
Text Mining e Linguagem Natural para a deteção de padrões ... · Para fazer a análise das notas...
54
João Francisco Pereira Ribeiro Text Mining e Linguagem Natural para a deteção de padrões no registo de notas clínicas (PCE) Projeto de Dissertação de Mestrado Mestrado em Engenharia e Gestão de Sistemas de Informação Trabalho efetuado sob a orientação do Professor Doutor Manuel Filipe Vieira Torres dos Santos e do Professor Doutor Júlio Marques Duarte Janeiro de 2018
Transcript of Text Mining e Linguagem Natural para a deteção de padrões ... · Para fazer a análise das notas...

João Francisco Pereira Ribeiro
Text Mining e Linguagem Natural para a
deteção de padrões no registo de notas
clínicas (PCE)
Projeto de Dissertação de Mestrado
Mestrado em Engenharia e Gestão de Sistemas de
Informação
Trabalho efetuado sob a orientação do
Professor Doutor Manuel Filipe Vieira Torres dos Santos
e do Professor Doutor Júlio Marques Duarte
Janeiro de 2018


RESUMO
Esta pré-dissertação enquadra-se no projeto de dissertação de mestrado em Engenharia
e Gestão de Sistemas de Informação da Universidade do Minho.
O tema de dissertação é “Text Mining e Linguagem Natural para a deteção de padrões
no registo de notas clínicas (PCE)” e irá ser realizado no Departamento de Sistemas de
Informação da Universidade em conjunto com o Centro Hospitalar do Porto (CHP) – Hospital
Santo António.
A importância de um tratamento padronizado para os doentes é enorme, pois poderá
reduzir tempos de espera, custos nos Hospitais, e tornar mais eficazes os tratamentos aos
doentes. Com isso, a criação de uma ferramenta que poderá fazer a admissão de texto livre
pode ser um importante passo para a área da medicina.
Para o apoio à decisão em tempo-real e para o aumento da qualidade do processo de
decisão é fundamental ter disponível todos os dados clínicos de relevância sobre um doente
pelo que é fulcral a utilização da informação presente nos diários.
Este projeto de dissertação terá como principal objetivo a interpretação de informação
clínica que permita de forma automática interpretar o que é escrito sobre um doente e ajudar
os médicos a tomar uma decisão rápida e eficaz.
O maior desafio deste projeto será fazer a análise do texto que constitui as notas clínicas
para, posteriormente, criar um sistema de suporte à decisão que irá ajudar os médicos a tomar
a melhor decisão para o tratamento do doente.
Para fazer a análise das notas clínicas irão ser utilizadas duas técnicas na área da análise
e da compressão de texto, o Text Mining e o Processamento de Linguagem Natural (PLN). O
trabalho desenvolvido no projeto seguirá a metodologia Cross Industry Standard Process for
Data Mining (CRISP-DM) e a metodologia de investigação Design Science Research (DSR).
Palavras-chave: Text mining, Processamento de Linguagem Natural, Notas Clínicas

ABSTRACT
This pre-dissertation fits in a dissertation project in Engineering and Management of
Information Systems of University of Minho.
The dissertation theme is “Text Mining and Natural Language to detect patterns on the
registration of medical notes (PCE)” and the theme is going to be made in the Information
Systems Department in the University along side with Centro Hospitalar do Porto (CHP) –
Hospital Santo António.
The value of a standardized treatment for the patients is huge, because it can reduce
waiting times, medical costs, and make the patients’ treatment more effective. With that, the
designing of a tool which can admit free text can be an important step for the medicine area.
For the decision support in real-time and for the quality growth of the decision-making
process is fundamental to have available every relevant medical data about a patient, because
it’s important to use day-to-day information in the medical notes.
This dissertation project’s main goal is the interpretation of medical information, which
allows automatically to interpret what is written about a patient and help doctors to make an
effective and fast decision.
The biggest challenge about this project will be to analyze the medical notes text to
create a decision support system which will help doctors to make the best decision regarding
the treatment of the patient.
For the analysis of the medical notes, will be used two analysis and comprehension of
text techniques, Text Minning and Natural Language Processing (NLP). All the developed work
will follow Cross Industry Standard Process for Data Mining (CRISP-DM) methodology and
Design Science Research (DSR) investigation methodology.
KEYWORDS: Text mining, Natural Language Processing, Clinical Notes

ÍNDICE
Resumo ...................................................................................................................................... iii
Abstract ..................................................................................................................................... iv
Lista de Figuras ......................................................................................................................... vii
Lista de Tabelas ....................................................................................................................... viii
Lista de Abreviaturas, Siglas e Acrónimos ................................................................................. ix
1. Introdução ........................................................................................................................... 1
1.1 Motivação .................................................................................................................... 1
1.2 Enquadramento e Objetivos ........................................................................................ 1
1.3 Estrutura do Documento ............................................................................................. 2
2. Revisão de Literatura .......................................................................................................... 5
2.1 Estratégia de Pesquisa ................................................................................................. 5
2.2 Text Mining .................................................................................................................. 5
2.2.1 Contextualização .................................................................................................. 5
2.2.2 Historia e Evolução ............................................................................................... 7
2.2.3 Arquitetura ........................................................................................................... 7
2.2.4 Técnicas Mais Utilizadas ..................................................................................... 10
2.2.5 Áreas de Aplicação ............................................................................................. 11
2.2.6 Text Mining na Medicina .................................................................................... 12
2.3 Linguagem Natural .................................................................................................... 14
2.3.1 Contextualização ................................................................................................ 14
2.3.2 Historia e Evolução ............................................................................................. 16
2.3.3 Níveis de Linguagem........................................................................................... 17
2.3.4 Abordagens ........................................................................................................ 20
2.3.5 Áreas de Aplicação ............................................................................................. 21
2.4 Notas Clínicas ............................................................................................................. 22
2.4.1 Contextualização ................................................................................................ 22
2.4.2 Processo Clínico Eletrónico (PCE) ....................................................................... 23
2.4.3 Tipos de Notas Clínicas ....................................................................................... 24
2.4.4 Exemplos de Notas Clínicas ................................................................................ 25

2.5 Terminologias Clínicas ............................................................................................... 28
2.5.1 Classificação Internacional de Doenças ............................................................. 28
2.5.2 Health Level Seven (HL7) .................................................................................... 29
2.5.3 SNOMED-CT ........................................................................................................ 30
2.6 Open Access ............................................................................................................... 31
2.6.1 OpenEHR ............................................................................................................. 32
3. Abordagem Metodológica ................................................................................................ 35
3.1 DSR ............................................................................................................................. 35
3.2 Crisp-DM .................................................................................................................... 36
4. Gestão do Projeto ............................................................................................................. 39
4.1 Plano de Atividades ................................................................................................... 39
4.2 Lista de Riscos ............................................................................................................ 42
Bibliografia ............................................................................................................................... 43

LISTA DE FIGURAS
Figura 1 - Arquitetura básica do Text Mining ............................................................................. 8
Figura 2 - Arquitetura do Text Mining ........................................................................................ 9
Figura 3 - Exame Médico .......................................................................................................... 25
Figura 4 - Relatórios de Radiologia ........................................................................................... 26
Figura 5 - Processo Clínico Eletrónico ...................................................................................... 26
Figura 6 - Relatório de Especialidade ....................................................................................... 27
Figura 7 - Exemplo de notas clínicas em texto livre ................................................................. 27
Figura 8 - Modelo SNOMED-CT ................................................................................................ 30
Figura 9 - Arquitetura OpenEHR ............................................................................................... 33
Figura 10 - Fases da metodologia DSR ..................................................................................... 35
Figura 11 - Fases da metodologia CRISP-DM ........................................................................... 36
Figura 12 - Plano de atividades ................................................................................................ 41

LISTA DE TABELAS
Tabela 1 - Lista de Riscos .......................................................................................................... 42

LISTA DE ABREVIATURAS, SIGLAS E ACRÓNIMOS
CHP – Centro Hospitalar do Porto
CRISP-DM – Cross Industry Standard Process for Data Mining
DSR – Design Science Research
PCE – Processo clínico eletrónico
PLN – Processamento de Linguagem Natural
TDM – Text Data Mining
SADI – Sistemas de apoio à decisão inteligentes
HL7 – Health Level Seven
SNOMED-CT - Systematized Nomenclature of Medicine - Clinical Terms
EHR – Eletronic Health Regist


1
1. INTRODUÇÃO
1.1 Motivação
A criação deste projeto de dissertação prendeu-se com o facto de, que apesar do
aumento que se tem verificado na quantidade de dados recolhidos eletronicamente, a
verdade é que, na área médica ainda existir muita informação que é registada sem nenhum
padrão. Os diários clínicos e as decisões tomadas são normalmente registados pelos médicos
do Centro Hospitalar do Porto (CHP) e estes são realizados em texto livre, o que dificulta assim
a sua interpretação e admissão.
Os Sistemas de apoio à decisão inteligentes (SADI) podem beneficiar do cruzamento de
informações e da interpretação destes documentos. Nos hospitais várias decisões são
tomadas todos os dias, no entanto, as mesmas normalmente não são utilizadas como fator de
melhoria dos SADIs existentes.
Para o apoio à decisão em tempo-real e para o aumento da qualidade do processo de
decisão é fundamental ter disponível todos os dados clínicos de relevância sobre um doente
pelo que é fulcral a utilização da informação presente nos diários.
1.2 Enquadramento e Objetivos
Este trabalho irá ser realizado no Departamento de Sistemas de Informação da
Universidade em conjunto com o Centro Hospitalar do Porto – Hospital Santo António.
Esta dissertação vem tentar encontrar padrões para os doentes com base nas notas
clínicas e tratamentos efetuados, pretende-se também tentar atribuir um papel de maior
importância ao Text Mining e ao PLN na área da saúde.
A importância de um tratamento padronizado para os doentes é enorme, pois poderá
reduzir tempos de espera, custos nos Hospitais, e tornar mais eficazes os tratamentos aos
doentes. Com isso, a criação de uma ferramenta que poderá fazer a admissão de texto livre
pode ser um importante passo para a área da medicina, bem como, muitas outras áreas.
Este projeto de dissertação terá como principal objetivo a interpretação de informação
clínica que permita de forma automática interpretar o que é escrito sobre um doente e ajudar

2
os médicos a tomar uma decisão rápida e eficaz, para isso irá ser necessário criar um dicionário
clínico com as palavras utilizadas pelos médicos de forma a posteriormente se encontrar
padrões importantes nas notas clínicas dos pacientes. Os modelos serão produzidos e
testados através da indução de modelos de Text Mining, utilizando dados reais provenientes
do Centro Hospitalar do Porto.
Para a concretização deste objetivo é necessário a criação de pequenos objetivos que
complementem este objetivo final, como tal irá ser necessário efetuar:
➢ A tradução de notas clínicas baseadas em linguagem natural de dados úteis para
análise;
➢ Uma deteção automática de padrões clínicos e tradução automática de notas;
➢ Uma ferramenta capaz de analisar e interpretar notas clínicas;
➢ Novos algoritmos de interpretação de informação clínica;
➢ Um dicionário clínico;
➢ Um novo conhecimento na área dos Sistemas de Informação aplicados à saúde;
O cumprimento destes objetivos torna-se fulcral para a concretização do objetivo
principal.
1.3 Estrutura do Documento
Este documento encontra-se estruturado da seguinte forma:
• Introdução – Neste capítulo é apresentada a Introdução, onde é descrita a motivação
para o problema proposto e onde é enquadrado o projeto de dissertação, assim como,
são definidos os objetivos para este projeto;
• Estado da Arte – Neste Capitulo está presente o Estado da Arte de todos os temas
relacionados com o projeto de dissertação. Abordando primeiramente o Text Mining,
com uma breve contextualização, história e evolução, a sua arquitetura, as técnicas
mais utilizadas, as áreas de aplicação e por fim abordar a utilização do Text Mining na
Medicina. De seguida uma abordagem à Linguagem Natural, apresentando as
definições de vários autores, a sua historia e evolução, os níveis de linguagem, as suas
abordagens e áreas de aplicação. Nas notas clínicas será efetuada também uma
contextualização, uma breve abordagem ao processo clínico eletrónico e ao AIDA e

3
serão identificados alguns tipos de notas clínicas existentes. De seguida é feita uma
abordagem às terminologias clínicas onde foram identificadas como principais grupos de
terminologias a Classificação Internacional de Doenças (CID), o Health Level Seven (HL7), e o
Systematized Nomenclature of Medicine - Clinical Terms (SNOMED CT). Por fim uma breve
descrição do Open Access, do Open Data e do OpenEHR.
• Abordagem Metodológica – Neste capítulo será efetuada a descrição das
metodologias a utilizar neste projeto. Na parte da investigação será utilizada a
metodologia o Design Science Research (DSR), e na parte de desenvolvimento será
utilizada a metodologia Cross Industry Standard Process for Data Mining (CRISP-DM).
• Gestão do Projeto – Neste capítulo será elaborada a descrição detalhada do
planeamento, com o tempo estimado para cada tarefa a realizar, a descrição das
tarefas com base nas metodologias utilizadas, incluirá também uma tabela de riscos,
para precaver possíveis acontecimentos que possam prejudicar o projeto.
• Conclusão – Neste capítulo é apresentada a Conclusão da pré-dissertação, que incluirá
uma síntese do trabalho realizado até ao momento.
• Referências – Neste capítulo irão conter todas as referências bibliográficas utilizadas
na pré-dissertação.


5
2. REVISÃO DE LITERATURA
2.1 Estratégia de Pesquisa
O desenvolvimento deste projeto de dissertação, principalmente a realização do estado
da arte, consistiu na recolha de informação tendo como base pesquisas bibliográficas
relevantes ao tema de projeto de dissertação escolhido.
O principal objetivo deveu-se com a necessidade de compreender os principais
conceitos referentes ao tema selecionado, bem como, pesquisar trabalhos semelhantes na
área e identificar os seus resultados. Inicialmente o professor doutor orientador do projeto
forneceu um conjunto de livros que iriam ajudar-me ao desenvolvimento de todo o projeto.
Para além dos livros indicados pelo orientador foi também necessário efetuar uma
pesquisa na web. Os motores de pesquisa que foram utilizados para a obtenção dos artigos
científicos foram o Google e o Google Scholar. Para efetuar a pesquisa foinecessário definir
algumas palavras-chave, como por exemplo: “Text Mining”, “Evolution of Text Mining”, “Text
Mining in Medicine”, “Natural Language Processing”, “Aplications of Natural Language”,
“Clinical Notes”, “Electronic Clinical Process”, “Clinical Terminologies”, “Open Access”, “Open
Data”, “OpenEHR”, “Eletronic Health Register”.
2.2 Text Mining
2.2.1 Contextualização
Text Mining pode ser amplamente definido como um processo intensivo usando um
conjunto de ferramentas de análise com o objetivo descobrir conhecimento em documentos
de texto ao longo do tempo. O Text Mining procura extrair informação úteis de fontes de
dados através da identificação e exploração de padrões. (Feldman & Sanger, 2007)
O Text Mining ou análise de texto é um termo abrangente descrevendo uma variedade
de técnicas que buscam extrair informações úteis de um conjunto de documentos através da
identificação e exploração de padrões nos textos não estruturados. (Truyens & Van Eecke,
2014)

6
O Text Mining, também conhecido como “Text Data Mining” (TDM) ou descoberta de
conhecimento de “Text Data Base”, refere-se geralmente ao processo de extração de padrões
ou conhecimentos não triviais de documentos de texto não estruturados. Pode ser visto como
uma extensão do Data Mining. (Tan, 1999)
O Data Mining ou Text Mining constitui um conjunto de técnicas computadorizadas que
permitem o processamento automático de informações digitais. Utilizando esses sistemas,
toda a informação é processada e novos conhecimentos são gerados. (Piedra, Ferrer, & Gea,
2014)
Por exemplo, ambos os tipos de sistemas dependem de rotinas de pré-processamento,
algoritmos de descoberta de padrões e elementos de camada de apresentação, como
ferramentas de visualização para aprimorar a navegação de conjuntos de respostas. (Feldman
& Sanger, 2007)
A mineração implica a extração de pedras preciosas de minério de uma rocha sem valor.
Se o Data Mining, bem como o Text Mining, realmente seguisse essa metáfora, isso significaria
que as pessoas estavam descobrindo informação relevante dentro da base de dados existente.
No entanto, na prática, este não é realmente o caso. Em vez disso, as aplicações de Data
Mining e Text Mining tendem a ser descobertas através de tendências e padrões em conjuntos
de dados muito grandes, geralmente para fins de tomada de decisão. (Hearst, 1999)
Com base nas definições acima descritas, podemos dizer então que o Text Mining é uma
nova área de pesquisa da ciência da computação que pretende resolver as sobrecargas de
informação existentes.
O principal objetivo do Text Mining é ajudar o utilizador a reter toda a informação
importante e necessária para tomadas de decisão mais eficazes, tendo como base grandes
quantidades de informação. Sem o Text Mining, o estudo de informação em formato de texto
seria muito mais difícil e demorado. Diz-se que o Text Mining é uma continuação ou extensão
do Data Mining devido ao seu objetivo principal ser, tal como no Data Mining, a geração de
conhecimento com base em dados, mas neste caso os dados com que se trabalha são dados
não estruturados. Um outro motivo da justificação dessa extensão é o facto de os sistemas de
Text Mining e Data Mining terem muitas semelhanças na sua arquitetura.

7
2.2.2 Historia e Evolução
O desafio de explorar a grande proporção de informações na forma "não estruturada"
foi reconhecido há décadas. É reconhecido na primeira definição de inteligência de negócios
(BI), em um artigo do IBM Journal de outubro de 1958, de H.P. Luhn, um sistema de
inteligência de negócios, que descreve um sistema que:
“... utilizar máquinas de processamento de dados para auto extração e auto codificação
de documentos e para criar perfis de interesse para cada um dos "pontos de ação" de uma
organização. Ambos os documentos recebidos e gerados internamente são automaticamente
abstraídos, caracterizados por uma palavra padrão e enviado automaticamente para os
“pontos de ação” apropriados”.
O texto em documentos "não estruturados" é difícil de processar.
Durante quase uma década, a comunidade de linguagem computacional viu grandes
coleções de texto como um recurso a ser aproveitado para produzir melhores algoritmos de
análise de texto. Neste artigo, tentei sugerir um novo significado: o uso de grandes coleções
de texto online para descobrir novos factos e tendências sobre o próprio mundo. Sugiro que,
para avançar, não precisamos de analisar texto totalmente artificial e inteligente, em vez
disso, uma mistura de análise conduzida por computação e orientada pelo utilizador pode
abrir a porta para novos e excitantes resultados.(Hearst, 1999)
A declaração de necessidade de Hearst em 1999 descreve bastante bem o estado da
tecnologia de análise de texto e a sua prática uma década depois.
2.2.3 Arquitetura
O sistema de Text Mining recebe como inputs um conjunto de documentos brutos e
gera vários tipos de outputs, como por exemplo, padrões, mapas de conexões e tendências.
(Feldman & Sanger, 2007)

8
Figura 1 - Arquitetura básica do Text Mining
A nível funcional, os sistemas de Text Mining seguem o modelo geral fornecido por
algumas aplicações clássicas de Data Mining e são então divisíveis em quatro áreas principais:
(Feldman & Sanger, 2007)
➢ tarefas de pré-processamento: onde se inclui todas as rotinas, processos e métodos
necessários para preparar toda a informação para, posteriormente, realizar as
operações de descoberta de conhecimento do núcleo de um sistema de Text Mining.
As tarefas de pré-processamento, geralmente, convertem as informações originais em
documentos com um formato comum para, posteriormente, se aplicar vários tipos de
métodos de extração de recursos nesses documentos, de forma a criar um novo
conjunto de informação totalmente representados por conceitos.
➢ operações de “mining”: é o elemento principal de um sistema de Text Mining e inclui
a descoberta de padrões, análise de tendências e algoritmos incrementais de
descoberta de conhecimento. As operações de “mining” também podem se preocupar
com comparações entre a identificação dos níveis de "interação" em alguns desses
padrões. Os sistemas de Text Mining avançados podem, também, aumentar a
qualidade das várias operações aumentando as fontes de conhecimento.
➢ componentes da camada de apresentação: incluem a funcionalidade de navegação
de padrões GUI e também o acesso à linguagem de consulta. As ferramentas de
visualização, os editores e os otimizadores de consultas para o utilizador enquadram-
se nesta área.
➢ técnicas de refinamento: esta área inclui métodos que filtram as informações
redundantes e agrupam os dados estreitamente relacionados. Mas apesar do nome
contém também métodos que podem fazer crescer a informação existente, utilizando

9
um determinado sistema de Text Mining, para representar um conjunto completo e
abrangente de alternativas de supressão, ordenação e generalização para garantir a
otimização de descoberta de conhecimento.
Com um nível de maior detalhe o conjunto de documentos processados é influenciado
pelas operações de “mining” por alguma forma de representação plana, comprimida ou
hierarquizada dos seus dados para melhor suporte das várias operações de “mining”, como a
navegação hierárquica na árvore. Isso está ilustrado na figura seguinte. O esquema da figura
seguinte também influencia o posicionamento típico da funcionalidade de refinamento,
acrescentando, também, um pouco mais de detalhe em relação ao funcionamento relativo
dos algoritmos de Text Mining principais. Muitos sistemas de Text Mining podem beneficiar
significativamente do acesso a origens especiais ou fontes de dados específicas de domínio.
(Feldman & Sanger, 2007)
Figura 2 - Arquitetura do Text Mining

10
2.2.4 Técnicas Mais Utilizadas
Existem inúmeras técnicas de Text Mining possíveis de ser utilizadas nas diferentes áreas
de aplicação. Chauhan Shrihari e Amish Desai definem de seguida as técnicas que na
perspetiva deles são as mais utilizadas. (Shrihari & Desai, 2015)
1 – Extração da Informação: A extração de informação é o primeiro passo para analisar
um texto não estruturado e a sua relação. Este processo é executado por correspondência de
padrões, sendo usado para procurar sequencias de texto predefinidos. A extração de
informação inclui duas técnicas, a inclusão da verificação e a segmentação das frases, que são
muitos importantes para documentos com textos maiores.
2 – Clustering: O Clustering é um método não supervisionado. A técnica de clustering
é, normalmente, usada para agrupar documentos semelhantes. Esse método é baseado no
conceito de dividir texto similar no mesmo cluster e por sua vez cada cluster contém uma série
de documentos similares.
3 – Sumarização: Devido a uma grande quantidade de dados que existe atualmente, é
necessário sumarizar os dados sem alterar o significado do conteúdo e o tamanho dos dados.
Irá assim, produzir um resumo do grupo de documentos sumarizados. Por isso, todo o
conjunto de documentos é substituído posteriormente pelo seu resumo. A sumarização é útil
para o usuário ler um breve resumo do documento em vez de ler os documentos longos.
4 – Visualização: No Text Mining, a visualização torna mais simples a descoberta da
informação. Um grupo de documento ou um único documento de texto é utilizado para
mostrar documentos e a cor usada. Este método fornece informações mais rápidas e
compreensíveis, ajudando a descobrir ou explorar o padrão no conjunto de documentos.
5 – Categorização: A categorização é uma técnica supervisionada porque é baseada
em exemplos de input e de output para a classificar. Um processo típico de categorização de
texto consiste em pré-processamento, indexação, reduções de dimensões e classificação. O
objetivo da categorização é treinar o classificador com base em exemplos conhecidos e
desconhecidos categorizados automaticamente.
Para além das técnicas apresentadas em cima, Yuen-Hsien Tseng, Chin-Jen Lin e Yu-I Lin,
definiram também as técnicas seguintes como, em conjunto com as anteriores apresentadas,
bastante utilizadas para análise de documentos de pacientes. (Tseng, Lin, & Lin, 2007)

11
1 – Stopwords and stemming: é uma técnica de Text Mining em que a sua principal
tarefa é de remover palavras que em nada influenciem o texto inicial, permitindo assim aos
analistas realizarem as suas pesquisas mais rapidamente. As palavras removidas são
principalmente os advérbios. Para combinar melhor os conceitos entre os termos, as palavras
são derivadas do algoritmo de Porter (Porter, 1980).
2 – Associação de termos: existem várias abordagens para extrair termos relevantes
para os mesmos tópicos de todo o conjunto de documentos. Num conjunto de documentos a
ocorrência de um determinado termo tem um peso mais elevado que a ocorrência de outros
termos esse termo torna-se assim um termo relevante.
3 – Mapeamento: para mapear as estruturas de conhecimento são, principalmente,
utilizadas duas técnicas. Com base nas semelhanças pré-calculadas entre cada tópico, um
método organiza os tópicos de forma hierárquica. Isso cria uma estrutura prontamente
disponível para a representação em árvore. Da mesma forma a outra técnica calcula as
coordenadas de cada tópico em dimensões especificadas do espaço para facilitar a
interpretação visual. Com essas coordenadas pode ser criado um mapa de tópicos por uma
ferramenta de traçado.
2.2.5 Áreas de Aplicação
Segundo Gupta e Lehal, as principais aplicações de Text Mining são mais utilizadas nas
seguintes áreas (Gupta & Lehal, 2009):
➢ Publicidade e comunicação social;
➢ Telecomunicações e outros serviços industriais;
➢ Setor de tecnologia da informação e Internet;
➢ Bancos, seguros e mercados financeiros;
➢ Instituições políticas e administração pública;
➢ Empresas farmacêuticas e de cuidados de saúde.
É possível identificar algumas especificações setoriais no uso da TM, ligadas ao tipo de
produção e aos objetivos do gerenciamento do conhecimento levando-os a usar TM. O setor
de publicação, por exemplo, é marcado pela prevalência de aplicações de Transformação de
extração para a catalogação, produção e otimização da recuperação de informações.

12
Nos setores bancário e de seguros, por outro lado, as aplicações de CRM são
predominantes e visam melhorar a gestão da comunicação com clientes, por sistemas
automáticos de reencaminhamento de mensagens e com aplicativos que suportam os
mecanismos de pesquisa fazendo perguntas em linguagem natural.
Nos setores médico e farmacêutico, as aplicações de Inteligência Competitiva e
Vigilância Tecnológica são generalizadas para análise, classificação e extração de informações.
de artigos, resumos científicos e patentes.
Um setor das telecomunicações é um setor com vários tipos de aplicações: os objetivos
mais importantes dessas indústrias são que todas as aplicações encontram uma resposta,
desde análise de mercado até à gestão dos recursos humanos, da correção ortográfica ao
questionário de opinião do cliente.
2.2.6 Text Mining na Medicina
Os avanços na tecnologia de informação significam que, atualmente, enormes
quantidades de informação relativo à área da saúde são analisadas. Atualmente, as notas
clínicas de pacientes são gravadas em formato eletrónico. Isso inclui dados pessoais dos
pacientes, mas também diagnósticos, resultados de testes laboratoriais, testes de função e
medicação, e detalhes sobre os contatos do paciente com o sistema de saúde. Existem três
grandes vantagens na gravação desta quantidade de dados em formato digital: (Piedra et al.,
2014)
➢ a qualidade é melhorada;
➢ o tempo que os profissionais de saúde gastam com tarefas improdutivas é
reduzido;
➢ os dados podem ser usados em sistemas automáticos, como Text Mining ou
Data Mining.
Um estudo realizado na faculdade de ciências de informação e tecnologia na
universidade de Drexel permitiu conhecer e compreender os resultados e a precisão de
algumas abordagens de Text Mining para o registo de notas clínicas.
Os registros médicos do paciente contêm uma riqueza em informação que pode ser
inestimável para a realização de pesquisas clínicas. As notas clínicas escritas pelos médicos

13
são em formato de texto livre. Assim, é necessário utilizar técnicas de extração de informações
que irão permitir, posteriormente, utilizar um método confiável e eficiente para extrair
informações estruturadas a partir do Data Mining, conseguindo, no fim, retirar muitos lucros
com os esforços de pesquisa.
Neste estudo é relatado o desenvolvimento de um sistema de extração de informação
MEDical (MedIE) que extrai informações dos pacientes com queixas de mama nos registros
clínicos de texto livre. A MedIE faz parte de um grande projeto de pesquisa referente ao cancro
da mama, este projeto está sendo conduzido na Faculdade de Medicina da Universidade
Drexel. Antes que os pesquisadores possam realizar qualquer análise ou Text Mining, eles
devem primeiro criar um dicionário para codificar os registros clínicos dos pacientes.
As tarefas de extração do estudo podem ser classificadas em três grupos. O primeiro é
a extração de termos médicos, o segundo é a classificação do texto e por fim é sobre relação
entre dois termos. Neste estudo foi proposto três abordagens para abordar essas tarefas de
extração.
➢ Extração de termos tendo por base a Ontologia
Os clínicos estão sempre interessados no historial médico e no historial cirúrgico dos
pacientes. A extração de um termo médico, geralmente, pertence à tarefa de reconhecimento
de uma entidade nomeada. Contudo, os termos médicos estão cheios de sinônimos. É, então,
necessário criar um dicionário com os termos clínicos e efetuar uma associação, mas os
termos médicos são muitas vezes frases, dificultando assim a pesquisa de todas as
combinações de palavras na frase. Em vez disso, no estudo tentaram utilizar um método de
padrões de fala para gerar candidatos a termo e depois verificar se os termos selecionados
existiam no dicionário. A abordagem baseada em ontologia para extração de termos médicos
pode atingir um desempenho superior ao abordado pelo reconhecimento geral de entidade,
no entanto, requer uma pesquisa intensiva.
➢ Extração de relações baseada em Gráficos
A extração de relações refere-se a uma tarefa que encontra pares de dois termos no
texto. Um tipo de informação para extração é o atributo numérico, como pressão arterial,
pulso, idade e peso de um paciente. Outro tipo de informação é a associação de doenças ou
sintomas com as pessoas. Por exemplo, o vestígio do historial familiar de cancro.

14
A abordagem baseada em gráficos para a extração de relações em comparação com a
abordagem baseada em padrões, é mais flexível e robusta. Esta abordagem é composta por
quatro componentes seguintes, extração de termos, substituição de termo médico, análise de
gramática e criação de gráficos.
➢ Classificação de texto com base em árvores de decisão
A classificação de texto é outro tipo de tarefas de extração de informações utilizada
no estudo. Uma técnica de aprendizagem automática não depende do conhecimento do
domínio e, sendo assim, a abordagem pode ser facilmente generalizada. Neste estudo, foi
utilizada uma árvore de decisão.
Concluindo o trabalho realizado no estudo, o tamanho do conjunto de dados utilizado
pelo mesmo foi pequeno e obteve assim poucas conclusões fundamentadas. Como as notas
clínicas eram textos livres o desempenho da extração da informação por vezes não foi o mais
espectável. Além disso, o analisador de gramática contém muitos erros ao analisar texto no
domínio biomédico.
As abordagens propostas neste estudo podem oferecer um novo meio pelo qual o
médico pode obter grandes volumes de dados das notas clínicas do paciente que irá beneficiar
e ajudará nas tomadas de decisão mais eficientes. Atualmente, este recurso não se encontra
disponível, pois não conseguiram meios efetivos para extrair a informação relevante. (Zhou,
Han, Chankai, Prestrud, & Brooks, 2006)
2.3 Linguagem Natural
2.3.1 Contextualização
O Processamento da Linguagem Natural (PLN) é uma área de pesquisa e aplicação que
explora a forma como os computadores podem ser usados para entender e manipular o texto
da linguagem natural. Os pesquisadores da PLN visam reunir conhecimento sobre a maneira
como os seres humanos entendem e usam a linguagem, de forma a que as ferramentas e
técnicas adequadas possam ser desenvolvidas, para que, os sistemas informáticos
compreendam e manipulem linguagens naturais para realizar as tarefas desejadas. Os
fundamentos da PLN estão em várias áreas, tais como, a informática, a linguística, a

15
matemática, a engenharia elétrica e eletrônica, a inteligência artificial e robótica, a psicologia,
entre outras. (Gobinda G. Chowdhury, 2003)
O processamento de linguagem natural é um conjunto de técnicas computacionais
motivadas por interesse de análise e representação de textos com o objetivo de obter o
processamento de linguagem semelhante ao humano para uma variedade de tarefas ou
aplicações. (Liddy, 2001)
O processamento de linguagem natural (PLN) é a tentativa de extrair uma representação
de significado mais completa a partir de texto livre. O PLN utiliza os conceitos linguísticos
como a parte da fala (substantivo, verbo, adjetivo, etc.) e estrutura gramatical. (Kao & Poteet,
2007)
Liddy (1998) e Feldman (1999) sugerem que, para entender as línguas naturais, é
importante distinguir os sete níveis interdependentes que as pessoas usam para extrair o
significado do texto ou das línguas faladas:
➢ nível fonético ou fonológico que trata da pronúncia;
➢ nível morfológico que lida com as partes mais pequenas das palavras, que trazem um
significado, e sufixos e prefixos;
➢ nível lexical que lida com o significado lexical de palavras e partes de análises de fala;
➢ nível sintático que lida com a gramática e a estrutura das frases;
➢ nível semântico que trata do significado de palavras e frases;
➢ nível de discurso que trata da estrutura de diferentes tipos de texto usando estruturas
de documentos;
➢ nível pragmático que lida com o conhecimento que vem do mundo exterior, ou seja,
de fora dos conteúdos do documento.
Um sistema de processamento de linguagem natural pode envolver todos ou alguns
desses níveis de análise. (Gobinda G. Chowdhury, 2003)
O objetivo do Processamento da Linguagem Natural é de realizar um processamento de
linguagem semelhante ao humano.
Um sistema de Compreensão da Linguagem Natural é capaz de: (Liddy, 2001)
➢ Explicar um texto;
➢ Traduzir o texto para outro idioma;
➢ Responder a perguntas sobre o conteúdo do texto;

16
➢ Efetuar deduções sobre o texto.
O objetivo do sistema de PLN é representar o verdadeiro significado e intenção da
consulta do utilizador. (Liddy, 2001)
2.3.2 Historia e Evolução
Haas em 1996 e Warner em 1987 descreveram uma série de desenvolvimentos teóricos
que influenciaram a pesquisa no PLN. Os desenvolvimentos teóricos mais recentes podem ser
agrupados em quatro classes:
➢ métodos estatísticos e baseados em “corpus” no PNL;
➢ esforços recentes para usar a pesquisa do WordNet para PNL;
➢ o ressurgimento do interesse em estados finitos e outras abordagens simples para o
PLN;
➢ o início de projetos colaborativos para criar ferramentas de gramática e PLN para
grandes dimensões.
Os métodos estatísticos são utilizados no PLN para vários fins, por exemplo, para a
desambiguação dos sentidos das palavras, para gerar gramáticas e análise, para determinar
evidências estilísticas de autores.
Charniak em 1995 aponta que uma precisão de 90% pode ser obtida na atribuição de
parte de fala a uma palavra, aplicando medidas estatísticas simples.
Jelinek, em 1999, define uma fonte amplamente citada sobre o uso de métodos
estatísticos na PLN, especialmente no processamento de fala. Mihalcea e Moldovan, também
em 1999 mencionam que, embora até agora as abordagens estatísticas tenham sido
consideradas as melhores para a desambiguação dos sentidos das palavras, elas são úteis
apenas em um pequeno conjunto de textos. Eles propõem o uso do WordNet para melhorar
os resultados das análises estatísticas de textos de linguagem natural. O WordNet é um
sistema de referência lexical online desenvolvido na Princeton University. Uma das principais
aplicações do “WordNet” no PLN foi na Europa com a formação do “EuroWordNet” em 1996.
O “EuroWordNet” é uma base de dados de multilinguagem com “WordNets” para vários
idiomas europeus.

17
Diferentes aplicações dos métodos do estado finito no PLN foram discutidas por Jurafsky
& Martin (2000), Kornai (1999) e Roche & Shabes (1997). O trabalho dos pesquisadores do
PLN foi facilitado pela disponibilidade de gramática em larga escala para análise e geração.
Outro desenvolvimento significativo nos últimos anos é a formação de vários congressos
nacionais e internacionais e grupos de pesquisa que podem facilitar e ajudar a compartilhar
conhecimentos e pesquisas sobre o PLN. A associação “Global WordNet” recentemente
formada é mais um exemplo de cooperação. É uma organização não comercial que fornece
uma plataforma para discutir e compartilhar “WordNets” para todas as línguas do mundo. A
primeira conferência internacional do “WordNet” foi realizada na Índia no início de 2002.
2.3.3 Níveis de Linguagem
O método mais explicativo para apresentar o que realmente acontece dentro de um
sistema de processamento de linguagem natural é através de uma abordagem aos níveis da
linguagem utilizada. Pesquisas psicolinguísticas sugerem que o processamento de linguagem
é muito mais dinâmico, pois os níveis podem interagir em uma variedade de pedidos. A
introspeção revela que usamos frequentemente informações que obtemos do que
normalmente é considerado um nível de processamento mais alto para ajudar um outro nível
de análise mais baixo. Por exemplo, o conhecimento pragmático de que o documento que
você está lendo é sobre biologia será usado quando uma palavra específica que tenha vários
sentidos possíveis seja encontrada, e a palavra será interpretada como tendo o sentido da
biologia.
Apresentamos agora os diferentes níveis de processamento de linguagem natural.
(Liddy, 2001)
➢ Fonologia
Este nível aborda a interpretação de sons de fala de uma palavra ou entre palavras.
Existem três tipos de regras usadas na análise fonológica:
1) regras fonéticas - para sons de palavras;
2) regras fonémicas - para variações de pronúncia quando se fala as palavras em conjunto;
3) regras prosódicas - para flutuação na entonação de uma frase.
Num sistema de PLN que aceita a entrada de fala, as ondas sonoras são analisadas e
codificadas através de um sinal digitalizado para a interpretação ser realizada com várias

18
regras ou através da comparação com o modelo de linguagem particular que está sendo
utilizado.
➢ Morfologia
Este nível lida com a natureza da composição das palavras, ou seja, compostos de
morfemas que são as unidades mais pequenas do significado da palavra. Como o significado
de cada morfema permanece o mesmo em todas as palavras, os seres humanos podem
quebrar uma palavra desconhecida em seus morfemas constituintes para entender seu
significado. Dessa mesma forma, um sistema PLN pode reconhecer o significado transmitido
por cada morfema para representar o seu significado.
➢ Lexical
Neste nível, os seres humanos, bem como os sistemas de PLN, interpretam o significado
de palavras individuais. Vários tipos de processamento contribuem para a compreensão do
nível de palavra. Neste processamento, as palavras que podem funcionar como mais do que
uma parte da fala são atribuídas com a “tag part-of-speech” com base no contexto em que
elas ocorrem. Além disso, no nível lexical, as palavras que têm apenas um sentido ou
significado possível podem ser substituídas por uma representação semântica desse
significado. A natureza da representação varia de acordo com a teoria semântica utilizada no
sistema PLN. Dado que existe um conjunto de primitivas semânticas usadas em todas as
palavras, essas representações lexicais simplificadas permitem unificar o significado entre as
palavras e produzir interpretações complexas, da mesma forma que as pessoas.
➢ Sintático
Este nível tem como principal foco analisar as palavras numa frase de modo a descobrir
a estrutura gramatical da frase. Isso requer uma gramática ou dicionário e um analisador. O
output desse nível de processamento é uma representação da frase que revela as relações de
dependência estrutural entre as palavras. Existem várias gramáticas que podem ser utilizadas
e que, por sua vez, irão influenciar a escolha do analisador. Nem todos os aplicativos de PLN
exigem uma análise completa das frases, portanto, os desafios resultantes na análise das
frases preposicionais e o conjunto de “scoping” não impedem as aplicações para os quais as
dependências são suficientes. A sintaxe transmite significado na maioria das línguas porque a
ordem e a dependência contribuem para o significado. Por exemplo, as duas frases: "O cão

19
perseguiu o gato" e "O gato perseguiu o cão". Diferem apenas em termos de sintaxe, mas
transmitem significados bastante diferentes.
➢ Semântico
Este é o nível em que a maioria das pessoas pensa que o significado da palavra é
determinado, no entanto, são todos os níveis que contribuem para o significado das palavras.
O processamento semântico determina os possíveis significados de uma frase, concentrando-
se nas interações entre os significados do nível de palavra na frase. Esse nível de
processamento pode incluir a desambiguação semântica de palavras com múltiplos sentidos.
A desambiguação semântica permite que apenas um significado de palavras polissêmicas seja
selecionado e incluído na representação semântica da frase. Uma ampla gama de métodos
pode ser implementada para realizar a desambiguação, alguns que necessitam de informação
sobre a frequência com que cada sentido ocorre num determinado “corpus” de interesse, ou
em geral, alguns que exigem a consideração do contexto local, e outros que utilizam o
conhecimento pragmático do domínio do documento.
➢ Discurso
Enquanto a sintaxe e a semântica funcionam com unidades de cumprimento da frase, o
nível de discurso do PLN funciona com unidades de texto mais longas do que apenas uma
única frase, ou seja, não interpreta frases concatenadas onde cada uma das frases pode ser
interpretada individualmente. Em vez disso, o discurso concentra-se nas propriedades do
texto como um todo que transmitem significado fazendo conexões entre as frases existentes
no texto. Vários tipos de processamento do discurso podem ocorrer a este nível, sendo dois
dos mais comuns a resolução da anáfora e o reconhecimento da estrutura do texto. A
resolução da anáfora é a substituição de palavras, como os pronomes, que são
semanticamente vagos, com a entidade apropriada a que se referem. O reconhecimento de
estrutura do texto determina as funções das frases no texto que, por sua vez, contribui para
a representação significativa do texto.
➢ Pragmático
Este nível está preocupado com o uso correto da linguagem nas diversas situações e
utiliza o contexto além dos conteúdos do texto para entender o mesmo. O objetivo é explicar
como o significado extra é lido nos textos sem realmente ser codificado. Isso exige muito
conhecimento mundial, incluindo a compreensão de intenções, planos e objetivos.

20
Uma vez que os seres humanos demonstraram usar todos os níveis de linguagem para
ganhar entendimento, quanto mais capaz for um sistema de PLN mais níveis de linguagem irá
utilizar.
2.3.4 Abordagens
Existem 4 categorias de abordagem ao processamento de linguagem natural, sendo
elas: (Liddy, 2001)
➢ Abordagem Simbólica
As abordagens simbólicas realizam análises profundas dos fenômenos linguísticos e são
baseadas em representação explícita dos factos sobre a linguagem através de esquemas de
representação de conhecimento bem entendidos e algoritmos associados.
As abordagens simbólicas foram usadas por algumas décadas em diversas áreas de
pesquisa e aplicações como extração de informações, categorização de texto, resolução de
ambiguidade e aquisição lexical. As técnicas típicas incluem: aprendizagem baseada em
explicações, aprendizagem baseada em regras, programação de lógica indutiva, árvores de
decisão, agrupamento conceitual e algoritmos de vizinhança mais próxima.
➢ Abordagem Estatística
As abordagens estatísticas utilizam várias técnicas matemáticas e muitas vezes usam
textos grande para desenvolver modelos generalizados de fenómenos linguísticos, baseados
em exemplos reais desses fenómenos fornecidos pelos textos sem adicionar conhecimento
linguístico ou mundial. As abordagens estatísticas utilizam dados observáveis como a principal
fonte de evidência.
➢ Abordagem Conectora
A abordagem conectora desenvolve modelos generalizados a partir de exemplos de
fenómenos linguísticos. O que diferencia a abordagem conectora dos outros métodos
estatísticos é que os modelos conectores combinam a aprendizagem estatística com várias
teorias de representação, assim, as representações conectoras permitem a transformação e
manipulação de fórmulas lógicas. Além disso, nos sistemas conectores, os modelos linguísticos
são mais difíceis de observar devido ao fato de as arquiteturas conectoras serem menos
restritas do que as arquiteturas estatísticas.

21
➢ Abordagem Híbrida
As três abordagens anteriores são bastante complementares então os pesquisadores
começaram a desenvolver técnicas híbridas que utilizam os pontos fortes de cada abordagem
na tentativa de abordar os problemas de PLN de forma mais eficaz e de forma mais flexível.
2.3.5 Áreas de Aplicação
O Processamento de Linguagem Natural contem inúmeras implementações para
diversas aplicações. As aplicações que utilizam o PLN são: (Liddy, 2001)
➢ Recuperação da Informação: dada a grande quantidade de texto, é
surpreendente, que tão poucas implementações utilizem o PLN. Recentemente, as
abordagens estatísticas para a realização do PLN têm aumentado a sua utilização,
mas poucos sistemas baseados em PLN diferentes dos de Liddy e Strzalkowski
foram desenvolvidos;
➢ Extração de Informação: é uma área de aplicação mais recente, a extração de
informação concentra-se no reconhecimento e na extração de uma
representação estruturada, identificando certas palavras-chave presentes na
informação obtida. Essas extrações podem então ser utilizadas para uma
variedade de aplicações, incluindo questionários de atendimento, visualização e
Data Mining;
➢ Pergunta-Resposta: fornece ao utilizador o texto da própria resposta ou apenas
algum excerto que fornece a resposta;
➢ Sumarização: são os níveis mais altos de PLN, em particular o nível do discurso,
podem capacitar uma implementação que reduz um texto maior em uma
representação narrativa abreviada mais curta, mas capaz de reconstituir o
documento original;
➢ Tradução Automática: talvez o mais antigo de todos as aplicações de PLN, é
possível efetuar uma abordagem "baseada em palavras" para as aplicações que
incluem níveis mais altos de análise;
➢ Sistemas de diálogo: talvez a aplicação do futuro. A utilização de todos os níveis
de processamento de linguagem explicados anteriormente oferece um enorme
potencial para os sistemas de diálogo.

22
2.4 Notas Clínicas
2.4.1 Contextualização
As notas clínicas são um componente essencial para o tratamento de um paciente, pelo qual
a informação deve ser precisa, objetiva e necessária somente para o objetivo em questão. (K.
Lyndon)
As notas clinicas são um registo que contem informações sobre o seu estado de saúde,
histórico pessoal, medicação atual, contactos com os serviços de saúde, bem como, exames,
terapias e cirurgias já realizados.
A nota clínica é um registo que contém toda a informação clínica resultante de todas as
idas a entidades de saúde de um determinado paciente. Habitualmente as notas são feitas
por médicos, enfermeiros e outros profissionais de saúde. Este registo contém considerações,
resultados de meios complementares de diagnóstico e informações sobre o tratamento do
processo patológico. Acedendo ás notas clinicas de um determinado paciente é possível
visualizar todos os seus dados. Esses registos são realizados em texto livre, o que dificulta o
trabalho do médico em compreender e absorver a totalidade da informação existente nas
notas clinicas, desperdiçando assim grande parte do seu trabalho a entender o que se
encontra escrito.
Detalhes importantes para incluir nas notas clínicas do paciente: (K. Lyndon)
➢ Historial do paciente e detalhes clínicos;
➢ Datas de entrada na unidade hospitalar, incluindo correspondência escrita e
telefônica;
➢ Programação sem compromisso, cancelamento ou chegada tardia;
➢ Detalhes de supervisão, consulta e coordenação referente ao paciente;
➢ Plano de avaliação e intervenção do paciente;
➢ O progresso do paciente de acordo com os objetivos estabelecidos;
➢ Detalhes de auxiliares de saúde ou aparelhos necessários;
➢ Julgamentos clínicos e conclusões, isso pode incluir evidência para apoiar ações
profissionais e demonstrar competência profissional;
➢ Detalhes das próximas sessões;

23
➢ Avisos, instruções ou conselhos pré e pós interventivos fornecido ao paciente, isto
inclui a comunicação sobre opções e custos de tratamento, e qualquer mudança
subsequente do plano de tratamento.
2.4.2 Processo Clínico Eletrónico (PCE)
O Processo Clínico Eletrónico (PCE) pode ser definido como um sistema de informação
clínica de suporte às necessidades dos profissionais de saúde em todos os departamentos clínicos
hospitalares e respetivas áreas funcionais. (M. B. Martins, 2011)
A solução informática de PCE consiste, portanto num processo complexo, que obriga a um
esforço de todos os intervenientes enfrentando um conjunto de desafios significativos: (M. B.
Martins, 2011)
➢ Garantir a interoperabilidade entre os sistemas informáticos e aplicações em uso nas
diferentes áreas do hospital;
➢ Dispor de mecanismos e procedimentos que garantam a integridade e confidencialidade
da informação disponível no PCE, garantindo segurança em todas as fases de registo,
consulta, transmissão e armazenamento de dados;
➢ Criar normas, procedimentos e enquadramento jurídico e regulamentar que permitam ao
doente o consentimento para acesso aos seus dados por parte dos profissionais de saúde;
➢ Fomentar e estimular a adoção ao PCE por parte do corpo médico, salvaguardando as
dificuldades e impedimentos que um processo de mudança desta natureza implica.
As fontes de informação em Unidades Hospitalares são distribuídas, heterogéneas, vastas e
complexas, são construídas com recurso a sistemas de informação concebidos por diferentes
empresas que usam os mais diversos sistemas operativos, linguagens e hardware. (A. Abelha, J.
Machado, J. Neves)
A solução é integrar, difundir e arquivar a informação de forma a partilhá-la. É neste
ponto que entra a agência AIDA (Agência para a Integração, Difusão e Arquivo de Informação),
que não é mais do que um sistema multiagente que disponibiliza trabalhadores eletrónicos
que têm como tarefa principal comunicar com os restantes sistemas, gerir, arquivar, enviar e
receber informação, como por exemplo, relatórios, imagens, conjuntos de dados, assim como
responder a pedidos em tempo útil e com fiabilidade. A AIDA disponibiliza também serviços
baseados em tecnologia WEB, de acordo com princípios de simplicidade, a confirmação da

24
concretização de objetivos comuns e o endereçamento de responsabilidades. (A. Abelha, J.
Machado, J. Neves)
São inúmeras as vantagens que se podem associar a um PCE, relativamente ao processo
clínico baseado em papel, vantagens estas que vão desde um melhor acesso, segurança, apoio
à tomada de decisão, à partilha dos dados entre instituições, e consequentemente uma
melhoria dos cuidados de saúde prestados. (A. Abelha, J. Machado, J. Neves)
Apesar da conformidade geral dos potenciais benefícios dos registros de saúde
eletrónicos e outras formas de tecnologia da informação de saúde, os médicos nos EUA
demoraram a adotar essas práticas. Usando uma definição bem especificada de registos de
saúde eletrónica em um estudo de 2009, encontramos que apenas 17% dos médicos dos EUA
usavam um sistema de registro eletrónico minimamente funcional ou abrangente. (Jha et al.,
2009)
Com a implementação do PCE o Centro Hospitalar do Porto atingiu os seguintes
resultados: (M. B. Martins, 2011)
➢ Aumento do rigor e fiabilidade dos dados registados no processo clínico;
➢ Diminuição de custos de armazenamento e transporte dos documentos;
➢ Diminuição de erros, omissões e ambiguidades;
➢ Disponibilidade permanente na rede;
➢ Aumento de segurança de armazenamento e utilização da informação;
➢ Rapidez e segurança no acesso à informação sobre o Cidadão, o seu historial,
resultados de exames e prescrições;
Com o PCE, poupa-se tempo no acesso à informação, elimina-se a circulação de papel
dentro do hospital, sendo o passo mais importante para o chamado paper free no hospital. O
uso de terminologias standard para o registo e a investigação clínica permite a criação de
cenários a partir do repositório do PCE, favorecendo a gestão e o suporte à tomada de decisão
inteligente. O PCE é também o ponto de partido para a implementação de sistemas
inteligentes em unidades hospitalares. (A. Abelha, J. Machado, J. Neves)
2.4.3 Tipos de Notas Clínicas
Em baixo encontram-se algumas das utilidades das notas clínicas nos centros
hospitalares.
25
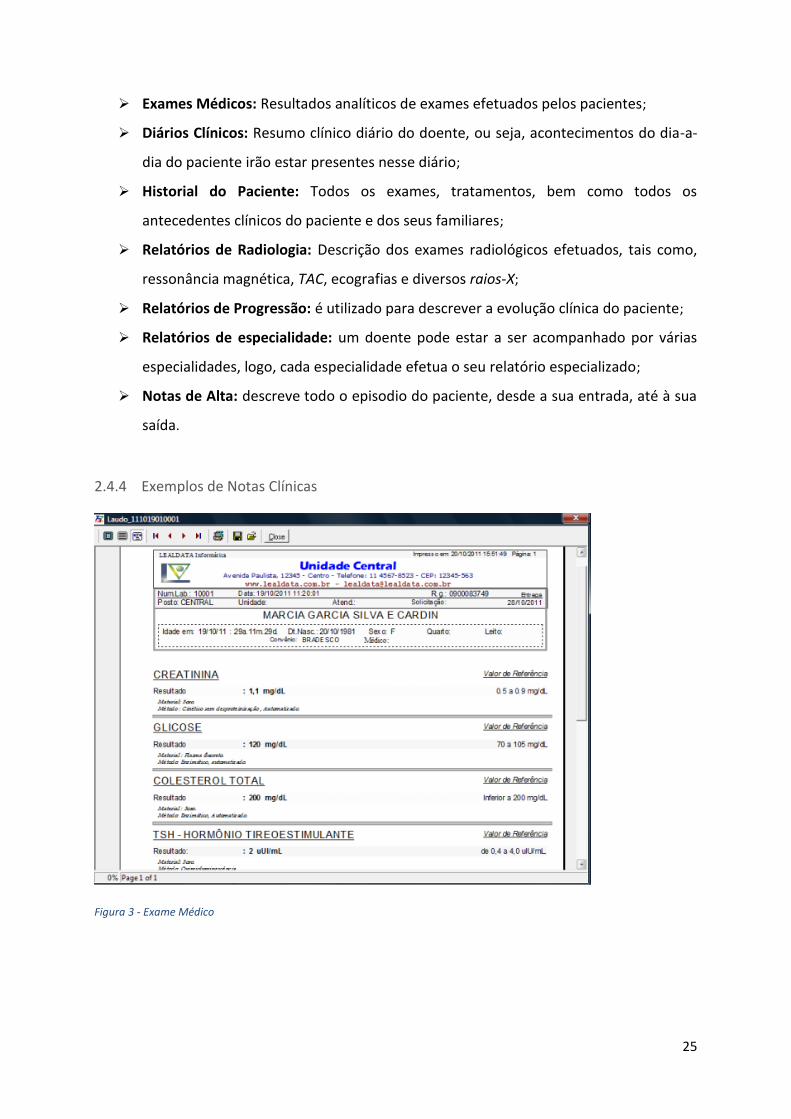
➢ Exames Médicos: Resultados analíticos de exames efetuados pelos pacientes;
➢ Diários Clínicos: Resumo clínico diário do doente, ou seja, acontecimentos do dia-a-
dia do paciente irão estar presentes nesse diário;
➢ Historial do Paciente: Todos os exames, tratamentos, bem como todos os
antecedentes clínicos do paciente e dos seus familiares;
➢ Relatórios de Radiologia: Descrição dos exames radiológicos efetuados, tais como,
ressonância magnética, TAC, ecografias e diversos raios-X;
➢ Relatórios de Progressão: é utilizado para descrever a evolução clínica do paciente;
➢ Relatórios de especialidade: um doente pode estar a ser acompanhado por várias
especialidades, logo, cada especialidade efetua o seu relatório especializado;
➢ Notas de Alta: descreve todo o episodio do paciente, desde a sua entrada, até à sua
saída.
2.4.4 Exemplos de Notas Clínicas
Figura 3 - Exame Médico
26
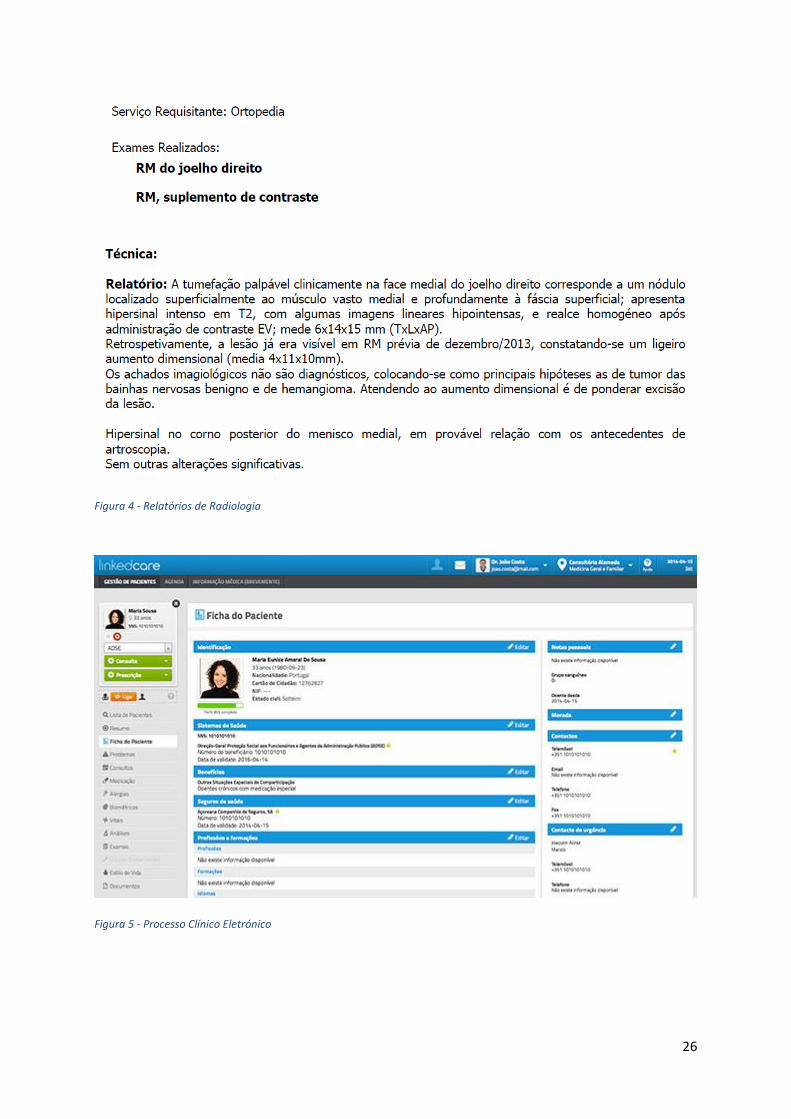
Figura 4 - Relatórios de Radiologia
Figura 5 - Processo Clínico Eletrónico

27
Figura 6 - Relatório de Especialidade
Figura 7 - Exemplo de notas clínicas em texto livre

28
2.5 Terminologias Clínicas
A terminologia clínica ou ontologia clínica é definida como a descrição do conhecimento
sobre um determinado domínio, ou seja, as terminologias estabelecem padrões de significado
universal através de identificadores de semântica.(Freitas, Schulz, & Moraes, 2009)
A medicina é caracterizada por um vasto conjunto de terminologias, melhor descritas
como artefactos linguísticos que unem os diversos sentidos ou significados das entidades
linguísticas.(Freitas et al., 2009)
Em Portugal foi criado um centro de terminologias clínicas, o CTCPT. Esta é uma iniciativa
dos serviços partilhados do ministério da saúde, o SPMS e tem como finalidade criar uma rede
de partilha de conhecimento e de competências na área das terminologias, bem como apoiar
a introdução de boas práticas de clarificação do significado e utilidade da informação.
Neste capítulo irá ser analisado um conjunto de terminologias que representam a ampla
variedade existente neste conceito. Identifiquei como principais grupos de terminologias a
Classificação Internacional de Doenças (CID), o Health Level Seven (HL7), e o Systematized
Nomenclature of Medicine - Clinical Terms (SNOMED CT).
2.5.1 Classificação Internacional de Doenças
Em 1880 foi criada a Classificação Internacional de Doenças (CID) que distinguia
aproximadamente 200 causas de morte, e fornecia códigos para todas as doenças conhecidas
naquela época.
Atualmente existem duas categorias para a CID, sendo elas: (Freitas et al., 2009)
➢ A Classificação Internacional de Doenças 10ª edição – Modificação Clínica (CID -10-
MC) é a modificação feita pelos Estados Unidos ao CID-10 desenvolvido pela OMS
(Organização Mundial de Saúde). O CID-10 fornece cerca de 68.000 classes para a
classificação de doenças e formas de contração. Os códigos são alfanuméricos e até
sete dígitos, possibilitando um maior número de subcategorias. Para alem da criação
da CID-10-CM que apenas substitui o vol. 1 e 2 da CID-9-CM, foi necessário criar a CID-
10-PCS para codificar os procedimentos a utilizar e assim substituir o vol.3 da CID-9-
CM.

29
➢ A Classificação Internacional de Doenças Oncológicas (CID-O) é criada e
constantemente atualizada pela Organização Mundial de saúde e efetua a
categorização de todos os tumores existentes na atualidade bem como as suas taxas
de sobrevivência. Com esta classificação é possível também distinguir duas divisões
principais efetuadas para cada tumor, os topográficos que permitem descrever a
localização do tumor e os morfológicos que caracteriza o tipo de tumor existente.
2.5.2 Health Level Seven (HL7)
O HL7 é um protocolo internacional de transmissão de dados eletrónicos de
equipamentos médicos, sistemas administrativos e bases de dados médicas em todas as
unidades da área da saúde, integrando toda a informação de natureza clínica e administrativa.
O HL7 é uma organização que se dedica a definir e fornecer padrões para trocas,
partilhas e recuperações de informações eletrónicas na área da saúde, credenciada pelo
American National Standards Institute (ANSI).
Os padrões HL7 suportam a prática clínica e toda a sua gestão, entrega e avaliação dos
serviços de saúde, sendo assim reconhecidos como os mais utilizados na atualidade.
O “Level Seven” refere-se ao sétimo nível do modelo de comunicação da Organização
Internacional de Normalização (ISO) para os Open Systems Interconnection (OSI) - o nível de
aplicação.
O padrão mais primário e mais utilizado do HL7 é a Arquitetura de Documentos Clínicos
que é um padrão que especifica a estrutura e a semântica dos documentos clínicos,
permitindo a troca de informação.
A Arquitetura de Documentos Clínicos pode conter qualquer conteúdo clínico e a sua
utilização mais popular é a troca de informações relevantes, permitindo a reutilização de
dados clínicos para relatórios de saúde pública, monitoramento de qualidade, segurança do
paciente e ensaios clínicos.
A necessidade de um padrão de documento clínico decorre do desejo de desbloquear o
considerável conteúdo clínico atualmente armazenado em notas clínicas de texto livre e
permitir a comparação de conteúdo com documentos criados em sistemas de informação de
características amplamente variáveis.

30
2.5.3 SNOMED-CT
O SNOMED-CT permite o registo de toda a informação de um paciente num processo
clínico eletrónico, contendo todos os sinais vitais, sintomas e informação pessoal do paciente.
O SNOMED-CT permite também toda a troca de informação na área da saúde, através
da definição dos melhores padrões de terminologia na área da saúde.(Freitas et al., 2009)
O SNOMED-CT tem como principal objetivo o desenvolvimento de uma linguagem global
para a saúde, unificando todo o sistema de saúde e permitindo assim trocas universais da
informação clínica.
Toda a sua terminologia encontra-se organizada em conceitos que se relacionam entre
si, permitindo assim obter um maior detalhe da informação clínica. Esta funcionalidade
permite aumentar a riqueza e, consequentemente, a qualidade dos dados inseridos,
promovendo a partilha e recolha eficazes da informação clínica.
Os principais componentes identificados no SNOMED-CT são os conceitos, as descrições
e os relacionamentos.
O modelo lógico representa a estrutura de conceitos utilizados. Na figura seguinte é
possível visualizar esse modelo.
Figura 8 - Modelo SNOMED-CT
Na componente de descrições é atribuído a cada conceito um nome completamente
especificado, o “Fully Specified Name (FSN)” e um Sinónimo.

31
O FSN descreve sucintamente o significado de um conceito, este não é apresentado nos
registos clínicos, mas corresponde ao significado do conceito. Cada conceito existente contem
apenas um FSN.
Um sinónimo é um termo que corresponde a um conceito, podendo assim cada conceito
conter vários sinónimos a si associados. A cada conceito é associado um sinónimo principal,
todos os outros sinónimos são considerados apenas como aceitáveis.
A componente de relacionamento representa uma associação entre dois conceitos
existentes. Estes relacionamentos podem ser utilizados para definir o significado de um novo
conceito, sendo criado um terceiro conceito que terá o nome de atributo que irá representar
essa relação criada. No SNOMED-CT existem muitos tipos de relacionamentos criados.(Freitas
et al., 2009)
2.6 Open Access
O Open Access é a informação que está livre de restrição de acesso e de seu uso, isto é,
as publicações que são disponíveis on-line para toda a gente sem qualquer custo relacionado
e com muito poucas restrições de utilização. (Peter Suber, 2009)
Existem dois grandes grupos para permitir o acesso à informação pretendida: (Peter
Suber, 2009)
➢ Golden Open Access – permite o acesso a informação de uma forma livre e
permanente para todos. Os documentos ou artigos são publicados na sua totalidade
em revistas de Open Access e permite a sua reutilização desde que sejam citados os
autores do referido documento.
➢ Green Open Access – permite o acesso à informação de forma gratuita através de
repositórios onde os documentos se encontram, isto é, os documentos encontram-se
acessíveis para todos no repositório em que este foi colocado.
Existe também o Open Data que tal como o Open Access, o Open Data são os dados que
podem ser utilizados novamente por todos, isto é, os dados devem estar disponíveis on-line
para a sua utilização, onde todos devem ser capazes de os utilizar.

32
O OpenEHR é um exemplo de um sistema de Open Access, bem como de Open Data,
para a área da saúde. O OpenEHR será explicado mais detalhadamente no ponto que se
encontra em baixo.
2.6.1 OpenEHR
O OpenEHR é uma especificação do Open Access na área da saúde que trabalha em
meios para transformar os dados de saúde da forma física em forma eletrônica e garantir a
interoperabilidade universal entre todas as formas de dados eletrônicos, descrevendo todo o
armazenamento e troca de dados de saúde em processos clínicos eletrónicos. No openEHR,
todos os dados de saúde de um paciente são armazenados em um "EHR", isto é um registo de
saúde eletrónico centrado no paciente.
Segundo a Organização Internacional de “Standardização” o EHR é um repositório de
informações eletrónicas sobre a saúde de um paciente, armazenado e transmitido de forma
segura e acessível por diversos utilizadores autorizados. Possui um modelo de informação
lógica comum que é independente dos sistemas EHR. O seu principal objetivo é o suporte de
cuidados de saúde integrados contínuos, eficientes e de qualidade. (Garde, Knaup, Hovenga,
& Heard, 2007)
Características principais de um EHR:(Garde et al., 2007)
➢ O EHR é centrado no paciente, ou seja, um EHR refere-se a cuidados para com
o paciente;
➢ O EHR é longitudinal, isto é um registro eletrónico a longo prazo, ou seja, todos
os pacientes contêm um registo eletrónico possivelmente desde o seu
nascimento até à sua morte;
➢ O EHR é abrangente pois inclui todos os registos de um determinado paciente
independentemente da instituição ou profissional de saúde a que recorreu;
➢ O EHR é prospetivo: não só os eventos anteriores são registrados, mas também
instruções e informações prospetivas, como planos, objetivos, ordens e
avaliações também são registadas no EHR.
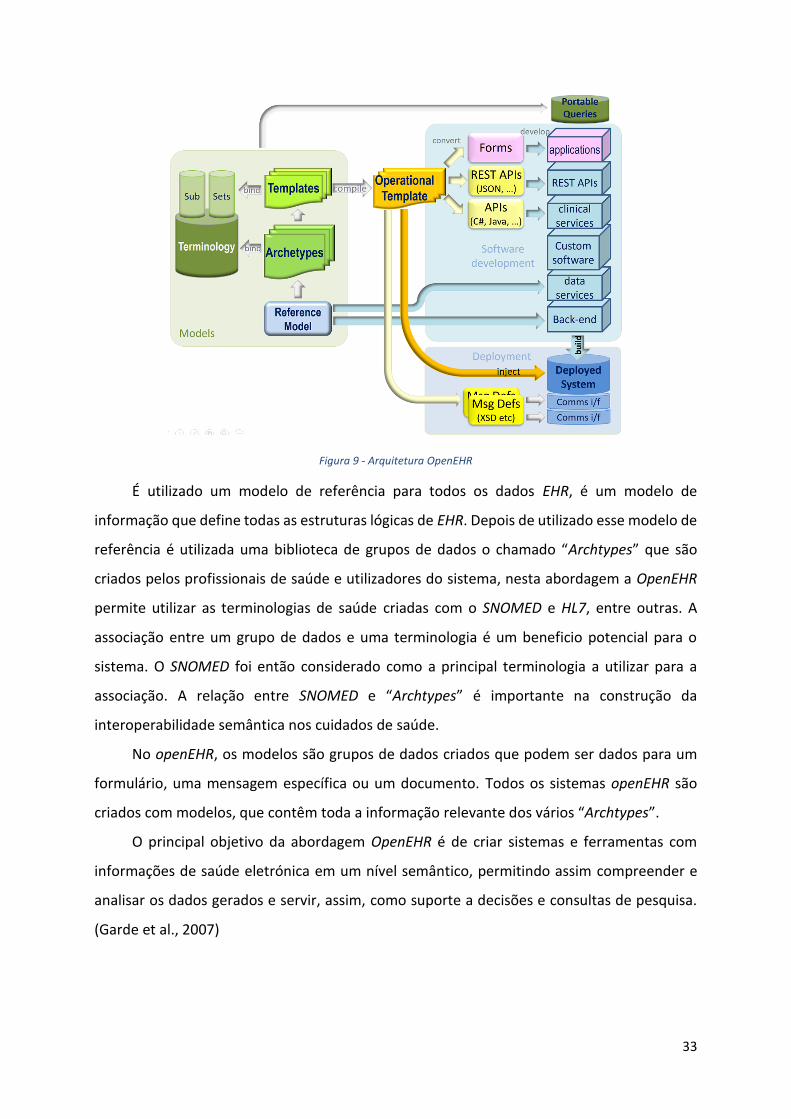
A imagem seguinte representa todo toda a arquitetura OpenEHR a seguir para os dados
EHR.
33
Figura 9 - Arquitetura OpenEHR
É utilizado um modelo de referência para todos os dados EHR, é um modelo de
informação que define todas as estruturas lógicas de EHR. Depois de utilizado esse modelo de
referência é utilizada uma biblioteca de grupos de dados o chamado “Archtypes” que são
criados pelos profissionais de saúde e utilizadores do sistema, nesta abordagem a OpenEHR
permite utilizar as terminologias de saúde criadas com o SNOMED e HL7, entre outras. A
associação entre um grupo de dados e uma terminologia é um beneficio potencial para o
sistema. O SNOMED foi então considerado como a principal terminologia a utilizar para a
associação. A relação entre SNOMED e “Archtypes” é importante na construção da
interoperabilidade semântica nos cuidados de saúde.
No openEHR, os modelos são grupos de dados criados que podem ser dados para um
formulário, uma mensagem específica ou um documento. Todos os sistemas openEHR são
criados com modelos, que contêm toda a informação relevante dos vários “Archtypes”.
O principal objetivo da abordagem OpenEHR é de criar sistemas e ferramentas com
informações de saúde eletrónica em um nível semântico, permitindo assim compreender e
analisar os dados gerados e servir, assim, como suporte a decisões e consultas de pesquisa.
(Garde et al., 2007)


35
3. ABORDAGEM METODOLÓGICA
Para elaborar todo o projeto de dissertação iremos utilizar duas metodologias, uma para
auxiliar na investigação e a outra para orientar o projeto de desenvolvimento em Text Mining.
A metodologia de Investigação é a Design Science Research (DSR) e a metodologia para o
projeto de Text Mining é o Cross Industry Standard Process for Data Mining (CRISP-DM). Para
uma utilização correta das metodologias, estas terão de ser respeitadas em todas as fases do
projeto.
3.1 DSR
Figura 10 - Fases da metodologia DSR
A metodologia DSR é constituída pelas seguintes fases: (Peffers, Tuunanen,
Rothenberger, & Chatterjee, 2008)
➢ Identificação do enquadramento e motivação: identificar o problema a resolver,
procurar o máximo de informações possíveis, os objetivos a atingir e a solução do
problema;
➢ Definição dos objetivos e solução: definir um modelo que seja eficaz e eficiente para
o problema, incluindo orientações para a sua adoção em termos de estruturas,
processos e mecanismos de relacionamento;
➢ Conceção e desenvolvimento: criação de um artefacto tendo em conta os métodos,
técnicas de Text Mining, para ser no problema;

36
➢ Demonstração: demonstração da eficiência e eficácia do modelo desenvolvido para a
plataforma em desenvolvimento recorrendo a simulações;
➢ Avaliação: após a criação do protótipo é feita a avaliação deste, seguindo um conjunto
de métricas de definidas ou através de questionários, para verificar se este vai ao
encontro dos requisitos impostos na proposta inicial;
➢ Comunicação: para finalizar nesta fase corresponde à dissertação desenvolvida e
apresentação dos resultados obtidos ao longo do desenvolvimento desta investigação.
Neste projeto a aplicação do DSR tem como principal problema o facto das notas clínicas
médicas dos doentes serem de texto livre, e então ser necessário um sistema que apoie a
tomada de decisão mais correta no que toca ao acompanhamento dos doentes. Para isso
acontecer é preciso elaborar um artefacto que com base nos dados existentes, que
essencialmente são em texto livre, seja possível determinar os melhores procedimentos,
criando assim uma possível solução para o problema inicialmente formulado.
No Paradigma de Design Science, o conhecimento e o entendimento de um determinado
problema e a sua solução são alcançados através da construção da aplicação definida pelo
artefacto desenhado (Hevner, March, & Park, 2004).
3.2 Crisp-DM
Figura 11 - Fases da metodologia CRISP-DM

37
A metodologia CRISP-DM é constituída pelas seguintes fases: (Pete et al., 2000)
➢ Entender o Negócio: esta fase inicial concentra-se na compreensão dos objetivos e
requisitos do projeto de uma perspetiva de negócios, em seguida definir um plano para
atingir os objetivos e avaliar os recursos necessários.
➢ Entender os Dados: a fase de compreensão de dados começa com recolha da
informação e prossegue com atividades de identificação dos principais problemas ou
desafios.
➢ Preparação dos Dados: a fase de preparação de dados cobre todas as atividades
necessárias para a construção do conjunto de dados final a partir dos dados iniciais.
Este processo decorre várias vezes no processo até obter a informação final
necessária.
➢ Modelação: nesta fase, várias técnicas de modelação são aplicadas, e os seus
parâmetros são calibrados para valores ótimos. Normalmente, existem várias técnicas
para o mesmo tipo de problema de Text Mining. Algumas técnicas têm requisitos
específicos sobre a forma de dados. Portanto, voltar para a fase de preparação de
dados é muitas vezes necessário.
➢ Avaliação: nesta fase do projeto é realizada a construção de um modelo que parece
ter alta qualidade a partir de uma perspetiva de análise de dados. Antes de proceder
à implantação final do modelo, é importante avaliá-lo minuciosamente e revisar as
etapas executadas para criá-lo, para ter certeza de que o modelo atinge
adequadamente os objetivos de negócios.
➢ Implementação: a criação do modelo geralmente não é o fim do projeto. Mesmo que
o objetivo do modelo seja aumentar o conhecimento dos dados, o conhecimento
adquirido precisará ser organizado e apresentado de forma que o cliente possa usá-lo.
Dependendo dos requisitos, a fase de implementação pode ser tão simples como gerar
um relatório ou tão complexo quanto implementar um processo de mineração de
dados repetitivo em toda a empresa. O conhecimento adquirido pelo modelo é
organizado e apresentado de uma maneira que o cliente possa utilizar.


39
4. GESTÃO DO PROJETO
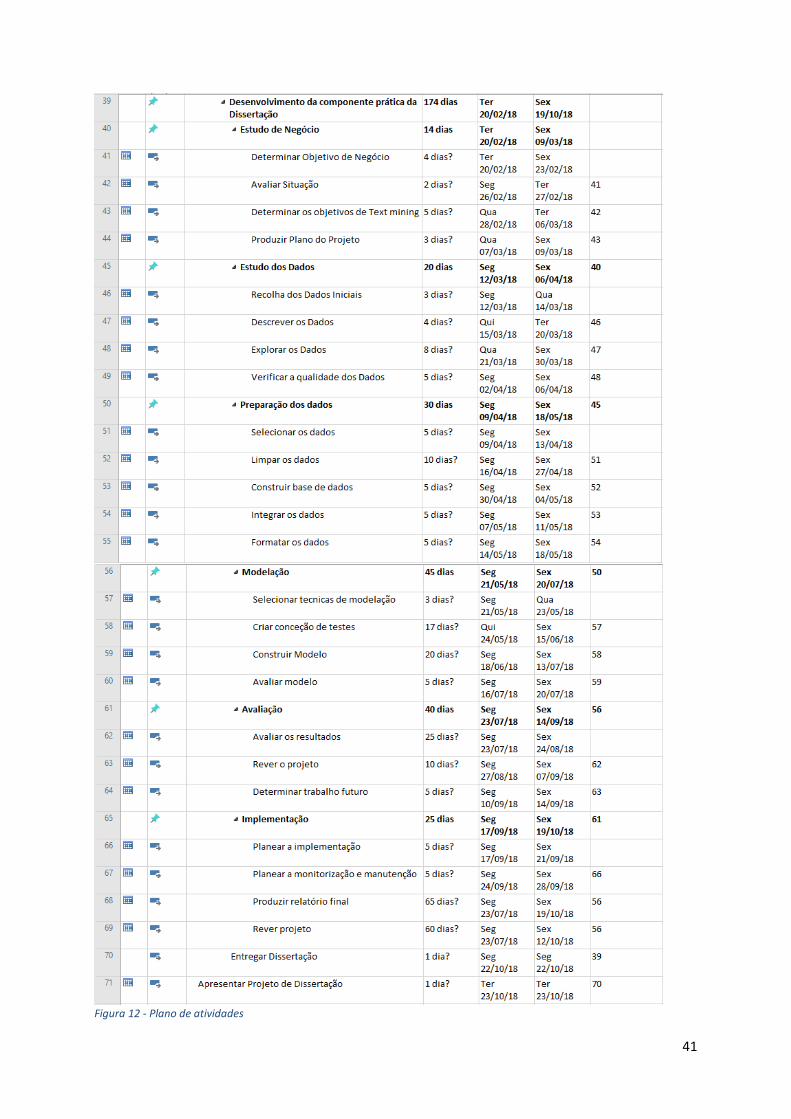
4.1 Plano de Atividades
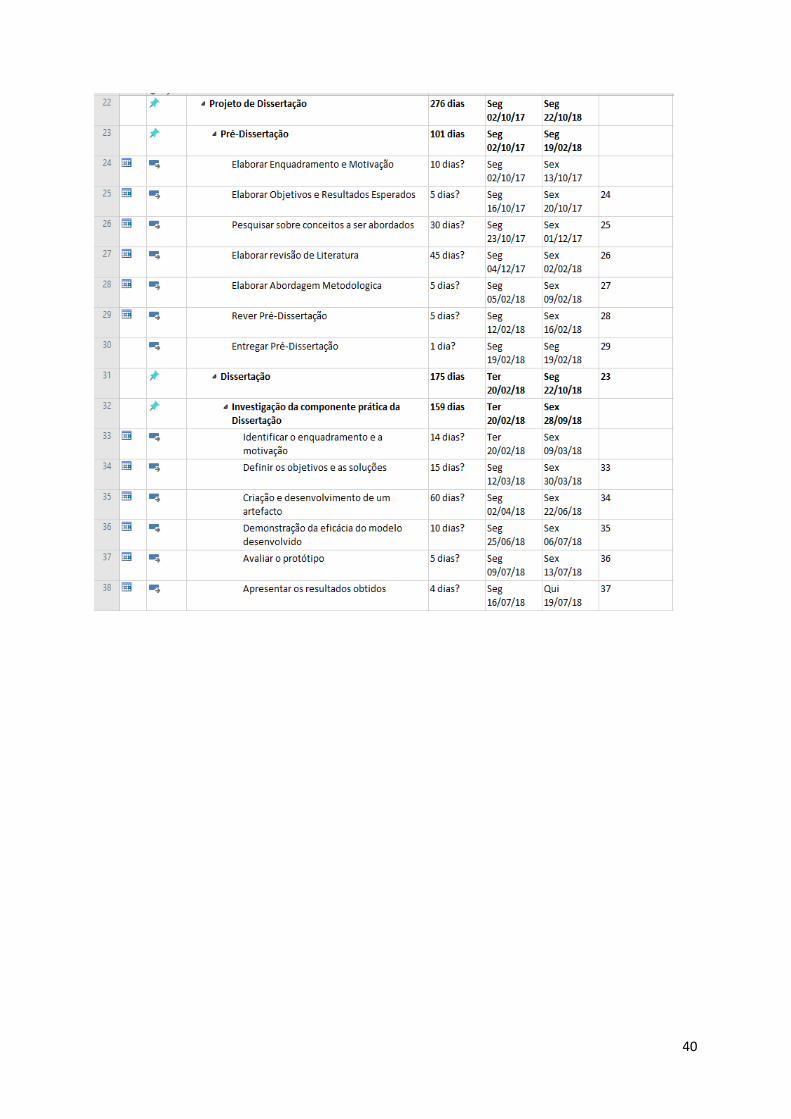
Foi elaborado um cronograma com base nas tarefas necessárias para o cumprimento
das duas metodologias selecionadas. Abaixo pode-se ver o cronograma com o detalhe das
tarefas ao longo do projeto e o tempo previsto de realização das mesmas.
40
41
Figura 12 - Plano de atividades

42
4.2 Lista de Riscos
Na tabela abaixo são apresentados os riscos identificados, com a sua previsão e o impacto
para o projeto, assim como a ação atenuante ao risco.
Tabela 1 - Lista de Riscos
Descrição Probabilidade Impacto Seriedade Atenuante
Incumprimento
do tempo
previsto
3 5 15
Procurar libertar mais
tempo para tarefas mais
complexas
Dificuldade do
projeto 3 5 15
Procurar utilizar a
melhor abordagem ao
projeto e manter
orientador sempre
informado da situação
Os dados das
notas clínicas
serem
incompreensíveis
3 5 15
Pedir auxilio ao
orientador na
compreensão dos dados
Falta de
experiencia 3 4 12
Dispensar mais tempo
na aprendizagem das
ferramentas a utilizar
Metodologias
utilizadas serem
inadequadas
2 4 8
Procurar metodologia
que mais se enquadra
ao projeto

43
BIBLIOGRAFIA
Feldman, R., & Sanger, J. (2007). The text mining handbook: advanced approaches in
analyzing unstructured data. Imagine, 34, 410.
https://doi.org/10.1179/1465312512Z.00000000017
Shrihari, C., & Desai, A. (2015). A Review on Knowledge Discovery using Text
Classification Techniques in Text Mining. International Journal of Computer
Applications, 111(6), 975–8887. Retrieved from
http://research.ijcaonline.org/volume111/number6/pxc3900784.pdf
Tseng, Y.-H., Lin, C.-J., & Lin, Y.-I. (2007). Text mining techniques for patent analysis.
Information Processing & Management, 43(5), 1216–1247.
https://doi.org/10.1016/j.ipm.2006.11.011
Tan, A. H. (1999). Text mining: The state of the art and the challenges. Proceedings of the
PAKDD 1999 Workshop on Knowledge Disocovery from Advanced Databases, 65–70.
https://doi.org/10.1.1.38.7672
Hearst, M. A. (1999). Untangling text data mining. In Proceedings of the 37th annual meeting
of the Association for Computational Linguistics on Computational Linguistics - (pp. 3–
10). https://doi.org/10.3115/1034678.1034679
Truyens, M., & Van Eecke, P. (2014). Legal aspects of text mining. Computer Law &
Security Review, 30(2), 153–170. https://doi.org/10.1016/j.clsr.2014.01.009
Gupta, V., & Lehal, G. S. (2009). A survey of text mining techniques and applications.
Journal of Emerging Technologies in Web Intelligence.
https://doi.org/10.4304/jetwi.1.1.60-76
Piedra, D., Ferrer, A., & Gea, J. (2014). Text Mining and Medicine: Usefulness in Respiratory
Diseases. Archivos de Bronconeumología (English Edition), 50(3), 113–119.
https://doi.org/10.1016/j.arbr.2014.02.008
Liddy, E. D. (2001). Natural Language Processing. In Encyclopedia of Library and
Information Science (Vol. 37, pp. 51–89). https://doi.org/10.1017/S0267190500001446
Gobinda G. Chowdhury. (2003). Natural Language Processing. Annual review of information
science and technology (Vol. 37). https://doi.org/10.1017/S0267190500001446
Kao, A., & Poteet, S. R. (2007). Natural language processing and text mining. Natural
Language Processing and Text Mining. https://doi.org/10.1007/978-1-84628-754-1
Peffers, K., Tuunanen, T., Rothenberger, M., & Chatterjee, S. (2008). A Design Science
Research Methodology for Information Systems Research. J. Manage. Inf. Syst.,
24(January), 45–77. https://doi.org/10.2753/MIS0742-1222240302

44
Pete, C., Julian, C., Randy, K., Thomas, K., Thomas, R., Colin, S., & Wirth, R. (2000).
CRISP-DM 1.0: Step-by-step data minning guide. CRISP-DM Consortium, 76.
Jha, A. K., DesRoches, C. M., Campbell, E. G., Donelan, K., Rao, S. R., Ferris, T. G., …
Blumenthal, D. (2009). Use of electronic health records in U.S. hospitals. New England
Journal of Medicine, 360(16), 1628–1638. https://doi.org/NEJMsa0900592
[pii]\r10.1056/NEJMsa0900592
Zhou, X., Han, H., Chankai, I., Prestrud, A., & Brooks, A. (2006). Approaches to Text
Mining for Clinical Medical Records. Proceedings of the 2006 ACM Symposium on
Applied Computing, 235–239. https://doi.org/10.1145/1141277.1141330
Peter Suber. (2009). Open Access Overview. Exploring Open Access: A Practice Journal.
https://doi.org/10.1109/ASPDAC.2006.1594722
Garde, S., Knaup, P., Hovenga, E. J. S., & Heard, S. (2007). Towards semantic
interoperability for electronic health records: Domain knowledge governance for
openEHR archetypes. Methods of Information in Medicine, 46(3), 332–343.
https://doi.org/10.1160/ME5001
Freitas, F., Schulz, S., & Moraes, E. (2009). Pesquisa de terminologias e ontologias atuais
em biologia e medicina. Reciis, 3(1), 8–20. https://doi.org/10.3395/reciis.v3i1.239pt
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., & Ives, Z. (2007). DBpedia: A
nucleus for a Web of open data. In Lecture Notes in Computer Science (including
subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics)
(Vol. 4825 LNCS, pp. 722–735). https://doi.org/10.1007/978-3-540-76298-0_52
Luhn, H. P. (1958). The Automatic Creation of Literature Abstracts. IBM Journal of Research
and Development, 2(2), 159–165. https://doi.org/10.1147/rd.22.0159


















