







Línguas
Páginas
Legal


Fábio Lumertz Garcia
Implementação de um Codificador LDPC para um Sistema de TV Digital usando Ferramentas de
Prototipagem Rápida
Dissertação apresentada à Faculdade de Engenharia Elétrica e Computação como parte dos requisitos exigidos para a obtenção do título de Mestre em Engenharia Elétrica. Área de concentração: Telecomunicações e Telemática. Orientador: Prof. Dr. Dalton Soares Arantes Co-orientador: Dr. Fabbryccio A. Cardoso
Campinas, SP 2006

ii
FICHA CATALOGRÁFICA ELABORADA PELA BIBLIOTECA DA ÁREA DE ENGENHARIA E ARQUITETURA - BAE - UNICAMP
G165i
Garcia, Fábio Lumertz Implementação de um codificador LDPC para um sistema de TV digital usando ferramentas de prototipagem rápida / Fábio Lumertz Garcia. --Campinas, SP: [s.n.], 2006. Orientadores: Dalton Soares Arantes, Fabbryccio Akkazzha Chaves Machado Cardoso. Dissertação (Mestrado) - Universidade Estadual de Campinas, Faculdade de Engenharia Elétrica e de Computação. 1. Televisão digital. 2. Códigos de controle de erros (Teoria da informação). 3. FPGA. I. Arantes, Dalton Soares. II. Cardoso, Fabbryccio Akkazzha Chaves Machado. III. Universidade Estadual de Campinas. Faculdade de Engenharia Elétrica e de Computação. IV. Título.
Título em Inglês: Implementation of an LDPC encoder for a digital TV system using rapid prototyping tools.
Palavras-chave em Inglês: Digital television, Error-correcting codes (Information theory), Field programmable gate arrays.
Área de concentração: Telecomunicações e Telemática Titulação: Mestre em Engenharia Elétrica Banca examinadora: Renato Baldini Filho, José Raimundo de Oliveira e Maria Cristina
Felippetto de Castro. Data da defesa: 21/12/2006.

iii
Fábio Lumertz Garcia
Implementação de um Codificador LDPC para um Sistema de TV Digital usando Ferramentas de
Prototipagem Rápida
Dissertação apresentada à Faculdade de Engenharia Elétrica e Computação como parte dos requisitos exigidos para a obtenção do título de Mestre em Engenharia Elétrica. Área de concentração: Telecomunicações e Telemática. Banca Examinadora: Prof. Dr. Dalton Soares Arantes – UNICAMP Prof. Dr. Renato Baldini Filho – UNICAMP Prof. Dr. José Raimundo de Oliveira – UNICAMP Profa. Dra. Maria Cristina Felippetto de Castro – PUCRS
Campinas, SP 2006

iv
Resumo
O objetivo deste trabalho é apresentar as diversas etapas de implementação de um codificador
LDPC para um sistema de televisão digital, desenvolvido através do emprego de algumas
tecnologias inovadoras de prototipagem rápida em FPGA. O codificador implementado foi
baseado em um código LDPC eIRA, que consiste em uma classe estendida de códigos de
repetição e acumulação irregulares, com palavra-código de 9792 bits e taxa de 3/4. Visando
agregar outras tecnologias emergentes ao projeto de TV Digital, o sistema proposto foi
desenvolvido para operar sobre o Protocolo de Internet - IP. Os esforços para a realização deste
trabalho fizeram parte de um esforço mais amplo de um consórcio de universidades brasileiras,
visando à concepção, ao projeto, à simulação e à implementação em hardware de um Sistema de
Modulação Inovadora para o SBTVD. A grande sinergia obtida neste projeto e o uso intensivo
de ferramentas de prototipagem rápida em FPGA possibilitaram a obtenção de uma prova de
conceito implementada e testada em um prazo de apenas 12 meses.
Palavras-chave: LDPC, FPGA, System Generator, Prototipagem Rápida.
Abstract
This work presents the several phases in the implementation of an LDPC encoder for a digital
television system, developed using innovative technologies for rapid prototyping on Field
Programmable Gate Array devices - FPGAs. The implemented encoder was based on an eIRA -
extended Irregular Repeat Accumulate - LDPC code with codeword-length equal to 9792 bits and
rate 3/4. The proposed system was developed to work with video streaming over the Internet
Protocol- IP. This work is part of a more ambitious project that resulted in the development of an
advanced Modulation System for the Brazilian Digital TV System - SBTVD.
Key-Words: LDPC, FPGA, System Generator, DSP Rapid Prototyping.

v
Agradecimentos
Primeiramente ao Bom Deus, fonte de todo bem, toda felicidade e toda sabedoria. Sem Ele nada
teria sentido, nem mesmo a busca do conhecimento.
Ao meu orientador, professor Dr. Dalton Arantes, pelas suas orientações, tanto as profissionais
quanto as pessoais. Faço uso destas poucas linhas para expressar minha gratidão e estima.
À minha família. Agradeço à minha mãe e aos meus irmãos pelo amor e pela presença. Apesar de
longe, nunca estivemos separados. Especialmente, agradeço à Valéria que tem sido meu porto
seguro nestes últimos anos.
Ao meu co-orientador, ao qual tenho o privilégio de chamar de amigo, Dr. Fabbryccio Cardoso.
Deus permita que eu possa um dia adquirir um pouco de sua humildade e boa vontade.
Ao meu colega, Tarciano Pegoraro, pela ajuda nas implementações e auxílio nos estudos de
codificação.
Aos colegas do laboratório ComL@b e aos companheiros de muitos almoços no RA.
À minha amiga Adriane Sartori, pela amizade desde a primeira viagem de Porto Alegre a
Campinas e pelo companheirismo, principalmente nas dificuldades do primeiro ano...
A todas as senhoras que lavaram minha roupa, limparam minha casa e prepararam minhas
refeições durante estes anos.

vi
Por último, mas não em último, aos amigos do Rio Grande do Sul. Agradeço a amizade apesar da
distância.
Ao Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), Financiadora de
Estudos e Projetos (Finep), bem como à Fundação de Amparo à Pesquisa do Estado de São Paulo
(Fapesp) pelo apoio financeiro e material.

vii
“Não tenhas medo homem querido. Anima-te! Sim, anima-te! Coragem!”
Daniel 10,19

viii
Sumário
Lista de Figuras .......................................................................................................................xi
Lista de Tabelas .....................................................................................................................xiv
Lista de Variáveis ...................................................................................................................xv
Lista de Siglas e Abreviações..............................................................................................xviii
1. Introdução .............................................................................................................................1
1.1 A Importância das Ferramentas de Prototipagem Rápida nas Soluções de DSP .......1
1.2 Contextualização Política e Temporal da Dissertação ................................................8
2. Tecnologias para Implementação de Sistemas em FPGAs .............................................11
2.1 Introdução as FPGAs.................................................................................................11
2.1.1 Introdução, Conceitos Fundamentais e Origem das Tecnologias .................11
2.1.2 Arquiteturas e Configurações .......................................................................23
2.1.3 Formas de Desenvolvimento e Implementação ............................................31
2.1.3.1 Linguagem Esquemática ..................................................................31
2.1.3.2 Linguagem de Descrição de Hardware (HDL) .................................34
2.1.3.3 Linguagem C, SVP e DSP ................................................................37
2.1.4 Principais Fornecedores e Parceiros .............................................................40
2.2 ISE Design Flow e System Generator .......................................................................42
2.2.1 Project Navigator ..........................................................................................42
2.2.2 System Generator .........................................................................................48
2.2.3 Simulação HDL ............................................................................................52

ix
2.3 AccelChip (AccelDSP) e AccelWare ........................................................................53
2.3.1 AccelChip (AccelDSP) .................................................................................53
2.3.2 AccelWare e Núcleos de Propriedade Intelectual (NPIs ou IP Cores) .........60
3. O Sistema de TV Digital sobre IP .....................................................................................63
3.1 Vídeo Bruto ..............................................................................................................64
3.2 Codificador/Decodificador de Vídeo .......................................................................65
3.3 Empacotador UDP/IP ...............................................................................................68
3.4 Conversor Camada MAC .........................................................................................70
3.5 Aleatorizador/Desaleatorizador ................................................................................71
3.6 Codificador/Decodificador Reed-Solomon ..............................................................71
3.7 Codificador/Decodificador LDPC ...........................................................................72
3.8 Mapeador/Demapeador e LLR .................................................................................72
3.9 Modulador/Demodulador e Alamouti ......................................................................74
3.10 Conversores A/D e D/A ..........................................................................................77
3.11 Conversores Elevador e Rebaixador ......................................................................78
3.12 Amplificador de Potência .......................................................................................79
3.13 Amplificador de Baixo Ruído e Controle Automático de Ganho ..........................79
4. Codificação LDPC ..............................................................................................................81
4.1 Introdução à Codificação de Canal............................................................................81
4.2 Reed-Solomon ...........................................................................................................86
4.3 LDPC.........................................................................................................................89
4.3.1 Codificação ...................................................................................................95
4.3.2 Decodificação ...............................................................................................97
5. Implementação do Codificador LDPC .............................................................................99
5.1 Codificador LDPC.....................................................................................................99
5.1.1 Estrutura da Codificação ...............................................................................99
5.1.2 Implementação em System Generator.........................................................101
5.2 Descrição do Hardware Empregado ........................................................................105
5.3 Detalhamento da Implementação do Sistema..........................................................111
6. Resultados, Demonstrações e Comparações ..................................................................119
6.1 Quanto ao Desempenho e Comprimento do Código LDPC....................................119
6.2 Comparações de Modelos de Implementação .........................................................121
6.2.1 System Generator Versus AccelChip ..........................................................121

x
6.2.2 System Generator Versus VHDL ................................................................122
6.2.3 Otimização em Área Versus Otimização em Velocidade ...........................124
6.3 Demonstrações de Ocupação dos Dispositivos .......................................................125
7. Considerações Finais e Trabalhos Futuros ....................................................................129
Referências Bibliográficas ...................................................................................................131
Apêndice A ...........................................................................................................................135

xi
Lista de Figuras
1 – Diagrama temporal das tecnologias relacionadas com FPGAs.........................................16
2 – Arquitetura de arranjo de células básicas com canais.......................................................18
3 – Estrutura genérica de um ASIC estruturado......................................................................20
4 – Configuração de um ASIC com FPGA associada...............................................................22
5 – Visão intercamada da FPGA................................................................................................24
6 – Diagrama esquemático de descrição de hardware.............................................................31
7 – Netlist ao nível de portas lógicas...........................................................................................32
8 – Níveis de abstração de um modelo HDL genérico..............................................................34
9 – Design Flow da Xilinx............................................................................................................42
10 – Etapa de descrição do Design Flow da Xilinx...................................................................43
11 – Interface da ferramenta Project Navigator da Xilinx......................................................44
12 – Interface da ferramenta IMPACT.....................................................................................47
13 – Browser das bibliotecas do Simulink mostrando os toolboxes da Xilinx........................49
14 –Fluxo de desenvolvimento a partir do System Generator até a etapa de download na
FPGA............................................................................................................................................51
15 – Fluxo de desenvolvimento da ferramenta AccelChip (Accel DSP).................................53
16 – Interface do AccelChip para definição das ferramentas utilizadas................................55
17 – Interface do AccelChip mostrando a tabela de quantização...........................................56
18 – Interface do AccelChip mostrando o recurso de exportação para o System
Generator......................................................................................................................................57
19 – Interface do AccelChip mostrando o relatório final de desenvolvimento......................58
20 – Seleção de parâmetros da FFT do AccelWare..................................................................60
21 – Diagrama de blocos do sistema de televisão digital proposto..........................................62

xii
22 – Quadro MAC.......................................................................................................................69
23 – Mapeamento feito para a modulação QPSK.....................................................................72
24 – Mapeamento feito para a modulação 16QAM..................................................................73
25 – Diagrama de blocos de um sistema de comunicação digital............................................79
26 – Demonstração de um código de bloco binário sistemático θ(4,3)....................................81
27 – Polinômios associados às palavras-código.........................................................................84
28 – Codificação )16,20(RS com 8=rsm ......................................................................................86
29 – Exemplo de matriz de paridade H.....................................................................................88
30 - Exemplo de gráfico de Tanner............................................................................................89
31 – Diagrama simplificado do codificador LDPC...................................................................94
32 – Esquema de troca de mensagens dos nós de bit para os nós de cheque (esquerda)
e dos nós de cheque para os nós de bit (direita)........................................................................95
33 – Modelo de referência da implementação do codificador LDPC...................................100
34 – Bloco do codificador LDPC em detalhes.........................................................................102
35 – Placa Nallatech Xtreme DSP Development Kit-IV com cabo paralelo IV em
destaque......................................................................................................................................105
36 – Entradas dos conversores da placa Nallatech Xtreme DSP Development Kit-IV.......105
37 – Placa Xilinx ML-402..........................................................................................................107
38 – Equipamentos de RF da National Instruments..............................................................108
39 – Visão global da implementação com definições de hardware.......................................109
40 – Diagrama simplificado da implementação do ajuste de taxa........................................111
41 – Implementação do aleatorizador......................................................................................113
42 – Curva de desempenho de código LDPC em função do comprimento do código.........116
43 – Curva característica de um código LDPC em função do comprimento do mesmo.....117
44 – Relatório de ocupação da FPGA com o código do codificador LDPC desenvolvido em
AccelChip....................................................................................................................................118
45 – Relatório parcial de ocupação da FPGA com o código do codificador LDPC
desenvolvido no bloco M-Code do System Generator............................................................119
46 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC
desenvolvido em VHDL.............................................................................................................120

xiii
47 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC, com
otimização em termos de velocidade e desenvolvido em System Generator........................120
48 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC,
otimização em termos de área e desenvolvido em System Generator...................................121
49 – Relatório parcial de ocupação da primeira FPGA empregada no protótipo. Nesta
FPGA, estão implementados o MAC Ethernet, o ajuste de taxa, o aleatorizador e o
codificador LDPC......................................................................................................................123
50 – Relatório parcial de ocupação da segunda FPGA empregada no protótipo. Nesta
FPGA, estão implementados o mapeador, o multiplexador, o modulador e Alamouti e a
inserção de prefixo cíclico.........................................................................................................123
51 – Relatório parcial de ocupação da terceira FPGA empregada no protótipo. Nesta
FPGA, estão implementados o filtro passa-baixa, o demodulador e Alamouti, o demapeador
e a LLR................................................................................................................................................................. 124
52 – Relatório parcial de ocupação da quarta FPGA empregada no protótipo. Nesta
FPGA, está implementado o decodificador LDPC.................................................................125
53 – Relatório parcial de ocupação da quinta FPGA empregada no protótipo. Nesta
FPGA, estão implementados o desaleatorizador, o ajuste de taxa e o MAC Ethernet.......125

xiv
Lista de Tabelas
2.1. Fabricantes de FPGAs ....................................................................................................39
2.2 Desenvolvedores de ferramentas completas para FPGAs ............................................40
2.3 Especialistas e desenvolvedores independentes de ferramentas para FPGAs ............40
2.4 Consultores e desenvolvedores especiais de ferramentas para FPGAs.......................41

xv
Lista de Variáveis A - Conjunto de alfabeto-código; Amap - Conjunto de símbolos ou alfabeto do mapeador; a - Número de linhas da submatriz M em um código LDPC; b - Número de colunas da submatriz M em um código LDPC; C - Conjunto de palavras-código; c - Palavra-código;
ic - I-ésimo bit da palavra-código c; dv - Maior grau de nós de bit em um código LDPC; DC – Nível contínuo de sinal; dc - Maior grau de nós de cheque em um código LDPC; GF – Corpo de Galois; G - Matriz geradora de um código;
ig - EXIT chars elementares do processo de evolução de densidade num código LDPC; H - Matriz de paridade;
1H - Parte da matriz de paridade H, com dimensões (n-k)xk;
2H - Parte da matriz de paridade H, com dimensões (n-k)x(n-k); I - Matriz identidade;

xvi
i - Grau de um ramo ou nó em um código LDPC; k - Número de símbolos de uma mensagem a ser codificada;
iL - LLR (Log-Likelihood Ratio); M - Submatriz de 1H em um código LDPC, m vezes menor do que a mesma; m - Grau de paralelização de um código LDPC, relação entre as matrizes 1H e M;
rsm - Número de bits por símbolo em um código Reed-Solomon; MM - Tamanho do conjunto X; Mmap - Número de símbolos de um alfabeto Amap; n - Número de símbolos de uma palavra-código; nmap - Número de bits utilizados para representar um símbolo do mapeador; Nquant - Número de valores de tensão representados por um conversor A/D ou D/A; P – Parte do conjunto das palavras-código correspondente às paridades; p – Parte da palavra-código correspondente às paridades associadas a x;
inp - Taxa de erro das mensagens de entrada de um código LDPC;
outp - Taxa de erro das mensagens de saída de um código LDPC; Q – Número de elementos de um dado corpo de Galois; q – Variável utilizada para representar o produto entre 1H e a mensagem a ser codificada em um código LDPC; r - Seqüência de bits recebidos em um decodificador RS; resbits – Resolução de conversor A/D ou D/A, dada em bits; S – Matriz auxiliar usada no cálculo de 1H em um código LDPC; s – Elementos da matriz S;

xvii
T – Estrutura compacta que permite emular a matriz 1H através de permutações no contexto de um código LDPC; t – Número máximo de símbolos que pode ser corrigido por um código; u – Mensagem de um nó de cheque para um nó de bit em um código LDPC; v – Mensagem de um nó de bit para um nó de cheque em um código LDPC; X – Conjunto de mensagens a ser codificado; x – Mensagem a ser codificada;
ix - I-ésimo bit da palavra-código x; θ – Notação de código;
xλ - Fração dos ramos conectados a nós de bit de grau x;
vw - Número total de nós de bit em um código LDPC; cw - Número total de nós de cheque em um código LDPC;
xρ - Fração dos ramos conectados a nós de cheque de grau x;

xviii
Lista de Siglas e Abreviações
• AGC – Automatic Gain Control;
• ARP – Address Resolution Protocol;
• ASIC – Application Specific Integrated Circuit;
• ASSP – Application Specific Standard Part;
• AVHDL – Altera Very high speed Hardware Description Language;
• bps – Bits por segundo;
• C – Linguagem de programação de propósito geral;
• C++ – Linguagem de programação de propósito geral, orientada a objeto, baseada em C;
• CI – Integrated Circuit;
• CAD –Computer Aided Design;
• CAE – Computer Aided Engineering;
• CPLD – Complex Programmable Logic Device;
• DAC – Developing Automation Conference;
• DCM – Digital Clock Manager;
• EDA – Electronic Design Automation;
• EEPROM – Electrically Erasable Programmable Read Only Memory;
• EPROM – Erasable Programmable Read Only Memory;
• FIFO – First In First Out;
• FPGA – Field Programmable Gate Array;
• GAL – Gate Array Logic;
• Gbps – Giga bits por segundo;

xix
• GHz – Giga Hertz;
• Hz – Hertz;
• IEEE – Institute of Electrical and Electronics Engineer (http://www.ieee.org);
• IP – Internet Protocol;
• IP (2) – Intellectual Property;
• ISP – In System Programmable;
• ITU – International Telecommunication Union (http://www.itu.int/home/);
• JTAG – Joint Test Action Group (IEEE 1149.1);
• Kbps – Kilo bits por segundo;
• KHz – Kilo Hertz;
• LDPC – Low Density Parity Check;
• LNA – Low Noise Amplifier;
• MAC – Media Access Control;
• Mbps – Mega bits por segundo;
• MHz – Mega Hertz;
• MOSFET MOS – Metal Oxide Semiconductor Field Effect Transistor;
• MPEG – Moving Picture Experts Groups (www.mpeg.org);
• MSPS – Mega Sample Per Seconds;
• NPI – Núcleo de Propriedade Intelectual;
• OFDM - Orthogonal Frequency Division Multiplexing;
• PAL – Programmable Array Logic;
• PCI – Peripheral Component Interconnect;
• PLD – Programmable Logic Device;
• PLL – Phase-locked loop;
• PMCD – Phase Matched Clock Divider;
• PROM – Programmable Read Only Memory;
• RAM – Random Access Memory;
• RFP – Requisição Formal de Proposta;
• ROM – Read Only Memory;
• RS – Reed-Solomon;

xx
• RTL – Register Transfer Level;
• SBTVD – Sistema Brasileiro de Televisão Digital;
• SPLD – Simple Programmable Logic Device;
• SVP – Silicon Virtual Prototyping;
• TTL – Transistor-Transistor Logic;
• UDP – User Datagram Protocol;
• USB – Universal Serial Bus;
• Verilog – Linguagem de Descrição de Hardware (IEEE 1364);
• VHDL –Very high speed Hardware Description Language (IEEE1164);
• VHSIC – Very High Speed Integrated Circuit;

1
1
Capítulo 1 Introdução 1.1 A Importância das Ferramentas de Prototipagem Rápida nas
Soluções de DSP
Aplicações que envolvem Processamento Digital de Sinais (DSP) são cada vez mais
freqüentes e importantes na vida cotidiana, e a utilização de ferramentas que possibilitem seu
desenvolvimento e emprego é de essencial importância. Em um mundo que exige cada vez mais
rapidez e agilidade na demonstração de resultados de pesquisas científicas e no desenvolvimento
de novos produtos, encontrar soluções de uma forma eficiente e rápida é fundamental para
manter-se competitivo. Desta forma, este trabalho apresenta a implementação de um codificador
LDPC (Low Density Parity Check) para um sistema de televisão digital, desenvolvido através do
emprego de tecnologias inovadoras de prototipagem rápida baseadas em FPGA (Field
Programmable Gate Array).
A concepção de um projeto de DSP, assim como qualquer outro projeto, demanda alguns
cuidados que antecedem à etapa de aplicação das ferramentas de desenvolvimento. Ao iniciar-se
um projeto, o primeiro passo é determinar quais as suas finalidades, objetivos e quais
necessidades que ele visa suprir. Depois, necessita-se definir quais serão os recursos empregados.
Em seguida, deve-se especificar uma metodologia de desenvolvimento bem definida a ser
empregada. Finalmente, determinam-se quais serão as ferramentas utilizadas para executar-se o
projeto. Um bom e simples exemplo de comparação para esta concepção é o projeto de
construção de uma casa. Inicialmente o arquiteto necessita definir as finalidades do projeto, ou

Capítulo 1 – Introdução 2
seja, delimitar questões iniciais relativas ao seu objetivo, como, por exemplo, quantas pessoas
habitarão a casa, qual o tamanho da mesma, quantas peças ela terá etc. Depois, visando aos
objetivos do projeto da casa, ele deverá determinar os recursos que serão empregados, se a casa
será construída de madeira, de alvenaria, com acabamentos de gesso etc. A próxima etapa refere-
se à metodologia empregada, ou seja, por qual parte começará a obra, quais as primeiras paredes
a serem alicerçadas, entre outras. Finalmente ele deverá especificar as ferramentas a serem
utilizadas de acordo com os recursos escolhidos, por exemplo, espátula e betoneira, caso a obra
seja de alvenaria, serra e plaina, caso a casa seja de madeira e assim por diante.
Assim, tal qual o arquiteto deparando-se com o projeto da casa, quando uma equipe de
desenvolvimento está diante de uma aplicação de DSP a ser implementada, ela depara-se com o
mesmo tipo de processo descrito anteriormente: objetivos, recursos, metodologias e ferramentas.
Para a definição desses pontos, fatores diretamente relacionados a questões como custo,
qualidade e tempo de desenvolvimento do produto são fortemente pertinentes, bem como
questões tais quais: a solução será implementada em software ou hardware? Se em software, usar
processadores de uso geral (Power PC ou ARM) ou processadores de uso específico (Analog
Device Sharc e Blackfin, Texas Instruments C6000 ou Motorola i350)? Se a implementação for
feita em hardware, utilizar FPGA, ASIC ou ASIC estruturado? Será possível utilizar algum
Núcleo de Propriedade Intelectual (NPI ou IP Core) existente? Qual linguagem de
desenvolvimento deve ser utilizada (C, C++, VHDL, Matlab)? Essas são questões que
corriqueiramente encontram-se na mente de desenvolvedores nas etapas iniciais de projeto [1].
Os processadores de DSP de uso geral apresentam uma grande penetração de mercado,
especialmente por disporem de uma flexibilidade relativamente elevada, uma vez que seu
desenvolvimento é totalmente baseado em software, o que facilita a correção de erros e
atualizações. Além disso, geralmente apresentam plataformas de desenvolvimento relativamente
amigáveis, utilizando, em sua maioria, linguagens de programação difundidas como C ou C++.
No entanto, os requisitos atuais dos sistemas eletrônicos e de comunicações excedem a
capacidade dos processadores de DSP de uso geral, ou seja, eles estão deixando de atender a atual
demanda de processamento [2] [1]. A lacuna criada entre a capacidade de desempenho dos
processadores de DSP de uso geral e os requisitos das novas tecnologias de comunicações tende a

Capítulo 1 – Introdução 3
aumentar ainda mais nos próximos anos [1]. A solução para os desenvolvedores de sistemas em
processadores de DSP de uso geral é colocar seus algoritmos “em silício” para uma “aceleração”
em hardware, uma vez que a demanda de desempenho de sistemas de DSP está forçando os
limites das tecnologias de software existentes e a capacidade de desempenho em hardware está
aumentando. Ademais, os processadores DSP de uso geral possuem recursos fixos e cada
processador possui um número limitado de funções computacionais básicas.
As principais tecnologias disponíveis para implementação de sistemas de DSP em
hardware são FPGA, ASIC, ASIC estruturado e processadores de DSP. Quando da
implementação em silício, as principais questões que são consideradas são relativas ao
desempenho, flexibilidade ou capacidade de reprogramação, custo por unidade, tempo de
fabricação e flexibilidade dos recursos dos dispositivos (recursos ditos embarcados) como
memórias, somadores etc. Algoritmos de DSP implementados em ASIC, quando comparados
com FPGAs, têm a vantagem de ter o melhor desempenho, pois operam com freqüências de
relógio (clock) maiores do que 1GHz. A implementação em FPGA reduz o desempenho em
comparação ao ASIC, atingindo uma freqüência de operação máxima em torno de 500MHz.
Além disso, as implementações em FPGA exigem o maior custo por unidade e possuem a menor
flexibilidade dos recursos embarcados, dependendo da família de dispositivos adotada. Ademais,
dispositivos ASIC possibilitam um menor custo por unidade quando produzidos em larga escala.
Entretanto, os ASICs sacrificam a flexibilidade ou capacidade de reprogramação, possuem um
alto custo inicial de implementação e um longo processo de prototipagem (algo em torno de seis
meses de desenvolvimento mais três meses de fabricação, de acordo com [1]), além de exigirem a
compra de ferramentas de desenvolvimento relativamente caras. Por sua vez, os algoritmos de
DSP implementados em FPGAs possuem a vantagem de apresentar o menor tempo de fabricação
(tipicamente de um a três meses, de acordo com [1]) e o maior grau de flexibilidade ou
capacidade de reprogramação. Uma vantagem das FPGAs sobre processadores DSP é que elas
permitem que o desenvolvedor “ajuste a arquitetura ao algoritmo”. Isso significa dizer, por
exemplo, que é possível implementar na FPGA um grau de paralelismo tal qual necessário para
atingir-se o desempenho desejado. Como nos processadores de DSP de uso geral os recursos são
fixos no dispositivo, ocorre que o “algoritmo tem que ser ajustado à arquitetura”. Já a solução de
desenvolvimento em ASIC estruturado é uma solução híbrida entre as soluções em ASIC e

Capítulo 1 – Introdução 4
FPGA. Assim, ela proporciona ao desenvolvedor uma solução intermediária entre os dois tipos de
solução.
Diante do desenvolvimento das novas famílias de FPGAs, especialmente dos maiores
fabricantes como Xilinx e Altera, uma nova e viável alternativa de hardware tornou-se disponível
para desenvolvedores de algoritmos de DSP, combinando as vantagens dos processadores de DSP
de uso geral com as vantagens de desempenho dos ASICs. Soluções de alto desempenho que
antes só eram atingidas através de ASICs agora são implementáveis em FPGA [3].
Além da determinação do uso do recurso (no caso a FPGA), a metodologia e as
ferramentas de desenvolvimento são determinantes para o sucesso de um projeto. Durante os
anos 70, observou-se uma proliferação dos semicondutores, aflorada principalmente pela
introdução de sistemas como o IC CAD. A tecnologia das memórias dinâmicas explodiu nos anos
80, quando ferramentas de simulação permitiram que um modelo preciso do comportamento das
células de memórias fosse simulado, aumentando significativamente a capacidade das memórias.
Também as tecnologias de microprocessadores, ASICs e FPGAs, deram um grande salto nos
anos 90 quando os desenvolvedores deixaram de lado suas velhas ferramentas esquemáticas e
acreditaram nas metodologias de fluxo top-down de síntese lógica e em linguagens como o
VHDL. Todo crescimento rápido, em qualquer setor de tecnologia, necessitou da introdução de
uma nova metodologia de desenvolvimento e ferramentas para aumentar consideravelmente a
produtividade. O desafio com o qual os desenvolvedores de DSP se deparam hoje é o mesmo
com o qual os desenvolvedores de ASIC se depararam nos anos 90: quais as mudanças em termos
de ferramentas e em suas metodologias de desenvolvimento que devem ser feitas para utilizar
FPGAs ao invés de processadores de DSP de uso geral; como obter essas habilidades; como
migrar de uma tecnologia para outra sem perder os projetos atuais? Comercialmente, muitas
vezes, ao escolher-se a ferramenta de desenvolvimento, a metodologia de projeto já está incutida
no fluxo de utilização da própria ferramenta.
O desenvolvimento tradicional de soluções de DSP, geralmente, dá-se dividido entre duas
equipes, uma de desenvolvimento de sistemas/algoritmos e outra de implementação em
software/hardware. Algumas vezes, em grandes empresas, essas equipes chegavam a ficar

Capítulo 1 – Introdução 5
fisicamente distantes umas da outras. Desenvolvedores de algoritmos deveriam criar, analisar e
refinar os algoritmos de DSP, usando ferramentas de análise matemática, visando a um
comportamento que não se preocupasse com a arquitetura de hardware ou software que seria
implementada [2]. Enquanto estes experientes desenvolvedores de sistemas possuem
familiaridade com implementação de algoritmos em software, eles, em geral, apresentam
dificuldades na hora de adaptar seus projetos às limitações de silício. Na outra equipe por sua
vez, o engenheiro de implementação também necessita conhecer teoria de comunicações e
processamento de sinais para poder interpretar a especificação escrita pelos engenheiros de
algoritmo. Além disso, o processo de criar um RTL (Register Transfer Mode) para a
implementação em hardware consome um longo período de trabalho devido à necessidade de
verificação manual do RTL com o modelo feito em Matlab ou em outra linguagem utilizada pela
equipe de desenvolvimento de algoritmo [2]. Esse processo se mostra lento, custoso e pouco
produtivo para a atualidade. Assim que o modelo RTL e o ambiente de simulação são criados, o
engenheiro de implementação interage com os engenheiros desenvolvedores do algoritmo para
analisar desempenho, ocupação de área de silício etc. É bastante comum que o algoritmo original
necessite ser modificado, porque os engenheiros de algoritmo não possuem uma visão física do
projeto durante o desenvolvimento. Existe a necessidade de iteração nos processos.
A produção de circuitos integrados em larga escala continua seguindo um avanço
exponencial (lei de Moore) gerando um incremento no desempenho e no número de componentes
lógicos, enquanto a produtividade de projeto, no entanto, avança linearmente [4]. Desta forma,
existe a criação de uma nova lacuna entre o número de portas lógicas realmente disponíveis e o
número de portas lógicas “projetáveis”, de tal forma que novos produtos acabam sendo
particularmente vulneráveis a se tornarem prematuramente produtos de uma tecnologia obsoleta.
Segundo [4], “o único desafio com o qual se deparam os engenheiros de projeto/desenvolvimento
atualmente é conceber sistemas cada vez mais complexos em um time-to-market (janela de tempo
de desenvolvimento até sua chegada ao mercado) comprimido, para produtos que possuem ciclos
de vida cada vez mais curtos”.
O cenário mostrava que, embora FPGAs oferecessem grandes vantagens como baixo
consumo de energia e bom desempenho, sua programação ainda parecia difícil quando

Capítulo 1 – Introdução 6
comparada com a programação dos processadores de DSP. Anteriormente, enquanto para
programar-se um processador de DPS bastava escrever um programa em C, para programar-se
uma FPGA necessitava-se de um vasto conhecimento da arquitetura de hardware e um
conhecimento avançado em uma linguagem de implementação em hardware como, por exemplo,
VHDL. Felizmente, a comunidade científica observou esse problema e trabalhou no sentido de
alcançar um modo que tornasse mais viável e mais rápido o caminho do desenvolvimento à
implementação. Os novos modelos de desenvolvimento em FPGA provêm do uso de fontes de
núcleos de propriedade intelectual (NPIs) e de programação feita em linguagens de mais alto
nível, como Matlab e Simulink, e são conhecidos como geradores ou sintetizadores. Linguagens
de uso geral como C, C++, SYSTEM C, VHDL e VERILOG não oferecem eficiência para criar
funções matemáticas complexas de uma maneira eficiente em termos de tempo de
desenvolvimento. Atualmente, Matlab sozinho corresponde ao desenvolvimento de 90% das
aplicações de DSP [5].
Em [4], é apresentado um exemplo de comparação entre a implementação, desde a
especificação do projeto até a etapa de verificação e layout, feita em ASIC pelo modo tradicional
de desenvolvimento e utilizando a metodologia de projeto com geradores de VHDL. Observou-se
uma redução de três a dez vezes no tempo de projeto com as novas tecnologias, dependendo da
complexidade do mesmo. O ponto-chave das novas tecnologias de desenvolvimento é o suporte
para rápida exploração de relações de compromisso (trade-offs) de área, velocidade e consumo de
energia do algoritmo e da arquitetura já nas etapas iniciais do projeto. O poder dos geradores está
no encapsulamento do conhecimento e do know-how do especialista em arquitetura e micro-
arquitetura, pois os parâmetros dos geradores providenciam um mecanismo de especificação de
alto nível para características como paralelismo e ocupação. Quando se busca aumentar o
desempenho de um sistema através de técnicas de pipelining e ou de paralelismo, há um aumento
da ocupação de área de silício do dispositivo. Com o uso de ferramentas de desenvolvimento
rápido, essa relação de compromisso pode ser facilmente acompanhada e o projeto facilmente
reestruturado de forma a atingir-se a relação de compromisso ideal. Este recurso de exploração de
relação de compromisso é essencialmente útil para traçar-se, ainda na etapa de desenvolvimento,
a curva de desempenho versus área ocupada, o que pode auxiliar na determinação da família de
dispositivos a ser utilizada e na avaliação de fatores que constituem o custo final da solução.

Capítulo 1 – Introdução 7
Um fato bastante considerável é que até pouco tempo atrás, apenas companhias com
experientes engenheiros e grandes orçamentos podiam dispor de implementações em hardware
como FPGAs e ASICs. Atualmente, com a nova classe de ferramentas disponíveis, existe a
possibilidade que implementações de algoritmos de DSP possam ser amplamente empregadas,
introduzindo um novo paradigma no desenvolvimento de DSP que é a síntese de algoritmos.
Como já exposto anteriormente, velocidade de desenvolvimento e o time-to-market são vitais no
desenvolvimento de um produto. Transcendendo a questão comercial, porém, existe também a
questão do crescimento científico e tecnológico da sociedade. Este crescimento pode ser
impulsionado pela disponibilidade de ferramentas que possibilitem, em um período relativamente
curto de tempo, a obtenção de um protótipo capaz de comprovar conceitos teóricos e de alicerçar
o desenvolvimento de tecnologias futuras.
Um perfeito exemplo de quão custoso pode ser o desenvolvimento de uma tecnologia sem
a possibilidade de uma rápida implementação é a forma como se deu o avanço das técnicas de
OFDM, ao qual foi aplicado o codificador LDPC. A origem do desenvolvimento do OFDM deu-
se no final dos anos 50 com a introdução da multiplexação por divisão de freqüência (FDM) para
a comunicação de dados. Em 1966, um engenheiro chinês chamado Chang patenteou a estrutura
do OFDM e publicou o conceito do uso de freqüências ortogonais. Em 1971, outro engenheiro,
Weinstein, introduziu a idéia de usar transformada discreta de Fourier (DFT) para a
implementação da geração e de recepção de sinais OFDM, eliminando os bancos de osciladores
analógicos que eram necessários até então. Estes avanços proporcionaram uma implementação
menos complexa do OFDM, especialmente com o uso posterior da transformada rápida de
Fourier (FFT) ao invés da DFT. Isto conduz a pensar que a forma mais fácil de implementar
técnicas de OFDM é através de processadores de DSP que possibilitem a implementação de FFT.
Contudo, a viabilidade desse tipo de implementação é bem recente. A dependência da
implementação da FFT “amarrou” a difusão do OFDM durante o seu desenvolvimento, e seu
emprego de uma forma mais ampla só se deu nos anos 80, quando o uso de processadores de DSP
tornou-se mais viável, quase 30 anos depois do início dos trabalhos.
Diante do exposto, considerando-se custo e desempenho das atuais FPGAs, combinados
com outras de suas vantagens, as FPGAs tornaram-se a melhor alternativa para implementação de

Capítulo 1 – Introdução 8
aplicações de DSP de alto desempenho. Por esta razão, as ferramentas de rápido desenvolvimento
de soluções baseadas nestes dispositivos constituem o foco central desta dissertação. Desta
forma, este texto apresenta ainda nesta introdução uma contextualização temporal e política dos
trabalhos desenvolvidos. Posteriormente, é delineada uma introdução às FPGAs, descrição de
algumas ferramentas e metodologias de desenvolvimento - especialmente às aplicadas no projeto
do sistema de televisão digital em que está inserido este trabalho-, uma breve introdução teórica
no que tange às principais tecnologias envolvidas no projeto de televisão digital e uma descrição
sobre a codificação de canal utilizada no projeto. Em seguida, os detalhes de implementação são
apresentados e também os mais significativos resultados obtidos. Por fim, apresentam-se as
considerações finais e as sugestões para trabalhos futuros.
1.2 Contextualização Política e Temporal da Dissertação
No ano de 2005, entre os meses de março e dezembro, o Governo Federal brasileiro
financiou pesquisas científicas visando ao desenvolvimento de um sistema brasileiro de televisão
digital (SBTVD). Esse projeto, financiado pelo Ministério das Comunicações, deveria empregar
as técnicas mais inovadoras de radiodifusão. O SBTVD tinha como objetivos, ao menos
teoricamente: promover a inclusão social e a diversidade cultural do país visando à
democratização da informação; estimular a pesquisa e o desenvolvimento e propiciar a expansão
de tecnologias brasileiras e da indústria nacional relacionadas à tecnologia de informação e
comunicação; planejar o processo de transição da televisão analógica para a digital, de modo a
garantir a gradual adesão de usuários a custos compatíveis com sua renda; aperfeiçoar o uso do
espectro de radiofreqüências; contribuir para a convergência tecnológica e empresarial dos
serviços de comunicações e aprimorar a qualidade de áudio, vídeo e serviços, consideradas as
atuais condições do parque instalado de receptores no Brasil [6].
Para alcançar os seus objetivos, o SBTVD foi dividido em vinte e dois grupos,
denominados consórcios, onde a distribuição dos trabalhos foi realizada através de Requisições
Formais de Propostas (RFPs). Estes consórcios foram formados por setenta e nove universidades
e instituições brasileiras de pesquisa e contou com a atuação de mais de mil e trezentos

Capítulo 1 – Introdução 9
pesquisadores em todo o país. Um dos consórcios responsáveis pelo segmento do projeto
denominado Modulação Inovadora (MI-SBTVD), correspondente à RFP18, foi constituído pelo
Instituto Nacional de Telecomunicações (INATEL), Universidade Estadual de Campinas
(UNICAMP), Universidade Federal de Santa Catarina (UFSC), Centro Federal de Educação
Tecnológica do Paraná (CEFET-PR) e pela Linear Equipamentos Eletrônicos S.A. Esta
dissertação de mestrado, por sua vez, foi desenvolvida no âmbito deste consórcio. Desta forma,
os conhecimentos adquiridos nos trabalhos desenvolvidos durante o SBTVD auxiliaram na
elaboração desta dissertação e vice-versa, apesar das propostas serem parcialmente diferentes.
Até a data da elaboração desta dissertação, a comunidade científica, bem como toda a
sociedade brasileira, não tem uma definição sobre o futuro da televisão digital no Brasil. Neste
cenário, faz-se importante destacar que os trabalhos propostos pelo SBTVD foram
satisfatoriamente concluídos e apresentados ao Ministério das Comunicações brasileiro.

10
10

11
11
Capítulo 2 Tecnologias para Implementação de Sistemas em FPGAs 2.1 Introdução às FPGAS 2.1.1 Introdução, Conceitos Fundamentais e Origem das Tecnologias
Dispositivos FPGAs (Field Programmable Gate Arrays) são circuitos integrados digitais
que contêm blocos reconfiguráveis de lógica com interconexões entre eles. Programadores
podem configurar estes dispositivos de forma a desempenhar as mais diferentes tarefas. A parte
do nome referenciada como “campo programável” refere-se ao fato de que sua programação se
dá “em campo”, diferentemente dos dispositivos nos quais as funcionalidades internas são
fortemente “amarradas” pelo fabricante. Isto significa que as FPGAs podem ser configuradas
tanto nos laboratórios como podem ser modificadas depois de já estarem em seus locais
definitivos de operação.
Uma questão bastante interessante é saber por que as FPGAs são tão empregadas, sendo
que existem muitos tipos de circuitos integrados – alguns deles já comentados no capítulo
introdutório deste trabalho – onde as FPGAs poderiam ser apenas mais um deles. Assim, buscar-
se-á expor as tecnologias de dispositivos lógicos programáveis (PLDs), ASICs, ASSPs
(Application Specific Standard Part) e FPGAs. O histórico e os conceitos apresentados neste
capítulo são amplamente difundidos e encontram-se pleonasticamente disponíveis em inúmeras

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 12
bibliografias. Para tanto, este trabalho fundamentalmente baseou-se em [3], considerando o
reconhecido know-how e autoridade deste autor sobre o tema.
PLDs são dispositivos os quais, apesar da arquitetura interna ser pré-determinada pelo
fabricante, são criados de maneira a serem programados por desenvolvedores para
desempenharem inúmeras funções. A grande dificuldade em trabalhar-se com estes dispositivos
encontra-se no número relativamente baixo de portas lógicas disponíveis quando comparados às
FPGAs e na natureza simples e pequena das funções que podem implementar. No outro extremo
encontram-se os ASSPs e os ASICs (estes brevemente abordados no capítulo introdutório), que
podem conter centenas de milhares de portas lógicas e serem usados para implementar funções
bastante grandes e complexas. Tanto os ASICs quanto os ASSPs são desenvolvidos para
aplicações específicas, onde a principal diferença é que um ASIC é projetado e construído
endereçado a uma única empresa, enquanto um ASSP é destinado a inúmeros clientes. Como já
apresentado anteriormente, apesar dos ASICs oferecerem a melhor solução em tamanho,
capacidade de processamento e desempenho, eles possuem um alto custo de desenvolvimento,
consomem um grande período de desenvolvimento até sua chegada ao mercado (time-to-market),
além de não possuírem flexibilidade alguma. Assim, dentre as soluções de implementação em
hardware, as FPGAs representam um meio termo entre os PLDs e os ASICs, porque sua
funcionalidade pode ser customizada em campo como os PLDs e, ao mesmo tempo, eles podem
conter milhões de portas lógicas. Também, o custo de desenvolvimento de soluções em FPGA é
muito menor do que em ASICs, além das FPGAs apresentarem um time-to-market muito menor.
Quando da aparição das primeiras FPGAs no mercado, em meados dos anos 80, elas eram
usadas apenas para implementar as chamadas “lógicas de cola” (lógicas simples usadas para
“colar” grandes blocos ou dispositivos lógicos), máquinas de estado de complexidade média e
algumas simples tarefas de processamento. No começo dos anos 90, com o aumento da
capacidade lógica das FPGAs, seu uso começou a crescer principalmente estimulado pelo
mercado das telecomunicações, o qual necessitava de grandes blocos de processamentos de
dados. Posteriormente, iniciou-se o uso das FPGAs também na indústria automobilística e em
outras aplicações industriais. Freqüentemente, as FPGAs são usadas para implementar protótipos
de ASICs e para comprovar a implementação de algoritmos em hardware. Entretanto, devido ao

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 13
seu baixo custo de desenvolvimento e curto time-to-market, mais e mais FPGAs são usadas para
produtos finais, competindo diretamente com os ASICs.
No começo dos anos 2000, o desempenho das FPGAs deu um grande salto,
disponibilizando milhares de portas lógicas, microprocessadores embarcados, além de pinos de
alta velocidade para serem usados como entradas e saídas. O resultado disto foi que hoje FPGAs
são usadas para implementar basicamente tudo, incluindo dispositivos de comunicações, funções
de DSP, funções de processamento de imagens, entre outros. Resumindo, as FPGAs estão
ganhando fatias importantes de mercado que antes pertenciam aos ASICs, DSPs, micro-
controladores e circuitos integrados de comunicações de camada física. As FPGAs criaram um
novo mercado, conhecido como computação reconfigurável.
Sabe-se que a regra básica para distinguir uma FPGA de um ASIC é o termo
reconfigurável, presente na composição do nome FPGA. Porém, para que um dispositivo de
hardware seja reconfigurável, alguns mecanismos básicos devem estar presentes no mesmo. O
primeiro passo dado pelas tecnologias de hardware configurável foi a tecnologia de fusão de
conexão (fusible link), uma das primeiras técnicas que permitia ao usuário programar o seu
próprio dispositivo de hardware. Nesta técnica, o componente é fabricado com várias conexões
nas quais existem fusíveis que podem ser fundidos (rompidos) pelo usuário. Em seu estado
inicial, todas as conexões encontram-se intactas e para montar a lógica desejada, ao usuário é
permitido fundir o fusível (rompendo a conexão) de forma irreversível.
Posteriormente, surgiu a tecnologia de antifusão de conexão (antifuse link). Nesta
tecnologia, em seu estado inicial de programação, cada caminho ou trilha possui uma resistência
tal que o circuito pode ser considerado um circuito aberto. Assim, estes dispositivos podem ser
facilmente programados através da aplicação de pulsos de corrente com tensão relativamente
elevada em suas entradas. Então, em termos físicos, a conexão pode ser formada através de
saturação do material semicondutor utilizado na sua fabricação. Um período de tempo
ligeiramente anterior ao das tecnologias de fusão e antifusão de conexões, os dispositivos
programados por máscaras (mask-programmed devices) surgiram, fazendo uso de memórias
apenas de leitura (ROM) e de memórias de acesso randômico (RAM).

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 14
Memórias são componentes fundamentais na constituição de um dispositivo eletrônico e
por essa razão é necessário conhecê-las, ao menos, ao nível básico. As memórias ROM são ditas
não voláteis, pois os dados, uma vez gravados, permanecem nas mesmas ainda quando a energia
do sistema é retirada. Em geral, memórias ROM são de baixa capacidade de armazenamento. Já
as memórias do tipo RAM são ditas voláteis por perderem todos os dados uma vez retirada a
energia do sistema. Memórias ROM básicas são ditas programadas por máscara, pois todos os
dados contidos nelas são gravados durante a construção do dispositivo através de foto-máscaras,
as quais são usadas para criar os transistores e as faixas de metal que os conectam ao silício do
chip.
A geração seguinte às memórias ROM foi a das memórias programáveis somente de
leitura (PROM), criadas em 1970 para solucionar o problema de que as memórias programadas
por máscara eram feitas a partir de um processo altamente custoso. Além disso, para obter-se as
memórias programadas por máscara, muitos componentes eram usados nas etapas de
desenvolvimento e precisavam ser alterados freqüentemente, o que não era possível. As
memórias PROM foram criadas baseadas na tecnologia de fusão de conexão. Em seu estado não
programado, tal qual entregue pelo fabricante, todas as fusões de conexões estão intactas. Assim,
engenheiros de desenvolvimento podem selecionar as conexões a serem fundidas (rompidas).
Quando rompida a conexão, a célula lógica desta dada conexão aparece com nível lógico ‘1’.
Faz-se importante destacar que estes dispositivos eram inicialmente desejados para serem usados
como memórias capazes de armazenar programas de computador e valores constantes de dados.
Entretanto, engenheiros notaram sua grande utilidade para implementar simples funções lógicas
como tabelas de lookup. A grande vantagem da memória PROM para a ROM é que a primeira
poderia ser gravada pelo usuário, ainda que uma única vez.
O passo seguinte na evolução de dispositivos de memória foi o da criação, em 1971, pela
Intel, da memória apenas de leitura programável e apagável (EPROM). As memórias existentes
até então (ROM e PROM) só podiam ser programadas uma única vez, pois eram baseadas em
fusão ou antifusão de conexões, processos ditos irreversíveis e, por isso, menos eficientes em
termos de ocupação de silício. Havia a necessidade de poder-se programar, apagar e reprogramar
uma memória não volátil com novos dados. A estrutura básica de uma memória EPROM é a

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 15
mesma de uma PROM, com a diferença de que ao invés de um diodo, é utilizado um transistor do
tipo MOS e no lugar do fusível para a fusão da conexão é utilizado um transistor MOS com gate
flutuante. Assim, através de tensões relativamente altas, consegue-se armazenar carga no gate
flutuante. Então, se o gate tem carga, na linha de endereço selecionada aparecerá o nível lógico
zero, do contrário, se o gate não estiver carregado, aparecerá o nível lógico ‘1’. As memórias do
tipo EPROM são regraváveis através de descarga de elétrons no gate flutuante, aplicadas através
de uma pequena janela de quartzo. A energia necessária para tal processo é provida por raios
ultravioletas. O principal problema do uso deste tipo de memória é o custo da janela de quartzo e
o longo tempo (em torno de vinte minutos) necessário para apagar os dados do dispositivo.
O degrau subseqüente na evolução das memórias apenas de leitura foi o surgimento da
memória apenas de leitura programável e apagável eletricamente (EEPROM). Uma célula de
memória EEPROM é aproximadamente duas vezes e meia maior do que sua equivalente na
versão EPROM, pois possui dois transistores onde na EPROM era apenas um. Uma alteração na
dopagem do silício é o que torna possível que a propriedade de apagar os dados seja feita de
forma elétrica. Após (não necessariamente em ordem cronológica, mas em ordem de evolução)
as memórias EPROMs, foram apresentadas as memórias flash. O nome flash surgiu justamente
da comparação com o longo tempo que as EPROMs despendiam para apagar dados, uma vez que
as memórias flash podiam apagar os dados eletricamente, embora não parcialmente.
Chegando ao campo das memórias de acesso randômico (RAM) depara-se com dois tipos
dessas memórias, uma tecnologia de memória dinâmica de acesso randômico (DRAM) e outra de
memória estática de acesso randômico (SRAM). No caso das memórias DRAM, cada célula é
formada por um par transistor/capacitor que consome muito pouco silício. O adjetivo “dinâmica”
é usado porque o capacitor perde sua carga a cada ciclo de tempo e, então, cada célula deve
periodicamente recarregar-se, se a mesma necessitar manter o dado. A esta operação é dado o
nome de refresh. Quando o custo das operações de refresh é amortizado pelos milhões de bits em
uma memória DRAM, esse modelo se torna muito viável, especialmente por possuir um consumo
de energia muito baixo e por ter uma alta densidade de integração. O custo de uma memória
DRAM é bem mais baixo que o de uma SRAM. Já as memórias do tipo SRAM guardam os dados
enquanto as mesmas forem alimentadas por energia, sem precisar do recurso de refresh. Estas

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 16
operam em uma freqüência dez vezes superior às memórias DRAM, mas possuem capacidade de
integração bastante baixa e consumo de energia e de silício bastante significativos.
Muitos dos dispositivos desenvolvidos no passado possuíam um time-to-market
relativamente grande em comparação a outros, ou seja, alguns chegaram ao mercado tão logo
foram desenvolvidos, enquanto outros levaram grandes períodos de tempo para serem
efetivamente absorvidos pelo mercado. A Figura 1 apresenta o time-to-market de diversas
tecnologias. Como pode ser observado na mesma figura, por exemplo, as FPGAs, desenvolvidas
em meados dos anos 80, só foram incorporadas ao mercado em meados nos anos 90. Assim, ao
longo deste capítulo, apresentar-se-ão alguns dados referentes ao surgimento das tecnologias
presentes nas FPGAs ou que, de alguma forma, contribuíram para o surgimento das mesmas.
Em dezembro de 1947, nos laboratórios Bell nos Estados Unidos, surgia o primeiro
transistor, desenvolvido por William Shockley e Walter Brattain, obtido a partir de germânio. Já
nos anos 50, viu-se o emprego de transistores bipolares (BJT), os quais eram mais baratos e
fáceis de serem fabricados. No final dos anos 50, os transistores começaram finalmente a ser
fabricados com silício, elemento bem mais barato. Com os transistores BJT, surgiram as portas
lógicas implementadas nos famosos TTL (lógica transistor-transistor), que eram relativamente
rápidos e possuíam um consumo de energia consideravelmente elevado. Surgiram também as
portas lógicas implantadas nos ECL (lógica par emissor), que eram mais rápidas que os TTLs e
consumiam ainda mais energia. Em 1962, surgiram os transistores MOSFET, desenvolvidos nos
laboratórios RCA por Steven Hofstein e Frederic Heiman. A grande vantagem destes transistores
era o preço baixo, dimensões físicas menores e um consumo de energia significativamente
menor. Os transistores MOSFET deram origem aos transistores CMOS, ainda menores e de
consumo de energia bastante pequeno, comparado ao seu principal concorrente, a família dos
transistores TTL.
As discussões acerca da implementação de circuitos inteiros em pequenas peças de
semicondutores foram apresentadas em 1952 por um britânico especialista em radar, chamado
Dummer. No entanto, o primeiro circuito integrado foi apresentado em 1958 por Jack Kilby que
desenvolveu nos laboratórios da Texas Instruments um CI oscilador de fase que continha cinco

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 17
componentes. Em meados dos anos 60, a Texas Instruments difundiu de uma forma bastante
significativa diferentes famílias de CIs implementadas em famílias TTL. Apenas em 1968, a
RCA desenvolveu CIs equivalentes utilizando tecnologias CMOS.
1945
Transistor
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000
CI (Geral)
SRAM e DRAM
Microprocessadores
SPLDs
CPLDs
ASICs
FPGAs
- Fabricação
- Real entrada no mercado
1945
Transistor
1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000
CI (Geral)
SRAM e DRAM
Microprocessadores
SPLDs
CPLDs
ASICs
FPGAs
- Fabricação
- Real entrada no mercado
Figura 1 – Diagrama temporal das tecnologias relacionadas com FPGAs.
No final dos anos 60 e início dos anos 70, dava-se um desenfreado desenvolvimento no
âmbito dos CIs. Em 1970, a Intel apresentou a primeira memória DRAM de 1.024 bits e no ano
seguinte, o primeiro microprocessador, com aproximadamente 2.300 transistores e a capacidade
de executar até 60.000 operações por segundos. A razão para esta seção abordar as tecnologias de
memórias SRAM e microprocessadores está no fato de que, além da importância desta análise da
evolução dos dispositivos, as atuais FPGAs são baseadas em memórias SRAM e podem possuir
núcleos de microprocessadores embarcados no dispositivo.
Os primeiros CIs programáveis disponíveis no mercado foram os PLDs, que sugiram por
volta dos anos 70 e, pode-se afirmar, eram simples memórias PROMs [3]. Apenas no final dos
anos 70 surgiram versões mais complexas de PLDs. Assim, as versões mais rudimentares de PLD
foram denominadas de SPLDs e as posteriores e mais desenvolvidas denominadas PLDs

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 18
complexos ou CPLDs. Além disso, a categoria dos dispositivos lógicos programáveis menos
complexos (SPLDs) é dividida entre PROM (sua primeira versão), PLA, PAL e GAL e outras.
Entre os circuitos integrados de aplicação específica, ASICs, tais quais conhecidos
atualmente, existem quatro tipos que, por ordem de complexidade, são: arranjo de portas lógicas
(Gate Arrays), ASIC estruturados, célula padrão e ASIC completamente customizado. Assim, os
tipos de dispositivos ASICs serão brevemente abordados nos parágrafos seguintes.
O ASIC completamente customizado surgiu quando só existiam dois tipos de circuitos
integrados (sem considerar os circuitos de memória). Um era a categoria mais simples, vendido
como padrão para qualquer usuário e o outro era a categoria desenvolvida para uma única
aplicação específica, o ASIC completamente customizado. Neste tipo de ASIC, os engenheiros de
desenvolvimento possuem um total controle sobre cada camada da máscara usada para fabricar o
chip de silício. O fabricante não pré-desenvolve qualquer componente no silício e não provê
qualquer biblioteca de lógica pré-definida. Através de ferramentas próprias, é possível controlar
as dimensões de cada transistor e assim criar funções de alto nível baseadas nestes componentes.
O desenvolvimento de um ASIC completamente customizado é extremamente complexo, além de
exigir um período de tempo bastante longo. Entretanto, o resultado final é um chip com máxima
otimização, com uma grande quantidade de lógica em uma área otimizada de silício.
A concepção de arranjo de portas lógicas (Gate Arrays) surgiu em companhias como IBM
por volta dos anos 60, mas apenas para uso interno. Para o mercado, seu “surgimento” foi bem
posterior. O conceito de arranjo de portas lógicas é baseado na idéia de uma célula básica
constituída a partir de uma coleção de transistores e resistores desconectados. Cada fabricante de
ASIC determina qual é a combinação ideal de componentes para formar uma célula básica. Os
fabricantes começam pré-fabricando chips de silício contendo arranjos destas células básicas. Em
geral estas células básicas são representadas por arranjos de colunas, simples ou duplas, e uma
área livre entre elas chamada de canal. A Figura 2 apresenta a arquitetura de arranjo de portas
lógicas com canais e arranjos de células básicas em colunas duplas. No caso de dispositivos livres
de canais, as células básicas são representadas como um grande e único arranjo. A superfície do
dispositivo é coberta em um “mar” de células básicas e não existem canais dedicados para

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 19
interconexões. Assim, estes dispositivos, nesta configuração, são comumente chamados de “mar
de células”. O fabricante ASIC define o grupo de funções lógicas (multiplexadores, registradores
etc.) que podem ser usados pelo desenvolvedor. Cada um desses blocos de funções é referenciado
como célula – que não é a célula básica – e o grupo de funções suportadas pelo fabricante ASIC é
conhecido como biblioteca de células. Arranjos de portas lógicas oferecem vantagens em termos
de custo, uma vez que o transistor e outros componentes são pré-fabricados. Assim, somente as
camadas de metalização são customizadas. As desvantagens deste tipo de componente são que
muitos recursos internos podem acabar não sendo utilizados, a posição dos gates de entrada e
saída são fixos e o roteamento das trilhas internas não é otimizado.
CélulasBásicas
Canais
Células deEntradae Saída
CélulasBásicas
Canais
Células deEntradae Saída
Figura 2 – Arquitetura de arranjo de células básicas com canais.
Para tentar superar algumas das desvantagens do arranjo de portas lógicas, no começo dos
anos 80 tornaram-se disponíveis os CIs de célula padrão, que contêm muitas semelhanças com o
arranjo de portas lógicas. Também neste tipo de tecnologia o fabricante define a biblioteca da
célula que pode ser usada pelo desenvolvedor. O fabricante também disponibiliza bibliotecas de

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 20
elementos como processadores, funções de comunicações e funções de memória RAM e ROM.
Ademais, o desenvolvedor pode optar por reutilizar funções previamente desenvolvidas ou
comprar blocos de funções de propriedade intelectual. Diferentemente do arranjo de portas
lógicas, os dispositivos de célula padrão não utilizam o conceito de célula básica e nem
componentes pré-fabricados no chip. O conceito de célula padrão permite que cada função lógica
possa ser criada usando o menor número de transistores sem a redundância de componentes, e as
funções podem ser dispostas de forma a facilitar as conexões entre elas. Desde a introdução dos
dispositivos de célula padrão, a indústria previu uma queda nos dispositivos de arranjo de portas
lógicas, entretanto o uso desta tecnologia continuou tendo seu nicho de mercado e, contrariando a
previsão de algumas indústrias, vem apresentando um forte ressurgimento nos últimos anos.
A tecnologia dos circuitos integrados estruturados apareceu no começo dos anos 90,
quando os fabricantes de ASIC iniciaram uma grande busca por uma forma inovadora para
reduzir os altos custos e tempo de desenvolvimento destes circuitos integrados de aplicação
específica. Cada ASIC estruturado inicia com um elemento fundamental chamado módulo, o
qual pode conter uma combinação de lógica genérica pré-desenvolvida (tabelas de lookup,
multiplexadores etc.), um ou mais registradores e uma memória RAM local. Um arranjo destes
elementos é então pré-desenvolvido na face do chip. Alternativamente, outras estruturas iniciam-
se com uma célula base (ou módulo base) contendo apenas lógica genérica na forma de portas
lógicas, multiplexadores ou tabelas de lookup pré-desenvolvidas. Um arranjo desse tipo de base
forma então uma base mestra (ou módulo mestre) e, mais uma vez, um arranjo dessas unidades
mestras é pré-fabricado na face do chip. Não obstante, blocos de RAM e geradores de relógio são
especialmente úteis e, por isso, geralmente encontram-se embarcados no dispositivo. A Figura 3
exibe um modelo genérico de ASIC estruturado com quatro blocos de memória RAM e entradas
e saídas pré-desenvolvidas.
A idéia do ASIC estruturado é de que o dispositivo pode ser customizado usando somente
as camadas de metalização (assim como o padrão arranjo de portas lógicas, sendo que a diferença
é que, devido a maior sofisticação da estrutura do módulo do ASIC estruturado, a maioria das
camadas de metalização também é pré-definida). Assim, muitas arquiteturas de ASIC estruturado
necessitam customizar apenas duas ou três camadas de metalização, o que reduz drasticamente o

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 21
tempo e o custo de desenvolvimento. Estima-se que os ASIC estruturados consomem três vezes
mais silício e apresentam um consumo de energia duas vezes maior do que dispositivos de célula
padrão, para implementar a mesma função, embora estes resultados possam variar de acordo com
o tipo de projeto e de arquitetura.
Entradase Saídas
Pré-fabricadas
Blocos deRAM
Embarcados
Arranjo deMódulos
Entradase Saídas
Pré-fabricadas
Blocos deRAM
Embarcados
Arranjo deMódulos
Figura 3 – Estrutura genérica de um ASIC estruturado.
Dentre as opções de implementação em hardware disponíveis em meados dos anos 80,
parecia evidente a existência de dois extremos. Em uma ponta, encontravam-se os práticos e de
fácil desenvolvimento SPLDs e CPLDs, os quais possuíam grandes limitações que
impossibilitavam o desenvolvimento de funções complexas. No outro extremo, permaneciam os
ASICs, que podiam suportar funções robustas, entretanto sob pena de um alto custo e um longo
tempo de desenvolvimento, além de sua característica de inflexibilidade. Assim, visando
aproximar estes extremos, a Xilinx desenvolveu, em 1984, a primeira FPGA, a qual era baseada
em CMOS e utilizava células SRAM para configuração. Apesar de este primeiro modelo
apresentar uma pequena capacidade de implementação e poucos pinos de entrada e saída, muitos
aspectos de sua arquitetura são utilizados nos FPGAs atuais. Estes primeiros dispositivos foram
baseados no conceito de blocos lógicos programáveis, os quais continham três tabelas de lookup
(LUTs), um registrador que poderia funcionar como flip-flop ou latch, um multiplexador e outros
elementos menores. Assim, cada FPGA possuía um grande número destes blocos lógicos

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 22
programáveis, além de células SRAM apropriadas, as quais permitiam que cada um desses blocos
pudesse ser configurado de forma a desempenhar uma função diferente. Cada registrador poderia
ser configurado para conter um valor lógico de inicialização. Uma FPGA completa possui um
grande número de blocos lógicos programáveis ilhados em um “mar” de interconexões. Estas
conexões, por sua vez, podem ser caminhos de interconexões globais, os quais podem transportar
sinais através do chip sem ter que passar por elementos múltiplos e roteamento.
Existem casos nos quais núcleos de FPGAs são utilizados como parte de um projeto de
ASIC de célula padrão, caracterizando uma solução híbrida FPGA-ASIC. Uma razão para
embarcar material de FPGA em ASIC é que isso facilita o desenvolvimento de uma plataforma
de conceito. Neste caso, a plataforma seria o ASIC e o material da FPGA embarcado poderia
formar um dos mecanismos usados para customizar e diferenciar subprojetos. Uma outra razão é
que nos últimos anos tem-se percebido um crescente aumento no emprego de FPGA para
desenvolvimento de ASICs. Neste cenário, vê-se ainda uma alternativa com um grande e
complexo ASIC que possui uma FPGA associada, localizada muito próximo à placa do ASIC.
Esta configuração pode ser visualizada na Figura 4.
A razão para este cenário está no fato de ser extremamente custoso, além de consumir
muito tempo, corrigir um eventual erro de programa em ASIC ou modificar suas funcionalidades
de forma a acomodar qualquer mudança em sua especificação original. Entretanto, se o ASIC for
desenvolvido de maneira correta, a FPGA associada pode ser usada para implementar qualquer
modificação de atualização. Um problema nesta configuração é o tempo gasto pelos sinais para
navegarem entre o ASIC e a FPGA, pois estes sinais que trafegam entre os componentes não
terão a mesma velocidade das conexões internas do chip. Sendo este o problema, a solução é
realmente utilizar um modelo híbrido com material da FPGA embarcada no ASIC. Uma área de
interesse para estruturas híbridas FPGA-ASIC são os ASIC estruturados porque eles também
podem ser considerados como dispositivos baseados em blocos. Isto significa dizer que, quando
se procura por ferramentas de desenvolvimento, fabricantes de ASIC estruturados falam com
fornecedores de tecnologias de síntese e roteamento de FPGAs, além de ASIC. Em suma, isso
significa que soluções híbridas FPGA-ASIC baseadas em ASICs estruturados apontam para uma
ferramenta unificada ao fluxo de desenvolvimento, pois as mesmas ferramentas de síntese e

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 23
roteamento baseadas em blocos poderiam ser usadas para ambas as partes do projeto, FPGA e
ASIC.
Ligação para outrochip da placa
Ligação para outrochip da placa
Ligação para outrochip da placa
ASICFPGA
Ligação para outrochip da placa
Ligação para outrochip da placa
Ligação para outrochip da placa
ASICFPGA
Ligação para outrochip da placa
Ligação para outrochip da placa
Ligação para outrochip da placa
ASICFPGA
Figura 4 – Configuração de um ASIC com FPGA associada.
2.1.2 Arquiteturas e Configurações
A maioria das FPGAs atuais é desenvolvida baseada no uso de configurações de células
SRAM, o que significa que elas podem ser configuradas inúmeras vezes. A principal vantagem
desta técnica é que novas idéias de projeto podem ser rapidamente implementadas e testadas.
Outra grande vantagem do modelo baseado em SRAM é que seus dispositivos estão em uma
posição de vantagem tecnológica, pois muitas empresas do ramo de memórias investem bastante
em pesquisa de desenvolvimento. Além disso, as células SRAM foram desenvolvidas usando
exatamente tecnologia CMOS. Assim, nenhum novo processamento especial é necessário para
criar esses componentes. Uma desvantagem dos dispositivos baseados em SRAM é que uma
memória SRAM, por ser volátil, deve ser recarregada toda vez que o sistema for reinicializado.
Frente a isto, é necessário o uso de memória externa especial, não volátil.
As atuais FPGAs baseadas em SRAM suportam o conceito de criptografia bitstream. Os
dados da configuração final do sistema são criptografados em um bitstream antes de serem

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 24
armazenados na memória externa. A chave criptográfica é carregada para um registrador especial
baseado em SRAM através de sua porta JTAG. Assim, em conjunto com lógica adicional, esta
chave criptográfica permite que o bitstream criptografado seja interpretado e carregado no
dispositivo. O processo de carregar o bitstream criptografado automaticamente desabilita a
capacidade de leitura reversa (read-back) da FPGA. Isso significa que o desenvolvedor usará
dados de configuração não criptografados durante o processo de desenvolvimento (onde se
necessita usar read-back) e iniciar o uso de dados criptografados somente quando for mover os
dados para o dispositivo. Em geral, na maioria das plataformas de desenvolvimento, esse
processo é transparente ao usuário. O principal aspecto deste esquema é a necessidade de uma
bateria de backup na placa do circuito para manter o conteúdo do registrador da chave
criptográfica na FPGA quando a energia é removida do sistema. No entanto, esta bateria terá uma
vida útil de anos ou décadas.
Diferentemente das FPGAs baseadas em SRAM, as quais são programadas enquanto
residentes no sistema, FPGAs baseadas em antifusão de conexão são programadas em off-line
usando um dispositivo programador especial. Os proponentes das FPGAs baseadas na tecnologia
de antifusão de conexão orgulham-se em apontar uma variedade de vantagens. Primeiramente,
esses dispositivos não são voláteis (as configurações são mantidas, mesmo quando a energia é
subtraída do circuito), o que significa dizer que estes componentes estão prontos para serem
usados tão logo seja aplicada energia ao sistema. Também por serem não voláteis, estes
dispositivos não necessitam de bateria externa para armazenar as suas configurações. As FPGAs
baseadas nesta tecnologia também apresentam a grande vantagem de serem relativamente imunes
aos efeitos de radiação. Essa é uma vantagem extremamente útil no desenvolvimento de
aplicações para fins militares e aeroespaciais, especialmente porque FPGAs baseadas em SRAM
podem ter suas configurações de células de configuração alteradas quando expostas à radiação.
FPGAs baseadas em antifusão de conexão consomem apenas vinte por cento da energia
consumida por uma FPGA equivalente baseada em SRAM, aproximadamente, além dos atrasos
provocados por interconexões serem menores e de seus componentes serem fisicamente de menor
porte [3]. Obviamente que a grande desvantagem na operação com FPGAs baseadas em antifusão
de conexão é que uma vez programado o dispositivo, as fusões estão rompidas e uma nova
programação não pode ser feita, tornando este tipo de dispositivo muito pouco competitivo no

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 25
cenário de desenvolvimento e de prototipagem. FPGAs podem ainda ser baseadas em memórias
EPROM, EEPROM e em soluções híbridas flash-SRAM. Contudo, são soluções rejeitadas tanto
pelos fabricantes quanto pelo mercado e, portanto, não serão abordadas neste trabalho.
InterconexõesReprogramáveis
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
InterconexõesReprogramáveis
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
BlocoLógico
Figura 5 – Visão intercamada da FPGA.
Freqüentemente, as FPGAs são caracterizadas por sua granularidade. É importante
lembrar que o que diferencia as FPGAs de outros componentes é que sua construção se dá
baseada em um grande número de “ilhas” de blocos lógicos reprogramáveis relativamente
simples em meio a um “mar” de conexões programáveis, conforme pode ser observado na Figura
5. No caso da arquitetura de granularidade fina, significa que cada bloco lógico pode ser usado
para implementar apenas uma única e simples função. Elas são capazes de implementar de forma
satisfatória “lógicas de cola” e estruturas irregulares como máquinas de estado. Em suma,
arquiteturas de granularidade fina são eficientes para implementar funções nas quais os
benefícios derivam da implementação massiva de estruturas paralelas. Por volta de 1995,
arquiteturas finas de FPGA foram bastante utilizadas, entretanto com o passar do tempo viu-se
que a esmagadora maioria das FPGAs desenvolvidas é de arquitetura espessa. As arquiteturas de
FPGAs denominadas espessas quanto à granularidade são aquelas onde cada bloco lógico possui
uma quantidade relativamente grande de lógica. É conveniente destacar que as implementações

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 26
em arquiteturas finas necessitam de um número muito maior de conexões dentro e fora dos
blocos lógicos, comparando-se com as arquiteturas espessas. Inversamente proporcional ao
aumento da granularidade dos blocos, está o número de conexões dos blocos. Este aspecto é
especialmente importante no estudo dos efeitos dos atrasos no transporte de sinais, causados
pelas interconexões de blocos. Um fato concreto é que os grandes fabricantes de FPGAs não têm
mostrado interesse pela fabricação de dispositivos com arquiteturas de granularidade fina,
diminuindo assim o número de nós de conexões dos dispositivos. As FPGAs atualmente
fabricadas baseadas em tabelas de lookup são, em geral, consideradas de granularidade média.
Existem basicamente duas formas para que blocos lógicos sejam usados como
arquiteturas de granularidade média. São elas, arquiteturas de multiplexadores (Mux) e
arquiteturas de tabela de lookup (LUT). No modelo baseado em multiplexadores, o dispositivo
pode ser programado de forma que cada entrada do bloco lógico é representado por um sinal
digital, verdadeiro ou falso, proveniente de outro bloco lógico ou da entrada primária do
dispositivo. Isso permite que cada bloco seja configurado de inúmeras maneiras para implementar
uma grande quantidade de possibilidades de funções. Já o conceito do modelo baseado em
tabelas de lookup é bastante simples. Um grupo de sinais de entrada é usado com um indexador
(ponteiro) de uma tabela de lookup. O conteúdo desta tabela é organizado de forma que a célula
apontada por cada combinação das entradas contenham o valor desejado. A tabela de lookup pode
ser desenvolvida em cima de memórias SRAM, EEPROM ou células flash. Em termos práticos, o
modelo LUT é bastante eficiente quanto à utilização de área de silício e de atrasos de entrada e
saída de sinais e quando se deseja implementar uma grande quantidade de lógica com muitas
camadas de profundidade. A expressão “muitas camadas de profundidade”, neste caso, significa
uma grande quantidade de lógica entre as entradas e as saídas. Entretanto, a desvantagem das
arquiteturas baseadas no modelo de LUT aparece quando se deseja implementar uma função
pequena em algum lugar do projeto, pois a mesma ocupará a mesma tabela de lookup inteira para
essa simples implementação. Este fato gera um grande desperdício de recursos, podendo resultar
em atrasos na implementação de funções simples. É o famoso caso do “canhão utilizado para
matar um simples pássaro”.
Após os anos 90, as FPGAs foram amplamente utilizadas em aplicações de
telecomunicações e em soluções de redes. Estas aplicações requeriam, e de fato ainda requerem,

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 27
processamento de grandes quantidades de dados, onde arquiteturas baseadas em LUT
apresentavam o melhor desempenho. Ademais, com o crescimento dos projetos e da capacidade
dos dispositivos e com a sofisticação das tecnologias de síntese, o desenvolvimento manual de
circuitos acabou virando coisa do passado. O resultado disso é que, atualmente, a maioria das
FPGAs possui arquiteturas baseadas em LUT. Um dos pontos-chave no desenvolvimento das
FPGAs é o questionamento sobre a dimensão de entrada da LUT, da qual depende também o
número de combinações de funções lógicas. Adicionando-se mais entradas, permite-se
representar funções mais complexas, entretanto para cada nova entrada adicionada, dobra-se o
número de memórias (em geral SRAM) onde as LUTs são implementadas.
Alguns fabricantes permitem que as células que formam uma LUT sejam usadas como
pequenos blocos de memória RAM. Este mecanismo é conhecido como RAMs distribuídas, por
dois motivos. Primeiro, porque as LUTs são distribuídas ao longo da superfície do chip e,
segundo, porque isto diferencia estas memórias dos grandes blocos de memórias conhecidos
como BRAMs. Resumindo, uma vez programado o dispositivo, alguns fabricantes permitem que
o projetista use a célula SRAM que forma a LUT como um registrador.
Um detalhe importante na configuração das FPGAs é que cada fabricante possui um nome
diferente para as partes que constituem os dispositivos. Neste trabalho serão apresentadas apenas
as nomenclaturas utilizadas pelos dois maiores fabricantes, Xilinx e Altera. No caso da Xilinx, o
bloco lógico é chamado de LC (célula lógica) e contém uma LUT de quatro entradas (a qual pode
exercer a função de uma RAM de 16x1 ou de um registrador de deslocamento de 16 bits), um
registrador e um multiplexador. O registrador oferece a possibilidade de ser usado com um flip-
flop ou como latch. Além destes elementos principais, a LC possui ainda outros elementos
menores como, por exemplo, bit de transporte (carry) lógicos rápidos especiais. Para os
dispositivos Altera, o bloco lógico é denominado elemento lógico ou LE. Um conceito
importante é o que a Xilinx chama de slices, podendo ter outras denominações para outros
fabricantes. A definição de slice é uma forma de medição de células lógicas. É importante
destacar que a quantidade de células lógicas que caracterizam um slice pode variar, bem como a
definição de célula lógica.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 28
Subindo um nível na hierarquia da construção das FPGAs, chega-se até o que a maioria
dos fabricantes (entre eles a Xilinx) chama de CLB ou bloco lógico configurável. A definição
sobre o que constitui um CLB pode também variar com o passar do tempo. Inicialmente, um
CLB era composto por duas LUTs de três entradas e um registrador. Outras versões posteriores
suportavam duas LUTs de quatro entradas e dois registradores. Atualmente, um CLB contém
quatro slices, onde cada slice contém duas LUTs de quatro entradas e dois registradores. A
importância de ter-se a hierarquia da FPGA bem definida (um bloco lógico configurável – CLB –
que é formado por quatro slices, onde um slice é formado por duas células lógicas – LC –) está na
possibilidade de se definir uma hierarquia equivalente para as interconexões. Assim, existem
conexões rápidas entre LCs em um slice, conexões mais lentas entre slices dentro de um CLB e
ainda conexões entre os CLBs. O objetivo principal desta hierarquia de interconexões é conectar
os elementos sem ocasionar atrasos excessivos de conexões.
Conforme visto anteriormente, cada tabela de lookup (LUT) de quatro entradas pode ser
usada como uma memória RAM de 16x1. Assumindo o já exposto (de se possuir quatro slices
por CLB), pode-se então implementar, através de um slice, qualquer uma das alternativas abaixo:
• RAM de porta simples de 16x8 bits;
• RAM de porta simples de 32x4 bits
• RAM de porta simples de 64x2 bits
• RAM de porta simples de 128x1 bit
• RAM de porta dupla de 16x4 bits;
• RAM de porta dupla de 32x2 bits;
• RAM de porta dupla de 64x1 bit;
Utilizando-se slices (e conseqüentemente CLBs) para implementar memórias RAM,
consome-se uma área maior de silício do componente. No entanto, obtêm-se vantagens em
termos de velocidade no acesso aos dados contidos nas memórias, se comparado ao processo
equivalente concebido nos blocos específicos de memórias RAM embarcados no dispositivo, os
quais serão vistos em breve. Além disso, de forma alternativa à implementação de memórias

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 29
RAM implementadas com uso das LUTs do dispositivo, cada LUT de quatro entradas pode
também ser utilizada como um registrador de deslocamento de 16 bits.
Uma característica importante das FPGAs mais recentes são as interconexões e lógica
especial para implementar cadeias rápidas de carry. Cada LC contém um carry lógico especial
através de interconexões dedicadas entre os dois LC de um mesmo slice, entre os slices dentro de
um CLB e também entre os próprios CLBs. Este recurso melhora o desempenho de funções
lógicas como contadores e de funções aritméticas como somadores. De fato, são os carry rápidos
que, juntamente com características introduzidas pelos multiplicadores embarcados e pelos
registradores de deslocamento implementados em LUTs, viabilizam implementações de funções
rápidas de DSP em FPGAs.
Muitas aplicações implementadas em FPGAs necessitam do uso de memórias, e de fato as
FPGAs atuais possuem um número relativamente grande de dispositivos de memória RAM
embarcados, chamados de blocos de memória RAM ou simplesmente BRAMs. Dependendo da
arquitetura do dispositivo, as BRAMs podem ser distribuídas pela periferia do componente,
espalhadas pela superfície do chip ou então organizadas em colunas de BRAMs. Dependendo do
dispositivo, ele pode conter por toda parte, desde dezenas até centenas de BRAMs, provendo uma
grande capacidade de armazenamento que vai de poucas centenas a milhões de bits. Cada bloco
de memória RAM pode ser usado de forma independente, ou múltiplos blocos podem ser
combinados de forma a implementar um grande bloco. Não obstante, BRAMs podem ser usadas
para as mais diversas aplicações, como implementar memórias RAM de porta simples ou dupla,
sistemas FIFO (First In First Out), máquinas de estado, entre outras aplicações.
As FPGAs atuais também possuem outros recursos embarcados que visam otimizar suas
implementações. Algumas funções, como as desempenhadas pelos multiplicadores e somadores,
são consideravelmente lentas se implementadas através da interconexão de um grande número de
blocos lógicos. Uma vez que vários tipos de aplicações demandam estas funções, a maioria das
FPGAs já incorpora blocos especiais de multiplicadores e somadores, os quais, em geral são
localizados próximos às BRAMs, porque estas funções freqüentemente são usadas em conjunto.
Uma operação muito utilizada nas aplicações de processamento digital de sinais é exercida por

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 30
um componente conhecido como multiplicador acumulador (MAC). Como o próprio nome
sugere, em um único ciclo de relógio são efetuadas as operações de multiplicar dois números e
somar seu resultado com o valor presente em um acumulador. A maioria das FPGAs atuais
possui blocos MAC no dispositivo.
Quase todas as partes de um projeto de hardware podem ser feitas através de hardware
(portas lógicas, registradores etc.) ou software (com instruções a serem executadas por um
microprocessador). O fato é que muitos dos projetos desenvolvidos usam microprocessadores e,
até tempos atrás, estes apareciam como discretos componentes na placa. Assim, as FPGAs
começaram a disponibilizar um ou mais microprocessadores embarcados, conhecidos como
“núcleos de microprocessadores”. Neste caso, faz sentido transferir as funções que eram
realizadas por um microprocessador externo para um núcleo interno. Essa técnica oferece
algumas vantagens como, por exemplo, o fato de reduzir o custo por poupar um componente,
eliminar um grande número de trilhas, pinos e conexões na placa e ainda permitir a utilização de
uma placa fisicamente menor.
Todos os elementos de sincronismo dentro de uma FPGA necessitam de um sinal de
relógio. Como geralmente um sinal de relógio se origina do “mundo externo”, ele chega até a
FPGA através de um pino especial de relógio para então ser roteado através do dispositivo e
conectado aos registradores. Existem, também, dentro do dispositivo, estruturas chamadas de
“árvores de relógio”, que recebem este nome porque o sinal principal de relógio se ramifica
várias vezes através delas. Estas estruturas são usadas para garantir que todos os flip-flops
enxerguem a sua versão de um mesmo sinal de um relógio principal tão próximo quanto for
possível. Se o sinal de relógio fosse distribuído por uma simples trilha orientando todos os flip-
flops, um após o outro, o primeiro flip-flop enxergaria o sinal de relógio muito antes de um dos
últimos da cadeia, por exemplo. Esse efeito é denominado efeito “skew” (ou oblíquo) e pode
causar muitos problemas no circuito. Também, usando uma “árvore de relógio”, é possível que
alguns efeitos skew sejam visualizados no circuito. Ao invés de configurar um pino de sinal de
relógio para ser diretamente conectado em uma “árvore de relógio”, o pino pode ser usado para
conduzir uma função (bloco) especial denominada de gerenciador de relógio, o qual gera sinais
de relógios derivados do sinal de relógio principal e amarrados a ele. Estes sinais de relógio

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 31
derivados podem ser usados para orientar “árvores de relógio” ou usados como pinos de saída
para prover serviços de sinais de relógio para outros circuitos. No universo Xilinx, esse
gerenciador de sinais de relógio recebe o nome de DCM (Digital Clock Manager) ou gerenciador
digital de relógio.
Uma comparação inusitadamente interessante, e apresentada em [3], diz respeito à vida
útil de desenvolvimento de uma dada FPGA comparada à vida humana. Esta comparação é
apresentada da seguinte maneira: um dispositivo FPGA que tem permanecido no mercado por
dois anos corresponde a trinta anos na vida de um homem. Assim, com dois anos, pode-se
começar a pensar neste dispositivo como um dispositivo maduro, bem conhecido e no auge de
suas atividades. Após três anos, o que corresponde a quarenta e cinco anos na vida humana, a
FPGA começa a se tornar algo de meia idade. Com quatro anos, correspondendo a uma pessoa de
sessenta anos, deve-se tratar este dispositivo com respeito, certificando-se de que não se está o
maltratando com um esforço demasiadamente grande.
2.1.3 Formas de Desenvolvimento e Implementação
Definir o roteamento das conexões de um dispositivo reconfigurável era algo que parecia
viável quando os dispositivos disponíveis eram baseados em fusão de conexões do tipo PAL,
GAL etc. No entanto, estes métodos manuais são completamente inviáveis para tratar-se com
dispositivos como FPGAs. Existem muitas maneiras de se programar estes dispositivos, como
através de diagramas esquemáticos, linguagem de descrição de hardware (HDL), compiladores de
linguagens de alto nível e ferramentas de mais alto nível baseadas na síntese de algoritmos.
Desta forma, esta seção objetiva expor estes métodos.
2.1.3.1 Linguagem Esquemática
Quando do surgimento do circuito integrado, próximo aos anos 60, os diagramas dos
circuitos a serem implementados eram totalmente desenhados à mão e, posteriormente, estes
diagramas em papel eram analisados por um grupo de engenheiros. Este ato configurava o

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 32
processo de verificação da época. Evidentemente que esta forma de trabalho era por demais
custosa em termos de tempo, além de muito suscetível a erros. Apenas no começo dos anos 70,
viu-se o surgimento de algumas ferramentas rudimentares de simulação lógica.
O desenvolvimento baseado em esquemático parte de uma representação elementar ao
nível de portas lógicas, como, por exemplo, a representação mostrada na Figura 6. O primeiro
passo para viabilizar a implementação e a simulação de uma forma mais automática foi a criação
de uma representação textual, chamada de netlist ao nível de portas lógicas.
Figura 6 – Diagrama esquemático de descrição de hardware.
A Figura 7 apresenta o netlist ao nível de portas lógicas, correspondente à representação
esquemática apresentada na Figura 6.
Baseando-se em descrições de netlist ao nível de portas lógicas, surgiram as ferramentas
de simulação e verificação dos circuitos que se desejava implementar fisicamente. Essas
ferramentas eram inicialmente classificadas como CAE (Computer Aided Engineering).
Posteriormente, surgiram ferramentas de implementação que permitiam o roteamento de
conexões para os dispositivos, as quais eram classificadas como CAD (Computer Aided Design).

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 33
Finalmente, durante os anos 80, surgiu a tecnologia EDA (Electronic Design Automation), que
encampou as tecnologias CAD e CAE.
BEGIN CIRCUIT = FIGURA7INPUT CONFIG_A, CONFIG_B, DADOS, LIMPA_A, LIMPA_B;OUTPUT Q, NQ;WIRE CONFIG, DADOS_N, LIMPA;
GATE G1 = NAND ( IN1 = CONFIG_A, IN2 = CONFIG_B, OUT1 = CONFIG);GATE G2 = NOT ( IN1 = DADOS, OUT1 = DADOS_N);GATE G3 = OR ( IN1 = LIMPA_A, IN2 = LIMPA_B, OUT1 = LIMPA);GATE G4 = DFF ( IN1 = CONFIG, IN2 = DADOS_N, IN3 = CLOCK,
IN4 = LIMPA, OUT1 = Q, OUT2 = N-Q);
END CIRCUIT = FIGURA7
Figura 7 – Netlist ao nível de portas lógicas.
No final dos anos 70 e início dos 80, começaram a surgir ferramentas que permitiam a
captura gráfica do esquemático para criação iterativa de circuitos, uso de recursos como algumas
bibliotecas de símbolos esquemáticos, possibilidade de conexão através de cabos feitos
facilmente através do mouse e a geração automática de netlist. Nesta época, o arquivo netlist já
podia ser repassado a um simulador que analisava o funcionamento do circuito. Também, estas
ferramentas já possibilitavam fazer a distribuição e o roteamento das conexões dos dispositivos.
Quando as FPGAs entraram no mercado, entre os anos de 1984 e 1985, era natural que
seu desenvolvimento se desse em cima de plataformas de desenvolvimento esquemáticas, já
difundidas na época. Entretanto, as plataformas necessitaram de algumas pequenas mudanças
para migrar do mundo de desenvolvimento ASIC para o mundo FPGA. No mundo ASIC, após
obter-se o netlist do circuito, partia-se diretamente para as etapas de simulação, distribuição e
roteamento. Devido às características da estrutura da FPGA (formada por blocos lógicos
reconfiguráveis, slices, células lógica etc.) duas novas etapas foram necessárias. A primeira era o
mapeamento, que se refere ao processo de associar entidades, como funções descritas no netlist
ao nível de portas lógicas, com as LUTs disponíveis na FPGA. O mapeamento não é uma função
trivial, especialmente porque existe uma infinidade de formas destas associações serem feitas. A
segunda nova etapa acrescida com o surgimento das FPGAs foi o empacotamento, no qual os

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 34
LUTs e os registradores são empacotados para os CLBs específicos. Também o empacotamento
não é um processo trivial devido ao grande número de possibilidades existentes, onde uma
possibilidade ótima deve ser buscada. Após estas duas novas etapas inclusas à metodologia,
segue-se a seqüência habitual do processo, com as etapas de simulação e de distribuição e
roteamento de conexões. O desenvolvimento feito através de linguagem esquemática ainda é
utilizado, muito embora para muitos engenheiros conceber seus projetos de forma esquemática é
algo muito distante na memória. Alguns fabricantes dispõem de apenas alguns recursos de
desenvolvimento baseados nesta forma para seus dispositivos mais novos e mantêm suas
bibliotecas completas para dispositivos mais antigos. Contudo, a captura esquemática ainda
encontra seu espaço no mercado, principalmente entre engenheiros mais antigos e entre pessoas
que precisam fazer pequenas alterações em seus legados de projetos.
2.1.3.2 Linguagem de Descrição de Hardware (HDL)
Ao longo dos anos 80, os projetos foram crescendo significativamente em complexidade e
tamanho, de forma que ferramentas esquemáticas não suportavam mais o desenvolvimento dos
mesmos de uma forma eficiente. Além disso, grandes projetos desenvolvidos em esquemático
mostravam-se por demais sensíveis a erros e consumiam muito tempo de desenvolvimento. Foi
neste cenário que algumas empresas desenvolvedoras de ferramentas de EDA começaram a
produzir ferramentas e fluxos de desenvolvimento baseados em linguagem de descrição de
hardware (HDL). Inicialmente, serão apresentados conceitos genéricos e comuns a todos HDL,
uma vez que existem diferentes HDLs padronizados (como VHDL e Verilog), além de HDLs
proprietários.
A idéia contida em uma linguagem HDL, considerando-se inicialmente um HDL
genérico, é que a funcionalidade de um circuito digital pode ser representada através de diferentes
níveis de abstração e que diferentes HDLs suportam estes níveis de abstração até um grau maior
ou menor. O primeiro e mais baixo nível de abstração corresponde ao nível de switch, o qual se
refere à habilidade de descrever um circuito como um netlist de transistores. Subindo um pouco o
nível de abstração, tem-se o nível das portas lógicas, o qual se refere à capacidade de descrever
um circuito como um netlist de funções de portas lógicas primitivas. Tanto o nível de switch

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 35
como o nível de portas lógicas, podem ser classificados como representações estruturais. O
próximo nível na escala superior de abstração HDL é a habilidade em suportar representações
funcionais, descrevendo funções usando equações booleanas, através de uma linguagem genérica
para qualquer tipo de HDL. O nível funcional de abstração engloba a representação de nível de
registro de transferência (RTL). O termo RTL cobre uma multidão de ações, mas a maneira mais
fácil de descrever este conceito é um projeto formado por uma coleção de registradores
interligados através de lógica combinacional. Na lógica combinacional que interconecta estes
registradores, comandos como when, rise, if, then, else são palavras-chave das quais a semântica
é definida pelo HDL específico. O nível de abstração mais alto suportado pelos HDL tradicionais
é conhecido como behavioral ou comportamental, o qual se refere à capacidade de descrever o
circuito usando construções como loops e processos. Este nível de abstração mais elevado
também suporta elementos como multiplicadores e somadores em equações. A Figura 8 apresenta
os diferentes níveis de abstração suportados por um HDL genérico.
Figura 8 – Níveis de abstração de um modelo HDL genérico.
Em 1985 surgiu no mercado a linguagem HDL chamada Verilog, desenvolvida pela
Gateway Design Automation. O Verilog era apresentado juntamente com um simulador lógico

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 36
chamado Verilog XL. Como linguagem, o Verilog original mostrava-se razoavelmente forte
quanto ao nível de abstração estrutural (níveis de switch e de portas lógicas), nível de abstração
funcional (equações booleanas e RTL), além de suportar algumas construções ao nível de
comportamento (algoritmos). Em 1989, a linguagem Verilog foi adquirida pela Cadence Design
Systems e, posteriormente, em 1995, o Verilog foi padronizado pela norma IEEE1364 devido à
popularidade obtida ao longos dos anos.
Em 1980, o departamento de defesa americano lançou o programa do circuito integrado
de altíssima velocidade (VHSIC), o qual objetivava avançar o estado da arte na tecnologia de CIs.
Baseado no VHSIC, em 1981, foi lançado o VHDL (Very high integrated circuit Hardware
Description Language), processo no qual a indústria se envolveu desde o começo, diferente do
ocorrido com o Verilog. Em 1983, um grupo de empresas iniciou um trabalho de padronização do
VHDL o que de fato ocorreu em 1985, mas de forma definitiva em 1993 através da norma
IEEE1076. Como linguagem, o VHDL possui fortes níveis de abstração funcional (equações
booleanas e RTL) e de comportamento (algoritmo) e ainda suporta alguma construção de
desenvolvimento ao nível de sistemas. Entretanto, se comparado ao Verilog, o VHDL é um
pouco fraco no que tange ao nível de abstração estrutural (nível de switch e de portas lógicas),
especialmente considerando sua capacidade de modelagem de atrasos. Facilmente, percebeu-se
que o VHDL não possui suficiente precisão de timing para ser usado como simulador. Por esta
razão, a conferência de desenvolvimento e automação (DAC) lançou em 1992 o VITAL, uma
solução para possibilitar ao VHDL habilidades para modelagem de timing tanto em FPGAs
quanto em ASICs.
Finalizando, torna-se importante destacar que devido ao uso de linguagens de descrição
de hardware mistas e pela chamada “guerra dos HDL” (ocorrida no começo dos anos 90), alguns
fabricantes optaram por lançar soluções proprietárias de HDL, como foi o caso do AHDL pela
Altera e do UDL/I pela associação japonesa de desenvolvimento da indústria eletrônica. Estas
soluções eram baseadas principalmente em Verilog e VHDL. Acredita-se que a razão de,
atualmente, o VHDL possuir uma penetração de mercado bem maior que o Verilog é que o
VHDL apresenta maior capacidade de reusabilidade, melhor estrutura de gerenciamento de
projeto além de suportar replicação de estruturas. Ou seja, enquanto o Verilog avança pouco ao

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 37
nível de abstração de comportamento (algoritmo) o VHDL preenche totalmente este nível
chegando a alcançar um nível de abstração superior, que seria o nível de sistema.
2.1.3.3 Linguagem C, SVP e DSP
Trabalhando-se com dispositivos que contêm milhões de portas lógicas, como, por
exemplo, ASICs, tem-se o problema de que, operando-se através do fluxo padrão de
desenvolvimento, muitos detalhes do projeto não são perceptíveis até a análise de timing. Este
fato suscitou a necessidade de visualização de alguns comportamentos específicos do sistema
antes de toda a etapa de desenvolvimento do dispositivo mostrar-se concluída. Uma solução
encontrada foi a criação da prototipagem virtual em silício (SVP). SVP é uma representação de
projeto que pode ser gerada de uma maneira relativamente rápida e que contém um nível mínimo
de informações, de forma a permitir que os desenvolvedores identifiquem e localizem problemas
em potencial antes de perder tempo desempenhando as tarefas de distribuição e roteamento de
conexões dos dispositivos. Teoricamente, o tempo investido em iterações no projeto usando SVP
é medido em horas, enquanto o tempo gasto em iterações no projeto, depois das etapas de
distribuição e roteamento, é medido em dias ou semanas. Um aspecto fundamental do fluxo SVP
é a habilidade deste ser gerado de uma forma fácil e rápida. A maioria dos SVPs para ASIC são
baseados na representação de netlist ao nível de portas lógicas. Como, em geral, as ferramentas
de síntese são pesadas e lentas, os SVPs utilizam um tipo de síntese “suja" e rápida.
Com o desenvolvimento das FPGAs atuais, com milhões de portas lógicas, o mesmo
problema com o qual se depararam os ASICS, depararam-se também as FPGAs, incluindo o fato
de que seu desenvolvimento consome tempo de distribuição, roteamento de conexões e análise de
timing. Assim, surgiram os SVPs para FPGAs. Um aspecto negativo deste processo é que, para
qualquer mudança que seja feita no projeto, as etapas de síntese, roteamento de conexões e outras
devem todas ser refeitas. Visando resolver este problema, muitos desenvolvedores de ferramentas
de desenvolvimento começaram a oferecer suporte ao conceito de SVP. Os geradores SVPs
desempenham seu próprio método de disposição e roteamento dos recursos (LUTS, CLBs, slices,
BRAMs etc.) oferecendo ao usuário uma análise prévia do funcionamento e ocupação dos
recursos do dispositivo. Em termos práticos, é importante antecipar que este tipo de recurso está

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 38
presente nas ferramentas que constituem os fluxos de desenvolvimento modernos, as quais serão
apresentadas em seções seguintes.
Uma opção de desenvolvimento que merece ser citada, muito mais por mostrar-se
interessante do que por sua receptividade entre desenvolvedores, é o modelo no qual a captura
inicial do projeto é feita usando a linguagem de programação C ou sua extensão C++. Um
exemplo deste tipo de modelo é o que utiliza uma ferramenta denominada System C, a qual pode
oferecer simulações de cinco a dez vezes mais rápidas que em VHDL ou Verilog, para
posteriormente ferramentas de síntese converterem programas em System C para netlist ao nível
de portas lógicas. Na verdade, System C, que é um ambiente open-source, é uma classe de
bibliotecas que facilita a representação de noções como timing, concorrência em execuções e
pinos de entrada e saída. Através destas bibliotecas, desenvolvedores poderiam capturar projetos
ao nível RTL de abstração. O lado fraco deste modelo, além de sua baixa penetração entre
desenvolvedores, está em ser consideravelmente mais difícil capturar um projeto ao nível RTL
em System C do que diretamente em VHDL. De acordo com [3], quando do surgimento das
ferramentas de síntese baseadas na linguagem C, seu foco principal era operar com fluxos de
desenvolvimento para ASICs, e assim, elas não desempenharam um bom trabalho direcionado
para FPGAs, apresentando especialmente problemas relacionados ao uso de elementos como
BRAMs, multiplicadores e assim por diante.
Outras ferramentas de desenvolvimento baseadas em linguagem C, C++ foram
desenvolvidas posteriormente, entretanto estas, tais quais o System C, não apresentaram uma
satisfatória penetração de mercado e não constituem o foco deste trabalho. A principal diferença
entre os fluxos de desenvolvimento baseados em linguagem C, C++ refere-se ao nível de
abstração que cada uma delas pode suportar. Em geral, apesar de elas oferecerem um bom nível
de sistema (algoritmos) e satisfatória capacidade de modelagem ao nível de transição, seus
conjuntos de funções sintetizáveis apresentam um nível de abstração relativamente baixo. Essa
falta de abstração de síntese faz com que as representações baseadas em C, C++ sejam utilizadas
apenas para aplicações específicas e não para qualquer tipo de projeto. Para uma difusão deste
modelo, existe a necessidade de um incremento considerável no conjunto de funções
sintetizáveis, bem como na confiabilidade das mesmas.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 39
Conforme apresentado anteriormente neste trabalho, aplicações de DSP são as aplicações
mais promissoras e atraentes implementáveis em FPGA. Os projetos desenvolvidos atualmente,
mais e mais, requerem mais velocidade, tamanho e complexidade. Visando resolver este
problema e aumentar a produtividade, é necessário continuar-se aumentando o nível de abstração
usado para capturar as funcionalidades dos sistemas. Por esta razão, o desenvolvimento baseado
em linguagem esquemática apresentado previamente foi superado pela representação em VHDL.
Também, a tentativa de fluxos de desenvolvimento baseados em linguagem C, C++ deu-se
devido ao desejo de capturar aplicações e conceitos complexos de uma forma mais simples e
direta. No caso de áreas especializadas como DSPs, arquiteturas de sistemas podem alcançar um
fabuloso aumento de produtividade através de linguagens específicas de domínio (DSLs), as
quais oferecem uma forma mais concisa de representar tarefas específicas do que linguagens
como VHDL ou C. Algumas destas linguagens são Matlab e Simulink, as quais permitem que
desenvolvedores de DSP utilizem funções complexas que podem ocupar até mesmo uma FPGA
inteira, através de uma simples linha de comando ou um bloco de operação. Segundo [3], é uma
realidade que o padrão atual da indústria para verificação de algoritmos de DSP é Matlab.
Atualmente o termo Matlab se refere tanto a uma linguagem de desenvolvimento como a um
ambiente de simulação.
O nível de sistemas de desenvolvimento e ambientes de simulação são, conceitualmente,
de mais alto nível do que DSLs. Um bom exemplo disto é o Simulink, que, para uns, é apenas a
interface gráfica do Matlab e, para outros, é uma aplicação de modelagem dinâmica. O ponto-
chave desta questão é que não há uma regra fixa para a definição. Alguns desenvolvedores de
DSP preferem usar Matlab como ponto inicial de seus projetos, enquanto outros optam por
Simulink. Alguns dizem que isso depende da experiência de cada desenvolvedor, se este é mais
voltado para FPGA ou para DSP. Entretanto, esta divisão tende a sumir. Independentemente de se
optar pelo trabalho em Matlab ou Simulink, o primeiro passo é sempre a modelagem feita em
ponto flutuante. Números em ponto flutuante possuem a vantagem de oferecer uma precisão
extremamente. Entretanto, tentar operar com algoritmos em ponto flutuante em dispositivos como
FPGA exige um consumo demasiadamente grande de silício, além de que as operações tornam-se
bastante lentas. Assim, em algum momento do desenvolvimento, existirá a migração de ponto

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 40
flutuante para ponto fixo, uma representação que determina um número fixo de bits para
representar cada elemento. A este processo é dado o nome de quantização.
Anteriormente, algumas equipes de desenvolvimento iniciaram um processo de conceber
suas aplicações de DSP e fazer suas validações em Matlab para, posteriormente, migrar suas
aplicações manualmente para hardware, através de VHDL ou Verilog. Como já apresentado no
capítulo introdutório deste trabalho, este fluxo apresentava muitos problemas relacionados ao
tempo empregado no desenvolvimento, a grande complexidade envolvida e a vulnerabilidade a
erros. Também, eram encontradas dificuldades devido a grande diferença entre os domínios de
sistemas/algoritmos e o domínio RTL. Muitas vezes, o que significava uma otimização em um
domínio, não necessariamente representava a mesma otimização no outro, ou, ainda pior, poderia
até mesmo significar uma piora no desempenho do sistema.
Diante do exposto nesta seção, verificou-se a capacidade das FPGAs de atenderem as
aplicações de DSP. Entretanto, verificou-se também a necessidade de um fluxo de
desenvolvimento mais dinâmico, direto e confiável. Desta forma, estes fluxos de
desenvolvimento serão abordados nas Seções 2.2.2 e 2.3.1 deste trabalho.
2.1.4 Principais Fornecedores e Parceiros
O foco deste trabalho não é concentrar-se exclusivamente no estudo das FPGAs e nem
tampouco apresentar soluções de fabricante ‘A’ ou ‘B’. No entanto, torna-se especialmente útil a
seção presente, tanto para consulta como para conhecimento, a qual objetiva proporcionar uma
lista de fabricantes de FPGAs e de soluções relacionadas a simulações e implementações nas
mesmas.
Fabricantes de FPGAs:
Companhia Website
Actel Corporation www.actel.com
Altera Corporation www.altera.com

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 41
Anadigm Incorporated www.anadigm.com
Atmel Corporation www.atmel.com
Lattice Semiconductor Corporation www.latticesemi.com
QuickLogic Corporation www.quicklogic.com
Xilinx Incorporated www.xilinx.com Tabela 2.1 – Fabricantes de FPGAs.
Desenvolvedores de ferramentas completas de automatização de projetos eletrônicos
(EDA) para FPGAs:
Companhia Website Comentário
Altium Limited www.altium.com Ambiente de desenvolvimento em software e hardware
Cadence Design Systems www.cadence.com Ferramentas de simulação e ambiente de desenvolvimento inicial
Mentor Graphics Corporation www.mentor.com Ferramentas de simulação e síntese
Synopsys Incorporated www.synopsys.com Ferramentas de simulação e síntese Tabela 2.2 – Desenvolvedores de ferramentas completas para FPGAs.
Especialistas e desenvolvedores independentes de ferramentas de automatização de
projetos eletrônicos (EAD) para FPGAs:
Companhia Website Comentário
0-In Design Automation www.0-in.com Verificação
AccelChip Incorporated www.accelchip.com Soluções de DSP para FPGAs
Aldec Incorporated www.aldec.com Simulação de linguagens misturadas
Celoxica Limited www.celoxica.com Síntese e desenvolvimento de sistemas
Elanix Incorporated www.elanix.com Soluções de DSP e algoritmos de verificação
Fintronic USA Incorporated www.fintronic.com Simulação
First Silicon Solution Incorporated
www.fs2com Processadores embarcados e instrumentação de chip
Green Hills Software Incorporated
www.ghs.com Softwares embarcados
Hier Design Incorporated www.hierdesign.com Prototipagem virtual

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 42
Novas Software Incorporated www.novas.com Verificação e análise de resultados
Simucad Incorporated www.simucad.com Simulação
Synplicity Incorporated www.synplicity.com Síntese
The Math Works Incorporated www.mathworks.com Desenvolvimento de sistemas e verificação
TransEDA PLC www.transeda.com Verificação de propriedade intelectual
Verisity Design Incorporated www.verisity.com Linguagens e ambientes de verificação
Wind River Systems Incorporated
www.windriver.com Softwares embarcados
Tabela 2.3 – Especialistas e desenvolvedores independentes de ferramentas para FPGAs.
Consultores e desenvolvedores de ferramentas especiais para FPGAs:
Companhia Website Comentário
Dillon Engineering Incorporated www.dilloneng.com Arquiteturas de cores
Launchbird Incorporated www.launchbird.com Linguagem de desenvolvimento de junção de sistemas e compilação
Tabela 2.4 – Consultores e desenvolvedores especiais de ferramentas para FPGAs.
2.2 ISE Design Flow e System Generator
2.2.1 Project Navigator
O fluxo de desenvolvimento utilizado neste trabalho é baseado no ISE (Integrated
Software Environment) Design Flow da Xilinx Inc. Esse fluxo de desenvolvimento é aplicado
através da ferramenta chamada Project Navigator ou então pode ser desenvolvido diretamente
através do System Generator (o qual será abordado na seção seguinte) de uma forma mais
simples e direta. O fluxo de desenvolvimento é constituído pelas etapas de descrição (entrada),
síntese e implementação do projeto, além da etapa de programação do dispositivo [7]. Estas
etapas e a relação entre elas são apresentadas na Figura 9.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 43
A etapa de descrição do projeto pode ser feita através da forma esquemática, de
linguagem HDL, através da entrada de arquivos de terminação edif, ngc ou ngo, obtidos a partir
de ferramentas de síntese, os quais serão apresentados em seguida, ou ainda através de projetos
em System Generator. Esta escolha determinará de qual tipo será o arquivo de mais alto nível que
descreverá o sistema. Nesta etapa de descrição, também é feita a caracterização do projeto quanto
à família do dispositivo onde o projeto será implementado e a descrição das ferramentas de
simulação e síntese que serão utilizadas, conforme pode ser observado na Figura 10 para o caso
da utilização do Project Navigator.
Descrição(entrada)
Síntese
Implementação
ProgramaçãoDo
Dispositivo
DESENVOLVIMENTO VERIFICAÇÃO
Simulação deComportamento
Simulação deFuncional
Análise de Timing
Simulação de Timing
Verificaçãono circuito
Descrição(entrada)
Síntese
Implementação
ProgramaçãoDo
Dispositivo
ProgramaçãoDo
Dispositivo
DESENVOLVIMENTO VERIFICAÇÃO
Simulação deComportamento
Simulação deComportamento
Simulação deFuncional
Simulação deFuncional
Análise de Timing
Análise de Timing
Simulação de Timing
Simulação de Timing
Verificaçãono circuitoVerificaçãono circuito
Figura 9 – Design Flow da Xilinx.
Uma vez determinado o dispositivo e a forma de descrição do projeto, o usuário pode
operar normalmente na interface do Project Navigator, mostrada na Figura 11.
O ponto número um da Figura 11 mostra a barra de ferramentas da interface. O ponto
número dois apresenta a janela de fontes, ou seja, a janela dos arquivos fontes que constituem o
projeto. Um projeto completo é constituído por várias fontes e diferentes tipos de arquivo. O
ponto número três da figura indica a janela de processos. Os processos como síntese, simulação,
geração da implementação, entre outros, ficam disponíveis nesta janela e podem ser acessados de

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 44
uma forma direta através da mesma. O ponto número quatro aponta a área de trabalho. Por
exemplo, se um arquivo do tipo esquemático for selecionado, a interface gráfica esquemática
estará disponível na área de trabalho. Se for selecionado um arquivo do tipo VHDL, o editor
VHDL estará visível na área de trabalho. Por fim, a área representada pelo ponto número cinco
da figura é a janela de transcrição, onde é exibido o status das operações em processamento bem
como das já processadas.
Figura 10 – Etapa de Descrição do Design Flow da Xilinx.
Na etapa de descrição do projeto, podem ser utilizados Núcleos de Propriedade Intelectual
(NPI ou IP Cores), tanto se a entrada for feita na forma esquemática quanto na forma textual de
VHDL ou Verilog. Existe uma ferramenta do Design Flow chamada CORE Generator, que
oferece um grande leque de funções já otimizadas para linguagens de descrição de hardware.
Através desta ferramenta, cria-se um componente NPI desejado (um decodificador de Viterbi, por
exemplo) e adiciona-se este componente ao projeto. A inserção no Project Navigator é dada de
uma forma direta e intuitiva apenas acrescentando o arquivo gerado ao projeto. Uma vez o NPI
inserido no projeto ele já encontra-se disponível para ser utilizado. No caso da entrada ser através
de descrição HDL, é necessário apenas criar um componente e utilizá-lo normalmente, o que é
uma tarefa relativamente usual para programadores de HDL. Para o caso da entrada do sistema
ser feita de forma esquemática, é necessário criar-se o símbolo esquemático a partir do arquivo
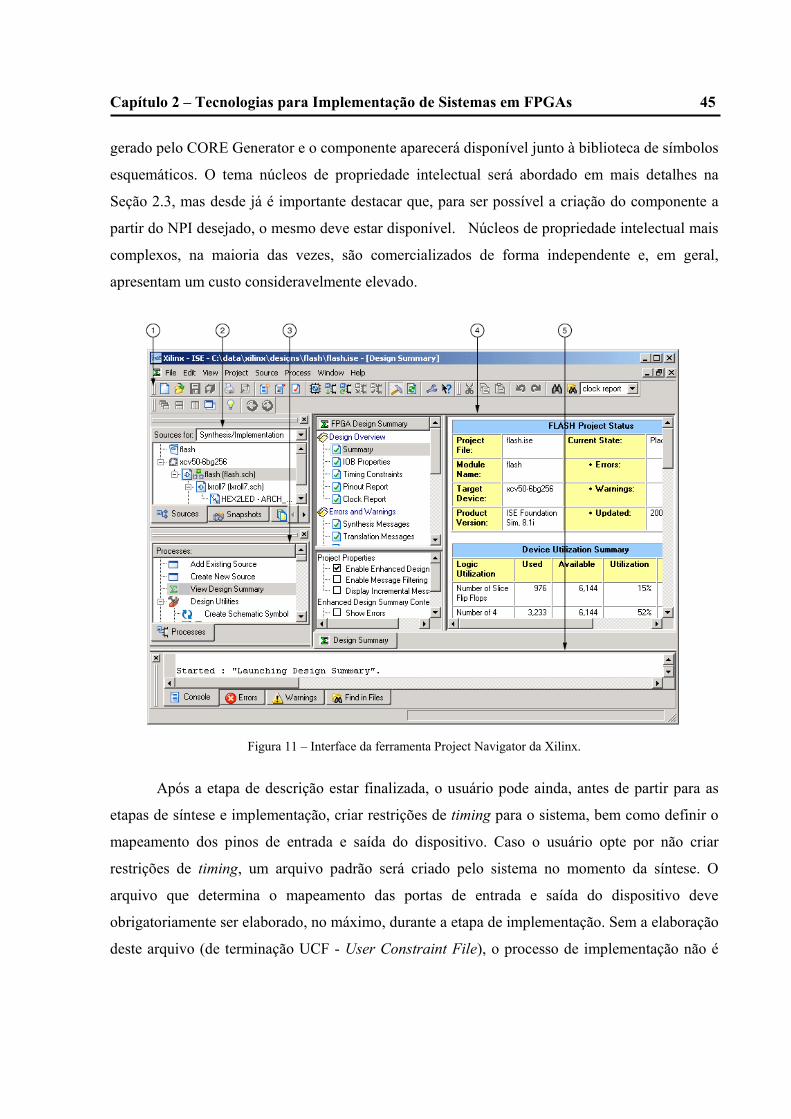
Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 45
gerado pelo CORE Generator e o componente aparecerá disponível junto à biblioteca de símbolos
esquemáticos. O tema núcleos de propriedade intelectual será abordado em mais detalhes na
Seção 2.3, mas desde já é importante destacar que, para ser possível a criação do componente a
partir do NPI desejado, o mesmo deve estar disponível. Núcleos de propriedade intelectual mais
complexos, na maioria das vezes, são comercializados de forma independente e, em geral,
apresentam um custo consideravelmente elevado.
Figura 11 – Interface da ferramenta Project Navigator da Xilinx.
Após a etapa de descrição estar finalizada, o usuário pode ainda, antes de partir para as
etapas de síntese e implementação, criar restrições de timing para o sistema, bem como definir o
mapeamento dos pinos de entrada e saída do dispositivo. Caso o usuário opte por não criar
restrições de timing, um arquivo padrão será criado pelo sistema no momento da síntese. O
arquivo que determina o mapeamento das portas de entrada e saída do dispositivo deve
obrigatoriamente ser elaborado, no máximo, durante a etapa de implementação. Sem a elaboração
deste arquivo (de terminação UCF - User Constraint File), o processo de implementação não é

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 46
iniciado, pois é ele que determina para quais pinos do dispositivo as entradas e saídas do sistema
serão mapeadas.
O processo de síntese é desempenhado pelo XST (Xilinx Synthesis Technology), uma
ferramenta da Xilinx que sintetiza o projeto após sua descrição para criar um arquivo específico
de netlist chamado NGC (Netlist File). O arquivo NGC é um netlist que contém tanto dados
lógicos como restrições que levam aos arquivos EDIF (Electronic Design Interchange Format) e
NCF (Netware Command File). O processo de implementação é dado pelo próprio ISE com
interação com o XST.
Em geral, os projetos são compostos de macros e lógica combinatória. Exemplos de
macros são registradores, acumuladores, multiplexadores, operadores aritméticos e RAMs. A
utilização de macros pode melhorar consideravelmente o desempenho da síntese de projetos.
Assim, é importante usar algumas técnicas de codificação para modelar os macros de forma que
estes possam ser processados da melhor maneira possível pelo XST. Durante a execução, a
ferramenta XST primeiro tenta identificar o maior número de macros possíveis, que são passados
para o próximo nível - Low Level Optimization. Informações detalhadas sobre o processamento
de macros podem ser encontradas no arquivo XST LOG, que apresenta informações como o
conjunto de macros e sinais associados inferidos pela ferramenta XST com código VHDL,
estatísticas totais de reconhecimento de macros e o número e tipos de macros preservados pelo
Low Level Optimization. Os passos executados pelo XST durante a síntese e otimização são o
mapeamento e otimização numa entity/module por entity/module basis além da otimização global
em todo o projeto.
As etapas de síntese e implementação podem ser otimizadas para melhorar o desempenho
de velocidade ou para minimizar a área ocupada de circuito. A otimização para velocidade
prioriza a redução no número de níveis lógicos e, além disso, aumenta a freqüência de operação
do circuito. Por outro lado, na otimização para minimização de área, a prioridade é a redução da
quantidade de lógica utilizada para execução do projeto. No final da síntese, a ferramenta XST
relata informações de timing para o projeto. O relatório mostra a informação para todos os
domínios possíveis do arquivo netlist. A ferramenta XST também tenta mapear lógica para
memórias RAM do dispositivo durante a etapa de síntese avançada. Se algumas das exigências de

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 47
velocidade ou timing não forem satisfeitas, o XST não mapeia a lógica para blocos de memória
RAM e gera uma mensagem de advertência. Se a lógica não puder ser colocada em um único
bloco RAM, o XST pode ainda utilizar vários blocos de memória RAM para implementá-la.
É considerável o fato de que existe a possibilidade de utilizar-se outras ferramentas de
síntese além do XST que constitui o Design Flow da Xilinx. Ferramentas de síntese como
Leonardo Spectrum da Mentor Graphics Corporation e Synplify da Synplicity Incorporated
podem ser perfeitamente integradas ao fluxo de desenvolvimento, embora elas, ainda que
reconhecidamente eficientes, apresentem um valor de compra bastante elevado e,
conseqüentemente, um acréscimo no custo de desenvolvimento.
Além disso, na etapa de implementação é feito também o roteamento e a definição física
dos recursos lógicos do dispositivo que serão utilizados.
O um ponto interessante de se trabalhar com o Project Navigator está no fato de que as
etapas descritas anteriormente podem, cada uma delas, ser acompanhada pela janela de
transcrição, apontada como item cinco da Figura 11.
A etapa de implementação física do projeto consiste na programação do dispositivo e
também na geração do arquivo binário que será efetivamente gravado na FPGA. Essas tarefas são
diretamente selecionadas na janela de processos, indicada pelo número três na Figura 11. Para
este processo é gerado então um arquivo bitstream de extensão .bit (para ser gravado diretamente
na FPGA). Posteriormente, é possível gerar um arquivo específico para ser gravado na memória
flash que acompanha a FPGA (formato este que pode ser .bit, .tec, .ufp, .exo, .hex, .bin, .isc).
Embora possuam diferentes formatos, todos estes arquivos carregam a mesma informação. A
vantagem da geração de arquivos destinados à memória flash é que, uma vez gravado na
memória, o projeto será automaticamente carregado para a FPGA toda vez que o circuito for
alimentado. No caso de arquivos de extensão .bit gravados diretamente na FPGA, a cada
interrupção na alimentação, o dispositivo deve ser reprogramado pelo usuário, via computador. A
programação dos dispositivos, tanto diretamente na FPGA como via memória flash, é dada
através da ferramenta IMPACT, que também constitui o Design Flow e também pode ser

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 48
acessada via Project Navigator. A interface do IMPACT, mostrada na Figura 12, é bastante
intuitiva. Uma observação pertinente a ser feita sobre esta figura é que a placa identificada pelo
IMPACT no momento da captura da mesma possui cinco dispositivos programáveis,
representados pelas cinco estruturas de cor cinza, localizadas na parte superior da figura.
A última etapa do fluxo de desenvolvimento, que não é uma etapa obrigatória uma vez
que ela se dá após o programa estar efetivamente rodando no dispositivo, refere-se à verificação
do circuito já gravado na FPGA. Esse processo se dá com o uso da ferramenta da Xilinx
denominada ChipScope. O ChipScope é um analisador lógico avançado que serve para que os
sinais internos do projeto possam ser analisados. É importante destacar que a memória de
amostragem do ChipScope será limitada pelos recursos da própria FPGA, onde estará rodando o
circuito gravado. Outro detalhe significativo está na taxa de amostragem do ChipScope que será
definida através da escolha de um sinal de relógio entre os disponíveis no circuito.
Figura 12 – Interface da ferramenta IMPACT.
2.2.2 System Generator
O System Generator é a ferramenta de linguagem de mais alto nível que faz parte do
Design Flow da Xilinx. O System Generator oferece um ambiente de desenvolvimento para
modelagem de sistemas, bem como uma forma de implementação fiel ao sistema modelado. A

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 49
grande vantagem do System Generator, no entanto é que ele é desenvolvido sobre a plataforma
Simulink do Matlab, como descrito na Seção 2.1, uma referência no desenvolvimento de
algoritmos de DSP. No System Generator, a partir do esquema modelado, é possível gerar o
código do projeto para implementação em hardware. O System Generator não visa substituir o
VHDL ou Verilog, mas ele torna possível focar outras dificuldades de projeto que não a
linguagem, obtendo-se um ganho de produtividade bastante significativo [8].
A implementação em System Generator torna-se especialmente eficiente a partir do uso
dos núcleos de propriedade intelectual (NPIs), dos mais simples aos mais complexos, de
operações aritméticas até algoritmos complexos de DSP, que aparecem dispostos nos toolboxes
do Simulink tal qual mostrado pela Figura 13.
A chave para utilização do System Generator é o emprego de dois blocos chamados
Gateway In e Gateway Out. O bloco Gateway In representa a entrada do sistema. Em
desenvolvimentos e simulações feitas no ambiente Simulink, ele representa a interface entre o
universo de ponto flutuante, Simulink, e o universo de ponto fixo, que é efetivamente
implementada no hardware. Em termos de implementação, cada bloco Gateway In representa
uma entrada (fisicamente falando, pinos da FPGA) do dispositivo. No Gateway In é necessário
informar o tipo de dado de entrada (booleana, ponto fixo com sinal ou ponto fixo sem sinal) e o
tamanho, em bits, do mesmo. Já o Gateway Out, por sua vez, representa a saída do universo de
ponto fixo para ponto flutuante, quando em simulação no Simulink, e representa pinos de saída
no dispositivo (pinos do chip) em termos de implementação.
Todo sistema desenvolvido em System Generator deve obrigatoriamente possuir um
bloco também denominado System Generator, disponível nos toolboxes Xilinx do Simulink e o
qual pode ser identificado no canto superior direito da Figura 13. Este bloco determina
características do projeto como a família do dispositivo a ser utilizado, freqüência de operação do
circuito, ferramenta utilizada para síntese, linguagem de descrição de hardware utilizada (VHDL
ou Verilog) além do tipo de compilação a ser feita. O tipo de compilação pode ser, por exemplo,
HDL netlist. Nesta compilação, é gerado um arquivo de netlist baseados em arquivos VHDL ou
Verilog que contém tanto a lógica quanto às informações de restrição de desenvolvimento. Isso
significa que todo HDL, NPIs e arquivos de restrição que correspondem ao System Generator

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 50
estarão interligados por um netlist através de um arquivo ngc. O arquivo gerado pode ser
considerado um NPI e ser então aproveitado para reutilização em outros projetos.
Figura 13 – Browser das bibliotecas do Simulink mostrando os toolboxes da Xilinx.
Uma alternativa considerável de compilação é o modo bitstream. Com este modo de
compilação, a partir do System Generator, gera-se diretamente o arquivo binário para ser gravado
na FPGA. No caso deste tipo de compilação, duas observações são importantes. Primeira, todos
os blocos Gateway In e Gateway Out devem ser informados sobre os pinos do dispositivo para os
quais serão mapeados, possibilitando desta forma, a geração do arquivo de terminação .ucf.
Segunda, depois de gerado, o arquivo bitstream deverá ser normalmente carregado para a FPGA,
através da ferramenta IMPACT mostrada na Figura 12.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 51
Outra importante opção de compilação é a compilação para co-simulação em hardware.
Este recurso de co-simulação em hardware é bastante importante, pois permite que um sistema
inteiro seja modelado e apresentado dentro de uma “caixa preta” para ser utilizado no ambiente
Simulink, enquanto, na verdade, sua função é executada na FPGA. A interface de transferência
de dados entre a FPGA e o microcomputador pode ser feita, durante a co-simulação em hardware,
através de um barramento PCI ou de um cabo JTAG/Paralelo proprietário Xilinx. O que esta
compilação faz, na verdade, é gravar o projeto na FPGA e disponibilizar um bloco no ambiente
Simulink que representa este projeto. Desta forma, duas grandes vantagens são obtidas. A
primeira refere-se ao tempo de simulação. As restrições para processamento de funções
complexas passam do processador do computador para a FPGA. Segunda, este recurso torna
possível incorporar uma FPGA diretamente no ambiente Simulink, podendo-se, assim, observar
seu efeito dentro de um sistema. A partir desta co-simulação em hardware, a FPGA acrescentada
ao Simulink passa a ser também uma “caixa preta” no projeto.
Percebe-se que, no momento da compilação, tudo que estiver entre os Gateway In e
Gateway Out serão convertidos para a linguagem de hardware. É importante destacar que, entre
os blocos de Gateway In e Gateway Out, somente podem existir funções do universo Xilinx,
toolboxes que podem ser identificados por serem estilizados com um logotipo da Xilinx,
conforme podem ser observados na coluna do lado direito da Figura 13. Destes blocos, não todos
constituem núcleos de propriedade intelectual. Alguns, como os da biblioteca de elementos
básicos casualmente mostrados na Figura 13, são apenas operadores que poderiam ser
desenvolvidos com poucas linhas de código. Porém, existem NPIs mais complexos que, em geral,
apenas suas versões para demonstração acompanham o kit básico de desenvolvimento, como é o
caso da maioria dos codificadores de canal utilizados em telecomunicações.
Um outro importante recurso disponível no System Generator é o bloco chamado “Black-
Box”. Ele permite que uma função ou até mesmo um projeto inteiro, já descrito em VHDL, possa
ser incorporado ao projeto. A vantagem deste recurso está primeiramente na reutilização de
antigas funções escritas em VHDL, e depois, na integração em um único arquivo de mais alto
nível para a geração do arquivo bitstream. Além disso, com o emprego de um outro bloco
denominado “ModelSim” é possível inclusive integrar a simulação do HDL com a simulação de
todo o circuito. Este recurso da integração da simulação HDL com a integração Simulink é

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 52
essencialmente importante quando o desenvolvedor não possui uma placa disponível para realizar
a co-simulação em hardware, por exemplo.
O fluxo de desenvolvimento, a partir do System Generator até a etapa de gravação do
programa na FPGA, é exibido pela Figura 14.
Figura 14 – Fluxo de desenvolvimento a partir do System Generator até a etapa de download na FPGA.
2.2.3 Simulação HDL
Algumas ferramentas, como as que compõem o Design Flow da Xilinx, são projetadas
para serem usadas de forma integrada com várias ferramentas de simulação. O simulador HDL
torna-se importante na medida em que valida toda a implementação feita em linguagem de
hardware, independentemente da forma de entrada do projeto (seja ela em VHDL, esquemático
ou System Generator). Enquanto a simulação feita, por exemplo, no System Generator se dá pelo
modelo de simulação do próprio Simulink, a simulação realizada por simuladores HDL é feita a
partir do netlist após a síntese.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 53
O modelo padrão de simulação HDL do Design Flow da Xilinx é o ModelSim da Mentor
Graphics Corporation. O ModelSim é um ambiente de simulação HDL onde podem ser
verificados os modelos de funções, timing do projeto e o código fonte HDL. Além disso, o
ModelSim é otimizado para ser usado com todas as configurações do Design Flow. Tanto o
System Generator quanto o Project Navigator, geram um arquivo para utilização do simulador
ModelSim durante a etapa de síntese. Na etapa de síntese do Project Navigator, existe uma “sub-
etapa” chamada de “Geração de Modelo de Simulação”. Através desta tarefa, o netlist em
linguagem de hardware gerado contém as primitivas e a biblioteca de simulação (denominada
UNISIM) para ser usada pelo ModelSim. As simulações podem ser executadas de forma
independente ou associadas ao Project Navigator. No entanto, antes que o projeto seja compilado,
faz-se necessária a compilação das suas bibliotecas (NPIs) com o ModelSim. Há basicamente
duas maneiras de se compilar bibliotecas de NPIs: a primeira é através da interface gráfica,
utilizando o Project Navigator; a segunda é mais complexa e exige compilação via linha de
comando. No entanto, as duas opções nem sempre estão disponíveis, já que são disponibilizadas
dependendo da versão do programa que compila as bibliotecas via linha de comando [9]. No
System Generator, para a criação dos arquivos de simulação, é necessário selecionar a opção
“Create Testbench” no momento da compilação. Por fim, cabe ressaltar a existência de outras ferramentas de simulação HDL que podem
também ser utilizadas, como o Riviera da Aldec Incorporation e o NC-Sim da Cadence Design
Systems.
2.3 AccelChip (AccelDSP) e AccelWare
2.3.1 AccelChip (AccelDSP)
AccelDSP é uma ferramenta de síntese de alto nível que permite transformar projetos do
Matlab, descritos em ponto flutuante, para um módulo de hardware, em ponto fixo, para ser
implementado em silício. O AccelChip, ferramenta de desenvolvimento também utilizada nos
trabalhos apresentados nesta dissertação, foi desenvolvido pela AccelChip Incorporation,
empresa até então localizada na Califórnia. No primeiro semestre de 2006, a AccelChip foi

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 54
adquirida pela Xilinx, a qual alterou o nome da ferramenta de AccelChip DSP para AccelDSP e
fez com que esta passasse a fazer parte das soluções do Xilinx Xtreme DSP. Como durante o
desenvolvimento dos trabalhos práticos a ferramenta possuía um nome e durante a elaboração
deste documento possuía outro, ainda que sendo a mesma ferramenta, ambos os nomes são
apresentados. Em termos práticos, o fluxo de desenvolvimento e os recursos disponíveis, apesar
da alteração de nome, continuaram os mesmos. Contudo, destaca-se que os relatórios e imagens
de interfaces com usuário foram obtidos a partir do AccelChip, recurso efetivamente utilizado ao
longo do projeto. A única mudança substancial foi que a possibilidade de operar-se com FPGAs
de diferentes fabricantes foi substituída pela utilização restrita a FPGAs Xilinx.
Modelo RTL
(VHDL/ Verilog)
1
2
3
4 5
6
7
8 9
1011
Netlist(EDIF)
ArquivoConfig
Modelode
SimulaçãoHDL
Relatóriode
Simulação
Relatóriode
Simulação
Diretóriode
Projeto
Modeloem
Ponto Fixo
Modeloem
Ponto Flutuante
Diretivasde
Projeto
Projetona
Memória
VerifyFloating
Point
Verify Fixed PointProject
Generate Fixed PointAnalyse
Verify RTL Synthesize RTL
Generate RTL
ImplementVerify Gate Level
Comparação
PONTO FIXOPONTO FLUTUANTE
Verificação do código fonte
Modelo RTL
(VHDL/ Verilog)
11
22
33
44 55
66
77
88 99
10101111
Netlist(EDIF)
ArquivoConfig
Modelode
SimulaçãoHDL
Relatóriode
Simulação
Relatóriode
Simulação
Diretóriode
Projeto
Modeloem
Ponto Fixo
Modeloem
Ponto Flutuante
Diretivasde
Projeto
Projetona
Memória
VerifyFloating
Point
Verify Fixed PointProject
Generate Fixed PointAnalyse
Verify RTL Synthesize RTL
Generate RTL
ImplementVerify Gate Level
Comparação
PONTO FIXOPONTO FLUTUANTE
Verificação do código fonte
Figura 15 – Fluxo de desenvolvimento da ferramenta AccelChip (Accel DSP).

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 55
A Figura 15 apresenta as onze etapas do fluxo de desenvolvimento, dadas através do
AccelChip. No interior desta figura, é possível observar pequenos blocos com legendas em
inglês, os quais assim foram intencionalmente mantidos para indicar que estas são as etapas
acessadas através da interface do AccelChip e que estes são os ícones que representam cada
etapa, tal qual empregados no programa. Estas etapas serão descritas em seguida e mostradas
através da janela de processos, localizada no canto esquerdo das Figuras 16, 17 e 18.
O ponto de partida para a implementação em hardware através do AccelChip é o mesmo
utilizado pela maioria dos desenvolvedores de programas de DPS, que é escrever o algoritmo em
ponto flutuante, usando o Matlab. No entanto, o programa deve ser escrito de forma a respeitar
algumas regras de implementação impostas pelo AccelChip, as quais são descritas no “Guia de
Estilo de Matlab para Síntese” [10]. Uma vez escrito o programa respeitando tais regras, o
usuário pode começar a interagir com a ferramenta. Essa etapa corresponde ao item um da Figura
15.
O programa a ser implementado deve ser organizado em forma de função (M-File
Function), sendo os parâmetros de entrada da função os próprios pinos de entrada da FPGA, e os
parâmetros de saída, os pinos de saída do dispositivo. Um outro programa (do tipo Script M-File)
deve ser criado. Neste segundo arquivo, os parâmetros de entrada devem ser inicializados, e o
primeiro programa deve ser chamado de dentro de uma rotina de repetição (loop) feito por um
comando do tipo for. Esta rotina de repetição deverá variar do valor um até o número de amostras
desejado. Tendo-se estes dois arquivos, pode-se abrir a interface gráfica do AccelChip e iniciar-se
o uso da ferramenta, caracterizando-se desta maneira a etapa descrita pelo item número dois da
Figura 15.
Dentro do ambiente AccelChip, o primeiro passo é a criação do projeto. O projeto poderá
ser inteiramente novo ou pode-se fazer uso de algum NPI disponibilizado pelo AccelWare, o qual
será visto na seção seguinte. No ato da criação do projeto, o usuário deverá informar o tipo de
FPGA a ser utilizada e a linguagem de hardware para qual o projeto deve ser sintetizado, se
VHDL ou Verilog. O passo seguinte, descrito pela Figura 16, representa a indicação das
ferramentas de síntese, roteamento, simulação HDL, bem como versão do System Generator e
Matlab utilizados.
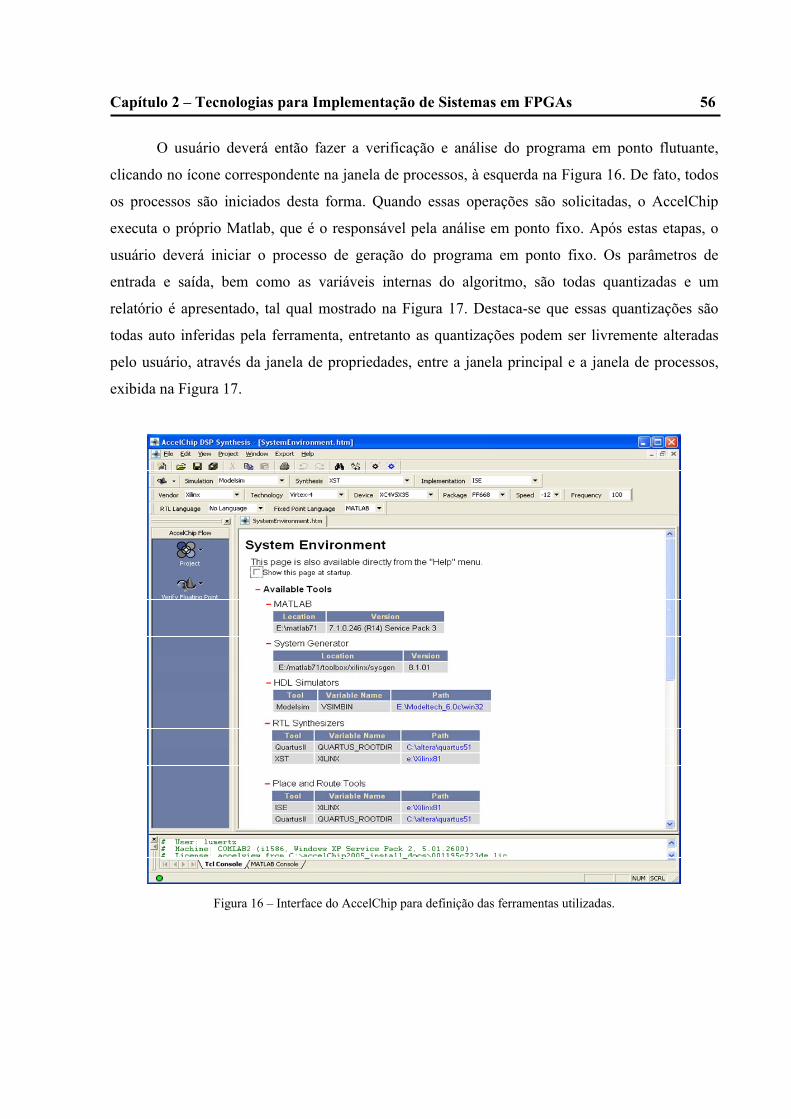
Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 56
O usuário deverá então fazer a verificação e análise do programa em ponto flutuante,
clicando no ícone correspondente na janela de processos, à esquerda na Figura 16. De fato, todos
os processos são iniciados desta forma. Quando essas operações são solicitadas, o AccelChip
executa o próprio Matlab, que é o responsável pela análise em ponto fixo. Após estas etapas, o
usuário deverá iniciar o processo de geração do programa em ponto fixo. Os parâmetros de
entrada e saída, bem como as variáveis internas do algoritmo, são todas quantizadas e um
relatório é apresentado, tal qual mostrado na Figura 17. Destaca-se que essas quantizações são
todas auto inferidas pela ferramenta, entretanto as quantizações podem ser livremente alteradas
pelo usuário, através da janela de propriedades, entre a janela principal e a janela de processos,
exibida na Figura 17.
Figura 16 – Interface do AccelChip para definição das ferramentas utilizadas.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 57
O processo de verificação de ponto fixo, o qual corresponde ao sexto passo no fluxo de
desenvolvimento, é vital para uma correta implementação do algoritmo, inicialmente
desenvolvido em Matlab. Uma cautelosa análise é imprescindível para observar se a quantização
se deu de forma satisfatória ou não. Pode ocorrer da quantização ser realizada com um número
não ideal de bits. Excesso de bits causará uma ocupação desnecessária de área de silício do
dispositivo e maior tempo de processamento, enquanto a escassez de bits pode conduzir a não
convergência do algoritmo. Outra informação importante fornecida pela ferramenta é a
ocorrência ou não de erros de overflow. Um recurso bastante útil para este tipo de comparação é
graficar os resultados do algoritmo em ponto fixo e em ponto flutuante e compará-los, tal qual
mostrado na parte superior direita da Figura 15. Para tanto, basta inserir um comando plot no
corpo do arquivo do tipo Script M-File.
Figura 17 – Interface do AccelChip mostrando a tabela de quantização.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 58
A sétima e oitava etapas no fluxo de desenvolvimento referem-se à geração e à
verificação do modelo em RTL (Register Transfer Level, como já apresentado na Seção 2.1, em
VHDL ou Verilog), respectivamente. Após, finalmente, chega-se à nona etapa, a de síntese RTL.
Um dos melhores recursos do AccelChip, provavelmente o mais interessante deles, é que, após a
etapa de síntese, é disponibilizada ao usuário a opção de exportar todo o projeto para o System
Generator, conforme mostra a Figura 18. Em outras palavras, todo o projeto convertido para
linguagem de hardware torna-se agora disponível no System Generator, como mais uma
biblioteca dos toolboxes do Simulink, disponíveis para implementação em hardware. Além da
facilidade de uso, essa facilidade possibilita um recurso adicional extraordinário, o da
reusabilidade diretamente no ambiente Simulink.
Figura 18 – Interface do AccelChip mostrando o recurso de exportação para o System Generator.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 59
As etapas seguintes são as de implementação e verificação, etapas dez e onze
respectivamente. A etapa de implementação é dada através das ferramentas de roteamento (no
caso da Xilinx, o XST) e a etapa de simulação através do simulador HDL. Após, pode-se operar o
projeto no ISE para geração do arquivo binário para gravação no dispositivo.
Após cada etapa do processo, é exibido, na área de trabalho da ferramenta, um relatório,
como pode ser observado, por exemplo, nas Figuras 17 e 18. No entanto, após a última etapa, é
apresentado um relatório sobre os dados de implementação, baseado em aproximações fornecidas
pelo software, mostrado na Figura 19. Este relatório apresenta informações importantes como
área de silício que o programa ocupará no dispositivo, taxa atingida, ocupação dos pinos de
entrada e saída, entre outros dados [11].
Figura 19 – Interface do AccelChip mostrando o relatório final de desenvolvimento.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 60
2.3.2 AccelWare e Núcleos de Propriedade Intelectual (NPIs ou IP Cores)
Os projetos atualmente desenvolvidos para FPGA são tão grandes e complexos que é
praticamente inviável criar-se cada parte do sistema a cada novo projeto. Uma solução para este
problema é a reutilização de partes prontas como solução para grandes sistemas. Qualquer bloco
funcional existente é tipicamente referenciado como núcleo de propriedade intelectual (NPI ou IP
Core). As três fontes principais destes núcleos são, em ordem, blocos criados em projetos
anteriores, blocos fornecidos por fabricantes de FPGA e blocos fornecidos por desenvolvedores
de NPIs [3].
Em geral, os NPIs oferecidos são feitos ao nível de netlist, pois os desenvolvedores destes
núcleos não pretendem que seus códigos fontes, descritos em linguagem RTL (VHDL/Verilog),
circulem sem algum tipo de proteção. Para o usuário final, a única vantagem de operar com esta
forma de núcleos é que eles são bastante otimizados se comparados aos que porventura são
oferecidos em linguagem RTL. Geralmente neste tipo de caso, o desenvolvedor do núcleo oferece
também (o que é transparente ao usuário final) um modelo de verificação para viabilizar
simulações. Infelizmente, não existe uma padronização quanto à criptografia dos núcleos de
propriedade intelectual oferecidos, e cada desenvolvedor usa seu próprio método. Assim, núcleos
desenvolvidos por fabricantes de FPGAs como Xilinx e Altera são implementáveis apenas nos
chips de seus respectivos fabricantes. A principal vantagem deste cenário é que os provedores
dos núcleos já investiram bastante tempo e esforço na síntese avançada e na otimização de
funções, alcançando assim uma implementação ótima.
O AccelWare é um vasto conjunto de bibliotecas de funções do Matlab sintetizáveis para
FPGA, ou seja, um conjunto de núcleos de propriedade intelectual de funções disponíveis no
Matlab, o qual é oferecido juntamente com o AccelChip. Uma grande vantagem do AccelWare,
até antes da aquisição da AccelChip pela Xilinx, era que os núcleos oferecidos pelo AccelWare
eram implementáveis em FPGAs de qualquer fabricante. Após a aquisição, por razões comerciais
óbvias, estes núcleos passaram a ser implementáveis apenas em FPGAs Xilinx.
O Accelware oferece um caminho direto para implementações em hardware a partir de
complexos toolboxes do Matlab. Tanto é possível mapear as funções do AccelWare para modelos

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 61
RTL, sintetizáveis para a inclusão em um projeto em RTL maior, quanto o código AccelWare
também pode ser chamado a partir do arquivo Matlab para ser sintetizado pelo AccelChip. As
funções do Accelware são criadas usando código Matlab voltadas para implementação. Por
exemplo, a função FFT original do Matlab calcula a resposta em freqüência de um sinal sem o
senso de throughput de relógio. Entretanto, o throughput realizado em hardware é determinado
pelas configurações de BRAMs, pontos de amostra etc., e pode variar em centenas de ciclos de
relógio dependendo da escolha destes parâmetros. As funções do AccelWare possibilitam a
configuração de uma série de parâmetros de implementação, como no caso da FFT, mostrado na
Figura 15.
Figura 20 – Seleção de parâmetros da FFT do AccelWare.

Capítulo 2 – Tecnologias para Implementação de Sistemas em FPGAs 62
Adicionalmente, os NPIs do AccelChip utilizam automaticamente métodos heurísticos
para selecionar a arquitetura ótima de hardware para uma função auto inferida. Por exemplo, uma
função seno auto inferida será implementada utilizando CORDIC (algoritmo de rotação de
coordenada usado para calcular funções trigonométricas), tabelas bipartidas ou uma arquitetura
com tabelas de lookup interpoladas linearmente, incluindo diferentes combinações de
compartilhamento de recursos pipelining, baseado nas requisições feitas pelo usuário como
tamanho de variáveis, ocupação e área de silício. O AccelChip considera todos estes fatores antes
de selecionar qual será a arquitetura ótima para a função ser auto inferida.

63
63
Capítulo 3 O Sistema de TV Digital sobre IP
O desenvolvimento de um sistema de televisão digital envolve diversas tecnologias de
diferentes áreas. Por isso, é essencial que uma visão sistêmica global dos assuntos relacionados a
este trabalho seja apresentada. A proposta inicial do modelo a ser implementado é apresentada na
forma de diagrama de blocos, de acordo com a concepção do autor, na Figura 21. Desta maneira,
busca-se, neste capítulo, introduzir, de uma forma simples e direta, as principais tecnologias
envolvidas neste trabalho, enquanto os tópicos considerados mais pertinentes ao mesmo serão
abordados com mais detalhes nas seções posteriores.
Vídeo “Bruto”
Codificadorde Vídeo
Empacotador UDP / IP
Conversor Camada
MAC
CodificadorReed Solomon
Mapeador Codificador LDPC
Conversor D/A
Amplificador de Potência
Moduladore
Alamouti
LNAe
AGC
ConversorA/D
Demapeador e LLR
DesempacotadorUDP / IP
Decodificadorde Vídeo
Reprodutor de Vídeo
Demoduladore
Alamouti
DecodificadorLDPC
Aleatorizador
ConversorRebaixador
Conversor Camada
MACDesaleatorizador
DecodificadorReed
Solomon
TRANSMISSOR
RECEPTOR
ConversorElevador
Figura 21 – Diagrama de blocos do sistema de televisão digital proposto.

Capítulo 3 – O Sistema de TV Digital sobre IP 64
3.1 Vídeo Bruto
Para representar uma imagem bidimensional preto-e-branco com uma tensão
unidimensional, na produção/reprodução do vídeo, ocorre uma rápida varredura de feixe de
elétrons no sentido horizontal e lenta no sentido vertical, captando-se a intensidade de luz. O
resultado dessa varredura é denominado quadro. O vídeo colorido adota o mesmo princípio de
funcionamento, diferenciando-se no fato de que, ao invés da utilização de um único feixe, três
deles são utilizados. Os padrões de cor mais utilizados na captura e na reprodução, de acordo com
[12], são o RGB (vermelho, verde e azul), o CMY (ciano, magenta e amarelo) e o YIQ
(luminância, em fase e quadratura).
A varredura do vídeo pode ser entrelaçada ou progressiva. Na varredura entrelaçada, o
quadro é formado por dois campos tomados em instantes distintos. O primeiro campo é formado
pelas linhas pares do quadro, e o segundo, pelas linhas ímpares. Além disso, o tipo do quadro
também pode variar. Por exemplo, no padrão de TV analógica em cores NTSC, o quadro
apresenta 525 linhas de varredura, uma relação horizontal/vertical (razão de aspecto) 4:3 e uma
taxa de reprodução de 30 quadros por segundo. Por sua vez o padrão PAL (B, G, H, I e N) possui
quadros com 625 linhas e taxa de 25 quadros por segundo.
Posteriormente a essas tecnologias, surgiu o conceito de televisão de alta definição
(HDTV) que proporcionava um significativo incremento na qualidade devido ao aumento do
número de linhas de varredura. Finalmente, surgiu a digitalização do vídeo e o uso de tecnologias
digitais para suas respectivas gerações, transmissões e reproduções. O primeiro sistema de alta
definição foi analógico, desenvolvido pela NHK Science and Technical Research Laboratories
(STRL) em 1980, apresentava uma resolução de 1125 linhas e foi denominado MUSE.
Entretanto, o sistema não teve penetração de mercado, devido às limitações técnicas da época e
pelo advento dos padrões digitais.
O sistema digital mais rudimentar é dado através da seqüência de quadros, os quais são
formados por elementos de imagem chamados pixels. Assim, uma imagem é formada por vários
pixels. Um pixel deve conter no mínimo um único bit no caso de uma imagem monocromática

Capítulo 3 – O Sistema de TV Digital sobre IP 65
elementar. Uma imagem pode também ser representada com pixels de 8 bits, onde cada pixel
representa um dos 256 níveis possíveis de uma escala de cinza. Dessa forma, é possível
representar-se uma imagem preto-e-branco de alta resolução. Em geral, as imagens coloridas são
compostas por pixels de 24 bits, onde 8 bits representam a componente de luminância (Y) e cada
8 bits restantes representam uma componente de crominância (Cb, Cr).
3.2 Codificador/Decodificador de Vídeo
Imaginando-se um sistema de televisão digital de alta definição com 25 quadros por
segundos, cada quadro na resolução de 1920x1080 pixels e cada pixel com 24 bits, seria
necessária uma banda de 1,24 Gbps para permitir a transmissão de tal sistema. De uma maneira
pragmática, percebe-se que a transmissão de vídeo sem codificação é algo inviável. De fato, a
codificação de vídeo é, na verdade, um algoritmo de compressão, e a decodificação, um
algoritmo de descompressão.
As compressões de imagens de vídeo podem ser classificadas em dois tipos: sem perdas
(lossless compression) e com perdas (lossy compression). Compressão sem perdas é aquela na
qual o decodificador reconstitui completamente o sinal, de forma que as amostras de entrada e
saída do sistema de codificação são idênticas. Compressão com perdas é aquela na qual não se
necessita de dados idênticos na entrada e saída do sistema e, neste caso, define-se a quantidade de
dados que pode ser perdida. A maioria dos processamentos de compressão de áudio e vídeo é
com perdas e, devido a essas perdas, eles são chamados de processos irreversíveis.
Em sinais de áudio e vídeo, existem redundâncias consideráveis em alguns fatores que
diminuem a quantidade de informação que necessita ser efetivamente transmitida [13]. A
redundância espacial (correlação entre os pixels de um mesmo quadro) e a redundância temporal
(correlação entre quadros vizinhos) estão entre os principais fatores que possibilitam a
compressão de vídeo [13].

Capítulo 3 – O Sistema de TV Digital sobre IP 66
Para o sistema proposto, o perfeito funcionamento dar-se-á com qualquer tipo de
codificação de vídeo, desde que esta opere dentro da taxa de transmissão do sistema, como será
visto posteriormente. Os principais codificadores de vídeo atualmente são o MPEG-2 e o H.264
(MPEG-4 V10).
O primeiro padrão MPEG foi publicado no ano de 1993, apresentando um modelo que
compreendia aspectos de sistema, codificação de áudio e codificação de vídeo. Desta forma, o
MPEG-1 (norma ISO/IEC 11172) foi desenvolvido para suportar operações com taxas de até 1,5
Mbps. Posteriormente, em 1994, foi publicado o padrão MPEG-2 (ISSO/IEC 13818 ou ITU
H.262), concebido inicialmente para suportar aplicações de 5 a 10Mbps e depois expandido para
aplicações de alta definição com taxas de transmissão de até 30Mbps. Em seguida, no ano de
1999, foi publicado o padrão MPEG-4 (ISSO/IEC 14496) visando abranger as áreas de televisão
digital, aplicações gráficas iterativas e multimídia iterativa para internet. Em 2003, foi publicado
o MPEG-4 parte 10 (ISO/IEC 14496-10 ou ITU H.264) ou, como é conhecido, o H.264 (devido à
nominação do ITU para codificação de vídeo) ou ainda codificação avançada de vídeo (AVC). O
MPEG-4 surgiu objetivando um padrão capaz de prover boa qualidade de vídeo para taxas de
transmissão mais baixas do que os padrões até então existentes.
O mais interessante dos padrões MPEG é que eles definem apenas a sintaxe, a semântica
das seqüências de bits e a metodologia de decodificação. Eles não determinam como é a
codificação, possibilitando assim liberdade para propostas de codificação que podem ser voltadas
a aplicações específicas. A seguir, serão apresentadas algumas das principais técnicas utilizadas
nos padrões MPEG.
Uma das técnicas de compressão utilizada no padrão MPEG é a subamostragem de cor.
Essa técnica é baseada na característica humana de percepção de cores, de tal forma que a
percepção da diferenciação de intensidade luminosa pelo sistema olho-cérebro é maior do que
para diferenciação de cores. Por esta razão, freqüentemente os quadros de crominância
apresentam metade ou um quarto da quantidade de pixels dos quadros de luminância e raramente
uma quantidade equivalente.

Capítulo 3 – O Sistema de TV Digital sobre IP 67
Os padrões MPEG se utilizam também da transformada discreta do co-seno (DCT) para
extrair redundância espacial por meio da concentração da energia do sinal em um número
relativamente pequeno de coeficientes. A transformada co-seno discreta é aplicada a cada um dos
blocos subconjuntos da matriz de luminância ou de uma das matrizes de crominância e o tamanho
deste bloco é de 8x8 pixels no MPEG-1 e no MPEG-2. A transformada DCT é um processo
reversível o qual realiza o mapeamento da representação bidimensional da imagem para a sua
representação no domínio da freqüência, onde o primeiro elemento, denotado (0,0), indica o valor
médio ou nível DC da luminância ou de uma das crominâncias, dependendo da matriz que se está
utilizando. É significativo enfatizar que a DCT não reduz de forma direta o número de
coeficientes. O resultado da DCT sobre um bloco de n elementos será um bloco de n coeficientes.
A redução de informação, através da remoção de redundância, provém da característica da DCT
de, para blocos de imagens naturais, concentrar a energia nos coeficientes de baixa freqüência
próximos ao elemento do valor médio. Assim, as demais componentes têm valor próximo a zero
e podem ser descartadas. Após a aplicação da transformada DCT e da respectiva quantização dos
coeficientes, utilizam-se métodos de varredura em Zig-Zag, codificação run-length e codificação
de comprimento variável (VLC) para então se eliminar a redundância espacial. Por não se
referirem ao escopo deste trabalho, estes tópicos não serão abordados. Entretanto, para os
mesmos, sugere-se como referência [14] e [15].
Outra técnica utilizada pelos padrões MPEG para compressão é a predição interquadros
com compensação de movimento, que visa remover a redundância temporal. Segundo [16] a
forma mais eficiente de se remover redundância temporal é através de predição interquadro com
compensação de movimento. Essa técnica é baseada na característica de que inúmeras vezes em
um vídeo, um quadro muda relativamente pouco em comparação ao seu predecessor ou ao seu
sucessor. Esse gênero de predição visa compensar movimentos de translação que tenham
ocorrido entre um dado bloco codificado e o seu respectivo bloco no quadro de referência. A
forma mais difundida de como encontrar o movimento ocorrido entre o bloco codificado e o
quadro de referência é denominada block-matching. Os padrões MPEG permitem que a predição
por compensação de movimento seja obtida por vários métodos. Por exemplo, a predição pode
ser feita por predição para frente (a partir de uma imagem futura), para trás (a partir de uma
imagem passada) ou interpolada através da média de ambas. Não obstante, é possível fazer uma

Capítulo 3 – O Sistema de TV Digital sobre IP 68
predição nula (Intra). Desta forma, os padrões MPEG adotam os seguintes tipos de quadros para
tornar possíveis essas predições:
Quadro tipo I (Intracodificado) - quando o quadro é codificado sem referência a outros quadros,
com predição nula. Proporciona pontos de referência, pontos de acesso onde pode começar a
decodificação e por isso eles são fundamentais ao sistema. Apresenta compressões pequenas,
similares à compressão JPEG.
Quadro tipo P (Preditivo) - quando o quadro é codificado em relação ao quadro anterior a partir
de outro quadro tipo P ou tipo I. Em geral, apresenta um terço do tamanho de um quadro tipo I.
Quadro tipo B (Bidirecional) - quando o quadro é codificado a partir da interpolação entre um
quadro anterior do tipo I ou P e um quadro posterior do tipo I ou P. Os quadros tipo B possuem
alto grau de compressão, da ordem de duas a cinco vezes maior que de um quadro P.
Quadro tipo D (Codificação DC) - quando o quadro é codificado a partir da média de blocos para
possibilitar recurso de avanço rápido. Não são todas as versões do padrão MPEG que apresentam
este tipo de quadro.
3.3 Empacotador UDP/IP
O bloco denominado Empacotador UDP/IP do esquema de televisão digital representado
pela Figura 21 corresponde à camada de transporte e à parte da camada Inter-Redes do modelo de
referência TCP/IP de uma rede de transmissão de dados. Os dados ingressantes no bloco são
dados de vídeo codificado que são empacotados para o protocolo de rede IP (Internet Protocol) e
para o protocolo de transporte UDP (User Datagram Protocol). Para fazer esse empacotamento
de vídeo codificado para pacotes UDP/IP é utilizado o software VLC, o qual é um executor de
mídia e servidor de streaming gratuito [17].

Capítulo 3 – O Sistema de TV Digital sobre IP 69
O protocolo IP é o protocolo da camada de rede que mantém a internet interligada e foi
projetado com o objetivo de fornecer a melhor forma possível de transportar datagramas da
origem para o destino, independentemente dessas máquinas estarem na mesma rede ou haver
outras redes entre elas [18]. Por datagramas entendem-se as unidades de mensagem com as quais
protocolos (como o IP) lidam e são transportados pela rede de computadores, ou ainda as
entidades de dados completas e independentes que contêm informações suficientes para serem
roteadas da origem ao destino sem precisar confiar em permutas anteriores entre essa fonte, o
destino e a rede de transporte [19]. Para a transmissão de dados, a camada de transporte recebe os
fluxos de dados e os divide em datagramas e cada um destes é transmitido, talvez fragmentado.
Quando todos esses fragmentos chegam ao destino, eles são remontados pela camada de rede e
entregues à camada de transporte. Um datagrama IP é constituído de um cabeçalho e de uma
parte de texto. O cabeçalho IP apresenta uma parte fixa de vinte bytes e uma parte opcional de
tamanho variável. Informações como versão do protocolo, tempo de vida do datagrama, endereço
de origem e de destino, tipo de serviço, tamanho total do datagrama, identificação de ordem do
datagrama e informações de fragmentação são expressas no cabeçalho do protocolo. Os
endereços IPs são constituídos de trinta e dois bits que informam a rede, a sub-rede e a máquina
específica proprietária daquele dado endereço. Basicamente, um endereço IP é dividido entre os
bits que informam a rede a qual pertence aquele endereço e o host que o abriga. Dependendo de
como é feita a alocação destes bits entre o endereço de rede e o de host, o endereço IP recebe uma
dada classe A, B, C ou D (esta última usada para transmissões de broadcasting). As
considerações citadas sobre o protocolo IP referem-se à sua versão mais difundida, o IPV4,
embora haja uma tendência, ainda não muito clara, da futura utilização da versão mais recente do
protocolo, o IPV6. Para informações complementares sobre o protocolo IP, como informações de
cabeçalho, versões e opções, sugere-se consultar [18].
Em um sistema de transmissão de dados, o usuário não tem controle sobre a camada de
rede, mas sim sobre a camada de transporte, pois é a camada de transporte que define como os
datagramas irão trafegar pela rede. O protocolo UDP é um protocolo de transporte sem conexões
que faz esta definição. Um transporte orientado a conexões consiste em ocultar as imperfeições
do serviço da rede, de modo que os processos do usuário possam simplesmente supor a existência
de um fluxo de bits livre de erros. Por outro lado, a camada de transporte também pode oferecer

Capítulo 3 – O Sistema de TV Digital sobre IP 70
um serviço não-confiável de datagramas, este determinado serviço sem conexão [18]. Assim, o
UDP oferece uma forma simples para as aplicações enviarem datagramas IP encapsulados sem
que seja necessário estabelecer uma conexão. Ele transmite segmentos que formam um cabeçalho
de oito bytes seguido pela carga útil. O cabeçalho do protocolo UDP apresenta apenas quatro
campos: porta de origem, porta de destino, tamanho de datagrama UDP e um campo de
verificação. É importante destacar que, em contrapartida à simplicidade do UDP, ele não realiza
importantes tarefas como controle de fluxo, controle de erros, retransmissão. O que o UDP faz é
prover uma interface simples ao protocolo IP com o recurso adicional de multiplexação de vários
processos que utilizam as portas. Para maiores conhecimentos sobre o protocolo UDP, sugere-se
consultar [20] e [18].
3.4 Conversor Camada MAC
Após o encapsulamento do vídeo codificado para pacotes UDP/IP, percebe-se que a
informação ainda está dentro de um microcomputador. A forma mais convencional de saída dos
dados de um microcomputador é através de sua placa de rede, utilizando a interface Ethernet
(padrão IEEE 802.3) com conector do tipo RJ-45. Inclusive, por razões convenientes ao sistema
de televisão proposto, é extremamente vantajoso que a saída de dados seja desta forma, devido à
compatibilidade com as interfaces do hardware utilizado.
6 Bytes 6 Bytes 2 Bytes 1344 Bytes
EndereçoMAC Destino
EndereçoMAC Origem
InformaçãoTi-po
Figura 22 – Quadro MAC.
Embora os pacotes UDP/IP já contenham os endereços IP de origem e destino, os pacotes
ainda não podem ser enviados, pois o hardware (neste caso a interface Ethernet) não compreende
endereços IP. O tipo de endereço utilizado pelas interfaces Ethernet é o endereço MAC (Controle
de Acesso de Mídia). Os endereços MAC são identificadores únicos de quarenta e oito bits (6

Capítulo 3 – O Sistema de TV Digital sobre IP 71
bytes), padronizados e distribuídos pelo IEEE. Assim, deve existir algum mecanismo responsável
por fazer com que o endereço IP (compreendido pelos protocolos de rede) seja mapeado para um
endereço MAC (compreendido pela interface Ethernet) e vice-versa. Esta é justamente a função
do protocolo de resolução de endereço (ARP). Desta forma, a comunicação entre
microcomputador e hardware de implementação do sistema será feita através do protocolo MAC.
A Figura 22 apresenta o formato do quadro MAC.
3.5 Aleatorizador/Desaleatorizador
Antes da seqüência de bits ser entregue à codificação de canal propriamente dita, ela
necessita ser aleatorizada. Para um sistema de transmissão OFDM, o qual será abordado
posteriormente, deve-se utilizar um aleatorizador a fim de evitar a repetição de longas seqüências
de bits. Sem a aleatorização dos dados, pode-se gerar, após a transformada inversa de Fourier
implementada no modulador, uma forte concentração de energia em uma única amostra no
tempo, o que seria extremamente danoso em termos de Relação entre Potência Média e de Pico
(PAPR -Peak-to-Average Power Ratio). Além disso, o aleatorizador possibilita a melhor
utilização do espectro e facilita a sincronização do receptor.
3.6 Codificador/Decodificador Reed-Solomon
Reed-Solomon é um código corretor de erros baseado na superamostragem de um
polinômio construído a partir dos dados. Representando o polinômio com bem mais pontos do
que o necessário, é possível corrigir erros de um bloco de dados pela recuperação dos
coeficientes do polinômio que desenharam a curva polinomial original. Para dar uma idéia da
capacidade de correção, no codificador proposto pelo MI-SBTVD, é possível corrigir até 8 bytes
de um bloco de 188 bytes, codificados em uma palavra de 204 bytes (188 bytes originais mais 16
bits de paridade). O codificador/decodificador Reed-Solomon constituem a primeira parte da
codificação de canal do sistema proposto e, portanto, serão apresentados no capítulo seguinte, o
qual aborda exclusivamente codificação de canal.

Capítulo 3 – O Sistema de TV Digital sobre IP 72
3.7 Codificador/Decodificador LDPC
A codificação LDPC (Low Density Parity Check) é um código corretor de erros baseado
em matrizes de baixa densidade. É uma técnica de inserção de redundância utilizada na
codificação de canal do sistema apresentado. Assim como o Reed-Solomon, o codificador e
decodificador serão apresentados mais detalhadamente no capítulo seguinte.
3.8 Mapeador/Demapeador e LLR
A saída do codificador de canal será uma seqüência de bits, que é uma forma de
informação discreta no domínio do tempo. Então, antes desta informação ser entregue ao
modulador propriamente dito para ser transformada em um sinal contínuo no domínio do tempo,
ela necessita ser mapeada para uma representação vetorial, a qual determinará o tipo de
modulação empregado. Esta é a função do mapeador e o processo inverso é a função do
demapeador. Os tipos mais comumente utilizados de modulação digital são PSK (baseada em
fase) e QAM (Modulação em amplitude de duas portadoras defasadas de 90°). Assim, os bits
oriundos da saída da codificação de canal serão agrupados em um número nmap de bits sendo
mapeados em Mmap símbolos de um alfabeto (ou constelação) Amap. Independentemente se a
modulação utilizada for baseada em fase ou amplitude, o alfabeto Amap deve possuir média zero
visando evitar um nível contínuo (nível DC) residual o que implica perda de potência útil à
transmissão de informação [16]. Novamente, observa-se aqui a importância do aleatorizador
explicado na Seção 3.5.
Quando a modulação PSK é utilizada, todo o conjunto de símbolos Amap pode ser
representado sobre um círculo, uma vez que todos os símbolos possuem a mesma amplitude (o
mesmo nível DC), diferenciando-se apenas em fase. Por exemplo, na modulação quaternária PSK
(QPSK) o conjunto Amap possui quatro elementos e os bits da saída do codificador de canal são
agrupados de dois em dois (nmap =2). Esse exemplo pode ser visualizado através da Figura 23.

Capítulo 3 – O Sistema de TV Digital sobre IP 73
11
01
Q
I
10
00
Figura 23 – Mapeamento feito para a modulação QPSK.
Quando a modulação QAM é empregada, os símbolos possuem dois valores de amplitude,
um para cada uma das portadoras que estão em quadratura, ou seja, cada um dos Mmap símbolos
do alfabeto é um número complexo e, devido à simetria dos quadrantes da constelação, existirão
4mapM
diferentes níveis de amplitude. A Figura 24 apresenta um exemplo de mapeamento
16QAM.
Na recepção, dificilmente um símbolo coincide exatamente com o ponto para o qual ele
foi mapeado no transmissor, mas sim para uma região em torno dele. Esse desvio, ou erro dado
pela dispersão do canal, pode fazer com que um símbolo possa ser interpretado erroneamente na
recepção. A interferência dada entre símbolos, denominada interferência intersimbólica, é a
grandeza que mede quanto os símbolos de um sistema de comunicação digital se superpõem a
outros símbolos, como conseqüência da dispersão do canal. Quanto maior for o número de
símbolos de uma constelação, maior será também a probabilidade de erros para uma mesma
relação sinal ruído.
O teste da máxima LLR (relação de verossimilhança) é uma técnica largamente
empregada para a detecção de sinais na presença de ruído [22]. Em um sistema de modulação
digital, a detecção ótima dos símbolos é aquela que conduz à menor probabilidade de erro de

Capítulo 3 – O Sistema de TV Digital sobre IP 74
símbolo. Contudo, devido a características intrínsecas dos sistemas de comunicações digitais,
principalmente características provenientes do emprego de códigos corretores de erro binário em
conjunto com o esquema de modulação, é necessário fornecer ao decodificador uma métrica de
confiabilidade de cada bit associado ao símbolo. Essa métrica, por sua vez, depende do tipo de
mapeamento utilizado para associar os padrões de bit aos símbolos da constelação, sendo comum
o emprego do código Gray, pois o mesmo garante a ocorrência de apenas um erro de bit quando o
erro ocorre entre símbolos que possuem entre si a distância mínima [23], conforme também pode
ser observado na Figura 23.
Q
I1111
1110
1101
1100 1000
1001
1011
101001100010
01110011
01010001
01000000
Figura 24 – Mapeamento feito para a modulação 16-QAM.
Assim, a função do demapeador e da LLR é dar confiabilidade à amostra recebida
selecionando o símbolo do alfabeto Amap que corresponde à amostra. Para um estudo mais
peculiar de LLR, sugere-se consultar [22].
3.9 Modulador/Demodulador e Alamouti
O estágio da modulação no transmissor é a última parte do sistema que opera com dados
digitais. Nesta etapa, são aplicadas as últimas técnicas de transmissão antes que informações
digitais sejam entregues ao conversor digital analógico (DA). De forma equivalente, o

Capítulo 3 – O Sistema de TV Digital sobre IP 75
demodulador é a entrada dos dados digitais no sistema de recepção. O modulador e demodulador
são os blocos onde são aplicadas as técnicas de transmissão baseada em múltiplas portadoras,
através da multiplexação por divisão ortogonal de freqüência (OFDM).
Modulação é o processo pelo qual um sinal denominado portadora tem alguma
característica variada de acordo com o valor instantâneo do sinal modulante que é o sinal o qual
contém a informação que se deseja transmitir [16]. Em sistemas de radiodifusão, este conceito de
modulação é essencialmente utilizado, buscando-se a forma de modulação pela qual os dados
serão transmitidos: se por variação em fase, variação em amplitude, variação em freqüência, com
portadora única, múltiplas portadoras etc.
Na etapa do modulador é acrescida a etapa de conversor elevador digital. Até esta etapa, o
sinal encontra-se em banda básica e é, então, convertido para uma freqüência intermediária. Após
a etapa de modulação, o sinal já apresenta portadora, não contendo mais componentes complexas,
mas sim um sinal real. Uma vantagem de se utilizar essa técnica no domínio digital está na
utilização de apenas um conversor digital analógico (ao invés de dois como seria para o sinal
complexo) e a entrada do conversor elevador seguinte (responsável por passar o sinal de
freqüência intermediária para banda passante) é simplificada. Conseqüentemente, no bloco do
demodulador, encontra-se a etapa de conversor rebaixador digital onde o sinal é passado, então,
da freqüência intermediária para a banda básica novamente.
O OFDM é um esquema de transmissão cujo fundamento é a multiplexação por divisão
em freqüência, onde diferentes freqüências transportam diferentes sinais. O OFDM utiliza um
grande número de portadoras de banda estreita espaçadas em freqüência de forma regular,
formando um bloco de espectro. Então, o espaçamento de freqüência e o tempo de sincronismo
das portadoras são escolhidos tal que as portadoras sejam ortogonais. Um sinal de portadora
OFDM é, na verdade, o somatório de um número de subportadoras, com dados em banda-base
em cada sub-portadora sendo modulado independentemente [24].
Muitos benefícios são alcançados através do uso das técnicas do OFDM, principalmente
relacionados à alta eficiência do espectro de freqüência e à resistência causada pela interferência

Capítulo 3 – O Sistema de TV Digital sobre IP 76
de multipercurso. Também, a robustez a multipercurso pode ser convenientemente variada no
OFDM, simplesmente alocando mais ou menos portadoras para um dado propósito. A taxa de
transmissão é definida no tempo pelo período de amostragem da IFFT, considerando-se também
a inserção do prefixo cíclico. Isto significa que a taxa de transmissão é a mesma,
independentemente do número de subportadoras utilizadas. Conseqüentemente, um benefício
extremamente interessante, obtido pelo uso de múltiplas subportadoras, está no fato de, ao se
aumentar o número de subportadoras, cada uma passa a operar a uma taxa de transmissão
relativamente mais baixa, aumentando-se a duração do símbolo OFDM, de tal forma a manter a
taxa total de transmissão inalterada. Por exemplo, para uma dada transmissão muito elevada, de
milhões de bps, efetuada sobre um único canal, a duração de cada bit será muito curta e isso
implicará significativas limitações de sincronismo e dificuldades no cancelamento da
interferência de multipercurso. No entanto, se essa mesma taxa elevada de milhões de bps for
distribuída por várias subportadoras, a duração de cada bit será maior, diminuindo assim a
sensibilidade ao multipercurso e a dificuldade de lidar-se com sincronismo [25].
A modulação OFDM é geralmente implementada através da transformada rápida de
Fourier Inversa (IFFT). Após o mapeador (vide Figura 21), o fluxo principal é convertido de
serial para paralelo. Podem ser gerados, no sistema MI-SBTVD, 2048, 4096 ou 8192 fluxos de
mais baixa taxa, que correspondem ao número de subportadoras disponíveis. Na taxa resultante, a
cada instante de símbolo OFDM, aplica-se a IFFT aos fluxos em paralelo. Este processo gera um
novo fluxo, agora no domínio do tempo, com a mesma taxa do fluxo principal. O sinal resultante
no tempo contém todas as subportadoras multiplexadas em freqüência. A ortogonalidade das
subportadoras é gerada pela própria IFFT. Finalmente, após a IFFT, é inserido um prefixo em
cada símbolo OFDM (bloco de amostras da IFFT) correspondente a uma fração do símbolo
OFDM. Por exemplo, para 2048 portadoras, haverá 2048 amostras da IFFT no tempo. Se for
utilizado um prefixo de 1/16, então serão inseridas 128 amostras no início do símbolo OFDM.
Como as amostras inseridas correspondem às amostras finais de um símbolo OFDM, então as
mesmas são denominadas de extensão cíclica ou prefixo cíclico. Inversamente, no receptor, o
prefixo cíclico deverá ser removido, e os dados deverão ser convertidos para o domínio da
freqüência através da FFT. Desta forma, os fluxos das subportadoras são recuperados e passados
por um conversor de paralelo para serial para recuperar o fluxo original.

Capítulo 3 – O Sistema de TV Digital sobre IP 77
É importante destacar que o OFDM apresenta algumas desvantagens, como, por exemplo,
ser susceptível a desvio Doppler e problemas de sincronização de freqüência. O desvio Doppler
ocorre principalmente nas aplicações veiculares, onde o receptor pode se deslocar em alta
velocidade. Se, por um lado, a ortogonalidade das subportadoras torna a utilização do espectro
mais eficiente, eliminando a necessidade de subportadoras de guarda, por outro lado, uma
imperfeita sincronização de freqüência ou um desvio Doppler pode causar perda da
ortogonalidade das subportadoras, gerando interferência cruzada entre as subportadoras (cross-
talk), o que diminui significativamente o desempenho do sistema. Além disso, como o sinal
OFDM é um somatório de um grande número de subportadoras, ele tende a apresentar uma alta
relação entre potência de pico e potência média, o que dificulta o uso eficiente dos amplificadores
de potência [24].
O sistema de TV Digital proposto, também faz uso de um esquema de diversidade
espacial com duas antenas transmissoras e uma antena receptora. A diversidade de transmissão
foi implementada utilizando a técnica de Alamouti [26], adaptada para o OFDM, utilizando
codificação espaço-temporal em pares de símbolos OFDM.
Por fim, o desempenho do sistema poderá ser aperfeiçoado com a utilização de técnicas
robustas de sincronismo, técnicas de estimação de canal e outras técnicas de diversidade de
transmissão/recepção. Contudo, as abordagens destes tópicos evadiriam a finalidade deste
trabalho. Desta maneira, para estudos mais completo sobre técnicas de OFDM, sugere-se [24] e
[25].
3.10 Conversores A/D e D/A
Após todas as técnicas que realmente caracterizam o sistema serem aplicadas através de
dispositivos digitais, o sinal de saída do modulador é entregue ao conversor digital analógico
(DA), responsável por transformar uma seqüência de valores discretos em um sinal analógico
contínuo no tempo, representado, por exemplo, através de variações de tensão ao longo do tempo.
De forma análoga, no receptor do sistema, os sinais recebidos de forma analógica, através de

Capítulo 3 – O Sistema de TV Digital sobre IP 78
variações no nível de tensão, serão digitalizados pelo conversor analógico digital (AD) para
serem entregues ao demodulador na forma de uma seqüência discreta de valores quantizados.
A resolução de um conversor A/D ou D/A (resbits), expressa em bits, indica o número de
valores discretos que podem ser produzidos na gama de valores de tensão. O número de valores
que podem ser reproduzidos (Nquant) é a base 2 elevada à potência da resolução do conversor, ou
seja,
2 .bitsresquantN=
Como pode ser deduzido, quanto maior a resolução dos conversores A/D e D/A melhor
será a qualidade do sinal digitalizado e mais bits serão necessários para representar os sinais de
forma discreta.
3.11 Conversor Elevador e Rebaixador
O conversor elevador e o rebaixador são o que tornam possível que uma dada informação
seja transmitida por radiodifusão através do sistema indicado na Figura 21, pois há a necessidade
dos sinais serem transmitidos em freqüências elevadas e devidamente canalizados. Assim, no
transmissor, o conversor elevador eleva a freqüência do sinal para ser transmitido pela atmosfera
em uma freqüência exclusiva, ou seja, da freqüência intermediária para uma freqüência mais
elevada correspondente ao seu canal. Posteriormente, no receptor, o conversor rebaixador reduz a
freqüência do sinal de banda passante para freqüência intermediária novamente.
Segundo [27], a translação em freqüência que resulta do processo de modulação, a qual
eleva o espectro do sinal para freqüências mais elevadas, permite que a informação contida no
sinal seja transmitida para o meio físico do canal através de irradiadores de dimensão física
praticável. Isto ocorre porque a freqüência para qual o sinal é transladado possui um valor muito
mais elevado que sua freqüência intermediária e, assim, a nova freqüência necessita de um
irradiador muito menor.
(3.1)

Capítulo 3 – O Sistema de TV Digital sobre IP 79
3.12 Amplificador de Potência
No transmissor, o amplificador de potência tem como função elevar o nível de potência
do sinal de portadora de tal forma que o sinal recebido no receptor tenha um nível razoavelmente
alto para superar a degradação proveniente das interferências e ruídos intrínsecos ao canal de
transmissão.
3.13 Amplificador de Baixo Ruído e Controle Automático de Ganho
O bloco denominado ‘LNA e AGC’, ilustrado no primeiro bloco do receptor da Figura 21,
é constituído por duas partes. A primeira delas é o Amplificador de Baixo Ruído ou LNA (Low
Noise Amplifier). O LNA é um amplificador de alto ganho que amplifica o sinal de entrada para
um nível apropriado para alimentar o receptor. O LNA é desenvolvido de forma a minimizar o
ruído que é inevitavelmente adicionado ao sinal no processo de amplificação.
Já a segunda parte do bloco é o Controle Automático de Ganho ou AGC (Automatic Gain
Control). O AGC tem como objetivo controlar o ganho de um sistema, de tal forma a manter seu
desempenho apropriado, para diferentes níveis do sinal de entrada. Como a intensidade do sinal
recebido pode variar bastante de acordo com a localização do receptor e com outras
características do canal, é necessário que o AGC ajuste o ganho do receptor a fim de se obter um
sinal constante na saída, baseando-se na medição da intensidade do sinal. Quando o sinal
apresenta uma intensidade elevada o AGC tende a reduzir o ganho do sistema. Por outro lado,
quando o sinal for de baixa intensidade o AGC atuará de forma a aumentar o ganho do sistema.

Capítulo 3 – O Sistema de TV Digital sobre IP 80

81
81
Capítulo 4 Codificação LDPC 4.1 Introdução à Codificação de Canal
Nos últimos vinte anos, tem havido um crescimento significativo na busca por soluções
eficientes e confiáveis na transmissão e no armazenamento de dados digitais. Obviamente este
processo é impulsionado pelas atuais redes de dados de alta velocidade e pelas elevadas
capacidades de transmissão, armazenamento e principalmente de processamento. Contudo, o
grande obstáculo em um sistema de transmissão está relacionado ao controle de erros, o qual, se
não obtiver um resultado satisfatório, pode inviabilizar a aplicação de um dado sistema de
transmissão digital [28]. Especialmente, essa dificuldade está associada a ruídos e interferências
existentes em qualquer canal real de transmissão.
Transdutor de entrada
Canal deTransmissão
Codificadorde Fonte
ModuladorDigital
AmplificadorDe potência
Amplificadorde Sinal
DemoduladorDigital
Decodificadorde Fonte
Transdutor de saída
Transmissor Digital
Receptor Digital
Seqüência deInformação
Codificadorde Canal
Decodificadorde Canal
Seqüência Codificada
Transdutor de entradaTransdutor de entrada
Canal deTransmissão
Codificadorde Fonte
Codificadorde Fonte
ModuladorDigital
ModuladorDigital
AmplificadorDe potênciaAmplificadorDe potência
Amplificadorde Sinal
Amplificadorde Sinal
DemoduladorDigital
DemoduladorDigital
Decodificadorde Fonte
Decodificadorde Fonte
Transdutor de saída
Transdutor de saída
Transmissor Digital
Receptor Digital
Seqüência deInformação
Codificadorde Canal
Codificadorde Canal
Decodificadorde Canal
Decodificadorde Canal
Seqüência Codificada
Figura 25 – Diagrama de blocos de um sistema de comunicação digital.

Capítulo 4 – Codificação LDPC 82
Desta forma, no contexto de um sistema de comunicação digital conforme mostrado na
Figura 25, o codificador de canal, através de técnicas baseadas principalmente na inserção de
redundância, desempenha a função de manter a taxa de erro de um sistema de comunicação
dentro de um limite dado como aceitável. De fato, em um sistema de codificação de canal três
condições devem ser aspiradas, conforme [28], são elas:
• que a informação seja transmitida em um ambiente ruidoso de forma tão rápida quanto
possível;
• que a informação possa ser reproduzida de uma maneira confiável na saída do
decodificador de canal;
• que o custo de implementação da codificação e decodificação seja reduzido a limites
aceitáveis.
Estruturalmente, os códigos corretores de erro podem ser classificados como códigos
convolucionais ou códigos de blocos. Os códigos de bloco dividem a seqüência da informação a
ser codificada em blocos de k bits tal que a palavra-código resultante dependa apenas desta
seqüência. Os códigos convolucionais também separam a mensagem a ser codificada em blocos
de k bits, porém cada conjunto de informação codificada não depende apenas de sua mensagem,
mas também de conjuntos de mensagens anteriores. No presente trabalho, apenas códigos de
bloco serão usados.
Imagine inicialmente um conjunto X de mensagens a serem codificadas e um conjunto C
de palavras-código resultantes. Imagine também um alfabeto A. Um código de bloco é aquele
onde cada um dos símbolos do alfabeto fonte (conjunto X) tem associada a ele uma seqüência
fixa de símbolos do alfabeto-código A. Assim, um operador θ faz o mapeamento de cada símbolo
do conjunto X para um símbolo correspondente do conjunto A, de tal forma que }{xC θ= .
Para códigos binários, pode-se dizer que o tamanho do conjunto X será dado por K
MM 2= , onde k é o tamanho de cada mensagem de X, em bits. O resultado da codificação será

Capítulo 4 – Codificação LDPC 83
novamente o conjunto C que possuirá MM palavras-código binárias, cada uma delas com n bits.
Como o codificador de canal insere redundância à informação a ser codificada, n > k, assim, para
a especificação de um código de bloco binário, usa-se a notação ),( knθ .
1 1 1 1
Mensagem
Palavra-Código
Paridades
Observa-se que o bit “1”representa o número ímpar de ‘1’s contido namensagem [0 1 0]
0 0 00 0 10 1 00 1 11 0 01 0 11 1 0
0 0 0 00 0 1 10 1 0 10 1 1 01 0 0 11 0 1 01 1 0 0
MENSAGEM PALAVRA-CÓDIGO
Mensagem
1 1 1 1 1 1 1
Mensagem
Palavra-Código
Paridades
Observa-se que o bit “1”representa o número ímpar de ‘1’s contido namensagem [0 1 0]
0 0 00 0 10 1 00 1 11 0 01 0 11 1 0
0 0 0 00 0 1 10 1 0 10 1 1 01 0 0 11 0 1 01 1 0 0
MENSAGEM PALAVRA-CÓDIGO
Mensagem
1 1 1
Figura 26 – Demonstração de um código de bloco binário sistemático θ(4,3).
Um código de bloco também pode ser sistemático ou não. Um código é dito sistemático
quando é possível, de uma forma direta e sem manipulação alguma, identificar na palavra-código
os bits da mensagem e os bits de paridade, ou seja, os bits de paridade são justapostos à
mensagem a ser codificada, formando assim palavra-código. O exemplo mais elementar de
código sistemático é o conhecido teste de paridade. Essa codificação simplesmente justapõe um
bit ‘1’ à mensagem, caso o número total de uns da mensagem a ser codificada seja ímpar ou
justapõe um bit “0”, caso esse número seja par. Assim, pode-se deduzir que em um código de
teste de paridade 1+= kn . A Figura 26 mostra um exemplo de codificação de teste de paridade
onde é possível visualizar de forma direta que o código é sistemático.
Cada código ),( knθ possui uma matriz geradora G de n linhas por k colunas. Assim,
considera-se aqui ix a mensagem binária a ser codificada, onde o índice i indica a coluna da
matriz X, matriz esta que representa todas as mensagens a serem codificadas e seja C uma matriz
com todas as palavras-código geradas a partir das mensagens contidas em X. Cada coluna ic da

Capítulo 4 – Codificação LDPC 84
matriz C representa a palavra-código associada a ix . Desta forma, a matriz geradora G deve ser
multiplicada por cada vetor coluna ix , para obter-se a palavra-código ic , na forma
ou, na forma matricial,
1 111 1
2 2
1
.
i ik
i i
n nkni ki
c xG G
c x
Gc x
=
O conjunto C (que possui 2k palavras-código) é um subespaço de dimensão k.
Considerando-se cada coluna da matriz G como um vetor (pode-se referir como cada vetor
coluna da matriz G), é imprescindível que os k vetores coluna que constituem a matriz G sejam
linearmente independentes para gerar o subespaço C em k dimensões [28].
A partir de permutações em suas linhas e operações elementares em suas colunas,
qualquer matriz geradora G pode ser convertida a uma matriz geradora sistemática, a qual gerará
um código sistemático. A forma de uma matriz geradora sistemática G é tal que se pode, através
de uma análise intuitiva, observar que ela possui uma matriz identidade concatenada com a
própria matriz paridade, ou seja,
xx
( )x
k kn k
n k k
IG
P −
=
onde I é matriz identidade kxk e P a matriz das paridades (n-k)xk. Propõe-se daqui por diante
considerar-se sempre a matriz G como uma matriz sistemática.
,i ic Gx= (4.1)
(4.2)
(4.3)

Capítulo 4 – Codificação LDPC 85
Cada coluna ic da matriz C pode ser descrita como
ii
i
xc
p
=
onde,
.i ip Px=
Logo, como a operação é módulo dois,
0,i iPx p+ =
o que é o mesmo que
[ ] 0.in k
i
xP I
p−
=
Por definição, a matriz de paridade é representada por H e dada por
[ ],n kH P I −=
o que faz com que
0.iHc =
Conforme demonstrado, a matriz de paridade H pode ser usada tanto para obter-se uma
palavra-código a partir de uma mensagem a ser codificada (codificação) como pode ser utilizada
para obter-se a mensagem original a partir de uma palavra-código (decodificação). Também,
através da utilização da matriz de paridade H na decodificação, é possível detectar a ocorrência
de erro na transmissão de dados através da regra destacada na Equação 4.9. Sempre que a
multiplicação da matriz de paridade H pela palavra-código recebida for diferente de zero, existem
erros.
(4.4)
(4.5)
(4.6)
(4.7)
(4.8)
(4.9)

Capítulo 4 – Codificação LDPC 86
4.2 Reed-Solomon
O processo de codificação/decodificação de um código de bloco alicerça-se na teoria
algébrica de que um conjunto de palavras-código pode ser mapeado em um conjunto de
polinômios. Deste modo, os componentes do vetor de uma dada palavra-código iC
correspondem aos coeficientes do polinômio ( )iC x . De forma análoga, o conjunto de mensagens
a serem transmitidas pode também ser mapeado para um conjunto de polinômios. Por essa razão,
os códigos de bloco são também chamados de códigos polinomiais [16]. Como exemplo, a
Figura 27 exibe a representação polinomial de uma série de palavras-código onde cada uma
representa a i-ésima palavra-código associada a i-ésima mensagem a ser codificada.
0 0 00 0 10 1 00 1 11 0 01 0 11 1 01 1 1
PALAVRA-CÓDIGO POLINÔMIO
01x
x+1x2
x2+1x2+x
x2+x+1
0 0 00 0 10 1 00 1 11 0 01 0 11 1 01 1 1
PALAVRA-CÓDIGO POLINÔMIO
01x
x+1x2
x2+1x2+x
x2+x+1
( )iC xiC
Figura 27 – Polinômios associados às palavras-código.
Assim, em 1960, Irving Reed (1923-), engenheiro, matemático e doutor pelo Instituto de
Tecnologia da Califórnia, e Gustave Solomon (1930-1996), engenheiro, matemático e doutor
pelo Instituto de Tecnologia de Massachussets, apresentaram o artigo chamado “Códigos
Polinomiais em Campos Finitos” [29] e nascia dessa forma um dos mais difundidos códigos
corretores de erro, o Reed-Solomon (RS).
Os códigos Reed-Solomon são códigos usados na codificação de canal, pertencendo à
classe de códigos de bloco lineares que operam com símbolos. Esses códigos pertencem a uma
subclasse de códigos cíclicos, denominada códigos BCH (Bose – Chaudhuri - Hocquenghem)

Capítulo 4 – Codificação LDPC 87
[28]. Sua gama de aplicações é bastante amplo em comunicações digitais (comunicações
celulares, links de satélite etc.), bem como em armazenamento de dados (fitas magnéticas, CDs,
DVDs etc.).
Em um código corretor de erros, os coeficientes dos polinômios contidos em )( pCi
devem ser tais que pertençam a um campo algébrico. O conceito de campo algébrico encontra-se
claramente apresentado em [30]. Quando um campo algébrico possui um número definido Q de
elementos, ele é chamado de campo finito ou corpo de Galois ( ( )GF Q ). Para que seja possível a
formação de um corpo de Galois, é necessário que todas as operações de soma e multiplicação no
( )GF Q sejam ( )MOD Q . Isso garante que qualquer operação de soma ou multiplicação dentro
do corpo de Galois apresentará um resultado pertencente a esse mesmo campo. Os códigos Reed-
Solomon são baseados na teoria de corpo de Galois e necessitam que operações de soma e
multiplicação sejam implementadas nos procedimentos de codificação e decodificação RS. Já o
polinômio do código é calculado em função do número de símbolos da palavra-código, n, e do
número de símbolos da informação, k. De fato, o polinômio gerador representa na verdade a
matriz geradora do código, pois é através dele que se obtém a palavra-código.
Como citado anteriormente, os códigos Reed-Solomon operam com símbolos. Cada
símbolo possui rsm bits. Obrigatoriamente as operações entre os polinômios são todas realizadas
dentro de (2 )rsmGF . A notação usada para representar os códigos Reed-Solomon é ( , )RS n k . A
capacidade de correção de um código RS, dada em símbolos e denominada t, é dada por
.2
n kt −=
Por exemplo, para um código (20,16)RS com 8=rsm , a capacidade e correção t é de 2
símbolos e a paridade será de 4 símbolos, conforme se pode observar na Equação 4.10. A Figura
28 mostra o exemplo descrito.
(4.10)

Capítulo 4 – Codificação LDPC 88
n
012 098100255 120 003 233 111 077 163 000 001 088 200 101 007 208 107 221 076
2tk
n
012012 098098100100255255 120120 003003 233233 111111 077077 163163 000000 001001 088088 200200 101101 007007 208208 107107 221221 076076
2tk
Figura 28 – Codificação )16,20(RS com 8=rsm .
Como a capacidade de correção do código é dada em símbolos, o código irá corrigir no
máximo t símbolos errados independentemente do número de bits incorretos dentro do símbolo.
Supondo que t símbolos apresentem erro, no melhor caso, t bits serão corrigidos (um bit em cada
símbolo) e no pior caso serão corrigidos rsm t bits (todos os m bits de cada símbolo). Esta
característica é extremamente vantajosa para a concepção de um codificador de canal de um
sistema de telecomunicações, uma vez que o código se torna capaz de corrigir uma rajada de
erros de até rsm t bits, desde que eles ocorram dentro de um mesmo bloco Reed-Solomon.
Também, no caso do código detectar a presença de mais de t símbolos errados dentro de um
bloco RS existe a possibilidade de uma flag ser setada para avisar a ocorrência desta situação.
Além da capacidade de correção t dos códigos RS, essa classe de código também é capaz
de detectar apagamentos. Apagamentos ocorrem quando a posição de um símbolo errado é
conhecida. Um decodificador Reed-Solomon pode corrigir t símbolos ou 2t apagamentos.
Apagamentos de informação podem ocorrer freqüentemente introduzidos pelo demodulador de
um sistema de comunicação digital [31].
Um recurso bastante utilizado e útil na codificação RS é o encurtamento de código. O
encurtamento implica zerar um dado número de símbolos na codificação, não transmiti-los e
então re-inserir estes símbolos zeros no estágio de decodificação. A regra para o encurtamento de
código diz que a diferença entre número de símbolos da palavra-código (n), e o número de
símbolos da informação (k) deve ser a mesma tanto no código original (gerador do polinômio)
quanto no código reduzido. Isso significa dizer que haverá a mesma quantidade de símbolos de
paridade para uma quantidade menor de informação transmitida. Conseqüentemente, haverá um
aumento na confiabilidade do sistema de transmissão pelo canal e diminuirá a probabilidade do
código não conseguir corrigir os dados corrompidos.

Capítulo 4 – Codificação LDPC 89
Uma medida bastante importante em um sistema de comunicação digital é o ganho da
codificação. Quando um sistema de comunicação digital é projetado para operar com uma dada
taxa de erro de bit existem basicamente duas maneiras de se atingir isso. Uma forma é
aumentando a relação sinal ruído através do aumento da potência do sinal transmitido. Outra
forma é através da implementação de um código corretor, que permita atingir a mesma taxa de
erro sem o aumento de potência transmitida. Essa “economia” de potência, em decibéis, é
denominada como o ganho do código [31]. Torna-se difícil exemplificar ganhos típicos de
codificadores Reed-Solomon neste trabalho, pois ele depende essencialmente do canal de
transmissão e da taxa de erro de bit almejada.
4.3 Low Density Parity Check
Códigos Low Density Parity Check (LDPC), ou códigos de matriz de paridade de baixa
densidade, são códigos de bloco binários lineares onde a principal característica é que a matriz de
paridade H é esparsa, ou seja, de baixa densidade de elementos não nulos. Uma matriz é dita
esparsa ou de baixa densidade quando a maioria dos seus elementos é nula.
Os códigos LDPC foram apresentados pela primeira vez por Robert Gallager (1931-) em
1962 [32] e posteriormente em sua tese de doutorado em 1963 [33]. Por quase 20 anos a teoria de
Gallager ficou praticamente esquecida, até que em 1981 Tanner [34] apresentou uma nova
interpretação para o LDPC, a partir de um ponto de vista gráfico, técnica esta chamada de gráfico
de Tanner ou gráfico bipartido. Novamente o LDPC foi ignorado pelos estudiosos de codificação,
desta vez por mais 14 anos. Finalmente, em meados dos anos 90, quando do advento dos códigos
turbo e do interesse por algoritmos iterativos de decodificação, o LDPC foi como que
redescoberto, passando, então, por evoluções, especialmente no que se refere à regularidade dos
códigos [35]. Gallager também propôs um algoritmo iterativo de decodificação, conhecido como
Belief Propagation ou algoritmo de soma e produto (SPA). Apesar de Gallager ter proposto o uso
do LDPC como corretor de erro, ele não propôs um método específico para a construção
algébrica e sistemática dos códigos.

Capítulo 4 – Codificação LDPC 90
O método gráfico desenvolvido por Tanner oferece, entre outras coisas, uma forma muito
mais conveniente de representar a matriz H. O número de colunas da matriz H é representado por
pequenos círculos chamados de nós de variável (ou mais especificamente de nós de bit) e o
número de linhas é representado por pequenos quadrados chamados de nós de paridade (ou mais
comumente de nós de cheque). Cada bit na palavra-código corresponde a um nó de bit e cada
equação de cheque de paridade corresponde a um nó de cheque. A ligação entre um nó de bit e
um nó de cheque é chamada de ramo e é empregado para representar que um dado ‘1’da matriz H
pertence à coluna representada pelo nó de bit de origem do ramo e também pertencente à linha
representada pelo nó de cheque de destino do ramo. O número total de ramos corresponde ao
número total de uns da matriz de paridade H. A Figura 29 apresenta um exemplo de matriz de
paridade que facilita a compreensão deste conceito, ainda que a mesma não corresponda a um
código LDPC.
0C1 C2 C3 C8C4 C6C5 C7
V1
V2
V3
V4
1 1
1H = 1
11
1
1
1
1
10
0 0 0
0
0
0
0 0 0 0
0 0 0 0
1 1 1 1
1
Figura 29 – Exemplo de matriz de paridade H.
Para a matriz de paridade da Figura 29, é apresentado o seu respectivo gráfico de Tanner
na Figura 30 seguinte, visando facilitar o entendimento de sua construção. Observa-se que o
elemento ‘1’ em negrito e itálico (e na cor vermelha para a versão colorida deste impresso) na
matriz H aparece também com linha tracejada (e na cor vermelha para a versão colorida deste
impresso) do Gráfico de Tanner da Figura 30 para facilitar a compreensão.
O grau de um dado nó de bit ou nó de cheque pode ser determinado de duas formas.
Através da matriz H, o grau de um nó corresponde ao número de uns presentes em sua respectiva

Capítulo 4 – Codificação LDPC 91
linha - no caso de nós de cheque - ou coluna - no caso de nós de bit -. Graficamente, o grau de um
nó pode ser determinado através do número de ramos que sai do nó.
c1c1V1V1
Nós de variável(nós de bit)
Nós de Paridade(nós de cheque)
V2V2
V3V3
V4V4
c2c2
c3c3
c4c4
c5c5
c6c6
c7c7
c8c8
Figura 30 - Exemplo de gráfico de Tanner.
Outro conceito bastante importante é referente à regularidade do código. Um código é
dito regular quando o número de uns é o mesmo em todas as linhas e colunas da matriz H, ou
graficamente, quando todos os nós de cheque e todos os nós de bit apresentam o mesmo grau.
Quando Gallager desenvolveu os códigos LDPC, nos anos de 60, ele apresentou apenas códigos
regulares. Segundo [36], em termos de desempenho, os códigos irregulares são melhores do que
os regulares, embora apresentem uma complexidade maior de projeto. No exemplo da Figura 30
observa-se que se trata de um código regular, pois todos os nós de bit apresentam o mesmo grau -
grau dois - assim como todos os nós de cheque - grau quatro-.

Capítulo 4 – Codificação LDPC 92
Um ciclo dentro de um código representa um caminho fechado. Na Figura 30 percebe-se
um ciclo em destaque mostrado com linhas pontilhadas (e na cor verde para a versão colorida
deste impresso). Esse ciclo pode ser tanto percebido no gráfico de Tanner ou na matriz H. O
número de saltos dentro de um ciclo é conhecido como grau do ciclo. No exemplo do ciclo da
Figura 30 mostrado com linhas pontilhadas (e na cor verde para a versão colorida deste
impresso), referenciado acima, seu respectivo grau é quatro. Este mesmo ciclo pode ser
observado na matriz de paridade da Figura 29, através dos uns sublinhados (e na cor verde para a
versão colorida deste impresso). É conveniente ressaltar que ciclos de baixo grau são também
referenciados como ciclos curtos, devido à representação dos gráficos de Tanner.
Segundo [37], ciclos curtos, especialmente de grau quatro devem ser evitados para o
projeto de códigos eficientes, pois provocam um elevado grau de erro (saturação na probabilidade
de erro de bit - error floor).
Para um código irregular, o índice i representa o grau do ramo. Desta forma, iλ expressa
a fração dos ramos conectados a nós de bit de grau i. A distribuição de graus para nós de bit é
dada por
1
2.
dvi
x ii
xλ λ −
=
=∑
De forma análoga, para os ramos conectados aos nós de cheque (número de uns das linhas
da matriz H) usa-se a variável iρ para representar a fração dos ramos ligados aos nós de cheque
de grau i, tal que
1
2,
dci
x ii
xρ ρ −
=
=∑
onde dv representa maior grau de nós de bit e dc o maior grau de nós de cheque.
(4.11)
(4.12)

Capítulo 4 – Codificação LDPC 93
Para a obtenção da matriz de paridade H, este trabalho considerará as técnicas propostas
em [37][38][39], usando códigos eIRA (extended Irregular Repeat Accumulate), que visam
principalmente à viabilidade e diminuição da complexidade de implementação do código.
Inicialmente, a matriz H deve ser dividida em duas matrizes 1H e 2H , tal que
[ ]1 2 .H H H=
A matriz 1H apresenta as dimensões ( - )xn k k e será gerada aleatoriamente de forma a
atender a distribuição necessária de graus. Já a matriz 2H , de dimensões ( - )x( - )n k n k , é dada
por
2
1 0 0 0 01 1 0 0 00 1 1 0 0
.
0 0 0 1 00 0 0 1 1
H
=
Uma vez que a estrutura de 2H é conhecida, o projeto de um código LDPC eIRA consiste
em duas tarefas:
• Otimização da distribuição dos graus de xλ e xρ ;
• Construção da matriz 1H .
A otimização de xλ e xρ é uma tarefa com um alto custo computacional e nem um pouco
trivial. Em geral, essas otimizações empregam técnicas complexas, entre as quais se destaca a
técnica de evolução de densidade apresentada em [40]. Esse tema, todavia, não será apresentado
por não compor um dos tópicos fundamentais deste trabalho. Sugere-se, em caso de interesse por
bibliografias mais amplas e uma visão global dessa questão, consultar [41].
(4.13)
(4.14)

Capítulo 4 – Codificação LDPC 94
Para a obtenção da matriz 1H , deve-se recordar que a mesma tem dimensões ( - )xn k k . O
primeiro passo para a sua construção, segundo [41], é criar uma matriz M, submatriz de 1H e m
vezes menor do que ela, de dimensões axb. O fator m determinará o maior grau de paralelização
que poderá ser implementado. A matriz M não apenas deverá ser criada respeitando a otimização
de xλ e xρ como também evitando ciclos de baixa ordem, especialmente de grau quatro,
conforme descrito previamente.
Uma vez obtida a matriz M, cada elemento nulo de M deve ser substituído por uma matriz
nula de ordem m e cada elemento ‘1’ de M deverá ser substituído por permutações da matriz
identidade de ordem m, construindo assim uma nova matriz chamada S, com as mesmas
dimensões de 1H . De posse da matriz S monta-se a matriz 1H , da seguinte forma
( )
1
1
( 1) 1
21
2
1 2
,
m
a m
m
a m
n k
ss
ssH
ss
s
+
− +
+
− +
−
=
onde is é a i-ésima linha da matriz S.
Finalmente, uma vez obtida a matriz 1H , a matriz de paridade H pode ser auferida
através da Equação 4.13.
É importante salientar que as técnicas descritas anteriormente diminuem
significativamente o aparecimento de ciclos curtos, embora estes não sejam totalmente
eliminados.
(4.15)

Capítulo 4 – Codificação LDPC 95
4.3.1 Codificação
Para obter-se a codificação de uma dada mensagem x , deve-se substituir as Equações 4.4
e 4.13 em 4.9. Desta forma, tem-se que
[ ]1 2 0.x
H Hp
=
Desta forma,
1 2 .H x H p=
Finalmente, a paridade p é dada por
1
2 1 .p H H x−=
Devido à forma apresentada na Equação 4.3, 12−H assume
12
1 0 0 0 01 1 0 0 01 1 1 0 0
.
1 1 1 1 01 1 1 1 1
H −
=
Sendo 12−H a matriz triangular inferior mostrada na Equação 4.19, sua implementação
pode ser feita com um acumulador simples. Desta forma, a estrutura do codificador pode ser
ilustrada pela Figura 31.
(4.16)
(4.17)
(4.18)
(4.19)

Capítulo 4 – Codificação LDPC 96
HT
1 D11 px’
c’ = [x’ p’]
x
HT
1HT
1 D1 D11 px’
c’ = [x’ p’]
x
Figura 31 – Diagrama simplificado do codificador LDPC.
Uma vez tendo-se implementado 12H − , o grande obstáculo da codificação passa ser a
manipulação de 1H x .
O processo direto para a codificação é então simplificado à tarefa de armazenar toda a
matriz de paridade 1H em hardware e prover a multiplicação pela mensagem a ser codificada,
produto esse que chamar-se-á iq . Posteriormente, aplicando-se uma operação de ou-exclusivo
(xor) de iq com 1−iq obtém-se a paridade ip , descrito analiticamente como
1.i i ip q q −= ⊕
Um problema bastante expressivo é que a matriz 1H , embora esparsa, é
significativamente grande. Nem sempre é possível armazená-la devido a limitações na quantidade
de memórias do dispositivo onde a implementação do código se dará. Nesses casos, uma técnica
bastante difundida é aplicada onde uma estrutura T, significativamente menor que 1H , é criada
de tal forma que T possa emular a estrutura de 1H através de simples permutações. Ao invés de
armazenar-se toda a matriz 1H , é necessário apenas registrar a estrutura T, a qual armazena os
índices dos nós de cheque conectados aos km
nós de bit indexados pelos múltiplos de m. Dessa
forma, a cada bloco de m bits da mensagem de k bits a ser codificada, a estrutura T será
permutada.
(4.20)

Capítulo 4 – Codificação LDPC 97
4.3.2 Decodificação
O principal objetivo de qualquer algoritmo de decodificação é determinar a probabilidade
máxima a posteriori (MAP) dos bits transmitidos. Para sistemas binários, o logaritmo da razão de
verossimilhança [22], ou LLR (Log-Likelihood Ratio), é dada por
Pr( 0 | )log ,Pr( 1| )
ii
i
c rLc r=
==
onde r é a seqüência de bits recebidos, de modo que o bit recebido é mais provável ser 0=ic
quando 0>iL e 1=ic para os demais casos. Através do gráfico de Tanner, é possível derivar
algoritmos iterativos que obtêm boas aproximações para LLR. Os algoritmos iterativos são
baseados na troca de mensagens entre os nós de bit e os nós de cheque. Isso pode ser
compreendido melhor através da Figura 32, onde vw e cw representam o número total de nós de
bit e nós de cheque respectivamente.
No lado esquerdo da Figura 32, nota-se que o nó de variável combina as informações
provenientes dos nós de cheque ( iu ) (para i = 2,3,... vw ) com a informação do canal. Na parte
direita da Figura 32 é exibido o processo equivalente, porém em um dos nós de cheque de grau
cw . É importante destacar que os nós de cheque não têm contato com a informação proveniente
do canal.
......Recebedo Canal
v1 u1
v2u2
vwvcwu............Recebe
do Canal
v1 u1
v2u2
vwvcwu
Figura 32 – Esquema de troca de mensagens dos nós de bit para os nós de cheque (esquerda) e
dos nós de cheque para os nós de bit (direita).
(4.21)

Capítulo 4 – Codificação LDPC 98
O Belief Propagation de Gallager é, na verdade, uma aproximação do MAP e nele para
um dado nó de bit j, a mensagem de j para um nó de cheque i é computada como
.i jj i
v u≠
=∑
Já a mensagem de um dado nó de cheque j para um nó de bit i é dado por
12 tanh tanh .2
ji
j i
vu −
≠
=
∏
A complexidade do Belief Propagation depende do número de ramos incidentes em cada
nó, onde poucos ramos significam uma baixa complexidade. Entretanto, poucos ramos significam
também que a matriz de paridade é esparsa e essa é a causa pela qual os códigos LDPC podem
ser decodificados com algoritmos de complexidade relativamente baixa como o Belief
Propagation [41]. Estudos mais específicos sobre a decodificação LDPC podem ser encontrados
em [42].
(4.22)
(4.23)

99
99
Capítulo 5 Implementação do Codificador LDPC 5.1 Codificador LDPC 5.1.1 Estrutura da Codificação
No modelo de codificação LDPC proposto na Seção 4.3, a estrutura apresentada era, até
então, dada em função de certos parâmetros. O código eIRA proposto foi apresentado justamente
por visar, principalmente, à diminuição da complexidade de implementação, ao passo que
nenhum dos parâmetros havia sido definido. O primeiro passo para a implementação do
codificador é a definição do próprio código, ou seja, determinar os parâmetros que o
caracterizam. A fixação das características do código LDPC implementado nesta dissertação está
em congruência com os parâmetros definidos no projeto denominado MI-SBTVD para
desenvolvimento de modulação inovadora para o Sistema Brasileiro de Televisão Digital
(SBTVD), cujas particularidades de implementação podem ser observadas em [41] e [21].
Baseado nas características de robustez frente ao ruído e às interferências presentes no
canal, necessárias a um sistema de televisão digital, o comprimento de código foi definido em
9792 bits. O comprimento da palavra-código cogitado inicialmente para o código LDPC era de
39168 bits. No entanto, na especificação final optou-se por reduzir o comprimento do código para
o tamanho apresentado. Os critérios utilizados nesta decisão envolvem fatores distintos, como
complexidade de implementação, latência e desempenho [21]. A análise de desempenho para
diferentes comprimentos de códigos LDPC é apresentada na Seção 6.1. A taxa de código

Capítulo 5 - Implementação do Codificador LDPC 100
escolhida para implementação do protótipo foi de 3/4, ou seja, dos 9792 bits da palavra-código,
7344 bits são de informação enquanto 2448 são bits de paridade. De posse do comprimento e taxa
do código, adotando o descrito na Seção 4.3, sabe-se que a matriz de paridade H terá dimensões
2448(n-k) x 9792(n), sendo a matriz H1 uma matriz de dimensões 2448(n-k) x 7344(k) e H2 uma
matriz de dimensões 2448(n-k) x 2448(n-k).
Dando continuidade à etapa de projeto do código, determinou-se o grau máximo de
paralelização m como sendo igual a 51. Isso significa dizer que no máximo 51 ramos podem ser
processados em paralelo. Essa determinação reproduz com fidelidade o determinado em [41], no
qual também encontram-se expostos os critérios utilizados para a otimização de iλ e de iρ . O
grau máximo de paralelização m foi determinado para a construção da matriz M respeitando a
distribuição de iλ e de iρ e também respeitando os ciclos de baixa ordem. Essa matriz foi
desenvolvida por dois dos autores (Lopes e Pegoraro) de [41] que forneceram a estrutura T,
definida na Seção 4.3.1, que representa a tabela compacta a partir da qual pode-se montar a
matriz H1, viabilizando assim o desenvolvimento do código. A estrutura T é de tamanho
equivalente à quantidade de bits ‘1’ contidos na matriz M, porém o que ela armazena de fato são
as posições em que estes bits se encontram na matriz H1. A estrutura T possui 720 elementos, de
onde pode-se concluir que a matriz H1 possui 720x51 elementos não nulos, ou seja, 36720.
Como anteriormente demonstrado, a codificação LDPC, representada pela Figura 31,
consiste na multiplicação da mensagem x pela matriz transposta de H1 seguido de um acumulador
correspondente à multiplicação pela matriz inversa de H2. Assim, uma vez definidos os
parâmetros do código, se considerou duas formas de desenvolvimeto para implementar a
multiplicação pela matriz transposta de H1, as quais serão expostas nos parágrafos seguintes.
A primeira forma consiste em armazenar a estrutura T em memória, processando grupos
de m=51, colunas de H1, através de permutações das informações das linhas de T. Uma linha da
estrutura T apresenta a informação sobre a localização dos bits ‘1’ em uma coluna da matriz H1.
Porém, através de permutações implementadas no algoritmo do codificador, essa mesma
informação possibilita estimar-se a posição dos bits ‘1’ nas 50 colunas subseqüentes, baseando-se
no grau de paralelismo m=51, utilizado para a otimização de iλ e iρ , que deram origem à matriz

Capítulo 5 - Implementação do Codificador LDPC 101
H1. A estrutura T possui 114 linhas, das quais as primeiras 112 possuem três elementos e as
últimas 32 possuem doze, de onde se conclui que as primeiras 5712 (112x51) colunas de H1
possuem três bits ‘1’ e as demais 1632 (32x51) possuem doze. Somando-se o número de
colunas, totaliza-se as 7344 colunas de H1. Esta primeira forma de implementação foi
desenvolvida em liguagem VHDL e implementada em dispositivos da Altera para o
funcionamento do primeiro protótipo do transmissor apresentado em [41].
A segunda alternativa consiste em, ao invés de se utilizar a estrutura T, fazer-se uso de
uma estrutura maior, que já contenha de uma forma direta todas as posições dos bits ‘1’ ao longo
matriz H1. Esta proposta é vantajosa em um cenário no qual os blocos de memória estão
disponíveis no dispositivo de hardware onde o código será implementado e quando visa-se um
incremento em velocidade de processamento e diminuição da áera de silício ocupada, uma vez
que as permutações das linhas da estrutura T não serão mais necessárias.
Assim, dentre as duas propostas descritas para o desenvolvimento da multiplicação da
matriz transposta de H1, a segunda alternativa foi a efetivamente implementada neste trabalho e
será apresentada a seguir. Os dois motivos principais para esta escolha foram que, primeiro, o
autor deste trabalho já havia trabalhado na implementação da primeira alternativa em [41] e,
segundo, haviam recursos de memória disponíveis no dispositivo de hardware onde o codificador
foi implementado.
5.1.2 Implementação em System Generator
O codificador LDPC foi implementado na plataforma System Generator da Xilinx. Um
detalhe da implementação é que a palavra-código foi definida pela justaposição dos bits de
paridade ao final da mensagem a ser codificada. Esta ordem poderia ser invertida sem problema
algum, desde que o mesmo padrão fosse considerado na decodificação.
Para a implementação do codificador LDPC, fez-se necessária a utilização de blocos de
memória para operarem em forma de buffer de entrada e de saída (conhecidas como memórias

Capítulo 5 - Implementação do Codificador LDPC 102
FIFO – First In First Out), bem como de alguns sinais de controle. O modelo da implementação
do codificador é apresentado na Figura 33.
Figura 33 – Modelo de referência da implementação do codificador LDPC.
A Figura 33 auxilia na compreensão do funcionamento do codificador, muito embora a
implementação do bloco denominado FIFO_IN exija um esclarecimento adicional. Como o
codificador LDPC insere redundância à mensagem para formar a palavra-código, existe a
necessidade de que o sistema opere em uma velocidade maior (maior taxa) depois do bloco
FIFO_IN de forma que o sistema tenha um fluxo constante de dados. Assim, para a
implementação do bloco FIFO_IN utiliza-se, ao invés de um bloco comum de memória FIFO,
como no caso do bloco FIFO_OUT, um bloco de memória especial chamado Shared Memory, o
qual permite o emprego de diferentes taxas de entrada saída de dados da memória. Em outras
palavras, a Shared Memory permite que a entrada e a saída do bloco de memória operem em
freqüências de operação diferentes. Os pinos de entrada do conjunto do codificador LDPC (por
conjunto subentende-se os blocos de memória, o codificador em si e as construção das conexões
mostradas na Figura 33) são assim constituídos.

Capítulo 5 - Implementação do Codificador LDPC 103
• DataIn – entrada binária dos bits da mensagem a ser codificada;
• Write_Enable – entrada binária destinada a informar quando a entrada presente no pino
DataIn é válida;
• Reset – entrada binária destinada às configurações iniciais do sistema;
Os pinos de saída, por sua vez, são descritos como:
• Data_Out – saída binária dos bits da palavra-código;
• Valid – saída binária destinada a informar quando a saída presente no pino Data_Out é
válida.
Os controles internos do conjunto codificador são dispostos de forma a evitar que o
mesmo opere sem a alimentação de dados, como também para evitar que dados possam ser
jogados para o buffer de saída sem que este esteja disponível.
O algoritmo que descreve o funcionamento da codificação (retângulo central da Figura
33) foi implementado através de um bloco do System Generator denominado M-Code. O M-Code
permite descrever uma função em linguagem MATLAB, utilizando-se a biblioteca de ponto fixo
da Xilinx. Os parâmetros de entrada da função constituirão as portas de entrada no novo bloco, e
os argumentos de saída serão as portas de saída. Esse bloco é essencialmente importante porque
permite integrar funções descritas em MATLAB (desde que obedecendo às regras da biblioteca
de ponto fixo da Xilinx) ao System Generator e possibilita sua conversão para linguagem de
hardware HDL.
O bloco do codificador é apresentado em detalhes na Figura 34. O bloco denominado
Tabel é uma memória ROM que contém a estrutura que apresenta todas as posições dos bits ‘1’
ao longo matriz H1. O bloco chamado Parity_Block é, na verdade, uma memória RAM do tipo
porta dupla, ou seja, um mesmo dispositivo de memória com duas interfaces de acesso. A

Capítulo 5 - Implementação do Codificador LDPC 104
primeira entrada foi usada somente para escrita, sendo a saída Write_Parity seu pino de
habilitação de escrita, New_Parity o dado a ser gravado e Parity_Addr_Write o endereço da
memória para gravação. Já a segunda interface de acesso à memória é utilizada apenas para a
leitura, onde Parity_Addr determina o endereço de leitura e o valor é realimentado para a entrada
do codificador através da entrada Parity. A memória do bloco Parity_Block contém espaço para
armazenar os 2448 bits de paridade. Já o algoritmo do codificador, implementado através de M-
Code, aparece na parte esquerda da Figura 34. Para o funcionamento do codificador, as entradas
Reset, Empty e Full devem estar setadas em zero. Após sua inicialização o codificador encontra-
se em estado de espera de mensagens, setando para nível lógico alto a saída Read_Fifo, que
solicita dados na entrada do codificador.
Figura 34 – Bloco do codificador LDPC em detalhes.
Um contador implementado no algoritmo controla o processamento de cada bit da
mensagem. Este tempo de processamento varia proporcionalmente a 3 (na verdade,
proporcionalmente ao grau de paralelização (m=51), vezes 3) ou proporcionalmente a 12 (na

Capítulo 5 - Implementação do Codificador LDPC 105
verdade, 51 vezes 12), de acordo com a estrutura da matriz H1, como já discutido anteriormente.
Após cada bit da mensagem ser processado, ele já pode ser encaminhado para a saída do
codificador, uma vez que a primeira parte da palavra-código é constituída justamente dos bits da
mensagem. Assim, cada bit da mensagem é dirigido à saída Data_Out_Enc e a saída Valid é
setada para nível lógico alto. Ao mesmo tempo, é calculada a operação ou-exclusivo (xor) do bit
que está sendo processado com a paridade do instante anterior, a qual entra no codificador pela
entrada Parity. Esse valor será conduzido à saída New_Parity e armazenado na memória do bloco
Parity_Block no endereço fornecido pela estrutura do bloco Tabel através da saída
Parity_Addr_Write. O endereço de acesso da estrutura contida no bloco Tabel é acessado
seqüencialmente. Após processar todos os bits da mensagem e já tê-los encaminhado para
construção da palavra-código através da saída Data_Out_Enc, a saída Read_Fifo é setada para
nível lógico baixo, a fim de avisar que o codificador não poderá mais receber bits na entrada.
Essa situação de impossibilidade de recepção de novas mensagens se dará até que os 2448 bits de
paridade sejam processados para finalizar, assim, a construção da palavra-código. Desta forma, as
paridades começam a ser tiradas seqüencialmente do bloco Parity_Block e a entrar no codificador
através da entrada Parity, a fim de que o bit de paridade seja o resultado da operação ou-
exclusivo (xor) com paridade anterior, implementado assim o acumulador correspondente à
multiplicação pela matriz inversa de H2.
O código contido no bloco M-Code da Figura 34 encontra-se no apêndice A desta
dissertação.
5.2 Descrição do Hardware Empregado
Para a implementação de todo o protótipo do sistema de televisão Digital sobre IP, foram
utilizados basicamente quatro tipos de elementos de hardware:
• microcomputador (duas unidades);
• placa do Xtreme DSP Development Kit-IV, da Nallatech (duas unidades);

Capítulo 5 - Implementação do Codificador LDPC 106
• placa de desenvolvimento ML-402, da Xilinx (três unidades);
• equipamentos de RF, da National Instruments (três módulos);
Os microcomputadores utilizados foram microcomputadores comuns, não necessitando de
nenhuma característica especial. As únicas exigências são que eles possuam placa de rede
instalada e uma configuração mínima para executar o player VLC [17] ou similar para efetuar a
codificação e decodificação de vídeo. Os demais hardwares envolvidos serão apresentados em
mais detalhes a seguir.
• Placa Nallatech Xtreme DSP Development Kit-IV
A placa Xtreme DSP Development Kit-IV foi desenvolvida pela Nallatech
(www.nallatech.com) e tem sua arquitetura montada a partir de uma FPGA principal Xilinx
Virtex-4 XC4VSX35, cujas características serão apresentadas posteriormente. Além da FPGA
principal, esta placa possui outras duas FPGAs secundárias e de menor porte. A primeira é uma
Virtex-2 XC2V80-4CS144, usada para fazer o gerenciamento dos sinais de relógio, e a segunda,
uma Spartan-II, usada para controlar as interfaces da placa. Além dos sinais de relógio
gerenciados pela Virtex-2 e gerados a partir do cristal contido na placa, é permitido ao usuário
utilizar um sinal externo de relógio.
Um benefício considerável desta placa são as formas de comunicação entre placa e
microcomputador. Ela dispõe de interface USB, porta JTAG-Paralela e barramento PCI. Através
do barramento PCI, por exemplo, é possível conectar-se a placa ao microcomputador e efetuar as
co-simulações descritas na Seção 2.2.2. A Figura 35 exibe a placa Xtreme DSP Development Kit-
IV com destaque para a comunicação feita pelo cabo JTAG Paralelo-IV e onde também é possível
observar, ao pé da figura, o barramento PCI.
A principal vantagem desta placa, porém, está na presença de conversores A/D e D/A de
boa qualidade. Ela possui dois conversores A/D de quatorze bits de resolução, taxa de
amostragem de 105MSPS (mega amostras por segundo), filtro de ordem três nas entradas
analógicas para limitação de banda do sinal (-3db em 59MHz) e sinais de relógio diferenciais.

Capítulo 5 - Implementação do Codificador LDPC 107
Também possui dois conversores D/A com quatorze bits de resolução, taxa máxima de entrada de
dados de 160MSPS e dispositivo interno multiplicador de sinais de relógio (PLL). A Figura 36
mostra a interface dos conversores A/D e D/A bem como o pino de sinal de relógio externo.
Figura 35 – Placa Nallatech Xtreme DSP Development Kit-IV com cabo paralelo IV em destaque.
A/D 2Entrada
Analógica A/D 1Entrada
Analógica
D/A 2Saída
Analógica
D/A 1Saída
Analógica
Entradade clockExterna
Figura 36 – Entradas dos conversores da placa Nallatech Xtreme DSP Development Kit-IV.

Capítulo 5 - Implementação do Codificador LDPC 108
Por outro lado, a maior desvantagem da placa Xtreme DSP Development Kit-IV é que ela
não possui uma memória não volátil, como uma memória flash, por exemplo, para sua FPGA
principal. Desta maneira, como apresentado na Seção 2.1.2, toda vez que a alimentação de
energia for suprimida da placa, o programa deverá ser recarregado para o dispositivo através de
conexão com o microcomputador.
O preço de mercado desta placa, praticado no ano de execução deste trabalho, é de
aproximadamente US$2.495,00 (preço para o mercado americano). Para informações referentes a
outros recursos e detalhes da placa, sugere-se [43].
A FPGA principal da placa Xtreme DSP Development Kit-IV é uma Virtex-4 XC4VSX35
10FF668. Esta é uma FPGA de aproximadamente 35 mil células lógicas. Dadas as formas de
medição de elementos lógicos descritos na Seção 2.1.2, este dispositivo contém
aproximadamente 15 mil slices, 30 mil flip-flops e 30 mil LUTS de 4 entradas (cada slice contém
duas LUTS). Outras características importantes desta FPGA especificamente é que ela possui 16
pinos de entrada e saída para sinais de relógio, 12 regiões de sinais de relógio, 8 DCMs
(gerenciadores digitais de sinais de relógio), 4 PMCDs (divisores de sinais de relógio), 192
BRAMs de 18 Kb e 192 DSP48, que são multiplicadores (duas entradas de 18 bits e precisão de
36 bits na saída) e acumuladores (48 bits de precisão). No capítulo seguinte, na exposição da
utilização dos recursos, estes dados certamente ficarão mais familiares. Para informações mais
detalhadas sobre FPGAs da família Virtex-4, sugere-se [44].
• Placa de desenvolvimento ML-402, da Xilinx
A placa ML-402 da Xilinx, apesar de não contar com os conversores A/D e D/A como a
placa da Nallatech, apresenta uma série de interfaces que a tornam uma plataforma de
desenvolvimento extremamente atrativa. Provavelmente a mais atrativa delas seja a interface de
rede Ethernet para conector padrão RJ-45 para operar em 10, 100 ou até 1000 Mbps. Através
desta interface, é possível a troca de dados com qualquer equipamento que possua placa de rede
ou até mesmo tornar a própria placa ML-402 um dispositivo disponível na rede.

Capítulo 5 - Implementação do Codificador LDPC 109
A placa também contém outras interfaces com alto grau de atratividade como a porta
RS232, entrada para cartão externo de memória Compact Flash, porta USB e conector JTAG
para cabo paralelo-IV, o que também torna disponível o uso desta placa para realização de co-
simulação, descrito na Seção 2.2.2. A placa possuiu também display de LCD de duas linhas,
saída VGA e entrada PS2 para teclado e mouse, algumas chaves seletoras e alguns botões do tipo
push botton. Devido às várias opções de comunicação com outros equipamentos, esta placa pode
ser usada nas mais variadas aplicações. Além do mais, a placa ML-402 oferece um codificador de
áudio de 16 bits que pode operar em uma freqüência de amostragem de até 48KHz. A Figura 37
exibe a placa ML-402.
Figura 37 – Placa Xilinx ML-402.
Assim como na placa Xtreme DSP Development Kit-IV, na placa ML-402, a FPGA
principal também é uma Virtex-4 XC4VSX35. Entretanto, umas das grandes vantagens da placa
ML-402 está no fato de ela conter memória flash não volátil, o que permite que este dispositivo

Capítulo 5 - Implementação do Codificador LDPC 110
seja utilizado para confecção de soluções finais. Uma vez os dados gravados na placa, a mesma
pode ser posta em operação e, mesmo em caso de falta de energia, os dados ficarão armazenados
na memória flash de forma que a FPGA pode ser carregada automaticamente sempre que for
alimentada.
Na data de elaboração deste trabalho, o valor aproximado da placa ML-402 é de
US$595,00 (preço para o mercado americano). Para mais detalhes da placa ML-402, sugere-se
[45].
• Equipamentos de RF da National Instruments
Três módulos de equipamentos da National Instruments foram utilizados. Os dois
primeiros foram os conversores elevadores (up converters), usados na transmissão, e o terceiro
foi o conversor rebaixador (down converter), usado na recepção. Esses equipamentos permitem
operações em uma banda de 9KHz a 2.7GHz. A Figura 38 apresenta os dois tipos de módulos,
conversor rebaixador à esquerda e elevador à direita, utilizados na implementação do protótipo.
Figura 38 – Equipamentos de RF da National Instruments.
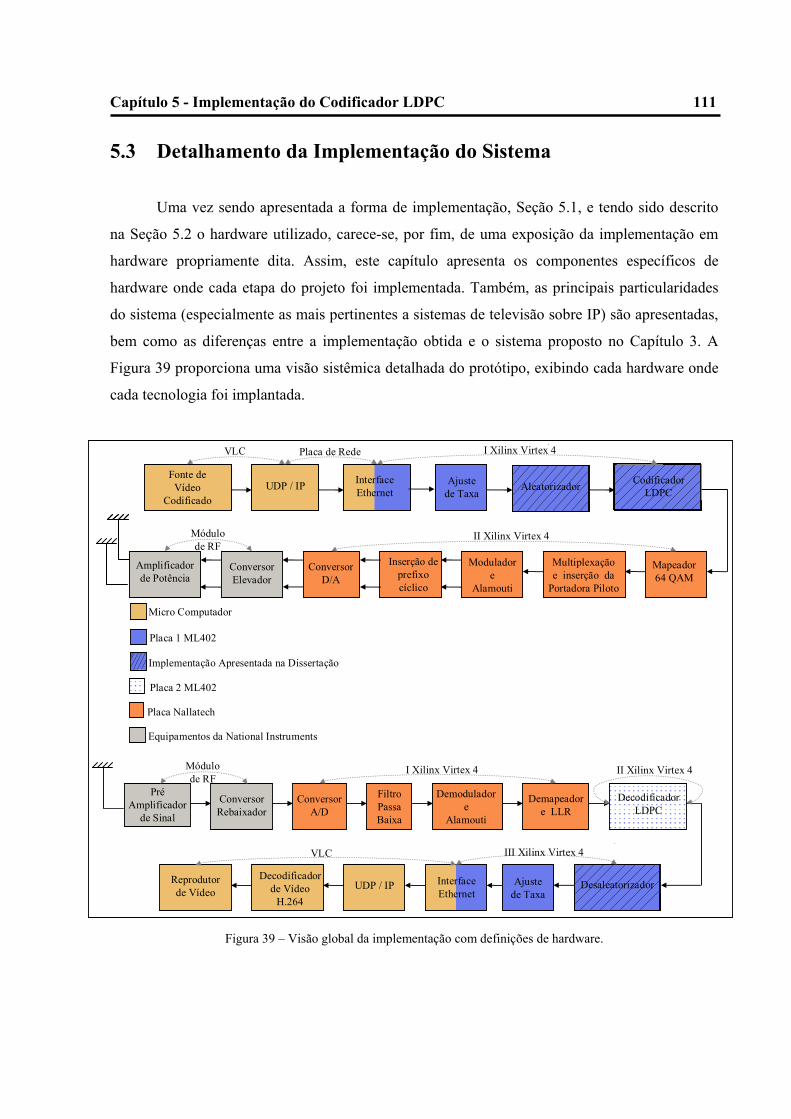
Capítulo 5 - Implementação do Codificador LDPC 111
5.3 Detalhamento da Implementação do Sistema
Uma vez sendo apresentada a forma de implementação, Seção 5.1, e tendo sido descrito
na Seção 5.2 o hardware utilizado, carece-se, por fim, de uma exposição da implementação em
hardware propriamente dita. Assim, este capítulo apresenta os componentes específicos de
hardware onde cada etapa do projeto foi implementada. Também, as principais particularidades
do sistema (especialmente as mais pertinentes a sistemas de televisão sobre IP) são apresentadas,
bem como as diferenças entre a implementação obtida e o sistema proposto no Capítulo 3. A
Figura 39 proporciona uma visão sistêmica detalhada do protótipo, exibindo cada hardware onde
cada tecnologia foi implantada.
Micro Computador
Placa 1 ML402
Placa Nallatech
Equipamentos da National Instruments
Fonte de Vídeo
Codificado
Fonte de Vídeo
CodificadoUDP / IPUDP / IP Interface
EthernetInterfaceEthernet
Mapeador64 QAM
Conversor D/A
Conversor Elevador
Amplificador de Potência
Amplificador de Potência
Moduladore
Alamouti
Inserção de prefixocíclico
Multiplexaçãoe inserção da
Portadora Piloto
PréAmplificador
de Sinal
ConversorRebaixador
ConversorA/D
Demapeador e LLR
DecodificadorLDPC
UDP / IPDecodificador
de VídeoH.264
Reprodutor de Vídeo
InterfaceEthernet
FiltroPassa Baixa
Demoduladore
Alamouti
Demoduladore
Alamouti
Ajuste de TaxaAjuste
de Taxa
Ajuste de TaxaAjuste
de Taxa
Placa 2 ML402
Placa de RedeVLC
II Xilinx Virtex 4Módulo de RF
Módulode RF
II Xilinx Virtex 4I Xilinx Virtex 4
VLC
AleatorizadorAleatorizadorAleatorizador
I Xilinx Virtex 4
Codificador LDPC
Codificador LDPC
DesaleatorizadorDesaleatorizador
III Xilinx Virtex 4
Implementação Apresentada na Dissertação
Figura 39 – Visão global da implementação com definições de hardware.

Capítulo 5 - Implementação do Codificador LDPC 112
O microcomputador utilizado no transmissor executa o VLC como gerador de transport
stream, onde é feita a configuração para geração de dados no formato UDP/IP e setado o
endereço IP de destino. Este endereço IP deve ser o mesmo endereço IP da interface de rede (RJ-
45) da placa ML-402 do transmissor. É importante salientar que, na solução de resolução de
protocolos, implementada na placa ML-402, não existe troca de mensagens para alimentação de
tabelas ARP. Desta forma, o microcomputador não sabe qual o endereço IP associado à interface
de rede da placa ML-402, placa esta conectada a ele através de um cabo do tipo cross-over. Tudo
o que o computador consegue “enxergar” é o endereço MAC da interface. Por isso, antes do
início da transmissão, o operador deverá editar manualmente a tabela ARP do computador, de
forma a associar o endereço IP gravado na interface de rede da placa ML-402 ao seu endereço
MAC. Suponha que o endereço IP gravado na placa transmissora ML-402 seja 192.168.8.113 e
que o endereço MAC de sua interface de rede seja 00-A5-BB-BB-55-36. Essa edição da tabela é
feita através do comando <ARP –s 192.168.8.13 00-A5-BB-BB-55-36>, digitado a partir do prompt do
DOS. Este comando autoriza o computador a associar em sua tabela ARP o endereço IP
192.168.8.13 à interface proprietária do endereço MAC 00-A5-BB-BB-55-36. Uma vez efetuado
este procedimento, os dados gerados pelo VLC destinados ao endereço IP da placa ML-402 serão
encaminhados à interface de rede da placa. Também, os quadros do tipo MAC que serão
encaminhados à placa ML-402 possuirão em seu cabeçalho, no campo “tipo” (2 bytes), o valor
#0800#, informando que os dados contidos no campo da mensagem correspondem a dados do
tipo IP. O formato do quadro MAC pode ser visualizado na Figura 22.
Uma das exigências do sistema de televisão digital desenvolvido é que ele opere na taxa
de 19,33Mbps. Quando o quadro MAC é entregue à placa ML-402 transmissora, ele passa pelo
processo de ajuste de taxa, o qual está implementado no mesmo dispositivo Virtex-4 da placa, tal
qual o controle da interface Ethernet. Esse ajuste de taxa é necessário para garantir o throughput
de 19,33Mbps mesmo quando o vídeo transmitido é gerado com uma taxa inferior. Assim, de
uma maneira bastante simplória, pode-se dizer que, efetivamente, o ajuste de taxa do transmissor
acrescenta quadros nulos à informação, a fim de que a taxa de transmissão seja mantida constante
em 19,33Mbps. Um diagrama simplificado da implementação do ajuste de taxa é exibido na
Figura 40.

Capítulo 5 - Implementação do Codificador LDPC 113
A idéia básica do controle de taxa consiste em transmitir pacotes de dados nulos, ou seja,
pacotes que não contêm informação útil, sempre que for solicitado um dado pelo sistema e este
dado ainda não esteja disponível. Isto ocorre quando a taxa do vídeo a ser transmitido é menor
que a vazão do sistema, sendo necessário preencher a diferença com pacotes nulos. Desta forma,
existem dois tipos de pacote que podem ser transmitidos. Uma vez iniciada a transmissão de um
pacote, de um tipo, a mesma deverá ser feita até o final do mesmo, para só então poder transmitir
um pacote de um outro tipo. Apesar de aparentemente evidente, esta regra é bastante importante
para poder distinguir, no receptor, entre os dois tipos de pacotes, para poder descartar os pacotes
nulos e, então, recuperar o fluxo de vídeo original.
Quadro MACdisponível
de LeituraSolicitação
Entrada Byte
Valido
Índice do
Quadro
Fonte Pacotes Nulos
Garante ciclode 1358bytes
Válido Pacotes Nulos
Habilita Leitura Fifo
Saída Byte
Saida Válido
Figura 40 – Diagrama simplificado da implementação do ajuste de taxa.
Desta forma, dois estados são definidos para o circuito de ajuste de taxa: ler pacote de
dados ou ler pacote nulo. Este estado é representado pelo registrador “Garante Ciclo de 1358
bytes” e, como o próprio nome indica, permanece em um mesmo estado pelo menos durante 1358
bytes consecutivos, que é o tamanho de um pacote de dados ou de um pacote nulo. O objetivo
deste registrador é informar se existem, ou não, pacotes de dados disponíveis para leitura. Essa

Capítulo 5 - Implementação do Codificador LDPC 114
informação é atualizada sempre que é terminada a leitura de um pacote. Deste modo, sempre que
for iniciar a leitura de um novo pacote, ou seja, quando o “Índice do Quadro” for igual a 1357, o
sinal de controle “Quadro MAC disponível” é verificado e armazenado no registrador. Observe
que os termos quadro e pacote são utilizados aqui sem distinção.
Com estes conceitos em mente, fica fácil entender os sinais de saída do controle de taxa.
O estado do circuito (“Garante ciclo de 1358 bytes”) controla os seletores que conduzem as
saídas “Saída Byte” e “Saída Válido”. Quando o estado é “0”, ou seja, não existe pacote de dados
disponível para leitura, então, o pacote nulo é lido a partir de uma memória ROM. O endereço de
leitura é fornecido pelo contador “Índice do Quadro”. O sinal de válido neste caso é a própria
solicitação de leitura proveniente do sistema.
Por outro lado, quando o estado do circuito é “1”, significa que há pelo menos um pacote
de dados disponível para leitura, e então o sinal “Solicitação de Leitura”, proveniente do sistema,
é passado para a FIFO que armazena os pacotes de dados. Deste modo, os dados do pacote, lidos
da FIFO de entrada, são disponibilizados nas entradas “Entrada Byte” e “Valido” do circuito do
controle de taxa, e passados adiante para as saídas “Saída Byte” e “Saída Valido”.
No receptor, conforme pode ser observado na Figura 39, também existe um bloco de
ajuste de taxa. Esse bloco consiste em simplesmente ler o cabeçalho dos quadros MAC, após este
ser desaleatorizado, e descartar todos os pacotes que contêm o valor hexa #FFFF# no campo
“tipo” do cabeçalho MAC. Vale destacar que todos os pacotes nulos inseridos no sistema contêm
o valor #FFFF# no referido campo.
Concluída a etapa do ajuste de taxa, a informação passa pelo aleatorizador, o qual foi
implementado de acordo com a Figura 41. Tal qual mostrado na figura, o aleatorizador garante
que o comportamento na distribuição dos bits será aleatório, graças ao bloco lógico que executa a
operação ou-exclusivo entre os dados provenientes do estágio de ajuste de taxa e uma seqüência
pseudo-aleatória, pn. Apesar de suas entradas serem dadas em byte, o aleatorizador funciona ao
nível de bit, pois a operação ou-exclusivo apresentada é feita bit a bit. Um cuidado tomado na
implementação do aleatorizador foi o de não aleatorizar os primeiros quatorze bytes do cabeçalho

Capítulo 5 - Implementação do Codificador LDPC 115
do quadro MAC, referentes ao endereçamento, uma vez que estas informações são utilizadas no
sincronismo de quadro.
No lado do receptor, tal qual no microcomputador transmissor, também o
microcomputador receptor necessita efetuar o processo de atualização da tabela ARP a fim de
que ele associe o endereço MAC da placa ML-402 interligada a ele via cabo cross-over ao
endereço IP da mesma. Outro ponto bastante interessante utilizado na implementação foi o de
usar o mesmo endereço IP para a placa ML-402 do transmissor e placa de rede do
microcomputador receptor. De igual forma, manteve-se o mesmo endereço IP do
microcomputador transmissor com a placa ML-402 que está ligada via cabo cross-over ao
microcomputador receptor. Este recurso é especialmente vantajoso por evitar que o cabeçalho
MAC necessite ser editado ao longo de todo processamento realizado nas FPGAs. Em outras
palavras, o roteamento IP foi implementado manualmente.
Figura 41 – Implementação do aleatorizador.
Os demais blocos encontram-se normalmente implementados conforme a Figura 39. As
partes de modulação e demodulação OFDM, sincronismo, multiplexação, inserção de portadora-
piloto, conversor rebaixador digital, conversor elevador digital, mapeamento, LLR, foram
implementados em uma placa Nallatech Xtreme DSP Development Kit-I para o transmissor e uma
para o receptor. A implementação do decodificador LDPC necessitou de uma placa ML-402

Capítulo 5 - Implementação do Codificador LDPC 116
exclusiva. Assim, conforme evidenciado na Figura 39, o transmissor exigiu uma placa ML-402 e
uma placa Nallatech Xtreme DSP Development Kit-IV, enquanto o receptor demandou duas
placas ML-402 e uma placa Nallatech Xtreme DSP Development Kit-IV.
Os equipamentos na National Instruments foram utilizados para operar na freqüência da
banda passante do sistema, sendo utilizados como conversores elevadores no transmissor
(diversidade de transmissão) e como conversor rebaixador no receptor. A potência por eles
irradiada não é elevada, uma vez que seu objetivo é apenas oferecer uma situação de teste ao
protótipo.
Por fim, faz-se necessário informar a não-implementação do codificador e decodificador
Reed-Solomon do modelo apresentado no Capítulo 3. A idéia de implementação do codificador
Reed-Solomon analisada foi de um modelo similar ao proposto em [39]; um código encurtado
RS(204,188) derivado de um código RS(255,239) com polinômio 8 4 3 2 1X X X X+ + + + . Tanto
o codificador quanto o decodificador Reed-Solomon fazem parte dos NPIs disponíveis no
AccelWare (Seção 2.3.2).
Na configuração inicial da proposta, não havia nenhum entrelaçador entre os
codificadores LDPC e Reed-Solomon. Porém, através de simulações, verifica-se que, para este
caso, a taxa de erro de bit na saída do decodificador Reed-Solomon é praticamente a mesma da
saída do decodificador LDPC, para os tamanhos de bloco usados. Esse fenômeno se dava
especialmente, porque as estatísticas de erro na saída do decodificador LDPC mostraram que os
erros ocorriam de forma bastante dispersa dentro da palavra-código e isso resultava no
comprometimento do desempenho do decodificador Reed-Solomon, devido ao fato de que sua
melhor atuação se dá quando os erros ocorrem em rajadas [21]. Para solucionar este problema,
mantendo a codificação Reed-Solomon, é necessário fazer com que o número médio de bits em
erro por bloco Reed-Solomon se mantivesse dentro da capacidade do código (Seção 4.2).
Visando solucionar este problema, é necessária a colocação de um entrelaçador, de forma que ele
opere entre os codificadores Reed-Solomon e LDPC e, conseqüentemente, que um
desentrelaçador equivalente opere entre os respectivos decodificadores.

Capítulo 5 - Implementação do Codificador LDPC 117
Diante do exposto, de que, de acordo com [21], para este modelo de implementação o
desempenho com e sem codificação Reed-Solomon é praticamente o mesmo quando não se
utiliza um sistema entrelaçador/desentrelaçador entre a codificação LDPC e Reed-Solomon,
optou-se pela não-implementação da codificação Reed-Solomon.

Capítulo 5 - Implementação do Codificador LDPC 118

119
119
Capítulo 6 Resultados, Demonstrações e Comparações 6.1 Quanto ao Desempenho e Comprimento do Código LDPC
Na seção correspondente à descrição da implementação do código LDPC, observou-se
que a idéia inicial de projeto do código LDPC previa um comprimento de bloco da ordem de
40Kb e que, no entanto, optou-se por um código de palavra-código da ordem de 10Kb. Quanto
maior o comprimento de bloco de um código LDPC, para uma mesma taxa, menor será a taxa de
erro de bit para uma mesma relação sinal ruído, como se pode perceber na Figura 42.
Curva de desempenho para canal AWGN e taxa=0,5
Eb/N0 (dB)
BE
R
Figura 42 – Curva de desempenho de código LDPC em função do comprimento do código.
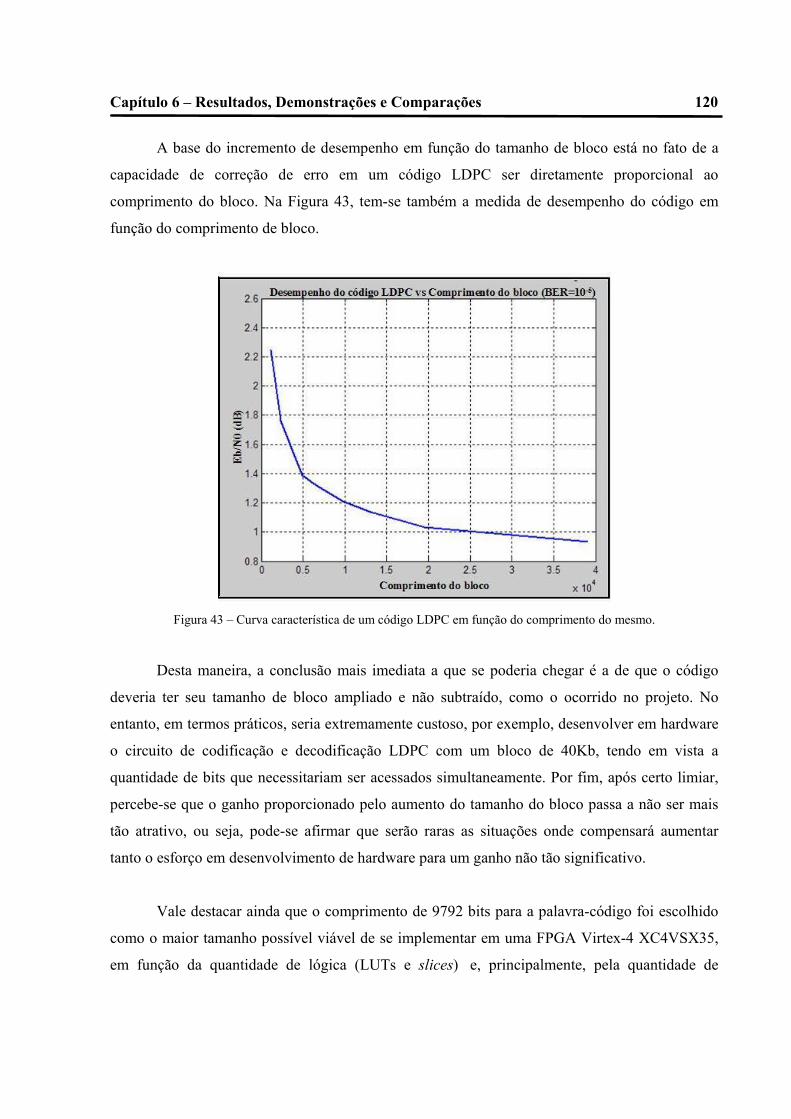
Capítulo 6 – Resultados, Demonstrações e Comparações 120
A base do incremento de desempenho em função do tamanho de bloco está no fato de a
capacidade de correção de erro em um código LDPC ser diretamente proporcional ao
comprimento do bloco. Na Figura 43, tem-se também a medida de desempenho do código em
função do comprimento de bloco.
Figura 43 – Curva característica de um código LDPC em função do comprimento do mesmo.
Desta maneira, a conclusão mais imediata a que se poderia chegar é a de que o código
deveria ter seu tamanho de bloco ampliado e não subtraído, como o ocorrido no projeto. No
entanto, em termos práticos, seria extremamente custoso, por exemplo, desenvolver em hardware
o circuito de codificação e decodificação LDPC com um bloco de 40Kb, tendo em vista a
quantidade de bits que necessitariam ser acessados simultaneamente. Por fim, após certo limiar,
percebe-se que o ganho proporcionado pelo aumento do tamanho do bloco passa a não ser mais
tão atrativo, ou seja, pode-se afirmar que serão raras as situações onde compensará aumentar
tanto o esforço em desenvolvimento de hardware para um ganho não tão significativo.
Vale destacar ainda que o comprimento de 9792 bits para a palavra-código foi escolhido
como o maior tamanho possível viável de se implementar em uma FPGA Virtex-4 XC4VSX35,
em função da quantidade de lógica (LUTs e slices) e, principalmente, pela quantidade de

Capítulo 6 – Resultados, Demonstrações e Comparações 121
memórias (BRAMs) disponíveis. De fato, o projeto do decodificador, como será mostrado
adiante, ocupou praticamente todos os recursos da FPGA. Além disso, este comprimento foi
escolhido de forma a facilitar a implementação do sistema, de tal modo que seja múltiplo de 8, de
6 e de 204. Além disso, o tamanho do quadro OFDM, que corresponde a 34 símbolos OFDM
(34×6×1248 bits), também deveria ser múltiplo do comprimento da palavra código, onde 1248 é
o número de portadoras efetivas de dados entre as 2048 possíveis.
6.2 Comparações de Modelos de Implementação 6.2.1 System Generator Versus AccelChip
Para efeito de comparação, desenvolveu-se o mesmo algoritmo do codificador LDPC
(exibido no apêndice A deste trabalho), implementado através da linguagem de ponto fixo da
Xilinx no bloco M-Code, em linguagem Matlab, para que este pudesse ser implementado em
hardware através da ferramenta AccelChip. Os resultados referentes à ocupação do dispositivo
Xilinx Virtex-4 XC4VSX35XC, com a implementação dada através da ferramenta AccelChip,
encontram-se exibidos na Figura 44.
Figura 44 – Relatório de ocupação da FPGA com o código do codificador LDPC desenvolvido em AccelChip.

Capítulo 6 – Resultados, Demonstrações e Comparações 122
Por sua vez, os resultados mais significativos, referentes à ocupação do dispositivo,
obtidos pela implementação feita em System Generator, são apresentados na Figura 45.
Figura 45 – Relatório parcial de ocupação da FPGA com o código do codificador LDPC
desenvolvido no bloco M-Code do System Generator.
Com base nos dados apresentados, percebe-se que a implementação feita em AccelChip
consome mais área do dispositivo ou, em outras palavras, que a implementação dada em System
Generator é mais otimizada. É importante destacar que a diferença entre as implementações está
na plataforma utilizada para geração do código em linguagem de hardware HDL, uma vez que
ambos foram submetidos à mesma ferramenta de síntese, XST. Embora o algoritmo do
codificador LDPC ocupe uma área relativamente pequena do dispositivo, a diferença de ocupação
de lógica entre as duas soluções foi em torno de cinqüenta por cento. Contudo, como apenas um
percentual muito pequeno da lógica do dispositivo é consumido, uma análise absoluta dos
números pode ser mais razoável do que uma análise em termos percentuais.
6.2.2 System Generator Versus VHDL
Para a comparação das formas de implementação dadas em System Generator e VHDL,
tomou-se todo o conjunto codificador LDPC, apresentado na Figura 34, para que o mesmo fosse
também implementado na linguagem VHDL. O desenvolvimento em VHDL deu-se da forma
mais fiel possível ao código concebido no bloco M-Code, de modo a tornar a comparação mais
eqüitativa. Os resultados são apresentados a seguir, onde a Figura 46 é relativa aos resultados da

Capítulo 6 – Resultados, Demonstrações e Comparações 123
implementação realizada em VHDL, e a Figura 47, aos resultados da implementação dada em
System Generator.
Figura 46 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC desenvolvido em VHDL.
A análise comparativa do desempenho permite confirmar o já esperado, o
desenvolvimento em VHDL resultou em uma melhor otimização. No entanto, merece
considerável destaque o fato de a implementação em System Generator ter apresentado um
desempenho bastante satisfatório em termos de ocupação de slices. Apesar de haver ocorrido um
aumento na área de silício ocupada, este aumento acrescido pela ferramenta de automação foi de
apenas dezoito por cento, aproximadamente.
Figura 47 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC, com otimização em termos
de velocidade e desenvolvido em System Generator.

Capítulo 6 – Resultados, Demonstrações e Comparações 124
No caso deste esquema (Figura 33), de apenas três blocos interligados, acrescidos de um
código relativamente curto, é possível desenvolver o código em VHDL com um grau de
dificuldade não muito elevado. Contudo, percebe-se que, para sistemas mais complexos, se
aplicaria o paradigma descrito no capítulo introdutório, ou seja, seria necessário dispor de um
especialista na aplicação em desenvolvimento e um especialista em hardware. A relativamente
pequena quantidade de lógica adicional exigida pelo System Generator é justificada pela
simplificação que sua utilização proporciona.
6.2.3 Otimização em Área versus Otimização em Velocidade
Uma das grandes vantagens de se operar com ferramentas de síntese é que o
desenvolvedor pode informar à ferramenta qual a sua principal prioridade, se ocupação de área de
silício do dispositivo ou velocidade de processamento. Dentro das suas limitações, a ferramenta
tentará atender às solicitações, sacrificando uma em detrimento da outra. Esta é a principal
relação de compromisso ao trabalhar-se com FPGAs. Para atender às solicitações, antes de mais
nada a ferramenta tentará garantir as restrições editadas no arquivo de restrições ucf.
Almejando uma forma de melhor analisar essa situação, implementou-se o conjunto
codificador priorizando a otimização em virtude de velocidade e, em uma segunda
implementação, priorizando a otimização da ocupação de área do dispositivo.
Figura 48 – Relatório parcial de ocupação da FPGA com o conjunto codificador LDPC, otimização em termos de
área e desenvolvido em System Generator.

Capítulo 6 – Resultados, Demonstrações e Comparações 125
A síntese priorizando a velocidade é a mesma exibida pela Figura 47. Já a Figura 48
apresenta o mesmo projeto, porém com a síntese priorizando a otimização da ocupação de área
do dispositivo.
Quando foi utilizada a otimização em função da área de ocupação do dispositivo,
observou-se uma redução na lógica consumida pelo circuito, como mostrado pelo número de
slices na Figura 48. Embora a redução de área tenha sido pequena, em circuitos maiores e mais
complexos esse índice de redução tende a ser superior.
A medida de quanto será otimizado em função de área ou velocidade, depende
essencialmente da ferramenta de síntese. Em todos os casos apresentados neste trabalho, a
ferramenta de síntese utilizada foi o XST, que acompanha o Design Flow da Xilinx. Ferramentas
de síntese, reconhecidamente mais eficientes, como, por exemplo, o Leonardo Spectrum da
Mentor Graphs, tendem a oferecer resultados mais satisfatórios.
6.3 Demonstrações de Ocupação dos Dispositivos
Terminada a implementação do protótipo do sistema, verificou-se que não houve
subdimensionamento de hardware especificado. Ao contrário, em praticamente todas as placas
utilizadas, houve uma considerável folga de segurança no que se refere à ocupação dos
dispositivos.
Até esta seção do trabalho, todos os relatórios de ocupação apresentados foram gerados
exclusivamente para demonstrações, em função da metodologia adotada. Partes isoladas do
sistema foram implementadas, a fim de se saber, de uma forma exata, sua ocupação e possíveis
problemas. A seguir, são apresentados os relatórios de ocupação de área de todos os componentes
programáveis efetivamente empregados no sistema. Alguns componentes aparecem com vários
módulos implementados. A ordem será a partir do transmissor para o receptor. A descrição
acompanha a mesma referência da Figura 39.
A Figura 49 apresenta a ocupação da primeira FPGA Virtex-4, da Placa ML-402. Nela
estão implementados o ajuste de taxa, aleatorizador e codificador LDPC. Observa-se que o

Capítulo 6 – Resultados, Demonstrações e Comparações 126
sistema foi implementado com considerável sobra de recursos, dada uma ampla quantidade de
elementos lógicos disponíveis no dispositivo.
Figura 49 – Relatório parcial de ocupação da primeira FPGA empregada no protótipo. Nesta FPGA, estão
implementados o MAC Ethernet, o ajuste de taxa, o aleatorizador e o codificador LDPC.
A segunda FPGA do sistema, também uma Virtex-4, é a FPGA principal da placa Xtreme
DSP Development Kit-IV. Nela está o mapeador QAM, o sistema de multiplexação, inserção de
portadora piloto, modulador OFDM (com a IFFT) e Alamouti, conversor elevador digital e
inserção de prefixo cíclico. A ocupação deste dispositivo ultrapassa os oitenta por cento, mas
garante uma folga considerável para atualizações e implementação de lógica para correção de
possíveis erros. A ocupação da segunda FPGA do sistema é mostrada pela Figura 50.
Figura 50 – Relatório parcial de ocupação da segunda FPGA empregada no protótipo. Nesta FPGA, estão
implementados o mapeador, o multiplexador, o modulador e Alamouti e a inserção de prefixo cíclico.
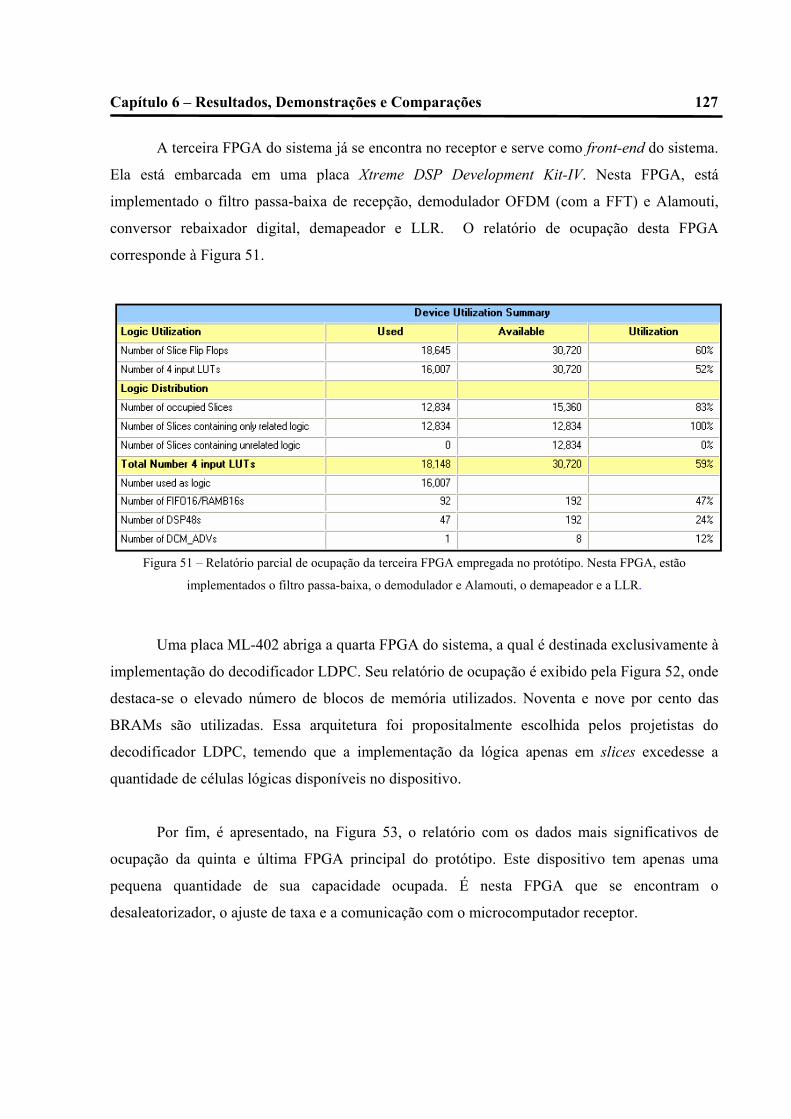
Capítulo 6 – Resultados, Demonstrações e Comparações 127
A terceira FPGA do sistema já se encontra no receptor e serve como front-end do sistema.
Ela está embarcada em uma placa Xtreme DSP Development Kit-IV. Nesta FPGA, está
implementado o filtro passa-baixa de recepção, demodulador OFDM (com a FFT) e Alamouti,
conversor rebaixador digital, demapeador e LLR. O relatório de ocupação desta FPGA
corresponde à Figura 51.
Figura 51 – Relatório parcial de ocupação da terceira FPGA empregada no protótipo. Nesta FPGA, estão
implementados o filtro passa-baixa, o demodulador e Alamouti, o demapeador e a LLR.
Uma placa ML-402 abriga a quarta FPGA do sistema, a qual é destinada exclusivamente à
implementação do decodificador LDPC. Seu relatório de ocupação é exibido pela Figura 52, onde
destaca-se o elevado número de blocos de memória utilizados. Noventa e nove por cento das
BRAMs são utilizadas. Essa arquitetura foi propositalmente escolhida pelos projetistas do
decodificador LDPC, temendo que a implementação da lógica apenas em slices excedesse a
quantidade de células lógicas disponíveis no dispositivo.
Por fim, é apresentado, na Figura 53, o relatório com os dados mais significativos de
ocupação da quinta e última FPGA principal do protótipo. Este dispositivo tem apenas uma
pequena quantidade de sua capacidade ocupada. É nesta FPGA que se encontram o
desaleatorizador, o ajuste de taxa e a comunicação com o microcomputador receptor.
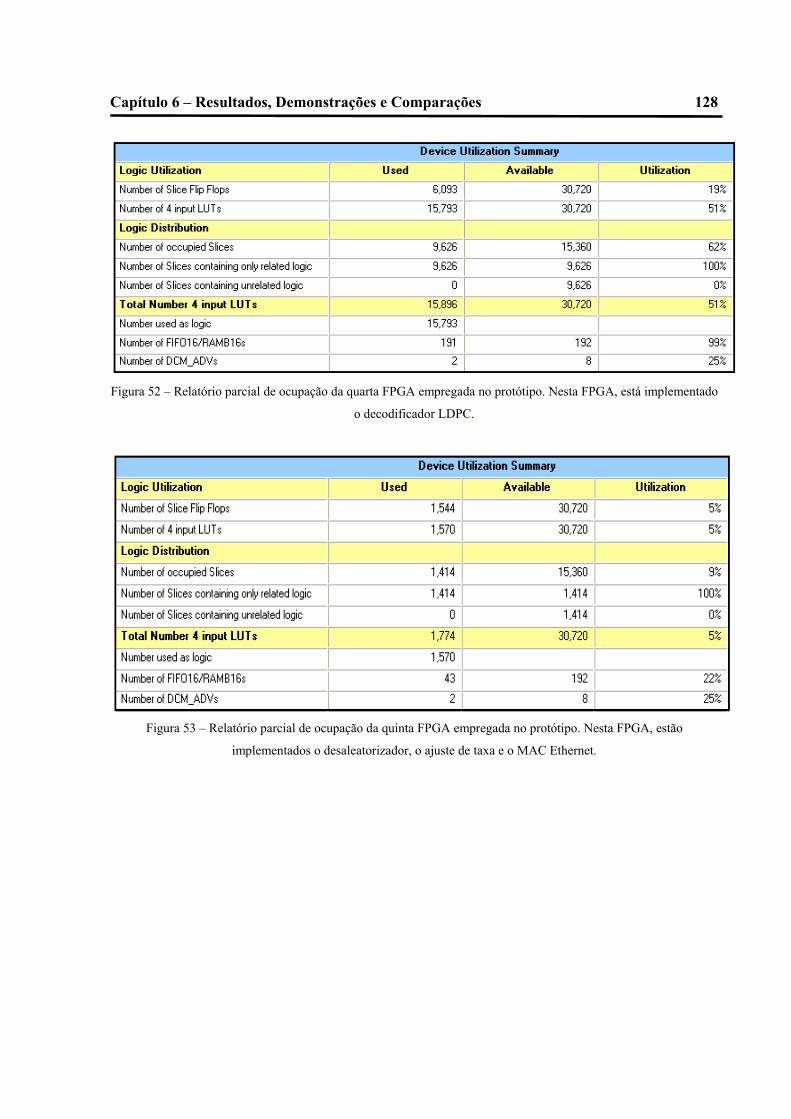
Capítulo 6 – Resultados, Demonstrações e Comparações 128
Figura 52 – Relatório parcial de ocupação da quarta FPGA empregada no protótipo. Nesta FPGA, está implementado
o decodificador LDPC.
Figura 53 – Relatório parcial de ocupação da quinta FPGA empregada no protótipo. Nesta FPGA, estão
implementados o desaleatorizador, o ajuste de taxa e o MAC Ethernet.

129
129
Capítulo 7 Considerações Finais e Trabalhos Futuros
Este trabalho apresentou a implementação em hardware de um codificador LDPC para um
sistema de televisão digital através da utilização de ferramentas de prototipagem rápida para
FPGAs. No esquema implementado, o codificador seguiu os preceitos de um código eIRA
(extended Irregular Repeat Accumulate), com palavra-código de 9792 bits de comprimento e taxa
3/4. Da mesma forma, as ferramentas inovadoras de prototipagem rápida, empregadas no
desenvolvimento, foram introduzidas.
Um dos aspectos importantes abordados neste trabalho refere-se à união da etapa de
concepção do código com sua efetiva implementação em um dispositivo de hardware.
Recentemente, dois pontos-chave têm recebido essencial importância. Primeiro, as FPGAs têm
mostrado ser a melhor solução para a implementação em hardware, especialmente nas etapas de
desenvolvimento e de prototipagem. Segundo, as ferramentas de projeto têm sido projetadas para
proporcionar soluções de desenvolvimento de alto nível e que propiciem ganho de produtividade.
Desta forma, este trabalho expôs propostas de desenvolvimento e tendências de novas tecnologias
de projeto, apresentando resultados concretos através de uma implementação dada em FPGA.
De fato, o cenário atual exige que o desenvolvimento de soluções tecnológicas seja cada
vez mais ágil e rápido. Constatou-se na elaboração deste trabalho, que as ferramentas de

Capítulo 7 – Considerações Finais e Trabalhos Futuros 130
prototipagem rápida apresentadas possibilitam inúmeras vantagens no que se refere ao tempo de
desenvolvimento, testes, análise de relações de compromisso e facilidade de alteração do projeto.
Não obstante, em um contexto mais geral, foi oferecida uma visão sistêmica do sistema de
televisão digital, desenvolvido para operar sobre o protocolo de internet (IP). Esta apresentação, a
qual foi antecedida de uma introdução, visou contextualizar os trabalhos oferecidos nesta
dissertação, bem como exemplificar as potencialidades das ferramentas de prototipagem rápida
apresentadas. Algumas particularidades do sistema proposto também foram apresentadas como
forma de elucidar as características peculiares do sistema, tal qual foi o caso da explanação sobre
o ajuste de taxa necessário para o funcionamento do protótipo.
Como possíveis extensões a este trabalho, a implementação de diferentes estruturas de
códigos LDPC podem proporcionar uma amplo leque de análises, principalmente, referentes ao
desempenho e à ocupação destes em FPGAs. Estruturas de códigos regulares e irregulares podem
ser experimentadas. Da mesma forma, estudos mais elaborados e desenvolvimento de modelos de
implementação, ambos relativos à decodificação LDPC, podem ser desenvolvidos com mais
apreço.
Ademais, ferramentas de síntese mais poderosas podem ser aplicadas à etapa de
desenvolvimento, a fim de otimizar as implementações, especialmente no que se refere à
ocupação de área de silício do dispositivo. Uma vez obtidos resultados satisfatórios, pode-se
estudar a viabilidade de futuras implementações em dispositivos de hardware de menor porte.

131
131
Referências Bibliográficas
[1] Cesear, T.M.; “Optimizing Performance of DSP Systems through Block-Level Design”,
Embedded Conference of San Francisco, 2005.
[2] Ganousis, D.; “Top-Down DSP Design Flow to Silicon Implementation”, FPGA and
Programmable Logic Journal, March of 2004.
[3] Maxfield, C.; “The Design Warrior’s Guide to FPGAs – Devices, Tools and Flows”,
Elsevier, 2004.
[4] Powell, S.R.; Cesear T.M.; “Rapid Design and Exploration of Signal Processing using a
VHDL Model Generator Based Paradigm”, Second Annual RASSP (Rapid Prototyping
of Application Specific Signal Processors) Conference, 1996.
[5] AccelChip Inc.; “Automated Conversation of Floating-point to Fixed-point Matlab”.
Disponível em http://www.accelchip.com/papers.html, 2004. Acessado em janeiro de
2006.
[6] Presidência da República, Casa Civil, Subchefia para Assuntos Jurídicos; “Decreto
Presidencial número 5820”, 26 de Novembro de 2003, Brasília, Brasil. Disponível em
https://www.planalto.gov.br/ccivil/decreto/2003/D4901.htm. Acessado em outubro de
2006.
[7] Xilinx Inc.; “FPGA Design Flow Overview”; Disponível em
http://toolbox.xilinx.com/docsan/xilinx7/help/iseguide/html/ise_fpga_design_flow_over
view.htm . Acessado em outubro de 2006.
[8] Xilinx Inc.; “System Generator For DSP”; Disponível em
http://www.xilinx.com/support/sw_manuals/sysgen_ug.pdf. Acessado em outubro de
2006.

Referências Bibliográficas 132
[9] Xilinx Inc.; “Simulation Models”; Disponível em
http://support.xilinx.com/techdocs/15338.htm. Acessado em dezembro de 2005.
[10] AccelChip Inc.; “Matlab for Synthesis Style Guide”; California, USA, 2005.
[11] AccelChip Inc.; “AccelChip DSP Synthesis User Guide”, California, USA, 2005.
[12] Gonzales, R.C.; Woods, R.E.; “Digital Image Processing”; USA: Addison-Wesley
Publishing Company, 1993.
[13] Bhaskaran; Vasudev; Konstantinides; Konstantinos; “Image and Video Compression
Standards”; Kluwer Academic Publishers 2nd Edition, 1997.
[14] Y. Wang; J. Ostermann, Y. Zhang; “Video Processing and Communications”; Prentice
Hall, Signal Processing Series, 2002.
[15] C. Poynton; “Digital Video and HDTV Algorithms and Interfaces”; Morgan Kaufman
Publishers, 2003.
[16] F.C.C. de Castro; M.C.F. de Castro; “Codificação de Sinais”, PUCRS, Porto Alegre.
Disponível em http://www.ee.pucrs.br/~decastro/pdf/cs5.pdf . Acessado em outubro de
2006.
[17] VideoLAN; “Software Development Project”. Disponível em www.videolan.org. Acessado
em julho de 2006.
[18] Tanenbaum, A.S.; “Computer Networks”; USA, Prentice Hall, 4th Edition, 2003.
[19] Pinheiro, J.M.S.; “Frames, Pacotes e Datagramas”. Disponível em
http://www.projetoderedes.com.br/artigos/artigo_frames_datagramas_pacotes.php .
Acessado em julho de 2006.
[20] IETF (Internet Engineering Task Force); “Request For Comment 0768 - User Datagram
Protocol”. Disponível em http://www.ietf.org/rfc/rfc0768.txt. Acessado em julho de
2006.
[21] José Marcos Câmara Brito; José Santo Guiscafré Panaro; Dayan Adionel Guimarães;
Cristiano Magalhães Panazio; Luciano Leonel Mendes; Geraldo Gil Ramundo Gomes;
“Recomendações para Modelo de Referência”; Convênio 0026/05 em atendimento a
carta convite MC/MCT/FINEP/FUNTTEL- TV Digital - 18/2004, fevereiro de 2006.
[22] T. Kailath, “A general likelihood-ratio formula for signals in Gaussian noise” ; IEEE
Trans. Inf. Theory, vol. IT-15, pp. 350-361; May of 1969.

Referências Bibliográficas 133
[23] M. K. Simon and R. Annavajjala; “On the Optimality of Bit Detection of Certain Digital
Modulations”; IEEE Trans. on Communications, vol. 53, nº 2, February of 2005.
[24] Ahmad R. S. Bahai and Burton R. Saltzberg; “Multi-Carrier Digital Communications:
Theory and Applications of OFDM”; Kluwer Academic Publishers, 2002.
[25] K. Fazel and S. Kaiser; "Multi-Carrier and Spread Spectrum Systems"; John Wiley & Sons,
2003.
[26] S. Alamouti; "A simple transmit diversity technique for wireless communications"; IEEE J.
Select. Areas Communications; volume 16, no 8, pp. 1451-1458, October of 1998.
[27] A.B. Carlson; “Communications Systems”; McGraw-Hill, 1965.
[28] Shu Lin, Daniel Costello Jr.; “Error Control Coding”; Pearson Prentice Hall, Second
Edition, 2004.
[29] I.S. Reed, G. Solomon; “Polynomial Codes Over Certain Finite Fields” ; Journal of the
society for Industrial and Applied Mathematics, vol. 8, nº2, 1960.
[30] Chi-Tsong Chen; “Linear System Theory and design”; Harcourt Brace College Publisher,
1984.
[31] 4i2i IP Cores Supplier; “Reed-Solomon Tutorial”. Disponível em
http://www.4i2i.com/reed_solomon_codes.htm. Acessado em novembro de 2006.
[32] R. G. Gallager; “Low-density parity-check codes”; IRE Transactions on Information
Theory, vol. IT-8, pp. 21–28, January of 1962.
[33] R.G. Gallager; “Low Density parity-check codes”; Monography, MIT Press, 1963.
[34] R. M. Tanner; “A recursive approach to low-complexity codes”; IEEE Trans. Information
Theory, pp. 533–547, September of 1981.
[35] D. MacKay; “Good error-correcting codes based on very sparse matrices”; IEEE Trans.
Information Theory, pp. 399–431, March of 1999.
[36] M. Luby; M. Mitzenmacher; A. Shokrollahi; D. Spielman; “Improved low-density parity-
check codes using irregular graphs”; IEEE Transactions on Information Theory, vol.47,
pp.585-598, February of 2001.
[37] M. Yang; W. Ryan; and Y. Li; “Design of efficiently encodable moderate-length high-rate
irregular LDPC codes”; IEEE Trans. Communications, vol. 52, nº 4, pp. 564-571, April
of 2004.

Referências Bibliográficas 134
[38] Y. Zhang; W. Ryan; and Y. Li; “Structured eIRA codes with low floors”; Proceedings of the
International Symposium on Information Theory - ISIT2005, pp. 74–178, September of
2005.
[39] ETSI (European Telecommunications Standards Institute); “DVB-S.2 Standard
Specification”. Disponível em http://webapp.etsi.org/action/PU/20050322/en
302307v010101p.pdf. Acessado em junho de 2006.
[40] T. J. Richardson and R. Urbanke; “The capacity of low-density parity check codes under
message-passing decoding”; IEEE Transactions on Information Theory, Vol. 27, nº 2.
February of 2001.
[41] Tarciano F. Pegoraro; Fábio A. L. Gomes; Renato R. Lopes; Roberto Gallo; José S. Panaro;
Marcelo C. Paiva; Fabrício C. A. Oliveira and Fabio Lumertz; “Design, Simulation and
Hardware Implementation of a Digital Television System: LDPC channel coding”;
IEEE 9th International Symposium on Spread Spectrum Techniques and Applications
(ISSSTA), Manaus, Brazil, August 2006.
[42] Tarciano F. Pegoraro; Fábio A. L. Gomes; Fábio Lumertz; Renato R. Lopes; Fabrício C. A.
Oliveira; Roberto Gallo; Marcelo C. Paiva e José S. Panaro; “Codificação LDPC em
Sistemas de Televisão Digital”; Revista Telecomunicações, vol.9, Santa Rita do Sapucaí,
MG, Brasil, dezembro de 2006.
[43] Nallatech Inc.; “Xtreme DSP Development KIT-IV User Guide”; April of 2005.
[44] Xilinx Inc.; “Virtex-4 User Guide”; version 1.6, October of 2006. Disponível em
http://www.xilinx.com/bvdocs/userguides/ug070.pdf. Acessado em novembro de 2006.
[45] Xilinx Inc.; “ML40x Evaluation Platform User Guide”; version 1.0.1, June of 2006.
Disponível em http://www.xilinx.com/bvdocs/userguides/ug210.pdf . Acessado em
novembro de 2006.

135
135
Apêndice A Código Fonte do Bloco M-Code que Implementa o Codificador LDPC function [Read_Fifo, Write_Enable, Data_Out_Enc, Write_Parity, Parity_Addr_Write, Parity_Addr, New_Parity,AddrAddr] = ENCODER(Reset, Empty, Full, Data_In, Parity, Parity_Addr_Tabel) %% Registrar as saídas: persistent Write_Enable_sc, Write_Enable_sc = xl_state(0,{xlUnsigned,1,0}); persistent Data_Out_Enc_sc, Data_Out_Enc_sc = xl_state(0,{xlUnsigned,1,0}); Write_Enable = Write_Enable_sc; Data_Out_Enc = Data_Out_Enc_sc; %% Constantes: idle = 0; first = 1; second = 2; third = 3; fourth = 4; init = 0; %% Estados Internos: persistent count_vc, count_vc = xl_state(init, {xlUnsigned,16,0}); % Conta as posições ate 36720; persistent auxcount_vc, auxcount_vc = xl_state(init, {xlUnsigned,4,0}); % conta até 3 ou até 12; persistent tmp, tmp = xl_state(init, {xlUnsigned,1,0}); persistent parWrite, parWrite = xl_state(init, {xlUnsigned,12,0}); persistent state, state = xl_state(idle, {xlUnsigned, 3, 0}); if Reset==1 count_vc = init; auxcount_vc = init; tmp = init; parWrite = init; state = idle; Read_Fifo = 0; Write_Enable_sc = 0; Write_Parity = 0; AddrAddr = 0; Data_Out_Enc_sc = 0;

Apêndice A 136
Parity_Addr_Write = 0; Parity_Addr = 0; New_Parity = 0; else if((Empty == xfix({xlUnsigned,1,0},0))& (Full_sc == xfix({xlUnsigned,1,0},0))) switch state case idle state = first; Read_Fifo = 1; Write_Enable_sc = 0; Write_Parity = 0; AddrAddr = 0; Data_Out_Enc_sc = 0; Parity_Addr_Write = 0; Parity_Addr = 0; New_Parity = 0; case first parWrite = xfix( {xlUnsigned,12,0}, 22); count_vc = 2; auxcount_vc = 1; state = second; Read_Fifo = 0; Write_Enable_sc = 0; Write_Parity = 1; AddrAddr = xfix( {xlUnsigned,16,0}, 2); % AddrAddr; Data_Out_Enc_sc = 0; Parity_Addr_Write = xfix( {xlUnsigned,12,0}, 21); Parity_Addr = xfix( {xlUnsigned,12,0}, 22); New_Parity = xfix( {xlUnsigned,1,0}, Data_In); case second Write_Parity = 1; if (count_vc <= 17136)% 17136 = 51 * 112 * 3 top_v = xfix( {xlUnsigned,12,0}, 2); else top_v = xfix( {xlUnsigned,12,0}, 11); end if (auxcount_vc == top_v) Data_Out_Enc_sc = xfix( {xlUnsigned,1,0}, Data_In); Write_Enable_sc = xfix( {xlUnsigned,1,0}, 1); if (count_vc < 36720) % = 7344 * 5; 5=720/144 média; Read_Fifo = xfix( {xlUnsigned,1,0}, 1); else Read_Fifo = xfix( {xlUnsigned,1,0}, 0); end auxcount_vc = 0; % conta até 3 ou até 12; else auxcount_vc = auxcount_vc + 1; Data_Out_Enc_sc = xfix( {xlUnsigned,1,0}, 0); Write_Enable_sc = xfix( {xlUnsigned,1,0}, 0);

Apêndice A 137
Read_Fifo = xfix( {xlUnsigned,1,0}, 0); end New_Parity = xfix({xlUnsigned,1,0},xl_xor(Parity,Data_In)); Parity_Addr_Write = xfix( {xlUnsigned,12,0}, parWrite); parWrite = Parity_Addr_Tabel; if (count_vc == 36720)% 36720 = 51*720 Parity_Addr = xfix( {xlUnsigned,12,0}, 0); AddrAddr = xfix( {xlUnsigned,16,0}, 0); count_vc = 0; state = third; else Parity_Addr = xfix( {xlUnsigned,12,0}, Parity_Addr_Tabel); count_vc = count_vc + 1; if (count_vc < 36720) AddrAddr = xfix( {xlUnsigned,16,0}, count_vc); else AddrAddr = xfix( {xlUnsigned,16,0}, 0); end end case third tmp = xfix( {xlUnsigned,1,0}, Parity); count_vc = xfix( {xlUnsigned,16,0}, 1); state = fourth; Read_Fifo = 0; Write_Enable_sc = xfix( {xlUnsigned,1,0}, 1); Write_Parity = 1; AddrAddr = 0; Data_Out_Enc_sc = xfix( {xlUnsigned,1,0}, Parity); Parity_Addr_Write = xfix( {xlUnsigned,12,0}, 0); Parity_Addr = xfix( {xlUnsigned,12,0}, 1); New_Parity = xfix( {xlUnsigned,1,0}, 0); case fourth %Habilita saída da paridade fazendo o xor acumulador tmp = xfix( {xlUnsigned,1,0}, xl_xor(Parity, tmp)); Data_Out_Enc_sc = xfix( {xlUnsigned,1,0}, tmp); Write_Enable_sc = xfix( {xlUnsigned,1,0}, 1); Parity_Addr_Write = xfix( {xlUnsigned,12,0}, count_vc); if (count_vc == 2447); Read_Fifo = xfix( {xlUnsigned,1,0}, 1); Parity_Addr = 0; state = first; else count_vc = count_vc + 1; Parity_Addr = xfix( {xlUnsigned,12,0}, count_vc); Read_Fifo = xfix( {xlUnsigned,1,0}, 0 ); end Write_Parity = 1; AddrAddr = 0; New_Parity = xfix( {xlUnsigned,1,0}, 0); otherwise

Apêndice A 138
Read_Fifo = 0; Write_Enable_sc = 0; Write_Parity = 0; AddrAddr = 0; Data_Out_Enc_sc = 0; Parity_Addr_Write = 0; Parity_Addr = 0; New_Parity = 0; end else Read_Fifo = 0; Write_Enable_sc = 0; Write_Parity = 0; AddrAddr = 0; Data_Out_Enc_sc = 0; Parity_Addr_Write = 0; Parity_Addr = 0; New_Parity = 0; end end’
Top Related