Rede Bayesiana para Estimação de Falhas Incipientes em...
120
Universidade Federal de Goiás Escola de Engenharia Elétrica, Mecânica e de Computação Pedro Henrique da Silva Palhares Rede Bayesiana para Estimação de Falhas Incipientes em Transformadores de Potência Utilizando Dados de Ensaios de Detecção de Descargas Parciais por Emissão Acústica Goiânia 3 de outubro de 2012
Transcript of Rede Bayesiana para Estimação de Falhas Incipientes em...

Universidade Federal de GoiásEscola de Engenharia Elétrica, Mecânica e de Computação
Pedro Henrique da Silva Palhares
Rede Bayesiana para Estimação de FalhasIncipientes em Transformadores de PotênciaUtilizando Dados de Ensaios de Detecção de
Descargas Parciais por Emissão Acústica
Goiânia
3 de outubro de 2012

TERMO DE CIÊNCIA E DE AUTORIZAÇÃO PARA DISPONIBILIZAR AS TESES E
DISSERTAÇÕES ELETRÔNICAS (TEDE) NA BIBLIOTECA DIGITAL DA UFG
Na qualidade de titular dos direitos de autor, autorizo a Universidade Federal de Goiás (UFG) a disponibilizar, gratuitamente, por meio da Biblioteca Digital de Teses e Dissertações (BDTD/UFG), sem ressarcimento dos direitos autorais, de acordo com a Lei nº 9610/98, o documento conforme permissões assinaladas abaixo, para fins de leitura, impressão e/ou download, a título de divulgação da produção científica brasileira, a partir desta data.
1. Identificação do material bibliográfico: [ X ] Dissertação [ ] Tese 2. Identificação da Tese ou Dissertação
Autor (a): Pedro Henrique da Silva Palhares E-mail: [email protected] Seu e-mail pode ser disponibilizado na página? [ X ]Sim [ ] Não
Vínculo empregatício do autor Agência de fomento: Sigla: País: UF: CNPJ: Título: Rede Bayesiana para Estimação de Falhas Incipientes em Transformadores de Potência
Utilizando Dados de Ensaio de Detecção de Descargas Parciais por Emissão Acústica Palavras-chave: transformadores de potência, redes bayesianas, emissão acústica Título em outra língua: Bayesian Networks for Estimation of Incipient Faults in Power Trans-
formers Using Data from Partial Discharge Detection by Acoustic Emission Trials
Palavras-chave em outra língua: power transformers, bayesian networks, acoustic emission Área de concentração: Engenharia de Computação Data defesa: (dd/mm/aaaa) 16/08/2012 Programa de Pós-Graduação: Programa de Pós-Graduação em Engenharia Elétrica e de
Computação Orientador (a): Leonardo da Cunha Brito E-mail: [email protected] Co-orientador (a):* E-mail:
*Necessita do CPF quando não constar no SisPG 3. Informações de acesso ao documento: Concorda com a liberação total do documento [ X ] SIM [ ] NÃO1
Havendo concordância com a disponibilização eletrônica, torna-se imprescindível o envio do(s) arquivo(s) em formato digital PDF ou DOC da tese ou dissertação.
O sistema da Biblioteca Digital de Teses e Dissertações garante aos autores, que os arquivos con-tendo eletronicamente as teses e ou dissertações, antes de sua disponibilização, receberão procedimen-tos de segurança, criptografia (para não permitir cópia e extração de conteúdo, permitindo apenas im-pressão fraca) usando o padrão do Acrobat. ________________________________________ Data: _03_ / _10_ / 2012_ Assinatura do (a) autor (a)
1 Neste caso o documento será embargado por até um ano a partir da data de defesa. A extensão deste prazo suscita justificativa junto à coordenação do curso. Os dados do documento não serão disponibilizados durante o período de embargo.

Universidade Federal de GoiásEscola de Engenharia Elétrica, Mecânica e de Computação
Pedro Henrique da Silva Palhares
Rede Bayesiana para Estimação de FalhasIncipientes em Transformadores de PotênciaUtilizando Dados de Ensaios de Detecção de
Descargas Parciais por Emissão Acústica
Dissertação apresentada à Escola de Enge-nharia Elétrica, Mecânica e de Computaçãoda Universidade Federal de Goiás, comoparte dos requisitos para o obtenção do tí-tulo de Mestre em Engenharia Elétrica e deComputação.Área de Concentração: Engenharia deComputaçãoLinha de Pesquisa: Sistemas Inteligentes,Planejamento e Computação Aplicada
Orientador:
Prof. Dr. Leonardo da Cunha Brito
Goiânia
3 de outubro de 2012

Dados Internacionais de Catalogação na Publicação (CIP) GPT/BC/UFG
P161r
Palhares, Pedro Henrique da Silva.
Rede Bayesiana para estimação de falhas incipientes em transformadores de potência utilizando dados de ensaios de detecção de descargas parciais por emissão acústica [manuscrito] / Pedro Henrique da Silva Palhares. – 2012.
xv, 118 f. : il., figs, tabs. Orientador: Prof. Dr. Leonardo da Cunha Brito. Dissertação (Mestrado) – Universidade Federal de Goiás,
Escola de Engenharia Elétrica, Mecânica e de Computação, 2012. Bibliografia.
Inclui lista de figuras, abreviaturas, siglas e tabelas. Apêndices. 1.


Dedico esta dissertação a Deus, por estar
sempre comigo e me levantar a cada tropeço,
à minha noiva, pelo amor e paciência demonstrados nos
momentos mais difíceis, e a minha mãe, que me deu a
instrução necessária para que eu pudesse caminhar até aqui.

Agradecimentos
Dedico meus sinceros agradecimentos:
– à minha noiva, Simone Nascimento Araújo, cujo suporte emocional e revisão do
texto foram imprescindíveis para a finalização deste trabalho;
– ao meu sogro, Barnabé de Souza Araújo, pela colaboração na revisão do texto;
– ao professor doutor Leonardo da Cunha Brito, orientador, cujo constante apoio,
incentivo, conhecimento, desafios propostos e amizade formada durante o período,
forneceram motivação extra ao longo desta caminhada;
– à professora doutora Cacilda de Jesus Ribeiro e aos colaboradores da CELG D,
M.Eng. André Pereira Marques e M.Eng. Cláudio Henrique B. Azevedo, pelo forneci-
mento de dados e auxílio em diversos momentos de dúvidas;
– à Capes, pelo suporte financeiro.

"Aprender é a única coisa de que
a mente nunca se cansa,
nunca tem medo e nunca se arrepende."
(Leonardo da Vinci)

Resumo
É apresentada nesta dissertação uma metodologia para estimação de falhas incipi-entes em transformadores de potência, com base em resultados de ensaios de detec-ção de descargas parciais pelo método de emissão acústica, propiciando às equipes deengenharia de manutenção uma importante ferramenta de avaliação do estado des-tes equipamentos sob a ótica desta emergente técnica preditiva. Para esse objetivo, éproposta uma abordagem utilizando uma Rede Bayesiana associada ao algoritmo Hill-Climbing para a discretização dos parâmetros da rede. O discretizador trabalha faixasajustáveis de intervalos contínuos, associados a valores discretos.
Os resultados mostram que o método é eficaz, apresentando empiricamente umaprecisão de classificação de 89%, enquanto que uma abordagem alternativa, na qualuma Rede Neural Perceptron de Múltiplas Camadas foi aplicada ao mesmo problema,ofereceu uma precisão de 83%. A abordagem através da Rede Bayesiana associada aum discretizador foi planejada de forma a ser adaptável para resolução de problemassemelhantes, onde têm-se valores contínuos e deseja-se encontrar uma classificaçãodiscreta. O discretizador apresenta a vantagem de otimizar as faixas de valores contí-nuos e, desta forma, melhorar a classificação.

Abstract
It is presented on this dissertation a methodology for estimating incipient faultsin power transformers, based on tests results for detecting partial discharges by theacoustic emission method, providing to the maintenance engineering teams an impor-tant tool for evaluating the state of the equipment from the perspective of this emer-ging predictive technique. For this purpose, an approach using a Bayesian networkassociated with the Hill Climbing algorithm for discretization of network parametersis proposed. The discretization tool works with adjustable continuous boundaries, as-sociated with discrete values.
The results show that the method is effective, empirically presenting a classificationaccuracy of 89%, while an alternative approach, in which a Multiple Layer PerceptronNeural Network was applied to the same problem, provided a precision of 83%. Theapproach using the Bayesian Network associated with a discretization tool was plan-ned in order to be adaptable to solve similar problems, which have continuous valuesand wishes to find a discrete classification. The discretization tool has the advantageof optimizing the continuous range of values and, thereby, improve the classification.

Lista de Figuras
1 Transformador Monofásico de Núcleo Envolvido . . . . . . . . . . . . . p. 25
2 Transformador Monofásico de Núcleo Envolvente . . . . . . . . . . . . p. 26
3 Transformador de Potência na subestação Goiânia Leste da Celg . . . . p. 27
4 Sensor utilizado para monitorar o transformador . . . . . . . . . . . . . p. 30
5 Equipamentos de aquisição de dados dos sensores . . . . . . . . . . . . p. 31
6 Tenda que abriga os computadores responsáveis pela coleta de dados . p. 32
7 Forma idealizada do sinal acústico . . . . . . . . . . . . . . . . . . . . . p. 33
8 Distribuição Gaussiana: (a) função de distribuição de probabilidade e
(b) função de densidade de probabilidade . . . . . . . . . . . . . . . . . p. 39
9 Exemplo de Rede Bayesiana com 4 parâmetros . . . . . . . . . . . . . . p. 41
10 Aprendizagem de Parâmetros: (a) Estrutura e (b) base de dados com-
pletos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 47
11 Rede Bayesiana do exemplo 3 . . . . . . . . . . . . . . . . . . . . . . . . p. 49
12 Passo E do método EM de aprendizado de parâmetros . . . . . . . . . p. 50
13 Exemplo de maximização: (a) fator a ser maximizado (b) fator maxi-
mizado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 55
14 Exemplo de uma rede bayesiana dinâmica . . . . . . . . . . . . . . . . . p. 63
15 Estrutura da RB ingênua utilizada no gerador de casos . . . . . . . . . p. 71
16 Desempenho mínimo, médio e máximo dos otimizadores: (a) pontu-
ação rígida e (b) pontuação suave . . . . . . . . . . . . . . . . . . . . . . p. 75
17 Tela de login do sistema . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 93
18 Tela inicial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 93
19 Tela de consulta de papéis . . . . . . . . . . . . . . . . . . . . . . . . . . p. 94

27 Tela de consulta de ensaio . . . . . . . . . . . . . . . . . . . . . . . . . . p. 95
28 Tela de cadastro de ensaio . . . . . . . . . . . . . . . . . . . . . . . . . . p. 96
29 Tela de upload de arquivos relacionados à AGD . . . . . . . . . . . . . . p. 97
31 Seleção de ensaio para carregamento de arquivos ASCII . . . . . . . . . p. 98
32 Preenchimento dos canais do transformador . . . . . . . . . . . . . . . p. 98
33 Carregamento de arquivos ASCII . . . . . . . . . . . . . . . . . . . . . . p. 99
34 Tela de consulta de tarefas . . . . . . . . . . . . . . . . . . . . . . . . . . p. 99
35 Gráfico Energia x Tempo . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 100
36 Ensaio com indicação de DPs nos canais 6 e 12 . . . . . . . . . . . . . . p. 101
37 Ensaio sem indicação de DPs . . . . . . . . . . . . . . . . . . . . . . . . p. 102
38 Gráfico da figura 38 plotado sem a correção dos valores de acordo com
a fase do hit. Observa-se atividade em torno dos 180para os canais
com indicação de DPs; . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 102
39 Gráfico de Distribuição de Hits (Dispersão) com indicação de DPs . . . p. 103
40 Gráfico de Distribuição de Hits (Dispersão) sem indicação de DPs . . . p. 103
41 Gráfico da figura 47 plotado sem a correção dos valores de acordo com
a fase do hit. Observa-se atividade em torno dos 180. . . . . . . . . . . p. 103
42 Gráfico Ângulo x Tempo com indicação de DPs . . . . . . . . . . . . . . p. 104
43 Gráfico Ângulo x Tempo sem indicação de DPs . . . . . . . . . . . . . . p. 104
44 Gráfico de Amplitude x Fase com indicação de DPs . . . . . . . . . . . p. 105
45 Gráfico de Amplitude x Fase sem indicação de DPs . . . . . . . . . . . p. 105
46 Tela de configuração do sistema . . . . . . . . . . . . . . . . . . . . . . . p. 106
47 Tela de treinamento da RB . . . . . . . . . . . . . . . . . . . . . . . . . . p. 108
48 Resultado do classificador . . . . . . . . . . . . . . . . . . . . . . . . . . p. 110
20 Tela de cadastro de papéis . . . . . . . . . . . . . . . . . . . . . . . . . . p. 112
21 Tela de consulta de usuários . . . . . . . . . . . . . . . . . . . . . . . . . p. 112
22 Tela de cadastro de usuários . . . . . . . . . . . . . . . . . . . . . . . . . p. 113

23 Tela de consulta de fabricantes . . . . . . . . . . . . . . . . . . . . . . . p. 113
24 Tela de cadastro de fabricantes . . . . . . . . . . . . . . . . . . . . . . . p. 114
25 Tela de consulta de transformadores . . . . . . . . . . . . . . . . . . . . p. 115
26 Tela de cadastro de transformadores . . . . . . . . . . . . . . . . . . . . p. 115
30 Tela de upload de arquivos relacionados à EA . . . . . . . . . . . . . . . p. 116

Lista de Tabelas
1 Gases emitidos devido a defeitos . . . . . . . . . . . . . . . . . . . . . . p. 29
2 Dados coletados por meio dos sensores . . . . . . . . . . . . . . . . . . p. 32
3 Base de dados completa . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 41
4 Base de dados incompleta . . . . . . . . . . . . . . . . . . . . . . . . . . p. 42
5 Tabela de Probabilidade Condicional P(B|A) . . . . . . . . . . . . . . . p. 47
6 Tabela com dados incompletos para o exemplo 3 . . . . . . . . . . . . . p. 49
7 Fator f . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 52
8 Fator (∑C f ) (B) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 53
9 Fator f1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 58
10 Fator f2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 59
11 Fator f1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 59
12 Fator f e1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 59
13 Fator f2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 60
14 Nós da Rede Bayesiana . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 65
15 Valores possíveis para classificação . . . . . . . . . . . . . . . . . . . . . p. 66
16 Intervalos de valores de energia . . . . . . . . . . . . . . . . . . . . . . . p. 71
17 Intervalos de Valores de Quantidade de DPs e ruído . . . . . . . . . . . p. 71
18 Valores discretos para valores de energia . . . . . . . . . . . . . . . . . p. 72
19 Valores discretos para valores de DPs e ruído . . . . . . . . . . . . . . . p. 73
20 Faixas de energia ao longo das iterações (suave) . . . . . . . . . . . . . p. 73
21 Faixas das quantidades de DPs e ruído ao longo das iterações (suave) . p. 73
22 Faixas de energia ao longo das iterações (rígida) . . . . . . . . . . . . . p. 73

23 Faixas das quantidades de DPs e ruído ao longo das iterações (rígida) . p. 74
24 Taxa de acerto da Rede Bayesiana . . . . . . . . . . . . . . . . . . . . . . p. 74
25 Saída da RN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 76
26 Transformador 1 da subestação A . . . . . . . . . . . . . . . . . . . . . . p. 85
27 Transformador 2 da subestação A . . . . . . . . . . . . . . . . . . . . . . p. 86
28 Transformador 1 da subestação B . . . . . . . . . . . . . . . . . . . . . . p. 86
29 Transformador 2 da subestação B . . . . . . . . . . . . . . . . . . . . . . p. 87
30 Transformador 1 da subestação C . . . . . . . . . . . . . . . . . . . . . . p. 87
31 Transformador 2 da subestação C . . . . . . . . . . . . . . . . . . . . . . p. 88
32 Transformador 1 da subestação D . . . . . . . . . . . . . . . . . . . . . . p. 88
33 Transformador 2 da subestação D . . . . . . . . . . . . . . . . . . . . . . p. 89
34 Transformador 1 da subestação E . . . . . . . . . . . . . . . . . . . . . . p. 89
35 Transformador 2 da subestação E . . . . . . . . . . . . . . . . . . . . . . p. 90
36 Transformador 1 da subestação F . . . . . . . . . . . . . . . . . . . . . . p. 90
37 Transformador 2 da subestação F . . . . . . . . . . . . . . . . . . . . . . p. 91

Lista de abreviaturas e siglas
AGD Análise de Gases Dissolvidos
BIC Bayesian Information Criterion
DP Descarga Parcial
EM Expectation Maximization
MAP Maximum a Posterior Hypothesis
MLE Maximum Likelihood Estimation
MLP Multilayer Perceptron
MPE Most Probable Explanation
RB Rede Bayesiana
RBD Rede Bayesiana Dinâmica
RN Rede Neural
SEM Structural Expectation Maximization
SGBD Sistema Gerenciador de Banco de Dados
TDC Tabela de Distribuição Conjunta
TPC Tabela de Probabilidade Condicional

Lista de símbolos
π(ui) Conjunto de pais do nó ui.
θ Parâmetro de uma Rede Bayesiana.
θmax Estimativa da Máxima Verossimilhança
Amax Valor máximo de DPs e ruído.
D Base de Dados utilizados para treinamento.
Emax Valor máximo de energia.
f (x) Fator sobre variáveis x
g(i,π(ui)) Pontuação K2 relativa a π(ui).
M Rede Bayesiana com estrutura S e parâmetro θ
N(X) Quantidade de casos em que a X ocorre.
Ni jk Número de casos na base de treinamento em que a variável
ui é instanciada com o valor vik.
qi Quantidade de instanciações possíveis de π(ui).
rui Quantidade de valores possíveis discretos de ui.
S Estrutura de uma Rede Bayesiana.
ui Nó de uma Rede Bayesiana.
vik Valor de uma instância de ui.
var( f ) Variáveis de f

Sumário
1 Introdução p. 20
1.1 Trabalhos Correlatos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 21
1.2 Organização do Texto . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 22
2 Transformadores p. 24
2.1 Funcionamento do Transformador Ideal . . . . . . . . . . . . . . . . . . p. 24
2.2 Princípios Construtivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 25
2.2.1 Núcleos Envolvidos e Núcleos Envolventes . . . . . . . . . . . . p. 26
2.2.2 Resfriamento de Transformadores . . . . . . . . . . . . . . . . . p. 26
2.3 Transformadores de Potência . . . . . . . . . . . . . . . . . . . . . . . . p. 27
2.4 Falhas e Defeitos em Transformadores de Potência . . . . . . . . . . . . p. 28
2.5 Manutenção e Técnicas Preditivas . . . . . . . . . . . . . . . . . . . . . p. 28
2.5.1 Análise de Gases Dissolvidos . . . . . . . . . . . . . . . . . . . . p. 29
2.5.2 Emissão Acústica . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 30
3 Fundamentos de Probabilidade p. 34
3.1 Cálculo Probabilístico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 34
3.1.1 Axiomas da Probabilidade . . . . . . . . . . . . . . . . . . . . . p. 34
3.1.2 Atribuição de Probabilidade e Probabilidade a Priori . . . . . . p. 35
3.1.3 Probabilidade a Posteriori . . . . . . . . . . . . . . . . . . . . . . p. 35
3.1.4 O Teorema de Bayes . . . . . . . . . . . . . . . . . . . . . . . . . p. 36
3.1.5 Função de Distribuição de Probabilidade . . . . . . . . . . . . . p. 38

3.1.6 Função de Densidade de Probabilidade . . . . . . . . . . . . . . p. 38
3.1.7 Distribuição Gaussiana . . . . . . . . . . . . . . . . . . . . . . . p. 38
4 Rede Bayesiana p. 40
4.1 Aprendizado com Dados Completos . . . . . . . . . . . . . . . . . . . . p. 42
4.1.1 Algoritmo K2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 43
4.1.2 Aprendizagem Hill-Climbing . . . . . . . . . . . . . . . . . . . . p. 44
4.1.3 Aprendizado de Parâmetros através da Estimativa da Máxima
Verossimilhança (MLE). . . . . . . . . . . . . . . . . . . . . . . . p. 46
4.2 Aprendizado com Dados Incompletos . . . . . . . . . . . . . . . . . . . p. 48
4.2.1 Aprendizado de Parâmetros com o EM Paramétrico . . . . . . . p. 48
4.2.2 Aprendizado de Estrutura com o EM Estrutural . . . . . . . . . p. 50
4.3 Inferência em Redes Bayesianas pelo método da Eliminação de Variáveis p. 51
4.3.1 Fatores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 51
4.3.1.1 Eliminação de Variáveis . . . . . . . . . . . . . . . . . . p. 52
4.3.1.2 Operação de Multiplicação . . . . . . . . . . . . . . . . p. 53
4.3.1.3 Operação de Maximização . . . . . . . . . . . . . . . . p. 54
4.3.1.4 Ordem das Variáveis . . . . . . . . . . . . . . . . . . . p. 55
4.3.2 Otimizando a Estrutura da Rede . . . . . . . . . . . . . . . . . . p. 56
4.3.2.1 Podas de Nós . . . . . . . . . . . . . . . . . . . . . . . . p. 56
4.3.2.2 Podas de Arestas . . . . . . . . . . . . . . . . . . . . . . p. 57
4.3.3 Respondendo Consultas a Priori . . . . . . . . . . . . . . . . . . p. 58
4.3.4 Respondendo Consultas a Posteriori . . . . . . . . . . . . . . . . p. 59
4.3.5 Most Probable Explanation (Explicação Mais Provável) . . . . . . p. 61
4.3.6 Maximum a Posteriori Hypothesis (Hipótese Máxima a Posteriori) p. 61
4.4 Redes Bayesianas Variantes no Tempo . . . . . . . . . . . . . . . . . . . p. 62
5 Metodologia Proposta p. 64

5.1 Construção da Rede Bayesiana . . . . . . . . . . . . . . . . . . . . . . . p. 64
5.1.1 Escolha dos Nós . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 64
5.1.2 Estrutura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 66
5.1.3 Aprendizagem de Paramêtros . . . . . . . . . . . . . . . . . . . p. 67
5.1.4 Discretização dos Parâmetros da Rede Bayesiana . . . . . . . . p. 67
5.2 Geração de Casos de Treinamento e Validação . . . . . . . . . . . . . . p. 69
5.3 Estimação de Falhas Incipientes em Transformadores de Potência . . . p. 70
6 Resultados e Discussão p. 72
6.1 Comparação com Rede Neural . . . . . . . . . . . . . . . . . . . . . . . p. 76
6.2 Considerações sobre os Resultados . . . . . . . . . . . . . . . . . . . . . p. 77
7 Conclusão p. 79
7.1 Perspectivas Futuras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 80
Publicações p. 81
Referências Bibliográficas p. 82
Apêndice A -- Tabelas com Dados dos Ensaios de Emissão Acústica p. 85
Apêndice B -- Sistema DPTrafo p. 92
B.1 Tela de Login . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 92
B.2 Tela Inicial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 92
B.3 Tela de Papéis (Permissões ao usuário) . . . . . . . . . . . . . . . . . . . p. 93
B.4 Cadastro de Usuários . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 94
B.5 Cadastro de Fabricantes e Projetos . . . . . . . . . . . . . . . . . . . . . p. 94
B.6 Cadastro de Transformadores . . . . . . . . . . . . . . . . . . . . . . . . p. 94
B.7 Cadastro de Ensaios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 95

B.8 Carregamento de arquivos de ensaios AGD . . . . . . . . . . . . . . . . p. 96
B.9 Carregamento de arquivos de ensaios de EA . . . . . . . . . . . . . . . p. 97
B.10 Arquivo Ascii gerado pelo AEWIN . . . . . . . . . . . . . . . . . . . . . p. 97
B.11 Tela de consulta de tarefas (linhas de execução ou threads) . . . . . . . . p. 99
B.12 Gráficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 99
B.12.1 Gráfico de Energia x Tempo . . . . . . . . . . . . . . . . . . . . . p. 100
B.12.2 Gráfico polar de distribuição de hits . . . . . . . . . . . . . . . . p. 101
B.12.3 Gráfico de dispersão de distribuição de hits . . . . . . . . . . . . p. 103
B.12.4 Gráfico Ângulo x Tempo . . . . . . . . . . . . . . . . . . . . . . . p. 104
B.12.5 Gráfico Amplitude x Fase . . . . . . . . . . . . . . . . . . . . . . p. 104
B.13 Configurador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 105
B.13.1 Estrutura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 106
B.13.2 Tipo de Classificador . . . . . . . . . . . . . . . . . . . . . . . . . p. 106
B.13.2.1 Pior Caso . . . . . . . . . . . . . . . . . . . . . . . . . . p. 106
B.13.2.2 Canal a Canal . . . . . . . . . . . . . . . . . . . . . . . p. 107
B.13.3 Otimizador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 107
B.13.4 Quantidade de Hits com 180para considerar DP . . . . . . . . p. 107
B.14 Treinamento da Rede Bayesiana . . . . . . . . . . . . . . . . . . . . . . . p. 108
B.15 Classificador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 109
B.16 Relatórios . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 110
Anexo A -- Relatório Geral p. 117
Anexo B -- Relatório Específico p. 118

20
1 Introdução
A energia elétrica é uma das formas de energia mais utilizadas pelo homem. É
possível afirmar que, na sociedade moderna, é virtualmente impossível separar a vida
humana da eletricidade. Esta forma de energia possibilita o funcionamento de inúme-
ros dispositivos, como computadores, aparelhos médicos e telefones.
Para que a energia elétrica produzida nas usinas chegue ao consumidor final com o
mínimo de perda possível, seja em residências ou indústrias, a alta tensão é empregada
através da utilização de transformadores de potência. Os transformadores de potência
são responsáveis pela elevação da tensão e diminuição da corrente, reduzindo as per-
das por efeito Joule nas linhas de transmissão. Ao alcançar o destino, a utilização da
energia elétrica em alta tensão torna-se inviável e perigosa. É necessária então a utiliza-
ção de transformadores, presentes em subestações, que diminuem consideravelmente
a tensão. Ainda assim a tensão distribuída pelas subestações não é suficientemente
baixa para o consumo nas residências, que utilizam transformadores menores e mais
baratos para tornar a tensão apropriada para o consumo residencial.
De fundamental importância para a transmissão e para a distribuição de energia
elétrica, os transformadores de potência são equipamentos de custo elevado. Durante
sua operação, podem surgir defeitos em sua isolação, provocando uma diminuição de
sua capacidade dielétrica (1). Segundo a referência (2), a diminuição desta capacidade
pode provocar o surgimento de descargas parciais (DPs) dentro do transformador de
forma inesperada e de difícil detecção. Detectar defeitos incipientes de funcionamento
nesses transformadores é de interesse econômico e operacional, uma vez que permite
intervenções preventivas que evitem danos graves ao equipamento o que, por con-
sequência, garante maior continuidade e eleva a confiabilidade do fornecimento de
energia elétrica aos - cada vez mais exigentes - consumidores.
Atualmente, têm-se utilizado vários métodos de detecção de descargas parciais
como o elétrico, o químico (análise de gases dissolvidos ou AGD) e o acústico. Neste
trabalho, destaca-se o método de detecção por emissão acústica que apresenta a van-

21
tagem de localização da descarga dentro do equipamento sem que haja a necessidade
de se retirá-lo de operação (2), evitando-se descontinuidade no fornecimento da ener-
gia elétrica. A aplicação de métodos de inteligência artificial nos permitem analisar os
dados colhidos e então classificar o transformador de acordo com a possibilidade de
falha do equipamento.
Na seção 1.1 são apresentados algumas abordagens para classificação de transfor-
madores de potência. Nestes trabalhos, apresentam-se métodos computacionais diri-
gidos à identificação dos possíveis defeitos no interior dos transformadores, aplicando
métodos de Inteligência Artificial. Diferentemente dos trabalhos referenciados, este
propõe fornecer, ao engenheiro de manutenção, uma metodologia capaz de auxiliá-lo
na tomada de decisões quanto à manutenção preventiva dos transformadores, indi-
cando provável severidade de degradação da isolação do mesmo e, consequentemente,
sugerindo uma ação preventiva. Neste caso, a tomada de decisão subjetiva, caracte-
rizada como um processo de inferência probabilística, é realizada por meio de uma
Rede de Crença Bayesiana, a qual apresenta as seguintes vantagens qualitativas frente
à abordagem por RN:
1. uma RN tem uma representação limitada, mapeando entrada-saída unidireci-
onalmente na forma de uma "caixa-preta", impossibilitando a identificação de
correlações entre as variáveis do problema de decisão;
2. uma RB permite constatar essas correlações diretamente, além de explicitamente
trabalhar com probabilidades (graus de crença) reais.
A desvantagem clara de uma RB em relação à RN é a sua dificuldade em traba-
lhar com valores contínuos. Neste trabalho também é apresentado um algoritmo para
discretização de valores contínuos para alimentação da RB.
Investiga-se também o desempenho quantitativo da RB frente a uma RN.
1.1 Trabalhos Correlatos
Vários trabalhos na literatura abordam o problema de estimação de falhas em
transformadores de potência. Dentre eles, destacam-se aqueles que tomam os resul-
tados obtidos pela técnica AGD, conforme as referências (3), (4), (5) e (6).
Em (3) é apresentada uma metodologia baseada em Redes Bayesianas utilizando

22
dados de ensaios AGD. Utiliza-se uma tabela de valores fixos para conversão entre
valores contínuos e discretos da Rede Bayesiana, indicando falhas térmicas e descargas
parciais.
Também utilizando a análise de gases dissolvidos, a referência (4) apresenta uma
abordagem baseada em uma Rede Imunológica Artificial, utilizando 720 casos de trans-
formadores defeituosos e, assim como o trabalho (3), indicando possíveis falhas térmi-
cas e descargas parciais.
O trabalho (5) apresenta uma metodologia baseada em um otimizador por enxame
de partículas (PSO) associado a uma Rede Neural de múltiplas camadas. Possui a
vantagem de indicar o elemento causador da descarga parcial.
O artigo (6) apresenta abordagem semelhante ao artigo (3), utilizando uma Rede
Neural para a classificação.
1.2 Organização do Texto
No segundo capítulo é introduzido o conceito de transformador, assim como con-
ceitos de defeito, descarga parcial, falha e falha incipiente.
No terceito capítulo são apresentados conceitos de teoria de probabilidade neces-
sários para entendimento do funcionamento das Redes Bayesianas. Inclui axiomas
da probabilidade, probabilidades a priori e a posteriori, conceito do Teorema de Bayes,
função de distribuição de probabilidade, função de densidade de probabilidade e dis-
tribuição gaussiana.
No quarto capítulo é descrita a teoria de Rede Bayesiana necessária para enten-
dindo da metodologia proposta. É descrito, inicialmente, o conceito de Rede Baye-
siana, seguido pelos processos de aprendizagem de estrutura da rede, aprendizagem
dos parâmetros e inferência. Para aprendizagem de estrutura, são descritos dois algo-
ritmos, o K2 e o Hill-Climbing. Para aprendizagem de parâmetros, o método do MLE.
Por fim, é apresentado um método para inferência em Redes Bayesianas. Neste ca-
pítulo também são descritos algoritmos para aprendizagem com dados incompletos,
porém sem muita ênfase, visto que não é utilizado na metodologia proposta.
No quinto capítulo é proposta a metodologia para estimação de falhas incipientes
em transformadores de potência. Neste capítulo é tratada a escolha dos nós e apren-
dizagem de uma RB capaz de classificar os equipamentos. Posteriormente é descrito

23
um algoritmo para discretização dos nós contínuos da RB. Em seguida, é mostrado
um algoritmo para geração de casos de treinamento e validação da RB e, por fim, a
metodologia para classificação dos transformadores de potência.
No capítulo seis são expostos os resultados da aplicação da metodologia e discute-
se a eficácia da mesma. É feita uma comparação a uma Rede Neural de Múltiplas
Camadas (MLP) também.
Finalmente, no sétimo capítulo, são apresentadas as conclusões do trabalho reali-
zado, destacando-se as perspectivas futuras.

24
2 Transformadores
Exigências de cunho técnico e econômico resultam na necessidade construção de
usinas elétricas, que, no Brasil, é, em sua maioria, suprida por usinas hidrelétricas.
Tais usinas utilizam o potencial energético armazenado em rios e lagos localizados em
lugares de altitude elevada. A energia hidráulica, dentro de uma usina, é convertida
em energia elétrica.
Devido à localização restrita das usinas, torna-se necessária o transporte da ener-
gia elétrica à longas distâncias. As seções dos condutores são limitadas por restrições
construtivas e econômicas, o que torna limitada a intensidade de corrente nas mes-
mas (7). Torna-se necessário a utilização de tensões elevadas, que em determinadas
circunstâncias, atingem centenas de milhares de volts.
Os equipamentos que elevam e reduzem a tensão são chamados de transformado-
res. A seguir, é apresentada uma introdução sobre o funcionamento básico de transfor-
madores monofásicos ideais, seus aspectos construtivos e metodologias para detecção
de falhas através de descargas parciais.
2.1 Funcionamento do Transformador Ideal
Os transformadores operam através do princípio da indução magnética, consis-
tindo de dois ou mais enrolamentos sobre um núcleo magnético de pequena relutân-
cia (7), ilustrada pela Figura 1.

25
Figura 1: Transformador Monofásico de Núcleo Envolvido
Aplica-se a tensão alternada V1 nos terminais de entrada (enrolamento primário),
que produzirá um fluxo alternado cuja amplitude dependerá da tensão V1, da frequên-
cia e do número de espiras N1 (8). O fluxo magnético induz uma tensão V2 no outro
enrolamento (secundário), cujo valor depende do número de espiras N2, da magnitude
do fluxo e da frequência. O enrolamento com maior quantidade de espiras é chamado
de enrolamento de alta tensão e o de menor espiras, enrolamento de baixa tensão. Sa-
bendo que a transformação de tensão é reversível (7), o transformador atuará como
elevador de tensão quando a tensão for aplicada no enrolamento de baixa tensão e atu-
ará como redutor, quando for aplicada no enrolamento de alta tensão. A relação entre
V1 e V2 em um núcleo a vazio (sem carga) é (7):
V1
V2=
N1
N2(2.1)
2.2 Princípios Construtivos
A seguir serão introduzidos alguns conceitos sobre a construção de transformado-
res.

26
2.2.1 Núcleos Envolvidos e Núcleos Envolventes
Segundo a referência (7), existem dois tipos de circuitos magnéticos: com núcleo
envolvido e com núcleo envolvente. O primeiro é mostrado na Figura 1, em que os
enrolamentos não são envolvidos pelo circuito magnético. O segundo é representado
pela Figura 2, em que o circuito magnético envolve os enrolamentos.
Figura 2: Transformador Monofásico de Núcleo Envolvente
2.2.2 Resfriamento de Transformadores
Durante sua operação, os transformadores perdem energia em forma de calor. A
imobilidade torna difícil a dispersão do calor, aumentando a necessidade de um meca-
nismo de resfriamento. Um meio conveniente de resfriar o núcleo é através da utiliza-
ção de um líquido refrigerante, sendo mais eficaz do que o ar, onde o transformador é
imergido em um recipiente com líquido. O refrigerante mais utilizado atualmente é o
óleo mineral, que, além de ter uma capacidade térmica superior ao ar, possui uma ri-
gidez elétrica superior, permitindo redução considerável do volume do transformador
(exige uma superfície de resfriamento menor). Para que sua utilização seja efetiva, é
necessário que se tenha ausência de umidade e que o mesmo esteja em contato direto
com o núcleo.

27
2.3 Transformadores de Potência
Os transformadores de potência (Figura 3) são equipamentos associados à trans-
ferência de energia entre um circuito e outro, normalmente localizados em grandes
distâncias. Sua função é diminuir as perdas nos condutores, alterando os valores de
corrente e tensão, fixando a frequência.
Figura 3: Transformador de Potência na subestação Goiânia Leste da Celg
As principais partes que compõem um transformador de potência, segundo (9),
são:
a) Parte ativa composta por enrolamento e núcleo;
b) Buchas;
c) Comutador;
d) Sistema de refrigeração;
e) Sistema de proteção e controle;
f) Tanque e acessórios;

28
g) Sistema isolante (óleo).
2.4 Falhas e Defeitos em Transformadores de Potência
Em conformidade com a referência (9), esta dissertação utilizará os seguintes con-
ceitos de falha e defeitos em transformadores:
1. Defeito é o estado do transformador que o leva a falhar a médio ou a curto prazo.
Assim, é dito que um transformador possui defeito(s) quando surge a neces-
sidade de remoção do mesmo para manutenção a fim de evitar uma falha no
mesmo. Alguns defeitos são:
(a) Descargas elétricas incipientes;
(b) Aquecimento acima do normal;
(c) Gotejamento do líquido isolante.
2. A falha ocorre quando o funcionamento do equipamento é interrompido devido
a alguma anomalia, tendo como motivo fenômenos elétricos e mecânicos como
o rompimento da rigidez dielétrica do sistema isolante. A falha incipiente usu-
almente se desenvolve lentamente, não estando sempre presente, e na forma de
uma deterioração gradual do sistema isolante (10). Quando a condição do equi-
pamento se degrada decorrente de efeitos elétricos, térmicos ou químicos, falhas
incipientes começam a persistir no sistema. Se não detectadas, podem levar a
uma falha catastrófica (10), causando interrupção do serviço, que só poderá ser
restaurado caso a falha seja reparada. Caso a falha incipiente seja detectada an-
tes da ocorrência de um dano maior, os reparos podem, geralmente, ser feitos de
forma mais rápida e o serviço pode ser restaurado sem demora.
2.5 Manutenção e Técnicas Preditivas
Existem dois tipos de manutenção a serem observados em transformadores de po-
tência: corretiva e preventiva. A corretiva visa eliminar falhas e defeitos no transfor-
mador. Pode acontecer de forma programada, em um ambiente controlado, ou em
situações de emergência, em que uma falha ocorre ou está na eminência de ocorrer.
A preventiva por sua vez trata de reduzir ou evitar defeitos e desgastes naturais do

29
aparelho. É este tipo de manutenção a desejada, uma vez que é mais barata e prolonga
a vida útil do equipamento.
Segundo a referência (6), as manutenções preventivas em transformadores de po-
tência consistiam em inspeções de rotina com intervalos de tempo sugeridas pelo fa-
bricante ou pela experiência da prática. Esta medida, apesar de evitar muitas falhas,
provoca a interrupção desnecessária do equipamento. Neste contexto, com consumi-
dores cada vez mais exigentes e subestações cada vez mais complexas, surgiram técni-
cas que tentam antecipar a ocorrência de defeitos e falhas, indicando ao engenheiro de
manutenção a necessidade da intervenção.
A seguir, são apresentadas duas técnicas preditivas utilizadas em transformado-
res de potência. Ambas detectam descargas parciais que, conforme (11), tratam-se de
descargas elétrica localizadas, cujo caminho percorrido não une duas superfícies con-
dutoras submetidas a uma diferença de potencial. A detecção de descargas parciais é
muito importante como técnica preditiva, ou seja, na antecipação da ocorrência (seja
defeito ou falha incipiente), devido a indicação de que algum processo químico, mecâ-
nico ou térmico possa ter causado defeitos na isolação do equipamento (12).
2.5.1 Análise de Gases Dissolvidos
Em condições naturais, a degradação e decomposição do óleo e papel presentes
no núcleo do transformador geram uma pequena quantidade de gases que se dissol-
vem no óleo (13). A alteração desta taxa de gases dissolvidos é frequentemente uma
indicação do mau funcionamento do equipamento (6).
A cromatografia é uma técnica de separação e análise de misturas de compostos
voláteis (14). Alguns gases predominantes estão associados a ocorrência de defeitos e
falhas no transformador (15):
Gás Chave Característica do DefeitoHidrogênio H2 Descarga Parcial
Etano C2H6 Falha Térmica < 300 CEtileno C2H4 300 C ≤ Falha Térmica < 700 C
Acetileno C2H2 e Etileno C2H4 Falha Térmica ≥ 700 CAcetileno C2H2 e Hidrogênio H2 Descarga de Energia
Tabela 1: Gases emitidos devido a defeitos

30
2.5.2 Emissão Acústica
Devido à grande dificuldade e custo da interrupção do funcionamento dos trans-
formadores, tornou-se necessário o desenvolvimento de um método que fosse capaz
de detectar descargas parciais (DPs) sem que houvesse o desligamento dos transforma-
dores. O método da AGD, discutido na subseçao 2.5.1, permite que isso seja alcançado,
porém não permite a localização de onde a falha incipiente está ocorrendo. Para agra-
var a situação, segundo (12), o método de análise de gases dissolvidos é pouco sensível
para a detecção de descargas parciais. Tais fatos aumentaram a necessidade de desen-
volvimento de um método que fosse capaz de indicar a possível localização da falha
incipiente, com um maior grau de sensibilidade.
Surgiu então o método da Emissão Acústica (EA), não invasivo, no qual são utiliza-
dos sensores acústicos (Figura 4) posicionados estrategicamente na superfície externa
do transformador (levando em consideração, entre outros fatores, o projeto do trans-
formador), com o intuito de monitorar todo o interior do equipamento.
Figura 4: Sensor utilizado para monitorar o transformador
Cada DP age como uma fonte de ondas acústicas, as quais propagam no interior
do transformador, através do óleo, e podem ser detectadas nas paredes exteriores do
tanque do equipamento (2). Como são utilizados diversos sensores (neste trabalho

31
foram utilizados quatorze para cada transformador monitorado), é possível realizar a
triangulação dos sinais de forma a localizar a fonte de emissões.
Para capturar os dados coletados pelos sensores é necessário a utilização de um
microcomputador posicionado próximo ao transformador, pois os sensores se comu-
nicam com o computador através de cabos. Os computadores são abrigados por uma
tenda, para que estejam protegidos caso chova. A Figura 5 mostra o arranjo utilizado
para aquisição dos dados oriundos dos sensores e a Figura 6, a localização da tenda
em relação ao transformador.
Figura 5: Equipamentos de aquisição de dados dos sensores
Os parâmetros mais importantes coletados pelo instrumento de ensaio que regis-
tra os sinais acústicos gerados por DPs (captados pelos sensores) são apresentados na
tabela 2, com ilustração na Figura 7. Todos eles são medidos com referência ao limiar
de recepção dos sensores.
De posse desses dados, é necessário estabelecer uma maneira de diferenciar os ruí-
dos emitidos pela operação do transformador e as DPs. As descargas mais intensas
ocorrem nos picos e vales de tensão, ou seja, a 90e a 270da tensão senoidal (inici-
ada em zero) de fornecimento de energia elétrica, respectivamente. Sabendo-se que a
frequência da tensão é de 60Hz e que t1 e t2 são os tempos de ocorrência do primeiro e

32
Figura 6: Tenda que abriga os computadores responsáveis pela coleta de dados
Grandeza DescriçãoTempo(s) Instante de tempo em que o evento foi detectado pelo sensor
Amplitude (dB) A amplitude máxima do sinal durante a detecção do eventoEnergia (J) Energia acumulada durante a detecção
Duração (µs) Duração do eventoTempo de Subida (µs) Tempo entre o início do evento e o pico da amplitude
Tabela 2: Dados coletados por meio dos sensores

33
Figura 7: Forma idealizada do sinal acústico
do segundo evento, a diferença angular entre estes dois eventos consecutivos pode ser
calculada por:
∆t = (t2 − t1) · 360 · 60 (2.2)
θ = ∆t−⌊
∆t360
⌋· 360 (2.3)
Sabendo-se que as descargas parciais ocorrem nos picos e vales de 90o e 270o, res-
pectivamente, pode-se ajustar o ângulo correto utilizando 180 − θ/2 para θ ≤ 180 e
θ/2 + 180 para θ > 180. Desta forma, para que duas descargas sejam consideradas
indícios de DP, é necessário estarem afastadas por 180.
Tendo-se a quantidade de descargas ocorridas, o nível de ruído e o montante de
energia, é possível então criar um método para identificação dos transformadores em
melhor estado e os de estado mais precário, sob a ótica das descargas parciais.

34
3 Fundamentos de Probabilidade
Para a compreensão do funcionamento de Redes Bayesianas, se faz necessário co-
nhecer a teoria da probabilidade, por se tratar de uma forma de raciocínio probabilís-
tica. O objetivo deste capítulo é introduzir os conceitos da teoria da probabilidade e
variáveis aleatórias, que servirão como base para o estudo de Redes Bayesianas, que é
o método de raciocínio automatizado utilizado para a criação do classificador utilizado
na metodologia proposta.
3.1 Cálculo Probabilístico
Na teoria da probabilidade, considera-se a utilização de experimentos, chamados
de aleatórios, cujos resultados não podem ser preditos com certeza. Assume-se que
podem ser reproduzidos diversas vezes nas mesmas condições e todos os valores pos-
síveis são conhecidos e chamados de espaço amostral (16). Cada resultado possível
para o experimento é chamado de ponto de amostragem. Subconjuntos do espaço
amostral com um ou mais pontos de amostragem são denominados eventos.
Segundo a referência (16), o espaço amostral varia com o ponto de vista adotado.
Um exemplo disso são resistores de 100Ω produzidos por um determinado fabricante.
Seus valores reais, devido à imprecisões inerentes ao processo de fabricação, variam
de 99Ω a 101Ω. Para o cliente A, seus valores variam de 99 a 100,2Ω. Para o cliente B,
seus valores variam de 99,5 a 101Ω. Tem-se então um espaço amostral diferente para
cada cliente e que diferem do espaço amostral do fabricante.
3.1.1 Axiomas da Probabilidade
Dado um evento A contido em um espaço amostral S, define-se a função P(A)
como sendo a medida de probabilidade de A. A função P possui os seguintes axio-
mas (16):

35
- P(A) ≥ 0 (não negativo);
- P(S) = 1 (normalizado);
- Sendo An um conjunto de eventos disjuntos em S, a equação (3.1) representa a
propriedade aditiva.
P (A1 ∪ A2 ∪ ... ∪ An) = P
(n
∑i=1
An
)=
n
∑i=1
P (An) (3.1)
Os três postulados definem a função P.
3.1.2 Atribuição de Probabilidade e Probabilidade a Priori
Os axiomas da probabilidade não definem a maneira com que se atribui uma pro-
babilidade aos eventos. Uma maneira natural é através do cálculo de sua frequência
relativa (16). Levando-se em consideração que um experimento tenha sido realizado n
vezes e na a quantidade de vezes em que o evento A foi observado, tem-se na/n como
sendo a frequência relativa de A. Em condições normais esta frequência tende a um
único limite, à medida que n aumenta.
Uma outra maneira de se atribuir uma probabilidade, quando não é viável ou pos-
sível a repetição do experimento por uma quantidade suficientemente grande de vezes,
é a utilização da verossimilhança relativa, utilizando-se de um conhecimento subjetivo
do assunto. Um exemplo seria: "existe uma probabilidade de 40% de chover ama-
nhã" (16). Em ambos os casos, a probabilidade de ocorrência do evento A no experi-
mento, P(A), é chamada de probabilidade a priori do evento A, uma vez que não se
leva em consideração nenhum conhecimento sobre o experimento.
3.1.3 Probabilidade a Posteriori
A probabilidade a priori não permite a atualização da probabilidade à medida em
que aparecem novas evidências. Esse cálculo é realizado através da probabilidade con-
dicional, ou a posteriori. Sendo A e B eventos de um experimento aleatório, a probabili-
dade P(A|B) define a probabilidade a posteriori, de A, dado que B já ocorreu e P(B|A)
define a verossimilhança de A dado B . Sabendo-se que P (A, B) = P (A ∩ B):
P (A|B) = P (A, B)P (B)
(3.2)

36
A equação (3.2) pode ser reescrita de forma a se obter o teorema fundamental do
cálculo probabilístico (17):
P (A|B) · P(B) = P (A, B) (3.3)
O teorema fundamental permite que se calcule a probabilidade de dois eventos acon-
tecerem simultaneamente (A e B), sabendo a probabilidade de A dado B e a probabili-
dade de B. A aplicação deste teorema sucessivas vezes leva a regra da cadeia:
P (A1, A2, . . . , An) = P (A1|A2, . . . , An)P (A2|A3, . . . , An) . . . P (An) (3.4)
3.1.4 O Teorema de Bayes
O Teorema de Bayes provê um método para atualização da crença em um determi-
nado evento, A, quando se há informação sobre um outro evento, B, isto é, calcular a
probabilidade a posteriori dada uma evidência (18). Ele mostra a relação entre uma pro-
babilidade condicional e a sua verossimilhança. O Teorema de Bayes, conforme (18), é:
Teorema 3.1 (Teorema de Bayes) Sejam A e B dois eventos arbitrários em que P(A) 6= 0 e
P(B) 6= 0. Então:
P (A|B) = P (B|A) · P (A)
P (B)(3.5)
Exemplo 1 Sabe-se que um paciente teve um resultado positivo em um exame para uma deter-
minada doença. Uma em cada quinhentas pessoas tem a doença. É conhecido que o teste também
não é confiável: ele possui uma taxa de falsos positivos de 3% e falsos negativos de 6%. Sabendo
que P(D) é a probabilidade a priori do paciente ter a doença, P(E) a probabilidade a priori do
resultado do exame ser positivo, calcule P(D|E) (exemplo adaptado da referência (18)):
P (D) =1
500= 0, 002
Como o número de falsos positivos é de 3%, tem-se que:
P (E|¬D) = 0, 03
P (¬E|¬D) = 1, 00− P (E|¬D)
= 0, 97

37
O número de falsos negativos de 6% leva a:
P (¬E|D) = 0, 06
P (E|D) = 1, 00− P (¬E|D)
= 0, 94
A probabilidade de um exame ser positivo, P(E), pode ser computada através da regra
da cadeia:
P (E) = P (E|D)P (D) + P (E|¬D)P (¬D)
=94
100· 1
500+
3100· 499
500= 0, 00188 + 0, 02994 = 0, 03182 ≈ 3, 2%
Logo, através do teorema de Bayes:
P (D|E) = P (E|D) · P (D)
P (E)
=0, 94 · 0, 002
0, 032≈ 5, 87%
P (¬D|E) = 1, 00− P (D|E)
= 94, 13%
O resultado demonstra que existe uma probabilidade de 94,13% de que o paciente
não tenha a doença, dado um exame positivo. É possível que a resposta intuitiva neste
caso sugerisse uma maior chance do paciente estar doente. Isto acontece porque fre-
quentemente as probabilidades a priori são ignoradas (a fração original das pessoas
que possuem a doença e a fração das pessoas que não tem a doença e recebem falsos
positivos) focando apenas na porção das amostras que recebem resultados positivos.
O exemplo 1 demonstra a utilização do teorema de Bayes para a atualização de
crenças. A inserção de novas informações, o exame neste exemplo, não substitui a
informação inicial. Neste caso, um resultado positivo aumenta a probabilidade e um
resultado negativo, diminui. O senso comum induz a substituição da probabilidade
inicial pela probabilidade de uma evidência, ao invés de utilizarem o raciocínio do
Teorema de Bayes para atualizá-la. A probabilidade de um paciente com exame posi-
tivo ter a doença, P(D|E), não é a mesma de um paciente com a doença ter um exame
positivo, P(E|D).

38
3.1.5 Função de Distribuição de Probabilidade
Dado um experimento aleatório associado a uma variável X e sendo a probabili-
dade P(X ≤ x), onde x é um número real. A função de distribuição de probabilidade,
ou função de distribuição cumulativa é definida (16):
Fx(x) = P(X ≤ x) (3.6)
A Equação (3.6) mostra que a função de distribuição de probabilidade é a probabi-
lidade de X assumir um valor igual ou a esquerda de x, aumentando até o valor 1 (ou
100%) (16).
3.1.6 Função de Densidade de Probabilidade
Seja Fx(x) a função de distribuição de probabilidade de uma variável contínua x, a
função de densidade de probabilidade, função não negativa, é definida por (16):
fx(x) =dFx(x)
dx(3.7)
Tanto a função de densidade de probabilidade quanto a função de distribuição
de probabilidade descrevem totalmente o comportamento de uma variável randô-
mica (16). A função fx(x) mostra as regiões com maior ou menor probabilidade da
variável X assumir um determinado valor em um intervalo. Observa-se que somente
existe em variáveis contínuas, uma vez que Fx(x) não é diferenciável nos pontos de
descontinuidade.
3.1.7 Distribuição Gaussiana
A distribuição Normal ou Gaussiana (figura 8) é a distribuição mais importante
da teoria da probabilidade. Uma variável aleatória X é gaussiana, ou normal, se sua
função de distribuição de probabilidade é (16):
Fx (x) =1
(2π)1/2σ
∫ x
−∞ exp
[− (u−µ)2
2σ2
]du (3.8)

39
e sua função de densidade de probabilidade:
fx (x) =1
(2π)1/2σexp
[− (x−µ)2
2σ2
](3.9)
sendo σ e µ o desvio padrão e a média respectivamente. O desvio padrão e a média
caracterizam completamente uma distribuição normal, sendo normalmente represen-
tada pela notação N(µ,σ2).
(a)
(b)
Figura 8: Distribuição Gaussiana: (a) função de distribuição de probabilidade e (b)função de densidade de probabilidade

40
4 Rede Bayesiana
Segundo (17), Redes Bayesianas (RB) são grafos acíclicos direcionais (GAD) com-
postos por:
- Um conjunto de variáveis (nós do grafo);
- Cada variável possui um conjunto exclusivo e finito de estados;
- Para cada nó A com pais B1,...,Bn, existe uma tabela de probabilidade condicio-
nal(TPC).
A Figura 9 exemplifica uma rede bayesiana, RB, com quatro nós: A, B, C e D. O pa-
râmetro A não possui pai, apenas dois nós filho B e C, enquanto que o nó D é filho de B
e C. Desta forma, os parâmetros são compostos porθA,θB|A,θC|A,θD|BC que respresen-
tam, respectivamente, as probabilidades a posteriori P(A), P(B|A), P(C|A) e P(D|BC).
O conjunto de nós e arestas que formam o grafo é denominado de estrutura e a tabela
de probabilidade condicional associada a cada nó é chamada de parâmetro. Quando as
variáveis de uma rede recebem valores, são nomeadas de instâncias. Quando todas as
variáveis de uma rede bayesiana são instanciadas, é chamado de instância da rede (19).
Uma instância de um conjunto vazio de variáveis é chamada de trivial.

41
A θA
V 0,75
F 0,25
A B θB|A
V V 0,30
V F 0,70
F V 0,60
F F 0,40
A C θC|A
V V 0,80
V F 0,20
F V 0,05
F F 0,95
B C D θD|BC
V V V 0,90
V V F 0,10
V F V 0,85
V F F 0,15
F V V 0,95
F V F 0,05
F F V 0,00
F F F 1,00
Figura 9: Exemplo de Rede Bayesiana com 4 parâmetros
Com uma base de dados de tamanho razoável é possível aprender tanto a estru-
tura, quanto os parâmetros de uma RB, dependendo apenas da completude dos dados.
Quando todos os casos na base de dados estão completos, isto é, os valores de todas
as variáveis são conhecidos, é chamada de base de dados completa, de acordo com a
tabela 3. Se um ou mais casos não estiverem completos, a base de dados é chamada de
incompleta (19), como mostrado na tabela 4.
Caso Gripe? Febre? Garganta Inflamada? Dor de Cabeça?1 Verdadeiro Verdadeiro Verdadeiro Falso2 Verdadeiro Falso Verdadeiro Falso3 Verdadeiro Falso Verdadeiro Falso4 Falso Verdadeiro Falso Verdadeiro5 Falso Verdadeiro Verdadeiro Verdadeiro6 Falso Falso Falso Verdadeiro7 Falso Falso Verdadeiro Verdadeiro8 Falso Verdadeiro Falso Verdadeiro...
......
......
Tabela 3: Base de dados completa

42
Caso Gripe? Febre? Dor de Cabeça? Administrou Remédio?1 Verdadeiro Verdadeiro Falso Verdadeiro2 Verdadeiro Falso Falso ?3 Verdadeiro Falso Falso ?4 Falso ? Verdadeiro Falso5 ? Verdadeiro Verdadeiro Falso6 Falso ? Verdadeiro Verdadeiro7 Falso Falso Verdadeiro ?8 Falso Verdadeiro Verdadeiro Verdadeiro...
......
......
Tabela 4: Base de dados incompleta
4.1 Aprendizado com Dados Completos
Na ausência de um especialista para definição da RB, é necessário estabelecer uma
estrutura e parâmetros que se aproximem do ideal. A princípio, isso pode ser feito
através do aprendizado de parâmetros em todas as possíveis estruturas e escolhendo
aquela que se encaixe mais no conjunto de dados utilizado, isto é, aquela que possuir
maior pontuação na função de avaliação. A dificuldade desta abordagem por força
bruta é a quantidade de estruturas a serem comparadas, uma vez que a quantidade
f (n) de estruturas possíveis, cresce super-exponencialmente (exponencial iterada) com
o número de nós n (17):
f (n) =n
∑i=1
(−1)i+1 n!(n− 1)!n!
2i(n−i) f (n− 1) (4.1)
Na tentativa de contornar este problema, alguns algoritmos foram desenvolvidos,
como o K2 e o Hill-Climbing, para aprendizado de estrutura com dados completos.
Ambos tentam otimizar a estrutura através de uma busca gulosa sobre as possíveis
estruturas da rede.
Ao contrário do aprendizado de estrutura, o aprendizado de parâmetros com da-
dos completos é um processo simples, que se reduz a uma tarefa de contagem. O
método utilizado por este trabalho foi o MLE (Maximum Likelihood Estimation ou Esti-
mativa da Máxima Verossimilhança), apresentado na subseção 4.1.3.

43
4.1.1 Algoritmo K2
O algoritmo K2 é um algoritmo de busca gulosa em que a ordem dos nós é conhe-
cida (17) e a quantidade de pais para cada nó é limitada, reduzindo a execução a tempo
polinomial. Sendo Ni jk o número de casos na base de treinamento em que a variável
ui é instanciada com o valor vik, π(ui) os pais de ui, qi a quantidade de instanciações
possíveis de π(ui) e rui a quantidade de valores possíveis discretos de ui, a equação
(4.3) como método de pontuação da busca heurística:
Ni j =
rui
∑k=1
Ni jk (4.2)
g(i,π(ui)) =qi
∏j=1
(rui − 1)!(Ni j + rui − 1)!
rui
∏k=1
Ni jk! (4.3)
O algoritmo K2 está incluído abaixo (20).
Algoritmo 1: K2 para aprendizado de estruturas em redes bayesianasInput: Conjunto U de nós ordenados da rede, lista de casos para treinamento,
limite p de pais para cada nó.
Output: Grafo Acíclico Direcional.
1 foreach ui ∈U do
2 π(u′i) = ∅;3 Pantigo = g(i,π(ui));
4 FLAG = verdadeiro;
5 while FLAG ≡ verdadeiro e π(ui) < p do
6 [x, y] = argmax(g(i,π(ui) ∪ y));7 y = y− π(ui);
8 Pnovo = g(i,π(ui) ∪ y);9 if Pnovo > Pantigo then
10 Pantigo = Pnovo;
11 π(ui) = π(ui) ∪ y;12 else
13 FLAG = f also;
14 end
15 end
16 end

44
4.1.2 Aprendizagem Hill-Climbing
O hill-climbing é um método de busca local, guloso, que se utiliza de uma técnica
iterativa de otimização (21). A técnica é aplicada ao ponto corrente e, a cada iteração,
um novo ponto, um vizinho, é selecionado para ser o ponto corrente. O conjunto de
todos os pontos próximos ao ponto corrente é chamado de vizinhança e cada membro
da vinhança é um vizinho, que pode ser gerado através de pequenas pertubações no
ponto atual. Para que seja possível a comparação de dois vizinhos diferentes, é ne-
cessário um método que possa quantificar a qualidade de cada ponto. Este método é
chamado de pontuação.
Para que um vizinho seja selecionado como o ponto corrente, é necessário:
- Que o novo ponto corrente leve o algoritmo para uma posição melhor que a atual;
- Que ele tenha a maior pontuação da vizinhança.
Os pontos acima decorrem da otimização gulosa, que sempre progride para o ponto
com maior ganho imediato. Essa abordagem leva a uma implementação facil e rápida,
mas que não garante um resultado ótimo global. O que se pode garantir é que a solução
final é equivalente ou melhor do que a inicial.
O método de pontuação varia de acordo com o problema, uma vez que a pontuação
depende do tipo de solução a ser avaliada. Neste trabalho, em que se deseja otimizar a
estrutura da Rede Bayesiana, o método de pontuação utilizado foi o Bayesian Informa-
tion Criterion (BIC), que mede quão bem a base de dados se encaixa no modelo, além
de penalizar a complexidade da estrutura (17).
BIC(G|D) =n
∑i=1
qi
∑j=1
ri
∑k=1
Ni jk log2
(Ni jk
Ni j
)− log2N
2
n
∑i=1
qi (ri − 1) , (4.4)
onde n é a quantidade de nós, N a quantidade de casos na base de dados, D a base
de dados, G o GAD a ser pontuado e as demais variáveis assumem o mesmo valor
das variáveis declaradas na subseção 4.1.1. A pontuação BIC é uma boa maneira de
se comparar duas estruturas, pois além de levar em consideração a adequação do mo-
delo aos dados e a complexidade da estrutura, leva em consideração a equivalência
da estrutura, isto é, se apesar de diferentes, possuem a mesma verossimilhança (22).
Além disso, pode ser decomposta, o que permite o cálculo de apenas uma mudança
na estrutura da rede. Por exemplo, se for inserido um arco de Xi para X j na estrutura

45
D, então apenas a pontuação de X j irá mudar, o que permite que seja feita apenas a
avaliação do ganho de pontuação (17):
∆(Xi→ X j) = score(X j, pa(X j) ∪ Xi, D)− score(X j, pa(X j), D) (4.5)
onde pa(X j) é o conjunto dos pais de X j.
As operações válidas para geração dos vizinhos no método do Hill-Climbing, desde
que gerem grafos acíclicos, são:
- Adicionar um arco;
- Remover um arco;
- Inverter a direção de um arco.
A utilização do Hill-Climbing para aprendizado de estruturas em Redes Bayesianas,
descrito por (17) e (23), é:
Algoritmo 2: Hill-Climbing utilizado para aprendizado de estruturas em Redes
BayesianasInput: Estrutura Inicial S (caso não exista, consideram-se todos os nós
desconexos), base de dados D.
Output: Grafo Acíclico Direcional.
1 repeat
2 foreach operação legal em A do
3 ∆(A) = BIC(S, D);
4 end
5 ∆∗ = max∆(A);
6 A∗ = argmax∆(A);
7 if ∆∗ > 0 then
8 S = op(S, A∗);
9 end
10 until ∆∗ ≤ 0;
A execução do algoritmo prossegue até que não seja possível melhorar a estru-
tura. Usualmente leva a bons resultados, porém a sua natureza gulosa pode levar o
algoritmo à convergir prematuramente. Por se tratar de um método heurístico, não há
como prever esta ocorrência.

46
4.1.3 Aprendizado de Parâmetros através da Estimativa da MáximaVerossimilhança (MLE).
O aprendizado de parâmetros com dados completos é o caso mais simples de
aprendizado em uma rede bayesiana (24). Este trabalho apresenta o cálculo da esti-
mativa da máxima verossimilhança como método de aprendizado de parâmetros para
dados completos que, de acordo com (17), trata-se apenas de um caso de contagem.
Para cada caso de aprendizagem d ∈ D, a probabilidade P(d|M) é chamada de ve-
rossimilhança de M dado d, sendo M o modelo. Assumindo-se que D é é independente
do modelo, a verossimilhança de M em relação a D é (17):
L(M|D) = ∏d∈D
P(d|M) (4.6)
De forma semelhante, a log-verossimilhança:
LL(M|D) = ∑d∈D
log2 P(d|M) (4.7)
O princípio da máxima verossimilhança permite que seja escolhido o modelo que
melhor se encaixe à base de dados:
θmax = argmax(L(Mθ|D)) = argmax(LL(Mθ|D)) (4.8)
Segundo (17) e (19), obtêm-se a máxima verossimilhança calculando-se a relação
entre número de casos que satisfazem a instanciação e número de casos no banco de
dados. A equação abaixo calcula a probabilidade condicional P(A = a, B = b|C = c, D =
d):
P(A = a, B = b|C = c, D = d) =N(A = a, B = b, C = c, D = d)
N(C = c, D = d)(4.9)
onde N(X) é a quantidade de casos em que a X ocorre.
Exemplo 2 Aprenda o parâmetro P(B|A) da Rede Bayesiana da Figura 10.
De acordo com a base de dados, os nós A, B e C podem assumir dois valores: V
ou F. Para calcular a tabela de probabilidade condicional P(B|A), é suficiente aplicar a

47
Caso A B C1 V V V2 V F V3 F F F4 V V F5 V V V6 V V F7 F F F8 F V F9 V V F
10 F V V(a) (b)
Figura 10: Aprendizagem de Parâmetros: (a) Estrutura e (b) base de dados completos
equação (4.9) para cada possível instância de A e B:
P(B = V|A = V) =N(A = V, B = V)
N(A = V)=
56≈ 83, 33%,
P(B = F|A = V) =N(A = V, B = V)
N(A = V)=
16≈ 16, 67%,
P(B = V|A = F) =N(A = V, B = V)
N(A = V)=
24= 50, 00%,
P(B = F|A = F) =N(A = V, B = V)
N(A = V)=
24= 50, 00%
Logo, a tabela de probabilidade condicional é:
A B θB|A
V V 83,33%
V F 16,67%
F V 50,00%
F F 50,00%
Tabela 5: Tabela de Probabilidade Condicional P(B|A)
Através do cálculo observa-se que o resultado obtido é normalizado, ou seja, P(B =
V|A = V) + P(B = F|A = V) = 1 e P(B = V|A = F) + P(B = F|A = F) = 1.
A utilização do método MLE para aprendizado de parâmetros é extremamente útil
quando se tem uma base de dados disponível. O método é capaz de detectar cada
alteração (inserção, remoção, alteração) feita na base de dados e assim atualizar os

48
parâmetros da Rede Bayesiana. Como se trata de apenas um método de contagem, a
implementação computacional é simples e a execução é rápida.
4.2 Aprendizado com Dados Incompletos
O aprendizado com dados incompletos se trata de uma tarefa mais difícil como a
apresentada anteriormente, cujos dados eram completos, pois deve-se estimar os da-
dos que estão faltando. Nesta seção, será demonstrado inicialmente o algoritmo EM
(Expectation Maximization) para aprendizado de parâmetros, conhecido também como
EM paramétrico. Após a compreensão do algoritmo EM para aprendizado de parâ-
metros, o algoritmo EM será utilizado para aprendizado de estruturas, EM estrutural
(Structure EM).
Por tratarem de algoritmos aplicados quando os dados estão incompletos, de maior
complexidade por envolver estimativa de dados, existe uma menor abordagem por
parte da literatura em relação aos algoritmos de aprendizagem com dados completos.
4.2.1 Aprendizado de Parâmetros com o EM Paramétrico
O algoritmo EM é uma ferramenta para estimar parâmetros de um modelo quando
os dados são incompletos (25). O algoritmo é dividido em dois passos:
1. Passo E: São utilizadas as estimativas atuais dos parâmetros para calcular espec-
tativas para os valores futuros. É neste passo onde os valores incompletos são
preenchidos.
2. Passo M: Neste passo é calculado o MLE para os parâmetros. Essa estimativas são
utilizadas então na próxima iteração do algoritmo, no passo E, para completar os
valores faltantes.
O algoritmo é executado até que o número máximo de iterações seja alcançado, ou o
algoritmo tenha convergido.
Definição 4.2.1 O passo E é calculado por (19):
PD,θk(α)de f=
1N
N
∑i=1
Pθk(ci|di) (4.10)

49
onde α é um evento, θk é a tabela de probabilidade condicional na iteração k e ci são
as variáveis faltantes de di, N é a quantidade de casos na base de treinamento e Pθk a
probabilidade calculada sobre os dados completos.
Exemplo 3 Calcule PD,θ1(c1|a2) da rede representada na Figura 11, utilizando os dados da
tabela 6 (retirados da referência (19)):
A θ0a
a1 0, 20a2 0, 80
A B θ0b|a
a1 b1 0, 75a1 b2 0, 25a2 b1 0, 10a2 b2 0, 90
A C θ0c|a
a1 c1 0, 50a1 c2 0, 50a2 c1 0, 25a2 c2 0, 75
B D θ0d|b
b1 d1 0, 20b1 d2 0, 80b2 d1 0, 70b2 d2 0, 30
(a) (b) (c) (d) (e)
Figura 11: Rede Bayesiana do exemplo 3
D A B C Dd1 ? b1 c2 ?d2 ? b1 ? d2d3 ? b2 c1 d1d4 ? b2 c1 d1d5 ? b1 ? d2
Tabela 6: Tabela com dados incompletos para o exemplo 3
Para o cálculo θ1c1|a2
, é necessário conhecer todos os casos em que A = a2. Como os
dados estão incompletos, é necessário completá-los. O cálculo do passo E é mostrado
na Figura 12.
A Figura 12 (b) mostra os dados completados. Para terminar a iteração é necessário
executar o passo M, de Maximização, onde utiliza-se o método MLE para aprendizado
de parâmetros:
θ1(c1|a2) =PD,θ0(c1, a2)
PD,θ0(a2)=
0, 035 + 0, 3510, 035 + 0, 018 + 0, 176 + 0, 351
≈ 0, 666
Este exemplo demonstra os passos E e M do método EM para aprendizado de pa-
râmetros com dados incompletos. O método EM não é tão eficiente como o MLE, de-

50
di A B C D Pθ0(ci|di)d1 ? b1 c2 ?
a2 b1 c2 d1 0,089a2 b1 c2 d2 0,356
d2 ? b1 ? d2a2 b1 c1 d2 0,087a2 b1 c2 d2 0,261
d3 ? b1 ? d2a2 b2 c1 d1 0,878
d4 ? b1 ? d2a2 b2 c1 d1 0,878
d5 ? b1 ? d2a2 b1 c1 d2 0,087a2 b1 c2 d2 0,261
A B C D PD,θ0
a2 b1 c1 d1 0a2 b1 c1 d2 0,035a2 b1 c2 d1 0,018a2 b1 c2 d2 0,176a2 b2 c1 d1 0,351a2 b2 c1 d2 0a2 b2 c2 d1 0a2 b2 c2 d2 0
(a) (b)
Figura 12: Passo E do método EM de aprendizado de parâmetros
monstrado na subseção 4.1.3, pois além do passo de maximização, necessita do passo
E, onde os dados faltantes são completados. A implementação do método é itera-
tiva, isto é, repete-se até que os parâmetros calculados sejam satisfatórios. Usualmente
utiliza-se a diferença entre θk e θk−1 como critério de parada. O algoritmo EM nunca
piora os parâmetros aprendidos, conforme equação (4.11), em que D é a base de dados,
θk os parâmetros na iteração k e θk+1 os parâmetros na iteração k + 1:
LL(θk+1|D) ≥ LL(θk|D) (4.11)
4.2.2 Aprendizado de Estrutura com o EM Estrutural
Trata-se do caso mais difícil do aprendizado de Redes Bayesianas, já que para se
aprender a estrutura, é necessário que os dados estejam completos. Atualmente é o
que mais carece de algoritmos de aprendizado e não é muito comentado na literatura,
tendo no algoritmo EM estrutural (26) o método mais comum para aprendizado de
estruturas com dados incompletos. Conforme a referência (22), os passos do algoritmo
SEM são:
1. Inicia-se o algoritmo com um modelo aleatório (estrutura e parâmetros aleató-
rios), que será o modelo corrente;
2. Aplica-se o passo E do algoritmo EM para complemento dos dados faltantes;

51
3. Para o passo M utiliza-se as estatísticas calculadas no passo E para aprendizado
de um novo modelo;
4. Para este novo modelo, calcula-se os parâmetros θ;
5. Repete-se o procedimento de busca e pontuação até que não haja melhora no
modelo.
O modelo final terá uma pontuação maior do que o modelo inicial, indicando maior
ajuste dos dados ao modelo.
4.3 Inferência em Redes Bayesianas pelo método da Eli-minação de Variáveis
Após o aprendizado de uma Rede Bayesiana, é importante ter em mãos um bom
método para inferências. A inferência é o processo em que são feitas consultas à rede e
uma resposta, baseada na probabilidade, é dada ao usuário. A inferência, ou raciocínio,
desencarrega o usuário de calcular as probabilidades manualmente, respondendo as
consultas à rede de forma automatizada (19). É importante ressaltar que, em muitos
casos, o processo de inferência torna-se impossível sem o uso de um computador, pois
podem envolver uma quantidade muito grande de variáveis.
Existem duas classes de algoritmos para inferência: exatos e aproximados. Os algo-
ritmos exatos garantem uma resposta correta e exata para cada consulta, demandando
mais recursos computacionais. Os algoritmos aproximados demandam menos recur-
sos computacionais, a resposta pode, porém, não ser exata. Por se tratar de um assunto
extenso, esta dissertação se limita a descrever o método de inferência por eliminação
de variáveis, por ser um dos métodos mais simples. É capaz de responder consultas de
probabilidades a priori, a posteriori, MPE (Most Probable Explanation) e MAP (Maximum
a Posterior Hypothesis). As definições, algoritmos e exemplos a seguir foram retirados
e/ou adaptados da referência (19).
4.3.1 Fatores
Fatores são ferramentas chave no processo de eliminação de variáveis. Inicialmente
os fatores são inicializados com a probabilidade da instanciação e, conforme as opera-
ções são realizadas sobre ele, o valor é atualizado.

52
Definição 4.3.1 O fator f de variáveis X é uma função que mapeia cada instanciação x de X à
um valor não negativo, f (x).
B C fVerdadeiro Verdadeiro 0,35Verdadeiro Falso 0,05
Falso Verdadeiro 0,40Falso Verdadeiro 0,20
Tabela 7: Fator f
Existem algumas operações que podem ser realizadas em fatores e que viabilizam
o processo de inferência. A seguir, serão definidas as operações, assim como exemplos
e algoritmos, conforme (19).
4.3.1.1 Eliminação de Variáveis
A primeira operação a ser definida é a eliminação de variáveis:
Definição 4.3.2 Seja f um fator sobre variáveis X e x é uma variável em X. O resultado de
eliminar x de f é um fator ∑x sobre variáveis Y = X− x, sendo y instância de Y, definido por:(∑x
f)(y)
de f= ∑
xf (x, y) (4.12)
Algoritmo 3: Eliminação de VariáveisInput: Fator f (X) sobre variáveis X, variáveis Z a serem eliminadas
Output: Fator ∑z f
1 Y = X - Z;
2 foreach instanciação de Y = y do
3 f ′(y) = 0;
4 foreach instanciação de z do
5 f ′(y) = f ′(y) + f (yz);
6 end
7 end
8 return f ′
Através de sucessivas eliminações de variáveis, é facilmente calculado a distribui-
ção marginal de variáveis e, a partir dela, resolve-se consultas a priori e a posteriori.

53
Definição 4.3.3 A distribuição marginal P(x1, x2, ..., xm) é definida por:
P(x1, x2, ..., xm|e) = ∑xm+1 ,...xn
P(x1, x2, ..., xn|e), (4.13)
em que m ≤ n.
Seguindo a definição 4.3.2, é possível aplicar a operação ∑C f (B, C) no fator f da
tabela 7. O fator resultante, também distribuição marginal P(C), é:
B fVerdadeiro 0,40
Falso 0,60
Tabela 8: Fator (∑C f ) (B)
A operação de eliminação de variáveis, também conhecida por marginalização,
mostra-se útil para o cálculo da distribuição de marginais. Porém, para que seja feita,
é necessário o conhecimento da tabela de distribuição conjunta da rede bayesiana (ins-
tâncias da rede com sua probabilidade correspondente), que pode ser obtida através
da regra da cadeia, conforme equação (3.4).
4.3.1.2 Operação de Multiplicação
A operação de multiplicação surge como uma alternativa mais rápida para cálculo
da tabela de distribuição conjunta. Pode-se entender cada parâmetro como sendo um
fator e então aplicar a operação de multiplicação, conforme será mostrado a seguir.
Definição 4.3.4 A operação de multiplicação de dois fatores, f1(x) e f2(y), resulta em um
terceiro fator f1 f2:
( f1 f2)(z)de f= f1(x) f2(y), (4.14)
em que z = x ∪ y.

54
Algoritmo 4: Multiplicação de FatoresInput: f1(X1),..., fm(Xm)
Output: Fator f ′
1 Z =⋃m
i=1 Xi;
2 foreach instanciação z de Z do
3 f (z) = 1;
4 for i = 1 to m do
5 xi = Instancia de Xi consistente com z;
6 f (z) = f (z) fi(xi);
7 end
8 end
Logo, para calcular a TDC da rede da Figura 11:
P(A, B, C, D) = θD|B ·θB|A ·θC|A ·θA
4.3.1.3 Operação de Maximização
Para o cálculo de probabilidades MPE e MAP, é necessária a definição da operação
de maximização. Similar à operação de eliminação de variáveis, a maximização tam-
bém elimina variáveis, porém, ao invés de somar os fatores, o maior fator permanece.
Definição 4.3.5 Seja Z um conjunto de variáveis e X uma variável contida em Z. O resultado
de maximizar a variável X do fator f (Z) é um novo fator f2(Y), em que Y = Z− X.(max
Xf)(y)
de f= max
Xf (x, y) (4.15)

55
Algoritmo 5: Maximizar FatorInput: Fator f (X) sobre variáveis X, variáveis Z a serem eliminadas
Output: Fator (maxX f ) (y)
1 Y = X - Z;
2 foreach instanciação de y do
3 f ′(y) = 0;
4 foreach instanciação de z do
5 if f ′(y) < f (yz) then
6 f ′(y) = f (yz);
7 end
8 end
9 end
10 return f ′
O algoritmo resulta na operação de maximização. Uma importante extensão do
método é armazenar a instância removida a cada operação. Desta forma, a operação é
capaz de fornecer a instância maximizada, além da probabilidade.
Exemplo 4 Calcular (maxX f ) (y).
A Figura 13 mostra a operação de maximização no fator f . Em (a), o fator f antes
da maximização. Em (b), depois da maximização, guardando em fext a instância cuja
probabilidade é máxima.
X Y f
V V 0,15
V F 0,50
F V 0,15
F F 0,20
Y f fext
V 0,50 X = V
(a) (b)
Figura 13: Exemplo de maximização: (a) fator a ser maximizado (b) fator maximizado
4.3.1.4 Ordem das Variáveis
Todas as operações definidas acima são comutativas, isto é, independente da or-
dem das variáveis, o resultado será o mesmo. Porém a ordem das variáveis a serem

56
eliminadas altera a quantidade de operações necessárias para se chegar ao resultado.
Sabe-se que escolher a melhor alternativa é um problema NP-difícil (difícil de se resol-
ver de forma eficiente, não possuíndo um algoritmo de tempo polinomial conhecido),
tornando a escolha da ordem, desafiadora. Descreve-se, em (19), algumas estratégias
para otimização da ordem dos nós, que não serão descritas pois não foram aplicadas
durante a execução do projeto.
4.3.2 Otimizando a Estrutura da Rede
Em geral, uma consulta à rede bayesiana recebe dois parâmetros: o conjunto de
variáveis Q e a evidência e. Dependendo destes parâmetros, frequentemente é possível
reduzir a quantidade de nós e arestas, de modo à tornar a consulta mais rápida, sem
prejuízo no resultado. Este processo é chamado de poda da rede, composto pela poda
de nós e pela poda de arestas.
4.3.2.1 Podas de Nós
Dada uma rede bayesiana N e uma consulta P(Q, e), é possível eliminar qualquer
nó folha (nó que não possui filhos) desde que não pertença as variáveis do conjunto
Q ∪ E, sendo executada iterativamente, até que não existam nós a serem removidos.
Teorema 4.1 Seja N uma rede bayesiana. Se N′ = podarNos(N, Q ∪ E), então P(Q, e) =
P′(Q, e), onde P e P′ são as distribuições marginais inferidas em N e N’, respectivamente.

57
Algoritmo 6: Podas de NósInput: Rede Bayesiana N, consulta P(Q, e)
Output: Rede Bayesiana N’
1 Seja N’ uma rede com a mesma estrutura e parâmetros de N;
2 remover = VERDADEIRO;
3 while remover ≡ VERDADEIRO do
4 remover = FALSO;
5 L← conjunto de nós folha de N’;
6 foreach X ∈ L do
7 if X /∈ (Q ∪ E) then
8 Remover X de N’;
9 remover = VERDADEIRO;
10 end
11 end
12 end
13 return N′
4.3.2.2 Podas de Arestas
Dada uma rede bayesiana N e uma consulta P(Q, e), é possível eliminar algumas
arestas da rede, sem afetar o resultado da consulta.
Teorema 4.2 Seja N uma rede bayesiana. Se N′ = podarArestas(N, e), então P(Q, e) =
P′(Q, e), onde P e P′ são as distribuições marginais inferidas em N e N’, respectivamente.
Algoritmo 7: Podas de ArestasInput: Rede Bayesiana N, consulta P(Q, e)
Output: Rede Bayesiana N’
1 Seja N’ uma rede com a mesma estrutura e parâmetros de N;
2 Seja U→ X uma aresta que parte de U até X onde X ∈ E;
3 foreach U→ X em N’ do
4 Remover U→ X;
5 Remover de θX|U as instâncias em que U diverge do valor u da instância e;
6 Trocar θX|U por ∑UθX|U;
7 end
8 return N′

58
4.3.3 Respondendo Consultas a Priori
As duas operações (eliminação e multiplicação), utilizadas em conjunto, são capa-
zes de responder consultas de probabilidade a priori, sendo suficiente calcular a tabela
de distribuição conjunta e então aplicar sucessivas eliminações de variáveis. Abaixo
será mostrado um teorema importante para diminuir a quantidade de multiplicações
necessárias (19) e um exemplo de como é feita a reposta de consultas a priori em uma
rede bayesiana. Posteriormente, será definido um algoritmo genérico, capaz de calcu-
lar TDC sem evidências(destinada a probabilidades a priori) e com evidência(a posteri-
ori).
Teorema 4.3 Sejam f1 e f2 são fatores e X aparece apenas em f2, então:
∑X
f1 f2 = f1 ∑X
f2 (4.16)
Exemplo 5 Calcular P(B = b1) da rede representada na Figura 11.
Para calcular a probabilidade a priori utilizaremos as operações de eliminação e
multiplicação. Inicialmente é necessário calcular a TDC:
f1 = θB|A ·θA
A B fa1 b1 0,15a1 b2 0,05a2 b1 0,08a2 b2 0,72
Tabela 9: Fator f1
Utilizando da multiplicação foi calculado o fator f1, contendo P(A, B). Para calcu-
lar P(B) é suficiente eliminar a variável A do fator:
f2 = ∑A
f1
Através do fator f2 é possível se obter a probabilidade P(B = b1) = 0, 23.

59
B fb1 0,23b2 0,77
Tabela 10: Fator f2
4.3.4 Respondendo Consultas a Posteriori
Consultas a posteriori, P(V, e), recebem dois parâmetros como entrada: conjunto de
variáveis V e a instância e que funciona como evidência. É possível ver distribuições
marginais a priori como sendo distribuições a posteriori cuja evidência e é uma instância
trivial. Logo, é possível criar um único procedimento para calcular ambos, o que será
apresentado a seguir.
Exemplo 6 Calcular P(C = c1|A = a1) para a rede representada na Figura 11.
Para calcular P(C = c1|A = a1), é necessário conhecermos P(A, C):
f1 = θC|A ·θA
A C f1a1 c1 0,10a1 c2 0,10a2 c1 0,20a2 c2 0,60
Tabela 11: Fator f1
O fator resultante, f2, contém as informações necessárias para terminarmos o pro-
cessamento da consulta. Neste exemplo, é dado uma única evidência, a instância
A = a1, que utilizaremos para continuar o processo. É então eliminada as instâncias
dos fatores que contradizem a evidência, isto é, A 6= a1. O fator resultante f e1 representa
o fator f 1 dada a evidência e.
A C f e1
a1 c1 0,10a1 c2 0,10
Tabela 12: Fator f e1

60
Elimina-se a variável A:
f2 = ∑A
f e1
C fc1 0,10c2 0,10
Tabela 13: Fator f2
A tabela 13 apresenta as probabilidades P(C = c1, A = a1) e P(C = c2, A = a1). Para
calcular a probabilidade a posteriori P(C = c1|A = a1) é preciso normalizar o fator f2:
P(C = c1|A = a1) = P(C = c2|A = a1)
=P(C = c1|A = a1)
P(C = c1|A = a1) + P(C = c2|A = a1)
= 0, 50 = 50%
Logo, a probabilidade P(C = c1|A = a1) = 50%, conforme parâmetro θC|A.
Como foi mostrado, as operações de multiplicação e soma podem, em conjunto,
responder consultas a posteriori e, consequentemente, a priori. A seguir é apresentado
um algoritmo para cálculo de distribuições marginais a posteriori, conforme de (19).
Algoritmo 8: Cálculo de Distribuições Marginais
Input: Rede Bayesiana N, Variáveis Q, evidência e;
Output: Fator contendo P(Q, e);
1 N’ = podarRede(N, Q, e);
2 π =ordenação de variáveis /∈ Q computadas a partir de N’;
3 S = f e : f é TPC da Rede Bayesiana N’;4 for i = 1to quantidade de nós em π do
5 f = ∏k fk, onde fk ∈ S e menciona variável π(i);
6 fi = ∑π(i) f ;
7 trocar todos os fatores fk ∈ S por fi;
8 end
9 return ∏ f ∈ S f

61
4.3.5 Most Probable Explanation (Explicação Mais Provável)
O alvo do cálculo do MPE é identificar qual a instância da rede mais provável, dada
evidência.
Definição 4.3.6 Sendo X1, ..., Xn todas as variáveis de uma rede bayesiana, o conjunto e a
evidência, então:
MPE(e)de f= max(P(x1, ..., xn|e)) (4.17)
De acordo com a equação (4.18), o MPE irá calcular a instância com maior probabili-
dade de ocorrência dada a evidência. Conforme (19), o MPE não pode ser obtido dire-
tamente do cálculo de distribuições marginais a posteriori. Suponha que deseja-se maxi-
mizar P(A, B, C|C = C1). Instanciando as variáveis A e B de acordo com max(P(A|C =
D1)) e max(P(B|C = C1)), é possível que não se encontre uma MPE. É proposto o
algoritmo para cálculo do MPE abaixo (19):
Algoritmo 9: MPEInput: Variáveis Q, evidência e
Output: P(Q, e)
1 S = f e f é TPC da Rede Bayesiana;2 for i = 1to quantidade de nós da rede que não estão em Q do
3 f = ∏k fk, onde fk ∈ S e menciona variável π(i);
4 fi = maxπ(i) f ;
5 trocar todos os fatores fk em S por fi;
6 end
7 return fator trivial ∏ f ∈ S f
4.3.6 Maximum a Posteriori Hypothesis (Hipótese Máxima a Posteri-ori)
O MPE se trata de um caso específico do MAP, onde deseja-se saber a instância da
rede. Ao contrário do MPE, o MAP calcula a probabilidade máxima da instanciação
de um conjunto de variáveis, não necessariamente de todas as variáveis como o MPE,
dada alguma evidência. Essa distinção existe, entre MAP e MPE, pois calcular o MPE
é bem mais simples de se calcular do que o MAP.
Definição 4.3.7 Sabendo que Q são variáveis de uma rede bayesiana composta por variáveis

62
N (Q ⊂ N), e e o conjunto de evidências, tem-se:
MAP(X,e)de f= max
x(P(x|e)) (4.18)
Algoritmo 10: MAPInput: Rede Bayesiana N, Variáveis Q, evidência e
Output: Fator Trivial contendo o MAP
1 N’ = podarRede(N,Q,e);
2 π = ordem de eliminação de variáveis de N’, em que Q aparece por último.;
3 S = f e f é TPC da Rede Bayesiana N’;4 for i = 1to quantidade de variáveis em π do
5 f = ∏k fk, onde fk ∈ S e menciona variável π(i);
6 if π(i) ∈Q then
7 fi = maxπ(i) f ;
8 else
9 fi = ∑π(i) f ;
10 end
11 trocar todos os fatores fk em S por fi;
12 end
13 return fator trivial ∏ f ∈ S f
4.4 Redes Bayesianas Variantes no Tempo
Conhecidas por Redes Bayesianas Dinâmicas (RBD), introduzem a idéia de varia-
ção temporal em Redes Bayesianas. São construídas a partir da utilização de múltiplas
cópias da mesma varíavel, em que cada cópia representa diferentes estados assumidos
pelo tempo (19).
A Figura 14 mostra um exemplo de RBD. Para cada instante de tempo i, a rede
possui duas variáveis, Ai e Bi, que possuem 4 cópias cada. Uma RBD possui modelos
repetitivos, isto é, que se repetem em cada instante de tempo.

63
Figura 14: Exemplo de uma rede bayesiana dinâmica

64
5 Metodologia Proposta
Este trabalho propõe a utilização de uma metodologia baseada em rede bayesi-
ana para estimação de falhas incipientes em transformadores de potência, utilizando o
método de detecção de descargas parciais por emissão acústica. A utilização da Rede
Bayesiana é particularmente adequada ao processo de identificação de transformado-
res defeituosos, pois configura-se como uma ferramenta probabilística de representa-
ção do conhecimento, capaz de gerar classificadores que, utilizando dados captados
de ensaios de emissão acústica, permite a identificação de possíveis transformadores
defeituosos.
5.1 Construção da Rede Bayesiana
Será apresentada, a seguir, a construção da Rede Bayesiana da metodologia pro-
posta.
5.1.1 Escolha dos Nós
A escolha dos nós que compõem a rede deve levar em consideração os itens que
influenciam a classificação. Para o classificador proposto, foram analisados relatórios
de ensaios de EA realizados pela empresa Celg D, onde foi identificado a quantidade
de DPs detectadas pelo método de emissão acústica e a energia como indicadores de
falhas nos transformadores. Foi utilizada a quantidade de ruído detectada (atividades
cuja diferença de fase é diferente de 180) como elemento penalizador da classificação,
em que uma quantidade grande de ruídos atenua uma classificação ruim.
A metodologia leva em consideração o pior caso, isto é, o canal com maior quanti-
dade de DPs, pois deseja-se detectar o pior cenário. Assim, qualquer anormalidade já é
suficiente para indicar ou não possível defeito no transformador. Não foram utilizadas
as informações de todos os sensores, pois necessitariam de uma quantidade de casos
muito grande, para treinamento da RB.

65
Os nós da RB foram selecionados pelos especialista e estão são apresentados na
tabela 24.
Nó Descrição
DPsQuantidade de atividades associadas à DPs detectada no
canal com maior atividade.
RuídoQuantidade de atividades ruído detectado no canal com
maior atividade.
EnergiaEnergia acumulada das atividades detectadas pelo pior ca-
nal.
Classificação
Avaliação do estado do equipamento sob a ótica da técnica
preditiva de Emissão Acústica. Indica o nível de atividade
acústica detectada.
Tabela 14: Nós da Rede Bayesiana
É necessária a utilização de um critério para diferenciar uma atividade associada
à ruído de uma associada à DPs. Conforme descrito na subseção 2.5.2, as descargas
parciais ocorrem nas tensões de maior intensidade (picos e vales do sinal). Utilizando
a equação 2.3, é possível calcular a diferença de fase entre duas atividades consecutivas
e, caso a diferença de fase seja aproximadamente 180 , é associada à DP. Caso não seja,
a atividade é associada a ruído.
O nó de energia assume o valor acumulado da energia de cada atividade detectada
no canal.
O nó de classificação, conforme elencado pelos especialistas, pode assumir os se-
guintes valores apresentados na Tabela 15:

66
Classificação Avaliação Ação Recomendada
A Satisfatório Continuar a operar normalmente.
B Dentro da normalidade
Continuar a operar normalmente es-
tando atento à evolução de DPs nos
próximos registros
C Preocupante
Dar continuidade na investigação e
realizar outros ensaios o mais breve
possível para confirmar resultados e
tendências de DPs
D Grave
Planejar uma retirada do equipa-
mento de operação em caráter de ur-
gência para uma inspeção interna, lo-
calização e correção de defeito.
Tabela 15: Valores possíveis para classificação
5.1.2 Estrutura
Percorrer todo o espaço de estruturas possíveis da RB em busca de um modelo
ótimo torna-se impraticável devido à quantidade de estruturas possíveis, conforme
mostrado na seção 4.1. Para o problema de detecção de descargas parciais pelo método
da EA, por se tratar de uma técnica nova, a estrutura da RB é desconhecida. Desta
forma, o aprendizado de estrutura torna-se necessário.
Para aprendizado da estrutura da RB, propõe-se a utilização dos métodos K2 e Hill
Climbing. O método K2 é rápido, porém exige-se o conhecimento da ordem dos nós do
grafo da estrutura da RB. O método do Hill Climbing por sua vez não exige tal conhe-
cimento, entretanto corre-se o risco da convergência prematura a um ótimo local. Na
tentativa de escolha de uma estrutura que represente bem a base de dados, é sugerida
a execução dos dois métodos, selecionando a estrutura que tenha uma pontuação BIC

67
melhor.
Algoritmo 11: Aprendizagem de estruturaInput: Estrutura Inicial S (caso não exista, consideram-se todos os nós
desconexos), base de dados D.
Output: Grafo Acíclico Direcional.
1 U = conjunto de nós de S;
2 DAGK2 = K2(U, D, 3);
3 DAGHill = HillClimbing(S, D);
4 if BIC(DAGK2, D) >= BIC(DAGHill , D) then
5 return DAGK2
6 else
7 return DAGHill
8 end
5.1.3 Aprendizagem de Paramêtros
O aprendizado de parâmetros pode ser feito utilizando o método descrito na sub-
seção 4.1.3, por se tratar de dados completos.
5.1.4 Discretização dos Parâmetros da Rede Bayesiana
Conforme elencado na seção 5.1.1, os nós da RB, com exceção da classificação, pos-
suem valores contínuos. As Redes Bayesianas são capazes de trabalhar com valores
discretos e contínuos, mas a utilização de valores contínuos impõem algumas limita-
ções, conforme descrito em (17) e (19).
Esta dissertação propõe a discretização dos parâmetros contínuos através da utili-
zação de intervalos, isto é, a criação de intervalos de valores contínuos associados a um
valor discreto. Os intervalos funcionam como categorias, quando um valor contínuo
estiver entre valores cobertos pelo intervalo, é associado a um valor discreto daquele
nó. Assim pode ser mantida a mesma teoria de RB descrita no capítulo 4, sem as limi-
tações impostas pela utilização de valores contínuos.
O procedimento de discretização dos valores contínuos dos nós levanta a dificul-
dade de se estabelecer intervalos de valores que representem adequadamente o pro-
blema. Para essa tarefa, a utilização de um otimizador Hill-Climbing mostra-se apro-
priada, uma vez que, partindo de um ponto inicial, ajustar-se-ão o número de faixas

68
e seus limites de tal forma que a taxa de classificação correta aumente. Desta forma,
pode-se garantir, por se tratar de um algoritmo de busca gulosa, conforme apresentado
na subseção 4.1.2, que os novos limites serão tão bons ou melhores que o existente. É
descrito em (27) uma regra conhecida como "regra do 1/5 de sucesso", em que é utili-
zada uma distribuição gaussiana com desvioσ que ajusta os valores aleatórios gerados.
Através desta regra, é possível dificultar a convergência prematura do algoritmo, que é
guloso (conforme descrito na subseção 4.1.2). O desvioσ é ajustado a cada k iterações.
O Procedimento Hill-Climbing de otimização dos limites é mostrado a seguir.
Algoritmo 12: Hill-Climbing para discretização dos parâmetrosInput: Limites Atuais L, Número de vizinhos V, Número Máximo de Iterações
Max, Número k de iterações com que σ é ajustado.
Output: Limites quase-ótimos.
1 Patual = pontuacao(L);
2 i = 0;
3 repeat
4 Latual = clonar(L);
5 Para cada intervalo existente, crie uma cópia, divida em 2 intervalos em
proporção aleatória (ajustada por σ) e verifique se a pontuação é melhor que
Patual. Se sim, substitua Patual e Latual;
6 Para cada intervalo existente, crie uma cópia, remova o intervalo e verifique
sua pontuação. Se melhor ou igual a Patual, substitua Patual e Latual;
7 Faça uma cópia dos limites e V tentativas aleatórias (ajustada por σ) de
alteração. Se a pontuação de algum deles for melhor que Patual, substitua
Patual e Latual;
8 Substitua os limites atuais por Latual. A cada k iterações, ajuste σ de acordo
com a regra do 1/5 de sucesso;
9 i ++;
10 until i < Max;
O algoritmo 12 utiliza um método de pontuação para verificar o melhoramento
do algoritmo. É possível a utilização de um método de pontuação suave (soft scoring)
ou de pontuação rígida (hard scoring). Na pontuação rígida, conta-se a quantidade de
acertos de classificação que a RB provê. Cada acerto, pela RB, do nó de classificação,
corresponde a um ponto. O algoritmo converge à medida que a quantidade de acer-
tos aumenta. Na pontuação suave, conta-se com um mecanismo de penalização, que
subtrai, a cada erro, o déficit para o acerto ideal (100%). Assim, a pontuação suave é

69
menos gulosa e evolui à medida que a RB se aproxima da classificação correta.
Para os parâmetros referentes às quantidades de atividades associadas à DPs e
ruído, assumiram-se os mesmos intervalos, uma vez que possuem a mesma ordem de
grandeza e unidade (são contagens feitas a partir de ocorrência de atividades). O nó
de energia possui limites diferentes dos demais, por se tratar de grandezas e unidades
diferentes.
5.2 Geração de Casos de Treinamento e Validação
A maior dificuldade para aprendizado de uma RB é a disposição de uma base de
treinamento suficientemente grande e diversificada para a realização de classificações
confiáveis. Para este caso particular, a obtenção de novos casos é trabalhosa, envol-
vendo uma equipe de técnicos, engenheiros, rotinas da companhia (CELG D), medi-
das de segurança, transporte e instalação de equipamentos (sensores). Para contornar
a dificuldade de obtenção de novos ensaios, foi construído um gerador de casos fictí-
cios, que é subsidiado por casos reais. O funcionamento, mostrado no algoritmo 13, é
basicamente aprender uma Rede Bayesiana com os casos reais e originar novos casos
através das probabilidades presentes na RB.
Algoritmo 13: Gerador de CasosInput: Casos reais utilizados para treinamento, quantidade de casos a serem
gerados imax.
Output: Casos para a base de treinamento.
1 Treine uma Rede Bayesiana D com os casos reais;
2 repeat
3 Crie instâncias vik das variáveis randômicas ui que possuem π(ui) = utilizando as probabilidades a priori dessas variáveis da Rede D;
4 Instancie as demais variáveis ui com probabilidades a posteriori de D.
5 until i ++ < imax;

70
5.3 Estimação de Falhas Incipientes em Transformadoresde Potência
Propõe-se então, aplicando-se em conjunto os procedimentos descritos, uma me-
todologia para estimativa de falhas incipientes em transformadores de potência, apre-
sentada no Algoritmo 14.
Algoritmo 14: Metodologia para EstimaçãoInput: Limites Atuais, Número de vizinhos V, Número Máximo de Iterações
Max, Número k de iterações com que σ é ajustado, quantidade N1 de
casos de treinamento e quantidade N2 de casos para validação.
Output: -
1 Definem-se limites L para treinamento da RB. Caso existam casos suficientes
para treinamento e validação da RB, salte para o passo 4;
2 Cria-se uma RB com amostras reais (utiliza-se a estrutura de um classificador
ingênuo conforme figura 15). Para parâmetros, utiliza-se o método do MLE
(subseção 4.1.3) para aprendê-los;
3 Utiliza-se o Gerador de Casos (Algoritmo 13) para criação de N1 casos para
treinamento da RB e criação de casos que, em conjunto com os casos reais,
formarão N2 casos que serão utilizados para validação;
4 Utiliza-se o método o algoritmo 11 para aprender a estrutura da RB. A ordem
dos nós definidas para o K2 é: classificação, descarga parcial, ruído e energia. A
quantidade máxima de pais para K2 é 3. Para o Hill Climbing, são considerados
todos os nós desconectados. Utiliza-se o método MLE (subseção 4.1.3) para
aprender os parâmetros da RB;
5 Mede-se a quantidade de acertos utilizando os casos para validação;
6 Definem-se os limites de acordo com as Tabelas 16 e 17;
7 Utiliza-se o algoritmo para otimização dos limites 12, utilizando a pontuação
rígida e a pontuação suave, utilizando V vizinhos, Imax iterações e k iterações
para redefinição do valor do desvio (regra do 1/5 de sucesso). Repete-se este
passo Ni vezes, a fim de encontrar limites quase-ótimos;
8 Verifica-se o desempenho da rede com os limites criados;
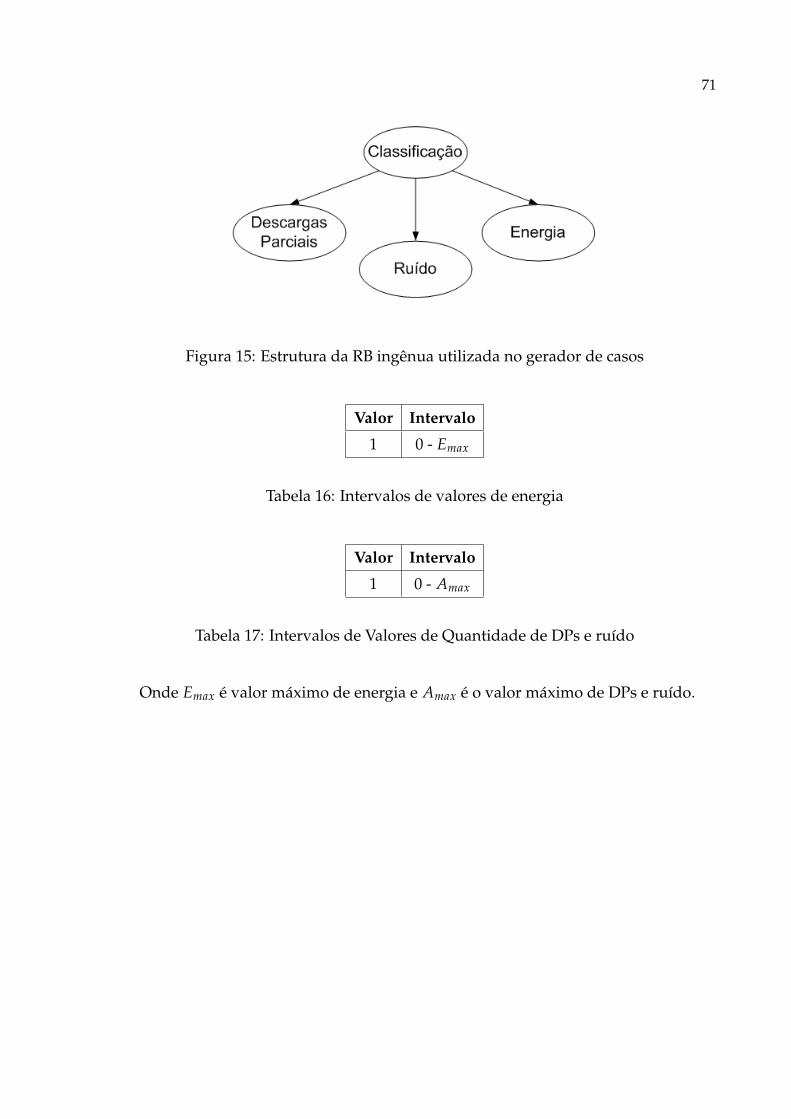
71
Figura 15: Estrutura da RB ingênua utilizada no gerador de casos
Valor Intervalo
1 0 - Emax
Tabela 16: Intervalos de valores de energia
Valor Intervalo
1 0 - Amax
Tabela 17: Intervalos de Valores de Quantidade de DPs e ruído
Onde Emax é valor máximo de energia e Amax é o valor máximo de DPs e ruído.

72
6 Resultados e Discussão
Para se construir o classificador, foram utilizados resultados de seis ensaios reali-
zados em transformadores (todos os ensaios que se tinham até então), sendo que, em
cada ensaio, foram monitorados dois transformadores simultaneamente. Têm-se doze
amostras para se construir a RB, cujos valores de classificação, energia, quantidade
de DPs e ruído estão listados no Apêndice A. Foi aplicada a metodologia descrita no
algoritmo 14 para a verificação do seu desempenho utilizando os limites L das Tabe-
las 18 e 19, N1 = 100, N2 = 100, V = 5, Imax = 100, Ni = 2, k = 5, Emax = 999999999
e Amax = 999999999. Para fins de associação com descargas parciais, utilizou-se va-
lores entre 179 e 181 (180±1) para a diferença angular entre dois hits consecutivos
(equação 2.3). Os valores de N1, N2, V, Imax, Ni e k foram encontrados através de várias
execuções do algoritmo e forneceram melhores resultados.
A execução algoritmo 14 com os parâmetros acima resulta na criação de 188 casos,
que em conjunto com as doze amostras, formam 200. Destes, 100 são utilizados para
treinamento e os demais para validação, sendo que os doze casos reais pertencem ao
conjunto de validação.
Os limites encontrados através do algoritmo 12, utilizando a pontuação suave e
rígida são apresentados nas Tabelas 20 a 23. As linhas correspondem aos índices das
faixas e as colunas às iterações do algoritmo 12.
Valor Intervalo
1 0 - 50.000
2 50.001 - 7.000.000
3 7.000.001 - Emax
Tabela 18: Valores discretos para valores de energia

73
Valor Intervalo
1 0 - 1.000
2 1.001 - 5.000
3 5.001 - 100.000
4 100.001 - Amax
Tabela 19: Valores discretos para valores de DPs e ruído
0 100 200
1 0 - Emax 0 - 50.269 0 - 50.269
2 50.270 - 1.826.677 50.270 - 238.793
3 1.826.678 - Emax 238.794 - 1.826.677
4 1.826.678 - 6.737.032
5 6.737.033 - Emax
Tabela 20: Faixas de energia ao longo das iterações (suave)
0 100 200
1 0 - Amax 0 - 10 0 - 10
2 11 - 5.115 11 - 5.115
3 5.116 - 729.902 5.116 - 729.902
4 729.903 - 131.863.007 729.903 - 131.863.007
5 131.863.008 - Amax 131.863.008 - Amax
Tabela 21: Faixas das quantidades de DPs e ruído ao longo das iterações (suave)
0 100 200
1 0 - Emax 0 - 851.400 0 - 321.179
2 851.401 - Emax 321.180 - Emax
Tabela 22: Faixas de energia ao longo das iterações (rígida)

74
0 100 200
1 0 - Amax 0 - 17 0 - 17
2 18 - 4.772 18 - 4.772
3 4.773 - 257.013 4773 - 49.333
4 257.014 - Amax 49.334 - 257.013
5 257.014 - Amax
Tabela 23: Faixas das quantidades de DPs e ruído ao longo das iterações (rígida)
A Tabela 11 compara as taxas de acerto da base de validação da Rede Bayesiana
utilizando cada limite:
Limite Taxa
L 83%
Pontuação Rígida 89%
Pontuação Suave 89%
Tabela 24: Taxa de acerto da Rede Bayesiana
O Algoritmo 14, proposto no capítulo 5, foi executado 60 vezes, metade utilizando
pontuação suave e metade utilizando pontuação rígida, sendo o melhor caso detalhado
acima. Com a pontuação rígida se obteve uma média de acertos de 86,5% e um desvio
padrão de 1,14%. A pontuação suave obteve uma media de 86,57% e um desvio padrão
de 1,48%. Na Figura 6 é mostrado o desempenho mínimo, médio e máximo, utilizando
a pontuação rígida (esquerda) e suave (direita).
Foi também testado o mesmo algoritmo utilizando o parâmetro Ni = 3, totalizando
300 iterações no algoritmo de otimização Hill-Climbing. Verificou-se que, a partir de 200
iterações, não houve progresso no processo de otimização.

75
(a)
(b)
Figura 16: Desempenho mínimo, médio e máximo dos otimizadores: (a) pontuação
rígida e (b) pontuação suave

76
6.1 Comparação com Rede Neural
Para o propósito de comparação, foi implementada uma Rede Neural (RN) Per-
ceptron de Múltiplas Camadas (MLP), feed-forward (sem realimentação) e com backpro-
pagation (retropropagação do erro), conforme (21) e (28). Como função de ativação,
utilizou-se a função tangente hiperbólica para as camadas ocultas e a função linear
para a camada de neurônios de saída.
Como entrada da Rede Neural, foram utilizadas as mesmas informações fornecidas
à Rede Bayesiana (energia, quantidade de DPs, ruído), porém aplicando logaritmo
de base 10. A camada de neurônios de saída, a classificação, está representada na
tabela 25:
Valor Significado
1 Irrelevante
2 Baixo
3 Médio
4 Alto
Tabela 25: Saída da RN
O pré-processamento do vetor de entrada (aplicação de log10 em seus valores) se
mostrou eficaz para o aumento da precisão da RN, visto que a ordem de grandeza das
entradas do conjunto de treinamento da RN varia consideravelmente. Treinou-se a RN
com 100 exemplos, validou-se com mais 50 e testou-se com outros 50. Variaram-se o
número de neurônios sigmoidais da camadas ocultas de um a dez e a quantidade de ca-
madas ocultas de uma a três, executando-se 100 treinamentos independentes para cada
configuração da RN, sendo aplicado o algoritmo de otimização Levenberg-Marquardt.
Obteve-se um máximo de 83% de classificações corretas com cinco neurônios na ca-
mada oculta, sendo esta, inferior à abordagem por Rede Bayesiana proposta neste tra-
balho.
O mesmo pré-processamento aplicado à Rede Bayesiana (aplicação de log10 em
seus valores) não apresentou melhoria.

77
6.2 Considerações sobre os Resultados
Os seguintes pontos foram observados durante a execução do método:
- O mesmo pré-processamento aplicado à MLP, quando aplicado à Rede Bayesi-
ana, não levou à melhorias no resultado. Isto deve-se ao fato dos valores contí-
nuos passarem pelo algoritmo otimizador-discretizador Hill-Climbing (subseção
5.1.4), que, de acordo com os valores encontrados, divide em intervalos otimiza-
dos;
- Para melhores resultados, os valores Emax e Amax devem ser iguais ao valor má-
ximo de energia e ruído, respectivamente, obtidos nos ensaios envolvidos. Isto
assegura que todos os valores possíveis sejam considerados pelo otimizador. Es-
tipular valores desnecessariamente altos para Emax e Amax torna o espaço de
busca maior que o suficiente, o que diminui a qualidade do otimizador;
- Quanto maior e mais diversificada for a amostra utilizada para treinamento, me-
lhor será a classificação, pois a Rede Bayesiana utiliza-se de ocorrências e pro-
babilidades para aprendizado dos padrões (A, B, C e D). Com a utilização do
gerador de casos, a quantidade de casos é aumentada, mas não conhecimento
sobre o assunto não é aumentado, pois o gerador de casos utiliza o conhecimento
contido nos casos reais e replica-o em novos casos;
- A pontuação suave não se mostrou superior a pontuação rígida. Indica-se, por-
tanto, a utilização da pontuação rígida, pois provoca a criação de menos interva-
los que a pontuação suave (um novo intervalo apenas é criado caso haja melhora
na classificação), o que leva a uma otimização mais rápida e uma Rede Bayesiana
com menos valores discretos. Quanto menos valores discretos, mais rápida é a
inferência na RB;
- Valores em que Ni > 2 não resultaram em melhora na classificação realizada pela
Rede Bayesiana;
- Verifica-se que não houve progresso na otimização para valores de I (iteração)
entre 70-100 e 120-200;
- O único critério de parada utilizado pelo otimizador é o número de iterações;
- Não há indicação de que a RN MLP apresentada na seção 6.1 seja a mais recomen-
dada para o problema de classificação de transformadores de potência segundo

78
a ótica do ensaio acústico, apenas de que ela é adequada ao problema. Portanto,
a comparação entre a RN (MLP) e a RB seguem os critérios estabelecidos anteri-
ormente (comparar a RB proposta a uma RN).

79
7 Conclusão
Nesta dissertação, apresentou-se uma metodologia capaz de criar uma Rede Baye-
siana adequada à classificação de níveis de falhas incipientes em transformadores de
potência. A RB é capaz de indicar não somente o estado do transformador, mas tam-
bém qual a porcentagem de crença no resultado, dadas as evidências apresentadas.
Foi proposto um método de otimização dos limites dos parâmetros usados pela Rede
Bayesiana, em que um exemplo ilustrou a capacidade do algoritmo de aumentar a taxa
de classificações corretas da Rede. Foram dadas duas alternativas de pontuação a se-
rem usadas no otimizador: pontuação suave e pontuação rígida. Obteve-se, com a
pontuação suave, um desempenho equivalente ao da pontuação rígida. A metodolo-
gia proposta foi comparada à uma abordagem por Rede Neural, tendo-se obtido um
melhor desempenho por parte da primeira.
Uma comparação quantitativa com os trabalhos apresentados na seção 1.1 não é
possível, pois utilizam diferentes fontes de dados e uma quantidade diferente de amos-
tras para treinamento. Qualitativamente é possível verificar as seguintes vantagens:
1. Utilização de um discretizador em alternativa a utilização de faixas com valores
fixos;
2. Classificação do grau de severidade de possível degradação do equipamento;
3. Informação da probabilidade de ocorrência de cada classificação.
As desvantagens são:
1. Não indica o tipo de defeito existente;
2. Não indica o elemento causador da descarga parcial;
3. Quantidade inferior de amostras para treinamento.

80
7.1 Perspectivas Futuras
Uma melhoria que já foi implementada, apresentada no apêndice B, mas ainda
carece de ensaios para testes, é a utilização de todos os canais na classificação. Desta
forma, será possível dar um tratamento diferenciado a cada canal, por parte da RB. Esta
abordagem é importante, pois permite que determinados canais sejam privilegiados
em detrimento de outros (o comutador, por exemplo, pode ser ignorado por se tratar
de uma parte mecânica). A dificuldade encontra-se na quantidade de casos necessários
para o treinamento da Rede Bayesiana.
Outra melhoria ainda não implementada seria a adição de informações da AGD
dentro da Rede Bayesiana para aumentar a taxa de acerto das classificações. Por se tra-
tar de um método bastante conhecido e com muitos ensaios realizados, pode auxiliar
na correta classificação da Rede Bayesiana.
Novos ensaios em transformadores de potência estão sendo programados para se-
rem realizados na concessionária de energia, os quais servirão para alimentar a Rede
Bayesiana. A contínua adição de novos casos é de alta relevância, pois:
- Permite a consolidação do treinamento da Rede Bayesiana, tornando-a cada vez
mais eficaz em classificar transformadores de potência;
- Possibilitará ao especialista a agregação de novas informações ao processo de
classificação;
- É possível que, na medida em que novas informações forem agregadas ao pro-
cesso de classificação, a metodologia seja ampliada para, não somente indicar o
estado do equipamento, mas também identificar o tipo de defeito no transforma-
dor.
À medida com que se popularizem os sensores acústicos utilizados e se torne viá-
vel o monitoramento em tempo integral do transformador, a metodologia poderá ser
modificada para gerar classificações em tempo real, aumentando a possibilidade de
resposta do engenheiro de manutenção na prevenção de falhas no equipamento.

81
Publicações
1 PALHARES, P. H. da S. et al. Rede bayesiana para estimação de falhas incipientesem transformadores de potência utilizando detecção de descargas parciais. In: VIIICONPEEX - CONGRESSO DE PESQUISA, ENSINO E EXTENSãO. [S.l.], 2011.Resumo Extendido.
2 PALHARES, P. H. da S. et al. Metodologia para apoio à decisão baseada em redebayesiana para estimação de grau de degradação de transformadores de potência. In:XLIII SBPO - SIMPóSIO BRASILEIRO DE PESQUISA OPERACIONAL. Ubatuba, SP,2011.
3 PALHARES, P. H. da S. et al. Rede bayesiana para suporte à decisão no processode manutenção preventiva de transformadores de distribuição de energia elétrica. In:SBAI 2011 - X SIMPóSIO BRASILEIRO DE AUTOMAçãO INTELIGENTE. São JoãoDel Rei, MG, 2011.
4 PALHARES, P. H. da S. et al. Rede bayesiana para estimação de falhas incipientesem transformadores de potência utilizando detecção de descargas parciais poremissão acústica. In: CBIC 2011 - X CONGRESSO BRASILEIRO DE INTELIGêNCIACOMPUTACIONAL. Fortaleza, CE, 2011.
5 PALHARES, P. H. da S. et al. Classificador bayesiano associado à técnica de ensaiosde emissão acústica para a análise de descargas parciais em transformadores depotência. In: IV SBSE - SIMPóSIO BRASILEIRO DE SISTEMAS ELéTRICOS. Goiânia,GO, 2012.

82
Referências Bibliográficas
1 AZEVEDO, C. H.; RIBEIRO, C. J.; MARQUES, A. P. Methodology for thedetection of partial discharges in power transformers using the acoustic method. In:EUROCON. San Petersburg, 2009.
2 MOHAMMADI, E. et al. Partial discharge localization and classification usingacoustic emission analysis in power transformer. In: 31st INTERNATIONALTELECOMMUNICATIONS ENERGY CONFERENCE - INTELEC. San Petersburg,2009.
3 TANG, W. H.; LU, Z.; WU, Q. H. A bayesian network approach to powersystem asset management for transformer dissolved gas analysis. In: THIRDINTERNATIONAL CONFERENCE ON ELECTRIC UTILITY DEREGULATION ANDRESTRUCTURING AND POWER TECHNOLOGIES. [S.l.], 2008.
4 HAO, X.; CAI-XIN, S. Artificial immune network classification algorithm for faultdiagnosis of power transformer. IEEE TRANSACTIONS ON POWER DELIVERY, v. 22,n. 2, 2007.
5 KUO, C. Artificial recognition system for defective types of transformer by acousticemission. Expert Systems with Applications, v. 36, n. 7, 2009.
6 MORAIS, D. R.; ROLIM, J. G. A neural network for detection of incipient faults intransformers based on the dissolved gas analysis of insulating oil. In: VI INDUSCON.Joinville, 2004.
7 MARTIGNONI, A. Transformadores. 8. ed. [S.l.]: Globo, 1991. 307 p.
8 FITZGERALD, A. E.; KINGSLEY, J. C.; UMANS, S. D. Máquinas Elétricas. 6. ed.[S.l.]: Bookman, 2003. 651 p.
9 SOUZA, D. C. P. Falhas e defeitos ocorridos em transformadores de potência do sistemaelétrico da Celg, nos últimos 28 anos: um estudo de caso. 101 f. Dissertação (Mestradoem Engenharia Elétrica e de Computação) — Escola de Engenharia Elétrica e deComputação da Universidade Federal de Goiás, Goiânia, 2008.
10 BUTLER-PURRY, K. L.; BAGRIYANIK, M. Identifying transformer incipientevents for maintaining distribution system reliability. In: Proceedings of the 36th HawaiiInternational Confererence on System Sciences. [S.l.: s.n.], 2003.
11 AZEVEDO, C. H. B. Metodologia para a Eficácia da Detecção de Descargas Parciais porEmissão Acústica como Técnica Preditiva de Manutenção em Transformador de Potência. 89 f.Dissertação (Mestrado em Engenharia Elétrica e de Computação) — UniversidadeFederal de Goiás, Goiânia, 2009.

83
12 AZEVEDO, C. H.; RIBEIRO, C. J.; MARQUES, A. P. Requisitos e procedimentospara a melhoria na detecção de descargas parciais em transformadores de potênciapelo método de emissão acústica. In: XX SNPTEE SEMINÁRIO NACIONAL DEPRODUÇÃO E TRANSMISSÃO DE ENERGIA ELÉTRICA. Recife, 2009.
13 LEE, J. P. et al. Dissolved gas analysis of power transformer using fuzzy clusteringand radial basis function neural network. Journal of Electrical Engineering & Technology,v. 2, n. 2, p. 157–164, 2007.
14 ARANTES, J. G. Diagnóstico de Falhas em Transformadores de Potência pela Análise deGases Dissolvidos em Óleo Isolante Através de Redes Neurais. 115 f. Dissertação (Mestradoem Ciências) — Universidade Federal de Itajubá, Itajubá, 2005.
15 JúNIOR, A. L. Manutenção pré-corretiva em transformadores de potência - um novoconceito de manutenção. 186 f. Tese (Doutorado em Engenharia Elétrica) — Escola deEngenharia de São Carlos, Universidade de São Paulo, São Carlos, 2009.
16 SOONG, T. T. Fundamentals of Probability and Statistics for Engineers. 1. ed. [S.l.]:Wiley, 2004. 391 p.
17 JENSEN, F. V.; NIELSEN, T. D. Bayesian Networks and Decision Graphs. 2. ed. [S.l.]:Springer, 2007. 447 p.
18 MITCHELL, T. M. Machine Learning. 1. ed. [S.l.]: McGraw-Hill, 1997. 432 p.
19 DARWICHE, A. Modeling and Reasoning with Bayesian Networks. 1. ed. [S.l.]:Cambridge University Press, 2009. 548 p.
20 COOPER, G. F.; HERSKOVITS, E. A bayesian method for the induction ofprobabilistic networks from data. In: Machine Learning. [S.l.: s.n.], 1992. p. 309–347.
21 MICHALEWICS, Z.; FOGEL, D. B. How to Solve It: Modern Heuristics. 1. ed. [S.l.]:Springer, 2000. 467 p.
22 RIGGELSEN, C. Approximation Methods For Efficient Learning of Bayesian Networks.160 f. Tese (Doutorado em Ciências da Computação) — Department of Informationand Computing Sciences, Utrecht University, Holanda, 2006.
23 ALCOBé, J. R. a. 140 f. Tese (Doutorado) — Escola Universitària Politècnica deMataró, Av. Puig i Cadafalch 101-111, 08303 Mataró, Catalonia, Spain, 2006.
24 HECKERMAN, D. A Tutorial on Learning With Bayesian Networks. Redmond, WA98052, 1996. 57 p.
25 TSURUOKA, Y.; TSUJII, J. Training a naive bayes classifier via the em algorithmwith a class distribution constraint. In: Proceedings of the seventh conference on Naturallanguage learning at HLT-NAACL 2003 - Volume 4. Stroudsburg, PA, USA: Associationfor Computational Linguistics, 2003. (CONLL ’03), p. 127–134. Disponível em:<http://dx.doi.org/10.3115/1119176.1119193>. Acesso em: 14 maio 2011.
26 FRIEDMAN, N. The bayesian structural em algorithm. In: Proceedings of theFourteenth Conference Annual Conference on Uncertainty in Artificial Intelligence (UAI-98).San Francisco, CA: Morgan Kaufmann, 1998. p. 129–13.

84
27 EIBEN, A. E.; SMITH, J. E. Introduction to Evolutionary Computing. [S.l.]: Springer,2003. 293 p.
28 HAYKIN, S. Redes Neurais - Princípios e Prática. 2. ed. [S.l.]: Bookman, 2000. 906 p.

85
APÊNDICE A -- Tabelas com Dados dos Ensaiosde Emissão Acústica
As tabelas abaixo mostram o resultado do pré-processamento dos dados adquiri-
dos pelos sensores acústicos dos ensaios de EA realizados. As colunas representam os
nós da RB conforme a subseção 5.1.1.
Classificação Canal Ruído DPs Energia Acumulada
B
01 5721 102 18851402 8168 138 35127103 6245 101 24932204 16816 294 74549905 9253 158 32035106 7125 125 55016907 10341 188 33329808 17372 321 83045409 8515 161 17297510 34498 6566 41148911 12145 205 18048612 6543 131 21352813 6397 112 28173814 22013 388 573317
Tabela 26: Transformador 1 da subestação A

86
Classificação Canal Ruído DPs Energia Acumulada
B
15 12710 254 32485216 22180 411 64470217 27227 679 68924318 81617 2970 222787919 80364 3633 165047020 60870 2106 202160321 31450 845 69570422 65584 2323 191421623 11556 212 23599824 24326 446 54369625 24992 479 31592626 11573 239 29298427 31384 775 73291428 215948 13137 3943731
Tabela 27: Transformador 2 da subestação A
Classificação Canal Ruído DPs Energia Acumulada
C
1 383 8 1034922 1156 37 1333833 655 12 1619734 3180 112 3142095 2602 81 2569926 472759 27490 5274407 498 2 1742618 29681 1290 2062239 378 5 75450
10 770 17 15824611 1143 33 8586212 153 3 4203713 9040 380 18763814 2107 41 343638
Tabela 28: Transformador 1 da subestação B

87
Classificação Canal Ruído DPs Energia Acumulada
B
15 154 3 7091516 241 5 14722817 270 8 14857818 428 8 37089319 4823 1061 17746220 4090 180 68057821 432 14 14140622 4075 107 55715723 915 21 7872924 972 31 23354825 732 35 5269626 146 2 5107927 327 6 23707528 616 14 352633
Tabela 29: Transformador 2 da subestação B
Classificação Canal Ruído DPs Energia Acumulada
A
1 73 0 271112 91 0 537133 56 0 199454 64 1 542795 52 0 1527846 105 0 3881537 85 1 1950038 130 0 3302659 52 1 170937
10 68 2 35926511 67 1 2820612 69 1 2824013 64 1 6617014 58 1 130123
Tabela 30: Transformador 1 da subestação C

88
Classificação Canal Ruído DPs Energia Acumulada
B
15 86 3 4206916 151 21 6035317 61 1 3129318 63 2 4560119 78 0 17711320 122 5 39268521 137 3 18647222 721 24 53315823 85 4 20192824 118 1 35891225 58 1 2430626 80 0 3412927 99 1 5274328 125 3 103737
Tabela 31: Transformador 2 da subestação C
Classificação Canal Ruído DPs Energia Acumulada
A
1 5 0 112 12 0 803 3 0 324 5 0 1695 4 0 476 1 0 1347 0 0 118 3 0 1439 4 0 21
10 0 0 011 4 0 1412 1 0 3213 1 0 1014 3 0 84
Tabela 32: Transformador 1 da subestação D

89
Classificação Canal Ruído DPs Energia Acumulada
D
15 23 0 5216 545 777238 615309717 3 0 7818 356 8 310919 449 7 218320 70997 668754 6242321 111 2 86222 24662 14703 308123 408 9 209924 9 0 10325 477 777310 24889026 333628 444156 529925727 36 0 4928 411 777554 16101057
Tabela 33: Transformador 2 da subestação D
Classificação Canal Ruído DPs Energia Acumulada
C
1 2997 57 1426622 4844 109 3253733 23258 17296 1398474 1679 28 2166095 3328 50 8221626 5248 92 15345867 7419 118 10165868 11420 148 15406369 2153 43 942512
10 3240 63 165948111 2213 41 12292412 2174 45 16499913 17183 301 36278214 13962 234 579521
Tabela 34: Transformador 1 da subestação E

90
Classificação Canal Ruído DPs Energia Acumulada
B
15 23 0 5216 545 777238 615309717 3 0 7818 356 8 310919 449 7 218320 70997 668754 6242321 111 2 86222 24662 14703 308123 408 9 209924 9 0 10325 477 777310 24889026 333628 444156 529925727 36 0 4928 411 777554 16101057
Tabela 35: Transformador 2 da subestação E
Classificação Canal Ruído DPs Energia Acumulada
B
1 3592 68 1429202 2495 43 2464893 1315 29 928994 4859 95 17478235 4709 95 7603126 6079 109 14988177 1400 17 1972888 5106 80 12815629 1758 28 58167
10 2040 21 8345611 4803 295 42454612 3313 54 11556713 4505 94 94399614 5722 106 1018297
Tabela 36: Transformador 1 da subestação F

91
Classificação Canal Ruído DPs Energia Acumulada
B
15 2851 42 10367116 1236 23 10745517 1051 25 6137618 5121 928 217202519 7613 738 114065820 9171 1109 235719021 4144 123 76438122 8791 696 159473823 1234 21 4902024 3411 50 18269725 4864 87 51707626 3323 59 8216127 4938 84 159320528 8020 1046 1206076
Tabela 37: Transformador 2 da subestação F

92
APÊNDICE B -- Sistema DPTrafo
Durante a elaboração da metodologia proposta, foi desenvolvido um sistema, DP-
Trafo, que, entre outras funções, inclui a metodologia apresentada. Utiliza-se de um
banco de dados gerenciado por um SGBD, Postgre, para armazenamento dos dados
recolhidos pelos ensaios de EA, dos transformadores e de seus fabricantes. O sistema
possibilita o cadastro e atualização destes dados, geração de gráficos e, principalmente,
a classificação dos transformadores de acordo com a metodologia apresentada.
Todos os dados utilizados a seguir são fictícios, criados apenas para demonstração
das funcionalidades do software.
B.1 Tela de Login
Na tela de login, o cliente deverá entrar com seu usuário e senha previamente ca-
dastrados. Caso algum dos dois esteja incorreto, o sistema informará o erro ao cliente.
B.2 Tela Inicial
É a tela inicial do sistema. É composta por uma barra superior contendo o nome
do usuário, o botão sair, o menu com as telas do sistema e um quadro inferior onde
são carregadas as telas do sistema. Inicialmente, é carregada uma tela com os usuários
conectados no sistema.

93
Figura 17: Tela de login do sistema
Figura 18: Tela inicial
B.3 Tela de Papéis (Permissões ao usuário)
Os papéis definem as permissões de cada tipo de usuário no sistema. Desta forma,
é possível separar cada classe de usuários (Administradores do Sistema, Engenheiros
e Técnicos) e suas permissões. Inicialmente é listado cada papel cadastrado e, caso o
usuário tenha permissão, é dada a opção de cadastrar novos papéis, editá-los e excluí-
los. É localizado no menu "Controle de Acesso" e no item "Papel".

94
Figura 19: Tela de consulta de papéis
B.4 Cadastro de Usuários
A figura 21 mostra a tela de consulta de usuários cadastrados. Caso o usuário
tenha permissão, será disponibilizado a opção de excluir, editar e incluir um novo
usuário no sistema. Na figura 22, é mostrada a tela de cadastro de um novo usuário.
Para cadastrar um novo usuário é necessário preencher os campos, selecionar os papéis
(pelo menos um papel é requerido) e selecionar permissões individuais para o usuário.
É localizado no menu "Controle de Acesso" e no item "Usuário".
B.5 Cadastro de Fabricantes e Projetos
A tela de consulta de fabricantes é mostrada na figura 23. Clicando em novo,
pode-se cadastrar um novo fabricante, assim como seus projetos, como é mostrado
na figura 24. É necessário o preenchimento das informações, adição de projetos e o sal-
vamento através do clique no botão verde. É localizado no menu "Tabelas" e no item
"Fabricantes e Projetos".
B.6 Cadastro de Transformadores
O cadastro de transformadores é feito como os demais cadastros do sistema. Con-
forme mostrado na figura 26, é possível informar a tensão de até três enrolamentos,
potência, número de série, número identificador da CELG D, ano de fabricação, co-
mutador, fabricante, projeto, se é ou não um autotransformador e se é trifásico ou
monofásico. Após preenchidas as informações, pode ser salvo através do botão verde.
É localizado no menu "Tabelas" e no item "Transformadores".

95
B.7 Cadastro de Ensaios
Após ter sido cadastrado fabricante, família e transformadores, é possível cadastrar
o ensaio. A figura 28 mostra a tela de cadastro do mesmo. É possível inserir quaisquer
transformadores ou autotransformadores no ensaio. Durante o cadastro do ensaio,
o usuário é obrigado a informar a classificação do transformador pelo método AGD,
além das demais informações sobre o ensaio. É localizado no menu "Ensaio" e no item
"Cadastro".
Figura 27: Tela de consulta de ensaio

96
Figura 28: Tela de cadastro de ensaio
B.8 Carregamento de arquivos de ensaios AGD
Permite upload de arquivos relacionados à análise de gases dissolvidos. Escolhe-se
o transformador, o tipo de arquivo e então adiciona-se os arquivos. Após adicionar
todos os arquivos, clica-se no botão Upload, que realizará o salvamento dos arquivos
no banco de dados. O limite do tamanho do arquivo é o disponível na memória do
servidor, uma vez que o arquivo precisa estar na memória para ser persistido no banco
de dados. É localizado no menu "Ensaio" e no item "Arquivos AGD".

97
Figura 29: Tela de upload de arquivos relacionados à AGD
B.9 Carregamento de arquivos de ensaios de EA
A rotina para carregamento de arquivos de ensaios de EA funciona de maneira
idêntica ao de arquivos AGD. É localizado no menu "Ensaio" e no item "Arquivos EA".
B.10 Arquivo Ascii gerado pelo AEWIN
O sistema para coleta de dados dos sensores é o AEWIN. Para trabalhar com os
dados coletados é necessário uma forma de exportação de dados, que é feita através
de um arquivo ASCII. O DPTRAFO permite a importação desse arquivo. Para que
isso fosse possível, foi implementada uma rotina de multithreading (múltiplas linhas de
execução em concorrência com o software principal), que é responsável por processar,
em plano de fundo, os arquivos. É localizado no menu "Ensaio" e no item "Carregar
Arquivos ASCII".
Antes da importação devemos escolher o ensaio e definir quais os canais envolvi-
dos em cada transformador, para que o sistema possa vincular cada dado importado
ao seu devido transformador.
A rotina fez-se necessária por causa do crescimento exponencial do arquivo gerado

98
por ensaios onde existem transformadores com suspeita de defeito. Um exemplo é o
ensaio realizado em A, onde o arquivo é de cerca de 400kb, que é processado em cerca
de segundos. Já o arquivo do ensaio B tem cerca de 220mb, com aproximadamente três
milhões e 900 mil hits. O processamento deste arquivo, após múltiplas otimizações no
código, demora cerca de 40 minutos em um Core i5 de 2.53GHz e 4gb de RAM DDR3.
O arquivo, além de importado, também é persistido de forma compactadada (zip).
Figura 31: Seleção de ensaio para carregamento de arquivos ASCII
Figura 32: Preenchimento dos canais do transformador

99
Figura 33: Carregamento de arquivos ASCII
B.11 Tela de consulta de tarefas (linhas de execução outhreads)
Quando importamos um arquivo ASCII, o sistema gera uma tarefa que pode ser
consultada na tela de consulta de tarefas.
Figura 34: Tela de consulta de tarefas
B.12 Gráficos
Os gráficos a seguir estão localizados no menu "Gráficos". Todos são gerados a
partir de um transformador, podendo-se escolher vários ensaios através de um sistema
de abas. Todos os ensaios possuem filtragem por tempo (em segundos e milisegundos).
Todos, com excessão do gráfico descrito em B.12.1, possuem as opções a seguir:
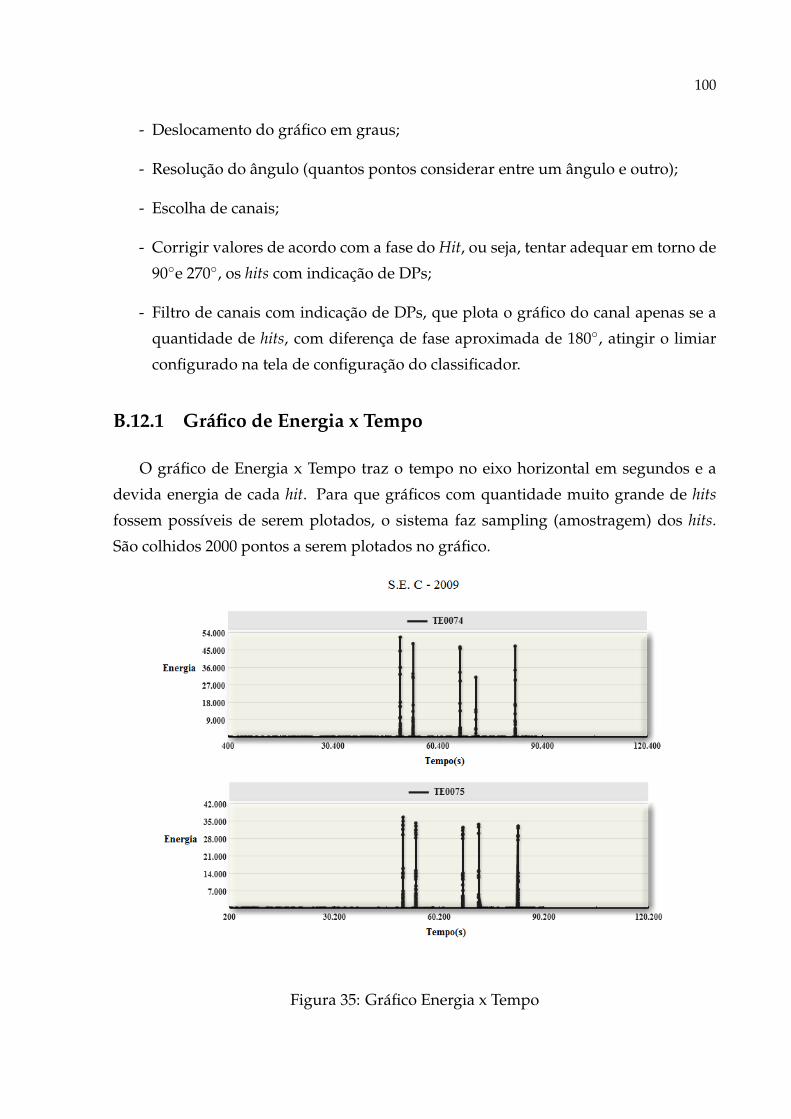
100
- Deslocamento do gráfico em graus;
- Resolução do ângulo (quantos pontos considerar entre um ângulo e outro);
- Escolha de canais;
- Corrigir valores de acordo com a fase do Hit, ou seja, tentar adequar em torno de
90e 270, os hits com indicação de DPs;
- Filtro de canais com indicação de DPs, que plota o gráfico do canal apenas se a
quantidade de hits, com diferença de fase aproximada de 180, atingir o limiar
configurado na tela de configuração do classificador.
B.12.1 Gráfico de Energia x Tempo
O gráfico de Energia x Tempo traz o tempo no eixo horizontal em segundos e a
devida energia de cada hit. Para que gráficos com quantidade muito grande de hits
fossem possíveis de serem plotados, o sistema faz sampling (amostragem) dos hits.
São colhidos 2000 pontos a serem plotados no gráfico.
Figura 35: Gráfico Energia x Tempo

101
B.12.2 Gráfico polar de distribuição de hits
O relatório de distribuição polar de hits analisa a diferença de ângulo entre dois
hits consecutivos e então plota, em um gráfico polar, a quantidade de hits com aquela
defasagem. Existe a opção de correção de valores de acordo com a fase do hit, que irá
ajustar o ângulo do hit em torno dos 180. Caso esteja desmarcada, o sistema levará
em consideração apenas a diferença de fase e não a fase do hit em si. Vale ressaltar que
diferenças de 180indicam presença de descargas parciais.
Figura 36: Ensaio com indicação de DPs nos canais 6 e 12

102
Figura 37: Ensaio sem indicação de DPs
Figura 38: Gráfico da figura 38 plotado sem a correção dos valores de acordo com a
fase do hit. Observa-se atividade em torno dos 180para os canais com indicação de
DPs;

103
B.12.3 Gráfico de dispersão de distribuição de hits
Similar ao gráfico polar, contendo os mesmos dados, porém em forma de um grá-
fico de dispersão.
Figura 39: Gráfico de Distribuição de Hits (Dispersão) com indicação de DPs
Figura 40: Gráfico de Distribuição de Hits (Dispersão) sem indicação de DPs
Figura 41: Gráfico da figura 47 plotado sem a correção dos valores de acordo com a
fase do hit. Observa-se atividade em torno dos 180.

104
B.12.4 Gráfico Ângulo x Tempo
Este gráfico traz as defasagens dos hits pelo tempo em que eles ocorrem. Nova-
mente, como no gráfico Energia x Tempo, o sistema faz sampling (amostragem) dos
valores, plotando no total de 2000 pontos.
Figura 42: Gráfico Ângulo x Tempo com indicação de DPs
Figura 43: Gráfico Ângulo x Tempo sem indicação de DPs
B.12.5 Gráfico Amplitude x Fase
Este gráfico plota a amplitude dos pontos pela fase em que ocorreram. Também é
feito uma amostragem com 2000 pontos.

105
Figura 44: Gráfico de Amplitude x Fase com indicação de DPs
Figura 45: Gráfico de Amplitude x Fase sem indicação de DPs
B.13 Configurador
Esta tela é responsável por configurar as principais funções do sistema. Deve ser
utilizada com cautela, pois altera funções de extrema importância para o classificador.
Localiza-se no menu "Classificação" e no item "Configurador".

106
Figura 46: Tela de configuração do sistema
B.13.1 Estrutura
O sistema fornece dois mecanismos a serem utilizados na estrutura da Rede Baye-
siana. O primeiro utiliza o algoritmo apresentado em 5.1.2, onde utiliza-se de um
mecanismo de escolha entre o método Hill-Climbing e o o método do K2. o segundo
utiliza-se da estrutura de um classificador ingênuo, semelhante ao Gerador de Casos,
ilustrado na figura 15.
O mecanismo preferido é o de aprendizagem, pois consegue captar a estrutura,
baseado nos dados do treinamento. Porém sugere-se que seja utilizado a estrutura
ingênua enquanto não houver casos suficientes para aprendizado da mesma. Deter-
minar uma quantidade aproximada de casos necessários não é possível, pois varia de
acordo com a quantidade de nós da Rede Bayesiana.
B.13.2 Tipo de Classificador
B.13.2.1 Pior Caso
O classificador atuará no canal com maior atividade com indicação de DP, con-
forme apresentado na metodologia do capítulo 5. Difere, porém, no nó energia, que foi
dividido em dois: energia acumulada associada a DP e energia acumulada associada a
ruído.

107
B.13.2.2 Canal a Canal
O classificador irá utilizar as informações de todos os canais para estruturar a Rede
Bayesiana. Os seguintes nós serão adicionados, canal a canal:
- Hits associados à DPs.
- Hits associados à ruído.
- Energia acumulada associada à DPs.
- Energia acumulada associada à ruído.
Desta forma, é possível priorizar certos canais, em detrimento de outros, para se cal-
cular a classificação, porém necessita-se de uma quantidade maior de casos para trei-
namento, por possuir mais nós que a RB utilizada no pior caso.
B.13.3 Otimizador
Conforme apresentado na subseção 5.1.4, a metodologia utiliza um otimizador
Hill-Climbing para discretizar os valores contínuos dos nós da RB. O configurador exibe
duas configurações relacionadas ao otimizador:
- Iterações do Otimizador;
- Repetições.
O primeiro item representa a quantidade de iterações realizadas no laço do Hill-Climbing,
afim de encontrar o valor ótimo. O segundo item representa quantas vezes o otimiza-
dor será executado(reiniciado). Logo, sendo X iterações e N repetições, o otimizador
será executado X · N vezes.
B.13.4 Quantidade de Hits com 180para considerar DP
Esta configuração alimenta o filtro de canais associados à DPs nos gráficos do sis-
tema.

108
B.14 Treinamento da Rede Bayesiana
Localizada no menu "Classificação" e no item "Manual (Treinamento)", é a tela uti-
lizada pelo especialista para informar manualmente a classificação do sistema. Além
da classificação, é possível informar a quantidade de clusters, a região, interpretação
do resultado, observação e responsável pelo treinamento, informações que serão utili-
zadas em relatórios. Um ensaio que possui uma classificação manual não deverá ser
classificado pela RB, pois considera-se a classificação manual no treinamento da rede.
A alteração de um treinamento deve ser feita adicionando um novo treinamento.
Figura 47: Tela de treinamento da RB

109
B.15 Classificador
A tela do classificador, localizada no menu "Classificação", item "Classificador", é
responsável por realizar a classificação dos transformadores. Possui três opções para
treinamento da Rede Bayesiana:
• Utilizar informações exclusivamente do transformador selecionado;
• Utilizar informações de ensaios de transformadores com o mesmo projeto;
• Utilizar informações de todos os ensaios.
Após selecionar uma das opções, o sistema verificará a necessidade de execução
do otimizador. Esta verificação é automática e, caso seja necessário, o otimizador será
executado. Em seguida, a Rede Bayesiana será construída e o sistema realizará a clas-
sificação de acordo com as configurações do sistema. Será apresentada a classificação
anterior e dada a opção do preenchimento de informações utilizadas no relatório espe-
cífico: quantidade de clusters, região, interpretação, observação e responsável.

110
Figura 48: Resultado do classificador
B.16 Relatórios
O sistema disponibiliza duas formas de relatório, geradas a partir de um modelo
criado por engenheiros da Celg e localizados no menu "Relatórios". Seus dados são
preenchidos por:
- Cadastro dos transformadores, fabricantes e projetos;
- Cadastro do ensaio, onde são informadas as temperaturas inicial e final, umidade
inicial e final, subestação, instrumento de medição, duração do ensaio e classifi-
cação do transformador pelo método AGD;

111
- Durante o treinamento ou classificação, onde são informadas a quantidade e lo-
calização de clusters, interpretação dos resultados, conclusão, observações e res-
ponsável técnico;
- Durante a geração do relatório geral, é solicitada as observações e o nome do
responsável técnico.
Os modelos dos relatórios, propostos neste trabalho, estão no Anexo A e Anexo B.

112
Figura 20: Tela de cadastro de papéis
Figura 21: Tela de consulta de usuários

113
Figura 22: Tela de cadastro de usuários
Figura 23: Tela de consulta de fabricantes

114
Figura 24: Tela de cadastro de fabricantes

115
Figura 25: Tela de consulta de transformadores
Figura 26: Tela de cadastro de transformadores

116
Figura 30: Tela de upload de arquivos relacionados à EA

117
ANEXO A -- Relatório Geral
Pro
jeto
de
P&
D263
Rel
ató
rio
Ger
al
- E
nsa
io d
e D
etec
ção
de
Des
carg
as
Pa
rcia
is
em T
ran
sform
ad
or
de
Po
tên
cia
Equip
amen
to
TD
0000089
Núm
ero t
ota
l de
Ensa
io d
o E
quip
amen
to
03
Fab
rica
nte
T
osh
iba
Potê
nci
a
(MV
A)
33,3
3
Ten
são
(kV
) 138/1
3,8
Data
* C
Qu
an
tid
ad
e d
e si
nais
-hits
ass
oci
ad
os
às
DP
s/h
ora
(En
ergia
acu
mu
lad
a a
ssoci
ad
a à
s D
Ps/
hora
) n
os
Can
ais
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
20/0
9/2
011
AA
Nív
el 1
100
(500)
0
25/0
2/2
012
BA
Nív
el 2
200
(600)
0
28/0
7/2
013
CB
Nív
el 1
300
(800)
0
13/0
9/2
014
DC
Nív
el 4
1000
(2000)
0
* C
: C
lass
ific
ação
atu
al d
os
resu
ltad
os
asso
ciad
os
entr
e as
téc
nic
as p
redit
ivas
de
emis
são a
cúst
ica
e d
e an
ális
e de
gas
es d
isso
lvid
os.
Obse
rvaç
ões
:
Dat
a: 2
7/0
9/2
011
___________________________________
Nom
e do R
esponsá
vel
Téc
nic
o

118
ANEXO B -- Relatório Específico
Projeto de
P&D-263
Relatório de Ensaio de Detecção de Descargas Parciais
em Transformador de Potência
Equipamento: TD0000089 Data do
Ensaio: 05/07/2011
Número do Ensaio
do Equipamento: 1/1
Fabricante: Toshiba Potência:
(MVA) 33,33 Tensão (kV) 138/13,8
Subestação AER-S Instrumento de Medição: DISP -28
Duração do ensaio
(hh:mm:ss) 24:00:00 Temperatura (
oC) Umidade do ar (%)
Canais
com sinais
associado à
descargas
parciais
Quantidade
de cluster no
gráfico de
três
dimensões
Região de localização dos
clusters no equipamento Interpretação dos resultados
3, 5, 9 4 1. Buchas de AT e BT;
2. Região do CDC;
3. Parte superior do núcleo
1. Descargas parciais nas buchas
de AT e BT;
2. Ruído no CDC;
3. Descargas parciais na parte
superior do núcleo
Classificação do resultado Conclusão da
Ação Recomendada Emissão
Acústica
Análise de gases
dissolvidos Geral
B A BA Continuar a operar normalmente
Dentro da
normalidade Satisfatório Nível 1
Nota Técnica e Observações:
Continuar a operar o equipamento normalmente. Realizar novo ensaio de EA e AGD daqui a 12 meses.
Data: 29/09/2011
Nome do Responsável Técnico