
Área de Sistemas de Informação por Frederico Guilherme ...siaibib01.univali.br/pdf/Frederico...
102
UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR CURSO DE CIÊNCIA DA COMPUTAÇÃO CONSTRUÇÃO DE UM DATA MART PARA APOIO ÀS TOMADAS DE DECISÃO DAS EMPRESAS PROEMBARQUE E CASACON Área de Sistemas de Informação por Frederico Guilherme Mariani do Espírito Santo Luis Carlos Martins Orientador Itajaí (SC), junho de 2006
Transcript of Área de Sistemas de Informação por Frederico Guilherme ...siaibib01.univali.br/pdf/Frederico...

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
CONSTRUÇÃO DE UM DATA MART PARA APOIO ÀS TOMADAS DE DECISÃO DAS EMPRESAS PROEMBARQUE E CASACON
Área de Sistemas de Informação
por
Frederico Guilherme Mariani do Espírito Santo
Luis Carlos Martins Orientador
Itajaí (SC), junho de 2006

UNIVERSIDADE DO VALE DO ITAJAÍ CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
CONSTRUÇÃO DE UM DATA MART PARA APOIO ÀS TOMADAS DE DECISÃO DAS EMPRESAS PROEMBARQUE E CASACON
Área de Sistemas de Informação
por
Frederico Guilherme Mariani do Espírito Santo Relatório apresentado à Banca Examinadora do Trabalho de Conclusão do Curso de Ciência da Computação para análise e aprovação. Orientador: Luis Carlos Martins, Esp
Itajaí (SC), junho de 2006

ii
SUMÁRIO
LISTA DE ABREVIATURAS.................................................................iv
LISTA DE FIGURAS ...............................................................................v
RESUMO ..................................................................................................vi ABSTRACT .............................................................................................vii 1. INTRODUÇÃO .....................................................................................8 1.1 PROBLEMATIZAÇÃO ................................................................................... 11 1.1.1 Formulação do Problema ............................................................................... 11 1.1.2 Solução Proposta ............................................................................................. 12 1.2 OBJETIVOS ...................................................................................................... 12 1.2.1 Objetivo Geral ................................................................................................. 12 1.2.2 Objetivos Específicos ...................................................................................... 12 1.3 METODOLOGIA.............................................................................................. 12 1.4 ESTRUTURA DO TRABALHO ..................................................................... 13
2. FUNDAMENTAÇÃO TEÓRICA......................................................15 2.1 SISTEMA DE APOIO A DECISÃO................................................................. 16 2.2 DATA WAREHOUSE ........................................................................................ 18 2.2.1 Características .................................................................................................. 22 2.2.2 Granularidade .................................................................................................. 24 2.2.3 DATA MART ................................................................................................... 25 2.3 MODELAGEM DIMENSIONAL ..................................................................... 28 2.3.1 OLTP E OLAP ................................................................................................. 29 2.3.2 Fatos................................................................................................................... 32 2.3.3 Dimensões.......................................................................................................... 33 2.3.4 Esquema Estrela ............................................................................................... 34 2.4 Agregações ........................................................................................................... 36 2.5 ÁREA DE TRANSIÇÃO DE DADOS .............................................................. 37 2.5.1 Extração ............................................................................................................ 38 2.5.2 Limpeza e Transformação............................................................................... 38 2.5.3 Carga ................................................................................................................. 39 2.6 FERRAMENTAS DE APOIO ........................................................................... 40 2.6.1 Microsoft SQL Server (MS SQL) – Enterprise Manager ............................ 40 2.6.2 DTS – Data Transformation Service .............................................................. 41 2.6.3 Analysis Manager............................................................................................ 45 2.6.4 MS Excel .......................................................................................................... 48 2.7 CONSIDERAÇÕES DA FUNDAMENTAÇÃO .............................................. 49
3. PROJETO ............................................................................................51 3.1 ÁREA DE NEGÓCIOS DAS EMPRESAS ...................................................... 51

iii
3.2 COMUNICAÇÃO DOS SISTEMAS................................................................. 54 3.2 LEVANTAMENTO DAS NECESSIDADES GERENCIAIS......................... 55 3.2.1 Modelo Dimensional......................................................................................... 56
4. DESENVOLVIMENTO......................................................................61 4.1 CRIAÇÃO DA BASE DE DADOS.................................................................... 61 4.2 GERAÇÃO DAS TABELAS FATOS E DIMENSÃO .................................... 61 4.3 PROCESSO DE EXTRAÇÃO E CARGA DOS DADOS............................... 62 4.4 CONSTRUÇÃO DO CUBO OLAP................................................................... 64 4.5 IMPORTAÇÃO DO CUBO PARA O MS EXCEL......................................... 68 4.6 VALIDAÇÃO JUNTO AOS GESTORES........................................................ 72
5. CONCLUSÕES ...................................................................................76
REFERÊNCIAS BIBLIOGRÁFICAS ..................................................79
GLOSSÁRIO ...........................................................................................82

iv
LISTA DE ABREVIATURAS
DW Data Warehouse DM Data Mart DTS Data Transformation Service MSSQL Microsoft SQL Server OLAP Online Analytical Processing OLTP On-Line Transaction Processing - Processamento de Transações On-Line SAD Sistemas de Apoio à Decisão SIG Sistemas de Informação Gerenciais SGBD Sistema de Gerenciamento de Banco de Dados SQL Structured Query Language TCC Trabalho de Conclusão de Curso UNIVALI Universidade do Vale do Itajaí VPN Virtual Private Network BD Banco de Dados TI Tecnología da Informação PO Pedido de Orçamento POC Pedido de Orçamento Cotado OC Orden de Compra PI Pedido de Importação ETL Extraction, Transform, Loading SPT Sistemas Subjacentes de Processamento de Transações

v
LISTA DE FIGURAS
Figura 1. Modelo de Data Warehouse 19 Figura 2. Data Warehouse incremental 26 Figura 3. O Modelo dimensional de um negócio 29 Figura 4. Exemplo de esquema estrela 35 Figura 5. Enterprise Manager 42 Figura 6. Seleção da fonte de dados no DTS 43 Figura 7. Seleção das tabelas fonte e destino 43 Figura 8. Seleção dos dados a serem transferidos 44 Figura 9. Script em Visual Basic para transformação de dados 45 Figura 10. Analysis Manager 46 Figura 11. Seleção de Servidor e banco de dados fonte no Analysis Manager 47 Figura 12. Seleção da tabela fato 47 Figura 13. Seleção da tabela de dimensão 48 Figura 14. Esquema estrela 48 Figura 15. Cubo importado para o MS Excel 49 Figura 16. Diagrama de Processos 54 Figura 17. Diagrama de componentes 55 Figura 18. Modelo Dimensional 61 Figura 19. Criando nova base de dados 62 Figura 20. Tabelas do DM 63 Figura 21. Visualização do DTS 64 Figura 22. Bases de dados fonte e destino 64 Figura 23. Seleção dos dados a serem transferidos 65 Figura 24. Criação de nova fonte de dados 66 Figura 25. Seleção do tipo de fonte de dados 66 Figura 26. Parâmetros da conexão 67 Figura 27. Cubo Fato Preço Produtos 68 Figura 28. Fórmula para o cálculo do Lucro Bruto 68 .

vi
RESUMO
ESPÍRITO SANTO, Frederico Guilherme Mariani do Espírito Santo. Construção de um data mart para apoio às tomadas de decisão das empresas Proembarque e Casacon. Itajaí, 2005. 54f. Trabalho de Conclusão de Curso (Graduação em Ciência da Computação)–Centro de Ciências Tecnológicas da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2005. No mundo dos negócios as empresas que melhor souberem utilizar as informações que produzem terão um forte diferencial sobre as concorrentes. No cenário descrito, os Sistemas de Apoio à Decisão (SAD) se apresentam como alternativa para dar suporte às necessidades dos executivos das corporações. O objetivo do presente trabalho é a construção de um SAD, implementado através de um Data Mart (DM), para atender as necessidades gerenciais dos departamentos de Compras e Logística das empresas Proembarque e Casacon. As duas empresas trabalham em conjunto, sendo que a primeira faz a exportação dos produtos comprados no Brasil e que são comercializados pela segunda, que fica localizada em Angola. Para atender essas consultas um DM foi construído, utilizando como fonte de informação, o banco de dados operacional das empresas. O DM é disponibilizado aos gestores através de planilhas publicadas no Servidor de Aplicativos da empresa. Inicialmente foram levantadas as necessidades gerenciais e, após, foi construído o modelo lógico dimensional. Posteriormente foram criadas as tabelas do sistema que armazenam as informações necessárias para a construção do DM. O MS SQL Server e o ErWin foram as ferramentas utilizadas na construção do modelo dimensional e do DM. Para publicação das consultas para os gestores se utiliza o MS Excel. O trabalho se mostra positivo também pelo fato de ter conquistado a confiança e interesse dos gestores em apoiar futuros projetos de TI. Palavras-chave: Data Mart. Sistema de Apoio a Decisão. OLAP. Comércio Exterior.

vii
ABSTRACT
At the businesses world the companies that best knows how to use the information that produce will have a good differential on the contestants. In this described context, the Decision Support Systems (DSS) come as alternative to give support to the executives issues. The objective of the present work is the construction of a DSS, implemented through a Data Mart (DM), to assist the managerial needs of the departments of Purchases and Logistics of the companies Proembarque and Casacon. The two companies work together, and the first makes the export of the products bought in Brazil and that you/they are marketed by the second, that is located in Angola. To take care of to these consultations a DM it was constructed, using as information source, the operational data base of the companies. The DM will be shown to the managers through spread sheets published in the Intranet of the corporation. Knowing the needs, the dimensional model was built and, after, the system’s tables that store the information necessary for the construction of DM. MS SQL Server and ErWin are the tools used for construction of the dimensional model and DM. For publication of the consultations for the managers should be used MS Excel. Keywords: Data Mart. Decision Support Systems. OLAP. World Commerce

1. INTRODUÇÃO
A forte concorrência entre as empresas impulsiona cada vez mais a buscas por soluções
alternativas focando em resultados melhores. A boa utilização da informação é considerada
fundamental para atingir bons resultados. Como já é sabido, as empresas perceberam que com uma
boa administração da informação se tornam preparadas para encarar o mundo competitivo e
globalizado.
Este Trabalho de Conclusão de Curso (TCC) está baseado em conceitos de Sistemas de
Apoio a Decisão utilizando técnicas OLAP, disponibilizando um ambiente onde o executivo pode
elaborar e executar suas consultas.
Habitualmente as empresas desenvolvem sistemas computacionais que têm a finalidade de
capturar as transações dos negócios do empreendimento e dar suporte às suas atividades. Esses
sistemas rotineiramente também são referenciados como sistemas operacionais, sistemas fonte ou,
ainda, como sistemas On-Line Transaction Processing - Processamento de Transações On-Line
(OLTP) (KLAUER e BROBST, 1998).
Como exemplo de sistemas OLTP, cita-se sistemas de contas a pagar e receber, controle de
estoque, controle de pessoal, controle financeiro e contábil, controle de material, entre outros. O
objetivo desses sistemas é suportar as funcionalidades do negócio de uma empresa através do
processamento de transações de forma precisa e eficiente, muitas vezes referenciados como
aplicações de processamento de missão crítica.
Sistemas OLTP executam as atividades básicas de inserção, atualização, consulta e
eliminação de dados em um Banco de Dados (BD) operacional, normalmente sendo permitido ao
usuário ler e gravar dados (KLAUER e BROBST, 1998).
Na maioria das vezes, esses BDs servem somente como apoio ao trabalho operacional da
empresa, não sendo aproveitado o registro histórico das informações para uso na estratégia e
tomada de decisão da empresa. (DWINF, 2002).
Os gerentes e diretores, nessa situação, tomam suas decisões baseados em suas intuições
executivas, sem considerar a evolução da empresa registrada nos dados de seus sistemas. De acordo
com a uma pesquisa realizada pela Aspect International Consulting em 1997 (DWINF,2002), 88%

9
dos diretores de empresa consultados admitem dedicar 75% de seu tempo a tomadas de decisão
apoiadas em análises subjetivas, sendo que 100% deles têm acesso a computadores. Inúmeros
motivos podem levar a esse desperdício. Por exemplo, o uso de sistemas diferentes por cada setor
da empresa, o que dificulta o cruzamento de informações e a consistência das mesmas. Outro
motivo seria o fato desses sistemas estarem focados, obviamente, para o uso operacional e não
estarem preparados para responder as questões gerenciais de cada empresa. Mesmo quando todas as
informações da corporação estão centralizadas em um único BD, o enorme volume de dados
dificulta a análise dos mesmos.
Entretanto, cada vez mais, as empresas e corporações vêm sendo obrigadas a tomar decisões
rápidas, oportunas e com maior qualidade, de modo a garantir, inclusive, a sua sobrevivência ou
existência no setor público ou privado. Inúmeros fatores vêm contribuindo para isso, tais como o
grande aumento da competitividade entre empresas, a globalização dos mercados, a necessidade do
aumento da eficiência e redução de custos operacionais, projetos de privatização e qualidade total,
dentre muitos outros aspectos. Nesse cenário iniciado nos anos 90, para atender as necessidades dos
usuários, vêm destacando-se cada vez mais os SADs (KEEN e MORTON, 1978), que realizam
tipicamente o processamento analítico de informações, muitas vezes referenciado também como
processamento informacional.
No mesmo contexto, aparece o conceito de Data Warehouse (DW), que visa filtrar os dados
e organizá-los em um outro BD, paralelo ao já utilizado pela empresa. Neste outro BD os dados
corporativos são organizados para atender as necessidades dos gerentes e diretores da empresa. Esse
processo de organização dos dados ocorre com novos métodos de armazenamento, estruturação e
novas tecnologias para geração e recuperação das informações.
Segundo Kimball (1998), DW é um conjunto de ferramentas e técnicas de projeto, que
quando aplicadas às necessidades específicas dos usuários e aos bancos de dados específicos
permitirá o planejamento e construção de um DW. Essas tecnologias já estão bem consolidadas no
mercado na forma de diversas ferramentas para cumprir todas essas etapas. Os sistemas de DW, que
são um tipo de SAD, realizam o processamento de grande quantidade de dados históricos,
possibilitando a verificação de problemas e situações, de modo a identificar perfis, padrões,
comportamentos e tendências, facilitando a tomada de decisões táticas e estratégicas.
O DW pode ser derivado em DMs. Segundo Machado (2000), Data Mart representa um
subconjunto de dados do DW. Os dados do DM são direcionados a um departamento ou a uma área

10
especifica do negócio. O DM, normalmente, é modelado em um esquema estrela, de acordo com as
necessidades especificas do usuário final. Uma das principais vantagens de seu emprego é a
possibilidade de retorno rápido, garantindo um maior envolvimento do usuário final, capaz de
avaliar os benefícios extraídos de seu investimento.
Geralmente os DMs armazenam dados referentes a um assunto em especial como vendas,
estoque, fornecedores, clientes e compras, por exemplo, ou em diferentes níveis de sumarização
como vendas em diferentes intervalos de tempo.
Observando o conceito de DM percebeu-se a possibilidade de aplicá-lo na empresa
Proembarque Comércio Internacional, que é uma comercial exportadora que faz o envio de
produtos para outra empresa do mesmo grupo localizada em Angola, na África. Esta última, o
Home Center Casacon, é uma loja de departamentos onde são comercializados os mais diversos
tipos de produtos e de onde partem os pedidos de compra para a Proembarque.
As empresas utilizam desde 2003 os sistemas desenvolvidos pela RM Sistemas, a qual foi
apontada, pelo segundo ano consecutivo, pela Revista INFO EXAME (INFO, 2005) como maior
empresa nacional de desenvolvimento de sistemas. O Sistema RM atende aos mais diversos perfis
de empresas, estando dividido em módulos específicos para controle financeiro, contábil, estoque,
logístico, comercial entre outros. O Sistema Gerenciador do Banco de Dados utilizado pelo RM é o
Microsoft SQL Server, onde um único arquivo fornece suporte à utilização de todos os módulos
oferecidos pela RM Sistemas, isto é, não existe um banco de dados para cada módulo.
No período desde a implantação inicial do sistema em 2003 até o primeiro bimestre de 2005,
os sistemas das duas empresas não eram integrados, isto é, não havia consistência em várias
informações como no cadastro de produtos, vendedores, condições de pagamento e fornecedores.
Os processos logísticos também eram independentes, muitas informações eram enviadas por e-mail
entre as empresas ao invés de estarem presentes nos sistemas. Entretanto, a partir de fevereiro de
2005 iniciou-se o projeto de integração das bases de dados das duas empresas. O projeto foi
concluído em agosto de 2005 com a integração do cadastro de produtos e fornecedores, requisitos
obrigatórios para que a troca de informações operacionais entre as bases fosse possível. O projeto
contou com a infra-estrutura de uma Virtual Private Network (VPN) para a transferência segura dos
dados através da Internet, a configuração do Microsoft SQL Server 2000 para realizar a
sincronização das bases e todo o planejamento de quais tabelas precisam ser usadas na

11
sincronização. O projeto foi desenvolvido pela equipe de Tecnologia da Informação (TI) da
empresa, sem a interferência ou suporte da RM Sistemas.
Antes da integração os relatórios gerenciais eram retirados de cada sistema e analisados
pelos gerentes e diretores das empresas, muitas vezes, apresentando distorções nas informações.
Hoje, com a atual infra-estrutura entre as empresas, espera-se que esse cenário mude, e as
informações possam ser usadas seguramente para apoiar o trabalho estratégico do grupo, e é nesse
cenário que o presente trabalho se enquadra.
Este trabalho se justifica em nível de Trabalho de Conclusão de Curso para o Curso de
Ciência da Computação por se tratar do estudo e implementação de conceitos e tecnologias que
fazem parte dos interesses de grande parte das corporações. Durante a execução deste trabalho
tecnologias e ferramentas serão revisadas e estudadas como, por exemplo, VPN, MS SQL Server,
tratamento de dados, administração de BD etc. O desenvolvimento de um Data Mart focado nas
operações comerciais e logísticas das duas empresas será importante para análise dessas operações
em busca da minimização de problemas, como por exemplo, reabastecimento de estoque.
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
O cenário deste trabalho engloba o mundo negócios, onde o tempo e a precisão são
fundamentais para o sucesso. Como detalha-se nas próximas seções, os pedidos de compra
originados pela Casacon não levam em consideração uma análise histórica das vendas por período,
o tempo de reposição em estoque e outros detalhes que poderiam, por exemplo, aumentar as vendas
da Casacon ou que evitassem a falta de determinado produto em estoque.
Em algumas épocas como o fim de ano, por exemplo, os importadores sabem que as vendas
apresentam certo crescimento, mas não sabem precisamente quais são os produtos envolvidos nesse
cenário e qual é o percentual médio desse crescimento. Em relação ao estoque não existem níveis
mínimos que levem em consideração o tempo médio que determinado produto é vendido, sabendo
que o período mínimo para que uma nova remessa enviada do Brasil chegue nas prateleiras é de
quarenta dias.

12
1.1.2 Solução Proposta
No contexto apresentado na seção anterior evidencia-se a necessidade de alguma ferramenta
que auxilie os executivos na tomada de decisões, de maneira a minimizar os custos de transporte e
armazenagem, bem como maximizar os resultados das vendas.
Espera-se também despertar o interesse dos gestores em apoiar e participar de projetos de
TI.
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Construir um Data Mart para as áreas Comercial e de Logística das empresas Proembarque e
Casacon, visando apoiar o processo decisório.
1.2.2 Objetivos Específicos • Estudar os conceitos de Data Warehouse, Data Mart, Sistemas de Apoio a Decisão,
OLAP, Área de Negócios das empresas;
• Identificar as necessidades de informações executivas para tomada de decisão;
• Construir o Modelo Dimensional;
• Identificar as fontes de dados (tabelas do RM) ;
• Implementar o modelo físico do DM;
• Preparar a área de transição de dados (Extração, Tratamento, Carga);
• Executar os processos de carga e testes do modelo dimensional;
• Construir as consultas ao DM, aplicando técnicas OLAP;
• Validar as consultas pelos gestores e
• Documentar o projeto.
1.3 Metodologia
A metodologia do desenvolvimento deste projeto contemplou todos os objetivos propostos e
baseiou-se nas seguintes etapas: (1) levantamento bibliográfico, (2) levantamento dos requisitos de

13
negócio, (3) construção do modelo dimensional, (4) desenvolvimento do DM e (5) validação das
consultas junto aos gestores.
Etapa 1) Levantamento bibliográfico: nesta estapa foi pesquisado e estudado os conceitos e
técnicas para construção de SAD e Data Mart, utilização de técnicas e ferramentas OLAP, Sistema
Gerenciador de Banco de Dados Microsoft SQL Server. Também deu-se a contextualização do
cenário das empresas Proembarque e Casacon pertinentes ao projeto.
Etapa 2) Levantamento dos requisitos de negócio: através de algumas entrevistas formais e
informais com alguns gerentes e diretores discutiu-se e identificaram-se as necessidades de
informações para tomada de decisão pelos executivos.
Etapa 3) Construção do modelo dimensional: nesta etapa foi definido o nível de
granularidade dos dados, a estrutura das tabelas de dimensão e fatos que darão suporte às
informações gerenciais, assim como identificou-se quais são as tabelas do sistema RM que foram
utilizadas no DM e descreveu-se os dados contidos delas.
Etapa 4) Desenvolvimento do DM: foi construído, através do SGBD MS SQL Server, as
tabelas que representam as dimensões e os fatos; foram configurados e executados os mecanismos
de extração, transformação e limpeza dos dados; e consultas ao DM foram construídas, utilizando-
se de técnicas OLAP.
Etapa 5) Validar consultas junto aos gestores: nesta etapa o sistema de consultas foi
apresentado para alguns gestores, mostrando como é o funcionamento, deixando-os aptos para
realizarem suas análises.
1.4 Estrutura do trabalho
Este documento estrutura-se em cinco capítulos: Introdução, Fundamentação Teórica,
Projeto, Desenvolvimento e Conclusões.
No Capítulo 1, Introdução, descreve-se o cenário geral do trabalho, justificativa do projeto,
motivação, objetivos gerais e específicos, a metodologia e a estrutura do trabalho.
O Capítulo 2, Fundamentação Teórica, apresenta-se uma revisão bibliográfica sobre os
conceitos relacionados ao projeto como Data Warehouse, Data Mart, Sistemas de Apoio a Decisão
e OLAP.

14
O capítulo seguinte, Projeto, apresenta o projeto detalhado do sistema desenvolvido, como o
mesmo foi implementado, telas do sistema, configurações etc. Mostra-se o cenário do projeto e o
levantamento das informações necessárias para se criar a base de sustentação que suportou a criação
do projeto.
O Capítulo Desenvolvimento, apresenta as tarefas de desenvolvimento, a criação das bases
de dados, os processos de transferência de dados, a criação dos cubos OLAP, as planilhas
concluídas e o parecer dos gestores.
O capítulo final, Conclusões, apresenta as considerações do trabalho realizado, alguns
detalhes relativos ao desenvolvimento do sistema, a relevância do trabalho, objetivos alcançados e
sugestões de melhorias para projetos futuros.
O documenta é finalizado com um Apêndice, no qual estão detalhes mais aprofundados do
desenvolvimento do Projeto.

15
2. FUNDAMENTAÇÃO TEÓRICA
O presente capítulo descreve detalhadamente os conceitos que serão amplamente utilizados
no projeto e citados neste documento. A revisão e o estudo desses conceitos são de extrema
importância para capacitar o projetista na implementação do projeto. Para isso, são abordados temas
como SAD, Bancos de Dados, Data Warehouse, Data Mart, Modelo Dimensional, Ferramentas de
Apoio e OLAP.
A primeira seção, Sistemas de Apoio a Decisão, apresenta os conceitos e características dos
sistemas de informação gerencial e apoio a decisão.
Na seção seguinte, Data Warehouse, são apresentados os conceitos do DW, suas vantagens e
características. Essa seção também apresenta as características e conceitos do sub-segmento do DW,
o Data Mart.
Os conceitos e características do Modelo Dimensional são descritos na seção seguinte. São
apresentados os conceitos de tabela Fato e Dimensão, assim como as técnicas OLAP e OLPT. No
final dessa seção é mostrado o esquema estrela de modelagem dimensional.
De grande importância para o trabalho, a seção seguinte, Área de Transição de Dados,
mostra a intenção e os procedimentos para realizar a extração, limpeza e carga dos dados. Aqui se
começa a mostrar e associar as etapas de construção real do sistema.
A penúltima seção apresenta as características do Microsoft SQL Server, ambiente no qual
será implementado praticamente todo o sistema, com exceção da parte de apresentação dos dados
que será feito pelo Microsoft Excel.
Concluindo o Capítulo de Fundamentação Teórica, destacam-se os principais conceitos
abordados e a relação deles com o desenvolvimento e conclusão do trabalho.

16
2.1 Sistema de Apoio a Decisão
Esta seção da fundamentação teórica descreve o conceito e as características dos Sistemas de
Apoio a Decisão (SAD), assim como o foco de sua utilização.
Laudon e Laudon (1999) define os Sistemas de Informação como sendo um conjunto de
componentes inter-relacionados que coletam, recuperam, processam, armazenam e distribuem
informações com o propósito de facilitar o planejamento, o controle, a coordenação, a análise e a
tomada de decisões nas organizações.
De acordo com Oliveira (1997), sistemas de informação compreendem um conjunto de
ações, metodicamente organizadas, para prover informações passadas, presentes e futuras,
decorrentes das operações internas e do serviço de inteligência externo, com o propósito de dar
apoio para as funções de planejamento, controle e operação das organizações, num padrão de tempo
e qualidade apropriados para assistir o tomador de decisões.
Com base no conceito de Sistemas de Informação é possível conceituar o (SAD) como:
Um Sistema de Apoio à Decisão (SAD) auxilia o processo de decisão gerencial
combinando dados, ferramentas e modelos analíticos sofisticados e software amigável ao
usuário em um único e poderoso sistema que pode dar suporte à tomada de decisão semi-
estruturada e não-estruturada. Um SAD fornece aos usuários um conjunto flexível de
ferramentas e capacidades para analisar dados importantes. (LAUDON e LAUDON, 2004)
Para Pereira (2000), “Sistemas de Apoio à Decisão são sistemas que realizam o
processamento analítico e provêem as informações necessárias ao usuário decisor, permitindo a
análise de situações e a tomada de decisões”.
Segundo Hoffman (2001), o objetivo do SAD não é assimilar a experiência dos executivos
para a resolução dos problemas semelhantes no futuro, mas sim ajudar o executivo no uso de
manipulação de dados e aplicações heurísticas.

17
Baptista (2001), sintetiza os SADs como uma classe de sistemas mais complexos e
independentes, focados nos aspectos relacionados com a tomada de decisões. São aptos para tratar
problemas semi-estruturados e fornecer respostas a questões não rotineiras, agindo interativamente
com o usuário.
Pode-se dizer que os SADs são uma evolução dos Sistemas de Informação Gerenciais (SIG).
Os SIGs são os mais antigos aplicativos de apoio para o processo de decisão gerencial. Laudon e
Laudon (2004) afirmam que os SIGs primeiramente fornecem informações sobre o desempenho da
empresa para ajudar os gerentes a monitorá-la e controlá-la. Produzem relatórios fixos,
programados periodicamente, com base em dados extraídos e resumidos dos sistemas subjacentes
de processamento de transações (SSPT). Já o SAD oferece novos conjuntos de capacitação para
decisões não rotineiras, dando ênfase a mudança, flexibilidade e resposta rápida. SAD é um
assistente para quem o executivo delega atividades envolvendo a recuperação de dados, computação
e divulgação de informações (PEREIRA, 2000).
De acordo com Tomasi (2003), os SADs possuem as seguintes características:
• São utilizados para a solução de problemas de maior complexidade, menos estruturados
e geralmente são comuns no dia-a-dia dos altos executivos;
• São mais adaptáveis e flexíveis à mudanças no ambiente;
• Possuem uma interface que facilita o usuário, onde não haja perda de tempo para
aprender a utilizar o sistema;
• Não devem ficar limitados apenas aos altos executivos, e sim abranger todos os níveis
gerenciais da empresa;
• Devem fornecer subsídios para a implementação dos resultados após a tomada de
decisão; e
• São sistemas que tentam combinar funções tradicionais de processamento de dados com
métodos de gerenciamento, bem como possibilitar ao seu usuário a aplicar nas
informações, técnicas de análise qualitativa e quantitativa.
De acordo com Prates (1994) o processo decisório se desenrola, através da interação
constante do usuário com um ambiente de apoio à decisão, especialmente criado para alimentar e
orientar a tarefa de decidir.

18
2.2 Data Warehouse
Para Centenaro (2003,p.23), as organizações procuram ativamente tornarem-se mais
competitivas e rentáveis. Para obter vantagem competitiva, essas companhias precisam acelerar o
processo de tomada de decisão, devendo, para isso, reagir rapidamente às modificações do
ambiente, normalmente através da análise, planejamento e execução de ações táticas ou estratégicas
adequadas. Tais empresas se vêem em posição de ter que deixar de lado modelos fixos de gestão
para se concentrar em conhecer melhor o seu negócio, ou seja, seus produtos e clientes.
Os sistemas são projetados para gerar e armazenar dados, e as necessidades de hoje são de
extrair informações destes dados já armazenados e permitir uma análise com alto desempenho.
Como os BDs atuais não atendem todos estes requisitos uma nova abordagem foi introduzida nos
sistemas das empresas: o DW.
Segundo Haisten (1999), a origem do DW vem dos estudos do MIT (Massachusetts Institute
of Technology) nos anos 70 que focavam o desenvolvimento de uma arquitetura técnica mais
eficiente para sistemas de informação. Pela primeira vez foi feita uma distinção entre os sistemas
operacionais e aplicações analíticas, e surgiu o principio de separar esses dois tipos de
processamento em projetos e armazéns de dados diferentes.
Saber fazer uso da informação é o grande diferencial competitivo das organizações
atualmente. A Tecnologia da Informação é vista como uma ferramenta estratégica central na busca
pela vantagem competitiva (ZIULKOSKI, 2003, p. 9).
As raízes da construção de DWs estão no aprimoramento das tecnologias de bancos de
dados, que cada vez mais são capazes de manipular grandes volumes de dados. Muitas organizações
construíram DWs como solução para integrar dados de diversos bancos de dados operacionais e
suportar a tomada de decisão com informações qualificadas. Um DW é uma coleção de dados
integrados, orientados por assunto, não-voláteis e variáveis com relação ao tempo, de apoio às
tomadas de decisão gerenciais (INMON, 1997).
Não há uma definição precisa sobre o que é e o que constitui um DW. Observa-se dentre os
vários autores que escrevem sobre o assunto, uma grande quantidade e diversidade de definições.
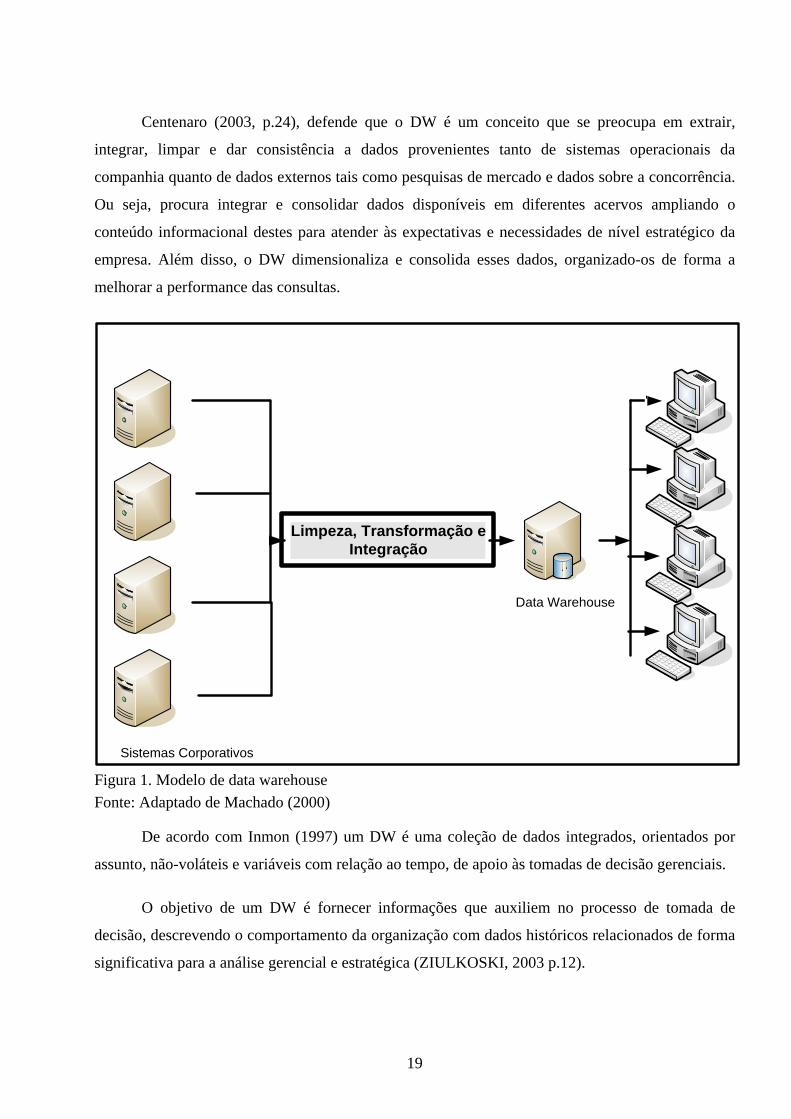
19
Centenaro (2003, p.24), defende que o DW é um conceito que se preocupa em extrair,
integrar, limpar e dar consistência a dados provenientes tanto de sistemas operacionais da
companhia quanto de dados externos tais como pesquisas de mercado e dados sobre a concorrência.
Ou seja, procura integrar e consolidar dados disponíveis em diferentes acervos ampliando o
conteúdo informacional destes para atender às expectativas e necessidades de nível estratégico da
empresa. Além disso, o DW dimensionaliza e consolida esses dados, organizado-os de forma a
melhorar a performance das consultas.
Limpeza, Transformação e Integração
'
Sistemas Corporativos
Data Warehouse
Figura 1. Modelo de data warehouse Fonte: Adaptado de Machado (2000)
De acordo com Inmon (1997) um DW é uma coleção de dados integrados, orientados por
assunto, não-voláteis e variáveis com relação ao tempo, de apoio às tomadas de decisão gerenciais.
O objetivo de um DW é fornecer informações que auxiliem no processo de tomada de
decisão, descrevendo o comportamento da organização com dados históricos relacionados de forma
significativa para a análise gerencial e estratégica (ZIULKOSKI, 2003 p.12).

20
Para Imhoff (1995) DW é uma coleção integrada de base de dados, orientada por assunto e
otimizada, projetada para suportar a função SAD, onde cada unidade de dados é relevante para
algum momento do tempo.
Segundo Kimball (1998), o DW fornece acesso a dados corporativos ou organizacionais,
seus dados são consistentes podendo ser separados e combinados usando-se qualquer medição
possível no negócio, um DW não consiste apenas em dados, mas em um conjunto de ferramentas
para consultar, analisar e apresentar informações, é um local onde se publica dados confiáveis sendo
a qualidade desses um impulso à reengenharia de negócios.
Corey e Abbey (1997) conceituam o DW como uma coleção de informações corporativas,
derivadas diretamente de sistemas operacionais e algumas fontes externas. Tem o propósito
específico de suportar decisões de negócios e não operações de negócios.
Baptista (2001, p.34) afirma que o DW é uma tecnologia vital que está revolucionado a
maneira com que as empresas têm acesso à informação e a utilizam para criar estratégias de
negócio, melhorando a competitividade e o retorno do investimento e transformando os processos
de negócios.
De acordo com HARRISON (1998), um banco DW é projetado para atender a necessidade
dos executivos por informações sobre o desempenho comercial de suas organizações de maneira
mais completa e rápida.
Na prática, segundo CAMPOS (1997), Data Warehouse é um banco de dados, alimentado
continuamente com dados oriundos dos sistemas operacionais, devidamente selecionados,
depurados e integrados, com o propósito de gerar uma visão única e real da empresa, predispostos
de maneira a agilizar o processamento de consultas e preferencialmente isentos de procedimentos
transacionais.
Para Kimball (1998) um DW deve:
• Tornar as informações de uma organização acessíveis: o conteúdo de um DW deve ser
compreensível e navegável e o acesso aos dados deve ser feito com bom desempenho;
• Tornar as informações de uma organização consistentes: as informações oriundas de
diferentes áreas da organização devem ter garantidas a integridade semântica, ou seja,

21
combinadas sem problemas de nomes iguais para coisas diferentes, ou nomes diferentes
para a mesma coisa;
• Ser uma fonte de informações flexível e adaptável: um DW deve suportar contínuas
modificações estruturais para inserção de novos dados, que responderão a novas
questões dos usuários, sem comprometer a estrutura já existente; e
• Ser o alicerce para a tomada de decisão: o DW deve conter os dados certos na forma
certa para suportar a tomada de decisão. Só há uma verdadeira saída de um DW: as
decisões que forem tomadas após o DW apresentar as evidências. Um termo que
antecede DW ainda é a melhor descrição do que um DW se propõe a fazer: um sistema
de apoio à decisão.
Resumindo, um DW é um grande ambiente, o qual integra e gerencia as informações
provenientes dos vários sistemas operacionais da empresas, bem como de fontes externas à
empresa. As informações disponíveis em um DW são disponibilizadas para todos os tipos de
consultas gerenciais, estando isolados dos sistemas de produção da empresa.

22
2.2.1 Características
Partindo dos conceitos de DW apresentados anteriormente, podem-se citar as seguintes
características implícitas ao DW:
1. Orientado ao assunto: Para Machado (2000), o DW armazena dados direcionados aos
principais assuntos ou negócios de interesse da empresa, em vez de sistemas
operacionais clássicos direcionados a processos de negócios desenvolvidos para
manter as transações diárias da empresa.
Sintetizando, os DWs procuram armazenar e separar os dados da empresa buscando atender
as necessidades específicas dos negócios das corporações.
Para Ziulkoski (2003, p.13), um usuário de DW está interessado em temas importantes para
o negócio da organização, então ele espera visualizar os dados por áreas (finanças ou vendas, por
exemplo), encontrando os indicadores e métricas do negócio em cada área. No ambiente
operacional, os bancos de dados são geralmente acessíveis apenas através de aplicações e, por isso,
a estrutura de um banco de dados operacional reflete a divisão existente entre as aplicações. Já em
um DW, espera-se que o usuário trabalhe diretamente sobre o banco de dados e, por isso, sua
estrutura deve refletir a divisão que os usuários estão acostumados a usar.
Pereira (2000, p.16) afirma que os dados são organizados da forma como os usuários se
referem a eles. São os processos de negócio de um empreendimento em vez de sistemas
operacionais que realizam transações individuais.
2. Variável com o tempo: Segundo Ziulkoski (2003, p.13) os dados de um DW refletem
situações ao longo do tempo, ou seja, são dados históricos por natureza. Esta
característica é essencial do ponto de vista de avaliação do negócio da organização,
pois é preciso manter séries históricas do comportamento dos negócios para que seja
possível analisar os resultados mais recentes. Baptista (2001, p.35) reconhece que o
desempenho do negocio é medido em pontos cronológicos e comparado com relação
ao tempo. Segundo Inmon (1997), todos os dados no DW são precisos em algum
instante no tempo. Como eles podem estar corretos somente em um determinado
momento, é dito que esses dados variam com o tempo.

23
Outro parâmetro importante a ser definido é o período de atualização dos dados oriundos
dos sistemas operacionais para o DW. O problema é definir de quanto em quanto tempo esta
atualização deve ocorrer. Segundo Inmon (1997), 24 horas deve-se passar entre o momento em que
a alteração é observada pelo ambiente operacional e sua repercussão no DW. O correto
estabelecimento deste período evita problemas de informações incorretas no DW, pois os dados
podem ainda não estar estáveis no ambiente operacional além de diminuir a complexidade da
tecnologia envolvida na replicação.
3. Não-volátil: no DW não existem alterações de dados, apenas a carga inicial e as
consultas, buscando manter o histórico dos dados. A atualização de registros,
existente nos bancos transacionais, exige um esforço muito grande para garantir a
integridade e a consistência dos dados, o que dificultaria o maior objetivo do DW.
Por esse motivo a redundância dos dados em um DW é aceitável, pois eles
provavelmente não estarão representando o mesmo aspecto gerencial dentro do DW.
Kimball e Ross (2002) sobre atualizações nos DW afirmam que os DW modernos
também podem ser atualizados, mas, em geral, essas são atualizações de carga
gerenciada e não atualizações transacionais.
Para Ziulkoski (2003, p.13) os dados que são inseridos no DW são estáticos. São dados que
refletem situações consolidadas, que não sofrerão atualizações.
4. Localização: afirma que em um DW, pode-se encontrar os dados armazenados
fisicamente de três formas (Centenaro, 2003, p.32):
• Armazenados em um único local, centralizando em um DW integrado onde
se procura maximizar o poder de processamento e busca dos dados;
• Distribuídos por áreas de interesse, também conhecida como estrutura
federativa, onde se separam os dados contábeis em um servidor, dados
financeiros em outro e assim por diante;

24
Armazenados por níveis de detalhes em que as unidades de dados são
mantidas no DW. Os dados em um DW podem estar dispostos em diferentes
níveis de detalhamento, ou seja, dados altamente resumidos podem ser
armazenados em um servidor, dados atômicos podem ser armazenados em
outros e níveis intermediários em outro, sempre lembrando que cada servidor
poderá (ou porque não dizer deverá) ser parametrizado para otimizar ao
máximo as consultas destinadas ao seu processamento.
5. Integrado: Inmon (1997) afirma que os dados que são inseridos no DW devem estar
consistentes entre si em termos de nomes, formatos e unidades de medida. Em geral,
os dados são provenientes de diversos sistemas de origem, internos ou até mesmo
externos à organização, de tal forma que não existe padronização na nomeação de
atributos, no formato de representação ou nas unidades de medida de valores
numéricos. No processo de integração dos dados, também pode ser preciso corrigir
dados que estejam inconsistentes na origem, devido à não-integração dos sistemas
transacionais que provêem os dados.
Pereira (2000, p.16) resume a afirmação de Inmon, ressaltando que os dados são limpos e
convertidos para um estado uniforme, sendo ainda removidas as inconsistências.
2.2.2 Granularidade
A granularidade refere-se ao nível de detalhe ou resumo com o qual serão armazenados os
dados no DW (INMON, 1997), quanto maior o detalhamento, mais baixo será o nível de
granularidade e vice-versa. A definição da granularidade afeta diretamente o volume de dados do
DW, bem como a qualidade e desempenho das consultas a serem feitas. Como exemplo, pode-se
citar que uma granularidade alta garante maior rapidez nas consultas feitas, porém diminui a riqueza
de informações que se pode extrair, enquanto uma menor granularidade possibilita a extração de
qualquer informação, mas acarreta maior volume de dados, conseqüentemente, maior tempo de
resposta à consulta e maior investimento em hardware.

25
Um DW pode ser implementado em níveis duais de granularidade ao longo do tempo. É
possível manter as informações mais recentes em um baixo nível de granularidade, aumentando
assim as possibilidades de extração de informações. À medida que os dados vão ficando obsoletos,
é possível resumi-los em um alto nível de granularidade de forma a manter a performance (INMON,
1997).
Segundo Sell (2001), o nível adequado de granularidade deve ser definido de tal forma que
atenda as necessidades do usuário, tendo como limitação os recursos disponíveis, ou seja, é
necessário encontrar um ponto de equilíbrio (CENTENARO, 2003, p. 59). Para Baptista (2001,
p.97) a granularidade é conseqüência das necessidades de visualização e análise dos dados que o
usuário vai se permitir. Mais detalhado o dado, menor a granularidade. Mais resumido o dado,
maior o grau de granularidade. Estes fatores impactam fortemente no volume de dados armazenados
e na complexidade de gerenciamento do processo. Num momento inicial não devem ser
estabelecidos todos os níveis de granularidade possíveis para o banco DW. Deve prevalecer o bom
senso incrementando a medida que o usuário utilize o sistema e sinta novas necessidades.
Segundo Campos (1998), a granularidade é uma questão fundamental no projeto de um DW
porque afeta diretamente o volume de dados armazenados e ao mesmo tempo, o tipo de consulta
que pode ser respondida, havendo, portanto a necessidade de um acerto entre estes dois aspectos
(INMON, 1997).
2.2.3 Data Mart
Sucintamente, Kimball (1998) define DM como um subconjunto lógico de um DW
completo (KIMBALL, 1998). Esse termo é usado para se referir a um DW de pequena capacidade
usado para atender especificamente a uma unidade estratégica de negócio ou a um departamento da
corporação (GRAY, 1998).
Para Inmon (1997), um Data Mart pode ser definido como um SGBD multidimensional que
fornece uma estrutura bastante flexível de acesso a dados. Enquanto o DW extrai, transforma e
limpa os dados dos sistemas transacionais, mantendo-os integrados em quantidades massivas e em
seu nível mais baixo, o DM se serve destes dados, extraindo dados para um departamento ou uma
área de negócio, oferecendo flexibilidade e controle ao usuário final, pois com o DM é possível
fatiar e agrupar dados de diversas maneiras (CENTENARO, 2003, p. 33).

26
Para Machado (2000), os dados do Data Mart são direcionados a um departamento ou a uma
área específica do negócio e representam um subconjunto do DW corporativo. (CENTENARO,
2003, p.33)
O conjunto de todos os DM da organização, construídos de forma incremental,
compartilhando dimensões e fatos comuns, segundo um planejamento prévio, formam o DW lógico
da organização (KIMBALL, 1998). A figura 2 representa este cenário:
Sistemas Corporativos
Data Mart A
Data Mart B
Data Mart C
Data Mart A
Data Mart B
Data Mart C
Data WarehouseData Marts
Figura 2. Data Warehouse incremental Fonte: Adaptado de Machado (2000)
Então fica bem clara a idéia de que DM é um DW reduzido focado em numa área do
negócio e que a integração de diversos DM completam um DW.
O DM muitas vezes é visto como uma alternativa ao DW, pois custa menos e leva menos
tempo para ser projetado e implementado. É criado para um grupo dirigido de usuários,
normalmente um setor da empresa (CENTENARO, 2003, p.33).

27
Gray (1998) reforça essas idéias ao afirmar que os altos custos de implementação de um DW
limitam o seu uso por grandes companhias, as quais muitas vezes não estão dispostas a correr riscos
no investimento em um empreendimento que não se tem certeza do sucesso e, conseqüentemente, o
retorno do investimento, tornando os DM, nesse caso, uma alternativa reduzida e de baixo custo.
A integração de DM para composição de um DW exige uma compatibilidade entre os
mesmos.
Na fase de planejamento do Data Mart é importante entrevistar algumas pessoas de outras
áreas que tenham relação com a área alvo. Com isso, pode-se adotar uma estratégia de
desenvolvimento integrada, mantendo a compatibilidade à medida que o DW vai incorporando
novas áreas de negócio. É preciso obter um entendimento do vocabulário comum de toda a empresa
para garantir que não se está modelando um DW que será uma ilha dentro da organização
(ZIULKOSKI, 2003, p. 17).

28
2.3 Modelagem Dimensional
Na presente seção apresenta-se os conceitos fundamentais para construção do Data Mart.
Serão abordados: os conceitos e as características da modelagem dimensional; as diferenças e
objetivos dos sistemas OLTP e OLAP; o conceito e importância das tabelas Fato e Dimensão; e o
esquema Estrela de estrutura dimensional.
Modelagem dimensional é um nome novo para uma técnica antiga usada para criar banco de
dados simples e compreensíveis (KIMBALL, 1998).
KIMBALL (1998) define modelagem dimensional como uma técnica lógica de projeto de
banco de dados Data Warehouse que busca apresentar os dados dentro de uma estrutura padrão e
intuitiva, permitindo ainda o acesso de alto desempenho.
Machado (2000, p.09) descreve a modelagem dimensional como uma técnica estruturada
desenvolvida para a obtenção de modelos de dados de simples entendimento e alta performance de
acesso aos dados.
O modelo dimensional é muito assimétrico. Apresenta uma tabela dominante no centro do
diagrama, a tabela de fatos, que está conectada com uma série de tabelas menores chamadas de
tabelas de dimensões (BAPTISTA, 2001, p. 38).
São tabelas que armazenam medidas numéricas totalizáveis relacionadas a um determinado assunto ou processo de negócio. Cada registro em uma tabela de fato está relacionado a um conjunto de dimensões que determinam a granularidade dos fatos armazenados e definem qual o escopo dessas medidas. Quanto menor a granularidade de um fato, maior será o nível de detalhe armazenado (KIMBALL e ROSS, 2002).
Kimball e Ross (2002) definem a modelagem dimensional como uma técnica estruturada
desenvolvida para a obtenção de um modelo de dados dimensional. Em sua composição típica esse
modelo possui uma grande entidade central (fato) que reflete a evolução dos negócios do dia-a-dia
de uma organização e um conjunto de entidades menores (dimensões) arranjadas ao redor da
entidade central e utilizadas de forma combinada como variáveis de análise do fato (TISSOT, 2004,
p. 29).
A modelagem dimensional permite ao usuário observar seu banco de dados no formato de
um cubo contendo duas, três ou quantas dimensões forem possíveis e aplicáveis. Esta modelagem

29
proporciona um ganho de tempo na consulta, uma melhor organização do sistema e principalmente
a sua utilização de forma intuitiva para o usuário (CENTENARO, 2003, p.48).
Harrison (1998) assegura que o modelo dimensional produz um projeto de banco de dados
consistente com o modo como o usuário entra e navega num banco DW (BAPTISTA, 2001, p.38).
A origem do termo dimensional está relacionada com a idéia de que os dados devem ser
agrupados de maneira a formar um cubo, ou hipercubo, que seria a estrutura padrão para visualizar
os dados. (ZIULKOSKI, 2003, p. 21)
Figura 3 - O modelo dimensional de um negócio: cada ponto interno ao cubo contém as medições para uma combinação de Produto, Mercado e Tempo Fonte: Kimbal (1998)
2.3.1 OLTP e OLAP
Pereira (2000) define OLTP (On-line Transaction Processing – Processamento de
Transações On-line) como o processamento realizado por sistemas computacionais que tem o
objetivo de obter as transações dos negócios do empreendimento e dar apoio às atividades diárias de
uma organização.
Pereira (2000) destaca ainda que nos sistemas OLTP os registros são continuamente
atualizados, e os bancos de dados armazenam pouca quantidade de dados históricos. Devido a isso,
declara-se que os bancos de dados OLTP têm seus dados altamente voláteis.
Sistemas OLTP executam as atividades básicas de inserção, atualização, consulta e
eliminação de dados em um banco de dados operacional, normalmente sendo permitido ao usuário
ler e gravar dados (POE, 1998)

30
Martins (2001) complementa afirmando que por este motivo os sistemas OLTP são
inadequados para aplicação de DW, pois eles foram projetados com capacidade de transações
maximizadas e tipicamente tendo centenas de tabelas.
Segundo Kimball (1998), um sistema OLTP pode processar milhares, ou até mesmo
milhões, de transações por dia mas envolvem uma pequena quantidade de dados, um DW
normalmente processa poucas transações por dia mas cada transação poderá conter milhares ou até
mesmo bilhões de registros.
Kimball (1998), afirma ser OLAP um termo inventado para descrever uma abordagem
dimensional para o suporte a decisão. Assegura igualmente que a filosofia OLAP está plenamente
alinhada com a estrutura do modelo dimensional, ou com o esquema tipo estrela como também é
chamado.
Segundo O´Brien (2001), OLAP é a capacidade dos sistemas de apoio a decisão em permitir
aos usuários manipular e examinar de forma interativa grande quantidade de dados detalhados e
consolidados a partir de várias perspectivas.
Pereira (2000, p.40) menciona que no âmbito comercial OLAP representa um conjunto de
ferramentas que possibilita efetuar a exploração dos dados contidos em Data Warehouse, através da
análise multidimensional permitindo ao usuário ter uma ampla visão da empresa através da
combinação de diversas dimensões.
Para Bispo (1999), OLAP constitui um conjunto de tecnologias especialmente projetadas
para dar suporte ao processo decisório através de consultas, análises e cálculos mais sofisticados
dos dados corporativos, estejam estes armazenados em Data Warehouse ou não, realizadas pelos
seus usuários – analistas, gerentes e executivos.
Pereira (2000) lembra que a redundância de dados é aceita no ambiente OLAP, onde é dada
uma maior importância ao alto desempenho na recuperação de dados em vez da economia de
espaço de armazenamento.

31
Sob o aspecto funcional, as ferramentas OLAP (On-Line Analytical Processing), utilizadas
para acessar dados em uma base de dados dimensional, disponibilizam operações para seus
usuários, sendo as principais (KIMBALL, 1996) (MACHADO, 2000):
• Drill Down: Esta operação pode ser descrita como a maneira de "obter mais detalhes". A
operação de drill down adiciona atributos das dimensões para o detalhamento de
resultados. Exemplo: Em uma consulta o gestor está visualizando produtos vendidos em
uma determinada loja. Então ele passa a adicionar colunas para refinar sua pesquisa,
como o nome do cliente, bairro onde mora, data da primeira compra, idade etc. Percebe-
se que o detalhamento foi ficando maior pela exploração da dimensão feita pelo gestor,
essa exploração é o drill down;
• Roll Up: a operação roll up retira do resultado as colunas adicionadas, não
necessariamente na mesma ordem em que estas foram adicionadas, gerando
sumarizações com menor nível de detalhamento. Esta é a operação inversa da primeira
apresentada, na qual a consulta fica mais resumida, somente com as colunas
fundamentais para análise;
• Slice: é a operação que corta o cubo mantendo a mesma perspectiva de visualização dos
dados. Por exemplo, em uma consulta o gestor está visualizando as compras feitas por
todos os clientes, considerando somente os cinco produtos mais comprados em comum
por esses clientes em um determinado período. Uma operação de slice é feita quando o
gestor escolhe somente visualizar as informações um desses clientes; e
• Dice: é a operação que realiza a mudança de perspectiva da visão.
Machado (2000, p.71) resume as operações de drill down como ato de aumentar o nível de
detalhes indo para o menor grão e drill up como diminuir o nível de detalhes, para subir ao maior
grão.
Tomasi (2003, p.12) cita algumas diferenças entre OLTP e OLAP:
• Acesso aos dados: geralmente as empresas possuem vários OLTP independentes. O DW
é um recurso centralizado que integra vários dados provenientes de banco de dados
OLTP e de fontes externas;

32
• Qualidade dos dados: os sistemas OLTP atualizam constantemente os status de um
negócio à medida que as transações são concretizadas, em conseqüência uma mesma
consulta analítica feita a uma base de dados operacional em diferentes tempos que
provavelmente obterá diferentes resultados, mas para o ponto de vista analítico seria
desastroso para o empreendimento. Dentro do conceito básico de DW, os usuários não
precisam observar e entender se os dados estão corretos, mas sim procurar identificar o
que significa as informações obtidas e quais ações devem ser tomadas; e
• Desempenho: os sistemas OLAP realizam consultas sobre grandes massas de dados
históricos de um empreendimento, devendo apresentar a resposta no menor tempo
possível. Já os sistemas OLTP apresentam status instantâneo do empreendimento em
uma empresa, atualizando-os constantemente à medida que as transações são
concretizadas, devendo estar disponíveis no momento exigido. A utilização de ambos os
sistemas pode provocar conflito pelos recursos de máquina, aumentando o tempo de
resposta dos sistemas OLTP.
Alguns modelos de negócio exigem uma mistura de capacidades para que o OLAP atinja
todos os requisitos. De acordo com Thomsen (2002), algumas empresas passaram a vender camadas
de produtos OLAP em cima dos sistemas operacionais (banco de dados relacional) das empresas,
dando origem ao termo ROLAP (Relational OLAP). Esse tipo de OLAP, a partir da entrada do
usuário, executa consultas SQL ao banco de dados. Considerando esse fato, os sistemas OLAP não
ROLAP passaram a ser chamados de MOLAP, em referência ao termo Multidimensional. Outros
termos surgiram como, por exemplo, DOLAP (Desktop OLAP e Database OLAP), HOLAP
(Hybrid OLAP), MROLAP (Móbile and Remote OLAP).
2.3.2 Fatos
Os fatos são medições do negócio. Geralmente são dados numéricos e aditivos, ou seja,
podem ser agregados por soma, média ou outras funções. A aditividade dos fatos é uma propriedade
muito desejável, pois permite que os dados sejam resumidos, o que é essencial quando se está
lidando com grandes volumes de dados. Exemplos de fatos aditivos são: valor total da venda,
quantidade de unidades vendidas (ZIULKOSKI, 2003, p. 22).

33
Machado (2000, p.63) afirma que fato é uma coleção de itens de dados, composta de dados
de medidas e de contexto. Cada fato representa um item de negocio, uma transação de negocio ou
um evento de negocio, e é utilizado para analisar o processo de negócio de uma empresa.
Segundo Gray (1998) a tabela fato armazena instâncias da realidade, referenciadas como
“fato”, sobre as quais tipicamente são realizadas operações matemáticas e estatísticas. Representa as
medidas do negócio, que podem ser mensuradas de forma quantitativa.
Um atributo do fato que é de fundamental importância é o grão do fato, isto é, o nível mais
detalhado que se deseja para o fato (KIMBALL, 1998).
Segundo Machado (2000, p.64) a característica básica de um fato é que ele é representado
por valores numéricos e implementado em tabelas denominadas tabelas de fato.
Para Pereira (2000, p.18) as tabelas fato possuem ainda as seguintes características:
• Normalmente são centrais, dependendo entretanto do tipo de esquema dimensional
adotado;
• Armazenam grande quantidade de dados (de gigabytes a terabytes), dependendo
diretamente do nível de detalhes que se deseja armazenar na base de dados;
• Possuem chave primária composta, formada por chaves estrangeiras, através das quais se
ligam as chaves primárias das tabelas dimensão.
Outra característica importante, levantada por Machado (2000, p.80), para identificar um
fato é que este é evolutivo, muda suas medidas com o tempo, podendo ser sempre questionado
sobre esta evolução ao longo de um espaço de tempo. Medidas são os atributos numéricos que
representam um fato, representam a performance de um indicador de negócios relativo às
dimensões que participam desse fato.
2.3.3 Dimensões
Tabelas de dimensões armazenam descrições textuais de um processo de negócio, podendo
cada uma ser formada por um conjunto de atributos, denominados hierarquias, que servem como
base para determinar regras de agrupamento, quebras e filtros em consultas a uma tabela de fato
(KIMBALL; ROSS, 2002).

34
Sucintamente, Machado (2000, p.64), define conceitualmente dimensões como os elementos
que participam de um fato ou assunto de negócios.
Dimensões determinam o contexto em que ocorreram os fatos. No modelo dimensional,
cada dimensão está associada a um ou mais fatos, sendo estas usualmente mapeadas em entidades
não numéricas e informativas (BALLARD et al., 2001)
Uma dimensão é um conjunto de objetos que descrevem e classificam os fatos através de
seus atributos. Os atributos de uma dimensão Loja, por exemplo, podem incluir uma hierarquia de
bairro, cidade e estado e atributos descritivos como o nome do estabelecimento. Geralmente uma
dimensão corresponde a um objeto, processo ou evento real para os quais existem dados.
(ZIULKOSKI, 2003, p. 23)
Em geral, os atributos de dimensão são dados textuais. Quando um valor numérico é obtido
nas fontes de dados podem existir dúvidas se ele é um atributo de dimensão ou um fato. Uma forma
de resolver esta dúvida é observar se ele se modifica para cada combinação das dimensões. Se o
valor se mantém constante ao longo de uma ou mais dimensões ele não é um fato, é um atributo de
dimensão (ZIULKOSKI, 2003, p.23).
Kimball (1998), ressalta que cada tabela de dimensão tem uma chave primária que
corresponde exatamente a um dos componentes da chave composta da tabela de fatos.
A cada chave primária da tabela dimensão deve haver exatamente uma chave estrangeira em
cada uma das tabelas de fatos que utilizam esta dimensão para descrever um acontecimento e,
diferentemente dos fatos, as dimensões podem possuir campos numéricos que não variam
continuamente a cada nova amostra (CENTENARO, 2003, p.58).
2.3.4 Esquema Estrela
Os projetistas têm implementado o modelo dimensional usando um banco de dados
multidimensional, ou relacional através do esquema estrela (star join schema) (KIMBALL, 1998).
Harrison (1998), ressalta que o modelo dimensional é referenciado com freqüência através
do termo “esquema estrela” devido à organização de seu projeto lógico de banco de dados.
Este esquema utiliza a abordagem relacional com algumas importantes restrições para
representar o modelo dimensional. São usados os mesmos componentes de um diagrama ER lógico,

35
como entidades, relacionamentos, chaves primária e estrangeira, cardinalidade etc. (ZIULKOSKI,
2003, p. 24).
No esquema estrela os fatos são representados na Tabela de Fatos, que é única num
diagrama e ocupa a posição central. As dimensões são representadas cada uma em sua Tabela de
Dimensão, que se posicionam ao redor da tabela de fatos, com a qual deve existir um
relacionamento um-para-muitos. Esta disposição cria o padrão radial que dá nome ao esquema. Na
Figura 4 é apresentado um exemplo de esquema estrela.
Figura 4 - Exemplo de esquema estrela Fonte: Ziulkoski (2003, p.24)
Um modelo dimensional implementado no esquema estrela possui todas as características desejáveis para um modelo de dados para DW: é bastante simples, sua analogia com um hipercubo de dados facilita a compreensão pelos usuários e pela sua simplicidade é possível memorizar os elementos mais importantes. É um modelo que facilmente suporta inclusão de novos elementos, como novas dimensões, novos atributos ou novos fatos, sem comprometer a estrutura existente. Finalmente, sua implementação tanto em bancos de dados multidimensionais ou bancos de dados relacionais tem um desempenho muito bom (ZIULKOSKI, 2003, p. 25).

36
Há também outras vantagens no modelo dimensional com esquema estrela (KIMBALL,
1998):
• Primeiro, a estrutura padronizada e regular de um modelo como esse permite que tanto o
sistema de gerência do banco de dados quanto as ferramentas de acesso aos dados
assumam premissas sobre os dados que facilitam a apresentação e o desempenho;
• Segundo, há um bom número de abordagens padrão para resolver problemas comuns no
mundo dos negócios;
• Terceiro, a grande maioria dos softwares e pacotes para navegação e agregação de dados
dependem de uma estrutura de fatos e dimensões do modelo dimensional.
2.4 Agregações
Pereira (2000) define agregação como o processo de acumulação de dados das tabelas fato
ao longo de atributos pré-definidos. Singh (1999), afirma que os dados são previamente
sumarizados e inseridos em tabelas fato que armazenam informações sumarizadas ou agregadas.
Para Kimball (1998, p.16), estas informações servem para otimizar enormemente o desempenho das
consultas.
Sell (2001) define agregados como sumários dos dados contidos no modelo original,
organizados de forma a atender consultas rotineiras de forma mais ágil, constituindo-se como uma
das formas mais eficientes de melhorar a performance das consultas em um DW.
Um registro de agregação é formado por grupos de vários registros detalhados e sempre está
associado a um ou mais registros de tabela de dimensões agregadas (KIMBALL, 1998).
De acordo com Pereira (2000), dentro do contexto de um projeto de banco de dados
analítico, deve-se tomar a decisão sobre a criação de agregados durante o processo de integração e
carga dos dados pré-calculados dentro do DW, processos que serão descritos nas seções seguintes.
Para Singh (1999) existem duas formas de agregação de dados operacionais em um único registro,
uma é saber quais registros de agregação que oferecerão melhor desempenho à execução de
consultas de maior freqüência para o usuário final. A segunda forma é saber onde os dados serão
inseridos e em que elementos da dimensão o número de linhas possa aumentar gradativamente.

37
A definição de um agregado pode ser baseada na redução que este gerará no volume de
dados, geralmente um bom agregado pode reduzir na razão de 10 ou mais vezes este volume
(CENTENARO, 2003, p.55).
Kimball (1998), considera que a utilização de agregados pré-calculados é o recurso de maior
eficiência que o projetista de DW dispõe para controlar o desempenho. Por terem os seguintes
objetivos básicos, de acordo com Pereira (2000):
• Otimizar o tempo de resposta de consultas para o usuário final, uma vez que os dados
são organizados de forma compacta e prática;
• Melhorar o tempo de processamento e ciclos de máquina, uma vez que as tabelas
agregadas possuem, normalmente, uma quantidade significativamente menor de dados;
• Reduzir o espaço de armazenamento, tendo em vista o agrupamento de vários dados
básicos em um único registro.
O projetista precisa ter o cuidado para que não ocorra a perda de detalhes importantes no
processo de agregação (TOMASI, 2003, p.17). Para Pereira (2000, p.17), existem dois métodos para
evitar a perda de dados pertinentes:
• Criar os agregados iterativamente com o usuário. Inicialmente deve-se disponibilizar
uma agregação mais ampla, que servirá de base para as iterações seguintes, até se chegar
ao nível desejado; e
• Criar níveis duais de granularidade, garantindo-se assim que independentemente do
tempo e custo envolvido, todo e qualquer dado pode ser recuperado.
2.5 Área de Transição de Dados
Esta seção descreve os processos responsáveis pela carga dos dados das fontes internas e
externas. Domênico (2001) afirma que essa é uma das etapas mais críticas na construção de um DW
por não existir um produto capaz de oferecer suporte adequado a todas as fases desta etapa. Souza
(2002) reforça essa idéia, considerando um processo trabalhoso, complexo e muito detalhado, sendo
que seu sucesso depende de uma boa definição dos requisitos de extração e transformação.

38
O processo de organização de dados pode ser conduzido utilizando-se programas
desenvolvidos pela equipe do DW ou através da utilização de ferramentas e técnicas
disponibilizadas pela indústria.
Mesmo empregando ferramentas automatizadas, as atividades que ocorrem na área interna
são complexas e, normalmente, consomem parcela considerável do tempo destinado ao
desenvolvimento do projeto de um DW (KIMBALL, 1998).
A seguir, são apresentadas os conceitos executados na Área de Transição de Dados.
2.5.1 Extração
Pereira (2000) apresenta como primeiro passo para obtenção de dados do DW a Extração
dos dados. Basta simplesmente ler e entender as fontes de dados extraídas serão colocados para
receberem os tratamentos necessários antes de serem atualizados no DW (DOMENICO, 2001).
Sell (2001), afirma que a extração de dados dos sistemas operacionais consiste da concepção
ou aquisição e parametrização das ferramentas que realizarão as tarefas de coleta, limpeza,
transformação e migração dos dados operacionais ao DW. Estas tarefas, quando da sua realização,
constituem um dos processos mais morosos e delicados no DW.
Tissot (2004, p. 27), destaca que durante o processo de extração os dados são lidos das
fontes externas e compreendidos. Os dados necessários para o DW são, então, copiados para a área
de preparo para futuras manipulações.
Tomasi (2003, p.31) afirma que geralmente se utiliza uma área de trabalho temporária para
o armazenamento destes dados, iniciando-se o processo de padronização destes dados.
2.5.2 Limpeza e Transformação
Após a extração, o processo de transformação executa algumas operações, tais como
limpeza dos dados, correções de escrita, conflitos de domínio dos dados, tratamento de elementos
ausentes e transformações para formatos padronizados (TISSOT, 2004, p. 27).
A transformação de dados consiste em uma série de atividades realizadas sobre os dados de
modo a convertê-los em algo apresentável para o usuário e valioso para os negócios (PEREIRA,
2000, p. 27).

39
Para Pereira (2000), o processo de limpeza serve para corrigir o uso incorreto ou
inconsistente de caracteres especiais; códigos contidos na base de dados operacionais; solucionar
problemas de conflito de domínios; corrigir os valores duplicados ou errados. Independente do
problema a ser solucionado, seu objetivo é deixar os dados padronizados, não duplicados, com
qualidade que forneça ao usuário capacidade de tomada de decisão baseada em valores reais.
Baptista (2001, p.99), explica que geralmente os sistemas de origem têm atributos de dados
que exigem um processo de transformação. As especificações desta rotina devem garantir um
mapeamento consistente de códigos e chaves entre os sistemas de origem e o DW e prever que
dados da mesma natureza, extraídos de mais de uma área ou versão de origem, sejam corretamente
integrados em um único modo.
2.5.3 Carga
Segundo Pereira (2000, p.28), os dados após serem devidamente transformados são
carregados no servidor de apresentação. As tabelas a serem atualizadas no DW devem ser montadas
utilizando-se agregações, sumarizações e ordenações dos dados (Souza, 2003)
Come (2001, p.54) reforça essa idéia afirmando que somente após a carga dos dados, a
indexação, a criação de agregados apropriados e a qualidade garantida desses dados é que estes são
disponibilizados para a comunidade de usuários.
Para Pereira (2000), as funcionalidades necessárias durante o processo de carga de dados
são, em grande maioria, em função da plataforma de destino de dados, como as seguintes:
• Suporte para múltiplos destinos: o destino dos dados no servidor de apresentação poderá
ser para DM atômico ou DM agregado. Cada alvo dos dados tem sua própria sintaxe e
detalhes. Nessa situação, o processo de carga deve conhecer essas diferenças e utilizá-las
ou evitá-las da forma mais apropriada;
• Otimização do processo de carga: todo banco de dados possui um conjunto de técnicas
para otimizar o processo de carga, tais como evitar a geração de log durante o processo,
criar índices e agregar dados. Muitas dessas características podem ser invocadas dos
bancos de dados ou registradas em scripts através da utilização de ferramentas sobre a
área de organização de dados;

40
• Suporte completo ao processo de carga: o serviço também precisa suportar as exigências
antes e depois da carga atual, como eliminar e recriar índices e particionamento físico de
tabelas e índices.
Tissot (2004, p.27), aconselha que somente após a carga dos dados, a indexação, a criação
de agregados apropriados e a qualidade garantida desses dados é que os dados devem ser
disponibilizados para a comunidade de usuários.
2.6 Ferramentas de Apoio
Nesta seção, apresenta-se o SGBD Microsoft SQL Server, de grande importância para o
desenvolvimento deste projeto. Descrevem-se as vantagens de sua utilização, suas características e
as ferramentas que são utilizadas no projeto.
Basicamente, serão utilizados: o Enterprise Manager para criação e manutenção do banco de
dados; o DTS (Data Transformation Service) que realiza as operações de extração, limpeza,
transformação e carga dos dados; o Analysis Manager onde em síntese são criados os cubos OLAP;
e o MS Excel onde é feita a publicação das consultas.
2.6.1 Microsoft SQL Server (MS SQL) – Enterprise Manager
O Enterise Manager é a ferramenta central de administração de banco de dados do MSSQL
Server. Nela é feita a criação do banco de dados, visualização de tabelas, colunas, triggers, views,
chaves primárias, chaves estrangeiras, usuários, permissões, backup, restore, enfim, todas as tarefas
relacionadas a administração e manutenção do banco de dados.
Além dos recursos já esperados de um SGBD, Petkovic (1999), destaca os seguintes
vantagens:
• O SQL Server é relativamente fácil de gerenciar, através do uso de um ambiente gráfico
para quase todas as tarefas de sistema e administração de banco de dados;
• O SQL Server usa serviços do Windows para fornecer recursos de banco de dados, como
envio e recebimento de mensagens e o gerenciamento de segurança de login;
• O SQL Server é adaptável, podendo ser passado de um notebook para sistemas de
multiprocessamento simétrico; e

41
• O SQL Server fornece recursos de armazenamento de dados que até então estavam
disponíveis apenas para Oracle e outros sistemas mais caros.
Considerando essas vantagens a utilização do MS SQL Server no contexto deste trabalho se
torna fundamental por ser o mesmo SGBD utilizado pelos sistemas de operação das empresas, o
ERP RM Sistemas. Ainda deve-se considerar a compatibilidade com o MS Excel para publicação
das consultas e o conhecimento de alguns gestores da ferramenta.
Abaixo, a figura 5 mostra o ambiente gráfico do Enterprise Manager:
Figura 5: Enterprise Manager
2.6.2 DTS – Data Transformation Service
Um dos recursos mais relevantes para o desenvolvimento deste projeto é o DTS. Segundo
Microsoft, O DTS é um conjunto de ferramentas gráficas e objetos de programação que se pode
utilizar para extrair, transformar e carregar (ETL) dados a partir de fontes diferentes e movê-los
para um único ou múltiplo destino.
A configuração de um pacote do DTS inicia-se com a escolha do Servidor fonte, conforme a
figura 6. Nesse servidor escolhe-se o banco de dados de onde serão extraídos os dados.

42
Figura 6. Seleção da fonte de dados no DTS
Após escolher os bancos de dados, selecionam-se as tabelas a serem utilizadas, como mostra
a figura 7.
Figura 7. Seleção das tabelas fonte e destino.
Concluída esta etapa, repete-se esses passos para a seleção do servidor, banco de dados e
tabelas de destino.

43
Concluída essa etapa inicial, na qual se definem as fontes e destinos de dados, já é possível
salvar o pacote. O pacote pode ser agendado para ser executado conforme a necessidade do sistema,
isto é, de hora em hora, diariamente, semanalmente, mensalmente etc. Também é possível definir
através de uma consulta SQL os dados que devem ser transferidos, por exemplo, pode-se executar
uma consulta select onde somente as linhas com data de criação do mês anterior são transferidas,
como mostra a figura 8.
Figura 8. Seleção dos dados a serem transferidos, através de consulta SQL
Em alguns casos, quando é necessário alterar algum valor da fonte antes de transferir para o
destino pode-se utilizar linguagens de programação como o vb.script, por exemplo, para fazer essa
transformação nos dados, assim como é mostrado na figura seguinte.
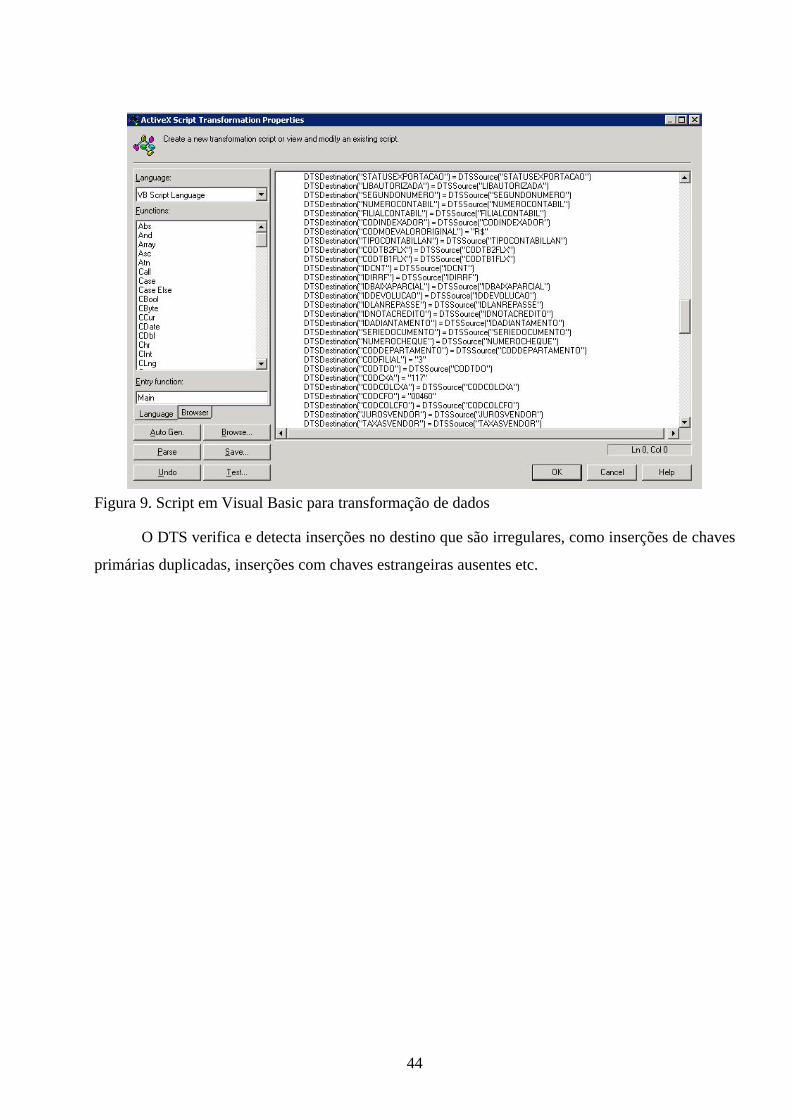
44
Figura 9. Script em Visual Basic para transformação de dados
O DTS verifica e detecta inserções no destino que são irregulares, como inserções de chaves
primárias duplicadas, inserções com chaves estrangeiras ausentes etc.

45
2.6.3 Analysis Manager
Esse é o ambiente no qual acontece a construção dos cubos OLAPs. A figura 10 mostra a
tela inicial do Analysis Manager.
Figura 10. Analysis Manager
O primeiro passo dentro do Analysis Manager é definir qual será o banco de dados fonte que
será usado como base para a criação do Cubo. A figura 11 mostra a seleção do Servidor e banco de
dados utilizados como fonte.

46
Figura 11. Seleção de Servidor e banco de dados fonte no Analysis Manager.
Após a seleção da fonte de dados é possível iniciar a construção do cubo. Durante a criação
é perguntada qual é a tabela fato que a ser utilizada, conforme a figura 12, e exibe-se as colunas da
tabela selecionada.
Figura 12. Seleção da tabela fato
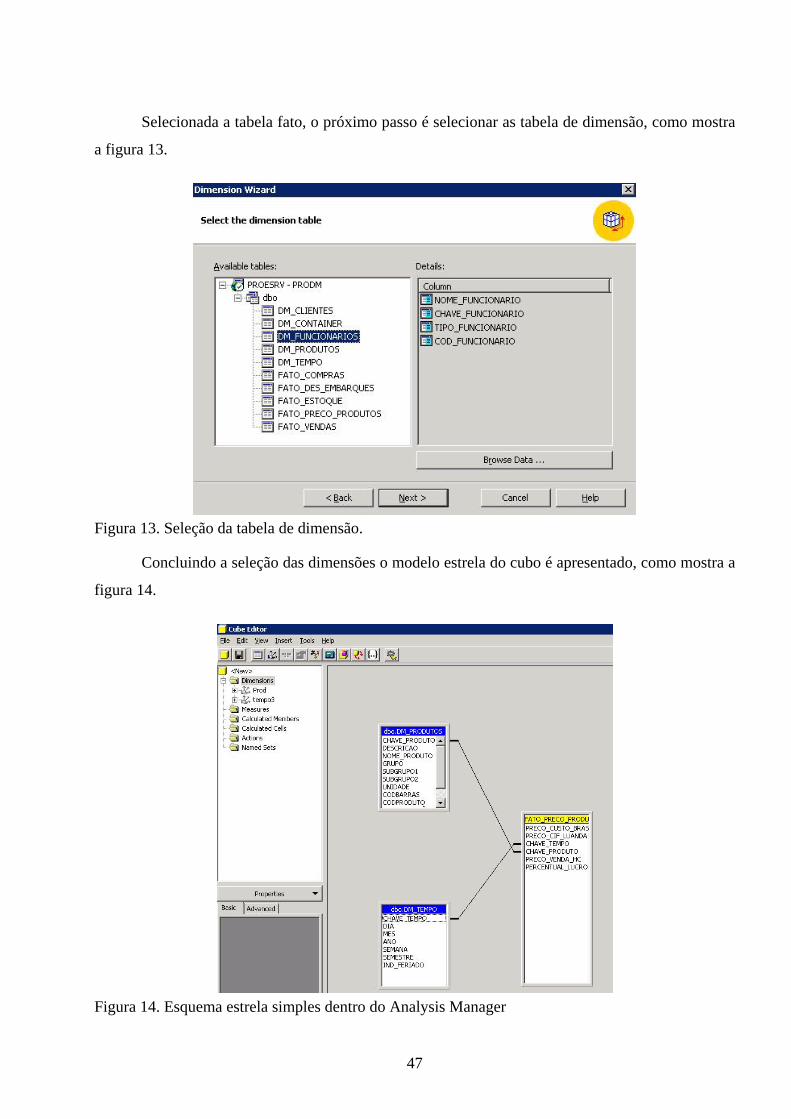
47
Selecionada a tabela fato, o próximo passo é selecionar as tabela de dimensão, como mostra
a figura 13.
Figura 13. Seleção da tabela de dimensão.
Concluindo a seleção das dimensões o modelo estrela do cubo é apresentado, como mostra a
figura 14.
Figura 14. Esquema estrela simples dentro do Analysis Manager

48
Antes de finalizar a apresentação no Analysis Manager, é preciso salvar e processar o Cubo.
Nessa etapa são feitas todas as customizações e otimizações, pela ferramenta, necessárias para
utilização do cubo.
2.6.4 MS Excel
O MS Excel é a ferramenta escolhida para realizar a publicação dos dados. Por ser uma
ferramenta da família Microsoft já possui compatibilidade com o MS SQL Server e Analysis
Manager.
A importação do cubo para o MS Excel é feita através de um assistente, o que facilita ainda
mais o processo. Na figura 15 é mostrada uma planilha já com o cubo importado.
Figura 15. Cubo importado para o MS Excel

49
Na parte direita da planilha estão as dimensões e medidas do cubo. Os gestores então
arrastam os campos que desejam utilizar em sua consulta.
2.7 CONSIDERAÇÕES DA FUNDAMENTAÇÃO
Na presente seção faz-se uma revisão dos principais conceitos abordados na fundamentação
teórica e a contribuição deles para o desenvolvimento deste projeto. Como já é sabido, o objetivo
principal deste projeto é a construção de um Data Mart, utilizando técnicas OLAP, para dar apoio as
tomadas de decisão dos gestores das empresas Proembarque e Casacon.
Na primeira da seção deste capítulo, foi visto o conceito de SAD. Essa é a solução
encontrada para se conseguir dar suporte as questões do dia a dia dos executivos que não eram
solucionáveis através dos sistemas operacionais das empresas. O que normalmente se vê nas
empresas é um grande volume de dados gerado pelos sistemas operacionais sem ser aproveitado. A
qualidade de utilização da informação faz diferença nas empresas que buscam resistir a
globalização e a forte concorrência comercial. Os SADs são sistemas que estão focados em resolver
questões especificas, portanto aproveitam somente as informações necessárias geradas pelos
sistemas operacionais.
Dentro desse contexto, o data warehouse foi apresentado como a estrutura física por trás do
SAD. O data warehouse é um banco de dados orientado a um assunto específico que tem
características particulares em relação a um banco de dados relacional. Entre elas pode-se destacar o
fato do DW estar preparado para armazenar grandes volumes de dados, não sofrer atualizações de
dados e não ser volátil, isto é, evitar-se ao máximo a exclusão e atualização de registros.
Após, descrito o DW, apresentou-se o DM, que em síntese é um subconjunto do DW. Em
muitos casos as empresas iniciam o desenvolvimento de DM para cada departamento e depois
integra-os em um único DW. Além disso, o custo e tempo de implantação de um DM fica bem
abaixo de um DW.
Tanto no caso do DW como no DM, o desenvolvimento desses sistemas precisa contar com
o apoio fundamental dos gestores e pessoas que poderão ser usuários futuros do sistema, para
garantir que não se esteja desenvolvendo um sistema de gaveta, isto é, que ninguém saberá utilizar e
acabara esquecido.

50
Na seção de modelagem dimensional viu-se que esta é uma técnica de projeto de banco de
dados DW que busca apresentar os dados dentro de uma estrutura padrão e intuitiva, buscando um
acesso de alto desempenho.
Seguindo, foi mostrada a diferença entre os sistemas OLTP e OLAP, que basicamente está
associada ao fato dos sistemas OLTP em suportar as transações diárias das empresas e no OLAP em
dar suporte a visualização de grandes volumes de dados sob diferentes perspectivas.
Nas seções de fatos e dimensões foi visto que os fatos são onde estão as medições das
consultas, isto é, onde estão os dados importantes para análise gerencial. As dimensões são os
elementos que participam destes fatos, contendo as informações provenientes dos bancos de dados
operacionais.
A seção onde apresentou-se os processos da área de transição de dados, mostrou a intenção
dos processos de extração, transformação e carga dos dados. Em síntese, a extração é feita a partir
do sistema operacional da empresa. Nessa etapa são selecionados somente os campos pertinentes ao
sistema. Após, é feito o tratamento desses dados, dando uma imagem mais amigável a eles quando
necessário, sempre pensando em facilitar a utilização dos mesmos pelos gestores. No processo de
carga os dados são importados para dentro do DM e então estão prontos para serem visualizados.
Na última seção do capítulo de fundamentação teórica foram apresentadas as ferramentas
que deram suporte ao desenvolvimento deste trabalho. O MS SQL Server é o ambiente principal
para o desenvolvimento do projeto. Nele está o Enterprise Manager que suporta as tarefas de
criação, administração e manutenção do BD. Já o DTS é a ferramenta utilizada para realizar os
processos de extração, tratamento e carga das informações. Foi mostrado todo o potencial do DTS
em realizar essas tarefas de maneira simples e direta. Em seguida apresentou-se o Analysis
Manager, ambiente de criação e manipulação dos cubos OLAP. E, finalmente, a etapa de
visualização das consultas foi mostrada através do MS Excel, que já tem toda uma compatibilidade
para importar o cubo OLAP e permitir o manuseio das informações pelos gestores.
Alguns detalhes mais a aprofundados das ferramentas foram abstraídos dessa seção, sendo
que estes serão destacados no capítulo de desenvolvimento e no Apêndice 1.

51
3. PROJETO
3.1 Área de Negócios das empresas
De acordo com os objetivos, o presente trabalho se propõe à construção de um Data Mart
para as empresas Casacon Home Center e a Proembarque Comércio Internacional. As duas
corporações fazem parte do mesmo grupo empresarial e o trabalho de ambas está intimamente
ligado desde do início das operações, em 2003.
O Home Center Casacon é uma loja de departamentos localizada em Angola, na África.
Dentre da enorme variedade de produtos comercializados pode-se citar jogos de cozinha; sala;
sofás; armários; brinquedos; artigos de vestuário; artigos de cama; mesa e banho; luminárias;
ferramentas; material de construção etc. A empresa com um armazém de trinta metros quadrados
para o estoque das mercadorias.
No Brasil, precisamente no estado de Santa Catarina, está a Proembarque Comércio
Internacional. A empresa concentra seu Departamento de Compras e Diretoria no centro de Itajaí,
enquanto o Departamento Logístico localiza-se na mesma cidade, porém próximo a uma área onde
estão concentrados diversos terminais de armazenamento de cargas e containeres; junto ao
armazém de produtos (PROLOG).
O processo entre as empresas envolve, resumidamente, as seguintes etapas:
• Cadastro do Pedido de Orçamento (PO): os importadores das Casacon iniciam o
processo logístico com o cadastro no sistema de um Pedido de Orçamento. Neste pedido
são listados os produtos e as quantidades para serem cotados;
• Cotação do PO, Orçamento: o PO é cotado pela equipe de compras da Proembarque, que
negocia todos os detalhes com os fornecedores como, por exemplo, data de entrega,
forma de pagamento, frete e demais informações;
• Envio do Pedido de Orçamento Cotado (POC): depois de cotado, o Orçamento é enviado
via sistema para os importadores da Casacon, que analisam os preços, condições
propostas e podem realizar mudanças na quantidade a ser comprada, conforme interesse.
Caso o importador aceite o POC, o mesmo é enviado para a Proembarque como um
Pedido de Importação (PI);

52
• Geração da Ordem de Compra (OC): a partir do Pedido de Importação é gerada a OC, a
qual é enviada aos fornecedores para concretizar a compra. Nessa etapa são acertados os
detalhes de local e data de entrega;
• Entrada da mercadoria na PROLOG: A recepção das mercadorias é feita na PROLOG
em Itajaí-SC, onde os produtos são armazenados até a estufagem no container. Nesse
processo de estufagem são listados todos os produtos que estão no container e o número
do embarque. A cada embarque é gerado um Packing List, que é uma listagem de todos
os produtos que estão sendo enviados separados em seus respectivos containeres.
Através do Packing List os importadores da Casacon verificam a data prevista para
chegada da mercadoria em Angola; e

53
• Com a chegada do embarque no porto de Luanda, em Angola, é feita a checagem e
atualizado o estoque da empresa.
A figura seguinte mostra o diagrama detalhado do processo logístico entre as empresas:
Figura 16. Diagrama de Processos - Proembarque

54
3.2 COMUNICAÇÃO DOS SISTEMAS
A presente seção descreve o cenário de comunicação do sistema, focando na infra-estrutura
entre as bases de dados.
Como já foi citado, uma VPN permite a comunicação entre os servidores de banco de dados.
Dois computadores com Sistema Operacional Debian/Linux estão localizados em cada empresa
realizando o serviço de VPN e Firewall. A VPN é uma estrutura de comunicação que permite a
transferência de dados através da internet de maneira segura. Considerando que cada empresa
possui sua rede em particular, a VPN faz com que as duas redes se integrem podendo trocar dados.
Cada servidor de banco de dados está por trás desses servidores Linux não sendo acessíveis
externamente, a não ser pelo redirecionamento dos servidores VPN. O serviço de firewall desses
servidores realiza o controle de acessos permitindo somente que as duas redes em especifico tenham
acesso as informações e dados. A figura 17 mostra o diagrama de componentes que provêm essa
comunicação.
Nuvem
VPN/FIREWALL
VPN/FIREWALL
BRASIL
ANGOLA
INTERNET
Figura 17. Diagrama de componentes

55
O método de publicação escolhido é a através do serviço de Terminal Services do servidor
da Proembarque. Nos últimos meses esse foi o método definido para publicação de todas as
planilhas operacionais e gerenciais das empresas. Cada colaborador possue seu usuário e senha de
acesso para ao servidor. Ao entrar no servidor o usuário tem em sua tela inicial uma pasta com os
atalhos para as planilhas que lhe competem. Dessa maneira o usuário pode-se conectar de qualquer
lugar geograficamente remoto e ter acesso as informações que procura.
3.2 Levantamento das Necessidades Gerenciais
O levantamento das necessidades gerenciais desenvolveu-se através de entrevistas formais e
informais com diretores e gerentes das empresas. O diretor da Proembarque, Rodrigo Zeggio e o
gerente financeiro da Casacon Magdiel Souza apoiaram o levantamento das necessidades
gerenciais. Um fator favorável com a participação dos dois é o vasto conhecimento do sistema
utilizado pela empresa (RM Sistemas) e alguns conhecimentos básicos de DW. Houve algumas
tentativas para que outros gestores apoiassem o desenvolvimento do projeto. Porém, a falta de
conhecimento, aliado à falta de tempo e disponibilidade para explicar os conceitos e passar o
conhecimento necessário para esses gestores, limitou a pesquisa somente aos dois primeiros
profissionais citados.
Primeiramente, foram reforçadas as vantagens da implantação de um DM em relação à
utilização direto do banco de dados do sistema RM. Alguns exemplos, de consultas gerenciais
foram retirados dos mesmos livros utilizados como fundamentação neste trabalho e apresentados
aos gestores. A partir desses exemplos, os gestores analisaram os processos entre as empresas e
definiram quais consultas ou relatórios dariam suporte as suas decisões. Os gestores não definiram
precisamente as informações que necessitam, mas forneceram uma idéia ampla de suas
necessidades, deixando a cargo do projetista o refinamento das necessidades nos moldes necessários
para desenvolver o projeto. As principais idéias lançadas pelos gestores foram:
• Relatório de vendas da Casacon por períodos, mostrando clientes, vendedores, itens
vendidos e totais;
• Relatório de Estoques, mostrando a quantidade em estoque, quantidade vendida em
meses anteriores, preços dos produtos, data de entrada e saída do estoque;
• Relatório de produtos, mostrando a variação de preços dos mesmos (preço de compra no
Brasil, preço de entrada em Angola, preço de venda em Angola);

56
• Relatório de Embarques/Desembarques, mostrando o total de containeres por períodos,
produtos embarcados, despesas com containeres, data de saída do Brasil, data de
chegada na Casacon;
• Relatório dos procurements (compradores da Proembarque), mostrando os detalhes das
compras realizadas, como por exemplo, valor da compras, fornecedor e condições de
pagamento.
3.2.1 Modelo Dimensional
Para responder as consultas gerenciais foram criadas cinco tabelas de dimensão e cinco
tabelas fatos. Inicialmente, será mostrado abaixo as dimensões e fatos para cada consulta e, após, é
apresentado um modelo unificado com todos os fatos e dimensões.
O primeiro Fato, Preço_Produtos, contêm basicamente os preços de compra no Brasil, os
preços de entrada com os impostos sobre os produtos e o preço de venda ao consumidor final. Com
esses preços gera-se o último atributo, lucro_bruto.
O Fato Vendas apresenta as informações de quantidade vendida, preço unitário dos
produtos, preço total comprado, valor de desconto e despesas, quando houver, e a condição de
pagamento negociada.
DIMENSÃO TEMPOCHAVE_TEMPO
DIAMESANOSEMANASEMESTREIND_FERIADO
DIMENSÃO_PRODUTOSCHAVE_PRODUTO
DESCRICAONOMEGRUPOSUBGRUPOSUBGRUPO2CODBARRASUNIDADECODPRODUTOCLASSIFICAÇÃO FISCALFORNECEDOR
FATO PRECO_PRODUTOSCHAVE_TEMPO (FK)CHAVE_PRODUTO (FK)
PRECO_CUSTO_BRASILPRECO_CIF_LUANDAPRECO_VENDA_HCPERCENTUAL_LUCRO

57
O terceiro Fato, Compras, refere-se às compras realizadas no Brasil pela Proembarque.
Neste fato concentram-se os preços unitários e totais da compra junto ao fornecedor, valor do
desconto, valor do frete e a condição de pagamento.
O Fato Estoque, registra as informações da quantidade em estoque dos produtos, quantidade
que entrou no estoque e saiu no período em análise, e o estoque mínimo de produtos.
D IM E N S Ã O TE M P OC H A V E _ TE M P O
D IAM E SA N OS E M A N AS E M E S TR EIN D _ F E R IA D O
D IM E N S Ã O _ F U N C IO N Á R IO SC H A V E _ F U N C IO N A R IO
N O M E _ F U N C IO N A R IOC O D _ F U N C IO N A R IOTIP O _ F U N C IO N A R IO
D IM E N S Ã O _ P R O D U TO SC H A V E _ P R O D U TO
D E S C R IC A ON O M EG R U P OS U B G R U P OS U B G R U P O 2C O D B A R R A SU N ID A D EC O D P R O D U TOC L A S S IF IC A Ç Ã O F IS C A LF O R N E C E D O R
F A TO _ C O M P R A SC H A V E _ TE M P O (F K )C H A V E _ F U N C IO N A R IO (F K )C H A V E _ P R O D U TO (F K )
P R E C O _ U N ITA R IOP R E C O _ TO TA LTIP O _ F R E TEQ TD _ C O M P R A D AV A L O R _ D E S C O N TOC O N D _ P A G A M E N TOV A L O R _ F R E TE
DIM E NS Ã O TE M P OCHA V E _TE M P O
DIAM E SA NOS E M A NAS E M E S TREIND_FE RIA DO
DIM E NS Ã O _CLIE NTE SCHA V E _CLIE NTE
NO M E _CLIE NTECIDA DETE LE FO NEE NDE RE COB A IRROTE LE FO NE 2CO D_CLIE NTE
DIM E NS Ã O _F UNCIO NÁ RIO SCHA V E _F UNCIO NA RIO
NO M E _FUNCIO NA RIOCO D_FUNCIO NA RIOTIP O _FUNCIO NA RIO
DIM E NS Ã O _P RO DUTO SCHA V E _P RO DUTO
DE S CRICA ONO M EG RUP OS UB G RUP OS UB G RUP O 2CO DB A RRA SUNIDA DECO DP RO DUTOCLA S S IF ICA ÇÃ O F IS CA LF O RNE CE DO R
F A TO _V E NDA SCHA V E _CLIE NTE (FK )CHA V E _TE M P O (F K )CHA V E _P RO DUTO (F K )CHA V E _F UNCIO NA RIO (FK )
Q TD_V E NDIDAP RE CO _UNITA RIOP RE CO _TO TA LV LR_DE S CO NTOV LR_DE S P E S A SCO ND_P A G TO

58
Finalmente, o último Fato, Embarques/Desembarques permite uma análise do fluxo de
embarques e desembarques. Esse fato contém as datas de saída do Brasil e de chegada no Porto de
Luana dos navios, a data que o container foi ovado no Brasil, desovado em Angola e teve seus
produtos colocados em estoque, data da proforma de compra, data da entrega da mercadoria no
terminal PROLOG, peso líquido embarcado e peso bruto embarcado.
A Dimensão Tempo apresenta os atributos dia, mês, ano, semana, semestre e um indicador
de feriado.
A Dimensão Funcionários armazena tanto os compradores da Proembarque como os
vendedores na Casacon. Através do atributo tipo_funcionario eles são diferenciados. A tabela no
sistema RM que armazena esses funcionários é a TVEN. O atributo cod_funcionario faz a ligação
com BD do sistema RM, onde o nome do campo similar é codven.
DIMENSÃO TEMPOCHAVE_TEMPO
DIAMESANOSEMANASEMESTREIND_FERIADO
DIMENSÃO_CONTAINERCHAVE_CONTAINER
ARMADORTAMANHONUMERO_SERIE
DIMENSÃO_PRODUTOSCHAVE_PRODUTO
DESCRICAONOMEGRUPOSUBGRUPOSUBGRUPO2CODBARRASUNIDADECODPRODUTOCLASSIFICAÇÃO FISCALFORNECEDOR
FATO_DES/EMBARQUESCHAVE_PRODUTO (FK)CHAVE_TEMPO (FK)CHAVE_CONTAINER (FK)
DATA_EMBARQUEDATA_DESEMBARQUEDATA_PROFORMADATA_MERCADORIA_PROLOGDATA_CONTAINER_OVADODATA_ESTOQUE_LUANDAPESO_TOTAL_LIQ_EMBPESO_TOTAL_BRUTO_EMB
DIMENSÃO TEMPOCHAVE_TEMPO
DIAMESANOSEMANASEMESTREIND_FERIADO
DIMENSÃO_PRODUTOSCHAVE_PRODUTO
DESCRICAONOMEGRUPOSUBGRUPOSUBGRUPO2CODBARRASUNIDADECODPRODUTOCLASSIFICAÇÃO FISCALFORNECEDOR
FATO_ESTOQUECHAVE_PRODUTO (FK)CHAVE_TEMPO (FK)
QTD_ESTOQUEQTD_ENTRADAS_PERIODOQTD_SAIDA_PERIODOESTOQUE_MIN_PERIODO

59
Na Dimensão Clientes estão relacionados os consumidores que realizam compras na
Casacon. É possível visualizar os dados relevantes desses clientes como cidade, bairro, endereço e
telefones. A tabela FCFO, do sistema RM, armazena essas informações e está ligada com essa
dimensão a partir do campo CODCFO com o atributo cod_cliente.
A tabela TPRD, do Sistema RM da empresa dá suporte as informações da dimensão
Produtos. Essa dimensão apresenta informações como nome do produto no Brasil (atributo nome),
nome do produto em Angola (atributo descricao), unidade do produto, classificação fiscal do
Mercosul, o fornecedor do produto e os grupos de classificação do produto. Através do atributo
codproduto é feita a ligação com o campo codigoprd da tabela TPRD, no Sistema RM.
Concluindo, a Dimensão Container armazena as informações de tamanho, armador e
número de série do container, o qual faz a ligação com sistema RM permitindo identificar os
atributos do container em análise.
Tinha-se a intenção de criar uma dimensão particular para os Fornecedores, porém no
sistema operacional da empresa não está sendo feito o cadastro correto dessa informação, então
optou-se pela única forma viável, que era resgatar essa informação do cadastro de produtos.
Na dimensão produtos, os campos Grupo, Subgrupo1 e Subgrupo2 iriam permitir aos
gestores filtrar somente produtos de determinado grupo. Porém, a inserção dessa classificação ainda
não está sendo feita no sistema fonte de dados, impedindo a utilização desse artifício.
As tabelas principais do RM que armazenam todos os movimentos operacionais da empresa
são a TMOV e TITMMOV. A TMOV armazena as informações topo do movimento, como
fabricante, preço total, nome do comprador, data do movimento etc. A TITMMOV armazena os
itens do movimento, isto é, o nome dos produtos envolvidos, unidade e quantidade dos mesmos.
Todas as tabelas aqui citadas estão em ambas bases de dados, tanto na Casacon quanto na
Proembarque. Para evitar conflitos entre chaves primárias, essas tabelas têm suas geração de chaves
primárias dividas em faixas bem espaçadas, por exemplo, a chave primária da tabela TMOV é a
coluna idmov. No BD da Casacon os idmovs são gerados a partir do número 4000000 e na
Proembarque 0000001. O mesmo ocorre em todas as demais tabelas que tem infomações replicadas.
A tabela onde esses parâmetros de geração de ids são definidos é a GAUTOINC.

60
Portanto, completa-se aqui a apresentação do Modelo Dimensional e as tabelas do Sistema
RM que serão utilizadas.
Na próxima página está o Modelo Dimensional tipo estrela unificado com todas as
dimensões e fatos.
FATO PRECO_PRODUTOSCHAVE_TEMPO (FK)CHAVE_PRODUTO (FK)
PRECO_CUSTO_BRASILPRECO_CIF_LUANDAPRECO_VENDA_HCPERCENTUAL_LUCRO
DIMENSÃO TEMPOCHAVE_TEMPO
DIAMESANOSEMANASEMESTREIND_FERIADO
DIMENSÃO_FUNCIONÁRIOSCHAVE_FUNCIONARIO
NOME_FUNCIONARIOCOD_FUNCIONARIOTIPO_FUNCIONARIO
DIMENSÃO_CLIENTESCHAVE_CLIENTE
NOME_CLIENTECIDADETELEFONEENDERECOBAIRROTELEFONE2COD_CLIENTE
DIMENSÃO_PRODUTOSCHAVE_PRODUTO
DESCRICAONOMEGRUPOSUBGRUPOSUBGRUPO2CODBARRASUNIDADECODPRODUTOCLASSIFICAÇÃO FISCALFORNECEDOR
FATO_VENDASCHAVE_CLIENTE (FK)CHAVE_TEMPO (FK)CHAVE_PRODUTO (FK)CHAVE_FUNCIONARIO (FK)
QTD_VENDIDAPRECO_UNITARIOPRECO_TOTALVLR_DESCONTOVLR_DESPESASCOND_PAGTO
FATO_COMPRASCHAVE_TEMPO (FK)CHAVE_FUNCIONARIO (FK)CHAVE_PRODUTO (FK)
PRECO_UNITARIOPRECO_TOTALTIPO_FRETEQTD_COMPRADAVALOR_DESCONTOCOND_PAGAMENTOVALOR_FRETE
FATO_ESTOQUECHAVE_PRODUTO (FK)CHAVE_TEMPO (FK)
QTD_ESTOQUEQTD_ENTRADAS_PERIODOQTD_SAIDA_PERIODOESTOQUE_MIN_PERIODO
FATO_DES/EMBARQUESCHAVE_PRODUTO (FK)CHAVE_TEMPO (FK)CHAVE_CONTAINER (FK)
DATA_EMBARQUEDATA_DESEMBARQUEDATA_PROFORMADATA_MERCADORIA_PROLOGDATA_CONTAINER_OVADODATA_ESTOQUE_LUANDAPESO_TOTAL_LIQ_EMBPESO_TOTAL_BRUTO_EMB
DIMENSÃO_CONTAINERCHAVE_CONTAINER
ARMADORTAMANHONUMERO_SERIE
Figura 18. Modelo Dimensional - Estrela

61
4. DESENVOLVIMENTO
Este capítulo apresenta a construção do DM e as considerações dos gestores. Alguns
detalhes são abstraídos dessa seção e inseridos no Apêndice A, para os leitores que quiserem ter
acesso a detalhes mais aprofundados.
4.1 Criação da base de dados
O primeiro passo do desenvolvimento é a criação da base de dados que dará suporte a
construção do DM. Inicialmente é aberto o Enterprise Manager, acessa-se o servidor abrindo a
árvore de pastas, até chegar na pasta de Databases. Então, clicando com o botão direito escolhe-se a
opção new database. A figura 19 representa essa seqüência de passos.
Figura 19. Criando nova base de dados
O nome escolhido para a base deste trabalho é TCC. Após preencher o nome da base,
escolhe-se o local onde será salvo o arquivo de dados e log de transações da base de dados. Feito
isso a base de dados já aparece entre as demais bases do banco de dados.
4.2 Geração das tabelas fatos e dimensão
A etapa de construção do modelo dimensional contou com o suporte da ferramenta ERWin.
Nela foram definidos os nomes das tabelas, das colunas e o tipo dos dados das colunas. O próprio
ERWin faz a geração de um script SQL para a criação das tabelas dentro da base de dados no MS
SQL Server. O script encontra-se por inteiro no Apêndice A. Executando esse script no Query

62
Analyzer, ferramenta para execução de sentenças SQL do MS SQL Server, as tabelas são geradas e
podem ser visualizadas no Enterprise Manager, como mostra a figura 20.
Figura 20. Tabelas do DM Criadas as tabelas, já se tem condição de iniciar os processos de ETL, como será mostrado na seção seguinte.
4.3 Processo de extração e carga dos dados
Nessa etapa utilizou-se a ferramenta DTS, a qual também está localizada na árvore de pastas
do Enterprise Manager, como mostra a figura 21. Para iniciar um novo pacote DTS deve-se
escolher a opção export data.
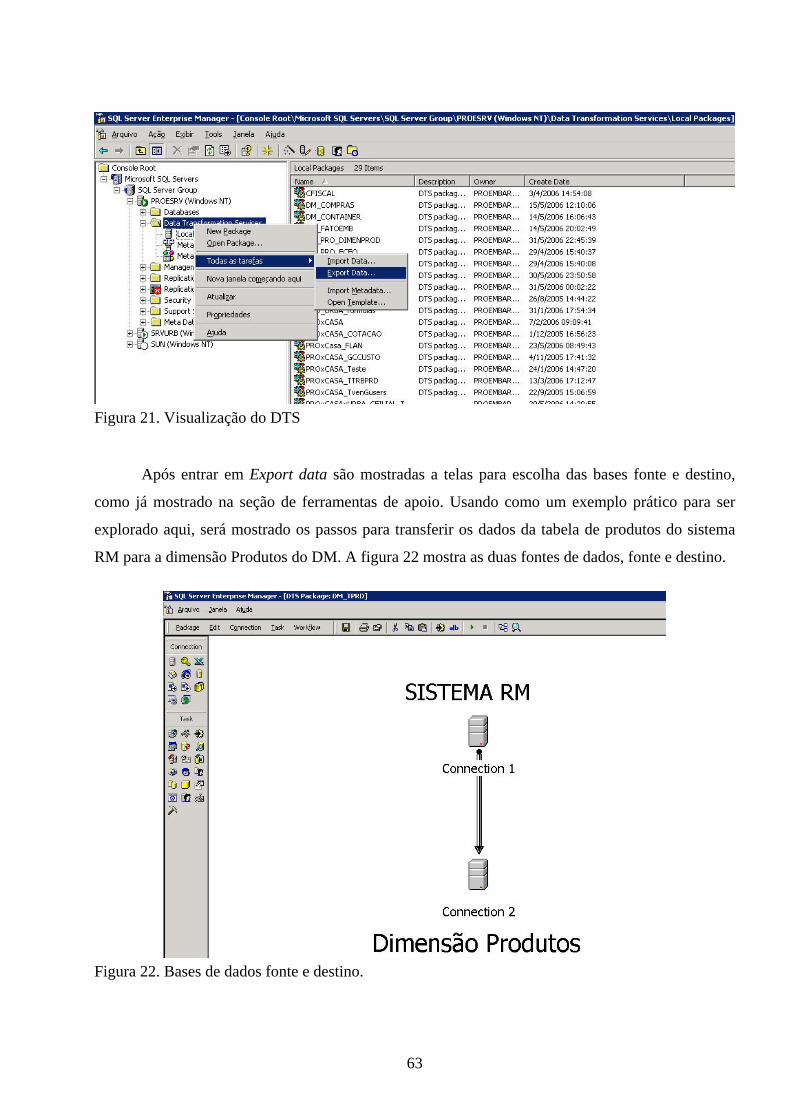
63
Figura 21. Visualização do DTS
Após entrar em Export data são mostradas a telas para escolha das bases fonte e destino,
como já mostrado na seção de ferramentas de apoio. Usando como um exemplo prático para ser
explorado aqui, será mostrado os passos para transferir os dados da tabela de produtos do sistema
RM para a dimensão Produtos do DM. A figura 22 mostra as duas fontes de dados, fonte e destino.
Figura 22. Bases de dados fonte e destino.

64
Entre elas está a task de transformação onde são definidas as ligações entre as fontes e a
seleção dos dados a serem transferidos, que é feita através de uma consulta Select., como mostra a
figura 23.
Figura 23. Seleção dos dados a serem transferidos
Em seguida é executado o pacote e os dados são inseridos na tabela do DM, a dimensão
Produtos. As demais consultas SQL de carga são apresentadas no Apêndice A.
Cada pacote é agendado para executar uma vez a cada semana através do gerenciador de
tarefas do SQL Server, fazendo a carga dos dados da semana anterior.
4.4 Construção do Cubo OLAP
A próxima etapa envolve a ferramenta Analysis Manager e mostra a construção do cubo
OLAP. Será utilizado como exemplo prático e real a construção do cubo dos Preços dos Produtos.
O processo inicia-se com a escolha da fonte de dados, no caso, a base de dados TCC, que
tem as tabelas do DM. A figura 24 mostra a criação de uma nova fonte de dados.

65
Figura 24. Criação de nova fonte de dados
Na janela que se abre, deve-se selecionar o tipo da fonte de dados, no caso, SQL Server,
como mostra a figura 25.
Figura 25. Seleção do tipo da fonte de dados.

66
Na aba Conexão deve-se escolher o Servidor onde se encontra a fonte de dados, inserir o
nome e senha de usuário com permissão de acesso ao banco de dados. Por fim, a base de dados, um
teste deve ser feito para verificar que o acesso está correto, e então é retornada uma mensagem
validando a conexão, como é mostrada na figura 26.
Figura 26. Parâmetros da conexão
Completada essa etapa, pode-se começar a criação do cubo, através do Editor. Escolhe-se as
tabelas fatos e dimensão que participam do cubo, etapas que já foram apresentadas na descrição do
Analysis Manager.
A figura 27 mostra a janela do Cube Editor. No lado esquerdo pode-se ver as dimensões
utilizadas e as medidas de análise.
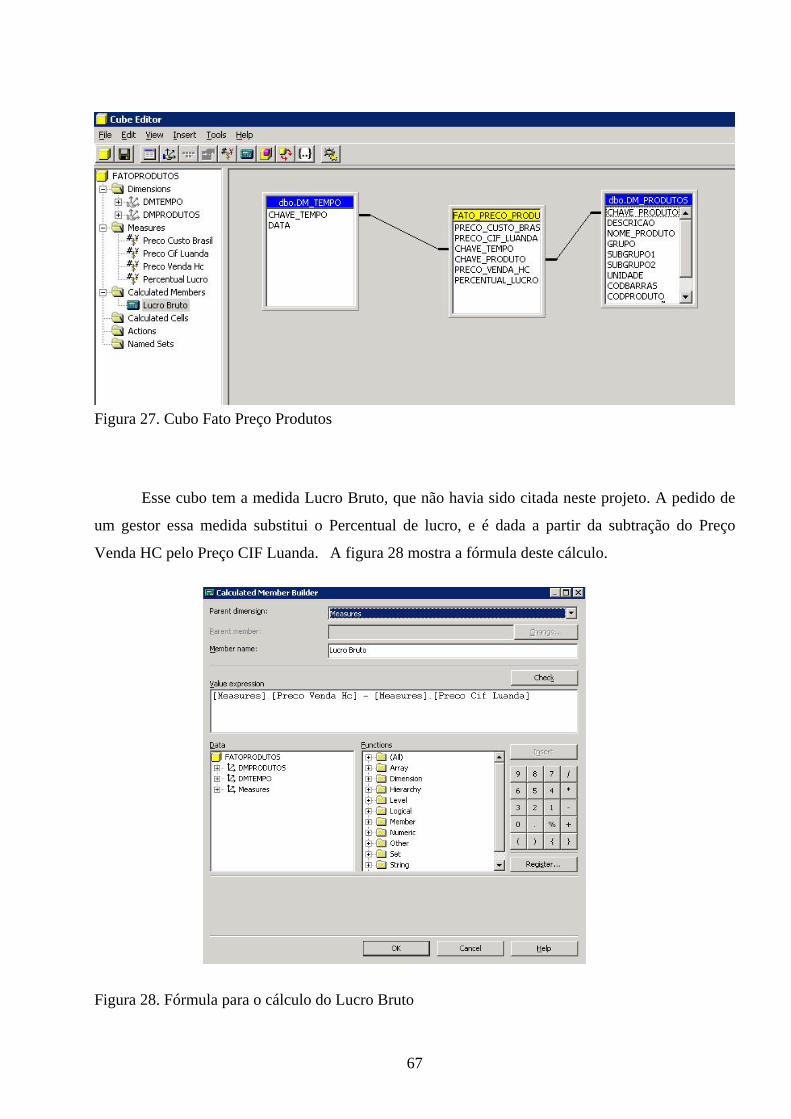
67
Figura 27. Cubo Fato Preço Produtos
Esse cubo tem a medida Lucro Bruto, que não havia sido citada neste projeto. A pedido de
um gestor essa medida substitui o Percentual de lucro, e é dada a partir da subtração do Preço
Venda HC pelo Preço CIF Luanda. A figura 28 mostra a fórmula deste cálculo.
Figura 28. Fórmula para o cálculo do Lucro Bruto

Finalizado a configuração do cubo, é preciso acessar o menu Tools e escolher a opção
process cube. Será aberta uma janela mostrando as interações realizadas pelo Analysis Manager
durante o processamento do cubo, como mostra a figura 29.
Figura 29. Processamento do Cubo.
Terminado o processamento do cubo com sucesso, pode-se passar para a próxima e última
etapa que é a visualização do cubo no MS Excel.
4.5 Importação do Cubo para o MS Excel
Nessa seção é mostrado os passos para importar o cubo OLAP para dentro do MS Excel e
como manipulá-lo.

69
Inicialmente deve-se acessar o menu Dados e, posteriormente, Relatório de Tabela e
Gráficos Dinâmicos. Será aberta a janela mostrada na figura 30, nela deve-se selecionar Fonte de
Dados Externos como a localidade onde estão os dados a serem importados e Tabela Dinâmica
como o tipo de relatório que deseja-se criar.
Figura 30. Criação da tabela dinâmica para visualizar os cubos.
Na janela seguinte é feita a conexão com o Cubo o OLAP. A figura 31 mostra a escolha do
nome da fonte de dados, o tipo de OLAP que vai prover a conexão e o botão conectar.
Figura 31. Conexão com a fonte de dados.

70
Ao entrar no botão Conectar é aberta a janela para conexão com o Analysis Server, como
mostra a figura 32. Nessa etapa deve-se colocar o nome do servidor e o usuário e senha para
conexão.
Figura 32. Conexão com o Analysis Server
Avançando no assistente é apresentada a lista de bases disponíveis no Analysis Server.
Seleciona-se então a base em que foram criados os cubos e em seguida pode-se selecionar o cubo
desejado, como é apresentado na figura 33.
Figura 33. Seleção do Cubo
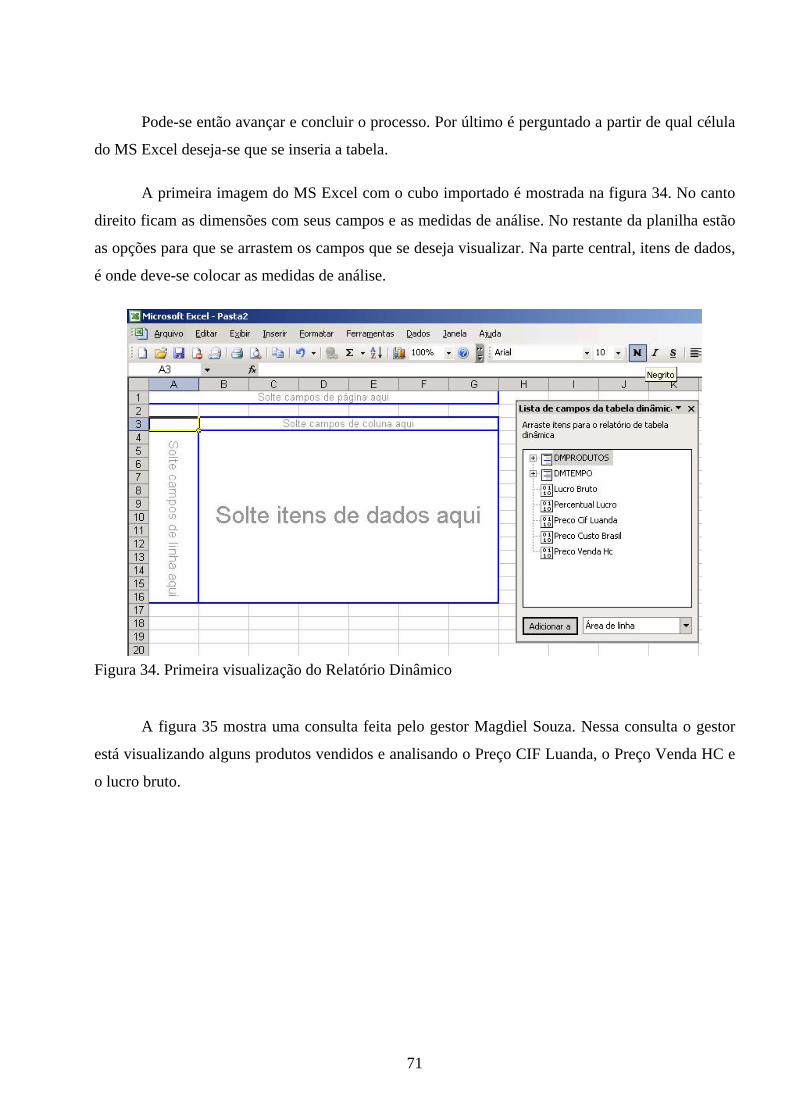
71
Pode-se então avançar e concluir o processo. Por último é perguntado a partir de qual célula
do MS Excel deseja-se que se inseria a tabela.
A primeira imagem do MS Excel com o cubo importado é mostrada na figura 34. No canto
direito ficam as dimensões com seus campos e as medidas de análise. No restante da planilha estão
as opções para que se arrastem os campos que se deseja visualizar. Na parte central, itens de dados,
é onde deve-se colocar as medidas de análise.
Figura 34. Primeira visualização do Relatório Dinâmico
A figura 35 mostra uma consulta feita pelo gestor Magdiel Souza. Nessa consulta o gestor
está visualizando alguns produtos vendidos e analisando o Preço CIF Luanda, o Preço Venda HC e
o lucro bruto.

72
Figura 35. Consulta do gestor
Aqui finaliza-se a criação de uma consulta do inicio ao fim. Mais detalhes podem ser
encontrados no Apêndice A, como as demais cargas de dados e consultas.
Na próxima seção será apresentado o parecer dos gestores que utilizaram as consultas.
4.6 Validação junto aos gestores
As planilhas foram apresentadas aos gestores Magdiel Souza, Sabrina Wolff, Rafael
Maccarini, Jair Goulart e Rodrigo Zeggio. Os três primeiros estão envolvidos com os departamentos
de compra, o colaborador Jair com o departamento logístico e o último com todas as áreas da
Proembarque por ser o diretor geral da empresa.
As planilhas foram apresentadas com auxílio do projetista para facilitar o primeiro contato
com as mesmas. Durante o trabalho com os gestores foi-se anotando as principais considerações
feitas e adaptadas para este documento.
O primeiro colaborador a utilizar algumas das planilhas foi o procurement Rafael Maccarini:
“Falando primeiramente da planilha de Compras, pode-se avaliar o desempenho das compras

73
realizadas. Verificar casos onde poderia se ter conseguido algum desconto pelo volume da compra.
Alguns outros casos também percebe-se a possibilidade de uma melhor negociação de fretes com
fornecedores com quem compramos a mais tempo. Analisando a planilha de preços de produtos,
verifica-se que em alguns casos houve inclusive a venda de produtos por um preço menor do que
aquele que foi gasto até que o produto chegasse as prateleiras, isto é, um erro grave que deve ser
analisado mais profundamente”.
A segunda colaboradora Sabrina Wolff fez as seguintes considerações: “Analisando a
planilhas que mostra a variação dos preços percebo a importância do departamento de compras em
conseguir negociar sempre um preço cada vez mais baixo com os fornecedores, tendo em vista o
forte acréscimo que os produtos sofrem devido aos impostos. Essa redução no preço dos produtos
está associada não só em conseguir diminuir o preço unitário dos produtos, mas em também
negociar melhores fretes, condições de pagamentos e descontos nos valores finais da compra. Para
apoiar essas diretrizes a planilha de compras faz o seu papel, permitindo visualizar quais são os
fornecedores mais maleáveis em fornecer descontos, melhores condições de pagamentos e fretes.
Também pode-se listar os fornecedores com que trabalhamos mais tempo, porém ainda mostram
resistência em oferecer benefícios. Confesso que esse tipo de planilha era desconhecido até então,
mas se mostra bem útil e dá abertura para se pensar em novas planilhas como essas que podem nos
auxiliar em outras tarefas”.
Seguindo a apresentação das considerações dos gestores, o próximo colaborador
entrevistado foi o gerente financeiro da Casacon: “Primeiramente gostaria de parabenizar a
iniciativa do projetista em desenvolver seu trabalho de conclusão de curso focado na empresa em
que trabalha. Aproveitando meu conhecimento sobre o sistema da empresa e em banco de dados, sei
da dificuldade que deve ter sido extrair algumas informações que ainda estão amadurecendo dentro
do sistema da empresa. Por ainda estarmos passando por alguns refinamentos de processo, algumas
rotinas do sistema ainda apresentam poucos dados ou em algumas vezes informações
desencontradas. Também percebo que no desenvolvimento desse tipo de projeto precisa-se contar
com um forte apoio dos gerentes, porém o pouco conhecimento de alguns dificulta a explicação do
que se pretende com esse tipo de planilha e sistema. Entretanto, a partir dessa primeira amostra fica
facilitado o entendimento do que se pretende com a criação desse sistema de auxilio, por isso
acredito que em novos trabalhos o apoio será maior e melhor. Agora falando das planilhas nas quais
participei do projeto, a planilha de consulta de preços auxilia na definição dos preços dos produtos
em prateleira, pois permite que eu analise o preço do produto com os impostos e também o preço

74
das últimas vendas realizadas. Permite que eu analise o lucro obtido em todo o histórico de vendas,
percebendo qual o preço a se definir buscando não assustar o cliente com preços altos e também não
estipular um preço baixo demais perdendo a oportunidade de se ter um lucro maior. Analisando a
planilha de vendas posso visualizar o perfil das compras dos clientes, saber quem são eles e suas
preferências. Também consigo verificar os vendedores que tem facilidade em vender determinados
produtos, tentando fazer um remanejamento deles, buscando com que eles permaneçam próximos
aos departamentos da loja nos quais eles tem mais facilidade de venda e consequentemente mais
conhecimento dos produtos. Ao mesmo tempo permite com que eu trabalhe com suas deficiências,
já que o interessante mesmo é que eles tenham um conhecimento bom e geral de todos os
departamentos da loja. Facilita o conhecimento de quais são os melhores vendedores incentivando
também aqueles que estão com um desempenho um pouco abaixo que busquem seu
reconhecimento. Analisando o histórico dos dados posso ver a variação do faturamento conforme os
meses do ano e os dias da semana, facilitando o planejamento das compras através da Proembarque.
A planilha de estoque também auxilia no planejamento das compras, permitindo que se visualize os
meses em que a quantidade dos produtos em estoque estava acima do necessário ou meses em que
ficamos com o estoque zerado de produtos com alta freqüência de vendas. Porém, acredito que essa
planilha tenha sido prejudicada pelas constantes mudanças que foram feitas no sistema para o
controle de estoque e também pelo fato desse controle ter sido implantado recentemente dentro do
sistema das empresa, mas futuramente acredito que se tenha uma maior consistência dos dados nela
apresentados”.
O penúltimo colaborador entrevistado foi Jair Goulart, supervisor do departamento de
logística da empresa. Suas considerações foram as seguintes: “A planilha de Embarque e
Desembarque permite um planejamento financeiro dos gastos logísticos a partir do histórico do
volume dos embarques conforme o período do ano. Como já era de se esperar, os primeiros meses
dos anos se tem uma menor quantidade de containeres embarcados, provavelmente pelo grande
volume de vendas que ocorrem nas datas festivas de fim do ano. Com o avanço dos meses o volume
dos embarques aumenta, sendo que entre os meses de julho e outubro chegam ao seu pico devido as
compras feitas para abastecer o estoque da Casacon para as vendas do fim do ano. Também posso
visualizar quais são os produtos mais embarcados, sabendo que estes devem sempre ter uma
atenção especial pois consequentemente são os mais vendidos na Casacon”.
Finalizando as considerações dos gestores, o diretor Rodrigo Zeggio: “Esse projeto
representa bem o momento em que a empresa vive principalmente em relação a maturidade da

75
empresa. Como expliquei na defesa da primeira parte desse projeto, a empresa pode ser considerada
como jovem no cenário empresarial. Nos primeiros anos o corpo de funcionários era cerca de um
quarto do que é hoje. Muitas informações eram armazenadas em simples documentos de texto ou
em planilhas eletrônicas até que foi-se iniciada a implantação do sistema ERP e os processos foram
sendo importados para dentro do sistema. Hoje a empresa já esta bem avançada nesse cenário e as
informações cada vez mais consolidadas. Infelizmente, alguns erros iniciais da implantação
comprometem a análise de algumas informações, principalmente as mais antigas. Entretanto, esse
trabalho incentiva a aproximação dos gestores junto ao projetista para apoiar e participar de futuros
trabalhos. Primeiramente analiso a planilha de Preço de Produtos. Nela fica claro alguns erros como
vendas de produtos por preços abaixo do que aquele gasto para importar o produto. Em outros casos
é possível ver acertos e vendas bem realizadas, como em alguns meses em que a diminuição do
preço de venda ao consumidor foi acertada para limpar o estoque de produtos que estavam
acumulados, afirmação que faço com base na analise da planilha de Estoque. As planilhas de
compras e vendas permitem que eu visualize quais são os fornecedores os quais eu devo estreitar os
laços buscando parcerias para conseguir melhores condições de compra. Especificamente na
planilha de compras, vejo quais são os procurements mais eficientes, isto é, aqueles que conseguem
os melhores descontos e melhores compras. A planilha de embarques me auxilia em verificar onde
está ocorrendo maior downtime no processo de exportação. Consigo ver a data onde foi iniciado o
processo da compra, quanto tempo levou até que a mercadoria chegasse a PROLOG, o tempo que
essa mercadoria ficou parada no armazém, a data do embarque e data da chegada da mercadoria em
Angola”.
Finaliza-se aqui a apresentação das considerações dos gestores a respeito das planilhas.

76
5. CONCLUSÕES
O DM construído foi a solução proposta para auxiliar os gestores das empresas Proembarque
e Casacon em suas decisões rotineiras. A idéia deste projeto nasceu da evolução natural por qual
passou a utilização e potencialidades do Sistema RM dentro das corporações. O sistema, que em
meados de 2003 foi implantado nas empresas, apresentava como problema principal o desencontro
de informações, justificado basicamente pela falta de integração entre os sistemas das duas
empresas. Percebendo a possibilidade de realizar essa integração através de uma VPN, os
profissionais de TI da Proembarque e Casacon parametrizaram novas bases de dados, passando a se
preocupar em construir um cadastro de fornecedores e produtos unificados, que permitissem a
movimentação dos processos de exportação entre as bases.
Tendo essa confiabilidade maior nas informações armazenadas nas bases de dados, os
gestores passaram a sentir mais confiança em analisar as informações. Contundo, não tinham os
relatórios que extraíssem as informações que eles necessitavam. Então, planilhas de
acompanhamento de fluxo de caixa, contas a pagar, contas a receber, entre outras, foram
desenvolvidas e utilizadas pelos gestores.
Percebendo esse último avanço citado surgiu a idéia de oferecer um sistema que desse apoio
a decisão dos gestores. A dificuldade encontrada nessa etapa foi em explicar esses novos conceitos
aos gestores no espaço de tempo que eles disponibilizaram. Por esse motivo que o desenvolvimento
das consultas foi feito com o apoio dos gestores que tem conhecimento, mesmo que intermediário,
do sistema RM, da lógica de BD e de DW. Esses gestores também têm pleno conhecimento dos
desejos dos demais gestores, então, pode-se afirmar que não houve prejuízo em desenvolver as
consultas gerenciais com base na ajuda de apenas dois gestores, fato consumado através das
considerações de outros gestores.
Na etapa da construção do modelo dimensional utilizou-se como ferramenta o software
ErWin, por suportar os modelos lógicos, físicos e dimensionais, além de maior flexibilidade na
geração do modelo para diversos tipos de SGBD.
Para a etapa que contemplou a Extração, Limpeza e Carga dos dados no DM optou-se pelo
DTS do MS SQL Server, por ser uma ferramenta amplamente estudada durante a evolução dos
sistemas RM dentro das empresas. Hoje, o DTS é responsável por toda integração que existe entre

77
as bases das empresas, extraindo os dados de uma base, fazendo as transformações e mudanças
necessárias e carregando esses dados na base da outra empresa.
Percebem-se pontos satisfatórios como a apresentação desse novo conceito de análise e de
planilhas nas considerações dos gestores que destacaram o auxílio das mesmas. Também se mostra
satisfatório o interesse e o entendimento adquirido pelos gestores que já mostram interesse em
sugerir novas planilhas.
A seguir são apresentados os objetivos específicos propostos no Capítulo 1 deste TCC e as
tarefas realizadas pra cumpri-los:
Objetivo Tarefa Estudar os conceitos de Data Warehouse, Data Mart, Sistemas de Apoio a Decisão, OLAP, Área de Negócios das empresas
No Capitulo de Fundamentação Teórica estudou-se e apresentou-se os conceitos citados e o cenário das empresas
Identificar as necessidades de informações executivas para tomada de decisão
Na segunda seção do Capítulo Projeto, foram mostradas as necessidades levantadas para serem atendidas pelas planilhas
Construir o Modelo Dimensional Dentro da seção citada anteriormente apresentou-se o Modelo dimensional construído
Identificar as fontes de dados (tabelas do RM) Ao final da seção 3.2.1 cita-se as tabelas do sistema RM que foram utilizadas como fonte de dados para o DM.
Implementar o modelo físico do DM A seção 4.2 mostrou a criação das tabelas fato e dimensão do DM
Preparar a área de transição de dados (Extração, Tratamento, Carga)
A seção 2.6.2 mostrou o conhecimento adquirido para implementar os processos de ETL
Executar os processos de carga e testes do modelo dimensional
A seção 4.3 apresentou os processos de carga realizados ao DM.
Construir as consultas ao DM, aplicando técnicas OLAP
As seções 4.4 e 4.5 mostraram a criação dos cubos OLAP e das planilhas em Excel com para serem manuseadas pelos gestores
Validar as consultas pelos gestores A seção 4.6 apresentou as considerações feitas pelos gestores e a satisfação dos mesmos
Este trabalho além ter desenvolvido um sistema de grande impacto e importância dentro das
empresas em questão, fornece o conhecimento teórico para implementação de SADs no cenário
cientifico e tem um caráter didático levando em consideração os detalhes de implementação
apresentados. Praticamente todas as telas das ferramentas utilizadas foram apresentadas com
explicações passo a passo de como deve ser feita a configuração das mesmas.

78
O projetista concretizou sua preferência pelas sub-áreas de Banco de Dados e Sistemas de
Informação dentro da área de Ciência da Computação, e busca futuramente, após a conclusão,
especializar-se e aprofundar-se nesses assuntos.
Ainda, pretende-se realizar o desenvolvimento do projeto utilizando a versão mais recente
do SGBD MS SQL Server, versão 2005. O desenvolvimento chegou a ser iniciado utilizando essa
ferramenta, entretanto, por se tratar de uma versão recém lançada, a falta de documentação
detalhada e suporte capacitado fez com que se desistisse da idéia, pois ate se ter acesso ao suporte
que se buscava, quando achava, muito tempo era desperdiçado, podendo comprometer a conclusão
do Projeto caso de insistisse.
Como trabalhos futuros, espera-se que os gestores, agora com um maior entendimento,
sugiram novas consultas que possam ajudá-los. Pretende-se estudar e aplicar MS Web Components,
que integrado com o IIS, permite a visualização dos Cubos no browser Internet Explorer.
Um Datamining também é considerado como um trabalho futuro que possa a vir ser
desenvolvido, tendo como foco o extenso cadastro de produtos das empresas.

REFERÊNCIAS BIBLIOGRÁFICAS
BAPTISTA, Evaristo. Um modelo para análise gerencial na área de vendas. Florianópolis 2001. 108f. Dissertação (Mestrado Engenharia de Produção) – Departamento de Engenharia de Produção e Sistemas, Universidade Federal de Santa Catarina.
CENTENARO, Antonio César. Desenvolvimento e implantação de um Data Warehouse Corporativo com Data Marts Distribuídos em uma Cooperativa agroindustrial. Florianópolis, 2003. 105f. Tese (Mestrado em Engenharia de Produção) - Universidade Federal de Santa Catarina. Disponível em: <http://teses.eps.ufsc.br/tese.asp>. Acesso em: 22 de Agosto de 2005.
COME, Gilberto de. Contribuição ao Estudo da Implementação de Data Warehousing: Um Caso no Setor de Telecomunicações. São Paulo, 2001. 144f. Dissertação (Mestrado em Administração de Empresas) – FEA/USP. Disponível em: < http://www.saber.usp.br/>. Acesso em: 20 de Agosto de 2005.
COREY, M, Abbey, M.. Oracle Data Warehousing. Osborne McGraw-Hill: Oracle Press, CA, 1997.
DWINF. Data Mart. 2002. Disponível em:<http://www.datawarehouse.inf.br/artigos/datamart.asp> Acessado em: 10 de agosto de 2005.
GRAY, Paul, WATSON, Hugh J. Decision Support in the Data Warehouse. New Jersey: Prentice Hall PTR, 1998.
HAISTEN, M. Real time data warehouse: the next stage in data warehouse evolution, part 1. DM Review, 1999.
HARRISON, Thomas H.. Intranet Data Warehouse. São Paulo: Berkeley Brasil, 1998.
HOFFMAN, Leandro Toss. Sistema de apoio à decisão em escalada alpina. Graduação de Análise de Sistemas – Universidade do vale do Rio dos Sinos – UNISINOS. Disponível em: < http://www.inf.unisinos.br/~hoffmann/pesquisas;publicacoes/2001c01.pdf >
Inmon, W.H., Imhoff, C., and Battas, G. Building the Operational Data Store 2nd Edition, New York: John Wiley, 1999.
INMON, William H. Como construir o Data Warehouse. Rio de Janeiro: Campus,1997. 388p
INFO Exame. Setembro de 2005. Editora Abril.
KEEN, Peter G. W., MORTON, Michael S. Scott. Decision Support Systems: on organizational perspective. Addison-Wesley Publishing Company, 1978.
KIMBALL, R. e ROSS M. The Data Warehouse Toolkit. Guia completo para modelagem dimensional. Rio de Janeiro: Campus, 2002.
KIMBALL, Ralph. Data Warehouse Toolkit. Tradução Mônica Rosemberg. Revisão Técnica Ronal Stevis Cassiolato. São Paulo: Makron Books, 1998. 388p

80
KLAUER, Vidette, BROBST, Patricia Stephen. Building a data warehouse for decision support. New Jersey: Prentice Hall PTR, 1998.
LAUDON, Kenneth C., LAUDON, Jane P. Sistemas de Informação. 4.ed. Rio de Janeiro: LTC S.A., 1999. 389p.
LAUDON, KENNETH C, LAUDON, Jane P. Sistemas de Informações gerenciais: administrando a empresa digital. Tradução Arlete Símile Marques; São Paulo. Prentice Hall, 2004
MACHADO, Felipe Nery Rodrigues. Projeto de Data Warehouse: uma visão multidimensional. São Paulo: Érica, 2000. 248p
Microsoft. Microsoft SQL Server . 2005. Disponível em: <http://www.microsoft.com/brasil/sql/2005/productinfo/top30features.mspx>. Acessado em: 25 de Setembro de 2005.
OLIVEIRA, Djalma de P. Rebouças. Sistemas de Informações Gerenciais. 4.ed. São Paulo: Atlas, 1997. 274p.
PEREIRA, Walter Adel Leite. Uma metodologia de inserção de tecnologia de Data Warehouse em organizações. 2000. Tese (Mestrado em Ciência da Computação) - Faculdade de Informática, Pontifícia Universidade Católica do Rio Grande Do Sul. Disponível em: <http://www.inf.pucrs.br/~wpereira/dw_ti_2.pdf> Acesso em: 22 de Agosto de 2005.
POE, Vidette, KLAUER, Patricia, BROBST, Stephen. Building a data warehouse for decision support. New Jersey: Prentice Hall PTR, 1998.
PETKOVIC, Dusan. SQL Server 7: A Beginner's Guide. New Jersey: Osborne Publishing, 1999.479p.
PRATES, Maurício. Conceituando Sistemas de Informação do ponto de vista do gerenciamento. Revista do Instituto de Informática, Campinas, mar/set, 1994.
SELL, D. Uma Arquitetura para distribuição de componentes tecnológicos de sistemas de informações baseados em Data Warehouse. Florianópolis, 2001. 90 f. Dissertação (Mestrado em Engenharia de Produção) – Departamento de Engenharia de Produção e Sistemas, Universidade Federal de Santa Catarina. Disponível em: <http://teses.eps.ufsc.br/tese.asp>. Acesso em: 22 de Agosto de 2005.
TISSOT, Hegler Correa. Proposta para documentação de requisitos em projetos de Data Warehouse. Florianópolis, 2004. 159f. Tese (Mestrado em Engenharia de Produção) - Universidade Federal de Santa Catarina – Engenharia de Produção da Universidade Federal de Santa Catarina. Disponível em: <http://teses.eps.ufsc.br/tese.asp>. Acesso em: 22 de Agosto de 2005.
TOMASI, Cláudio Luis. Sistema de apoio à decisão para terminais portuários. Itajaí, 2003.68f Projeto de Graduação (Bacharelado em Ciência da Computação). Universidade do Vale do Itajaí – Curso de Ciência da Computação.
ZIULKOSKI, L. Cláudio Chaves. Coleta de requisitos e modelagem de dados para Data Warehouse: um Estudo de Caso Utilizando Técnicas de Aquisição de Conhecimento. Porto Alegre,

81
2003. 63f. Projeto de Graduação (Bacharelado em Ciência da Computação). Universidade Federal do Rio Grande do Sul. Instituto de Informática. Disponível em: <http://volpi.ea.ufrgs.br/teses_e_dissertacoes/default.asp>. Acesso em: 28 de Agosto de 2005.

GLOSSÁRIO
Ovar Termo Logístico que significa o ato de colocar as mercadorias dentro do container. Desovar significa o ato de retirar as mercadorias do container.
Proforma Fatura Comercial que descreve os detalhes das compras.

83
APÊNDICE A – DETALHES APROFUNDADOS DA CRIAÇÃO DO DM
1. SCRIPT DE CRIAÇÃO DAS TABELAS DO DM
Abaixo encontra-se o script de criação das tabelas fato e dimensões do dm:
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_VEND__CHAVE__1273C1CD]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_VENDAS] DROP CONSTRAINT
FK__FATO_VEND__CHAVE__1273C1CD
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_DES___CHAVE__0BC6C43E]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_DES_EMBARQUES] DROP CONSTRAINT
FK__FATO_DES___CHAVE__0BC6C43E
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_COMP__CHAVE__0AD2A005]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_COMPRAS] DROP CONSTRAINT
FK__FATO_COMP__CHAVE__0AD2A005
GO

84
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_VEND__CHAVE__15502E78]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_VENDAS] DROP CONSTRAINT
FK__FATO_VEND__CHAVE__15502E78
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_COMP__CHAVE__09DE7BCC]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_COMPRAS] DROP CONSTRAINT
FK__FATO_COMP__CHAVE__09DE7BCC
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_DES___CHAVE__0CBAE877]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_DES_EMBARQUES] DROP CONSTRAINT
FK__FATO_DES___CHAVE__0CBAE877
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_ESTO__CHAVE__0EA330E9]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)

85
ALTER TABLE [dbo].[FATO_ESTOQUE] DROP CONSTRAINT
FK__FATO_ESTO__CHAVE__0EA330E9
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_PREC__CHAVE__108B795B]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_PRECO_PRODUTOS] DROP CONSTRAINT
FK__FATO_PREC__CHAVE__108B795B
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_VEND__CHAVE__1367E606]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_VENDAS] DROP CONSTRAINT
FK__FATO_VEND__CHAVE__1367E606
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_COMP__CHAVE__08EA5793]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_COMPRAS] DROP CONSTRAINT
FK__FATO_COMP__CHAVE__08EA5793
GO

86
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_DES___CHAVE__0DAF0CB0]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_DES_EMBARQUES] DROP CONSTRAINT
FK__FATO_DES___CHAVE__0DAF0CB0
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_ESTO__CHAVE__0F975522]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_ESTOQUE] DROP CONSTRAINT
FK__FATO_ESTO__CHAVE__0F975522
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_PREC__CHAVE__117F9D94]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)
ALTER TABLE [dbo].[FATO_PRECO_PRODUTOS] DROP CONSTRAINT
FK__FATO_PREC__CHAVE__117F9D94
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FK__FATO_VEND__CHAVE__145C0A3F]') and OBJECTPROPERTY(id,
N'IsForeignKey') = 1)

87
ALTER TABLE [dbo].[FATO_VENDAS] DROP CONSTRAINT
FK__FATO_VEND__CHAVE__145C0A3F
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[DM_CLIENTES]') and
OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[DM_CLIENTES]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[DM_CONTAINER]')
and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[DM_CONTAINER]
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[DM_FUNCIONARIOS]') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[DM_FUNCIONARIOS]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[DM_PRODUTOS]')
and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[DM_PRODUTOS]
GO

88
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[DM_TEMPO]') and
OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[DM_TEMPO]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FATO_COMPRAS]')
and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[FATO_COMPRAS]
GO
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FATO_DES_EMBARQUES]') and OBJECTPROPERTY(id, N'IsUserTable') =
1)
drop table [dbo].[FATO_DES_EMBARQUES]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FATO_ESTOQUE]')
and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[FATO_ESTOQUE]
GO

89
if exists (select * from dbo.sysobjects where id =
object_id(N'[dbo].[FATO_PRECO_PRODUTOS]') and OBJECTPROPERTY(id, N'IsUserTable') =
1)
drop table [dbo].[FATO_PRECO_PRODUTOS]
GO
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[FATO_VENDAS]')
and OBJECTPROPERTY(id, N'IsUserTable') = 1)
drop table [dbo].[FATO_VENDAS]
GO
CREATE TABLE [dbo].[DM_CLIENTES] (
[NOME_CLIENTE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[CHAVE_CLIENTE] [int] NOT NULL ,
[CIDADE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[TELEFONE1] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[ENDERECO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[BAIRRO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[TELEFONE2] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[COD_CLIENTE] [int] NULL
) ON [PRIMARY]
GO

90
CREATE TABLE [dbo].[DM_CONTAINER] (
[CHAVE_CONTAINER] [char] (18) COLLATE Latin1_General_CI_AS NOT
NULL ,
[ARMADOR] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[TAMANHO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[NUMERO_SERIE] [char] (18) COLLATE Latin1_General_CI_AS NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DM_FUNCIONARIOS] (
[NOME_FUNCIONARIO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[CHAVE_FUNCIONARIO] [int] NOT NULL ,
[TIPO_FUNCIONARIO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[COD_FUNCIONARIO] [int] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DM_PRODUTOS] (
[CHAVE_PRODUTO] [int] NOT NULL ,
[DESCRICAO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,

91
[NOME_PRODUTO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[GRUPO] [money] NULL ,
[SUBGRUPO1] [money] NULL ,
[SUBGRUPO2] [money] NULL ,
[UNIDADE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[CODBARRAS] [char] (10) COLLATE Latin1_General_CI_AS NULL ,
[CODPRODUTO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[CLASSIFICAÇÃO_FISCAL] [char] (18) COLLATE Latin1_General_CI_AS
NULL ,
[FORNECEDOR] [char] (18) COLLATE Latin1_General_CI_AS NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[DM_TEMPO] (
[CHAVE_TEMPO] [datetime] NOT NULL ,
[DATA] [datetime] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[FATO_COMPRAS] (
[CHAVE_TEMPO] [datetime] NOT NULL ,

92
[CHAVE_FUNCIONARIO] [int] NOT NULL ,
[CHAVE_PRODUTO] [int] NOT NULL ,
[VALOR_TOTAL] [numeric](18, 0) NULL ,
[TIPO_FRETE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[QTD_COMPRADA] [int] NULL ,
[VALOR_DESCONTO] [numeric](18, 0) NULL ,
[PRECO_UNITARIO] [numeric](18, 0) NULL ,
[COND_PAGAMENTO] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[VALOR_FRETE] [numeric](18, 0) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[FATO_DES_EMBARQUES] (
[CHAVE_PRODUTO] [int] NOT NULL ,
[CHAVE_TEMPO] [datetime] NOT NULL ,
[CHAVE_CONTAINER] [char] (18) COLLATE Latin1_General_CI_AS NOT
NULL ,
[DATA_EMBARQUE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[DATA_DESEMBARQUE] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[PESO_TOTAL_BRUTO_EMB] [char] (18) COLLATE Latin1_General_CI_AS
NULL ,

93
[PESO_TOTAL_LIQ_EMB] [char] (18) COLLATE Latin1_General_CI_AS NULL
,
[DATA_PROFORMA] [char] (18) COLLATE Latin1_General_CI_AS NULL ,
[DATA_MERCADORIA_PROLOG] [char] (18) COLLATE
Latin1_General_CI_AS NULL ,
[DATA_CONTAINER_OVADO] [char] (18) COLLATE Latin1_General_CI_AS
NULL ,
[DATA_ESTOQUE_LUANDA] [char] (18) COLLATE Latin1_General_CI_AS
NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[FATO_ESTOQUE] (
[CHAVE_PRODUTO] [int] NOT NULL ,
[QTD_ESTOQUE] [int] NULL ,
[QTD_ENTRADAS_PERIODO] [int] NULL ,
[QTD_SAIDA_PERIODO] [int] NULL ,
[ESTOQUE_MIN_PERIODO] [int] NULL ,
[CHAVE_TEMPO] [datetime] NOT NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[FATO_PRECO_PRODUTOS] (

94
[PRECO_CUSTO_BRASIL] [money] NULL ,
[PRECO_CIF_LUANDA] [money] NULL ,
[CHAVE_TEMPO] [datetime] NOT NULL ,
[CHAVE_PRODUTO] [int] NOT NULL ,
[PRECO_VENDA_HC] [money] NULL ,
[PERCENTUAL_LUCRO] [numeric](18, 0) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[FATO_VENDAS] (
[CHAVE_CLIENTE] [int] NOT NULL ,
[CHAVE_TEMPO] [datetime] NOT NULL ,
[CHAVE_PRODUTO] [int] NOT NULL ,
[CHAVE_FUNCIONARIO] [int] NOT NULL ,
[QTD_VENDIDA] [int] NULL ,
[PRECO_UNITARIO] [numeric](18, 0) NULL ,
[PRECO_TOTAL] [numeric](18, 0) NULL ,
[VLR_DESCONTO] [numeric](18, 0) NULL ,
[VLR_DESPESAS] [numeric](18, 0) NULL ,
[COND_PAGTO] [char] (18) COLLATE Latin1_General_CI_AS NULL
) ON [PRIMARY]

95
2. SCRIPTS DE EXTRAÇÃO DE DADOS
2.1 CONSULTA DE CARGA DA DIMENSÃO PRODUTOS
select idprd, codigoprd, nomefantasia, descrição, codfab, codundcompra, codtb2fat,
codigoauxiliar, preco2, preco3, preco4 from [corpore_pro2005].[dbo].[TPRD]
Figura 29. Campos fonte e destino para carga da dimensão Produtos
2.2 CONSULTA DE CARGA DA DIMENSÃO TEMPO
select datacriacao from tmov group by datacriacao
2.3 CONSULTA DE CARGA DA DIMENSÃO FUNCIONÁRIOS
select
[CODCOLIGADA],[CODVEN],[NOME],[CARGO],[CODFILIAL],[CODLOC],[COMISSAO1],[
COMISSAO2],[COMISSAO3],[CODPESSOA],[VENDECOMPRA],[CODUSUARIO],[SENHA],
[INATIVO],[PFVENDEDOR],[PFCAIXA],[PFSUPERVISOR],[PFGERENTE],[IDFUNCIONARI
O],[COMISSAO4],[DESCMAXIMO] from [corpore_pro2005].[dbo].[TVEN]

96
Figura 30. Campos das fontes de dados e destino.
2.4 CONSULTA DE CARGA DA DIMENSÃO CLIENTES
Select codcfo, nomefantasia, cidade, rua, bairro, telefone, fax, idcfo from
[corpore_pro2005].[dbo].[FCFO]
Figura 31. Campos das fontes de dados e destino.

97
2.5 CONSULTA DE CARGA DA DIMENSÃO CONTAINER
select tmovcompl.idmov,tipocontainter,container,codtb3flx from tmovcompl
where tipocontainter is not null
2.6 CONSULTA DE CARGA DO FATO PREÇO PRODUTOS
select distinct titmmov.idprd, titmmov.precounitario / 2.20 as 'precobrasil',
precocasacon.precounitario, tprd.preco3, titmmov.dataemissao
from titmmov,tprd,tmov,precocasacon
where codtmv = '1.1.30' and tprd.idprd = titmmov.idprd and
tmov.idmov = titmmov.idmov and precocasacon.idprd = titmmov.idprd
order by titmmov.idprd
2.7 CONSULTA DE CARGA DO FATO COMPRAS
select dmdimensaotempo.chave_tempo as 'Chave Tempo',
TITMMOV.IDPRD AS 'Chave Produto',
TITMMOV.precounitario AS 'Preco Unitario',
TITMMOV.quantidade AS 'Quantidade',
dmcompras.VALORFRETE as 'Frete',
dmcompras.CODCPG as 'Cond Pagto',
dmcompras.CODVEN2,
(TITMMOV.precounitario * TITMMOV.quantidade) as 'Preco Total',
dmcompras.valorliquido,dmcompras.cifoufob as 'Tipo Frete'
from dmdimensaotempo,dmfuncionarios,dmcompras,TITMMOV

98
WHERE (datepart(dd,dmcompras.DATACRIACAO) = dmdimensaotempo.dia) AND
(datepart(mm,dmcompras.DATACRIACAO) = dmdimensaotempo.mes) AND
(datepart(yy,dmcompras.DATACRIACAO) = dmdimensaotempo.ano) AND
dmcompras.codven2 = dmfuncionarios.chave_funcionario AND
DMCOMPRAS.IDMOV = TITMMOV.IDMOV
2.8 CONSULTA DE CARGA DO FATO VENDAS
select dmdimensaotempo.chave_tempo as 'Chave Tempo',
TITMMOV.IDPRD AS 'Chave Produto',
dmvendas.codcfo as ‘Chave Cliente’,
TITMMOV.precounitario AS 'Preco Unitario',
TITMMOV.quantidade AS 'Quantidade',
dmvendas.CODCPG as 'Cond Pagto',
dmvendas.CODVEN2 as ‘Chave funcionario’,
dmvendas.desconto as ‘Desconto’,
dmvendas.despesas as ‘Despesas’,
(TITMMOV.precounitario * TITMMOV.quantidade) as 'Preco Total',
from dmdimensaotempo,dmfuncionarios,dmvenda,TITMMOV,tmov
WHERE (datepart(dd,dmvenda.DATACRIACAO) = dmdimensaotempo.dia) AND
(datepart(mm,dmvendas.DATACRIACAO) = dmdimensaotempo.mes) AND
(datepart(yy,dmvendas.DATACRIACAO) = dmdimensaotempo.ano) AND
dmvendas.codven2 = dmfuncionarios.chave_funcionario AND

99
dmvendas.IDMOV = TITMMOV.IDMOV
2.9 CONSULTA DE CARGA DO FATO ESTOQUE
select dmdimensaotempo.chave_tempo as 'Chave Tempo',
TPRD.IDPRD AS 'Chave Produto',
TPRD.estoqueminimo1 as ‘Estoque mínimo’,
dmcompras.quantidade as ‘Entrada’,
dmvendas.quantidade as ‘Saida’
from dmdimensaotempo,tprd,dmvendas,dmcompras
where tprd.idprd = dmcompras.idprd and tprd.idprd = dmvendas.idprd
2.10 CONSULTA DE CARGA DO FATO DES/EMBARQUES
select dmdimensaotempo.chave_tempo as 'Chave Tempo',
TPRD.IDPRD AS 'Chave Produto',
dmcontainer.chave_container,
tmov.codtb2flx as ‘Data Embarque’,
tmovcasa.codtb2flx as ‘Data Desembarque’,
dmproforma.dataemissao as ‘Data Proforma’,
dmlog.dataemissao as ‘Data Prolog’,
tmovcasalog.dataemissao as ‘Data estoque’
from tmov, dmcontainer,tmovcasalog,tmovcasa,dmlog,dmcontainer,tprd,dmdimensaotempo
where tmov.idmov = tmovcasalog.idmov

100
3. CRIAÇÃO DA DIMENSÃO TEMPO NO CUBO OLAP
Apesar de ter sido amplamente explicada as etapas para criar dimensões do cubo OLAP, é
importante descrever algumas particularidades a respeito da dimensão tempo. O Analysis Manager
tem uma estrutura especial para facilitar o trabalho com a dimensão tempo.
Deve se seguir os passos normais já explicados para criação de uma nova dimensão dentro
do Cube Editor. Seleciona-se a tabela da dimensão tempo e avança para a próxima tela. O assistente
detecta os campos do tipo datetime e pergunta se essa é uma dimensão padrão ou uma dimensão de
tempo, como mostra a figura 32.
Figura 32. Configuração da dimensão tempo

101
Na tela seguinte é possível escolher a estrutura dos dados da dimensão tempo, como mostra
a figura 33, e concluir a inclusão da dimensão. Quando o cubo é exportado para o MS Excel o
trabalho de análise fica bem facilitado.
Figura 33. Estrutura da dimensão tempo











![MD Sistemas Operacionais (Diag.1) - ufsm.br fileEQUIPE DE DESIGN PROJETO GRÁFICO C972s Cunha, Guilherme Bernardino da Sistemas operacionais [recurso eletrônico] / Guilherme Bernardino](https://static.fdocumentos.tips/doc/165x107/5cd02fd188c9932e738d3bc3/md-sistemas-operacionais-diag1-ufsmbr-de-design-projeto-grafico-c972s-cunha.jpg)






