Pré-processamento de dados -...
53
Pr´ e-processamento de dados Clodoaldo A. M. Lima, Sarajane M. Peres 13 de agosto de 2015 Programa de P´os-Gradua¸c˜ ao em Sistemas de Informa¸c˜ ao Mestrado acadˆ emico - EACH - USP http://ppgsi.each.usp.br Clodoaldo A. M. Lima, Sarajane M. Peres Pr´ e-processamento de dados 13 de agosto de 2015 1 / 53
Transcript of Pré-processamento de dados -...

Pre-processamento de dados
Clodoaldo A. M. Lima, Sarajane M. Peres
13 de agosto de 2015
Programa de Pos-Graduacao em Sistemas deInformacaoMestrado academico - EACH - USPhttp://ppgsi.each.usp.br
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 1 / 53

Pre-processamento de dados textuais
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 2 / 53

Pre-processamento de dados textuais
Dados textuais
Para realizacao da analise automatica de textos, seja com fins de resolucao de tarefas de mineracao sobre
dados textuais, processamento de linguagem natural ou recuperacao de informacao, e necessario preparar
a colecao de documentos textuais (o corpus) a fim de adequa-los ao processamento automatico. Alguns dos
procedimentos apresentados ao longo dessa aula sao comumente aplicados a todas as areas citadas, outros
sao mais adequados para uso em uma ou outra area citada.
Um conjunto de dados organizado a partir de um corpus
Um conjunto de n documentos X = {doc1, doc2, ..., docn}. Cada um dos documentos, por sua vez, e
definido como um conjunto de m termos (radicais, palavras ou conjunto de palavras), na forma
doci = {wt1,wt2, ...,wtm}, sendo que wtj pode assumir valores boolenos ou reais.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 3 / 53
Pre-processamento de dados textuais
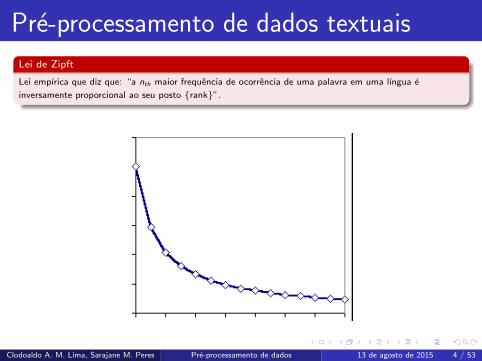
Lei de Zipft
Lei empırica que diz que: “a nth maior frequencia de ocorrencia de uma palavra em uma lıngua e
inversamente proporcional ao seu posto {rank}”.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 4 / 53
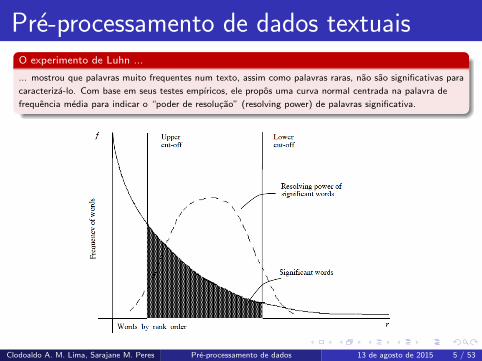
Pre-processamento de dados textuaisO experimento de Luhn ...
... mostrou que palavras muito frequentes num texto, assim como palavras raras, nao sao significativas para
caracteriza-lo. Com base em seus testes empıricos, ele propos uma curva normal centrada na palavra de
frequencia media para indicar o “poder de resolucao” (resolving power) de palavras significativa.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 5 / 53

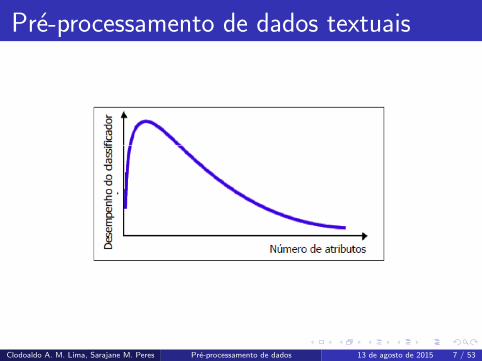
Pre-processamento de dados textuaisAlta dimensionalidade e alto grau de espasidade
Os conjunos de dados X gerados a partir de um corpus possuem alta dimensionalide e alto grau de
esparsidade (a proporcao de zeros na matriz e muito alta).
Maldicao da dimensionalidade
Diz respeito ao aumento exponencial do volume associado quando se adiciona dimensoes extras a um
espaco matematico. Assim, quanto mais caracterısticas descritivas for necessario processar, maior a
quantidade de exemplares necessarios para obter um modelo que explique os dados (em algum sentido).
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 6 / 53
Pre-processamento de dados textuais
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 7 / 53

Pre-processamento de dados textuais
Preparacao dos documentos
Ha uma serie de procedimentos que sao uteis para preparar uma colecao de documentos antes que ela seja
representada como um conjunto de dados X .
analise lexica (tokenizing)
eliminacao de stopwords;
reducao dos termos aos seus radicais;
Vector Space Model - VSM
Modelo de representacao dos textos em um espaco de vetores. Cada documento e um vetor de termos
(index term).
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 8 / 53

Pre-processamento de dados textuais
Analise lexica
eliminacao de caracteres de pontuacao e outros caracteres;
determinacao de um separador para separacao das palavras (criacao da lista de termos inicial);
eliminacao de dıgitos e acentos;
alteracao da capitalizacao das palavras.
Problemas
U.S → us ou u s;
campo grande → Campo Grande;
510 D.C → dc;
manga → manga;
http://www.each.usp.br/sarajane → http www each usp br sarajane;
Tomada de decisao dependente do contexto.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 9 / 53

Pre-processamento de dados textuais
Eliminacao de stopwords
Stopwords e uma lista de palavras muito comum em uma lıngua, e que nao tem potencial para contribuir
para a caracterizacao do conteudo presente no texto. Nessa lista geramente estao: artigos definidos e
indefinidos, preposicoes, pronomes, numerais, conjuncoes e adverbios. Alem das palavras pertencentes a
essas classes gramaticais, podem entrar na lista as palavras muito comuns dentro do contexto referente aos
documentos do corpus.
Exemplos
“Leia mais” num portal de notıcias
“escola” ou “professor” → tem textos de monografias de uma especializacao em “Etica, valores e
cidadania na escola”;
A eliminacao de stopwords pode representar uma reducao de 30% a 50% o tamanho dos textos.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 10 / 53

Pre-processamento de dados textuais
Reducao dos termos aos seus radicais
Um termo no documento pode sofrer variacoes como plural, gerundio, verbos flexionados, aumentativo, diminutivo e etc.
Com a reducao do termo ao seu radical, processo tambem conhecido por stemming, os prefixos e sufixos sao eliminados,
possibilitando a uniformizacao de termos.
Exemplos - Snowball para portugues
quilos → quil / boia → boi / boiando → boi
Stemmers
Snowball → http://snowball.tartarus.org/algorithms/portuguese/stemmer.html
PTStemmer → http://code.google.com/p/ptstemmer/
Problemas - exemplos no ingles
factual → fact (sufixo UAL) © equal → eq (sufixo UAL) §
absorb → absor (sufixo B) © absorpt → absor (sufixo PT) ©
Esse processo tambem tem o efeito de reduzir o tamanho de um documento. Ha experimentos que apontam 5% de reducao.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 11 / 53

Pre-processamento de dados textuais
Space Vector Model - construcao do conjunto C
representacao binaria
representacao por frequencia
representacao tf-idf
representacao tf-idf normalizado
Representacao binaria
Representacao simplificada na qual valores binarios (ou pesos binarios) indicam a presenca ou ausencia do
termo em um documento. Os termos presentes possuem todos a mesma importancia na representacao de
um documento.
doc1 = {0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1}
Os dois mais importantes fatores ...
... que direcionam a efetividade de uma representacao: exaustividade (completude) da indexacao e
especificidade da representacao.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 12 / 53
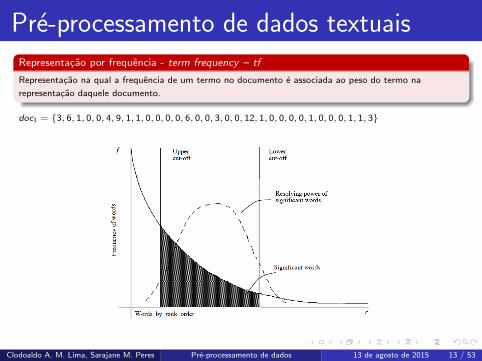
Pre-processamento de dados textuaisRepresentacao por frequencia - term frequency – tf
Representacao na qual a frequencia de um termo no documento e associada ao peso do termo na
representacao daquele documento.
doc1 = {3, 6, 1, 0, 0, 4, 9, 1, 1, 0, 0, 0, 0, 6, 0, 0, 3, 0, 0, 12, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 3}
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 13 / 53
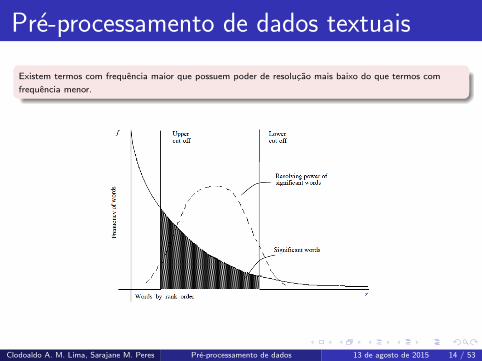
Pre-processamento de dados textuais
Existem termos com frequencia maior que possuem poder de resolucao mais baixo do que termos com
frequencia menor.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 14 / 53

Pre-processamento de dados textuais
Exaustividade (completude) da indexacao - exhaustivity of indexing
Numero de termos associados a um dado documento.
Numero de topicos diferentes que foram indexados.
Especificidade da representacao - specificity of the index language
Numero de documentos ao qual um dado termo esta associado dentro de uma colecao de
documentos.
Habilidade de representacao em descrever um topico precisamente.
Nosso problema e encontrar um trade-off entre os objetivos acima. E necessario atribuir pesos aos ındices
de forma maximizar a chance de encontrar esse trade-off.
Precisao X Revocacao - Precision X Recall - na recuperacao de informacao
Precisao: proporcao de documentos recuperados que sao relevantes
Revocacao: proporcao de documentos relevantes recuperados
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 15 / 53

Pre-processamento de dados textuais
Frequencia inversa nos documentos – inverse document frequency idf
idf (tj ) = logn
ntj(1)
em que n e o numero de documentos no corpus e ntj e o numero de documentos nos quais o termo t
aparece.
Representacao por td-idf
Representacao na qual o peso associado a uma palavra e calculando considerando tanto a frequencia com a
qual ele aparece no texto, quanto ao numero de documentos no qual ele aparece.
tf idf (tj , doci ) = tf (tj , doci ) ∗ idf (tj ) (2)
Nessa representacao
quanto maior a frequencia do termo no documento, maior e a representatividade do termo para
aquele documento;
quanto maior o numero de documentos no qual um termo aparece, menos discriminante o termo e;
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 16 / 53

Pre-processamento de dados textuais
Representacao por td-idf normalizado
Representacao na qual o peso associado a uma palavra e calculando considerando tanto a frequencia com a
qual ele aparece no texto, quanto o numero de documentos no qual ele aparece.
tf idfnormalizado (tj , doci ) =tf idf (tj , doci )√∑s=1
ntermos(tf idf (ts , doci ))2
(3)
Essa representacao e util pois coloca os pesos dentro do intervalo [0, 1] e tambem suaviza o efeito de
diferencas entre os tamanhos dos documentos.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 17 / 53

Interpretacoes geometricas esimilaridades
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 18 / 53

Interpretacoes geometricas e similaridades
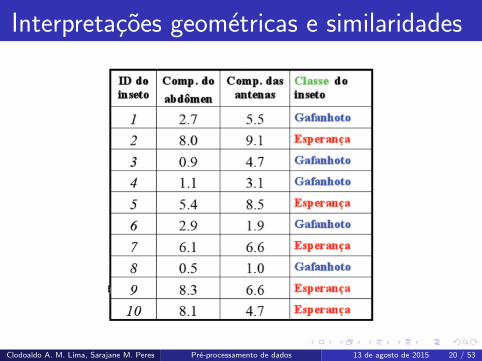
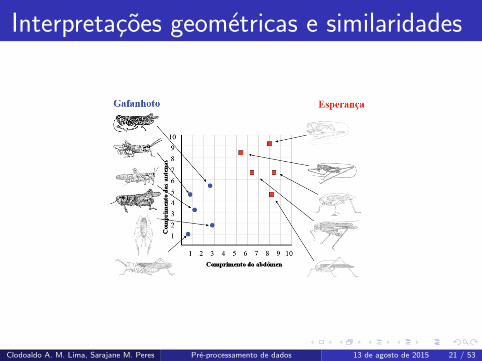
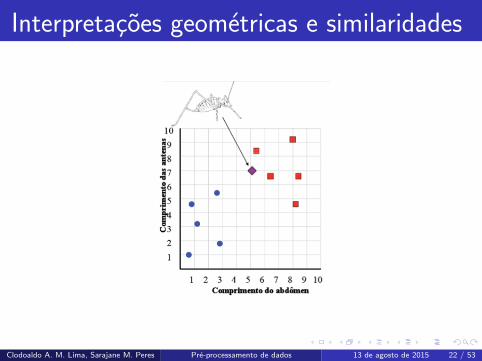
Interpretacoes geometricas
Nossos exemplares, de um conjunto de dados, podem ser interpretados
geometricamente (ou podem ser vistos como vetores em um espaco vetorial).
Considere o exemplo dos “gafanhotos” e “esperancas”
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 19 / 53
Interpretacoes geometricas e similaridades
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 20 / 53
Interpretacoes geometricas e similaridades
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 21 / 53
Interpretacoes geometricas e similaridades
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 22 / 53

Interpretacoes geometricas e similaridades
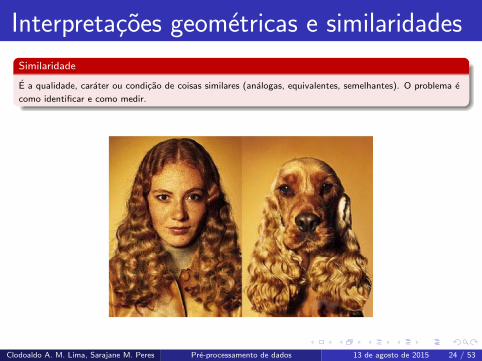
Similaridade
E a qualidade, carater ou condicao de coisas similares (analogas, equivalentes,
semelhantes). O problema e como identificar e como medir.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 23 / 53
Interpretacoes geometricas e similaridades
Similaridade
E a qualidade, carater ou condicao de coisas similares (analogas, equivalentes, semelhantes). O problema e
como identificar e como medir.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 24 / 53

Interpretacoes geometricas e similaridades
Distancias sao normalmente usadas como medida de similaridade entre objetos. Ha uma variedade enorme
de medidas de distancias, e algumas delas sao mais comuns nos algoritmos de mineracao de dados:
Manhattan, Hamming, Euclidiana. Alternativas ao uso de medidas de distancias sao medida como entropia,
correlacao e concordancias; a comparacao entre os dados e de outra natureza. Outras alternativas podem
aparecer por aı ....
Propriedade de uma medida de distancia:
d(i, j) ≥ 0;
d(i, i) = 0
d(i, j) = d(i, j)
d(i, j) ≤ d(i, k) + d(k, j)
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 25 / 53

Interpretacoes geometricas e similaridadesDistancia Euclidiana
d(i, j) =√
(xi1 − xj1)2 + (xi2 − xj2)2 + ... + (xip − xjp)2 (4)
Distancia de Hamming
Considerando duas strings de mesmo comprimento, a distancia de Hamming fornece o numero de posicoes
nas quais as strings diferem.
Entropia
Comumente associada ao que se entende por desordem.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 26 / 53

Normalizacao de dados
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 27 / 53

Normalizacao de dados
Normalizacao e um procedimento de pre-processamento de dados cujo objetivo e escalar os valores dos
atributos de forma que todos fiquem ou dentro de um intervalo especıfico, por exemplo [0, 1] ou [-1, 1], ou
distribuıdos em torno de sua media de acordo com seu desvio padrao.
Esse procedimento e especialmente util quando os algoritmos de analise de dados sao baseados em distancia
(similaridades e diferencas sao mensuradas usando metricas de distancia). Tambem e util para acelerar o
processo de “convergencia” de um algoritmo de Machine Learning (como por exemplo, redes neurais
artificiais).
Valores normalizados sao mais faceis de interpretar.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 28 / 53

Normalizacao de dados
(a) Conjunto de dados (b) Atributo X (c) Atributo Y
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 29 / 53
Normalizacao de dados
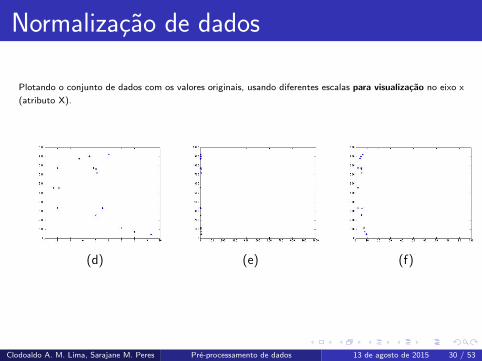
Plotando o conjunto de dados com os valores originais, usando diferentes escalas para visualizacao no eixo x
(atributo X).
(d) (e) (f)
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 30 / 53

Normalizacao de dados
Distancia euclidiana entre exemplares (entre os vetores), considerando apenas o
atributo X, apenas o atributo Y (vetores unidimensionais) e considerando ambos os
atributos (vetores bidimensionais) - ilustrando apenas a parte inicial da matriz de
distancias:
(g) Dist. X (h) Dist. Y (i) Dist. XY
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 31 / 53
Normalizacao de dados
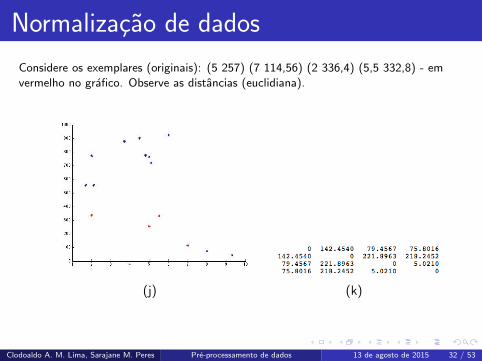
Considere os exemplares (originais): (5 257) (7 114,56) (2 336,4) (5,5 332,8) - em
vermelho no grafico. Observe as distancias (euclidiana).
(j) (k)
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 32 / 53

Normalizacao de dados
Normalizacao Min-max
Trata-se de uma transformacao linear sobre os valores originais de um atributo A. Sendo minA e maxA os
valores mınimos e maximos de um atributo, o procedimento mapeia um valor v de A para v ′ no intervalo
[new minA, new maxA, estabelecidos pelo analista de dados, computando:
v ′ =v − minA
maxA − minA
(new maxA− new minA) + new minA (5)
Essa transformacao preserva o relacionamento entre os valores originais.
Observe que os valores minA e maxA precisam ser defindos com cuidado, ou uma entrada futura pode cair
fora desses intervalos e causar um problema na preservacao dos relacionamentos originais.
Os minA e maxA precisam ser armazenados para que possam ser usados na normalizacao de novos
exemplares.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 33 / 53

Normalizacao de dados
Plotando o conjunto de dados normalizado - Min-max - intervalo [0,1]
(l) Min-max (m) Original (n) Normalizado
Os valores de mınimo e maximo do atributo A foram tomados dentre os valores existentes no atributo.
minx = 1.7
miny = 45.2
maxx = 9.3
maxy = 924.5
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 34 / 53

Normalizacao de dados
Plotando o conjunto de dados normalizado - Min-max - intervalo [0,1]
(o) Min-max (p) Original (q) Normalizado
Os valores de mınimo e maximo do atributo A foram tomados nos limites do domınio dos atributos.
minx = 0
miny = 10
maxx = 10
maxy = 1000
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 35 / 53

Normalizacao de dados
Considerando cada um dos casos de escolha dos valores de mınimo e maximo do atributo A, e tomando
como entrada para a normalizacao, um novo exemplar:
novo exemplar = (10, 999)
novo exemplar x = 10 e novo examplar y = 999
Seguindo a primeira normalizacao (mınimo e maximo dentro dos valores dos exemplaresexistentes:
x norm = 1.09
y norm = 1.08
Seguindo a segunda normalizacao (mınimo e maximo dentro dos limites do domınio
x norm = 1
y norm = 0.999
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 36 / 53

Normalizacao de dados
Distancia euclidiana entre exemplares (entre os vetores), considerando o conjunto de
dados original e o conjunto de dados normalizado (Minmax)
(r) Dist. XY (s) Dist. XY norm
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 37 / 53
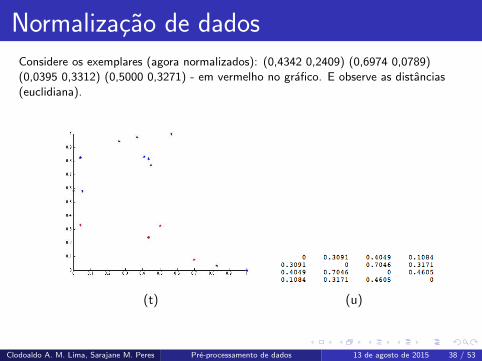
Normalizacao de dadosConsidere os exemplares (agora normalizados): (0,4342 0,2409) (0,6974 0,0789)
(0,0395 0,3312) (0,5000 0,3271) - em vermelho no grafico. E observe as distancias
(euclidiana).
(t) (u)
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 38 / 53

Normalizacao de dadosNormalizacao z-score
Nesse caso, a normalizacao dos valores de um atributo A e realizada com base na media e no desvio padrao
dos valores existentes no atributo. O valor v de A e transformado para v ′ computando:
v ′ =v − A
σA
(6)
onde A e a media dos valores existentes no atributo A e σA e o desvio padrao do mesmo conjunto de vaores.
Esse procedimento de normalizacao e util principalmente quando os valores limites do domınio do atributo
nao sao conhecidos, ou quando existem outliers no conjunto de valores.
Essa normalizacao pode alterar levemente os relacionamentos originais entre os exemplares, inclusive
contribuindo para suavizar efeitos de outliers. A suavizacao da presenca de outliers pode ser melhorada
tambem pela substuicao da media pela mediana e do desvio padrao para o desvio padrao abosulto
(σabsA =∑m
i=1 |xi − µ|, onde xi e o i th valor do atributo A, m e o numero de valores assumido pelo
atributo A, e µ e ou a media ou a mediana dos valores do atributo A).
Os valores A e σA precisam ser armazenados para que possam ser usados na normalizacao de novos
exemplares.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 39 / 53

Normalizacao de dadosPlotando o conjunto de dados normalizado - z-score
(v) z-score (w) Original (x) Normalizado
Os valores de media e desvio padrao do conjunto original de valores assumido por A sao:
x = 4.78
y = 534.1547
σx = 2.25
σy = 315.5809
Os coeficientes de variacao (desvio padrao / media) sao:
cvx = 0.4721
cvy = 0.5908
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 40 / 53
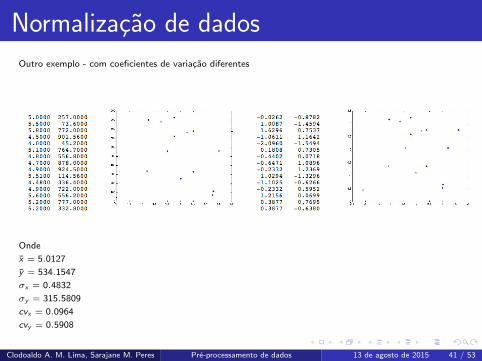
Normalizacao de dados
Outro exemplo - com coeficientes de variacao diferentes
Onde
x = 5.0127
y = 534.1547
σx = 0.4832
σy = 315.5809
cvx = 0.0964
cvy = 0.5908
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 41 / 53

Normalizacao de dados
Normalizacao por escalonamento decimal
Transforma os valores para decimais, da seguinte forma:
v ′ =v
10j(7)
onde j e igual a 1 se o maior valor absoluto no conjunto de valores do atributo A e < 10, e igual a 2 se o
maior valor absoluto no conjunto de valores do atributo A e ≥ 10 e < 100, e assim por diante.
Essa normalizacao pode alterar os relacionamentos originais entre os exemplares.
O valor j precisam ser armazenado para que possa ser usado na normalizacao de novos exemplares.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 42 / 53
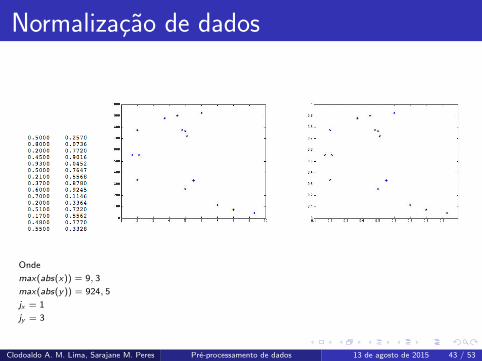
Normalizacao de dados
Onde
max(abs(x)) = 9, 3
max(abs(y)) = 924, 5
jx = 1
jy = 3
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 43 / 53
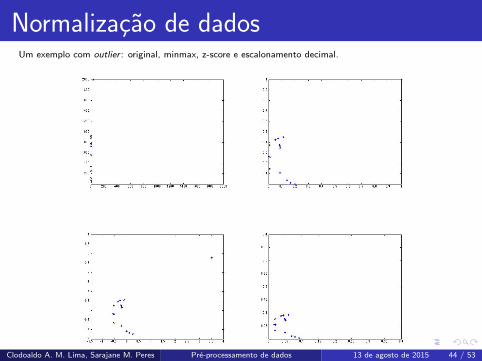
Normalizacao de dadosUm exemplo com outlier : original, minmax, z-score e escalonamento decimal.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 44 / 53

Valores faltantes (missing values),outliers e ruıdos
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 45 / 53

Valores faltantes, outliers e ruıdos
Valores faltantes
Nao raramente, exemplares do conjunto de dados apresentam a atributos sem valores associados. E um
problema para o trabalho em mineracao de dados, pois os algoritmos se baseiam sua tomada de decisao
levando em consideracao todos os valores associados a um exemplar.
Considere uma revisao sistematica
Valores faltantes ocorrem pode diferentes motivos:
um estudo pode ser perdido porque nao foi possıvel encontra-lo em sua versao completa (falta);
um estudo pode ser perdido porque as informacoes presentes nele nao sao relevantes para a revisao
(irrelevancia);
um estudo pode ser perdido porque o responsavel por analisa-lo nao entendeu o conteudo do
arquivo, ou nao apresentou o resultado da analise (perda);
um estudo pode ser perdido porque o conteudo dele nao esta relacionado ao assunto da revisao
(inaplicavel);
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 46 / 53

Valores faltantes (missing values), outlierse ruıdos
Consider o conjunto de dados referente a registros de um hospital:
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 47 / 53

Valores faltantes (missing values), outlierse ruıdos
E interessante analisar porque os valores estao faltando. Ha diferentes cenarios:
missing at random: se o motivo pelo qual eles se perderam nao esta relacionado aos proprios
valores faltantes. Imagine que alguns questionarios sobre satisfacao dos clientes, respondidos por
entrevistados foram extraviados nos Correios. A perda nao esta relacionada com a satisfacao dos
clientes (esperamos que nao §). Esses casos tendem a nao ser importantes, e as analises dos
dados sofrerao por se ter uma amostra menor para estudo.
not missing at random: se o motivo pelo qual eles se perderam esta relacionado aos proprios
valores dos dados. Se um teste de medicamento esta sendo feito com pacientes que possuem
depressao, alguns participantes podem ser mais suscetıveis a nao seguir as regras do experimento, e
por isso faltar em uma entrevista, nao fazer uma medicao, ou tomar a medicacao de forma
inadequada. Esses problemas nao podem ser ignorados pois podem levar a analises tendenciosas.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 48 / 53

Valores faltantes (missing values), outlierse ruıdos
Como lidar com os valores faltantes
analisar somente os dados disponıveis (isso pode implicar em excluir exemplares ou atributos);
imputar os valores faltantes usando estrategias estatısticas (media, mediana, moda, regressao ...)
imputar os valores faltantes e levar em consideracao a incerteza relacionada (fazer multiplas
imputacoes, usar media considerando desvio padrao, considerar a tendencia da distribuicao)
usar estrategias estatısticas considerando assercoes sobre o relacionamento com os exemplares
disponıveis
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 49 / 53
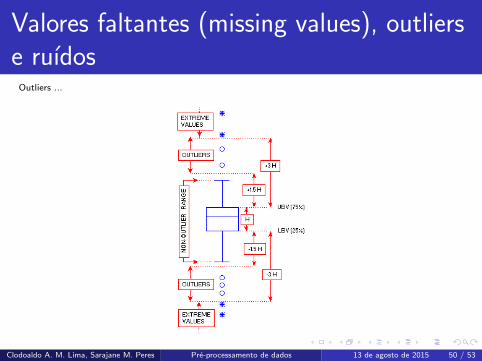
Valores faltantes (missing values), outlierse ruıdos
Outliers ...
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 50 / 53

Valores faltantes (missing values), outlierse ruıdos
Ruıdo
Exemplares imperfeitos que podem ser derivados do processo de aquisicao, transformacao ou rotulacao, por
exemplo.
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 51 / 53

Valores faltantes (missing values), outlierse ruıdos
Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 52 / 53

Clodoaldo A. M. Lima, Sarajane M. Peres Pre-processamento de dados 13 de agosto de 2015 53 / 53