
Algoritmos Evolucionários e Suas Aplicações na Simulação ... · ponto na superfície...
79
© 2015 Dr. Walter F. de Azevedo Jr. 1 101101011010 000010000100 000001111111 100111100111 111110011000 000001011010 000010111100 110100111100 11010011 1010 10110101 1100 100110011000 1111 111100111 101101011010 100111100111 111110011000 110100111100 Algoritmos Evolucionários e Suas Aplicações na Simulação de Docking Molecular Prof. Dr. Walter F. de Azevedo Jr. [email protected] ou [email protected]
Transcript of Algoritmos Evolucionários e Suas Aplicações na Simulação ... · ponto na superfície...
©2
01
5 D
r. W
alter
F.
de
Aze
ve
do
Jr.
1
101101011010
000010000100
000001111111
100111100111
111110011000
000001011010
000010111100
110100111100
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
110100111100
Algoritmos Evolucionários e Suas Aplicações
na Simulação de Docking MolecularProf. Dr. Walter F. de Azevedo Jr.
ou
O que é evolução?
O que é um algoritmo?
Podemos simular a evolução no computador?
Podemos usar as ideias da evolução na
resolução de problemas de otimização?
2

A resolução de problemas computacionais,
a partir do uso de princípios biológicos, não
é algo novo, propostas relacionadas à
aplicação de princípios biológicos em
programação de computadores remontam
as ideias de Alan Turing, um dos pais da
computação moderna. Alan Turing foi o
cientista responsável pela quebra do código
secreto “Enigma”, usado pelos nazistas
durante a Segunda Guerra Mundial. Os
nazistas usavam um sistema de
criptografia, que evitava que os aliados
descobrissem o conteúdo das mensagens
secretas enviadas via rádio.
O Alan Turing estava interessado no uso de
modelos biológicos, como paradigmas
de programação de computadores.
3
Inspiração Biológica
Simplificação das estruturas de um organismo vivo,
mostradas como um anel circular. Alan Turing tinha
como objetivo usar princípios biológicos como
inspiração para programas de computador.
Foto feita por Linus S. Azevedo (3/2/2013). Science
Museum, London-UK.

A Teoria da Evolução de Darwin tem
papel fundamental no entendimento da
evolução, e seu sucesso como teoria
científica fez Theodosius Dobzhansky
(1900-1975) a propor:
“Nothing in Biology makes sense except in
the light of evolution”.
Esta proposição tem sido usada como
introdução em muitos livros e seminários,
para destacar a importância da teoria de
Darwin.
Embora sistemas biológicos são
normalmente difíceis de se serem
submetidos à modelagem computacional,
os conceitos da evolução são simples,
sendo a seleção natural o conceito mais
importante.
4
Evolução, um Paradigma Computacional
Foto feita por Linus S. Azevedo (4/2/2011). Natural
History Museum, London-UK.
Viste a página do museu: http://www.nhm.ac.uk/

Normalmente os críticos da teoria de
Darwin compartilham dois aspectos em
comum.
1) Total desconhecimento do método
científico. Toda teoria científica é uma
modelagem da natureza, usando de um
arcabouço teórico para explicar
fenômenos naturais. Como tal pode ser
aprimorada, sem contudo, em essência,
está errada.
2) Desconhecimento da biologia
molecular, onde aspectos moleculares
da vida revelam a abrangência da
evolução, que manifesta-se no nível
molecular, como no caso da mioglobina
de mamíferos marinhos.
5
Foto feita por Linus S. Azevedo (4/2/2011). Natural
History Museum, London-UK.
Viste a página do museu: http://www.nhm.ac.uk/
Evolução, um Paradigma Computacional
O sucesso da Teoria da Evolução de Darwin, levou
seus conceitos a serem usados por outras áreas do
conhecimento, como, por exemplo, na computação.
Há um conjunto de algoritmos baseados na teoria
da evolução.
Mas o que é um algoritmo?
Algoritmos são descrições passo a passo de uma
tarefa, passível de implementação
computacional. Por exemplo, uma descrição passo
a passo de como resolver uma equação de primeiro
grau é um algoritmo. Cada programa de computador
é a materialização de um algoritmo ou vários
algoritmos. Quando você usa um programa, nada
mais está fazendo que usando a implementação de
algoritmos.
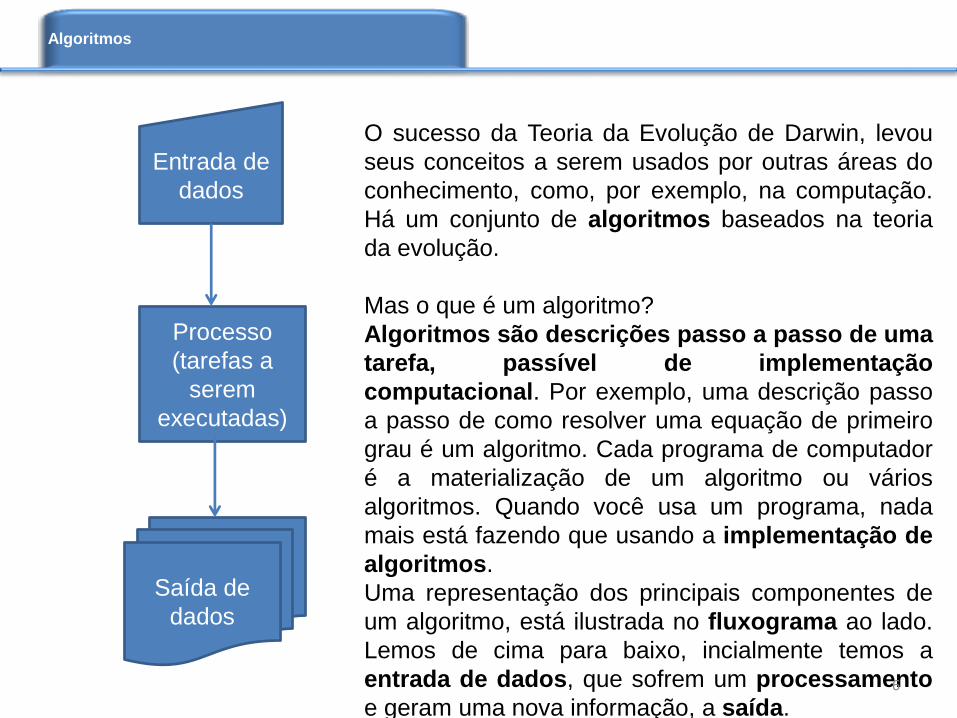
Uma representação dos principais componentes de
um algoritmo, está ilustrada no fluxograma ao lado.
Lemos de cima para baixo, incialmente temos a
entrada de dados, que sofrem um processamento
e geram uma nova informação, a saída.
Entrada de
dados
Processo
(tarefas a
serem
executadas)
Saída de
dados
6
Algoritmos

Colocando de uma forma mais simples
ainda, podemos pensar no algoritmo
como uma receita de bolo, por exemplo,
a receita para prepararmos um bolo de
leite condensado sem farinha de trigo.
Para o bolo temos os seguintes
ingredientes:
-1 lata de leite condensado;
-4 ovos pequenos (ou 3 grandes);
-1 medida de leite igual ao volume da
lata de leite condensado;
-100 g de coco ralado e
-uma colher de fermento.
Os ingredientes são as entradas do
algoritmo.
.
Ingredientes do nosso delicioso bolo de leite condensado
sem farinha de trigo
7
Algoritmos

O processo do algoritmo é a receita, no nosso bolo é a
seguinte: coloque todos os ingredientes num
liquidificador e mexa tudo (foto 1). Unte uma forma de
bolo com manteiga (foto 2). Coloque o conteúdo do
liquidificador na forma untada. Asse no forno
convencional a 260º por aproximadamente 40 minutos
(foto 3). Depois de 40 minutos temos o nosso bolo (foto
4)! A saída é nosso bolo de leite condensado. Assim, na
solução de muitos problemas científicos e tecnológicos,
temos algoritmos. O uso da inspiração da evolução
biológica no desenvolvimento de algoritmos é chamado
de algoritmo evolucionário (evolutionary algorithm).
Foto 1
Foto 2
Foto 3 8
Algoritmos
Foto 4
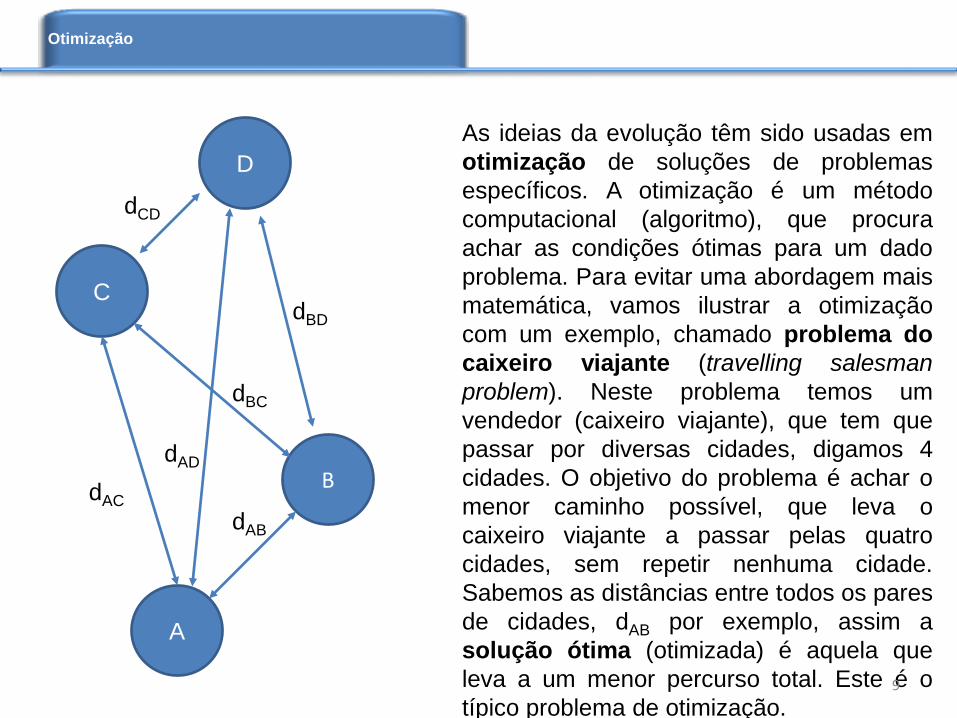
As ideias da evolução têm sido usadas em
otimização de soluções de problemas
específicos. A otimização é um método
computacional (algoritmo), que procura
achar as condições ótimas para um dado
problema. Para evitar uma abordagem mais
matemática, vamos ilustrar a otimização
com um exemplo, chamado problema do
caixeiro viajante (travelling salesman
problem). Neste problema temos um
vendedor (caixeiro viajante), que tem que
passar por diversas cidades, digamos 4
cidades. O objetivo do problema é achar o
menor caminho possível, que leva o
caixeiro viajante a passar pelas quatro
cidades, sem repetir nenhuma cidade.
Sabemos as distâncias entre todos os pares
de cidades, dAB por exemplo, assim a
solução ótima (otimizada) é aquela que
leva a um menor percurso total. Este é o
típico problema de otimização.
C
D
A
BdAC
dAD
dAB
dBD
dBC
dCD
9
Otimização
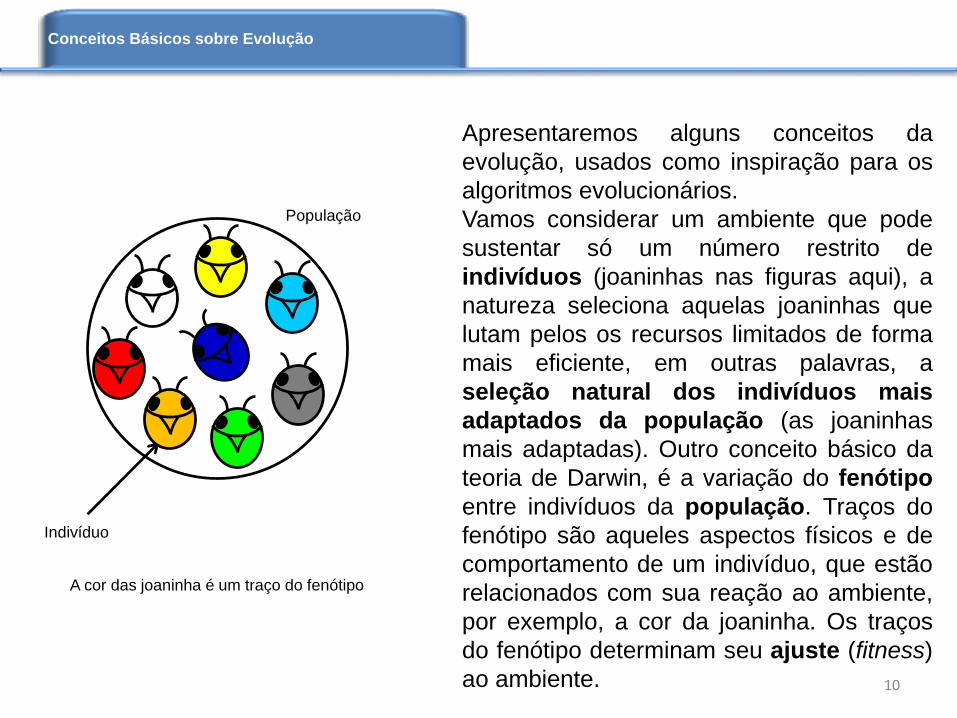
Apresentaremos alguns conceitos da
evolução, usados como inspiração para os
algoritmos evolucionários.
Vamos considerar um ambiente que pode
sustentar só um número restrito de
indivíduos (joaninhas nas figuras aqui), a
natureza seleciona aquelas joaninhas que
lutam pelos os recursos limitados de forma
mais eficiente, em outras palavras, a
seleção natural dos indivíduos mais
adaptados da população (as joaninhas
mais adaptadas). Outro conceito básico da
teoria de Darwin, é a variação do fenótipo
entre indivíduos da população. Traços do
fenótipo são aqueles aspectos físicos e de
comportamento de um indivíduo, que estão
relacionados com sua reação ao ambiente,
por exemplo, a cor da joaninha. Os traços
do fenótipo determinam seu ajuste (fitness)
ao ambiente. 10
Indivíduo
População
A cor das joaninha é um traço do fenótipo
Conceitos Básicos sobre Evolução
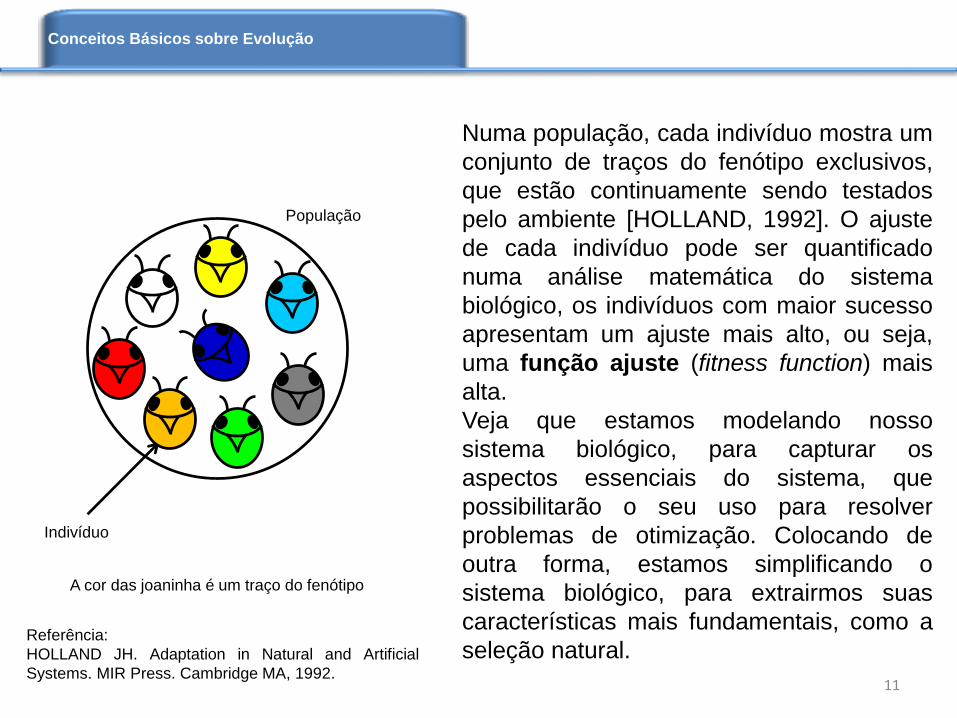
Numa população, cada indivíduo mostra um
conjunto de traços do fenótipo exclusivos,
que estão continuamente sendo testados
pelo ambiente [HOLLAND, 1992]. O ajuste
de cada indivíduo pode ser quantificado
numa análise matemática do sistema
biológico, os indivíduos com maior sucesso
apresentam um ajuste mais alto, ou seja,
uma função ajuste (fitness function) mais
alta.
Veja que estamos modelando nosso
sistema biológico, para capturar os
aspectos essenciais do sistema, que
possibilitarão o seu uso para resolver
problemas de otimização. Colocando de
outra forma, estamos simplificando o
sistema biológico, para extrairmos suas
características mais fundamentais, como a
seleção natural.
11
Conceitos Básicos sobre Evolução
Indivíduo
População
A cor das joaninha é um traço do fenótipo
Referência:
HOLLAND JH. Adaptation in Natural and Artificial
Systems. MIR Press. Cambridge MA, 1992.
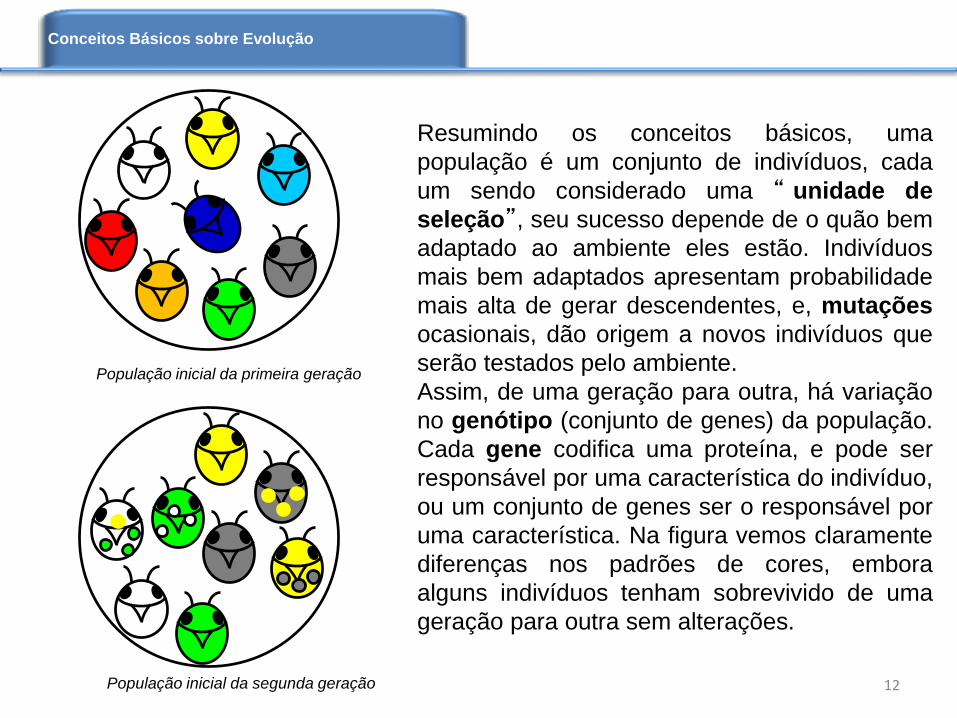
População inicial da primeira geração
População inicial da segunda geração
Resumindo os conceitos básicos, uma
população é um conjunto de indivíduos, cada
um sendo considerado uma “ unidade de
seleção”, seu sucesso depende de o quão bem
adaptado ao ambiente eles estão. Indivíduos
mais bem adaptados apresentam probabilidade
mais alta de gerar descendentes, e, mutações
ocasionais, dão origem a novos indivíduos que
serão testados pelo ambiente.
Assim, de uma geração para outra, há variação
no genótipo (conjunto de genes) da população.
Cada gene codifica uma proteína, e pode ser
responsável por uma característica do indivíduo,
ou um conjunto de genes ser o responsável por
uma característica. Na figura vemos claramente
diferenças nos padrões de cores, embora
alguns indivíduos tenham sobrevivido de uma
geração para outra sem alterações.
12
Conceitos Básicos sobre Evolução

O processo de evolução pode ser
visualizado usando uma superfície
adaptativa (adaptive surface). No gráfico
ao lado, a altura z representa a função
ajuste (fitness function), também chamada
de função escore (scoring function). Aqui,
quanto maior a altura na superfície, melhor
o ajuste do indivíduo. Os eixos x-y
representam todas as combinações
possíveis de dois traços do fenótipo. Cada
ponto na superfície representa um
indivíduo, com a combinação de traços do
fenótipo representados pelo valores de x e
y. Para exemplificar, o eixo x pode
representar a capacidade de mimetismo
(camuflagem) das joaninhas, e o eixo y a
capacidade de escalar obstáculos. A
combinação de x e y dará a função ajuste.
Os picos mais altos na figura representam
os indivíduos mais bem adaptados. 13
Conceitos Básicos sobre Evolução
Ajuste
x
y
Superfície adaptativa (adaptive surface)
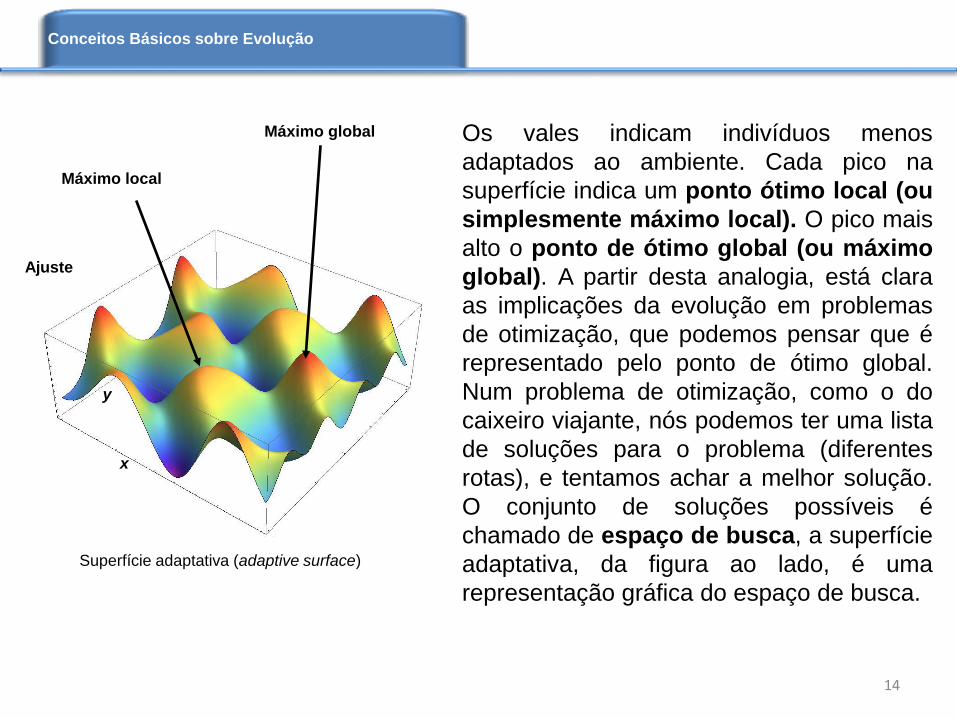
Os vales indicam indivíduos menos
adaptados ao ambiente. Cada pico na
superfície indica um ponto ótimo local (ou
simplesmente máximo local). O pico mais
alto o ponto de ótimo global (ou máximo
global). A partir desta analogia, está clara
as implicações da evolução em problemas
de otimização, que podemos pensar que é
representado pelo ponto de ótimo global.
Num problema de otimização, como o do
caixeiro viajante, nós podemos ter uma lista
de soluções para o problema (diferentes
rotas), e tentamos achar a melhor solução.
O conjunto de soluções possíveis é
chamado de espaço de busca, a superfície
adaptativa, da figura ao lado, é uma
representação gráfica do espaço de busca.
Ajuste
x
y
14
Conceitos Básicos sobre Evolução
Máximo local
Máximo global
Superfície adaptativa (adaptive surface)

75 2
1 37 2
1 18 2
0 9 2
1 4 2
0 2 2
0 1
Um dos primeiros algoritmos evolucionários foi o
algoritmo genético (genetic algorithm). Na
abordagem original dos algoritmos genéticos,
foram usados números binários para a
representação de cromossomos
[GOLDENBERG, 1989]. Faremos uma
introdução (ou revisão) da matemática básica
envolvida na conversão de um sistema para
outro. Um número binário é um número que usa
somente os algarismos “zero” e “um” , para
representar uma quantidade. Por exemplo, 101
em binário representa 5 no decimal. Veremos
exemplos para esclarecer o processo. Vamos
converter 75 em decimal para sua representação
binária. Para isto temos que dividir
continuamente “75” por “2”, o resto da divisão é
o último algarismo do número binário equivalente
ao 75, como mostrado ao lado. O último
resultado da divisão “1” é o algarismo mais
significativo do número binário. 15
Números Binários
75 = 100101110 2
Referência:
GOLDBERG DE. Genetic Algorithms in Search,
Optimization, and Machine Learning. Addison
Wesley Longman, Ins.,Indiana, USA, 1989.

Para converter de binário (subscrito 2) de
volta para decimal (subscrito 10), é ainda
mais fácil. Temos que multiplicar “0” ou “1”por 2 elevado à potencia, que é a posição
do número binário, começando na posição
zero no lado direito, até o último número na
sequência, como segue:
1.26 + 0.25 +0.24 + 1. 23 + 0.22 + 1.21 + 1.20
=64 + 0 + 0 + 8 + 0 + 2 + 1 = 75
Como ilustrado acima, somamos os
resultados parciais das multiplicações, o
resultado final é 75, o número na base
decimal.
16
75 2
1 37 2
1 18 2
0 9 2
1 4 2
0 2 2
0 1
75 = 100101110 2
Números Binários

Agora que sabemos como operar com
números binários, usaremos tais números
nos algoritmos genéticos. Em muitos
algoritmos genéticos os indivíduos são
representados por números binários, tal
método tem o benefício de ser rápido na
aplicação dos operadores genéticos,
como mutação e crossover. Num número
binário a mutação é simplesmente uma
mudança de “0” para “1” ou vice-versa.
A essência de um algoritmo genético é o
uso das ideias da evolução, por isso são
classificados como algoritmo evolucionário.
17
75 2
1 37 2
1 18 2
0 9 2
1 4 2
0 2 2
0 1
75 = 100101110 2
Números Binários

Assim, a implementação de um algoritmo genético usa as ideias da evolução de
Darwin, de forma que os indivíduos de uma dada população são submetidos aos
princípios da evolução, tais como, seleção natural, cruzamento (crossover) e mutação.
Veja abaixo, um indivíduo será representado por uma string binária. Uma string
binária é uma sequência de “0” e “1”. No algoritmo genético a string binária é
convertida num número decimal, usando as operações matemáticas já vistas.
18
011011110001
Representação do genoma de um indivíduo
na abordagem de algoritmo genéticos
1777
String binária Decimal relacionado à string binária
Números Binários
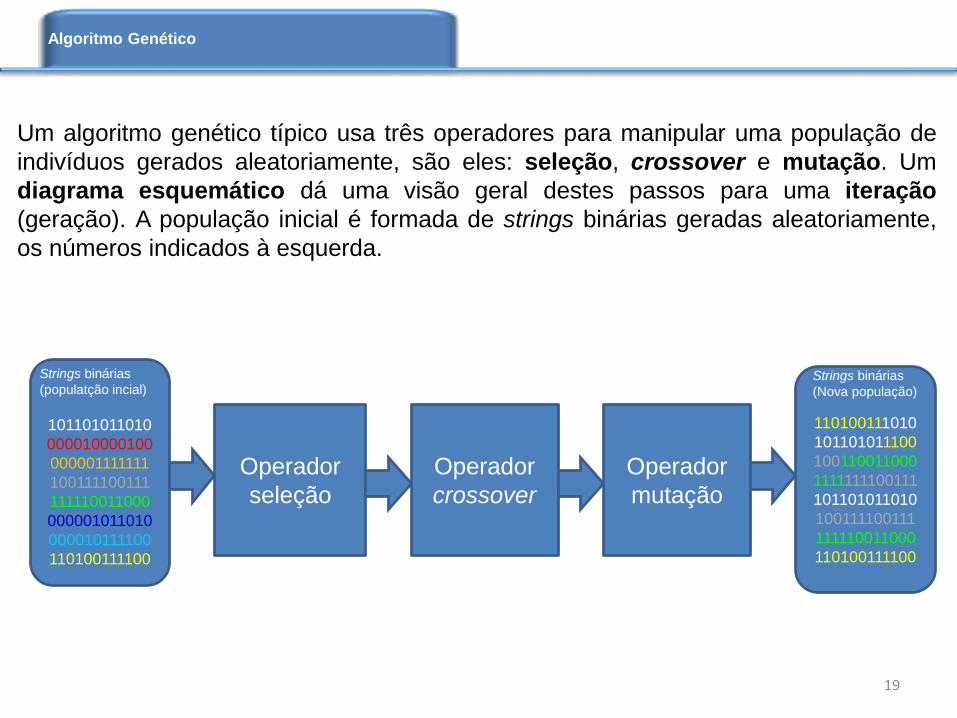
Um algoritmo genético típico usa três operadores para manipular uma população de
indivíduos gerados aleatoriamente, são eles: seleção, crossover e mutação. Um
diagrama esquemático dá uma visão geral destes passos para uma iteração
(geração). A população inicial é formada de strings binárias geradas aleatoriamente,
os números indicados à esquerda.
101101011010
000010000100
000001111111
100111100111
111110011000
000001011010
000010111100
110100111100
Strings binárias
(populatção incial)
Operador
seleção
Operador
crossover
Operador
mutação
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
110100111100
Strings binárias
(Nova população)
19
Algoritmo Genético
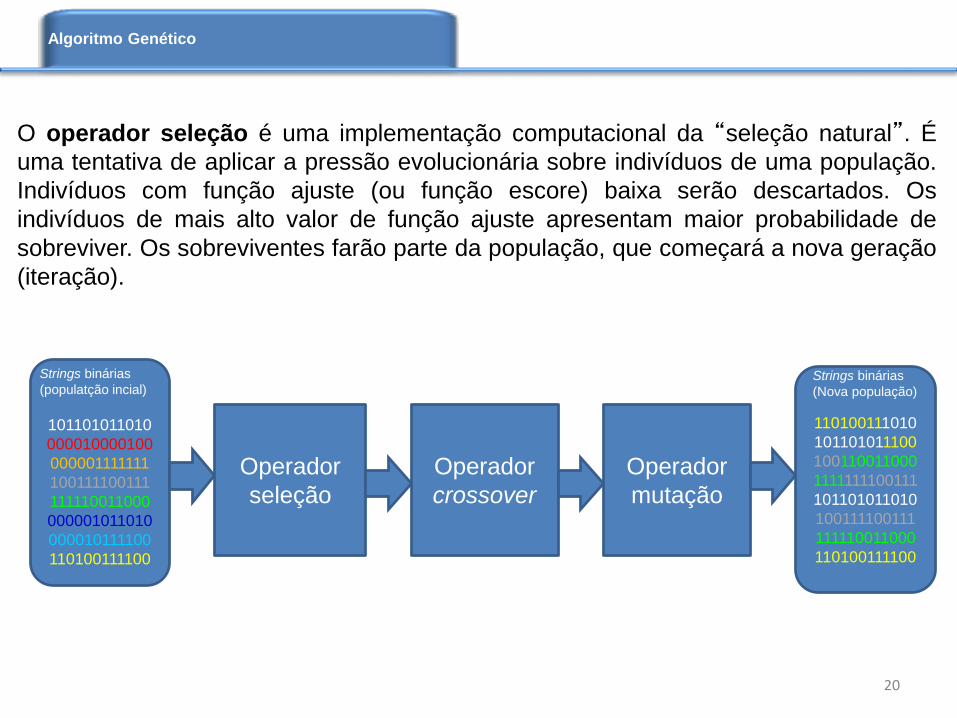
O operador seleção é uma implementação computacional da “seleção natural”. É
uma tentativa de aplicar a pressão evolucionária sobre indivíduos de uma população.
Indivíduos com função ajuste (ou função escore) baixa serão descartados. Os
indivíduos de mais alto valor de função ajuste apresentam maior probabilidade de
sobreviver. Os sobreviventes farão parte da população, que começará a nova geração
(iteração).
20
101101011010
000010000100
000001111111
100111100111
111110011000
000001011010
000010111100
110100111100
Strings binárias
(populatção incial)
Operador
seleção
Operador
crossover
Operador
mutação
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
110100111100
Strings binárias
(Nova população)
Algoritmo Genético
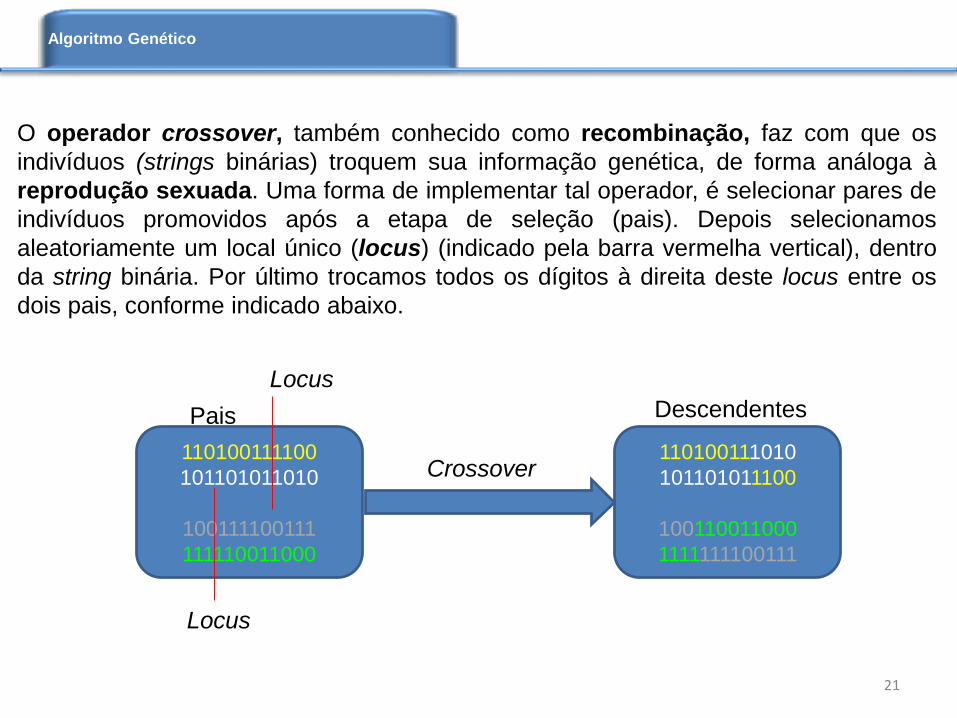
O operador crossover, também conhecido como recombinação, faz com que os
indivíduos (strings binárias) troquem sua informação genética, de forma análoga à
reprodução sexuada. Uma forma de implementar tal operador, é selecionar pares de
indivíduos promovidos após a etapa de seleção (pais). Depois selecionamos
aleatoriamente um local único (locus) (indicado pela barra vermelha vertical), dentro
da string binária. Por último trocamos todos os dígitos à direita deste locus entre os
dois pais, conforme indicado abaixo.
110100111010
101101011100
100110011000
1111111100111
110100111100
101101011010
100111100111
111110011000
Locus
Locus
Pais Descendentes
Crossover
21
Algoritmo Genético
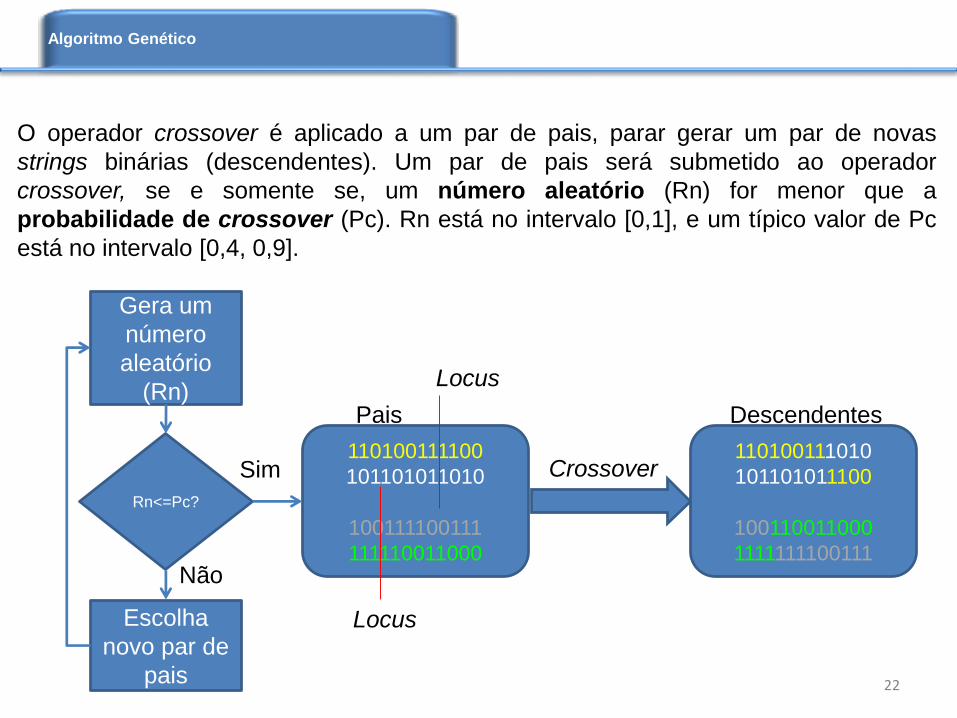
O operador crossover é aplicado a um par de pais, parar gerar um par de novas
strings binárias (descendentes). Um par de pais será submetido ao operador
crossover, se e somente se, um número aleatório (Rn) for menor que a
probabilidade de crossover (Pc). Rn está no intervalo [0,1], e um típico valor de Pc
está no intervalo [0,4, 0,9].
110100111010
101101011100
100110011000
1111111100111
110100111100
101101011010
100111100111
111110011000
Locus
Locus
Pais Descendentes
Crossover
Gera um
número
aleatório
(Rn)
Rn<=Pc?
Escolha
novo par de
pais
Sim
Não
22
Algoritmo Genético

Para ilustrar os princípios básicos do algoritmo genético, vamos resolver o seguinte
problema simples, qual o número entre 0 e 4095 maximiza a função quadrática
(f(x)=x2)? OK, não precisamos de um algoritmo genético para saber a resposta deste
problema, tal problema é só para ilustrar o algoritmo. Na implementação deste
algoritmo temos strings binárias de comprimento 12 (11111111112 = 409510). Assim,
vamos gerar números aleatórios entre 0 e 4095, como mostrado parcialmente na
tabela abaixo. Esta faixa de números é nosso espaço de busca.
String binária Decimal
0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1 1
0 0 0 0 0 0 0 0 0 0 1 0 2
0 0 0 0 0 0 0 0 0 0 1 1 3
0 0 0 0 0 0 0 0 0 1 0 0 4
0 0 0 0 0 0 0 0 0 1 0 1 5
0 0 0 0 0 0 0 0 0 1 1 0 6
0 0 0 0 0 0 0 0 0 1 1 1 7
0 0 0 0 0 0 0 0 1 0 0 0 8
.......... .....
1 1 1 1 1 1 1 1 1 1 1 0 4094
1 1 1 1 1 1 1 1 1 1 1 1 409523
Algoritmo Genético

Neste algoritmo simples, o operador seleção escolherá a melhor metade da
população, usando a função quadrática como função ajuste (fitness function).
Inicialmente temos que gerar a população de forma aleatória. Tal população é
formada por strings binárias (genótipo), também chamados de cromossomos no
jargão dos algoritmos genéticos. As strings binárias que serão convertidas em
números decimais, e então a função quadrática será calculada. A função quadrática é
nossa função ajuste. Nós classificamos a metade dos melhores indivíduos da
população e, então, aplicamos o operador crossover. Estes novos indivíduos gerados
pelo operador crossover serão submetidos ao operador mutação. Na mutação nem
todos os indivíduos serão submetidos a este operador, só aqueles que passarem no
critério de probabilidade de mutação (Pm). Na implementação do algoritmo
genético, usaremos o critério de número de iterações (gerações), como critério de
parada. Um típico conjunto de entrada para tal algoritmo é o seguinte:
Population size (tamanho da população):
Maximum number of iterations (Número máximo de iterações):
Probability of crossover (probabilidade de crossover):
Length of strings (tamanho das strings):
Probability of mutation (probabilidade de mutação): 24
Implementação de um Algoritmo Genético Simples
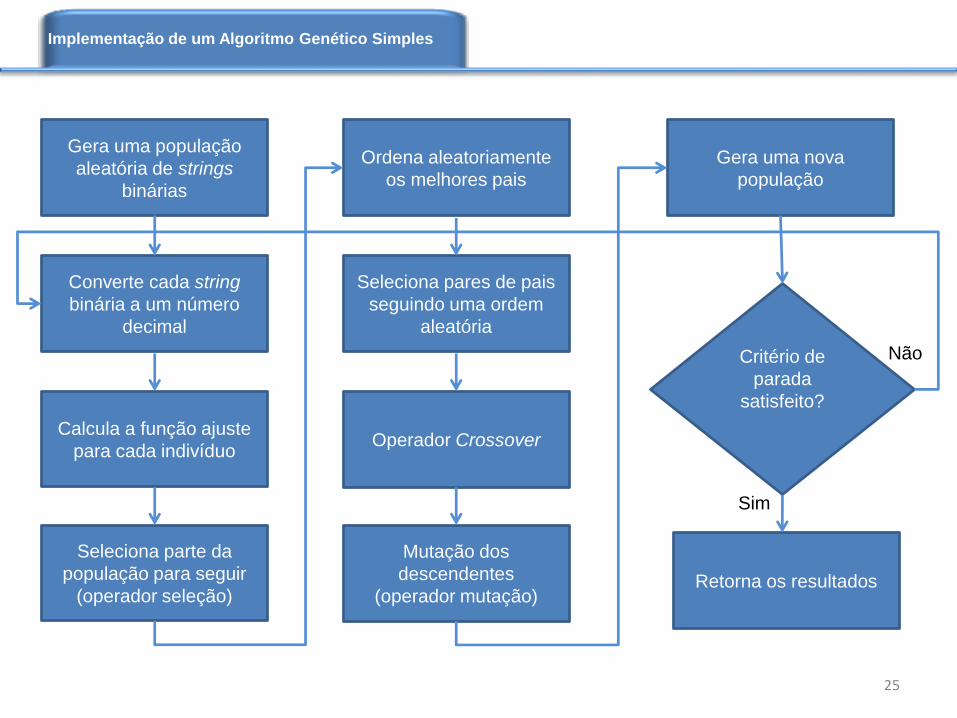
Gera uma população
aleatória de strings
binárias
Converte cada string
binária a um número
decimal
Calcula a função ajuste
para cada indivíduo
Seleciona parte da
população para seguir
(operador seleção)
Seleciona pares de pais
seguindo uma ordem
aleatória
Operador Crossover
Mutação dos
descendentes
(operador mutação)
Gera uma nova
população
Critério de
parada
satisfeito?
Retorna os resultados
Não
Sim
Ordena aleatoriamente
os melhores pais
25
Implementação de um Algoritmo Genético Simples
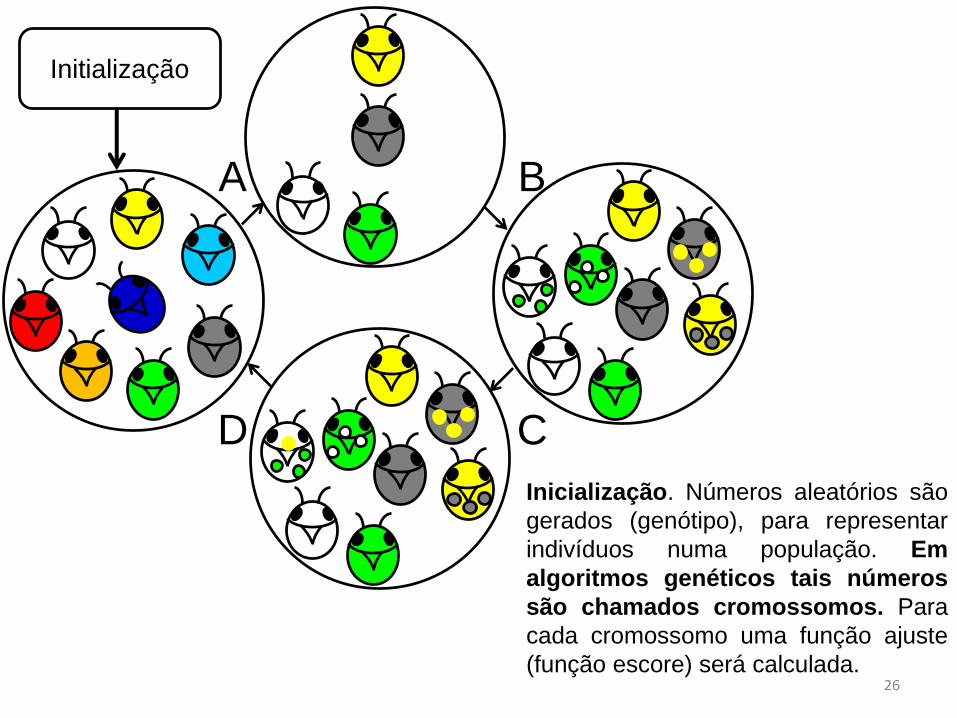
Inicialização. Números aleatórios são
gerados (genótipo), para representar
indivíduos numa população. Em
algoritmos genéticos tais números
são chamados cromossomos. Para
cada cromossomo uma função ajuste
(função escore) será calculada.26
Initialização
A B
CD
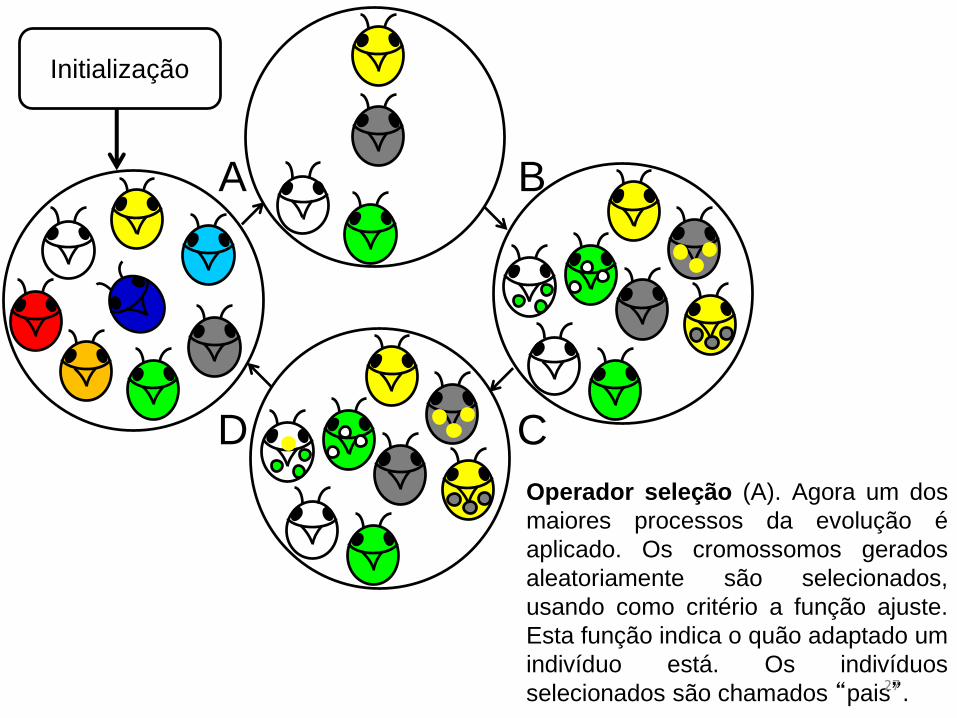
Operador seleção (A). Agora um dos
maiores processos da evolução é
aplicado. Os cromossomos gerados
aleatoriamente são selecionados,
usando como critério a função ajuste.
Esta função indica o quão adaptado um
indivíduo está. Os indivíduos
selecionados são chamados “pais”.27
Initialização
A B
CD
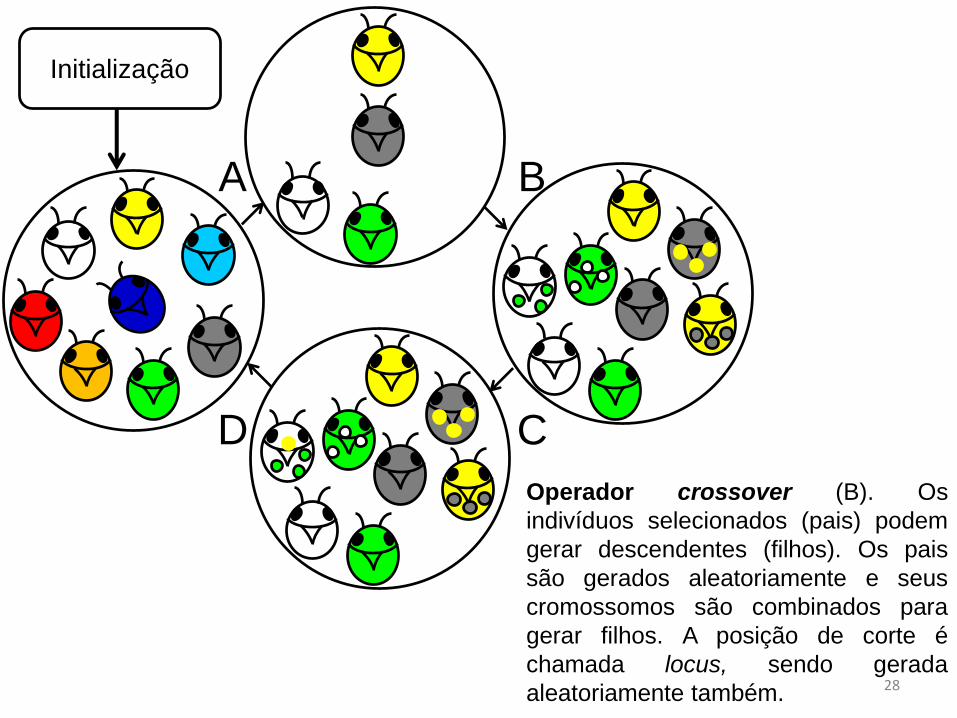
Operador crossover (B). Os
indivíduos selecionados (pais) podem
gerar descendentes (filhos). Os pais
são gerados aleatoriamente e seus
cromossomos são combinados para
gerar filhos. A posição de corte é
chamada locus, sendo gerada
aleatoriamente também.
.
28
Initialização
A B
CD
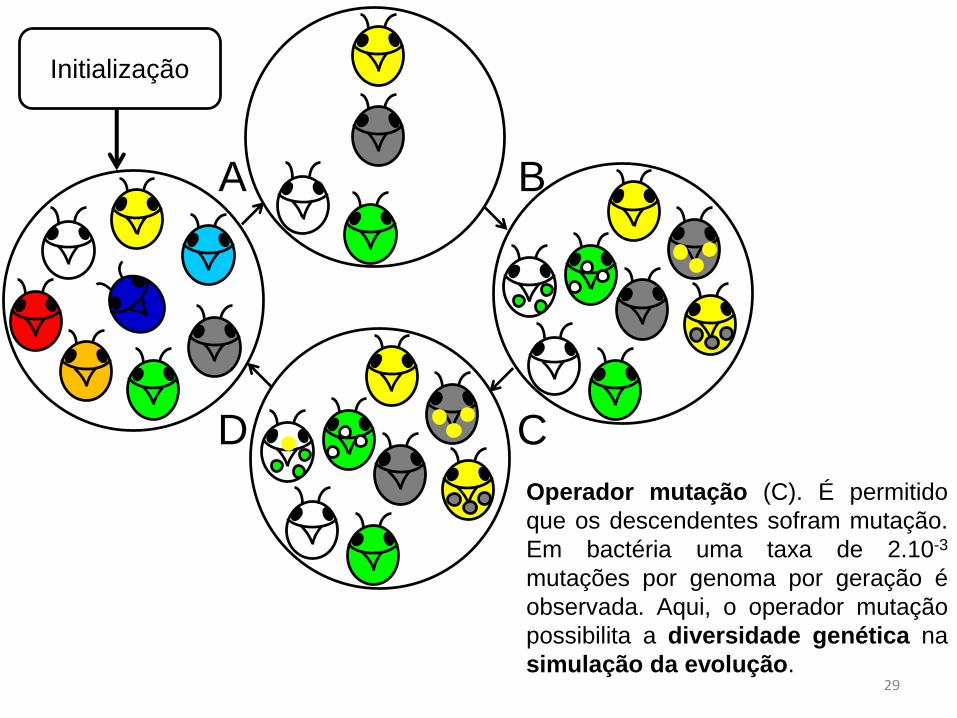
Operador mutação (C). É permitido
que os descendentes sofram mutação.
Em bactéria uma taxa de 2.10-3
mutações por genoma por geração é
observada. Aqui, o operador mutação
possibilita a diversidade genética na
simulação da evolução.29
Initialização
A B
CD
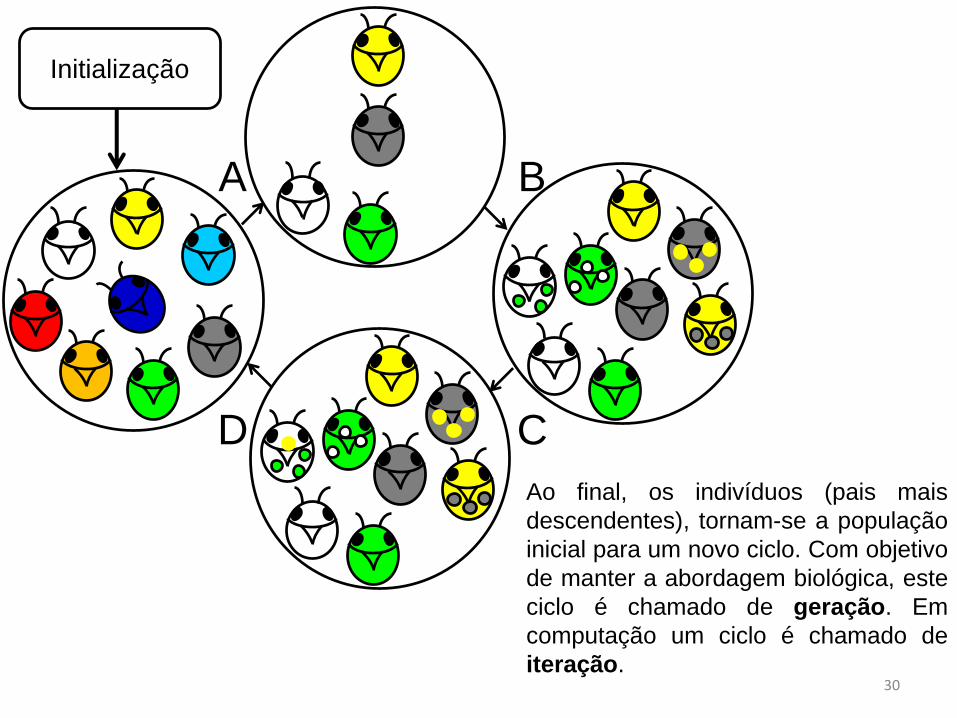
Ao final, os indivíduos (pais mais
descendentes), tornam-se a população
inicial para um novo ciclo. Com objetivo
de manter a abordagem biológica, este
ciclo é chamado de geração. Em
computação um ciclo é chamado de
iteração.30
Initialização
A B
CD
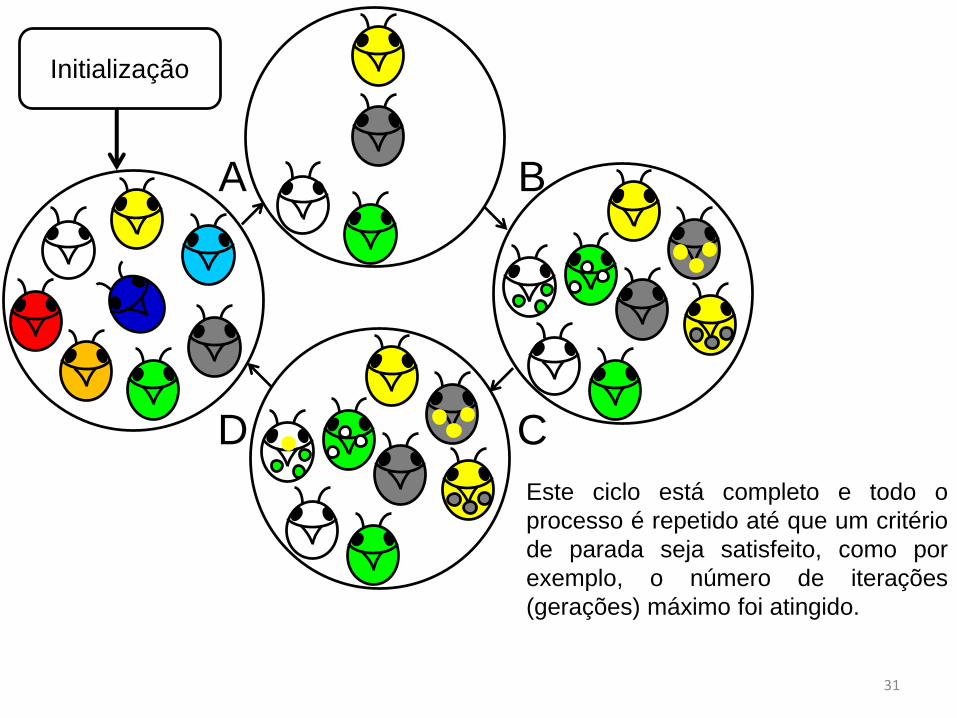
Este ciclo está completo e todo o
processo é repetido até que um critério
de parada seja satisfeito, como por
exemplo, o número de iterações
(gerações) máximo foi atingido.
31
Initialização
A B
CD
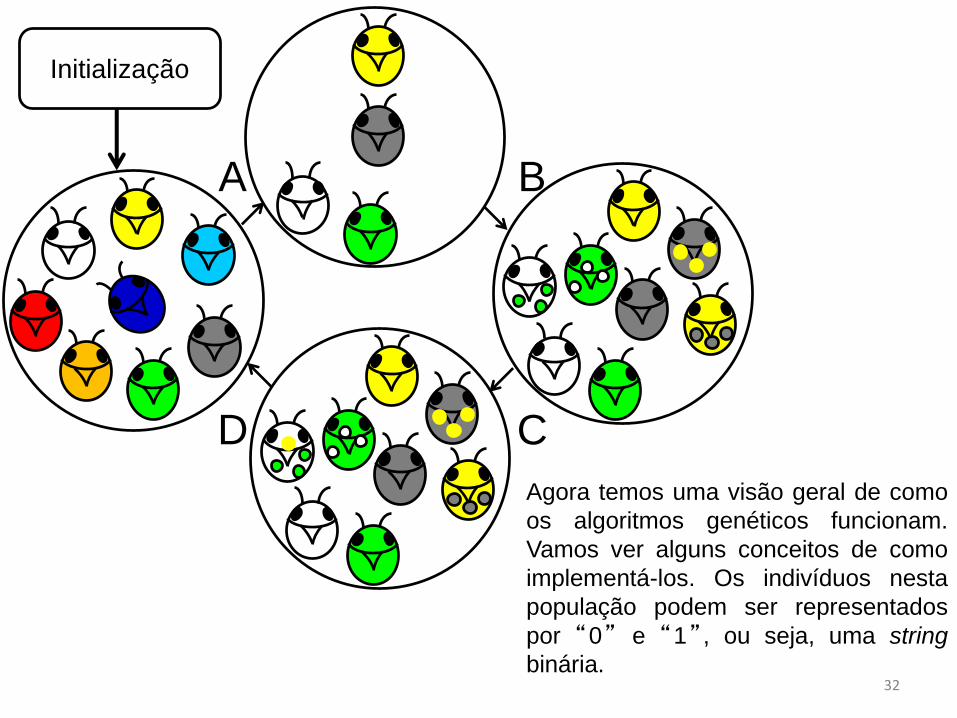
Agora temos uma visão geral de como
os algoritmos genéticos funcionam.
Vamos ver alguns conceitos de como
implementá-los. Os indivíduos nesta
população podem ser representados
por “0” e “1” , ou seja, uma string
binária.32
Initialização
A B
CD
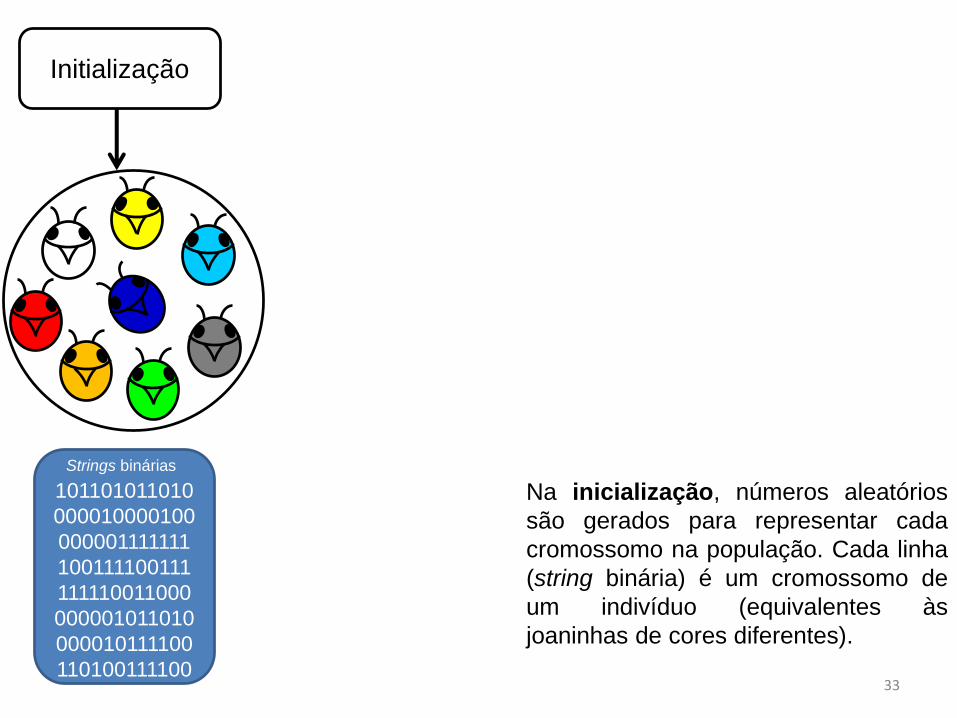
Na inicialização, números aleatórios
são gerados para representar cada
cromossomo na população. Cada linha
(string binária) é um cromossomo de
um indivíduo (equivalentes às
joaninhas de cores diferentes).
101101011010
000010000100
000001111111
100111100111
111110011000
000001011010
000010111100
110100111100
Strings binárias
33
Initialização
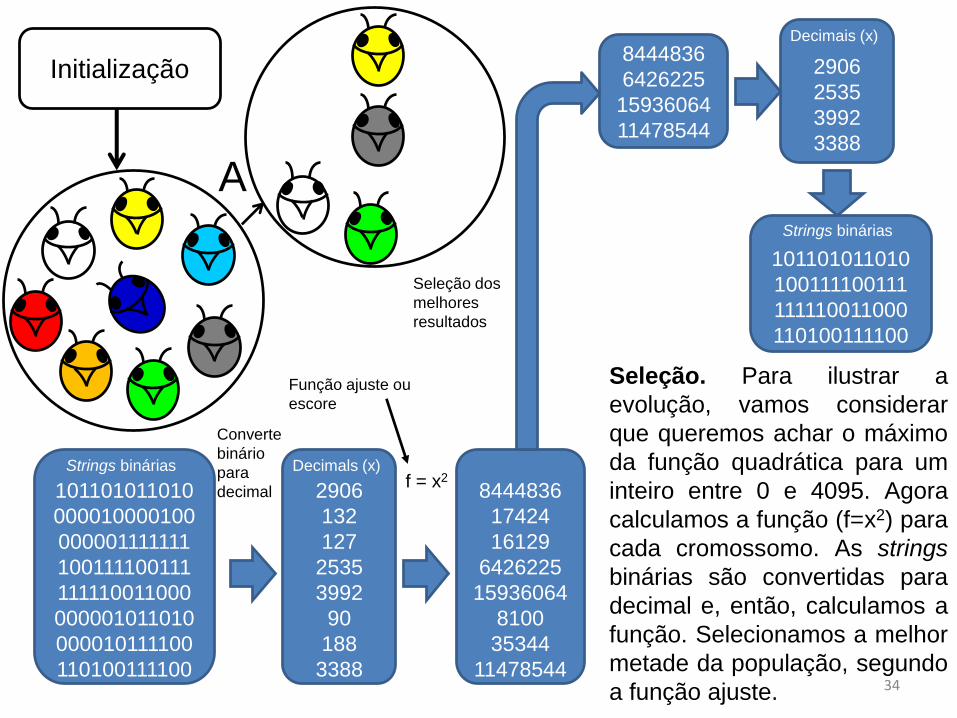
Initialização
A
Seleção. Para ilustrar a
evolução, vamos considerar
que queremos achar o máximo
da função quadrática para um
inteiro entre 0 e 4095. Agora
calculamos a função (f=x2) para
cada cromossomo. As strings
binárias são convertidas para
decimal e, então, calculamos a
função. Selecionamos a melhor
metade da população, segundo
a função ajuste.
101101011010
000010000100
000001111111
100111100111
111110011000
000001011010
000010111100
110100111100
101101011010
100111100111
111110011000
110100111100
f = x2
2906
132
127
2535
3992
90
188
3388
Converte
binário
para
decimal
2906
2535
3992
3388
Strings binárias Decimals (x)
8444836
17424
16129
6426225
15936064
8100
35344
11478544
Decimais (x)
8444836
6426225
15936064
11478544
Strings binárias
Seleção dos
melhores
resultados
34
Função ajuste ou
escore
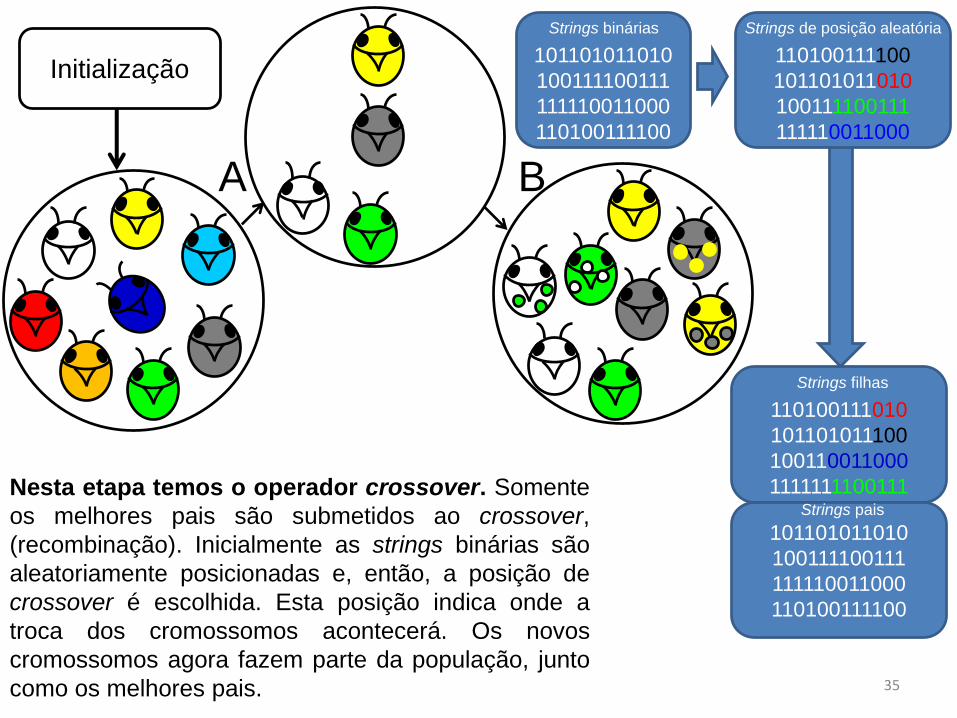
Nesta etapa temos o operador crossover. Somente
os melhores pais são submetidos ao crossover,
(recombinação). Inicialmente as strings binárias são
aleatoriamente posicionadas e, então, a posição de
crossover é escolhida. Esta posição indica onde a
troca dos cromossomos acontecerá. Os novos
cromossomos agora fazem parte da população, junto
como os melhores pais.
101101011010
100111100111
111110011000
110100111100
Strings binárias
110100111010
101101011100
100110011000
1111111100111
110100111100
101101011010
100111100111
111110011000
101101011010
100111100111
111110011000
110100111100
Strings filhas
Strings de posição aleatória
35
Strings pais
Initialização
A B
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
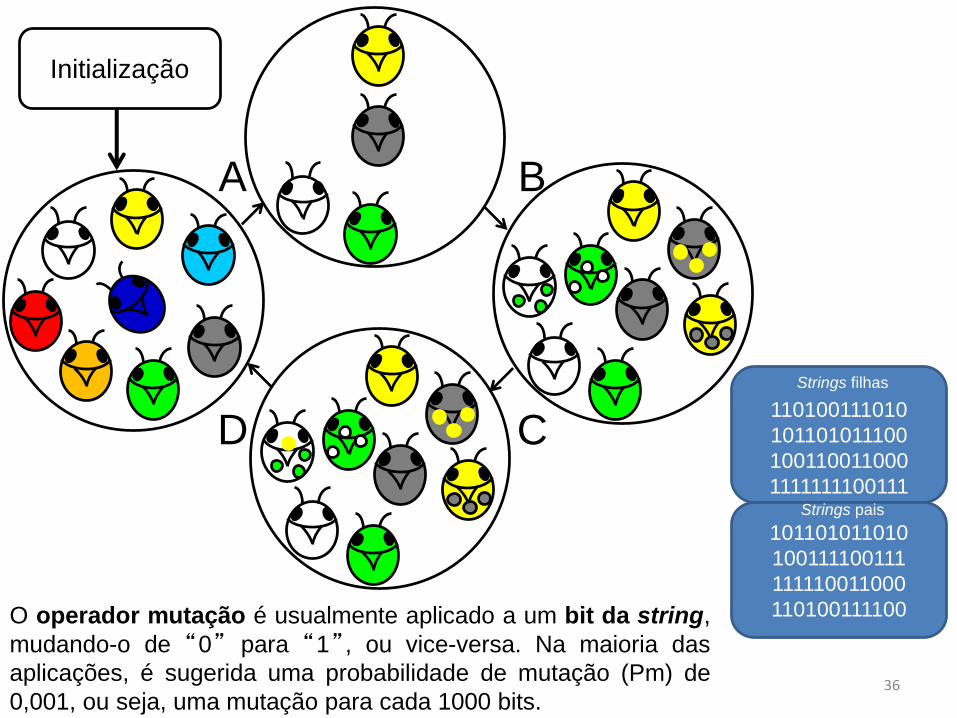
110100111100O operador mutação é usualmente aplicado a um bit da string,
mudando-o de “0” para “1”, ou vice-versa. Na maioria das
aplicações, é sugerida uma probabilidade de mutação (Pm) de
0,001, ou seja, uma mutação para cada 1000 bits.36
Strings pais
Strings filhas
Initialização
A B
CD
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
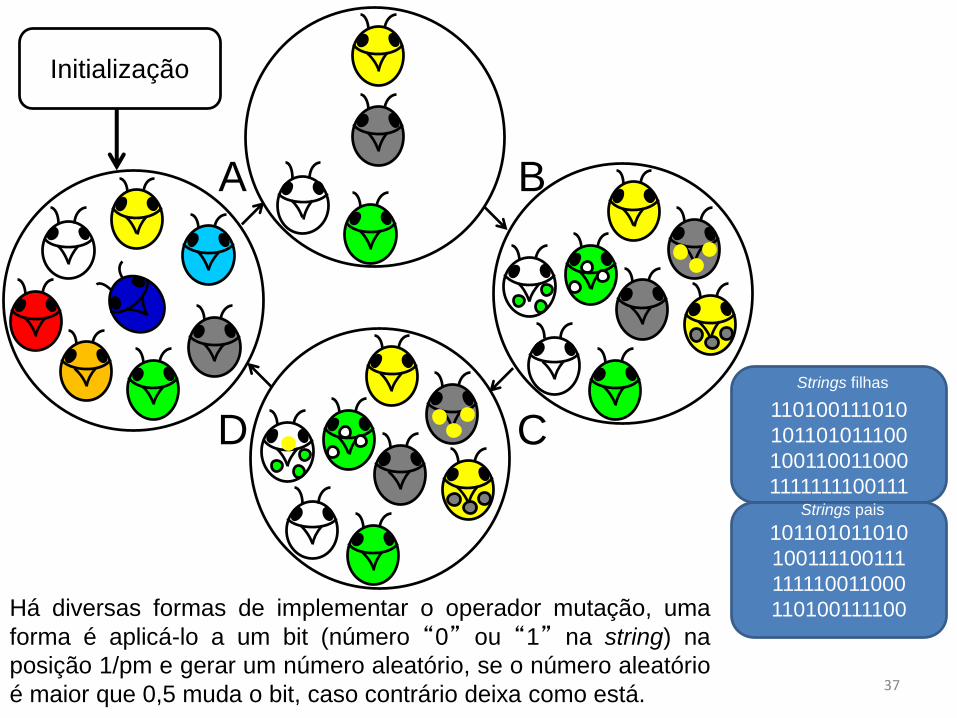
110100111100Há diversas formas de implementar o operador mutação, uma
forma é aplicá-lo a um bit (número “0” ou “1” na string) na
posição 1/pm e gerar um número aleatório, se o número aleatório
é maior que 0,5 muda o bit, caso contrário deixa como está.37
Strings filhas
Strings pais
Initialização
A B
CD
110100111010
101101011100
100110011000
1111111100111
101101011010
100111100111
111110011000
110100111100
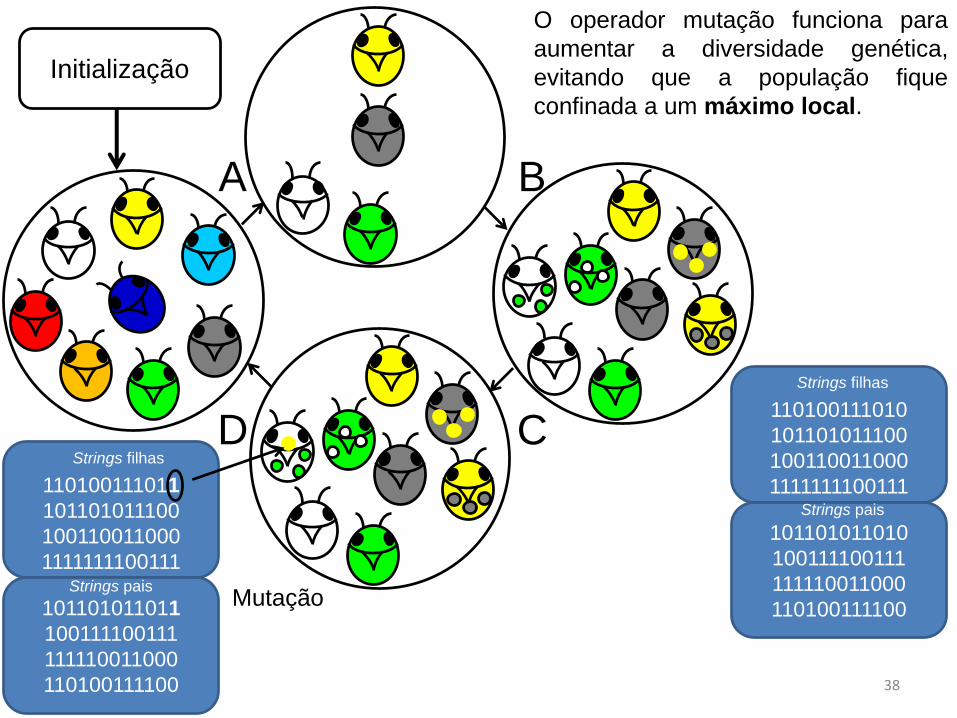
O operador mutação funciona para
aumentar a diversidade genética,
evitando que a população fique
confinada a um máximo local.
110100111011
101101011100
100110011000
1111111100111
Strings filhas
101101011011
100111100111
111110011000
110100111100
Mutação
38
Strings pais
Strings filhas
Strings pais
Initialização
A B
CD
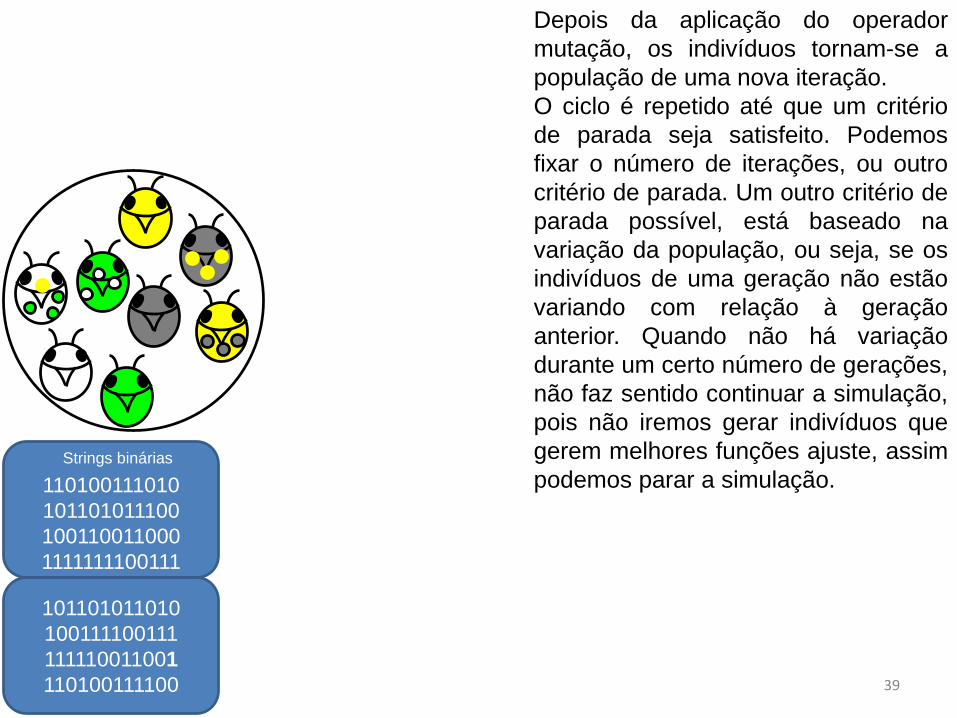
Depois da aplicação do operador
mutação, os indivíduos tornam-se a
população de uma nova iteração.
O ciclo é repetido até que um critério
de parada seja satisfeito. Podemos
fixar o número de iterações, ou outro
critério de parada. Um outro critério de
parada possível, está baseado na
variação da população, ou seja, se os
indivíduos de uma geração não estão
variando com relação à geração
anterior. Quando não há variação
durante um certo número de gerações,
não faz sentido continuar a simulação,
pois não iremos gerar indivíduos que
gerem melhores funções ajuste, assim
podemos parar a simulação.110100111010
101101011100
100110011000
1111111100111
Strings binárias
101101011010
100111100111
111110011001
110100111100 39
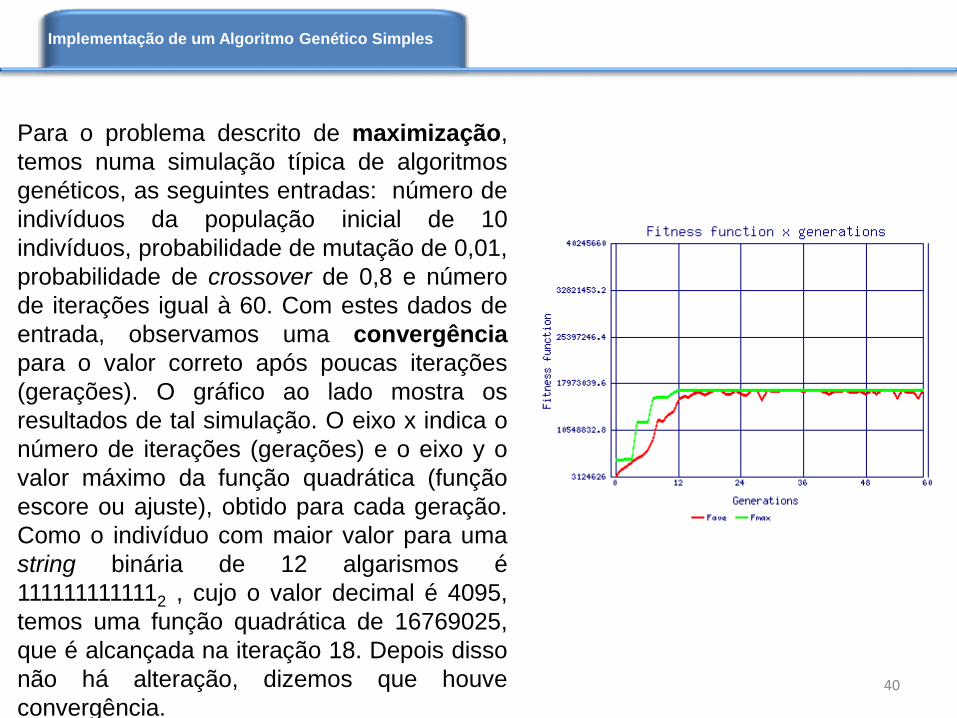
Para o problema descrito de maximização,
temos numa simulação típica de algoritmos
genéticos, as seguintes entradas: número de
indivíduos da população inicial de 10
indivíduos, probabilidade de mutação de 0,01,
probabilidade de crossover de 0,8 e número
de iterações igual à 60. Com estes dados de
entrada, observamos uma convergência
para o valor correto após poucas iterações
(gerações). O gráfico ao lado mostra os
resultados de tal simulação. O eixo x indica o
número de iterações (gerações) e o eixo y o
valor máximo da função quadrática (função
escore ou ajuste), obtido para cada geração.
Como o indivíduo com maior valor para uma
string binária de 12 algarismos é
1111111111112 , cujo o valor decimal é 4095,
temos uma função quadrática de 16769025,
que é alcançada na iteração 18. Depois disso
não há alteração, dizemos que houve
convergência.40
Implementação de um Algoritmo Genético Simples
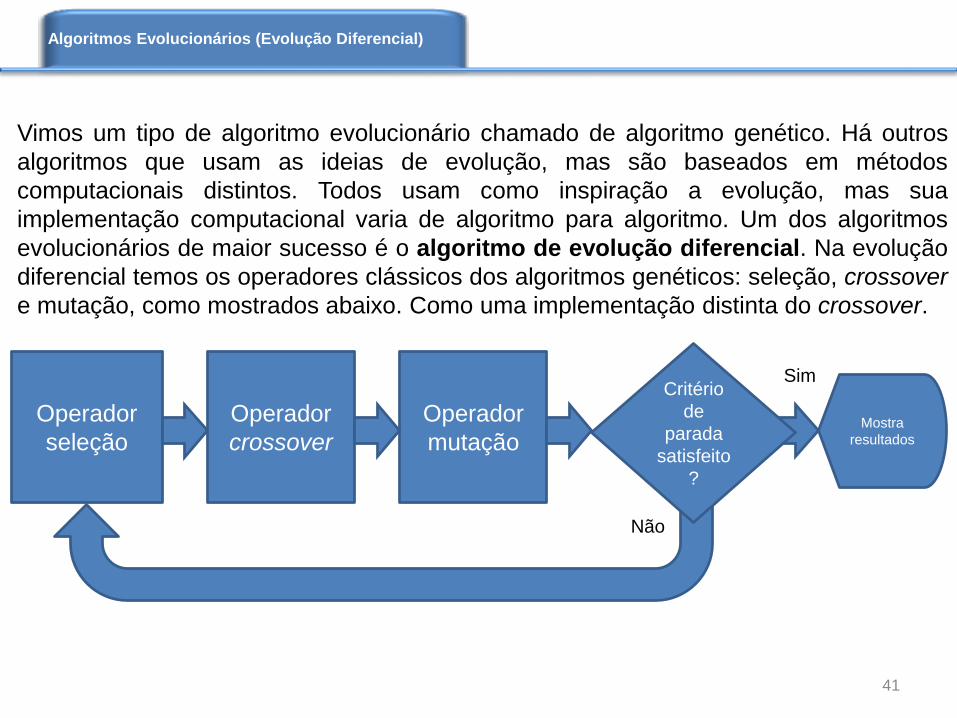
Vimos um tipo de algoritmo evolucionário chamado de algoritmo genético. Há outros
algoritmos que usam as ideias de evolução, mas são baseados em métodos
computacionais distintos. Todos usam como inspiração a evolução, mas sua
implementação computacional varia de algoritmo para algoritmo. Um dos algoritmos
evolucionários de maior sucesso é o algoritmo de evolução diferencial. Na evolução
diferencial temos os operadores clássicos dos algoritmos genéticos: seleção, crossover
e mutação, como mostrados abaixo. Como uma implementação distinta do crossover.
41
Algoritmos Evolucionários (Evolução Diferencial)
Operador
seleção
Operador
crossover
Operador
mutação
Critério
de
parada
satisfeito
?
Mostra
resultados
Sim
Não

O algoritmo de evolução diferencial executa a parte inicial de geração aleatória de uma
população com N cromossomos, em seguida avalia a função ajuste de cada
cromossomo. A novidade está na formação cromossomos filhos. O filhos são gerados
da seguinte forma, para cada cromossomo pai na população, chamado aqui
cromossomo j, são escolhidos aleatoriamente três outros cromossomos pais distintos,
cromossomos k, l e m. Calcula-se um novo cromossomo, chamado aqui de n, da
seguinte forma:
cromossomo(n) = cromossomo(m) + peso.[cromossomo(k) - cromossomo(l)]
o peso varia entre 0 e 2.
O cromossomo novo (n) será incorporado à população se ao gerarmos um número
aleatório entre 0 e 1, este for menor que a probabilidade de crossover, caso não seja, o
cromossomo filho não é considerado. Um último teste é realizado no cromossomo filho
n, se este apresenta função escore maior que o cromossomo pai j, caso seja, o
cromossomo j é deletado e substituído pelo cromossomo n. As etapas seguintes são
idênticas ao algoritmo genético original. Estamos considerando aqui que a função
ajuste de maior valor é a que representa um indivíduo mais bem adaptado. Veja, este
critério depende do tipo de problema a ser resolvido pelo algoritmo evolucionário.
42
Algoritmos Evolucionários (Evolução Diferencial)
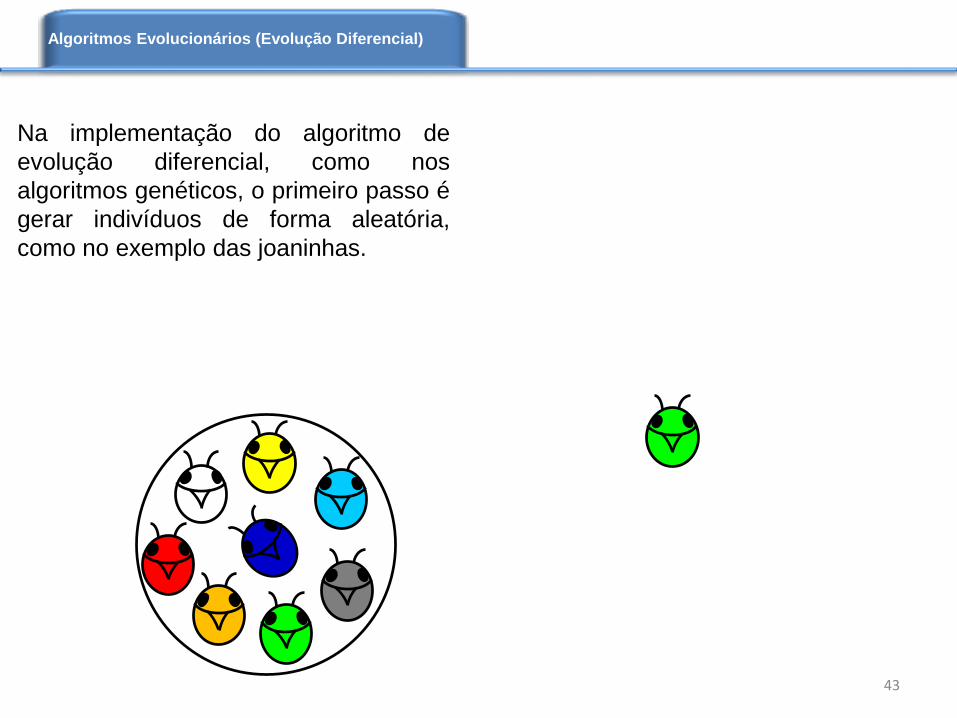
Na implementação do algoritmo de
evolução diferencial, como nos
algoritmos genéticos, o primeiro passo é
gerar indivíduos de forma aleatória,
como no exemplo das joaninhas.
43
Algoritmos Evolucionários (Evolução Diferencial)
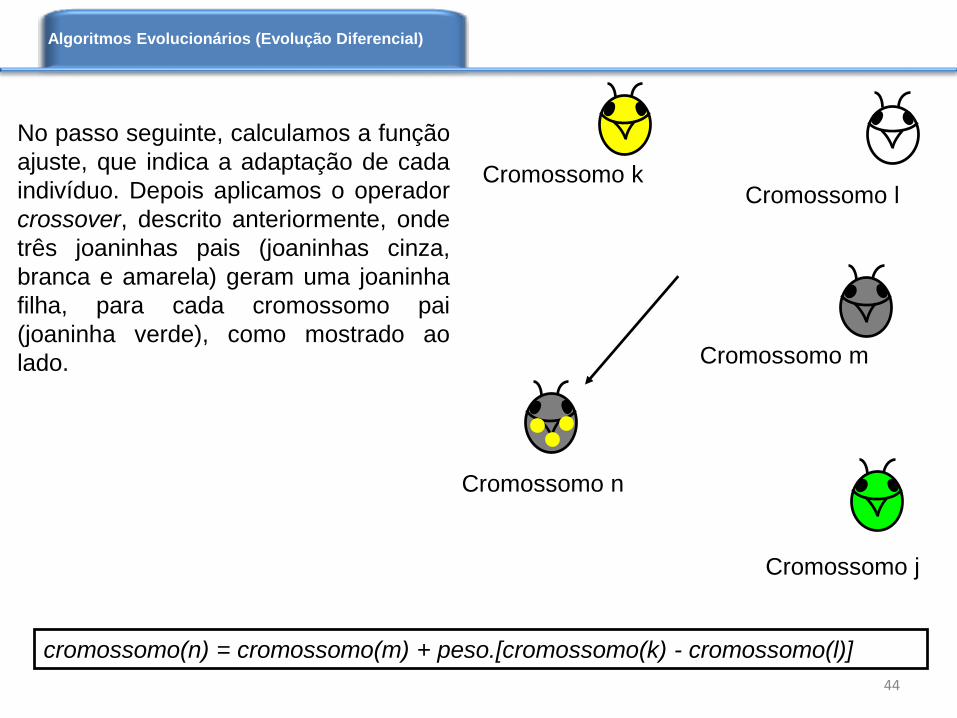
No passo seguinte, calculamos a função
ajuste, que indica a adaptação de cada
indivíduo. Depois aplicamos o operador
crossover, descrito anteriormente, onde
três joaninhas pais (joaninhas cinza,
branca e amarela) geram uma joaninha
filha, para cada cromossomo pai
(joaninha verde), como mostrado ao
lado.
44
Cromossomo kCromossomo l
Cromossomo m
cromossomo(n) = cromossomo(m) + peso.[cromossomo(k) - cromossomo(l)]
Algoritmos Evolucionários (Evolução Diferencial)
Cromossomo n
Cromossomo j
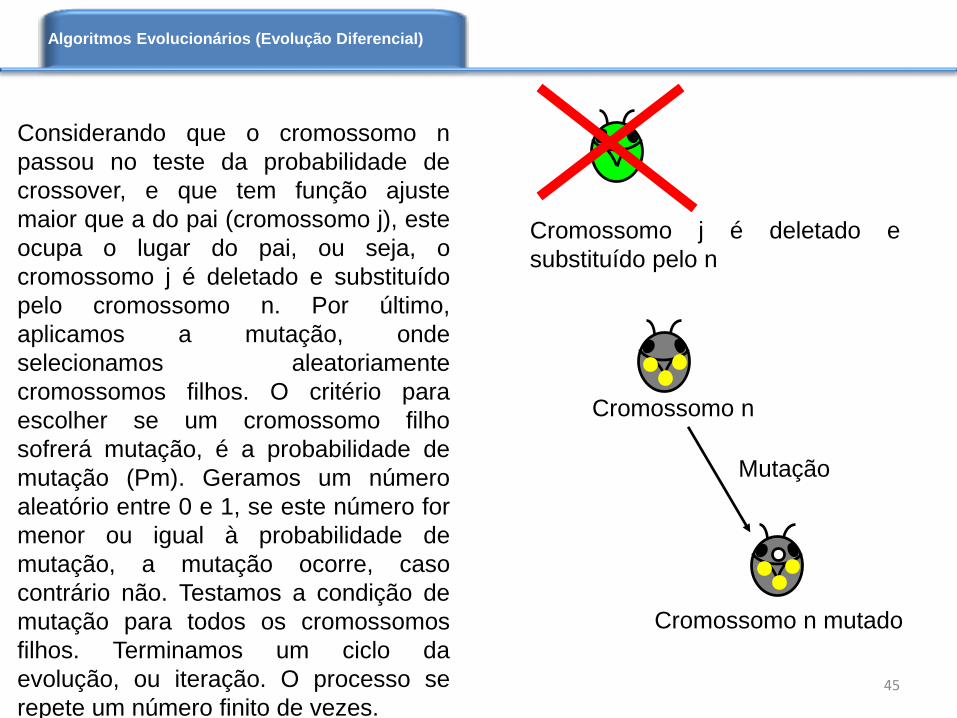
Considerando que o cromossomo n
passou no teste da probabilidade de
crossover, e que tem função ajuste
maior que a do pai (cromossomo j), este
ocupa o lugar do pai, ou seja, o
cromossomo j é deletado e substituído
pelo cromossomo n. Por último,
aplicamos a mutação, onde
selecionamos aleatoriamente
cromossomos filhos. O critério para
escolher se um cromossomo filho
sofrerá mutação, é a probabilidade de
mutação (Pm). Geramos um número
aleatório entre 0 e 1, se este número for
menor ou igual à probabilidade de
mutação, a mutação ocorre, caso
contrário não. Testamos a condição de
mutação para todos os cromossomos
filhos. Terminamos um ciclo da
evolução, ou iteração. O processo se
repete um número finito de vezes.45
Cromossomo n
Cromossomo n mutado
Mutação
Algoritmos Evolucionários (Evolução Diferencial)
Cromossomo j é deletado e
substituído pelo n

Como toda metodologia, a simulação de
docking tem uma etapa de validação e
refinamento do protocolo. Tal etapa é o
que chamamos de re-docking, onde
achamos o melhor protocolo capaz de
recuperar a posição cristalográfica de
um ligante acoplado ao sítio ativo de uma
enzima. A condição para que possamos
validar nosso protocolo de docking, é que
haja informações sobre pelo menos uma
estrutura cristalográfica de um complexo
proteína-ligante. A estrutura
cristalográfica é uma informação
experimental precisa, sendo usada como
padrão para verificarmos se o nosso
programa de docking é capaz de achar a
posição do ligante no sítio ativo.
Chamamos da posição obtida computacionalmente de pose
(em vermelho) e a comparamos com a cristalográfica (em
cinza claro) a partir do RMSD (Root-Mean Square Deviation)
que pode ser pensado como uma régua que mede a
distância da posição cristalográfica da pose.
Bio-Inspired Algorithms Applied to Molecular Docking
Simulations. Heberlé G, De Azevedo WF Jr. Curr Med Chem
2011; 18 (9): 1339-1352.
46
Docking Molecular

A estrutura cristalográfica tem que estar
presente como um “padrão ouro”, ou
seja, antes de usarmos a simulação de
docking, temos que verificar se o nosso
protocolo de docking está funcionando
adequadamente. Neste aspecto o
trabalho em bioinformática é similar ao
trabalho em bancada experimental.
Quando vamos testar um novo protocolo
experimental, normalmente recorremos
ao um padrão, para validarmos o
protocolo novo. No caso do docking, o
padrão é a estrutura cristalográfica.
Assim, visamos achar a posição do
ligante usando o docking e, ao final,
comparamos com a posição
cristalográfica, como mostrado ao lado.
47
Posição cristalográfica (cinza claro) e posição obtida pela
simulação de docking (vermelha).
Docking Molecular

No re-docking, vamos “recolocar” o ligante no sítio ativo e comparar com a posição
cristalográfica. A comparação se faz por meio do cálculo do desvio médio
quadrático, ou RMSD (root-mean square deviation). Podemos pensar no RMSD
como uma média das distâncias atômicas entre a posição cristalográfica ( xcristal, ycristal,
zcristal) e a posição do ligante obtida pela simulação de docking ( xpose, ypose, zpose).
Chamamos esta posição de pose. Abaixo temos em vermelho a posição do ligante,
obtida pela simulação de docking (pose), e, em branco, a posição cristalográfica.
Vemos que temos uma boa concordância entre as duas posições. A equação para o
cálculo do RMSD está mostrada abaixo, onde N indica que a soma é feita para todos
os átomos do ligante.
48
N
j
/
cristal,jpose,jcristal,jpose,jcristal,jpose,j - zz - yy - xx RMSD 1
21222
Docking Molecular

As posições dos átomos nas moléculas
são representadas por coordenadas
atômicas, x, y e z. As coordenadas
identificam a posição do centro do
átomo no espaço, como as posições
dos átomos mostradas ao lado. São
essas coordenadas atômicas que são
usadas para o cálculo do RMSD. Como
as coordenadas atômicas estão na
unidade angstrom (Å), o valor calculado
para o RMSD é dado também em Å.
49
Posição do átomo é indicada pelas coordenadas (x,y,z)
Docking Molecular
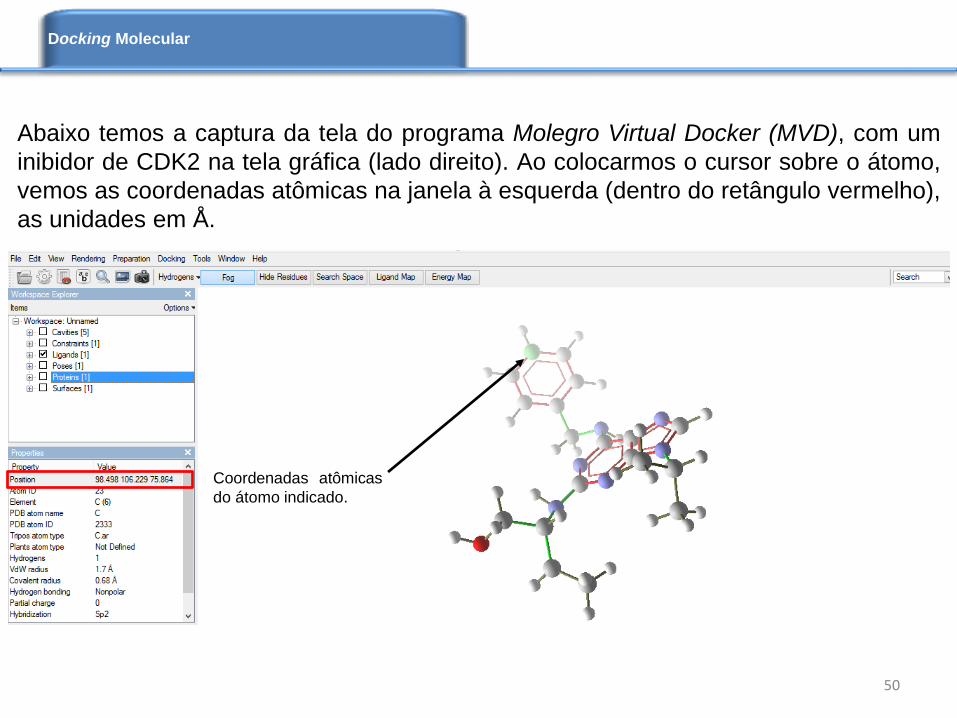
Abaixo temos a captura da tela do programa Molegro Virtual Docker (MVD), com um
inibidor de CDK2 na tela gráfica (lado direito). Ao colocarmos o cursor sobre o átomo,
vemos as coordenadas atômicas na janela à esquerda (dentro do retângulo vermelho),
as unidades em Å.
50
Coordenadas atômicas
do átomo indicado.
Docking Molecular
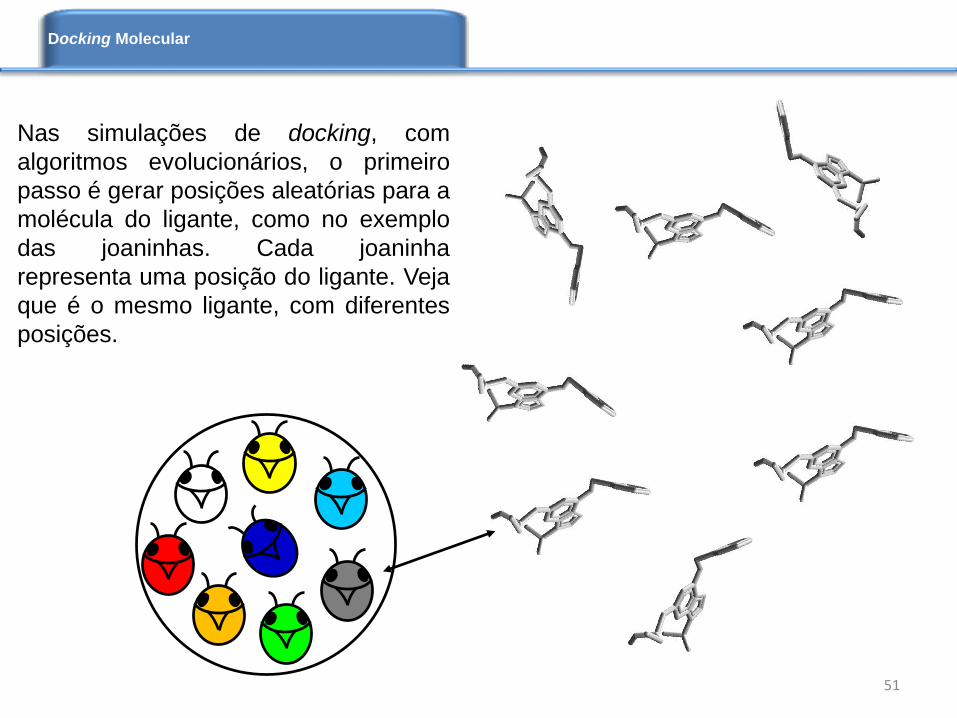
Nas simulações de docking, com
algoritmos evolucionários, o primeiro
passo é gerar posições aleatórias para a
molécula do ligante, como no exemplo
das joaninhas. Cada joaninha
representa uma posição do ligante. Veja
que é o mesmo ligante, com diferentes
posições.
51
Docking Molecular

No passo seguinte, calculamos a função
ajuste (função escore), que indica a
adaptação de cada indivíduo, no caso
do docking a energia de ligação de cada
posição da molécula. Como a energia
de ligação de Gibbs, só que agora
usamos as coordenadas atômicas para
calcularmos a energia de ligação.
Depois aplicamos o operador crossover,
como descrito para o algoritmo da
evolução diferencial, onde três posições
da molécula (pais) geram uma posição
filha, como mostrado ao lado. Veja que
a função escore não é uma função
energia de fato, podemos chamar a
função escore, como o Moldock Score,
de pseudoenergia.
52
Cromossomo kCromossomo l
Docking Molecular
Cromossomo m
cromossomo(n) = cromossomo(m) +
peso.[cromossomo(k) - cromossomo(l)]
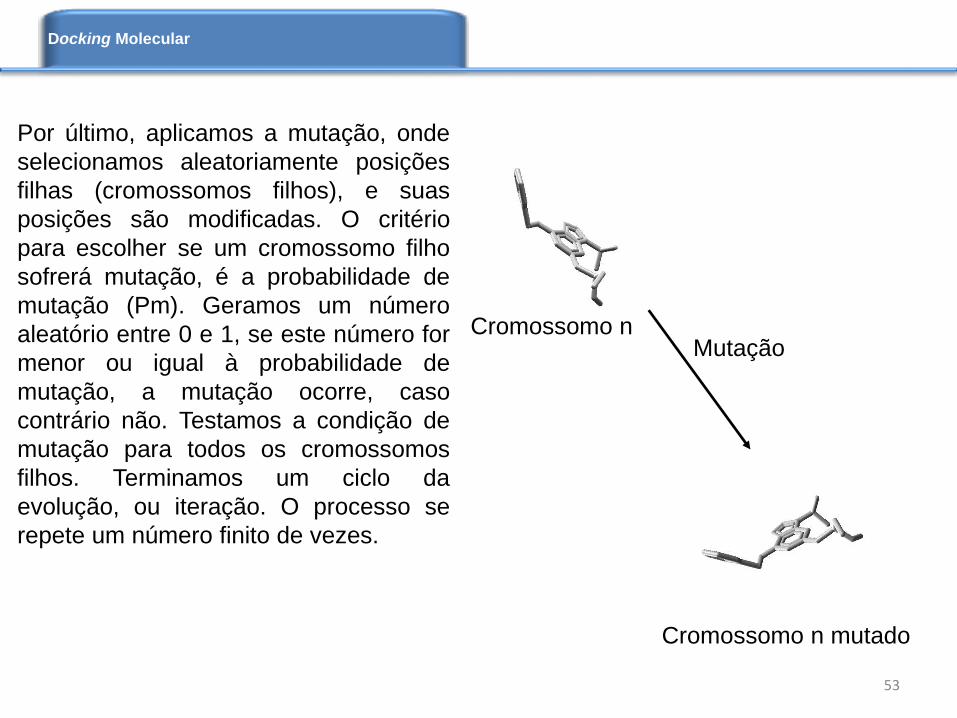
Por último, aplicamos a mutação, onde
selecionamos aleatoriamente posições
filhas (cromossomos filhos), e suas
posições são modificadas. O critério
para escolher se um cromossomo filho
sofrerá mutação, é a probabilidade de
mutação (Pm). Geramos um número
aleatório entre 0 e 1, se este número for
menor ou igual à probabilidade de
mutação, a mutação ocorre, caso
contrário não. Testamos a condição de
mutação para todos os cromossomos
filhos. Terminamos um ciclo da
evolução, ou iteração. O processo se
repete um número finito de vezes.
53
Cromossomo n
Cromossomo n mutado
Mutação
Docking Molecular

Ao final temos a posição obtida da
simulação de docking (pose),
comparada com a cristalográfica, como
mostrada ao lado. Consideramos que
a simulação de docking está
funcionando bem, se o RMSD da
sobreposição for menor que 2,00 Å,
no exemplo ao lado o RMSD foi de 1,68
Å.
54
Docking Molecular
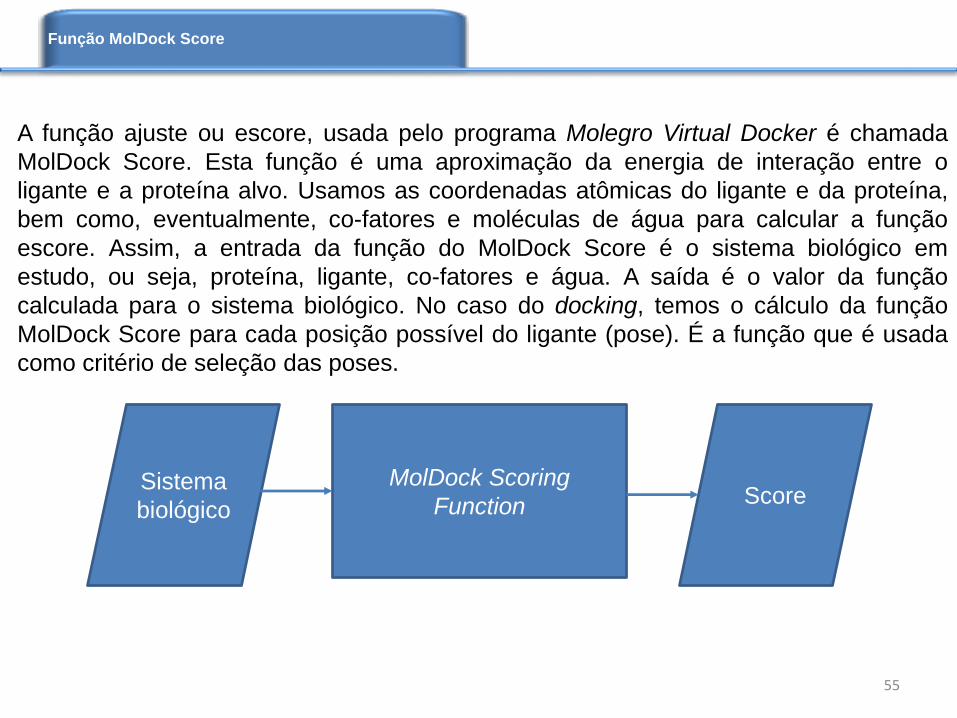
A função ajuste ou escore, usada pelo programa Molegro Virtual Docker é chamada
MolDock Score. Esta função é uma aproximação da energia de interação entre o
ligante e a proteína alvo. Usamos as coordenadas atômicas do ligante e da proteína,
bem como, eventualmente, co-fatores e moléculas de água para calcular a função
escore. Assim, a entrada da função do MolDock Score é o sistema biológico em
estudo, ou seja, proteína, ligante, co-fatores e água. A saída é o valor da função
calculada para o sistema biológico. No caso do docking, temos o cálculo da função
MolDock Score para cada posição possível do ligante (pose). É a função que é usada
como critério de seleção das poses.
55
MolDock Scoring
FunctionSistema
biológicoScore
Função MolDock Score
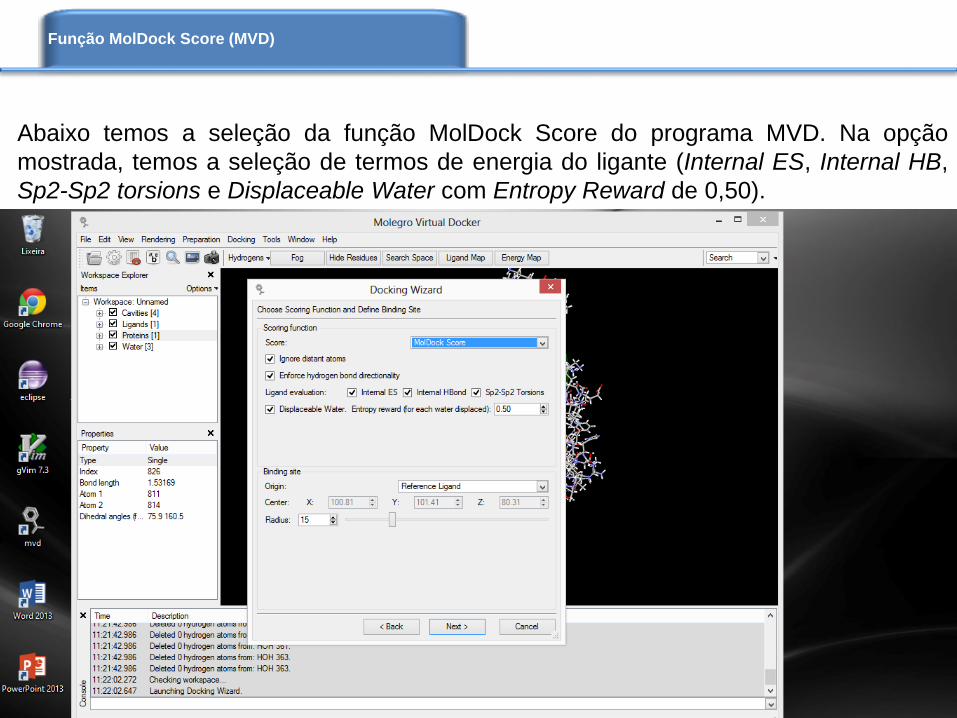
Abaixo temos a seleção da função MolDock Score do programa MVD. Na opção
mostrada, temos a seleção de termos de energia do ligante (Internal ES, Internal HB,
Sp2-Sp2 torsions e Displaceable Water com Entropy Reward de 0,50).
56
Função MolDock Score (MVD)
Para realizar a simulação de re-docking precisamos da estrutura cristalográfica. Tdos
estruturas resolvidas encontram-se disponíveis no site do Protein Data Bank:
www.rcsb.org/pdb .
57
Busca no Protein Data Bank
Para ilustrarmos o processo de buscas por estruturas de proteínas, vejamos uma
procura no Protein Data Bank (www.rcsb.org/pdb) por estruturas tridimensionais da
CDK2. Abaixo temos a página de entrada do PDB, como vista no dia 27 de maio de
2015.
58
Busca no Protein Data Bank
Podemos digitar diretamente o nome da proteína no campo indicado abaixo, ou
podemos realizar uma busca avançada, clicando em “Advanced Search”.
59
Busca no Protein Data Bank
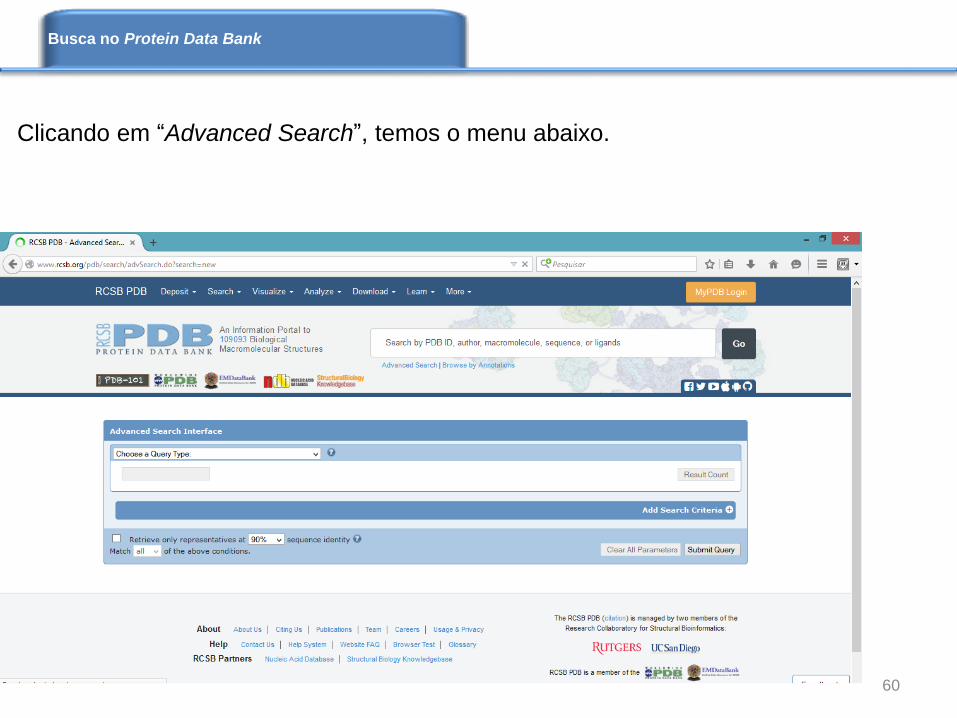
Clicando em “Advanced Search”, temos o menu abaixo.
60
Busca no Protein Data Bank
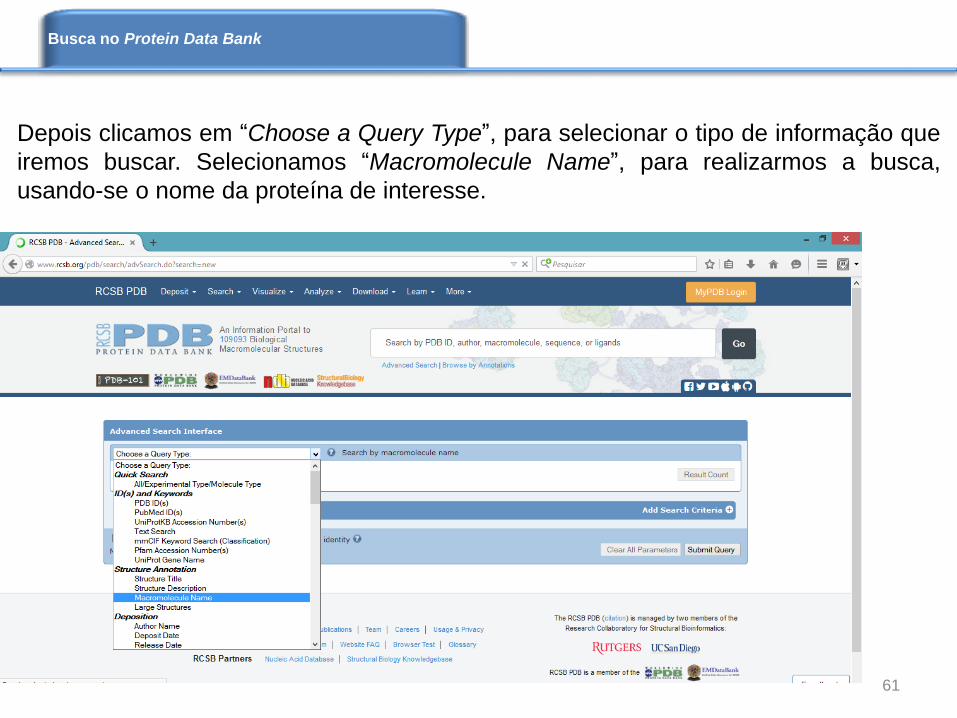
Depois clicamos em “Choose a Query Type”, para selecionar o tipo de informação que
iremos buscar. Selecionamos “Macromolecule Name”, para realizarmos a busca,
usando-se o nome da proteína de interesse.
61
Busca no Protein Data Bank
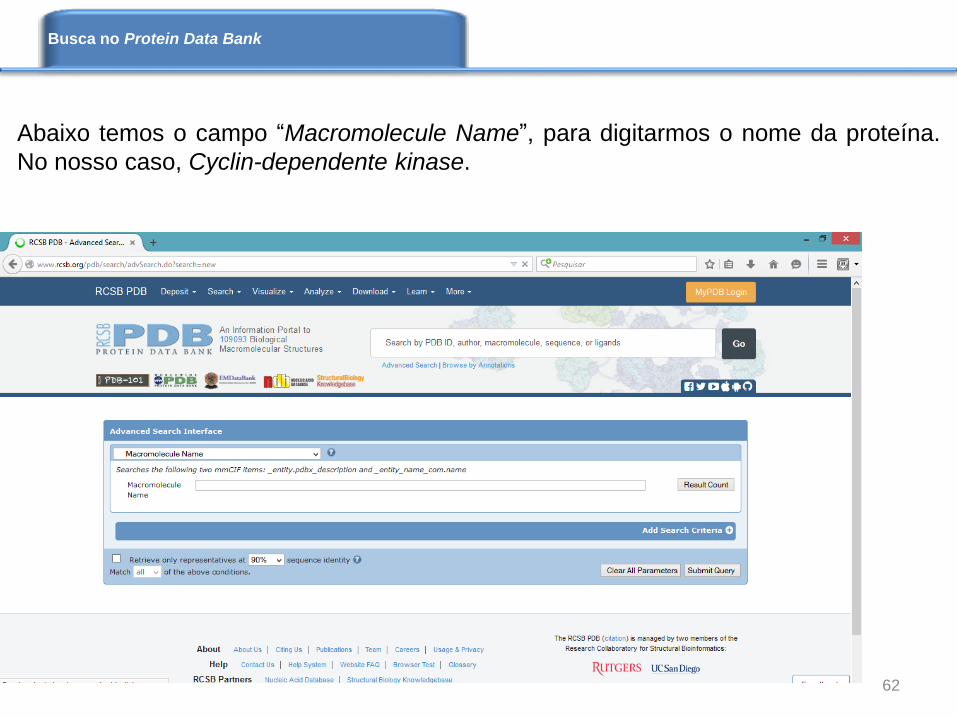
Abaixo temos o campo “Macromolecule Name”, para digitarmos o nome da proteína.
No nosso caso, Cyclin-dependente kinase.
62
Busca no Protein Data Bank
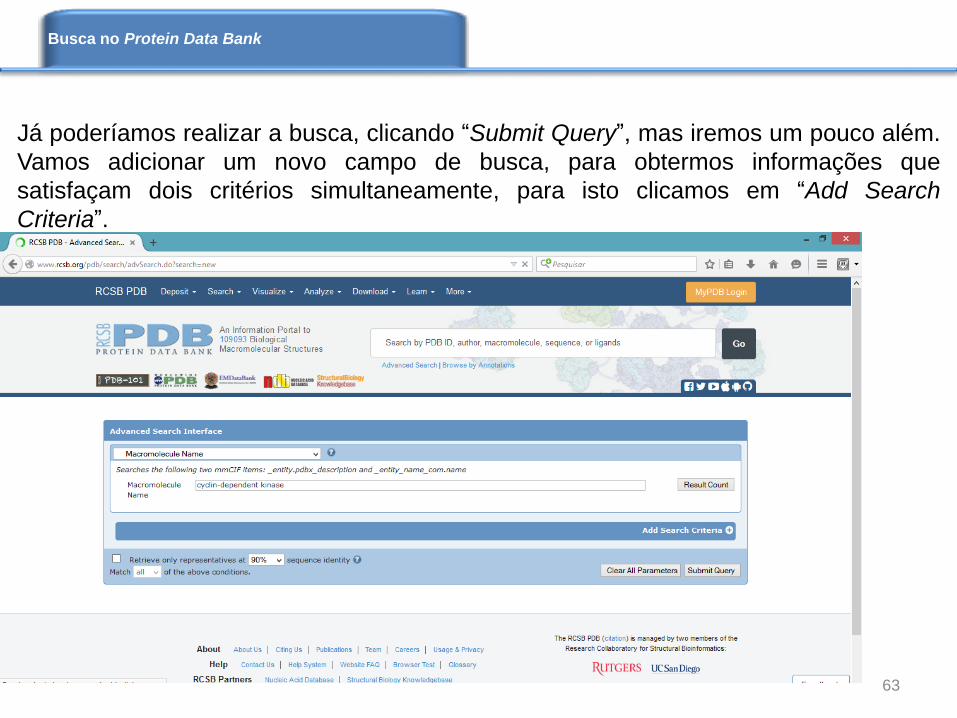
Já poderíamos realizar a busca, clicando “Submit Query”, mas iremos um pouco além.
Vamos adicionar um novo campo de busca, para obtermos informações que
satisfaçam dois critérios simultaneamente, para isto clicamos em “Add Search
Criteria”.
63
Busca no Protein Data Bank
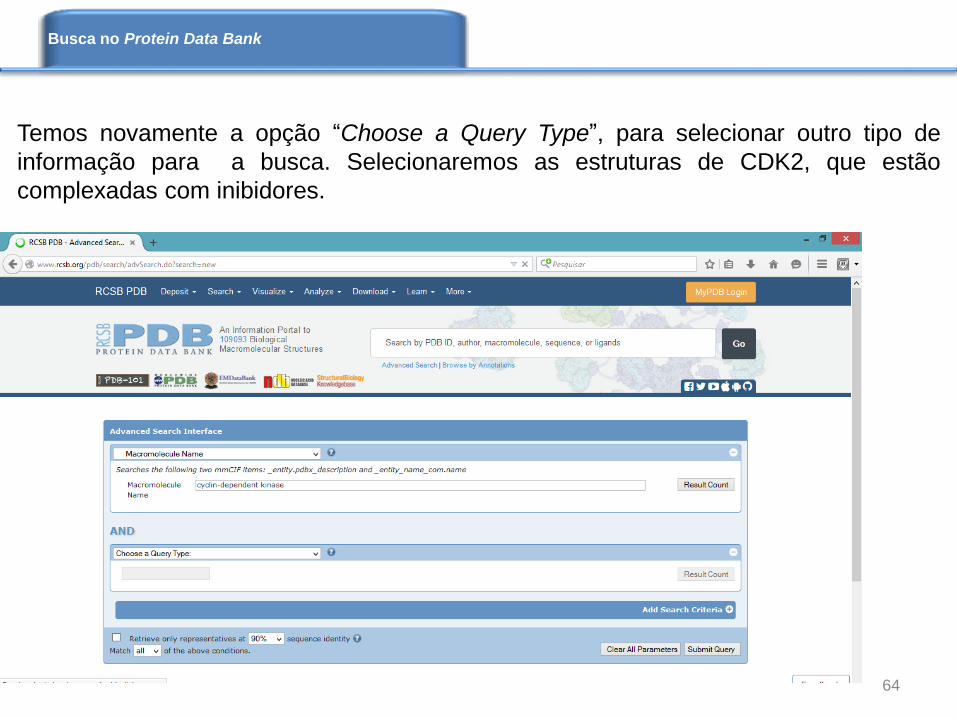
Temos novamente a opção “Choose a Query Type”, para selecionar outro tipo de
informação para a busca. Selecionaremos as estruturas de CDK2, que estão
complexadas com inibidores.
64
Busca no Protein Data Bank
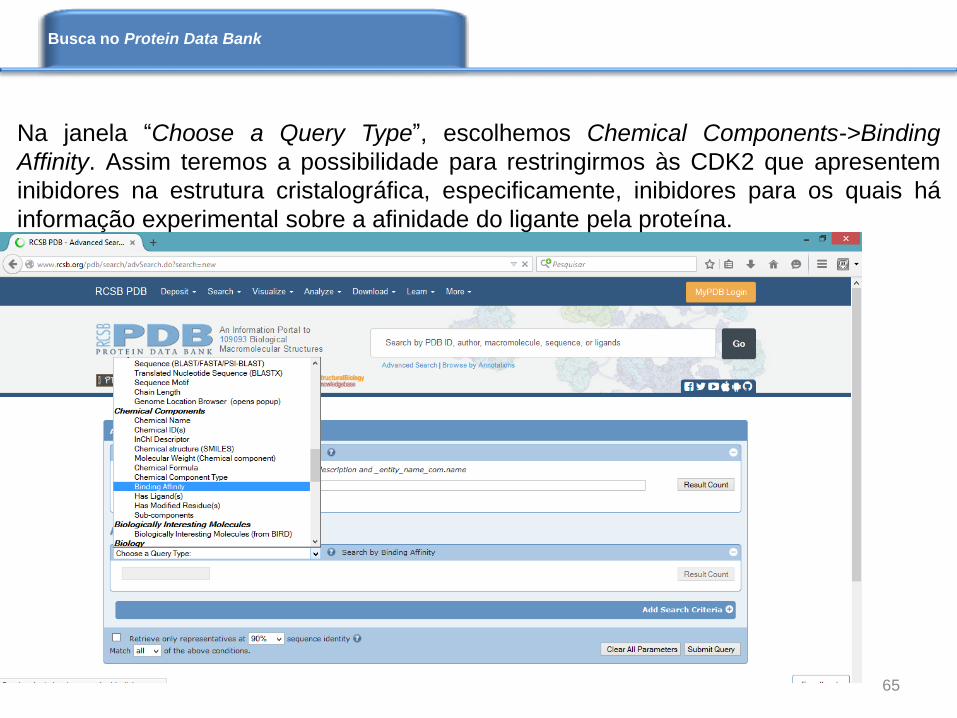
Na janela “Choose a Query Type”, escolhemos Chemical Components->Binding
Affinity. Assim teremos a possibilidade para restringirmos às CDK2 que apresentem
inibidores na estrutura cristalográfica, especificamente, inibidores para os quais há
informação experimental sobre a afinidade do ligante pela proteína.
65
Busca no Protein Data Bank
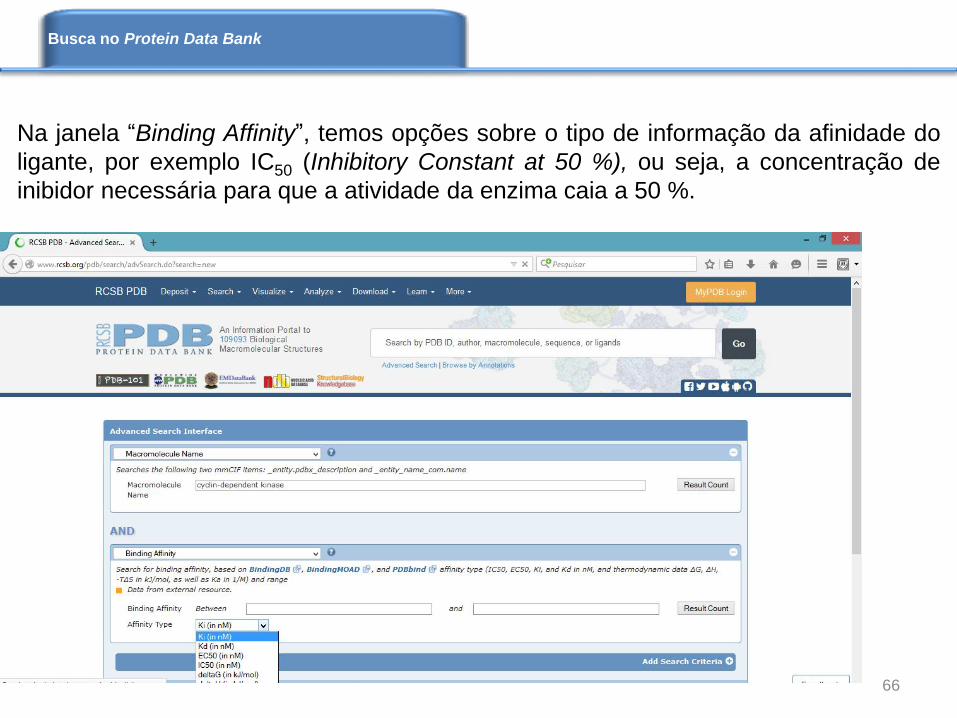
Na janela “Binding Affinity”, temos opções sobre o tipo de informação da afinidade do
ligante, por exemplo IC50 (Inhibitory Constant at 50 %), ou seja, a concentração de
inibidor necessária para que a atividade da enzima caia a 50 %.
66
Busca no Protein Data Bank
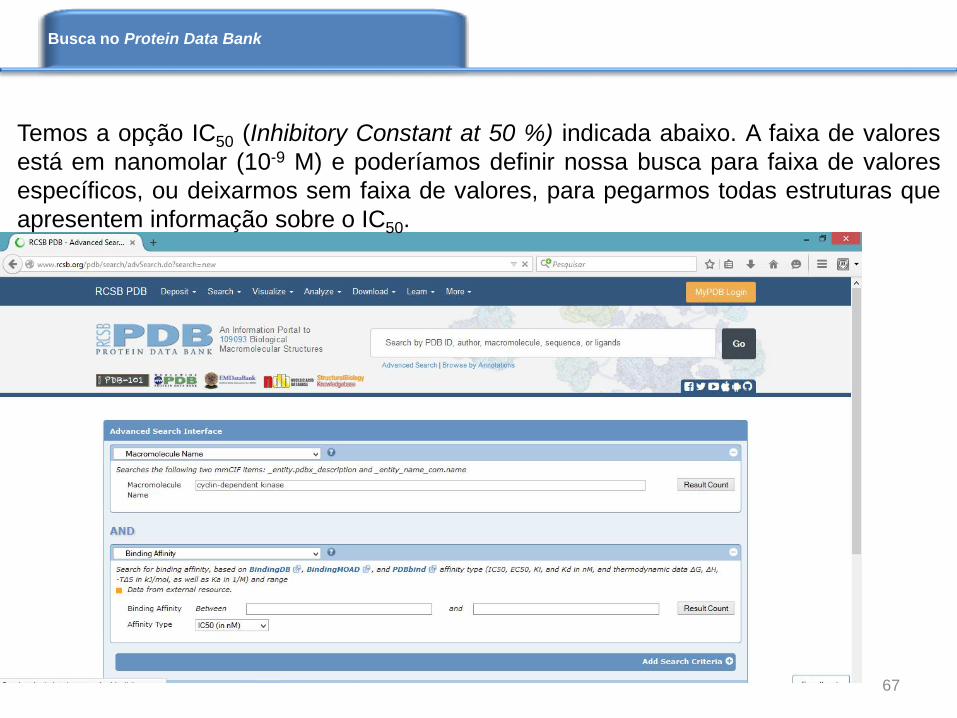
Temos a opção IC50 (Inhibitory Constant at 50 %) indicada abaixo. A faixa de valores
está em nanomolar (10-9 M) e poderíamos definir nossa busca para faixa de valores
específicos, ou deixarmos sem faixa de valores, para pegarmos todas estruturas que
apresentem informação sobre o IC50.
67
Busca no Protein Data Bank
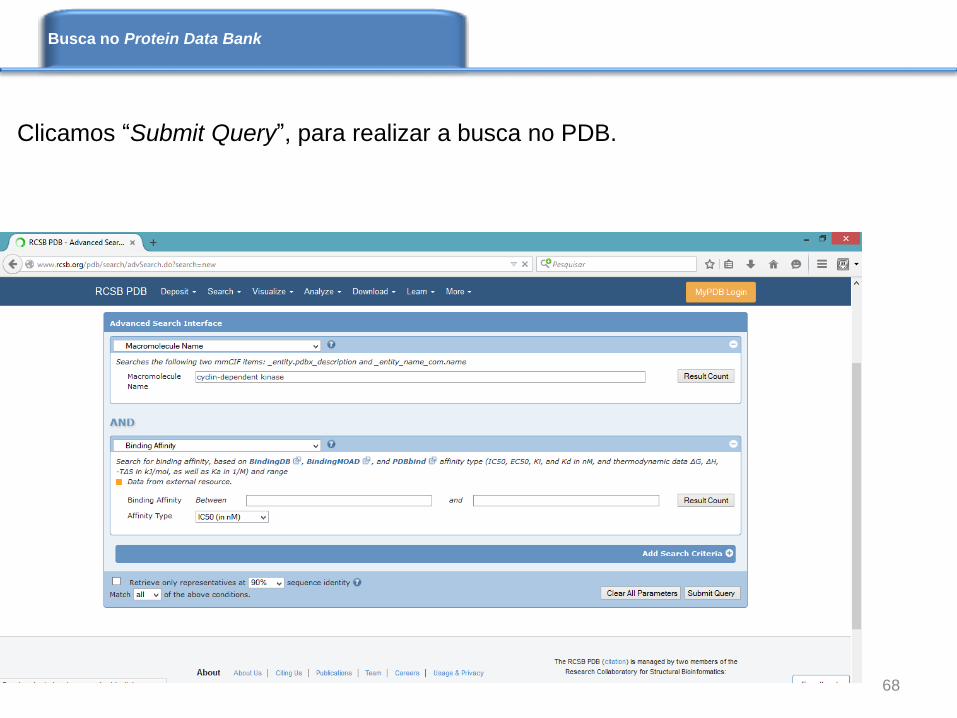
Clicamos “Submit Query”, para realizar a busca no PDB.
68
Busca no Protein Data Bank
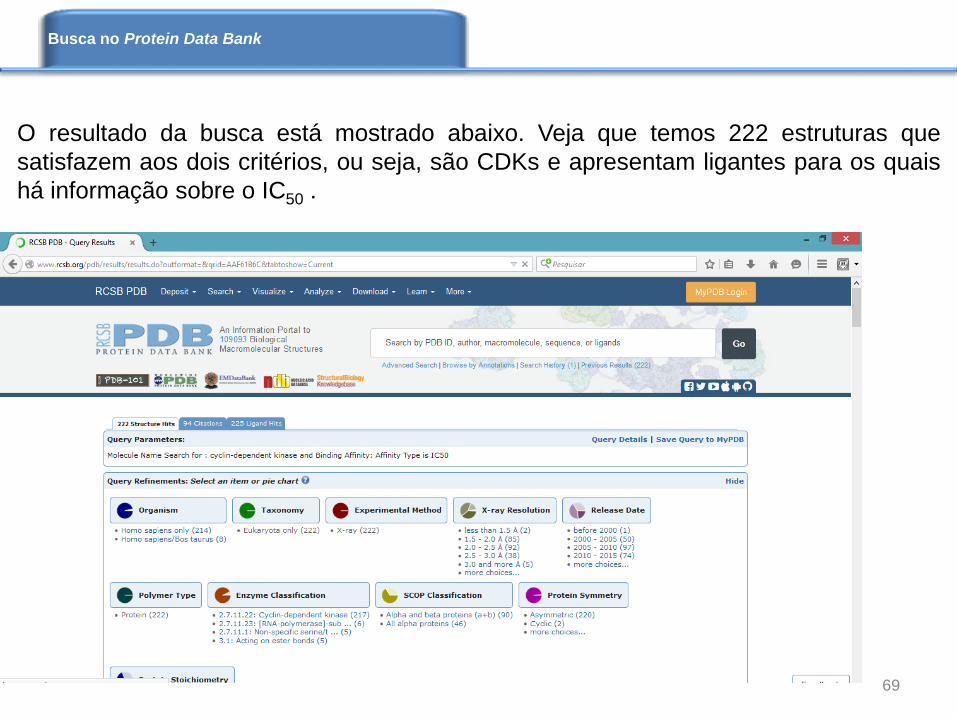
O resultado da busca está mostrado abaixo. Veja que temos 222 estruturas que
satisfazem aos dois critérios, ou seja, são CDKs e apresentam ligantes para os quais
há informação sobre o IC50 .
69
Busca no Protein Data Bank
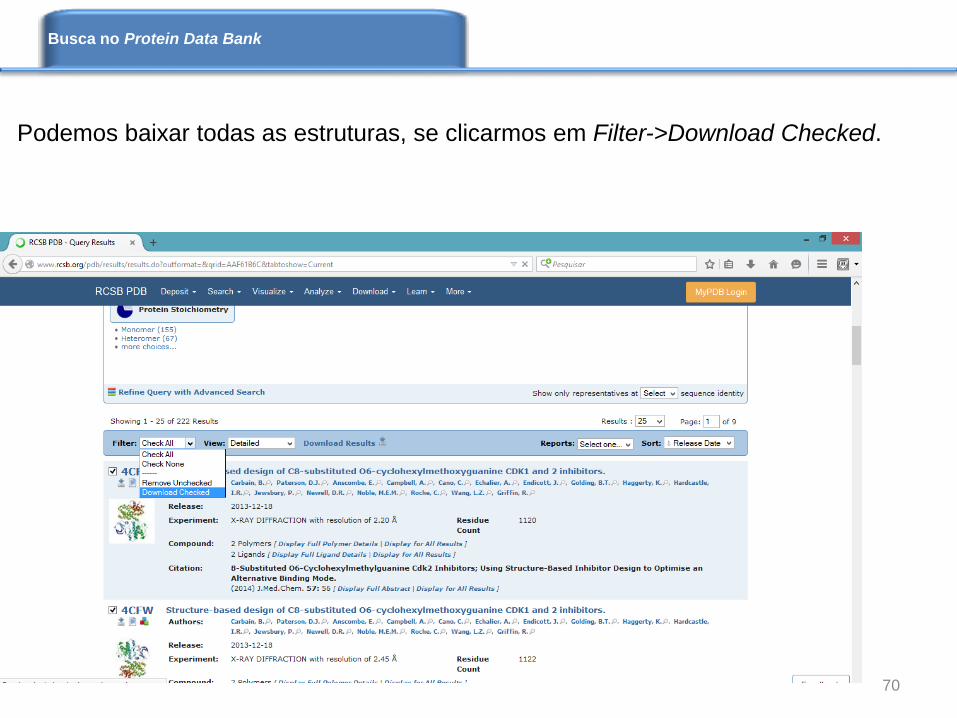
Podemos baixar todas as estruturas, se clicarmos em Filter->Download Checked.
70
Busca no Protein Data Bank
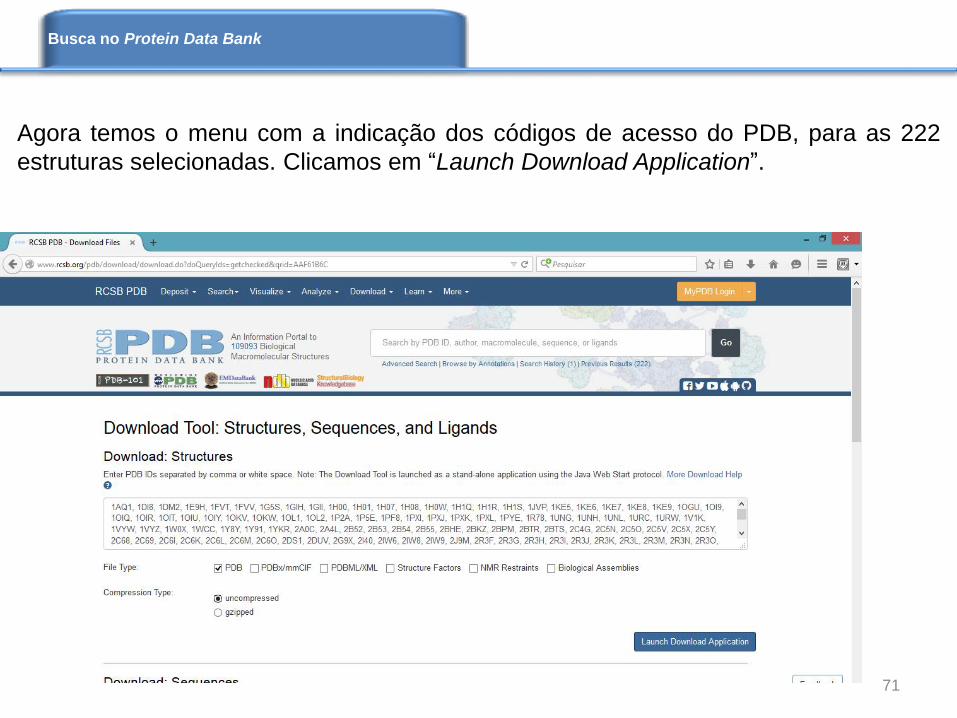
Agora temos o menu com a indicação dos códigos de acesso do PDB, para as 222
estruturas selecionadas. Clicamos em “Launch Download Application”.
71
Busca no Protein Data Bank
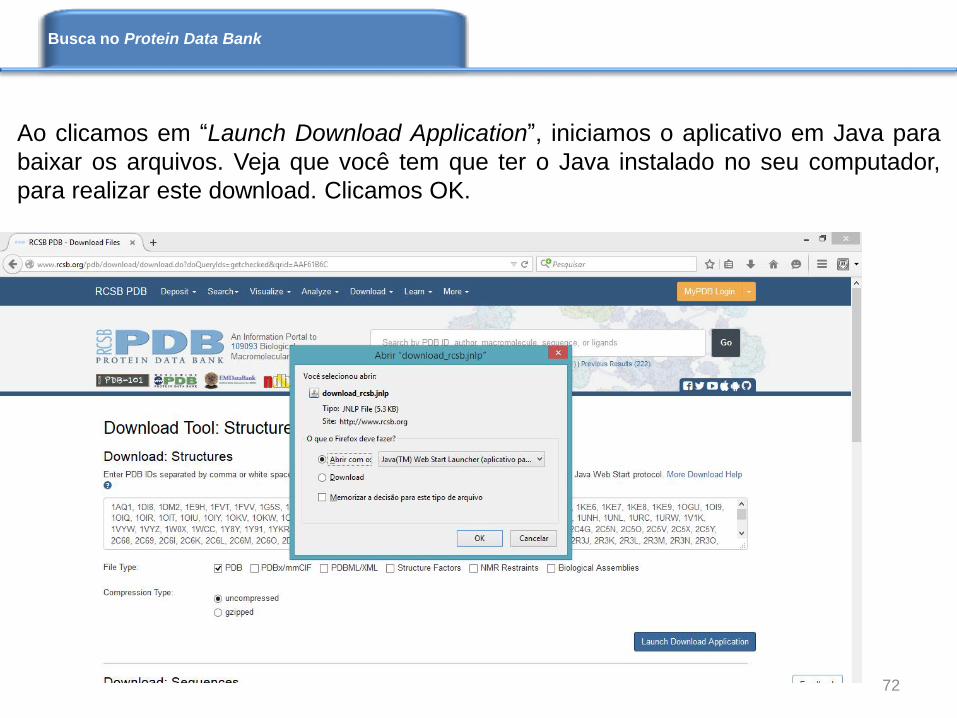
Ao clicamos em “Launch Download Application”, iniciamos o aplicativo em Java para
baixar os arquivos. Veja que você tem que ter o Java instalado no seu computador,
para realizar este download. Clicamos OK.
72
Busca no Protein Data Bank
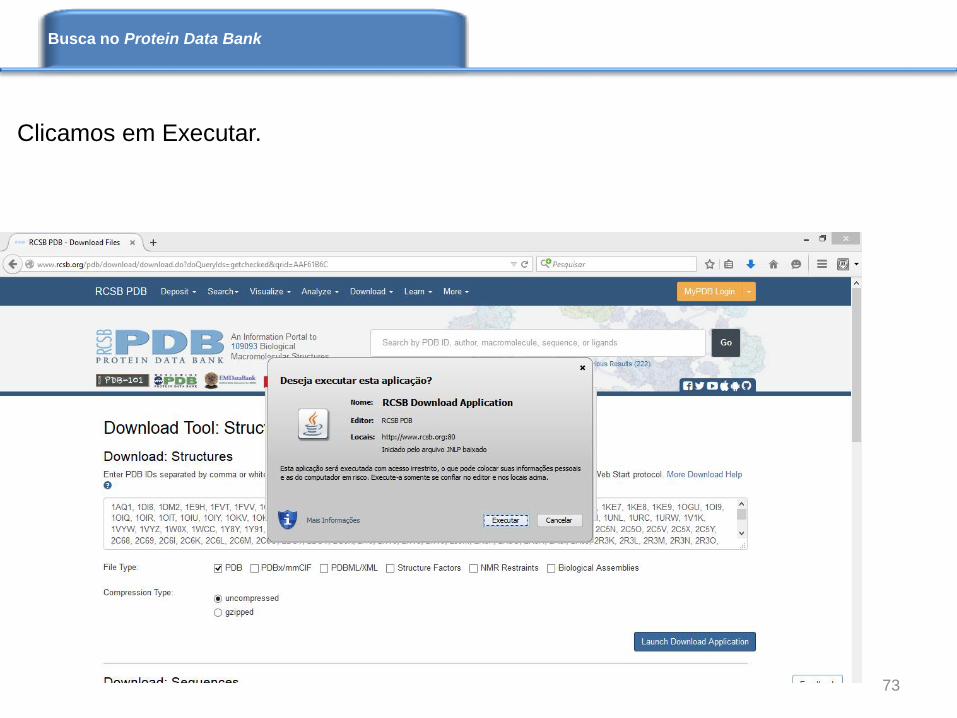
Clicamos em Executar.
73
Busca no Protein Data Bank
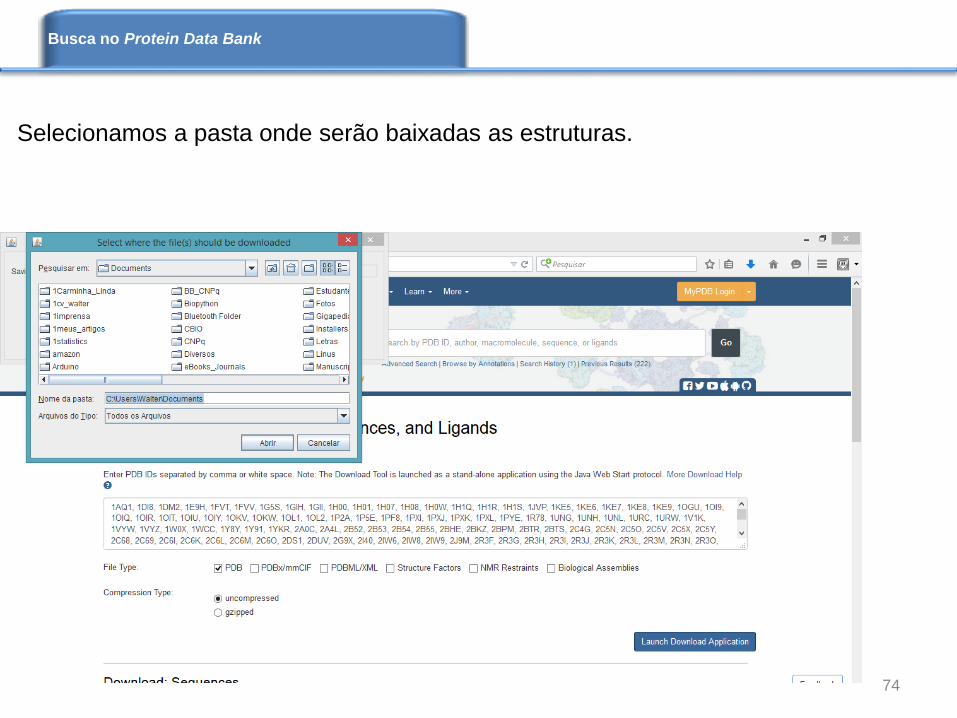
Selecionamos a pasta onde serão baixadas as estruturas.
74
Busca no Protein Data Bank
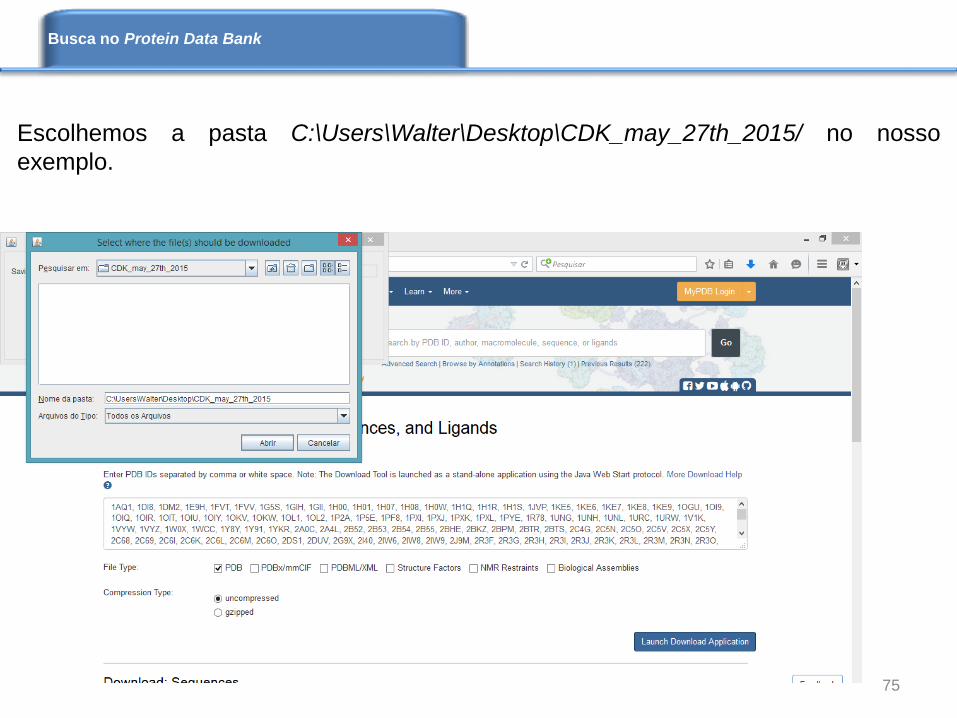
Escolhemos a pasta C:\Users\Walter\Desktop\CDK_may_27th_2015/ no nosso
exemplo.
75
Busca no Protein Data Bank
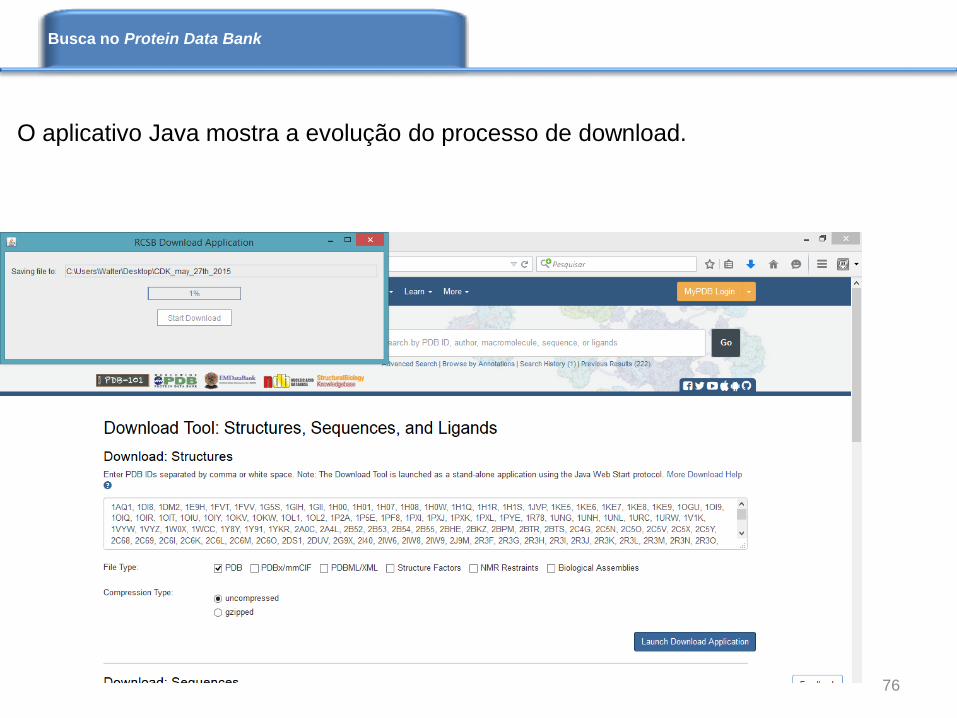
O aplicativo Java mostra a evolução do processo de download.
76
Busca no Protein Data Bank
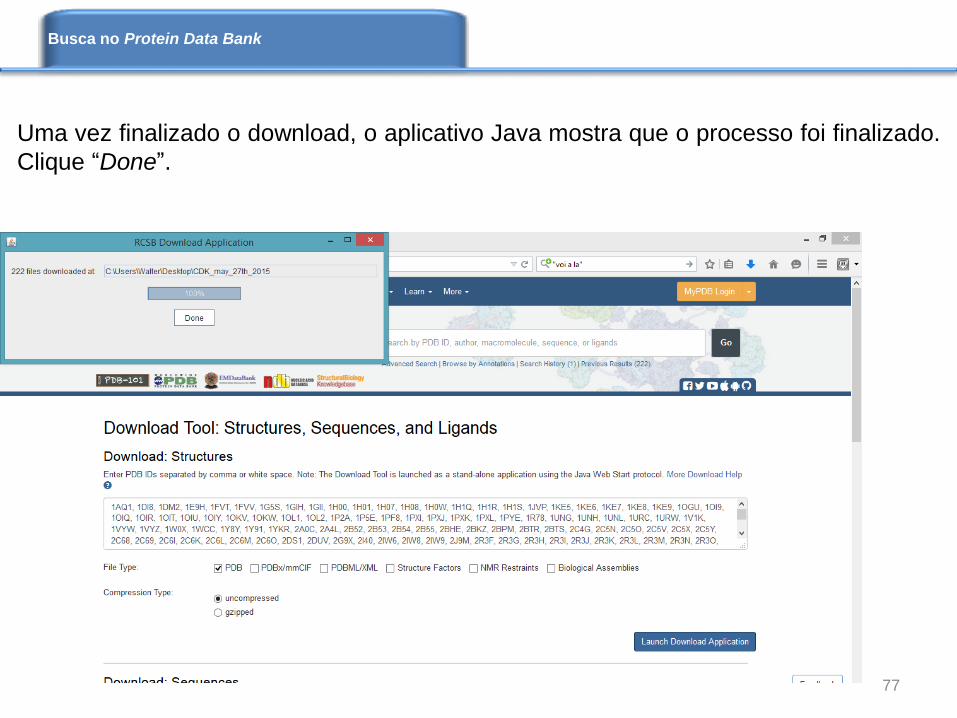
Uma vez finalizado o download, o aplicativo Java mostra que o processo foi finalizado.
Clique “Done”.
77
Busca no Protein Data Bank
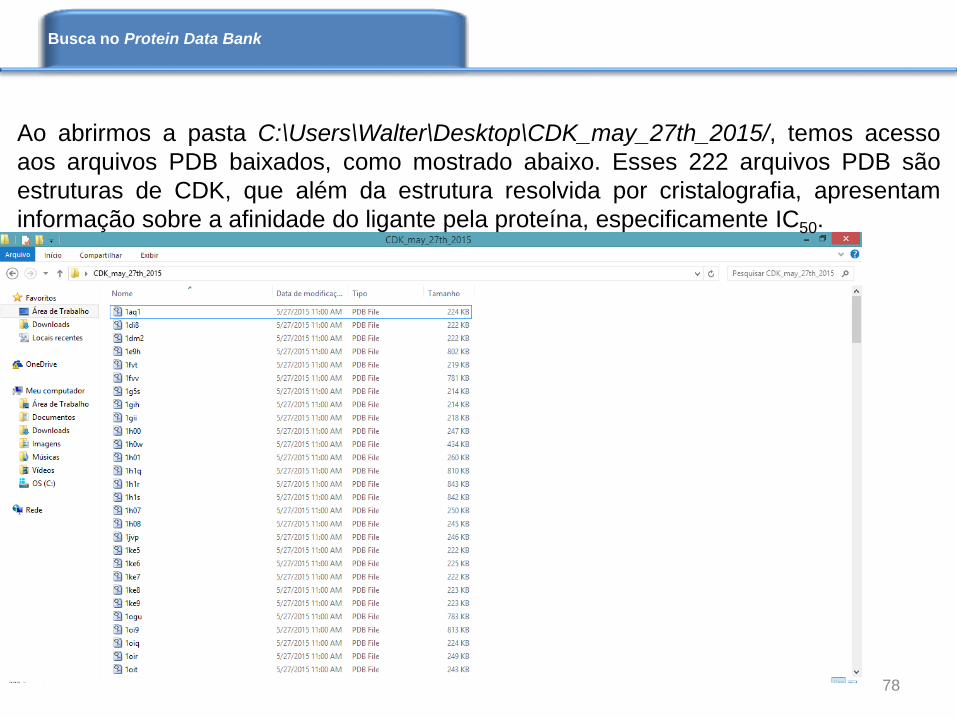
Ao abrirmos a pasta C:\Users\Walter\Desktop\CDK_may_27th_2015/, temos acesso
aos arquivos PDB baixados, como mostrado abaixo. Esses 222 arquivos PDB são
estruturas de CDK, que além da estrutura resolvida por cristalografia, apresentam
informação sobre a afinidade do ligante pela proteína, especificamente IC50.
78
Busca no Protein Data Bank

COLEY DA. An Introduction to Genetic Algorithms for Scientist
and Engineers. World Scientific Publishing Co. Pte. Ltd. Toh Tuck
Link, Singapore, 1999.
EIBEN AE, SMITH SJ. Introduction to Evolutionary Computing.
Springer-Verlag, Berlin, 2007.
FOGEL DB. Evolutionary Computation: Toward a New Philosophy
of Machine Intelligence, IEEE Press, 1995.
GOLDBERG DE. Genetic Algorithms in Search, Optimization, and
Machine Learning. Addison Wesley Longman, Ins.,Indiana, USA,
1989.
Analysis of Quantum-Inspired Evolutionary Algorithm . IEEE
Transactions on Evolutionary Computation, Vol .6, No. 6, 2002.
HOLLAND JH. Adaptation in Natural and Artificial Systems. MIR
Press. Cambridge MA, 1992.
MICHALEWICZ Z.Genetic Algorithms + Data Structures =
Evolution Programs, Springer-Verlag, 3rd, revised and extended
edition, 1999.
SCHWEFEL H-P. Evolution and Optimum Seeking,Wiley Inter-
Science, 1995.
Storn R,Price K. Differential evolution – A simple and efficient
adaptive scheme for global optimization over continuous spaces.
Technical Report TR-95-012, International Computer Science
Institute, Berkeley, CA, 1995.79
Referências
Última atualização em: 26 junho 2015.


















