
Arquitetura e Organização de Computadores 2 -...
20
19/05/2015 1 Arquitetura e Organização de Computadores 2 Capítulo 2: Projeto da Hierarquia de Memória Otimizações Memory Performance Gap 2
-
Upload
nguyencong -
Category
Documents
-
view
213 -
download
0
Transcript of Arquitetura e Organização de Computadores 2 -...

19/05/2015
1
Arquitetura e Organização de
Computadores 2
Capítulo 2: Projeto da Hierarquia de Memória
Otimizações
Memory Performance Gap
2

19/05/2015
2
Memory Hierarchy
3
Introdução Programadores desejam quantidades ilimitadas de memória e de
baixa latência.
Tecnologia empregadas em memórias rápidas são mais caras do que as mais lentas.
Solução: organizar o Sistema de memória de forma hierárquica e multinível… Todo o espaço de memória endereçável está mapeado para a memória de
maior capacidade e mais lenta…
Os níveis mais próximos do processador são menores, mais rápidas e mais caras do que os níveis mais distantes…
(quase sempre) - Os dados contidos em um nível inferior (próximo ao processador) são um subconjunto do nível superior seguinte…
O princípio da localidade temporal e espacial asseguram que todas as referências num future próximo serão encontradas nas memórias mais rápidas… Cria a ilusão ao processador de acesso a um sistema de memória ideal...
4

19/05/2015
3
Projeto da Hierarquia do Sistema de Memória
O projeto ganha importância com o uso crescente de processadores multi-cores… O pico agregado da largura de banda (bandwidth) cresce com o
número de cores: Intel Core i7 pode gerar duas referências por núcleo (core) por ciclo de
clock Quatro núcleos e clock de 3.2 GHz
25.6 billion 64-bit data references/second + 12.8 billion 128-bit instruction references = 409.6 GB/s!
A largura de banda para a DRAM é de somente 6% desta exigência (25 GB/s)...
Tradicionalmente, projetistas investem na otimização do tempo médio de acesso a memória, que é determinado pelo tempo de acesso à cache, taxa de falta e penalidade da falta... Requer:
Multi-port, pipelined caches Two levels of cache per core Shared third-level cache on chip
5
Desempenho e Consumo de Energia
Microprocessadores de última geração possuem caches ≈10 MB Consome grande quantidade de área e potência...
O problema é mais sério nos processadores utilizados em equipamentos móveis ...
Princípio de projeto atual – considerar a relação desempenho e consumo de energia...
6

19/05/2015
4
Fundamentos Básicos da Memória Hierárquica
Quando uma palavra não é encontrada no cache, uma falta ocorre (cache miss): Buscar uma palavra em um nível mais baixo da hierarquia,
requererá uma latência maior para a referência… O nível mais baixo pode ser um outro cache ou a memória
primária (DRAM)… Múltiplas palavras, chamadas bloco, são movidas por questão de
eficiência Obtém vantagem da localidade especial…
Onde colocar os blocos? – o esquema mais popular é o de associação por conjuntos (set associative), onde conjunto é uma coleção de blocos no cache… Primeiro o bloco é colocado no cache em qualquer localização do
conjunto determinado pelo seu endereço… Encontrar o bloco consiste em mapear o endereço do bloco para o
conjunto e depois examinar o conjunto… O conjunto é escolhido pelo endereço da referência:
(endereço do bloco) MOD (número de conjuntos da cache)
7
Fundamentos Básicos da Memória Hierárquica
Associativo por conjunto de n vias (n-way set associative)
Mapeamento direto (direct-mapped) one block per set
Totalmente associativo (fully associative) one set
Políticas de escrita no cache: Write-through
Atualiza a informação em todos os níveis do cache...
Write-back Somente realiza a atualização nos níveis inferiores do cache (mais
lentos) quando o bloco atualizado for substituído...
As duas estratégias utilizam um buffer de escrita para permitir que a cache prossiga assim que os dados forem colocadas no buffer (escrita assíncrona)
8

19/05/2015
5
Fundamentos Básicos da Memória Hierárquica
Uma medida dos benefícios de diferentes organizações de cache é a taxa de falta (miss rate) Miss rate – fração de acessos a cache que resultam em faltas
Causas da falta (miss) – categorias: Compulsória
Primeira referência a um bloco
Capacidade Blocos descartados e posteriormente recuperados
Conflito O programa realiza repetidas referências a múltiplos endereços de
diferentes blocos que mapeiam para uma mesma localização no cache.
9
A taxa de falta (falta por referência de memória) pode ser uma medida confusa, projetistas preferem a medida de faltas por instrução – (as duas estão relacionadas)
Observe que um processador especulativos e multithreadedpode executar outras instruções durante a falta... O que reduz a penalidade efetiva da falta
Para obter vantagem de tais técnicas de tolerância de latência, precisamos de caches que possam atender requisições e, ao mesmo tempo, lidar com uma falat proeminente.
Fundamentos Básicos da Memória Hierárquica
10

19/05/2015
6
Fundamentos Básicos da Memória Hierárquica
Seis otimizações básicas para o cache: Tamanho do bloco maior (block size)
Reduz a falta compulsória
Aumenta as faltas por capacidade e conflito, em caches menores, o que aumenta a penalidade da perda...
Caches maiores para reduzir a taxa de falta Tempo de acerto (hit time) potencialmente maior, aumenta o consumo de energia
Associatividade mais alta para reduzir a taxa de falta Reduz faltas por conflito
Tempo de acerto (hit time) potencialmente maior, aumenta o consumo de energia
Caches multiníveis para reduzir a penalidade da falta Reduz o tempo de acesso a memória global
Dar prioridades as faltas de leitura, em vez de faltas de escrita Reduz a penalidade da falta
Evitar a tradução de endereço durante a indexação da cache Reduz o tempo de acerto
11
Dez Otimizações Avançadas para o Cache
1. Caches pequenas e simples – reduz o tempo de acerto e potência
Caminho crítico de tempo em um acerto: addressing tag memory, then
comparing tags, then
selecting correct set
Caches mapeadas diretamente podem sobrepor a comparação da tag e a transmissão dos dados...
Associatividade menor reduz a potência devido a quantidade menor de linhas cache acessadas
12
19/05/2015
7
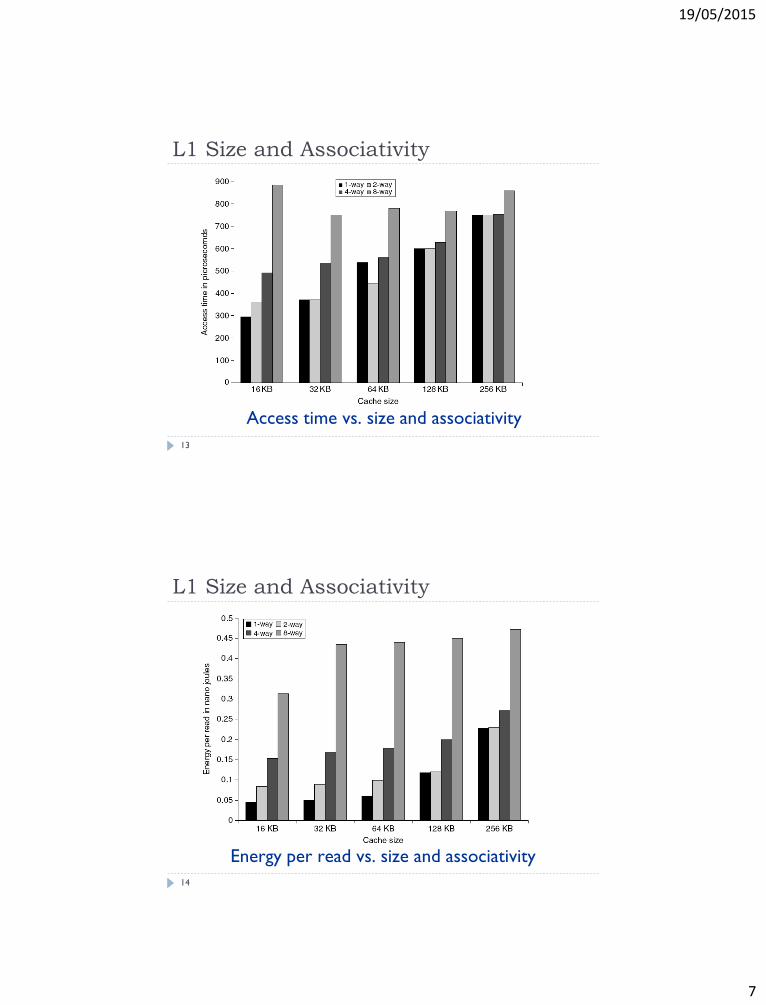
L1 Size and Associativity
Access time vs. size and associativity
13
L1 Size and Associativity
Energy per read vs. size and associativity
14

19/05/2015
8
Dez Otimizações Avançadas para o Cache
2. Previsão de Via (way prediction) Reduz o tempo de acesso, prevê a via ou o bloco dentro do
conjunto do próximo acesso ao cache (pre-set mux) Erros de previsão determinam um tempo de acesso maior
Precisão de previsão > 90% para two-way set associative
> 80% para four-way set associative
I-cache e mais preciso do que D-cache
Usado primeiramente no MIPS R10000 metade da década de 90.
Hoje, usado no ARM Cortex-A8
Uma forma estendida de previsão de via é utilizada para reduzir o consumo de energia, decidindo qual será o bloco acessado. “Way selection”
Aumenta a penalidade por uma má previsão.
15
Dez Otimizações Avançadas para o Cache
3. Pipelining Cache Acesso à cache em pipeline para aumentar a largura de
banda da cache Exemplos:
Pentium: 1 cycle
Pentium Pro – Pentium III: 2 cycles
Pentium 4 – Core i7: 4 cycles
Aumenta a penalidade para desvios mal previstos e mais ciclos de clock entre carregamento e uso dos dados.
Possibilita a incorporação de altos graus de associatividade...
16

19/05/2015
9
Dez Otimizações Avançadas para o Cache4. Nonblocking Caches
Permite o cache fornecer acertos de cache durante uma falta.
“Hit under miss”
“Hit under multiple miss”
L2 devem suportar isso
Em geral, os processadores fora de ordem ocultam grande parte da penalidade da falta no nível L, mas não ocultam a penalidade no nível L2.
17
Dez Otimizações Avançadas para o Cache
5. Multibanked Caches
Organizar o cache em bancos independentes para facilitar o acesso simultâneo. ARM Cortex-A8 suporta1-4 bancos para o L2
Intel i7 suporta 4 bancos para o L1 e 8 bancos para o L2
Bancos de cache intercalados em quatro vias
18

19/05/2015
10
Dez Otimizações Avançadas para o Cache6. Palavra crítica primeiro e reinício antecipado
Técnica baseada na observação de que o processador precisa de apenas uma palavra do bloco de cada vez.
Palavra crítica primeiro Solicite primeiro a palavra que falta e envie-a para o
processador assim que ela chegar; deixe o processador continuar a execução enquanto preenche o restante das palavras no bloco.
Reinício antecipado Busque as palavras na ordem normal, mas assim que a palavra
solicitada chegar, envie-a para o processador e deixe que ele continue a execução.
Os benefícios dessa estratégia dependem do tamanho do bloco e da probabilidade de outro acesso à parte do bloco que ainda não foi acessada.
19
Dez Otimizações Avançadas para o Cache7. Mesclagem da Escrita (MergingWrite Buffer)
Quando armazenar em um bloco que já está pendente no buffer de escrita, atualize o buffer de escrita
Reduz stalls devido a ao buffer de escrita estar cheio.
Não se aplica a endereços de E/S (I/O)
No write
buffering
Write buffering
20

19/05/2015
11
Dez Otimizações Avançadas para o Cache
8. Otimizações de Compilador
Permuta de Loop – (Loop Interchange) Troca loops aninhados para acessar a memória em sequência
Bloqueio – (Blocking) No lugar de acessar a matriz por linhas e colunas, divida a
matriz em blocos
Requer mais acesso a memória, mas melhora a localidade do acesso.
21
Dez Otimizações Avançadas para o Cache
9. Hardware Prefetching
Busca dois blocos na falta (inclui o próximo bloco na sequência)
Pentium 4 Pre-fetching
22

19/05/2015
12
Dez Otimizações Avançadas para o Cache
10. Compiler Prefetching
O compilador insere no código instruções de pré-busca (prefetch) antes que os dados sejam necessários.
Non-faulting: pré-busca não causa exceções.
Pré-busca de registrador - (Register prefetch) Carrega valor de dados em regitrador
Pré-busca de Cache – (Cache prefetch) Carrega os dados apenas na cache, e não no registrador.
Combina com desenrolar de laços (loop unrolling) e software pipelining.
23
Resumo
24

19/05/2015
13
Tecnologia de Memórias
Memory Technology Performance metrics
Latency is concern of cache
Bandwidth is concern of multiprocessors and I/O
Access time Time between read request and when desired word arrives
Cycle time Minimum time between unrelated requests to memory
DRAM used for main memory, SRAM used for cache
26

19/05/2015
14
Memory Technology SRAM
Requires low power to retain bit
Requires 6 transistors/bit
DRAM Must be re-written after being read
Must also be periodically refeshed Every ~ 8 ms
Each row can be refreshed simultaneously
One transistor/bit
Address lines are multiplexed: Upper half of address: row access strobe (RAS)
Lower half of address: column access strobe (CAS)
27
Memory Technology Amdahl:
Memory capacity should grow linearly with processor speed
Unfortunately, memory capacity and speed has not kept pace with processors
Some optimizations: Multiple accesses to same row
Synchronous DRAM
Added clock to DRAM interface
Burst mode with critical word first
Wider interfaces
Double data rate (DDR)
Multiple banks on each DRAM device
28

19/05/2015
15
Memory Optimizations
29
Memory Optimizations
30

19/05/2015
16
Memory Optimizations DDR:
DDR2 Lower power (2.5 V -> 1.8 V)
Higher clock rates (266 MHz, 333 MHz, 400 MHz)
DDR3 1.5 V
800 MHz
DDR4 1-1.2 V
1600 MHz
GDDR5 is graphics memory based on DDR3
31
Memory Optimizations Graphics memory:
Achieve 2-5 X bandwidth per DRAM vs. DDR3 Wider interfaces (32 vs. 16 bit)
Higher clock rate Possible because they are attached via soldering instead of socketted DIMM
modules
Reducing power in SDRAMs: Lower voltage
Low power mode (ignores clock, continues to refresh)
32

19/05/2015
17
Memory Power Consumption
33
Flash Memory Type of EEPROM
Must be erased (in blocks) before being overwritten
Non volatile
Limited number of write cycles
Cheaper than SDRAM, more expensive than disk
Slower than SRAM, faster than disk
34

19/05/2015
18
Memory Dependability Memory is susceptible to cosmic rays
Soft errors: dynamic errors Detected and fixed by error correcting codes (ECC)
Hard errors: permanent errors Use sparse rows to replace defective rows
Chipkill: a RAID-like error recovery technique
35
Virtual Memory Protection via virtual memory
Keeps processes in their own memory space
Role of architecture: Provide user mode and supervisor mode
Protect certain aspects of CPU state
Provide mechanisms for switching between user mode and supervisor mode
Provide mechanisms to limit memory accesses
Provide TLB to translate addresses
36

19/05/2015
19
Virtual Machines Supports isolation and security
Sharing a computer among many unrelated users
Enabled by raw speed of processors, making the overhead more acceptable
Allows different ISAs and operating systems to be presented to user programs “System Virtual Machines”
SVM software is called “virtual machine monitor” or “hypervisor”
Individual virtual machines run under the monitor are called “guest VMs”
37
Impact of VMs on Virtual Memory
Each guest OS maintains its own set of page tables VMM adds a level of memory between physical and
virtual memory called “real memory”
VMM maintains shadow page table that maps guest virtual addresses to physical addresses Requires VMM to detect guest’s changes to its own page table
Occurs naturally if accessing the page table pointer is a privileged operation
38

19/05/2015
20
Bibliografia
39
David Patterson e John Hennessy,
Arquitetura e Organização de
Computadores – uma abordagem
quantitativa, 5ª Edição, ed. Campus.


















