
Versão 11.1.0 IBM Cognos Analytics...1.Na página de boas-vindas, se o ativo de dados que você...
94
IBM Cognos Analytics Versão 11.1.0 Guia do Usuário de Explorações IBM
Transcript of Versão 11.1.0 IBM Cognos Analytics...1.Na página de boas-vindas, se o ativo de dados que você...

IBM Cognos AnalyticsVersão 11.1.0
Guia do Usuário de Explorações
IBM


Índice
Capítulo 1. Getting started with Explorations......................................................... 1Explorações..................................................................................................................................................1
Fazendo upload de dados...................................................................................................................... 1Iniciando uma exploração em um painel ou história existente ........................................................... 1Iniciando uma nova exploração a partir do menu Novo....................................................................... 1Iniciando uma nova exploração a partir de um ativo de dados na página de boas-vindas..................2Incluindo uma origem de dados............................................................................................................ 2
Capítulo 2. Exploring relationships.........................................................................3Explorar relacionamentos em seus dados.................................................................................................. 3
Abrindo o diagrama de relacionamento................................................................................................ 7
Capítulo 3. Visualizations...................................................................................... 9Visualizações................................................................................................................................................9
Visualizando cartões no painel de navegação ...................................................................................... 9Criando uma única visualização.............................................................................................................9Comparando duas visualizações......................................................................................................... 10Comparando dois pontos de dados em uma visualização.................................................................. 11Analítica de dados avançados..............................................................................................................11Escolhendo um tipo de visualização diferente....................................................................................11Insights em visualizações.................................................................................................................... 42Escolhendo insights correlacionados.................................................................................................. 43Escolhendo visualizações recomendadas...........................................................................................43Escolhendo visualizações relacionadas.............................................................................................. 43
Capítulo 4. Forecasting........................................................................................ 45Forecasting.................................................................................................................................................45
Recursos de previsão........................................................................................................................... 45Opções de previsão.............................................................................................................................. 46Tipos de visualização que suportam previsão.....................................................................................49Dados de previsão................................................................................................................................ 49Detalhes estatísticos da previsão........................................................................................................ 52Modelos de previsão............................................................................................................................ 55
Capítulo 5. Principles of advanced data analytics................................................. 59Princípios da análise de dados avançada..................................................................................................59
Preparação de dados............................................................................................................................59Preparação de dados para campos núméricos................................................................................... 60Preparação de dados para campos categóricos................................................................................. 60Preparação de dados para campos de destino................................................................................... 61Drivers de chaves unidirecionais......................................................................................................... 62Drivers de chaves bidirecionais........................................................................................................... 62Árvore de decisão.................................................................................................................................63Insights em visualizações.................................................................................................................... 65Detalhes da língua natural................................................................................................................... 74Relacionamentos..................................................................................................................................78Diferenças entre o Cognos Analytics e o Watson Analytics referente à análise de dados
avançado......................................................................................................................................... 79
Capítulo 6. Assistant............................................................................................85
iii

Assistente.................................................................................................................................................. 85Comandos no Assistant........................................................................................................................86
iv

Capítulo 1. Getting started with Explorations
ExploraçõesO Explore é uma área de trabalho flexível onde é possível descobrir e analisar dados. Também é possívelexplorar uma visualização existente a partir de um painel ou história. Descubra relacionamentos ocultos eidentifique padrões que transformam seus dados em insights. Os insights correlacionados sãorepresentados por um ícone verde com um número no eixo x, no eixo y ou no título de um gráfico.
Iniciando as explorações
Use um dos vários métodos para iniciar as explorações.
Fazendo upload de dadosFaça upload de um ativo de dados para a pasta Meu conteúdo para ser usada em sua exploração.
Procedimento
1. Clique no ícone Novo e, em seguida, clique em Fazer upload de arquivos.
2. Navegue para onde você salvou seu ativo de dados e selecione-o.O ativo de dados aparece na pasta My content.
Iniciando uma exploração em um painel ou história existenteQuando estiver trabalhando em um painel ou história, é possível criar ou editar uma exploraçãodiretamente de uma visualização.
Sobre Esta TarefaConclua essas etapas para abrir uma visualização em uma nova exploração ou para incluir em umaexploração existente:
Procedimento
1. Abra um painel ou uma história existente.2. Selecione uma visualização.
3. Clique no ícone Explorações na barra de ferramentas.4. Selecione Nova exploração ou Incluir em existente.
Iniciando uma nova exploração a partir do menu NovoNa página de boas-vindas, é possível iniciar uma nova exploração a partir do menu Novo.
Procedimento
1. Clique em Novo e, em seguida, clique em Exploração.2. Selecione uma origem de dados e clique em Incluir.
Uma página de pontos de início é gerada por meio da origem de dados selecionada.
© Copyright IBM Corp. 2018, 2020 1

Iniciando uma nova exploração a partir de um ativo de dados na página de boas-vindasÉ possível selecionar o menu Ação em um ativo de dados usado recentemente na página de boas-vindas.
Procedimento
1. Na página de boas-vindas, se o ativo de dados que você deseja usar for exibido como um ladrilho na
área Recente, clique no ícone do menu Ação .2. Selecione Criar exploração.
Incluindo uma origem de dadosInclua uma origem de dados em sua exploração para explorar seus dados.
Procedimento
1. Na área de janela Origens selecionadas, clique no ícone Incluir uma origem .2. Acesse a pasta Meu conteúdo ou Conteúdo da equipe e selecione a origem de dados que deseja
incluir. Clique em Adicionar.3. Expanda a origem de dados na área de janela Origens selecionadas para ver o que está disponível.4. Use a página de pontos de início para gerar um diagrama de relacionamento por meio de seus dados.
2 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Capítulo 2. Exploring relationships
Explorar relacionamentos em seus dadosAo criar uma exploração, é possível começar a partir de uma origem de dados. Uma página de pontos deinício é exibida com sugestões de introdução.
É possível digitar um nome de coluna que aparece em sua origem de dados ou clicar em uma das colunassugeridas que foram identificadas pelo sistema como interessantes. Se não souber por qual colunacomeçar, clique em Ignorar - mostre-me qualquer coisa para ver um diagrama de relacionamento comalgumas visualizações de ponto de início sugeridas.
No diagrama de relacionamento, a coluna com a qual você começa é o foco principal e ela é representadapor um nó azul escuro. Os campos relacionados são representados por nós roxos. As linhas conectam osnós e representam relacionamentos. A espessura da linha indica a intensidade do relacionamento.
© Copyright IBM Corp. 2018, 2020 3

Os relacionamentos primários mais fortes são exibidos por padrão e são os relacionamentos diretos entreo foco principal e os campos relacionados. Os relacionamentos secundários são os relacionamentos entreoutros campos direta ou indiretamente relacionados com o destino.
Para visualizar os relacionamentos primários e secundários, marque a caixa de seleção Relacionamentossecundários em Editar diagrama.
4 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

O diagrama de relacionamento plota esses campos com base em uma avaliação estatística de itensrelacionados. O diagrama de relacionamento não é uma figura do modelo de dados. No entanto, o modelopode ser um fator de influência na análise. Para melhorar o desempenho quando há muitas linhas naorigem de dados, a análise é baseada em uma amostra representativa de todos os dados.
É possível interagir com o diagrama de relacionamento selecionando um nó no qual você estejainteressado. Ao fazer isso, a lista de visualizações de pontos de início sugeridos à direita do diagrama éatualizada para incluir os nós selecionados. Também é possível usar Ctrl+clique para selecionar diversosnós.
Clique em Reconfigurar para original se desejar reconfigurar o escopo e a visualização de todos oscampos no diagrama de relacionamento para a configuração padrão.
Pontos de início sugeridos
As visualizações de ponto de início sugeridas são exibidas como miniaturas ao lado do diagrama derelacionamento. Selecione nós únicos ou diversos nós no diagrama de relacionamento para gerar essasvisualizações.
Clique em uma visualização para incluí-la em sua exploração e visualizá-la ao mesmo tempo. Clique no
ícone sinal de mais na visualização de ponto de início para incluí-la em sua exploração e manter avisualização atual.
Capítulo 2. Exploring relationships 5

6 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Abrindo o diagrama de relacionamentoQuando você estiver em uma visualização e quiser retornar ao diagrama de relacionamento, use o Cartãode relacionamentos de dados para retornar à visualização dos pontos de partida.
Sobre Esta Tarefa
Conclua as seguintes etapas para retornar à visualização de pontos de início para ver um diagrama derelacionamento e os pontos de início sugeridos.
Procedimento
1. Clique no ícone Explorações na área de janela lateral.
2. Clique no Cartão de relacionamentos de dados.
Dica: O Cartão de relacionamentos de dados também está disponível no menu Novo cartão da barrade ferramentas.
Capítulo 2. Exploring relationships 7

8 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Capítulo 3. Visualizations
VisualizaçõesÉ possível mudar o tipo de visualização ou mudar as colunas que são usadas na visualização.
Visualizando cartões no painel de navegaçãoVisualize miniaturas de suas visualizações, chamadas de cartões, no painel de navegação à esquerda davisualização principal.
Sobre Esta Tarefa
Cartões são uma coleção de visualizações em sua Exploração. Use os cartões para abrir as visualizaçõespara visualizar os detalhes e modificá-los usando os slots de dados.
Procedimento
1. Clique no ícone Explorações no painel lateral.
Seus cartões estão listados aqui.2. Clique no cartão que exibe uma miniatura de visualização que você deseja abrir.
A visualização é aberta na visualização principal.3. Visualize o texto gerado sob a guia Detalhes ou inclua mais itens de dados sob a guia Slots de dados.
Se não vir a guia Detalhes e a guia Slots de dados, clique no ícone Mostrar detalhes e slots .
Visualizando detalhes da visualizaçãoAo abrir uma visualização, ela é exibida na área de exploração principal. A área de janela de exploraçãoexibe a guia Detalhes, a guia Campos e a guia Propriedades.
Se você não vir o painel de exploração, clique no ícone Mostrar detalhes e campos .
Detalhes de visualização
A guia Detalhes exibe texto que é gerado para descrever aspectos dos dados representados nasvisualizações. Esses detalhes não são óbvios de ver na visualização. Por exemplo, os detalhes podemrevelar uma média dos valores ao longo do tempo.
Campos
A guia Campos é o local em que é possível incluir colunas para construir e modificar visualizações. Incluauma coluna em cada campo obrigatório.
Propriedades
A guia Propriedades é o local em que é possível modificar propriedades que se aplicam às suasvisualizações.
Criando uma única visualizaçãoEnquanto trabalha com sua exploração, você pode decidir que precisa de outra visualização.
© Copyright IBM Corp. 2018, 2020 9

Sobre Esta TarefaConclua as seguintes etapas para criar uma única visualização.
Procedimento
1. Na barra de ferramentas, selecione Novo.2. Selecione o cartão Único em branco.3. Na janela Origens, expanda o ativo de dados que você deseja usar.
Se um ativo de dados diferente estiver aberto, clique em Voltar próximo ao nome do ativo de dadosque está aberto.
4. Para criar uma nova visualização, conclua uma das seguintes ações:
• Arraste e solte itens de dados para a área Criar uma visualização.
O IBM®Cognos Analytics cria uma visualização para corresponder aos itens de dados. Por exemplo,ao incluir Ano ou Departamento, uma tabela é criada. Arraste em uma medida, como Renda, e umavisualização de barra é criada.
• Clique em Escolher um tipo e selecione um tipo de visualização. Em seguida, inclua um item dedados em cada slot de dados.
Comparando duas visualizaçõesÉ possível criar sua própria comparação para analisar os dados entre duas visualizações ou começar comuma comparação recomendada. Nos dois casos, um resumo das principais informações e diferençasentre as duas visualizações é gerado.
Sobre Esta Tarefa
Conclua as seguintes etapas para criar uma comparação entre duas visualizações.
Nota: Quando você cria uma nova visualização, é possível selecionar um cartão de comparação embranco com dois slots para visualizações.
Procedimento
1. Clique no ícone Explorações na área de janela lateral.A área de janela Cartões se abre.
2. Selecione um cartão para criar uma comparação.Uma visualização é exibida.
3. Na barra de ferramentas, clique em Comparar.A página Como deseja comparar? é exibida com orientações sobre como criar sua própriacomparação ou começar com uma recomendação.
4. Clique no ícone Incluir cartão em uma miniatura de cartão para incluí-lo na lista de cartões dopainel de navegação ou na miniatura do cartão para incluir o novo cartão e visualizá-lo imediatamente.
5. Opcionalmente, modifique os dados em uma visualização para realizar a comparação com a outravisualização.a) Selecione uma duas visualizações.b) Na guia Slots de dados, modifique a visualização de algumas das maneiras a seguir, por exemplo:
• Remova filtros.• Mostre a contagem superior ou inferior.• Remova itens de dados.
10 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

• A partir da área de janela Origens, inclua novos itens de dados ou filtros.
Comparando dois pontos de dados em uma visualizaçãoÉ possível selecionar dois pontos de dados em uma visualização existente e comparar os dados.
Procedimento
1. Clique no ícone Explorações na área de janela lateral.A área de janela Cartões se abre.
2. Na área de janela Cartões, selecione o cartão que exibe uma miniatura da visualização que vocêdeseja abrir.A visualização é aberta na visualização principal.
3. Selecione dois pontos de dados na visualização.4. Clique com o botão direito e, em seguida, clique em Comparar por.5. Digite uma coluna para comparar os dois pontos de dados.
Uma tabela exibe informações sobre como os dois pontos de dados se comparam um com o outro.
Analítica de dados avançadosO IBMCognos Analytics é uma ferramenta de inteligência de negócios para gerenciar e analisar dados. Eleinclui vários recursos de autoatendimento que possibilita que os usuários preparem, explorem ecompartilhem dados. Como parte dessa oferta, o Cognos Analytics inclui várias técnicas preditivas,descritivas e exploratórias, conhecidas como inteligência numérica. O Cognos Analytics usa muitos testesestatísticos para analisar seus dados. É importante entender as definições desses testes, pois eles seaplicam ao Cognos Analytics .
Para obter mais informações, consulte o Guia de painel e histórias do IBM Cognos Analytics.
Escolhendo um tipo de visualização diferenteAs visualizações comunicam comparações, relacionamentos e tendências. Eles enfatizam e clarificam osnúmeros. Para escolher um tipo de visualização, considere o que deseja que a visualização ilustre e o queatrai o público para a visualização.
Antes de Iniciar
Para obter mais informações sobre tipos de visualização, consulte a documentação de visualização noGuia do usuário de painéis e histórias do IBM Cognos Analytics.
Procedimento
1. Na área de janela Cartões, selecione o cartão que representa a visualização que você deseja abrir.
2. Clique no ícone Escolher o tipo de visualização na barra de ferramentas.3. Clique no tipo de visualização que você deseja usar.
Observe como cada tipo de visualização comunica dados de forma diferente. Por exemplo, use umavisualização de barra, de coluna ou de linha para comparar um conjunto de valores. Utilize umavisualização de linha ou de área para rastrear relacionamentos. Use uma visualização de mapa deárvore ou de pizza para ver as partes de um todo.
ÁreaUtilize uma visualização de área para enfatizar a magnitude da mudança ao longo do tempo.
Os gráficos de áreas são como gráficos de linhas, porém, as áreas abaixo das linhas são preenchidas comcores ou padrões. Os gráficos empilhados são úteis para comparar as contribuições proporcionais emuma categoria. Eles representam os valores relativos que cada série de dados contribui para com o total.
Capítulo 3. Visualizations 11

Como uma visualização de área empilha os resultados de cada coluna ou item, o total de todos osresultados é facilmente visto.
Por exemplo, uma visualização de área é excelente para observar a renda ao longo do tempo de váriosprodutos.
Por exemplo, esta visualização de área mostra o valor de tempo de vida do cliente para cada classe deveículo por mês. Como a visualização de área empilha os resultados, os totais de cada mês são exibidos.
A visualização de área foi criada arrastando os seguintes itens de dados a partir do painel Origens:
• Arraste o tipo Mês de validade para o campo Eixo X.• Arraste Classe do veículo para o campo Cor.• Arraste Valor de tempo de vida do cliente para o campo Eixo Y
12 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Amostras
É possível ver um exemplo de uma visualização de nuvem de palavras no relatório de amostra Análise devalor de tempo de vida do cliente. É possível localizar a amostra aqui: Conteúdo da equipe > Amostras> Relatórios > Análise de valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
BarrasUse uma visualização de barras para comparar valores de uma ou mais colunas, como vendas deprodutos ou de vendas de produtos por mês.
Visualizações em barra usam marcadores de dados horizontais organizados em grupos para compararvalores individuais. É possível usar visualizações de barra para comparar dados discretos ou para mostrartendências ao longo do tempo.
Uma visualização de barras pode mostrar mudanças durante um período de tempo específico ou podecomparar e contrastar duas ou mais colunas em um período de tempo ou ao longo do tempo. Se houvermuitas barras que impossibilitam a leitura dos rótulos, filtre os dados para focar em um subconjunto dosdados ou use um mapa de árvore.
Use o campo Destino para mostrar as medidas que precisam ser comparadas com um valor de destino.
Use o campo Início y para definir onde a medida deve iniciar.
BolhaUse uma visualização de bolhas para mostrar relacionamentos entre colunas que contenham valoresnuméricos, como renda e lucro.
Uma visualização de bolhas usa pontos de dados e bolhas para plotar medidas em qualquer lugar aolongo de uma escala. Uma medida é representada ao longo de cada eixo. O tamanho da bolha representauma terceira medida. Use visualizações de bolhas para representar dados financeiros ou quaisquer dadosem que os valores de medida estejam relacionados.
As bolhas estão em diferentes tamanhos e cores. O eixo X representa uma medida. O eixo Y representaoutra medida, e o tamanho das bolhas representa a terceira medida. No exemplo mostrado abaixo, a coré representada por uma quarta medida.
O exemplo que é mostrado representa os meses desde a concepção da apólice.
Capítulo 3. Visualizations 13

Crie a visualização de Bolha arrastando os itens de dados a seguir a partir de Análise do cliente na área
de janela Origens :
• Arraste Meses desde a concepção da política para o campo Eixo x.• Arraste Quantia total de reclamações para o campo Eixo Y.• Arraste Valor de tempo de vida do cliente para o campo Tamanho.• Arraste Status do emprego para Cor
É possível customizar o gráfico de bolhas. Por exemplo, para fazer com que o eixo X do gráfico de bolhastenha a mesma aparência na amostra, execute as etapas a seguir:
1. Clique na visualização e, em seguida, na área de janela Dados, clique no item de dados <Quantidadetotal de reclamações>.
2. Clique em
3. Ao lado de Formato de dados, clique em e configure as opções a seguir:
• Tipo de formato: Moeda• Símbolo monetário: K• Posição do símbolo de moeda: Término• Número de casas decimais: 0• Escala: -3 (isso apresenta valores em milhares).
4. Clique em OK.
Para mudar o tamanho da visualização, clique na visualização e, em seguida, configure a opção a seguirna área de janela de propriedades:
• Tamanho - Largura: 700 px, Altura: 300 px
Clique em para fechar a área de janela Propriedades.
Amostras
É possível ver exemplos de visualizações no relatório de amostra Análise de valor de tempo de vida docliente. É possível localizar as amostras aqui: Conteúdo da equipe > Amostras > Relatórios > Análisede valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
MarcadorUse gráficos marcadores para mostrar medidas que precisam ser comparadas com um valor de destino.
14 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Em uma central de atendimento, um gráfico marcador pode ser usado para medir métricas, como volumede chamadas, velocidade de resposta de chamada e porcentagem de chamadas abandonadas.
Na manufatura, um gráfico marcador pode ser usado para rastrear métricas, como o número de defeitos epedidos que são enviados.
Em um contexto fitness, um gráfico marcador pode ser usado para medir métricas, como passoscaminhados e calorias que são queimadas.
As visualizações de marcadores comparam uma medida real (o marcador) com a medida de destino (odestino). As visualizações de marcadores também relacionam as medidas comparadas com regiõescoloridas no segundo plano que fornecem medidas mais qualitativas, como bom, satisfatório e ruim. Asvisualizações de marcadores podem ser mostradas em tamanhos pequenos enquanto ainda transportaminformações efetivamente.
Uma visualização de marcador apresenta uma medida primária e única. Por exemplo, renda do ano até adata. E compara essa medida com uma ou mais outras medidas para enriquecer seu significado. Porexemplo, comparado a um destino. A medida primária é exibida no contexto de um intervalo qualitativode desempenho, como ruim, satisfatório e bom.
Se você selecionar uma visualização da marcadores, especifique os campos a seguir:
• O campo Barra real especifica a medida real.• O campo Destino especifica a medida de destino.• O campo Intervalo mínimo especifica o intervalo qualitativo mínimo.• O campo Intervalo médio especifica o intervalo qualitativo médio.• O campo Intervalo máximo especifica o intervalo qualitativo superior.
Nota: O drill through não está disponível para uma visualização de marcador.
Certifique-se de que os intervalos mínimo, médio e máximo se relacionem com a medida real e dedestino.
A visualização de marcador foi criada arrastando os itens de dados a seguir a partir do painel Origens:
• Arraste Intervalo mínimo para o campo Intervalo mínimo.• Arraste Intervalo mínimo para o campo Intervalo mínimo.• Arraste Intervalo máximo para o campo Intervalo máximo• Arraste Intervalo máximo para o campo Barras reais• Arraste Destino para o campo Destino• Arraste Classe do veículo para o campo Dados extras
Capítulo 3. Visualizations 15

Amostras
É possível ver um exemplo de uma visualização de marcador no relatório de amostra Análise de valor detempo de vida do cliente. É possível localizar a amostra aqui: Conteúdo da equipe > Amostras >Relatórios > Análise de valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
ColunaUse uma visualização de coluna para comparar valores de uma ou mais colunas, como vendas deprodutos ou vendas de produtos por mês.
Visualizações em coluna usam marcadores de dados verticais organizados em grupos para compararvalores individuais. Use visualizações de coluna para comparar dados discretos ou mostrar tendências aolongo do tempo.
Uma visualização de coluna mostra a mudança em um período de tempo específico ou pode comparar econtrastar duas ou mais colunas em um período de tempo ou ao longo do tempo. Se houver muitas barrasque impossibilitam a leitura dos rótulos, filtre os dados para focar em um subconjunto dos dados ou useum mapa de árvore.
Por exemplo, a renda para cada linha de produto é agrupada por trimestre, que enfatiza o desempenhoem cada trimestre.
Use o campo Destino para mostrar as medidas que precisam ser comparadas com um valor de destino.
Use o campo Início y para definir onde a medida deve iniciar.
Tabela cruzadaUse uma crosstab quando desejar mostrar os relacionamentos entre três ou mais colunas. As crosstabsmostram dados em linhas e em colunas com informações resumidas nos pontos de interseção.
Por exemplo, esta crosstab mostra os custos de curso para cada departamento por organização.
16 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

A partir do Cognos Analytics versão 11.1.4, é possível arrastar dados da área de janela Origensselecionadas e inserir dados em uma coluna/linha ou soltar os dados sobre os dados existentes parasubstituí-los.
Reprodutor de dadosUse um reprodutor de dados para ver uma animação do impacto de uma coluna na outra visualização.
Árvore de decisãoUma árvore de decisão mostra uma hierarquia conectada de caixas para representar os valores deregistros.
Os registros são segmentados em grupos, que são chamados de nós. Cada nó contém registros que sãoestatisticamente semelhantes uns com os outros com relação ao campo de destino. Por exemplo, um nópode conter os registros para homens que têm mais de 18 anos de escolaridade. Os nós podem então serusados para prever o valor do campo de um destino. Por exemplo, o nó sobre homens e educação podeser usado para prever salário.
Cada ramificação em uma árvore de decisão corresponde a uma regra de decisão. Para obter informaçõesadicionais sobre regras de decisão, consulte “Visualizando regras de decisão” na página 20
Para melhorar o desempenho, devido ao número de linhas na origem de dados, a análise é baseada emuma amostra representativa de todos os dados.
Por exemplo, uma visualização de árvore de decisão pode ser semelhante a esta:
Capítulo 3. Visualizations 17

Nota: Filtros não são suportados para visualizações de árvore de decisão.
Para obter mais informações, consulte “Explorando uma visualização de árvore de decisão” na página18.
Explorando uma visualização de árvore de decisãoUma visualização de árvore de decisão é usada para ilustrar como os dados subjacentes preveem umdestino escolhido e destacam os principais insights sobre a árvore de decisão.
Sobre Esta Tarefa
A intensidade preditiva de uma árvore de decisão determina o grau em que as decisões representadaspor cada ramificação que é mostrada na árvore preveem o valor do destino.
As árvores de decisão têm um único destino. Se o campo de destino da árvore de decisão for contínuo, osindicadores de insight-chave destacarão grupos extraordinariamente altos ou baixos. Se o campo dedestino da árvore de decisão for categórico, o insight-chave será o modo do nó. O modo do nó é acategoria ou categorias que ocorrem com mais frequência do campo de destino dentro do grupo.
Para melhorar o desempenho, devido ao número de linhas na origem de dados, a análise é baseada emuma amostra representativa de todos os dados.
Ao revisar uma árvore de decisão:
• Se desejar ver todos os drivers, use a guia Diagrama de árvore ou a guia Regras.• Se desejar se concentrar em drivers principais, use a guia Explosão solar de árvore.
Para editar ou incluir drivers principais, clique no no campo de destino.
Os insights são diferentes, dependendo do tipo de seu destino. Se estiver prevendo uma medidacontínua, por exemplo, receita, idade ou lucro, a árvore de decisão mostrará dentro do nó o valor médiodo destino, dadas as condições até agora dentro do grupo que é representado pelo nó. Por exemplo, sevocê tiver uma árvore que está prevendo a receita e tiver uma ramificação que tem gênero e, em seguida,cidade. Se você seguir o caminho de homens para Chicago, o valor que está no nó Chicago será a receitamédia de homens em Chicago.
Procedimento
1. Se você tiver uma medida contínua, o exemplo a seguir ilustra a árvore de decisão.
18 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

A cor mostra se o valor do nó está associado a valores altos, médios ou baixos do destino. A cor do nóé baseada na média do destino para a medida. Quanto maior o valor médio do destino para um nó,mais escura será a cor.
Por exemplo, a seguir é mostrada a visualização detalhada para Gastos com restaurante. O terminalinternacional é um forte preditor para os gastos com restaurante altos para os viajantes de negócios. Alimpeza ruim do aeroporto é um preditor de baixos gastos para viajantes de conferência/convenção.
O minimapa ajuda a se mover pelas áreas da árvore. O minimapa é útil, especialmente se houvermuitos nós.
Neste exemplo, os cinco principais valores de destino mais altos são indicados com um número. Épossível escolher entre as seguintes opções:
• Árvore completa. Especificamente, não são indicados valores mais altos ou mais baixos.
• Cinco principais valores de destino mais altos. Os cinco principais valores de destino mais altos sãomostrados.
• Cinco principais valores de destino mais baixos. Os cinco valores de destino mais baixos sãomostrados.
Se você tiver uma medida categórica, selecione a categoria para a qual deseja ver os cinco principaisou os cinco destinos inferiores do menu 5 principais nós para: ou do menu 5 nós inferiores para:.
Caso você tenha aumentado muito o zoom, os cinco principais ou os cinco nós inferiores não estarãovisíveis.
2. Se você tiver uma medida categórica, o exemplo a seguir ilustra a árvore de decisão.
A cor mostra qual valor ou valores de campo são os mais representados.
Na guia Explosão solar de árvore, é possível ver que se as medidas na árvore de decisão forem fortespreditores para um valor de destino ou valores de destino, as cores prevalecerão nesse nó. Os valoresnão significativos são deixados de fora.
Capítulo 3. Visualizations 19
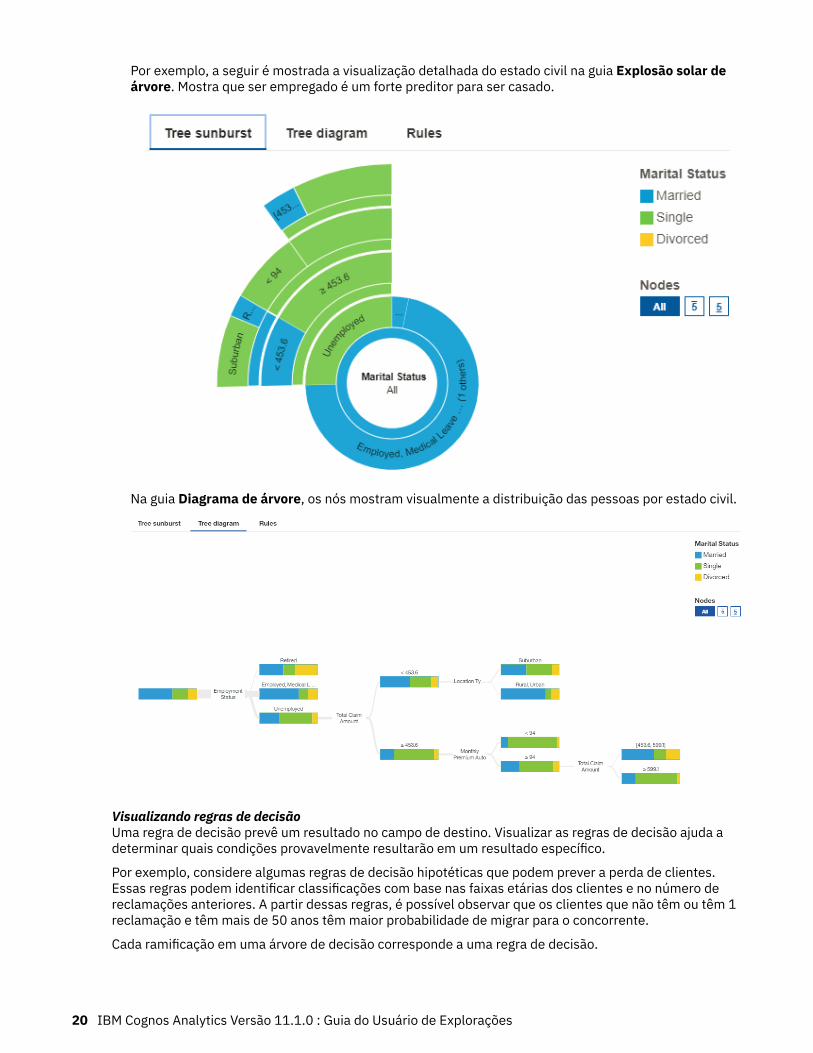
Por exemplo, a seguir é mostrada a visualização detalhada do estado civil na guia Explosão solar deárvore. Mostra que ser empregado é um forte preditor para ser casado.
Na guia Diagrama de árvore, os nós mostram visualmente a distribuição das pessoas por estado civil.
Visualizando regras de decisãoUma regra de decisão prevê um resultado no campo de destino. Visualizar as regras de decisão ajuda adeterminar quais condições provavelmente resultarão em um resultado específico.
Por exemplo, considere algumas regras de decisão hipotéticas que podem prever a perda de clientes.Essas regras podem identificar classificações com base nas faixas etárias dos clientes e no número dereclamações anteriores. A partir dessas regras, é possível observar que os clientes que não têm ou têm 1reclamação e têm mais de 50 anos têm maior probabilidade de migrar para o concorrente.
Cada ramificação em uma árvore de decisão corresponde a uma regra de decisão.
20 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Procedimento
1. Em uma árvore de decisão, dê um toque em Regras.2. Revise as regras de decisão.3. Para retornar à visualização, dê um toque em Diagrama de árvore.
A análise do DriverUma visualização de análise de driver mostra os drivers principais, ou preditores, para um destino.Quanto mais próximo o driver estiver da direita, mais forte ele será.
O IBMCognos Analytics usa algoritmos sofisticados para entregar insights altamente interpretáveis quesão baseados em modelagem complexa. Você não precisa saber quais testes estatísticos devem serexecutados em seus dados. O Cognos Analytics seleciona os testes corretos para os dados.
Os drivers principais para as variáveis respostas contínuas e as variáveis respostas categóricas estãodisponíveis na visualização de análise de driver nos painéis e nas explorações.
Para obter mais informações, consulte a documentação Testes estatísticos no Guia do usuário de painéise histórias do IBM Cognos Analytics.
Por exemplo, essa visualização de análise de driver mostra que a combinação de satisfação geral,classificação de sinalização, classificação de segurança e classificação de arte são os drivers mais fortesda classificação do aeroporto de destino.
Para editar ou incluir drivers principais, clique em no slot de dados de destino.
Para melhorar o desempenho, devido ao número de linhas na origem de dados, a análise é baseada emuma amostra representativa de todos os dados.
Se você passar o mouse sobre um ponto de dados, a visualização de análise de driver mostrará o quedireciona a classificação geral do aeroporto.
Se você clicar em um ponto de dados na árvore, outras visualizações recomendadas serão mostradas.
Capítulo 3. Visualizations 21

Nota: Filtros não são suportados para visualizações de análise do driver.
Mapa de calorUse uma visualização de mapa de calor para visualizar o relacionamento entre as colunas, representadasem uma visualização de tipo de matriz.
Uma visualização de mapa de calor usa cor e intensidade da cor para mostrar o relacionamento entreduas colunas.
Por exemplo, esta visualização de mapa de calor mostra o valor de tempo de vida médio do cliente porsexo e educação.
Crie a visualização de mapa de calor arrastando os itens de dados a seguir a partir do painel Origens
:
• Arraste Sexo para o campo Linhas.• Arraste Educação para o campo Colunas.• Arraste Valor de tempo de vida do cliente para o campo Calor.
Amostras
É possível ver exemplos de visualizações no relatório de amostra Análise de valor de tempo de vida docliente. É possível localizar as amostras aqui: Conteúdo da equipe > Amostras > Relatórios > Análisede valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
HierarquiaUse uma hierarquia quando desejar ver os dados em linhas e colunas.
Por exemplo, esta hierarquia mostra tipos de produto.
22 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Hierarquia de bolhaUse uma visualização de bolha de hierarquia quando desejar mostrar relacionamentos entre colunas quecontêm valores, como perda líquida. Ela é semelhante à visualização de bolhas, mas as bolhas sãoestreitamente compactadas em vez de ficarem espalhadas em uma grade. As bolhas usam aninhamentopara representar a hierarquia. Uma visualização de bolha de hierarquia mostra uma grande quantidade dedados em um espaço pequeno.
O tamanho de cada bolha mostra uma dimensão quantitativa de cada ponto de dados. Ele mostra muitosníveis em uma hierarquia e relacionamentos entre grupos com base em atributos designados. Ele usa otamanho e a cor da bolha para transmitir informações comparativas sobre as categorias.
As bolhas estão em diferentes tamanhos e cores.
Por exemplo, esta visualização de bolha de hierarquia mostra o valor de tempo de vida do cliente porclasse de veículo e tamanho do veículo. Cada bolha é uma classe de veículo diferente em uma das trêsdimensões de veículo. O tamanho de cada bolha é determinado pelo valor de tempo de vida do clientedessa classe de veículo. As cores das bolhas são determinadas pelo tamanho do veículo.
Capítulo 3. Visualizations 23

A visualização de bolhas compactadas hierárquica foi criada arrastando os seguintes itens de dados apartir do painel Origens:
• Arraste Classe do veículo e Tamanho do veículo para o campo Bolhas.• Arraste Valor de tempo de vida do cliente para o campo Tamanho.• Arraste Tamanho do veículo para o campo Cor
Amostras
É possível ver um exemplo de uma visualização de nuvem de palavras no relatório de amostra Análise devalor de tempo de vida do cliente. É possível localizar a amostra aqui: Conteúdo da equipe > Amostras> Relatórios > Análise de valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
KPIUse uma visualização de KPI para exibir um KPI (principal indicador de desempenho) que contenha duasmedidas relacionadas, como renda real e renda de destino. Opcionalmente, é possível exibir um gráficode linhas e uma forma significativa em suas visualizações de KPI.
Uma visualização de KPI compara um valor base a um valor de destino e mostra a variação entre as duasmedidas.
24 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Por exemplo, essa visualização de KPI mostra a renda real em vermelho com uma seta para baixo paraindicar que a receita está caindo em comparação com o destino. Nesse caso, o valor de destino é a rendade destino. Um gráfico de linhas exibe a forma da variação ao longo do tempo e tem a mesma cor do valorbase.
Crie uma visualização de KPI semelhante arrastando medidas da sua própria origem de dados para oscampos em uma visualização de KPI vazia:
1. Na barra lateral, clique no ícone de visualizações e, em seguida, clique em KPI.2. Arraste uma medida para o campo Valor de destino.3. Arraste outra medida para o campo Valor base. Este valor é o objetivo real.4. Arraste outra medida para o campo Tempo. Este valor cria um gráfico de linhas para sua visualização
de KPI. É possível incluir múltiplas medidas, por exemplo, Anos e Meses, no campo Tempo.
Use as propriedades para customizar uma visualização de KPI. Por exemplo, as propriedades estãoconfiguradas por padrão para exibir uma cor condicional verde quando o objetivo é atingido e uma corcondicional vermelha quando ele não é. Para exibir o destino real em outra cor, é possível selecionar ocomutador Cor condicional para desativar o recurso e, em seguida, selecionar uma cor em Cor doelemento.
Conclua as etapas a seguir para desativar o recurso Cor condicional e selecionar uma cor customizadapara o valor base e os gráficos de linhas:
1. Selecione a visualização de KPI em seu painel.
2. Clique no ícone de propriedades .3. Na guia Visualização, clique em Cor. A alternância Cor condicional é ativada por padrão.4. Selecione a alternância Cor condicional para desativar as cores condicionais vermelha e verde.5. Em Cor do elemento, selecione uma cor.
Capítulo 3. Visualizations 25

Quando a Cor condicional é ativada, é possível customizar as propriedades de visualização de KPI. Asinformações a seguir descrevem cada uma das propriedades de KPI em Configurar intervalo:
• Escala
Use a propriedade Escala para escolher entre Numérico ou Percentual para os valores selecionadospara seus intervalos. Selecione Numérico para comparar o intervalo com o o valor base. SelecionePercentual para ver uma comparação do percentual do valor base com relação ao valor de destino.
• Número de intervalos
É possível escolher de 1 a 3 intervalos.
As informações a seguir descrevem as propriedades de KPI em Intervalo selecionado:
• Valor semente e Valor de término
Selecione um intervalo e configure o Valor semente e o Valor de término.
Dica: Não é possível digitar Mín. e Máx. como valores. Para reconfigurar o valor Mín. para o Valorsemente no primeiro intervalo ou o valor Máx. para o Valor de término no último intervalo, exclua ocampo que deseja reconfigurar.
• Cor do texto
Selecione um intervalo e configure a cor para o valor base, o gráfico de linhas e a forma do indicador.• Forma do indicador
Selecione um intervalo e escolha uma forma para exibir na visualização de KPI quando o valor baseestiver dentro do valor semente e do valor de término para esse intervalo. Por exemplo, é possível quevocê queira exibir uma seta para baixo quando seu valor base estiver abaixo de um determinado limiteem comparação com o valor de destino.
As informações a seguir descrevem como ocultar o gráfico de linhas:
• Para ocultar o gráfico de linhas, na guia Visualização, sob Gráfico, selecione o comutador Mostrargráfico de linhas para desativar o recurso.
Mapa anteriorUse um mapa anterior quando desejar ver padrões em seus dados por geografia. É possível usar um mapaanterior quando não estiver conectado à Internet.
Por exemplo, essa visualização de mapa anterior mostra a renda por país do varejista com a cor maisescura, indicando uma renda mais alta.
Para obter informações adicionais, consulte https://www.ibm.com/support/knowledgecenter/SSEP7J_11.1.0/com.ibm.swg.ba.cognos.ug_ca_legacymaps.doc/ug_ca_legacymaps.pdf.
26 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
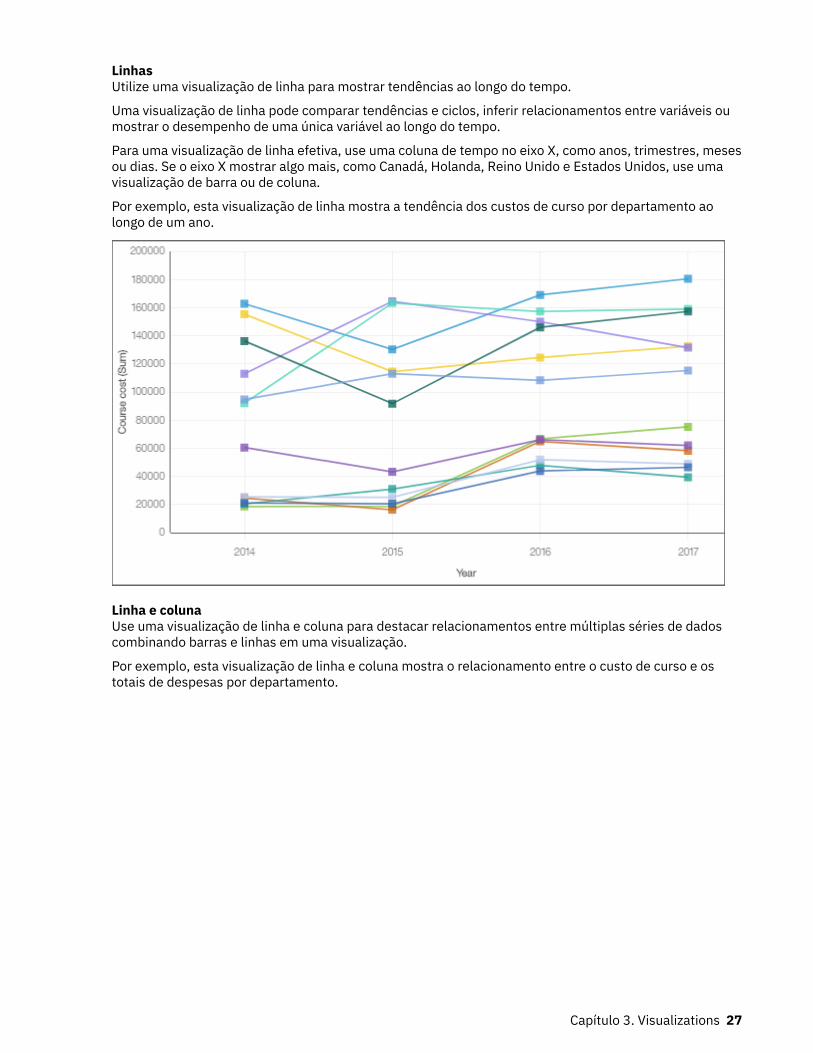
LinhasUtilize uma visualização de linha para mostrar tendências ao longo do tempo.
Uma visualização de linha pode comparar tendências e ciclos, inferir relacionamentos entre variáveis oumostrar o desempenho de uma única variável ao longo do tempo.
Para uma visualização de linha efetiva, use uma coluna de tempo no eixo X, como anos, trimestres, mesesou dias. Se o eixo X mostrar algo mais, como Canadá, Holanda, Reino Unido e Estados Unidos, use umavisualização de barra ou de coluna.
Por exemplo, esta visualização de linha mostra a tendência dos custos de curso por departamento aolongo de um ano.
Linha e colunaUse uma visualização de linha e coluna para destacar relacionamentos entre múltiplas séries de dadoscombinando barras e linhas em uma visualização.
Por exemplo, esta visualização de linha e coluna mostra o relacionamento entre o custo de curso e ostotais de despesas por departamento.
Capítulo 3. Visualizations 27

ListaUse uma visualização de lista para criar uma visão geral dos dados de uma maneira hierárquica.
Outro uso da visualização de lista é criar o widget de filtro. O próximo exemplo mostra como é possívelusar a visualização de lista como um widget de filtro.
28 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
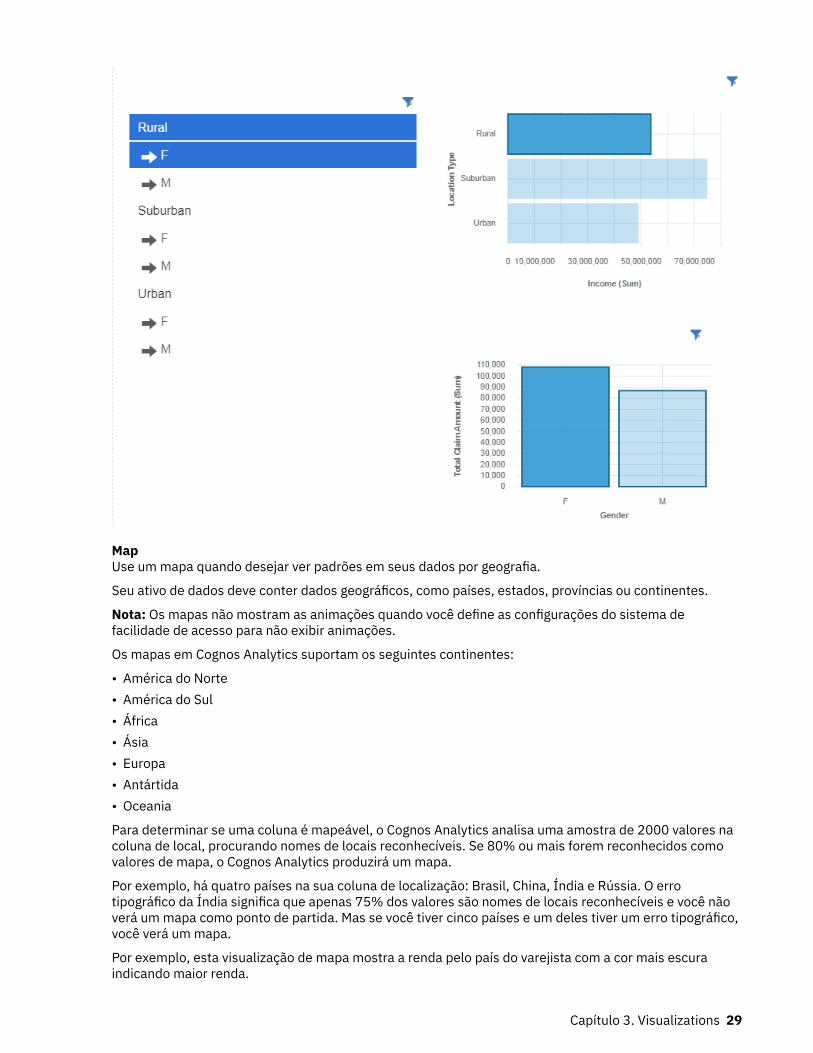
MapUse um mapa quando desejar ver padrões em seus dados por geografia.
Seu ativo de dados deve conter dados geográficos, como países, estados, províncias ou continentes.
Nota: Os mapas não mostram as animações quando você define as configurações do sistema defacilidade de acesso para não exibir animações.
Os mapas em Cognos Analytics suportam os seguintes continentes:
• América do Norte• América do Sul• África• Ásia• Europa• Antártida• Oceania
Para determinar se uma coluna é mapeável, o Cognos Analytics analisa uma amostra de 2000 valores nacoluna de local, procurando nomes de locais reconhecíveis. Se 80% ou mais forem reconhecidos comovalores de mapa, o Cognos Analytics produzirá um mapa.
Por exemplo, há quatro países na sua coluna de localização: Brasil, China, Índia e Rússia. O errotipográfico da Índia significa que apenas 75% dos valores são nomes de locais reconhecíveis e você nãoverá um mapa como ponto de partida. Mas se você tiver cinco países e um deles tiver um erro tipográfico,você verá um mapa.
Por exemplo, esta visualização de mapa mostra a renda pelo país do varejista com a cor mais escuraindicando maior renda.
Capítulo 3. Visualizations 29

Marimekko.Uma visualização marimekko é semelhante a uma visualização de colunas empilhadas. Ela mostra dadosatravés de alturas variadas e inclui uma dimensão de dados incluída através de larguras de colunasvariadas. A largura das colunas é baseada no valor que é designado ao campo de largura. A altura dosegmento individual é uma porcentagem do valor total da respectiva coluna.
É possível localizar rapidamente grandes segmentos, como um vertical específico que tem uma grandeparte de uma região. Também é possível identificar o espaço em branco, como um vertical sub-representado em uma região específica.
A visualização marimekko é útil para comparações de parte ao todo, em que é necessário mostrar umamedida/variável extra.
A visualização marimekko permite que dados sejam mostrados ao longo de duas dimensõessimultaneamente. Por exemplo, os segmentos de mercado são frequentemente organizados ao longo doeixo X, com a largura de cada coluna correspondente ao valor financeiro de um segmento. Você usavisualizações marimekko em casos, por exemplo, onde deseja mostrar a contribuição de renda por linhade produto. Ou o produto interno bruto por país.
A visualização marimekko pode exibir o número total ou parcial. Se desejar usar porcentagensempilhadas em vez do número, use a opção Exibir como gráfico de porcentagem empilhado.
O exemplo a seguir mostra a contribuição do valor de tempo de vida do cliente e o status do emprego emdiferentes classes de veículo com a opção Exibir como gráfico de porcentagem empilhada ativada.
30 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

A visualização Marimekko foi criada arrastando os itens de dados a seguir a partir do painel Origens:
• Arraste o tipo Classe do veículo para o campo Barras.• Arraste Valor de tempo de vida do cliente para o campo Comprimento.• Arraste Status do emprego para o campo Cor
Amostras
É possível ver um exemplo de uma visualização de nuvem de palavras no relatório de amostra Análise devalor de tempo de vida do cliente. É possível localizar a amostra aqui: Conteúdo da equipe > Amostras> Relatórios > Análise de valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
RedeUtilize uma visualização de rede quando desejar ver as conexões entre colunas em seu ativo de dados.Uma visualização de rede é uma boa opção para mostrar conexões, redes e pontos de interseção.
As visualizações de rede exibem um conjunto de nós, representados por símbolos e links, representadospor caminhos, para mostrar o relacionamento entre entidades ou itens.
Use os campos De e Para para definir o relacionamento que você deseja investigar.
Por exemplo, uma visualização de rede pode mostrar aceitação de oferta por Classe de veículo.
Capítulo 3. Visualizations 31

Crie a visualização de Rede arrastando os itens de dados a seguir a partir da seção Ofertas na área de
janela Origens :
• Arraste Oferta para o campo De.• Arraste Classe do veículo para o campo Para.• Arraste Aceito para o campo Largura da linha.
Em seguida, configure as propriedades de tamanho e de nó.
1. Clique na visualização e, em seguida, clique em . Configure o conjunto de opções a seguir na áreade janela Propriedades:
• Tamanho - Largura: 500 px, Altura: 300 px• Tamanho mínimo dos nós: 20• Tamanho máximo dos nós: 100
2. Clique em para fechar a área de janela Propriedades.
Amostras
É possível ver exemplos de visualizações no relatório de amostra Análise de valor de tempo de vida docliente. É possível localizar as amostras aqui: Conteúdo da equipe > Amostras > Relatórios > Análisede valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
Bolhas compactadasUse uma visualização de bolhas compactadas quando quiser mostrar os relacionamentos entre colunasque contenham valores numéricos, como renda. Ela semelhante à visualização de bolhas, mas as bolhassão estreitamente compactadas em vez de ficarem espalhadas em uma grade. Uma visualização debolhas compactadas mostra uma quantia grande de dados em um pequeno espaço.
As bolhas estão em diferentes tamanhos e cores.
Por exemplo, esta visualização de bolhas compactadas mostra contratações externas por departamento.Cada bolha é um departamento diferente. O tamanho de cada bolha é determinado pelo número decontratações externas para esse departamento.
32 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Setor CircularUtilize uma visualização em pizza para destacar as proporções. Cada fatia mostra o relacionamentorelativo de cada parte com o todo.
Por exemplo, esta visualização em pizza mostra o número de dias de curso para cada departamento.
PontoUse uma visualização de ponto para mostrar tendências ao longo do tempo.
Uma visualização de ponto pode comparar tendências e ciclos, inferir relacionamentos entre variáveis oumostrar o desempenho de uma única variável ao longo do tempo.
Capítulo 3. Visualizations 33
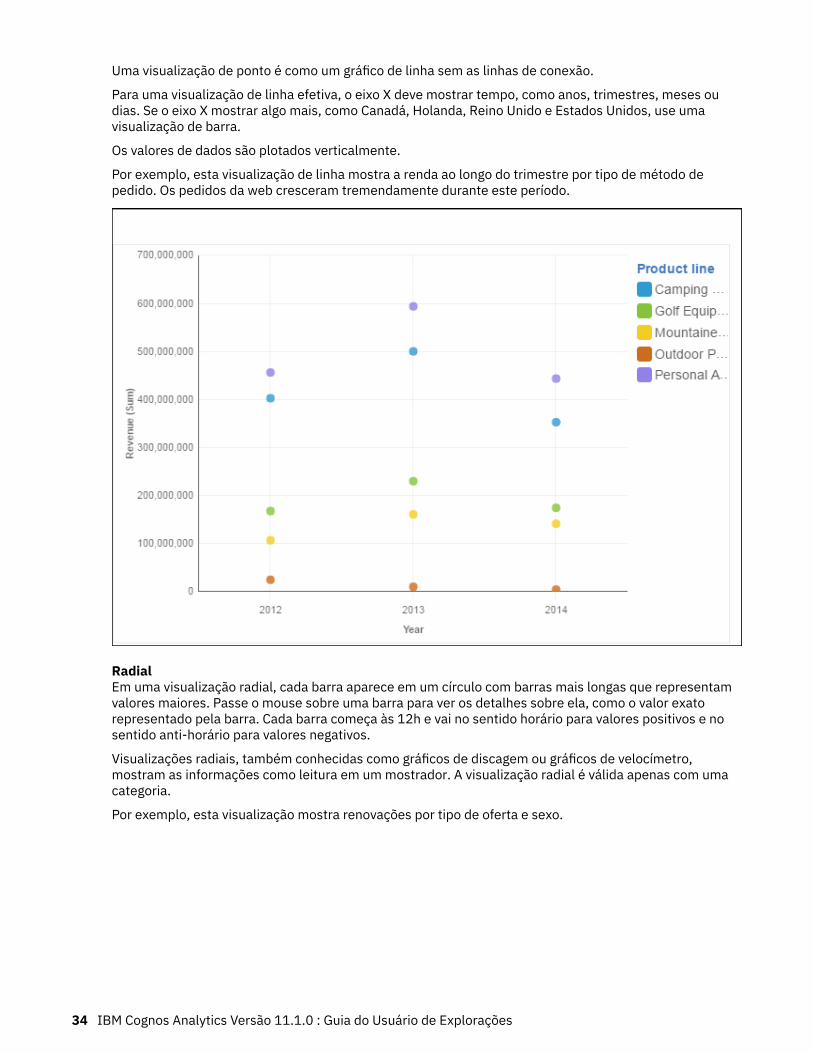
Uma visualização de ponto é como um gráfico de linha sem as linhas de conexão.
Para uma visualização de linha efetiva, o eixo X deve mostrar tempo, como anos, trimestres, meses oudias. Se o eixo X mostrar algo mais, como Canadá, Holanda, Reino Unido e Estados Unidos, use umavisualização de barra.
Os valores de dados são plotados verticalmente.
Por exemplo, esta visualização de linha mostra a renda ao longo do trimestre por tipo de método depedido. Os pedidos da web cresceram tremendamente durante este período.
RadialEm uma visualização radial, cada barra aparece em um círculo com barras mais longas que representamvalores maiores. Passe o mouse sobre uma barra para ver os detalhes sobre ela, como o valor exatorepresentado pela barra. Cada barra começa às 12h e vai no sentido horário para valores positivos e nosentido anti-horário para valores negativos.
Visualizações radiais, também conhecidas como gráficos de discagem ou gráficos de velocímetro,mostram as informações como leitura em um mostrador. A visualização radial é válida apenas com umacategoria.
Por exemplo, esta visualização mostra renovações por tipo de oferta e sexo.
34 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Crie a visualização Radial arrastando os itens de dados a seguir a partir da seção Análise do cliente na
área de janela Origens :
• Arraste Renovar tipo de oferta para o campo Barras.• Arraste Número de políticas para o campo Comprimento.• Arraste Sexo para o campo Cor.
A próxima etapa é configurar as propriedades de classificação para Renovar tipo de oferta e Sexo.
1. Clique na visualização e, em seguida, na área de janela Dados, clique no item de dados <Renovar tipode oferta>.
2. Clique em 3. Na área de janela Propriedades, para Ordem de Classificação, selecione Crescente.4. Na área de janela Dados, clique no item de dados <Sexo>.5. Na área de janela Propriedades, para Ordem de classificação, selecione Decrescente.
6. Clique em para fechar a área de janela Propriedades.
Amostras
É possível ver exemplos de visualizações no relatório de amostra Análise de valor de tempo de vida docliente. É possível localizar as amostras aqui: Conteúdo da equipe > Amostras > Relatórios > Análisede valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
DispersãoVisualizações de dispersão usam pontos de dados para plotar duas medidas em qualquer lugar ao longode uma escala, e não somente em marcações regulares.
As visualizações de dispersão são úteis para explorar correlações entre diferentes conjuntos de dados.
O exemplo a seguir mostra a correlação entre renda e lucro bruto para cada tipo de produto.
Capítulo 3. Visualizations 35
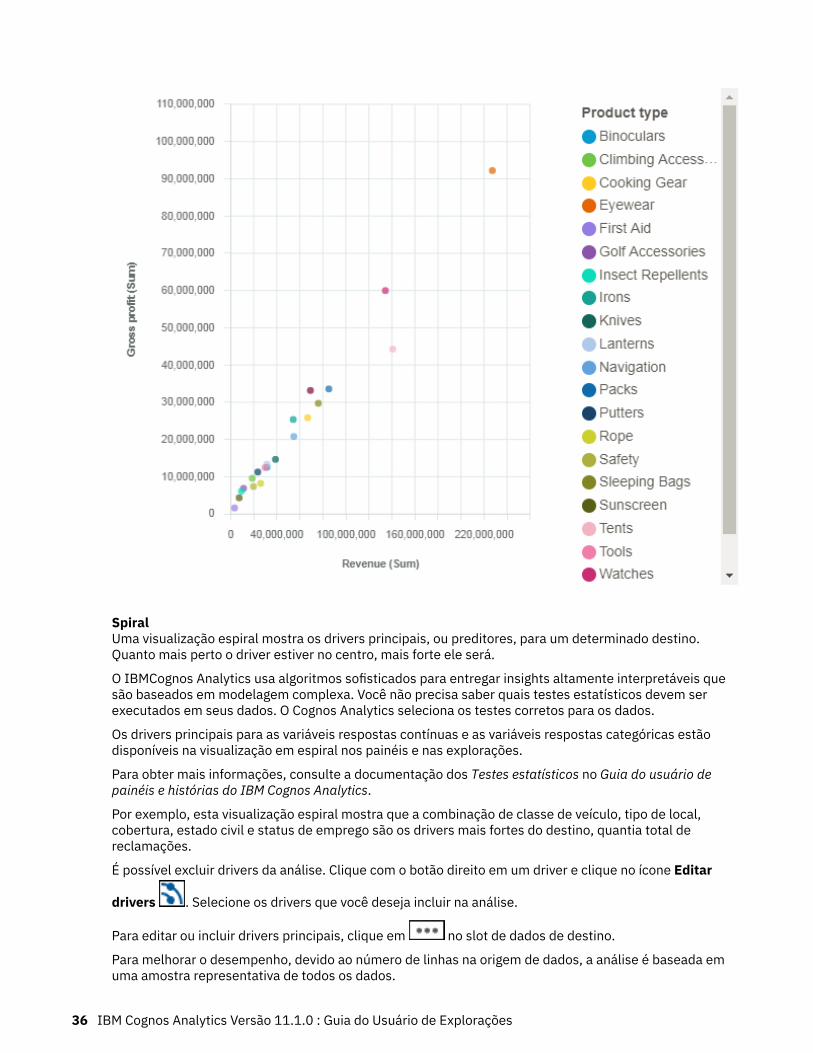
SpiralUma visualização espiral mostra os drivers principais, ou preditores, para um determinado destino.Quanto mais perto o driver estiver no centro, mais forte ele será.
O IBMCognos Analytics usa algoritmos sofisticados para entregar insights altamente interpretáveis quesão baseados em modelagem complexa. Você não precisa saber quais testes estatísticos devem serexecutados em seus dados. O Cognos Analytics seleciona os testes corretos para os dados.
Os drivers principais para as variáveis respostas contínuas e as variáveis respostas categóricas estãodisponíveis na visualização em espiral nos painéis e nas explorações.
Para obter mais informações, consulte a documentação dos Testes estatísticos no Guia do usuário depainéis e histórias do IBM Cognos Analytics.
Por exemplo, esta visualização espiral mostra que a combinação de classe de veículo, tipo de local,cobertura, estado civil e status de emprego são os drivers mais fortes do destino, quantia total dereclamações.
É possível excluir drivers da análise. Clique com o botão direito em um driver e clique no ícone Editar
drivers . Selecione os drivers que você deseja incluir na análise.
Para editar ou incluir drivers principais, clique em no slot de dados de destino.
Para melhorar o desempenho, devido ao número de linhas na origem de dados, a análise é baseada emuma amostra representativa de todos os dados.
36 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Nota: Filtros não são suportados para visualizações espirais.
Barras empilhadasUtilize uma visualização de barras empilhadas para comparar as contribuições proporcionais de cadaitem com o total, como vendas de produtos e vendas de produtos por mês.
Uma visualização de barras empilhadas pode mostrar mudanças durante um período de tempo específicoou comparar as contribuições proporcionais de cada item com o total. Se houver muitas barras queimpossibilitam a leitura dos rótulos, filtre os dados para focar em um subconjunto dos dados ou use ummapa de árvore.
Coluna empilhadaUse uma visualização de colunas empilhadas para comparar as contribuições proporcionais de cada itemcomo total, como vendas de produtos e vendas de produtos por mês.
Capítulo 3. Visualizations 37

Uma visualização de colunas empilhadas pode mostrar mudanças durante um período de tempoespecífico ou pode comparar as contribuições proporcionais de cada item com o total. Se houver muitasbarras que impossibilitam a leitura dos rótulos, filtre os dados para focar em um subconjunto dos dadosou use um mapa de árvore.
ResumoUtilize uma visualização de resumo quando desejar ver o total de uma medida ou a contagem de umacoluna categórica.
Por exemplo, esta visualização de resumo mostra a renda total de todos os tipos de produto.
Por exemplo, esta visualização de resumo mostra o número de departamentos em sua organização.
38 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
SunburstUma visualização sunburst é usada para ilustrar como os dados subjacentes preveem um destinoescolhido e destacam os principais insights.
Para obter informações adicionais sobre a visualização sunburst, consulte “Explorando uma visualizaçãode árvore de decisão” na página 18.
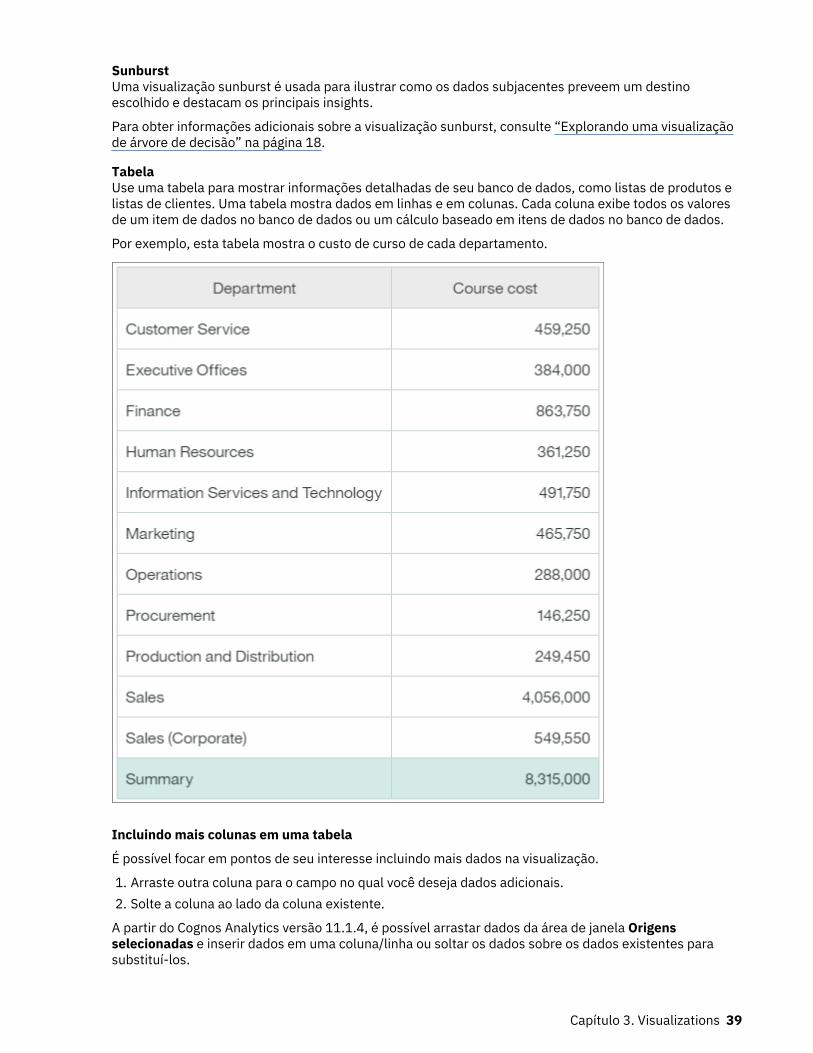
TabelaUse uma tabela para mostrar informações detalhadas de seu banco de dados, como listas de produtos elistas de clientes. Uma tabela mostra dados em linhas e em colunas. Cada coluna exibe todos os valoresde um item de dados no banco de dados ou um cálculo baseado em itens de dados no banco de dados.
Por exemplo, esta tabela mostra o custo de curso de cada departamento.
Incluindo mais colunas em uma tabela
É possível focar em pontos de seu interesse incluindo mais dados na visualização.
1. Arraste outra coluna para o campo no qual você deseja dados adicionais.2. Solte a coluna ao lado da coluna existente.
A partir do Cognos Analytics versão 11.1.4, é possível arrastar dados da área de janela Origensselecionadas e inserir dados em uma coluna/linha ou soltar os dados sobre os dados existentes parasubstituí-los.
Capítulo 3. Visualizations 39
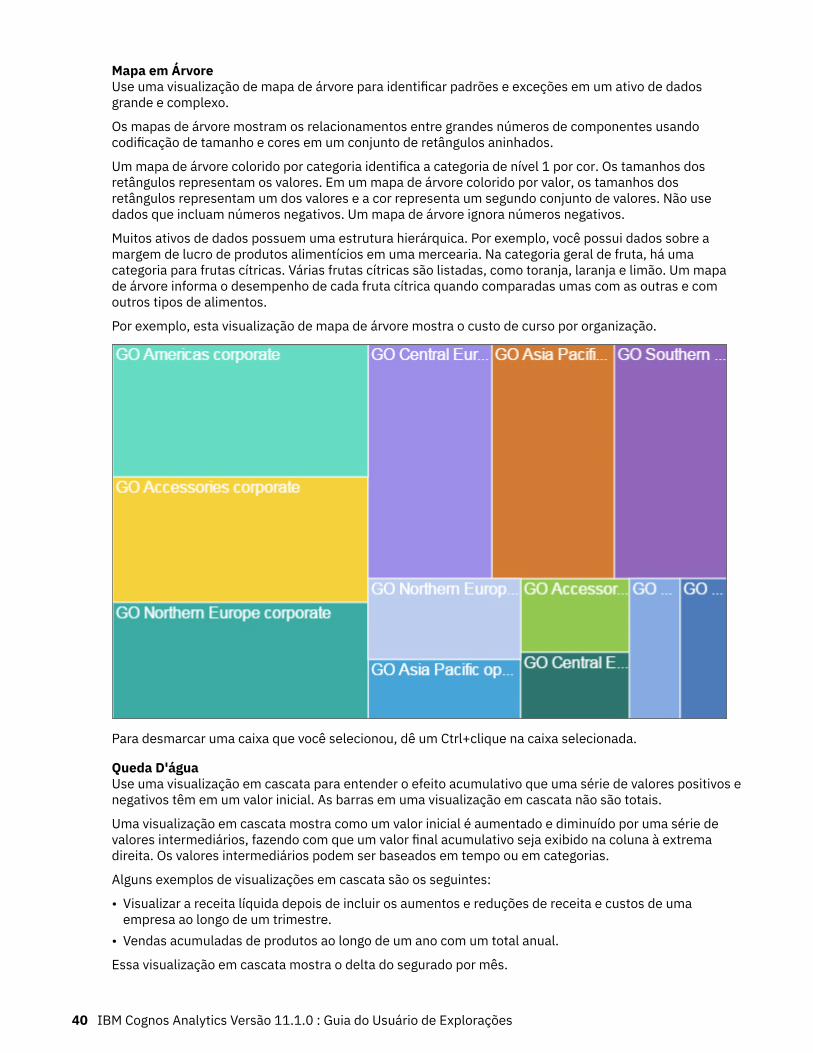
Mapa em ÁrvoreUse uma visualização de mapa de árvore para identificar padrões e exceções em um ativo de dadosgrande e complexo.
Os mapas de árvore mostram os relacionamentos entre grandes números de componentes usandocodificação de tamanho e cores em um conjunto de retângulos aninhados.
Um mapa de árvore colorido por categoria identifica a categoria de nível 1 por cor. Os tamanhos dosretângulos representam os valores. Em um mapa de árvore colorido por valor, os tamanhos dosretângulos representam um dos valores e a cor representa um segundo conjunto de valores. Não usedados que incluam números negativos. Um mapa de árvore ignora números negativos.
Muitos ativos de dados possuem uma estrutura hierárquica. Por exemplo, você possui dados sobre amargem de lucro de produtos alimentícios em uma mercearia. Na categoria geral de fruta, há umacategoria para frutas cítricas. Várias frutas cítricas são listadas, como toranja, laranja e limão. Um mapade árvore informa o desempenho de cada fruta cítrica quando comparadas umas com as outras e comoutros tipos de alimentos.
Por exemplo, esta visualização de mapa de árvore mostra o custo de curso por organização.
Para desmarcar uma caixa que você selecionou, dê um Ctrl+clique na caixa selecionada.
Queda D'águaUse uma visualização em cascata para entender o efeito acumulativo que uma série de valores positivos enegativos têm em um valor inicial. As barras em uma visualização em cascata não são totais.
Uma visualização em cascata mostra como um valor inicial é aumentado e diminuído por uma série devalores intermediários, fazendo com que um valor final acumulativo seja exibido na coluna à extremadireita. Os valores intermediários podem ser baseados em tempo ou em categorias.
Alguns exemplos de visualizações em cascata são os seguintes:
• Visualizar a receita líquida depois de incluir os aumentos e reduções de receita e custos de umaempresa ao longo de um trimestre.
• Vendas acumuladas de produtos ao longo de um ano com um total anual.
Essa visualização em cascata mostra o delta do segurado por mês.
40 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Criando uma visualização em cascata
1. Crie uma nova exploração. Para obter informações adicionais, consulte “Iniciando uma novaexploração a partir do menu Novo” na página 1.
2. Abra o módulo de dados de amostra: Selecionar uma origem > Conteúdo da equipe > Amostras >Dados > Análise do cliente.
3. Clique em Visualizações e em Cascata para incluir a visualização em cascata na exploração.4. Clique em Origens
5. Arraste os itens de dados a seguir da seção Segurados:
• Arraste Mês para o Eixo X.• Arraste Delta para o Eixo Y.
Nuvem de palavrasUse uma visualização de nuvem de palavras quando desejar ter uma visualização baseada em texto deuma coluna. A altura do texto representa a escala. O nome em si representa os diferentes membros dacoluna.
Dica: O ativo de dados deve conter pelo menos 15 colunas e pelo menos 100 linhas para criar umanuvem de palavras efetiva.
Por exemplo, essa visualização de nuvem de palavras mostra o valor de tempo de vida do cliente portamanho e classe de veículo.
Capítulo 3. Visualizations 41

A nuvem de palavras foi criada arrastando os itens de dados a seguir do painel Origens:
• Arraste Tamanho do veículo para o campo Palavras.• Arraste CLTV médio para o campo Tamanho.• Arraste Classe do veículo para o campo Cor
Amostras
É possível ver um exemplo de uma visualização de nuvem de palavras no relatório de amostra Análise devalor de tempo de vida do cliente. É possível localizar a amostra aqui: Conteúdo da equipe > Amostras> Relatórios > Análise de valor de tempo de vida do cliente.
Se algum dos objetos de amostra estiver ausente, entre em contato com o administrador.
Insights em visualizaçõesO IBMCognos Analytics fornece insights analíticos que ajudam a detectar e validar relacionamentosimportantes e diferenças significativas com base nos dados que são apresentados pela visualização.
Os insights estão disponíveis clicando no ícone Insights de visualizações elegíveis. Ao ativar insights, oresumo aparece na caixa Insights e os elementos de visualização relacionados são destacados e osdetalhes fornecidos na mensagem de dica de ferramenta correspondente. É possível controlar cadainsight disponível separadamente.
Procedimento
1. Em uma visualização que suporta insights, clique no ícone Insights .2. Dependendo da visualização, os seguintes insights são mostrados:
• Média Fornece a média do valor de destino exibido.• Intensidade preditiva: mostra a intensidade preditiva do relacionamento entre os campos de
destino e explicativos.• Linha de ajuste: mostra quando um relacionamento linear ou quadrático existe entre os campos de
destino e explicativos.
42 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

• Diferenças significativas: mostra valores que são significativamente mais altos ou menores do quea média ou tendência.
• Mais frequente: mostra valores que são relatados com mais frequência.
Escolhendo insights correlacionadosCom base em sua visualização, são apresentados insights correlacionados, baseados em estatísticas.
Sobre Esta Tarefa
Se estiverem disponíveis insights correlacionados que estão relacionados relacionados à visualização
principal, um ícone verde com um número é mostrado no eixo X ou no eixo Y. O número indica osinsights correlacionados disponíveis.
Para acessar as visualizações correlacionadas, conclua as seguintes ações:
Procedimento
1. Na visualização, clique no ícone verde .2. Clique em qualquer um dos insights baseados em estatísticas que são apresentados no menu.
Um novo cartão é criado.
Escolhendo visualizações recomendadasVisualizações recomendadas são miniaturas que exibem visualizações que podem ser apropriadas paraseus dados.
Procedimento
1. Na área de janela Cartões, selecione o cartão que representa a visualização que você deseja abrir.
2. Clique em Escolher tipo de visualização na barra de ferramentas.As visualizações recomendadas são exibidas.
3. Clique na miniatura para a visualização recomendada com a qual você deseja trabalhar.
Escolhendo visualizações relacionadasQuando uma visualização está em foco em sua exploração, o sistema recomenda algumas visualizaçõesrelacionadas que não são especificamente o que você solicitou. Com base na análise de dados, essasvisualizações relacionadas podem ser de seu interesse.
Sobre Esta TarefaAs visualizações relacionadas substituem um dos elementos de dados na visualização ou incluem outroelemento de dados para criar uma nova visualização. As visualizações relacionadas usam umacombinação de interações de usuário experiente, estatísticas e interesse para sugerir próximas etapasúteis.
Para acessar visualizações relacionadas, conclua as seguintes ações:
Procedimento
1. Na área de janela Cartões, selecione o cartão que representa a visualização que você deseja abrir.
2. Clique em Relacionado na barra de ferramentas.
Capítulo 3. Visualizations 43

44 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Capítulo 4. Forecasting
ForecastingUse a previsão em IBMCognos Analytics para descobrir e modelar tendência, sazonalidade e dependênciado tempo em dados.
É possível prever em IBMCognos Analytics usando ferramentas automatizadas que modelam dadosdependentes do tempo. A seleção e o ajuste de modelos automatizados torna a previsão fácil de usar,mesmo que você não esteja familiarizando com a modelagem de séries temporais.
As previsões e seus limites de confiança são exibidos em visualizações como uma continuação dos dadoshistóricos. Também é possível visualizar os detalhes estatísticos para modelos gerados se você desejaver o plano de fundo técnico.
A especificação de séries temporais em previsões geralmente requer manipulação de dados. O CognosAnalytics suporta uma ampla variedade de séries temporais sem a necessidade de manipulação, que vãodesde tipos padrão de data e hora, até campos de tempo periódicos e cíclicos aninhados. Quando osdados são reconhecidos como uma série temporal, a preparação de dados é automatizada. A tendência eos períodos sazonais apropriados são detectados e os modelos são selecionados a partir de um conjuntode nove tipos de modelos diferentes.
É possível prever em visualizações de linha, barra e coluna. A previsão permite a análise de centenas deséries temporais por visualização. As previsões e os limites de confiança são calculados para cada sérietemporal e exibidos na visualização como extensões dos dados atuais. É possível inspecionar cada sérietemporal separadamente e adaptar a previsão e resultados aos seus próprios dados e requisitos.
Se você estiver familiarizado com modelos de previsão, será possível visualizar o tipo de modeloselecionado, os parâmetros de modelo estimados, as medidas de precisão padrão e as informações deresumo do processamento.
Recursos de previsãoA previsão fornece modelagem de dados de série temporal e previsões com base em dados nasvisualizações.
Para usar a previsão, a visualização deve ser uma visualização de linha, barra ou coluna, os dados devemser suportados para previsão e a previsão deve ser ativada. Quando a previsão é ativada, uma caixa de
diálogo Previsão fica disponível no canto superior direito de uma visualização, na qual é possívelmodificar as configurações de modelo e previsão, além dos limites de confiança. Os modelos de sérietemporal apropriados para a visualização são estimados e as previsões são exibidas na visualização.Também é possível ver a especificação do modelo de série temporal e o resumo de processamento dedados na bandeja de dados.
O exemplo a seguir mostra valores de previsão e limites de confiança em uma visualização.
© Copyright IBM Corp. 2018, 2020 45

Opções de previsãoÉ possível modificar suas previsões configurando um número de opções de nível de período e de
confiança na caixa de diálogo Previsão .
46 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Um período é o menor intervalo de tempo entre os pontos vizinhos nos dados.
As opções a seguir estão disponíveis.
Períodos de previsãoO número de etapas a serem previstas com antecipação.O valor padrão é Automático, que é 20% do comprimento dos dados históricos. Qualquer valorausente no final de uma determinada série também será previsto, mas ele não contará para o númeroespecificado de períodos de previsão.
Últimos períodos ignoradosIgnora um número especificado de pontos de dados no final de uma série temporal ao construir omodelo e calcular as previsões. Quaisquer valores ausentes no final de uma parte não ignorada deuma série também serão previstos. O valor dos últimos períodos ignorados deve ser especificadocomo um número inteiro não negativo, como: 0, 1, 2 e 3.O valor padrão é 0. Se não houver valores ausentes, todos os dados históricos serão usados nageração de modelos e o primeiro ponto de previsão será após o último ponto de dados históricos. Até100 pontos de dados podem ser ignorados.Ignorar o último período de dados pode ser útil quando os dados estão incompletos. Por exemplo,você pode estar fazendo uma previsão na metade de um mês. Exclua esse mês da previsãoconfigurando Ignorar últimos períodos como 1.
A visualização a seguir mostra uma previsão que ignora os resultados de setembro configurandoIgnorado últimos períodos para 1.
Capítulo 4. Forecasting 47

Nível de ConfiançaA certeza com a qual se espera que o valor verdadeiro esteja dentro do intervalo especificado. Épossível ver o intervalo de confiança correspondente em uma dica de ferramenta ao passar o mousesobre qualquer valor de previsão. O intervalo de confiança é exibido como limites superior e inferior.É possível selecionar três níveis de confiança diferentes: 90%, 95% e 99%. O padrão é 95% e oslimites inferior e superior definem o intervalo no qual você pode ter 95% de confiança de que o valorverdadeiro estará dentro desse intervalo.
Período sazonalA sazonalidade com a qual construir o modelo. A sazonalidade é quando a série temporal tem umavariação cíclica previsível. Por exemplo, durante um período de férias a cada ano.
O valor padrão é Automático. Automático detecta automaticamente a sazonalidade construindovários modelos com diferentes períodos sazonais e escolhendo o melhor.
É possível especificar a sazonalidade inserindo um número inteiro não negativo, como: 0, 1, 2, 3 comoo período sazonal.Para especificar um modelo não sazonal, configure o Período sazonal como 0 ou 1. Um modelo comsazonalidade especificada pelo usuário é exibido apenas se o modelo sazonal é mais preciso do quetodos os modelos não sazonais.
Insights
Quando as visualizações possuem Insights e Previsões ativados e disponíveis, a caixa de diálogo Insightsaparece ao lado da caixa de diálogo Previsão. Cada recurso fornece um conjunto independente deresultados analíticos. Para obter mais informações, consulte “Insights em visualizações” na página 65.
48 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Tipos de visualização que suportam previsãoA previsão é suportada em visualizações de linha, barra e coluna.
A tabela a seguir compara os recursos de exibição de previsão para cada visualização.
Recursos de previsão Gráfico de Linha Gráficos de barras Gráfico de colunas
Pontos de previsão Círculo aberto Barra dividida Coluna dividida
Exibição de intervalo deconfiança
Região sombreada Linha sólida Linha sólida
Ativar intervalo deconfiança
Clique em qualquerponto
Clique em uma barra deprevisão
Clique em uma colunade previsão
Número de intervalos deconfiança exibidos
Todos 1 1
A imagem a seguir mostra uma previsão nas visualizações de linha e barra com intervalos de barrasativados.
Insights e previsão
Os insights nas visualizações fornecem informações analíticos que podem ajudar os usuários a detectar evalidar quaisquer relacionamentos importantes e diferenças significativas com base nos dados que sãoapresentados pela visualização. Os insights trabalham ao lado da previsão em visualizações suportadas.Os insights fornecem um conjunto separado de resultados analíticos e os resultados são apenas paravalores de histórico. Para obter mais informações, consulte “Insights em visualizações” na página 65.
Dados de previsãoOs dados que são adequados para a previsão têm valores de medida que correspondem a momentosespaçados regularmente. Você especifica o tempo e as medidas em visualizações arrastando os camposde tempo e campos de medida para intervalos de visualização. Opcionalmente, também é possívelespecificar os campos de grupo que dividem os valores de medidas por categorias.
A tabela a seguir é um resumo dos tipos de campo e intervalos de visualização correspondentes que sãosuportados na previsão:
Slot Campos de tempo(obrigatório)
Campos de medida(obrigatório)
Campos de grupo(opcional)
Slot de gráfico de linha eixo X eixo-y Cor
Slot de gráfico de barras Barras Comprimento Cor
Capítulo 4. Forecasting 49

Slot Campos de tempo(obrigatório)
Campos de medida(obrigatório)
Campos de grupo(opcional)
Slot de gráfico decolunas
Barras Comprimento Cor
Nenhuma outra visualização ou intervalo de visualização é suportado, com exceção do intervalo Filtroslocais
Campos de tempo em dados de previsãoUm campo de tempo é identificado por um ícone de tempo na frente do rótulo de campo na área de janelaDados.
É possível especificar propriedades do campo de tempo usando as propriedades a seguir: Tipo de dadosou Representa horário.
Tipo de dado
Um campo é reconhecido como um campo de tempo se ele possui um dos tipos de dados a seguir: Data,Hora ou Registro de Data e Hora. O tipo de dados é herdado da origem de dados e não pode ser mudado.
Os tipos de dados Data, Hora e Registro de Data e Hora foram projetados para suportar a gama completade formatos de data e hora que são cobertos pelos formatos básico e estendido do ISO 8601. A tabela aseguir mostra os tipos de dados suportados em conjunto com um exemplo de formato e um exemplo dedados para cada um.
Tipo de dado Exemplo de formato Exemplo de dados
data aaaa-mm-dd 01/07/2019
Horário hh:mm:ss 12:34:56
Registro de data e hora aaaa-mm-dd’T’hh:mm:ss 2019-07-01T12:34:56
Representa horário
Um campo é reconhecido como um campo de tempo se a propriedade de dados Representa estáconfigurada como Horário. Os campos de Texto e Número Inteiro que contêm dados de tempo tambémsão reconhecidos como campos de tempo. Os campos de tempo são definidos automaticamente durantea importação ou o enriquecimento de dados. As definições possíveis são Data, Ano, Trimestre,Temporada, Mês, Semana, Dia, Hora, Minuto ou Segundo.
Se os campos de tempo não forem reconhecidos automaticamente, será possível especificá-los comocampos de tempo. Assegure-se de que os valores do campo estejam em um dos formatos suportados,caso contrário, você poderá receber um erro Formato de data não suportado.
Campos de tempo aninhados
É possível arrastar diversos campos de tempo para o mesmo intervalo de visualização para especificarum campo de tempo aninhado. Por exemplo, um campo que representa a Semana pode ser arrastadopara o intervalo juntamente com um campo que representa o Dia para criar uma previsão por Dias daSemana.
Os campos aninhados no intervalo devem estar em ordem de hierarquia temporal. Por exemplo, aSemana deve ser colocada acima do Dia.
50 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Os campos aninhados não podem ignorar níveis na hierarquia temporal que resultarão em ambiguidade.A tabela a seguir descreve as hierarquias aceitáveis.
Campo de tempo Campos inferiores aceitáveis
Ano Trimestre, Mês, Semana, Dia
Trimestre Mês
Mês Dia
Semana Dia
Dia (do Ano, Mês ou Semana) Hora, Tempo
Hora Minuto
Minuto Segundo
Se Year estiver ausente na hierarquia de tempo, então o sistema será padronizado para o ano atual. Issopode causar problemas devido às diferenças entre os anos bissexto e não bissexto. Considere fornecer oAno em tais instâncias.
Ordem cronologica de dados
Os campos de tempo especificados definem uma ordem cronológica para os pontos de tempo navisualização. Eles são usados para classificar os pontos na visualização em ordem cronológica quando aprevisão está ativada. A ordem cronológica inclui os pontos históricos, juntamente com os novos pontosprevistos. Quaisquer outros critérios de classificação que sejam especificados para a visualização serãoignorados quando a previsão for ativada.
Todos rótulos de tempo inválidos são movidos para o início da sequência e excluídos da construção domodelo e do cálculo da previsão.
Detecção de intervalo de tempo
A detecção de intervalo de tempo é possível quando os dados são ordenados cronologicamente. Ointervalo de tempo é o tamanho do menor intervalo entre quaisquer dois pontos de tempo adjacentes,como "2 semanas". Se intervalos de tempo variados forem detectados, todos eles deverão ser múltiplosde número inteiro do menor intervalo. Caso contrário, os dados serão considerados irregulares e nãopoderão ser previstos. Os pontos de tempo ausentes que surgem como resultado de diversos intervalossão preenchidos para o intervalo detectado. Valores de medida correspondentes são configurados comoausentes. Se o número de valores ausentes for maior que 33% do comprimento da série, um erro Muitosvalores ausentes erro será relatado.
Campos de medida
Um ou mais campos de qualquer tipo podem ser especificados como campos de medida para análise deprevisão, incluindo-os em um intervalo de visualização correspondente. Cada campo de medida éanalisado separadamente. Múltiplas séries temporais também podem ser especificadas incluindo umcampo no intervalo Cor, dividindo os valores de medidas pelas categorias do campo especificado.
Todos os valores de campo de medida que correspondem ao mesmo ponto de tempo são resumidosusando um dos níveis de resumo a seguir: Soma, Mínimo, Máximo, Média, Contagem e Contagemdistinta. O campo deve ser numérico para suportar a sumarização Soma, Mínimo, Máximo ou Média.Todos os tipos de dados e níveis de resumos possíveis são suportados para previsão. No entanto,considere os seguintes pontos:
• Um pequeno número de valores de medida diferentes pode resultar em previsões inesperadas ou nãoinformativas. Por exemplo, quando o resumo de Contagem distinta é usado.
• Os valores de medida zero podem influenciar indevidamente os resultados, especialmente quandorepresentam medições ausentes.
Capítulo 4. Forecasting 51

Interpolando valores ausentes
Os valores ausentes são calculados e preenchidos pelo algoritmo Interpolação linear. O cálculo ébaseado nos vizinhos mais próximos em uma série temporal cronologicamente ordenada com intervalode tempo detectado. O novo valor é (valor anterior + próximo valor)/2. Por exemplo, com osvalores [3, 6, ausente, 12], o valor interpolado para substituir o valor ausente é (6 + 12) / 2 ou 9. Oalgoritmo de interpolação também pode manipular valores ausentes contíguos.
Os pontos de dados com valores ausentes no primeiro ou nos últimos pontos de tempo históricos sãoexcluídos da série antes da construção de um modelo. Os valores ausentes nos últimos momentoshistóricos também são previstos.
Detalhes estatísticos da previsãoUma execução de previsão gera previsões e detalhes estatísticos de previsão. Os detalhes estatísticos daprevisão estão localizados na bandeja de dados na parte inferior de cada visualização. Há uma única linhade detalhes estatísticos para cada série temporal na visualização. Os detalhes de previsão serão gerados,desde que os pontos de tempo estejam espaçados uniformemente.
As informações de previsão contêm o Status de previsão para a série temporal fornecida. Quando ostatus é Sucesso, os outros campos fornecem detalhes sobre o modelo e os dados usados para previsão.Quando o status é Falha, alguns dos outros campos, incluindo as Observações, fornecem detalhes arespeito da causa da falha. Os resumos de falhas são sempre fornecidos nos avisos de visualização.
As informações do Modelo especificam os tipos de Tendência e Sazonalidade selecionados para estimaros dados da série temporal em caso de sucesso. A tabela a seguir lista os diferentes tipos disponíveis.
Componente detendência
Componente sazonal
N
NENHUM
A
ADITIVO
M
MULTIPLICATIVO
N
NENHUM
(N, N) (N, A) (N, M)
52 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Componente detendência
Componente sazonal
A
ADITIVO
(A, N) (A, A) (A, M)
Ad
ADITIVO_AMORTECIDO
(Ad, N) (Ad, A) (Ad, M)
Medidas de precisão
As medidas de precisão do modelo Erro Médio Absoluto (MAE), Erro Médio Escalado Absoluto (MASE),Percentual de Precisão, Erro Quadrático Médio Raiz (RMSE), Erro Médio de Percentual Absoluto (MAPE) eCritério de Informações de Akaike (AIC) são baseadas nos dados da série temporal que são usados paragerar o modelo. Todas as medidas de precisão baseiam-se nos dados históricos. As medidas de precisãotambém podem ser usadas como indicador da precisão de previsão, mas elas não são transferidas paravalores futuros.
Erro Médio Absoluto (MAE)Calculado como a diferença média absoluta entre os valores ajustados pelo modelo (um passo àfrente na previsão de amostra) e os dados históricos observados.
Erro Médio Escalado Absoluto (MASE)A medida de erro que é usada para obter a precisão de modelo. É o MAE dividido pelo MAE do modelosimples. O modelo simples é aquele que prevê o valor no momento t como o valor de históricoanterior. Escalar por esse erro significa que é possível avaliar o quão bom o modelo é em comparaçãocom o modelo simples. Se o MASE é maior que 1, o modelo é pior do que o modelo simples. Quantomenor for o MASE, melhor será o modelo em comparação com o modelo simples.
Percentual de Precisão (% de Precisão)O indicador primário da precisão do modelo com base nos valores ajustados. Ele é especificado comoa porcentagem de redução do erro absoluto médio em relação ao modelo naive. Ele é calculadosubtraindo o MASE de 1 e expressando-o como porcentagem. Se o MASE for maior ou igual a 1, aprecisão será definida como 0% porque o modelo não melhora sobre o modelo naive. A precisãosuperior indica um erro de modelo inferior em relação ao modelo naive.
Erro Quadrático Médio (MSE)A soma da diferença quadrática entre os valores que são ajustados pelo modelo e os valoresobservados que são divididos pelo número de pontos históricos, menos o número de parâmetros nomodelo. O número de parâmetros no modelo é subtraído do número de pontos históricos para serconsistente com uma estimativa de variância do modelo imparcial.
Erro Quadrático Médio Raiz (RMSE)A raiz quadrada do MSE. Ele está na mesma escala que os valores de dados observados.
Erro Médio de Percentual Absoluto (MAPE)A diferença média absoluta de percentual entre os valores que são ajustados pelo modelo e osvalores de dados observados.
Critério de Informações de Akaike (AIC)Uma medida de seleção de modelo. O AIC penaliza modelos com muitos parâmetros e, portanto,tenta escolher o melhor modelo com uma preferência em relação aos modelos mais simples. O AIC éa soma do logaritmo de MSE não ajustado multiplicado pelo número de pontos históricos e o númerode parâmetros de modelo e estados de suavização iniciais que são multiplicados por 2.
Parâmetros
O período sazonal detectado e as estimativas para outros parâmetros que são usados no modelo desuavização exponencial selecionado estão disponíveis.
Capítulo 4. Forecasting 53

Período sazonalO número de etapas de tempo em um período sazonal usado no modelo de suavização exponencial.
AlfaO fator de suavização para os estados de nível no modelo de suavização exponencial. Pequenosvalores de alpha aumentam a quantidade de suavização, ou seja, mais história é considerada quandoo alpha é pequeno. Valores grandes de alpha reduzem a quantidade de suavizações, o que significaque mais peso é colocado sobre as observações mais recentes. Quando o alpha é 1, todo o peso écolocado sobre a observação atual.
BetaO fator de suavização para os estados de tendência no modelo de suavização exponencial. Esseparâmetro se comporta de maneira similar ao alpha, mas destina-se à tendência em vez de a estadosde nível.
GamaO fator de suavização para os estados de sazonalidade no modelo de suavização exponencial. Atendeà função semelhante como o alpha, mas para o componente sazonal do modelo.
FiO coeficiente de amortecimento no modelo de suavização exponencial. As previsões longas podemlevar a resultados irrealistas e é útil ter um fator de amortecimento para amortecer a tendência aolongo do tempo e produzir previsões mais conservadoras.
Diagnostics
As informações incluem Contagem de ausentes, Comprimento da série, Períodos ignorados, Intensidadede tendência, Força da sasonalidade e Intervalo de data/hora.
Contagem ausenteIndica o número de linhas de dados que têm valores ausentes ou pontos de tempo ausentes e queestão posicionadas entre o primeiro e o último valor da série válido. Os pontos de tempo inválidos,bem como os pontos com valores ausentes no primeiro ou nos últimos pontos de tempo histórico nãoestão incluídos.
Comprimento da sérieIndica o número de pontos de dados usados para modelagem de séries temporais. Apenas os pontosentre o primeiro e o último valor de série válido estão incluídos.
Períodos ignoradosUm número inteiro, m, que ignora os últimos m pontos de dados da série ao construir o modelo desuavização exponencial e calcular as previsões. Quaisquer valores ausentes no final de uma parte nãoignorada de uma série também serão previstos. O valor padrão para esse parâmetro é 0, o quesignifica que todos os dados históricos são usados na geração do modelo quando não há valoresausentes. Um potencial máximo de 100 pontos pode ser ignorado. Os períodos ignorados excluem ospontos de dados ao construir um modelo, portanto, a previsão pode falhar devido a fatores comorequisitos mínimos de comprimento de dados e proporção de valor ausente que excede 33%.
Força de tendênciaCompara o modelo original, M, com o mesmo modelo, mas com o componente de tendênciaremovido. A intensidade da tendência de M é a diferença na precisão entre o modelo M e o modelo Mcom o componente de tendência removido.
Força de sazonalidadeCompara o modelo original, M, e o mesmo modelo com o componente sazonal removido. Aintensidade da sazonalidade de M é a diferença na precisão entre o modelo M e o modelo M com ocomponente sazonal removido.
Intervalo de data/horaO intervalo de data/hora representa o intervalo de tempo detectado dos dados classificadoscronologicamente. O intervalo de tempo é identificado como a menor diferença entre os pontosvizinhos nos dados quando classificados na ordem cronológica.
54 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Modelos de previsãoOs modelos de suavização exponencial são uma classe popular de modelos de séries temporais.
Os modelos de suavização exponencial são aplicáveis a um único conjunto de valores que são registradosapenas sobre incrementos de tempo igual. No entanto, eles suportam propriedades de dados que sãofrequentemente localizadas em aplicativos de negócios, como tendência, sazonalidade e dependência detempo. Todos os recursos de modelo especificados são estimados com base nos dados observadosdisponíveis. Um modelo estimado pode, então, ser usado para prever valores futuros e fornecer limites deconfiança superiores e inferiores para os valores de previsão.
Cada tipo de modelo é adequado para modelar uma combinação diferente de propriedades que estãolocalizadas nos dados. O tipo de modelo que pode fornecer a melhor correspondência para os dadosobservados é selecionado para modelar os dados observados e é usado para prever quaisquer valoresfuturos.
Algoritmos de estimação do modelo
Os modelos são especificados pelas equações de suavização que incluem os parâmetros do modelo e osestados de suavização iniciais. Os parâmetros do modelo são estimados com valores que minimizam oerro do modelo.
Equações de suavização
Os modelos de suavização exponencial derivam seus nomes das equações de suavização queespecificam o modelo. Eles fornecem fórmulas para os estados de suavização de cálculo para cada pontoobservado usando o valor observado atual e os estados de suavização anteriores. As equações desuavização fornecem médias ponderadas do valor atual e dos estados anteriores na série temporal. Opeso para o valor ou estado atual é dado por um parâmetro de modelo entre 0 e 1, enquanto os pesospara os valores anteriores estão diminuindo exponencialmente.
Equações de suavização de nível
Todos os tipos de modelo calculam um estado de nível para cada ponto de série temporal usando aequação de suavização de nível correspondente. Os estados de nível para o modelo sem tendência ecomponentes sazonais são calculados como a média ponderada do valor da série temporal no ponto atuale no estado do nível no ponto anterior. O peso que está associado ao valor atual é um parâmetro, alpha,com seu valor restrito entre 0 e 1. Para outros modelos, a tendência e os estados sazonais anteriorestambém estão incluídos na equação de suavização de nível.
Equações de suavização de tendência
Tipos de modelos com tendência aditiva ou aditiva amortecida calculam um estado de tendência paracada ponto de série temporal usando a equação de suavização de tendência correspondente. O estado detendência para o ponto atual baseia-se na diferença de estados de nível no ponto atual e no pontoanterior, e no estado de tendência no ponto anterior. O peso que está associado à diferença de estadosde nível nos pontos atual e anterior é um parâmetro que é denominado beta, com seu valor restrito entre0 e 1. Um parâmetro extra, phi, é incluído nas equações de suavização de tendência amortecida. Phimultiplica a contribuição do estado de tendência do ponto anterior e seu valor também é restrito entre 0e 1. O propósito desse parâmetro é estimar o grau de amortecimento de tendência de um ponto para oseguinte.
Equações de suavização sazonal
Tipos de modelo que suportam sazonalidade aditiva ou multiplicativa calculam um estado sazonal paracada ponto de série temporal. Os estados sazonais são calculados usando equações de suavizaçãosazonais. O estado sazonal para o ponto atual inclui a diferença do valor da série temporal e o estado denível atual para a sazonalidade aditiva ou a proporção dos dois mesmos valores para a sazonalidademultiplicativa. O peso que está associado a esse termo é um parâmetro, gamma, com o seu valor restritoentre 0 e 1. O restante da contribuição provém do estado sazonal correspondente no período sazonal
Capítulo 4. Forecasting 55

anterior. Observe que o período sazonal tem um comprimento fixo e, enquanto o estado sazonal podemudar para cada ponto, apenas índices sazonais correspondentes de diferentes períodos sãoconsiderados em conjunto nas equações sazonais de suavização.
Estados de suavização iniciais
Os valores devem ser especificados para os estados de nível, tendência e sazonalidade para pontos queantecedem a série temporal. Os valores são necessários para as equações de suavização. Para calcular osvários estados no primeiro ponto da série temporal, são requeridos valores de estado nos pontosanteriores correspondentes.
Parâmetros do modelo
Cada equação de suavização usa parâmetros de modelo correspondentes:
alphaControla os estados de nível.
betaControla os estados de tendência.
gammaControla os índices sazonais entre períodos sazonais.
phiUm parâmetro extra que é usado para especificar a tendência amortecida.
Todos os quatro parâmetros têm valores entre 0 e 1. Valores mais altos de alpha, beta e gammasignificam que observações mais recentes têm peso maior, enquanto valores mais baixos significampesos mais altos para observações mais antigas. Um valor maior de phi corresponde a um grau superiorde amortecimento da tendência de previsão.
Estimação do modelo
Os parâmetros do modelo nas equações de suavização são estimados com base nos dados da sérietemporal. Os parâmetros não podem ser estimados diretamente usando uma fórmula. Eles sãoestimados por um processo iterativo que procura valores de parâmetros que minimizam o erro domodelo. O erro de modelo é calculado como Média de Erro Escalado Absoluto (MASE). As iteraçõesparam quando nenhuma redução adicional no erro do modelo pode ser obtida. Os valores de parâmetroscorrespondentes, juntamente com os estados de suavização iniciais, especificam totalmente o modeloestimado. Eles são usados para calcular os estados do modelo para todos os outros pontos de dados egeram as previsões do modelo usando uma equação de previsão correspondente.
Algoritmos de previsãoInúmeros algoritmos são usados na previsão.
Um passo à frente
Todo modelo suporta previsões um passo à frente com base na equação de previsão correspondente. Asprevisões um passo à frente são necessárias para calcular erros de modelo durante o processo deestimação do modelo.
As previsões um passo à frente são calculadas sequencialmente para cada ponto de dados usando o nívelcalculado e os estados de tendência para o ponto atual, além dos estados sazonais para o último períodosazonal.
O erro de previsão é calculado subtraindo valor de previsão no ponto anterior a partir do valor observadono ponto atual. O erro geral do modelo, que é usado para estimar o modelo, é calculado como um valormédio de erros de previsão absolutos. Erros menores correspondem a um ajuste de modelo melhor. Asmedidas de precisão exibidas em Detalhes estatísticos da previsão fornecem vários resumos de modelodos erros de previsão um passo à frente.
56 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

k-passo à frente
As previsões k-passo à frente são usadas para fazer previsões para qualquer número de valores futurosseguindo os dados da série temporal observada. Elas são baseadas nas mesmas equações de previsãoque as previsões um passo à frente para o modelo especificado.
O número de valores de previsão que são gerados é 20% do comprimento da série de dados históricospor padrão. É possível especificar um número exato de valores a serem previstos na caixa de diálogoPrevisão. Qualquer valor ausente no final de uma determinada série também será previsto, mas ele nãocontará para o número especificado de períodos de previsão.
Limites de confiança
Os limites de confiança fornecem o nível de incerteza que está associado a cada valor de previsão. Oslimites geralmente se tornam mais amplos no futuro, pois as previsões mais distantes são menosconfiáveis. Os limites de confiança fornecem insights relevantes sobre o comportamento futuro da sérietemporal observada.
O cálculo de limites de confiança baseia-se na variação geral dos erros de previsão que são estimadosnos dados observados e um fator que depende do modelo especificado e do número de etapas a partir doúltimo ponto observado.
Seleção de modelo automatizado em previsõesVários tipos de modelo são usados para criar modelos de candidatos para cada série temporal em umaprevisão. Todos os nove tipos de modelo disponíveis normalmente são usados, exceto quando umcomponente sazonal está ausente. Existem apenas três tipos de modelos disponíveis que não sãocontabilizados para a sazonalidade nos dados.
O valor padrão, Automático, para a opção de período Sazonal, detecta o período sazonal comparandovários modelos, cada um com um período sazonal de candidato diferente.
Vários modelos são comparados usando um erro de modelo e o número de parâmetros do modelo. Porexemplo, quando os erros de modelo são iguais para dois modelos, o modelo com menos parâmetros épreferencial. O último modelo fornece uma representação mais condensada dos dados observados etambém tende a gerar previsões mais confiáveis.
Capítulo 4. Forecasting 57

58 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Capítulo 5. Principles of advanced data analytics
Princípios da análise de dados avançadaO IBMCognos Analytics é uma ferramenta de inteligência de negócios para gerenciar e analisar dados. Eleinclui recursos de autoatendimento para que os usuários se preparem, explorem e compartilhem dados.O Cognos Analytics inclui técnicas preditivas, descritivas e exploratórias, também conhecidas comointeligência numérica. O Cognos Analytics usa muitos testes estatísticos para analisar seus dados.
É importante entender as definições desses testes, pois eles se aplicam ao Cognos Analytics .
Os algoritmos numéricos usados como parte do fluxo de trabalho fornecem ao usuário recursos quecomunicam informações sobre as propriedades numéricas e os relacionamentos em seus dados.
Orientado a negócios
Ao contrário do software estatístico tradicional, em que o público-alvo é um analista de dados experiente,os algoritmos do Cognos Analytics são direcionados a usuários que estão familiarizados com a análise dedados, mas não são especialistas. Isso significa que, ao considerar as alternativas, o Cognos Analyticsescolhe a utilidade e não a complexidade.
Confiança
Os dados de negócios são muito mais complicados do que os exemplos contidos nos livros didáticosusados em cursos estatísticos ou em procuras e exemplos da web. O Cognos Analytics usa algoritmosrobustos e capazes de lidar com uma variedade de dados incomuns. O Cognos Analytics faz isso porque,embora os algoritmos mais frágeis possam obter resultados ligeiramente melhores do que os algoritmosrobustos, eles requerem que o usuário verifique sua aplicabilidade e construa transformações de dadoscorretas para que os resultados sejam significativos. Uma pequena diminuição na precisão vale asegurança que é fornecida por um algoritmo que não dá resultados errados quando os dados não sãoexatamente como deveriam ser.
Inteligente
Quase todos os algoritmos requerem a tomada de decisões; níveis de confiança, quais combinações decampo devem ser exploradas, transformações de dados. Os detalhes dessas decisões podem serencontrados nas descrições.
O Cognos Analytics escolhe os valores adequados automaticamente, examinando as propriedades dosdados. Como um usuário, você pode não descobrir todas as decisões tomadas.
Resumo
No Cognos Analytics , os algoritmos numéricos e procedimentos são desenvolvidos para produzirresultados confiáveis automaticamente. Para obter a melhor predição, classificação ou análise possível,um estatístico profissional analisa os dados utilizando o IBM SPSS Statistics ou o IBM SPSS Modeler. Oobjetivo do Cognos Analytics é fornecer insights de qualidade, que o ajudem a entender seus dados eseus relacionamentos e fazer isso de forma automática, para uma grande variedade de tipos de dados. OCognos Analytics visa fornecer resultados semelhantes aos de um estatístico profissional, sem atrapalharo usuário corporativo.
Preparação de dadosA preparação de dados é uma etapa anterior à análise que é usada pela maioria dos algoritmos analíticosde dados para assegurar que os dados sejam adequados para uso analítico.
© Copyright IBM Corp. 2018, 2020 59

Visão geral
A preparação de dados é crítica no IBMCognos Analytics. Somente dados preparados são inseridos naanálise para drivers de chaves, árvores de decisão e relacionamentos que são exibidos nas visualizaçõesavançadas de análise de dados: Espiral, Análise de driver, Árvore de decisão, Explosão Solar e Explorarrelacionamentos. Os dados não são preparados automaticamente para outras visualizações e seusinsights correspondentes.
Algoritmos
Todos os algoritmos aplicados são baseados em valores de um único campo por vez. Os valores ausentessão removidos ou manipulados para cada campo e todos os campos do driver do preditor numérico sãocategorizados. Todos os campos categóricos são ajustados para um grande número de categorias e osvalores discrepantes são manipulados no campo de destino. Embora toda a preparação de dadosinfluencie os resultados da análise, atualmente os resumos de preparo de dados correspondentes nãosão relatados a você.
Detalhes
Quando os dados originais são maiores, a preparação de dados e os drivers de chaves, as árvores dedecisão e os relacionamentos subsequentes são baseados em uma amostra de dados comaproximadamente 10.000 linhas. A amostragem aleatória de Bernoulli, que é a probabilidade igual sem aamostra aleatória de substituição, é aplicada aos dados transferidos por upload e a quaisquer origens dedados conectadas que estejam apoiando a amostragem aleatória. Caso contrário, será utilizada umaamostragem sistemática.
Preparação de dados para campos núméricosUm campo é tratado como numérico sempre que contém informações numéricas e sua propriedade deuso é configurada como medida.
Visão geral
Como pode haver variações na distribuição dos dados numéricos, o IBMCognos Analytics transforma oscampos numéricos não de destino em categorias ordinais, reduzindo a dependência que os algoritmosanalíticos têm do formato dos dados numéricos.
Algoritmos
O algoritmo básico utilizado é a categorização de frequência igual. Os dados numéricos são divididos emum número fixo de categorias que estão tentando colocar um número igual de linhas de dados em cadacategoria. Os valores omissos são colocados em sua própria categoria. O Cognos Analytics tenta usar seuconhecimento sobre valores omissos nos campos de preditor para construir um modelo melhor. Porexemplo, se um campo de dados representar o momento em que um item foi testado, o Cognos Analyticsusará os valores omissos (que podem representar que um item nunca foi testado) para ajudar a prever osvalores de outros campos.
Detalhes
Alguns critérios de exclusão de campo se aplicam a campos numéricos. Um campo numérico é excluídoda análise adicional caso tenha apenas um valor único, incluindo o valor omisso. Caso contrário, o camponumérico é categorizado e o número padrão de categorias é 5. Se um campo não tiver mais de 10 valoresnuméricos exclusivos, não haverá tentativa de categorização e cada valor exclusivo receberá sua própriacategoria. Se um valor zero ocorrer em mais de 40% das linhas, ele sempre receberá uma categoriaseparada. Os valores omissos são colocados em sua própria categoria e não afetam o procedimento decategorização.
Preparação de dados para campos categóricosUm campo é tratado como categórico sempre que sua propriedade de uso estiver configurada comoatributo ou identificador.
60 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Visão geral
A principal informação extraída dos campos categóricos é a frequência observada para cada valor decategoria exclusivo. Métodos analíticos adequados são aplicados aos campos categóricos, mas suaprecisão e desempenho podem ser afetados negativamente quando o número de categorias diferentes setorna grande. A principal etapa de preparação de dados é iniciar a mesclagem de categorias quando seunúmero se tornar grande.
Algoritmos
O algoritmo básico utilizado é a mesclagem de categorias. As categorias são classificadas de acordo comsua frequência, em ordem decrescente e as categorias além do número padrão são mescladas em umaúnica categoria. Os valores omissos são tratados como uma única categoria separada. Em outraspalavras, o IBMCognos Analytics usa os valores omissos de forma semelhante da usada para camposnuméricos. Os campos categóricos são tratados como nominais. A ordem intrínseca não é assumida entreas categorias.
Detalhes
Alguns critérios de exclusão de campo se aplicam a campos categóricos. Um campo categórico é excluídoda análise adicional caso tenha somente um único valor ou o número de categorias exclusivas nãomescladas exceda 50% do número de linhas de dados válidas.
Caso contrário, o campo categórico será mesclado e o número padrão de categorias não mescladas será49. O restante das categorias é mesclado em uma única categoria adicional. Todas as categorias comcontagens de linhas menores que 3 também são mescladas. Um campo categórico também será excluídose a porcentagem de linhas de dados válidas correspondentes à categoria mesclada exceder 25%.
Os valores omissos são tratados como uma categoria separada e assim considerados na etapa demesclagem.
Preparação de dados para campos de destinoA especificação do campo de destino é necessária para os drivers de chaves e as visualizações da árvorede decisão.
Visão geral
Sempre especifique o campo de destino e pelo menos um campo adicional. Os modelos são treinadosusando os valores de destino fornecidos e são usados para detectar relacionamentos preditivos e,eventualmente, para prever valores de destino, de acordo com os valores do campo de entrada. Apreparação de dados para o campo de destino difere da preparação de dados para o restante doscampos. Os valores omissos no destino não são usados para a construção de modelos, mas o restantedas informações é preservado e, às vezes, ajustado para a obtenção de valores imparciais.
Algoritmos
A etapa de preparação de dados principal relacionada aos campos de destino é a remoção de todas aslinhas de dados com valores de destino omissos. Isso ocorre antes de quaisquer outras etapas depreparação de dados. Embora essa etapa assegure que apenas informações confiáveis sejam usadaspara a construção do modelo, o número de linhas removidas pode ser substancial. O modelo resultantepode ter um escopo limitado nessas instâncias. Os campos de destino numéricos não são categorizados,mas os valores discrepantes extremos são manipulados de forma a não afetar negativamente os modeloscriados posteriormente. Os campos de variáveis resposta categóricas são tratados de forma semelhanteaos outros campos categóricos. A única diferença é que os valores omissos são removidos das variáveisresposta categóricas.
Detalhes
Os valores discrepantes extremos são detectados com base nos limites inferior e superior. O limitesuperior é construído usando um percentil superior, de forma que apenas 2,5% dos valores de destino
Capítulo 5. Principles of advanced data analytics 61

tenham um valor superior. A diferença entre o percentil superior e a média é multiplicada por 2,5 esomada à média para obter o limite superior. Etapas semelhantes são aplicadas para a obtenção do limiteinferior. Os valores de destino localizados além dos limites calculados são substituídos pelo valor delimite correspondente em todas as análises subsequentes.
Drivers de chaves unidirecionaisOs drivers de chaves unidirecionais são uma ferramenta exploratória baseada em modelo.
Visão geral
Dado um campo de destino, a ferramenta usa um modelo estatístico para analisar qualquer outro campode dados disponível e estima sua intensidade ao prever os valores de destino. Esses campos de dadossão chamados preditores de destino ou drivers. Cada campo de dados potencialmente relevante éanalisado e são exibidos apenas os principais drivers em relação à intensidade preditiva. É possível obterinsights a respeiro dos drivers disponíveis e sua classificação de acordo com sua intensidade preditivapara o destino especificado nos dados. Os resultados da análise do driver unidirecional ficam disponíveisna análise do driver em nas visualizações em espiral. O drill down visual em cada driver separado éativado apenas para a visualização da análise do driver na Exploração.
Algoritmos
A análise para cada driver unidirecional é baseada em um modelo estatístico que inclui o destino e umpreditor categórico único. O modelo é aplicado após a etapa de preparação de dados para o campo dedestino e todos os campos de preditores em potencial. Por exemplo, todos os campos de preditoresnuméricos são categorizados durante a etapa de preparação de dados e tratados como categóricos naanálise. O ANOVA unidirecional é aplicado para destinos numéricos, já o teste qui-quadrado deindependência é aplicado para variáveis respostas categóricas com o ajuste de qui-quadrado para dadosesparsos.
Para cada campo na lista de drivers em potencial, é executado um teste de hipótese que determina se ocampo tem um impacto significativo no destino. Apenas os campos aprovados no teste e cuja intensidadepreditiva é suficientemente alta são selecionados como drivers de chaves unidirecionais possíveis.
Detalhes
Em alguns casos, a análise preliminar baseada em recursos inteligentes reduz o número de drivers empotencial. O objetivo é remover os campos irrelevantes ou redundantes. A lista de drivers utilizados ficadisponível na IU e é possível incluir na análise quaisquer drivers inicialmente excluídos. Os 20 principaisdrivers resultantes com intensidade preditiva superior a 10% ficam disponíveis para exibição.
Algumas restrições são aplicadas no tamanho dos dados para melhorar o desempenho e a velocidade. Seos dados contiverem mais de 250 campos, os campos menos relevantes serão excluídos antes da análisedo driver. É possível usar a IU para incluir novamente na análise os campos excluídos, conforme descritoacima. Caso os dados especificados contenham mais de 10.000 linhas, eles podem ser reduzidos parauma amostragem de aproximadamente 10.000 linhas, para fins de análise do driver. Um aviso é exibidonessas instâncias: Para melhorar o desempenho, devido ao número de linhas na origem de dados, aanálise é baseada em uma amostra representativa de todos os dados. Espera-se que os resultadosfiquem próximos dos resultados que seriam obtidos usando todas as linhas nos dados originais.
Drivers de chaves bidirecionaisOs drivers de chaves bidirecionais dependem de pares de modelagem e de classificação de preditorescategóricos de uma só vez.
Visão geral
Dado um campo de destino, o IBMCognos Analytics usa um modelo estatístico para análise de um par deoutros campos de dados e estima sua intensidade na predição de valores de destino. A procura por paresde preditores diferentes geralmente não é abrangente e, além disso, alguns pares de alta classificaçãopodem ser retirados dos resultados finais. O objetivo é fornecer uma visão geral e uma variedade de
62 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

pares de preditores que melhoram com a intensidade preditiva de modelos de preditor únicos que sãoexibidos como drivers unidirecionais. Assim, os insights obtidos a partir de drivers unidirecionais sãoexpandidos e o usuário obtém informações relevantes sobre os pares de campos nos dados. Osresultados das análises de drivers unidirecionais e bidirecionais ficam disponíveis na análise do driver enos gráficos em espiral. Eles podem ser visualizados separadamente, selecionando uma opção devisualização de gráfico correspondente. Cada driver unidirecional ou bidirecional exibido pode serexpendido em uma nova visualização diretamente a partir da visualização de análise do Driver emExploração.
Algoritmos
A análise de cada driver bidirecional é baseada em um modelo estatístico que inclui o destino e um par depreditores categóricos. O modelo é aplicado após a preparação dos dados e a construção de todos osdrivers unidirecionais. O primeiro preditor no par é selecionado a partir dos 50 drivers unidirecionaisprincipais e o segundo é selecionado a partir dos 25 drivers unidirecionais principais. Essa estratégia deprocura assegura que a maioria dos pares de preditores principais seja considerada para a modelagem. Aanálise ANOVA bidirecional (análise de variação) é aplicada para destinos numéricos, e o teste qui-quadrado de independência é aplicado para variáveis respostas categóricas com o ajuste de qui-quadrado para dados esparsos.
Para cada par de campos considerado, é executado um teste de hipótese que determina se o par tem umimpacto significativo no destino. Somente os pares aprovados no teste e que têm intensidade preditivasuficientemente alta são selecionados como drivers bidirecionais possíveis.
Detalhes
A restrição na seleção de campos de dados e linhas de dados para drivers unidirecionais aplica-setambém aos drivers bidirecionais. Isso é esperado, uma vez que os campos de preditores em potencialpara drivers bidirecionais são selecionados a partir dos principais drivers unidirecionais, com base em suarespectiva intensidade preditiva. No entanto, a significância do modelo de um driver unidirecional e aintensidade preditiva mínima não são necessárias para sua entrada em um modelo bidirecional. Umdriver bidirecional resultante deve ter uma intensidade preditiva superior a 10% e fornecer uma melhoriarelativa superior a 10% sobre a intensidade preditiva para cada um dos driver unidirecionais contidos. Amelhoria relativa é calculada como a porcentagem da diferença entre 100% e a intensidade preditiva dodriver unidirecional aninhado. Os drivers bidirecionais resultantes que satisfazem a esses critérios sãoclassificados de acordo com sua intensidade preditiva e os 20 principais são disponibilizados paraexibição.
Árvore de decisãoAs árvores de decisão são modelos mais complexos do que os drivers unidirecionais e bidirecionais. Elasampliam a sequência, assim como os modelos de combinação. A principal diferença é que as árvores dedecisão suportam a descoberta de interação entre vários preditores e, portanto, oferecem insights maisprofundos do que os drivers.
Visão geral
Dado o campo de destino, o algoritmo procura em todos os outros campos de dados e os inclui no modelopara aprimorar sua intensidade na previsão de valores de destino. A procura em diferentes preditores éiterativa; depois de incluir um preditor, a procura continua a incluir preditores, sempre buscando um quemelhore o modelo ainda mais. O objetivo é encontrar o melhor conjunto de preditores e a melhor maneirade combiná-los, permitindo calcular um modelo ideal. Os insights obtidos a partir de árvores de decisãosão apresentados na forma de regras de decisão, em que a combinação de preditores e valorescorrespondentes fornece uma única predição para o valor de destino. As regras de decisão sãoclassificadas por intensidade, o que permite localizar facilmente as regras que são mais relevantes einteressantes. As regras de decisão geradas pela árvore de decisão são mutuamente exclusivas. Asregras de decisão também fornecem um conjunto de regras completo, para que exista uma regracorrespondente para qualquer combinação dos valores do preditor nos dados. Além disso, estádisponível também a intensidade preditiva geral da árvore de decisão, que fornece uma melhoria relativa
Capítulo 5. Principles of advanced data analytics 63

em relação ao modelo básico. Os resultados ficam disponíveis por meio de três visualizações diferentes:explosão solar, árvore e regras de decisão. Cada um deles possui certas vantagens, exibindo a estruturada árvore de decisão e o conteúdo das regras de decisão correspondentes. A intensidade preditiva geralda árvore de decisão também está disponível na visualização de análise do driver.
Algoritmos
O modelo de árvore de decisão é calculado após a preparação de dados e a construção de todos osdrivers unidirecionais. O primeiro preditor de árvore é selecionado como o driver unidirecional superior.As categorias do preditor são mescladas quando o impacto negativo na intensidade preditiva é menor queum determinado limite. A próxima etapa é encontrar o melhor preditor para dividir cada nó da árvore queé composto pelas categorias mescladas. O processo continua até que uma regra de parada se aplique aum nó da árvore. As opções possíveis para a parada são que todas as categorias para cada preditorcandidato sejam mescladas em um único nó ou que o número de nós exceda o número máximodeterminado. As categorias com menos de um número mínimo de linhas são sempre mescladas comoutra categoria. Isso significa que nenhum dos nós na árvore pode conter menos do que o númeromínimo de linhas. O mesmo procedimento é usado para metas contínuas e categóricas, apenas a funçãode impurezas é diferente.
DetalhesFunções de impureza
Os valores da função de impureza são usados como o principal critério para a divisão e mesclagemdos nós da árvore em potencial. O valor total para a função de impureza para árvores contínuas é asoma dos quadrados por nó, enquanto a medida de impureza de Gini é usada para variáveis respostacategóricas. O valor total de impureza de Gini é calculado como a soma dos quadrados dasproporções de contagem em todas as variáveis resposta categóricas por nó que são subtraídas de ume os resultados que são multiplicados pelo número de linhas. A melhoria no valor da função deimpureza é o ganho de informação.
Ao dividir cada nó, o IBMCognos Analytics procura um campo de preditor com um maior ganho deinformações, calculado como o valor total de impurezas em todos os potenciais nós filhos subtraídodo valor de impureza do nó pai. Antes que o Cognos Analytics selecione o preditor, o Cognos Analyticstenta mesclar alguns dos nós filhos em potencial que inicialmente correspondem a cada categoria depreditor. A perda de informações é calculada subtraindo as impurezas de nós não mesclados dasimpurezas de nós mesclados. Desde que a perda de informações seja menor que um limite, os nósserão mesclados. Esse processo ajuda a criar árvores relativamente pequenas, que são de fácilvisualização e compreensão, enquanto ainda preserva a intensidade geral da árvore.
Regras de parada
Os nós candidatos são sempre mesclados se forem baseados em menos de 25 linhas. Se todas ascategorias de um preditor forem mescladas, ele não poderá ser usado para a divisão de umdeterminado nó. Quando nenhum dos preditores puder dividir o nó específico, o processo parará parao nó. O processo geral de geração da árvore para quando nenhum dos nós pode ser dividido ouquando o número de nós gerados excede 36.
Importância da variável
A importância da variável corresponde a uma redução de erro relativa da árvore quando o preditorcorrespondente é incluído na árvore. Ela é calculada comparando os erros de uma árvore inicial e deuma árvore restrita que é gerada pelo restante dos preditores na árvore inicial. O erro da árvore inicialé subtraído do erro da árvore restrita e o resultado é dividido pelo erro da árvore restrita. As variáveiscom importância zero ou negativa são removidas da árvore. O erro da árvore é calculado como a somade quadrados para variáveis resposta contínuas e como o erro de classificação para variáveis respostacategóricas.
Intensidade preditiva
A intensidade preditiva de uma árvore com variável resposta contínua é calculada de formasemelhante à usada para drivers de chave. O conteúdo dos nós folha é considerado. A contribuição de
64 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

variação para cada nó folha é incluída e dividida pela variação geral dos dados. Este é um erro relativopara a árvore. Ele é subtraído de um para obter a intensidade preditiva que é compatível com amedida quadrada de R usada para drivers de chaves.
Para variáveis resposta categóricas, o Cognos Analytics calcula a precisão da classificação com baseno erro de classificação incluído a partir de todos os nós folha. A melhoria relativa da precisão declassificação em relação ao modelo básico, também conhecida como R-quadrado de contagemajustada, é relatada como a intensidade preditiva da árvore. Ela é calculada subtraindo o erro daárvore do erro do modelo básico e dividindo o resultado pelo erro do modelo básico. Por exemplo, aprecisão de classificação do modelo pode ser de 95%, mas, se a classe de maioria aparecer para 90%das linhas nos dados, a intensidade preditiva da árvore será relatada como apenas 50%. Isso ocorreem paralelo com o caso da variável resposta contínua, em que o modelo é representado pelo valor damédia geral. A intensidade preditiva medida pelo R-quadrado é baseada na melhoria relativa daárvore ao reduzir a variação geral.
O Cognos Analytics exibe apenas as árvores cuja intensidade preditiva é superior a 10%. Uma árvorepara uma variável resposta contínua é exibida em uma análise de driver ou visualização em espiral sesua intensidade preditiva for superior à intensidade preditiva do driver de chaves mais forte. Casocontrário, ela não é exibida nesses gráficos, uma vez que os drivers de chaves já fornecem todos osinsights relevantes.
A intensidade preditiva de uma árvore de decisão é calculada usando os mesmos dados usados paraa geração da árvore de decisão. Sabe-se que esse processo introduz viés e fornece estimativasotimistas do desempenho da árvore de decisão em dados semelhantes da mesma origem de dados. OCognos Analytics reduziu a discrepância, ajustando o algoritmo para minimizar o super ajuste dosdados de treinamento.
Insights em visualizaçõesOs insights nas visualizações fornecem informações analíticos que podem ajudar os usuários a detectar evalidar quaisquer relacionamentos importantes e diferenças significativas com base nos dados que sãoapresentados pela visualização.
Visão geral
Os insights são controlados e resumidos na caixa Insights, disponível em todas as visualizaçõeselegíveis. Ao ativar os insights, o resumo aparece na caixa Insights e os elementos de visualizaçãorelacionados são destacados. Os detalhes são fornecidos na mensagem de dica de ferramentacorrespondente. É possível controlar cada insight disponível separadamente.
Algoritmos
O tipo de insight depende dos dados exibidos pela visualização. Os tipos de insights disponíveis sãoMédia, Intensidade preditiva, Diferenças significativas, Linha de ajuste e Mais frequente. A médiafornece a média dos resumos exibidos e a categoria que aparece com mais frequência nos dados. Orestante dos insights depende de analítica e testes estatísticos mais avançados. O objetivo é fornecerinformações confiáveis que possam ser usadas para fornecer uma descrição aprimorada dos dadosvisualizados e da descoberta de quaisquer relacionamentos que sejam esperados na populaçãorepresentada por esses dados.
Detalhes
A análise de insights é sempre baseada nas mesmas linhas de dados que são usadas para criar osresumos exibidos na visualização. Isso significa que os insights utilizam os dados completos, a menosque alguma filtragem seja aplicada aos dados originais.
Algumas análises e testes estatísticos usados nos insights requerem não somente os resumos de dadosexibidos na visualização, mas também alguns resumos adicionais. Por exemplo, o teste de diferençassignificativas entre diversas categorias de um campo explicativo requer as contagens e variações de cadacategoria, além dos dados exibidos. Esses resumos adicionais são obtidos a partir de um banco de dados,juntamente com os resumos que são necessários para a visualização. Todos os resumos são processados
Capítulo 5. Principles of advanced data analytics 65

pelos insights, mas apenas os necessários ficam disponíveis na visualização. A análise de insights ésempre baseada nas mesmas linhas de dados que são usadas para criar os resumos exibidos navisualização.
Restrições
Caso os insights não fiquem imediatamente disponíveis em uma visualização, um dos motivos aseguir pode se aplicar:
• O tipo de visualização em si não suporta insights.• Os dados na visualização podem ter sido cortados.• A combinação de nível de resumo, tipo de campo e função de campo de um campo selecionado não
corresponde aos requisitos para qualquer um dos insights disponíveis.
Tipos de visualização suportados para insights
Os seguintes tipos de visualização suportam insights:
• Área• Barras• Bolha• Coluna• Mapa de calor• Hierarquia de bolha• Linhas• Linha e coluna• Map• Bolhas compactadas• Setor Circular• Ponto• Radial• Dispersão• Barras empilhadas• Coluna empilhada• Mapa em Árvore• Nuvem de palavras
Múltiplas extensões pequenas são suportadas para alguns insights, incluindo o Mais frequente e asDiferenças significativas.
Níveis de resumo
Os níveis de sumarização suportados são Contagem, Média, Soma, Mínimo e Máximo. Quaisqueroutros valores, como Contagem distinta, podem evitar a sugestão de insights. Alguns algoritmossuportam apenas níveis de resumo específicos. Alterar o nível de resumo padrão para um dos valoressuportados pode possivelmente ajudar na ativação de insights.
Tipos de campo
Os tipos de campo podem ser designados internamente como contínuos ou categóricos, dependendodos valores do campo selecionado.
Tipo de campo Descrição
Categórico Uma variável que pode assumir um determinado valor dentre um númerolimitado e geralmente fixo de valores possíveis. Uma variável categóricadesigna a cada indivíduo ou outra unidade de observação a um
66 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Tipo de campo Descrição
determinado grupo ou categoria nominal, com base em algumapropriedade qualitativa. Por exemplo, o país em que uma pessoa vive.
Contínuo Uma variável que é usada para descrever valores numéricos, como umintervalo de 0 a 100 ou de 0,75 a 1,25. Um valor contínuo pode ser umnúmero inteiro, um número real ou uma data e hora.
Funções de campo
O IBMCognos Analytics designa uma função para cada um dos slots de campo em uma visualizaçãosuportada. Uma função de campo pode ser designada como um dos seguintes itens, dependendo doslot da visualização.
Função de campo Descrição
Resposta Uma variável que é prevista e pode também ser citada como a variável dedestino ou dependente. Ela fica normalmente no eixo Y.
Explicação Uma variável que ajuda a explicar as mudanças na resposta e também éreferida como a variável de previsão ou independente. Ela geralmente ficano eixo X.
Grupo Uma variável que é tratada como explicativa ou um fator agrupadoopcional que ajuda a determinar o número de modelos construídos noalgoritmo. Por exemplo, isso pode corresponder ao slot de Cor de umavisualização de Coluna.
Peso Uma variável que define os pesos de regressão opcionais, que são usadospara calcular o modelo de regressão. Por exemplo, isso pode corresponderao slot de Tamanho de uma visualização de Bolha.
Repetição Uma variável que cria pequenos múltiplos, com a visualização repetidauma vez para cada valor distinto da variável. Por exemplo, isso podecorresponder ao slot de Repetição (linhas) de uma visualização em pizza.
Pontos Uma variável que define o formato dos dados e pontos de dados usadospara calcular o modelo. Por exemplo, isso pode corresponder ao slot dePontos de uma visualização de Dispersão.
Como exemplo geral, em uma visualização de barra com os slots a seguir, os mapeamentos de funçãonessa visualização são definidos como:
• Barras (eixo y), explicativo• Comprimento (eixo x), resposta• Cor, grupo
Insights em visualizações para contagensOs insights de contagens estão disponíveis sempre que a contagem é exibida para cada categoria de umúnico campo categórico.
Eles também estão disponíveis quando a contagem é exibida para cada combinação de categorias de umpar de campos categóricos na visualização. Neste último caso, o par pode ser dois campos explicativos,como nas linhas e colunas de um mapa de utilização, ou um campo explicativo e um de repetição, comonas barras e na repetição (coluna) de um gráfico de barras.
Os insights de contagens de categorias combinadas de três campos categóricos são suportados para umexplicativo e a combinação de dois campos de repetição, como nos segmentos, repetição (coluna) erepetição (linha) de uma visualização em pizza.
Capítulo 5. Principles of advanced data analytics 67

Visão geral
Use essas visualizações quando quiser comparar o número de itens em diferentes categorias ou em umacombinação de categorias.
Algoritmos
O IBMCognos Analytics relata a contagem média entre todas as categorias do campo de respostaespecificado e aplica testes estatísticos para detectar as categorias nas quais as contagens sãoestatisticamente mais diferentes da média.
As visualizações com dois ou três campos categóricos e as contagens para cada combinação decategorias são tratadas de forma diferente. O Cognos Analytics não apenas compara as contagens entreas categorias, mas também detecta qualquer relacionamento entre os campos categóricos. O CognosAnalytics trata um campo como o campo de resposta e os outros como o campo explicativo.
O Cognos Analytics relata a categoria mais frequente nas visualizações com um campo explicativocategórico, um ou dois campos de repetição categóricos e um campo de resposta de contagem.
DetalhesCampo categórico único
O primeiro teste aplicado é o teste qui-quadrado de frequências iguais, para determinar se há algumacontagem disponível que seja significativamente diferente da média. Se o resultado do teste forsignificativo, o Cognos Analytics aplicará o teste qui-quadrado de influência para cada categoriaseparadamente. O Cognos Analytics calcula o tamanho do efeito para categorias nas quais o teste deinfluência é estatisticamente significativo e relata as categorias com o maior tamanho de efeito nasdiferenças significativas.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos
Insight
Exatamente 1
Nível de resumo =contagem
N/D N/D N/D N/D Média
Diferenças Significadas
Dois campos categóricos
O Cognos Analytics trata um campo categórico como o campo de resposta e o outro como o campoexplicativo. O campo de contagem original é usado como entrada para os algoritmos.
O teste de qui-quadrado de independência com o ajuste para dados esparsos é usado paraestabelecer se um relacionamento existe entre o campo de resposta e o campo explicativo. Se oresultado do teste for significativo, o Cognos Analytics calculará a intensidade preditiva desse modelocomo o R-quadrado de contagem ajustada, com as categorias de baixa frequência filtradas. Orelacionamento é declarado confiável e a intensidade preditiva é relatada caso seja superior a 10%.
Se o resultado do teste acima for significativo, todas as combinações de categorias explicativas e deresposta serão analisadas adicionalmente por meio da aplicação do teste qui-quadrado de influênciapara cada combinação. As combinações de categorias explicativas e de resposta em que o teste deinfluência é significativo são consideradas influentes. O tamanho do efeito é calculado para cadacombinação influente de categorias e as combinações com o maior tamanho de efeito são relatadasem diferenças significativas.
Se as funções dos dois campos categóricos forem explicativas e repetidas, o algoritmo mais frequenteserá aplicado. As contagens são somadas em relação a cada categoria distinta do campo explicativo.A maior soma é relatada, juntamente com o número de categorias que possuem essa soma. Observe
68 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
que o campo de repetição não é usado por este algoritmo, mas apenas é acionado quando o algoritmoé aplicado.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo
Peso
Pontos
Repetição Insight
Exatamente 1
Nível de resumo =contagem
Exatamente 2
Categórico
N/D
N/D
N/D
N/D Intensidadepreditiva
DiferençasSignificadas
Exatamente 1
Nível de resumo =contagem
Exatamente 1
Categórico
N/D
N/D
N/D
Exatamente 1
CategóricoIntensidadepreditiva
DiferençasSignificadas
Mais frequente
Três campos categóricos
Esses algoritmos são aplicados apenas quando há um campo explicativo e dois campos de repetição. Acombinação dos dois campos de repetição é tratada como se fosse um único campo categórico, no qualas categorias são os pares de categorias dos dois campos de repetição.
A intensidade preditiva é calculada exatamente como no caso dos dois campos categóricos usando oscampos de repetição em par como os preditores do campo explicativo. O teste qui-quadrado deindependência com o ajuste para dados esparsos é usado para testar a significância do relacionamento, eo R-quadrado de contagem ajustada com as categorias de baixa frequência filtradas é usado paralocalizar a intensidade preditiva.
As diferenças significativas são calculadas exatamente como no caso dos dois campos categóricos,identificando combinações do campo explicativo e os campos de repetição em par para os quais acontagem é incomum. O teste qui-quadrado de influência é usado para testar a significância de cadacombinação e as combinações com o maior tamanho de efeito são relatadas.
O algoritmo mais frequente é aplicado exatamente como no caso dos dois campos categóricos, somandoas contagens sobre cada categoria distinta do campo explicativo. A maior soma é relatada, juntamentecom o número de categorias que possuem essa soma. Observe que os campo de repetição não sãousados por este algoritmo, mas apenas são acionados quando o algoritmo é aplicado.
Resposta Explicação Grupo
Peso
Pontos
Repetição Insight
Exatamente 1
Nível de resumo =contagem
Exatamente 1
Categórico
N/D N/D N/D Exatamente 2
CategóricoIntensidadepreditiva
DiferençasSignificadas
Mais frequente
Capítulo 5. Principles of advanced data analytics 69

Diferenças entre o Cognos Analytics versão 11.1 R2 e R3
Para visualizações com dois campos categóricos, quando o campo de resposta tem uma categoriarepresentando dados ausentes (a categoria "(sem valor)"):
• No Cognos Analytics versão 11.1 R2, o cálculo de R-quadrado de contagem ajustada da intensidadepreditiva omitia os valores de dados da categoria de dados ausentes. No Cognos Analytics versão 11.1R3, os valores são incluídos. Isso pode afetar a intensidade preditiva relatada para os mapas deutilização nos quais o slot de dados de utilização possui dados agregados de contagem, e as linhas ecolunas são dois campos categóricos.
• No Cognos Analytics versão 11.1 R2, as diferenças significativas não relatavam nenhuma célulaincomum associada à categoria de dados ausentes. No Cognos Analytics versão 11.1 R3 as células sãorelatadas. Isso pode afetar as diferenças significativas mostradas para os mapas de utilização nos quaiso slot de dados de utilização possui dados agregados de contagem, e as linhas e colunas são doiscampos categóricos.
Insights em visualizações para resumos por um ou mais campos explanatóriosOs insights para resumos ficam disponíveis quando o nível de resumo é médio, soma, mínimo ou máximopara um campo de resposta contínua. Os insights são computados e exibidos em cada categoria de umúnico campo explicativo categórico, ou em cada combinação de categorias de um par de camposexplicativos categóricos na visualização.
Visão geral
Use essas visualizações quando estiver interessado em comparar valores de um campo de resposta entrediferentes categorias, ou em combinações de categorias de campos explicativos.
Algoritmos
Se o nível de resumo for médio, o IBMCognos Analytics detectará qualquer relacionamento entre ocampo de resposta e os campos explicativos e calculará a intensidade preditiva do modelocorrespondente. Caso as diferenças de valores médios nas categorias explicativas sejamestatisticamente significativas, o Cognos Analytics identificará as categorias explicativas ou a combinaçãode categorias mais diferentes nas diferenças significativas.
Quando o nível de resumo de resposta é sum, Cognos Analytics calcula a soma média em categoriasexplicativas ou combinações de categorias. Se as diferenças de somas nas categorias foremestatisticamente significativas, o Cognos Analytics identificará as categorias explicativas ou a combinaçãode categorias mais diferentes nas diferenças significativas.
Para todos os gráficos aplicáveis, o insight médio exibe o valor médio de resposta resumido em todas ascategorias explicativas. Quando o nível de resumo para a resposta é médio, a média ponderada écalculada usando o valor exibido e a contagem para cada categoria explicativa.
DetalhesMédia por campo explicativo único
Quando o nível de resumo para o campo de resposta é médio e há um único campo explicativocategórico disponível, o Cognos Analytics aplica a análise ANOVA unidirecional. O Cognos Analyticsusa a estatística F para testar se os valores médios nas categorias explicativas são iguais. Se houverdiferenças significativas, o Cognos Analytics calculará o R-quadrado ajustado como a intensidadepreditiva do relacionamento entre o campo de resposta e o campo explicativo. O relacionamentoconfiável e sua intensidade preditiva são relatados para o usuário se a intensidade preditiva exceder10%.
Se a diferença entre as médias for significativa, o Cognos Analytics conduzirá um teste t de influênciapara detectar as categorias que são mais diferentes da média geral. Isso envolve o cálculo do erropadrão para cada média de categoria e a comparação da média com a média geral utilizando aestatística do teste t. Para categorias com diferenças significativas, o Cognos Analytics calcula
70 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

também o tamanho do efeito correspondente e relata as categorias com o maior tamanho de efeitonas diferenças significativas.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =médio
Contínuo
Exatamente 1
Categórico
N/D Opcional
Qualquer
N/D Média
Intensidadepreditiva
DiferençasSignificadas
Média por dois campos explicativos
Para os gráficos em que o nível de resumo para o campo de resposta é médio e há dois camposexplicativos categóricos disponíveis, o Cognos Analytics aplica a análise ANOVA bidirecional. OCognos Analytics usa a estatística F para testar se os valores médios nas combinações de categoriasexplicativas são iguais. Caso as diferenças sejam significativas, o Cognos Analytics calculará o R-quadrado ajustado como a intensidade preditiva do relacionamento entre o campo de resposta e osdois campos explicativos. O Cognos Analytics também calcula o R-quadrado ajustado para modelosunidirecionais que incluem um único campo explicativo cada. Se a intensidade preditiva de ummodelo bidirecional for superior a 10% e a melhoria de sua intensidade preditiva relativa sobre osmodelos unidirecionais correspondentes for superior a 10%, o Cognos Analytics exibirá a intensidadepreditiva do modelo bidirecional e relatará um relacionamento confiável entre o campo de resposta eos dois campos explicativos. Caso contrário, se a intensidade preditiva máxima de modelosunidirecionais exceder 10%, o Cognos Analytics relatará um relacionamento confiável entre aresposta e o campo explicativo único correspondente, juntamente com sua intensidade preditiva. Se aintensidade preditiva máxima de modelos unidirecionais não exceder 10%, o Cognos Analytics nãorelatará nenhum relacionamento entre os campos de resposta e explicativos.
Quando a diferença entre as médias em todas as combinações de categorias for significativa, oCognos Analytics também conduzirá um teste t de influência para detectar as combinações decategorias que são mais diferentes da média geral. Este teste é semelhante ao teste usado para umúnico campo explicativo. A principal diferença é que, em vez de considerar as categorias de um únicocampo explicativo, o Cognos Analytics considera combinações de categorias a partir de dois camposexplicativos. As combinações de categorias com o maior tamanho de efeito são relatadas nasdiferenças significativas.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =médio
Contínuo
Exatamente 2
CategóricoOpcional(tratar comoExplanatório)
Categórico
Opcional N/D Média
Intensidadepreditiva
DiferençasSignificadas
Soma por um ou dois campos explicativos
Para gráficos em que o nível de resumo para o campo de resposta é soma e há um ou dois camposexplicativos categóricos disponíveis, o Cognos Analytics aplica o teste de comparação de soma. Este
Capítulo 5. Principles of advanced data analytics 71
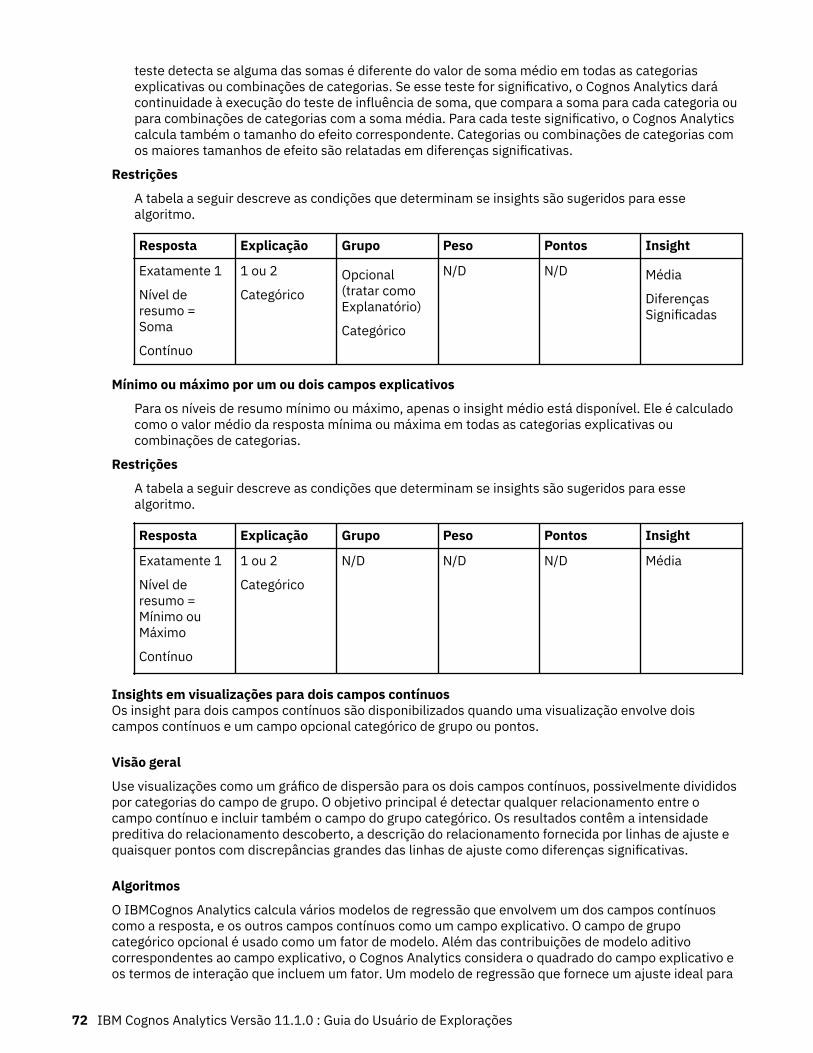
teste detecta se alguma das somas é diferente do valor de soma médio em todas as categoriasexplicativas ou combinações de categorias. Se esse teste for significativo, o Cognos Analytics darácontinuidade à execução do teste de influência de soma, que compara a soma para cada categoria oupara combinações de categorias com a soma média. Para cada teste significativo, o Cognos Analyticscalcula também o tamanho do efeito correspondente. Categorias ou combinações de categorias comos maiores tamanhos de efeito são relatadas em diferenças significativas.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =Soma
Contínuo
1 ou 2
CategóricoOpcional(tratar comoExplanatório)
Categórico
N/D N/D Média
DiferençasSignificadas
Mínimo ou máximo por um ou dois campos explicativos
Para os níveis de resumo mínimo ou máximo, apenas o insight médio está disponível. Ele é calculadocomo o valor médio da resposta mínima ou máxima em todas as categorias explicativas oucombinações de categorias.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =Mínimo ouMáximo
Contínuo
1 ou 2
Categórico
N/D N/D N/D Média
Insights em visualizações para dois campos contínuosOs insight para dois campos contínuos são disponibilizados quando uma visualização envolve doiscampos contínuos e um campo opcional categórico de grupo ou pontos.
Visão geral
Use visualizações como um gráfico de dispersão para os dois campos contínuos, possivelmente divididospor categorias do campo de grupo. O objetivo principal é detectar qualquer relacionamento entre ocampo contínuo e incluir também o campo do grupo categórico. Os resultados contêm a intensidadepreditiva do relacionamento descoberto, a descrição do relacionamento fornecida por linhas de ajuste equaisquer pontos com discrepâncias grandes das linhas de ajuste como diferenças significativas.
Algoritmos
O IBMCognos Analytics calcula vários modelos de regressão que envolvem um dos campos contínuoscomo a resposta, e os outros campos contínuos como um campo explicativo. O campo de grupocategórico opcional é usado como um fator de modelo. Além das contribuições de modelo aditivocorrespondentes ao campo explicativo, o Cognos Analytics considera o quadrado do campo explicativo eos termos de interação que incluem um fator. Um modelo de regressão que fornece um ajuste ideal para
72 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
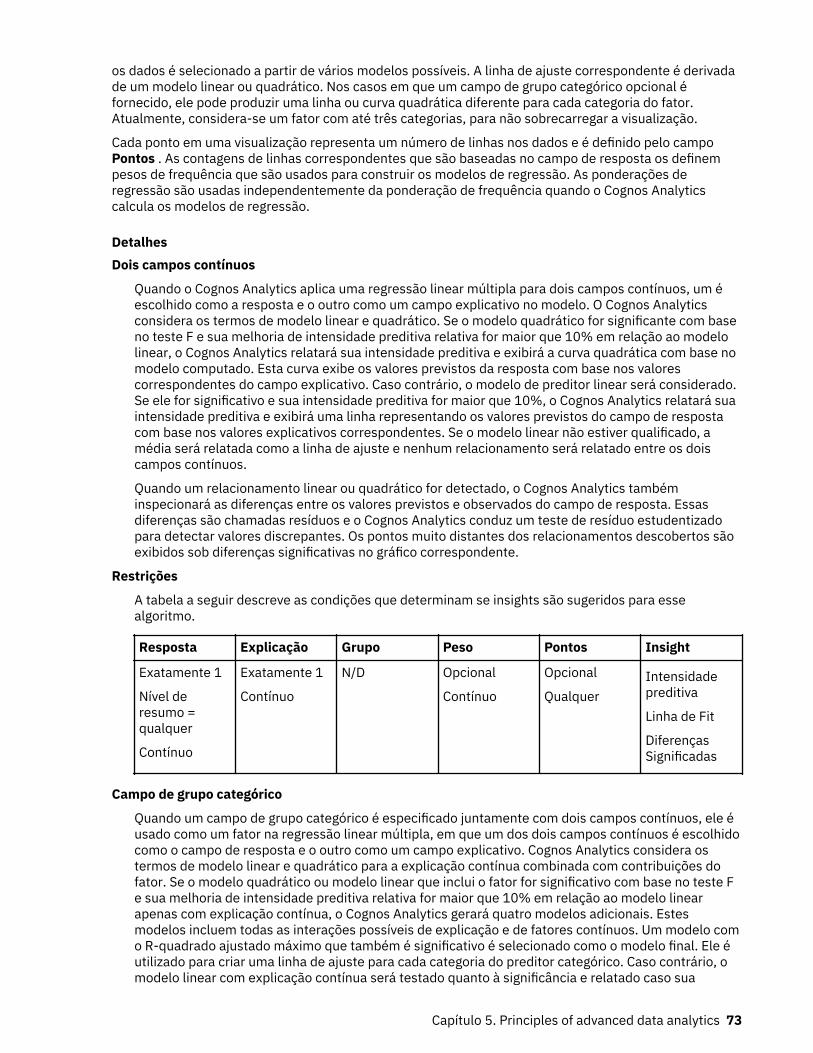
os dados é selecionado a partir de vários modelos possíveis. A linha de ajuste correspondente é derivadade um modelo linear ou quadrático. Nos casos em que um campo de grupo categórico opcional éfornecido, ele pode produzir uma linha ou curva quadrática diferente para cada categoria do fator.Atualmente, considera-se um fator com até três categorias, para não sobrecarregar a visualização.
Cada ponto em uma visualização representa um número de linhas nos dados e é definido pelo campoPontos . As contagens de linhas correspondentes que são baseadas no campo de resposta os definempesos de frequência que são usados para construir os modelos de regressão. As ponderações deregressão são usadas independentemente da ponderação de frequência quando o Cognos Analyticscalcula os modelos de regressão.
DetalhesDois campos contínuos
Quando o Cognos Analytics aplica uma regressão linear múltipla para dois campos contínuos, um éescolhido como a resposta e o outro como um campo explicativo no modelo. O Cognos Analyticsconsidera os termos de modelo linear e quadrático. Se o modelo quadrático for significante com baseno teste F e sua melhoria de intensidade preditiva relativa for maior que 10% em relação ao modelolinear, o Cognos Analytics relatará sua intensidade preditiva e exibirá a curva quadrática com base nomodelo computado. Esta curva exibe os valores previstos da resposta com base nos valorescorrespondentes do campo explicativo. Caso contrário, o modelo de preditor linear será considerado.Se ele for significativo e sua intensidade preditiva for maior que 10%, o Cognos Analytics relatará suaintensidade preditiva e exibirá uma linha representando os valores previstos do campo de respostacom base nos valores explicativos correspondentes. Se o modelo linear não estiver qualificado, amédia será relatada como a linha de ajuste e nenhum relacionamento será relatado entre os doiscampos contínuos.
Quando um relacionamento linear ou quadrático for detectado, o Cognos Analytics tambéminspecionará as diferenças entre os valores previstos e observados do campo de resposta. Essasdiferenças são chamadas resíduos e o Cognos Analytics conduz um teste de resíduo estudentizadopara detectar valores discrepantes. Os pontos muito distantes dos relacionamentos descobertos sãoexibidos sob diferenças significativas no gráfico correspondente.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =qualquer
Contínuo
Exatamente 1
Contínuo
N/D Opcional
Contínuo
Opcional
QualquerIntensidadepreditiva
Linha de Fit
DiferençasSignificadas
Campo de grupo categórico
Quando um campo de grupo categórico é especificado juntamente com dois campos contínuos, ele éusado como um fator na regressão linear múltipla, em que um dos dois campos contínuos é escolhidocomo o campo de resposta e o outro como um campo explicativo. Cognos Analytics considera ostermos de modelo linear e quadrático para a explicação contínua combinada com contribuições dofator. Se o modelo quadrático ou modelo linear que inclui o fator for significativo com base no teste Fe sua melhoria de intensidade preditiva relativa for maior que 10% em relação ao modelo linearapenas com explicação contínua, o Cognos Analytics gerará quatro modelos adicionais. Estesmodelos incluem todas as interações possíveis de explicação e de fatores contínuos. Um modelo como R-quadrado ajustado máximo que também é significativo é selecionado como o modelo final. Ele éutilizado para criar uma linha de ajuste para cada categoria do preditor categórico. Caso contrário, omodelo linear com explicação contínua será testado quanto à significância e relatado caso sua
Capítulo 5. Principles of advanced data analytics 73

intensidade preditiva seja superior a 10%. Se o modelo linear não for qualificado, nenhuma relaçãoconfiável entre os campos será estabelecida e a média geral será relatada como a linha de ajuste.
Quando um relacionamento confiável é detectado, o Cognos Analytics também verifica a diferençaentre os valores previstos e observados do campo de resposta. O Cognos Analytics conduz um testede resíduo estudentizado para detectar valores discrepantes e exibi-los em diferenças significativasno gráfico correspondente.
Restrições
A tabela a seguir descreve as condições que determinam se insights são sugeridos para essealgoritmo.
Resposta Explicação Grupo Peso Pontos Insight
Exatamente 1
Nível deresumo =qualquer
Contínuo
Exatamente 1
Contínuo
Exatamente 1
Categórico
Opcional
Qualquer
Opcional
QualquerIntensidadepreditiva
Linha de Fit
DiferençasSignificadas
Campo de pesos de regressão
Um campo contínuo opcional pode ser usado para especificar pesos de regressão para o modelo. Aponderação de regressão para um valor disponível corresponde à influência da observação nosparâmetros de modelo calculados.
Detalhes da língua naturalDetalhes da língua natural é um recurso de texto que aumenta as visualizações exibidas, fornecendo maisresumos. Os detalhes fornecem insights que são obtidos a partir de uma análise de dados adequada,relevante para você.
Visão geral
Esse recurso está disponível para as visualizações que são criadas em uma exploração e os detalhestextuais são exibidos na área de janela de detalhes correspondente. Com esse conhecimento, é possívelobter informações que são as mais relevantes para os dados visualizados em um formato de línguanatural. São mostrados também outros resumos e detalhes que não estão disponíveis na visualização.
Algoritmos
Os detalhes básicos fornecem resumos simples dos dados que não são vistos de imediato na visualizaçãoexibida. Embora seja possível obter essas informações especificando outras visualizações relacionadas,essas etapas de exploração tornam-se desnecessárias, porque os resumos relacionados sãodisponibilizados como detalhes textuais.
Os detalhes baseados nos insights contidos nas visualizações fornecem uma descrição de texto dasinformações que podem ser obtidas, através da caixa Insights na visualização exibida ou nasvisualizações relacionadas. Eles esclarecem melhor os insights exibidos e também permitem a inclusãode insights adicionais que não estão disponíveis na visualização exibida.
Detalhes
Os detalhes são baseados nos campos que são exibidos na visualização correspondente. A análiserelacionada pode desenhar resumos adicionais, mas não inclui nenhum campo não especificado navisualização. Os resumos e detalhes são convertidos em um texto traduzível utilizando modelos, em vezde por meio de um recurso completo de geração de língua natural. Isso resulta em algumas repetições delinguagem no texto renderizado, mas não diminui a quantidade ou a qualidade das informações exibidas.
74 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Detalhes básicos da língua naturalOs detalhes básicos da língua natural fornecem resumos adicionais dos dados que são exibidos navisualização ou destacam as informações disponíveis com detalhes adicionais.
Visão geral
Essas informações fornecem uma visualização mais precisa dos dados e ainda são relevantes para osresumos exibidos que estão sendo considerados. Alterar o nível de resumo que é especificado para ocampo de resposta também altera alguns ou todos os detalhes básicos, uma vez que o foco davisualização foi alterado. Informações adicionais são fornecidas no contexto da tarefa principal.
Algoritmos
Os detalhes básicos calculados dependem do nível de resumo que é especificado para o campo deresposta na visualização correspondente. Os níveis de resumo de resposta possíveis são contagensdistintas e contagens para qualquer campo e soma, média, mínimo e máximo para campos numéricos.Embora detalhes baseados em contagem sejam usados para a maioria dos níveis de resumo de resposta,resumos adicionais correspondentes são fornecidos com os níveis de resumo de resposta soma, média,mínimo e máximo. Os mesmos resumos baseados em contagens são gerados para os níveis de resumo deresposta de contagem e contagem distinta.
DetalhesContagem geral
A contagem geral é exibida para a resposta e para qualquer campo explicativo na visualização. Acontagem não inclui os valores omissos da resposta e é calculada, exceto se o nível de resumo para aresposta for soma ou média. Todos os campos categóricos especificados na visualização são tratadoscomo campos explicativos para fins de detalhes.
Contagem para campos explicativos
A contagem também é calculada para cada categoria de campo explicativo exibido, exceto se o nívelde resumo para a resposta for soma. O algoritmo seleciona e relata as principais categorias,contagens correspondentes e porcentagens de contagens em relação à contagem geral para o campoexplicativo. Este procedimento é aplicado a cada campo explicativo no gráfico.
Soma
Quando o nível de resumo exibido para um campo de resposta numérico é soma, o IBMCognosAnalytics resume a soma total correspondente para o campo de resposta. Caso a visualizaçãocontenha vários campos categóricos explicativos, a soma será calculada para cada categoria e cadacampo explicativo. O algoritmo seleciona e relata as principais categorias, somas correspondentes eporcentagens de soma em relação à soma total para cada campo explicativo.
Média
Quando o nível de resumo exibido para um campo de resposta numérico é média, o Cognos Analyticsresume a média geral correspondente para o campo de resposta.
Intervalo
Os resumos de intervalo são obtidos pelos valores mínimo e máximo quando o nível de resumo somaou média é calculado para um campo de resposta numérico nas categorias de combinação de camposexplicativos especificados. Se apenas um único campo explicativo for especificado, serão exibidastambém as categorias nas quais ocorrem mínimos e máximos.
Mínimo e máximo
Quando o nível de resumo exibido é um valor mínimo ou máximo para um campo de respostanumérico, o Cognos Analytics exibe o valor mínimo ou máximo correspondente em todas ascategorias de um campo categórico explicativo. Se vários campos categóricos explicativos foremespecificados, o valor mínimo ou máximo será calculado em todas as combinações de categoriaspossíveis.
Capítulo 5. Principles of advanced data analytics 75

Detalhes básicos da língua natural em insightsOs detalhes que são baseados em insights fornecem uma descrição de texto das informações que podemser obtidas, através da caixa de diálogo Insights na visualização.
Visão geral
Os detalhes baseados em insights também fornecem informações de visualizações relacionadas que sãoinformativas e facilmente compreendidas no contexto do gráfico atual. Isso permite a obtenção dedetalhes mais abrangentes, relacionados à visualização atual.
Algoritmos
Os detalhes que são baseados em insights usam diretamente o escopo completo de cálculos e testesestatísticos que são suportados pelo insights. Os detalhes também obtêm os resultados paravisualizações relacionadas e os compilam juntos em uma mensagem significativa. Esses detalhestambém fornecem algumas análises adicionais com base na saída do insights, produzindo detalhesadicionais adequados para a saída textual.
DetalhesCampo explicativo único
Com base em um campo de resposta e um campo explicativo categórico, os detalhes usam insightspara detectar o relacionamento entre a resposta e o campo explicativo. A análise é aplicada se o nívelde resumo de resposta for médio ou a contagem e a intensidade preditiva forem relatadas, caso umrelacionamento relevante seja descoberto.
Se o campo explicativo for numérico e os insights gerarem uma linha de ajuste, o IBMCognosAnalytics relatará uma inclinação positiva ou negativa para ajuste linear e apontará caso umrelacionamento quadrático seja detectado. Se o relacionamento for quadrático, o Cognos Analyticstambém relatará o ponto extremo. O Cognos Analytics calcula o valor mínimo ou máximo da respostae o valor explicativo em que a resposta extrema ocorre.
Dois campos explicativos
Quando houver dois campos explicativos disponíveis, o Cognos Analytics detectará o relacionamentoentre a resposta e ambos os campos explicativos e o relacionamento entre a resposta e cada campoexplicativo separadamente. Se a intensidade preditiva para o relacionamento com ambos os camposexplicativos fornecer uma melhoria relativa superior a 10% em relação a cada relacionamentoseparado, o Cognos Analytics relatará que a resposta é afetada por ambos os campos explicativos.Caso contrário, ela será afetada por um único campo explicativo ou por cada campo explicativoseparadamente, mas não juntos.
Diferenças Significadas
Os detalhes relatam todas as diferenças significativas descobertas pelos insights para os dadosutilizados quando o nível de resumo de resposta for contagem, média ou soma. Elas são relatadasseparadamente para as categorias de cada campo explicativo, bem como para as combinações decategorias de dois campos explicativos. São fornecidas também indicações caso os valores sejamexcepcionalmente altos ou baixos.
Árvores de decisão
Os detalhes relatam a força preditiva de uma árvore de decisão e uma lista de campos de preditor quesão usados para dividir os nós da árvore. Um campo de preditor com a maior importância variável esua melhoria de proporção da importância variável em relação aos outros campos nas árvores dedecisão são relatados caso a proporção seja maior que dois. Um detalhe semelhante pode ser exibidopara um campo com a menor importância variável.
Detalhes da língua natural para séries temporaisOs detalhes para séries temporais fornecem insights de texto com base na análise dos dados de sériestemporais e dos modelos de previsão correspondentes.
76 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Visão geral
O IBMCognos Analytics relata detalhes para séries temporais para uma visualização que é criada em umaexploração sempre que os dados de visualização contêm uma única série temporal e sempre que ummodelo de previsão é calculado. Se os dados forem adequados, os insights de séries temporais serãogerados, mesmo se a caixa de diálogo Previsão não estiver presente na visualização. Quando a caixa dediálogo Previsão está presente, ela produz o mesmo modelo padrão na ativação que os insights de sériestemporais. Os pontos de séries temporais são classificados automaticamente em ordem cronológica parapropósitos de detecção de insights, mas, ao contrário do recurso de previsão, os pontos de tempo quesão exibidos na visualização não são classificados.
Algoritmos
Os detalhes para séries temporais são baseados em um modelo de suavização exponencial para os dadosde séries temporais observados. Os valores de séries temporais observados e os componentes demodelo calculado são usados para criar insights para as séries temporais: valores incomuns, efeitossazonais e insight de tendência. Cada tipo de insight depende de uma combinação diferente de dados ede componentes de modelo de suavização exponencial correspondentes.
Detalhes
Valores incomuns
Um modelo de suavização exponencial fornece um valor predito para cada ponto de tempo observado.Um valor predito em um ponto de tempo é a previsão de um passo à frente no ponto de tempo anterior.Um intervalo de confiança para cada valor predito é calculado, que usa a variância de valor preditocorrespondente que depende do modelo. Um valor de série temporal observado que é localizado fora dointervalo de confiança para o valor predito correspondente com base no modelo é considerado um valorincomum.
Valores incomuns são detectados com base no modelo de suavização exponencial selecionado para asérie temporal. O nível de confiança que é usado para o cálculo dos intervalos de confiança da predição éde 99,74%. Até cinco valores incomuns são relatados listando os pontos de tempo correspondentes. OCognos Analytics não lista os pontos em ordem cronológica, mas sim em ordem decrescente de distânciaa partir do intervalo de confiança. Mais pontos incomuns são listados em primeiro lugar. Os valoresincomuns são especificados como anormalmente altos ou anormalmente baixos quando possível.
Um valor incomum que é detectado no último ponto de tempo é relatado separadamente. Isso podeindicar que os dados estão incompletos. Por exemplo, um valor resumido para o último mês pode refletirdados diários somente da última quinzena do mês.
Efeitos sazonais
O insight efeitos sazonais revela o comprimento sazonal para uma série temporal que é identificado pelomodelo. O comprimento sazonal corresponde a uma duração fixa de um padrão sazonal estabelecido nasérie temporal. Por exemplo, a variação de temperatura média durante 12 meses estabelece um padrãoanual. Esse insight também fornece a intensidade dos efeitos sazonais e relata períodos com os maiorese os menores valores sazonais.
O comprimento sazonal é obtido a partir do modelo selecionado. Ele é derivado do período sazonal e dointervalo de data ou hora que é relatado nos detalhes estatísticos de previsão. Um modelo sazonal éselecionado apenas quando ele fornece um ajuste superior a todos os modelos não sazonais. O períodosazonal para o modelo sazonal selecionado é obtido por meio da comparação de modelos com múltiplosperíodos sazonais candidatos.
Os efeitos sazonais são relatados como fracos, moderados ou fortes, dependendo do valor da intensidadecalculado. A intensidade dos efeitos sazonais é calculada como uma redução no erro de modelo pelomodelo sazonal em comparação com o modelo não sazonal correspondente e dividida pelo erro demodelo não sazonal. Isso é diferente da intensidade de sazonalidade relatada nos detalhes estatísticosde previsão em que a diferença de precisão entre os dois modelos é relatada.
Os maiores e menores valores sazonais são calculados com base nas médias de componentes do modelosazonal subjacente em todos os padrões sazonais nas séries temporais. Os períodos correspondentes
Capítulo 5. Principles of advanced data analytics 77

serão relatados se os valores médios forem consistentemente os maiores ou os menores, sobre a maioriados padrões sazonais.
Tendência
O insight de tendência relata uma direção positiva ou negativa geral dos valores de séries temporais,quando presente. Também relata a intensidade da tendência.
Ambos os componentes de nível e tendência são extraídos do modelo de suavização exponencialcorrespondente. Apenas o componente de nível será usado se o modelo não tiver nenhum componentede tendência. Isso define uma curva de tendência para os dados de séries temporais. A medida tau deassociação de Kendall e o teste estatístico correspondente são, então, calculados para a curva detendência. Eles detectam uma direção positiva ou negativa geral dos valores de séries temporais.Intervalos de valores tau diferentes definem o grau de intensidade relatado para a tendência: fraco,moderado ou forte.
Para obter mais informações sobre modelos de suavização exponencial, consulte “Modelos de previsão”na página 55.
RelacionamentosAs visualizações de relacionamentos em uma exploração são inicialmente exibidas ao especificar dadospara exploração.
Visão geral
O IBMCognos Analytics fornece uma visão geral rápida dos relacionamentos entre pares de campos quese concentram em um único campo de interesse. A visualização inclui várias guias, cada uma para umcampo de interesse diferente. Essas informações são muito úteis para fornecer orientação a respeito dediversos relacionamentos relevantes disponíveis nos dados, que podem passar por exploraçõesadicionais, caso necessário.
Algoritmos
Embora o campo de interesse inicial seja determinado com base na análise de dados semânticos, épossível especificar um campo de interesse diferente. Cada guia fornece um gráfico de rede com camposcomo nós e links entre pares de nós que representam a intensidade relativa do relacionamento entre osnós. Embora os links do campo de interesse predominem no gráfico, são exibidos também outros paresde campos associados e que têm relacionamentos fortes. É possível ajustar uma régua de controle paravisualizar um número maior ou menor de nós na rede.
DetalhesDados para análise
Os relacionamentos usam dados não resumidos para calcular a intensidade do relacionamento entretodos os pares de campos considerados. Para padronizar a medida da intensidade do relacionamentoe torná-la comparável em todos os pares de campos, todos os campos numéricos são categorizadoscomo na primeira etapa. Todos os campos nos dados são tratados como categóricos. A categorizaçãoaplicada é a categorização de frequência igual, que gera cinco categorias. Há mais detalhesdisponíveis na seção sobre preparação de dados para campos numéricos.
Intensidade do relacionamento
Os dados para cada par de campos categóricos são primeiro tabulados para todas as combinações decategorias de campos localizadas nos dados. Com base nos dados tabulados, o IBMCognos Analyticsaplica o teste qui-quadrado de independência para avaliar se os campos são independentes. Se apartida de independência for significativa, o Cognos Analytics calcula o tamanho do efeito com basena estatística qui-quadrado. Este é o V de Cramer, que é amplamente utilizado como uma medida deassociação entre dois campos categóricos. Os valores dessa medida estão no intervalo de 0 a 1 e oCognos Analytics relata o valor da intensidade do relacionamento, que é expresso como uma
78 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
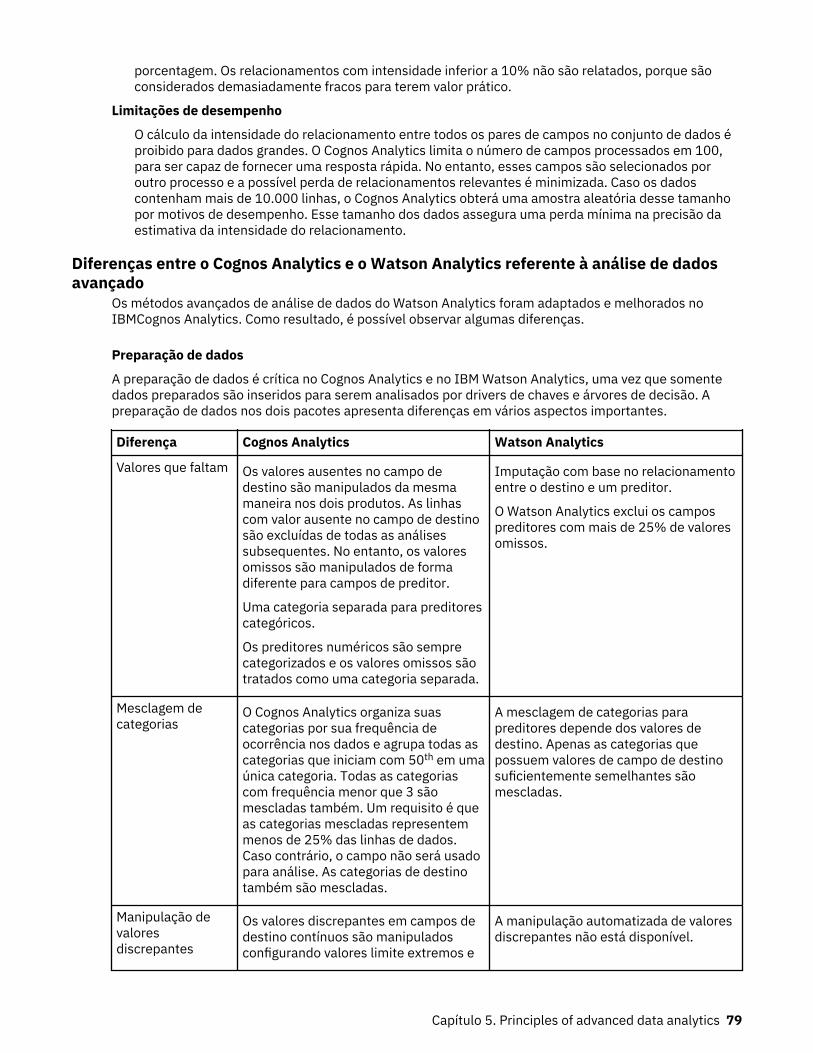
porcentagem. Os relacionamentos com intensidade inferior a 10% não são relatados, porque sãoconsiderados demasiadamente fracos para terem valor prático.
Limitações de desempenho
O cálculo da intensidade do relacionamento entre todos os pares de campos no conjunto de dados éproibido para dados grandes. O Cognos Analytics limita o número de campos processados em 100,para ser capaz de fornecer uma resposta rápida. No entanto, esses campos são selecionados poroutro processo e a possível perda de relacionamentos relevantes é minimizada. Caso os dadoscontenham mais de 10.000 linhas, o Cognos Analytics obterá uma amostra aleatória desse tamanhopor motivos de desempenho. Esse tamanho dos dados assegura uma perda mínima na precisão daestimativa da intensidade do relacionamento.
Diferenças entre o Cognos Analytics e o Watson Analytics referente à análise de dadosavançado
Os métodos avançados de análise de dados do Watson Analytics foram adaptados e melhorados noIBMCognos Analytics. Como resultado, é possível observar algumas diferenças.
Preparação de dados
A preparação de dados é crítica no Cognos Analytics e no IBM Watson Analytics, uma vez que somentedados preparados são inseridos para serem analisados por drivers de chaves e árvores de decisão. Apreparação de dados nos dois pacotes apresenta diferenças em vários aspectos importantes.
Diferença Cognos Analytics Watson Analytics
Valores que faltam Os valores ausentes no campo dedestino são manipulados da mesmamaneira nos dois produtos. As linhascom valor ausente no campo de destinosão excluídas de todas as análisessubsequentes. No entanto, os valoresomissos são manipulados de formadiferente para campos de preditor.
Uma categoria separada para preditorescategóricos.
Os preditores numéricos são semprecategorizados e os valores omissos sãotratados como uma categoria separada.
Imputação com base no relacionamentoentre o destino e um preditor.
O Watson Analytics exclui os campospreditores com mais de 25% de valoresomissos.
Mesclagem decategorias
O Cognos Analytics organiza suascategorias por sua frequência deocorrência nos dados e agrupa todas ascategorias que iniciam com 50th em umaúnica categoria. Todas as categoriascom frequência menor que 3 sãomescladas também. Um requisito é queas categorias mescladas representemmenos de 25% das linhas de dados.Caso contrário, o campo não será usadopara análise. As categorias de destinotambém são mescladas.
A mesclagem de categorias parapreditores depende dos valores dedestino. Apenas as categorias quepossuem valores de campo de destinosuficientemente semelhantes sãomescladas.
Manipulação devaloresdiscrepantes
Os valores discrepantes em campos dedestino contínuos são manipuladosconfigurando valores limite extremos e
A manipulação automatizada de valoresdiscrepantes não está disponível.
Capítulo 5. Principles of advanced data analytics 79

Diferença Cognos Analytics Watson Analytics
substituindo os valores que estão alémdos limites pelos valores limitecorrespondentes para fins de análise.Isso aprimora a análise dos drivers dechaves e das árvores de decisão, poisfacilita a detecção de quaisquerrelacionamentos com o destino. Osvalores discrepantes manipulados napreparação de dados preditivos não sãorelatados na visualização.
Amostragem O Cognos Analytics analisa amostras dedados que contêm cerca de 10.000linhas, caso os dados originais excedamesse tamanho. Um aviso é exibidosempre que a análise correspondente éfeita em uma amostra de dados, mas aintensidade preditiva dos drivers dechaves e das árvores de decisão geradosdeve ficar próxima da intensidadepreditiva dos modelos obtidos a partirdos dados completos correspondentes.
O Watson Analytics usa conjuntocompleto de linhas nos dados para gerardrivers de chaves e árvores de decisão.Isso pode causar um desempenho lento.
Drivers principais
Diferença Cognos Analytics Watson Analytics
Drivers principais O Cognos Analytics oferece driversprincipais para as variáveis respostascontínuas e categóricas na visualizaçãoem espiral e de análise de driver.
Embora as etapas de preparação dedados afetem os drivers de chavesunidirecionais e bidirecionais, a análisedo Cognos Analytics para drivers dechaves bidirecionais é diferente da doWatson Analytics, devido aos critériosusados para a seleção dos drivers aserem exibidos para o usuário.
Os drivers principais para os destinoscategóricos e contínuos estãodisponíveis em uma visualização emespiral.
Testes estatísticos Para destinos categóricos, o CognosAnalytics usa o teste qui-quadrado deindependência para determinar se doiscampos categóricos são independentes.
O Watson Analytics usa teste de razãode verossimilhança para variáveisrespostas categóricas.
Critério de seleção O Cognos Analytics requer que aintensidade preditiva do driver de chavebidirecional forneça uma melhoriarelativa superior a 10% quandocomparada à intensidade preditiva dosdrivers unidirecionais correspondentes.A melhoria relativa da intensidadepreditiva é medida pela porcentagem deredução do valor de erro do driver dechave bidirecional em relação ao valor
O Watson Analytics usa a interação dedois fatores como um critério de seleçãopara os drivers de chaves bidirecionais.Um driver principal bidirecional precisater um tamanho de efeito de interaçãomaior do que um determinado limitepara ser selecionado.
80 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Diferença Cognos Analytics Watson Analytics
de erro mínimo para os dois drivers dechaves unidirecionais correspondentes.Esse critério assegura que somente osdrivers bidirecionais relevantes fiquemvisíveis.
Intensidadepreditiva
A intensidade preditiva da espiral e daanálise do driver com uma variávelresposta contínua é calculada como R-quadrado ajustado.
A intensidade preditiva da variávelresposta categórica é calculada como oR-quadrado de contagem ajustada. Ela éobtida calculando a melhoria deprecisão de classificação do modelosobre o modelo constante e dividindo-apelo erro de classificação do modeloconstante. O modelo constante sempreprevê o modo de destino e sua precisãode classificação é estimada pelafrequência de modo. O relacionamentopreditivo confiável é relatado quando aintensidade preditiva do modelo é maiorque um limite padrão de 10%.
Como resultado, a intensidade preditivade uma visualização em espiral comuma variável resposta categórica podeser diferente no Watson Analytics e noCognos Analytics, mesmo para destino eentradas comparáveis.
A intensidade preditiva da variávelresposta contínua é calculada como R-quadrado.
A intensidade preditiva da variávelresposta categórica é calculada como aprecisão de classificação.
Árvore de decisão
Diferença Cognos Analytics Watson Analytics
Árvore de decisão Além da árvore e das visualizações deregras de decisões, o Cognos Analyticsfornece uma nova visualização sunburst.As diferenças na geração de uma árvorede decisão no Cognos Analytics ou noWatson Analytics dependem da variávelresposta contínua ou categórica. Aintensidade preditiva das árvores dedecisão é exibida na visualização emespiral e na de análise de driver noCognos Analytics , mas apenas quando émaior que a intensidade preditiva dodriver principal superior.
As visualizações de árvore de decisão ede regras de decisão estão disponíveis.A intensidade preditiva da árvore estásempre disponível na visualização emespiral.
Variável respostacontínua
As árvores de decisão para uma variávelresposta contínua são geradas com basena soma dos quadrados no WatsonAnalytics e no Cognos Analytics .
O Watson Analytics usa o algoritmoCHAID e os testes F correspondentes aomesclar e dividir os nós da árvore. Issofornece separações diversas para nós deárvore de decisão.
Capítulo 5. Principles of advanced data analytics 81

Diferença Cognos Analytics Watson Analytics
Cognos Analytics O usa diretamente oganho informativo relacionado aotamanho do efeito do teste F no WatsonAnalytics ao mesclar e separar os nós deárvores. Isso fornece separaçõesdiversas para nós de árvore de decisão.
Regras de parada O Cognos Analytics limita o número denós da árvore a 36.
O número mínimo de linhascorrespondentes aos nós da árvore é 25.
Os campos sem contribuição deintensidade preditiva são removidos dasárvores Cognos Analytics do. CognosAnalytics O produz árvores menores eque são mais adequadas paravisualização e obtenção de insights emcomparação às árvores geradas peloWatson Analytics, cuja precisão às vezesé mais alta.
O Watson Analytics limita o tamanho daárvore limitando o número de níveis deárvore para 5.
O número mínimo de linhascorrespondentes aos nós da árvore é 50.
As árvores no Watson Analytics tendema ser mais precisas apenas quandocontêm um número muito maior de nós.
Importância davariável
A importância variável é calculada comoa melhoria relativa na intensidadepreditiva quando a variável é incluída naárvore de decisão. Os preditores comuma importância de variável igual ouinferior a um limite são excluídos daárvore de decisão. O limite éconfigurado como zero para a maioriadas árvores. O limite é ligeiramenteaumentado para árvores baseadas emum número menor de linhas de dados eque têm intensidade preditiva menor,para reduzir os possíveis efeitos desuper ajuste.
A importância variável é calculada combase na sensibilidade dos resultadosquando a variável usa valoresdiferentes.
Intensidadepreditiva
A intensidade preditiva das árvores dedecisão com variáveis respostascontínuas é calculada como R-quadrado.
A intensidade preditiva da variávelresposta categórica é calculada como oR-quadrado de contagem ajustada.
O R-quadrado da contagem ajustadosubtrai o erro de classificação da árvoredo erro de classificação básico, que éobtido ao selecionar sempre a categoriade destino mais frequente, e divide oresultado pelo erro de classificaçãobásico. Ele representa a melhoriarelativa alcançada pela árvore dedecisão. Como resultado, a intensidadepreditiva das árvores de decisão com
A intensidade preditiva das árvores dedecisão com variáveis respostascontínuas é calculada como R-quadrado.
A intensidade preditiva da variávelresposta categórica é calculada como aprecisão de classificação.
82 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações
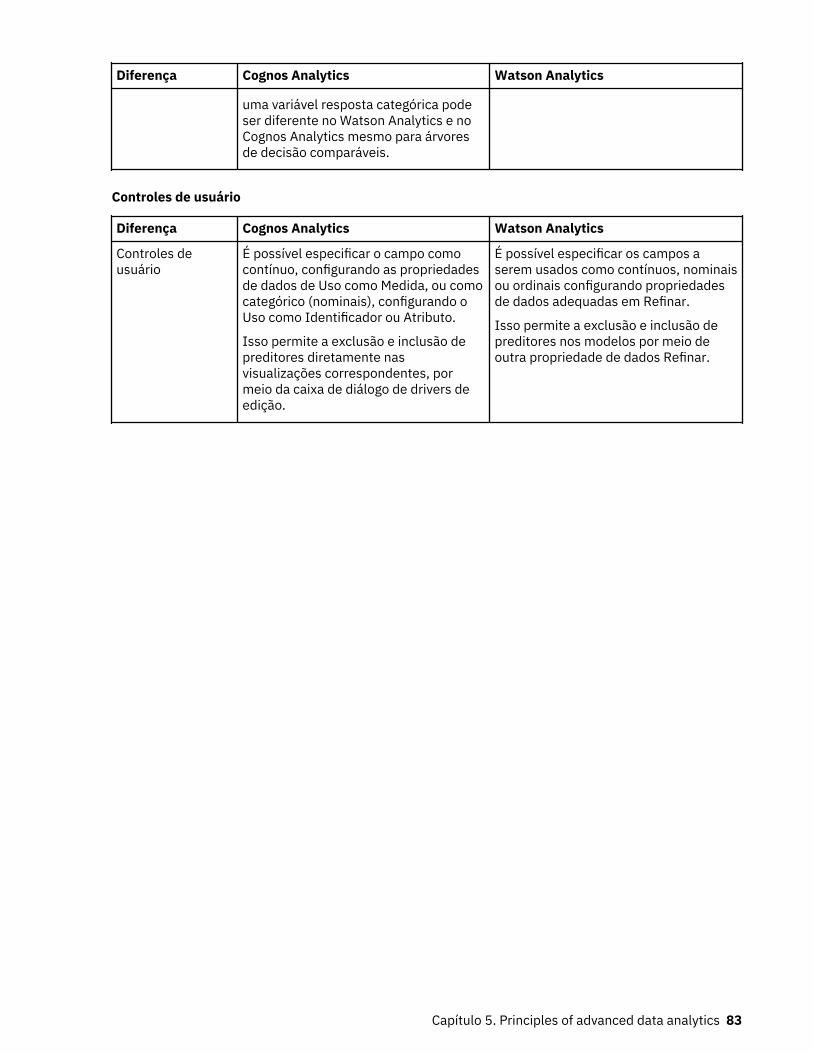
Diferença Cognos Analytics Watson Analytics
uma variável resposta categórica podeser diferente no Watson Analytics e noCognos Analytics mesmo para árvoresde decisão comparáveis.
Controles de usuário
Diferença Cognos Analytics Watson Analytics
Controles deusuário
É possível especificar o campo comocontínuo, configurando as propriedadesde dados de Uso como Medida, ou comocategórico (nominais), configurando oUso como Identificador ou Atributo.
Isso permite a exclusão e inclusão depreditores diretamente nasvisualizações correspondentes, pormeio da caixa de diálogo de drivers deedição.
É possível especificar os campos aserem usados como contínuos, nominaisou ordinais configurando propriedadesde dados adequadas em Refinar.
Isso permite a exclusão e inclusão depreditores nos modelos por meio deoutra propriedade de dados Refinar.
Capítulo 5. Principles of advanced data analytics 83

84 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

Capítulo 6. Assistant
AssistenteO IBM Cognos Analytics inclui um assistente integrado que suporta entrada baseada em texto para ajudá-lo a obter insights rápidos em seus dados e simplificar sua análise de dados. Em apenas algumas etapas,é possível acessar origens de dados-chave, criar visualizações e arrastá-las para sua tela Exploração ouPainel. A entrada de texto é suportada somente em inglês.
É possível usar duas interfaces:
1. Painel de assistente completo2. Painel de assistente compacto
Painel de assistente completo
O painel de assistente completo é composto de três seções: barra de ferramentas, saída e campo deentrada. É possível executar ações na barra de ferramentas, como reconfigurar seu histórico. A saída éexibida em uma área rolável que inclui todas as respostas anteriores. O campo de entrada, chamadoFazer uma pergunta, por padrão, permite a inserção de entrada de conversa baseada em texto.
Abra a visualização do painel completo clicando no ícone Assistente . Se estiver usando o painelcompacto, apenas na Exploração, é possível alternar para o painel completo clicando em Abrir navisualização completa.
Painel de assistente compacto
O painel compacto está disponível apenas na interface de Exploração. É possível abrir o painel compactoclicando em Fazer uma pergunta na área do painel compacto.
O painel compacto mostra apenas a última entrada e a resposta. Para visualizar o histórico completo,
clique no link Abrir na visualização completa no painel compacto ou no ícone Assistente .
No campo Fazer uma pergunta, é possível clicar na seta para cima do teclado ou na seta para baixo paraver uma lista de comandos recomendados. À medida que você insere texto, um recurso de digitaçãoantecipada oferece sugestões sobre o que você pode perguntar. Essa é uma ótima maneira de formularperguntas adequadas e digitar menos.
Para repetir sua última pergunta, clique na bolha de resposta ou use o atalho de teclado (Shift + seta paracima) e, em seguida, pressione Enter. É possível rolar nas perguntas anteriores pressionando Shift + setaspara cima/para baixo.
As visualizações que aparecem no painel Assistente são condensadas e podem excluir algumasinformações. É possível visualizar os detalhes completos da visualização em Explorar ou Painel. NoAssistente, é possível arrastar visualizações para uma tela Exploração ou Painel.
© Copyright IBM Corp. 2018, 2020 85
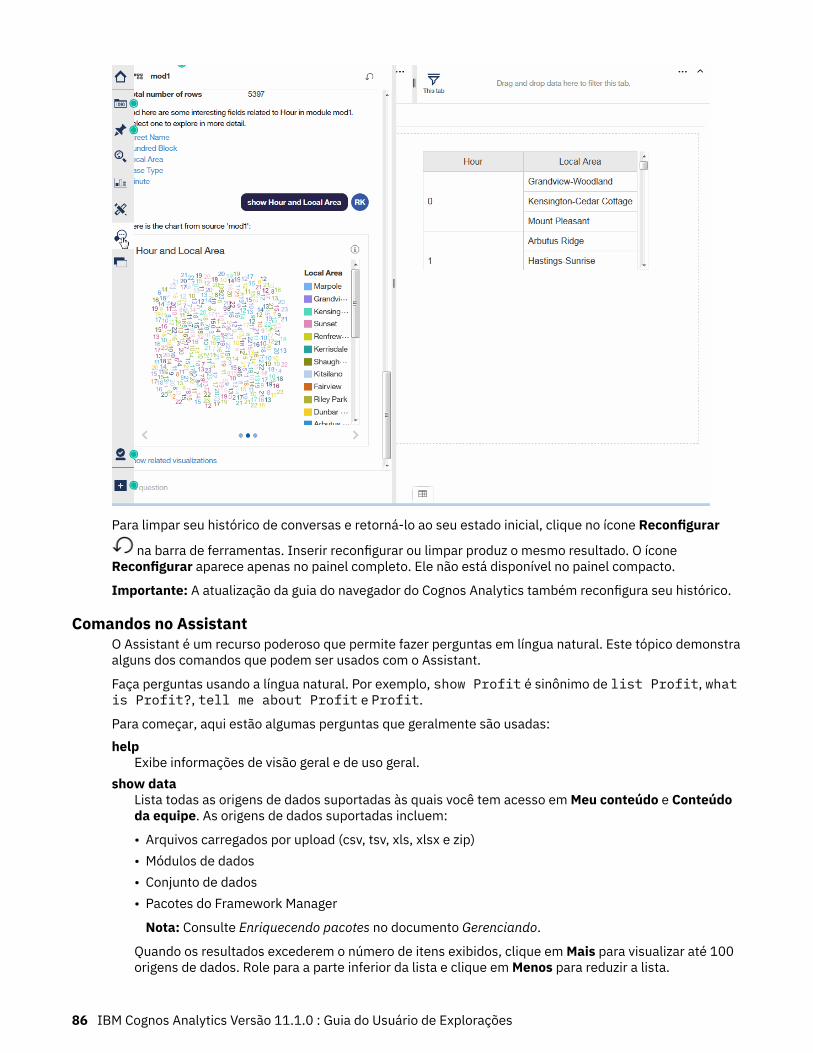
Para limpar seu histórico de conversas e retorná-lo ao seu estado inicial, clique no ícone Reconfigurar
na barra de ferramentas. Inserir reconfigurar ou limpar produz o mesmo resultado. O íconeReconfigurar aparece apenas no painel completo. Ele não está disponível no painel compacto.
Importante: A atualização da guia do navegador do Cognos Analytics também reconfigura seu histórico.
Comandos no AssistantO Assistant é um recurso poderoso que permite fazer perguntas em língua natural. Este tópico demonstraalguns dos comandos que podem ser usados com o Assistant.
Faça perguntas usando a língua natural. Por exemplo, show Profit é sinônimo de list Profit, whatis Profit?, tell me about Profit e Profit.
Para começar, aqui estão algumas perguntas que geralmente são usadas:help
Exibe informações de visão geral e de uso geral.show data
Lista todas as origens de dados suportadas às quais você tem acesso em Meu conteúdo e Conteúdoda equipe. As origens de dados suportadas incluem:
• Arquivos carregados por upload (csv, tsv, xls, xlsx e zip)• Módulos de dados• Conjunto de dados• Pacotes do Framework Manager
Nota: Consulte Enriquecendo pacotes no documento Gerenciando.
Quando os resultados excederem o número de itens exibidos, clique em Mais para visualizar até 100origens de dados. Role para a parte inferior da lista e clique em Menos para reduzir a lista.
86 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações

show source <source-name>
Exibe uma lista de campos e detalhes relevantes para a origem de dados especificada. A barra deferramentas exibe o <source-name> que está no contexto. Por padrão, o Cognos Analytics usa aorigem ativa no painel ou no painel de exploração. A partir dos resultados, é possível clicar nos nomesde campo para obter mais informações sobre esses campos específicos. Clicar em nomes de campo éequivalente a perguntar show column <column-name>.
Quando os resultados excederem o número de itens exibidos, clique em Mais para visualizar até 100origens de dados. Role para a parte inferior da lista e clique em Menos para reduzir a lista.
show column <column-name>Para a coluna especificada, as informações e os campos relacionados são exibidos. Clicar nos camposrelacionados é equivalente a perguntar show chart <column1> and <column2>. Se for determinadoque a coluna especificada tem influenciadores, será possível inserir what influences <column-name>para ver sua lista de influenciadores.
what influences column <column-name>Exibe uma lista de campos que influenciam os resultados na coluna especificada.
show chart <column1> and <column2>Exibe visualizações que mostram o relacionamento entre a <column1> e a <column2>. Role pelasvisualizações clicando nas setas à esquerda e à direita. Cada visualização inclui um ícone deinformações no canto superior direito. Passe o mouse sobre o ícone para ver descrições sobre osdados subjacentes. Opcionalmente, é possível inserir mais colunas, porém colunas excessivas podemresultar em visualizações menos efetivas.
Clicar em Show related visualizations retorna visualizações com base em campos influentese relacionados.
Clicar em Create dashboard from the charts cria um novo painel com base nos gráficosgerados mais recentemente. Digitar Create related dashboard produz o mesmo painelresultante. Se os gráficos contiverem agregações superiores ou inferiores, estes modificadores serãoaplicados no painel gerado.
A aplicação de agregações e filtros pode ajudar a incluir foco e a criar visualizações maisconvincentes. As agregações comuns incluem total, média, contagem, máximo/mínimo, superior/inferior, melhor/pior, e assim por diante. Aqui estão alguns exemplos de agregação:show top <num> <column1> by <column2>
Exibe os valores superiores de <column1> com base no contexto de <column2>. Por exemplo,show top 5 Sales by Region. Se <num> não for especificado, um valor padrão igual a 10será usado.
<column1> é uma medida agregada ou não agregada, enquanto <column2> é uma colunacategórica.
show average <column-name>Exibe a média entre todos os valores localizados em <column-name>.
how many <column-name>Se <column-name> for uma categoria, o número de itens distintos será retornado. Se <column-name> for uma medida, a soma total será retornada.
show maximum <column-name>Exibe o valor mais alto localizado em <column-name>.
show minimum <column-name>Exibe o valor mais baixo localizado em <column-name>.
show total <column-name>Exibe a soma total de todos os valores localizados em <column-name>.
É possível incluir filtros para sequências geográficas (como Country ou State) ou sequênciastemporais (como Month ou Year). A filtragem por data não é suportada, neste momento. Agregaçõese filtros podem ser combinados para produzir resultados mais granulares. Aqui estão algunsexemplos, com base em dados de amostra:
Capítulo 6. Assistant 87

• show Education by Income where Income is less than 1000• show Education by Income where Income > 100K
Optionally use K (to denote thousands) or M (to denote millions).• show Revenue in 2017 and 2018• show Income by Month for New York City• what are the top 5 States by average Inventory, excluding California
As visualizações filtradas incluem um ícone de filtro ( ), localizado no canto superior direito dográfico. Passe o mouse sobre o ícone para exibir a filtragem aplicada.
create dashboardGera um novo painel com base na origem de dados selecionada atualmente. É possível modificar asvisualizações, as guias, a ordem, etc. e salvar o novo painel. Por padrão, o painel gerado incluiráanalítica avançada e gráficos preditivos.
Gerar painéis automaticamente para origens de dados maiores pode resultar em problemas dedesempenho. Para contornar isso, é possível inserir create simple dashboard para gerar umpainel básico. Em seguida, é possível modificar o painel substituindo os gráficos por visualizaçõesmais sofisticadas, como análise de driver ou gráficos em espiral.
88 IBM Cognos Analytics Versão 11.1.0 : Guia do Usuário de Explorações


IBM®


















