
BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
12
17 Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007 INTRODUÇÃO Se “uma imagem vale por mil palavras”, pode-se dizer que para uma descrição total do que vemos em um comercial de televisão de 30 segundos, precisaríamos de cerca de 720 mil palavras. É um número expressivo, mas para um sistema eficiente de recuperação de informação audiovisual não é necessário chegar a valor tão elevado de descritores. Neste artigo serão relatados alguns avanços da pesquisa cujo objeto de estudo é a correspondência entre elementos visuais e significados verbais, e que se desenvolve integrando áreas como a psicologia da cognição, a inteligência artificial, a produção audiovisual e a ciência da informação. Desde as tábuas sumérias até a atualidade, muitos materiais duráveis serviram para preservar i nformações mas, o que se pode prever para o que hoje é acondicionado em suportes eletrônicos, e que já constitui em grande escala a nossa herança cultural e intelectual para as futuras gerações? No caso do audiovisual, as vantagens do registro eletromagnético estão condicionadas à enorme fragilidade dos meios, se comparados ao material fotográfico, pois a informação digital, dependente da alta rotatividade da informática, para permanecer exige cuidados especiais, desde a sua criação até a sua conservação. Somente a manutenção de uma política duradoura e de cooperação entre os fabricantes de hardware e desenvolvedores de software, os distribuidores e produtores de mídia, e com a participação de bibliotecas, arquivos e museus poderemos esperar que nossas mensagens sejam ainda acessadas no futuro. A invenção do cinema e a rápida multiplicação dos meios e processos, que geraram enorme quantidade de material audiovisual, literalmente transformaram a face do mundo e continuam modificando os padrões da atividade humana. Em alguns países, tal acervo é reconhecidamente um repositório valiosíssimo de informações, mas ainda assim é na prática um tesouro oculto, pois as descrições sobre os conteúdos poucas vezes incluem algo mais que títulos e curtas sinopses. No Brasi l porém, pouco mais do que 5 % de todo o material em película produzido até os anos 40 permanece atualmente preservado. A criação de ferramentas que podem permitir a pesquisa por entidades e conceitos registrados em filmes está sendo empreendida não somente por filmotecas e museus, mas também de forma intensa pelos produtores de mídia, que se preparam para oferecer conteúdo audiovisual personalizado via internet e televisão digital. Juliano Serra Barreto Mestre em artes. Professor da Universidade de Brasília (UnB). E-mail: [email protected] RESUMO Exposição sobre processos e métodos utilizados para a indexação e recuperação textual da informação semântica em vídeo, tendo como base a identificação e classificação do seu conteúdo visual e sonoro. PALAVRAS-CHAVE Sistemas de recuperação da informação visual. Indexação de vídeos. Recuperação do conteúdo audiovisual. Challenges and advancements in automatic retrieval of audiovisual information ABSTRACT Presentation of methods and processes applied to classification and retrieval of semantic information of video programs, through identification of sound and visual content. KEYWORDS Content based image retrieval. Video indexing. Multimedi a content retrieval. Desafios e avanços na recuperação automática da informação audiovisual IBICT Ciencia da Informacao V36N3 v6 grafica.indd 17 09/09/2008 10:19:09
-
Upload
vanessa-s-cavalcante -
Category
Documents
-
view
219 -
download
0
Transcript of BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 1/12

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 2/12
18
(61) 8142-1476 - Formato 21 x 29,7cm - 1/1 BLACK - Fechamento e Editoração
Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
Na implementação de aplicações que vão de bibliotecas digitaisa sistemas de segurança, serão necessárias novas ferramentasque permitam o acesso facilitado ao conteúdo de audiovisuais.A seguir apresentam-se as tendências atuais e propostas desolução para a interpretação semântica automática do queé genericamente denominado produto audiovisual, e que
abrange toda a produção de imagens em movimento feitaatravés de câmeras de diversos formatos, utilizadas em ritmocrescente na sociedade contemporânea.
INFORMAÇÃO AUDIOVISUAL
A humanidade vem produzindo ícones há pelo menos7.000 anos, porém com a revolução digital estamos agoraexperimentando uma relação muito íntima e quase absolutacom a imagem, alcançando novo patamar que pode nos levarinclusive a situações extremas de vigilância total, como a do BigBrother imaginado por George Orwell no romance “1984”.
A informação visual tem sido armazenada de forma analógicae indexada manualmente, mas hoje muitos sistemas de basede dados digitais são utilizados para armazenar imagens,juntamente com seus metadados e taxonomias associados.Sistemas híbridos, com indexação automática e análise deconteúdo supervisionada devem ser desenvolvidos, poisexistem sérias limitações ao uso de indexadores manuais,uma vez que requerem anotação individual, dificultando seuuso em grandes arquivos, e que sofrem influência tanto dodomínio de aplicação quanto do conhecimento da pessoaque realiza a tarefa. O reconhecimento de imagens e sons éparte da área de sistemas de recuperação da informação, emque se colocam grandes desafios relativos ao armazenamento,
indexação, formulação de consultas e recuperação de conteúdosemântico.
Ao se considerarem seqüências de imagens, o problema deindexação torna-se mais difícil, pois envolve a identificaçãoe o entendimento de cenas longas e complexas para que sejapossível obter uma recuperação precisa e eficiente. Atualmenteexistem sistemas que permitem aos usuários especificar buscasem repositórios de imagens por meio da seleção de elementosvisuais, como cor e textura, pelas comparações de imagens-exemplo e pelo reconhecimento de padrões espaciais, outemporais no caso do vídeo.
Nas seções seguintes serão consideradas as consequênciasdo aumento da produção audiovisual, assim como as formasde registro e preservação de vídeo. Também serão revistos osprocessos utilizados na análise fílmica e os padrões propostospara a indexação de materiais audiovisuais.
A aceleração da produção midiática
As estimativas produzidas por Kompatsiaris (2006) revelaramalguns números impressionantes para a produção audiovisualnos anos vindouros. Em todo o mundo, 1-2 exabytes (bilhõesde gigabytes) de conteúdo eletrônico serão produzidos e 80
bilhões de imagens digitais serão feitas anualmente. Mais deum bilhão de imagens relacionadas a transações comerciaisestão disponíveis e devem aumentar dez vezes nos próximosdois anos. A cada ano, 4 mil novos filmes serão produzidos,além dos 300 mil já disponíveis em todo o globo. E serãoultrapassadas as 100 bilhões de horas de material audiovisualdistribuídas por 33 mil estação de televisão e 43 mil de rádio.Como podemos lidar com tal quantidade de documentos emetadados, que já é assustadoramente denominado sobrecargainformacional? Que ferramentas podem viabilizar a organizaçãode tal produção? Nesse contexto, como encontrar a informaçãonecessária, no momento preciso?
A rápida transformação dos procedimentos e materiais dereprodução audiovisual permite grande variedade de formatose suportes, mas alguns fundamentos básicos ainda prevalecem.A câmera obscura ainda é o design básico de qualquer aparelhoutilizado para registrar imagens da realidade visível, embora oprocesso eletrônico já não comporte o uso da prata nem as reaçõesquímicas. Entretanto, a conservação de documentos baseadosem prata, como filmes e fotografias, embora seja delicada, éconhecida e eficiente, obtendo-se documentos que podem semanter inalterados por até mais de um século. Tais produtospresumidamente terão vida útil mais longa do que os documentosguardados, em meio magnético, e mesmo em dispositivos óticos,sobretudo quando dependem de software e hardware específicospara serem lidos. Com estas e outras preocupações, já vêm sendo
pesquisados parâmetros mais permanentes para a preservação dainformação em formatos digitais, como é possível encontrar nasdefinições propostas pela British Library em 1998, que têm sidoaprimoradas desde então (BEAGRIE, 1998).
Os sistemas de redes distribuídas estão também modificandoprofundamente a estrutura e a linguagem da experiênciacinemática. Novas possibilidades de interação entre autores epúblicos permitem a criação de filmes adaptativos, multiplicandoos níveis de leitura e explorando eventos em tempo real. ParaPaul Virilio, estamos mesmo inaugurando um novo estatuto paraa imagem, uma era da lógica paradoxal, em que a imagem seimpõe à coisa representada, e que desestabiliza as representaçõespúblicas tradicionais, em benefício de uma apresentação, deuma presença paradoxal que supre a própria existência. Emsuas palavras: “Esta virtualidade que domina a atualidade,subvertendo a própria noção de realidade” (VIRILIO, 1994).
O custo da produção audiovisual, no que concerne à geração egravação de imagem e som, tem caído progressivamente, à medidaque componentes eletrônicos são fabricados em maior quantidadee com maior capacidade, e consumidos em larga escala. Assim
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 18 09/09/2008 10:19:10

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 3/12

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 4/12
20
(61) 8142-1476 - Formato 21 x 29,7cm - 1/1 BLACK - Fechamento e Editoração
Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
a preocupação obstinada pela manutenção do arquivo originalvem diminuindo à medida que aumenta a compreensão acercados processos informáticos, e difunde-se a idéia de que o focoda preservação não precisa estar na retenção do objeto físico,mas na conservação da experiência sensorial produzida poresse objeto, que abrange um escopo maior do que o próprio
documento audiovisual. Assim, uma política de preservaçãodeverá descrever claramente as estratégias adotadas paraassegurar a preservação dos materiais em cada um dos níveisde abstração do vídeo, quais sejam, o físico, o lógico e oconceitual, e ao mesmo tempo não pode negligenciar os níveissuperiores, como o social, o econômico e o organizacional.
Análise do conteúdo fílmico
NoDicionário Teórico e Crítico do Cinema, Jaques Aumont diz queas teorias de análise fílmica produzidas até os anos 70 carregavamprincipalmente um ideal estruturalista, e pesquisadores daImagem como Raymond Bellour, Roland Barthes e JaquesMonod: “...procuravam no próprio texto, em sua estruturaçãoe em sua ligação com as condições de sua gênese a explicaçãode sua forma e de sua relação com o espectador.” (AUMONT,2003). E continua explicando que somente após Cristian Metz esua sintagmática, da linguística gerativa de Colin e Carrol, e dapsicologia da montagem de Jean Mitry, é que Jean Louis Scheferrecuperou uma dimensão figurativa na interpretação do filme,em oposição às tentativas de codificação vistas anteriormente,abrindo espaço para conceitos e processos originários da psicologiacognitiva, que são hoje extensamente aplicados na recuperaçãotextual de conteúdos visuais. De fato, a partir daí, e apoiando-sena gestalt e no entendimento de aspectos linguísticos no cinemae na fotografia, chega-se mesmo a construir uma sintaxe dalinguagem visual, como na proposição de Dondis (1997) e na
gramática fílmica de Arijon (1991).Em extenso trabalho sobre a análise de filmes, Tárin (2006)considera que a elaboração de uma descrição e de umainterpretação do filme são as etapas básicas, mas que devemser acompanhadas por outras avaliações externas ao objetoestudado. Assim, inicialmente é necessário:
1) decompor o filme em seus elementos constituintes(desconstruir= descrever);
2) estabelecer relações entre tais elementos paracompreender e explicar a constituição de um “todosignificante” (reconstruir= interpretar).
Mas este processo se estende na inclusão de parâmetroscontextuais que revelam uma situação e uma história para oproduto audiovisual:
o estudo sobre as condições técnicas de produção do filme; a reflexão sobre a situação econômico-político-social nomomento de sua produção; a incorporação de princípios ordenadores, tais comogênero; estilos autorais, star-system , movimentoscinematográficos, etc;
o estudo sobre a recepção do filme, tanto em seusurgimento quanto no correr dos anos; a utilização ou não em algum modelo de representaçãodeterminado.
Estes pontos são extremamente relevantes, pois a recuperaçãoeficaz do conteúdo visual e sonoro só é possível com uma
indexação significativa e discriminante, e que deve estarrelacionada com intenções e procedimentos do usuário quandofaz a consulta no ambiente real.
O conteúdo visual de imagens pode ser classificado em doistipos principais:
conteúdo primitivo de imagens – refere-se aos elementosbásicos que compõem a imagem; são característicasvisuais que podem ser reconhecidas e extraídasautomaticamente pelo computador com reconhecimentode padrões e visão computacional. Conteúdos primitivossão em geral de natureza quantitativa; conteúdo complexo de imagens – refere- se aos padrõesde uma imagem que são percebidos por seres humanoscomo fontes de significados. Dificilmente podem seridentificados por máquinas e são principalmente denatureza qualitativa.
Os índices ou metadados, sejam extraídos automaticamente ouanotados manualmente, podem ser classificados de acordo com arelação que eles têm com a imagem ou vídeo nos seguintes tipos:
metadados independentes do conteúdo – dados quenão concernem diretamente ao conteúdo da imagemou vídeo, mas estão relacionados com este, como oformato da imagem, autoria, data, local, condições deiluminação, etc.; metadados dependentes do conteúdo – dados que se
referem a características consideradas de nível baixoe médio, como cor, textura, forma, relações espaciais,movimento e combinações destes. Para alguns tiposde imagens, como as provenientes de satélites, dabiomedicina, como tomografias, etc., é possível descrevero conteúdo destas em termos da geometria intrínseca ede configurações topológicas; metadados descritivos do conteúdo – dados que sereferem ao conteúdo semântico e que concernem àsrelações das entidades da imagem com entidades domundo real ou eventos temporais, emoções e significadosassociados a sinais visuais e cenas.
A maior vantagem associada com a indexação de conteúdo
primitivo é que sua extração pode ser automatizada. Entretanto,este conteúdo pode não ser suficientemente rico para grandevariedade de aplicações, uma vez que tipos de objetos ecaracterísticas significativas que podem ser reconhecidos pelamáquina são ainda limitados. Em contrapartida, o conteúdocomplexo da imagem é semanticamente rico, mas sua extraçãoe indexação são custosos, uma vez que um envolvimentomanual considerável é geralmente necessário.
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 20 09/09/2008 10:19:10

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 5/12
21Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Desafios e avanços na recuperação automática da informação audiovisual
Padrões de Indexação
A informação visual tem sido tradicionalmente produzida econservada em suporte analógico e indexada manualmente,mas com a digitalização dos processos de captura, registro emanipulação da imagem fotográfica, hoje as bases de dados em
memórias magnéticas e óticas são utilizadas para armazenarimagens e sons, juntamente com os metadados, taxonomiase tesauros associados.
As diferentes iniciativas para indexação de audiovisuais, quandodefinem taxonomias específicas, podem valorizar diferentesvisões do problema: por um prisma implementacional, maisvoltado para aspectos técnicos; ou uma aproximação conceitual,preocupada com a semântica; ou ainda uma visão contextual, queleva em conta a utilização do material. As etapas que geralmenteestruturam a indexação de vídeos são as seguintes:
segmentação do programa em cenas e planos; descrição de planos – identificação de elementos deconteúdo; descrição de cenas – localização temporal e sumáriotextual; transcrição de voz e classificação de áudio; descrição de metadados independentes de conteúdo.
Das inúmeras aplicações desse processo, destacamos a possibilidadeda oferta de vídeo sob demanda, de forma que apenas determinadosegmento do programa pode ser apresentado como respostaa uma busca, ou oferecido em um cardápio personalizado depreferências em um sistema de televisão interativa e a utilizaçãodo conceito de hipervídeo, ou seja, a navegação por meio desegmentoshiperlinkados. Modificações profundas na nossa relaçãocom o audiovisual serão provocadas pelo desenvolvimento
de sistemas eficientes de indexação, e afetarão boa parte dasatividades humana, da cultural à produção industrial, da educaçãoà segurança, da medicina à astronomia.
O que acontecerá mais rapidamente se houver consenso nadefinição de um arcabouço comum de metodologias pararecuperação semântica de imagem e som, o que no entanto aindanão aconteceu. Alguns dos padrões recentemente propostos eaplicados para indexação de audiovisuais são os seguintes:
Dublin Core –linguagem para descrição de metadados queutiliza duas classes de termos: elementos - organizadosem três categorias, conteúdo, propriedade intelectual einstanciação; e qualificadores - divididos em duas classes,elementos de refinamento e esquemas de codificação.
Inicialmente criado para descrição de objetos textuais,por meio de diversas extensões e acréscimos tem sidoaplicado também em conteúdos audiovisuais.
RDF – Resource Description Framework – tem porobjetivo a definição de recursos que podem ser operadosindependentemente do domínio específico da aplicação,facilitando e automatizando a troca de informações entremáquinas e entre plataformas distintas. O modelo básico
compõe-se de recursos, propriedades e declarações, em umsistema de classes extensível, que utiliza a sintaxe XML. MPEG-7 – Multimidia Content Description Interface –é um padrão para descrição de objetos multimídia eprevê o suporte a certo grau de interpretação semântica.Busca a interoperabilidade em recuperação, indexação,
filtragem e acesso a conteúdos audiovisuais entrerecursos e aplicações que manipulam esses conteúdos.Para isso utiliza descritores, esquemas de descrição e umalinguagem de definições de descritores, criados com asintaxe XML, fornece ferramentas que permitem a gestãodo conteúdo e sua descrição estrutural e conceitual, alémde navegação e acesso randômico e interação com ousuário, inclusive com um histórico da utilização dosistema.
LOM – Learnig Objects Metadata – estrutura metadadospara objetos de aprendizagem, que são definidos como umaentidade que pode ser usada para aprendizagem e educação.Objetiva o compartilhamento e a troca desses objetos emdiferentes ambientes e contextos, por meio de classificaçãohierárquica em categorias gerais e específicas.
RECUPERAÇÃO AUTOMÁTICA DECONTEÚDO
Os sistemas de recuperação de imagens por conteúdo sãodenominados CBIR (Content Based Image Retrieval) ou CBVIRquando incluem o vídeo, e podem ser construídos para encontrarimagens de duas formas: a busca por exemplo, em que se utilizamcomo chave de busca as características visuais de uma imagemou esboço de referência; e a busca textual, realizada a partir datranscrição de significados ou conceitos contidos na imagem
que foram previamente relacionados a características visuaisespecíficas. Na pesquisa em texto, as palavras serão procuradasna base criada a partir da análise de significados implícitos noconteúdo visual, processo denominado recuperação semântica,pois fundamentalmente diz respeito à relação entre um signo eaquilo a que ele se refere.
A pesquisa em CBIR é muito abrangente e envolve diversasáreas das ciências sociais e outras mais tecnológicas quecontribuem com as ferramentas computacionais necessáriaspara determinar a informação sintática presente emimagens, especialmente as que estudam a visão artificial eo reconhecimento de padrões. Por exemplo, na ColumbiaUniversity uma pesquisa multidisciplinar desenvolveu o
Persival (Personalized Retrieval and Summarization of Image, Video And Language resources), sistema automático de identificaçãode metadados dependentes de conteúdo, especializado emimagens e gráficos úteis na medicina. Na Universidade deWinsconsin, além de ferramentas de análise, pesquisa-se umsistema videográfico autônomo, capaz de produzir vídeosinformativos de qualidade simulando os métodos de operaçãode câmera usados por profissionais(GLEICH, 2002).
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 21 09/09/2008 10:19:11
7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 6/12
22
(61) 8142-1476 - Formato 21 x 29,7cm - 1/1 BLACK - Fechamento e Editoração
Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
No campo da ciência da informação, a Tufts University de Boston, nos Estados Unidos, propôs a iniciativa “DigitalLibrary for the Humanities”5, suportada também por outrasuniversidades americanas, que pretende definir novospadrões para a produção de audiovisuais. Este novo formatode mídia permitiria, aos documentos assim formatados, uma
auto-atualização, fruto da interação com outros documentoseletrônicos, e também com seus usuários.
A indexação do produto audiovisual e a extração de dadosrelevantes apresenta desafios teóricos enfrentados por muitosautores, e é uma discussão extremamente atual diante dastransformações midiáticas anteriormente apontadas. Arecuperação de informações semânticas contidas em fotografias éainda uma meta a ser alcançada, mas ao consideramos seqüênciasde imagens, o problema de indexação torna-se muito maisdesafiador, pois envolve a identificação e o entendimento decenas longas e complexas, compostas por centenas de imagens.
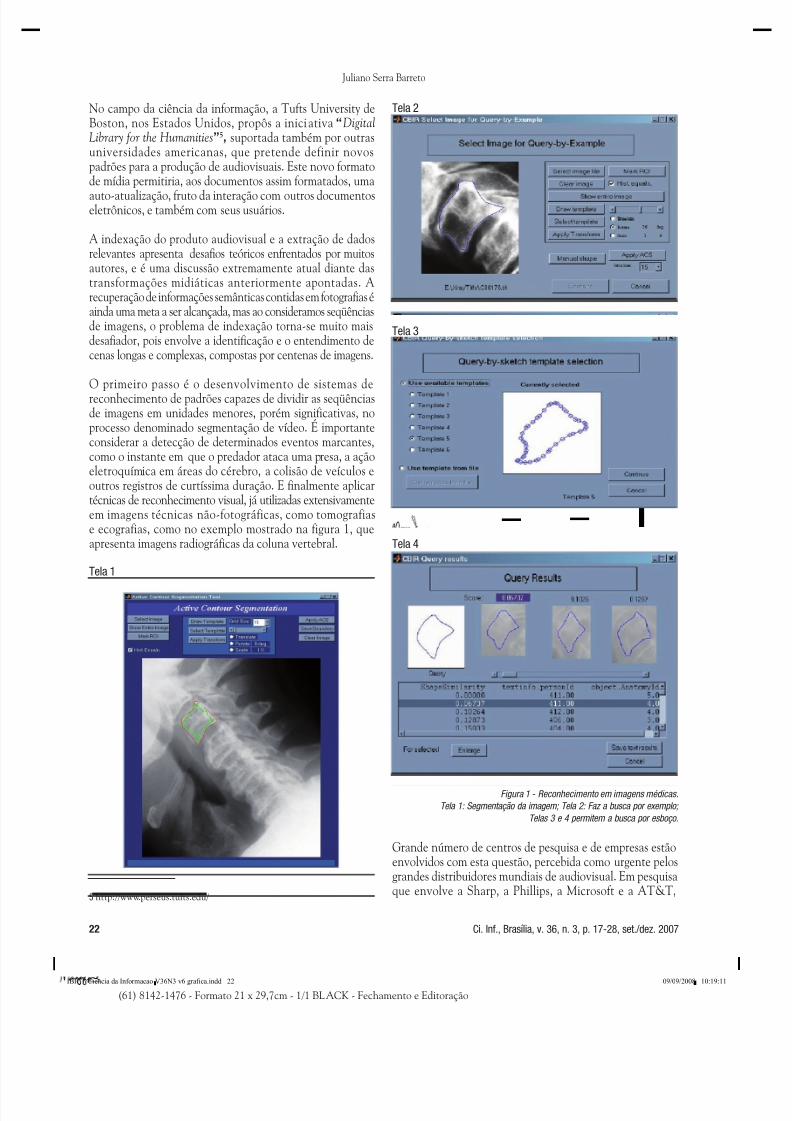
O primeiro passo é o desenvolvimento de sistemas dereconhecimento de padrões capazes de dividir as seqüênciasde imagens em unidades menores, porém significativas, noprocesso denominado segmentação de vídeo. É importanteconsiderar a detecção de determinados eventos marcantes,como o instante em que o predador ataca uma presa, a açãoeletroquímica em áreas do cérebro, a colisão de veículos eoutros registros de curtíssima duração. E finalmente aplicartécnicas de reconhecimento visual, já utilizadas extensivamenteem imagens técnicas não-fotográficas, como tomografiase ecografias, como no exemplo mostrado na figura 1, queapresenta imagens radiográficas da coluna vertebral.
Tela 1
5 http://www.perseus.tufts.edu/
Tela 2
Tela 3
Tela 4
Figura 1 - Reconhecimento em imagens médicas.
Tela 1: Segmentação da imagem; Tela 2: Faz a busca por exemplo;
Telas 3 e 4 permitem a busca por esboço.
Grande número de centros de pesquisa e de empresas estãoenvolvidos com esta questão, percebida como urgente pelosgrandes distribuidores mundiais de audiovisual. Em pesquisaque envolve a Sharp, a Phillips, a Microsoft e a AT&T,
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 22 09/09/2008 10:19:11

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 7/12
23Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Desafios e avanços na recuperação automática da informação audiovisual
desenvolvida nas universidades de Berkley e de Illinois,são explorados quatro processos coordenados: extração deelementos, análise de estruturas, abstração e indexação,para a obtenção de um sistema automático de segmentaçãoe identificação de conteúdos em qualquer tipo de vídeo(DIMITROVA, 2002).
Na Holanda, o projeto DMW6(Digital Media Warehouses)trouxe muitos avanços na modelagem multimodal e inteligentepara o reconhecimento de padrões em vídeos e a identificaçãode conceitos sobre eventos e objetos. Os pesquisadores doDMW definiram soluções lógicas e físicas, além de padrões paraaquisição e indexação do produto multimidiático, que formamuma arquitetura integrada para armazenagem de metadadosacoplada a uma linguagem de consulta de alto nível.
No Brasil, a Universidade Federal de São Carlos desenvolveo sistema SisRMi-CN (Serrano, 2003), um ambiente paraa criação e gestão de aplicações multimídia, oferecendodiferentes formas de recuperação de informações, usandológica nebulosa. E na UFMG, o Núcleo de ProcessamentoDigital da Imagem vem apresentando pesquisas consistentesna área, oferecendo workshops e implementando programasde preservação junto ao Patrimônio Histórico do Estado deMinas Gerais (ARAÚJO, 2003).
Antologias, catálogos, resenhas e inúmeras outras fontesde informação sobre filmes, vídeos e programas televisivossão publicados regularmente para suprir as necessidadesestratégicas de uma indústria cultural cada vez mais profícua.À medida que redes de televisão vão ocupando os canais naInternet e integrando-os em um sistema mundial multimídia,os mecanismos de classificação, busca e indexação de
programas e eventos tornam-se serviços essenciais. Algumasdas grandes difusoras mundiais de TV e rádio já permitem oacesso livre à parte de seus arquivos de programas. No Brasil,os distribuidores de mídia principais são a All TV, a RedeTV,a TV Vírgula, o Globo Media Center, o canal do portalTerra, a TV Cultura, e também a InterneTV. E à semelhançado YouTube, filmes curtos podem ser vistos no PortaCurtase no CurtaoCurta. No entanto, as descrições de conteúdosão obtidas em bancos de dados manualmente indexadose resumem-se a curta sinopse e comentários ou críticas deusuários. O Internet Movie Database7 é provavelmente o maiscompleto registro da produção cinematográfica disponívelatualmente na rede.
Identificação de elementos visuais
Muitos sistemas de CBIR utilizam a similaridade decaracterísticas como formas, bordas, cores ou textura paracriar índices, o que tem produzido bons resultados, quando
6 http://monetdb.cwi.nl/acoi/DMW/index.html7 http://imdb.org
utilizado para imagens em movimento. O projeto Informedia8,da Universidade Carnagie Mellon, foi pioneiro na área aoutilizar estas técnicas e a segmentação do vídeo para indexarprogramas de notícias em tempo real. A figura 2 mostra umatela da interface de busca textual em noticiários, e a figura 3apresenta as etapas de processamento do sistema Informedia,
evidenciando os diferentes domínios em que são extraídos osmetadados.
Figura 2
Projeto Informedia – Tela do aplicativo de busca e anotaçãosupervisionada
Figura 3
Projeto Informedia – Esquema conceitual do sistema
Outras linhas de pesquisa experimentam o levantamento degráficos estatísticos de características dinâmicas no vídeo. Notrabalho de Guimarães (2003), o fluxo de vídeo é transformadoem fatias espaço-temporais por amostragem dos pixels queformam as imagens. Cada quadro 2-D é transformado em umalinha vertical. O gráfico resultante representa o ritmo visual deum vídeo, e estas fatias podem indicar os pontos de transição,onde há grandes mudanças no conteúdo da imagem.
Os sistemas mais reportados para extração de metadadosdependentes de conteúdo são os que reconhecem semelhançasentre características visuais, onde usualmente temos como
8 http://www.informedia.cs.cmu.edu/
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 23 09/09/2008 10:19:13

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 8/12
24
(61) 8142-1476 - Formato 21 x 29,7cm - 1/1 BLACK - Fechamento e Editoração
Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
base de pesquisa a similaridade de cores, de formas ou detexturas, ou uma combinação destes parâmetros:
A cor é uma das características mais utilizadas pelos sereshumanos para reconhecimento e discriminação visual. Aaparência de uma cor em objetos do mundo real geralmente
é alterada pela textura da superfície, pela iluminação esombra de outros objetos, e pelas condições de observaçãoe captura. As operações de reconhecimento de similaridadespermitem encontrar as seguintes imagens: que contêm umacor especificada por meio de proporções aditivas; cujas coressão próximas daquelas de uma imagem exemplo; que contêmregiões coloridas como especificado em esboço; que contêm umobjeto conhecido com base nas propriedades de composiçãoespectral. A extração de cores automatizada ainda não é capazde fazer referências ao contexto, o que dificulta a distinçãoentre uma informação de cor do objeto e de uma alteraçãocromática introduzida pelo ambiente.
A percepção da textura é um fator importante da visãohumana, pois ajuda a identificar em uma cena a profundidade eorientação das superfícies, além de revelar suas característicastácteis. A textura refere- se a um padrão visual que temalgumas propriedades de homogeneidade que não resultamsimplesmente da cor ou da incidência da luz, como a repetiçãode linhas e as características físicas superficiais dos objetos. Pelaextração de características de textura obtém-se um descritorimportante para indexar imagens da natureza, e muito útil naspesquisas em grandes repositórios de imagens .
Forma é um critério que permite identificar na projeçãobidimensional parte da estrutura física dos objetos. Paraaplicações de recuperação, as características da forma podem
ser consideradas como sendo globais ou locais. Característicasglobais são propriedades derivadas da forma inteira, comosimetria, circularidade, localização de eixos, etc. Característicaslocais são aquelas derivadas do processamento parcial da forma,incluindo tamanho e orientação de segmentos consecutivosde bordas, pontos de curvaturas e ângulos de curvas. Ascaracterísticas de forma podem também ser classificadas emparâmetros internos, que descrevem a região envolvida pelocontorno do objeto, e parâmetros externos, que descrevemas bordas do objeto. Na figura 4 pode-se ver a filtragem debordas nas imagens de uma aplicação CBIR que usa a formapara a identificação de veículos em trânsito.
Para indexar imagens fixas extraindo-se os metadadosdependentes do conteúdo (cor, textura, forma), pode sernecessário pré-calcular para cada imagem um conjuntode características distintivas, e então as consultas sãoexpressas como comparações com exemplos visuais. Paracomeçar a consulta, o usuário seleciona as característicasque são relevantes e define uma medida de similaridade.Os exemplos tanto podem ser esboços preparados pelousuário (com ajuda de um programa de desenho) quanto
imagens selecionadas em um banco de dados, dentreamostras preparadas. O sistema verifica a similaridade entreo conteúdo da imagem usada na consulta e das imagensda base de dados. Como nem sempre os resultados obtidosem resposta a uma consulta são plenamente satisfatórios,em geral procura-se melhorar este resultado com uma
metodologia em que se mantém o número de objetos nãoencontrados o mais baixo possível, às custas de um númeromais alto de falsas respostas.
Figura 4
Filtragem de imagens para o reconhecimento de formas noprograma ImprovQT
As técnicas de reconhecimento aplicadas em imagens fixassão empregadas nos quadros obtidos na fase de segmentaçãodo vídeo, apresentada a seguir.
Segmentação do vídeo
Métodos estruturados de representação compacta do conteúdo
dos produtos audiovisuais têm sido desenvolvidos com objetivode facilitar o acesso ao vídeo não só para navegação por imagensrelevantes, ou quadros-chave, como para a recuperação epesquisa via texto. Tais métodos buscam modelar os dados deforma que todas as informações estejam disponíveis de maneiraclara e rápida para os usuários que a estão requisitando, alémde tornar transparentes as informações pertinentes sobre osdados (metadados).
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 24 09/09/2008 10:19:14

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 9/12
25Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Desafios e avanços na recuperação automática da informação audiovisual
O desafio para a indexação e recuperação de imagens orientadaspelo conteúdo está no desenvolvimento de mecanismosautomáticos e precisos, porém genéricos e abrangentes. Umapossibilidade é começar com a extração de conteúdo primitivoe subseqüentemente fazer uso de regras de conhecimentoe aprendizado sobre a informação contextual relevante,
permitindo uma identificação, ou inferência automática, doconteúdo significativo que uma pessoa observaria em umafotografia ou vídeo. Essa solução é adequada em algumassituações específicas.
No noticiário televisivo típico, por exemplo, podem-seconsiderar algumas características particulares importantesque facilitam o trabalho de indexação automática: a trilhasonora é composta na maior parte por falas de entrevistados ounarradores; usam-se extensivamente as legendas e letreiros; e aimagem é freqüentemente uma ilustração do tema tratado.
O vídeo digital é uma apresentação de eventos dinâmicosque possuem imagens, sons, textos e gráficos, uma estruturacomplexa que pode ser dividida em partes mais simples. Oproblema da segmentarão em vídeo começa na identificaçãodos momentos de mudança radical do conteúdo visual, noscortes de montagem e na seqüência de quadros estáticosdo filme. A abordagem clássica para resolver este problemaé baseada no cálculo de medidas de dissimilaridade oudiferenças entre os quadros. Em novas abordagens, asegmentação em vídeo é transformada em um problemade detecção de padrões, no qual cada evento de vídeo évisto como padrões em um imagem espaço-temporal 2D,que constituem um ritmo visual. Nesse caso, são utilizadasbasicamente ferramentas morfológicas e topológicas como objetivo de identificar os padrões específicos que são
relacionados a eventos do vídeo, como cortes, fades, dissolves, flashings e outros.
Figura 5
Identificação de planos
Na segmentação do vídeo, a unidade fundamental é oPLANO, que é capturado a partir de uma operação contínuada câmera. O plano é constituído por uma seqüênciaininterrupta de QUADROS ou fotogramas gerados pelacâmera, e pode ser uma imagem estática no tempo ou mostrartanto o movimento produzido pela própria câmera, como
por exemplo, zoom ou panorâmica, quanto o realizado porobjetos da cena.
Uma CENA é usualmente composta de número pequenode planos seqüenciais unificados pela posição temporal oucaracterísticas similares. Enquanto o plano é uma unidadefísica do vídeo, a cena representa uma unidade semântica domesmo, possuindo algum significado intrínseco. O processode identificação destas unidades, a segmentação do vídeo,começa por determinar os limites (início e fim) dos planos ecenas. (figura 5).
Figura 6
Um navegador visual de vídeos, exibindo os quadros-chave, e aduração das cenas identificadas.
Uma cena é um agrupamento de planos, que por sua vezsão constituídos por seqüências de quadros. Por ser grande aquantidade de cenas contidas em um filme, e para facilitar arepresentação, os planos podem ser sintetizados e apresentadosde forma resumida, por meio de quadros selecionadosque representam o conteúdo da cena, e são chamados deQUADROS-CHAVE.
Quadros-chave são um ou mais quadros que representam todo
o conteúdo visual de um plano da maneira mais aproximadapossível. Técnicas para a extração de quadros-chave lidamcom os limites do plano (isolamento dos quadros inicial efinal), e com padrões de conteúdo visual (a ocorrência dedeterminado elemento, ou em agrupamentos de elementosdistintos). A taxa de amostragem pode variar em função dograu de precisão desejado.
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 25 09/09/2008 10:19:15

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 10/12
26
(61) 8142-1476 - Formato 21 x 29,7cm - 1/1 BLACK - Fechamento e Editoração
Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
Para a identificação das cenas pode-se recorrer à similaridadevisual e a medidas de proximidade temporal. A similaridadevisual pode ser medida com a análise de histogramas (gráficoda distribuição de pixels), de estatísticas de fluxo ótico, eda localização de elementos visuais recorrentes. A figura 6apresenta uma tela de aplicativo para seleção de quadros-
chave e identificação de cenas, desenvolvido na UniversidadeChinesa de Hong-Kong.
A IBM, em sua unidade de Watson, Califórnia, tem se dedicadoespecialmente à pesquisa em recuperação de informaçãoaudiovisual e desenvolvido inúmeros projetos relacionados,a começar por um ambiente de programação sofisticado parapesquisa semântica, o UIMA (Unstructured InformationManagement Architecture), que permite a integração comprogramas em JAVA de ferramentas de análise capazes dedescobrir significados, relações e fatos mediante análise dedocumentos de texto, imagens, e-mail, áudio e vídeo. A indexaçãode imagens e vídeo é feita com o sistema denominado MARS9 (Multimedia Analysis and Retrieval System), que usa técnicasde inteligência artificial para inferir conceitos semânticos a partirde uma biblioteca de modelos. Assim é possível a busca combase no conteúdo primário, a partir de similaridade em cores,texturas e formas, por conceitos semânticos que descrevemcenas, objetos e eventos. O sistema também faz a pesquisa pormetadados e textos contidos na imagem, além da transcriçãode diálogos e identificação de gênero musical. Ainda limitadoem sua biblioteca de conceitos, com o MARS é possível extrairelementos como prédios ou o tipo de cenário (p. ex. praia, neve,mar, céu), e transcrever locuções treinadas.
Recuperação da informação em áudio
Para o reconhecimento e representação do conteúdosonoro deve-se inicialmente discriminar os três níveis quecostumam compor a trilha sonora de filmes; o nível da fala,sejam diálogos ou narrações; o de ruídos; e a trilha musical,quando houver. O segundo e terceiro níveis também contêminformações semânticas, porém as pesquisas se concentramna identificação de palavras faladas, portanto na extraçãoimediata de significantes lingüísticos. O reconhecimentoda fala ou ASR ( Automatic Speech Recognition) consiste emdiscriminar fonemas, sílabas e palavras para recuperar umamensagem de voz, e geralmente acontece em três etapas:
1) aquisição do sinal de voz – a simples transformação dosinal mecânico em sinal elétrico, feita normalmente
por microfones, conectados a uma placa de captura desom, e acionada por um software de gravação;
2) extração paramétrica – filtragem, quantização epreparação do sinal digital, através de software deedição e tratamento de sons;
9 http://www.alphaworks.ibm.com/tech/imars
3) reconhecimento de padrões – a identificação depalavras e frases na representação matemáticadiscreta de sinais contínuos. Algumas das técnicas deprocessamento digital de sinais usadas são CodificaçãoPreditiva Linear, baseada na diferença entre os tiposde sons; Modelo de Mistura Gaussiano, baseada em
classes vocais individualizadas; Transformada Rápidade Fourier (FFT), modelagem do sinal de palavrasisoladas.
O reconhecimento de voz é feito por um algoritmo capazde segmentar o áudio em pequenos trechos que isolam osfonemas. A transcrição é específica para cada língua e cadasom individual pode ser identificado e comparado a umalista previamente construída de palavras ou frases. Existembasicamente dois tipos de transcrição da voz humana:o primeiro permite ativar comandos predefinidos, como“Negrito” ou “Abrir programa”, com a fala de um usuárioespecífico. Os do segundo tipo são os chamados programasde ditado, que permitem transcrever textos. Estes podem serdependentes de locutor, do qual se exige treino prévio e quesão comuns hoje em dia, ou independentes de locutor, sistemasainda em desenvolvimento e que apresentam grandes desafiosna sua implementação (NETO, 2006).
Para a classificação da informação musical foram reportadosresultados consistentes na busca, por exemplo, ou QBE (Queryby Example), método por comparação, capaz de identificardiversos gêneros musicais. Uma segunda linha de pesquisatrabalha no reconhecimento de ritmos e melodias parapermitir a busca por solfejo, ou QBH (Query by Humming).Ambos os processos são de interesse especial para a telefoniamóvel(AHMAD, 2006).
Métodos de inteligência artificial
Com a consolidação da Internet, o tratamento da informaçãomodifica-se e busca alternativas para uma nova ordem decatalogação e pesquisa, conseqüentemente revolucionandoos métodos tradicionais de difusão do conhecimento. Novaspráticas impõem a redefinição dos Gêneros de Informação,observando-se a nova demanda marcada pela produçãomultimídia, que absorve múltiplos formatos e subverteas categorias tradicionais que distinguem os tipos deinformação; e da noção de Campos de Informação, pois oprocesso de dividir grupos de informações por temas já nãocorresponde ao potencial da rede, que nos permite navegarde uma informação à outra, correlata, e consolida umagrande infoteca sem divisões rígidas e que facilita a pesquisainterdisciplinar e sem fronteiras; além da flexibilização doconceito de Agentes da Informação, a distinção entre emissore receptor se torna ambígua com a enorme interatividadepermitida pela rede, pois surgem os co-autores e os co-leitores. E também se transforma, é claro, o processo decriação, pois a obra agora pode ser modificada por aquele
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 26 09/09/2008 10:19:15

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 11/12
27Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Desafios e avanços na recuperação automática da informação audiovisual
que a usufrui e que com ela interage em diversos níveis. Apar destas mudanças paradigmáticas, o acesso aleatório àinformação sugere que o acaso pode se tornar importanteferramenta de pesquisa para obtenção de soluções, ajudandona correção de erros e mesmo na otimização dos resultadosda pesquisa.
O equilíbrio entre a revocação e a relevância em procedimentosde busca e a criação de sistemas de reconhecimento de padrõescapazes de interpretar aquilo que identificam são questõescríticas das tecnologias da recuperação da informação,atualmente. As soluções podem estar no desenvolvimentode máquinas inteligentes, aptas à compreensão de conteúdos eobservação dos contextos, e também na criação de interfacesinstrutivas entre usuários e sistemas. Algumas ferramentasde inteligência artificial utilizadas atualmente para isto sãoas seguintes:
Redes Neurais – uma classe de modelagem de prognósticorealizado por ajuste repetido de parâmetro. A rede neuralconsiste em um número de elementos interconectados eorganizados em camadas, que aprendem pela modificaçãoda conexão, criando vínculos entre as diversas camadas.
Modelos de Markov –representações matemáticasutilizadas para prever comportamentos de um sinalatravés de uma seqüência de observações. Em umacadeia de Markov supõe-se uma fonte gerando tais saídasobserváveis, denominada Fonte de Markov. Os símbolosgerados a partir dessa fonte são dependentes apenas deobservações anteriores, as quais foram geradas da mesmaforma e assim sucessivamente. O número de seqüênciasanteriores consideradas para gerar uma saída é conhecido
como ordem da Cadeia de Markov. Cada estado de umacadeia de Markov representa uma observação/símbolo deum evento físico correspondente, o que permite computar,a partir de uma dada seqüência de símbolos, quaisforam os estados que geraram tal seqüência. No ModeloEscondido de Markov (MEM) cada estado representa umaprobabilidade, de certa forma “escondida” no conjuntodos símbolos que está representado. Um MEM, portanto,possibilita computar a seqüência de estados com maiorprobabilidade de ter gerado o conjunto observado desímbolos do estado corrente.
Lógica Nebulosa – também chamada fuzzy, é um algoritmoque permite simular um aspecto do raciocínio humano, a
habilidade de tomar decisões racionais em condições deincerteza e imprecisão. Ao manipular inteligentementeinformações imprecisas e conceitos indefinidos, pode inferiruma resposta precisa para um problema cujo enunciado éinexato e incorporar tanto o conhecimento objetivo quantoo conhecimento subjetivo.
Algoritmos Genéticos – desenvolvidos a partir dosprincípios da evolução das espécies de Darwin, e em leise procedimentos da genética. A partir de uma populaçãode indivíduos, representados por cromossomas (palavrasbinárias), cada um associado a uma aptidão (funções), que sãosubmetidos a um processo de evolução (seleção, reprodução,
cruzamento e mutação), repetido em vários ciclos em direçãoà sobrevivência dos mais bem adaptados.
Para Sims (1991), podemos desenvolver modelos proceduraisa partir da seleção interativa com humanos, levando osistema ao aprendizado das estratégias de preferências dousuário e da lógica de sobrevivência dos resultados maiscomplexos e interessantes. Significa que poderemos ter oauxílio da inteligência artificial não somente para aplicaçõesde reconhecimento de padrões, indexação e busca, mastambém para a própria estruturação e modelagem do sistemae obtenção de modelos de indexação semântica adaptáveis adiferentes domínios.
CONCLUSÕES
A preservação de documentos garante a análise histórica e éfundamental como política de consolidação de uma identidadenacional e planetária, mas diante de gigantesca massadocumental, muitas são as dificuldades que se apresentam.A tecnologia digital pode nos ajudar a resolvê-las, porém assoluções não são triviais e exigirão muitos anos de pesquisae desenvolvimento. A fragilidade dos meios e a inovaçãocontínua de processos e padrões são grandes desafios quedevem ser encarados por iniciativas integradoras de longoprazo, que sustentem a conservação e o acesso futuro ao que
estamos produzindo hoje em suporte eletrônico.Verificamos que a recuperação de conteúdos em audiovisuaisvem obtendo sucesso especialmente na área de reconhecimentode padrões e na identificação de imagens de cunho técnico,porém a pesquisa pela decodificação semântica de imagens,a extração automática de metadados descritivos estáapenas começando, e faz parte da criação da máquina ideal,semelhante a nós mesmos. No caso da visão, provavelmentemelhor em certos aspectos, não somente pela capacidadeampliada de perceber outras freqüências luminosas, mastambém na possibilidade de analisar maior quantidade deinformação visual, uma vez que estejam maduros os sistemasde recuperação da informação audiovisual que foram aqui
brevemente examinados.
Artigo recebido em 21/08/2007e aceito para publicação em 16/05/2008
IBICT Ciencia da Informacao V36N3 v6 grafica.indd 27 09/09/2008 10:19:15

7/21/2019 BARRETO, Juliano Serra. Desafios e Avanços Na Recuperação Automática Da Informação Audiovisual
http://slidepdf.com/reader/full/barreto-juliano-serra-desafios-e-avancos-na-recuperacao-automatica-da 12/12
28 Ci. Inf., Brasília, v. 36, n. 3, p. 17-28, set./dez. 2007
Juliano Serra Barreto
REFERÊNCIAS
AHMAD, I. et al. Audio-based queries for video retri eval ove r java enabled mobiledevices. [S.l.]: Nokia Corporation, 2006. Disponível em: <http://muvis.cs.tut.fi/ Documents/SPIE_05_06.pdf >. Acesso em: 2008.
ARAÚJO, A. de A. RIBC recuperação de informação com base no conteúdo visual. Belo
Horizonte: Universidade Federal de Minas Gerais, 2003.
ARIJON, Daniel. Grammar of the film language. Los Angeles, CA: Silman-JamesPress, 1991.
AUMONT, J.; MARIE, M. Dicionário teórico e crítico do cinema. Campinas, SP:Papirus Editora, 2003.
BEAGRIE l.; GREENSTEIN, D. A strategic framework for creating and preserving digitalcollections. London, UK: UK’s Arts and Humanities Data Service, 1998. Disponívelem: <http://ahds.ac.uk/strategic.pdf >. Acesso em: 2008.
DIMITROVA, N. et al. Applications of video-content analysis and retrieval. IEEEMultiMedia, v. 9/3, p. 42–56, 20-?. Disponível em: <http://2002.csdl.computer.org/comp/mags/mu/2002/03/u3toc.htm >. Acesso em: 2008.
DOLLER, M.; LEFIN, N.; KOSCH, H. Evaluation of available MPEG-7 annotation
tools. Germany: University of Passau, 2007. Disponível em: <https://www.i-know.at/content/download/870/3615/file/D%C3%B6ller.pdf >. Acesso em: 2008.
DONDIS, D. A. Sintaxe da linguagem visual. São Paulo: Martins Fontes, 1997.
FERREIRA, M. Introdução à preservação digital: conceitos, estratégias e actuais con-sensos. Minho: Editora Escola de Engenharia da Universidade do Minho, 2006. Dis-ponível em: <https://repositorium.sdum.uminho.pt/bitstream/1822/5820/1/ livro.pdf >. Acesso em: 2008.
GLEICHER, M.; HECK, R.; WALLICK, M. A framework for virtual videography.2002. Disponível em: <http://www.cs.wisc.edu/graphics/Papers/Gleicher/Vi-deo/smartgraphics-2002.pdf >. Acesso em: 2008.
GUIMARÃES, S. J. F. Video transition identification based on 2D image analysis. 2003.Tese (Doutorado)- Departamento de Ciência e de Computação, UFMG, 2003.
KOMPATSIARIS, Y. Multimedia semantic analysis technologies and their potential uses. 2006. Disponível em: <http://www.samt2006.org/presentations/ITI_MM%20Analysis.pdf >. Acesso em: 2008.
NETO, N.; SILVA, E.; SOUSA, E. Software usando reconhecimento e síntese de voz:
o estado da arte para o português brasileiro. In: 2005 LATIN AMERICAN CON-FERENCE ON HUMAN-COMPUTER INTERACTION, 2005, México. Electronic proceedings… Disponível em: <http://doi.acm.org/10.1145/1111360.1111396>.Acesso em: 2008.
SERRANO, M. Um sistema de recomendação para mídias baseado em conteúdo nebuloso. 2003. Dissertação (Mestrado)- UFSCar, São Paulo, 2003.
SIMS, Karl. Artificial evolution for computer graphics. In: SIGGRAPH ‘91, 1991.Proceedings... [S.l.: s.n.], 1991.
TARÍN, F. J. G. El análisis del texto fílmico. [S.l.]: Biblioteca Central da Universidadeda Beira Interior, 2006. Disponível em: <http://www.recensio.ubi.pt/modelos/ documentos/documento.php3?coddoc=1597 >.Acesso em: 2008.
VIRILIO, Paul. A máquina de visão. Rio de Janeiro: José Olympio, 1994.
URL DAS FIGURAS
Figura 1 - http://archive.nlm.nih.gov/pubs/long/spie-sd2003/spie-sd2003.php
Figuras 2 e 3 - http://www.informedia.cs.cmu.edu/dli2/
Figura 4 - http://www.ee.uwa.edu.au/~braunl/improv/
Figura 5 - http://www.irishscientist.ie/DCUAS125.htm
Figura 6 - http://www.2002.org/CDROM/alternat/XS3/ima-
ge006.jpg


















