
TDC2017 | POA Trilha Programacao Funicional - (Nunca) Ouvi falar de Rust... mas como faço um site?
Upload
ambiente-livreCategory
view
466download
2
Misturando Dados com Pentaho para Insights mais significativos!
Trilha: Big DataPalestrante: Marcio Junior VieiraCEO e Data Scientist na Ambiente [email protected]

Marcio Junior Vieira
● 17 anos de experiência em informática, vivência em desenvolvimento e análise de sistemas de Gestão empresarial e Analise de Dados.
● Trabalhando com Free Software e Open Source desde 2000 com serviços de consultoria e treinamento.
● Graduado em Tecnologia em Informática(2004) e pós-graduado em Software Livre(2005) ambos pela UFPR.
● Palestrante FLOSS em: CONISLI, SOLISC, FISL, LATINOWARE, SFD, JDBR, Campus Party, Pentaho Day, TDC.
● Organizador Geral do Pentaho Day 2017,2015 e apoio nas edições 2013 e 2014.
● CEO da Ambiente Livre.● Data Scientist, Instrutor e Consultor de Big Data com tecnologias abertas.

Nosso Ecossistema

Algumas informações
● Não confundir Misturar com “Ofuscar Dados”● Misturar no contexto de Mesclar!● Vamos programar através de muitos
componentes prontos, mas não se preocupe temos como codificar muitas vezes por prazer :)

O V do Valor
● V que torna Big Data relevante: tudo bem ter acesso a uma quantidade massiva de informação a cada segundo, mas isso não adianta nada se não puder gerar valor.
● É importante que empresas entrem no negócio do Big Data, mas é sempre importante lembrar dos custos e benefícios e tentar agregar valor ao que se está fazendo.

Desafios em misturar dados
● Conhecer diversas tecnologias ( HDFS, Mapreduce, Spark, Pig, Java, Shell , Amazon AWS, NoSQL, Hashmap, etc) .
● Conhecer diversos formatos ( JSON, XML, CSV, HL7, YAML, ESRI, RSS, Serialized)
● Conhecer diversas APIs (Google Maps, Google Analytics Twitter, etc) .
● Conhecer diversas linguagens de consulta (CQL, SQL, MDX, CMIS, HiveQL, MQL, Table Scan )
● Acessos incorretos ou com baixo conhecimento podem acarretar em performance
● Governança de dados e SOX ( Quem pode, Quando pode , Quando fez).


Desafio dos Dados
● Dados Inconsistentes (Ex. Campo sexo tem valor M, F, X , Z, H, 1, ?, null ou vazio )
● Regras de Relacionamento Complexas ( Ex. É cliente “master” se comprou produto tal na loja tal no período tal junto com produto tal e choveu no dia! )
● Tipos de Dados Distintos para mesma informação ( ex. String X Int X Float )
● Dados Faltantes ou incompletos (Ex. Campo sexo tem valor null ou vazio )
● Os famosos “de → para”● Tratamento dos Dados gerais dos dados o T do ETL ( transformations )● O desafio dos 5 V do Big Data!

Capturar Dados
● Dados Abertos● Parcerias (Cartões de crédito, lojas, sites, Waze, etc)● Rastreamento Web (Crawler, Spiders, Robot, Scutter)● Redes Sociais e Web Sites.● IOT Plataforms● Tradicionais Databases corporativos (ERP, CRM, CDRs,
E-Commerce, etc)● E-mails, Documentos

Armazenamento
● Antes de tratar já armazene sua fonte original!● Amazon S3, Hadoop HDFS, Amazon EMR,
Data Lake, etc.● Armazene dado tratado.● Espaço e barato $! , processamento e
indisponibilidade é caro $$$$!
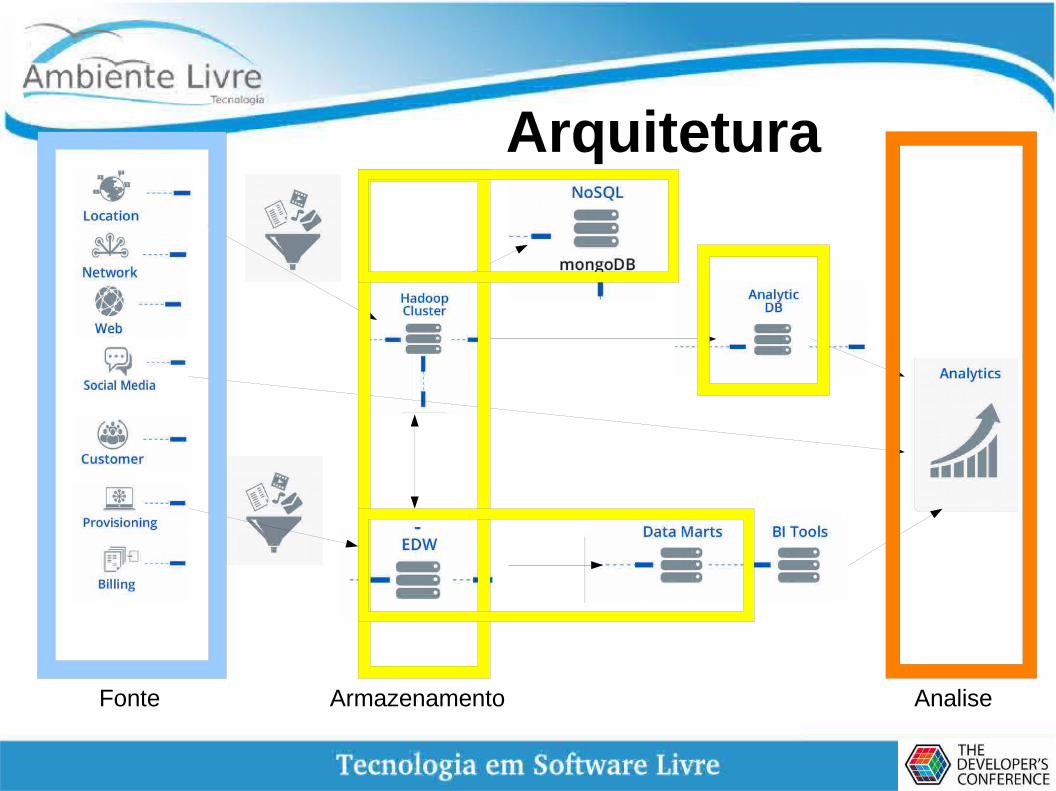
Arquitetura
Fonte Armazenamento Analise

Insights Significativos (Ex. Saúde)
● Dados Climáticos (Dados externos - API )● Histórico de medicamentos consumidos (Compras em farmácias ou prontuários
– CSVs mensal )● Histórico de Parentes ( Documentos Digitalizados, OCR )● Histórico de procedimentos (Plano de Saúde – databases “atenção as normas
e leis” , HL7 Internacional )● Consumo em Redes de Varejo (Cartão Fidelidade – API Rest ) ● Medições com Apps de Saúde e Atividades Físicas (Rest/Apis ) ● Medições de atividades físicas e de saúde com IOT (logs/stores locais e
sincronia com nuvens)● Dados Geo Referenciados, Rotas ( Waze, GMaps, Shapes, etc)● Dados Espaciais de Satélites e Sensores ( Nasa, AEB, INPE, Monitoramento
de Desastres )
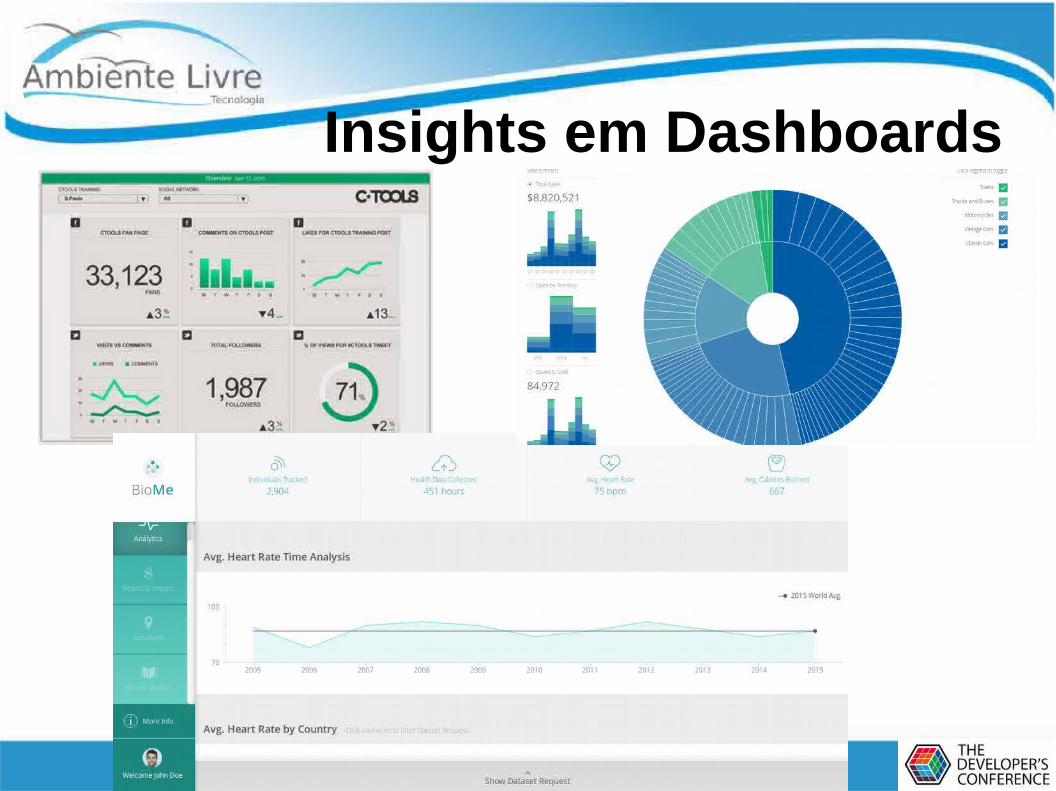
Insights em Dashboards

Equipe envolvida● 1 Dev MongoDB● 1 Dev Java / MapReduce● 1 Dev Cassandra● 1 Dev Sales Force, SuiteCRM● 2 Consultor do ERP (RH, Finan ) ● 1 Dev Front-End (Gráficos)● 1 WebDesigner● 3 DBAs (Oracle, MSSQL, PostgreSQL)● 1 Dev ElasticSearch● 1 Dev Spark com escala● 1 Analista de Negócio● 1 Estatístico● 1 Arquiteto de Soluções● 1 Gerente de projetos
Como nasce um Mito
Reunião do RH
Gerencia deProjetos
e Administradores
Data Scientist

Pentaho
● Plataforma completa para Business Intelligence e Business Analytics e Big Data Analytics.
● ETL, Reporting, Data Mining, OLAP e Dashbards.
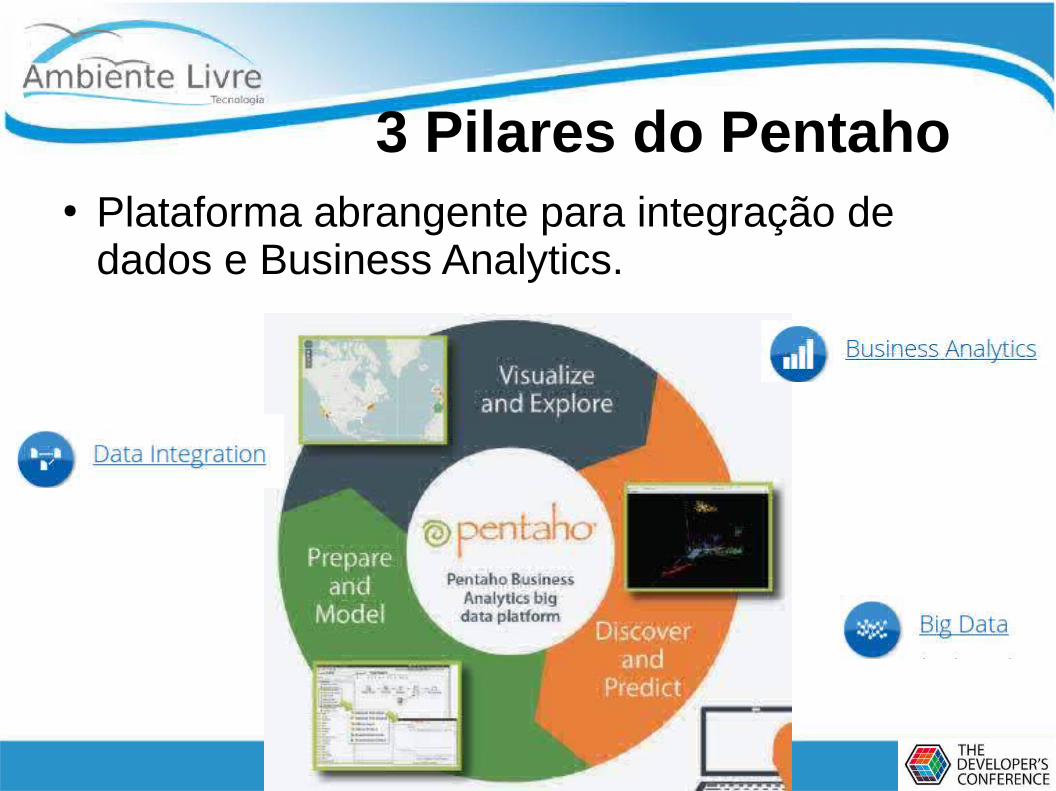
3 Pilares do Pentaho● Plataforma abrangente para integração de
dados e Business Analytics.

Pentaho Data Integration
● Ferramenta completa de ETL● “Programação e Fluxo Visual”● Aproximadamente 350 steps diferentes
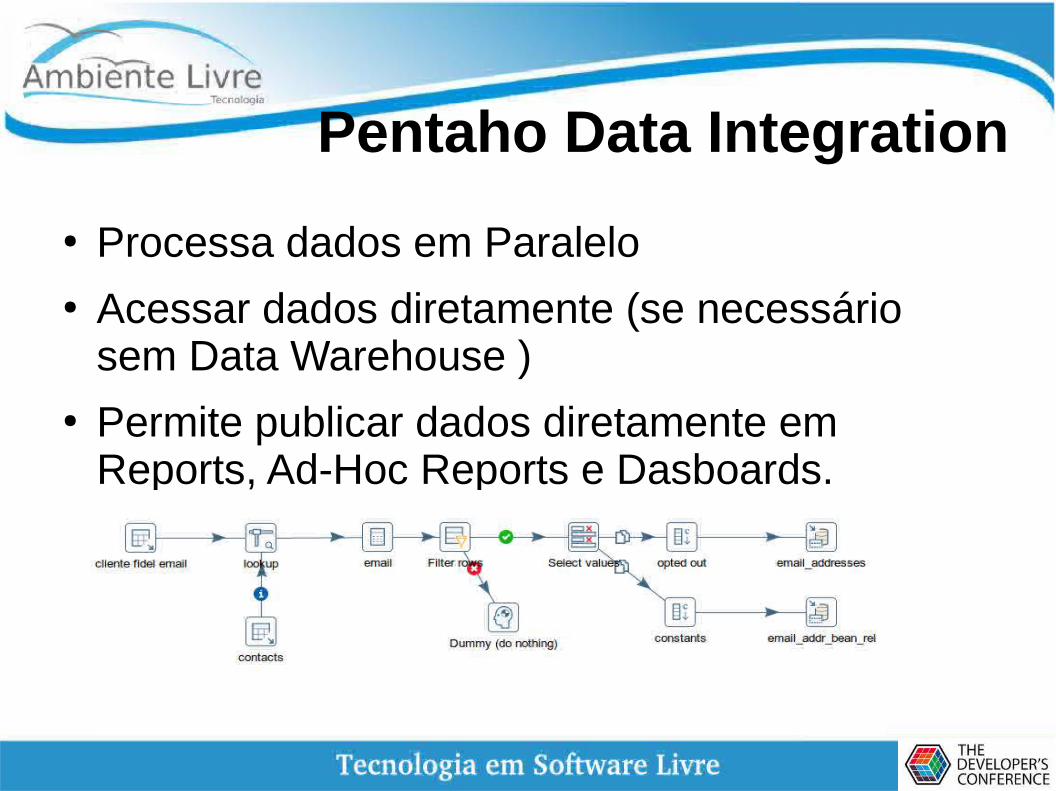
Pentaho Data Integration
● Processa dados em Paralelo● Acessar dados diretamente (se necessário
sem Data Warehouse )● Permite publicar dados diretamente em
Reports, Ad-Hoc Reports e Dasboards.

PDI Debuggers
● Previews de dados ● Tratamento de fluxos por erros ou condições● Geração de logs de erros● Break points

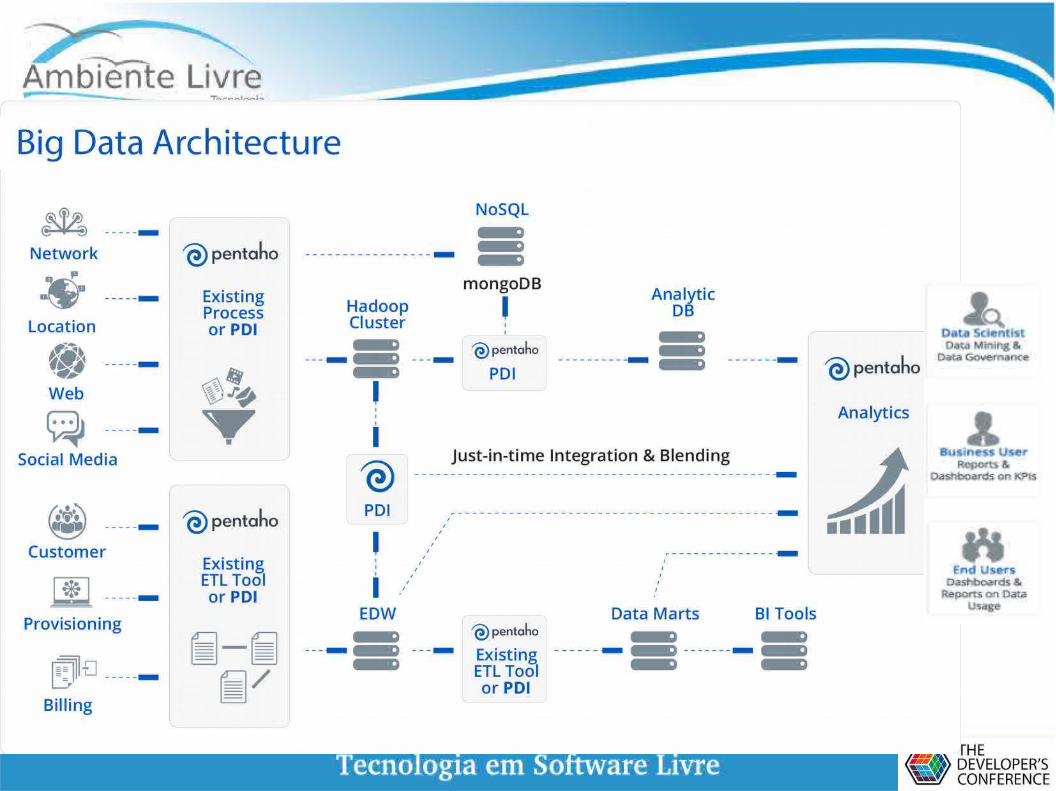
Integração ampla e adaptável de Big Data
● Conexões nativas e camada adaptável de Big Data e acesso funcionalidades dos populares big data stores.
● Capacidade de acessar dados, processá-los, combiná-los e consumi-los em qualquer lugar.
● Flexibilidade, isolamento das mudanças no ecossistema de dados
● Suporte a distros Hadoop (Cloudera, Hortonworks, MapR e Amazon)
● Acessar dados para preparação via SQL no Spark e orquestrar aplicativos Spark (Scala, Java e Python)
● Integração com NoSQL stores, incluindo MongoDB e Cassandra
● Conectividade a BDs analíticos (Vertica, Redshift, SAP HANA , etc.
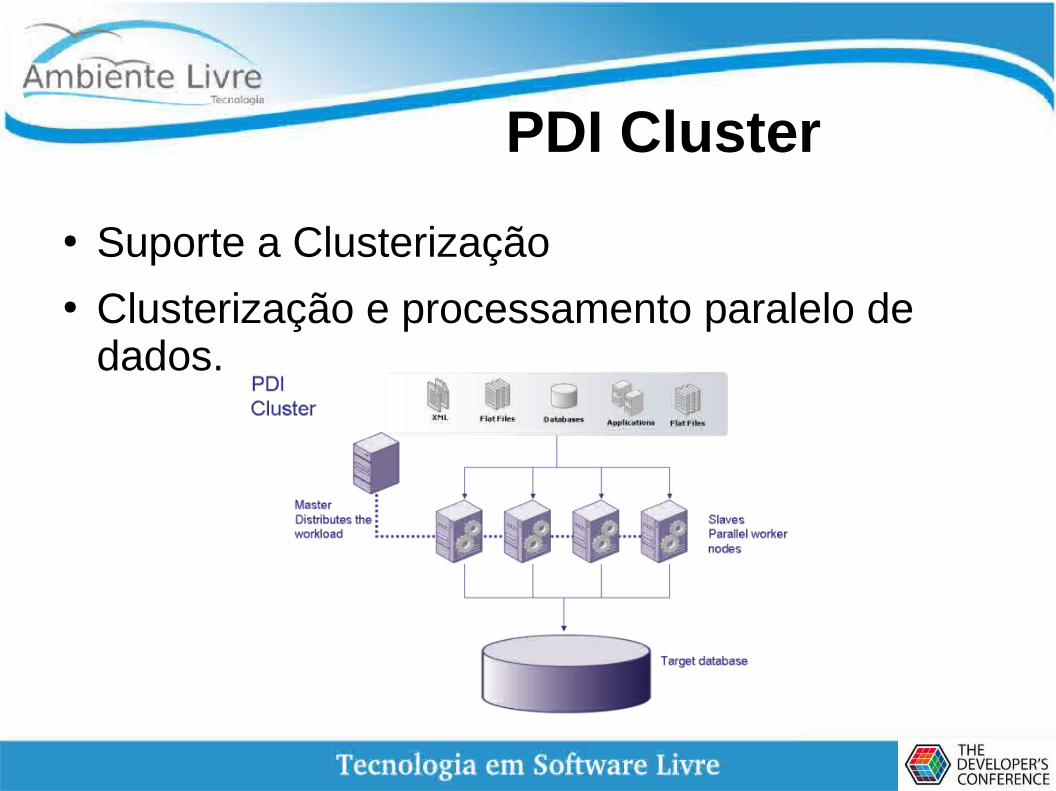
PDI Cluster
● Suporte a Clusterização● Clusterização e processamento paralelo de
dados.
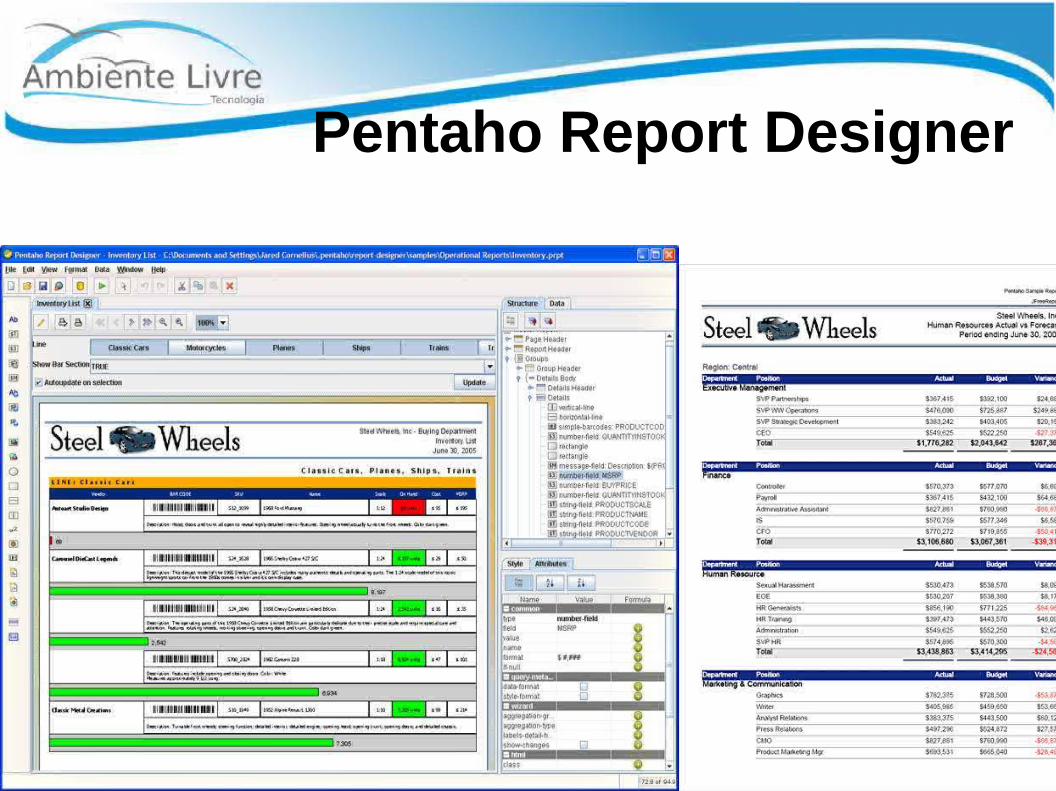
Pentaho Report Designer

Pentaho Report Designer
● Visualização Web ou Embed.● Assistente de geração de relatórios● Amplo suporte de fonte de dados, incluindo
relacionais, OLAP, XML e Pentaho Analysis, arquivos flat, objetos Java e ...
● Big Data Reports ( integra-se com PDI )
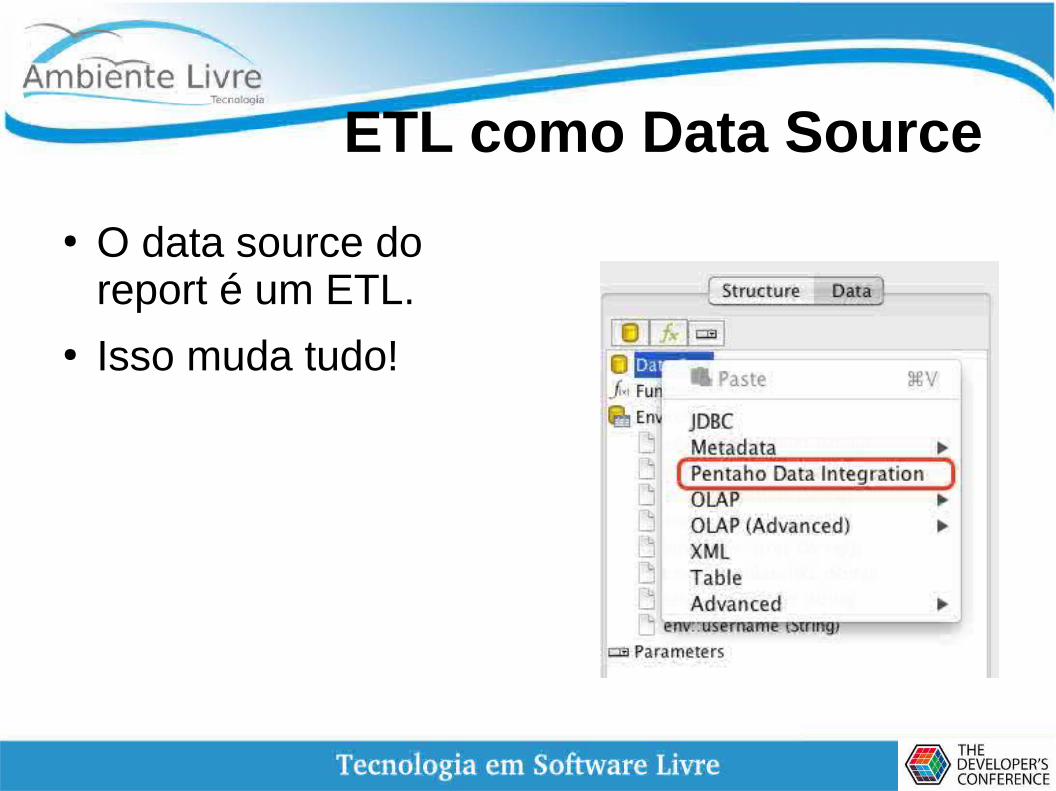
ETL como Data Source
● O data source do report é um ETL.
● Isso muda tudo!

Exemplo de dados do Twitter Report
● Libere na API acesso● Crie seu ETL no PDI ( Pentaho Data
Integration )● Defina onde quer os dados ( database,
hadoop, Report ou dashboard )

CTools - Dashboards
● CTools – Tem um conjunto de Ferramentas para Desenvolvimento de Dashboars
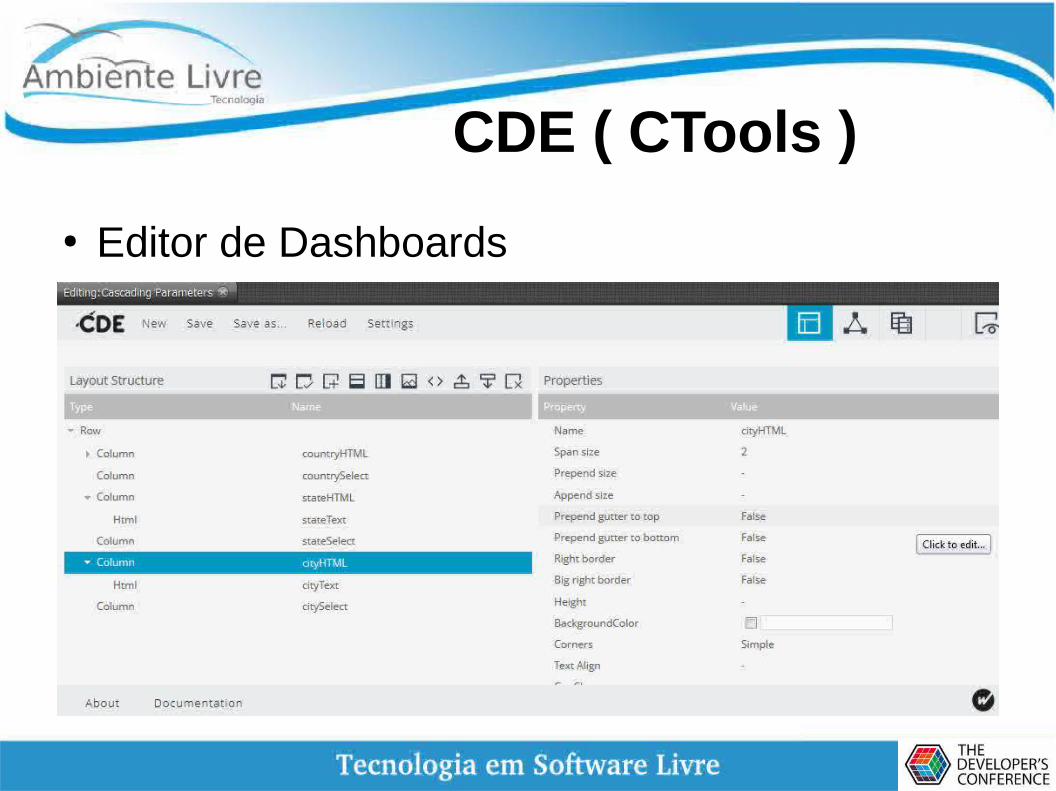
CDE ( CTools )
● Editor de Dashboards
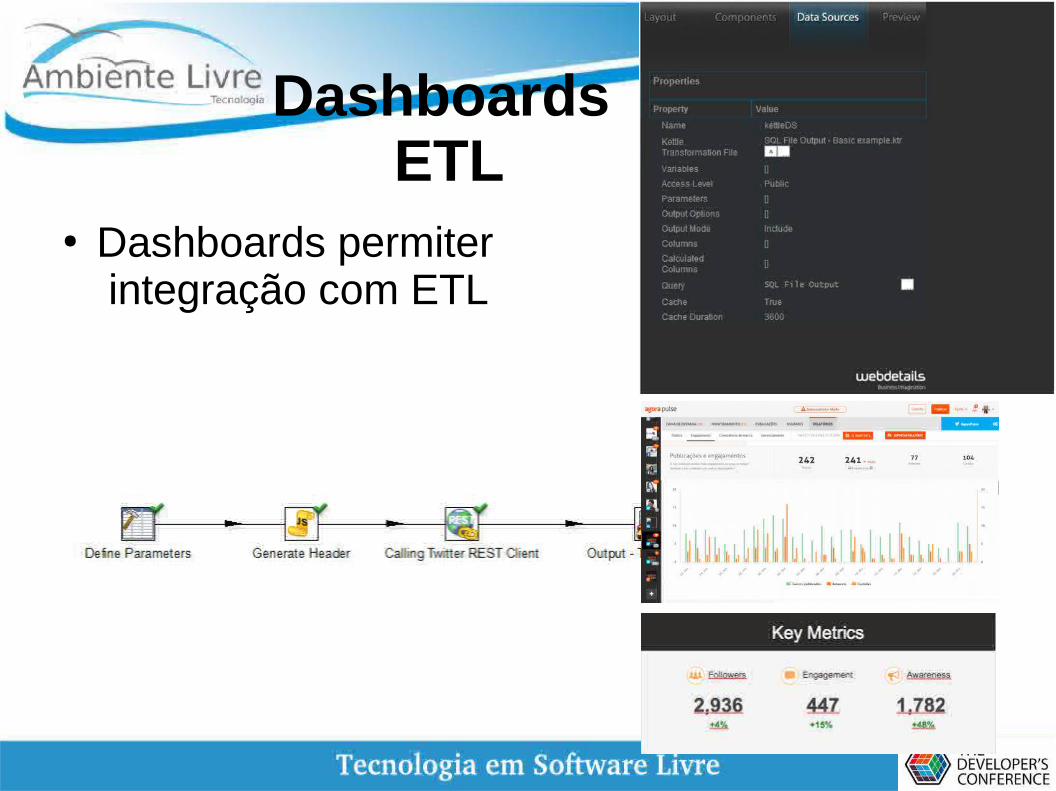
Dashboards ETL
● Dashboards permiter integração com ETL

ETL para datasets D3.js
http://romsson.github.io/dragit/example/nations.html
https://bl.ocks.org/mbostock/1136236
http://bl.ocks.org/brattonc/5e5ce9beee483220e2f6

Pentaho Sparkl
● Fremawork que usa o PDI como “fonte”● App Builder que permite desenvolver plugins de
Big Data Analytics e outros em alguns passos.● Menus = Dados● Campos = metaDados● Botão = Dispara Serviço● Filtros = Lista Dados● Todos mais faça JS/Jquery :)
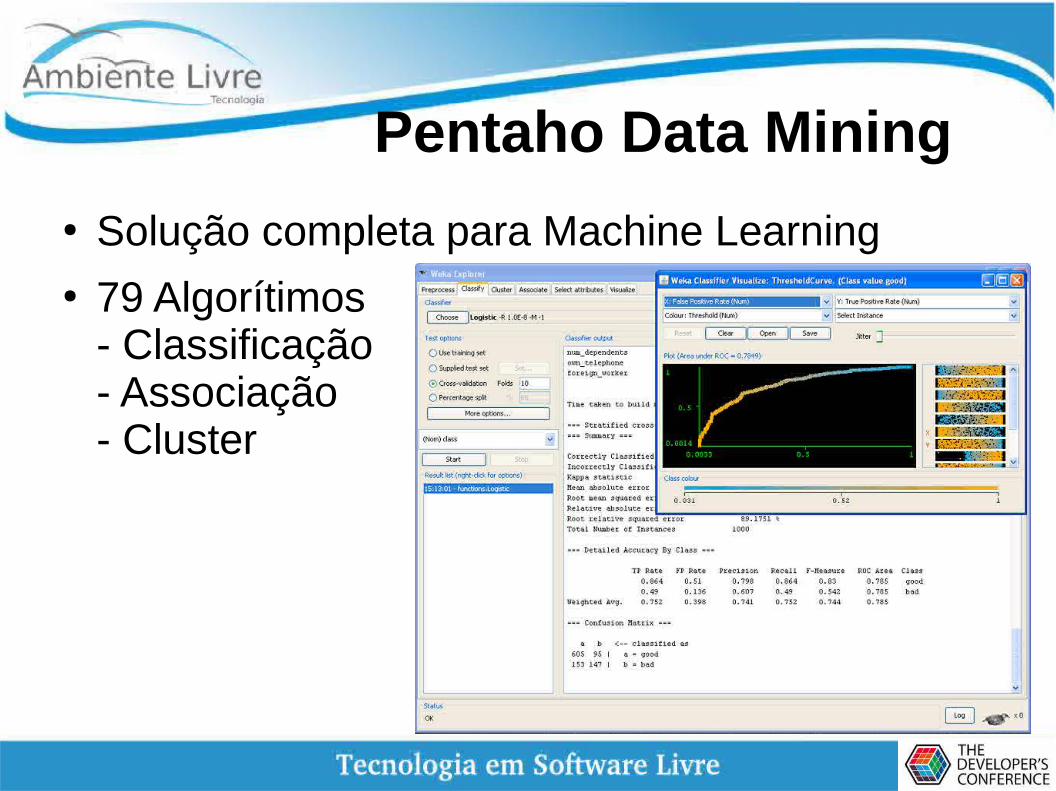
Pentaho Data Mining
● Solução completa para Machine Learning● 79 Algorítimos
- Classificação- Associação- Cluster

ETL com Data Mining
● Novamente o PDI se integra,e pode fazer analise de sentimento com os posts do twitter!
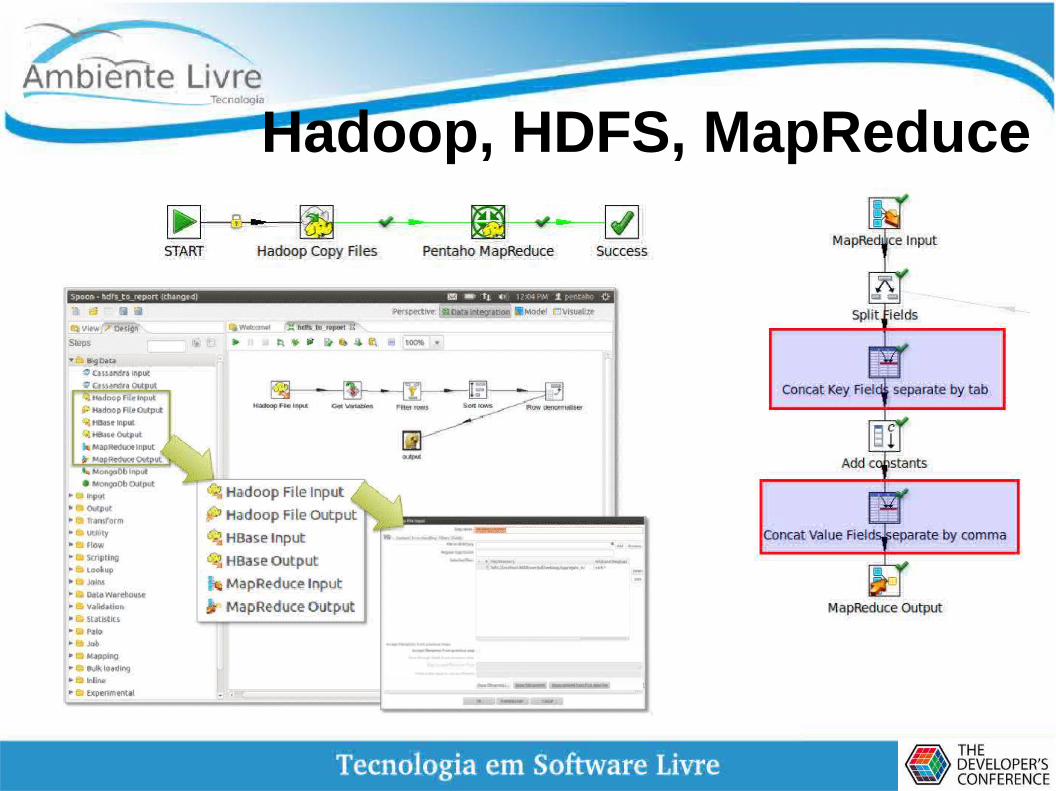
Hadoop, HDFS, MapReduce
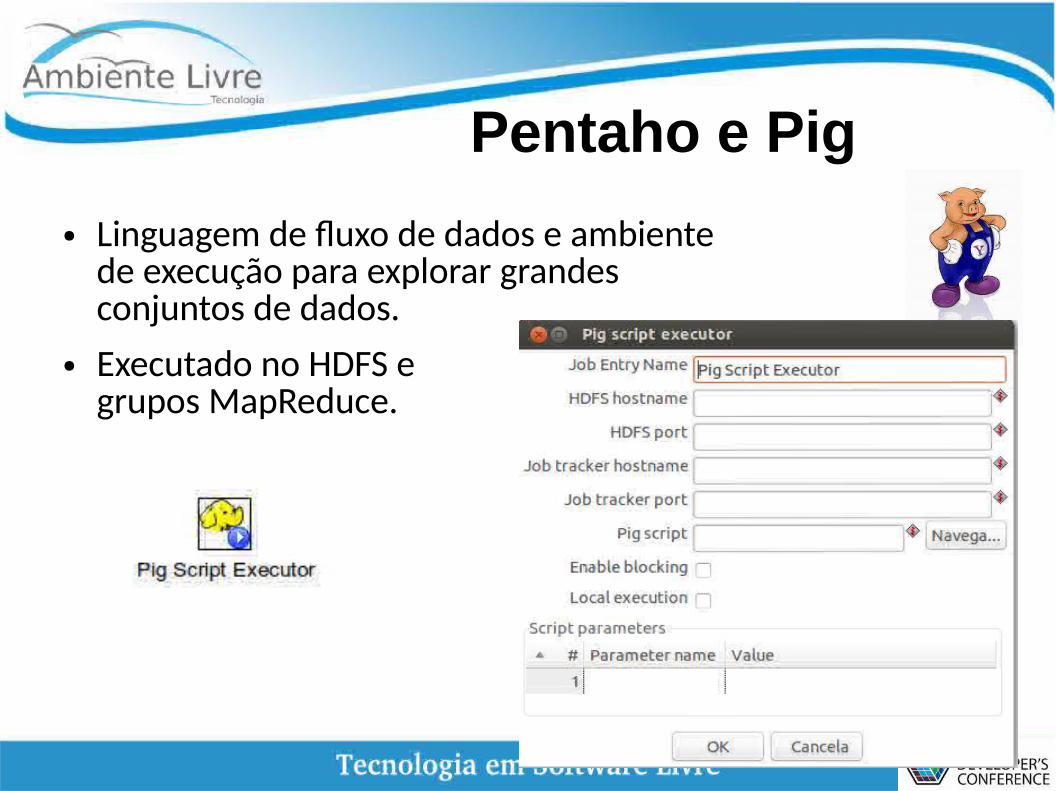
Pentaho e Pig
● Linguagem de fluxo de dados e ambiente de execução para explorar grandes conjuntos de dados.
● Executado no HDFS e grupos MapReduce.
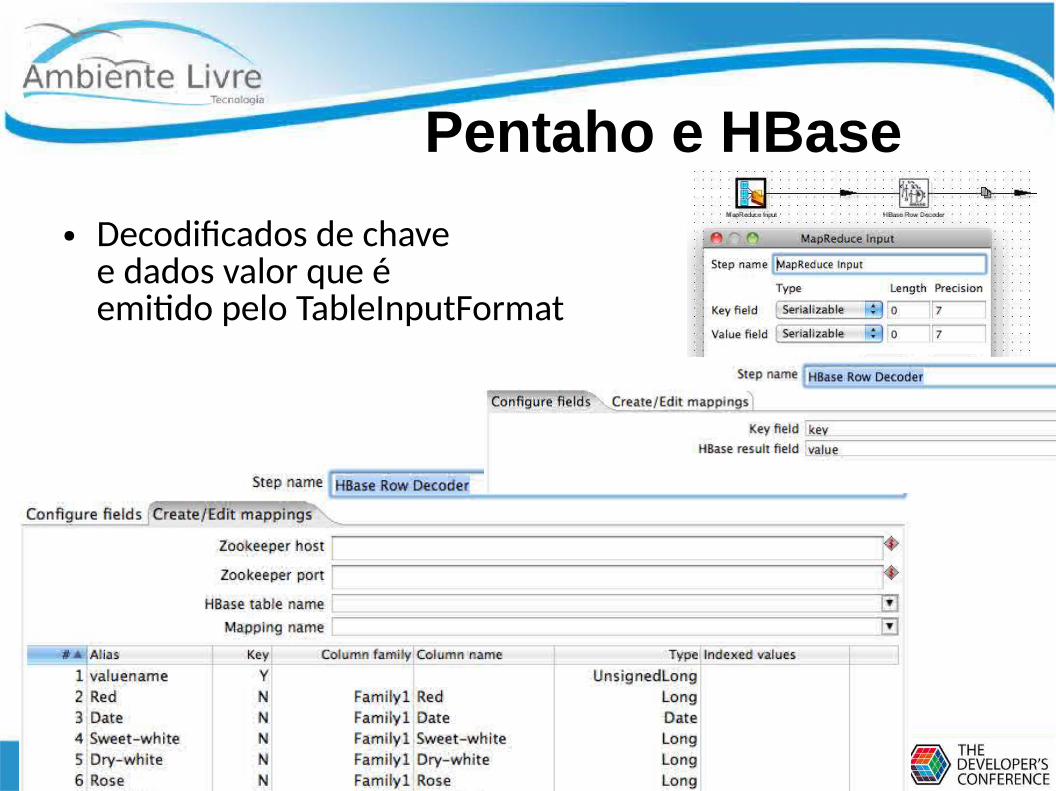
Pentaho e HBase
● Decodificados de chave e dados valor que é emitido pelo TableInputFormat
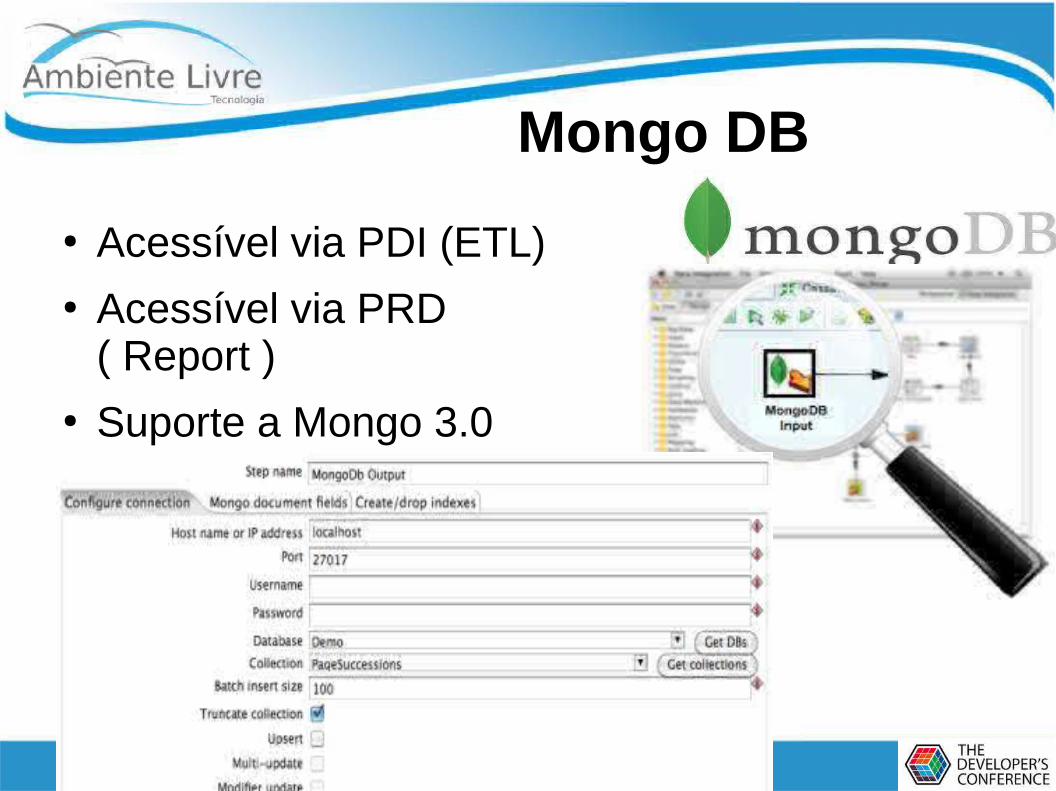
Mongo DB
● Acessível via PDI (ETL)● Acessível via PRD
( Report )● Suporte a Mongo 3.0
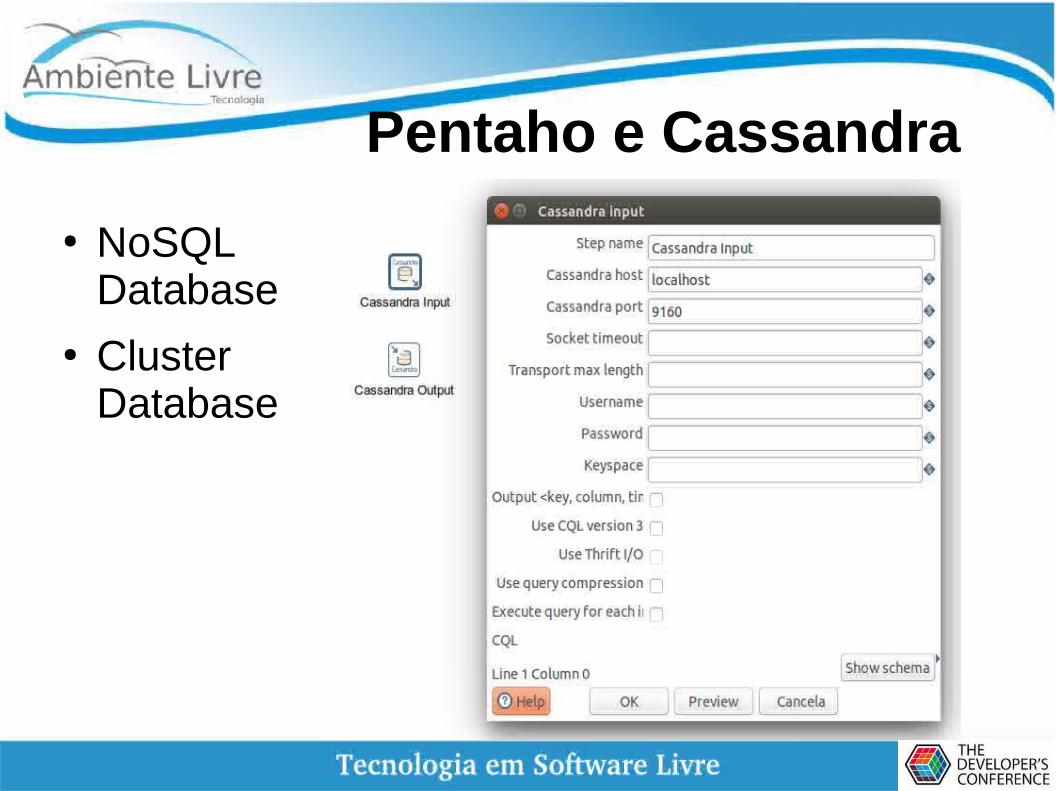
Pentaho e Cassandra
● NoSQL Database
● Cluster Database
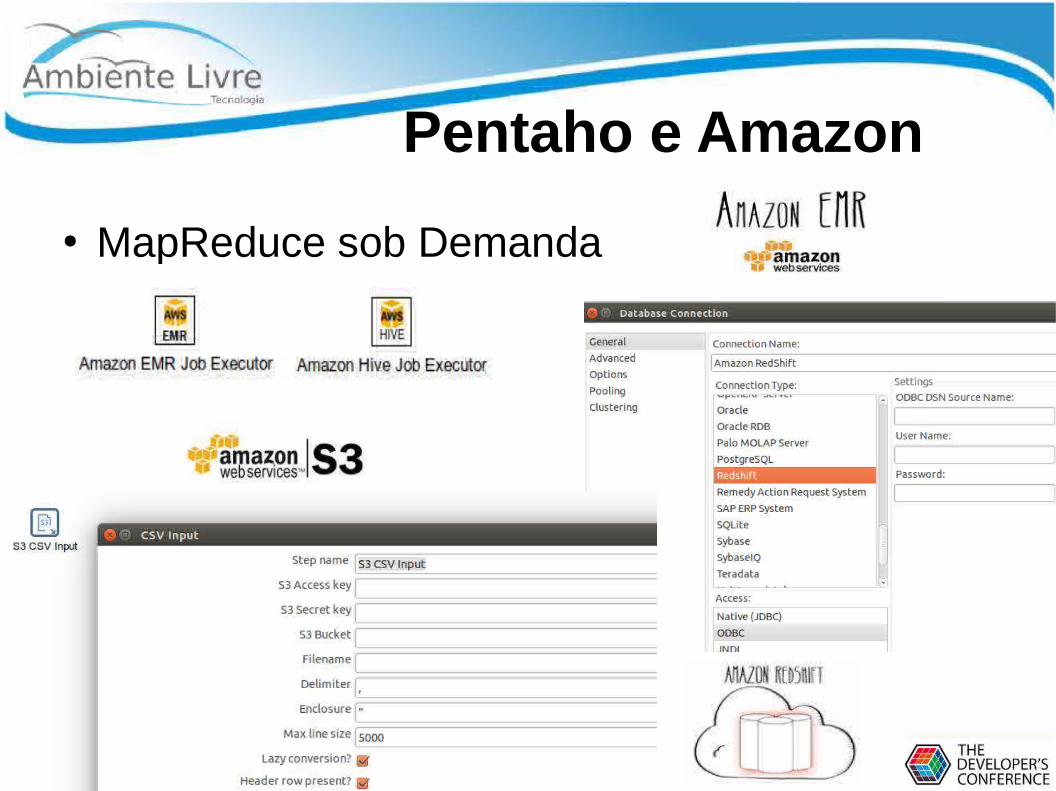
Pentaho e Amazon
● MapReduce sob Demanda●
●
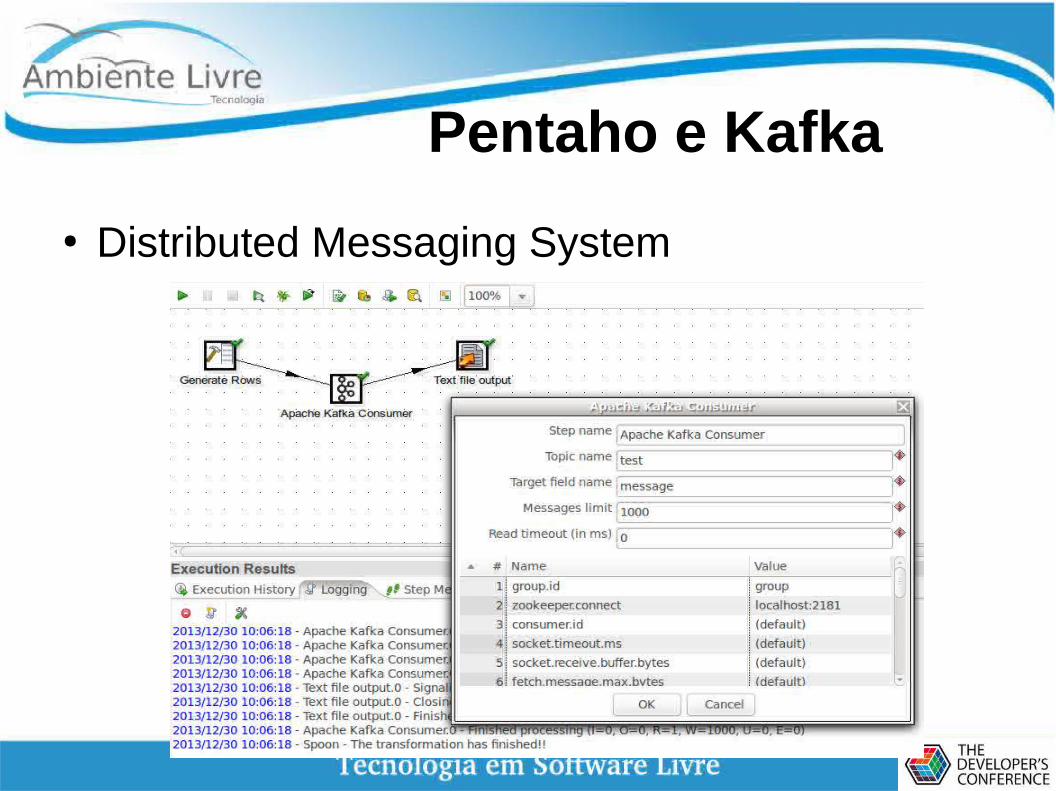
Pentaho e Kafka
● Distributed Messaging System
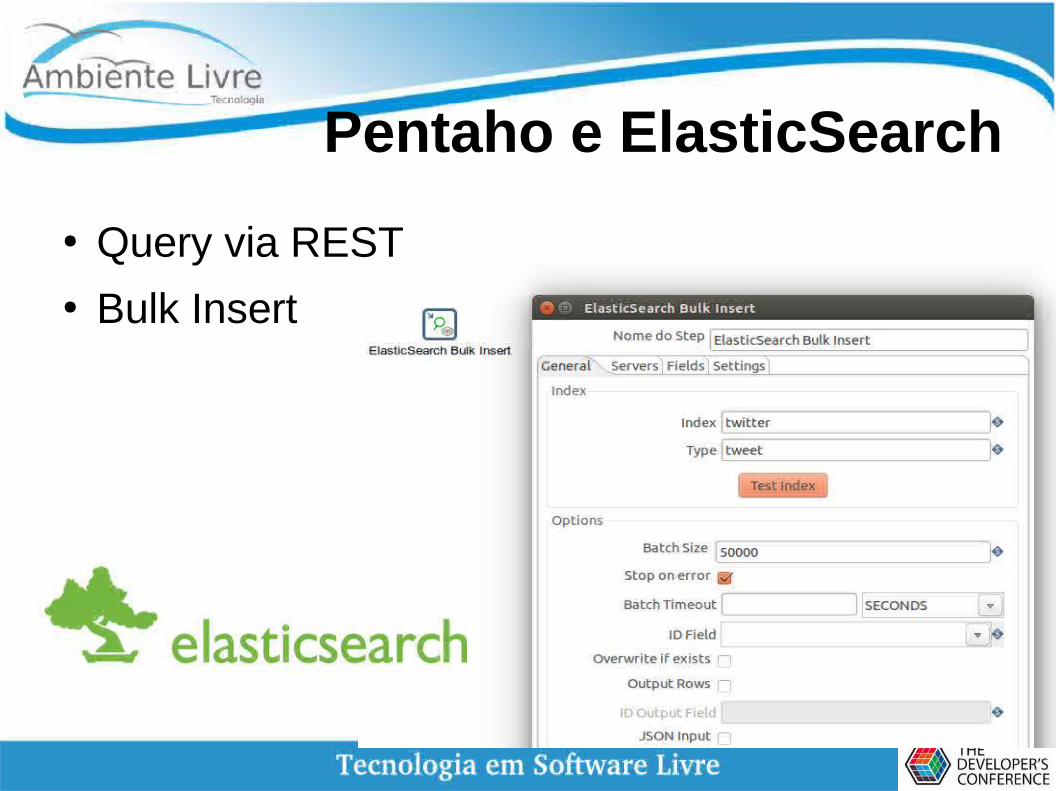
Pentaho e ElasticSearch
● Query via REST● Bulk Insert
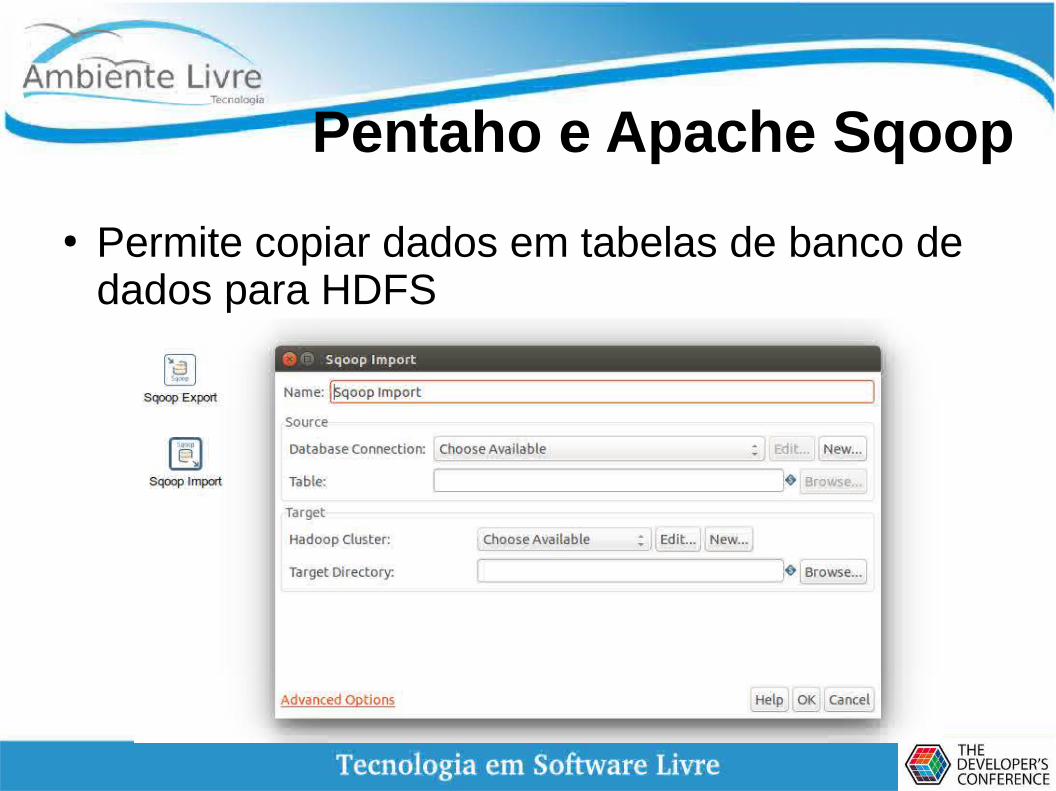
Pentaho e Apache Sqoop
● Permite copiar dados em tabelas de banco de dados para HDFS
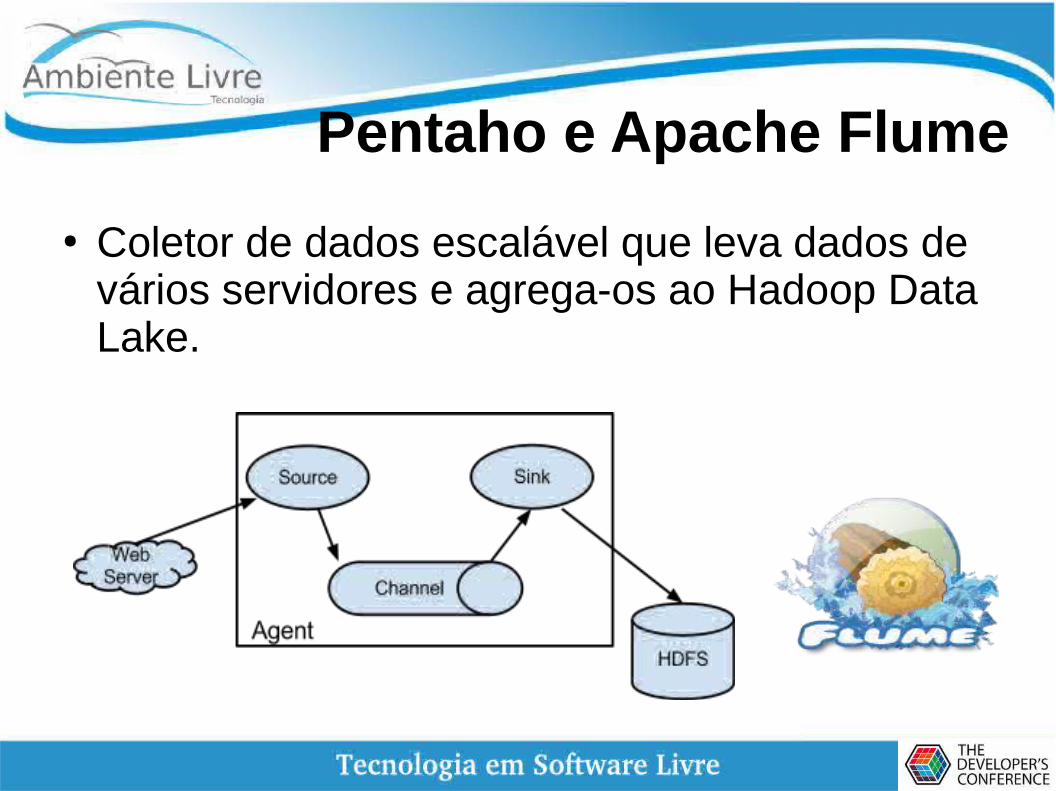
Pentaho e Apache Flume
● Coletor de dados escalável que leva dados de vários servidores e agrega-os ao Hadoop Data Lake.

Pentaho e Storm
● Distributed real-time computation system● https://github.com/pentaho/kettle-storm ●
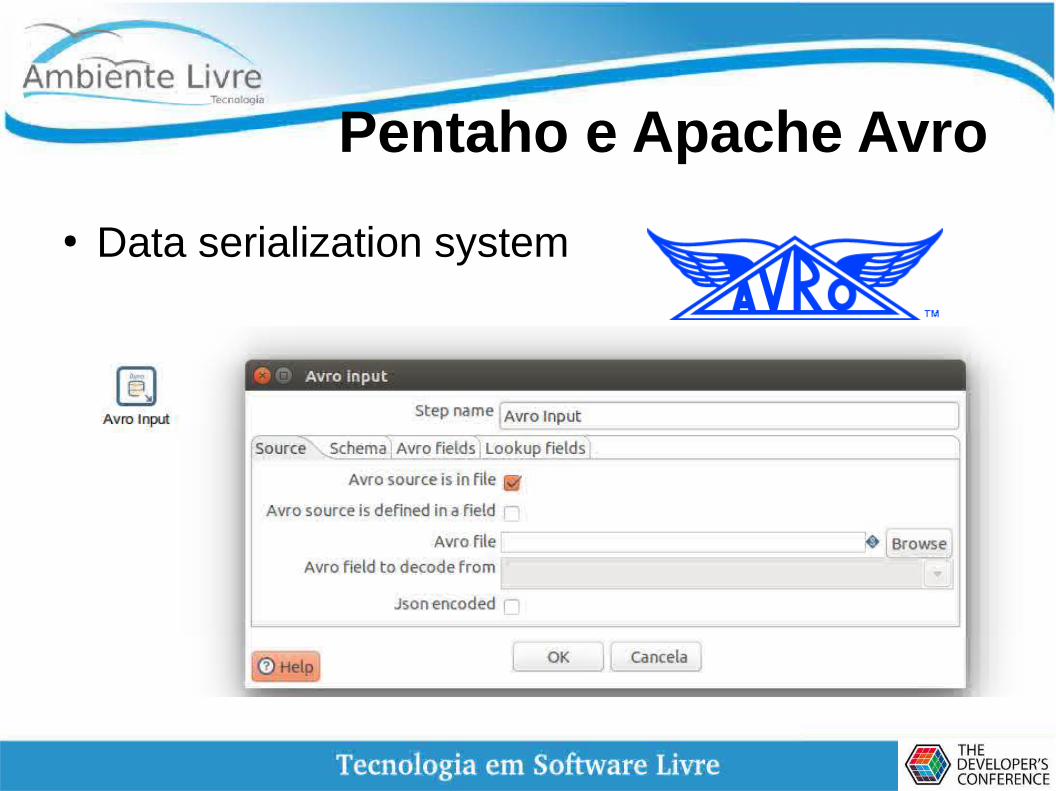
Pentaho e Apache Avro
● Data serialization system

Pentaho com Spark
● Spark é um mecanismo de processamento na memória que podem ser agrupados / escalado usando Hadoop.
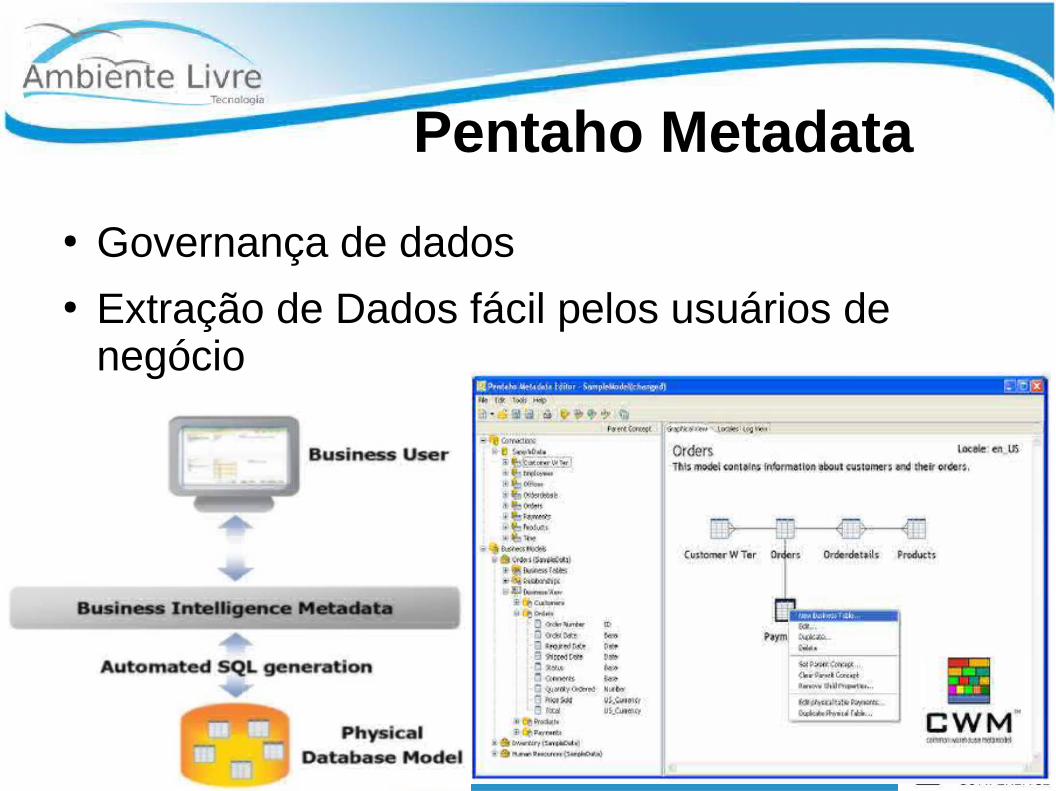
Pentaho Metadata
● Governança de dados● Extração de Dados fácil pelos usuários de
negócio●
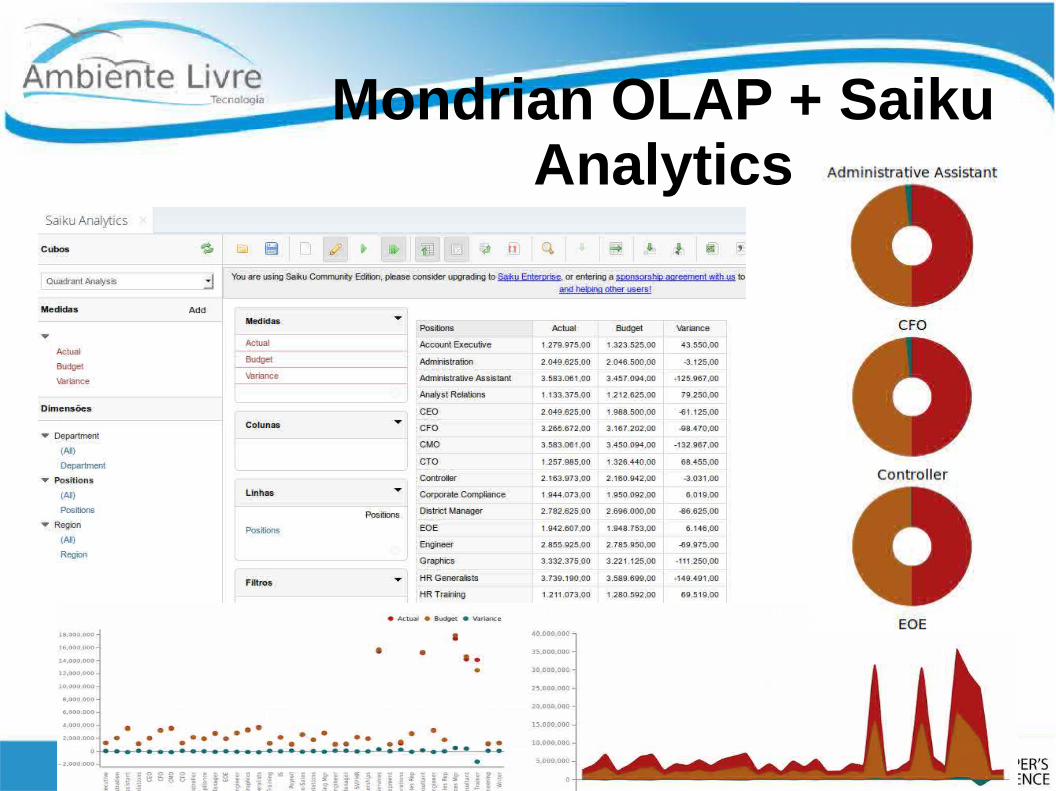
Mondrian OLAP + Saiku Analytics
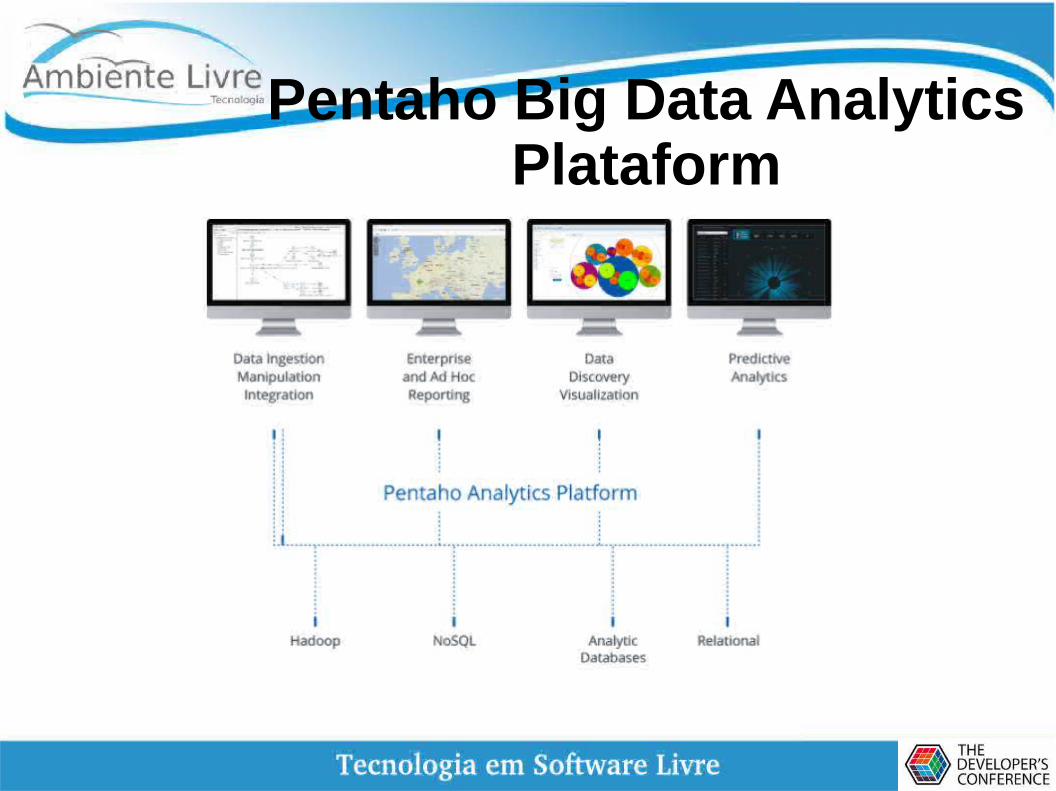
Pentaho Big Data Analytics Plataform

Vantagens
● Integração de dados fortemente acoplada e plataforma de análise de negócios acelerando a realização do valor de dados misturados.
● Conjunto de análises: acesso e integração de dados à visualização de dados e análise preditiva.
● Permite aos usuários arquivar grandes misturas de dados na fonte e enviá-las diretamente para análises mais completas e precisas
● Capacidade de detectar dados online com acesso imediato a análises, incluindo gráficos, visualizações e relatórios, a partir de qualquer etapa da preparação de dados
● Suporta amplo espectro de fontes de Big Data, aproveitando as capacidades específicas e exclusivas de cada tecnologia.
● A arquitetura aberta e baseada em padrões torna fácil integrar ou estender a infra-estrutura existente.

Tempo de Dev com Hadoop
● O Uso de Pentaho em projetos com Hadoop e Big Data pode diminuir em 15x o tempo do Projeto.
Codificação Java ETL com Pentaho
X

Magic Quadrant for BI & Analytics Platforms

Comunidade Brasileira

Comunidade Brasileira● Maior comunidade do Mundo!● Lista de Discussão com + de 1900 membros● Organiza a 6 anos o Pentaho Day Brasil● Composta por desenvolvedores, usuários , empresas e
acadêmia.● Utilizado em mais de 185 países.● +10.000 Produtos desenvolvidos sobre a plataforma Pentaho. ● + 4 milhões de Downloads● Em 2015 +- 60.000 downloads dia

Contatos e Convite!
● Pentaho Day 2017 em Curitiba● 39 palestrantes● 35 palestras ( 2 internacionais)● 11 minicursos● http://pentahobrasil.com.br● Contatos ● marcio @ ambientelivre.com.br ● @ambientelivre / @marciojvieira / Linkedin● blogs.ambientelivre.com.br/marcio● Facebook/ambientelivre


















