de Fourier tem como base a Transformada de Hilbert (TH), para
extração do envelope do sinal e extração de fase instantânea.

10
A TH é uma operação linear que gera como saída uma função no mesmo
domínio e ortogonal à função de entrada. Para sinais contínuos, a TH pode ser definida
como (BENDAT e PIERSOL, 2010):
�̃�(𝑡) = ℋ[𝑥(𝑡)] = 𝑥(𝑡) ∗ 1
𝜋𝑡= ∫
𝑥(𝜏)
𝜋(𝑡−𝜏)
∞
−∞𝑑𝜏 (Equação 2.1)
Como a integral é imprópria, é necessário calcular o valor principal de Cauchy.
Para sinais discretos esta preocupação não é necessária, já que a operação de integração
passa a ser de somatório (OPPENHEIM, 2010).
A TH também pode ser definida a partir de um sinal analítico. Um sinal analítico
é um sinal que não apresenta componentes negativos de frequência e que, por
consequência, é complexo no tempo (Figura 2.8).
É possível demonstrar a relação entre a TH e o sinal analítico.
Aplicando o teorema da convolução à equação 2.1:
ℱ{�̃�(𝑡)} = ℱ{𝑥(𝑡)}ℱ {1
𝜋𝑡}
�̃�(𝑓) = −𝑖𝑋(𝑓)𝑠𝑔𝑛(𝑓) (Equação 2.2)
Em que a função sgn é definida como :
𝑠𝑔𝑛(𝑓) = {
−1, 𝑠𝑒 𝑓 < 0 0, 𝑠𝑒 𝑓 = 01, 𝑠𝑒 𝑓 > 0
(Equação 2.3)
Substituindo a definição de sgn na equação 2.2:
�̃�(𝑓) = {
𝑖𝑋(𝑓), 𝑠𝑒 𝑓 < 0 0, 𝑠𝑒 𝑓 = 0
−𝑖𝑋(𝑓), 𝑠𝑒 𝑓 > 0 (Equação 2.4)
Logo
�̃�(𝑓) = −𝑖𝑋(𝑓+) + 𝑖𝑋(𝑓−) (Equação 2.5)
Multiplicando ambos os lados da equação 2.5 por 𝑖 :

11
𝑖�̃�(𝑓) = 𝑋(𝑓+) − 𝑋(𝑓−) (Equação 2.6)
Somando 𝑋(𝑓) em ambos os lados da equação 2.6:
𝑋(𝑓) + 𝑖�̃�(𝑓) = 𝑋(𝑓) + 𝑋(𝑓+) − 𝑋(𝑓−) (Equação 2.7)
Substituindo 𝑋(𝑓) por 𝑋(𝑓−) + 𝑋(𝑓0) + 𝑋(𝑓+) no lado direito da equação 2.7:
𝑋(𝑓) + 𝑖�̃�(𝑓) = 𝑋(𝑓0) + 2𝑋(𝑓+) (Equação 2.8)
Observa-se que o lado direito da equação 2.8 não possui componentes negativos
de frequência, o que está de acordo com a definição de sinal analítico.
Sendo:
𝑍(𝑓) = {
2𝑋(𝑓), 𝑠𝑒 𝑓 > 0 𝑋(𝑓), 𝑠𝑒 𝑓 = 0
0, 𝑠𝑒 𝑓 < 0 (Equação 2.9)
e
𝑧(𝑡) = ℱ−1[𝑍(𝑓)] (Equação 2.10)
Aplicando a definição da equação 2.9 no lado direito da equação 2.8:
𝑋(𝑓) + 𝑖�̃�(𝑓) = 𝑍(𝑓) (Equação 2.11)
e, calculando-se a Transformada Inversa de Fourier na equação 2.11:
ℱ−1[𝑋(𝑓)] + 𝑖ℱ−1[�̃�(𝑓)] = ℱ−1[𝑍(𝑓)]
𝑥(𝑡) + 𝑖�̃�(𝑡) = 𝑧(𝑡) (Equação 2.12)
Aplicando a definição da equação 2.1 na 2.12:
𝑥(𝑡) + 𝑖ℋ[𝑥(𝑡)] = 𝑧(𝑡) (Equação 2.13)
Observa-se que o sinal é complexo e que sua parte imaginária corresponde à TH
de sua parte real.
Um sinal puramente real possui transformada de Fourier simétrica. Sendo assim,
ele pode ser representado como um sinal analítico anulando-se os componentes de
frequência negativa, de acordo com a equação 2.9. Observa-se que a energia do sinal
analítico resultante é mantida, já que o valor dos componentes positivos de frequência
são multiplicados por 2.

12
A partir do sinal analítico, é possível calcular a amplitude instantânea do sinal:
𝐴(𝑡) = √𝑥2(𝑡) + �̃�2(𝑡) (Equação 2.14)
e a fase instantânea, definida por :
𝜃(𝑡) = tan−1 [�̃�(𝑡)
𝑥(𝑡)] (Equação 2.15)
Para sinais de banda-estreita, a amplitude instantânea pode ser interpretada como
o envelope do sinal.
Outro atributo que pode ser obtido a partir do sinal analítico é a frequência
instantânea, definida por:
𝜔(𝑡) =𝑑𝜃(𝑡)
𝑑𝑡 (Equação 2.16)
em radianos por segundo, ou:
𝑓(𝑡) =1
2𝜋
𝑑𝜃(𝑡)
𝑑𝑡 (Equação 2.17)
em Hertz.
2.5 Analisador de Fourier
Este subcapítulo trata da definição do Analisador de Fourier, além de prover
uma aplicação prática para servir como teste de validação. Conforme visto no capítulo
2.3, o FA relaciona a resposta gravada a uma frequência de referência que não precisa
necessariamente ser estacionária.
Definição
Uma forma simples de compreender o FA por meio de sua comparação com a
DFT.
Seja a DFT definida por :
𝑋(𝑘) = ∑ 𝑥(𝑛)𝑒−𝑖2𝜋𝑘𝑛
𝑁𝑁−1𝑛=0 = ∑ 𝑥(𝑛) [cos (
2𝜋𝑘𝑛
𝑁) − 𝑖 sin (
2𝜋𝑘𝑛
𝑁)]𝑁−1
𝑛=0 (Equação 2.18)

13
Assim, notamos que :
𝑋(𝑘) é um vetor de números complexos.
𝑋(𝑘) é a correlação cruzada da sequência de entrada x(n) com a exponencial
complexa na frequência k/N, atuando como um filtro casado para tal frequência.
Seja o FA definido por :
𝑋 = ∑ 𝑥(𝑛)𝑒−𝑖𝜃𝑁−1𝑛=0 = ∑ 𝑥(𝑛)[cos(𝜃𝑛) − 𝑖 sin(𝜃𝑛)]𝑁−1
𝑛=0 (Equação 2.19)
onde 𝜃 é a fase instantânea (obtida pela equação 2.15) de um sinal utilizado
como referência.
Assim, notamos que :
𝑋 é um número complexo.
O FA correlaciona cada amostra 𝑥(𝑛) com um fasor, cuja fase específica é
dada pela fase instantânea de um sinal de referência.
O FA pode, então, seguir as variações de frequência (do sinal de referência)
que ocorrem dentro de uma janela de análise (AIKEN e PICTON, 2006).
Seja X o valor obtido pela equação 2.19, teremos que :
A amplitude do FA é dada por :
√𝑅𝑒{𝑋}2 + 𝐼𝑚{𝑋}22 (Equação 2.20)
Sua fase é dada por :
tan−1 (𝐼𝑚{𝑋}
𝑅𝑒{𝑋}) (Equação 2.21)
Implementação no Matlab
Seja x(n) um tom chirp linear amostrado a 1 kHz, de amplitude 0.55, cuja
frequência varia linearmente para t = 0 de 0 Hz a t = 10s para 250 Hz, cujo
espectograma é dado por :
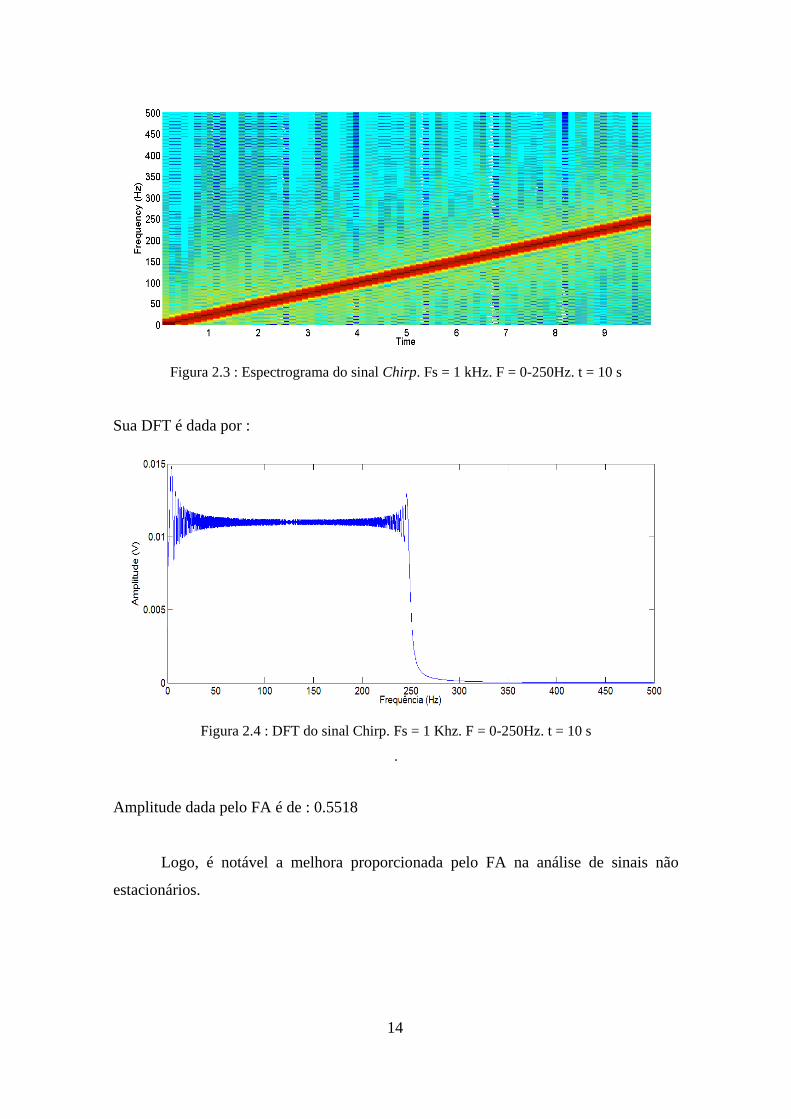
14
Figura 2.3 : Espectrograma do sinal Chirp. Fs = 1 kHz. F = 0-250Hz. t = 10 s
Sua DFT é dada por :
Figura 2.4 : DFT do sinal Chirp. Fs = 1 Khz. F = 0-250Hz. t = 10 s
.
Amplitude dada pelo FA é de : 0.5518
Logo, é notável a melhora proporcionada pelo FA na análise de sinais não
estacionários.

15
2.6 Técnicas de Detecção Objetiva de Resposta
A ASSR pode ser detectada no sinal de EEG por meio da aplicação de técnicas
detecção objetiva de resposta (ORD, do inglês Objective Response Detection). Em
geral, essas técnicas utilizam o teste de hipótese estatístico como critério de avaliação,
através da designação de uma hipótese nula H0, que representa a inexistência de
resposta no sinal de EEG. Dada a distribuição de probabilidade de um parâmetro do
sinal e um nível de significância, delimita-se um valor crítico. Este valor é confrontado
com a estimativa do parâmetro para que a hipótese nula H0 possa ser aceita ou rejeitada
(KAY, 1998).
As técnicas ORD comumente aplicadas são o Teste F Espectral (TFE), a Medida
de Sincronismo de Fase (MSF) e a Magnitude Quadrática da Coerência (MSC).
2.6.1 Teste F Espectral Local
O Teste F Espectral Local (TFE Local) é dado pela razão entre o módulo ao
quadrado do espectro do sinal 𝑦[𝑘] em uma frequência de estimulação (𝑓𝑜) e a média
dos módulos ao quadrado das 𝐿 frequências vizinhas mais próximas. Sendo que, 𝑌(𝑓𝑜) é
o valor da transformada de Fourier na frequência 𝑓𝑜 e 𝑌(𝑓𝑖) são os valores da
transformada de Fourier de cada 𝑖-ésima frequência vizinha à 𝑓𝑜 do sinal 𝑦[𝑘]
(ZUREK, 1992).
∅̂𝑦(𝑓0) =|𝑌(𝑓0)|2
1
𝐿∑ |𝑌(𝑓𝑖)|2𝑜+𝐿/2
𝑖=𝑜−𝐿/2𝑖≠𝑜
(Equação 2.22)
O TFE Local analisa se a distribuição dada por |Y (fo)|2 é estatisticamente
diferente de suas frequências adjacentes. Considerando o presente estudo, no qual a
análise em questão trata de um sinal de EEG, podemos supor que a hipótese nula (𝐻0) é
a ausência de resposta evocada, de modo que a única contribuição para o sinal de EEG é
a atividade de fundo, isto é, 𝑦[𝑘] = 𝑛[𝑘] (ruído branco gaussiano de média nula).
Sabendo que uma variável x tal que x = ∑ 𝑥𝑖2𝑣
𝑖=1 , onde 𝑥𝑖 possui distribuição gaussiana

16
de média zero e variância 𝜎, onde cada 𝑥𝑖 é considerado independente e identicamente
distribuído (IID), x possuirá uma distribuição Qui-quadrada central (KAY, 1998):
1
𝜎2∑ 𝑥𝑖
2~𝑥𝑣2𝑣
𝑖=1 (Equação 2.23)
Observe que tanto o numerador quanto o denominador da equação 2.22 possuem
distribuição Qui-quadrada independentes e com 2 e 2𝐿 graus de liberdade (parte
imaginária e real), respectivamente. Uma vez que a razão de duas distribuições Qui-
quadradas gera uma distribuição F, então �̂�𝑦(𝑓𝑜) sob 𝐻0 possui distribuição F com 2 e
2𝐿 graus de liberdade:
∅̂𝑦(𝑓0)|𝐻0~𝐹2,2𝐿 (Equação 2.24)
O limiar escolhido para aceitar ou rejeitar 𝐻0 é o valor crítico, dado em
conformidade com a distribuição estatística e o nível de significância 𝛼 (normalmente
de 0,05 ou 0,01 para aplicação de detecção de ASSR) empregado.
Enfim, a presença de resposta evocada será aceita quando o valor do TFE local
for maior que o valor crítico :
∅̂𝑦(𝑓𝑜) > 𝐹𝑐𝑟𝑖𝑡2,2𝐿,𝛼 (Equação 2.25)

17
3 Materiais e Métodos
3.1 Sistema de Estimulação e Detecção de ASSR
O sistema utilizado no presente Projeto de Graduação foi desenvolvido pelos
membros do Laboratório de Processamento de Sinais e Imagens Médicas do Programa
de Engenharia Biomédica da Universidade Federal do Rio de Janeiro
(LAPIS/PEB/UFRJ), e o Núcleo de Estudos e Pesquisa em Engenharia Biomédica
(NEPEB) da Universidade Federal de Minas Gerais (UFMG). Esta seção aborda apenas
os pontos principais do sistema (organização funcional), necessários para a
compreensão da metodologia abordada neste estudo. Para maiores detalhes, recomenda-
se ler a referência (LARREA, 2015).
As funcionalidades do sistema foram estabelecidas considerando os parâmetros
necessários para aplicações direcionadas a análise da ASSR. O sistema utilizado possui
as seguintes funções :
Estimulação auditiva múltipla binaural de tons modulados em amplitude ou
frequência;
Aquisição das respostas eletrofisiológicas ASSR por meio de múltiplas
derivações de EEG, gravadas em sincronia com o estímulo;
Apresentação em computador dos sinais de EEG adquiridos, tanto no
domínio do tempo quanto no domínio da frequência;
Processamento de sinais on-line para detecção das ASSRs;
Gravação em disco dos dados de EEG para processamento off-line.
A implementação adotou uma solução de arquitetura modular, composta de 4
elementos com componentes de hardware e software:
Módulo de interface com o usuário GUI (Graphical User Interface) (M_Gui)
- contém as interfaces de usuário necessárias para controle das funções do
estimulador auditivo, aquisição de sinais de EEG e processamento de sinais
por meio das técnicas objetivas de detecção de resposta.

18
Módulo de estimulação auditiva (M_Estim) – recebe informação digital de
áudio e gera os sinais elétricos analógicos que são convertidos em pressão
sonora pelos transdutores (fones de ouvido). Este módulo configura a saída
de áudio de acordo às especificações definidas na interface do usuário no
M_Gui.
Módulo de aquisição de EEG de múltiplas derivações (M_Aq) - encarregado
da aquisição dos sinais analógicos de EEG, e sua apresentação na tela por
meio da interface do usuário no M_Gui.
Módulo de controle e comunicação interna (M_Com) - sistema de hardware
que permite a comunicação entre os módulos.
A interface de usuário M_Gui estabelece os parâmetros do protocolo de
estimulação e da aquisição de sinais de EEG. Os dados da estimulação são enviados
através do M_Com para serem reproduzidos no M_Estim, e posteriormente ajustados
com sistema de calibração. O M_Aq adquire os sinais eletrofisiológicos de múltiplas
derivações de EEG e, por meio do M_Com, envia os dados digitais para o M_Gui no
computador, onde serão processados pela interface de Processamento (Figura 4.1).
Figura 3.1: Estrutura funcional do sistema de aquisição e análise de ASSR.

19
3.2 Voluntários
Foram registrados sinais de EEG de 10 voluntários – 8 selecionados para
elaboração dos resultados – com faixa etária entre 18 e 30 anos, sem histórico de
doenças auditivas ou neurológicas (verificadas por anamnese audiológica). Os
experimentos tiveram aprovação do comitê de ética em pesquisa local (CEP) do
Hospital Universitário Clementino Fraga Filho (HUCFF), CAAE-
40844414.3.0000.5257, e todos os voluntários assinaram um termo de consentimento
livre e esclarecido (TCLE).
Critérios de Inclusão
Os voluntários realizaram os procedimentos de: anamnese otológica e
audiometria tonal liminar no Laboratório de Análise e Processamento de Sinais e
Imagens Médicas (LAPIS) do Programa de Engenharia Biomédica (PEB) da
Universidade Federal do Rio de Janeiro (UFRJ). Esses procedimentos foram realizados
em colaboração com os alunos do curso de Fonoaudiologia, filiados ao laboratório.
A anamnese obteve informações sobre a idade, gênero e audição (antecedentes
familiares, passado otológico e uso de medicamentos ototóxicos) do voluntário. Os
voluntários considerados aptos na anamnese (todos, portanto 10 voluntários,
prosseguiram para a realização da Audiometria Tonal Liminar.
A Audiometria Tonal Liminar foi realizada em uma cabine de isolamento
acústico, com níveis de pressão sonora de acordo com os níveis exigidos pela norma
ANSI S3.-1991. O método para a determinação dos limiares tonais aéreos foi
descendente (em intensidade sonora) (FROTA, 2003) nas frequências de 250, 500,
1000, 2000, 3000, 4000, 6000 e 8000 Hz. Utilizou-se um audiômetro da marca
Interacoustic, modelo CE 10 padrão ANSI-69 e fone TDH–39.
Os limiares obtidos em dBNA por meio da audiometria tonal estão relacionados
com a escala de dBSPL de acordo com a norma ISO 389-2:1994 para fones de inserção,
com correções de +6, +0, +3 e +6 dB para as frequências de 500, 1000, 2000 e 4000 Hz,
respectivamente.
Os voluntários considerados aptos no teste de Audiometria Tonal (aqueles que
não excederam a intensidade de 20 dBNA para frequências entre 500 e 8000 Hz; 10

20
voluntários) foram encaminhados para etapa da coleta de sinais de EEG. A duração
total desses exames audiológicos foi de aproximadamente 20 minutos.
3.3 Estímulos
Para gerar uma ASSR de qualidade, é imprescindível que os estímulos utilizados
sejam adequados ao experimento. No que tange aos estímulos por sons vocálicos
naturais, a qualidade pode ser garantida através da utilização de microfones e
conversores analógico-digitais de alta qualidade e ambiente de captação do som livre de
ruído sonoro. Além dessas especificações de caráter técnico, também são necessários
cuidados com a fonação, por isso é importante garantir que a emissão vocal seja a mais
constante possível, evitando alterações de articulação e entonação ao longo da gravação
sonora.
Os sons vocálicos escolhidos para estudo neste projeto foram /a/, /i/ e /u/ (sons
vocálicos das vogais “a”, “i” e “u” do idioma Português, de acordo com o Alfabeto
Fonético Internacional), porque possuem estruturas harmônicas bem definidas,
facilitando sua identificação.
Após serem digitalizados, os fonemas são formatados no computador utilizando
os softwares Audacity e Matlab, para que possuam as características necessárias para a
estimulação.
Digitalização do Sinal
Os fonemas /a/, /i/ e /u/, produzidas naturalmente em vários trechos de
aproximadamente 5 segundos pelo autor deste projeto, foram gravados em uma cabine
de isolamento acústico. Para a gravação do sinal foram utilizados um headset modelo
“Pc 3 Chat” da marca Sennheiser e um notebook “Lenovo, modelo Yoga 510 (placa de
som Realtek HD audio)”, utilizando uma frequência de amostragem de 32 kHz e uma
resolução de 32 bits.
21
Formatação do Sinal
Para formatação do sinal digital, utilizou-se o software Audacity. Para gerar o
estímulo vocálico, é necessário selecionar um trecho do sinal que deve possuir
exatamente 1,5 segundo (48.000 amostras), poucas variações nos picos de amplitude,
possuir um número inteiro de ciclos de pitch, além de cruzamentos em zero tanto no
início quanto no fim do trecho. Dessa forma o trecho poderá ser reproduzido num loop
contínuo. Uma vez que o sinal não possui cruzamento em zero em exatamente 48.000
amostras, o sinal teve que ser reamostrado a uma taxa sutilmente diferente da taxa de
amostragem, para obter exatamente as 48.000 amostras necessárias, gerando uma
alteração desprezível no pitch da voz. Logo, os sinais foram considerados como se
tivessem sido amostrados a 32.000 kHz (AIKEN e PICTON, 2006).
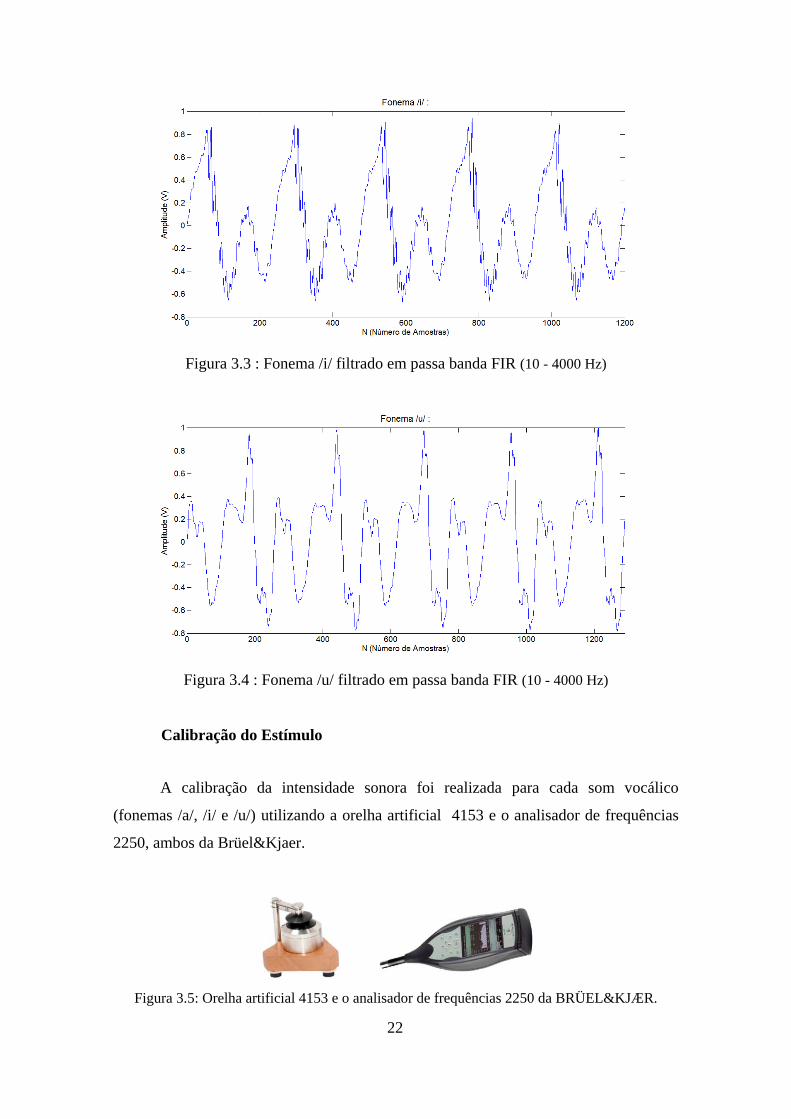
Esses estímulos foram filtrados (direta e inversamente - sem defasagem) por um
filtro FIR passa-banda de frequências de corte de 10 e 4000 Hz, utilizando o software
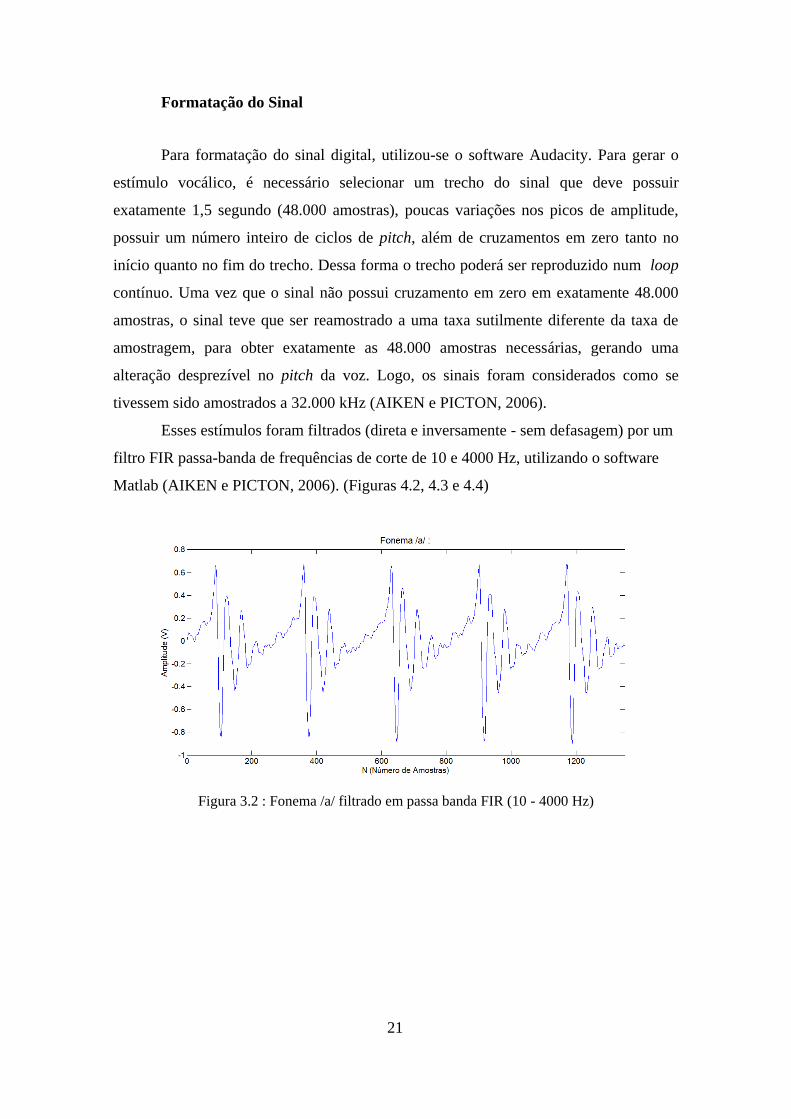
Matlab (AIKEN e PICTON, 2006). (Figuras 4.2, 4.3 e 4.4)
Figura 3.2 : Fonema /a/ filtrado em passa banda FIR (10 - 4000 Hz)
22
Figura 3.3 : Fonema /i/ filtrado em passa banda FIR (10 - 4000 Hz)
Figura 3.4 : Fonema /u/ filtrado em passa banda FIR (10 - 4000 Hz)
Calibração do Estímulo
A calibração da intensidade sonora foi realizada para cada som vocálico
(fonemas /a/, /i/ e /u/) utilizando a orelha artificial 4153 e o analisador de frequências
2250, ambos da Brüel&Kjaer.
Figura 3.5: Orelha artificial 4153 e o analisador de frequências 2250 da BRÜEL&KJÆR.
23
A calibração utilizou como método de ponderação espectral a curva A-weighting
(figura 4.5), uma vez que esta curva representa satisfatoriamente a sensibilidade
auditiva humana, possuindo maior seletividade entre 500 Hz e 6 kHz (GRACEY &
ASSOCIATES, 2018).
Figura 3.6: Curvas de ponderação espectral sonora A,C e Z.
Foi utilizado como referência o valor LAeq (Valor RMS do nível de pressão
sonora calculado ao longo de um intervalo de tempo, utilizando a curva de ponderação
espectral “A-Weighting”) calculado ao longo de 30 segundos. A figura 4.6 e a Tabela
4.1 mostram a calibração do estímulo para 70 e 55 dBSPL.

24
Figura 3.7 : Calibração para fonemas /a/, /i/ e /u/ para 70 dBSPL
Tabela 3.1 : Calibração dos fonemas para aplicação no sistema de estimulação e aquisição de
sinais eletrofisiológicos.
Fonema Estimulador Auditivo
[dBSPL]
LAeq [dBSPL]
/a/ 80 70
/i/ 81 70
/u/ 81 70
/a/ 65 55
/i/ 66 55
/u/ 66 55
3.4 Formantes do Trato Vocal
O cálculo das formantes do trato vocal é essencial para avaliar as características
dos fonemas. Para calcular as formantes do trato vocal de cada fonema, os sinais
formatados foram reamostrados a 8 kHz. Foi selecionada uma janela de 50ms,
possuindo como início a posição temporal de 500 ms do sinal. Finalmente, foi estimado
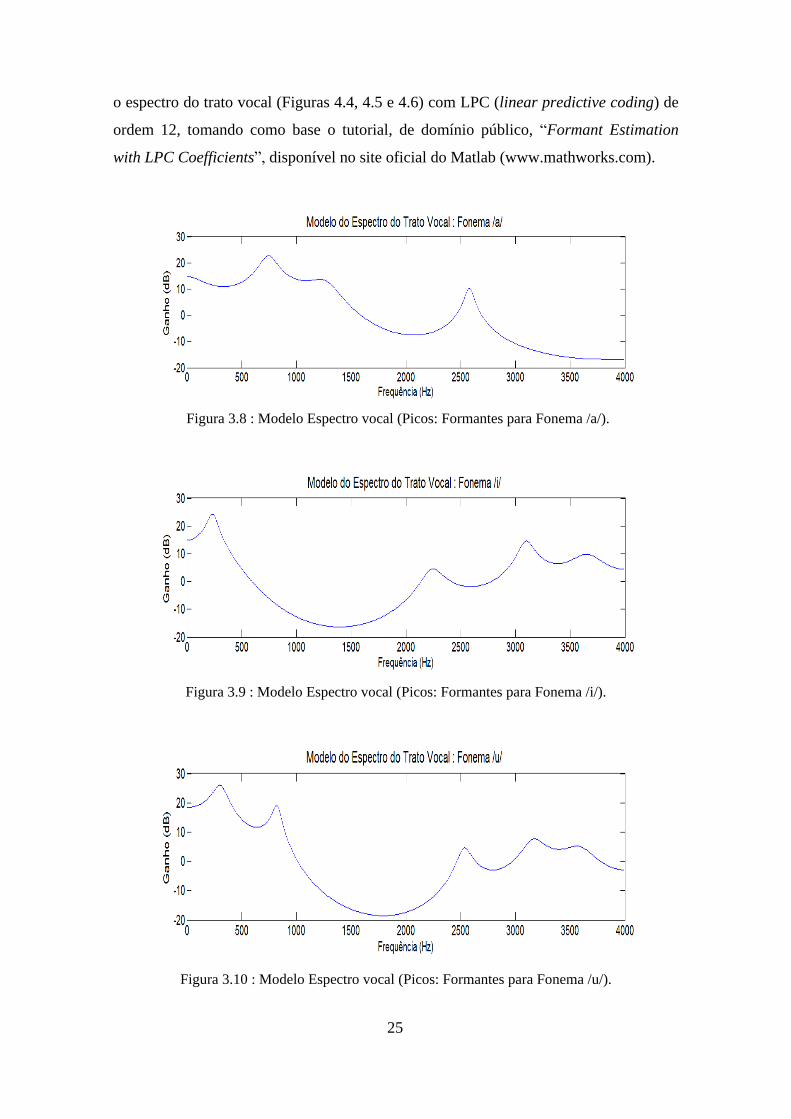
25
o espectro do trato vocal (Figuras 4.4, 4.5 e 4.6) com LPC (linear predictive coding) de
ordem 12, tomando como base o tutorial, de domínio público, “Formant Estimation
with LPC Coefficients”, disponível no site oficial do Matlab (www.mathworks.com).
Figura 3.8 : Modelo Espectro vocal (Picos: Formantes para Fonema /a/).
Figura 3.9 : Modelo Espectro vocal (Picos: Formantes para Fonema /i/).
Figura 3.10 : Modelo Espectro vocal (Picos: Formantes para Fonema /u/).

26
3.5 Protocolo Experimental
Toda parte experimental, tanto de aquisição quanto de estimulação, foi realizada
utilizando o sistema descrito no capítulo 4.1.
A coleta foi realizada numa sala silenciosa do LAPIS. O voluntário foi
acomodado em uma cadeira confortável, de encosto reclinável, e orientado a dormir ou
permanecer tranquilo.
Aquisição de Sinais
A atividade eletroencefalográfica foi gravada com os eletrodos de prata/cloreto
de prata (Ag/AgCl) posicionado nas derivações mastoide esquerdo (M1), mastoide
direito (M2) e Inion (Oz), com eletrodo de referência posicionado no vertex (Cz) e o
eletrodo de terra posicionado na região fronto-central (Fpz), conforme elucidado no
capítulo 2.3.3 (Registro multicanal ASSR).
Como as respostas ASSR encontram-se numa faixa de tensão de baixíssima
amplitude (ordem nV), qualquer interferência elétrica pode ser significativa. Para evitar
as interferências acarretadas pelo ruído da rede elétrica, o sistema de coleta de EEG foi
alimentado por uma bateria DC e os equipamentos do laboratório foram desligados da
tomada. Além disso, os fios dos eletrodos foram trançados e posicionados a uma
distância razoável do transdutor auditivo para evitar interferência.
Para melhor condutância elétrica entre os eletrodos e a pele do voluntário, foi
feita a limpeza do local com álcool 70%, além da utilização de pasta condutora de EEG
para casamento de impedância eletrodo-pele. Também foram utilizadas fitas
microporosas hipoalergênicas para que os eletrodos não se desprendessem da cabeça do
voluntário ao longo da coleta.
Os sinais de EEG foram adquiridos com frequência de amostragem de 4000 Hz e
resolução de 24 bits. Os sinais registrados passam por um filtro de decimação passa-
baixas do conversor analógico-digital ADS1299, cuja frequência de corte corresponde a
um quarto da frequência de amostragem (1000 Hz).
Aplicação de Estímulos

27
Foram colocados fones de inserção E-A-RTONETM 3A-10Ω em ambas orelhas,
porém somente a orelha esquerda foi estimulada. Foram aplicados os estímulos sonoros
vocálicos (/a/,/i/,/u/) por 6 minutos para duas intensidades sonoras de 55 e 70 𝑑𝐵𝑠𝑝𝑙
calibrados de acordo com a tabela 4.1.
Teste de Interferência Elétrica
A possível interferência elétrica do gerador de sinais analógicos - para produzir
o som no sistema - e os condutores até os fones de estimulação de coleta foi avaliada.
Para tanto, foi necessário aferir se existe ASSR quando os estímulos são gerados, porém
o voluntário não os escuta (orelha sem estimulação).
Para tal, o seguinte procedimento foi adotado :
O fone de inserção E-A-RTONETM 3A-10Ω foi retirado da orelha esquerda do
paciente e acomodado numa região próxima ao ombro (moveu-se apenas o fio
localizado após o transdutor eletromecânico do fone, que conduz o som para o
ouvido. O fio que conduz a corrente elétrica ao transdutor permaneceu intacto).
Como a orelha direita não é estimulada neste experimento, o fone de inserção
desta orelha não foi retirado.
Foi inserido um plug EAR na orelha esquerda do voluntário e foi colocado um
ruído branco de intensidade próxima a 60 𝑑𝐵𝑠𝑝𝑙 no ambiente de coleta, através
do alto falante de um celular. Este procedimento visa garantir que o voluntário
de fato não escute o estímulo.
Foram aplicados estímulos vocálicos (/a/,/i/,/u/) por 6 minutos para a intensidade
sonora de 70 𝑑𝐵𝑠𝑝𝑙 e a atividade eletroencefalográfica foi registrada.
3.6 Análise da ASSR a Sons Vocálicos
Este subcapítulo objetiva a implementação do Analisador de Fourier para análise
da amplitude da ASSR evocada por sons vocálicos (fonemas /a/, /i/ e /u/), cujos fins e
teoria estão elucidados no subcapítulo 2.3.1 (Análise da ASSR a sons vocálicos
naturais) e 2.5 (Analisador de Fourier) respectivamente. Em seguida, é aplicado TFE
local para detecção de respostas.
28
4.6.1 Pré-processamento dos Sinais de EEG
Foi aplicada filtragem digital passa-faixa entre 30 e 950 Hz e o sinal foi
segmentado em trechos de 1,5 segundo. Foi realizada a média dos 240 trechos de 1,5s
(6 min. de coleta). Finalmente, os trechos do sinal de EEG foram sincronizados com o
estímulo auditivo.
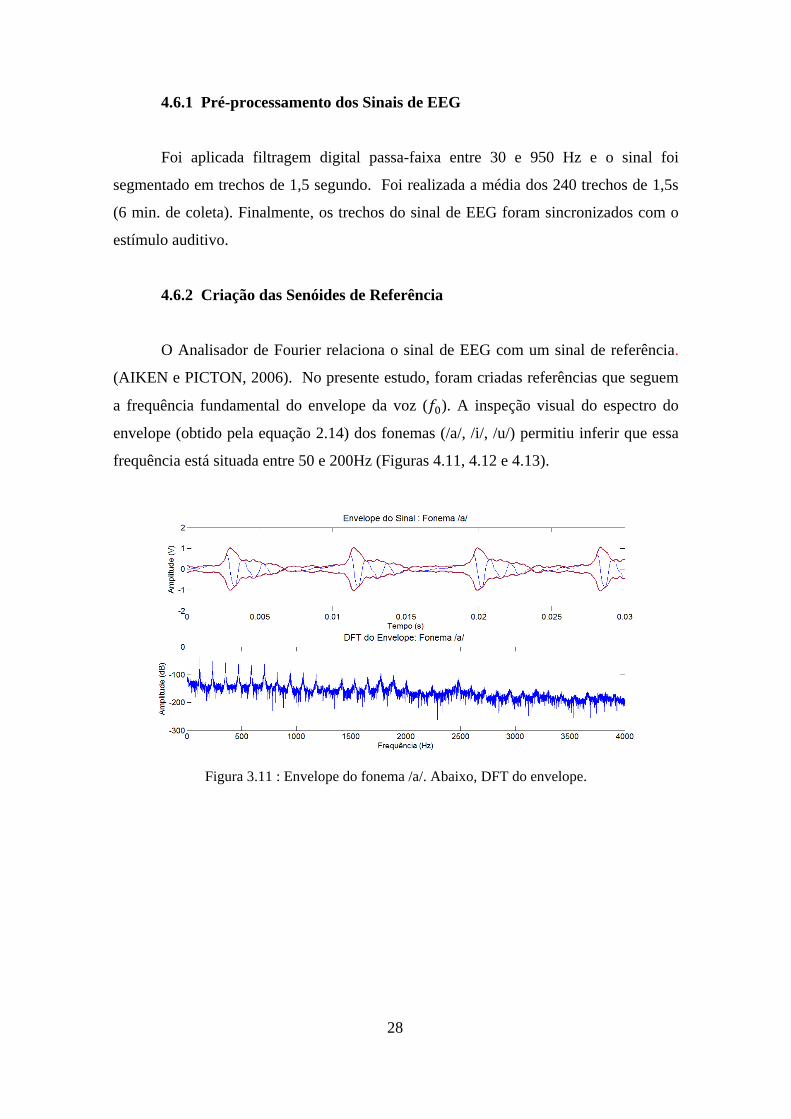
4.6.2 Criação das Senóides de Referência
O Analisador de Fourier relaciona o sinal de EEG com um sinal de referência.
(AIKEN e PICTON, 2006). No presente estudo, foram criadas referências que seguem
a frequência fundamental do envelope da voz (𝑓0). A inspeção visual do espectro do
envelope (obtido pela equação 2.14) dos fonemas (/a/, /i/, /u/) permitiu inferir que essa
frequência está situada entre 50 e 200Hz (Figuras 4.11, 4.12 e 4.13).
Figura 3.11 : Envelope do fonema /a/. Abaixo, DFT do envelope.
29
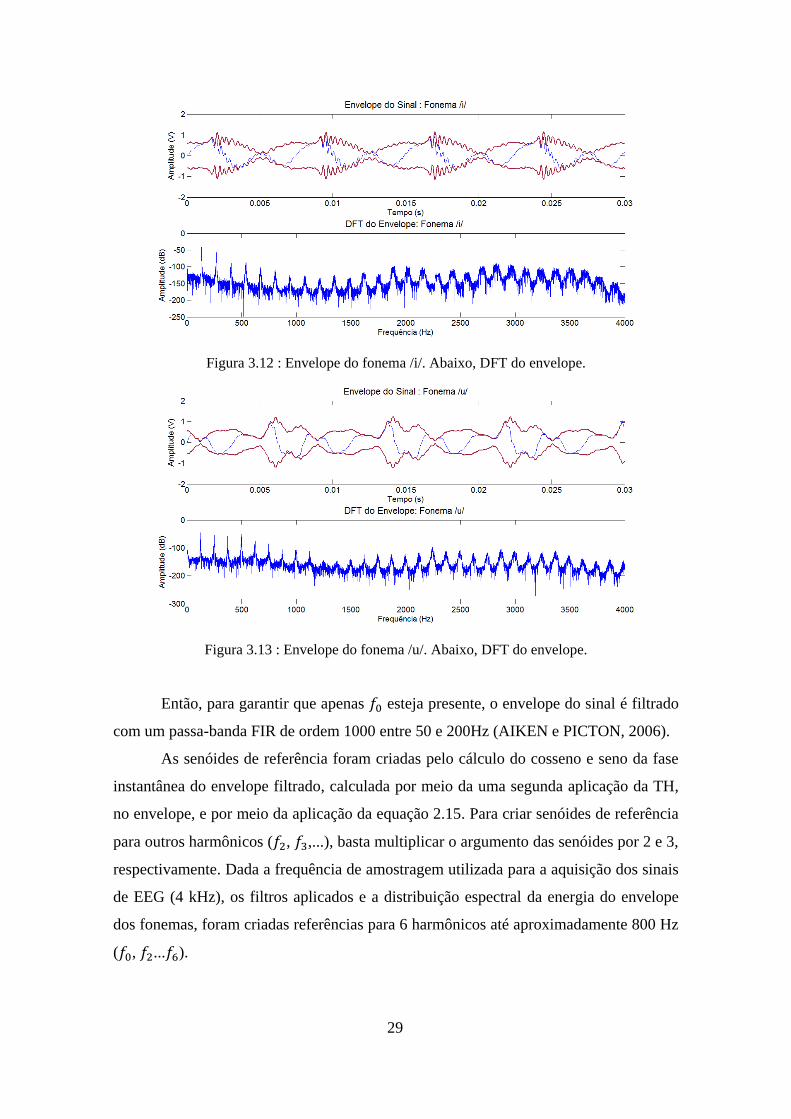
Figura 3.12 : Envelope do fonema /i/. Abaixo, DFT do envelope.
Figura 3.13 : Envelope do fonema /u/. Abaixo, DFT do envelope.
Então, para garantir que apenas 𝑓0 esteja presente, o envelope do sinal é filtrado
com um passa-banda FIR de ordem 1000 entre 50 e 200Hz (AIKEN e PICTON, 2006).
As senóides de referência foram criadas pelo cálculo do cosseno e seno da fase
instantânea do envelope filtrado, calculada por meio da uma segunda aplicação da TH,
no envelope, e por meio da aplicação da equação 2.15. Para criar senóides de referência
para outros harmônicos (𝑓2, 𝑓3,...), basta multiplicar o argumento das senóides por 2 e 3,
respectivamente. Dada a frequência de amostragem utilizada para a aquisição dos sinais
de EEG (4 kHz), os filtros aplicados e a distribuição espectral da energia do envelope
dos fonemas, foram criadas referências para 6 harmônicos até aproximadamente 800 Hz
(𝑓0, 𝑓2...𝑓6).
30
Também foram criadas referências para 16 frequências adjacentes (espaçadas
em 2 Hz, 8 referências acima dos harmônicos e 8 referências abaixo) para cada
formante, a fim de medir a energia em frequências não estimuladas.
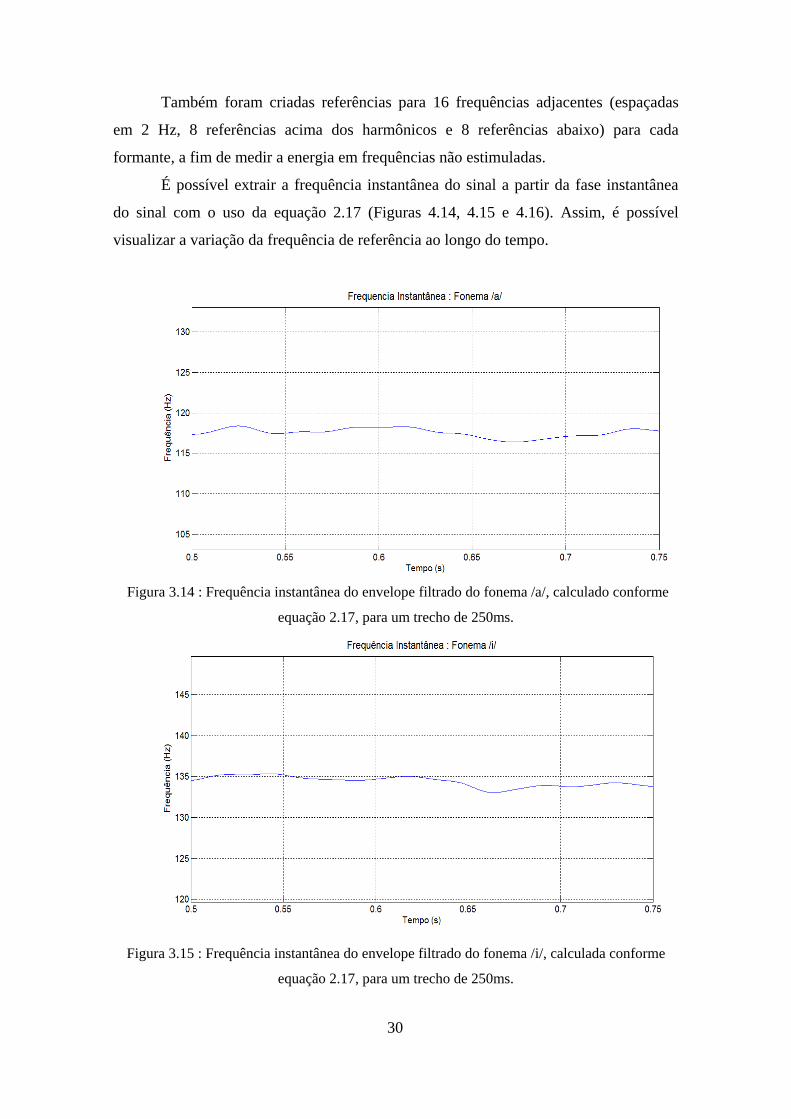
É possível extrair a frequência instantânea do sinal a partir da fase instantânea
do sinal com o uso da equação 2.17 (Figuras 4.14, 4.15 e 4.16). Assim, é possível
visualizar a variação da frequência de referência ao longo do tempo.
Figura 3.14 : Frequência instantânea do envelope filtrado do fonema /a/, calculado conforme
equação 2.17, para um trecho de 250ms.
Figura 3.15 : Frequência instantânea do envelope filtrado do fonema /i/, calculada conforme
equação 2.17, para um trecho de 250ms.
31
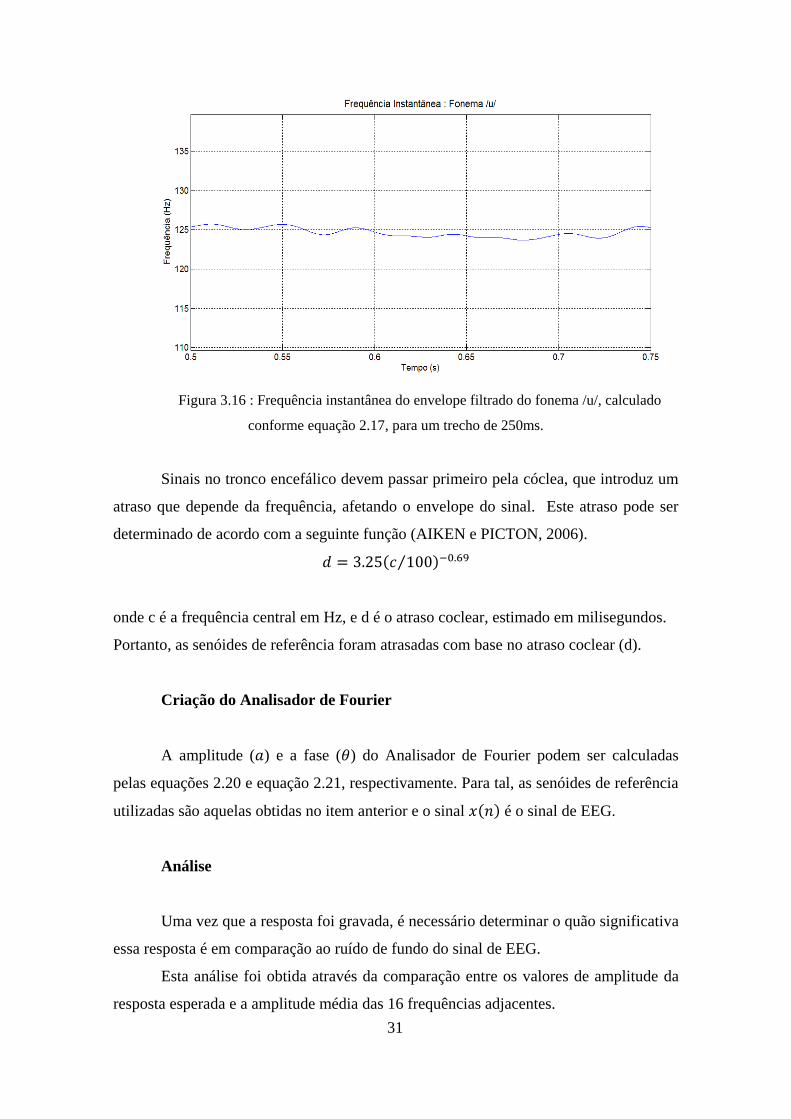
Figura 3.16 : Frequência instantânea do envelope filtrado do fonema /u/, calculado
conforme equação 2.17, para um trecho de 250ms.
Sinais no tronco encefálico devem passar primeiro pela cóclea, que introduz um
atraso que depende da frequência, afetando o envelope do sinal. Este atraso pode ser
determinado de acordo com a seguinte função (AIKEN e PICTON, 2006).
𝑑 = 3.25(𝑐 100⁄ )−0.69
onde c é a frequência central em Hz, e d é o atraso coclear, estimado em milisegundos.
Portanto, as senóides de referência foram atrasadas com base no atraso coclear (d).
Criação do Analisador de Fourier
A amplitude (𝑎) e a fase (𝜃) do Analisador de Fourier podem ser calculadas
pelas equações 2.20 e equação 2.21, respectivamente. Para tal, as senóides de referência
utilizadas são aquelas obtidas no item anterior e o sinal 𝑥(𝑛) é o sinal de EEG.
Análise
Uma vez que a resposta foi gravada, é necessário determinar o quão significativa
essa resposta é em comparação ao ruído de fundo do sinal de EEG.
Esta análise foi obtida através da comparação entre os valores de amplitude da
resposta esperada e a amplitude média das 16 frequências adjacentes.

32
Finalmente, aplicou-se o teste de hipótese TFE local, para inferir
estatisticamente sobre a existência ou não da resposta cerebral nas frequências do
envelope do fonema (fundamental e seus harmônicos), comparando a sua energia com a
energia média das 16 frequências adjacentes. Assim, o TFE local foi aplicado com
(2,32) graus de liberdade e nível de significância de 0,05, de acordo com a equação
2.22. Para este teste, considera-se o sinal de EEG como um ruído branco gaussiano de
média zero.
Estas análises foram realizada para todos os fonemas (/a/,/i/ e /u/) para as
intensidades sonoras de 55 e 70 dBSPL.
4 Resultados e Discussão
Todas os resultados obtidos no presente estudo foram baseadas na média dos
trechos de 1,5 segundo (visualmente sem artefatos), segmentados do sinal de EEG de 6
minutos. As análises foram realizadas de forma off-line. As amplitudes foram calculadas
com o uso do Analisador de Fourier. Ao todo, foram utilizados os sinais de EEG de 8
voluntários para elaboração dos resultados (2 voluntários foram excluídos devido a alta
presença de artefatos em suas coletas). Embora o experimento possua 3 derivações
ativas (M1, M2 e inion) para análise da ASSR, os resultados foram elaborados
utilizando apenas a derivação inion, para fins de comparação com estudos acadêmicos
relevantes da área.
4.1 Resultados
Amplitude e Taxa de Detecção da ASSR
Os valores mostrados nos gráficos e tabelas abaixo utilizaram o seguinte
procedimento :
Amplitude Referência (AR): Média das amplitudes do ASSR nas frequências de
referências (𝑓0, 𝑓2...𝑓6) dos 8 voluntários (n=8).
Amplitude Média das Frequências Vizinhas (AMFV): Média das amplitudes das
16 frequências adjacentes, a cada frequência de referência, dos 8 voluntários (n=8x16).
33
% TFE local : Quantidade percentual de detecção da ASSR, com o uso do TFE
local para os 8 voluntários. A aplicação do TFE local utilizou um nível de significância
de 0.05, com (2,32) graus de liberdade.
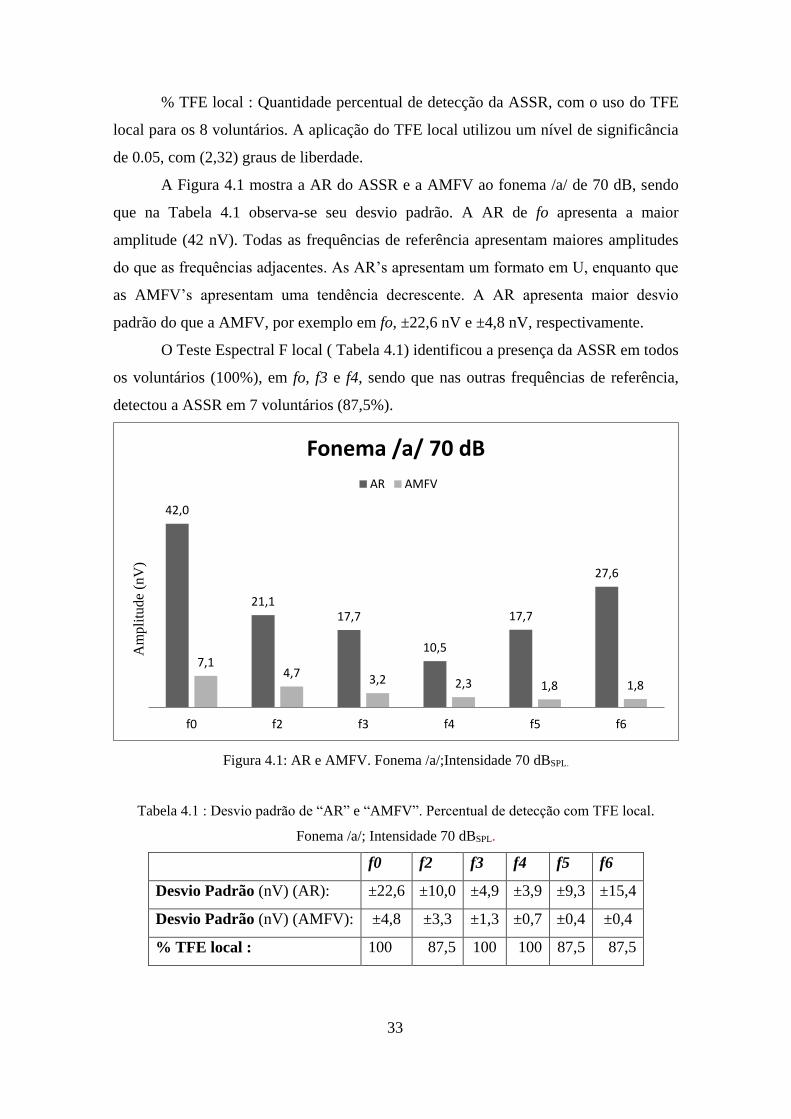
A Figura 4.1 mostra a AR do ASSR e a AMFV ao fonema /a/ de 70 dB, sendo
que na Tabela 4.1 observa-se seu desvio padrão. A AR de fo apresenta a maior
amplitude (42 nV). Todas as frequências de referência apresentam maiores amplitudes
do que as frequências adjacentes. As AR’s apresentam um formato em U, enquanto que
as AMFV’s apresentam uma tendência decrescente. A AR apresenta maior desvio
padrão do que a AMFV, por exemplo em fo, ±22,6 nV e ±4,8 nV, respectivamente.
O Teste Espectral F local ( Tabela 4.1) identificou a presença da ASSR em todos
os voluntários (100%), em fo, f3 e f4, sendo que nas outras frequências de referência,
detectou a ASSR em 7 voluntários (87,5%).
Figura 4.1: AR e AMFV. Fonema /a/;Intensidade 70 dBSPL.
Tabela 4.1 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /a/; Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR): ±22,6 ±10,0 ±4,9 ±3,9 ±9,3 ±15,4
Desvio Padrão (nV) (AMFV): ±4,8 ±3,3 ±1,3 ±0,7 ±0,4 ±0,4
% TFE local : 100 87,5 100 100 87,5 87,5
42,0
21,117,7
10,5
17,7
27,6
7,14,7 3,2 2,3 1,8 1,8
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /a/ 70 dB
AR AMFV
34
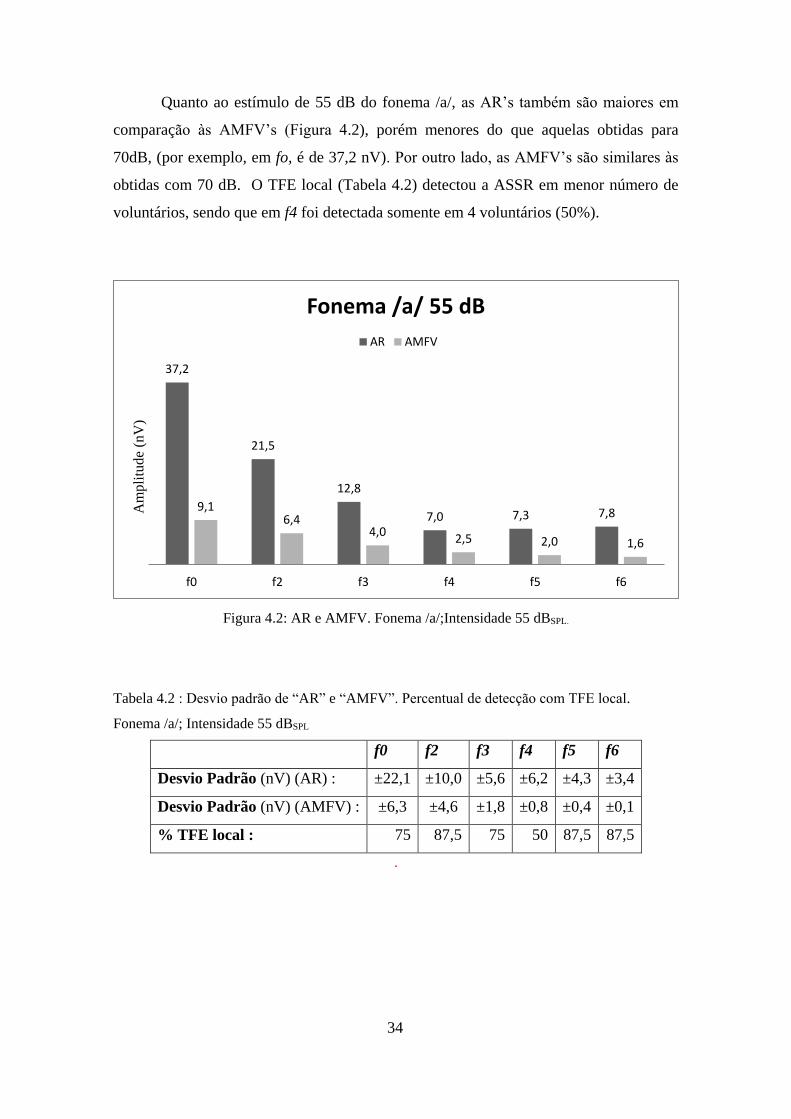
Quanto ao estímulo de 55 dB do fonema /a/, as AR’s também são maiores em
comparação às AMFV’s (Figura 4.2), porém menores do que aquelas obtidas para
70dB, (por exemplo, em fo, é de 37,2 nV). Por outro lado, as AMFV’s são similares às
obtidas com 70 dB. O TFE local (Tabela 4.2) detectou a ASSR em menor número de
voluntários, sendo que em f4 foi detectada somente em 4 voluntários (50%).
Figura 4.2: AR e AMFV. Fonema /a/;Intensidade 55 dBSPL.
Tabela 4.2 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /a/; Intensidade 55 dBSPL
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR) : ±22,1 ±10,0 ±5,6 ±6,2 ±4,3 ±3,4
Desvio Padrão (nV) (AMFV) : ±6,3 ±4,6 ±1,8 ±0,8 ±0,4 ±0,1
% TFE local : 75 87,5 75 50 87,5 87,5
.
37,2
21,5
12,8
7,0 7,3 7,89,16,4
4,02,5 2,0 1,6
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /a/ 55 dB
AR AMFV
35
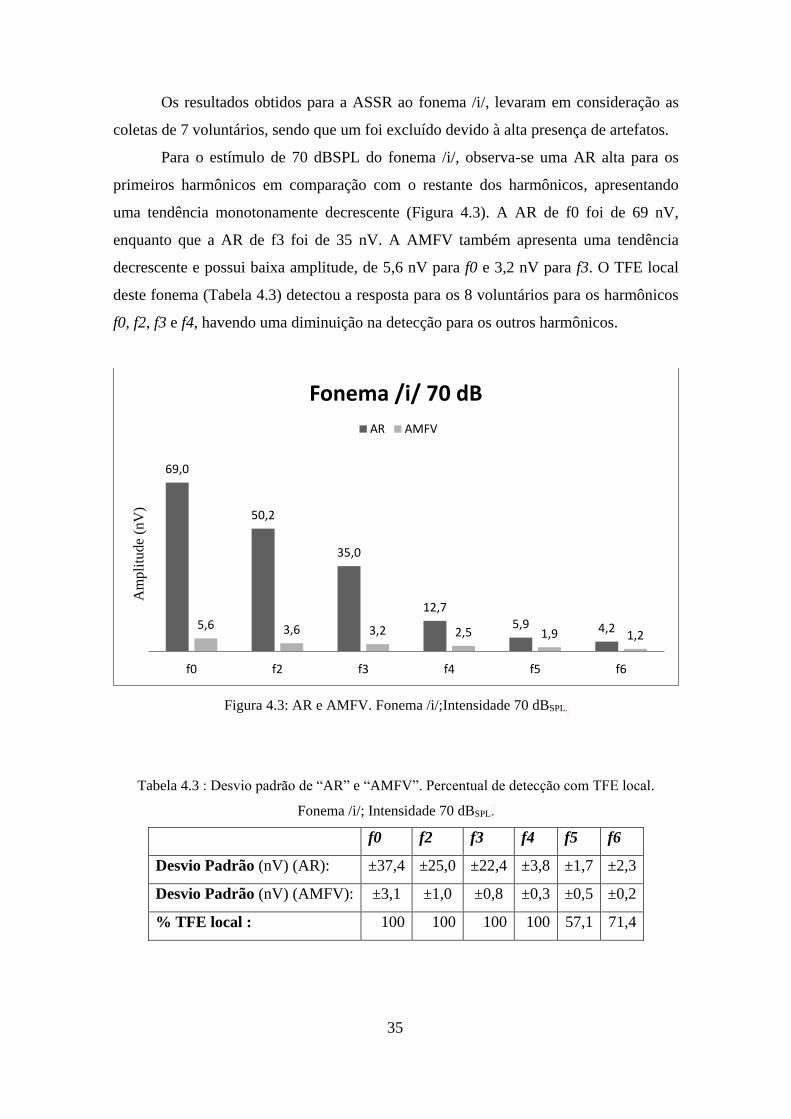
Os resultados obtidos para a ASSR ao fonema /i/, levaram em consideração as
coletas de 7 voluntários, sendo que um foi excluído devido à alta presença de artefatos.
Para o estímulo de 70 dBSPL do fonema /i/, observa-se uma AR alta para os
primeiros harmônicos em comparação com o restante dos harmônicos, apresentando
uma tendência monotonamente decrescente (Figura 4.3). A AR de f0 foi de 69 nV,
enquanto que a AR de f3 foi de 35 nV. A AMFV também apresenta uma tendência
decrescente e possui baixa amplitude, de 5,6 nV para f0 e 3,2 nV para f3. O TFE local
deste fonema (Tabela 4.3) detectou a resposta para os 8 voluntários para os harmônicos
f0, f2, f3 e f4, havendo uma diminuição na detecção para os outros harmônicos.
Figura 4.3: AR e AMFV. Fonema /i/;Intensidade 70 dBSPL.
Tabela 4.3 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /i/; Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR): ±37,4 ±25,0 ±22,4 ±3,8 ±1,7 ±2,3
Desvio Padrão (nV) (AMFV): ±3,1 ±1,0 ±0,8 ±0,3 ±0,5 ±0,2
% TFE local : 100 100 100 100 57,1 71,4
69,0
50,2
35,0
12,75,9 4,25,6 3,6 3,2 2,5 1,9 1,2
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /i/ 70 dB
AR AMFV
36
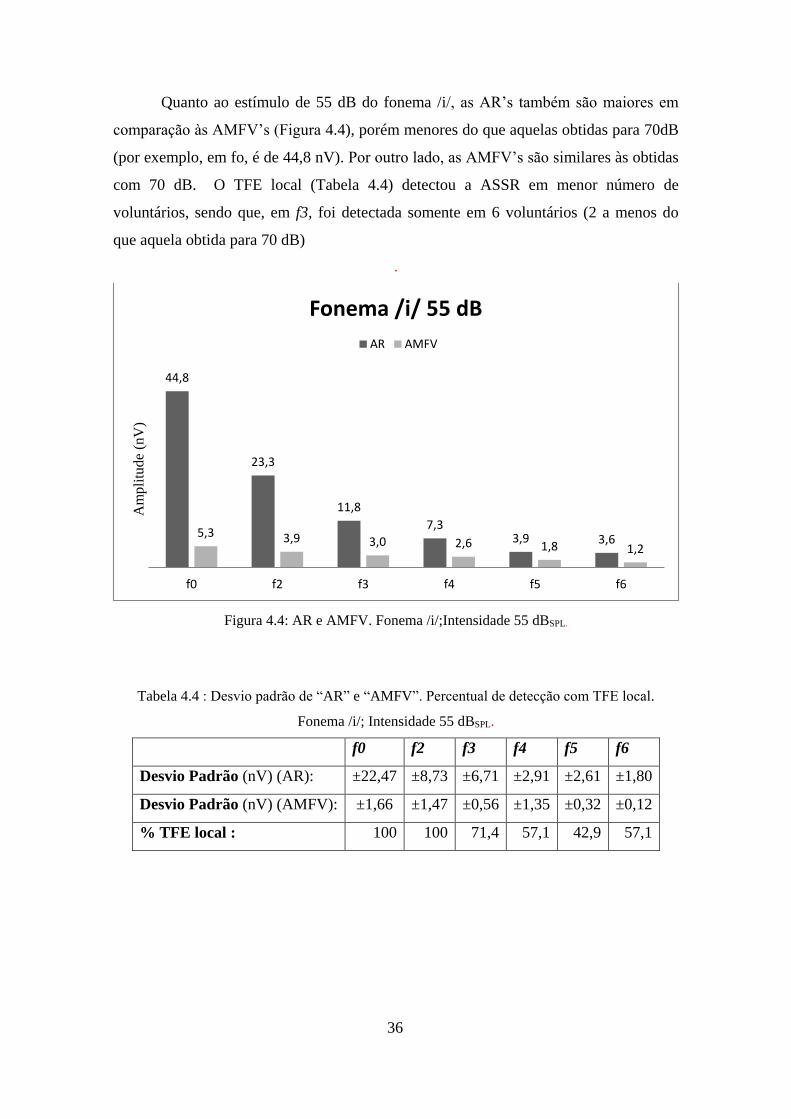
Quanto ao estímulo de 55 dB do fonema /i/, as AR’s também são maiores em
comparação às AMFV’s (Figura 4.4), porém menores do que aquelas obtidas para 70dB
(por exemplo, em fo, é de 44,8 nV). Por outro lado, as AMFV’s são similares às obtidas
com 70 dB. O TFE local (Tabela 4.4) detectou a ASSR em menor número de
voluntários, sendo que, em f3, foi detectada somente em 6 voluntários (2 a menos do
que aquela obtida para 70 dB)
.
Figura 4.4: AR e AMFV. Fonema /i/;Intensidade 55 dBSPL.
Tabela 4.4 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /i/; Intensidade 55 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR): ±22,47 ±8,73 ±6,71 ±2,91 ±2,61 ±1,80
Desvio Padrão (nV) (AMFV): ±1,66 ±1,47 ±0,56 ±1,35 ±0,32 ±0,12
% TFE local : 100 100 71,4 57,1 42,9 57,1
44,8
23,3
11,8
7,33,9 3,6
5,3 3,9 3,0 2,6 1,8 1,2
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /i/ 55 dB
AR AMFV
37
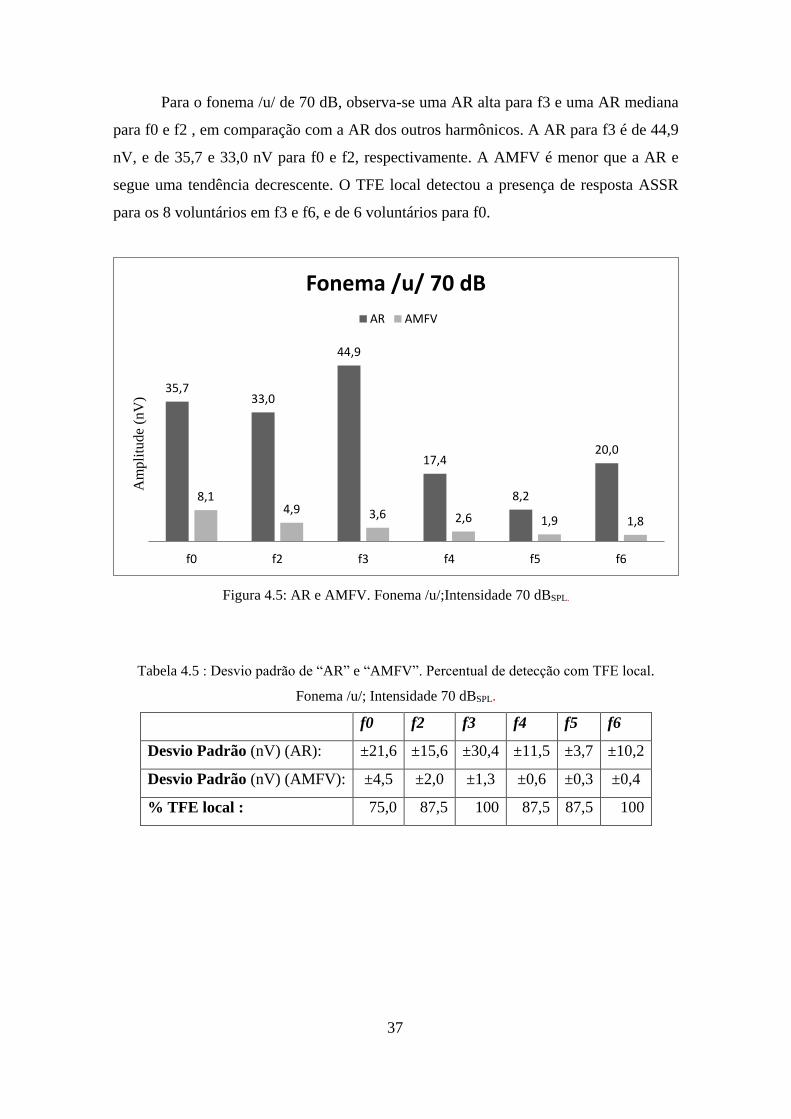
Para o fonema /u/ de 70 dB, observa-se uma AR alta para f3 e uma AR mediana
para f0 e f2 , em comparação com a AR dos outros harmônicos. A AR para f3 é de 44,9
nV, e de 35,7 e 33,0 nV para f0 e f2, respectivamente. A AMFV é menor que a AR e
segue uma tendência decrescente. O TFE local detectou a presença de resposta ASSR
para os 8 voluntários em f3 e f6, e de 6 voluntários para f0.
Figura 4.5: AR e AMFV. Fonema /u/;Intensidade 70 dBSPL.
Tabela 4.5 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /u/; Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR): ±21,6 ±15,6 ±30,4 ±11,5 ±3,7 ±10,2
Desvio Padrão (nV) (AMFV): ±4,5 ±2,0 ±1,3 ±0,6 ±0,3 ±0,4
% TFE local : 75,0 87,5 100 87,5 87,5 100
35,733,0
44,9
17,4
8,2
20,0
8,14,9 3,6 2,6 1,9 1,8
f0 f2 f3 f4 f5 f6
Am
pli
tud
e (n
V)
Fonema /u/ 70 dB
AR AMFV
38
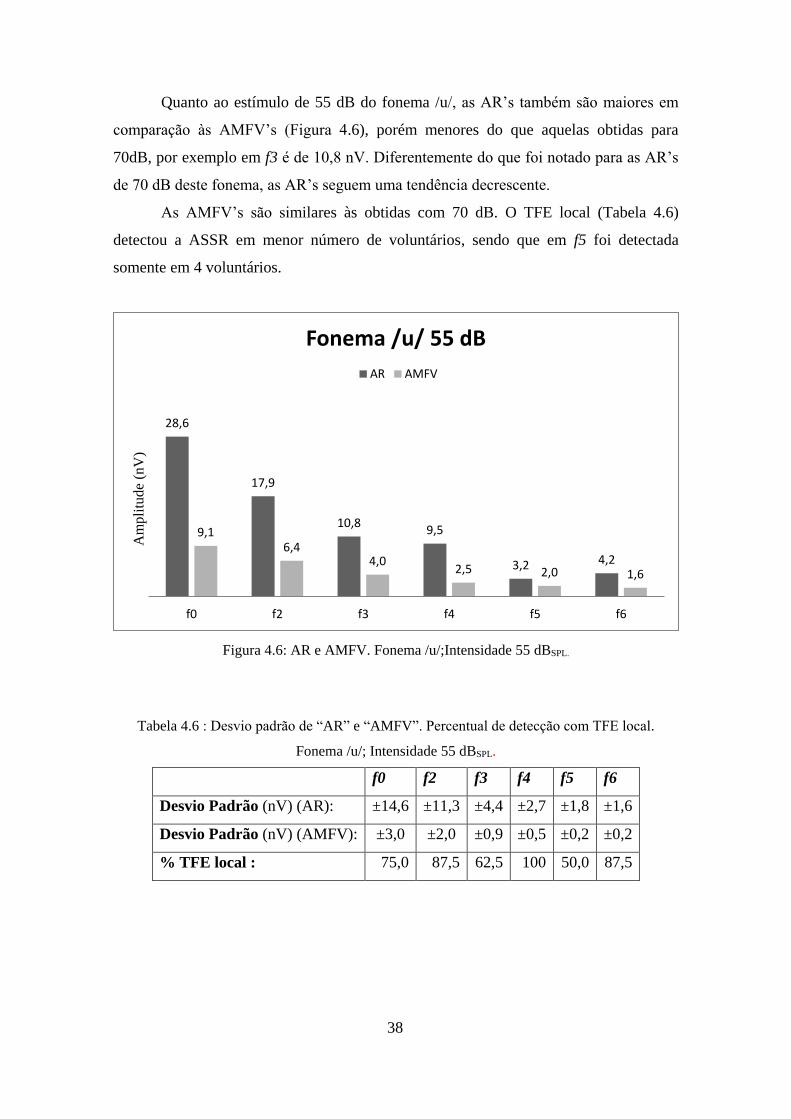
Quanto ao estímulo de 55 dB do fonema /u/, as AR’s também são maiores em
comparação às AMFV’s (Figura 4.6), porém menores do que aquelas obtidas para
70dB, por exemplo em f3 é de 10,8 nV. Diferentemente do que foi notado para as AR’s
de 70 dB deste fonema, as AR’s seguem uma tendência decrescente.
As AMFV’s são similares às obtidas com 70 dB. O TFE local (Tabela 4.6)
detectou a ASSR em menor número de voluntários, sendo que em f5 foi detectada
somente em 4 voluntários.
Figura 4.6: AR e AMFV. Fonema /u/;Intensidade 55 dBSPL.
Tabela 4.6 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /u/; Intensidade 55 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR): ±14,6 ±11,3 ±4,4 ±2,7 ±1,8 ±1,6
Desvio Padrão (nV) (AMFV): ±3,0 ±2,0 ±0,9 ±0,5 ±0,2 ±0,2
% TFE local : 75,0 87,5 62,5 100 50,0 87,5
28,6
17,9
10,89,5
3,2 4,2
9,16,4
4,02,5 2,0 1,6
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /u/ 55 dB
AR AMFV
39
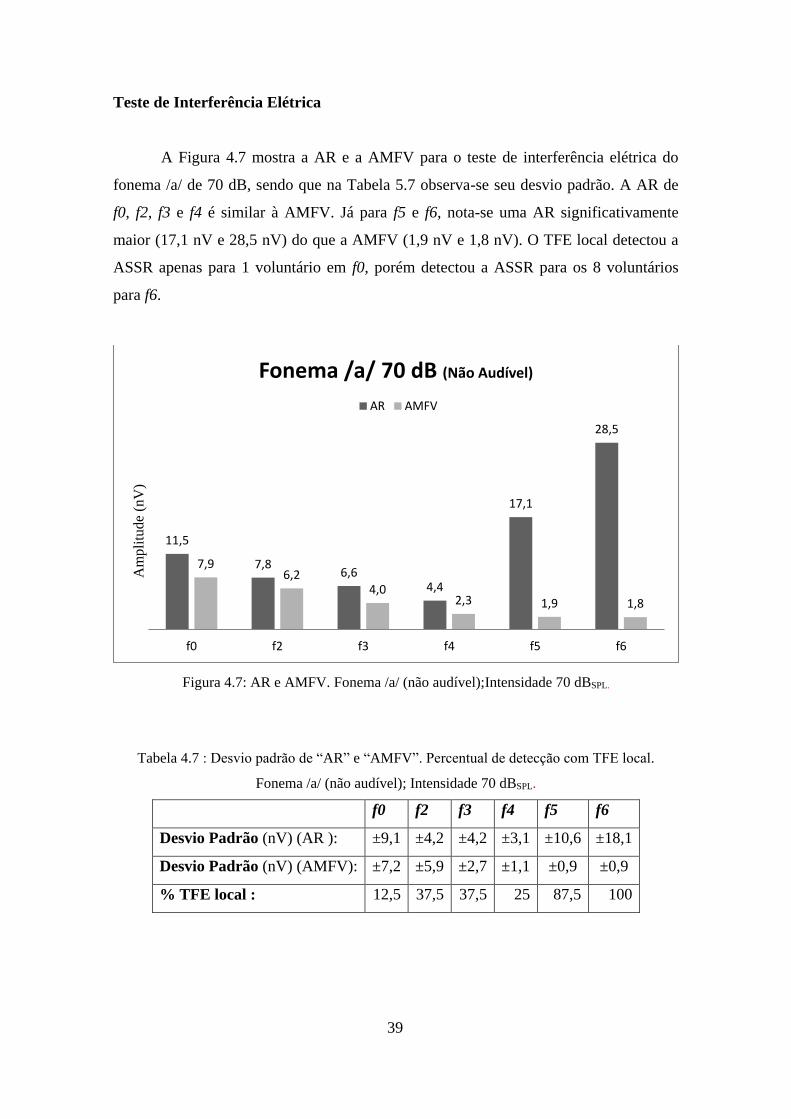
Teste de Interferência Elétrica
A Figura 4.7 mostra a AR e a AMFV para o teste de interferência elétrica do
fonema /a/ de 70 dB, sendo que na Tabela 5.7 observa-se seu desvio padrão. A AR de
f0, f2, f3 e f4 é similar à AMFV. Já para f5 e f6, nota-se uma AR significativamente
maior (17,1 nV e 28,5 nV) do que a AMFV (1,9 nV e 1,8 nV). O TFE local detectou a
ASSR apenas para 1 voluntário em f0, porém detectou a ASSR para os 8 voluntários
para f6.
Figura 4.7: AR e AMFV. Fonema /a/ (não audível);Intensidade 70 dBSPL.
Tabela 4.7 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /a/ (não audível); Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR ): ±9,1 ±4,2 ±4,2 ±3,1 ±10,6 ±18,1
Desvio Padrão (nV) (AMFV): ±7,2 ±5,9 ±2,7 ±1,1 ±0,9 ±0,9
% TFE local : 12,5 37,5 37,5 25 87,5 100
11,5
7,86,6
4,4
17,1
28,5
7,96,2
4,02,3 1,9 1,8
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /a/ 70 dB (Não Audível)
AR AMFV
40
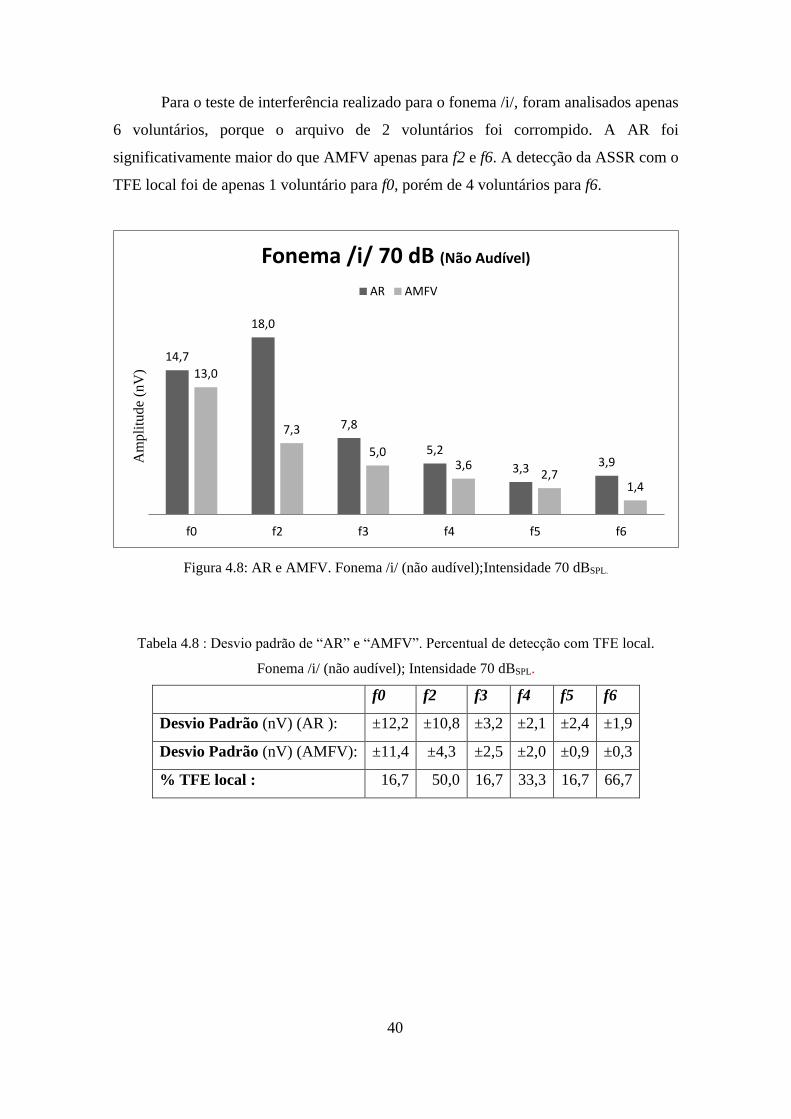
Para o teste de interferência realizado para o fonema /i/, foram analisados apenas
6 voluntários, porque o arquivo de 2 voluntários foi corrompido. A AR foi
significativamente maior do que AMFV apenas para f2 e f6. A detecção da ASSR com o
TFE local foi de apenas 1 voluntário para f0, porém de 4 voluntários para f6.
Figura 4.8: AR e AMFV. Fonema /i/ (não audível);Intensidade 70 dBSPL.
Tabela 4.8 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /i/ (não audível); Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR ): ±12,2 ±10,8 ±3,2 ±2,1 ±2,4 ±1,9
Desvio Padrão (nV) (AMFV): ±11,4 ±4,3 ±2,5 ±2,0 ±0,9 ±0,3
% TFE local : 16,7 50,0 16,7 33,3 16,7 66,7
14,7
18,0
7,8
5,2
3,3 3,9
13,0
7,3
5,03,6
2,71,4
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /i/ 70 dB (Não Audível)
AR AMFV
41
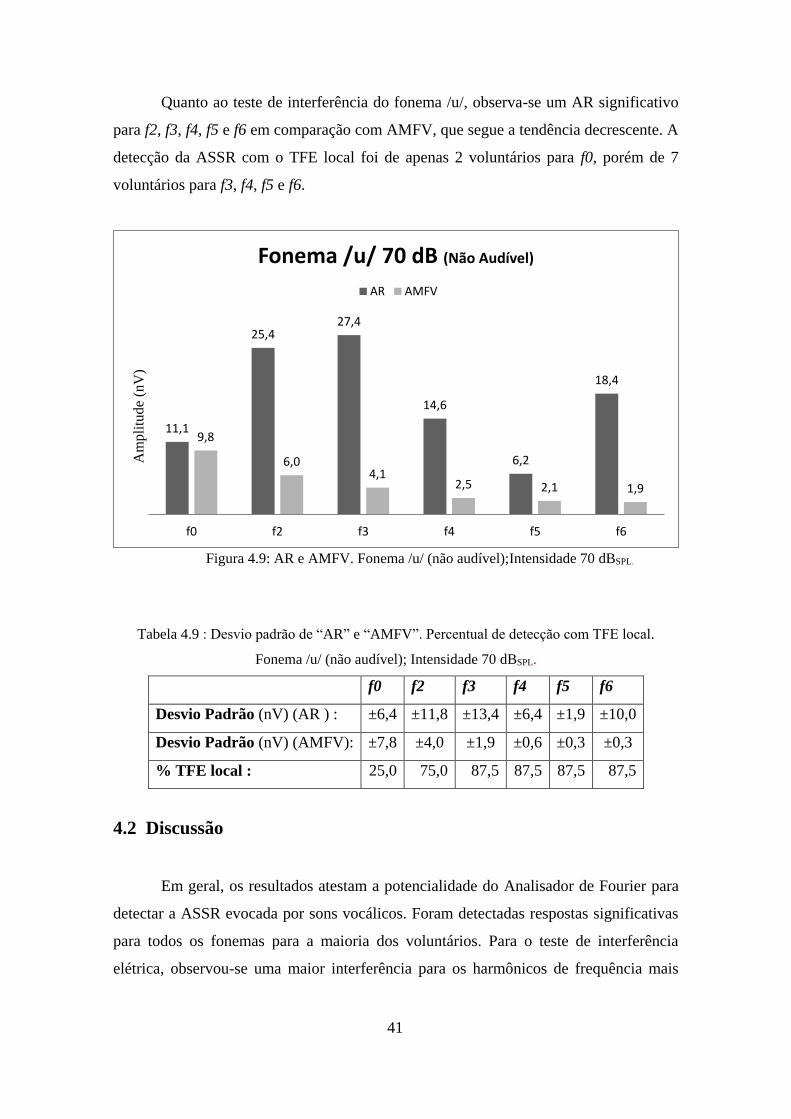
Quanto ao teste de interferência do fonema /u/, observa-se um AR significativo
para f2, f3, f4, f5 e f6 em comparação com AMFV, que segue a tendência decrescente. A
detecção da ASSR com o TFE local foi de apenas 2 voluntários para f0, porém de 7
voluntários para f3, f4, f5 e f6.
Figura 4.9: AR e AMFV. Fonema /u/ (não audível);Intensidade 70 dBSPL.
Tabela 4.9 : Desvio padrão de “AR” e “AMFV”. Percentual de detecção com TFE local.
Fonema /u/ (não audível); Intensidade 70 dBSPL.
f0 f2 f3 f4 f5 f6
Desvio Padrão (nV) (AR ) : ±6,4 ±11,8 ±13,4 ±6,4 ±1,9 ±10,0
Desvio Padrão (nV) (AMFV): ±7,8 ±4,0 ±1,9 ±0,6 ±0,3 ±0,3
% TFE local : 25,0 75,0 87,5 87,5 87,5 87,5
4.2 Discussão
Em geral, os resultados atestam a potencialidade do Analisador de Fourier para
detectar a ASSR evocada por sons vocálicos. Foram detectadas respostas significativas
para todos os fonemas para a maioria dos voluntários. Para o teste de interferência
elétrica, observou-se uma maior interferência para os harmônicos de frequência mais
11,1
25,427,4
14,6
6,2
18,4
9,8
6,04,1
2,5 2,1 1,9
f0 f2 f3 f4 f5 f6
Am
pli
tude
(nV
)
Fonema /u/ 70 dB (Não Audível)
AR AMFV

42
alta, sugerindo a presença de acoplamento capacitivo entre os fios de estimulação e os
fios utilizados para aquisição do sinal de EEG.
Abaixo, segue uma discussão mais específica, levando em consideração as
características de cada estímulo, além de comparações com os estudos de (AIKEN e
PICTON, 2006) e (AIKEN e PICTON, 2008), uma vez que possuem metodologia
similar àquela utilizada neste projeto. Pequenas discrepâncias entre os resultados
obtidos por este estudo e os resultados obtidos em estudos acadêmicos da área são
naturais, uma vez que inúmeros fatores podem influenciar na avaliação da ASSR a sons
vocálicos. Por exemplo, embora os estímulos utilizados sejam os mesmos fonemas, de
acordo com o Alfabeto Fonético Internacional, eles não são iguais, uma vez que os
fonemas utilizados neste projeto são peculiares do autor deste projeto (características do
trato voca e entonação).
As diferenças significativas entre este projeto e a referência em questão são
listadas a seguir (o restante pode ser considerado similar):
(AIKEN e PICTON, 2006) :
Duração da coleta : 10 min
Intensidade do estímulo : 66 dBSPL
Aplicação de rejeição de artefatos, através de ponderação de trechos baseada
na variância da resposta.
Quantidade de voluntários : 10.
Analisa apenas f0.
(AIKEN e PICTON, 2008) :
Duração da coleta : 5 min.
Intensidade do estímulo : 60 dBA (RMS) num acoplador de 2-cm3
Aplicação de rejeição de artefatos.
Quantidade de voluntários : 10.
Analisou apenas os fonemas /a/ e /i/.

43
Fonema /a/
O espectro do envelope do fonema /a/ possui energia bem distribuída para todos
os harmônicos analisados neste estudo (figura 4.10), sugerindo a presença de resposta
para a maioria dos harmônicos.
Aiken e Picton (2006), obtiveram uma AR de 63±22 nV e uma AMFV de 6±4
nV para f0, sendo que neste estudo foi encontrado uma AR de 45±24 nV e uma AMFV
de 8±6 nV para o estímulo de 70 dBSPL. Aiken e Picton (2008), obtiveram
aproximadamente, AR’s de 60, 30, 12, 15, 5, 2 nV e AMFV’s de 3, 2, 2, 1, 1, 1 nV para
f0, f2, f3, f4, f5 e f6, respectivamente.
Logo, é possível notar a semelhança entre as respostas obtidas neste estudo e as
referências para f0, f2, f3 e f4. Porém, a discrepância que ocorre para f5 e f6 pode ser
explicada como consequência de interferência elétrica, uma vez que essa discrepância
não ocorre de forma tão acentuada para o estímulo de 50 dBSPL, além do fato de que o
teste de interferência elétrica deste estudo diagnosticou interferências elétricas
relevantes para estes harmônicos.
Fonema /i/
O espectro do envelope do fonema /i/ possui mais energia nos harmônicos f1 e
f2 (figura 4.11), sugerindo a presença de resposta de alta amplitude para os primeiros
harmônicos.
Aiken e Picton (2006), obtiveram e uma AR de 93±32 nV e uma AMFV de 6±3
nV para f0, sendo que, neste estudo, foi encontrado uma AR de 69±37 nV e uma AMFV
de 6±3 nV para o estímulo de 70 dBSPL. Aiken e Picton (2008), obtiveram,
aproximadamente, AR’s de 90, 28, 18, 9, 2, 5 nV e AMFV’s de 2, 2, 1, 1, 1, 1 nV para
f0, f2, f3, f4, f5 e f6, respectivamente.
Sendo assim, as respostas encontradas neste estudo corroboram com a teoria
para todos os harmônicos. Porém, o teste de interferência elétrica registrou uma alta
interferência elétrica para f2, o que pode explicar, de certa forma, o valor elevado de
AR neste harmônico.

44
Fonema /u/
O espectro do envelope do fonema /u/ possui mais energia nos harmônicos f0,
f2, f3 e f4 (figura 4.12), sugerindo a presença de resposta para a maioria dos
harmônicos.
Aiken e Picton (2006), obtiveram uma AR de 62±20 nV e uma AMFV de 6±4
nV para f0, sendo que neste estudo foi encontrado uma AR de 36±22 nV e uma AMFV
de 8±4 nV para o estímulo de 70 dBSPL. Aiken e Picton (2008), não utilizaram o
fonema /u/ como estímulo, portanto não é possível realizar uma análise comparativa
para f2,f3,f4,f5,f6.
Sendo assim, a resposta encontrada neste estudo corrobora a teoria para f0. Para
f2, f3, f4, f5 e f6, é possível notar uma alta taxa de detecção, bem como uma alta
discrepância para o estímulo de 70 dBSPL e 55 dBSPL. Vale notar que o teste de
interferência elétrica registrou alta interferência para todos estes harmônicos (f2, f3, f4,
f5 e f6), o que pode explicar, de certa forma, os valores elevados de AR para o estímulo
de 70 dBSPL, porém suscita apreensão, devido ao excesso de interferência.

45
5 Conclusão
Os sons vocálicos naturais podem ser considerados como os estímulos ideais
quando o objetivo é atestar se o sistema auditivo transmitiu e processou corretamente a
informação sonora. Para tal, é considerado e aprovado com êxito o uso do Analisador de
Fourier como ferramenta de análise para ASSR a sons vocálicos naturais. No presente
estudo, vale ressaltar os resultados promissores obtidos para o harmônico fundamental
do envelope dos fonemas, dada sua alta taxa de detecção e baixa interferência elétrica.
Para avaliação dos harmônicos f5 e f6, recomenda-se cautela, dada a elevada
interferência elétrica que ocorreu para essas frequências.
Existem aspectos que podem ser melhorados para uma análise mais completa.
Como trabalhos futuros, sugere-se a implementação de algoritmos com técnicas de
rejeição de artefatos, processamento on-line e entendimento profundo sobre as causas de
interferência elétrica, bem como a implementação de técnicas para mitigá-las.

46
6 Bibliografia
AIKEN S., PICTON T: Envelope Following Responses to Natural Vowels. Audiol
Neurotol 2006;11:213–232.
AIKEN S., PICTON T: Envelope and spectral frequency-following responses to vowel
sounds. Hearing Research 245 (2008) 35–47
ASHA, American Speech-Language Hearing Association. The Prevalence and
Incidence of Hearing Loss in Children. Disponível em :
https://www.asha.org/public/hearing/Prevalence-and-Incidence-of-Hearing-Loss-in
Children/ (Acesso em 22 de Julho de 2018).
BEAR, M. F., CONNORS, B. W., PARADISO, M. A. Neuroscience. Lippincott
Williams & Wilkins, 2007. v. 2
BENDAT, J. S., PIERSOL, A. G. Random data: analysis and measurement procedures.
Hoboken, New Jersey, Wiley, 2010.
CUNNINGHAM J, NICOL T, ZECKER S, BRADLOW A, KRAUS N: Neurobiologic
responses to speech in noise in children with learning problems: deficits and strategies
for improvement. Clin Neurophysiol 2001; 112: 758–767.
DOBIE AR e WILSON JM, A comparison of t test, F test, and coherence methods of
detecting steady-state auditory-evoked potentials, distortion-product otoacoustic
emissions, or other sinusoids. 1996.
FROTA, S. Fundamentos em Fonoaudiologia-Audiologia. 2a / 2003 ed. Rio de Janeiro:
Guanabara, 2003.
GALBRAITH GC, AMAYA EM, DE RIVERA JM, DONAN NM, DUONG MT, HSU
JN, TRAN K, TSANG LP: Brain stem evoked response to forward and reversed speech
in humans. Neuroreport 2004; 15: 2057–2060.
GRACEY & ASSOCIATES: Frequency Weightings : Definitions, Terms, Units,
Measurements. Disponível em : http://www.acoustic-glossary.co.uk/frequency-
weighting.htm (Acesso em 22 de Julho de 2018).
HEKIMOGLU, Y., OZDAMAR, O., DELGADO, R. E. Chirp and click evoked
auditory steady state responses. Proceedings of the 23rd Annual International
Conference of the IEEE Engineering in Medicine and Biology Society. 2001
JCIH, Joint Committee on Infant Hearing.Year 2007 Position Statement: Principles and
Guidelines for Early Hearing Detection and Intervention Programs. Disponível em :
https://www.asha.org/policy/PS2007-00281/ (Acesso em 22 de Julho de 2018)

47
JOHN, M. S., DIMITRIJEVIC, A., PICTON, T. W. Auditory steady-state responses to
exponential modulation envelopes. Ear and hearing, v. 23, n. 2, p. 106–117, 2002.
JOHN, M. S., DIMITRIJEVIC, A., PICTON, T. W. Efficient stimuli for evoking
auditory steady-state responses: Ear and Hearing, v. 24, n. 5, p. 406–423, out. 2003.
JOHN, M. S., LINS, O. G., BOUCHER, B. L., et al. Multiple auditory steady-state
responses (MASTER): stimulus and recording parameters. International Journal of
Audiology, v. 37, n. 2, p. 59–82, 1998.
JOHNSON, K.L., NICOL, T.G., ZECKER, S.G., KRAUS, N., 2007. Auditory
brainstem correlates of perceptual timing deficits. J. Cognit. Neurosci. 19 (3), 376–385.
KAY, S. M. Fundamentals of Statistical Signal Processing, Volume 2: Detection
Theory, volume II, 199.
KING C, WARRIER CM, HAYES E, KRAUS N: Deficits in auditory brainstem
pathway encoding of speech sounds in children with learning problems. Neurosci Lett
2002; 319: 111–115.
KRISHNAN A: Human frequency following responses: representation of steady-state
synthetic vowels. Hear Res 2002; 166: 192–201.
LARREA, Pablo Fernando Cevallos: Detecção da Resposta Auditiva em Regime
Permanente a Tom com Modulante Exponencial utilizando Múltiplas Derivações de
Eletroencefalografia / Rio de Janeiro: UFRJ/COPPE, 2015.
LEVI, E. C., FOLSOM, R. C., DOBIE, R. A. Amplitude-modulation following
response (AMFR): effects of modulation rate, carrier frequency, age, and state. Hearing
Research, v. 68, n. 1, p. 42–52, jun. 1993.
LINS, O. G., PICTON, P. E., PICTON, T. W., et al. Auditory steady‐state responses to
tones amplitude‐modulated at 80–110 Hz. The Journal of the Acoustical Society of
America, v. 97, n. 5, p. 3051–3063, 1995.
MAUER, G. AND DÖRING, W.H. Generators of amplitude modulation following
response (AMFR). Paper presented at 16th meeting of the Evoked Response
Audiometry Study Group, Tromsø, Norway, June, 1999.
MELO, Thiago Marques de. Aplicação da Transformada de Hilbert e Separação em
Bandas Clínicas para Redução do Eletroencefalograma de Longa Duração/ Thiago
Marques de Melo. – Rio de Janeiro: UFRJ/COPPE, 2015.
OPPENHEIM, A. V., SCHAFER, RONALD W. Discrete-time signal processing. Upper
Saddle River, Pearson, 2010.
PICTON TW, JOHN MS, DIMITRIJEVIC A, PURCELL D: Human auditory steady-
state responses. Int J Audiol 2003; 42: 177–219.

48
PURCELL, D. W., JOHN, S. M., SCHNEIDER, B. A., et al. Human temporal auditory
acuity as assessed by envelope following responses. The Journal of the Acoustical
Society of America, v. 116, n. 6, p. 3581–3593, dez. 2004.
RANCE, G., DOWELL, R. C., RICKARDS, F. W., et al. Steady-state evoked potential
and behavioral hearing thresholds in a group of children with absent click-evoked
auditory brainstem response. Ear and hearing, v. 19, n. 1, p. 48–61, fev. 1998.
REGAN D: Human Brain Electrophysiology: Evoked Potentials and Evoked Magnetic
Fields in Science and Medicine. New York, Elsevier, 1989.
RESEARCH GATE, Sistema 10-20. https://www.researchgate.net/profile/
Alejandro_Torres16/publication/320409762/figure/download/fig1/AS:55103497285222
4@1508388383651/Figura-1-Sistema-Internacional-de-montaje-10-2014.png (Acesso
em 24 de Julho de 2018)
SANTOS J.M. : Aspectos acústicos e fisiológicos do sistema ressonantal vocal como
ferramenta para o ensinoaprendizagem do canto lírico. 2010.
SCOLLIE SD, SEEWALD RC: Evaluation of electroacoustic test signals. I.
Comparison with amplified speech. Ear Hear 2002; 23: 477–487.
SILVERTHORN, D. U., HILL, D. Human physiology: an integrated approach : student
workbook. San Francisco, Calif.; London: Benjamin Cummings ; Pearson Education,
2010.
VAN DER REIJDEN, C. S. VAN DER. Improving the signal to noise ratio of the
auditory steady-state response. 2005.
VIEIRA M. N., Uma introdução à acústica da voz cantada. I Seminário Música Ciência
Tecnologia: Acústica Musical. 2004.
WHO (WORLD HEALTH ORGANIZATION). Deafness and hearing loss. Disponível
em http://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss.(Acesso
em 22 de Julho de 2018)
ZEMLIN, W.R., Princípios de anatomia e fisiologia em fonoaudiologia. Porto Alegre:
Artmed, 2000.
ZUREK, P. Detectability of transient and sinusoidal otoacoustic emissions. Ear and
hearing, 13(5):307-310,1992.
Top Related