
Síntese de voz utilizando avatares GPVOZ
13
Síntese de voz utilizando avatares GPVoz Gabriel de Albuquerque Styve Stallone
-
Upload
danilo-sousa -
Category
Education
-
view
51 -
download
3
Transcript of Síntese de voz utilizando avatares GPVOZ

Síntese de voz utilizando avatares
GPVoz
Gabriel de AlbuquerqueStyve Stallone

Roteiro
O que foi feito na áreaPotenciais parceirosPossíveis soluções para o problema

O que foi feito na área
DOXVOX desenvolvido na UFRJ, utiliza a síntese de difones. Gratuito e Open Souce.
síntese de difones é baseada em concatenação de difones, que são pequenas seqüências de áudio que amostram a transição da metade de um fonema para a metade de outro.
O mecanismo utiliza-se de uma tabela onde são guardados grafemas e seus respectivos fonemas. Palavras que fogem a regra podem ser guardadas por inteiro.
Um dos sistemas de acessibilidade mais usados no país.

O que foi feito na area
UFRGS , desenvolveu o Spoltech Buscava tornar o CSLU toolkit, desenvolvido no (CSLU),
localizado no Oregon Graduate Instítute funcional para o nosso português brasileiro;
CSLU toolkit: " um sistema que torna possível a criação de sistemas de processamento de fala de maneira simples, disponibilizando, inclusive, uma ferramenta visual para concepção rápida e intuitiva de aplicações de síntese e reconhecimento de fala.“
Buscou parceria com os desenvolvedores do CSLU toolkit; Parceria gerou resultados, a síntese já opera em português
e o reconhecimento já atinge 98% de acerto ao reconhecer dígitos.

Potenciais parceiros
Na UFRGS, aluno está desenvolvendo um projeto de leitor de livros com o sintetizador de voz Open Souce eSpeek.UFRJ criadora do DOXVOXA UFRGS depois da parceria com a CSLU, reforçou a necessidade de buscar parcerias com outras instituições.
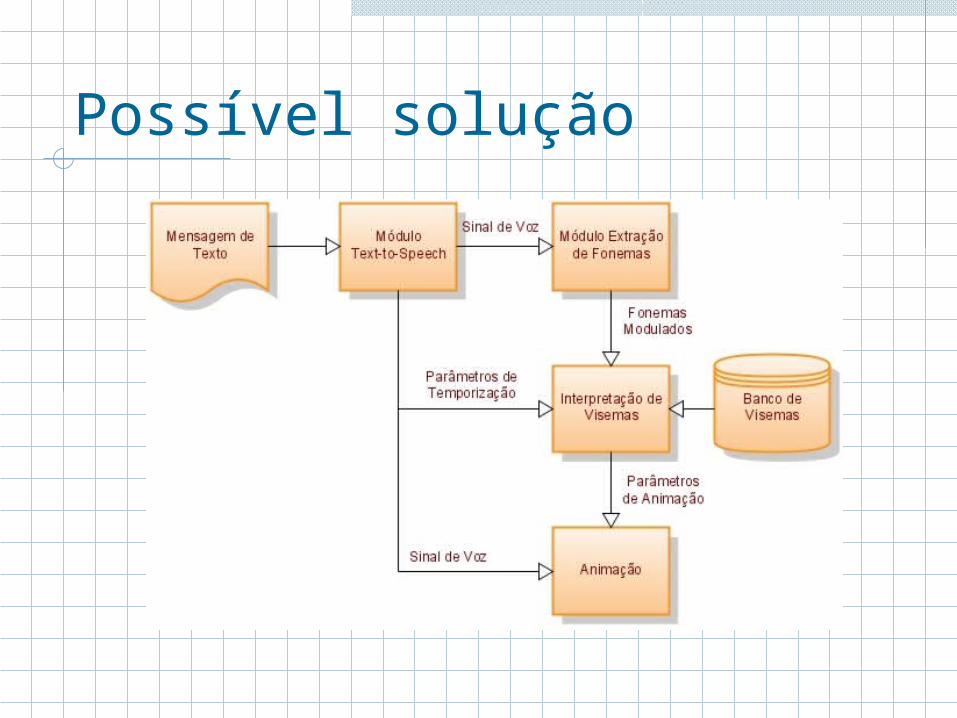
Possível solução

Módulos Text-To-Speech
O modulo TTS faz a transformação de texto para fala. Atualmente existem muitos sintetizadores disponíveis no mercado.Podemos dividir o modulo TTS em 2 partes A primeira parte pega o texto e transforma em uma seqüências de fonemas (pode ser uma tabela de associação), também faz a conversão de datas, números e demais símbolos para fonemas.A segunda parte que através da seqüência de fonemas e parâmetros como intensidade e duração, realiza a síntese da voz.
Pré-processamento sintese vozTexto

Tabela de conversão grafema – fonema (DOXVOX)

Módulos Extração do Fonema
O Modulo Extração de Fonemas é um reconhecedor de padrões, que podemos dividir em também duas partes.O modulo de extração de características que ao receber o arquivo de áudio, captura as informações mais importantes para o reconhecimento. EX: Taxa que o sinal cruza o eixo horizontal, distancia entre picos.
O outro módulo é um módulo de comparação que irá usar um algoritmo para comparar com padrões previamente treinados. ( Redes Neurais, Quantização Vetorial, etc)Deixaremos como próximo passo o estudo das técnicas de reconhecimento de padrões.
Voz FonemaExtração de Parametos comparação

Modulo TTS e Extração do fonemas
Resumidamente o primeiro módulo realiza a síntese, e o segundo modulo realiza um reconhecimento.Mais em todos os mecanismos de síntese já está embutida a parte que faz a tradução de grafemas para fonemas (tabelas de conversão).Podemos utilizar dessa tabela para obter os fonemas resultantes sem precisar do segundo modulo.
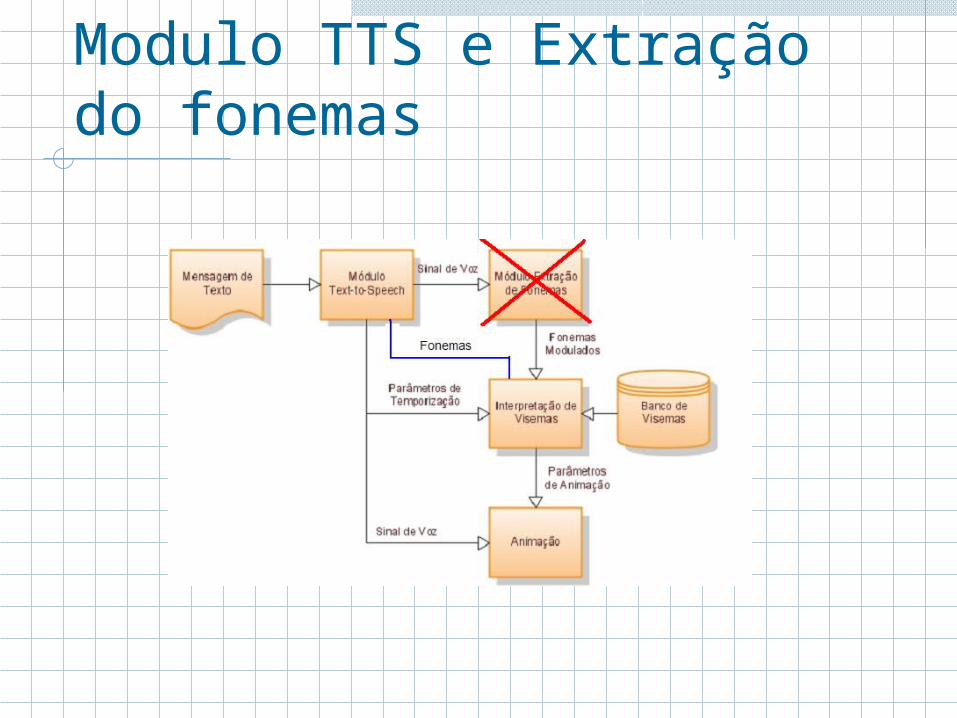
Modulo TTS e Extração do fonemas

Módulos Interpretação do Visema
O módulo interpretação faz a associação de um fonema recebido pelo modulo extração do fonema com o visema correspondente no banco de visemas.Uma simplificação utilizada na pratica, é fazer os visemas para representar apenas sons de vogais.

Módulo Animação
O modulo de animação receberá os visemas e sua intensidade e duração.Visemas alem dos movimentos labias, podem representar expressões. Ex: surpresaPara isso o texto precisa ser adaptado para conter informações emocionais.

![[com aplicações em síntese voz & reconhecimento de locutor]hmo/aula_DEN.pdf · Aparelho fonador O trato vocal pode ser modelado como uma rede linear. A título de exemplo, ...](https://static.fdocumentos.tips/doc/165x107/5c48d62293f3c3521c58e002/com-aplicacoes-em-sintese-voz-reconhecimento-de-locutor-hmoauladenpdf.jpg)










