







Línguas
Páginas
Legal


UNIVERSIDADE FEDERAL DE ITAJUBA
PROGRAMA DE POS-GRADUACAO
EM CIENCIA E TECNOLOGIA DA COMPUTACAO
Uma analise sobre as metricas para escalonamento dinamicode processos em simulacao distribuıda usando protocolos
otimistas
Emerson Assis de Carvalho
Itajuba, Agosto de 2013

UNIVERSIDADE FEDERAL DE ITAJUBA
PROGRAMA DE POS-GRADUACAO
EM CIENCIA E TECNOLOGIA DA COMPUTACAO
Emerson Assis de Carvalho
Uma analise sobre as metricas para escalonamento dinamicode processos em simulacao distribuıda usando protocolos
otimistas
Dissertacao submetida ao programa de
Pos-Graduacao em Ciencia e Tecnologia
da Computacao como parte dos requisi-
tos para obtencao do tıtulo de Mestre em
Ciencia e Tecnologia da Computacao.
Area de Concentracao: Sistemas de Computacao
Orientador: Prof. Dr. Edmilson Marmo Moreira
Co-orientador: Prof. Dr. Otavio A. S. Carpinteiro
Agosto de 2013
Itajuba

UNIVERSIDADE FEDERAL DE ITAJUBA
PROGRAMA DE POS-GRADUACAO
EM CIENCIA E TECNOLOGIA DA COMPUTACAO
Emerson Assis de Carvalho
Uma analise sobre as metricas para escalonamento dinamicode processos em simulacao distribuıda usando protocolos
otimistas
Dissertacao aprovada por banca examinadora
em 22 de Agosto de 2013, conferindo ao autor
o tıtulo de Mestre em Ciencia e Tecnologia
da Computacao.
Banca Examinadora:
Prof. Dr. Edmilson Marmo Moreira (Orientador)
Prof. Dr. Otavio A. S. Carpinteiro (Co-orientador)
Profa. Dra. Sarita Mazzini Bruschi (USP-Sao Carlos)
Prof. Dr. Guilherme Souza Bastos
Itajuba
2013

Resumo
Esta dissertacao apresenta uma avaliacao sobre as metricas utilizadas pelosprincipais algoritmos de balanceamento de carga para simulacao distribuıda oti-mista que operam sobre o protocolo Time Warp. Propoe uma nova metrica e umalgoritmo de balanceamento que opera independente da metrica utilizada, o quepermite uma avaliacao das metricas em um mesmo ambiente de execucao, com osmesmos modelos de simulacao e com os mesmos fatores de desbalanceamento decarga. A metrica proposta e baseada nos principais fatores que causam o desba-lanceamento de uma simulacao distribuıda e o algoritmo foi projetado de maneiraabstrata, visando nao beneficiar qualquer uma das metricas. Considerando todosos modelos avaliados, a metrica proposta neste trabalho teve um bom desempenho,mas a metrica mais eficiente foi a metrica baseada na taxa de avanco do relogiolocal (LVT).

Abstract
This work presents a comparison of the metrics used by the main load balancingalgorithms for optimistic distributed simulation executed under the Time Warpprotocol. Introduces a new metric and a load balancing algorithm that is metricindependent, allowing a metric evaluation under the same execution environment,with the same simulation models and the same load imbalance factors. The newmetric proposed is based on the main load imbalance factors, and the load balancingalgorithm was designed to not benefiting anyone of the metrics. With the modelsevaluated, the proposal metric archieved a good performance, but the most efficientmetric was that based on the variance between processes Local Virtual Time (LVT).

Agradecimentos
Primeiramente, agradeco a Deus, por ter tantas pessoas especiais para agra-
decer, pela saude e pela fe.
Aos meus pais, Noe Lourenco de Carvalho e Rosania Fatima de Carvalho que,
mesmo nao entendendo grande parte do que eu faco, sempre confiaram em mim e
apoiaram minhas escolhas.
A toda minha famılia, por apoiar e compreender minha ausencia em momentos
especiais.
Aos meus amigos, Anderson Oliveira Faria, Vanderlucio de Araujo, Lenio Oli-
veira Prado Junior, Ricardo Emerson Julio, Julio Cesar Almeida, Flavio Emılio
Borges e Roberto Ribeiro Rocha, simplesmente pelas amizades verdadeiras.
Ao professor, Dr. Edmilson Marmo Moreira, pelos ensinamentos na graduacao,
por ter me aceitado, quando coordenador deste programa, como aluno de mestrado,
pelas discussoes e ensinamentos nas aulas da pos e, principalmente, pela confianca
e empenho em me orientar neste trabalho.
Ao professor, Dr. Otavio Augusto Salgado Carpinteiro, por me co-orientar
neste trabalho, pelos ensinamentos nas aulas da pos e pelo apoio financeiro conse-
guido junto a CAPES quando coordenador deste programa.
A todos os meus colegas de mestrado, em especial ao meu amigo Lenio Oli-
veira Prado Junior, pelo companheirismo constante nesses quase quatro anos de
mestrado. Um agradecimento especial tambem ao amigo Roberto Ribeiro Rocha,
pelas dicas de Linux e de programacao.

A UNIFEI e a todos os seus funcionarios, em especial aos demais professores
da pos, pelos ensinamentos e sugestoes em relacao a este trabalho.
Ao LEMAF, especialmente ao coordenador de T.I, o Sr. Samuel Campos, por
ter me liberado para as aulas da pos. Agradeco tambem a todos os meus antigos
colegas de trabalho, que nunca questionaram minhas ausencias.
A Devex, especialmente ao meu ex-diretor, o Sr. Luiz Thomaz do Nascimento,
por ter me liberado para as aulas da pos. Agradeco tambem a todos os integrantes
da minha equipe de trabalho mais recente, por terem suprido minha ausencia
com louvor. Agradeco em especial ao meu amigo Anderson Oliveira Faria, por ter
realizado muitas das minhas tarefas gerencias enquanto me ausentava para realizar
este trabalho.
A todos os meus professores da UNIFENAS, hoje meus atuais colegas de tra-
balho, pelos ensinamentos de outrora e pelo apoio no final deste trabalho. Um
agradecimento especial aos professores Marcos Alberto de Carvalho e Alexandre
Martins Dias.
Por fim, agradeco a CAPES, pelo apoio financeiro fornecido em um perıodo
deste trabalho.

Sumário
Lista de Figuras
Lista de Tabelas
Lista de Siglas p. 13
1 Introdução p. 15
1.1 Motivacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 17
1.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 18
1.3 Estrutura da dissertacao . . . . . . . . . . . . . . . . . . . . . . . p. 19
2 Simulação e simulação distribuída p. 21
2.1 Sistemas Distribuıdos . . . . . . . . . . . . . . . . . . . . . . . . . p. 21
2.2 Ambiente paralelo distribuıdo . . . . . . . . . . . . . . . . . . . . p. 22
2.3 Simulacao e simulacao distribuıda . . . . . . . . . . . . . . . . . . p. 23
2.4 MRIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 26
2.5 SRIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 27
2.5.1 Protocolos de sincronismo . . . . . . . . . . . . . . . . . . p. 28
2.5.2 Protocolos conservativos . . . . . . . . . . . . . . . . . . . p. 29
2.5.3 Protocolos Otimistas . . . . . . . . . . . . . . . . . . . . . p. 30

2.5.3.1 Time Warp . . . . . . . . . . . . . . . . . . . . p. 31
2.5.3.2 Algoritmo de Mattern para o calculo do GVT . p. 34
2.6 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . p. 36
3 Escalonamento de Processos e Balanceamento de Carga em Simulações
Distribuídas p. 37
3.1 Escalonamento de processos em sistemas distribuıdos . . . . . . . p. 38
3.2 Classificacao dos tipos de balanceamento para simulacoes distri-
buıdas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 39
3.3 Migracao de processos . . . . . . . . . . . . . . . . . . . . . . . . p. 41
3.4 Fatores que causam desbalanceamento da carga em simulacoes
distribuıdas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 41
3.5 Algoritmos de escalonamento para simulacao distribuıda . . . . . p. 43
3.5.1 Algoritmo da utilizacao efetiva do processador . . . . . . . p. 44
3.5.2 Algoritmo da metrica do relogio local . . . . . . . . . . . . p. 47
3.5.3 Algoritmo probabilıstico . . . . . . . . . . . . . . . . . . . p. 50
3.5.4 SGs - Strong Groups . . . . . . . . . . . . . . . . . . . . p. 51
3.5.5 BGE - Background Execution . . . . . . . . . . . . . . p. 55
3.5.6 Outros Algoritmos . . . . . . . . . . . . . . . . . . . . . . p. 59
3.6 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . p. 62
4 Adaptações na implementação do protocolo Time Warp e migração
de processos p. 64
4.1 Arquitetura original do ambiente . . . . . . . . . . . . . . . . . . p. 65

4.2 Implementacao do algoritmo de Mattern para calculo do GVT . . p. 70
4.3 Gerenciamento de memoria . . . . . . . . . . . . . . . . . . . . . p. 73
4.4 Salvamento das informacoes da simulacao . . . . . . . . . . . . . . p. 75
4.5 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . p. 76
5 Algoritmo de balanceamento e métricas avaliadas p. 78
5.1 Metricas avaliadas . . . . . . . . . . . . . . . . . . . . . . . . . . p. 78
5.1.1 Metrica do relogio local . . . . . . . . . . . . . . . . . . . . p. 78
5.1.2 Utilizacao efetiva do processador . . . . . . . . . . . . . . p. 79
5.1.3 PAT - Processor Advance Time . . . . . . . . . . . . . p. 79
5.1.4 EEW - Expected Effective Work . . . . . . . . . . . . p. 80
5.2 Calculo das metricas . . . . . . . . . . . . . . . . . . . . . . . . . p. 81
5.3 Algoritmo de escalonamento desenvolvido . . . . . . . . . . . . . . p. 84
5.4 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . p. 88
6 Modelos de simulação e variações de carga p. 89
6.1 Configuracoes dos parametros da simulacao . . . . . . . . . . . . . p. 89
6.2 Cluster de execucao . . . . . . . . . . . . . . . . . . . . . . . . . p. 91
6.3 Modelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 92
6.3.1 Modelo de grupos . . . . . . . . . . . . . . . . . . . . . . . p. 92
6.3.2 Hierarchical Network Model - hnet . . . . . . . . . . p. 94
6.3.3 Distributed Network Model - dnet . . . . . . . . . . . p. 96
6.4 Variacoes de carga . . . . . . . . . . . . . . . . . . . . . . . . . . p. 97

6.5 Simulacoes realizadas . . . . . . . . . . . . . . . . . . . . . . . . . p. 99
6.6 Consideracoes Finais . . . . . . . . . . . . . . . . . . . . . . . . . p. 100
7 Análises dos resultados p. 101
7.1 Analise de desempenho com o modelo dnet . . . . . . . . . . . . p. 102
7.2 Analise de desempenho com o modelo de grupos . . . . . . . . . . p. 106
7.3 Analise de desempenho com o modelo hnet . . . . . . . . . . . . p. 109
7.4 Analise de desempenho em relacao a todos os modelos . . . . . . p. 112
8 Conclusão p. 117
8.1 Contribuicoes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 119
8.2 Trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 120
Referências p. 121

Lista de Figuras
1 Violacao da relacao de causa e efeito. . . . . . . . . . . . . . . . . p. 25
2 Exemplos de cortes. C1 consistente e C2 inconsistente. . . . . . . p. 34
3 Cortes usados para determinar mensagens transientes. . . . . . . . p. 35
4 Modelo de fila, grafo de interconexao, SCCs e SGs (SOM; SAR-
GENT, 2000). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 52
5 Strong Groups e Mapeamento (SOM; SARGENT, 2000). . . . . . . . p. 54
6 Diagrama de atividades do processo mestre na migracao coletiva
de processos (JUNQUEIRA, 2012). . . . . . . . . . . . . . . . . . . p. 67
7 Atividades da thread principal dos processos da simulacao (JUN-
QUEIRA, 2012). . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 69
8 Atividades da thread de sincronismo dos processos da simulacao
(JUNQUEIRA, 2012). . . . . . . . . . . . . . . . . . . . . . . . . . p. 71
9 Interacao entre o processo mestre e os processos da simulacao para
coletar informacoes. . . . . . . . . . . . . . . . . . . . . . . . . . . p. 74
10 Modelo de grupos . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 94
11 Modelo hierarquico . . . . . . . . . . . . . . . . . . . . . . . . . . p. 95
12 Modelo distribuıdo . . . . . . . . . . . . . . . . . . . . . . . . . . p. 97
13 Eficiencia das metricas no modelo dnet . . . . . . . . . . . . . . . p. 103
14 Tempo de execucao para cada metrica no modelo dnet . . . . . . p. 104

15 Numero de migracoes para cada metrica no modelo dnet . . . . . p. 105
16 Eficiencia das metricas no modelo de grupos . . . . . . . . . . . . p. 107
17 Tempo de execucao para cada metrica no modelo de grupos . . . p. 108
18 Numero de migracoes para cada metrica no modelo de grupos . . p. 109
19 Eficiencia das metricas no modelo hnet . . . . . . . . . . . . . . . p. 110
20 Tempo de execucao para cada metrica no modelo hnet . . . . . . p. 111
21 Numero de migracoes para cada metrica no modelo hnet . . . . . p. 112
22 Eficiencia das metricas em relacao aos tres modelos (grupos, hnet
e dnet) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 113
23 Numero de migracoes para cada metrica em relacao aos tres mo-
delos (grupos, hnet e dnet) . . . . . . . . . . . . . . . . . . . . . . p. 114
24 Tempo de execucao para cada metrica em relacao aos tres modelos
(grupos, hnet e dnet) . . . . . . . . . . . . . . . . . . . . . . . . . p. 115

Lista de Tabelas
1 Carga e recebimento de mensagens de um processo de cada grupo
em relacao a toda a carga . . . . . . . . . . . . . . . . . . . . . . p. 93

13
Lista de Siglas
BGE Background Execution
CAT Cluster Advance Time
CPC Cluster-to-Processor Communication
CPU Unidade Central de Processamento
EEW Expected Effective Work
GVT Global Virtual Time
LVT Local Virtual Time
MPI Message Passing Interface
MRIP Multiple Replication in Parallel
NOW Network of Workstations
PAT Processor Advance Time
PCS Processor Communication Speed
PPC Processor-to-Processor Communication
SCC Strongly Connected Components
SD Sistema Distribuıdo
SGs Strong Groups

SRIP Single Replication in Parallel
STF Smallest Timestamp First

15
1 Introdução
O processo de desenvolvimento de sistemas complexos necessita de ferramentas
de apoio ao desenvolvimento e de avaliacao, pois e importante identificar a abor-
dagem mais apropriada. As ferramentas de apoio sao as solucoes mais indicadas
em situacoes onde a criacao de prototipos pode ser difıcil ou nao apropriada em
relacao a tempo e custo (FUJIMOTO, 2000).
Uma simulacao e um processamento que modela o comportamento de algum
sistema e vem sendo cada vez mais utilizada devido a sua flexibilidade e baixo
custo (AGARWAL; HYBINETTE; XIONG, 2005). Uma simulacao resulta da modela-
gem de um processo ou sistema e permite realizar experimentos com um modelo,
permitindo uma analise sobre seu comportamento.
A simulacao vem sendo usada em diversas areas, tais como: aplicacoes mili-
tares (simuladores de guerra, tanques, voos), entretenimento (criacao de mundos
virtuais para jogos), educacao (como o treinamento de medicos cirurgioes), na area
de redes (avaliacao de hardwares, softwares e/ou protocolos), desenvolvimento de
circuitos digitais e sistemas computacionais, transportes (no controle de trafego,
por exemplo), manufatura (planejamento de producao), dentre outros (KASSAB et
al., 2011; BANKS et al., 2008; MEDINA; CHWIF, 2007; FUJIMOTO, 2000).
Um Sistema Distribuıdo (SD) e um sistema formado por um conjunto de com-
putadores (nos) independentes, que colaboram entre si e aparecem para seus usua-
rios como um sistema unico. O escalonamento de processos e responsavel pela
alocacao e redistribuicao dos processos, com o objetivo de balancear a carga e

16
alcancar um melhor desempenho. Um ambiente paralelo e uma colecao de fer-
ramentas de software executando sobre um cluster, possibilitando a execucao de
aplicacoes distribuıdas (TANENBAUM; STEEN, 2006).
Simular um modelo complexo de maneira sequencial, em um unico processa-
dor, pode requerer muito recurso de processamento e levar muito tempo para ser
executado. Esse fator justifica a utilizacao de ambientes paralelos para a execucao
de simulacoes. A simulacao distribuıda consiste na execucao de um programa de
simulacao em um SD. A paralelizacao do modelo visa aumentar a velocidade de
execucao da simulacao, objetivando simular sistemas complexos em menor tempo
(CHWIF; PAUL; BARRETTO, 2006; FUJIMOTO, 2003).
Uma simulacao sequencial necessita de algumas estruturas de dados para con-
trolar a execucao da simulacao. Os eventos da simulacao precisam ser executados
em ordem, normalmente seguindo uma ordem cronologica, para evitar inconsis-
tencias conhecidas como erros de causa e efeito. Essa natureza sequencial de uma
simulacao faz com que as simulacoes distribuıdas, alem de necessitar das estruturas
de dados de uma simulacao sequencial, tambem necessitem de outras estruturas
especıficas para garantir a ordenacao dos eventos. Essas estruturas especıficas
dependem da abordagem de sincronizacao de processos adotada, sendo a sincroni-
zacao de processos o problema central das simulacoes distribuıdas (CAROTHERS;
FUJIMOTO, 2000).
Os protocolos de sincronizacao de processos sao classificados como conserva-
tivos ou otimistas. Nos protocolos conservativos, a execucao dos eventos so e
permitida quando e certo que a ordenacao dos eventos nao sera violada. Os proto-
colos otimistas nao restringem a execucao dos eventos. Partem da ideia otimista
de que nao havera erros de ordenacao. No entanto, esses erros podem ocorrer e,
quando ocorrerem, os protocolos otimistas devem ser capazes de retornar a com-
putacao ao ultimo ponto consistente, ou seja, aquele imediatamente anterior ao
erro de ordenacao. O Time Warp, proposto por Jefferson (1985), e o Rollback
Solidario, proposto por Moreira (2005) sao exemplos de protocolos otimistas.

17
Sao muitas as tecnicas utilizadas para otimizacao do desempenho de simulacoes
distribuıdas. Fujimoto (2000) afirma que, dentre essas tecnicas, as que mais se des-
tacam sao as tecnicas de balanceamento de carga. Os algoritmos de balanceamento
de carga desenvolvidos especificamente para simulacao distribuıda apresentam me-
lhor desempenho que os desenvolvidos para aplicacoes paralelas tradicionais.
Os algoritmos de escalonamento estaticos baseiam-se em uma analise estatica
do modelo, realizam a alocacao dos processos no inıcio da execucao do sistema e
essa alocacao inicial nao e mais alterada ate o fim da execucao. O escalonamento
dinamico de processos realiza o balanceamento da carga em tempo real, ou seja,
durante a execucao do sistema e, atraves de migracoes, distribui os processos na
tentativa de equilibrar a carga. De Grande e Boukerche (2011) afirmam que o
balanceamento estatico e limitado a alguns tipos de aplicacoes, sendo incapaz de
tratar as variacoes dinamicas de carga presentes em muitas aplicacoes distribuıdas.
1.1 Motivação
Diversos mecanismos de balanceamento de carga para simulacao distribuıda fo-
ram propostos, como, por exemplo, o algoritmo da utilizacao efetiva do processador
(REIHER; JEFFERSON, 1990), o algoritmo da metrica do relogio local (BURDORF;
MARTI, 1993) e o BGE (CAROTHERS; FUJIMOTO, 2000). Cada mecanismo apre-
senta suas regras especıficas e se baseia em metricas, ou variacoes de uma mesma
metrica, que estimam a carga do sistema e sao utilizadas na tentativa de um melhor
balanceamento da carga.
A motivacao para a proposta deste trabalho vem do fato de que os estudos
anteriores nao avaliam as metricas individualmente, os objetivos eram avaliar os
algoritmos como um todo. Nesses trabalhos, as metricas sao avaliadas conside-
rando diferentes algoritmos, modelos e fatores de desbalanceamento de carga, ou
seja, nao avaliam as metricas sob a otica de um mesmo algoritmo de balancea-
mento, usando os mesmos modelos e com os mesmos fatores de desbalanceamento

18
de carga.
Considerando o desempenho superior dos protocolos otimistas em relacao aos
protocolos conservativos, o desempenho superior dos mecanismos de balancea-
mento dinamicos em relacao aos mecanismos de balanceamento estaticos e o fato de
que o balanceamento de carga e a principal tecnica de otimizacao para simulacoes
distribuıdas, esse trabalho realizou uma analise sobre as principais metricas para
escalonamento dinamico de processos em simulacao distribuıda usando o protocolo
otimista Time Warp, o mais conhecido dentre os protocolos otimistas.
O estudo dos algoritmos de balanceamento de carga e dos fatores que contri-
buem para o desbalanceamento de uma simulacao tambem motivou a proposta de
uma nova metrica para balanceamento de carga para simulacoes distribuıdas que
utilizam protocolos otimistas.
1.2 Objetivos
O objetivo deste trabalho e avaliar as metricas de balanceamento de carga
utilizadas pelos principais algoritmos de balanceamento de carga para simulacoes
distribuıdas que utilizam os protocolos otimistas, bem como propor uma nova
metrica que podera ser utilizada por algoritmos de balanceamento executando
nesses ambientes.
Durante a pesquisa, foram realizadas as seguintes atividades:
• Implementacao de um algoritmo de balanceamento de carga dinamico para
simulacao distribuıda que permite o uso de diferentes metricas. Desenvolvido
com o proposito de avaliar as metricas sob a otica de um unico mecanismo
de balanceamento;
• Desenvolvimento de uma nova metrica para ındices de carga baseada nos
diversos fatores que causam o desbalanceamento da carga, alem de uma

19
avaliacao dessa metrica juntamente com as outras metricas propostas ante-
riormente;
• Execucao do algoritmo de balanceamento implementado para cada uma das
metricas, considerando os mesmos modelos de simulacao, as mesmas varia-
coes de carga e o mesmo ambiente de execucao.
Com o intuito de analisar as metricas, este trabalho apresenta as especificacoes
das mesmas, a forma como foram calculadas, o algoritmo de escalonamento desen-
volvido, o ambiente onde as simulacoes foram executadas, os modelos de simulacao
utilizados e as variacoes de carga impostas.
1.3 Estrutura da dissertação
A dissertacao foi estruturada de forma que a parte conceitual necessaria para
seu entendimento fosse apresentada no Capıtulo 2. Esse capıtulo faz uma introdu-
cao sobre SDs, ambientes paralelos, simulacao e simulacao distribuıda. Apresenta
tambem a classificacao das simulacoes distribuıdas e os principais mecanismos de
sincronizacao de processos.
O Capıtulo 3 aborda o escalonamento de processos e o balanceamento de carga.
Apresenta os principais fatores do desbalanceamento de carga e os principais algo-
ritmos de balanceamento de carga para simulacoes distribuıdas.
As adaptacoes na implementacao do protocolo Time Warp e no mecanismo de
migracao de processos, necessarias para a realizacao do trabalho, sao apresentadas
no Capıtulo 4.
O Capıtulo 5 apresenta as metricas avaliadas, a forma como elas foram cal-
culadas e o algoritmo de balanceamento proposto para avalia-las. Esse capıtulo
tambem introduz a nova metrica proposta.
As configuracoes dos parametros das simulacoes, o ambiente de execucao, os

20
modelos de simulacao propostos e as variacoes de carga impostas sao detalhados
no Capıtulo 6.
O Capıtulo 7 apresenta uma analise dos resultados obtidos e o Capıtulo 8
apresenta as conclusoes, contribuicoes e sugestoes para trabalhos futuros.

21
2 Simulação e simulação distribuída
Este capıtulo apresenta conceitos importantes para o entendimento de simula-
cao e simulacao distribuıda.
2.1 Sistemas Distribuídos
Diversas definicoes sobre SDs sao apresentadas na literatura, sendo, muitas
vezes, discordantes entre si.
Lamport, Shostack e Paese (1982) definem um SD como aquele onde a falha de
uma maquina, cuja existencia e desconhecida pelo usuario, impede que o mesmo
obtenha um determinado servico solicitado.
Segundo Coulouris, Dollimore e Kindberg (2005), um SD e um sistema cujos
componentes, de hardware ou software, localizados em uma rede de computadores,
se comunicam e coordenam suas acoes apenas atraves da troca de mensagens.
Para Tanenbaum e Steen (2006), um SD e um conjunto de computadores
independentes, cooperando entre si e apresentando-se para os usuarios de forma
transparente, como se fosse um unico sistema.
Ja Belapurkar et al. (2009) definem um SD como aquele que envolve a interacao
entre entidades diferentes e independentes, se comunicando atraves de linguagens
e protocolos estabelecidos e trabalhando em um objetivo comum.
Os SDs possuem diversas vantagens em relacao aos sistemas centralizados,

22
tais como, a extensibilidade, capacidade de crescer gradativamente, o comparti-
lhamento de recursos, a replicacao, que aumenta a disponibilidade do sistema, e a
mobilidade dada aos usuarios, que podem acessar o sistema de diferentes lugares.
Como desvantagens, podem ser destacadas as dificuldades no controle de acesso dos
usuarios, na manutencao da integridade dos dados replicados, no gerenciamento de
acesso aos recursos, como por exemplo, alocacao de tempo de CPU, na garantia de
desempenho, que depende da arquitetura fısica da rede, e em relacao a seguranca
das informacoes colocadas na rede (TANENBAUM; STEEN, 2006; BELAPURKAR et
al., 2009).
2.2 Ambiente paralelo distribuído
Os SDs dao suporte a computacao paralela por meio de clusters de computa-
dores, tambem conhecidos como redes de estacoes de trabalho (Network of Works-
tations - NOW) . Um cluster e um conjunto de computadores conectados por uma
rede de comunicacao. Alem de dar suporte as aplicacoes paralelas, os clusters
sao utilizados para outras finalidades, como, por exemplo, alta disponibilidade de
aplicacoes (TANENBAUM; STEEN, 2006).
Pitanga (2003) classifica os clusters da seguinte forma:
• Cluster de alto desempenho: permite que computadores comuns possam
lidar com uma grande carga de processamento;
• Cluster de alta disponibilidade: capaz de permanecer ativo por longos
perıodos de tempo;
• Cluster para balanceamento de carga: controla a distribuicao de carga
entre os nos.
Para Tanenbaum e Steen (2006), um ambiente paralelo distribuıdo e uma cole-
cao de ferramentas de software executando sobre um cluster, criando uma camada

23
onde aplicacoes distribuıdas podem ser executadas, possuindo as seguintes funcoes:
• Gerenciamento de recursos: conhecimento sobre a estrutura do cluster.
Numero de hosts, configuracao dos hosts e informacoes de enderecamento,
por exemplo;
• Gerenciamento de processos: gerenciamento das aplicacoes e processos
em execucao. Criacao, destruicao e alocacao de processos;
• Passagem de mensagens entre processos: permite a comunicacao entre
os processos. Com o auxilio do ambiente, a troca de mensagens entre os
processos e realizada de forma transparente.
O Capıtulo 4 descreve o ambiente distribuıdo sobre o qual foram realizados os
experimentos deste trabalho.
2.3 Simulação e simulação distribuída
Schriber e Brunner (2002) afirmam que uma simulacao resulta da modelagem
de um processo ou sistema, de modo que o modelo imite as respostas do sistema
real em uma sequencia de eventos.
Uma simulacao consiste em avaliar um modelo matematicamente, onde os
dados gerados sao utilizados para estimar as caracterısticas relevantes do modelo
(LAW, 2007; CASSANDRAS; LAFORTUNE, 2008).
Atraves da simulacao computacional, e possıvel modelar sistemas existentes
e/ou conceituais. E a representacao de um processo do mundo real sobre o tempo,
com a geracao de um historico artificial do sistema que permite inferir sobre as
caracterısticas do sistema real (BANKS et al., 2008).
Para Law (2007), ha problemas complexos do mundo real que so podem ser
analisados atraves de simulacoes.

24
Em uma simulacao computacional, o programa representa as mudancas de
estados do sistema fısico simulado. A simulacao deve possuir algumas informacoes
que possibilitem a representacao do sistema fısico, sao elas: (1) uma estrutura
que represente os estados do sistema, (2) uma forma de mostrar as mudancas de
estados e a evolucao do sistema e (3) alguma forma de representar o tempo.
O tempo de simulacao segue algumas regras diferentes das regras de tempo
fısico. O tempo de simulacao e um conjunto de valores ordenados (tempos logicos),
onde cada valor representa um instante do tempo fısico do sistema que esta sendo
simulado. Essa ordenacao do tempo segue as seguintes regras: seja L1 o tempo
logico que representa o tempo fısico F1 e L2 o tempo logico que representa o
tempo fısico F2. Se L1 < L2, entao F1 ocorreu antes de F2 e L1 ocorreu antes de
L2. Se L1 > L2, entao F1 ocorreu depois de F2 e L1 ocorreu depois de L2. Essa
natureza sequencial dos eventos de uma simulacao sequencial e o grande problema
enfrentado quando se deseja converter uma simulacao sequencial em uma simulacao
distribuıda.
Lamport (1978) observou que, em um sistema centralizado, o conhecimento do
tempo real e irrelevante para a ordenacao dos eventos. Sendo assim, concluiu que,
em um SD, o importante e conhecer a ordem de execucao dos eventos e nao o tempo
real de cada um deles. Propos que um SD deve ser visto como uma sequencia de
eventos discretos, possibilitando a construcao de uma relacao de causalidade entre
os eventos. Essa relacao de precedencia causal diz que, se um evento x precede um
evento y, entao, todos os processos devem concordar com o fato de que x ocorre
antes de y. A relacao de causa e efeito acontece se: (1) x e y sao eventos do
mesmo processo e se x ocorre antes de y ou (2) se x e o evento de envio de uma
mensagem por um processo Pi e y e o evento de recebimento, em um processo Pj,
da mensagem enviada pelo evento x. Um erro de causa e efeito ocorre quando a
relacao de precedencia causal e violada.
A Figura 1 ilustra um erro de causa e efeito. A mensagem enviada pelo processo
P01 ao processo P02, com timestamp 3, viola a precedencia causal, pois o processo

25
P02 ja esta no tempo logico 4. Uma mensagem que viola a precedencia causal e
normalmente conhecida como mensagem straggler. O relogio local de um processo
e conhecido como Local Virtual Time (LVT) e o relogio logico global da simulacao,
que e o menor LVT dentre todos os LVTs dos processos da simulacao, e conhecido
como Global Virtual Time (GVT). Cada evento possui um timestamp, um valor
que indica quando uma mudanca deve acontecer no estado do sistema e os ordena
cronologicamente.
Figura 1: Violacao da relacao de causa e efeito.
Para projetar uma simulacao, e necessario construir uma descricao do sistema a
ser simulado. Essa descricao caracteriza um modelo, que contem as caracterısticas
representativas do sistema real. A simulacao do modelo potencializa resultados
mais precisos sem a necessidade de intervencao no sistema real.
Os modelos devem ser complexos o suficiente para responder as questoes levan-
tadas, mas nao devem ser tao complexos quanto o sistema real. O modelo e uma

26
simplificacao do sistema real, aproximando-se de seu comportamento. Se o modelo
tiver uma complexidade maior que a do sistema real, passa a ser um problema, e
nao apenas um modelo (MEDINA; CHWIF, 2007).
Os modelos podem ser classificados como discretos ou contınuos. Os modelos
discretos representam sistemas onde as mudancas de estado ocorrem em pontos
especıficos e nao contınuos no tempo simulado. Um banco e um exemplo de um
modelo discreto, onde o estado do sistema muda discretamente no tempo (numero
de clientes no banco, que e alterado quando um cliente entra ou sai do banco, por
exemplo). Os modelos contınuos simulam sistemas onde as mudancas de estado
ocorrem continuamente ao longo da simulacao. Um aviao em voo e um exemplo de
um modelo contınuo, com o estado do sistema mudando continuamente no tempo
(posicao e velocidade do aviao, por exemplo) (LAW, 2007). Os modelos discretos
sao mais indicados para a representacao de sistemas computacionais, devido ao
comportamento discreto desses sistemas.
A utilizacao de SDs vem se tornando a forma mais viavel para a execucao
de simulacoes distribuıdas. Duas abordagens vem sendo utilizadas, a Multiple
Replication in Parallel (MRIP) e a Single Replication in Parallel (SRIP).
2.4 MRIP
A MRIP considera a paralelizacao de replicas de um programa de simulacao.
O programa de simulacao nao precisa ser dividido em varias entidades de processa-
mento. Ao inves disso, sao utilizadas multiplas instancias do mesmo programa de
simulacao sequencial, porem, executando em paralelo, cada instancia executando
em um processador de forma independente (BAUSE; EICKHOFF, 2003).
As instancias independentes enviam continuamente informacoes para um pro-
cesso controlador, que faz uma analise global dos parametros da simulacao. Atraves
da analise dos parametros, o analisador global determina se ha simulacoes sufici-
entes para a precisao requerida para tomada de decisao e, quando essa precisao e

27
alcancada, a simulacao pode ser encerrada.
As principais vantagens da abordagem MRIP sao:
1. Pode ser aplicada a qualquer programa de simulacao, sem a necessidade de
altera-lo;
2. Facilidade de uso e aplicacao;
3. Devido a independencia das simulacoes, se n simulacoes estao sendo execu-
tadas, entao serao produzidos n resultados. O speedup e relativo ao numero
de processares;
4. Apresenta alta tolerancia a falhas, pois a falha em uma simulacao nao afeta
as outras. O ponto fraco e o analisador global que, em caso de falhas, com-
promete toda a simulacao.
A abordagem MRIP so nao se aplica quando o tamanho do modelo e grande
e a replicacao em um unico processador levaria muito tempo para ser executada
ou quando o resultado de cada replicacao e semelhante, tornando a replicacao
ineficiente.
2.5 SRIP
A SRIP considera a paralelizacao de um mesmo programa de simulacao. Di-
vide o modelo de simulacao e simula cada uma das partes em um processador
diferente. A utilizacao de diversos processadores requer uma adaptacao em rela-
cao a simulacao sequencial. Dois pontos sao identificados nessa adaptacao: (1)
o sincronismo entre os processos concorrentes e (2) as ferramentas usadas para
implementar o paralelismo do programa (KUMAR, 2003). Nessa abordagem, o pro-
grama de simulacao e dividido em varios processos. Os processos interagem uns
com os outros exclusivamente pela troca de mensagens (eventos com timestamps).

28
Uma simulacao sequencial necessita de algumas estruturas, que sao as variaveis
de estado, uma lista de eventos futuros e um relogio global. Os eventos precisam
ser executados em sua ordem cronologica de timestamps, para evitar erros de causa
e efeito. A simulacao consiste basicamente em continuamente retirar e executar
eventos da lista de eventos futuros. Uma simulacao distribuıda, alem de neces-
sitar das estruturas de uma simulacao sequencial, tambem necessita de outras
estruturas especıficas para a simulacao distribuıda, que depende da abordagem de
sincronizacao de processos adotada (FUJIMOTO, 2000).
2.5.1 Protocolos de sincronismo
Uma simulacao sequencial se baseia em uma lista de eventos futuros, ordenada
pelo tempo em que eles devem ser executados. Na abordagem SRIP, onde a simu-
lacao e dividida em diversos elementos de processamento, e necessaria a utilizacao
de um protocolo de sincronismo para garantir que a execucao dos eventos siga a
ordem cronologica.
Uma simulacao executada de forma distribuıda deve apresentar os mesmos
resultados de quando executada de maneira sequencial. Isso so e possıvel atraves
de mecanismos de sincronizacao, nao necessarios em uma simulacao sequencial,
pois os eventos ja ocorrerem naturalmente ordenados. Sincronizar uma simulacao
distribuıda consiste em evitar ou corrigir erros de causalidade no sistema sendo
simulado. Fujimoto (2000) afirma que esse e um problema central na simulacao
distribuıda e que os mecanismos de sincronizacao, classificados como conservativos
ou otimistas, foram desenvolvidos visando tratar esse problema de ordenacao da
execucao dos eventos.
Nos protocolos conservativos, a execucao de um evento x so e permitida
se nao houver possibilidade da ocorrencia de um novo evento y com o tempo
cronologico anterior ao tempo cronologico de x, ou seja, impede a ocorrencia de
erros de causa e efeito. Ja os protocolos otimistas nao se preocupam se e seguro
executar um determinado evento. Baseiam-se na ideia de que erros de causa e

29
efeito nao irao acontecer, mas, caso ocorram, os protocolos otimistas devem ser
capazes de retornar a computacao ao ultimo ponto consistente.
2.5.2 Protocolos conservativos
Os primeiros protocolos de sincronizacao criados se basearam na abordagem
conservativa, que tem como principal funcao determinar quando e seguro processar
um determinado evento (FUJIMOTO, 2000). Um processo da simulacao so pode
processar um evento da sua lista de eventos futuros se houver garantia de que a
execucao do evento nao levara a ocorrencia de erros de causa e efeito.
Um conceito importante para os protocolos conservativos e o lookahead. O
lookahead e definido como sendo o intervalo de tempo em que um processo pode
prever, com certeza, o que ira acontecer na simulacao, sendo possıvel avancar ate
um determinado ponto sem a possibilidade de receber mensagens de outros proces-
sos com timestamp menor que o intervalo de duracao do lookahead. Um lookahead
l indica que o processo nao recebera nenhuma mensagem com timestamp menor
que t + l, sendo t o LVT do processo. O lookahead e o principal responsavel pelo
desempenho de uma simulacao distribuıda que utiliza protocolos de sincronizacao
conservativos. Em geral, tenta-se buscar o maior lookahead possıvel para aumentar
o desempenho da simulacao (BRYANT, 1977; CHANDY; MISRA, 1979).
Um processo poderia determinar se e seguro executar o proximo evento da sua
lista de eventos futuros observando o timestamp das ultimas mensagens recebidas
dos processos com os quais ele se comunica. Se o seu LVT for menor que o menor
timestamp entre as ultimas mensagens recebidas de cada processo, entao e seguro
executar o proximo evento de sua lista de eventos futuros.
Um problema comum, com o qual os protocolos conservativos precisam convi-
ver, e a ocorrencia de deadlocks, que podem ocorrer quando os processos esperam
por uma possibilidade de ocorrencia de erros de causa e efeito, ficando parados e
nao avancando na simulacao.

30
O protocolo Chandy Misra Bryant (CMB), desenvolvido de maneira indepen-
dente por BRYANT (1977) e CHANDY e MISRA (1979), e o mais conhecido dos
protocolos conservativos e leva em seu nome uma homenagem aos seus criadores.
2.5.3 Protocolos Otimistas
Os protocolos otimistas nao se previnem da ocorrencia de erros de causalidade.
Nao impedem que os processos executem os eventos da lista de eventos futuros
mesmo que isso leve a erros de causa e efeito. Na ocorrencia de tais erros, os
protocolos otimistas possuem mecanismos para corrigir os erros, permitindo que a
simulacao se mantenha consistente.
Nos protocolos otimistas, nao e necessario que os processos enviem mensagens
na ordem de seus timestamps, os canais de comunicacao nao precisam garantir a
entrega das mensagens na mesma ordem de envio, processos podem ser criados ou
encerrados durante a execucao da simulacao e tambem nao e necessario definir,
previamente, com quais processos um determinado processo pode se comunicar.
A maneira de restaurar a simulacao para um estado consistente e conhecida
como rollback. Um rollback retorna a computacao a um ponto especifico consis-
tente, simulando novamente os eventos afetados. Ao receber uma mensagem com
timestamp menor que seu LVT, o processo restaura o estado salvo imediatamente
anterior ao timestamp da mensagem, processa a mensagem recebida e prossegue
com a simulacao a partir desse ponto.
Os protocolos otimistas precisam tratar de dois fatores que podem compro-
meter o desempenho de uma simulacao, que sao a ocorrencia de rollbacks e a
necessidade de armazenar, continuamente, os estados de cada processo para pos-
sibilitar um possıvel rollback. A ocorrencia de um rollback, alem de fazer um
processo perder o tempo gasto com a execucao dos eventos desfeitos, o obriga a
avisar os processos aos quais ele tenha enviado mensagens anteriores ao rollback,
podendo causar rollbacks nesses processos. A necessidade de armazenar os estados

31
dos processos eleva o consumo da memoria e requer que seja implementado um
bom mecanismo para o seu gerenciamento.
A principal vantagem dos protocolos otimistas em relacao aos protocolos con-
servativos e possibilitar uma melhor exploracao do paralelismo, pois nao bloqueiam
processos em situacoes de possıveis erros de causalidade que acabam nao aconte-
cendo. O tratamento dos erros de causalidade permite que os protocolos otimistas
explorem o paralelismo dos modelos, apresentando desempenhos superiores em
relacao aos protocolos conservativos (LAW, 2007).
O Time Warp, proposto por Jefferson (1985), e o protocolo otimista para sin-
cronizacao de simulacoes distribuıdas mais conhecido (MALIK; PARK; FUJIMOTO,
2009). Os conceitos e mecanismos fundamentais, tais como rollback, anti-mensagens
e controle local e global do tempo de simulacao, usados pelos protocolos otimistas,
foram inicialmente introduzidos pelo Time Warp.
O Rollback Solidario (Solidary Rollback), proposto por (MOREIRA, 2005), e um
outro protocolo otimista para sincronizacao de simulacoes distribuıdas. O Rollback
Solidario (Solidary Rollback) utiliza o conceito de checkpoints globais consistentes
(BABAOGLU; MARZULLO, 1993) para identificar os pontos da simulacao para onde
os processos deverao retroceder em caso de rollbacks.
Esses protocolos se diferenciam na forma como realizam o procedimento para
recuperar a computacao a um estado consistente.
2.5.3.1 Time Warp
O protocolo Time Warp e constituıdo por duas partes distintas: (1) um con-
trole local, interno a cada processo e responsavel por garantir que os eventos do
processo sejam executados em ordem cronologica, utilizando a polıtica de escalo-
namento Smallest Timestamp First (STF) e (2) um controle global responsavel
por questoes globais, tais como gerenciamento de memoria e calculo do GVT da
simulacao (JEFFERSON, 1985).

32
Cada processo no Time Warp possui as seguintes informacoes e caracterısticas:
• LVT: relogio virtual local do processo;
• Estado: conjunto de variaveis que caracterizam o estado corrente do pro-
cesso;
• Lista de eventos futuros: inclui todos os eventos que foram escalonados
ao processo e ainda nao foram processados. Os eventos escalonados podem
ser resultantes de mensagens recebidas de outros processos da simulacao e
sao ordenados pela ordem cronologica de seus timestamps ;
• Lista de mensagens negativas: tambem conhecidas como anti-mensagens,
sao as mensagens enviadas a outros processos. Essa lista so e utilizada em
caso de rollbacks ;
• Lista de estados: os processos salvam copias de seu estado a cada evento
processado, para permitir a restauracao em caso de rollbacks ;
• As mensagens carregam duas marcas de tempo: o tempo virtual de
envio, que e o LVT do processo emissor, e o tempo virtual de recebimento,
que representa o tempo de simulacao e e chamado de timestamp;
Duas situacoes podem levar um processo a realizar um rollback. A chegada de
uma mensagem straggler ou a chegada de uma anti-mensagem.
Uma mensagem recebida por um processo, contendo um timestamp menor do
que o seu LVT (straggler), leva o processo a realizar um rollback conhecido como
rollback primario.
Quando um processo realiza um rollback primario, para cada mensagem envi-
ada por ele com timestamp maior que o LVT de retorno, o processo devera enviar
uma mensagem indicando que ele realizou um rollback. Essas mensagens sao as que
ficam armazenadas na lista de mensagens negativas. Para cada mensagem existe

33
uma anti-mensagem. As duas mensagens sao iguais, apenas com o sinal invertido.
Uma mensagem possui sinal positivo e sua anti-mensagem correspondente possui
sinal negativo.
Ao receber uma anti-mensagem, um processo executa uma das duas seguintes
acoes:
1. Se o evento correspondente a anti-mensagem ainda nao foi processado, ou
seja, ainda esta em sua na lista de eventos futuros, o processo remove o
evento da sua lista de eventos; ou
2. Se o evento correspondente a anti-mensagem ja foi processado, o processo
deve realizar um rollback para o estado imediatamente anterior ao times-
tamp da anti-mensagem. Esse tipo de rollback e conhecido como rollback
secundario.
Em redes que nao garantem a ordenacao das mensagens, pode acontecer de
uma anti-mensagem chegar antes de sua mensagem correspondente. Caso isso
aconteca, o processo deve armazenar a anti-mensagem e, quando a mensagem
correspondente chegar, eliminar ambas.
O mecanismo de controle global, usado em atividades como o gerenciamento
da memoria e como informacao de entrada para algoritmos de balanceamento de
carga, tem como ponto central o calculo do GVT. Jefferson (1985) define o GVT
no tempo real r como sendo o menor valor entre: (1) os LVTs de todos os processos
da simulacao no tempo r e (2) os timestamps de todas as mensagens em transito
no tempo r. O GVT serve como limite inferior para os tempos virtuais, indicando
que qualquer informacao anterior a esse tempo pode ser descartada.
O algoritmo de Mattern (1993) e um dos mecanismos mais eficientes para o
calculo do GVT e sera explicado a seguir por ter sido o mecanismo implementado
no presente trabalho.

34
2.5.3.2 Algoritmo de Mattern para o cálculo do GVT
Esse mecanismo faz uso do conceito de corte consistente, dividindo a execucao
da simulacao em partes, que permitem obter uma fotografia da simulacao e, dessa
forma, calcular o GVT.
Um corte e um subconjunto dos eventos executados pela simulacao distribuıda
e o conjunto formado pelo ultimo evento de cada processo contido no corte e
conhecido como a fronteira do corte. Um corte e dito consistente se todas as
mensagens que atravessam o corte tem sua origem a esquerda do corte. Dessa
forma, um corte consistente e fechado a esquerda em relacao a precedencia causal.
Na Figura 2, o corte C1, fronteira P01(3), P02(2), P03(3), e consistente, pois
a unica mensagem que passa pelo corte possui sua origem a esquerda do corte.
O corte C2, fronteira P01(3), P02(2), P03(4), nao e consistente, pois umas das
mensagens que passa pelo corte possui sua origem a direita do corte.
Figura 2: Exemplos de cortes. C1 consistente e C2 inconsistente.

35
A fronteira de um corte consistente inclui os estados locais dos processos e todas
as mensagens transientes que passam pelo corte. O algoritmo de Mattern (1993)
usa essas informacoes para realizar o calculo do GVT. O algoritmo determina
as mensagens transientes utilizando dois cortes e calcula o GVT na fronteira do
segundo corte, como mostra a Figura 3.
Figura 3: Cortes usados para determinar mensagens transientes.
O primeiro corte (C1) solicita aos processos que iniciem o registro do menor
timestamp das mensagens que enviarem. Essas mensagens podem ser transientes,
no caso de atravessarem o segundo corte, e devem ser consideradas no calculo do
GVT. Tomando como base a Figura 3, os timestamps das mensagens M2 e M3 sao
considerados no calculo do GVT. O segundo corte (C2) deve garantir que todas
as mensagens enviadas antes do primeiro corte ja foram entregues aos destinata-
rios, fazendo com que todas as mensagens que estao atravessando o segundo corte
tenham sido enviadas apos o primeiro corte, sendo assim, incluıdas no calculo do
GVT. Pelo exemplo da Figura 3, o segundo corte so podera ser realizado apos o
recebimento da mensagem M1.

36
O algoritmo usa um esquema de cores para determinar o momento em que
cada processo esta em relacao aos dois cortes. Todos os processos iniciam com
a cor branca, no primeiro corte sao marcados com a cor vermelha e retornam a
cor branca no segundo corte. As mensagens enviadas pelos processos carregam a
cor que o processo estava quando as enviaram. Quando um processo esta branco,
envia mensagens brancas, ja quando esta vermelho, envia mensagens vermelhas.
Todas as mensagens brancas devem ser recebidas antes do segundo corte. Por-
tanto, o segundo corte so podera ser feito quando todas as mensagens brancas
forem recebidas. Assim, todas as mensagens que passam pelo segundo corte serao
vermelhas. O GVT e calculado como o menor valor entre: (1) os timestamps das
mensagens vermelhas enviadas por todos os processos e (2) os LVTs de todos os
processos da simulacao. Ou seja, e o menor valor entre os LVTs dos processos e
os timestamps das mensagens em transito.
2.6 Considerações Finais
Esse capıtulo apresentou conceitos basicos sobre SDs, Simulacao, Simulacao
Distribuıda, com suas principais abordagens, e sobre os principais protocolos uti-
lizados para sincronizacao de processos. Esses conceitos sao importantes para a
compreensao do restante deste trabalho.
Foram apresentadas as duas principais abordagens para Simulacao Distribuıda
(MRIP e SRIP). A abordagem SRIP recebeu um foco maior, assim como os pro-
tocolos otimistas, em especial o Time Warp, pois formam a base para o ambiente
desenvolvido neste trabalho.
O proximo capıtulo apresenta uma revisao sobre escalonamento de processos
e balanceamento de carga para Simulacao Distribuıda.

37
3 Escalonamento de Processos eBalanceamento de Carga emSimulações Distribuídas
Um processo e um programa em execucao. Cada processo possui seu espaco de
enderecamento, uma lista de posicoes de memoria que o processo pode acessar. No
espaco de enderecamento estao o codigo executavel, os dados do programa e a pilha
de execucao. O processo tambem armazena sua atividade corrente, representada
pelo contador de programa e pelo conteudo de seus registradores. Em sua pilha de
execucao ficam armazenados dados temporarios, como por exemplo, parametros
de funcoes, enderecos de retorno e variaveis locais. Na secao de dados ficam ar-
mazenadas as variaveis globais. Um processo tambem possui outros recursos, tais
como, uma lista de arquivos abertos, uma lista de processos relacionados, um heap
de memoria, que e a memoria dinamicamente alocada durante sua execucao, e
outras informacoes necessarias para a execucao do programa (TANENBAUM, 2010;
SILBERSCHTZ; GALVIN; GAGNE, 2009).
O escalonamento de processos e a atividade responsavel pela alocacao dos pro-
cessos aos processadores, com o objetivo de atender as demandas especıficas e/ou
manter a carga do sistema equilibrada. E importante diferenciar bem quando o
escalonamento e realizado em um ambiente com um unico processador e quando e
realizado em um ambiente com diversos processadores (varias estacoes de traba-
lho). Dois nıveis de escalonamento sao definidos de acordo com o ambiente e tipo
da aplicacao.

38
Tanenbaum (2010) apresenta um nıvel onde o escalonador de processos e res-
ponsavel por monitorar a execucao dos processos no sistema operacional, cuidando
de questoes como: a ordem de execucao dos processos, em qual processador cada
processo sera alocado (em caso de arquiteturas com mais de um processador) e a
fatia de tempo (Time Slice) que cada processo tera para executar no processador.
Um segundo nıvel, muitas vezes chamado de escalonamento global de pro-
cessos, e responsavel por determinar qual estacao de trabalho do SD e a mais
adequada para a execucao de um determinado processo. Nesse nıvel, os objetivos
da aplicacao e a plataforma como um todo sao considerados, para que se consiga
uma melhor alocacao dos processos (TANENBAUM; STEEN, 2006; SOUZA, 2000;
CASAVANT; KUHL, 1988).
Geralmente, algoritmos de escalonamento de processos sao desenvolvidos para
ambientes paralelos onde sao executados programas paralelos, esses compostos
por muitos e, possivelmente, diferentes processos. A decisao sobre a alocacao dos
processos e tomada com base em informacoes sobre a plataforma, o hardware, as
aplicacoes e a carga do sistema. Um programa de simulacao distribuıda, alem de
ser afetado por todos os fatores citados, tambem sofre desbalanceamento causado
pelas caracterısticas do proprio modelo da simulacao.
3.1 Escalonamento de processos em sistemas distribuídos
Balancear a carga em um SD consiste em alocar os processos aos processadores
de forma que as cargas desses processadores estejam equilibradas. Essa alocacao
pode ser feita apenas no inıcio da execucao da aplicacao ou atraves da migracao
de processos entre os processadores. Os objetivos dos algoritmos de distribuicao
de carga sao: (1) a maximizacao da velocidade de execucao das aplicacoes e (2) a
busca pelo nivelamento da carga entre os diversos processadores.
A carga de um sistema e medida atraves de ındices de carga. Um ındice de
carga mede a utilizacao de algum elemento do sistema (BRANCO, 2004). Diversos

39
ındices de carga podem ser usados para o balanceamento da carga de um sistema.
A escolha do(s) melhor(es) ındice(s) a ser(em) usado(s) depende das caracterısticas
da aplicacao. A utilizacao do processador, o tamanho da fila de processamento e a
quantidade de memoria disponıvel sao alguns exemplos de recursos utilizados para
se calcular ındices de carga.
Cada tipo de aplicacao paralela possui suas particularidades. Com a simulacao
distribuıda nao e diferente e muitos algoritmos foram desenvolvidos voltados espe-
cificamente para o balanceamento de carga desse tipo de aplicacao. Os algoritmos
desenvolvidos especificamente para simulacao distribuıda, utilizando informacoes
sobre parametros da simulacao, apresentam melhores desempenhos que aqueles
desenvolvidos para aplicacoes paralelas em um ambito geral (VOORSLUYS, 2006).
Os problemas de balanceamento de carga se tornam ainda mais complexos em
simulacoes distribuıdas executando sobre protocolos otimistas. Nesses ambientes,
as simulacoes sao executadas com o objetivo de completar a simulacao o mais ra-
pido possıvel, os mecanismos de balanceamento de carga trabalham para atender a
esse proposito, ao inves de simplesmente tentar maximizar a utilizacao dos recur-
sos, uma vez que muito do trabalho realizado podera ser desfeito no futuro devido
aos rollbacks. Apenas fazer com que todos os processadores operem com a mesma
carga nao garante que uma simulacao distribuıda esteja equilibrada. Em geral, os
algoritmos de escalonamento para simulacao distribuıda otimista operam com o
intuito de reduzir ao maximo a ocorrencia de erros de causa e efeito.
3.2 Classificação dos tipos de balanceamento para simula-ções distribuídas
Carvalho Junior (2008) propos uma classificacao para os algoritmos de balan-
ceamento de carga, especificamente os que executam sobre protocolos otimistas,
baseada no momento em que os algoritmos realizam suas atividades de monitora-
mento, avaliacao e alocacao dos processos. Essa classificacao separa os algoritmos

40
em tres grupos, balanceamento em tempo de execucao, balanceamento em
tempo de mapeamento e balanceamento misto.
Os algoritmos que fazem o balanceamento em tempo de mapeamento
fazem um mapeamento dos dados antes que a execucao da simulacao inicie. Base-
ado na analise dos dados do modelo da simulacao, dados coletados em execucoes
anteriores ou dados de avaliacao da plataforma, tomam as decisoes de como reali-
zar a alocacao dos processos aos processadores e essa alocacao inicial nao e mais
alterada. Essa caracterıstica de comportamento faz com que esses mecanismos
sejam classificados como de balanceamento estatico.
Os algoritmos que fazem o balanceamento em tempo de execucao moni-
toram informacoes especıficas da simulacao e/ou da carga do sistema em tempo
de execucao e tomam decisoes de realocacao dos processos durante a execucao da
simulacao. Alguns autores classificam esses algoritmos como de balanceamento
dinamico. Esses algoritmos fazem uso de mecanismos de migracao de processos
para poder deslocar processos entre os nos da aplicacao.
Os algoritmos de balanceamento misto realizam tanto uma analise no mo-
delo e plataforma para realizar a alocacao inicial dos processos quanto monitoram
os dados da simulacao e/ou ambiente para, caso necessario, efetuar a realocacao
de processos.
O balanceamento de carga e um componente importante para melhorar o de-
sempenho das aplicacoes que executam em ambientes distribuıdos. Muitas tecnicas
de balanceamento dinamico foram desenvolvidas ate chegar a um desempenho bom
o suficiente para tornar o balanceamento dinamico viavel. O balanceamento es-
tatico torna-se inviavel devido a variacao no comportamento dos processos e da
carga de cada processador durante a execucao (DE GRANDE; BOUKERCHE, 2011).

41
3.3 Migração de processos
A migracao de processos e necessaria para permitir que os algoritmos de es-
calonamento equilibrem a carga do sistema, pois permite modificar a distribuicao
dos processos entre os computadores dinamicamente.
Os objetivos da migracao de processos sao: (1) o balanceamento dinamico da
carga, (2) aproximar os processos dos recursos que acessam, (3) permitir tolerancia
a falhas, (4) melhoria no desempenho da comunicacao entre os processos e (5) a
administracao do sistema (MILOJICIC et al., 2000).
Migrar um processo em execucao significa transferir seu estado entre dois com-
putadores de um SD, permitindo que a execucao do processo possa continuar no
computador de destino do mesmo ponto em que foi suspensa no computador de
origem. Assim que for determinado o processo que sofrera migracao, o mecanismo
de migracao de processos e responsavel por suspender a execucao do processo no
computador de origem, enviar o estado do processo para o computador de destino
e reiniciar a execucao do processo.
Um bom mecanismo de migracao de processos e fundamental para o traba-
lho dos algoritmos de balanceamento de carga dinamicos. Mais detalhes sobre a
migracao de processos podem ser obtidos em (JUNQUEIRA, 2012) e (RAVASI, 2009).
3.4 Fatores que causam desbalanceamento da carga emsimulações distribuídas
Carothers e Fujimoto (2000) afirmam que simulacoes distribuıdas, executando
sobre protocolos otimistas, estao sujeitas a diversos fatores que afetam o balancea-
mento de carga. Esses fatores podem ser internos ou externos a simulacao. Sao tres
os fatores internos que podem causar desbalanceamento da carga, a populacao de
eventos, a granularidade dos eventos e a comunicacao. Sao dois os fatores
externos, a carga dos usuarios e a heterogeneidade dos processadores. Os

42
fatores externos se manifestam quando as simulacoes estao sendo executadas em
ambientes nao dedicados a simulacao, onde uma carga externa ao sistema provida
por usuarios do ambiente pode existir e variar no tempo.
E importante ressaltar que e possıvel ter diversas combinacoes desses fatores.
Determinar ou simular todos esses fatores e suas possıveis combinacoes nao e uma
tarefa simples.
Se a populacao de eventos estiver irregular, o numero de eventos processados
em um determinado perıodo de tempo pode ser diferente entre os processos da
simulacao. Processos executando um grande numero de eventos, com um valor
muito superior em relacao a outros processos, podem levar a situacoes de alta carga
em seus respectivos processadores. Por outro lado, processos com um numero
menor de eventos podem levar a situacoes de baixa carga em seus respectivos
processadores. Estas situacoes de desbalanceamento farao processos alocados em
processadores com baixa carga sofrer rollbacks causados por processos alocados em
processadores com alta carga. Um caso especial de irregularidade na populacao de
eventos e quando todos os processos da simulacao possuem uma quantidade similar
de eventos, mas o numero de processos alocados em cada processador difere muito.
Uma granularidade diferente dos eventos, e causada quando o montante de
tempo gasto para processar os eventos varia significativamente entre os processos.
E assumido que o tempo de CPU gasto para o salvamento de estado faz parte dos
custos da execucao dos eventos. Dessa forma, mesmo se a populacao de eventos
for semelhante entre os processos, os processos com eventos que levam mais tempo
para executar irao sobrecarregar seus processadores, enquanto processos que levam
menos tempo farao com que seus processadores tenham uma carga menor. Esta
situacao de desbalanceamento tambem fara com que processos alocados em pro-
cessadores com baixa carga sofram rollbacks causados por processos alocados em
processadores com alta carga.
O desbalanceamento de carga, devido a comunicacao entre os processos, esta
relacionado ao tempo de CPU gasto para receber e enviar mensagens e ao custo de

43
comunicacao (em termos de latencia). A variacao no padrao de troca de mensagens
entre os processos pode levar a situacoes de desbalanceamento de carga. Proces-
sadores com gastos de CPU elevados devido as tarefas de comunicacao dos seus
processos causarao rollbacks em processos alocados em processadores com menor
carga de comunicacao. Carothers e Fujimoto (2000) evidenciam a dificuldade em
simular esse tipo de desbalanceamento.
Em um ambiente nao dedicado exclusivamente a simulacao, usuarios externos
podem executar diversos programas que irao competir com os processos da simu-
lacao por recursos do ambiente, como tempo de CPU. Esta situacao pode levar a
sobrecarga de alguns processadores e consequentemente a um desbalanceamento
na carga. Para a simulacao, significa que processos alocados em processadores
sobrecarregados terao sua taxa de avanco reduzida, o que levara a situacoes de
rollback.
A heterogeneidade dos processadores e um outro fator de desbalanceamento
de carga. Ocorre em ambientes onde as caracterısticas dos processadores variam
entre os nos. Processos executando em processadores com menor poder de pro-
cessamento tendem a ter uma taxa de avanco menor do que processos executando
em processadores com maior capacidade de processamento, fazendo com que haja
um desbalanceamento da carga. Em um ambiente heterogeneo, processadores com
menor capacidade de processamento podem ser comparados com processadores
sobrecarregados pertencentes a um ambiente homogeneo.
3.5 Algoritmos de escalonamento para simulação distri-buída
Os algoritmos de balanceamento de carga especıficos para simulacao distri-
buıda, por meio da utilizacao de informacoes da propria simulacao, procuram con-
trolar os fatores que causam o desbalanceamento da carga da simulacao. No caso
de simulacoes distribuıdas usando protocolos otimistas, os algoritmos de balance-

44
amento visam a reducao do numero de rollbacks.
3.5.1 Algoritmo da utilização efetiva do processador
Para Reiher e Jefferson (1990), o balanceamento dinamico de carga tem os
objetivos de equilibrar o desempenho da simulacao, tratar efetivamente a criacao
e destruicao de processos e eliminar a necessidade de intervencao dos usuarios
no escalonamento dos processos. Acreditam que as tecnicas de balanceamento
de carga baseadas na utilizacao do processador nao sao aplicaveis as simulacoes
otimistas. Propuseram uma tecnica que realiza o balanceamento de carga atraves
de uma metrica mais generalizada, chamada de utilizacao efetiva do processador,
de agora em diante citada como utilizacao efetiva.
Em uma simulacao otimista, o trabalho executado pode ou nao sofrer rollbacks.
O trabalho executado que nao sofreu rollback e chamado de trabalho efetivo. A
fracao de trabalho efetivo realizado, em relacao a todo trabalho realizado por um
processador, e a utilizacao efetiva. Um processador com alta utilizacao efetiva
esta contribuindo muito com a simulacao, enquanto um processador com baixa
utilizacao efetiva esta contribuindo menos. A polıtica baseia-se em equilibrar a
utilizacao efetiva de todos os processadores da simulacao. O escalonador deve
tentar transferir carga de processadores realizando muito trabalho efetivo para
processadores realizando pouco trabalho efetivo.
O algoritmo calcula a utilizacao efetiva dos processos e tambem dos processa-
dores. A utilizacao efetiva de um determinado processador e a soma das utilizacoes
dos processos alocados nesse processador. Quando ha desbalanceamento na carga,
processos sao migrados dos processadores mais carregados, maior utilizacao efe-
tiva, para processadores menos carregados, menor utilizacao efetiva. O processador
mais sobrecarregado faz par com o processador menos sobrecarregado. O segundo
processador mais sobrecarregado com o segundo menos sobrecarregado e assim su-
cessivamente. Apenas pares de processadores onde as utilizacoes efetivas diferem
em um determinado valor participam da migracao de processos. Esse valor de di-

45
ferenca deve ser superado para que haja migracao. Ele determina o quao sensitivo
sera o mecanismo de migracao. Valores baixos irao causar migracoes desnecessarias
e valores altos farao com que migracoes necessarias nao sejam realizadas.
A migracao objetiva igualar o tempo de processamento que cada processo re-
cebe, para que os processos tenham taxas de progresso proximas. Assim, processos
com baixa utilizacao sao migrados para processadores mais carregados e recebem
menos tempo de processamento, ja que baixa utilizacao significa muito tempo de
processamento em relacao a outros processos e, consequentemente, muitos roll-
backs. Processos com alta utilizacao sao migrados para processadores mais ociosos
e recebem mais tempo de processamento, ja que alta utilizacao significa pouco
tempo de processamento e consequentemente poucos rollbacks, mas, no entanto,
causam muitos rollbacks em outros processos.
O mecanismo calcula, dinamicamente, o trabalho efetivo para realizar o balan-
ceamento da carga. Uma determinada porcao de trabalho so podera ser contabili-
zada como trabalho efetivo quando nao puder mais sofrer rollbacks, o que faz com
que a utilizacao efetiva so possa ser calculada levando em consideracao os eventos
que nao possam mais sofrer rollbacks.
A Equacao 3.1 exibe a primeira forma de calcular a utilizacao efetiva de um
processo.
utilizacao efetiva =numero de eventos efetivados
numero de eventos processados(3.1)
Essa forma de calcular a utilizacao efetiva possui uma deficiencia, pois apenas
podem ser considerados como eventos efetivados aqueles cujo LVT sao menores
ou iguais ao GVT, pois nao se pode garantir que eventos com LVT maiores que o
GVT nao sofrerao rollbacks.
Para resolver esse problema, deve ser usada uma estimativa para o trabalho
efetivo. Essa estimativa e baseada em contabilizar quantos ciclos de processador
foi usado por cada evento. Esse valor deve ser adicionado a estimativa de trabalho
efetivo do processo. Se houver rollbacks, o trabalho dispensado para realiza-los,

46
ciclos de processador, deve ser subtraıdo da estimativa do trabalho efetivo. Ja que
a utilizacao efetiva e a fracao de tempo gasto em trabalho efetivo e sendo o trabalho
efetivo uma estimativa, a utilizacao efetiva, quando calculada dessa forma, tambem
sera uma estimativa. Essa estimativa pode estar errada e resultar em migracoes
desnecessarias em alguns momentos.
Nessa abordagem, o calculo da utilizacao efetiva de um processo e feito de
acordo com Equacao 3.2.
utilizacao efetiva =total de ciclos de processamento - total de ciclos perdidos
total de ciclos de processamento(3.2)
Uma possıvel metrica para o balanceamento e fazer com que os LVTs de todos
os processadores progridam uniformemente, medindo a carga pelo LVT. LVT muito
alto, em relacao aos outros processadores, significa baixa carga. LVT baixo significa
alta carga. Segundo os autores, o balanceamento baseado na utilizacao efetiva e
melhor do que o balanceamento baseado na taxa de progresso dos LVTs, pois e
invariante em relacao a ordem dos LVTs. O problema em considerar o LVT como
metrica e que nem todos os eventos, que incrementam o LVT em um determinado
valor, levam o mesmo tempo de processador para ser executado.
Como exemplo, consideremos que, para ser executado, o evento de LVT 100
gaste menos processamento em relacao ao evento de LVT 200. Do ponto de vista
do tempo virtual, o tratamento de ambos os eventos faz com que o LVT avance em
n unidades. No entanto, se o objetivo do balanceamento de carga for aproximar a
taxa de progresso dos LVTs o mesmo tratamento deveria ser realizado em ambos
os casos. Porem, como ha mais processamento gasto no evento de LVT 200, o
balanceamento de carga deveria dedicar mais esforcos em garantir que essa parte
da simulacao execute adequadamente, deveria haver mais migracoes nessa etapa do
que no evento de LVT 100, por exemplo. Na realidade, o que deve ser balanceado e
a porcao de ciclos de processador uteis sendo gastos e nao a propagacao dos LVTs.
Considere duas aplicacoes iguais, exceto pelo fato de que cada evento na se-

47
gunda aplicacao tem LVT diferente ao seu evento correspondente da primeira apli-
cacao. Sao os mesmos eventos gerando as mesmas instrucoes na mesma ordem,
apenas os LVTs sao diferentes, nao uniformemente diferentes. Um conjunto de
migracoes suficiente para a primeira aplicacao deveria ser bom para a segunda. No
entanto, se a decisao de migrar for baseada na taxa de progresso dos LVTs, uma
variacao nos LVTs da segunda aplicacao levara a diferentes conjuntos de migra-
cao. Em uma polıtica baseada em utilizacao efetiva, considerando que as mesmas
instrucoes sejam realizadas, a utilizacao efetiva sera a mesma e o mesmo conjunto
de migracao seria suficiente.
Os resultados obtidos nos testes realizados por Reiher e Jefferson (1990) apon-
tam para um aumento de desempenho de, em media, 13% a 19% quando usado o
algoritmo de balanceamento proposto. Para algumas configuracoes ha ainda me-
lhor desempenho, no entanto, para algumas configuracoes houve uma queda no
desempenho. Diversos testes foram realizados, inclusive variando o parametro que
determina quando havera migracao entre dois processadores que foram considera-
dos, respectivamente, o mais e o menos carregado. Os resultados mostram que,
para um valor muito alto, os resultados nao sao bons, pois nao houve migracoes
sugestivas, e que, geralmente, valores mais baixos sao mais adequados, podendo
variar de acordo com outras configuracoes, como por exemplo, o numero de pro-
cessadores.
3.5.2 Algoritmo da métrica do relógio local
Nessa tecnica, proposta por Burdorf e Marti (1993), o escalonador de processos
determina qual o processador mais ocioso e entao migra processos para esse pro-
cessador. Alem dos processos da simulacao, considera outros processos de usuarios
no calculo da carga do sistema. Usa tanto o balanceamento estatico quanto o
balanceamento dinamico.
O balanceamento estatico determina como sera a atribuicao inicial dos pro-
cessos aos processadores. Verifica o peso de cada processador antes de atribuir

48
processos aos mesmos. Os pesos dos processadores sao estabelecidos de acordo
com o tempo relativo de execucao de uma simulacao sequencial previamente exe-
cutada. Os processos tambem tem pesos associados a eles. O peso de cada processo
pode ser determinado pelo programador da simulacao ou ajustados com um valor
padrao. Em tempo de carga, os pesos dos processos sao combinados para deter-
minar a melhor distribuicao dos processos aos processadores. Uma vez feita a
atribuicao inicial o balanceamento estatico termina seu trabalho e nao tem mais
nenhuma influencia na simulacao. Burdorf e Marti (1993) afirmam que esse mo-
delo de alocacao estatico e 10% mais efetivo que o modelo Round Robin, pois cada
processador recebe uma carga compatıvel com sua capacidade.
Para minimizar o numero de rollbacks, o balanceamento dinamico procura
diminuir a variacao dos LVTs entre todos os processos da simulacao.
Seja M = {m1, ...,mn} o conjunto de todos os processadores da simulacao, T o
tempo de simulacao de um determinado processo e X = {x1, ..., xn} o conjunto com
o menor LVT entre os processos alocados em cada processador. Calcula-se entao
a media, x, e o desvio padrao, s, dos valores em X. Nao devem ser considerados
valores em X que tendem ao infinito, pois esses inviabilizariam o uso do desvio
padrao calculado.
A media dos valores em X e calculada pela Equacao 3.3.
x =
∑ni=1 LV Tin
(3.3)
As Equacoes 3.4, 3.5 e 3.6 mostram como o desvio padrao e calculado.
si = LV Ti − x (3.4)
variancia =
∑ni=1(si)
2
n(3.5)
s =√
variancia (3.6)
Calculados a media e o desvio padrao, δ deve ser ajustado subtraindo a media

49
pelo desvio padrao, conforme mostra a Equacao 3.7.
δ = x− s (3.7)
Se existir um T (xj) < δ, move-se o processo mais atrasado, xj, para o proces-
sador mais adiantado mk, onde mk e representado pelo maior LVT em X.
Para evitar o problema da flutuacao (BARAK; SHILOH, 1985), que mostra uma
flutuacao da carga logo apos um processo de migracao, podendo levar a informacoes
enganosas, o escalonador espera que o GVT seja calculado 3 vezes depois da ultima
migracao antes de analisar a carga novamente. Nesse momento, o sistema ja esta
em equilıbrio e a carga pode ser analisada com mais seguranca.
Essa abordagem pode falhar se for considerado um ambiente onde um pro-
cessador esta bem a frente e os demais possuem valores menores e proximos, nao
havendo migracao de processos. Para resolver esse problema, γ deve ser calculado
como a soma da media com o desvio padrao, Equacao 3.8.
γ = x+ s (3.8)
Se existir um T (xk) > γ, move-se o processo xj, o processo mais atrasado
do processador mais atrasado, para mk, onde mk e representado pelo maior LVT
em X. Assim, o processo mais atrasado do processador mais atrasado e migrado
para o processador onde se encontra o processo mais adiantado, pois ele e um dos
processos que tem mais trabalho a fazer.
Os resultados apresentados por Burdorf e Marti (1993) mostram que, baseado
nas simulacoes executadas, o algoritmo proposto tem melhores resultados que o
algoritmo da utilizacao efetiva proposto por Reiher e Jefferson (1990), quando
calculada baseada no numero de mensagens que sofreram rollbacks pelo numero
de mensagens processadas.
Um outro algoritmo que tambem trabalha na tentativa de minimizar a dife-

50
renca entre os LVTs dos processos da simulacao e o algoritmo apresentado por
Glazer e Tropper (1993). Os autores definiram a taxa de avanco da simulacao
como sendo a taxa de avanco do tempo de simulacao de um processo em funcao
do tempo de CPU dado a ele. Essa taxa depende do tempo gasto para proces-
sar um evento, do quanto o LVT avanca por evento processado e da frequencia
de eventos. A diferenca entre os LVTs dos processos e minimizada controlando a
quantidade de tempo de processamento destinado a cada processo. Processos mais
lentos recebem, proporcionalmente, mais tempo de processador. Por exemplo, se
um processo P tem o dobro da taxa de avanco de simulacao em relacao a um
processo Q, pode ser atribuıdo a P a metade do tempo de CPU atribuıda a Q.
Pode ser necessario migrar processos para outros processadores caso o ajuste do
tempo de processamento dos processos resulte em um desequilıbrio na carga do
processador.
3.5.3 Algoritmo probabilístico
A ideia basica, proposta por Som e Sargent (1998), e estimar, explicitamente,
a probabilidade de que um evento, uma vez processado, sofra rollback causado
devido ao recebimento de uma mensagem straggler. O metodo usa algoritmos
probabilısticos para determinar a sequencia de eventos a ser executada em um
determinado processador.
Sendo L1 e L2 processos alocados em um processador P . A fila de entrada
de L1 contem um evento processado a(5), onde 5 e o timestamp do evento, e dois
eventos nao processados b(9) e c(11). A fila de entrada de L2 contem um evento
processado x(4) e dois eventos nao processados y(10) e z(14). Suponha que x
tenha sido processado anteriormente e que a acabou de ser processado. Sendo o
menor timestamp considerado como mecanismo de escalonamento, tanto b quanto
y sao candidatos a ser o proximo evento a ser executado.
Na abordagem probabilıstica sao utilizadas distribuicoes aleatorias baseadas
em informacoes de eventos passados para determinar a probabilidade de uma men-

51
sagem, com timestamp menor que o de b, nao ser recebida no futuro. Uma esti-
mativa similar e feita para y. O evento com a maior probabilidade, de nao sofrer
rollback, e selecionado como o proximo evento a ser executado por P . O evento
com menor probabilidade nao e, necessariamente, o evento de menor timestamp.
O algoritmo efetua essa previsao em varios nıveis, determinando a sequencia de
eventos mais adequada para ser executada.
O algoritmo mais comum para ordenar a lista de eventos a ser executadas e o
STF, que ordena os eventos do menor para o maior timestamp, considerando que
eventos com timestamp menores sao menos propensos a sofrer rollbacks por uma
mensagem straggler. Comparando com o STF, a abordagem proposta por Som e
Sargent (1998) reduz a ocorrencia de rollbacks em porcentagens que variam de 2%
a 42%, essa variacao e devida ao uso de diferentes modelos, com diferentes padroes
de comunicacao, incremento de timestamps e granularidade dos eventos (tempo de
CPU gasto para processar os eventos).
3.5.4 SGs - Strong Groups
Som e Sargent (2000) utilizaram-se do conceito de utilizacao efetiva, identifi-
cando algumas fraquezas na abordagem apresentada por Reiher e Jefferson (1990).
Consideraram a estrutura do modelo para realizar o escalonamento dos processos.
A simulacao e vista como um conjunto de SGs. Cada SG e uma colecao de proces-
sos, onde todos os processos pertencentes a um mesmo SG tem uma forte influencia
na taxa de progresso uns dos outros.
Os SGs sao identificados analisando o grafo de interconexao criado a partir
do modelo da simulacao. Para cada modelo de simulacao, pode-se construir um
grafo direcionado, onde cada no do grafo representa um processo do modelo. Uma
aresta do processador Li para o processador Lj indica que Li pode enviar uma
mensagem para Lj.
A Figura 4, (a) e (b), mostram o modelo e o grafo direcionado respectivamente.

52
Figura 4: Modelo de fila, grafo de interconexao, SCCs e SGs (SOM; SARGENT,2000).
Um processo Li pode afetar, diretamente, outro processo Lj, se existir uma aresta
de Li para Lj ou pode afetar, indiretamente, se houver um caminho entre eles no
grafo direcionado. De acordo com a Figura 4 (b), L1 pode afetar, diretamente, L2
e, indiretamente, L3.
Um grafo direcionado pode ter uma ou mais componentes fortemente conecta-
das, Strongly Connected Components (SCC) ( Figura 4 (c)). Em um grafo direci-
onado, uma SCC e um conjunto de vertices tal que, para cada par de vertices u e
v, ha um caminho de u para v e um caminho de v para u.
E possıvel que um processo Li raramente envie mensagens para um processo
Lj. Nesse caso, a aresta que liga Li a Lj, no grafo direcionado, e considerada
um link fraco. As arestas que sao mais frequentemente usadas sao consideradas
links fortes. Todos os links fracos do grafo direcionado podem ser removidos.
Por exemplo, se o link entre os processos L3 e L2 for considerado fraco, ele pode

53
ser removido. Essa remocao quebra a SCC SCC2 nos SGs SG2 e SG2′ . Apos a
remocao de todos os links fracos, as SCCs resultantes sao os SGs, Figura 4 (d).
O algoritmo assume que processos dentro da mesma SCC nao podem progredir
muito a frente uns dos outros. A diferenca na taxa de progresso depende de quao
frequentemente os processos de uma SCC interagem uns com os outros, estando
diretamente ligado ao numero de links fracos da SCC em questao. SCCs com
muitos links fracos levam a um limite alto e vice-versa. Considerando que um SG
e uma SCC sem links fracos, conclui-se que os progressos dos processos de um
mesmo SG permanecem proximos uns dos outros. Assim, os SGs podem ser vistos
como uma unica entidade.
No entanto, diferentes SGs nao sao restringidos, por propriedades estruturais,
a progredirem no mesmo ritmo e essa taxa desigual de progresso entre os SGs pode
causar:
1. Problemas de balanceamento;
2. Longo perıodo de tempo para completar a execucao;
3. Rollbacks em cadeia.
Quando dois processos, um mais rapido e outro mais lento, pertencem a SGs di-
ferentes, duas situacoes podem ocorrer: nao haver rollbacks ou, quando ocorrerem,
os rollbacks serao tardios. Enquanto nao houver rollbacks, havera possıveis pro-
blemas de sobrecarga e ociosidade. Quando houver um rollback, podera ocasionar
uma cascata de rollbacks e consequentemente uma variacao grande na utilizacao.
Por isso, Som e Sargent (2000) consideram que a utilizacao efetiva nao e adequada
quando processos mais rapidos e processos mais lentos nao pertencem ao mesmo
SG. Isso devido ao fato da utilizacao ser calculada baseada no numero de rollbacks,
que podem nao ocorrer ou podem ocorrer em demasia.
A abordagem de balanceamento baseado em utilizacao efetiva pode ser modi-
ficada para equilibrar o progresso de todos os processos em um modelo baseado em

54
SGs. No trabalho de Reiher e Jefferson (1990), os valores da utilizacao efetiva sao
utilizados para alterar o mapeamento. Ja no trabalho de Som e Sargent (2000),
as informacoes sobre o mapeamento sao utilizadas para alterar os valores da uti-
lizacao efetiva. O objetivo e encontrar valores ideais de utilizacao para igualar a
taxa de progresso dos SGs da simulacao.
Primeiramente, observa-se a relacao entre a utilizacao efetiva e o mapeamento
dos processos nos processadores. A utilizacao observada e usada para fazer o
mapeamento dos processos e alcancar o mapeamento desejado. Por outro lado, a
mudanca no mapeamento dos processos altera o valor de utilizacao observado.
O mapeamento mostrado na Figura 5 esta balanceado. Se objetiva-se reduzir
a utilizacao de L3, L1 pode ser movido do Processador 1 para o Processador 2.
Suponha que a meta seja reduzir a utilizacao de L3 para 0.1 sem mudar a utilizacao
dos demais processos. Com a meta de utilizacao para L3 a utilizacao observada
para esse cenario, com apenas L2 no Processador 1, e: Processador1 = L2(0.4)
e Processador2 = L1(0.1), L3(0.1), L4(0.2). O novo mapeamento tambem esta
balanceado, mostrando que o mapeamento pode ser guiado pela meta de utilizacao.
Figura 5: Strong Groups e Mapeamento (SOM; SARGENT, 2000).

55
A questao e como computar a meta de utilizacao para equilibrar o progresso
dos SGs. Esse equilıbrio pode ser conseguido desacelerando os SGs mais rapidos
em relacao aos SGs mais lentos. Uma vez que a utilizacao esta relacionada com a
taxa de progresso, se o objetivo for reduzir a taxa de progresso de um processo em
um fator k, deve-se reduzir sua utilizacao observada em um fator k.
Como a taxa de progresso de todos os processos de um determinado SG se
mantem equilibrada, para reduzir a taxa de progresso de um SG em um fator k,
a utilizacao de todos os processos do SG deve ser reduzida em um fator k. Vale
ressaltar que, quanto mais rapido um SG for, em relacao aos demais SGs, maior
sera seu fator k e sua meta de utilizacao sera nitidamente menor que a utilizacao
observada. Utilizar os valores de metas de utilizacao leva a um equilıbrio entre os
SGs, onde os mais rapidos sao desacelerados e os mais lentos sao acelerados.
Nao e necessario atingir os valores da meta de utilizacao apos um novo mapea-
mento. Se os valores de utilizacao observados apos o mapeamento estao proximos
aos valores da meta, as taxas de progresso de todos os SGs estarao aproximada-
mente equilibradas e, consequentemente, a carga tambem. Se as taxas de progresso
ainda estiverem desequilibradas, mais uma interacao computando as metas de uti-
lizacao e remapeamento pode ser feita.
3.5.5 BGE - Background Execution
Carothers e Fujimoto (2000) consideraram que a maioria dos estudos ante-
riores nao levaram em consideracao qualquer interferencia externa ao modelo da
simulacao, considerando o ambiente totalmente dedicado a simulacao. Citam como
possıveis interferencias os processos dos usuarios, a adicao ou remocao de novos
processadores ao ambiente, as caracterısticas de desempenho dos diferentes pro-
cessadores e ate mesmo o proprio modelo de simulacao, onde, em alguns casos, o
tempo de CPU gasto para processar um evento pode variar entre os LPs e a popu-
lacao de eventos dos processos pode ser diferente. Acreditam que uma simulacao
distribuıda bem balanceada, em um ambiente totalmente dedicado, pode tornar-se

56
mal balanceada em um ambiente nao dedicado e que ambientes nao dedicados,
como as redes de computadores, continuara sendo um paradigma comum.
Os autores observam que os problemas de desempenho, mesmo que originados
de diferentes fontes, sao similares na maneira em que afetam a simulacao. Definem
que, para uma simulacao otimista estar equilibrada, o tempo real necessario para
avancar um processo em uma unidade de tempo logico deve ser o mesmo para
todos os processadores da simulacao.
Executar uma simulacao usando o protocolo Time Warp em uma plataforma
NOW estende os problemas de balanceamento de tres maneiras. Primeiro, as
cargas impostas ao sistema por computacoes externas nao podem ser controladas
pelo gerenciador de carga da simulacao. Segundo, o conjunto dos processadores
utilizados na simulacao pode mudar de maneira imprevisıvel e, por ultimo, os
processadores do conjunto de processadores utilizados podem ter caracterısticas
de desempenho diferentes.
A diferenca fundamental entre os outros mecanismos e o BGE e a nao utilizacao
do tempo logico para o balanceamento de carga. A polıtica de balanceamento BGE
trabalha com duas componentes principais:
• Alocacao dinamica de processadores: que determina o conjunto de pro-
cessadores que fara parte da simulacao, sendo que esse conjunto pode variar
dinamicamente durante a simulacao. Essa componente cuida da adicao e/ou
remocao de processadores ao ambiente da simulacao;
• Balanceamento de carga: que gerencia a carga e migra processos entre
os processadores considerando a variacao da carga externa nos processadores
da simulacao.
Devido ao fato da migracao de processos individualmente ser, computacional-
mente, mais caro do que migrar um conjunto de processos, o BGE trabalha com a
migracao de conjuntos de processos. Sendo assim, agrupa os processos em clusters

57
e trabalha cada conjunto de processos como sendo uma unidade atomica, tanto
para calculo de carga quanto para migracao. Para diminuir a quantidade de mi-
gracoes, procura manter processos que se comunicam mais no mesmo processador,
agrupando-os no mesmo cluster. Assumem conhecer bem o modelo da simulacao
para que sejam criados os clusters, ja que, uma vez em um cluster, o processo
permanece nele ate o fim da simulacao.
A metrica central do algoritmo e a Processor Advance Time (PAT), que e o
montante de tempo real necessario para um processador avancar uma unidade do
tempo logico, nao considerando eventos que sofreram rollback. Considera apenas
o trabalho efetivo, que nao sera mais desfeito. A razao para nao considerar a
computacao desfeita e devido ao fato de que ela e dependente da aplicacao e nem
sempre e causado pela carga nao estar balanceada. Segundo os autores, considerar
a computacao desfeita para analisar o balanceamento de carga pode gerar decisoes
erradas.
Quanto maior o valor de PAT, mais sobrecarregado esta o processador. A po-
lıtica move clusters de processadores com valores de PAT altos para processadores
com PAT menores, a fim de minimizar a diferenca dos PATs entre os processos
da simulacao. O cluster a ser migrado e escolhido com base na afinidade (troca
de mensagens) em relacao ao processador que recebera o cluster. A migracao so
e realizada se a diferenca entre os PATs de quaisquer pares de processadores ex-
cederem uma porcentagem predefinida. Essa porcentagem e definida pelo usuario
da simulacao e evita a realizacao de migracoes que iriam causar pouco ou nenhum
benefıcio a simulacao.
Outra metrica, a Cluster Advance Time (CAT), e utilizada para estimar o
tempo real que um cluster gasta para avancar uma unidade do tempo logico. A
metrica CAT e calculada de acordo com a Equacao 3.9.
CATc,i =CPUc,i
∆GV T, (3.9)
onde CPUc,i e o montante de tempo de CPU gasto pelo cluster c, alocado no

58
processador i, para processar eventos salvos no ultimo intervalo de tempo entre
os calculos de carga (TSchedule) e ∆GV T e o incremento do GVT no ultimo
TSchedule.
A metrica PAT e o somatorio das metricas CAT dos cluster alocados em um
determinado processador e e calculada de acordo com a Equacao 3.10.
PATi =
Ci−1∑i=0
CATc,iTWFraci
, (3.10)
onde TWFraci e a fracao do tempo total de CPU gasto pela simulacao no proces-
sador i no ultimo TSchedule, Equacao 3.11.
TWFraci =TotalCPUi
TSchedule, (3.11)
sendo TotalCPUi o tempo total de CPU dado pelo processador no ultimo TSche-
dule.
A componente que cuida do gerenciamento dos processadores retira do con-
junto de processadores utilizaveis pela simulacao aqueles processadores que perde-
ram todos os seus processos devido as migracoes realizadas. Um processador so
retorna ao conjunto se sua carga se tornar duas vezes menor do que quando foi
retirado do conjunto.
Com excecao do desbalanceamento causado por problemas de comunicacao, o
BGE se propoe a combater todas as outras causas de desbalanceamento em uma
simulacao distribuıda executando sobre o protocolo Time Warp apontadas pelos
autores.
Segundo os testes executados, o algoritmo proposto e capaz de:
• Identificar novos processadores disponıveis e adiciona-los, em tempo de exe-
cucao, a simulacao, migrando partes da simulacao para esses processadores;
• Identificar processadores muito carregados por agentes externos e retira-los
da simulacao, redistribuindo a carga desses processadores aos processadores

59
remanescentes;
• Equilibrar a carga nos processadores a medida que ha variacao na carga de
trabalho. Seja essa variacao de carga inerente a simulacao ou externa.
Os resultados apresentados pelos autores, para diferentes modelos de simulacao
e com variacao interna na carga, variam de 29% a 127% de melhoria no speedup.
Para variacao externa na carga os resultados apresentam melhorias que vao de
24% a 260%. Os resultados apresentados quando o ambiente era composto por
processadores com diferentes capacidades de processamento variam de 27,5% a
70%. A ultima analise apresentada foi realizada sobre simulacoes executando em
um ambiente misto, onde houve variacao de carga interna e processadores com
capacidades diferentes. Os resultados para essa analise final mostram melhorias
de 100%. As comparacoes foram realizadas executando simulacoes com e sem o
uso do algoritmo de carga BGE.
3.5.6 Outros Algoritmos
Low (2002) apresentou um algoritmo que realiza o balanceamento da carga
de processamento, da carga de comunicacao e do lookahead dos processadores de
uma simulacao distribuıda. O algoritmo de balanceamento e executado a cada
n (n >= 1) calculos de GVT. As metricas utilizadas para analise de carga no
ambiente sao o lookahead entre os processos (o quanto um processo esta a frente
de um processo comunicante), a carga de processamento e o numero de mensagens
trocadas entre os processos.
Jiang, Anane e Theodoropoulos (2004) criaram uma variacao do algoritmo
BGE, considerando a latencia de comunicacao e o padrao de comunicacao entre os
processos. Definem duas metricas adicionais, a Processor-to-Processor Communi-
cation (PPC) e a Cluster-to-Processor Communication (CPC). As metricas PPC
e CPC indicam, respectivamente, o total de mensagens trocadas entre dois pro-
cessadores (entre quaisquer dois processos alocados nesses dois processadores) e o

60
total de mensagens trocadas entre um cluster e um processador (qualquer processo
do processador em questao). Baseando-se nesses valores, o algoritmo migra carga
de um processador Pi com alta PAT para um processador Pj com baixa PAT de
acordo com a Equacao 3.12.
PCSij =PPCij · LATENCYij
PATj(3.12)
onde PCSij e a velocidade de comunicacao de processador (Processor Communica-
tion Speed) do processador Pj em relacao a conexao (link) de Pi a Pj. A migracao
ocorrera do processador Pi para o processador Pj de maior PCSij, ou seja, a carga
sera migrada para um processador menos carregado (com um valor baixo de PAT)
que tenha um nıvel alto de comunicacao com o processador de origem Pi. O cluster
que migrara de Pi para Pj e aquele de maior (CAT · CPC), ou seja, aquele com
alta carga e que contribui mais para o trafico de mensagens entre os processadores
Pi e Pj.
Outros algoritmos que consideram a carga da computacao e o padrao de co-
municacao podem ser vistos em (PESCHLOW; HONECKER; MARTINI, 2007), (AJAL-
TOUNI; BOUKERCHE; ZHANG, 2008) e (DE GRANDE; BOUKERCHE, 2011).
Meraji, Zhang e Tropper (2010) apresentaram um algoritmo de balanceamento
de carga dinamico para simulacao otimista baseado no aprendizado de maquina.
Nessa abordagem, um agente interage com o ambiente. A cada interacao com
o ambiente, o agente determina o estado (s) do ambiente e determina uma acao
(a) a ser executada, entao o ambiente retorna um sinal (r) indicando a eficacia
da acao executada. Como vantagens dessa abordagem, pode ser destacado a nao
necessidade de conhecimento do ambiente, pois a polıtica e baseada em feedbacks.
Como desvantagem, o custo de implementacao e o overhead.
O algoritmo proposto por Meraji, Zhang e Tropper (2010) trabalha com a
juncao de dois algoritmos, um que visa equilibrar a carga entre os processadores,
algoritmo de carga, e o outro que visa minimizar a carga de comunicacao, algo-
ritmo de comunicacao. Esses dois algoritmos fazem uso de quatro parametros,

61
que sao computados durante os intervalos entre duas execucoes do algoritmo de
balanceamento:
1. Carga do processo (LpLoad): a carga de cada processo e determinada
como o numero de eventos processados;
2. Carga do processador (PLoad): e a soma das LpLoads dos processos
alocados no processador;
3. Carga de comunicacao do processo (LpComm[]): e representada por
um vetor de tamanho n−1, onde n representa o numero de processadores na
simulacao. Cada elemento do vetor e o numero de mensagens que o processo
enviou para os outros processadores da simulacao;
4. Carga de comunicacao do processador (PComm[]): tambem e repre-
sentada por um vetor de tamanho n− 1, cada elemento do vetor e o numero
de mensagens que o processador, soma das mensagens enviadas por todos os
processos alocados no processador, enviou para os outros processadores da
simulacao.
No algoritmo de carga, cada processador envia seus valores dos parametros
PLoad e PComm[] para um processo mestre, o processo mestre determina os P
processadores mais e menos carregados (maiores e menores PLoads), sendo P um
parametro configurado pelo usuario. Para cada par de processadores, mais e menos
carregados, o processador mais carregado seleciona L, outro parametro fornecido
pelo usuario, processos e os envia para seu correspondente processador menos car-
regado. Os processos selecionados para migrarem sao aqueles que possuem os
maiores valores de PComm[] em relacao ao processador de destino da migracao.
No algoritmo de comunicacao, cada processador Pi envia os valores dos parametros
PLoadi e PCommi[] para o processo mestre. O processo mestre determina o maior
valor PCommi[j] em PCommi[]. Para os processos Pi e Pj que tiveram a maior
comunicacao entre as ultimas duas execucoes do algoritmo de balanceamento, de

62
acordo com os valores de PCommi[j] e PCommj[i], o algoritmo migra processos
entre esses dois processadores, de forma que o processador de maior PLoad e o pro-
cessador que envia processos. Os processos selecionados para migrarem sao aqueles
que tambem possuem os maiores valores de PComm[] em relacao ao processador
de destino da migracao.
Um ultimo parametro utilizado pelo algoritmo determina qual dos dois algo-
ritmos sera utilizado, o algoritmo de carga ou o algoritmo de comunicacao. Para
o algoritmo de aprendizado, ha quatro estados possıveis na simulacao:
1. BcompBcomm : carga e comunicacao balanceadas;
2. BcompUcomm : carga balanceada e comunicacao desbalanceada;
3. UcompBcomm : carga desbalanceada e comunicacao balanceada;
4. UcompUcomm : carga e comunicacao desbalanceadas.
No primeiro estado, a computacao esta balanceada. No segundo estado, e
executado o algoritmo de comunicacao. No terceiro estado e executado o algoritmo
de carga e no quarto estado, onde ambos os parametros estao desbalanceados, e
escolhida a melhor acao a ser tomada de acordo com os parametros, que pode
ser executar o algoritmo de comunicacao ou o algoritmo de carga. Mais detalhes
podem ser vistos em (MERAJI; ZHANG; TROPPER, 2010).
Outros trabalhos, focados em balancear a carga de simulacoes distribuıdas em
ambientes multi-core de memoria compartilhada, podem ser vistos em (CHEN et
al., 2011) e (CHILD; WILSEY, 2012).
3.6 Considerações Finais
Uma importante revisao sobre escalonamento de processos foi realizada nesse
capıtulo. Comecando pela definicao do que e um processo e pela diferenciacao entre

63
os nıveis de escalonamento, passando ainda por conceitos relacionados a ındices de
carga e como cada ambiente possui particularidades em relacao a sua carga.
Um estudo sobre a classificacao dos algoritmos de escalonamento, aqueles vol-
tados as simulacoes que executam sobre protocolos otimistas, tambem foi reali-
zada. Esse estudo justifica a escolha dos algoritmos de escalonamento apresenta-
dos, considerando adequados aqueles que trabalham sob uma abordagem dinamica
ou mista.
O capıtulo ainda apresentou conceitos basicos sobre a migracao de processos,
mecanismo necessario quando se trata de abordagens dinamicas para o escalona-
mento de carga.
Por fim, o capıtulo apresentou os principais fatores que causam o desbalance-
amento de carga em ambientes de Simulacao Distribuıda. O entendimento desses
fatores e importante para a compreensao dos algoritmos de escalonamento para
Simulacao Distribuıda otimista, tambem apresentados nesse capıtulo e dos quais
foram extraıdas as metricas avaliadas.
O proximo capıtulo apresenta as adaptacoes realizadas na implementacao do
protocolo Time Warp e no mecanismo de migracao de processos para atender
algumas necessidades do mecanismo de balanceamento de carga proposto.

64
4 Adaptações na implementação doprotocolo Time Warp e migraçãode processos
Junqueira (2012) apresentou dois mecanismos para migracao de processos em
aplicacoes de simulacao distribuıda baseados no protocolo Time Warp. Um me-
canismo de migracao coletiva onde, durante uma migracao, ocorre o encerramento
e recriacao de todos os processos da simulacao e outro mecanismo de migracao
individual onde, durante uma migracao, apenas os processos que realmente irao
migrar sao encerrados e recriados posteriormente. Junqueira (2012) demonstrou,
teoricamente, que os dois mecanismos propostos podem melhorar o desempenho
de uma simulacao.
Para implementar os mecanismos de migracao, Junqueira (2012) fez uso da
implementacao inicial do protocolo Time Warp desenvolvida por Azevedo (2012),
que realizou um trabalho de projeto e implementacao dos protocolos de sincro-
nizacao para simulacoes distribuıdas, Time Warp e Rollback Solidario. Azevedo
(2012) tambem especificou e desenvolveu um framework para o desenvolvimento de
aplicacoes de simulacao e realizou um estudo comparativo entre os dois protocolos.
Apesar de Azevedo (2012) ter desenvolvido a versao final de seu projeto com
a plataforma Java, as primeiras implementacoes do protocolo Time Warp foram
desenvolvidas com a linguagem de programacao C/C++. Por questoes de para-
lelismo nos desenvolvimentos dos projetos de Azevedo (2012) e Junqueira (2012),

65
este realizou seu projeto de implementacao sobre a primeira implementacao do pro-
tocolo Time Warp desenvolvida por Azevedo (2012), essa desenvolvida em C/C++
e com o ambiente de passagem de mensagem MPI, com a implementacao OpenMPI
na versao 1.5.4.
Para aproveitar os mecanismos de migracao de processos desenvolvidos por
Junqueira (2012), e assim agilizar o desenvolvimento do presente trabalho, toda
nova implementacao, melhoria e/ou adaptacao desenvolvidas foram realizadas so-
bre o codigo do projeto de Junqueira (2012). Devido a alguns requisitos do projeto,
principalmente em relacao aos dados que sao necessarios para o calculo das me-
tricas que guiam o algoritmo de escalonamento, foi observada a necessidade de
algumas adaptacoes nas implementacoes de Junqueira (2012) e Azevedo (2012).
As adaptacoes realizadas sao apresentadas nas proximas secoes.
4.1 Arquitetura original do ambiente
Em Junqueira (2012), o ambiente de execucao de simulacoes distribuıdas e
controlado por um processo mestre, responsavel por iniciar o ambiente, criar os
processos da simulacao, recolher dados sobre a simulacao, executar os mecanismos
de balanceamento de carga, migrar os processos quando necessario e finalizar a
simulacao.
Devido a estabilidade do codigo de migracao coletiva desenvolvido por Jun-
queira (2012), quando o presente trabalho foi iniciado, e tambem devido ao fato
do mecanismo de migracao nao interferir nas analises comparativas de desempenho
das metricas de balanceamento de carga usadas pelo algoritmo de escalonamento,
o mecanismo de migracao usado no projeto foi o mecanismo de migracao coletiva.
Segundo Junqueira (2012), as principais atividades do processo mestre na mi-
gracao coletiva de processos sao:
1. Aplicar o algoritmo de balanceamento: quando o processo mestre e

66
inicializado, a simulacao ainda nao iniciou, havendo um mapeamento estatico
dos processos da simulacao;
2. Iniciar ou reiniciar os processos: de acordo com o resultado do algoritmo
de balanceamento, o processo mestre criara ou reiniciara os processos nos
processadores adequados;
3. Iniciar um temporizador: durante este tempo, o processo mestre perma-
nece ocioso deixando a simulacao executar sem interferencia;
4. Iniciar a coleta das metricas de desempenho: o processo mestre soli-
cita aos processos da simulacao que coletem as informacoes necessarias, que
depende do algoritmo de balanceamento empregado;
5. Receber as informacoes sobre a simulacao: apos solicitar informacoes
dos processos sobre a simulacao, o mestre aguarda ate receber os dados de to-
dos os processos. Com as informacoes, o mestre pode ainda decidir se alguma
condicao de termino foi satisfeita e, em caso positivo, todos os processos da
simulacao sao informados de que devem encerrar sua execucao;
6. Aplicar o algoritmo de balanceamento: caso nenhuma condicao de pa-
rada tenha sido satisfeita, o algoritmo de balanceamento e executado. O
algoritmo deve informar a necessidade de migracao e determinar onde cada
processo deve ser reiniciado;
7. Anunciar migracao: havendo necessidade de migracao, todos os processos
sao informados que sofrerao migracao;
8. Aguardar o encerramento dos processos: em caso de migracao, os
processos da simulacao deverao ser encerrados e reiniciados. Para manter a
consistencia das informacoes que ainda possam estar sendo trocadas entre
os processos, o processo mestre aguarda o termino de todos os processos da
simulacao;
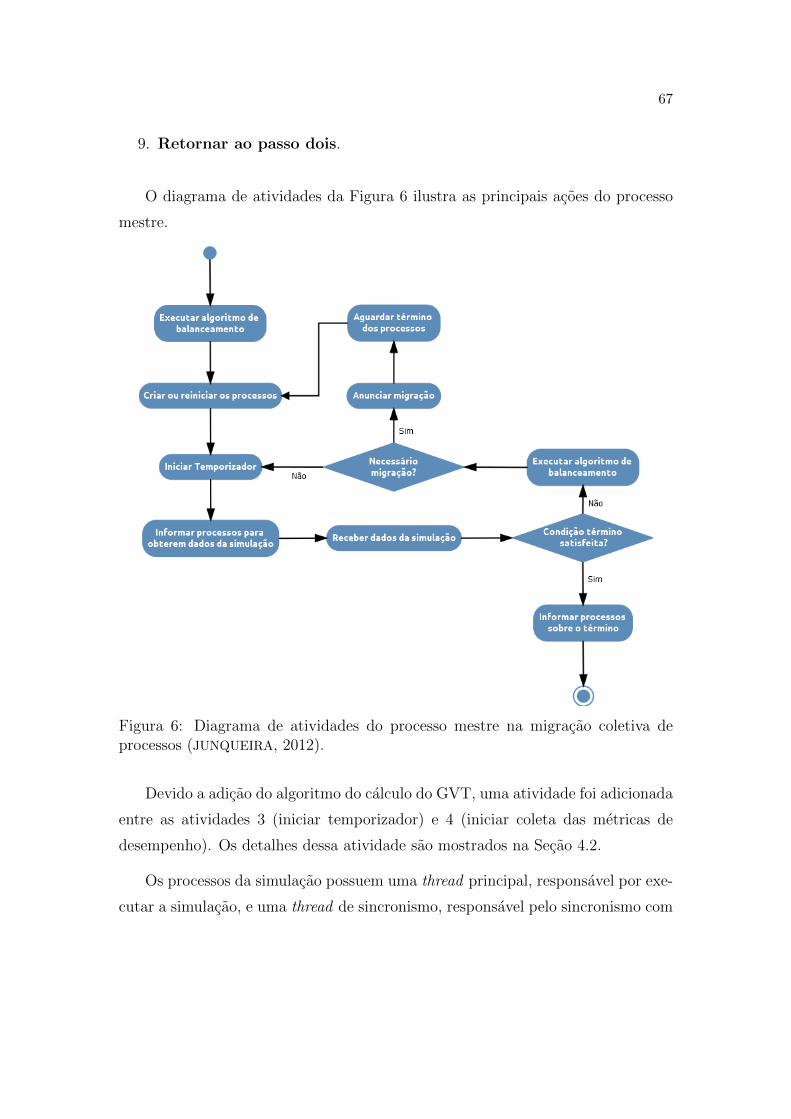
67
9. Retornar ao passo dois.
O diagrama de atividades da Figura 6 ilustra as principais acoes do processo
mestre.
Figura 6: Diagrama de atividades do processo mestre na migracao coletiva deprocessos (JUNQUEIRA, 2012).
Devido a adicao do algoritmo do calculo do GVT, uma atividade foi adicionada
entre as atividades 3 (iniciar temporizador) e 4 (iniciar coleta das metricas de
desempenho). Os detalhes dessa atividade sao mostrados na Secao 4.2.
Os processos da simulacao possuem uma thread principal, responsavel por exe-
cutar a simulacao, e uma thread de sincronismo, responsavel pelo sincronismo com

68
o processo mestre, pelo envio das metricas necessarias ao algoritmo de balancea-
mento e pela interacao com a thread principal.
Segundo Junqueira (2012), as principais atividades da thread principal na mi-
gracao coletiva de processos sao:
1. Inicializar a thread de sincronismo: antes de entrar no loop principal
da simulacao, a thread de sincronismo e inicializada;
2. Verificar se e a primeira execucao do processo: caso o processo ja
tenha passado por migracoes, suas variaveis e mensagens recebidas durante
o processo de migracao devem ser recuperadas. Essas informacoes sao sal-
vas em arquivos previamente criados e recuperadas no momento da recriacao
dos processos. Esses arquivos sao salvos em um servidor de arquivos e in-
dependente do host que cada processo seja reiniciado, terao acesso as suas
informacoes;
3. Verificar condicao de termino: uma variavel fica responsavel por infor-
mar se o criterio de parada da simulacao foi satisfeito. A thread de sin-
cronismo atualiza essa variavel de acordo com informacoes que recebe do
processo mestre;
4. Verificar se ha necessidade de migracao: outra variavel fica responsavel
por informar se o processo sera migrado. A thread de sincronismo tambem
atualiza essa informacao que e enviada pelo processo mestre;
5. Realizar a iteracao: se a condicao de termino nao foi satisfeita e nao houver
necessidade de migracao, a proxima iteracao da simulacao e executada;
6. Retorna ao passo 3.
O diagrama de atividades da Figura 7 ilustra as principais atividades da thread
principal dos processos da simulacao.

69
Figura 7: Atividades da thread principal dos processos da simulacao (JUNQUEIRA,2012).
O estado de pre-migracao, citado no diagrama da Figura 7, foi introduzido
por Junqueira (2012) e e um estado entre: (1) a notificacao enviada pelo processo
mestre aos processos da simulacao indicando que havera uma migracao e (2) o
termino dos processos da simulacao propriamente dito. Quando sao informados
de que serao migrados, os processos nao podem encerrar imediatamente, pois isso
levaria a perda das mensagens da simulacao em transito na rede. No estado de
pre-migracao, os processos apenas recebem as mensagens em transito, nao enviam
mais mensagens da simulacao aos outros processos, apenas enviam uma mensagem
a cada processo da simulacao informando que irao migrar. Cada processo aguarda
receber de todos os outros processos a mensagem de que estao migrando, so assim
o processo pode terminar, tendo a certeza de que nao ha nenhuma mensagem
pendente na rede enderecada a ele. O processo de pre-migracao pode ser visto
com mais detalhes em (JUNQUEIRA, 2012).

70
A thread de sincronismo presente nos processos da simulacao tem a funcao de
receber as solicitacoes do processo mestre e aplica-las sobre o processo da simula-
cao. Junqueira (2012) lista as seguintes atividades para a thread de sincronismo:
1. Verificar se ha mensagens para o processo: se nao houver mensagens,
a thread dorme por um pequeno perıodo de tempo;
2. Identificar instrucao recebida: a thread identifica o tipo de mensagem
recebida do processo mestre. Se for uma mensagem informando que havera
migracao, a thread modifica a variavel que identifica essa situacao e como a
thread principal tem acesso a essa variavel, da inicio ao processo de migracao.
O mesmo ocorre caso a mensagem recebida seja de termino da simulacao,
onde e iniciado o processo de encerramento da simulacao.
3. Obter dados da simulacao: se a mensagem recebida for uma solicitacao
de informacoes da simulacao, a thread coleta as informacoes da simulacao,
geralmente dados necessarios para o algoritmo de balanceamento, e envia
para o processo mestre;
4. Retorna ao passo 1.
O diagrama de atividades da Figura 8 ilustra as principais atividades da thread
de sincronismo dos processos da simulacao.
4.2 Implementação do algoritmo de Mattern para cálculodo GVT
Algumas das principais metricas utilizadas pelos algoritmos de balanceamento
de carga para simulacao distribuıda sao calculadas utilizando o GVT da simulacao.
Dessa forma, como ainda nao havia sido implementado, o calculo do GVT precisou
ser adicionado ao projeto.
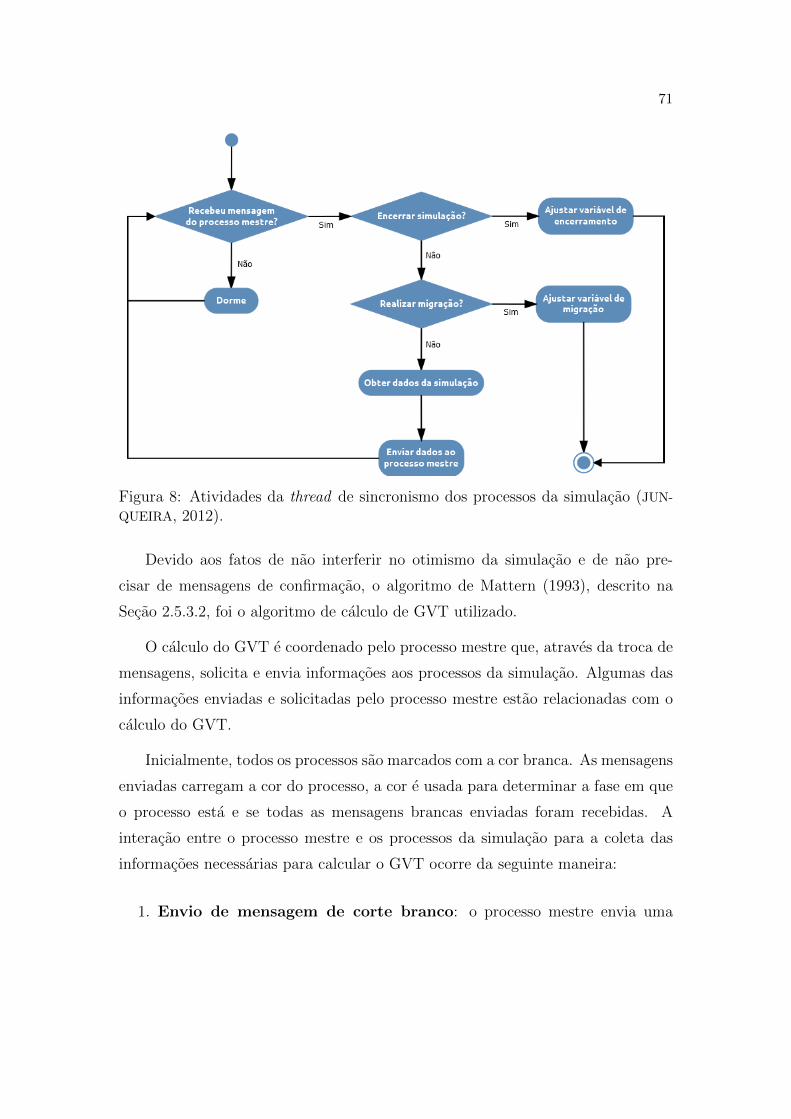
71
Figura 8: Atividades da thread de sincronismo dos processos da simulacao (JUN-
QUEIRA, 2012).
Devido aos fatos de nao interferir no otimismo da simulacao e de nao pre-
cisar de mensagens de confirmacao, o algoritmo de Mattern (1993), descrito na
Secao 2.5.3.2, foi o algoritmo de calculo de GVT utilizado.
O calculo do GVT e coordenado pelo processo mestre que, atraves da troca de
mensagens, solicita e envia informacoes aos processos da simulacao. Algumas das
informacoes enviadas e solicitadas pelo processo mestre estao relacionadas com o
calculo do GVT.
Inicialmente, todos os processos sao marcados com a cor branca. As mensagens
enviadas carregam a cor do processo, a cor e usada para determinar a fase em que
o processo esta e se todas as mensagens brancas enviadas foram recebidas. A
interacao entre o processo mestre e os processos da simulacao para a coleta das
informacoes necessarias para calcular o GVT ocorre da seguinte maneira:
1. Envio de mensagem de corte branco: o processo mestre envia uma

72
mensagem de corte branco a todos os processos da simulacao, solicitando
que informem a quantidade de mensagens brancas enviadas a cada processo
da simulacao;
2. Recebimento de mensagem de corte branco: ao receber a mensagem
de corte branco, cada processo se coloca na cor vermelha. Como resposta,
envia ao processo mestre um vetor de inteiros, uma entrada para cada outro
processo da simulacao, indicando quantas mensagens brancas foram envia-
das antes do corte (mudanca de cores). A partir desse momento, o processo
comeca a armazenar o menor timestamp entre as mensagens vermelhas en-
viadas;
3. Resposta de mensagem de corte branco: apos receber a resposta de
todos os processos, o processo mestre sabe que todos os processos da simu-
lacao estao na cor vermelha. Nesse momento, utilizando das informacoes
de mensagens brancas enviadas que recebeu na resposta, o processo mestre
calcula o total de mensagens brancas que foram enviadas a cada processo;
4. Envio do total de mensagens brancas enviadas: apos calcular quantas
mensagens brancas foram enviadas a cada processo da simulacao, o processo
mestre envia essa informacao a todos os processos;
5. Recebimento do total de mensagens brancas enviadas: ao receber a
informacao de quantas mensagens brancas foram enviadas a ele, cada pro-
cesso da simulacao verifica se ja recebeu a quantidade de mensagens brancas
informada. Caso ja tenha recebido, o processo envia ao processo mestre o
menor valor entre: (1) seu LVT e (2) o menor timestamp entre as mensa-
gens vermelhas enviadas. Caso o processo ainda nao tenha recebido todas as
mensagens brancas enviadas, ele deve aguardar ate que receba;
6. Resposta do total de mensagens brancas enviadas: apos receber a
resposta de todos os processos, o processo mestre tem a informacao do menor
valor estimado para o LVT de cada processo. Esse valor pode ser o proprio

73
LVT do processo ou o timestamp de alguma mensagem vermelha enviada,
desde que seja menor que o LVT do processo. Com essas informacoes, o
processo mestre calcula o GVT da simulacao, que e o menor entre esses
valores recebidos dos processos;
7. Envio de mensagem de corte vermelho: o processo mestre envia uma
mensagem de corte vermelho a todos os processos da simulacao. Junto a
essa solicitacao, o processo mestre tambem envia o GVT da simulacao recem
calculado;
8. Recebimento de mensagem de corte vermelho: ao receber a mensagem
de corte vermelho, cada processo se coloca na cor branca. Como resposta,
cada processo envia ao processo mestre as informacoes relativas as metri-
cas de balanceamento de carga. E nesse momento que as informacoes sobre
as metricas sao enviadas ao mestre. No entanto, essas informacoes sao cal-
culadas a todo instante pelos processos da simulacao. A forma como cada
metrica e calculada sera detalhada na Secao 5.2;
9. Resposta de mensagem de corte vermelho: apos receber a resposta de
todos os processos e verificar que nenhuma condicao de parada foi satisfeita,
o processo mestre usa as informacoes da metrica selecionada para chamar o
algoritmo de balanceamento.
10. Processo mestre aguarda um perıodo de tempo e retorna ao passo
1.
A interacao entre o processo mestre e os processos da simulacao para coletar
informacoes e calcular o GVT e ilustrada na Figura 9.
4.3 Gerenciamento de memória
Para nao limitar a estrutura dos modelos, nao limitar o tempo de execucao
das simulacoes e principalmente nao prejudicar o desempenho da simulacao, foi
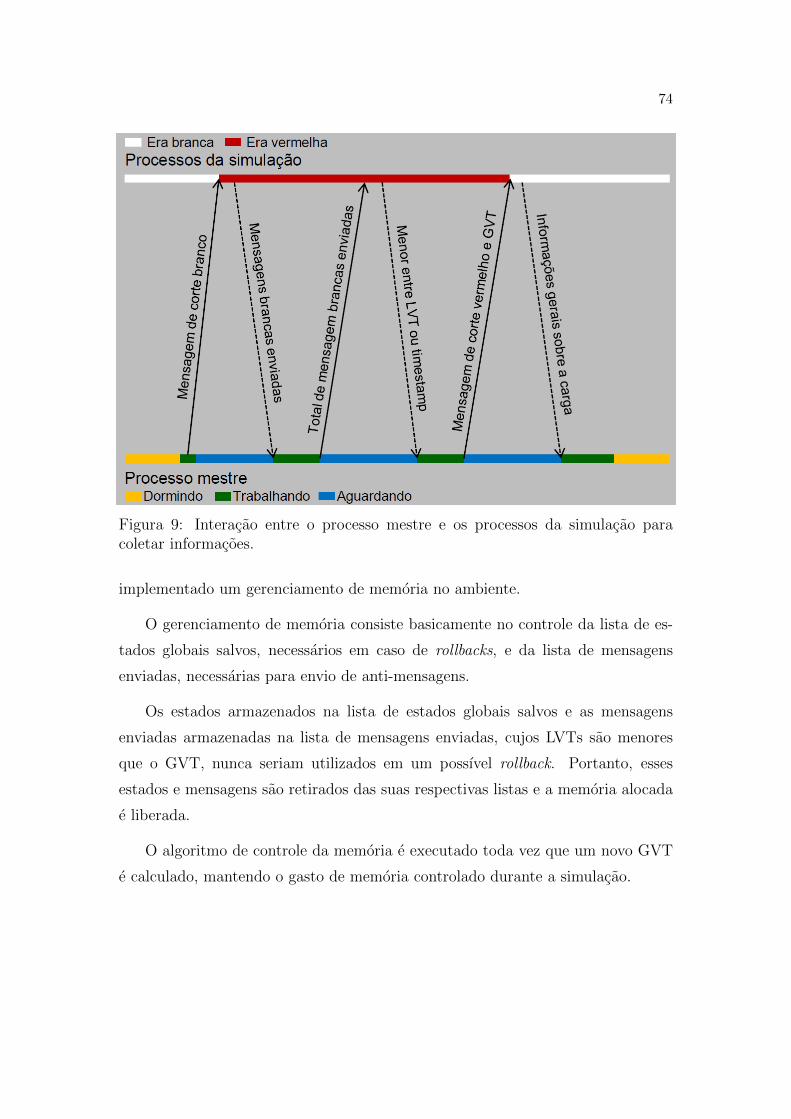
74
Figura 9: Interacao entre o processo mestre e os processos da simulacao paracoletar informacoes.
implementado um gerenciamento de memoria no ambiente.
O gerenciamento de memoria consiste basicamente no controle da lista de es-
tados globais salvos, necessarios em caso de rollbacks, e da lista de mensagens
enviadas, necessarias para envio de anti-mensagens.
Os estados armazenados na lista de estados globais salvos e as mensagens
enviadas armazenadas na lista de mensagens enviadas, cujos LVTs sao menores
que o GVT, nunca seriam utilizados em um possıvel rollback. Portanto, esses
estados e mensagens sao retirados das suas respectivas listas e a memoria alocada
e liberada.
O algoritmo de controle da memoria e executado toda vez que um novo GVT
e calculado, mantendo o gasto de memoria controlado durante a simulacao.

75
4.4 Salvamento das informações da simulação
Todas as informacoes necessarias para restaurar o estado dos processos apos
uma migracao ja eram salvos pelo ambiente implementado por Azevedo (2012).
Algumas outras informacoes, como, por exemplo, o total de eventos processados,
o total de mensagens enviadas, o total de mensagens recebidas etc, tambem eram
coletadas pelo ambiente. Porem, essas informacoes eram zeradas a cada migracao
e nao eram mantidas em memoria ou em disco.
Para possibilitar as analises sobre o desempenho do algoritmo de balancea-
mento de carga, foi necessario realizar o salvamento dessas informacoes da simula-
cao antes de cada migracao. Isso possibilitou ter, no final da simulacao, um resumo
geral da mesma, que foi utilizado para a avaliacao do algoritmo de balanceamento
de carga.
Na pratica, essas informacoes nao sao persistidas, elas sao apenas mantidas
na memoria do processo mestre, que mantem as informacoes de execucao de cada
processo da simulacao. Antes de migrar, um processo da simulacao envia suas
informacoes para o processo mestre, que soma essas informacoes com as informa-
coes anteriormente recebidas, mantendo assim as informacoes de cada processo e,
consequentemente, da simulacao como um todo.
As informacoes de cada processo da simulacao, mantidas pelo processo mestre,
e utilizadas para analise do desempenho da simulacao sao as seguintes:
1. O total de eventos processados: o total de eventos processados por cada
processo e utilizado para o calculo de algumas metricas de balanceamento
de carga. Tambem e utilizado para ter a informacao do total de eventos
processados em toda a simulacao. Essa informacao e importante para o
calculo da eficiencia do algoritmo de balanceamento;
2. O total de eventos cancelados: assim como o total de eventos proces-
sados, o total de eventos cancelados e utilizado para o calculo de algumas

76
metricas de balanceamento de carga, do total de eventos cancelados em toda
a simulacao e da eficiencia do algoritmo de balanceamento;
3. Total de mensagens enviadas: utilizado para possıveis analises no modelo
da simulacao;
4. Total de mensagens recebidas: utilizado para possıveis analises no mo-
delo da simulacao;
5. Total de anti-mensagens enviadas: utilizado para possıveis analises no
modelo da simulacao;
6. Total de anti-mensagens recebidas: utilizado para possıveis analises no
modelo da simulacao;
7. Total de rollbacks: utilizado para analise de desempenho do algoritmo de
balanceamento de carga;
8. Total de mensagens straggler : utilizado para possıveis analises no mo-
delo da simulacao e para o calculo da metrica para balanceamento de carga
proposta neste trabalho.
Atraves dessas informacoes, foi possıvel avaliar o desempenho das simulacoes
executadas.
4.5 Considerações Finais
Esse capıtulo apresentou o ambiente sobre o qual as simulacoes realizadas
foram executadas, mostrando em detalhes a estrutura do ambiente, seus compo-
nentes e a forma de interacao entre eles.
Apresentou tambem as adaptacoes importantes que foram necessarias. Adap-
tacoes relacionadas a coleta de informacoes para o calculo dos ındices de carga,

77
coleta de informacoes para avaliar o desempenho da simulacao e para o gerencia-
mento da memoria, fator importante por impactar diretamente no desempenho do
mecanismo de migracao de processos.
O proximo capıtulo apresenta o algoritmo de balanceamento proposto para
avaliacao das metricas e tambem as metricas que foram avaliadas.

78
5 Algoritmo de balanceamento emétricas avaliadas
As metricas avaliadas foram extraıdas de algoritmos classicos de balanceamento
de carga para simulacao distribuıda otimista que utilizam o protocolo Time Warp.
Esse trabalho tambem propos uma metrica para ser usada em algoritmos de
balanceamento de carga para simulacao distribuıda. A metrica foi chamada de
Expected Effective Work (EEW) e a forma como e calculada sera descrita na Se-
cao 5.1.4.
Foi desenvolvido um algoritmo de balanceamento para avaliacao das metri-
cas. O algoritmo possui caracterısticas de alguns dos algoritmos classicos e trata
algumas limitacoes ao dinamismo de alguns desses algoritmos.
5.1 Métricas avaliadas
As proximas secoes listam as metricas que foram avaliadas e descrevem a me-
trica proposta neste trabalho.
5.1.1 Métrica do relógio local
O algoritmo da metrica do relogio local, descrito na Secao 3.5.2, usa o LVT dos
processos como metrica para o algoritmo de balanceamento. Esse algoritmo e ci-
tado em diversos trabalhos relacionados e tambem usado em algumas comparacoes

79
de desempenho.
O algoritmo da taxa de avanco da simulacao tambem utiliza a taxa de avanco
do relogio local para derivar a fatia de tempo de processamento de cada processo,
visando minimizar a diferenca entre os LVTs dos processos da simulacao.
Um ponto favoravel dessa metrica e o fato de nenhum esforco extra ser neces-
sario para seu calculo, uma vez que e uma informacao ja presente em um ambiente
de simulacao, o LVT.
5.1.2 Utilização efetiva do processador
A metrica da utilizacao efetiva, proposta no algoritmo da utilizacao efetiva
do processador, Secao 3.5.1, e tambem utilizada no algoritmo Strong Groups, Se-
cao 3.5.4, tambem e muito conhecida e citada em trabalhos relacionados, alem
da possibilidade de ser calculada de duas formas. Pode ser calculada a partir de
informacoes ja presentes em um ambiente de simulacao, o numero de eventos pro-
cessados e o numero de eventos efetivados, ou a partir de informacoes de ciclos
de processamento, o numero de ciclos de processamento e o numero de ciclos de
processamento perdidos devido a rollbacks.
5.1.3 PAT - Processor Advance Time
A metrica PAT, introduzida no algoritmo BGE, Secao 3.5.5, sera avaliada por
fazer parte de um dos algoritmos mais completos para o balanceamento de carga
em simulacao distribuıda. O fator que mais pesou para a escolha dessa metrica foi
o fato do algoritmo BGE ser bastante complexo e utilizar de diversos mecanismos,
incluindo ate mesmo a possibilidade de um processador deixar de ser utilizado
pela simulacao, na tentativa de balancear uma simulacao distribuıda. A questao a
ser tratada e se os bons resultados do algoritmo sao devido a sua complexidade e
amplitude ou se e devido a qualidade da metrica.

80
5.1.4 EEW - Expected Effective Work
A metrica do trabalho efetivo esperado, proposta nesse trabalho, e calculada
com base na taxa de rollbacks ocorridos.
A taxa de rollbacks e calculada pelo fator de mensagens stragglers recebidas
em relacao ao total de mensagens recebidas, de acordo com a Equacao 5.1.
RollbackFactorP =TotalStragglerPTotalMessagesP
(5.1)
A taxa de rollbacks permite calcular o montante de trabalho que, provavel-
mente, sera desfeito. Esse montante de trabalho que, possivelmente, sera desfeito
e a porcentagem do montante de trabalho a fazer que sofrera rollbacks
O trabalho efetivo esperado e a diferenca entre o montante de trabalho a fazer
pelo montante de trabalho que provavelmente sera desfeito. E uma relacao entre os
eventos impostos a um processo e a quantidade de mensagens stragglers recebidas
por ele. A Equacao 5.2 resume o calculo do trabalho efetivo esperado.
ExpectedEffectiveWorkP = 1−RollbackFactorP (5.2)
A metrica representa a porcentagem de trabalho realizada por um processo
que se tornara trabalho efetivo, ou seja, trabalho que nao sera desfeito. O calculo
da metrica considera apenas os rollbacks primarios, aqueles realizados devido ao
recebimento de mensagens stragglers. Rollbacks secundarios nao sao considerados
devido ao fato de que nao existiriam sem a ocorrencia de um rollback primario
e de que sua quantidade fica dependente de uma serie de fatores relacionados ao
modelo da simulacao, que sao difıceis de controlar.
Apesar do calculo da metrica proposta nao estar relacionada diretamente ao
relogio local, indiretamente, o relogio local dos processos tendem a estar proximos,
uma vez que a diferenca entre LVTs de processos comunicantes e a causa das
mensagens stragglers.

81
Para a metrica, quanto maior o valor do trabalho efetivo esperado, maior e a
carga do processo, pois o processo nao esta sofrendo com rollbacks ou, por qualquer
outro motivo, nao consegue lidar com a carga imposta a ele e, provavelmente, esta
causando rollbacks em outros processos da simulacao.
Os algoritmos que utilizarem essa metrica devem operar na tentativa de equi-
librar o trabalho efetivo esperado entre os processadores da simulacao, migrando
processos dos processadores mais carregados para os processadores menos carre-
gados.
Em geral, os algoritmos de balanceamento de carga para ambientes de simula-
cao distribuıda que utilizam o protocolo Time Warp buscam reduzir a ocorrencia
de rollbacks. A metrica proposta procura, justamente, trabalhar na raiz desse
problema, as mensagens stragglers, usando o fator de ocorrencia desse tipo de
mensagens e tentando controlar fatores que podem causa-las, tais como a variacao
da quantidade de eventos e do tempo de servico entre os processos.
5.2 Cálculo das métricas
As metricas avaliadas pertencentes a outros algoritmos foram calculadas exa-
tamente como descrito nos trabalhos originais que as introduziram.
A metrica do relogio local, Secao 5.1.1, ja e calculada pelo proprio protocolo
de sincronizacao, pois o LVT e uma informacao necessaria para manter o sincro-
nismo entre os processos. O LVT de cada processo fornece informacao suficiente
para o calculo da metrica.
A utilizacao efetiva e calculada em duas versoes, conforme descrito na Se-
cao 5.1.2. A utilizacao efetiva calculada a partir do numero de eventos efetivados e
do numero total de eventos processados, informacoes ja disponıveis no ambiente de
simulacao, e uma estimativa da utilizacao efetiva calculada a partir do numero to-
tal de ciclos de processamento gastos para processamento dos eventos e do numero

82
de ciclos de processamento perdidos com rollbacks.
As informacoes de ciclos de processamento precisaram ser implementadas no
ambiente de execucao das simulacoes, para que fosse possıvel o calculo dessa me-
trica e tambem da metrica PAT.
Para computar os ciclos de processamento gastos para execucao dos eventos,
foi utilizada a funcao clock_gettime. A funcao clock_gettime permite a
obtencao do tempo de relogio em alta resolucao (LINUXMANPAGES, 2013a). Essa
funcao retorna a informacao de tempo em dois campos, segundo e nanosegundos,
bilionesima parte de um segundo (10−9 segundos), permitindo a obtencao do tempo
por meio de diferentes relogios providos pelo sistema, como por exemplo:
1. CLOCK_REALTIME: relogio de tempo real do sistema;
2. CLOCK_PROCESS_CPUTIME_ID: relogio de alta resolucao que a CPU prove
para cada processo;
3. CLOCK_THREAD_CPUTIME_ID: relogio de alta resolucao que a CPU prove
para cada thread.
Outros relogios podem ser fornecidos pelo sistema, mas esses tres sao suficientes
para obtencao de tempos de execucao em nıvel de sistema, processos e threads.
Para obter o tempo de execucao de uma funcao e necessario realizar duas
chamadas a funcao clock_gettime. Uma antes da funcao ser chamada e outra
apos a execucao da funcao, subtraindo os valores para obter o tempo de execucao,
que no caso dessa funcao pode ser na resolucao de nanosegundos. Foi necessario
a utilizacao dessa funcao porque as funcoes classicas de timers nao oferecem a
resolucao necessaria e, na pratica, nao conseguiam identificar o tempo de execucao
de blocos de codigos de execucao muito rapida.
Fazendo uso dessa funcao, os ciclos de processamento utilizados pelo processo
para execucao de todos os eventos foi contabilizado, assim como os ciclos de pro-

83
cessamento gastos pelo processo na execucao de rollbacks, fornecendo assim as
informacoes necessarias para o calculo da estimativa da utilizacao efetiva.
O calculo da metrica PAT, Secao 5.1.3, alem de utilizar a funcao de tempo
clock_gettime, tambem utiliza a funcao getrusage. A funcao getrusage
retorna diversas estatısticas de uso sobre o processo chamador, tais como tempo
de processamento e memoria utilizada, sendo util para uma analise sobre os recur-
sos utilizados pelo processo (LINUXMANPAGES, 2013b). Para usar a funcao, basta
chama-la quando se deseja obter as informacoes do processo necessarias para al-
guma analise. Essa funcao foi utilizada para calcular o tempo total de CPU gasto
pelos processos. Como a resolucao dessa informacao e a nıvel de segundos, a fun-
cao foi suficiente. Essas funcoes sao as mesmas que foram utilizadas por Carothers
e Fujimoto (2000).
Originalmente, o algoritmo de Carothers e Fujimoto (2000) agrupa os processos
em clusters para calcular a metrica CAT, como o algoritmo que sera apresentado
na Secao 5.3 nao faz qualquer analise estatica do modelo da simulacao, a metrica
CAT e calculada individualmente para cada processo e os processos tambem sao
migrados individualmente.
Seguindo a abordagem de calculo realizada por Carothers e Fujimoto (2000),
a computacao efetiva e calculada somando os ciclos de processamento utilizados
para insercao e remocao de eventos na fila de eventos futuros, salvamento de estado
global e processamento dos eventos. Desse montante de ciclos, sao subtraıdos os
ciclos de processamentos utilizados na execucao de rollbacks. A metrica CAT e
calculada dividindo o total de ciclos de computacao efetiva pelo total de ciclos
dado ao processo. Finalmente, a metrica PAT de um determinado processador e
o somatorio das metricas CAT de todos os processos alocados no processador.
Conforme descrito na Secao 5.1.4, a metrica EEW tambem utiliza dados da
simulacao para ser calculada.
Conforme sera descrito na Secao 6.1, as metricas, assim como os parametros

84
necessarios para obte-las, sao calculadas em intervalos de tempo regulares. Esse
intervalo de tempo e determinado pelo processo mestre que solicita as informacoes
aos processos da simulacao. A cada inıcio de interacao do processo mestre com os
processos da simulacao, os processos da simulacao zeram os fatores utilizados para
calcular as metricas, ou seja, as metricas sao calculadas levando em consideracao
a situacao atual da simulacao, sem considerar valores do passado distante.
5.3 Algoritmo de escalonamento desenvolvido
O algoritmo de escalonamento desenvolvido para avaliar as metricas trabalha
da mesma forma para todas as metricas avaliadas e tem como objetivo equilibrar
a carga dos processadores em relacao a metrica utilizada.
Primeiramente, o algoritmo calcula a carga de cada processador. A carga
de um processador e calculada pela soma das cargas dos processos alocados no
processador em questao. Apos calcular a carga de cada processador, o algoritmo
calcula alguns valores que serao necessarios para determinar se havera ou nao
migracao e quais processos serao migrados. Os valores calculados sao os seguintes:
• Determinar os processadores mais e menos carregados;
• Determinar qual o processo que sera migrado. O processo a ser migrado
e o processo mais lento do processador mais carregado;
• Determinar a diferenca atual de carga entre o processador mais carregado
e o processador menos carregado. Determinar tambem a diferenca futura
entre esses dois processadores caso haja a migracao do processo mais lento
do processador mais carregado para o processador menos carregado. A dife-
renca futura e uma estimativa e e calculada subtraindo a carga do processa-
dor mais carregado pela carga do processo a ser migrado, somando a carga
do processo a ser migrado ao processador menos carregado e subtraindo a

85
carga estimada do processador originalmente mais carregado pela carga do
processador originalmente menos carregado;
• Calcular a media, o desvio padrao, δ e γ da carga dos processadores.
Onde δ e a subtracao da media pelo desvio padrao, enquanto γ e a soma da
media pelo desvio padrao.
Calculados esses valores, resta determinar se havera ou nao uma migracao.
Uma migracao sera realizada se as duas condicoes a seguir forem verdadeiras:
• Se existir um processador cuja carga seja menor que δ ou existir um proces-
sador cuja carga seja maior que γ. Essa abordagem se baseia no algoritmo
de balanceamento utilizando a taxa de avanco do LVT (BURDORF; MARTI,
1993), apresentado na Secao 3.5.2;
• Se as diferencas, atual e a estimativa futura, entre a carga dos processadores,
mais e menos carregados, obedecerem uma das seguintes regras:
– A diferenca futura estimada ainda ser maior que zero, ou seja, mesmo
retirando o processo mais lento do processador originalmente mais car-
regado e migrando para o processador originalmente menos carregado,
o processador originalmente mais carregado ainda tera uma carga maior
que a do processador originalmente menos carregado. Nesse caso, a mi-
gracao e permitida pois o processador originalmente mais carregado esta
muito mais carregado que o processador originalmente menos carregado;
– Caso a carga do processador originalmente menos carregado, apos a
estimativa de migracao do processo mais lento, se torne maior que a
carga do processo originalmente mais carregado, o quanto a carga do
processador originalmente menos carregado pode ser maior que a carga
do processador originalmente mais carregado nao pode ser maior que
a metade da diferenca atual. Assim, pela estimativa, o processador
originalmente mais carregado passara a ter uma carga menor que a carga

86
do processador originalmente menos carregado. Nesse caso, a migracao
so sera realizada em casos onde a inversao entre os processadores mais e
menos carregados leve a uma diferenca que, segundo a estimativa, seja
menor ou igual a metade da diferenca atual.
Definido que havera migracao, o processo mais lento do processador mais car-
regado e migrado para o processador menos carregado. Essa e uma caracterıstica
presente nos algoritmos de Carothers e Fujimoto (2000) e Reiher e Jefferson (1990).
Conforme dito anteriormente, o algoritmo trabalha sempre da mesma forma. O que
varia e a metrica usada para calcular a carga dos processos e, consequentemente,
dos processadores.
A listagem 5.1 apresenta um pseudocodigo ilustrando os passos principais exe-
cutados pelo algoritmo.
Listagem 5.1: Algoritmo de escalonamento utilizado para avaliacao das metricas
1 void schedule(int* processMetricValue) {
2 bool shouldMigrate = false;
3 calculateMetricValueOnNodes(processMetricValue);
4
5 int loadedNode = findLoadedNode();
6 int unLoadedNode = findUnLoadedNode();
7
8 int nodesMean = calculateNodesMean();
9 int nodesStandardDeviation = calculateNodesStandardDeviation();
10
11 int deltaNodes = nodesMean - nodesStandardDeviation;
12 int gammaNodes = nodesMean + nodesStandardDeviation;
13
14 int differenceBetweenLoadedAndUnLoadedNodes = loadedNode -
unLoadedNode;
15
16 int newDifferenceBetweenLoadedAndUnLoadedNodes = (loadedNode
17 - processMetricValue[loadedProcessFromLoadedNode])

87
18 - (unLoadedNode + processMetricValue[
loadedProcessFromLoadedNode]);
19
20 if (newDifferenceBetweenLoadedAndUnLoadedNodes > 0)
21 shouldMigrate = true;
22 else {
23 int newAbsDiff = abs(newDifferenceBetweenLoadedAndUnLoadedNodes);
24
25 if (newAbsDiff <= (differenceBetweenLoadedAndUnLoadedNodes / 2))
26 shouldMigrate = true;
27 }
28
29 if ((unLoadedNode < deltaNodes || loadedNode > gammaNodes)
30 && (shouldMigrate))
31 {
32 migrateProcessTo(loadedProcessFromLoadedNode, unLoadedNodeName
);
33 }
34 }
A carga media e o desvio padrao entre os processadores, aliados as diferencas,
atual e estimada, entre a carga dos processadores, se mostraram eficientes em ser-
vir como condicao de decisao para a migracao. Em conjunto, esses fatores evitam
que os processadores fiquem com cargas muito diferentes e evitam a migracao des-
necessaria de processos, ou seja, aquelas migracoes que causam pouco ou nenhum
efeito no balanceamento da carga.
A cada migracao, o algoritmo migra apenas um processo. Apos uma migracao,
ou mesmo uma avaliacao de carga que nao resultou em migracao, e aguardado um
perıodo de tempo, previamente configurado, ate que uma nova avaliacao de carga
seja realizada. Optou-se pela migracao individual de um processo para se fazer a
menor quantidade de suposicao possıvel em relacao a carga da simulacao, quando
realizada a estimativa de diferencas entre os processadores. Isso e alcancado mi-
grando apenas um processo a cada identificacao de desbalanceamento, analisando o

88
efeito da migracao na carga da simulacao e tomando as proximas decisoes baseadas
em informacoes atualizadas que ja refletem a nova distribuicao dos processos.
O algoritmo resolve tambem o problema citado por Carothers e Fujimoto
(2000) e Reiher e Jefferson (1990) em relacao ao ajuste do fator de diferenca entre
as cargas que determina se havera migracao. Dessa forma, os valores da propria
metrica sao suficientes para a tomada de decisao, nao necessitando de nenhuma
informacao externa a simulacao.
5.4 Considerações Finais
Esse capıtulo apresentou as metricas avaliadas e justificou suas escolhas, tam-
bem mostrou como cada uma das metricas foi calculada.
O capıtulo tambem introduziu uma nova metrica (EEW), mostrando como foi
elaborada e como usa-la em um algoritmo de balanceamento.
Por fim, foi apresentado, em detalhes, o algoritmo de balanceamento dinamico
que foi utilizado para avaliacao das metricas. Nao foi identificada nenhuma carac-
terıstica no algoritmo proposto que possa beneficiar ou punir qualquer uma das
metricas avaliadas, sendo considerado suficiente para a avaliacao das metricas, que
e uma das propostas deste trabalho.
O proximo capıtulo apresenta os modelos, variacoes de carga e demais para-
metros utilizados nas simulacoes realizadas.

89
6 Modelos de simulação e variações decarga
O ambiente de execucao permite que varias informacoes da simulacao e tambem
de controle do proprio ambiente sejam configuradas. A configuracao dessas infor-
macoes e que determina a estrutura do modelo, as variacoes de cargas e algumas
informacoes de controle, como, por exemplo, o momento de encerrar a simulacao.
A variacao de carga tambem pode ser produzida por carga externa, que nao faz
parte das configuracoes e e obtida na forma de um programa desenvolvido para
sobrecarregar o processador.
Este capıtulo descreve os parametros das simulacoes, o ambiente computacional
onde foram executadas, os modelos de simulacao utilizados e as variacoes de carga
impostas. Apresenta tambem as simulacoes que foram executadas considerando
todas as variacoes de ambiente configuradas.
6.1 Configurações dos parâmetros da simulação
As principais configuracoes utilizadas para realizar a modelagem da simulacao,
determinar parametros para variacao de carga e ajustar as informacoes de controle
do ambiente sao as seguintes:
1. Metrica de carga: o ambiente permite que se defina qual das metricas
sera utilizada pelo algoritmo de balanceamento para a execucao de uma

90
simulacao;
2. Intervalo de tempo entre calculos de GVT: determina a periodicidade
com que o processo mestre ira realizar a solicitacao de informacoes aos pro-
cessos da simulacao e tambem realizar o calculo do GVT;
3. Calculos de GVT para migrar: determina a periodicidade com que o al-
goritmo de balanceamento sera executado. Essa periodicidade e determinada
em relacao aos calculos de GVT. Por exemplo, uma configuracao possıvel se-
ria chamar o algoritmo de balanceamento a cada dois calculos de GVT;
4. Parametro de parada: informa qual parametro sera usado para encerrar
a simulacao. Os valores possıveis sao o GVT e o numero de eventos reais
processados.
5. Geracao de eventos: determina o padrao de geracao de eventos dos pro-
cessos, a probabilidade de geracao de eventos a cada ciclo de execucao do
processo. Permite configurar um valor para cada processo;
6. Tempo de servico: determina o tempo de servico, tempo de processamento
estimado para se processar um evento. Tambem permite que se configure um
valor para cada processo;
7. Probabilidade de mensagens: determina quais os processos que se co-
municam e com qual probabilidade. Configura o modelo da simulacao e a
frequencia de envio de mensagens entre os processos.
8. Quantidade de processos: numero de processos executando a simulacao.
Algumas das configuracoes citadas foram ajustadas com o mesmo valor para
todos os modelos e variacoes de carga testados. Outros parametros sao justamente
responsaveis pela configuracao dos modelos e variacao de carga e serao descritos
nas secoes 6.3 e 6.4, respectivamente.
Os valores para esses parametros em todas as simulacoes sao os seguintes:

91
• Metrica de carga: cada uma das metricas listadas a Secao 5.1;
• Intervalo de tempo entre calculos de GVT: 15 segundos;
• Calculos de GVT para migrar: a cada 1 calculo do GVT;
• Parametro de parada: 250.000 eventos reais processados;
• Geracao de eventos: aleatorio, conforme Secao 6.4;
• Tempo de servico: aleatorio, conforme Secao 6.4;
• Probabilidade de mensagens: varia de acordo com o modelo, Secao 6.3;
• Quantidade de processos: 25 processos;
6.2 Cluster de execução
O ambiente de execucao foi composto por um cluster de cinco computadores.
Em um dos computadores executava apenas o processo mestre que coordenava a
simulacao. Nos outros quatro computadores executavam os processos da simulacao.
Todos os cinco computadores possuıam a seguinte configuracao:
• Processador: Intel Core2Quad 2,66GHz;
• Nucleos: 4;
• Cache: L2:8MB;
• Memoria RAM: 2 GB;
• Placa de Rede: Ethernet 100 Mbps.
• Arquitetura: 32 bits.
• Sistema operacional: Linux Fedora 13;

92
6.3 Modelos
As simulacoes foram realizadas com tres modelos diferentes. Cada modelo
apresenta diferencas entre a conectividade dos processos, com quais processos um
determinado processo se comunica, e a probabilidade de troca de mensagens, qual
a frequencia de envio de mensagens de um processo em relacao aos processos com
os quais se comunica. E considerado que dois processos, P1 e P2, se comunicam
quando P1 envia mensagens para P2 e/ou P1 recebe mensagens enviadas por P2.
6.3.1 Modelo de grupos
No modelo de grupos, os processos sao divididos em quatro grupos, cada grupo
de processos com caracterısticas diferentes. Sao eles:
• Grupo vermelho: 7 processos;
• Grupo verde: 6 processos;
• Grupo amarelo: 6 processos;
• Grupo azul: 6 processos.
Os grupos, vermelho e verde, se comunicam da seguinte forma: os processos
do grupo vermelho nao enviam mensagens a nenhum processo do grupo verde,
enquanto cada processo do grupo verde envia mensagens a todos os processos do
grupo vermelho a uma frequencia de 1% para cada processo com o qual se comu-
nica. Isso significa que, em um dado intervalo de tempo, suficiente para geracao
de 100 eventos em cada processo, os processos do grupo vermelho processam 106
eventos cada, enquanto os processos do grupo verde processam 93 eventos cada,
o que faz com que os processos do grupo vermelho tenham uma carga de 57%,
enquanto os processos do grupo verde tenham uma carga de 43%, ou seja, os
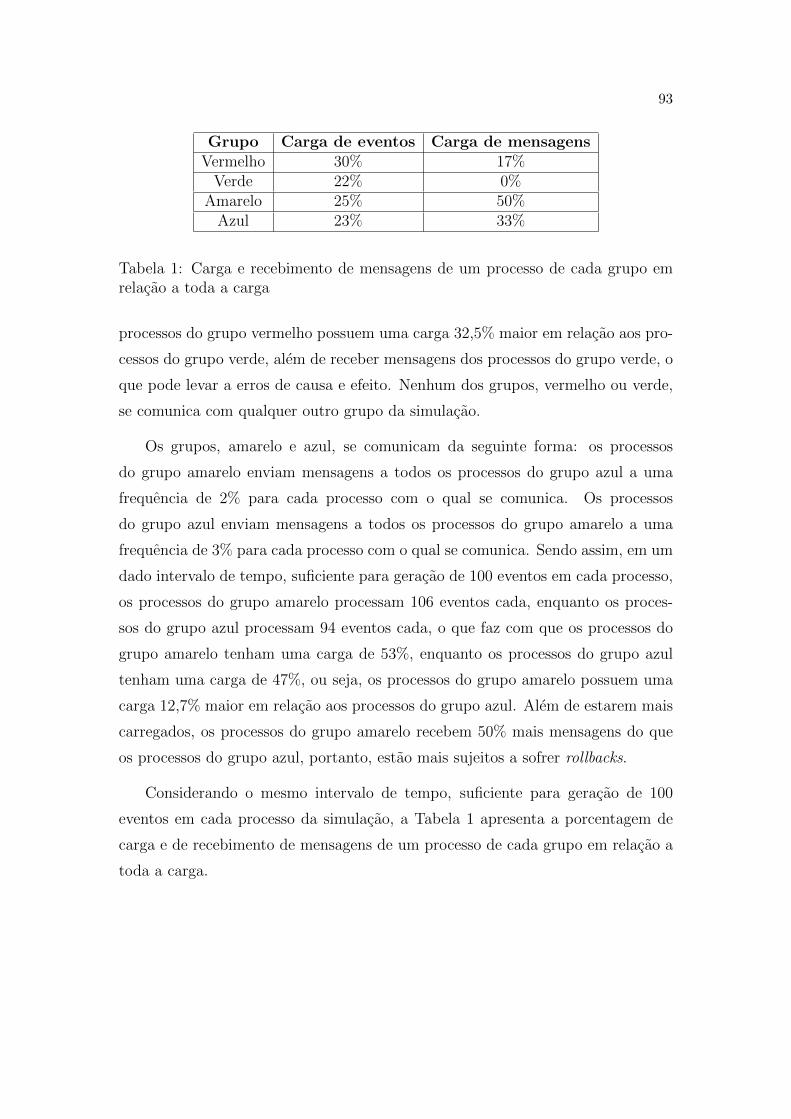
93
Grupo Carga de eventos Carga de mensagensVermelho 30% 17%
Verde 22% 0%Amarelo 25% 50%
Azul 23% 33%
Tabela 1: Carga e recebimento de mensagens de um processo de cada grupo emrelacao a toda a carga
processos do grupo vermelho possuem uma carga 32,5% maior em relacao aos pro-
cessos do grupo verde, alem de receber mensagens dos processos do grupo verde, o
que pode levar a erros de causa e efeito. Nenhum dos grupos, vermelho ou verde,
se comunica com qualquer outro grupo da simulacao.
Os grupos, amarelo e azul, se comunicam da seguinte forma: os processos
do grupo amarelo enviam mensagens a todos os processos do grupo azul a uma
frequencia de 2% para cada processo com o qual se comunica. Os processos
do grupo azul enviam mensagens a todos os processos do grupo amarelo a uma
frequencia de 3% para cada processo com o qual se comunica. Sendo assim, em um
dado intervalo de tempo, suficiente para geracao de 100 eventos em cada processo,
os processos do grupo amarelo processam 106 eventos cada, enquanto os proces-
sos do grupo azul processam 94 eventos cada, o que faz com que os processos do
grupo amarelo tenham uma carga de 53%, enquanto os processos do grupo azul
tenham uma carga de 47%, ou seja, os processos do grupo amarelo possuem uma
carga 12,7% maior em relacao aos processos do grupo azul. Alem de estarem mais
carregados, os processos do grupo amarelo recebem 50% mais mensagens do que
os processos do grupo azul, portanto, estao mais sujeitos a sofrer rollbacks.
Considerando o mesmo intervalo de tempo, suficiente para geracao de 100
eventos em cada processo da simulacao, a Tabela 1 apresenta a porcentagem de
carga e de recebimento de mensagens de um processo de cada grupo em relacao a
toda a carga.

94
As diferencas na carga de eventos para os grupos, menos e mais carregados,
variam em 36,4%, aproximadamente. Em relacao as mensagens, enquanto os pro-
cessos do grupo verde nao recebem mensagens, 50% das mensagens enviadas tem
como destinos os processos do grupo amarelo.
A Figura 10 ilustra o modelo de grupos.
Figura 10: Modelo de grupos
6.3.2 Hierarchical Network Model - hnet
Baseado no modelo usado por Glazer e Tropper (1993), esse modelo organiza os
processos em quatro nıveis hierarquicos, nıvel 01, nıvel 02, nıvel 03 e nıvel 04. Ha
geracao de eventos em todos os nıveis e os processos podem enviar mensagens tanto

95
para o nıvel superior quanto para o nıvel inferior. Nessa estrutura hierarquica, ha
um unico caminho entre quaisquer pares de processos.
A Figura 11 ilustra o modelo hierarquico e apresenta a quantidade de processos
em cada nıvel.
Figura 11: Modelo hierarquico
A frequencia de envio de mensagens esta relacionada ao nıvel que o processo
pertence. 20% dos eventos nos processos de nıvel 01 geram eventos para os proces-
sos do nıvel 02. 12% dos eventos nos processos de nıvel 02 geram eventos para os
processos do nıvel 01 e para os processos do nıvel 03. 8% dos eventos nos processos
de nıvel 03 geram eventos para os processos do nıvel 02 e para os processos do nıvel
04 e 3% dos eventos nos processos de nıvel 04 geram eventos para os processos do
nıvel 03.
A frequencia de envio de mensagens de um processo e dividida entre os pro-
cessos com os quais este processo se comunica. Por exemplo, os 20% de frequencia
do processo de nıvel 01 e dividido entre os dois processos do nıvel 02, ou seja, 10%

96
para cada processo. Para os nıveis centrais, cujos processos se comunicam tanto
com o nıvel superior quanto com o nıvel inferior, a divisao e feita da mesma forma,
independente dos processos estarem no nıvel superior ou inferior. Por exemplo, os
12% de frequencia dos processos de nıvel 02 sao divididos entre o processo de nıvel
01 e os processos de nıvel 03, com 3% para cada um dos quatro.
6.3.3 Distributed Network Model - dnet
Tambem baseado no modelo usado por Glazer e Tropper (1993), esse modelo
simula uma rede de computadores, podendo ser comparado aos roteadores da In-
ternet, que conectam sub-redes e hosts. Os processos sao divididos em 5 regioes.
Uma regiao central conecta as outras 4 regioes.
A frequencia de mensagens e a mesma para todos os processos e e uniforme-
mente dividida entre os processos comunicantes. No modelo proposto, 6% dos
eventos processados por cada processo geram mensagens para os processos comu-
nicantes. A taxa de mensagens que um processo pode receber depende de com
quantos processos cada processo se comunica.
A Figura 12 ilustra a estrutura do modelo distribuıdo.
A frequencia de envio de mensagens de um processo, 6% para todos os pro-
cessos desse modelo, e dividida uniformemente entre seus processos comunicantes.
Por exemplo, um processo que se comunica com 3 processos tera um frequencia
de envio de 2% para cada processo, enquanto um processo que se comunica com
2 processos tera uma frequencia de envio de 3% para cada evento. Em relacao ao
recebimento de mensagens, quanto maior for o numero de processos que um deter-
minado processo se comunica, maior sera sua taxa de recebimento de mensagens.

97
Figura 12: Modelo distribuıdo
6.4 Variações de carga
A carga imposta a cada processo da simulacao e afetada pela variacao de tres
fatores: (1) a probabilidade de geracao de eventos, (2) o tempo gasto para o proces-
samento de cada evento e (3) cargas externas impostas por um programa externo
a simulacao. Essa variacao de carga foi baseada nos fatores de desbalanceamento
de carga levantados por Carothers e Fujimoto (2000), Secao 3.4.
A probabilidade de geracao de eventos e o tempo gasto para o processamento
de cada evento sao determinados de maneira aleatoria no momento da criacao
de cada processo. Os valores possıveis para cada um desses parametros sao os
seguintes:

98
• Probabilidade de geracao de eventos: a probabilidade de geracao de
eventos de um processo e aleatoriamente determinada dentre um dos seguin-
tes valores: 40%, 60% ou 80%. Isso significa que, a cada ciclo do processo, sao
esses os valores que indicam a probabilidade de geracao de um novo evento.
• Tempo gasto para o processamento de cada evento: o tempo gasto
para o processamento de cada evento e aleatoriamente determinado dentre
um dos seguintes valores: 10, 15 ou 20. Isso significa que, ao executar um
processo, sao esses os valores que determinam o tempo de processamento de
cada evento.
Os parametros citados acima sao determinados no inıcio da execucao do pro-
cesso e nao mudam durante a simulacao. Por exemplo, se ao iniciar o processo P1
foi determinado que sua probabilidade de geracao de eventos e x e seu tempo de
servico e y, esses valores serao os mesmos ate o final da execucao da simulacao.
A mudanca desses parametros acontece a cada execucao de uma nova simula-
cao. Conforme sera explicado na secao 6.5, para cada metrica e para cada modelo
foram executadas 10 simulacoes. Cada uma dessas simulacoes possuem sementes
de aleatoriedade diferentes, ou seja, para uma mesma metrica e um mesmo mo-
delo, foram executadas 10 simulacoes com variacao de carga diferentes, baseadas
na aleatoriedade da probabilidade de geracao de eventos e tempo de servico de
cada processo.
A variacao do tempo de servico dos processos implica que, para um processo
com tempo de servico igual a 20, o tempo de execucao de cada evento desse processo
sera duas vezes maior do que o tempo de execucao dos eventos de um processo com
o tempo de servico igual a 10. Dentro do ambiente de execucao das simulacoes, isso
foi alcancado fazendo com que uma atividade fosse realizada quantas vezes fosse
o valor do parametro durante a execucao de cada evento. Por exemplo, para um
processo com tempo de servico igual a 10, a cada evento processado, uma atividade
de processamento, que no caso foi uma multiplicacao de matrizes, e executada 10

99
vezes.
A carga externa consiste em um programa desenvolvido apenas para consumir
recursos de processamento do ambiente. O programa inicializa algumas threads,
as quais executam uma multiplicacao de matrizes. O programa consome mais ou
menos poder de processamento dependendo da quantidade de threads realizando
as multiplicacoes. A quantidade de threads a ser executadas e passada como pa-
rametro para o programa.
Em relacao a carga externa, os quatro computadores que executaram as simu-
lacoes possuıam as seguintes configuracoes:
• Computador 1: processador com aproximadamente 75% da capacidade
dedicada a simulacao, com os outros 25% da capacidade sendo consumida
por carga externa;
• Computador 2: processador com aproximadamente 50% da capacidade
dedicada a simulacao, com os outros 50% da capacidade sendo consumida
por carga externa;
• Computador 3: processador totalmente dedicado a simulacao;
• Computador 4: processador totalmente dedicado a simulacao.
Essa configuracao de carga faz com que haja uma diferenca mınima de 33% e
uma diferenca maxima de 100% entre as capacidades de processamento dedicadas
a simulacao. Essa configuracao de carga externa se manteve fixa para todas as
metricas e para todos os modelos.
6.5 Simulações realizadas
As simulacoes realizadas foram executadas com cada um dos modelos apre-
sentados, combinados com as variacoes de carga aleatoriamente determinadas e

100
tambem com as metricas utilizadas pelo algoritmo de balanceamento. Por exem-
plo, para o modelo hnet e metrica EEW, foram executadas 10 simulacoes. Cada
uma dessas 10 simulacoes possui uma semente diferente.
Essa abordagem se repetiu para cada um dos modelos (grupos, hnet e dnet) e
para cada uma das metricas (taxa de avanco do LVT, utilizacao efetiva, utilizacao
efetiva baseada em ciclos, PAT e EEW). Para cada um dos modelos, tambem foram
executadas 10 simulacoes com o algoritmo de balanceamento Round Robin. Os da-
dos nas execucoes realizadas com o Round Robin foram utilizados para realizar a
analise do desempenho do algoritmo de balanceamento proposto. No ambiente, o
algoritmo de Round Robin divide os processos igualmente entre os processadores
disponıveis, essa foi tambem a distribuicao inicial dos processos para o algoritmo
de balanceamento proposto. Ou seja, inicialmente, quando ainda nao se tem ne-
nhuma informacao sobre a execucao da simulacao, o Round Robin foi usado como
distribuicao inicial.
6.6 Considerações Finais
Esse capıtulo apresentou todas as informacoes necessarias para compreender
como as simulacoes foram realizadas, evidenciando todos os parametros importan-
tes, tais como, informacoes dos modelos, do ambiente e das variacoes de carga.
Essas informacoes tambem sao importantes para que se possa reproduzir os expe-
rimentos, caso necessario.
O proximo capıtulo apresenta uma analise sobre o desempenho do algoritmo
de escalonamento e das metricas avaliadas.

101
7 Análises dos resultados
As analises dos resultados obtidos com a execucao das simulacoes realizadas
foram feitas com base em tres fatores: (1) a eficiencia, (2) o numero de migracoes
realizadas e (3) o tempo total de execucao da simulacao.
A eficiencia e a relacao entre o numero de eventos reais processados, aqueles
que nao sofreram rollbacks, pelo numero total de eventos processados. Por exemplo,
se em uma simulacao foram executados 100 eventos no total, dos quais 60 sofreram
rollbacks, entao a eficiencia dessa simulacao foi de 40%.
O numero de migracoes realizadas indica quantos processos sofreram mi-
gracoes no decorrer da execucao da simulacao e o tempo total de execucao
determina o tempo real (em segundos) gasto para executar a simulacao.
A analise foi feita em relacao a esses tres fatores devido ao fato da eficiencia
nao ser diretamente afetada pelo numero de migracoes realizadas, o que ja pode
ocorrer em relacao ao tempo de execucao, uma vez que a acao de migrar processos
consome recursos de processamento e tempo.
Foi realizada uma analise individual sobre cada modelo utilizado e tambem uma
analise geral envolvendo os tres modelos. Os tres fatores utilizados nas analises sao
comparados ao algoritmo estatico utilizado na distribuicao inicial dos processos, o
Round Robin. Os valores apresentados nos graficos sao a media das 10 execucoes
realizadas para cada modelo com cada uma das metricas. O desvio padrao tambem
e exibido no grafico, a fim de mostrar o quanto houve de variacao dos fatores entre
as execucoes. O percentual de melhora de cada metrica tambem e exibido.

102
7.1 Análise de desempenho com o modelo dnet
Conforme pode ser visto no grafico da Figura 13, a metrica que alcancou a
melhor eficiencia foi a taxa de avanco do LVT, com aproximadamente 13% de
melhora. Em relacao a metrica PAT, que alcancou a menor melhora na eficien-
cia, aproximadamente 7%, a melhora alcancada pela taxa de avanco do LVT foi,
aproximadamente, 88% maior. A melhora de eficiencia das outras metricas estao
proximas a media de todas as metricas. A melhora na eficiencia alcancada pela
taxa de avanco do LVT foi aproximadamente 23% maior em relacao a media de
todas as metricas, que foi de aproximadamente 11%, sendo que a metrica PAT
teve uma melhora aproximadamente 31% abaixo da media. O algoritmo de ba-
lanceamento, considerando a media de todas as metricas, obteve uma melhora na
eficiencia de aproximadamente 11% em relacao ao Round Robin.
Para esse modelo, o tempo de execucao das simulacoes nao refletiu diretamente
na eficiencia, ou seja, as metricas mais eficientes nao foram as que obtiveram os
menores tempos de execucao das simulacoes, conforme pode ser visto no grafico
da Figura 14. Por exemplo, as duas metricas mais eficientes, a taxa de avanco
do LVT e a utilizacao efetiva, obtiveram o segundo e terceiro maior tempo de
execucao, respectivamente. No entanto, as diferencas entre o tempos de execucao
de cada metrica sao muito pequenos, com excecao da metrica PAT, que obteve
uma reducao no tempo de execucao de aproximadamente 82% abaixo da media
das metricas. Em media, o algoritmo de balanceamento obteve uma reducao de
aproximadamente 5% no tempo de execucao das simulacoes. Ja em relacao a
eficiencia, a media de melhora foi de aproximadamente 11%.
Para melhor entender esse cenario, e importante analisar tambem o numero
de migracoes realizadas por cada metrica. Essas informacoes podem ser vistas no
grafico da Figura 15.
Em relacao ao numero de migracoes, houve uma diferenca grande entre a me-
trica que mais migrou processos, a taxa de avanco do LVT, com uma media superior
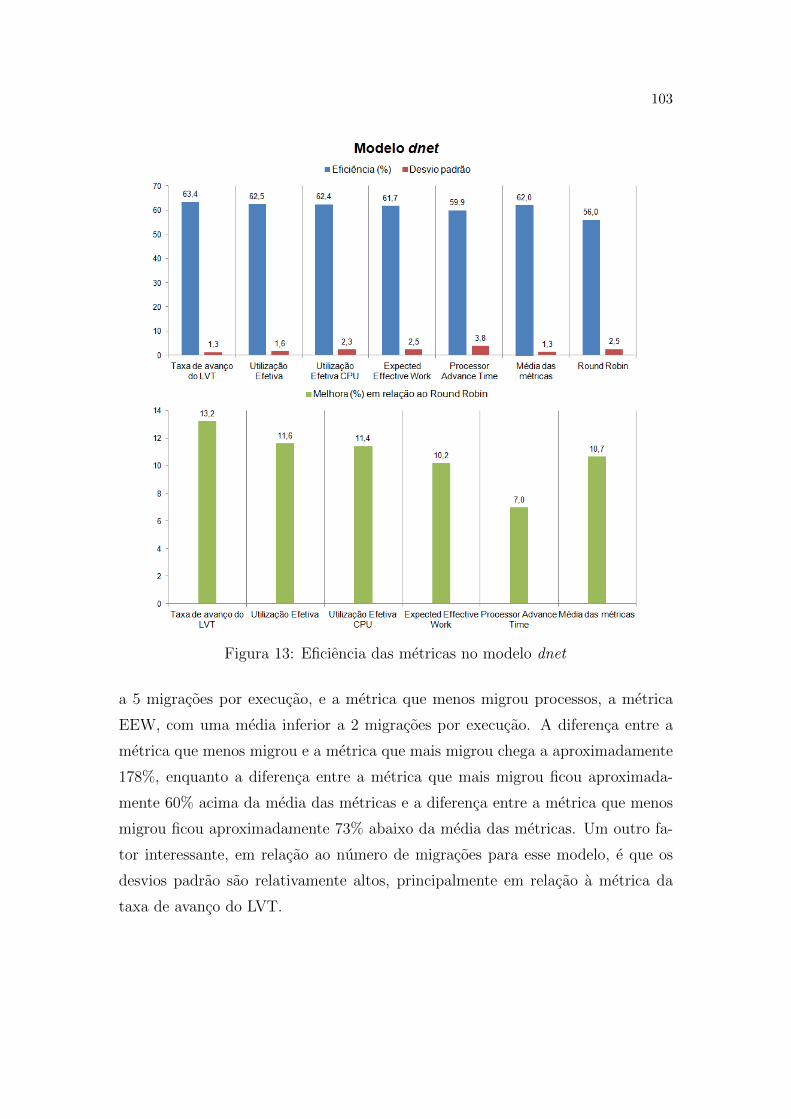
103
Figura 13: Eficiencia das metricas no modelo dnet
a 5 migracoes por execucao, e a metrica que menos migrou processos, a metrica
EEW, com uma media inferior a 2 migracoes por execucao. A diferenca entre a
metrica que menos migrou e a metrica que mais migrou chega a aproximadamente
178%, enquanto a diferenca entre a metrica que mais migrou ficou aproximada-
mente 60% acima da media das metricas e a diferenca entre a metrica que menos
migrou ficou aproximadamente 73% abaixo da media das metricas. Um outro fa-
tor interessante, em relacao ao numero de migracoes para esse modelo, e que os
desvios padrao sao relativamente altos, principalmente em relacao a metrica da
taxa de avanco do LVT.

104
Figura 14: Tempo de execucao para cada metrica no modelo dnet
Tomando como base esse modelo, observa-se algumas caracterısticas em rela-
cao a eficiencia, o numero de migracoes e o tempo de execucao. Um numero de
migracoes alto nem sempre leva a uma alta eficiencia. Pelo modelo, isso pode ser
observado pela metrica PAT, a segunda que mais migra e a pior em eficiencia. Ja
um numero de migracoes mais baixo leva a uma reducao no tempo de execucao
da simulacao, considerando que a metrica tenha uma boa eficiencia, como pode
ser visto em relacao a metrica EEW. Se o numero de migracoes necessario para
alcancar uma boa eficiencia for alto, uma boa eficiencia pode nao levar a uma boa
reducao do tempo de execucao, como pode ser visto em relacao a metrica da taxa
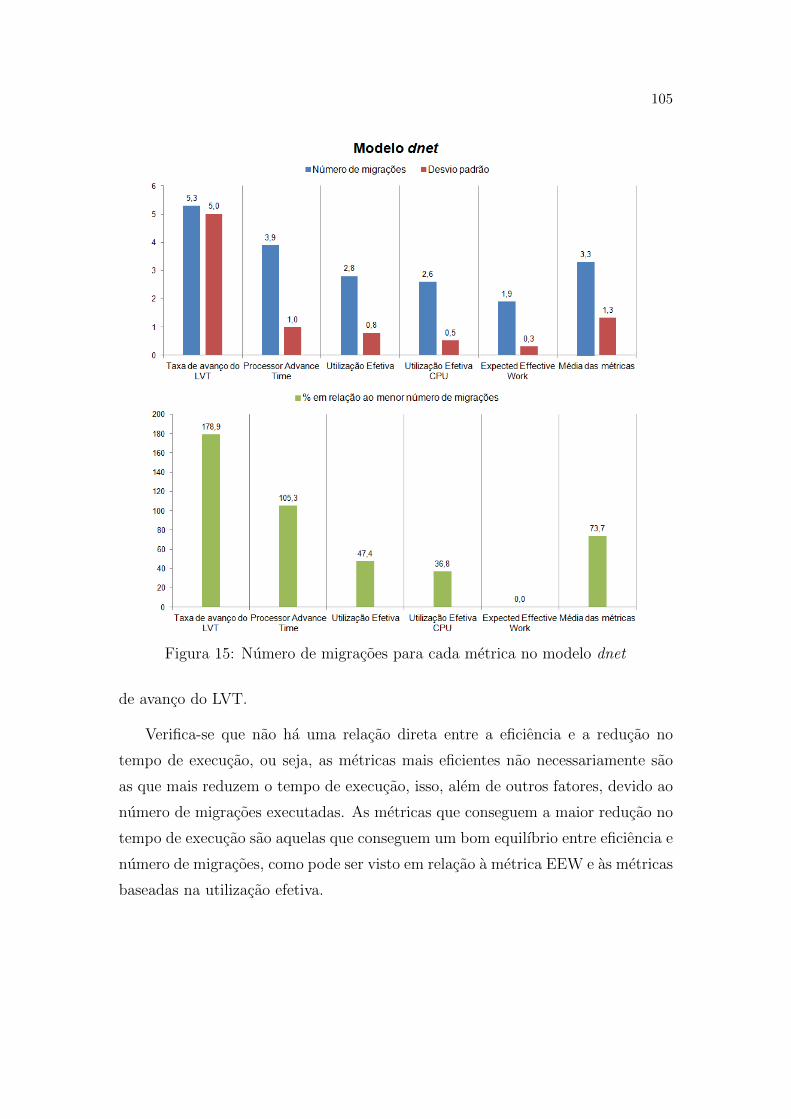
105
Figura 15: Numero de migracoes para cada metrica no modelo dnet
de avanco do LVT.
Verifica-se que nao ha uma relacao direta entre a eficiencia e a reducao no
tempo de execucao, ou seja, as metricas mais eficientes nao necessariamente sao
as que mais reduzem o tempo de execucao, isso, alem de outros fatores, devido ao
numero de migracoes executadas. As metricas que conseguem a maior reducao no
tempo de execucao sao aquelas que conseguem um bom equilıbrio entre eficiencia e
numero de migracoes, como pode ser visto em relacao a metrica EEW e as metricas
baseadas na utilizacao efetiva.

106
7.2 Análise de desempenho com o modelo de grupos
Os resultados obtidos para o modelo de grupos sao consideravelmente diferentes
dos resultados obtidos para o modelo dnet. Conforme pode ser visto no grafico da
Figura 16, a metrica PAT, que obteve a menor eficiencia no modelo dnet, obteve a
melhor eficiencia para o modelo de grupos, obtendo uma melhora aproximadamente
44% maior que a metrica EEW, que obteve a menor eficiencia em relacao ao modelo
de grupos, e uma melhora aproximadamente 16% maior que a media das metricas.
Em relacao a metrica da taxa de avanco do LVT, a melhora na eficiencia da metrica
PAT foi de aproximadamente 19%, bem menor em relacao aos 88% alcancados pela
taxa de avanco do LVT no modelo dnet.
Observa-se uma oscilacao grande entre a eficiencia alcancada pela metrica PAT
em relacao ao modelo dnet (7%) e o modelo de grupos (15%), uma variacao de
aproximadamente 114%, enquanto as outras metricas oscilam bem menos. Por
exemplo, a segunda metrica que mais oscilou foi a metrica da utilizacao efetiva
calculada com base em ciclos de CPU, com uma variacao de aproximadamente
25%.
Mais uma vez, a eficiencia nao refletiu diretamente na reducao do tempo de
execucao das simulacoes. Conforme pode ser visto no grafico da Figura 17, a
metrica mais eficiente, a metrica PAT, obteve apenas o terceiro melhor tempo de
execucao, que, a proposito, foi praticamente o mesmo em relacao ao Round Robin,
ou seja, apesar de uma eficiencia 15% melhor, praticamente nao houve melhora
no tempo de execucao. Dois casos ainda piores sao os das metricas baseadas
na utilizacao efetiva que, apesar de ter alcancado eficiencias superiores a media,
obtiveram tempos de execucao maiores que o tempo de execucao do Round Robin.
Por outro lado, a metrica da taxa de avanco do LVT, com uma eficiencia proxima
a media de todas as metricas, obteve o menor tempo medio de execucao.
O grafico da Figura 18 reforca que o numero de migracoes afeta a relacao da
eficiencia com o tempo de execucao. Apesar das tres metricas que mais migraram,

107
Figura 16: Eficiencia das metricas no modelo de grupos
a metrica PAT e as duas metricas baseadas em utilizacao efetiva, terem obtido os
maiores valores de eficiencia, elas obtiveram as piores valores em relacao a reducao
do tempo de execucao. Ja a metrica EEW, que migrou menos e obteve a menor
eficiencia para esse modelo, ainda obteve a segunda melhor reducao em relacao ao
tempo de execucao.
Em media, para o modelo de grupos, o algoritmo de balanceamento obteve
uma eficiencia 13% melhor que o algoritmo Round Robin. Esse valor foi superior a
melhora alcancada pelo algoritmo no modelo dnet. No entanto, enquanto a reducao
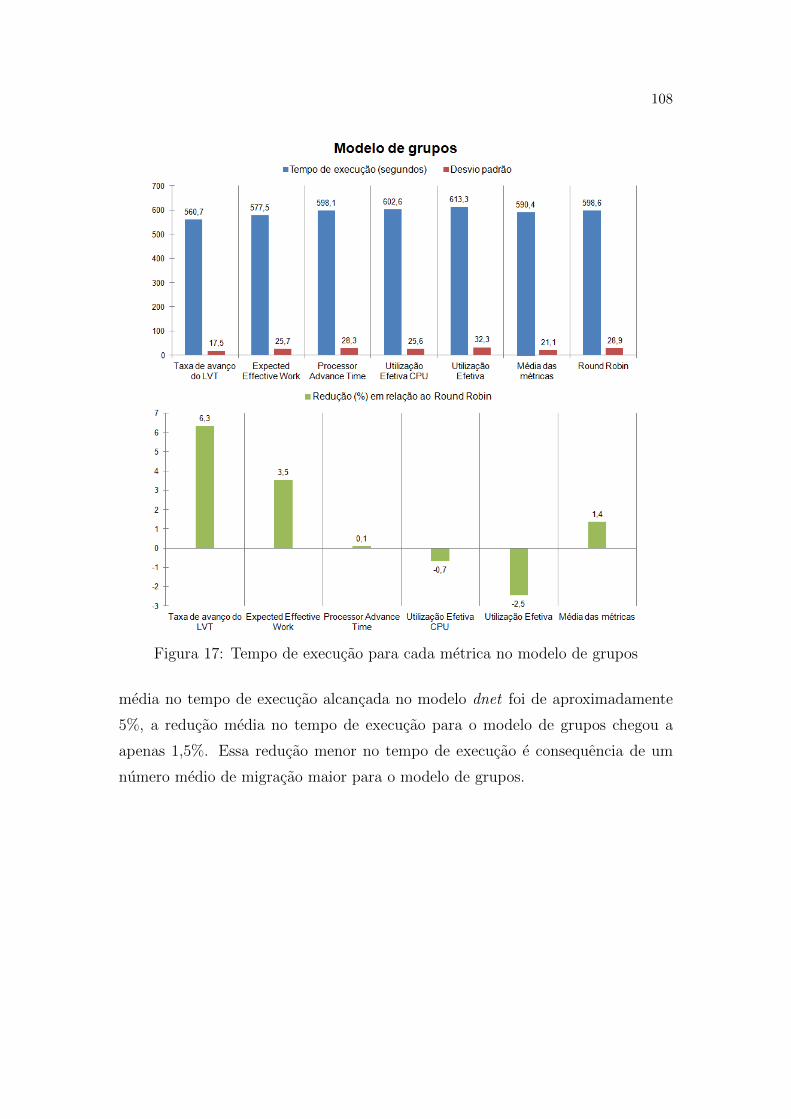
108
Figura 17: Tempo de execucao para cada metrica no modelo de grupos
media no tempo de execucao alcancada no modelo dnet foi de aproximadamente
5%, a reducao media no tempo de execucao para o modelo de grupos chegou a
apenas 1,5%. Essa reducao menor no tempo de execucao e consequencia de um
numero medio de migracao maior para o modelo de grupos.
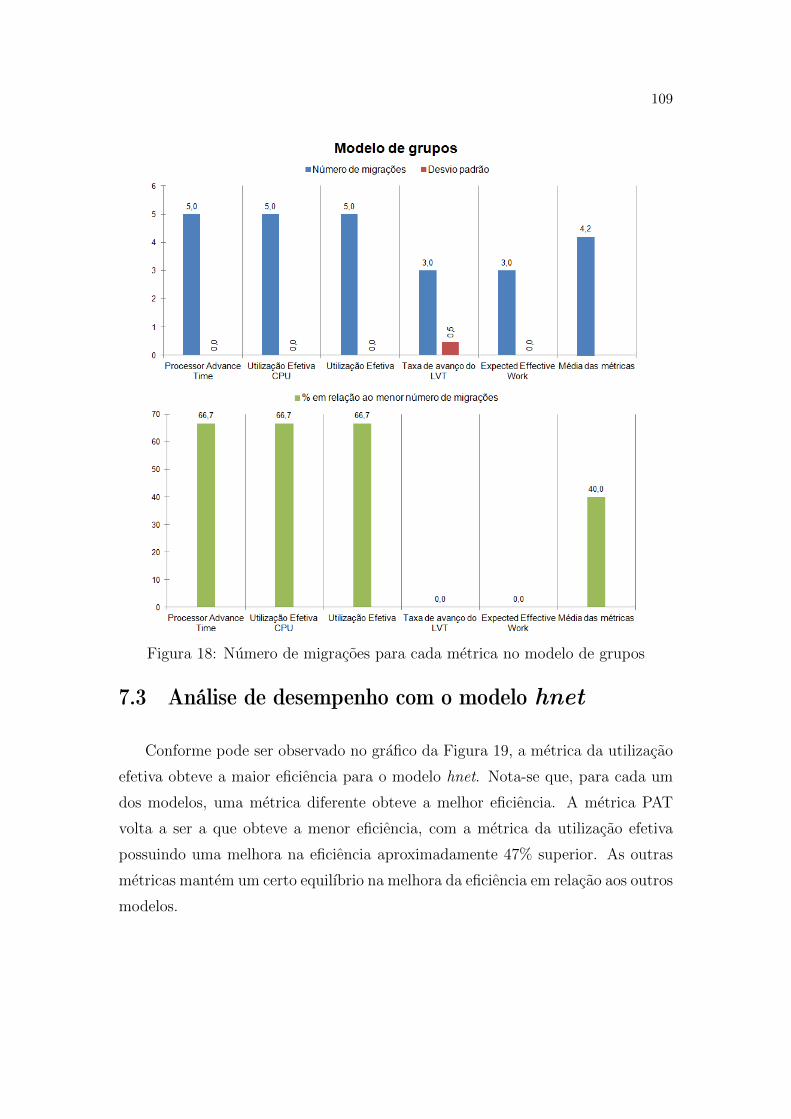
109
Figura 18: Numero de migracoes para cada metrica no modelo de grupos
7.3 Análise de desempenho com o modelo hnet
Conforme pode ser observado no grafico da Figura 19, a metrica da utilizacao
efetiva obteve a maior eficiencia para o modelo hnet. Nota-se que, para cada um
dos modelos, uma metrica diferente obteve a melhor eficiencia. A metrica PAT
volta a ser a que obteve a menor eficiencia, com a metrica da utilizacao efetiva
possuindo uma melhora na eficiencia aproximadamente 47% superior. As outras
metricas mantem um certo equilıbrio na melhora da eficiencia em relacao aos outros
modelos.
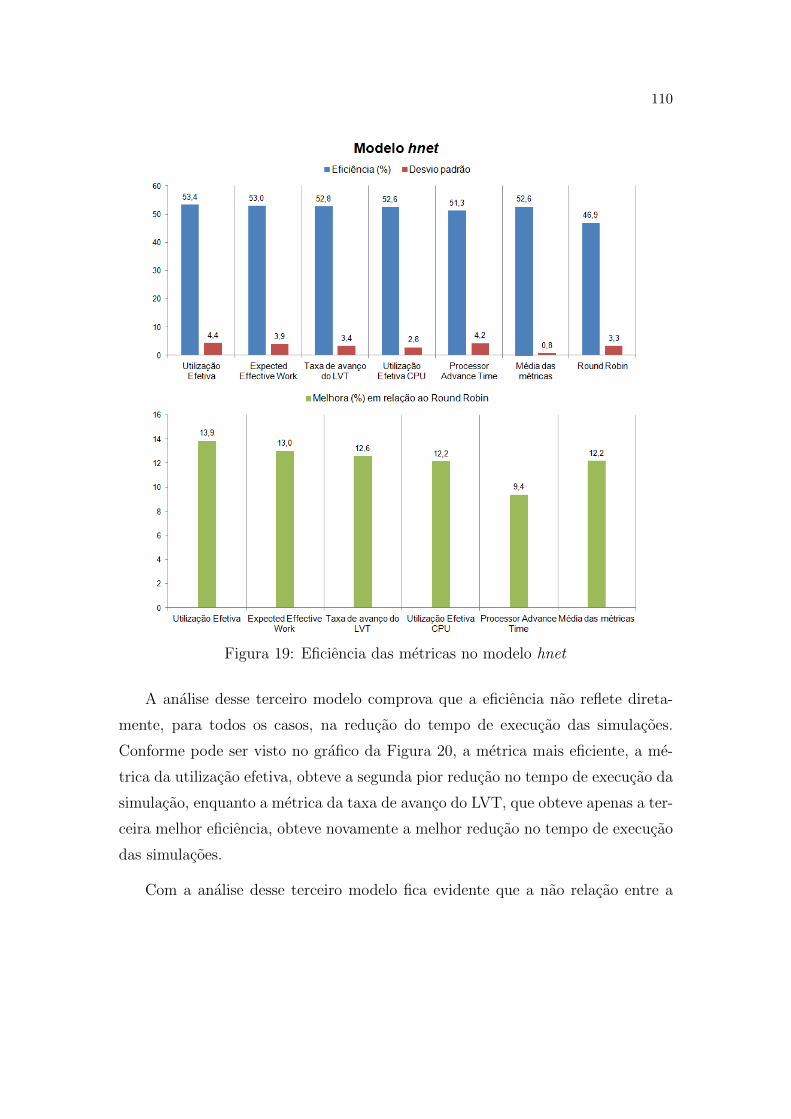
110
Figura 19: Eficiencia das metricas no modelo hnet
A analise desse terceiro modelo comprova que a eficiencia nao reflete direta-
mente, para todos os casos, na reducao do tempo de execucao das simulacoes.
Conforme pode ser visto no grafico da Figura 20, a metrica mais eficiente, a me-
trica da utilizacao efetiva, obteve a segunda pior reducao no tempo de execucao da
simulacao, enquanto a metrica da taxa de avanco do LVT, que obteve apenas a ter-
ceira melhor eficiencia, obteve novamente a melhor reducao no tempo de execucao
das simulacoes.
Com a analise desse terceiro modelo fica evidente que a nao relacao entre a
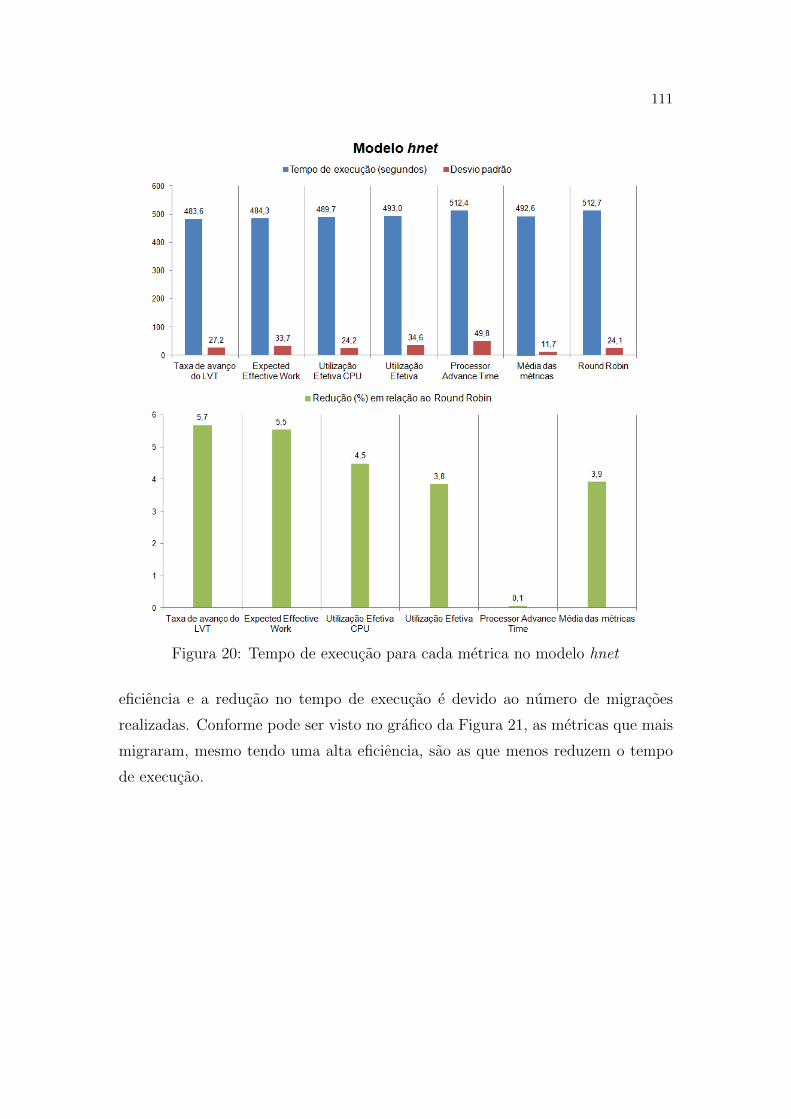
111
Figura 20: Tempo de execucao para cada metrica no modelo hnet
eficiencia e a reducao no tempo de execucao e devido ao numero de migracoes
realizadas. Conforme pode ser visto no grafico da Figura 21, as metricas que mais
migraram, mesmo tendo uma alta eficiencia, sao as que menos reduzem o tempo
de execucao.

112
Figura 21: Numero de migracoes para cada metrica no modelo hnet
7.4 Análise de desempenho em relação a todos os modelos
O grafico da Figura 22 mostra a media da eficiencia para cada metrica em
relacao aos tres modelos. A metrica da taxa de avanco do LVT foi a mais eficiente
considerando todos os modelos, com uma eficiencia 13% maior que o Round Robin,
uma melhora na eficiencia de aproximadamente 18% em relacao a metrica menos
eficiente, a metrica PAT, e uma melhora na eficiencia de aproximadamente 8%
em relacao a media de todas as metricas. A segunda metrica mais eficiente foi a
metrica da utilizacao efetiva, com a mesma eficiencia para a utilizacao calculada
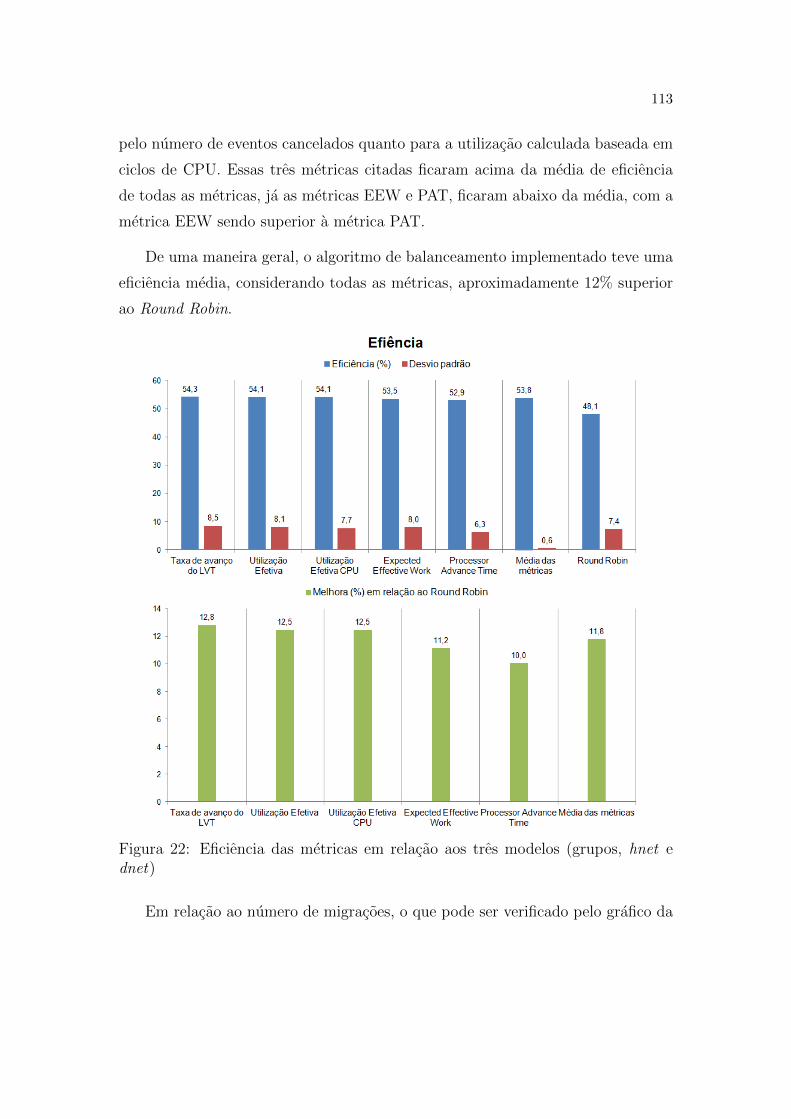
113
pelo numero de eventos cancelados quanto para a utilizacao calculada baseada em
ciclos de CPU. Essas tres metricas citadas ficaram acima da media de eficiencia
de todas as metricas, ja as metricas EEW e PAT, ficaram abaixo da media, com a
metrica EEW sendo superior a metrica PAT.
De uma maneira geral, o algoritmo de balanceamento implementado teve uma
eficiencia media, considerando todas as metricas, aproximadamente 12% superior
ao Round Robin.
Figura 22: Eficiencia das metricas em relacao aos tres modelos (grupos, hnet ednet)
Em relacao ao numero de migracoes, o que pode ser verificado pelo grafico da
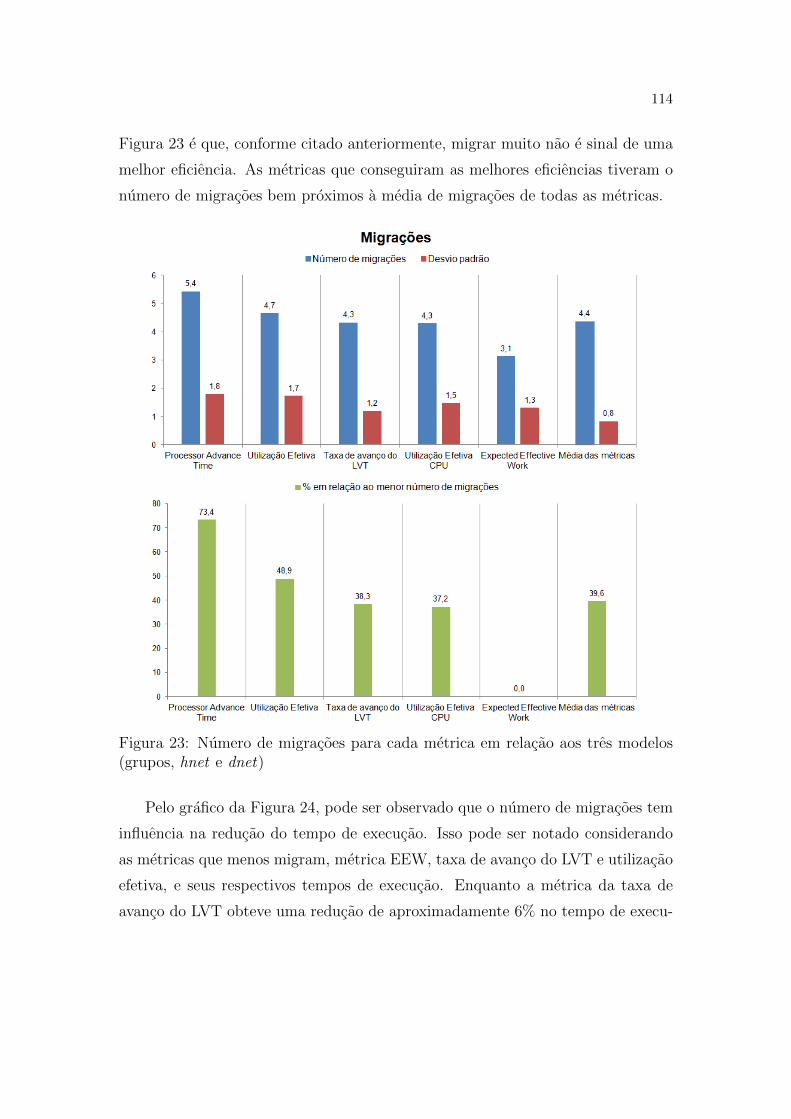
114
Figura 23 e que, conforme citado anteriormente, migrar muito nao e sinal de uma
melhor eficiencia. As metricas que conseguiram as melhores eficiencias tiveram o
numero de migracoes bem proximos a media de migracoes de todas as metricas.
Figura 23: Numero de migracoes para cada metrica em relacao aos tres modelos(grupos, hnet e dnet)
Pelo grafico da Figura 24, pode ser observado que o numero de migracoes tem
influencia na reducao do tempo de execucao. Isso pode ser notado considerando
as metricas que menos migram, metrica EEW, taxa de avanco do LVT e utilizacao
efetiva, e seus respectivos tempos de execucao. Enquanto a metrica da taxa de
avanco do LVT obteve uma reducao de aproximadamente 6% no tempo de execu-
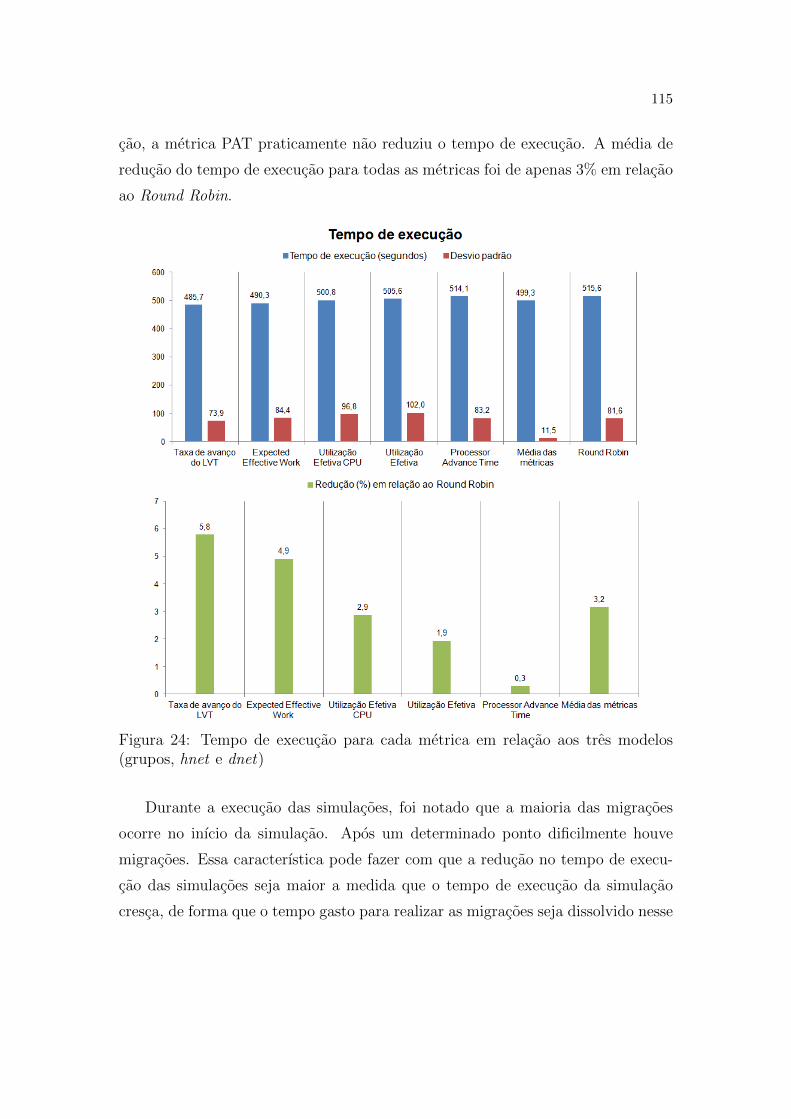
115
cao, a metrica PAT praticamente nao reduziu o tempo de execucao. A media de
reducao do tempo de execucao para todas as metricas foi de apenas 3% em relacao
ao Round Robin.
Figura 24: Tempo de execucao para cada metrica em relacao aos tres modelos(grupos, hnet e dnet)
Durante a execucao das simulacoes, foi notado que a maioria das migracoes
ocorre no inıcio da simulacao. Apos um determinado ponto dificilmente houve
migracoes. Essa caracterıstica pode fazer com que a reducao no tempo de execu-
cao das simulacoes seja maior a medida que o tempo de execucao da simulacao
cresca, de forma que o tempo gasto para realizar as migracoes seja dissolvido nesse

116
tempo total. Uma alternativa tambem seria estudar melhorias no mecanismo de
migracao. Vale lembrar que o mecanismo de migracao utilizado nesse trabalho foi
o mecanismo de migracao coletiva de (JUNQUEIRA, 2012).
Essa analise com todos os modelos e importante para determinar as metricas
mais eficientes, independente do modelo. As diferencas notadas nas analises indi-
viduais de cada modelo mostraram que cada um foi capaz de produzir diferentes
resultados, ou seja, esses modelos puderam alcancar uma abrangencia suficiente
para uma generalizacao dos resultados. Essa abrangencia pode ser percebida pelo
fato de que, para cada modelo, uma metrica diferente alcancou a melhor eficiencia.

117
8 Conclusão
Esse trabalho apresentou uma comparacao entre diferentes metricas utilizadas
para o balanceamento de carga em ambientes de simulacao distribuıda otimistas
que operam com o protocolo Time Warp, bem como a proposta de uma nova
metrica de balanceamento. A metrica proposta foi baseada nos principais fatores
causadores de desbalanceamento de carga nesses ambientes.
Para realizar a comparacao entre as metricas, foi proposto um algoritmo de
balanceamento de carga dinamico que opera independente da metrica utilizada
para determinar a carga do sistema. Esse algoritmo foi proposto de forma a nao
beneficiar ou prejudicar nenhuma das metricas avaliadas.
Ainda com o objetivo de submeter cada uma das metricas a um mesmo ambi-
ente, foram propostos modelos e sementes de aleatoriedade arbitrarios, de forma
que todas as metricas fossem avaliadas com uma sequencia de simulacoes identi-
cas. Identicas no sentido de ser o mesmo modelo, com a mesma conectividade e
probabilidades de comunicacao entre os processos.
Para cada modelo e metrica diferentes, foram realizadas 10 simulacoes, cada
uma das simulacoes com os valores dos fatores de desbalanceamento aleatorios.
Essa aleatoriedade permitiu que, para um mesmo modelo, cada uma das simulacoes
possuısse uma variacao de carga diferente, objetivando afetar a forma de trabalho
do mecanismo de balanceamento. A variacao da carga imposta ao ambiente de
simulacao considerou a variacao na taxa de geracao de eventos, o tempo de servico
e ainda cargas externas a simulacao.

118
Pela analise dos resultados, foi observado que os modelos foram genericos o
suficiente, apresentando resultados diferentes em relacao a eficiencia, numero de
migracoes e tempo de execucao das simulacoes, para cada um deles.
Com uma analise geral sobre todos os modelos verificou-se que a metrica da
taxa de avanco do LVT e a mais eficiente, com uma eficiencia aproximadamente
13% superior ao Round Robin. As metricas baseadas na utilizacao efetiva sao quase
tao eficientes quanto a metrica da taxa de avanco do LVT, com uma eficiencia
aproximadamente 12,5% superior ao Round Robin. Essas tres metricas tambem
foram bem semelhantes em relacao ao numero de migracoes que realizaram e aos
tempos gastos para execucao das simulacoes. A reducao no tempo de execucao
ficou condicionada ao numero de migracoes realizadas, pois as metricas que migram
mais acabam reduzindo menos o tempo de execucao das simulacoes. Para as
metricas que tem uma media de numero de migracoes iguais, as que possuıam um
desvio padrao maior reduziram menos o tempo de execucao.
A metrica PAT e a metrica EEW tiveram eficiencias abaixo da media de todas
as metricas. A metrica EEW, proposta nesse trabalho, teve uma eficiencia quase
igual a media, apenas 5% abaixo, enquanto a metrica PAT teve uma eficiencia 15%
abaixo da media. Em relacao a metrica mais eficiente, que foi a taxa de avanco do
LVT, a metrica EEW obteve uma eficiencia 12,5% inferior e a metrica PAT uma
eficiencia 22% inferior. Vale ressaltar que, apesar de uma eficiencia 12,5% inferior,
a metrica EEW apresentou uma reducao do tempo de execucao quase identica,
menos de 1% inferior.
Os resultados mostram que todas as metricas avaliadas sao capazes de tratar
todos os fatores de desbalanceamento de carga impostos as simulacoes executadas,
ja que todas alcancaram eficiencia superior ao Round Robin. Mesmo as metricas
que nao sao calculadas a partir de unidades de processamento, ciclos de CPU,
sao capazes de tratar o desbalanceamento causado por carga externa. Na verdade,
tais metricas obtiveram resultados ate melhores que as metricas calculadas a partir
desse tipo de informacao.

119
Alem de ser a mais eficiente, a metrica da taxa de avanco do LVT e a mais
simples de ser calculada, pois essa informacao ja faz parte do ambiente de uma
simulacao distribuıda. Metricas como a PAT e a utilizacao efetiva com base em
ciclos de CPU sao mais difıceis de serem calculadas, alem de estarem sujeitas a
caracterısticas da plataforma.
Como a avaliacao das metricas foi realizada em uma mesma plataforma, com
a mesma biblioteca de passagem de mensagens, nesse caso o OpenMPI, com os
mesmos modelos e com o mesmo algoritmo de balanceamento, ela e considerada
generica o suficiente para a validade dos resultados apresentados.
8.1 Contribuições
A principal contribuicao desse trabalho foi a construcao de um ambiente de
simulacao distribuıda, com diferentes modelos de simulacao, diferentes variacoes
de carga e com um algoritmo de balanceamento capaz de avaliar as metricas de
balanceamento sob as mesmas condicoes, sem beneficiar ou punir qualquer uma
delas. Outra contribuicao importante foi a avaliacao realizada, com modelos e va-
riacoes de carga que se mostraram genericos o suficiente para valida-la, mostrando
as metricas mais eficientes que podem ser consideradas em projetos de algoritmos
de balanceamento de carga par simulacoes distribuıdas.
A metrica EEW e o algoritmo de balanceamento dinamico, que pode operar
com diferentes metricas, tambem foram uma contribuicao significativa. A metrica
EEW nao foi a mais eficiente, mas ficou proxima a media de eficiencia das metricas
avaliadas e pode ser otimizada a fim de melhorar seu desempenho.
Uma ultima contribuicao desse trabalho foram as melhorias na implementa-
cao do protocolo Time Warp e no mecanismo de migracao de processos. Essas
melhorias foram descritas no Capıtulo 4.

120
8.2 Trabalhos futuros
Novos estudos podem ser desenvolvidos a partir das implementacoes e analises
realizadas nesse trabalho.
Podem ser estudadas algumas possibilidades de melhorias no mecanismo de
migracao, a fim de melhorar a reducao no tempo de execucao das simulacoes.
Uma avaliacao de melhoria da metrica EEW ou do algoritmo de balanceamento
pode ser realizada, considerando outras abordagens.
Podem ser realizados mais testes, considerando configuracoes e modelos de
simulacao diferentes, visando completar ainda mais as analises realizadas neste
trabalho.
Pode ser considerada a proposta de um algoritmo de balanceamento capaz de
alternar entre as metricas, de forma a usar a metrica que melhor se adapte ao
modelo. Como foi visto na analise dos resultados, para cada modelo uma metrica
diferente foi a mais eficiente. Um algoritmo capaz de identificar a metrica mais
eficiente para cada modelo obteria um resultado superior a um algoritmo que
optasse pela melhor metrica avaliada sobre diferentes modelos.

121
Referências
AGARWAL, A.; HYBINETTE, M.; XIONG, Y. Merging parallel simulationprograms. In: The 18Th Workshop on Parallel and Distributed Simulation -PADS2005. [S.l.: s.n.], 2005.
AJALTOUNI, E. E.; BOUKERCHE, A.; ZHANG, M. An efficient dynamicload balancing scheme for distributed simulations on a grid infrastructure. In:Distributed Simulation and Real-Time Applications, 2008. DS-RT 2008. 12thIEEE/ACM International Symposium on. [S.l.: s.n.], 2008. p. 61–68.
AZEVEDO, M. E. C. V. de. Implementacao e comparacao dos protocolos TimeWarp e Rollback Solidario. Dissertacao (Mestrado em Ciencia e Tecnologia daComputacao) — Universidade Federal de Itajuba - Instituto de Engenharia deSistemas e Tecnologias da Informacao, Itajuba - MG, 2012.
BABAOGLU, O.; MARZULLO, K. Consistent global states of distributedsystems: Fundamental concepts and mechanisms. MULLENDER DistributedSystems, p. 55–96, 1993.
BANKS, J. et al. Discrete-Event System Simulation. 4. ed. India: Prentice Hall,2008.
BARAK, A.; SHILOH, A. A distributed load-balancing policy for a multicomputer.Softw. Pract. Exper., v. 15, n. 9, p. 901–913, 1985.
BAUSE, F.; EICKHOFF, M. Truncation point estimation using multiplereplication in parallel. In: The 2003 winter simulation conference. [S.l.: s.n.],2003. p. 414–421.
BELAPURKAR, A. et al. Distributed systems security issues, processes andsolutions. 1. ed. USA: John Wiley & Sons, Inc, 2009.
BRANCO, K. R. L. J. C. Indices de carga e desempenho em ambientesparalelos/distribuıdos - modelagem e metricas. Tese (Doutorado em Cienciasde Computacao e Matematica Computacional) — Universidade de Sao Paulo -Instituto de Ciencias Matematicas e de Computacao, Sao Carlos - SP, 2004.

122
BRYANT, R. E. Simulation of packet communication architecture computersystems. MIT-LCS-TR-188 - Massachussets, v. 7, n. 3, p. 404–425, 1977.
BURDORF, C.; MARTI, J. Load balancing strategies for Time Warp onmulti-user workstations. The Computer Journal, 1993.
CAROTHERS, C. D.; FUJIMOTO, R. Efficient execution of time warpprograms on heterogeneous, NOW platforms. IEEE Transactions on Parallel andDistributed Systems, PDS-11, n. 3, p. 299–317, 2000.
Carvalho Junior, O. A. de. Avaliacao de polıticas de escalonamento para execucaode simulacoes distribuıdas. Dissertacao (Mestrado em Ciencias de Computacao eMatematica Computacional) — Universidade de Sao Paulo - Instituto de CienciasMatematicas e de Computacao, Sao Carlos - SP, 2008.
CASAVANT, T. L.; KUHL, J. G. A taxonomy of scheduling in general-purposedistributed computing systems. IEEE Transactions on Software Engineering,v. 14, n. 2, 1988.
CASSANDRAS, C. G.; LAFORTUNE, S. Introduction to Discrete Event Systems.2. ed. USA: Springer, 2008.
CHANDY, K. M.; MISRA, J. Distributed simulation: A case study in design andverification of distributed programs. IEEE Transactions on Software Engineering,n. 5, p. 440–452, 1979.
CHEN, L.-l. et al. A well-balanced time warp system on multi-core environments.In: Proceedings of the 2011 IEEE Workshop on Principles of Advanced andDistributed Simulation. [S.l.]: IEEE Computer Society, 2011. (PADS ’11), p. 1–9.
CHILD, R.; WILSEY, P. Dynamically adjusting core frequencies to acceleratetime warp simulations in many-core processors. In: Principles of Advanced andDistributed Simulation (PADS), 2012 ACM/IEEE/SCS 26th Workshop on. [S.l.:s.n.], 2012. p. 35 –43.
CHWIF, L.; PAUL, R. J.; BARRETTO, M. R. P. Discrete event simulationmodel reduction: A causal approach. Simulation Modelling Practice and TheoryEUA, v. 4, p. 930–944, 2006.
COULOURIS, G. F.; DOLLIMORE, J.; KINDBERG, T. Distributed systems:concepts and design. 4. ed. England: Pearson Education, 2005.
De Grande, R. E.; BOUKERCHE, A. Dynamic balancing of communication andcomputation load for HLA-based simulations on large-scale distributed systems.Journal of Parallel and Distributed Computing, v. 71, n. 1, p. 40–52, 2011.

123
DE GRANDE, R. E.; BOUKERCHE, A. Dynamic balancing of communicationand computation load for HLA-based simulations on large-scale distributedsystems. Journal of Parallel and Distributed Computing, v. 71, n. 1, p. 40–52,2011.
FUJIMOTO, R. M. Parallel and distributed simulation systems. 1. ed. USA: JohnWiley & Sons, Inc, 2000.
FUJIMOTO, R. M. Distributed simulation systems. In: Proceedings of the 2003Winter Simulation Conference. [S.l.: s.n.], 2003. p. 124–135.
GLAZER, D. W.; TROPPER, C. On process migration and load balancing intime warp. IEEE Transactions on Parallel and Distributed Systems, v. 4, n. 3, p.318–327, 1993.
JEFFERSON, D. R. Virtual time. ACM Transactions on Programming Languagesand Systems, v. 7, n. 3, p. 404–425, 1985.
JIANG, M.; ANANE, R.; THEODOROPOULOS, G. Load balancing indistributed simulations on the grid. In: Systems, Man and Cybernetics, 2004IEEE International Conference on. [S.l.: s.n.], 2004. v. 4.
JUNQUEIRA, M. A. F. C. Mecanismos para Migracao de Processos na SimulacaoDistribuıda. Dissertacao (Mestrado em Ciencia e Tecnologia da Computacao)— Universidade Federal de Itajuba - Instituto de Engenharia de Sistemas eTecnologias da Informacao, Itajuba - MG, 2012.
KASSAB, E. et al. Blowing up the barriers in surgical training: Exploring andvalidating the concept of distributed simulation. Annals of surgery, LWW, v. 254,n. 6, p. 1059–1065, 2011.
KUMAR, V. Introduction to parallel computing design and analysis of algorithms.2. ed. USA: Addison Wesley Publishing Company, 2003.
LAMPORT, L. Time, clocks, and the ordering of events in a distributed system.Communications of the ACM, v. 21, n. 7, p. 558–565, 1978.
LAMPORT, L.; SHOSTACK, R.; PAESE, M. Byzantine generals problem. ACMTransactions on Programming Languages and Systems, v. 4, n. 3, p. 382–401,1982.
LAW, A. M. Simulation modeling and analysis. 4. ed. USA: McGraw-Hill, 2007.

124
LINUXMANPAGES. Clock and time functions. 2013. http://linuxmanpages.net/manpages/fedora13/man2/clock_getres.2.html. Acessado em 27/02/2013.
LINUXMANPAGES. Getrusage function. 2013. http://linuxmanpages.net/manpages/fedora13/man2/getrusage.2.html. Acessado em27/02/2013.
LOW, M. Y. H. Dynamic load-balancing for bsp time warp. In: In Proceedingsof the 35th Annual Simulation Symposium. [S.l.]: IEEE Computer Society, 2002.(SS’02), p. 267–274.
MALIK, A. W.; PARK, A. J.; FUJIMOTO, R. M. Optimistic synchronizationof parallel simulations in cloud computing environments. IEEE InternationalConference on Cloud Computing, p. 49–56, 2009.
MATTERN, F. Efficient algorithms for distributed snapshots and global virtualtime approximation. Journal of Parallel and Distributed Computing, v. 18, n. 4,p. 423–434, 1993.
MEDINA, A. C.; CHWIF, L. Modelagem e Simulacao de Eventos Discretos -Teoria e Aplicacoes. 2. ed. [S.l.]: Bravarte, 2007.
MERAJI, S.; ZHANG, W.; TROPPER, C. A multi-state q-learning approachfor the dynamic load balancing of time warp. In: Proceedings of the 2010 IEEEWorkshop on Principles of Advanced and Distributed Simulation. [S.l.]: IEEEComputer Society, 2010. (PADS ’10), p. 142–149.
MILOJICIC, D. S. et al. Process migration. ACM Computing Surveys, v. 32, n. 3,p. 241–299, 2000.
MOREIRA, E. M. Rollback Solidario: Um Novo Protocolo Otimista paraSimulacao Distribuıda. Tese (Doutorado em Ciencias de Computacao eMatematica Computacional) — Universidade de Sao Paulo - Instituto de CienciasMatematicas e de Computacao, Sao Carlos - SP, 2005.
PESCHLOW, P.; HONECKER, T.; MARTINI, P. A flexible dynamic partitioningalgorithm for optimistic distributed simulation. In: Principles of Advanced andDistributed Simulation, 2007. PADS ’07. 21st International Workshop on. [S.l.:s.n.], 2007. p. 219–228.
PITANGA, M. Computacao em cluster. 1. ed. Sao Paulo: BRASPORT, 2003.

125
RAVASI, J. F. JUMP: Uma polıtica de escalonamento unificada com migracaode processos. Dissertacao (Mestrado em Ciencias de Computacao e MatematicaComputacional) — Universidade de Sao Paulo - Instituto de Ciencias Matematicase de Computacao, Sao Carlos - SP, 2009.
REIHER, P. L.; JEFFERSON, D. Virtual time based dynamic load managementin the time warp operating system. Transactions of the Society for ComputerSimulation, v. 7, n. 2, p. 103–111, 1990.
SCHRIBER, T. J.; BRUNNER, T. D. Inside discrete-event simulation software:How it works and why it matters. In: Proceedings of the 34th Winter SimulationConference. [S.l.: s.n.], 2002. v. 1, p. 97–107.
SILBERSCHTZ, A.; GALVIN, P. B.; GAGNE, G. Operating System Concepts. 8.ed. USA: John Wiley & Sons, Inc, 2009.
SOM, T. K.; SARGENT, R. G. A probabilistic event scheduling policy foroptimistic parallel discrete event simulation. In: Proceedings of the 12th Workshopon Parallel and Distributed Simulation (PADS-98). [S.l.]: IEEE ComputerSociety, 1998. p. 56–63.
SOM, T. K.; SARGENT, R. G. Model structure and load balancing in optimisticparallel discrete event simulation. In: Procedings of the 14th Workshop on Paralleland Distributed Simulation (PADS-00). [S.l.]: IEEE Press, 2000. p. 147–156.
SOUZA, P. S. L. AMIGO: Uma contribuicao para a convergencia na area deescalonamento de processos. Tese (Doutorado em Fısica Aplicada Opcao EmFısica Computacional) — Universidade de Sao Paulo - Instituto de Fısica de SaoCarlos, Sao Carlos - SP, 2000.
TANENBAUM, A. S. Sistemas Operacionais Modernos. 3. ed. Sao Paulo - SP:Pearson Prentice Hall, 2010.
TANENBAUM, A. S.; STEEN, M. V. Distributed systems: principles andparadigms. 2. ed. Upper Saddle River: Prentice Hall, 2006.
VOORSLUYS, B. L. Influencias de polıticas de escalonamento no desempenhode simulacoes distribuıdas. Dissertacao (Mestrado em Ciencias de Computacao eMatematica Computacional) — Universidade de Sao Paulo - Instituto de CienciasMatematicas e de Computacao, Sao Carlos - SP, 2006.
Top Related