
Revisitando MLD para fam lia exponencial p-dimensional · distribui˘c~ao de probabilidade...
94
Revisitando MLD para fam´ ılia exponencial p-dimensional Ra´ ıra Marotta Bastos Vieira Universidade Federal do Rio de Janeiro Instituto de Matem´ atica Departamento de M´ etodos Estat´ ısticos 2018
Transcript of Revisitando MLD para fam lia exponencial p-dimensional · distribui˘c~ao de probabilidade...

Revisitando MLD para famılia exponencial
p-dimensional
Raıra Marotta Bastos Vieira
Universidade Federal do Rio de Janeiro
Instituto de Matematica
Departamento de Metodos Estatısticos
2018

Revisitando MLD para famılia exponencial
p-dimensional
Dissertacao de Mestrado submetida ao Programa de Pos-Graduacao em Estatıstica
do Instituto de Matematica da Universidade Federal do Rio de Janeiro - UFRJ, como
parte dos requisitos necessarios a obtencao do tıtulo de Mestre em Estatıstica.
Raıra Marotta Bastos Vieira
Orientadores:
Mariane B. Alves
Helio dos Santos Migon
Rio de Janeiro, RJ - Brasil
2018
ii

Revisitando MLD para famılia exponencial
p-dimensional
Raıra Marotta Bastos Vieira
Dissertacao de Mestrado submetida ao Programa de Pos-Graduacao em Estatıstica
do Instituto de Matematica da Universidade Federal do Rio de Janeiro - UFRJ, como
parte dos requisitos necessarios a obtencao do tıtulo de Mestre em Estatıstica.
Aprovada por:
Mariane Branco Alves
DME/IM - UFRJ - Orientadora.
Dani Gamerman
DME/IM - UFRJ.
Heudson Mirandola
IM - UFRJ
Rio de Janeiro, RJ - Brasil
2018
iii

Dei sub numine viget
iv

Agradecimentos
A minha famılia, por todo amor, suporte e compreensao.
Aos meus amigos, por tornarem esta jornada mais leve e cheia de alegrias.
Ao Matheus Rebelo, por todo carinho, cuidado e apoio.
Aos meus orientadores Mariane e Migon, por serem fonte inesgotavel de inspiracao.
Alem da paciencia e suporte durante essa jornada.
Ao professor Heudson Mirandola, por acreditar no trabalho e ser extramente solıcito,
nos ajudando a desenvolve-lo.
v

Resumo
Os modelos lineares generalizados dinamicos sao uma extensao de modelos lineares
dinamicos (no sentido de considerar respostas nao gaussianas) e para modelos lineares
generalizados, que consideram respostas na famılia exponencial, mas presumem efeitos
fixos ao longo do tempo. O presente trabalho revisita metodos de inferencia para essa
classe de modelos nao so no que concerne a famılia exponencial uniparametria como
k-parametrica. Metodos como Conjugate Updating, Conjugate Updating Estendido e
modelos nao estruturados sao apresentados. Neste trabalho apresenta-se uma extensao
do metodo Conjugate Updating Estendido para o caso Multinomial. Alem do mais,
uma nova abordagem via geometria da informacao para estimacao de modelos lineares
dinamicos generalizados e proposta. Conceitos como Divergencia de Kullback-Leibler e
Teorema da Projecao sao utilizados no desenvolvimento do metodo. Estudos simulados
bem como aplicacao a dados reais foram feitos e apresentaram resultados satisfatorios.
Palavras-Chaves: inferencia bayesiana, modelos lineares dinamicos generalizados, ge-
ometria da informacao, conjugate updating.
vi

Abstract
Dynamic generalized linear models are an extension of dynamic linear models (in the
sense of considering non-Gaussian responses) and for generalized linear models, which
consider responses in the exponential family, but assume fixed effects over time. The
present work revisits inference methods for this class of models, not only for the one-
parameter exponential family but also for the k-parameter. Methods such as Conjugate
Updating, Extended Conjugate Updating, and unstructured models are presented. In this
work we extend the Extended Conjugate Updating method for the Multinomial case.
Moreover, a new approach via information geometry is proposed for estimating dynamic
generalized linear models. Concepts such as Kullback-Leibler Divergence and Projection
Theorem are used in the development of the method. Simulation studies as well as
application to real data were made and satisfactory results were obtained.
Keywords: bayesian inference, dynamic generalized linear models, information geo-
metry, conjugate updating.
vii

Sumario
1 Introducao 1
2 Conceitos Basicos 5
2.1 Famılia Exponencial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Conjugacao na Famılia Exponencial . . . . . . . . . . . . . . . . . 7
2.2 Geometria da Informacao . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1 Divergencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1.1 Divergencia de Bregman . . . . . . . . . . . . . . . . . . 10
2.2.1.2 Divergencia de Kullback-Leibler . . . . . . . . . . . . . . 11
2.2.2 Teoremas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.3 Exemplos de Projecoes . . . . . . . . . . . . . . . . . . . . . . . . 15
2.2.3.1 Projetando a Distribuicao Log-Normal na Gama . . . . 15
2.2.3.2 Projetando a Distribuicao Logito-Normal na Beta . . . . 18
3 Modelos Dinamicos Generalizados 20
3.1 Modelos Lineares Dinamicos . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2 Modelos Lineares Dinamicos Generalizados . . . . . . . . . . . . . . . . . 25
3.2.1 Conjugate Updating . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2.2 Modelos Dinamicos de Nıvel Local . . . . . . . . . . . . . . . . . 30
4 MLDG via Geometria da Informacao 35
4.1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2 Metodo proposto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
viii

4.2.1 Modelo Linear Dinamico Generalizado Poisson . . . . . . . . . . . 38
4.2.2 Modelo Linear Dinamico Generalizado Bernoulli/Binomial . . . . 41
4.2.3 Estudo de Simulacao . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.3.1 Modelo Poisson . . . . . . . . . . . . . . . . . . . . . . . 43
4.3 Compatibilizando diferentes modelos . . . . . . . . . . . . . . . . . . . . 44
4.3.1 Modelo Linear Dinamico Generalizado Poisson . . . . . . . . . . . 46
4.3.2 Modelo Linear Dinamico Generalizado Bernoulli/Binomial . . . . 49
4.3.3 Aplicacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5 Conjugate Updating estendido 58
5.1 Distribuicao Gama . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.2 Distribuicao Normal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.3 Distribuicao Multinomial . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.3.1 Estudo Simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.4 Aplicacoes a dados reais . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
6 Conclusao 77
A Resultados secundarios referentes a serie de vendas 79
A.1 Tabela de resultados do modelo Poisson via Geometria da Informacao que
compatibiliza modelos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
A.2 Cadeias obtidas pelo MCMC . . . . . . . . . . . . . . . . . . . . . . . . . 80
ix

Lista de Tabelas
4.1 Resultados da estimacao dos parametros do modelo de nıvel local . . . . 54
4.2 Tempo computacional gasto em cada um dos metodos . . . . . . . . . . . 54
4.3 Comparacao dos modelos via geometria da informacao compatibilizando
modelos e sem compatibilizar, Conjugate Updating e modelo de nıvel local 57
A.1 Tabela com os resultados obtidos de acordo com os parametros s e ω para
os 10 melhores modelos. . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
x

Lista de Figuras
2.1 Exemplo do Teorema da Projecao . . . . . . . . . . . . . . . . . . . . . . 13
2.2 Exemplo de Compatibilizacao de Variaveis . . . . . . . . . . . . . . . . . 14
2.3 Distribuicoes Log-Normal e Gama aproximadas atraves da minimizacao da
divergencia de Kullback-Leibler quando utilizados diferentes parametros
para as distribuicoes Log-Normal. . . . . . . . . . . . . . . . . . . . . . . 17
2.4 Distribuicoes Logito-Normal e Beta aproximadas atraves da minimizacao
da divergencia de Kullback-Leibler quando utilizados diferentes parametros
para as distribuicoes Logito-Normal. . . . . . . . . . . . . . . . . . . . . 19
3.1 Ilustracao da evolucao do sistema . . . . . . . . . . . . . . . . . . . . . . 23
4.1 Boxplots resultantes das replicas para a media a posteriori do parametro
natural e seus valores verdadeiros representados pela linha vermelha . . . 44
4.2 Media a posteriori da distribuicao preditiva a um passo para diferentes
tamanhos de amostra junto ao seu intervalo de credibilidade. As escalas
dos graficos diferem para facilitar a visualizacao. . . . . . . . . . . . . . . 44
4.3 Serie Observada . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.4 Predicao 1 passo a frente via geometria da informacao compatibilizando
modelos e sem compatibilizar, Conjugate Updating e modelo de nıvel local
junto a serie observada. Considerou-se que apos 10 passos todos os modelos
ja tinham aprendido o comportamento da serie. . . . . . . . . . . . . . . 55
4.5 E(αt|DT ) estimado por diferentes metodos . . . . . . . . . . . . . . . . . 55
4.6 Media a posteriori suavizada para o par de harmonicos. . . . . . . . . . . 56
xi

5.1 Boxplots para as medias a posteriori dos parametros λ1t e λ2t junto aos
seus valores verdadeiros (linha vermelha). . . . . . . . . . . . . . . . . . . 72
5.2 E(η1t|Dt) e E(η2t|Dt) (linha pontilhada azul) junto aos seus valores verda-
deiros (linha contınua preta). . . . . . . . . . . . . . . . . . . . . . . . . 73
5.3 E(Y1t+1|Dt), E(Y2t+1|Dt) e E(Y3t+1|Dt) (linha pontilhada azul) junto a serie
observada (linha contınua preta). . . . . . . . . . . . . . . . . . . . . . . 74
5.4 Serie mensal do log-retorno da SP500 . . . . . . . . . . . . . . . . . . . . 75
5.5 Serie observada junto a predicao 1 passo a frente e seu respectivo intervalo
de credibilidade. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.6 Media a posteriori filtrada e suavizada junto ao intervalo de credibilidade
da media suavizada para o parametro da media e de precisao. . . . . . . 76
A.1 Cadeias resultantes obtidas pelo metodo MCMC para cada um dos parametros
β e para o parametro ω. . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
xii

Capıtulo 1
Introducao
Propostos por Nelder and Wedderburn (1972), os modelos lineares generalizados sao
uma extensao dos modelos lineares que permitem que a variavel resposta tenha uma
distribuicao de probabilidade diferente da gaussiana, desde que sua distribuicao pertenca
a famılia exponencial de distribuicoes. Entretanto, no contexto de series temporais seu
uso nao e o mais adequado, pois e assumida a independencia entre as observacoes, o que
nao ocorre em series temporais.
Harrison and Stevens (1976) definiram a classe dos modelos lineares dinamicos e
desenvolveram uma abordagem bayesiana para tal tipo de modelagem e previsao. A
ideia e que os parametros possam variar no tempo. Desta forma, a relacao entre as
covariaveis e variavel resposta e dinamica, mantendo, condicionalmente aos estados a
independencia dos observaveis.
Smith (1979) propoe uma extensao da metodologia de Harrison and Stevens (1976)
na qual considera a modelagem de dados com distribuicao diferente da gaussiana. O
autor busca encontrar formas alternativas para atualizar o nıvel da serie, uma vez que a
simples adicao de termos de erro para inflacao de incerteza acarreta intratabilidade para
a priori, em contextos mais genericos que o normal. E utilizado entao um processo de
tomada de decisao bayesiano, de forma que sejam satisfeitas as seguintes condicoes: as
decisoes relacionadas a uma determinada funcao perda deverao permanecer constantes
enquanto nao houver informacoes futuras, ja perda esperada associada a essas decisoes
aumentara no decorrer deste intervalo. A ideia e que a priori para os estados no tempo
1

t e proporcional a priori do tempo t− 1 elevada a uma determinada potencia ω. Dessa
forma, mantem-se a media da distribuicao e a incerteza aumenta. Uma explicacao mais
detalhada sobre tal modelo podera ser encontrada na Secao 3.2.2.
Nessa linha de pensamento, Harvey and Fernandes (1989) apresentam uma forma de
modelar a media da serie para dados qualitativos e de contagem. Um hiperparametro e
introduzido no modelo de forma que as observacoes passadas sao descontadas ao se fazer
previsoes. O metodo de estimacao escolhido para este hiperparametro foi o de maxima
verossimilhanca. Variaveis explicativas podem ser inseridas atraves da funcao de ligacao
do Modelo Linear Generalizado (MLG). Tambem e permitido que efeitos sazonais e de
tendencia sejam considerados na modelagem, contudo nao e permitido que estes sejam
estocasticos.
Gamerman et al. (2013) introduzem a classe dos Modelos Dinamicos da Famılia Gama.
Tambem e apresentada uma especificacao expandida para a evolucao do sistema que,
assim como em Harvey and Fernandes (1989), utiliza um hiperparametro na distribuicao
da componente do nıvel do modelo que atua como um fator de desconto. Como metodos
de inferencia para tal, sao utilizados o Metodo de Maxima Verossimilhanca e estimadores
Bayesianos. Uma vantagem do metodo e que a forma analıtica da verossimilhanca e
mantida.
Uma outra alternativa de inferencia para modelos lineares dinamicos generalizados e
o metodo via compatibilizacao de momentos proposto por West et al. (1985). Este utiliza
metodos de aproximacao para obter as estimativas do modelo, uma vez que somente as
distribuicoes do parametro canonico e da preditiva tem forma analıtica fechada. Uma das
dificuldades encontradas e que ha duas distribuicoes a priori para o parametro natural da
famılia exponencial: uma induzida pelo vetor de estados e outra obtida por conjugacao
da famılia exponencial. A solucao encontrada por West et al. (1985), foi compatibilizar
os momentos de tais prioris.
No que concerne a compatibilizacao de prioris, Poole and Raftery (2000) e referencias
citadas neste artigo propoem uma metodologia denominada Bayesian Melding. Sao su-
geridas duas formas de compatibilizacao: linear pooling e logarithm pooling. No primeiro
caso, sugere-se uma combinacao convexa de prioris, isto e, atribui-se pesos para cada
2

uma delas. Ja no segundo caso, e proposta uma multiplicacao de prioris, de forma que
cada uma e elevada a um determinado peso. Argumenta-se que o segundo caso e mais
eficiente no sentido de que pode-se compatibilizar e depois atualizar a priori via Teorema
de Bayes, ou atualizar e depois compatibilizar, obtendo-se a mesma posteriori, o que nao
acontece quando utilizada a metodologia linear pooling.
Nesta dissertacao, sera proposta uma outra forma de compatibilizacao de prioris
que utiliza conceitos de Geometria da Informacao tais como Teorema da Projecao e
Divergencia de Kullback-Leibler. A ideia e projetar a priori induzida para o parametro
canonico pelo vetor de estados no espaco da priori conjugada para este parametro e depois
compatibiliza-las. Uma vez que as prioris sao compatibilizadas, torna-se simples atualiza-
las. Duas distribuicoes a posteriori sao obtidas para o preditor linear: uma induzida pela
conjugacao do parametro canonico e outra induzida pela distribuicao assumida para os
estados. A solucao encontrada foi projetar a distribuicao induzida pela conjugacao do
parametro natural no espaco da distribuicao induzida pelo vetor de estados. Uma vez que
tal compatibilizacao seja feita, utilizamos o metodo Linear Bayes para obter os momentos
do vetor de estados.
Souza et al. (2016) expandem a metodologia proposta por West et al. (1985) para a
famılia exponencial biparametrica. Tal expansao nao e simples de ser feita, pois ha de
se resolver um sistema que conta, eventualmente, com mais equacoes, referentes aos mo-
mentos relacionados a media e precisao do vetor de preditores lineares, do que parametros
provenientes da priori conjugada da famılia exponencial. Como solucao, foi utilizado o
Metodo de Momentos Generalizado. Serao apresentado neste trabalho aplicacoes de tal
metodologia, bem como uma solucao para o caso Multinomial, sendo esta uma extensao
do trabalho de Souza et al. (2016).
Este trabalho esta organizado em 6 capıtulos, incluindo este. O segundo capıtulo
contem conceitos basicos de famılia exponencial e geometria da informacao para desen-
volvimento das metodologias a serem propostas. O capıtulo 3 revisita os metodos de
estimacao para MLDG sugeridos por West et al. (1985) e Gamerman et al. (2013). O
quarto capıtulo traz uma proposta de inferencia para os MLDG da famılia exponencial
uniparametrica via geometria da informacao. O capıtulo 5 apresenta uma abordagem via
3

metodo Conjugate Updating estendido para a famılia exponencial k-parametrica, sugerida
por Souza et al. (2016). Por fim, o ultimo capıtulo apresenta as conclusoes e trabalhos
futuros desta pesquisa.
4

Capıtulo 2
Conceitos Basicos
Ao longo deste capıtulo serao apresentados conceitos basicos que serao utilizados no
desenvolvimento do modelo proposto. As secoes deste capıtulo estao divididas entre
Famılia Exponencial e Geometria da Informacao.
2.1 Famılia Exponencial
Uma distribuicao e pertencente a famılia exponencial se a sua funcao densidade de
probabilidade, p(y|η), pode ser escrita da seguinte forma (Bernardo and Smith (2001)):
p(y|η) = f(y)g(η)exp
k∑i=1
ciφihi(y)
(2.1)
onde h = (h1, . . . , hk), φ(η) = (φ1, . . . , φk) e dadas as funcoes f, h, φ e as constantes ci,
1
g(η)=
∫Y
f(y)exp
k∑i=1
ciφihi(y)
dy <∞. (2.2)
Ademais, se y1, . . . , yn ∈ Y e uma sequencia permutavel tal que, dada a famılia
exponencial regular k-parametrica,
p(y1, . . . , yn) =
∫H
n∏i=1
p(y|η)dQ(η), (2.3)
5

para algum dQ(η), entao,
Tn = Tn(y1, . . . , yn) =
[n∑i=1
h1(yi), . . . ,n∑i=1
hk(yi)
], n = 1, 2, . . . (2.4)
e uma sequencia de estatısticas suficientes.
Usualmente, a famılia exponencial e apresentada em sua forma canonica. Tal repre-
sentacao pode ser obtida apos algumas tranformacoes na definicao apresentada, resul-
tando na seguinte expressao:
p(x|ψ) = c(x)expxtψ − b(ψ)
. (2.5)
Em que x = (x1, . . . , xk), xi = hi(y), ψi = ciφi(η) e ψ = (ψ1, . . . , ψk) onde i = 1, . . . , k.
Utilizando elementos de sua representacao na forma canonica, podemos encontrar
media e variancia da distribuicao em analise, isto e,
E(x|ψ) = ∇b(ψ), V (x|ψ) = ∇2b(ψ) (2.6)
A seguir serao apresentados exemplos de distribuicoes pertencentes a famılia exponencial.
Exemplo 2.1.1 Poisson(η):
p(y|η) =ηye−η
y!
=1
y!exp y log(η)− η.
Dessa forma, a distribuicao Poisson pertence a famılia exponencial uniparametrica
com: x = h(y) = y, c(y) = 1/y!, ψ = log(η) e b(ψ) = η.
6

Exemplo 2.1.2 Normal(µ, σ2):
p(y|µ, σ2) =1√2πσ
exp
−1
2σ2(y − µ)2
=
1√2πσ
exp
−1
2σ2(y2 − 2µy + µ2)
=
1√2π
exp
−y2
2σ2+µy
σ2− µ2
σ2− 1
2log(σ2)
.
Portanto a distribuicao Normal pertence a famılia exponencial biparametrica com
vetor parametrico η = (µ, σ2), onde: x1 = h1(y) = y, x2 = h2(y) = y2, c(y) =
1√2π
,
ψ = [(−µ/σ2) , (−1/2σ2)] e b(ψ) = (1/2) (µ2/σ2) + log(σ2).
Exemplo 2.1.3 Bernoulli(η):
p(y|η) = ηy(1− η)1−y
= exp
y log
(η
1− η
)+ log(1− η)
.
Assim, a distribuicao Bernoulli pertence a famılia exponencial uniparametrica onde: x =
h(y) = y, c(y) = 1, ψ = log(
η1−η
)e b(ψ) = log(1− η).
Exemplo 2.1.4 Multinomial com p categorias, assumindo∑p
i=1 yi = n e∑p
i=1 ηi = 1:
p(y|η) =n!∏pi=1 yi!
p∏i=1
ηyii
=n!∏pi=1 yi!
exp
p∑i=1
yi log(ηi)
.
Portanto a distribuicao Multinomial pertence a famılia exponencial p-parametrica com
vetor parametrico η = (η1, . . . , ηk), onde: x1 = h1(y) = y1, x2 = h2(y) = y2, . . . , xp =
hp(y) = yp, c(y) = n!∏pi=1 yi!
e ψ = (log(η1), . . . log(ηp)).
2.1.1 Conjugacao na Famılia Exponencial
Uma caracterıstica importante da famılia exponencial e que existe uma estatıstica
suficiente para o vetor parametrico com dimensao fixa. Assim, torna-se simples encontrar
7

a distribuicao a priori conjugada a distribuicoes pertencentes a tal famılia. A ideia
e que, uma vez atribuıda uma distribuicao a priori para os parametros, e sendo esta
pertencente a famılia exponencial, a distribuicao a posteriori pertencera a mesma classe
de distribuicoes da priori havendo apenas uma mudanca nos hiperparametros.
Seja y = (y1, . . . , yn) uma amostra de uma distribuicao pertencente a famılia expo-
nencial tal que
p(y|η) =n∏i=1
f(yj) [g(η)]n exp
k∑i=1
ciφi(η)
(n∑j=1
(yj)
),
entao a conjugada para η tera a seguinte forma (Bernardo and Smith (2001)):
p(η|τ) = [K(τ)]−1 [g(η)]τ0 exp
k∑i=1
ciφi(η)τi
, η ∈ H,
onde τ e tal que K(τ) =∫H
[g(η)]τ0 exp∑k
i=1 ciφi(η)τi
dη <∞.
Exemplo 2.1.5 Poisson(η):
p(y|η) =η∑ni=1 yie−nη∏ni=1 yi!
=
[n∏i=1
yi!
]−1exp −nη exp
log(η)
n∑i=1
yi
.
Logo,
p(η|τ0, τ1) ∝ exp −τ0η exp τ1 log(η)
=1
K(τ0, τ1)ητ1 exp −τ0η (2.7)
Sendo este o nucleo da distribuicao Gama, pois e da forma ηae−bη. Assim, a priori
conjugada sera η ∼ G(α, β), onde α = τ1 + 1 e β = τ0.
8

Exemplo 2.1.6 Bernoulli(p):
p(y|p) = p∑ni=1 yi(1− p)n−
∑ni=1 yi
= (1− p)n exp
log(p)
n∑i=1
yi − log(1− p)n∑i=1
yi
.
Assim,
p(p|τ0, τ1, τ2) ∝ (1− p)τ0 exp
τ1log
(p
1− p
)=
1
K(τ0, τ1)pτ1(1− p)τ0−τ2 .
Dessa forma, o nucleo encontrado remete a distribuicao Beta.
Exemplo 2.1.7 Multinomial com k categorias, assumindo∑k
i=1 yi = n,∑k
i=1 ηi = 1 e
ηk = 1−∑k−1
i=1 ηi:
p(y|η) =n!∏k−1i=1 yi!
(k∏i=1
ηyii
)η(n−
∑k−1i=1 yi)
k
=n!∏ki=1 yi!
exp
k∑i=1
yi log
(ηiηk
)+ n log(ηk)
.
Deste modo,
p(η|τ1, . . . , τp) ∝ exp
k∑i=1
τi
(ηiηk
)+ τ0 log(ηk)
=1
K(τ0, . . . , τk)exp
k∑i=1
τi
(ηiηk
)+ τ0 log(ηk)
,
que e o nucleo da distribuicao Dirichlet onde cada αi = τi + 1, i = 1, . . . , n.
9

2.2 Geometria da Informacao
2.2.1 Divergencias
No presente trabalho, a nocao de divergencia sera aplicada da seguinte forma: ad-
mitiremos que o vetor de estados que governam o preditor linear em um MDLG siga,
a priori, distribuicao gaussiana. Como veremos adiante, tal hipotese induz uma distri-
buicao de probabilidade para o parametro canonico da famılia exponencial. Entretanto,
como visto na subsecao anterior, e possıvel obter distribuicao a priori conjugada para tal
parametro. Buscaremos compatibilizar a distribuicao conjugada e a distribuicao induzida
pelos estados por meio da minimizacao da divergencia entre estas.
A seguir, serao apresentadas as condicoes para que uma determinada divergencia seja
valida .
Sejam duas distribuicoes p(y) e q(y) em um espaco Y , que possuem como parametros
ξP e ξQ, respectivamente. A divergencia entre estas, D[p : q], e uma funcao de tais
parametros que satisfazem os seguintes criterios:
1. D[p : q] ≥ 0.
2. D[p : q] = 0, se e somente se p = q.
3. Se p(y) e q(y) sao distribuicoes suficientemente proximas, denotando suas coorde-
nadas como ξq = ξp + dξ, a expansao de Taylor de D pode ser escrita como:
D[ξP : ξQ + dξ] =1
2
∑gij(ξP )dξidξj +O(|dξ|3),
e a matrix G = (gij) e positiva definida, dependendo de ξP .
2.2.1.1 Divergencia de Bregman
Sejam duas distribuicoes de probabilidade p(y) e q(y), parametrizadas por ξP e ξQ,
respectivamente. A divergencia de P para Q, derivada de uma funcao convexa ψ, pode
ser escrita como:
10

Dψ[p(y) : q(y)] = ψ(ξP )− ψ(ξQ)−∇ψ(ξQ)T (ξP − ξQ), (2.8)
onde ∇ representa o gradiente da funcao.
Se ψ(u) for definida como∑
i uilog(ui), obtem-se a divergencia de Kullback-Leibler a
ser apresentada a seguir.
2.2.1.2 Divergencia de Kullback-Leibler
Uma das metricas mais utilizadas para se medir dissimilaridades entre distribuicoes e
a divergencia de Kullback-Leibler. Podemos defini-la da seguinte forma: sejam p(y) e q(y)
duas distribuicoes de probabilidade da variavel aleatoria Y , a divergencia de Kullback-
Leibler sera dada por:
DKL[p(y) : q(y)] =
∫p(y) log
p(y)
q(y)dy (2.9)
Se Y for uma variavel discreta, a integral e substituıda pelo somatorio. A seguir
encontra-se a prova de que a divergencia de KL e de fato uma divergencia.
Prova das condicoes:
(a) DKL[p(y) : q(y)] ≥ 0:
Seja D = Y : p(y) > 0 o espaco de p(y). Admita Y variavel aleatoria contınua,
−DKL[p(y) : q(y)] = −∫p(y) log
p(y)
q(y)dy (2.10)
=
∫p(y) log
q(y)
p(y)dy (2.11)
≤ log
∫p(y)
q(y)
p(y)dy (2.12)
= 0 (2.13)
Logo, DKL[p(y) : q(y)] ≥ 0. A equacao (2.12) e resultado obtido da Desigualdade de
Jensen.
11

(b) Se p(y) = q(y):
DKL[p(y) : p(y)] =
∫p(y) log
p(y)
p(y)dy
= 0
(c) Por expansao de Taylor:
f(ξ) = f(ξ0) + fi(ξ)(ξ − ξ0)i +1
2fij(ξ0)(ξ − ξ0)i(ξ − ξ0)j +O(|dξ|3)...
Onde fi(ξ) representa a primeira derivada e fij(ξ) a segunda derivada da funcao a
ser expandida em serie de Taylor; no caso em tela, a propria Divergencia de KL.
Conforme observado anteriormente, temos que f(ξ0) = 0 pois DKL[p(y) : p(y)] e
igual a zero por (a). Temos inclusive que fi(ξ) tambem e igual a zero, pois e a ponto
mınimo da funcao e a derivada do mınimo e zero.
Sejam as disribuicoes p(y) e q(y) parametrizadas por ξp e ξq + dξ, respectivamente.
Assim,
DKL[ξp : ξq + dξ] =1
2
∑gij(ξp)dξidξj +O(|dξ|3),
onde,∑gij(ξp) = fij(ξ0)(ξ − ξ0)i(ξ − ξ0)j
2.2.2 Teoremas
Os teoremas apresentados aqui servirao como base para o desenvolvimento da metodo-
logia proposta para a classe dos Modelos Lineares Dinamicos Generalizados. O teorema
da projecao nos indica que a menor distancia entre duas distribuicoes vai ser equivalente
a minimizar a Divergencia de KL entre elas, o que tambem equivale a igualar os momenos
na famılia exponencial. Ja o teorema seguinte nos auxilia no que concerne a abordagem
que compatibiliza modelos.
12

Teorema 2.2.1 (Teorema da projecao) Seja p(y) uma distribuicao de probabilidade
em um espaco Y. Considere S um modelo da famılia exponencial em Y. O Teorema de
Projecao afirma que a distribuicao q(y) que minimiza a divergencia DKL [p : q] , q(y) ∈ S
e tal que Eq(hi(y)) = Ep(hi(y)) ∀i.
x
xP
Qp
S
M
Figura 2.1: Exemplo do Teorema da Projecao
Prova:
Seja τ = argminτDKL[p : q] =∫p log p−
∫p log q . Observe que a primeira integral
nao depende dos parametros em q(y), portanto focaremos na segunda integral. Temos
que
−∫p(y) log q(y) = −
∫p(y) h(y)η − b(η)
∂ηi =
∫p(y)hi(y) + ∂ηib(η)
= −Ep(hi(y)) + µi = 0
µi = Ep(hi(y)) (2.14)
Teorema 2.2.2 Sejam R, Q e U distribuicoes de probabilidade equivalentes e pertencen-
tes a famılia exponencial, parametrizadas respectivamente por ξr, ξq e ξu. Por definicao,
estas estao sob a mesma geodesica e portanto uma combinacao convexa pode ser feita nos
13

parametros de forma que ξx pode ser escrito da seguinte forma:
ξu = sξq + (1− s)ξr (2.15)
De forma que o uso dos teoremas (2.2.1) e (2.2.2) simultaneamente, resultam na
compatibilizacao das distribuicoes em uma das abordagens propostas.
x
xP
Qp
SSR
x
xU
Figura 2.2: Exemplo de Compatibilizacao de Variaveis
14

2.2.3 Exemplos de Projecoes
2.2.3.1 Projetando a Distribuicao Log-Normal na Gama
Seja p(y) a distribuicao Log-Normal. Queremos encontrar a distribuicao Gama que
melhor aproxima tal distribuicao segundo a divergencia de Kullback-Leibler. Tal distri-
buicao esta representada aqui por q(y).
Pelo Teorema (2.2.1) apresentado, sabe-se que devemos encontrar a Gama que mini-
miza a divergencia de Kullback Leibler.
Assim, deseja-se encontrar os parametros da Gama que minimizam a distancia de
Kullback-Leibler. Ou seja, tem-se por objetivo encontrar o
minξ DKL(p : q) = min
∫p(y) log
p(y)
q(y)dy
onde, p(y) e a distribuicao Log-Normal(µ, σ2) e q(y) e a distribuicao Gama(a, b).
Podemos reescrever a divergencia como
DKL(p : q) =
∫p(y) log p(y)dy −
∫p(y) log q(y)dy. (2.16)
Observe que minimizar a divergencia de Kullback-Leibler e equivalente a maximizar a
segunda integral, pois∫p(y) log p(y)dy e uma constante que nao depende dos parametros
a e b.
Como,
log q(y) = a log b+ (a− 1) log y − by − logΓ (a).
l(a, b) =
∫p(y) log q(y)dy = a log b+ (a− 1)Ep(log y)− bEp(y)− logΓ (a)
= a log b+ (a− 1)µ− b exp(µ+ (1/2)σ2)− logΓ (a).
(2.17)
Derivando e igualando a equacao (2.17) a zero e possıvel encontrar os parametros da
Gama que melhor aproxima uma distribuicao Log-Normal.
15

Dessa forma,
∂l(a, b)
∂a= log b+ µ− Ψ(a) (2.18)
∂l(a, b)
∂b=a
b− exp(µ+ (1/2)σ2) (2.19)
onde Ψ(a) e a funcao digamma de a.
Igualando as derivadas acima a zero temos que:
b = exp(Ψ(a)− µ) (2.20)
a = b exp(µ+ (1/2)σ2). (2.21)
Nas equacoes (2.20) e (2.21), os parametros a e b ainda nao puderam ser isolados de
forma que um nao dependesse mais do outro. Assim, o log foi aplicado nas equacoes
como forma de contornar esse problema. Alem disso, aplicou-se uma aproximacao para
Ψ(a) como proposto por Abramovitz:
Ψ(a) = log a− 1
2a+O
(1
a2
), se a →∞.
Dessa forma,
log b = log a− 1
2a− µ
log a = log b+ µ+ (1/2)σ2. (2.22)
Resolvendo esse sistema de equacoes,
1
2a= (1/2)σ2
a =1
σ2(2.23)
16
b = a exp(−µ− (1/2)σ2)
=1
σ2exp(−µ− (1/2)σ2). (2.24)
Foi possıvel, portanto, encontrar os valores de a e b
a = σ−2 e b = σ−2 exp−µ− (1/2)σ2
. (2.25)
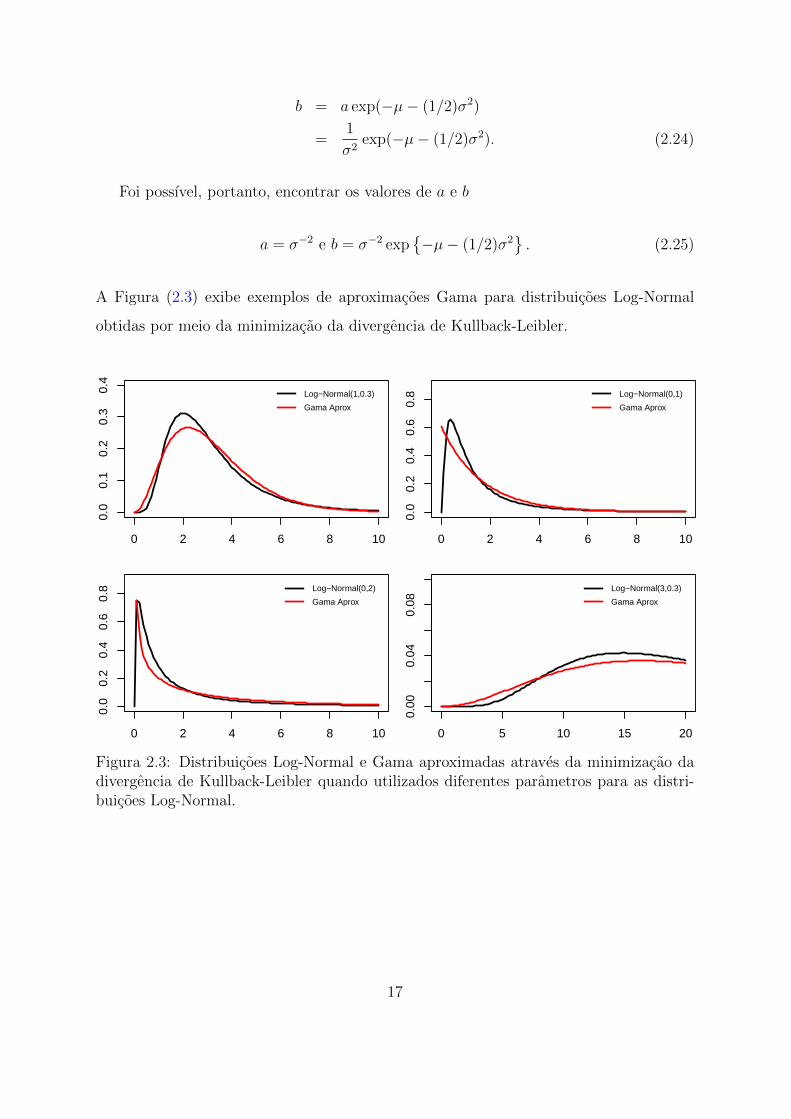
A Figura (2.3) exibe exemplos de aproximacoes Gama para distribuicoes Log-Normal
obtidas por meio da minimizacao da divergencia de Kullback-Leibler.
0 2 4 6 8 10
0.0
0.1
0.2
0.3
0.4
Log−Normal(1,0.3)
Gama Aprox
0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8
Log−Normal(0,1)
Gama Aprox
0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8 Log−Normal(0,2)
Gama Aprox
0 5 10 15 20
0.00
0.04
0.08
Log−Normal(3,0.3)
Gama Aprox
Figura 2.3: Distribuicoes Log-Normal e Gama aproximadas atraves da minimizacao dadivergencia de Kullback-Leibler quando utilizados diferentes parametros para as distri-buicoes Log-Normal.
17

2.2.3.2 Projetando a Distribuicao Logito-Normal na Beta
Seja p(y) a distribuicao Logito-Normal(µ, σ2). Queremos encontrar a distribuicao
Beta(a, b) que melhor aproxima tal distribuicao segundo a distancia de Kullback-Leibler.
Tal distribuicao Beta esta representada aqui por q(y).
DKL(p : q) =
∫p(y) log p(y)dy −
∫p(y) log q(y)dy. (2.26)
Assim, basta maximizar a segunda integral, pois a primeira nao depende dos parametros
da Beta que se deseja obter.
log q(y) = (a− 1) log(y) + (b− 1) log(1− y) + log
Γ (a+ b)
Γ (a)Γ (b)
.
l(a, b) =
∫p(y) log q(y)dy = (a− 1)Ep(log(y)) + (b− 1)Ep(log(1− y)) + log
Γ (a+ b)
Γ (a)Γ (b)
Os momentos da distribuicao Logito-Normal nao tem solucao analıtica. Para contor-
nar esse problema, foi utilizado o metodo de Monte-Carlo para encontrar E(log(y)) e
E(log(1− y)). Uma vez encontrado tais valores esperados, segue-se para o proximo
passo, que e encontrar os parametros a e b da Beta.
Dessa forma,
∂l(a, b)
∂a= E(log(y)) + Ψ(a+ b)− Ψ(a) (2.27)
∂l(a, b)
∂b= E(log(1− y)) + Ψ(a+ b)− Ψ(b) (2.28)
onde, Ψ(θ) representa a funcao digamma de θ. Aqui tambem utilizou-se como apro-
ximacao de Ψ(θ) como proposto por Abramovitz:
Ψ(θ) = log (θ)− 1
2θ.
Dessa forma,
18
log b− 1
2b= E(log(1− y)) + Ψ(a+ b);
log a− 1
2a= E(log(y)) + Ψ(a+ b). (2.29)
Observe que nao e possıvel isolar os parametros a e b analiticamente. Para que tais
resultados pudessem ser encontrados, foi utilizado o metodo de Newton-Raphson.
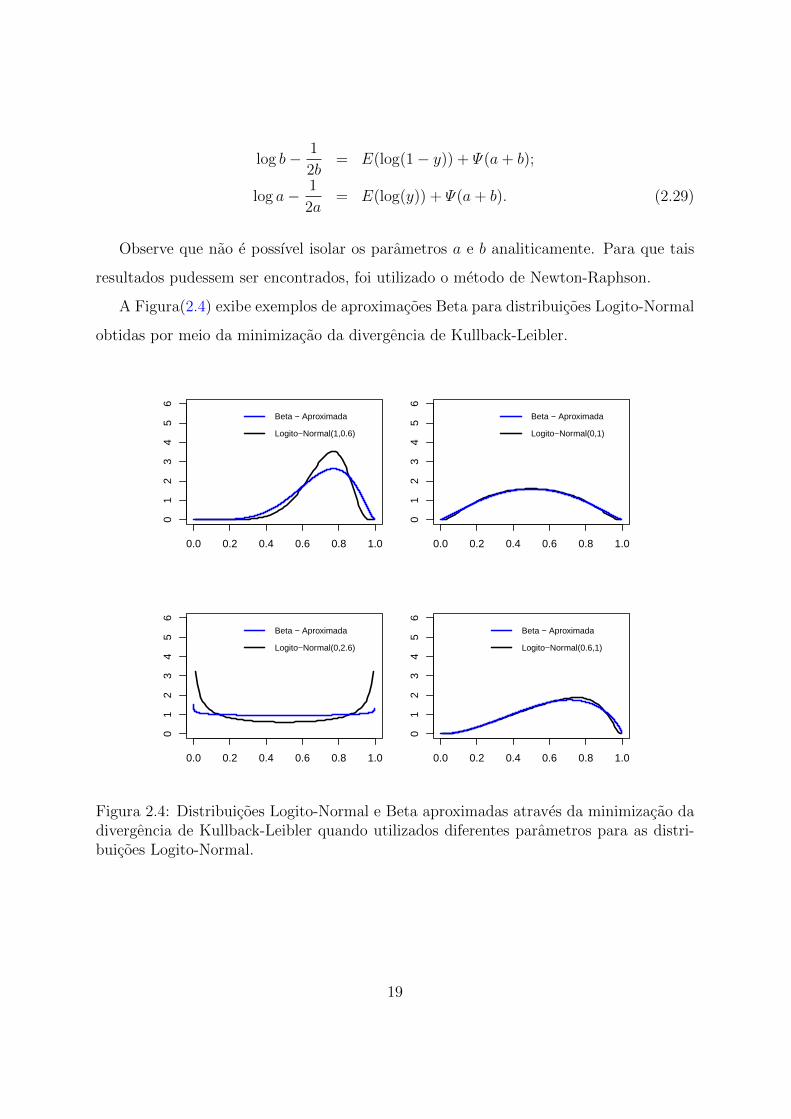
A Figura(2.4) exibe exemplos de aproximacoes Beta para distribuicoes Logito-Normal
obtidas por meio da minimizacao da divergencia de Kullback-Leibler.
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
Beta − Aproximada
Logito−Normal(1,0.6)
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
Beta − Aproximada
Logito−Normal(0,1)
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
Beta − Aproximada
Logito−Normal(0,2.6)
0.0 0.2 0.4 0.6 0.8 1.0
01
23
45
6
Beta − Aproximada
Logito−Normal(0.6,1)
Figura 2.4: Distribuicoes Logito-Normal e Beta aproximadas atraves da minimizacao dadivergencia de Kullback-Leibler quando utilizados diferentes parametros para as distri-buicoes Logito-Normal.
19

Capıtulo 3
Modelos Dinamicos Generalizados
E bastante usual ter-se interesse na modelagem de variaveis que nao sao acomodadas
por uma distribuicao normal. Por exemplo, variaveis binarias ou de contagem e variaveis
com comportamento assimetrico. Este capıtulo tem por objetivo apresentar a classe
dos modelos lineares generalizados tanto na sua forma estatica quanto dinamica. No
que se refere a inferencia na classe dos modelos lineares dinamicos generalizados, serao
apresentados os metodos de inferencia via Conjugate Updating e via modelos dinamicos
que admitem evolucao somente da media o qual denominaremos de modelos dinamicos
nao estruturados.
Os modelos dinamicos lineares generalizados podem ser vistos como uma generalizacao
dos modelos lineares generalizados, no sentido de aliar a flexibilidade de respostas nao
gaussianas, efeitos dinamicos associados a covariaveis e outras componentes estruturais.
Tal mecanismo de dinamica naturalmente acomoda a autocorrelacao inerente a dados
temporalmente observados.
Os modelos lineares generalizados sao uma extensao dos modelos lineares para res-
posta gaussiana. Propostos por Nelder e Wedderburn (1972), estes permitem que a
variavel que se deseja analisar tenha uma distribuicao de probabilidade diferente da
gaussiana, uma vez que sua distribuicao pertenca a famılia exponencial de distribuicoes.
Os modelos lineares generalizados contem tres componentes, sendo:
(a) a variavel resposta Y, que e a componente aleatoria do modelo e para o qual assume-se
20

distribuicao pertencente a famılia exponencial na forma canonica.
(b) componente sistematica dada por um preditor linear λ construıdo com base nas
variaveis explicativas do modelo, x = (x1, . . . , xp);
(c) uma funcao g monotona e diferenciavel que liga o valor esperado de T , µ = E(Y ),
ao preditor linear λ denominada funcao de ligacao. Embora a funcao de ligacao
possa ser especificada arbitrariamente, uma forma de se determinar g e atraves da
parametrizacao natural (canonica) da famılia exponencial. Tem-se entao:
λi = g(µi) (3.1)
onde λi e o preditor linear, µi e a media e g a funcao de ligacao.
E assumido que a media transformada segue um modelo linear, de forma que:
λi = xTi β. (3.2)
Como a funcao e um-a-um,
µi = g−1(xTi β). (3.3)
Ha diversas formas de se escolher a funcao de ligacao a ser utilizada, sendo o metodo
mais usual e considerar ψi = λi, onde ψi e chamado parametro canonico da distri-
buicao. Dessa forma, esse tipo de funcao de ligacao e chamada de funcao de ligacao
canonica.
21

3.1 Modelos Lineares Dinamicos
Um caso particular dos modelos dinamicos lineares generalizados sa os modelos li-
neares dinamicos, para os quais pressupoe-se resposta gaussiana. Harrison and Stevens
(1976) definiram a classe dos modelos lineares dinamicos e desenvolveram uma aborga-
gem Bayesiana para tal tipo de modelagem e previsao. A ideia e que os parametros
possam variar no tempo. Desta forma, a relacao entre as covariaveis e a variavel resposta
e dinamica. E importante ressaltar que os MLG (e os Modelos Lineares normais, que sao
um de seus casos particulares) nao dao tratamento a dependencia temporal inerente a da-
dos observados ao longo do tempo, o que ocorre no caso dos Modelos Lineares Dinamicos.
Sejam:
θt o vetor de estados de dimensao p× 1;
Yt o vetor de observacoes de dimensao r × 1;
Ft a matriz que contem as covariaveis no tempo t de dimensao p× r;
Gt a matriz de evolucao parametrica no tempo t de dimensao p× p ;
Vt e Wt matrizes de covariancia, sendo a primeira relacionada ao erro observacional e a
segunda ao erro evolutivo.
Um modelo dinamico e caracterizado pela quadrupla Ft, Gt, Vt,Wt e sua estrutura
mais geral pode ser definida da seguinte forma:
Equacao Obs.: Yt = F ′tθt + νt onde νt ∼ N(0, Vt) (3.4)
Equacao Evol.: θt = Gtθt−1 + ωt onde ωt ∼ N(0,Wt) (3.5)
onde a primeira equacao e a observacional e a segunda e a de evolucao.
Seja Dt o historico das informacoes ate o tempo t e admita Dt = Dt−1 ∪ Yt, com D0
denotanto a informacao que se tem antes da primeira observacao. Assuma a informacao
inicial como (θ0|D0) ∼ N(m0, C0).
Condicionalmente a θt, yt independe de yt−1, ..., y1. Observe-se, entretanto, a asso-
22

ciacao entre θt e θt−1, explicitada na equacao de evolucao em 3.5. O tratamento da
autocorrelacao temporal entre as quantidades observaveis y1, ..., yt e viabilizado por tal
relacao, como ilustra a figura 3.1:
yt−1 yt
θt−1 θt
Figura 3.1: Ilustracao da evolucao do sistema
Os erros observacionais e evolutivos sao independentes ao longo do tempo e uns com os
outros. Os erros ωt controlam a evolucao atraves de sua variancia, elementos da diagonal
principal de Wt. Quanto maior (menor) seu valor, mais erratica (suave) a variacao da
media sera e a media zero dos erros garante constancia local. A relacao entre Wt e Vt
fornece indıcios para avaliar de onde vem o movimento da serie. No caso W/V pequeno
teremos que boa parte deste movimento se da devido as observacoes. Enquanto W/V
grande implica que o movimento se da devido as observacoes, mas tambem as variacoes
do nıvel da serie, sendo este F ′tθt.
Considere o caso Y escalar e a variancia observacional constante e conhecida igual
a Vt = V = 1/φ. Assim, as distribuicoes a priori para o vetor de estados, posteriori e
previsao um passo a frente serao dadas por:
(a) priori :
(θt|Dt−1) ∼ N(at, Rt) (3.6)
at = Gtmt−1,
Rt = GtCt−1G′t +Wt.
(b) Previsao 1 passo a frente:
(Yt|Dt−1) ∼ N(ft, qt) (3.7)
23

ft = F ′tat,
qt = F ′tRtFt + V.
(c) posteriori :
(θt|Dt) ∼ N(mt, Ct) (3.8)
mt = at +RtFt(et)φ/(qtφ+ 1), (3.9)
Ct = Rt −RtFt(FtRt)′φ/(qtφ+ 1) (3.10)
et = Yt − ft
Harrison and Stevens (1976) indicam que a especificacao de Wt pode ser difıcil de
ser feita, entao, uma alternativa que foi proposta por Ameen and Harrison (1984) e
utilizada. Eles propuseram a utilizacao de fatores de desconto, sendo estes a porcentagem
de informacao que passa de um perıodo a outro. Desta forma, a matriz Wt passa a ser
especificada a partir de uma matriz de fatores de desconto Bt e Rt passa a ser dada por:
Rt = BtGtCt−1G′tBt,
sendo B a matriz diagonal r × r de descontos 1√δi
com 0 < δi < 1 para i = 1, ..., p.
A ideia de fator de desconto e a seguinte: a medida que a informacao ”envelhece”, torna-
se menos util e, portanto, seu peso deve diminuir. Ou seja, o fator de desconto δ pode
ser pensado como a porcentagem de informacao passada, a cada tempo t, aos tempos
posteriores. Quanto mais proximo de 1 for o desconto, mais suave sera a evolucao dos
estados, enquanto quanto menor, mais brusca ela sera, pois teremos mais incerteza para a
predicao. Se o desconto for 1, desde que G seja a matriz identidade e os erros de evolucao
tenham media nula, o estado sera fixo no tempo, ou seja, o modelo e estatico no tempo.
Caso haja mais de uma componente no modelo, seja de tendencia ou sazonalidade, e im-
portante ressaltar a aplicacao pratica sugerida por (West and Harrison, 1996, p. 193:202)
de aplicar nao aplicar desconto fora da diagonal de GtCt−1G′t.
24

3.2 Modelos Lineares Dinamicos Generalizados
Esta secao tem por objetivo discutir metodos de inferencia para a classe dos modelos
lineares dinamicos generalizados (MLDG). Com o intuito de tornar mais claro o objetivo
da discussao de tais metodos de inferencia, segue como exemplo o caso Poisson.
Seja yt|ηt ∼ Poisson(ηt). Observe que a densidade desta distribuicao pode ser escrita
na famılia exponencial da seguinte forma:
p(yt|ηt) =ηytt e
−ηt
yt!
=1
yt!exp yt log(ηt)− ηt.
Vimos na Secao 2.1.1 que, uma vez que a distribuicao e pertencente a famılia exponencial,
torna-se simples encontrar a conjugada para seu parametro. Nessa mesma secao foi
mostrado que a distribuicao conjugada para o parametro ηt e uma Gama.
Alguns metodos de inferencia para a classe dos MLDG como os propostos por Smith
(1979), Harvey and Fernandes (1989) e Gamerman et al. (2013), atribuem uma evolucao
na media a cada tempo t, utilizando propriedades de conjugacao. Desta forma, nao
e necessario que se faca uso de nenhuma forma de aproximacao, uma vez que tanto a
distribuicao a posteriori para o parametro ηt como a distribuicao preditiva, terao formas
analıticas fechadas e conhecidas. Contudo, os modelos propostos por tais autores, embora
permitam a presenca de componentes sazonais e de tendencia, nao permitem que estas
sejam estocasticas.
Por outro lado, West et al. (1985) propoe que a media nao seja modelada diretamente
e sim atraves de uma funcao de ligacao que relaciona a tais componentes de tendencia
e sazonalidade. No caso da Poisson especificada anteriormente, e sabido que a media e
igual a ηt. Suponha que a funcao de ligacao escolhida, seja a canonica, ou seja, log(ηt).
g(ηt) = log(ηt) = F ′tθt (3.11)
onde Ft e o vetor de planejamento, que pode conter ou nao covariaveis, e θt e o vetor
25

de estados que, conforme visto na equacao 3.5, estao relacionados as componentes de
tendencia e sazonalidade. Observe que uma vez atribuıda uma distribuicao a priori para
θt, teremos uma distribuicao a priori induzida para ηt. Contudo, a adocao de distri-
buicao a priori conjugada e conveniente, entre outros motivos, pela decorrente existencia
de forma analıtica fechada para a distribuicao preditiva de futuras observacoes.. Dessa
forma, a solucao encontrada por West et al. (1985) foi igualar os momentos dessa dis-
tribuicao a priori induzida pelos estados aos momentos da priori conjugada. Observe
inclusive que os autores nao atribuem uma distribuicao especıfica para θt, sendo esta
especificada somente em termos de primeiro e segundo momentos. Uma vez definidos os
momentos da priori conjugada para ηt, e possıvel incorporar a nova informacao obtida
para que a posteriori para tal parametro seja definida. Veja que ηt e um escalar, en-
quanto θt e um vetor. Assim, a atualizacao dos estados a partir da posteriori de ηt nao
e trivial, sendo necessario o uso de um metodo de aproximacao chamado Linear Bayes.
Dessa forma, a distribuicao a posteriori para θt e obtida. E importante relembrar que,
embora sejam utilizados metodos de aproximacao, o modelo permite que sejam atribuıdas
componentes de tendencia e sazonalidade estocastimente e que a media seja decomposta
em termos de cada uma delas.
No metodo que proporemos no capıtulo seguinte, sugerimos que seja atribuıda uma
distribuicao Normal para o vetor de estados e que a priori induzida, por essa especificacao,
para o vetor canonico e sua priori conjugada sejam compatibilizadas a partir do uso de
conceitos de Geometria da Informacao.
Ao longo desta secao serao apresentados os modelos citados nesta breve introducao,
de forma mais aprofundada.
3.2.1 Conjugate Updating
Modelos lineares dinamicos generalizados (MLDG) sao uma extensao para os modelos
lineares dinamicos e para os modelos lineares generalizados. Os MLDG:
(a) Acomodam respostas pertencentes a famılia exponencial;
(b) Nao pressupoem, necessariamente, efeitos fixos associados a covariaveis no tempo.
26

West et al. (1985) propuseram uma extensao do tradicional modelo linear generalizado
relacionando µt a um preditor dinamico F ′tθt, atraves de uma funcao de ligacao monotona
e diferenciavel g(µt):
λt = g(µt) = F ′tθt. (3.12)
Admite-se, nesta classe de modelos, que Yt pertence a famılia exponencial e que o
parametro natural ψt tem priori conjugada da forma PC(αt, βt) para algum αt e βt,
podendo ser escrita da seguinte forma
p(ψt|Dt−1) = c(αt, βt) exp(αtψt − βta(ψt)).
O problema e que impor (3.12) traria muitas restricoes para a priori ψt, entao, para
contornar o problema, foi sugerido que a relacao entre g(ψt) e λt seria usada somente
como guia para formar a priori ψt, sendo notada por g(ψt) ≈ λt
As distribuicoes a priori e posteriori nao serao normalmente distribuıdas, contudo,
por analogia ao MLD, os primeiro e segundo momentos do vetor de estados θt serao dados
por
(θt−1|Dt−1) ∼ (mt−1, Ct−1), (3.13)
(θt|Dt−1) ∼ (at, Rt), (3.14)
onde,
at = Gtmt−1 e Rt = BtGtCt−1G′tBt
com matriz de evolucao Gt e matriz de desconto Bt conhecidas.
De (3.12),
ft = E(λt|Dt−1) = F ′tat,
qt = V ar(λt|Dt−1) = F ′tRtFt.
Ate aqui, a priori natural para o parametro ψt e somente parcialmente especificada,
27

tendo a forma
(ψt|Dt−1) ∼ PC(αt, βt)
sem nenhuma restricao a αt e βt. Esses valores serao escolhidos de acordo com a relacao
g(ψt) ≈ λt, de modo que fixando os dois primeiros momentos de g(ψt), sera possıvel
determinar αt e βt atraves de ft e qt.
Dessa forma, fica claro que a preditiva tem forma
p(Yt|Dt−1) =c(αt, βt)
c(αt + φYt, βt + φ)(3.15)
Enquanto a posteriori para (ψt|Dt) tem forma conjugada
PC(αt + φYt, βt + φ)
Uma analise Bayesiana completa requere tambem a distribuicao a posteriori para θt,
mas esta nao esta disponıvel porque a priori(θt|Dt−1) e apenas parcialmente especificada
e o modelo nao fornece uma verossimilhanca para θt. Entretanto, conforme visto anteri-
ormente o modelo nao precisa da especificacao completa da distribuicao para passar para
o tempo t+ 1 e sim dos primeiros e segundo momentos. Estes podem ser encontrados da
seguinte forma:
mt = E(E(θt|ψt, Dt)), (3.16)
Ct = V ar(E(θt|ψt, Dt)) + E(V ar(θt|ψt, Dt)). (3.17)
Como no caso normal, (θt|ψt, Dt) e condicionalmente independente de It = (Yt, Ft), sabe-
se que os momentos (3.16) e (3.17) sao de (θt|ψt, Dt−1). Na maioria das vezes, esses
momentos nao serao conhecidos e as unicas informacoes diponıveis serao os momentos
da conjunta (g(ψt), θ′t|Dt−1),
28

g(ψt)
θt|Dt−1
∼ ft
at
,
qt (RtFt)′
(RtFt) Rt
,onde a matriz de covariancia completa e singular. Assim, uma abordagem alternativa e
necessaria para que a informacao em It seja incorporada de de volta a θt.
O metodo Linear Bayes pode ser usado para fornecer o retorno da informacao em It
para θt. A densidade p(θt|ψt, Dt−1) e a distrbuicao preditiva desconhecida de (θt|ψt). A
media e o preditor no sentido de minimizar traco do risco quadratico [At(d)] com respeito
a d onde
At(d) = E[(θt − d)(θt − d)′|ψt, Dt−1].
A matriz de covariancia da distribuicao e o valor de At(d) na media. Dado que a media
e desconhecida, adota-se uma funcao linear g(ψt) como preditor de θt. Especificamente,
d deve ser escolhido de forma que d = d0 + d1g(ψt) para algum d0,d1 e d minimize a
soma de variancias dada por
rt(d) = traco E(At(d)|Dt−1), (3.18)
com esperanca em relacao a p(ψt|Dt−1).
Nesse modelo, os momentos da conjunta sao suficientes para determinar o preditor
requerido. Minimizando diretamente rt(d) com respeito a d0 e d1, mostra-se que o ponto
de mınimo e obtido em d = at, onde
at = at +RtFt(g(ψt)− ft)
qt. (3.19)
Assim, o resultado de E(At(d)|Dt−1 no ponto de mınimo e
Rt = Rt −RtFt(RtFt)
′
qt. (3.20)
Os valores at e Rt fornecem um preditor linear otimo de p(θt|ψt, Dt−1). O retorno da
informacao It pode ser completado agora, substituindo a media e covariancia condicionais
29

em (3.16) (3.17) por at e Rt para encontrar o preditor esperado e risco relativo dados por
mt = at +Rt(gt − ft)/qt, (3.21)
Ct = Rt −RtFt(RtFt)
′(1− pt/qt)qt
. (3.22)
onde gt = E(g(ψt|Dt) e pt = V ar(g(ψt)|Dt) podem ser calculados a partir da posteriori
(ψt|Dt).
3.2.2 Modelos Dinamicos de Nıvel Local
Smith (1979) estende a metodologia de Harrison and Stevens (1976) no sentido de
considerar a modelagem de dados com distribuicao diferente da gaussiana. A ideia pro-
posta e pensar na evolucao dos estados como um processo de decisao bayesiano de forma
que as decisoes com respeito a uma certa funcao perda permanecam constantes enquanto
nao houver novas observacoes e a perda esperada associada a essas decisoes aumente
durante esse intervalo. Verificou-se que a funcao (de calibre b) que satisfaz esses criterios
e tal que so assume dois valores, ou seja:
Lb(θ − d) =
0, |θ − d| ≤ b, b > 0
1, caso contrario.(3.23)
Smith (1979) demonstrou que a distribuicao a priori de hoje (tempo t) para os estados
e proporcional a posteriori do tempo anterior (tempo t− 1) elevada a uma determinada
potencia ω, tais criterios sao satisfeitos. Assim,
f(θt|Dt−1) ∝ f(θt−1|Dt−1)ωt , onde 0 < ω < 1. (3.24)
Dessa forma, garante-se que a media da distribuicao seja mantida e que a incerteza
aumente a cada tempo t.
Seja θt−1|Dt−1 ∼ N(mt−1, Ct−1)︸ ︷︷ ︸ft−1(·)
.
30

Desse modo,
ft−1(·) ∝ exp
−(θt −mt−1)
2
2Ct−1
. (3.25)
De (3.24),
θt|Dt−1 ≡ ctft−1(·)ω;
∝ ft−1(·)ω. (3.26)
De (3.25) e (3.26),
f(θt|Dt−1) ∝ exp
−(θt −mt−1)
2
2Ct−1
ω;
∝ exp
−(θ2t − 2mt−1θt)ω
2Ct−1
;
∝ exp
−1
2
θ2t1ωCt−1
− θtmt−11ωCt−1
.
Assim,
at = E(θt|Dt−1) = mt−1 = E(θt−1|Dt−1);
Rt = V (θt|Dt−1) =1
ωCt−1 =
1
ωV (θt−1|Dt−1).
Verifica-se, portanto, que a media da posteriori foi equivalente a da priori enquanto a
variancia foi inflacionada por um fator 1/ω
Uma vantagem desta forma de atualizacao proposta por Smith (1979) e a capacidade de
se poder compatibilizar e depois atualizar a priori via Teorema de Bayes, ou atualizar
e entao compatibilizar posterioris, preservando-se o mesmo resultado.. A distribuicao
a priori utilizada para formular o modelo de nıvel local com essas caracterısticas foi a
conjugada natural da famılia exponencial. Foi observado que seus procedimentos deram
origem a previsoes do tipo media movel exponencial ponderada. Harvey and Fernandes
(1989), tambem interessados em modelagem de dados qualitativos e de contagem, se ba-
seiam neste modelo. De forma analoga, introduzem hiperparametro que atua da mesma
forma que um fator de desconto. A diferenca se da na forma de estimacao desse hiper-
31

parametro: enquanto o primeiro nao menciona um metodo especıfico, o segundo sugere
o uso do estimador de maxima verossimilhanca. Smith and Miller (1986) generalizam a
metodologia de Smith (1979); consideram a equacao de evolucao exata, de forma que nao
sejam necessarias aproximacoes para a obtencao da distribuicao preditiva e dos estados.
Gamerman et al. (2013) se baseiam em Smith and Miller (1986), introduzem a classe
dos Modelos Dinamicos da Famılia Gama e apresentam uma forma de suavizacao para a
componente do nıvel do modelo.
E importante salientar que os modelos propostos por tais autores, embora permitam
a presenca de componentes sazonais e de tendencia, nao permitem que estas sejam es-
tocasticas. Os autores argumentem que esta nao e uma grave limitacao. Outro ponto
que deve ser mencionado e que a modelagem proposta permite que a distribuicao dos
dados sejam tanto uniparametricas, como k parametricas, sendo esta uma vantagem do
metodo. Sera apresentada nesta secao uma breve descricao dos modelos mencionados.
Mais detalhes podem ser encontrados em Smith (1979),Smith and Miller (1986), Harvey
and Fernandes (1989) e Gamerman et al. (2013).
Seja o Modelo Dinamico da Famılia Gama (MDFG) como definido em Gamerman
et al. (2013):
p(yt|µt, φ) = a(yt, φ)µb(yt,φ)t exp −µtc(yt, φ) (3.27)
Onde, yt ∈ H(φ) ⊂ < e p(yt|µt, φ) = 0, caso contrario.
Variaveis explicativas, podem ser inseridas em vetor de covariaveis xt. Este vetor se
relacionara com µt atraves da funcao de ligacao, de forma que µt = λtg(x′tβ), onde β
se refere aos coeficientes da regressao e λt e um parametro referente ao nıvel do modelo
dinamico. Tal parametro e definido atraves da equacao de evolucao λt = ω−1λt−1ζt, onde
ζt ∼ Beta(ωat−1, (1− ω)at−1), isto e,
ωλt
(1− λt)∼ Beta(ωat−1, (1− ω)st−1). (3.28)
As informacoes iniciais acerca do nıvel sao definidas atraves da priori λ0|D0 ∼
Gama(a0, b0).
Resultados referentes ao modelo apresentado em 3.27, sao apresentados a seguir.
32

A priori para λt|Dt−1 e uma distribuicao Gama(at|t−1, bt|t−1), onde :
at|t−1 = ωat−1; (3.29)
bt|t−1 = ωbt−1; (3.30)
0 ≤ ω ≤ 1.
Dessa forma,
E(λt|Dt−1) = ωat−1/ωbt−1 = at−1/bt−1, (3.31)
V ar(λt|Dt−1) = ωat−1/(ωbt−1)2 = ω−1V ar(λt−1|Dt−1). (3.32)
Nota-se, portanto, que a media se mantem e a variancia e inflacionada por um fator
1/ω a cada tempo t. Pode-se observar que ω atua conforme um fator de desconto.
Sendo µt = λtg(x′tβ), a distribuicao µt|Dt−1 e uma Gama com parametros a∗t|t−1 e
b∗t|t−1, onde tais parametros podem ser definidos como:
at|t−1 = ωat−1; (3.33)
bt|t−1 = ωbt−1g(x′tβ). (3.34)
Dada uma nova observacao a distribuicao a posteriori, µt|Dt, e uma Gama(a∗t , b∗t )
com parametros especificados por:
a∗t = a∗t|t−1 + b(yt, φ); (3.35)
b∗t = b∗t|t−1 + c(yt, φ). (3.36)
Desta maneira, a distribuicao a posteriori para λt|Dt tambem sera uma Gama com
parametros at e bt, com
at = at|t−1 + b(yt, φ); (3.37)
bt = bt|t−1 + c(yt, φ)g(x′tβ). (3.38)
33

A distribuicao preditiva um passo a frente, de forma que:
p(yt|Dt−1) =
∫ ∞0
p(yt|µt)p(µt|Dt−1dµt)
=Γ(a∗t|t−1 + b(yt, φ)
)c(yt, φ)(b∗t|t−1)
a∗t|t−1
Γ(a∗t|t−1
) [c(yt, φ) + b∗t|t−1
]b(yt,φ)+a∗t|t−1
(3.39)
34

Capıtulo 4
MLDG via Geometria da Informacao
4.1 Introducao
Ate o momento foram apresentados dois metodos de estimacao para a classe de mo-
delos lineares dinamicos generalizados: Conjugate Updating e Modelos de Nıvel Local. O
primeiro utiliza Linear Bayes para obter as estimativas do modelo, uma vez que somente
as distribuicoes do parametro canonico e da preditiva tem forma analıtica fechada. A
evolucao dos estados e descrita somente pelos primeiro e segundo momentos. Uma das
dificuldades encontradas e que ha duas distribuicoes a priori para o parametro natural
da famılia exponencial: uma induzida pelo vetor de estados e outra vinda por conjugacao
da famılia exponencial. A solucao encontrada por West, Harrison e Migon, foi igualar
os momentos de primeira e segunda ordem de tais prioris. Abre-se mao de ter forma
analıtica fechada para as distribuicoes associadas ao vetor de estados, mas preserva-se a
conveniencia das formas analıticas fechadas para a distribuicao a posteriori do parametro
canonico e para a distribuicao preditiva. Um dos objetivos do presente trabalho e pro-
por uma forma alternativa de compatibilizacao de prioris. Para isso, sao utilizados
conceitos de Geometria da Informacao tais como teorema da Projecao e divergencia de
Kullback-Leibler.No metodo proposto, assume-se evolucao gaussiana para os estados.E
importante ressaltar que, diferentemente dos modelos apresentados em 3.2.2, esta meto-
dologia permite que componentes de sazonalidade e de tendencia possam ser incorporadas
estocasticamente e que as regressores tenham parametros associados variando no tempo.
35

4.2 Metodo proposto
O metodo a ser apresentado e muito similar ao proposto por West et. al (1985)
e utiliza grande parte de sua estrutura. De forma analoga, e um metodo de inferencia
proposto para a famılia exponencial uniparametrica. A diferenca aqui se da na forma com
que duas prioris para o parametro canonico sao compatibilizadas: a priori conjugada
para tal parametro e a priori implicada pela suposicao de normalidade dos parametros
de estado que controlam o preditor linear do modelo.
Sabe-se que,
λt = g(ηt) = F ′tθt; (4.1)
Onde, Ft e uma matriz de forma de tamanho p×n, θt e o vetor de estados de tamanho
o p × 1, ηt e o parametro da distribuicao uniparametrica de interesse e g(ηt) e a funcao
de ligacao escolhida.
Observe que uma vez atribuıda uma priori para θt, havera duas prioris para a mesma
quantidade ηt: de um lado a priori implicada pela conjugacao na famılia exponencial e
de outro, a priori induzida pelo vetor de estados.
A metodologia proposta no presente trabalho funciona da seguinte forma: uma vez
atribuıda uma distribuicao a priori para o vetor de estados, obtenha a priori para o
parametro natural induzida por tal vetor. Projete-a no espaco da distribuicao conjugada
da famılia exponencial. Esta sera a priori utilizada no prosseguimento do metodo.
Como esta e conjugada da famılia exponencial, sua posteriori pode ser facilmente
encontrada. Contudo, observe que agora temos duas posterioris para o preditor linear:
uma induzida pela conjugacao do parametro natural e outra Normal (ja que o preditor
e uma funcao linear dos estador que, sob normalidade, tem distribuicao a posteriori
normal). A solucao adotada, para lidar com essa duplicidade, foi projetar a distribuicao
a posteriori induzida pela conjugacao do parametro natural no espaco da distribuicao
Normal. Dessa forma, gostarıamos de encontrar a Normal que melhor aproxima tal
distribuicao. Uma vez que tal compatibilizacao seja feita, utilizamos o metodo Linear
Bayes para obter os momentos do vetor de estados. Observe que a normalidade e mantida.
36

O uso do metodo Linear Bayes se faz necessario porque, enquanto o preditor linear e um
escalar, o vetor de estados e p-dimensional. Desta forma, escolhemos o esse metodo para
que tal expansao pudesse ser feita.
Um resumo da metodologia proposta e apresentado a seguir.
• Modelo yt|ηt ∼ FamExp(ηt)
ηt|Dt−1 ∼ C − FamExp(τt−1)
• Funcao de Ligacao
g(ηt) = F ′tθt = λt,
onde g e uma funcao contınua, monotona e duas vezes diferenciavel.
• Evolucao do Vetor de Estados
θt = Gtθt−1 + ωt, ωt ∼ N(0,W ),
o que implica em
p(ηt|Dt−1) = pθt|Dt−1(g−1(ηt))
∣∣∣ ∂θt∂ηtg−1(ηt)
∣∣∣• Distribuicoes a priori resultantes
ηt|Dt−1 ∼ C − FamExp(τt−1)
p(ηt|Dt−1) = pθt|Dt−1(g−1(ηt))
∣∣∣ ∂θt∂ηtg−1(ηt)
∣∣∣• Metodologia Proposta
Seja q(x) a distribuicao a priori conjugada e seja p(x) a priori induzida pelo vetor
de estados. Obtem-se parametros τ ∗ tais que
τ ∗ = argminτDKL[p : q] (4.2)
37

Uma vez que esse vetor parametrico seja definido,
ηt|Dt−1 ∼ C − FamExp(τ ∗t−1). (4.3)
Uma vez que obtemos a priori compatibilizada para ηt, podemos incorporar facil-
mente novas informacoes atraves da conjugacao. Observe que agora, duas distri-
buicoes a posteriori para o preditor linear devem ser combinadas:
λt|Dt ∼ pηt|Dt(g(ηt))∣∣∣ ∂ηt∂λtg(ηt)
∣∣∣λt|Dt ∼ N(ht, pt)
Em seguida, projetamos a distribuicao a posteriori obtida atraves da conjugacao no
espaco da distribuicao Normal, encontrando seus momentos. Observe que λt e um
escalar, para cada tempo t, enquanto θt e um vetor parametrico p− dimensional.
Uma vez que a distribuicao a posteriori para λt e obtida, gostarıamos de obter
a posteriori para θt, levando em consideracao a diferenca de dimensoes para es-
sas quantidades. Usamos o metodo Linear Bayes para encontrar os momentos de
(θt|Dt).
Nas subsecoes 4.2.1 e 4.2.2, detalha-se a metodologia descrita, considerando-se
MLDGs para respostas Poisson e Binomial, respectivamente. Na subsecao 4.2.3,
aplica-se o metodo a dados artificialmente gerados, seguindo um MLDG para res-
posta Poisson.
4.2.1 Modelo Linear Dinamico Generalizado Poisson
Seja (yt|ηt) ∼ Poisson (ηt):
p(yt|ηt) =ηytt e
−ηt
yt!. (4.4)
Esta densidade pode ser reescrita na forma da famılia exponencial da seguinte forma:
38

p(yt|ηt) =1
yt!exp yt log(ηt)− ηt . (4.5)
Assim temos que a precisao φ e igual a 1, o preditor linear λt e igual ao log(ηt),
que e o parametro canonico, neste caso. Tem-se, ainda, b(λt) = ηt = eλt . Assim, a
media e variancia da distribuicao sao dadas por b(λt) = ηt = eλt e b(λt) = ηt = eλt ,
respectivamente.
No caso da distribuicao Poisson, sabemos que a a priori conjugada para o parametro
ηt e a Gama(αt, βt) e portanto, a priori implicada para o preditor linear λt, adotando-se
a especificacao conjugada, e a Log-Gama.
(ηt|Dt−1) ∼ PC(αt, βt) ≡ Gama(αt, βt). (4.6)
Onde,
λt = log(ηt) = F ′tθt. (4.7)
Por outro lado, a informacao inicial (θ0|D0) tem distribuicao Normal com parametros
(m0, C0) e usando θt = Gtθt − 1 + ωt, tem-se que
(θt|Dt−1) ∼ N(at, Rt) e (λt|Dt−1) ∼ N(ft, qt) (4.8)
em que ft = F ′tat e qt = F ′tRtFt.
Dessa forma, desejamos projetar a priori induzida pelo vetor de estados 4.8 no espaco
da distribuicao conjugada. Sabendo que a priori induzida tem distribuicao Log-Normal,
gostarıamos de projeta-la no espaco da distribuicao Gama com o intuito de preservar a
conveniencia de se trabalhar com a conjugada.
Temos portanto que
(ηt|Dt−1) ∼ Log −Normal(ft, qt) e desejamos obter (ηt|Dt−1) ∼ Gama(αt, βt)
Como visto na Secao (2.2), os parametros da Gama deduzida da Log-Normal sao:
39

αt =1
qt(4.9)
βt = qt−1 exp −ft − 0.5qt (4.10)
Uma vez encontrada a priori compatibilizada para ηt, pertencente a famılia de prioris
conjugadas, sua posteriori e facilmente obtida por conjugacao. Agora temos que
(λt|Dt) ∼ Log −Gama(α∗t , β∗t ) e desejamos obter (λt|Dt) ∼ Normal(µt, σ
2t ).
Projeta-se entao a Log-Gama no espaco da distribuicao Normal e aplica-se o metodo Li-
near Bayes para encontrar os momentos de (θt|Dt). Tal distribuicao tera como parametros
(mt, Ct). Sendo estes:
mt = mt−1 +RtFt(gt − ft)/qt,
Ct = Rt −RtFt(RtFt)′(1− pt/qt)/qt,
onde gt = E(f(ηt)|Dt) e pt = V ar(f(ηt)|Dt) podem ser calculados a partir da posteriori
(ηt|Dt) ja compatibilizada, onde f(ηt) = log(ηt).
Observe que no modelo Poisson via Conjugate Updating os parametros α e β sao
dados por:
αt =1
qtβt = qt
−1 exp −ft (4.11)
Dessa forma, nota-se que os parametros sao bem similares nos dois metodos, havendo
diferenca somente no parametro β.
40

4.2.2 Modelo Linear Dinamico Generalizado Bernoulli/Binomial
Seja (yt|pt) ∼ Bernoulli (pt):
p(yt|pt) = pytt (1− pt)(1−yt). (4.12)
Pode-se escrever a funcao de probabilidade acima na famılia exponencial da seguinte
forma:
p(Yt|pt) = exp
yt
log(pt)
log(1− pt)
+ log(1− pt)
. (4.13)
Assim temos que a precisao φ e igual a 1, o preditor linear λt e igual ao log
pt1−pt
, sendo
este o parametro natural ou canonico, e b(λt) = log(1− pt). Assim, a media e variancia
da distribuicao sao dadas por b(λt) = pt =(
11+e−λt
)e b(λt) = pt(1 − pt) =
e−λt
(1+e−λt )2
,
respectivamente.
No caso da distribuicao Bernoulli, sabemos que a a priori conjugada para o parametro
pt e a Beta(αt, βt) e portanto, a priori implicada para o preditor linear λt e a Logito-Beta.
(pt|Dt−1) ∼ PC(αt, βt) ≡ Beta(αt, βt), (4.14)
de forma que,
λt = logito(pt) = F ′tθt ∼ Logito−Beta(αt, βt). (4.15)
Por outro lado a informacao inicial (θ0|D0) tem distribuicao Normal com parametros
(m0, C0), tem-se que
(θt|Dt−1) ∼ N(at, Rt) e (λt|Dt−1) ∼ N(ft, qt) (4.16)
em que ft = F ′tat e qt = F ′tRtFt.
Conforme mencionado anteriormente, a ideia e projetar a priori induzida pelo vetor
de estados no espaco da distribuicao conjugada. Sabendo que a priori induzida e Logito-
41

Normal, deseja-se projeta-la no espaco da distribuicao Beta.
(pt|Dt−1) ∼ Logito−Normal(ft, qt) e buscamos (pt|Dt−1) ∼ Beta(αt, βt).
Como visto na Secao (2.2), os parametros da Beta compatibilizada nao tem solucao
analıtica, portanto foram utilizados metodos computacionais como Newton-Raphson e
Monte Carlo para que esses pudessem ser obtidos. A cada tempo t, esses metodos devem
ser utilizados para calcula-los.
Uma vez encontrada a priori compatibilizada para pt na famılia de prioris connjuga-
das,, sua posteriori e facilmente obtida via Teorema de Bayes.
Agora temos que
(λt|Dt) ∼ Logito−Beta(α∗t , β∗t ) e desejamos obter (λt|Dt) ∼ Normal(µt, σ
2t ).
Projeta-se entao a distribuicao Logito-Beta no espaco da distribuicao Normal e aplica-se
o metodo Linear Bayes para encontrar os momentos de (θt|Dt). Tal distribuicao tera
como parametros (mt, Ct). Sendo estes:
mt = mt−1 +RtFt(gt − ft)/qt,
Ct = Rt −RtFt(RtFt)′(1− pt/qt)/qt,
onde gt = E(f(pt)|Dt) e pt = V ar(f(pt)|Dt) podem ser calculados a partir da posteriori
(pt|Dt) ja compatibilizada, onde f(pt) = logito(pt).
4.2.3 Estudo de Simulacao
Um estudo simulado e apresentado nesta secao com o intuito de verificar o compor-
tameto da metodologia proposta no que concerne a estimativas pontuais e predicao a
um passo. Visando avaliar a eficacia do metodo quando comparado a outros que fazem
inferencia para esta mesma classe de modelos, tambem sera apresentado o fator de Bayes
comparando-os.
42

4.2.3.1 Modelo Poisson
Seja Yt|ηt ∼ Poisson(ηt) em que:
λt = log(ηt) = F ′tθt,
θt = Gtθt−1 + εt, εt ∼ N(0, 0.0012).
Ft e Gt foram definidas da seguinte forma:
Ft = [1, 0, 1, 0] ∀t, t = 1, . . . , 80,
Gt =
1 1 0 0
0 1 0 0
0 0 cos(w) sen(w)
0 0 −sen(w) cos(w)
, onde w = π/2.
Foram geradas 50 replicas de um modelo Poisson com essa estrutura. No processo
inferencial foram utilizados fatores de desconto tanto para as componentes de tendencia
quanto de sazonalidade. Esses foram iguais a 0.95 e 0.99, respectivamente. A Figura 4.1
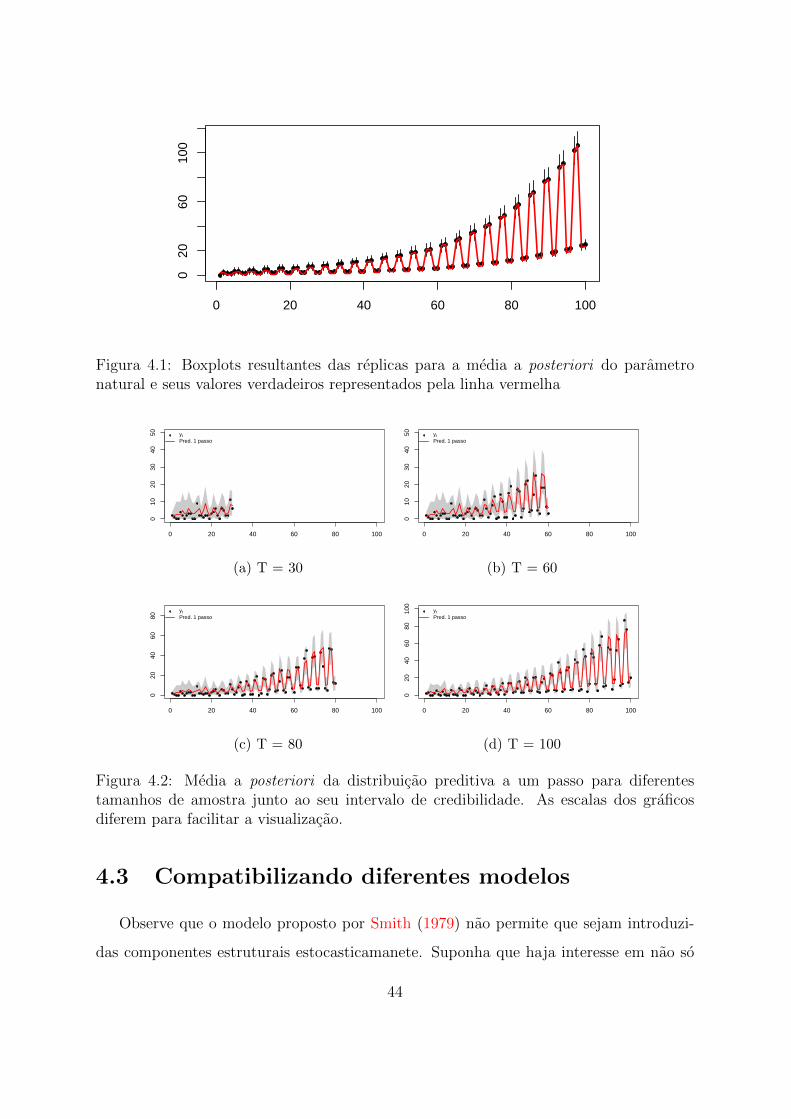
exibe os boxplots obtidos atraves de tais replicas para a media a posteriori do parametro
natural ηt e seu valor verdadeiro (linha vermelha). Nota-se que o modelo e capaz de
captar bem a estrutura do dado, de forma que o E(ηt|Dt) ficou bem proximo ao valor
verdadeiro em todo tempo t. E importante ressaltar que o custo computacional da
metodologia proposta e muito baixo, com cada modelo levando em media 0.2 segundos
para ser estimado em um computador com processador Intel Core i5-6500, com 4GB de
RAM e sistema operacional de 64 Bits.
Verifica-se, atraves da Figura 4.2, que o metodo proposto e capaz de fazer predicoes
a um passo que acompanham a estrutura dos dados observados independentemente do
tamanho da amostra. Nota-se que a grande maioria dos valores observados encontram-se
dentro do intervalo de credibilidade obtido. Nota-se, inclusive, que tanto a sazonalidade
quanto a tendencia crescente, sao captadas pelo modelo, resultado indicativo de um bom
ajuste.
43
0 20 40 60 80 100
020
6010
0
Figura 4.1: Boxplots resultantes das replicas para a media a posteriori do parametronatural e seus valores verdadeiros representados pela linha vermelha
0 20 40 60 80 100
010
2030
4050
yt
Pred. 1 passo
(a) T = 30
0 20 40 60 80 100
010
2030
4050
yt
Pred. 1 passo
(b) T = 60
0 20 40 60 80 100
020
4060
80
yt
Pred. 1 passo
(c) T = 80
0 20 40 60 80 100
020
4060
8010
0
yt
Pred. 1 passo
(d) T = 100
Figura 4.2: Media a posteriori da distribuicao preditiva a um passo para diferentestamanhos de amostra junto ao seu intervalo de credibilidade. As escalas dos graficosdiferem para facilitar a visualizacao.
4.3 Compatibilizando diferentes modelos
Observe que o modelo proposto por Smith (1979) nao permite que sejam introduzi-
das componentes estruturais estocasticamanete. Suponha que haja interesse em nao so
44

utilizar a estrutura de inferencia proposta em artigo, mas tambem em inserir compo-
nentes de tendencia e sazonalidade estocasticamente no modelo. Uma combinacao entre
os metodos propostos por Smith (1979) e West et al. (1985) pode ser feita utilizando
conceitos de geometria da informacao. A descricao de tal metodologia sera apresentada
ao longo desta secao.
O funcionamento do metodo e similar ao explicitado anteriormente com o acrescimo
de um novo passo referente a combinacao das distribuicoes de probabilidade a priori e a
posteriori, baseadas em ambas as especificacoes. De um lado, tem-se um modelo como o
apresentado por West et al. (1985), completamente especificado. De outro, um modelo
como o retratado por Smith (1979) e outros, fazendo uso da priori conjugada para o
parametro canonico da famılia exponencial. Analogamente o procedimento apresentado
na secao 4.2, projeta-se a priori para o parametro usual da famılia exponencial, induzida
pelo vetor de estados, no espaco da distribuicao conjugada da famılia exponencial.Uma
vez que tal projecao tenha sido feita, torna-se simples encontrar a priori compatibilizada
que leva em consideracao as informacoes do modelo de nıvel local (priori conjugada) e
do modelo estruturado (priori induzida pelo vetor de estados), utilizando-se, para tanto,
o teorema 2.2.2.
Observe-se que os parametros da priori conjugada nao serao obtidos atraves da com-
patibilizacao dos momentos, como e feito em West et al. (1985), o que faz com que seja
necessario atribuir uma estrutura evolutiva para esses parametros que independe do ve-
tor de estados. O metodo escolhido foi evoluir da posteriori no tempo t-1 para priori no
tempo t, preservando-se a media a posteriori e inflacionando-se a variancia da posteriori
por um fator multiplicativo 1/ω, 0 < ω < 1.
Assim, os parametros da priori compatibilizada para o parametro canonico depen-
derao tanto dos parametros da priori conjugada quanto da priori induzida.
Como as duas distribuicoes a priori compatibilizadas pertencem ao espaco das prioris
conjugadas para o parametro canonico (a primeira, projetada neste espaco utilizando-se
o teorema da projecao e a segunda, ja naturalmente pertencente a este espaco), tambem
a priori resultante da aplicacao do teorema 2.2.2, para o parametro canonico, sera conju-
gada a famılia exponencial. Tal distribuicao a priori tera seus parametros influenciados
45

tanto pelas componentes estruturais do modelo baseado em um preditor dinamico com
componentes estruturais, quanto pelo modelo dinamico, mas de nıvel local, especificado
somente com base na informacao vinda da variavel resposta. Sao fatores relevantes, na
ponderacao entre esses dois modelos, tanto o parametro s , que controla a combinacao
convexa apresentada no teorema 2.2.2, quanto as precisoes associadas a cada uma das
prioris a serem combinadas. Uma vez obtida a priori compatibilizada, pertencente a
famılia de prioris conjugadas a famılia exponencial, sua posteriori pode ser facilmente
encontrada. Contudo, observe que agora temos duas posterioris para o preditor linear:
uma induzida pela conjugacao do parametro natural da famılia exponencial e outra pro-
veniente da normalidade dos estados. A solucao encontrada foi projetar a distribuicao
induzida pela conjugacao do parametro natural no espaco da distribuicao Normal. Dessa
forma, gostarıamos de encontrar a Normal que melhor aproxima tal distribuicao. Uma
vez que tal aproximacao seja feita, utilizamos o metodo Linear Bayes para obter os mo-
mentos do vetor de estados, dada a diferenca de dimensao entre o preditor linear (escalar)
e tal vetor (p-dimensional).
Nas subsecoes 4.3.1 e 4.3.2, detalha-se a metodologia descrita, considerando-se MLDGs
para respostas Poisson e Binomial, respectivamente. Na subsecao 4.3.3, aplica-se o
metodo a dados de vendas, seguindo um MLDG para resposta Poisson.
4.3.1 Modelo Linear Dinamico Generalizado Poisson
Seja (yt|ηt) ∼ Poisson(ηt):
p(yt|ηt) =ηytt e
−ηt
yt!. (4.17)
A distribuicao a priori conjugada para o parametro ηt e a Gama(αt, βt) e, portanto,
a priori implicada para o preditor linear e a Log-Gama. Isto e,
(ηt|Dt−1) ∼ PC(αt, βt) ≡ Gama(αt, βt). (4.18)
ηt = exp(λt) = exp(F ′tθt). (4.19)
46

Observe que uma vez atribuıda uma priori para θt, havera duas prioris para a mesma
quantidade ηt: de um lado a distriuicao a priori conjugada da famılia exponencial e de
outro, a priori induzida pelo vetor de estados.
Assumindo que a informacao inicial (θ0|D0) tem distribuicao Normal com parametros
(m0, C0), tem-se que
(θt|Dt−1) ∼ N(at, Rt) e (λt|Dt−1) ∼ N(ft, qt),
onde ft = F ′tat e qt = F ′tRtFt.
De forma que as duas prioris a serem compatilizadas serao:
(ηt|Dt−1) ∼ Log −Normal(ft, qt) e (ηt|Dt−1) ∼ Gama(αt, βt).
Como visto na Secao 2.2, os parametros da Gama ja compatibilizada sao:
a∗t = s1
qt+ (1− s)αt (4.20)
b∗t = s(qt−1 exp −ft − 0.5qt) + (1− s)βt (4.21)
Observe aqui, que αt e βt nao sao atualizados de acordo com a estrutura do vetor de
estados, portanto e necessario que se crie uma estrutura de atualizacao para os mesmos.
A forma escolhida foi a proposta por Smith (1979):
αt = ω(a∗t−1 + yt−1)
βt = ω(b∗t−1 + 1)
Com essa estrutura de atualizacao, nota-se que, ao se passar da posteriori no tempo
t− 1 a priori no tempo t, a media da distribuicao Gama e mantida e que dua variancia
e inflacionada por um fator multiplicativo 1ω
onde 0 < ω ≤ 1.
Nesta etapa do procedimento, tem-se duas distribuicoes Gama, a priori, para o
parametro ηt, que devem ser compatibilizadas via teorema 2.2.2. Uma vez encontrada a
priori compatibilizada para ηt pertencente a famılia de prioris conjugadas, sua posteriori
47

e facilmente obtida via Teorema de Bayes. Agora temos que
(λt|Dt) ∼ Log −Gama(α∗∗t , β∗∗t ) e desejamos obter (λt|Dt) ∼ Normal(µt, σ
2t ).
Projeta-se, entao, a distribuicao Log-Gama no espaco da distribuicao Normal e aplica-se
o metodo Linear Bayes para encontrar os momentos de (θt|Dt). Tal distribuicao tera
como parametros (mt, Ct). Sendo estes:
mt = mt−1 +RtFt(gt − ft)/qt,
Ct = Rt −RtFt(RtFt)′(1− pt/qt)/qt,
onde gt = E(f(ηt)|Dt) e pt = V ar(f(ηt)|Dt) podem ser calculados a partir da posteriori
(ηt|Dt) ja compatibilizada, onde f(ηt) = log(ηt).
48

4.3.2 Modelo Linear Dinamico Generalizado Bernoulli/Binomial
Seja (yt|pt) ∼ Bernoulli(pt):
p(yt|pt) = pytt (1− pt)(1−yt). (4.22)
No caso da distribuicao Bernoulli, sabemos que a distribuicao a priori conjugada para
o parametro pt e a Beta(αt, βt) e portanto, a priori implicada para o preditor linear λt e
a Logito-Beta.
(pt|Dt−1) ∼ PC(αt, βt) ≡ Beta(αt, βt), (4.23)
λt = logito(pt) = F ′tθt. (4.24)
Observe novamente que, uma vez atribuıda uma priori para θt, havera duas prioris
para a mesma quantidade ηt: de um lado a priori conjugada da famılia exponencial e de
outro, a priori induzida pelo vetor de estados.
Assuma-se que a informacao inicial (θ0|D0) tem distribuicao Normal com parametros
(m0, C0). Assim,
(θt|Dt−1) ∼ N(at, Rt) e (λt|Dt−1) ∼ N(ft, qt)
onde ft = F ′tat e qt = F ′tRtFt.
As duas prioris a serem compatilizadas serao:
(pt|Dt−1) ∼ Logito−Normal(ft, qt) e (pt|Dt−1) ∼ Beta(αt, βt).
Como visto na Secao (2.2), os parametros da Beta compatibilizada nao tem solucao
analıtica, portanto metodos como Newton-Raphson e Monte Carlo sao necessarios para
que tais parametros possam ser obtidos.
Novamente os parametros da priori naturalmente conjugada, αt e βt nao sao atuali-
zados de acordo com a estrutura do vetor de estados, portanto e necessario que se crie
uma estrutura de atualizacao para os mesmos. Como ja descrito, adota-se a proposta de
49

Smith (1979):
αt = ω(a∗t−1 + yt−1)
βt = ω(b∗t−1 + n− yt−1), sendo n o numero de ensaios de Bernoulli associados a distribuicao Binomial
Com essa estrutura de atualizacao, nota-se que a media da distribuicao Gama e
mantida e que sua variAncia e inflacionada por um fator multiplicativo 1ω
, 0 < ω ≤ 1.
Tem-se duas prioris Beta para o parametro pt, que sao compatibilizadas por meio do
teorema 2.2.2. Uma vez encontrada a distribuicao a priori compatibilizada para pt, sua
posteriori e facilmente obtida por Teorema de Bayes. Agora temos que
(λt|Dt) ∼ Logito−Beta(α∗t , β∗t ) e desejamos obter (λt|Dt) ∼ Normal(µt, σ
2t ).
Projeta-se, entao, a distribuicao Logito-Beta no espaco da distribuicao Normal e aplica-
se o metodo Linear Bayes para encontrar os momentos de (θt|Dt). Tal distribuicao tera
como parametros (mt, Ct). Sendo estes:
mt = mt−1 +RtFt(gt − ft)/qt,
Ct = Rt −RtFt(RtFt)′(1− pt/qt)/qt,
onde gt = E(f(pt)|Dt) e pt = V ar(f(pt)|Dt) podem ser calculados a partir da posteriori
(pt|Dt) ja compatibilizada, onde f(pt) = logito(pt).
4.3.3 Aplicacao
A seria ser analisada e uma serie trimestral de vendas com padrao sazonal conhecido
na literatura. Adota-se um modelo Poisson para a contagem de vendas.
E observado que essa possui uma mudanca de padrao sazonal a partir, aproximada-
mente, do tempo 20, alem de possuir uma tendencia crescente. O intuito do uso dessa
serie e verificar se o modelo consegue captar essa mudanca de padrao sazonal. Alem
da estimacao via metodologia que compatibiliza modelos (GI - com comp), apresentada
50
0 5 10 15 20 25 30 35
2040
6080
Figura 4.3: Serie Observada
nesta subsecao, foram feitas estimacoes via geometria da Informacao sem compatibilizar
modelos (GI - sem comp), Conjugate Updating e Modelos de Nıvel Local (MNL) conforme
descrito na secao 3.2.2.
No que concerne a estimacao via GI - sem comp. e com comp., componentes de
sazonalidade foram introduzidas no modelo atraves da matriz G de forma que o primeiro
e segundo harmonicos foram considerados. Como fatores de desconto foram utilizados
0.9 para componentes de tendencia e 0.7 para componentes de sazonalidade. Nao e usual
que o desconto atribuıdo para a sazonalidade seja maior que o da tendencia, entretanto
os resultados encontrados por Pole et al. (1994) foram similares a esses apresentados,
fornecendo o melhor resultado no que concerne a funcao de log-verossimilhanca.
51

Por conseguinte, considera-se o modelo
yt|ηt ∼ Poisson(ηt)
λt = log(ηt) = F ′tθt
θt = Gtθt−1.
De modo que,
θt = (α1t, α2t, β1t, β2t, β3t, β4t);
Ft = [1, 0, 1, 0, 1, 0] ;
Gt =
1 1 0 0 0 0
0 1 0 0 0 0
0 0 cos(w) sen(w) 0 0
0 0 −sen(w) cos(w) 0 0
0 0 0 0 cos(2w) sen(2w)
0 0 0 0 −sen(2w) cos(2w)
, sendo w = 2π/4.
Essas mesmas matrizes de desenho e de evolucao foram utilizadas no metodo de
geometria da informacao que compatibiliza modelos estruturado e nao estrurado e no
metodo Conjugate Updating. De forma analoga, os fatores de desconto foram os mesmos.
Conforme mencionado anteriormente,os parametros da priori conjugada nao serao
mais obtidos atraves da compatibilizacao dos momentos, fazendo com que seja necessario
atribuir uma evolucao para eles que independe do vetor de estados. O metodo escolhido
foi evoluir da posteriori no tempo t-1 para priori no tempo t, preservando-se a media a
posteriori e inflacionando-se a variancia da posteriori por um fator multiplicativo 1/ω,
como em Smith (1979); Harrison and Stevens (1976); Gamerman et al. (2013). Para que
tal parametro fosse definido, foi especificada uma grade de valores possıveis e o modelo
estimado com cada um desses valores. Como este atua como um fator de desconto,
os possıveis valores foram definidos como (0.5, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 0.975, 0.99, 1).
Na abordagem baseada em compatibilizacao de modelos estruturado e de nıvel local, s,
52

necessario a aplicacao do teorema 2.2.2, tambem deve ser escolhido e portanto uma grade
de valores para tal foi definida. Essa foi igual a (0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9,
1.0), com menores valores atribuindo menor peso ao modelo estrurado que ao modelo
de nıvel local. Em seguida foi criada uma grade unica com as todas as combinacoes
possıveis para esses parametros. Exemplo: ω = 0.5, s = 0.1;ω = 0.975, s = 0.8 e assim
por diante. O melhor modelo foi definido como aquele que forneceu maior valor para
a log-verossimilhanca preditiva. A tabela resultante pode ser encontrada no apendice 1
deste trabalho. Segundo esse criterio, s = 0.9 e ω = 0.5. Este modelo tambem foi o que
forneceu o menor EQM preditivo.
Para aplicacao do modelo de nıvel local baseado em covariaveis sem efeito dinamico
e que, portanto, apresentando apenas um nıvel dinamico, foram definidas 3 covariaveis:
x1 = cos(wt), x2 = sen(wt), x3 = cos(2wt), onde t=1, . . . , 35 e w = 2π/4. Observe-se
que, para este valor de w, sen(2wt) e sempre nulo. Dessa forma o modelo foi definido
como:,
Yt|ηt ∼ Poisson(ηt)
ηt = αt exp(β1x1t + β2x2t + β3x3t)
Alem dos coeficientes atrelados as covariaveis,o fator de inflacao do modelo tambem
deve ser determinado. Tal estimacao foi feita a partir do metodo de Monte Carlo via
Cadeia de Markov com algoritmo Metropolis-Hastings. A priori para o parametro natu-
ral, ηt, foi definida como ηt ∼ G(0.01, 0.01). Para o parametro ω, uma Uniforme(0,1) foi
atribuıda e para os coeficientes atrelado as covariaveis (βk, k = 1, . . . 3.) foram definidas
como prioris distribuicoes Normal(0, 100). As amostras da distribuicao a posteriori fo-
ram obtidas utilizando o metodo MCMC com 100.000 iteracoes, descartando-se um burn-
in de 1000 iteracoes e aplicando um espacamento de tamanho 20, resultando em uma
amostra de tamanho 4951. A convergencia pode ser verificada com auxılio de metodos de
diagnostico presentes no pacote coda no R (Plummer et al. (2006)). O modelo tambem
foi estimado seguindo abordagem classica.
A tabela 4.1 indica que as estimativas classica e bayesiana ficaram bem proximas. Os
53

EMV EB-Mediana 2.5% via MCMC 97.5% via MCMCω 0.65 0.61 0.36 0.74β1 -0.41 -0.41 -0.52 -0.30β2 -0.43 -0.44 -0.53 -0.35β3 -0.13 -0.12 -0.19 -0.05
Tabela 4.1: Resultados da estimacao dos parametros do modelo de nıvel local
estimadores bayesianos foram considerados para futuras analises.
Metodo segundosMCMC 456.225
GI - sem comp. 0.178GI - com comp. 0.235
Conjugate Updating 0.199
Tabela 4.2: Tempo computacional gasto em cada um dos metodos
Analisando a tabela 4.2, nota-se que o metodo MCMC foi o mais custoso computa-
cionalmente. Por outro lado, todos os metodos sequenciais levaram menos de 1 segundo
para obter as estimativas do modelo.
Nota-se que a predicao a 1 passo via GI - sem comp. e bem proxima a estimativa
obtida atraves do metodo Conjugate Updating (Figura 4.4). Assim como no modelo de
geometria via compatibilizacao de modelos,esses modelos conseguem captar a mudanca no
padrao sazonal, sem necessidade de uma intervencao manual. As estimativas do modelo
GI - com comp. diferem ligeiramente das obtidas pelos modelos citados anteriormente,
mas ainda assim estao proximas aos valores observados. O modelo de nıvel local nao
capturou a mudanca no padrao sazonal. Harvey and Fernandes (1989) afirma em seu
artigo que nao permitir que componentes de sazonalidade sejam estocasticas nao e uma
grave limitacao do metodo, contudo o que pode ser visto que melhores resultados sao
obtidos quando se permite que esssas sejam estocasticas. Isso se da porque modelos mais
estruturados tem vantagem, pois permitem que tais componentes variem no tempo, ou
seja, ha uma flexibilidade maior para os parametros que capturar mudancas estruturais
no dado.
54
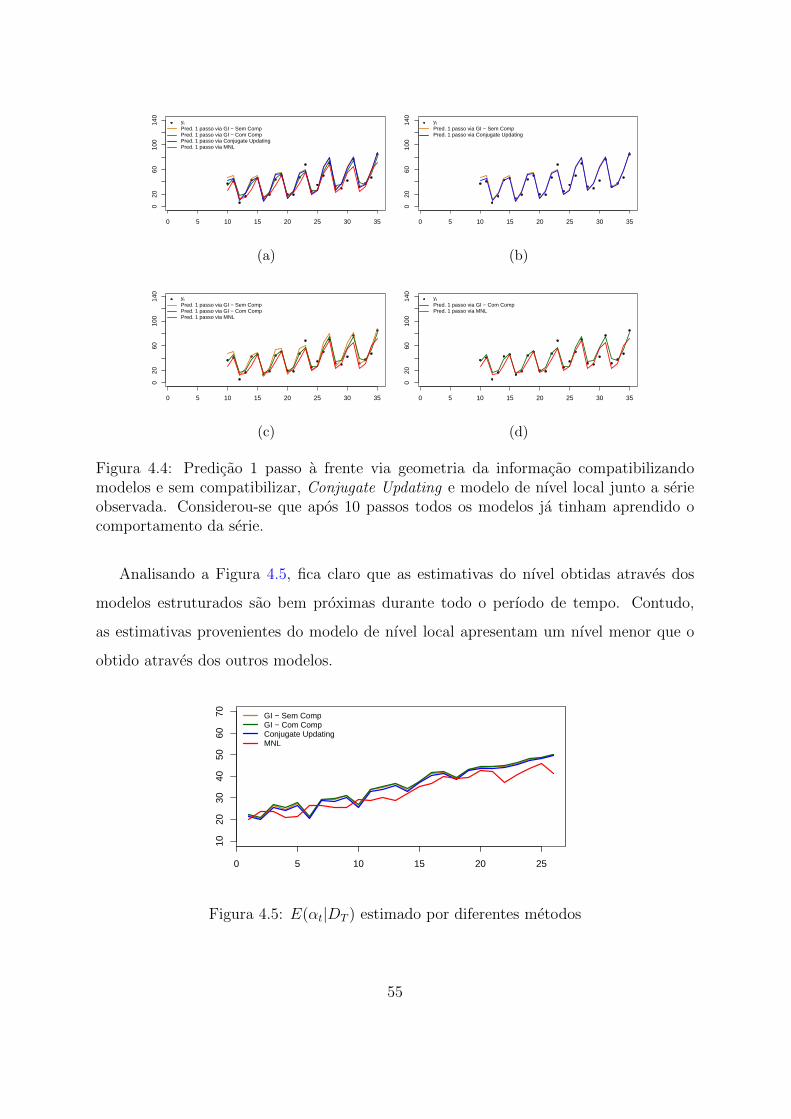
0 5 10 15 20 25 30 35
020
6010
014
0
yt
Pred. 1 passo via GI − Sem CompPred. 1 passo via GI − Com CompPred. 1 passo via Conjugate UpdatingPred. 1 passo via MNL
(a)
0 5 10 15 20 25 30 35
020
6010
014
0
yt
Pred. 1 passo via GI − Sem CompPred. 1 passo via Conjugate Updating
(b)
0 5 10 15 20 25 30 35
020
6010
014
0
yt
Pred. 1 passo via GI − Sem CompPred. 1 passo via GI − Com CompPred. 1 passo via MNL
(c)
0 5 10 15 20 25 30 350
2060
100
140
yt
Pred. 1 passo via GI − Com CompPred. 1 passo via MNL
(d)
Figura 4.4: Predicao 1 passo a frente via geometria da informacao compatibilizandomodelos e sem compatibilizar, Conjugate Updating e modelo de nıvel local junto a serieobservada. Considerou-se que apos 10 passos todos os modelos ja tinham aprendido ocomportamento da serie.
Analisando a Figura 4.5, fica claro que as estimativas do nıvel obtidas atraves dos
modelos estruturados sao bem proximas durante todo o perıodo de tempo. Contudo,
as estimativas provenientes do modelo de nıvel local apresentam um nıvel menor que o
obtido atraves dos outros modelos.
0 5 10 15 20 25
1020
3040
5060
70 GI − Sem CompGI − Com CompConjugate UpdatingMNL
Figura 4.5: E(αt|DT ) estimado por diferentes metodos
55
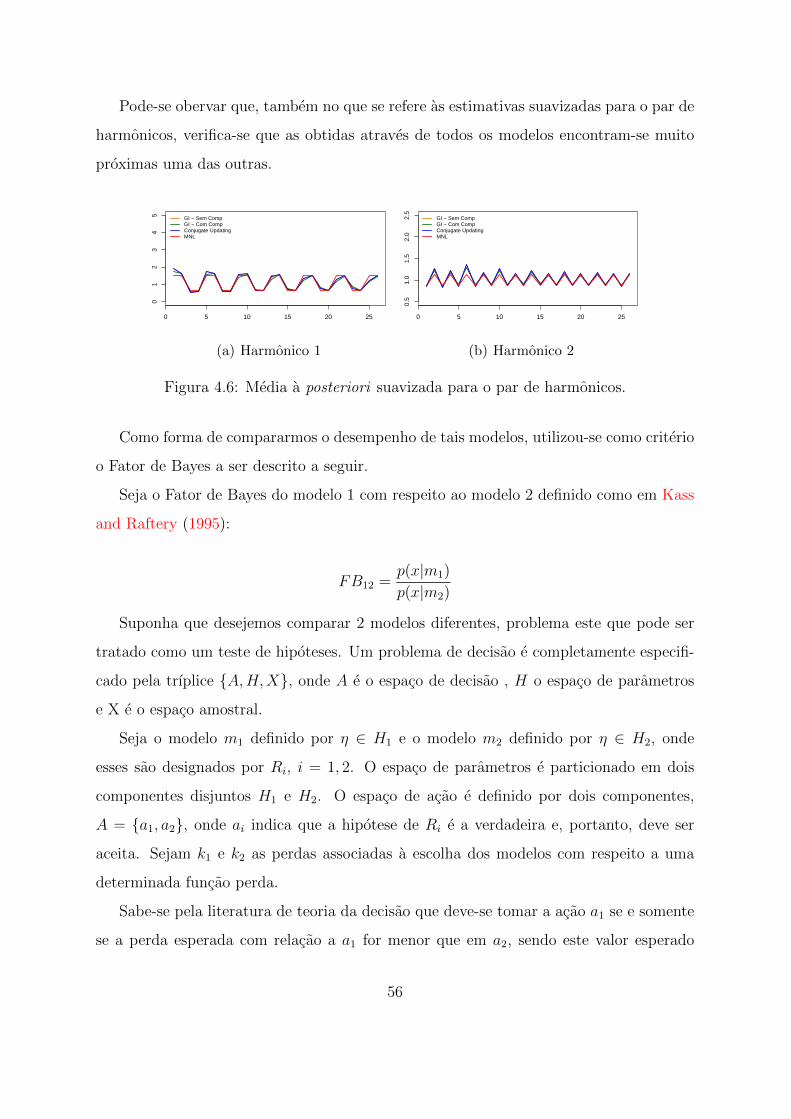
Pode-se obervar que, tambem no que se refere as estimativas suavizadas para o par de
harmonicos, verifica-se que as obtidas atraves de todos os modelos encontram-se muito
proximas uma das outras.
0 5 10 15 20 25
01
23
45 GI − Sem Comp
GI − Com CompConjugate UpdatingMNL
(a) Harmonico 1
0 5 10 15 20 25
0.5
1.0
1.5
2.0
2.5
GI − Sem CompGI − Com CompConjugate UpdatingMNL
(b) Harmonico 2
Figura 4.6: Media a posteriori suavizada para o par de harmonicos.
Como forma de compararmos o desempenho de tais modelos, utilizou-se como criterio
o Fator de Bayes a ser descrito a seguir.
Seja o Fator de Bayes do modelo 1 com respeito ao modelo 2 definido como em Kass
and Raftery (1995):
FB12 =p(x|m1)
p(x|m2)
Suponha que desejemos comparar 2 modelos diferentes, problema este que pode ser
tratado como um teste de hipoteses. Um problema de decisao e completamente especifi-
cado pela trıplice A,H,X, onde A e o espaco de decisao , H o espaco de parametros
e X e o espaco amostral.
Seja o modelo m1 definido por η ∈ H1 e o modelo m2 definido por η ∈ H2, onde
esses sao designados por Ri, i = 1, 2. O espaco de parametros e particionado em dois
componentes disjuntos H1 e H2. O espaco de acao e definido por dois componentes,
A = a1, a2, onde ai indica que a hipotese de Ri e a verdadeira e, portanto, deve ser
aceita. Sejam k1 e k2 as perdas associadas a escolha dos modelos com respeito a uma
determinada funcao perda.
Sabe-se pela literatura de teoria da decisao que deve-se tomar a acao a1 se e somente
se a perda esperada com relacao a a1 for menor que em a2, sendo este valor esperado
56

relacionado as distribuicoes a posteriori. Isso equivale a aceitar H1 se e somente se
P (R1|x)P (R2|x) >
k2k1
, que e equivalente a
FB12 >k2P (R2)
k1P (R1).
Se considerarmos k1 = k2, teremos que
FB12
(1 + FB12)>
p(R2)
p(R1) + p(R2).
Esse resultado sera usado neste trabalho para escolha de um modelo dentre os modelos
de interesse.
Seja Kij =FBij
(1+FBij), i 6= j, i = 1, 2, 3, 4 e j = 1, 2, 3, 4, onde 1 representa o metodo
via Geometria da Informacao - Sem compatibilizar modelos, 2 - o metodo via Geometria
da Informacao - Compatibilizando Modelos, 3 - O metodo Conjugate Updating e 4 - o
modelo de nıvel local.
Temos que
Comparacao de ModelosK12 = 0.4768K13 = 0.4959K14 = 0.7222K23 = 0.5191K24 = 0.7404K34 = 0.7254
Tabela 4.3: Comparacao dos modelos via geometria da informacao compatibilizandomodelos e sem compatibilizar, Conjugate Updating e modelo de nıvel local
Assim fica claro que os modelos estruturados, com estimacao via via geometria da
informacao e Conjugate Updating sao muito proximos, pois as probabilidades variaram
em torno de 0.5. Tais modelos apresentaram desempenho superior ao modelo de nıvel
local de forma que as probabilidades variaram em torno de 0.7, indicando que o modelo
de nıvel local seria escolhido em cerca de apenas 30% dos casos.
57

Capıtulo 5
Conjugate Updating estendido
O metodo Conjugate Updating estendido sugerido por Souza et al. (2016) e uma
extensao ao modelo proposto por West et al. (1985) para a famılia exponencial bipa-
rametrica. De modo igual, destaca-se por sua rapidez computacional quando comparado
a metodos como MCMC. A estimacao para os parametros da distribuicao do vetor de
estados e preditiva e feita de forma sequencial, assim cada nova observacao que chega e
imediatamente incorporada. A seguir, uma breve descricao do metodo e feita.
Seja a famılia exponencial biparametrica definida como em Bernardo and Smith
(2001):
p(yt|ηt, φt) = f(yt)exp φt [ηtd1(yt) + d2(yt)]− ρ(ηt, φt) , (5.1)
sendo f(yt) uma funcao nao negativa, ηt e φt parametros desconhecidos, d1(·), d2(·) e
ρ(ηt, φt) funcoes conhecidas.
A partir de 5.1, pode-se encontrar a media do processo, denotada por µt = E(yt|ηt, φt).
Suponha que tanto as medias como os parametros de precisao podem ser descritos por um
conjunto de variaveis explicativas a cada tempo t atraves de funcoes de ligacao diferentes.
Assim,
λ1t
λ2t
=
g(µt)
g(φt)
= F ′tθt (5.2)
A priori para o vetor (ηt, φt), tambem seguindo a forma proposta por Bernardo and
58

Smith (2001), pode ser definida como:
p(ηt, φt|Dt−1) ∝ exp ηtφtτ1 + φtτ2 − τ0ρ(ηt, φt) (5.3)
Desta forma, fica claro que a posteriori sera tal que
p(ηt, φt|Dt) ∝ exp ηtφtτ ∗0 + φtτ∗2 − τ ∗0 ρ(ηt, φt) , (5.4)
de forma que τ ∗0 = τ0 + 1, τ ∗1 = τ1 + d1(yt) e τ ∗2 = τ2 + d2(yt).
O primeiro passo do metodo consiste na evolucao dos estados e da preditiva dado mt−1
e Ct−1. Tal evolucao e feita do mesmo modo como apresentado em West et al. (1985).
Sejam: mt = E(θt|Dt), Ct = V ar(θt|Dt), at = E(θt|Dt−1), Rt = V ar(θt|Dt−1), ft =
E(λt|Dt−1), Qt = V ar(λt|Dt−1). Tem-se entao:
at = Gtmt−1
Rt = GtCt−1G′t +Wt
ft = F ′tat
Qt = F ′tRtFt (5.5)
Seguidamente, deseja-se encontrar os parametros τ0t, τ1t e τ2t. Para tal utiliza-se os
momentos a priori de (µt|Dt−1) e (φt|Dt−1). A partir destes, e possıvel encontrar os
momentos a priori de (λ1t|Dt−1) e (λ2t|Dt−1) em funcao de τ0t, τ1t e τ2t.
Seguindo a notacao de Souza et al. (2016), tem-se que:
E(λ1t|Dt−1) = h1(τ0t, τ1t, τ2t),
E(λ2t|Dt−1) = h2(τ0t, τ1t, τ2t),
V (λ1t|Dt−1) = h3(τ0t, τ1t, τ2t),
V (λ2t|Dt−1) = h4(τ0t, τ1t, τ2t),
Cov(λ1t, λ2t|Dt−1) = h5(τ0t, τ1t.τ2t).
(5.6)
59

De modo que ao compatibilizar com as equacoes em 5.5, o seguinte sistema e obtido:
f1t = h1(τ0t, τ1t, τ2t),
f2t = h2(τ0t, τ1t, τ2t),
q11t = h3(τ0t, τ1t, τ2t),
q22t = h4(τ0t, τ1t, τ2t),
q12t = h5(τ0t, τ1t.τ2t). (5.7)
Pode-se observar que este sistema e superespecificado, ou seja, ha mais equacoes do que
parametros, portanto nao ha uma solucao unica para o sistema. A abordagem adotada
para lidar com esse problema, em Souza et al. (2016) e no presente trabalho foi utilizar
o Metodo de Momentos Generalizado. Este metodo consiste em encontrar a solucao que
minimiza a funcao
gn(τ ,ft,Qt)Ωngn(τ ,ft,Qt), (5.8)
onde, τ = (τ0t, τ1t, τ2t) e gn(τ ,ft,Qt) e a seguinte funcao vetorial:
gn(τ ,ft,Qt) =
f1t − h1(τ0t, τ1t, τ2t)
f2t − h2(τ0t, τ1t, τ2t)
q11t − h3(τ0t, τ1t, τ2t)
q22t − h4(τ0t, τ1t, τ2t)
q12t − h5(τ0t, τ1t.τ2t)
. (5.9)
Neste trabalho considerou-se a matriz Ωn como sendo uma matriz identidade, isto
e, considerou-se que todas equacoes possuem o mesmo peso. Uma vez que o argumento
mınimo da funcao e encontrado, e feita a atualizacao dos parametros com base na nova
observacao. Obtem-se τ ∗0 , τ∗1 , τ
∗2 , tornando possıvel, portanto, encontrar os momentos
atualizados da posteriori do preditor linear e por fim, os estados. A seguir, alguns
exemplos serao apresentados.
60

5.1 Distribuicao Gama
• Modelo Observacional:
Seja αt = φtµ2t e βt = φtµt, de forma que:
µt =αtβt
e φt = αt.
p(yt|µt, φt) = y−1t exp
−φµyt + φt log(yt)
× exp
−[log(Γ (φt))− (φt)log
(φtµt
)],
= y−nt exp
(φtµ
2t )
t∑i=1
log(yt)
.
• Distribuicao a priori conjugada:
p(µt, φt|τ0t, τ1t, τ2t) ∝ exp
(φtµ2t )τ1t − (φtµt)τ2t
× exp
−τ0t
[log(Γ (φtµ
2t ))− (φtµ
2t )log(φtµt)
].
Onde, µt > 0 e φt > 0.
• Aproximando os momentos da priori conjugada:
Como a priori nao tem formula analıtica fechada, obtou-se por encontrar sua moda
e curvatura. Sejam λ1t e λ2t dois preditores dinamicos para mut e φt, respectiva-
mente e considere funcoes de ligacao logarıtimicas relacionando tais preditores aos
parametros de interesse:
λ1t = log(µt),
λ2t = log(φt).
61

• Equacoes Resultantes no Modelo Dinamico:
Nota-se que a disribuicao a priori conjugada nao tem forma conhecida. Desse
modo, obtou-se por encontrar sua moda e matriz de curvatura, que resultou em:
f1t = E(log(µt)|Dt−1) = log
(τ1tτ0t
),
f2t = E(log(φt)|Dt−1) = log
τ0t
2[τ0t log
(τ1tτ0t
)− τ2t
] ,
Q1t = V ar(log(µt)|Dt−1) =2
τ 20t
[τ0t log
(τ1tτ0t
)− τ2t
],
Q2t = E(log(φt)|Dt−1) =2
τ0t.
• Restricoes:
Como as quantidades Q1t e Q2t representam variancias e estas sao positivas por
definicao, o uso de restricoes se faz necessario. Assim,
τ0t > 0, τ1t > 0,τ2tτ0t
> f1t.
• Atualizacao:
τ ∗0t = τ0t + 1
τ ∗1t = τ1t + yt
τ ∗2t = τ2t + log(yt)
62

5.2 Distribuicao Normal
• Modelo Observacional:
p(yt|µt, φ) =
(φt2π
)1/2
exp
−φt
2(yt − µt)2
,
= (2π)t/2[φ1/2t exp
−φtµ2
t
2
]× exp
µtφtyt −
1
2φty
2t
.
• Distribuicao a priori conjugada:
p(µt, φt|τ0t, τ1t, τ2t) ∝[φ1/2t exp
−1
2φtµ
2t
]τ0texp
µtφtτ1t −
1
2φtτ2t
,
∝[φτ0t/2t
]exp
−1
2φtτ2t
exp
−1
2φtτ0t
(µ2t − 2µt
τ1tτ0t
),
∝[φτ0t/2t
]exp
−1
2φtτ2t
exp
−1
2φtτ0t
(µ2t − 2µt
τ1tτ0t
+
(τ1tτ0t
)2)
× (φtτ0t)1/2exp
−φtτ0t
2
(−τ
21t
τ 20t
)(φtτ0t)
−1/2,
=1
κ(τ0t, τ1t, τ2t)φ(τ0t−1)/2t exp
−φt
2
(τ2t −
τ 21tτ0t
)× φ
1/2t exp
φtτ0t
2
(µt −
τ1tτ0t
)2.
Sendo este o nucleo da densidade da distribuicao Normal-Gama. Esta distribuicao
e especificada de acordo com os parametros (γ, V, αt, βt), nesta ordem. Dessa forma,
temos que: γ = τ1tτ0t, V = τ0t, αt = (τ0t+1)
2, βt = 1
2
(τ2t − τ21t
τ0t
).
63

• Equacoes Resultantes nos Modelo Dinamico:
f1t = E(µt|Dt−1) =τ1tτ0t,
f2t = E(log(φt)|Dt−1) = log
((τ0t + 1)
2
[1
2
(τ2t −
τ 21tτ0t
)]−1),
Q1t = V ar(µt|Dt−1) =
(τ2t −
τ 21tτ0t
)τ−10t
(τ0t + 1
2− 1
)−1,
Q2t = V ar(log(φt)|Dt−1) =2
(τ0t + 1).
• Restricoes:
Como as quantidades Q1t e Q2t representam variancias e estas sao positivas por
definicao, o uso de restricoes se faz necessario. Assim,
τ0t > 1, τ2t > τ 21t/τ0t
• Atualizacao:
τ ∗0t = τ0t + 1
τ ∗1t = τ1t + yt
τ ∗2t = τ2t + (yt)2
64

5.3 Distribuicao Multinomial
A seguir uma extensao da metodologia proposta por Souza et al. (2016) e apresentada
para o caso Multinomial.
• Modelo Observacional:
p(yt|η1t, η2t) =
(N
y1t y2t y3t
)ηy1t1t η
y2t2t (1− η1t − η2t)N−y1t−y2t ,
=
(N
y1t y2t y3t
)(η1t
1− η1t − η2t
)y1t ( η2t1− η1t − η2t
)y2t+ (1− η1t − η2t)N .
onde 0 < η1t, η2t < 1 e yt ∈ R+.
• Distribuicao a priori conjugada:
p(η1t, η2t) ∝(
η1t1− η1t − η2t
)τ1 ( η2t1− η1t − η2t
)τ2+ (1− η1t − η2t)τ0 ,
∝ ητ11tητ22t (1− η1t − η2t)τ0−τ1−τ2 ,
que representa o nucleo da funcao densidade de probabilidade Dirichlet com parametros
α1 = τ1 + 1, α2 = τ2 + 1 e α3 = τ0 − τ1 − τ2 + 1.
• Funcoes de ligacao:
λ1t = log
(η1t
1− η1t − η2t
),
λ2t = log
(η2t
1− η1t − η2t
).
• Aproximando os momentos das funcoes de ligacao:
65

Observe que nao ha forma analıtica fechada para as distribuicoes das funcoes de
ligacao. Optou-se, portanto, em utilizar expansao de Taylor bivariada para que os
momentos pudessem ser encontrados.
Seja z = < x, y > e a = (a,b), a serie de Taylor pode ser escrita como:
f(z) = f(a) + [(z− a)∇f(a)] + [(z− a)TH(z)(z− a))].
Sendo H(x) a matriz de segundas derivadas (Hessiana):
H(x, y) =
fxx(x, y) fxy(x, y)
fyx(x, y) fyy(x, y)
.A expansao de Taylor de segunda ordem pode ser reescrita como:
f(x, y) = f(a, b) + fx(a, b)(x− a) + fy(a, b)(y − b)
+1
2
[fxx(x− a)2 + 2fxy(x− a)(y − b)fyy(y − b)2
].
No caso da multinomial, considere
f1(η1t, η2t) = log
(η1t
1− η1t − η2t
),
f2(η1t, η2t) = log
(η2t
1− η1t − η2t
),
a = E(η1t),
b = E(η2t).
Para que a expansao de Taylor seja feita, e necessario que as primeiras e segundas
derivadas, assim como os momentos de η1t e η2t, sejam encontrados. Os resultados
encontram-se dispostos a seguir.
66

∂f1(η1t, η2t)
∂η1t=
1− η2tη1t(1− η1t − η2t)
,
∂f1(η1t, η2t)
∂η2t=
1
1− η1t − η2t,
∂f1(η1t, η2t)
∂η1t∂η1t=
(1− η2t)(2η1t + η2t − 1)
η21t(1− η1t − η2t)2,
∂f1(η1t, η2t)
∂η2t∂η2t=
1
(1− η1t − η2t)2,
∂f1(η1t, η2t)
∂η1t∂η2t=
1
(1− η1t − η2t)2.
∂f2(η1t, η2t)
∂η2t=
1− η1tη1t(1− η1t − η2t)
,
∂f2(η1t, η2t)
∂η1t=
1
1− η1t − η2t,
∂f2(η1t, η2t)
∂η2t∂η2t=
(1− η1t)(2η2t + η1t − 1)
η22t(1− η1t − η2t)2,
∂f2(η1t, η2t)
∂η1t∂η1t=
1
(1− η1t − η2t)2,
∂f2(η1t, η2t)
∂η1t∂η2t=
1
(1− η1t − η2t)2.
67

E(η1t|Dt−1) =α1
α1 + α2 + α3
=τ1 + 1
τ0 + 3= η1t,
E(η2t|Dt−1) =α2
α1 + α2 + α3
=τ2 + 1
τ0 + 3= η2t,
V ar(η1t|Dt−1) =α1(α2 + α3)
(α1 + α2 + α3)2(α1 + α2 + α3 + 1)
=(τ1 + 1)(τ0 − τ1 + 2)
(τ0 + 3)2(τ0 + 4)= σ2
1,
V ar(η2t|Dt−1) =α2(α1 + α3)
(α1 + α2 + α3)2(α1 + α2 + α3 + 1)
=(τ2 + 1)(τ0 − τ2 + 2)
(τ0 + 3)2(τ0 + 4)= σ2
2,
Cov((η1t, η2t)|Dt−1) = − α1α2
(α1 + α2 + α3)2(α1 + α2 + α3 + 1)
= − (τ1 + 1)(τ2 + 1)
(τ0 + 3)2(τ0 + 4)= σ1σ2.
68

Dessa forma,
E
(log
(η1t
1− η1t − η2t
)|Dt−1
)≈ log
(η1t
1− η1t − η2t
)+
1
2
(1− η2t)(2η1t + η2t − 1)σ21
η21t(1− η1t − η2t)2
+1
2
σ22
(1− η1t − η2t)2+
σ1σ2(1− η1t − η2t)2
E
(log
(η2t
1− η1t − η2t
)|Dt−1
)≈ log
(η2t
1− η1t − η2t
)+
1
2
(1− η1t)(2η2t + η1t − 1)σ22
η22t(1− η1t − η2t)2
+1
2
σ21
(1− η1t − η2t)2+
σ1σ2(1− η1t − η2t)2
V ar
(log
(η1t
1− η1t − η2t
)|Dt−1
)≈
(1− η2t
η1t(1− η1t − η2t)
)2
σ21 +
(1
1− η1t − η2t
)2
σ22
+
(1
1− η1t − η2t
)(1− η2t
η1t(1− η1t − η2t)
)σ1σ2
V ar
(log
(η2t
1− η1t − η2t
)|Dt−1
)≈
(1− η1t
η2t(1− η1t − η2t)
)2
σ22 +
(1
1− η1t − η2t
)2
σ21
+
(1
1− η1t − η2t
)(1− η1t
η2t(1− η1t − η2t)
)σ1σ2
Seja f(η1t, η2t) =(log(
η1t1−η1t−η2t
)log(
η2t1−η1t−η2t
))
f(η1t, η2t) ≈ f(η1t, η2t) +
η1t − η1tη2t − η2t
′ ∇f(η1t, η2t)|(η1t,η2t)=(η1t,η2t)
= log
(η1t
1− η1t − η2t
)log
(η2t
1− η1t − η2t
)
+
η1t − η1tη2t − η2t
′ ∇f(η1t, η2t)|(η1t,η2t)=(η1t,η2t)
69

Onde,
∇f(η1t, η2t)|(η1t)=(η1t) =
((1− η2t)
(η1t
1− η1t − η2t
)+ η1tlog
(η2t
1− η2t − η1t
))× 1
η1t(1− η1t − η2t)
∇f(η1t, η2t)|(η2t)=(η2t) =
((1− η1t)
(η2t
1− η1t − η2t
)+ η2tlog
(η1t
1− η2t − η1t
))× 1
η2t(1− η1t − η2t)
Mas, se aproximarmos E(η1t|Dt−1) = η1t e E(η2t|Dt−1) = η2t
η1t − η1tη2t − η2t
′ =
0
0
′
E, portanto,
E(λ1tλ2t|Dt−1) = log
(η1t
1− η1t − η2t
)log
(η2t
1− η1t − η2t
)Assim, a covariancia entre as funcoes de ligacao sera dada por:
Cov(λ1t, λ2t|Dt−1) = log
(η1t
1− η1t − η2t
)log
(η2t
1− η1t − η2t
)− log
(η1t
1− η1t − η2t
)log
(η2t
1− η1t − η2t
)= 0
70

O sistema a ser resolvido sera tal que:
f1t = log
(τ1 + 1
τ0− τ1 − τ2 + 1
)f2t = log
(τ2 + 1
τ0− τ1 − τ2 + 1
)q1t =
((τ0 + 3)(τ0 − τ2 + 2)
(τ1 + 1)(τ0− τ1 − τ2 + 1)
)2((τ1 + 1)(τ0 − τ1 + 2)
(τ0 + 3)2(τ0 + 4)
)+
(τ0 + 3
τ0− τ1 − τ2 + 1
)2((τ2 + 1)(τ0 − τ2 + 2)
(τ0 + 3)2(τ0 + 4)
)+
((τ0 + 3)(τ0 − τ2 + 2)
(τ1 + 1)(τ0− τ1 − τ2 + 1)
)(τ0 + 3
τ0− τ1 − τ2 + 1
)(− (τ1 + 1)(τ2 + 1)
(τ0 + 3)2(τ0 + 4)
)q2t =
((τ0 + 3)(τ0 − τ2 + 2)
(τ1 + 1)(τ0− τ1 − τ2 + 1)
)2((τ2 + 1)(τ0 − τ2 + 2)
(τ0 + 3)2(τ0 + 4)
)+
(τ0 + 3
τ0− τ1 − τ2 + 1
)2((τ1 + 1)(τ0 − τ1 + 2)
(τ0 + 3)2(τ0 + 4)
)+
((τ0 + 3)(τ0 − τ2 + 2)
(τ1 + 1)(τ0− τ1 − τ2 + 1)
)(τ0 + 3
τ0− τ1 − τ2 + 1
)(− (τ1 + 1)(τ2 + 1)
(τ0 + 3)2(τ0 + 4)
)
71

5.3.1 Estudo Simulado
Visando avaliar o comportamento da metodologia proposta, um estudo simulado foi
feito e seus resultados serao apresentados ao longo desta secao.
Considere (Yt|η1t, η2t, η3t) ∼ Multinomial(η1t, η2t, η3t) e seja a estrutura do modelo a
seguinte:
at = at−1 + ωt,W ∼ N(0, 0.12)
bt = bt−1 + ωt,W ∼ N(0, 0.12)
η1t =exp(at)
1 + exp(at)
η2t =exp(bt)
1 + exp(bt)
De modo que at e bt sao parametros auxiliares e
λ1t = log
(η1t
1− η1t − η2t
),
λ2t = log
(η2t
1− η1t − η2t
).
Para analise, foram geradas 50 amostras de um modelo com essa estrutura, sendo a1 = 1.1
e b1 = 0.8. A Figura 5.1 mostra que o metodo foi capaz de capturar a estrutura dos
0 50 100 150
−2
02
46
8
(a) E(λ1t|Dt)
0 50 100 150
−2
02
46
8
(b) E(λ2t|Dt)
Figura 5.1: Boxplots para as medias a posteriori dos parametros λ1t e λ2t junto aos seusvalores verdadeiros (linha vermelha).
parametros λ1 e λ2 duranto todo o perıodo de tempo, conforme esperado. Nota-se que
72
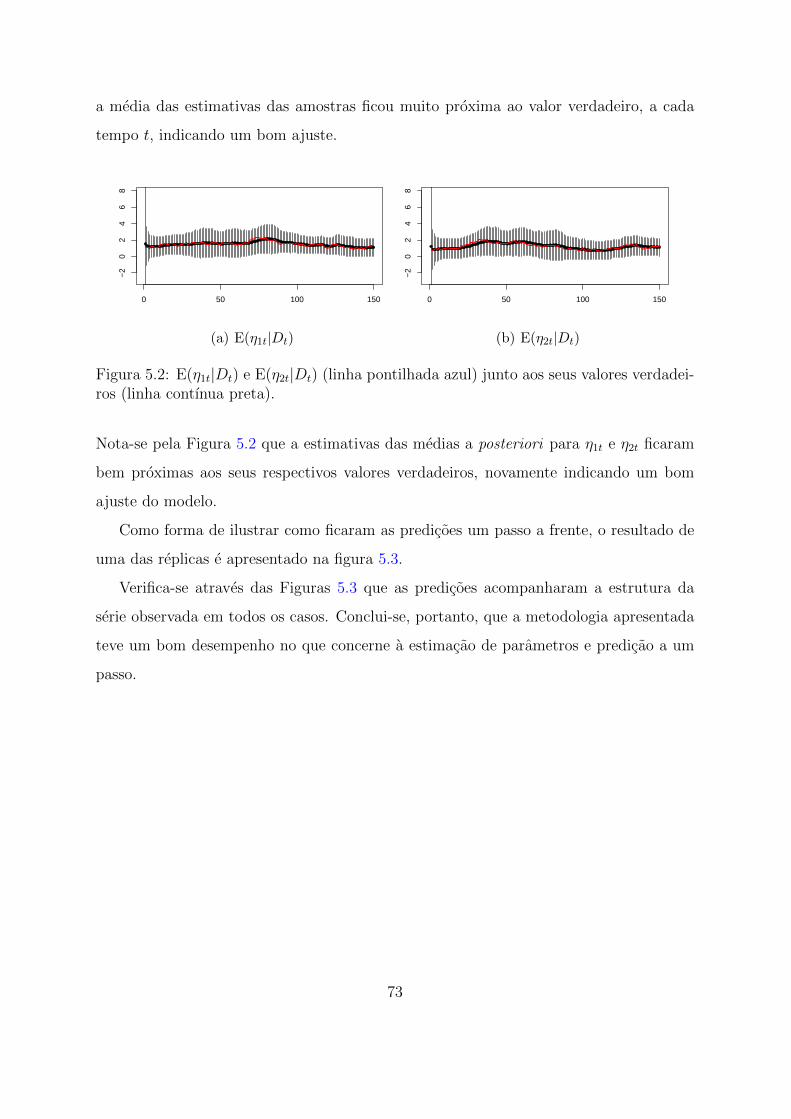
a media das estimativas das amostras ficou muito proxima ao valor verdadeiro, a cada
tempo t, indicando um bom ajuste.
0 50 100 150
−2
02
46
8
(a) E(η1t|Dt)
0 50 100 150
−2
02
46
8
(b) E(η2t|Dt)
Figura 5.2: E(η1t|Dt) e E(η2t|Dt) (linha pontilhada azul) junto aos seus valores verdadei-ros (linha contınua preta).
Nota-se pela Figura 5.2 que a estimativas das medias a posteriori para η1t e η2t ficaram
bem proximas aos seus respectivos valores verdadeiros, novamente indicando um bom
ajuste do modelo.
Como forma de ilustrar como ficaram as predicoes um passo a frente, o resultado de
uma das replicas e apresentado na figura 5.3.
Verifica-se atraves das Figuras 5.3 que as predicoes acompanharam a estrutura da
serie observada em todos os casos. Conclui-se, portanto, que a metodologia apresentada
teve um bom desempenho no que concerne a estimacao de parametros e predicao a um
passo.
73
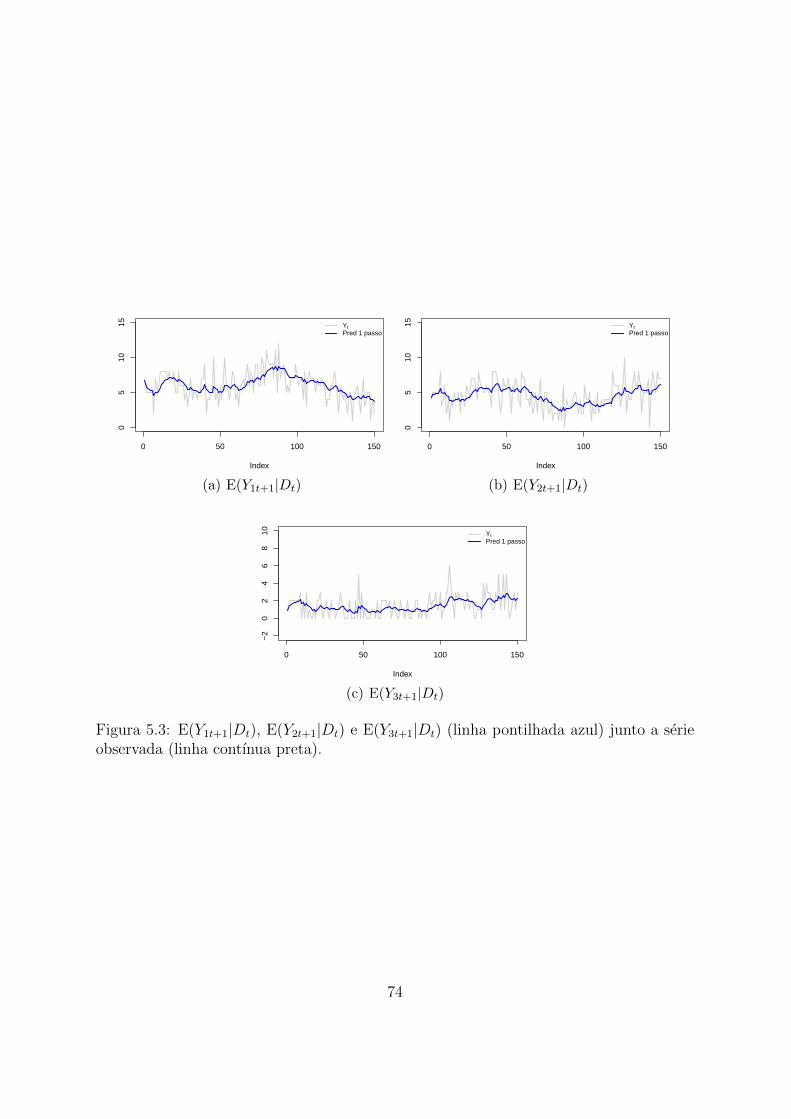
0 50 100 150
05
1015
Index
YtPred 1 passo
(a) E(Y1t+1|Dt)
0 50 100 150
05
1015
Index
YtPred 1 passo
(b) E(Y2t+1|Dt)
0 50 100 150
−2
02
46
810
Index
YtPred 1 passo
(c) E(Y3t+1|Dt)
Figura 5.3: E(Y1t+1|Dt), E(Y2t+1|Dt) e E(Y3t+1|Dt) (linha pontilhada azul) junto a serieobservada (linha contınua preta).
74
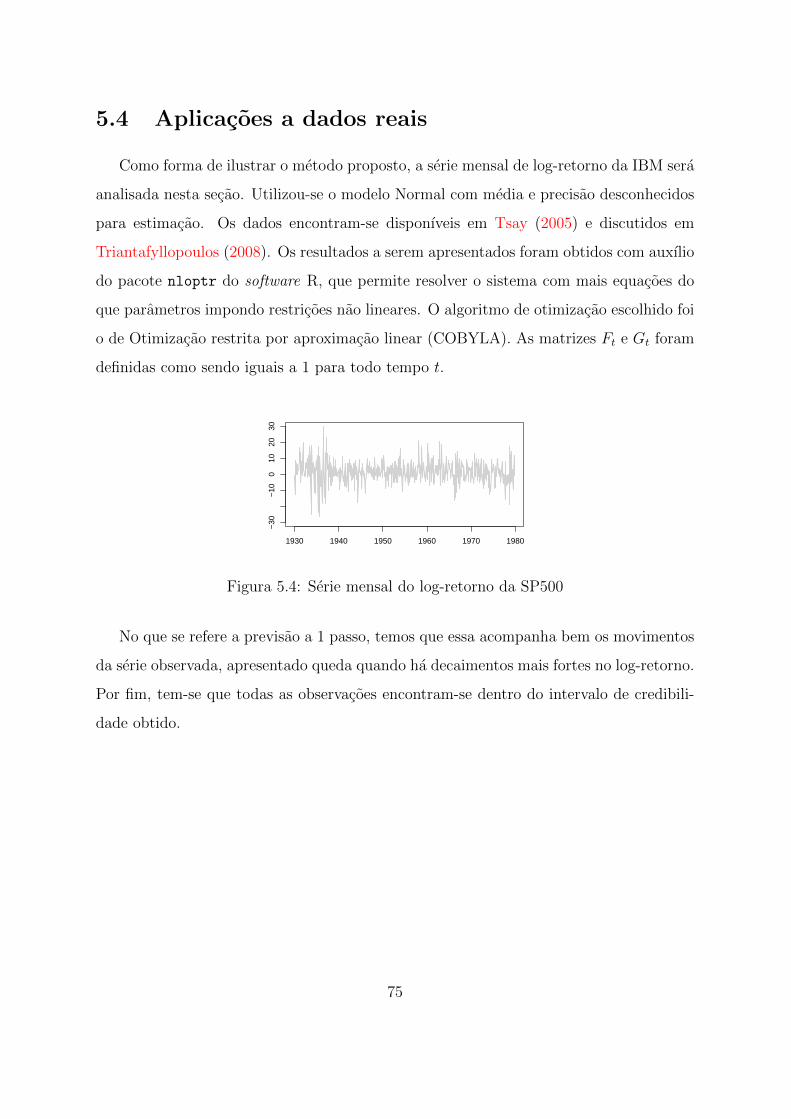
5.4 Aplicacoes a dados reais
Como forma de ilustrar o metodo proposto, a serie mensal de log-retorno da IBM sera
analisada nesta secao. Utilizou-se o modelo Normal com media e precisao desconhecidos
para estimacao. Os dados encontram-se disponıveis em Tsay (2005) e discutidos em
Triantafyllopoulos (2008). Os resultados a serem apresentados foram obtidos com auxılio
do pacote nloptr do software R, que permite resolver o sistema com mais equacoes do
que parametros impondo restricoes nao lineares. O algoritmo de otimizacao escolhido foi
o de Otimizacao restrita por aproximacao linear (COBYLA). As matrizes Ft e Gt foram
definidas como sendo iguais a 1 para todo tempo t.
1930 1940 1950 1960 1970 1980
−30
−10
010
2030
Figura 5.4: Serie mensal do log-retorno da SP500
No que se refere a previsao a 1 passo, temos que essa acompanha bem os movimentos
da serie observada, apresentado queda quando ha decaimentos mais fortes no log-retorno.
Por fim, tem-se que todas as observacoes encontram-se dentro do intervalo de credibili-
dade obtido.
75
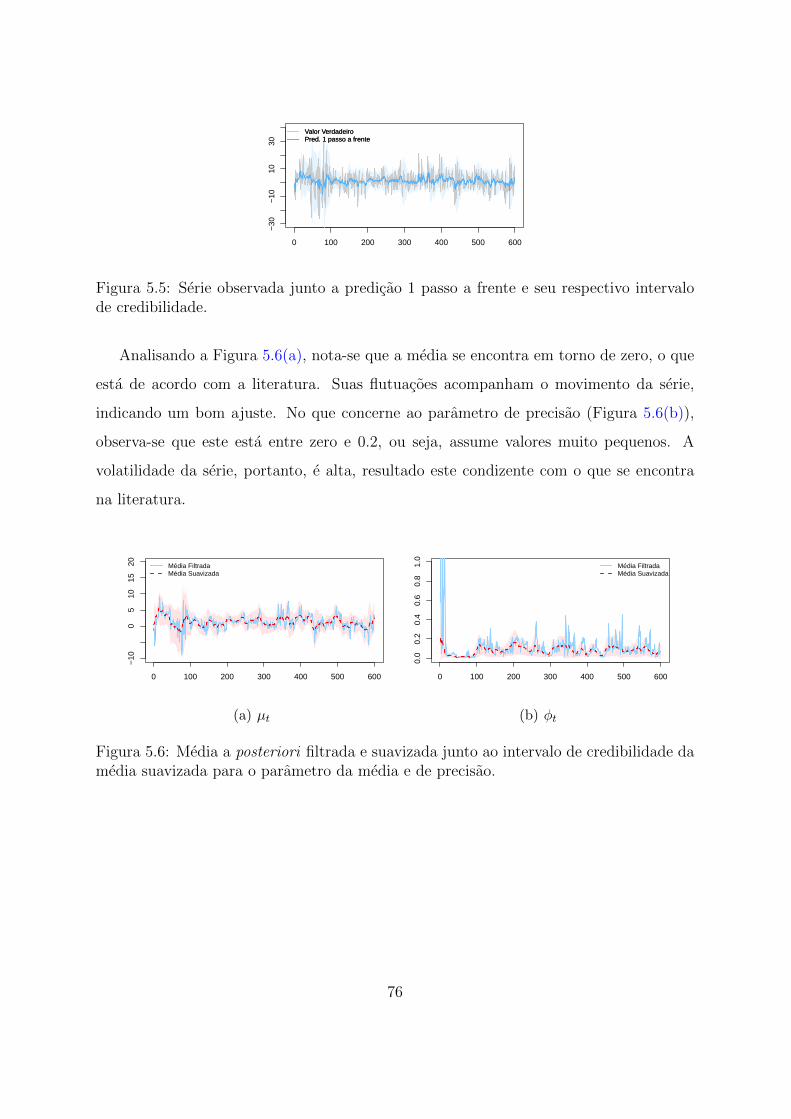
0 100 200 300 400 500 600
−30
−10
1030
Valor VerdadeiroPred. 1 passo a frenteValor VerdadeiroPred. 1 passo a frente
Figura 5.5: Serie observada junto a predicao 1 passo a frente e seu respectivo intervalode credibilidade.
Analisando a Figura 5.6(a), nota-se que a media se encontra em torno de zero, o que
esta de acordo com a literatura. Suas flutuacoes acompanham o movimento da serie,
indicando um bom ajuste. No que concerne ao parametro de precisao (Figura 5.6(b)),
observa-se que este esta entre zero e 0.2, ou seja, assume valores muito pequenos. A
volatilidade da serie, portanto, e alta, resultado este condizente com o que se encontra
na literatura.
0 100 200 300 400 500 600
−10
05
1015
20
Média FiltradaMédia Suavizada
(a) µt
0 100 200 300 400 500 600
0.0
0.2
0.4
0.6
0.8
1.0
Média FiltradaMédia Suavizada
(b) φt
Figura 5.6: Media a posteriori filtrada e suavizada junto ao intervalo de credibilidade damedia suavizada para o parametro da media e de precisao.
76

Capıtulo 6
Conclusao
O presente trabalho teve por objetivo discutir metodos de inferencia para a classe de
modelos lineares dinamicos para a famılia exponencial p-dimensional. Foram visitadas
metodologias propostas por West et al. (1985), Gamerman et al. (2013), Smith (1979) e
Souza et al. (2016), alem de apresentar-se novas abordagens para inferencia nessa classe
de modelos via elementos de geometria da informacao.
Foi verificado que, uma vez que se atribui uma distribuicao a priori para o vetor de
estados, uma priori induzida para o parametro canonico da famılia exponencial e obtida.
Por outro lado, ha tambem a priori conjugada natural nesta famılia. Por motivos de
conveniencia, uma vez que conhecemos as propriedades de tal distribuicao, deseja-se
trabalhar com a conjugada.
Uma abordagem de geometria da informacao apresentada sugere que a distribuicao
induzida seja projetada no espaco da distribuicao conjugada via minimizacao da di-
vergencia de Kullback-Leibler. Outra sugere que nao apenas se faca tal projecao, mas
tambem que se compatibilize tal informacao com a proveniente de um modelo de nıvel
local. A vantagem do segundo e que, o modelo de nıvel local por si nao permite que as
componentes de tendencia e sazonalidade sejam estocasticas, enquanto o metodo aqui
proposto admite essa propriedade.
Verificou-se, atraves de exercıcios de simulacao e aplicacao a dados reais que tal
metodologia tem um bom desempenho no que concerne a estimacao do vetor de estados
e predicao a um passo. Foi verificado, inclusive, que mudancas no padrao sazonal sao
77

captadas sem necessidade de intervencao manual. Ficou claro que as estimativas do
modelo via geometria da informacao - sem compatibilizar modelos ficam muito proximas
das obtidas via Conjugate Updating (West et al. (1985)). No que se refere oo modelo
via geometria que compatibiliza informacoes de um modelo estrurado e de um modelo de
media local, nota-se que suas estimativas vao dependender do peso dado a cada modelo,
podendo se aproximar mais de Conjugate Updating, ou do modelo de nıvel local. Quanto
ao ultimo, foi verificado que nao consegue captar mudancas no padrao sazonal, o que
pode estar relacionado ao fato de nao permitir que as componentes de sazonalidade
sejam estocasticas, conforme mencionado anteriormente. Embora Harvey and Fernandes
(1989) argumentem que essa nao e uma forte limitacao, acreditamos que e sim.
No que concerne a famılia exponencial k-parametrica o metodo apresentado por Souza
et al. (2016) foi visitado. Uma vez utilizada a priori definida por Bernardo and Smith
(2001), nos casos aqui apresentados, 3 parametros devem ser estimados. Entretanto
neste caso ha 2 funcoes de ligacao: uma para o parametro da media e outra para o
parametro de precisao. Observe que cada uma dessas tera sua media e variancia, alem
da covariancia que pode existir entre elas, totalizando ate 5 equacoes. Dessa forma,
nota-se que o sistema e super especificado: 5 equacoes para 3 parametros. A solucao
encontrada pelos autores foi utilizar o metodo de momentos generalizado para reducao
do sistema. Apresentou-se nesse trabalho uma extensao do metodo para a distribuicao
Multinomial. Foi verificado, atraves de simulacao, que a metodologia proposta consegue
captar o nıvel dos parametros, assim como a predicao a um passo acompanha a estrutura
dos dados observados.
Como trabalhos futuros, pretende-se desenvolver uma metodologia baseada em geo-
metria da informacao para a famılia exponencial k-parametrica. Alem disso, a expansao
da metodologia para dados composicionais.
78

Apendice A
Resultados secundarios referentes a
serie de vendas
A.1 Tabela de resultados do modelo Poisson via Ge-
ometria da Informacao que compatibiliza mode-
los
s ω EQM Preditivo Log- verossimilhanca1 0.90 0.50 74.62 -131.322 0.90 0.70 87.89 -132.663 0.90 0.75 91.78 -133.124 0.90 0.80 95.82 -133.625 0.90 0.85 99.97 -134.166 0.90 0.90 104.21 -134.747 0.90 0.95 108.50 -135.348 0.90 0.97 110.67 -135.659 0.90 0.99 111.97 -135.8410 0.90 1.00 112.84 -135.97
Tabela A.1: Tabela com os resultados obtidos de acordo com os parametros s e ω paraos 10 melhores modelos.
79

A.2 Cadeias obtidas pelo MCMC
0 1000 2000 3000 4000 5000
−0.
6−
0.4
−0.
2
Iterações
(a) β1
0 1000 2000 3000 4000 5000
−0.
6−
0.4
−0.
2
Iterações
(b) β2
0 1000 2000 3000 4000 5000
−0.
25−
0.15
−0.
050.
05
Iterações
(c) β3
0 1000 2000 3000 4000 5000
0.3
0.5
0.7
Iterações
(d) ω
Figura A.1: Cadeias resultantes obtidas pelo metodo MCMC para cada um dosparametros β e para o parametro ω.
80

Referencias Bibliograficas
Amari, S.-i. (2016). Information geometry and its applications. Springer.
Ameen, J. and Harrison, P. (1984). Discount weighted estimation. Journal of Forecasting,
3(3):285–296.
Bernardo, J. M. and Smith, A. F. (2001). Bayesian theory.
Gamerman, D., Santos, T. R., and Franco, G. C. (2013). A non-gaussian family of
state-space models with exact marginal likelihood. Journal of Time Series Analysis,
34(6):625–645.
Harrison, P. J. and Stevens, C. F. (1976). Bayesian forecasting. Journal of the Royal
Statistical Society. Series B (Methodological), pages 205–247.
Harvey, A. C. and Fernandes, C. (1989). Time series models for count or qualitative
observations. Journal of Business & Economic Statistics, 7(4):407–417.
Kass, R. E. and Raftery, A. E. (1995). Bayes factors. Journal of the american statistical
association, 90(430):773–795.
Nelder, J. A. and Wedderburn, R. W. M. (1972). Generalized linear models. Journal of
the Royal Statistical Society, Series A, General, 135:370–384.
Plummer, M., Best, N., Cowles, K., and Vines, K. (2006). Coda: Convergence diagnosis
and output analysis for mcmc. R News, 6(1):7–11.
Pole, A., West, M., and Harrison, J. (1994). Applied Bayesian forecasting and time series
analysis. CRC press.
81

Poole, D. and Raftery, A. E. (2000). Inference for deterministic simulation models:
the bayesian melding approach. Journal of the American Statistical Association,
95(452):1244–1255.
Powell, M. J. (1994). A direct search optimization method that models the objective and
constraint functions by linear interpolation. In Advances in optimization and numerical
analysis, pages 51–67. Springer.
Smith, J. (1979). A generalization of the bayesian steady forecasting model. Journal of
the Royal Statistical Society. Series B (Methodological), pages 375–387.
Smith, R. and Miller, J. (1986). A non-gaussian state space model e application to pre-
diction of records. Journal of the Royal Statistical Society. Series B (Methodological),
pages 79–88.
Souza, M. A. d. O., Migon, H. d. S., and Pereira, J. (2016). Extended dynamic generalized
linear models: the two-parameter exponential family. Computational Statistics & Data
Analysis.
Triantafyllopoulos, K. (2008). Dynamic generalized linear models for non-gaussian time
series forecasting. arXiv preprint arXiv:0802.0219.
Tsay, R. S. (2005). Analysis of financial time series, volume 543. John Wiley & Sons.
West, M. and Harrison, P. J. (1996). Bayesian forecasting. Wiley Online Library.
West, M., Harrison, P. J., and Migon, H. S. (1985). Dynamic generalized linear models
and bayesian forecasting. Journal of the American Statistical Association, 80(389):73–
83.
82


















