
Redes Bayesianas - Tec · Una red bayesiana es una representación gráfica que representa las...
73
Redes Bayesianas Manuel Valenzuela-Rendón Centro de Sistemas Inteligentes Tecnológico de Monterrey, Campus Monterrey Noviembre 2008 M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 1 / 53
Transcript of Redes Bayesianas - Tec · Una red bayesiana es una representación gráfica que representa las...

Redes Bayesianas
Manuel Valenzuela-Rendón
Centro de Sistemas InteligentesTecnológico de Monterrey, Campus Monterrey
Noviembre 2008
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 1 / 53

Temario I1 Probabilidad
NotaciónNotación vectorialNormalizaciónAxiomas de probabilidadProbabilidad conjunta y probabilidad marginalProbabilidad condicionalIndependencia
2 Redes BayesianasTeorema de BayesTeorema de Bayes con normalizaciónDefiniciones de PearlRedes bayesianasInferencia en redes BayesianasO-ruidoso (Noisy-OR)Ejemplo mínimo
3 Bayesian Networks ToolboxInferencias en BNTOtro ejemplo de red bayesianaUn ejemplo más
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 2 / 53

Temario IIEjemplo de PearlProblema 14.12 del texto
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 3 / 53

Notación de probabilidad
Se usarán mayúsculas para indicar variables estocásticas y minúsculas paraindicar los valores que pueden tomar.
P(A = verdadero) = P(A = a) = P(a) (1)
P(A = falso) = P(A = a′) = P(a′) (2)
P(a ∧ b ∧ c) ≡ P(a,b,c) ≡ P(a b c) (3)
P(¬a) ≡ P(a′) ≡ P(a) (4)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 4 / 53

Notación vectorial
Usaremos la notación vectorial de la siguiente manera.
P(A) = 〈P(a), P(a′)〉 (5)
P(B, C) ≡ 〈P(b′, c′), P(b′, c), P(b, c′), P(b, c)〉 (6)
Por ejemplo, P(X, Y) = P(X|Y)P(Y) es equivalente a
P(x′, y′) = P(x′|y′)P(y′)P(x′, y) = P(x′|y)P(y)P(x, y′) = P(x|y′)P(y′)P(x, y) = P(x|y)P(y)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 5 / 53

Notación vectorial
Usaremos la notación vectorial de la siguiente manera.
P(A) = 〈P(a), P(a′)〉 (5)
P(B, C) ≡ 〈P(b′, c′), P(b′, c), P(b, c′), P(b, c)〉 (6)
Por ejemplo, P(X, Y) = P(X|Y)P(Y) es equivalente a
P(x′, y′) = P(x′|y′)P(y′)P(x′, y) = P(x′|y)P(y)P(x, y′) = P(x|y′)P(y′)P(x, y) = P(x|y)P(y)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 5 / 53

Normalización
La probabilidad P(X|y) es:
P(X|y) = 〈P(x′|y, P(x|y)〉 (7)
donde
P(x′|y) =P(x′, y)
P(y)
P(x|y) =P(x, y)P(y)
Otra forma es la siguiente
P(x′|y) = αP(x′, y)P(x|y) = αP(x, y)
donde α representa la constante de normalización que sea necesaria paralograr que P(x′|y) + P(x|y) = 1.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 6 / 53

Los axiomas de probabilidad
1 0 ≤ P(a) ≤ 12 P(verdadero) = 1 y P(falso) = 03 P(a ∨ b) = P(a) + P(b) − P(a ∧ b)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 7 / 53

Probabilidad conjunta y probabilidad marginal
La distribución de probabilidad conjunta es una tabulación de laprobabilidad de todos los valores que pueden tomar las variablesaleatorias y la probabilidad para cada combinación.
La distribución de probabilidad marginal para un subconjunto devariables se obtiene sumando sobre las demás variables.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 8 / 53

Probabilidad conjunta y probabilidad marginal
La distribución de probabilidad conjunta es una tabulación de laprobabilidad de todos los valores que pueden tomar las variablesaleatorias y la probabilidad para cada combinación.
La distribución de probabilidad marginal para un subconjunto devariables se obtiene sumando sobre las demás variables.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 8 / 53

Ejemplo
Consideremos el ejemplo de la siguiente distribución de probabilidad conjuntaque depende de tres variables:
toothache ¬toothachecatch ¬catch catch ¬catch
cavity 0.108 0.012 0.072 0.008¬cavity 0.016 0.064 0.144 0.576
La distribución de probabilidad marginal de Toothache es la siguiente:
P(toothache) = 0.108 + 0.012 + 0.016 + 0.064 (8)
P(¬toothache) = 0.072 + 0.008 + 0.144 + 0.576 (9)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 9 / 53

Ejemplo
Consideremos el ejemplo de la siguiente distribución de probabilidad conjuntaque depende de tres variables:
toothache ¬toothachecatch ¬catch catch ¬catch
cavity 0.108 0.012 0.072 0.008¬cavity 0.016 0.064 0.144 0.576
La distribución de probabilidad marginal de Toothache es la siguiente:
P(toothache) = 0.108 + 0.012 + 0.016 + 0.064 (8)
P(¬toothache) = 0.072 + 0.008 + 0.144 + 0.576 (9)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 9 / 53

Probabilidad condicional
Probabilidad condicional, o probabilidad posterior, es la probabilidad de queA = a dado que se sabe B = b. Se define como
P(a|b) ≡ P(a ∧ b)P(b)
(10)
De lo anterior se puede obtener lo siguiente:
P(a ∧ b) = P(a|b) P(b) = P(b|a) P(a) (11)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 10 / 53

Independencia
A y B son variables aleatorias independientes, si y sólo si se cumplen lassiguientes condiciones que son equivalentes entre sí:
P(a|b) = P(a) (12)
P(b|a) = P(b) (13)
P(a ∧ b) = P(a) P(b) (14)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 11 / 53

Teorema de Bayes
A partir de la ecuación 11 se obtiene la siguiente expresión que es conocidacomo el teorema de Bayes:
P(b|a) =P(a|b) P(b)
P(a)(15)
En el caso de variables que pueden tomar múltiples valores, el teorema deBayes se puede expresar en forma vectorial de la siguiente manera:
P(Y|X) =P(X|Y) P(Y)
P(X)(16)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 12 / 53

Teorema de Bayes
A partir de la ecuación 11 se obtiene la siguiente expresión que es conocidacomo el teorema de Bayes:
P(b|a) =P(a|b) P(b)
P(a)(15)
En el caso de variables que pueden tomar múltiples valores, el teorema deBayes se puede expresar en forma vectorial de la siguiente manera:
P(Y|X) =P(X|Y) P(Y)
P(X)(16)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 12 / 53

EjemploRelación entre meningitis y dolor de cuello
S: dolor de cuello
M: meningitis
Se conocen las siguientes probabilidades:
Meningitis causa dolor de cuello en 50% de los casos:
P(s|m) = 0.5 (17)
La probabilidad de tener meningitis es de 1/50,000:
P(m) = 1/50,000 = 2 × 10−5 (18)
La probabilidad de tener dolor de cuello es P(s) = 1/20
P(s) = 1/20 = 5 × 10−2 (19)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 13 / 53

EjemploRelación entre meningitis y dolor de cuello
Si tenemos un paciente con dolor de cuello, podemos calcular la probabilidadde que tenga meningitis utilizando el teorema de Bayes de la siguientemanera:
P(m|s) =P(s|m) P(m)
P(s)= 0.0002 = 2 × 10−4 (20)
A pesar de que la meningitis causa dolor de cuello en una gran cantidad decasos, P(s|m) = 0.5, el que un paciente tenga dolor de cuello no es un buenindicador de que tenga meningitis, P(m|s) = 2 × 10−4.Esto es debido a que la probabilidad anterior de dolor de cuello es muchomayor que la probabilidad anterior de meningitis.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 14 / 53

EjemploRelación entre meningitis y dolor de cuello
Si tenemos un paciente con dolor de cuello, podemos calcular la probabilidadde que tenga meningitis utilizando el teorema de Bayes de la siguientemanera:
P(m|s) =P(s|m) P(m)
P(s)= 0.0002 = 2 × 10−4 (20)
A pesar de que la meningitis causa dolor de cuello en una gran cantidad decasos, P(s|m) = 0.5, el que un paciente tenga dolor de cuello no es un buenindicador de que tenga meningitis, P(m|s) = 2 × 10−4.Esto es debido a que la probabilidad anterior de dolor de cuello es muchomayor que la probabilidad anterior de meningitis.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 14 / 53

EjemploRelación entre meningitis y dolor de cuello
Este ejemplo demuestra como dadas las probabilidades anteriores de unasvariables, S y M, y la probabilidad condicional entre ellas, P(s|m), se puedecalcular la probabilidad posterior P(m|s) utilizando el teorema de Bayes. Engeneral, podemos expresar el teorema de Bayes como
P(h|e) =P(e|h) P(h)
P(e)(21)
donde la variable H representa una hipótesis y la variable E representa unaevidencia.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 15 / 53

Teorema de Bayes con normalización
La forma general del teorema de Bayes con normalización es la siguiente
P(Y|X) = αP(X|Y) P(Y) (22)
donde α es la constante necesaria para hacer que la suma de todas lasprobabilidades sea igual a 1.0.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 16 / 53

Definiciones de Pearl
Prior odds
O(h) =P(h)P(h′)
=P(h)
1 − P(h)(23)
Likelihood ratio
L(e|h) =P(e|h)P(e|h′)
(24)
Posterior odds
O(h|e) =P(h|e)P(h′|e) = L(e|h) o(h) (25)
donde H es una hipótesis y E es una evidencia.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 17 / 53

Redes bayesianas
Una red bayesiana es una representación gráfica que representa lasdependencias entre variables y da una especificación concisa de cualquierdistribución de probabilidad conjunta completa.
Las relaciones de causa/efecto (o hipótesis/evidencia) se representan conarcos dirigidos de la causa al efecto.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 18 / 53

Red BayesianaEjemplo
cavity
toothache catch
weather
En este ejemplo, toothache y catch son evidencias de cavity. Además,weather es independiente de las demás variables.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 19 / 53

Inferencia en redes Bayesianas
La tarea básica de un sistema de inferencia probabilística es calcular lasdistribuciones de probabilidad posteriores para un conjunto de variables dadoun evento observado, es decir, dada una asignación de valores a un conjuntode variables de evidencia.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 20 / 53

Inferencia exacta por enumeración
La probabilidad de la hipótesis H dada la evidencia e:
P(H|e) =P(H, e)
P(e)(26)
En caso de varias evidencias e1, e2, . . . , en:
P(H|e1, e2, . . . , en) =P(e1|H)P(e2|H) · · ·P(en|H)
P(e1)P(e2) · · ·P(en)P(H) (27)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 21 / 53

O-ruidoso (Noisy-OR)
El O-ruidoso permite que haya incertidumbre acerca de la capacidad de cadapadre para hacer que el hijo sea verdadero—la relación causal entre padre ehijo puede ser inhibida, de manera que un paciente puede tener gripe, perono tener fiebre.Dos suposiciones:
1 Todas las causas posibles han sido listadas.2 La inhibición de cada padre es independiente de las inhibiciones de los
demás padres.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 22 / 53

Ejemplo de O-ruidoso
Se tienen las siguientes probabilidades:
P(fiebre′|gripe, influenza′, malaria′) = 0.6
P(fiebre′|gripe′, influenza, malaria′) = 0.2
P(fiebre′|gripe′, influenza′, malaria) = 0.1
gripe influenza malaria P(fiebre) P(fiebre′)F F F 0.0 1.0F F T 0.9 0.1F T F 0.8 0.2F T T 0.98 0.02 = 0.2 × 0.1T F F 0.4 0.6T F T 0.9 0.06 = 0.6 × 0.1T T F 0.8 0.12 = 0.6 × 0.2T T T 0.98 0.012 = 0.6 × 0.2 × 0.1
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 23 / 53

Ejemplo de O-ruidoso
Se tienen las siguientes probabilidades:
P(fiebre′|gripe, influenza′, malaria′) = 0.6
P(fiebre′|gripe′, influenza, malaria′) = 0.2
P(fiebre′|gripe′, influenza′, malaria) = 0.1
gripe influenza malaria P(fiebre) P(fiebre′)F F F 0.0 1.0F F T 0.9 0.1F T F 0.8 0.2F T T 0.98 0.02 = 0.2 × 0.1T F F 0.4 0.6T F T 0.9 0.06 = 0.6 × 0.1T T F 0.8 0.12 = 0.6 × 0.2T T T 0.98 0.012 = 0.6 × 0.2 × 0.1
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 23 / 53

Ejemplo mínimo
B
AP(a′) P(a)
0.5 0.5
A P(b′) P(b)
F 1 0T 0.1 0.9
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 24 / 53

Función de distribución de probabilidad conjunta
P(a′, b′) = P(b′|a′)P(a′) = 1 × 0.5 = 0.5
P(a′, b) = P(b|a′)P(a′) = 0 × 0.5 = 0
P(a, b′) = P(b′|a)P(a) = 0.1 × 0.5 = 0.05
P(a, b) = P(b|a)P(a) = 0.9 × 0.5 = 0.45
P(b′) P(b)P(a′) 0.5 0P(a) 0.05 0.45
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 25 / 53

Probabilidades anteriores
P(a′) = P(a′, b′) + P(a′, b) = 0.5
P(a) = P(a, b′) + P(a, b) = 0.5
P(b′) = P(a′, b′) + P(a, b′) = 0.55
P(b) = P(a′, b) + P(a, b) = 0.45
P(b′) P(b)P(a′) 0.5 0 0.5P(a) 0.05 0.45 0.5
0.55 0.45
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 26 / 53

Probabilidades posteriores
P(a′|b′) =P(a′, b′)
P(b′)=
0.50.55
=P(b′|a′)P(a′)
P(b′)=
1 × 0.50.55
= 0.9091
P(a|b′) =P(a, b′)P(b′)
=0.050.55
=P(b′|a)P(a)
P(b′)=
0.1 × 0.50.55
= 0.0909
P(a′|b) =P(a′, b)
P(b)=
00.45
=P(b|a′)P(a′)
P(b′)=
0 × 0.50.55
= 0
P(a|b) =P(a, b′)
P(b)=
0.450.45
=P(b|a)P(a)
P(b)=
0.9 × 0.50.45
= 1
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 27 / 53

Bayesian Networks Toolbox
El BNT (Bayesian Networks Toolbox) permite implementar redes bayesianasen MATLAB. Los siguientes comandos implmentan el ejemplo mínimoanterior.Primero, definimos la topología de la red, y se cargan las distribuciones deprobabilidad condicionales:
N=2;dag=zeros(N,N);dag(1,2)=1;node_sizes=2*ones(1,N);bnet=mk_bnet(dag,node_sizes);bnet.CPD{1}=tabular_CPD(bnet,1,[0.5 0.5]);bnet.CPD{2}=tabular_CPD(bnet,2,[1 0.1 0 0.9]);
Los nodos deben numerarse a partir de 1, de de nodos padres a nodos hijos.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 28 / 53

Inferencias en BNT
Para realizar inferencias en BNT es necesario escoger una máquina deinferencias. La evidencia se carga en una lista (en este caso están vacíos loselementos).
engine = jtree_inf_engine(bnet);evidence = cell(1,N);[engine, loglik] = enter_evidence(engine, evidence);
Las probabilidades marginales se obtienen con el comandomarginal_nodes. En este caso obtenemos la probabilidad conjunta:
marg = marginal_nodes(engine, [1 2]);marg.T
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 29 / 53

Inferencias en BNT
Para realizar inferencias en BNT es necesario escoger una máquina deinferencias. La evidencia se carga en una lista (en este caso están vacíos loselementos).
engine = jtree_inf_engine(bnet);evidence = cell(1,N);[engine, loglik] = enter_evidence(engine, evidence);
Las probabilidades marginales se obtienen con el comandomarginal_nodes. En este caso obtenemos la probabilidad conjunta:
marg = marginal_nodes(engine, [1 2]);marg.T
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 29 / 53

Probabilidades anteriores y posteriores
marg = marginal_nodes(engine, 1);marg.T
marg = marginal_nodes(engine, 2);marg.T
evidence=cell(1,N);evidence{2}=1;[engine, loglik] = enter_evidence(engine, evidence);marg = marginal_nodes(engine,1);marg.T
evidence{2}=2;[engine, loglik] = enter_evidence(engine, evidence);marg = marginal_nodes(engine,1);marg.T
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 30 / 53

Otro ejemplo de red bayesiana
C
A BP(a′) P(a)
0.5 0.5P(b′) P(b)
0.2 0.8
B A P(c′) P(c)F F 0.4 0.6F T 0.1 0.9T F 0.2 0.8T T 0.05 0.95
Nótese que en la tabla de probabilidad P(C|A, B) se intercambió el orden delas columnas de A y B para que A se tome como el nodo 1, y B como el nodo2.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 31 / 53

Función de distribución de probabilidad conjunta
P(b′) P(b)P(a′) 0.1 0.4P(a) 0.1 0.4
P(a′, b′, c′) = P(c′|a′, b′)P(a′, b′) = 0.4 × 0.1 = 0.04
P(a′, b′, c) = P(c|a′, b′)P(a′, b′) = 0.6 × 0.1 = 0.06
P(a, b′, c′) = P(c′|a, b′)P(a, b′) = 0.1 × 0.1 = 0.01
P(a, b′, c) = P(c|a, b′)P(a, b′) = 0.9 × 0.1 = 0.09
P(a′, b, c′) = P(c′|a′, b)P(a′, b) = 0.2 × 0.4 = 0.08
P(a′, b, c) = P(c|a′, b)P(a′, b) = 0.8 × 0.4 = 0.32
P(a, b, c′) = P(c′|a, b)P(a, b) = 0.05 × 0.4 = 0.02
P(a, b, c) = P(c|a, b)P(a, b) = 0.95 × 0.4 = 0.38
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 32 / 53

Probabilidades anteriores
P(a) = P(a, b′, c′) + P(a, b′, c) + P(a, b, c′) + P(a, b, c)= 0.01 + 0.09 + 0.02 + 0.38 = 0.5
P(b) = P(a′, b, c′) + P(a′, b, c) + P(a, b, c′) + P(a, b, c)= 0.08 + 0.32 + 0.02 + 0.38 = 0.8
P(c) = P(a′, b′, c) + P(a′, b, c) + P(a, b′, c) + P(a, b, c)= 0.06 + 0.09 + 0.32 + 0.38 = 0.85
P(a, b) = P(a, b, c′) + P(a, b, c)= 0.02 + 0.38 = 0.4
P(a, c) = P(a, b′, c) + P(a, b, c)= 0.09 + 0.38 = 0.47
P(b, c) = P(a′, b, c) + P(a, b, c)= 0.32 + 0.38 = 0.7
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 33 / 53

Probabilidades posteriores
P(a, b|c) =P(a, b, c)
P(c)=
0.380.85
= 0.4471
=P(c|a, b)P(a, b)
P(c)=
0.95 × 0.40.85
= 0.4471
P(a|b, c) =P(a, b, c)P(b, c)
=0.380.7
= 0.5429
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 34 / 53

Probabilidad de nodo hijo dado nodo padre
P(c|a) = P(b′)P(c|a, b′) + P(b)P(c|a, b) (28)
=∑
B
P(B)P(c|a, B) (29)
= 0.2(0.9) + 0.85(0.95) = 0.94 (30)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 35 / 53

Probabilidad de nodo padre dado nodo hijoForma “tradicional”
P(a|c) =P(c|a)P(a)
P(c)(31)
=P(a)P(c)
[P(b′)P(c|a, b′) + P(b)P(c|a, b)] (32)
=P(a)P(c)
∑
B
P(B)P(c|a, B) (33)
= P(a)
∑
B
P(B)P(c|a, B)
∑
A
∑
B
P(c|A, B)P(A, B)(34)
donde
P(c) =∑
A
∑
B
P(c|A, B)P(A, B) =∑
A
∑
B
P(c|A, B)P(A)P(B) (35)
porque A y B son independientes.M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 36 / 53

Probabilidad de nodo padre dado nodo hijoForma “tradicional”
P(a|c) =P(c|a)P(a)
P(c)(31)
=P(a)P(c)
[P(b′)P(c|a, b′) + P(b)P(c|a, b)] (32)
=P(a)P(c)
∑
B
P(B)P(c|a, B) (33)
= P(a)
∑
B
P(B)P(c|a, B)
∑
A
∑
B
P(c|A, B)P(A, B)(34)
donde
P(c) =∑
A
∑
B
P(c|A, B)P(A, B) =∑
A
∑
B
P(c|A, B)P(A)P(B) (35)
porque A y B son independientes.M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 36 / 53

Probabilidad de nodo padre dado nodo hijoForma “tradicional”
P(a|c) =P(c|a)P(a)
P(c)(31)
=P(a)P(c)
[P(b′)P(c|a, b′) + P(b)P(c|a, b)] (32)
=P(a)P(c)
∑
B
P(B)P(c|a, B) (33)
= P(a)
∑
B
P(B)P(c|a, B)
∑
A
∑
B
P(c|A, B)P(A, B)(34)
donde
P(c) =∑
A
∑
B
P(c|A, B)P(A, B) =∑
A
∑
B
P(c|A, B)P(A)P(B) (35)
porque A y B son independientes.M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 36 / 53

Probabilidad de nodo padre dado nodo hijoForma “tradicional”
P(a|c) =P(c|a)P(a)
P(c)(31)
=P(a)P(c)
[P(b′)P(c|a, b′) + P(b)P(c|a, b)] (32)
=P(a)P(c)
∑
B
P(B)P(c|a, B) (33)
= P(a)
∑
B
P(B)P(c|a, B)
∑
A
∑
B
P(c|A, B)P(A, B)(34)
donde
P(c) =∑
A
∑
B
P(c|A, B)P(A, B) =∑
A
∑
B
P(c|A, B)P(A)P(B) (35)
porque A y B son independientes.M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 36 / 53

Probabilidad de nodo padre dado nodo hijoForma “tradicional”
P(a|c) =P(c|a)P(a)
P(c)(31)
=P(a)P(c)
[P(b′)P(c|a, b′) + P(b)P(c|a, b)] (32)
=P(a)P(c)
∑
B
P(B)P(c|a, B) (33)
= P(a)
∑
B
P(B)P(c|a, B)
∑
A
∑
B
P(c|A, B)P(A, B)(34)
donde
P(c) =∑
A
∑
B
P(c|A, B)P(A, B) =∑
A
∑
B
P(c|A, B)P(A)P(B) (35)
porque A y B son independientes.M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 36 / 53

Probabilidad de nodo padre dado nodo hijoUtilizando notación vectorial
P(A|c) = α 〈P(c|a′)P(a′), P(c|a)P(a)〉 (36)
donde
P(c|a′) =∑
B
P(B)P(c|a′, B) (37)
= P(b′)P(c|a′, b′) + P(b)P(c|a′, b) (38)
= 0.2(0.6) + 0.8(0.8) = 0.76 (39)
P(c|a) =∑
B
P(B)P(c|a, B) (40)
= P(b′)P(c|a, b′) + P(b)P(c|a, b) (41)
= 0.2(0.9) + 0.8(0.95) = 0.94 (42)
de dondeP(A|c) = α 〈0.38, 0.47〉 = 〈0.4470, 0.5529〉 (43)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 37 / 53

Probabilidad de nodo padre dado nodo hijoUtilizando notación vectorial
P(A|c) = α 〈P(c|a′)P(a′), P(c|a)P(a)〉 (36)
donde
P(c|a′) =∑
B
P(B)P(c|a′, B) (37)
= P(b′)P(c|a′, b′) + P(b)P(c|a′, b) (38)
= 0.2(0.6) + 0.8(0.8) = 0.76 (39)
P(c|a) =∑
B
P(B)P(c|a, B) (40)
= P(b′)P(c|a, b′) + P(b)P(c|a, b) (41)
= 0.2(0.9) + 0.8(0.95) = 0.94 (42)
de dondeP(A|c) = α 〈0.38, 0.47〉 = 〈0.4470, 0.5529〉 (43)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 37 / 53

Probabilidad de nodo padre dado nodo hijoUtilizando notación vectorial
P(A|c) = α 〈P(c|a′)P(a′), P(c|a)P(a)〉 (36)
donde
P(c|a′) =∑
B
P(B)P(c|a′, B) (37)
= P(b′)P(c|a′, b′) + P(b)P(c|a′, b) (38)
= 0.2(0.6) + 0.8(0.8) = 0.76 (39)
P(c|a) =∑
B
P(B)P(c|a, B) (40)
= P(b′)P(c|a, b′) + P(b)P(c|a, b) (41)
= 0.2(0.9) + 0.8(0.95) = 0.94 (42)
de dondeP(A|c) = α 〈0.38, 0.47〉 = 〈0.4470, 0.5529〉 (43)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 37 / 53

Un ejemplo más
A
B C
P(a′) P(a)
0.3 0.7
A P(b′) P(b)
F 0.4 0.6T 0.6 0.4
A P(c′) P(c)F 0.8 0.2T 0.1 0.9
Probabilidad posterior
P(a|c) =P(c|a)P(a)
P(c)=
0.9 × 0.70.69
= 0.9130 (44)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 38 / 53

Ejemplo de Pearl
Como aparece en el texto:
JohnCalls MaryCalls
Alarm
Burglary Earthquake
B E P(a)
t t 0.95t f 0.94f t 0.29f f 0.001
P(b)
0.001P(e)
0.002
A P(j)t 0.90f 0.05
A P(m)
t 0.70f 0.01
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 39 / 53

Ejemplo de Pearl
Como se debe cargar en BNT:
JohnCalls MaryCalls
Alarm
Burglary Earthquake
E B P(a′) P(a)
F F 0.999 0.001F T 0.06 0.94T F 0.71 0.29T T 0.05 0.95
P(b′) P(b)
0.999 0.001P(e′) P(e)0.998 0.002
A P(j′) P(j)F 0.95 0.05T 0.10 0.90
A P(m′) P(m)
F 0.99 0.01T 0.30 0.70
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 40 / 53

BNT (Bayesian Networks Toolbox)
Creación de la red
N = 5;dag = zeros(N,N);B = 1; E = 2; A = 3; J = 4; M = 5;dag(B,A) = 1;dag(E,A) = 1;dag(A,[J M]) = 1;node_sizes = 2*ones(1,N);bnetP = mk_bnet(dag, node_sizes);
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 41 / 53

Se cargan las distribuciones de probabilidad conjuntas:
bnetP.CPD{B} = tabular_CPD(bnetP, B, [0.999 0.001]);bnetP.CPD{E} = tabular_CPD(bnetP, E, [0.998 0.002]);bnetP.CPD{A} = tabular_CPD(bnetP, A, ...
[0.999 0.06 0.71 0.05 ...0.001 0.94 0.29 0.95]);
bnetP.CPD{J} = tabular_CPD(bnetP, J, [0.95 0.10 0.05 0.90])bnetP.CPD{M} = tabular_CPD(bnetP, M, [0.99 0.30 0.01 0.70])
Se escoge una máquina de inferencia:
engine = jtree_inf_engine(bnetP);
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 42 / 53

Probabilidad de robo dado que sonó la alarma
Se carga la evidencia (A = 2):
evidence = cell(1,N);evidence{A} = 2;[engine, loglik] = enter_evidence(engine, evidence);
Se calcula la probabilidad marginal de robo:
m = marginal_nodes(engine, B);m.T
que produce el resultado:
ans =
0.90800.0920
es decir, P(B|A) = 0.0920.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 43 / 53

Probabilidad de robo dado que John llamó
evidence = cell(1,N);evidence{J} = 2;[engine, loglik] = enter_evidence(engine, evidence);m = marginal_nodes(engine, B);m.T
El resultado
ans =
0.99440.0056
indica que P(B|J) = 0.0056.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 44 / 53

Probabilidad de nodo padre dado nodo hijo
P(B|a) = α 〈P(a|b′)P(b′), P(a|b)P(b)〉 (45)
P(a|b′) =∑
E
P(E)P(a|b′, E) = 0.998(0.001) + 0.002(0.29) = .0016 (46)
P(a|b) =∑
E
P(E)P(a|b, E) = 0.998(0.94) + 0.002(0.95) = 0.9400 (47)
P(B|a) = α 〈0.0016(0.999), 0.94(0.001)〉 (48)
= α 〈0.0016, 0.0009〉 (49)
= 〈0.6400, 0.3600〉 (50)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 45 / 53

Probabilidad de nodo padre dado nodo hijo
P(B|a) = α 〈P(a|b′)P(b′), P(a|b)P(b)〉 (45)
P(a|b′) =∑
E
P(E)P(a|b′, E) = 0.998(0.001) + 0.002(0.29) = .0016 (46)
P(a|b) =∑
E
P(E)P(a|b, E) = 0.998(0.94) + 0.002(0.95) = 0.9400 (47)
P(B|a) = α 〈0.0016(0.999), 0.94(0.001)〉 (48)
= α 〈0.0016, 0.0009〉 (49)
= 〈0.6400, 0.3600〉 (50)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 45 / 53

Probabilidad de nodo padre dado nodo hijo
P(B|a) = α 〈P(a|b′)P(b′), P(a|b)P(b)〉 (45)
P(a|b′) =∑
E
P(E)P(a|b′, E) = 0.998(0.001) + 0.002(0.29) = .0016 (46)
P(a|b) =∑
E
P(E)P(a|b, E) = 0.998(0.94) + 0.002(0.95) = 0.9400 (47)
P(B|a) = α 〈0.0016(0.999), 0.94(0.001)〉 (48)
= α 〈0.0016, 0.0009〉 (49)
= 〈0.6400, 0.3600〉 (50)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 45 / 53

Probabilidad de nodo padre dado nodo hijo
P(B|a) = α 〈P(a|b′)P(b′), P(a|b)P(b)〉 (45)
P(a|b′) =∑
E
P(E)P(a|b′, E) = 0.998(0.001) + 0.002(0.29) = .0016 (46)
P(a|b) =∑
E
P(E)P(a|b, E) = 0.998(0.94) + 0.002(0.95) = 0.9400 (47)
P(B|a) = α 〈0.0016(0.999), 0.94(0.001)〉 (48)
= α 〈0.0016, 0.0009〉 (49)
= 〈0.6400, 0.3600〉 (50)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 45 / 53

Probabilidad de nodo padre dado un nodo hijo
P(A|j) = α 〈P(j|a′)P(a′), P(j|a)P(a)〉 (51)
P(a) =∑
B
∑
E
P(a|B, E)P(B)P(E) =∑
B
P(B)∑
E
P(E)P(a|B, E) (52)
= 0.999 (0.998(0.001) + 0.002(0.29))+ 0.001 (0.998(0.94) + 0.002(0.95)) = 0.0025 (53)
pause y por lo tanto, P(a′) = 1 − 0.025 = 0.9975, es decir,
P(A) = 〈0.9975, 0.0025〉 (54)
P(A|j) = α 〈0.05(0.9975), 0.90(0.0025)〉 (55)
= α 〈0.0500, 0.0023〉 (56)
= 〈0.9560, 0.0440〉 (57)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 46 / 53

Probabilidad de nodo padre dado un nodo hijo
P(A|j) = α 〈P(j|a′)P(a′), P(j|a)P(a)〉 (51)
P(a) =∑
B
∑
E
P(a|B, E)P(B)P(E) =∑
B
P(B)∑
E
P(E)P(a|B, E) (52)
= 0.999 (0.998(0.001) + 0.002(0.29))+ 0.001 (0.998(0.94) + 0.002(0.95)) = 0.0025 (53)
pause y por lo tanto, P(a′) = 1 − 0.025 = 0.9975, es decir,
P(A) = 〈0.9975, 0.0025〉 (54)
P(A|j) = α 〈0.05(0.9975), 0.90(0.0025)〉 (55)
= α 〈0.0500, 0.0023〉 (56)
= 〈0.9560, 0.0440〉 (57)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 46 / 53

Probabilidad de nodo padre dado un nodo hijo
P(A|j) = α 〈P(j|a′)P(a′), P(j|a)P(a)〉 (51)
P(a) =∑
B
∑
E
P(a|B, E)P(B)P(E) =∑
B
P(B)∑
E
P(E)P(a|B, E) (52)
= 0.999 (0.998(0.001) + 0.002(0.29))+ 0.001 (0.998(0.94) + 0.002(0.95)) = 0.0025 (53)
pause y por lo tanto, P(a′) = 1 − 0.025 = 0.9975, es decir,
P(A) = 〈0.9975, 0.0025〉 (54)
P(A|j) = α 〈0.05(0.9975), 0.90(0.0025)〉 (55)
= α 〈0.0500, 0.0023〉 (56)
= 〈0.9560, 0.0440〉 (57)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 46 / 53

Probabilidad de nodo padre dados dos nodos hijos
P(A|j, m) = α 〈P(j, m|a′)P(a′), P(j, m|a)P(a)〉 (58)
= α 〈P(j|a′)P(m|a′)P(a′), P(j|a)P(m|a)P(a)〉 (59)
como P(A) = 〈0.9975, 0.0025〉
P(A|j, m) = α 〈0.05(0.01)0.9975, 0.90(0.70)0.0025〉 (60)
= α 〈0.0005, 0.0016〉 (61)
= 〈0.2410, 0.7711〉 (62)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 47 / 53

Probabilidad de nodo padre dados dos nodos hijos
P(A|j, m) = α 〈P(j, m|a′)P(a′), P(j, m|a)P(a)〉 (58)
= α 〈P(j|a′)P(m|a′)P(a′), P(j|a)P(m|a)P(a)〉 (59)
como P(A) = 〈0.9975, 0.0025〉
P(A|j, m) = α 〈0.05(0.01)0.9975, 0.90(0.70)0.0025〉 (60)
= α 〈0.0005, 0.0016〉 (61)
= 〈0.2410, 0.7711〉 (62)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 47 / 53

Probabilidad de nodo padre dados dos nodos hijos
P(A|j, m) = α 〈P(j, m|a′)P(a′), P(j, m|a)P(a)〉 (58)
= α 〈P(j|a′)P(m|a′)P(a′), P(j|a)P(m|a)P(a)〉 (59)
como P(A) = 〈0.9975, 0.0025〉
P(A|j, m) = α 〈0.05(0.01)0.9975, 0.90(0.70)0.0025〉 (60)
= α 〈0.0005, 0.0016〉 (61)
= 〈0.2410, 0.7711〉 (62)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 47 / 53

Probabilidad de nodo abuelo dado un nodo nieto
De acuerdo a lo que obtuvimos antes,
P(b|j) = P(b|a)P(a|j) = 0.3600(0.0440) = 0.0150 (63)
Pero los números anteriores tienen errores de redondeo. Utilizando BNT seobtiene que
P(b|j) = P(b|a)P(a|j) = 0.3736(0.0434) = 0.0162 (64)
que corresponde al resultado que arroja BNT.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 48 / 53

Probabilidad de nodo abuelo dados dos nodos nietos
De acuerdo a lo que se obtuvo antes,
P(b|j, m) = P(b|a)P(a|j, m) = 0.3600(0.7711) = 0.2776 (65)
De nuevo, hay arroes de redondeo. Utilizando BNT se obtiene
P(b|j, m) = P(b|a)P(a|j, m) = 0.3736(0.7607) = 0.2842 (66)
que es el resultado que arroja BNT.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 49 / 53
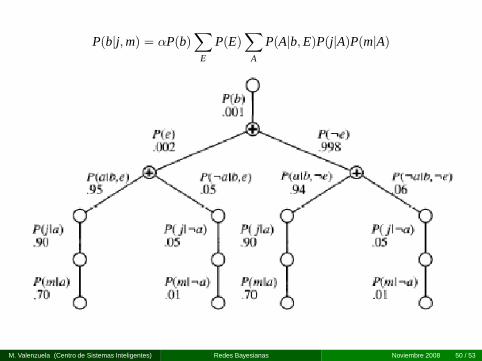
P(b|j, m) = αP(b)∑
E
P(E)∑
A
P(A|b, E)P(j|A)P(m|A)
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 50 / 53

Problema 14.12 del texto
A B C
AB AC BC
A, B, y C representan las calidades de los equipos, y pueden tomarvalores en {0, 1, 2, 3}.
AB, AC, y BC representan los resultados de los juegos entre los equipos,y pueden tomar valores en {p, e, g} donde p representa que el primerequipo pierda, e representa empate, y g representa que el primer equipogane.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 51 / 53

Probabilidades anteriores
Asumimos que todos los equipos son iguales inicialmente, es decir,
P(A = 0) P(A = 1) P(A = 2) P(A = 3)0.25 0.25 0.25 0.25
Y de la misma manera para B y C.
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 52 / 53

Probabilidades condicionales
Escojemos la probabilidad de un resultado de un juego en términos de lasdiferencias de calidades.
diferencia P(p) P(e) P(g)−3 0.55 0.40 0.05−2 0.40 0.50 0.10−1 0.30 0.55 0.150 0.20 0.60 0.20
+1 0.15 0.55 0.30+2 0.10 0.50 0.40+3 0.05 0.40 0.55
M. Valenzuela (Centro de Sistemas Inteligentes) Redes Bayesianas Noviembre 2008 53 / 53


















