
Rota hipertextual baseada em tags -...
126
Rota hipertextual baseada em tags: Discussão de processos de produção e leitura como sistemas complexos no contexto da Web Semântica LUANA TEIXEIRA DE SOUZA CRUZ BELO HORIZONTE, 2014
Transcript of Rota hipertextual baseada em tags -...

Rota hipertextual baseada em tags:
Discussão de processos de produção e leitura como sistemas complexos
no contexto da Web Semântica
LUANA TEIXEIRA DE SOUZA CRUZ
BELO HORIZONTE, 2014

CENTRO FEDERAL DE EDUCAÇÃO TECNOLÓGICA DE MINAS GERAIS
LUANA TEIXEIRA DE SOUZA CRUZ
Rota hipertextual baseada em tags:
discussão de processos de produção e leitura como sistemas complexos
no contexto da Web Semântica
BELO HORIZONTE (MG)
2014

LUANA TEIXEIRA DE SOUZA CRUZ
Rota hipertextual baseada em tags:
discussão de processos de produção e leitura como sistemas complexos
no contexto da Web Semântica
Dissertação apresentada ao Programa de Pós-
Graduação Stricto Sensu em Estudos de
Linguagens (POSLING) do Centro Federal de
Educação Tecnológica de Minas Gerais
(CEFET-MG) como requisito parcial para a
obtenção do título de Mestre em Estudos de
Linguagens.
Área de concentração: Processos Discursivos e
Tecnologia
Orientador: Prof. Dr. Vicente Aguimar
Parreiras
BELO HORIZONTE (MG)
2014

LUANA TEIXEIRA DE SOUZA CRUZ
Rota hipertextual baseada em tags: discussão de processos de produção e leitura como
sistemas complexos no contexto da Web Semântica
Dissertação apresentada ao Programa de Pós-Graduação Stricto Sensu em Estudos de Linguagens
do Centro Federal de Educação Tecnológica de Minas Gerais - CEFET-MG, em 15 de outubro
de 2014, como requisito parcial para obtenção do título de Mestre em Estudos de Linguagens,
aprovada pela Banca Examinadora constituída pelos professores:
____________________________________________________
Prof. Dr. Vicente Aguimar Parreiras.- CEFET/MG – (Orientador)
____________________________________________________
Prof. Dr. Carlos Frederico de Brito D’Andréa (UFMG)
____________________________________________________
Profª. Drª. Ana Elisa Ribeiro (CEFET-MG)
____________________________________________________
Profª. Drª. Giani David Silva (CEFET-MG - suplente)

Dedico este trabalho aos meus pais, Neide e Teixeira,
responsáveis pela minha base sólida de educação; ao meu irmão, Léo, por
ser um exemplo profissional que me motiva a progredir, e ao meu noivo
(quase marido) Marcos, pela paciência nesses anos de estudos.

AGRADECIMENTOS
Aos amigos do Cefet-MG e Estado de Minas Rafael Passos e Emerson Campos, pela
parceria nos dois anos de estudos. Vocês são parte desta trajetória!
Ao amigo João Henrique do Vale Almeida pelas trocas de horários de trabalho e
disponibilidade para entrevista em um dos estudos de caso. Você é um bom companheiro!
A Deus, fonte de energia que mantém minha fé no trabalho. “Tu és, Senhor, o meu pastor;
por isso nada em minha vida faltará!”
A todos os colegas de sala do mestrado, com carinho especial a Michel Montandon, por
dividir o orientador, as angústias e saberes. Você serviu de espelho!
Ao professor Dr. Vicente Aguimar Parreiras – mais do que um orientador, um
incentivador. Você me fez acreditar e me motivou nesta caminhada!
Aos Diários Associados pelo apoio na pesquisa, permitindo acesso aos dados necessários
ao trabalho.
Ao meu noivo (quase marido) Marcos Queiroga, pelo amor constante. Você é minha
inspiração!
À minha família, por acreditar nos meus esforços e incentivar uma vida de estudos. Amo
amar vocês!
A todos os meus amigos, com carinho especial para Frederico Emediato, Maria Dulce
Crisóstomo, Gabriela Aguiar, Natália Luciana Soares, sempre prontos para me distrair nas horas
de descanso. Vocês são eternos!
Aos professores do mestrado, em especial Prof.ª Dr.ª Giani, David Silva, Prof.ª Dr.ª Ana
Maria Nápoles Villela, Prof. Dr. Rogério Barbosa da Silva, Prof. Dr. Renato Caixeta da Silva e
Prof. Dr. Flávio Luiz Teixeira de Sousa Boaventura, pelas contribuições valiosas na preparação
para a dissertação. Vocês são grandes mestres!
Aos pareceristas e membros da banca – Prof. Dr. Carlos D’Andréa e Dr.ª. Ana Elisa
Ferreira Ribeiro, que disseram coisas certas na hora certa. Vocês deram uma luz!

RESUMO
Esta pesquisa apresenta uma discussão sobre a rota hipertextual baseada em tags e sobre
processos de produção jornalística e de leitura no contexto da Web Semântica, sob a perspectiva
da Teoria da Complexidade. Esse tópico foi investigado com o objetivo de mapear a evolução
desses processos. Os objetivos específicos foram: (1) discutir como as tags mudaram as
estruturas de significação de conteúdos que circulam na rede, com a finalidade de inferir as
razões pelas quais as tags são responsáveis pela navegação nômade, pela colaboração em rede e
pela alteração de processos comunicativos; e (2) avaliar a adequação do uso de um modelo não
linear de comunicação em rede para compreender como a Web Semântica possibilita o
aproveitamento dos efeitos da rede pelas empresas de comunicação. A fundamentação teórica
deste trabalho tem como pilares as noções de complexidade e de Web Semântica, e de como eles
se relacionam com as tags quando operam como atratores na rota hipertextual da Web. O
conceito de folksonomia foi usado para articular as ideias de “tagueamento” e de classificação na
Web para abordagem dos processos de indexação e de organização popular na rede e das suas
influências nos processos de produção jornalística e de leitura na Web. Optei por desenvolver
uma pesquisa qualitativa baseada no paradigma construtivista na perspectiva do estudo de caso.
A intenção foi a de problematizar os modelos lineares de navegação na Web, disponibilizados
pelos produtores, que não correspondem às expectativas do leitor que tende a fazer uma
navegação nômade, própria dos sistemas complexos. A partir dessa problematização, buscaram-
se possibilidades de soluções na literatura e nos dois casos estudados que compuseram o corpus
da pesquisa formado pelo conjunto de estatísticas e observações da pesquisadora sobre as ações
dos jornalistas. O desenho metodológico da pesquisa consistiu-se de três etapas: (1) análise dos
aspectos de resultado de audiência pelo Google Analytics; (2) análise temporal de tags por meio
do Google Trends para discussão do aspecto linguístico do uso de etiquetagem na Web; e (3)
análise dos depoimentos dos jornalistas envolvidos nos dois casos investigados. As principais
contribuições desta pesquisa foram: um conceito mais “comunicacional” da Web Semântica e a
perspectiva do gerenciamento de tags como ferramenta de trabalho para produtores de conteúdo,
além da cadência de conceitos que ligam complexidade, semântica e folksonomia, neste caso
com aplicabilidade ao jornalismo baseado em tags, mas que pode servir como arcabouço teórico
para outras perspectivas da produção de conteúdo online.
Palavras-chave: Sistemas Complexos; Web Semântica; jornalismo baseado em tags;
leitura hipertextual nômade; folksonomia;

ABSTRACT
This research presents a discussion about hypertext route based on tags and about journalistic
production and reading processes in the context of the Semantic Web from the Complexity
Theory perspective. This topic has been investigated with the goal of mapping the evolution of
these processes advancing to the Semantic Web field. The specific objectives were: (1) discuss
how the tags have changed the structures of content signification on the web, in order to infer the
reasons why the tags are responsible for nomadic navigation, for collaborative networking and
for the changes in the communicative processes; (2) analyze how the tags have become key to
the constitution of globalized discussions in hypermedia environment and (3) evaluate the
suitability of using a nonlinear model of network communication to understand how the
Semantic Web allows the exploitation of network effects by communication companies. The
theoretical framework of this research has as its pillars the notions of complexity and Semantic
Web, and how they relate to the tags when they operate as attractors in the Web hypertext route.
The “Folksonomy” concept was used to articulate the ideas of "tagging" and of web
classification processes in order to approach the indexing and the popular organization in the
network and their influences in the process of news production and of reading in the web. Given
the characteristics of the type of research and in terms of the data that make up the corpus of this
research we opted to develop a qualitative research based on the constructivist paradigm in a
case study perspective. The intention was to discuss the linear models of Web surfing, offered by
producers that do not match the expectations of the reader who tends to make nomad navigation
peculiar of complex systems. From this questioning, we sought possibilities for solutions in the
literature and in the two cases studied that made up the research corpus formed by the set of
statistics and observations of the researcher about the journalists’ actions. The research
methodological design consisted of three steps: (1) analysis of aspects of outcome audience
through Google Analytics; (2) temporal analysis of tags through Google Trends for discussion of
the linguistic aspect of the use of tagging in the Web; and (3) analysis of interviews with the
journalists involved in the two cases investigated. I Evaluate that the major contributions of this
research were: a more "communicational" concept of the Semantic Web and the prospect of
managing tags as working tool for content producers, besides the rate of concepts linking
complexity, semantics and folksonomy, in this case with applicability to journalism based on
tags, but that can serve as a theoretical framework for other perspectives in the production of
online content.
Keywords: Complex Systems; Semantic Web; journalism based on tags; nomadic hypertext
reading; folksonomy

LISTA DE FIGURAS
FIGURA 1 - METÁFORA DO EFEITO DOMINÓ ........................................................................................................................... 32
FIGURA 2 – METÁFORA DA BOLA DE NEVE ............................................................................................................................. 32
FIGURA 3 – IMAGEM DE BARRET LYON .................................................................................................................................. 40
FIGURA 4 – DIAGRAMA EM NUVEM DO DBPEDIA (LINKING OPEN DATA) ..................................................................................... 40
FIGURA 5 – VÓRTICE ......................................................................................................................................................... 53
FIGURA 6 – VÓRTICE DE REDEMOINHO.................................................................................................................................. 53
FIGURA 7 – GOOGLE ANALYTICS .......................................................................................................................................... 86
FIGURA 8 – GOOGLE TRENDS COM TAG “PAPA” ...................................................................................................................... 88
FIGURA 9 –GALERIA DE FOTOS “INCÊNDIO EM SANTA MARIA” .................................................................................................. 95
FIGURA 10 – NÚMEROS INCÊNDIO EM SANTA MARIA .............................................................................................................. 98
FIGURA 11 – GOOGLE TRENDS - INTERESSE PELA TAG “SANTA MARIA” EM BUSCAS DO GOOGLE...................................................... 100
FIGURA 12 – MODELO DE HIERARQUIA MIELNICZUK E PALÁCIOS .............................................................................................. 105
FIGURA 13 – CAPA DO UAI EM JUNHO DE 2013, MESMO MODELO DE NOVEMBRO 2013 ............................................................. 106
FIGURA 14 –MATÉRIA “VÍDEO MOSTRA MOMENTO EM QUE CARRO DE ATOR PAUL WALKER FICA EM CHAMAS APÓS ACIDENTE” ........... 107
FIGURA 17 – NÚMEROS MORTE PAUL WALKER .................................................................................................................... 110
FIGURA 18 - GOOGLE TRENDS - INTERESSE PELA TAG “PAUL WALKER” EM BUSCAS DO GOOGLE ...................................................... 112
FIGURA 19 – ATRATOR DE LOREZ: MODELO PARA IDENTIDADE VISUAL ....................................................................................... 120

LISTA DE ESQUEMAS
ESQUEMA 1 – ORGANIZAÇÃO DA DISSERTAÇÃO....................................................................................................................... 26
ESQUEMA 2 – PROCESSO DE AUTO-ORGANIZAÇÃO .................................................................................................................. 37
ESQUEMA 3 – PROCESSO DE AUTO-ORGANIZAÇÃO NO FENÔMENO “INCÊNDIO EM SANTA MARIA” ................................................. 102
ESQUEMA 4 – PROCESSO DE AUTO-ORGANIZAÇÃO MORTE PAUL WALKER ................................................................................. 113
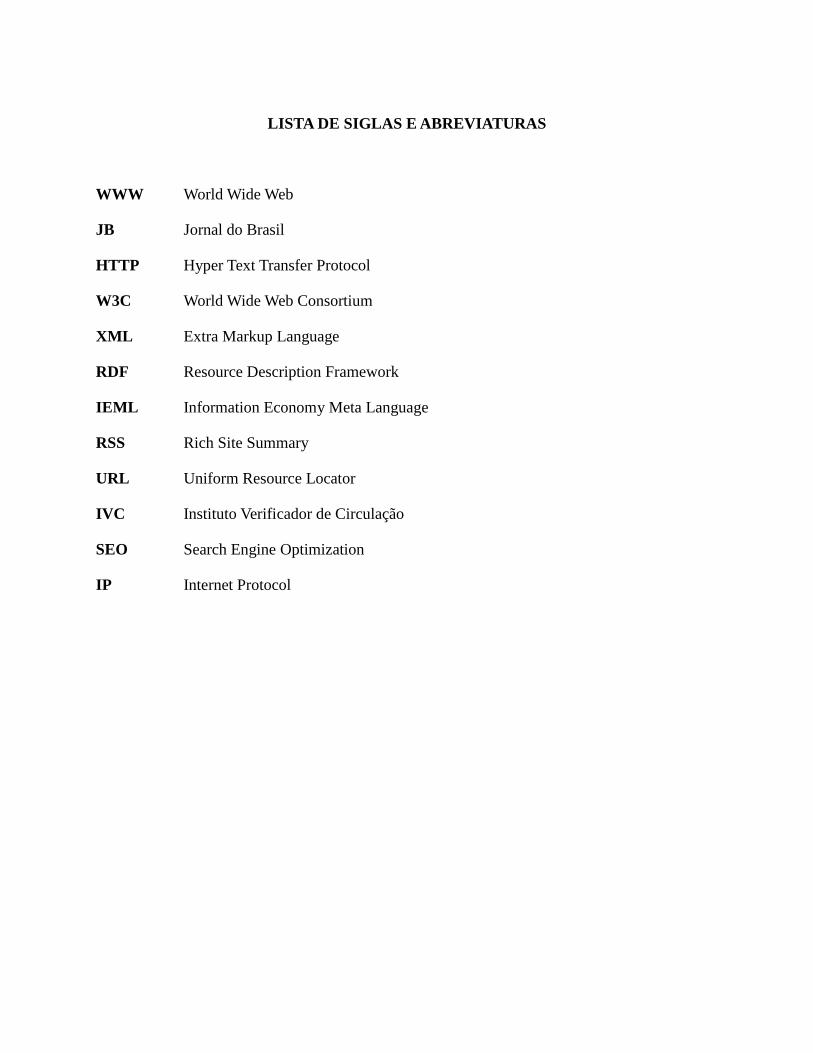
LISTA DE SIGLAS E ABREVIATURAS
WWW World Wide Web
JB Jornal do Brasil
HTTP Hyper Text Transfer Protocol
W3C World Wide Web Consortium
XML Extra Markup Language
RDF Resource Description Framework
IEML Information Economy Meta Language
RSS Rich Site Summary
URL Uniform Resource Locator
IVC Instituto Verificador de Circulação
SEO Search Engine Optimization
IP Internet Protocol

SUMÁRIO
1 APRESENTAÇÃO DA DISSERTAÇÃO ................................................................................................... 14
1.1 INTRODUÇÃO................................................................................................................................................ 14
1.2 CONTEXTUALIZAÇÃO ...................................................................................................................................... 17
1.3 JUSTIFICATIVA ............................................................................................................................................... 23
1.4 PROBLEMA DE PESQUISA ................................................................................................................................. 25
1.5 OBJETIVO GERAL ........................................................................................................................................... 25
1.5.1 Objetivos específicos ....................................................................................................................... 26
1.6 ORGANIZAÇÃO DESTE TRABALHO ...................................................................................................................... 26
2 COMPLEXIDADE E A WEB SEMÂNTICA ............................................................................................ 28
2.1 O TERMO COMPLEXIDADE E AS METÁFORAS ........................................................................................................ 28
2.2 ENTRE A ORDEM E O CAOS .............................................................................................................................. 35
2.3 A COMPLEXA ROTA HIPERTEXTUAL NA WEB ........................................................................................................ 37
2.4 WEB SEMÂNTICA: CARACTERÍSTICAS E FERRAMENTAS ........................................................................................... 42
2.5 GESTÃO DA INFORMAÇÃO E CONHECIMENTO ....................................................................................................... 46
2.5.1 O computador imitando a mente humana ...................................................................................... 50
2.6 ATRATORES .................................................................................................................................................. 52
3 FOLKSONOMIA ................................................................................................................................... 55
3.1 O TERMO FOLKSONOMIA: CUNHAGEM E DEFINIÇÃO ............................................................................................. 55
3.2 FOLKSONOMIA E SEMÂNTICA ........................................................................................................................... 59
3.3 NARRATIVAS TAGUEADAS ................................................................................................................................ 63
4 JORNALISMO BASEADO EM TAGS ...................................................................................................... 65
4.1 RUPTURAS E CONTINUÍSMOS ........................................................................................................................... 65
4.2 QUEM É ESSE LEITOR? .................................................................................................................................... 68
4.3 QUEM É ESSE JORNALISTA/PRODUTOR? ............................................................................................................. 70
4.4 AUDIÊNCIA .................................................................................................................................................. 73
4.5 BUSCADORES ............................................................................................................................................... 74
4.6 SEO PARA JORNALISMO .................................................................................................................................. 78
5 METODOLOGIA ................................................................................................................................. 81
5.1 MÉTODO ..................................................................................................................................................... 81
5.2 CONTEXTO DE PRODUÇÃO NO EM.COM.BR ...................................................................................................... 84
5.3 COLETAS NO GOOGLE ANALYTICS ...................................................................................................................... 85
5.4 COLETAS NO GOOGLE TRENDS ......................................................................................................................... 87

5.5 DEPOIMENTOS DOS JORNALISTAS ...................................................................................................................... 90
6 ESTUDOS DE CASOS ........................................................................................................................... 92
6.1 INCÊNDIO EM SANTA MARIA ........................................................................................................................... 92
6.1.1 Estatísticas do Google Analytics ...................................................................................................... 95
6.1.2 Google Trends como balizador dos termos “santa maria” .............................................................. 98
6.1.3 Análise de dados............................................................................................................................ 100
6.2 MORTE DE PAUL WALKER ............................................................................................................................. 103
6.2.1 Google Trends como balizador dos termos “paul walker”............................................................. 110
6.2.2 Análise de dados............................................................................................................................ 112
7 CONSIDERAÇÕES FINAIS ................................................................................................................. 114
7.1 CONCLUSÕES .............................................................................................................................................. 114
7.2 FINALIZANDO ............................................................................................................................................. 117
7.3 BASTIDORES ............................................................................................................................................... 118
8 REFERÊNCIAS BIBLIOGRÁFICAS .................................................................................................... 121
APÊNDICE A .......................................................................................................................................... 126

14
“O problema pode muito bem ser recoberto pelas soluções, nem por isso ele
deixa de subsistir na Ideia que o refere às suas condições e organiza a gênese
das próprias soluções. Sem esta Ideia as soluções não teriam sentido”
(DELEUZE, 2007, p. 57).
1 Apresentação da dissertação
A Ideia desta pesquisa surgiu nas andanças como jornalista e pesquisadora em um
caminho não muito longo, mas cheio de novidades: do projeto experimental no fim da graduação
sobre modelos de comunicação hipermidiáticos, cujo ponto final foi o início da “tal” Web
Semântica, à iniciação científica com projeto sobre produção colaborativa na Wikipédia, quando
o gosto pela pesquisa ficou acirrado. Da experiência contrastante como repórter de jornal
impresso, quando entendi o jornalismo diário, à rotina como repórter multimídia de portal de
notícias, quando entendi a diária do jornalismo.
Tudo isso está misturado ao convívio multidisciplinar com os colegas do mestrado em
Estudo de Linguagens, onde conversam pessoas de vários campos – Letras, Comunicação,
Biblioteconomia, Informática, engenharias e outros. As raízes no CEFET-MG como aluna do
curso técnico em Eletrônica, antes mesmo de iniciar o Jornalismo, também fazem parte da
origem. Na construção deste estudo, reúno os questionamentos que surgem na rotina do mercado
de trabalho com a possibilidade de respondê-los com pesquisa acadêmica. A dissertação traz
problemas fabricadores de Ideias, que, por usa vez, darão sentido às soluções.
1.1 Introdução
O jornalismo digital, a difusão das redes sociais e a hipermidiatização do relacionamento
entre empresas e consumidores fazem nascer uma nova era para a produção e leitura na Web.
Muito se discutiu sobre o formato da comunicação e da linguagem na cultura pautada pela lógica
de rede, principalmente na Internet, mas ainda há o que falar sobre as nuvens de informação, em

15
alguns momentos organizadas e, em outros, desorganizadas.
Os estudos sobre efeitos das novas tecnologias na comunicação servem como base para
passos futuros, nos quais o grande desafio é pensar as formas de interação na Web a partir de uma
estética do banco de dados, baseada em tags e remixada na rede. Segundo Moherdaui (2010),
uma tag é uma palavra (relevante) ou termo associado com uma informação – uma imagem, um
artigo, um vídeo – que a descreve e permite uma classificação da informação baseada nessa
etiquetagem. Quando se pensa na perspectiva da recepção, o viés para leitura na Web é de uma
navegação nômade, agenciada pelos usuários, cuja trilha é baseada em tags. A perspectiva da
produção também deve ser ancorada nesse nomadismo, por isso é preciso que os distribuidores de
conteúdo se acostumem com a ideia de gerenciar as tags.
Moherdaui (2010) considera que os produtores – os agentes comunicadores,
principalmente empresas de comunicação – ainda não entraram nesse circuito e continuam
fincados na teoria transmissionista1. Eles não exploram a potencialidade hipertextual da Web. Os
modelos de navegação disponibilizados pelos produtores apresentam estruturas lineares,
enquanto o usuário tende a fazer um caminho próprio pelos sistemas complexos. O que proponho
nesta pesquisa é mostrar que essa realidade está mudando e os produtores incorporaram, mesmo
que timidamente, estratégias de gerenciamento de tags na rotina, pois sabem que a Internet não é
um ambiente para receber e disponibilizar conteúdos, mas um território a ser desenvolvido
cotidianamente pelos leitores (BEIGUELMAN, 2009).
A intenção desta pesquisa foi dar um passo à frente na análise da interferência de
tecnologias nos processos de produção e leitura, avançando para o campo da Web Semântica. A
proposta é substituir a análise isolada de produção e recepção por uma visão complexa sobre o
que está “espalhado” na rede. A metáfora conceitual adotada neste trabalho para ilustrar os
caminhos do leitor no ambiente digital é dos sistemas complexos, numa fundamentação que
engloba Teoria da Complexidade e Teoria do Caos. A metáfora conceitual serviu como elemento
1 Teoria Matemática da Informação (1949): Claude Shannon e Warren Weaver elaboraram o modelo
comunicacional que se apresenta como uma extensão de um modelo de engenharia de telecomunicações. Nesse
modelo, uma fonte passa a informação a um transmissor; este a coloca em um canal e a leva a um receptor/
destinatário. No entanto, o modelo foi criticado pela sua linearidade, incompletude e estatismo.

16
retórico para compor a argumentação, mas além de ser um ornamento do discurso neste trabalho,
será uma ferramenta de compreensão estendendo a capacidade de conceituação.
Outras metáforas que explicam a lógica da rede também foram levantadas na
contextualização, porque ajudam a entender o percurso da Web 1.0 até a Web Semântica. A partir
desses levantamentos, casos reais foram identificados na produção de conteúdo no portal de
notícias em.com.br para evidenciar o gerenciamento de tags e a influência direta delas no
trabalho do profissional de jornalismo digital. Também foi aberto um espaço para entender como
as tags funcionam como elo na rota hipertextual do leitor, trabalhando como “atratoras” e
ganhando novos valores semânticos na Web por causa da lógica de navegação.
Ao aplicar a metáfora dos sistemas complexos à realidade do ambiente digital, parti para a
pesquisa com a hipótese de que os atratores que surgem vão guiar estratégias de etiquetagem de
informações para atrair o leitor. Pela natureza complexa da teoria escolhida, parti da premissa de
que o caminho do leitor na Web não é linear. Também havia a hipótese de que o gerenciamento
das tags entraria na rotina dos produtores de conteúdo na Web e a forma como isso acontece é
uma lacuna preenchida pela pesquisa. Especificamente no jornalismo digital, a relação entre
folksonomia2, os motores de busca na Web e audiência foi uma descoberta na coleta e análise de
dados. Também não havia hipóteses sobre o comportamento semântico das tags em processos de
captura3 do leitor na Web, outro ponto que a pesquisa revelou.
Busquei suporte em estudos desenvolvidos pela Linha de Pesquisa II (Escrita, Leitura e
Processos Interdiscursivos) para ajudar a responder questionamentos como: qual é o terreno de
linkagens temporárias e relações rizomáticas em que a comunicação atualmente “pisa”? O que
mudou desde o início da primeira fase Web para a terceira geração? A Web Semântica possibilita
melhor aproveitamento dos efeitos da rede pelas empresas de comunicação? Como a etapa da
comunicação baseada em tags, que promete inovação no fluxo de informações e uma experiência
estética ancorada em base de dados, está virando realidade? Por que a ferramenta tag é
2 Termo que nomeia a etiquetagem de conteúdos pelas pessoas na Web. O capítulo 3 é dedicado à definição de
folksonomia no contexto desta pesquisa.
3 O termo captura será usado neste trabalho sem a intenção de dizer que o leitor é indiscriminadamente “pego” na
rota hipertextual. O leitor tem sua contribuição em leitura e compreensão, mas foi o termo mais adequado para
retratar a realidade do processo de produção jornalístico na web.

17
responsável pela navegação nômade, pela colaboração em rede e pela alteração de processos
comunicativos? Como o processo de navegação, sob influência de motores de busca, alteram
audiência de sites? Enfim, procurei responder às perguntas com exemplos práticos em dois casos
escolhidos como objeto de estudo: as coberturas jornalísticas do Incêndio em Santa Maria e a
Morte de Paul Walker. As considerações parciais e finais sobre tudo isso estão nos capítulos que
seguem nesta pesquisa, cuja organização está explicada na sessão 1.6.
1.2 Contextualização
A partir da década de 90, alguns autores direcionaram os estudos para a metáfora da rede,
conceito que eles acreditam ser a metáfora da produção, da leitura e da comunicação
contemporâneas. Para França (2002), por exemplo, rede é a metáfora que surgiu no final do
século XX e substitui o modelo do telégrafo, no qual alguns polos de produção possuíam
onipotência sobre os homens, que foram reduzidos ao papel de receptores passivos.
Para Castells (1999), rede é um conjunto de nós interconectados capaz de encurtar
distâncias e integrar novos nós rapidamente. Os nós podem ser textos, pessoas, computadores,
empresas, comunidades, países etc. Segundo ele, a rede pode ser pensada como uma experiência
prática de usuários conectados a espaços virtuais ou como um modelo amplo de funcionamento
social.
Lévy (2003) usa o hipertexto sob a terminologia de uma metáfora para a rede, à luz de
dois paradigmas, o técnico e o funcional. Tecnicamente, hipertexto é um conjunto de nós ligados
por conexões. Os itens de informação não são ligados linearmente, como uma corda com nós,
mas cada um deles, ou a maioria, estende suas conexões em estrela, de modo reticular4.
Funcionalmente, hipertexto é um tipo de estrutura para a organização de conhecimentos ou
dados, a aquisição de informações e a comunicação. Assim como a metáfora da rede, a metáfora
do hipertexto é usada para pensar a comunicação que rompe como o esquema transmissionista.
4 Outra referência de metáfora para rede é o conceito desenvolvido por Deleuze e Guattari, o rizoma (raízes que se
elevam para fora da terra), termo inspirado na botânica e adaptável ao ambiente digital. Rizomas são como linhas
suplementares, que não se ligam a um ponto; emergem de vários pontos, sem exatidão nem destino.

18
Isso porque o papel do hipertexto não é só reunir textos, mas também as redes de associações
capazes de vincular pessoas e ideias na elaboração coletiva de um “hiperssignificado”.
Outra visão é de Jenkins (2008), que cria um paradigma definido como Cultura da
Convergência, uma das visões mais sistêmicas que se pode encontrar sobre a realidade midiática
do século XXI. Uma mudança cultural na forma de pensar e fazer comunicação eclodiu com
ambiente virtual. As novas e antigas mídias começam a interagir de forma cada vez mais
complexa por causa da convergência dos meios de comunicação, da cultura participativa e da
inteligência coletiva.
Por convergência refiro-me ao fluxo de conteúdos através de múltiplos suportes
midiáticos, à cooperação entre múltiplos mercados midiáticos e ao
comportamento migratório dos públicos dos meios de comunicação, que vão a
quase qualquer parte em busca de experiências de entretenimento que desejam.
[...] a convergência representa uma mudança no modo como encaramos nossa
relações com a mídia. (JENKINS, 2008, p.27 e p.49).
Jenkins (2008) fala em “interação complexa” dos meios. Nesse caso, o termo complexo
significa muito mais do que a definição de complicado e intrincado dada pelo dicionário. Para
Morin (2003), a carga semântica da palavra complexidade está atrelada à desordem. Usar a
complexidade para tentar explicar a produção de conteúdo e leitura no ambiente hipermidiático é
a minha escolha nesta pesquisa, um desafio que se justifica pelas características desse ambiente:
ubiquidade, interconectividade, hibridização, interatividade, colaboratividade e imprevisibilidade
(CRUZ et al., 2009). Pensar em todos esses aspectos isoladamente seria um risco de incorrer em
simplismo.
De acordo com Morin (2003), o pensamento complexo integra os modos simplificadores.
Segundo ele, a complexidade é construída junto com a convivência do uno e do múltiplo. É um
tecido de interações e retroações que geram ambiguidade e incerteza. Daí a necessidade de um
pensamento complexo que enfrente a confusão e a contradição geradas.
Usar os sistemas complexos como metáfora nesta pesquisa também é transferir um
conceito da física para estudos das relações humanas, de comunicação e mediação. “Um sistema
complexo pode ser definido como sendo constituído por muitos componentes independentes que
interagem localmente produzindo um comportamento geral, organizado e bem definido

19
independente da estrutura interna dos componentes” (PALAZZO, 1999, p.11). Os estudos da
termodinâmica explicam a troca de energia dentro de um sistema e o caminho de caos e
desordem das partes desse sistema até chegar ao equilíbrio. Da Física vem a ideia da dinâmica
não linear, de um sistema onde as partes são entrelaçadas e trocam feedbacks. A produção e a
leitura online também têm essa característica da não linearidade.
A tecnologia digital está ajudando na construção do que Morin (2003) chama de
pensamento complexo, no qual passamos de uma visão linear da comunicação para uma ideia
circular com auto-organização e conectividade.
Produção e leitura na Internet nem sempre foram dotados dessa hipercomplexidade,
apesar de a plataforma oferecer as possibilidades. Tudo começou quando, em 1992, Tim Berners-
Lee desenvolveu a World Wide Web (rede de alcance mundial), também conhecida como WWW.
A Web foi responsável pelo conceito de navegação, dando ao usuário os links clicáveis que levam
para outros sites.
A Web 1.0, a primeira geração desse novo modo de navegar, era uma espécie de canal de
transmissão de informações, com aplicativos fechados e a adoção de um fluxo de comunicação
unidirecional. O jornalismo, por exemplo, protagonizou uma fase transpositiva nessa época, em
que o conteúdo do jornal impresso invadia a Internet. No Brasil, o primeiro jornal online, lançado
em 1995, foi o Jornal do Brasil (JB)5. Logo depois, o jornalismo se associou ao comércio
eletrônico e tornou-se comum o termo portal, materializando a ideia de uma Internet em
miniatura, simplificada e acessível.
Posteriormente, mas não de forma substitutiva, surgiram as ferramentas de Web 2.0. Essa
nova fase é baseada na colaboração e na produção de conteúdo. O marco inicial para a etapa é o
surgimento do e-commerce como novo canal de vendas e o aumento vertiginoso das ações das
empresas pontocom. A Web 2.0 apresenta aspectos que não eram explorados na Web 1.0, como a
5 Foi também o primeiro jornal a deixar de existir em versão impressa, ficando somente online em 2010. A
mudança de plano de negócio foi resultado de uma crise na venda de jornais.

20
produção coletiva de conteúdo, maior interatividade6 e o usuário como produtor. A nova fase
apontou para o dinamismo e a capacidade de interação, principalmente pelas redes sociais.
Utilizado para descrever a segunda geração da WWW, o termo Web 2.0 foi criado por O’Reilly
(2006):
Web 2.0 é a revolução de negócios na indústria de computadores causada pela
mudança da Internet como plataforma e um entendimento das regras para obter
sucesso nesta nova plataforma. Entre outras, a regra mais importante é
desenvolver aplicativos que aproveitem os efeitos de rede para se tornarem cada
vez melhores quanto mais forem usados pelas pessoas. Isso é o que eu chamo de
aproveitamento da inteligência coletiva. (O’REILLY, 2006 – tradução minha)7.
Na segunda fase, evoluíram muito as ferramentas de busca online otimizada e
principalmente o uso da folksonomia, a produção de conteúdo baseada na ação tagging8. A
folksonomia é uma maneira de indexar informações e surge como uma analogia à taxonomia. O
prefixo folks, palavra da língua inglesa, significa pessoas – ou seja, cada usuário da informação
pode classificá-la com uma ou mais palavras-chave. Assim, abriu-se caminho para a nova etapa
para completar a Web 2.0. “A Web Semântica não é uma Web separada, mas uma extensão da
atual. Nela a informação é dada com um significado bem definido, permitindo melhor interação
entre os computadores e as pessoas.” (BERNERS-LEE, 2001, p.1). A Web Semântica se constitui
com a organização e o uso de maneira mais inteligente de todo o conhecimento já disponível na
plataforma. As informações são compartilhadas na rede digital e uma possível potencialização de
recursos pode reduzir o tempo gasto pelo usuário em buscas frustradas.
A Web foi construída predominantemente para o consumo humano. Aos poucos começam
6 Conforme Primo (2007), interatividade ocorre quando dois ou mais participantes desenvolvem atividade mútua e
simultânea, geralmente buscando o mesmo objetivo. Ela vai além do argumento comercial dos sites ditos
dinâmicos por causa das possibilidades de clicks, pois une pessoas num processo de comunicação mediada por
computador.
7 Web 2.0 is the business revolution in the computer industry caused by the move to the Internet as platform, and
an attempt to understand the rules for success on that new platform. Chief among those rules is this: Build
applications that harness network effects to get better the more people use them. (This is what I've elsewhere
called "harnessing collective intelligence)." (O’REILLY, 2006).
8 Escrita na qual os leitores podem incluir metadados (dados sobre dados) sob forma de palavras-chave para
compartilhar conteúdo. Esse modo de fazer/ler cresceu, sobretudo em redes sociais. A informação publicada é
categorizada para facilitar a busca não só pelo usuário que a marcou, mas por qualquer pessoa com interesses em
comum. (MOHERDAUI, 2012). O conceito será explorado no capítulo 3 desta pesquisa.

21
a aparecer dados legíveis por máquinas, que são distribuídos em um formato específico, sendo
muito limitada a correspondência entre humanos e as versões dos computadores. Segundo
Peixinho (2010), quando os dados na Internet são significativos para o ser humano e são
aumentados com dicas de significado para os programas de computador, esses programas se
tornam muito mais úteis, porque eles começam a compreender a estrutura dos dados.
Essa harmonia de linguagem, que promete ser o futuro da Internet, tem influência na
produção e na leitura na Web, quando esta é pensada como uma mídia. Nesta pesquisa, os casos
estudados (duas coberturas jornalísticas) são voltados para essa perspectiva. Conforme Lima
Júnior (2012), o jornalismo, como braço da mídia, é um dos que se defrontam com as novas
lógicas de produção. Um dos principais pontos é que as empresas de comunicação podem se
apropriar da captura inteligente de leitores na Web usando de forma eficaz as tags.
Essa etapa está proporcionando espantosa produção e armazenamento de dados.
Em vários formatos, esses dados estão disponíveis para serem cruzados e
relacionados por jornalistas que possuem habilidades multidisciplinares ou por
pessoas que possuem conhecimento sobre tecnologias digitais conectadas.
(LIMA JÚNIOR, 2012, p. 69).
O que alguns autores chamam de jornalismo convergente, jornalismo de dados, jornalismo
inteligente ou jornalismo semântico - mesmo não sendo sinônimos - estão incluídos nessa terceira
geração da Web. No jornalismo, é visível a apropriação de ferramentas semânticas no processo de
produção. Os exemplos surgem vertiginosamente: sites como BBC9 e The Economist
10 usam
instrumentos que facilitam a organização do conteúdo e a recuperação de informações.
A BBC, por exemplo, enfrentava um sério problema de falta de integração de conteúdo
porque tem oito canais nacionais de televisão, além de programações regionais, 10 estações de
rádio nacionais, 40 estações de rádio local e um site extenso. Mas a empresa conseguiu se
organizar com uma lógica totalmente baseada em tags, usando a inteligência de buscadores
semânticos e de base de dados disponibilizadas, como DBpedia11
.
9 BBC. Disponível em: <http://www.bbc.co.uk>. Acesso em 10 jul. 2013.
10 THE ECONOMIST. Disponível em: <http://www.economist.com/conversation-cloud>. Acesso em 10 jul. 2013.
11 DBpedia. Disponível em: <http://dbpedia.org/About>. Acesso em 15 jul. 2013.

22
Já o The Economist criou uma nuvem de tags dos tópicos mais comentados do site. Por
meio de palavras-chave, o usuário acessa milhares de conteúdos interconectados e a nuvem
funciona de uma maneira realimentadora para a audiência do portal. É como se ler uma tag
puxasse a leitura de outra e assim a navegação se tornasse infinita sem sair do ambiente do The
Economist. O que se observa nas ações desses dois jornais é o gerenciamento da informação de
uma forma que não era feita antes.
Parte dos processos que descrevo neste trabalho se refere não somente às mudanças na
produção e na leitura, mas às consequências disso para o futuro da Internet. Assange (2012)
discute a liberdade, a vigilância, a censura e novas relações de poder geradas pela divulgação de
dados na Web. O editor de Wikileaks12
, preso pela publicação de informações secretas do
governo americano, relata as batalhas digitais, proporcionadas principalmente pela evolução da
Web até a terceira geração. Ele chama de “guerra furiosa pelo futuro da sociedade”.
O mundo não está deslizando, mas avançando a passos largos na direção de uma
nova distopia transnacional. Esse fato não tem sido reconhecido de maneira
adequada fora dos círculos de segurança nacional. Antes, tem sido encoberto
pelo sigilo, pela complexidade e pela escala. (ASSANGE, 2012, p. 25).
Assange (2012) é apocalíptico, um visionário com motivações políticas, mas deixa um
recado que muito se encaixa nesta pesquisa: mais do que ter em mãos bases de dados e
ferramentas semânticas, a reflexão para produtores e leitores em geral deve ser o que fazer com
esse arcabouço tecnológico. O gerenciamento de informações tem consequências socioculturais.
Nesse gerenciamento incluído na terceira fase da Web, o desafio para uso de tags é
encontrar uma maneira de controlar simultaneamente o lógico e o semântico. O que descrevo nas
situações escolhidas como corpus deste trabalho são exemplos em que os softwares passaram a
fazer parte de estratégias arquitetadas pelos produtores de conteúdo. Ao comunicador – seja ele
jornalista, empresário, membro do governo ou blogueiro – cabe dominar as ferramentas para
entender os resultados do processo como um todo. A analogia de Manovich (2008) é de que os
softwares são os motores das sociedades contemporâneas. Segundo ele, as empresas estão
essencialmente focando seus negócios em softwares: otimização de sites, aplicativos em mapas,
12
WIKILEAKS. Disponível em: <http://wikileaks.org>. Acesso em 3 ago. 2014.

23
mensagens instantâneas e plataformas que possibilitam a criação de outros softwares.
Facebook, Unix, Windows e Android são o centro da economia global, cultural,
vida social e, cada vez mais, política. Esta cultura do software – em que milhares
de pessoas carregam átomos (mídia e informação bem como interações no
entorno dessas mídias e informações) – é apenas a parte visível de um universo
muito maior de softwares. Software é uma cola invisível que amarra nós todos
juntos. Se a eletricidade e a engenharia de combustão fizeram a Sociedade
Industrial, os softwares similarmente permitem a Sociedade da Informação.
Software é o que dirige o processo de globalização. Software é invisível para a
maioria dos acadêmicos, artistas e críticos. Eles se limitam a criticar as noções
de cyber, digital, redes e mídias sociais. Nós nunca olhamos o que está por trás
da nova representação comunicacional. (MANOVICH, 2008, p. 4 – tradução
minha).
Os softwares estão submetidos à inteligência humana. Muitos são criados para repetir,
imitar ou reproduzir ações do homem, sejam eles como extensões – na ideia de McLuhan (1969)
de que todos os meios são o prolongamento de alguma faculdade humana (psíquica ou física) –
ou sejam eles como símbolos da tecnologia da inteligência – uma releitura de Lévy (2004) em
que escrita, leitura, visão, audição e criação são capturados por uma informática cada vez mais
avançada. Os instrumentos da Web Semântica refletem bem a evolução dessa inteligência,
mostrando caminhos e possibilidades aos produtores de conteúdos na Internet.
1.3 Justificativa
A pesquisa é relevante para as áreas de Comunicação Social e Estudo de Linguagens na
medida em que mapeia a evolução de produção e leitura na Web e discute o modo como esses
processos chegaram à Era da Estética de Banco de Dados. São particularmente importantes para a
área acadêmica resultados que apontem especificidades das novas mídias e as mudanças nas
mídias tradicionais, sob a perspectiva de como a comunicação e a linguística se desenvolvem e se
adequam às realidades hipermidiáticas, conforme constata Santaella (2005):
Um dos aspectos evolutivos mais significativos dessa conjuntura revolucionária
está no aparecimento rápido de desenvolvimento de uma nova linguagem: a
hipermídia. Antes da era digital, os suportes estavam separados por serem
incompatíveis: o desenho, a pintura e a gravura nas telas, o texto e as imagens

24
gráficas no papel, a fotografia e o filme na película química, o som e o vídeo na
fita magnética. Depois de passarem pela digitalização, todos esses campos
tradicionais de produção de linguagem e processos de comunicação humanos
juntaram-se na constituição da hipermídia. (SANTAELLA, 2005, p.390).
Para Santaella (2013), a hipermídia como linguagem é o principal ponto da cultura que
emergiu com o universo virtual das redes. Antes dessa cibercultura, a humanidade passou por,
pelo menos, outras cinco fases enumeradas pela autora em palestra na PUC do Rio Grande do
Sul13
: 1) oralidade: externalização do conhecimento – o cérebro morre, mas o conhecimento fica;
2) escrita: dá um status para a memória humana fora do corpo – o ser humano prova o mundo dos
signos; 3) Gutemberg: início das mediações tecnológicas – tecnologia eletromecânica e a cultura
da reprodução; 4) cultura de massa: tecnologia eletroeletrônica, e 5) cultura de mídias: tecnologia
do disponível.
Por fim, segundo a autora, a humanidade entrou na sexta fase – cultura digital – com a
tecnologia do acesso e a interatividade. Ainda assim, uma nova etapa já se inicia com as
possibilidades de mobilidade e miniaturização da tecnologia, o que Santaella (2013) chama de
fase sete – cultura da conexão. Para a entrada dessa nova etapa, nada mais lógico que a evolução
inteligente da Web que esta pesquisa discute. Seria o cenário perfeito para o que a autora
denomina “fusão indissociável entre inteligência do corpo e inteligência artificial”, daí a
relevância em abordar o tema.
Outro aspecto que justifica esta pesquisa é trazer de forma metafórica para as Ciências
Humanas o conceito de sistemas complexos, que vem da Física. Também se buscou uma
definição menos técnica da Web Semântica, muito comum nos trabalhos da área de Computação
e Ciências da Informação. O tema que perpassa esses conceitos na pesquisa é o gerenciamento de
tags na produção e leitura, principalmente as estratégias usadas por produtores ancorados nas
palavras-chave.
A importância das tags está na possibilidade de que a Web deixe de ser um mar de
documentos para se tornar um mar de dados. Os instrumentos da Web Semântica criam
13
O crescimento extrassomático do cérebro humano. Porto Alegre: Pontifícia Universidade Católica do Rio Grande
do Sul, 2013. (Comunicação oral).

25
mecanismos para agenciar esse território de dados. O que pode ser um mar aparentemente caótico
de informações é decodificado pelo navegador/leitor. A comunicação que se processa no
ambiente em rede é de natureza distinta da comunicação de massa, o que motiva a discussão a
respeito do suporte teórico da comunicação, principalmente na Era do Banco dos Dados.
1.4 Problema de pesquisa
Venho observando que os modelos lineares de navegação na Web, disponibilizados pelos
produtores, não correspondem à expectativa do leitor que tende a fazer uma navegação nômade,
própria dos sistemas complexos.
1.5 Objetivo Geral
Mapear a evolução de produção e leitura na Web e discutir o modo como eles chegaram à Era
da Estética de Banco de Dados, avançando para o campo da Web Semântica. Para alcançar este
objetivo busquei casos reais de produção jornalística que evidenciam o gerenciamento de tags
com resultados diretos na audiência desses conteúdos. Com a coleta e análise de dados no Google
Analytics foi possível mostrar a relação entre o uso consciente de determinadas tags para a
captura do leitor na rota hipertextual, uma característica da produção na era semântica da Web -
bem diferente do que se produz quando o foco é a organização de dados online.
Esta pesquisa também esteve focada em aplicar a metáforas escolhida para explicar processos
de produção e leitura na Web, conceituando sistemas complexos no contexto da pesquisa,
definindo a função dos atratores e criando um quadro conceitual usado para a análise de dados.
Outro procedimento foi discutir a produção jornalística e leitura a partir uma estética do banco de
dados, baseada em tags para contextualizar a lógica da rede e a estrutura rizomática em que esses
processos estão inseridos. A ideia era descobrir o que mudou desde o início da primeira fase Web
para a terceira geração, levantando um breve histórico e montando conceitos para Web Semântica
e folksonomia.

26
1.5.1 Objetivos específicos
- Discutir como as tags mudaram as estruturas de significação de conteúdos que circulam a rede:
saber por que as tags são responsáveis pela navegação nômade, pela colaboração em rede e pela
alteração de processos comunicativos.
- Analisar a adequação do uso de um modelo não linear de comunicação em rede: saber como a
Web Semântica possibilita o aproveitamento dos efeitos da rede pelas empresas de comunicação.
1.6 Organização deste trabalho
Além do capítulo de introdução, a dissertação tem mais seis capítulos que ajudam no
entendimento de uma estrutura circular (conforme o Esquema 1) de conceitos e ideias. A proposta
foi trazer a complexidade também para a estruturação do trabalho, em uma montagem menos
simplista e mais integrada possível. Conforme o esquema abaixo, o trabalho foi desenvolvido
para que os temas se englobem e tenham um ponto de interseção.
Esquema 1 – Organização da dissertação
Fonte: Elaborado pela autora
O capítulo 2 traz os conceitos base para o trabalho, complexidade e Web Semântica, e
deixa clara a forma como vou relacioná-los. Uma abordagem fundamental desse capítulo é como
as tags operam como atratores na rota hipertextual da Web.

27
O capítulo 3 trata somente da folksonomia, conceito importante para articular as ideias de
“tagueamento” e classificação na Web. É nesse capítulo que são abordados processos de
indexação e organização popular na rede e as influências disso nos processos de produção e
leitura na Web.
O capítulo 4 especifica processo de produção jornalístico na Web, cujos casos reais são
usados como corpus da pesquisa. Nele contextualiza-se quem é o leitor e o produtor da Web,
além de mostrar qual a influência de motores de busca.
O capítulo 5 é dedicado à metodologia de coleta e análise de dados. São detalhadas as
duas ferramentas de coleta: Google Analytics e Google Trends. Também é apresentada a
importância dos depoimentos dos jornalistas do portal em.com.br, especificamente sobre as
coberturas analisadas.
O capítulo 6 traz os dois estudos de caso, “Incêndio em Santa Maria” e “Morte de Paul
Walker”, com a exposição e análise de dados de forma qualitativa. O capítulo 7 é de
considerações finais para amarrar a análise com as perguntas iniciais da pesquisa.

28
“O círculo do eterno retorno é um círculo sempre excêntrico para um
centro sempre descentrado” (DELEUZE, 2007, p.270)
2 Complexidade e a Web Semântica
O centro é a pesquisadora (descentrada) tentando organizar neste trabalho a
excentricidade da Web. Os círculos são as ideias caóticas para chegar a um consenso sobre o
fenômeno da complexidade, que neste capítulo é explorado junto à construção do conceito – mais
comunicacional do que técnico – de Web Semântica. É neste capítulo que articulo os sistemas
complexos como metáfora conceitual. A metáfora tem um pé na poesia e outro na retórica, por
isso será uma janela muito útil para arremessar as ideias por aqui.
2.1 O termo complexidade e as metáforas
A complexidade é uma palavra problema e não uma solução, mesmo assim ela vem para
resolver o que modos simplificadores de pensamento (como o cartesianismo) mutilaram por anos
ao analisar fenômenos da comunicação e linguagem. Morin (2003) desmistifica a primeira
impressão de que complexidade remete à confusão e à incerteza. O autor prova que algumas
ilusões prejudicam o entendimento da complexidade: 1) muitos pensam que a complexidade
elimina a simplicidade, mas na verdade o pensamento complexo integra os modos
simplificadores; 2) há confusão entre complexidade e completude, na verdade, o pensamento
complexo aspira ao conhecimento multidimensionar, mas esbarra na impossibilidade de
omnisciência ou totalidade. “Se a complexidade não é a chave do mundo, mas o desafio a
enfrentar, o pensamento complexo não é o que evita ou exprime o desafio, mas o que ajuda a
relevá-lo e, por vezes, mesmo a ultrapassá-lo” (MORIN, 2003, p.11).
Mas, afinal o que é a complexidade? É tudo que fica tecido junto com a convivência do

29
uno e do múltiplo, um emaranhado de interações e retroações que geram desordem, mas podem
ser entendidos pelo pensamento complexo. De acordo com Morin (2003), quem não pratica a
complexidade vive na inteligência cega que substitui disjunção por distinção, redução por
conjunção e reducionismo por holismo. “A patologia moderna do espírito está na
hipersimplificação que a torna cega perante a complexidade do real” (MORIN, 2003, p. 22).
Para chegar ao conceito de complexidade, Morin (2003) retoma algumas perspectivas que
deixaram como legado para a análise do conhecimento ciência e comportamento social. Ele
pontua e critica essas teorias, levando em conta os critérios do que considera pensamento
complexo.
A Teoria dos Sistemas, por exemplo, coloca no centro a unidade complexa (um todo que
não se reduz à soma das partes) e situa-se em nível transdisciplinar. Uma vantagem da teoria é
analisar uma causalidade unilinear, ajudando as pessoas a parar de classificar e linearizar as
coisas. No entanto, Morin (2003) critica a teoria pelo fato de ela trazer a noção de sistema como
ambígua ou fantasma. Para completar a teoria, o autor sugere explorar melhor o holismo e a auto-
organização.
A Teoria da Informação, segundo Morin (2003), apresenta a informação como um
conceito em constante construção – o que é positivo. Em contrapartida, a origem física e
matemática da teoria, pensada por Shannon e Weaver, restringe a complexidade. “A informação é
um conceito indispensável, mas não é ainda um conceito elucidado e elucidativo” (MORIN,
2003, p.39). Para completar essa teoria, Morin (2003) sugere a inserção da auto-organização
como mecanismo inseparável da informação.
Outra teoria criticada pelo autor é da Auto-organização, feita originalmente para
compreender o ser vivo, mas que se associou, segundo ele, à cibernética de maneira infeliz. Para
Morin (2003), a aplicação da auto-organização às máquinas artificiais atrofiou o desenvolvimento
teórico porque sugeriu autossuficiência sem interferência do meio externo. O autor sugere como
melhoria para a teoria a inserção da ideia de que o meio faz parte do processo como um
coorganizador.
Por fim, o autor reúne algumas das boas características de todas essas perspectivas e

30
chega à Teoria da Complexidade tratando de incertezas, indeterminações e fenômenos aleatórios.
É uma teoria proposta para compreender unidades e interações que desafiam as nossas
possibilidades de cálculo. De acordo com Morin (2003), um dos saltos da complexidade foi a
associação competente dela à cibernética, que precisou do pensamento complexo para contornar a
famosa caixa-preta (sistemas fechados de alta complexidade e estrutura interna desconhecida).
O desafio do pensamento complexo é entrar na caixa-preta, usando uma visão diferente do
cartesianismo, que elimina ambiguidades. A intenção na complexidade é aceitar certa imprecisão
de conceitos e fenômenos como parte da busca pelo conhecimento. Para isso, três princípios são
fundamentais, conforme Morin (2003): o dialógico, que permite manter a dualidade no seio da
unidade, associando dois termos ao mesmo tempo complementares e antagônicos; a recursão
organizacional, em que produtos e efeitos são ao mesmo tempo causas e produtores daquilo que
os produziu em um ciclo autoconstrutivo, auto-organizador e autoprodutor que quebra a ideia
linear de causa/efeito; e o princípio hologramático, que é a ideia de conceber o todo levando em
conta as partes.
Aos três pontos, acrescento um: o princípio da linguagem, um entendimento de que os
componentes dos sistemas complexos interagem com uma linguagem sofisticada. Não é à toa que
“o pensamento complexo não resolve ele próprio os problemas, mas constitui uma ajuda à
estratégia que pode resolvê-los” (MORIN, 2003, p.121).
Uma forma de cercar melhor a complexidade, com a intenção que esta pesquisa tem de
comparar a produção e a leitura na Web Semântica a um sistema complexo, é levantar as
características desse tipo de sistema. O conceito que aqui será moldado tem como base a ideia
epistemológica de que a “complexidade comporta nela a impossibilidade de unificar, de
acabamento, uma parte da incerteza, uma parte da irresolubilidade e reconhecimento do frente a
frente final com o indizível.” (MORIN, 2003 p.139). Não pecar pela simplificação é muito difícil,
mesmo quando se aspira – como nesta pesquisa – alcançar o pensamento complexo. Mesmo
assim, a imperfeição é parte também da complexificação.
No sentido mais geral, senso comum, o fenômeno da complexidade reside entre a
simplicidade e a “era do caos”. Quando a leis que governam um sistema são relativamente
simples, ele se comporta de forma fácil de compreender e explicar. Por outro lado, quando o

31
sistema é aleatório e não linear (como a Web), pequenas variações de funcionamento podem
alterar bastante o resultado final, fazendo com que esse sistema fique taxado como caótico. Os
sistemas complexos estão entre esses dois extremos, conforme explica Sawyer (2005).
Segundo Palazzo (1999), o melhor “desenho” para explicar um sistema complexo é a
rede, onde há nós, conexões e arcos. De acordo com o autor, a complexidade vem do termo
complexus, que significa entrelaçado ou torcido junto. A explicação muito se assemelha à
metáfora da tapeçaria, usada por Morin (2003) para explicar sistemas não lineares. Segundo o
autor francês, uma tapeçaria contemporânea comporta fios de espessura, cor e textura variadas,
mas nada seriam essas características isoladas se não fosse possível contemplar a globalidade dos
tecidos que se formam com os desenhos originários dos fios entrelaçados. O trabalho final parece
o resultado de uma construção aleatória, mas é fruto de uma organização. Assim também é a
metáfora do rizoma, de Deleuze e Guattari, que já foi citada nesta pesquisa e que faz parecer mais
adequado o uso da complexidade como metáfora conceitual para falar sobre produção e a leitura
na Web.
Os sistemas complexos têm componentes interligados que formam uma estrutura estável,
composição que une distinção e conexão de elementos e que não pode ser analisada
separadamente. Palazzo (1999) usa duas metáforas – da bola de neve (Figura 1) e do efeito
dominó (Figura 2) – para explicar uma característica fundamental dos sistemas complexos: o
feedback. Por meio desse conceito é possível abandonar uma visão linear e simplista para
entender o movimento cíclico de um sistema complexo, composto de autoamplificação e junção
de causa e efeitos em módulos circulares – o que o autor chama de “laço causal”. A principal
vantagem do feedback é ser autoamplificador. Quanto mais complexo é um sistema, mais
estruturas de feedback ele apresenta. Na visão linear, os processos são classificados nos tempos
passado e presente, mas na visão circular tudo ocorre em um mesmo ciclo.
A metáfora da bola que rola e cresce ao mesmo tempo em que aumenta a
velocidade ladeira abaixo, além de representar muito bem o fenômeno
demonstra também dois modos completamente diferentes de perceber o
processo. A bola de neve apresenta dois movimentos diferentes: quando se
acompanha a bola com os olhos, verifica-se que ela possui um movimento
circular de rotação sobre si própria. Por outro lado, quando se observa a bola
rolando ladeira abaixo vê-se que sua trajetória descreve uma linha reta. Os dois
movimentos correspondem a duas formas fundamentalmente diversas de

32
perceber o tempo. [...] Causa grande impressão observar os dominós caírem
sucessivamente, derrubados pela queda de seus antecessores, produzindo assim
uma onda. Entretanto, se este é um padrão emergente, deve haver um ciclo em
algum lugar. Observando cuidadosamente o efeito-dominó pode-se considerar o
mesmo comparável ao efeito produzido por uma esfera invisível, rolando sobre
os dominós e derrubando-os em sequência. (PALAZZO, 1999, p. 7).
Figura 1 - Metáfora do efeito dominó
Fonte: http://www.esquerda.net/
Figura 2 – Metáfora da bola de neve
Fonte: http://algol.dcc.ufla.br/

33
Com essas metáforas e as ideias apresentadas por Palazzo (1999), é possível destacar uma
série de características dos sistemas complexos que ajudarão a articular conceitualmente a
produção e a leitura no ambiente digital. Nos sistemas complexos, consegue-se verificar alguns
padrões, expressos no quadro a seguir. Explorar o ambiente digital pode, também, ajudar a
revelar como surgem padrões de interação. O Quadro 1, baseado na argumentação de Palazzo
(1999), foi montado com a intenção de servir como operador conceitual na análise dos estudos de
caso das coberturas jornalísticas escolhidas como corpus da pesquisa.
Quadro 1 – Características de sistemas complexos
Fonte: Elaborado pela autora

34
O que há de comum entre os padrões apresentados e os artefatos tecnológicos da Web que
permitem caracterizá-los como complexos? Certamente são propriedades que não são
encontradas somente nas partes – as partes são distintas, mas se interconectam. Certamente é
também a tendência de desintegrar-se, mas poder lutar contra a desintegração por meio da
capacidade de criar soluções para os problemas. Segundo Parreiras (2005), para estudar o
ambiente digital é importante avaliar os elementos sem perder as dimensões dinâmicas das
interações, principalmente quando se pretende observar processos passíveis de gerenciamento por
parte do produtor de conteúdo, como no caso desta pesquisa. Não se perdem de vista, em
momento algum, os caminhos do leitor, como observa Santaella (2004):
Quando o usuário “pilota” o computador ele está dentro de um espaço
informacional, um ambiente de signos híbridos no qual imagens, gráficos,
desenhos, figuras, palavras, textos, sons e mesmo vídeos misturam-se na
constituição de uma metamídia complexa. Essa complexidade não é devida
apenas à complexidade dos signos que aciona, mas também devida às exigências
que ela demanda do usuário. É preciso movimentar-se no ambiente, é preciso
encontrar caminhos nessa floresta de signos e de rotas. Em suma: navegar é
preciso. (SANTAELLA, 2004, p.144).
Lévy (2004) corrobora dizendo que as modelizações sistêmicas e cibernéticas usadas por
muitos anos para explicar processos de produção e de leitura são no mínimo insuficientes.
Segundo o autor, elas consistem quase sempre em designar um certo número de agentes de
emissão e recepção, depois em traçar o percurso de fluxos informacionais, com tantos anéis de
retroação quanto se desejar. Assim, interação e comunicação ficam mal representadas.
Os diagramas sistêmicos reduzem a informação a um dado inerte e descrevem a
comunicação como um processo unidimensional de transporte e decodificação.
Entretanto, as mensagens e seus significados se alteram ao deslocarem-se de um
ator a outro na rede, e de um momento a outro do processo de comunicação. O
diagrama dos fluxos de informação é apenas a imagem congelada de uma
configuração de comunicação em determinado instante, sendo geralmente uma
interpretação particular desta configuração, um “lance” no jogo da comunicação.
(LÉVY, 2004, p. 13).
Com a complexidade, por usa vez, é possível discutir características da Web, mas sem
racionalizar demais esses aspectos, porque, no mundo virtual, nem tudo é coerente. Para discutir
a fase da Web em que estamos é necessária desintegração. Essa agitação é importante para a

35
organização do universo em perspectiva complexa, porque une ordem e desordem. Um dia será
possível organizar todas as informações, aceitando a complexidade delas sem eliminar paradoxos
e ambiguidades, que são características constitutivas. “A complexidade está lá onde não se pode
vencer a contradição ou mesmo uma tragédia” (MORIN, 2003, p. 93).
2.2 Entre a ordem e o caos
Palazzo (1999) define a ordem como um conjunto de estruturas simétricas e invariáveis
cuja previsibilidade espaço-temporal pode ser alcançada com facilidade. Parreiras (2005) citando
Williams (1997) define o caos como o vazio primaz do universo antes do início da existência das
coisas, um abismo existente abaixo do mundo. O caos não pode ser incluído em leis porque é
improvável. Os processos de produção e de leitura na Web estão justamente entre a ordem e o
caos, entre padrões de publicação de conteúdo online e total de imprevisibilidade dos caminhos
de navegação do leitor.
Para abordar a complexidade desses processos é necessário descrever o espaço
compreendido entre a ordem e o caos, chamado por Palazzo (1999) de fronteira do caos. Segundo
o autor, a fronteira do caos na Web é o resultado da navegação de leitores que saltam de link em
link, deixando um rastro de conhecimento. Para ele, a WWW é baseada na descentralização de
operações e controle, o que possibilita a interação direta entre produtores e consumidores, com
apelo para uma interface agradável aos leitores da informação. O protocolo Hyper Text Transfer
Protocol (HTTP) é responsável por essa integração entre informação e interface em uma única
representação. Assim, na Web adota-se um princípio de distribuição na representação do
conhecimento, o que significa que este é armazenado como uma rede de nós e links.
Os leitores navegam nessa rede perseguindo os links que lhe são mais significativos entre
um nó e outro, por meio de um julgamento associativo. As contribuições do leitor na rota
hipertextual – criadas a cada navegação – se juntam às projeções estruturais e semânticas dos
desenvolvedores (Web Developers), expandindo o conhecimento da rede como um todo. O
estágio de fronteira do caos permanente na Web se dá por causa do dinamismo na modificação de

36
nós e links (conexões entre eles, exclusões de alguns deles ou inclusão de novos). Toda essa
dinâmica poderia ser sistematizada em uma organização virtual por meio de memória associativa,
no entanto isso não é feito, segundo Palazzo (1999), o que é a grande perda da Web.
Quebrar a fronteira do caos não é tarefa simples, mapear caminhos fortes e fracos é uma
missão de grandeza estatística e semântica enorme, por isso ainda caminhamos para esse
conhecimento. Mesmo com grande aparato tecnológico, vivendo a era em que os softwares
tomaram o comando, conforme avalia Manovich (2008), a organização da informação ainda é
desafiadora porque a tendência é que nós e links se relacionem de forma cada vez mais complexa.
Uma das possibilidades de pensar a fronteira do caos é desenhá-la como um ciclo em que
ordem e desordem giram junto com a interação entre produtores e leitores, que também estão
diretamente ligados à organização. Esta última, quando ocorre – mesmo parcial ou momentânea –
faz emergir espontaneamente novas estruturas e de novas formas de comportamento do processo
de produção e de leitura. A espontaneidade desse ciclo está no fato de que não é necessária
sobreposição ou supervisão de nenhuma das partes (produtores e leitores) ou de instâncias
externas para que os processos continuem acontecendo. A organização é natural e ocorre o tempo
todo a cada advento de reestruturação das formas de interação online. Os próprios processos dão
um rumo ao dinamismo do ciclo, sem linearidade e permeados pelo caos do meio.

37
Esquema 2 – Processo de auto-organização
Fonte: Elaborado pela autora.
2.3 A complexa rota hipertextual na Web
Para entender como a lógica da rede influencia a comunicação, é preciso pensar que a
leitura e a escrita possibilitadas no ambiente hipermidiático apresentam características
específicas. Trata-se de uma escrita não sequencial, não linear, trata-se de hipertexto.
Popularmente os hipertextos são concebidos como uma série de textos conectados por links que
oferecem ao leitor diferentes caminhos, conforme definiu Ted Nelson14
no início dos anos 60.
Sobre esse conceito, Landow (2006) diz:
Hipertexto, como o termo é usado neste trabalho, denota texto composto de
blocos de textos e links eletrônicos que neles se juntam. A hipermídia
14
Theodor Holm Nelson, ou simplesmente Ted Nelson, é um filósofo e sociólogo estadunidense nascido em 1937.
Pioneiro da Tecnologia da Informação, inventou os termos hipertexto e hipermídia, em 1963, e os publicou em
livro, no ano de 1965. Disponível em: <http://pt.wikipedia.org/wiki/Theodor_Nelson> Acesso em: 10 jun.2014.

38
simplesmente estende a noção de texto em hipertexto ao incluir informação
visual, som, animação e outras formas de dados. Desde que um hipertexto ligue
um discurso verbal a imagens, mapas, diagramas e sons tão facilmente como a
outra passagem verbal, pode-se expandir a noção de texto para além do apenas
verbal, não distinguido entre hipertexto e hipermídia. Hipertexto denota um
meio de informação que liga verbal e não verbal. Nessa rede, uso a hipermídia e
hipertexto como termos intercambiáveis. (LANDOW, 2006, p. 3)
Ribeiro (2006) se baseia em Lévy quando afirma o hipertexto como um modelo de
pensamento ou de funcionamento da mente. O conceito de hipertexto do filósofo é um dos que
“foge ao domínio informático e traduz-se em domínios como o das cidades e o das bibliotecas
(físicas)” (RIBEIRO, 2006, p.4). Depois de levantar dezenas de perspectivas sobre o hipertexto,
Ribeiro (2006) não escolhe uma definição ideal, mas sugere que a leitura hipertextual transcende
as telas de computador, considerando que os hipertextos já existiam anteriormente aos meios
digitais.
A conclusão de Ribeiro (2006) é fundamental nesta pesquisa porque considera-se que a
rota hipertextual construída pelos leitores ultrapassa o ato de navegação, daí a complexidade da
qual está dotada a leitura na Web. Daí também a dificuldade do produtor em traçar estratégias
para capturar esse leitor. É possível montar algumas dessas estratégias, como será mostrado nos
casos reais deste trabalho, mas o desafio para cercar a imprevisibilidade da leitura é muito
grande.
Lévy (2004) fala de hipertexto como um mundo de significações baseado em seis
princípios: da metamorfose, heterogeneidade, multiplicidade e de encaixe das escalas,
exterioridade, topologia e mobilidade dos centros. Todos são importantes, mas é essencial
destacar a exterioridade – que resume o conceito de não unidade da rede e dependência de um
exterior indeterminado – e mobilidade dos centros – que significa dizer que a rede não tem
centro, os nós são responsáveis pelas ramificações ao redor de si. O primeiro conceito lembra,
conforme o Esquema 2, o meio externo caótico. O segundo conceito será muito importante
quando este trabalho tratar da função dos atratores, que são os formadores dos centros cambiáveis
no rizoma.
O hipertexto é dinâmico, está perpetuamente em movimento. Com um ou dois
cliques, obedecendo por assim dizer ao dedo e ao olho, ele mostra ao leitor uma

39
de suas faces, depois entra, um certo detalhe ampliado, uma estrutura complexa
esquematizada. Ele se redobra e desdobra à vontade, muda de forma, se
multiplica, se corta e se cola outra vez de outra forma. Não é apenas uma rede de
microtextos, mas sim um grande metatexto de geometria variável, com gavetas,
com dobras. (LÉVY, 2004, p. 24).
Para tratar da fase semântica da Web é preciso pensar no hipertexto como a potencialidade
da rede que permite seu funcionamento e dinamismo. De acordo com Lima Júnior (2012), a
proliferação de dados digitais está produzindo bases de dados gigantescas, espalhadas pelo
mundo e podendo ser acessadas de qualquer lugar do planeta, o que cientistas da computação e
engenheiros cunharam de Big Data. No entanto, somente 5% da informação criada na Web é
estruturada, ou seja, está no padrão de palavras ou números que podem ser lidas pelos
computadores.
O que está ajudando a mudar esse cenário de “desestruturação” é o progressivo
tagueamento do conteúdo na Web. A configuração tecnológica atual ocasiona a conexão entre
bases de dados, por isso surgem novas arquiteturas com níveis informacionais (uma malha) que
tendem ao infinito. Segundo Lima Júnior (2012), para se entender as bases de dados, de modo
conceitual, é preciso conhecer duas importantes definições: Open Data e Linked Data. O
primeiro é a ideia de dados como propriedade pública e o segundo representa a noção de unir
dados que não estavam previamente relacionados. A conformação desses dois conceitos
acrescenta às características da Web 2.015
um valor diferente para o tratamento e a mineração da
informação online, o que nos leva à fase semântica.
A imagem da Internet construída por Barret Lyon16
mostra a estrutura descentralizada
(Figura 3) da Web 2.0, aquela colaborativa e interativa em que as conexões são imensuráveis e
caóticas. Já o digrama de nuvem (Figura 4) revela uma proposta de organização trazida pela Web
Semântica e suas bases de dados. Tanto a imagem de Barret quanto o diagrama são
15
Cf. seção 1.2.
16 Barret Lyon é um empresário americano. É criador do Opte Project, um projeto de mapeamento da Internet que
faz uma representação precisa da extensão da Internet usando gráficos visuais. O projeto começou em 2003, em
um esforço para fornecer um mapa útil da Internet com código-fonte aberto. O projeto reuniu apoio em todo o
mundo e faz parte dos catálogos do Museu de Ciência de Boston e do Museu de Arte Moderna. Disponível em
<http://en.wikipedia.org/wiki/Barrett_Lyon>. Acesso em 15 mai. 2014.

40
representações da hipermídia, o mundo de rotas hipertextuais cambiantes. No entanto, na era Big
Data há um tratamento semântico da informação, o que os cientistas da computação chamam de
estruturação.
Figura 3 – Imagem de Barret Lyon
Fonte http://www.waynebarry.com/
Figura 4 – Diagrama em nuvem do DBPedia (Linking Open Data)
Fonte: http://en.wikipedia.org/wiki/Linked_data

41
Observa-se na Figura 4 como é possível separar por cores cada grupo de informações
correspondentes a classes como mídia, geografia, governamental entre outros. O DBPedia,
exemplo já citado nesta pesquisa17
, funciona com essa organização. O sistema extrai informações
estruturadas da Wikipedia e disponibiliza abertamente na Web, fazendo clara articulação entre
Open data e Linked Data. O que se tem no contexto da Web Semântica é o uso mais
especializado da rota hipertextual proporcionada pelo ciberespaço, que se torna um “lugar”
multidimensional. Este “lugar” é dependente da interação de usuários, permite a eles o acesso, a
manipulação, a transformação e o intercâmbio de seus fluxos codificados de informação. É o
espaço que se abre quando o usuário conecta-se com a rede. (SANTAELLA, 2005).
Pelas inúmeras possibilidades de alterar o conteúdo, esses construtores da rota
hipertextual são chamados por muitos de prosumers (produtores e consumidores de informação) e
produsers (usuários de ambientes colaborativos que se comprometem com conteúdo
intercambiável tanto como consumidores quanto como produtores. Fazem o que agora se chama
de produsage – produção e uso). (BRUNS, 2009).
Para Santaella (2005), a tecnologia da informação digital, aliada às telecomunicações das
redes eletrônicas, conduziu à disseminação da Web, que resultou da associação de dois conceitos
básicos: o de servidores da informação com o de hipertexto. O leitor pode navegar de um texto
em um servidor para qualquer outro, bastando para isso seguir protocolos muito simples. O ato de
navegar é simples, mas a rota gerada pelos caminhos do leitor é extremamente complexa, no
sentido mais “moriniano”. Sobre essa complexificação, Lévy (2004) contribui:
Que isto fique claro: a sucessão da oralidade, da escrita e da informática como
modos fundamentais de gestão social do conhecimento não se dá por simples
substituição, mas antes por complexificação e deslocamento de centros de
gravidade. O saber oral e os gêneros de conhecimento fundados sobre a escrita
ainda existem, é claro, e sem dúvida irão continuar existindo sempre. Não se
trata aqui, portanto, de profetizar uma catástrofe cultural causada pela
informatização, mas sim de utilizar os trabalhos recentes da psicologia cognitiva
e da história dos processas de inscrição para analisar precisamente a articulação
entre gêneros de conhecimento e tecnologias intelectuais. (LEVY, 2004, p.5).
17
Cf. seção 1.2.

42
2.4 Web Semântica: características e ferramentas
A sociedade da informação vive um momento de interoperabilidade semântica e uma
tarefa aguarda os especialistas: aprisionar o caos digital descobrindo sob a sua “aparente”
desordem um cosmos de ideias que deverá funcionar como espelho da inteligência coletiva.
“Aparente” porque, conforme já foi explicado, entre o caos e a desordem existe um quadro de
equilíbrio formador natural de sistemas complexos. O grande desafio desses especialistas é a
gestão do conhecimento, o domínio pessoal dos fluxos de informação, a exploração colaborativa
dos dados e a partilha dos saberes, pois, segundo Lévy (2004), as mensagens que se acumulam e
transitam na esfera midiática derivam de sistemas simbólicos diferentes.
Uma memória digital participativa comum ao conjunto da humanidade está em
vias de construção. Mas no início do século XXI, a exploração dessa memória
por todos e por cada um é limitada por problemas de opacidade semântica, de
incompatibilidade dos sistemas de classificação e de fragmentação linguística e
cultural. Na ausência de modelos computáveis, nós não conseguimos
automatizar a maior parte das operações cognitivas de análise, de filtragem, de
síntese e de interconexão das informações que permitiriam utilizar
vantajosamente a imensa massa de dados que se nos oferecem. Nós não sabemos
ainda como transformar sistematicamente esse oceano digital em observatório
reflexivo de nossa inteligência coletiva. (LÉVY, 2004, p.23)
Uma das propostas para mudar o cenário de opacidade são as ferramentas da Web
Semântica ou Web de Dados. Bernes Lee (2001) a descreve como “uma nova forma de conteúdo
que [...] desencadeará uma revolução de novas possibilidades”. O uso dos metadados18
é a aposta
para aprimorar a Web, pois eles possibilitam a classificação do conteúdo e tornam as buscas mais
eficazes. A Web Semântica tem exercido um papel relevante no estabelecimento de padrões
tecnológicos para a recuperação da informação.
Bernes Lee comanda o projeto World Wide Web Consortium (W3C)19
, que pretende
18
“‘Meta’ é um prefixo de autorreferência, de forma que ‘metadados’ sejam ‘dados sobre dados’. [...]. Em
documentos na Web, têm a função de especificar características dos dados que descrevem a forma com que serão
utilizados, exibidos, ou mesmo seu significado em um contexto.” (ALVARENGA; SOUZA, 2004, p. 134).
19 WORLD WIDE WEB CONSORTIUM (W3C). Disponível em: <http://www.w3.org/Consortium/>. Acesso em
10 jul. 2013.

43
alcançar um elevado nível de resultados de buscas na rede por meio do desenvolvimento de
regras semânticas visando a comunicação entre homem-máquina, de forma que, mesmo sem
deter mais conhecimentos acerca de estratégias de busca, qualquer usuário seja capaz de
recuperar a informação de forma precisa. Essa tecnologia permite que a máquina “compreenda” a
necessidade de informação de quem a busca.
A proposta da Web Semântica é fazer com que a máquina possa executar atividades
simples para os usuários e ajudar a decidir qual serviço usar. Para que os softwares façam isso, é
necessário interpretar informações. A nova fase da Web está maximizando as perspectivas de
compartilhamento e de integração de recursos e aumentando o grau de automatização. Junto às
ferramentas da Web Semântica estão as operações de gestão de conteúdos informacionais que
envolvem classificação, indexação e compatibilização de linguagem. Citando Pierre Guiraud20
,
Alvarenga e Souza (2004) explicam o termo Web Semântica afirmando que a expressão só se
justifica se observarmos as aumentadas possibilidades que o uso de metadados traz:
Embora “semântica” signifique “estudo do sentido das palavras”, Guiraud
(1975) reconhece três ordens principais de problemas semânticos: 1) a ordem
dos problemas psicológicos, que relaciona os estados fisiológicos e psíquicos
dos interlocutores nos processos de comunicação de signos; 2) a ordem dos
problemas lógicos, que estabelece as relações dos signos com a realidade no
processo de significação; 3) a ordem dos problemas linguísticos, que estabelece
a natureza e as funções dos vários sistemas de signos. [...] O uso da conotação
“semântica” para a Web está ancorado na segunda definição, e se justifica se
observarmos as aumentadas possibilidades de associações dos documentos a
seus significados por meio dos metadados descritivos. (ALVARENGA; SOUZA,
2004, p.133)
Esse tratamento de dados está diretamente ligado ao uso de palavras-chave, que são a
representação da metalinguagem Extra Markup Language (XML), uma ampliação da linguagem
HTML (usada para incluir hipertextos na Internet)21
. A nova fase da Web engloba a característica
de criação de redes e comunidades, por isso, Moherdaui (2010) afirma que a noção de
collaborative tagging, com a qual os usuários podem incluir metadados sob forma de palavras-
20
Linguista francês que contribuiu muito para estudos da semântica e análise de dados textuais.
21 Para saber mais sobre HTML e XML, cf. W3C Interaction Domain. Disponível em:
<http://www.w3.org/MarkUp/>. Acesso em 20 jun. 2014.

44
chave, ajuda na publicação de informações categorizadas, um sinal da organização proposta pela
Web Semântica. No capítulo 3, esse aspecto será explorado mais detalhadamente.
Corroborando Alvarenga e Souza (2004), Moura (2009) afirma que a estrutura da Web
Semântica requer três camadas distintas: a lógica, a ontológica e a camada esquema. A primeira é
a mais importante para esta pesquisa porque envolve a interface de conversação e os motores de
busca. A segunda trata das representações semânticas presentes em estruturas taxonômicas e, por
fim, a terceira camada diz respeito ao Resource Description Framework (RDF) e ao XML no
provimento das definições do documento e dos significados a eles associados.
Na visão de Moura (2009), a semântica é parte das constituições da Web 2.0, não podendo
se firmar como etapa evolutiva. Portanto, ela reforça o aspecto de complementaridade que já foi
abordado nesta pesquisa. Conforme Cunha (2006), a Web Semântica faz com que a máquina
consiga entender semanticamente uma determinada busca, o que se torna possível por meio da
utilização da RDF para descrever padrões de metadados e padrões representados por ontologias.
A Web Semântica vem eliminar a dependência de predefinições do usuário e aumentar a
potencialidade de recursos disponíveis para integrar redes, plataformas e sistemas. Isso permite
automatizar a colaboração entre aplicações, por meio de buscas mais efetivas e integração. “Se,
na primeira geração da Web, os documentos eram ligados entre si, deixando para o usuário o
papel de interpretar a natureza destas ligações, a nova geração da Web pretender ter ligações
semanticamente mais ricas, capazes de dar suporte às aplicações em suas negociações”.
(CAMPOS, 2006, p.57).
O aspecto tecnológico dessa integração só será possível com a criação de ontologias,
arquiteturas de metadados padrões, controle de linguagem, modelos de representação,
vocabulários e taxonomias capazes de maximizar o entendimento comum entre homens/máquinas
e máquina/máquina, principalmente tornando as informações compreensíveis para os softwares.
O foco desta pesquisa não é o aspecto tecnológico, mas sim os resultados do uso dessas
ferramentas na produção e na leitura na Web, principalmente do conteúdo jornalístico. Mesmo
assim, é necessário entender o que se passa por trás das operações semânticas e principalmente o
que ainda as impede de acontecer.

45
Um desses impedimentos é a incompatibilidade. A interoperabilidade de documentos e
sistemas na Web depende muito da forma como os dados armazenados são descritos ou definidos
nesses sistemas. Os elementos de descrição (metadados) são fundamentais para qualquer
processo de integração. Eles documentam, com elementos descritores, qualquer recurso
disponível na Web. Se esses elementos descritores tiverem um padrão para todos os sistemas, fica
mais fácil alcançar a operabilidade, por sua vez, facilita a transferência de conhecimento
semântico entre sistemas – situação base do funcionamento da Web Semântica.
Ainda sobre a interoperabilidade, é preciso que haja linguagem comum com etiquetas que
fazem parte do conteúdo do mapa dos sites. Assim é possível criar um vocabulário controlado,
por exemplo, com tesauros22
. A construção de ontologias – conjunto básico de conceitos, relações
entre termos e informações assertivas – também ajuda a promover uma base semântica para
esquemas de metadados, facilitando a comunicação entre sistemas e agentes. Ela ajuda a aliviar o
problema da heterogeneidade semântica, mas não o resolve por completo – sendo esse um dos
maiores desafios da Web Semântica.
Avançando da parte tecnológica para a prática mais próxima da realidade da produção e
leitura de conteúdo, um exemplo oferecido por Campos (2006) ajuda a entender a função da
inteligência da Web Semântica para os conteúdos. Ela pode tornar mais fácil a vida das pessoas
respondendo uma pergunta muito ampla em apenas um ato de busca. Por exemplo: “Qual o
melhor programa de pós-graduação sobre gestão da informação na região sudeste no Brasil?”.
Um resultado eficaz para essa pergunta poderia ser dado por um agente inteligente que “correria”
pela Web, compararia a pontuação das universidades de acordo coma a avaliação da Capes e
traria a lista de nomes. Em seguida, apanharia o formulário de inscrição e os dados sobre auxílio
financeiro dos programas de melhor colocação. Assim, entregaria não só a resposta completa,
mas uma oferta de inscrição para a “melhor” pós-graduação.
Parece mágico, mas é apenas uma possibilidade de busca inteligente em que sites estejam
22
“Vocabulário controlado e dinâmico de termos relacionados semântica e genericamente, cobrindo um domínio
específico do conhecimento, funcionando como dispositivo de controle terminológico usado na tradução de
linguagem natural dos documentos, dos indexadores ou dos usuários para uma linguagem do sistema mais
restrita”. (CAMPOS 2006, p.61, apud UNESCO, 1973, p.6).

46
integrados com padrões que dão maior clareza para o significado da informação manipulada.
Outro exemplo interessante é a possibilidade de que em apenas uma busca a máquina apresente
respostas para palavras de mesmo significado e grafia diferente. O buscador seria capaz de
entender que macaxeira, aipim e mandioca são diferentes expressões do mesmo conceito.
Enfim, surgem vertiginosamente ações tecnológicas e estudos que convergem para o
desenvolvimento da Web Semântica, na tentativa de estabelecer uma forma de navegar não
apenas por palavras-chave, mas por unidades conceituais que possam ajudar a encontrar
documentos de uma forma contextual. (CUNHA, 2006, p.22).
O que se pode perceber é que a Web Semântica é mais do que um conjunto de ferramentas
ou uma plataforma, ela impera com um modelo de produção e leitura cujas prioridades estão no
rearranjo inteligente de dados. Esse modelo é de natureza complexa, dotado de dinamismo, auto-
organização, emergência, feedbacks e ressonâncias. Tem efeitos em grande escala e um
comportamento baseado na linguagem. É por meio dela que será possível realizar processos de
cognição que relacionam volume de dados com objetos do mundo real e permitem que pessoas ou
máquinas movam-se por um infinito de informações conectadas não mais por fios.
2.5 Gestão da informação e conhecimento
A informação ganhou status de insumo básico para a construção do conhecimento e para
tomada de decisão. As condições técnicas da construção colaborativa da memória na Web nos
obrigam a repensar radicalmente as maneiras tradicionais de organizar os arquivos online. Na
rede, as informações estão dispersas em volumes imensuráveis por causa da característica de
liberdade de publicação, autonomia das fontes, descentralização e facilidade no uso da linguagem
natural. O alerta é que a informação, como um bem econômico e social, precisa ser bem cuidada,
por isso todos os profissionais envolvidos no processo de organização e de difusão devem se
empenhar na gestão rápida e de qualidade. “A memória do além-Web clama por um novo suporte
simbólico da conversação criativa, uma esfera semântica aberta, universal, democrática e
computável”. (LÉVY, 2014, p. 139).

47
As ferramentas da Web Semântica são opções para organizar o que Lévy (2014) chama de
“cérebro fractal planetário”, esse conjunto de memórias espalhadas na rede e que ainda não
dispõem de um sistema simbólico que lhes deem consciência reflexiva. A criação desse sistema
poderia ser um foco de políticas públicas, mas certamente serão muito mais resultado de
construções coletivas do que de iniciativa governamental. Lévy (2014) critica as expressões
“capital social” e “desenvolvimento humano” (que pautam políticas públicas de vários países)
dizendo que elas não estão ancoradas na gestão do conhecimento e que deveriam levar em conta
o funcionamento cognitivo das relações humanas.
Para ele, a gestão do canal semiótico está marginalizada, em detrimento de índices não
confiáveis (como as taxas de produto interno bruto, inflação, crescimento, alfabetização,
escolaridade, emprego e renda). O que o autor propõe é um conjunto coerente de dados que
expressem a realidade da sociedade do conhecimento para reunir esses polos. Ele cria um sistema
de coordenadas para endereçar significações e o chama de matriz IEML23
. As combinações
criadas por Lévy (2004) não serão exploradas nesta pesquisa, mas sim as ideias dele para chegar
à formação do sistema.
Lévy (2004) traça os passos da gestão coletiva do conhecimento começando pela gestão
pessoal do conhecimento, aquele em que o leitor exposto ao grande fluxo de informações faz suas
escolhas cognitivas, capta, reúne, filtra, sintetiza, compartilha e retoma o ciclo criativo na rede. O
autor explica como cada leitor pode gerir o próprio conhecimento, começando pela seletividade
da informação – que está associada à escolha de fontes – e terminando com o compartilhamento
dos dados selecionados.
Para ficar mais claro como esse ciclo se completa, vejamos um exemplo: um leitor recolhe
informações, via RSS feed24
, de todos os sites de notícia e blogs de que gosta. O recolhimento
23
IEML: Information Economy Meta Language: novo sistema de codificação das significações, graças ao qual as
operações de sentido na nova memória digital poderiam se tornar transparentes, interoperáveis e computáveis. É
uma linguagem formal de programação em que cada uma das suas expressões válidas modaliza um circuito
semântico próprio que canaliza fluxos de informação. (LÉVY, 2014).
24 Aplicação que permite que alguém não apenas acesse uma página, mas faça uma assinatura sendo notificado cada
vez que haja mudanças na página.

48
pode ser feito também via Twitter25
e Facebook26
, selecionando fontes de informação
preferenciais. O leitor filtra a informação e categoriza esses dados inserindo tags ou comentários
pessoais ao conteúdo. Com essa classificação, ele contribui para a gestão do conhecimento
coletivo, porque constitui redes de compartilhamento e amplia a linguagem natural da rede. Essa
informação categorizada poderá ser usada em curto prazo na memória coletiva (busca de
hashtags em Twitter ou Facebook) ou a longo prazo (como no Delicious27
).
O próximo passo é o leitor sintetizar e fazer um tratamento crítico da informação antes de
partilhar, para que a síntese dele seja útil no processo de colaboração open source e também
visível aos motores de busca. Em breve, após o compartilhamento, o leitor receberá feedback
sobre o conteúdo distribuído e ajudará as pessoas que fazem parte da sua rede a construir projetos
e pensamentos temporários. O exemplo citado pode ser repetir com outras ferramentas online,
pois, segundo Lévy (2004), independente da técnica usada, a função cognitiva do leitor continua
acontecendo. Esse ciclo sempre aconteceu, mas foi potencializado pela Web. Mas como explorar
todos os recursos do meio digital para aumentar a inteligência coletiva? Como a informação
poderia fazer do globo inteiro e do ser humano uma consciência única?
O desafio está lançado, ainda sem respostas concretas. Que a informática atual é capaz de
manipular quase automaticamente símbolos e dados, isso é claro. Mas não é capaz de manipular
conceitos. Os dois grandes embargos são, como já discutimos, o fato de os computadores serem
cegos semanticamente porque só compreendem sintaxe e, em segundo lugar, o fato de o código
usado (línguas naturais) ser irregular. A matriz IEML criada por Lévy (2014) elimina o segundo
problema porque lança um sistema simbólico cujas funções sintáticas e semânticas são paralelas.
O que ele propõe é uma metodologia complementar à Web Semântica proposta pela WWW
Consortium, de Bernes Lee, que ainda se baseia nos “opacos” URL. Lévy é otimista sobre o
futuro: “as pegadas que deixamos na Internet mostram o que fazemos e o que somos. Se somos
capazes de ver a imagem da nossa ação com algoritmos, seremos capazes de controlar a
25
TWITTER. Disponível em: <https://twitter.com/>. Acesso em: 20 ago. 2014.
26 FACEBOOK. Disponível em: <www.facebook.com>. Acesso em: 20 ago. 2014.
27 DELICIOUS SCIENCE LLC. Disponível em: <https://delicious.com/>. Acesso em: 20 ago. 2014.

49
inteligência coletiva na direção do desenvolvimento humano”28
. Santaella (2004) também tem
uma visão sobre essa inteligência:
Simular a inteligência não implica a construção de máquinas com hardwares
específicos, mas sim o desenvolvimento de programas computacionais operando
sobre dados ou representações. (...) inteligência passa a ser definida como
capacidade para produzir e manipular símbolos, tendo em vista a resolução de
problemas (SANTAELLA, 2004, p. 76)
Para Cunha (2006), a possibilidade de uso da Web de forma mais qualitativa viabilizará
uma maior velocidade ao processo de construção do conhecimento e este, por sua vez, promoverá
uma aceleração no alcance da inteligência coletiva. Para que cumpram seu papel transformador,
as informações precisam ser acessadas no tempo e espaço no qual se fazem necessárias. Precisam
também ser organizadas e transformadas em conhecimento. Morin (2003) corrobora as
afirmações:
Hoje, considero prioridade criticar o mito da comunicação. Existem afirmações,
verdadeiros slogans, que não contam do real e geram novos reducionismos. Diz-
se que estamos na “sociedade da informação”, na “sociedade da comunicação”
ou na “sociedade do conhecimento”. Refuto. Estamos em sociedades de
informação, de comunicação e de conhecimento. Claro que estamos em
sociedades de informações, até do ponto de vista físico, da teoria da informação,
basta pensarmos nas tecnologias digitais (DVD, televisão digital etc.), que são
aplicações da teoria da informação. Mas a informação, mesmo no sentido
jornalístico da palavra, não é conhecimento, pois o conhecimento é o resultado
da organização da informação. [...] temos excesso de informação e insuficiência
de organização, logo carência de conhecimento. (MORIN, 2003. p.8).
Por fim, destaca-se que a evolução cultural aponta para uma reunião da esfera midiática
em uma única estrutura digital de registro, de comunicação e de cálculo. Segundo Lévy (2014),
em um futuro próximo – que já se pode tocar, a esfera midiática tece um único meio social da
inteligência coletiva humana. Esta se auto-organiza em um meio para recolher os dados que ela
produz e explorar os dados que ela recolhe. Para o autor, não importa o nome – Web das pessoas,
Web dos dados, Web das coisas, Web local e ubíqua, Web dos saberes e dos tesouros culturais – a
grande rede constitui um único meio digital.
28
Palestra L’inteligence algorithmque, 5 de novembro de 2013, PUC do Rio Grande do Sul. Seminário Imaginário
em Rede.

50
2.5.1 O computador imitando a mente humana
Quando Lévy (2014) fala de “cérebro fractal planetário”, ele critica a incapacidade
informática de juntar dados e ideias. Um passo para sair dessa inércia semântica seria fazer com
que a rede tenha a capacidade de processar signos simbólicos, assim como fazemos nós,
humanos, quando nossa mente se insere no mundo físico retirando dele os significados. Tentar
fazer com que as operações da Web imitem o pensamento humano é o que Santaella (2005)
chama de “modelo computacional da mente”. A ideia surge da união de competências das
ciências cognitivas, da computação e da informação. O princípio fundamental é encarar o cérebro
humano e o computador como sistemas processadores de informação, com alguns aspectos que
os diferenciam. Apesar de distintos, os dois fazem processamento.
De acordo com Santaella (2005), a função intelectual da máquina é processar algoritmos
infinitamente sem qualquer conhecimento sobre seus significados, sendo que esse
“entendimento” torna-se o grande desafio da informática. As máquinas podem fazer operações
numéricas e eletrônicas sofisticadas, mas não são capazes de diferenciar os vários sentidos para a
palavra Lima, por exemplo, que tem pelo menos quatro significados conhecidos na língua
portuguesa: a cidade, a fruta, a ferramenta de amolar facas e o sobrenome. O ser humano, por sua
vez, consegue desmembrar as representações simbólicas dos algoritmos e incorporam o que
Santaella (2005), baseada nos estudos de Allen Newell29
, chama de “sistemas simbólicos físicos”.
Para o computador ter uma boa capacidade semântica ainda é necessário, além da criação
de processadores simbólicos, o desenvolvimento de uma linguagem natural – que envolva a
habilidade de manipular símbolos – para compor a automatização competente. O grande desafio é
simular computacionalmente a linguagem humana. Santaella (2005) propõe que as operações
realizadas no ciberespaço externalizam as operações da mente e as interatividades nas redes
29
Allen Newell foi um pesquisador da ciência da computação e psicólogo cognitivo americano que contribuiu para
a linguagem de processamento de informação e dois dos primeiros programas de inteligência artificial, a Logic
Theorist (1956) e o General Problem Solver (1957) (com Herbert Simon). Disponível em
<http://pt.wikipedia.org/wiki/Allen_Newell> Acesso em 20 jun. 2014.

51
externalizam a essência mais profunda do dialogismo de Bakhtin e Pierce30
, quando estes
colocam em primeiro plano a natureza coletiva dos sentidos da linguagem e o caráter
eminentemente social do signo. Morin (2003) corrobora as afirmações:
Uma das conquistas preliminares no estudo do cérebro humano é compreender
que uma das suas superioridades sobre o computador é poder trabalhar com o
insuficiente e com o vago; é preciso doravante aceitar uma certa ambiguidade e
uma ambiguidade certa (na relação sujeito/objeto ordem//desordem auto-hetero-
organização). É preciso reconhecer fenômenos, como liberdade e criatividade,
inexplicáveis fora do quadro complexo, o único que permite a sua aparição.
(MORIN, 2003, p.53).
Baseada em Pierce, Santaella (2005) postula que não existe pensamento sem signos.
Segundo ela, o pensamento acaba sendo uma extensão dos signos. “Qualquer coisa que esteja
presente à mente, seja ela de uma natureza similar a frases verbais, a imagens, a diagramas de
relações de quaisquer espécies, a reações ou a sentimentos, isso deve ser considerado
pensamento” (SANTAELLA, 2005, p.55). Em palestra na PUC do Rio Grande do Sul, em 2013,
a autora retomou essa ideia quando falou do crescimento extrassomático do cérebro humano.
Rompendo com o pensamento cartesiano de que o signo está separado do pensamento (matéria x
mente), ela conectou a semiosfera (mundo dos signos) com a noosfera (reino das ideais).
De acordo com Santaella (2013), os signos mais relevantes para todas as pessoas estão
externados e compartilháveis para formar o conhecimento e a memória coletiva. “Os signos são
mais eternos do que os mármores e os metais”, afirmou, parafraseando Shakespeare. “A única
entidade que pode estar dentro da mente e fora dela é o signo. O ser humano traduz pensamentos
em signos quando consegue materializar isso”, disse em apresentação no Seminário Imaginário
em Rede. Em suma, a ideia de Santaella (2013) é de que o cérebro humano se expande para fora
do corpo biológico por meio dos signos. Essas extensões de pensamento aliadas à tecnologia
acabam criando o que ela chamou de corpo biocibernético.
30
Santaela trabalha a comparação de ideias dos dois autores partindo da afirmação de Pierce de que todo
pensamento é dialógico na forma e de Bakhtin de que não é o nosso ego que dá significado à linguagem, mas é a
linguagem que dá significado ao ser humano e esse significado só pode emergir nas interações de vozes, nas
trocas e interseções entre o falante e seu ouvinte. Para Santaella, os dois autores constroem o conceito de
dialogismo como importante tese anticartesiana.

52
O mais importante para esta pesquisa é entender o momento em que o signo é
“extrojetado” do pensamento e se manifesta em meios ou suportes exteriores. Desenhos, escrita,
fotografia, cinema e música exemplificam esse “pulo” do signo para fora do cérebro. De acordo
com Santaella (2013), quando o pensamento toma corpo, principalmente em mídias específicas,
há uma enorme profusão da linguagem. A discussão que levanto sobre o uso das tags e a busca
delas na Web reflete esse encontro entre signo e linguagem, o lugar onde os campos semânticos
individuais e senso comum borbulham – local chamado por Santaella de matriz da linguagem e
pensamento.
2.6 Atratores
Para completar o ciclo em que se define a produção e a leitura na Web Semântica como
um sistema complexo, falta trazer uma das ideias fundamentais desta pesquisa em que as tags
protagonizam a sustentação teórica. As tags assumem o papel de articuladoras da complexidade
na Web, como será mostrado nos casos escolhidos para análise na dissertação, e fazem isso
essencialmente como atratoras de leitores na rota hipertextual.
O conceito de atratores, que vem da Física, se encaixa no contexto da análise da produção
e da leitura na Web Semântica. Segundo Parreiras (2005), os atratores definem rotas descritas
pelos sistemas complexos, servindo como pontos de concentração de “energias” do sistema.
Atrator é “o conjunto sobre o qual se move o ponto P que representa o estado de um sistema
dinâmico determinista quando [...] as forças exteriores que [estejam agindo] sobre ele sejam
independentes do tempo” (RUELLE, 1993 apud PARREIRAS, 2005, p. 92).
Palazzo (1999), por sua vez, explica os atratores com as metáforas do redemoinho nas
águas e de tornados no céu, que exemplificam uma força central sugando as massas dos sistemas
a partir de um ponto impreciso ou padrões de trajetória desses sistemas (Figura 5 e Figura 6). Para
ele, a força que atua nos atratores pode ter origem no próprio sistema e talvez seja essa uma
noção fundamental para entender a complexidade. Os dois exemplos usados são desenhos do
fenômeno chamado vórtice, justamente esse ponto de atração que se forma no movimento

53
circular dos sistemas a partir de duas bases: o desequilíbrio do sistema e o feedback contínuo.
Figura 5 – Vórtice
Fonte: http://www.mdig.com.br/
Figura 6 – Vórtice de redemoinho
Fonte: http://valentimeccel.no.comunidades.net/

54
D’Andréa (2011) enxerga os atratores como estados preferenciais e frequentes dos
sistemas complexos, os mais fáceis de serem observados e precisados quando se acompanha um
sistema dinâmico. Os atratores seriam os agentes na busca pela ordem, sem interrupção do
dinamismo, para o alcance da auto-organização. Só é possível observar esses atratores em
situações de constante transformação. Esta pesquisa mostrará que a produção e a leitura na Web,
muitas vezes, são regidas por atratores, reforçando a ideia do ambiente digital como um sistema
complexo que se auto-organiza a partir da dinâmica das redes hipertextuais.
No caso da Web, o atrator é aquele que puxa o fluxo da informação, que agencia, anima e
movimenta. Os padrões da leitura que serão mostrados nesta pesquisa estão cercados de atratores,
representados na Web pelas tags. Essas palavras-chave assumem a responsabilidade de controlar
simultaneamente o lógico e o semântico na rede. A Figura 5 e Figura 6 ajudam a entender essa
lógica de atração, de forma metafórica, porém descritiva. Afinal, conforme Parreiras (2005), uma
maneira de abordar o assunto da complexidade, considerando a ausência de definição satisfatória,
é descrever os espaços compreendidos entre o caos e a ordem.
De forma similar a D'Andréa (2001), que usou a complexidade para explicar os processos
editoriais da Wikipédia, concluindo a plataforma como um sistema adaptativo complexo regido
por uma dinâmica potencialmente auto-organizada e emergente, adoto a mesma lógica para
compreender a produção e a leitura na Web Semântica. Como já definido, esse modelo representa
um processo de comunicação multidimensional, feita de emissores e de receptores e que não se
esgota na presunção de eficácia do emissor, pois existe sempre um receptor dotado de
inteligência na outra ponta da relação comunicacional. Segundo Morin (2003), a complexidade
da comunicação continua a enfrentar o desafio da compreensão e “equilíbrio energético”. Parte
importante desse equilíbrio é a participação dos leitores dando sentido aos conteúdos online,
conforme será mostrado no próximo capítulo.

55
“O sentido não é nunca princípio ou origem, ele é produzido. Ele não é algo
de descoberto, restaurado ou reempregado, mas algo a produzir por meio de
novas maquinações. Não pertence a nenhuma altura, não está em nenhuma
profundidade, mas é efeito de superfície, inseparável da superfície como de
sua dimensão própria”. (DELEUZE, 2007, p. 75).
3 Folksonomia
É de maquinações de sentido que este capítulo vai falar, dos processos de inserção de
significado popular e espontâneo na Web. As combinações de sentido na rede têm origem na
participação e na colaboração, produzindo uma profundidade – antes unilateral, por parte dos
produtores de conteúdo onipotentes – e agora multifacetada. As inúmeras facetas fazem crescer a
memória deixada por essa maquinação de sentidos, com um legado online recuperável e
explorável para busca de conhecimento coletivo.
3.1 O termo folksonomia: cunhagem e definição
Thomas Vander Wal é o pai do termo folksonomia, um neologismo em alusão ao sistema
de classificação biológica de organismos, a taxonomia. O próprio criador conta que desde os anos
80 estudava as tags e o sentido adicionado por elas aos documentos. Nos anos 90, as pessoas
podiam adicionar palavras-chave a documentos e imagens compartilhadas usando serviços
pioneiros em conexão à Internet. Nos anos 2000, começaram as noções de colaboração nos
processos de tagging até que, em 2003, foi criado o Delicious, um classificador social de
favoritos.
Pouco tempo depois, o Flickr31
começou a usar o colaborative tagging, inserção
colaborativa de palavras-chave pelos usuários, como ferramenta de organização de conteúdo. No
período, Wal estudou essa lógica de organização, trocou e-mails e ideias em fóruns sobre o
assunto, por fim, um dia recebeu uma pergunta como esta: existe um nome para a classificação
31
FLICKR. Disponível em: <https://www.flickr.com/>. Acesso em: 20 ago. 2014.

56
social informal de pessoas que usam Flickr e Delicious e definem etiquetas e tags para a
informação compartilhada? Depois de inúmeras respostas dentro do fórum, um dos participantes
propôs: “folk classification”. Daí as ideias fervilharam na cabeça de Wal que, pouco depois,
cunhou o termo folksonomy.
Folksonomia é o resultado da atribuição livre e pessoal de etiquetas a
informações ou objetos (qualquer coisa com URL), visando sua recuperação. A
atribuição de etiquetas é feita num ambiente social (compartilhado e aberto a
outros). Folksonomia é feita pelo próprio consumidor da informação. (WAL,
2007 – tradução minha).
Para Wal (2007), a folksonomia tem um tripé como sustentação: a tag (etiqueta), o objeto
tagueado e a identidade – são todos fundamentais para desambiguação do conteúdo e fornecem
um rico entendimento do objeto marcado. De acordo com Assis e Moura (2013), as atribuições de
palavras-chave geram uma classificação popular que se origina das ações de representação da
informação, desempenhadas por usuários de diversos serviços da Web. É como se o uso de tags
agregasse manifestações da linguagem de sujeitos no processo de colaboração.
As tags são signos que se manifestam como símbolos, mas possuem nuances icônicas –
porque sugerem um compromisso do sujeito com o conteúdo que ele descreve – e indiciais –
porque representam a semiose do sujeito no momento em que escolhe a palavra (JOHANSEN,
1993 apud ASSIS; MOURA, 2013, p. 99). As palavras-chave na Web se transformaram em base
de renovação e sedimentação de linguagem, uma construção cíclica (complexa) de novas
significações, principalmente com o uso nas mídias sociais.
Primo (2010) traz alguns exemplos em que as hashtags32
são usadas como demonstração
de afetos entre tuiteiros33
, como se fizessem uma função da linguagem não-verbal (gesto, boca
torta, sobrancelha franzida): #prontofalei e #rialto. O autor acredita na naturalidade dessa
linguagem que não surgiu, necessariamente, com a intenção de fazer uma rota de informações a
32
Hashtags são compostos pela palavra-chave do assunto antecedida pelo símbolo cerquilha (#). As
hashtags viram hiperlinks dentro da rede, indexáveis pelos mecanismos de busca. Sendo assim, outros usuários
podem clicar nas hashtags ou buscá-las em mecanismos como o Google, para ter acesso a todos que participaram da
discussão. (Disponível em http://pt.wikipedia.org/wiki/Hashtag. Acesso em dezembro de 2014)
33 Usuários Twitter.

57
serem recuperadas, mas sim como um uso menos estruturado. Cabe aos produtores de conteúdo
online – como jornalistas – aproveitarem para estruturar essas informações de forma favorável,
quer seja para capturar os olhares do leitor na rota hipertextual por meio desses atratores, quer
seja para criar padrões de busca e recuperação para memória da informação. Afinal, é nesses
vórtices que estão concentrados os leitores, pois as tags “manifestam a linguagem compartilhada
e modelada continuamente pelas redes sociais que se agregam em torno da organização e do
compartilhamento da informação em contextos digitais colaborativos” (ASSIS; MOURA, 2013,
p.101).
Outros exemplos de serviços que permitem processos de folksonomia são LastFM,
LiveJournal, Youtube, entre outros. Os exemplos operam de forma diferente o uso de tags, mas
criam comunidades em torno dessas palavras-chave de forma bem natural em conjunto com a
operação do sistema. Com tantas ferramentas disponíveis, o produtor de conteúdo online precisa
se enxergar mais como gerenciador de dados na Web, pois, segundo Assis e Moura (2013), a
folksonomia pode ajudar a resolver gaps históricos na organização da informação: a distância
entre a linguagem de indexação e a linguagem do usuário, além do buraco entre produção de
conhecimento e a representação da informação.
A digitalização das informações, a redução dos rituais sincrônicos e a produção
da informação sob demanda provocaram mudanças radicais na disseminação da
informação e, consequentemente, exigem que sejam realizadas alterações nas
metodologias de elaboração dos instrumentos verbais de representação da
informação. Hoje, verificam-se grandes transformações nas formas de agregação
e de arbitragem em torno da informação e do conhecimento (MOURA, 2009, p.
60).
Sabbatini (2011) enxerga a folksonomia como agenciadora de novas narrativas midiáticas
e cria o termo folkcomunicação, compartilhado no pensamento de Jenkins (2008) sobre
convergência e sobre “spreadable media”34
(JENKINS, 2013). As camadas populares florescem
na Web, potencializadas pelo processo tagging, e encontram voz e vez. Elas operam a
participação online como sistema paralelo à comunicação hegemônica e, além de criar um novo
34
Conceito usado para descrever a mídia contemporânea a partir das metáforas que envolvem os virais na Internet,
ou conteúdos que se espalham com facilidade.

58
fluxo de informações, quebram os modelos de negócios de mídia construídos durante anos.
As ideias dos dois autores se encontraram quando pensam em uma mídia com
envolvimento público, em ambiente de participação e com distribuição da informação de forma
“viral”. Para Sabbatini (2011), os receptores se tornam produtores, até mesmo de conhecimento.
Ele considera a folksonomia como catalogação dos excluídos e, junto com a convergência de
mídias, uma agente potencializadora do acervo cognitivo e da bagagem cultural de camadas antes
classificadas apenas como receptoras.
O uso de tags pelos leitores estabelece novos fluxos informacionais e determinam
assuntos, temas, fontes que interessam muito mais ao conjunto de sujeitos que estão “capturados”
no entorno dessas palavras-chave. Como a folksonomia é uma classificação orientada não por
especialistas ou produtores de conteúdo, mas sim pelos usuários das informações e documentos,
ela abre espaço para contrapontos. De acordo com Moreno (2012), a folksonomia gera riqueza
semântica versus polissemia, baixo custo versus baixa precisão, inexistência de padrões de
vocabulário versus baixo controle de sinônimos. Toda essa imprecisão acontece porque a
folksonomia opera como um processo de comunicação que deixa vestígios de comportamento e,
por sua vez, consolida práticas culturais e discursivas de cada indivíduo. No entanto, não há
problema nessa imprecisão, pois ela resulta em processo de construção de conhecimento mais
espontâneo, conforme afirma Sterling (2005):
Ela [folksonomia] oferece um comportamento de rebanho muito barato e
assistido por máquinas; senso comum ao quadrado; uma corrida às nascentes da
semântica. É como se você jogasse um caiaque em um rio agitado e deslizasse
não apenas pelas páginas da Web, mas também por rótulos, conceitos e ideias.
(STERLING, 2005, p. 2).
A etiquetagem popular surge da combinação de máquinas capazes de automatizar, pelo
menos em parte, o necessário para classificação da informação e softwares sociais que tornam os
leitores dispostos a participar do trabalho em troca de nada. O que se forma aparentemente é um
vocabulário descontrolado com o uso de neologismos e gírias como etiquetas. Para Amstel
(2007), no entanto, o que se tem é a movimentação de regulação da cultura horizontal. Isso
conota a intenção de pertencer a determinados grupos de falantes que possuem vocábulos
próprios, a expressão da identidade do leitor em relação a esses grupos e a maximização das

59
trocas linguísticas dentro e fora dos grupos na Web. “A escolha das etiquetas para registrar a
visão do indivíduo sobre um determinado recurso a ser catalogado é um ato de identificação com
um grupo, mesmo que o indivíduo não esteja consciente disso”. (AMLSTEL, 2007, p. 18).
Diante disso, Van Amstel (2007) conclui que os vocabulários não são tão descontrolados
como parecem. Existe controle, mas este não é centralizado nem forçado. Trata-se de
movimentos reguladores da cultura no sentido horizontal, que se propagam pelos laços da rede
social do indivíduo. Essas escolhas se baseiam na identidade cultural de cada sujeito, habilidades
discursivas e cognitivas. Assim, a folksonomia acomoda certa diversidade cultural, no momento
em que muitos pensaram que a solução para a organização de dados na rede seria homogeneizá-
los. O simplismo da homogeneização não caberia na complexidade da Web Semântica.
Por fim, muitos autores discutem se os resultados da folksonomia ficam como legado para
recuperação e indexação de informações na Web, alguns acreditam que, por ser uma etiquetagem
não intencionada, não serviria para formação de memória formal, mas outros acham que tem
utilidade. Nesta pesquisa, considerando a folksonomia como um paradigma de classificação,
aceita-se que é possível que seja uma ferramenta de recuperação, como será mostrado em dois
exemplos práticos de cobertura jornalística em que um processo de classificação beneficiou a
distribuição de conteúdo online e, por sua vez, gerou mais audiência. O que fica como desafio é a
criação de aplicações que mantenham o caráter colaborativo da folksonomia e consigam atingir
qualidade na indexação de tags.
3.2 Folksonomia e semântica
Os sistemas de classificação e indexação sempre existiram, independente da Web, para
organização de conteúdos de bibliotecas diversas. O mesmo raciocínio de organização não
poderia ser usado online? A resposta é não, porque o ambiente físico de bibliotecas é mais
organizável do que a esfera semântica formada por um mar de documentos espalhados em rede
mundial. Além disso, a possibilidade de etiquetagem variada, feita pelos leitores, amplia ainda
mais a escala de palavras ou expressões a serem indexadas.

60
A solução para os problemas advindos da folksonomia seria, segundo Lévy (2014), a
criação de uma escrita de segunda classe, ou uma metalinguagem capaz de guiar o fluxo de dados
na Web. A nova geração de escrita seria, conforme o autor, universal (porque exprime uma
memória mundial), democrática (porque a manipulação não é exclusiva de especialistas e sim de
todos os leitores) e calculável (porque permitiria informatização – criação de computação
ubíqua). Essa metalinguagem viria “para transformar o dilúvio de informação em memória útil,
organizada, portadora de conhecimento, além das barreiras da língua” (LÉVY, 2014, p. 169). É
utópico o que o autor propõe? Talvez sim, mas ele mesmo cria uma linguagem simbólica que, por
enquanto, é única nessa nova geração de escrita, como já foi abordado, o IEML.
As trocas construtivas na Web são muitas vezes agenciadas por hashtags. As mensagens
do Twitter apontam para uma URL com dados multimídias. Segundo Lévy (2014), as mensagens
categorizam esses dados por meio de um breve comentário e/ou por meio de uma hashtag (nesse
caso uma etiqueta metadado). “Em particular as hashtags servem para reunir e encontrar nos
motores de pesquisa especializados – como Twitter search, Twazzup e Topsy – os URLs, os fios
de discussão ou os comentários que concernem o mesmo assunto” (LÉVY, 2014, p. 154).
Dessa forma, dados são filtrados, categorizados e re-categorizados na Web em um
movimento cíclico. Assim, os motores de busca acumulam dados e organizam metadados à sua
memória automatizada. O uso dessa memória pelos leitores transforma os dados iniciais
acumulados em conhecimento. Simetricamente os saberes viram novos dados no ambiente digital
e metadados – por meio da atividade de categorização (em tags ou hashtags). Por causa desses
processos cíclicos, um leitor na Web acaba criando uma identidade semântica e sendo encontrado
por motores de pesquisa justamente pelos seus “marcadores de zona semântica” (LÉVY, 2014, p.
158). É como se um leitor, pelos caminhos na rota hipertextual, criasse um campo de etiquetas
que declaram os interesses desse leitor (em assuntos específicos, notícias, jogos, pessoas etc.). O
fluxo de informações que chegam até ele – de forma automatizada ou natural na Web – ou que ele
busca, provavelmente será de conteúdos relacionados/codificados ao interesse.
A confluência de milhares e milhares de marcadores de zona semântica forma uma grande
esfera onde se encontram a memória coletiva e a inteligência. O mais incrível é quando essa
esfera sai do ambiente virtual e se materializa em projetos temporários e cambiantes como

61
manifestações populares – o caso do movimento35
, em junho de 2013, no Brasil agenciado, por
exemplo, pelas hashtags #vemprarua e #ogiganteacordou.
O cenário cíclico de construção da memória coletiva estaria perfeito se não fosse a
transversalidade de saberes, de comunidades, de pessoas, de mídias sociais e de sistemas. Ainda
não conseguimos tirar partido desse potencial de conhecimento de forma automática porque não
temos uma codificação única e inteligente capaz de ler toda essa esfera semântica e reuni-la. Uma
mesma pessoa pode usar o Twitter, o Facebook, um feed de notícia do Globo.com, um blog na
plataforma Wordpress, o Delicious e criar em cada uma dessas plataformas sua zona semântica,
sendo que essas zonas podem nunca “se comunicar” por uma incompatibilidade de sistemas.
Algumas dessas plataformas “se comunicam”, como quando alguém posta no Twitter ou no
Instagram e aparece na timeline do Facebook, mas segundo Lévy (2014), ainda estamos longe de
uma circulação transparente – que transponha a concorrência entre essas mídias – e permita a
gestão do conhecimento.
Da mesma forma que a informática conheceu uma verdadeira revolução nos
anos 1990, com a generalização dos computadores pessoais, é possível que a
gestão dos conhecimentos conheça no curso do século 21 uma verdadeira
revolução descentralizadora, dando mais poder e autonomia às pessoas e aos
grupos auto-organizados. Mas isso só poderá acontecer por meio da adoção de
um protocolo comum para a expressão dos metadados semânticos que permitirá
a conversação criativa dos limites impostos pelos grandes atores centrais da
Web. (LÉVY, 2014, p. 161).
Além da tríade proposta por Wal (2007) (tag-objeto-identidade), o aspecto semântico ou a
rede de conceitos gerada pela folksonomia é um elemento muito importante. Conforme Assis e
Moura (2013), a classificação popular permite a emergência de padronização de terminologias
quando o “crivo” de vários sujeitos fortalece determinados termos e enfraquece outros. A
autoridade ou credibilidade desses termos surge de acordos coletivos propiciados pelo contexto
dinâmico e auto-organizado da rede. É neste ponto que o uso de tags ajuda a cada vez mais firmar
e manter a Web como sistema complexo, em clico autopoético principalmente no aspecto
semântico.
35
Manifestações em todo o Brasil durante a Copa das Confederações.

62
Segundo Assis e Moura (2013), como a folksonomia tem origem na indexação social,
acaba constituindo espaços sociais semânticos nos quais ocorre agregação de subjetividade e
objetividade – as duas baseadas em linguagem natural. Isso confere à folksonomia elevado grau
de semanticidade, mas baixo grau de formalidade na linguagem. Para as autoras, o intercâmbio
entre essas duas características é historicamente observado em processos de organização da
informação. O equilíbrio delas ajuda a sanar problemas próprios de processos folksonômicos,
como sinonímia e polissemia.
Com efeito, os tags de folksonomia são incoerentes por causa dos fenômenos de
sinonímia, sem falar do ruído introduzido pelos erros de ortografia, os plurais, as
abreviações, etc. Além disso, os tags correspondem a graus de generalidade
muito diferentes e se organizam mal em classes e subclasses. Enfim, a
multiplicidade de línguas naturais (nas quais os tags são geralmente expressos)
ainda fragmenta gravemente as conversações criativas que começaram há alguns
anos a organizar a memória mundial. (LÉVY, 2014, p. 167).
No contexto da Web, algumas ferramentas surgem como promessa de solução para a
busca inteligente de palavras do mesmo significado e grafia diferente ou vice-versa. Os sistemas
de busca foram os que primeiro atentaram para a análise semântica do conteúdo da Web, com
objetivo de retornar resultados superando ambiguidades associadas. Os sistemas de busca
convencional apresentam baixo suporte para informações contextuais, analisando o conteúdo da
página (por meio de links) sem eficiência de informações semânticas. Atualmente surgiram os
buscadores semânticos que usam uma lista de operações coordenadas, ou seja, algoritmos que
geram estatísticas a partir das palavras e seus significados. Alguns exemplos são o
WolframAlpha36
, Swoogle37
e Kartoo38
. Mesmos com os avanços, é preciso pensar mais
rapidamente em um futuro de interoperabilidade e competente recuperação de informações na
Web.
Em última instância, nenhum cérebro humano, nenhum planeta cheio de
cérebros humanos, poderia catalogar o oceano escuro e em expansão de dados
que produzimos. Em um futuro de informação auto-organizada pela
36
WOLFRAM ALPHA. Computational knowledge engine. Disponível em: <http://www.wolframalpha.com/>.
Acesso em: 5 jul. 2014.
37 SWOOGLE. Semantic Web Search. Disponível em: <http://swoogle.umbc.edu/>. Acesso em: 5 jul. 2014.
38 KARTOO. Disponível em: <http://www.kartoo.com/>. Acesso em: 5 jul. 2014.

63
“folksonomy”, poderemos nem ter palavras para o tipo de classificação que
estará ocorrendo; como as verificações matemáticas com 30 mil etapas, ela
poderá estar além da compreensão. Mas permitirá buscas vastas e incrivelmente
poderosas. Não surfaremos mais com as máquinas de busca. Faremos arrastão
com as máquinas de significado. (STELING, 2005, p.2).
3.3 Narrativas tagueadas
A narrativa social, informativa e feita pelo usuário tornou-se possível graças aos avanços
da Web baseada em tags e da computação em nuvem. Essa narrativa é composta em parte pelos
processos de folksonomia e pela noção transmidiática trazida com a participação dos leitores nos
conteúdos online. É uma narrativa que surge como a convergência das mídias e prevê uma
estética que faz novas exigências aos consumidores, dependendo da colaboração deles. “A
narrativa transmídia é a arte da criação em um universo” (JENKINS, 2009, p.49).
O diferencial das narrativas transmídia – da qual fazem parte as narrativas tagueadas – em
relação ao contar história tradicional, é que elas requerem abordagens plurimidiáticas, conforme
definem Alzamora e Tárcia (2013). A narrativa assumiu, por muito tempo, uma forma textual
(monomidiática), no entanto se descobriu que ela pode ser adaptada a qualquer mídia porque a
essência de narrar está na composição estrutural da história, na ordem dos fatos, nos personagens
e na presença de um narrador. Na versão transmídia, o leitor (antigamente destinatário da
história) compartilha o ato de narrar, resultando em um processo de formação de sentido
fragmentado e multifacetado (ALZAMORA; TÁRCIA, 2013).
O jornalismo tem experimentado dessas diversas faces quando incorpora histórias
contadas por meio de várias plataformas (vídeo/TV, áudio/rádio, infografia/Web) e com o
enriquecimento da participação de leitores (comentários, tuítes, compartilhamentos). Para Jenkins
(2009), uma história transmídia se desenrola por meio de múltiplas plataformas de mídia, com
cada novo texto contribuindo de maneira distinta e valiosa para o todo. Para ele, cada ponto de
acesso à história ou ao fato deve ser autônomo e cada um deles deve garantir acesso aos demais.
A compreensão obtida por meio de diversas mídias sustenta uma profundidade de experiência que
motiva mais consumo (JENKINS, 2009, p. 138).

64
A questão que se apresenta ao jornalismo nesse sentido, conforme o trabalho de Campos
(2013), é até que ponto os conteúdos – muitas vezes reunidos em matérias online – não se
complementam. Alguns modelos vendem uma falsa convergência, quando na verdade as
narrativas apresentam tanta autonomia que não podem ser vinculadas como uma produção
convergente. Nem todo conteúdo disperso na rede pode ser considerado narrativa transmidiática,
às vezes as peças do quebra-cabeça não foram geridas para a concepção de um produto com um
planejamento na origem (ALZAMORA; TÁRCIA, 2013). Por isso, considero as narrativas
tagueadas uma parte para alcançar a forma transmidiática.
O ato de compartilhar nas redes sociais exemplifica o tagueamento de narrativas, levando
em conta que as marcações inseridas pelo leitor quando posta um conteúdo é um complemento à
história já contada, seja esse complemento em forma de comentário, hashtag, foto, ou até mesmo
um emoticon39
. Uma pessoa que recebe em sua timeline40
uma matéria jornalística sobre as
organizações do Brasil para receber os turistas na Copa do Mundo em 2014, acompanhada da
hashtag #naovaitercopa, que foi inserida por um amigo, tem elementos “além-texto” que vão
contribuir para a formação de sentido sobre aquele conteúdo.
O amigo que partilhou a reportagem inseriu uma categorização popular, influenciando a
passagem da narrativa, que chega reconstruída ao novo leitor. Isso não significa que se completou
uma produção transmidiática, mas influenciou o processo de leitura. Um compartilhamento como
esse poderia, sim, gerar uma retroalimentação para os produtores de conteúdo (neste caso
jornalistas) planejarem uma narrativa transmídia levando em conta o que a inserção
#naovaitercopa traz como contexto, considerando-a uma tag atratora de engajamento temporário.
A mudança do jornalismo digital, embasado na mídia impressa, para o jornalismo semântico e
tagueado traz aflições e também novas perspectivas, que serão exploradas no próximo capítulo,
baseado na expressão criada por Moherdaui (2010), o jornalismo baseado em tags.
39
Os emoticons são fenômenos de popularidade na internet. São formas de comunicação extralinguística pelas quais
se expressa emoção por meio de um ícones (uma carinha triste ou feliz, uma careta ou um coração). A palavra
emoticons une (emotion) emoção + ícone. Muitas vezes os ícones demonstram uma expressão facial que a pessoa
faria “ por trás” das telas naquele contexto.
40 Timeline é linha do tempo. No contexto da Web significa a exibição de atualizações e conteúdos para o leitor
quando ele usa uma rede social como Twitter ou Facebook.

65
“A linguagem é tornada possível pelo que a distingue. O que separa os sons e
os corpos faz dos sons os elementos para uma linguagem. O que separa falar
e comer torna a palavra possível, o que separa as proposições e as coisas
torna as proposições possíveis. O que torna possível é a superfície e o que se
passa na superfície: o acontecimento como expresso”. (DELEUZE, 2007, p.
191).
4 Jornalismo baseado em tags
O trabalho jornalístico se revela quando a linguagem traduz um acontecimento dando
origem à notícia. Como saber se um fato merece a publicidade de notícia? É como separar corpos
de sons. É retirar do acontecimento o que ninguém vê: o melhor ângulo, a melhor frase, a melhor
fala e a melhor história. A notícia é “tornada possível pelo que a distingue”. Quem diz o que é
notícia é o leitor, a audiência para o “acontecimento como expresso” (DELEUZE, 2007, p. 191).
A essência do jornalismo é a notícia (prevista ou imprevista). Atualmente ela é costurada em uma
série de mudanças tecnológicas e de modos de fazer diferentes. É desse emaranhado de linhas,
pontos e agulhas que este capítulo vai falar.
4.1 Rupturas e continuísmos
A “união” entre comunicação, computação, informação e memória é um mecanismo de
mudança social. O jornalismo, por sua vez, acompanha essas mudanças se apropriando de
tecnologias e ferramentas que elucidem essa “união” com objetivo de melhorar produção e
distribuição de conteúdo. O jornalismo baseado em tags é resultado de um uso não trivial da Web
para produção de conteúdo ancorado na mistura entre o pensamento computacional definido por
Wing (2006) e pensamento comunicacional definido Miège (2000):
Pensar computacionalmente é pensar recursivamente. É processamento paralelo.
É interpretar o código como dado e o dado como código. É a verificação de tipo
como a generalização da análise dimensional. [...] É julgar um programa não
somente pela exatidão e eficiência, mas pela estética e o design do sistema pela
simplicidade e elegância. É usar abstração e decomposição quando se ataca uma
grande e complexa tarefa ou se projeta um grande sistema complexo. [...] É ter a

66
confiança que podemos seguramente usar, modificar, influenciar grandes
sistemas complexos sem entender de todos os detalhes. (WING, 2006, p. 33 –
tradução minha).
O pensamento comunicacional não é estático. Ele é o produto da história
humana. Não é, porém, uma criação constantemente renovável, ele é
profundamente marcado por suas origens, e as etapas por que passou ao longo
dos últimos 50 anos são particularmente esclarecedoras por causa disso.
(MIÈGE, 2000, p. 15).
Juntar esses dois pensamentos é uma ação que provoca rupturas e continuísmos no
processo de produção jornalística. A principal ruptura do jornalismo baseado em tags para o
jornalismo digital que se fez por muitos anos é o encerramento da cultura da página, com a
organização da informação baseada no mecanismo de o leitor folhear o conteúdo, passando para a
noção do leitor navegando pela rota hipertextual.
O que se tem na verdade como ruptura é a implosão do processo comunicacional pautado
em hierarquia, conforme mostrou a tese de doutorado de Luciana Moherdaui. Focada em
características de interface, a autora mostra que a produção baseada na lógica das tags leva à
morte do browser no formato de leitura ancorado ao modelo do impresso. Para a autora, é hora de
pensar um jornal como rede social – um “facejournal” – no qual o leitor faz login e vira jornalista
automaticamente produzindo notícias.
Alguns exemplos de construções jornalísticas baseadas em tags, que fogem da hierarquia
tradicional, podem ser vistos em sites como os agregadores de notícias 10x1041
e Digg42
, a
reportagem especial sobre Hiroshima na plataforma Google Earth43
, o mapa open source44
usado
na cobertura da greve de metrô em Londres pela BBC, o rastreador de tweets relacionados ao
escândalo da decisão de Rupert Murdoch em fechar o News of The World45
. Há também outras
41
10x10. Disponível em: <http://www.tenbyten.org/10x10.html>. Acesso em: 28 ago. 2014. 42
DIGG. Disponível em: <http://digg.com/>. Acesso em: 28 ago. 2014.
43 http://hiroshima.mapping.jp/ge_en.html
44 LONDON Tube Strike Map. November 28th/29th 2010. Disponível em:
<https://tubestrike.crowdmap.com/main>. Acesso em: 28 ago. 2014.
45 THE GUARDIAN. Disponível em: <http://www.theguardian.com/media/interactive/2011/jul/13/news-of-the-
world-phone-hacking-twitter>. Acesso em 28 ago. 2014.

67
iniciativas, não necessariamente jornalísticas, mas que informam e usam ferramentas
interessantes de semântica como o balizador de termos Google Flu Trends46
. Por meio dele, o
Google monitora palavras-chave relacionadas à gripe (como sintomas, posologia, entre outras) e
monta um mapa indicando mês a mês quais as localidades do mundo que mais buscaram aqueles
termos. Com isso, constrói um banco de dados que reflete exatamente a realidade da gripe pelo
mundo, em estações diferentes do ano, podendo servir até como base para políticas públicas de
saúde. Outro exemplo é a aplicação We Feel Fine47
, que reúne tags de sentimentos (feliz, triste,
entediado, entre outros) postadas por tuiteiros e assim traça o humor da população online no
microblog segundo a segundo. Um terceiro exemplo é o Geoplay48
, que traça uma rota em mapa
de um destino inicial e final mostrando todas as fotos postadas na Web sobre monumentos,
prédios ou ruas que fazem parte daquele caminho.
Nenhuma dessas ferramentas deve excluir os veículos de comunicação, mas incluí-los e
motivá-los a usar instrumentos novos de produção e distribuição de notícias, conforme constata a
autora:
A interface jornalística deveria ser pensada não só a partir de um coletivo
inteligente, mas do input de dados e tags, pois ela opera por revezamento entre
informação e contrainformação; poder e contrapoder. É resultado de alteridades.
Não há uma estética definitiva. As redes colocam em xeque a estética
PowerPoint de Manovich e os formatos portal e site não cabem nessa nova
abordagem. É como afirmou o escritor Clay Shirky: uma das razões pelas quais
o Google foi bem-sucedido é o entendimento de que não há arquivos, não há
prateleiras. (MOHERDAUI, 2013, p. 231).
O principal continuísmo do jornalismo baseado em tags é a rotina de pensar a notícia com
uma experiência social, em uma rota hipertextual do leitor que é compartilhada, principalmente,
por meio das redes sociais. Essa experiência cria um ambiente cíclico para circulação e
reverberação de notícias. Na maioria das vezes, essa reverberação é responsável pela
multiplicação de dados e campos semânticos de um assunto/conteúdo. Quando os jornais
46
TENDÊNCIAS da gripe. Google.org. Disponível em: <http://www.google.org/flutrends/>. Acesso em: 28 ago.
2014/.
47 WE feel fine. Disponível em: <http://wefeelfine.org/>. Acesso em: 28 ago. 2014.
48 GEOPLAY. Disponível em: <http://geoplay.info/pt/>. Acesso em: 28 ago. 2014.

68
entendem essa leitura social, vão em busca da captura do leitor, muitas vezes agenciada por tags
ou hashtags.
Além da ruptura e do continuísmo apontados, é preciso destacar o trabalho jornalístico
permeado pela habilidade em lidar com dados. Um levantamento feito pelo fabricante de
equipamentos Cisco49
mostra que há previsão de que o tráfego online cresça para 767 exabytes
em 2014. Um exabyte equivale a 1 bilhão de gigabytes e uma pessoa levaria 72 milhões de anos
para ver todo o conteúdo de vídeo circulando pela rede nos 365 dias do ano. No jornalismo
baseado em tags, o repórter dever estar pronto para cruzar dados e relacioná-los com seus
objetivos de audiência, como é mostrado nos casos desta pesquisa.
Como pesquisadora e repórter da área, admito as mudanças e tento entendê-las. Melhor do
que insistir na ideia, quase senso comum, de que o jornalismo como segmento cultural e
profissional está em uma crise intransponível. É possível transpor e o caminho está na rota
hipertextual. Os estudos desta pesquisa são APENAS exemplos do que pode ocorrer no contexto
da Web Semântica, que tem um mundo de ferramentas e possibilidades de uso não trivial. No
jornalismo, ainda podem ser trabalhadas as perspectivas do lead semântico, hacking jornalístico,
jornalismo computacional, mashups e uso de programação no jornalismo, mineração de dados
para aproximação e agregação de informações, além dos temidos bots, que publicam textos em
massa. O que não se pode perder de vista é que a “a informação como forma é indissociável de
uma constelação onde ela se associa às noções de código, de transmissão, de tradução, de ruído e
de redundância”. (LÉVY, 2014, p. 90).
4.2 Quem é esse leitor?
Quem é esse leitor? É o cidadão que está em rede. É o prosumer/produser que está pronto
para obter a informação e transformá-la em notícia. “Ele reconfigura a lógica dos critérios de
49
TRÁFEGO online será quatro vezes maior até 2014. Olhar Digital. 03 jun.2010. Disponível em
<http://olhardigital.uol.com.br/noticia/trafego-online-sera-quatro-vezes-maior-ate-2014/12145>. Acesso em: 28
ago. 2014.

69
noticiabilidade, muda a agenda da imprensa e inclui fatos ao noticiário que circula na Internet.
Ele não só produz como valida e recomenda uma informação. É dessa maneira e dá a legitimação
na rede. E isso se reflete na interface, na maneira como ela se constitui”. (MOHERDAUI, 2012,
p.111).
O leitor agenciador da rota hipertextual baseada em tags é o sujeito a ser capturado pelos
produtores de conteúdo. É aquele que o jornalista não quer ver disperso, mas sim tê-lo como
audiência, seguindo os atratores na rede e se concentrando nos vórtices do sistema complexo.
Esse leitor participa diretamente do processo de organização da informação, principalmente
quando pratica folksonomia, ajudando a construir novas narrativas e agenciando comunidades em
torno de conteúdos específicos.
Conforme Santaella (2004), tendo a multimídia como suporte e a hipermídia como
linguagem, só é possível pensar no surgimento de um tipo de leitor, o imersivo – aquele que se
depara com a tela. Mesmo havendo semelhanças no modo de leitura, o leitor imersivo é obrigado
a escolher entre nexos, direções e rotas para concluir a atividade de leitura.
[...] conectado na tela, por meio de movimentos e comandos de um mouse, os
nexos eletrônicos dessas infovias, o leitor vai unindo, de modo a-sequencial,
fragmentos de informação de natureza diversas, criando e experimentando, na
sua interação com o potencial dialógico da hipermídia, um tipo de comunicação
multilinear e labiríntica. (SANTAELLA, 2004, p.11).
Segundo Santaella (2004), esse leitor está transitando em arquiteturas líquidas. Uma
comparação interessante da autora é dos leitores online com a identidade do homem moderno,
chamada de flâneur, aquele que passeia pela cidade com olhar contemplativo, ondulante e aberto
à vertigem de alteridades. Esse expectador-visitante é o leitor exposto a uma multiplicidade de
imagens, registros e tipos de estímulos.
Mais importante para esta pesquisa é pensar nesse leitor sem a visão cartesiana em que
corpo e mente estão separados – assim como foi representado historicamente em filmes, livros e
estudos científicos. Nessa visão incompleta, o corpo é visto como inerte e a mente como o
elemento que se junta ao tecnológico em uma navegação virtual. No entanto, segundo Santaella
(2004), o que não se enxerga, muitas vezes, é que essa visão é carregada de um dualismo

70
simplificado porque corpo e mente são indissociáveis. Por exemplo, quando um leitor busca uma
palavra-chave na Web, reage aos resultados, seja pelo movimento aplicado ao mouse ou ao
teclado. Os caminhos que o click do mouse farão o leitor tomar são imprevisíveis, mas a reação
de interagir é quase certa. O fato é que o corpo também influencia a mente e vise versa, em
reações cíclicas.
No contexto do jornalismo baseado em tags, a leitura é e sempre foi mais do que uma
experimentação, é uma ação. No desenho da Web Semântica, a parcela interativa do leitor se dá
pela inserção de dados e metadados. Sobre isso Santaella (2004) define uma contrapartida, que
será tema do próximo tópico da pesquisa:
[...] nesse contexto, o emissor não emite mais mensagens, mas constrói um
sistema com rotas de navegação e conexões. [...] O que se tem aí, portanto, não é
só um tipo de interatividade interpessoal mediada pela máquina, mas também
uma interatividade transindividual, em que a pessoalidade do cibernauta se
pulveriza em tramas infinitas de nexos e passagens por situações e sítios virtuais,
nos quais emissor e receptor perdem seus limiares definidos para ganhar uma
face plural, universal, global. (SANTAELLA, 2004, p.163).
4.3 Quem é esse jornalista/produtor?
Quem é esse jornalista/produtor? É o profissional polivalente50
da atividade humana usada
para compartilhar e colocar em comum: a comunicação, conforme define Charaudeau (2010).
Especificamente na comunicação mediada por computador, durante o processo de “colocar em
comum”, o jornalista lida com termos como “transmissão, publicação e recepção para incorporar,
anotar, comentar, responder, agregar, cortar, compartilhar, além dos termos em inglês download,
upload, input e output” (MANOVICH apud MOHERDAUI, 2010, p.214).
Além disso, é o agente da comunicação que tenta pensar com a cabeça do leitor para
capturá-lo na rota hipertextual e entendê-lo como audiência. Para isso, o produtor, no contexto do
jornalismo baseado em tags, lida com duas inferências da lógica agindo ora com indução, ora
50
No sentido construído por Mielniczuk (2011) em que o profissional é multimídia ao narrar para diferentes
suportes/formatos; multiplataforma ao modular para várias plataformas; multitarefa porque encara várias
editorias.

71
com dedução.
A prática da indução acontece quando o jornalista parte de um caso isolado (ou vários
casos) que já experimentou e do resultado obtido chega à conclusão generalizada de uma regra.
Numa relação de audiência entre produtor e leitor, esse argumento estatístico acontece quando o
jornalista de conteúdos online começa a observar quais tipos de reportagens geram maior número
de cliques e pageviews51
. Se ele, usando ferramentas de medição de audiência, conclui que
futebol é o conteúdo de maior acesso, obviamente poderá direcionar a produção para matérias
sobre esse assunto. Se souber também que palavras-chave, como nome de celebridades, atraem
muita leitura quando colocadas em títulos de matérias, pode optar por essa estratégia de atração.
O pensamento indutivo pode oferecer, ao longo do caminho, conclusões bem corretas a partir de
premissas verdadeiras, no entanto é um pensamento muito dependente de casos concretos ou
operações práticas. (SANTAELLA, 2004). Esta é a lógica:
Caso: Esta notícia é de futebol.
Resultado: Esta notícia de futebol gera alta audiência.
Regra: Todas as notícias de futebol geram alta audiência.
A prática da dedução é menos empírica e ocorre quando se parte de uma regra geral e
deduz-se a propriedade de um caso isolado. Numa situação como essa, o jornalista deveria partir
de situações hipotéticas definidas pelas características das notícias – critérios de noticiabilidade52
,
conhecimento geral do público-alvo, especificidades do veículo onde trabalha – para levantar
uma inferência. A dedução só acontece para que seja validada a conclusão retirada do raciocínio.
(SANTELLA, 2004). Assim, o jornalista de um portal de veículos, sabendo que conteúdos de
lançamentos de carros no mercado geram alta audiência, se depara com a notícia sobre o novo
carro utilitário da Fiat e conclui que uma matéria sobre esse carro vai gerar bons page views. Ele
praticou o tão conhecido silogismo. Esta é a lógica:
51
Número de vezes que uma página da internet é visualizada em um navegador. É uma conta de acessos registrados
por um site. Não engloba o total de pessoas que visitaram o portal, mas, sim, o número de vezes que ele foi
acessado.
52 Critérios usados para selecionar as notícias entre os vários acontecimentos. A noticiabilidade depende do
interesse da empresa jornalística, além de critérios de relevância flexíveis e variáveis a cada veículo.

72
Regra: Todas as notícias de lançamento de carros geram alta audiência.
Caso: Esta matéria é sobre o lançamento do novo utilitário da Fiat.
Resultado (conclusão): Logo, esta matéria sobre utilitário da Fiat gera audiência.
A prática das duas lógicas é muito viva na rotina do jornalismo baseado em tags,
principalmente quando as habilidades do produtor são associadas a ferramentas tecnológicas que
ajudam a capturar o leitor, conforme será exposto nas seções adiante nesta pesquisa. A junção é
útil na medida em que o jornalista contribui para a construção do conhecimento coletivo e
conhece suas funções cognitivas no processo de produção.
O virtuosismo técnico só produz seu efeito completo quando consegue deslocar
os eixos e os pontos de contato das relações entre homens e máquinas,
reorganizando assim, indiretamente, a ecologia cognitiva como um todo. Separar
o conhecimento das máquinas da competência cognitiva e social é o mesmo que
fabricar artificialmente um cego (o informata "puro") e um paralítico (o
especialista "puro" em ciências humanas), que se tentará associar em seguida;
mas será tarde demais, pois os danos já terão sido feitos. (LÉVY, 2014, p.33).
O leitor está exposto a muita informação e quer encontrar a notícia com mais valor para
ele no ambiente digital. O que o jornalista precisa fazer é atribuir cada vez mais valor para as
informações que publica, ser capaz de modalizar os contextos significativos e os ambientes
práticos onde se determina o sentido (LÉVY, 2014). Ainda precisa ser construído um dispositivo
sociotécnico baseado em tags capaz de facilitar a buscas de informações, mas enquanto isso o
jornalista pode fazer bem o papel de produtor de significação e pertinência na Web (e ele tem
ferramentas para isso, como está sendo mostrado nesta pesquisa).
Mais do que manipular palavras – em uma capacidade sintática –, o jornalista deve se
preparar para manipular conceitos – numa visão semântica de produção. Os conceitos organizam
a memória coletiva e agem sobre contextos sociais, facilitando a captura de público por questões
afetivas – que aproximam o texto/conteúdo desse leitor. O jornalista precisa pensar em dar mais
sentido aos dados que expõe na Web.
Com base em estudo da Rede Ibero-Americana de Comunicação Digital, no Projeto
Comunicadores Digitais, Barbosa (2007) traçou algumas recomendações ao jornalista para atuar

73
nas redações: manter-se atualizado no uso de softwares; conhecer o potencial da tecnologia de
base de dados e suas aplicações no jornalismo, as linguagens de programação, recursos para
difundir e compartilhar conteúdos, técnicas para investigar novas formas de produção e
prospecção de informações com metadados e a mineração de dados; compreender o entorno que
o circunda e as questões relacionadas com a cibercultura; entender o funcionamento e as
potencialidades das redes sociais e comunidades virtuais; conhecer bases de jornalismo
participativo e ambientes wiki e blog e compreender a legislação vigente relativa a direito de
autor, delitos, privacidade, copyleft, creative commons e software livre.
Ao pensar quem é o leitor e quem é o produtor, conclui-se que eles são as partes do ato de
linguagem que é a navegação na Web. Nesse ato, há uma encenação linguageira com dois
circuitos, o externo – da relação contratual entre os dois parceiros – e interno – da encenação do
dizer com os dois protagonistas (CHARAUDEAU, 2001). Por isso, os velhos emissor e receptor
foram deixados de lado por transmitirem uma falsa ideia do que sejam atos de linguagens.
4.4 Audiência
A audiência na Web está relacionada à necessidade de informação que as pessoas têm.
Dentro do processo de comunicação, a audiência é o conjunto de respostas dos leitores aos
conteúdos. Segundo Ruótolo (1998), essas respostas podem ser internas (como uma mudança de
opinião) ou externas (como a compra de um produto ou um page view). As respostas que os
indivíduos dão aos conteúdos da comunicação são resultados de contextos sociais, considerando
interesses culturais e as formas de conhecimento dos leitores de sites noticiosos.
Os estudos sobre audiência se desenvolveram a partir da década de 40, baseados em
análises de recepção focadas na programação televisiva. De acordo com Ruótolo (1998), não se
encontram no escopo dos estudos de audiência aspectos muito importantes da comunicação social
que não fazem parte das respostas do leitor. Para o autor, os aspectos tecnológicos (novos meios,
novas tecnologias), a produção de conteúdos e a transnacionalização dos fluxos de comunicação
estão fora dos estudos de audiência e recepção por não tratarem de entender e explicar

74
precipuamente as respostas da audiência. Os aspectos tecnológicos citados por Ruótolo (1998),
agora mais do que nunca, alteram os resultados de audiência nas mídias porque permitem ao
leitor traçar caminhos imprevisíveis.
A exploração mercadológica da audiência pela grande mídia é uma ideia já conhecida:
mais leitores, mais audiência e mais possibilidades de anunciantes nas páginas online. No
entanto, aqui não nos interessa discutir essa questão, pois o simbólico, a rota do leitor e a
experiência do produtor são muito mais importantes, conforme considera Charaudeau (2010):
Por que analisar o discurso midiático, se as mídias parecem viver uma lógica
comercial onde só haveria lugar para estudos econômicos, tecnológicos ou de
marketing? Seria para torná-las mais performáticas e mais rentáveis nos
mercados mundiais? É claro que a resposta é negativa para quem acredita que,
para além da economia e da tecnologia, há o simbólico, essa máquina de fazer
viver as comunidades sociais, que manifesta a maneira como os indivíduos,
seres coletivos, regulam o sentido social ao construir sistemas de valores. Sendo
o papel do pesquisador em ciências humanas e sociais o de descrever os
mecanismos que presidem a esse simbólico e às diferentes configurações que o
tornam visível. (CHARAUDEAU, 2010, p.17).
Nesse contexto, o jornalismo vive um desafio diário de equilíbrio entre critérios de
noticiabilidade e interesses empresariais para conquistar a audiência. Os novos aspectos desse
jogo são as estratégias computacionais – ferramentas de busca, uso de tags e otimização de sites,
que agora compõem o trabalho diário.
4.5 Buscadores
Os buscadores ou motores de busca são ferramentas para recuperação de informação que
vêm influenciando muito a rotina jornalística na Web, na medida em que alteram lógicas de
audiência, porque direcionam os leitores a URL – antes mesmo que esse leitor procure o
conteúdo em um portal de notícias. Os títulos dados pelos repórteres às matérias, galerias de fotos
e outros conteúdos compõem a URL da página, ou seja, aparecem descritos no link criado para

75
aquela publicação53
. Os buscadores indexam e incorporam nos resultados as atualizações de
milhões de sites, por isso entram como fator a mais na concorrência online. Apesar da hegemonia
do Google, existem mais opções como Bing, Yahoo, Teoma, Lycos, All The Web, Cuil, AltaVista,
entre outros.
A importância dos motores de busca para o resultado de audiência no Brasil é
incontestável porque têm direcionado os leitores aos sites noticiosos de maneiras surpreendentes.
De acordo com estudo54
do Instituto Verificador de Circulação (IVC) – entidade sem fins
lucrativos que certifica as métricas de desempenho de veículos impressos e digitais – a origem de
acesso em sites no país pode ser dividida em quatro categorias: buscadores, direto (quando o
leitor digita o nome do site), redes sociais e outros. Uma pesquisa do IVC selecionou dados de 75
sites nacionais, coletando informações de audiência uma semana por mês entre janeiro de 2011 e
janeiro de 2013. Para o acesso em browsers na Web, a primeira categoria detém em média 34%
do tráfego da rede; a segunda, 40%; a terceira, 20% e a quarta, 6%.
Apesar de não liderar o ranking, a representatividade de buscadores é muito grande
levando em conta que o acesso direto tem como vantagens a afinidade do leitor com sites
específicos e a gravação de URL em favoritos (acesso também contabilizado na categoria
“direto”). Os motores de busca, por sua vez, contam com a automatização algorítmica em uma
dimensão inalcançável ao controle humano.
Os mecanismos de busca, para indexarem na Web, possuem programas que
visitam páginas por página da Web, percorrem o texto de cada página, extraindo
daí palavras-chave e armazenando em uma base de dados estas palavras-chave,
associadas ao URL da página. É sobre esta base de dados que os usuários fazem
suas buscas nos sites dos mecanismos. (MARCONDES, 2006, p.97).
A desvantagem que levam os buscadores está no fato de serem desprovidos de informação
53
Por exemplo, o caso da matéria que será usada no estudo de caso da morte do ator Paulo Walker. O título
da matéria é “Vídeo mostra momento em que carro de ator Paul Walker fica em chamas após acidente”. Este é o
URL gerado para o conteúdo:
http://www.em.com.br/app/noticia/internacional/2013/12/01/interna_internacional,475257/video-mostra-
momento-em-que-carro-de-ator-paul-walker-fica-em-chamas-apos-acidente.shtml 54
Estudo sobre audiência de websites. Base IVC: Jan 2011 a Jan 2013. International Federation of Audit Bureaux of
Circulations (IFABC)/ Instituto Verificador de Circulação (IVC). A pesquisa completa está disponível em
<http://www.ivcbrasil.org.br/conteudos/pesquisas_estudos/AudienciaWeb2012.pdf>. Acesso em 25 jun.2014.

76
contextual, pois a indexação automática com base em palavras isoladas não tem um controle
terminológico. Vale ressaltar, no entanto, que nada disso impede a influência dos motores de
busca na audiência da Web.
De forma simplificada, os buscadores vão coletar dados nos sites enviando bots
conhecidos como web crawler (rastreador web, também chamado de aranha eletrônica). O
conteúdo do site é copiado e armazenado no banco de dados do mecanismo de busca. As
“aranhas” são projetadas para seguir os links de uma página, copiar e assimilar o conteúdo. Elas
coletam informações todos os dias, criando uma base de dados com bilhões de informações. As
“aranhas” fazem a leitura conteúdo do site começando no canto superior esquerdo e seguindo
para o direito inferior – como uma leitura convencional de página de revista em países ocidentais.
Se encontrar um link que pode seguir, a “aranha” grava e envia outra “aranha” para seguir e
copiar o conteúdo. A web crawler vai prosseguir no site até que tudo esteja registrado. Para
acompanhar as mudanças, os buscadores fazem visitas regulares, cujas frequências variam de
acordo com as atualizações do site55
.
Para Santaella (2004), os buscadores são exemplos de ferramentas que ajudam a orientar o
leitor imersivo na rede e minimizar o desconcerto ou a frustração de não conseguir ajustar os
alvos pretendidos na leitura. Segundo a autora, os programas de busca são indicativos do grau de
controle de uso que provavelmente estará disponível em todas as mídias daqui a não muito
tempo.
Exemplo disso é o recurso do Google de oferecer publicidade ao leitor de acordo com a
palavra-chave que ele busca. As empresas se inscrevem para que seus anúncios sejam exibidos na
página de ranqueamento de links. Há a possibilidade de uma organização pagar para que uma tag
específica seja associada ao seu site, assim alcança resultados importantes em receitas com
publicidade. Outro exemplo é o recurso de uso dos cookies56
do visitante para exibição de
anúncios relacionados ao interesse dele. Então, se alguém procurava na Web por tênis de corrida
55
Notas da autora em curso de SEO da empresa Nautilus.
56 Cookies são pequenos arquivos que os sites colocam no disco rígido do computador quando o leitor os visita pela
primeira vez. O QUE é cookie? MICROSOFT. Central de Proteção e Segurança. Recursos. 2012. Disponível em
<http://www.microsoft.com/pt-br/security/resources/cookie-whatis.aspx>. Acesso em: em 25 jun.2014.

77
ontem, não deve estranhar que hoje o browser esteja lhe oferecendo inúmeras ofertas de lojas
especializadas em esporte ou dos modelos pesquisados no dia anterior. Os exemplos descritos
fazem parte das tecnologias do Google AdSense57
e Google AdWords58
.
Para o jornalismo, mais importante que entender tecnicamente os buscadores, é saber que
as estatísticas dos motores de pesquisa fornecem indicações sobre a variação da popularidade de
certas palavras-chave no curso do tempo. Saber agenciar essas tags faz parte do trabalho de
conquista do leitor, que, muitas vezes, recorre aos buscadores para encontrar as rotas. A escolha
de uma tag no momento da busca impulsiona uma rede semântica do leitor, com a qual o
produtor de conteúdo precisa ter afinidade. Segundo Lévy (2014), o leitor ativa um contexto e
seleciona uma minirrede centrada sobre a palavra que vai digitar: “Quando ouço uma palavra,
isto ativa imediatamente em minha mente uma rede de outras palavras, de conceitos, de modelos,
mas também de imagens, sons, odores, sensações proprioceptivas, lembranças, afetos etc.”
(LÉVY, 2004, p.14).
De acordo com o autor, o contexto serve para determinar o sentido de uma palavra, sendo
ainda mais judicioso considerar que cada palavra contribui para produzir o contexto, ou seja,
forma uma configuração semântica reticular, que se mostra composta de imagens, de modelos, de
lembranças, de sensações, de conceitos e de pedaços de discurso.
Tomando os termos leitor e texto no sentido mais amplo possível, diremos que o
objetivo de todo texto é o de provocar em seu leitor um certo estado de excitação
da grande rede heterogênea de sua memória, ou então orientar sua atenção para
uma certa zona de seu mundo interior, ou ainda disparar a projeção de um
espetáculo multimídia na tela de sua imaginação. Não somente cada palavra
transforma, pela ativação que propaga ao longo de certas vias, o estado de
excitação da rede semântica, mas também contribui para construir ou remodelar
a própria topologia da rede ou a composição de seus nós (LÉVY, 2004, p.14).
Segundo Lévy (2004), os jornalistas se transformam em “arquitetos cognitivos do futuro”,
levando em conta na produção a possibilidade de seus conteúdos serem encontrados na rede pela
busca de palavras-chave. O salto que o profissional pode dar é saber administrar essa ecologia
57
GOOGLE Anúncios. Google AdSense. Disponível em: <http://www.google.com/adsense/>. Acesso em: em 25
jun.2014.
58 GOOGLE AdWords. Disponível em: <https://adwords.google.com>. Acesso em: 25 jun.2014.

78
cognitiva, conhecendo as tags mais procuradas pelo seu leitor ou as palavras que mais resumem
as ideias de conteúdos e poderiam ser potencialmente buscadas. O caminho de ativação iniciado
por uma tag (atratora) é percorrido intensamente em alguns momentos, mas caem em desuso. A
rede associativa dos leitores é parte do universo mental e está em metamorfose permanente, assim
como a necessidade desses leitores por informação.
4.6 SEO para jornalismo
Os portais de notícia estão fazendo de tudo para serem encontrados na Web. As empresas
querem que as matérias estejam na rota do leitor. Um dos recursos é aparecer no topo dos sites de
busca, um resultado de estratégias de Search Engine Optimization (SEO), traduzido para o
português como otimização de sites. Uma grande discussão, que não será feita nesta pesquisa, é
até que ponto a otimização faz empresas jornalísticas priorizarem o interesse privado em
audiência em detrimento do interesse público, aquele descrito no Código de Ética dos
Jornalistas59
como sendo uma das prerrogativas de produção. O debate não será feito aqui, mas
não passou em vão aos olhos da pesquisadora.
Os mecanismos de busca usam um algoritmo – embasado em um cálculo matemático –
que interpreta a relevância de uma página da Web. Entre os critérios de ranqueamento está a
indexação de palavras-chave ideais, por isso elas precisam ser bem contextualizadas nos títulos
das páginas, domínio do site, corpo dos textos, espaços reservados para tags e na etiquetagem de
imagens. As empresas de comunicação nem sempre se preocupam especificamente com a
matemática algorítmica dos motores de busca, mas querem entender o comportamento do leitor
para escolher as palavras-chave certeiras.
A ideia é pensar além da pauta: “O que o meu leitor buscaria no Google para encontrar o
conteúdo sobre o qual estou escrevendo?”. Esse pensar além da pauta é planejar um ciclo de
complexidade que começa em um contexto desordenado – da enorme prateleira de informações
59
Disponível em http://www.fenaj.org.br/materia.php?id=1811. Acesso em dezembro de 2014.

79
da Web, segue com a articulação de etiquetas atratoras capazes de agenciar a captura do leitor e
encerra na ordenação do conteúdo para alcançar a rede semântica no entorno do vórtice gerado
por essas tags.
Muitas empresas de comunicação ensinam estratégias de SEO para os jornalistas dentro
das redações e outras mantêm um profissional especialista em otimização para auxiliar em tarefas
diárias dos produtores de conteúdo. Algumas também incluem rotinas de produção diferenciadas
para facilitar o ranqueamento de conteúdos como, por exemplo, o em.com.br, que criou uma
agenda de datas comemorativas/aniversários para que os repórteres tentem fazer pautas
relacionadas ao tema do dia. Se dia 28 de outubro é dia de São Judas Tadeu, a busca no Google
pelas palavras-chave relacionadas ao santo aumenta naquela data, o que seria uma oportunidade
de indexação para um site de notícias que tiver matérias com tais tags nos títulos. O conteúdo
poderia ser desde a agenda das festas comemorativas pelo santo na cidade até o mercado religioso
no entorno da paróquia que leva o nome de Judas. Importante é que as matérias com esse campo
semântico específico sejam publicadas naquele dia, tendo, é claro, o valor jornalístico associado
ao valor semântico para motores de busca.
Segundo Formaggio (2008), os passos que um site de notícias deve seguir na elaboração
de um plano para que seja encontrado em mecanismos de busca são: 1) identificar e elaborar as
tags importantes para o site, 2) identificar quais requisitos de SEO (mudanças ou adaptações na
construção da página) são necessários para que o site seja encontrado, 3) identificar as páginas de
entrada desejadas para essas tags, 4) saber qual o posicionamento dos concorrentes sobre aquelas
tags importantes para seu site. Muitos desses aspectos dizem respeito ao trabalho do
desenvolvedor do site e não ao jornalista, mas o repórter pode, sim, ajudar e aumentar a
relevância do site escolhendo títulos assertivos, inserindo tags competentes em suas matérias ou
relacionando conteúdos de forma mais contextualizada possível.
Hoje não basta agradar somente aos robôs dos mecanismos de busca, o usuário
se tornou prioridade. É preciso agradar muito mais aos usuários, entregar-lhes
boas experiências de navegação, bem como orientá-los a uma conversão de
forma adequada. Só assim um site terá vantagem competitiva frente a seus
concorrentes nos mecanismos de busca. (FORMAGGIO, 2008, p.9).
Por exemplo, o Google, durante o processo de indexação, capta URL com no máximo 70

80
caracteres, ou seja, o ideal é que o título de uma página (ou de uma matéria no caso de um portal
de notícias) tenha esse limite. O que há além desse número de caracteres o buscador ignora,
tornando os termos em excesso irrelevantes para o ranqueamento da página. Para a rotina do
jornalista digital, cuja função, além de apurar e escrever o texto, é atribuir títulos para as
matérias, ter conhecimento em SEO é essencial.
São quatro os passos para alcançar bons resultados com as estratégias de SEO: indexação,
ranqueamento, conquista do visitante e, por fim, a chamada taxa de conversão. Esta última é a
grande meta de empresas que investem em otimização, sendo considerado o resultado para o uso
de todas as técnicas. Conversão para os portais de notícias são o alcance de uma audiência
diferenciada, que aumente o número geral de acessos para a página, além de compartilhamentos,
comentários e outras ações responsivas que leitores possam fazer para espalhar o conteúdo.
Nos capítulos que seguem será possível articular a interseção entre complexidade,
folksonomia e o jornalismo baseado em tags. Mais que isso, ficará mais clara com os estudos de
caso a relação complexa entre leitura hipertextual, uso de tags, SEO, audiência e as
consequências dessa mistura para o jornalista no contexto da Web Semântica.

81
“Um minuto pode ser infinito em uma ordem de convergência e, no entanto,
ter uma energia finita, e esta ordem ser limitada”, (DELEUZE, 2007, p. 114).
5 Metodologia
Quando um pesquisador sistematiza uma coleta de dados e converge essas informações ao
arcabouço teórico de anos de pesquisa, ele está criando uma situação limitada relativa ao minuto
em que coletou os dados. No entanto, abre a possibilidade de energia infinita quando aquele
trabalho chega aos pares e estes, por sua vez, fazem daquele minuto uma base para outros
estudos, para outras hipóteses ou para reformulações de teses. Uma das grandes contribuições em
criar uma ordem de convergência é que ela faça parte da construção de conhecimento.
5.1 Método
O desenvolvimento de um método de pesquisa, baseado na consciência científica, consiste
em não aceitar algo como verdadeiro sem antes comprovar, dividir os problemas da pesquisa em
partes tão pequenas que se possa resolvê-los, conduzir os pensamentos em uma ordem e, por fim,
fazer um levantamento completo sobre o tema estudado para que nada seja omitido. Esses
princípios, apesar de úteis, inviabilizam uma metodologia de trabalho que não tenha como base o
pensamento complexo, aquele que compreende as partes do conhecimento e faz dele o resultado
mais importante em um processo de pesquisa. Esta pesquisa tenta trabalhar com um método
ancorado na complexidade que permite transitar entre teorias.
A pesquisa aqui desenvolvida é qualitativa baseada no paradigma construtivista, segundo
Guba e Lincoln (2006), pois explora a realidade do leitor ao traçar caminhos pela rede e as
estratégias dos produtores de conteúdo para capturar esse leitor. Os autores classificam como
construtivista a metodologia que inclui o relativismo, quando é analisada uma realidade local e

82
especificamente construída. Além disso, a pesquisa lida com uma teoria de natureza construtivista
– a complexidade – que nasceu para criticar o positivismo lógico. Por fim, é uma pesquisa que
trata da Web, um ambiente dinâmico, ambíguo, incerto e contraditório, o que contribui ainda mais
para classificação construtivista.
A escolha da pesquisa qualitativa se deu, principalmente, pelo ponto forte desse tipo de
trabalho: usar dados que ocorrem naturalmente para encontrar sequências (“como”) em que os
significados dos participantes (“o quê”) são exibidos e, assim, estabelecer o caráter de algum
fenômeno. Silverman (2009) representou essa lógica: [os quês → o fenômeno → os comos].
O principal ponto forte da pesquisa qualitativa é a capacidade para estudar
fenômenos simplesmente indisponíveis em qualquer lugar. Os pesquisadores
qualitativos estão corretamente preocupados em estabelecer correlações entre
variáveis. (SILVERMAN, 2009, p. 51).
Os saberes da pesquisa advêm da experiência da autora (como pesquisadora e jornalista)
com os casos em que o gerenciamento de tags alterou o processo de comunicação e na
experimentação de ferramentas da Web Semântica. A problemática da pesquisa é comunicativa e
descritiva, conforme Charaudeau (2010), pois o objeto de estudo é empírico – determinado a
partir da observação. Além disso, no corpus selecionado, foi possível observar diferentes tipos de
situações comunicativas. Conforme Charadeau (2010), essas situações determinam as condições
de produção e de interpretação, além de dar legitimidade aos discursos em um processo de
interação.
O que foi feito nos capítulos anteriores faz parte da revisão bibliográfica e construção
teórica que ajudaram na análise dos dados. As características de sistemas complexos retratadas no
Quadro 1 (página 33) e os padrões de interação do Esquema 2 (página 37) são trazidos para a
análise de dados na tentativa de identificá-los nos casos reais e, assim, mostrar a complexidade
nos processos de produção e de leitura no contexto da Web Semântica. Da mesma forma, o
processo de folksonomia, criado especificamente em cada caso analisado, retoma o conceito de
etiquetagem de forma bem particular.
A maior parte da coleta de dados e depoimentos de jornalistas ocorreram na terça-feira
subsequente a dois fatos jornalísticos de relevância em 2013. O primeiro deles é o incêndio da

83
boate Kiss em Santa Maria/RS, em 27 de janeiro, e o segundo é a morte do ator Paul Walker, em
30 de novembro. As duas coberturas feitas pelo site do jornal Estado de Minas (em.com.br)
apresentaram características exclusivas de audiências por fatores relacionados ao uso de tags,
buscadores e captura do leitor na rota hipertextual. Com os dados coletados naquelas terças-
feiras, foi possível levantar os padrões de audiência para a pesquisa. No entanto, os dados foram
observados e atualizados até julho de 2014, porque há pequenas mudanças de valores.
Os aspectos de resultado de audiência foram observados por meio do Google Analytics60
e
as estatísticas são exploradas nesta pesquisa de forma qualitativa. Os dois casos aconteceram em
finais de semana – um no domingo e outro no sábado – por isso a terça-feira foi escolhida para
coleta, considerando que os dados do Google Analytics estavam, de certa forma, mais estáveis.
Há um delay de atualização desses dados que precisou ser considerado antes da coleta.
O Google Trends61
é usado para a análise temporal de tags, que é importante para
discussão do aspecto linguístico do uso dessas etiquetas na Web. O corpus da pesquisa é formado
pelo conjunto de estatísticas e observações da pesquisadora sobre as ações dos jornalistas nessas
coberturas, ações que mudaram o cenário de taxa de conversão.
O incêndio foi escolhido porque uma galeria de fotos produzida durante a cobertura
alcançou, em número absoluto, a maior audiência do portal desde o início das produções, em
setembro de 2010. A morte do ator foi escolhida porque uma das matérias da cobertura
jornalística – aquela em que há um vídeo com o acidente automobilístico que resultou na morte –
alcançou a maior audiência que o site já teve, em número absoluto, na categoria “tempo real”62
.
60
GOOGLE Analytics. Disponível em: < http://www.google.com/analytics/>. Acesso em: 25 jun.2014.
61 GOOGLE Trends. Disponível em: <http://www.google.com/trends/>. Acesso em: 25 jun.2014.
62 Cf. explicação da categoria em 5.3 Coletas no Google Analytics.

84
5.2 Contexto de produção no EM.COM.BR
O em.com.br é o site de notícias do Jornal Estado de Minas que faz parte do grupo Diários
Associados, fundado pelo jornalista Assis Chateaubriand, em 1924, e que conta com portais de
notícia em cinco estados brasileiros, além do Distrito Federal. A empresa de comunicação
também tem 10 emissoras de TV, 12 rádios, 11 jornais impressos e cinco revistas.
O em.com.br surgiu em setembro de 2010 para substituir a produção de notícias do Portal
Uai, no ar desde 1996. A ideia era que o público identificasse melhor o conteúdo do Estado de
Minas, tendo um site que levasse as iniciais do nome do jornal. Assim, passou a abrigar o
conteúdo das editorias de Política, Economia, Nacional, Gerais, Internacional, entre outros canais
que surgiram com o tempo. O Portal Uai começou a funcionar como um grande “guarda-chuva”
de sites do grupo de comunicação – em.com.br, Divirta-se, Vrum, Lugar Certo e Admite-se.
Como porta de entrada, o Portal Uai é responsável por grande parte da origem de audiência de
todos os sites que estão ancorados nele. O em.com.br é um dos carros-chefes da empresa porque
nele é produzido todo o conteúdo factual, o chamado hard news63
. O site conta atualmente com
uma equipe formada de editor, editora assistente, três subeditoras, infografista, quatro estagiários
e cerca de 20 repórteres.
O trabalho dos repórteres de apuração, elaboração de texto, edição de imagens, escolha de
títulos e bigodes para cada matéria é o que resume o conceito de produção nesta pesquisa. Cada
jornalista é responsável por uma editoria, monitorando os temas e produzindo setorialmente. Nos
casos analisados, as duas coberturas ocorreram em finais de semana – quando a equipe não segue
a divisão de tarefas dos dias úteis – ficando todos os repórteres envolvidos nas coberturas de
destaque durante o plantão (uma espécie de “todo mundo faz tudo”). Os dois casos analisados
foram produzidos respectivamente nas editorias de Nacional e Internacional com trabalho de
repórteres que normalmente atual em outros “setores”.
Esta pesquisa, apesar de ter um caráter descritivo, não foge às críticas necessárias ao
63
Notícias de grande atualidade, marcadas de temporalidade e, principalmente, de uma construção com pirâmide
invertida – aquela em que é priorizada no lead a informação mais importante.

85
processo de produção jornalística e os apontamentos para o futuro do jornalismo, mesmo sendo a
pesquisadora repórter do Estado de Minas. Os dados da coleta serão apresentados em percentuais,
que permitem a comprovação da mudança de audiência com gerenciamento de tags sem expor
números absolutos e estratégicos para o negócio da empresa, o que não é o objetivo. Descrevo a
seguir as duas ferramentas usadas na coleta de dados, detalhando como o trabalho foi feito.
5.3 Coletas no Google Analytics
O Google Analytics é uma ferramenta gratuita que pode ser usada por qualquer produtor
de conteúdo para medir audiência na Internet. É necessário cadastrar o site a ser monitorado e
definir usuários que podem visualizar as informações disponibilizadas. A medição direta de
acessos é feita por meio da contagem de vezes que as páginas dos sites são carregadas pelos
usuários. Coloca-se um código em todas as páginas do site e, quando alguém acessa a página, o
código é lido pelo programa que fica “anotando” a quantidade de leitores, o tempo que eles
gastam na página, de onde eles “vieram” (origem de tráfego), entre outros parâmetros. Há outras
ferramentas parecidas que fazem Web analytics, como, por exemplo, o Omniture64
. O em.com.br
usa o Google Analytics para medição de audiência.
A tela capturada (Fig. 7) mostra, como os destaques em vermelho, a disposição de dados
no Analytics. Na esquerda, o repórter vê qual a matéria está monitorando – por meio do URL – e
na direita visualiza a quantidade de pageviews em tempo real. A aplicação traça automaticamente
os gráficos na parte superior da tela.
64
ADOBE MARKETING CLOUD. Disponível em: <http://www.omniture.com>. Acesso em: 25 jun.2014.

86
Figura 7 – Google Analytics
Fonte: Captura de tela pela autora (25 jun.2014)
Para o jornalismo online, essas ferramentas de análise tornaram-se essenciais na rotina
dos repórteres que acompanham em tempo real as matérias mais escolhidas pelos leitores,
podendo controlar quais são as notícias preferidas, quais devem permanecer em destaque nas
capas dos portais e quais assuntos rendem continuidade. Pela URL (endereço da página) da
matéria, a ferramenta do Google faz um ranking de notícias quase em tempo real. Existe um
delay de leitura do comportamento em tempo real, mas que não atrapalha a análise de audiência.
O acompanhamento da ferramenta é essencialmente uma função do repórter e se torna
também parâmetro de medição de produtividade para os editores. O monitoramento em tempo
real é usado de minuto em minuto por jornalistas na redação, por trazer essa noção instantânea. É
possível também fazer levantamentos de audiência mensal, semestral ou de qualquer período
determinado, porém esses dados não ajudam tanto na produção diária. É possível analisar dados
gerais ou divididos por editorias.
Uma das principais vantagens de medir audiência é poder “brincar” com o efeito cauda
longa (ANDERSON, 2004), em que a infinita prateleira jornalística da Web consegue oferecer
conteúdo por nicho. Se as especificidades do leitor são conhecidas, passa-se a produzir para ele.

87
O em.com.br, por exemplo, tem grande enfoque no conteúdo local. A editoria carro-chefe é
Gerais, aquela que trata de conteúdos regionais de Minas.
O que esta pesquisa vai mostrar é que esse público habitualmente conquistado pelo
conteúdo do site não é exatamente aquele capturado pelos buscadores na rota hipertextual.
Quando os motores de busca entram em ação e os jornalistas percebem alterações de audiência
provocadas pelo gerenciamento de tags, leitores novos – que nunca visitaram o site nem mesmo
pelo conteúdo de nicho – entram para as estatísticas de audiência. Os casos estudados nesta
pesquisa são das editorias de Nacional e Internacional, as mais beneficiadas pela ação de motores
de busca, conforme mostrará a análise de dados.
5.4 Coletas no Google Trends
O Google Trends é uma ferramenta que aponta o volume de busca de uma palavra-chave
no Google. Com esse sistema, é possível ver padrões de busca ao longo do tempo. Digitando uma
tag ou expressão, o programa traça um gráfico sobre o comportamento de busca daquela palavra
desde 2004 até o dia da solicitação, sendo o eixo horizontal a representação do tempo e o vertical,
a frequência com que o termo é procurado globalmente. É possível saber em quais localidades a
palavra é mais “googlada”, em quais períodos aconteceram mais buscas e as combinações que
geralmente os internautas usam para buscar a palavra.
Usar o Trends nesta pesquisa ajudou a revelar padrões linguísticos e de campo semântico
que ajudam a aproximar o trabalho dos Estudos de Linguagem. Para explicar melhor, escolhi usar
a tag “papa” que servirá como exemplo para mostrar o que é o comportamento linguístico na
Web que será mostrado nos estudos de caso. Vejamos:
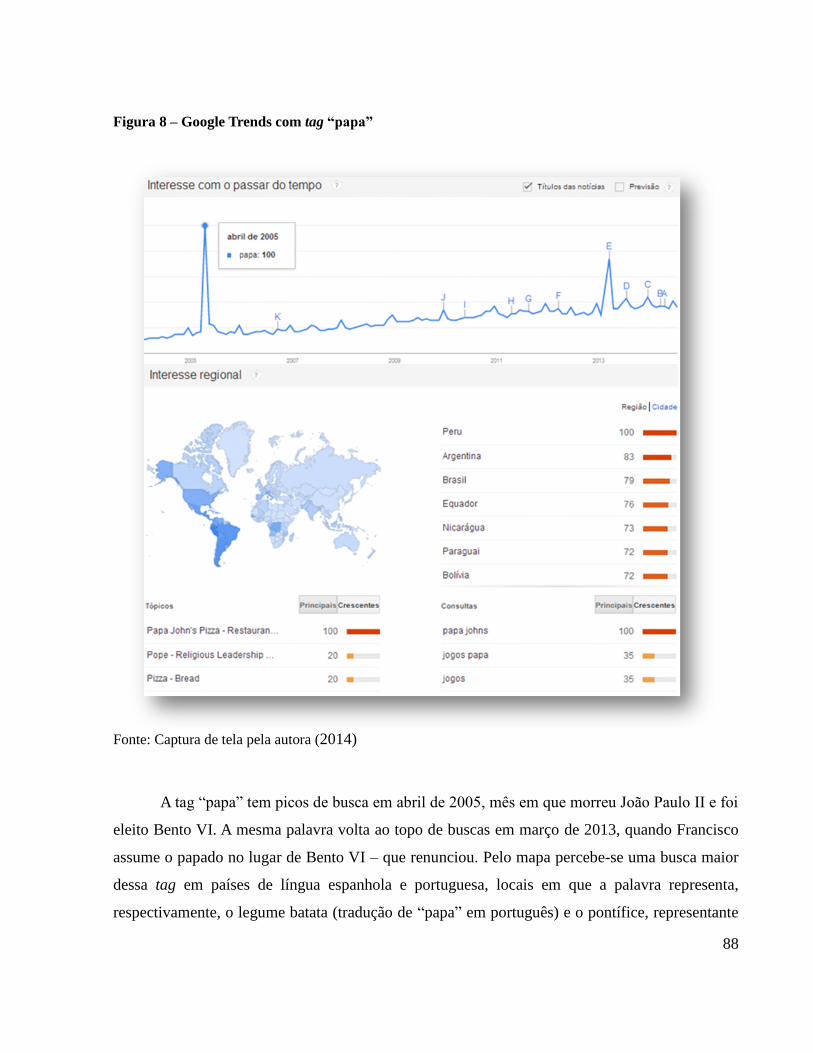
88
Figura 8 – Google Trends com tag “papa”
Fonte: Captura de tela pela autora (2014)
A tag “papa” tem picos de busca em abril de 2005, mês em que morreu João Paulo II e foi
eleito Bento VI. A mesma palavra volta ao topo de buscas em março de 2013, quando Francisco
assume o papado no lugar de Bento VI – que renunciou. Pelo mapa percebe-se uma busca maior
dessa tag em países de língua espanhola e portuguesa, locais em que a palavra representa,
respectivamente, o legume batata (tradução de “papa” em português) e o pontífice, representante

89
máximo da igreja católica. É claro que se analisarmos a tag “pope” (papa em inglês) haverá um
comportamento diferente. No Google Trends também é possível saber em quais combinações a
etiqueta “papa” é mais procurada. O campo semântico referente ao maior volume de buscas da
tag “papa” no Google não se refere ao pontífice – o que seria mais lógico aos leitores da língua
portuguesa -, mas sim a um restaurante norte-americano de nome “Papa Johns”65
e a um site de
games chamado “Papa Jogos”66
. Quais as lições que essa análise da tag papa deixam?
Primeiramente, que acontecimentos podem mudar os rumos do volume de buscas na Web,
como é o exemplo do que ocorreu com as trocas no Vaticano. Os fatos alteram a rotina de
buscadores e vice-versa, como será mostrado nos casos reais desta pesquisa. As pessoas se
interessam por temas da atualidade, motivadas por outros veículos noticiosos (TV, rádio, jornais)
ou pela agenda setting67
, que inclui o assunto na rotina de cada um, fazendo o leitor recorrer à
Web para mais informações ou atualizações.
A segunda lição é que, pelo caráter global dos buscadores e da Web, o uso de uma tag
com vários significados em línguas diferentes pode ser uma armadilha semântica. Ao mesmo
tempo em que o jogo semântico pode se tornar útil para transformar a tag em “atratora” de
leitores na rota hipertextual, ele pode capturar leitores em busca de resultados muito diferentes.
Se uma pessoa no Brasil, buscando a tag “papa”, esteja querendo mesmo saber sobre a pizzaria
americana, e não sobre o pontífice; o Google tem recursos para amenizar esses “erros de
resultado”. Nem todos os recursos são claramente conhecidos, mas existe, por exemplo, um
direcionamento por localidade. Se um endereço IP68
dos EUA procura pela tag “papa”, o
buscador provavelmente oferecerá links no ranqueamento relacionados ao restaurante, diferente
se a busca for de um IP no Brasil. Mesmo assim, o idioma fica como desafio não resolvido na
65
http://www.papajohns.com.
66 http://www.papajogos.com.br/.
67 A Teoria do Agendamento ou Agenda-setting Theory, no original, em inglês, é uma teoria de Comunicação
formulada por Maxwell McCombs e Donald Shaw na década de 1970. De acordo com este pensamento, a mídia
determina a pauta para a opinião pública ao destacar determinados temas e preterir ofuscar ou ignorar outros
tantos. Disponível em <http://pt.wikipedia.org/wiki/Agendamento>. Acesso em 16 jul. 2014.
68 Endereço IP, de forma genérica, é uma identificação de um dispositivo (computador, impressora etc.) em uma
rede local ou pública. Cada computador na internet possui um IP (Internet Protocol ou Protocolo de internet)
único, que é o meio que as máquinas usam para se comunicarem na Internet. Disponível em
<http://pt.wikipedia.org/wiki/Endere%C3%A7o_IP>. Acesso em 16 jul. 2014.

90
análise temporal do Trends.
A terceira lição é a importância do uso do Trends nesta pesquisa, para ajudar a entender a
alteração de campos semânticos causados por coberturas jornalísticas e também para o uso da
ferramenta no dia a dia do produtor, que pode conhecer as redes semânticas de cada termo usado
em títulos e bigodes de matérias. Se ele conhece as tags associadas a papa - “johns” e “jogos” –
sabe que nem sempre o conteúdo que carrega a tag “papa” será encontrado na Web em buscas
relacionadas ao pontífice. Assim, consegue alterar no processo de produção um filtro de
associação dessa tag, talvez juntando-a sempre ao nome do pontífice como Francisco ou Bento.
Ao invés de optar pelo título “Papa pede desculpas a vítimas de abuso e critica cumplicidade da
Igreja”, talvez escolhesse “Papa Francisco pede desculpas a vítimas de abuso e critica
cumplicidade da Igreja”, para resultados mais certeiros nos motores de busca.
Por fim, fica como lição a utilidade do Trends para avaliar a regularidade de termos e
influência que os buscadores exercem não só no jornalismo baseado em tags, mas também na
linguagem usada para organização da informação online. O Trends é um balizador de termos:
Acredita-se que o movimento capturado pelos algoritmos nas buscas evidencia a
configuração sobreposta das garantias de uso, literária e estrutural manifestas no
contexto digital para o termo pesquisado. A referida sobreposição se deve ao fato
de no contexto digital estarem em ação múltiplos atores sociais, dentre os quais
usuários, autores e gestores de informação. Evidentemente, ao apresentarmos
essa ponderação, não se trata de afirmar que o Google Trends poderá sozinho
resolver o problema das garantias preconizadas no processo de composição das
linguagens de indexação. Entretanto, acredita-se que ele pode ser um
instrumento auxiliar importante na medida em que tem a capacidade de
evidenciar o nascedouro de um termo, a representação das necessidades
informacionais dos sujeitos no espaço e no tempo e ainda, fornecer os indícios
da obsolescência de um tópico no contexto digital.” (MOURA, 2009, p. 67).
5.5 Depoimentos dos jornalistas
Juntamente com a coleta de dados, foi recolhido depoimento de um repórter de cada uma
das coberturas jornalísticas estudadas. A pesquisadora apresentou duas perguntas prontas como
estímulo aos entrevistados, com os quais havia um rapport mínimo e um entendimento, por parte
deles, sobre a pesquisa desenvolvida. Assim, as perguntas foram colocadas de forma objetiva,
mas com possibilidade de respostas que poderiam render outras questões – sem um roteiro

91
rigoroso.
O objetivo das entrevistas foi entender o contexto de gerenciamento de tags do ponto de
vista dos repórteres que participaram dos trabalhos na redação e saber o nível de consciência
deles em relação aos atos que fizeram dessas duas coberturas fenômenos de audiência. Além
disso, as respostas serviram como padrão para contar a história da rotina desenvolvida naqueles
dias (27 de janeiro e 1° de dezembro) pelos produtores.
Foi importante para a pesquisa comparar os dados naturais do Analytics com as
representações indiretas de experiências dos repórteres em relação aos fatos, corroborando o que
afirma Silverman (2009): “O que uma entrevista produz é uma representação particular ou um
relato das visões ou das opiniões de um indivíduo.” (p. 114).
O roteiro com os depoimentos dos repórteres está disponível no APÊNDICE A.

92
“São os acontecimentos que tornam a linguagem possível. Mas tornar
possível não significa fazer começar. Começamos sempre na ordem da
palavra, mas não na da linguagem em que tudo deve ser dado
simultaneamente, em um golpe único. Há sempre alguém que começa a falar;
aquele que fala é manifestante; aquilo de que se fala é o designado; o que se
diz são as significações. O acontecimento não é nada disto: ele não fala mais
do que dele se fala ou do que se diz.” (DELEUZE, 2007, p. 187).
6 Estudos de casos
Os casos estudados neste capítulo são nada mais que acontecimentos, no sentido mais
puro apresentado por Deleuze (2007). São fatos que surpreendem e exigem que falemos deles.
Escolhi falar deles não apenas com olhar jornalístico, mas como objetos de estudo numa
perspectiva da semântica. O estudo prova, pela grandeza da audiência, que os temas produziram,
que muito se falou sobre esses acontecimentos. A cobertura de tragédias pode surpreender porque
elas despertam interesse global – são acontecimentos que não falam mais do que deles se fala.
6.1 Incêndio em Santa Maria
No dia 27 de janeiro de 2013, o Brasil assistiu a uma das maiores tragédias de todos os
tempos. Morreram 242 jovens no incêndio da Boate Kiss, na cidade de Santa Maria, no Rio
Grande do Sul. Era um domingo e todas as atenções da imprensa nacional, assim como dos
brasileiros, se voltaram para o fato. Os jovens, maioria universitários, participavam de uma festa
na casa de shows, quando um integrante da banda – que comandava a noite – usou pirotecnia na
apresentação e acabou provocando o incêndio.
A notícia, provavelmente, se tornou o topo da audiência nos sites de notícias. Um dos
fatores responsáveis é a própria essência jornalística que atribui valor ao fato – os critérios de
noticiabilidade. É um acontecimento que, por si só, atrai o olhar do leitor imersivo e até mesmo
do disperso. A tragédia englobou os seguintes aspectos, segundo experiência da pesquisadora
como repórter: 1) interesse social – suscitou questões de segurança em casas noturnas que se
aplicam a qualquer cidade, 2) imprevisibilidade – surpreendeu a população brasileira, 3)

93
significância e singularidade – foi um fato intenso, com centenas de envolvidos que sofreram
consequências, além de ser inédito; 4) atualidade – naquele domingo, o que havia de recente nos
noticiários eram as informações de cada momento sobre a tragédia; 5) continuidade – as notícias
sobre o caso perpetuaram durante dias, semanas e meses; 6) emoção – o fato foi tratado como
imagem da comoção nacional porque sensibilizou a população brasileira; 7) proximidade afetiva
e geográfica – familiares e amigos das vítimas se tornaram leitores potenciais pelo interesse em
informações; 8) negatividade – no senso comum é tratado como interesse pela tragédia do outro;
esse desvio que as pessoas têm para notícias trágicas é psicanaliticamente um sistema emocional
de autodefesa que dá uma sensação de alívio ou tensão ao saber que outra pessoa passou pela
situação violenta.
No caso específico do em.com.br, a cobertura do incêndio aconteceu à distância, com
informações apuradas pelos repórteres, por telefone, junto ao Corpo de Bombeiros, polícia,
autoridades envolvidas nos atendimentos, além de textos de agências de notícias. No dia da
tragédia, foram publicadas 27 matérias relacionadas ao conteúdo e uma galeria de fotos. Além do
trabalho tradicional do jornalismo, no em.com.br o gerenciamento de tags potencializou a
audiência da cobertura, conforme relata o jornalista Emerson Campos:
A gente já tava com uma audiência que era bem atípica para o dia de domingo
porque o fato em si pedia, gerava essa audiência grande. Então a gente já tinha
notado que obviamente a audiência tinha subido muito, só que a partir de certo
momento a gente viu que ela se multiplicou quatro, cinco, seis, sete vezes. Foi
aumentando e a gente ficou meio sem entender. Quando a gente entrou nessa
notícia em si que tava dando mais audiência do que todas as outras e não estava
com destaque tão grande na capa quanto as outras, a gente foi ver o que tinha de
diferente nela e a gente percebeu que era a tag, as palavras-chave de Santa
Maria. A gente até deu uma olhada nos outros sites e ninguém tava usando, tava
todo mundo puxando como tragédia sul, boate, incêndio, mas não usava Santa
Maria. A gente usou o mesmo artifício para colocar em outros conteúdos que
estavam no ar, usando a mesma tag. A partir do momento que a gente colocou
essa mesma tag nos outros conteúdos, os outros conteúdos também começaram a
responder e a audiência a subir. Não subiu tanto como essa primeira, acho que
foi uma coisa inicial. Ela veio antes das outras, ela teve e gerou mais acesso no
Google do que as demais, mas as outras também responderam em algum nível e
começaram a gerar acesso pelo Google e não mais pela capa do nosso portal. A
galeria que começou a dar muito acesso era de fotos iniciais. O conteúdo em si
não justificava tanto a quantidade de acesso. A gente sabia que não era por causa
do destaque na capa, porque não tinha uma foto tão boa ainda para chamar
acesso pela capa e a gente foi notar que era mais a semântica da coisa mesmo, de

94
ser a palavra-chave que estava buscando acesso e não o conteúdo em si.
(Depoimento de Emerson Campos – grifos meus).
O conteúdo citado pelo jornalista e que fez disparar os acessos do site no dia 27 foi a
galeria de fotos intitulada “Incêndio em Santa Maria”, expressão que formou a URL do conteúdo
na publicação. O que foi descrito pelo repórter é uma situação real em que os conteúdos foram
publicados, monitorados com a ferramenta de medição de audiência e retroalimentados com a
recolocação da palavra-chave propositadamente para gerar acessos. Aproveitando o relato do
jornalista, é possível entender que ele descreve uma situação de folksonomia reversa, em que os
produtores de conteúdo perceberam qual tag estava capturando leitores na rota hipertextual. Eles
usaram essa etiqueta para multiplicar a atração e, consequentemente, os acessos.
As palavras grifadas ajudam a traçar um ciclo para entendimento da situação atípica, que
será corroborada com os números extraídos do Google Analytics. Inicialmente se tem alta
audiência, justificada pelo valor-notícia da tragédia. Em seguida, uma multiplicação desses
acessos por motivo não relacionado ao valor-notícia, pois a galeria sequer estava em local de
destaque na capa do site. O que aumenta a audiência é a indexação do conteúdo pelo Google
mediante a busca da palavra-chave “santa maria”. As matérias que normalmente apresentam alta
audiência são aquelas expostas com algum recurso nas capas dos portais, no Twitter ou Facebook
do em.com.br. Esse não era o caso da galeria de fotos “Incêndio em Santa Maria”.
O jornalista só fez a descoberta sobre a tag porque a ferramenta de medição de audiência
permite saber a origem de tráfego da leitura do site. Adiante, o artifício de taguear outros
conteúdos com a mesma etiqueta é a ação efetiva de consciência do repórter sobre a captura do
leitor na rota hipertextual, produto do que ele chamou de “semântica da coisa”. O ciclo se fecha
com o acesso inesperado dos leitores e com a taxa de conversão muito positiva.
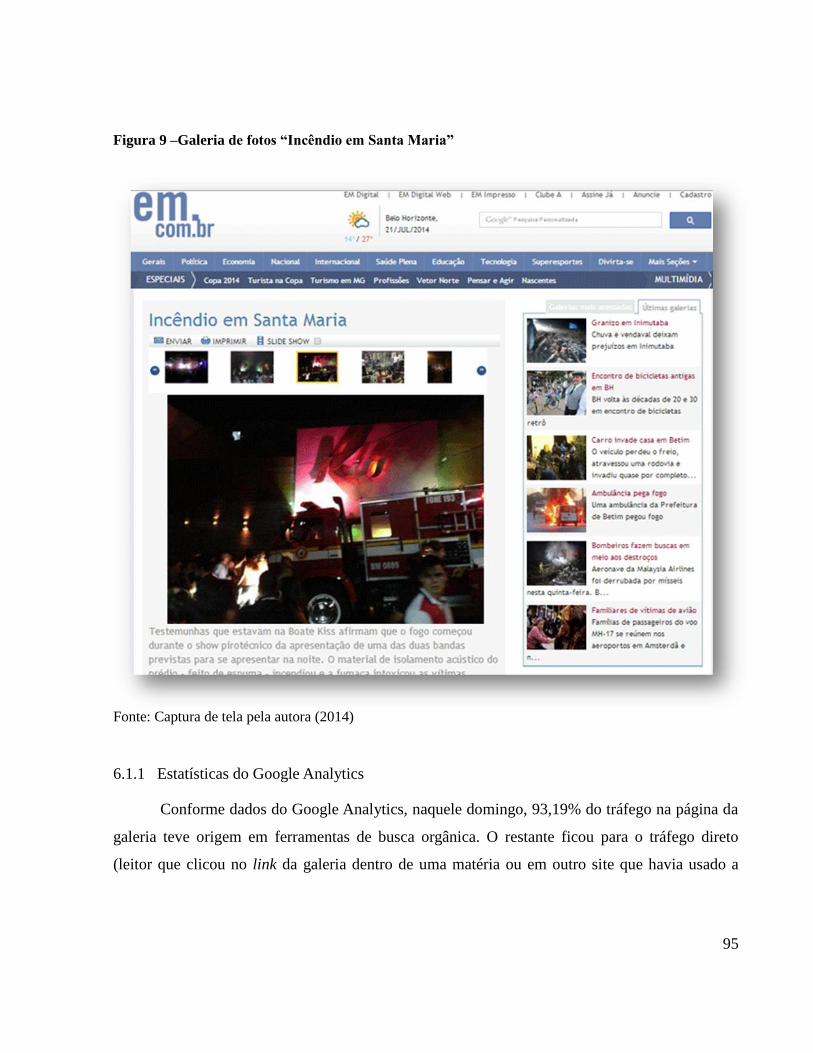
95
Figura 9 –Galeria de fotos “Incêndio em Santa Maria”
Fonte: Captura de tela pela autora (2014)
6.1.1 Estatísticas do Google Analytics
Conforme dados do Google Analytics, naquele domingo, 93,19% do tráfego na página da
galeria teve origem em ferramentas de busca orgânica. O restante ficou para o tráfego direto
(leitor que clicou no link da galeria dentro de uma matéria ou em outro site que havia usado a

96
galeria), e para o tráfego de referência69
(leitores que chegaram até a galeria pelas capas do Portal
Uai, em.com.br, Google News, estaminas.com.br ou Facebook). De todo esse tráfego, 98,19%
veio do buscador Google. As combinações procuradas nos buscadores que renderam maior
audiência à galeria foram “incendio em santa maria” (18,81%), “fotos do incendio em santa
maria” (12,92%) e “fotos incendio santa maria”(5,42%).70
A diferença entre as combinações de tag parecem sutis, podem ser por apenas uma
preposição, mas mudam o cenário da audiência. Considerando que o site do Estado de Minas tem
o domínio em.com.br, a busca das preposições “em” no Google juntamente com as palavras-
chave “santa maria” pode ter ajudado no ranqueamento da página e impulsionado acessos para o
site mineiro.
Os números mostram que a maior parte da audiência para esse conteúdo é de leitores
capturados pela oferta que o Google fez do link para o site do Estado de Minas. É claro que são
leitores interessados no assunto, mediante todos os critérios de noticiabilidade citados, mas que
não chegaram à galeria de fotos de forma completamente espontânea. Esse leitor fez suas
escolhas baseado em um processo de cognição individual, porém optou dentro de uma oferta
preparada pelo buscador. Um dos impactos disso é a mudança imediata que o produto de
conteúdo precisou fazer para se “aproveitar” desse direcionamento de leitores.
Para se ter uma ideia da importância desse exemplo de gerenciamento de tag, o número
absoluto de acessos dessa galeria de fotos a colocou em primeiro lugar como a mais clicada de
todos os tempos desde o surgimento do portal em.com.br, em setembro de 2010. A audiência,
medida desde o dia da tragédia até julho de 201471
, é o dobro da galeria que vem em segundo
lugar – fotos da mulher Barbie. É também uma audiência quase três vezes maior que a galeria de
69
Esses sites do tráfego de referência são definidos pelo proprietário do site e passam a ser monitorados como
origens importantes de “porta de entrada” dos leitores.
70 Lembrando que os dados de palavras-chave ficam muito nebulosos porque existe uma variável do Google
chamada de not provided – não fornecido. São tags que não se conseguem definir. Isso causa uma distorção no
resultado final, porque o not provided fica com percentual altíssimo e não é possível saber quais palavras estão
incluídas no grupo. Especialistas em SEO discutem e rediscutem o tema, criam soluções alternativas, mas a
dificuldade de análise por causa do not provided permanecem. No caso do Incêndio em Santa Maria, o valor not
provided foi de 26,96%.
71 Data de fechamento de dados da pesquisa

97
fotos de um grave acidente na Avenida Nossa Senhora do Carmo em Belo Horizonte, que está no
ar desde 6 de junho de 2012. O incêndio consegue vencer qualquer conteúdo relacionado a
manifestações de julho de 2013, que foram fenômenos de audiência para o site. Nem mesmo o
fator regional do portal, a proximidade, o ineditismo e tantos outros critérios de noticiabilidade
associados ao acidente e às manifestações em Belo Horizonte venceram a competência da
semântica na indexação pelo Google.
Outro dado fundamental é o número de novos visitantes que a galeria atraiu,
comprovando que o gerenciamento de tags capturou leitores que nunca haviam visitado o site,
nem mesmo pelo conteúdo de nicho. São esses os leitores alvo dessa captura em rota hipertextual,
aqueles que habitualmente não clicariam na capa do em.com.br em busca de notícia. As novas
visitas não significam novos leitores imersivos para o site, talvez eles nunca mais tenham
voltado. No entanto, engrossaram as estatísticas daquele domingo. É possível conferir o resumo
dos números que fazem da galeria de fotos “Incêndio em Santa Maria” um diferencial histórico
de audiência no em.com.br na Figura 10:

98
Figura 10 – Números Incêndio em Santa Maria
Fonte: Elaborado pela autora
6.1.2 Google Trends como balizador dos termos “santa maria”
O uso de uma combinação de tags específica alterou o processo de produção dos
repórteres – que passaram a incluir a expressão “santa maria” em todo o conteúdo sobre a

99
tragédia – e capturaram leitores quase72
automaticamente. Possivelmente, antes da tragédia, a
expressão “santa maria” tivesse alguns valores semânticos associados quando procurada em
buscadores na Web. Agora não é mais possível testar essas antigas combinações, porque a
palavra-chave assumiu o significado atrelado ao incêndio, com novo campo semântico
construído. Essa rede de palavras muda com frequência, influenciada, muitas vezes, por
acontecimentos.
Uma rede semântica, segundo Santaella (2013), é a junção de um mecanismo por trás da
memória, o crescimento do significado e o entendimento de símbolos. Tudo isso é mantido
mutuamente na estrutura do conhecimento. É provável que, antes do incêndio, os resultados de
busca remetessem à santa – mãe de Jesus –, alguma cidade que não fosse aquela do Rio Grande
do Sul, alguma música, bairro, avenida, porto, peça teatral, igreja, enfim, a uma centena de
significados a que a expressão pode se referir.
No Google Trends, a tag alcançou o topo máximo de buscas em janeiro de 2013 e ganhou
combinações improváveis, que ficaram registradas por quase mais de ano: “tragédia santa maria”,
“santa maria tragédia”, “kiss santa maria”, “fotos santa maria”, “incêndio santa maria”. Uma
nova rede de conhecimento se formou no entorno da expressão a partir do acontecimento no Rio
Grande do Sul e da cobertura jornalística sobre o fato.
Quando outros portais de notícia escolheram, no processo de tagging de conteúdos, usar
as etiquetas “boate” ou “kiss”, podem ter perdido uma boa oportunidade de indexação certeira e a
consequente taxa de conversão. Essas duas palavras têm um campo semântico infinito,
principalmente aquela que pertence à língua inglesa. O em.com.br acertou na folksonomia reversa
de “santa maria”, conquistando novos visitantes e alta audiência.
72
“Quase automaticamente” porque, mesmo tendo como oferta o link do Estado de Minas em primeiro lugar, o
leitor poderia ter escolhido outra rota.

100
Figura 11 – Google Trends - interesse pela tag “santa maria” em buscas do Google
Fonte: Captura de tela pela autora (2014)
6.1.3 Análise de dados
A operação jornalística e linguística da cobertura Incêndio em Santa Maria é dotada de
dinamismo porque o acompanhamento de números da audiência em tempo real gera
comportamentos diferentes nos repórteres responsáveis pelo trabalho. Gera também uma variação
de ações do leitor a cada fato diferente sobre o incêndio e a cada caminho que ele assume na rota
hipertextual para chegar ao conteúdo do em.com.br. Falando em ações do leitor no contexto da
Web Semântica, leva-se em conta o ciclo de escolha a partir do momento em que digita palavras-
chave no buscador até a opção final pelo conteúdo. O leitor não para por aí, devido às inúmeras
possibilidades de reverberação e compartilhamento da leitura feita.
Percebe-se que o processo de produção e leitura no entorno do incêndio encontra ordem
no caos de um fato tão consternador, que exige competência para seleção de fontes de notícias,
além de uma minuciosidade no texto tão carregado pela tragédia. Essa auto-organização
alcançada durante a cobertura foi um resultado natural da adaptação do sistema de produção
numa situação caótica.
A característica mais marcante para se observar no episódio do “Incêndio em Santa

101
Maria” é a não-linearidade na produção do conteúdo – reforçada pela folksonomia reversa – e na
leitura que aconteceu em grande percentual por meio da captura em motores de busca. A
cobertura de Santa Maria marcou o processo jornalístico com um “algo a mais” diante de todas as
outras coberturas feitas no em.com.br porque destacou um padrão de produção diferenciado pelo
gerenciamento de tags. Essa cobertura em específico, como parte de um todo, fez surgir a
emergência para uma nova potencialidade ser cada vez mais explorada: a captura de leitor na rota
hipertextual.
O resultado da folksonomia reversa parecia ao repórter, conforme relatou Emerson
Campos, uma interação em pequena escala, mas os números do Analytics mostram que teve um
efeito em grande escala, principalmente quando se analisa a perspectiva de taxa de conversão. A
medida desse efeito está clara na autoamplificação em feedbacks dessa cobertura. O maior dos
retornos é a audiência gerada em efeito bola-de-neve a partir do uso da atratora “santa maria”.
O feedback ressoou e hoje observa-se a cobertura do incêndio como um fenômeno único
para o site, porque nele é possível ver o caos (no “estourar” das notícias) se transformando numa
perspectiva meta-balanceada de alcance de audiência. A cobertura do incêndio evoluiu durante
aquele domingo e tantos outros dias em que o conteúdo perpetuou. Os repórteres aprenderam a
eficiência do tagueamento para este caso – ação que foi “filtrada” como essencial para o
jornalismo que se fez a partir dali. O ciclo de quebra da fronteira do caos na cobertura pode ser
exemplificado da seguinte forma:

102
Esquema 3 – Processo de auto-organização no fenômeno “Incêndio em Santa Maria”
Fonte: Elaborado pela autora.
O ciclo remete ao Esquema 3 desta pesquisa. Em uma leitura mais refinada desse
esquema, poderia ser sugerido que cada um dos círculos fosse também um ciclo, pensando na
produção jornalística. Há uma auto-organização em cada uma das partes, daí a ideia de
dinamismo complexo onde quatro processos giram dentro de um sistema macro e integrado. A
ideia é semelhante quando se pensa no aspecto linguístico, resultado desse ciclo. A tag “santa
Maria”, além de atratora, pode ter funcionado como chave para a renovação da linguagem, com
novos elementos incorporados à rede de conceitos. Essa renovação pode representar uma situação
caótica inicialmente, mas logo se torna uma consolidação ou uma sedimentação da linguagem.

103
6.2 Morte de Paul Walker
No dia 30 de novembro de 2013, morreu o ator Paul Walker, 40 anos, muito conhecido
por protagonizar a sequência de filmes Velozes e Furiosos interpretando Brian O'Conner. A
notícia da morte ganhou destaque em sites nacionais e internacionais por se tratar de uma
celebridade e, além disso, pela forma trágica como o artista morreu: um acidente de trânsito. A
repercussão no Brasil ocorreu no domingo, dia 1° de dezembro. Paul era passageiro de um Porshe
dirigido por um amigo, que perdeu o controle do veículo, bateu em uma árvore e um poste. Eles
voltavam de evento beneficente da organização Reach Out Worldwide na cidade californiana de
Santa Clarita, ao norte de Los Angeles. Muito se especulou sobre as causas do acidente e as
investigações apontaram uma velocidade excessiva de 160 km/h. Com o impacto na árvore, o
carro explodiu e incendiou matando os dois ocupantes.
Uma tragédia automobilística com imagens fortes como a desse acidente geralmente atrai
olhares dos leitores de portais de notícias pela proximidade geográfica, singularidades ou pelo
critério da negatividade. Nesse caso específico, o valor-notícia se multiplica porque o acidente
envolve uma celebridade, atraindo ainda mais audiência para o fato. As oportunidades de
publicações naquele domingo sobre o tema foram inúmeras, tendo o em.com.br divulgado quatro
matérias sobre o acidente. A cobertura foi feita com informações de agências de notícias e dados
de sites locais da Califórnia, mas o trabalho de gerenciamento de tags fez, novamente, a diferença
para a audiência do conteúdo. O repórter João Henrique do Vale Almeida relata o que ocorreu:
Quando chegamos na redação, por volta das 7h, vimos que o ator tinha morrido
em um acidente de carro. Fomos nos sites dos EUA e apuramos as informações
para fazer a matéria, que ainda não tinha saído em agências de notícias.
Escrevemos uma pequena reportagem com as informações básicas e contando
um pouco a vida do artista. Como não tinha fotos do acidente, colocamos uma
imagem dele que tinha no nosso banco. Na capa do Uai, ficou em um destaque
com foto pequena no lado direito. Com o passar das horas, notamos que a
matéria começou a subir de audiência assustadoramente, coisa muito difícil de
acontecer, principalmente no fim de semana, quando a audiência é baixa. A
audiência estava vindo do Google. Nossa matéria era a primeira quando buscava
pela morte do ator. Por causa disso, começamos a investir na reportagem.
Colocamos uma foto do acidente e um vídeo do carro em chamas. Também

104
mudamos o destaque de lugar na capa. Subimos a reportagem para o rotacional.
Para não deixar a audiência cair, fizemos outras duas ou três matérias sobre o
caso. Elas também tiveram muito acesso, mas não chegaram a ter o acesso da
reportagem do vídeo que foi a mais lida. (Depoimento de João Henrique do Vale
Almeida – grifos meus).
O que se percebe no relato do João Almeida é uma reação um pouco diferente dos
repórteres que participaram da cobertura do Incêndio em Santa Maria e também se depararam
com uma situação de audiência extraordinária. No caso da morte do ator, o processo de indexação
e o sucesso do conteúdo não motivaram a folksonomia reversa, mas uma espécie de hierarquia e
produção reversas. É possível constatar isso no momento em que os jornalistas começaram a
“investir” no conteúdo ao perceberem o potencial de audiência para aquele domingo.
As palavras grifadas ajudam, novamente, a traçar um ciclo para entendimento da situação
atípica levando em conta o depoimento do entrevistado. Percebe-se que o conteúdo relacionado à
morte de Paul Walker começa a ser publicado com um destaque tímido (foto pequena) na capa do
Portal Uai até que a audiência assustadora altera a avaliação dos repórteres e motiva mudanças. A
primeira matéria ganha mais informações e outros conteúdos – como o vídeo do acidente – viram
prioridades na cobertura.
Quando o repórter diz: “a audiência estava vindo do Google”, nada mais é do que um
resumo de todo o processo de indexação e captura de leitores do qual esta pesquisa trata. Por
causa dos resultados de indexação, os jornalistas dão mais valor àquela notícia, escolhendo
posicioná-la em local mais destacado na capa do Portal Uai, o “guarda-chuva” responsável pela
maior visibilidade de produtos dos Diários Associados. Eles optam também por produzir mais
textos relacionados: “Subimos a reportagem para o rotacional. Para não deixar a audiência cair,
fizemos outras duas ou três matérias sobre o caso”.
A primeira ação representa uma mudança na hierarquia da informação na capa do site,
sendo importante destacar que o “rotacional” é um trecho nobre da capa, localizado no primeiro
scroll do site. Para entender como funciona uma distribuição de matérias na capa de um portal e
saber da importância da mudança que a indexação provocou, trago uma breve explicação sobre
estratégias de exibição das notícias em portais. Mielniczuk e Palácios (2001) dão uma

105
contribuição com um modelo73
de hierarquia das notícias:
Figura 12 – Modelo de hierarquia Mielniczuk e Palácios
A
C B1
B2 D
Fonte: Adaptado de Mielniczuk; Palácios (2001).
Segundo os autores, a Zona A corresponde ao cabeçalho do produto, contendo o nome do
jornal, o nome do portal e links para outras seções do portal. A Zona B é dedicada às notícias,
sendo que na parte superior (B1) há matérias mais novas e na parte inferior (B2) são colocados
apenas os títulos das notícias mais antigas. A Zona C é constituída prioritariamente por links que
conectam a todos os canais do portal. A Zona D tem links apontados para fora do conteúdo do
portal. Há espaço para publicidade, serviços ou sites externos relacionados com o material
jornalístico. O que se percebe é que a maioria dos portais de notícias segue esse padrão de
disponibilização de matérias. Nas zonas B1 e C estão geralmente notícias destacadas em letras
maiores (manchetes) e acompanhadas de fotos. A Zona B2 traz os chamados “destaques textos”
de fatos que já perdem valor-notícia. A Zona C atende a outras necessidades do leitor que não
seja a informação factual.
Essa matriz corrobora com um aspecto fundamental da lógica editorial do jornalismo na
Web: a multimodalidade. Segundo Kress e Leeuwen (1998), todos os textos são multimodais.
Quando falamos, nossa mensagem não vai apenas por meio das palavras, mas também por gestos,
entonações e expressão facial. Da mesma forma, quando escrevemos, a mensagem não é expressa
apenas linguisticamente, mas por meio de um visual marcado na página. As empresas
jornalísticas se preocupam muito com o layout e a apresentação das notícias. A importância dada
para cada destaque e o posicionamento dele na página expressam o valor do fato para aquele
veículo.
Os jornalistas que montam as capas de portais, geralmente, se apoiam em uma estrutura
que Kress e Leeuwen (1998) chamam de Given-News, um equilíbrio entre notícias que já são de
73
Modelo criado pelos autores em análise do site Último Segundo, jornal desenvolvido exclusivamente para Web.

106
conhecimento do público (Given), mas geram interesse e familiaridade, por isso precisam estar
nas capas, e os fatos novos (News), que as pessoas ainda não leram e aos quais vão dedicar certa
atenção durante a navegação no site. O balanceamento desses aspectos é uma tarefa complexa,
porém a chave para uma estrutura editorial.
A capa do Portal Uai na época da morte do ator era montada conforme a Figura 113 e o
conteúdo sobre a tragédia entrou na sessão de fotos que giram na capa – o rotacional. Se a captura
de leitores por tags, a indexação e o aumento imediato de audiência não ocorressem, as mudanças
de hierarquia não teriam acontecido. O jornalista foi motivado a fazer as alterações por causa da
audiência, resultado da captura de leitores na rota hipertextual. Dessa forma, fica demonstrado
que o modelo de Mielniczuk e Palácios (2001) e de Kress e Leeuwen (1998) ganharam a
indexação em buscadores como aliada, ficando ela no papel de “gatekeeper” para hierarquização
de matérias e capas nos portais.
Figura 13 – Capa do Uai em Junho de 2013, mesmo modelo de novembro 2013
Fonte: Captura de tela pela autora (2013).
Rotacional

107
A matéria de grande acesso à cobertura sobre a tragédia envolvendo Paul Walker é aquela
em que é inserido o vídeo do acidente automobilístico. O título dessa reportagem, ou seja, a URL
dela, tem palavras-chave importantes quando se pensa em captura do leitor em motores de busca:
“vídeo”, “paul walker” e “acidente”. Uma ação natural do repórter, acostumado com estratégias
de SEO, seria pensar quais palavras o leitor buscaria no Google para saber mais sobre a morte do
ator de Velozes e Furiosos. Muitas combinações de tags poderiam ser certeiras nesse caso, mas as
três etiquetas citadas acima foram eficientes quando se trata da curiosidade do leitor sobre o
assunto. Não é à toa que a matéria “Vídeo mostra momento em que carro de ator Paul Walker fica
em chamas após acidente” alcançou o maior acesso74
em tempo real do site em.com.br, pico de
audiência causada pelo ranqueamento eficiente da matéria Google.
Figura 14 –Matéria “Vídeo mostra momento em que carro de ator Paul Walker fica em chamas
após acidente”
Fonte: Captura de tela pela autora (2013).
74
Vale lembrar que a pesquisa encerrou a coleta de dados em julho de 2014. Por curiosidade, verificaram-se os
dados após o encerramento e o recorde de acessos em tempo real foi superado em 13 de agosto de 2014, com a
morte do candidato Eduardo Campos.

108
Estatísticas do Google Analytics
Conforme dados do Google Analytics, naquele domingo, 82,49% dos acessos à matéria
com o vídeo sobre a morte do ator vieram de busca orgânica, sendo 82,15% do Google. O mais
importante desses números foi o resultado dos motores de busca na audiência em tempo real, um
recorde para o portal em.com.br. A matéria alcançou milhares de pageviews simultâneos nesse
mesmo link, valores que permaneceram estáveis por mais de 24 horas. Para se ter uma ideia, um
conteúdo local de Minas Gerais sobre protestos em junho de 2013 alcançava, no auge de conflitos
entre policiais e manifestantes – em matérias com muitos vídeos, informações, fotos e galerias –,
metade dos acessos simultâneos registrados na cobertura da morte de Paul Walker.
As combinações procuradas nos buscadores que renderam maior audiência foram as tags
“paul walker” (5,02%), “morte de paul walker” (1,4%), “ator de velozes e furiosos morre”
(0,76%) e “morre ator de velozes e furiosos (0,55%)”75
. O número de novos visitantes na matéria
do vídeo também é relevante: 74,40% das pessoas que clicaram eram estreantes.
Os números mostram que a maior parte da audiência para este conteúdo é de leitores
capturados pela oferta que o Google fez do link para o site do Estado de Minas. A importância
jornalística dos resultados nesta cobertura vai além das mudanças demonstradas com a hierarquia
e produção reversas. A audiência assustadora em tempo real é estrategicamente fundamental para
um portal, porque demonstra sua saliência em relação a concorrentes e sua relevância na Web.
A origem de audiência para o conteúdo local é geralmente tráfego direto e tráfego de
referência, mas no conteúdo internacional – como no caso da morte de Paul Walker – o
em.com.br tem contado cada vez mais com a busca orgânica. Cria-se, assim, um desafio de
planejamento de acessos aos portais de notícia locais, como o em.com.br, que focam o negócio
nas notícias de Minas e, muitas vezes, perdem o time para a ação de motores de busca. Para uma
empresa de comunicação, toda e qualquer audiência é sempre bem-vinda, mas é necessário
repensar planos e produção quando uma ferramenta tecnológica como a busca orgânica influencia
muito na audiência.
Se um site tem, por exemplo, um plano de metas de audiência por repórter ou por editoria
75
Cf. nota 70 sobre not provided. Neste caso, o valor foi de 82,04%.

109
e os resultados são influenciados por fatores do meio (Web Semântica), a meta precisa ser refeita
considerando essa variável. Se está planejado um crescimento X para a editoria Internacional e
um crescimento Y para a editoria Gerais, as proporcionalidades de origem de tráfego precisam
fazer parte do plano, senão, a editoria local ficará com crescimento distorcido em relação àquelas
que ganham muito com a busca orgânica. O conteúdo local quase nunca se beneficia da
indexação de matérias no Google, diferente de matérias nacionais ou internacionais, pois conta
mais com o tráfego direto.
Audiência é apenas um dos fatores jornalísticos que precisam ser levados em conta numa
produção, mas se há ferramentas que ajudam na reverberação automática de acessos, nada melhor
do que administrá-las com inteligência. O em.com.br começou a fazer isso recentemente, de
forma bem primária, porque vive tomado pela rotina de produção e o processo de análise e
estudos de SEO fica em segundo plano.
Vejamos o resumo de números que fazem da matéria “Vídeo mostra momento em que
carro de ator Paul Walker fica em chamas após acidente” um diferencial histórico de audiência no
em.com.br:

110
Figura 15 – Números Morte Paul Walker
Fonte: Elaborado pela autora
6.2.1 Google Trends como balizador dos termos “paul walker”
O comportamento da tag “paul walker” tem um perfil parecido com “santa maria” por
causa do pico de buscas no período da morte do ator. No caso da morte, é possível fazer uma
análise diferente do campo semântico atualmente associado ao nome do artista. Os fatores de

111
busca que possivelmente vinham acompanhados de tags como “ator”, “filme”, “velozes e
furiosos” agora ficam eternizados como uma procura associada a palavras-chave como “dead”,
“death”, “crash”.
Na análise da tag “paul walker”, é difícil balizar o termo com uma língua específica –
inglês ou português – porque a expressão é um nome próprio usado com esta grafia em qualquer
língua. A tag “santa maria”, por exemplo, ainda poderá retomar os significados anteriores,
porque, passado um bom tempo da tragédia, as buscas no Google voltam a associar essa etiqueta
a outros campos semânticos. No caso de “paul walker”, dificilmente haverá a reversão do campo
semântico relacionado ao acidente fatal. O sétimo filme da série Velozes e Furiosos está marcado
para estrear em 2015 com homenagens ao ator e participação dos irmãos dele. A estreia, como
fato jornalístico, poderá alterar a marca semântica que o nome de Paul Walker agora carrega na
Web – com associação à morte.
O estudo dessa tag poderia nos levar até a uma reflexão mais profunda sobre memória na
Web, o que não é o objetivo deste estudo. Uma análise temporal de tags específicas mostraria o
rastro deixado pelas marcas linguísticas na história relacionada àquela etiqueta (neste caso,
história do ator), mas isso é assunto para outra pesquisa. Lévy tem uma contribuição sobre essa
perspectiva de semântica e memória na Web:
O mundo virtual contém dados simbolicamente codificados da memória pessoal
e social, bem como todos os jogos de interpretação e de avaliação desses dados.
Mesmo se os dados e suas interpretações sejam necessariamente sustentados por
entidades ou processos materiais, as suas significações e os seus valores
pertencem ao mundo virtual. Pois, do ponto de vista dos céus de ideias, os dados
são percebidos como vetores do sentido donde escapa uma multiplicidade
inesgotável de conceitos pensados pelo intelecto discursivo e pela sua atividade
hermenêutica. Os significados, as classes, as categorias gerais e os seus valores
simbólicos não possuem endereços espaço-temporais. (LÉVY, 2014, p.118).

112
Figura 16 - Google Trends - interesse pela tag “paul walker” em buscas do Google
Fonte: Captura de tela pela autora (2014).
6.2.2 Análise de dados
O esquema cíclico criado na cobertura da Morte de Paul Walker, em que o repórter
reverteu a produção por causa da audiência, mostra uma operação jornalística e linguística
dinâmica, baseada em um comportamento de constante mudança: variação de page views x
mudanças no processo de produção e hierarquização das notícias. A ação da tag “paul walker”
como atratora de leitores na rota hipertextual alterou não somente a audiência do portal, mas
também o trato da notícia pelos jornalistas.
O processo caótico de noticiabilidade naquele domingo de intensa produção se auto-
organizou e se manteve até o dia seguinte, quando a audiência ainda estava com a origem de
tráfego no ranqueamento do Google. Os resultados vieram de uma adaptação natural do sistema
criado no entorno da cobertura. Não foi necessária qualquer ação externa para que a audiência se
mantivesse; o que os repórteres fizeram alterando hierarquia e produção foi apenas consequência
do resultado já alcançado quase automaticamente pela indexação da tag na URL. Conclui-se que
a captura do leitor na rota hipertextual por meio de tags atratoras indexadas pelos motores de
busca se autossutenta em uma estrutura reticular e não linear.
O efeito em grande escala, resultado números de acesso alcançados pela matéria do vídeo,

113
marca não somente um recorde em audiência tempo real como a emergência de um padrão de
potencialidades relacionadas às estratégias de SEO para editorias que muito se beneficiam com a
busca orgânica. Essas editorias e suas coberturas – como sistemas – alcançam um nível de auto-
organização muito maior do estado anterior sem os processos de captura quase automática do
leitor.
Os feedbacks em audiência amplificaram as ações dos repórteres e consequentemente a
reverberação de taxa de conversão para todo o conteúdo relacionado à morte do ator Paul Walker.
Como consequência direta também – em efeito bola-de-neve – o em.com.br como um todo
alcançou bons números naquele fim de semana de produção. Nesse ciclo de feedbacks é
interessante pensar que há protagonismo de leitor e produtor igualmente envolvidos no ciclo de
interação que vai da desordem à ordem, com ressonância constante.
Esquema 4 – Processo de auto-organização Morte Paul Walker
Fonte: Elaborado pela autora.

114
O todo não pode, pois, ser descrito por um movimento simples, mas por um
movimento de ida e volta, de ação e reação linguísticas, que representa o
círculo de proposição. (DELEUZE, 2007, p.189).
7 Considerações finais
O todo desta pesquisa não se encerra aqui nas considerações finais, porque o objetivo é
que este estudo continue representando círculos de proposições, da autora ou de outros. O
resultado de dois anos de pesquisa não pode ser descrito por um movimento simples, por isso
idas e vindas do texto ajudam a fechar este primeiro ciclo. No entanto, o fechamento não é o
limite, sempre fica a chance de um algo a mais.
7.1 Conclusões
Modelos lineares de navegação na Web, ainda disponibilizados por muitos produtores,
não correspondem à expectativa do leitor que tende a fazer uma navegação nômade, própria dos
sistemas complexos. No jornalismo, por exemplo, o leitor tem chegado aos conteúdos de formas
diferentes pela rota hipertextual, nem sempre pelo tráfego direto a portais de notícias. O uso de
buscadores impacta os processos de produção e de leitura, como foi mostrado nos casos das
coberturas jornalísticas desta pesquisa, em duas situações comunicativas distintas. Nesse sentido,
o jornalismo digital fica cada vez mais baseado em tags e remixado na rede.
É nesse contexto que as palavras-chave surgem como atratoras no sistema complexo
guiando produtores nas estratégias de etiquetagem de conteúdo e capturando os leitores para
conteúdos direcionados em um caminho não linear. Elas emergem como articuladoras da
complexidade. Por causa disso, o gerenciamento de tags entra de vez como atividade parte da
rotina de produção, mesmo que timidamente, puxada pelas ferramentas da Web Semântica e
SEO.

115
Os processos de dedução e indução do produtor também são potencializados pelo
gerenciamento de dados, influenciando diretamente em resultados e regras na lógica produtiva.
Para o jornalismo, esse gerenciamento passa pelo monitoramento de audiência e origem de
tráfego das matérias online, que geram ações de folksonomia (reversa) ou mudanças de hierarquia
(reversa) na distribuição da informação em portais. A folksonomia, em especial, ganha status de
paradigma de classificação, considerada como ferramenta de distribuição de conteúdo online e
recuperação de informação.
Os resultados linguísticos para toda essa lógica complexa de produção e leitura no
contexto da Web são as construções de novos valores semânticos para as tags - quando se pensa
em memória de navegação. As palavras-chave se enchem de campos semânticos variados, um
reflexo do encontro entre signo e linguagem. A rede se torna o lugar onde o signo “extrojetado”
de cada pensamento se manifesta em ambiente conjunto, de compartilhamento e construção
coletiva de conhecimento. Este ambiente agora tem como desafio operar significados de forma
não fragmentada.
Esses significantes estão bem interconectados, mas não os seus significados. As
camadas de complexidade das mensagens e as formações discursivas, as
ressonâncias semânticas entre as multiplicidades dialógicas, as longas linhas
solidárias de transformações hermenêuticas, tudo que faz a sutileza, a riqueza a
própria essência da cultura, permanecem quase opaco ao cálculo. E é por esse
motivo que ainda hoje a inteligência coletiva fragmentada não pode representar
para si mesma os seus próprios processos cognitivos, segundo a ordem de
grandeza do novo meio digital (LÉVY, 2014, p. 81).
A produção e a leitura regidas por atratores reforçam a ideia do ambiente digital como um
sistema complexo que se auto-organiza a partir da dinâmica das redes hipertextuais. As
possibilidades da Web Semântica ajudam a entender o que se passa na cabeça do leitor, a atraí-lo
na rota tentando adiantar a lógica de pensamento dele quando navega. As ferramentas inteligentes
trazem todo o potencial que tem origem, nada mais nada menos, que no pensamento humano.
Para Lévy (2014), as ações dos jornalistas e comunicadores farão com que o leitor entenda as
mensagens por meio de contextos. Dar sentido ao texto é o mesmo que ligá-lo, conectá-lo a
outros textos, portanto é o mesmo que construir um hipertexto. Uma observação do autor que
casa com as considerações finais desta pesquisa é que “todos os documentos estão virtualmente

116
interconectados, formando, no limite, um único hipertexto movente, lido e relido por uma
multiplicidade de autores e leitores de línguas, de culturas e de ética diferentes” (LÉVY, 2014, p.
191). O que se pode perceber é que no meio digital, a língua não é mais apenas a memória
autônoma que a escrita lhe confere, pois ela possui uma capacidade de ação e de interação
autônoma.
A Web Semântica está fornecendo estruturas e dando significado ao conteúdo, criando um
ambiente onde agentes de softwares e leitores possam trabalhar de forma cooperativa. A
tecnologia está ajudando na construção do que Morin (2003) chama de pensamento complexo, no
qual passamos de uma visão linear para uma ideia circular com conectividade.
O terreno de linkagens temporárias e relações rizomáticas que a comunicação em
ambiente digital “pisa” é resultado do uso de potencialidades da Web, que mudou muito desde a
primeira geração até a fase de gerenciamento de dados que alcança atualmente. São mudanças de
visão de navegação e leitura, essenciais para a produção mais competente de conteúdo que reflita
a hipercomplexidade do ambiente. Ainda há muito que fazer, principalmente no aspecto da
interoperabilidade entre linguagens e sistemas, mas a Web Semântica possibilita melhor
aproveitamento dos efeitos da rede pelas empresas de comunicação. Haja vista os exemplos de
aumento expressivo de taxa de conversão para em.com.br nos dois casos estudados.
Acredita-se que as principais contribuições deixadas pela pesquisa são um conceito mais
“comunicacional” da Web Semântica, a perspectiva do gerenciamento de tags como ferramenta
de trabalho para produtores de conteúdo, além da cadência de conceitos que ligam complexidade,
semântica e folksonomia, neste caso com aplicabilidade ao jornalismo baseado em tags, mas que
pode servir como arcabouço teórico para outras perspectivas da produção de conteúdo online.
As consequências dos aspectos aqui estudados para a Web são um sinal de que o futuro
está no alcance de mais claridade semântica. Se a humanidade quiser produzir conteúdos
significativos e recuperáveis na rede, é preciso construir instrumentos para observação capazes de
canalizar uma complexidade inesgotável. Canalizar a complexidade não é limitar, mas sim
explorar de forma funcional toda tecnologia disponível. Isso em todas as dimensões, da menor –
quando um jornalista percebe a audiência com origem de tráfego em uma tag e incorpora essa
palavra-chave na produção – até a criação de uma esfera semântica como Lévy propõe com o

117
IEML. Organizar os sentidos dos dados na Web: esse é o próximo passo.
O sentido de uma palavra não é outro senão a guirlanda cintilante de conceitos e
imagens que brilham por um instante ao seu redor. A reminiscência desta
claridade semântica orientará a extensão do grafo luminoso, disparado pela
palavra seguinte, e assim por diante, até que uma forma particular, uma imagem
global, brilhe por um instante na noite dos sentidos. Ela transformará, talvez
imperceptivelmente, o mapa do céu, e depois desaparecerá para abrir espaço
para entras constelações. (LÉVY, 2004, p. 14)
7.2 Finalizando
Considero que consegui mapear a evolução de produção e leitura na Web, avançando para o
campo da Web Semântica por meio dos casos usados como exemplo nesta pesquisa. Foi possível
mostrar os novos posicionamentos do produtor de conteúdo, no que diz respeito ao
gerenciamento de tags e as ações do leitor na rota hipertextual - características proporcionadas
pela era semântica da Web de uma forma que não era observada antes.
Os aspectos que indicam essa evolução de posturas do produtor são a inserção do S.E.O na
realidade diária, a prática de uma folksonomia e uma hierarquia da informação ordenadas pelo
indicativo de audiência. A folksonomia e hierarquia reversas praticadas pelos repórteres se
assemelham como processo de gerenciamento de tags, mas se diferenciam como estratégia
jornalística, porque mobilizam os repórteres de formas distintas. Para concluir as duas práticas, o
jornalista usa ferramentas, programas e habilidades diferentes. Mesmo assim, o objetivo das duas
ações – que nasceram durante o processo de produção – foi o alcance de mais audiência.
Os produtores percebem que modelos lineares de navegação na Web frustram expectativas do
leitor e inserem – mesmo que timidamente ou inconscientemente – estratégias semânticas na
produção. Quando digo inconscientemente é porque os jornalistas talvez não tenham essa noção
global de linearidade x não-linearidade, mas veem a necessidade de mudança na disponibilização
de conteúdo.
O que indica a mudança na perspectiva do leitor é o uso de buscadores para dar início a um
processo de navegação ordenado primeiramente pelo que passa na cabeça desse leitor, depois
pelos termos que ele procura e depois pelo link que ele escolhe para iniciar a rota hipertextual. É
por isso que o jornalista agora pensa além da pauta na tentativa de acertar o que o leitor buscaria
no Google para encontrar o conteúdo sobre o qual está escrevendo. É por isso, também, que a

118
Web Semântica está criando um ambiente onde agentes de softwares, jornalistas e leitores
trabalham de forma coordenada, potencializando resultados de audiências para empresas de
comunicação - um aproveitamento muito melhor da rede por essas organizações.
Por fim, considero que ficou claro o gerenciamento das tags mudando a estrutura de
significação de conteúdos na Web porque altera o campo semântico no em torno de etiquetas
associados a uma informação, tópico ou discussão. Foi isso que aconteceu com “santa maria” e
“paul walker” logo depois das duas tragédias. A indexação incorporou a essas tags novas
significações relacionadas ao incêndio e ao acidente automobilístico.
As estratégias exemplificadas nesta pesquisa poderiam ser aplicadas a qualquer cobertura
jornalística e em qualquer site. Este trabalho não é um serviço para empresas jornalísticas, mas
sim, um debate que inclui até a tal essência jornalística citada na página 92. Em que medida, o
jornalismo não é pretensioso demais em definir critérios para transformar fatos em notícias? As
demonstrações nos dois casos desta pesquisa revelam um processo muito mais espontâneo de
interesse do leitor aos conteúdos do que uma criação produtora pré-determinada. Sendo assim,
esta pesquisa é muito mais um serviço para o leitor, porque discute um movimento de escolhas
em rota hipertextual, que talvez o leitor nem perceba que faz.
7.3 Bastidores
Escolhi Deleuze para iniciar cada capítulo porque, em a Lógica do Sentido, ele ensina
como explorar as inter-relações dos sentidos como estrutura. Deleuze não se satisfaz com o plano
formal dado para o sentido, assim o explora de maneira mais complexa, enredada. O que ele faz
nesse livro dialoga muito com a organização do meu trabalho e, metalinguisticamente, com o
tema. A identidade visual da dissertação também não é por acaso. Ao fundo das imagens criadas

119
está a foto do sistema dinâmico conhecido como atrator de Lorez76
. Os círculos se amarram com
a metodologia criada por Deleuze, uma lógica circular com interseção de sentidos.
76
O Atractor de Lorenz foi introduzido por Edward Lorenz em 1963, que o derivou a partir das equações
simplificadas de rolos de convecção que ocorrem nas equações da atmosfera. É um mapa caótico que mostra
como o estado de um sistema dinâmico evolui no tempo num padrão complexo, não-repetitivo e cuja forma é
conhecida por se assemelhar a uma borboleta. Disponível em <http://pt.wikipedia.org/wiki/Atractor_de_Lorenz>.
Acesso em 8 ago.2014.

120
Figura 17 – Atrator de Lorez: modelo para identidade visual
Fonte: www.ima.umn.edu

121
8 Referências Bibliográficas
ALVARENGA, Lídia; SOUZA, Renato Rocha. A Web Semântica e suas contribuições para a
ciência da informação. Ci. Inf., Brasília, v. 33, n. 1, p. 132-141, 2004,. Disponível em
<http://revista.ibict.br/index.php/ciinf/article/viewArticle/50>. Acesso em 10 jun. 2014.
ALZAMORA, Geane; TÁRCIA, Lorena. A narrativa transmidiática: considerações sobre prefixo
trans. In: D’ANDREA, Carlos et al (Org.) Jornalismo Convergente: reflexões, apropriações,
experiências. Florianópolis: Insular, 2012.
ANDERSON, Chris. "The Long Tail" Wired, 2004.
ASSANGE, Julian. Cypherpunks: liberdade e futuro da internet. São Paulo: Boitempo, 2013.
ASSIS, Juliana; MOURA, Maria Aparecida. Folksonomia: a linguagem das tags. Encontros
Bibli: Revista Eletrônica de Biblioteconomia - Ciência da Informação, v. 18, n. 36, p. 85-106.
Florianópolis, 2013.
BAPTISTA, Ana Alice; CATARINO, Maria Elisabete. Folksonomia: um novo conceito para
organização de recursos digitais na web. Data Grama Zero, Revista de Ciência da Informação.
v. 8, n. 3, 2007.
BARBOSA, Suzana. Jornalismo Digital em Base de Dados (JDBD): um paradigma para
produtos jornalísticos digitais dinâmicos. 2007. Tese (Doutorado). Universidade Federal da
Bahia, Bahia, 2007.
BEIGUELMAN, G. Processos de criação e produção do conhecimento em hipermídia e em
redes fixas e móveis: pressupostos críticos e criativos no Design de Interfaces. Programa de
Pós-Graduação em Cultura e Semiótica. PUC/SP, fev-jun. 2009.
BERNERS-LEE, T., LASSILA, Ora; HENDLER, James. The semantic Web. Scientific
America, 2001.
Bruns, Axel. From Prosumer to Produser: Understanding User-Led Content Creation. In
Transforming Audiences 2009, 3-4 Sep, London, 2009.
CAMPOS, E. G. Convergência de mídias: uma análise da união de linguagens em notícias do
Portal Uai. Belo Horizonte, 2013.
CAMPOS, Maria Luiza Machado; CAMPOS, Maria Luiza de Almeida; CAMPOS, Linair Maria.
Web Semântica e a gestão de conteúdos informacionais. In: MARCONDES, Carlos H. et al
(Orgs.). Bibliotecas digitais: saberes e práticas. Brasília, 2006.
CASTELLS, Manuel. A sociedade em rede. A era da informação: economia, sociedade e cultura,

122
v.1, 9. ed. São Paulo: Paz e Terra, 1999.
CHARAUDEAU, Patrick. Discurso das mídias. São Paulo: 2. ed. Contexto, 2010.
______. Uma teoria dos sujeitos da linguagem. In: MARI, H. et al. Análise do discurso:
fundamentos e práticos. Belo Horizonte, Núcleo de Análise do Discurso/ FALE UFMG, 2001.
CRUZ, Luana; FERREIRA, Priscila; GODINHO, Poliana; GOMES, Alba; PEIXOTO, Giuliano.
Discussão dos modelos teóricos de comunicação em rede e suas aplicações práticas em
produtos para hipermídia: um estudo de caso do iGoogle. Disponível em
<http://www.bocc.ubi.pt/pag/gomes-peixoto-cruz-pires-ferreira-discussao-dos-modelos-
teoricos.pdf>. Acesso em 18 jun. 2014.
CUNHA, Jaqueline de Araújo. Web Semântica: o estado da arte. Universidade Federal do Rio
Grande do Norte. Centro de Ciências Sociais Aplicadas. Natal, 2006.
D'ANDRÉA, Carlos Frederico de Brito. Processos editoriais auto-organizados na Wikipédia
em português: a edição colaborativa de “biografias de pessoas vivas”. Belo Horizonte, 2011.
Disponível em <http://www.bibliotecadigital.ufmg.br/dspace/handle/1843/DAJR-8MYFZQ>
Acesso em 31 ago.2014.
DELEUZE, Gilles; GUATTARI, Félix. Mil Platôs - Capitalismo e esquizofrenia. São Paulo:
Editora 34, v. 5, 2007.
DELEUZE, Gilles. Lógica do sentido. São Paulo: Perspectiva 2007.
FERRARI, Pollyana. Narrativas tagueadas: uma narrativa social, informativa e feita pelo usuário.
Revista Select, São Paulo, 2012.
FRANÇA, Vera R. Do telégrafo à rede: o trabalho dos modelos e a apreensão da comunicação.
In: PRADO, José L. (Org.). Crítica das práticas midiáticas: da sociedade de massa às
Ciberculturas. São Paulo: Hacker Ed, 2002-a., p. 57-76.
FORMAGGIO, Erick Beltrami. SEO – otimização de sites: aplicando técnicas de otimização de
sites com uma abordagem prática. Rio de Janeiro: Brasport, 2008.
GOUVÊA, Cleber; LOH, Stanley. Jornalismo semântico: uma visão em direção ao futuro do
jornalismo online. In.: D’ANDREA, Carlos et al (Org.) Jornalismo Convergente: reflexões,
apropriações, experiências. Florianópolis: Insular, 2012.
GUBA, E.; LINCOLN, Y. Controvérsias paradigmáticas, contradições e confluências emergentes.
In: DENZIN, N.K.; LINCOLN, Y.S. O planejamento da Pesquisa Qualitativa. 2. ed., Porto
Alegre, 2006.
JENKINS, Henry. Cultura da Convergência. São Paulo, Editora Aleph, 2009.

123
JENKINS, Henry; FORD, Sam; GREEN, Joshua. Spreadable Media: Creating Value and
Meaning in a Networked Culture. New York, NY: New York University Press, 2013.
LANDOW. George P. Hypertext 3.0: critical theory and new media in era of globalization. Rev.
ed. Hypertext 2.0 1997. Baltimore, The Johns Hopkins University Press, 2006.
LÉVY, Pierre. Pela ciberdemocracia. In: MOARAES, de Denis (Org). Por uma outra
comunicação. Mídia mundialização cultural e poder. Rio de Janeiro: Record, 2003.
______. As tecnologias da Inteligência: o futuro do pensamento na era da informática. Rio de
Janeiro, Editora 34, 2004.
_____________ A esfera semântica. Tomo I: computação, cognição, economia da
informação. São Paulo, Annablume 2014.
LIMA JÚNIOR, Walter Teixeira. “Era do Big Data” impulsiona crescimento do Jornalismo
Computacional. In: D’ANDREA, Carlos et al (Org.) Jornalismo Convergente: reflexões,
apropriações, experiências. Florianópolis: Insular, 2012.
MCLUHAN, Marshall; FIORE, Quentin. O meio são as massa-gens. 2. ed. Rio de Janeiro:
Record, c1969.
MANOVICH, Lev. Softwares takes command. 2008. Disponível em <http://migre.me/fublx>
Acesso em 31 ago. 2014.
MARCONDES, Carlos Henrique. Metadados: descrição e recuperação de informação na Web. In:
MARCONDES, Carlos H. et al (Org.). Bibliotecas digitais: saberes e práticas, Brasília, 2006.
MIELNICZUK, Luciana. Sistemas de Publicação em Ciberjornalismo: Rotinas produtivas.
Universidade Federal do Maranhão, 2011.
MIÈGE, Bernard. O pensamento comunicacional. Rio de Janeiro: Vozes, 2000.
MOHERDAUI, Luciana. Jornalismo baseado em tags. In: RIBEIRO, Ana Elisa et al (Org.).
Leitura e escrita em movimento. São Paulo: Peirópolis, p.214-228, 2010.
______. Interfaces nômades: uma proposta para orientar o fluxo noticioso na Web. São Paulo,
2012.
MORIN, Edgar. Introdução ao pensamento complexo. Lisboa: Instituto Piaget, 2003.
______. A comunicação pelo meio (teoria complexa da comunicação). Revista FAMECOS.
Porto Alegre, 2003.
MOURA, Maria Aparecida. Informação, ferramentas ontológicas e redes sociais ad hoc: a
interoperabilidade na construção de tesauros e ontologias. Revista Informação & Sociedade.

124
João Pessoa, v.19, n.1, p.59-73, 2009.
MORENO, Josyane; ROCHA, Ana Karolina. A folksonomia como ferramenta para a
representação do conhecimento na web sob a ótica das redes sociais. XXXV Encontro Nacional
de Estudantes de Biblioteconomia, Documentação, Ciência da Informação e Gestão da
Informação Escola de Ciência da Informação, UFMG, Belo Horizonte, 2012.
PALAZZO, L.A.M. Complexidade, caos e auto-organização. 1999. Disponível em:
<http://algol.dcc.ufla.br/~monserrat/isc/Complexidade_caos_autoorganizacao.html>. Acesso em
31 ago. 2014.
PARREIRAS, Vicente. A sala de aula digital sob a perspectiva dos sistemas complexos: uma
abordagem qualitativa. Tese. UFMG, 2005.
PRIMO, Alex. Interação mediada por computador: comunicação, cibercultura, cognição.
Porto Alegre: Sulina, 2007.
PRIMO, Alex. As tags como informação contextual de afeto. 2010.
RIBEIRO, Ana Elisa. Leituras sobre hipertexto: trilhas para o pesquisador. Trabalho apresentado
no GT Hipertexto: que texto é esse?, no XI Simpósio Nacional de Letras e Linguística e I
Simpósio Internacional de Letras e Linguística, Uberlândia, nov. 2006.
RUÓTOLO, A. C. Audiência e recepção: perspectivas. Comunicação & Sociedade. São
Bernardo do Campo, PósCom-Umesp, 1998.
SABBATINI, Marcelo. A folkcomunicação na era da convergência midiática digital: da
folksonomia às narrativas folkmidiáticas transmídia. Revista Eletrônica Razón y Palabra. 2011
SANTAELLA, Lucia. Navegar no ciberespaço: o perfil cognitivo do leitor imersivo. São Paulo:
Paulus, 2004.
______. Matrizes da Linguagem e Pensamento: sonora, visual, verbal. 3. ed. São Paulo:
Iluminuras/Fapesp, 2005.
______. O crescimento extrassomático do cérebro humano. Porto Alegre, Pontifícia
Universidade Católica do Rio Grande do Sul, 2013. (Comunicação oral)
STERLING. Bruce. Folksonomia. Observatório da Imprensa, n. 326, 26 abr. 2005. Entre Aspas.
O'REILLY, Tim. Web 2.0 Compact Definition: Trying Again. 2006. Disponível em:
<http://radar.oreilly.com/2006/12/web-20-compact-definition-tryi.html >. Acesso em 21 abr.
2014.
SAWYER, R. Keit. Social Emergence: societies as complex systems. Washington University,
2005.

125
SILVERMAN, David. Interpretação de dados qualitativos: método para análise de entrevistas,
textos e interações. Tradução: Magda Franca Lopes – Porto Alegre: Artmed, 2009.
VAN AMSTEL, Frederick. Folksonomia: vocabulário descontrolado, anarquitetura da informação
ou samba do crioulo doido? In: Encontro Brasileiro de Arquitetura da Informação, São Paulo,
2007. Disponível em:
<http://www.usabilidoido.com.br/arquivos/folcsonomia_anarquitetura.pdf>. Acesso em 31
ago.2014
WAL, Thomas Vander. Folksonomy Coinage and Definition. 2007. Disponível em
<http://vanderwal.net/folksonomy.html>. Acesso em: 31 ago.2014.
WING, Jeannete M. Computacional Thinking. Communication of the Association for Comuting
Machinery. v. 49. n 3, março 2006.

126
APÊNDICE A
Roteiro de entrevistas com repórteres
Incêndio em Santa Maria - I
Pergunta padrão 1: O que aconteceu na redação no dia da cobertura?
Pergunta padrão 2: O que vocês fizeram quando perceberam aquela audiência atípica?
Pergunta livres: E aquela galeria, o que havia de diferente nela?
Morte de Paul Walker – II
Pergunta padrão 1: O que aconteceu na redação no dia da cobertura?
Pergunta padrão 2: O que vocês fizeram quando perceberam aquela audiência atípica?


















