








Línguas
Páginas
Legal


De Scikit-Learn para MLLibCLASSIFICAÇÃO EM LARGA ESCALA

Agenda
● O quê: Spark● O quê: MLlib● Exemplo KMeans em "Toy Dataset" ● DataFrames● Classificação de Spam em Produção● Por quê?

Quem Somos

● Computação genérica distribuída● Até 10 a 100x mais rápido que Hadoop MapReduce
O Quê: Spark
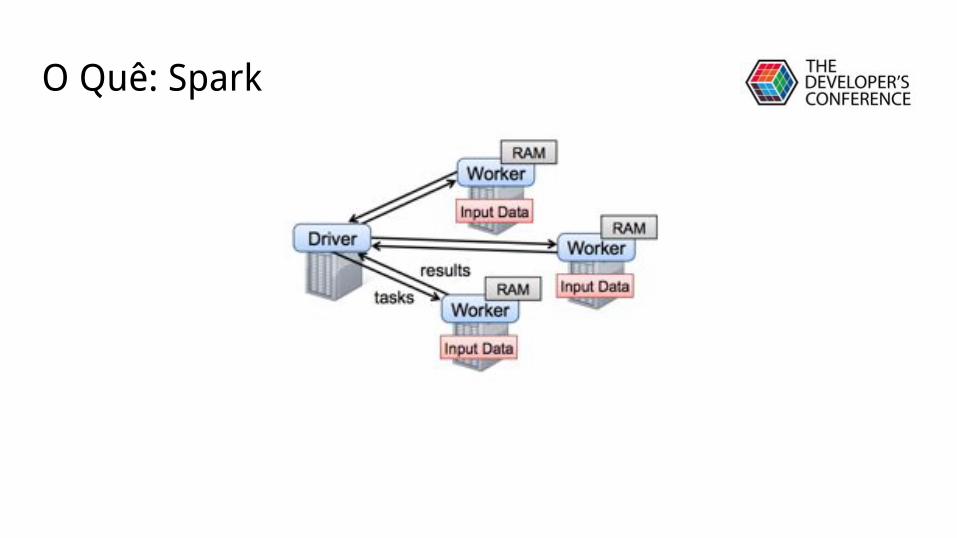
O Quê: Spark
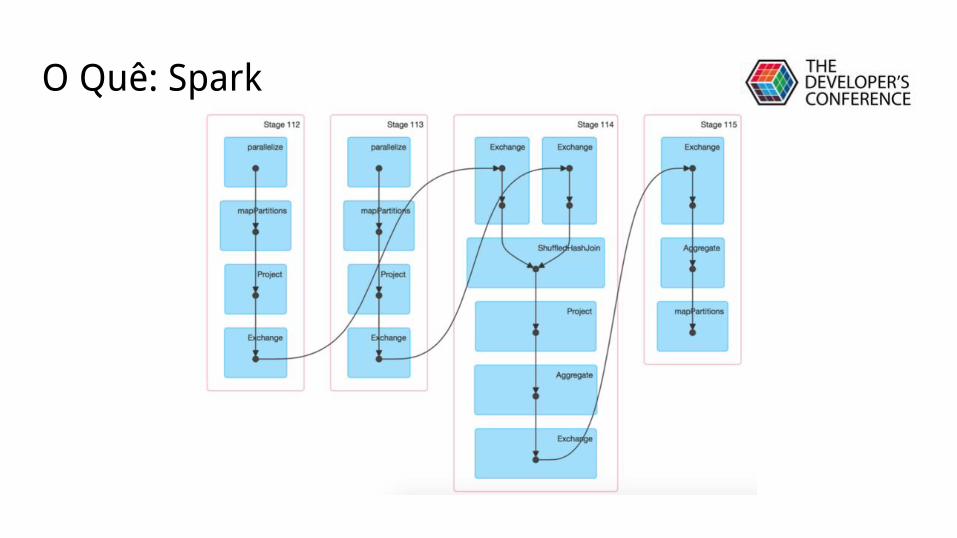
O Quê: Spark

● Machine Learning escalável● Construído em cima do Spark
O Quê: MLLib

● Clustering [KMeans, LDA]● Classificação [SVM, Naïve Bayes, Random Forests]● Regressão● Extração de características● Recomendação, timização de parâmetros, avaliação de
modelos...
Algoritmos
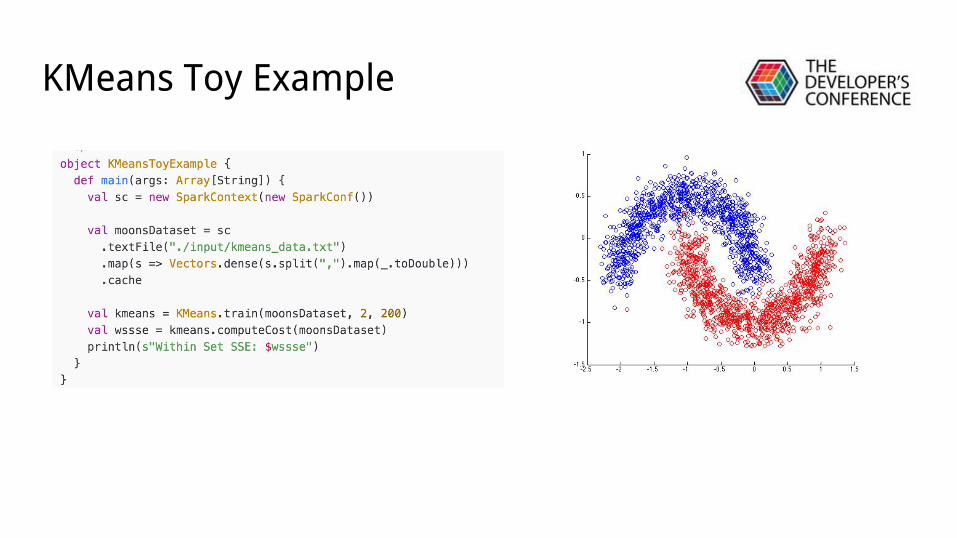
KMeans Toy Example

DataFrames
● Schema definido● Formato tabular● Operações, queries otimizadas● Pipelines

Pipelines
● Transformer○ Gera um DF a partir de outro DF
● Estimator○ Abstrai o conceito de um algoritmo que é treinado sob um
conjunto

Classificação de Spam em Produção

Classificação de Spam em Produção

Classificação de Spam em Produção
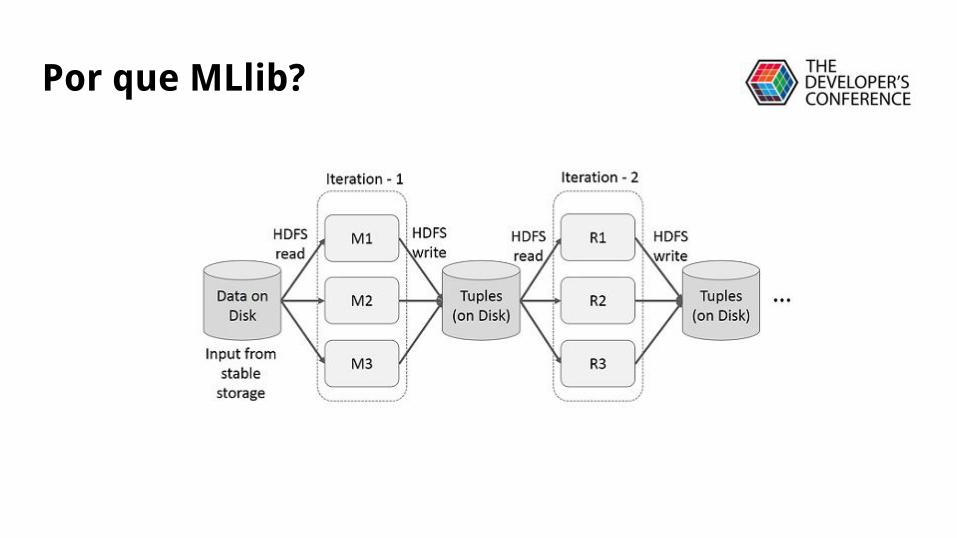
Por que MLlib?
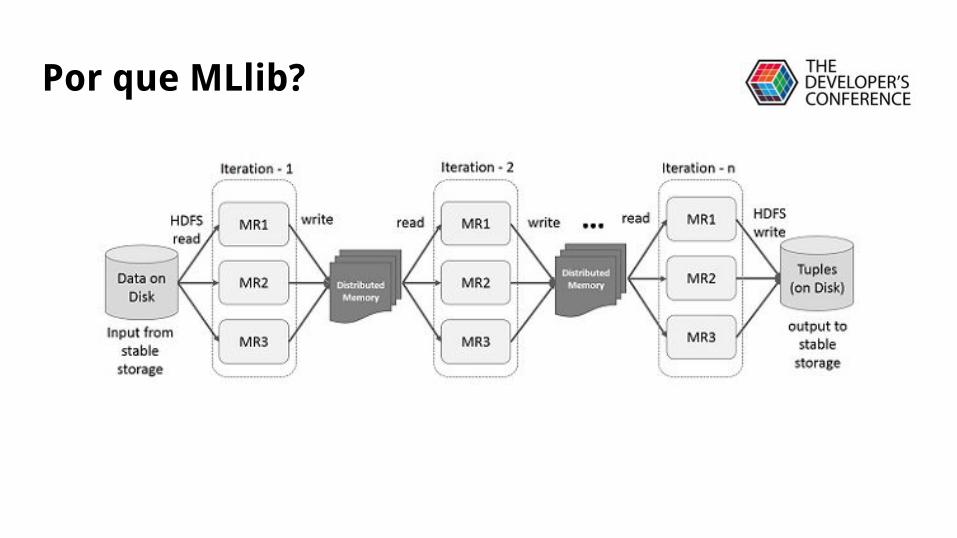
Por que MLlib?
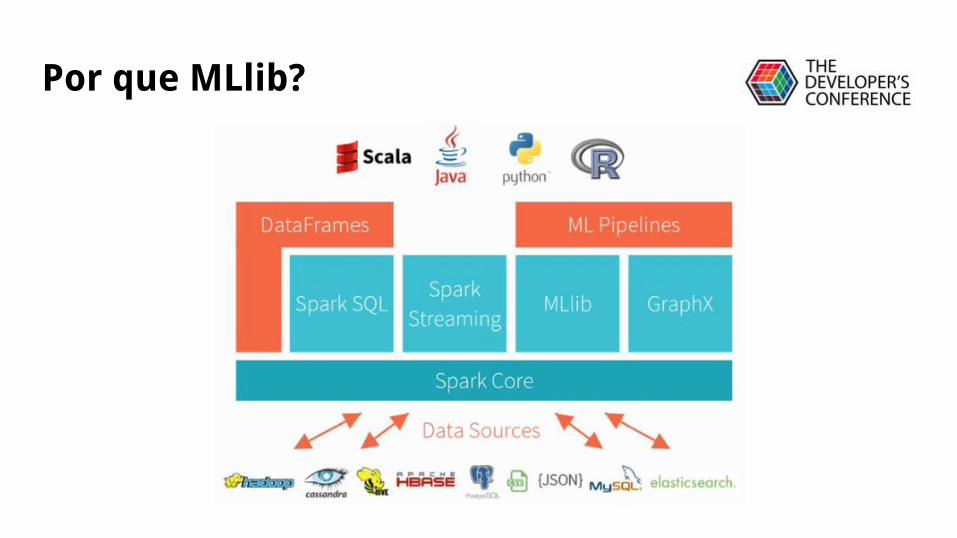
Por que MLlib?
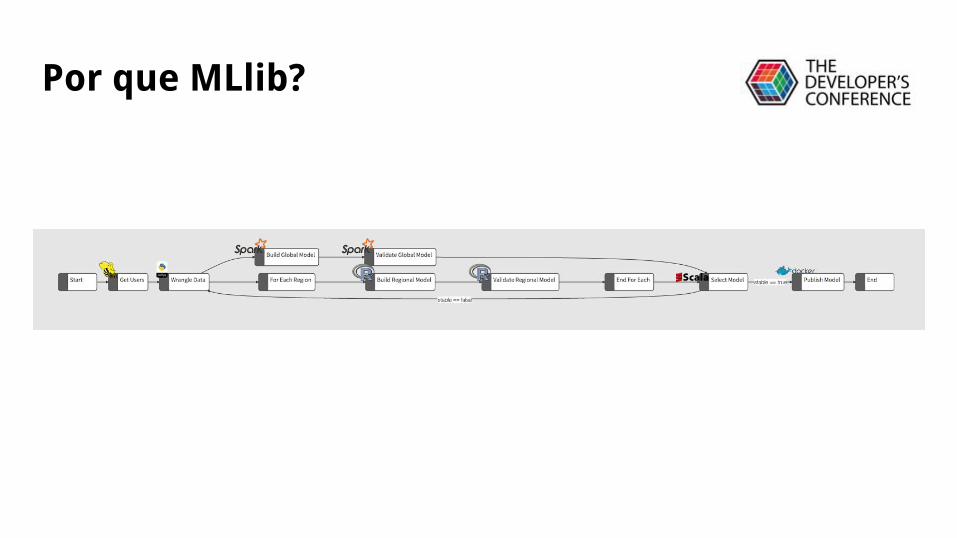
Por que MLlib?

Desenvolvimento ~== Produção
Por que MLlib?