Representação e Compressão de Texto
66
Representação e Compressão de Texto Joaquim Macedo Departamento de Informática da Universidade do Minho & Faculdade de Engenharia da Universidade Católica de Angola
-
Upload
hilel-burnett -
Category
Documents
-
view
43 -
download
0
description
Representação e Compressão de Texto. Joaquim Macedo Departamento de Informática da Universidade do Minho & Faculdade de Engenharia da Universidade Católica de Angola. Sumário. Introdução Representação do Texto Princípios de compressão de texto Redundância Estatística - PowerPoint PPT Presentation
Transcript of Representação e Compressão de Texto

Representação e Compressão de Texto
Joaquim MacedoDepartamento de Informática da Universidade do Minho & Faculdade de Engenharia da Universidade Católica de
Angola

Sumário Introdução Representação do Texto Princípios de compressão de texto Redundância Estatística
Função densidade de probablidade e entropia Teorema de Shannon para codificação de fonte sem
ruído Codificação de Huffman Codificação Aritmética
Compressão baseada em dicionário Técnica LZ77 Técnica LZ782

Introdução O texto é o media mais importante
para representar informação Media mais antigo para armazenar e
transmitir informação Maior parte da informação actual é
mantida em texto Objecto desta aula
Representação digital de texto e técnicas de compressão

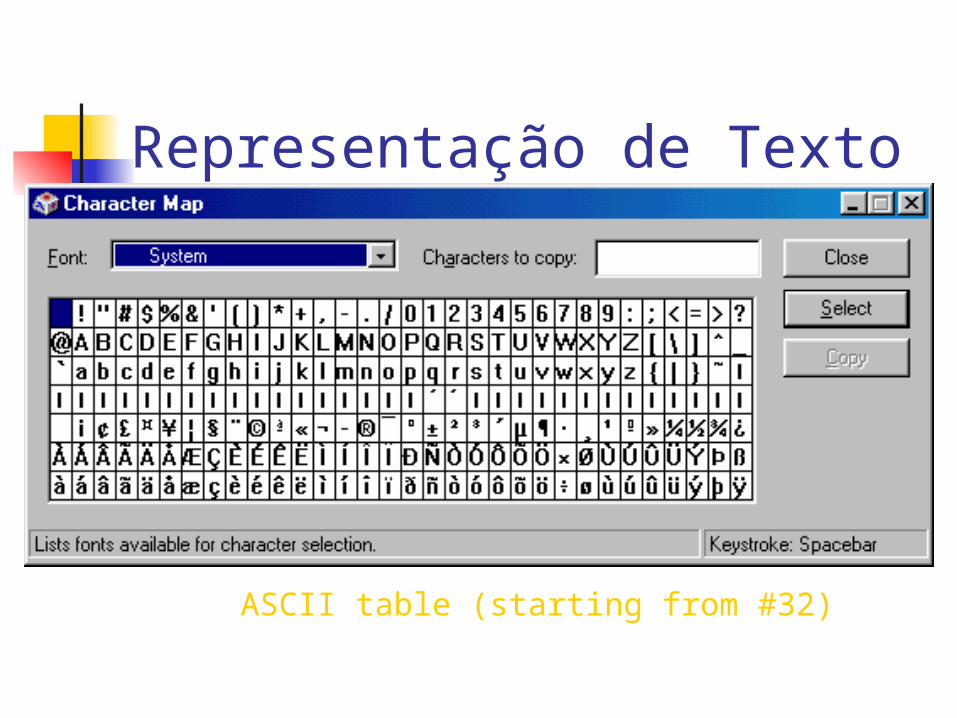
Representação de TextoASCII (American National Standards Institute ANSI)American Standard Code for Information Interchange
O código ASCII é um código de 8 bits para representação de caracteres.
Por exemplo o código para H é 01001000, para e é 01100101.A mensagem Hello pode ser representada como
01001000 01100101 01101100 01101100 01101111 00101110
Representação de Texto
ASCII table (starting from #32)

Tabela ASCII

Tabela ASCII extendida

Representação de Texto
ISO= International Organization for Standardization
Código bits Caracteres
ASCII 8 256
Unicode 16 65536
ISO 36 17M

Representação de textoRequisitos de espaço de armazenamento
Como o texto é usado extensivamente em muitos tipos de documentos como livros, jornais e outros periódicos É necessário representá-lo
eficientemente para reduzir os requisitos do espaço de armazenamento

Representação de textoRequisitos de espaço de armazenamento
Exemplo 6.1 Considere um livro com 800 páginas.
Cada página contém em média 40 linha e cada linha 80 caracteres (incluindo espaços). Se o livro for armazenado em formato digital que espaço de armazenamento é necessário?
Resposta: 2.44 Mbytes

Representação de textoRequisitos de espaço de armazenamento
Um documento típico requer alguns Mbytes de espaço de armazenamento É possível representar o mesmo
documento usando menos espaço? Isso é verdade
É possível compactar texto sem perder informação!
Muitos de nós já usaram o winzip (Windows) ou o gzip (Linux)

Princípios para Compressão de Texto
Os textos típicos têm informação redundante As técnicas de compressão reduzem ou eliminam
essa redundância Tipos de redundância
Estatística Probabilidade não uniforme de ocorrência de
caracteres ou símbolos (menos bits ao símbolos de maior ocorrência
Conhecimento Quando o texto a codificar é limitado em termos
de âmbito, pode ser associado conhecimento comum ao codificador e descodificador; nesse caso é enviada a informação indispensável para reconstruir o texto original.

Redundância Estatística Métodos de redução de redundância
estatística Baseados na teoria de codificação das
fontes Cada amostra de dados (caracter) tratado
com símbolo gerado por uma fonte de informação
Conjunto de todos símbolos é o alfabeto Lida com a compressão de dados gerados
por uma fonte que emite uma sequência de símbolos escolhidos dum alfabeto finito.

Teoria de Codificação de Fontes 2 conceitos fundamentais
Entropia Medida da informação contida na fonte Define a quantidade mínima do débito
médio de bits para reconstrução perfeita dos símbolos da fonte
Taxa de distorção Define um limite inferior no débito médio
de bits para uma dada distorção nos símbolos reconstruídos.

Função densidade de probabilidade
k
k
k
k
sNkhkp
s
n
Niix
sssS
de ocorrência de adeprobabilid a é /][][
símbolo o
por dosrepresenta caracteres de nº o é que em ,nh[k] discreta
função uma é x aleatória variávelda histograma O
1],[por darepresenta N, tamanho
com caracteres de sequência de amostra uma Considere
tes.independen amenteestatístic símbolos)
dos qqpor ados(represent caracteres produz fonteA
símbolosk com ,,...,, alfabeto um com
S discreta memória sem informação de Fonte
k
21

Exemplo 6.2 Considere a string
X=¨aaabbbbbbccaaabbcbbbb¨ Determine o alfabeto Determine o histograma e a função
densidade de probabilidade dos caracteres.
Mostre que a soma das probabilidades dos símbolos do alfabeto é 1.

Entropia
][log][)(][)(
fonte da Entropia
][
1log)(
símbolo cada a associada média Informação
211
kpkpsIkpSH
kpsI
K
kk
K
k
k

EntropiaBlocos de símbolos
rabits/amost )(log)(1
bits/fonte )(log)()(
s 2
s 2
todos
todos
spspN
spspsH

Exemplo 6.3 Considere a fonte do exemplo
anterior. Calcule a entropia de 1ª e 2ª ordem.

Teorema de ShannonCodificação de Fontes sem Ruído
Considere uma fonte de texto com um alfabeto de tamanho K e entropia H(S) e a codificação de blocos de N símbolos da fonte
Para qualquer é possível, escolhendo N sufuicientemente grande, construir um código em que número médio de bits por símbolo
cumpra a seguinte relação
)()(_
SHRSH
0_
R

Teorema de ShannonCodificação de Fontes sem Ruído
Pode ser mostrado que a entropia é limitada por
)(logaRedundânci
log)(0
2
2
SHK
KSH

Exemplo 6.4 Considere uma fonte de informação
com alfabeto {a,b,c,d}. Os símbolos têm igual probabilidade de ocorrência. Calcule a entropia e a redundância da fonte Qual o débito de bits médio necessário para
transmitir os símbolos gerados pela fonte? Conceba um código adequado para os
símbolos da fonte.

Exemplo 6.5 Qual a o débito de bits médio para
uma fonte de três símbolos? Qual o débito necessário para a fonte do exemplo 6.2. Calcule a redundância da fonte. Quando é que redundância é zero?

Interpretação do Teorema de Shannon
O Teorema estabelece que o limite mínimo para o débito de bits Mas não nos indica como fazê-lo. É
muito difícil conseguir um débito igual à entropia.
Normalmente é superior de um valor inferior a delta

Métodos estatísticos de compressão
Duas estratégias de codificaçãoHuffman
Atribui um código de bits de comprimento variável a cada símbolo
Relativamente rápido e acesso aleatório Semi-estático versus adaptativo
Aritmética Texto de entrada representado por número reais entre 0 e 1 Símbolos de entrada com maiores probabilidades reduzem
menos o intervalo que símbolos com menor probabilidade e portanto adicionam menos bits ao código de saída
Mais lento que o de Huffman e a decompressão não pode começar a meio do ficheiro

Código de Huffman Inventado por Huffman a fazer um trabalho
de casa em 1950..Usados em muitos algoritmos de compressão
gzip, bzip, jpeg (como opção), fax,…
Propriedades: Gera códigos de prefixo óptimos Fácilidade na
Geração de códigos Codificação e descodificação
Comprimento médio=H se as propabilidades forem potências de 2

Codificação de Huffman Uma frase é codificada substituindo cada
um dos seus símbolos com o respectivo código dado por uma tabela
A codificação de Huffman gera códigos para um conjunto de símbolos, dada uma distribuição de probabilidade dos símbolos
O tipo de código é chamada código de prefixo Nenhuma palavra de código é prefixo de outra
palavra de código

Códigos de PrefixoUm código de prefixo é um código de
comprimento variável onde nenhuma palavra de código é prefixo de outra palavra de código
Exemplo a = 0, b = 110, c = 111, d = 10Pode ser visto como uma árvore binária com
valores de mensagens nos nós terminais e 0 e 1 nos seus ramos
a
b c
d
0
0
0 1
1
1

Códigos de descodificação única
Um código de comprimento variável atribui uma sequência de bits (palavra de código) de comprimento variável a todos valores de mensagem
i.e. a = 1, b = 01, c = 101, d = 011A sequência de bits 1011o que significa ?É aba, ca, ou, ad?Um código de descodificação única é um código
de comprimento variável em que as sequências de bits podem sempre ser decomposta de forma únoca nas suas palavras de código.

Codificação de Huffman As palavras de código podem ser
armazenadas numa árvore Árvore de descodificação
O algoritmo de Huffman funciona construindo a árvore de descodificação de baixo para cima

Codificação de HuffmanAlgoritmo
Algoritmo cria para cada símbolo um nó terminal
contendo o símbolo e a sua propabibilidade. Os dois nós com as probabilidades mais
pequenas tornam-se irmãos sob um novo nó pai, cuja probabilidade é a soma da dos filhos
A operação de combinação é repetidad até haver um único nó raiz.
Todos os ramos de todos nós não terminais são então etiquetados com 0 1.

Codificação de Huffman A codificação de Huffman é geralmente
rápida quer na codificação como na descodificação desde que a probabilidade seja estática. Codificação de Huffman adaptativa é possível
mas ou precisa de muito memória ou é lenta Acoplada com um modelo baseado em
palavras (em vez dum baseado em caracter), fornece uma boa compressão.

Codificação de Huffman Frequências de caracter
A: 20% (.20) B: 9% (.09) C: 15% D: 11% E: 40% F: 5%
Não há mais caracteres no documento

Codificação de Huffman
C .15
A.20
D.15
F.05
BF.14
B.09
0 1
E.4

Codificação de Huffman
Códigos A: 010 B: 0000 C: 011 D: 001 E: 1 F: 0001
ABCDEF1.0
E.4
C .15
A.20
D.15
F.05
BF.14
AC.35
BFD.25
ABCDF.6
B.09
0
0
0
0
0
1
1
11
1

Exemplo 6.4 Determine o código de
Huffman para os símbolos da tabela
Codifique a tring “baecedeac!”
Descodifique 00011000100110000010
111
Símbolo Probabilidade
a 0.2
b 0.1
c 0.2
d 0.1
e 0.3
! 0.1

Exemplop(a) = .1, p(b) = .2, p(c ) = .2, p(d)
= .5a(.1) b(.2) d(.5)c(.2)
a(.1) b(.2)
(.3)
a(.1) b(.2)
(.3) c(.2)
a(.1) b(.2)
(.3) c(.2)
(.5)
(.5) d(.5)
(1.0)
a=000, b=001, c=01, d=1
0
0
0
1
1
1Passo 1
Passo 2Passo 3

Codificação e Descodificação
Codificação: Começar no nó terminal da árvore de huffman e seguir o percurso para a raiz. Inverter a ordem dos bits e enviar.
Descodificação: Começar na raiz da árvore e seguir o ramo de acordo com o bit recebido. Quando chegar à um no terminal enviar o símbolo e regressar à raiz.
a(.1) b(.2)
(.3) c(.2)
(.5) d(.5)
(1.0)0
0
0
1
1
1
Há metodos mais rápidos que podem processar 8 ou 32 bits de cada vez

Limitações dos Códigos de Huffman
Precisa de pelo menos 1 bit para representar a ocorrência de cada símbolo Não podemos arranjar um código de Huffman
que gaste 0.5 bits/símbolo Se a entropia da fonte for menor que 1
bit/simbolo o código de Huffman não é eficiente! Não se adapta eficientemente a um fonte
com estatísticas variáveis. Embora haja códigos de Huffman dinâmicos, são
difíceis de concretizar

Codificação aritmética Outra técnica baseada na entropia
Maior relação de compressão que a codificação de Huffman
Pode disponibilizar débito de bits infeiores a 1 O débito aproxima-se do limite teórico da entropia
da fonte Técnica de codificação diferente da de
Huffman Huffman: codificação independente por símbolo
Resultado: concatenação do código de cada símbolo Aritmética: uma palavra de código para toda a
mensagem

Exemplo Considere o alfabeto inglês com 26
letras. Calcule o número máximo de strings diferentes com comprimento
i. 1ii. 2iii. 100

Codificação Aritmética O código é para todo o texto como um
sub-intervalo da unidade. Cada símbolo é representado por um
sub-intervalo do intervalo que tem um comprimento proporcional à probabilidade do símbolo.
O comprimento do intervalo final é o produto das probabilidades de todos símbolos no texto.

Codificação AritméticaSímbolo Probabilidad
eGama (para o codificador aritmético)
a 0.2 [0,0.2)
b 0.1 [0.2,0.3)
c 0.2 [0.3,0.5)
d 0.1 [0.5,0.6)
e 0.3 [0.6,0.9)
! 0.1 [0.9,1.0)

Codificação AritméticaSub-intervalo Intervalo
binárioString de bits gerada
Começar
[0,1.0)
b [0.2,0.3) [0.0,0.5) 0
Depois a [0.2,0.22) [0.0,0.25) 0
de a [0.2,0.204) [0.125,0.25) 1
ver d [0.2020,0.2024)
[0.1875,0.25) 1
! [0.20236.0.2024)
[0.1875,0.21875)
0

Codificação AritméticaOutro exemplo
_
_
_
_
a
b
c
0
1/3
2/3
1
_
_
_
b
c
a
_
_
_
_
a
b
c
_
_
_
a
b
c
1/3
1/3
1/3
1/4
2/4
1/4
1/5
2/5
2/5
1/6
2/6
3/6
.3333
.4167
.5834
.6667
.5834
.6001
.6334
.6667
.6334
.6390
.6501
.6667
Qualquer valor no intervalo [.6334,.6390) codifica ‘bcca’

Codificação Aritmética Adaptativa Podemos assumir
Probabilidades iguais para todos símbolos no início
Fazer a contagem dos símbolos para nos aproximarmos das suas probabilidades reais no texto
Durante a descodificação Usar as mesmas contagens e seguir
precisamente os mesmos sub-intervalos.

Modelos baseado em dicionário
Métodos de compressão baseados em dicionário usam o princípio de substituir substrings num texto com uma palavra de código que iedntifica essa substring no dicionário
O dicionário contém uma lista de substrings e uma palavra de código para cada substring
Normalmente usam-se palavras de código fixas Obtem-se mesmo assim uma compressão
razoável

Modelos baseado em dicionário
Os métodos mais simples de compressão usam pequenos dicionários
Por exemplo, codificação de digramas pares de letras seleccionadas são
substituídas por palavras de código Um dicionário para o código de caracteres
ASCII pode conter os 128 caracteres bem como 128 pares de letras mais comuns.

Modelos baseado em dicionário
Codificação com digramas… As palavras de código de saída têm 8 bits cada A presença do conjunto completo de caracteres
ASCII assegura que qualquer entrada (ASCII) pode ser representada.
No melhor dos casos, cada par de caracteres é substituído por uma palavra de código, reduzindo de 7 bits/caracter para 4 bits/caracter
No pior dos casos, cada caracter de 7 bits é expandido para 8 bits

Modelos baseado em dicionário
Expansão natural: Colocar no dicionário sequências com mais
caracteres nomeadamente palavras comuns ou componentes comuns das palavras.
Um conjunto pré-definido de frases do dicionário tornam a compressão dependente do domínio ou se usam fazes muito curtas ou não se
consegue uma boa compressão

Modelos baseado em dicionário
Uma maneira de evitar o problema do dicionário ser desadequado para o texto a manipular é usar um dicionário semi-estático construir um novo dicionário para todo texto a
compactar A sobrecarga de transmitir e armazenar o
dicionário é significativo A decisão de que frases incluir no dicionário é
um problema difícil de resolver

Modelos baseado em dicionário
Solução: usar um esquema de dicionário adaptativo
Codificadores Ziv-Lempel (LZ77 e LZ78) Uma substring de texto é substituída por
um apontador para uma ocorrência préviano texto.
Dicionário: todo o texto anterior à posição corrente.
Palavras de código: apontadores.

Modelos baseado em dicionário
Ziv-Lempel… O texto anterior torna-se normalmente
um dicionário muito bom, pois normalmente está no mesmo estilo e linguagem do texto seguinte.
O dicionário é transmitido implicitamente sem custo extra, porque o descodificador tem acesso a todo texto previamente descodificado.

LZ77 Vantagens chave:
Relativamente fácil de concretizar A descodificação pode ser feita
facilmente usando apenas uma pequena porção de memória.
apropriada quando os recursos necessários para descodificar devem ser minimizados

LZ77
A saída do codificador consiste duma sequência de triplas , i.e <3,2,b> O primeiro componente da tripla indica
quão longe se deve olhar para o texto previamente descodificado para encontrar a próxima frase
O segundo componente indica o comprimento da frase
O terceiro componente dá o próximo caracter da entrada

LZ77 O componente 1 e 2 constituem
um apontador para o texto prévio O componente 3 só é necessário
se o caracter a ser codificado não ocorreu previamente.

LZ77 Codificação
Para o texto presentemente na entrada: busca da maior unificação no texto anterior devolver a tripla que regista a posição e o
comprimento da unificação A busca pode devolver um comprimento zero,
situação em que a posição da unificação não é relevante.
A busca pode ser acelarada indexando o texto prévio com estruturas de dados adequadas

LZ77
Há limitações de quanto para trás o apontador pode referir e o máximo tamanho da string referenciada:
para texto em inglês, uma janela de poucos milhares de caracteres
o comprimento da frase tem um máximo de 16 caracteres
Senão gasta-se muito espaço sem benefício

LZ77 O programa de descodificação é muito
simples, de forma que pode ser incluído com os dados com muito pequeno custo
De facto os dados compactados são colocados como parte do programa de descodificação, que torna os dados com capacidade de auto-extracção.
Forma comum de distribuição de ficheiros

Exemplo 6.8 Considere um dicionário de vinte
caracteres (ou janela deslizante) e uma janela de antevisão de 8 caracteres. A string de entrada é RYYXXZERTYGJJJASDERRXXREFEERZXYURPP Calcule a saída do compressor de texto

LZ78 Outra técnica base Usada por vários compressores de texto
muito eficientes Em vez de uma janela deslizante de
tamanho fixo como o LZ77 Constrói um dicionário com as strings que
unificaram previamente. Não há restrições de distância no texto para
unificação Aumenta a probabilidade de unificação

Exemplo 6.9 O texto a codificar é “PUB PUB
PUPPY...” Mostre como se constrói o dicionário
e os primeiros símbolos de saída do compressor.
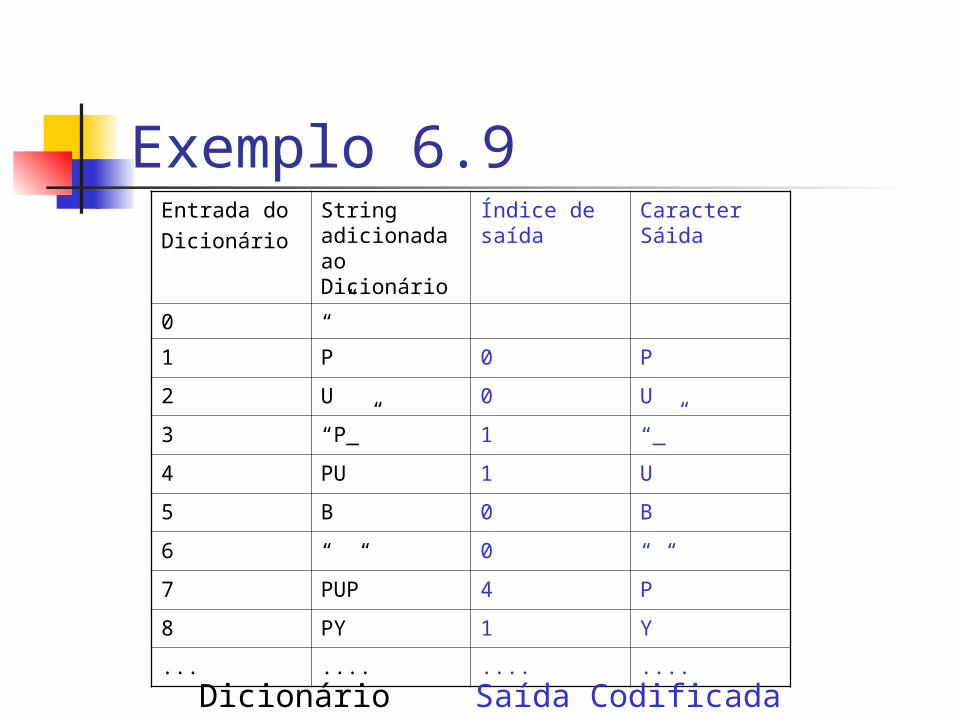
Exemplo 6.9Entrada doDicionário
String adicionada ao Dicionário
Índice de saída
Caracter Sáida
0 “”
1 P 0 P
2 U 0 U
3 “P_” 1 “_”
4 PU 1 U
5 B 0 B
6 “ “ 0 “ “
7 PUP 4 P
8 PY 1 Y
... .... .... ....
Dicionário Saída Codificada
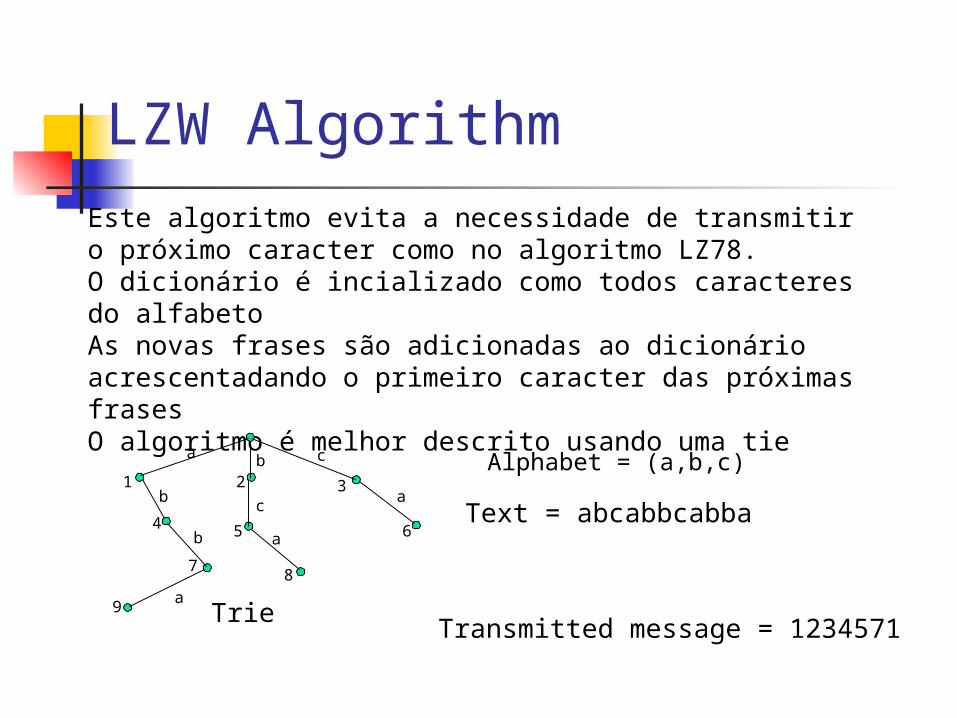
LZW AlgorithmEste algoritmo evita a necessidade de transmitir o próximo caracter como no algoritmo LZ78.O dicionário é incializado como todos caracteres do alfabetoAs novas frases são adicionadas ao dicionário acrescentadando o primeiro caracter das próximas frasesO algoritmo é melhor descrito usando uma tie
a b c
bc
a
b
a
a
Alphabet = (a,b,c)
Text = abcabbcabba
Transmitted message = 1234571
1 2 3
4 5 6
78
9 Trie

a cb1 2 3
4b1 2 3
ab c
a cb1 2 3
4b c
5
a cb1 2 3
4
b c
5 6a
a cb1 2 3
4b c
5 6a
7b
a cb1 2 3
4b c
5 6a
7b a
8
a cb1 2 3
4b c
5 6a
7b a
8
9a
Final Trie and its HeightBalanced Binary Tree
Transmitted Code= 1234571=‘001001100101010011000’
0 1
0 1
0 1
0 1
0 1
0 1 0 1
0 1
1
4
7
2
95 8
63
Text =a b.. ..b c..
..c a.. ..ab . b.. ..bc a..
..abb a
Text=abcabbcabba

Resumo Foram apresentadas várias
tecnicas de compressão sem perdas Baseadas na entropia
Também usadas para áudio e imagem Baseadas em dicionário
Usadas por muitos esquemas de compressão de texto para conseguir altas taxas de compressão





![Texto - Algumas considerações sobre Representação de Interesses - Lobato[1]](https://static.fdocumentos.tips/doc/165x107/5571fa074979599169910f9c/texto-algumas-consideracoes-sobre-representacao-de-interesses-lobato1.jpg)