
Coalescência DNA é capaz de replicar - ufscar.brevolucao/popgen/coalesc2007.pdf · Tal modelo...
13
1 Por causa da replicação, um único tipo de gene pode existir no tempo e no espaço de forma que transcenda os indivíduos que temporariamente carregam o gene. Alguns alelos são idênticos por serem descendentes replicados de um único alelo ancestral DNA é capaz de replicar Coalescência Coalescência do DNA Replicação do DNA Árvore de genes todas as cópias de DNA homólogo coalescem em uma molécula ancestral comum Teoria do coalescente Se μ << 1 e Prob (coal) << 1 DNA não replica e sofre mutação em uma mesma geração Tempo Tempo Coalescência Cada reprodução pode envolver qualquer um dos N indivíduous, e é um evento independente de outras • Assim, a probabilidade de que dois gametas venham do mesmo parental é de 1/N • Em diplóides, a probabilidade de ibd / coalescência é 1/(2N) • Populações não são ideais, logo a probabilidade de coalescência em uma geração é de 1/2N ef Coalescência em uma população ideal de N diplóides
Transcript of Coalescência DNA é capaz de replicar - ufscar.brevolucao/popgen/coalesc2007.pdf · Tal modelo...

1
Por causa da replicação, um únicotipo de gene pode existir no tempo e no espaço de forma quetranscenda os indivíduos quetemporariamente carregam o gene.
Alguns alelos são idênticos porserem descendentes replicados de um único alelo ancestral
DNA é capaz de replicarCoalescência
Coalescênciado DNA
Replicação do DNA
Árvore de genes
todas as cópias de DNA homólogo coalescem
em uma moléculaancestral comum
Teoria do coalescente
Se μ << 1 e Prob (coal) << 1DNA não replica e sofre mutaçãoem uma mesma geração
Tempo
TempoCoalescência
Cada reprodução pode envolver qualquer um dos N indivíduous, e é um evento independente de outras• Assim, a probabilidade de que dois gametas venham do mesmo parental é de 1/N• Em diplóides, a probabilidade de ibd / coalescência é 1/(2N) • Populações não são ideais, logo a probabilidade de coalescência em uma geração é de 1/2Nef
Coalescência em uma população ideal de N diplóides

2
Pcoalesce há exatamente t gerações é a probabilidade de nãocoalescência pelas 1as t-1 gerações no passado seguida por um evento de coalescência na geração t:
Amostrando dois genes ao acaso
probabilidade de não coalescênciaem t-1 gerações
probabilidadede coalescência
na geração t
A variância do tempo médio de coalescência de doisgenes (σ2
ct) é a média da espectativa de (t - 2Nef)2 :
O tempo médio de coalescência será:
Amostrando dois genes ao acaso
• Se n = 10, o tempo coberto por eventos de coalescência devevariar entre 0.0444Nef e 3.6Nef.
• Se n = 100, o tempo coberto por eventos de coalescência devevariar entre 0.0004Nef e 3.96Nef.
Não precisa grande amostra para inferir coalescências antigas, masprecisa de muitas para inferir coalescências recentes
Amostrando n genes ao acasoOs tempos médios para a 1a e a última coalescência são:
4Nef/[n(n-1)] e 4Nef(1-1/n)
Árvore de Coalescência
E(T5,4) = 2N/10
E(T2,1) = 2Ngerações
E(T3,2)=2N/3
E(T4,3)=2N/6
Tempo
presente
• Tanto para 2 quanto n- coalescências, o tempo médio de coalescência é proporcional a Nef enquanto a variância é a Nef
2.• O relógio molecular segue Poisson em que a média = variância.• O coalescente é um processo evolutivo irregular, com muitavariação inerente que não pode ser eliminada por n maiores; é inato ao processo evolutivo e chamado de estocasticidadeevolutiva.
A variância do tempo de coalescência de n genes é:
Amostrando n genes ao acaso Experimento de Buri em deriva genética
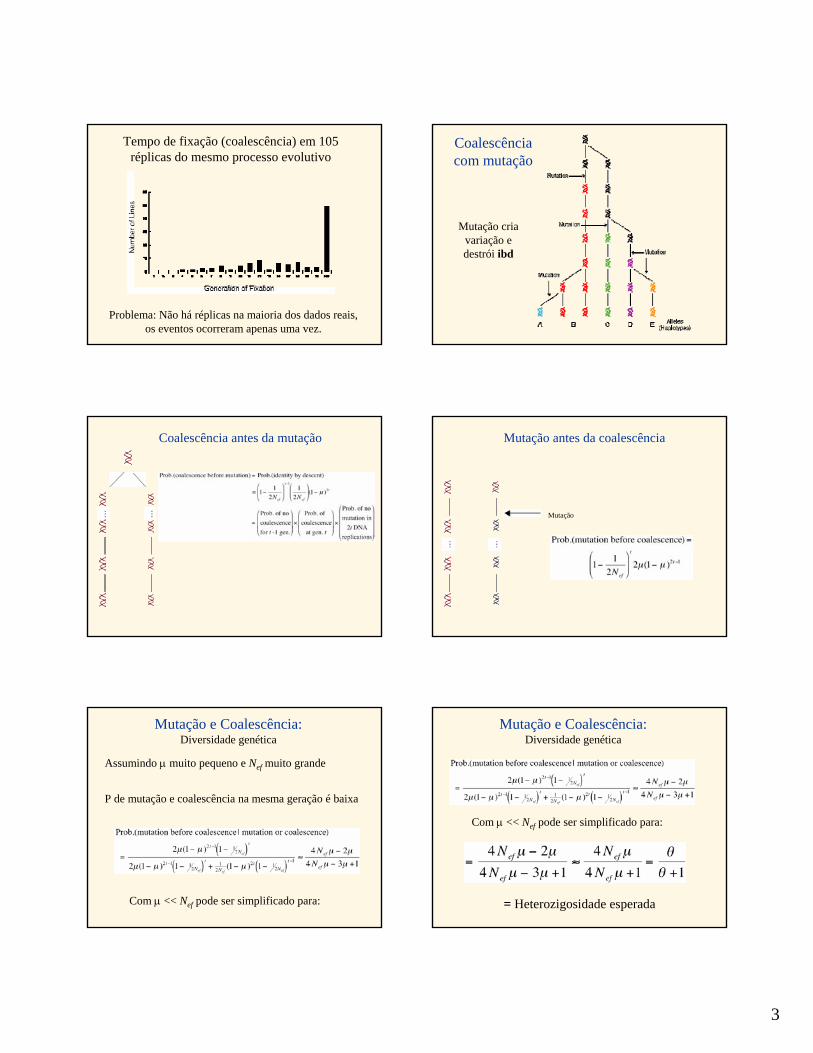
3
Problema: Não há réplicas na maioria dos dados reais, os eventos ocorreram apenas uma vez.
Tempo de fixação (coalescência) em 105 réplicas do mesmo processo evolutivo
Mutação criavariação e destrói ibd
Coalescênciacom mutação
Coalescência antes da mutação
Mutação
Mutação antes da coalescência
Assumindo μ muito pequeno e Nef muito grande
P de mutação e coalescência na mesma geração é baixa
Mutação e Coalescência:Diversidade genética
Com μ << Nef pode ser simplificado para: = Heterozigosidade esperada
Com μ << Nef pode ser simplificado para:
Mutação e Coalescência:Diversidade genética

4
Árvores de Genes são genealogias de genes. Como cópiasdiferentes em loci homólogos estão relacionados pela ordem de eventos de coalescência.
Árvore de gene e árvore de haplótipos
Únicos passos quepodemos “ver” são osmarcados por eventosmutacionais
Árvores de Genes são genealogias de genes. Como cópiasdiferentes em loci homólogos estão relacionados pela ordem de eventos de coalescência.
Árvore de gene e árvore de haplótipos
A esta árvore de maisbaixa resoluçãochamamos de árvorede haplótipos ou de alelos.
Árvore de haplótipo -- Antigas e recentes
Dobzhansky & Sturtevant (1936): An Inversion Tree for Drosophila pseudoobscura (A) and D.persimilis (B)
Idealmente cada inversão ocorre apenas uma vez na árvore e a árvoreminimiza o número total de mutações – Modelo de Alelos Infinitos
Idealmente cada inversão ocorre apenas uma vez na árvore e a árvoreminimiza o número total de mutações -- Máxima Parcimônia
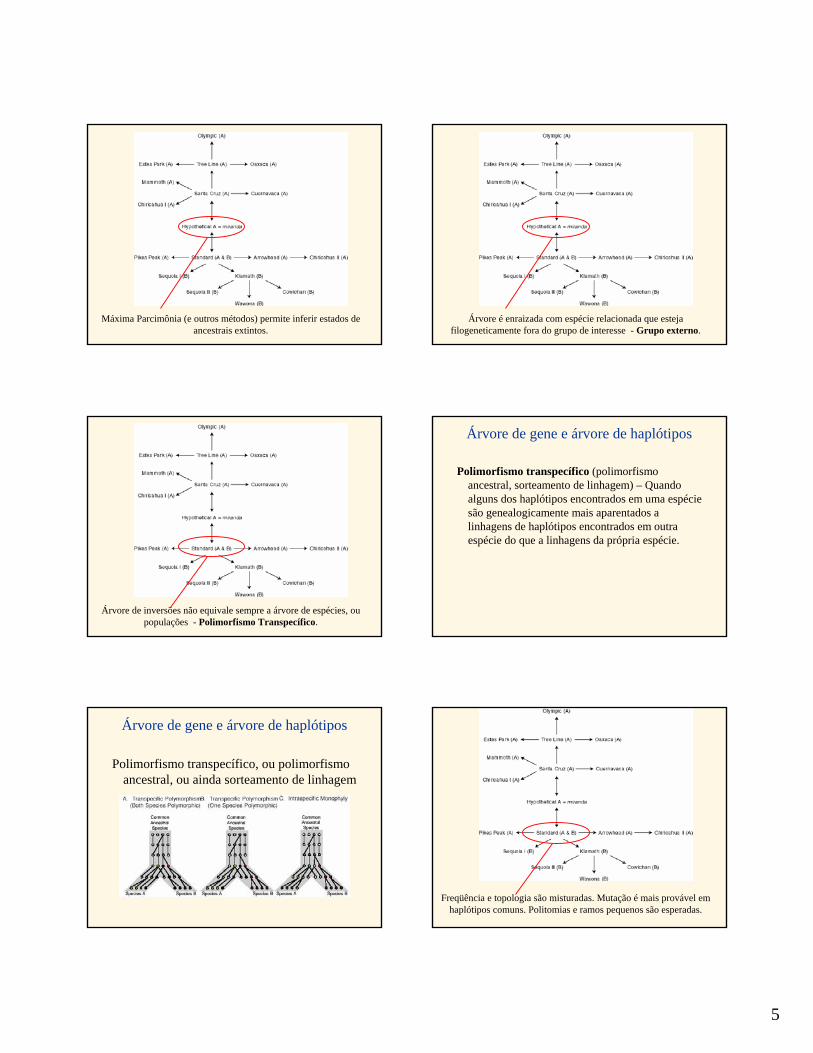
5
Máxima Parcimônia (e outros métodos) permite inferir estados de ancestrais extintos.
Árvore é enraizada com espécie relacionada que estejafilogeneticamente fora do grupo de interesse - Grupo externo.
Árvore de inversões não equivale sempre a árvore de espécies, oupopulações - Polimorfismo Transpecífico.
Árvore de gene e árvore de haplótipos
Polimorfismo transpecífico (polimorfismoancestral, sorteamento de linhagem) – Quandoalguns dos haplótipos encontrados em uma espéciesão genealogicamente mais aparentados a linhagens de haplótipos encontrados em outraespécie do que a linhagens da própria espécie.
Árvore de gene e árvore de haplótipos
Polimorfismo transpecífico, ou polimorfismoancestral, ou ainda sorteamento de linhagem
Freqüência e topologia são misturadas. Mutação é mais provável em haplótipos comuns. Politomias e ramos pequenos são esperadas.

6
LPL Has 10 Exons Over 30 kb of DNA on Chromosome 8p22
Sequenced 9,734 bp from the 3’ End of Intron 3 to the 5’ End of Intron 9
Sequenced:24 Individuals from North Karelia, Finland (World’s Highest Frequency of CAD)23 European-Americans from Rochester, Minnesota24 African-Americans from Jackson, Mississippi
Found 88 Variable Sites
Ignored Singleton and Doubleton Sites and Variation Due to a Tetranucleotide Repeat, but Phased the Remaining 69 Polymorphic Sites by a Combination of Using Allele Specific Primer Pairs and Haplotype Substraction
The Phased Site Data Identified 88 Distinct Haplotypes
Genetic Survey of Lipoprotein Lipase
Ln-Likelihood ratio teste de homogeneidade = 99.8, 3 df, p = 1.75 x 10-7
Ln-Likelihood ratio teste de homogeneidade nas 3 classes mutáveis = 12.3, 2 df, p = 0.002
Análise de sítios altamente mutáveis
Type of Site # Nt # polym % polym p/ nt
CPG
198 19
9.6% Mononucleotide runs > 5
456 15
3.3% Poly α arrest site ± 3 nucleotides [TG(A/G)(A/G)GA]
264
8 3.0%
All other nucleotides
8,866 46
0.5%
Região Tipo do Sítio 0-1 Homoplasias >2 Homoplasias
5’ e 3’ Altamente mutável
11 14 Flanqueadora
Todos os outros
22 5
Sítios altamente mutáveis em LPL e homoplasia
Recombinational Hotspot
Altamente mutável
3 7 Todos os
outros 5 2
Todos Altamente mutável
14 21 Todos os
outros 27 7
Fisher's Exact Test: P = 0.0013 sob a hipótese nula de homogeneidade
Fisher's Exact Test: P = 0.0013 sob a hipótese nula de homogeneidade
ε4
ε3ε2
Árvore de haplótipos
da Apolipo-protein E
Árvore de haplótipos da Apolipoproteína E
4036
Coalescente de haplótipos de Apo E
ε4
Anos(x 105)
ε2 ε39 16 6 27 2 28 1 14 29 30 12 13 17 20 5 31
3.2
1.6
0.0
0.8
2.43937
4075
5229B
624
308
3673
545
2440
3106
19981163
1522 3701 2907
4714951
73

7
Árvore de haplótipos
da Apolipo-proteína E
560
560
560
560560
560
1575
624
624624
624
1522
5361
5361
5361
4951
4951
4951
832
83224401998 19983937
5229B
4075
1163 4036
73
471
14
1119
17 20 18
23
1512
25
13
10 16
24
2
22
67 5
1
1575
560
624 624
21
26
4
3
31
3106
28545
27 3673
308
29 3701
8
302907
9
ε3
ε2
ε4
Sítios 560 e 624 estão em umarepetição Alu
Muitos testes estatísticos usados na evolução molecular baseiam-se no modelo de sítios infinitos no qual cada mutação ocorre em um sítio novo.
Tal modelo não permite mutações recorrentes em um sítio único.
Para regiões como hotspots mutacionais existem, este modelo podeser muito enviesado.
Modelo de Sítios Finitos
Modelo de Sítios Infinitos
1
2
3
4
5
Mutações1 2 3 4 5 6
Seqü
ênci
as
7
Cada mutação ocorre em um nucleotídeo diferente
Uso de métodos não apropriados para estudosintraspecíficos
Porque não apropriados:• baixa divergência• ancestral não está extinto• Politomia• reticulação• tamanho amostral grande
Parcimônia estatística
Redes ou árvores que alocam homoplasia entrehaplótipos menos divergentes com probabilidademenor do que 0.05 são eliminadas em favor de outras que alocam tais homoplasias entrehaplótipos mais divergentes
Árvore genealógicaEm estudos intraspecíficos:
•NÃO esperamos que o ancestral esteja extinto;• Politomias são esperadas. Na verdade, politomiassão PROVÁVEIS;• Como alelo ancestral não está extinto, esperamosque alelos mais antigos tenham maior freqüência. Por outro lado, novos alelos devem ter baixafreqüência;• É mais provável que um alelo raro seja derivadode um alelo comum do que de outro raro;
Podemos usar estasesperanças para resolver“loops” ou homoplasias nosdados

8
Árvore de haplótipos
Em estudos intraspecíficos:•NÃO esperamos que o ancestral esteja extinto;• Politomias são esperadas. Na verdade, politomiassão PROVÁVEIS;• Como alelo ancestral não está extinto, esperamosque alelos mais antigos tenham maior freqüência. Por outro lado, novos alelos devem ter baixafreqüência;• É mais provável que um alelo raro seja derivadode um alelo comum do que de outro raro;
Podemos usar estas esperanças para resolver“loops” ou homoplasias nos dados
Máxima parcimônia Parcimônia estatística
Árvore genealógicaEm estudos intraspecíficos:
•NÃO esperamos que o ancestral esteja extinto;• Politomias são esperadas. Na verdade, politomiassão PROVÁVEIS;• Como alelo ancestral não está extinto, esperamosque alelos mais antigos tenham maior freqüência. Por outro lado, novos alelos devem ter baixafreqüência;• É mais provável que um alelo raro seja derivadode um alelo comum do que de outro raro;
Podemos usar estasesperanças para resolver“loops” ou homoplasias nosdados
Árvore de haplótipos
• Geralmente NÃO sabemos a raiz;• Alelos antigos tem mais chance de serem nósinternos, ao invés de pontas (tips).
560
560
560
560560
560
1575
624
624624
624
1522
5361
5361
5361
4951
4951
4951
832
83224401998 19983937
5229B
4075
1163 4036
73
471
14
1119
17 20 18
23
1512
25
13
10 16
24
2
22
67 5
1
1575
560
624 624
21
26
4
3
31
3106
28545
27 3673
308
29 3701
8
302907
9
ε3
ε2
ε4
Árvore de haplótiposda Apo- E
Um único haplótipo pode ter segmentos de DNA que tiverampadrões de mutação e coalescência diferentes no passado.Não existe uma única história evolutiva para estes haplótiposrecombinantes.Quando a recombinação é comum e uniforme, mesmo a idéiade uma árvore de haplótipos torna-se biologicamente semsentido.
Importante investigar sua presença!
Coalescência e recombinação
A recombinação ocorre em todos os genótipos, masmuda o estado do gametaparental apenas em duplosheterozigotos.
A recombinação muda a fasede marcadores polimórficos.
Para se detectar e estudar a recombinação, é essencial terdados com fase conhecida(como haplótipos)
PROBLEMA: Queremos estimar os haplótipos e suas freqüênciasno pool gênico, mas não podemos observá-los em todos osindivíduos.
GENOTIPAGEM N HAPLÓTIPOSPOSSÍVEIS
A/A A/A T/T HOMOZIGOTO 21 AATG/G A/A T/T HOMOZIGOTO 19 GATA/A C/A T/T HETEROZIGOTO SIMPLES 9 ACT/AATA/G A/A T/T HETEROZIGOTO SIMPLES 39 AAT/GATA/G C/A T/T DUPLE HETEROZIGOTO 9 ACT/GAT ou AAT/GCTA/G A/A T/C DUPLO HETEROZIGOTO 2 AAT/GAC ou AAC/GATA/G C/A T/C TRIPLO HETEROZIGOTO 1 ACT/GAC ou AAT/GCC ou
ACC/GAT ou AAC/GCT

9
1a Solução: Subtração de Haplótipos (Clark, Mol. Biol. Evol. 7: 111-122, 1990).
GENOTIPAGEM N HAPLÓTIPOSPOSSÍVEIS
A/A A/A T/T HOMOZIGOTO 21 AATG/G A/A T/T HOMOZIGOTO 19 GATA/A C/A T/T HETEROZIGOTO SIMPLES 9 ACT/AATA/G A/A T/T HETEROZIGOTO SIMPLES 39 AAT/GATA/G C/A T/T DUPLE HETEROZIGOTO 9 ACT/GAT ou AAT/GCTA/G A/A T/C DUPLO HETEROZIGOTO 2 AAT/GAC ou AAC/GATA/G C/A T/C TRIPLO HETEROZIGOTO 1 ACT/GAC ou AAT/GCC ou
ACC/GAT ou AAC/GCT
Os haplótipos neste grupo são conhecidos!
1a Solução: Subtração de Haplótipos (Clark, Mol. Biol. Evol. 7: 111-122, 1990).
GENOTIPAGEM N HAPLÓTIPOSPOSSÍVEIS
A/A A/A T/T HOMOZIGOTO 21 AATG/G A/A T/T HOMOZIGOTO 19 GATA/A C/A T/T HETEROZIGOTO SIMPLES 9 ACT/AATA/G A/A T/T HETEROZIGOTO SIMPLES 39 AAT/GATA/G C/A T/T DUPLE HETEROZIGOTO 9 ACT/GAT ou AAT/GCTA/G A/A T/C DUPLO HETEROZIGOTO 2 AAT/GAC ou AAC/GATA/G C/A T/C TRIPLO HETEROZIGOTO 1 ACT/GAC ou AAT/GCC ou
ACC/GAT ou AAC/GCT
Os haplótipos neste grupo são conhecidos!
Tais haplótipos são também possibilidades em genótiposcom fase ambígua
1a Solução: Subtração de Haplótipos (Clark, Mol. Biol. Evol. 7: 111-122, 1990).
GENOTIPAGEM N HAPLÓTIPOSPOSSÍVEIS
A/A A/A T/T HOMOZIGOTO 21 AATG/G A/A T/T HOMOZIGOTO 19 GATA/A C/A T/T HETEROZIGOTO SIMPLES 9 ACT/AATA/G A/A T/T HETEROZIGOTO SIMPLES 39 AAT/GATA/G C/A T/T DUPLE HETEROZIGOTO 9 ACT/GAT ou AAT/GCTA/G A/A T/C DUPLO HETEROZIGOTO 2 AAT/GAC ou AAC/GATA/G C/A T/C TRIPLO HETEROZIGOTO 1 ACT/GAC ou AAT/GCC ou
ACC/GAT ou AAC/GCT
Os haplótipos neste grupo são conhecidos!
A solução que inferir menos haplótipos novos será a preferida
2a Solução: Algoritmo EM (Estimation-Maximization) (Templeton et al. Genetics 120: 1145-1154, 1988).
Estima probabilidades de várias fases de genótipos pelo uso dasfreqüências dos haplótipos em um modelo de Hardy-Weinberg.
2a Solução: Algoritmo EM (Estimation-Maximization) (Templeton et al. Genetics 120: 1145-1154, 1988).
Estima probabilidades de várias fases de genótipos pelo uso dasfreqüências dos haplótipos em um modelo de Hardy-Weinberg.Repetir tal procedimento até que as freqüências se estabilizem.
2a Solução: Algoritmo EM (Estimation-Maximization) (Templeton et al. Genetics 120: 1145-1154, 1988).
Nem tão bem resolvido quanto o algoritmo de Haplotype Substraction.Pode ser uma vantagem, e uma desvantagem.

10
3a Solução: Algoritmo Bayesiano (Stephens et al., Am J. Hum Gen. 68: 978-989,2001) Divide the individuals into those with unambiguous haplotypes and those with ambiguous haplotypes. Unlike haplotype subtraction and like EM, ambiguous individuals always remain ambiguous (although the probabilities could become very small). Then:
1. Let G be the vector of genotypes and H(0) some initial guess of the vector of haplotypes (just like EM).
2. Choose an individual, i, uniformly and at random (thus avoiding order effects) from the set of ambiguous individuals.
3. Sample Hi(t+1) from P(Hi|G,H-I
(t))where H-I is the set of haplotypes excluding individual i.
Go back to 2 and keep repeating until converge to a stationary distribution (they show this will always occur). Thus, you now have P(H|G).
Contudo, de onde tiramos P(Hi|G,H-I(t))?
Como detectar eventos de recombinação em LPL
5NR
2JNR 79R70R
7
8
13
20
29 31 33 56 53
5
65
25
7 813
16
11J
611931J
66 29 36 69
5
16
1236J
Branch "A" {Como detectar eventos de recombinação em LPL
α=3, β=5, κ=3, p =0.0179, crossover between sites 13 and 29.1 10 20 30 40 50 60 69
2JNR CAGTTTCCCT CAGCACGATC GCAATTGCAC CTCAATGTAT AGTTGTAACC GAGTCCGCAT AACTATAGG5NR CAGTTTATCT CACCACGATA GCAATTGCAC CTCAATGTAT AGTTGTAACC GAGTCCGCAT AACTATAGGNode a CAGTTTATCT CACCACGATC GCAATTGCTC TTTAATGTAT AGTTGTAACC GAATCAGCAT AACTATAGG
α=2, β=7, κ=2, p =0.0278, crossover between sites 16 and 19.
Node d CAGTTTATCT CACCACGATC GCAACTGCTC TTTAATGTAT AGTTGTAACC GAATCAGCAT AACTATAGG11J CAGTATATCT CACCATGATC GCAACTGCTC TTTAATGTAT AGTTGTAACC GAATCAGCAT AACTATAGGNode e CAGTATATCT CACCATGAGC GCAATTGCAC TTTAA?GTAT AGTTGTAACC GAATCAGCAT CACTGGAGA
11J CAGTATATCT CACCATGATC GCAACTGCTC TTTAATGTAT AGTTGTAACC GAATCAGCAT AACTATAGGNode e CAGTATATCT CACCATGAGC GCAATTGCAC TTTAA?GTAT AGTTGTAACC GAATCAGCAT CACTGGAGAT-1 CAGTTTATCT CACCACGAGC GCAATTGCAC TTTAA?GTAT AGTTGTAACC GAATCAGCAT CACTGGAGA
Distribuição de recombinantes em LPL
LD e recombinational Hotspot em LPL
Reich, D. E. et al. Nature Genetics 32, 135-142, 2002.“recombination 'hot spots' are a general feature of the human genome and have a principal role in shaping genetic variation inthe human population.”
Recombinação cria novas fases em sítios polimórficos, quepodem ser medidas por:
D = gABgab-gAbgaB
• D mede o grau de associação entre dois sítios naquelapopulação
• D é criado por várias forças evolutivas e eventos históricos, inclusive a mutação.

11
Hardy Weinberg em 2 loci
Ou seja, evolução ocorre!
O equilíbrio é alcançadogradualmente, na taxa r.Informações históricas sãomedidas por D, que decai com o tempo.Em loci com alta ligação podepersistir por grandes períodos.
Hardy Weinberg em 2 loci
Dt = D0(1-r)t
Existe a tendência de usar D como medida daproximidade na molécula de DNA
Isto se justifica quando r >> μ
Quando r < μ ou r ≈ μ ; o desequilíbrio está medindoproximidade no processo de coalescência.
Desequilíbrio e Coalescência
ε4
ε3ε2
Árvore de haplótiposda Apo- E
O gene ApoE
Stengård et al. (1996) mostraram quesubstituições de amino ácidos em ApoE tem grande impacto namortalidade por doençascoronarianas em um estudo longitudinal.
01234567
CAD MortalityRelative to
CAD Mortalityof 3/3
3/33/42/4 & 4/4
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Região Gênica da Apo E

12
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Estes dois sítios estão em desequilíbrio
Região Gênica da Apo E
560
560
560
560560
560
1575
624
624624
624
1522
5361
5361
5361
4951
4951
4951
832
83224401998 19983937
5229B
4075
1163 4036
73
471
14
1119
17 20 18
23
1512
25
13
10 16
24
2
22
67 5
1
1575
560
624 624
21
26
4
3
31
3106
28545
27 3673
308
29 3701
8
302907
9
Árvore de haplótiposda Apo- E
560
560
560
560560
560
1575
624
624624
624
1522
5361
5361
5361
4951
4951
4951
832
83224401998 19983937
5229B
4075
1163 4036
73
471
14
1119
17 20 18
23
1512
25
13
10 16
24
2
22
67 5
1
1575
560
624 624
21
26
4
3
31
3106
28545
27 3673
308
29 3701
8
302907
9
Estes haplótipos sãoT no sítio 832 e C
em 3937
Estes haplótipos são G no sítio 832 e T em 3937
Árvore de haplótiposda Apo- E
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Sítio 3937 é um polimorfismo de a.a. queafeta a função de ApoE e infarto
Região Gênica da Apo E
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Sítio 3937 é um polimorfismo de a.a. queafeta a função de ApoE e infarto
Suponha que apenas esta região tenhasido sequenciada
Região Gênica da Apo E
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Sítio 832 está associado na árvore de haplótipos com o sítio 3937
Região Gênica da Apo E
Suponha que apenas esta região tenhasido sequenciada
Sítio 3937 é um polimorfismo de a.a. queafeta a função de ApoE e infarto

13
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Região Gênica da Apo E
Sítio 832 pareceria com a maiorassociação com função de ApoE e infarto
Suponha que apenas esta região tenhasido sequenciada
0. 0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. 5.5
Exon
1
Exon
2
Exon
3
Exon
4
73 308
471545560624832
1163
15221575
1998
2440
2907
3106
3673
393740364075
4951
5229A
5229B5361
3701*
Você seriacapaz de
inferir destaassociação que
o marcadormais perto do sítio funcionalestaria aqui?
Região Gênica da Apo E
Sítio 832 pareceria com a maiorassociação com função de ApoE e infarto
Suponha que apenas esta região tenhasido sequenciada
Para que servem árvores de haplótipo
• As árvores de haplótipo estimam umahistória evolutiva que pode gerar hipótesessobre o significado atual da variaçãogenética
• Fornecem uma ferramenta poderosa para se detectar associações entre genótipo e fenótipo


















