
Reordenamento Serviço de Convivência e Fortalecimento de Vínculos

Brenno Albino Lugon
Algoritmos de reordenamento de matrizesesparsas aplicados a precondicionadores
ILU(p)
Vitória - ES2013


Brenno Albino Lugon
Algoritmos de reordenamento de matrizesesparsas aplicados a precondicionadores
ILU(p)
Trabalho de conclusão de curso apresentadoa Universidade Federal do Espírito Santo,para a obtenção de Título de Graduação,na Área de Ciência da Computação.
Orientadora: Prof𝑎 Lucia Catabriga
Vitória - ES2013

Lugon, Brenno A. Algoritmos de reordenamento de ma-trizes esparsas aplicados a precondicionadores ILU(p) 63páginas Trabalho de conclusão de curso - UniversidadeFederal do Espírito Santo. Centro Tecnológico. Departa-mento de Informática.
1. reordenamentos
2. matrizes esparsas
3. precondicionadores
I. Universidade Federal do Espírito Santo. Centro Tecnoló-gico. Departamento de Informática.
Comissão Julgadora:
Prof𝑎 Lucia Catabriga Prof𝑎 Maria Cristina RangelOrientadora
Prof𝑎 Andrea Maria Pedrosa Valli

Epígrafe
Passion.
It lies in all of us.
Sleeping, waiting, and though unwanted, unbidden.
It will stir, open its jaws, and howl.
It speaks to us, guides us.
Passion rules us all.
And we obey.
What other choice do we have?
Passion is the source of our finest moments.
The joy of love, the clarity of hatred, and the ecstasy of grief.
It hurts sometimes more than we can bear.
If we could live without passion, maybe we’d know some kind of peace.
But we would be hollow.
Empty rooms, shuttered and dank.
Without passion, we’d be truly dead.
—AngelusS02E17 "Passion"
Buffy the Vampire Slayer

Agradecimentos
A Deus.
Aos meus pais, Sérgio e Gezella, por todo o apoio.
Ao meu irmão Ryann. E meus cachorros Boby e Meg.
A todos da minha família que são presentes.
Ao meu namorado Robson, que há cinco anos me completa.
Aos meus verdadeiros amigos.
Em especial a minha orientadora Lucia, por toda a ajuda, orientação e paciência.

Resumo
O uso de precondicionadores é uma técnica eficiente para acelerar a convergência
de métodos iterativos não estacionários. Nesse contexto, podemos reduzir o tempo de
execução desses métodos aplicando uma simples troca de linhas e colunas em uma matriz
esparsa. Esse processo, chamado de reordenamento, visa reduzir o número de operações
com ponto flutuante durante a montagem das matrizes precondicionadoras. Este trabalho
faz um estudo comparativo dos algoritmos de reordenamento: Sloan, Reverse Cuthill
Mckee, Espectral, Nested Dissection e Approximate Minimum Degree, avaliando o impacto
que causam quando utilizamos o método de resolução GMRES com o precondicionador
baseado na fatoração LU incompleta, ILU(p).
Palavras-chave: matrizes esparsas, reordenamento, precondicionadores, GMRES

Abstract
The use of preconditioning is an efficient technique to accelerate the convergence of
nonstationary iterative methods. In this context, we can reduce runtime of these methods
by applying a simple exchange of rows and columns in a sparse matrix. This process,
called reordering, aims to reduce the number of floating point operations during the
preconditioner matrices computation. This work makes a comparative study of reordering
algorithms: Sloan, Reverse Cuthill Mckee, Spectral, Nested Dissection and Approximate
Minimum Degree, evaluating the impact they have when using the solver method GMRES
applied to a preconditioner based on incomplete LU factorization, ILU(p).
Keywords: sparse matrix, reordering, ILU preconditioner, GMRES

Lista de Figuras
1.1 Representações da matriz 𝑛𝑒𝑡125 . . . . . . . . . . . . . . . . . . . . . . . 2
3.1 Armazenamento CSR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 Configurações da matriz 𝐴 e fill-in . . . . . . . . . . . . . . . . . . . . . . 12
3.3 Grafo, Matriz e Reordenamento . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1 Exemplo de execução do Algoritmo 5 . . . . . . . . . . . . . . . . . . . . . 18
4.2 Terminologia do algoritmo Sloan . . . . . . . . . . . . . . . . . . . . . . . 19
4.3 Grafo rerrotulado - RCM . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.4 Grafo rerrotulado - Espectral . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.5 Bisseção de 𝐺: Vértices separadores 𝑆 e partições 𝐴 e 𝐵 . . . . . . . . . . 25
4.6 Exemplo de Grafo de Eliminação . . . . . . . . . . . . . . . . . . . . . . . 26
4.7 Funcionamento dos algoritmos de Grau Mínimo . . . . . . . . . . . . . . . 26
5.1 𝑟𝑎𝑖𝑙_5177 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.2 𝑟𝑎𝑖𝑙_5177 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.3 𝑟𝑎𝑖𝑙_5177 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
5.4 𝑟𝑎𝑖𝑙_5177 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.5 𝑎𝑓𝑡01 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.6 𝑎𝑓𝑡01 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.7 𝑎𝑓𝑡01 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35

5.8 𝑎𝑓𝑡01 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.9 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 - Esparsidade . . . . . . . . . . . . . . . . . . . . . 37
5.10 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 - Preenchimento . . . . . . . . . . . . . . . . . . . . 38
5.11 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 - Iterações . . . . . . . . . . . . . . . . . . . . . . . 38
5.12 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 - Tempo de CPU . . . . . . . . . . . . . . . . . . . 39
5.13 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . 40
5.14 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . 41
5.15 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.16 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . 42
5.17 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.18 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.19 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
5.20 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.21 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.22 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.23 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.24 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.25 𝑏𝑜𝑛𝑒𝑆01 - Esparsidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.26 𝑏𝑜𝑛𝑒𝑆01 - Preenchimento . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.27 𝑏𝑜𝑛𝑒𝑆01 - Iterações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.28 𝑏𝑜𝑛𝑒𝑆01 - Tempo de CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . 51

Lista de Tabelas
4.1 Exemplo de execução - RCM . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2 Exemplo de execução - Espectral . . . . . . . . . . . . . . . . . . . . . . . 24
5.1 Características das matrizes testadas . . . . . . . . . . . . . . . . . . . . . 29
5.2 Medições - 𝑟𝑎𝑖𝑙_5177 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3 Medições - 𝑎𝑓𝑡01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.4 Medições - 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 . . . . . . . . . . . . . . . . . . . . . . . 37
5.5 Medições - 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.6 Medições - 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.7 Medições - 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.8 Medições - 𝑏𝑜𝑛𝑒𝑆01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6.1 Análise Final . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53

Sumário
1 Introdução 1
2 Sistemas Lineares 5
2.1 Resolução de Sistemas Lineares . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 Método do Resíduo Mínimo Generalizado (GMRES) . . . . . . . . 7
2.2 Precondicionadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Fatoração LU incompleta (ILU) . . . . . . . . . . . . . . . . . . . . 9
3 Matrizes Esparsas 11
3.1 Armazenamento Otimizado . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2 Métricas de Minimização . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2.1 Fill-in . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2.2 Largura de Banda . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2.3 Envelope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 Grafos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.4 Permutação e Reordenamento . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Algoritmos de Reordenamento 17
4.1 Sloan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2 Reverse Cuthill McKee (RCM) . . . . . . . . . . . . . . . . . . . . . . . . 21
4.3 Espectral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22

4.4 Nested Dissection (ND) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.5 Approximate Minimum Degree (AMD) . . . . . . . . . . . . . . . . . . . . 25
5 Testes Computacionais 29
5.1 Matriz 𝑟𝑎𝑖𝑙_5177 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.2 Matriz 𝑎𝑓𝑡01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.3 Matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1 . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.4 Matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.5 Matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.6 Matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.7 Matriz 𝑏𝑜𝑛𝑒𝑆01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
6 Conclusões 53
Referências Bibliográficas 56
A Implementações CSR 60


Capítulo 1
Introdução
No processo de solução numérica de muitas aplicações é comum recairmos na necessidade
de manipular matrizes de grande porte vinculadas a sistemas lineares. Tais aplicações
possuem milhares de variáveis, mas cada variável individual depende apenas de algumas
poucas, e por isso a maior parte dos coeficientes dessas matrizes são nulos. Dinâmicas
de fluidos computacionais, otimização, simulação de problemas físicos e químicos, grafos,
sistemas eletromagnéticos são exemplos de aplicações cujos processos de solução recaem
na necessidade de manipular matrizes esparsas.
Na Figura 1.1 podemos observar representações provenientes de um problema de
otimização. A matriz 𝑛𝑒𝑡125 de Alexander Andrianov, SAS Institute Inc. (Timothy
A. Davis, 2013a) representada como um grafo não-direcionado (Figura 1.1a) e como uma
matriz esparsa (Figura 1.1b).
O uso de estruturas de dados otimizadas para armazenar matrizes esparsas visa re-
duzir a quantidade de memória usada e a quantidade de operações de ponto flutuante.
Tipos de armazenamentos como o Compressed Sparse Row (CSR) ou Compressed Sparse
Column (CSC) são exemplos de estruturas eficientes onde se armazenam apenas os ele-
mentos não nulos da matriz e consequentemente melhoram o desempenho dos algoritmos
que necessitam executar operações com matrizes esparsas.

Capítulo 1. Introdução 2
(a) Grafo não-direcionado (b) Matriz esparsa
Figura 1.1: Representações da matriz 𝑛𝑒𝑡125
Para solução de sistemas lineares de grande porte, Saad (2003) sugere a utilização de
métodos iterativos baseados em projeções de subespaços de Krylov por suas boas proprie-
dades numéricas e computacionais. Além disso, técnicas de precondicionamento baseadas
na decomposição LU incompleta (Benzi et al., 1999) (Camata et al., 2012) aceleram a
convergência e consequentemente melhoram a eficiência desses métodos na obtenção da
solução. Neste trabalho, iremos estudar classes de algoritmos de reordenamento que têm
como objetivo a redução do preenchimento (ou fill-in) que ocorre ao utilizarmos pre-
condicionador baseado na decomposição LU incompleta. Assim, diminui-se o número de
operações com ponto flutuante, melhorando o tempo de execução dos métodos iterativos
não estacionários.
Por fim, iremos comparar a eficiência de cada método quanto ao tempo de execução,
calculando o tempo gasto para resolver o sistema linear sem nenhum pré-processamento,
e o tempo para resolvê-lo após o pré-processamento, avaliando os resultados de acordo
com algumas métricas como Envelope, Largura de Banda e quantidade de preenchimento.
Poucos estudos têm sido feitos atualmente com relação a algoritmos de reordena-
mento. Artigos como Sloan (1986) e Sloan (1989), descrevem um algoritmo de reordena-

3
mento que parece ter sido pouco estudado, sem muitas outras referências na literatura.
Além disso, esses artigos possuem implementações de códigos antigos e pouco estrutura-
dos, na linguagem de programação FORTRAN. Dos artigos referenciados, a maior parte
se preocupa em estudar algoritmos individualmente, de forma que poucos estudos se pre-
ocupam em compará-los. Uma exceção é o estudo feito por Ghidetti (2011). Nele, a
autora compara algoritmos de reordenamentos também estudados neste trabalho, como
RCM e Espectral, além de outra abordagem do algoritmo Nested Dissection. Carmo
(2005) também compara a influência de algoritmos de reordenamento como o RCM e
AMD aplicados em matrizes esparsas no desempenho do método Cholesky controlado
gradiente conjugado.
Os capítulos estão divididos de forma a facilitar a compreensão do leitor. No se-
gundo capítulo, revisa-se alguns conceitos básicos sobre sistemas de equações lineares e
sobre métodos de resolução desses sistemas. No terceiro capítulo, apresenta-se matrizes
esparsas e as vantagens computacionais que podemos obter ao armazená-las adequada-
mente. No quarto capítulo, descreve-se sobre os algoritmos de reordenamento escolhidos
para estudo, com uma breve explicação do funcionamento de cada um deles. No quinto
capítulo, expõe-se os resultados obtidos através de testes computacionais, em uma aná-
lise detalhada de cada uma das matrizes testadas. No sexto capítulo, apresenta-se as
conclusões e considerações finais, sintetizando todos os resultados obtidos. Por fim, o
Apêndice A apresenta pseudocódigos em formato CSR de alguns algoritmos utilizados
neste trabalho.


Capítulo 2
Sistemas Lineares
Seja uma equação linear de 𝑛 incógnitas definida como 𝑎𝑖1𝑥1 + 𝑎𝑖2𝑥2 + ... + 𝑎𝑖𝑛𝑥𝑛 = 𝑏𝑖,
um sistema linear é um conjunto de 𝑚 equações lineares da forma
⎧⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎩
𝑎11𝑥1 + 𝑎12𝑥2 + ...+ 𝑎1𝑛𝑥𝑛 = 𝑏1
𝑎21𝑥1 + 𝑎22𝑥2 + ...+ 𝑎2𝑛𝑥𝑛 = 𝑏2...
𝑎𝑚1𝑥1 + 𝑎𝑚2𝑥2 + ...+ 𝑎𝑚𝑛𝑥𝑛 = 𝑏𝑚
onde 𝑎𝑖𝑗 , 𝑏𝑖, para 1 ≤ 𝑖 ≤ 𝑚, 1 ≤ 𝑗 ≤ 𝑛, são números reais (ou complexos) chamados de
coeficientes do sistema.
Assim, podemos representar um sistema linear na forma matricial 𝐴𝑥 = 𝑏
⎛⎜⎜⎜⎜⎜⎜⎜⎝
𝑎11 𝑎12 · · · 𝑎1𝑛
𝑎21 𝑎22 · · · 𝑎2𝑛...
......
𝑎𝑚1 𝑎𝑚2 · · · 𝑎𝑚𝑛
⎞⎟⎟⎟⎟⎟⎟⎟⎠.
⎛⎜⎜⎜⎜⎜⎜⎜⎝
𝑥1
𝑥2...
𝑥𝑛
⎞⎟⎟⎟⎟⎟⎟⎟⎠=
⎛⎜⎜⎜⎜⎜⎜⎜⎝
𝑏1
𝑏2...
𝑏𝑚
⎞⎟⎟⎟⎟⎟⎟⎟⎠A matriz 𝐴 é chamada de matriz do sistema, o vetor coluna 𝑥 são as incógnitas do
sistema e o vetor coluna 𝑏 é o vetor de termos independentes (Boldrini et al., 1986).

Capítulo 2. Sistemas Lineares 6
Seja 𝐴 uma matriz. 𝐴 é dita quadrada se possui o mesmo número de linhas e colunas
(𝑚 = 𝑛). 𝐴 é diagonal se 𝑎𝑖𝑗 = 0, para 𝑖 ̸= 𝑗. A matriz transposta de 𝐴, denotada
por 𝐴𝑇 , é uma matriz onde 𝑎𝑖𝑗 = 𝑎𝑗𝑖. 𝐴 é chamada de matriz triangular superior (U)
se 𝑎𝑖𝑗 = 0 para 𝑖 > 𝑗 e, matriz triangular inferior (L) se 𝑎𝑖𝑗 = 0 para 𝑖 < 𝑗. 𝐴 é dita
identidade se 𝑎𝑖𝑗 = 1 quando 𝑖 = 𝑗 e 𝑎𝑖𝑗 = 0 quando 𝑖 ̸= 𝑗. 𝐴 é simétrica se 𝐴 = 𝐴𝑇 . 𝐴
é estruturalmente simétrica se, quando 𝑎𝑖𝑗 ̸= 0 então 𝑎𝑗𝑖 ̸= 0, mas não necessariamente
𝑎𝑖𝑗 = 𝑎𝑗𝑖. Seja um vetor 𝑣, 𝑣 ̸= 0, e um escalar 𝜆 ∈ R tais que 𝐴𝑣 = 𝜆𝑣, 𝜆 é um autovalor
de 𝐴 e 𝑣 um autovetor de 𝐴 associado a 𝜆 (Boldrini et al., 1986) (Saad, 2003).
2.1 Resolução de Sistemas Lineares
A solução de um sistema linear pode ser encontrada através de métodos Diretos ou
métodos Iterativos. Os métodos Diretos são capazes de encontrar a solução exata, sujeita
a erros de arredondamento, em um número finito de passos. Apesar disso, não são eficazes
quando aplicados em matrizes esparsas de grande porte.
O processo de encontrar a solução de uma matriz triangular superior ou inferior,
baseado na Eliminação de Gauss, é um exemplo de método Direto. Os cálculos envolvidos
nos Algoritmos 1 e 2 são triviais, sendo feitos através de substituições sucessivas (resolve
o sistema 𝐿𝑥 = 𝑐) ou retroativas (resolve o sistema 𝑈𝑥 = 𝑑).
Algoritmo 1: Substituição Sucessiva
1 𝑥1 = 𝑏1/𝑎112 𝑠𝑜𝑚𝑎 = 03 para 𝑖 = 2,...,𝑛 faça
4 𝑠𝑜𝑚𝑎 = 𝑏𝑖5 para 𝑗 = 1,...,𝑖 faça6 𝑠𝑜𝑚𝑎 = 𝑠𝑜𝑚𝑎− 𝑎𝑖𝑗𝑥𝑗7 fim
8 𝑥𝑖 = 𝑠𝑜𝑚𝑎/𝑎𝑖𝑖9 fim

7 2.1. Resolução de Sistemas Lineares
Algoritmo 2: Substituição Retroativa
1 𝑥𝑛 = 𝑏𝑛/𝑎𝑛𝑛2 𝑠𝑜𝑚𝑎 = 03 para 𝑖 = 𝑛− 1,...,1 faça4 𝑠𝑜𝑚𝑎 = 𝑏𝑖5 para 𝑗 = 𝑖+ 1,...,𝑛 faça
6 𝑠𝑜𝑚𝑎 = 𝑠𝑜𝑚𝑎− 𝑎𝑖𝑗𝑥𝑗7 fim
8 𝑥𝑖 = 𝑠𝑜𝑚𝑎/𝑎𝑖𝑖9 fim
Já os métodos Iterativos são técnicas mais eficazes para resolver sistemas lineares de
grandes porte. Essa classe de métodos depende de uma tolerância pré-fixada e propor-
cionam uma boa qualidade de solução quanto a erros de arredondamento, uma vez que
não alteram a matriz 𝐴 e o vetor 𝑏 no processo iterativo. (Saad, 2003).
Os métodos Iterativos dividem-se ainda em estacionários e não-estacionários. Os es-
tacionários possuem uma matriz de iteração constante, enquanto que os não-estacionários
procuram obter em cada iteração a melhor aproximação utilizando informações das ite-
rações anteriores. Eles se baseiam em projeções de subespaços de Krylov, formados a
partir de
𝐾𝑚(𝐴,𝑟0) = 𝑠𝑝𝑎𝑛{︀𝑟0,𝐴𝑟0,𝐴
2𝑟0,...,𝐴𝑚−1𝑟0
}︀(2.1)
onde 𝑚 é a dimensão do subespaço, 𝑟0 = 𝑏 − 𝐴𝑥0 e 𝑠𝑝𝑎𝑛{︀𝑟0,𝐴𝑟0,𝐴
2𝑟0,...,𝐴𝑚−1𝑟0
}︀representa a base geradora do subespaço vetorial 𝐾𝑚. Esses métodos têm como objetivo
transformar o sistema 𝐴𝑥 = 𝑏 em um problema de minimização do resíduo 𝑟 = 𝑏 − 𝐴𝑥,
para 𝑥 ∈ 𝐾𝑚.
2.1.1 Método do Resíduo Mínimo Generalizado (GMRES)
Ométodo do Resíduo Mínimo Generalizado (GMRES) desenvolvido por Saad and Schultz
(1986) é um método iterativo não-estacionário utilizado para determinar a solução apro-
ximada de um sistema linear da forma 𝐴𝑥 = 𝑏.

Capítulo 2. Sistemas Lineares 8
O algoritmo usa o processo de Arnoldi para calcular uma base ortonormal do subes-
paço de Krylov. A base ortonormal 𝑥𝑘 é dada por 𝑥0 + 𝑉 𝑦𝑘, onde 𝑉 é a matriz cujas
colunas são os vetores 𝑣𝑘 calculados pelo processo de Arnoldi. Já o vetor 𝑦𝑘 é obtido
pela solução do sistema 𝐻𝑘𝑦𝑘 = 𝛽𝑘𝑒1, onde 𝐻𝑘 é uma matriz superior chamada Hessen-
berg, cujos elementos são calculados durante a ortogonalização do processo de Arnoldi,
𝛽𝑘 = ‖𝑟0‖2, 𝑟0 = 𝑏−𝐴𝑥0 e 𝑒1 é o vetor canônico de dimensão 𝑘 (Gonçalez, 2005).
A fim de reduzir o número de operações de ponto flutuante e o armazenamento, o
algoritmo pode ser implementado considerando um número fixo de elementos na base.
Este procedimento é conhecido como reinicialização (ou restart) (Saad, 2003). A cada
𝑘 iterações é gerado um novo espaço vetorial de Krylov com 𝑘 elementos na base. Para
valores grandes de 𝑘, o método fica mais robusto e converge com menos iterações, en-
quanto que para valores pequenos de 𝑘, o método necessita de mais iterações, porém
cada iteração é menos custosa.
2.2 Precondicionadores
Com objetivo de acelerar a convergência dos métodos iterativos baseados em espaços de
Krylov, o precondicionamento consiste em encontrar uma matriz 𝑀 que seja simples de
construir e que reduza o número de iterações ao resolver um sistema linear. Um bom
precondicionador 𝑀 deve ser uma aproximação de 𝐴 que possa ser facilmente invertível,
de forma que utilizar 𝑀−1𝐴 ou 𝐴𝑀−1, ao invés de 𝐴 nas operações matriz × vetor,
melhore a convergência do método iterativo.
Para o precondicionamento do método GMRES consideramos neste trabalho o pre-
condicionador à esquerda. Algebricamente, considerando o sistema 𝐴𝑥 = 𝑏 e aplicando
o precondicionador, temos o sistema equivalente 𝑀−1𝐴𝑥 = 𝑀−1𝑏. No processo itera-
tivo, devemos agora adicionar a matriz precondicionada aos produtos matriz × vetor.
Portanto, ao invés de resolvermos 𝑣 = 𝐴𝑥, iremos resolver 𝑣 = 𝑀−1𝐴𝑥.

9 2.2. Precondicionadores
Esta operação é feita em duas etapas:
1. Calcula-se 𝑝 = 𝐴𝑥
2. Calcula-se 𝑣 = 𝑀−1𝑝, resolvendo o sistema 𝑀𝑣 = 𝑝.
Porém a matriz 𝑀 é decomposta em 𝐿𝑈 pela fatoração 𝐿𝑈 incompleta (seção 2.2.1).
Logo, resolver o sistema 𝑀𝑣 = 𝑝 equivale a resolver o sistema 𝐿𝑈𝑣 = 𝑝. Essa operação
também é feita em duas etapas:
1. Seja 𝑈𝑣 = 𝑥, calcula-se 𝐿𝑥 = 𝑝 por substituições sucessivas (Algoritmo 1)
2. Calcula-se 𝑈𝑣 = 𝑥 por substituições retroativas (Algoritmo 2)
2.2.1 Fatoração LU incompleta (ILU)
Dada uma matriz quadrada 𝐴, podemos decompô-la em uma matriz triangular superior
𝑈 e uma matriz triangular inferior 𝐿, onde 𝐴 = 𝐿𝑈 . Este método é conhecido como
fatoração 𝐿𝑈 .
Porém, construir um precondicionador𝑀 baseado na fatoração 𝐿𝑈 completa, de uma
matriz esparsa 𝐴, resultaria no preenchimento (fill-in) de muitas posições originalmente
nulas, isto é, muitos elementos nulos em 𝐴 seriam não nulos em 𝑀 . Assim, considerando
que um precondicionador precisa ser somente uma boa aproximação de 𝐴, podemos
utilizar uma fatoração aproximada 𝑀 = �̃��̃� ≈ 𝐴 chamada de fatoração incompleta.
Algoritmo 3: Fatoração ILU(0)
1 para 𝑖 = 2,...,𝑛 faça
2 para 𝑘 = 1,...,𝑖− 1 e 𝑎𝑖𝑘 ̸= 0 faça3 𝑎𝑖𝑘 = 𝑎𝑖𝑘/𝑎𝑘𝑘4 para 𝑗 = 𝑘 + 1,...,𝑛 faça
5 𝑎𝑖𝑗 = 𝑎𝑖𝑗 − (𝑎𝑖𝑘 * 𝑎𝑘𝑗)6 fim
7 fim
8 fim

Capítulo 2. Sistemas Lineares 10
O precondicionador ILU(0), descrito pelo Algoritmo 3, não admite preenchimentos em
nenhuma etapa da fatoração. Portanto �̃� e �̃� possuem o mesmo padrão de esparsidade
e a mesma quantidade de elementos não nulos de 𝐴.
Diferente do ILU(0) que somente permite computar a fatoração de elementos não
nulos, o ILU(p), descrito pelo Algoritmo 4, admite preenchimento até o nível 𝑝. Quando
𝑝 = 𝑛− 1 temos a fatoração 𝐿𝑈 completa. Além disso, a fatoração é menos exata e mais
rápida quanto menor o valor de 𝑝. Em termos de programação, é criada uma matriz
auxiliar 𝑙𝑒𝑣 que é inicializada no algoritmo como:
𝑙𝑒𝑣𝑖𝑗 =
{︂0 𝑎𝑖𝑗 ̸= 0
𝑛− 1 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟�́�𝑟𝑖𝑜
Algoritmo 4: Fatoração ILU(p)
1 para todo 𝑎𝑖𝑗 ̸= 0 faça2 𝑙𝑒𝑣𝑖𝑗 = 03 fim
4 para 𝑖 = 2,...,𝑛 faça
5 para 𝑘 = 1,...,𝑖− 1 e 𝑎𝑖𝑘 ̸= 0 faça6 se 𝑙𝑒𝑣𝑖𝑗 ≤ 𝑝 então7 𝑎𝑖𝑘 = 𝑎𝑖𝑘/𝑎𝑘𝑘8 fim
9 para 𝑗 = 𝑘 + 1,...,𝑛 faça
10 𝑎𝑖𝑗 = 𝑎𝑖𝑗 − (𝑎𝑖𝑘 * 𝑎𝑘𝑗)11 𝑙𝑒𝑣𝑖𝑗 = 𝑚𝑖𝑛{𝑙𝑒𝑣𝑖𝑗 ,𝑙𝑒𝑣𝑖𝑘 + 𝑙𝑒𝑣𝑘𝑗 + 1}12 fim
13 fim
14 se 𝑙𝑒𝑣𝑖𝑗 > 𝑝 então15 𝑎𝑖𝑗 = 016 fim
17 fim
O algoritmo é similar ao ILU(0), porém a matriz auxiliar 𝑙𝑒𝑣 controla o nível de
preenchimento de cada elemento (linha 11 do Algoritmo 4). No final do algoritmo, na
linha 14, se o nível de preenchimento do elemento 𝑖𝑗 for maior do que o 𝑝 dado como
entrada, esse elemento é zerado.

Capítulo 3
Matrizes Esparsas
(Stoer and Bulirsch, 2002) define uma matriz esparsa como uma matriz onde a maioria
de seus elementos são nulos. (Saad, 2003) contesta que, na verdade, uma matriz é dita
esparsa quando podemos tirar vantagens da grande quantidade de zeros, uma vez que
estes não precisam ser armazenados. Para isso, é preciso definir estruturas de dados
adequadas para uma implementação eficiente de métodos de solução numéricos, sejam
eles diretos ou iterativos.
3.1 Armazenamento Otimizado
Uma forma de reduzir os gastos computacionais de operações em matrizes esparsas é
otimizar a forma de armazenamento dessa matriz. Neste trabalho utiliza-se o método
chamado Compress Sparse Row (CSR). No armazenamento CSR tradicional substitui-se
o armazenamento denso da matriz 𝐴, por três vetores auxiliares: 𝐴𝐴, 𝐽𝐴 e 𝐼𝐴. O vetor
𝐴𝐴 armazena todas as contribuições não nulas da matriz 𝐴 linha a linha. O vetor 𝐽𝐴
armazena a coluna correspondente que cada coeficiente não nulo ocuparia em 𝐴. Já o
vetor 𝐼𝐴 diz a posição em 𝐴𝐴 do primeiro elemento não nulo de cada linha de 𝐴 com
seu último elemento sendo igual ao número de elementos não nulos acrescido de um.

Capítulo 3. Matrizes Esparsas 12
Figura 3.1: Armazenamento CSR
3.2 Métricas de Minimização
3.2.1 Fill-in
O processo de fatoração 𝐿𝑈 quando aplicado em uma matriz esparsa tende a preencher
muitos elementos nulos, diminuindo consideravelmente o grau de esparsidade da ma-
triz. Com isso, o tempo computacional para resolver o sistema por um método iterativo
não-estacionário com precondicionador pode aumentar muito, uma vez que precisamos
calcular os fatores �̃� e �̃� da matriz precondicionada 𝑀 como visto na seção 2.2.1.
Várias heurísticas, baseadas simplesmente na troca de linhas e colunas, foram cria-
das para reduzir o preenchimento (ou fill-in) das matrizes. Algoritmos como o Nested
Dissection ou de Grau Mínimo visam simplesmente reduzir o fill-in, enquanto que RCM,
Sloan e Espectral tentam aproximar os elementos não-nulos da diagonal principal, o que
consequentemente também causa redução do fill-in.
⎛⎜⎜⎜⎜⎝× × × × ×× ×× ×× ×× ×
⎞⎟⎟⎟⎟⎠(a)
⎛⎜⎜⎜⎜⎝× × × × ×× × � � �× � × � �× � � × �× � � � ×
⎞⎟⎟⎟⎟⎠(b)
⎛⎜⎜⎜⎜⎝× ×× ×× ×× ×
× × × × ×
⎞⎟⎟⎟⎟⎠(c)
⎛⎜⎜⎜⎜⎝× ×× ×× ×× ×
× × × × ×
⎞⎟⎟⎟⎟⎠(d)
Figura 3.2: A configuração da matriz em (a) causa muito preenchimento, representadopor � em (b). Em (c), a simples troca das linhas e colunas 1 e 5 de (a), reduz opreenchimento a zero na matriz em (d).

13 3.2. Métricas de Minimização
3.2.2 Largura de Banda
Seja 𝐴 uma matriz estruturalmente simétrica, a largura de banda de 𝐴 é definida como:
𝑙𝑏(𝐴) = max𝑖=1,..,𝑛
{𝑏𝑖}
𝑏𝑖 = (𝑖− 𝑗) ∀ 𝑎𝑖𝑗 ̸= 0, 𝑖 = 1,...,𝑛
ou seja, a largura de banda pode ser definida como a maior distância entre o primeiro
elemento não-nulo da linha 𝑖 até a diagonal principal (Alan George, 1994).
Exemplo: 𝐴 =
⎛⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎝
× × ×× ×
× × ×× × ×
× × ×× × ×
× × ×× × × × ×
× × × ×× × ×
⎞⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎠→ 𝑙𝑏(𝐴) = 7
3.2.3 Envelope
Seja 𝐴 uma matriz estruturalmente simétrica, o envelope de 𝐴 é definido como:
𝑒𝑛𝑣(𝐴) =
𝑛∑︁𝑖=1
𝑏𝑖
Assim, podemos definir o envelope como a soma das distâncias entre o primeiro elemento
não-nulo de cada linha 𝑖 até a diagonal principal (Alan George, 1994).

Capítulo 3. Matrizes Esparsas 14
Exemplo: 𝐴 =
⎛⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎝
× × ×× ×
× × ×× × ×
× × ×× × ×
× × ×× × × × ×
× × × ×× × ×
⎞⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎠→ 𝑒𝑛𝑣(𝐴) = 27
3.3 Grafos
Conceitos importantes em teoria de grafos são fundamentais para o entendimento deste
trabalho e dos algoritmos estudados. Isto porque o problema de reordenamento de ma-
trizes pode ser visto como um problema de rerrotulação em grafos.
Seja 𝐺 = (𝑉,𝐸) um grafo formado pelos vértices 𝑉 = {𝑣1,𝑣2,𝑣3,...,𝑣𝑛} e um conjunto
de arestas 𝐸 = {𝑒1,𝑒2,𝑒3,...,𝑒𝑛}, dizemos que um vértice é adjacente a outro se há uma
aresta que é incidente nesses dois vértices. O conjunto de vizinhos de um vértice consiste
de todos os vértices adjacentes a ele. O número de vizinhos de 𝑣 ∈ 𝑉 (𝐺) designa-se grau
do vértice 𝑣, denotado por 𝑑𝐺(𝑣).
Considere o subconjunto de vértices 𝑋 = 𝑥1,𝑥2,...,𝑥𝑛 ⊆ 𝑉 (𝐺) e suponha que a aresta
𝑥𝑖𝑥𝑖+1 ∈ 𝐸(𝐺) para todo 𝑖 ∈ 1,2,...,𝑘 − 1. Se os vértices de 𝑋 são todos distintos, diz-se
que 𝑋 define um caminho. Um ciclo é um caminho com mesmo vértice final e inicial.
Um grafo é dito conexo se possui um caminho entre qualquer par de vértices. Uma árvore
é um grafo conexo sem ciclos. Definimos estrutura de nível 𝐸𝑁(𝑣) = 𝑁1, 𝑁2,...,𝑁𝑘 uma
árvore com níveis denotados por 𝑁1, 𝑁2,...,𝑁𝑘.
Seja 𝑣,𝑤 ∈ 𝑉 (𝐺), denomina-se distância 𝑑(𝑣,𝑤) de um grafo como sendo o com-
primento do menor caminho entre 𝑣 e 𝑤. A excentricidade de um vértice 𝑣 é a maior
distância de 𝑣 a todos os outros vértices de 𝐺. Definimos diâmetro de 𝐺 como sendo a

15 3.4. Permutação e Reordenamento
maior excentricidade do grafo 𝐺 e o pseudo-diâmetro é uma excentricidade alta de 𝐺,
porém não necessariamente a maior. Dado um grafo 𝐺, os vértices periféricos de 𝐺 são
vértices cuja excentricidade é igual ao diâmetro de 𝐺. Vértices com altas excentricidades,
porém não necessariamente a maior definem os vértices pseudo-periféricos.
Dados dois grafos 𝐻 e 𝐺, diz-se que 𝐻 é um subgrafo de 𝐺 quando 𝑉 (𝐻) ⊆ 𝑉 (𝐺) e
𝐸(𝐻) ⊆ 𝐸(𝐺). Um grafo 𝐺 = (𝑉 (𝐺),𝐸(𝐺)) diz-se bipartido se seu conjunto de vértices
admite uma partição em subconjuntos 𝑉1 e 𝑉2 tal que não existem arestas que unem dois
vértices de 𝑉1 ou 𝑉2.
Definimos como matriz de adjacência de um grafo 𝐺, a matriz 𝐴𝐺 = 𝑎𝑖𝑗 , tal que
𝑎𝑖𝑗 =
{︂1 se 𝑖𝑗 ∈ 𝐸(𝐺)0 caso contrário
Por fim, a matriz Laplaciana 𝐿 de um grafo 𝐺 pode ser definida como 𝐿 = 𝐷 − 𝐴,
onde 𝐷 é uma matriz diagonal contendo os graus de cada vértice 𝑣𝑖 do grafo 𝐺 e 𝐴 é a
matriz de adjacência de 𝐺. Ou seja,
𝑙𝑖𝑗 =
⎧⎨⎩𝑔𝑟𝑎𝑢(𝑣𝑖) se 𝑖 = 𝑗−1 se 𝑖 ̸= 𝑗 e 𝑣𝑖 é adjacente a 𝑣𝑗0 caso contrário
3.4 Permutação e Reordenamento
Permutações de linhas e/ou colunas são operações muito utilizadas na manipulação de
matrizes. A técnica consiste em multiplicar a matriz original 𝐴 com uma matriz de
permutação 𝑃 , construída a partir da matriz identidade. Seja, por exemplo, 𝐴 uma
matriz 5× 5. A matriz 𝑃 correspondente a uma permutação das linhas 1 e 4 seria:
𝑃 =
⎛⎜⎜⎜⎜⎝0 0 0 1 00 1 0 0 00 0 1 0 01 0 0 0 00 0 0 0 1
⎞⎟⎟⎟⎟⎠Assim, a nova representação para o sistema linear é (𝑃𝐴𝑃 𝑇 )(𝑃𝑥) = 𝑃𝑏.
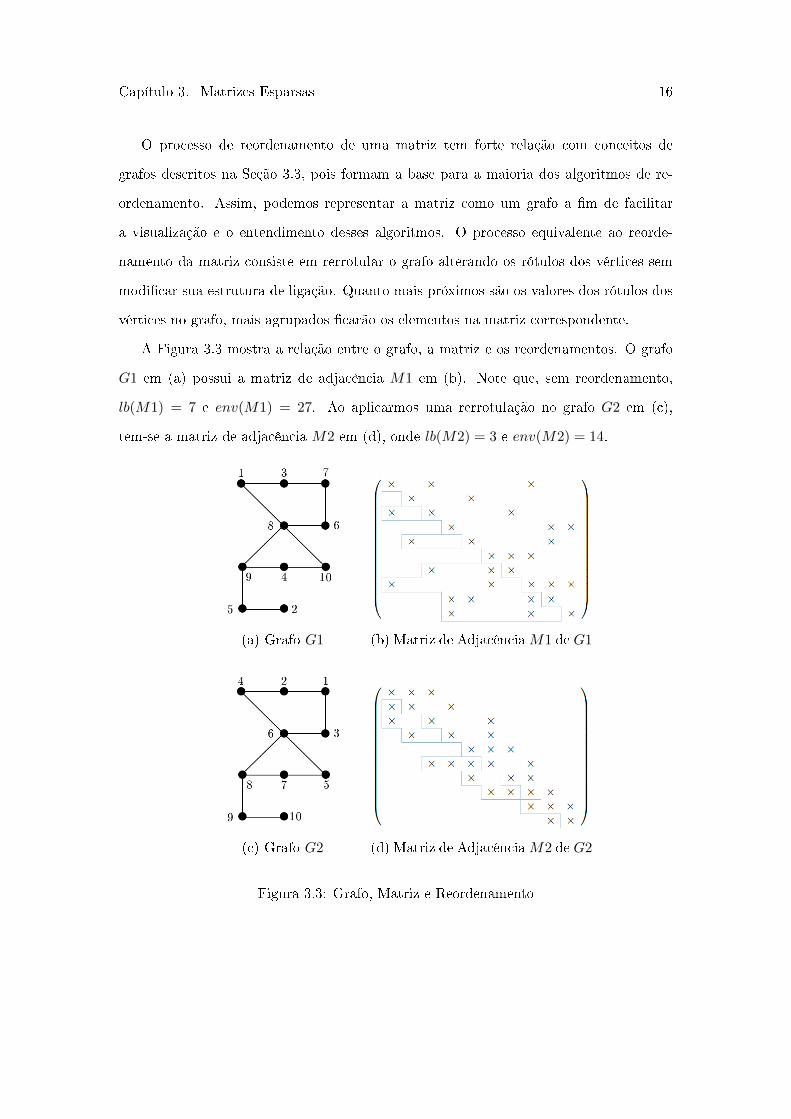
Capítulo 3. Matrizes Esparsas 16
O processo de reordenamento de uma matriz tem forte relação com conceitos de
grafos descritos na Seção 3.3, pois formam a base para a maioria dos algoritmos de re-
ordenamento. Assim, podemos representar a matriz como um grafo a fim de facilitar
a visualização e o entendimento desses algoritmos. O processo equivalente ao reorde-
namento da matriz consiste em rerrotular o grafo alterando os rótulos dos vértices sem
modificar sua estrutura de ligação. Quanto mais próximos são os valores dos rótulos dos
vértices no grafo, mais agrupados ficarão os elementos na matriz correspondente.
A Figura 3.3 mostra a relação entre o grafo, a matriz e os reordenamentos. O grafo
𝐺1 em (a) possui a matriz de adjacência 𝑀1 em (b). Note que, sem reordenamento,
𝑙𝑏(𝑀1) = 7 e 𝑒𝑛𝑣(𝑀1) = 27. Ao aplicarmos uma rerrotulação no grafo 𝐺2 em (c),
tem-se a matriz de adjacência 𝑀2 em (d), onde 𝑙𝑏(𝑀2) = 3 e 𝑒𝑛𝑣(𝑀2) = 14.
(a) Grafo 𝐺1 (b) Matriz de Adjacência𝑀1 de 𝐺1
(c) Grafo 𝐺2 (d) Matriz de Adjacência𝑀2 de 𝐺2
Figura 3.3: Grafo, Matriz e Reordenamento

Capítulo 4
Algoritmos de Reordenamento
Alguns dos algoritmos de reordenamento descritos abaixo necessitam encontrar um vér-
tice inicial. A escolha desse vértice impacta diretamente na qualidade da solução. Se-
gundo George and Liu (1979), vértices pseudo-periféricos geralmente produzem bons
resultados e por isso são boas escolhas de vértice inicial. O Algoritmo 5 constrói a estru-
tura de nível dos vértices, comparando a profundidade dessas estruturas, encontrando os
vértices mais distantes entre si.
Algoritmo 5: Escolha do vértice pseudo-periférico
1 Escolha um vértice 𝑠 de grau mínimo2 Construa a estrutura de nível de 𝑠: 𝐿(𝑠) = {𝑙1, 𝑙2,..., 𝑙ℎ(𝑠)}3 Ordene os vértices em 𝑙ℎ(𝑠) em ordem crescente de graus4 Percorra 𝑙ℎ(𝑠) ordenado e forme uma lista 𝑞 contendo um vértice de cada grau5 para cada 𝑥 ∈ 𝑞 faça6 Construa a estrutura de nível de 𝑥7 se ℎ(𝑥) > ℎ(𝑠) e 𝑤(𝑥) < 𝑤(𝑠) então8 𝑠 = 𝑥9 fim
10 fim
11 𝑠 é o vértice pseudo-periférico

Capítulo 4. Algoritmos de Reordenamento 18
No Algoritmo 5, ℎ é a profundidade da estrutura de nível, ou seja, o número total
de níveis da estrutura de nível. Já 𝑤 refere-se a máxima quantidade de vértices em
um determinado nível, dentre todos os níveis. A Figura 4.1, representa a estrutura de
nível do grafo ilustrado na Figura 3.3a na Seção 3.4, e exemplifica a escolha do vértice
pseudo-periférico.
(a) ℎ(2) = 6 e 𝑤(2) = 3 (b) ℎ(3) = 6 e 𝑤(3) = 2
Figura 4.1: Exemplo de execução do Algoritmo 5
O algoritmo inicia escolhendo o vértice de menor grau, o vértice 2, gerando sua
estrutura de nível representado em (a). Os vértices do último nível são ordenados por
grau e forma-se 𝑞 contendo um vértice de cada grau. Como o último nível possui os
vértices 3 e 7 com mesmo grau, vamos escolher apenas um deles, o 3.
O próximo passo então é gerar a estrutura de nível do vértice 3, representado em
(b), e comparar com a do vértice 2. A estrutura de nível dos vértices 2 e 3 possuem seis
níveis, portanto ℎ(2) = 6 e ℎ(3) = 6. Já a máxima quantidade de vértices 𝑤(2) = 3 em
𝑁5 e 𝑤(3) = 2. Logo, como ℎ(2) = ℎ(3), o algoritmo não satisfaz a condição no passo 7
e termina com 2 como vértice pseudo-periférico.

19 4.1. Sloan
4.1 Sloan
Proposto por Sloan (1986), o método visa reduzir o envelope e largura de banda de
matrizes esparsas estruturalmente simétricas, podendo ser eficientemente usado para ro-
tulação de malhas no método de elementos finitos. Segundo Sloan (1986), testes feitos
em uma coleção de matrizes coletadas por Everstine (1979) mostrou o Sloan sendo mais
eficiente do que métodos como Reverse Cuthill-McKee (George, 1971) e Gibbs (Gibbs
et al., 1976). Entretanto, essa coleção é muito antiga e possui matrizes que, atualmente,
podem ser consideradas de pequeno porte. Por isso a necessidade de novos testes em
uma coleção de matrizes de ordem maior, oriundas de problemas mais atuais.
Figura 4.2: Terminologia do Algoritmo Sloan
O algoritmo funciona atribuindo estados a cada vértice. Um vértice que ainda não
recebeu nenhuma rotulação recebe o estado chamado pós-ativo. Todo vértice que é adja-
cente a um vértice pós-ativo, mas não tem estado pós-ativo é definido com estado ativo.
Os vértices adjacentes a um vértice ativo, mas não possuem um estado ativo ou pós-ativo,
são definidos com estado pré-ativo. Já aqueles que não possuem estados ativo, pós-ativo
ou pré-ativo, são definidos como inativos (Figura 4.2).

Capítulo 4. Algoritmos de Reordenamento 20
A partir de dois vértices pseudo-periféricos, um vértice inicial e um vértice final dados
como entrada, é criado uma fila de prioridades. Essa fila, formada apenas por vértice
ativos ou pré-ativos, vai sendo atualizada com informações do grafo e o vértice com a
maior prioridade é o próximo a ser escolhido para receber o novo rótulo. A prioridade de
cada vértice se relaciona com o estado desse vértice e com sua distância até o vértice final.
Por fim, após todos os vértices serem escolhidos e rerrotulados, o processo é finalizado.
O Algoritmo 6 descreve os passos para o reordenamento de uma matriz como apre-
sentado em Sloan (1986) e Sloan (1989). Ainda segundo Sloan (1989), testes empíricos
sobre grandes coleções de problemas sugerem que, atribuindo 𝑊1 = 1 e 𝑊2,= 2, conse-
guimos obter bons reordenamentos. Porém, apesar deste trabalho seguir a sugestão de
Sloan (1989) com 𝑊1 = 1 e 𝑊2 = 2, alguns testes empíricos com outros valores de 𝑊1
e 𝑊2 melhoraram a qualidade da solução. Portanto, seria necessário um estudo mais
aprofundando sobre a escolha desses parâmetros.
Algoritmo 6: Sloan
1 Entre com os vértices pseudo-periféricos, o vértice inicial 𝑠 e o vértice final 𝑒2 Gere a estrutura de nível do vértice final, 𝐸𝑁(𝑒) = {𝑙1,𝑙2,...,𝑙ℎ(𝑒)}, e construa umvetor de distâncias 𝛿𝑖 de cada vértice 𝑖 até o vértice final. Note que se o vértice 𝑖se encontra no nível 𝑗 de 𝐿(𝑒), então 𝛿𝑖 = 𝑗 − 1
3 Para cada vértice do grafo, atribua estado inativo e prioridade inicial, 𝑃𝑖, sendo𝑃𝑖 ←𝑊1 * 𝛿𝑖 −𝑊2 * (𝑑𝑖 + 1)
4 Insira 𝑠 na fila de vértices a serem escolhidos e atribua e ele estado pré-ativo5 Enquanto a fila não estiver vazia, faça os passos 6-96 Procure na fila de vértices a serem escolhidos o vértice 𝑖 de maior prioridade7 Exclua o vértice 𝑖 da fila. Se 𝑖 não for pré-ativo, vá para o passo 8. Caso contrário,examine cada vértice 𝑗 que é adjacente a 𝑖 e faça 𝑃𝑗 = 𝑃𝑗 +𝑊2. Se 𝑗 for inativo,insira 𝑗 na fila de vértices a serem escolhidos e atribua a ele estado pré-ativo
8 Atribua ao vértice 𝑖 um novo rótulo e dê a ele estado pós-ativo9 Examine cada vértice 𝑗 que é adjacente a 𝑖. Se 𝑗 não for pré-ativo, não faça nada.Caso contrário, faça 𝑃𝑗 = 𝑃𝑗 +𝑊2, atribua a 𝑗 estado ativo e examine cadavértice 𝑘 adjacente a 𝑗. Se 𝑘 for ativo ou pré-ativo, faça 𝑃𝑘 = 𝑃𝑘 +𝑊2. Casocontrário, se 𝑘 for inativo, faça 𝑃𝑘 = 𝑃𝑘 +𝑊2, insira 𝑘 na fila de vértices a seremescolhidos, e atribua a ele estado pré-ativo
10 Termine com uma nova ordenação de vértices

21 4.2. Reverse Cuthill McKee (RCM)
4.2 Reverse Cuthill McKee (RCM)
Proposto por Cuthill and McKee (1969), o algoritmo Cuthill Mckee é um método de re-
ordenamento aplicado a matrizes esparsas para redução do envelope e largura de banda.
Estudos feitos posteriormente por George (1971) mostraram que a solução do Cuthill
Mckee pode ser melhorada simplesmente invertendo a ordem de numeração. Foi então
definido o Reverse Cuthill Mckee, que passou a ser umas das heurísticas mais utiliza-
das para o problema de minimização da largura de banda e do envelope devido a boa
qualidade de solução, o baixo tempo de execução e a facilidade de implementação.
O Algoritmo 7 tenta rotular os vértices de maneira que os nós adjacentes recebam
rótulos da forma mais ordenada possível. Recebendo como entrada um grafo, ele percorre-
o a partir de um vértice inicial e caminha pelos vértices adjacentes em ordem crescente
de graus. A qualidade da solução do RCM depende criticamente da escolha do vértice
inicial. George and Liu (1979) mostrou que vértices com altas excentricidades são boas
escolhas. O Algoritmo 5 descreve os passos para encontrar os vértices pseudo-periféricos.
Algoritmo 7: Reverse Cuthill Mckee
1 Encontrar um vértice inicial 𝑥2 para 𝑖 = 1,...,𝑛 faça
3 Encontrar todos os vértices adjacentes a 𝑖 que ainda não foram rerrotulados eatribuir a eles um novo rótulo por ordem crescente de graus
4 fim
5 Inverter a ordem de numeração
Uma maneira mais eficiente de implementar o RCM, descrito no Algoritmo 7, foi
proposto por Ghidetti (2011). A autora percebeu que o processo de percorrer os vértices
adjacentes do grafo em ordem crescente de graus é equivalente a uma busca em largura
neste grafo. Portanto, como o Algoritmo 5 já faz uma busca em largura para encontrar o
vértice inicial, basta guardar a estrutura de nível desse vértice e percorrer essa estrutura
em ordem crescente de graus. Esses passos estão descritos no Algoritmo 8.

Capítulo 4. Algoritmos de Reordenamento 22
Algoritmo 8: Reverse Cuthill Mckee
1 Encontrar um vértice inicial 𝑥 e sua respectiva estrutura de nível2 para 𝑖 = 1,...,𝑛 faça
3 Renumerar todos os vértices pertencentes ao nível 𝑖 da estrutura de nível de 𝑥em ordem crescente de graus
4 fim
5 Inverter a ordem de numeração
A Tabela 4.1 mostra um exemplo de execução do algoritmo RCM, aplicado no grafo
da Figura 3.3a. A primeira coluna refere-se a ordem de escolha dos vértices. A segunda
coluna refere-se a fila de vértices adjacentes. A última coluna mostra os novos rótulos
que cada vértice irá receber. Essa rerrotulação é mostrada na Figura 4.3.
Escolha Fila Novos rótulos
2 5 7 → 1
5 9 3 → 2
9 4, 8 6 → 3
4 8, 10 1 → 4
8 10, 1, 6 10 → 5
10 1, 6 8 → 6
1 6, 3 4 → 7
6 3, 7 9 → 8
3 7 5 → 9
7 - 2 → 10
Tabela 4.1: Exemplo de execução do RCM Figura 4.3: Grafo rerrotulado
4.3 Espectral
Proposto por Barnard et al. (1993), o algoritmo Espectral tem como principal objetivo re-
duzir o tamanho do envelope. O novo reordenamento é calculado a partir da permutação
do vetor de autovetores associado ao segundo menor autovalor 𝜆2 da matriz laplaciana
associada ao grafo.

23 4.3. Espectral
Segundo Fiedler (1973), o segundo menor autovalor 𝜆2 define a conectividade algé-
brica e seu autovetor associado tem relação com a distância entre os vértices do grafo.
Posteriormente Juvan and Mohar (1992) aplicou o uso desses autovetores para problemas
de minimização de largura de banda para reordenamentos.
A grande vantagem do algoritmo em relação a outros algoritmos de reordenamento
apresentados é a facilidade de implementá-lo em paralelo. Diferente do RCM ou do
Sloan que necessitam gerar estruturas de nível, o Espectral envolve apenas uma grande
quantidade de operações de ponto flutuante, tais como multiplicações e produtos de
matrizes, e por isso a implementação em paralelo pode ser feita sem esforço através de
métodos como Lanczos ou abordagens Multinível (Barnard et al., 1993).
Algoritmo 9: Espectral
1 Calcular o 2𝑜 menor autovalor da matriz laplaciana 𝐿 e o autovetor 𝑣 associado2 Ordenar 𝑣 em ordem crescente (ou decrescente)
A maior dificuldade na implementação do Algoritmo 9 é encontrar os autovalores e
autovetores de uma matriz, em particular, o segundo menor autovalor e seu autovetor
associado. Para isto, utiliza-se neste trabalho a biblioteca CHACO 2.2 (Hendrickson and
Leland, 2013) que implementa o algoritmo Multilevel Symmlq/RQI para o cálculo desses
autovalores e autovetores. Este algoritmo é baseado no método iterativo RQI (Rayleigh
Quocient Iteration) cuja qualidade da solução depende da tolerância escolhida.
O Algoritmo 9 apresenta algumas modificações com relação ao algoritmo definido em
Barnard et al. (1993). Na versão original, ordena-se o autovetor em ordem crescente
e decrescente, e em seguida escolhe-se o melhor resultado com relação a redução do
envelope. Entretanto, testes realizados em um conjunto de matrizes não mostrou uma
diferença considerável de redução e portanto, a fim de reduzir o tempo de CPU para esse
algoritmo, foi considerado apenas a ordenação decrescente do autovetor.
A Tabela 4.2 mostra um exemplo de execução do algoritmo Espectral, também apli-
cado no grafo da Figura 3.3a. A primeira coluna refere-se aos vértices e a segunda coluna

Capítulo 4. Algoritmos de Reordenamento 24
refere-se ao autovetor associado ao segundo menor autovalor da matriz Laplaciana do
grafo. Esse autovetor está ordenado decrescentemente e a nova ordem dos vértices define
os novos rótulos na terceira coluna. A rerrotulação é mostrada na Figura 4.4.
Vértice Autovetor Novos rótulos
2 0.610905 2 → 1
5 0.447214 5 → 2
9 0.163692 9 → 3
4 0.094507 4 → 4
10 0.000000 10 → 5
8 -0.094507 8 → 6
1 -0.258199 1 → 7
6 -0.258199 6 → 8
3 -0.352706 3 → 9
7 -0.352706 7 → 10
Tabela 4.2: Exemplo de execução do Espectral Figura 4.4: Grafo rerrotulado
4.4 Nested Dissection (ND)
O algoritmo Nested Dissection, proposto por George (1973), tem como objetivo reduzir
o preenchimento (fill-in) em fatorações de matrizes esparsas. Consiste em encontrar
um conjunto 𝑆 de vértices separadores de um grafo 𝐺, cuja remoção divide 𝐺 em dois
subgrafos disjuntos, 𝐴 e 𝐵. O subgrafo 𝐴 é rerrotulado primeiro, em seguida 𝐵, e por
último o conjunto de vértices separadores 𝑆. Assim, os vértices separadores são movidos
para o final da matriz, e o processo é aplicado recursivamente para 𝐴 e 𝐵.
Algoritmo 10: Nested Dissection
1 Particione 𝐺 = (𝑉,𝐸) em subgrafos 𝐴, 𝐵, e 𝑆2 Repita o passo 1 até que |𝐴|,|𝐵| ≤ 𝜖 ou |𝐴|,|𝐵| = 13 Obtenha a ordenação fazendo a recursão em pós-ordem, rerrotulando os vérticesde 𝐴, em seguida os de 𝐵 e por último os vértices de 𝑆

25 4.5. Approximate Minimum Degree (AMD)
Figura 4.5: Bisseção de 𝐺: Vértices separadores 𝑆 e partições 𝐴 e 𝐵
A complexidade do algoritmo é encontrar o conjunto de vértices separadores, que
divide 𝐺 em duas partições. Logo, um bom método para bisseção de 𝐺 impacta dire-
tamente na qualidade da solução. Este trabalho faz uso da biblioteca METIS (Karypis,
2013), que implementa heurísticas eficientes baseadas em algoritmos multinível (Karypis
and Kumar, 1998). A proposta desses algoritmos é reduzir o tamanho de 𝐺 eliminando
vértices e arestas, particionando-o em grafos menores. Em seguida essas partições são
refinadas e projetadas de volta ao grafo original (Hendrickson and Leland, 1995).
4.5 Approximate Minimum Degree (AMD)
Algoritmos de Grau Mínimo são heurísticas muito usadas para redução de preenchimento
(fill-in) da fatoração LU aplicadas em matrizes esparsas de grande porte. Muitos algorit-
mos baseados no Grau Mínimo surgiram nas últimas décadas como Quotient Minimum
Degree (George and Liu, 1981), Multiple Minimum Degree (Liu, 1985), e Approximate
Minimum Degree (Davis et al., 1994). Esses algoritmos baseiam-se na evolução do grau
dos vértices, eliminando a cada passo o vértice de menor grau, fazendo com que seus vi-
zinhos se tornem adjacentes. O novo grafo gerado pela remoção de um vértice é chamado
de Grafo de Eliminação, exemplificado na Figura 4.6.

Capítulo 4. Algoritmos de Reordenamento 26
(a) Grafo Original (b) Grafo de Eliminação
Figura 4.6: Exemplo de Grafo de Eliminação. O grafo original em (a) e o Grafo deEliminação em (b) criado após a remoção do vértice 1
Como tratamos os grafos através de suas matrizes de representação (adjacência),
eliminar o vértice de menor grau é equivalente a deslocar a coluna (da matriz reduzida)
com o menor número de elementos não nulos para a posição 𝑖. As linhas e colunas 1
até 𝑖 − 1 já estão ordenadas, portanto o número de elementos não nulos dessas linhas e
colunas é fixo, já que elas não serão mais acessadas (Figura 4.7).
Figura 4.7: Funcionamento dos algoritmos de Grau Mínimo

27 4.5. Approximate Minimum Degree (AMD)
O AMD usa técnicas baseadas em grafos quocientes que permite obter aproximações
com baixo custo computacional para o grau mínimo. Davis et al. (1994) mostra que
essas aproximações são frequentemente iguais ao grau do vértice, e melhoram o tempo
do algoritmo AMD com relação aos outros algoritmos de Grau Mínimo.
Neste trabalho a biblioteca de Timothy A. Davis (2013b), versão 2.3.1, implementa o
AMD. Algumas modificações foram feitas nesse código para permitir que os programas
tivessem a leitura e a saída compatíveis com as estruturas e códigos adotados no restante
das implementações.
Algoritmo 11: AMD
1 para 𝑖 = 1,...,𝑛 faça
2 Escolher um vértice 𝑣𝑖 de menor grau no Grafo de Eliminação 𝐺𝑖−1
3 Eliminar 𝑣𝑖 de 𝐺𝑖−1 para formar o novo Grafo de Eliminação 𝐺𝑖
4 fim


Capítulo 5
Testes Computacionais
Neste capítulo iremos comparar os resultados obtidos pelos testes computacionais. A
Tabela 5.1 apresenta as principais características de um conjunto de matrizes estrutu-
ralmente simétricas, mostrando o nome da matriz, o número de vetores 𝑘 usado no
GMRES, o número de elementos não-nulos 𝑛𝑛𝑧, a dimensão 𝑛 da matriz, a tolerância 𝜀
estabelecida no GMRES, a porcentagem de esparsidade da matriz calculada pela fórmula
𝑠𝑝𝑎(𝐴) = ((𝑛 * 𝑛)− 𝑛𝑛𝑧)/(𝑛 * 𝑛) * 100, e a área de aplicação.
Nome k nnz n 𝜀 spa(.) Área de Aplicação
RAIL_5177 200 35.185 5.177 10−10 99,87 Transferência de Calor
AFT01 50 125.567 8.205 10−10 99,81 Problema Acústico
FEM_3D_THERMAL1 5 430.740 17.880 10−10 99,87 Problema Térmico
THERMOMECH_TK 150 711.558 102.158 10−6 99,99 Problema Térmico
BAUMANN 200 748.331 112.211 10−10 99,99 Problema Químico
DUBCOVA2 20 1.030.225 65.025 10−10 99,97 Problema de EDP
BONES01 300 6.715.152 127.224 10−10 99.96 Modelagem 3D
Tabela 5.1: Características das matrizes testadas
Vale ressaltar que a tolerância usado no algoritmo Espectral foi de 10−4 para todas
as matrizes testadas. As matrizes estão no formato Matrix Market disponíveis nos re-
positórios da Universidade da Flórida em (Timothy A. Davis, 2013a). A tolerância 𝜀

Capítulo 5. Testes Computacionais 30
do GMRES foi escolhida de forma que a solução convergisse para o valor esperado. A
maioria das matrizes apresentadas tiveram boa qualidade de solução com 10−10, exceto
a matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 que foi suficiente a tolerância 10−6. Já a quantidade de ve-
tores na base 𝑘 foi escolhido empiricamente, buscando o menor tempo de execução do
GMRES. Por último, os testes foram realizados em um notebook com processador Intel
Core i5-460M 2.53GHz, com 4GB de memória RAM e sistema operacional Ubuntu 12.10.
Cada seção abaixo contém três páginas com informações e análises de cada matriz da
Tabela 5.1. A primeira página inicia-se com uma figura que mostra a esparsidade da ma-
triz após o reordenamento com cada um dos algoritmos. Em seguida, há uma tabela com
os valores do envelope, largura de banda da nova matriz gerada por cada algoritmo, além
do tempo de processamento (em segundos) desse algoritmo. Lembrando que, como os
algoritmos ND e AMD não são baseados na redução do envelope e largura de banda, esses
valores não são mostrados nessa tabela. Na segunda página, dois gráficos/tabelas apre-
sentam informações sobre a quantidade de elementos não-nulos criados (preenchimento)
e número de iterações gerados na execução do GMRES em seis níveis diferentes, para
cada algoritmo de reordenamento. Como não há preenchimento no nível 0, a respectiva
coluna não apresenta nenhum dado. Na terceira página, um último gráfico/tabela com o
tempo de processamento final (em segundos) para cada algoritmo em cada um dos níveis
de preenchimento seguido de uma sucinta análise. O tempo de processamento final mos-
trado equivale ao tempo de construção da matriz precondicionada + tempo de resolução
do algoritmo GMRES + tempo de execução do respectivo algoritmo de reordenamento.
O símbolo † significa que o algoritmo GMRES não convergiu. O critério decisivo
para a não-convergência foi a análise da redução do resíduo a cada iteração externa. Nas
tabelas de Tempo de CPU o símbolo ∙ indica o melhor resultado para cada nível de
preenchimento. Já o símbolo ∙ indica os tempos que não foram vantajosos, ou seja, o
tempo para resolver a matriz reordenada não foi melhor que o tempo para resolvê-la sem
reordenamento.

31 5.1. Matriz 𝑟𝑎𝑖𝑙_5177
5.1 Matriz 𝑟𝑎𝑖𝑙_5177
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.1: Esparsidades da matriz 𝑟𝑎𝑖𝑙_5177
env(.) lb(.) Tempo de CPU
Original 6.082.739 5.147 -
Sloan 187.682 842 0,035
RCM 261.319 115 0,014
Espectral 237.296 323 0,043
ND - - 0,029
AMD - - 0,003
Tabela 5.2: Medições da matriz 𝑟𝑎𝑖𝑙_5177

Capítulo 5. Testes Computacionais 32
ILU(0) ILU(1) ILU(2) ILU(20) ILU(40) ILU(60)
S/ reord. - 47.046 82.934 805.104 1.323.816 1.471.592
Sloan - 5.768 15.358 217.214 313.080 341.922
RCM - 13.856 24.348 245.810 355.846 394.960
Espectral - 14.422 29.674 291.408 419.836 444.556
ND - 13.460 24.550 90.756 94.780 94.944
AMD - 12.958 22.614 79.728 82.968 83.130
Figura 5.2: Preenchimento da matriz 𝑟𝑎𝑖𝑙_5177
ILU(0) ILU(1) ILU(2) ILU(20) ILU(40) ILU(60)
S/ reord. 11420 169 102 16 7 3
Sloan 176 112 92 33 5 3
RCM 187 114 89 48 5 2
Espectral 188 115 95 92 21 1
ND 771 141 108 26 3 3
AMD 779 139 102 28 4 1
Figura 5.3: Iterações da matriz 𝑟𝑎𝑖𝑙_5177

33 5.1. Matriz 𝑟𝑎𝑖𝑙_5177
ILU(0) ILU(1) ILU(2) ILU(20) ILU(40) ILU(60)
S/ reord. 73,85 1,22 0,70 31,78 169,98 243,62
Sloan 1,08 ∙ 0,60 ∙ 0,49 0,78 1,40 1,78
RCM 1,18 0,62 0,47 ∙ 1,04 1,88 2,55
Espectral 1,22 0,66 0,55 1,92 3,20 2,58
ND 4,93 0,84 0,61 0,40 0,37 0,36
AMD 5,06 0,80 0,53 0,33 ∙ 0,28 ∙ 0,27 ∙
Figura 5.4: Tempo de CPU da matriz 𝑟𝑎𝑖𝑙_5177
Analisando os algoritmos de reordenamento, a Tabela 5.2 nos mostra que o Sloan foi
o algoritmo que mais reduziu o envelope da matriz, porém foi o que reduziu menos a
largura de banda. Já o RCM teve uma ótima qualidade de redução da largura de banda
e o pior resultado de envelope. O Espectral teve uma solução intermediária. Com relação
ao tempo de CPU, o AMD foi o mais rápido, enquanto o Espectral foi o mais lento.
Analisando os precondicionadores na Figura 5.2, podemos observar uma redução drás-
tica do preenchimento nos níveis 20, 40 e 60 para os algoritmos ND e AMD com relação
os demais algoritmos, o que não foi tão evidente nos níveis 0, 1 e 2. O preenchimento
neste caso impactou diretamente no tempo de CPU mostrado na Figura 5.4. Apesar de
todos os casos terem sido vantajosos, em comparação aos tempos sem reordenamento
nenhum, o ND e, em especial o AMD, se destacaram para ILU’s grandes enquanto que
o Sloan se destacou para ILU’s pequenos. O algoritmo AMD com ILU(60) produziu o
menor tempo de CPU.
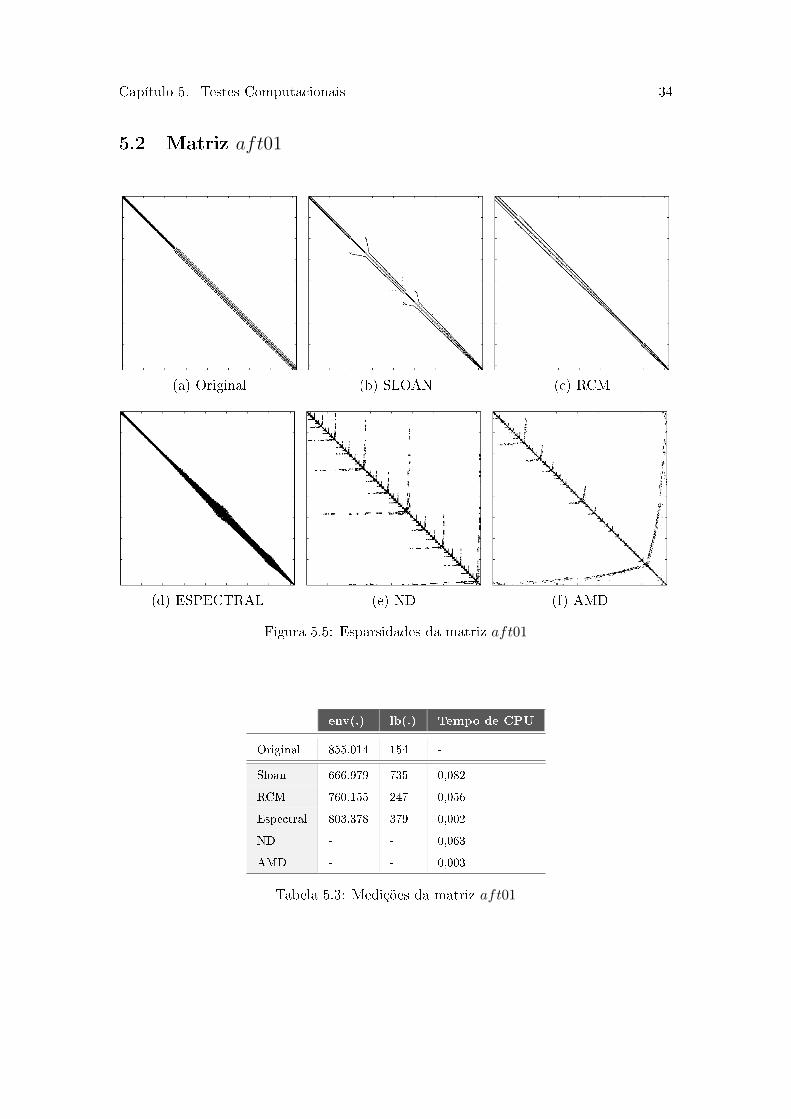
Capítulo 5. Testes Computacionais 34
5.2 Matriz 𝑎𝑓𝑡01
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.5: Esparsidades da matriz 𝑎𝑓𝑡01
env(.) lb(.) Tempo de CPU
Original 855.014 154 -
Sloan 666.979 735 0,082
RCM 760.155 247 0,056
Espectral 803.378 379 0,002
ND - - 0,063
AMD - - 0,003
Tabela 5.3: Medições da matriz 𝑎𝑓𝑡01

35 5.2. Matriz 𝑎𝑓𝑡01
ILU(0) ILU(1) ILU(2) ILU(10) ILU(20) ILU(30)
S/ reord. - 77.190 152.070 667.950 1.104.900 1.376.850
Sloan - 50.744 111.008 503.196 826.876 1.025.196
RCM - 50.744 108.924 518.464 878.632 1.110.540
Espectral - 78.650 172.986 830.138 1.298.146 1.465.700
ND - 111.284 204.066 432.674 483.260 492.796
AMD - 117.684 166.274 379.886 432.542 442.472
Figura 5.6: Preenchimento da matriz 𝑎𝑓𝑡01
ILU(0) ILU(1) ILU(2) ILU(10) ILU(20) ILU(30)
S/ reord. 358 94 44 15 9 7
Sloan 298 97 43 13 7 5
RCM 478 144 50 16 9 7
Espectral 351 93 41 13 7 5
ND 1050 297 106 19 8 3
AMD 1607 263 141 16 8 5
Figura 5.7: Iterações da matriz 𝑎𝑓𝑡01
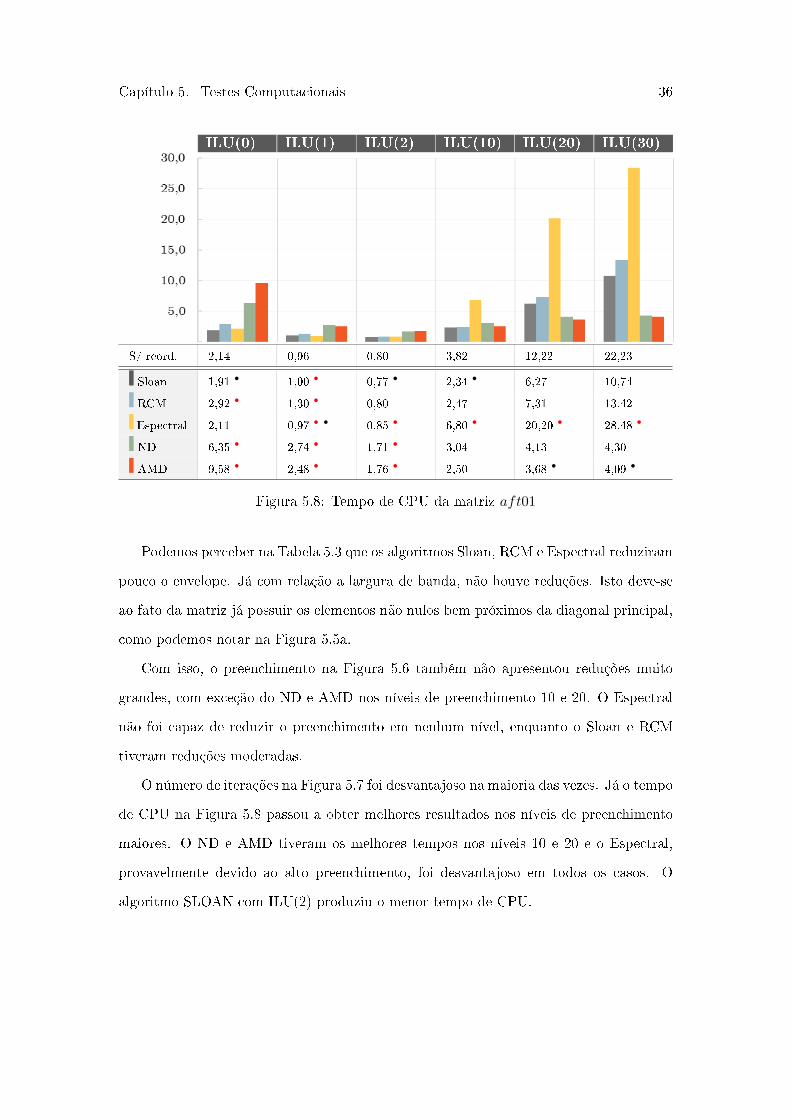
Capítulo 5. Testes Computacionais 36
ILU(0) ILU(1) ILU(2) ILU(10) ILU(20) ILU(30)
S/ reord. 2,14 0,96 0,80 3,82 12,22 22,23
Sloan 1,91 ∙ 1,00 ∙ 0,77 ∙ 2,34 ∙ 6,27 10,74
RCM 2,92 ∙ 1,30 ∙ 0,80 2,47 7,31 13,42
Espectral 2,11 0,97 ∙ ∙ 0,85 ∙ 6,80 ∙ 20,20 ∙ 28,48 ∙
ND 6,35 ∙ 2,74 ∙ 1,71 ∙ 3,04 4,13 4,30
AMD 9,58 ∙ 2,48 ∙ 1,76 ∙ 2,50 3,68 ∙ 4,09 ∙
Figura 5.8: Tempo de CPU da matriz 𝑎𝑓𝑡01
Podemos perceber na Tabela 5.3 que os algoritmos Sloan, RCM e Espectral reduziram
pouco o envelope. Já com relação a largura de banda, não houve reduções. Isto deve-se
ao fato da matriz já possuir os elementos não nulos bem próximos da diagonal principal,
como podemos notar na Figura 5.5a.
Com isso, o preenchimento na Figura 5.6 também não apresentou reduções muito
grandes, com exceção do ND e AMD nos níveis de preenchimento 10 e 20. O Espectral
não foi capaz de reduzir o preenchimento em nenhum nível, enquanto o Sloan e RCM
tiveram reduções moderadas.
O número de iterações na Figura 5.7 foi desvantajoso na maioria das vezes. Já o tempo
de CPU na Figura 5.8 passou a obter melhores resultados nos níveis de preenchimento
maiores. O ND e AMD tiveram os melhores tempos nos níveis 10 e 20 e o Espectral,
provavelmente devido ao alto preenchimento, foi desvantajoso em todos os casos. O
algoritmo SLOAN com ILU(2) produziu o menor tempo de CPU.

37 5.3. Matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
5.3 Matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.9: Esparsidades da matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
env(.) lb(.) Tempo de CPU
Original 11.445.306 13.787 -
Sloan 4.544.347 1.459 0,414
RCM 4.749.868 683 0,243
Espectral 4.965.437 703 0,110
ND - - 0,248
AMD - - 0,004
Tabela 5.4: Medições da matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1

Capítulo 5. Testes Computacionais 38
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(10)
S/ reord. - 506.308 1.159.012 1.900.916 2.667.348 6.791.596
Sloan - 482.840 1.123.284 1.832.960 2.561.460 3.245.652
RCM - 485.368 1.106.022 1.804.328 2.520.478 6.497.798
Espectral - 499.950 1.185.736 1.991.768 2.809.940 7.194.790
ND - 703.240 1.483.266 2.288.314 2.814.588 4.516.090
AMD - 716.224 1.384.644 2.164.284 2.773.006 5.952.004
Figura 5.10: Preenchimento da matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(10)
S/ reord. 10 7 6 5 4 3
Sloan 12 8 5 4 2 1
RCM 15 9 6 5 4 2
Espectral 12 8 5 4 3 1
ND 25 15 12 9 8 3
AMD 28 14 11 7 7 3
Figura 5.11: Iterações da matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1

39 5.3. Matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(10)
S/ reord. 0,63 2,72 7,74 20,13 43,38 444,29
Sloan 1,08 ∙ 2,96 ∙ 7,12 16,73 34,48 ∙ 397,83
RCM 0,97 ∙ 2,82 ∙ 6,99 ∙ 16,53 ∙ 34,84 465,32 ∙
Espectral 0,78 ∙ ∙ 2,76 ∙ ∙ 7,63 20,28 ∙ 44,11 ∙ 613,41 ∙
ND 1,07 ∙ 5,27 ∙ 16,76 ∙ 44,87 ∙ 77,37 ∙ 369,46 ∙
AMD 0,84 ∙ 4,83 ∙ 13,20 ∙ 39,69 ∙ 78,52 ∙ 902,20 ∙
Figura 5.12: Tempo de CPU da matriz 𝐹𝐸𝑀_3𝐷_𝑡ℎ𝑒𝑟𝑚𝑎𝑙1
Analisando a Tabela 5.4, o Sloan teve a melhor redução de envelope e pior redução
de largura de banda. Foi também o algoritmo que teve o maior tempo computacional.
Com relação ao preenchimento na Figura 5.10, podemos perceber pouca redução em
relação a matriz sem reordenamentos. O ND e o AMD foram vantajosos apenas em
ILU(10), enquanto o Espectral apenas em ILU(1). O Sloan e o RCM tiveram comporta-
mento semelhante até ILU(4), e em ILU(10) o Sloan reduz o preenchimento em mais da
metade comparado com o RCM.
As iterações na Figura 5.11 tem comportamento bem coerente. Apesar disso, os
tempos de processamento na Figura 5.12 não foram muito vantajosos, principalmente
em ILU(0) e ILU(1). Apenas nos níveis 2, 3 e 4 o Sloan e o RCM conseguem reduzir um
pouco o tempo final. Em ILU(10) o ND passou a ter o melhor resultado, mesmo tendo
gerado mais preenchimento que o Sloan, e ter convergido em mais iterações. Contudo,
observamos que o menor tempo de CPU ocorre em ILU(0) na matriz sem reordenamentos.

Capítulo 5. Testes Computacionais 40
5.4 Matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.13: Esparsidades da matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
env(.) lb(.) Tempo de CPU
Original 2.667.823.445 102.138 -
Sloan 16.072.717 676 2,112
RCM 17.882.411 253 0,581
Espectral 14.635.485 389 2,738
ND - - 0,863
AMD - - 0,192
Tabela 5.5: Medições da matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾

41 5.4. Matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
ILU(0) ILU(4) ILU(8) ILU(12) ILU(16) ILU(20)
S/ reord. - 2.418.982 6.234.694 11.386.296 17.735.910 25.168.278
Sloan - 1.299.766 2.794.478 4.281.708 5.745.876 7.175.972
RCM - 1.377.086 3.012.390 4.648.154 6.261.578 7.840.310
Espectral - 1.416.644 3.031.658 4.619.810 6.168.354 7.666.906
ND - 1.594.042 2.563.166 3.137.532 3.530.792 3.833.678
AMD - 1.505.844 2.445.502 3.118.058 3.636.438 4.055.210
Figura 5.14: Preenchimento da matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
ILU(0) ILU(4) ILU(8) ILU(12) ILU(16) ILU(20)
S/ reord. † † 141 97 75 59
Sloan † 607 99 68 51 41
RCM † 748 100 68 51 42
Espectral † 606 98 66 51 41
ND † † 143 111 75 70
AMD † † 138 104 72 65
Figura 5.15: Iterações da matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾

Capítulo 5. Testes Computacionais 42
ILU(0) ILU(4) ILU(8) ILU(12) ILU(16) ILU(20)
S/ reord. † † 95,87 244,41 797,94 2155,92
Sloan † 105,90 ∙ 44,07 45,71 50,32 ∙ 59,32 ∙
RCM † 123,45 43,45 ∙ 45,11 ∙ 52,04 63,24
Espectral † 107,80 45,45 47,09 54,03 64,46
ND † † 52,72 51,90 54,73 59,82
AMD † † 55,94 55,47 57,61 66,34
Figura 5.16: Tempo de CPU da matriz 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
É interessante observar as esparsidades de cada matriz reordenada na Figura 5.13. Os
algoritmos Sloan, RCM e Espectral foram capazes de aproximar os elementos não nulos
bastante dispersos em 5.13a para perto da diagonal principal em 5.13b, 5.13c e 5.13d.
Com relação a Tabela 5.5, podemos destacar o Espectral com melhor redução do
envelope, porém maior tempo de CPU, e o RCM com melhor redução de largura de
banda e pior redução de envelope.
Todos os algoritmos reduziram consideravelmente o preenchimento na Figura 5.14,
mantendo um comportamento bem semelhante ao longo dos ILU’s. Quanto as iterações
(Figura 5.15) e tempo de CPU (Figura 5.16) percebemos que as matrizes geradas pelos
algoritmos não convergem para o ILU(0). A não-convergência se mantém em ILU(4) para
o ND e AMD, passando a convergir com o Sloan, RCM e Espectral. Destaque para todos
os tempos terem sido vantajosos, sendo o melhor resultado para o RCM em ILU(8).

43 5.5. Matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
5.5 Matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.17: Esparsidades da matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
env(.) lb(.) Tempo de CPU
Original 123.444.210 1.111 -
Sloan 82.970.162 1.086 11,074
RCM 82.970.162 1.086 0,056
Espectral 95.022.625 2.210 3,656
ND - - 1,191
AMD - - 0,174
Tabela 5.6: Medições da matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛

Capítulo 5. Testes Computacionais 44
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. - 624.000 1.605.400 3.501.600 6.021.000 9.076.800
Sloan - 624.000 1.605.400 2.756.986 4.198.838 5.784.542
RCM - 624.000 1.605.400 2.756.986 4.198.838 5.784.542
Espectral - 648.546 1.588.858 3.301.846 5.461.180 7.936.288
ND - 907.156 1.247.136 2.685.224 3.282.956 5.036.818
AMD - 935.080 939.692 2.662.204 2.669.012 4.901.296
Figura 5.18: Preenchimento da matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 181 183 179 160 † 175
Sloan 181 147 † † 391 143
RCM † 169 70 57 50 69
Espectral † 140 143 125 74 42
ND † † † 394 326 92
AMD † † † 176 176 102
Figura 5.19: Iterações da matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛

45 5.5. Matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 23,38 57,73 79,39 87,9 † 148,95
Sloan 34,45 ∙ ∙ 60,66 ∙ † † 180,63 97,11
RCM † 54,27 ∙ 46,43 ∙ 44,99 ∙ 50,83 ∙ 58,66∙
Espectral † 63,67 ∙ 66,84 58,91 64,61 69,92
ND † † † 123,29 ∙ 111,84 73,56
AMD † † † 75,25 76,59 76,63
Figura 5.20: Tempo de CPU da matriz 𝐵𝑎𝑢𝑚𝑎𝑛𝑛
Analisando a Tabela 5.6, os algoritmos RCM e o Sloan tiveram a mesma qualidade
com relação a redução do envelope e largura de banda, porém o tempo de execução do
Sloan foi de 184.5 vezes maior.
As Figuras 5.19 e 5.20 revelam um comportamento peculiar e fora do esperado. A
matriz reordenada com Sloan, após convergir em ILU(1), passa a não convergir em ILU(2)
e ILU(3). O mesmo ocorre com a matriz sem reordenamentos em ILU(4). O melhor
tempo de CPU foi do RCM, apesar do ND e AMD possuírem o menor preenchimento.
Uma consideração importante é o fato de que apesar do Sloan e RCM possuírem a
mesma qualidade de solução, a convergência e tempo de CPU final da matriz com esses
reordenamentos foram discrepantes. Isso sugere que um reordenamento pode alterar
muito o condicionamento da matriz. Para essa matriz, os algoritmos de reordenamento
não reduziram o tempo final de execução. O menor tempo de CPU ocorreu em ILU(0)
na matriz sem reordenamentos.
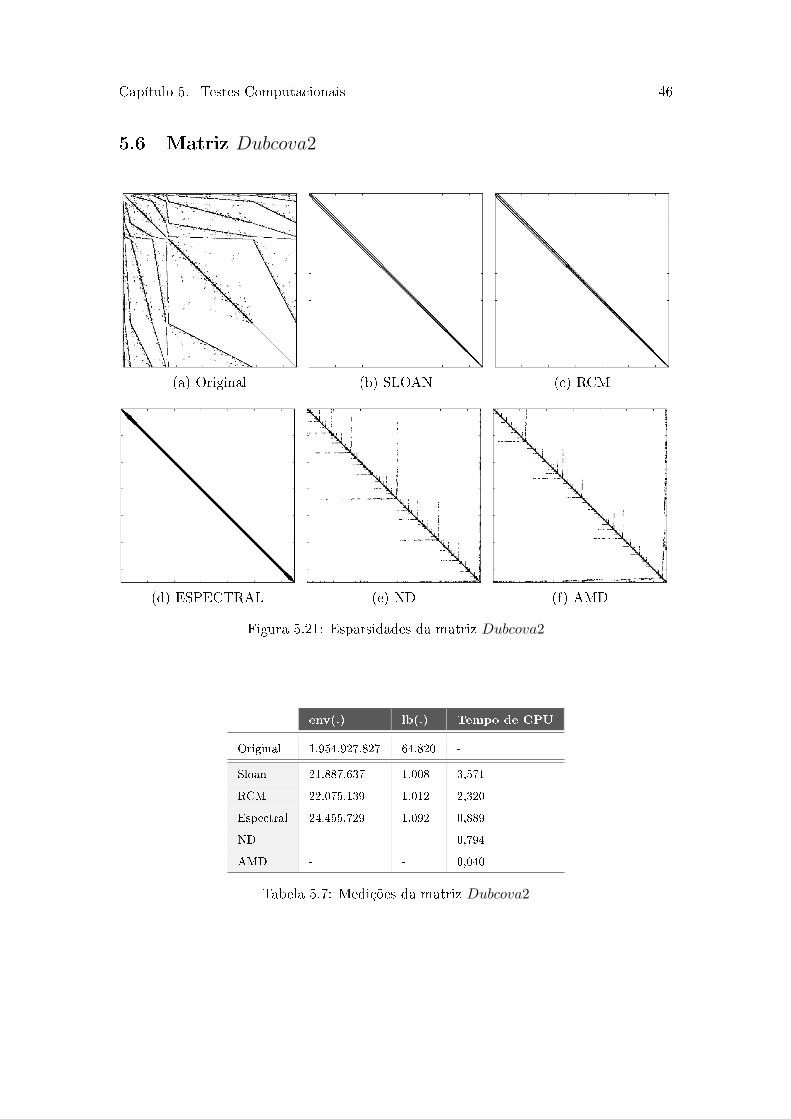
Capítulo 5. Testes Computacionais 46
5.6 Matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.21: Esparsidades da matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
env(.) lb(.) Tempo de CPU
Original 1.954.927.827 64.820 -
Sloan 21.887.637 1.008 3,571
RCM 22.075.139 1.012 2,320
Espectral 24.455.729 1.092 0,889
ND - - 0,794
AMD - - 0,040
Tabela 5.7: Medições da matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
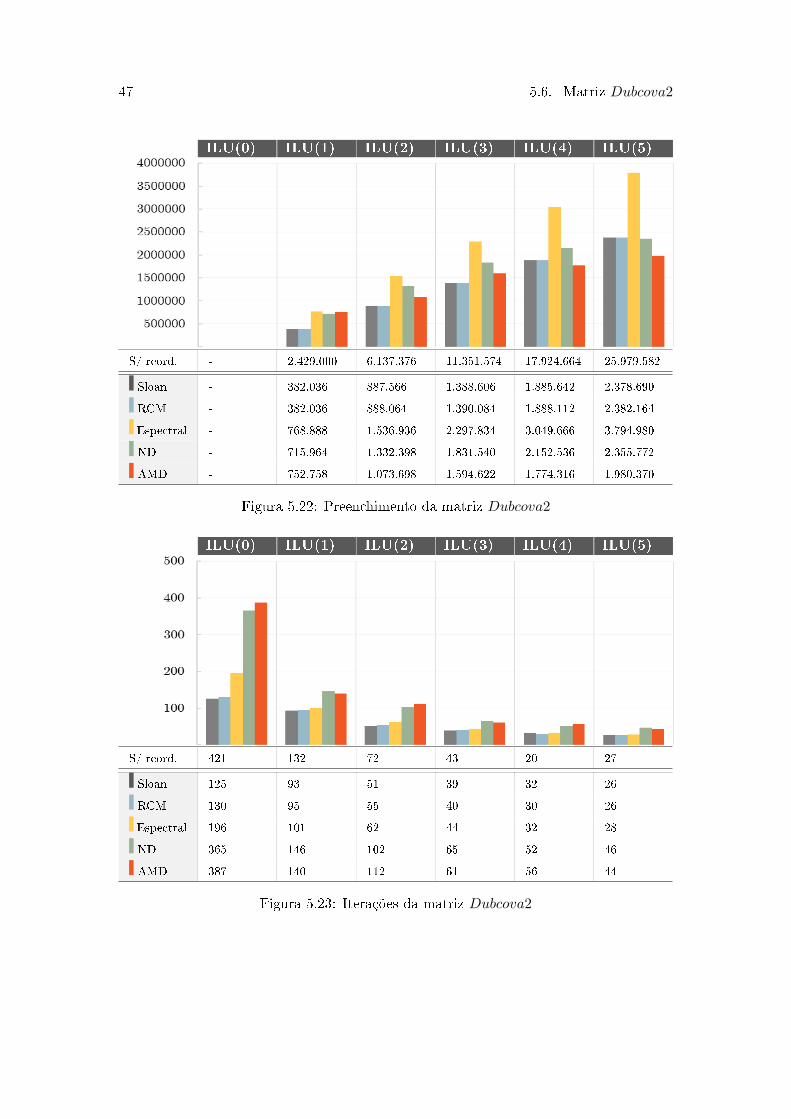
47 5.6. Matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. - 2.429.000 6.137.376 11.351.574 17.924.664 25.979.582
Sloan - 382.036 887.566 1.388.606 1.885.642 2.378.690
RCM - 382.036 888.064 1.390.084 1.888.112 2.382.164
Espectral - 768.888 1.536.936 2.297.834 3.049.666 3.794.980
ND - 715.964 1.332.398 1.831.540 2.152.536 2.355.772
AMD - 752.758 1.073.698 1.594.622 1.774.316 1.980.370
Figura 5.22: Preenchimento da matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 421 132 72 43 20 27
Sloan 125 93 51 39 32 26
RCM 130 95 55 40 30 26
Espectral 196 101 62 44 32 28
ND 365 146 102 65 52 46
AMD 387 140 112 61 56 44
Figura 5.23: Iterações da matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2

Capítulo 5. Testes Computacionais 48
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 16,56 31,32 82,33 302,63 978,78 2734,07
Sloan 9,11 19,25 18,50 19,25 20,37 21,94
RCM 8,01 ∙ 18,20 ∙ 17,46 ∙ 18,06 ∙ 18,99 ∙ 20,76 ∙
Espectral 9,18 18,26 18,54 20,43 23,24 27,55
ND 15,55 20,59 21,37 22,14 23,82 25,46
AMD 15,64 19,67 19,70 20,16 21,24 22,68
Figura 5.24: Tempo de CPU da matriz 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2
Na Tabela 5.7 podemos perceber que todos os algoritmos reduziram bastante as
métricas analisadas. O Sloan se destaca, apesar de ter tido o maior tempo computacional.
Em todos os níveis de preenchimento há um melhora significativa na redução do
preenchimento para todos os algoritmos na Figura 5.22. O Sloan e RCM mantiveram o
preenchimento similar, liderando até o nível 3 de preenchimento. A partir desse nível o
AMD passa a ter a melhor redução. Já na Figura 5.23 podemos reparar que nem sempre
as iterações das matrizes reordenadas foi menor do que da matriz sem reordenamentos.
Os tempos de CPU finais na Figura 5.24 apresentaram um excelente comportamento.
Além de ter havido melhora em todos os níveis de preenchimento, os tempos são bastante
equiparáveis entre os algoritmos de reordenamento. Destaque para os níveis maiores, que
reduziram muito o tempo de CPU e possuem pouca discrepância dos tempos do nível
anterior. Ainda assim, o menor tempo ocorreu em ILU(0) com o RCM.
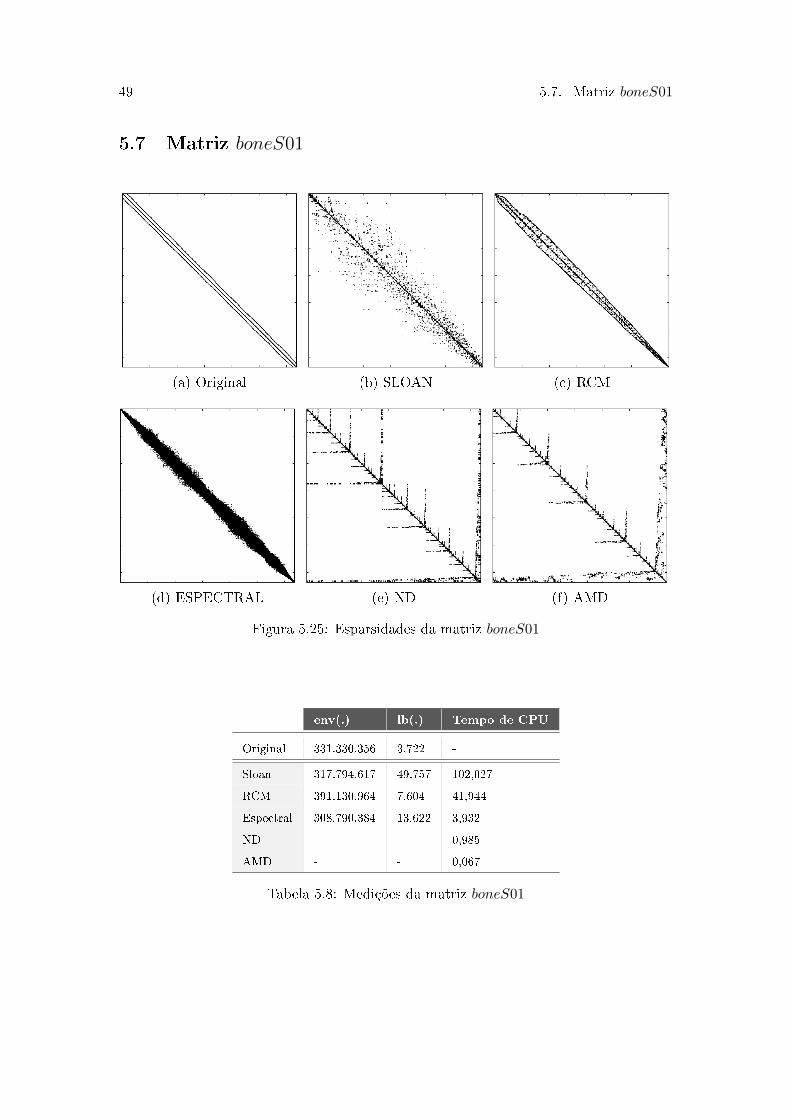
49 5.7. Matriz 𝑏𝑜𝑛𝑒𝑆01
5.7 Matriz 𝑏𝑜𝑛𝑒𝑆01
(a) Original (b) SLOAN (c) RCM
(d) ESPECTRAL (e) ND (f) AMD
Figura 5.25: Esparsidades da matriz 𝑏𝑜𝑛𝑒𝑆01
env(.) lb(.) Tempo de CPU
Original 331.330.356 3.722 -
Sloan 317.794.617 49.757 102,027
RCM 391.130.964 7.604 41,944
Espectral 308.790.384 13.622 3,932
ND - - 0,985
AMD - - 0,067
Tabela 5.8: Medições da matriz 𝑏𝑜𝑛𝑒𝑆01

Capítulo 5. Testes Computacionais 50
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. - 6.467.202 13.943.844 22.348.404 31.932.252 42.936.012
Sloan - 4.622.274 10.519.650 17.157.564 24.662.070 33.182.568
RCM - 4.586.148 10.233.648 16.854.336 24.583.032 33.636.384
Espectral - 5.967.684 13.586.562 21.973.428 31.306.446 41.928.624
ND - 6.116.868 12.221.472 17.629.524 22.429.008 26.729.430
AMD - 5.932.548 11.569.346 17.072.138 22.464.376 27.746.400
Figura 5.26: Preenchimento da matriz 𝑏𝑜𝑛𝑒𝑆01
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 1992 558 206 142 109 89
Sloan 629 267 187 137 107 86
RCM 739 264 180 133 104 86
Espectral 705 252 170 125 100 84
ND 3881 551 228 171 132 107
AMD 2342 322 213 158 124 100
Figura 5.27: Iterações da matriz 𝑏𝑜𝑛𝑒𝑆01

51 5.7. Matriz 𝑏𝑜𝑛𝑒𝑆01
ILU(0) ILU(1) ILU(2) ILU(3) ILU(4) ILU(5)
S/ reord. 850,93 372,92 439,06 786,47 1641,07 3300,51
Sloan 364,73 307,84 417,29 605,25 1047,95 1884,14
RCM 335,38 242,10 336,44 ∙ 513,85 ∙ 958,76 ∙ 1835,23 ∙
Espectral 303,54 ∙ 221,28 ∙ 405,99 753,66 1551,48 3082,77
ND 1582,48 ∙ 392,03 ∙ 538,84 ∙ 1001,08 ∙ 1570,17 2651,05
AMD 981,76 ∙ 307,08 492,61 ∙ 983,66 ∙ 1761,45 ∙ 3287,21
Figura 5.28: Tempo de CPU da matriz 𝑏𝑜𝑛𝑒𝑆01
Os dados da Tabela 5.8 mostram que o Espectral foi o algoritmo que mais reduziu o
envelope. Já a largura de banda aumentou em todos os algoritmos, com destaque para o
Sloan que além de ter tido a pior largura de banda, teve pior desempenho computacional.
Já na Figura 5.26 podemos perceber que o Sloan e RCM tiveram o menor preenchi-
mento em ILU(1), ILU(2) e ILU(3), perdendo para o ND e AMD nos níveis seguintes.
Apesar disso, a redução do preenchimento no ND e AMD não foi capaz de melhorar o
número de iterações nem o tempo computacional, como podemos ver nas Figuras 5.27 e
5.28. Mais do que isso, os tempos finais do ND e AMD não foram, na maioria das vezes,
ao menos vantajosos. Diferente dos algoritmos Sloan, RCM e Espectral que, apesar de
pouco, reduziram os tempos de CPU em todos os níveis de preenchimento. O menor
tempo ocorreu com o algoritmo Espectral em ILU(1).


Capítulo 6
Conclusões
Para cada algoritmo estudado, a Tabela 6.1 mostra suas principais características, com
base no conjunto de matrizes testadas (que foram além do conjunto apresentado), e em
toda compreensão que tive deste trabalho.
tttttttttttttttttttttt
Preenchimento
Iterações
Tem
podeCPU
Implementação
Condicionamento
Sloan G# G# s n n
RCM s n
Espectral G# s s n
ND s s s n n n
AMD G# G# G# s s s n n n
Tabela 6.1: Análise final
A primeira coluna da tabela refere-se a quantidade de preenchimento gerado por
cada algoritmo. Quanto mais , maior é o preenchimento gerado pelo algoritmo. Como
pudemos perceber nos testes, os algoritmos ND e AMD foram os que, no geral, mais
reduziram o preenchimento, enquanto que o Espectral foi o que causou menos reduções.
Já o Sloan e o RCM tiveram reduções bem próximas.

Capítulo 6. Conclusões 54
O número de iterações, apresentado na segunda coluna da tabela, também deve ser
lido da mesma forma que o preenchimento. Quanto mais , maior o número necessário de
iterações para a matriz reordenada convergir pelo método GMRES. Podemos notar que
os algoritmos que tiveram pouco preenchimento, como ND e AMD, tiveram que realizar
mais iterações para convergir. Da mesma forma, o elevado preenchimento causado pelo
Espectral fez diminuir a quantidade de iterações necessárias.
Quanto ao tempo de CPU final na terceira coluna, temos o RCM como o mais van-
tajoso, seguido pelo Sloan e Espectral. Analisando alguns dos testes, podemos reparar
na tendência do algoritmo RCM de reduzir mais a largura de banda do que o envelope.
Já o Sloan e o Espectral tendem a reduzir mais o envelope ao invés da largura de banda.
Podemos conjecturar, então, que a redução da largura de banda tem um impacto mais
positivo no tempo final de CPU do que a redução do envelope. Tal análise não inclui os
algoritmos ND e AMD que não reordenam segundo essas métricas.
A quarta coluna mede o quão fácil é a implementação de cada algoritmo. Quanto me-
nos s, mais fácil é a implementação. Portanto, o RCM foi categorizado como o mais fácil
de se implementar, seguido pelo Sloan. Esses dois algoritmos foram os únicos totalmente
implementados por mim, e, na minha opinião a única dificuldade que possa surgir ao de
implementá-los é na construção da estrutura de nível para encontrar os vértices pseudo-
periféricos. Para os algoritmos Espectral, ND e AMD foram utilizadas bibliotecas, cujos
códigos foram adaptados para minhas estruturas. Esses algoritmos foram classificados
como médio, difícil e difícil, respectivamente. Para o Espectral, não é simples construir
um algoritmo para encontrar o autovetor associado ao segundo menor autovalor. O ND
recai na necessidade de construir um método de bisseção que divide o grafo em duas par-
tições, além de precisar encontrar o conjunto de vértices separadores. Já o AMD precisa
construir um Grafo de Eliminação a cada passo, tornando sua implementação não trivial.
Por fim, a quinta coluna refere-se ao condicionamento das novas matrizes geradas
pelos reordenamentos. Muitos n significam que o reordenamento, no geral, piorou o

55
condicionamento da matriz. Logo, baseado nos testes com as matrizes 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾
e 𝐵𝑎𝑢𝑚𝑎𝑛𝑛, podemos reparar que o RCM, o Sloan e o Espectral tendem a melhorar o
condicionamento, enquanto que o com o ND e AMD isso não ocorreu.
Analisando globalmente a Tabela 6.1, os algoritmos com menos itens, são considerados
os melhores. Logo, nessa análise, o RCM foi o que apresentou melhores resultados,
seguido do Sloan e Espectral. Apesar disso, o ND e AMD tiveram casos muito mais
vantajosos para níveis de preenchimento grandes.
Um fato interessante é que, as matrizes com os elementos não nulos muito dispersos,
longe da diagonal principal, tiveram todos os tempos de CPU vantajosos para todos os
algoritmos. Podemos perceber isso analisando as figuras da configuração da esparsidade
das matrizes 𝑟𝑎𝑖𝑙_5177, 𝑡ℎ𝑒𝑟𝑚𝑜𝑚𝑒𝑐ℎ_𝑇𝐾 e 𝐷𝑢𝑏𝑐𝑜𝑣𝑎2. A qualidade de redução do
tempo já não foi tão boa para matrizes que já possuem os elementos não nulos muito
próximos da diagonal principal.
Como trabalhos futuros, destaco o estudo do comportamento dos algoritmos em um
conjunto de matrizes com elementos não nulos muito dispersos da diagonal. Esse conjunto
de matrizes poderia influenciar no resultado final comparativo da Tabela 6.1. Além disso,
analisar a escolha dos parâmetros 𝑊1 e 𝑊2 do algoritmo Sloan, já que esse algoritmo
foi o que mais se aproximou, em qualidade, do RCM. Talvez com uma melhor escolha
de parâmetros, poderíamos obter resultados mais satisfatórios. Seria importante estudar
também implementações de alguns desses algoritmos em paralelo. Um estudo atual de
Manguoglu et al. (2010) sugere uma implementação em paralelo baseada no algoritmo
Espectral titulada Weighted Espectral Ordering.

Referências Bibliográficas
Alan George, Joseph Liu, E. N. (1994). Computer Solution of Sparse Linear Systems.
Barnard, S. T., Pothen, A., and Simon, H. D. (1993). A spectral algorithm for envelope
reduction of sparse matrices. In Proceedings of the 1993 ACM/IEEE conference on
Supercomputing, Supercomputing ’93, pages 493–502, New York, NY, USA. ACM.
Benzi, M., Szyld, D. B., and Duin, A. V. (1999). Orderings for incomplete factorization
preconditioning of nonsymmetric problems. SIAM J. SCI. COMPUT, 20(5):1652–1670.
Boldrini, J. L., Costa, S. I. R., Figueiredo, V. L., and Wetzler, H. G. (1986). Algebra
Linear. 3ª edition.
Camata, J., Rossa, A., Valli, A., Catabriga, L., Valli, A. M. P., Carey, G., and Coutinho,
A. (2012). Reordering and incomplete preconditioning in serial and parallel adaptive
mesh refinement and coarsening flow solutions. International Journal for Numerical
Methods in Fluids, 69:802–823.
Carmo, F. C. (2005). Análise da influência de algoritmos de reordenação de matrizes
esparsas no desempenho do método CCCG(n). Master’s thesis, Universidade Federal
de Minas Gerais.
Cuthill, E. and McKee, J. (1969). Reducing the bandwidth of sparse symmetric matrices.
In Proceedings of the 1969 24th national conference, ACM ’69, pages 157–172, New
York, NY, USA. ACM.

57 Referências Bibliográficas
Davis, T. A., Amestoy, P., Duff, I. S., Iain, and Duff, S. (1994). An approximate minimum
degree ordering algorithm. SIAM Journal on Matrix Analysis and Applications, 17:886–
905.
Delebecque, F. and Steer, S. (2013). Scilab 5.4.1 - open source software for numerical
computation. https://www.scilab.org/.
Everstine, G. C. (1979). A comparasion of three resequencing algorithms for the reduc-
tion of matrix profile and wavefront. Internacional Journal for Numerical Methods in
Engineering, 14:837–853.
Fiedler, M. (1973). Algebraic connectivity of graphs. Czechoslovak Mathematical Journal,
23:298–305.
George, A. (1973). Nested dissection of a regular finite element mesh. SIAM Journal on
Numerical Analysis, 10(2):345–363.
George, A. and Liu, J. W. H. (1979). An implementation of a pseudoperipheral node
finder. ACM Trans. Math. Softw., 5(3):284–295.
George, A. and Liu, J. W. H. (1981). Computer Solution of Large Sparse Positive Definite
Systems. Prentice Hall, Englewood Cliffs, NJ.
George, J. A. (1971). Computer implementation of the finite element method. PhD thesis,
Calif School of Humanities and Sciences Stanford Department of Computer Science,
Stanford, CA, USA. AAI7205916.
Ghidetti, K. R. (2011). O impacto do reordenamento de matrizes esparsas nos métodos
iterativos não estacionários precondicionados. Master’s thesis, Universidade Federal
do Espírito Santo.
Gibbs, N. E., Poole, W. G., and Stockmeyer, P. K. (1976). An algorithm for reducing
the profile and bandwidth of a sparse matrix. SIAM J. Numer. Anal., 13:236–250.

Referências Bibliográficas 58
Gonçalez, T. T. (2005). Algoritmos adaptativos para o método GMRES(m). Master’s
thesis, Universidade Federal do Rio Grande do Sul.
Hendrickson, B. and Leland, R. (1995). A multilevel algorithm for partitioning graphs.
In Proceedings of the 1995 ACM/IEEE conference on Supercomputing (CDROM), Su-
percomputing ’95, New York, NY, USA. ACM.
Hendrickson, B. and Leland, R. (2013). Chaco: Software for partitioning graphs.
http://www.sandia.gov/ bahendr/chaco.html.
Juvan, M. and Mohar, B. (1992). Optimal linear labelings and eigenvalues of graphs.
Discrete Appl. Math., 36(2):153–168.
Karypis, G. (2013). METIS - a software package for partitioning unstructured graphs,
partitioning meshes, and computing fill-reducing orderings of sparse matrices.
Karypis, G. and Kumar, V. (1998). A fast and high quality multilevel scheme for parti-
tioning irregular graphs. SIAM J. Sci. Comput., 20(1):359–392.
Liu, J. W. H. (1985). Modification of the minimum-degree algorithm by multiple elimi-
nation. ACM Trans. Math. Softw., 11(2):141–153.
Manguoglu, M., Koyutürk, M., Sameh, A. H., and Grama, A. (2010). Weighted matrix
ordering and parallel banded preconditioners for iterative linear system solvers. SIAM
J. Sci. Comput., 32(3):1201–1216.
Saad, Y. (2003). Iterative Methods for Sparse Linear Systems. Society for Industrial and
Applied Mathematics, Philadelphia, PA, USA, 2nd edition.
Saad, Y. and Schultz, M. H. (1986). GMRES: a generalized minimal residual algorithm
for solving nonsymmetric linear systems. SIAM J. Sci. Stat. Comput., 7(3):856–869.
Sloan, S. W. (1986). An algorithm for profile and wavefront reduction of sparse matrices.
Internacional Journal for Numerical Methods in Engineering, 23:239–251.

59 Referências Bibliográficas
Sloan, S. W. (1989). A fortran program for profile and wavefront reduction. An Algorithm
for Profile and Wavefront Reduction of Sparse Matrices, 28:2651–2679.
Stoer, J. and Bulirsch, R. (2002). Introduction to Numerical Analysis. Springer, New
York, 3 edition.
Timothy A. Davis, Yifan Hu, A. R. (2013a). The University of Florida Sparse Matrix
Collection. http://www.cise.ufl.edu/research/sparse/matrices/.
Timothy A. Davis, Patrick R. Amestoy, I. S. D. (2013b). AMD: approximate minimum
degree ordering. http://www.cise.ufl.edu/research/sparse/amd/.

Apêndice A
Implementações CSR
Algoritmo 12: Elemento 𝑎𝑖𝑗 → 𝑎𝑖𝑗 = (𝐴,𝑖,𝑗)
1 para 𝑘 = 𝐼𝐴(𝑖) até 𝐼𝐴(𝑖+ 1)− 1 faça
2 se 𝐽𝐴(𝑘) = 𝑗 então3 𝑎𝑖𝑗 = 𝐴𝐴(𝑘)4 fim
5 fim
6 𝑎𝑖𝑗 = 0
Algoritmo 13: Produto matriz × vetor → 𝑏 = (𝐴,𝑥)
1 para 𝑖 = 1 até 𝑛 faça
2 𝑠𝑜𝑚𝑎 = 03 para 𝑗 = 𝐼𝐴(𝑖) até 𝐼𝐴(𝑖+ 1)− 1 faça
4 𝑠𝑜𝑚𝑎 = 𝑠𝑜𝑚𝑎+𝐴𝐴(𝑗) * 𝑥(𝐽𝐴(𝑗))5 fim
6 𝑏(𝑖) = 𝑠𝑜𝑚𝑎
7 fim

61
Algoritmo 14: Substituição Sucessiva → 𝑥 = (𝐴,𝑏)
1 𝑥(𝑛) = 𝑏(1)/𝑎𝑖𝑗(𝐴,1,1)2 𝑠𝑜𝑚𝑎 = 03 para 𝑖 = 2 até 𝑛 faça
4 𝑠𝑜𝑚𝑎 = 𝑏(𝑖)5 para 𝑗 = 𝐼𝐴(𝑖) até 𝐼𝐴(𝑖+ 1)− 1 faça
6 se 𝐽𝐴(𝑗) = 𝑖 então7 𝑑𝑖𝑎𝑔𝑜𝑛𝑎𝑙 = 𝐴𝐴(𝑗)8 fim
9 se 𝐽𝐴(𝑗) < 𝑖 então10 𝑠𝑜𝑚𝑎 = 𝑠𝑜𝑚𝑎−𝐴𝐴(𝑗) * 𝑥(𝐽𝐴(𝑗))11 fim
12 fim
13 𝑥(𝑖) = 𝑠𝑜𝑚𝑎/𝑑𝑖𝑎𝑔𝑜𝑛𝑎𝑙
14 fim
Algoritmo 15: Substituição Retroativa → 𝑥 = (𝐴,𝑏)
1 𝑥(𝑛) = 𝑏(𝑛)/𝑎𝑖𝑗(𝐴,𝑛,𝑛)2 𝑠𝑜𝑚𝑎 = 03 para 𝑖 = 𝑛− 1 até 1 faça
4 𝑠𝑜𝑚𝑎 = 𝑏(𝑖)5 para 𝑗 = 𝐼𝐴(𝑖) até 𝐼𝐴(𝑖+ 1)− 1 faça
6 se 𝐽𝐴(𝑗) = 𝑖 então7 𝑑𝑖𝑎𝑔𝑜𝑛𝑎𝑙 = 𝐴𝐴(𝑗)8 fim
9 se 𝐽𝐴(𝑗) > 𝑖 então10 𝑠𝑜𝑚𝑎 = 𝑠𝑜𝑚𝑎−𝐴𝐴(𝑗) * 𝑥(𝐽𝐴(𝑗))11 fim
12 fim
13 𝑥(𝑖) = 𝑠𝑜𝑚𝑎/𝑑𝑖𝑎𝑔𝑜𝑛𝑎𝑙
14 fim
Algoritmo 16: ILU(0) →𝑀 = (𝐴)
1 𝑀 = 𝐴2 para 𝑖 = 2 até 𝑛 faça
3 para 𝑘 = 𝐼𝐴𝐴(𝑖) até 𝑖 ̸= 𝐽𝐴𝐴(𝑘) faça4 𝐴𝐴𝑀 (𝑘) = 𝐴𝐴𝑀 (𝑘)/𝑎𝑖𝑗(𝑀,𝐽𝐴𝑀 (𝑘),𝐽𝐴𝑀 (𝑘))5 para 𝑗 = 𝑘 + 1 até 𝐼𝐴𝐴(𝑖+ 1)− 1 faça
6 𝐴𝐴𝑀 (𝑗) = 𝐴𝐴𝑀 (𝑗)− (𝐴𝐴𝑀 (𝑘) * 𝑎𝑖𝑗(𝑀,𝐽𝐴𝑀 (𝑘),𝐽𝐴𝑀 (𝑗))7 fim
8 fim
9 fim

Apêndice A. Implementações CSR 62
Algoritmo 17: ILU(p) →𝑀 = (𝐴,𝑝)
1 para 𝑖𝑖 = 1 até 𝑛 faça2 𝐿𝐸𝑉 𝑝 → 𝑛𝑒𝑥𝑡 = 𝑁𝑈𝐿𝐿3 𝐿𝐸𝑉 𝑝 → 𝑛 = 04 para 𝑖 = 1 até 𝑛 faça5 𝐿𝐸𝑉 𝑖𝑖(𝑖) = 06 fim7 para 𝑖 = 𝐼𝐴𝐴(𝑖𝑖) até 𝐼𝐴𝐴(𝑖𝑖+ 1)− 1 faça8 𝑤(𝐽𝐴𝐴(𝑖)) = 𝐴𝐴𝐴(𝑖)9 𝐿𝐸𝑉 𝑖𝑖(𝐽𝐴𝐴(𝑖)) = 1
10 𝐿𝐸𝑉 𝑝 = 𝑖𝑛𝑠𝑒𝑟𝑒(𝐿𝐸𝑉 𝑝,𝐽𝐴𝐴(𝑖))
11 fim12 𝑗𝑗 = 013 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 = 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 → 𝑛𝑒𝑥𝑡14 enquanto 𝑗𝑗 < 𝑖𝑖 faça15 𝑗𝑗 = 𝑎𝑢𝑥 → 𝐽𝐴16 se 𝑗𝑗 ≥ 𝑖𝑖 então17 𝑏𝑟𝑒𝑎𝑘18 fim19 𝑗𝑙𝑒𝑣 = 𝐿𝐸𝑉 𝑖𝑖(𝑗𝑗)20 se 𝑗𝑙𝑒𝑣 ≤ 𝑝+ 1 então21 𝑚𝑢𝑙𝑡𝑖𝑝𝑙𝑖𝑐𝑎𝑑𝑜𝑟 = 𝑤(𝑗𝑗)/𝑎𝑖𝑗(𝑀,𝑗𝑗,𝑗𝑗)22 para 𝑘 = 𝐼𝐴𝑀 (𝑗𝑗) até 𝐼𝐴𝑀 (𝑗𝑗 + 1)− 1 faça23 se 𝐽𝐴𝑀 (𝑘) ≥ 𝑗𝑗 então24 𝑗 = 𝐽𝐴𝑀 (𝑘)25 𝑡𝑒𝑚𝑝 = 𝑎𝑖𝑗(𝐿𝐸𝑉 𝑠,𝑗𝑗,𝑗) + 𝑗𝑙𝑒𝑣26 se 𝐿𝐸𝑉 𝑖𝑖(𝑗) = 0 então27 se 𝑡𝑒𝑚𝑝 ≤ 𝑝+ 1 então28 𝑤(𝑗) = −𝑚𝑢𝑙𝑡𝑖𝑝𝑙𝑖𝑐𝑎𝑑𝑜𝑟 *𝐴𝐴𝑀 (𝑘)29 𝐿𝐸𝑉 𝑝 = 𝑖𝑛𝑠𝑒𝑟𝑒(𝐿𝐸𝑉 𝑝,𝑗)30 𝐿𝐸𝑉 𝑖𝑖(𝑗) = 𝑡𝑒𝑚𝑝
31 fim
32 senão33 𝑤(𝑗) = 𝑤(𝑗)−𝑚𝑢𝑙𝑡𝑖𝑝𝑙𝑖𝑐𝑎𝑑𝑜𝑟 *𝐴𝐴𝑀 (𝑘)34 𝐿𝐸𝑉 𝑖𝑖(𝑗) = 𝑚𝑖𝑛(𝐿𝐸𝑉 𝑖𝑖(𝑗), 𝑡𝑒𝑚𝑝)
35 fim
36 fim
37 fim38 𝑤(𝑗𝑗) = 𝑚𝑢𝑙𝑡𝑖𝑝𝑙𝑖𝑐𝑎𝑑𝑜𝑟;
39 fim40 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 = 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 → 𝑛𝑒𝑥𝑡
41 fim42 para 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 = 𝐿𝐸𝑉 𝑝 → 𝑛𝑒𝑥𝑡 até 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 ̸= 𝑁𝑈𝐿𝐿 faça43 𝐴𝐴𝑀 (𝑚_𝐽𝐴) = 𝑤(𝑎𝑢𝑥 → 𝐽𝐴)44 𝐽𝐴𝑀 (𝑚_𝐽𝐴) = 𝑎𝑢𝑥 → 𝐽𝐴45 𝑚_𝐼𝐴 = 𝑚_𝐼𝐴+ 146 𝑚_𝐽𝐴 = 𝑚_𝐽𝐴+ 147 se 𝑎𝑢𝑥 → 𝐽𝐴 ≥ 𝑖𝑖 então48 𝐴𝐴𝐿𝐸𝑉 𝑠(𝑙𝑒𝑣_𝐽𝐴) = 𝐿𝐸𝑉 𝑖𝑖(𝑎𝑢𝑥 → 𝐽𝐴)49 𝐽𝐴𝐿𝐸𝑉 𝑠(𝑙𝑒𝑣_𝐽𝐴) = 𝑎𝑢𝑥 → 𝐽𝐴50 𝑙𝑒𝑣_𝐼𝐴 = 𝑙𝑒𝑣_𝐼𝐴+ 151 𝑙𝑒𝑣_𝐽𝐴 = 𝑙𝑒𝑣_𝐽𝐴+ 1
52 fim
53 fim54 𝐼𝐴𝑀 (𝑖𝑖+ 1) = 𝑚_𝐼𝐴55 𝐼𝐴𝐿𝐸𝑉 𝑠(𝑖𝑖+ 1) = 𝑙𝑒𝑣_𝐼𝐴56 𝑛𝑛𝑧𝑀 = 𝑚_𝐼𝐴− 1
57 fim

63
A implementação do Algoritmo 17 não foi tão simples. O código é extenso e difícil
de relacionar com o Algoritmo 4 que foi descrito na seção 2.2.1 utilizando a matriz no
formato denso. Esse algoritmo foi baseado no código 𝑠𝑝𝑖𝑙𝑢_𝑖𝑙𝑢𝑘𝑀 implementado para
o software científico para computação numérica Scilab (Delebecque and Steer, 2013). O
pacote contendo esse código pode ser encontrado em http://forge.scilab.org/index.
php/p/spilu/source/tree/HEAD/macros. Com relação ao Algoritmo 17, abaixo estão
informações das variáveis utilizadas:
� 𝑤 e 𝐿𝐸𝑉 𝑖𝑖 são vetores esparsos, ou seja, vetores de tamanho 𝑛 onde um futuro
elemento que será criado pelo preenchimento na coluna 𝑗 será inserido na posição
𝑗 nesses vetores. Dessa forma, sabendo a posição 𝑗 (guardada em 𝐿𝐸𝑉 𝑝 descrito
abaixo), o acesso a esse elemento é direto. Ao final de cada passo do algoritmo
(linha 42), 𝑤 terá os valores da linha 𝑖 de 𝑀 . Da mesma forma, 𝐿𝐸𝑉 𝑖𝑖 terá o nível
de preenchimento da linha 𝑖 de 𝑀 .
� 𝐿𝐸𝑉 𝑝 é uma lista encadeada com cabeça e inserção ordenada. Essa estrutura
guarda os valores de colunas (𝐽𝐴), e é usada para acessar o vetor 𝑤 e 𝐿𝐸𝑉 𝑖𝑖.
Guardando os valores de coluna que há preenchimento, podemos acessar 𝑤 e 𝐿𝐸𝑉 𝑖𝑖
diretamente. É preciso que a inserção nessa lista seja feita ordenadamente, para
simular o armazenamento CSR. Essa abordagem foi utilizada, pois o armazena-
mento CSR foi implementado com vetores. Logo, quando há preenchimento fica
difícil inserir dados no meio do vetor.
� 𝐿𝐸𝑉 𝑝_𝑎𝑢𝑥 é simplesmente uma lista auxiliar para percorrer 𝐿𝐸𝑉_𝑝.
� 𝑀 e 𝐿𝐸𝑉 𝑠 são matrizes esparsas. 𝑀 guarda a matriz precondicionada e 𝐿𝐸𝑉 𝑠 os
níveis de preenchimento de cada elemento.
� 𝑚_𝐼𝐴, 𝑚_𝐽𝐴, 𝑙𝑒𝑣_𝐼𝐴, 𝑙𝑒𝑣_𝐽𝐴 são variáveis inteiras, iniciadas com 1.


















