UNIVERSIDADE FEDERAL DO MARANHÃO DEPARTAMENTO …acmo/grad/telp/ACParalela.pdf · departamento de...
97
UNIVERSIDADE FEDERAL DO MARANHÃO DEPARTAMENTO DE INFORMÁTICA CURSO DE CIÊNCIA DA COMPUTAÇÃO TÓPICOS ESPECIAIS EM LINGUAGEM DE PROGRAMAÇÃO: APLICAÇÕES PARALELAS EM AMBIENTES DE PASSAGEM DE MENSAGENS Prof. Alexandre César Muniz de Oliveira SÃO LUÍS 2005
Transcript of UNIVERSIDADE FEDERAL DO MARANHÃO DEPARTAMENTO …acmo/grad/telp/ACParalela.pdf · departamento de...

UNIVERSIDADE FEDERAL DO MARANHÃO
DEPARTAMENTO DE INFORMÁTICA
CURSO DE CIÊNCIA DA COMPUTAÇÃO
TÓPICOS ESPECIAIS EM LINGUAGEM DE PROGRAMAÇÃO: APLICAÇÕES PARALELAS EM
AMBIENTES DE PASSAGEM DE MENSAGENS
Prof. Alexandre César Muniz de Oliveira
SÃO LUÍS
2005

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 2
1 Apresentação da disciplina

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 3
Motivação A computação paralela tem se tornado uma importante aliada na tarefa de resolver
problemas computacionalmente dispendiosos e complexos
Existem máquinas paralelas escaláveis baseadas em hardware e software com custo
razoavelmente acessível
O programador deve ter em mente conceitos que permitam o máximo aproveitamento do
paradigma de programação paralela
Questões inerentes ao novo paradigma:
o A escolha equivocada da plataforma em que o programa paralelo será
executado pode comprometer o desempenho do programa, mesmo que ele
tenha sido construído de maneira eficiente e elegante.
o A análise do problema a ser decomposto para que se escolha a ferramenta de
software mais adequada à construção de um programa paralelo eficiente.
Objetivos Visão geral da computação paralela:
o Apresentação de diversos tipos de hardware disponíveis à execução de uma
aplicação paralela;
o Foco sobre aspectos de software para construção e execução de um programa
paralelo.
Estudo de um ambiente de desenvolvimento de aplicações paralelas
Abordagem prática baseada em estudos de casos;

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 4
Metodologia Aulas teóricas expositivas seguidas de uma avaliação teórica motivando o aluno a estudar
conceitos relativos à Computação Paralela
Estudo da biblioteca MPI possibilitando que o aluno esteja apto a compreender os casos a
serem estudados posteriormente e a desenvolver aplicações em paralelo
Estudos de problemas simples encontrados na computação, de pleno conhecimento do
aluno, cujos algoritmos possam ser paralelizados.
Estudo de problemas mais específicos encontrados em áreas como inteligência artificial,
otimização, e outras
Seminários teóricos abrangendo funções avançadas de MPI
Seminários teóricos comparando MPI com outros ambientes, como o PVM
Seminários práticos apresentando as soluções encontradas para problemas estudados em
sala de aula
Programa Módulo 1: Introdução à Computação Paralela: conceitos, medidas de desempenho,
arquiteturas paralelas, software e ambientes de apoio. (8 aulas)
Módulo 2: Biblioteca para Troca de Mensagens: Message-Passing Interface (MPI): comandos básicos. Avaliação escrita sobre conceitos em computação paralela. (12 aulas)
Módulo 3: Estudo de caso 1: solução de problemas clássicos na computação usando algoritmos paralelos e definição dos trabalhos finais. (12 aulas)
Módulo 4: Estudo de caso 2: algoritmo genético paralelo; aplicações em inteligência artificial e otimização (12 aulas)
Módulo 5: Seminários 1: apresentação dos trabalhos teóricos: comandos avançados MPI e comparação com outros ambientes. (8 aulas)
Módulo 6: Seminários 2: apresentação dos trabalhos práticos: solução de problemas computacionais usando algoritmos paralelos (8 aulas)

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 5
Módulo 1: Introdução à Computação Paralela
1.1 Introdução

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 6
Conceito de Processamento Paralelo Divisão de uma determinada aplicação, de forma que esta possa ser
executada por vários elementos de processamento, que deverão
cooperar entre si (comunicação e sincronismo) (FOSTER et al.,
2003),
Ganho de eficiência por meio da quebra da execução seqüencial do
fluxo de instruções da máquina de von Neumann (ALMASI &
GOTTLIEB, 1994).
Histórico Em 1920, Vanevar Bush, do MIT (Massachussets Institute of
Technology), apresentou um computador analógico que resolvia
equações diferenciais em paralelo.
Von Neumann, em seus artigos, por volta de 1940, também sugeriu
utilizar paralelismo como forma de se resolver equações
diferenciais.
O surgimento do computador ILLIAC IV (supercomputador
composto por 64 processadores), projeto iniciado na década de 60 e
colocado em operação em 1972, na Universidade de Illinois, foi
considerado o marco inicial do processamento paralelo (ROSE &
NAVAUX, 2003).

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 7
Motivação pelo paralelismo Basicamente: ganho de desempenho.
Especificamente (ALMASI & GOTTLIEB, 1994):
• Restrições físicas à melhoria de desempenho de um único
processador: velocidade da luz, as leis da Termodinâmica, a
dimensão física dos componentes e o custo;
• O desenvolvimento tecnológico permitiu a construção de
microprocessadores de alto desempenho, que agrupados,
possibilitam um ganho significativo de poder computacional.
• Microprocessadores de alto desempenho possibilitam uma
melhor relação custo/desempenho quando comparadas aos
supercomputadores de custo extremamente alto;
• Agrupamento de microprocessadores em módulos permite a
expansão do sistema através da inclusão de novos módulos;
• Maior facilidade em incorporar o conceito de tolerância à
falhas devido à redundância de hardware.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 8
Motivação pelo paralelismo Aplicações instaladas que usam processamento paralelo
Comércio de serviços

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 9
Concorrência e Paralelismo A concorrência existe quando dois ou mais processos
iniciaram a sua execução e ainda não foram finalizados, sem
que haja uma relação com o número de elementos de
processamento utilizados.
Quando existe apenas um elemento de processamento e vários
processos estão sendo executados de maneira concorrente
existe um pseudo-paralelismo ou paralelismo lógico
Figura 1: Paralelismo Lógico.
e3
e2 e2
e1
e2
e3
e1
t1 t
tempo
processos

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 10
Concorrência e Paralelismo
O usuário tem a impressão que os processos estão sendo
executados ao mesmo tempo, mas ocorre apenas o
compartilhamento do elemento de processamento entre os
processos em execução.
Em um determinado instante de tempo, apenas um processo
está em execução, enquanto os demais estão aguardando a
liberação do processador.
Quando se tem mais de um elemento de processamento e
existem processos sendo executados ao mesmo tempo, há um
paralelismo físico ou simplesmente paralelismo.
Figura 2: Paralelismo Físico.
t1
t
tempo
processos
e3
e2
e1

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 11
Granulosidade ou granularidade (grained) A granulosidade (ou nível de paralelismo) representa o
tamanho das tarefas submetidas aos processadores e pode ser
classificada em fina, média e grossa (GRAMA et al., 2003).
Este conceito está intimamente ligado ao tipo de máquina
paralela em que o programa será executado.
o A granulosidade fina indica que o paralelismo está
sendo realizado em nível de operações ou instruções.
Geralmente, requer um número maior de
comunicação por parte das unidades de
processamento.
Desvantagem: alto custo de sincronização.
Vantagem: uso de processadores mais simples.
Os computadores multiprocessados são mais
adequados a processos paralelos de
granulosidade fina,

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 12
Granulosidade ou granularidade (grained) o A granulosidade média indica o paralelismo obtido
através da execução de blocos ou sub-rotinas do
programa.
o A granulosidade grossa relaciona o paralelismo em
nível de processos.
Geralmente, requer um número menor de
comunicação e sincronismo entre os
processadores.
Uso de processadores mais genéricos e
complexos do que os destinados à execução de
programas de granulosidade fina.
Os multicomputadores executam melhor os
processos paralelos com granulosidade de
média a grossa (FOSTER, 1995).
o Taxa de granulosidade:
G = P /C
Onde C e P se referem respectivamente aos
tempos de comunicação e processamento local;
o G alto significa granulosidade grossa, isto é, muito
processamento local e pouca comunicação.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 13
1.2 Medidas de Desempenho de Computação Paralela

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 14
Ganho obtido de desempenho (GRAMA et al., 2003):
Speed up: medida utilizada para determinar o aumento de
velocidade obtido durante a execução de um programa
(código paralelo) em p processadores, em relação à execução
desse programa (código seqüencial) em um único
processador.
Sp = T1 / Tp
o Onde T1 é o tempo de execução em um processador e Tp
é o tempo de execução em p processadores.
o Ideal
todos os processadores realizam trabalho útil;
não existem processadores ociosos;
não são realizadas operações duplicadas
raramente é atingido,
exceto para algumas aplicações assíncronas.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 15
Ganho obtido de desempenho (GRAMA et al., 2003):
Speed up
o O caso ideal é quando Sp = p, isto é, o ganho de speed
up tende a p, indicando que a velocidade de
processamento é diretamente proporcional ao número de
processadores.
o Dificuldades para a obtenção do caso ideal são:
o sobrecarga da comunicação entre processadores,
o partes do código executável estritamente
seqüencial (que não podem ser paralelizadas)
o nível de paralelismo utilizado (devido à
granulosidade ser inadequada ao tipo de
arquitetura utilizada).
o Eventualmente Sp > p (superlinear) ocorre quando o
tempo de execução de um programa seqüencial é bem
superior ao tempo gasto pelo seu correspondente
paralelo para solucionar um determinado problema.
o Fatores:
o limitações de hardware da máquina que
executou o programa seqüencial
o má formulação do algoritmo seqüencial,
deteriorando o tempo total de sua execução.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 16
Ganho obtido de desempenho (GRAMA et al., 2003):
Eficiência (Ep): trata da relação entre o Speed up e o número
de processadores.
Ep = Sp / p ∈ [0,1]
o A eficiência fornece o “quanto” os processadores estão
sendo utilizados. O caso ideal é obtido quando Ep =1,
indicando uma eficiência de 100%.
o Exemplo: Se o tempo da melhor versão sequencial é 8
segundos e o algoritmo paralelo leva 4 segundos
utilizando 5 processadores, então:
o S=8/4=2
o E(%) = (2/5) * 100 = 20%
Fatores que contribuem para a queda da eficiência: o Atraso introduzido pela comunicação entre
processadores;
o Overhead devido ao nível de sincronismo entre tarefas:
tarefas dependentes alocadas em processadores
diferentes, levando ao desbalanceamento de carga entre
processadores.
o Overhead devido ao esforço despendido por alguns
processadores quando mais de um deles executa a
mesma tarefa, necessitando de coordenação do processo
todo.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 17
Lei de Amdahl o Speed up sofre limitações devido aos trecho(s) não
paralelizável(is) de um programa (AMDAHL, 1967):
Sp ≤ 1 / (T<f> + T<1–f> /p)
o Onde:
o f é a fração inerentemente seqüencial de um
programa.
o (1-f) é a parte paralelizável de um programa.
o p é o número de processadores, sendo p > 1.
o Uma estimativa de ganho ideal:
I = Ts / (T<f> + T<1–f> /p)
Toda solução paralela, em um dado momento, possui um
ponto de saturação onde o speed up não apresenta mais
ganhos significativos e a eficiência cai.
O programa paralelo não atende mais de maneira satisfatória à
escalabilidade da máquina paralela.
Tanto o speed up e quanto a eficiência continuam a cair com o
incremento de p.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 18
1.3 Arquiteturas Paralelas

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 19
Classificação de Flynn
O processo computacional deve ser visto como um fluxo de instruções
executando sobre um fluxo de dados (FOSTER et al., 2003).
A classificação de Flynn acomoda as arquiteturas em quatro classes de
máquinas: SISD, SIMD, MISD e MIMD.
SISD - Single Instruction Stream / Single Data Stream
o Fluxo único de instruções / Fluxo único de dados:
corresponde ao tradicional modelo de Von Neumann (apenas
um processador).
o Um processador executa seqüencialmente um conjunto de
instruções sobre um conjunto de dados
UC UP M
FI
FI = Fluxo de Instruções UC = Unidade de Controle UP = Unidade de Processamento M = Memória
Figura 3: Exemplo de Arquitetura SISD.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 20
SIMD - Single Instruction Stream / Multiple Data Stream
o Fluxo único de instruções / Fluxo múltiplo de dados: envolve
múltiplos processadores executando simultaneamente a
mesma instrução em diversos conjuntos de dados.
o Exemplos: as máquinas paralelas com processadores Array
como CM-2 e MasPar (ROSE & NAVAUX, 2003).
UP
UP
UP
M
M
M
FI
Memória
FI = Fluxo de Instruções UC = Unidade de Controle UP = Unidade de ProcessamentoM = Memória
… …
UC
Figura 4: Exemplo de Arquitetura SIMD.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 21
MISD - Multiple Instruction Stream / Single Data Stream
o Fluxo múltiplo de instruções / Fluxo único de dados: envolve
múltiplos processadores executando diferentes instruções em
um único conjunto de dados.
o Nenhuma arquitetura é classificada como MISD, mas alguns
autores consideram o pipeline como um representante dessa
categoria.
Pipeline implementa um paralelismo temporal,
caracterizado quando existe a execução de eventos
sobrepostos no tempo.
A tarefa que será executada é dividida em sub-tarefas,
cada uma destas sendo executada por um estágio de
hardware especializado que trabalha de maneira
concorrente com os demais estágios envolvidos na
computação (PATTERSON & HENNESSY, 2000).
UP = Unidade de Processamento FD = Fluxo de Dados M = Memória UC = Unidade de Controle FI = Fluxo de Instruções
M
M
M
FI
FI
FI
UC
UC
UC
FI
FI
FI
UP
UP
UP
FD
FD
... ...
Figura 5: Exemplo de Arquitetura MISD.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 22
MIMD - Multiple Instruction Stream / Multiple Data Stream
o Fluxo múltiplo de instruções / Fluxo múltiplo de dados:
envolve múltiplos processadores executando diferentes
instruções em diferentes conjuntos de dados,
o A interação entre os processadores é feita pela memória.
o Cada processador executa o seu próprio programa sobre seus
próprios dados de forma assíncrona.
o O princípio MIMD é bastante genérico, daí cabe ainda ua
subdivisão, de acordo com o tipo de acesso à memória.
Máquinas com memória compartilhada são conhecidas
como multiprocessadores ou sistemas fortemente
acoplados,
Máquinas que possuem memória não compartilhada
(distribuída) são ditas multicomputadores ou sistemas
fracamente acoplados.
UP = Unidade de Processamento
FD = Fluxo de Dados M = Memória UC = Unidade de Controle FI = Fluxo de Instruções
UC
UC
UC
UP
UP
UP
FI
FI
FI
FD
FD
FD
M
M
M
FI
FI
FI
... ... ... ...
Figura 6: Exemplo de Arquitetura MIMD.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 23
Outras classificações
ALMASI & GOTTLIEB, 1994
DUNCAN, 1990
Classificação segundo o Compartilhamento de Memória Arquiteturas que compartilham memória são classificadas como
máquinas MIMD (ROSE & NAVAUX, 2003).
Multiprocessadores
o Acesso Uniforme à Memória (UMA - Uniform Memory
Access): a memória é centralizada e encontra-se à mesma
distância de todos os processadores.
A latência de acesso à memória é igual para todos os
processadores do sistema.
Figura 7: Máquina UMA.
Rede de Interconexão
Memória
P P P P P P P P

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 24
Classificação segundo o Compartilhamento de Memória o Acesso Não Uniforme à Memória (NUMA - Non-Uniform
Memory Access): a memória é organizada em módulos que
são associados, de um para um, aos processadores.
O espaço de endereçamento é único e cada
processador pode endereçar toda a memória do
sistema.
A latência de acesso à memória depende se o
endereço, gerado por um processador, encontra-se no
módulo de memória diretamente ligado a ele ou não.
Um processador deve utilizar a rede de interconexão
para acessar informações mantidas em outros módulos
de memória.
Figura 8: Máquina NUMA.
P P P P P P P P
Rede de Interconexão
M M M M M M M M
espaço de endereçamento

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 25
Classificação segundo o Compartilhamento de Memória o Acesso Não Uniforme à Memória: Dependendo da forma
com o problema de consistência é tratado (ou não), essa
classe pode ser subdividida em (ROSE & NAVAUX, 2003)
(FOSTER et al., 2003):
- Acesso Não Uniforme à Memória Sem Consistência de
Cache (NCC-NUMA – Non-Cache-Coherent Non-
Uniform Memory Access): Variação de uma NUMA em
que não há dispositivo de hardware que garanta a
consistência de cache.
- Acesso Não Uniforme à Memória Com Consistência de
Cache (CC-NUMA – Cache-Coherent Non-Uniform
Memory Access): Variação de uma NUMA em que há
dispositivo de hardware que garanta a consistência de
cache.
- Acesso Não Uniforme à Memória Com Consistência de
Cache em Software (SC-NUMA – Software-Coherent
Non-Uniform Memory Access): nesse caso, a consistência
de cache não está implementada em hardware como nas
máquinas CC-NUMA, mas em software, de forma
transparente ao usuário. Essa camada de software é
também conhecida como DSM (Distributed Shared
Memory) e pode ser utilizada tanto em máquinas NCC-
NUMA quanto em máquinas NORMA que não possuem
consistência de cache em hardware.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 26
Classificação segundo o Compartilhamento de Memória o Arquiteturas de Memória Somente com Cache (COMA -
Cache-only Memory Architecture): todas as memórias locais
são estruturadas como memória cache e são chamadas de
COMA caches.
As COMA caches têm muito mais capacidade que uma
cache tradicional.
A memória principal é composta pelas COMA caches,
sendo que as gerências de caches e de memória ficam
a cargo de um hardware de suporte, implementado
somente nesse tipo de máquina.
Essa complexidade faz com que essa estrutura seja
mais cara de implementar que as máquinas NUMA.
Figura 9: Máquina COMA.
P P P P P P P P
Rede de Interconexão
M M M M M M M M

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 27
Multicomputadores
o Sem Acesso a Variáveis Remotas (NORMA - Non-Remote
Memory Access): cada processador possui sua própria
memória local, à qual apenas ele tem acesso direto.
As memórias dos outros processadores são
consideradas remotas e possuem espaços de
endereçamento distintos.
Como não é possível o uso de variáveis
compartilhadas nesse ambiente, a comunicação com
outros processos é realizada através de troca de
mensagens via rede de interconexão.
A diferença básica entre as máquinas NORMA e as
demais (UMA, NUMA e COMA) é que na primeira há
uma replicação de toda a arquitetura convencional
(processador, memória e I/O) para formar uma
máquina paralela, e não apenas do componente
processador como nos multiprocessadores.
Figura 2.10: Máquina NORMA.
Rede de Interconexão
P
M M M M M M M M
P P P P P P P

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 28
Resumo
A linha tracejada na Figura 2.11 indica que as máquinas das classes
NCC-NUMA e NORMA podem ser transformadas em máquinas SC-
NUMA através da inclusão de uma camada de software que
implemente consistência de cache (ROSE & NAVAUX, 2003).
Figura 11: Visão geral da classificação segundo o compartilhamento de memória (HWANG, 1998).
Multiprocessadores (espaço de endereçamento único)
Multicomputadores (múltiplos espaços de endereçamento)
UMA (memória central)
NUMA (memória distribuída)
COMA
CC-NUMA
NCC-NUMA
SC-NUMA
MIMD
NORMA

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 29
Exemplos de Modelos Físicos de Máquinas MIMD
Multiprocessadores Simétricos (SMP – Symmetric
Multiprocessors): são sistemas constituídos de processadores
comerciais, também chamados de “off-the-shelf” (de prateleira),
conectados a uma memória compartilhada geralmente por meio de um
barramento de alta velocidade (FOSTER et al., 2003).
o O fato de todos os processadores terem acesso igual ao
barramento e à memória, não ocorrendo privilégios a nenhum
dos processadores no atendimento de requisições, fornece o
caráter simétrico ao sistema, o que caracteriza essas
máquinas como multiprocessadores UMA.
o A comunicação se dá através do compartilhamento de
memória.
o Uma única cópia do sistema operacional está ativa em todos
processadores.
o Um fator limitante à escalabilidade dessas máquinas é o uso
de barramento como rede de interconexão.
o Com o objetivo de reduzir a quantidade de acesso à memória,
esses sistemas utilizam memória cache junto a cada
processador, reduzindo a comunicação no barramento e
aumentando o número de processadores no sistema.
o Pode-se encontrar desde máquinas SMP com dois
processadores até sistemas SMP com 64 processadores
(ROSE & NAVAUX, 2003).
Exemplos: IBM R50, SGI Power Challenger, Sun
Ultra Enterprise 10000, HP/Convex Exemplar X-Class
e DEC Alpha Server 8400.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 30
Exemplos de Modelos Físicos de Máquinas MIMD
Máquinas Maciçamente Paralelas (MPP – Massively Parallel
Processors): são sistemas compostos por centenas, em alguns casos
milhares, de nós (processador e memória) independentes,
interconectados por redes proprietárias e de alta velocidade.
o Cada nó possui um ou mais processadores, sua própria
memória local com um espaço de endereçamento próprio.
o O acesso à memória das máquinas vizinhas não é direto,
precisando utilizar o paradigma de troca de mensagens para
realizar a comunicação entre os nós do sistema.
o Cada nó executa uma cópia distinta do sistema operacional.
Devido a essas características, esses sistemas são
classificados como multicomputadores NORMA.
Exemplos: Intel Paragon, Connection Machine CM-5 e
o IBM SP2.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 31
Exemplos de Modelos Físicos de Máquinas MIMD
Redes de Estações de Trabalho (NOW – Network of Workstations):
são sistemas compostos por várias estações de trabalho ou
computadores pessoais interligados por tecnologia tradicional de rede,
como a Ethernet ou ATM.
o Na prática, uma rede local de estações usada na execução de
aplicações paralelas.
o Sob o prisma das arquiteturas paralelas, a rede local pode ser
vista como uma máquina paralela em que vários
processadores, com suas memórias locais, são interligados
por uma rede, constituindo uma máquina NORMA de baixo
custo (ROSE & NAVAUX, 2003).
o As diferenças em relação à arquitetura MPP consistem
basicamente na hierarquia de barramento utilizada nas
estações, além da presença de um disco local nos nós e da
rede de interconexão utilizada.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 32
Exemplos de Modelos Físicos de Máquinas MIMD
Máquinas Agregadas (COW – Cluster of Workstations): são
sistemas, assim como as NOWs, compostos por várias estações de
trabalho ou computadores pessoais - Cluster Beowulf (BECKER et al.,
1995) - interligados através de uma rede de comunicação.
o A diferença entre uma e outra é que as máquinas COWs, ou
simplesmente Cluster, são projetadas com o objetivo
específico de executar aplicações paralelas, retirando o
caráter genérico das NOWs.
o Geralmente os clusters são classificados em dois grupos
(STERLING, 2002):
Agregados Homogêneos: são clusters onde todos os
nós são idênticos, ou seja, todas as máquinas são
exatamente as mesmas.
• São mais simples de se trabalhar, pois como as
máquinas são idênticas tem-se a certeza que o
software vai funcionar da mesma maneira em
todos os nós.
Agregados Heterogêneos: é o oposto dos clusters
homogêneos, ou seja, as máquinas diferem umas das
outras
• Máquinas totalmente diferentes umas das outras,
como estação UltraSparc trabalhando em
conjunto com CPUs 486, etc.;
• Máquinas da mesma arquitetura, mas de
diferentes gerações, como CPUs Pentium
trabalhando com outras CPUs Pentium II,
Pentium III, Pentium IV, 486, etc

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 33
Exemplos de Modelos Físicos de Máquinas MIMD
Máquinas Agregadas
o Quanto à rede de interconexão:
clusters interligados por redes padrão:
• baseados em Ethernet, usando-se chaveadores
(switches) em detrimento aos hubs que
funcionam como grandes barramentos, (RUEDA
& MAHESWARAN, 2003);
• baixo custo das placas permite muitos nós
clusters interligados por redes de baixa latência:
• placas de interconexão específicas que
implementam protocolos de rede de baixa
latência otimizados para as características de
comunicação de aplicações paralelas.
• O custo mais alto das placas torna muito caro
construir máquinas com muitos nós.
• A máquina resultante fica mais equilibrada na
relação poder de processamento do nó e
desempenho da rede
• Obtém-se um bom desempenho, mesmo com
aplicações que necessitem muita comunicação
(ROSE & NAVAUX, 2003).

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 34
Exemplos de Modelos Físicos de Máquinas MIMD
Máquinas Agregadas
o Em relação ao tipo de aplicação, têm-se dois tipos de clusters
(TAVANGARIAN, 2001):
Clusters de Alto Desempenho (HPC – High
Performance Cluster): são destinados a resolver
problemas complexos, que exigem alto poder de
processamento. Em geral, os relacionados a cálculos
científicos.
Clusters de Alta Disponibilidade (HAC – High
Availability Cluster): são destinados a manter em
operação por quase 100% do tempo alguns serviços ou
evitar que os mesmos sofram “panes” de operação por
excesso de requisições.
o O projeto de HA Clusters depende de quais serviços (Páginas
Web, e-mail, FTP, Banco de dados) se deseja manter em
operação.
o O importante durante o projeto é definir onde se encontram
possíveis pontos de falhas e a partir daí instituir políticas de
redundância.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 35
Exemplos de Modelos Físicos de Máquinas MIMD
Máquinas agregadas
o Apesar de ser uma alternativa atrativa e bem sucedida à
execução de aplicações paralelas, os clusters ainda
apresentam alguns inconvenientes:
A configuração dos nós não é trivial. É necessário ter
boa experiência e conhecimento de administração de
sistemas clone-Unix;
Há poucos softwares de gerenciamento de cluster. O
mais conhecido é o Mosix (BARAK & LA’ADAN,
1998).
Como em geral são de caráter dedicado, especialmente
os HPCs, tem-se ter um certo grau de ociosidade na
utilização desse tipo de sistema.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 36
Exemplos de Modelos Físicos de Máquinas MIMD
Grids são sistemas mais fracamente acoplados, diversos e complexos
que outras plataformas de execução de processos paralelos e/ou
distribuídos.
o São considerados o passo natural depois das NOWs, no
sentido de maior heterogeneidade e maior distribuição
(FOSTER et al, 2001).
o As características básicas de um sistema grid são (LI &
CORDE, 2005):
Heterogeneidade de seus componentes;
Alta dispersão geográfica: até em escala mundial;
Compartilhamento: não precisa ser dedicado a uma
aplicação;
Múltiplos domínios administrativos: podem congregar
recursos de várias instituições; e
Controle distribuído: tipicamente não há uma única
entidade que tenha poder sobre todo o grid.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 37
Exemplos de Modelos Físicos de Máquinas MIMD
Grids
o Outras características
Os componentes de um grid não se restringem a
processadores, podendo ser, por exemplo, SMPs e
MPPs.
Grids tipicamente não fornecem uma imagem comum
do sistema para seus usuários (FOSTER et al., 2002).
Componentes de um grid podem variar sobremaneira
em capacidade, software instalado, sistemas de arquivo
montados e periféricos instalados.
Um dado usuário pode ter acesso e permissões
bastante diversas nos diferentes componentes de um
grid (LI & CORDE, 2005).
O grid não pode ser dedicado a um usuário, embora
seja possível que algum componente possa ser
dedicado (um MPP, por exemplo).
Uma aplicação grid deve estar preparada para lidar
com todo este dinamismo e variabilidade da
plataforma de execução,
Adaptação da aplicação ao cenário que se apresenta
com o intuito de obter o melhor desempenho possível
no momento (CIRNE & MARZULLO, 2003).

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 38
Questões quanto ao tipo da aplicação
Assim como os demais tipos de computadores paralelos vistos até o
momento, também nos grids computacionais alguns tipos de
aplicações são beneficiados ao utilizarem essa estrutura, tais como
aplicações que requerem pouca ou nenhuma comunicação são as mais
beneficiadas.
Bag of Tasks são aquelas cujas tarefas são independentes, isto é, não se
comunicam e podem ser executados em qualquer ordem.
Devido à alta dispersão geográfica, são mais indicadas para aplicações
que trocam muita informação as SMPs, MPPs e Clusters.
Pode-se utilizar uma variação das NOWs para possibilitar a execução
eficiente de aplicações paralelas, mesmo as que requeiram uma boa
taxa de troca de informações.
O custo final dessa alternativa é mínimo, já que se utiliza uma estrutura
de rede já existente.
As alterações que suportam de forma eficiente a execução de
aplicações paralelas basicamente são realizadas no nível de software.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 39
1.4 Software para Provimento de Computação Paralela

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 40
Requisitos para emprego eficiente de Computação Paralela
A infra-estrutura computacional: hardware paralelo
O algoritmo paralelo: envolve muito mais que apenas determinar uma
seqüência de passos, como nos algoritmos seqüenciais.
o Essa necessidade de incorporar os conceitos de paralelismo
em um algoritmo requer do programador uma análise e
modelagem do problema mais cuidadosa do que a dispensada
na modelagem de algoritmos seqüenciais.
o Durante a fase de modelagem de um algoritmo paralelo deve-
se determinar pontos onde um trecho de código depende dos
resultados de alguma outra parte do mesmo código
(ANDREWS, 2003).
Dependência de Dados: Existe quando uma operação
não pode proceder até que dados provenientes de outra
operação estejam disponíveis.
Dependência de Controle: Existe quando uma linha de
controle depende de outra para poder ser executada.
o Dependências de controle são mais comuns que as
dependências de dados.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 41
1.5 Suporte à Programação Paralela

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 42
Necessidades inerentes à programação paralela
A programação seqüencial utiliza recursos disponíveis através de uma
linguagem de máquina ou de uma maneira mais usual, por meio de
linguagens de alto nível como C, Pascal e Fortran, que permitem o uso
de abstrações (por exemplo, if, else, while) que são traduzidas
automaticamente em código executável.
A programação paralela necessita de recursos não disponíveis
diretamente nessas linguagens.
São necessários métodos (ALMASI & GOTTLIEB, 1994):
o para definir quais tarefas serão executadas paralelamente,
o para a ativação e finalização da execução dessas tarefas

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 43
Programação concorrente
O objetivo é suprir essas necessidades, fornecendo ferramentas para a
construção de programas paralelos que utilizam o hardware disponível,
seja esse paralelo ou não.
Para a construção de programas concorrentes se faz necessária a
utilização de ferramentas que incorporem os mecanismos para a
ativação, comunicação e sincronização de processos concorrentes.
A escolha de uma dessas ferramentas deve ser feita levando-se em
conta vários aspectos, tais como: a granulosidade e a arquitetura que
serão utilizadas.
Ferramentas para construção de programas paralelos
Ambientes de paralelização automática:
o tentam absorver o paralelismo existente em um código fonte,
escrito geralmente em uma linguagem imperativa, para que
seja gerado, de maneira automática, um programa paralelo.
o o trabalho do programador é reduzido, mas as heurísticas de
paralelização devem ser muito abrangentes, levando à
geração de códigos ineficientes.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 44
Ferramentas para construção de programas paralelos
Extensões paralelas para linguagens imperativas, que são
caracterizadas por modificar um estado implícito do programa através
de comandos.
o são bibliotecas que tentam complementar determinadas
linguagens seqüenciais já existentes.
o O programador possui um trabalho maior no processo de
paralelização do código, mas se existir um conhecimento
prévio da linguagem, esse é aproveitado,
o não é necessário a aprendizagem de uma nova linguagem.
o Exemplos
linguagens procedurais e orientadas a objetos
(bibliotecas/ambientes de passagem de mensagens)
• MPI, PVM
linguagens concorrentes (não imperativas): escritas
para a programação concorrente, possuem
compiladores que geram programas paralelos de
desempenho satisfatório e caracterizam-se como não
imperativas, permitindo uma boa estruturação do
código.
• a linguagem Occam (baseada no paradigma CSP
Communicating Sequential Processes (HOARE,
1978)) e Ada (GEHANI, 1983)

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 45
Ferramentas para construção de programas paralelos

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 46
1.6 Ambientes de Passagem de Mensagens

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 47
Passagem (ou troca) de mensagens (Message Passing)
Consiste em um conjunto de diretivas que torna possível a
comunicação e a sincronização entre processos quando não existe
compartilhamento de memória.
Para permitir que linguagens seqüenciais, como C e Fortran,
incorporassem esses paradigmas, foram definidas extensões para essas
linguagens, geralmente na forma de bibliotecas, chamadas de
ambientes de passagem de mensagens.
Desenvolvidos inicialmente para máquinas com processamento
maciçamente paralelo (MPP), esses ambientes foram construídos para
uso específico nas arquiteturas em que eles eram utilizados, gerando
vários sistemas independentes e incompatíveis entre si.
Exemplos: o CROS da Caltech, NX1 e X2 da Intel, PSE da nCUBE,
EUI da IBM, CS da Meiko e CMMD da Thinking Machines
(FOSTER, 1995).
Passagem de mensagens ou troca de mensagens (Message Passing)
Plataformas de portabilidade (FADLALLAH et al., 2000).
o consiste em um ambiente de passagem de mensagens que é
implementado em várias arquiteturas.
o Programas escritos sobre uma arquitetura são portáveis para
outros sistemas.
o Os ambientes de passagem de mensagens mais conhecidos e
utilizados são:
PVM –Parallel Virtual Machine (GEIST et al., 1994)
MPI – Message Passing Interface (MPI Forum, 1997).
BSP - Bulk Synchronous Parallelism (Leslie Valiant
at Harvard; Communications ACM, 33,8, Aug 1990)

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 48
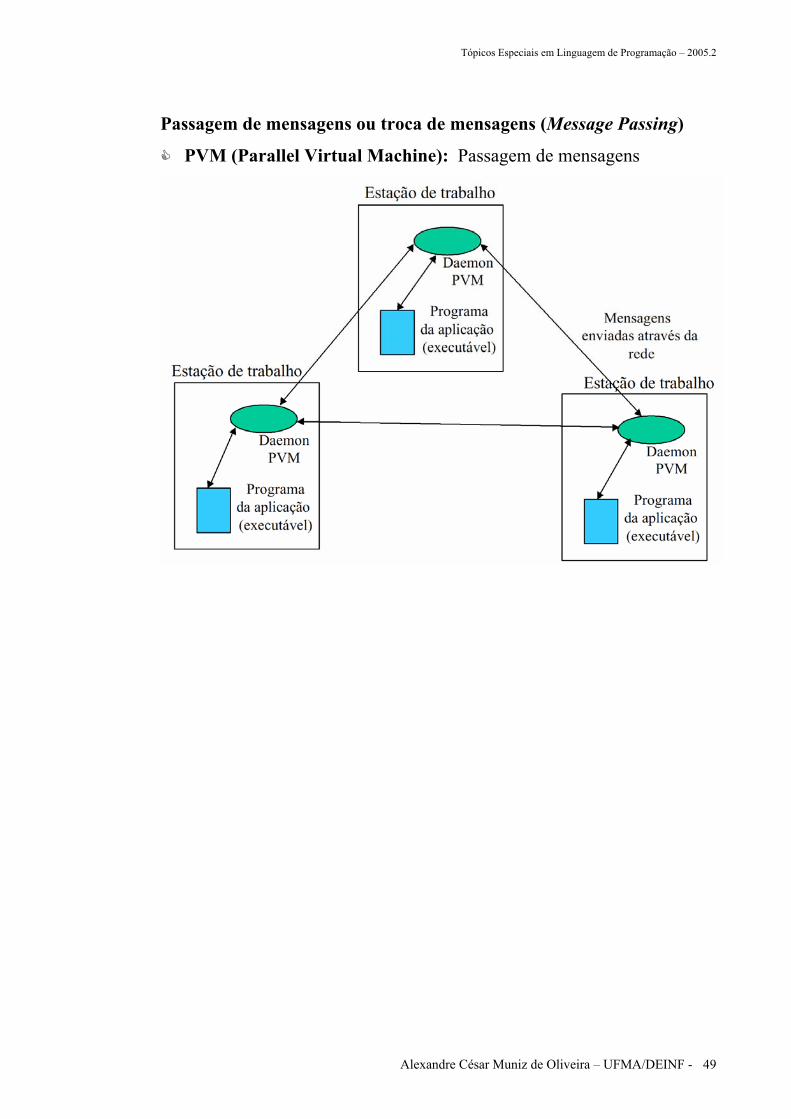
Passagem de mensagens ou troca de mensagens (Message Passing)
PVM (Parallel Virtual Machine): desenvolvida pelo Oak Ridge
National Laboratories para utilizar um cluster de estações de trabalho
como uma plataforma multiprocessada provê rotinas para passagem de
mensagens entre máquinas homogêneas e heterogêneas que podem ser
utilizadas com programas escritos em C ou Fortran.
o O programador decompõe o programa em programas separados
o Cada um deles é escrito em C ou Fortran e compilado para ser executado nas diferentes máquinas da rede
o O conjunto de máquinas que será utilizado para processamento deve ser definido antes do início da execução dos programas
o Cria-se um arquivo (hostfile) com o nome de todas as máquinas disponíveis que será lido pelo PVM
o O roteamento de mensagens é feito pelos processos daemon do PVM
Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 49
Passagem de mensagens ou troca de mensagens (Message Passing)
PVM (Parallel Virtual Machine): Passagem de mensagens

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 50
Passagem de mensagens ou troca de mensagens (Message Passing)
BSP - Bulk Synchronous Parallelism: Modelo de programação
paralela que se abstrai dos passos de baixo-nível em favor de super-
passos.
o Um super-passo consiste de um conjunto de computações
locais idependentes, seguidas por uma fase de comunicação
global e uma barreira de sincronização.
o Estruturar programas dessa forma permite que cada super-
passo tenha seu custo meticulosamente calculado a partir de
parâmetros arquiteturais simples:
permeability of the communication network to
uniformly-random traffic and
the time to synchronise
o O processo que requisita uma mensagem só necessita invocar
um FETCH
o O usuário não necessita se preocupar com o buffering de
mensagens: suprido pela biblioteca
o Otimização de comunicação também é responsabilidade do
BSP e não do código do usuário
o Diferentes métodos de comunicação
Passagem de mensagem
Acesso a memória direto e remoto

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 51
Passagem de mensagens ou troca de mensagens (Message Passing)
BSP - Bulk Synchronous Parallelism: Diferença para o PVM:
o O PVM se baseia em ter pares casados de SENDs and
RECEIVEs, enquanto no BSP o requisitante de dados
necessita tão somente dar entrada em uma instrução FETCH;
o O buffering é responsabilidade do programador;
o O programador também está ciente do tipo de comunicação
do sistema (ethernet, tokenring, shared memory etc) e tem
que tomar a melhor ação para assegurar um melhor
desempenho;
o A BSPLIB toma todas as decisões no sentindo de encontrar o
melhor ponto de desempenho;
o Áreas remotamente acessadas devem ser registradas por
comandos BSP:
bsp_push_reg- registra o início de uma area local
disponível para uso remoto remoto global
bsp_put - deposita dado local em uma área registrada
bsp_get – copia dado de uma area resgistrada
bsp_pop_reg- libera área
o Exemplo: int reverse(int x)
{
bsp_push_reg(&x, sizeof(int));
bsp_sync();
bsp_put(bsp_nprocs() - bsp_pid() - 1, &x, &x, 0, sizeof(int));
bsp_sync();
bsp_pop_reg(&x);
return x;
}

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 52
Passagem de mensagens ou troca de mensagens (Message Passing)
MPI – Message Passing Interface
o A “Interface de Passagem de Mensagens” é um padrão criado
pelo MPI Committee, formado por especialistas
representantes da indústria de processamento de alto
desempenho e de centros de pesquisa que se reuniram entre
novembro de 1992 e janeiro de 1994.
o O objetivo principal do MPI é padronizar a criação de
aplicações paralelas que se comunicam através da troca de
mensagens, incorporando aspectos de portabilidade,
praticidade, flexibilidade e facilidade de uso a esses
programas paralelos (CENAPAD, 1999).
o O MPI não deve ser confundido como linguagem paralela,
pois apenas propõe uma biblioteca que especifica nomes,
seqüências de chamadas de sistema, sub-rotinas ou funções
que são executadas a partir de programas Fortran, C/C++ ou
Java.
o Por ser uma biblioteca, o MPI trata o paralelismo de forma
explícita, ou seja, o programador é responsável por
identificar o paralelismo e implementar o algoritmo
utilizando as chamadas aos comandos MPI.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 53
Passagem de mensagens ou troca de mensagens (Message Passing)
MPI – Message Passing Interface
o Atualmente existem diversas implementações MPI, algumas
delas são:
IBM MPI: Implementação IBM para SP e clusters
MPICH: Argonne National Laboratory/Mississipi
State University
UNIFY: Mississipi State University
CHIMP: Edinburgh Parallel Computing Center
LAM: Ohio Supercomputer Center
PMPIO: NASA
MPIX: Mississippi State University NSF Engineering
Research Center
o Destacam-se:
LAM- (Local Area Multicomputer) MPI (SQUYRES
& LUMSDAINE, 2003)
MPICH (MPIChameleon) (GROPP & LUSK, 2000).
o Incorporam uma série de funcionalidades adicionais como,
por exemplo, suporte a máquinas SMP e interoperabilidade
entre máquinas heterogêneas (MPICH). A distribuição LAM
já vem incluída no pacote Red Hat Linux e por isso ela se
tornou uma das mais populares entre os usuários
GNU/Linux.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 54
Passagem de mensagens ou troca de mensagens (Message Passing)
Razões para uso do MPI
MPI é considerado um padrão para troca de mensagens
Existe suporte para MPI em quase todas as plataforma de alto
desempenho
Portabilidade de código fonte
Desempenho garantido pelo uso de instruções nativas da plataforma de
alto desempenho.
Funcionalidade em 115 rotinas especificadas para a biblioteca
Construção de clusters para troca de mensagem

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 55
1.7 Dificuldades Encontradas na Programação Paralela

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 56
Sincronização entre processos (BATCHU et al., 2001) A sincronização é necessária para que exista um controle de seqüência e um
controle de acesso durante a execução de processos concorrentes.
O controle de seqüência é utilizado quando existe a necessidade de
estabelecer uma determinada ordem na execução dos processos.
O controle de acesso é utilizado quando é importante o acesso organizado aos
recursos do sistema que são compartilhados pelos processos concorrentes.
Determinar a seqüência de eventos para garantir a sincronização entre
processos concorrentes não é um trabalho trivial.
Uma tarefa fora de ordem pode desencadear uma seqüência errada de
eventos, comprometendo o desempenho final da aplicação paralela.
Conversão de algoritmo seqüencial em paralelo Há um considerável tempo consumido pelo programador em analisar o
código serial para depois recodificá-lo de forma paralela.
Basicamente (FOSTER et al., 2003):
o rever o programa seqüencial,
o avaliar como será particionado,
o definir seus pontos de sincronização,
o determinar quais partições poderão ser executadas em paralelo e
o decidir qual a forma de comunicação será empregada de acordo
com a arquitetura utilizada.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 57
Compiladores e ferramentas automáticas em fase de amadurecimento Ainda há pouca disponibilidade de compiladores e ferramentas que auxiliem
a criação de códigos paralelos eficientes.
O trabalho de depuração é razoavelmente complicado em aplicações
paralelas.
Na prática, as técnicas utilizadas por esses compiladores e ferramentas
automáticas não se adequam a todos os tipos de programas.
As ferramentas automáticas não podem ser consideradas a “solução
definitiva” para a programação paralela, pois tendem a não resolver
problemas de dependências, o que limita sua atuação sobre partes restritas do
código (FADLALLAH et al., 2000).
Dificuldades de paralelizar programas (GRAMA et al., 2003).
Se o programador não tiver uma boa experiência, ele poderá tentar paralelizar
problemas que tenham uma alta taxa de dependências.
Por isso, é necessário realizar uma análise do problema ou do algoritmo
seqüencial, verificando-se quais pontos podem ser executados em paralelo,
assim como descobrir quais partes não são paralelizáveis

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 58
Depuração (Debug) Os processos são distribuídos e executados em vários processadores
simultaneamente, entretanto não existe uma forma eficiente de acompanhar
passo-a-passo as alterações das variáveis durante a execução de diversas
tarefas em paralelo.
Uma alternativa é utilizar arquivos de rastro de execução, chamados
tracefiles, que contêm um conjunto de dados gerados durante a execução da
aplicação paralela.
Existem programas com interface gráfica que permitem ao usuário
acompanhar a evolução do desempenho durante o processamento de tarefas
(FADLALLAH et al., 2000).:
o Xmpi para Lam MPI,
o Paragraph, Pablo e Paradyn

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 59
Módulo 2: Message Passing Interface (MPI)
2.1 Arquiteturas

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 60
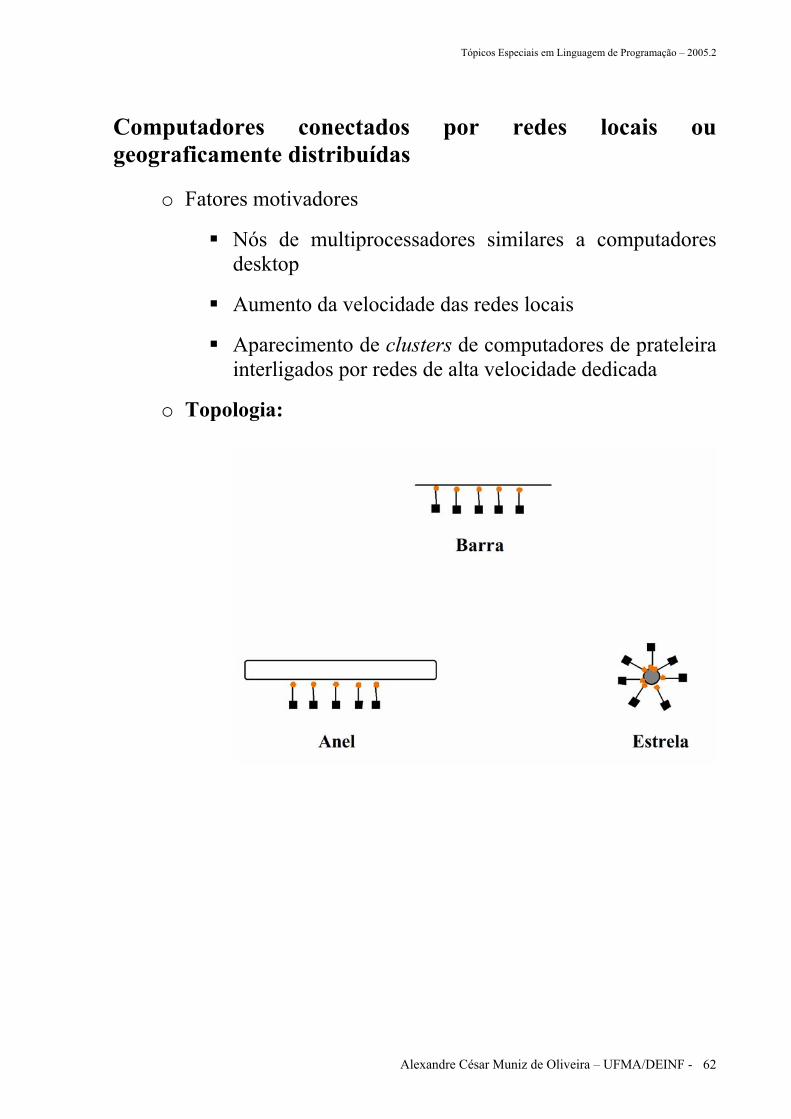
Arquitetura de computadores que utilizam passagem de mensagens
o Topologia:

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 61
Arquitetura de computadores que utilizam passagem de mensagens
Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 62
Computadores conectados por redes locais ou geograficamente distribuídas
o Fatores motivadores
Nós de multiprocessadores similares a computadores desktop
Aumento da velocidade das redes locais
Aparecimento de clusters de computadores de prateleira interligados por redes de alta velocidade dedicada
o Topologia:

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 63
Exemplo de Clusters Home / DOE/NNSA/LLNL / BlueGene/L - eServer Blue Gene Solution
BlueGene/L - eServer Blue Gene Solution DOE/NNSA/LLNL Livermore, United States
Rankings: Ranking List Rmax (GFlops)
1 06/2005 136800 System: BlueGene/L - eServer Blue Gene Solution
System Type: eServer Blue Gene Solution
System Model: eServer Blue Gene Solution
System Family: IBM BlueGene/L
Manufacturer: IBM
System URL: http://www.research.ibm.com/bluegene/
Application area: Not Specified
Installation Year: 2005 System Details
Processor: PowerPC 440 700 MHz (2.8 GFlops)
Topology/Interconnect: Proprietary
Operating System: CNK/Linux Linpack
Processors: 65536
Rpeak (GFlops): 183500
Rmax (GFlops): 136800
Nmax: 1277951
Lista completa de supercomputadores http://www.top500.org/

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 64
2.2 Processos

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 65
Criação e execução de processos
Propositalmente não são definidos e dependem de cada implementação
MPI versão 1
o Criação estática de processos: processos devem ser definidos antes da execução e inicializados juntos
o Utiliza o modelo de programação SIMD, mas pode simular o MIMD
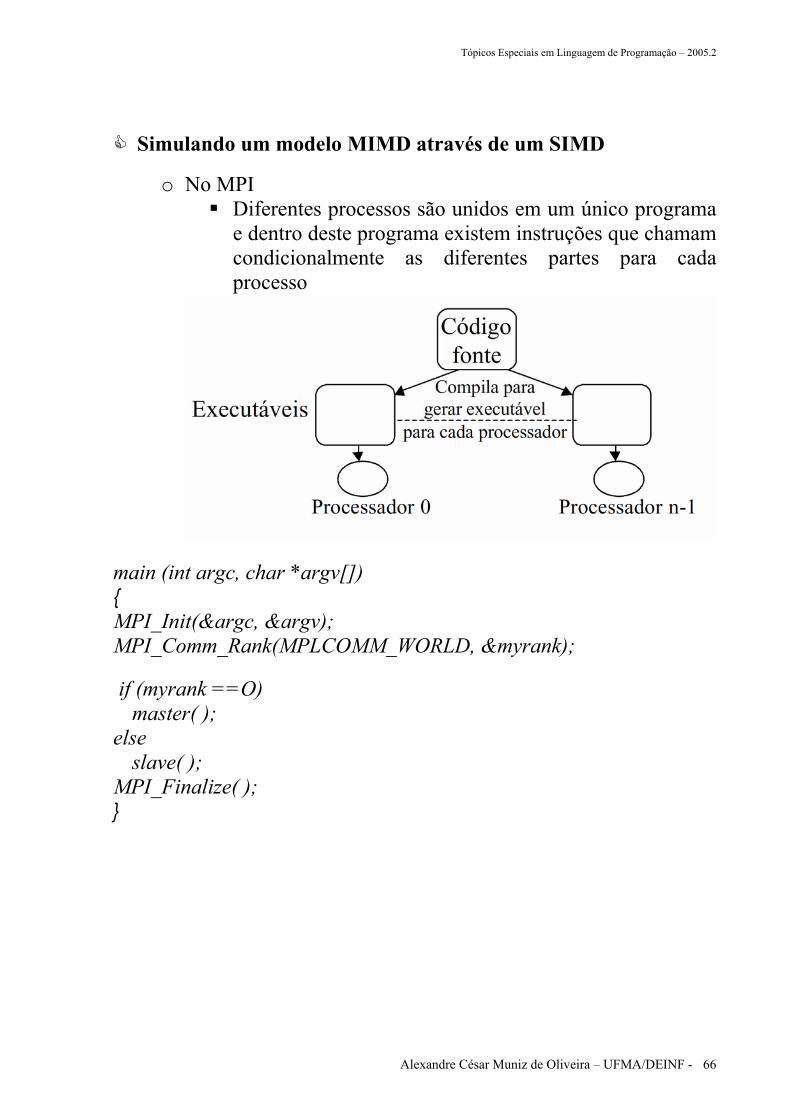
Simulando um modelo MIMD através de um SIMD
o Uma aplicação no MIMD legítima (mestre-escravo)
Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 66
Simulando um modelo MIMD através de um SIMD
o No MPI Diferentes processos são unidos em um único programa
e dentro deste programa existem instruções que chamam condicionalmente as diferentes partes para cada processo
main (int argc, char *argv[]) { MPI_Init(&argc, &argv); MPI_Comm_Rank(MPLCOMM_WORLD, &myrank);
if (myrank ==O) master( ); else slave( ); MPI_Finalize( ); }

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 67
2.3 Rotinas

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 68
Rotinas básicas MPI MPI_Send e MPI_Receive
MPLComm_rank(MPLCOMM_WORLD, &myrank); if (myrank ==O) { intx; MPI_Send(&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD); } else if(myrank ==1) { intx; MPI_Recv(&x, 1, MPI_INT, O, msgtag, MPI_COMM_WORLD, status); }

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 69
Rotinas básicas MPI MPI_Send e MPI_Receive
Comunicadores

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 70
Rotinas básicas MPI Passagem de mensagens síncronas
o Rotinas que realmente retornam somente após a transferência de mensagens ter sido completada.
o Não necessita de um buffer de sistema. o Rotinas síncronas transferem os dados e sincronizam os processos
Ilustração 1: Slides for Parallel Programming: Techniques and Applications - Barry Wilkinson and Michael Alien © Prentice Hall, 1999.
Redefinição dos termos Blocking e Non-Blocking o Blocking – retorna após completar suas ações locais (local), mesmo
que a transferência não tenha sido efetivamente concluída. o Non-blocking – retorno imediato, assumindo que a área de
armazenagem não será modificada por instruções subseqüentes antes dos dados serem usados para a transferência.
o Em ambos os casos, o sistema realmente não bloqueia a execução até que a transferência seja completada, como seria de se supor admitindo-se o sentido exato e conhecido desses termos.
Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 71
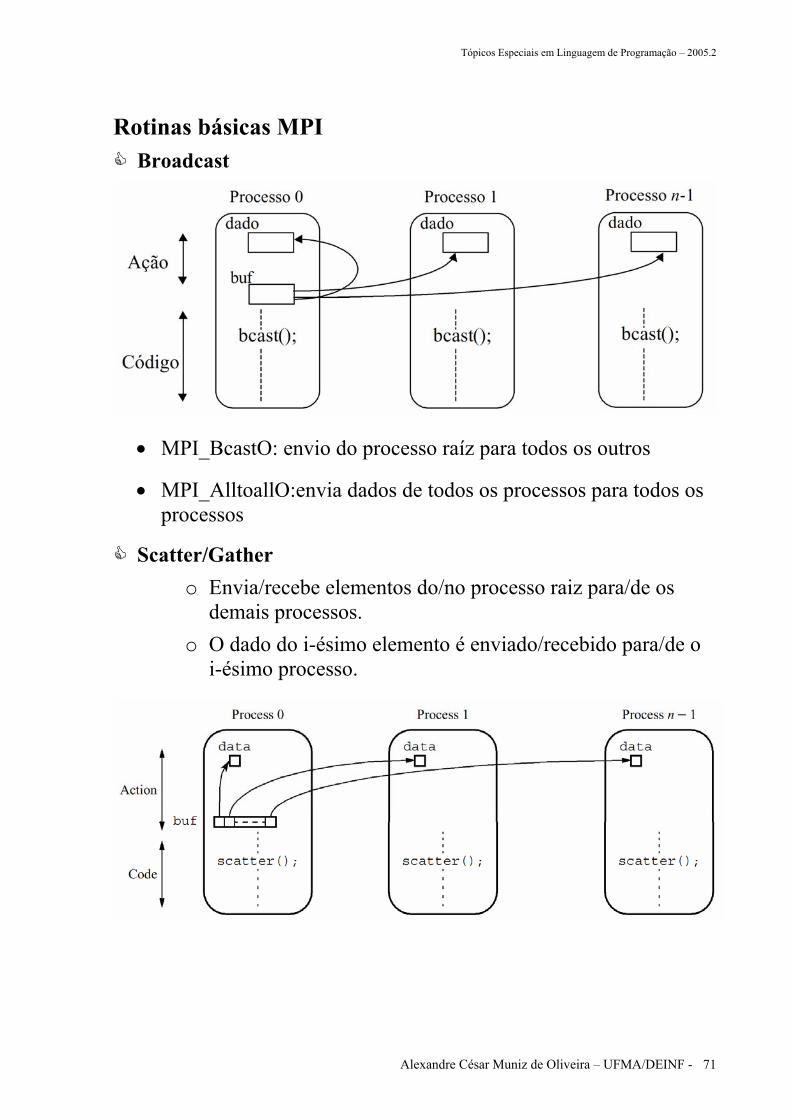
Rotinas básicas MPI Broadcast
• MPI_BcastO: envio do processo raíz para todos os outros
• MPI_AlltoallO:envia dados de todos os processos para todos os processos
Scatter/Gather o Envia/recebe elementos do/no processo raiz para/de os
demais processos. o O dado do i-ésimo elemento é enviado/recebido para/de o
i-ésimo processo.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 72
Reduce o MPI_Gather aliada a uma operação aritmético-lógica.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 73
2.4 Tempo

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 74
Tempo de execução paralela Composto de duas partes:
o tcomp: parte de computação o tcomm: parte de comunicação
tp = tcomp + tcomm o Tempo de computação estimado como em algoritmo
seqüencial o Tempo de comunicação:
tcomm = tstartup + n tdata o tstartup : tempo para enviar uma mensagem sem dados o tdata : tempo para transmitir uma palavra de dados o n: número de palavras a transmitir
Medindo tempo de execução
time(&t1); time(&t2); elapsed_time = difftime (t2,t1); printf(”Elapsed_time = %5.2f segundos”, elapsed_time);
Rotina MPI_ Wtime() provê hora em segundos

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 75
Tempo de execução paralela
Bloqueio de mensagens

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 76
Módulo 3: Estudo de caso 1: solução de problemas clássicos na computação usando algoritmos paralelos e definição dos trabalhos finais
3.1 Estratégias de paralelismo

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 77
Os quatro passos de Foster

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 78
Particionamento (ou Decomposição): O objetivo principal desta etapa é encontrar oportunidades de paralelização. Daí a principal atividade consiste em realizar a decomposição fina do problema, definindo as várias pequenas tarefas que o compõe. São duas as técnicas principais empregadas com este fim:
o Função (funcional): neste caso, a ênfase é dada na divisão da computação envolvida no problema.
Particionar o processamento em tarefas disjuntas, Análise dos dados necessários a cada tarefa. Se puderem ser divididos em conjuntos disjuntos, a
decomposição está completa. Se não, pode-se tentar: outro particionamentodo
processamento; replicação dos dados; ou compartilhamento dos mesmos.
Se a sobreposição de dados seja grande, pode ser mais indicado o emprego da decomposição de domínio;
o Domínio: nesta técmca, Particionar os dados associados ao problema, Divisão do processamento, associando aos dados
(divididos de forma disjunta) conjunto de operações pertinentes.
Algumas operações poderão envolver dados de mais de uma tarefa: será necessário realizar comunicação entre as tarefas, sincronisando as mesmas;
o O particionamento do problema é feito com a intenção de executar as tarefas definidas de forma concorrente e, se possível, de forma independente. Contudo, a computação associada a uma tarefa tipicamente envolve dados associados a uma outra tarefa,

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 79
Comunicação (Communication) : Preocupação com a necessidade de troca de dados entre processadores;
o Objetivo de analisar o fluxo de informações e de coordenação entre as tarefas, definindo uma estrutura de comunicação.
o A natureza do problema e o método de decomposição empregado serão determinantes na escolha do modelo de comunicação entre tarefas a ser utilizado.
o Foster divide os modelos de comunicação em quatro categorias (ortogonais):
Local/Global: no modelo de comunicação local cada tarefa se comunica com um pequeno grupo de outras tarefas (suas “vizinhas”), enquanto que no modelo global as tarefas podem comunicar-se arbitrariamente;
Estruturado/Não estruturado: no modelo estruturado as tarefas formam uma estrutura regular (e.g. árvore), já no modelo não estruturado elas formam grafos arbitrários;
Estático/Dinâmico: no modelo estático a comunicação se dá sempre entre as mesmas tarefas, enquanto que no modelo dinâmico a comunicação não possui parceiros definidos, dependendo dos valores calculados em tempo de execução;
Síncrono/Assíncrono: há, no modelo síncrono, uma coordenação entre as tarefas comunicantes, enquanto no modelo assíncrono não existe coordenação na comunicação.
o

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 80
Aglomeração (Agglomeration) : As tarefas e a estrutura de comunicação definida nos passos anteriores são avaliados em termos de custo de implementação e requisitos de desempenho.
o Se for necessário tarefas podem ser combinadas, ou aglomeradas, em tarefas maiores a fim de reduzir o custo de implementação ou aumentar a desempenho
o Pode-se efetuar a replicação de dados e/ou processarnento. o Três objetivos, algumas vezes conflitantes, devem nortear
as decisões por aglomeração e/ou replicação: Aumento da Granularidade: redução dos custos de
comunicação pelo aumento da granularidade do processamento e da comunicação;
Preservação da Flexibilidade: a granularidade deve ser controlada por um parâmetro em tempo de execução ou de compilação, a fim de que o número de tarefas possa ser adaptado ao número de elementos de processamento;
Redução dos custos de engenharia de software: deve se buscar o aproveitamento de código, sempre que possível, e a compatibilização com módulos já existentes.

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 81
Mapeamento (Mapping) ou Escalonamento: Aatribuição de tarefas a elementos de processamento, de forma a minimizar o tempo de execução.
o Como objetivos intermediários, busca-se também maximizar a utilização dos recursos computacionais disponíveis (e.g. CPU) e minimizar os custos relativos à comunicação.
o Este é o problema que a literatura denomina de escalonamento (ou scheduling).

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 82
3.2 Aplicações

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 83
Aplicações em Ordenação e Busca Shellsort, QuickSort, MergeSort: cada processador contem uma porção da lista a ser ordenada.
o Ordena as porções o Realize troca entre todos os processadores o Intercala as porções em um nó central
Busca em Matrizes: divide cada linha com um processador Caixeiro Viajante: divide cada subárvore de permutação com um
processador, com troca de limitantes Caminho Mais Curto: verifica cada possível caminho através de um
processador Integral usando o método dos trapézios: divide o intervalo de integração
entre processaodres Geração de números primos: cada processador recebe um número para ser
testado se é ou não primo

Tópicos Especiais em Linguagem de Programação – 2005.2
Alexandre César Muniz de Oliveira – UFMA/DEINF - 84
QuickSort Paralelo /*Librerias a utilizar*/ #include <stdio.h> #include <stdlib.h> #include <errno.h> #include <sys/times.h> #include <sys/types.h> #include <mpi.h> #define SIZE 50000 const intVector VP[SIZE]; void quicksort(int *X[]); int quicksortr(const int *X[], const int left); /************************************************ Globais *************************************************/ int i; /********************** Principal **********************************/ int main(int argc, char *argv[]) { int X[SIZE]; system("clear"); for(i=0;i<SIZE;i++) *(X+i) = random(SIZE); printf("\nArreglo Inicial:\n"); for(i=0;i<SIZE;i++) printf("%d ",X[i]); MPI_Init(&argc,&argv); /*Quicksort paralelo*/ quicksort(&X); /*Imprime a lista ordenada*/ printf("\nResultado Final:\n"); for(i=0;i<SIZE;i++) printf("%d ",X[i]); return(0); } /******************************* Procedimento de Quicksort Paralelo ************************************/ void quicksort(int *X[]) { int P[SIZE]; P = quicksortr(&X, 0); printf("\nPermuta:\n"); for(i=0;i<SIZE;i++) printf("%d",P[i]); X = permute(X, P); return; }
/********************************************* Procedimento de Ordenação *****************************************/ int quicksortr(const int *X[], const int left) { int n; int P[SIZE]; int splitter; int splitVP; int middle, right; MPI_Comm_size(MPI_COMM_WORLD,&n); if (n <= 0) ; /*nada a fazer*/ else if (n == 1) P = left; else if (n == 2) { if (VP == min_index(X)) P = left; else P = left+1; } else { /* n >= 3*/ splitter = first(X); splitVP = first_index(X); ifp (X <= splitter && VP != splitVP) { P = quicksortr(X, left); middle = left + n_active(X); } ifp (VP == splitVP) { P = middle; right = middle + 1; } ifp (X > splitter) { P = quicksortr(X, right); } } return P; }

Múltiplas estratégias de buscas

Módulo 4: Estudo de caso 2: algoritmo genético paralelo; aplicações em inteligência artificial e otimização
4.1 Algoritmos Genéticos Paralelos

Parallel Evolutionary Models The strategies to parallel evolutionary algorithms is based on:
a) how individual's evaluation and genetic operators are performed; b) whether single or multiple (how many?) subpopulations (demes)
are used; c) how individuals are exchanged; etc.
Models found in the literature [3]: d) Master-Slave (global) parallelization; e) Subpopulations with migration; f) Subpopulations with static overlapping; g) Subpopulations with dynamic overlapping.
In Master-Slave model, only evaluation of individuals and genetic operators are paralleled and such parallel processes are all dependents of the master process. This kind of global parallelization simply shows how easy it can be to transpose any genetic algorithm onto a parallel processor, without changing anything of the nature of the algorithm.

Parallel Evolutionary Models Multiple-deme (subpopulations) GAs are the most popular
parallelization model. Depending upon number and the size of the demes, they can be called coarse or fine-grained models.
Coarse-grained algorithms are a general term for a subpopulation model with a relatively small number of demes with many individuals. These models are characterized by the relatively long time they require for processing a generation within each deme, and by their occasional communication for exchanging individuals (migration operator).
In fine-grained models, on the other hand, the population is divided into a large number of small demes. Inter-deme communication is performed either by using a migration operator, or by using overlapping demes.
The communication between demes can be performed, basically, by migration or overlapping (static or dynamic). The migration of individuals is controlled by several parameters, such as:
a) The topology that defines the connections between demes; b) The frequency of migration and the amount of individuals
exchanged; c) The strategy of migration, i.e., the profile of the individuals to be
exchanged.

Parallel Evolutionary Models In overlapping schema, overlapping areas are defined between
demes, following some kind of topology, where some individuals belong to more than one deme. The improvement obtained by one deme is propagated through all demes by these areas.
In coarse-grained models, many topologies can be defined to connect the demes, but the most common models are the island model and the stepping-stones model. In the basic island model, migration can occur between any subpopulations, whereas in the stepping stone demes are disposed on a ring and migration is restricted to neighboring demes.
Choosing the frequency for migration and which individuals should migrate appears to be more complicated than the choice of the topology. Migrations should occur after a time long enough for allowing the development of goods characteristics in each subpopulation.

Hierarchical Fair Competition model The premature convergence of genetic algorithms is a problem to
be overcome. The convergence is desirable, but must be controlled in order that the population does not get trapped in local optima. Even in dynamic-sized populations, the high-fitness individuals supplant the low-fitness or are favorites to be selected, dominating the evolutionary process. The philosophy of evolution of the species, which is copied by evolutionary algorithms, is unfair because individuals with different skills are put in the same scenario and are evaluated in one-dimensional way: only the best will survive.
On the other hand, the population diversity is important to keep samples of solutions dispersed in search space, increasing the probability of finding out the global optima in multi-modal optimization problems. The population diversity could be reached keeping the competition among individuals fairer.
The Hierarchical Fair Competition (HFC) model is originated from an effort to avoid the premature convergence in traditional evolutionary algorithms[2]. The fair competition is obtained in HFC model by dividing the individuals in independent castes or classes according with their skills.
Such model is frequently observed in several advanced societies. In human society, competitions are often organized in to hierarchy of levels. None of them will allow unfair competition. For example, a primary student will not normally compete against graduate students in academic system. Even in cruel ecological systems, one can observe mechanisms of parental care to protect the young and allowing them to grow up and develop their full potentials.

Hierarchical Fair Competition model
In HFC model, multiple demes are organized in a hierarchy, in which each deme can only accommodate individuals within a specified range of fitness. The universe of fitness values must have a deme correspondence. Each deme has an admission threshold that determines the profile of the fitnesses in each deme. Individuals are moved from low-fitness to higher-fitness subpopulations if and only if they exceed the fitness-based admission threshold of the receiving subpopulations. Thus, one can note that HFC model adopts a unidirectional migration operator, where individuals can move to superior levels, but not to inferior ones.

Hierarchical Fair Competition model With respect to topology, HFC model is a specific case of island
model, where only some moves are allowed. Considering, the frequency of migration, authors have proposed
that individuals must be moved away in regular intervals, using admission buffers to collect qualified candidates from other populations. The strategy to determine what individuals must be exchanged is not flexible. All individuals with fitness outside the fitness range of their deme (superior individuals) must be exported to admission buffer of the appropriate subpopulation. The amount of individuals to be exchanged cannot be determined and will depend upon the number of superior individuals of each level at each exchange time.
An important feature can be incorporated to the HFC model: to work with a heterogeneous evolutionary environment. Once each subpopulation evolves individuals with different profiles, subpopulations can have different sizes, evolutionary operators and other parameters [2]. The HFC model allows employing different strategies of exploration and exploitation in each subpopulation.

Algoritmo Genético Paralelo /*********************************************************************************** MPI Initialization ************************************************************************************/ MPI_Init (&argc,&argv); MPI_Comm_size (MPI_COMM_WORLD,&numprocs); MPI_Comm_rank (MPI_COMM_WORLD,&meurank); /*********************************************************************************** Parameter dealing ************************************************************************************/ funcao=atoi(argv[1]); strcpy(nomarq,GARE); strcat(nomarq,FuncoesTeste[funcao].nom); strcat(&nomarq[strlen(FuncoesTeste[funcao].nom)],argv[5]); strcat(&nomarq[strlen(nomarq)],nomeproc[meurank]); MAXVAR = atoi(argv[2]); PASSOS = atoi(argv[3]); FCGA_MAX_AVA = atoi(argv[4]); semente = atoi(argv[6]); if (!(saida=fopen(nomarq,"w"))){ fprintf(saida, "ABEND 003"); MPI_Finalize(); } srand((unsigned) time(0)+semente+meurank*numprocs); /*********************************************************************************** Genetic Initialization: cast, population to obtain mapped ranges ************************************************************************************/ IniciaPop(&P, FCGA_MAX_POP, MAXVAR, FCGA_MAX_BIN, FCGA_MAX_BOU); IniciaCas(&Casta, numprocs, meurank, FCGA_MAX_BOU); IniciaPar(&Casta); GeraIndividuos(&P,FCGA_MAX_POP, MAXVAR, 0, funcao); /*********************************************************************************** Map computation by Reduce operation of overall range of fitness ************************************************************************************/ MPI_Reduce(&fitInf, &fitaux, 1, MPI_DOUBLE, MPI_MIN, numprocs-1, MPI_COMM_WORLD); fitInf = fitaux; MPI_Reduce(&fitSup, &fitaux, 1, MPI_DOUBLE, MPI_MAX, numprocs-1, MPI_COMM_WORLD); fitSup = fitaux; MPI_Bcast (&fitInf, 1, MPI_DOUBLE, numprocs-1, MPI_COMM_WORLD); MPI_Bcast (&fitSup, 1, MPI_DOUBLE, numprocs-1, MPI_COMM_WORLD); SOLUMAP = ConvSolFit(SOLUCAO, fitInf, fitSup, DOMESC);

/*********************************************************************************** Preview evolution ************************************************************************************/ start_time = MPI_Wtime(); GeraIIndividuos(&P,FCGA_MAX_POP, MAXVAR, 0, funcao); // ######## Calibration Stage EvoluiSemCasta (P, FCGA_SET_ITE); Casta.media = P.sumFit/P.tamPop; // ######################### gerAtual = 1; MapInd.contRed[meurank]=0; for (i=0; i < numprocs; i++) MapInd.vetoRed[i]=i; MapInd.tamAtu=numprocs; /*********************************************************************************** First exchange of message, consolidating average and desviation Now to do once! ************************************************************************************/ CalcDesvAciMedia(&P, &Casta); MPI_Reduce(&Casta.dvpad, &dvpaux, 1, MPI_DOUBLE, MPI_MIN, numprocs-1, MPI_COMM_WORLD); MPI_Reduce(&Casta.media, &medaux, 1, MPI_DOUBLE, MPI_MIN, numprocs-1, MPI_COMM_WORLD); MPI_Reduce(&Casta.stats, &varaux, 1, MPI_INT , MPI_BOR, numprocs-1, MPI_COMM_WORLD); if (meurank == numprocs-1) { dvpaux += FCGA_PER_ELT*(medaux - dvpaux); } MPI_Bcast (&medaux, 1, MPI_DOUBLE,numprocs-1, MPI_COMM_WORLD); MPI_Bcast (&dvpaux, 1, MPI_DOUBLE,numprocs-1, MPI_COMM_WORLD); MPI_Bcast (&varaux, 1, MPI_INT ,numprocs-1, MPI_COMM_WORLD); /*********************************************************************************** Evolution actually begins ************************************************************************************/ do { /*********************************************************************************** Ranges computation, followed by sending of cast values ************************************************************************************/ if (!((gerAtual-1)%FCGA_GER_SET) || (Casta.stats & FCGA_SUC_ESS) ) { MPI_Reduce(&Casta.stats, &varaux, 1, MPI_INT , MPI_BOR, numprocs-1, MPI_COMM_WORLD); MPI_Bcast (&varaux, 1, MPI_INT, numprocs-1, MPI_COMM_WORLD); Casta.stats = varaux; // O status geral é testado e pode encerrar o programa no mesmo ponto if ( (Casta.stats & 0x02) || (Casta.stats & 0x10) || (Casta.stats & 0x20) ) break; // Se não terminou, vai reestruturar o mapeamento no nó ELITE e se ainda houver espaço MPI_Gather(&Atividade, 1, MPI_INT, MapInd.contRed,1,MPI_INT, numprocs-1, MPI_COMM_WORLD); if (meurank == numprocs-1 && gerAtual > 1 && MapInd.tamAtu < FCGA_TAM_RED) { ReestruturaMapeamento (&MapInd, numprocs); } // Reestruturado ou não, o mapeamento é distribuído MPI_Bcast (&(MapInd.tamAtu),1, MPI_INT , numprocs-1, MPI_COMM_WORLD); MPI_Bcast (&(MapInd.vetoRed), MapInd.tamAtu, MPI_INT , numprocs-1, MPI_COMM_WORLD); Atividade = 0; }//if Re-set

// ***************************************** Evolution itself nIteracoes = (nIteracoes < FCGA_EVO_ITE ? nIteracoes : FCGA_EVO_ITE); EvoluiComCasta (P, &Casta, &MapInd, nIteracoes, gerAtual); // ****************************************** for (i=0; i < Casta.posDes; i++){ P.nEnvio++; P.indiv[P.iniBou+i].var[P.tamInd] = P.indiv[P.iniBou+i].fit; P.indiv[P.iniBou+i].var[P.tamInd+1] = P.indiv[P.iniBou+i].sol; MPI_Send(P.indiv[P.iniBou+i].var, P.tamInd+2, MPI_DOUBLE,Casta.dests[i], 1, MPI_COMM_WORLD); } // resseta bufferout P.posBou = P.iniBou; Casta.posDes=0; if(Casta.meurank == 0) { GeraIIndividuos(&P, (int) (P.tamPop+FCGA_GER_BIN*P.tamBin), P.tamInd, P.posBin, funcao); nIteracoes = P.tamBin; } else { MPI_Iprobe(MPI_ANY_SOURCE, 1, MPI_COMM_WORLD, &chegou, &status); nIteracoes=0; while ((chegou) && (P.posBin < P.iniBou)) { P.nReceb++; nIteracoes++; MPI_Recv(P.indiv[P.posBin].var, P.tamInd+2, MPI_DOUBLE,MPI_ANY_SOURCE, 1, MPI_COMM_WORLD, &status); P.indiv[P.posBin].fit=P.indiv[P.posBin].var[P.tamInd]; P.indiv[P.posBin].sol=P.indiv[P.posBin].var[P.tamInd+1]; if (P.indiv[P.posBin].fit < P.indiv[P.melhor].fit){ P.melhor = P.posBin; Casta.stats = (maxi(P.indiv[P.melhor].sol-SOLUCAO-FCGA_TAX_ERR,0.0F) <= FCGA_TAX_ERR ? FCGA_SUC_ESS : FCGA_NAO_ERR); } MPI_Iprobe(MPI_ANY_SOURCE, 1, MPI_COMM_WORLD, &chegou, &status); P.posBin++; } } gerAtual++; Atividade += nIteracoes; if (gerAtual > FCGA_MAX_GER) Casta.stats = (int) (Casta.stats | FCGA_GER_MAX); }while(1); /*********************************************************************************** Ending evolution ************************************************************************************/ finish_time = MPI_Wtime(); total_time = finish_time - start_time; P.temMelhor = (double) P.gerMelhor/gerAtual* total_time; MPI_Barrier(MPI_COMM_WORLD); MPI_Reduce(&total_time, &max_time, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD); fprintf(saida,"\n Justo(%d); %s (%d); %.4f; %.4f; %.4f; %.4f; %d ; %.4f ; %d ; %.4f; %d; %.4f ; %d; %d ; %d; %d \n", Casta.stats, FuncoesTeste[funcao].nom, P.tamInd, SOLUCAO+FCGA_TAX_ERR, MPI_Finalize(); }

4.2 Outras aplicações

REFERENCIAS IGNACIO, Aníbal Alberto Vilcapona and FERREIRA FILHO, Virgílio José Martins. MPI: uma ferramenta para implementação paralela. Pesqui. Oper., Jan./June 2002, vol.22, no.1, p.105-116. ISSN 0101-7438. PACHECO, Peter - Parallel Programming with MPI WILKINSON, Barry e ALIEN, Michael Parallel Programming: Techniques and Applications … - Prentice Hall, 1999