
Sobre o Impacto do Uso de Rastros de Execução em ...
14
Sobre o Impacto do Uso de Rastros de Execução em Atividades de Manutenção de Software Raquel Lafetá 1 , Marcelo Maia 1 1 Faculdade de Computação, Universidade Federal de Uberlândia, Av. João Naves de Ávila, 2121. Bloco B. 38400-902 Uberlândia, Minas Gerais, Brazil [email protected], [email protected] Resumo. É reconhecido que a tarefa de compreensão de software requer um esforço significativo durante a execução de tarefas de manutenção. Diversas alternativas têm sido propostas para amenizar este esforço. Entretanto, ainda não existe nenhuma alternativa que seja amplamente reconhecida para ser usada em um contexto geral. Informações extraídas de rastros de execução vêm sendo bastante utilizadas como alternativas para facilitar a compreensão de características dos programas. O presente estudo pretende contribuir com a avaliação do impacto do uso de informações de rastros de execução em atividades de manutenção de software. Este estudo mostra benefícios do uso sistemático de informação de rastros de execução na diminuição do tempo de execução e no aumento da taxa de correção na procura de informação durante atividades de manutenção de software. Entretanto, este estudo também revela alguns desafios para aplicação desta abordagem em larga escala. Palavras Chave: localização de características, análise dinâmica, rastros de execução e compreensão de sistemas. 1 Introdução Nos anos 70, Lehman estabeleceu leis, ou hipóteses empíricas, que sugerem que qualquer software que seja usado regularmente deve passar por modificações contínuas para satisfazer seus usuários [4]. De fato, até os dias atuais é amplamente reconhecido que a modificação é uma necessidade inerente à grande parte do software existente. Os desenvolvedores responsáveis por modificações sejam elas, corretivas, adaptativas, evolutivas ou preventivas tem a necessidade de compreender o código, o qual possivelmente não foi escrito por eles. Assim, antes de executar uma modificação, desenvolvedores devem explorar o código fonte do sistema, achar e entender um subconjunto de estruturas e o comportamento do programa que é relevante à modificação proposta. Quanto maior é o sistema em avaliação e maiores são as pressões normais do ambiente de desenvolvimento, tanto maior será o nível de dificuldade colocado para os desenvolvedores [9].
Transcript of Sobre o Impacto do Uso de Rastros de Execução em ...

Sobre o Impacto do Uso de Rastros de Execução em
Atividades de Manutenção de Software
Raquel Lafetá1 , Marcelo Maia1
1 Faculdade de Computação, Universidade Federal de Uberlândia,
Av. João Naves de Ávila, 2121. Bloco B.
38400-902 Uberlândia, Minas Gerais, Brazil
[email protected], [email protected]
Resumo. É reconhecido que a tarefa de compreensão de software requer um
esforço significativo durante a execução de tarefas de manutenção. Diversas
alternativas têm sido propostas para amenizar este esforço. Entretanto, ainda
não existe nenhuma alternativa que seja amplamente reconhecida para ser usada
em um contexto geral. Informações extraídas de rastros de execução vêm sendo
bastante utilizadas como alternativas para facilitar a compreensão de
características dos programas. O presente estudo pretende contribuir com a
avaliação do impacto do uso de informações de rastros de execução em
atividades de manutenção de software. Este estudo mostra benefícios do uso
sistemático de informação de rastros de execução na diminuição do tempo de
execução e no aumento da taxa de correção na procura de informação durante
atividades de manutenção de software. Entretanto, este estudo também revela
alguns desafios para aplicação desta abordagem em larga escala.
Palavras Chave: localização de características, análise dinâmica, rastros de
execução e compreensão de sistemas.
1 Introdução
Nos anos 70, Lehman estabeleceu leis, ou hipóteses empíricas, que sugerem que
qualquer software que seja usado regularmente deve passar por modificações
contínuas para satisfazer seus usuários [4]. De fato, até os dias atuais é amplamente
reconhecido que a modificação é uma necessidade inerente à grande parte do software
existente. Os desenvolvedores responsáveis por modificações sejam elas, corretivas,
adaptativas, evolutivas ou preventivas tem a necessidade de compreender o código, o
qual possivelmente não foi escrito por eles. Assim, antes de executar uma
modificação, desenvolvedores devem explorar o código fonte do sistema, achar e
entender um subconjunto de estruturas e o comportamento do programa que é
relevante à modificação proposta. Quanto maior é o sistema em avaliação e maiores
são as pressões normais do ambiente de desenvolvimento, tanto maior será o nível de
dificuldade colocado para os desenvolvedores [9].

Em [7], Salah e colegas afirmam que conforme relatado na literatura [8] até 90%
do custo de desenvolvimento de software é gasto em atividades de manutenção e
evolução. Ao executar uma tarefa de manutenção, é necessário identificar e localizar a
porção de código que precisa ser alterada. A localização desta parte do código que
precisa ser alterada é relativamente fácil quando o sistema está documentado
corretamente e é possível rastrear documentos de alto nível para o código-
fonte. Entretanto, a suposição da existência de documentação suficiente e consistente
não é normalização válida, pois um dos problemas mais freqüentemente enfrentado é
a localização do código para características específicas, as quais são importantes para
o entendimento de requisitos de software [11]. Características encapsulam o domínio
do conhecimento e, portanto, em um sistema de software são fontes valiosas de
informações para uma engenharia reversa. Existem diferentes definições para
características1 na comunidade de engenharia de software e de fato não existe
consenso sobre uma definição precisa deste conceito. Neste trabalho, definimos
característica como um conceito externo do ponto de vista do usuário que pode ser
mapeada em elementos de código.
Uma possível solução para obtenção do mapeamento de característica em código-
fonte é a utilização de análise dinâmica, pois é possível associar a uma característica
os trechos de código-fonte utilizados durante a execução da mesma. Diversos
trabalhos relacionados que serão discutidos na Seção 5 estudaram esta alternativa e
avaliaram aspectos positivos e negativos da mesma. Apesar de ser intuitiva, a
abordagem de análise dinâmica impõe algumas restrições, tais como: dependência do
cenário escolhido para a execução e excesso de informação provida pela coleta de
rastros de execução. O fato é que o uso de informação dinâmica como mecanismo de
localização de característica ainda é pouco difundido como prática abrangente entre
os desenvolvedores, basta verificar a escassez de ferramentas amplamente difundidas
em IDEs para este propósito.
Neste sentido este trabalho propõe o estudo do uso de uma abordagem de análise
de rastros de execução para auxílio durante a execução de tarefas de manutenção de
software. E pretende responder algumas perguntas sobre a contribuição da abordagem
proposta, a fim de responder ao seguinte objetivo: O1) Auxilio na compreensão do
código que implementa as características de interesse, ao tornar mais rápida a
localização do interesse, com informações que direcionam a compreensão do sistema
e propiciam maior taxa de acerto nas atividades de manutenção.
A seguir será apresentada a abordagem de análise dinâmica proposta, na Seção 3,
os estudos realizados para verificação do objetivo, Seção 4, os resultados e os discute,
Seção 5, resumo dos trabalhos relacionados e, finalmente, na Seção 6 são
apresentadas as conclusões deste trabalho.
2 Uma Abordagem de Análise Dinâmica
A abordagem apresentada neste trabalho pretende ajudar o desenvolvedor na
compreensão dos códigos das características de software, utilizando análise dinâmica
1 Do inglês, features

e estática para obter informações necessárias aplicada a sistemas orientados a objeto
desenvolvidos em JAVA, e para tanto o método utilizado envolve visões e filtragens.
A decisão de se trabalhar com análise de características partiu da necessidade e
importância de se investigar o sistema a partir de suas funcionalidades ou conjunto de
funcionalidades.
Em [20] os autores realizaram uma análise de 176 artigos, criteriosamente
selecionados, relacionados à análise dinâmica aplicada a compreensão de sistema. E
verificaram que a análise de características constitui o terceiro maior grupo de
atividades com 30 representações no conjunto 176 artigos, contando com
contribuições muito importantes para a literatura correlata.
Este trabalho tem como objetivo os sistemas orientados a objetos – OO
desenvolvidos em JAVA. Optou-se trabalhar com OO e Java por ser amplamente
utilizada e pela facilidade de instrumentação. Além do mais, existe uma facilidade
maior de encontrar sujeitos para o estudo, sejam pessoas ou software. Em [20], 79 de
114 artigos analisados foram desenvolvidos em linguagem JAVA ou Smalltalk.
A abordagem aqui proposta utilizou visualizações refinadas por filtros, pois o
volume de informações coletada nos rastros é grande e estas informações devem ser
passadas para o analista desenvolvedor de forma que o ajude a compreender o código
e não ficar mais confuso devido ao volume de informações. Em [20], observou-se que
o uso de visualizações constitui o maior grupo de métodos utilizado. Na abordagem
aqui apresentada, as quatro visões são obtidas a partir dos rastros de execução das
características e montadas a fim de auxiliar na compreensão das características são: o
mapeamento, grafo de chamada, classificação das classes e o mapeamento com
classificação.
A abordagem foi dividida em passos sendo estes: o planejamento dos roteiros,
extração dos rastros de execução, geração das visões e, finalmente, análise das visões
geradas e análise estática. Também serão introduzidas as ferramentas:
TraceExtractor, TraceToConcern, TraceToVisions, ConcernMapper e Graphviz,
utilizadas na abordagem. Estas ferramentas, exceto a Graphviz, são executadas dentro
do Eclipse, a fim de atender a necessidade do analista de interagir com o código fonte
dentro de um IDE, e de obter informações estáticas que complementam e refinam os
resultados da análise dinâmica.
No primeiro passo desta abordagem, os rastros de execução que dão origem às
visões são obtidos por meio de roteiros pré-definidos. Estes roteiros definem o
caminho de execução a fim de apenas coletar as características de interesse visando
contribuir para localização das características no código fonte.
Toda abordagem baseada em análise dinâmica precisa de alguns mecanismos para
a extração dos dados durante a execução do programa. Para isso, o sistema alvo deve
passar por um processo de instrumentação para a captura de eventos gerados durante
sua execução. Utilizaremos um método não-intrusivo no código fonte baseado em
interceptação de métodos com AspectJ [17].
Para a coleta dos rastros, o usuário da abordagem irá executar as características
desejadas do sistema conforme o roteiro predefinido. Durante a captura ocorre a
marcação do início e fim da coleta do rastro de uma característica, a intercepção e
registro dos elementos de código executados separados por threads.
Após a coleta de rastros, podem ser extraídas 4 visões para o desenvolvedor:

Visão 1 – Mapeamento. O Mapeamento das características para os elementos de
código: classes e métodos, que as implementam é a principal visão gerada por esta
abordagem, pois é a que apresenta a localização das características. Este mapeamento
é gerado automaticamente contendo os elementos de código executados para cada
característica desejada no formato de leitura da ferramenta ConcernMapper [10]. Para
cada característica é criado um nó na árvore de interesse com o respectivo nome da
característica e associada a esta todas as classes e métodos que a implementam. Desta
maneira, os elementos de código, que antes se encontravam espalhados e entrelaçados
pelo código fonte, se apresentam de maneira organizada ao desenvolvedor. O
programador tem acesso às unidades de código do mapeamento diretamente no
ambiente de codificação (IDE – Eclipse).
Visão 2 – Grafo de Chamada dos Métodos. A partir dos métodos obtidos para cada
característica, o analista pode selecionar os métodos de interesse e obter o grafo de
chamadas destes métodos. Este grafo é apresentado graficamente com o auxílio da
ferramenta Graphviz.
Visão 3 – Classificação de Classes. Assim como nas abordagens de localização de
características de Eisenberg [2] e [1], este trabalho propõem classificar as classes que
implementam as características baseando-se nos níveis de participação das mesmas na
implementação do conjunto de características em questão. São distinguidos quatro
níveis de participação das classes nas características em análise, calculados a partir do
número de características avaliadas e do número de características que a classe
implementa, onde NOF é o número de características presentes na avaliação e NOFC
é o número de características implementadas pela classe em avaliação.
1. Única Característica (UC) é uma classe que participa em apenas uma
característica da análise, cuja fórmula para cálculo é (NOFC = 1).
2. Baixo Número de Características (BNC) é uma classe que participa em
mais de uma característica, mas em menos da metade das características em
análise, cuja fórmula para cálculo é (NOFC> 1) ∧ (NOFC <NOF / 2).
3. Alto Número de Características (ANC) é uma classe que participa na
metade ou mais das características em avaliação, mas não em todas. A
fórmula para cálculo é (NOFC> 1) ∧ (NOFC> = NOF / 2).
4. Presente em Todas (PT) é uma classe que participa de todas as
características em análise, cuja fórmula para cálculo é (NOFC = NOF).
Visão 4 – Classificação de Classes por Características. Enquanto na Visão 3 tem-se
uma visão das classes em relação ao conjunto de todas as características, na Visão 4
teremos a apresentação organizada por características. Seguem os critérios de
classificação definidos:1) Específica: a classe somente implementa a característica
em questão; 2) Compartilhada: a classe implementa a característica e implementa
outra(s) característica(s) analisadas, mas não todas;3)Presente em Todas: é uma
classe que implementa todas as características em análise.
O resultado obtido ao final da aplicação da abordagem são as 4 visões apresentadas
anteriormente. Para entender completamente o interesse, o desenvolvedor poderá
precisar de mais informações sobre o sistema. Neste caso, a integração com o IDE
Eclipse permite uma busca por informação adicional guiada pelas visões obtidas.
Trabalhos relacionados como [13], [14] e [1], relataram a importância do uso da
análise dinâmica conjuntamente com a análise estática para uma melhoria da
compreensão e abrangência da informação. Eisenbarth e colegas realizaram estudos

de caso apresentados em [1] e [15] e concluíram que a combinação de análise
dinâmica refinada pela análise estática reduz o espaço de busca drasticamente.
3 Descrição do Estudo
O estudo que será apresentado a seguir foi elaborado para verificar se a abordagem
atinge os objetivos apresentados na Seção 1. Foram realizados um estudo preliminar e
experimentos, os quais envolvem atividades de manutenção em sistemas. Para cada
objetivo foram definidas perguntas associadas que serão respondidas pelos resultados
dos estudos experimentais. Para cada pergunta da pesquisa, apresenta-se uma hipótese
com sua respectiva argumentação teórica [3]. Em seguida, é descrito o cenário do
estudo e seus resultados. Em seguida, o projeto do estudo preliminar e do experimento
é apresentado. A seção é finalizada com as ameaças à validade do estudo.
3.1 Hipóteses
Para verificar os objetivos, foram montadas as seguintes perguntas de pesquisa:
P1) O uso da abordagem torna a resposta à compreensão de um sistema
desconhecido mais rápida, ao se comparar com o não uso da abordagem?
P2) Com o uso da abordagem, as respostas dadas pelo analista para uma atividade
de manutenção em um sistema desconhecido são menos erradas? Em outras palavras,
a correção das respostas do desenvolvedor é maior em relação ao não uso da
abordagem?
A seguir são apresentadas as hipóteses e suas respectivas argumentações teóricas
que serão verificadas através dos estudos de caso.
H1) Analistas que utilizam a abordagem apresentam melhor tempo de execução em
atividades de manutenção sobre sistemas desconhecidos do que analistas utilizando
uma abordagem tradicional. Argumentação: Quando a abordagem é utilizada sobre
sistemas desconhecidos, a localização do interesse potencialmente seria mais rápida
do que quando não utilizada e, conseqüentemente, a resposta a uma atividade ligada à
compreensão do sistema que requeresse a localização do interesse, também, seria
mais rápida. A localização de características utilizando análise dinâmica reduz e
organiza o espaço de busca do analista pela característica de interesse, que geralmente
se encontra dispersa no código fonte.
H2) Analistas que utilizam a abordagem apresentam maior correção nas respostas
durante a execução de atividades de manutenção em sistemas desconhecidos do que
analistas que utilizam a abordagem tradicional. Argumentação. As visões desta
abordagem auxiliam o desenvolvedor provêem informações dinâmicas para a
compreensão do sistema, como as classes e métodos executados para uma
característica de interesse, a presença de elementos de código em comum entre
características de interesse e as chamadas entre os métodos executados para as
características. O não uso da abordagem usualmente implica em navegação em
informações estáticas, que apesar de ser potencialmente útil, ocorre sem

necessariamente a aplicação de nenhum filtro. Porém, com o uso da abordagem
apresentada, ocorre um direcionamento para informações das características de
interesse potencialmente induzindo respostas mais precisas.
3.2 Estudo Preliminar
O estudo preliminar foi definido para avaliação da precisão e correção da
abordagem e para coletar ―feedback‖ qualitativo da satisfação do usuário, com
objetivo de fornecer informações sobre possíveis ajustes nesta. Os sistemas avaliados
foram: Jogos de Tabuleiro e Cotação da Bolsa, estes foram desenvolvidos pelos
próprios analistas que avaliaram os resultados. Estes analistas apontaram valores
sobre a presença de elementos de código VP,VN, FN e FP (ver definição abaixo) e
foram questionados sobre sua satisfação, onde (VP), são elementos que aparecem nas
visões, e segundo o analista, implementam a característica; (VN), elementos que não
aparecem nas visões, e segundo o analista, não implementam a característica.; (FN),
elementos que não aparecem nas visões, e segundo o analista, implementam a
característica.; (FP), elementos que aparecem nas visões, e segundo o analista, não
implementam a característica.
Fórmulas Jogos de Tabuleiro Cotação da Bolsa
Precisão Classes 0.91 1
Precisão Métodos 0.72 1
Correção Classes 0.91 0.97
Correção Métodos 0.69 1
Tabela 1. Cálculo da Precisão e Correção da abordagem.
Diante dos valores de precisão e correção apresentados, os resultados foram
considerados satisfatórios, dentro do esperado. Entretanto, durante a execução dos
estudos de caso, a experimentadora pode perceber possíveis melhorias na usabilidade
do ferramental da abordagem que foram realizadas.
3.3 Projeto Experimental
Nesta seção serão apresentados experimentos que pretendem responder as
perguntas de avaliação deste trabalho. Foram realizados três experimentos. No
primeiro, os grupos de analistas implementaram uma melhoria com reuso de código
no sistema Jogos de Tabuleiro. No segundo experimento, os grupos realizaram uma
correção na funcionalidade Undo e Redo do sistema JHotDraw 7.1, um framework de
médio porte para criação de figuras. O terceiro, realizou-se uma atividade de
verificação da evolução de um sistema, realizada sobre o JHotDraw versões 7.1 e
5.3, que sofreu melhorias nas funcionalidade Undo e Redo.
A variável independente do experimento controlado foi a disponibilidade das
visões da abordagem, variando conforme o grupo. Para avaliar diferentes pontos da
abordagem, três tipos de grupos foram montados. A diferença entre estes grupos é
disponibilidade das visões apresentadas: 1) grupo (Controle) que não utiliza a

abordagem, mas somente as funcionalidades do IDE Eclipse; 2) grupo (Parcial) que
utiliza somente a visão de Mapeamento, e também as funcionalidades do IDE Eclipse;
3) grupo (Completa) que utiliza todas as visões (Mapeamento, Classificação de
Classes, Mapeamento com Classificação e Grafo de Chamadas) e também as
funcionalidades do IDE Eclipse. As diferenças entre estes três grupos irá permitir a
verificação dos ganhos com o uso da abordagem e da visão Mapeamento em relação
às demais visões, considerando o desempenho (tempo e taxa de acerto) destes grupos
e relacionando este resultado ao uso ou não da abordagem.
As variáveis dependentes são o tempo necessário para executar a atividade de
manutenção e a taxa de acerto das soluções. A primeira variável foi medida enquanto
as atividades foram executadas e a segunda foi determinada após o experimento com
a verificação da taxa e acerto na atividade.
Variáveis não controladas são familiaridade do participante com o ferramental da
abordagem e ambiente utilizado; efeitos experimentador: como os participantes são
instruídos, o que o pesquisador espera que a partir da experiência; disposição do
participante para o experimento; instrumentação: como as variáveis dependentes são
medidas; ruídos (FP e FN) gerados por roteiros mal definidos ou por ocorrência de
eventos invisíveis a observação do usuário; subjetividade da definição sobre quais
elementos de código são relevantes para a implementação das características de
interesse, sob o ponto de vista do participante; o nível de conhecimento em
desenvolvimento na linguagem Java dos participantes. Procurou-se minimizar os
impactos das variáveis não controladas com a atribuição aleatória de participantes em
grupos.
Definição dos Grupos. A seleção dos analistas, que participaram dos estudos de
caso, foi realizada sobre uma lista de contatos pessoais e profissionais da primeira
autora. Participaram dos experimentos um total de 22 analistas desenvolvedores,
voluntários, sendo que, 95.45% destes analistas são profissionais que trabalham com
análise de sistemas e estão inseridos no mercado de trabalho e 4.55% são alunos do
mestrado da Faculdade de Computação – UFU. Sobre o grau de formação, 78% são
formados e os 22% restantes cursam os últimos períodos do Bacharelado em Ciência
da Computação da UFU. Ao todo participaram analistas de 6 diferentes empresas de
Uberlândia-MG e de uma universidade (UFU). Os voluntários, também, foram
entrevistados e questionados sobre os conhecimentos específicos. Os principais
requisitos para seleção e formação dos grupos foram: conhecimento em
desenvolvimento JAVA e experiência em manutenção de software. Estes analistas
foram classificados conforme o grau de conhecimento, como: júnior, pleno ou sênior,
seguindo critérios pré-estabelecidos.
Cada grupo montado foi formado por 3 analistas, sendo um júnior, um pleno e um
sênior, e portanto, 9 sujeitos participaram de cada um dos três experimentos,
resultando em 27 observações ao todo. A homogeneidade de conhecimento dos
grupos é um fator importante para não influenciar os resultados, e isto foi levado em
consideração. A seleção dos integrantes dos grupos (Controle, Parcial ou Completa)
para cada estudo de caso foi aleatória, levando em consideração a disponibilidade do
analista na data do experimento e a sua classificação (júnior, pleno e sênior). Ao final
deste processo, foram obtidos grupos qualificados e homogêneos para a execução dos
três estudos de caso executados.

Sistemas analisados. Os experimentos foram realizados sobre os seguintes
sistemas: Jogos de Tabuleiro e JHotDraw. O principal critério de seleção dos sistemas
alvo era atender as premissas da abordagem: desenvolvido em Java com código
aberto para análise, e que fosse bem documentado e versionado para que houvesse as
informações necessárias para a verificação dos resultados e definição das
manutenções a serem executadas nos experimentos. Também foi critério de seleção a
necessidade de executar os experimentos com sistemas de diferentes portes, portanto,
selecionou-se um sistema pequeno (Jogos de Tabuleiro) e um de médio porte
(JHotDraw). A Tabela 2 apresenta alguns dados sobre os sistemas selecionados. Sistema # Classes # Métodos Manutenção
Jogos de Tabuleiro 1.0 16 72 Reuso
JHotDraw 7.1 466 4078 Localizção e Correção
JHotDraw 5.3 215 1793 Localização
Tabela 2. Caracterização dos sistemas utilizados nos experimentos
Atividades de Manutenção. Para cada experimento foi definida uma atividade de
manutenção diferente, visando verificar os resultados da abordagem para diferentes
tipos de atividade. Os diferentes tipos de atividades definidas foram reuso de código
para implementar nova funcionalidade no sistema, correção de um erro, localização
dos elementos de código que implementam as mesmas características em diferentes
versões do sistema e apontamento da evolução que ocorreu entre as versões para estas
características.
Reuso. Foi avaliado neste experimento o sistema Jogos de Tabuleiro. A atividade
que deve ser desempenhada envolve as características: Contar Partidas, Contar
Vitórias, Menu Principal e Novo Jogo. Estas características estão presentes no menu
lateral do jogo Connect, e devem ser reutilizadas para que o Jogo da Velha tenha este
mesmo menu lateral.
Correção. O sistema JHotDraw é um framework para traçar gráficos bi-
dimensionais (2D). Para este experimento foi selecionado um erro presente a versão
7.1, apresentado na lista de correção de erros no site oficial do JHotDraw, onde
inclusive a correção foi postada. O erro selecionado foi denominado Text Area Tabs,
e é referente ao uso das funcionalidades TextTool, ferramentas de texto, que permite
criar e modificar novos objetos do tipo textos dentro e fora de figuras. A
funcionalidade Undo e Redo (desfazer e refazer) sobre os objetos do tipo TextTool
não funciona. Para este experimento foi solicitada a correção deste erro.
Localização de Evolução. O sistema alvo deste experimento é o JHotDraw nas
versões 5.3 e 7.1. Este sistema sofreu substanciais alterações na versão 7.1. Estas duas
versões são claramente diferentes. As características Undo e Redo foi uma das que
sofreu maior alteração. Para este experimento, foi solicitado aos participantes que
analisassem as duas versões deste sistema e apontassem todas as classes e métodos
envolvidos na implementação das características Undo e Redo para cada versão e
logo depois descrevesse a modificação/evolução que estas características sofreram de
uma versão para a outra.
Execução Experimental. Para execução dos experimentos de maneira controlada,
a autora treinou e instruiu os participantes, preparou o laboratório, verificou as
soluções e aplicou um questionário quantitativo e qualitativo. A experimentadora

buscou garantir os mesmos procedimentos para todos os experimentos, estes
procedimentos serão descritos a seguir.
Treinar e instruir os participantes. Foram realizados treinamentos sobre a
abordagem com o objetivo de preparar os participantes dos grupos parcial e completa,
para que estes fossem aptos a utilizar a abordagem de forma eficaz, principalmente no
momento de investigação do sistema alvo. Foi apresentado um exemplo de uso da
abordagem, com demonstração de utilização das ferramentas e sua integração com o
IDE Eclipse. Antes de cada experimento, os participantes foram instruídos sobre a
atividade e sistema alvo, receberam material descritivo sobre a atividade, que foi lido
e explicado detalhadamente pela experimentadora. Esta instrução foi passada para os
três grupos, visando garantir o máximo de normalidade entre estes, e durou em média
meia hora. Após a explicação, os participantes puderam esclarecer dúvidas.
Infraestrutura para os experimentos. Os experimentos foram realizados nos
laboratórios da Faculdade de Computação da UFU – Universidade Federal de
Uberlândia, onde as máquinas foram previamente configuradas para cada
experimento, os sistemas utilizados foram instalados, a internet foi bloqueada e todas
as máquinas foram testadas, garantindo assim que o ambiente disponibilizado estava
em perfeito funcionamento e padronizado, visando diminuir os desvios nos resultados
dos experimentos.
Execução dos experimentos. Cada experimento teve a duração fixa de 4 horas, 50
minutos foram utilizados com adaptação ao ambiente de trabalho, utilizando o
ferramental, e com as instruções sobre a atividade. Os participantes, independente do
grupo, tiveram um prazo de três horas e dez minutos para executar a atividade de
manutenção para o qual foram selecionados. Os participantes, após instrução sobre a
atividade a ser executada, tendo em mãos o material de instrução, iniciaram
individualmente a análise dos sistemas alvo. Ao final da execução, por parte do
analista, a solução apresentada foi verificada pela autora. Os tempos gastos com a
execução da atividade e com o questionário foram registrados, separadamente. Cada
participante do estudo de caso respondeu a um questionário, inclusive, os que não
concluíram a atividade com sucesso.
Ameaças à validade. Alguns fatores devem ser considerados para análise sobre a
validade dos resultados:
diferenças individuais dos participantes. Essas diferenças foram minimizadas
pela atribuição aleatória de participantes em grupos.
Número pequeno de participantes em cada grupo. Estes possuem habilidades
distintas e pode haver desvios nos resultados devido a este número que inviabilizem
as conclusões. Entretanto, as conclusões serão tomadas sobre os resultados dos três
experimentos que nos fornece um dado mais confiável, devido ao volume de 27
observações individuais, 9 experimentos individuais para o grupo controle e 14
utilizando a abordagem, respondendo as mesmas perguntas.
Diferenças nos treinamentos e instruções. O treinamento e instruções que os
diferentes grupos receberam podem ter sido diferentes em detalhes, embora tenha sido
definido e seguido o mesmo procedimento e apresentação para todos.
Percepção dos participantes: subjetividade da definição sobre quais
elementos de código são relevantes para a implementação das características de
interesse. Cada participante pode definir uma solução, que podem ser diferentes entre
si, porém corretas.

Existem também fatores externos que afetam a generalização dos resultados:
Representatividade do sistema alvo. A representatividade dos sistemas
escolhidos para esta experiência é de certa forma limitada, porém foram realizados
com dois sistemas distintos, de diferentes portes e sendo um de um porte de
complexidade representativa.
Familiaridade com o sistema. O desenvolvedor se deparar com um sistema
completamente desconhecido não é a situação comum na manutenção de software.
Logo os resultados não podem ser generalizados para tal situação.
Experiência com o uso da abordagem. A abordagem é um novo conceito para
todos os participantes. Indivíduos com mais experiência no uso da abordagem
poderiam apresentar um desempenho diferente.
Efeito do experimentador: O experimentador é a mesma pessoa que inventou
a abordagem. Isso pode ter influenciado qualquer aspecto da experiência.
4. Resultados e Discussões
Nesta seção serão apresentados e discutidos os resultados obtidos nos
experimentos. Primeiramente serão apresentados e discutidos os resultados em
relação ao tempo de execução e em seguida em relação à taxa de acerto.
4.1 Sobre o tempo de execução
Os resultados do primeiro estudo são apresentados na Figura 1 (a). Os grupos que
utilizaram a abordagem tiveram uma média de tempo gasto inferior ao grupo controle
o tempo médio gasto pelo grupo completa foi de 95.66 minutos, do grupo parcial foi
136 minutos e do grupo controle foi 167 minutos, este último teve variação em
relação ao grupo que utilizou a abordagem completa de 71.34 minutos a mais, um
valor considerável, 37,54% do tempo dado aos participantes para a atividade. Observe
que o desvio para os grupos Controle e Completa nos permite concluir que o uso da
abordagem Completa foi significativamente superior.
Em relação ao segundo estudo, os grupos que utilizaram a abordagem tiveram uma
média de tempo gasto inferior ao grupo controle conforme se pode ver na Figura 1
(b). Comparando o tempo do grupo controle com o do grupo parcial que obteve o
melhor desempenho em tempo, tem-se uma diferença de 65 minutos, o que
corresponde a 34.21% do tempo para execução da atividade, um valor novamente
considerável. Os desvios de tempo apresentados pelos grupos Parcial e Completa
foram significativos e, portanto, tornam a comparação entre estes dois grupos menos
confiável. Entretanto, o desempenho da abordagem Parcial foi significativamente
melhor do que da abordagem Controle, apesar dos desvios.
Em relação ao terceiro estudo, observou-se que a média dos tempos dos grupos que
utilizaram a abordagem neste experimento foi superior ao grupo controle. Esta
atividade não envolveu alteração no código, e por isto teve um tempo médio geral
menor do que os outros experimentos. O tempo médio de 70 minutos e 90 minutos
dos grupos parcial e completa contempla o tempo que estes grupos gastaram para
executar a abordagem, obter as visões e analisar o código das características de
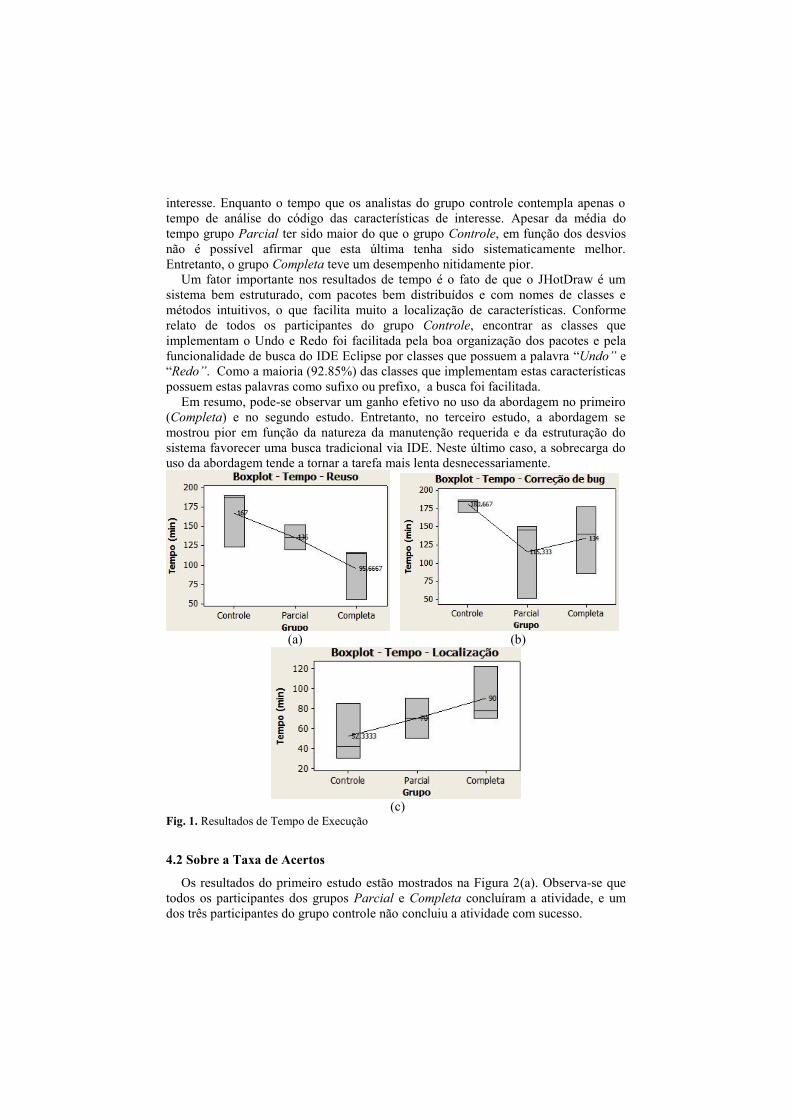
interesse. Enquanto o tempo que os analistas do grupo controle contempla apenas o
tempo de análise do código das características de interesse. Apesar da média do
tempo grupo Parcial ter sido maior do que o grupo Controle, em função dos desvios
não é possível afirmar que esta última tenha sido sistematicamente melhor.
Entretanto, o grupo Completa teve um desempenho nitidamente pior.
Um fator importante nos resultados de tempo é o fato de que o JHotDraw é um
sistema bem estruturado, com pacotes bem distribuídos e com nomes de classes e
métodos intuitivos, o que facilita muito a localização de características. Conforme
relato de todos os participantes do grupo Controle, encontrar as classes que
implementam o Undo e Redo foi facilitada pela boa organização dos pacotes e pela
funcionalidade de busca do IDE Eclipse por classes que possuem a palavra ―Undo” e
―Redo”. Como a maioria (92.85%) das classes que implementam estas características
possuem estas palavras como sufixo ou prefixo, a busca foi facilitada. Em resumo, pode-se observar um ganho efetivo no uso da abordagem no primeiro
(Completa) e no segundo estudo. Entretanto, no terceiro estudo, a abordagem se
mostrou pior em função da natureza da manutenção requerida e da estruturação do
sistema favorecer uma busca tradicional via IDE. Neste último caso, a sobrecarga do
uso da abordagem tende a tornar a tarefa mais lenta desnecessariamente.
(a) (b)
(c)
Fig. 1. Resultados de Tempo de Execução
4.2 Sobre a Taxa de Acertos
Os resultados do primeiro estudo estão mostrados na Figura 2(a). Observa-se que
todos os participantes dos grupos Parcial e Completa concluíram a atividade, e um
dos três participantes do grupo controle não concluiu a atividade com sucesso.

Em relação ao segundo estudo, pode se observar na Figura 2(b), que nenhum
participante do grupo controle obteve sucesso na atividade e todos os participantes
dos grupos que utilizaram a abordagem obtiveram sucesso. Este é um resultado
bastante significativo. Obter sucesso nesta atividade significa corrigir o problema
conforme requisitado no tempo delimitado pelo experimento. Ao término do tempo,
todos os analistas do grupo Controle, ao responderem as perguntas do questionário,
apontaram corretamente os elementos de código que deveriam ser corrigidos, apesar
de demonstrarem dúvida se estavam corretos, pois nenhum havia iniciado a atividade
de correção em si. Talvez com mais tempo de experimento, estes tivessem executado
a atividade com sucesso, porém em um tempo ainda maior de execução.
Em relação ao terceiro estudo, todos os grupos apresentaram 100% de acerto para a
Pergunta 3 do questionário e um percentual médio de erros muito próximo para as
Pergunta 1 e 2 do questionário, apesar de o grupo Controle ter apresentado em média
um resultado ligeiramente melhor. Os desvios dos grupos Controle e Parcial foram
maiores do que o grupo Completa. Neste estudo não se pode afirmar que existe uma
diferença significativa entre os grupos.
Em resumo, o uso das abordagens se mostra efetivo em relação à taxa de acerto,
especialmente se considerarmos a atividade de localização de bugs. Em relação, às
demais atividades não se observou uma melhoria efetiva.
(a) (b)
(c) (d) Fig. 2. Resultados de Taxa de Acerto
5. Trabalhos Relacionados
A localização de características em código fonte tem sido uma área ativa de
pesquisa nos últimos anos. Dentre estes trabalhos destacam-se Wilde e Scully [12]
como pioneiros na localização de características com o método Software
Reconnaissance, que usa casos de testes para localizar as características. Esta técnica

é baseada na comparação dos rastros dos diferentes casos de teste. Os casos de teste
são conduzidos com as características desejadas e outros sem, a fim de obter os
elementos de código que são específicos da característica. Este método lida com uma
característica por vez e não foca no relacionamento entre estas como o nosso trabalho.
Em [16], apresenta-se uma abordagem baseada em análise dinâmica, estática e
conceitual. A análise de conceito é utilizada para identificar quais unidades
computacionais contribuem para os comportamentos das características. Esta
distingue as unidades computacionais entre gerais e específicas e usa cenários para
invocar características. Na validação da abordagem, eles apontaram os ganhos da
abordagem e que a combinação de análise dinâmica refinada pela análise estática
reduz o espaço de busca drasticamente. As visões do trabalho apresentado neste
artigo, tiveram seus critérios de classificação inspirados por este trabalho, porém a
técnica é distinta. Em [2], Eisenberg e Volder introduzem técnica baseada em uma
heurística simples denominada Dynamic Feature Traces, que usa ranking heurístico
para determinar a relevância de um elemento de código para uma característica. Foi
constatado que esta técnica apresenta melhores resultados quando aplicado a um
conjunto grande de testes na coleta dos rastros. E, roteiros mal definidos podem gerar
resultados incompletos. Esta técnica é totalmente diferente da apresentada neste
artigo, porém, a visão Classificação de Classes pode ser compara ao ranking de
relevância de Eisenberg, pois ambos pretendem classificar a relevância de um
elemento para a característica. E apresentam os mesmos pontos fracos. O trabalho
[10], apresenta a ferramenta ConcernMappe para o mapeamento manual dos
Interesses para o código fonte que os implementa. E contribuiu para a definição desta
como ferramenta a ser utilizada na montagem e manutenção do mapeamento das
características para os elementos de código que as implementam. [17] propõe um
abordagem chamada Featincode para a análise do espalhamento de características
através da interpretação gráfica da interseção entre características e elementos do
código fonte. Este trabalho utilizou o mesmo modelo de extração para a obtenção dos
rastros de execução. Em [19], Quante introduz uma técnica para extrair informações
de arquitetura denominada Object Dynamic Process Grafos. Esta gera grafos que
descrevem o fluxo de controle de uma aplicação a partir da perspectiva de um objeto.
Os experimentos controlados que validaram empiricamente a utilidade na prática,
constaram que a técnica pode ser útil para alguns sistemas e atividades, mas não para
todos. A técnica de Quante apresenta uma visão arquitetural totalmente diferente das
visões apresentadas neste artigo. Porém, a metodologia de avaliação desta técnica foi
a mesma utilizada para este artigo, confirmando que seguimos todos os passos para
controle de um experimento deste porte e dificuldade.
6. Conclusões
Neste foi apresentado um estudo experimental controlado utilizando sujeitos humanos
com o objetivo de avaliar o impacto do uso de rastros de execução em atividades de
manutenção de software. Conforme afirmado em [20], experimentos como este são
raramente executados devida a dificuldade de execução e a participação de pessoas
nas avaliações é importante para o campo compreensão de sistemas e constituem
importantes contribuições.

O estudo contou com 27 observações divididas em 3 atividades de manutenção,
cada uma aplicada a 3 grupos distintos (controle, abordagem completa e abordagem
parcial). O resultado mostrou que:
1. O tempo de execução com o uso da abordagem foi melhor em situações onde
as características ou interesses a serem localizados não estavam bem
modularizados em unidades específicas.
2. A taxa de acertos com o uso da abordagem foi pelo menos similar ao não
uso da abordagem, tendo porém um desempenho claramente superior em
atividade de correção de erro.
Como trabalho futuro, sugere-se a avaliação de técnicas de localização de
características utilizando rastros dedicadas a tarefas específicas de manutenção.
Referências
1. Eisenbarth, T., Koschke, R., Simon, D.: Locating Features in Source Code. IEEE
Transactions on Software Engineering, 29(3), pp. 210—224, 2003.
2. Eisenberg, A., de Volder, K.: Dynamic Feature Traces: Finding Features in Unfamiliar
Code, 21st Intl. Conf. on Software Maintenance, pp. 337—346, 2005.
3. Kitchenham, B., et al.: Preliminary guidelines for empirical research in software
engineering. IEEE Transactions on Software Engineering, 28(8), pp. 721—734, 2002.
4. Lehman, M.: Programs, Life Cycles, and Laws of Software Evolution. Proc. IEEE, 68 (9),
pp. 1060—1076, 1980.
5. Quante, J.: Do Dynamic Object Process Graphs Support Program Understanding? A
Controlled Experiment. In: 16th IEEE ICPC, pp. 73--82 2008.
6. Yin, R.: Case study research: design and methods. London: Sage, 1984.
7. M. Salah and S. Mancoridis: Toward an Environment for Comprehending Distributed
Systems, Proc. 10th Working Conf. Reverse Eng., pp. 238-247, 2003.
8. M. Sefika, A. Sane, and R.H. Campbell: Architecture-Oriented Visualization, Proc. 11th
OOPSLA, pp. 389-405, 1996.
9. Robillard, M. P. and Murphy, G. C.: Representing concerns in source code. ACM Trans.
Softw. Eng. Methodol., 16(1):3:1–38, (2007).
10. Robillard, M. P. and Weigand-Warr, F.: Concernmapper: simple viewbased separation of
scattered concerns. In Proc. of the 2005 OOPSLA workshop on Eclipse, pp. 65–69, (2005).
11. Wilde, N., et al.: A comparison of methods for locating features in legacy software. Journal
of Systems and Software, 65(2):105–114, (2003).
12. Wilde, N., Scully, M.: Software reconnaissance: mapping program features to code. Journal
of Software Maintenance: Research and Practice 7 (January), 49–62, 1995. 13. S. Simmons, et al: Industrial Tools for the Feature Location Problem: An Exploratory
Study, J. Soft. Maint. and Evolution: Research and Practice, 18(6), pp. 457-474, 2006.
14. Giuliano Antoniol and Yann-Gael Gueheneuc, Feature Identification: A Novel Approach
and a Case Study, Proceedings of the 21st IEEE ICSM, 2005.
15. T. Eisenbarth, R. Koschke, and D. Simon: Aiding Program Comprehension by Static and
Dynamic Feature Analysis, Proc. ICSM, pp. 602-611, Nov. 2001.
16. Eisenbarth, T., Koschke, R., Simon, D.: Incremental location of combined features for
large-scale programs. In: Proc ICSM 2002, Montreal, Canada, pp. 273– 282. 2002. 17. V. Sobreira, and M. Maia: A Visual Trace Analysis Tool for Understanding Feature
Scattering. In: Proc. of the 15th WCRE, pp.337-338. Antwerp, Belgium, 2008.
19. J. Quante: Do Dynamic Object Process Graphs Support Program Understanding?—A
Controlled Experiment, Proc. 16th Int’l Conf. Program Comprehension, pp. 73-82, 2008.
20. B. Cornelissen, et al: A Systematic Survey of Program Comprehension through Dynamic
Analysis, IEEE Transactions on Software Engineering, vol. 35, no.5, pp. 684-702, 2009.










![3 - Rastros de proposições crianceirasbooks.scielo.org/id/zdx9x/pdf/chiste-9788579837081-05.pdf · 3 raStroS de ProPoSiçõeS crianceiraS Eles ficam comendo bostas [...] Eles ficam](https://static.fdocumentos.tips/doc/165x107/5f3ba6525c6cad07b924b68c/3-rastros-de-proposies-3-rastros-de-proposies-crianceiras-eles-ficam-comendo.jpg)







