
FERNANDA ZERBIN...Figura 15 - Configuração de novo frontend no GSA para resultado de busca 57...
76
FERNANDA ZERBIN INDEXAÇÃO DE VOZ POR MEIO DE TRANSCRIÇÃO AUTOMÁTICA CANOAS, 2012
Transcript of FERNANDA ZERBIN...Figura 15 - Configuração de novo frontend no GSA para resultado de busca 57...

FERNANDA ZERBIN
INDEXAÇÃO DE VOZ POR MEIO DE TRANSCRIÇÃO AUTOMÁTICA
CANOAS, 2012

FERNANDA ZERBIN
INDEXAÇÃO DE VOZ POR MEIO DE TRANSCRIÇÃO AUTOMÁTICA
Trabalho de conclusão apresentado para a banca examinadora do curso de Ciência da Computação do Centro Universitário La Salle - Unilasalle, como exigência parcial para a obtenção do grau de Bacharel em Ciência da Computação.
Orientação: Profª. Dra. Patrícia Kayser Vargas Mangan
CANOAS, 2012

TERMO DE APROVAÇÃO
FERNANDA ZERBIN
INDEXAÇÃO DE VOZ POR MEIO DE TRANSCRIÇÃO AUTOMÁTICA
Trabalho de conclusão aprovado como requisito parcial para a obtenção do grau de bacharel em Ciência da Computação do Centro Universitário La Salle – Unilasalle.
Aprovado pela banca examinadora em 3 de julho 2012.
BANCA EXAMINADORA:
Prof. Me. Alexandre Gaspary Haupt
Unilasalle
Prof. Me. Rafael Kunst
Unilasalle

Dedico este trabalho a meu pais,
Armindo e Solange que me
incentivaram a estudar sempre,
a minhas irmãs, Patricia e Bruna
pelo apoio, paciência e atenção,
Obrigada.

AGRADECIMENTOS
Agradeço a meus padrinhos Cecília e Fernando pelo carinho e por estarem
sempre presentes, a minha afiliada Júlia que me incentiva sempre com sua alegria.
Agradeço a meus tios e tias pela confiança, primos e primas pelos momentos de
descontração. Agradeço ao Thomas pela paciência, carinho e atenção no período de
produção deste trabalho.
A minha Orientadora Patrícia Kayser Vargas Mangan pela atenção e por
auxiliar no desenvolvimento deste trabalho, indicando o melhor caminho. Também
devo agradecer a meus professores Marcos Barreto, Mozart Lemos de Siqueira,
Lincoln Rabelo, Rafael Kunst, Roberto Petry e Simão Sirineo Toscani, que
participaram da minha formação acadêmica e contribuíram para meu crescimento
pessoal e profissional.
Agradeço a meus colegas do Unilasalle, Marco Gomes de Assunção, Roberto
Dedomenico, Marcelo Menger, Andrio Costa, Luis Wolf, Leandro Tavares e demais
colegas que se tornaram amigos ao correr do curso.
Também agradeço a paciência e colaboração dos meus colegas de trabalho,
Breno Hoffmeister, Marcos Fofonka , Jefferson Schwantes e toda a equipe de
trabalho, agradeço a meu Gestor Leandro Siminovich e a meu ex-gestor Alejandro
Halon.
Agradeço a todos que colaboraram e compartilharam seu conhecimento
comigo. Obrigada.

RESUMO
A quantidade de informação digital aumenta exponencialmente, são normalmente
documentos em modo texto, páginas na web, livros e revistas digitais, sites de
compras e inclusive informação não textual. Para a recuperação de dados de texto,
há um grande número de buscadores e indexadores, mas há pouca eficiência na
busca por dados não textuais como os dados da voz, sejam vídeos ou áudios, este
tipo de documento digital precisa ser indexado e hoje em dia são utilizados métodos
antigos para este tipo de indexação, um método comum é a indexação por
metadados. Para aperfeiçoar a busca de dados de áudio é preciso indexar o
conteúdo do áudio por completo, a fala por si não pode ser indexada, por outro lado
a transcrição da fala sim. Este trabalho propõe uma nova ferramenta para
transcrição e indexação automática de documentos de áudio, tais como
depoimentos, entrevistas, vídeo-aula e áudio-aula, utilizando tecnologia da
informação para transformar áudio em texto e permitir que este texto seja alvo de
busca. Este trabalho resulta em uma aplicação que permite que arquivos de áudio
sejam encontrados de maneira prática, exatamente como outros arquivos em
formato de texto. A contribuição deste trabalho é acrescentar conteúdo a pesquisas
relacionadas a busca de dados, a busca está cada vez mais presente no dia-a-dia
das pessoas, busca por palavra-chave, que substitui o método de busca por
navegação.
Palavras-chave: Transcrição, indexação, recuperação de dados, busca,
reconhecimento de fala.

ABSTRACT
The quantity of digital information increases exponentially, usually in text mode, web
Page, digital books and digital magazines, e-commerce and even non-text
information. For text-data recovery, today we have a large number of search engines
and indexes, but we do not have the same efficiency in the search for non-textual
data such as voice data, videos or audios, these types of digital documents need to
be indexed and today they are indexed in the same way that books and documents
were indexed years ago, by metadata. To optimize the search of audio data is
necessary to index the contents of the audio completely, speaks for itself can not be
indexed, but rather its transcription. This paper proposes a new tool for transcription
of automatic indexing of audio documents such as depositions, interviews, video-and
audio-school class, using information technology to transform audio into text and
allow this text to target search. This work results in an application that allows audio
files are found in a practical way, just like other files in text format. The contribution of
this work is to add content to research related to data search, the search is
increasingly present in lives, search by keyword, which replaces the search method
for navigation.
Keywords: Transcription, indexing, data recovery, search, speech recognition.

LISTA DE FIGURAS
Figura 1 - As Quatro Representações de Fourier ......................................... 23
Figura 2 - Representação de transições de estado de um HMM ................. 28
Figura 3 - Diagrama de classe do framework SRM ....................................... 33
Figura 4 - Arquitetura Sphinx-4, No bloco principal estão a Interface, o Decodificador,
e a Linguística. ....................................................................... 44
Figura 5 - Configuração de rede do GSA. ..................................................... 48
Figura 6 - Visão do VMWare com a VM do GSA executando....................... 49
Figura 7 - Interface de resultado de Busca.................................................... 49
Figura 8 - GSA Página Inicial Administrativa................................................ 50
Figura 9 - Arquitetura do sistema de indexação de voz por meio de transcrição
automática. ....................................................................................................... 51
Figura 10 - Exemplo de feed incremental....................................................... 54
Figura 11 - Configuração para o rastreador de URLs .................................. 55
Figura 12 - Criação de uma nova fonte de dados ......................................... 55
Figura 13 - Disponibilização do Cache de dados ......................................... 56
Figura 14 - Página de busca personalizada .................................................. 57
Figura 15 - Configuração de novo frontend no GSA para resultado de busca 57
Figura 16 - Configuração de novo front-end no GSA para caixa de busca 58
Figura 17 - Diagrama de Caso de uso da ferramenta proposta ................... 59

LISTA DE QUADROS
Quadro 1 - Progressos tecnológicos no reconhecimento de fala ................. 35
Quadro 2 - Trabalhos Relacionados................................................................. 39
Quadro 3 - Conceitos e tecnologias utilizados nos trabalhos relacionados. 39
Quadro 4 - Casos de teste mais e menos eficientes........................................ 65
Quadro 5 - Casos de teste na média de acerto................................................. 65

LISTA DE TABELAS
Tabela 1: Resultado do teste separado por intervalo de palavras................... 64
Tabela 2: A média de acerto em relação ao intervalo de tempo....................... 65
Tabela 3: Porcentagem de acerto........................................................................ 65
Tabela 4: Índice de confiança de acordo com a amostra.................................. 66
Tabela 5: Resultado do teste para o processo de busca.................................. 68
Tabela 6: Média da porcentagem de palavras encontradas com e sem filtro. 68

LISTA DE ABREVIATURAS E SIGLAS
API Application Programming Interface
ASR Sistema de Reconhecimento Automático
CMU Carnegie Mellon University
CSR Continuous Speech Recognition
CUED Cambridge University Engineering Department
DARPA Defense Advanced Research Projects Agency
DFT Discrete Fourier Transform
DFS Discrete Fourier Serie
DNA Ácido Desoxirribonucleico
DTW Dynamic Time Warping
FFT Fast Fourier Transform
GQM Goal Question Metric
GSA Google Search Appliance
HMM Hidden Markov Models
HTK Hidden Markov Model Toolkit
HTML Hypertext Markup Language
JDK Java Development Kit
LDAP Lightweight Directory Access Protocol
LIT Sistema Linear invariante no tempo
MFCC Mel-Frequency Cepstral Coefficients
MFM Markov Family Model
PDF Portable Document Format
PLN Processamento de Linguagem Natural
PSD Processamento de Sinal Digital
RNA Redes Neurais Artificias
SIG Sistema de Informação Geográfica
SQL Structured Query Language
SRM Sound Recognizer ME
TDF Transformada Discreta de Fourier
TF Transformada de Fourier
TL Transformada de Laplace
TRF Transformada Rápida de Fourier

TZ Transformada Z
URL Uniform Resource Locator
VM Virtual Machine
XML eXtensible Markup Language
XSLT eXtensible Stylesheet Language for Transformation

SUMÁRIO
1 INTRODUÇÃO ............................................................................................................................... 15
1.1 Objetivo Geral .......................................................................................................................................... 16
1.2 Objetivos Específicos ............................................................................................................................ 17
1.3 Estrutura do Texto ................................................................................................................................. 17
2 RECONHECIMENTO DE FALA PARA INDEXAÇÃO POR MEIO DE TRANSCRIÇÃO
AUTOMÁTICA .................................................................................................................................. 18
2.1 Processamento de Sinal Digital ......................................................................................................... 18
2.2 Modelo de Representação da Fala .................................................................................................... 19
2.3 Indexação e Busca .................................................................................................................................. 21
2.3.1 Mecanismos de Indexação e Busca ...................................................................................................................... 22
2.3.1.1 Oracle Text .................................................................................................................................................................... 22
2.3.1.2 Google Search Appliance (GSA) ........................................................................................................................... 22
2.4 Considerações Finais ............................................................................................................................ 23
3 TRABALHOS RELACIONADOS ................................................................................................ 24
3.1 Transcrição e Processamento do sinal da voz ..................................................................................................... 24
3.2 Indexação e Recuperação de dados .......................................................................................................................... 28
3.3 Análise dos Trabalhos relacionados ......................................................................................................................... 32
4 DESENVOLVIMENTO ................................................................................................................. 33
4.1 Ferramentas no estado da arte ......................................................................................................... 33
4.1.1 Sistemas direcionados à pesquisa em reconhecimento de voz ................................................................. 33
4.1.2 Sistemas direcionados à pesquisa em indexação e busca de dados. ...................................................... 34
4.2 Ferramenta para Reconhecimento de Fala Contínua................................................................ 35
4.2.1 Arquitetura Sphinx ....................................................................................................................................................... 36
4.2.2 Ferramenta de treinamento ..................................................................................................................................... 38
4.2.3 Utilização da Ferramenta de Transcrição ......................................................................................................... 38
4.3 Ferramenta para Indexação e Recuperação de Dados ............................................................. 39
4.3.1 Utilização da Ferramenta para Indexação e Recuperação de Dados ................................................... 40
4.4 Arquitetura proposta ............................................................................................................................ 42
4.5 Utilização da Ferramenta Proposta ................................................................................................. 51
4.6 Considerações Finais ............................................................................................................................ 52
5 AVALIAÇÃO ................................................................................................................................... 53
5.1 Metodologia de Avaliação ................................................................................................................... 53
5.2 Avaliação do Processo de Transcrição ........................................................................................... 54

5.2.1 Treinamento .................................................................................................................................................................... 54
5.2.2 Aplicação do GQM para o processo de Transcrição ...................................................................................... 55
5.2.3 Resultado da Avaliação do Processo de Transcrição .................................................................................. 56
5.3 Avaliação do Processo de Busca ....................................................................................................... 58
5.3.1 Aplicação do GQM para o processo de busca .................................................................................................... 58
5.3.2 Resultado da Avaliação do processo de busca ................................................................................................. 59
5.4 Avaliação da Ferramenta completa ................................................................................................. 60
5.5 Considerações Finais da Avaliação .................................................................................................. 61
6 CONCLUSÃO E TRABALHOS FUTUROS ................................................................................ 62
REFERÊNCIAS .................................................................................................................................. 64
APENDICE A – Fundamentação matemática para o processamento digital de sinais
.............................................................................................................................................................. 69

15
1 INTRODUÇÃO
A necessidade da utilização de dados gravados em conversas levou ao
desenvolvimento de técnicas de transcrição que servem como elemento de
percepção. O ato de transcrever uma cena ou conversa deve ser planejado antes de
ser iniciado. A transcrição é a representação de um evento, esta representação deve
estar bem próxima do evento real. Existem padronizações e regras para transformar
os registros de áudio em texto. Muitos pesquisadores ainda hoje fazem isso de
forma totalmente manual. Autores enfatizam a transcrição como a fiel representação
do evento, a transcrição de dados exige ética e fidelidade ao conteúdo (SCHNACK
et al, 2005).
Este trabalho investiga uma forma adequada de transcrever áudio
automaticamente para indexação de dados, isto é, além da geração de transcrições,
deseja-se estabelecer mecanismos de indexação e busca diretamente no áudio, tem
como tema principal arquivos de multimídia que possam ser indexados através da
transcrição automática utilizando conversão de voz para texto. Segundo Afonso
(2002), “cada documento de multimídia pode ser encontrado se for devidamente
indexado”, e para isso pode-se utilizar de metadados.
Um dado audível é caracterizado pelo seu som. O som é a propagação de uma
frente de compressão mecânica ou onda mecânica (LEAL, 2001). A voz quando
passa pelo microfone é convertida em corrente elétrica (GREF, 1991). Uma
gravação de voz pode ser ouvida, mas não pode ser indexada por um mecanismo
de busca, pode ser gravada em uma base de dados, mas seu formato não pode ser
reconhecido por mecanismos de busca atuais, causando dificuldade na recuperação
de dados. Assim, para indexar fala contínua é preciso transcrevê-la, ou seja,
transformar os dados de voz em texto. Extrair informações de voz e fala de um sinal
de forma digital, utilizando equações matemáticas, modelos de representação
computacional e tecnologia da informação é o que se chama de transcrição
automática.
Na última década a evolução tecnológica foi significativa no reconhecimento de
voz, houve crescimento em relação à banco de dados, treinamento de sistemas de
reconhecimento, com este crescimento, um padrão para treinamento de sistemas,
se fez necessário a frente da impossibilidade de comparar eficiência dos
reconhecedores. Hoje em dia com uma grande base de dados pública e com um

16
padrão de pesquisa, a confiabilidade nas avaliações de desempenho é viável
(TEVAH, 2006).
Um sistema de reconhecimento de fala contínua (Continuous Speech
Recognition - CSR) associado à um grande vocabulário é baseado nos princípios do
reconhecimento probabilístico de padrões (TEVAH, 2006). Um CSR não está livre de
erros, pelo contrário, a probabilidade de erro ainda é muito grande devido à
variabilidade das fontes de sinal acústico, os sistemas são vulneráveis e menos
tolerantes há falhas. Por outro lado, segundo Amaral (1999), “a transcrição manual
está sujeita a falha humana, enquanto os erros na transcrição automática são de
natureza sistemática, facilitando a correção”.
Sobre a busca de dados audíveis, neste quesito ainda há um atraso
significativo, hoje o reconhecimento de voz está voltado para serviços rápidos, traçar
rotas, acionar um dispositivo com comando de voz específico, não para a transcrição
de mídia, com um longo período falado. O Google deu um grande passo neste
campo, iniciou um projeto chamado Gaudi (SAHUGUET, 2008), onde alguns vídeos
foram transcritos e indexados. Uma característica deste sistema é a linha de tempo
do vídeo, onde a palavra que foi buscada, caso encontrada dentro do vídeo fica
enfatizada no minuto e o segundo que foi dita. Este serviço foi descontinuado como
ferramenta livre, o intuito do projeto visa comercializá-lo, logo que foi lançado foi
amplamente divulgado, mas foi encerrado para pesquisas.
A presente pesquisa visa dar continuidade aos estudos sobre transcrição e
indexação de voz, sendo que o problema de pesquisa em questão pode ser
definido da seguinte maneira: como fazer a transcrição e a indexação de fala
contínua?
1.1 Objetivo Geral
O objetivo geral do trabalho é encontrar uma solução utilizando o estado da
arte no tema para o problema de registro e recuperação de dados de voz, através de
um sistema de transcrição e indexação automáticas.

17
1.2 Objetivos Específicos
Os objetivos específicos (metas) podem ser assim descritos:
• Selecionar uma forma de transcrever automaticamente sinais acústicos de voz
e transformá-los em dados de texto.
• Avaliar diferentes algoritmos de transcrição de áudio.
• Avaliar diferentes mecanismos de indexação e busca de dados.
• Selecionar um algoritmo de busca de dados de texto.
• Propor uma nova ferramenta que contenha o método de transcrição e o
algoritmo de busca selecionados.
1.3 Estrutura do Texto
Este trabalho foi segmentado conforme a ordem da estrutura do texto
detalhada nesta seção. O capítulo 2 deste trabalho apresenta os conceitos e as
tecnologias utilizadas para o desenvolvimento do sistema aqui proposto, explica
sobre os conceitos de representação de sinais em processamento de sinal digital,
em seguida explica sobre os conceitos de representação da fala utilizando os
Modelos Ocultos de Markov. No final do capítulo 2, são apresentados dois
mecanismos de indexação e busca.
O capítulo 3 apresenta trabalhos relacionados a essa pesquisa, com mais de
dez autores que estão relacionados quanto a representação da fala, indexação e
busca de dados.
No capítulo 4 o desenvolvimento da ferramenta proposta neste trabalho é
apresentado, sendo descritas algumas ferramentas que compõem o trabalho, e
porque cada ferramenta foi escolhida. Em seguida apresenta os detalhes da
ferramenta escolhida para o reconhecimento de fala contínua e em seguida os
detalhes da ferramenta escolhida para indexação e busca de dados, finaliza o
capítulo apresentando a arquitetura e utilização do sistema proposto.
O capítulo 5 apresenta as métricas de avaliação para os métodos de busca e
transcrição, ainda apresenta a avaliação da ferramenta proposta, o capítulo 6 finaliza
o trabalho concluindo e apresentando trabalhos futuros.

18
2 RECONHECIMENTO DE FALA PARA INDEXAÇÃO POR MEIO DE
TRANSCRIÇÃO AUTOMÁTICA
Sistemas de reconhecimento de fala transformam o sinal acústico na sua
representação fonética (YNOGUTI, 1999), pela aplicação de funções de
probabilidade e distribuição para encontrar a combinação correta de sinal acústico e
fonema. Segundo Moura (2010) a voz está associada à fala, na concretização da
comunicação verbal, e pode variar quanto à intensidade, altura, inflexão,
ressonância, articulação e muitas outras características. Conforme já foi definido, um
sistema de reconhecimento de fala contínua (CSR), associado à um grande
vocabulário é baseado nos princípios do reconhecimento probabilístico de padrões.
Este capítulo visa explicar os conceitos utilizados na implementação deste
trabalho. No inicio explica sobre o Processamento Digital de Sinais aprofundando o
assunto com conceitos sobre as equações transformadas de Fourier que fornecem
um método para manipular os dados em um domínio conhecido seguido de mais
duas técnicas de transformada de sinal.
Em seguida o modelo estatístico utilizado para reconhecer padrões de
palavras nas locuções, intitulado Modelo de Representação da Fala que explica
sobre os Modelos Ocultos de Markov (Hidden Markov Models - HMM). A seção 2.3
explica sobre o modo de indexação do texto extraído na transcrição, e por final faz
um comparativo entre os sistemas estudados e a ferramenta proposta.
2.1 Processamento de Sinal Digital
O Processamento de Sinal Digital (PSD) é a disciplina que estuda as regras
que governam os sinais, que são funções variáveis discretas, sendo fundamental
para análise e reconhecimento de fala. O processamento do sinal digital visa extrair
a informação que o sinal carrega. Esse processamento envolve a representação e a
manipulação dos sinais, a fim de classificar suas propriedades. Algumas ferramentas
para o processamento digital de sinais são importantes para projetar e analisar
sistemas que envolvam análise de sinal, as representações de sinais no tempo
discreto e as Transformadas discretas e seus algoritmos rápidos (DINIZ, 2004).

19
Para o estudo do processamento digital de sinais foi necessário aprofundar em
uma série de ferramentas matemáticas, dentre elas estão três equações que serão
apresentadas no Apêndice A.
• Transformadas de Fourier;
• Transformada de Laplace;
• Transformada Z.
2.2 Modelo de Representação da Fala
Os Modelos Ocultos de Markov (Hidden Markov Models - HMM) podem ser
definidos por processos estocásticos.
Um processo estocástico é definido por um conjunto de variáveis
pertencentes a um determinado intervalo de tempo. Segundo (DIMURO et al, 2011)
um processo de Markov é um processo estocástico, que não leva em consideração
as etapas em que o processo se desenvolveu, somente considera o seu estado
presente, ainda neste contexto os processos passam por uma sequência de
transições de estado.
Existem processos de Markov que são modelados como aproximações do mundo real, onde nem todos os estados são perfeitamente conhecidos. Nestes casos, diz-se que o modelo é escondido, e a questão central em torno desses modelos é o grau com que são capazes de capturar a essência do processo escondido sob eles. Os modelos ocultos de Markov surgiram originalmente para reconhecimento de fala (DIMURO et al, 2011, p.1).
O HMM é modelo de representação de fala mais popularmente utilizado nos
reconhecedores. No contexto de métodos estatísticos para o reconhecimento de
voz, o modelo de Markov (HMM) tornou-se uma abordagem bem conhecida e
amplamente utilizada para caracterizar as propriedades espectrais dos quadros de
fala. Como uma ferramenta de modelagem estocástica. (LIU,1994)
É interessante o uso de processos estocásticos quando a descrição de um
procedimento de um sistema opera sobre algum período de tempo.
No HMM o mecanismo de produção de fala é tratado como um processo
estocástico que gera os sinais de fala observados, este mecanismo pode ser
caracterizado por uma série de transições de estado, estados subsequentes
somente dependem do estado anterior, estados de transição não podem ser

20
observados diretamente, por isso são conhecidos como estados escondidos (LI; MA,
2005), na figura 2 podemos observar um diagrama de transição de estados.
Um HMM pode ser definido com base em um processo duplamente
estocástico, um estado finito de uma cadeia de Markov é um processo estocástico
escondido. Os outros processos estocásticos são a relação da sequência observada
com o estado da cadeia de Markov.
Figura 2: Representação de transições de estado de um HMM
Fonte: Adami, 1997.
Segundo Adami (1997), “Um HMM pode ser definido como uma máquina de
estados finita, onde as transições entre os estados são dependentes da ocorrência
de algum símbolo.” Na figura 2 as setas representam as transições de estados.
Sistemas de reconhecimento de fala não baseiam suas decisões no sinal puro
da fala, mas sim em um conjunto de características derivadas do sinal da fala. Como
na maioria dos sistemas de reconhecimento de fala, o sinal é parametrizado antes
de sofrer avaliações de probabilidade. Conforme a teoria de Fourier podemos
afirmar que uma onda periódica pode ser decomposta em pequenas ondas puras. A
transformada de Fourier é amplamente utilizada para obter o espectro a partir da
forma de uma onda (ARAOZ, 2007).
Inicio

21
As cadeias de Markov são adequadas para o reconhecimento de padrões, por
que proporcionam o cálculo da probabilidade da transição de estados. Segundo
(LIPSCHUTZ, 1968), uma cadeia é considerada cadeia de Markov se ela satisfaz as
seguintes propriedades:
• Os resultados pertencem a um conjunto finito de resultados, e cada resultado é
chamado de espaço estado do sistema;
• O próximo resultado depende, somente, da tentativa imediatamente anterior e
não de qualquer outro resultado prévio.
2.3 Indexação e Busca
A indexação é ainda uma área que abrange profissionais de biblioteconomia,
porém avanços tecnológicos mudaram de modo irreversível a maneira de se
armazenar, tratar e recuperar documentos, atingindo diretamente os serviços de
informação e as bibliotecas. Algumas bibliotecas mais modernas já possuem seu
acervo on-line.
Esta situação em que a tecnologia ajuda na organização da informação, traz
muitos ganhos a quem procura informação ou leitura, traz a informação específica e
demanda menos tempo de busca (FUJITA, 2009).
A indexação automática acontece quando nenhuma validação humana é feita,
os documentos são indexados automaticamente por seu conteúdo, e o termos chave
são armazenados automaticamente.
A busca de dados depende diretamente da maneira de indexação, se os
termos de busca forem encontrados em padrões previamente armazenados pelo
indexador a busca se torna eficiente, cabe ao indexador armazenar corretamente
seus padrões e suas palavras-chave (SANTOS, 2009).
Segundo Turban, Wetherbe e Mclean (2002, p.126), “os agentes indexadores
têm capacidade de executar grande volume de pesquisas autônomas para um
usuário ou para um mecanismo de busca.” Estes agentes indexadores, muitas vezes
chamados de robôs, pesquisam milhões de documentos formando índices,
organizados por palavras-chave, títulos e textos, que são parte do conteúdo dos
documentos indexados, assim os usuários tem condições de utilizar estas palavras-
chave nos buscadores.

22
2.3.1 Mecanismos de Indexação e Busca
Nesta seção duas ferramentas de Indexação e Busca são apresentadas como
possíveis soluções parciais para o trabalho proposto.
2.3.1.1 Oracle Text
Oracle text é uma ferramenta da Oracle que pode ser utilizada na web ou em
arquivos locais, serve para indexar, buscar e navegar por documentos em texto que
estão armazenados no banco de dados, a busca funciona por palavra-chave, por
contexto, por padrão e por tema e utiliza um padrão de SQL (Structured Query
Language) para fazer a indexação de documentos (FAGUNDES; KROTH, 2008).
É uma ferramenta de integração da Oracle, oferece uma solução de busca por
texto, possui índices especializados para aplicação de recuperação de texto, aceita
diferentes formatos de documentos como os documentos no formato Adobe PDF,
documentos no formato do MS Office, HTML (Hypertext Markup Language) e XML
(eXtensible Markup Language). Aceita diferentes tipos de linguagem, algumas mais
comuns (Inglês, Francês, Espanhol, Alemão e etc.).
Oracle Text provê três tipos de indexação, Standart, Catalog, Classification.
Devem ser utilizadas conforme os tipos de documentos, a Standart deve ser
utilizada para documentos grandes, é a mais utilizada, a Catalog deve ser utilizada
para textos menores ou fragmentos de texto e a Classification deve ser utilizada
para aplicações que catalogam documentos (FORD, 2007).
2.3.1.2 Google Search Appliance (GSA)
Google Search Appliance é uma ferramenta do Google, mais conhecida como
uma solução caixa-preta, pois seus algoritmos e arquitetura do sistema estão em um
servidor, sem divulgação dos detalhes de implementação. É utilizada para indexação
e busca de documentos em texto, utiliza seus próprios mecanismos de indexação e
inteligência artificial para sugestão de busca. Retorna o resultado das buscas em
menos de um segundo e é capaz de indexar milhões de documentos. É uma

23
ferramenta paga e sua licença funciona de acordo com o número de documentos
indexados. Existe uma versão limitada sem custos.
O GSA implementa busca segura, integração com sistemas de autenticação
como Lightweight Directory Access Protocol (LDAP), e todas suas configurações
podem ser feitas via interface gráfica. Este mecanismo de busca e indexação, aceita
muitos formatos de dados, se conecta diretamente em mais de 20 bancos de dados
diferentes, e pode indexar qualquer tipo de dado que seja manipulado via XML
(GSA, 2012).
2.4 Considerações Finais
Neste capítulo foram apresentadas algumas técnicas de processamento de
sinais digitais que estão diretamente relacionadas a um dos objetivos do trabalho
proposto, transcrever arquivos de áudio para indexação, nesta seção foram
explicadas as fórmulas de transformadas que são normalmente utilizadas para as
técnicas de PSD, após isso, temos um modelo de representação de padrões
utilizado para reconhecer os padrões da fala nas locuções, o Modelo Oculto de
Markov.
Também foram descritas duas ferramentas para indexação de texto. As
ferramentas GSA e OracleText, a ferramenta GSA será utilizada neste trabalho.
No próximo capítulo serão apresentados trabalhos que utilizaram-se das
técnicas, modelos e ferramentas descritos nesta seção.
No capítulo 4 será descrita a solução proposta, aplicando as técnicas de PSD e
os modelos de representação da fala nos algoritmos do reconhecedor de fala
Sphinx-4. Também será descrito o mecanismo de busca escolhido para o trabalho e
a integração das tecnologias propostas neste capítulo visando obter uma ferramenta
que faça a indexação de arquivos de áudio.

24
3 TRABALHOS RELACIONADOS
Este capítulo tem como objetivo mostrar trabalhos relacionados com o estudo
deste trabalho, está subdividido em duas seções que estão separados pelos critérios
de transcrição e recuperação de dados. Os trabalhos relacionados ao assunto em
questão servem tanto para comparação da proposta deste trabalho e conhecimento
do estado da arte, como também contribuem para o referencial teórico do estudo
proposto.
3.1 Transcrição e Processamento do sinal da voz
No trabalho de Ruaro e Silva (2011), foi implementado um reconhecedor de
voz de vocabulário pequeno e dependente de Locutor, um framework totalmente
desenvolvido em Java ME, que utiliza a extração de coeficientes MFCC derivados
da Transformada Rápida de Fourier utilizando filtros na escala de Mel, neste
trabalho a extração dos coeficientes MFCC teve sua implementação baseada no
framework Sphinx-4, após a posse do sinal foram utilizadas as técnicas de
Processamento de Sinais Digitais (PSD). Para o reconhecimento de padrões foi
utilizado o Dynamic Time Warping (DTW). Um dos objetivos do reconhecedor deste
trabalho relacionado, além do reconhecimento de som, é oferecer este recurso de
uma maneira simples e abstraída para que sua integração em aplicações seja de
forma rápida. Na figura 3 podemos observar o Diagrama de Classe do Sound
Recognizer ME (SRM), está composto basicamente em três pacotes sound, back-
end e front-end:
• O pacote sound é responsável pela aquisição, execução e manipulação das
amostras do som;
• O pacote front-end é dedicado as técnicas de PSD, é ele que passa as
informações necessárias para o pacote back-end;
• back-end que por sua vez faz o reconhecimento.

25
Figura 3: Diagrama de classe do framework SRM
Fonte: Ruaro e Silva (2011)
No trabalho de Rüncos (2008) o objetivo é desenvolver um reconhecedor de
trilhas de melodia de músicas, visando obter suas notas musicais e as propriedades
das notas, como intensidade e tempo de início e fim. Um dos objetivos deste
trabalho é extrair uma representação simbólica da música considerando
instrumentos melódicos, utiliza a análise tempo-frequência para a estimação de
métrica musical indicando o início das notas musicais, utiliza um detector de picos
para melhorar esta indicação. Utiliza a Transformada Rápida de Fourier em janelas
de tempo para extração dos parâmetros do sinal, utiliza algoritmos para estimar
picos na frequência que poderão ser classificados como notas, para o
processamento do sinal inicia um peso para uma nota pré-definida em frequência e
aplica uma equação com taxa de amostragem para descobrir os próximos padrões,
não segue nenhum modelo cognitivo para a análise e representação da fala.
O Projeto de um equipamento de reconhecimento de comandos de voz
(MORAES, 2007), este trabalho foi elaborado em cima de um equipamento
específico para reconhecimento de voz. A técnica escolhida para a análise de voz foi
a que utiliza quantização vetorial com coeficientes mel-cepstrais. Foi utilizado um
treinamento do equipamento para o reconhecimento dos comandos.
Para a análise mel-cepstral, os coeficientes são obtidos utilizando um banco de
filtros que são aplicados sobre a TRF do sinal, utiliza a escala de frequências mel
como filtro. Para modelagem dos comandos utiliza a quantização vetorial, a
construção de conjuntos de vetores chamados de dicionários são obtidos na fase de

26
treinamento. Utiliza o algoritmo K-Means para encontrar a menor distorção em
relação aos coeficientes mel-cepstrais. Após a construção do dicionário passa para
o reconhecimento de voz, efetuando todas as etapas novamente, a fim de extrair o
sinal que será comparado ao dicionário obtido anteriormente. Utilizou linguagem C
em cima de um hardware específico.
No trabalho de Amaral (2005), é proposto um identificador neural de comandos
de voz embutido em um robô lego mindstorms, inicia o trabalho apresentando os
conceitos de reconhecimento de fala humana por humanos, explica como funciona
para que o cérebro humano identifique os sinais da voz e os transforme em ideias,
palavras e conceitos. Para o reconhecimento dos padrões utiliza Redes neurais,
inicia este assunto com os conceitos de neurônios naturais e faz a associação com
neurônios artificiais. O autor se refere à Redes Neurais Artificias (RNA's), também
conhecidas como redes conexionistas ou computação neural, apresentam a própria
representação e semelhança de um neurônio artificial (ADAMI, 1997). Uma RNA é
uma estrutura que processa informação de forma paralela e distribuída e que
consiste de unidades computacionais interconectadas por canais unidirecionais
chamados de conexões. Este trabalho também apresenta um estudo sobre o
relacionamento da Robótica com Inteligência artificial, quando software e hardware
têm seus papéis.
A proposta inicial deste projeto era de construir um robô autônomo que se
locomove sobre rodas e responde a comandos direcionais de voz, como: frente,
pare, ré, direita e esquerda. Segundo autor não foi possível alcançar este objetivo
por falta de recursos de hardware. As dificuldades encontradas durante o
desenvolvimento do trabalho levaram a uma implementação dependente de
comunicação com uma máquina externa para o processamento e reconhecimento
dos comandos de voz, ficando a cargo do processador móvel somente executar os
comandos dos movimentos. Para programação foi utilizado o produto Matlab,
desenvolvido pela The Mathworks, que juntamente com frequência de amostragem
obteve o pré-processamento de sinal, e para o robô um kit Lego Mindstorms que é
um produto comercializado pela empresa Lego.
Segundo (KATTI; ANUSUYA, 2007), o reconhecimento de voz é o processo
de converter o sinal da fala para uma sequência de palavras.
No quadro 1 podemos ver os avanços tecnológicos no reconhecimento de
fala, podemos identificar algumas tecnologias estudadas neste trabalho como

27
modelos estatísticos (HMM), características cepstrais, reconhecimento independente
de locutor com grande vocabulário.
Quadro 1: Progressos tecnológicos no reconhecimento de fala Alguns progressos tecnológicos nos últimos anos
Passado (1970 a 2000) Presente (2000 a 2007) Modelos Correspondentes Modelos Estatísticos (HMM) Filtro Branco e ressonância espectral Característic as cepstrais Normalização Heurística DTW Reconhecimento de Palavras Isoladas Reconhecimento de Fala Contínua Vocabulário Pequeno Vocabulário Grande
Reconhecimento de fala limpa Reconhecimento de fala com ruído
Dependente de locutor Independente de Locutor Monólogo Diálogo e Conversação Hardware para reconhecimento Software para reconhecimento - Redes Neurais
Fonte: Autoria própria, baseado em Katti; Anusuya, 2007. *Baseado em Summary of the technological progress in the last 60 years.
Segundo Srinivasan (2011), o desempenho de um sistema de
reconhecimento de locutor utilizando modelos ocultos de Markov pode ser
comparado a um sistema que utilize Redes neurais artificiais para a função de
reconhecimento de padrões, o sistema que utiliza HMM precisa ser bastante
treinado. Na implementação deste trabalho foi utilizada a análise do formato de
onda, a quantização vetorial e os modelos ocultos de Markov (HMM).
No trabalho de Yuan (2012) foi proposto uma melhoria no HMM, um novo
modelo estatístico derivado do HMM, é o MFM (do inglês, Markov Family Model),
aplicado em um sistema de reconhecimento de fala e processamento de linguagem
natural. Com os experimentos utilizados neste projeto, foi comprovado que o MFM
tem melhor desempenho que o HMM, os estudos comprovaram que MFM aumenta
a precisão de acerto de 94% para 96% reduzindo o trabalho de correção em 11%.
Este trabalho combina vantagens que normalmente estão separadas, são modelos
de fonemas independentes de contexto e modelos de fonemas dependentes de
palavra, essa combinação está no modelo MFM.
Um estudo sobre indexação de fala trata sobre a indexação de fala natural
utilizando um mecanismo de transcrição manual, se preocupa com o ranking na
busca dos documentos falados. Utiliza a tecnologia Oracle para a indexação e não

28
utiliza nenhum Sistema de Reconhecimento Automático (ASR) de fala, inclusive
justifica não utilizar nenhum ASR pela falta de precisão dos sistemas que estão
disponíveis (CHELBA; ACERO, 2005).
3.2 Indexação e Recuperação de dados
Segundo Aires e Vaz (2007), o Modelo de Metadados Metamídia, um modelo
de indexação e recuperação de objetos multimídia, apresenta uma estrutura de
metadados para auxiliar no processo de indexação e recuperação desses objetos.
Ele armazena, recupera e indexa dados multimídia através de uma hierarquia de
metadados ou valores. A indexação é feita de maneira manual e semi-automática,
onde o usuário define o conjunto de metadados, e alguns deles são fornecidos
automaticamente.
O próximo trabalho é sobre indexação de dados espaciais, um estudo sobre a
indexação de dados espaciais presente na literatura é feito no trabalho (OLIVEIRA et
al, 2007), consiste na necessidade da utilização de busca de dados espaciais,
alguns exemplos destes dados são quantidade do volume de carbono em um limite
de área, lista de espécies da flora nativa e outras informações geográficas como
contorno de bacias hidrográficas e fronteiras municipais, resumindo o objetivo é
indexar um sistema de informação geográfica (SIG). Para este tipo de indexação foi
utilizado o Oracle Spatial que é um conjunto integrado de funções e procedimentos
que possibilita dados espaciais serem armazenados, acessados e analisados de
forma rápida e eficiente num banco de dados ORACLE 9i. (CHUCH, 2001). Uma
comparação feita pelos autores, com os quatro mecanismos de indexação Oracle
Spatial, PostgreSQL PostGIS, PostgreSQL com Tipos Geométricos e MySQL.
Entres estes, o Oracle Spatial é mais eficiente em requisitos importantes como
Operadores topológicos, Operadores de conjuntos e de buffer region. No caso desta
pesquisa o foco está em indexar dados espaciais, ou seja, dados que cobrem áreas
multidimensionais, a indexação utilizando algoritmos clássicos não traz eficiência,
pois as comparações para a busca precisam trabalhar com intervalos e não pode ser
uma comparação de igualdade.
A proposta do artigo dos autores (PIMENTEL FILHO; SANTOS, 2010), é prover
uma série de ferramentas para capturar e processar frames individuais de vídeo,
com alguns módulos para indexação, busca e navegação no conteúdo visual. O

29
principal objetivo do trabalho é a indexação de vídeo e a recuperação baseada em
características visuais. A arquitetura do sistema proposto está dividida em duas
grandes partes, a primeira é a análise do vídeo e a segunda, chamada de video
oracle é responsável pela parte de indexação, busca e navegação. Para análise do
vídeo é utilizado algumas tecnologias como C++ e uma API (original do inglês
Application Programming Interface) da Microsoft chamada DirectX API. Na segunda
parte é necessário que algum dado seja anexado ao vídeo, utilizando metadados.
Os vídeos são indexados através de camadas visuais, com suas características
visuais e além disso com seus metadados.
O próximo trabalho trata sobre indexação automática e recuperação de
documentos Web (SANTOS, 2009). Propõe um estudo interdisciplinar nos assuntos
de Indexação Automática e Processamento de Linguagem Natural (PLN). Tem como
objetivo geral realizar um estudo exploratório sobre os métodos ou modelos de
indexação automática de documentos textuais. Segundo autor um sistema de
indexação automática não possui nenhuma validação por parte do documentalista,
os termos de indexação são armazenados automaticamente como descritores do
documento. O estudo mostra 4 principais fatores que justificam a indexação
automática, são estes:
• Alto custo da indexação humana;
• Aumento exponencial da informação eletrônica;
• Gestão eletrônica de documentos;
• A automatização de processos cognitivos e a pesquisa crescente em
Processamento de linguagem natural.
Algumas áreas que contribuem com a indexação automática de documentos
são: Linguística, Terminologia, Informática, Linguística computacional, Estatística,
inteligência Artificial, Mineração de Texto e Categorização de Texto. O Universo de
indexação Web é formado por quatro elementos inter-relacionados, são: Metadados,
o posicionamento Web, Buscadores e Usuários. Cada um destes agentes tem seu
papel para a organização da informação.
A evolução dos sistemas de indexação automática se dá ao longo de três
gerações, os primeiros estudos estão relacionados a palavras como objeto, onde os
padrões estatísticos e de probabilidade eram empregados, em uma segunda
geração foram aplicadas as técnicas de Processamento de Linguagem Natural, e

30
atualmente é utilizada a indexação inteligente que se apoia em sistemas inteligentes
em combinação com os modelos da primeira e segunda geração.
Um caso com Google Search Appliance (GSA) é o trabalho feito juntamente
com o Portal SEBRAE, neste caso um sistema de taxonomia foi atrelado a
inteligência do GSA, a comunicação entre os sistemas é feita via web service, este
sistema pretende resolver parcialmente o problema da homografia que pode gerar
ambiguidade nos resultados de busca dos buscadores normais e visa também
ajudar no sistema de sugestão de palavras buscadas, um vocabulário controlado foi
construído e utilizado para complementar o sistema de busca de palavras-chave do
sistema do GSA. (SOUZA, 2010).
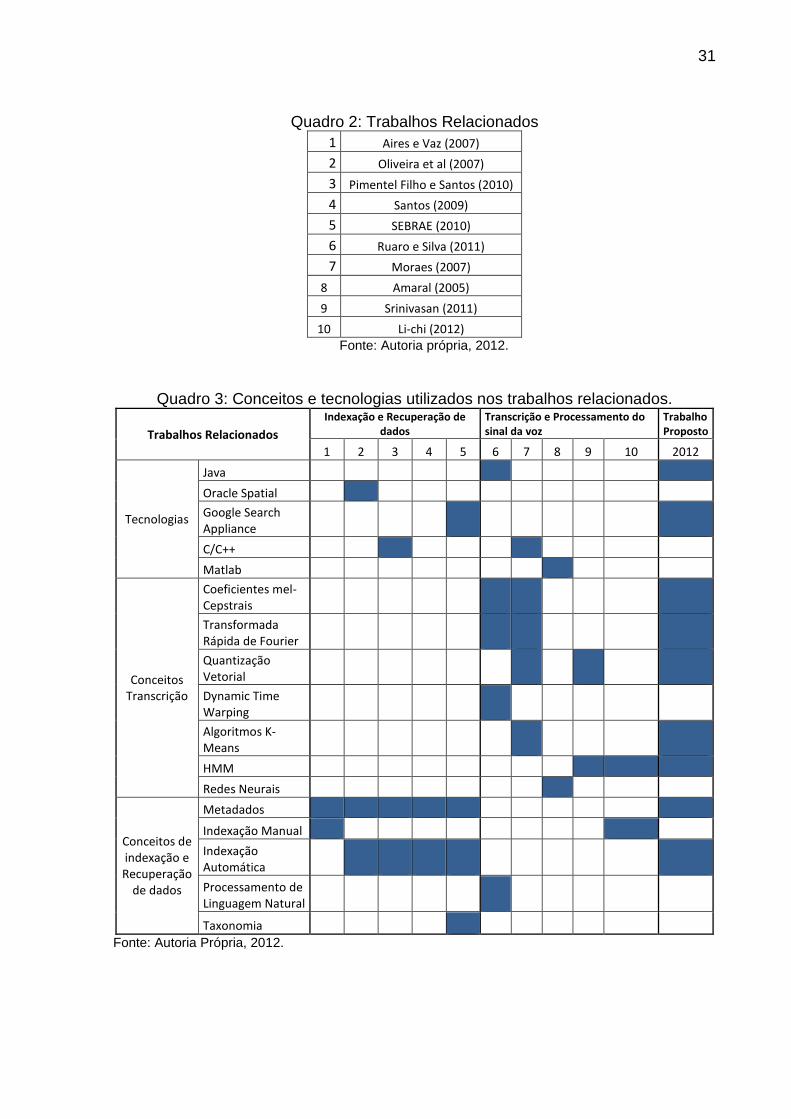
O quadro 2 mostra uma relação com os dez trabalhos relacionados numerados,
que servem como referência para o quadro 3. O quadro 3 mostra os conceitos e
tecnologias utilizados nos trabalhos relacionados e a ferramenta proposta neste
trabalho.
31
Quadro 2: Trabalhos Relacionados 1 Aires e Vaz (2007)
2 Oliveira et al (2007)
3 Pimentel Filho e Santos (2010)
4 Santos (2009)
5 SEBRAE (2010)
6 Ruaro e Silva (2011)
7 Moraes (2007)
8 Amaral (2005)
9 Srinivasan (2011)
10 Li-chi (2012)
Fonte: Autoria própria, 2012.
Quadro 3: Conceitos e tecnologias utilizados nos trabalhos relacionados.
Trabalhos Relacionados
Indexação e Recuperação de
dados
Transcrição e Processamento do
sinal da voz
Trabalho
Proposto
1 2 3 4 5 6 7 8 9 10 2012
Tecnologias
Java
Oracle Spatial
Google Search Appliance
C/C++
Matlab
Conceitos Transcrição
Coeficientes mel-Cepstrais
Transformada Rápida de Fourier
Quantização Vetorial
Dynamic Time Warping
Algoritmos K-Means
HMM
Redes Neurais
Conceitos de indexação e Recuperação
de dados
Metadados
Indexação Manual
Indexação Automática
Processamento de Linguagem Natural
Taxonomia
Fonte: Autoria Própria, 2012.

32
3.3 Análise dos Trabalhos relacionados
Neste capítulo foram apresentados trabalhos que compõe o estado da arte no
tema proposto, podemos observar no quadro 1 a evolução das pesquisas quanto a
algoritmos de transcrição. No último trabalho abordado na seção 3.1 a pesquisa tem
o foco na indexação de documentos falados, como proposto neste trabalho, mas não
se trata de indexação automática. Nos trabalhos onde os modelos estocásticos
estão associados a técnicas de processamento de sinal digital, como no trabalho de
Ruaro e Silva (2011), temos uma qualidade superior da transcrição.
Sobre os mecanismos de indexação e busca o mecanismo do Google, o GSA,
é fortemente indicado pelo autor por além de ter a tecnologia de busca do Google
como software embarcado, pode se conectar com uma série de banco de dados,
pode indexar uma grande variedade de tipos de arquivos e possui interface gráfica
conhecida por usuários comuns da internet.
Sobre as linguagens e ferramentas, fica claro que todas estão aptas para o
trabalho de transcrição, para este trabalho foi escolhida a tecnologia JAVA pois já
existe uma ferramenta que transcreve áudios em inglês, esta ferramenta será
adaptada para a indexação automática de arquivos de áudio.

33
4 DESENVOLVIMENTO
Este capítulo visa explicar as ferramentas utilizadas neste trabalho e como será
a integração entre elas, contém uma visão geral sobre a origem e tecnologia das
ferramentas, aprofundando nas características de recuperação e reconhecimento de
fala de cada uma.
A primeira seção fala sobre a ferramenta utilizada para o reconhecimento de
fala contínua, segue com a transcrição produzida pelo reconhecimento, na segunda
seção explica sobre a ferramenta utilizada para a indexação e recuperação dos
dados transcritos. Neste capítulo a forma de integração destas ferramentas será
explicada.
Ao final do capítulo a arquitetura do sistema proposto e a implementação geral
serão demonstradas finalizando com a comparação deste trabalho com o estado da
arte.
4.1 Ferramentas no estado da arte
Nesta seção estão descritas algumas ferramentas para transcrição, indexação
e busca de dados no estado da arte, destas ferramentas foram escolhidas duas para
compor a estrutura deste trabalho.
4.1.1 Sistemas direcionados à pesquisa em reconhecimento de voz
Serão listados nesta seção alguns dos sistemas mais citados pelo DARPA
(Defense Advanced Research Projects Agency) em avaliações de desempenho de
sistemas de reconhecimento (TEVAH, 2006). Estas ferramentas foram o ponto de
partida para muitos pesquisadores desta área.
O HTK (Hidden Markov Model Toolkit) é definido como um conjunto portátil de
ferramentas de software para a construção e manipulação de HMMs. Foi
desenvolvida pela Universidade de Engenharia de Cambridge (Cambridge University
Engineering Department - CUED), além de ser útil para o reconhecimento de voz, é
utilizada para o reconhecimento de caracteres de DNA (Ácido Desoxirribonucleico).
É composto por um conjunto de bibliotecas em linguagem C e possui a

34
funcionalidade de treino, porém não pode ser utilizada comercialmente e não utiliza
trigramas no modelo de linguagem.
O ATK é uma API para o HTK, consiste em uma interface de programação para
o HTK e facilita a implementação de novas aplicações. É uma camada de interface
que acessa bibliotecas do HTK, possui melhor desempenho que o HTK por fornecer
suporte a trigramas. ATK está diretamente atrelada ao HTK e por isso também não
pode ser utilizada comercialmente.
“O Sphinx (esfinge, em português), foi desenvolvido na Universidade Carnegie
Mellon de forma complacente aos projetos Sphinx fundados pelo DARPA”. Tem
como objetivo auxiliar na criação de ferramentas para o reconhecimento de fala,
possui módulo de treinamento e um tutorial on-line muito intuitivo, está na sua
versão 4 e implementa um sistema de reconhecimento baseado em HMMs. É
totalmente desenvolvido em Java e não possui restrições quanto ao uso comercial
(TEVAH, 2006).
O Sphinx foi escolhido para este trabalho, principalmente por ter um tutorial
muito intuitivo e por não possuir restrições quanto ao uso comercial, mas também
por obter um bom desempenho quanto ao acerto de palavras segundo a literatura
estudada.
4.1.2 Sistemas direcionados à pesquisa em indexação e busca de dados.
A primeira ferramenta a ser citada nesta seção é a Apache Lucene Core, uma
ferramenta completa para a busca de texto, é uma biblioteca escrita completamente
em Java e foi desenvolvida para cercar aplicações que necessitam de busca por
texto completo. É um projeto de código aberto e disponível para download.
Dependendo da versão que será utilizada do Lucene, alguns requisitos de software
são necessários como Java, ANT, JUnit, espaço em disco e memória suficiente para
executá-lo, possui fóruns de discussão e suporte ao desenvolvimento, requer
instalação do projeto e uma grande curva de aprendizado para desenvolver
aplicações utilizando esta ferramenta (ASF, 2011).
A segunda ferramenta é o GSA, é uma ferramenta paga, foi construída
principalmente na linguagem Python, está disponível para download uma versão
com características limitadas, possui interfaces auto-explicativas e tutoriais para
instalação, sua instalação é simples, pois o pacote que pode ser obtido via

35
download, já vem pronto em modo de Máquina Virtual, basta apenas importar a
máquina e o sistema já está funcionando, não é possível adicionar ou remover
funções tornando a ferramenta de fácil instalação, requer alguns recursos de
máquina como 2GB de memória e espaço em disco. Possui suporte do Google, e
uma grande documentação para implementação de aplicações utilizando esta
ferramenta (GSA, 2012).
Neste contexto as duas ferramentas citadas nos parágrafos acima preenchem
os requisitos para compor este trabalho, porém a ferramenta do GSA possui fácil
instalação e melhor documentação para comunicação com aplicações externas e
por isso é utilizada neste trabalho.
4.2 Ferramenta para Reconhecimento de Fala Contínua
A ferramenta escolhida para transcrição foi o Sphinx-4, é a última versão de
uma série de ferramentas de reconhecimento de fala, foi escrita completamente em
Java, se baseia em conceitos de reconhecimento de fala contínua, é utilizado em
outras línguas. Os modelos, conceitos e tecnologias utilizados nesse sistema
também serão abordados nesta seção.
Esta ferramenta é de domínio público, é mantida pela Carnegie Mellon
University (CMU), o desenvolvimento desta ferramenta tem como objetivo principal a
criação de um sistema de reconhecimento automático de fala.
Sistemas de reconhecimento de padrões incluem duas etapas, a primeira
etapa é chamada de extração, onde os parâmetros físicos relevantes são extraídos,
como o formato de onda da voz. Na segunda etapa o processamento e a
classificação do padrão reconhecido baseado nos valores extraídos no primeiro
estágio.
Sphinx é um sistema de reconhecimento de fala contínua baseado no Modelo
Oculto de Markov (HMM), independente de locutor. Tudo o que se conhece, sobre o
processo de fala humana, é muito limitado. Avanços significativos no
reconhecimento de voz não vem unicamente do reconhecimento estatístico de
padrões nem tão pouco unicamente do processamento de sinal, de qualquer
maneira estas duas áreas são muito importantes (CHEN; JOKINEN, 2010).

4.2.1 Arquitetura Sphinx
O software Sphinx foi inicialmente desenvolvido no ano 2000, desde sua
primeira versão é disponibilizado
modularizado e flexível, estas características auxiliam na implementação de nova
aplicações que utilizam o reconhecimento de fala contínua, pois seus módulos
podem ser facilmente substituídos, podemos ver a estrutura dos módulos na figura
4.
Na figura 4 podemos ver a principal estrutura do Sphinx
dividida em três módulos, são estes,
Figura 4: Arquitetura Sphi
Fonte: Traduzido de
Sabendo dos módulos existentes
funcionalidades do reconhecedor
• Interface :
Processamento de Sinal Digital acontece, é aqui que o sina
entra na aplicação;
o A saída do
utilizadas posteriormente por toda a aplicação;
Sphinx foi inicialmente desenvolvido no ano 2000, desde sua
disponibilizado em pacotes de código aberto. É um
modularizado e flexível, estas características auxiliam na implementação de nova
aplicações que utilizam o reconhecimento de fala contínua, pois seus módulos
podem ser facilmente substituídos, podemos ver a estrutura dos módulos na figura
Na figura 4 podemos ver a principal estrutura do Sphinx-4, esta arquitetura está
três módulos, são estes, front-end, decoder e linguist
Figura 4: Arquitetura Sphinx-4, No bloco principal estão a Interfacee a Linguística.
Traduzido de Sartori, Harti, Chenfour, 2007.
Sabendo dos módulos existentes na arquitetura do Sphinx
do reconhecedor:
Neste caso o front-end da aplicação é a etapa onde o
Processamento de Sinal Digital acontece, é aqui que o sina
entra na aplicação;
A saída do front-end traz as características do som, que são
utilizadas posteriormente por toda a aplicação;
36
Sphinx foi inicialmente desenvolvido no ano 2000, desde sua
em pacotes de código aberto. É um software
modularizado e flexível, estas características auxiliam na implementação de novas
aplicações que utilizam o reconhecimento de fala contínua, pois seus módulos
podem ser facilmente substituídos, podemos ver a estrutura dos módulos na figura
4, esta arquitetura está
linguist.
Interface, o Decodificador,
arquitetura do Sphinx-4 segue
da aplicação é a etapa onde o
Processamento de Sinal Digital acontece, é aqui que o sinal de áudio
icas do som, que são
utilizadas posteriormente por toda a aplicação;

37
• Linguística : Ou base de conhecimento, esta etapa provê a informação
que é utilizada pelo Decoder, é dividida em outras três etapas:
o Modelo Acústico : Contém a representação do som, criada pelo
treinamento utilizando dados acústicos;
o Dicionário: É responsável por determinar como a palavra é
pronunciada.
o Modelo de Linguagem : Contém a representação da
probabilidade de ocorrência de uma palavra.
• Gráfico de Busca : É a estrutura gráfica produzida, a gramática,
utilizando o dicionário, modelo acústico e o modelo de linguagem.
• Decodificador : Este é o bloco principal do sistema Sphinx4, este bloco
representa o trabalho massivo da aplicação. Neste ponto as
informações produzidas pelo front-end são lidas, as bases de
conhecimento são acessadas e a busca de padrão aciona o módulo
Linguist, uma sequência de palavras é a saída final, ou seja, uma série
de palavras que representam características extraídas de um sinal.
Para a instalação do Sphinx4 é preciso fazer o download do código que está
totalmente disponível no site do distribuidor CMU, está disponível para Linux e
Windows e requer alguns softwares adicionais como Java 2 SDK, Standart Edition
5.0, Java Runtime Enviroment e Ant (Software mantido pela Apache) (SARTORI,
HARTI, CHENFOUR, 2007).
Na etapa inicial vista na arquitetura do sistema, temos a Interface que é
responsável pelo Processamento de Sinal Digital, nesta etapa algumas das técnicas
de PSD são aplicadas, dentre elas vale destacar que é neste momento que os
coeficientes MFCC são extraídos, são filtrados, a Transformada Inversa de Fourier é
aplicada obtendo 11 coeficientes, sendo o primeiro coeficiente descartado, restam
10 coeficientes para cada janela de tempo (RUARO; SILVA, 2011).
O Sphinx-4 possui um pacote separado, que é implementado somente para
tratar da aplicação das Transformadas. Podemos ver algumas classes deste pacote
na Figura 3, no trabalho de Ruaro e Silva (2011), onde o Sphinx-4 foi utilizado.

38
4.2.2 Ferramenta de treinamento
O Software Sphinx-4 ainda possui um ambiente que possibilita o treinamento
de uma linguagem falada, chamada SphinxTrain, possui os scripts e a
documentação para modelos de dados que podem ser utilizados no sistema de
reconhecimento Sphinx. Com esta ferramenta as pessoas podem treinar o Sphinx
com qualquer linguagem, basta possuir o áudio e sua transcrição em base de dados
para que o treinamento seja efetivo, alguns requisitos são necessários e estão
disponíveis na documentação (SARTORI, HARTI, CHENFOUR, 2007).
Não é possível iniciar um reconhecimento de fala sem uma base de dados para
comparar modelos acústicos, este modelo deve ser construído com o SphinxTrain.
Para instalação do SphinxTrain é preciso fazer o download do código que está
totalmente disponível no site do distribuidor CMU. Para a execução do treinamento
alguns softwares adicionais são necessários como Active Perl e Microsoft Visual
Studio (CMU, 2012).
4.2.3 Utilização da Ferramenta de Transcrição
É o transcritor que recebe os dados de áudio, é ele que transcreve o áudio.
Para o processo de transcrição é utilizado o software Sphinx4 o qual sua arquitetura
está descrita na seção 4.1.1.
O transcritor é completamente escrito na linguagem de programação Java, é
considerado uma ferramenta para transcrição, não um software fechado, possui
várias opções de utilização, algumas delas estão definidas nos próximos parágrafos.
A ferramenta de transcrição pode ser obtida através do download no site oficial do
CMU, a universidade do projeto Sphinx4. Nos pacotes que pedem ser adquiridos
pelo site estão disponíveis versões executáveis da ferramenta, são arquivos Java
compilados no formato “jar”.
Dentre as versões executáveis do Sphix4 a primeira a ser executada por
recomendação dos autores é a HelloWorld onde três opções de frases combinadas
são apresentadas na tela para que o usuário faça a combinação e o transcritor
identifique qual foi a frase dita. Outra versão executável é o JSGFDemo que permite
que frases aleatórias sejam identificadas pelo transcritor em tempo real, é um
software que fica executando um processo computacional e fica escutando os sons

39
e tenta transcrever todos os sinais acústicos. O último executável que será tratado
neste trabalho é o mais importante, pois transcreve arquivos de áudio no formato
“wav”, se chama LatticeDemo que significa rede de demonstração. A versão que
está disponível do Sphinx4 vem com um dicionário e arquivos de configurações em
um padrão demonstrativo, para obter um desempenho elevado é necessário
configurar o Sphinx4 para utilizar arquivos e dicionários extraídos do treinamento de
linguagem também disponibilizado pelo Sphinx4, está descrito na seção 4.1.2 (CMU,
2012).
A partir do treinamento de uma nova linguagem para o Sphinx4 é possível
utilizar o resultado do treinamento configurando os arquivos extraídos do
treinamento na ferramenta (CMU, 2012), são os arquivos com extensão “.dic” que
contém um dicionário de palavras referente ao treinamento, outro arquivo “.lm.DMP”
que contém o modelo de linguagem, estes arquivos devem ser adicionados ao
projeto e configurados no arquivo config.xml.
4.3 Ferramenta para Indexação e Recuperação de Dado s
O Google Search Appliance (GSA), já mencionado, como ferramenta de busca,
neste trabalho na seção 2.3.1.2 é a ferramenta escolhida para a indexação e
recuperação dos dados da voz. O GSA é um hardware com o software de busca do
Google embarcado, neste trabalho será disponibilizada uma máquina virtual com o
software de busca (GOOGLE, 2012).
A máquina virtual do GSA está disponível para download e pode ser
encontrada em outros sites pela busca do Google, para a utilização da máquina é
preciso obter um software para virtualização, o tutorial recomenda que seja utilizado
o VMWare player, uma ferramenta livre que é suportada nos Sistemas Operacionais
Windows e Linux (VMWARE, 2012).
Esta máquina virtual do GSA está em um ambiente Linux, a máquina já vem
pronta para instalação e não é possível fazer muitas configurações nela além das
configurações de rede, como também não é permitido pelo Google chegar ao código
fonte do software de busca.
40
4.3.1 Utilização da Ferramenta para Indexação e Recuperação de Dados
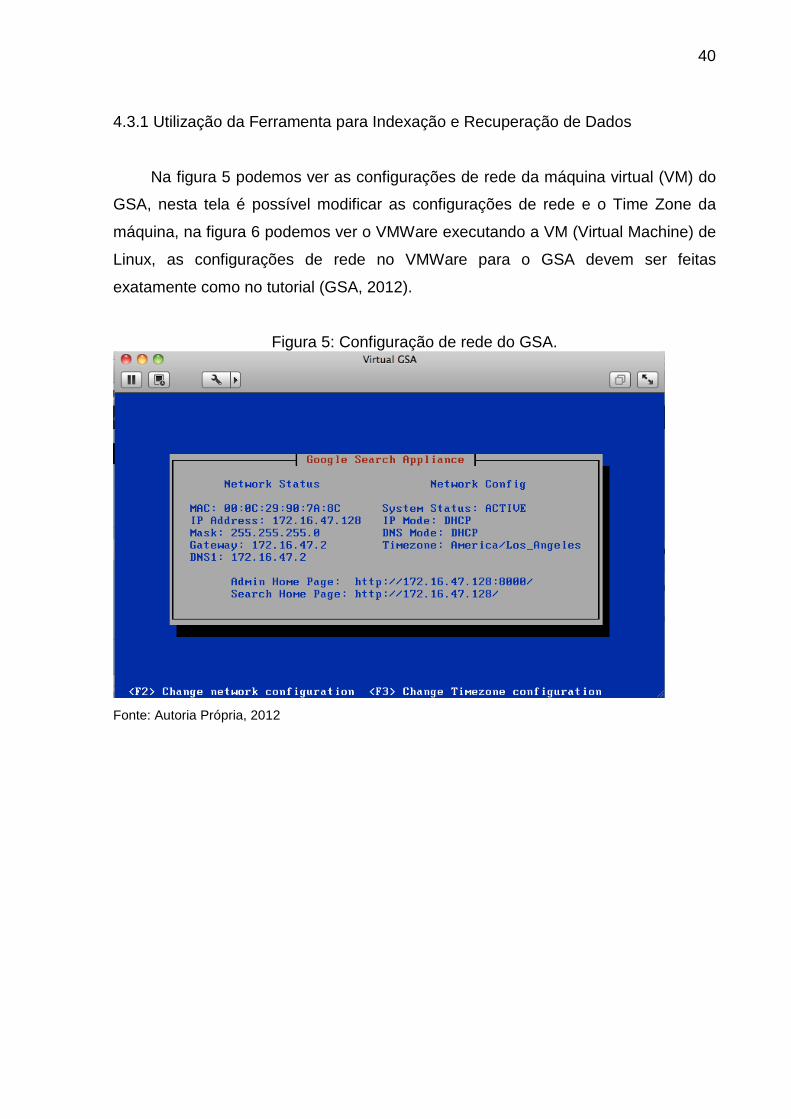
Na figura 5 podemos ver as configurações de rede da máquina virtual (VM) do
GSA, nesta tela é possível modificar as configurações de rede e o Time Zone da
máquina, na figura 6 podemos ver o VMWare executando a VM (Virtual Machine) de
Linux, as configurações de rede no VMWare para o GSA devem ser feitas
exatamente como no tutorial (GSA, 2012).
Figura 5: Configuração de rede do GSA.
Fonte: Autoria Própria, 2012

41
Figura 6: Visão do VMWare com a VM do GSA executando
Fonte: Autoria Própria, 2012
Na figura 7 podemos ver o GSA funcionando efetivamente, esta é a página de
interface do resultado de busca (GSA, 2012).
Figura 7:Interface de resultado de Busca
Fonte: Autoria Própria, 2012
Na figura 8 temos a interface de administração da ferramenta GSA, nesta
interface o conteúdo que será indexado é gerenciado, é nesta tela que o
administrador pode escolher o conteúdo que será exibido em cada perfil de busca e
ainda pode configurar uma nova interface de busca através da tecnologia XSLT
(eXtensible Stylesheet Language for Transformation) (GSA, 2012).

42
Figura 8: GSA Página Inicial Administrativa
Fonte: Autoria Própria, 2012
4.4 Arquitetura proposta
A arquitetura deste trabalho é composta por três processos principais, três
repositórios que armazenam dados de diferentes formatos e três interfaces, esta
arquitetura está disposta na figura 9. Nesta seção serão detalhadas cada etapa dos
três processos e as funções das interfaces. Os repositórios são utilizados por
processos e interfaces.
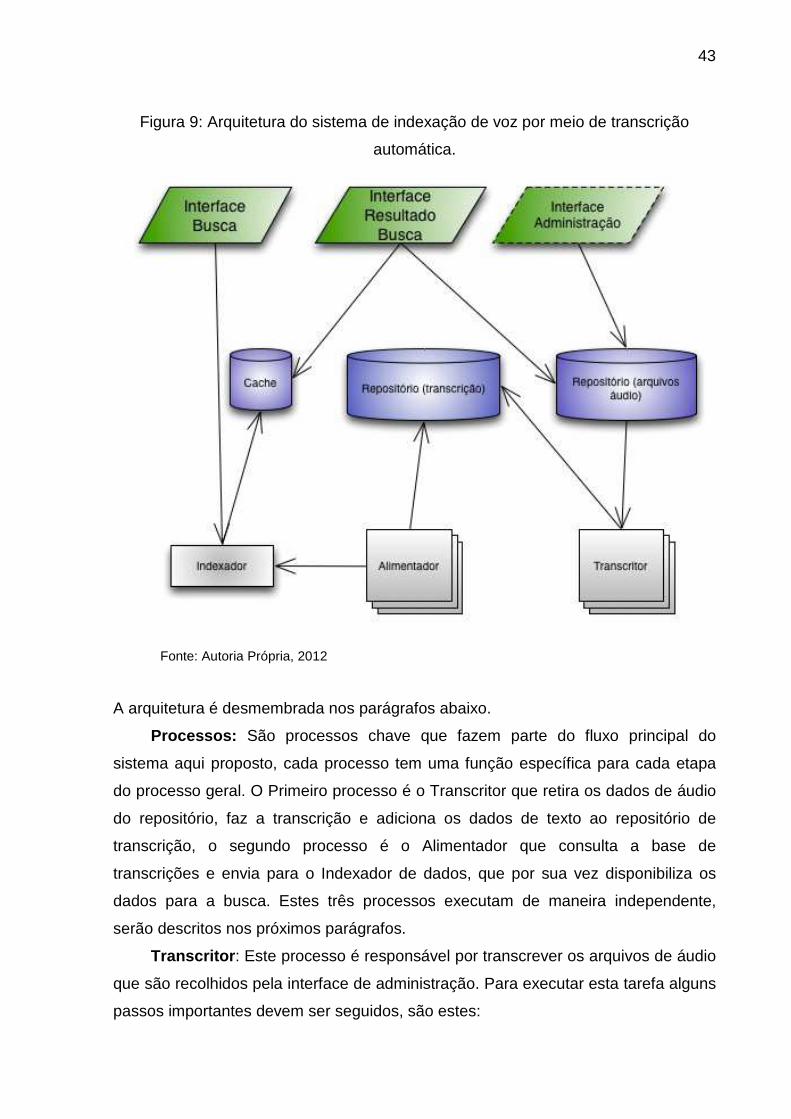
43
Figura 9: Arquitetura do sistema de indexação de voz por meio de transcrição
automática.
Fonte: Autoria Própria, 2012
A arquitetura é desmembrada nos parágrafos abaixo.
Processos: São processos chave que fazem parte do fluxo principal do
sistema aqui proposto, cada processo tem uma função específica para cada etapa
do processo geral. O Primeiro processo é o Transcritor que retira os dados de áudio
do repositório, faz a transcrição e adiciona os dados de texto ao repositório de
transcrição, o segundo processo é o Alimentador que consulta a base de
transcrições e envia para o Indexador de dados, que por sua vez disponibiliza os
dados para a busca. Estes três processos executam de maneira independente,
serão descritos nos próximos parágrafos.
Transcritor : Este processo é responsável por transcrever os arquivos de áudio
que são recolhidos pela interface de administração. Para executar esta tarefa alguns
passos importantes devem ser seguidos, são estes:

44
1. Localizar o arquivo wav que é disponibilizado pela interface de
administração;
2. Executar o Java que chama um processo do Sphix4 para transcrição;
3. Extrair a transcrição do áudio;
4. Guarda a transcrição em modo texto no repositório de transcrições.
Os diretórios em que os arquivos de áudio estarão disponíveis precisam ser
previamente decididos e configurados na aplicação, tanto o alimentador que está
descrito no próximo processo quanto o transcritor precisam ter esta informação.
Assim que o arquivo wav for localizado o programa LatticeDemo, que já está
configurado com os dicionários e os arquivos de treinamento, é executado passando
o arquivo de áudio como parâmetro. O Sphinx4 executa e extrai o texto do áudio, o
transcritor por final armazena a transcrição em modo texto no repositório de
transcrições.
A execução do Sphinx4 pode levar mais de um minuto e por isso os processos
não tem sincronia, são executados separadamente, o alimentador não espera pelo
transcritor, ele verifica se existem arquivos novos no repositório de arquivos
transcritos para executar seus processos.
Alimentador: Este processo é responsável por alimentar o indexador. A
alimentação do indexador tem alguns passos importantes e específicos na sua
implementação.
Este processo é totalmente implementado em Java e utiliza algumas
tecnologias específicas para realizar suas funções. As funções principais, para
alimentar o indexador, deste processo são:
1. Localizar o arquivo com extensão wav;
2. Localizar e carregar o arquivo de texto que é equivalente a transcrição do
arquivo wav;
3. Formar o feed;
4. Anexar ao feed a localização do arquivo wav;
5. Anexar ao feed o conteúdo do arquivo texto a transcrição do arquivo wav;
6. Enviar o feed ao Google Search Appliance.

45
Os arquivos de áudio devem ser disponibilizados em um ambiente que será
mapeado pelo indexador, esta disponibilização é feita pelo processo transcritor. Para
carregar os arquivos de texto a implementação conta com uma biblioteca que está
no pacote disponibilizado na JDK (Java Development Kit) desde sua versão 1.0
(ORACLE, 2010) é o pacote java.io que possui a classe File, dentre outras classes
que trabalham com a manipulação de arquivos em modo texto.
Para formar o feed também é utilizado o pacote java.io, mas neste passo do
processo o arquivo a ser manipulado está no formato XML. O Google Search
Appliance aceita que arquivos sejam indexados de forma arbitrária, onde uma
aplicação (que neste trabalho é o processo Alimentador) monta um arquivo XML
com o conteúdo que deve ser indexado, este conteúdo pode ser de vários formatos
como arquivos em PDF (Portable Document Format), em HTML ou em modo texto,
como é o caso deste trabalho (GSA, 2012).
O feed pode ser de três tipos, full, incremental ou metadata-and-url, o tipo full
indica que sempre que for submetido um feed com a mesma fonte de dados, será
substituído pelo novo feed. O tipo incremental indica que a fonte de dados irá
sempre incrementar os feeds acumulados, estes dois primeiros tipos alimentam o
GSA com conteúdo completo, ou seja, com URLs (Uniform Resource Locator) e o
conteúdo do feed que neste trabalho se tratam do caminho do arquivo de áudio e do
conteúdo transcrito respectivamente, também podem conter metadados. O tipo
metadata-and-url indica que o feed terá somente metadados e URLs.
A estrutura do XML do feed consiste em um cabeçalho XML, uma tag principal
chamada gsafeed uma tag header e uma ou mais tags group, uma tag é como se dá
marcação do XML, é dessa maneira que o feed é estruturado. A tag group carrega a
informação que deve ser indexada, ela tem uma tag interna chamada record que faz
referência ao registro que será indexado, esta tag record possui outra tag interna
chamada content que possui o conteúdo do registro. A tag group possui uma
propriedade chama action que determina a ação que será tomada no GSA com o
conteúdo enviado, esta ação pode ser de delete ou para adicionar conteúdo esta
propriedade não precisa ser declarada. Para um melhor entendimento da estrutura
do feed a figura 10 deve ser analisada.

46
Figura 10: Exemplo de feed incremental
Fonte: GSA, 2012.
Por fim este processo precisa enviar o feed construído ao GSA, para enviar
utiliza uma tecnologia específica do Java que é disponibilizada nas bibliotecas:
commons-httpclient.jar, commons-logging.jar e commons-codec.jar, as classes
HttpClient e MultipartRequestEntity são essenciais para o envio do arquivo via
método POST ao GSA que retorna HTTP 200 OK para confirmar o recebimento
(GSA, 2012).
Indexador: O processo de indexação pode ser feito de algumas formas
diferentes, tudo depende dos tipos de dados que serão indexados, todos os tipos de
dados podem ser indexados via feed onde o papel do Alimentador é fundamental,
mas o GSA possui algumas funcionalidades que facilitam a indexação de
determinados tipos de dados, como dados disponíveis na Web. Como vimos na
figura 8, a página inicial de administração do GSA, temos caixas de entrada de texto
que aceitam padrões de URLs que serão rastreadas pelo indexador, para isso o
GSA utiliza um rastreador de URLs (GSA, 2012).
Para configurar o rastreador de URLs, é preciso estar logado no console
administrativo do GSA e navegar até “Crawl and Index > Crawl URLs”, serão
exibidas três caixas de entrada de texto, a primeira é “Start Crawling from the
Following URLs” esta caixa deve conter o padrão de URL inicial a ser rastreado, a
segunda caixa “Follow and Crawl Only URLs with the Following Patterns” deve

47
conter o padrão de URL que deve ser seguido pelo rastreador, e a última caixa deve
conter o padrão de URL a não ser rastreado, a última caixa é a única que vem
preenchida e o Google recomenda que nada nesta caixa seja modificado, apenas
adicionar conteúdo. Na figura 11 podemos ver exemplos de padrões que podem ser
utilizados para iniciar o rastreamento de URLs pelo console administrativo do GSA.
Figura 11: Configuração para o rastreador de URLs
Fonte: Autoria Própria, 2012
Outro tipo de rastreamento permitido pelo GSA é uma ferramenta que conecta
diretamente no banco de dados podendo indexar uma tabela inteira ou dados
extraídos de uma consulta, está disponível na tela de “Database Crawling and
Serving” e pode ser configurado como no exemplo que podemos ver na figura 12.
Figura 12: Criação de uma nova fonte de dados
Fonte: Autoria Própria, 2012
Após o processo de indexação concluído o GSA disponibiliza uma tela onde é
possível consultar o conteúdo que foi indexado e se ele foi corretamente indexado.

48
Uma funcionalidade nesta consulta é acessar o que está armazenado em cache pelo
GSA. Na figura 13 podemos ver o cache de um documento de áudio que foi
indexado pelo GSA.
O processo de indexação é totalmente executado pelo GSA e os
desenvolvedores não tem acesso ao código fonte que indica a maneira como a
indexação é feita.
Figura 13: Disponibilização do Cache de dados
Fonte: Autoria Própria, 2012
Interfaces: As interfaces do sistema proposto neste trabalho estão divididas
em três principais, a interface de Busca, de Resultados e de Administração, as duas
primeiras estão diretamente relacionadas ao GSA, pois são interfaces
disponibilizadas por esta ferramenta e podem ser customizadas de acordo com a
preferência da empresa ou da administração da ferramenta.
Busca: Podemos ver a interface de Busca padrão disponibilizada pelo GSA na
figura 7, esta interface pode ser completamente customizada a partir do console de
administração do GSA, esta tela está construída em uma linguagem estilo chamada
XSLT é no XSLT que a imagem do Google é trocada pela imagem que pode ser
vista na figura 14.
49
Figura 14: Página de busca personalizada
Fonte: Autoria Própria, 2012
Resultado: A interface de resultado de busca é bem similar a interface de
busca e também pode ser complemente customizada utilizando XSLT, as figuras 15
e 16 ilustram o console de administração do GSA onde a tela pode ser customizada.
Figura 15: Configuração de novo frontend no GSA para resultado de busca
Fonte: Autoria Própria, 2012

50
Figura 16: Configuração de novo front-end no GSA para caixa de busca
Fonte: Autoria Própria, 2012
A interface de resultados de busca do GSA já vem implementada com um estilo
padrão, para sistemas que não precisam fazer um tratamento avançado da interface,
se utilizam desta padrão sem gerar problemas, mas para sistemas que precisam
aprimorar a interface de busca este padrão se torna trabalhoso para dar
manutenção, foi para este objetivo que o Google disponibilizou a API na linguagem
Java chamada de GSA-JAPI (INXIGHT, 2006). Esta é uma simples API para
consulta ao Google Search Appliance, para utilizar é preciso codificar uma aplicação
em java, passar os parâmetros de configuração do GSA e montar uma consulta, os
resultados são entregues em forma de Objeto Java e a partir deste ponto a interface
que exibe o resultado de busca pode ser formatada como for necessário.
Neste trabalho o sistema proposto não necessita de uma interface aprimorada
e por este motivo a interface padrão disponibilizada pelo GSA é suficiente sendo
customizada pelo XSLT.
Administração: Esta interface se resume em uma página html simples que faz
o upload de um arquivo de áudio, algumas restrições de arquivo são necessárias,
uma delas é restringir o tipo de arquivo que será feito o upload, deve ser do tipo
áudio com extensão de arquivo “.wav”. Se trata de uma simples interface com um
formulário, não está no escopo deste trabalho trabalhar com interfaces elaboradas,
uma interface simples atende ao requisito.

51
É a partir desta interface que todo o ciclo do sistema se inicia, tendo a
disponibilização do arquivo de áudio, ele poderá ser transcrito, indexado, encontrado
e exibido.
4.5 Utilização da Ferramenta Proposta
As duas ferramentas principais citadas nas seções 4.2 e 4.3 precisam se
comunicar e para obter melhor desempenho, tanto a máquina virtual, as aplicações
em Java e as interfaces se encontram na mesma máquina.
A figura 17 ilustra um caso de uso da ferramenta proposta neste trabalho, o
usuário terá acesso as interfaces de busca, resultado e administração, cada
interface está detalhada na seção 4.4. Na interface de administração o usuário
poderá submeter seus arquivos para indexação e disponibilização para busca e
exibição.
A limitação deste trabalho está nas limitações das ferramentas, em primeiro a
ferramenta de indexação e busca somente poderá indexar até cinquenta mil
documentos (GSA, 2012) e a interface de administração aceita somente arquivos de
até 5 mega bytes.
Figura 17: Diagrama de Caso de uso da ferramenta proposta
Fonte: Autoria Própria, 2012
Obter Transcrição é o nome do caso de uso apresentado na figura 16, onde o
Ator primário, o Administrador, utiliza o sistema para realizar a indexação de

52
arquivos de áudio. O administrador tem o papel de selecionar e fornecer os arquivos
de áudio ao sistema através da interface de administração.
O ator secundário é o usuário, ele vai acessar o sistema consultando as
informações desejadas. Assim que o usuário acessa o sistema, uma interface de
busca é carregada na página inicial, é através dessa página que o usuário faz a
busca por arquivos de áudio e a partir da página de resultados de busca o usuário
tem acesso a transcrição do áudio e pode obter o arquivo para ouvir o áudio. Para
obter a transcrição do áudio o usuário pode clicar no link da versão em texto
disponível na interface de resultado de busca e para obter o arquivo de áudio, deve
clicar no link principal que se refere ao documento buscado.
4.6 Considerações Finais
O capítulo de desenvolvimento deste trabalho demonstrou todas as etapas
necessárias para que seja possível construir o sistema proposto, iniciou com as
ferramentas disponíveis no estado da arte e a motivação pela escolha de cada
ferramenta, seguiu demonstrando a utilização de cada ferramenta escolhida. A
seção que trata da arquitetura do sistema mostra o sistema formatado como um todo
e também descreve o detalhe de cada processo necessário para que a função do
sistema esteja completa.
O sistema demonstrado no capítulo 4 pode ser comparado com os sistemas
descritos no capítulo 3, onde as tecnologias utilizadas são Java, Google Search
Appliance, Sphinx4, Metadados, XML e Indexação automática de dados. Os
trabalhos relacionados a este se utilizam destas tecnologias separadamente, ou
seja, cada um explora até três delas ao mesmo tempo.
A ultima consideração para este capítulo é que os trabalhos relacionados não
se utilizam da transcrição e indexação ao mesmo tempo para um objetivo geral,
usualmente os autores fazem a junção destas tecnologias para um objetivo
específico como no trabalho de Ruaro e Silva (2011), onde além de utilizar o
reconhecimento do som da fala proporciona que a saída deste processamento seja
disponível para utilização em outras aplicações, não para indexação de voz.

53
5 AVALIAÇÃO
Neste capitulo será descrito o método de avaliação, os casos de treinamento e
os casos de teste submetidos a ferramenta proposta neste trabalho, inicia avaliando
cada ferramenta separadamente para no final avaliar a ferramenta como um todo, na
primeira seção deste capítulo será apresentado o paradigma utilizado para
avaliação, na segunda seção além da avaliação do método de transcrição podemos
encontrar a comparação deste trabalho com o trabalho relacionado do autor Yuan
(2012) e na terceira seção encontramos a avaliação do método de busca, seguido
da avaliação da ferramenta como um todo.
5.1 Metodologia de Avaliação
Um paradigma bastante utilizado para medir produtos de software e processos
é o Paradigma GQM (Goal, Question, Metric), Goal significa objetivo e está no nível
de conceito, deve respeitar um modelo de qualidade a partir do estado da arte, que
neste caso se encaixa na meta deste trabalho. Question representa as questões que
a meta gera, está no nível operacional é uma questão que define como a avaliação
será feita. E Metric representa as metas que são necessárias para a avaliação do
produto, está no nível quantitativo e representa os dados que serão medidos
(ROCHA, 2006).
5.1.2 Aplicação do GQM
Para aplicar o paradigma a um produto, é necessário respeitar quatro fases de
desenvolvimento, é preciso Planejar, Definir, Coletar Dados e Interpretar.
Na fase do planejamento é necessário planejar o que será o alvo da medição,
na fase da Definição os objetivos, questões e métricas são definidos, na fase da
coleta de dados, os casos de teste são executados extraindo as informações para
aplicar as métricas definidas, e na fase da interpretação os dados coletados são
filtrados para responder as questões levantadas na segunda fase, e nesta última
fase os dados precisam ser analisados para verificar se atendem as expectativas
(ROCHA, 2006).

54
Nas seções seguintes podemos encontrar o paradigma GQM sendo aplicado
na avaliação do sistema proposto neste trabalho.
5.2 Avaliação do Processo de Transcrição
Esta seção está dividida em três seções que descrevem a aplicação e os
resultados da avaliação do processo de transcrição utilizado neste trabalho, e na
primeira seção, descreve o processo de treinamento da ferramenta Sphinx4 para a
língua portuguesa.
5.2.1 Treinamento
O software Sphinx4, descrito na seção 4.2, reconhece o sinal acústico da fala
somente se ele for treinado para fazer esta identificação, para isso o distribuidor
deste software disponibiliza uma ferramenta de treinamento, essa ferramenta é
chamada de Sphinxtrain e está disponível para download. O distribuidor do software
recomenda fazer o treinamento somente se houver tempo para isso (CMU, 2012).
Segue uma lista do que é necessário para poder iniciar o treinamento:
• Criar um novo modelo para uma nova linguagem;
• Dados para o treinamento:
o Uma hora de gravação de um locutor;
o Cinco horas de gravação com 200 locutores;
o Dez horas de gravação de um locutor ditando;
o Cinquenta horas de gravação com 200 locutores ditando;
• Conhecimento fonético da estrutura da linguagem;
• Tempo para treinar o modelo e otimizar os parâmetros
E quando não é preciso treinar:
• Quando é preciso melhorar a precisão de um modelo, então deve-se adaptar o
modelo existente;
• Quando não possui dados suficientes, então deve-se adaptar o modelo
existente;
• Quando não possui tempo suficiente;

55
• Quando não possui experiência suficiente.
Para este trabalho foi adaptado um modelo acústico existente, um vocabulário
com cerca de 65 mil palavras, o modelo foi criado com o software SphinxTrain.
Para o treinamento foi utilizado o “corpus Constituição da República Federativa
do Brasil. Foram treinados modelos trifones dependentes de contexto”
(FALABRASIL, 2009). O tutorial para o treinamento pode ser encontrado no site do
projeto CmuSphinx.
5.2.2 Aplicação do GQM para o processo de Transcrição
Para iniciar a aplicação da avaliação o alvo definido nesta etapa é o processo
de transcrição, o objetivo da avaliação está definido por avaliar a eficiência da
transcrição de arquivos de áudio na língua portuguesa.
As questões que estão no contexto deste trabalho, auxiliam na definição das
métricas necessárias para a avaliação do processo de transcrição, são estas:
• Qual a proporção de palavras que correspondem ao texto correto para que o
texto da transcrição seja entendido?
• Quanto ao tempo do áudio, em quais casos de teste o texto tem a proporção
da primeira questão?
Segundo a primeira questão a avaliação deve cobrir a quantidade de palavras
certas comparando a transcrição automática com a transcrição manual, já a segunda
questão se refere a essa métrica mas relacionando arquivos de áudio em tempos
diferentes, ou seja, arquivos maiores ou menores. As métricas definidas através das
questões são:
1. Porcentagem de palavras certas;
2. Média de tempo do áudio.
Para avaliar este processo e coletar os dados necessários, casos de teste são
executados na ferramenta que passou pelo treinamento. Os dados utilizados para os
casos de teste são arquivos de áudio no contexto da Constituição da República
Federativa do Brasil, neste contexto estão o Estatutos da criança e do adolescente,

56
Legislação sobre o Idoso, Acessibilidade, Lei Maria da Penha e o código de defesa
do consumidor com um total de mais de 100 arquivos de áudio.
O teste utiliza um processo que conta as palavras de cada texto e compara
com as palavras encontradas na transcrição, este teste é automatizado com um
processo.
Uma particularidade do sistema é que os arquivos tenham uma configuração
que está descrita no tutorial de treinamento da ferramenta, os requisitos são que o
arquivo seja no formato MS WAV, que a taxa de amostragem do sinal seja de
22.050 Hz, que a resolução seja de 16bits e que o sinal esteja somente em um
canal, ou seja, mono.
5.2.3 Resultado da Avaliação do Processo de Transcrição
O resultado da avaliação se dá a partir da coleta de dados que é feita através
do teste automatizado, o teste conta com mais de 100 arquivos de aúdio diferentes,
como explicado na seção anterior, este teste gera uma saída com três componentes,
primeiro a porcentagem de acerto da transcrição, segundo a quantidade de palavras
encontradas e o terceiro a quantidade de palavras do texto original. O resultado
compilado do teste automatizado pode ser visto na tabela 1.
Tabela 1: Resultado do teste separado por intervalo de palavras
NÚMERO DE PALAVRAS ORIGINAIS NÚMERO DE PALAVRAS ENCONTRADAS MÉDIA DE ACERTO (%)
18 - 39 16 - 34 82.88
40 - 49 27 - 44 79.86
50 - 59 45 - 43 80.58
60 - 69 42 - 58 81.50
70 - 85 58 - 73 80.64 Fonte: Autoria Própria, 2012
No quadro 4 podemos ver os casos extremos do teste, na primeira coluna
encontramos o caso menos eficiente e na segunda o caso mais eficiente, onde a
transcrição teve 96% de acerto, na terceira coluna o tempo de execução do áudio.
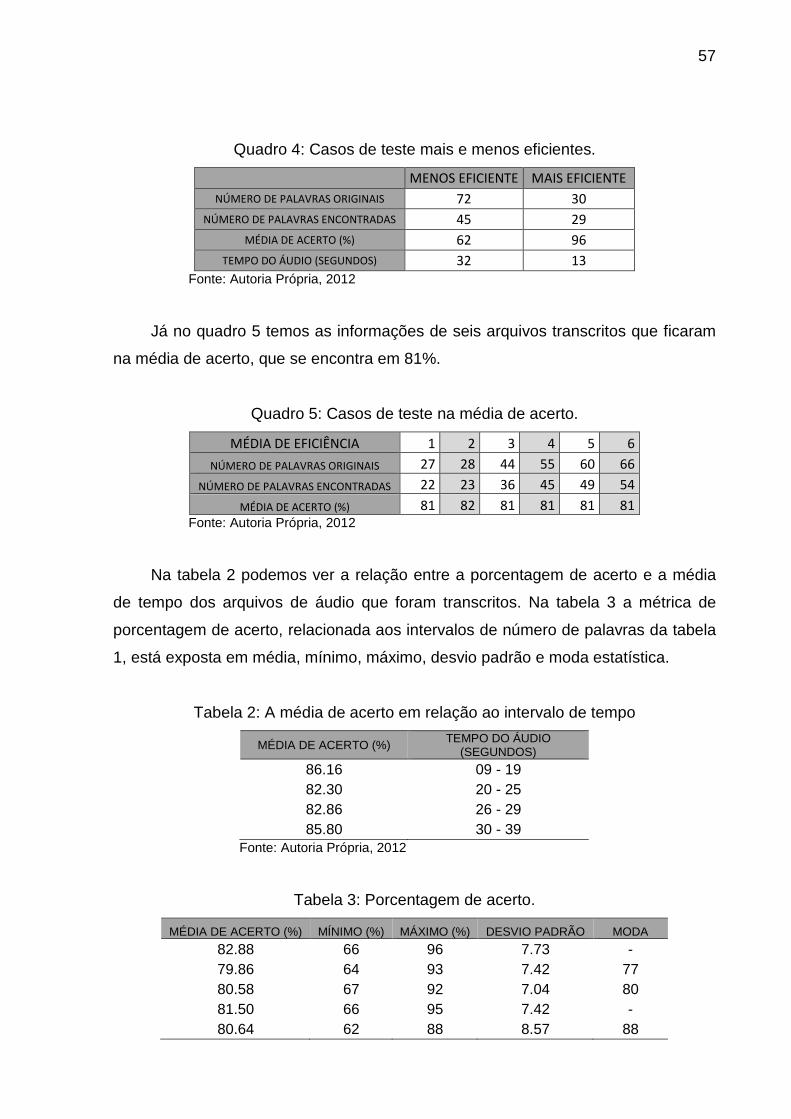
57
Quadro 4: Casos de teste mais e menos eficientes.
MENOS EFICIENTE MAIS EFICIENTE
NÚMERO DE PALAVRAS ORIGINAIS 72 30
NÚMERO DE PALAVRAS ENCONTRADAS 45 29
MÉDIA DE ACERTO (%) 62 96
TEMPO DO ÁUDIO (SEGUNDOS) 32 13 Fonte: Autoria Própria, 2012
Já no quadro 5 temos as informações de seis arquivos transcritos que ficaram
na média de acerto, que se encontra em 81%.
Quadro 5: Casos de teste na média de acerto.
MÉDIA DE EFICIÊNCIA 1 2 3 4 5 6
NÚMERO DE PALAVRAS ORIGINAIS 27 28 44 55 60 66
NÚMERO DE PALAVRAS ENCONTRADAS 22 23 36 45 49 54
MÉDIA DE ACERTO (%) 81 82 81 81 81 81 Fonte: Autoria Própria, 2012
Na tabela 2 podemos ver a relação entre a porcentagem de acerto e a média
de tempo dos arquivos de áudio que foram transcritos. Na tabela 3 a métrica de
porcentagem de acerto, relacionada aos intervalos de número de palavras da tabela
1, está exposta em média, mínimo, máximo, desvio padrão e moda estatística.
Tabela 2: A média de acerto em relação ao intervalo de tempo
MÉDIA DE ACERTO (%) TEMPO DO ÁUDIO (SEGUNDOS)
86.16 09 - 19 82.30 20 - 25 82.86 26 - 29 85.80 30 - 39
Fonte: Autoria Própria, 2012
Tabela 3: Porcentagem de acerto.
MÉDIA DE ACERTO (%) MÍNIMO (%) MÁXIMO (%) DESVIO PADRÃO MODA
82.88 66 96 7.73 - 79.86 64 93 7.42 77 80.58 67 92 7.04 80 81.50 66 95 7.42 - 80.64 62 88 8.57 88
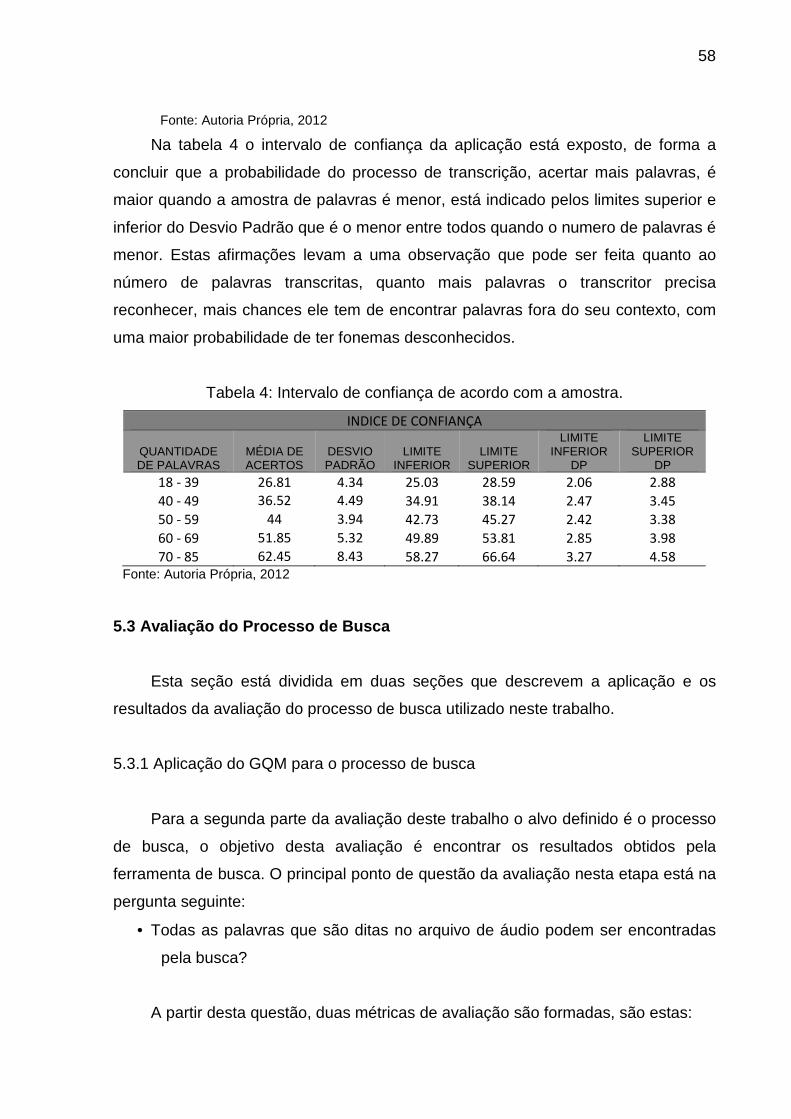
58
Fonte: Autoria Própria, 2012
Na tabela 4 o intervalo de confiança da aplicação está exposto, de forma a
concluir que a probabilidade do processo de transcrição, acertar mais palavras, é
maior quando a amostra de palavras é menor, está indicado pelos limites superior e
inferior do Desvio Padrão que é o menor entre todos quando o numero de palavras é
menor. Estas afirmações levam a uma observação que pode ser feita quanto ao
número de palavras transcritas, quanto mais palavras o transcritor precisa
reconhecer, mais chances ele tem de encontrar palavras fora do seu contexto, com
uma maior probabilidade de ter fonemas desconhecidos.
Tabela 4: Intervalo de confiança de acordo com a amostra.
INDICE DE CONFIANÇA
QUANTIDADE DE PALAVRAS
MÉDIA DE ACERTOS
DESVIO PADRÃO
LIMITE INFERIOR
LIMITE SUPERIOR
LIMITE INFERIOR
DP
LIMITE SUPERIOR
DP
18 - 39 26.81 4.34 25.03 28.59 2.06 2.88
40 - 49 36.52 4.49 34.91 38.14 2.47 3.45
50 - 59 44 3.94 42.73 45.27 2.42 3.38
60 - 69 51.85 5.32 49.89 53.81 2.85 3.98
70 - 85 62.45 8.43 58.27 66.64 3.27 4.58 Fonte: Autoria Própria, 2012
5.3 Avaliação do Processo de Busca
Esta seção está dividida em duas seções que descrevem a aplicação e os
resultados da avaliação do processo de busca utilizado neste trabalho.
5.3.1 Aplicação do GQM para o processo de busca
Para a segunda parte da avaliação deste trabalho o alvo definido é o processo
de busca, o objetivo desta avaliação é encontrar os resultados obtidos pela
ferramenta de busca. O principal ponto de questão da avaliação nesta etapa está na
pergunta seguinte:
• Todas as palavras que são ditas no arquivo de áudio podem ser encontradas
pela busca?
A partir desta questão, duas métricas de avaliação são formadas, são estas:

59
1. Porcentagem de palavras certas;
2. Porcentagem de palavras encontradas.
Para calcular estas porcentagens são feitos testes de busca na aplicação após
o processo de indexação de cada arquivo transcrito. O teste manual deve ser feito
buscando cada palavra do texto original e verificando se o arquivo transcrito é
encontrado.
Um teste automatizado foi implementado utilizando a API na linguagem Java
chamada de GSA-JAPI (INXIGHT, 2006), o teste utiliza a tecnologia Java para ler o
arquivo original e executar a busca de cada palavra, faz ainda a análise do resultado
para saber se o arquivo transcrito foi encontrado.
Existem duas situações onde o resultado de busca pode ser avaliado, a
primeira acontece quando todos os arquivos encontrados pela busca são
equiparados com o arquivo do termo buscado, a segunda situação acontece quando
somente os arquivos mais relevantes, arquivos posicionados pelo mecanismo de
busca, são equiparados com o arquivo do termo buscado. Estas duas situações são
avaliadas na próxima seção.
5.3.2 Resultado da Avaliação do processo de busca
O resultado da avaliação neste ponto é composto pela saída gerada pelo teste
automatizado da busca. No teste temos a saída com quatro componentes, o primeiro
componente é o número de palavras relevantes contidas no arquivo original , o
segundo é a quantidade de palavras encontradas pela busca, em terceiro a relação
de proporção entre as duas primeiras saídas e por final o número total de palavras
contidas no arquivo original. Na Tabela 5 podemos ver o resultado compilado do
teste automatizado.
O número de palavras relevantes contidas no arquivo original, é o número de
palavras do arquivo original menos 5 palavras que são muito genéricas e acabam
influenciando na busca, foram escolhidas estas cinco palavras por não possuírem
nenhuma relação com o contexto da busca e também por se tratar de palavras com
duas ou menos letras, são estas: a, e, o, da, de.
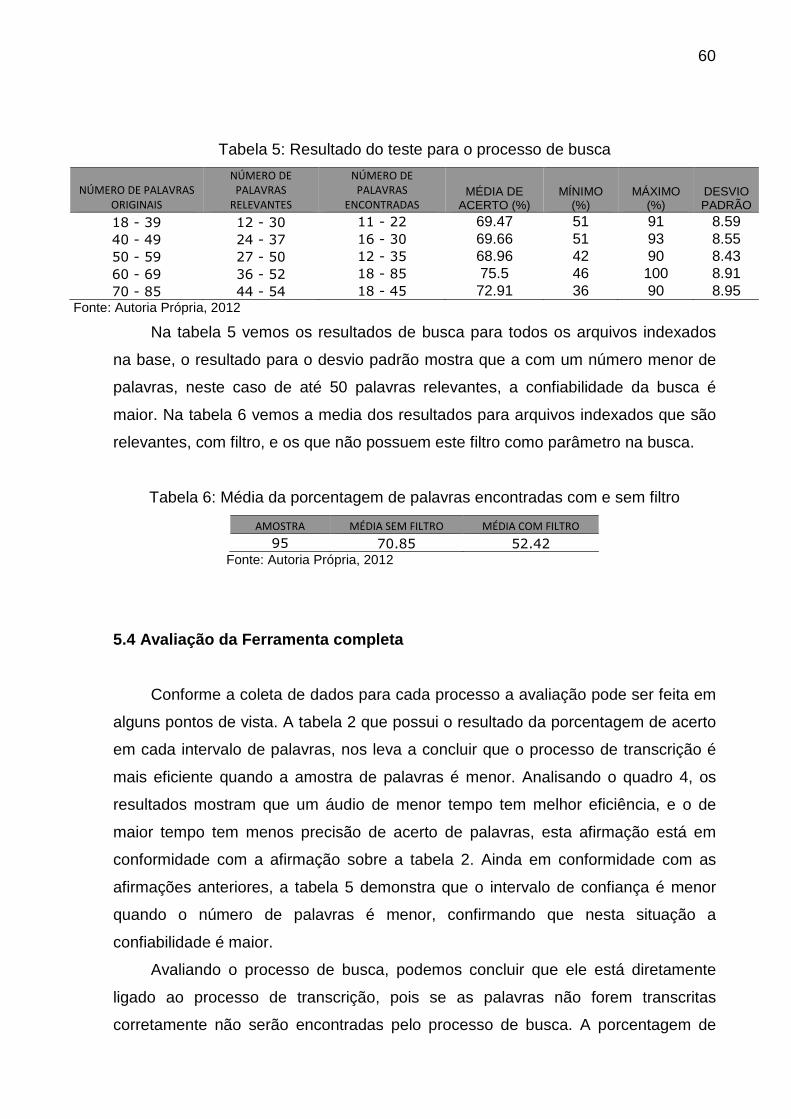
60
Tabela 5: Resultado do teste para o processo de busca
NÚMERO DE PALAVRAS ORIGINAIS
NÚMERO DE PALAVRAS
RELEVANTES
NÚMERO DE PALAVRAS
ENCONTRADAS MÉDIA DE
ACERTO (%) MÍNIMO
(%) MÁXIMO
(%) DESVIO PADRÃO
18 - 39 12 - 30 11 - 22 69.47 51 91 8.59 40 - 49 24 - 37 16 - 30 69.66 51 93 8.55 50 - 59 27 - 50 12 - 35 68.96 42 90 8.43 60 - 69 36 - 52 18 - 85 75.5 46 100 8.91 70 - 85 44 - 54 18 - 45 72.91 36 90 8.95
Fonte: Autoria Própria, 2012
Na tabela 5 vemos os resultados de busca para todos os arquivos indexados
na base, o resultado para o desvio padrão mostra que a com um número menor de
palavras, neste caso de até 50 palavras relevantes, a confiabilidade da busca é
maior. Na tabela 6 vemos a media dos resultados para arquivos indexados que são
relevantes, com filtro, e os que não possuem este filtro como parâmetro na busca.
Tabela 6: Média da porcentagem de palavras encontradas com e sem filtro
AMOSTRA MÉDIA SEM FILTRO MÉDIA COM FILTRO
95 70.85 52.42
Fonte: Autoria Própria, 2012
5.4 Avaliação da Ferramenta completa
Conforme a coleta de dados para cada processo a avaliação pode ser feita em
alguns pontos de vista. A tabela 2 que possui o resultado da porcentagem de acerto
em cada intervalo de palavras, nos leva a concluir que o processo de transcrição é
mais eficiente quando a amostra de palavras é menor. Analisando o quadro 4, os
resultados mostram que um áudio de menor tempo tem melhor eficiência, e o de
maior tempo tem menos precisão de acerto de palavras, esta afirmação está em
conformidade com a afirmação sobre a tabela 2. Ainda em conformidade com as
afirmações anteriores, a tabela 5 demonstra que o intervalo de confiança é menor
quando o número de palavras é menor, confirmando que nesta situação a
confiabilidade é maior.
Avaliando o processo de busca, podemos concluir que ele está diretamente
ligado ao processo de transcrição, pois se as palavras não forem transcritas
corretamente não serão encontradas pelo processo de busca. A porcentagem de

61
acerto neste processo é menor que a porcentagem de acerto da transcrição,
justamente pela afirmação que inicia este parágrafo.
5.5 Considerações Finais da Avaliação
Com os resultados compilados dos testes automatizados é possível concluir
que a eficiência do resultado de busca depende diretamente da eficiência da
transcrição do áudio. Com o teste feito no processo de transcrição a conclusão
visível é de que quanto menor a quantidade de palavras contidas no áudio, melhor é
o resultado da transcrição. E avaliando o resultado dos testes para o processo de
busca, vemos uma porcentagem menor de acerto comparando com os resultados do
processo de transcrição. Isso se dá pela dependência da eficiência da transcrição.

62
6 CONCLUSÃO E TRABALHOS FUTUROS
A aplicação proposta neste trabalho colabora com os estudos na área de
Tecnologia da Informação que visam indexar arquivos de áudio por meio de
transcrição. No decorrer do trabalho foram apresentadas as tecnologias necessárias
para alcançar os objetivos do trabalho, os trabalhos relacionados a este e a solução
proposta para indexar arquivos de áudio por meio de transcrição.
O modelo proposto neste trabalho vai além de uma aplicação independente, a
proposta vista aqui pode e deve ser adaptada e incorporada a sistemas existentes,
sistemas que tem a necessidade de encontrar documentos que estão fora do
formato de texto puro, e hoje são indexados via metadados. A vantagem de basear a
recuperação no texto transcrito é a dificuldade de expressar toda a riqueza de
conteúdo de um áudio mais extenso através apenas de metadados.
Neste trabalho foram utilizados dados de teste do corpus da Constituição da
República Federativa do Brasil, com arquivos de áudio de aproximadamente 25
segundos cada, bem como outros áudios relativos à legislação brasileira, com suas
respectivas transcrições originais, A base sistematizada poderá ser utilizada para
outros trabalhos que visam transcrever áudios na língua portuguesa.
A limitação que mais se destaca neste trabalho para a correta transcrição é a
existência da áudios com diferentes sotaques, isto é, uma maneira de falar a língua
portuguesa, diferente para cada região do país. Esta é uma limitação comum a
outras línguas e sistemas. Esta barreira pode ser quebrada ou minimizada através
do treinamento da ferramenta para diferentes sotaques. Outra limitação é o número
de arquivos que podem ser indexados que está limitado em cinquenta mil arquivos
pela utilização da versão gratuita do GSA.
Os resultados que esta pesquisa gerou estão no seu estado inicial, com o
objetivo de encontrar arquivos de áudio falados, conforme os objetivos apresentados
na proposta. Para que esta ferramenta se torne mais completa, podemos citar
alguns trabalhos futuros:
• Busca por palavra exata que retorne qual o tempo a palavra foi dita no áudio,
apresentando uma linha de tempo.
• Apresentar legenda em um tocador de áudio embutido na ferramenta de
apresentação.

63
• Tornar a ferramenta com mais capacidade de indexação, com aquisição de
licença ou com a utilização do outro software que está referenciado neste
trabalho, o Lucene.
• Ter a opção de correção manual do texto com sugestão de correção das
palavras, fazer um sistema de sugestão de correção de palavras, para que
seja agregado ao sistema atual.
• Treinar mais a ferramenta para que compreenda outros contextos, como o
português coloquial.
• Fazer um estudo que compara duas estruturas de sistemas computacionais
aplicados para o reconhecimento de linguagem natural, Redes Neurais
Artificiais e Modelos Ocultos de Markov.

64
REFERÊNCIAS
ADAMI, André Gustavo. Sistema de Reconhecimento de Locutor utilizando Redes Neurais Artificiais. Dissertação de Mestrado. SABI. Porto Alegre, Instituto de Informática UFRGS, 1997. AIRES, João P.; VAZ, Maria Salete M. G.. Modelo de Indexação e Recuperação de Metadados Distribuídos. UTFPR-PG: Ponta Grossa, 2007. AMARAL et al. Anotação fonética Automática de Corpora de Fala Tra nscritos Ortograficamente . Instituto de Engenharia de Sistemas e Computadores. Lisboa, 1999. ANTON, Howard; RORRES, Chris. Álgebra linear: com aplicações. 8. ed. Porto Alegre: Bookman, 2001. ARAOZ, Jorge H. N.. Transformada de Fourier : fundamentos matemáticos, implementação e aplicações musicais. Computação Musical, USP: São paulo, 2007. ASF. License to The Apache Software Foundation . 2011. Disponível em: <http:// lucene.apache.org/core/developer.html> Acesso em: 05 jun. 2012. CASELI et al. Computional Processing of the Portuguese Language : 10th international conference. Springer: Coimbra, Portugal, 2012. CHELBA, Ciprian; Acero, Alex. Position Specific Posterior Lattices for Indexing Speech. Association for Computational Linguistics: Redmond, 2005. CHEN, Fang; JOKINEM, Kristiina. Speech Technology: Theory and Application. Nova York : Springer, 2010. CHUCH, Murray. Oracle Spatial User´s Guide and Reference: Release 9.01. Red Wood: Oracle Corporation, 2001. Disponível em: < http://docs.oracle.com/html/A88805_01/title.htm>. Acesso em: 23 abr. 2012. CMU. How to Use Models from SphinxTrain in Sphinx-4 . 2004 Disponível em: <http://cmusphinx.sourceforge.net/sphinx4/doc/UsingSphinxTrainModels.html> Acesso em: 20 abr. 2012. DIMURO et al. Modelos de Markov e Aplicações . Universidade Católica de Pelotas: Pelotas, Universidade Federal do Rio Grande do Sul: Porto alegre. 2011. DINIZ, Paulo S. R.; SILVA, Eduardo A. B. da; LIMA, Sergio N.. Processamento digital de sinais: projeto e análise de sistemas. Porto Alegre: Bookman, 2004. EBLING, Cláudia M. da S. A.. Teoria geral do processo: uma crítica à teoria unitária do processo através da abordagem da questão da sumarização e do tempo no/do processo penal. Porto Alegre: Livraria do Advogado, 2004.

65
ENVIRONMENTAL SYSTEMS RESEARCH INSTITUTE – ESRI. ArcGIS Desktop help. Ver 9.3. ESRI, 2008. FAGUNDES, Ricardo Cassiano; KROTH, Eduardo. Aplicação de consultas baseadas em similaridade em ambientes de conhecimen to definidos por tesauros. Universidade de Santa Cruz do Sul (UNISC). Santa Cruz do Sul, 2008. FORD, Roger. Oracle text : an oracle technical white paper. Califórnia, 2007. Disponível em: <http://www.oracle.com/technetwork/database/enterprise-edition/11goracletexttwp-133192.pdf>. Acesso em: 23 abr. 2012. FUJITA, Mariângela S. L.. A indexação de Livros : A percepção de catalogadores e usuários de bibliotecas Universitárias. São Paulo: Cultura Acadêmica, 2009. GARNIER-RIZET et al. Call Surf : Automatic transcription, indexing and structuration of call center conversational speech for knowledge extraction and query by content. Cap Digital: Paris, 2008. GAZDA, Emmerson. Gravação das audiências dos JEF´s de Santa Catarina com baixo custo, amplo acesso e compatibilidade com o p rocesso eletrônico. 2007. Disponível em:<http://www.trf4.jus.br/trf4/upload/editor/apg_EMMERSON_GAZDA.pdf>. Acesso em: 16 jun. 2011. GOOGLE, Android D.. Speech Input . 2010. Disponível em: <http://developer.android.com/resources/articles/speech-input.html> Acesso em: 18 nov. 2011 GREF. Grupo de Reelaboração do Ensino de Física. Física 3 – Eletromagnetismo. 5. ed. São Paulo, Editora da Universidade de São Paulo, 2005. GSA, Google Search Appliance. Documentation for the Google Search Appliance. Califórnia, 2012. Disponível em: <https://developers.google.com/search-appliance/documentation/>. Acesso em: 2 abr. 2012. HAYES, M. H.. Teoria e problemas de processamento digital de sina is. Porto Alegre: Bookman, 2006. HAYKIN, S.; VEEN, B. V. Signals and Systems. Bookman: São Paulo, 2001. INGLE, Vinay K.; PROAKIS, John G.. Digital signal processing using MATLAB. 2nd ed. New York: Thomson, 2007. INXIGHT, Software. GSA-JAPI : Java API for interacting with the Google Search Apliance. 2006. Disponível em: <http://gsa-japi.sourceforge.net/gsa-japi.html> Acesso em: 02 jun. 2012. LATHI, Bhagawandas P.. Sinais e sistemas lineares . 2. ed. Porto Alegre: Bookman, 2007.

66
LEAL, Jossiano N.; RIBEIRO. Sistema de autenticação biométrica utilizando a voz. Canoas, RS, 2001. 59 f. : Trabalho de Conclusão (Ciência da Computação) - Centro Universitário La Salle, 2001. LI, Haizhou; MA, Bin. A Phonotactic Language Model for Spoken Language Identification. Association for Computational Linguistics. Institute for Infocomm Research: Singapore, 2005 LIPSCHUTZ, Seymour. Teoria e Problemas de Probabilidade. São Paulo: McGraw-Hill do Brasil, 1972. LIU, Jun S. The Collapsed Gibbs Sampler in Baysian Computations with Applications to a Gene Regulation Problem. Journal of the American Statistical Association : Califórnia, 1994. MELLO, Carlos A.. Processamento Digital de sinais . Centro de Informática, UFPE: Pelotas, 2012. MORAES, André Luiz K.. Projeto de um Equipamento de Reconhecimento de Comandos de Voz . Faculdade de tecnologia: Brasíla, 2007. MOURA, José F. S. de. A natureza da identificação da voz e suas repercuss ões no processo penal . 2010. Disponível em: <http://www.estig.ipbeja.pt/~ac_direito/JMoura.pdf> Acesso em: 15 nov. 2011. OLIVEIRA et al. Indexação dos dados espaciais do Banco de Dados do Inventário de Minas Gerais . Universidade Ferederal de Lavras: Minas Gerais, 2007. OPPENHEIM, Alan V.; WILLSKY Alan S. . Sinais e sistemas. 2. ed. São Paulo: Pearson, 2010. ORACLE, Technology. Oracle and Java . Califórnia: Oracle Corporation, 2010. Disponível em : < http://www.oracle.com/us/technologies/java/overview/index.html>. Acesso em: 12 mai. 2012. PALAZZO, Luiz A. M. (Org.) Conceitos . Pelotas, RS: 1997. PIMENTEL FILHO, Carlos A.F.;SANTOS, Celso A. Saibel. A New Approach for Video Indexing and Retrieval Based on Visual Featur es. UFMG: Minas Gerais, Brasil, 2010. PROAKIS, John G.; INGLE, Vinay K.. A self-study guide for digital signal processing. New Jersey: Prentice-Hall, 2004. ROCHA, Fabiana Zaffalon F.. Modelo para Avaliação da Qualidade da Tradução entre Requisitos e Casos de Uso . Dissertação de Mestrado. Faculdade de Informática, PUCRS: Porto Alegre, 2006.

67
RÜNCOS, Rudolfo Augusto E.. Transcrição Automática De Instrumentos Melódicos Harmônicos. Universidade Federal do Paraná: Cutitiba, 2008. SAHUGUET, Arnaud. Google Audio Indexing now on Google Labs . 2008. Disponível em: <http://googleblog.blogspot.com/2008/09/google-audio-indexing-now-on-google.html>. Acesso em: 15 Nov. 2011 SANTOS, Viviane Neves dos. Indexação Automática De Documentos Textuais: Iniciativas Dos Grupos De Pesquisa De Universidades Públicas Brasileiras. São Paulo, SP, 2009. 72 f. : Trabalho de Conclusão (Biblioteconomia) - Universidade de São Paulo, 2009. Sartori, H.; Harti, M.; Chenfour, N.. Introduction to Arabic Speech Recognition Using CMUSphinx System. UFR Informatique et Nouvelles Technologies d'Information et de Communication. França. 2007. SCHNACK, et al. Transcrição de Fala: Do Evento Real à Representação Escrita. 2005. Disponível em: <http://http://www.entrelinhas.unisinos.br/index.php ?e=2&s=9&a=12>. Acesso em: 4 de Set. 2011. SOUZA, Geraldo M.. Inovação disruptiva em portais corporativos : uso de taxonomias com integração tecnológica com base de dados legada, Google Search Appliance e Content Management System: a experiência do portal Sebrae. 2010 Disponível em: <http://www.congressoebai.org/wp-content/uploads/ebai10/EBAI10_artigo03.pdf> Acesso em: 9 mar. 2012. SRINIVASAN, A.. Speech Recognition Using Hidden Markov Model. Applied Mathematical Sciences. SASTRA University: India, 2011. TANENBAUM, Andrew S.; STEEN, Maarten V. Sistemas distribuídos: princípios e paradigmas. 2. ed. São Paulo: Pearson Prentice Hall, 2007. TEVAH, Rafael T. Implementação de um Sistema de Reconhecimento de Fa la Contínua com Amplo Vocabulário para o Português Bra sileiro. 2006. Disponível em: <http://http://teses.ufrj.br/COPPE_M/RafaelTeruszkinTevah.pdf>Acesso em: 02 out. 2011. TURBAN, Efrain; WETHERBE, James C.; MCLEAN, Ephraim. Tecnologia da Informação para Gestão : Transformando os negócios na economia digital. Porto Alegre: Bookman, 2002. WALKER et al. Sphinx-4: A Flexible Open Source Framework for Speech Recognition. Sun Microsystems: Califórnia, 2004. YNOGUTI, Carlos A.. Reconhecimento de Fala Contínua Usando Modelos Ocultos de Markov. Campinas, SP, 1999. 138f. Trabalho de Conclusão(Faculdade de Engenharia Elétrica e de Computação) – UNICAMP, 1999.

68
YUAN, Li-chi. Improved hidden Markov model for speech recognition and POS tagging. Jiangxi University of Finance and Economics: China. 2012.

69
APENDICE A – FUNDAMENTAÇÃO MATEMÁTICA PARA O PROCES SAMENTO
DIGITAL DE SINAIS
Para facilitar o estudo das transformadas, as próximas seções explicam alguns
conceitos sobre PSD.
1) Representação de sinais no tempo discreto
Um sinal no tempo discreto consiste em amostras de um sinal no tempo
contínuo. O intervalo de amostragens é o período de amostragens em um
determinado tempo, este conjunto forma um vetor de valores de amostras. Um sinal
de tempo discreto é uma sequência indexada de números reais ou complexos,
assim um sinal de tempo discreto é uma variável de valor inteiro, n, no caso da
representação do sinal da fala, n representa o tempo. Normalmente sinais de tempo
discreto apresentam valores complexos, embora estes sinais, que representam a
informação que deve ser extraída, sejam em sua maioria funções complicadas de
tempo, existem sinais que são utilizados com mais frequência por serem mais
simples, são amostras unitárias do sinal, estas amostras facilitam os cálculos das
transformadas de Fourier (LATHI, 2007), como poderá ser visto nos próximos
tópicos.
O teorema da amostragem é muito importante na análise, processamento e transmissão de sinais, pois ele nos permite substituir um sinal em tempo contínuo por uma sequência discreta de números. O processamento de um sinal em tempo contínuo é, então, equivalente ao processo de uma sequência discreta de números. Isso nos leva diretamente a área de filtragem digital (sistemas em tempo discreto). Na área de comunicações, a transmissão de mensagens em tempo contínuo se reduz para a transmissão de uma sequência de números. Isso abre portas para várias novas técnicas de comunicação de sinais em tempo contínuo por trens de impulso (LATHI, 2007, p.723).
O processo de amostragem pode ser dividido em dois grupos, primeiro pelo
trem de impulso e segundo pela conversão desse trem em uma sequência.
No estudo de sinais e sistemas de tempo discreto o interesse geral é na
manipulação dos sinais que consiste na combinação de alguns tipos de
transformação deste sinal, estas variações podem ser classificadas como de variável
dependente ou de variável independente (HAYES, 1999).

70
2) Sistemas de tempo discreto
Um sistema de tempo discreto mapeia uma sequência de entrada em uma
sequência de saída. Dependendo das propriedades do sistema ele pode ser
classificado de várias formas, as classificações mais básicas são quanto a ser linear
ou não, variante no tempo ou invariante, casual ou não-casual (DINIZ, 2004). Para
estudar a classificação dos sistemas existem algumas propriedades importantes,
como sistemas ditos sem memória, onde a saída depende somente da entrada,
sistemas aditivos onde a resposta de uma soma de entradas é equivalente a soma
das entradas somadas separadamente, ou homogêneo, quando um escalonamento
feito em uma entrada por uma constante resultar no mesmo escalonamento feito
com dados de saída.
Sabendo das propriedades do sistema, segue abaixo um breve conceito de
algumas das classificações:
• Sistema linear: Um sistema é dito linear se for ao mesmo tempo aditivo e
homogêneo, esse sistema obedece ao princípio da superposição (MELLO,
2012);
• Sistema invariante no tempo: Um sistema no qual um deslocamento no
tempo da sequência de entrada gera um deslocamento correspondente na
sequência de saída (HAYES, 1999);
• Sistema casual: É dito casual se ele não precisa ter conhecimento sobre os
eventos futuros da sequência (MELLO, 2012);
• Sistema estável: é dito estável se toda a entrada limitada tem uma saída
limitada (MELLO, 2012);
• Sistema linear invariante no tempo: Um sistema que é linear e também
invariante no tempo é considerado um Sistema Linear invariante no tempo
(LIT), este sistema é completamente caracterizado por sua resposta ao
impulso. Se encaixa nesta classificação se a resposta do sistema a qualquer
entrada, considerando uma variável de tempo, pode ser encontrada desde
que a amostra unitária desta variável de tempo seja conhecida (HAYES,
1999).

71
3) Sistemas lineares invariantes no tempo
Uma combinação linear de impulsos unitários deslocados pode representar a
entrada de um sistema linear invariante no tempo (LIT). Segundo Haykin e Veen
(2001) a resposta ao impulso é a saída de um sistema LIT, a saída de um sistema
LIT é dada pela superposição ponderada de respostas ao impulso deslocadas no
tempo. A superposição ponderada é definida pela soma de convolução em sistemas
de tempo discreto, e pela integral de convolução em sistemas de tempo contínuo.
Um sistema de filtros é um sistema LIT, é utilizado para a filtragem seletora de
frequência, essa filtragem é muito utilizada em PDS para remoção de ruído e para
análise espectral de sinais (MELLO, 2012).
4) Convolução
A relação entre a entrada de um sistema linear invariante no tempo e a sua
saída é dada pela soma de convolução, é uma operação matemática que a partir de
duas funções produz uma terceira. A convolução possui algumas propriedades, são
a propriedade da comutatividade, da associatividade e da distributividade. A soma
de uma convolução pode expressar a saída de um sistema linear invariante no
tempo (HAYES, 1999).
A integral de convolução se aplica em sistemas LIT de tempo contínuo,
também está na relação entre a entrada e a saída de um sistema LIT, mas neste
caso a superposição ponderada de impulsos deslocados no tempo é uma integral ao
invés de uma soma (HAYKIN; VEEN, 2001), superposição ponderada é a agregação
de valores diferentes, para análise integrada de dados, com uma média ponderada,
o cálculo da média pode utilizar fatores de influência (ESRI, 2008).
5) Análise de Fourier
A representação Fourier de sinais é importante para sinais de tempo discreto,
equivale a decomposição de um sinal no tempo discreto como uma soma infinita de
senoides complexas neste tempo. Os sinais de tempo discreto podem ser
caracterizados no domínio da frequência por sua transformada de Fourier.

72
A Transformada de Fourier modifica o sinal que está em um domínio de tempo
para um domínio de frequência, tornando o sinal controlável.
Como representamos e analisamos os Sistemas LIT fazendo a soma de
convolução, essas operações são baseadas na representação do sinal com
combinações lineares e impulsos deslocados. Podemos representar os Sistemas LIT
utilizando exponenciais complexas, as representações resultantes são conhecidas
como série e Transformada de Fourier de tempo contínuo ou de tempo discreto
(OPPENHEIM; WILLSKY, 2010).
Uma das principais vantagens dos sinais de tempo discreto se dá pela
possibilidade do processamento digital, para isso precisamos utilizar um
mapeamento diferente, que é solucionado pela Transformada discreta de Fourier
(DFT, da expressão em inglês Discrete Fourier Transform).
A DFT tem uma limitação que é o grande número de operações aritméticas
envolvidas no seu cálculo. Essa limitação foi resolvida com a transformada rápida de
Fourier (FFTs da expressão do inglês Fast Fourier Transform) (DINIZ, 2004).
Temos também nas seções subsequentes o estudo das transformadas z e de
Laplace, que possuem muitas das propriedades que tornam a análise Fourier útil.
Segundo Haykin e Veen (2001), existem quatro representações de Fourier
distintas, cada uma aplicável a uma classe diferente de sinais. Estas quatro
representações são diferenciadas por tempo contínuo ou discreto, sendo estas a
Série de Fourier, Transformada de Fourier, Série de Fourier de Tempo Discreto e a
Transformada de Fourier de Tempo discreto como podemos ver na figura 1.

73
Figura 1: As Quatro Representações de Fourier
Fonte: Haykin e Veen, 2001.
6) A Transformada de Fourier
Será discutida diretamente a Transformada de Fourier (TF) pois no contexto do
reconhecimento de fala a Transformada Discreta de Fourier é de maior interesse,
por seus algoritmos rápidos, de melhor desempenho e por ser a única que pode ser
descrita numericamente e manipulada no meio computacional. Passando de Série
para Transformada de Fourier.
Como podemos ver na Figura 1, a Transformada de Fourier está no contexto
de utilização de sinais não periódicos de tempo contínuo, a TF é um sinal de tempo
que envolve uma integral de frequência, pois segundo Haykin e Veen (2001), a
natureza contínua não-periódica de um sinal de tempo implica que a superposição
de senoides complexas envolve um continuum de frequências que variam de -∞ a ∞.
Na figura 1 na primeira fórmula da TF, podemos ver a utilização de todas as
frequências ω R disponíveis. F(ω) e F(t) estão relacionadas por suas equações de
síntese, denotamos esta relação desta maneira
f(t) � F(ω)

74
Assim podemos entender que F é a transformada de Fourier de f, e f é a
Transformada inversa de Fourier de F. Na figura 1 no quadro da TF temos duas
fórmulas que demonstram a transformada e a sua inversa.
7) A Transformada de Fourier de tempo discreto
Segundo Mello (2012), “o uso de transformadas serve para observar
características de um sinal que já estavam presentes nele, mas que podem não ser
observáveis em um domínio.”
Segundo Oppenheim e Willsky (2010), a representação em série de Fourier
de um sinal periódico de tempo discreto é uma série finita. As transformadas de
Fourier para sinais periódicos de tempo discreto podem ser incorporados dentro da
estrutura da transformada de Fourier de tempo discreto interpretando a transformada
de um sinal periódico como um trem de impulsos no domínio da freqüência.
Segundo Mello (2012), uma das formas de ver a transformada discreta de
Fourier está na representação de matrizes, considerando uma sequência periódica
x[n] de período N, tal que x[n] = x[n + k.N], para qualquer inteiro k, N é o período
fundamental da sequência, digamos que x e X são vetores coluna e correspondem
aos períodos primários das sequências x[n] e X[k], respectivamente, então podemos
dizer que
e
são suas equações de síntese e análise, onde WN é dada por:
A matriz WN é chamada de matriz DFS (Discrete Fourier Serie).

75
8) A Transformada Rápida de Fourier
A Transformada rápida de Fourier possui uma complexidade computacional
menor do que a Transformada discreta de Fourier. O algoritmo da Transformada
Rápida de Fourier é utilizado para calcular a Transformada Discreta de Fourier
(TDF).
Segundo Lathi (2007, p.719), “O número de cálculos necessários para executar
a TDF foi drasticamente reduzido por um algoritmo desenvolvido por Cooley e Tukey
em 1965, algoritmo chamado de Transformada Rápida de Fourier (TRF)”, ou seja, a
TDF pode ser calculada de forma eficiente pelos algoritmos da TRF.
Enquanto a complexidade computacional da TDF é N² a complexidade da TRF
é Nlog(N), com isso podemos afirmar que a TRF é mais rápida que a TDF. Segundo
Adami (1997), tendo em vista simular um ouvido humano, as componentes
espectrais dos sinais extraídos da TRF são distribuídos de forma logarítmica em
uma escala de frequência. Para este fim são propostas duas escalas, a escala de
Mel e a escala de Bark.
Aplicando-se a inversa da TDF se obtém os coeficientes cepstrais do sinal da
voz, para a obtenção dos coeficientes mel-ceptrais (mel-frequency cepstral
coefficients - MFCC), a partir dos coeficientes cepstrais, deve-se aplicar filtros
seguindo a escala acústica definida (escala de Mel).
9) A Transformada de Laplace
Para o estudo de problemas relacionados aos sinais e sistemas LIT as
ferramentas da análise de Fourier são muito úteis e eficientes. Segundo Oppenheim
e Willsky (2010), a transformada de Fourier de tempo contínuo oferece-nos uma
representação dos sinais como combinações lineares de exponenciais complexas.
A Transformada de Laplace (TL) possui duas variedades, ela pode ser
unilateral (de um único lado) e bilateral (de dois lados). Quando se trata da
transformada unilateral podemos resolver equações diferenciais com condições
iniciais, quando se trata da transformada bilateral tomamos um maior conhecimento
sobre algumas características do sistema, como estabilidade, casualidade e
resposta em frequência (HAYKIN; VEEN, 2001).

76
Segundo Haykin e Veen (2001), O principal papel da Transformada de Laplace
na Engenharia é a análise de transitórios e estabilidade de sistemas LIT causais
descritos por equações diferenciais.
10) A Transformada Z
Segundo Mello (2012), “A Transformada Z (TZ) é uma ferramenta matemática
poderosa para análise de sinais e sistemas. A transformada Z constitui a forma
discreta da transformada de Laplace”.
Na seção anterior falamos alguns conceitos sobre a transformada de Laplace,
por poder ser aplicada a uma classe mais ampla de sinais que a transformada de
Fourier, seguindo esta mesma motivação conceituaremos nesta seção a
transformada Z.
A TZ é idêntica a TL em suas motivações e suas propriedades, entretanto
algumas diferenças podem ser observadas, a TL se reduz a transformada de Fourier
no eixo imaginário, enquanto a magnitude da variável da TZ é a unidade
(OPPENHEIM; WILLSKY, 2010).













![,;j DokfyVh ykbQ baMsDl Z 2020 okfkZd viMsV · gSA blesa ,pvkboh/ ,M~l 4 eghuksa dh vkSj eysfj;k 3 eghuksa deh yk nsrk gSA ogha] fookn vkSj vkradokn ls blesa ek= 18 fnuksa dh deh](https://static.fdocumentos.tips/doc/165x107/60180f3306659842b6595fe6/j-dokfyvh-ykbq-bamsdl-z-2020-okfkzd-vimsv-gsa-blesa-pvkboh-ml-4-eghuksa-dh.jpg)




