
Um Método Automático de Teste Funcional para a Verificação...
144
Um Método Automático de Teste Funcional para a Verificação de Componentes Daniel Lima Barbosa Dissertação submetida à Coordenação do Curso de Pós-Graduação em Informática da Universidade Federal de Campina Grande – Campus I como parte dos requisitos necessários para obtenção do grau de Mestre em Informática. Área de Concentração: Ciência da Computação Linha de Pesquisa: Engenharia de Software Patricia Duarte de Lima Machado (Orientadora) Jorge César Abrantes de Figueiredo (Co-Orientador) Campina Grande, Paraíba, Brasil c Daniel Lima Barbosa, Junho de 2005
Transcript of Um Método Automático de Teste Funcional para a Verificação...

Um Método Automático de Teste Funcional para a
Verificação de Componentes
Daniel Lima Barbosa
Dissertação submetida à Coordenação do Curso de Pós-Graduação em
Informática da Universidade Federal de Campina Grande – Campus I
como parte dos requisitos necessários para obtenção do graude Mestre
em Informática.
Área de Concentração: Ciência da Computação
Linha de Pesquisa: Engenharia de Software
Patricia Duarte de Lima Machado
(Orientadora)
Jorge César Abrantes de Figueiredo
(Co-Orientador)
Campina Grande, Paraíba, Brasil
c©Daniel Lima Barbosa, Junho de 2005

Ficha Catalográfica Elaborada pela Biblioteca Central da UFCG
B238m Barbosa, Daniel Lima
Um método automático de teste funcional para a verificação de
componentes / Daniel Lima Barbosa. – Campina Grande: UFCG, 2005.
132 f. : il. color.
Referências.
Dissertação (Mestrado em Informática) – Centro de Ciênciase
Tecnologia, Universidade Federal de Campina Grande – UFCG.
Orientadores: Profa. Dra. Patrícia Duarte de Lima Machado.
Prof. Dr. Jorge César Abrantes de Figueiredo.
1 - Engenharia de Software 2 - Componentes de Software
3 - Teste Funcional 4 - Título
CDU 004.41(043)

Resumo
O desenvolvimento baseado em componentes vem sendo cada vezmais considerado para
a construção desoftwarede alta qualidade com baixo custo e tempo de desenvolvimento.
Entretanto, o reuso efetivo de componentes está fortementerelacionado à confiabilidade dos
mesmos. A maioria dos processos de desenvolvimento de componentes realiza as atividades
de teste de formaad hoce apenas no final do desenvolvimento, o que aumenta os custos
inerentes à correção dos defeitos detectados. Por outro lado, quando métodos de teste são
empregados, estes fazem uso de especificações complexas e/ou construídas especificamente
para as atividades de teste, além de nem sempre disporem de ferramentas de suporte para
automatizar estas atividades. Neste trabalho, propomos ummétodo que realiza, de forma
sistemática, a geração, execução e análise de resultados detestes funcionais para compo-
nentes de software a partir de especificações UML e restrições OCL. O método utiliza um
conjunto mínimo de artefatos UML, que constitui o requisitoprincipal para sua aplicação em
conjunto com uma metodologia de desenvolvimento. Uma ferramenta de suporte foi desen-
volvida para automatizar suas atividades e um estudo de casofoi realizado para demonstrar
a aplicação do método, assim como o funcionamento da ferramenta.
ii

Abstract
Component-based development has been even more used to build high quality software in
a cost-effective and reduced-time way. Nevertheless, effective reuse of components is closely
related to their reliability. The majority of component development processes execute test
activities in an ad hoc way and just at the end of development.This may lead to increased
correction costs of detected defects. On the other hand, when test methods are employed,
they use complex and/or test-only specifications. Futhermore, few of those methods have
support tools to automatize their activities. In this work,we propose a method to generate,
execute and analize the results of functional component tests in a systematic way from UML
specifications and OCL constraints. The method uses a minimum set of UML artifacts that
constitute the main requirements to its application in a development methodology. A support
tool has been developed to automatize the activities of the method and a case study was
performed to demonstrate its application as well as tool functionality.
iii

Agradecimentos
Agradeço primeiramente a Deus, por mais esta graça alcançada em minha vida. A meus
pais e irmãs, pelo apoio inestimável durante toda a minha formação. A minha amada esposa
Márcia, pelo carinho, compreensão e apoio constante, principalmente nos momentos mais
difíceis. A meus orientadores, Patrícia Duarte de Lima Machado e Jorge César Abrantes
de Figueiredo, por todo o empenho, dedicação, incentivo e confiança, sem os quais este
trabalho não seria possível. A Carina Machado, pela elaboração do trabalho que serviu
de base para este. Aos companheiros de pesquisa, Wilkerson Andrade, Helton Souza e
Cidinha Gouveia, pelo esforço empregado na busca por resultados. Aos demais amigos
integrantes do Grupo de Métodos Formais: Ana Emíla, André, Afrânio, Amâncio, Cássio,
Daniel Aguiar, Elthon, Emerson, Fabrício, Flávio, Jaírson, Paulo, Rogério e Taciano, pelos
dois anos incríveis compartilhados no LabPetri. Aos membros da Banca Examinadora, pela
atenção e ricas sugestões. Ao CNPq e à CAPES, pelo apoio financeiro. Por fim, gostaria
de agradecer a todos que, de uma forma ou de outra, através de palavras, gestos ou orações,
contribuíram para o sucesso deste trabalho.
iv

Conteúdo
1 Introdução 1
1.1 Objetivos do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Metodologia de Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Resultados e Relevância . . . . . . . . . . . . . . . . . . . . . . . . . . .4
1.4 Estrutura da Dissertação . . . . . . . . . . . . . . . . . . . . . . . . . .. 6
2 Fundamentação Teórica 8
2.1 Teste de Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Tipos de Teste . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.2 Terminologia de Teste . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2 Componentes de Software . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2.1 Definição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.2 Vantagens e Desvantagens do Desenvolvimento Baseadoem Com-
ponentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3 Teste de Componentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 O Método FCT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Planejamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.2 Especificação dos Testes . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.3 Construção, Execução e Análise de Resultados . . . . . . .. . . . 22
2.4.4 Empacotamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . .23
3 O Método AFCT 24
3.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
v

CONTEÚDO vi
3.2 Especificação de Teste . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.1 Seleção dos Casos de Teste . . . . . . . . . . . . . . . . . . . . . . 28
3.2.2 Geração de Oráculos . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.2.3 Seleção de Dados de Teste . . . . . . . . . . . . . . . . . . . . . . 36
3.3 Construção e Empacotamento dos Artefatos de Teste . . . . .. . . . . . . 39
3.4 Execução dos Testes e Análise de Resultados . . . . . . . . . . .. . . . . 41
3.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . .42
4 A Ferramenta SPACES 43
4.1 Características da Ferramenta . . . . . . . . . . . . . . . . . . . . .. . . . 43
4.2 Visão Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3 Projeto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.1 Gerenciador de Persistência . . . . . . . . . . . . . . . . . . . . .50
4.3.2 Parser XMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.3.3 Seletor de Casos de Teste . . . . . . . . . . . . . . . . . . . . . . . 53
4.3.4 Gerador de Oráculos . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.3.5 Seletor de Dados de Teste . . . . . . . . . . . . . . . . . . . . . . 63
4.3.6 Gerador de Artefatos de Teste . . . . . . . . . . . . . . . . . . . . 67
4.3.7 Empacotador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.4 Testador de Componentes . . . . . . . . . . . . . . . . . . . . . . . . . . .73
4.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . .76
5 Estudo de Caso 77
5.1 Descrição da Aplicação e Escolha do Componente . . . . . . . .. . . . . 77
5.2 Especificando o Componente . . . . . . . . . . . . . . . . . . . . . . . . .78
5.3 Aplicando o Método AFCT . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.3.1 Planejando o Teste . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.3.2 Especificando os Testes . . . . . . . . . . . . . . . . . . . . . . . . 87
5.3.3 Construindo e Empacotando os Artefatos de Teste . . . . .. . . . 91
5.3.4 Executando o Teste . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5.4 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . .96

CONTEÚDO vii
6 Conclusão 99
6.1 Contribuições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
6.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
A Mapeamento OCL – Java 109
A.1 Declaração de Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
A.2 Tipos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
A.3 Operadores (Numéricos, Relacionais e Lógicos) . . . . . . .. . . . . . . . 110
A.4 Operações sobre Strings . . . . . . . . . . . . . . . . . . . . . . . . . . .111
A.5 Construções Básicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
A.6 Construções Collection . . . . . . . . . . . . . . . . . . . . . . . . . . .. 112
B Subconjunto XMI Utilizado 117
C API UML 127

Lista de Figuras
2.1 Interfaces de Componentes . . . . . . . . . . . . . . . . . . . . . . . . .. 13
2.2 Teste de Componentes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Exemplo de Modelo de Uso de Método FCT . . . . . . . . . . . . . . . . .19
3.1 Integração entre Metodologias de Desenvolvimento de SBC e o Método de
Teste . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Algoritmo para a Criação de Modelos de Uso . . . . . . . . . . . . .. . . 29
3.3 Formato de Modelo de Uso do Método AFCT . . . . . . . . . . . . . . . .30
3.4 Algoritmo para a Criação de Diagramas de Seqüência a partir de Modelos
de Uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.5 Algoritmo para a Seleção de Caminhos em Modelos de Uso . . .. . . . . 32
3.6 Exemplo de Conversão de OCL para Pseudo-Código . . . . . . . .. . . . 35
4.1 Arquitetura da Ferramenta SPACES . . . . . . . . . . . . . . . . . . .. . 45
4.2 SPACES: Tela Principal . . . . . . . . . . . . . . . . . . . . . . . . . . . .47
4.3 SPACES: Menus Arquivo e Projeto . . . . . . . . . . . . . . . . . . . . .. 47
4.4 SPACES: Abrindo Arquivos XMI . . . . . . . . . . . . . . . . . . . . . . 48
4.5 Visão Geral do Projeto da Ferramenta SPACES . . . . . . . . . . .. . . . 49
4.6 SPACES: Tela Salvar Projeto . . . . . . . . . . . . . . . . . . . . . . . .. 50
4.7 SPACES: Gerenciador de Persistência . . . . . . . . . . . . . . . .. . . . 51
4.8 SPACES: Tela de Seleção de Casos de Teste . . . . . . . . . . . . . .. . . 53
4.9 SPACES: Modelo de Uso . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.10 SPACES: Tela de Edição de Probabilidades . . . . . . . . . . . .. . . . . 55
4.11 SPACES: Probabilidades Alteradas no Modelo de Uso . . . .. . . . . . . 55
4.12 SPACES: Seletor de Casos de Teste . . . . . . . . . . . . . . . . . . .. . 56
viii

LISTA DE FIGURAS ix
4.13 Dresden OCL: Integração entre os Módulos . . . . . . . . . . . .. . . . . 58
4.14 Dresden OCL: Exemplo de Árvore Sintática Abstrata . . . .. . . . . . . . 58
4.15 Integração Dresden OCL - SPACES: Acesso ao Modelo UML . .. . . . . 59
4.16 Dresden OCL: Gerador de Código . . . . . . . . . . . . . . . . . . . . .. 60
4.17 SPACES: Gerador de Oráculos . . . . . . . . . . . . . . . . . . . . . . .. 62
4.18 SPACES: Seletor de Dados . . . . . . . . . . . . . . . . . . . . . . . . . .64
4.19 SPACES: Gerador de Artefatos de Teste . . . . . . . . . . . . . . .. . . . 68
4.20 SPACES: Hierarquia do Código de Teste . . . . . . . . . . . . . . .. . . . 68
4.21 SPACES: Formato de Métodos de Teste para Cenários . . . . .. . . . . . . 69
4.22 JTestCase: Formato de Arquivos XML . . . . . . . . . . . . . . . . .. . . 70
4.23 SPACES: Formato XML para Descrição do Código de Teste Gerado . . . . 71
4.24 SPACES: Empacotador . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.25 Testador de Componentes: Tela Principal . . . . . . . . . . . .. . . . . . 74
4.26 Testador de Componentes: Tela de Alteração de Dados . . .. . . . . . . . 76
5.1 Diagrama de Componentes do Sistema de Reservas . . . . . . . .. . . . . 78
5.2 Diagrama de Funcionalidades para o ComponenteGerenciador de Hotéis. 79
5.3 Modelo Conceitual do ComponenteGerenciador de Hotéis. . . . . . . . . 80
5.4 Modelo de Informação do ComponenteGerenciador de Hotéis. . . . . . . 80
5.5 Diagrama que descreve o cenário de usoHotel Inexistenteda funcionalidade
Fazer Reserva. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.6 Diagrama que descreve o cenário de usoTipo de Quarto Inexistenteda fun-
cionalidadeFazer Reserva . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.7 Diagrama que descreve o cenário de usoPeríodo Inválidoda funcionalidade
Fazer Reserva. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.8 Diagrama que descreve o cenário de usoQuarto Não Disponívelda funcio-
nalidadeFazer Reserva. . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.9 Diagrama que descreve o cenário de usoSucessoda funcionalidadeFazer
Reserva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
5.10 Selecionando os casos de teste com SPACES . . . . . . . . . . . .. . . . 87
5.11 Modelo de Uso para a Funcionalidade Fazer Reserva . . . . .. . . . . . . 88

LISTA DE FIGURAS x
5.12 Modelo de Uso para a Funcionalidade Cancelar Reserva . .. . . . . . . . 89
5.13 Oráculo correspondente à pré-condição do cenárioPeríodo Inválidoda Fun-
cionalidadeFazer Reserva . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.14 Oráculo correspondente à pós-condição do cenárioPeríodo Inválidoda Fun-
cionalidadeFazer Reserva . . . . . . . . . . . . . . . . . . . . . . . . . . 91
5.15 Dados selecionados para o cenárioTipo de Quarto Inexistenteda funciona-
lidadeFazer Reserva. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
5.16 Hierarquia de Classes de Teste geradas para o Componente Gerenciador de
Hoteis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
5.17 Execução dos Testes: Detecção de Falhas . . . . . . . . . . . . .. . . . . 94
5.18 Execução dos Testes: Revisando os Dados de Teste . . . . . .. . . . . . . 95
5.19 Execução dos Testes: Testes Ok . . . . . . . . . . . . . . . . . . . . .. . 96
C.1 API UML: Visão Geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
C.2 API UML: Hierarquia de Tipo . . . . . . . . . . . . . . . . . . . . . . . . 129
C.3 API UML: Associação . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
C.4 API UML: Generalização e Abstração . . . . . . . . . . . . . . . . . .. . 130
C.5 API UML: Colaboração e Diagrama de Seqüência . . . . . . . . . .. . . . 131
C.6 API UML: Hierarquia de Ações . . . . . . . . . . . . . . . . . . . . . . . 132
C.7 API UML: Ator e Caso de Uso . . . . . . . . . . . . . . . . . . . . . . . . 132

Lista de Tabelas
2.1 Exemplo de Tabela de Decisão do Método FCT . . . . . . . . . . . . .. . 21
3.1 Esquema de Conversão de Restrições OCL para Código Fonte. . . . . . . 35
3.2 Padrões Lógicos para Identificação de Partições de Equivalência . . . . . . 37
3.3 Frameworks de TestexUnit . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5.1 Cenários de Uso das Funcionalidades do ComponenteGerenciador de Hotéis 81
5.2 Determinando o número de casos de teste a ser realizados para cada funcio-
nalidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
A.1 Mapeamento OCL – Java: Declaração de Context . . . . . . . . . .. . . . 109
A.2 Mapeamento OCL – Java: Tipos . . . . . . . . . . . . . . . . . . . . . . . 110
A.3 Mapeamento OCL – Java: Operadores . . . . . . . . . . . . . . . . . . .. 111
A.4 Mapeamento OCL – Java: Operações sobre Strings . . . . . . . .. . . . . 111
A.5 Mapeamento OCL – Java: Construções Básicas . . . . . . . . . . .. . . . 111
A.6 Mapeamento OCL – Java: Construções Collection . . . . . . . .. . . . . 116
xi

Capítulo 1
Introdução
O desenvolvimento de produtos de qualidade é hoje o maior desafio da indústria desoft-
ware. Para tanto, processos de teste bem planejados e executadossão necessários de forma a
garantir que o produto final do desenvolvimento seja o mais livre de defeitos possível. Entre-
tanto, como observado por McGregor[MS01], a concepção tradicional do processo de teste
como sendo uma fase final e independente do processo de desenvolvimento propriamente
dito, tem se mostrado muito ineficiente no que diz respeito aocusto necessário tanto para
reparar os erros encontrados quanto com a própria manutenção dosoftware.
Neste contexto, o teste funcional surge como uma técnica capaz de amenizar os custos
inerentes ao processo de teste, uma vez que, a partir da especificação dosoftware, casos de
teste podem ser obtidos paralelamente ao seu desenvolvimento. Em função disto, muitas
pesquisas vêm sendo desenvolvidas com o objetivo de produzir técnicas efetivas para a deri-
vação de casos de teste a partir da especificação dos sistemas. Entretanto, isso só é possível
se essa especificação for precisamente definida, caracterizando com exatidão o comporta-
mento desejado para o sistema[Bei95]. Uma forma de se alcançar essa precisão é a partir da
utilização de especificações formais.
Por outro lado, o desenvolvimento de especificações complexas e específicas para propó-
sitos de teste só é justificado para projetos de alta complexidade e risco, como, por exemplo,
sistemas de tempo real, em função dooverhead(número de atividades extras) necessário
para se gerar esses artefatos. Dessa forma, a utilização de especificações UML (Unified
Modeling Language) [OMG03b], tradicionalmente empregadas nas fases de análise e pro-
jeto dos processos de desenvolvimento desoftware, como fonte de informações relevantes
1

2
para teste, aparece como uma alternativa altamente atraente uma vez que não se faz mais
necessário a criação de artefatos específicos para propósitos de teste[BL01; OA99; FL00;
VDR00; RPG01; CCD+02]. Entretanto, é preciso, de alguma forma, compensar a falta de
formalidade das especificações UML para que estas possam serutilizadas na geração auto-
mática de casos de teste. Uma forma interessante de resolveresse problema é enriquecendo
os artefatos UML com restrições OCL (Object Constraint Language) [OMG03a], provendo,
desta forma, informações relacionadas a invariantes, pré epós-condições e outros compor-
tamentos mais específicos. Embora o OCL esteja cada vez mais presente nas especificações
UML, ainda não existem muitas pesquisas acerca de sua utilização como fator formalizador
de especificações UML para propósitos de teste.
Um ponto de convergência entre os pesquisadores e especialistas da área é a necessidade
de automação destas técnicas de forma que todo o processo de teste - geração, execução e
análise de resultados - possa ser executado (e re-executado) com a menor interferência hu-
mana possível. Entretanto, poucos são os trabalhos que apresentam ferramentas realmente
em produção[TB02; FJJV97]. A grande maioria destas ferramentas é composta por pro-
tótipos cujos projetos nunca vêm a ser finalizados. Além disso, as poucas ferramentas em
produção não abrangem todo o processo de teste - muitas realizam apenas a geração dos ca-
sos de teste - e a maioria delas faz uso de especificações mais complexas e menos utilizadas
do que o UML, a exemplo da ferramenta apresentada por Tretmans [TB02].
Aliada a esta busca por processos de teste mais eficientes, a composição de sistemas a
partir de componentes, em função de sua alta capacidade de reuso, também desponta como
um fator de determinação desoftwarede alta qualidade, rápida construção e baixo custo.
Para tanto os componentes precisam ser testados de forma a garantir a sua confiabilidade e,
conseqüentemente, a confiabilidade do sistema como um todo.
Do ponto de vista de um componente, os testes a serem realizados precisam satisfazer
duas expectativas distintas. Do lado do fornecedor, é preciso garantir que o componente se
comportará adequadamente sob os mais diferentes contextosem que venha a ser utilizado.
Do lado do cliente, é necessário assegurar que o componente apresente a funcionalidade
desejada quando integrado aos demais componentes para compor uma aplicação. Para que
isso seja possível, é necessário que os componentes apresentem interfaces bem especificadas.
Em função disto, métodos para a verificação funcional de componentes e da integração

1.1 Objetivos do Trabalho 3
destes na composição de sistemas vem sendo propostos[dF03; MTY01; GMF04; CWO03].
Em particular, em[dF03], Farias propõe o método FCT (Functional Component Testing),
um método de teste funcional aplicável a componentes desoftware. A principal contribuição
desse trabalho está em possibilitar a verificação de propriedades individuais dos compo-
nentes e empacotar artefatos e resultados de teste de forma adequada, facilitando o reuso e
a composição dos mesmos pelos clientes. Esta abordagem é complementada por Gouveia
[GMF04] que apresenta um método de teste de integração funcional para sistemas basea-
dos em componentes com a finalidade de testar o componente dentro do contexto onde ele
será inserido, isto é, testar a forma como ele irá interagir com a aplicação e com os demais
componentes que irão compor o sistema.
Entretanto, embora cubram todo o processo de teste, estes métodos não possuem fer-
ramentas de suporte e, em função de definições incompletas e/ou informais, apresentam
atividades bastante subjetivas e de difícil automação, o que constitui um obstáculo para a
construção destas ferramentas. Dessa forma, todas as suas etapas precisam ser manualmente
executadas. Com isso, até mesmo aplicações simples demandam um grande esforço por
parte das equipes de desenvolvimento em atividades de teste, tornando-se, assim, um pro-
cesso bastante oneroso. A redefinição destas atividades e o desenvolvimento de ferramentas
de suporte é, portanto, fundamental para garantir a viabilidade destes métodos em aplicações
práticas.
1.1 Objetivos do Trabalho
O objetivo maior deste trabalho é a definição de um novo métodode teste funcional para
componentes desoftwarecujas atividades sejam precisamente definidas de forma a possi-
bilitar o desenvolvimento de um ferramental de suporte que realize, de forma automática,
a geração, execução e análise de resultados de casos de testes. Esse método, que é forte-
mente baseado no método FCT[dF03], cobrirá inicialmente apenas a perspectiva de teste do
fornecedor e não estará limitado a uma única metodologia de desenvolvimento.
O ferramental de suporte a ser desenvolvido deverá apresentar, dentre outras, as seguintes
características:
• Suporte a múltiplas ferramentas de modelagem UML;

1.2 Metodologia de Trabalho 4
• Utilização de artefatos produzidos com a especificação UML durante as fases de aná-
lise e projeto dos processos de desenvolvimento desoftware;
• Geração, implementação, execução e análise de resultado decasos de teste para os
componentes;
• Empacotamento dos casos de teste e dados experimentais gerados para o componente
de forma a permitir a sua distribuição e a reexecução dos testes pelos usuários do
mesmo.
1.2 Metodologia de Trabalho
Com o intuito de se atingir o objetivo proposto para este trabalho, inicialmente foi feita
uma análise crítica do estado da arte em automação de teste funcional parasoftwareorientado
a objetos e/ou baseado em componentes. Em seguida fundamentamos o trabalho no estudo
das linguagens UML e OCL, das principais técnicas empregadas no teste de componentes
de software, e das atividades e técnicas empregadas no método FCT[dF03]. A partir das
conclusões tomadas e das metas traçadas, realizamos a definição de cada uma das atividades
e etapas do novo método de teste assim como o desenvolvimentodo ferramental de suporte.
Por fim, com o objetivo de guiar e fornecerfeedbackspara estas definições, construímos a
especificação e implementação de um componente a ser usado como estudo de caso.
1.3 Resultados e Relevância
O principal resultado deste trabalho é a disponibilização de um método para a geração,
execução e análise de resultados de casos de teste para componentes desoftwarede forma
automática e a partir de especificações UML e restrições OCL das fases de análise e projeto
dos processos de desenvolvimento.
No ciclo de desenvolvimento desoftware, o teste é, sem sombra de dúvidas, a ativi-
dade em que podemos observar a maior distância entre a teoria(métodos e técnicas de teste
propostas) e a prática (real aplicação destas técnicas). Uma das principais causas disso é
o impacto causado pela adoção destas propostas, seja em função dooverheadnecessário à

1.3 Resultados e Relevância 5
sua utilização, ou devido ao alto grau de complexidade e/ou formalismo das especificações
necessárias.
Ao contrário do que ocorre com outras propostas, o método utiliza uma especificação
usual, padronizada e de grande utilização pela indústria, eos artefatos necessários já são
comumente desenvolvidos pelas principais metodologias dedesenvolvimento, sendo des-
necessária a construção de artefatos específicos para propósitos de teste, fatores esses que
facilitam a sua adoção.
Estudos mostram que cerca de 50% do custo do desenvolvimentode umsoftwareé desti-
nado à atividade de teste[Har00; Bei90]. Com o uso do método, estes custos podem vir a ser
drasticamente reduzidos, uma vez que, faltas e/ou inconsistências na especificação podem ser
detectadas nas primeiras etapas dos processos de desenvolvimento, tornando mais simples e
barata a sua correção e evitando a sua propagação para as etapas futuras do desenvolvimento.
Outra contribuição do trabalho é o desenvolvimento e disponibilização do ferramental
de suporte necessário à automação das atividades do método de teste. Apesar de algumas
ferramentas desenvolvidas para teste funcional de sistemas orientados a objetos poderem ser
aplicadas também ao teste de componentes, muitas se baseiamem artefatos produzidos ex-
clusivamente para propósitos de teste e/ou em especificações pouco usuais[PBB97; Gra94;
TB02]. Além disso, nenhuma dessas ferramentas dá enfoque às características específicas
dos componentes desoftware, a exemplo da verificação de propriedades e da forma como es-
tes interagem entre si. Com tais ferramentas de suporte, o esforço empregado no processo de
teste dos componentes será minimizado, o que viabiliza a suautilização em sistemas comple-
xos e/ou de grande porte. Além disso, a diminuição do número de atividades manuais reduz a
chance de inserção de defeitos durante a execução do processo de teste, maximizando assim
a confiabilidade dos resultados obtidos e, conseqüentemente, a qualidade do produto final.
Por fim, o trabalho contribuirá com um estudo de caso a fim de demonstrar a aplicação
do método de teste e da ferramenta de suporte.

1.4 Estrutura da Dissertação 6
1.4 Estrutura da Dissertação
O restante deste documento foi organizado da seguinte forma:
Capítulo 2: Fundamentação Teórica Na fundamentação teórica, apresentaremos os prin-
cipais conceitos e terminologias relativos a teste e componentes desoftware, que foram
abordados neste trabalho. Por fim, será apresentado o métodoFCT, no qual este trabalho
está baseado, a partir da descrição de suas fases e atividades.
Capítulo 3: O Método de Teste AFCT Neste capítulo, será apresentado o método de
teste proposto. Serão enumerados os requisitos para a sua aplicação e serão descritas as suas
etapas e atividades assim como os algoritmos e técnicas utilizadas na sua definição.
Capítulo 4: A Ferramenta SPACES A ferramenta SPACES será apresentada neste capí-
tulo. A ferramenta foi construída para dar suporte às atividades do método AFCT. Será feita
uma descrição da sua arquitetura e, para cada módulo, serão apresentadas as funcionalidades
e os principais algoritmos.
Capítulo 5: Estudo de Caso Neste capítulo será demonstrada uma aplicação prática do
método AFCT e da ferramenta SPACES. Um componente será selecionado para ser especi-
ficado, implementado e testado segundo as diretrizes do método de teste proposto e com o
auxílio da ferramenta. Ao final, os resultados obtidos serãoanalisados.
Capítulo 6: Conclusões O trabalho será concluído neste capítulo a partir de uma avaliação
dos resultados obtidos assim como uma descrição das perspectivas de trabalhos futuros.
Apêndice A No Apêndice A, é apresentado o mapeamento proposto da linguagem OCL
para um subconjunto da linguagem de programação Java. Este mapeamento foi utilizado
para a geração dos oráculos de teste sob a forma de código-fonte Java a partir das restrições
OCL.

1.4 Estrutura da Dissertação 7
Apêndice B No Apêndice B, apresentamos um DTD que descreve o subconjunto dos ele-
mentos XMI considerados para a obtenção de informações do modelo UML a partir da fer-
ramenta SPACES.
Apêndice C No Apêndice C, são apresentados os diagramas que descrevem as classes
componentes da API UML, que é instanciada a partir do arquivoXMI para disponibilizar as
informações do modelo UML da especificação dos componentes para a ferramenta SPACES.

Capítulo 2
Fundamentação Teórica
Este capítulo tem como objetivo principal fornecer um suporte técnico para os leitores
com relação aos conceitos empregados neste trabalho. Serãoapresentados os principais
conceitos relacionados a teste, componentes e teste de componentes. O método FCT, no
qual este trabalho está baseado, também será apresentado neste capítulo a partir da descrição
de suas fases e atividades.
2.1 Teste de Software
À medida que cresce a utilização de sistemas desoftwarena execução de tarefas críticas,
cresce também a exigência de produtos cada vez mais qualificados. Teste é uma das técni-
cas de verificação desoftwaremais utilizadas na prática. Se usado de forma efetiva, pode
fornecer indicadores importantes sobre a qualidade e confiabilidade de um produto.
O teste desoftwareé uma atividade que consiste na descoberta de defeitos que possam
ter sido introduzidos em qualquer fase do desenvolvimento ou manutenção de sistemas de
softwaree que, em geral, são decorrentes de omissões, inconsistências ou mau entendimento
das especificações ou dos requisitos dos sistemas[MS01]. Trata-se de um processo de difícil
execução para o qual, raramente, os recursos necessários estão disponíveis.
O teste é importante porque contribui substancialmente para certificarmos que uma apli-
cação faz tudo o que era esperado que fizesse, embora existam também alguns esforços que
vão além disso, e tentam assegurar que as aplicações não fazem nada além do especificado.
De qualquer forma, eles fornecem meios de avaliar a existência de defeitos que poderiam
8

2.1 Teste de Software 9
resultar em perda de tempo, clientes ou até mesmo, no caso de sistemas críticos, de vidas.
Embora o principal objetivo do teste seja a detecção de defeitos, existem modalidades
de teste mais específicas que visam a certificação de alguns requisitos não funcionais das
aplicações, a exemplo dos testes de segurança, destresse de performance.
Por muito tempo o teste desoftwarefoi definido dentro dos processos de desenvolvi-
mento como uma atividade isolada e que só era realizada, de maneira informal, após a im-
plementação dos sistemas. Entretanto, o alto custo atribuído a esta etapa – cerca de 50% do
custo total de desenvolvimento, segundo alguns estudos[Har00; Bei90] – demonstrou que
essa não era uma prática adequada. Isso contribuiu para a definição de métodos e técnicas
sistemáticas de teste que constituíssem um processo a parteque pudesse ser aplicado, para-
lelamente, ao longo do processo de desenvolvimento[MS01]. Dessa forma, as atividades de
teste poderiam ser aplicadas cada vez mais cedo, contribuindo para a verificação não ape-
nas do código desenvolvido, mas também para a descoberta de faltas nos próprios artefatos
produzidos pelas etapas do processo de desenvolvimento, evitando, assim, a sua propagação
para as etapas subseqüentes e reduzindo drasticamente o esforço e o custo decorrente de sua
correção.
2.1.1 Tipos de Teste
Segundo Beizer[Bei95], três estratégias podem ser utilizadas para se realizar teste de
softwarecom o objetivo de detectar defeitos:
• Teste Funcional: Observa se um programa está de acordo com a sua especificação,
independentemente do código fonte. Teste funcional é também conhecido como teste
black-boxou teste comportamental.
• Teste Estrutural: Baseia-se na estrutura do objeto testado. Requer, portanto, acesso
completo ao código fonte do programa para ser realizado. É também conhecido por
testeglass-boxou testewhite-box.
• Teste Híbrido: Combina as duas estratégias de teste anteriores.
Os testes funcional e estrutural são técnicas complementares. Alguns defeitos são tão re-
lacionados à forma como uma determinada funcionalidade foiimplementada que só podem

2.1 Teste de Software 10
ser revelados a partir do desenvolvimento de testes baseadona implementação desta fun-
cionalidade, e portanto, estruturais. Por outro lado, a verificação da conformidade de uma
funcionalidade para com sua especificação através das técnicas funcionais, nos permite um
controle maior sobre o que osoftwarefaz, possibilitando a detecção de defeitos mais con-
ceituais e menos dependentes da implementação em si, a exemplo de inconsistência entre
modelos.
Segundo J. Chang et. al.[CR99], teste funcional é freqüentemente mais fácil de compre-
ender e realizar do que as técnicas de teste tradicionais baseadas em código, porque o teste
funcional baseia-se em uma descrição “black-box” da funcionalidade dosoftware, enquanto
que as técnicas de teste estrutural exigem um conhecimento mais detalhado da implementa-
ção. Neste trabalho, nos concentraremos apenas nas técnicas de teste funcional, estando as
técnicas estruturais fora de seu escopo.
Uma vez que são baseadas na especificação dosoftware, as técnicas de teste funcional
podem ser aplicadas antes mesmo da disponibilização da implementação, contribuindo para
o aperfeiçoamento dos próprios artefatos de desenvolvimento. Além disso, quando as espe-
cificações são construídas a partir de linguagens com semântica formal ou semi-formal, o
teste funcional pode ser realizado de forma parcial ou completamente automática, minimi-
zando o esforço necessário à sua aplicação assim como o riscode inserção de erros durante
a execução manual de suas atividades.
Em geral, os testes funcionais compreendem três componentes básicos:Casos de Teste,
Oráculose Dados de Teste. Estes e outros conceitos relacionados à atividade de testesão
apresentados na seção 2.1.2.
2.1.2 Terminologia de Teste
Teste desoftwareapresenta um vocabulário bem estabelecido. A seguir, são listados
alguns dos termos mais comumente usados[Bei95; Bin99]:
• Falha: É a manifestação dosoftwareem não executar de forma correta uma determi-
nada funcionalidade. Em função disso, o sistema em execuçãoapresenta algum tipo de
comportamento não esperado, ou seja, a saída produzida não coincide com o resultado
previsto.

2.2 Componentes de Software 11
• Defeito ou Falta: Termos equivalentes que são usados para indicar a ausênciade có-
digo ou a presença de código incorreto no sistema, o que pode ocasionar uma falha no
mesmo.
• Erro: É a ação humana que dá origem a uma falta.
• Caso de Teste: Aspecto ou funcionalidade a ser testado em um sistema, cujocompor-
tamento esperado é expresso por critérios de entrada e aceitação.
• Dados de Teste: Valores de entrada necessários para a execução de um caso deteste.
• Oráculo: Especificação de procedimentos responsáveis por verificarse uma dada exe-
cução do sistema (estimulada pelos dados de entrada) está deacordo com o comporta-
mento definido pelos casos de teste.
• Validação: Processo que avalia se a especificação de um objeto está de acordo com o
domínio do problema. Este processo assegura que osoftwareproduzido é osoftware
correto.
• Verificação: Processo que avalia se a implementação de um objeto satisfaz os requi-
sitos declarados em sua especificação. Assume-se neste processo que a especificação
está correta. Este processo assegura que osoftwareestá sendo produzido corretamente.
• Testabilidade: Propriedade fundamental que engloba todos os aspectos quefacilitam
a elaboração e execução dos testes dosoftware.
2.2 Componentes de Software
Na indústria desoftware, requisitos relativos a menores custos de produção e ma-
nutenção, maior rapidez na entrega de sistemas e aumento da qualidade estão cada vez
mais presentes, e a sua satisfação é determinante para o sucesso dos produtos em de-
senvolvimento assim como para a sobrevivência das própriasorganizações em um mer-
cado cada vez mais competitivo. Entre os pesquisadores, é consenso que tais requisi-
tos só podem ser atendidos pelo reuso generalizado e sistemático de software [Som03;

2.2 Componentes de Software 12
Szy98]. O desenvolvimento desoftwarebaseado em componentes é uma das técnicas de
reuso que vem apresentando melhores resultados na prática[Som03].
A engenharia desoftwarebaseada em componentes propõe a concepção de sistemas
a partir da combinação de unidades pré-desenvolvidas com o objetivo de reduzir o tempo
de desenvolvimento, facilitar o acoplamento de novas funcionalidades, ou a mudança de
funcionalidades já existentes e ainda promover o reuso de partes dosoftware. Contudo,
embora tenha havido interesse no reuso de componentes desdeo início da década de 80,
foi somente nos últimos anos que ele se tornou aceito como umaabordagem prática para o
desenvolvimento de sistemas desoftware[Som03].
2.2.1 Definição
Na engenharia desoftware, o termo Componente possui diversas definições. Uma das
definições mais usadas e a que consideramos neste trabalho é ade C. Szyperski[Szy98]:
"Um componente de software é uma unidade de composição com interfaces
especificadas através de contratos e dependências de contexto explícitas, que
pode ser distribuída independentemente e está sujeita a composição com outras
partes."
Desta definição podemos concluir que o componente é uma peça de software que pode
ser desenvolvida de forma isolada e que é projetada para utilização em diferentes contextos
de um determinado domínio de aplicação. A definição também indica que um componente
encapsula suas características, estando portanto bem separado de seu ambiente e de outros
componentes. Sua interação com o mundo exterior se dá através de especificações bem
definidas acerca do que o componente requer para o seu corretofuncionamento e de quais os
serviços por ele fornecidos.
Estas especificações são as interfaces que constituem o contrato de utilização do mesmo
(Figura 2.1). A interfacerequires(requer) especifica quais os serviços que devem ser for-
necidos pelo sistema ou, eventualmente, por outros componentes, para possibilitar o correto
funcionamento do componente. A interfaceprovides(fornece), por sua vez, define os servi-
ços fornecidos pelo componente.

2.2 Componentes de Software 13
Figura 2.1: Interfaces de Componentes
2.2.2 Vantagens e Desvantagens do Desenvolvimento Baseadoem Com-
ponentes
O desenvolvimento de sistemas baseado em componentes apresenta uma série de vanta-
gens em relação às técnicas de desenvolvimento tradicionais [Som03]:
• Maior confiabilidade. Os componentes reutilizados que são empregados nos siste-
mas em operação são, em geral, mais confiáveis do que os componentes novos. Eles já
foram experimentados e testados em diferentes ambientes. Os defeitos de projeto e im-
plementação são descobertos e eliminados no uso inicial doscomponentes, reduzindo,
assim, o número de falhas quando o componente é reutilizado.
• Redução dos riscos de processo. Se recorrermos a um componente já existente, serão
menores as incertezas sobre os custos relacionados ao reusodesse componente do que
sobre custos de desenvolvimento. Esse é um fator importantepara o gerenciamento de
projetos, pois reduz as incertezas nas estimativas de custos de projeto.
• Uso efetivo de especialistas. Em vez de os especialistas em aplicações fazerem o
mesmo trabalho em diferentes projetos, eles podem desenvolver componentes reutili-
záveis, que englobam seu conhecimento.
• Desenvolvimento acelerado. De modo geral, é mais importante fornecer um sis-
tema para o mercado o mais rápido possível do que se prender aos custos gerais de
desenvolvimento. O reuso de componentes acelera a produção, porque o tempo de
desenvolvimento e o de validação devem ser reduzidos.
Apesar das vantagens apresentadas, algumas desvantagens e/ou problemas também pre-
cisam ser considerados durante o projeto de sistemas baseados em componentes. Algumas

2.3 Teste de Componentes 14
destas desvantagens, que estão relacionadas aos requisitos para implantação do desenvolvi-
mento baseado em componentes em si e à mudança de culturas organizacionais, são listadas
a seguir[Som03].
• Aumento nos custos de manutenção. Se o código-fonte do componente não estiver
disponível, então os custos de manutenção poderão aumentar, uma vez que os ele-
mentos reutilizados no sistema podem se tornar crescentemente incompatíveis com as
mudanças do sistema.
• Síndrome do ‘não-foi-inventado-aqui’. Alguns engenheiros desoftwareàs vezes
preferem reescrever componentes porque acreditam que podem fazer melhor que o
componente reutilizável. Isso tem a ver em parte com a confiança e em parte com o fato
de que escrever umsoftwareoriginal é visto como mais desafiador do que reutilizar o
softwarede outras pessoas.
• Manutenção de uma biblioteca de componentes. Implementar uma biblioteca de
componentes e assegurar que os desenvolvedores desoftwareutilizem essa biblioteca
pode ser dispendioso, uma vez que as técnicas atuais de classificação, catalogação e
recuperação de componentes desoftwareainda são imaturas.
• Encontrar e adaptar componentes reutilizáveis. Os componentes desoftwarede-
vem ser encontrados em uma biblioteca, compreendidos e, algumas vezes, adaptados,
a fim de trabalharem em um novo ambiente. Os engenheiros precisam ter uma razoá-
vel certeza de poder encontrar um componente em uma biblioteca, antes de incluírem
a rotina de busca de componentes como parte de seu processo normal de desenvolvi-
mento.
2.3 Teste de Componentes
A qualidade dos sistemas construídos a partir da composiçãode componentes assim
como o reuso efetivo destes estão intimamente relacionadosa sua confiabilidade. O teste
é, na prática, uma das técnicas mais empregadas para se avaliar a qualidade e a confiabili-
dade dos componentes.

2.3 Teste de Componentes 15
De acordo com Harrold[Har00], o teste de componentes pode ser visto sob duas perspec-
tivas: a perspectiva do fornecedor do componente e a perspectiva do cliente do componente.
O fornecedor vê o componente independentemente do contextoem que ele será utilizado e
deve portanto, testar todas as configurações do componente de uma forma livre de contexto.
Já para o cliente, o componente estará inserido no contexto de uma aplicação, interagindo
com outros componentes para compor uma funcionalidade maior. Dessa forma, é mais in-
teressante testar os aspectos do componente que são relevantes no contexto específico da
aplicação, assim como a correta interação entre os componentes que a compõem.
Na Figura 2.2, vemos como se dá o teste de um sistema baseado emcomponentes atra-
vés dessas perspectivas. O fornecedor dos componentes ‘A’,‘B’ e ‘C’ precisa assegurar a
sua funcionalidade como unidade funcional, verificando se omesmo se comporta adequa-
damente sob as características comuns ao domínio de aplicações para o qual foi projetado.
O cliente, que está usando os componentes para compor o sistema ‘ABC’, precisa averi-
guar o correto funcionamento dos componentes neste contexto específico, o que implica na
verificação das interações estabelecidas entre eles.
<< component >>
<< component >>
Sistema ABC << component >>
B
C
A
Figura 2.2: Teste de Componentes
O teste dos componentes sob duas perspectivas distintas é fundamental para que esta
atividade seja realizada com sucesso. Embora estas perspectivas tenham como objetivo a
descoberta de diferentes classes de defeitos, uma falta nãodescoberta na funcionalidade de
um componente durante o teste na perspectiva do fornecedor pode resultar em falhas na
integração deste com outros componentes dentro de uma aplicação, contribuindo para o fun-
cionamento incorreto dos demais componentes, assim como daaplicação como um todo. Por
outro lado, a(s) funcionalidade(s) obtida(s) a partir da integração de componentes correta-

2.4 O Método FCT 16
mente testados de forma individual pode(m) apresentar falhas decorrentes desta integração,
e que, portanto, só podem ser identificadas a partir do teste na perspectiva do cliente.
2.4 O Método FCT
Este trabalho é baseado no método FCT (Functional Component Testing), proposto por
Farias em[dF03]. Este método tem como objetivo principal possibilitar o teste funcional
das propriedades individuais de componentes desoftware, sob a perspectiva do fornecedor, a
partir de especificações UML e restrições OCL. Para tanto, o método fornece um conjunto de
diretrizes e técnicas que auxiliam a execução e o acompanhamento de cada uma das etapas do
processo de teste: planejamento, especificação, construção, execução e análise de resultados,
além de uma etapa extra que compreende o empacotamento dos artefatos de teste gerados
para o componente para possibilitar a distribuição destes efavorecer o desenvolvimento de
novos testes na perspectiva do cliente.
O método, cujas atividades estão integradas à metodologiaUML Components[CD01]
de desenvolvimento de sistemas baseados em componentes, faz uso dos seguintes artefatos
UML:
• Diagrama de Classe, onde são descritos, de forma estrutural, o modelo conceitual, as
classes do sistema assim como as associações entre elas;
• Restrições OCLque especificam os contratos (pré e pós-condições) das operações das
interfaces do componente;
• Diagramas de Casos de Usoque representam as funcionalidades do componente;
• Diagramas de Seqüênciaque especificam os cenários de uso das funcionalidades do
componente.
A seguir, vemos uma descrição sucinta das fases e atividadesque constituem o método
FCT.

2.4 O Método FCT 17
2.4.1 Planejamento
A etapa de planejamento de teste do método FCT é iniciada logoapós a análise de requi-
sitos do componente e consiste na tomada de decisões relativas à atividade de teste a partir
dos artefatos produzidos pela análise de requisitos e dos recursos disponíveis. Estas decisões
se concentram em que partes do componente serão testadas e noquanto cada parte deverá ser
testada. Como o teste exaustivo nem sempre é passível de ser realizado frente aos recursos
disponíveis, é necessário aplicar uma técnica sistemáticaque ajude a selecionar um subcon-
junto das funcionalidades. Para tanto, é proposta a utilização da técnica de análise de riscos
discutida em[MS01].
O objetivo principal da análise de risco é identificar o riscoque cada caso de uso oferece
à conclusão do projeto. A análise de risco envolve três tarefas: identificar os riscos relativos
a cada caso de uso, quantificar estes riscos e produzir uma lista dos casos de uso, ordenada
pelo grau de risco.
A quantificação dos riscos pode variar de um projeto para outro. Ela deve ter níveis
suficientes para separar os casos de uso em grupos de tamanho razoável. De uma maneira
geral, podem ser considerados 3 graus de risco: baixo, médioe alto. A idéia é que os
casos de uso que se encaixam no grau mais alto de risco recebamuma atenção especial e,
conseqüentemente, um maior número de casos de teste.
Ao final desta fase, o plano de teste do componente deverá estar concluído, indicando
quantos casos de teste deverão ser desenvolvidos para cada caso de uso.
2.4.2 Especificação dos Testes
A especificação dos testes é a fase do método FCT em que são gerados os modelos de
teste a partir dos quais são derivados os casos de teste, oráculos e dados de teste. Os modelos
de teste são gerados a partir da especificação do componente,que contém informações im-
portantes sobre as funcionalidades a serem fornecidas pelomesmo. Esta fase é composta por
três etapas:Seleção de Casos de Teste, Geração de OráculoseSeleção de Dados de Teste.

2.4 O Método FCT 18
Seleção de Casos de Teste
Nesta etapa são selecionados os casos de teste a ser desenvolvidos para o componente.
Como dito anteriormente, o teste exaustivo é quase sempre impossível de ser realizado frente
aos recursos disponíveis. Isto leva à necessidade de selecionar um subconjunto dos casos de
teste possíveis que irão ser efetivamente desenvolvidos e testados. A análise de riscos rea-
lizada durante o planejamento diz quantos cenários de cada funcionalidade do componente
serão testados, mas não indica quais são esses cenários. Para preceder esta seleção, é usada
uma combinação de duas técnicas de teste existentes, TOTEM (Testing Object-orienTed sys-
tEms with the unified Modeling language) [BL01] e Cleanroom[PTLP99].
A técnica TOTEM propõe que os diagramas de seqüência que descrevem os cenários de
uso de uma funcionalidade, sejam expressos como expressõesregulares, uma forma mais
compacta e analisável dos mesmos. O alfabeto dessas expressões são os métodos públicos
dos objetos presentes nos diagramas. As expressões são então constituídas de termos que
apresentam o formatoOperacaoClasse, denotando qual é a operação que está sendo executada
e a que classe esta operação pertence. O método FCT faz uso da técnica TOTEM para derivar
expressões regulares a partir de cada cenário de uso das funcionalidades do componente e,
a partir da disjunção das expressões dos cenários, obtém umaúnica expressão regular para
cada funcionalidade. Assim, a expressão regular para as funcionalidades segue o formato:
<Exp_Cenario_1> ∨ <Exp_Cenario_2> ∨ ... ∨ <Exp_Cenario_n>.
De posse das expressões regulares das funcionalidades do componente, é feita a apli-
cação da técnica Cleanroom. Esta técnica de teste propõe a construção de um modelo de
uso do sistema que represente todos os possíveis usos do mesmo e suas probabilidades de
ocorrência. Este modelo é expresso normalmente por meio de um grafo direcionado, onde
um conjunto de estados são conectados através de arcos de transição. Cada arco representa
um estímulo para o sistema, que o faz mudar de estado, e possuium valor de probabilidade
associado. Os casos de teste são gerados percorrendo-se o modelo, partindo-se do seu estado
inicial até o estado final e a seqüência de estímulos que leva osistema do seu estado inicial
ao estado final, através de um determinado caminho no modelo,é definida baseando-se nas
probabilidades das transições.
O método FCT determina que seja construído um modelo de uso para cada expressão
regular e, conseqüentemente, para cada funcionalidade do componente, de forma que cada

2.4 O Método FCT 19
estímulo seja correspondente a um termo e cada caminho corresponda exatamente a uma
cláusula da expressão regular da funcionalidade. As probabilidades do modelo de uso são
atribuídas a partir da análise de risco realizada na etapa deplanejamento. Na Figura 2.3,
é apresentado um exemplo de modelo de uso gerado para uma funcionalidade denominada
Fazer Reserva. Como pode ser visto, o modelo de uso possui cinco caminhos distintos, o
que indica que a funcionalidade em questão possui cinco cenários de uso.
2
0
1
3
(Gerenciador de
Hoteis.getHotel, 1)
(Gerenciador de
Hoteis.fazerReserva, 1)
4
5
6 7
8
9
(Hotel inexistente, 0.1)(Hotel.fazerReserva, 0.9)
(Hotel.getTipoQuarto, 1)
(Tipo quarto inexistente, 0.2)
(Hotel.isPeriodoReservaOk, 0.8)
(Quarto indisponivel, 0.5)
(Periodo Invalido, 0.1)
(Hotel.verificarDisponibilidade, 0.9)
(Hotel.gerarCodReserva, 0.5)
(Reserva realizada com sucesso, 1)
(Reserva.Reserva, 1)
Figura 2.3: Exemplo de Modelo de Uso de Método FCT
Uma vez construído o modelo de uso da funcionalidade, a seleção dos casos de teste
é feita, segundo as diretrizes da técnica Cleanroom, até o número de casos de teste a ser
desenvolvidos para a funcionalidade em questão, de acordo com as decisões tomadas na fase
de planejamento do método.
O processo de seleção do método FCT é bastante sistemático. No entanto, estudando
a técnica TOTEM, observamos que ela realiza apenas a geraçãode casos de teste e que o
próprio algoritmo apresentado pela técnica para a conversão dos diagramas de seqüência
em expressões regulares utiliza um grafo para tanto. Dessa forma, para efeito de seleção
de casos de teste, o uso de expressões regulares é absolutamente dispensável uma vez que
os modelos de uso da técnica Cleanroom, que são grafos, podemser gerados diretamente a

2.4 O Método FCT 20
partir dos diagramas de seqüência. Além disso, a aplicação da técnica Cleanroom apresenta
o problema da seleção de casos de teste repetidos, uma vez queos casos de teste selecionados
não são desconsiderados a cada nova seleção, o que pode resultar em um conjunto de casos
de teste ineficiente.
Geração de Oráculos
Para realizar a geração dos oráculos, o método FCT novamentefaz uso da técnica
TOTEM. A técnica propõe que seja construída uma tabela de decisão para cada expressão
regular que representa os cenários de uso selecionados nas funcionalidades do componente.
Esta tabela deve conter as condições de realização do uso e asações que serão tomadas pelo
componente diante da sua ocorrência. A principal fonte de informação para construção desta
tabela de decisão são as pré e pós-condições definidas para asoperações das classes que im-
plementam as funcionalidades das interfaces do componente. Para cada cláusula da expres-
são regular é necessário identificar suas condições de execução e expressá-las em OCL. O
próximo passo é definir, também em OCL, que mudanças de estadoocorrem no componente
com a execução do caso de uso. Além disso, deve-se identificartambém quais mensagens
são retornadas para o ator do caso de uso.
Na Tabela 2.1, é apresentado um exemplo de tabela de decisão gerada para uma funcio-
nalidade com cinco cenários de uso selecionados. Cada cenário na tabela representa uma
cláusula da expressão regular correspondente. Para cada umdesses cenários são associadas
as condições de execução (A-E), as mensagens retornadas para o usuário após sua execução
(I-V) e a indicação se a sua execução causa ou não uma mudança de estado no componente.
As informações coletadas durante esta etapa do processo servirão de base para a imple-
mentação dos oráculos e poderão auxiliar na seleção dos dados de teste.
Este processo, embora sistemático, é de difícil implementação, uma vez que o resultado
dos testes só pode ser determinado após uma consulta à tabelapara verificar se a execução
de um determinado cenário produziu a mensagem de saída e a mudança de estado esperadas,
o que compromete a automação da posterior atividade de construção dos casos de teste.
Além disso, na construção das tabelas de decisão são consideradas apenas as pré e pós-
condições OCL dos cenários. Contudo, tanto para as condições de execução dos cenários
quanto para a verificação de mudança de estado, as invariantes da classe que especifica a

2.4 O Método FCT 21
Condições Ações
Mensagem Mudança
de Estado
Cenários A B C D E I II III IV V
1 X X Não
2 X X Não
3 X X Não
4 X X Não
5 X X Sim
Tabela 2.1: Exemplo de Tabela de Decisão do Método FCT
funcionalidade também devem ser consideradas uma vez que estas são pré e pós-condições
implícitas[MS01].
Seleção de Dados de Teste
A seleção de dados de teste significativos, i.e. que sejam capazes de revelar comporta-
mentos anômalos em uma dada funcionalidade, é ainda um dos maiores problemas enfren-
tados pelos testadores desoftware. Além disso, esta é uma atividade bastante subjetiva e
poucas são as técnicas sistemáticas existentes. Em função disso, o método FCT se limita a
fornecer orientações sobre como selecionar os dados necessários para a execução dos casos
de teste.
Para realizar a seleção dos dados de teste, o método propõe a utilização da técnica de
particionamento por equivalência[Som03; Bei90]. Essa técnica parte do princípio que os
dados de entrada de um programa podem ser agrupados em classes que apresentam caracte-
rísticas comuns e que o programa se comporta da mesma forma para todos os membros de
uma mesma classe. Usando essa técnica, o trabalho de selecionar os dados de teste consiste
em identificar as partições e escolher dados particulares dentro de cada partição. A iden-
tificação das partições deve ser baseada na especificação e documentação dosoftware. No
caso do método FCT, são usadas as condições de execução definidas durante a geração dos
oráculos para identificar partições adequadas ao teste. A escolha dos dados tanto pode ser
feita de forma aleatória, como de forma mais direcionada, a fim de obter dados mais prová-

2.4 O Método FCT 22
veis de revelar erros. Na escolha direcionada consideramosos dados encontrados nos limites
da partição, por representarem normalmente valores atípicos, e dados considerados típicos,
encontrados no meio da partição.
Embora a seleção dos dados seja realizada através da técnicade particionamento por
equivalência, reconhecidamente uma das mais eficientes, a falta de um mecanismo sistemá-
tico para a identificação das partições a partir das condições de execução dos cenários torna
esta atividade bastante subjetiva uma vez que a escolha de umconjunto de dados eficiente é
intimamente dependente da experiência de quem está realizando a atividade e do seu conhe-
cimento sobre o domínio de aplicação do componente.
2.4.3 Construção, Execução e Análise de Resultados
Nesta etapa, as informações geradas até o momento são utilizadas para implementar os
casos de teste e oráculos. As tabelas de decisão, que foram construídas durante a geração dos
oráculos, são especialmente úteis. Para facilitar a construção das classes de teste, o método
FCT propõe o uso da ferramenta JUnit1 para implementar os casos de teste e oráculos. A
ferramenta é utilizada para executar os testes e analisar osresultados obtidos.
Cada funcionalidade dá origem a uma classe de teste que contém um método para testar
cada cenário definido na tabela de decisão da mesma. Assim, para cada cenário, são im-
plementadas, no método correspondente, as condições de execução definidas na tabela. Por
fim, a mensagem retornada e a ocorrência ou não de mudança de estado são verificadas, de
acordo com as definições da tabela, para indicarmos se o testeobteve sucesso ou não.
2.4.4 Empacotamento
O método FCT define, como última atividade, o empacotamento ea distribuição dos tes-
tes produzidos juntamente com o componente desenvolvido demaneira a contribuir para a
sua re-avaliação por parte do cliente, i.e. dentro de um contexto de uso e integração especí-
fico. Entretanto, o formato de empacotamento a ser utilizadoe a forma de disponibilização
deste pacote não são definidos pelo método.
1http://www.junit.org

2.5 Considerações Finais 23
2.5 Considerações Finais
Neste capítulo fornecemos a fundamentação teórica necessária para a compreensão do
trabalho aqui proposto. Foram apresentados os principais conceitos e termos relacionados a
teste desoftware, assim como as diferentes estratégias de teste empregadas para a detecção
de defeitos em sistemas desoftware. Com relação a componentes desoftware, foi apresen-
tada a definição e as características dos componentes abordados neste trabalho, as vantagens
e desvantagens do desenvolvimento baseado em componentes,além das duas perspectivas
sob as quais os componentes precisam ser testados. Por fim, apresentamos o método FCT,
no qual este trabalho se baseia. Foram descritas as suas fases e atividades assim como as téc-
nicas empregadas na sua definição. Também foi feita uma análise dos principais problemas
do método que dificultam a sua aplicação de maneira automática.
No próximo capítulo, é feita a apresentação do método AFCT, um método de teste auto-
mático que foi concebido a partir das idéias apresentadas nométodo FCT.

Capítulo 3
O Método AFCT
Embora concebido para potencializar a automação, o método FCT [dF03] ainda apre-
sentava muitas atividades subjetivas e/ou pouco sistemáticas que, apesar de não representar
nenhum problema para sua aplicação manual, consistia em um grande empecilho do ponto
de vista de automação. Em função disso, definimos o método de teste AFCT, uma nova pro-
posta fortemente baseada em[dF03], cujas atividades foram projetadas segundo algoritmos
e técnicas pré-definidas com o objetivo de possibilitar a automação a partir do desenvolvi-
mento de uma ferramenta de suporte. Neste capítulo será apresentado o método de teste
proposto abordando desde os artefatos da especificação dos componentes necessários a sua
aplicação, até a descrição de suas atividades e algoritmos.
3.1 Introdução
O método AFCT (Automatic Functional Component Testing) procede a verificação de
componentes de software na perspectiva do fornecedor, fazendo uso da especificação des-
tes componentes, sob a forma de artefatos UML e restrições OCL produzidos nas fases de
análise e projeto dos processos de desenvolvimento, para derivar casos de teste, oráculos e
dados de teste, e, a partir destas informações, proceder a geração e a execução de código
de teste assim como a interpretação dos resultados obtidos.O método determina ainda, que
os artefatos de teste gerados sejam disponibilizados juntamente com os componentes forne-
cidos para favorecer a atividade de teste na perspectiva do cliente, ou seja, no momento da
montagem da aplicação[Mac00].
24

3.1 Introdução 25
As atividades do método AFCT, como apresentado em[BAMF04b], estão agrupadas em
5 fases:
• Planejamento de Teste, onde são tomadas decisões relativas ao processo de teste;
• Especificação de Teste, onde são derivados os casos de teste, oráculos e dados que
constituem a especificação dos testes;
• Construção, que é responsável pela geração do código de teste;
• Empacotamento, onde o código de teste é compilado e empacotado para distribuição;
• Execução e Análise de Resultados, que realiza a execução e análise de resultados dos
códigos de teste gerados sobre as implementações dos componentes.
A fase de Planejamento de Teste do método AFCT é realizada de forma idêntica à apre-
sentada na definição do método FCT, no Capítulo 2, o que torna desnecessária a sua re-
apresentação. As atividades que constituem as demais fasessão apresentadas ao longo deste
capítulo.
O método AFCT foi concebido para ser utilizado paralelamente às metodologias de de-
senvolvimento de sistemas baseados em componentes (SBC), sem, no entanto, estar asso-
ciado a nenhuma em especial. Para prover esta independência, procuramos definir a sua
integração ao longo do processo de desenvolvimento, a partir de atividades genéricas nor-
malmente realizadas e de artefatos comumente desenvolvidos por estas metodologias. Dessa
forma, constituímos uma metodologia abstrata que descreveas atividades e a especificação
necessárias à aplicação do método de teste. Estas atividades e os artefatos que compõem a es-
pecificação dos componentes são apresentados na Figura 3.1 que descreve como é realizada
a integração das atividades do método de teste ao longo do processo de desenvolvimento de
SBC.
Inicialmente, para cada componente a ser utilizado na aplicação, é feita a análise dos
requisitos. A partir desta análise, são produzidos oDiagrama de Funcionalidades, um dia-
grama de casos de uso que especifica as funcionalidades dos componentes e os relaciona-
mentos entre elas, e oModelo Conceitual, um diagrama de classe onde são representados os
conceitos envolvidos no domínio de problema para o qual o componente está sendo desen-
volvido. De posse destes artefatos, a atividade de planejamento do método de teste já pode

3.1 Introdução 26
Planejamento de Teste
Especificação deTeste e Construção
Empacotamento, Execuçãoe Análise de Resultados
Montagem
Diagrama de Funcionalidades
Requisitos
Modelo Conceitual
Implementação
Materialização
Modelo de Informação
Diagramas de Cenário de Uso
Contratos
Modelagem
Figura 3.1: Integração entre Metodologias de Desenvolvimento de SBC e o Método de Teste
ser realizada. Após o levantamento dos requisitos do componente, é feita a sua modelagem,
que engloba as fases de análise e projeto do processo de desenvolvimento. Nesta etapa são
produzidos oModelo de Informação, um diagrama de classe que especifica o conjunto de
elementos (classes e associações) que precisam ser explicitados para possibilitar a utilização
do componente, osDiagramas de Cenário de Uso, diagramas de seqüência que especificam
os cenários de uso das funcionalidades do componente, e osContratos, restrições OCL que
descrevem os contratos de uso (pré e pós-condições) das operações da(s) interface(s), assim
como das invariantes de classe do componente. Estes artefatos são utilizados para a realiza-
ção das fases de especificação de teste e construção do métodoAFCT. Uma vez concluída a
modelagem do componente, é realizada a sua materialização,que pode se dar tanto a partir
da implementação de um componente novo como através da aquisição de um componente
previamente desenvolvido que esteja de acordo com a modelagem realizada. De posse da
implementação do componente, o código de teste gerado pela fase de construção do método
é compilado, e são realizadas as fases de empacotamento e execução e análise de resultados,
concluindo assim o teste do componente na perspectiva do fornecedor. A última etapa do
processo de desenvolvimento é a montagem da aplicação a partir dos componentes desen-
volvidos e testados individualmente.
Conforme descrito, os artefatos necessários a aplicação dométodo AFCT, que são pro-
duzidos ao longo do processo de desenvolvimento, nada mais são do que adaptações de arte-

3.1 Introdução 27
fatos comumente desenvolvidos pelas metodologias de desenvolvimento baseadas na lingua-
gem UML. No entanto, para possibilitar a definição de um método passível de automação,
foi preciso estabelecer a forma como estes artefatos devem ser construídos, principalmente
no que diz respeito à associação entre eles, uma vez que, do ponto de vista de automação, é
impossível detectar a real associação entre os artefatos sem que essa informação seja expli-
citamente fornecida. Para tanto, a abordagem de especificação proposta, que assemelha-se a
apresentada por Larman[Lar98], consiste na construção dos artefatos da seguinte maneira:
• No diagrama de funcionalidades, cada funcionalidade da(s)interface(s) do com-
ponente deve ser especificada como um caso de uso que terá comoator, o sis-
tema/componente que faz uso da funcionalidade correspondente.
• No modelo de informação do componente, construído a partir do modelo conceitual,
deverão ser especificadas todas as informações necessáriasà utilização do componente
além das restrições OCL correspondentes às invariantes de classe.
• Para explicitar a relação existente com os casos de uso (funcionalidades) que descre-
vem, os diagramas de cenário de uso deverão ser nomeados de acordo com o formato:
<nome_do_caso_de_uso>‘->’<nome_do_cenario> .
• Nestes diagramas de seqüência, o primeiro objeto deverá seruma instância do sis-
tema/componente que é ator do caso de uso correspondente a funcionalidade, e o se-
gundo uma instância da classe do componente que fornece a funcionalidade. Além
disso, todos os objetos devem ter o tipo definido e presente nomodelo de informação
do componente.
• As mensagens dos diagramas de seqüência devem ser numeradasde acordo com sua
ordem de execução e, ou corresponder diretamente à chamada da operação no objeto
receptor ou especificar o retorno de uma chamada. A última mensagem do diagrama
deverá ser de retorno e corresponderá a mensagem de saída do cenário. Nos cenários
que terminem com exceção, esta deve ser especificada na mensagem de saída. Para os
demais cenários, a mensagem de saída deverá ser vazia ou conter aString ‘return’
seguida do valor de retorno da funcionalidade (caso haja um).

3.2 Especificação de Teste 28
• As restrições OCL que descrevem os contratos de uso deverão ser inseridas, sob a
forma de comentários, nos diagramas de cenário de uso, especificando suas condições
de execução e as mudanças de estado esperadas. Embora esta não seja a maneira mais
comum para a especificação de restrições OCL, é a única forma de associá-las aos
cenários de uso e, ao mesmo tempo, possibilitar que as especificações sejam cons-
truídas em ferramentas de modelagem UML simples que disponham do mecanismo
de notas de comentário. Estas restrições, respectivamente, pré e pós-condições, terão
como contexto a operação correspondente à funcionalidade em questão na interface
do componente. Para diferenciar de comentários comuns, cada um desses comentá-
rios deverá ser iniciado com aString ‘ <<constraint >>’ seguido da restrição OCL
(‘context...’ ).
Nas seções seguintes, são descritas as atividades que constituem cada uma das fases do
método AFCT assim como os algoritmos e técnicas utilizados em suas definições.
3.2 Especificação de Teste
A fase de especificação de testes do método AFCT consiste na derivação de casos de
teste, oráculos e dados de teste a partir da especificação do componente. É nesta fase que
reside a maior contribuição do método AFCT para a automação do processo de teste. Cada
uma das suas etapas foram sistematicamente definidas e algoritmos foram propostos para
possibilitar a sua automação. Nas subseções seguintes, vemos a definição das atividades
realizadas nesta fase assim como dos algoritmos e técnicas propostos.
3.2.1 Seleção dos Casos de Teste
Ao estudarmos a atividade de seleção de casos de teste do método FCT e, conseqüente-
mente, as técnicas TOTEM[BL01], responsável pela geração dos casos de teste, e Clean-
room[PTLP99], que realiza a seleção propriamente dita, observamos que haviam dois pontos
falhos na aplicação conjunta das técnicas. A técnica TOTEM define um procedimento para
a conversão dos diagramas de seqüência em expressões regulares que são utilizadas pelo
método para a construção dos modelos de uso (grafos) necessários à aplicação da técnica

3.2 Especificação de Teste 29
Cleanroom. No entanto, segundo o algoritmo de conversão apresentado na técnica TOTEM,
os diagramas são convertidos em grafos a partir dos quais sãogeradas as expressões regula-
res, o que demonstra a possibilidade de conversão dos diagramas diretamente em modelos
de uso. Além disso, a técnica TOTEM só realiza esta conversãoporque os casos de teste
precisam ser representados sob a forma de expressões regulares para serem utilizados pelas
demais atividades da técnica. Em função disso, procuramos simplificar este processo criando
um algoritmo para a conversão direta dos diagramas de seqüência para o modelo de uso. Este
algoritmo é apresentado na Figura 3.2.
UseModel createUseModel(Collection scenarioDiagrams){
UseModel um new UseModel();Collection stimuli;SequenceDiagram d;for each d in scenarioDiagrams{
stimuli sortStimuliByName(d.stimuli);
int numSt stimuli.size;for each s in stimuli{
if (numSt > 1){um.addAction(toUseModelAction(s));
}else{
um.addFinalAction(toUseModelAction(s));}
numSt numSt-1;}
}return um;
}
¬
¬
¬
¬
String toUseModelAction(Stimulus st){
Object sender st.sender;
}
¬
¬
¬
¬
¬
Object receiver st.receiver;
Action action st.dispatchAction;String actionSeparator;if (action is ReturnAction){
actionSeparator '|';}else{
actionSeparator '.';}return sender.instanceClassifier.name + '->' +
receiver.instanceClassifier.name +actionSeparator + action;
Figura 3.2: Algoritmo para a Criação de Modelos de Uso
A funçãocreateUseModelrecebe como parâmetro uma coleção de diagramas de seqüên-
cia, que especificam os cenários de uso da funcionalidade correspondente, e produz como
saída o modelo de uso da funcionalidade. Cada diagrama de seqüência possui, além do
nome, uma coleção de objetos, do tipoObject, e uma coleção de mensagens, do tipoStimu-
lus. Os objetos possuem um nome e um classificador (instanceClassifier), que determina o
tipo do objeto no modelo UML. Cada mensagem, por sua vez, é composta por um objeto
transmissor (sender), um objeto receptor (receiver) e uma ação (do tipoAction). O modelo
de uso (UseModel) nada mais é do que um grafo dirigido com dois vértices pré-definidos, o
inicial e o final, no qual cada vértice possui uma coleção de arcos de saída e cada arco de
saída possui uma ação, uma probabilidade de execução, que reflete as decisões tomadas na
fase de planejamento de testes, e uma referência para o vértice destino.

3.2 Especificação de Teste 30
O algoritmo consiste em, para cada mensagem de cada diagramade seqüência, inserir a
ação correspondente no modelo de uso. Essas ações vão sendo inseridas a partir do vértice
inicial e de tal forma que, para cada ação diferente, é criadoum novo vértice no modelo de
uso, que receberá a ação inserida e a partir do qual serão inseridas as novas ações até que a
ação correspondente a última mensagem de cada diagrama de seqüência seja inserida, tendo
como destino o vértice final. Para tanto, é usada a função auxiliar toUseModelActionque é
responsável por converter as mensagens dos diagramas de seqüência para os formatos que
definimos para a ação do modelo de uso:
<tipo_do_sender>‘->’<tipo_do_receiver>‘.’<acao_da_m ensagem_de_chamada>
<tipo_do_sender>‘->’<tipo_do_receiver>‘|’<acao_da_m ensagem_de_retorno>
Com o algoritmo, definimos um procedimento automático e maissimplificado para a
construção dos modelos de uso. Na Figura 3.3, vemos um exemplo de modelo de uso cons-
truído para uma funcionalidade denominadaFazer Reservaa partir da aplicação do algo-
ritmo. Nele podemos destacar a utilização de um formato bem definido para todas as ações
e a introdução de informações extras, a exemplo do tipo do objetosender, que não estavam
disponíveis a partir das expressões regulares produzidas pela técnica TOTEM.
03
7
8
1
9
6
2
4
5(Hotel−>Reserva.Reserva(), 1)
(SistemaReservas−>GerenciadorHoteis.fazerReserva(), 1)(GerenciadorHoteis−>GerenciadorHoteis.getHotel(), 1)
(GerenciadorHoteis−>SistemaReservas|Hotel inexistente, 0.1)
(Hotel−>SistemaReservas|Periodo invalido, 0.1)
(Hotel−>SistemaReservas|Quarto indisponivel, 0.5)
(Hotel−>Hotel.verificarDisponibilidade(), 0.9)
(Hotel−>Hotel.gerarCodReserva(), 0.5)
(Hotel−>SistemaReservas|Tipo de quarto inexistente, 0.2)
(GerenciadorHoteis−>Hotel.fazerReserva(), 0.9)
(Hotel−>Hotel.getTipoQuarto(), 1)
(Hotel−>Hotel.isPeriodoReservaOk(), 0.8)
(Reserva−>SistemaReservas|Reserva realizada com sucesso, 1)
Figura 3.3: Formato de Modelo de Uso do Método AFCT

3.2 Especificação de Teste 31
Observando a mesma figura, vemos que, tanto o conjunto de diagramas de seqüência
quando o modelo de uso, apresentam a mesma expressividade, ou seja, é possível obter os
diagramas de seqüência a partir do modelo de uso correspondente. Isto pode ser comprovado
com o algoritmo apresentado na Figura 3.4.
Collection toScenarioDiagrams(UseModel um){
Collection scenarios new Collection();
}
¬
¬
¬
¬
¬
Collection paths um.paths;Collection actions;SequenceDiagram diagram;Stimulus st;Path p;for each p in paths{
diagram new SequenceDiagram();
actions p.actions;for each a in actions{
st toStimulus(a);diagram.addObject(st.sender);diagram.addObject(st.receiver);diagram.addStimulus(st);
}scenarios.add(diagram);
}return scenarios;
Figura 3.4: Algoritmo para a Criação de Diagramas de Seqüência a partir de Modelos de
Uso
Neste algoritmo, o modelo de uso, recebido como parâmetro, dá origem a uma coleção de
diagramas de seqüência representando os cenários de uso da funcionalidade correspondente.
O algoritmo consiste na criação de um diagrama de seqüência para cada caminho (path) do
vértice inicial ao vértice final do modelo de uso. Para tanto,é feito uso do algoritmo auxiliar
toStimulus(), que não foi exibido porque apresenta a funcionalidade inversa dotoUseModel-
Action(), ou seja, recebe umString no formato da ação do modelo de uso e produz como
resultado o objetoStimuluscorrespondente.
O outro problema detectado ao analisarmos a atividade de seleção de casos de teste do
método FCT está relacionado ao mecanismo de seleção da técnica Cleanroom. Como os
caminhos selecionados no modelo de uso não são de alguma forma diferenciados dos cami-
nhos ainda não selecionados, o processo de seleção pode resultar em um conjunto de casos
de teste com repetições e, portanto, ineficiente. Dessa forma, desenvolvemos um algoritmo
de seleção baseado nas diretrizes da técnica Cleanroom, i.e. os caminhos são selecionados

3.2 Especificação de Teste 32
a partir da aplicação de uma função de distribuição de probabilidade ao caminhar no mo-
delo de uso do vértice inicial ao vértice final, mas com o diferencial de ignorar caminhos já
selecionados. Esse algoritmo é apresentado na Figura 3.5.
Collection selectPaths(UseModel um, Integer n){
}
selectPath(Path p, Node startNode){
}
Collection result new Collection();Path path;Integer i;for each i in 1..n{
path new Path();selectPath(path, um.firstNode);result.add(path);
}return result;
Collection links selectableLinks(startNode.links);if (not links.size = 0){
Real[links.size] probs;Link l;
Integer i 0;for each l in links{
probs[i] l.probability;
i i + 1;}
Integer position selectPosition(probs);
Link selectedLink links.get(position);P.addAction(selectedLink.label, probs[position]);
Node nodeTo selectedLink.nodeTo;selectPath(p, nodeTo);if (selectableLinks(nodeTo.links).size = 0){
l.visited <- true;}
}
¬
¬
¬
¬
¬
¬
¬
¬
¬
Collection selectableLinks(Collection links){
}
Integer selectPosition(Real[] probs){
}
fixProbs(Real[] probs){
}
Collection result new Collection();for each l in links{
if (not l.visited){result.add(l);
}}return result;
fixProbs(probs);Real[probs.length] storedProbs;
storedProbs[0] probs[0];Integer i;for each i in 1..probs.length{
storedProbs[i] storedProbs[i-1] + probs[i];}
Real randomNumber random();
Integer j 0;while (randomNumber > storedProbs[j]){
j j + 1;}return j;
Real total 0.0;Integer i;for each i in 0..probs.length{
total total + probs[i];}if (total <> 1){
for each i in 0..probs.length{
probs[i] probs[i] + ( (probs[i] / total) *(1 - total) );
}}
¬
¬
¬
¬
¬
¬
¬
¬
¬
Figura 3.5: Algoritmo para a Seleção de Caminhos em Modelos de Uso
A seleção dos casos de teste começa com a execução do algoritmo selectPathsque recebe
como parâmetros o modelo de uso (um) e o númeron de caminhos a serem selecionados no
modelo de uso. Este algoritmo consiste em caminharn vezes no modelo de uso e, a partir do
vértice inicial, selecionar um caminho por vez, o que é feitopelo algoritmoselectPath().
Para entender o funcionamento do algoritmoselectPath(), precisamos, primeiramente,

3.2 Especificação de Teste 33
definir o conceito de arco visitado. Um arco é dito visitado quando todos os caminhos a
partir dele já foram selecionados. Com a introdução desta característica no modelo de uso,
passamos a ter o conhecimento dos caminhos já selecionados apartir de um determinado
vértice, evitando, assim, a seleção de caminhos repetidos.Essa verificação é feita pela função
selectableLinksque recebe como parâmetro a coleção de arcos que saem de um determinado
vértice e retorna a coleção dos que ainda não foram visitadose que, portanto, estão aptos a
ser selecionados.
A partir das probabilidades dos arcos não visitados do vértice corrente (startNode), caso
existam, é criado um array que é utilizado pela funçãoselectPosition(). Esta função faz a
escolha de uma posição no array e, conseqüentemente, do arcocorrespondente, baseada na
distribuição das probabilidades. Para proceder tal escolha é preciso, primeiramente analisar
se a soma das probabilidades é 100% e, caso não seja, redistribuir de forma proporcional a
probabilidade complementar entre as probabilidades do array. Esse procedimento, realizado
pela funçãofixProbs(), é necessário pois, como os arcos visitados são desconsiderados pelo
processo de seleção, a soma das probabilidades dos arcos concorrentes a ele é inferior a
100%, existindo assim a possibilidade de nenhum dos arcos concorrentes ser selecionado.
Voltando para a funçãoselectPosition(), uma vez que o array de probabilidades é com-
pleto, para proceder a escolha de um índice baseado na distribuição das probabilidades,
criamos um segundo array de mesmo número de elementos no qualcolocamos as probabili-
dades acumuladas do array de probabilidades (probs), de tal forma que o primeiro elemento
do novo array (storedProbs) será a primeira probabilidade do array de probabilidades ere-
presentará a faixa de probabilidades de 0% até esse valor, e oúltimo elemento será 1, repre-
sentando a faixa de probabilidades do valor do penúltimo elemento até 100%. Em seguida,
geramos um número real aleatório entre 0 e 1 e verificamos a qual faixa de probabilidades
do array esse número pertence. O índice correspondente a essa faixa de probabilidade será
então a posição selecionada.
Uma vez selecionada a posição do array de probabilidades e, conseqüentemente, o arco
correspondente, na funçãoselectPath(), o rótulo contendo a ação deste é inserido no caminho
parcial (p) e a seleção do caminho continua a partir do vértice destino do arco selecionado.
Ao final da função, quando um caminho completo do vértice atual ao final tiver sido selecio-
nado, se todos os arcos do vértice destino do arco selecionado já tiverem sido visitados, então

3.2 Especificação de Teste 34
o arco selecionado também será marcado como visitado, o que,como vimos, impossibilita a
sua seleção em novos caminhos.
Com esses algoritmos estabelecemos a automação da atividade de seleção de casos de
teste a partir das informações do modelo UML. Uma última ressalva deve ser feita com
relação às probabilidades das ações do modelo de uso. Como sabemos, essa informação é
obtida a partir das decisões tomadas na fase de planejamento, o que torna a atribuição destas
probabilidades uma atividade manual, uma vez que depende dainteração humana. Assim,
para possibilitar que a atividade de seleção seja executadade forma totalmente automática,
propomos atribuir, por padrão, probabilidades iguais a arcos concorrentes do modelo de uso.
Dessa forma, caso não haja uma interação para alterar as probabilidades, a seleção se dará
de forma aleatória, segundo uma distribuição uniforme.
3.2.2 Geração de Oráculos
Como vimos no Capítulo 2, a atividade de geração de oráculos do método FCT também
é baseada na técnica TOTEM. A técnica propõe a construção de uma tabela de decisão para
cada expressão regular obtida na geração dos casos de teste.A idéia consiste em associar,
para cada termo da expressão (cenário de uso), sua condição de realização e as ações que
serão tomadas pelo componente diante da sua ocorrência, quepor sua vez são compostas
pela mensagem de saída esperada e pela verificação da ocorrência de mudança de estado do
componente. Este processo, embora sistemático, é de difícil implementação, o que compro-
mete a automação não só desta atividade mas também da fase posterior de construção do
código de teste. Além disso, a técnica TOTEM não considera asinvariantes definidas para a
funcionalidade do componente como parte da especificação das condições de realização dos
usos e da ocorrência de mudança de estado do componente.
Em função disso, definimos que a atividade de geração de oráculos do método AFCT
seria realizada a partir de um mapeamento sistemático das restrições OCL, que expressam
as pré e pós-condições dos cenários de uso (incluindo as invariantes), diretamente para frag-
mentos de código fonte. As mensagens de saída, por sua vez, são mapeadas para exceções
esperadas, ou seja, que deverão ser lançadas durante a execução da funcionalidade em decor-
rência da realização do cenário de uso correspondente. Os fragmentos de código resultantes,
que deverão ser incorporados ao código de teste a ser construído, são, basicamente, méto-

3.2 Especificação de Teste 35
dos responsáveis por determinar, em tempo de execução, se a condição expressa na restrição
OCL é verdadeira considerando-se o estado atual do componente. Para tanto, estes métodos
devem receber, como parâmetros, uma instância da classe contexto da restrição, os parâme-
tros da operação, no caso de restrições de pré e pós-condições, além do resultado da operação
para restrições de pós-condição. Na Tabela 3.1, é apresentado o esquema geral de conversão
proposto1, enquanto que, na Figura 3.6, vemos um exemplo de conversão.
OCL context <context> [ :: <operation> ( [<op_params>] ) [:<result_type>]]
inv | pre | post<const-name> ...
Código Fonte Boolean check_<const-name>(<context> self [, <op_params>]
[, <result_type> result]) { ... }
Tabela 3.1: Esquema de Conversão de Restrições OCL para Código Fonte
context Empresa inv idadeEmpregados:
empregados forAll (p : Pessoa | p.idade >= 18)
Boolean check_idadeEmpregados(Empresa self){
Boolean result true;
Collection empregados self.empregados;Pessoa p;for each p in empregados{
if (not (p.idade >= 18)){
result false;break;
}}return result;
®
¬
¬
¬
Figura 3.6: Exemplo de Conversão de OCL para Pseudo-Código
Uma vez que OCL é uma linguagem de restrições que atua sobre asclasses e operações
de um modelo UML, para simplificar o mapeamento, a linguagem de programação a ser
utilizada na implementação destes métodos deverá ser, necessariamente, orientada a objetos.
Além disso, por motivos óbvios, deverá ser a mesma linguagemutilizada na implementação
dos casos de teste, realizada na fase de construção. Neste trabalho, realizamos o mapeamento
1Construções dentro de [ ] são opcionais.

3.2 Especificação de Teste 36
das restrições OCL para código fonte na linguagem Java, entretanto, uma vez satisfeita as
condições descritas acima, qualquer outra linguagem poderia ser usada. O mapeamento pro-
posto das construções mais usuais de OCL para um subconjuntobem definido da linguagem
Java é apresentado no Anexo A.
De posse dos métodos que constituem o oráculo de um determinado cenário, a avaliação
do resultado do teste, em tempo de execução, é feita da seguinte forma: Inicialmente é
chamado o método correspondente à pré-condição do cenário para avaliar se o teste está
apto a ser realizado. Caso esse método retornefalse, indicando falha na avaliação da pré-
condição, o teste não pode ser realizado pois o contrato do cenário de uso não está sendo
respeitado. Neste caso, não é possível informar que o teste falhou nem que passou e o
resultado é considerado indefinido. Caso, por outro lado, o método retornetrue, então o teste
será realizado e o resultado obtido vai ser utilizado na chamada do método correspondente
à pós-condição do cenário, cujo retorno, juntamente com a mensagem de saída do cenário,
caso exista, indicarão se o teste obteve sucesso ou falhou.
O uso de código fonte na representação dos oráculos gerados elimina a necessidade de um
processo de conversão para que os mesmos sejam acessados a partir do código de teste para
avaliar os resultados obtidos. Além disso, essa abordagem contribui para a flexibilização do
método no que diz respeito às linguagens de especificação de contratos e de implementação
do código de teste a serem utilizadas, desde que seja elaborado um mapeamento entre as
duas linguagens, o que, apesar de não ser um trabalho trivial, é bastante válido em função da
possibilidade de geração automática de teste proporcionada pelo método.
3.2.3 Seleção de Dados de Teste
Vimos, no Capítulo 2, que a seleção de dados de teste significativos para uma dada fun-
cionalidade constitui uma das atividades mais complexas e subjetivas de todo o processo
de teste, o que resulta na existência de poucas técnicas sistemáticas para tanto. Uma das
técnicas mais eficientes para a seleção de dados de teste é a técnica de particionamento por
equivalência[Bei90; Som03], que é utilizada pelo método FCT. No entanto, como o pro-
cesso de identificação das partições de dados, necessário à aplicação da técnica, é bastante
subjetivo e dependente de conhecimentos de domínio da aplicação, é preciso prover meios
de sistematizar esse processo para promover a automação da atividade de seleção como um
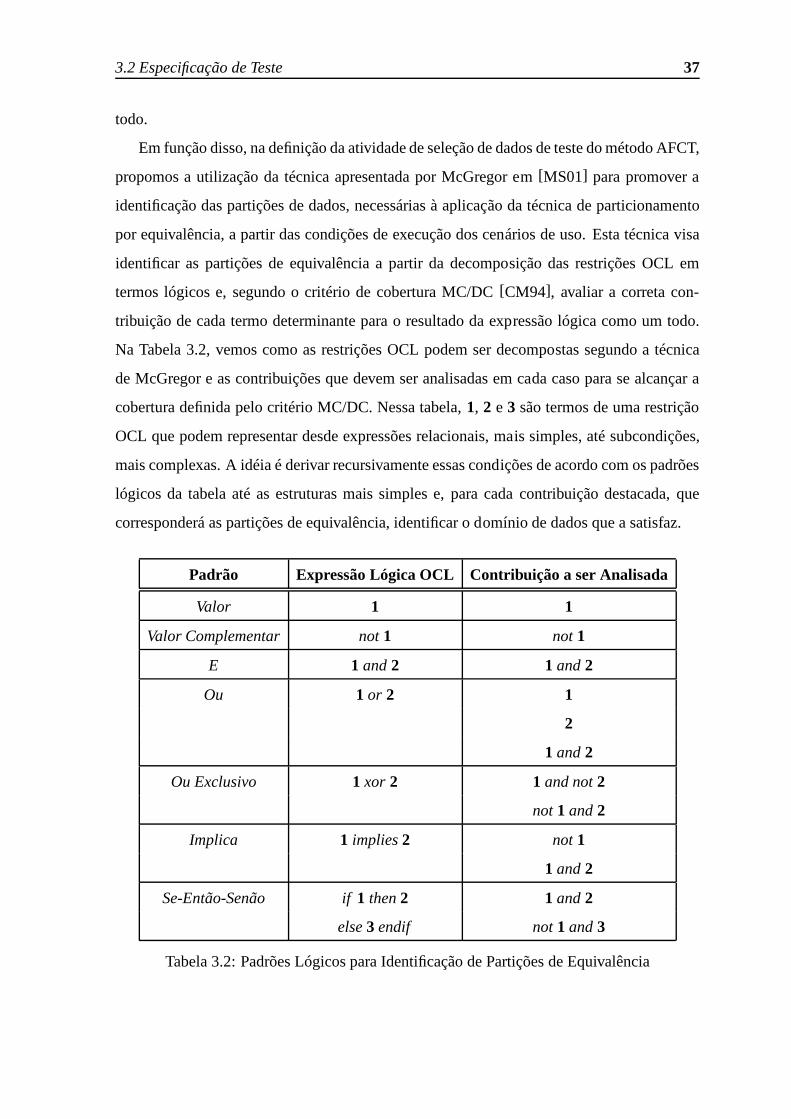
3.2 Especificação de Teste 37
todo.
Em função disso, na definição da atividade de seleção de dadosde teste do método AFCT,
propomos a utilização da técnica apresentada por McGregor em [MS01] para promover a
identificação das partições de dados, necessárias à aplicação da técnica de particionamento
por equivalência, a partir das condições de execução dos cenários de uso. Esta técnica visa
identificar as partições de equivalência a partir da decomposição das restrições OCL em
termos lógicos e, segundo o critério de cobertura MC/DC[CM94], avaliar a correta con-
tribuição de cada termo determinante para o resultado da expressão lógica como um todo.
Na Tabela 3.2, vemos como as restrições OCL podem ser decompostas segundo a técnica
de McGregor e as contribuições que devem ser analisadas em cada caso para se alcançar a
cobertura definida pelo critério MC/DC. Nessa tabela,1, 2 e 3 são termos de uma restrição
OCL que podem representar desde expressões relacionais, mais simples, até subcondições,
mais complexas. A idéia é derivar recursivamente essas condições de acordo com os padrões
lógicos da tabela até as estruturas mais simples e, para cadacontribuição destacada, que
corresponderá as partições de equivalência, identificar o domínio de dados que a satisfaz.
Padrão Expressão Lógica OCL Contribuição a ser Analisada
Valor 1 1
Valor Complementar not 1 not 1
E 1 and2 1 and2
Ou 1 or 2 1
2
1 and2
Ou Exclusivo 1 xor 2 1 and not2
not 1 and2
Implica 1 implies2 not 1
1 and2
Se-Então-Senão if 1 then2 1 and2
else3 endif not 1 and3
Tabela 3.2: Padrões Lógicos para Identificação de Partiçõesde Equivalência

3.2 Especificação de Teste 38
Uma vez identificada as partições de equivalência estabelecidas pela restrição OCL, a
seleção de dados consiste na escolha de dados limites e representativos dentro dos domínios
correspondentes a cada partição.
Para exemplificar a aplicação da atividade de seleção de dados do método AFCT, va-
mos considerar uma funcionalidadecontratar()em um componente hipotético para geren-
ciamento de uma empresa. A operação que implementa esta funcionalidade recebe, como
parâmetros, o objeto que representa a pessoa a ser contratada, o cargo a ser exercido e o nú-
mero de horas semanais. A empresa tem como política a contratação de estagiários apenas
em tempo parcial. A restrição OCL que especifica a condição deexecução para o cenário de
sucesso da funcionalidade poderia ser dada por:
context Empresa::contratar(p: Pessoa, cargo: String, hor as: Integer)
pre: if cargo=‘Estagiario’ then horas=20 else (horas >= 20 a nd horas <= 44)
endif
Aplicando-se a técnica de McGregor, observamos que a restrição se enquadra no pa-
drãoSe-Então-Senãoda Tabela 3.2. Assim1 representa o termocargo=‘Estagiario’ , 2
representa o termohoras=20 e 3 representa o termo(horas >= 20 and horas <= 44) .
Segundo a tabela, devem ser analisadas as contribuições dassubexpressões1 and2 e not 1
and3, que representam as duas maneiras possíveis de exercitar o cenário de uso em questão.
Neste momento, a técnica é aplicada de forma recursiva para cada contribuição. O primeiro
caso (1 and2) casa com o padrãoE, no qual a contribuição a ser analisada é a própria restri-
ção, o que indica que devem ser gerados dados que satisfaçam,ao mesmo tempo, os termos
1 e 2. Como ambos os termos são igualdades e envolvem variáveis diferentes (cargo e
horas ), os valores capazes de satisfazê-lo são dados pela própriaigualdade (‘Estagiario’
e20). No segundo caso (not1 and3), a expressão também pode ser vista segundo o padrãoE
(1’ and2’) em que1’ representa o termonot 1 (not cargo=‘Estagiario’ ) e2’ representa o
termo3 ((horas >= 20 and horas <= 44) ). Como vimos, o padrãoE implica na seleção
de dados que satisfaçam ambos os termos. O termo1’ (not cargo=‘Estagiario’ ) é ava-
liado segundo o padrãoValor Complementar, o que estabelece uma partição de equivalência
composta por todos os valores do tipo da variávelcargo à exceção do utilizado na expressão.
Como o tipo da variável é String, valores interessantes a serselecionados são a cadeia vazia
(‘’), que corresponde a um valor limite da partição, e um valor qualquer que seja diferente

3.3 Construção e Empacotamento dos Artefatos de Teste 39
do utilizado na expressão, por exemplo‘Cargo X’ , que representa um valor intermediário
na partição. Na avaliação do termo2’ (horas >= 20 and horas <= 44 ) mais uma vez é
aplicado o padrãoE (1” and2” ), sendo1” a subexpressãohoras >= 20 e2” a subexpressão
horas <= 44 . Neste caso, porém, como ambos os termos são referentes a umamesma va-
riável (horas ), estabelece-se uma única partição de equivalência composta pelos dados que
satisfazem, ao mesmo tempo, os dois termos. A partição estabelecida compreende o inter-
valo de valores inteiros entre20 e 44. Além desses valores, considerados críticos, também
devem ser selecionados valores intermediários, a exemplo de 30 e 40.
Dessa forma, concluímos a atividade selecionando, para a primeira forma de execução do
cenário de sucesso, o valor‘Estagiario’ para a variávelcargo e o valor20 para a variável
horas . Para a segunda forma de execução, selecionamos os valores‘’ (cadeia vazia) e
‘Cargo X’ para a variávelcargo e os valores20, 30, 40 e 44 para a variávelhoras . Esses
valores devem então ser combinados, dentro de cada forma de execução do cenário, para se
alcançar a cobertura de teste promovida pelo método.
Embora o processo de seleção de dados tenha sido demonstradoapenas para variáveis
de tipos simples (primitivos), nada impede a sua utilizaçãopara a construção de valores
complexos (objetos) desde que a estrutura destes seja conhecida e que sejam compostos por
tipos primitivos. Neste caso, são selecionados valores para os tipos primitivos que compõe o
tipo complexo.
É importante salientar que a atividade de seleção de dados deteste do método AFCT só
realiza a geração de valores significativos para as variáveis envolvidas nas restrições OCL.
Por este motivo não foram gerados dados para instanciação davariávelp (tipo Pessoa) da
restrição. Assim, todas as variáveis para as quais o processo de seleção não é realizado,
deverão ter valores fornecidos no momento da execução do teste. Por desconhecermos o
impacto que o valor dessas variáveis acarreta na execução das funcionalidades, aconselhamos
que estes sejam definidos de forma aleatória.
3.3 Construção e Empacotamento dos Artefatos de Teste
Uma vez terminada a fase de especificação de teste, os casos deteste, oráculos e dados
são utilizadas para a construção e o empacotamento dos artefatos de teste. Os artefatos de

3.3 Construção e Empacotamento dos Artefatos de Teste 40
teste a ser gerados compreendem as classes de teste e os arquivos de dados, que são criados
para permitir a modificação dos dados de teste sem a necessidade de alteração do código
fonte dos testes, o que é necessário para possibilitar o teste do componente, por parte do
cliente, com dados específicos ao contexto no qual será usado.
O método AFCT propõe que as classes de teste sejam implementadas a partir de API’s
(Application Programming Interfaces) de frameworksde execução de teste da família xUnit
e de acordo com a linguagem de programação usada na implementação sob teste. A idéia é
aproveitar toda a infra-estrutura provida por estesframeworkspara concentrar o trabalho no
que deve ser testado e não em como esses testes serão executados. Na Tabela 3.3, podemos
ver os principaisframeworksde teste existentes para algumas linguagens de programação
utilizadas no desenvolvimento de componentes.
Linguagem de Programação Framework de Teste
Java JUnit
C++ CppUnit
Visual Basic VBUnit
Object Pascal (Delphi) DUnit
Linguagens do Framework .NET NUnit
Tabela 3.3: Frameworks de TestexUnit
O código de teste é construído da seguinte forma: É criada umaclasse de teste para
cada funcionalidade do componente a ser testada e, nestas classes, são criados métodos de
teste, um para cada cenário de uso selecionado na funcionalidade. Estes métodos fazem uso
dos dados selecionados para executar a funcionalidade nos cenários de uso correspondentes
e, a partir dos oráculos de teste, determinar a correção da funcionalidade naquele cenário
de uso. Uma vez que, na fase anterior, os oráculos de teste foram gerados sob a forma de
fragmentos de código, estes devem ser inseridos nas classesde teste correspondentes para
poderem ser acessados pelos métodos de teste. Além disso, caso o cenário de uso apresente
uma mensagem de retorno, esta deverá ser tratada como uma exceção esperada e o método
de teste deverá assegurar que esta exceção é lançada durantea execução da funcionalidade
no cenário de uso correspondente.

3.4 Execução dos Testes e Análise de Resultados 41
Os arquivos de dados, por sua vez, são gerados a partir dos valores selecionados durante
a fase de especificação de teste. É criado um arquivo para cadaclasse de teste, i.e. para cada
funcionalidade a ser testada. Nestes arquivos ficam armazenados os dados selecionados para
as variáveis necessárias à execução dos testes dos cenáriosde uso da funcionalidade. Embora
não seja definido o formato exato destes arquivos, os mesmos deverão ser construídos de
forma a facilitar o acesso aos dados, em tempo de execução, a partir das classes de teste.
Uma vez construídos, os artefatos de teste devem ser empacotados e disponibilizados
junto com o componente desenvolvido para o cliente. Propomos que estes artefatos sejam
empacotados em algum formato que possibilite a execução e análise de resultados dos teste
nele contidos, seja de forma auto-suficiente, seja através de um aplicativo a ser fornecido
para esta função. Este pacote será então distribuído juntamente com o componente de forma
a possibilitar aos clientes o teste do mesmo sob contextos deutilização específicos.
3.4 Execução dos Testes e Análise de Resultados
A última fase do método é a execução dos testes e análise de resultados. Nesta fase, o
pacote contendo os artefatos de teste produzidos é utilizado para testar uma implementação
da especificação do componente. Uma vez que é disponibilizado juntamente com o compo-
nente desenvolvido, o pacote de artefatos permite que o cliente possa re-executar os testes
gerados pelo fornecedor, optando, a cada execução, por:
1. Avaliar a conformidade de um determinado cenário de uma funcionalidade;
2. Avaliar a conformidade de uma funcionalidade a partir do teste de todos os seus cená-
rios;
3. Avaliar a conformidade de todas as funcionalidades do componente.
Além disso, uma vez que o processo utilizado para a seleção dos dados visa a obtenção
de dados genéricos e independentes do contexto em que o componente venha a ser utili-
zado, é necessário prover ao cliente uma forma de execução dos casos de teste com dados
específicos da aplicação na qual o componente será usado, ou seja, dados que comprovem
a conformidade das funcionalidades do componente quando integrado a outros componen-
tes para compor uma aplicação. Em função disso, a mesma infra-estrutura que fornece os

3.5 Considerações Finais 42
meios para execução e avaliação de resultados dos testes contidos no pacote de artefatos do
componente deve possibilitar o acesso dos clientes aos dados contidos nos arquivos de dados
para permitir, além da utilização dos dados selecionados pelo método, a informação de novos
dados de teste em tempo de execução.
3.5 Considerações Finais
Apresentamos, neste capítulo, o método de teste automáticoAFCT que foi proposto neste
trabalho com o objetivo de suprir as deficiências do método FCT [dF03] no que diz respeito
à automação das atividade inerentes ao processo de teste. Asfases e atividades do método
foram definidas a partir de algoritmos e técnicas bem definidas e exemplos de sua aplicação
foram demonstrados. As definições aqui apresentadas, serviram de base para o projeto e
desenvolvimento da ferramenta de suporte SPACES, que é apresentada no Capítulo 4.

Capítulo 4
A Ferramenta SPACES
Neste capítulo, apresentaremos a ferramenta SPACES que foidesenvolvida para dar su-
porte à execução automática das atividades do método AFCT apresentado no Capítulo 3.
Inicialmente serão destacadas as características gerais para as quais o projeto da ferramenta
foi dirigido. A seguir, será apresentada uma visão geral da ferramenta a partir de sua ar-
quitetura e serão apresentados os detalhes de projeto e implementação de cada módulo da
ferramenta. Por fim, será apresentada a aplicação Testador de Componentes, responsável
pela execução dos testes gerados pela ferramenta.
4.1 Características da Ferramenta
A ferramenta SPACES, acrônimo deSPecification bAsed Component tESter, foi desen-
volvida para automatizar as atividades do método AFCT e, assim sendo, tem como objetivo
a geração de artefatos de teste para componentes de softwarea partir do conjunto de artefa-
tos UML e restrições OCL que constituem a especificação destes componentes, auxiliando o
fornecedor a maximizar a qualidade dos componentes disponibilizados. Entre suas caracte-
rísticas gerais destacam-se:
• Integração com ferramentas de modelagem UML que exportem para o formato XMI
(XML Metadata Interchange), padrão da OMG1 para troca de informações entre ferra-
mentas;1Object Management Group. http://www.omg.org
43

4.1 Características da Ferramenta 44
• Arquitetura adaptável para utilização de diferentes linguagens de especificação de res-
trições (OCL, Object Z, etc.) assim como a geração de código de teste para diferentes
linguagens de programação e/ou plataformas;
• Persistência de sessões de trabalho, permitindo que os usuários possam interromper
e posteriormente dá continuidade ao trabalho em qualquer etapa do processamento,
e minimizando, dessa forma, o impacto causado pela alteração da especificação do
componente durante o uso da ferramenta;
• Disponibilização dos testes gerados juntamente com o componente de forma a pos-
sibilitar a reexecução destes a partir de novos dados fornecidos dinamicamente tanto
pelos fornecedores quanto pelos clientes.
Além disso, para maximizar a usabilidade da ferramenta SPACES, alguns requisitos não-
funcionais também foram considerados:
Portabilidade Uma vez que ferramentas de modelagem UML estão disponíveis para di-
ferentes plataformas operacionais, a exemplo deWindows, Linuxe Mac, procuramos desen-
volver uma ferramenta de teste que fosse independente de plataforma. Em função disso,
resolvemos implementar a ferramenta com a linguagem de programação Java.
Autonomia Em uma ferramenta de automação, o número de interações humanas neces-
sárias deve ser minimizado. SPACES foi desenvolvida de forma a permitir as interações
indispensáveis à realização das atividades de teste, ao mesmo tempo em que possibilita um
comportamento padrão para cada uma dessas interações com o objetivo de melhor automa-
tizar o processo.
Confiabilidade Por se tratar de um software para a verificação e determinaçãoda confor-
midade de outros, a confiabilidade da ferramenta era uma característica imprescindível para
avaliar quais funcionalidades dos componentes estavam ou não corretamente implementadas.
Durante o projeto da ferramenta SPACES, procuramos assegurar a sua correta implementa-
ção a partir da realização de testes de unidade e de testes de aceitação. Além disso, como
pode ser visto no Capítulo 5, procedemos a aplicação da ferramenta em um estudo de caso
previamente escolhido.

4.2 Visão Geral 45
Rapidez e Escalabilidade Para alcançar uma maior escalabilidade no que se refere a
complexidade – medida em número de funcionalidades e cenários – dos componentes a
serem verificados, procuramos desenvolver a ferramenta de forma a minimizar a utilização
de recursos de sistema (i.e memória, processador, etc.), sem, no entanto, comprometer a
velocidade de execução do processo como um todo.
4.2 Visão Geral
Para alcançar as características desejadas, procuramos desenvolver a ferramenta SPACES
de forma modularizada. O projeto arquitetural foi elaborado levando-se em consideração as
funcionalidades que a mesma precisava prover para automatizar ao máximo as atividades do
método AFCT. As funcionalidades foram agrupadas em móduloscorrespondentes às fases
do processo de teste e a arquitetura inicial da ferramenta foi definida. Esta arquitetura foi
então aperfeiçoada dando origem a versão final, apresentadana Figura 4.1.
Testador deComponentes
Pacotede Teste
Ferramenta deModelagem
Diagrama deSequência
OCL
Diagrama deCasos de Uso
Diagramade Classe
XMI
API Java(Modelo UML)
ParserXMI
Gerador deOráculo
Gerador deArtefatos de Teste
Seletor de Casosde Teste
Seletor de Dadosde Teste Empacotador
SPACES
Casos de TestexUnit
Gerenciador dePersistência
Figura 4.1: Arquitetura da Ferramenta SPACES
Como pode ser visto na arquitetura, a ferramenta recebe comoentrada a especificação do
componente no formato XMI. Esse formato foi adotado para permitir a utilização de especi-
ficações construídas nas principais ferramentas CASE. Trata-se de um padrão desenvolvido
pela OMG para possibilitar a representação textual baseadaem XML (Extended Markup
Language) de instâncias do MOF (Meta-Object Facility), um metamodelo para metamodelos
orientados a objetos, a exemplo do metamodelo UML. Apesar dapadronização da OMG, os
arquivos exportados neste formato costumam apresentar pequenas diferenças e/ou elementos

4.3 Projeto 46
proprietários, ou seja, dependentes da ferramenta de modelagem. No entanto, em que pese o
fato de, tanto nos testes realizados durante o desenvolvimento da ferramenta SPACES quanto
na aplicação do estudo de caso apresentado no Capítulo 5, termos feito uso da ferramenta
Gentleware Poseidon for UML2 para produzir as especificações UML e exportá-las sob o
formato XMI, já existem ferramentas no mercado capazes de “traduzir” os dialetos XMI ex-
portados pelas principais ferramentas de modelagem UML, incluindo aIBM Rational Rose3
além da própriaPoseidon for UML.
De acordo com a arquitetura, podemos identificar claramenteo fluxo de execução da
ferramenta. Inicialmente, a especificação no formato XMI é processada pelo móduloParser
XMI com o objetivo de disponibilizar, a partir da instanciação das classes daAPI UML, as
informações do modelo UML para os demais módulos da ferramenta. No móduloSeletor
de Casos de Testesão identificadas as funcionalidades do componente e selecionados os
cenários a ser testados. A especificação de cada um desses cenários constitui a entrada
para os módulosGerador de Oráculose Seletor de Dados de Testeresponsáveis por gerar,
respectivamente, os procedimentos responsáveis pela avaliação dos resultados dos testes e
os dados necessários à sua execução. O móduloGerador de Artefatos de Teste, por sua vez,
recebe como entrada as informações processadas pelos módulosSeletor de Casos de Teste,
Gerador de Oráculose Seletor de Dados de Testepara promover a construção do código de
teste. Esse código de teste é empacotado pelo móduloEmpacotadordando origem aoPacote
de Testedo componente, que constitui o artefato de saída da ferramenta. Por fim, uma vez
gerado oPacote de Teste, fazemos uso da aplicaçãoTestador de Componentespara executar
e analisar os resultados dos testes de uma implementação da especificação do componente.
A seguir vemos os detalhes do projeto da ferramenta SPACES, cuja versão preliminar foi
apresentada em[BAMF04a].
4.3 Projeto
Desde o princípio, o foco do projeto da ferramenta SPACES foia funcionalidade. Sendo
assim, não foi dada muita importância ao desenvolvimento dausabilidade da interface grá-
2http://www.gentleware.com3http://www.rational.com

4.3 Projeto 47
fica, embora reconheçamos que esta é uma característica determinante para o uso efetivo da
ferramenta e que, portanto, merecerá uma atenção especial em trabalhos futuros. A inter-
face gráfica desenvolvida buscou centralizar o acesso às diversas funcionalidades fornecidas
pelos módulos da ferramenta na tela principal apresentada na Figura 4.2. Nesta tela, que se-
gue o padrão MDI (Multiple Document Interface), ou seja, que funciona como umcontainer
para as demais telas da ferramenta, as funcionalidades implementadas pelos módulos estão
agrupadas em dois menus: o menuArquivoe o menuProjeto, cujos itens são apresentados
na Figura 4.3.
Figura 4.2: SPACES: Tela Principal
Figura 4.3: SPACES: Menus Arquivo e Projeto
O menu Arquivo reúne as funcionalidades gerais da ferramenta acessadas a partir dos
submenusAbrir e Salvar Projetoe Ler Arquivo XMI. Na Figura 4.4, vemos a tela para
abertura de arquivos XMI acionada pela funcionalidadeLer Arquivo XMI.

4.3 Projeto 48
Figura 4.4: SPACES: Abrindo Arquivos XMI
A partir do menu Projeto são acessadas as funcionalidades correspondentes às etapas do
método AFCT. Essas funcionalidades foram implementadas emmódulos distintos da ferra-
menta e serão apresentadas durante a descrição destes.
A ferramenta foi projetada para possibilitar a sua expansão, o que pode ser visto, mais
claramente, no diagrama da Figura 4.5, onde é apresentada uma visão geral do projeto da
ferramenta SPACES.
Tanto no projeto de cada módulo como no projeto da ferramentaem si, fizemos uso do
padrão de projetoFacade[GHJV95]. A classeSpacesé a classefacadeda ferramenta, ou
seja, a classe que dá acesso à lógica da aplicação. Essa classe possui uma coleção de objetos
do tipoFunctionality, que representam as funcionalidades especificadas para o componente,
além de métodos-chave para prover acesso às funcionalidades dos diversos módulos da ferra-
menta. Cada objetoFunctionality, por sua vez, possui referência para todos os cenários (tipo
Scenario) especificados para a funcionalidade em questão. No diagrama, podemos observar,
que a implementação dos módulosGerador de Oráculos, Seletor de Dados de Teste, Ge-
rador de Artefatos de Teste, Gerenciador de Persistênciae Empacotador, respectivamente,
nos pacotesoraclegenerator, dataselector, testartifactsgenerator, persistencee packager, é
baseada em composição, ou seja, a lógica destes módulos é definida por uma interface cuja
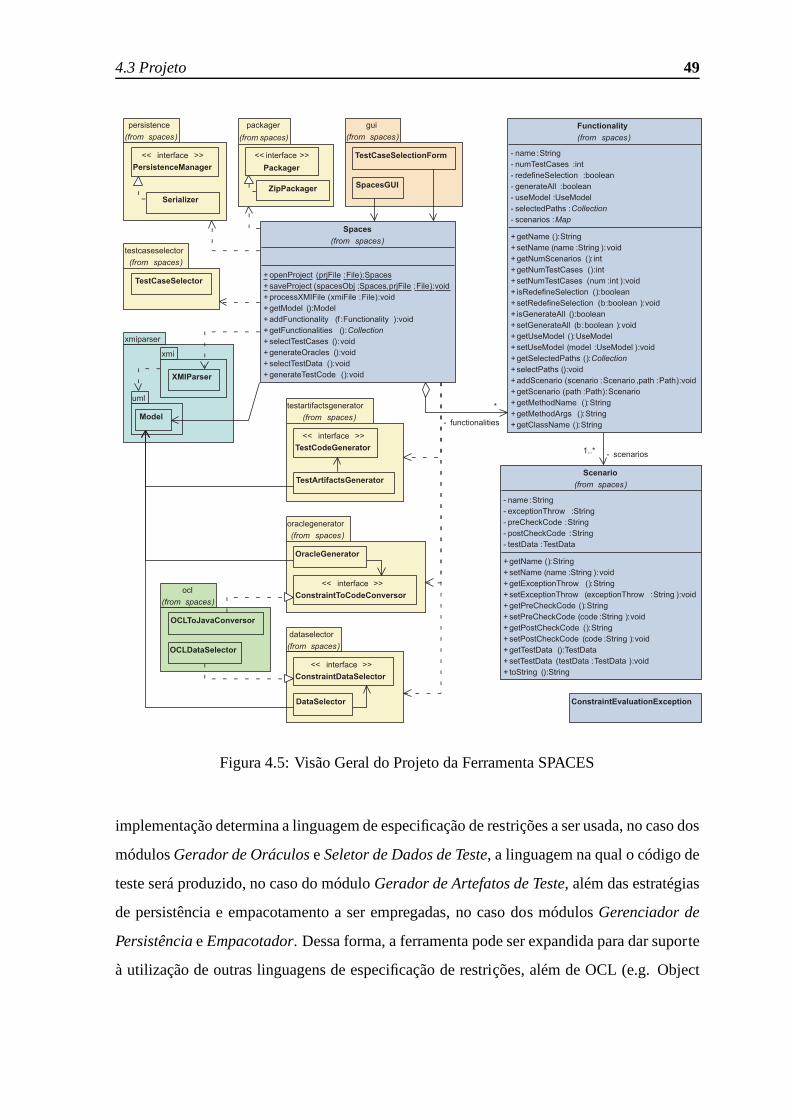
4.3 Projeto 49
testartifactsgenerator
(from spaces)
Scenario
(from spaces)
- name :String
- exceptionThrow :String
- preCheckCode :String
- postCheckCode :String
- testData :TestData
+ getName ():String
+ setName (name :String ):void
+ getExceptionThrow ():String
+ setExceptionThrow (exceptionThrow :String ):void
+ getPreCheckCode ():String
+ setPreCheckCode (code :String ):void
+ getPostCheckCode ():String
+ setPostCheckCode (code :String ):void
+ getTestData ():TestData
+ setTestData (testData :TestData ):void
+ toString ():String
Spaces
(from spaces)
+ openProject (prjFile :File):Spaces
+ saveProject (spacesObj :Spaces,prjFile :File):void
+ processXMIFile (xmiFile :File):void
+ getModel ():Model
+ addFunctionality (f:Functionality ):void
+ getFunctionalities ():Collection
+ selectTestCases ():void
+ generateOracles ():void
+ selectTestData ():void
+ generateTestCode ():void
Functionality
(from spaces)
- name :String
- numTestCases :int
- redefineSelection :boolean
- generateAll :boolean
- useModel :UseModel
- selectedPaths :Collection
- scenarios :Map
+ getName ():String
+ setName (name :String ):void
+ getNumScenarios (): int
+ getNumTestCases ():int
+ setNumTestCases (num :int ):void
+ isRedefineSelection ():boolean
+ setRedefineSelection (b:boolean ):void
+ isGenerateAll ():boolean
+ setGenerateAll (b:boolean ):void
+ getUseModel ():UseModel
+ setUseModel (model :UseModel ):void
+ getSelectedPaths ():Collection
+ selectPaths ():void
+ addScenario (scenario :Scenario ,path :Path):void
+ getScenario (path :Path):Scenario
+ getMethodName ():String
+ getMethodArgs ():String
+ getClassName ():Stringfunctionalities-
*
xmiparser
uml
Model
xmi
XMIParser
dataselector
(from spaces)
DataSelector
<< interface >>
ConstraintDataSelector
oraclegenerator
(from spaces)
OracleGenerator
<< interface >>
ConstraintToCodeConversor
persistence
(from spaces)
<< interface >>
PersistenceManager
Serializer
testcaseselector
(from spaces)
TestCaseSelector
gui
(from spaces)
TestCaseSelectionForm
SpacesGUI
ocl
(from spaces)
OCLToJavaConversor
OCLDataSelector
scenarios-1..*
ConstraintEvaluationException
packager
(from spaces)
<< interface >>
Packager
ZipPackager
TestArtifactsGenerator
<< interface >>
TestCodeGenerator
Figura 4.5: Visão Geral do Projeto da Ferramenta SPACES
implementação determina a linguagem de especificação de restrições a ser usada, no caso dos
módulosGerador de OráculoseSeletor de Dados de Teste, a linguagem na qual o código de
teste será produzido, no caso do móduloGerador de Artefatos de Teste, além das estratégias
de persistência e empacotamento a ser empregadas, no caso dos módulosGerenciador de
PersistênciaeEmpacotador. Dessa forma, a ferramenta pode ser expandida para dar suporte
à utilização de outras linguagens de especificação de restrições, além de OCL (e.g. Object

4.3 Projeto 50
Z), e à geração de código de teste em diferentes linguagens deprogramação, além de Java
(e.g. C++), bastando, para tanto, que estas interfaces sejam implementadas de acordo com
as características de cada linguagem. A seguir vemos os detalhes do projeto de cada módulo
da ferramenta.
4.3.1 Gerenciador de Persistência
As funcionalidadesAbrir e Salvar Projetoda ferramenta SPACES são implementadas
pelo módulo Gerenciador de Persistência. Esse módulo possibilita o salvamento e a posterior
recuperação das informações de um projeto, que ficam armazenadas na instância corrente da
classeSpaces, em qualquer etapa do processo. Estas informação são salvase recuperadas a
partir de arquivos com a extensão ‘spc’, Figura 4.6.
Figura 4.6: SPACES: Tela Salvar Projeto
Como pode ser visto na Figura 4.7, isso é feito através da interfacePersistenceManager
que define as operaçõesreadObject()e saveObject(). A primeira operação recebe como
parâmetro um objetoFile no qual estão armazenadas as informações, e retorna o objeto
salvo no mesmo estado em que se encontrava quando foi salvo. Asegunda operação recebe
o objeto a ser salvo e um objetoFile que indica o arquivo no qual serão armazenadas as
informações. A classeSerializeré a implementação desta interface a partir do mecanismo
de serialização de objetos da linguagem Java.

4.3 Projeto 51
<< interface >>
PersistenceManager
(from spaces::persistence )
+ readObject (file :File ):Object
+ saveObject (obj :Object ,file :File):void
Serializer
(from spaces::persistence )
Figura 4.7: SPACES: Gerenciador de Persistência
4.3.2 Parser XMI
O parser XMI é o módulo responsável pela recuperação e disponibilização das infor-
mações relacionadas à especificação dos componentes para o restante da ferramenta. Sua
funcionalidade é executada a partir do submenuLer Arquivo XMIdo menuArquivo. O par-
ser foi construído segundo a especificação 1.2 do padrão[OMG02], a mais utilizada pelas
ferramentas de modelagem. Apesar dos arquivos XMI gerados pelas ferramentas de modela-
gem conterem apenas elementos do metamodelo UML, o número deinformações passíveis
de representação torna estes arquivos bastante complexos.Em função disso e, uma vez que
as informações necessárias para a execução da ferramenta serestringem ao conjunto de arte-
fatos definidos pelo método AFCT, optamos por trabalhar apenas com um subconjunto dos
elementos XMI no metamodelo UML. Dessa forma, todos os elementos XMI externos ao
subconjunto, que representavam, portanto, informações inúteis para a ferramenta de teste,
eram ignorados durante oparse. O subconjunto dos elementos XMI considerados pelopar-
serpode ser visto no Anexo B.
Uma vez que arquivos XMI são arquivos XML em essência, fizemosuso de umpar-
serXML para implementar oparserXMI. O parserXML escolhido foi oXerces4, um dos
subprojetos mantidos pelaApache Software Foundation5. Além disso, analisamos a possi-
bilidade de utilização da técnica SAX (Simple API for XML) [Meg05], que é baseada em
eventos, ou da técnica DOM (Document Object Model) [W3C05], que é baseada em árvo-
res. Optamos pela primeira, pois é a mais indicada para o nosso contexto (parsede leitura
4http://xml.apache.org/xerces2-j/5http://www.apache.org/

4.3 Projeto 52
apenas) além de ser mais rápida. A técnica DOM é mais indicadapara situações de leitura e
escrita em arquivos XML, uma vez que é baseada em uma estrutura de dados[Idr05].
Para utilizar a técnica SAX é preciso implementar uma classeque realize o tratamento
dos eventos que são produzidos peloparserXML, principalmente os eventos de abertura e
fechamento de elementos (tags) do arquivo XML. Essa classe, denominadaHandler, é res-
ponsável pelo processamento das informações contida no arquivo XML. No nosso caso, em
função do grande número de elementos XMI que precisavam ser tratados, optamos por criar
não apenas uma classehandlermas um conjunto delas, uma para cada elemento XMI pas-
sível de tratamento, e, uma vez que boa parte do comportamento destas classes era comum,
abstraímos esse código em uma superclasse abstrata comum a todas. Assim, à medida que
os elementos eram lidos peloparserXML, o tratamento dos eventos era delegado aohandler
correspondente e este processava as informações.
API UML
As informações processadas peloparserXMI são disponibilizadas para os demais mó-
dulos da ferramenta sob a forma de uma API (Application Programming Interface) desenvol-
vida para possibilitar o acesso aos elementos de um modelo UML. Esta API é composta por
classes correspondentes ao subconjunto do metamodelo UML que especifica os artefatos uti-
lizados pelo método AFCT. Dessa forma, quando um elemento XMI é lido, a classehandler
que o trata instancia um objeto correspondente na API a partir das informações recuperadas.
No Anexo C são apresentadas as classes que compõem a API assimcomo o relacionamento
entre elas.
Como pode ser visto no Anexo B, cada elemento XMI possui um identificador (xmi.id)
que pode ser referenciado por outros elementos em diferentes partes do arquivo. Em fun-
ção disso, criamos uma tabela de identificação na qual associamos, para cada elemento XMI
lido, seu identificador e o objeto criado na API. Assim, quando um elemento XMI faz refe-
rência a outro, através do atributoxmi.idref, acessamos essa tabela com oxmi.idreferenciado
para obtermos uma referência ao objeto correspondente e estabelecer a associação entre este
objeto e o objeto criado para o elemento.
A classe Model (Figura C.1) é ofacadeda API. Ela armazena, dentre outros elementos,
as classes, interfaces, associações, pacotes, atores e casos de uso especificados no modelo

4.3 Projeto 53
UML. Em função disso, o objeto Model na tabela de identificação possui, além da entrada
associada aoxmi.id, outra associada a uma chave especial que é utilizada, ao final do parsedo
arquivo XMI, para recuperar este objeto e disponibilizar sua referência – e conseqüentemente
todas as informações que armazena – para os demais módulos daferramenta.
4.3.3 Seletor de Casos de Teste
Uma vez concluído oparsedo arquivo XMI, a ferramenta SPACES identifica as funcio-
nalidades e os respectivos cenários de uso especificados para o componente e inicia automa-
ticamente a Seleção de Casos de Teste (menuProjeto, submenuSelecionar Casos de Teste),
apresentando a tela de seleção, Figura 4.8. Nesta tela, são exibidos o nome e o número
de cenários identificados (CI) em cada funcionalidade. Para proceder a seleção, o usuário
precisa fornecer, na colunaCTS, o número de casos de testes a ser selecionado para cada
funcionalidade, ou optar por gerar todos os casos de teste possíveis (um para cada cenário
identificado), assinalando a colunaGT. A colunaRS, por sua vez, indica se a seleção reali-
zada para a funcionalidade correspondente deve ser redefinida, ou seja, quando desmarcada,
determina que o procedimento de seleção não deve ser realizado para a funcionalidade em
questão visto que o conjunto de casos de teste obtido anteriomente já é satisfatório. Em fun-
ção disso, o botãoSelecionarsó estará habilitado se esta coluna estiver assinalada em pelo
menos uma funcionalidade.
Figura 4.8: SPACES: Tela de Seleção de Casos de Teste

4.3 Projeto 54
Ao clicar no botãoSelecionar, a seleção dos casos de teste das funcionalidades cujas
colunasRSestejam marcadas será realizada conforme os procedimentosdo método AFCT.
Será criado um modelo de uso para cada funcionalidade cujas probabilidades dos arcos con-
correntes serão inicialmente iguais e, para cada funcionalidade na qual a colunaGT não
esteja marcada, será apresentado o modelo de uso correspondente destacando os caminhos
(casos de teste) escolhidos na seleção, Figura 4.9.
Figura 4.9: SPACES: Modelo de Uso
Neste momento, o usuário pode alterar as probabilidades do modelo de uso conforme
as decisões tomadas na fase de planejamento do método AFCT. Isso é feito clicando-se
com o botão direito do mouse sobre o vértice de onde partem os arcos concorrentes cujas
probabilidades devem ser alteradas. Dessa forma, será exibida a tela de alteração de proba-
bilidades, Figura 4.10, possibilitando a mudança no valor da probabilidade de todos os arcos
concorrentes do vértice em questão. Uma vez alteradas as probabilidades, o modelo de uso
correspondente é atualizado para exibir os novos valores, Figura 4.11.

4.3 Projeto 55
Figura 4.10: SPACES: Tela de Edição de Probabilidades
Figura 4.11: SPACES: Probabilidades Alteradas no Modelo deUso
Para que as novas probabilidades sejam consideradas, é preciso re-executar o procedi-
mento de seleção ativando novamente o submenuSelecionar Casos de Testedo menuProjeto
para ter acesso à tela de seleção. Esse procedimento deve serrepetido até que o conjunto de
casos de teste selecionado seja satisfatório para o usuário.
Implementação
Na Figura 4.12, vemos as classes que compõem o módulo seletorde casos de teste. A
classefacadedo módulo é a classeTestCaseSelectorque implementa a maioria dos algorit-
mos definidos pelo método AFCT e apresentados no Capítulo 3. As classesUseModel, Node
e Link representam, respectivamente, os modelos de uso criados para as funcionalidades,
seus vértices e seus arcos. A classePath, por sua vez, armazena a coleção das ações dos
arcos que constituem um caminho dentro do modelo de uso.
Cada modelo de uso possui referência para três vértices: o inicial e o final, que são
fixos e possuem, respectivamente, os valores 0 e 1; e o atual, que depende do estado do
modelo de uso e que, inicialmente, corresponde ao vértice inicial. Quando o modelo de uso
é criado, na classeTestCaseSelectora partir da coleção de diagramas de cenário recebida

4.3 Projeto 56
Link
- action :String
- probability :float
- traverse :boolean
- visited :boolean
+ getNodeTo ():Node
+ setNodeTo (node :Node ):void
+ getLabel ():String
+ setLabel (label :String ):void
+ getProbability ():float
+ setProbability (probability :float ):void
+ isTraverse ():boolean
+ setTraverse (v:boolean ):void
+ wasVisited ():boolean
+ setVisited (v:boolean ):void
Node
- value :int
- links :Collection
+ getValue ():int
+ setValue (value :int ):void
+ addLink (link :Link ):boolean
+ getLinks ():Collection
nodeTo-
TestCaseSelector
- getUseCaseScenarios (usecase:UseCase,diagrams :Collection ):Collection
+ createUseModel (scenarioDiagrams :Collection ):UseModel
+ selectPaths (um :UseModel ,n:int ):Collection
+ getAllPaths (uModel :UseModel ):Collection
+ toScenarioDiagrams (um :UseModel ):Collection
- toUseModelAction (st :Stimulus ):String
- toStimulus (action :String ):Stimulus
+ toPathString (sd :SequenceDiagram ):String
Path
- actions :Collection
+ addAction (action :String ):void
+ insertAction (action :String ):void
+ getActions ():Collection
+ toActionsString ():String
UseModel
+ getFirstNode ():Node
+ addAction (action :String ):void
+ addFinalAction (action :String ):void
~getPaths ():Collection
- getPaths (node :Node ):Collection
~selectPath (n:int ):Collection
- selectPath (p:Path,startNode :Node ):void
- selectableLinks (links :Collection ):Collection
~selectPosition (probs :float[] ): int
- fixProbs (probs :float[] ):void
+ reset ():void
FirstNode- LastNode-currentNode-
Figura 4.12: SPACES: Seletor de Casos de Teste
como parâmetro pela operaçãocreateUseModel(), as mensagens dos diagramas (Stimulus)
são convertidas em ações, através da operaçãotoUseModelAction(). Estas ações são então
adicionadas ao modelo de uso através da operaçãoaddAction(). Caso já exista no modelo
de uso um arco com a mesma ação partindo do vértice atual, o vértice atual passará a ser o
vértice destino do arco em questão. Por outro lado, caso não exista um arco com a ação a ser
adicionada partindo do vértice atual, será adicionado neste vértice um novo arco com a ação
em questão e este arco terá como destino um novo vértice que passará a ser o atual. Esse
processo é repetido para todas as ações do diagrama com exceção da última, que é adicionada
a partir da operaçãoaddFinalAction(). Esta operação, como a anterior, adiciona um novo
arco ao vértice atual, porém, este terá como destino o vértice final e o vértice atual passará a
ser novamente o inicial, reiniciando o processo para a adição das ações correspondentes às
mensagens do próximo diagrama.
A seleção dos caminhos no modelo de uso, e, conseqüentemente, dos casos de teste, é
feita a partir da operaçãoselectPaths()da classeTestCaseSelector. Esta operação recebe
como parâmetro o modelo de uso e o número de caminhos a ser selecionado, realizando a
seleção de acordo com os algoritmos do método AFCT.

4.3 Projeto 57
4.3.4 Gerador de Oráculos
Após a definição do conjunto de casos de teste selecionados para as funcionalidades do
componente, é preciso gerar oráculos que sejam responsáveis pelo veredicto destes casos de
teste. Esta funcionalidade, acessada através do submenuGerar Oráculos de Testedo menu
Projeto, consiste na derivação de fragmentos de código a partir de restrições, inicialmente
escritas na linguagem OCL, de invariantes, especificadas naclassefacadeque implementa as
funcionalidades do componente, e de pré e pós-condições, especificadas para os cenários de
uso correspondentes aos casos de teste selecionados para asfuncionalidades do componente.
Estes fragmentos são responsáveis, em tempo de execução, pela determinação do resultado
de cada caso de teste.
Para proceder tal geração era imprescindível a precisão e a correção, tanto sintática
quanto semântica, das restrições OCL. Dessa forma o geradorprecisava prover meios de
detectar antecipadamente qualquer problema existente nasrestrições. Em função disso, op-
tamos pela utilização da ferramentaDresden OCL[HDF00]. Em linhas gerais, Dresden OCL
é um conjunto de módulos de suporte à análise e ao processamento de restrições OCL. Entre
os módulos disponíveis estão:
• Um Parser, gerado pela ferramenta SableCC6 a partir da especificação 1.3 da lingua-
gem OCL e responsável pela análise léxica e sintática das restrições.
• Um Analisador Semântico, que realiza verificações de consistência e checagem de
tipos de acordo com o modelo UML.
• Um Normalizador, que simplifica as restrições OCL para facilitar a geração decó-
digo. Entre os passos de normalização implementados estão aqualificação explícita
de nomes, a inserção de iteradores e de informações de tipo, ea expansão de iteradores
múltiplos.
• Um Gerador de Código, responsável pela geração de código fonte Java para ser usado
em instrumentação (inserção de código de teste na própria implementação a ser tes-
tada). Este código é baseado em uma biblioteca de classes própria que representa o
sistema de tipos OCL.
6http://www.sablecc.org

4.3 Projeto 58
Cada módulo implementa interfaces bem definidas, o que tornapossível a redefinição de
suas funcionalidades de acordo com as necessidades dos usuários. A comunicação entre os
módulos se dá a partir de uma estrutura de dados denominadaÁrvore Sintática Abstrataque
é construída durante oparse, Figura 4.13. A estrutura dessa árvore, Figura 4.14, consiste
na instanciação das regras gramaticais da linguagem OCL[OMG03b] a partir das restrições
processadas pela ferramenta.
NormalizadorAnalisador Semântico
Árvore SintáticaAbstrata
Parser Gerador de Código
Figura 4.13: Dresden OCL: Integração entre os Módulos
Figura 4.14: Dresden OCL: Exemplo de Árvore Sintática Abstrata

4.3 Projeto 59
Para o correto funcionamento, a ferramenta Dresden OCL precisa acessar, além das res-
trições OCL, o modelo UML sob o qual foram especificadas as restrições. Isso é feito a
partir da implementação de uma interface denominadaModelFacade. Esta interface define
a operaçãogetClassifier()que recebe o nome do classificador e, caso este exista no modelo
UML, retorna um objeto correspondente do tipoAnyda biblioteca de classes da ferramenta.
Assim sendo, para possibilitar a integração desta ferramenta com SPACES, foi preciso criar
uma implementação da interfaceModelFacadeque permitisse o acesso as informações do
modelo UML usado por SPACES. Esta classe, denominadaSPACESModelFacade, assim
como as interfaces que constituem o mecanismo de acesso ao modelo UML da ferramenta
Dresden OCL, pode ser vista na hierarquia da Figura 4.15.
<< interface >>
Type
(from tudresden ::ocl::check ::types )
+ navigateQualified (name :Type ,qualifiers :Type[] ):Type
+ navigateParameterized (name :Type ,params :Type[] ):Type
+ hasState (stateName :String ):boolean
<< interface >>
Any
(from tudresden ::ocl ::check::types )
<< interface >>
ModelFacade
(from tudresden ::ocl ::check::types )
+ getClassifier (name :String ):Any
SPACESModelFacade
(from spaces::ocl)
+ getPrimitiveType (paramType :String ):void
+ getType (class:Class):Type
+ toString ():String
Class
(from xmiparser ::uml )
Model
(from xmiparser ::uml )
model-
Figura 4.15: Integração Dresden OCL - SPACES: Acesso ao Modelo UML
A partir da implementação da interfaceModelFacadepela classeSPACESModelFacadee
o conseqüente acesso da ferramenta DresdenOCL às informações do modelo UML contidas
nos objetos da API UML, SPACES passou a se beneficiar das funcionalidades de verificação
(sintática e semântica) e de normalização de restrições OCL, implementadas pelos módulos
desta ferramenta. No entanto, uma vez que o módulo gerador decódigo padrão do Dresden
OCL produz código para instrumentação e baseado em uma API própria, tivemos que re-
implementar esta funcionalidade para a sua utilização no nosso contexto, ou seja, a geração
de código Java puro a ser executado a partir de classes de teste para determinar o resultado
dos casos de teste do componente.

4.3 Projeto 60
O módulo gerador de código é acessado pelo Dresden OCL a partir da interfaceCode-
Generator. Esta interface define a operaçãogetCode()que recebe como parâmetro a árvore
sintática abstrata produzida peloparser (tipo OCLTree) e produz um array de fragmentos
de código (tipoCodeFragment), um para cada restrição OCL submetida ao Dresden OCL.
A hierarquia das classes que constituem o mecanismo de geração de código da ferramenta
pode ser vista, de forma simplificada, na Figura 4.16.
<< interface >>
CodeGenerator
(from tudresden ::ocl ::codegen )
+ getCode (tree :OCLTree):CodeFragment[]
<< interface >>
CodeFragment
(from tudresden ::ocl ::codegen )
+ getCode ():String
...
OCLTree
(from tudresden ::ocl )
#ast :Start
<< interface >>
Switch
(from tudresden ::ocl ::parser ::node )
<< interface >>
Analysis
(from tudresden ::ocl ::parser ::analysis )
+ caseA<Element> (node :A<Element> ):void
...
AnalysisAdapter
(from tudresden ::ocl ::parser ::analysis )
DepthFirstAdapter
(from tudresden ::ocl ::parser ::analysis )
+ caseA<Element> (node :A<Element> ):void
+ inA<Element> (node :A<Element> ):void
+ outA<Element> (node :A<Element> ):void
...
JavaCodeGenerator
(from tudresden ::ocl ::codegen )
<< interface >>
Switchable
(from tudresden ::ocl ::parser ::node )
+ apply (s:Switch ):void
Node
(from tudresden ::ocl ::parser ::node )
Start
(from tudresden ::ocl ::parser ::node )
Figura 4.16: Dresden OCL: Gerador de Código
Para redefinir esta funcionalidade foi preciso, primeiramente, entender como se dá o pro-
cesso de geração de código do Dresden OCL. Este processo é parecido com o definido pela
técnica SAX[Meg05], uma adaptação do padrão de projetoVisitor [GHJV95], utilizado pelo
framework SableCC[ÉGG98] para oparsede arquivos XML, formato este que compreende
a descrição das restrições OCL sob a estrutura da árvore sintática abstrata.
Como dito anteriormente, a classeOCLTreerepresenta a árvore sintática abstrata. A
classe abstrataNode, por sua vez, define uma hierarquia de classes para representação dos
elementos desta árvore. Nessa hierarquia, a classeNodearmazena as informações comuns a
todos os elementos, enquanto suas subclasses, a exemplo da classeStart, armazenam as in-
formações específicas de cada elemento. Ambas as classes (OCLTreeeNode) implementam
a interfaceSwitchableque define a operaçãoapply(). Esta operação delega o tratamento das

4.3 Projeto 61
informações contidas na subárvore iniciada peloNodecorrespondente ou, no caso da classe
OCLTree, peloNodeinicial (ast), para o objetoSwitchrecebido como parâmetro, de forma
semelhante ao que ocorre com os objetosHandlerna técnica SAX. A interfaceSwitchdefine
uma hierarquia de tipos que implementam estratégias de tratamento das informações conti-
das nos elementos da árvore. No caso da geração de código, fazemos uso da subinterface
Analysis. Esta interface define métodos cujos nomes seguem a formacaseA<Element>()
em queA<Element>é nome das subclasses deNodeque representam os diversos elemen-
tos da árvore. Cada método recebe como parâmetro um objeto dasubclasse correspondente
e, à medida que a árvore vai sendo analisada, eles vão sendo chamados, possibilitando,
assim, o tratamento das informações contidas nestes objetos. A classeAnalysisAdapterim-
plementa o padrão de projetoAdapter[GHJV95] fornecendo implementaçõesdefaultpara
os métodos da interfaceAnalysis, enquanto que sua subclasseDepthFirstAdapterredefine
essas implementações segundo a estratégia de busca em profundidade. Como conseqüência
dessa redefinição, essa classe disponibiliza, além dos métodoscaseA<Element>(), os mé-
todosinA<Element>()e outA<Element>(), possibilitando tratamentos diferenciados para o
início e o final do processamento dos elemento da árvore.
A nossa implementação consistiu na redefinição da classeJavaCodeGenerator. Esta
classe que implementa a interfaceCodeGeneratore herda as implementações de análise ba-
seada em busca em profundidade da classeDepthFirstAdapter, redefine o comportamento
dos métodosinA<Element>(), outA<Element>()e/oucaseA<Element>()para os elemen-
tos que armazenam as informações relevantes ao nosso contexto, procedendo a geração de
expressões Java de acordo com a seqüência em que os elementossão lidos e o mapeamento
proposto pelo método AFCT (Anexo A). Dessa forma, a implementação da operaçãoget-
Code()da interfaceCodeGeneratoré bastante trivial, consistindo na chamada da operação
apply()da classeOCLTreefornecendo como parâmetro a instância corrente (this) da classe
JavaCodeGenerator. Isso dá início à análise da árvore e ao processamento das informações
contidas nos seus elementos.
As expressões Java que são geradas vão sendo armazenadas dentro de métodos cujos no-
mes seguem a formacheck_<nome_do_cenário>_<tipo_da_restrição> para pré e pós-
condições oucheck_<nome_da_restrição> para invariantes. Para restrições de pré ou pós-
condições, esses métodos recebem como parâmetro, além do objeto contexto da restrição,

4.3 Projeto 62
todos os parâmetros especificados para a operação em questãoe, no caso de pós-condições
de operações cujo tipo de retorno seja diferente devoid, o resultado da operação. O va-
lor de retorno do método produzido é umbooleanque indica o resultado da avaliação da
restrição para os parâmetros recebidos. Ao final do processo, esse código é utilizado na cria-
ção do objetoCodeFragmentque é retornado, na forma de um array unitário, pela operação
getCode().
Uma vez redefinida a funcionalidade de geração de código do Dresden OCL, o módulo
gerador de oráculos foi diretamente implementado a partir dos módulos desta ferramenta.
Na Figura 4.17, vemos as classes que compõem este módulo.
OCLToJavaConversor
(from spaces::ocl )
OracleGenerator
(from spaces::oraclegenerator )
+ processScenarioConstraint (constraint :String ,scenario :Scenario ):String
+ processInvariant (constraint :String ):String
+ getConstraintToCodeConversor ():ConstraintToCodeConversor
+ setConstraintToCodeConversor (ccc:ConstraintToCodeConversor ):void
<< interface >>
ConstraintToCodeConversor
(from spaces::oraclegenerator )
+ getConstraintLanguage ():String
+ getCodeLanguage ():String
+ convert (constraint :String ,model :Model ):String
<< interface >>
CodeGenerator
(from tudresden ::ocl ::codegen )
DepthFirstAdapter
(from tudresden ::ocl ::parser ::analysis )
JavaCodeGenerator
(from spaces::ocl )
Model
(from xmiparser ::uml )
Figura 4.17: SPACES: Gerador de Oráculos
A classeOracleGeneratoré a classefacadedo módulo. Para cada cenário selecionado de
cada funcionalidade especificada para o componente, identificamos suas restrições OCL de
pré e pós-condição, especificadas nos diagramas de seqüência correspondentes à especifica-
ção destes cenários, além das invariantes das classesfacadedo componente que fornecem as
funcionalidades em questão. As restrições de pré e pós-condição são então submetidas, jun-
tamente com o objetoScenariocorrespondente, à operaçãoprocessScenarioConstraint()e as
invariantes são submetidas à operaçãoprocessInvariant(). Estas operações fazem uso de um
objeto do tipoConstraintToCodeConversorpara converter as restrições nos fragmentos de
código que irão compor o oráculo. A classeOCLToJavaConversorfornece a implementação
da interfaceConstraintToCodeConversorpara a conversão de restrições OCL em fragmentos
de código Java. Essa implementação faz uso da classeJavaCodeGeneratorque redefinimos

4.3 Projeto 63
anteriormente para submeter as restrições às funcionalidades do Dresden OCL e, caso estas
estejam isentas de erro, obter, ao final do processo, os fragmentos de código Java correspon-
dentes.
Cada oráculo de teste é então constituído a partir dos fragmentos de código derivados das
restrições de pré e pós-condição do cenário correspondentee do código derivado das invari-
antes da classe que fornece a funcionalidade, sendo este último comum a todos os oráculos
de teste correspondentes aos cenários de uso selecionados para esta funcionalidade. Caso
haja algum problema com alguma restrição OCL, tanto de ordemsintática (relacionado à
gramática OCL) quanto semântica (relacionada ao modelo UML), esse processo será inter-
rompido e será exibida uma mensagem indicando a funcionalidade e o cenário no qual o erro
foi encontrado.
4.3.5 Seletor de Dados de Teste
Os dados de teste constituem, juntamente com os casos de teste e os oráculos, a especifi-
cação do teste. O seletor de dados de teste é o módulo responsável pela escolha de dados que
possam exercitar os diferentes cenários selecionados paracada funcionalidade especificada
para o componente. Esta funcionalidade, acessada através do submenuSelecionar Dados
de Testedo menuProjeto, realiza a derivação de valores a partir das pré-condições de cada
cenário, fazendo uso da técnica de particionamento por equivalência e, parcialmente, da téc-
nica de identificação de partições, ambas apresentadas na definição do método AFCT, no
Capítulo 3.
A implementação parcial da técnica de identificação de partições na versão inicial da
ferramenta foi uma decisão de projeto que tomamos para o não compromentimento das de-
mais etapas do desenvolvimento em função da complexidade inerente a esta atividade. Dessa
forma, algumas restrições podem não ser analisadas corretamente, ocasionando a não sele-
ção de dados de partições estabelecidas por estas restrições. Como o comportamento padrão
da ferramenta é gerar valores aleatórios para as variáveis necessárias à execução do teste
que não tenham sido referenciadas nas restrições OCL, a não identificação de partições pode
fazer com que sejam atribuídos valores aleatórios às variáveis que são referenciadas nos ter-
mos não avaliados das restrições, o que pode ocasionar o descumprimento das pré-condições
e, conseqüentemente, um resultado incorreto na execução doteste. Isso ocorre, principal-

4.3 Projeto 64
mente, com restrições mais complexas, envolvendo tipos objeto e operações sobre coleções.
Nesses casos, torna-se necessária uma interação do usuáriopara revisar e/ou alterar os dados
selecionados, o que, como veremos adiante, poderá ser feitono momento da execução dos
testes.
Na Figura 4.18, vemos as classes que constituem o módulo seletor de dados e o relacio-
namento entre elas.
DepthFirstAdapter
(from tudresden ::ocl ::parser ::analysis )
Model
(from xmiparser ::uml )
TestData
(from spaces::dataselector )
+ addCreateAction (order_type :String ,variable :String ):void
+ getCreateActions ():Map
+ addAddAction (colExp :String ,variable :String ):void
+ getAddActions ():Map
+ addDataSet (dataSet :Map ):void
+ getDataSets ():Collection
+ addUncoveredExpression (uncoveredExpression :String ):void
+ getUncoveredExpressions ():Collection
DataSelector
(from spaces::dataselector )
+ selectTestData (pre_constraint :String ,scenario :Scenario ):void
+ getConstraintDataSelector ():ConstraintDataSelector
+ setConstraintDataSelector (cdc:ConstraintDataSelector ):void
OCLDataSelector
(from spaces::ocl )
Scenario
(from spaces)
OCLTree
(from tudresden ::ocl )
<< interface >>
ConstraintDataSelector
(from spaces::dataselector )
+ selectData (constraint :String ,model :Model ):TestData
Figura 4.18: SPACES: Seletor de Dados
A classefacadedo módulo é a classeDataSelector. Ela fornece a operaçãoselectTest-
Data() que recebe como parâmetro a restrição de pré-condição e o cenário correspondente
para o qual será feita a seleção. A funcionalidade desta operação é delegada a um objeto
do tipoConstraintDataSelector. Esta interface especifica a operaçãoselectData()a ser im-
plementada por classes especializadas na seleção dos dadosa partir de restrições expressas
em diferentes linguagens. Essa operação recebe, como parâmetros, a restrição e o modelo
UML, e retorna um objetoTestDatacontendo os dados selecionados a partir desta restrição.
Como, inicialmente, SPACES trata apenas de restrições OCL,a implementação padrão desta
interface é fornecida pela classeOCLDataSelector.
Assim como no módulo gerador de oráculos, optamos por uma implementação baseada
na ferramenta Dresden OCL em função do arcabouço fornecido por esta ferramenta para a

4.3 Projeto 65
análise e o processamento de restrições OCL, e da integraçãopreviamente realizada entre
as duas ferramentas. Da mesma forma que a classeJavaCodeGeneratordo módulo gera-
dor de oráculos, a classeOCLDataSelectorestende a classeDepthFirstAdapterdo Dresden
OCL, herdando seu comportamento de análise baseada em buscaem profundidade sobre a ár-
vore sintática abstrata (OCLTree). Dessa forma, redefinimos o comportamento dos métodos
inA<Element>(), outA<Element>()e/oucaseA<Element>()com o objetivo de identificar as
expressões lógicas, as variáveis e os valores que estas poderiam assumir para satisfazer as
restrições.
Toda restrição é composta por pelo menos uma expressão lógica. As variáveis em questão
são parâmetros aos quais valores (dados) precisam ser atribuídos para determinar o resultado
das expressões. Estes parâmetros podem ser explícitos, a exemplo dos parâmetros de uma
operação na pré-condição correspondente, ou implícitos, acessados a partir do objeto con-
texto. Uma variável é dita simples quando é explícita e seu tipo é primitivo, ao passo que as
variáveis compostas são aquelas que consistem em atributosde objetos, podendo ser explí-
citas ou implícitas. O nome das variáveis compostas é construído a partir do nome do objeto
e do nome do atributo separados pelo caracter‘.’ . Como as linguagens de especificação de
restrições são livres de efeitos colaterais, não existem operações de atribuição e, conseqüen-
temente, toda variável referenciada em uma restrição precisa ter um valor atribuído fora de
seu escopo. Quando na restrição, estas variáveis são associadas a valores, através de opera-
dores relacionais (<, <=, =, <>, >=, >), estabelecem-se relações que são satisfeitas por faixas
de valores delimitados pelos valores em questão. Essas faixas de valores são as partições
de equivalência. Neste caso, as relações são decompostas deacordo com os padrões lógicos
estabelecidos pelo método AFCT e, para cada partição obtida, a seleção atua identificando o
domínio de dados que satisfaz a relação correspondente e escolhendo, dentro deste domínio,
valores aleatórios e valores próximos ou iguais (dependendo do operador relacional) ao(s)
valor(es) limite(s). Quando, por outro lado, a variável é explícita mas não é referenciada
diretamente na restrição ou não esteja relacionada a valores, nenhuma partição é identificada
e serão selecionados valores aleatórios dentro do domínio do tipo da variável. Neste caso,
particularmente para variáveis do tipoString, serão geradas cadeias de caracteres de tamanho
nulo e aleatório cujos caracteres também serão escolhidos de forma aleatória, e, para variá-
veis do tipoCollection, serão geradas coleções vazias e coleções com um número aleatório

4.3 Projeto 66
de valores. Isso ocorre por exemplo em objetos nos quais apenas um atributo é referenciado
na restrição sendo necessária a geração de valores aleatórios para os demais atributos.
Os valores selecionados são armazenados no objetoTestDatasob a forma de estruturas
de dados denominadasDataSets. CadaDataSetcontém um valor selecionado para cada va-
riável referenciada na restrição, e eles são gerados a partir da permutação de todos os valores
selecionados para estas variáveis. Isso significa que, se por exemplo uma restrição referencia
3 variáveis e foram selecionados, respectivamente, 3, 2 e 1 valor para estas variáveis, tere-
mos 3x2x1=6DataSets, o que corresponde ao número de execuções distintas que um caso
de teste pode ter. Nós implementamos o conceito deDataSetsob a forma de umaMap de
Mapsna qual as duas chaves são constituídas a partir do nome da variável e o valor (daMap
interna) é o dado que deve ser atribuído. Quando a variável é composta, a chave do 1o nível
(Map externa) é o nome do objeto que detém o atributo e a chave do 2o nível (Map interna)
é o atributo. Quando, porém, a variável é simples, a chave do 1o nível é a própria variável e
a chave do 2o nível é o caracter‘.’ , indicando que o nome da variável é o contido na chave
de 1o nível. Para variáveis do tipo coleção, o valor noDataSettambém será uma coleção
enquanto que, para as demais variáveis, o valor será único e do mesmo tipo da variável.
Além dos dados propriamente ditos, o processo de seleção precisa prover as informações
necessárias à criação das variáveis, principalmente as queenvolvem, objetos e coleções. Es-
tas informações ficam armazenadas nos objetosTestDatasob a forma deCreateActions. As
ações de criação são armazenadas em umaMapna qual a chave é usada para indicar a ordem
na qual a variável deve ser criada e o tipo da variável, sendo estas informações separadas pelo
caracter‘_’ , e o valor é usado para armazenar a coleção dos nomes das variáveis a ser cria-
das. Opcionalmente, quando estas variáveis destinam-se aopreenchimento de uma coleção,
seus nomes serão precedidos por um número indicando quantasvezes a variável deverá ser
criada e pelo caracter de separação‘_’ . Neste caso, deverá ser criada uma coleção na qual a
variável será adicionada. As informações que indicam que variáveis devem ser adicionadas e
em que coleções elas devem ser adicionadas está contida no objeto TestDatasob a forma de
AddActions. Como as de criação, as ações de adição também são armazenadas em umaMap.
Neste caso, a chave é usada para indicar o nome da variável coleção e o valor armazena a
coleção de variáveis que devem ser armazenadas.
Os objetosTestDatapossuem ainda uma coleção deStringsdenominadaUncoveredEx-

4.3 Projeto 67
pressionsque é usada para armazenar as expressões lógicas a partir dasquais não foi possível
derivar de forma automática nenhum valor para as variáveis envolvidas. Isso ocorre princi-
palmente em restrições que envolvam expressões complexas usando operações aninhadas
sobre coleções e/ou chamadas a operações de classes. Neste caso, essas expressões devem
ser posteriormente analisadas e valores devem ser selecionados de forma manual.
Por fim, uma vez que o objetoTestDatafoi construído a partir da restrição de pré-
condição, ele é atribuído, ao final da operaçãoselectTestData()da classeDataSelector, ao
objetoScenariocorrespondente.
4.3.6 Gerador de Artefatos de Teste
Uma vez realizada a seleção dos casos de teste, a geração dos oráculos e a seleção dos
dados, as informações fornecidas por estas atividades são usadas para a construção dos ar-
tefatos de teste. Esta funcionalidade, acessada através dosubmenuGerar Artefatos de Teste
do menuProjeto, consiste na produção do código de teste e de arquivos contendo os dados
selecionados, que devem ficar separados do código de teste para possibilitar a sua alteração
em tempo de execução, sem a necessidade de recompilação do código fonte dos testes. Na
Figura 4.19, vemos as classes que compõem o módulo gerador deartefatos de teste assim
como os relacionamentos entre elas.
A classefacadedo módulo é a classeTestArtifactsGenerator. Essa classe possui dois
atributos:destdir, que indica o local no qual deverão ser gerados os artefatos de teste, ecom-
pileTestCode, que informa se o código de teste gerado deve ser compilado pela própria fer-
ramenta. Para produzir o código de teste, o módulo utiliza uma implementação da interface
TestCodeGenerator. Esta interface define operações a ser implementadas por classes espe-
cializadas na geração de código de teste em uma determinada linguagem de programação e
de acordo com umframeworkde teste xUnit adequado a esta linguagem. A implementação
desta interface fornecida com a ferramenta SPACES é dada pela classeJavaTestCodeGene-
rator que realiza a geração de código de teste na linguagem Java e segundo o framework de
teste JUnit[GB05]. A hierarquia na qual o código de teste é gerado pela ferramenta pode ser
vista na Figura 4.20.
Para cada classefacadedo componente, ou seja, as classes que exportam suas funcio-

4.3 Projeto 68
TestArtifactsGenerator
- destdir :String
- compileTestCode :boolean
+ getDestDir ():String
+ setDestDir (dir :String ):void
+ isCompileTestCode ():boolean
+ setCompileTestCode (value :boolean ):void
+ getTestCodeGenerator ():TestCodeGenerator
+ setTestCodeGenerator (tcg :TestCodeGenerator ):void
+ getCompiler ():Compiler
+ setCompiler (c:Compiler ):void
+ generateTestClassFile (facadeClassName :String ,invariantCheckCodes :Collection ):void
+ generateTestClassFiles (functionalities :Collection ):void
- generateXMLDescriptorFile ():void
+ generateXMLTestDataFiles (functionalities :Collection ):void
<< interface >>
TestCodeGenerator
+ generateTestClass (facadeClassName :String ,invariantCheckCodes :Collection ):TestClass
+ generateTestClass (functionality :Functionality ,model :Model ):TestClass
+ generateAllTestClass (testclasses :Collection ):TestClass
JavaTestCodeGenerator
XMLGenerator
+ write (dom :Document , fileaname :String ):void
Model
(from xmiparser ::uml )
TestClass
- className :String
- code:StringBuffer
+ getClassName ():String
+ setClassName (name :String ):void
+ getCode ():String
+ appendCode (code:String ):void
+ appendCode (code:StringBuffer ):void
<< interface >>
Compiler
+ compile (testClassFiles :Collection ,destdir :String ):void
JavaCompiler
Figura 4.19: SPACES: Gerador de Artefatos de Teste
TestCase
(from junit ::framework )
TestDataAccess
(from spaces)
+ getStringData (params :Hashtable ,variable :String ,posicao :int ):String
+ getIntData (params :Hashtable ,variable :String ,posicao :int ): int
+ getDoubleData (params :Hashtable ,variable :String ,posicao :int ):double
+ getBooleanData (params :Hashtable ,variable :String ,posicao :int ):boolean
+ getByteData (params :Hashtable ,variable :String ,posicao :int ):byte
+ getLongData (params :Hashtable ,variable :String ,posicao :int ): long
+ getFloatData (params :Hashtable ,variable :String ,posicao :int ):float
<Facade>Test
#check_invariants (self :<Facade> ):boolean
- check_<Invariant1> (self :<Facade> ):boolean
- check_<Invariant2> (self :<Facade> ):boolean
...
<Functionality>Test
- check_<Scenario1>_pre (self :<Facade> ,... :i):boolean
- check_<Scenario1>_post (self :<Facade> ,...: i):boolean
+ test<Scenario1> ():void
- check_<Scenario2>_pre (self :<Facade> ,... :i):boolean
- check_<Scenario2>_post (self :<Facade> ,...: i):boolean
+ test<Scenario2> ():void
...
tda#
JTestCase
(from net ::wangs ::jtestcase )
<< create >> + JTestCase(xmlFileName :String ,className :String ):JTestCase
+ getNameOfTestCases (methodName :String ):Vector
+ getTestCaseParams (methodName :String ,testCase :String ):Hashtable
Figura 4.20: SPACES: Hierarquia do Código de Teste
nalidades, será gerada, a partir da operaçãogenerateTestClassFile()da classeTestArtifacts-
Generator, uma classe de teste abstrata cujo nome será o nome da classefacadeseguido do
sufixo Test . O papel desta classe, que estende a classeTestCasedo frameworkde teste, é

4.3 Projeto 69
armazenar o código gerado pelo módulo gerador de oráculos a partir das invariantes defi-
nidas para esta classe. A operaçãogenerateTestClassFiles(), por sua vez, gera, para cada
funcionalidade do componente, uma classe de teste com o nomeda funcionalidade seguido
do sufixoTest . Esta classe terá como super-classe a classe de teste geradapara a classefa-
cadeque fornece a funcionalidade em questão. Nestas classes de teste são adicionados, para
cada cenário de uso selecionado, os códigos produzidos pelogerador de oráculos a partir das
pré e pós-condições, além do método de teste correspondente, cujo nome é composto pelo
nome do cenário precedido da palavratest , e que, de uma forma geral, possui o formato
apresentado na Figura 4.21.
public void test<Nome_Cenario>(){
...
If (check_invariants(self) &&check_<Nome_Cenario>_pre(self, <Variáveis>)) {
self.<Nome_Funcionalidade>(<Variáveis>);assertTrue(check_invariants(self) &&
check_<Nome_Cenario>_post(self, <Variáveis>));}else{
fail();}
}
/* Criação e instanciação de variáveis com dados externos *//* através do objeto TestDataAccess e da API JTestCase */
/* Violação de pré-condição ou invariantes - Resultado Indefinido */
Figura 4.21: SPACES: Formato de Métodos de Teste para Cenários
Os dados de teste usados na instanciação das variáveis necessárias a execução das funcio-
nalidades do componente, e que estão localizados em arquivos a parte, são acessados pelos
métodos de teste de cada cenário a partir de um objeto do tipoTestDataAccess. Esta classe
implementa operações para recuperação de dados de todos os tipos primitivos da linguagem
Java. Essas operações recebem como parâmetro uma tabelahash, que associa as variáveis
aos dados disponíveis para o cenário em questão, o nome da variável através do qual a tabela
deve ser acessada, além de um inteiro para possibilitar a escolha determinística de um valor
quando a variável for do tipo coleção e estivermos criando osseus elementos.
Para prover a separação dos dados de teste em arquivos a partee o acesso a esses dados
a partir do código de teste, fizemos uso da ferramenta JTestCase[Wan05]. Trata-se de uma
ferramenta livre que utiliza um formato XML bem definido paraa representação de dados

4.3 Projeto 70
de teste e disponibiliza a infra-estrutura necessária parao acesso a esses dados a partir de
classes de teste JUnit. Como pode ser visto na Figura 4.22, o formato XML definido por
esta ferramenta suporta a representação de valores tanto para variáveis simples, de tipos
primitivos, quanto para variáveis complexas, como coleções e tabelashash. Esses dados
ficam agrupados de acordo com a classe e o método de teste a que pertencem, representados
respectivamente pelos elementosclasse method, além do atributotest-casedo elemento
method, que a ferramenta define como “caso de teste”, mas que, na verdade, indica diferentes
conjuntos de dados que podem ser usados no caso de teste representado pelo método em
questão, constituindo assim diferentes execuções de um mesmo caso de teste. Dessa forma,
em um mesmo arquivo XML do JTestCase, podem ser armazenados dados de diferentes
classes, métodos e execuções de teste.
<?xml version ="1.0" encoding = "UTF-8"?><tests xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="<URI of jtestcase.xsd>"><class name="class name">
<method name="method name" test-case="name your test case here"><params>
<param name="variable name" type="variable type">variable value</param>
<param name="variable name" type="java.util.Vector"value-type="value type">
<param>value1</param><param>value2</param>
</param>
<param name="variable name" type="java.util.Hashtable"key-type="key type" value-type="value type">
<param name="key1">value1</param><param name="key2">value2</param>
</param>
</params></method>
</class>
</tests>
<!-- variáveis simples -->
<!-- variáveis coleção -->
<!-- outros valores -->
<!-- variáveis tabela hash -->
<!-- outros valores -->
<!-- outros parâmetros -->
<!-- outros métodos -->
<!-- outras classes -->
Figura 4.22: JTestCase: Formato de Arquivos XML
As classes de teste das funcionalidades do componente acessam a API JTestCase atra-
vés da classeJTestCase. Essa classe, cujos objetos são construídos a partir dos nomes do
arquivo XML que contém os dados e da classe de teste neste arquivo, possui duas operações
principais:getNameOfTestCases(), que retorna os conjuntos de dados especificados para um
método de teste no arquivo XML; egetTestCaseParams(), que retorna uma tabelahashdas

4.3 Projeto 71
variáveis e seus respectivos valores especificados em um conjunto de dados de um método no
arquivo XML. Cada classe de teste de funcionalidade (<FunctionalityTest>) cria um objeto
JTestCasea partir do arquivo XML correspondente e, nos métodos de teste de cada cenário,
recuperam a tabelahashdos dados de cada conjunto. Essas tabelashashsão então usadas
para executar as operações da classeTestDataAccesse, dessa forma, instanciar as variáveis
necessárias a execução da funcionalidade.
Os arquivos XML do JTestCase são gerados pelo módulo a partirda operaçãoGene-
rateXMLTestDataFiles()da classeTestArtifactsGenerator. Este método, que recebe como
parâmetro a coleção de funcionalidades do componente (tipoFunctionality), cria, a partir
dosDataSetsde cada cenário selecionado das funcionalidades, objetosDocumentda API
DOM [W3C05] que representam a estrutura em árvore dos elementos XML que compõem
o formato definido pelo JTestCase. É gerado umDocumentpara cada funcionalidade e este
irá conter os dados para os métodos de teste correspondentesaos cenários selecionados na
funcionalidade. Esses objetos são então usados pelo métodowrite() da classeXMLGenera-
tor para a geração dos arquivos XML de dados, que terão o mesmo nome das classes de teste
correspondentes.
Uma vez gerado o código de teste para as funcionalidades do componente, será criado,
a partir do métodogenerateXMLDescriptorFile()da classeTestArtifactsGenerator, um ar-
quivo XML com informações relacionadas ao código gerado. Este arquivo, denominado
Descriptor.xmle cujo formato pode ser visto na Figura 4.23, descreve a correspondência
entre as classes de teste e as funcionalidades, e entre os métodos de teste e os cenários
selecionados nas funcionalidades. As informações contidas neste arquivo serão usadas pos-
teriormente para auxiliar o procedimento de execução dos testes.
<?xml version ="1.0" encoding = "UTF-8"?><component name="component name">
<functionality name="functionality name" test-class="functionality test-class"><scenario name="scenario name" test-method="scenario test-method"/>
</functionality>
</component>
<!-- outros cenários -->
<!-- outras funcionalidades -->
Figura 4.23: SPACES: Formato XML para Descrição do Código deTeste Gerado
Ao final do processo de geração dos artefatos, SPACES pode, opcionalmente, realizar

4.3 Projeto 72
a compilação do código de teste produzido. Para tanto, é preciso que o atributocompile-
TestCodeda classeTestArtifactsGeneratorapresente o valortrue e que a ferramenta tenha
acesso à implementação do componente através da variável deambienteCLASSPATH. A
compilação é feita através de um objeto do tipoCompiler. Essa interface define a operação
compile(), que recebe como parâmetro a coleção dos arquivos que contêmas classes de teste
e o local no qual o código compilado deverá ser depositado, e deve ser implementada de
acordo com as características de cada linguagem de programação usada na construção do
código de teste. Como a ferramenta gera código de teste em Java, a implementação padrão
desta interface é a classeJavaCompiler, que realiza a compilação do código a partir de uma
API fornecida com o kit de desenvolvimento de software da linguagem.
4.3.7 Empacotador
A última etapa da ferramenta SPACES é a construção de um pacote contendo os artefatos
de teste gerados para o componente (classes de teste, arquivos XML de dados e o arquivo
XML de descrição) e que deve ser distribuído juntamente com este para possibilitar a execu-
ção dos testes. O responsável pela construção deste pacote éo módulo empacotador. Como
vemos na Figura 4.24, as funcionalidades deste módulo são definidas pela interfacePacka-
ger. A operaçãopack()é responsável pela geração de um pacote com o nome definido pelo
parâmetropackFileNamea partir dos arquivos contidos no diretóriodir. Caso este diretó-
rio não exista ou ocorra algum problema no acesso ao sistema de arquivos, como falta de
permissões de leitura ou escrita, será lançada a exceçãoPackagerException. A operaçãoun-
Pack()realiza a operação inversa a da operaçãopack(), ou seja, extrai os arquivos contidos
no pacotepackFileName. Por fim, temos a operaçãodelete()que é utilizada para remover os
arquivos gerados após a construção do pacote de teste. A classeZipPackageré a implemen-
tação padrão desta interface. Esta classe, que foi implementada segundo o padrão de projeto
Singleton[GHJV95], procede a construção de pacotes de teste no padrão de compressãoZIP
a partir da API da linguagem Java. Os pacotes de teste são gerados sob a forma de arquivos
JAR (Java Archive), o formato de empacotamento padrão da linguagem Java.

4.4 Testador de Componentes 73
ZipPackager
+ getInstance ():ZipPackager
PackagerException
<< interface >>
Packager
+ pack (dir :String ,packFileName :String ):void
+ unPack(packFileName :String ):void
+ delete (file :File ):void
Figura 4.24: SPACES: Empacotador
4.4 Testador de Componentes
Como vimos, ao final do processamento da ferramenta SPACES, obtemos um pacote
contendo os artefatos de teste produzidos pela ferramenta apartir da especificação do com-
ponente a ser testado. Esse pacote deve então ser distribuído juntamente com o componente
para possibilitar a execução dos testes gerados pela ferramenta. Para tanto, também deve ser
distribuída uma aplicação capaz de proceder a execução dos casos de teste. Essa aplicação é
o Testador de Componentes. Entre as suas características gerais destacam-se:
• Implementação baseada emframeworksde teste xUnit, fazendo uso de toda a infra-
estrutura provida por estes para a execução de casos de teste.
• Acesso à implementação do componente e ao pacote de testes deforma estática, ou
seja, através doCLASSPATH7.
• Possibilidade de execução dos testes em 3 níveis:
Cenário(Apenas um cenário de uma funcionalidade)
Funcionalidade(Todos os cenários de uma funcionalidade)
Componente(Todos os cenários de todas as funcionalidades)
• Três resultados possíveis para cada execução de teste:Falha, Sucessoe Indefinição,
sendo este último reservado para situações em que o caso de teste não é executado em
função de violação das pré-condições correspondentes.
• Possibilidade de edição (incluindo adição e remoção) e validação dos dados de teste
de cada cenário dinamicamente, i.e. em tempo de execução.
7Variável de ambiente que define a localização das bibliotecas de classes necessárias à execução de uma
aplicação JAVA.

4.4 Testador de Componentes 74
• Persistência das alterações feitas nos dados de teste nos respectivos arquivos XML de
dados do pacote de teste.
Como SPACES gera código de teste, por padrão, na linguagem Java e segundo ofra-
meworkJUnit, desenvolvemos o testador baseado nesteframework. A tela principal da apli-
cação pode ser vista na Figura 4.25.
Figura 4.25: Testador de Componentes: Tela Principal
A funcionalidade a ser testada é escolhida no campoFunctionality Nameque apresenta
a lista de funcionalidades disponíveis além do valorAll, que corresponde a escolha de todas
as funcionalidades. A partir da escolha da funcionalidade,são exibidos, no campoScenario
Resultse sob a forma de árvore, os cenários de uso que foram selecionados para a mesma.
Essas informações são recuperadas do arquivo descritor contido no pacote de teste gerado
por SPACES. Uma vez escolhida a funcionalidade, é possível proceder a execução do teste de
todos os seus cenários, a partir do botãoRunsuperior, ou escolher um determinado cenário
no campoScenario Resultse proceder a sua execução através do botãoRuninferior. Como
ocorre no JUnit, o resultado da execução do(s) teste(s) é apresentado na barra de progresso e
nos contadores estatísticos, a saber:
• Runs, que indica o número de testes executados em face ao número total;

4.4 Testador de Componentes 75
• Errors, que indica o número de erros decorrentes de exceções não previstas lançadas
durante a execução do(s) teste(s);
• Failures, que informa o número de falhas detectadas na execução do(s)teste(s);
• Undefineds, que informa o número de testes que não foram executados em função de
violações de pré-condições e que, portanto, apresentam resultado indefinido.
O resultadoUndefinedfoi implementado como uma especialização do resultadoFailure
padrão do JUnit. Após a execução, caso todos os testes tenhamalcançado sucesso, a barra de
progresso apresentará a cor verde. Se, entretanto, algum teste apresentar resultado indefinido,
a barra assumirá a cor amarela. Por fim, caso algum teste falhe, seja devido a ocorrência de
umaFailure ou de umError, a barra de progresso passará a ter a cor vermelha.
Quando um cenário é escolhido no campoScenario Results, é possível alterar os dados
utilizados para executar o teste deste cenário e que estão contidos nos arquivos XML do
pacote de teste. Isso é feito a partir do botãoTest Data. Ao pressionar o botão, é exibida a
tela de alteração de dados, Figura 4.26. Nesta tela é possível escolher entre editar, adicionar
ou remover conjuntos de dados (DataSets) para o cenário de uso em questão. Cada conjunto
de dados será utilizado, durante o teste do respectivo cenário, em uma execução distinta do
procedimento de teste. Os dados de cada conjunto são alterados na tabela localizada na parte
inferior da tela. Essa tabela possui uma entrada para cada variável relevante para o cenário de
uso. As colunasType, Variablee Valueinformam, respectivamente, o tipo, o nome e o valor
atual de cada variável. A edição é feita clicando-se na colunaValuee digitando o novo valor
para a variável. Caso a variável seja do tipo coleção, será aberta uma nova tabela contendo
os elementos atuais da coleção e será possível adicionar novos elementos e editar ou remover
os elementos atuais.
Os dados alterados e/ou inseridos são validados sintática esemânticamente. A validação
sintática ocorre no momento em que se edita o valor de uma variável e consiste em verificar
se o novo valor está de acordo com o tipo da variável. A validação semântica, por sua vez,
ocorre quando é requisitado, através do botãoSave, o salvamento das alterações no arquivo
XML. Neste instante os objetos que contêm as variáveis serãoinstanciados e os dados serão
atribuídos. Se alguma exceção for lançada durante a atribuição dos dados, estes serão consi-
derados inválidos para o contexto de uso no componente. Casoisso ocorra, será solicitada a

4.5 Considerações Finais 76
Figura 4.26: Testador de Componentes: Tela de Alteração de Dados
atribuição de novos valores para as variáveis correspondentes. Caso não haja problemas com
os novos dados, estes serão salvos no arquivo XML correspondente e passarão a ser usados
na execução dos testes.
4.5 Considerações Finais
Neste capítulo, apresentamos as características e funcionalidades da ferramenta SPACES.
Vimos como sua arquitetura foi definida a partir das etapas dométodo AFCT, como é feito o
processamento dos arquivos XMI para possibilitar a integração da ferramenta com ferramen-
tas de modelagem UML e como cada módulo foi projetado para fornecer as funcionalidades
necessárias para a seleção de casos de teste, a geração de oráculos, a seleção de dados de
teste, a geração de artefatos de teste e o empacotamento dos artefatos. Também foram apre-
sentadas as ferramentas Dresden OCL[HDF00] e JTestCase[Wan05] que são utilizadas pela
ferramenta SPACES para auxiliar as funcionalidades dos módulos. Por fim, apresentamos o
Testador de Componentes, que é a aplicação responsável pelaexecução dos testes gerados
pela ferramenta. Vimos como é feita a execução dos testes gerados para todo o compo-
nente, para uma funcionalidade ou para um cenário de uso de uma funcionalidade, e como é
realizada a alteração dinâmica dos dados de teste.

Capítulo 5
Estudo de Caso
Neste capítulo apresentaremos uma aplicação a partir da qual será escolhido um compo-
nente a ser utilizado como estudo de caso para a avaliação tanto do método AFCT quanto da
ferramenta SPACES. O componente escolhido será especificado segundo as diretrizes do mé-
todo e então submetido à ferramenta com o objetivo de, a partir de indícios reais, demonstrar
a aplicabilidade do método, assim como o comportamento esperado da ferramenta.
5.1 Descrição da Aplicação e Escolha do Componente
A aplicação selecionada consiste em um sistema responsávelpelo gerenciamento centra-
lizado das reservas de uma cadeia de hotéis. O sistema permite realizar reservas em qualquer
hotel da cadeia e as reservas podem ser efetuadas por telefone, em uma central de reservas,
via Internet, ou diretamente em cada hotel. Cada reserva é feita a partir das informações
referentes ao hotel, ao tipo de quarto e ao período (compostopor uma data inicial e uma
data final) desejado. Para agilizar o processo, o sistema cadastra os dados dos clientes no
momento em que estes efetuam reserva em algum hotel pela primeira vez. Por fim, o sistema
está integrado com um sistema de contas, previamente desenvolvido, que é responsável por
computar o valor total devido pelo cliente com base no período de estadia e consumo rea-
lizado. A especificação completa do sistema é apresentada em[CD01]. Um dos artefatos
desta especificação é o diagrama de componentes apresentadona Figura 5.1.
Como pode ser visto no diagrama, as funcionalidades do sistema de reserva são imple-
mentadas por três componentes:
77

5.2 Especificando o Componente 78
<< application >>
Sistema de Reservas
IFConta
IFCliente
IFHotel
<< comp spec >>
Sistema de Contas
<< comp spec >>
Gerenciador de Clientes
<< comp spec >>
Gerenciador de Hoteis
Figura 5.1: Diagrama de Componentes do Sistema de Reservas
• O Sistema de Contas, que é responsável por realizar, de forma transparente, a comuni-
cação entre o Sistema de Reserva e o Sistema de Contas de cada hotel;
• O Gerenciador de Clientes, que reune as funcionalidades relacionadas ao cadastra-
mento e à disponibilização dos dados dos clientes para a cadeia de hotéis; e
• O Gerenciador de Hotéis, que é responsável pelo controle das reservas, assim como
dos quartos e tipos de quartos disponíveis em cada hotel.
Como estudo de caso, escolhemos o componenteGerenciador de Hotéisvisto que este
implementa as principais funcionalidades do Sistema de Reserva. Para tornar mais objetiva
a apresentação do processo de aplicação do método, optamos por especificar e testar as três
principais funcionalidades deste componente: a funcionalidadeFazer Reserva, que realiza as
reservas na cadeia de hotéis, a funcionalidadeAlterar Reserva, que permite a alteração das
características de uma reserva previamente efetuada, e a funcionalidadeCancelar Reserva,
que procede a exclusão de uma reserva previamente realizada.
5.2 Especificando o Componente
Para construir os artefatos que constituem a especificação dos componentes, fizemos uso
da versãoCommunity Editionda ferramenta de modelagemPoseidon for UML. De acordo
com o método AFCT, inicialmente, devemos construir o diagrama de funcionalidades do

5.2 Especificando o Componente 79
componente. Esse diagrama pode ser visto na Figura 5.2. Foram especificados três casos de
uso, um para cada funcionalidade a ser testada no componente. Uma vez que a funcionali-
dadeAlterar Reservadepende da execução das outras duas funcionalidades, o casode uso
correspondente inclui os demais. OSistema de Reservas(tipo SistemaDeReserva) é o ator
dos casos de usos pois ele atua como um cliente, interagindo com o componente para fazer
uso de suas funcionalidades.
SistemaDeReserva
Fazer Reserva
Cancelar Reserva
Alterar Reserva
<< include >>
<< include >>
Figura 5.2: Diagrama de Funcionalidades para o ComponenteGerenciador de Hotéis
Após a construção do diagrama de funcionalidades, o próximopasso é a construção
do modelo conceitual do componente, que, juntamente com o anterior, auxilia a atividade
de planejamento do método AFCT. O modelo conceitual do componenteGerenciador de
Hotéisé apresentado na Figura 5.3. O tipoGerenciadorDeHoteisé composto pelos hotéis
pertencentes a cadeia gerenciada. CadaHotel possui uma coleção de tipos de quarto (tipo
TipoQuarto), uma coleção de quartos (tipoQuarto) de um determinado tipo e uma coleção
de reservas (tipoReserva) efetuadas para os diversos tipos de quarto.
O modelo de informação do componenteGerenciador de Hotéis, apresentado na Fi-
gura 5.4, é um refinamento do modelo conceitual. Nele, as principais entidades do compo-
nente, que foram apresentadas no diagrama anterior, são detalhadas com atributos e opera-
ções e surgem também os tipos auxiliaresTReservaeDateque contribuem para a implemen-
tação das funcionalidades do componente. O objetivo deste diagrama é a disponibilização da
mínima informação da qual é necessário ter conhecimento a fimde se utilizar o componente.

5.2 Especificando o Componente 80
GerenciadorDeHoteis Hotelhoteis+
1..*
Quarto
quartos+1..*
Reservareservas+
*
TipoQuarto
tiposQuarto+1..*
*
tipoQuarto+1..* tipo+
Figura 5.3: Modelo Conceitual do ComponenteGerenciador de Hotéis
GerenciadorDeHoteis
+ fazerReserva (reserva :TReserva,codCliente :String ):void
+ getHotel (codigo :String ):Hotel
+ cancelarReserva (codHotel :String ,codReserva :String ):void
+ alterarReserva (reserva :TReserva,codCliente :String ):void
IFHotel
+ fazerReserva (reserva :TReserva,codCliente :String ):void
+ cancelarReserva (codHotel :String ,codReserva :String ):void
+ alterarReserva (reserva :TReserva,codCliente :String ):void
TReserva
- codigo :String
- tipoQuarto :String
- dFim :Date
- dInicio :Date
- hotel :String
+ getCodigo ():String
+ setCodigo (_codigo :String ):void
+ getTipoQuarto ():String
+ setTipoQuarto (_tipoQuarto :String ):void
+ getDInicio ():Date
+ setDInicio (_dInicio :Date ):void
+ getDFim ():Date
+ setDFim (_dFim:Date):void
+ getHotel ():String
+ setHotel (_hotel :String ):void
<< realize >>
SistemaDeReservas
gerenciadorHoteis+
Hotel
- nome :String
- codigo :String
+ fazerReserva (reserva :TReserva,cliente :String ):void
+ getTipoQuarto (codigo :String ):TipoQuarto
+ isPeriodoReservaOK (inicio :Date ,fim :Date ):boolean
+ verificarDisponibilidade (reserva :TReserva):boolean
+ gerarCodReserva ():String
+ cancelarReserva (codigo :String ):void
+ getReserva (codigo :String ):Reserva
+ getCodigo ():String
+ setCodigo (_codigo :String ):void
+ getNome ():String
+ setNome (_nome:String ):void
hoteis+1..*
Reserva
- codigo :String
- dInicio :Date
- dFim :Date
- cliente :String
- cancelada :boolean
+ Reserva(codigo :String ,inicio :Date,fim :Date,tq :TipoQuarto ,cliente :String ):Reserva
+ cancelar ():void
+ getCodigo ():String
+ setCodigo (_codigo :String ):void
+ getDInicio ():Date
+ setDInicio (_dInicio :Date ):void
+ getDFim ():Date
+ setDFim (_dFim:Date):void
+ getCliente ():String
+ setCliente (_cliente :String ):void
+ isCancelada ():boolean
+ setCancelada (_cancelada :boolean ):void
reservas+
*
TipoQuarto
- nome :String
- codigo :String
- preco :double
+ getCodigo ():String
+ setCodigo (_codigo :String ):void
+ getNome ():String
+ setNome (_nome:String ):void
+ getPreco ():double
+ setPreco (_preco :double ):void
tiposQuarto+
1..*
*
tipoQuarto+
Quarto
- numero :String
+ getNumero ():String
+ setNumero (_numero :String ):void
quartos+1..*
1..*
tipo+
Date
- day:int
- month :int
- year:int
+ today ():Date
+ before (d:Date):boolean
+ after (d:Date ):boolean
+ getDay ():int
+ setDay (_day:int ):void
+ getMonth (): int
+ setMonth (_month :int ):void
+ getYear (): int
+ setYear (_year:int ):void
Figura 5.4: Modelo de Informação do ComponenteGerenciador de Hotéis
O próximo passo na especificação do componente é a construçãodos diagramas de ce-
nários de uso. Cada funcionalidade pode apresentar diferentes fluxos de execução que são
exercidos em função das diferentes possibilidades de dadosde entrada permitidos. Cada
forma diferente de executar uma mesma funcionalidade, constitui um cenário de uso da fun-
cionalidade. No caso do componenteGerenciador de Hotéis, os cenários de uso identificados
para as funcionalidades estão listados na Tabela 5.1.
As Figuras 5.5, 5.6, 5.7, 5.8 e 5.9 mostram os diagramas de cenários de uso da funcio-

5.2 Especificando o Componente 81
Funcionalidade Cenários de Uso
Fazer Reserva Hotel Inexistente
Tipo de Quarto Inexistente
Período Inválido
Quarto não Disponível
Sucesso
Cancelar Reserva Hotel Inexistente
Reserva Inválida
Reserva Já Cancelada
Sucesso
Alterar Reserva Hotel Inexistente
Quarto não Disponível
Sucesso
Tabela 5.1: Cenários de Uso das Funcionalidades do ComponenteGerenciador de Hotéis
nalidadeFazer Reserva. O diagrama 5.5 especifica o cenário onde a reserva não pode ser
realizada porque o hotel desejado não pertence à rede de hotéis. O diagrama 5.6 especifica
o cenário onde a reserva não pode ser realizada porque o tipo de quarto desejado não existe
no hotel desejado. O diagrama 5.7 mostra o cenário onde a reserva não pode ser realizada
porque o período não é válido. O diagrama 5.8 especifica a situação em que a reserva não
pode ser realizada porque não existe quarto disponível do tipo desejado no hotel e período
desejados. Por fim, o diagrama 5.9 representa o cenário principal, onde a reserva é realizada
com sucesso.
Os diagramas que especificam os cenários de uso das funcionalidadesCancelar Reserva
eAlterar Reservaforam construídos de forma análoga aos da funcionalidadeFazer Reserva,
sendo, portanto, desnecessária a sua apresentação.
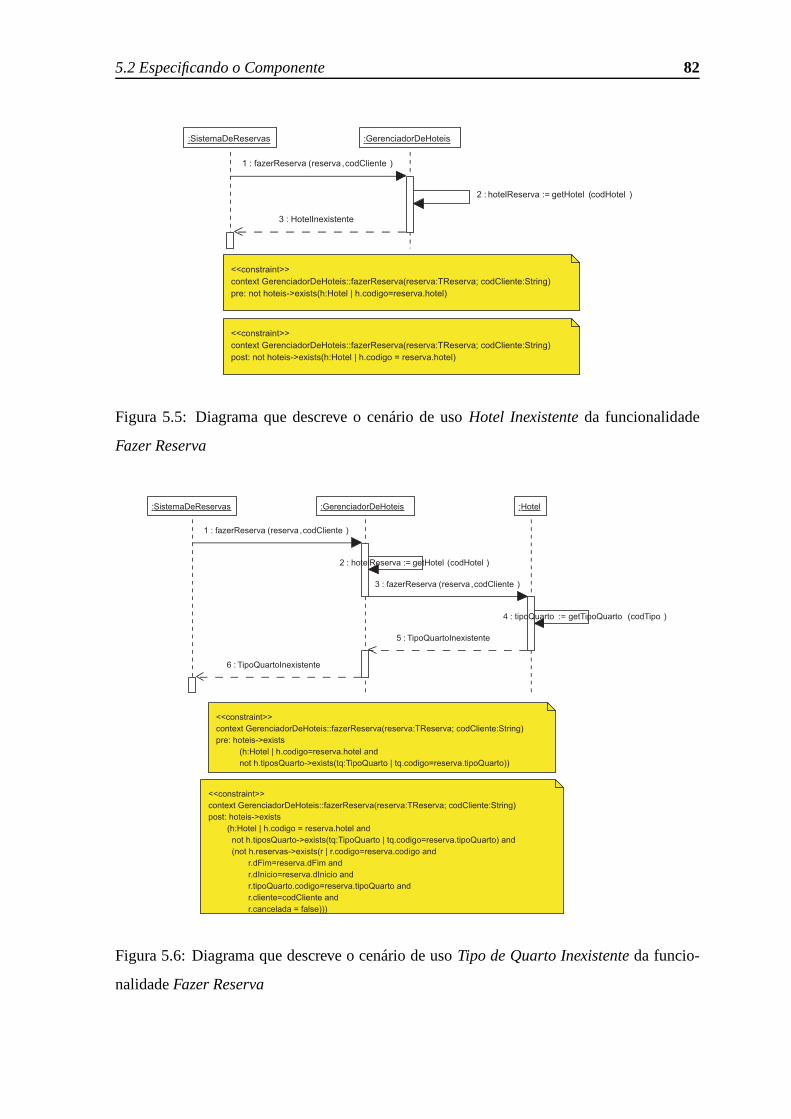
5.2 Especificando o Componente 82
:SistemaDeReservas :GerenciadorDeHoteis
1 : fazerReserva (reserva ,codCliente )
2 : hotelReserva := getHotel (codHotel )
3 : HotelInexistente
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
pre: not hoteis->exists(h:Hotel | h.codigo=reserva.hotel)
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
post: not hoteis->exists(h:Hotel | h.codigo = reserva.hotel)
Figura 5.5: Diagrama que descreve o cenário de usoHotel Inexistenteda funcionalidade
Fazer Reserva
:SistemaDeReservas :GerenciadorDeHoteis
1 : fazerReserva (reserva ,codCliente )
2 : hotelReserva := getHotel (codHotel )
:Hotel
3 : fazerReserva (reserva ,codCliente )
4 : tipoQuarto := getTipoQuarto (codTipo )
5 : TipoQuartoInexistente
6 : TipoQuartoInexistente
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
pre: hoteis->exists
(h:Hotel | h.codigo=reserva.hotel and
not h.tiposQuarto->exists(tq:TipoQuarto | tq.codigo=reserva.tipoQuarto))
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
post: hoteis->exists
(h:Hotel | h.codigo = reserva.hotel and
not h.tiposQuarto->exists(tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
(not h.reservas->exists(r | r.codigo=reserva.codigo and
r.dFim=reserva.dFim and
r.dInicio=reserva.dInicio and
r.tipoQuarto.codigo=reserva.tipoQuarto and
r.cliente=codCliente and
r.cancelada = false)))
Figura 5.6: Diagrama que descreve o cenário de usoTipo de Quarto Inexistenteda funcio-
nalidadeFazer Reserva
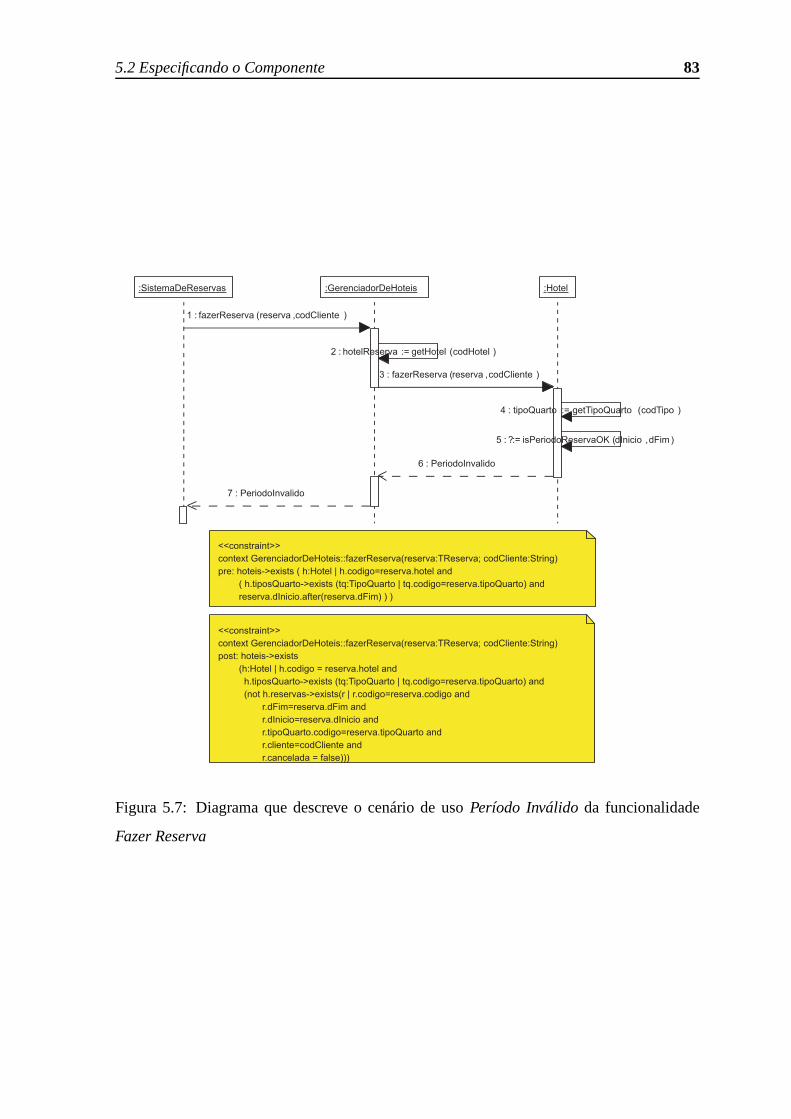
5.2 Especificando o Componente 83
:SistemaDeReservas :GerenciadorDeHoteis
1 : fazerReserva (reserva ,codCliente )
2 : hotelReserva := getHotel (codHotel )
:Hotel
3 : fazerReserva (reserva ,codCliente )
4 : tipoQuarto := getTipoQuarto (codTipo )
5 : ?:= isPeriodoReservaOK (dInicio ,dFim )
6 : PeriodoInvalido
7 : PeriodoInvalido
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
pre: hoteis->exists ( h:Hotel | h.codigo=reserva.hotel and
( h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
reserva.dInicio.after(reserva.dFim) ) )
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
post: hoteis->exists
(h:Hotel | h.codigo = reserva.hotel and
h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
(not h.reservas->exists(r | r.codigo=reserva.codigo and
r.dFim=reserva.dFim and
r.dInicio=reserva.dInicio and
r.tipoQuarto.codigo=reserva.tipoQuarto and
r.cliente=codCliente and
r.cancelada = false)))
Figura 5.7: Diagrama que descreve o cenário de usoPeríodo Inválidoda funcionalidade
Fazer Reserva

5.2 Especificando o Componente 84
:SistemaDeReservas :GerenciadorDeHoteis
1 : fazerReserva (reserva ,codCliente )
2 : hotelReserva := getHotel (codHotel )
:Hotel
3 : fazerReserva (reserva ,codCliente )
4 : tipoQuarto := getTipoQuarto (codTipo )
5 : ?:= isPeriodoReservaOK (dInicio ,dFim )
6 : ?:= verificarDisponibilidade (reserva )
7 : QuartoNaoDisponivel
8 : QuartoNaoDisponivel
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
pre: hoteis->exists ( h:Hotel | h.codigo=reserva.hotel and
( h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
reserva.dInicio.before(reserva.dFim) and
( h.reservas->select( cancelada=false and tipoQuarto.codigo=reserva.tipoQuarto and
( ((dInicio.before(reserva.dInicio) or dInicio = reserva.dInicio) and reserva.dInicio.before(dFim)) or
(dInicio.before(reserva.dFim) and (reserva.dFim.before(dFim) or reserva.dFim = dFim)) or
( (reserva.dInicio.before(dInicio) or reserva.dInicio = dInicio) and
(reserva.dFim.after(dFim) or reserva.dFim = dFim) ) )
)->size = h.quartos->select(tipo.codigo=reserva.tipoQuarto)->size ) ) )
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
post: hoteis->exists
(h:Hotel | h.codigo = reserva.hotel and
h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
(not h.reservas->exists(r | r.codigo=reserva.codigo and
r.dFim=reserva.dFim and
r.dInicio=reserva.dInicio and
r.tipoQuarto.codigo=reserva.tipoQuarto and
r.cliente=codCliente and
r.cancelada = false)))
Figura 5.8: Diagrama que descreve o cenário de usoQuarto Não Disponívelda funcionali-
dadeFazer Reserva
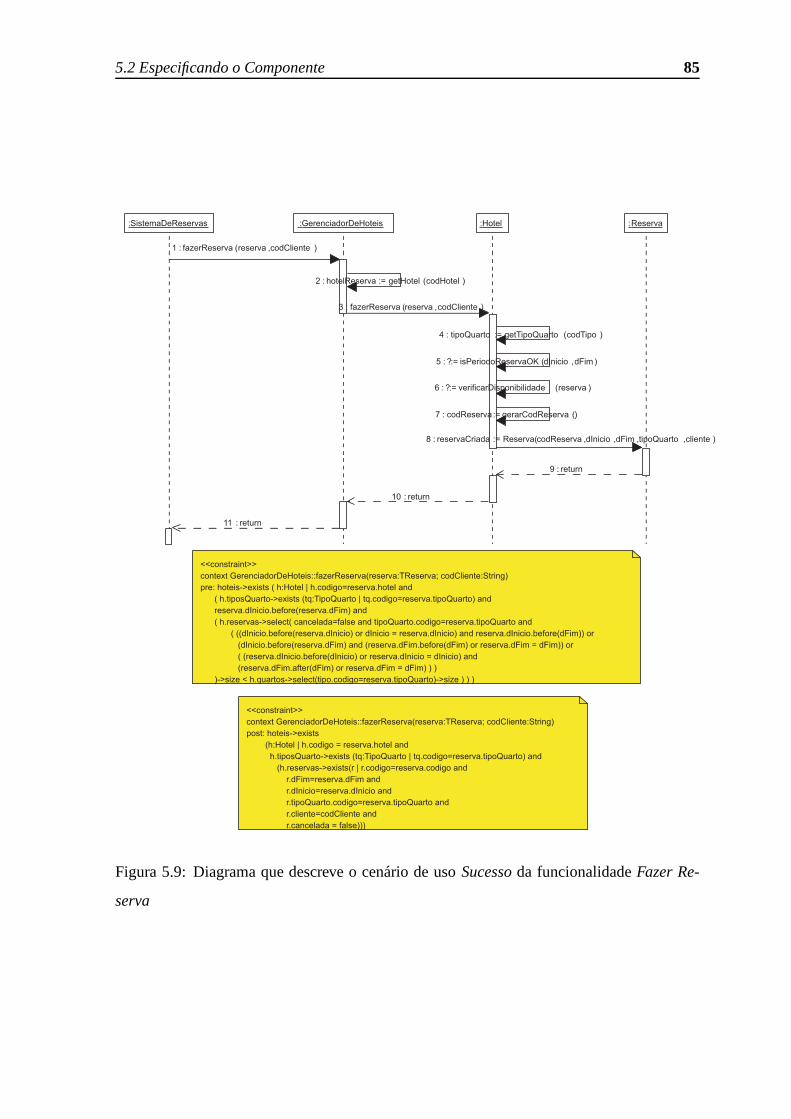
5.2 Especificando o Componente 85
:SistemaDeReservas :GerenciadorDeHoteis
1 : fazerReserva (reserva ,codCliente )
:Hotel
3 : fazerReserva (reserva ,codCliente )
2 : hotelReserva := getHotel (codHotel )
4 : tipoQuarto := getTipoQuarto (codTipo )
5 : ?:= isPeriodoReservaOK (dInicio ,dFim )
6 : ?:= verificarDisponibilidade (reserva )
7 : codReserva := gerarCodReserva ()
:Reserva
8 : reservaCriada := Reserva(codReserva ,dInicio ,dFim ,tipoQuarto ,cliente )
9 : return
10 : return
11 : return
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
pre: hoteis->exists ( h:Hotel | h.codigo=reserva.hotel and
( h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
reserva.dInicio.before(reserva.dFim) and
( h.reservas->select( cancelada=false and tipoQuarto.codigo=reserva.tipoQuarto and
( ((dInicio.before(reserva.dInicio) or dInicio = reserva.dInicio) and reserva.dInicio.before(dFim)) or
(dInicio.before(reserva.dFim) and (reserva.dFim.before(dFim) or reserva.dFim = dFim)) or
( (reserva.dInicio.before(dInicio) or reserva.dInicio = dInicio) and
(reserva.dFim.after(dFim) or reserva.dFim = dFim) ) )
)->size < h.quartos->select(tipo.codigo=reserva.tipoQuarto)->size ) ) )
<<constraint>>
context GerenciadorDeHoteis::fazerReserva(reserva:TReserva; codCliente:String)
post: hoteis->exists
(h:Hotel | h.codigo = reserva.hotel and
h.tiposQuarto->exists (tq:TipoQuarto | tq.codigo=reserva.tipoQuarto) and
(h.reservas->exists(r | r.codigo=reserva.codigo and
r.dFim=reserva.dFim and
r.dInicio=reserva.dInicio and
r.tipoQuarto.codigo=reserva.tipoQuarto and
r.cliente=codCliente and
r.cancelada = false)))
Figura 5.9: Diagrama que descreve o cenário de usoSucessoda funcionalidadeFazer Re-
serva

5.3 Aplicando o Método AFCT 86
5.3 Aplicando o Método AFCT
Nesta seção descrevemos a aplicação das atividades do método AFCT, através da fer-
ramenta SPACES, para proceder o teste funcional do componente Gerenciador de Hotéisa
partir da especificação anteriormente construída.
5.3.1 Planejando o Teste
Uma vez que optamos por especificar e testar apenas três funcionalidades do compo-
nente, vamos concentrar o planejamento de teste sobre o número de casos de teste a ser
selecionado para cada funcionalidade. Como vimos na definição do método AFCT, cada
cenário de uso é um caso de teste em potencial. Dessa forma, temos um total de 12 casos de
teste passíveis de realização e, assim sendo, não haveria problema algum em testar o com-
ponente de forma exaustiva. Porém, vamos optar por realizarapenas 10 casos de teste para
exemplificar a atividade de seleção do método AFCT.
Para determinar como os 10 casos de teste seriam distribuídos entre as funcionalidades,
analisamos estas de acordo com a sua Frequência de Uso e a Criticalidade da ocorrência de
uma falha. Os resultados desta análise são apresentados na Tabela 5.2.
Funcionalidade Freqüência de Uso Criticalidade No de Casos de Teste
Fazer Reserva Alta Alta 4
Alterar Reserva Baixa Alta 3
Cancelar Reserva Baixa Baixa 3
Tabela 5.2: Determinando o número de casos de teste a ser realizados para cada funcionali-
dade
Além disso, decidimos que, para cada funcionalidade, seriam priorizados o cenário de
sucesso e os cenários alternativos mais complexos. Uma vez concluída a etapa de planeja-
mento dos testes, passamos para a especificação dos testes.

5.3 Aplicando o Método AFCT 87
5.3.2 Especificando os Testes
A partir desta etapa, faremos uso da ferramenta SPACES para executar automaticamente
as atividades do método AFCT. Para tanto, precisamos exportar a especificação construída
para o componente na forma de um arquivo XMI e acessar o arquivo a partir da ferramenta
SPACES (menuArquivo/Abrir Arquivo XMI). No Poseidon, o arquivo XMI é obtido através
do menuFile/Export Project to XMI. A seguir, vemos como as atividades que constituem os
artefatos da especificação dos testes do componenteGerenciador de Hotéissão realizadas
pela ferramenta.
Selecionando os Casos de Teste
Ao iniciarmos a funcionalidade de seleção de casos de teste da ferramenta SPACES
(menuProjeto/Selecionar Casos de Teste), é exibida a tela apresentada na Figura 5.10. Nesta
tela indicamos qual o número de casos de teste que devem ser selecionados para cada fun-
cionalidade, de acordo com as decisões tomadas na etapa de planejamento.
Figura 5.10: Selecionando os casos de teste com SPACES
Ao clicar no botãoSelecionar, serão apresentados os modelos de uso gerados para as
funcionalidadesFazer Reservae Cancelar Reserva. No caso da funcionalidadeAlterar Re-
serva, um vez que o teste é realizado de forma exaustiva (coluna GT marcada), o modelo
de uso não é exibido pois os casos de teste serão gerados sem necessidade de seleção. Nos
modelos de uso apresentados, os cenários selecionados estarão em destaque. Caso a seleção

5.3 Aplicando o Método AFCT 88
não tenha priorizado os cenários principais e alternativosmais complexos, como decidido
no planejamento dos testes a serem realizados para cada funcionalidade, as probabilidades
do modelo deverão ser alteradas para refletir as decisões do planejamento e a seleção de-
verá ser refeita até obtermos um conjunto de testes satisfatório. Ao final, os modelos de uso
obtidos para as funcionalidadesFazer Reservae Cancelar Reservasão os apresentados nas
Figuras 5.11 e 5.12.
Figura 5.11: Modelo de Uso para a Funcionalidade Fazer Reserva

5.3 Aplicando o Método AFCT 89
Figura 5.12: Modelo de Uso para a Funcionalidade Cancelar Reserva
Gerando os Oráculos
Após a seleção dos casos de teste, a próxima etapa no método AFCT é a geração dos orá-
culos. Para tanto, acionamos o menuProjeto/Gerar Oráculosda ferramenta SPACES. Feito
isso, são gerados métodos Java correspondentes às restrições OCL de pré e pós-condição
especificadas para cada cenário de uso de cada funcionalidade. Caso invariantes tenham sido
especificadas para a classe responsável pela disponibilização das funcionalidades do com-
ponente (classefacade), estas também serão convertidas em métodos Java. No componente
Gerenciador de Hotéis não foram especificadas invariantes,sendo gerados métodos apenas
para as pré e pós-condições dos cenários. Os métodos Java gerados a partir das restrições
OCL do cenário de usoPeríodo Inválidoda funcionalidadeFazer Reservasão apresentados
nas Figuras 5.13 e 5.14.

5.3 Aplicando o Método AFCT 90
private boolean check_PeriodoInvalido_pre(GerenciadorDeHoteis self, TReserva reserva,String codCliente){
boolean value_1 = false;
}
java.util.Iterator it1 = self.getHoteis().iterator();Hotel h;while (it1.hasNext()){
h = (Hotel) it1.next();boolean value_2 = false;java.util.Iterator it2 = h.getTiposQuarto().iterator();TipoQuarto tq;while (it2.hasNext()){
tq = (TipoQuarto) it2.next();boolean value_3 = tq.getCodigo().equals(reserva.getTipoQuarto());if (value_3){
value_2 = true;break;
}}Date value_4 = reserva.getDFim();boolean value_5 = value_2 && reserva.getDInicio().after(value_4);boolean value_6 = h.getCodigo().equals(reserva.getHotel()) && value_5;if (value_6){
value_1 = true;break;
}}boolean value_7 = value_1;return value_7;
Figura 5.13: Oráculo correspondente à pré-condição do cenário Período Inválidoda Funcio-
nalidadeFazer Reserva
Selecionando os Dados de Teste
Com a funcionalidade de seleção de dados de teste, acionada pelo menu Pro-
jeto/Selecionar Dados de Testeda ferramenta SPACES, procedemos a derivação dos valores
de entrada necessários para a execução das funcionalidadesdo componenteGerenciador
de Hotéisnos diversos cenários de uso especificados. A partir das partições de equivalência
identificadas nas restrições de pré-condição, foram gerados, para cada cenário de uso, valores
aleatórios para os dados de entrada da funcionalidade, assim como valores necessários para
preparar o estado do componente para a execução da funcionalidade no cenário em questão.
Exemplos de dados de teste selecionados para o cenário de usoTipo de Quarto Inexistente
da funcionalidadeFazer Reservasão apresentados na Figura 5.15. Como vimos, durante a
apresentação da ferramenta SPACES, no Capítulo 4, apesar daatividade de seleção de dados
de teste ser realizada de forma automática, algumas vezes o conjunto de dados selecionados
para um determinado cenário pode ser inconsistente com a suapré-condição em função da
não avaliação de alguns trechos da restrição, o que torna necessária uma revisão dos dados

5.3 Aplicando o Método AFCT 91
private boolean check_PeriodoInvalido_post(GerenciadorDeHoteis self, TReserva reserva,String codCliente){
boolean value_1 = false;
value_6;
}
java.util.Iterator it1 = self.getHoteis().iterator();Hotel h;while (it1.hasNext()){
h = (Hotel) it1.next();boolean value_2 = false;java.util.Iterator it2 = h.getTiposQuarto().iterator();TipoQuarto tq;while (it2.hasNext()){
tq = (TipoQuarto) it2.next();boolean value_3 = tq.getCodigo().equals(reserva.getTipoQuarto());if (value_3){
value_2 = true;break;
}}boolean value_4 = false;java.util.Iterator it4 = h.getReservas().iterator();Reserva r;while (it4.hasNext()){
r = (Reserva) it4.next();boolean value_5 = r.getCodigo().equals(reserva.getCodigo()) &&
r.getDFim().equals(reserva.getDFim()) &&r.getDInicio().equals(reserva.getDInicio()) &&.getTipoQuarto().getCodigo().equals(reserva.getTipoQuarto()) &&
r.getCliente().equals(codCliente) && r.isCancelada() == false;f (value_5){
value_4 = true;break;
}}boolean value_6 = ! value_4;boolean value_7 = h.getCodigo().equals(reserva.getHotel()) && value_2 &&if (value_7){
value_1 = true;break;
}}boolean value_8 = value_1;return value_8;
r
i
Figura 5.14: Oráculo correspondente à pós-condição do cenário Período Inválidoda Funcio-
nalidadeFazer Reserva
de teste gerados para aferir o resultado correto dos testes.Como veremos adiante, durante a
execução dos testes, isso foi necessário para alguns cenários do componenteGerenciador de
Hotéis.
5.3.3 Construindo e Empacotando os Artefatos de Teste
Uma vez construída a especificação dos testes (casos de teste, oráculos e dados de teste)
partimos para a sua implementação. Ao acionar o menuProjeto/Gerar Artefatos de Testeda
ferramenta SPACES, será gerada a hierarquia de classes de teste apresentada na Figura 5.16.

5.3 Aplicando o Método AFCT 92
codCliente
codigo
eserva hoteltipoQuarto
reserva.dInicio monthyear
reserva.dFim monthyear
tq
codigo
= "<;X2HF"
= ["fRD9T)=^w/ZXSGXL>Z0%^iN?6+y6`{AM","6Ri<BUOEfIv1Jyy8itu:9pFE4",
"d;1-knsK,q#YT`fy)uO^xy#f_>8RM{m9P-W{@SX{OSqlRC{LiL-TC",
r = "BiYMc{rt>cIG+?]>#IA5W.RXTPB4r28n+4XQSPMl^]?zPS1"= "%#98b5@6"
= 28530= 7710
= 9193= 28766
1.1303589441531831E38,2.230561619400798E38]
= ["","(s@(uA;,%",“)"]
"7vD-xtqz_ODX)Qu@%,,t","}?dHcY#+65m}yR(uv9Ba_HwRUMQ#7dwbo?1pM{","BiYMc{rt>cIG+?]>#IA5W.RXTPB4r28n+4XQSPMl^]?zPS1"]
= ["?Yfc`lQ.zA]}7l,:1Q6`*3G",
"LHk(S^@0?*=n`3pqBNHh80;wb+V%c'zbZ","<52VDLiDw4Ebf","dr2'15|rQ>5"]
nome
= "{?e|uLXz<N[AU#XGR;-GQxYls?<oQ"
= 4266
= 31092
= ["'kSXNa[(A:9YTVhTDZ_}vF5_V[@c`:bvR_O.=19.5JcNa%l&wmJy","I&`spVd?7YN:Lu0Nf-=F^[WP#*ryUTbd@{1L6mXacK5","dw:2jhnYW9AQ[cG#{y"]
= [4.927761449765372E37,
h
codigo
day
day
nome
preco
{{
{{
{Figura 5.15: Dados selecionados para o cenárioTipo de Quarto Inexistenteda funcionalidade
Fazer Reserva
A classeGerenciadorDeHoteisTestestende a classeTestCasedo framework JUnit e é res-
ponsável por disponibilizar, via herança, a verificação dasinvariantes da classeGerencia-
dorDeHoteispara as classes de teste de cada funcionalidade. Estas classes de teste pos-
suem, além dos métodos de teste de cada cenário, os métodos para verificação das pré e
pós-condições dos cenários, que, juntamente com o método deverificação de invariantes
herdado, constituem os oráculos de teste gerados durante a especificação dos testes.
Além das classes de teste, também são gerados arquivos XML contendo os dados de teste
selecionados na etapa de especificação dos testes. Esses arquivos são acessados pelas classes
de teste a partir da API disponibilizada pela ferramenta JTestCase.
Por fim, o código de teste compilado e os arquivos de dados são empacotados na forma de
um arquivo JAR que será utilizado para testar a implementaçao do componente desenvolvido.

5.3 Aplicando o Método AFCT 93
junit.framework.TestCaseGerenciadorDeHoteisTest
+ check_invariants (self :GerenciadorDeHoteis ):boolean
FazerReservaTest
- check_TipoQuartoInexistente_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_TipoQuartoInexistente_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testTipoQuartoInexistente ():void
- check_PeriodoInvalido_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_PeriodoInvalido_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testPeriodoInvalido ():void
- check_QuartoNaoDisponivel_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_QuartoNaoDisponivel_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testQuartoNaoDisponivel ():void
- check_Sucesso_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_Sucesso_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testSucesso ():void
AlterarReservaTest
- check_HotelInexistente_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_HotelInexistente_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testHotelInexistente ():void
- check_QuartoNaoDisponivel_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_QuartoNaoDisponivel_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testQuartoNaoDisponivel ():void
- check_Sucesso_pre (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
- check_Sucesso_post (self :GerenciadorDeHoteis ,reserva :TReserva,codCliente :String ):boolean
+ testSucesso ():void
CancelarReservaTest
- check_ReservaInvalida_pre (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
- check_ReservaInvalida_post (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
+ testReservaInvalida ():void
- check_ReservaJaCancelada_pre (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
- check_ReservaJaCancelada_post (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
+ testReservaJaCancelada ():void
- check_Sucesso_pre (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
- check_Sucesso_post (self :GerenciadorDeHoteis ,codHotel :String ,codReserva :String ):boolean
+ testSucesso ():void
Figura 5.16: Hierarquia de Classes de Teste geradas para o ComponenteGerenciador de
Hoteis
5.3.4 Executando o Teste
A execução dos testes gerados pela ferramenta SPACES é feitapelo Testador de Com-
ponentes, uma aplicação baseada no framework JUnit. Para tanto, é preciso que o pacote
contendo os artefatos de teste gerados esteja presente noCLASSPATHda aplicação. Na Fi-
gura 5.17, vemos a tela de execução dos testes gerados para todas as funcionalidades do
componenteGerenciador de Hotéis. Nesta execução, testamos uma implementação da es-
pecificação do componente na qual a funcionalidadeCancelar Reservafoi incorretamente
codificada. A implementação da funcionalidade deveria lançar uma exceção correspondente
à mensagem de saída do cenárioReserva Já Canceladae, no cenárioSucesso, deveria alterar
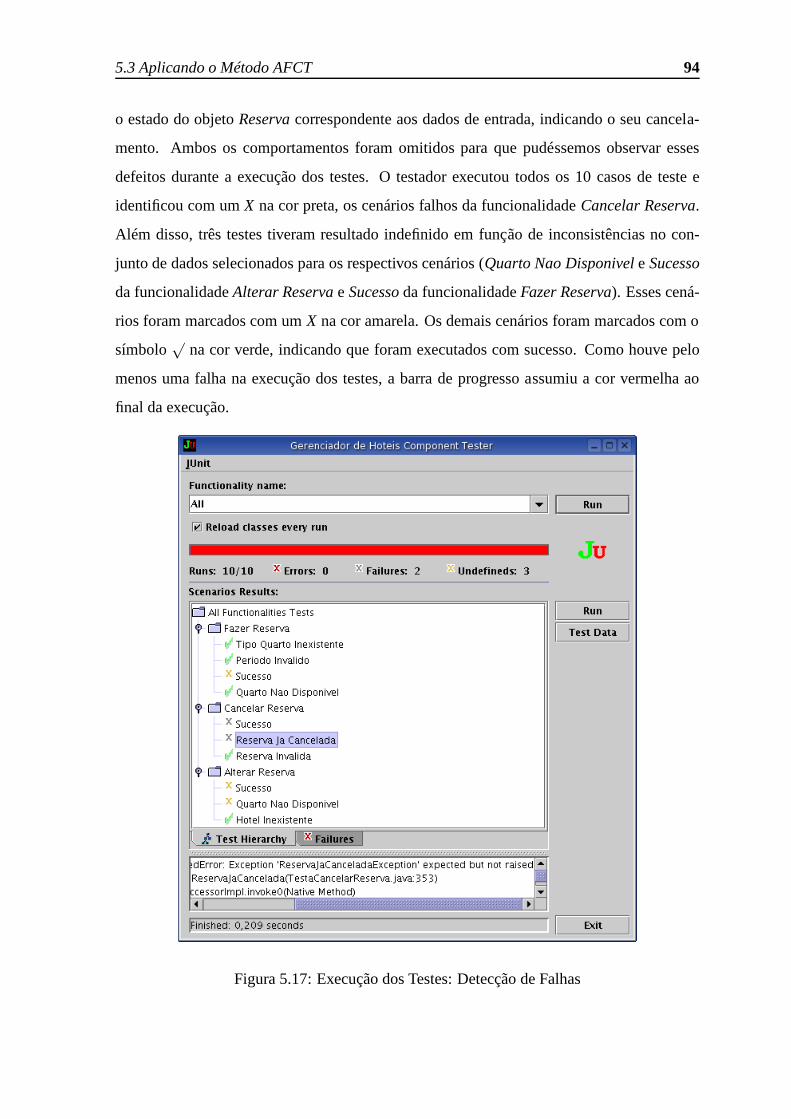
5.3 Aplicando o Método AFCT 94
o estado do objetoReservacorrespondente aos dados de entrada, indicando o seu cancela-
mento. Ambos os comportamentos foram omitidos para que pudéssemos observar esses
defeitos durante a execução dos testes. O testador executoutodos os 10 casos de teste e
identificou com umX na cor preta, os cenários falhos da funcionalidadeCancelar Reserva.
Além disso, três testes tiveram resultado indefinido em função de inconsistências no con-
junto de dados selecionados para os respectivos cenários (Quarto Nao Disponivele Sucesso
da funcionalidadeAlterar Reservae Sucessoda funcionalidadeFazer Reserva). Esses cená-
rios foram marcados com umX na cor amarela. Os demais cenários foram marcados com o
símbolo√
na cor verde, indicando que foram executados com sucesso. Como houve pelo
menos uma falha na execução dos testes, a barra de progresso assumiu a cor vermelha ao
final da execução.
Figura 5.17: Execução dos Testes: Detecção de Falhas
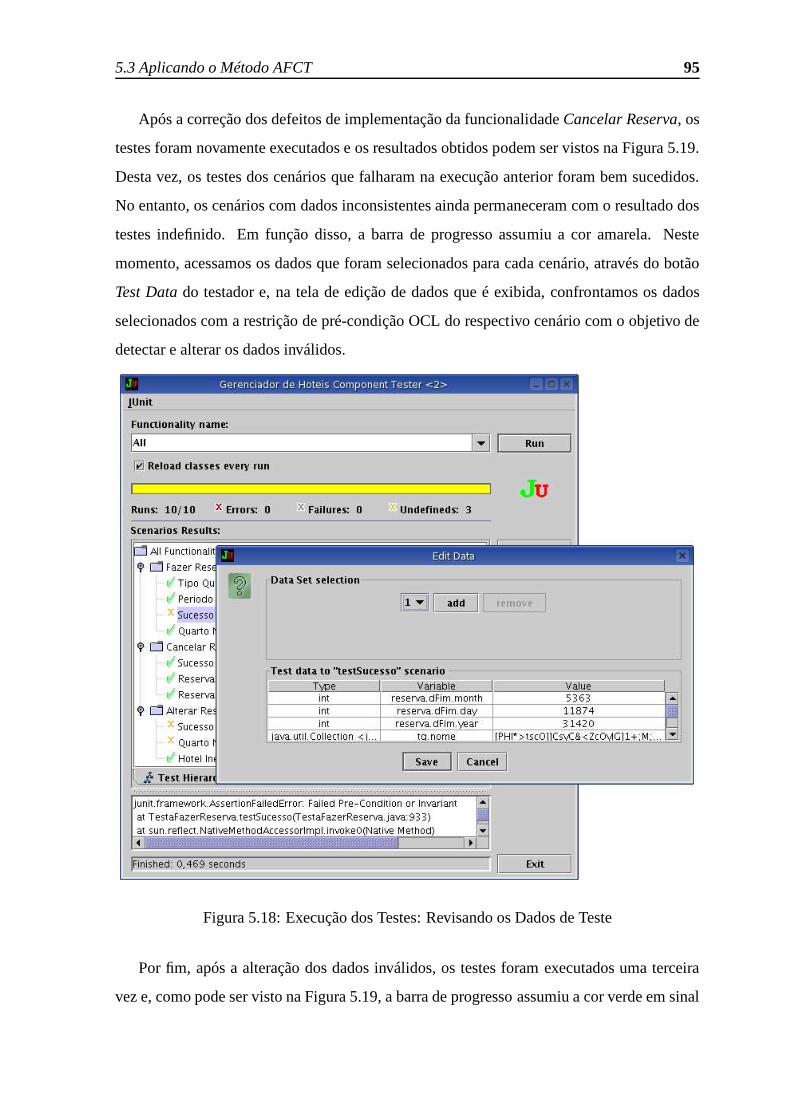
5.3 Aplicando o Método AFCT 95
Após a correção dos defeitos de implementação da funcionalidadeCancelar Reserva, os
testes foram novamente executados e os resultados obtidos podem ser vistos na Figura 5.19.
Desta vez, os testes dos cenários que falharam na execução anterior foram bem sucedidos.
No entanto, os cenários com dados inconsistentes ainda permaneceram com o resultado dos
testes indefinido. Em função disso, a barra de progresso assumiu a cor amarela. Neste
momento, acessamos os dados que foram selecionados para cada cenário, através do botão
Test Datado testador e, na tela de edição de dados que é exibida, confrontamos os dados
selecionados com a restrição de pré-condição OCL do respectivo cenário com o objetivo de
detectar e alterar os dados inválidos.
Figura 5.18: Execução dos Testes: Revisando os Dados de Teste
Por fim, após a alteração dos dados inválidos, os testes foramexecutados uma terceira
vez e, como pode ser visto na Figura 5.19, a barra de progressoassumiu a cor verde em sinal

5.4 Considerações Finais 96
da ausência de falhas.
Figura 5.19: Execução dos Testes: Testes Ok
5.4 Considerações Finais
Neste capítulo, apresentamos a aplicação do método AFCT e daferramenta SPACES na
especificação e teste de um componente de um sistema de reservas de hoteis. A especificação
do componente foi construída passo a passo, de acordo com as diretrizes do método AFCT.
Foi feito um levantamento das funcionalidades e cenários deuso do componente a partir dos
quais foi realizada a etapa de planejamento do método. Em seguida, já com o auxílio da
ferramenta SPACES, foi construída a especificação dos testes a partir da seleção de casos
de teste, da geração de oráculos e da seleção de dados de teste. Após a especificação dos

5.4 Considerações Finais 97
testes, as informações geradas foram utilizadas pela ferramenta para realizar a construção dos
artefatos de teste. Neste momento foram geradas as classes de teste e os arquivos XML de
dados, necessários à execução dos testes do componente. Estes artefatos foram empacotados
na forma de um arquivo JAR para possibilitar a execução dos testes por parte da aplicação
Testador de Componentes. Durante a execução, utilizamos inicialmente uma implementação
na qual uma das funcionalidades do componente havia sido incorretamente codificada em
relação à sua especificação. Ao executar os testes, o testador de componentes identificou as
falhas existentes nesta funcionalidade. Além das falhas, também foram obtidos resultados
indefinidos para alguns testes em função de uma limitação da atividade de seleção de dados
de teste da ferramenta SPACES. Após a correção das falhas de implementação e a alteração
dos dados incorretos, os testes foram novamente executadose todos obtiveram êxito.
Embora tenha sido realizada em um estudo de caso simples, a aplicação do método AFCT
provou ser, de fato, bastante fácil uma vez que os artefatos que foram desenvolvidos são
semelhantes aos que já são normalmente produzidos pelos processos de desenvolvimento.
Além disso, a utilização da ferramenta SPACES para a realização automática de tarefas
mais complexas e/ou sistemáticas do método fez com que estasatividades pudessem ser
realizadas rapidamente e, em que pese o fato de em alguns momentos precisarmos realizar
manualmente parte da atividade de seleção dos dados de teste, em função da limitação exis-
tente na ferramenta, ainda assim o processo de teste pode seraplicado de maneira bastante
prática mesmo em sistemas mais complexos, evitando a necessidade de alocação de grande
parte dos recursos organizacionais. Por fim, vimos que o conjunto de testes gerado pela
ferramenta SPACES aliado ao Testador de Componentes facilita o trabalho do fornecedor
do componente no que diz respeiro à execução e análise de resultado dos testes. Com a
distribuição de ambos para os clientes, os testes produzidos e a infra-estrutura de execução
podem auxiliar a verificação dos componentes do ponto de vista de integração, no momento
da composição das aplicações.
A aplicação do método AFCT nos permite ainda avaliar o quantoda especificação do
componente foi coberta. Caso optássemos pela seleção de todos os casos de teste, obte-
ríamos uma cobertura de 100% da especificação, o que nem sempre é possível em função
dos recursos disponíveis para a realização dos testes. No entanto, uma vez que foram se-
lecionados os cenários de uso mais críticos das funcionalidades, a cobertura obtida pode

5.4 Considerações Finais 98
ser considerada satisfatória e nos dá uma certa margem de segurança a cerca da confiabili-
dade do componente. É importante salientar que a cobertura da especificação é uma métrica
mais adequada para o teste funcional. A cobertura de código poderia ser medida durante a
execução dos testes, a partir do uso de ferramentas extras, aexemplo da ferramenta Clover1.
1http://www.cenqua.com/clover

Capítulo 6
Conclusão
Apresentamos neste trabalho a proposta de um método de testefuncional automático para
verificação de componentes de software a partir de especificações UML e restrições OCL.
A idéia de seu desenvolvimento surgiu a partir da necessidade de realizar adaptações em
um método semelhante que foi desenvolvido anteriormente dentro do Grupo de Pesquisa em
Teste de Software da UFCG, o método FCT (Functional Component Testing). As adaptações
precisavam ser realizadas para possibilitar o desenvolvimento de uma ferramenta de suporte
que automatizasse suas atividades. No entanto, essas adaptações levaram à redefinição de
boa parte das atividades do método FCT, o que acabou resultando na proposta de um novo
método de teste fortemente baseado no anterior, o método AFCT (Automatic Functional
Component Testing). Aliado a elaboração do método AFCT, o trabalho também contemplou
o desenvolvimento de uma ferramenta de suporte para a realização de suas atividades de
forma automática, a ferramenta SPACES (SPecification bAsed Component tESter).
Como mostrado, o método AFCT utiliza artefatos UML produzidos por processos de de-
senvolvimento durante as fases de análise e projeto. Estes artefatos, que são criados segundo
um formato apresentado neste trabalho, são utilizados à medida que vão sendo desenvolvi-
dos, possibilitando, assim, a aplicação do processo de teste de forma paralela ao processo
de desenvolvimento. A partir destes artefatos, é feito o planejamento de teste, quando são
tomadas decisões relacionadas a realização das atividadesde teste frente aos recursos dispo-
níveis. Uma vez definidos os recursos disponíveis para as atividade de teste, é realizada a
especificação dos testes. Essa fase consiste na geração de modelos de teste a partir dos quais
são derivados os casos de teste, oráculos e dados, que constituem os pilares para a realização
99

6.1 Contribuições 100
do teste funcional do componente. Essas informações são então utilizadas para a construção
do código de teste que será responsável pela aferição das funcionalidades do componente.
Por fim, o código de teste é executado e, com base nas informações produzidas, é feita a ava-
liação de conformidade entre a implementação e a especificação do componente. Cada uma
destas atividades foi sistematicamente especificada a partir de algoritmos ou da aplicação
de técnicas de eficiências reconhecidamente comprovadas. Aferramenta SPACES, que foi
desenvolvida a partir de características pré-determinadas e cujo projeto é descrito em um dos
capítulos deste documento, realiza a automação de todas as etapas do método, a exceção do
planejamento de teste, em função do alto grau de subjetividade presente nesta atividade. No
entanto, em função da complexidade relacionada à seleção dedados, a implementação atual
fornece um suporte parcial a essa atividade, tornando necessária uma revisão do conjunto
de dados selecionados a fim de garantir que os testes são executados dentro das condições
previstas.
Para avaliarmos a aplicabilidade do método proposto em um sistema real e a funciona-
lidade da ferramenta de suporte, um estudo de caso foi realizado e seus resultados foram
apresentados neste documento. No estudo de caso, um componente foi especificado e tes-
tado de forma automática, segundo as diretrizes do método AFCT, a partir da ferramenta
SPACES. Os resultados observados trouxeram indícios reaisda facilidade de aplicação do
método e da confiabilidade da ferramenta.
6.1 Contribuições
Antes da realização deste trabalho, haviam poucos métodos de teste funcional aplicados
a componentes de software e que dispusessem de ferramentas de suporte para automatizar as
suas atividades. O que ocorria de fato era que os trabalhos originalmente desenvolvidos para
softwares OO eram utilizados, de forma adaptada, para o teste de componentes de software.
Com isso essas técnicas não eram capazes de cobrir características específicas dos compo-
nentes, a exemplo do teste de propriedades. Outro problema era a distância normalmente
existente entre a definição destas técnicas e a sua real utilização pela indústria. Isso era de-
vido, principalmente, ao desenvolvimento de especificações exclusivamente para propósitos
de teste e em linguagens ou formalismos de difícil assimilação ou de uso extremamente res-

6.2 Trabalhos Futuros 101
trito. No nosso trabalho, definimos um método de teste funcional aplicado à componentes
de software, cujas atividades são quase que inteiramente automatizadas por uma ferramenta
de suporte. O método utiliza especificações UML, uma linguagem largamente utilizada na
indústria, e de artefatos normalmente desenvolvidos nas etapas de análise e projeto dos pro-
cessos de desenvolvimento. Além disso, como os artefatos são utilizados pelo método à
medida em que vão sendo produzidos, os defeitos podem ser descobertos cada vez mais
cedo, reduzindo assim, o custo de correção.
Durante o desenvolvimento da ferramenta SPACES, foram empregadas aplicações de
software livre para auxiliar a implementação de algumas funcionalidades. Com isso, tornou-
se necessário o estabelecimento de contatos com a comunidade desenvolvedora dessas apli-
cações para que pudéssemos adaptá-las as nossas necessidades. Dessa interação surgiram
propostas de novas funcionalidades e a decoberta de defeitos, o que acabou contribuindo
para o aperfeiçoamento das próprias aplicações[ALB+05]. Além disso, é de nosso interesse
que, ao final do seu desenvolvimento, a ferramenta SPACES seja disponibilizada sob alguma
licença livre, possibilitando, assim, a sua expansão para diferentes contextos de execução e
contribuindo para a difusão da prática de teste automático e, de forma mais ampla, para a
melhoria dos produtos de software desenvolvidos na comunidadeopen source.
Por fim, como contribuição indireta, as idéias e algoritmos propostos neste trabalho po-
dem servir de base para a automação de métodos semelhantes, contribuindo para um melhor
entendimento do problema de geração e execução automática de casos de teste.
6.2 Trabalhos Futuros
Com a finalização deste trabalho, tivemos a possibilidade defazer uma análise do mesmo,
a qual resultou no seguinte conjunto de propostas para a sua continuidade:
• Complementar o método em termos de sua abrangência: Assim como ocorre com
o método FCT, o método AFCT limita-se a verificar os componentes individualmente,
entretanto um método completo deveria considerar também a possibilidade de realiza-
ção de testes de integração e sistema. No Grupo de Pesquisa emTeste de Software da
UFCG já foi desenvolvido um trabalho acerca de testes de integração de componentes
[GMF04], assim, como trabalho futuro, propomos a incorporação das idéias apresen-

6.2 Trabalhos Futuros 102
tadas neste trabalho para compor um método de teste automático mais abrangente, que
contemple o teste dos componentes tanto na perspectiva do fornecedor quanto na do
cliente.
• Definir a licença de uso e distribuição da ferramenta: Como é nosso objetivo dis-
ponibilizar a ferramenta como um software livre, precisamos definir a sua política de
utilização e distribuição de forma compatível com as licenças dos softwares livres em-
pregados na implementação de suas funcionalidades. Além disso, precisamos definir
qual será a contribuição da comunidadeopen sourceno desenvolvimento das próximas
versões da ferramenta.
• Promover a evolução da ferramenta: Embora já tenhamos uma primeira versão
da ferramenta, algumas de suas funcionalidades ainda precisam ser aperfeiçoadas, a
exemplo da seleção de dados, que fornece um suporte parcial àatividade do método
AFCT, realizando-o de forma semi-automática. Nesse sentido, um ponto a ser estu-
dado pode ser a adoção de bancos de dados de teste para domínios de componentes,
de forma a maximizar o aproveitamento dos dados selecionados nesta etapa e diminuir
a complexividade desta atividade. Além disso, uma vez que propomos, como trabalho
futuro, o desenvolvimento de um método mais abrangente, é necessário que a fer-
ramenta SPACES também seja evoluída para incorporar funcionalidades referentes ao
teste de integração de componentes. Nesse sentido, os pacotes de teste atualmente pro-
duzidos para os componentes poderiam servir de base para o desenvolvimento de uma
infra-estrutura mais ampla de teste de integração. Outro ponto em que a ferramenta
deve evoluir diz respeito à incorporação das funcionalidades de execução e análise de
resultados dos testes, atualmente implementadas pelo Testador de Componentes. Isso
não foi possível de ser realizado neste trabalho porque era preciso realizar um estudo
mais aprofundado sobre técnicas de alteração dinâmica da variável CLASSPATHda
linguagem Java. Como, no início da execução, a ferramenta que gera o código de
teste não conhece as classes de teste que vão ser geradas durante a execução, é preciso
alterar dinamicamente a variávelCLASSPATHpara adicionar as classes geradas e pos-
sibilitar a sua instanciação e execução. Assim, a tendênciaé que a ferramenta SPACES
evolua para duas versões: uma versão voltada para os fornecedores, que seria capaz

6.2 Trabalhos Futuros 103
de gerar, executar e analisar o resultado de testes para os componentes individuais, e
uma versão voltada para os clientes, que forneça, a partir dos testes produzidos pela
primeira versão, a infra-estrutura necessária à geração, execução e análise de resultado
de testes de integração de componentes.
• Submeter o trabalho a outros estudos de caso: Apesar de desenvolvermos um estudo
de caso que nos forneceu uma visão prática da aplicação do método AFCT e do uso
da ferramenta SPACES, para adquirirmos uma maior confiança acerca da viabilidade
prática do método, precisamos aplicá-lo a um maior número deestudos de caso e
realizar um estudo experimental que possa exercitar cada uma de suas características
em diferentes contextos.

Bibliografia
[ALB+05] Wilkerson L. Andrade, Helton S. Lima, Daniel L. Barbosa, Patrícia D. L. Ma-
chado, and Jorge C. A. Figueiredo. Experiência no Uso de Ferramentas Livres
para o Teste Funcional de Componentes de Software. InVI Workshop Software
Livre (WSL), Porto Alegre, 2005.
[BAMF04a] Daniel L. Barbosa, Wilkerson L. Andrade, Patrícia D. L. Machado, and Jorge
C. A. Figueiredo. SPACES – Uma Ferramenta para Teste Funcional de Com-
ponentes. InAnais da Sessão de Ferramentas do XVIII Simpósio Brasileirode
Engenharia de Software (SBES), Brasília, 2004. Prêmio de Melhor Ferramenta
do Evento.
[BAMF04b] Daniel L. Barbosa, Wilkerson L. Andrade, Patrícia D. L. Machado, and Jorge
C. A. Figueiredo. Um Método Automático para Verificação Funcional de
Componentes. InIV Workshop de Desenvolvimento Baseado em Componentes
(WDBC), pages 23–28, João Pessoa, 2004.
[Bei90] Boris Beizer. Software Testing Techniques. Van Nostrand Reinhold, 2nd edi-
tion. 1990.
[Bei95] Boris Beizer.Black-Box Testing: Techniques for Functional Testing of Software
and Systems. John Wiley & Sons, 1995.
[Bin99] Robert V. Binder.Testing Object-Oriented Systems: Models, Patterns and To-
ols. Addison-Wesley, 1999.
[BL01] Lionel Briand and Yvan Labiche. A UML-Based Approach to System Testing.
In Proceedings of UML 2001 - The Unified Modeling Language. Modeling
104

BIBLIOGRAFIA 105
Languages, Concepts, and Tools, volume 2185 ofLecture Notes in Computer
Science, pages 194–208, 2001.
[CCD+02] A. Cavarra, C. Crichton, J. Davies, A. Hartman, T. Jeron, andL. Mounier.
Using UML for Automatic Test Generation. In Joost-Pieter Katoen and Per-
dita Stevens, editors,Proceedings of the 8th International Conference on Tools
and Algorithms for the Construction and Analysis of Systems(TACAS’2002),
volume 2280 ofLecture Notes in Computer Science, Grenoble, France, April
2002. Springer.
[CD01] John Cheesman and John Daniels.UML Components: A Simple Process for
Specifying Component-Based Software. Addison-Wesley, 2001.
[CM94] J. J. Chilenski and S. P. Miller. Applicability of modified condition/decision
coverage to software testing.Software Engineering Journal, 7(5):193–200,
1994.
[CR99] Juei Chang and Debra J. Richardson. Structural specification-based testing:
Automated support and experimental evaluation. In Oscar Nierstrasz and Mi-
chel Lemoine, editors,ESEC/FSE ’99, volume 1687 ofLecture Notes in Com-
puter Science, pages 285–302. Springer-Verlag / ACM Press, 1999.
[CWO03] MH. Chen, Y. Wu, and J. Offutt. UML-Based Integration Testing for
Component-Based Software. InProceedings of the 2nd International Con-
ference on COTS-Based Software Systems (ICCBSS), February2003, 2003.
[dF03] Carina M. de Farias. Um Método de Teste Funcional para Verificação de Com-
ponentes.Dissertação de Mestrado - COPIN, UFCG, 2003.
[FJJV97] Jean-Claude Fernandez, Claude Jard, Thierry Jeron, and Cesar Viho. An Expe-
riment in Automatic Generation of Test Suites for Protocolswith Verification
Technology.Science of Computer Programming, 29(1-2):123–146, 1997.
[FL00] P. Fröhlich and J. Link. Automated Test Case Generation fromDynamic Mo-
dels. InProceedings of ECOOP 2000, LNCS 1850, pages 472–491. Springer,
2000.

BIBLIOGRAFIA 106
[GB05] Erich Gamma and Kent Beck. JUnit Testing Framework. Disponível em
http://www.junit.org, Março, 2005.
[GHJV95] Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Design
Patterns: Elements of Reusable Object-Oriented Software. Addison Wesley,
Reading, MA, 1995.
[GMF04] Cidinha Costa Gouveia, Patrícia D. L. Machado, and Jorge C. A. Figueiredo.
Uma Estratégia de Teste de Integração de Componentes. InIV Workshop de
Desenvolvimento Baseado em Componentes (WDBC), pages 63–68, João Pes-
soa, 2004.
[Gra94] J. Grabowski. SDL and MSC Based Test Case Generation: An Overall View
of the SaMsTaG Method, 1994.
[Har00] Mary J. Harrold. Testing: A Roadmap. InProceedings of the 22th International
Conference on Software Engineering (ICSE-00), pages 61–72, NY, June 4–11
2000. ACM Press.
[HDF00] Heinrich Hussmann, Birgit Demuth, and Frank Finger. Modular Architecture
for a Toolset Supporting OCL. InProceedings of UML 2000 - The Unified
Modeling Language. Advancing the Standard. Third International Conference,
pages 278–293, York, UK, 2000.
[Idr05] Nazmul Idris. Should I use SAX or DOM? Disponível em
http://developerlife.com/saxvsdom/default.htm, Janeiro, 2005.
[Lar98] Craig Larman. Applying UML and Patterns: an Introduction to Object-
Oriented Analysis and Design. Prentice Hall PTR, Upper Saddle River/NJ,
1998.
[Mac00] Patrícia D. L. Machado. Testing from structured algebraic specifications. In
AMAST: 8th International Conference on Algebraic Methodology and Software
Technology, volume 1816 ofLecture Notes in Computer Science. Springer-
Verlag / ACM Press, 2000.

BIBLIOGRAFIA 107
[Meg05] David Megginson. SAX 2.0 - The Simple API for XML. Disponívelem
http://www.saxproject.org/, Janeiro, 2005.
[MS01] J. D. McGregor and D. A. Sykes.A Practical Guide to Testing Object-Oriented
Software. Addison-Wesley, 2001.
[MTY01] E. Martins, C. Toyota, and R. Yanagawa. Constructing Self-Testable Software
Components. InProceedings of the 2001 International Conference on Depen-
dable Systems and Networks (DSN ’01), Washington - Brussels- Tokyo, pages
151–160. IEEE, 2001.
[OA99] Jeff Offutt and Aynur Abdurazik. Generating Tests from UML Specifications.
In Robert France and Bernhard Rumpe, editors,UML’99 - The Unified Mode-
ling Language. Beyond the Standard. Second International Conference, Fort
Collins, CO, USA, October 28-30. 1999, Proceedings, volume 1723 ofLNCS,
pages 416–429. Springer, 1999.
[OMG02] OMG. XML Metadata Interchange (XMI) Specification - Version1.2, 2002.
[OMG03a] OMG. UML Object Constraint Language (OCL) Specification - Version 2.0,
2003.
[OMG03b] OMG. Unified Modeling Language (UML) Specification - Version1.5, 2003.
[PBB97] Cécile Péraire, Stéphane Barbey, and Didier Buchs. Test Selection for Object-
Oriented Software Based on Formal Specifications, 1997.
[PTLP99] Stacy J. Prowell, Carmen J. Trammell, Richard C. Linger, andJesse H. Poore.
Cleanroom Software Engineering - Technology and Process. The SEI Series in
Software Engineering. Addison-Wesley, 1999.
[RPG01] Matthias Riebisch, Ilka Philippow, and Marco Götze. UML-Based Statistical
Test Case Generation, 2001.
[Som03] Ian Sommerville.Engenharia de Software. Addison-Wesley Publishing Com-
pany, 2003.

BIBLIOGRAFIA 108
[Szy98] Clemens Szyperski.Component Software: Beyond Object-Oriented Program-
ming. ACM Press and Addison-Wesley, New York, NY, 1998.
[TB02] J. Tretmans and E. Brinksma. Côte de Resyste - Automated Model Based Tes-
ting. In M. Schweizer, editor,Proceedings of Progress 2002 - 3rd Workshop on
Embedded Systems, STW Technology Foundation, Utrecht, TheNetherlands,
pages 246–255, 2002.
[VDR00] M. E. Vieira, M. S. Dias, and D. J. Richardson. Object-Oriented Specification-
Based Testing Using UML Statechart Diagrams. InProceedings of ICSE2000
- Workshop on Automated Program Analysis, Testing, and Verification - June,
2000, Limerick, Ireland, 2000.
[W3C05] W3C. Document Object Model. Disponível em http://www.w3.org/DOM/, Ja-
neiro, 2005.
[Wan05] Yuqing Wang. JTestCase. Disponível em http://jtestcase.sourceforge.net/,
Março, 2005.
[ÉGG98] Étienne Gagnon and Etienne Gagnon. Sablecc, an object-oriented compiler
framework. InIn Proceedings of TOOLS, pages 140–154, 1998.

Apêndice A
Mapeamento OCL – Java
Neste apêndice, descrevemos o mapeamento proposto da linguagem de restrições OCL
para a linguagem de programação Java. Esta conversão teve como objetivo obter um código
fonte equivalente de forma que a mesma restrição descrita emOCL pudesse ser avaliada, em
tempo de execução, pelo código de teste gerado pelo método AFCT. Para tanto, procuramos
respeitar todas as características inerentes a linguagem OCL, a exemplo da ausência de efei-
tos colaterais, uma vez que trata-se de uma linguagem puramente de expressão. Além disso,
como OCL é uma linguagem de semântica formal, procuramos utilizar um sub-conjunto bem
definido e validado pela comunidade de desenvolvedores, de tipos, operadores, operações e
contruções da linguagem java. O mapeamento proposto para asconstruções mais usuais de
OCL pode ser visto a seguir.
A.1 Declaração de Context
OCL context <context> [ :: <operation> ( [<op_params>] ) [:<result_type>]]
inv | pre | post <const-name> ...
Java boolean check_<const-name>(<context> self [, <op_params>]
[, <result_type> result]) { ... }
Tabela A.1: Mapeamento OCL – Java: Declaração de Context
109

A.3 Operadores (Numéricos, Relacionais e Lógicos) 110
A.2 Tipos
OCL Java
Integer int
Real double
Boolean boolean
String java.lang.String
Model Type Model Type
Collection java.util.Collection
Set java.util.Set
Sequence java.util.ArrayList
Bag java.util.ArrayList
OCLAny java.lang.Object
Tabela A.2: Mapeamento OCL – Java: Tipos
A.3 Operadores (Numéricos, Relacionais e Lógicos)
OCL Java
+, -, *, /, - Unário +, -, *, /, - Unário
Módulo (mod) Resto da Divisão (%)
Divisão Inteira (div) /
Valor Absoluto (<numeric_expression>.abs)Math.abs(<numeric_expression>)
Truncamento (<real_expression>.floor) Math.floor(<real_expression>)
<, >, <=, >= <, >, <=, >=
Igualdade (=) == (Tipos Primitivos), equals (Objetos)
Diferença (<>) != (Tipos Primitivos), !equals (Objetos)
not !
and &&
or ||
xor ˆ
Tabela A.3: Mapeamento OCL – Java: Operadores(continua)

A.5 Construções Básicas 111
OCL Java
implies (a implies b) !a || (a && b)
Tabela A.3: Mapeamento OCL – Java: Operadores
A.4 Operações sobre Strings
OCL Java
<string_expression>.concat( <string_expression>.concat(
<string_expression2>) <string_expression2>)
<string_expression>.size <string_expression>.length()
<string_expression>.toLower <string_expression>.toLowerCase()
<string_expression>.toUpper <string_expression>.toUpperCase()
<string_expression>.substring( <string_expression>.substring(
<integer_expression>, <integer_expression2>)<integer_expression>, <integer_expression2>)
Tabela A.4: Mapeamento OCL – Java: Operações sobre Strings
A.5 Construções Básicas
OCL Java
false false
true true
Literal Integer Literal int
Literal Real Literal double
Literal String (‘...’) Literal java.lang.String (“...”)
self <Tipo> self (parâmetro do método check...)
parâmetros de entrada (pre e post) parâmetros do método check...
result <Tipo> result (parâmetro do método check...)
if <boolean_expression> then y else w endifif (<boolean_expression>) y; else w;
let x=y in <x_expression> <Tipo> x = y; <x_expression>
Tabela A.5: Mapeamento OCL – Java: Construções Básicas
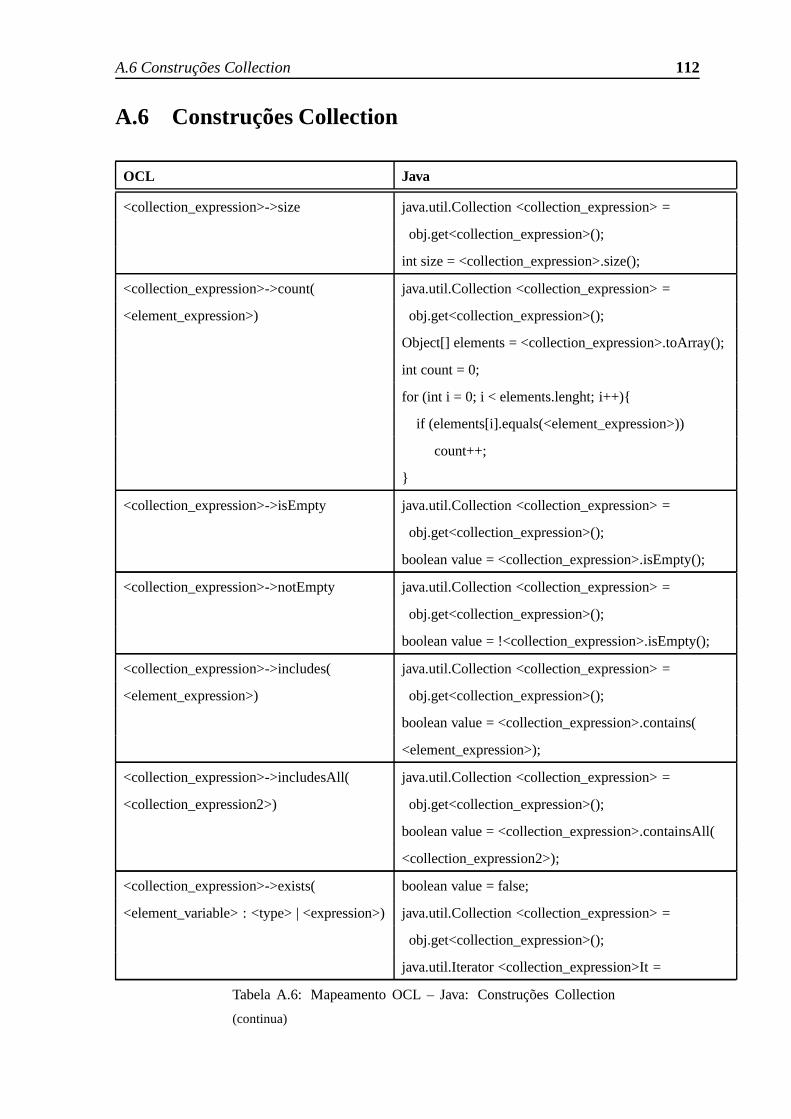
A.6 Construções Collection 112
A.6 Construções Collection
OCL Java
<collection_expression>->size java.util.Collection <collection_expression> =
obj.get<collection_expression>();
int size = <collection_expression>.size();
<collection_expression>->count( java.util.Collection <collection_expression> =
<element_expression>) obj.get<collection_expression>();
Object[] elements = <collection_expression>.toArray();
int count = 0;
for (int i = 0; i < elements.lenght; i++){
if (elements[i].equals(<element_expression>))
count++;
}
<collection_expression>->isEmpty java.util.Collection <collection_expression> =
obj.get<collection_expression>();
boolean value = <collection_expression>.isEmpty();
<collection_expression>->notEmpty java.util.Collection <collection_expression> =
obj.get<collection_expression>();
boolean value = !<collection_expression>.isEmpty();
<collection_expression>->includes( java.util.Collection <collection_expression> =
<element_expression>) obj.get<collection_expression>();
boolean value = <collection_expression>.contains(
<element_expression>);
<collection_expression>->includesAll( java.util.Collection <collection_expression> =
<collection_expression2>) obj.get<collection_expression>();
boolean value = <collection_expression>.containsAll(
<collection_expression2>);
<collection_expression>->exists( boolean value = false;
<element_variable> : <type> | <expression>)java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
Tabela A.6: Mapeamento OCL – Java: Construções Collection
(continua)
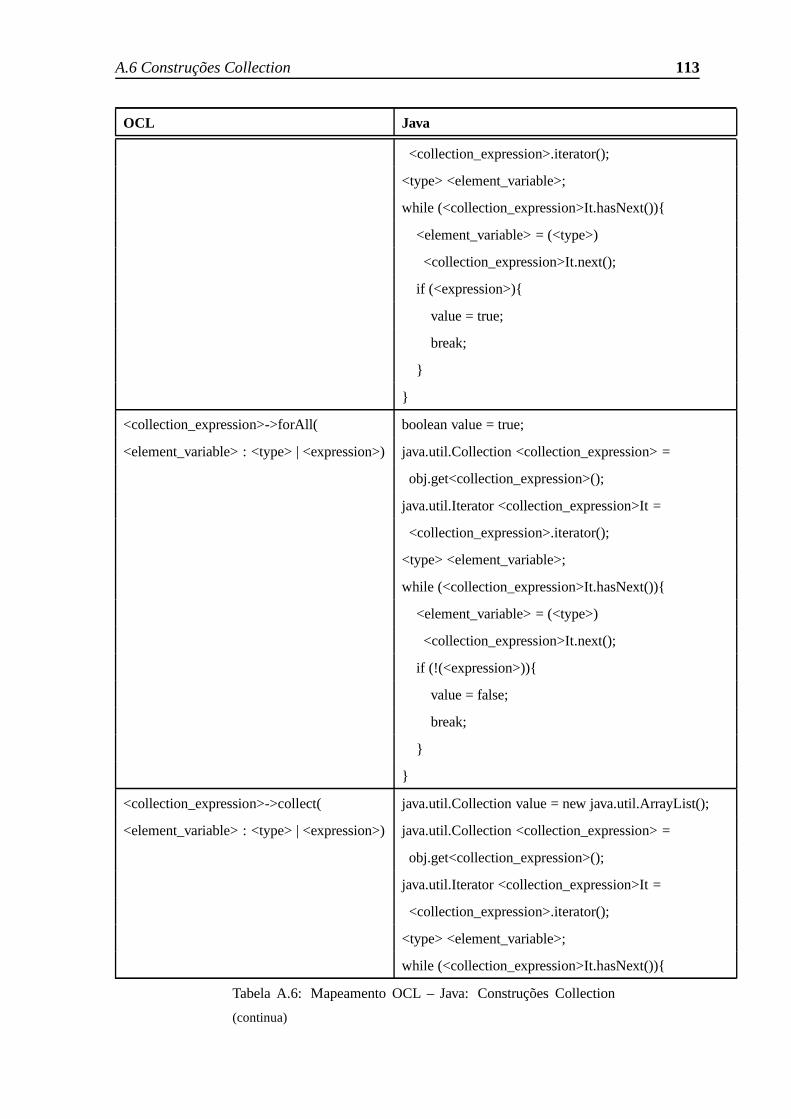
A.6 Construções Collection 113
OCL Java
<collection_expression>.iterator();
<type> <element_variable>;
while (<collection_expression>It.hasNext()){
<element_variable> = (<type>)
<collection_expression>It.next();
if (<expression>){
value = true;
break;
}
}
<collection_expression>->forAll( boolean value = true;
<element_variable> : <type> | <expression>)java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
<collection_expression>.iterator();
<type> <element_variable>;
while (<collection_expression>It.hasNext()){
<element_variable> = (<type>)
<collection_expression>It.next();
if (!(<expression>)){
value = false;
break;
}
}
<collection_expression>->collect( java.util.Collection value = new java.util.ArrayList();
<element_variable> : <type> | <expression>)java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
<collection_expression>.iterator();
<type> <element_variable>;
while (<collection_expression>It.hasNext()){
Tabela A.6: Mapeamento OCL – Java: Construções Collection
(continua)
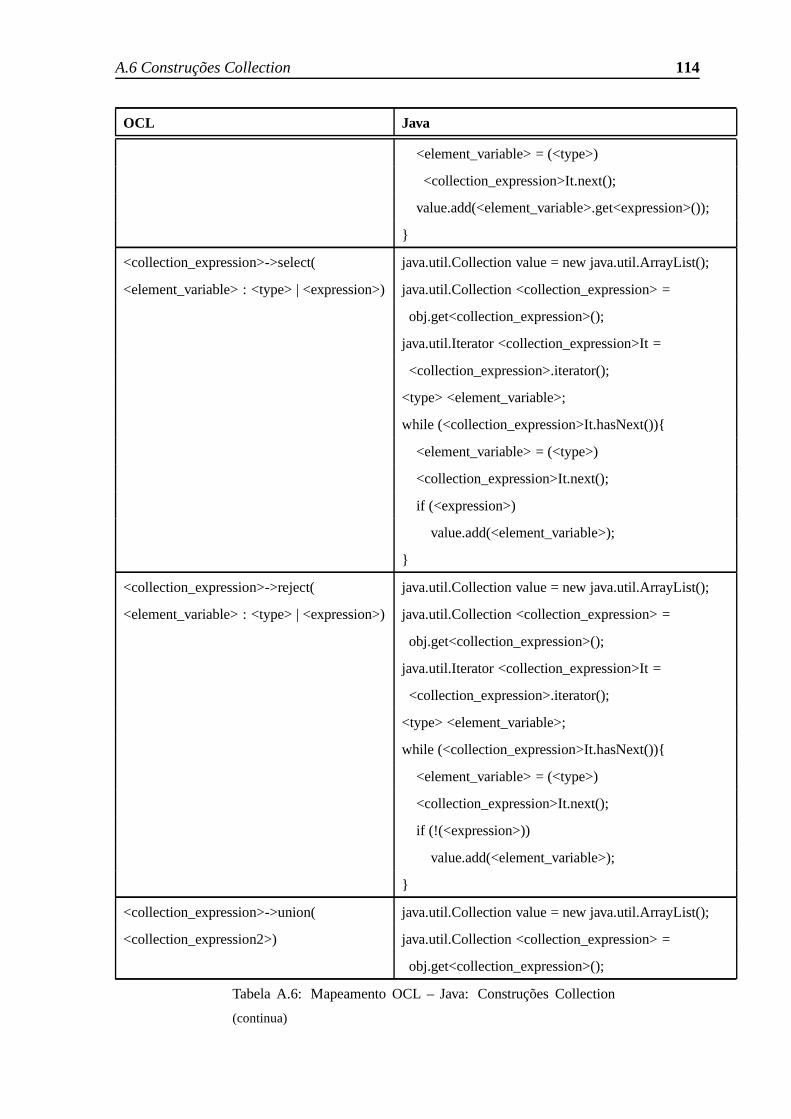
A.6 Construções Collection 114
OCL Java
<element_variable> = (<type>)
<collection_expression>It.next();
value.add(<element_variable>.get<expression>());
}
<collection_expression>->select( java.util.Collection value = new java.util.ArrayList();
<element_variable> : <type> | <expression>)java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
<collection_expression>.iterator();
<type> <element_variable>;
while (<collection_expression>It.hasNext()){
<element_variable> = (<type>)
<collection_expression>It.next();
if (<expression>)
value.add(<element_variable>);
}
<collection_expression>->reject( java.util.Collection value = new java.util.ArrayList();
<element_variable> : <type> | <expression>)java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
<collection_expression>.iterator();
<type> <element_variable>;
while (<collection_expression>It.hasNext()){
<element_variable> = (<type>)
<collection_expression>It.next();
if (!(<expression>))
value.add(<element_variable>);
}
<collection_expression>->union( java.util.Collection value = new java.util.ArrayList();
<collection_expression2>) java.util.Collection <collection_expression> =
obj.get<collection_expression>();
Tabela A.6: Mapeamento OCL – Java: Construções Collection
(continua)
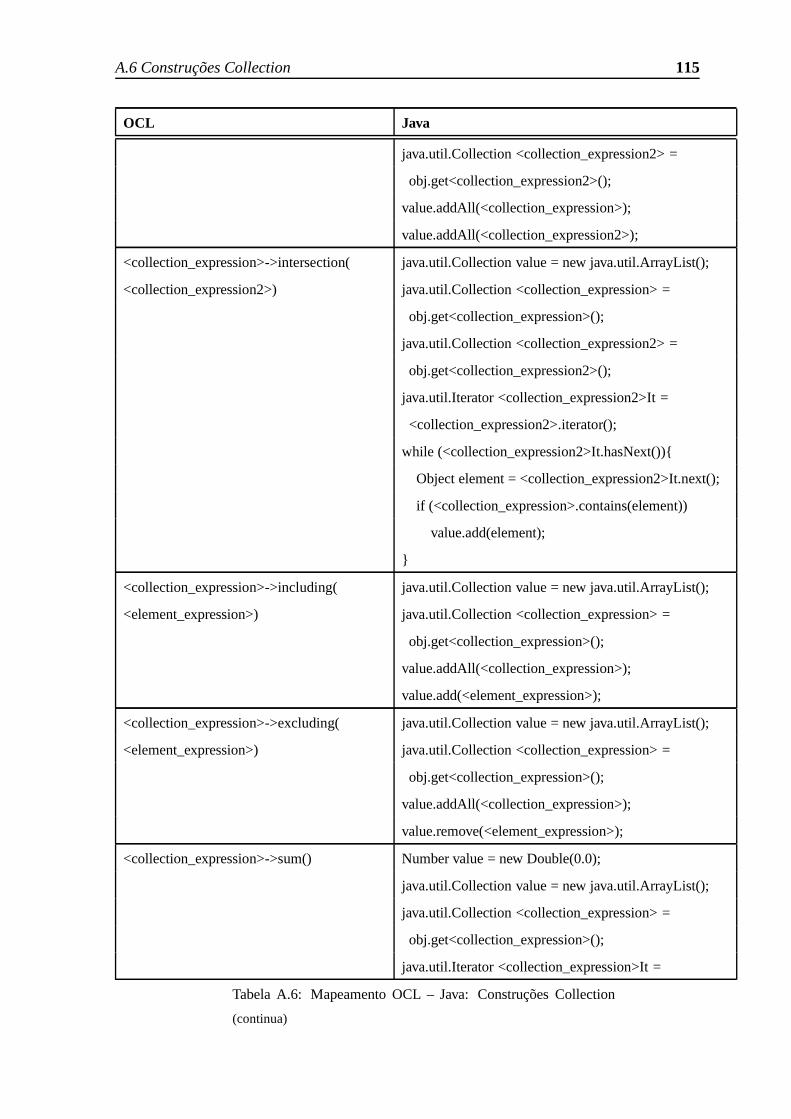
A.6 Construções Collection 115
OCL Java
java.util.Collection <collection_expression2> =
obj.get<collection_expression2>();
value.addAll(<collection_expression>);
value.addAll(<collection_expression2>);
<collection_expression>->intersection( java.util.Collection value = new java.util.ArrayList();
<collection_expression2>) java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Collection <collection_expression2> =
obj.get<collection_expression2>();
java.util.Iterator <collection_expression2>It =
<collection_expression2>.iterator();
while (<collection_expression2>It.hasNext()){
Object element = <collection_expression2>It.next();
if (<collection_expression>.contains(element))
value.add(element);
}
<collection_expression>->including( java.util.Collection value = new java.util.ArrayList();
<element_expression>) java.util.Collection <collection_expression> =
obj.get<collection_expression>();
value.addAll(<collection_expression>);
value.add(<element_expression>);
<collection_expression>->excluding( java.util.Collection value = new java.util.ArrayList();
<element_expression>) java.util.Collection <collection_expression> =
obj.get<collection_expression>();
value.addAll(<collection_expression>);
value.remove(<element_expression>);
<collection_expression>->sum() Number value = new Double(0.0);
java.util.Collection value = new java.util.ArrayList();
java.util.Collection <collection_expression> =
obj.get<collection_expression>();
java.util.Iterator <collection_expression>It =
Tabela A.6: Mapeamento OCL – Java: Construções Collection
(continua)

A.6 Construções Collection 116
OCL Java
<collection_expression>.iterator();
Number element;
while (<collection_expression>It.hasNext()){
element = (Number)<collection_expression>It.next();
value = new Double(value.doubleValue() +
element.doubleValue());
}
Tabela A.6: Mapeamento OCL – Java: Construções Collection

Apêndice B
Subconjunto XMI Utilizado
Neste apêndice, apresentamos o DTD (Document Type Definition) que descreve o sub-
conjunto dos elementos definidos pelo padrão XMI (XML Metadata Interchange) nos quais
estão contidas as informações referentes aos artefatos UMLnecessários para a aplicação do
método AFCT e que, portanto, foram considerados durante a construção do móduloParser
XMI da ferramenta SPACES. A seguir vemos a descrição destes elementos.
<!ENTITY % XMI.element.att
’xmi.id ID #IMPLIED’ >
<!ENTITY % XMI.link.att
’xmi.idref IDREF #IMPLIED’ >
<!ELEMENT XMI (UML:Model, UML:Diagram * ) >
<!ATTLIST XMI
xmi.version CDATA #FIXED "1.2" >
<!ELEMENT UML:Model (UML:Class | UML:Interface | UML:Asso ciation |
UML:Constraint | UML:DataType | UML:Stereotype |
UML:Generalization | UML:Abstraction | UML:Actor |
UML:UseCase | UML:Include | UML:Extend |
UML:Collaboration | UML:Comment | UML:Package ) * >
<!ATTLIST UML:Model
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
117

118
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Class (UML:Attribute | UML:Operation | UML: Constraint |
UML:Comment) * >
<!ATTLIST UML:Class
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
isActive CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Attribute (UML:Expression, UML:Structura lFeature.type) * >
<!ATTLIST UML:Attribute
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
ownerScope (instance|classifier) #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Expression >
<!ATTLIST UML:Expression
language CDATA #IMPLIED
body CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:StructuralFeature.type (UML:DataType | UM L:Class |
UML:Interface) >
<!ELEMENT UML:Operation (UML:Parameter) * >
<!ATTLIST UML:Operation
name CDATA #IMPLIED

119
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
ownerScope (instance|classifier) #IMPLIED
isQuery CDATA #IMPLIED
concurrency (sequential|guarded|concurrent) #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Parameter (UML:Parameter.type) * >
<!ATTLIST UML:Parameter
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
kind (in|inout|out|return) #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Parameter.type (UML:DataType | UML:Class | UML:Interface) >
<!ELEMENT UML:Interface (UML:Operation) * >
<!ATTLIST UML:Interface
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Association (UML:AssociationEnd) * >
<!ATTLIST UML:Association
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>

120
<!ELEMENT UML:AssociationEnd (UML:MultiplicityRange,
UML:AssociationEnd.participant) * >
<!ATTLIST UML:AssociationEnd
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
isNavigable CDATA #IMPLIED
ordering (unordered|ordered) #IMPLIED
aggregation (none|aggregate|composite) #IMPLIED
targetScope (instance|classifier) #IMPLIED
changeability (changeable|frozen|addOnly) #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:MultiplicityRange >
<!ATTLIST UML:MultiplicityRange
lower CDATA #IMPLIED
upper CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:AssociationEnd.participant (UML:Class | U ML:Interface |
UML:UseCase | UML:Actor) >
<!ELEMENT UML:Constraint (UML:BooleanExpression, UML:C lass) * >
<!ATTLIST UML:Constraint
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:BooleanExpression >
<!ATTLIST UML:BooleanExpression
language CDATA #IMPLIED
body CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:DataType >
<!ATTLIST UML:DataType

121
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Stereotype >
<!ATTLIST UML:Stereotype
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Generalization (UML:Generalization.chil d,
UML:Generalization.parent) * >
<!ATTLIST UML:Generalization
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Generalization.child (UML:Class | UML:Int erface |
UML:UseCase | UML:Actor) >
<!ELEMENT UML:Generalization.parent (UML:Class | UML:In terface |
UML:UseCase | UML:Actor) >
<!ELEMENT UML:Abstraction (UML:Stereotype, UML:Depende ncy.client,
UML:Dependency.supplier) * >
<!ATTLIST UML:Abstraction
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Dependency.client (UML:Class) >
<!ELEMENT UML:Dependency.supplier (UML:Interface | UML: Class) >

122
<!ELEMENT UML:Actor >
<!ATTLIST UML:Actor
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:UseCase >
<!ATTLIST UML:UseCase
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Include (UML:Include.addition, UML:Inclu de.base) * >
<!ATTLIST UML:Include
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Include.addition (UML:UseCase) >
<!ELEMENT UML:Include.base (UML:UseCase) >
<!ELEMENT UML:Extend (UML:Extend.base, UML:Extend.exte nsion) * >
<!ATTLIST UML:Extend
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Extend.base (UML:UseCase) >

123
<!ELEMENT UML:Extend.extension (UML:UseCase) >
<!ELEMENT UML:Collaboration (UML:CollaborationInstanc eSet,
UML:Object * , UML:Stimulus * ,
UML:CreateAction * , UML:CallAction * ,
UML:SendAction * , UML:ReturnAction * ,
UML:DestroyAction * , UML:Comment * ) * >
<!ATTLIST UML:Collaboration
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:CollaborationInstanceSet (UML:Collabora tion) * >
<!ATTLIST UML:CollaborationInstanceSet
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Object (UML:Instance.classifier, UML:Com ment * ) * >
<!ATTLIST UML:Object
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Instance.classifier (UML:Class | UML:Inte rface) >
<!ELEMENT UML:Stimulus (UML:Stimulus.sender, UML:Stimu lus.receiver,
UML:Stimulus.dispatchAction) * >
<!ATTLIST UML:Stimulus
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>

124
<!ELEMENT UML:Stimulus.sender (UML:Object) >
<!ELEMENT UML:Stimulus.receiver (UML:Object) >
<!ELEMENT UML:Stimulus.dispatchAction (UML:CreateActi on | UML:CallAction |
UML:SendAction | UML:ReturnAction |
UML:DestroyAction) >
<!ELEMENT UML:CreateAction >
<!ATTLIST UML:CreateAction
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isAsynchronous CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:CallAction (UML:Operation, UML:Argument * ) * >
<!ATTLIST UML:CallAction
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isAsynchronous CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Argument (UML:Expression) * >
<!ATTLIST UML:Argument
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:SendAction >
<!ATTLIST UML:SendAction
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isAsynchronous CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:ReturnAction >
<!ATTLIST UML:ReturnAction

125
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isAsynchronous CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:DestroyAction >
<!ATTLIST UML:DestroyAction
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isAsynchronous CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Comment (UML:Comment.annotatedElement) * >
<!ATTLIST UML:Comment
name CDATA #IMPLIED
visibility (public|protected|private|package) #IMPLIE D
isSpecification CDATA #IMPLIED
body CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Comment.annotatedElement (UML:Class | UML :Object) >
<!ELEMENT UML:Package (UML:Class | UML:Interface | UML:As sociation |
UML:Constraint | UML:DataType | UML:Stereotype |
UML:Generalization | UML:Abstraction | UML:Actor |
UML:UseCase | UML:Include | UML:Extend |
UML:Collaboration | UML:Comment | UML:Package) * >
<!ATTLIST UML:Package
name CDATA #IMPLIED
isSpecification CDATA #IMPLIED
isRoot CDATA #IMPLIED
isLeaf CDATA #IMPLIED
isAbstract CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:Diagram (UML:SimpleSemanticModelElement |
UML:GraphElement.contained | UML:Diagram.owner) * >

126
<!ATTLIST UML:Diagram
isVisible CDATA #IMPLIED
name CDATA #IMPLIED
zoom CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:SimpleSemanticModelElement >
<!ATTLIST UML:SimpleSemanticModelElement
presentation CDATA #IMPLIED
typeInfo CDATA #IMPLIED
%XMI.element.att; %XMI.link.att;>
<!ELEMENT UML:GraphElement.contained (UML:GraphElemen t.contained * ) >
<!ELEMENT UML:Diagram.owner (UML:CollaborationInstanc eSet?) >

Apêndice C
API UML
Neste apêndice apresentamos a estrutura dos classificadores (classes e interfaces) que
fazem parte daAPI UML cujos objetos são instanciados pelo móduloParser XMIda ferra-
menta SPACES, a partir da especificação do componente a ser testado, e que são utilizados
como entrada para os demais módulos da ferramenta. Para facilitar a apresentação, os clas-
sificadores foram agrupadas de acordo com as associações existentes e com o papel que
desempenham na API. Relacionamentos entre classificadoresde grupos diferentes são apre-
sentados a partir da atribuição da tonalidade cinza àquelesque não fazem parte do grupo
atual.
127

128
Element
(from xmiparser ::uml )
#name :String = ""
#_abstract :boolean
#leaf :boolean
#root :boolean
#specification :boolean
+ getName ():String
+ setName (_name:String ):void
+ isAbstract ():boolean
+ setAbstract (__abstract :boolean ):void
+ isLeaf ():boolean
+ setLeaf (_leaf :boolean ):void
+ isRoot ():boolean
+ setRoot (_root :boolean ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
Model
(from xmiparser ::uml )
+ getDiagrams ():Collection
+ addDiagram (diagram :Diagram ):void
+ removeDiagram (diagram :Diagram ):void
+ toString ():String
+ equals (obj :Object ):boolean
Package
(from xmiparser ::uml )
+ getAssociations ():Collection
+ addAssociation (association :Association ):void
+ removeAssociation (association :Association ):void
+ getInterfaces ():Collection
+ addInterface (_interface :Interface ):void
+ removeInterface (_interface :Interface ):void
+ getClasses ():Collection
+ addClass (_class:Class):void
+ removeClass (_class:Class ):void
+ getPackages ():Collection
+ addPackage (_package :Package):void
+ removePackage (_package:Package):void
+ getDataTypes ():Collection
+ addDataType (dataType :DataType ):void
+ removeDataType (dataType :DataType ):void
+ getAbstractions ():Collection
+ addAbstraction (abstraction :Abstraction ):void
+ removeAbstraction (abstraction :Abstraction ):void
+ getGeneralizations ():Collection
+ addGeneralization (generalization :Generalization ):void
+ removeGeneralization (generalization :Generalization ):void
+ getStereotypes ():Collection
+ addStereotype (stereotype :Stereotype ):void
+ removeStereotype (stereotype :Stereotype ):void
+ getActors ():Collection
+ addActor (actor :Actor ):void
+ removeActor (actor :Actor ):void
+ getUseCases ():Collection
+ addUseCase(usecase:UseCase):void
+ removeUseCase (usecase:UseCase):void
+ getIncludes ():Collection
+ addInclude (include :Include ):void
+ removeInclude (include :Include ):void
+ getExtends ():Collection
+ addExtend (extend :Extend ):void
+ removeExtend (extend :Extend ):void
+ getCollaborations ():Collection
+ addCollaboration (collaboration :Collaboration ):void
+ removeCollaboration (collaboration :Collaboration ):void
+ getComments ():Collection
+ addComment (comment :Comment ):void
+ removeComment (comment :Comment ):void
+ toString ():String
+ equals (obj :Object ):boolean
+ getClass (name :String ):Class
+ getAssociations (_class:Class):Collection
Stereotype
(from xmiparser ::uml )
+ toString ():String
Comment
(from xmiparser ::uml )
- name :String = ""
- visibility :String = ""
- specification :boolean
- body :String = ""
+ getBody ():String
+ getName ():String
+ isSpecification ():boolean
+ getVisibility ():String
+ setBody (string :String ):void
+ setName (string :String ):void
+ setSpecification (b:boolean ):void
+ setVisibility (string :String ):void
+ getAnnotatedElement ():Commentable
+ setAnnotatedElement (object :Commentable ):void
+ equals (obj :Object ):boolean
+ toString ():String
<< interface >>
Commentable
(from xmiparser ::uml )
+ addComment (comment :Comment ):void
+ getComments ():Collection
+ removeComment (comment :Comment ):void
annotatedElement-
Association
(from xmiparser ::uml )
AssociationElement
(from xmiparser ::uml )
DataType
(from xmiparser ::uml )
Collaboration
(from xmiparser ::uml )
comments-
Diagram
(from xmiparser ::uml )
diagrams-
associations#
packages#
dataTypes#
stereotypes#
collaborations#
comments
#
Class
(from xmiparser ::uml )
comments-
Interface
(from xmiparser ::uml )
interfaces#classes#
Abstraction
(from xmiparser ::uml )
stereotype-
client-
Generalization
(from xmiparser ::uml )
child-parent-
abstractions#
generalizations#
Actor
(from xmiparser ::uml )
Extend
(from xmiparser ::uml )
Include
(from xmiparser ::uml )
UseCase
(from xmiparser ::uml )
addition-
base-
base-extension-
actors#
usecases#
extends#
includes#
Figura C.1: API UML: Visão Geral

129
Class
(from xmiparser ::uml )
- active :boolean
- constraint :Collection = new ArrayList()
- comment :Collection = new ArrayList()
+ getFeatures ():Collection
+ addFeature (feature :Feature):void
+ removeFeature (feature :Feature ):void
+ getConstraints ():Collection
+ addConstraint (constraint :Constraint ):void
+ removeConstraint (constraint :Constraint ):void
+ getComments ():Collection
+ addComment (comment :Comment ):void
+ removeComment (comment :Comment ):void
+ isActive ():boolean
+ setActive (_active:boolean ):void
+ toResumedString ():String
+ toString ():String
+ equals (obj :Object ):boolean
Classifier
(from xmiparser ::uml )
+ toResumedString ():String
DataType
(from xmiparser ::uml )
+ toResumedString ():String
+ toString ():String
Feature
(from xmiparser ::uml )
+ SK_INSTANCE:String = "instance"
+ SK_CLASSIFIER:String = "classifier"
#visibility :String = ""
#_static :boolean
#name :String = ""
#specification :boolean
+ getVisibility ():String
+ setVisibility (_visibility :String ):void
+ isStatic ():boolean
+ setStatic (__static:boolean ):void
+ getName ():String
+ setName (_name:String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
Interface
(from xmiparser ::uml )
- operation :Collection = new ArrayList()
+ getOperations ():Collection
+ addOperation (operation :Operation ):void
+ removeOperation (operation :Operation ):void
+ toResumedString ():String
+ toString ():String
+ equals (obj :Object ):boolean
<< interface >>
Type
(from xmiparser ::uml )
+ getName ():String
+ toResumedString ():String
Operation
(from xmiparser ::uml )
- query :boolean
- concurrency :String = ""
- _abstract :boolean
- leaf :boolean
- root :boolean
+ getParameters ():Collection
+ addParameter (parameter :Parameter ):void
+ removeParameter (parameter :Parameter ):void
+ getExceptions ():Collection
+ addException (exception :Exception ):void
+ removeException (exception :Exception ):void
+ isQuery ():boolean
+ setQuery (_query :boolean ):void
+ getConcurrency ():String
+ setConcurrency (_concurrency :String ):void
+ isAbstract ():boolean
+ setAbstract (__abstract :boolean ):void
+ isLeaf ():boolean
+ setLeaf (_leaf :boolean ):void
+ isRoot ():boolean
+ setRoot (_root :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
+ getParametersWithoutReturnParameter ():Collection
+ getReturnParameter ():Parameter
Attribute
(from xmiparser ::uml )
- _final :boolean
- _transient :boolean
- _volatile :boolean
- initialValue :String = ""
+ getType ():Type
+ setType (type :Type ):void
+ isFinal ():boolean
+ setFinal (__final :boolean ):void
+ isTransient ():boolean
+ setTransient (__transient :boolean ):void
+ isVolatile ():boolean
+ setVolatile (__volatile :boolean ):void
+ getInitialValue ():String
+ setInitialValue (_initialValue :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
type-
Parameter
(from xmiparser ::uml )
+ DK_IN:String = "in"
+ DK_OUT:String = "out"
+ DK_INOUT:String = "inout"
+ DK_RETURN:String = "return"
- kind :String = ""
- _final :boolean
- name :String = ""
- specification :boolean
+ getType ():Type
+ setType (type :Type ):void
+ getKind ():String
+ setKind (_kind :String ):void
+ isFinal ():boolean
+ setFinal (__final :boolean ):void
+ getName ():String
+ setName (_name:String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
type-
parametros-
Commentable(from xmiparser ::uml )
Element
(from xmiparser ::uml )
AssociationElement
(from xmiparser ::uml )
features-
operations-
Comment
(from xmiparser ::uml )
annotatedElement-
Constraint
(from xmiparser ::uml )
- name :String = ""
- specification :boolean
- language :String = ""
- body :String = ""
+ getName ():String
+ setName (_name:String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ getLanguage ():String
+ setLanguage (_language :String ):void
+ getBody ():String
+ setBody (_body :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
comments-
constraints-
Exception
(from xmiparser ::uml )
- type :String = ""
+ getType ():String
+ setType (_type :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
exceptions-
Figura C.2: API UML: Hierarquia de Tipo
130
Association
(from xmiparser ::uml )
+ getAssociationEnds ():Collection
+ addAssociationEnd (associationEnd :AssociationEnd ):void
+ removeAssociationEnd (associationEnd :AssociationEnd ):void
+ toString ():String
+ equals (obj :Object ):boolean
AssociationEnd
(from xmiparser ::uml )
+ OK_UNORDERED:String = "unordered"
+ OK_ORDERED:String = "ordered"
+ AK_NONE:String = "none"
+ AK_AGGREGATE:String = "aggregate"
+ AK_COMPOSITE:String = "composite"
+ SK_INSTANCE:String = "instance"
+ SK_CLASSIFIER:String = "classifier"
+ CK_CHANGEABLE:String = "changeable"
+ CK_FROZEN:String = "frozen"
+ CK_ADDONLY:String = "addOnly"
- name :String = ""
- visibility :String = ""
- specification :boolean
- navegable :boolean
- ordering :String = ""
- aggregation :String = ""
- targetScope :String = ""
- changeability :String = ""
+ getMultiplicity ():MultiplicityRange
+ setMultiplicity (multiplicityRange :MultiplicityRange ):void
+ getParticipant ():AssociationElement
+ setParticipant (participant :AssociationElement ):void
+ getName ():String
+ setName (_name:String ):void
+ getVisibility ():String
+ setVisibility (_visibility :String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ isNavegable ():boolean
+ setNavegable (_navegable :boolean ):void
+ getOrdering ():String
+ setOrdering (_ordering :String ):void
+ getAggregation ():String
+ setAggregation (_aggregation :String ):void
+ getTargetScope ():String
+ setTargetScope (_targetScope :String ):void
+ getChangeability ():String
+ setChangeability (_changeability :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
associationEnds-
2
AssociationElement
(from xmiparser ::uml )
+ VK_PUBLIC:String = "public"
+ VK_PROTECTED:String = "protected"
+ VK_PACKAGE:String = "package"
+ VK_PRIVATE:String = "private"
#visibility :String = ""
+ getVisibility ():String
+ setVisibility (_visibility :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
participant-
MultiplicityRange
(from xmiparser ::uml )
- lower :int
- upper :int
+ getLower (): int
+ setLower (_lower :int ):void
+ getUpper ():int
+ setUpper (_upper :int ):void
+ toString ():String
+ equals (obj :Object ):boolean
multiplicity-
Element
(from xmiparser ::uml )
Figura C.3: API UML: Associação
Abstraction
(from xmiparser ::uml )
- specification :boolean
+ getStereotype ():Stereotype
+ setStereotype (stereotype :Stereotype ):void
+ getClient ():Class
+ setClient (client :Class):void
+ getSupplier ():Classifier
+ setSupplier (supplier :Classifier ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
Class
(from xmiparser ::uml )client-
Classifier
(from xmiparser ::uml )
supplier-
Stereotype
(from xmiparser ::uml )
stereotype-
Generalization
(from xmiparser ::uml )
- specification :boolean
+ getChild ():AssociationElement
+ setChild (child :AssociationElement ):void
+ getParent ():AssociationElement
+ setParent (parent :AssociationElement ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
AssociationElement
(from xmiparser ::uml )
child- parent-
Figura C.4: API UML: Generalização e Abstração
131
Collaboration
(from xmiparser ::uml )
+ getObjects ():Collection
+ addObject (object :Object ):void
+ removeObject (object :Object ):void
+ getStimulus ():Collection
+ addStimulus (stimulus :Stimulus ):void
+ removeStimulus (stimulus :Stimulus ):void
+ getCreateActions ():Collection
+ addCreateAction (createAction :CreateAction ):void
+ removeCreateAction (createAction :CreateAction ):void
+ getCallActions ():Collection
+ addCallAction (callAction :CallAction ):void
+ removeCallAction (callAction :CallAction ):void
+ getSendActions ():Collection
+ addSendAction (sendAction :SendAction ):void
+ removeSendAction (sendAction :SendAction ):void
+ getReturnActions ():Collection
+ addReturnAction (returnAction :ReturnAction ):void
+ removeReturnAction (returnAction :ReturnAction ):void
+ getDestroyActions ():Collection
+ addDestroyAction (destroyAction :DestroyAction ):void
+ removeDestroyAction (destroyAction :DestroyAction ):void
+ getComments ():Collection
+ addComment (comment :Comment ):void
+ removeComment (comment :Comment ):void
+ toString ():String
+ equals (obj :Object ):boolean
CollaborationInstanceSet
(from xmiparser ::uml )
- name :String = ""
- specification :boolean
+ getCollaboration ():Collaboration
+ setCollaboration (collaboration :Collaboration ):void
+ getName ():String
+ setName (_name:String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
collaboration-
Diagram
(from xmiparser ::uml )
+ DK_CLASS_DIAGRAM:String = "ClassDiagram"
+ DK_USECASE_DIAGRAM:String = "UseCaseDiagram"
+ DK_SEQUENCE_DIAGRAM:String = "SequenceDiagram"
#name :String = ""
#type :String = ""
+ getName ():String
+ setName (_name:String ):void
+ getType ():String
+ setType (_type :String ):void
+ toString ():String
+ equals (obj :Object ):boolean
Object
(from xmiparser ::uml )
- name :String = ""
- visibility :String = ""
- specification :boolean
+ getInstanceClassifier ():Classifier
+ setInstanceClassifier (instanceClassifier :Classifier ):void
+ getName ():String
+ setName (_name:String ):void
+ getVisibility ():String
+ setVisibility (_visibility :String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ getComments ():Collection
+ addComment (comment :Comment ):void
+ removeComment (comment :Comment ):void
+ toString ():String
+ equals (obj :Object ):boolean
objects-
2..*
SequenceDiagram
(from xmiparser ::uml )
+ getCollaboration ():Collaboration
+ setCollaboration (collaboration :Collaboration ):void
+ toString ():String
+ equals (obj :Object ):boolean
collaboration
-
Stimulus
(from xmiparser ::uml )
- name :String = ""
- specification :boolean
+ getSender ():Object
+ setSender (sender :Object ):void
+ getReceiver ():Object
+ setReceiver (receiver :Object ):void
+ getDispatchAction ():Action
+ setDispatchAction (dispatchAction :Action ):void
+ getName ():String
+ setName (_name:String ):void
+ isSpecification ():boolean
+ setSpecification (_specification :boolean ):void
+ toString ():String
+ equals (obj :Object ):boolean
sender- receiver-
stimuli-
1..*
Commentable(from xmiparser ::uml )
Element
(from xmiparser ::uml )
Classifier
(from xmiparser ::uml )
instanceClassifier-
Action
(from xmiparser ::uml )
dispatchAction-
ReturnAction
(from xmiparser ::uml )
SendAction
(from xmiparser ::uml )
DestroyAction
(from xmiparser ::uml )
CreateAction
(from xmiparser ::uml )
CallAction
(from xmiparser ::uml )
returnActions- destroyActions- sendActions- callActions-createActions-
Comment
(from xmiparser ::uml )
annotatedElement-
comments-
comments-
Figura C.5: API UML: Colaboração e Diagrama de Seqüência
132
Action
(from xmiparser ::uml )
#name :String = ""
#isSpecification :boolean
#isAsynchronous :boolean
+ isAsynchronous ():boolean
+ isSpecification ():boolean
+ getName ():String
+ setAsynchronous (isAsynchronous :boolean ):void
+ setSpecification (isSpecification :boolean ):void
+ setName (name :String ):void
+ equals (obj :Object ):boolean
+ toString ():String
+ toExpressionString ():String
CallAction
(from xmiparser ::uml )
+ getArguments ():Collection
+ addArgument (argument :Argument ):void
+ removeArgument (argument :Argument ):void
+ getOperation ():Operation
+ setOperation (operation :Operation ):void
+ equals (obj :Object ):boolean
+ toString ():String
+ toExpressionString ():StringCreateAction
(from xmiparser ::uml )
+ equals (obj :Object ):boolean
+ toString ():String
DestroyAction
(from xmiparser ::uml )
+ equals (obj :Object ):boolean
+ toString ():String
ReturnAction
(from xmiparser ::uml )
+ equals (obj :Object ):boolean
+ toString ():String
SendAction
(from xmiparser ::uml )
+ equals (obj :Object ):boolean
+ toString ():String
Argument
(from xmiparser ::uml )
- name :String = ""
- isSpecification :boolean
- value :String = ""
+ isSpecification ():boolean
+ getName ():String
+ setSpecification (isSpecification :boolean ):void
+ setName (name :String ):void
+ getValue ():String
+ setValue (value :String ):void
+ equals (obj :Object ):boolean
+ toString ():String
arguments-*
Operation
(from xmiparser ::uml )
operation
-
Figura C.6: API UML: Hierarquia de Ações
UseCase
(from xmiparser::uml)
+toString():String
Include
(from xmiparser::uml)
-specification:boolean
+getAddition():UseCase
+setAddition(addition:UseCase):void
+getBase():UseCase
+setBase(base:UseCase):void
+isSpecification():boolean
+setSpecification(_specification:boolean):void
+toString():String
+equals(obj:Object):boolean
addition-base-
Extend
(from xmiparser::uml)
-specification:boolean
+getBase():UseCase
+setBase(base:UseCase):void
+getExtension():UseCase
+setExtension(extension:UseCase):void
+isSpecification():boolean
+setSpecification(_specification:boolean):void
+toString():String
+equals(obj:Object):boolean
base-
extension-
Actor
(from xmiparser::uml)
+toString():String
AssociationElement
(from xmiparser::uml)
Figura C.7: API UML: Ator e Caso de Uso


















