
Modelo de Espaço Vetorial
21
Ordenação e Recuperação de Dados Prof. Alexandre Duarte - http://alexandre.ci.ufpb.br Centro de Informática – Universidade Federal da Paraíba Aula 7: Modelo de Espaço Vetorial 1 1
-
Upload
alexandre-duarte -
Category
Education
-
view
1.125 -
download
2
Transcript of Modelo de Espaço Vetorial

Ordenação e Recuperação de Dados
Prof. Alexandre Duarte - http://alexandre.ci.ufpb.br
Centro de Informática – Universidade Federal da Paraíba
Aula 7: Modelo de Espaço Vetorial
11

2
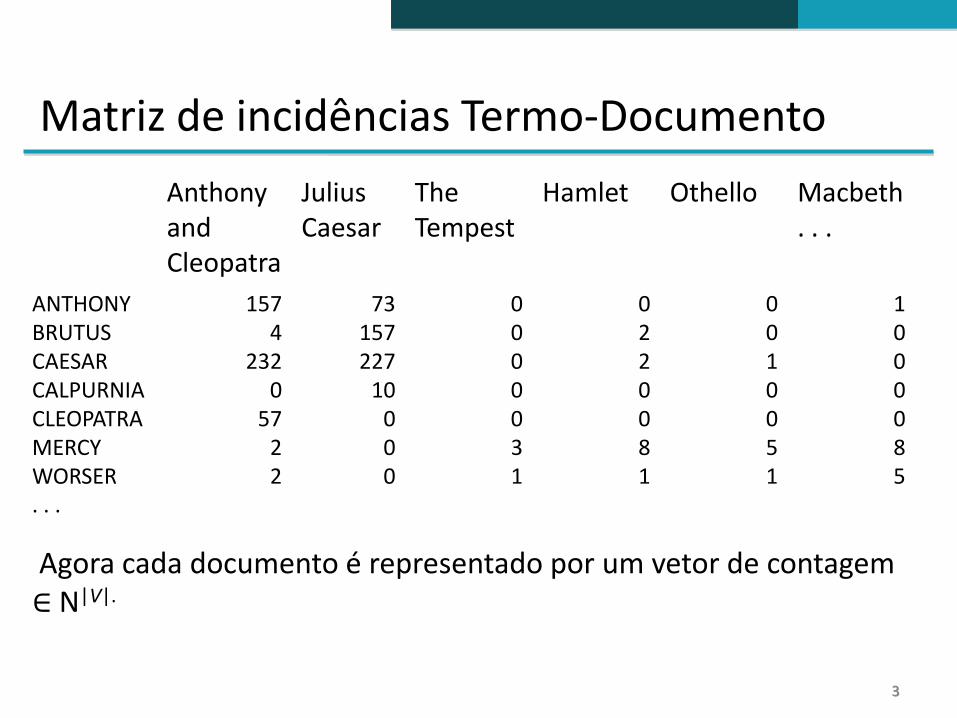
Matriz de incidências Termo-Documento
Cada documento é representado por um vetor binário ∈ {0, 1}|V|.
2
Anthony andCleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth . . .
ANTHONYBRUTUSCAESARCALPURNIACLEOPATRAMERCYWORSER. . .
1110111
1111000
0000011
0110011
0010011
1010010
3
Matriz de incidências Termo-Documento
Agora cada documento é representado por um vetor de contagem ∈ N|V|.
3
Anthony andCleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth . . .
ANTHONYBRUTUSCAESARCALPURNIACLEOPATRAMERCYWORSER. . .
1574
2320
5722
73157227
10000
0000031
0220081
0010051
1000085

4
Peso da frequência de um termo em um documento
4

5
Peso idf
A frequência de termo em documentos dft é definida como o número de documentos em que o termo t ocorre.
Definimos o peso idf de um termo t como segue:
idf é uma medida de quão informativo é um determinado termo.
5

6
Peso tf-idf
O peso tf-idf de um termo é o produto de seus pesos tf e idf.
6
7
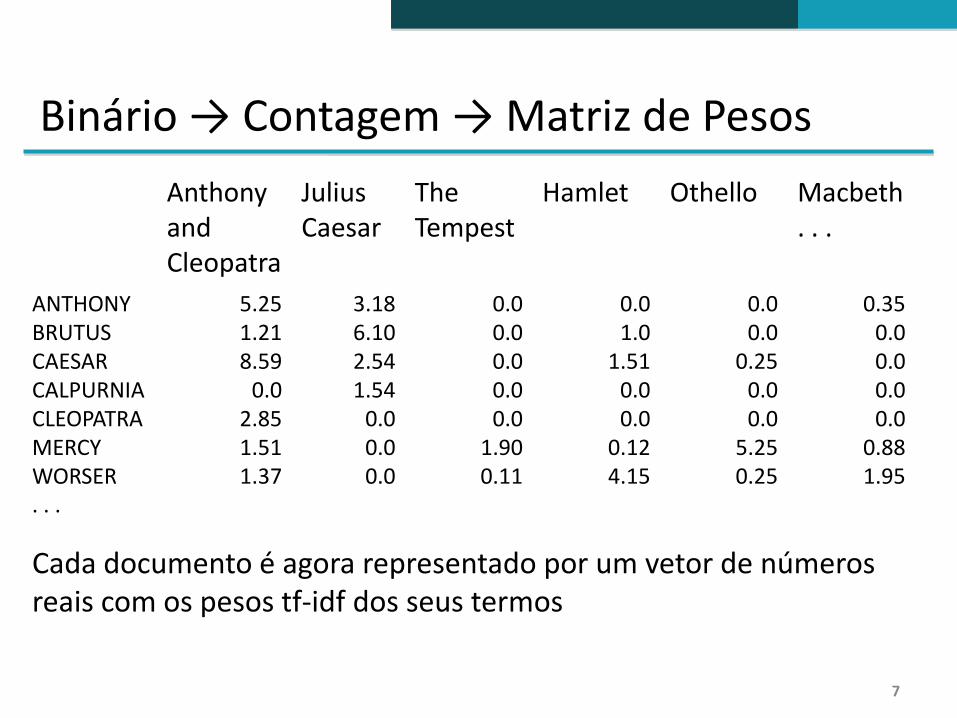
Binário → Contagem → Matriz de Pesos
Cada documento é agora representado por um vetor de númerosreais com os pesos tf-idf dos seus termos
7
Anthony andCleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth . . .
ANTHONYBRUTUSCAESARCALPURNIACLEOPATRAMERCYWORSER. . .
5.251.218.59
0.02.851.511.37
3.186.102.541.54
0.00.00.0
0.00.00.00.00.0
1.900.11
0.01.0
1.510.00.0
0.124.15
0.00.0
0.250.00.0
5.250.25
0.350.00.00.00.0
0.881.95

8
Documentos como vetores
Cada documento é agora representado por um vetor ∈R|V|
de números reais com os pesos tf-idf de cada um de seus termos.
Temos então um espaço vetorial |V|-dimensional.
Os termos são os eixos desse espaço vetorial.
Os documentos são pontos ou vetores neste espaço.
Dimensões muito grandes: dezenas de milhões quando se aplica a pesquisa na Web
Cada vetor é muito esparso – a maioria das entradas é zero.
8

9
Consultas como vetores
Ideia chave 1: fazer o mesmo para as consultas: representá-las como vetores neste espaço multi-dimensional
Ideia chave 2: Classificar os documentos de acordo com sua proximidade com a consulta
proximidade = similaridade
Relembrando: Estamos fazendo isso porque queremos fugir das limitações do modelo booleano.
Ao invés disso: queremos classificar melhor documentos relevantes em relação a documentos não-relevantes
9

10
Como formalizamos similaridade em um espaço vetorial?
Primeiro corte: distância entre dois pontos
( distância entre os pontos extremos dos dois vetores)
Distância Euclidiana?
Utilizar a Distância Euclideana é uma má ideia . . .
. . . Porque resulta em valores muito grandes para vetores de diferentes comprimentos.
10

11
Porque distância é uma má ideia
A Distância Euclidiana entre a consulta li e o documento é muito grande apesar de ambos terem uma distribuição similar de termos
11

12
Usar o ângulo ao invés da distância
Classificar os documentos de acordo com o seu ângulo em relação à consulta
Experimento: escolha um documento d e duplique seu conteúdo. Chame esse documento de d′.
Apesar de d’ ter o dobro do tamanho de d, eles representam “semanticamente” o mesmo conteúdo.
O ângulo entre os dois documentos é 0, correspondendo a similaridade máxima . . .
. . . mas a distância Euclidiana entre os dois pode ser muito grande.
12

13
De ângulos para cossenos
As duas noções a seguir são equivalentes.
Classificar os documentos de acordo com o ângulo entre a consulta e o documento em ordem crescente
Classificar os documentos de acordo com o cosseno (consulta,documento) em ordem decrescente
O cosseno é uma função decrescente de um ângulo no intervalo [0◦, 180◦]
13
14
Cosseno
14

15
Similaridade do cosseno entre consulta e documento
qi é o peso tf-idf do termo i da consulta.
di é o peso tf-idf de cada termo i do documento
| | e | | são os comprimentos dos vetores e
Esta é a similaridade do cosseno entre e
15

16
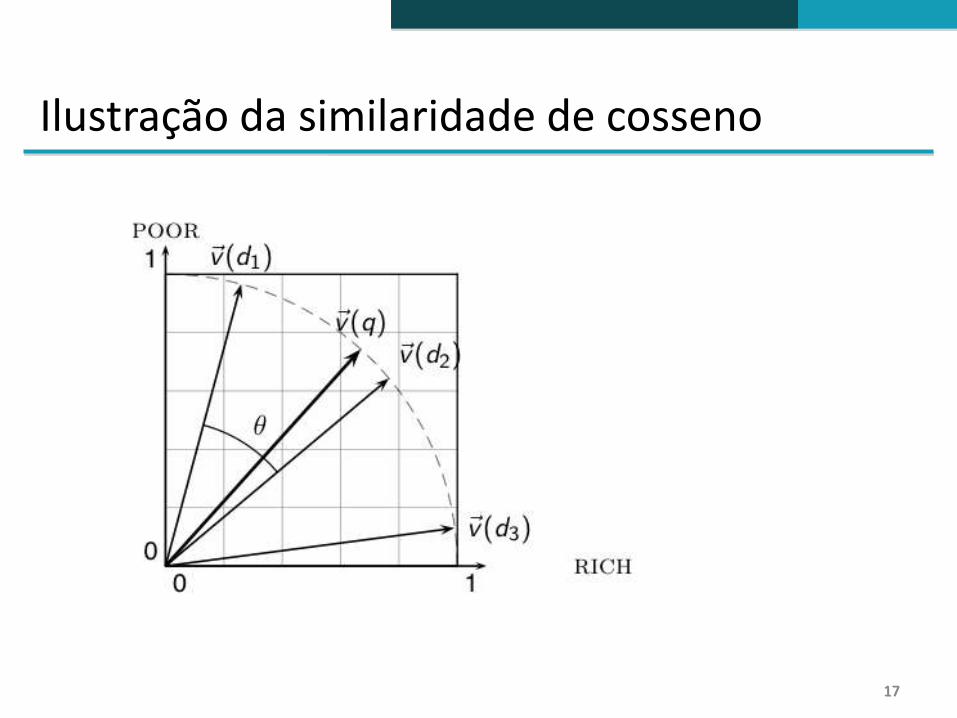
Cosseno de vetores normalizados
Para vetores normalizados, o cosseno é equivalente aoproduto escalar.
(se e foram normalizados em relação ao seucomprimento).
16
17
Ilustração da similaridade de cosseno
17
18
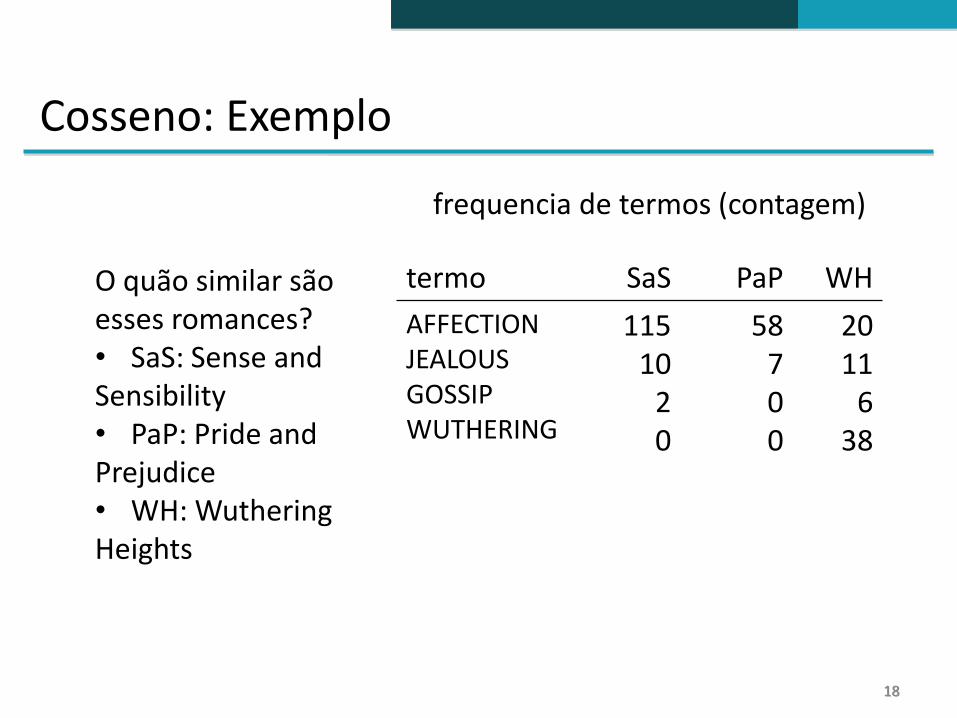
Cosseno: Exemplo
frequencia de termos (contagem)
O quão similar sãoesses romances? • SaS: Sense andSensibility• PaP: Pride andPrejudice• WH: WutheringHeights
18
termo SaS PaP WH
AFFECTIONJEALOUSGOSSIPWUTHERING
11510
20
58700
2011
638
19
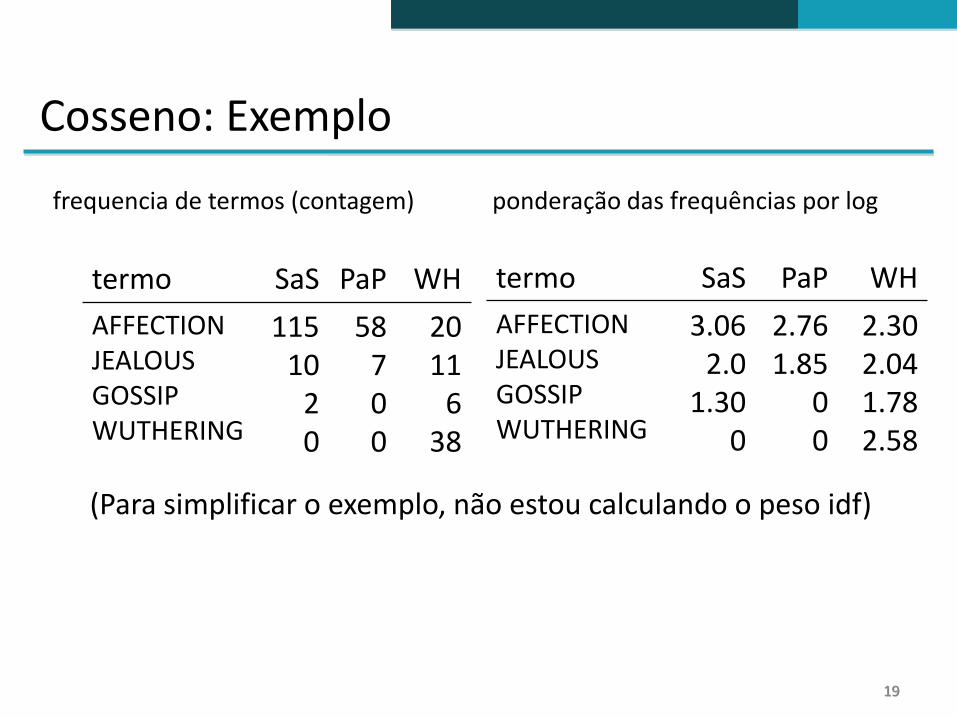
Cosseno: Exemplo
frequencia de termos (contagem) ponderação das frequências por log
(Para simplificar o exemplo, não estou calculando o peso idf)
19
termo SaS PaP WH
AFFECTIONJEALOUSGOSSIPWUTHERING
3.062.0
1.300
2.761.85
00
2.302.041.782.58
termo SaS PaP WH
AFFECTIONJEALOUSGOSSIPWUTHERING
11510
20
58700
2011
638
20
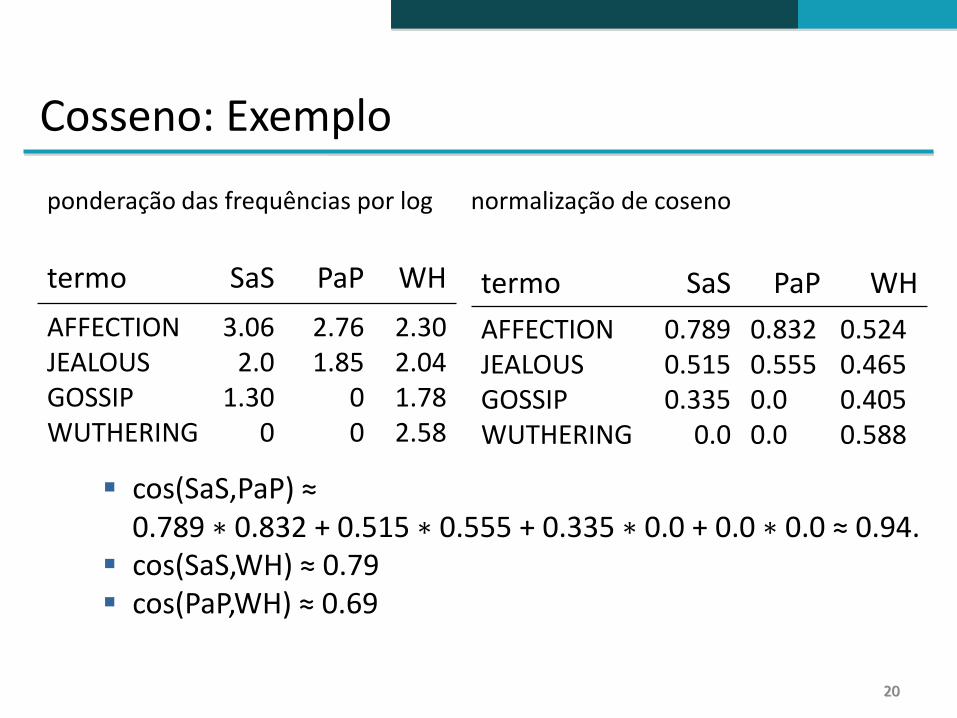
Cosseno: Exemplo
ponderação das frequências por log normalização de coseno
20
termo SaS PaP WH
AFFECTIONJEALOUSGOSSIPWUTHERING
3.062.0
1.300
2.761.85
00
2.302.041.782.58
termo SaS PaP WH
AFFECTIONJEALOUSGOSSIPWUTHERING
0.7890.5150.335
0.0
0.8320.5550.00.0
0.5240.4650.4050.588
cos(SaS,PaP) ≈ 0.789 ∗ 0.832 + 0.515 ∗ 0.555 + 0.335 ∗ 0.0 + 0.0 ∗ 0.0 ≈ 0.94.
cos(SaS,WH) ≈ 0.79 cos(PaP,WH) ≈ 0.69

21
Sumário: recuperação com classificação utilizando o modelo do espaço vetorial
Representar a consulta como um vetor de pesos tf-idf
Representar cada documento como um vetor de pesos tf-idf
Calcular a similiradade do cosseno entre o vetor da consulta e os vetores de cada documento na coleção
Classifique os documentos de acordo com a consulta
Retorne os primeiros K (ex., K = 10) documentos para o usuário
21


















![GABARITO PREC 2013 - politecnicos.com.br · Notação: Se v 1,...,vn são vetores de um espaço vetorial V, o subespaço vetorial de V gerado por eles será denotado por [v 1,...,vn].](https://static.fdocumentos.tips/doc/165x107/5c5e0cc909d3f2ca1f8bd797/gabarito-prec-2013-notacao-se-v-1vn-sao-vetores-de-um-espaco-vetorial.jpg)