
Template matching (casamento de máscara, ou casamento de ... · tem fatores de correção de...
29
Template matching (casamento de máscara, ou casamento de modelo) Template matching é uma técnica usada para achar as instâncias de uma máscara Q dentro de uma imagem a ser analisada A. Template matching torna-se mais complexa ao exigir invariância a: 1) Mudança de brilho e contraste; 2) Rotação; 3) Mudança de escala; 4) Mudança de ponto de vista (transformação em perspectiva). Template matching de imagens coloridas deve-se levar em conta que a cor de um objeto muda de acordo com as condições de iluminação. Neste caso, invariância a brilho e contraste tor- nam-se invariância à iluminação. A função matchTemplate do OpenCV utiliza internamente FFT para acelerar template mat- ching.
Transcript of Template matching (casamento de máscara, ou casamento de ... · tem fatores de correção de...

Template matching (casamento de máscara, ou casamento de modelo)
Template matching é uma técnica usada para achar as instâncias de uma máscara Q dentro deuma imagem a ser analisada A.
Template matching torna-se mais complexa ao exigir invariância a:1) Mudança de brilho e contraste;2) Rotação;3) Mudança de escala;4) Mudança de ponto de vista (transformação em perspectiva).
Template matching de imagens coloridas deve-se levar em conta que a cor de um objeto mudade acordo com as condições de iluminação. Neste caso, invariância a brilho e contraste tor-nam-se invariância à iluminação.
A função matchTemplate do OpenCV utiliza internamente FFT para acelerar template mat-ching.

Template matching (casamento de padrões ou casamento de modelos) para imagens bi-nárias usando filtro linear:
Por que usar filtro linear para fazer template matching? 1) Porque é possível acelerar o cálculo do filtro linear usando FFT.2) Porque é possível obter invariância a brilho usando filtro linear.3) Porque é possível obter invariância a brilho e contraste usando filtro linear modificado(correlação cruzada normalizada ou coeficiente de correlação normalizada).4) Porque dá para especificar pixels "don't care".
Exemplo unidimensional:
a = [ 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0]q1= [ 0, 1, 1]
Queremos achar as instâncias de Q1 em A: p1=filtro2d(a,q1)p1=[ 1, 1, 0, 1, 1, 1, 2, 2, 1, 1, 2, 1, 0]
Calculando simplesmente filtro linear, não é possível detectar Q1 (verde), pois há falso positi-vo (vermelho).
Calculando q2=dcReject(q1), isto é, subtraindo a média de q1:q2= [-0.67, 0.33, 0.33]
Calculando p2=filtro2d(a,q2)p2= [0.3, 0.3, -0.7, 0.3, 0.3, -0.3, 0.7, 0.0, -0.3, -0.3, 0.7, -0.3, -0.7]
É possível detectar as ocorrências de Q2 em A através dos picos de correlação.
Esta operação é invariante a brilho. Se somar uma constante nas instâncias, o resultado não sealtera:
a = [ 10, 11, 10, 10, 11, 10, 11, 11, 11, 10, 11, 11, 10]
Calculando q3=somaAbsDois(dcReject(q)), isto é, subtraindo a média de q e obrigando a so-matoria absoluta dar 2:q3= [-1, 0.5, 0.5]
Calculando p3=filtro2d(a,q3)p3= [0.5, 0.5, -1, 0.5, 0.5, -0.5, 1, 0, -0.5, -0.5, 1, -0.5, -1]
É possível detectar as ocorrências de Q2 em A, com a vantagem de saber a saída vai de -1 a+1.
A função dcReject(q) subtrai a média de q de todos os pixels de q.A função somaAbsDois(b) divide todos os pixels de b pela somatória de abs(b), onde
abs(b) calcula o módulo de cada pixel de b, depois multiplica todos por dois.

//match1d.cpp - grad2014#include <cekeikon.h>
int main(){ Mat_<FLT> a = ( Mat_<FLT>(1,13) << 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0); cout << a << endl; Mat_<FLT> q = ( Mat_<FLT>(1,3) << 0, 1, 1 ); cout << q << endl;
Mat_<FLT> p=filtroBorda0(a,q); cout << p << endl;
Mat_<FLT> q2=dcReject(q); cout << q2 << endl; Mat_<FLT> p2=filtroBorda0(a,q2); cout << p2 << endl;
Mat_<FLT> q3=somaAbsDois(dcReject(q)); cout << q3 << endl; Mat_<FLT> p3=filtroBorda0(a,q3); cout << p3 << endl;}
filtroBorda0 considera zero os pixels fora do domínio.

Template matching (casamento de padrões ou casamento de modelos) para imagens bi-nárias usando filtro linear:
Exemplo bidimensional:
Imagem A
Imagem Q
Imagem de saída P
//match2d.cpp - pos2016#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"bbox.bmp"); Mat_<FLT> q; le(q,"letramore.bmp"); q=somaAbsDois(dcReject(q)); Mat_<FLT> b=filtro2d(a,q); imp(b,"correlacao.pgm");
Mat_<FLT> d; threshold( b, d, 0.999, 1.0, THRESH_BINARY); dilate( d, d, Mat_<GRY>(31,31,255)); d = 1.0 - d; imp(d,"achei.pgm"); system("img sobrmcb bbox.bmp achei.pgm achei.ppm");}

Mudando limiar para 0.8, é possível achar padrões parecidos com “more”.
Segundo “more” foi alterado.
Com limiar 0.8, achou também o segundo “more”.
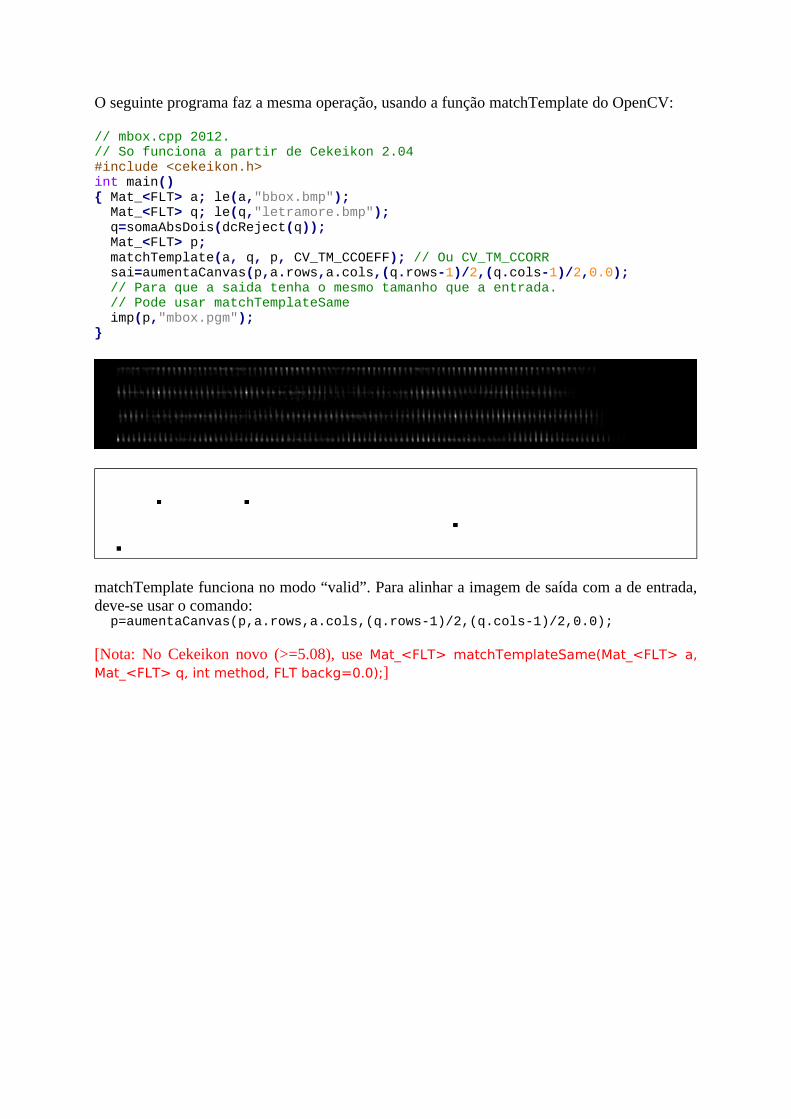
O seguinte programa faz a mesma operação, usando a função matchTemplate do OpenCV:
// mbox.cpp 2012. // So funciona a partir de Cekeikon 2.04#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"bbox.bmp"); Mat_<FLT> q; le(q,"letramore.bmp"); q=somaAbsDois(dcReject(q)); Mat_<FLT> p; matchTemplate(a, q, p, CV_TM_CCOEFF); // Ou CV_TM_CCORR sai=aumentaCanvas(p,a.rows,a.cols,(q.rows-1)/2,(q.cols-1)/2,0.0); // Para que a saida tenha o mesmo tamanho que a entrada. // Pode usar matchTemplateSame imp(p,"mbox.pgm");}
matchTemplate funciona no modo “valid”. Para alinhar a imagem de saída com a de entrada,deve-se usar o comando: p=aumentaCanvas(p,a.rows,a.cols,(q.rows-1)/2,(q.cols-1)/2,0.0);
[Nota: No Cekeikon novo (>=5.08), use Mat_<FLT> matchTemplateSame(Mat_<FLT> a,Mat_<FLT> q, int method, FLT backg=0.0);]

Sem aumentaCanvas, a localização fica marcada no canto superior esquerdo.
// mbox2.cpp pos-2014#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"bbox.bmp"); Mat_<FLT> q; le(q,"letramore.bmp"); q=somaAbsDois(dcReject(q)); Mat_<FLT> p; matchTemplate(a, q, p, CV_TM_CCOEFF); imp(p,"mbox.pgm");
Mat_<FLT> d; threshold( p, d, 0.999, 1.0, THRESH_BINARY); dilate( d, d, Mat_<GRY>(31,31,255)); d = 1.0 - d; imp(d,"mbox2.pgm"); system("img sobrmcb bbox.bmp mbox2.pgm mbox2.ppm");}

Template matching com pixels “don’t care”:
//match2d3.cpp - pos2016#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"bbox3.pgm"); Mat_<FLT> q; le(q,"letramore3.pgm");
q=somaAbsDois( dcReject(q, 128.0/255.0 ) ); //OU: q=trataModelo(q,128.0/255.0);
Mat_<FLT> b=filtro2d(a,q); imp(b,"correlacao.pgm");
Mat_<FLT> d; threshold( b, d, 0.999, 1.0, THRESH_BINARY); dilate( d, d, Mat_<GRY>(31,31,255)); d = 1.0 - d; imp(d,"achei3.pgm"); system("img sobrmcb bbox3.pgm achei3.pgm achei3.ppm");}
Nota: A função:Mat_<FLT> trataModelo(Mat_<FLT> k, FLT dontcare)
Faz somaAbsDois e dcReject levando em conta dontcare.
bbox3.pgm
letramore3.pgm. Pixels cinza são “don’t care”.
achei3.ppm

//letramore2.cpp - grad2015//com pixel don't care#include <cekeikon.h>
Mat_<FLT> trataModelo2(Mat_<FLT> k){ float soma=0.0; int conta=0; for (unsigned i=0; i<k.total(); i++) { if (k(i)==0.0 || k(i)==1.0) { soma+=k(i); conta++; } } float media=soma/conta; Mat_<FLT> r(k.size()); for (unsigned i=0; i<k.total(); i++) { if (k(i)==0.0 || k(i)==1.0) r(i)=k(i)-media; else r(i)=0.0; }
float somaabs=0.0; for (unsigned i=0; i<r.total(); i++) somaabs+=abs(r(i)); r = r / somaabs; r = 2 * r; return r;}
int main(){ Mat_<FLT> a; le(a,"bbox2.pgm"); Mat_<FLT> k; le(k,"letramore2.pgm"); k=trataModelo2(k); Mat_<FLT> b=filtro2d(a,k); imp(b,"letramore2.png"); Mat_<GRY> g(b.size(),0); for (unsigned i=0; i<b.total(); i++) if (b(i)>=0.9) g(i)=255; imp(g,"more2.png");}
Nota: A função trataModelo2 já está implementada em Cekeikon, com o nome de trataMode-lo. Aqui, estou chamando de trataModelo2 só para não dar conflito de duas funções com no-mes iguais.
[Nota: Para imagens coloridas use dcReject(Mat_<CORF> a, CORF dontcare);]

Invariância por Brilho e Contraste
Definimos que duas imagens x e y são equivalentes sob variação de brilho e contraste se exis-tem fatores de correção de contraste 0 (ou >0 se não admite imagens negativas) e de bri-lho tais que 1xy , onde 1 é a matriz de 1s.
O método de busca de padrão calculando “dcReject” e “somaAbsDois” do padrão, seguidopelo filtro linear (ou correlação cruzada), é invariante ao brilho mas não é invariante a con-traste. Para verificar como isso atrapalha a busca de padrão, vamos procurar dumbo.jpg em fi-gurinhas.jpg:
figurinhas.jpg
dumbo.jpg
// dumbo1.cpp 2012. So funciona a partir de Cekeikon 2.04#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"figurinhas.jpg"); Mat_<FLT> q; le(q,"dumbo.jpg"); q=2*somatoriaUm(dcReject(q)); // Mat_<FLT> p; matchTemplate(a, q, p, CV_TM_CCOEFF); // Ou CV_TM_CCORR p=aumentaCanvas(p,a.rows,a.cols,(q.rows-1)/2,(q.cols-1)/2,0.0); imp(p,"dumbo1.pgm");}
Pixels mais brilhantes

A saída não indica a localização de dumbo, pois os pontos mais brilhantes não estão localiza-dos nas posições onde “dumbo” aparece. O problema pode ser resolvido usando a correlaçãocruzada normalizada (NCC) que é invariante ao brilho e contraste:
// dumbo2.cpp 2012. So funciona a partir de Cekeikon 2.04#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"figurinhas.jpg"); Mat_<FLT> q; le(q,"dumbo.jpg"); //q=2*somatoriaUm(dcReject(q)); // Nao precisa deste comando!!! Mat_<FLT> sai; matchTemplate(a, q, sai, CV_TM_CCOEFF_NORMED); sai=aumentaCanvas(sai,a.rows,a.cols,(q.rows-1)/2,(q.cols-1)/2,0.0); imp(sai,"dumbo2.pgm");}
Ocorrência verdadeira de Dumbo:Correlação não-normalizada: 50Correlação normalizada: 1
Falsa ocorrência de Dumbo:Correlação não-normalizada:100Correlação normalizada: 0,7
Pixels mais brilhantes
dumbo padrão
ocorrência de dumbo
10
5
dumbo padrão
10 14
falsa ocorrência de dumbo

Para verificar a diferença entre correlação cruzada (filtro linear) e NCC (normalized cross cor-relation), vamos recorrer a um exemplo 1-D.
//unidim.cpp. So funciona com cekeikon >= 2.04#include <cekeikon.h>int main(){ Mat_<FLT> a(1,13, (FLT[]) {6, 7, 0, 10, 5, 4, 0, 2, 1, 5, 1, 5, 3}); cout << a << endl; Mat_<FLT> q(1,3, (FLT[]){2, 6, 4}); cout << q << endl; q=dcReject(q); cout << q << endl;
Mat_<FLT> p; matchTemplate(a, q, p, CV_TM_CCOEFF); cout << p << endl;
Mat_<FLT> q2=2*somatoriaUm(q); cout << q2 << endl; matchTemplate(a, q2, p, CV_TM_CCOEFF); cout << p << endl;
matchTemplate(a, q, p, CV_TM_CCOEFF_NORMED); cout << p << endl;}
Saída:a= [ 6, 7, 0, 10, 5, 4, 0, 2, 1, 5, 1, 5, 3]q= [ 2, 6, 4] (antes de dcReject)q= [ -2, 2, 0] (depois de dcReject)p= [ 2, -14, 20, -10, -2, -8, 4, -2, 8, -8, 8] (ccoeff com dcReject)q2=[ -1, 1, 0] (depois de dcReject e somaAbsDois)p= [ 1, -7, 10, -5, -1, -4, 2, -1, 4, -4, 4] (ccoeff com dcReject e somaAbsDois)p= [ 0.13,-0.68, 1.00,-0.78,-0.19,-1.00, 1.00,-0.24, 0.87,-0.87, 1.00] (ccoeff_normed)
A correlação cruzada (não-normalizada) é invariante a brilho mas não a contraste. Os picos da correlação cruzada (não-normalizada) não correspondem às instâncias de
q em a. A altura do pico depende do contraste. Há picos onde não há instância. A correlação cruzada (não-normalizada) não está limitada. Isto é, pode ter valor muito
alto. Isto pode ser remediado calculando “somaAbsDois”. Isto faz com que a saída es-teja no mesmo intervalo da entrada (-10 a 10).
Os picos da correlação cruzada normalizada ou coeficiente de correlação normalizadacorrespondem às instâncias de q em a (independente do brilho e contraste). Para usarcoeff_normed, não precisa fazer nem dcReject nem somaAbsDois.
A coeficiente de correlação normalizada (NCC) está limitada ao intervalo [-1,1]. Correlação normalizada é sempre melhor do que não-normalizada? Nem sempre. Cor-
relação normalizada detecta como ocorrência mesmo instâncias muito tênues, de baixocontraste. Se quiser detectar ocorrência de alto contraste, deve usar correlação não-normalizada.
Não se pode calcular NCC se a imagem A tiver regiões com nível de cinza constante.Neste caso, resultará numa divisão por zero, com valores de saída indefinidos.
Também não se pode calcular NCC com a imagem Q com nível de cinza constante.(Mas isto pode ser ignorado, pois ninguém vai querer buscar um modelo com nível decinza constante.)

É possível calcular NCC rapidamente usando convolução (acelerada pelo FFT). A fun-ção matchTemplate faz isto automaticamente.
Sejam dados vetores x e y (x é o conteúdo dentro da janela da imagem A. y é o conteúdo daimagem Q escrito na forma de vetor). Vamos denotar esses vetores após dcReject de x~ e y~
. Isto é, xxx ~ , onde x̄ é a média de x e o mesmo vale para y. A correlação não-normali-zada (ou produto escalar) é:
corr x , y=~x ~y=x~y
Ex: [0, 10, 5] [-1, 1, 0] = 10
Só precisa fazer dcReject em y. Fazendo dcReject em x e y, dá o mesmo resultado:Ex: [-5, 5, 0] [-1, 1, 0] = 10
O produto escalar está relacionada ao cosseno entre os vetores ~x e ~y :~x~y=‖~x‖‖~y‖cos (θ ) , onde é o ângulo formado por dois vetores.
Esta medida é calculada pixel a pixel (com janela móvel) com o comando:matchTemplate(x, y, sai, CV_TM_CCOEFF);
O produto escalar de vetores com média corrigida é invariante a “brilho” (“bias” ou“offset”) pois a média é subtraída, mas não é invariante ao “contraste” (ou “ganho” ou “am-plitude”). Para obter invariância a brilho e contraste, deve-se calcular o coeficiente de correla-ção normalizada entre os vetores ~x e ~y :
r~x ,~y=~x ~y
‖~x‖‖~y‖=cos(θ )
Isto pode ser constatado considerando que:r~x ,~y=cos (θ ) , onde é o ângulo formado por dois vetores.
Ex1:Correlação cruzada (não-normalizada): [−5,5,0 ]⋅[−1,1,0 ]=10
Coeficiente de correlação (normalizada): [−5,5,0 ]⋅[−1,1,0 ]
√(−5 )2+52⋅√(−1)2+12=1
Ex2: x=[3 7 5] y=[2 6 4]~x =[-2 2 0] ~y =[-2 2 0]rx,y = 1
Correlação cruzada normalizada (NCC) equivale a calcular o coeficiente de correlação paracada posição da janela. Isto é calculado com o comando:
matchTemplate(x, y, sai, CV_TM_CCOEFF_NORMED);

Propriedades:
O coeficiente de correlação (normalizada) é invariante por mudança de brilho e con-traste.
O coeficiente de correlação (normalizada) está limitado ao intervalo [-1,+1]. +1 indicaque as duas regiões são iguais (sob invariância por brilho e contraste). -1 indica que asduas regiões estão negativamente correlacionadas (preto numa imagem corresponde abranco na outra imagem). 0 indica a ausência total de correlação
Nota: No sistema Proeikon, há programas:>img tempmatg>pv tmatch>pv ncc que fazem o template matching proposto.
Nota: No sistema Cekeikon, há programas:>KCEK TMatchC = Template matching color>KCEK TMatchG = Template matching grayscale

Diferença prática entre usar NCC e Convolução://ncc-cc2.cpp#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"a.tga"); Mat_<FLT> q; le(q,"q.tga"); Mat_<FLT> cc; matchTemplate(a,q,cc,CV_TM_CCOEFF); cc=normaliza(modulo(cc)); Mat_<GRY> ccg; converte(cc,ccg); imp(ccg,"cc.tga"); Mat_<GRY> ccb=binariza(ccg,255-100); { using namespace Morphology; ccb=ccb+Mat_<GRY>(5,5,255); } imp(ccb,"cc.png");
Mat_<FLT> ncc; matchTemplate(a,q,ncc,CV_TM_CCOEFF_NORMED); ncc=normaliza(modulo(ncc)); Mat_<GRY> nccg; converte(ncc,nccg); imp(nccg,"ncc.tga"); Mat_<GRY> nccb=binariza(nccg,255-50); { using namespace Morphology; nccb=nccb+Mat_<GRY>(5,5,255); } imp(nccb,"ncc.png");}

a.tga
q.tga
ncc.tga ncc.png
cc.tga cc.png
Usando NCC, o algoritmo achou corretamente os 4 ursos. Usando correlação cruzada, achou3 ursos (um falso negativo) e detectou um urso onde não tinha (um falso positivo). Isto nãopode ser consertado mudando o valor de threshold. O tamanho de saída de xcorr é menor poispegou-se só a parte válida da imagem de saída.

// ursinho.cpp pos-2011#include <cekeikon.h>int main(){ Mat_<FLT> a; le(a,"a.tga"); Mat_<FLT> q; le(q,"q.tga"); //mostra(a); mostra(q); Mat_<FLT> r; matchTemplate(a,q,r,CV_TM_CCOEFF_NORMED); r=abs(r); for (int l=0; l<r.rows; l++) for (int c=0; c<r.cols; c++) if (r(l,c)>0.9) r(l,c)=0.0; else r(l,c)=1.0; mostra(r);}
Nota: Quando usar NCC (ou matchTemplate com CV_TM_CCOEFF_NORMED) tem que to-mar cuidado com possíveis divisões por zero. Isto ocorre nas regiões com nível de cinza cons-tante. Nestas regiões, a saída terá um valor indefinida.
Há um algoritmo que permite calcular rapidamente NCC usando imagem integral[Lewis1995].

Exemplo: Queremos achar o padrão abaixo:
Neste padrão, o vermelho é exatamente (b,g,r)=(0,0,255), preto é exatamente (0,0,0) e brancoé exatamente (255,255,255). Este padrão foi impresso numa impressora jato de tinta e captu-rado por webcam.
Nesta imagem, um pixel vermelho é tipicamente (70,63,176), um pixel preto é tipicamente(84,61,54) e um pixel branco é tipicamente (192,161,173). Assim, não é possível detectar ascores pelo módulo da diferença ou quadrado da diferença. NCC pode ser usada para detectar opadrão mesmo neste caso.
Para imagem colorida, o manual de referência de OpenCV diz como calcular NCC: “In caseof a color image, template summation in the numerator and each sum in the denominator isdone over all of the channels and separate mean values are used for each channel. That is, thefunction can take a color template and a color image. The result will still be a single-channelimage, which is easier to analyze.”

Vamos analisar a função matchTemplate do OpenCV: (este assunto é abordado em tmatch-simp)
void matchTemplate(InputArray image, InputArray templ, OutputArray result, intmethod)
Esta função é uma rotina de template matching altamente otimizada. Esta função coloca o re-sultado da comparação de image com templ na posição do pixel do canto superior esquerdodo templ. A imagem de saída result é menor que image.
imageImage where the search is running. It should be 8-bit or 32-bit floating-point.
templSearched template; must be not greater than the source image and the same data type as the image.
resultA map of comparison results; single-channel 32-bit floating-point. If image is W×H andtempl is w×h then result must be W-w+1×H-h+1.
methodSpecifies the way the template must be compared with image regions (see below).
“Method” pode ser:
CV_TM_SQDIFF: Calcula soma da diferença quadrática. Pode ser útil para compararduas imagens artificiais. Dividir o resultado pelo número de pixels de templ (Q).
CV_TM_SQDIFF_NORMED: Não vejo utilidade
CV_TM_CCORR: Calcula cross correlation, sem subtrair média. Pode obter casa-mento de modelos invariante por brilho, fazendo Q=somaAbsDois(dcReject(Q)). Us-ado para detectar instâncias de alto contraste.
CV_TM_CCORR_NORMED: Não vejo utilidade.
CV_TM_CCOEFF: Não vejo utilidade. CV_TM_CCOEFF_NORMED: Calcula coeficiente de correlação normalizada, sub-
traindo média. Casamento de modelos invariante por brilho e contraste. Não precisafazer Q=somaAbsDois(dcReject(Q)). Usado para detectar instâncias pela forma, inde-pendente de contraste. Pode resultar em divisão por zero, se tiver regiões de nível decinza constante em A.
The function slides through image, compares the overlapped patches of size w×h againsttempl using the specified method and stores the comparison results in result. Here are the for-mulae for the available comparison methods (I denotes image, T template, R result). The sum-mation is done over template and/or the image patch: x′=0...w − 1, y′= 0...h − 1
method=CV_TM_SQDIFF:
R( x , y )=∑x'
∑y'
[T ( x' , y ' )−I ( x+x ' , y+ y ' ) ]2
method=CV_TM_CCORR:

R( x , y )=∑x'
∑y'
[T ( x' , y ' )⋅I ( x+x ' , y+ y ' )]
method=CV_TM_CCOEFF_NORMED:
R( x , y )=∑
x '
∑y'
[~T (x ' , y ' )⋅~I ( x+x ' , y+ y ' )]
√∑x
'
∑y
'
[~T ( x ' , y ' ))]2∑x
'
∑y
'
[~I ( x+x ' , y+ y ' ))]2
After the function finishes the comparison, the best matches can be found as global mini-mums (when CV_TM_SQDIFF was used) or maximums (when CV_TM_CCORR orCV_TM_CCOEFF was used) using the minMaxLoc() function. In case of a color image, tem-plate summation in the numerator and each sum in the denominator is done over all of thechannels and separate mean values are used for each channel. That is, the function can take acolor template and a color image. The result will still be a single-channel image, which is eas-ier to analyze.
A função matchTemplateSame do Cekeikon>= 5.08 gera saída P do mesmo tamanho que en-trada A. Esta função coloca o resultado da comparação de A com Q na posição do pixel cen-tral do Q.
Mat_<FLT> matchTemplateSame(Mat_<FLT> A, Mat_<FLT> Q, int method, FLT backg)
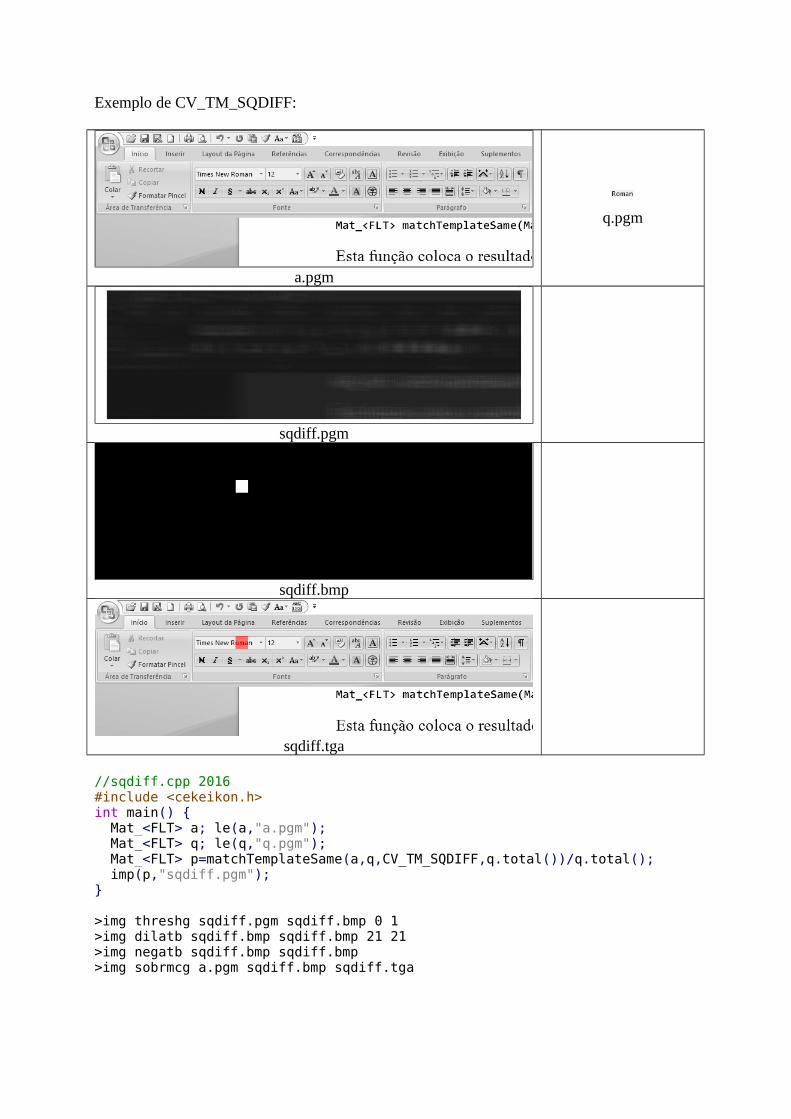
Exemplo de CV_TM_SQDIFF:
a.pgm
q.pgm
sqdiff.pgm
sqdiff.bmp
sqdiff.tga
//sqdiff.cpp 2016#include <cekeikon.h>int main() { Mat_<FLT> a; le(a,"a.pgm"); Mat_<FLT> q; le(q,"q.pgm"); Mat_<FLT> p=matchTemplateSame(a,q,CV_TM_SQDIFF,q.total())/q.total(); imp(p,"sqdiff.pgm");}
>img threshg sqdiff.pgm sqdiff.bmp 0 1>img dilatb sqdiff.bmp sqdiff.bmp 21 21>img negatb sqdiff.bmp sqdiff.bmp>img sobrmcg a.pgm sqdiff.bmp sqdiff.tga

Exemplo de CV_TM_CCOEFF_NORMED (coeficiente de correlação normalizada):
a.pgm
q.pgm
ccoeffn.pgm ccoeffn.tga
Defeito: Detectou mesmo o ursinho com muito pouco contraste.

Calculando o módulo (abs):
ccoeffna.pgm ccoeffna.tga
Detectou também os ursinhos com escuro/claro invertidos.Continua detectando o ursinho com baixíssimo contraste.
//ccoeffn.cpp 2016#include <cekeikon.h>int main() { Mat_<FLT> a; le(a,"a.pgm"); Mat_<FLT> q; le(q,"q.pgm"); Mat_<FLT> p=matchTemplateSame(a,q,CV_TM_CCOEFF_NORMED,0); imp(p,"ccoeffn.pgm"); p=abs(p); imp(p,"ccoeffna.pgm");} img threshg ccoeffn.pgm ccoeffn.bmp 240 255img dilatb ccoeffn.bmp ccoeffn.bmp 21 21img negatb ccoeffn.bmp ccoeffn.bmpimg sobrmcg a.pgm ccoeffn.bmp ccoeffn.tgaimg threshg ccoeffna.pgm ccoeffna.bmp 240 255img dilatb ccoeffna.bmp ccoeffna.bmp 21 21img negatb ccoeffna.bmp ccoeffna.bmpimg sobrmcg a.pgm ccoeffna.bmp ccoeffna.tga

Exemplo de CV_TM_CCORR (correlação cruzada não-normalizada):
a.pgm
q.pgm
ccorr.pgm ccorr.tgaDefeito: Detectou elipse de alto contraste como ursinho.
Calculando módulo:
ccorra.pfm ccorra.tgaDetectou cachorro e elipse como ursinho. Perdeu um ursinho.

//ccorr.cpp 2016#include <cekeikon.h>int main() { Mat_<FLT> a; le(a,"a.pgm"); Mat_<FLT> q; le(q,"q.pgm"); q=somaAbsDois(dcReject(q)); Mat_<FLT> p=matchTemplateSame(a,q,CV_TM_CCORR,0); imp(p,"ccorr.pgm"); p=abs(p); imp(p,"ccorra.pgm");}
img threshg ccorr.pgm ccorr.bmp 40 255img dilatb ccorr.bmp ccorr.bmp 21 21img negatb ccorr.bmp ccorr.bmpimg sobrmcg a.pgm ccorr.bmp ccorr.tgaimg threshg ccorra.pgm ccorra.bmp 40 255img dilatb ccorra.bmp ccorra.bmp 21 21img negatb ccorra.bmp ccorra.bmpimg sobrmcg a.pgm ccorra.bmp ccorra.tga
Para que serve este método (correlação cruzada não-normalizada)? Quando se deseja encon-trar padrões com alto contraste, pintados artificialmente.

Bibliografia para fast NCC:[Lewis1995] J.P. Lewis, “Fast normalized cross-correlation,” Vision Interface, pp. 120-123, 1995, url = "citeseer.ist.psu.edu/lewis95fast.html"
Bibliografia para detecção de rostos usando imagem integral:[Viola2004] P. Viola, M. J. Jones, “Robust Real-Time Face Detection,” International Journalof Computer Vision 57(2), 137–154, 2004.[Viola2001] P. Viola, M. J. Jones, “Rapid Object Detection using a Boosted Cascade of Sim-ple Features,” Conference on Computer Vision and Pattern Recognition, 2001.[Lienhart] R. Lienhart, J. Maydt, “An Extended Set of Haar-like Features for Rapid ObjectDetection,” Int. Conf. on Image Processing, 2002.

SPOMF
[a ser preenchido]

Aceleração de template matching usando FFT
Por que a função matchTemplate de OpenCV é tão rápido? Por que usa FFT. Vamos vercomo é possível acelerar template matching nos três casos:
1) method=CV_TM_CCORR (cross correlation)
R( x , y )=∑x' , y'
[T ( x ' , y ' )⋅I (x+x ' , y+ y ' )]
Para calcular rapidamente cross correlation, basta usar o Teorema da Convolução. A grossomodo, calcula-se FFT de T e I, multiplica ponto a ponto no domínio da frequência, e calculaIFFT da matriz complexa resultante. Há vários detalhes a serem levados em conta na imple-mentação.
2) method=CV_TM_SQDIFF (squared difference)
R( x , y )=∑x' , y'
[T ( x ' , y ' )−I ( x+x ' , y+ y ' ) ]2
R( x , y )=∑x' , y'
T 2( x ' , y ' )+∑x' , y'
I 2( x+x ' , y+ y ' )−2∑x' , y'
T ( x ' , y ' )⋅I ( x+x ' , y+ y ' )
O primeiro termo pode ser calculado uma única vez no pré-processamento.O segundo termo pode ser calculado rapidamente pela imagem integral (ou algum outro méto-do para acelerar o cálculo de média móvel) de I2.O terceiro termo pode ser calculado rapidamente usando FFT pelo Teorema da Convolução.

3) method=CV_TM_CCOEFF_NORMED (normalized correlation coefficient)
R( x , y )=∑
x '
∑y'
[~T (x ' , y ' )⋅~I ( x+x ' , y+ y ' )]
√∑x
'
∑y
'
[~T ( x ' , y ' ))]2∑x
'
∑y
'
[~I ( x+x ' , y+ y ' ) )]2
Os dois últimos termos podem ser calculados rapidamente respectivamente pela imagem inte-gral de f2 e pela imagem integral de f. Em vez de imagem integral, serve algum outro métodopara acelerar o cálculo de média móvel.


















