
projetos.inf.ufsc.br · Web viewA todos os meus amigos e pessoas próximas que me incentivaram a...
126
1 JEAN GONÇALVES (bolsista de iniciação científica) AVALIAÇÃO DO DESCRITOR SCD DO PADRÃO MPEG-7 E ÍNDICE MÉTRICO PARA RECUPERAR IMAGENS DO COPHIR POR SIMILARIDADE
Transcript of projetos.inf.ufsc.br · Web viewA todos os meus amigos e pessoas próximas que me incentivaram a...

1
JEAN GONÇALVES(bolsista de iniciação científica)
AVALIAÇÃO DO DESCRITOR SCD DO PADRÃO MPEG-7 E ÍNDICE MÉTRICO PARA RECUPERAR IMAGENS DO COPHIR POR
SIMILARIDADE
Florianópolis – SC 2013

2
UNIVERSIDADE FEDERAL DE SANTA CATARINADEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA
CURSO DE CIÊNCIAS DA COMPUTAÇÃO
AVALIAÇÃO DO DESCRITOR SCD DO PADRÃO MPEG-7 E ÍNDICE MÉTRICO PARA RECUPERAR IMAGENS DO COPHIR POR
SIMILARIDADE
JEAN GONÇALVES(bolsista de iniciação científica)
Orientador:Prof. Dr. Renato Fileto
Trabalho de conclusão de curso apresentado como parte dos requisitos para obtenção do grau de Bacharel em Ciências da Computação na Universidade Federal de Santa Catarina
Florianópolis – SC 2013

3
AGRADECIMENTOS
Agradeço a todos que me ajudaram direta e indiretamente na construção deste trabalho. Agradeço a meu pai e minha mãe por terem me dado todo o tipo de apoio durante todo este processo, principalmente a estrutura e o apoio moral, agradeço também a minha família e a todos os meus parentes que, com muito carinho e apoio, não mediram esforços para que eu chegasse até essa etapa da minha vida.
A todos os meus amigos e pessoas próximas que me incentivaram a continuar na luta e me reerguer diante de tantas dificuldades enfrentadas. Ao Marcelo Krüger que me deu suportes essenciais para viabilizar a realização deste trabalho. A todos os companheiros do laboratório LISA cujas opiniões me ajudaram e muito a desenvolver partes importantes do trabalho. A todos os professores do curso, que foram muito importantes na minha vida acadêmica.
Ao meu orientador Renato Fileto pelo seu incentivo, total apoio e devida orientação para que este trabalho tenha o seu devido andamento, ao meu coorientador Eros Comunello e ao Rogério Richa por me ajudarem em partes fundamentais deste trabalho.

4
RESUMO
A recuperação por similaridade de conteúdo pode ser aplicada a vários tipos de dados. No caso de um banco de dados de imagens, a recuperação por similaridade faz uso de duas componentes. Uma delas é um conjunto de vetores de características extraídos do conteúdo das imagens (e.g., referentes a cores, formas e texturas). A outra é uma métrica que mede a similaridade entre duas imagens quaisquer de uma coleção, com base nos respectivos vetores de características (e.g., histogramas de cores). As combinações de descritores e métricas que podem ser usados na recuperação por similaridade são inúmeras. Algumas delas são mais específicas e eficientes para determinadas coleções de dados e operações de recuperação. É importante escolher vetores de características e uma métrica de similaridade que permitam um bom desempenho das operações de recuperação de uma coleção de dados, tanto em termos do tempo de execução quanto em termos da qualidade (precisão e cobertura) dos resultados. O objetivo deste trabalho é estudar métricas e vetores de características apropriados para recuperar imagens de cunho geral descritas segundo o padrão MPEG-7. É necessário compactar os vetores de características para melhorar o processo de recuperação. A implementação efetuada utiliza o FMI-SiR, uma extensão do SGBD Oracle para a recuperação de dados complexos por similaridade de conteúdo. O trabalho inclui revisão bibliográfica, testes e experimentos com as métricas e descritores estudados na recuperação de imagens do CoPhIR por por conteúdo.
Palavras-chave: Recuperação de imagens por similaridade. Buscas por similaridade. Métricas de similaridade. Descritores de conteúdo de imagens.Metadados.Padrão MPEG-7.

5
ABSTRACT
Content-based similarity retrieval can be applied to many kinds of data. Similarity retrieval in image databases makes use of two components. One of them is a set of characteristics vectors extracted from images contents (e.g., regarding colors, shapes and textures). The other one is a metric thatmeasures the similarity between any given images of a collection, based on some chosen descriptors of these images (e.g., color histogram). The number of combinations of descriptorsand metrics that can be used in similarity retrieval is possibly unbounded.Some of them are more specific and effective to certain sets of data and retrieval operations. It is important to choose a metric and characteristics vectors that allow a good performance of retrieval operations, in terms of both execution time and results quality (precision and recall). The objective of this work is to study metrics and characteristics vectors suitable for retrieving images described according to the MPEG-7 standard. It is necessaryto compactthe characteristics vectors to improve the retrieval process. The implementationuses FMI-SiR, an extension of the Oracle SGBD for content-based complex data similarity retrieval. This work includes literature review, tests and experiments that employ the metrics and descriptors studied retrieving imagesof the CoPhIR dataset.
Keywords: Content-based image retrieval. Similarity search.Similarity metrics.Image content descriptors.Metadata. MPEG-7 standard descriptors.

6
SUMÁRIO
SUMÁRIO........................................................................................................................................61 INTRODUÇÃO.............................................................................................................................8
1.1 OBJETIVOS.........................................................................................................................101.1.1 OBJETIVO GERAL......................................................................................................111.1.2 OBJETIVOS ESPECÍFICOS........................................................................................11
1.2 METODOLOGIA.................................................................................................................121.3 MOTIVAÇÃO......................................................................................................................121.4 ORGANIZAÇÃO DO RESTANTE DO TRABALHO...................................................13
2 FUNDAMENTOS.......................................................................................................................152.1 DADOS COMPLEXOS.......................................................................................................152.2 RECUPERAÇÃO POR SIMILARIDADE DE CONTEÚDO.............................................152.3 ESPAÇO MÉTRICO E MÉTRICAS DE SIMILARIDADE...............................................162.4 CONSULTAS POR SIMILARIDADE.................................................................................232.5 ÍNDICES..............................................................................................................................24
2.5.1 B-TREE.........................................................................................................................252.5.1 SLIM-TREE..................................................................................................................26
2.6 PADRÃO MPEG-7...............................................................................................................272.6.1 ARQUITETURA DO MPEG-7.....................................................................................282.6.2 DESCRITORES MPEG-7.............................................................................................31
3 ESTUDOS DOS DESCRITORES DE CONTEÚDO E MÉTRICAS DE SIMILARIDADE PARA O PADRAO MPEG-7..........................................................................................................33
3.1 MEDIDAS DE DESEMPENHO PARA RECUPERAÇÃO DE INFORMAÇÃO..............333.2 ESTRATÉGIAS PARA RECUPERAÇÃO EFICIENTE DE IMAGENS POR SIMILARIDADE DE CONTEÚDO..........................................................................................36
3.2.1 MESCLAGEM DE PALETAS DE HISTOGRAMAS COM USO CONTÍNUO DE FEEDBACK...........................................................................................................................373.2.2 COMPACTAÇÃO NOS DESCRITORES SCD E HTD...............................................393.2.3 MODIFICAÇÃO NO DCD E EHD..............................................................................413.2.4 SÍNTESE E USO DO DESCRITOR DCSD (DOMINANT COLOR STRUCTURE DESCRIPTOR).......................................................................................................................433.2.5 COMBINAÇÃO DE UM DESCRITOR DE TEXTURA COM VÁRIOS DESCRITORES DE COR......................................................................................................443.2.6 OUTRAS ESTRATÉGIAS ESTUDADAS...................................................................473.2.7 QUADRO COMPARATIVO........................................................................................48
4 IMPLEMENTAÇÃO, EXPERIMENTOS E ANÁLISE DOS RESULTADOS..........................52

7
4.1 IMPLEMENTAÇÃO............................................................................................................534.2 EXPERIMENTOS E AVALIAÇÃO.....................................................................................62
5 TRABALHOS RELACIONADOS.............................................................................................775.1 USO DAS MÉTRICAS QHDM E MPHSM JUNTAMENTE COM FEEDBACK DE USUÁRIO..................................................................................................................................775.2 USO DA MÉTRICA MANHATTAN EM IMAGENS DE CUNHO ESPECÍFICO............78
6 CONCLUSÕES E TRABALHOS FUTUROS...........................................................................79REFERÊNCIAS.............................................................................................................................81ANEXOS........................................................................................................................................84
A.1 - CRONOGRAMA..............................................................................................................84A.2 - CUSTOS............................................................................................................................84A.3 - RISCOS.............................................................................................................................85A.4 - COMUNICAÇÃO.............................................................................................................85

8
1 INTRODUÇÃO
Atualmente a quantidade de dados armazenados pelo mundo tem crescido
tanto em quantidade quanto em complexidade. Um dos principais problemas
resultantes desse crescimento é a dificuldade para obter eficiência nas operações de
recuperação de informação realizadas sobre grandes volumes de dados complexos.
Nesse contexto, bancos de dados multimídia ganharam muita importância devido ao
seu uso intenso, pois podem armazenar dados que são usados tanto para o lazer
quanto para trabalhos profissionais. Segundo Rüger (2009), um banco de dados
multimídia inclui “duas ou mais mídias e se refere a diferentes modos de consumo
de informação, dentre eles: escutar, ver, ler, assistir, cheirar, etc...” e envolve aúdio,
vídeo e imagens. Tais dados são chamados complexos, porque não possuem a
representação de seu conteúdo na forma de simples números e cadeias de
caracteres, ou seja, não são considerados dados convencionais. Devido a esse fato,
eles não são manipuláveis somente através de técnicas tradicionais de
gerenciamento de dados, tornando-se necessário usar técnicas mais sofisticadas
para realizar tal tarefa. Os dados complexos (multimídia, séries temporais, etc.)
posssuem pelo menos uma dentre as seguintes características:
(i) representação em vários formatos (e.g. bases de dados, textos, imagens, sons, vídeos, ...); (ii) coleções podendo possuir estruturas diversificadas(e.g. banco de dados relacionais, documentos XML, ...); (iii) sua origem pode se dar em diversas fontes (e.g. ); (iv) podem ser descritos de diversas maneiras através de canais ou pontos de vista (e.g. um vídeo ou um texto que descrevem o mesmo fenômeno meteorológico, dados expressos em diferentes idiomas, ...); (v) mudam em termos de definição e valor ao longo do tempo (e.g. banco de dados temporais, ...). (DARMONT et al, 2005, apud MAHBOUBI et al, 2009, p.39, livre tradução nossa).
Dados complexos, diferentemente dos dados tradicionais, não podem ser
ordenados (e.g., imagens ou vídeos usualmente não podem ser ordenados de
maneira consistente e universalmente aceitável, tal como se ordenam números por
seu valor e cadeias de caracteres pela ordem léxica). Dependendo de como os
objetos complexos estiverem descritos ou armazendados e do objetivo das
consultas, estas podem incluir predicados sobre dois tipos de componentes de
dados: (i) predicados de comparação dos metadados usados para descrever objetos
complexos, tais como a sua data de criação ou palavras-chave que os descrevam;
ou (ii) predicados baseados em similaridade do conteúdo dos objetos em questão.

9
Este trabalho foca no segundo tipo de predicado de consulta, i.e., baseados em
similaridade de conteúdo. Segundo Barioni (2006) consultas por similaridade
“retornam objetos do conjunto de dados que sejam similares a um objeto de
referência (ou objeto de consulta), de acordo com um critério de similaridade”. Além
das consultas por similaridade, também foram propostos na literatura vários outros
operadores baseados em similaridade, incluindo junções por similaridade e o uso da
similaridade em métodos de classificação e agrupamento de dados complexos
(Datta et al. 2008).
No caso da recuperação de dados tradicionais, estes podem ser
representados através de cadeias de caracteres ou números. Tais dados simples
satisfazem a propriedade de relação de ordem total, que permite compará-los com
operadores como <, ≤, >, ≥ e =, ou seja, é possível comparar pares de strings ou de
números e dizer se são iguais ou qual deles é maior ou menor em comparação ao
outro, segundo a ordenação léxica e numérica, respectivamente. A maioria dos
domínios dos dados complexos não satisfaz a relação de ordem total. É muito raro o
uso do operador de igualdade com dados complexos, visto que, em um banco de
dados com dados complexos, a grande maioria dos dados não são idênticos.
Também não faz sentido em grande parte das aplicações comparar dados
complexos como imagens através de desigualdades.
Os dados complexos podem ser recuperados com busca por similaridade.
Barioni (2009) afirma que dados dessa categoria podem ser armazenadas no banco
de dados de duas formas: como vetores de características dos objetos complexos
(ela cita como exemplo posições geográficas dos dados que podem ser localizados
através de sua latitude e longitude) ou como um objeto binário largo (em inglês
BLOB, Binary Large Object). Caso os objetos complexos estejam armazenados da
primeira forma, pode-se fazer uma consulta por similaridade usando função de
similaridade dos vetores de características. No segundo caso, o dado armazenado é
chamado bruto (raw data) e somente ele não é suficiente para suportar a execução
de consultas por similaridade. Para resolver esse problema é necessário extrair um
conjunto de características do conteúdo e usar tais características, juntamente com
uma métrica de similaridade calculada a partir de tais caractrísticas, para realizar a
consulta por similaridade. A busca por similaridade pode usar vários tipos de
predicados. Um predicado kNN (k Nearest Neighbors) retorna os ‘k’ vizinhos mais
próximos de um objeto de consulta, de acordo com uma métrica de similaridade

10
escolhida, sendo ‘k’ um número inteiro positivo arbitrário. Um predicado dentro de
um raio (range), por outro lado, retornados objetos da base de dados a até uma
dada distância (raio) de um objeto de cosulta. Os processos de indexação e
recuperação por similaridade são usualmente mais caros, pois requerem
processamento do conteúdo (e.g., imagens) para a extração de características, o
cálculo de funções de similaridade que podem ser complexas e o uso de índices
métricos, muitas vezes menos eficientes que os convencionais. Dependendo de
como os dados forem tratados e indexados essa complexidade computacional pode
aumentar ou diminuir.
Buscas por similaridade em um espaço métrico (definido por uma coleção de
objetos e uma métrica de similaridade baseada em algum vetor de características
dos objetos) podem ser agilizadas por métodos de acesso métricos. Sem indexação
cada busca é sequencial, com complexidade linear no número de objetos da
coleção, podendo resultar em baixo desempenho. Índices podem reduzir o número
de cálculos de similaridade, permitindo melhorar o desempenho das consultas por
similaridade. Slim-tree, M-tree e BK-tree, dentre outras estruturas, são exemplos de
índices métricos (Zezula et al. 2006). O bom funcionamento dessas estruturas
depende de espaços métricos apropriados para permitir podas baseadas na
desigualdade triangular (e consequentemente processamento de consulta em
tempo) sub-linear ao mesmo tempo em que se gere resultados com bons níveis de
cobertura e precisão.
1.1 OBJETIVOS
O trabalho aqui apresentado visa estudar, selecionar e aplicar métricas de
similaridade e descritores de conteúdo de imagens do padrão MPEG-7 apropriados
para a recuperação de imagens. Segundo Rüger (2009, p.16, tradução nossa),
MPEG-7 é um padrão para descrição e procura de recursos audiovisuais. O
acrônimo MPEG refere-se ao Grupo de Especialistas em Imagens Animadas
(tradução nossa do inglês Moving Picture Expert Group). O objetivo é avaliar qual
métrica e descritores desse padrão conferem melhor desempenho à recuperação de
imagens de cunho geral por similaridade de conteúdo, em termos de tempo de
execução e qualidade dos resultados. Para isso, se realizam experimentos em uma
base de dados chamada CoPhIR (Content-based Photo Image Retrieval), um grande

11
repositório de vetores de características no formato MPEG-7, juntamente com
alguns metadados associados (tags, local, etc.). Esses metadados foram extraídos
de mais de 100 milhões de imagens do Flickr por pesquisadores europeus, os quais
disponibilizam os dados resultantes mediante contrato, para fins de pesquisa. Para
maiores informações sobre o CoPhIR, consultar a tese de Molková (2011). Essa
base de dados está armazenada em um computador no Laboratório para Aplicações
de Sistemas Avançados (LISA) na Universidade Federal de Santa Catarina e o
SGBD a ser usado será o Oracle Enterprise 11g versão 2. A realização de busca por
similaridade é feita em conjunto com uma ferramenta criada por Kaster (2010) cuja
abreviação é FMI-SiR (user-defined Features, Metrics and Indexes for Similarity
Retrieval), trata-se de uma ferramenta que permite o uso de índices específicos
sobre coleções de imagens. O FMI-SIR e permite a implementação e o uso de
descritores e métricas para indexação e recuperação eficiente de imagens usando
índice métrico, particularmente a Slim-Tree. Outros trabalhos serão feitos em
paralelo com o uso desse conjunto de ferramentas tais como a criação de
fragmentos dos dados, porém o foco desse trabalho se limita ao estudo de métricas
e descritores e suas implementações.
1.1.1 OBJETIVO GERAL
O objetivo geral deste trabalho é estudar as métricas e descritores
recomendados para se utilizar em processos de recuperação por similaridade,
selecionar os mais apropriados para recuperar imagens de cunho geral (extraídas de
rede social) e implementá-los no FMI-SiR, uma ferramenta criada por Kaster et al.
(2010), com o objetivo de se recuperar dados multimídia por similaridade sobre o
Oracle.
1.1.2 OBJETIVOS ESPECÍFICOS
Os objetivos específicos são:
1. Estudar a literatura sobre recuperação de dados multimídia por similaridade,
métricas de similaridade, descritores de imagens e ferramentas de software
para esta finalidade.
2. Selecionar a métrica e o descritor apropriado (ou descritores apropriados)
para a recuperação eficiente de imagens descritas segundo o padrão MPEG-

12
7.
3. Implementar o descritor e, se necessário, também, métrica selecionados na
ferramenta FMI-SiR sobre Oracle.
4. Realizar experimentos de recuperação de informações do CoPhIR com a
métrica e descritores de conteúdo selecionados, e de modo a avaliar seu
desempenho ao menos do ponto de vista da eficiência computacional
(memória utilizada, tempo de criação dos índices, tempo de execução,
número de acessos a disco e número de cálculos da métrica de similaridade
para executar as consultas).
1.2 METODOLOGIA
Este trabalho parte de uma revisão bibliográfica sobre recuperação por
similaridade de um modo geral, o padrão MPEG-7 e os descritores desse padrão.
Abrange também consultas por similaridade e funções de similaridadee distância. É
necessária uma busca mais abrangente no início do trabalho para se ter um
discernimento das métricas apropriadas ou não para os descritores do padrão em
questão. Após a realização da revisão bibliográfica e a obtenção de conhecimentos
teóricos e práticos necessários para se realizar operações com as ferramentas
propostas, deve-se implementar a métrica selecionada na ferramenta FMI-SiR caso
ela ainda não esteja implementada, implementar o descritor necessário (ou
descritores necessários) para a recuperação eficiente por similaridade e executar
diversas consultas para fins experimentais. Uma consulta por similaridade tem uma
imagem como entrada e outras imagens semelhantes à de entrada como resultado.
Seu processamento consiste em capturar as características da imagem de busca
submetida como entrada e filtrar os dados contidos e previamente indexados no
repositório de modo a obter as imagens próximas à imagem de consulta.
1.3 MOTIVAÇÃO
A recuperação de um conjunto de imagens pode ter um desempenho
diferente de acordo com as características extraídas, métrica de similaridade usada
na comparação dessas características e consultas realizadas. Determinadas
métricas podem ser eficientes para a recuperação de imagens médicas, mas as
mesmas métricas podem ser muito ineficientes para a recuperação de fotos que

13
envolvam paisagens, por exemplo.
A motivação para a realização deste trabalho é encontrar respostas para
questões que envolvem avaliações de métricas e descritores em relação a imagens
de um modo geral e elaborar uma metodologia de avaliação de métricas e
descritores. Outra motivação para o trabalho é explorar o uso do FMI-SiR, uma
alternativa para o uso de ferramentas mais pesadas e mais complexas tais como o
Oracle Intermedia (produto desenvolvido pela Oracle com documentação no site da
empresa) e o SiReN (desenvolvido por Barioni (2006)). Os resultados deste TCC
devem contribuir para a realização de experimentos sobre diversos fragmentos do
CoPhIR, no âmbito do projeto “Informação de Contexto e Similaridade de Conteúdo
para a Recuperação Eficiente de Dados Complexos” (Edital Universal MCT/CNPq
2011), visando validar algumas propostas teóricas já formalizadas e aguardando
validação para a publicação na forma de artigos.
1.4ORGANIZAÇÃO DO RESTANTE DO TRABALHO
Após uma breve introdução teórica do trabalho e apresentação dos objetivos
e motivações, o trabalho segue com a fundamentação teórica e, em seguida, com a
introdução, desenvolvimento e conclusão do projeto, assim como a relação com
possíveis trabalhos futuros.
A fundamentação teórica é muito importante para esclarecer conceitos que
serão abordados na parte de projetos e deixar o leitor desse trabalho ciente dos
mecanismos que serão usados com as ferramentas. O fato de o trabalho envolver
métricas implica a necessidade de se explicar vários conceitos relacionados ao seu
uso tais como dados complexos e espaço métrico, além disso torna-se necessário
exemplificar algumas das várias métricas existentes a fim de diferenciá-las quanto
ao caso de uso de cada uma em particular. A seguir, a abordagem do projeto visa
explicar como os trabalhos de implementação serão conduzidos dentro do LISA para
pôr em prática as fundamentações abordadas, conhecer as ferramentas de trabalho,
operar com elas, obter os resultados e documentar o que for necessário. A
documentação do processo será útil para o desenvolvimento do artigo e para a
conclusão deste trabalho.

14

15
2 FUNDAMENTOS
Este capítulo aborda fundamentos necessários para a solução do problema
proposto, incluindo o conceito dados complexos, métricas de similaridade, espaços
métricos, recuperação de informação por similaridade de conteúdo, descritores de
conteúdo de imagens, padrão MPEG-7 e sua estrutura.
2.1 DADOS COMPLEXOS
Ao se comparar dados complexos com tradicionais, observa-se que os dados
complexos possuem uma estrutura mais robusta, pois ocupam mais espaço no
banco de dados e a forma como esta se encontra organizada dificulta a sua
manipulação. Os dados complexos geralmente possuem muitas informações
atribuídas ao conteúdo eo tratamento desse tipo de conteúdo deve ser diferenciado
para a sua manipulação e recuperação. Trata-se de dados contidos em vários meios
de armazenamento que vão desde bibliotecas digitais até banco de dados
convencionais, e a principal dificuldade na sua manipulação é a diversidade de seu
formato. Darmont et al, 2005, apud Mahboudi et al, 2009 exemplifica esse fato
citando o ambiente médico como um exemplo onde ocorre essa diversidade de
formatos possíveis de caracterizar um dado complexo, nesse meio os dados de um
paciente podem ocorrer de diversos formatos tais como dados cadastrais (no caso
de um banco de dados clássico), histórico (formato texto), radiografias e
ultrassonografias (dados multimídia), diagnósticos médicos (textos ou gravações em
áudio), dentre outros. Os mesmos autores ainda afirmam que esses dados, em
geral, podem ser representados em XML devido ás características e formas de
representação que essa linguagem possui. De fato, os dados complexos podem ser
representados de forma relacional e serem armazenados em bancos de dados
relacionais, porém vale ressaltar que as operações mais simples que funcionam
sobre dados tradicionais não oferecem recursos para medir dissimilaridades, pois
um banco de dados relacional normalmente não contém as funções e complementos
necessários para se realizar tal tarefa.
2.2 RECUPERAÇÃO POR SIMILARIDADE DE CONTEÚDO

16
Recuperação de dados baseado em conteúdo é uma forma de se resgatar
dados que vem sendo muito estudada e que vem despertando muito interesse nas
últimas décadas devido ao rápido avanço da tecnologia e devido ao crescimento
contínuo na quantidade de dados. A recuperação de similaridade por conteúdo é
muito utilizada na comparação entre dados complexos, esta faz uso de consultas
cujos resultados são objetos similares a um determinado objeto alvo segundo alguns
critérios determinados pelo usuário. Segundo Barioni(2006), recuperação baseada
em conteúdo pode ser usada em vários tipos de dados tais como vídeos, imagens e
áudios, sendo que, historicamente, surgiram primeiro os métodos de recuperação
por conteúdo para imagens(Recuperação de imagens baseada em conteúdo, ou
Content Based Image Retrieval em inglês), depois o do restante.
Pattanaik e Bhalke (2012) afirmam que a recuperação por similaridade de
conteúdo é dividido em duas partes, elas são extração de características e
comparação por similaridade. Dependendo do tipo de dado a ser tratado o processo
de extração de características e comparação por similaridade serão diferentes,
desse modo não é possível extraírmos características de uma imagem da mesma
forma como extraímos características de áudios, tratam-se de dados de naturezas
diferentes. Para a recuperação de similaridade por conteúdo ocorrer, o SGBD deve
ser configurado para tais tarefas, além disso programas complementares devem ser
instalados.
2.3 ESPAÇO MÉTRICO E MÉTRICAS DE SIMILARIDADE
Um espaço métrico M é definido como um par {S, d()}no qual S é o conjunto
de dados e d() é uma função de distância que, segundo Zezula (2006, p.8) deve
atender as seguintes propriedades para ser considerada uma métrica:
Não negatividade: x, y S, d(x, y) ≥ 0
Simetria: x, y S, d(x, y) = d(y, x)
Identidade: x, y S, d(x, y) = 0
Desigualdade triangular: x, y, z S, d(x, z) ≤ d(x, y) + d(y, z)
As métricas, ou funções de distância, retornam um valor que mostram o quão
dissimilares são os dados entre sí dentro de um espaço métrico. As métricas
geralmente são feitas para se avaliar distâncias entre determinados tipos de dados
e, na prática, são especificadas por especialistas de domínios. A escolha de uma

17
métrica deve ser apropriada para a distância que se deseja calcular, isso implicará
na distância (ou dissimilaridade) adequada entre os objetos. A fórmula em questão
deve conter informações que sejam suficientes para um cálculo preciso da
dissimilaridade, o resultado desse cálculo deve se assemelhar á percepção humana
da realidade. Para se entender melhor essa linha de raciocínio, pode-se “aplicar”
uma “função de distância” entre duas pessoas quaisquer para ver o quão diferente
elas são e poderíamos pôr na fórmula somente a cor da camisa, assim duas
pessoas com camisas de cor preta seriam iguais, e caso as cores fossem diferentes
se avaliaria através do bom senso o quão diferente as cores são. Segundo a
percepção humana, estão faltando alguns elementos a mais nessa fórmula, pois
uma das pessoas pode ser homem e a outra mulher, ou as duas terem rostos
completamente diferentes, corpos completamente diferentes, dentre outros detalhes
que não são cobertos por essa “função de distância” e essa métrica seria
inadequada para esse fim.
De um modo geral, as métricas são classificadas em dois grupos, discretas ou
contínuas. As funções de distância discretas retornam apenas um pequeno e
predefinido conjunto de valores, enquanto que as contínuas retornam um conjunto
de valores muito largo ou infinito. Um exemplo de função contínua é a distância
euclidiana, usada para medir a distância entre dois vetores em um espaço n
dimensional, e um exemplo de uma função discreta é a distância de edição, usada
para medir dissimilaridade entre strings. Além da distância euclidiana e a distância
de edição, existem outras, porém as mais conhecidas são: a distância Minkowski
(incluindo a distância euclidiana), distância forma quadrática, distância de edição,
distância de edição de árvore, coeficiente de Jaccard e a distância Hausdorff.
A distância Minkowski forma uma família grande de funções de distância
conhecida como as métricas Lp e cada valor inteiro que o parâmetro p assume
equivale a uma função de distância diferente. A métrica está representada na Figura
1.

18
Figura 1 – Distância Minkowski
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006, )
A métrica L1 é conhecida como a distância Manhattan, L2 é conhecida como a
distância euclidiana e L∞ é a distância infinita, ou a distância do campo de xadrez. A
figura 2 mostra o conjunto de pontos cuja distância de cada um até o ponto central é
igual para parâmetros p diferentes. Uma observação a se fazer é com relação á
diferença entre duas dessas métricas, a distância Manhattan e a distância
euclidiana. A distância Manhattan entre dois pontos é o cálculo da diferença absoluta
entre as coordenadas dos dois pontos, desse modo a geometria de distância entre
dois pontos não leva em conta geometrias circulares e o espaço métrico acaba se
assemelhando a um conjunto de blocos onde as distâncias entre dois pontos são
calculadas a partir de movimentos entre os blocos, ou seja, a soma de movimentos
horizontais e verticais de um ponto até outro resultariam a distância. Já a distância
euclidiana é a fórmula de Pitágoras de distância entre dois pontos e o cálculo da
distância não é a soma dos movimentos horizontais e verticais de um ponto até
outro, e sim um cálculo que resulta em uma linha reta que liga os dois pontos. É
possível notar essa observação através da figura 2, que mostra os pontos
equidistantes ao ponto central.
Figura 2 - O conjunto de pontos á uma distância constante do ponto central para cada função
Lp diferente.
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006, )

19
A distância forma quadrática, diferentemente da distância Minkowski,
aplica alguns elementos diferentes na fórmula. Trata-se de um modelo satisfatório
para se trabalhar em histogramas de cores de imagens, nesse caso o histograma
tem diferentes dimensões, cada dimensão representa uma cor e as cores são
comparadas entre sí quanto á sua similaridade. Para um conjunto de vetores de n
cores com dimensão n cada, a distância forma quadrática usa uma matriz M = [m i,j]
em que mi,j representa a força da conexão entre os componentes i e j de dois vetores
x e y respectivamente, sendo que todos os pesos assumem valores 0 ≤ m i,j ≤ 1 e a
diagonal mi,i é igual a 1. Existem duas métricas correspondentes á forma quadrática,
a primeira, representada na Figura 3, é a distância forma quadrática generalizada e
a segunda, representada na Figura 4, é a distância euclidiana com pesos, obtida
através da forma quadrática generalizada com a matriz M = diag(w1, w2, ..., wn), o T
denota a operação de transposição de vetores.
Figura 3 – Fórmula da distância forma quadrática generalizada
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006, )
Figura 4 – Fórmula da distância euclidiana com pesos
Fonte: Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006, )
Como exemplo para ilustrar essa situação, podemos considerar
histogramas com três diferentes cores, vermelho, laranja e azul e estão
representadas como vetores 3-D. Ao assumirmos três histogramas normalizados de
uma imagem vermelha pura x = (0, 1, 0), uma imagem laranja pura y = (0, 0, 1) e
uma imagem azul pura z = (1, 0, 0), a distância euclidiana calcularia as distâncias
L2(x,y) = √2 e L2(x,z) = √2, o que implicaria dizer que a dissimilaridade entre as cores

20
vermelho e laranja é igual á dissimilaridade entre as cores vermelho e azul, o que
significaria dizer que no espaço métrico em questão as cores azul e laranja são
equidistantes do vermelho. Porém, para a percepção humana, essas
dissimilaridades são diferentes, para resolver esse problema a abordagem da
métrica deve ser diferente. Assim, usando a fórmula (1) e a matriz M da figura 5, a
distância entre x e y seria √0.2 e a distância entre x e z seria igual á √2, o que
implicaria dizer que as cores laranja e vermelho são mais similares entre sí do que
as cores vermelho e azul. Trata-se de um método que é computacionalmente mais
caro devido ás matrizes, mas seu custo pode subir ainda mais dependendo da
dimensionalidade dos vetores, pois histogramas de imagens de cores geralmente
usam vetores com uma dimensão muito grande.
Figura 5: Matriz M usada no problema envolvendo histograma de cores na distância forma
quadrática.
Fonte: :Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006)
A distância de edição mede a dissimilaridade entre duas cadeias de
strings a partir de operações de edição (inserção, deleção e reposição) que
transformam uma string na outra. O número de operações deve ser mínimo e a
função de distância retorna a soma dos pesos de cada operação, assim quanto mais
operações forem necessárias para a transformação de uma string em outra, maior a
dissimilaridade entre elas. Os pesos assinalados para as operações devem ser
iguais pois, caso contrário, a distância de edição não será simétrica, pois
desobedecerá a propriedade (p2) dos postulados de espaços métricos. Um exemplo
citado pelo próprio Zezula(2006, p.12) atribui peso 2 á operação de inserção e peso
1 á operação de deleção e reposição, após essas atribuições de pesos o exemplo
mostra o cálculo da distância de edição entre “combine” e “combination” e vice
versa. A figura 6 ilustra o exemplo citado. No caso, a distância de “combine” até
“combination” é de 9 unidades, enquanto que a distância de “combination” até
combine é de 5 unidades. Se o peso de todas as operações atômicas fossem 1, as

21
duas distâncias de edição citadas seriam 5.
Figura 6 - Aplicação da distância de edição entre “combine” e “combination” e vice versa.
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006).
A distância de edição de árvores mede a dissimilaridade entre duas
árvores e segue um processo análogo á distância de edição, sendo que um conjunto
predefinido de operações (elas podem ser de inserção, deleção e reposição
também) ocorrem nos nodos de uma árvore a fim de transformá-la em outra e medir
a distância. Os pesos das operações podem ser iguais ou diferentes no caso de se
considerar a diferença de inserção ou deleção em níveis diferentes da árvore. Essa
métrica pode ser usada no cálculo de similaridade entre documentos XML devido ao
fato de esses documentos serem modelados em formato árvore.
O coeficiente de Jaccard mede a distância entre dois conjuntos de
dados, trata-se de uma razão entre as cardinalidades de interseção e união entre um
conjunto A e um conjunto B e a métrica é dada por:
(j1) d(A,B) = 1 - |A∩B| / |AUB|
Essa métrica possui utilidade em várias situações que se possa usar
conjuntos, dentre elas pode-se citar, por exemplo, os campos de interesses que são
pesquisados na internet onde, no caso, cada pessoa seria um conjunto e cada área
de interesse seria um dado a entrar em um conjunto(por exemplo futebol, notícias,
saúde, música, dentre outros). O coeficiente de Jaccard pode medir o quão similar é
o conjunto de interesses de uma pessoa A e de uma pessoa B através da fórmula
(j1). A aplicação dessa métrica á vetores, representada na figura 7, é conhecida
como a similaridade de Tanimoto, sendo que x. y é o produto escalar dos vetores x e
y e ||x|| é a norma euclidiana do vetor x.

22
Figura 7: função de distância Tanimoto.
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006).
A distância Hausdorff também opera sobre conjuntos, porém não se
calcula a similaridade a partir de elementos que estão em ambos os conjuntos ou
não estão em nenhum deles. Dados dois conjuntos, X e Y, primeiramente para cada
elemento em Y se calcula a distância até o elemento mais próximo em X, a maior
distância calculada será armazenado em C, depois para cada elemento de X se
calcula a sua distância até o elemento mais próximo em Y, a maior distância
calculada será armazenado em D. Assim, o cálculo da distância será: dH(X, Y) =
max{C, D}.
As explicações acima sobre métricas visam esclarecer que a escolha
de métricas para se calcular a distância entre determinados elementos deve ser
cuidadosa.
2.4 CONSULTAS POR SIMILARIDADE
Uma consulta por similaridade é uma consulta que usa um objeto de
consultaq como o centro do espaço métrico (ou objeto de consulta), uma função (ou
algumas funções) de distância f para se medir a dissimilaridade entre o objeto
central q e os outros objetos oi (com i variando de 1 até n, sendo n a quantidade de
dados complexos no banco) e alguns predicados que dão algumas especificações a
mais para a pesquisa ocorrer. Os predicados em questão usam algumas diretrizes
para a seleção de resultados. A diretriz vai determinar qual o é tipo de consulta por
similaridade que está em execução.
As diretrizes mais usadas são: a seleção de elementos o i que estejam a uma
distância mínima do objeto q e a seleção dos k elementos o i mais próximos do objeto
q. A escolha de uma diretriz para a busca ocorrer depende da necessidade da
consulta. Buscas que adotam a primeira diretriz correspondem ás buscas por um
alcance r, ou Range Query, definida como:
(C1) R(q, r) = { o X, d(o, q) ≤ r }

23
Nessa definição, X é um subconjunto do conjunto que contém todos os dados
e d(o, q) é a distância entre o objeto o e o objeto q.Para se entender o
funcionamento dessa busca, basta imaginarmos o objeto q como sendo um
comércio em uma cidade e os elementos o como sendo comércios ao redor do
comércio q. A busca R(q, r) retorna todos os objetos o que estejam dentro de um raio
de distância r do objeto q. Porém, os dados retornados dependerão do valor
especificado para o parâmetro r, caso não se tenha certo conhecimento sobre os
dados e métricas, consequentemente pode-se ter um parâmetro r mal especificado e
os dados retornados podem não ser satisfatórios. Por exemplo, configurar o valor r =
4 para a consulta Range cuja métrica adotada é a edit distance vai retornar objetos
que são distantes entre sí por, no máximo, 4 edições, porém usar o mesmo valor
para uma busca sobre imagens pode ser arriscado, trata-se de um conjunto cujas
distâncias são números reais e o valor 4 pode ser muito pequeno (resultando em
uma quantidade de dados retornada muito aquém do desejado, podendo inclusive
ser nula) ou muito grande(resultando em uma quantidade enorme e indesejável de
dados retornados) para a consulta.
Buscas que adotam a segunda diretriz correspondem á buscas que retornam
os k vizinhos mais próximos a um objeto q e o nome delas é kNN(K-Nearest-
Neighbor), também definida como:
(C2) kNN(q) = { R ⊆ X, |R| = k ˄ x R, y X – R : d(q, x) ≤ d(q, y) }
Para se entender o funcionamento dessa busca basta nos situarmos no
mesmo cenário proposto para a busca Range, desse modo o objeto q é um
comércio em uma cidade e os elementos o são os comércios ao redor de q, uma
busca 4NN retorna os 4 objetos o mais próximos ao objeto q. Pode ocorrer um
empate entre a distância de q para outros dois ou mais objetos, nesse caso é
arbitrário o critério para se escolher qual dos objetos é o mais próximo.
Há várias outras buscas com diferentes diretrizes, porém essas duas são as
mais usadas. Há buscas que são derivadas de uma das duas principais citadas aquí
como, por exemplo, a consulta reversa pelos k vizinhos mais próximos. Outras são
mais específicas e podem não ter relação alguma com uma das duas principais
como, por exemplo, a junção por similaridade. Caso uma busca não sirva para um
propósito específico, é possível fazer uma combinação entre as consultas com o
objeto de satisfazer o propósito em questão como, por exemplo, especificar que os
dados retornados devem ser os k mais próximos ao dado q e estar dentro de um raio

24
de distância r ao mesmo tempo, trata-se de uma combinação de uma consulta
Range com uma consulta kNN.
2.5 ÍNDICES
Índices são estruturas de dados auxiliares usados para organizar arquivos, o
objetivo dessa organização é reduzir o tempo de acesso aos dados, se aplica o
índice a atributos considerados chave única. Em sua forma mais simples, o índice
caracteriza-se por pares com uma associação entre cada valor de chave com o
respectivo endereço do registro, esses pares ocupam espaços a mais em disco e na
memória, porém a ausência de índice faz com que o acesso aos dados seja
sequencial e mais demorado de um modo geral.
O uso de índices neste trabalho é essencial devido á enorme quantidade de
dados existente. Não fosse a presença de índices, algumas consultas durariam dias,
ou até semanas, para concluirem. Este trabalho faz uso de duas estruturas de
indexação, a B-Tree e a Slim-Tree.
2.5.1 B-TREE
B-Tree é uma lista ordenada de valores dividida em intervalos, cada intervalo
é formado por uma tupla ou conjunto de tuplas e á cada intervalo é associado um
ponteiro para outros intervalos. Trata-se de uma árvore que pode ser considerada
uma generalização natural das árvores de pesquisa binária, os seus nodos são os
intervalos da lista ordenada e os tamanhos desses nodos equivale ao dobro de um
número padrão atribuido á árvore, sendo que esse número padrão é a ordem da
árvore.
Cada operação que envolva esses nodos demanda balanceamento na árvore
e o objetivo é minimizar o número de operações de movimentação dos dados em
alguma pesquisa ou alteração. Trata-se de um algoritmo que mantém os elementos
ordenados dentro da árvore e o seu funcionamento é diferente dependendo do tipo
de alteração, se a alteração é inserção o algoritmo é mais simples, e se a alteração
for uma deleção o algoritmo é mais complexo. De fato, a B-Tree oferece um
excelente desempenho para grandes números de consultas que envolvam
operadores de igualdade e procura por alcances, é por esse motivo que os bancos
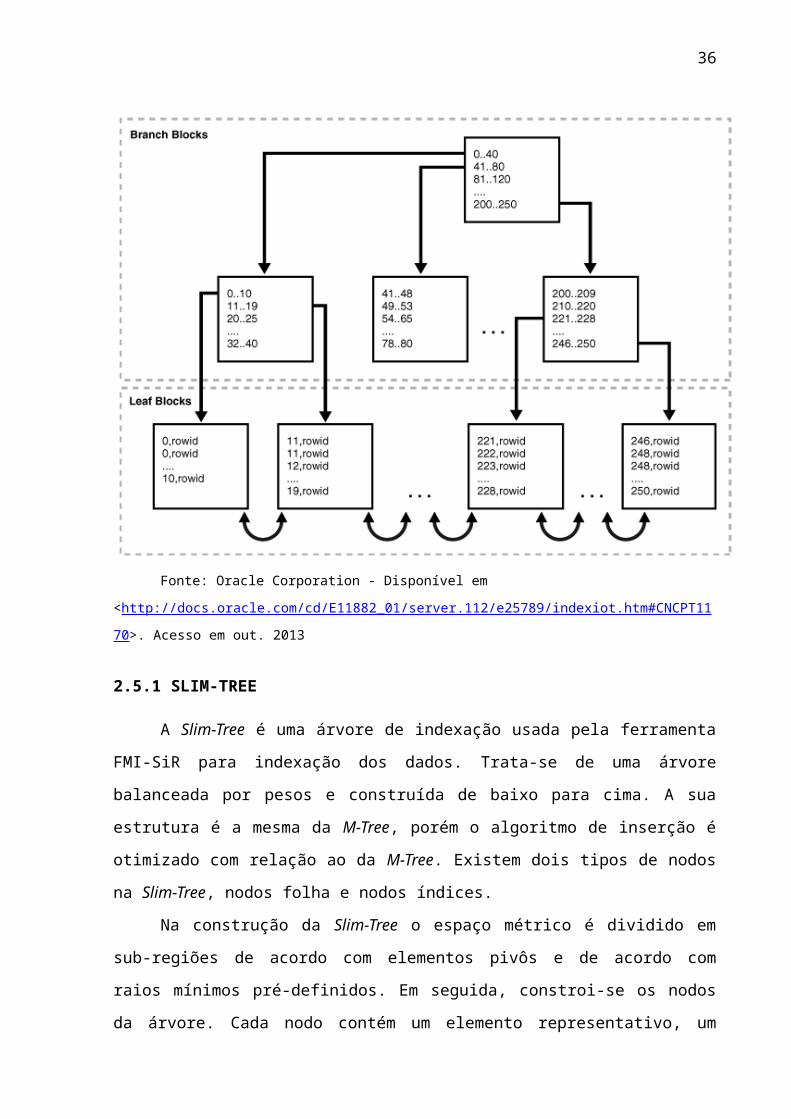
de dados da Oracle usam esta árvore como índice funcional padrão. A figura 8 ilustra

25
a organização de números inteiros em uma B-Tree, os nodos folha são os leaf blocks
e os nodos ramo são os branch blocks. Figura 8. Indexação através de B-Tree.
Fonte: Oracle Corporation - Disponível em
<http://docs.oracle.com/cd/E11882_01/server.112/e25789/indexiot.htm#CNCPT1170>. Acesso em out.
2013
2.5.1 SLIM-TREE
A Slim-Tree é uma árvore de indexação usada pela ferramenta FMI-SiR para
indexação dos dados. Trata-se de uma árvore balanceada por pesos e construída de
baixo para cima. A sua estrutura é a mesma da M-Tree, porém o algoritmo de
inserção é otimizado com relação ao da M-Tree. Existem dois tipos de nodos na
Slim-Tree, nodos folha e nodos índices.
Na construção da Slim-Tree o espaço métrico é dividido em sub-regiões de
acordo com elementos pivôs e de acordo com raios mínimos pré-definidos. Em
seguida, constroi-se os nodos da árvore. Cada nodo contém um elemento
representativo, um raio de distância mínima cuja função é considerar elementos não
representativos como sendo elementos do nodo, distância até elementos não

26
representativos e ponteiros para outros nodos caso não se trate de nodos folha. O
processo de construção começa pelos nodos folha e prossegue com a construção
dos nodos índices, e para isso ocorrer necessita-se que tenha replicação de
elementos representativos nas sub-árvores. Os elementos representativos são
importantes pois guiarão a busca que responde a uma consulta e permitirá a poda
das sub-árvores que não contém resultados significativos. A figura 9 ilustra um
exemplo de Slim-Tree construída, note que os elementos dos nodos índices são
replicados com relação ao nodo folha.Figura 9. Estrutura da M-Tree, a mesma estrutura da Slim-Tree.
Fonte: Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006).
2.6 PADRÃO MPEG-7
Este padrão foi desenvolvido por um grupo chamado MPEG (Moving Picture
Expert Group) que faz parte da Organização Internacional de Padrões/Comissão
Eletrônica Internacional (em inglês International Standard Organization / International
Electronic Comission ou ISO/IEC). Esse grupo é responsável por desenvolver
padrões internacionais para compressão, descompressão, processamento e
representação codificada de vídeos, imagens, aúdios e a combinação deles.
A motivação para a criação do MPEG-7 surgiu com a necessidade de atribuir

27
significado a conteúdos audiovisuais para se executar tarefas que transcendem
simples buscas e filtros como, por exemplo, compressão de imagens e conversão de
mídias. O grupo desenvolvedor que assumiu essa responsabilidade criou esse
padrão e fez dele uma extensão de outros padrões já criados por eles próprios tais
como MPEG-1, MPEG-2, MPEG-4 e MPEG-21. O primeiro dos quatro padrões
possui como característica principal a viabilização do armazenamento e resgate de
dados multimídia na mídia de armazenamento, o segundo possui como principal
característica o armazenamento de vídeos em diferentes níveis de qualidade,
inclusive trata-se de um padrão usado para se trabalhar com imagens de alta
definição. Esses dois primeiros padrões permitem o uso de vídeo MP3 de CD-ROM
em transmissão de áudio digital e em televisão digital via compressão dos dados. O
terceiro dos quatro padrões citados oferece tecnologias para satisfazer as
necessidades de autores, provedores de serviço e usuários finais de modo a,
respectivamente, evitar problemas com registros autorais, formatos incompatíveis e
reprodutores de mídias incompatíveis. O último deles, MPEG-21, é um padrão para
entrega de conteúdos e gerenciamento de direitos. O MPEG-7 é um padrão que
estende todos os outros três e tem como principal objetivo padronizar uma interface
comum para a descrição de materiais multimídia. Nesse contexto se faz o uso de
metadados para facilitar as operações sobre dados e oferecer suporte à
administração dos mesmos. Os três principais elementos do MPEG-7 são:
Descritores e Esquemas de Descrição: Segundo J.R. Smith (2001,
p.748, tradução nossa) Esquemas de Descrição são estruturas de
metadados que descrevem e registram conteúdos audiovisuais.
Descritores são informações que descrevem sintaticamente e
semanticamente alguma característica.
Linguagem para definição de descrição: com ela é possível definir e
criar os Descritores e os Esquemas de Descrição.
Ferramentas de sistema e implementação de referências: Elas se
tornam necessárias para suportar a representação em codificação
binária dos arquivos a fim de oferecer benefícios tais como transmissão
e armazenamento eficiente de dados, multiplexação de descrições,
sincronização de descrições com o conteúdo, dentre outros.
2.6.1 ARQUITETURA DO MPEG-7

28
Olivier Avaro e Philippe Salembier (2001, p. 760) afirmam que MPEG-7 é uma
“caixa de ferramentas” padrão e apresentam um resumo que explica como funciona
a estrutura de componentes responsáveis pelo processamento das informações
MPEG-7 anexadas ao conteúdo. Trata-se de um esquema que mostra o fluxo de
informações entre a mídia de armazenamento/transmissão e a aplicação em
questão, o projeto apresentado é um resumo, muitos detalhes foram abstraídos por
questões didáticas.
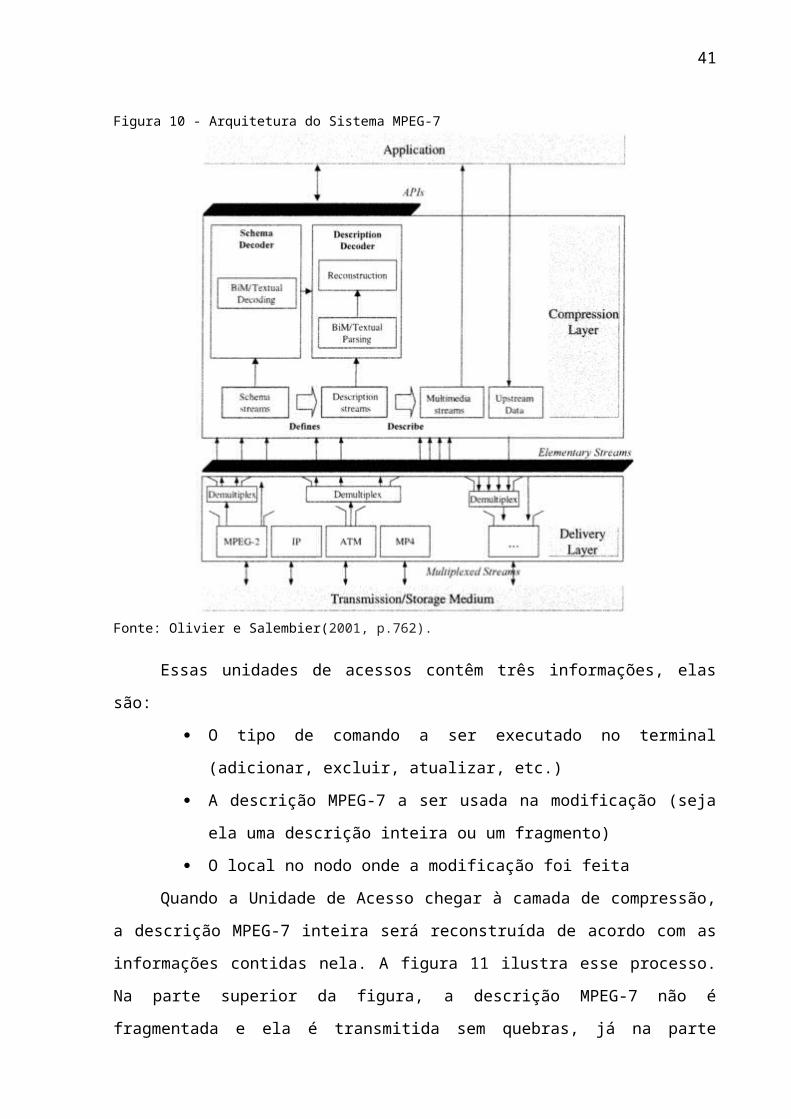
A arquitetura é formada por quatro camadas e a sua estrutura é mostrada na
figura 10. A primeira camada, de cima para baixo, é a mídia de transmissão e
armazenamento que manda dados MPEG-7 inteiros ou fragmentados para a
segunda camada, chamada de camada de entrega. Os dados MPEG-7 podem ter
chego na camada sem os seus conteúdos associados e para resolver isso ocorre a
demultiplexação das informações, ou seja, as informações que chegaram
multiplexadas e separadas se juntarão. Logo depois da demultiplexação as
informações são enviadas á terceira camada, chamada de camada de compressão.
Nessa fase Unidades de Acesso (tradução literal de “Acess Unit”) são enviadas á
essa terceira camada. Segundo Olivier Avaro e Philippe Salembier (2001, p. 761),
uma Unidade de Acesso é a menor unidade de informação á qual um dado temporal
pode ser atribuído. Elas podem ser descrições MPEG-7 inteiras ou um fragmento de
uma descrição MPEG-7, caso uma Unidade de Acesso seja um fragmento de uma
descrição, ela se unirá aos outros fragmentos com o auxílio de informações
anexadas a ela na camada de compressão.

29
Figura 10 - Arquitetura do Sistema MPEG-7
Fonte: Olivier e Salembier(2001, p.762).
Essas unidades de acessos contêm três informações, elas são:
O tipo de comando a ser executado no terminal (adicionar, excluir,
atualizar, etc.)
A descrição MPEG-7 a ser usada na modificação (seja ela uma
descrição inteira ou um fragmento)
O local no nodo onde a modificação foi feita
Quando a Unidade de Acesso chegar à camada de compressão, a descrição
MPEG-7 inteira será reconstruída de acordo com as informações contidas nela. A
figura 11 ilustra esse processo. Na parte superior da figura, a descrição MPEG-7 não
é fragmentada e ela é transmitida sem quebras, já na parte inferior da figura a
mesma descrição é quebrada em três pedaços, transmitida e reconstruída na
camada de compressão, assim ao chegar na camada de compressão olha-se o tipo
de comando a ser executado no terminal e o local no nodo onde a modificação foi
feita para se fazer a remontagem.

30
Figura 11 - Descrições MPEG-7 e Unidades de Acesso
Fonte: Olivier e Salembier(2001, p.763).
2.6.2 DESCRITORES MPEG-7
Esta seção explica os descritores MPEG-7 contidos nos dados do CoPhIR.
Trata-se de metadados que descrevem imagens no nível físico. Esses metadados
podem descrever características de cor, textura ou formato de uma imagem.
Segundo Bolettieri et al. (2009), constatou-se, através de experimentos, que a
importância desses descritores se deve ao fato de eles serem melhores para
recuperação de imagens de cunho geral. De fato, este trabalho usa imagens de
cunho geral e os descritores MPEG-7 devem ser muito úteis. Dos descritores
MPEG-7 existentes, o CoPhIR contém três descritores de cor e dois descritores de
textura, o conjunto de descritores de cor é formado pelos descritores Scalable Color
Descriptor (SCD), Color Layout Descriptor (CLD) e Color Structure Descriptor (CSD)
e o conjunto de descritores de textura é formado pelos descritores Edge Histogram
Descriptor (EHD) e Homogeneous Texture Descriptor (HTD). Dependendo da forma
como são extraídos, esses descritores podem ser detalhados de diversas formas.
Bolettieri et al. (2009) descreve a maneira como esses cinco descritores encontram-
se detalhados no CoPhIR. Vale lembrar que existem outros descritores do padrão
MPEG-7 além desses cinco citados, porém o CoPhIR contém somente esses cinco.

31
O descritor SCD é derivado de um histograma de cores definido no espaço de
cores Hue-Saturation-Value. Os seus valores, após extraídos, são normalizados,
não-linearmente mapeados em um formato inteiro de quatro bits e transformados
segundo a transformação Haar. Para esse descritor usa-se a versão de 64
coeficientes.
O descritor CSD é baseado no histograma de cores, mas o seu objetivo é
identificar a localização da distribuição de cores usando-se uma janela com pequena
estrutura. Usa-se uma versão de 64 coeficientes para esse descritor.
O descritor CLD tem origem na aplicação da transformação DCT em um array
2D com uma representação local de cores cujo espaço de cor é Y, Cr ou Cb. Trata-
se de um descritor que captura informações locais e espaciais. Usa-se uma versão
de 12 coeficientes para esse descritor.
O descritor EHD representa distribuição de bordas locais na imagem. A
imagem é dividida em 4x4 sub-imagens, depois cada sub-imagem é categorizada
em cinco tipos conforme a borda nela contida: vertical, horizontal, 45 graus na
diagonal, 135 graus na diagonal e bordas sem direção. Essas informações são
transformadas em um vetor de 80 coeficientes.
O descritor HTD usa informações de regiões de textura através de energia e
desvio de energia de um conjunto de 30 canais de frequência. Usa-se a versão mais
completa desse descritor, a qual contém 62 coeficientes.

32
3ESTUDOS DOS DESCRITORES DE CONTEÚDO E MÉTRICAS DE SIMILARIDADE PARA O PADRAO MPEG-7
Esta seção descreve e compara alguns descritores e métricas de similaridade
compatíveis com o padrão MPEG-7. Não é possível avaliar a eficiência de uma
métrica sem levar em conta os descritores usados no processo de recuperação por
similaridade. Por esse motivo, os estudos realizados avaliam o(s) descritor(es)
usado(s) e a métrica compatível com o(s) correspondente(s) descritor(es). Trata-se
de uma avaliação de estratégias para recuperação eficiente de imagens por
similaridade de conteúdo. Nos trabalhos estudados, observa-se o uso de várias
estratégias para se obter métricas e descritores eficientes. Cada estudo propõe uma
metodologia diferente para se atingir tal objetivo. Dentre as várias estratégias, estão:
fazer mudanças nos descritores das imagens para simplificar ou enfatizar
características específicas de certos descritores, fazer uso de dois descritores
(geralmente um de cor e outro de textura) em uma função de similaridade para
retornar imagens que melhor se assemelhem, fazer uso de feedback do usuário para
melhorar a busca, modificar o algoritmo de extração de características para se obter
descritores otimizados cujo uso resulte em maior eficiência. Em cada um dos
diferentes trabalhos, após a aplicação da estratégia em questão, se usa uma medida
de desempenho para se avaliar a eficiência das métricas e descritores dessa
estratégia.
O restante dessa seção está organizado da seguinte maneira. A seção 3.1
descreve medidas de desempenho para recuperação de informação e aborda em
detalhes a medida de desempenho sugerida pelo grupo MPEG para se avaliar o
mecanismo de busca. A seção 3.2 aborda as diferentes estratégias de obtenção de
um mecanismo eficiente de busca por similaridade e avalia as mais úteis e eficientes
para se usar na base de dados do CoPhIR.
3.1 MEDIDAS DE DESEMPENHO PARA RECUPERAÇÃO DE INFORMAÇÃO
Depois de se aplicar a busca por similaridade e se obter um conjunto de
dados similares a um dado de consulta, se avalia o quão similares os dados
resultantes são como dado de consulta. Medidas da qualidade de resultados avaliam
o desempenho das estratégias de recuperação de informação. Estas avaliações

33
podem ser diferentes de acordo com o tipo de dado com o qual se está trabalhando
(vídeos, imagens, áudio, dentre outros). Este trabalho aborda a avaliação de
resultados de buscas por similaridade sobre imagens.
Diferentes medidas de desempenho foram usadas nos trabalhos estudados.
Elas vão desde as clássicas cobertura e precisão até poluição de clusters de
imagens similares. Desse modo, não foi possível comparar vários dos estudos entre
si. Cada autor teve uma justificativa diferente para usar determinadas formas de
medição de desempenho. No entanto, algumas medidas foram adotadas por mais
de um autor. As medidas de eficiência que se verificou serem mais frequentemente
usadas nos trabalhos analisados são as desenvolvidas pelo grupo do MPEG:
Retrieval Rank (RR) e seus derivados tais como Normalized Modified Retrieval Rank
(NMRR) e Averaged Normalized Modified Retrieval Rank (ANMRR). Essas medidas
de desempenho estão descritas no trabalho de [Manjunath et al., 2009]. O clássico
conceito de cobertura e precisão não foi tão usado quanto essas medidas. Os
motivos são vários, porém a razão principal pode ser a credibilidade da medida RR e
seus derivados, pois foram desenvolvidos pelo próprio grupo MPEG, o mesmo grupo
que criou os descritores de cor e textura usados hoje. RR e seus derivados
penalizam a não recuperação de resultados relevantes e levam em conta o quão
relevante são os objetos relevantes recuperados. [Missaoui et al., 2001], por
exemplo, citam dois motivos pelos quais precisão e cobertura não seriam bons o
suficiente para avaliar efetivamente uma busca por similaridade sobre imagens: (i)
não levam em conta o peso de cada imagem no processo de recuperação de
imagens, sendo o peso da imagem definido pelo seu ranking nos resultados e (ii)
determinar um conjunto de imagens relevantes é algo mais subjetivo e dá mais
margem a diferentes interpretações do que determinar um conjunto de documentos
texto relevantes.
As medidas NMRR e ANMRR são baseadas em um teste feito pelo grupo
MPEG para recuperação de imagens similares de conjuntos de dados específicos. A
resposta conhecida (perfeita) é chamada regra ouro (Ground Truth). Pode-se incluir
a percepção humana para formar o conjunto de critérios perfeitos e obter a regra
ouro. Dada uma busca por similaridade, a regra ouro é a lista ordenada das imagens
mais similares a imagem de consulta. As medidas NMRR e ANMRR levam em
consideração a ordem que determinada imagem similar é recuperada, ou seja, se o
processo de recuperação coloca as imagens mais similares a imagem de consulta

34
no topo da lista ordenada de resultados. O cálculo de NMRR vem de uma
normalização de MRR (Modified Retrieval Rank) que, por sua vez, vem de uma
modificação de AVR (Average Ranking), sendo esse último uma média aritmética
dos valores do Rank k das imagens contidas no Ground Truth.
As fórmulas de (1) a (6) representam as medidas de desempenho da família
MPEG-7. O Rank de uma imagem na k-ésima posição no conjunto Ground Truth é a
posição dessa imagem na lista ordenada de resultados retornados por um método
de busca (primeira, segunda, terceira, ...). NG(q) é o número de imagens similares a
imagem q segundo algum critério. K(q), definido na equação (2), é uma constante
que define um valor máximo que o rank de uma imagem pode assumir. K(q) assume
o maior dentre os valores 4*NG(q), para q sendo a imagem da consulta em questão,
e 2*NG(q), para q sendo todas as imagens usadas para consulta até o momento.
Caso o rank de uma imagem seja maior que K(q), atribui-se ao seu rank o valor
1,25*K(q). Essa atribuição de valor para o rank da imagem é considerada uma
penalidade para o processo de recuperação de imagens porque o alto valor de um
ranking colabora para o valor do ANMRR e NMRR serem maiores. Maiores detalhes
podem ser encontrados em [Manjunath et al.] e [Ohm et al.].
Para exemplificar o uso dessas medidas de desempenho, suponhamos, para
uma dada imagem q, que NG(q) = 5, ou seja, temos um conjunto de 5 imagens
similares a imagem q segundo algum critério. Esse critério depende da montagem
do conjunto de dados ground truth. Se 4*NG(q), para q sendo o objeto de consulta
em questão, for o menor valor, então K(q) = 20. Para as imagens dentro do Ground
Truth, uma estratégia de busca por similaridade pode apresentar os seguintes
resultados:

35
Tabela 1. Valores de k e seu respectivo Rank(k), Rank*(k) e K(q)
K Rank(k) Rank*(k) K(q)1 8 8 82 50 25 203 143 25 204 2 2 25 200 25 20
O valor k é a ordem da imagem no Ground Truth, Rank(k) é a posição que a
imagem do Ground Truth retorna na busca, Rank*(k) é um número que avalia o
“peso” da imagem do Ground Truth, o cálculo de Rank*(k) é feito em (1). Através
desse exemplo vemos que, quanto mais cedo uma imagem dentro do Ground Truth
é recuperada, menor é o resultado das somas de Rank*(k). Os valores de AVR(q),
MRR(q) e NMRR(q) são calculados logo abaixo segundo as fórmulas descritas.
AVR(q) = 85/5 = 17
MRR(q) = 17 - 3 = 14
NMRR(q) = 14 / (25 - 3) = 14 / 22 = 7/11 = 0,64
Para se calcular ANMRR(q), é necessário se fazer outras consultas, calcular a
soma de todos os valores NMRR(q) obtidos com as outras consultas e dividir pelo
número de consultas. Assim, o valor final avaliaria melhor a implementação da busca
como um todo. Se a estratégia de busca por similaridade fosse diferente, para o
mesmo q poderíamos ter valores de Rank(k) diferentes e, consequentemente,
valores de AVR(q), MRR(q), NMRR(q) e ANMRR(q) diferentes.
3.2 ESTRATÉGIAS PARA RECUPERAÇÃO EFICIENTE DE IMAGENS POR SIMILARIDADE DE CONTEÚDO
Essa seção aborda as diferentes estratégias para recuperação eficiente de
imagens por similaridade de conteúdo. No geral, as estratégias diferem entre si pela
métrica e pelos descritores a serem usados com as métricas na busca por
similaridade em questão, porém algumas estratégias apresentam outras variações,
uma delas é uma otimização na extração de características e uso de mecanismo de
feedback continuo como um complemento para melhorar a eficácia da busca.
Os principais métodos abordados para uma possível solução encontram-se
em subseções separadas dentro dessa seção. Desse modo, A seção 3.1 aborda um
método de busca que usa mesclagem de paletas de histogramas com uso contínuo
de feedback. A seção 3.2 aborda um método de busca que usa compactação do
36
descritor de cor SCD (Scalable Color Descriptor) e HTD(Homogeneous Texture
Descriptor). A seção 3.3 aborda um método de busca que modifica um dos
descritores de cor (DCD, Dominant Color Descriptor) e um de textura(EHD, Edge
Histogram Descriptor) para fazer a busca ficar mais eficiente. A seção 3.4 aborda um
método de busca que usa um descritor sintetizado chamado DCSD (Dominant Color
Structure Descriptor). A seção 3.5 aborda a estratégia de junção de um descritor de
textura com um ou mais descritores de cor para fazer a busca ficar mais eficiente. A
seção 3.6 aborda estratégias estudadas que não puderam ser comparadas com as
outras estratégias devido ao método de avaliação usada no processo. A seção 3.7
exibe as tabelas referentes aos experimentos e mostra um quadro comparativo de
todos os experimentos realizados, sendo que os detalhes desse quadro dizem
respeito á métricas usadas, descritores usados e melhor índice obtido por cada
experimento.
3.2.1 MESCLAGEM DE PALETAS DE HISTOGRAMAS COM USO CONTÍNUO DE FEEDBACK
No trabalho de [Wong e Po, 2004], o autor sugere aplicar uma técnica
chamada histograma de mistura de paletas (Merged Palette Histogram, ou MPH)
nos descritores de cores dominantes (Dominant Color Descriptor, ou DCD) e usar
um mecanismo de relevância de feedback. Nesta técnica uma imagem Q serve
como objeto da busca e os objetos no banco de dados mais similares á Q são
resgatados. Duas métricas diferentes são usadas para esse resgate (por
consequência, se obtém dois resultados diferentes), uma das métricas é a distância
quadrática de histogramas (Quadratic Histogram Distance Measure em inglês, ou
QHDM) e a outra delas é a distância de histogramas com paletas mescladas
(Merged Palette Histogram Similarity Measure, ou MPHSM). O objetivo de se usar
as duas métricas é comparar o resultado que cada uma produz.
Após a primeira busca por similaridade ocorrer, o usuário irá selecionar as
imagens que ele considera mais similares á imagem Q. Essas imagens escolhidas
terão as suas paletas mescladas através de um método específico de mesclagem de
paletas e o resultado do processo fornecerá uma nova imagem com paletas
mescladas. O objetivo é obter uma nova paleta que represente as cores
selecionadas pelo usuário, porém a mesclagem de paletas torna-se necessária
devido á uma limitação imposta pelo próprio padrão MPEG para a definição do

37
descritor de cor, a limitação é o número de paletas permitido para o descritor. Essa
técnica de mistura de paletas contorna esse problema pois ela é um modo de
representar várias cores em uma paleta só sem aumentar o número de cores
diferentes. O processo de obter uma nova imagem com paletas fundidas é iterativo e
a iteração acaba quando houver uma distância euclidiana mínima entre as paletas
do descritor, essa distância mínima é um limite configurado arbitrariamente, porém o
autor sugere um número entre 10 e 15 para esse valor. Assim, se obtém uma nova
imagem com paletas mescladas que será usada como o objeto Q em uma nova
busca, a expectativa é para o desempenho dessa nova busca ser melhor que a
anterior, porém em alguns casos isso não acontece, esse resultado varia muito de
imagem para imagem.
Com relação ás métricas usadas e representação dos descritores,
esclarecidas em um dos trabalhos de [Wang e Po, 2003], os descritores de cor
dominante estão representados em (7), (8) e (9). O Descritor de Cor Dominante F é
representado por ci e pi , sendo que esses dois valores são, respectivamente, o vetor
de cor de índice i e a frequência de sua ocorrência. Para se calcular a distância
entre dois DCDs, usa-se a distância quadrática de histogramas (ou Quadratic
Histogram Distance Measure, ou QHDM) cuja fórmula está especificada em (10) e o
valor de a na fórmula está especificado em (11).
Td é a distância euclidiana mínima entre as cores da paleta e ela serve como
parâmetro para formar o componente aij. Sem essa consideração para o cálculo do
QHDM haveria cores não dominantes sendo dominantes.
O cálculo do MPHSM caracteriza-se pela obtenção de cor após mesclagem
de paletas e seguida intersecção dos novos histogramas de paletas mescladas. A
mesclagem de paletas, indicada pela fórmula (12), é uma junção entre uma cor i e

38
uma cor j. p1mi=p1i caso a distância entre cmi e cli seja menor ou igual a Td, 0 caso
contrário, pensamento análogo se tem com o valor de p2mi. O cálculo da MPHSM é
definida como a intersecção dos dois histogramas em (15):
Quanto maior o valor de I(F1m, F2m), mais similares são as duas imagens,
se esse valor for igual á 1 é porque as imagens são iguais. Essas métricas foram
aplicadas em um conjunto de dados com 1000 imagens do COREL e o resultado dos
experimentos estao na tabela 3. A idéia de usar um só descritor para a recuperação
dos dados não é tão recomendada segundo [Namuduri e Dorairaj, 2004], um
descritor de textura teria que ser usado juntamente com um de cor para tornar a
busca mais significativa e robusta. Porém, esse problema é compensado com o uso
de uma relevância de feedback que pega as imagens e mescla as paletas para
formar novas busca.
Há alguns questionamentos no uso dessa estratégia. Os resultados mostram
que o desempenho varia bastante de imagem para imagem com o passar das
iterações nas buscas, a mesma estratégia aplicada ao cophir pode originar uma
variação de desempenho maior ou menor, pois se trata de um banco de dados com
muito mais dados. Mesmo com a possibilidade de se considerar essa técnica uma
forte candidata a ser a mais eficiente na busca por similaridade, existem outras
estratégias que oferecem um desempenho melhor.
3.2.2 COMPACTAÇÃO NOS DESCRITORES SCD E HTD
Em [Namuduri e Dorairaj, 2004], o autor usa uma representação compacta do
descritor SCD (Scalable Color Descriptor) e HTD(Homogeneous Texture Descriptor)
para tornar a busca mais eficiente segundo as métricas de desempenho MPEG-7 já
mencionadas. O SCD é um descritor de histograma de cores computado a partir do
espaço de cores HSV(Hue, Saturation, Value, ou Matriz, Saturação e Valor em
português). O espaço HSV envolvido possui 16 níveis possíveis de representação
de H(Hue), 4 níveis de representação de S(Saturation) e 4 níveis de representação

39
de V(Value). Inicialmente, esse espaço de cor é representado através de 256 bins,
truncados com 11 bits de representação cada um e mapeado para uma
representação de 4 bits. Para representar de forma compacta esse descritor, é
usada a transformação Haar, trata-se de uma transformação que envolve adição e
subtração de bins adjacentes, sendo que a soma de bins adjacentes resulta em
coeficientes de passa-baixa e a subtração resulta em coeficientes de passa-alta. A
representação compacta consiste em usar os coeficientes de passa-alta e a
justificativa, segundo [Manjunath et al., 2001] é que esse coeficiente contém
informações da imagem em um nível melhor de resolução usando menos valores. O
processo é iterativo e, a cada iteração, o número de coeficiente se reduz até se
chegar em um nível com poucos bins de representação que, no caso citado, é 16
bins. A figura 12 exemplifica o processo citado. Figura 12. A transformação Haar e a obtenção de coeficientes passa-baixa e coeficientes
passa-alta
Fonte: Ohm et al. (2001, p.21)
O descritor de textura HTD é representado através de um vetor de valores
que mostram os níveis de energia calculados para a imagem. Níveis de energia são
variações de textura em determinadas regiões da imagem. Os dois primeiros
componentes do vetor, desvio médio e desvio padrão, são de domínio espacial, ou
seja, descrevem a mudança de textura na imagem de um modo geral, e os outros 60
componentes são partes do domínio de frequência, sendo que 30 deles representam
o componente energia e os outros 30 representam o componente desvio de energia.
O processo de extração desse descritor nos permite entender melhor o que é
cada componente do vetor de característica em questão. O extrator divide a imagem

40
em 30 áreas diferentes chamadas canais, primeiro se calcula os componentes
espaciais, para depois se calcular os componentes que dizem respeito á frequência
(energia e desvio de energia), no trabalho de [Shao et al., 2009] é possível analisar
com detalhes o processo de construção do descritor.
Existem três formas distintas de se representar a forma compacta desse
descritor, são elas: representação através de agrupamento de bits, representação
baseada em uma correlação com um padrão e o terceiro é a representação através
de pesos. Em ambos os 3 métodos se leva em consideração apenas 30 bits, sendo
cada bit o sinal da parte imaginária da energia ou desvio de energia (tanto energia
como desvio de energia são números complexos e possuem uma parte real e uma
parte imaginária). A primeira estratégia consiste em agrupar os 30 bits em 10 grupos
de 3 e, em cada grupo, somar os bits para se obter um digito, assim se obtém 10
dígitos, ou seja, se obtém um número de 10 dígitos que servirá como ctd. No
segundo método esses 30 bits passam por uma operação XOR com outro número
representado através de 30 bits(sendo esse o referencial) e, depois dessa operação,
se obtém 10 grupos de 3 bits que, juntos, formarão um número decimal de 10 dígitos
(cada grupo de 3 bits representaria um digito) para representar a textura (ctd, ou
compact texture descriptor). O terceiro método confere pesos a cada bit para depois
todos serem somados e se tornarem um só número. Os 16 bits de representação de
cor compacta são convertidos em um único número decimal que representará CCD,
o número obtido através da representação compacta de textura é o CTD. Seja CCDi
e CTDi os descritores obtidos da imagem no banco de dados e seja CCDq e CTDq
os descritores obtidos da imagem de consulta, a métrica que calcularia a distância
seria:
Os experimentos realizados com essas métricas tiveram seu desempenho
medido através da métrica ANMRR e está computada na tabela 4. A escolha dessa
estratégia é parcialmente satisfatória, pois se trata de uma estratégia que envolve
descritores já extraídos e o ANMRR obtido é satisfatório se comparado com os
outros experimentos realizados, porém o descritor EHD do autor que propôs essa
compactação não coincide com o EHD do CoPhIR.
3.2.3 MODIFICAÇÃO NO DCD E EHD
41
No trabalho de [Yanhong et al., 2009] a estratégia de busca por similaridade
eficiente ocorre de outra forma, usa-se descritor de cor dominante (Dominant Color
Descriptor, ou DCD) e descritor de bordas de histograma (Edge Histogram
Descriptor, ou EHD) modificados. Nos procedimentos, calculam-se os valores para o
descritor da maneira mostrada em (15), tal que h[i] é o valor do histograma de cores
após a extração, EH é o valor parcial do histograma, GH é a textura global do
histograma e SGH é a textura global dividida do histograma. Esses três valores de
histograma são obtidos através da extração de características da forma como o
autor propõe. A extração da característica de cor é feita através de uma otimização
no algoritmo generalizado de Lloyd e a extração do descritor de textura é feito
através de um algoritmo de divisão otimizada da imagem em segmentos e seguida
extração através desses segmentos, no entanto o autor não fornece o nome desse
último algoritmo. Os experimentos foram realizados em um conjunto de 1000
imagens de flores, animais e cenários naturais, a medida de desempenho MPEG-7
está especificada na tabela 5. Quanto ás métricas, a métrica para cor e textura estão
mencionadas em (17) e (18), sendo que (17) corresponde a d1 e (18) corresponde a
d2. Depois, d1 e d2 são normalizados da seguinte forma: se d1 é um valor no intervalo
[0, max1] e d2 é um valor no intervalo [0, max2], então d1 = (max1 – d1)/max1 e d2 =
(max2 – d2)/max2, sem essa normalização d1 e d2 teriam pesos diferentes no cálculo
da métrica final que envolve d1 e d2. Após a normalização, se calcula a medida final
d=w1*d1 + w2*d2 , sendo que w1 e w2 são os pesos referentes ao quão importante é a
medida d1 e d2 no cálculo de d.
Apesar do ótimo ANMRR obtido de 0,0920, o grande problema dessa técnica
é que o coração da otimização está na modificação da extração de características.
Para experimentos a serem realizados no cophir essa estratégia pode não servir,
pois o conteúdo disponível para experimentos são os vetores de características já
extraídos. Se o grupo de pesquisadores usa o algoritmo GLA otimizado para
extração de características e a extração otimizada de textura conforme indica
[Yanhong et al., 2009], é possível aplicar a estratégia.

42
3.2.4 SÍNTESE E USO DO DESCRITOR DCSD (DOMINANT COLOR STRUCTURE DESCRIPTOR)
No trabalho de [Wong et al., 2007] há a criação de um descritor de cor
chamado Dominant Color Structure Descriptor(DCSD), um descritor que possui
muitas semelhanças com o Dominant Color Descriptor (DCD). Com um novo
descritor que represente a organização das cores consideradas dominantes em uma
imagem é possível obter ótimos indices ANMRR, a prova disso encontra-se nos
experimentos feitos nesse trabalho. Através dos experimentos, realizados em cima
de uma base de dados com 5466 imagens, se obteve um índice ANMRR de 0.0993
com um DCSD de 8 cores, trata-se de um índice ótimo com relação a muitos outros
comumente obtidos em vários outros experimentos, o resultado encontra-se em
detalhes na tabela 8.
O nome desse descritor pode sugerir uma combinação dos descritores DCD e
CSD (Color Structure Descriptor, ou Descritor de Estrutura de Cor), porém a forma
de se obter esse descritor é diferente. O processo de obtenção desse descritor
ocorre através da extração de características da imagem em dois passos, o primeiro
chama-se quantização de cores e o segundo chama-se escaneamento de estruturas
de blocos. Primeiramente se aplica o algoritmo generalizado de Lloyd na imagem
para se obter um conjunto de cores dominantes Cq = {c1, c2, …, cn}, desse conjunto de
cores dominantes realiza-se o primeiro passo: aplicar um filtro para reduzir a
quantidade de cores nesse conjunto.
Para se realizar o filtro usa-se (19) e (20). Através de (19) e (20) observa-se

43
que cxy vai ser descartado (ter seu valor anulado) caso a distância entre ele e o
elemento c mais próximo a ele não exceder Td(um parâmetro pré estabelecido para
teste).
O segundo passo consiste em um escaneamento nos blocos da imagem para
se obter a frequência com que cada cor ocorre em cada bloco e para se obter a
posição das cores registradas. O processo encontra-se resumido na Figura 13 e o
seu fim já resulta o descritor DCSD. Figura 13. Obtenção do descritor DCSD em etapas
Fonte: Wong et al. (2007, p.613)
Embora o objetivo principal do trabalho de [Wong et al., 2007] tenha sido
desenvolver esse novo descritor, o experimento envolve testes com os outros
descritores modificados com o uso de métricas diferentes para cada um. Os
resultados obtidos, se comparados com os outros explorados nesse trabalho, é
considerado muito bom, porém houve modificações na forma de extração do
descritor para se obter descritores mais eficientes e, por esse motivo, essa
estratégia de uma busca por similaridade eficiente não é aplicável nos dados do
CoPhIR.
3.2.5 COMBINAÇÃO DE UM DESCRITOR DE TEXTURA COM VÁRIOS DESCRITORES DE COR
Em [Bleschke, 2009] o autor realiza buscas por similaridade em um conjunto
de 1000 imagens e divide essas buscas por similaridade em conjuntos que se
diferem pelos descritores e pela métrica usados em cada uma. Cada conjunto de
buscas por similaridade foi avaliado e comparado com os outros conjuntos. O autor
faz uso de quatro descritores em seu trabalho de avaliações de buscas, elas são: o

44
descritor de textura EHD (Edge Histogram Descriptor) e os descritores de cor SCD
(Scalable Color Descriptor), CSD (Color Structure Descriptor) e CLD (Color Layout
Descriptor). Primeiramente o autor apresenta informações sobre cada um dos
descritores tais como descrição, formas de extração e a métrica que usa o descritor
em questão, depois o autor apresenta um método para combinar diferentes métricas
usando uma outra métrica, desse modo se obtém o resultado da busca de ambas as
métricas.
Para o descritor EHD, o autor explica o método para a sua extração e a
métrica usada para este descritor em particular. O processo de extração já foi
executado pelo grupo de pesquisadores do CoPhIR e não vem ao caso, e a métrica
usada para o cálculo está especificada em (21). A Figura 14 fornece uma explicação
visual para cada componente da fórmula. Cada bloco de borda é composto de 5 bins
(5 valores em formato binário que representam o segmento em questão) e a imagem
é dividida em 16 blocos de bordas locais, um bloco de borda global e 13 blocos de
bordas semilocais, os somatórios em (21) levam em conta cada conjunto de blocos
multiplicados pelo respectivo número de bins em cada bloco, sendo que o conjunto
de blocos globais ainda recebe uma multiplicação a mais por ser considerado mais
relevante para se representar melhor a distância. Figura 14. Extração dos componentes do descritor EHD
Fonte: Pattanaik, Bhalke (2012, p.22)

45
O descritor SCD representa o espaço codificado de cores HSV para as figuras
envolvidas no processo. Para o descritor SCD, o autor esclarece o processo de
extração e a métrica para se calcular distâncias entre imagens usando SCD. A
métrica para seu cálculo se resume á norma L1, ou seja, se resume á distância
Manhattan entre os números que representam os bins do espaço de cores HSV.
Caso somente o sinal de bit seja usado, a norma L1 se transforma na distância de
Hamming, fato que reduz a complexidade computacional da busca.
O CSD é parecido com o histograma de cores, porém esse descritor
representa a frequência com que cada cor aparece na imagem e mostra
informações sobre a organização espacial das cores. O autor ressalta que esse
descritor é idêntico ao histograma de cores quanto á sua forma, porém os conteúdos
semânticos se diferenciam. Nesses experimentos realizados pelo autor, realiza-se o
cálculo da similaridade entre imagens usando esse descritor calculando-se a norma
L1 entre cada componente desse descritor, esse cálculo é simples pois a sua
estrutura consiste em um histograma de cores.
O CLD representa a distribuição espacial de cor nas imagens. Trata-se de um
descritor obtido através de uma DCT (Discrete Cosine Transform, ou Transformação
Discreta de Cosseno) dos valores em um espaço de cor YCrCb. O cálculo dessa
métrica, representado em (22), segue algumas diretrizes, a começar pelos pesos w.
Os pesos wyi , wci e wri entram no cálculo dessa métrica pois os componentes Y, Cr
e Cb possuem frequências diferentes após a transformação DCT e precisam ser
ajustados para se obter uma distância mais próxima da realidade. Outra diretriz a ser
seguida são os valores que i assume, os valores que i assume segue uma ordem
zigue-zague na matriz de elementos de Y, Cr e Cb.

46
A combinação dos valores das métricas segue o método Late Fusion Method
(a tradução ao pé da letra seria Método de Fusão Atrasada) que consiste em
calcular um valor normalizado de cor, um valor normalizado de textura e calcular um
valor Q que representa a soma dos pesos dos valores normalizados de cor e textura,
esses valores estão representados em (23), (24) e (25). O peso w é um valor tal que
0 ≤ w ≤ 1, o valor atribuído a w vai depender do enfoque que se dá ao descritor de
cor e ao descritor de textura, se o peso concedido a nT é w, o peso concedido a nC
é 1 - w.
Inicialmente o autor avalia a recuperação de dados em cima de buscas que
usam descritores individualmente, os resultados ANMRR estão expostos na tabela 6
e depois ele combina os descritores usando a métrica Late Fusion Method, os
valores combinados foram: EHD+CLD, EHD+SCD, EHD+CSD, EHD+(CLD, SCD,
CSD) e os resultados obtidos estão representados na tabela 7. O melhor resultado
ANMRR é satisfatório, porém o descritor que o autor usa na combinação de
descritores é composto pelo descritor Scalable Color Descriptor com 256
coeficientes, trata-se de um descritor que não consta nos dados do CoPhIR e não é
possível obtê-lo sem o processo de extração de características.
3.2.6 OUTRAS ESTRATÉGIAS ESTUDADAS
Outras sugestões de melhores métricas de desempenho também foram
sugeridas em vários outros trabalhos, tal como um comparativo entre as métricas

47
sugeridas pelo padrão MPEG-7 e as de uso geral para cada descritor feito por
[Eidenberger, 2003]. Nesse trabalho é proposto um modelo de quantização que
converte métricas baseadas em predicados para métricas baseadas em contagem, o
objetivo é ter a capacidade de se comparar essas duas naturezas de métricas entre
sí. Para se medir o desempenho de cada métrica com cada descritor o trabalho
sugere dividir os dados em clusters, onde teoricamente em cada cluster os objetos
devem ser similares entre sí, mas na prática é possível ter objetos não similares e
esse fenômeno é chamado de “poluição de clusters”, ele ocorre com maior ou menor
intensidade dependendo da métrica que se adota e de um parâmetro p usado no
modelo de quantização. Portanto, a medida de desempenho que foi usada no
trabalho em questão é a “poluição de clusters” para cada métrica. Apesar da boa
fundamentação do trabalho, não é possível comparar os resultados de trabalhos
como esse com os outros mencionados aquí devido ao critério usado, não temos
como comparar poluição de clusters com as métricas de desempenho do MPEG-7.
O mesmo aconteceu com a análise de outros trabalhos, tal como no trabalho de
[Pattanaik e Bhalke, 2012] e de [Missaoui et al., 2005].
3.2.7 QUADRO COMPARATIVO
Para se comparar as propostas estudadas na literatura é preciso analisar os
resultados obtidos em experimentos. O ANMRR foi usado neste trabalho como
principal critério de comparação de desempenho. A justificativa encontra-se no
capítulo 3.1.
Observa-se que os melhores resultados obtidos vêm de propostas usando
descritores distintos daqueles disponíveis no CoPhIR, é importante ressaltar que,
quanto menor o valor ANMRR, melhores os resultados obtidos. Caso o trabalho
envolvesse extração de descritores de um conjunto de imagens, seria válido aplicar
os trabalhos com os menores ANMRRs obtidos, porém a base de dados CoPhIR
contém os descritores já extraídos das imagens e seria inviável extrair novos
descritores de milhões de imagens. É importante notar que melhorar o desempenho
da consulta envolve manipular todo o processo de busca por similaridade sobre
conteúdo em imagens incluindo a parte da extração. A prova dessa observação
encontra-se na comparação entre os valores ANMRR obtidos com melhora no
processo todo e os valores ANMRR obtidos com melhora em somente poucas partes

48
do processo. Segue abaixo os experimentos, descritores usados, métricas usadas e
o melhor ANMRR obtido por experimento para comparações.
A tabela 2 compara os diferentes experimentos tendo em mente métricas
usadas, descritores usados e o melhor índice ANMRR obtido. A tabela registra o
melhor índice ANMRR obtido devido ao fato de alguns experimentos usarem mais de
uma configuração ou métrica. Vale lembrar que o conjunto de dados utilizados em
cada experimento é diferente e não encontram-se disponíveis as implementações,
porém a medida de desempenho usada em todos eles é a mesma. As conclusões
que surgem dessas comparações servirão para a seção de implementação,
experimentos e análise dos resultados.
Após esse estudo, optou-se por se compactar o descritor SCD e usar a
métrica Manhattan na seção 4 deste trabalho. Essa escolha se deve à viabilidade de
sua implementação. Não é possível implementar os estudos 3 e 4 por envolver
extração de descritores, não é possível também implementar o estudo 5 por
envolver um descritor que não consta nos dados do CoPhIR. O estudo 1 não oferece
um ANMRR superior ao experimento 2, portanto decidiu-se implementar a
compactação de descritor SCD proposto pelo experimento 2. Tabela 2 - Comparativo entre as propostas
Número Proposta Descritores Métrica Melhor ANMRR
1 Mesclagem de paletas de histogramas
DCD QHDM e MPHSM 0,3531
2 Compactação do descritor SCD
SCD L1 (Manhattan) 0,30152
3 Modificação no DCD e EHD
DCD e EHD Combinação de L1 (18) e (17)
0,0920
4 Síntese e uso do descritor DCSD
DCSD Color Matching Palette Similarity
Measure (CMPSM)
0,0993
5 Combinação de um descritor de textura com vários descritores de cor
EHD, SCD, CSD e CLD
Diversas combinações entre
L1 e L2
0,2982
As tabelas 3 a 8 mostram, com mais detalhes, os valores ANMRR obtidos nos
experimentos para recuperação eficiente de imagens por similaridade de conteúdo.

49
Tabela 3. É dividida em TABLE I e TABLE II, uma implementa o QHDM e a outra implementa o MPHSM
Fonte: Wong, Po (2004)
Tabela 4. Diferença de valores ANMRR para o uso compacto de CCD, CTD e CCD e CTD ao
mesmo tempo
Fonte: Dorairaj e Namuduri (2004, p.391)
Tabela 5. Modificação na extração dos descritores de cor dominante e histograma de textura
melhoram o índice ANMRR obtido
Fonte: Yanhong et al. (2009, p.132)

50
Tabela 6. Aplicação de descritores de forma individual e seguida obtenção de seus índices
ANMRR
Fonte: Bleschke et al. (2009, p.638)
Tabela 7. Aplicação de descritores de forma combinada e seguida obtenção de seus índices
ANMRR
Fonte: Bleschke et al. (2009, p.638)

51
Tabela 8. Descriptor DCSD e comparação de seu desempenho com a recuperação que usa
outros descritores
Fonte: Wong et al. (2007, p.614)
4 IMPLEMENTAÇÃO, EXPERIMENTOS E ANÁLISE DOS RESULTADOS
Esta seção descreve a implementação dos descritores e da métrica
selecionados, experimentos realizados com esses artefatos sobre a base de dados
CoPhIR e análise dos resultados obtidos nesses experimentos. O estudo
desenvolvido na seção 3 sugeriu o uso da métrica Manhattan juntamente com o
descritor SCD para a execução de buscas por similaridade. De fato, Krüger (2013)
afirma, através de experimentos com o próprio CoPhIR, que a métrica Manhattan é
mais efetiva do que a Euclideana quando se trata de usar descritores de cor para
recuperação de imagens por similaridade. Os seus experimentos também mostram
que essas duas métricas de cunho geral não são adequadas para recuperação de
imagens por similaridade usando-se descritores MPEG-7. Devido ao fato de os seus
experimentos não envolverem recuperação de imagens com descritores
compactados, decidiu-se compactar o descritor SCD das imagens e avaliar o
processo com o descritor em diferentes níveis de compactação.

52
Por padrão, o SCD do CoPhIR possui 64 coeficientes (ou dimensões). Nesse
trabalho esse descritor é referenciado por SCD64, versões compactas têm dimensão
menor. Os diferentes níveis de compactação são denotados por SCD32 (32
dimensões) e SCDINT (uma dimensão). O descritor SCD32 contém os coeficientes
passa-alta do SCD. Tratam-se de coeficientes resultantes da subtração de
coeficientes adjacentes da versão SCD64. Para se obter o SCDINT, obtém-se o
SCD32 e monta-se um novo vetor com 0s e 1s, onde em uma posição i do novo
vetor se assinala 1 quando o i-ésimo coeficiente do SCD32 é negativo, e 0 caso
contrário. Tomando-se a sequência de bits resultante como um número binário,
obtém-se o descritor SCDINT, com uma dimensão.
Em resumo, esta seção descreve:
A elaboração do compactador do descritor SCD.
Indexação da base de dados completa do CoPhIR pelo metadado tag.
Fragmentação por tag.
Compactação dos descritores no fragmento.
Realização de consultas, obtenção de resultados e análise dos resultados
obtidos.
4.1 IMPLEMENTAÇÃO
A implementação envolveu fragmentação do CoPhIR, compactação do
descritor SCD, conversão do novos descritores produzidos para blob e indexação
das imagens nos fragmentos com a métrica Manhathan e cada um desses
descritores. Trata-se da preparação do conjunto de dados antes de se iniciar os
experimentos que envolvem consultas por similaridade.
O CoPhIR (Content-based Photo Image Retrieval), base de dados de imagens
utilizada nos experimentos, é ums grande coleção de vetores de características de
imagens no formato MPEG-7, juntamente com alguns metadados associados (tags,
local, etc.). Esses metadados foram extraídos de mais de 100 milhões de imagens
do Flickr por pesquisadores europeus os quais disponibilizam os dados resultantes
mediante contrato, para fins de pesquisa. A quantidade de dados é muito grande e a
fragmentação torna-se necessária por dois motivos. O primeiro motivo é o grande
volume de imagens contido no banco de dados. Devido a isso, torna-se necessário
reduzir o espaço de busca das consultas para obter resultados em um tempo

53
aceitável. O segundo motivo é a realização de consultas com contendo predicados
convencionais lógicamente conectados com predicados baseados em similariade de
uma forma mais eficiente. Para tanto, a fragmentação a ser usada é a fragmentação
horizontal. Fragmentação horizontal é a divisão de tuplas em dois ou mais
fragmentos. Pode-se fragmentar manualmente ou segundo algum critério, tais como
valor de tag e autor. A relação original pode ser reconstruída por meio da união de
fragmentos.
Para os experimentos desse trabalho, houve a fragmentação por tags. Antes
de se criar fragmentos contendo descrições de imagens anotadas com diferentes
valores de tags, foi necessário criar um índice funcional baseado nas tags para o
processo de fragmentação ficar mais rápido O índice usado para isso foi a B-Tree,
estrutura de dado padrão da Oracle para aplicação de índices funcionais. De fato,
este índice oferece um melhor desempenho para consultas envolvendo operadores
de igualdade, tal como em uma seleção de dados cuja tag seja igual á ‘gato’. Depois
foram criados fragmentos com as descrições de imagens anotadas com as tags
‘gato’, ‘salsa’ e ‘pathetic’, os quais têm com 22.688, 16.211 e 372 imagens,
respectivamente. Note que uma tag pode se referir semanticamente a algo
totalmente diferente do que alguém imagina ao usá-la em uma consulta. Por
exemplo, observa-se a atribuição da tag ‘gato’ à imagem de uma pessoa bonita ao
invés da atribuição desta tag a um animal. A tag ‘salsa’, por outro lado, pode ser
referir à dança ou à planta usada como tempero.
A produção de um novo valor de SCD compactado implica adicionar novas
colunas e fazer operações sobre o descritor SCD. Para isso, foi necessário o uso de
programas Java e procedures no banco de dados. O programa Java serve para
manipular os descritores com mais praticidade e usar instruções SQL embutidas
para resgatar e armazenar descritores. As procedures são necessárias para
serializar os valores novos e transformá-los em valores tipo blob serializados Dessa
forma o FMI-SiR pode lê-los e manipulá-los com segurança.

54
Figura 15. Código Java para conexão com o banco de dados da Oracle.
A figura 15 ilustra as instruções para se conectar ao banco de dados da
Oracle. Essa conexão ocorre em dois programas Java produzidos pelo autor deste
trabalho, ReduzSCD e ReduzSCDint. O primeiro programa realiza a compactação
de SCD64 para SCD32, o segundo programa realiza a compactação de SCD32 para
SCDINT. Esse processo de compactação começa logo após a conexão, realiza-se a
declaração de variáveis para lidar com o fragmento, prepara-se a instrução sql a ser
usada e se usa a classe PreparedStatament para obter resultados do comando sql.
As declarações encontram-se na figura 16.Figura 16. Declaração de variáveis para execução de compactação.
O objeto result será o responsável por obter as tuplas retornadas das
consultas. Este objeto contém o resultado da consulta feita e possui um ponteiro que
se inicia na primeira tupla obtida, a instrução result.next() moverá o ponteiro para a a
próxima tupla, o acesso aos atributos da tupla ocorre através de métodos get().

55
Figura 17. Conversão de valores para um formato manipulável.
O processamento de cada tupla envolve converter os valores necessários da
tupla para um formato manipulável, manipular os valores de acordo com o esperado
e armazenar o novo valor em uma nova coluna. No banco de dados Oracle, os
valores dos descritores SCD das tuplas estão armazenados em varchar2(4000 byte),
é necessário converte-los para valores inteiros antes de se operar sobre eles, essa
conversão encontra-se descrita na figura 17. Trata-se de uma conversão de valores
que ocorre tanto em ReduzSCD como em ReduzSCDint, a manipulação de valores
dos dois programas já é diferente.
A figura 18 mostra a obtenção de coeficientes passa-alta para a formação do
descritor SCD32, esse processo ocorre no programa ReduzSCD. Subtraem-se
valores adjacentes de SCD64, armazena-os em uma nova variável do tipo int e
converte-se esse valor para um formato String, a conversão para um formato String
é essencial para o armazenamento do vetor através do uso de uma instrução sql
embutida.

56
Figura 18. Compactação do descritor SCD64 para obtenção do descritor SCD32.
A obtenção do SCDINT ocorre logo após a obtenção de SCD32. O método de
compactação em RedSCDint contém a obtenção de coeficientes passa-alta, porém a
conversão de valor para inteiro ocorre de outra forma. Primeiro obtém-se um número
binário cujo bit n desse vetor será 1 caso o coeficiente n do SCD32 seja negativo e 0
caso contrário, depois converte-se esse número binário para um inteiro e obtém-se o
SCDINT. O método para obtenção desse descritor encontra-se ilustrado na figura 19,
usa-se condicionais if-else para se decidir se o bit n do valor binário será 1 ou 0, logo
depois usa-se o construtor da clase BigInteger para se construir um valor grande em
formato string com base definida no segundo parâmetro, neste caso o segundo
parâmetro é dois, pois queremos construir um número binário.

57
Figura 19. Obtenção do descritor SCDINT.
Após a obtenção de um descritor compactado ocorre a abertura de um novo
posStatement do tipo PreparedStatement, armazenamento do novo descritor e o
fechamento desse novo PreparedStatement. É importante salientar, para fins de
programação, o fechamento de posStatement, pois caso contrário o programa irá
interromper a execução na presença de um número limite de posStatement abertos. Figura 20. Armazenamento de descritor compactado.
Logo após a redução dos descritores o FMI-SiR deve ler os valores,
processá-los e mostrar resultados. O parâmetro de entrada para métodos que
envolvam processamento dentro desta ferramenta são valores em formato blob
(Binary Large Object), o qual obtém-se através de duas formas. O Oracle contém um
método de conversão de valores para blob, porém os valores providos dessa
conversão não são serializados e tais valores não serão lidos pelo FMI-SiR por
questões de segurança da própria ferramenta. Resolveu-se o problema usando-se
procedures PLSQL para conversão de valores blob serializados. As figuras 21, 22 e
24 ilustram o processamento dos valores contidos no descritor SCD32 com o
objetivo de serializá-los e torná-los manipuláveis com o uso do FMI-SiR. O
procedimento é análogo para o processamento do descritor SCDINT, porém o que
muda são os valores scd_coef, scd_coeffred_blob e o parâmetro 32 como terceiro

58
parâmetro em READSIGNATUREFROMFILE(). O valor scd_coef é o descritor
SCD32, o valor scd_coeffred_blob é o descritor SCD32 convertido corretamente
para blob no final do processo e o parâmetro 32 é a dimensão do descritor SCD32
convertido. Entende-se por dimensão como sendo o tamanho do vetor que
representa o descritor SCD. O procedimento que converte o valor SCDINT usa os
valores scd_coeffredint, scd_coeffredint_blob e o parâmetro 1 como o terceiro
parâmetro da função READSIGNATUREFROMFILE(), o primeiro valor é o descritor
SCDINT, o valor scd_coeffredint_blob é o descritor SCDINT convertido corretamente
para blob no final do processo e o parâmetro 1 é a dimensão do descritor SCDINT
convertido.Figura 21. Primeira parte da procedure desenvolvida em PLSQL para conversão de valores
para formato BLOB.

59
Figura 22. Segunda parte da procedure desenvolvida em PLSQL para conversão de valores
para formato BLOB.
O próximo passo da implementação é indexar os elementos convertidos.
Diferentemente da indexação por tags, os índices usados para cálculos de
distâncias no FMI-SiR é a Slim-Tree, uma árvore de indexação mais otimizada que a
M-Tree. Como a busca por similaridade não trabalha com operadores de igualdade,
e sim com noções de similaridade, a B-Tree não seria uma boa escolha.
Realiza-se a indexação através de instruções específicas da Oracle. As
instruções, especificadas na figura 23, ilustram a indexação dos descritores SCD32
e SCDINT para a métrica Manhattan. O FMI-SiR contém a implementação de índices
Slim-Tree para as métricas Manhattan e Euclidean, porém é possível usar a Slim-
Tree para a indexação com base em outras métricas quaisquer que se implemente
na ferramenta.Figura 23. Indexação dos descritores SCD32 e SCDINTpara o fragmento FRAG_184

60
Figura 24. Terceira parte da procedure desenvolvida em PLSQL para conversão de valores
para formato BLOB.
A execução das instruções de criação de índice implicará a chamada do
método Index Create ilustrado na figura 25. É importante notar que esse e outros
métodos do FMI-SiR exigem um interfaceamento entre o Oracle e o Arboretum. O
primeiro passo deste método consiste em passar informações sobre o índice a ser
criado tais como o atributo de indexação e a tabela que possui o atributo. No
segundo passo, o FMI-SiR requisita o Arboretum a criar uma Slim-Tree vazia.
Depois, consulta-se os dados na tabela (assinatura e número da linha) no passo 3.
O passo 4 usa a assinatura da tupla retornada no passo anterior e usa uma função
para obter o dado BLOB do objeto. O passo 5 consiste em inserir o elemento na
Slim-Tree através do uso do Arboretum e o sexto passo retorna o código para o
processador de consultas da Oracle.

61
Figura 25. Criação de índices no FMI-SiR
Fonte: Kaster, Daniel S; Bugatti, Pedro H; Traina, Agma J M; Jr, Caetano Traina (2010,
p.236).
4.2 EXPERIMENTOS E AVALIAÇÃO
Essa seção contém buscas realizadas sobre os fragmentos e os resultados
obtidos delas, tais como tempo de execução, custo(acessos a disco) da consulta
pelo SGBD Oracle, distribuição de distâncias e visualização da precisão e cobertura.
Trata-se de buscas que, além de usarem predicados de similaridade, usam
predicados convencionais, tais como consultas envolvendo nome. Optou-se por
realizar consultas Range e Knn usando-se a métrica Manhattan devido ao seu
melhor desempenho para recuperação de imagens. Optou-se, também, por realizar
consultas por similaridade indexadas e não indexadas.
Seja a consulta da figura 26. A consulta ilustrada usa predicado convencional
(seleção de imagens com a tag igual a ‘gato’) e predicado de similaridade(seleção
das cinco imagens mais próximas, segundo a distância manhattan e descritor SCD,
á imagem 9435). Devido ao fato de essa consulta usar índice, dispara-se o comando
para o mecanismo de busca por similaridade indexada no FMI-SiR ilustrado na
figura 27. O FMI-SiR usa três métodos para se realizar tal tarefa, IndexStart,
IndexFetch e IndexClose. A sequência dos passos envolve, primeiramente, usar o
método IndexStart para inicializar o índice existente e isso envolve usar o arboretum,
na sequência tem o uso de IndexFetch para retornar os dados da consulta por

62
similaridade na ordem correta e, por último, tem o uso de IndexClose para fechar o
uso do índice e não deixá-lo aberto ocupando memória.Figura 26. Consulta envolvendo predicado convencional e predicado por similaridade
Figura 27. Execução de uma consulta por similaridade com índice.
Fonte: Kaster, Daniel S; Bugatti, Pedro H; Traina, Agma J M; Jr, Caetano Traina (2010, p.237).
Os primeiros experimentos realizados contam com a realização de consultas
pelos cinco vizinhos mais próximos usando-se a métrica Manhattan e os descritores
SCD64, SCD32 e SCDINT, logo a seguir se explica como as imagens retornadas
estão ilustradas.
O primeiro conjunto de cinco imagens diz respeito ao retorno da consulta
pelos cinco vizinhos mais próximos usando-se a métrica Manhattan e o descritor
SCD64. A imagem com borda vermelha é o centro do espaço métrico e, da esquerda
para a direita, estão registradas as imagens mais similares á imagem de consulta de
acordo com o nível de similaridade. Vale lembrar que a distância da imagem com
borda vermelha até ela mesma é zero. O segundo conjunto de imagens representa a
mesma consulta, porém com o descritor SCD32. De maneira análoga, o terceiro
conjunto de imagens representa a mesma consulta, porém com o descritor SCDINT.

63
O conjunto de imagens retornado muda conforme o a versão do descritor SCD que
se usa, porém observa-se uma diferença considerável entre os conjuntos
retornados. O conjunto de imagens retornado usando-se o descritor SCD32 contém
mais verde e tem uma similaridade visual maior com a imagem centro do espaço
métrico, porém quando se usa o descritor SCDINT a questão da similaridade visual
se perde a partir de uma determinada imagem na ordem de similaridade.

64
Figura 28. Imagens retornadas da consulta com imagens contendo a tag ‘gato’. Para a
primeira sequência de imagens, usa-se o descritor SCD64, para a segunda usa-se o descritor SCD32
e para a terceira usa-se o descritor SCDINT.
Outra forma de se medir a eficiência é através de um gráfico com distribuição
de distâncias. O gráfico registra uma relação entre imagem retornada na consulta e
a distância da imagem ao centro do espaço métrico, o eixo horizontal registra as
imagens e o eixo vertical registra a distância da imagem até o centro do espaço
métrico, é importante observar que as imagens mais á esquerda da relação são as
imagens mais similares á imagem do centro do espaço métrico, enquanto que á
direita estão as imagens menos similares, por conseguinte temos que a imagem
mais á esquerda do gráfico é a própria imagem do centro do espaço métrico. Outro

65
ponto importante a se observar são os valores normalizados, os valores das
distâncias calculados com cada descritor possuem uma abrangência de valores
diferente e a normalização foi importante para se comparar as distribuições de
distâncias entre sí.
A distribuição de distâncias é importante devido ao problema conhecido como
maldição da dimensionalidade e é decorrente do tamanho dos vetores com o qual se
trabalha, quanto maior o vetor maior o tempo de execução e menor é o efeito da
indexação nesse vetor. A maldição da dimensionalidade é um problema típico na
área de redes neurais que persiste, também, na área de processamento de imagens
quando se trata de desempenho de consultas. O descritor SCD64 é um vetor com
dimensão 64, o descritor SCD32 tem dimensão 32 e o SCDINT tem dimensão um.
Para o fragmento cujas imagens contêm a tag ‘gato’, a figura 29 mostra essa
distribuição. Observa-se que a distribuição de distâncias torna-se maior quando a
dimensionalidade fica menor. Para o descritor SCD64 e SCD32 as distâncias tem
uma distribuição menor, porém mais regular, já para o descritor SCDINT as
distâncias tem uma distribuição mais irregular, porém maior. Quando o quesito é a
distribuição de distâncias, o descritor SCDINT é mais eficiente para esse fragmento.
Observa-se a maldição da dimensionalidade através da análise do tempo e do custo
das operações com consultas por similaridade que usam o descritor SCD64, SCD32
e SCDINT, registrados nas tabelas 9, 10 e 11. O descritor SCD32 possui uma
distribuição de distânciasmais concentrada e o tempo de busca com índice acaba
sendo maior do que a busca com o descritor SCD64. Há uma observação a se fazer
nessa análise, o tempo de execução Range_Knn(busca por alcance seguido de
busca pelos ‘k’ vizinhos mais próximos)depende do parâmetro que se configurar
para o valor de Range, se o valor dessa configuração fosse menor para recuperar
imagens com SCDINT o tempo de execução também teria sido menor. As figuras 30
e 31 ilustram com mais detalhes as operações envolvidas com o custo da consulta,
nota-se uma redução enorme no custo final quando se usa índice.

66
Figura 29. Distribuição de distâncias para cada descritor.
Tabela 9. Tempo de execução e custo(acessos a disco) das consultas envolvendo o
fragmento cujas fotos são anotadas com a tag ‘gato’ e SCD64. A busca KNN(5) refere-se á uma
busca pelos 5 vizinhos mais próximos e a busca RANGE_KNN(60, 5) refere-se á aplicação de busca
por um raio de 60 unidades de distância seguido de uma busca pelos 5 vizinhos mais próximos.
Tabela 10. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘gato’ e SCD32.

67
Tabela 11. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘gato’ e SCDINT.
Figura 30. Custo das operações(acessos a disco realizados pelo SGBD) na consulta KNN(5)
para imagens contendo a tag ‘gato’.
Figura 31. Custo das operações na consulta KNN(5) indexada para imagens contendo a tag’
gato’.
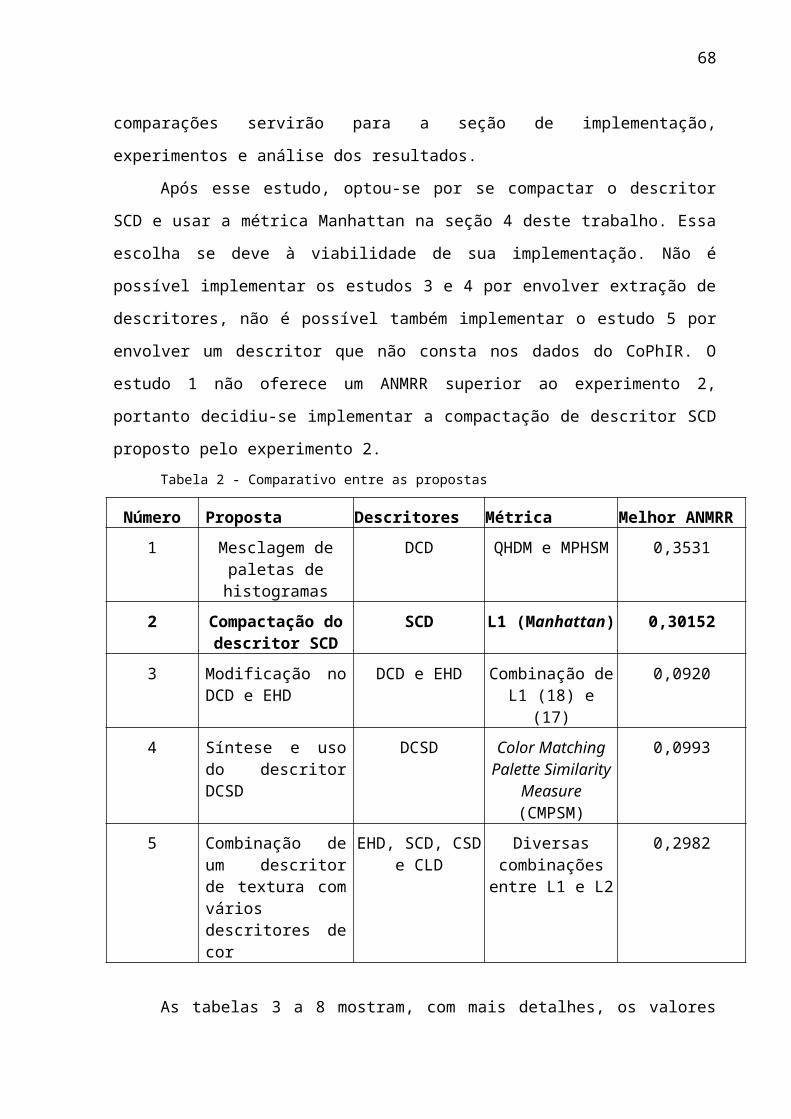
68
Os dados de desempenho referentes ao fragmento cujas imagens contêm a
tag ‘pathetic’ estão registrados nas figuras 32 e 33 e nas tabelas 12, 13 e 14. A
consulta com imagens contendo esta tag e com centro do espaço métrico igual á
imagem com identificador 111731 está na figura 32. A distribuição de distâncias
encontra-se ilustrado na figura 33 e os dados que relatam tempo de execução e
custo estão nas tabelas 12, 13 e 14.
Observa-se que, para as imagens retornadas da consulta contendo essa tag,
a segunda consulta parece ser melhor do que a primeira quando se trata de captar
melhor algumas características das imagens, tais como luminosidade no canto
inferior direito das imagens e as cores mais escuras um pouco mais á direita do
centro das imagens, porém há um gap semântico da segunda para a terceira
consulta. Com relação á distribuição de distâncias, o SCD32 possui mais variação
de distância se comparado ao SCD64 e o SCDINT é o que possui a maior variação,
essa distribuição de distâncias mostra o motivo pelo qual os tempos de execução
diminuem á medida que se compacta o descritor, trata-se de um fato que não
aconteceu nos experimentos com as imagens contendo a tag ‘gato’. Observa-se
que, nesse caso, o tempo de execução não é proporcional ao custo, o uso da
indexação fez o custo da operação aumentar em aproximadamente 30%, porém o
efeito que se teve sobre o tempo de execução foi inverso se comparar a consulta
KNN(5) normal com a KNN(5) indexada.
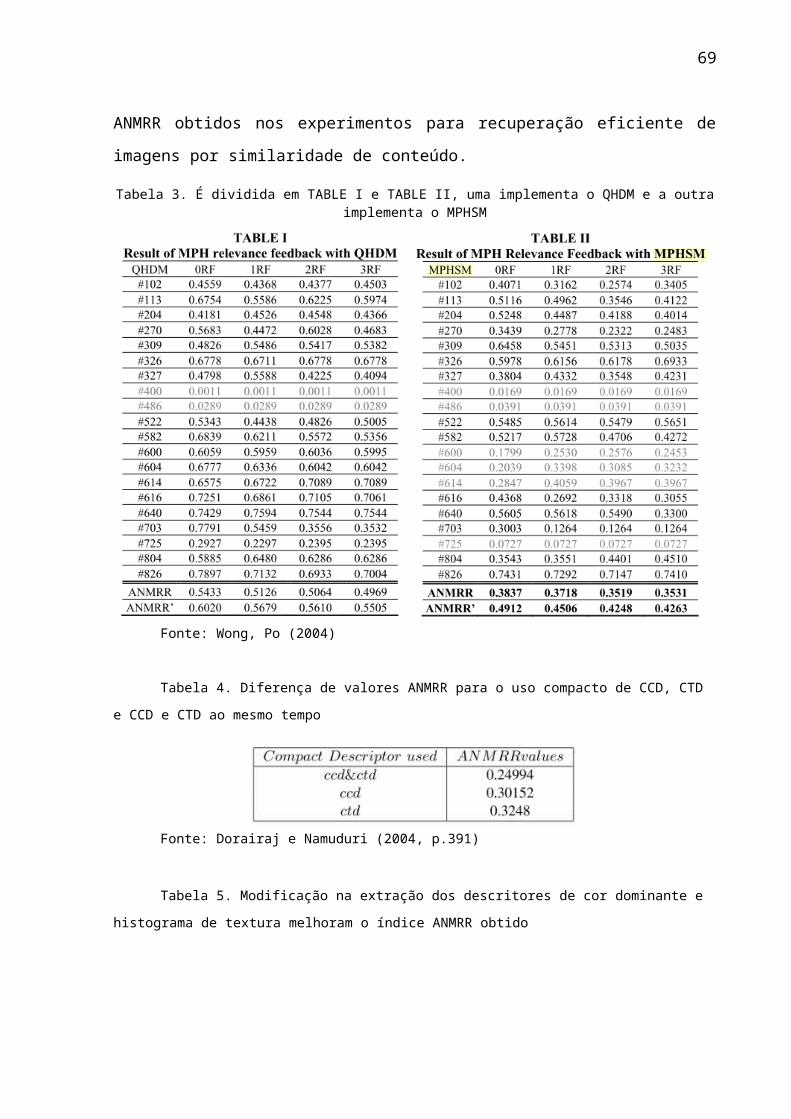
69
Figura 32. Imagens retornadas da consulta com imagens contendo a tag ‘pathetic’.

70
Figura 33. Distribuição de distâncias para cada descritor.
Tabela 12. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘pathetic ‘ e SCD64.
Tabela 13. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘pathetic‘ e SCD32.
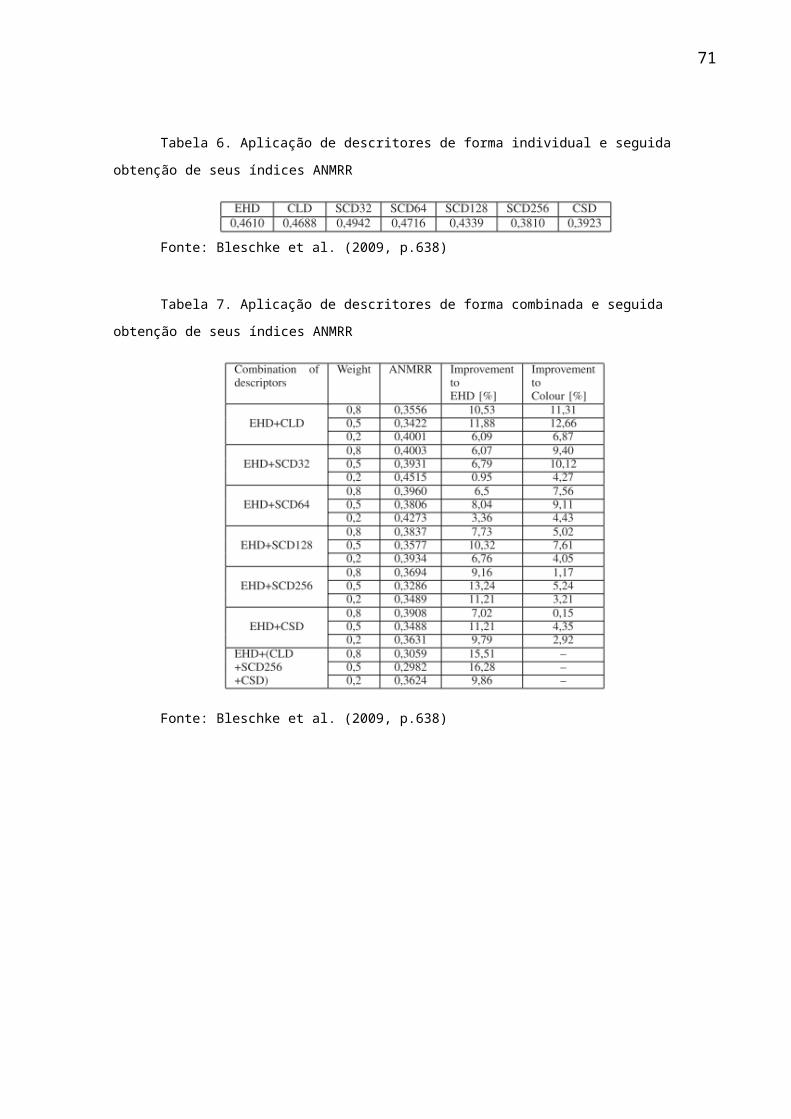
71
Tabela 14. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘pathetic’ e SCDINT.
Figura 34. Custo das operações na consulta KNN(5) para imagens contendo a tag ‘pathetic’.
Figura 35. Custo das operações na consulta KNN(5) indexada para imagens contendo a tag
‘pathetic’.
Os dados de desempenho referentes ao fragmento cujas imagens contêm a
tag ‘salsa’ estão registrados nas figuras 36 e 37 e nas tabelas 15, 16 e 17. A consulta
com imagens contendo esta tag e com centro do espaço métrico igual á imagem
com identificador 75681 está na figura 36, a distribuição de distâncias encontra-se
ilustrado na figura 37, os dados que relatam tempo de execução e custo estão nas
tabelas 15, 16 e 17 e as figuras 38 e 39 detalham as operações de custo.
Observa-se novamente uma troca na ordem de imagens mais similares
quando ocorre a compactação do descritor. Para as imagens contendo a tag ‘salsa’,
imagens mais similares se aproximam mais do centro de consulta, observa-se esse

72
fato quando, por exemplo, a terceira imagem mais próxima ao centro de consulta
para o descritor SCD64 se torna a segunda mais próxima ao centro para o descritor
SCD32, de fato as duas imagens contém a cena do céu nublado na parte de cima,
as árvores logo abaixo do céu e algumas cores no meio que se misturam na foto.
Por um lado, a precisão e cobertura visual parecem melhorar para essa
compactação, mas por outro lado a indexação nas imagens com descritor SCD32
não fornece uma melhora tão boa no tempo de execução quanto a indexação de
imagens com SCD64, esse problema com a indexação pode ser fruto da maldição
da dimensionalidade. Para esse conjunto de fotos, a compactação SCDINT parece
melhorar a cobertura e precisão visual e a melhora de tempo de execução com
indexação é proporcionalmente a maior de todas.
O gráfico de distribuição de distâncias, os tempos de execução e custo das
consultas mostram que há uma variação aparentemente menor de distâncias para o
descritor SCD32, uma variação enorme para o SCDINT como já esperado, um
ganho menor de tempo de consulta com a indexação das imagens através do
descritor SCD32 e uma diminuição considerável de custo com a indexação.
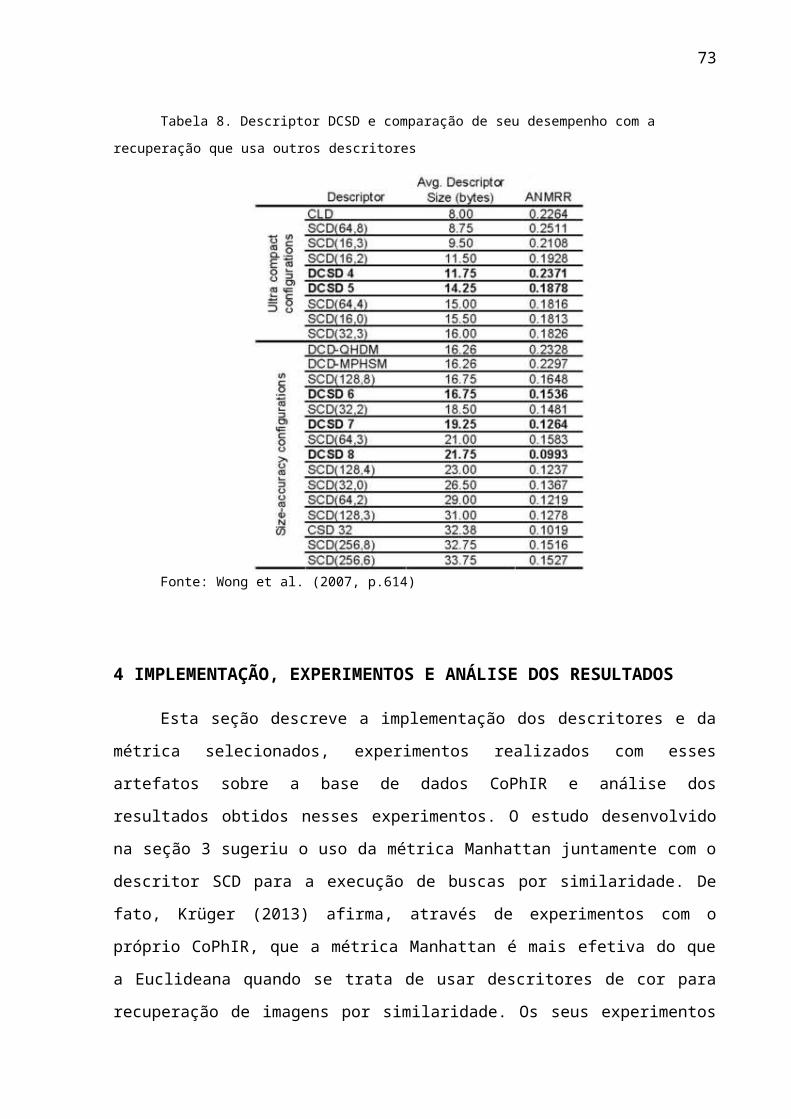
73
Figura 36. Imagens retornadas da consulta com imagens contendo a tag ‘salsa’.

74
Figura 37. Distribuição de distâncias para cada descritor.
Tabela 15. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘salsa‘ e SCD64.
Tabela 16. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘salsa‘ e SCD32.

75
Tabela 17. Tempo de execução e custo das consultas envolvendo o fragmento cujas fotos
possuem a tag ‘salsa‘ e SCDINT.
Figura 38. Custo das operações na consulta KNN(5) para imagens contendo a tag ‘salsa’.
Figura 39. Custo das operações na consulta KNN(5) indexada para imagens contendo a tag
‘salsa’.
De um modo geral, observa-se que a compactação do descritor SCD64
oferece uma melhora no tempo de execução, distribui menos as distâncias com a
compactação para SCD32 e distribui mais as distâncias com a compactação para
SCDINT, porém o custo pode aumentar caso o conjunto de imagens contendo
determinada tag seja pequeno demais. Outro fator observado é que, por um lado a
compactação desse descritor resolve o problema da dimensionalidade, mas por
outro, o gap semântico pode aumentar muito dependendo do conjunto de imagens
envolvido no processo.

76
5 TRABALHOS RELACIONADOS
Esta seção contém alguns trabalhos cujo tema envolve recuperação eficiente
de dados complexos e que estão relacionados com esse trabalho direta ou
indiretamente. O primeiro trabalho relacionado, desenvolvido por Wong e Po (2004),
é uma alternativa á compactação do descritor SCD para melhorar o processo de
recuperação de imagens, pelo menos sob o ponto de vista de qualidade dos
resultados obtidos, o trabalho relacionado em questão também faz uso de
descritores padrão MPEG-7 e medidas de desempenho ANMRR para fins de
comparação com outros trabalhos. O segundo trabalho relacionado, desenvolvido
por Chalechale et al. (2004), foi desenvolvido com o mesmo objetivo deste trabalho
e usa as mesmas medidas de desempenho, porém o conjunto de dados é de cunho
específico. Percebe-se que esta área de estudo ainda está em desenvolvimento e
não está madura o suficiente para se ter progressos significativos. Vários trabalhos
chegam a conclusões diferentes e não há como se tirar conclusões definitivas a
respeito da forma mais eficiente de se realizar recuperação por similaridade sobre
imagens.
5.1 USO DAS MÉTRICAS QHDM E MPHSM JUNTAMENTE COM FEEDBACK DE USUÁRIO
No trabalho de [Wong e Po, 2004], o autor sugere aplicar uma técnica
chamada histograma de mistura de paletas (Merged Palette Histogram, ou MPH)
nos descritores de cores dominantes (Dominant Color Descriptor, ou DCD) e usar
realimentação por relevância (relevance feedback), o propósito desta técnica é
supervisionar o processo de recuperação por similaridade com base na escolha das
imagens que o usuário achar mais relevante. Dado o objeto de busca Q, no início do
processo os objetos no banco de dados mais similares a Q são resgatados, após o
resgate um usuário seleciona as imagens consideradas mais semelhantes á Q, em
seguida o mecanismo de busca mescla as paletas de cores dessas imagens
selecionadas e, no final, a nova paleta mesclada passa a ser o parâmetro de entrada
para uma nova busca por similaridade, este ciclo se repete quantas vezes forem
necessárias. Duas métricas diferentes são usadas para esse resgate (por
consequência, se obtém dois resultados diferentes), uma das métricas é a distância
quadrática de histogramas (Quadratic Histogram Distance Measure em inglês, ou

77
QHDM) e a outra delas é a distância de histogramas com paletas mescladas
(Merged Palette Histogram Similarity Measure, ou MPHSM). O objetivo de se usar as
duas métricas é comparar o resultado que cada uma produz.
A figura 36 ilustra a mistura das paletas H1 e H2 para formar a nova paleta H’.
Este processo une duas paletas de cor DCD e obtém uma só que represente as
duas simultaneamente, essa mistura de paletas torna-se necessária para evitar o
uso de mais cores do que o permitido para o descritor. Este processo se repete de
acordo com a escolha do usuário em usar mais imagens como um feedback para o
processo de recuperação por similaridade. Figura 40. Mistura de duas paletas de dois DCDs
Fonte: Wong e Po (2004, p.434)
5.2 USO DA MÉTRICA MANHATTAN EM IMAGENS DE CUNHO ESPECÍFICO
Outro dos trabalhos semelhantes que envolvem recuperação de imagens de
uma forma eficiente foca em um conjunto específico de imagens. Trata-se de um
trabalho que aborda uma área pouco explorada pelos pesquisadores. O trabalho em
questão é o de Chalechale et al. (2004). O objetivo deste trabalho é buscar por
características da imagem que sejam invariantes a escalonamento, translação e
rotação. Essas características podem ser muito úteis para uso na recuperação
baseada em rascunhos. Para atingir este objetivo, usa-se um algoritmo de abstração
de imagens e decomposição espacial para extração de características, a esse
algoritmo atribui-se o nome de Abstract Image Decomposition and Transform(AIDT).
Primeiramente, o algoritmo AIDT transforma a imagem a ser tratada em uma
imagem em escala de cinza. Assim se elimina a saturação e a cor da imagem e se

78
mantém a iluminação. Depois de se obter a imagem em escala de cinza se extraem
as bordas com o uso de um operador chamado Canny e uma máscara Gaussiana. A
figura 37 ilustra o efeito do parâmetro no operador Canny sobre a obtenção da
imagem em escala de cinza para seguida extração de bordas. Depois, aplicam-se
procedimentos específicos para obter informações numéricas sobre a textura da
imagem rascunho, se usa a métrica Manhattan para medir a distância entre os dois
vetores extraídos e, por último, se usa as medidas de desempenho ANMRR para se
medir a eficiência do processo de recuperação de rascunhos por similaridade. Figura 41. Efeito do parâmetro nas bordas Canny com o trabalho sobre uma das imagens
Fonte: Chalechale et al. (2004, p. 434)

79
6 CONCLUSÕES E TRABALHOS FUTUROS
A pesquisa bibliográfica indicou que a combinação mais satisfatória para
recuperação eficiente de imagens é usar a métrica L1 e com a compactação do
descritor de cor SCD, sugerida por [Namuduri e Dorairaj, 2004].Dentre as métricas
que não exigem modificação no extrator de características, essa é a que oferece o
menor índice ANMRR. Outras estratégias podem oferecer uma medida ANMRR
melhor, porém não foram adotadas para os experimentos desse trabalho por motivos
específicos. Um dos motivos é o fato de algumas das estratégias requereriam extrair
descritores não disponíveis no CoPhIR.. Outro motivo é o uso de versões de
descritores que não constam na base de dados do CoPhIR. Decidiu-se por
implementar a compactação do descritor SCD após a pesquisa. Porém, após a
implementação, os experimentos indicaram que, dependendo do nível de
compactação, o gap semântico pode ser grande e pode ocorrer muita perda da
precisão e cobertura. Conclui-se que, apesar de a compactação de descritores
resolver o problema da dimensionalidade, surge o problema do gap semântico e o
desafio nesse contexto está em conseguir um balanceamento entre desempenho e
qualidade dos resultados. (fazer com mais experimentos, testar mais métricas e
descritores com outras bases de dados)
Para trabalhos futuros, sugere-se realizar experimentos com os descritores
SCD compactados com vários conjuntos de dados, isto inclui obter o tempo de
execução e custo das consultas e montar relações que apontem outras
observações, tais como tempo de execução e dimensão dos descritores com dados
indexados e não indexados. Há também outras sugestõespara trabalhos futuros,
dentre elas estão:
Resolver consultas com dois descritores, um de cor e um de textura, e
realizar implementação, experimentos e análise.
Verificar a possibilidade de se compactar outros descritores e obter resultados
positivos através de pesquisa bibliográfica e experimentos.
Trabalhar com outras bases de dados e trabalhar com recuperação eficiente
por similaridade de dados com a possibilidade de se interferir no processo de
extração de características.

80
REFERÊNCIAS
BARIONI, Maria Camila Nardini. Operações de consulta por similaridade em grandes bases de dados complexos. 2006. Tese(doutorado) - Universidade de São Paulo, Instituto de Ciências Matemáticas e de Computação, São Carlos.
MAHBOUBI, Hadj, et al. X-wacoda: An xml-based approach for warehousing and analyzing complex data. In: BELLATRECHE, Ladjel (Org.) .Data Warehousing Design and Advanced Engineering Applications: Methods for Complex Construction.Chicago: IGI Global, 2009. p.38-54.
RÜGER, Stefan. Multimidia Information Retrieval. Chapel Hill, Ca: Morgan & Claypool publishers, 2010
Nack, Frank, and Adam T. Lindsay. "Everything you wanted to know about MPEG-7. 1." Multimedia, IEEE 6.3 (1999): 65-77.
Avaro, Olivier, and Philippe Salembier. "MPEG-7 Systems: overview." Circuits and Systems for Video Technology, IEEE Transactions on 11.6 (2001): 760-764.
Zezula, P., Amato, G., Dohnal, V., & Batko, M. (2006). Similarity search, The Metric Space Approach. Springer.
Eidenberger, H. (2003, November). Distance measures for MPEG-7-based retrieval. In Proceedings of the 5th ACM SIGMM international workshop on Multimedia information retrieval (pp. 130-137).ACM.
Salembier, Philippe, and John R. Smith."MPEG-7 multimedia description schemes." Circuits and Systems for Video Technology, IEEE Transactions on11.6 (2001): 748-759.
Ritendra Datta, Dhiraj Joshi, Jia Li, and James Z. Wang. Image Retrieval: Ideas, Influences, and Trends of the New AgeACM Computing Surveys. University Park, April 2008, Vol. 40, No. 2, Article 5.
Molková.Lucie.Indexing Very Large Text Data. 2011. Tese(mestrado) – Masaryk University, Faculty of Informatic, Brno.
Pattanaik Swapnalini, Bhalke D. G..Efficient Content based Image Retrieval System using Mpeg-7 Features. International Journal of Computer Applications, Rajarshi Shahu College of Engineering, Pune, v.53, n.5, p.19-24,Setembro, 2012.
Kaster, Daniel S., et al. FMI-SiR: A flexible and efficient module for similarity searching on Oracle database. Journal of Information and Data Management .Sao Paulo, v. 1, n. 2, p.229-244, jun. 2010.
Barioni, M. C. N., Razente, H., Traina, A., & Traina Jr, C. SIREN: A similarity retrieval engine for complex data. InProc. of the 32nd Intl. Conf. on Very large data base, 2006, Seoul. VLDB Endowment, 2006, p. 1155-1158

81
Oracle Corporation. Oracle® interMedia User's Guide Disponível em: http://docs.oracle.com/cd/B19306_01/appdev.102/b14302/ch_intr.htm. Acesso em: 16 fev. 2013.
B.S Manjunath, J.R.Ohm, V.V Vasudevan and A.Yamada, Color and texture descriptors, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 11, No. 6, 2001, pp. 703-715
Ka-Man Wong; Lai-Man Po, MPEG-7 dominant color descriptor based relevance feedback using merged palette histogram, Acoustics, Speech, and Signal Processing, 2004. Proceedings. (ICASSP '04). IEEE International Conference on , vol.3, no., pp.iii,433-6 vol.3, 17-21 May 2004
Ka-Man Wong; Chun-Ho Chey; Tak-Shing Liu; Lai-Man Po, Dominant color image retrieval using merged histogram, Circuits and Systems, 2003. ISCAS '03. Proceedings of the 2003 International Symposium on , vol.2, no., pp.II-908,II-911 vol.2, 25-28 May 2003
J. Ohm, L. Ciepli´ (d) peo-026 (e) peo-061 (f) peo-038 nski, H. J. Kim, S. Krishnamachari, B. S. Manjunath, S. Messing, and A. Yamada, The MPEG-7 Colour Descriptors, IEEE Transactions on Circuits and Systems for Video Technology, 2001
Dorairaj, R.; Namuduri, K.R., Compact combination of MPEG-7 color and texture descriptors for image retrieval, Signals, Systems and Computers, 2004. Conference Record of the Thirty-Eighth Asilomar Conference on , vol.1, no., pp.387,391 Vol.1, 7-10 Nov. 2004
Zhao Yanhong; Wang Beizhan; Ye Su; Zheng Yinhuan; Shi Liang, Image retrieval based on improved MCD and EHD of MPEG-7, Test and Measurement, 2009. ICTM '09. International Conference on , vol.1, no., pp.127,132, 5-6 Dec. 2009
Hong Shao; Jun Ji; Yan Kang; Hong Zhao, Application Research of Homogeneous Texture Descriptor in Content-Based Image Retrieval, Information Engineering and Computer Science, 2009.ICIECS 2009. International Conference on , vol., no., pp.1,4, 19-20 Dec. 2009
Swapnalini Pattanaik and D G Bhalke.Efficient Content based Image Retrieval System using Mpeg-7 Features. International Journal of Computer Applications 53(5):19-24, September 2012
Lai-Man Po; Ka-Man Wong, A new palette histogram similarity measure for MPEG-7 dominant color descriptor, Image Processing, 2004. ICIP '04. 2004 International Conference on , vol.3, no., pp.1533,1536 Vol. 3, 24-27 Oct. 2004
Missaoui, R.; Sarifuddin, M.; Vaillancourt, J., Similarity measures for efficient content-based image retrieval, Vision, Image and Signal Processing, IEE Proceedings - , vol.152, no.6, pp.875,887, 9 Dec. 2005
Paolo Bolettieri, Andrea Esuli, Fabrizio Falchi, Claudio Lucchese, Raffaele Perego,

82
Tommaso Piccioli, Fausto Rabitti. “CoPhIR: a Test Collection for Content-Based Image Retrieval, CoRR, volume abs/0905.4627v2, Year 2009, http://arxiv.org/abs/0905.4627v2, http://cophir.isti.cnr.it
Bleschke, M.; Madonski, R.; Rudnicki, R., Image retrieval system based on combined MPEG-7 texture and Colour Descriptors, Mixed Design of Integrated Circuits & Systems, 2009. MIXDES '09. MIXDES-16th International Conference , vol., no., pp.635,639, 25-27 June 2009
Pattanaik, Swapnalini; Bhalke, D.G. Efficient Content based Image Retrieval System using MPEG-7 Features, International Journal of Computer Applications; Vol. 53, p19, 09 Jan. 2012
Ka-Man Wong; Lai-Man Po; Kwok-Wai Cheung, A Compact and Efficient Color Descriptor for Image Retrieval, Multimedia and Expo, 2007 IEEE International Conference on , vol., no., pp.611,614, 2-5 July 2007
Krüger, Marcelo. Fragmentação, caracterização e recuperação deInformação em base de dados de imagem. 2013. TCC – Universidade do Vale do Itajaí, Florianópolis.
Oracle Corporation. Indexes and Index-Organized Tables Disponível em:http://docs.oracle.com/cd/E11882_01/server.112/e25789/indexiot.htm#CNCPT88835. Acesso em 27 out. 2013

83
ANEXOS
A.1 - CRONOGRAMA
Etapas
2012 2013
N D J F M A M J J A S O N D
Redigir proposta X X
Entrega da proposta completa assinada e aprovada 18/02
Estudo da fundamentação teórica X X X X
Estudo da ferramenta FMI-SiR e realização de algumas consultas X X X
Implementação das métricas no FMI-SiR X X X X
Estudo e aplicação de índices métricos no FMI-SiR(se necessário) X X X X
Execução de experimentos com as métricas e índices métricos
implementados para colher resultado de desempenho
X X X
Documentação dos resultados dos experimentos no texto do relatório
final e em artigos científicosX X X
Redigir relatório de projeto I X X X
Redação do rascunho do TCC X X X
Preparação da defesa X
Ajuste no relatório final do TCC X X X
Entrega do TCC e defesa pública X X
A.2 - CUSTOS
Item Quantidade Valor unitário (R$) Valor Total (R$)Máquina para experimentos 1 2.300 2.300
PessoalOrientador 50 horas R$ 120 /hora R$ 6.000,00Coordenador de Projeto
10 horas R$ 120 /hora R$ 1.200,00
Membro da Banca 2x(10 horas) R$ 120 /hora R$ 2.400,00

84
A.3 - RISCOS
Risco Probabilidade Impacto Prioridade Estratégia de resposta
Ações de prevenção
Computador não funcionar mais Baixa Alto Alto Aceitar Utilização de
no-break.Alteração de
cronograma ou descontinuidade
do projeto no laboratório onde
recebo bolsa
Baixa Alto Alto
Mudar o tema do
trabalho ou mudar o enfoque
Obtenção constante de informações
sobre o andamento
geral do projeto
Queimar HD Média Alto AltoRecupera o
que for possível
Fazer backups com frequência
A.4 - COMUNICAÇÃO
O que precisar ser comunicado
Para quem Melhor forma de comunicação
Quando e com que frequência
Andamento do Projeto
Orientador Reunião ou email
Uma vez por semana
Estrutura do relatório e andamento
Coordenador de projetos
E-mail/reunião A cada 3 meses
Andamento do Projeto
Membros da banca
Reunião/E-mail 1ª vez no 4º mês do projeto 2ª vez no 10º mês















![Fique por dentro de tudo o que acontece em Caraguá e que ... · [que tornou possível] e juntos reerguer-mos dos escombros a nossa cidade, que hoje é progressista e radiante”,](https://static.fdocumentos.tips/doc/165x107/5f5dec8ea85e6e680742658e/fique-por-dentro-de-tudo-o-que-acontece-em-caragu-e-que-que-tornou-possvel.jpg)


