
Principais tipos de resíduos utilizados na análise de ...³rio Final.pdf · Ao Prof. Dr. João...
63
Francisco William Pereira Marciano Principais tipos de resíduos utilizados na análise de diagnóstico em MLG com aplicações para os modelos: Poisson, ZIP e ZINB Fortaleza – CE Setembro / 2009
Transcript of Principais tipos de resíduos utilizados na análise de ...³rio Final.pdf · Ao Prof. Dr. João...

Francisco William Pereira Marciano
Principais tipos de resíduos utilizados na análise dediagnóstico em MLG com aplicações para os
modelos: Poisson, ZIP e ZINB
Fortaleza – CE
Setembro / 2009

Francisco William Pereira Marciano
Principais tipos de resíduos utilizados na análise dediagnóstico em MLG com aplicações para os
modelos: Poisson, ZIP e ZINB
Relatório final de atividades apresentado à Pró-Reitoria de Pesquisa e Pós-Graduação referenteao projeto de Iniciação Científica de mesmo tí-tulo, período 2008/2009.
Orientadora:Profa. Dra. Sílvia Maria de Freitas
Co-orientador:
Prof. Dr. Juvêncio Santos Nobre
UNIVERSIDADE FEDERAL DO CEARÁ
CENTRO DE CIÊNCIAS
DEPARTAMENTO DE ESTATÍSTICA E MATEMÁTICA APLICADA - DEMACURSO DE ESTATÍSTICA
Fortaleza – CE
Setembro / 2009

AGRADECIMENTOS
A Deus e ao mestre Jesus, o primeiro pela oportunidade, saúde e disposição para
realizar este trabalho, o segundo pelos ensinamentos deixados que procuro vivenciar em minha
vida.
Ao CNPq, pelo suporte financeiro concedido.
À minha família, em especial aos meus pais, Moacir Marciano e Maria Pereira
Marciano, pelo carinho, confiança e união indispensáveis nessa caminhada e por todo o suporte
necessário para que eu chegasse até aqui.
À Profa. Dra. Silvia Maria de Freitas, pela orientação, paciência e ensinamentos
repassados, sem a qual esse trabalho não seria possível; incentivadora e guia nos momentos de
dificuldade, sem dúvida influenciou tomadas de decisões importantes em minha vida. Agradeço
a confiança depositada em meu trabalho, visto os dois projetos de iniciação científica ao qual
fui orientado.
Ao Prof. Dr. Juvêncio Santos Nobre, pela orientação, incentivo, colaboração e
ensinamentos prestados, sem o qual a realização desse trabalho seria bem mais difícil.
Ao Prof. Dr. João Maurício Araújo Mota, pela colaboração no primeiro projeto
de iniciação científica que serviu de suporte para a conclusão desse trabalho, além é claro, do
incentivo e dos ensinamentos prestados nas disciplinas ao qual fui seu aluno.
Aos demais Professores e funcionários do Departamento de Estatística e Matemá-
tica Aplicada que contribuíram na minha formação acadêmica.
Enfim, à todos os colegas e amigos do curso de Estatística que fizeram essa cami-
nhada ser mais agradável.

RESUMO
A distribuição de Poisson é muito utilizada para descrever dados de contagem. Umaimportante propriedade dessa variável aleatória é a igualdade entre a média e variância. Emsituações em que se tem uma variável resposta com dados de contagem e deseja-se estudar arelação com variáveis explicativas, uma escolha natural é o uso do modelo de regressão Poisson,que pertence à classe especial de Modelos Lineares Generalizados (MLG’s).
Na prática, não é raro encontrar conjuntos de dados de contagem que apresentemuma alta freqüência de valores “zero”, acima da freqüência esperada pelo modelo, fazendocom que a variância empírica (ou amostral) exceda à variância nominal do modelo - àquelaassumida pela suposição da distribuição em estudo. Este fenômeno é conhecido na literaturacomo superdispersão, que no caso da distribuição Poisson, é chamada variação extra-Poisson(Var(Yi) = µφ), sendo φ > 0 o parâmetro que ocasiona a fonte extra de variabilidade, oque pode causar sérios problemas como a subestimação do erro padrão dos estimadores e oconseqüente aumento do nível de significância.
Neste trabalho será abordado uma aplicação do Modelo Poisson padrão e dos Mode-los Inflacionados de Zeros para dados de contagem, Zero Inflated Poisson - ZIP e Zero InflatedNegative Binomial - ZINB, utilizando-se as técnicas dos MLG’s através de um conjunto de da-dos reais, onde algumas alterações foram implementadas no conjunto de dados a fim de aplicaros modelos supracitados. Após a realização dos ajustes uma análise de diagnóstico é discutidapara verificar possíveis transgressões aos ajustes dos modelos considerados juntamente com aanálise gráfica para verificar a adequabilidade dos modelos em questão em relação a variável deinteresse no estudo, o número de abelhas que coletam polens no decorrer do dia.

SUMÁRIO
Lista de Figuras
Lista de Tabelas
Introdução p. 9
1 Modelos Lineares Generalizados p. 11
1.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 11
1.2 Modelos de Dispersão Exponencial . . . . . . . . . . . . . . . . . . . . . . . p. 11
1.2.1 A Família Exponencial de Distribuições . . . . . . . . . . . . . . . . p. 12
1.2.2 A Família de Dispersão Exponencial de Distribuições . . . . . . . . . p. 13
1.3 O Modelo Linear Generalizado . . . . . . . . . . . . . . . . . . . . . . . . . p. 15
1.3.1 Modelagem Estatística . . . . . . . . . . . . . . . . . . . . . . . . . p. 15
1.3.2 Definição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 15
1.3.3 A medida de Deviance . . . . . . . . . . . . . . . . . . . . . . . . . p. 17
1.3.4 O Critério de Informação de Akaike - AIC . . . . . . . . . . . . . . p. 19
2 Modelos para Dados de Contagem p. 20
2.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 20
2.2 O Modelo Poisson Padrão . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 20
2.3 O Modelo Poisson Inflacionado de Zeros (ZIP) . . . . . . . . . . . . . . . . p. 21
2.4 O Modelo Binomial Negativo Inflacionado de Zeros (ZINB) . . . . . . . . . p. 22
3 Principais Tipos de Resíduos Utilizados em MLG’s p. 24

3.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 24
3.2 Resíduos de Pearson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 25
3.3 Resíduos de Pearson estudentizados . . . . . . . . . . . . . . . . . . . . . . p. 25
3.4 Resíduos Componentes do Desvio . . . . . . . . . . . . . . . . . . . . . . . p. 25
3.5 Resíduos Componentes do Desvio Estudentizados . . . . . . . . . . . . . . . p. 26
3.6 Tipos de Gráficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 26
3.6.1 Gráfico de índices . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 26
3.6.2 Resíduos versus valores ajustados . . . . . . . . . . . . . . . . . . . p. 26
3.6.3 Gráfico semi-normal de probabilidades (“half normal plots”) . . . . . p. 27
3.6.4 Gráfico normal de probabilidades (“normal plots”) com envelopes . . p. 27
4 Aplicação p. 28
4.1 Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 28
4.2 Modelo Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 28
4.3 Modelo Poisson Inflacionado de Zeros (ZIP) . . . . . . . . . . . . . . . . . . p. 30
4.4 Modelo Binomial Negativo Inflacionado de Zeros (ZINB) . . . . . . . . . . . p. 33
4.5 Ajuste do 2o grau para os modelos Poisson, ZIP e ZINB . . . . . . . . . . . . p. 36
4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB . . . . . . . . . . . . p. 37
Considerações Finais p. 44
Referências p. 46
Apêndice p. 48
Apêndice A - Função para construção do envelope simulado Poisson . . . . . . . . p. 48
Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados . . . p. 54
Modelo ZIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 54
Modelo ZINB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 58

LISTA DE FIGURAS
1 Valores observados e modelo ajustado Poisson . . . . . . . . . . . . . . . . . p. 29
2 Envelope simulado para os resíduos de Pearson no modelo Poisson . . . . . . p. 30
3 Envelope simulado para os Componentes do Desvio no modelo Poisson . . . p. 30
4 Valores observados e modelo ajustado ZIP . . . . . . . . . . . . . . . . . . . p. 32
5 Envelope simulado dos resíduos de Pearson para o modelo ZIP . . . . . . . . p. 32
6 Envelope seminormal de probabilidades para os resíduos de Pearson no mo-
delo ZIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 32
7 Envelope simulado dos resíduos Componentes do Desvio para o modelo ZIP . p. 33
8 Envelope seminormal de probabilidades para os resíduos Componentes do
Desvio no modelo ZIP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 33
9 Valores observados e modelo ajustado ZINB . . . . . . . . . . . . . . . . . . p. 35
10 Envelope simulado dos resíduos de Pearson para o modelo ZINB . . . . . . . p. 35
11 Envelope seminormal de probabilidades para os resíduos de Pearson no mo-
delo ZINB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 35
12 Envelope simulado para os resíduos Componentes do Desvio para o modelo
ZINB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 36
13 Envelope seminormal de probabilidades para os resíduos Componentes do
Desvio no modelo ZINB . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 36
14 Valores observados e modelos 2o grau ajustados . . . . . . . . . . . . . . . . p. 38
15 Envelope simulado dos resíduos de Pearson para o modelo Poisson 2o grau . p. 39
16 Envelope simulado dos resíduos Componentes do Desvio para o modelo Pois-
son 2o grau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 39
17 Envelope simulado dos resíduos de Pearson para o modelo ZIP 2o grau . . . . p. 39

18 Envelope simulado dos resíduos Componentes do Desvio para o modelo ZIP
2o grau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 39
19 Envelope simulado dos resíduos de Pearson para o modelo ZINB 2o grau . . . p. 39
20 Envelope simulado dos resíduos Componentes do Desvio para o modelo ZINB
2o grau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 39
21 Valores observados e modelos 3o grau ajustados . . . . . . . . . . . . . . . . p. 41
22 Envelope simulado dos resíduos de Pearson para o modelo Poisson 3o grau . p. 42
23 Envelope simulado dos resíduos Componentes do Desvio para o modelo Pois-
son 3o grau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 42
24 Envelope simulado dos resíduos de Pearson para o modelo ZIP 3o grau . . . . p. 42
25 Envelope simulado dos resíduos Componentes do Desvio para o modelo ZIP
3o grau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 42

LISTA DE TABELAS
1 Distribuições pertencentes à família de dispersão exponencial . . . . . . . . . p. 14
2 Funções de ligação canônicas para algumas distribuições conhecidas . . . . . p. 17
3 Estimativas dos parâmetros do modelo Poisson e nível descritivo . . . . . . . p. 29
4 Estimativas dos parâmetros do modelo ZIP e nível descritivo . . . . . . . . . p. 31
5 Estimativas dos parâmetros do modelo ZINB e nível descritivo . . . . . . . . p. 34
6 Estimativas dos parâmetros 2o grau dos modelos Poisson, ZIP e ZINB e nível
descritivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 37
7 Estimativas dos parâmetros 3o grau dos modelos Poisson, ZIP e ZINB e nível
descritivo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . p. 41

9
INTRODUÇÃO
Uma etapa importante na análise do ajuste de um modelo de regressão é a verifi-
cação de possíveis violações (falhas) das suposições feitas para o modelo, especialmente para
a parte aleatória e para a parte sistemática do modelo, bem como a existência de observações
extremas com alguma interferência desproporcional nos resultados do ajuste (Paula, 2004). As-
sim como ocorre no modelo linear clássico de regressão, essa falhas também acontecem nos
modelos lineares generalizados (MLG).
De acordo com Cordeiro e Demétrio (2007), o que acontece nos MLG’s, na prática,
é uma combinação de diferentes tipos de falhas: falhas sistemáticas, ocasionadas pela violação
do modelo (escolha inadequada da função de variância, da função de ligação e da matriz do
modelo, ou ainda pela definição errada da escala da variável dependente ou das variáveis ex-
planatórias) e falhas isoladas, causadas porque os pontos estão nos extremos da amplitude de
validade da covariável, ou porque eles estão realmente errados como resultado de uma leitura
errada ou uma transcrição mal feita, ou ainda porque algum fator não controlado influenciou a
sua obtenção.
A análise de diagnóstico refere-se a um conjunto de procedimentos utilizados para
realização de um “diagnóstico” das suposições associadas aos modelos em estudo, que teve
início com Cox e Snell (1968), com a chamada análise de resíduos, utilizada para detectar a
presença de pontos extremos e avaliar a adequação da distribuição proposta para a variável
resposta. De uma forma geral, as técnicas usadas para análise de resíduos e diagnósticos para
modelos lineares generalizados são semelhantes às utilizadas para modelos lineares clássicos,
resguardadas as devidas adaptações.
O modelo de Poisson inflacionado de zeros (ZIP) e o modelo Binomial Negativo
inflacionado de zeros (ZINB) estão descritos em Ridout, Demétrio e Hinde (1998), através de
uma revisão sobre modelos que se ajustam a dados de contagem inflacionados de zeros. Todos
estes modelos fazem parte, na realidade, de um conjunto de metodologia bem mais amplo,
denominado Modelos Lineares Generalizados (Cordeiro, 1986; McCullagh & Nelder, 1989).
O objetivo do trabalho é aplicar a metodologia dos (MLG’s) em um conjunto de dados reais,
onde foram acrescidos zeros no conjunto de dados para contemplar os modelos a ser ajustados

Introdução 10
e verificar o impacto desta característica de “excessos de zeros” na análise de diagnóstico dos
modelos em estudo.

11
1 MODELOS LINEARESGENERALIZADOS
1.1 Introdução
Os Modelos Lineares Generalizados (MLG’s) são ferramentas poderosas na análise
de dados onde o interesse é o estudo da relação entre uma variável resposta, medida em escala
contínua ou discreta, em função de diferentes variáveis preditoras (quantitativas e/ou qualita-
tivas). Ocorre em alguns casos que para se utilizar determinada metodologia de análise são
requeridas algumas pressuposições que nem sempre são atendidas e que, portanto, o estatís-
tico não pode negligenciar sob pena de incorrer em elevadas taxas de erros e inferências pouco
confiáveis. No intuito de validar a metodologia proposta, os estatísticos utilizam a mudança
adequada da escala da variável aleatória por meio de transformações nestes dados. Com o ad-
vento dos MLG’s, os problemas com escalas foram bastante reduzidos. Na verdade, trata-se de
uma extensão dos modelos lineares, desenvolvida por Nelder e Wedderburn (1972), para dados
não normalmente distribuídos. Esta metodologia motiva-se no fato que os efeitos sistemáti-
cos são linearizados por uma transformação adequada dos valores esperados, permitindo aos
valores ajustados variarem dentro da amplitude real das respostas.
1.2 Modelos de Dispersão Exponencial
Os Modelos Lineares Generalizados são restritos a membros de uma particular fa-
mília de distribuições que tem ótimas propriedades estatísticas. Na realidade, esta restrição
surge por puras razões técnicas: o algoritmo numérico, IWLS (Interated Weighted Least Squa-
res) usado para estimação, somente funciona dentro desta família. Com o desenvolvimento
computacional dos últimos anos, esta limitação seria facilmente ultrapassada; no entanto, ne-
nhum software, para uma família maior de modelos de regressão, está sendo atualmente distri-
buído. Agora trataremos mais especificamente desta família.

1.2 Modelos de Dispersão Exponencial 12
1.2.1 A Família Exponencial de Distribuições
Considere um conjunto de variáveis repostas aleatórias e independentes, Zi (i =
1, · · · ,n) e que a função de probabilidade, no caso discreto, ou função densidade de probabili-
dade, no caso contínuo, pode ser escrito da seguinte maneira
f (zi; ξi) = r(zi)s(ξi)exp[t(zi)u(ξi)]
= exp[t(zi)u(ξi) + v(zi) + w(ξi)] (1.1)
com ξi um parâmetro de localização indicando a posição onde a distribuição varia dentro do in-
tervalo dos valores possíveis da resposta. Qualquer distribuição que pode ser escrita deste modo
é dita membro da família exponencial uniparamétrica. Note a dualidade do valor observado, zi,
da variável aleatória e o parâmetro, ξi.
A forma canônica para a variável aleatória, o parâmetro, e a família é obtida por
fazer y = t(z) e θ = u(ξi). Se essas forem transformações 1 a 1, elas simplificam, mas não
muda fundamentalmente o modelo que agora torna-se
f (yi;θi) = exp[yiθi − b(θi) + c(yi)] (1.2)
onde b(θi) é a constante de normalização da distribuição. Agora, Yi (i = 1, · · · ,n) é um conjunto
de variáveis aleatórias independentes com médias µi, onde podemos escrever que yi = µi + εi.
Exemplos:
Duas das distribuições discretas mais conhecidas são incluídas nesta família.
1. Distribuição Poisson
f (yi;µi) =µi
yie−µi
yi!= exp[yi log(µi) − µi − log(yi!)]
onde θi = log(µi), b(θi) = exp(θi), e c(yi) = − log(yi!).
2. Distribuição Binomial
f (yi;µi) =
(ni
yi
)πi
yi(1 − πi)ni−yi
= exp[yi log
(πi
1 − πi
)+ ni log(1 − πi) + log
(ni
yi
)]onde θi = log
(πi
1−πi
), b(θi) = ni log[1 + exp(θi)], e c(yi) = log
(niyi
).

1.2 Modelos de Dispersão Exponencial 13
1.2.2 A Família de Dispersão Exponencial de Distribuições
A família exponencial pode ser generalizada por incluir um parâmetro de escala
(constante), em geral φ, na distribuição tal que
f (yi;θi, φ) = exp[
yiθi − b(θi)ai(φ)
+ c(yi, φ)]
(1.3)
onde θi também é a forma canônica do parâmetro de localização, alguma função da média µi.
Exemplos:
Duas das distribuições contínuas mais conhecidas são incluídas nesta família.
1. Distribuição Normal
f (yi;µi, σ2) =
1√
2πσ2exp
[−
(yi − µi)2
2σ2
]= exp
{[yiµi −
µi2
2
]1σ2 −
yi2
2σ2 −12
log(2πσ2)}
onde θi = µi, b(θi) = θi2/2, ai(φ) = σ2, e c(yi, φ) = −[yi
2/φ + log(2πφ)]/2.
2. Distribuição Gama
f (yi;µi, ν) =
(νµi
)ν yiν−1e−
νyiµi
Γ(ν)
= exp{[−
yi
µi− log(µi)
]ν + (ν − 1) log(yi) + ν log(ν) − log[Γ(ν)]
}onde θi = −1/µi, b(θi) = − log(−θi), ai(φ) = 1/ν, e c(yi, φ) = (ν− 1) log(yi) + ν log(ν)−
log[Γ(ν)].
Note que os exemplos acima para a família exponencial também são membros da
família de dispersão exponencial, com ai(φ) = 1. Com φ conhecido, esta família pode ser
tomada como um caso especial da família exponencial uniparamétrica; yi é então a estatística
suficiente para θi em ambas as famílias.
A Tabela (1) apresenta algumas Distribuições importantes na Família (1.3).

1.2 Modelos de Dispersão Exponencial 14
Tabela 1: Distribuições pertencentes à família de dispersão exponencial
Dis
trib
uiçã
oφ
θb(θ
)c(
y,φ
)
Nor
mal
:N(µ,σ
2 )σ
2µ
σ2 2
−1 2
[ y2
σ2
+lo
g(2πσ
2 )]Po
isso
n:P(µ
)1
logµ
eθ−
log
y!
Bin
omia
l:B
(n,π
)1
log( π 1−π
) nlo
g[1
+eθ
]lo
g( n y)
Bin
omia
lNeg
ativ
a:B
N(µ,k
)1
log( µ µ
+k) −
klog
(1−
eθ)
log[ Γ
(k+
y)Γ
(k)y
!
]G
ama:
G(µ,ν
)ν−
1−
1 µ−
log(−θ
)(ν−
1)lo
g(y i
)+ν
log(ν)−
log[
Γ(ν
)]
Nor
mal
Inve
rsa:
IG(µ,σ
2 )σ
2−
1 2µ2
−(−
2θ)1 2
−1 2
[ log(
2πσ
2y3 )+
1 yσ2
]FO
NT
E:C
orde
iro
eD
emét
rio
(200
7)

1.3 O Modelo Linear Generalizado 15
1.3 O Modelo Linear Generalizado
1.3.1 Modelagem Estatística
Modelos matemáticos são uma representação simplificada da realidade, sendo bas-
tante explorados com o desenvolvimento científico e tecnológico. Como Box já falara: “todos
os modelos são errados, mas alguns são úteis”, ratifica que não se deve acreditar que um mo-
delo seja verdadeiro, embora muito da inferência estatística teórica seja baseada somente nesta
suposição. Os modelos matemáticos podem ser determinísticos ou probabilísticos. Quando eles
envolvem uma componente probabilística, eles são chamados de modelos estatísticos.
A classe de modelos mais importante na atualidade, incluem os Modelos Lineares
Generalizados, assim chamados por generalizarem o modelo linear clássico baseado na distri-
buição normal. Esta generalização apresenta dois aspectos: diferente da regressão linear, esses
modelos podem envolver uma variedade de distribuições selecionadas de uma família especial,
a família dos modelos de dispersão exponencial, onde envolvem transformações da média, atra-
vés do que chamamos de “função de ligação”, ligando a parte regressora a média de uma dessas
distribuições.
1.3.2 Definição
Os modelos lineares generalizados podem ser definidos a partir de uma única va-
riável de interesse Y e a respectiva associação com outras variáveis, chamadas de variáveis
exploratórias x1, · · · , xn. Desta forma, para n observações de uma amostra, o modelo linear
generalizado envolve três componentes:
1. Componente aleatório: Os Yi (i = 1, · · · ,n) são variáveis aleatórias independentes com
médias µi. Elas compartilham da mesma distribuição pertencendo a família de dispersão
exponencial dada por (1.3), ou seja,
E(Yi) = µi, i = 1, · · · ,n,
sendo φ > 0 um parâmetro de dispersão e o parâmetro θi denominado de parâmetro
canônico. As funções b(.) e c(.) são conhecidas e podemos obter a E(Yi) e Var(Yi) como
segue abaixo:
E(Yi) = µi = b′(θi)

1.3 O Modelo Linear Generalizado 16
e
Var(Yi) = φb′′(θi) = φVi,
em que Vi = V(µi) = dµi/dθi é denominada de função de variância e depende unica-
mente da média µi. A família exponencial de distribuições desempenha um papel impor-
tante na teoria dos MLG’s uma vez que ela permite incorporar dados que exibem assime-
tria, dados de natureza discreta ou contínua e dados que são restritos a um intervalo do
conjunto dos reais, como o intervalo (0, 1).
2. Componente sistemático: A estrutura linear do modelo é composta pelas variáveis ex-
plicativas que entram na forma de uma soma linear de seus efeitos, ou seja
ηi =
p∑r=1
xirβ j = xtiβ ou η = Xβ, (1.4)
sendo X = (x1, · · · , xn)t a matriz de delineamento do modelo, β = (β1, · · · , βp)t o vetor de
parâmetros e η = (η1, · · · , ηn)t o preditor linear. Se um parâmetro tem valor conhecido, o
termo correspondente na estrutura linear é chamado offset.
3. Função de ligação: Se θi = ηi nossa definição de modelo linear generalizado está com-
pleta. Contudo, a generalização para transformações não canônicas da média requer um
componente adicional se a estrutura linear é rejeitada.
O relacionamento entre a média da i-ésima observação e o preditor linear serão dados por
uma função de ligação, gi(·):
ηi = gi(µi)
= xtiβ
Esta função deve ser monotônica e diferenciável. Geralmente a mesma função de ligação
é usada para todas as observações. Desta forma, a função de ligação canônica é a função
que transforma a média para um parâmetro de localização canônico de um membro da
família de dispersão exponencial.
Com a função de ligação canônica, todos os parâmetros desconhecidos da estrutura linear
apresenta estatística suficiente se a distribuição da resposta é um membro da família de
dispersão exponencial e o parâmetro de escala for conhecido. Contudo, a função de liga-
ção é somente um artifício para simplificar os métodos numéricos de estimação quando
um modelo envolve uma parte linear, isto é, permitir que o algoritmo IWLS funcione.
Para modelos de regressão não-linear ela perde o significado (Lindsey, 1974b).

1.3 O Modelo Linear Generalizado 17
Tabela 2: Funções de ligação canônicas para algumas distribuições conhecidas
Distribuição Função de ligação canônicaNormal Identidade: η = µPoisson Logarítmica: η = logµBinomial Logística: η = log
(π
1−π
)= log
(µ
n−µ
)Gama Recíproca: η = 1
µ
Normal Inversa Recíproca do quadrado: η = 1µ2
FONTE: Cordeiro e Demétrio (2007)
Como podemos perceber pelo exposto, para especificarmos o MLG, os parâmetros
θi da família de distribuições (1.3) não são de interesse direto (pois há um para cada observação)
mas sim um conjunto menor de parâmetros β1, · · · , βp tais que uma combinação linear dos β′s
seja igual a alguma função do valor esperado de Yi.
1.3.3 A medida de Deviance
No processo de seleção de um modelo, uma série de modelos de regressão estarão
sob consideração. É útil introduzir uma terminologia para descrever as várias possibilidades
que podem ser levadas em consideração.
Modelo Saturado ou Completo: O modelo tem n parâmetros especificados pelas médias
µ1, · · · , µn linearmente independentes. Como o modelo atribui toda a variação dos dados ao
componente sistemático, ele ajusta-se perfeitamente, reproduzindo os próprios dados, no en-
tanto, de difícil interpretação.
Modelo Nulo: Este modelo tem um valor médio comum para todas as observações. É o modelo
mais simples, no entanto, não representa adequadamente a estrutura dos dados.
Modelo Maximal: Neste caso, temos o maior e mais complexo modelo a ser considerado. Ele
inclui o maior número de termos que pode ser considerado.
Modelo Minimal: Este modelo contém o menor número de termos necessário para o ajuste;
por exemplo, marginais fixa para uma tabela de contingência.
Modelo Corrente ou Sob Pesquisa: Este modelo está entre os modelos maximal e minimal e
é o modelo que está sob investigação.
Levando em consideração os vários modelos possíveis, verificamos que o modelo
nulo é simples demais e o modelo saturado não é informativo, pois não resume os dados, sim-
plesmente os repete. Nesse ponto, o problema é determinar a utilidade de um parâmetro extra

1.3 O Modelo Linear Generalizado 18
no modelo corrente (sob pesquisa) ou, então, verificar a falta de ajuste induzida pela omissão
dele. Para avaliar os modelos é necessário introduzir medidas de discrepância para medir o
ajuste de um modelo. Nelder e Wedderburn (1972) propuseram, como medida de discrepância,
a “deviance” (traduzida como desvio por Cordeiro (1986)), com expressão dada por:
Sp = 2(l̂n − l̂p),
onde l̂n e l̂p são os máximos do logaritmo da função de verossimilhança para os modelos sa-
turado e corrente (sob pesquisa), respectivamente. Podemos observar que o modelo saturado
serve como base de medida do ajuste de um modelo sob pesquisa (modelo corrente). O loga-
ritmo da função de verossimilhança como função apenas de β (considerando-se o parâmetro de
dispersão φ conhecido) dado um vetor y, usando-se a expressão (1.3) tem-se:
l̂n =1φ
n∑i=1
[yiθ̃i − b(θ̃i)] +1φ
n∑i=1
c(yi, φ)
e
l̂p =1φ
n∑i=1
[yiθ̂i − b(θ̂i)] +1φ
n∑i=1
c(yi, φ),
sendo θ̃i = q(yi) e θ̂i = q(µi) as estimativas de máxima verossimilhança do parâmetro canônico
sob os modelos saturado e corrente, respectivamente.
Desta forma, temos que
Sp =Dp
φ=
2φ
n∑i=1
[yi(θ̃i − θ̂i) + b(θ̂i) − b(θ̃i)], (1.5)
onde Sp e Dp são denominados de desvio escalonado e desvio, respectivamente. O desvio é
definido apenas como função dos dados y e das médias ajustadas µ̂. O desvio escalonado pode
ainda ser expresso como segue
Sp =1φ
n∑i=1
di2,
sendo que di2 mede a discrepância dos logaritmos das funções de verossimilhança observada
e ajustada, para cada observação i, sendo denominado de componente do desvio. Podemos
verificar que o desvio equivale a uma constante menos duas vezes o máximo do logaritmo da
função de verossimilhança para o modelo corrente, isto é,
Sp = 2l̂n − 2l̂p = constante − 2l̂p.
Em geral, para os casos em que o desvio depende do parâmetro de dispersão φ−1,

1.3 O Modelo Linear Generalizado 19
em (Jorgensen, 1987) o seguinte resultado para a distribuição nula da função desvio pode ser
utilizado:
Sp ∼ χ2n−p, quando φ→∞.
Isto quer dizer, que quando a dispersão é pequena, é razoável comparar os valores de Sp com
os percentis da χ2n−p. Lembrar que a E(χ2
k) = k, isso significa que o valor do desvio próximo de
(n − p) pode ser uma indicação de que o modelo está bem ajustado.
1.3.4 O Critério de Informação de Akaike - AIC
O Critério de Informação de Akaike (Akaike, 1974) é uma medida da qualidade do
ajuste de um modelo estatístico estimado. Ele é baseado no conceito de entropia e fornece uma
medida relativa da informação perdida na adoção de um determinado modelo. De uma forma
geral o AIC é dado por:
AIC = 2k − 2 log(L),
onde K é o número de parâmetros no modelo e L é o valor máximo da função de verossimilhança
para o modelo estimado.
Algumas considerações devem ser feitas a respeito do AIC. Segundo (Basso, 2009),
muitos autores, como por exemplo (Celeux e Soromenho, 1996), comentam que o AIC é incon-
sistente em ordem, e neste caso, tende a superestimar a dimensão do modelo, isso quer dizer
no caso de misturas, que o AIC tende a selecionar modelos com um número de componentes
maior que o verdadeiro. Apesar disso, esse critério tem sido muito utilizado na prática para
determinar a ordem de uma mistura.

20
2 MODELOS PARA DADOS DECONTAGEM
2.1 Introdução
Em muitas áreas do conhecimento científico é frequente deparar-se com a investi-
gação de características, feitas em unidades experimentais, que apresentem resultados de con-
tagem. Por exemplo: o número de insetos que podem aparecer em uma determinada plantação
(Entomologia); o número de sinistros associados a uma carteira de seguros (Atuária); etc. Da-
dos deste tipo são denominados, em Estatística, como dados discretos, pois são expressos em
termos de contagem associados a uma característica de interesse. Em geral, dados desta na-
tureza são modelados, dentro da metodologia Estatística, usando-se a distribuição Poisson. A
ocorrência de excessos de zeros em dados de contagem é um fato bastante comum nas variadas
áreas do conhecimento, ocorrida devido a uma combinação de zeros estruturais e amostrais. Os
zeros estruturais são independentes da distribuição em estudo, e os zeros amostrais estão re-
lacionados a ocorrência de zeros devido o modelo probabilístico adotado, segundo Nagamine,
Candolo e Moura (2008). Os modelos inflacionados de zeros surgem como alternativas ao mo-
delo Poisson, misturando uma distribuição de probabilidade discreta com uma distribuição que
leve em conta o excesso de zeros. Desta forma, o modelo Poisson inflacionado de zeros (ZIP)
e o modelo Binomial Negativo inflacionado de zeros (ZINB) surgem como alternativas na mo-
delagem de dados de contagem, com excesso de zeros, na tentativa de modelar a variabilidade
presente.
2.2 O Modelo Poisson Padrão
Suponha que, para dados Poisson, nos quais se tem yi observações da característica
de interesse que acontecem a uma taxa média λi de ocorrência de tempo (espaço, área, volume,
etc), para i = {1, · · · ,n}, onde Yi ∼ Poisson(λi) de modo que a probabilidade de acontecer yi

2.3 O Modelo Poisson Inflacionado de Zeros (ZIP) 21
ocorrências da característica é:
P(Yi = yi) =e−λiλi
yi
yi!, yi ∈ {0, 1, 2, · · · } (2.1)
E(Yi) = λi = Var(Yi).
A regressão Poisson é uma forma de análise de regressão usada para modelar dados
de contagem e tabelas de contingência. A regressão Poisson assume que a variável resposta
Y tem uma distribuição Poisson, e assume o logaritmo do valor esperado ser modelado por
uma combinação linear de parâmetros desconhecidos. O modelo de regressão Poisson é tam-
bém conhecido como modelo log-linear, principalmente quando usado para modelar tabelas de
contingência, na verdade, ele é um caso especial dos modelos log-lineares.
No caso mais simples com uma única variável independente x, o modelo é da se-
guinte forma:
log{E(Y)} = a + bx. (2.2)
Se Yi são observações independentes com valores xi correspondendo as variáveis
preditoras, então a e b podem ser estimados por máxima verossimilhança se o número de valores
x distintos é pelo menos dois. As estimativas de máxima verossimilhança não possuem uma
expressão de forma fechada e devem ser encontradas por procedimentos numéricos.
Os modelos de regressão Poisson são modelos lineares generalizados com o loga-
ritmo como a função de ligação canônica, e a função de distribuição Poisson, já que na forma
da família exponencial o modelo Poisson possui o parâmetro natural como sendo θi = log(λi),
definindo então a função de ligação canônica g(λi) = log(λi).
2.3 O Modelo Poisson Inflacionado de Zeros (ZIP)
Quando nos deparamos com um número excessivo de zeros, a solução mais comum
é a de estimarmos um modelo que misture a Poisson com uma distribuição que leve em conta o
excesso de zeros. Desta forma, tem-se a hipótese que, com probabilidade p a variável resposta
assume o valor zero e com probabilidade (1 − p) assume o valor de uma variável aleatória com
distribuição Poisson de média λ.
Segundo Lambert (1992), o modelo Poisson Inflacionado de Zeros considera que
alguns zeros, os zeros estruturais, ocorrem com probabilidade pi e os zeros amostrais, com

2.4 O Modelo Binomial Negativo Inflacionado de Zeros (ZINB) 22
probabilidade 1 − pi e denotam o Modelo Poisson Inflacionado de Zeros como segue:
P(Yi = yi) =
pi + (1 − pi)e−λ, yi = 0
(1 − pi)e−λiλi
yi
yi!, yi > 0
(2.3)
O parâmetro pi tem a restrição 0 < pi < 1. A esperança e a variância de Yi são, respectivamente,
E(Yi) = (1 − pi)λi e Var(Yi) = µi + [pi/(1 − pi)]µi2.
Podemos observar que a variância da mistura é maior que a média da distribuição.
Quanto maior a probabilidade do excesso de zeros, maior a variância da variável. À medida
que p se aproxima de zero, a variância se aproxima de µ, ou seja, voltamos a lidar somente com
uma distribuição Poisson padrão.
A inclusão de covariáveis no modelo ZIP e a aplicação da teoria dos modelos linea-
res generalizados é feita com a definição das funções de ligação logarítmica e logística segundo
Lambert (1992), isto é,
log(λi) = Xiβ e log(
pi
1 − pi
)= Giγ (2.4)
onde X e G são as matrizes associadas às covariáveis, que podem ser, ou não, iguais, e β e γ
são os vetores de parâmetros do modelo tal que pi = (p1, · · · , pn)t e λi = (λ1, · · · , λn)t.
2.4 O Modelo Binomial Negativo Inflacionado de Zeros (ZINB)
Suponha um experimento aleatório, onde apenas dois resultados são possíveis: su-
cesso ou fracasso. Considere ainda que a probabilidade de sucesso é p e que a probabilidade
de fracasso é q = 1 − p. Se consideramos que o experimento ocorre indefinidamente e que
os ensaios são independentes, então a variável aleatória correspondendo ao número de repeti-
ções (ensaios) até que o k-ésimo sucesso ocorra segue uma distribuição Binomial Negativa de
parâmetros BN(p,k).
Muitas parametrizações são utilizadas para escrever a distribuição Binomial Nega-
tiva, porém, utilizaremos a notação de Nelder e Wedderburn (1972), onde p = kk+µ , 0 < p < 1 e
k−1 é o parâmetro de dispersão, k > 0. Desta forma, a distribuição de probabilidade da Binomial
Negativa de parâmetros BN(p,k) é dada por:
P(Y = y) =
(y + k − 1
y
) (k
k + µ
)k ( µ
k + µ
)y
, y = 0, 1, 2, · · · (2.5)

2.4 O Modelo Binomial Negativo Inflacionado de Zeros (ZINB) 23
Considerando uma distribuição de probabilidade binomial negativa Y, como a ci-
tada em (2.5), segue que a média é dada por E(Y) = µ e a variância é dada por Var(Y) = µ+µ2
k ,
segundo Paula (2004). É interessante observar que a variância da binomial negativa apresenta
um termo adicional µ2
k , comparativamente com a variância da distribuição Poisson, sendo bas-
tante útil no ajuste de conjunto de dados com superdispersão. A distribuição Binomial Negativa
aproxima-se da distribuição Poisson quando k−1→ 0 (Cameron e Trivedi (1998)).
O modelo Binomial Negativo Inflacionado de Zeros (ZINB) surge como alternativa
para dados de contagem com excesso de zeros, já que a superdispersão devida a esse excesso
pode causar sérios problemas como a subestimação dos erros padrão dos estimadores e o conse-
quente aumento do p-valor associado aos parâmetros do modelo, produzindo inferências pouco
confiáveis.
A distribuição ZINB surge como uma mistura da distribuição Binomial Negativa e
uma distribuição que leve em conta o excesso de zeros, sendo portanto, degenerada nesse ponto.
A notação usada por Yau et al. (2003), mostra que o modelo Binomial Negativo Inflacionado
de Zeros pode ser escrito como segue:
P(Yi = yi) =
pi + (1 − pi)
(k
k+µi
)k, yi = 0
(1 − pi)(yi+k−1
yi
) ( kk+µi
)k ( µik+µi
)yi, yi > 0
(2.6)
sendo que µi é a média da distribuição Binomial Negativa com parâmetros (pi, k). Novamente,
para o parâmetro pi existe a restrição de que 0 < pi < 1 e (1 − pi) representa a probabilidade
de zeros amostrais. A esperança e a variância de Yi são dadas respectivamente por, E(Yi) =
(1−pi)µi e Var(Yi) = (1−pi)(1+µi/k+piµi)µi. Segundo Montoya (2009), a distribuição ZINB
aproxima-se da ZIP quando k → 0 e aproxima-se da binomial negativa quando pi → 0. Se
ambas 1k e pi convergem para zero, então a distribuição ZINB é reduzida à distribuição Poisson
padrão. Assim como no modelo ZIP, as funções de ligação são a logarítmica e a logística, isto
é,
log(µi) = Xiβ e log(
pi
1 − pi
)= Giγ (2.7)
onde pi e µi denotam os vetores de parâmetros modelados pelas funções acima, sendo dados
por pi = (p1, · · · , pn)t e µi = (µ1, · · · , µn)t.

24
3 PRINCIPAIS TIPOS DE RESÍDUOSUTILIZADOS EM MLG’S
3.1 Introdução
Quando um modelo é ajustado a um conjunto de dados, uma etapa que merece
bastante atenção é a verificação de possíveis afastamentos das suposições feitas para o modelo,
levando-se em consideração a parte aleatória e sistemática do modelo, assim como verificar a
presença de observações com alguma influência desproporcional nos resultados do ajuste.
A análise de diagnóstico, esta etapa importante da análise de regressão, começou
com a análise de resíduos para detectar possíveis pontos extremos e avaliar a adequação da
distribuição proposta para a variável resposta. Assim como no modelo clássico de regressão, as
técnicas usadas para análise de resíduos e diagnóstico para os modelos lineares generalizados
são semelhantes, com uma ou outra adaptação, devido a estrutura dos MLG’s.
Os resíduos são importantes dentro da análise de diagnóstico, uma vez que eles
ajudam a detectar observações discrepantes que merecem uma análise mais detalhada. Segundo
Cox e Snell (1968), os resíduos devem expressar uma discrepância entre a observação yi e o seu
valor ajustado µ̂i, sendo dado por:
Ri = hi(yi, µ̂i) (3.1)
onde hi é conhecida e de fácil interpretação.
A matriz de projeção H, nos modelos lineares generalizados é definida por:
H = W1/2X(XTWX)−1XTW1/2 (3.2)
Observe que H depende das variáveis explicativas, da função de ligação e da função de vari-
ância, tornando mais difícil a interpretação da medida de “leverage”. Esta matriz desempenha
um papel importante na análise dos resíduos nos MLG’s e apresenta as seguintes propriedades
tr(H) = p e 0 ≤ hii ≤ 1.

3.2 Resíduos de Pearson 25
3.2 Resíduos de Pearson
Dentre os tipos de resíduos mais comuns nos MLG’s, encontra-se o resíduo de
Pearson, que é também o mais simples, sendo definido por:
riP =
yi − µ̂i
V̂1/2i
(3.3)
onde µ̂i e V̂i são respectivamente a média ajustada e a função de variância ajustada de Yi.
Este resultado surge como uma componente da estatística de Pearson generalizada
Xp2 =
∑ni=1 ri
P2, segundo Cordeiro e Demétrio (2007). Para os modelos log-lineares a expressão
(3.3) passa a ser dada por: riP = (yi − µ̂i)µ̂
−1/2i . A desvantagem do resíduo de Pearson é que sua
distribuição é bastante assimétrica para modelos não-normais.
3.3 Resíduos de Pearson estudentizados
riP′ =
yi − µ̂i√V(µ̂i)(1 − hii)
, (3.4)
onde hii é o i-ésimo elemento da diagonal da matriz de projeção ortogonal dada em (3.2). Os
resíduos de Pearson estudentizados têm, aproximadamente, variância igual a um quando o pa-
râmetro de dispersão φ→ 0 dado em (1.3).
3.4 Resíduos Componentes do Desvio
Um outro tipo de resíduo muito utilizado dentro da metodologia dos MLG’s, é
o resíduo componente do desvio, definido como a raiz quadrada da diferença entre as log-
verossimilhanças sob o modelo saturado e o modelo corrente para cada uma das observações,
com sinal dado pelo sinal de yi − µ̂i, ou seja,
riD = sinal(yi − µ̂i)
√2(l̂sat − l̂cor), (3.5)
onde l̂sat e l̂cor são as log-verossimilhanças sob o modelo saturado e corrente, respectivamente,
para cada observação i.
Como podemos observar, o resíduo riD representa uma distância da observação yi ao
seu valor ajustado µ̂i, medida na escala do logaritmo da função de verossimilhança. Cordeiro e

3.5 Resíduos Componentes do Desvio Estudentizados 26
Demétrio (2007) citam como vantagens do resíduo (3.5) o fato de não requerer o conhecimento
da função normalizadora; a computação simples após o ajuste do MLG e o fato de ser definido
para toda observação e, mesmo para observações censuradas, desde que estas forneçam uma
contribuição para o logaritmo da função de verossimilhança.
3.5 Resíduos Componentes do Desvio Estudentizados
Os resíduos componentes do desvio estudentizados são definidos a partir de (3.5),
como segue abaixo:
riD′ =
riD
√1 − hii
, (3.6)
onde hii é o i-ésimo elemento da diagonal da matriz de projeção ortogonal dada em (3.2).
Os resíduos aqui apresentados são os mais utilizados nas aplicações dos MLG’s,
juntamente com os resíduos de Anscombe, no entanto, no contexto do presente trabalho, os
resíduos de Pearson e Componentes do Desvio assim como os referidos resíduos estudentizados
para ambos, mostram-se bastante úteis nas aplicações de dados de contagem com excesso de
zeros, foco do trabalho e portanto utilizados aqui.
Diversas técnicas analíticas e gráficas podem ser utilizadas para detectar desvios do
modelo sob pesquisa, uma vez que estamos de posse dos resíduos e que possivelmente definimos
uma distribuição teórica adequada para eles.
3.6 Tipos de Gráficos
Basicamente utilizamos três tipos de gráficos para análise dos resíduos, a saber:
3.6.1 Gráfico de índices
Gráfico utilizado para localizar observações com resíduo, “leverage” (hii), distância
de Cook modificada etc, grandes. Pode ser útil na detecção de observações que destoam da
tendência geral das demais observações, indicando um possível “outlier”.
3.6.2 Resíduos versus valores ajustados
Muito utilizado para verificar a constância de variância (McCullagh e Nelder, 1989)
para a distribuição em uso, e em geral se utiliza algum tipo de resíduo estudentizado. O que

3.6 Tipos de Gráficos 27
se espera é que o gráfico apresente a distribuição dos resíduos em torno de zero com amplitude
constante, onde desvios sistemáticos podem ter algum tipo de curvatura ou uma amplitude muito
diferente com o valor ajustado.
3.6.3 Gráfico semi-normal de probabilidades (“half normal plots”)
A construção do gráfico semi-normal de probabilidades é o resultado do conjunto
de pontos obtidos por valores absolutos de um quantil amostral versus os valores do quantil
correspondente da distribuição normal (zi) em que zi = Φ−1(i + n − 0, 125)/(2n + 0, 5).
3.6.4 Gráfico normal de probabilidades (“normal plots”) com envelopes
Weisberg (2005) analisa que o gráfico normal de probabilidades destaca-se por dois
aspectos: a identificação da distribuição originária dos dados e a identificação de valores que
se destacam no conjunto de observações. Os envelopes, no caso dos MLG’s com distribuições
diferentes da normal, são construídos com os resíduos sendo gerados a partir do modelo ajustado
(Williams, 1987).

28
4 APLICAÇÃO
4.1 Introdução
Os dados considerados nesta seção foram retirados da dissertação de Rômulo Au-
gusto Guedes Rizzardo de 2007 através de um estudo realizado na área de apicultura com o
intuito de verificar o número de abelhas que polinizam determinada espécie de planta no de-
correr do tempo. Para isso, foram realizadas quatro coletas em um intervalo de tempo variável
segundo a hora do dia. Os horários de coletas considerados foram: 4, 5, 6, 8, 10, 12, 14, 16 e 18
horas, perfazendo um total de 36 observações. Os dados foram ajustados utilizando os Modelos
Lineares Generalizados para dados de contagem com distribuição Poisson, Binomial Negativo
inflacionado de zeros (ZINB) e Poisson inflacionado de zeros (ZIP), sendo considerada como
variável resposta o número de abelhas coletando polens.
4.2 Modelo Poisson
Inicialmente propomos um modelo Poisson em que o número de abelhas coletando
polens na i-ésima hora e j-ésima repetição é Yi j ∼ Poisson(λi), em que
log(λi) = α + βhorai (4.1)
para i = 1, 2, · · · , 9. Ajustando um modelo linear generalizado com apoio computacional do
R, o ajuste do modelo forneceu uma Deviance de 518.73 com 34 graus de liberdade, indicando
fortes indícios de superdispersão ocasionado possivelmente pelo excesso de zeros. A sintaxe
usada para obter os resultados acima no programa R é dada abaixo:
require(MASS)
mlg.poisson=glm(abelhas1~hora1,family=poisson())
summary(mlg.poisson)
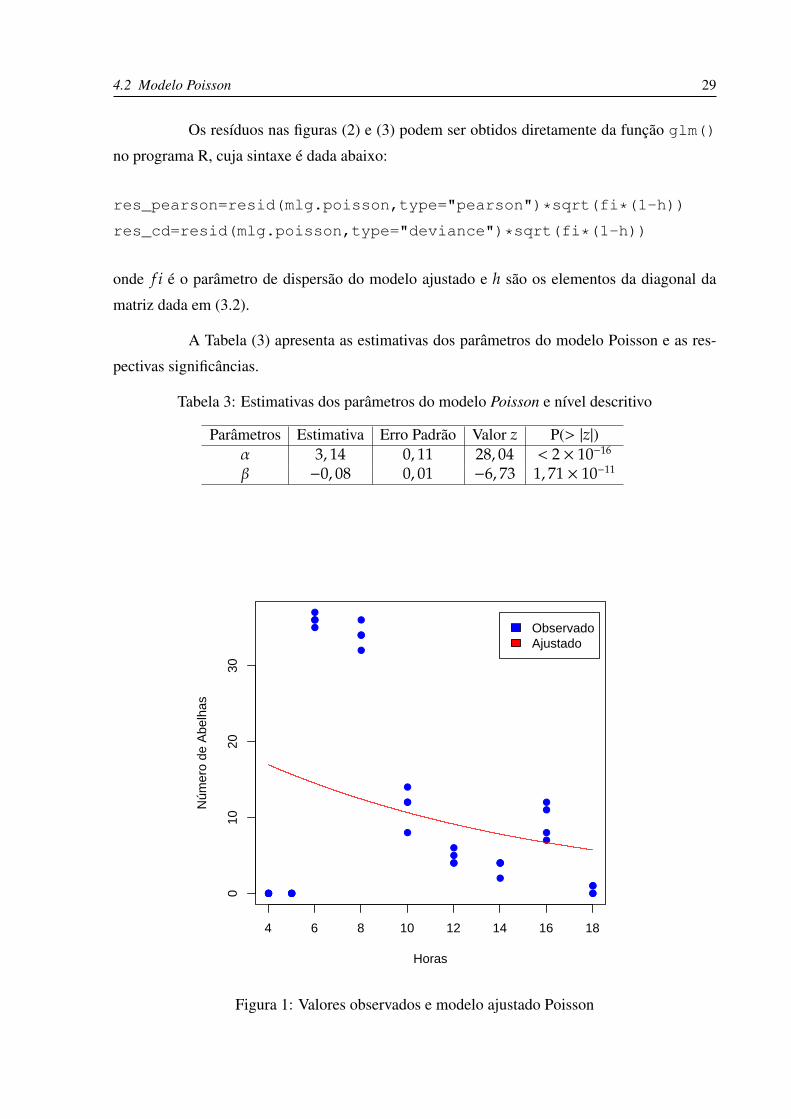
4.2 Modelo Poisson 29
Os resíduos nas figuras (2) e (3) podem ser obtidos diretamente da função glm()
no programa R, cuja sintaxe é dada abaixo:
res_pearson=resid(mlg.poisson,type="pearson")*sqrt(fi*(1-h))
res_cd=resid(mlg.poisson,type="deviance")*sqrt(fi*(1-h))
onde f i é o parâmetro de dispersão do modelo ajustado e h são os elementos da diagonal da
matriz dada em (3.2).
A Tabela (3) apresenta as estimativas dos parâmetros do modelo Poisson e as res-
pectivas significâncias.
Tabela 3: Estimativas dos parâmetros do modelo Poisson e nível descritivo
Parâmetros Estimativa Erro Padrão Valor z P(> |z|)α 3, 14 0, 11 28, 04 < 2 × 10−16
β −0, 08 0, 01 −6, 73 1, 71 × 10−11
●●●● ●●●● ●●
●●
●●
●
●
●●
●
●
●●
●●●
●
●
●●●
●
●
●
●
●●
4 6 8 10 12 14 16 18
010
2030
Horas
Núm
ero
de A
belh
as
ObservadoAjustado
Figura 1: Valores observados e modelo ajustado Poisson

4.3 Modelo Poisson Inflacionado de Zeros (ZIP) 30
● ● ● ● ● ●●●
●●●●●
●●●●●●
●●
●●●●
●
●
●
●●● ●
●● ●
●
−2 −1 0 1 2
−4
−2
02
46
Quantil da Normal Padrão
Res
íduo
de
Pea
rson
Pad
roni
zado
Figura 2: Envelope simulado para osresíduos de Pearson no modelo Poisson
● ● ● ● ● ●●●
●●
●●●
●●
●●●●
●●
●●●●
●
●●
●●● ●● ● ●
●
−2 −1 0 1 2
−4
−2
02
4
Quantil da Normal Padrão
Res
íduo
Com
pone
nte
do D
esvi
o
Figura 3: Envelope simulado para osComponentes do Desvio no modelo Poisson
Através da Figura (1) acima, verificamos que o ajuste não é muito bom. Ao analisar-
mos a Tabela (3) constamos que os parâmetros do modelo ajustado são altamente significativos,
no entanto, quando observamos a Deviance nula de 567, 14 com 35 graus de liberdade, corres-
pondendo ao modelo com apenas um parâmetro, ou seja, α, já podemos suspeitar da diferença
muito grande.
O valor da Deviance residual foi de 518.73 com 34 graus de liberdade, evidenciando
um ajuste não muito adequado, apesar da redução de 48, 41 com relação ao modelo nulo. Esse
fato é ocasionado possivelmente pela presença de superdispersão, devido ao excesso de zeros,
o que podemos constatar nas Figuras (2) e (3) através do envelopes simulado Poisson.
Podemos constatar também, uma outra medida da qualidade do ajuste, o AIC, que
mede o grau de informação que se perde ao adotar determinado modelo, desta forma, quanto
menor o AIC, melhor o ajuste. Para o modelo ZIP em questão, o Critério de Informação de
Akaike (AIC) foi de 629, 42. De posse dessas informações, modelos alternativos devem ser
considerados afim de melhor acomodar a extra variabilidade presente nos dados.
4.3 Modelo Poisson Inflacionado de Zeros (ZIP)
Na tentativa de controlar esse efeito de excesso de zeros, um modelo Poisson In-
flacionado de Zeros foi ajustado também com o auxilio computacional do R onde o ajuste do
modelo forneceu uma log-verossimilhança de −91.54 em 68 graus de liberdade, indicando um

4.3 Modelo Poisson Inflacionado de Zeros (ZIP) 31
ajuste mais adequado, onde temos um modelo ZIP em que o número de abelhas coletando po-
lens na i-ésima hora e j-ésima repetição é dado por:
log(
pi
1 − pi
)= α1 + β1horai (4.2)
onde (4.2) corresponde a função de ligação que modela a proporção de zeros.
log(λi) = α2 + β2horai (4.3)
onde (4.3) corresponde a função de ligação que modela as observações provenientes da Poisson.
Uma função interessante no programa R que ajusta o modelo ZIP e a sintaxe utili-
zada para obter os resultados da modelagem é descrita a seguir:
require(VGAM)
ajuste_zip = vglm(abelhas1 ~ hora1, zipoisson, trace=TRUE)
summary(ajuste_zip)
AIC(ajuste_zip)
Tabela 4: Estimativas dos parâmetros do modelo ZIP e nível descritivo
Parâmetros Estimativa Erro Padrão Valor t P(> |t|)α1 164, 71 422, 60 0, 04 0, 48α2 5, 13 0, 15 34, 40 < 2 × 10−16
β1 −29, 95 76, 60 −0, 04 0, 48β2 −0, 24 0, 02 −15, 03 < 2 × 10−16
Podemos constatar pela Figura (4) que o modelo ZIP ajustou-se bem aos dados,
quando comparado com o ajuste Poisson padrão. Verificamos através da Tabela (4) que os parâ-
metros relacionados a modelagem da proporção de zeros não são significativos a 5%, enquanto
os parâmetros relacionados as observações provenientes da Poisson são altamente significativos.
As estimativas dos parâmetros do modelo relacionada a Poisson quando comparadas
com o modelo Poisson padrão são ligeiramente diferentes, e uma observação interessante está
no erro padrão dos estimadores desses parâmetros, verificamos que no modelo ZIP o erro padrão
é ligeiramente superior ao erro padrão do modelo Poisson padrão, ratificando a superdispersão
e a consequente subestimação dos erros padrão.
O ajuste do modelo ZIP forneceu uma log-verossimilhança de −91.54 em 68 graus
de liberdade, o que nos dá um AIC de 191, 07, confirmando matematicamente que o modelo
ZIP melhor se ajusta aos dados do o modelo Poisson padrão, que forneceu um AIC de 629, 42.

4.3 Modelo Poisson Inflacionado de Zeros (ZIP) 32
●●●● ●●●● ●●
●●●●
●
●●●
●
●
●●
●●●●
●●●●
●
●
●
●
●●
4 6 8 10 12 14 16 18
−10
010
2030
4050
Horas
Núm
ero
de A
belh
as
ObservadoAjustado
Figura 4: Valores observados e modelo ajustado ZIP
●●●●●●●●
● ●
●●
●●
●
●
● ●
●
●
●●
●
●
●
●
●
●●●
●
●
●
●
●●
−2 −1 0 1 2
−2
−1
01
23
4
Percentis da N(0,1)
Res
íduo
s de
Pea
rson
Figura 5: Envelope simulado dos resíduos dePearson para o modelo ZIP
●●●●●●●●
●
●
●●●●●
●●●●●
●
●●●
●●
● ●● ●
● ●
● ●
●
●
0.0 0.5 1.0 1.5 2.0
01
23
4
Quantis Semi−Normais
Res
íduo
s de
Pea
rson
Figura 6: Envelope seminormal deprobabilidades para os resíduos de Pearson
no modelo ZIP

4.4 Modelo Binomial Negativo Inflacionado de Zeros (ZINB) 33
● ● ● ● ● ●●●●
●●
●●●●●●●●●●●●●●
●●●●
●
●
● ●
●
● ●
−2 −1 0 1 2
02
46
810
12
Percentis da N(0,1)
Res
íduo
s C
ompo
nent
es d
o D
esvi
o
Figura 7: Envelope simulado dos resíduosComponentes do Desvio para o modelo ZIP
●●●●●●●●●
●●
●●●●●●●●●●●●●●
● ● ● ●●
●
● ●
●● ●
0.0 0.5 1.0 1.5 2.0
05
1015
Quantis Semi−Normais
Res
íduo
s C
ompo
nent
es d
o D
esvi
o
Figura 8: Envelope seminormal deprobabilidades para os resíduos
Componentes do Desvio no modelo ZIP
4.4 Modelo Binomial Negativo Inflacionado de Zeros (ZINB)
Como uma forma de comparar os resultados obtidos, ajustou-se um modelo Bino-
mial Negativo Inflacionado de Zeros na tentativa de melhor acomodar o excesso de zeros, onde
foi obtido com auxilio computacional do R uma log-verossimilhança de −79.24 em 102 graus
de liberdade, indicando um ajuste melhor que os outros dois modelos ajustados. O modelo
ZINB em que o número de abelhas coletando polens na i-ésima hora e j-ésima repetição é dado
por:
log(
pi
1 − pi
)= α1 + β1horai (4.4)
onde (4.4) corresponde a função de ligação que modela a proporção de zeros.
log(µi) = α2 + β2horai (4.5)
onde (4.5) corresponde a função de ligação que modela as observações provenientes da Bino-
mial Negativa.
log(ki) = α3 + β3horai (4.6)
onde k é o parâmetro da distribuição Binomial Negativa associado a dispersão da distribuição.
Assim como para o modelo ZIP existe uma função desenvolvida no programa R,
também existe uma função para o modelo ZINB, no entanto, alguns aspectos da função carece
de ajuste, como podemos constatar pelas variações sofrida pelas estimativas dos parâmetros

4.4 Modelo Binomial Negativo Inflacionado de Zeros (ZINB) 34
relacionada a modelagem da proporção de zeros. Apesar disso, a função mostrou-se bastante
útil e ajustou-se bem aos dados, a seguir descrevemos a sintaxe utilizada para obter os resultados
do ajuste:
require(VGAM)
ajuste_zinb = vglm(abelhas1 ~ hora1,
zinegbinomial(zero=NULL), trace=TRUE)
summary(ajuste_zinb)
AIC(ajuste_zinb)
Tabela 5: Estimativas dos parâmetros do modelo ZINB e nível descritivo
Parâmetros Estimativa Erro Padrão Valor t P(> |t|)α2 5, 17 0, 22 23, 40 < 2 × 10−16
α3 7, 00 2, 00 3, 51 3.34 × 10−4
β2 −0, 25 0, 03 −9, 40 8, 66 × 10−16
β3 −0, 43 0, 14 −3, 08 1, 3 × 10−3
●●●● ●●●● ●●
●●●●
●
●●●
●
●
●●
●●●●
●●●●
●
●
●
●
●●
4 6 8 10 12 14 16 18
−10
010
2030
4050
Horas
Núm
ero
de A
belh
as
ObservadoAjustado
Figura 9: Valores observados e modelo ajustado ZINB

4.4 Modelo Binomial Negativo Inflacionado de Zeros (ZINB) 35
A Figura (9) mostra que o modelo ZINB ajusta-se bem aos dados, percebemos que
o ajuste é muito semelhante ao mostrado na Figura (4). A Tabela (5) confirma isso, verificamos
que as estimativas dos parâmetros do modelo são bem próximas e mostrando-se altamente sig-
nificativas para o modelo ajustado, no entanto, quando partimos para a análise de resíduos e as
medidas que quantificam a qualidade do ajuste, percebemos a diferença.
Uma outra observação interessante está no erro padrão dos estimadores dos parâ-
metros, como já foi constatado anteriormente, mais uma vez foi verificado o aumento do erro
padrão para os estimadores relacionados as observações que provém da distribuição Binomial
Negativa, mostrando que o modelo ZINB contempla de forma satisfatória, melhor que o modelo
ZIP, a superdispersão presente devido ao excesso de zeros.
Como já foi mencionado anteriormente, o modelo ZINB forneceu uma log-verossimilhança
de −79, 24 com 102 graus de liberdade, o que nos dá um AIC de 170, 49. Comparativamente
ao modelo ZIP, o modelo ZINB perde menos informação, já que o primeiro apresenta um AIC
de 191, 07 e comparativamente ao modelo Poisson padrão apresenta uma diferença bastante
significativa, mostrando ser o modelo mais adequado nesse caso.
●●●●●●●●
●● ● ●● ●
●
●● ●
●
●
●●
●●
●●
●●● ●
●
●
●
●
●●
−2 −1 0 1 2
05
10
Percentis da N(0,1)
Res
íduo
s de
Pea
rson
Figura 10: Envelope simulado dos resíduosde Pearson para o modelo ZINB
●●●●●●●●●
●●●●●●●●●●●●●●●●● ● ● ● ● ●
● ●●
●●
0.0 0.5 1.0 1.5 2.0
02
46
810
Quantis Semi−Normais
Res
íduo
s de
Pea
rson
Figura 11: Envelope seminormal deprobabilidades para os resíduos de Pearson
no modelo ZINB
Através dos envelopes simulados podemos observar o comportamento dos resíduos
de Pearson e Componentes do Desvio para o modelo ZINB. Constatamos através das Figuras
(10) e (11) que os resíduos de Pearson estão todos praticamente sobre uma linha, evidenciando
a suposição de distribuição adequada para o modelo em estudo, assim como os resíduos Com-
ponentes do Desvio, mostrando a maioria dos pontos dentro das bandas de confiança de 95%,

4.5 Ajuste do 2o grau para os modelos Poisson, ZIP e ZINB 36
como podemos verificar pelas Figuras (12) e (13).
● ● ● ● ● ●●●●
●●●●●●●●●●●●●●●●
●●
●●●
●● ● ●
● ●
−2 −1 0 1 2
02
46
810
Percentis da N(0,1)
Res
íduo
s C
ompo
nent
es d
o D
esvi
o
Figura 12: Envelope simulado para osresíduos Componentes do Desvio para o
modelo ZINB
●●●●●●●●●
●●●●●●●●●●●●●●●●
● ●
● ● ●
●● ● ●
● ●
0.0 0.5 1.0 1.5 2.0
02
46
810
12
Quantis Semi−Normais
Res
íduo
s C
ompo
nent
es d
o D
esvi
o
Figura 13: Envelope seminormal deprobabilidades para os resíduos
Componentes do Desvio no modelo ZINB
4.5 Ajuste do 2o grau para os modelos Poisson, ZIP e ZINB
Afim de obter uma análise geral dos dados em questão, um ajuste do 2o grau foi
realizado para os três modelos propostos no estudo. Para o modelo Poisson da mesma forma
como dado em (4.1), temos a inclusão de um parâmetro referente ao termo do 2o grau, ou seja,
log(λi) = α + βhorai + γhorai2 (4.7)
Para o modelo ZIP também temos a inclusão do termo do 2o grau, sendo o modelo
da mesma forma como dado em (4.2) e (4.3), ou seja,
log(
pi
1 − pi
)= α1 + β1horai + γ1horai
2 (4.8)
onde (4.8) corresponde a função de ligação que modela a proporção de zeros.
log(λi) = α2 + β2horai + γ2horai2 (4.9)
onde (4.9) corresponde a função de ligação que modela as observações provenientes da Poisson.
O modelo ZINB considerando o termo do 2o grau, passa a ser escrito da seguinte
4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 37
maneira,
log(
pi
1 − pi
)= α1 + β1horai + γ1horai
2 (4.10)
onde (4.10) corresponde a função de ligação que modela a proporção de zeros.
log(µi) = α2 + β2horai + γ2horai2 (4.11)
onde (4.11) corresponde a função de ligação que modela as observações provenientes da Bino-
mial Negativa.
log(ki) = α3 + β3horai + γ3horai2 (4.12)
onde k é o parâmetro da distribuição Binomial Negativa associado a dispersão da distribuição.
Tabela 6: Estimativas dos parâmetros 2o grau dos modelos Poisson, ZIP e ZINB e níveldescritivo
Modelo Parâmetro Estimativa Erro Padrão Valor z P(> |z|) Valor t P(> |t|)α −0, 44 0, 37 −1, 20 0, 23 - -
Poisson β 0, 79 0, 08 9, 48 < 2 × 10−16 - -γ −0, 04 4 × 10−3
−10, 13 < 2 × 10−16 - -α1 240, 30 6805, 80 - - 0, 04 0, 48β1 −57, 19 1611, 90 - - −0, 04 1, 86 × 10−18
γ1 2, 44 68, 61 - - 0, 04 0, 48ZIP α2 5, 81 0, 48 - - 11, 94 1, 12 × 10−4
β2 −0, 40 0, 10 - - −3, 90 0, 48γ2 7, 9 × 10−3 4, 8 × 10−3 - - 1, 66 0, 05α2 4, 60 0, 70 - - 6, 51 1, 56 × 10−9
β2 −0, 13 0, 15 - - −0, 84 0, 20γ2 −4, 6 × 10−3 7, 8 × 10−3 - - −0, 60 0, 27
ZINB α3 13, 78 10, 38 - - 1, 32 0, 09β3 −1, 68 1, 66 - - −1, 01 0, 15γ3 5, 3 × 10−2 6, 5 × 10−2 - - 0, 80 0, 20
4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB
Assim como no ajuste do 2o grau para os modelos propostos, também foi ajustado
modelos do 3o grau, uma vez que o gráfico das observações parece apresentar uma forma cúbica.
Desta forma temos a inclusão de um parâmetro referente ao termo do 3o grau para os três
modelos, ou seja, no caso Poisson temos,
log(λi) = α + βhorai + γhorai2 + δhorai
3 (4.13)
Já no modelo ZIP temos a inclusão do termo do 3o grau como é mostrado em (4.14)

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 38
●●●● ●●●● ●●
●●●●
●
●●●
●
●
●●
●●●●
●●●●
●
●
●
●
●●
4 6 8 10 12 14 16 18
−10
010
2030
4050
Horas
Núm
ero
de A
belh
as
AIC
Poisson:491,81ZIP:188,41ZINB:175,99
Figura 14: Valores observados e modelos 2o grau ajustados

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 39
● ● ● ●
● ●●●●●●●
●●●●
●
●●●
●●
●●
●
●●●
●
●
●● ●
● ●
●
−2 −1 0 1 2
−2
02
46
Quantil da Normal Padrão
Res
íduo
de
Pea
rson
Pad
roni
zado
Figura 15: Envelope simulado dosresíduos de Pearson para o modelo
Poisson 2o grau
● ● ● ●
● ●●●
●●●●
●●
●●
●
●●●●●
●●
●●
●●●●
●
● ●● ●
●
−2 −1 0 1 2
−4
−2
02
4
Quantil da Normal Padrão
Res
íduo
Com
pone
nte
do D
esvi
o
Figura 16: Envelope simulado dosresíduos Componentes do Desvio
para o modelo Poisson 2o grau
●●●●●●●●●
●●
●●
●
●●●●●●●●
●
●●
● ● ● ● ●
●
● ●
●
●
●
0.0 0.5 1.0 1.5 2.0
01
23
Quantis Semi−Normais
Res
íduo
s
Figura 17: Envelope simulado dosresíduos de Pearson para o modelo
ZIP 2o grau
●●●●●●●●●
●●●●●●●●●
●●●●●●●●● ●
● ●
● ● ●
●
● ●
0.0 0.5 1.0 1.5 2.0
05
1015
Quantis Semi−Normais
Res
íduo
s
Figura 18: Envelope simulado dosresíduos Componentes do Desvio
para o modelo ZIP 2o grau
●●●●●●●●●●●●●●●●●●●●●●●●●● ● ● ●
● ● ● ●●
●●
0.0 0.5 1.0 1.5 2.0
02
46
810
12
Quantis Semi−Normais
Res
íduo
s
Figura 19: Envelope simulado dosresíduos de Pearson para o modelo
ZINB 2o grau
●●●●●●●●●●●●
●●●●●●●●●●●●●● ●● ●
●● ● ● ●
●●
0.0 0.5 1.0 1.5 2.0
05
1015
Quantis Semi−Normais
Res
íduo
s
Figura 20: Envelope simulado dosresíduos Componentes do Desvio
para o modelo ZINB 2o grau

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 40
e (4.15), o modelo sendo definido da mesma forma como em (4.2) e (4.3), ou seja,
log(
pi
1 − pi
)= α1 + β1horai + γ1horai
2 + δ1horai3 (4.14)
onde (4.14) corresponde a função de ligação que modela a proporção de zeros.
log(λi) = α2 + β2horai + γ2horai2 + δ2horai
3 (4.15)
onde (4.15) corresponde a função de ligação que modela as observações provenientes da Pois-
son.
O modelo ZINB considerando o termo do 3o grau, pode ser escrito da seguinte
maneira,
log(
pi
1 − pi
)= α1 + β1horai + γ1horai
2 + δ1horai3 (4.16)
onde (4.16) corresponde a função de ligação que modela a proporção de zeros.
log(µi) = α2 + β2horai + γ2horai2 + δ2horai
3 (4.17)
onde (4.17) corresponde a função de ligação que modela as observações provenientes da Bino-
mial Negativa.
log(ki) = α3 + β3horai + γ3horai2 + δ3horai
3 (4.18)
onde k é o parâmetro da distribuição Binomial Negativa associado a dispersão da distribuição.
A Tabela (7) fornece informações acerca do ajuste 3o grau para os modelos Poisson,
ZIP e ZINB.
Como podemos perceber pelas Figuras (14) e (21), o modelo que melhor se ajusta
aos dados é o ajuste ZINB do 3o grau. Verificamos também que tanto no ajuste 2o grau, como no
3o grau, o modelo ZINB é o que melhor se ajusta aos dados. No ajuste 2o grau, como podemos
constatar pelos envelopes nas Figuras (19) e (20), o modelo ZINB é o que melhor se ajusta aos
dados, o que é evidenciado pelo critério de informação de Akaike, onde o modelo ZINB é o que
apresenta o menor AIC, 175, 99. Já o ajuste 3o grau, o modelo ZINB não apresenta o menor
AIC, no entanto, como pode ser observado na Figura (21) é o ajuste que melhor descreve os
dados observados.
Uma observação importante é que a função utilizada no programa R para ajustar os
modelos inflacionados, vglm(), como já citada anteriormente, apresenta uma instabilidade nas
estimativas dos parâmetros referente a proporção de zeros do modelo ZINB, essa instabilidade
fica ainda mais evidente quando se aumenta o número de parâmetros do modelo. Desta forma,

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 41
Tabela 7: Estimativas dos parâmetros 3o grau dos modelos Poisson, ZIP e ZINB e níveldescritivo
Modelo Parâmetro Estimativa Erro Padrão Valor z P(> |z|) Valor t P(> |t|)α −11, 12 1, 11 −9, 94 < 2 × 10−16 - -
Poisson β 4, 49 0, 36 12, 47 < 2 × 10−16 - -γ −0, 43 3, 6 × 10−2
−12, 00 < 2 × 10−16 - -δ 0, 01 0, 1 × 10−2 11, 18 < 2 × 10−16 - -α1 4, 74 422330 - - 1, 1 × 10−5 0, 49β1 41, 44 178290 - - 2, 3 × 10−4 0, 49γ1 −10, 01 22676 - - −4, 4 × 10−4 0, 49δ1 0, 43 781, 90 − - 5, 4 × 10−4 0, 49
ZIP α2 1, 50 1, 64 - - 0, 90 0, 18β2 0, 96 0, 50 - - 1, 90 0, 03γ2 −0, 12 4, 7 × 10−4 - - −2, 50 7, 4 × 10−3
δ2 4 × 10−3 1, 4 × 10−3− - 2, 77 3, 6 × 10−3
α2 −7, 40 1, 45 - - −5, 09 8, 8 × 10−7
β2 4, 00 0, 45 - - 8, 80 2, 8 × 10−14
γ2 −0, 44 4, 6 × 10−2 - - −9, 70 3, 2 × 10−16
δ2 1, 4 × 10−2 1, 5 × 10−3 - - 9, 84 1, 6 × 10−16
ZINB α3 −188, 18 16, 05 - - −11, 73 1, 5 × 10−20
β3 62, 32 3, 84 - - 16, 21 1, 5 × 10−29
γ3 −5, 01 0, 30 - - −16, 74 1, 5 × 10−30
δ3 0, 11 7, 5 × 10−3 - - 15, 60 2, 2 × 10−28
●●●● ●●●● ●●
●●●●
●
●●●
●
●
●●
●●●●
●●●●
●
●
●
●
●●
4 6 8 10 12 14 16 18
−10
010
2030
4050
Horas
Núm
ero
de A
belh
as
AIC
Poisson:356,80ZIP:184,95ZINB:276.69
Figura 21: Valores observados e modelos 3o grau ajustados

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 42
● ● ● ●●
●●●●
●●●●●●●
●●
●
●●●●●
●
●●●
●●●
● ●
●
●
●
−2 −1 0 1 2
−2
02
46
Quantil da Normal Padrão
Res
íduo
de
Pea
rson
Pad
roni
zado
Figura 22: Envelope simulado dosresíduos de Pearson para o modelo
Poisson 3o grau
● ● ● ●
●●●
●●●●●●●●
●●●
●
●●●
●●
●
●●●
●●
● ● ● ●
●
●
−2 −1 0 1 2
−4
−2
02
4
Quantil da Normal PadrãoR
esíd
uo C
ompo
nent
e do
Des
vio
Figura 23: Envelope simulado dosresíduos Componentes do Desvio
para o modelo Poisson 3o grau
●●●●●●●●
●●●●●
●●●●●●
●●
●●●●
●● ●
● ●●
●●
●
●
●
0.0 0.5 1.0 1.5 2.0
01
23
4
Quantis Semi−Normais
Res
íduo
s
Figura 24: Envelope simulado dosresíduos de Pearson para o modelo
ZIP 3o grau
●●●●●●●●●●
●●●●●●●●●●●●●
●●● ●●
● ●● ● ●
●
● ●
0.0 0.5 1.0 1.5 2.0
05
1015
Quantis Semi−Normais
Res
íduo
s
Figura 25: Envelope simulado dosresíduos Componentes do Desvio
para o modelo ZIP 3o grau

4.6 Ajuste do 3o grau para os modelos Poisson, ZIP e ZINB 43
o ajuste do 3o grau para o modelo ZINB, não apresenta uma consistência nas estimativas dos
parâmetros do modelo e varia consideravelmente conforme o número de interações aumente
ou diminua e ainda, por vezes, não obtém convergência. Com isso, a utilização dos envelopes
simulados para os resíduos em estudo não pôde ser utilizada para o modelo ZINB 3o grau, em
virtude dessa deficiência computacional da função observada ao longo do trabalho.

44
CONSIDERAÇÕES FINAIS
Este trabalho tem como objetivo principal apresentar os Modelos Inflacionados de
Zeros, dentro da metodologia dos MLG’s, bem como uma análise de diagnóstico para os mo-
delos em estudo com uma aplicação prática da metodologia utilizada. Embora seja bastante co-
mum encontrarmos conjuntos de dados que apresentem uma alta quantidade de valores “zero”,
e que uma quantidade razoável de material já tem sido publicado nessa área, a análise de diag-
nóstico é pouca explorada. Nesse sentido, procurou-se explorar essa temática dando ênfase na
análise de resíduos de Pearson e componentes do desvio. A restrição do trabalho a esses tipos
de resíduos deu-se pela dificuldade encontrada de obter material relativo a temática explorada.
A questão computacional nesse caso é de suma importância, dada a complexidade
dos algoritmos a serem utilizados. Um segundo objetivo, não menos importante, foi o de ajustar
estes modelos com um algoritmo implementado em ambiente R, um software estatístico livre,
como forma de divulgar o mesmo. A linguagem R, versátil, mostrou-se bastante útil com fun-
cionalidades já desenvolvidas para os modelos inflacionados de zeros, facilitando sobremaneira
o trabalho desenvolvido.
No exemplo abordado no Capítulo 4 observamos através das Tabelas (3), (4) e (5)
que as estimativas dos parâmetros correspondente aos zeros amostrais nos modelos inflaciona-
dos como na Poisson padrão são próximas, no entanto, quando verificamos o erro padrão das
estimativas percebemos uma diferença bastante significativa, principalmente do modelo Pois-
son padrão para o modelo Binomial Negativo Inflacionado de Zeros, onde temos o modelo mais
pobre e o modelo mais adequado aos dados respectivamente. Sabemos que a superdispersão
causa sérios problemas com a subestimação do erro padrão das estimativas, como podemos
constatar neste caso.
Uma análise do envelope simulado do modelo Poisson padrão mostra um ajuste
bem pobre dos dados em estudo, evidenciando a superdispersão dos dados devido ao excesso
de zeros. Uma análise dos resíduos de Pearson estudentizados do modelo Poisson Inflacionado
de Zeros mostra um comportamento aproximadamente normal com algumas obervações mere-
cendo uma atenção especial. Já o modelo Binomial Negativo Inflacionado de Zeros apresenta os
resíduos de Pearson estudentizados de forma mais homogênea, sem apresentar observações dis-

Considerações Finais 45
crepantes que mereçam atenção, indicando um ajuste mais adequado onde contempla de forma
satisfatória a superdispersão presente nos dados.
Com a inclusão dos termos do segundo e terceiro graus, uma nova análise deve
ser traçada e como podemos observar, o ajuste ZINB nos dois casos, também foi o mais ade-
quado. Através das Figuras e Tabelas podemos verificar que o ajuste ZINB terceiro grau foi
o mais adequado de todos os modelos considerados no trabalho, uma vez que ele melhor des-
creveu os dados observados. Como já citado anteriormente, a instabilidade da função utilizada
para descrever o ajuste ZINB prejudicou a análise de diagnóstico, dado a falta de consistência
nas estimativas dos parâmetros do modelo, principalmente quando se aumentou o número de
parâmetros no modelo.
Há muito a ser explorado na análise de diagnóstico dos modelos inflacionados de
zeros. Diversos temas podem ser explorados nesse sentido, como por exemplo a análise de
influência local para os modelos citados, inclusive esse tema já vem sendo estudado para publi-
cação de trabalhos futuros, desta forma procuramos contribuir de alguma forma com uma área
tão abrangente de problemas práticos.

46
REFERÊNCIAS
AKAIKE, H., A new look at the statistical model identification, Automatic Control, IEEETransactions on, v. 19, p. 716-723, 1974.
BASSO, R.M., Misturas finitas de misturas de escala Skew-Normal. 96f. Dissertação(Mestrado em Estatística) - Instituto de Matemática, Estatística e Computação Científica,Universidade Estadual de Campinas, Campinas, 2009.
CAMERON, A.C.; TRIVEDI, P.K., Regression Analysis of Count Data, Cambridge:Cambridge University Press, 1998.
CELEUX, G.; SOROMENHO, G., An entropy criterion for assessing the number of clusters ina mixture model, Classification Journal, v.13, p. 195-212, 1996.
CORDEIRO, G.M., Modelos Lineares Generalizados, Campinas: VII SINAPE, 1986.
CORDEIRO, G.M.; DEMÉTRIO, C.G.B., Modelos Lineares Generalizados. 52a reuniãoAnual da RBRAS 12a SEAGRO, Piracicaba: ESALQ, Departamento de Ciências Exatas, 2007.
COX, D.R.; SNEL, E.J., A general definition of residuals, Journal of the Royal StatisticalSociety B, v. 30, p. 248-275, 1968.
JORGENSEN, B., Exponential dispersion models (with discussion), Journal of the RoyalStatistical Society B, v. 49, p. 127-162, 1987.
LAMBERT, D., Zero-inflated poisson regression, with an application to defects inmanufacturing, Technometrics, v.34, p. 1-14, 1992.
LINDSEY, J.K., Construction and comparison of statistical models, Journal of the RoyalStatistical Society B, v. 36, p. 418-425, 1974b.
MCCULLAGH, P.; NELDER, J.A., Generalized Linear Models, New York: Chapman andHall, 1989.
MONTOYA, A.G.M., Inferência e diagnóstico em modelos para dados de contagem comexcesso de zeros. 107f. Dissertação (Mestrado em Estatística) - Instituto de Matemática,Estatística e Computação Científica, Universidade Estadual de Campinas, Campinas, 2009.
NAGAMINE, C.M.L.; CANDOLO, C.; MOURA, M.S.A., Uma aplicação de modelos paradados de contagem inflacionados de zeros na modelagem do número de ovos do mosquitoAedes aegypti, Revista Brasileira de Biometria , v. 26, p. 99-114, 2008.
NELDER, J.A.; WEDDERBURN, R.W.M., Generalized Linear Models, Journal of the RoyalStatistical Society A, v. 135, p. 370-384, 1972.

Referências 47
PAULA, G.A., Modelos de Regressão com Apoio Computacional, São Paulo: IME-USP,Versão preliminar, 2004.
R DEVELOPMENT CORE TEAM. R: A language and environment for statistical computing,R Foundation for Statistical Computing, Vienna, Austria, 2008. ISBN 3-900051-07-0,Disponível em <http://www.R-project.org>. Acesso em:26/04/2009.
RIDOUT, M.; HINDE, J.P.; DEMÉTRIO, C.G.B, Models for count data with many zeros,International Biometric Conference, Cape Town, p. 1-13, 1998.
RIZZARDO, R.A.G., O Papel de Apis mellifera L. como polinizador da Mamoneira(Ricinus communis L.): Avaliação da eficiência de polinização das abelhas e incremento deprodutividade da cultura. 80f. Dissertação (Mestrado em Zootecnia) - Faculdade de Zootecnia,Universidade Federal do Ceará, Fortaleza, 2007.
WEISBERG, S., Applied Linear Regression, New York: John Wiley, Terceira edição, 2005.
WILLIAMS, D.A., Generalized linear model diagnostic using the deviance and single casedeletion, Applied Statistics, v.36, p. 181-191, 1987.
YAU, K.K.W.; WANG, K.; LEE, A.H., Zero-inflated negative binomial mixed regressionmodeling of over-dispersed count data with extra zeros, Biometrical journal, v.45, p. 437-452,2003.
YEE, T.W., VGAM: Vector Generalized Linear and Additive Models, R package version 0.7-8,2009. Disponível em <http://www.stat.auckland.ac.nz/ yee/VGAM>. Acesso em:02/05/2009.

48
APÊNDICE
Apêndice A - Função para construção do envelope simuladoPoisson
Esta função foi obtida através do site http://www.poleto.com/funcoes.html, no dia
17 de dezembro de 2008 às 16 horas.
envel.pois <- function(modelo=fit.model,iden=0,
nome=seq(along = model.matrix(modelo)[,1]),sim=100,
conf=.90,res="D",offvar=NULL,
quad=T,maxit=20) {
if(class(modelo)[1] != "glm") {
stop(paste("\nA classe do objeto deveria ser glm e nao ",
class(modelo),"!!!\n"))
}
quasi<-F
if(modelo$family[[1]] != "Poisson" & modelo$family[[1]]
!= "poisson") {
if(modelo$family[[1]] == "quasipoisson" ||
( modelo$family[[1]] == "Quasi-likelihood" & modelo$family[[3]]
== "Identity: mu") ) {
quasi<-T
} else {
stop(paste("\nA familia do objeto deveria
ser Poisson e nao ",modelo$family[[1]],"!!!\n"))
}}
if(length(iden)>1) {
iden<--1
}
alfa<-(1-conf)/2
X <- model.matrix(modelo)

4.0 Apêndice A - Função para construção do envelope simulado Poisson 49
n <- nrow(X)
p <- ncol(X)
w <- modelo$weights
W <- diag(w)
H <- solve(t(X)%*%W%*%X)
H <- sqrt(W)%*%X%*%H%*%t(X)%*%sqrt(W)
h <- diag(H)
#para evitar divisão por 0 ao studentizar os
residuos, mas tentando manter o valor exagerado
da alavanca
h[round(h,15)==1]<-0.999999999999999
m<-predict(modelo,type="response")
y<-modelo$y
fi <- 1
if(quasi==T) {
fi <- 1/summary(modelo)$dispersion
}
if(is.null(version$language) == F) {
offvar<-modelo$offset
}
if(is.null(offvar)) {
offvar<-rep(0,n)
} else {
if (length(offvar)!=n) {
stop(paste("\nO vetor do offset deve conter o mesmo
comprimento das variaveis do modelo !!!\n"))
}}
if(res=="Q") {
cat("Ao utilizar o residuo Quantil para distribuicoes
discretas, sugere-se plotar pelo menos 4 graficos para
evitar conclusoes viesadas pela aleatoriedade que esta

4.0 Apêndice A - Função para construção do envelope simulado Poisson 50
sendo incluida.\n")
tipo<-"Resíduo Quantil"
r<-qnorm( runif(n=n,min=ppois(y-1,m),max=ppois(y,m)) *sqrt(fi) )
} else {
if(res=="D") {
tipo<-"Resíduo Componente do Desvio"
r<-resid(modelo,type="deviance")*sqrt(fi*(1-h))
} else {
if(res=="P") {
tipo<-"Resíduo de Pearson Padronizado"
r<-resid(modelo,type="pearson")*sqrt(fi*(1-h))
} else {
if(res=="A") {
tipo<-"Resíduo de Anscombe"
r<-1.5*sqrt(fi)*( y^(2/3) - m^(2/3) )/(m^(1/6))
} else {
if(res=="W") {
tipo<-"Resíduo de Williams"
r<-sign(y-m)*sqrt((1-h)*(( resid(modelo,type="deviance")*
sqrt(fi/(1-h)) )^2)+(h*( resid(modelo,type="pearson")*
sqrt(fi/(1-h)) )^2))
} else {
if(res=="C") {
tipo<-"Distância de Cook"
r<-(h/((1-h)*p))*((resid(modelo,type="pearson")/sqrt(1-h))^2)
} else {
stop(paste("\nVoce nao escolheu corretamente um dos
residuos disponiveis!!!\n"))
}}}}}}
link<-modelo$family[[2]]
e <- matrix(0,n,sim)
e1 <- numeric(n)
e2 <- numeric(n)
if (is.null(version$language) == T) {

4.0 Apêndice A - Função para construção do envelope simulado Poisson 51
#No S-Plus, a opção start é para entrar com o preditor linear
pm<-predict(modelo)
} else {
#No R, a opção start é para entrar com os coeficientes
pm<-coef(modelo)
}
mu<-m
for(i in 1:sim) {
resp <- rpois(n,mu)
if ( (is.null(version$language) == T && link ==
"Log: log(mu)") | (is.null(version$language) ==
F && link == "log") ) { fit <- glm(resp ~ X-1+offset(offvar),
family=poisson,maxit=maxit,start=pm)
} else {
if ( (is.null(version$language) == T && link ==
"Square Root: sqrt(mu)") | (is.null(version$language) ==
F && link == "sqrt") ) { fit <- glm(resp ~ X-1+offset(offvar),
family=poisson(link=sqrt),maxit=maxit,start=pm)
} else {
if ( (is.null(version$language) == T && link ==
"Identity: mu") | (is.null(version$language) == F
&& link == "identity") ) { fit <- glm(resp ~ X-1+
offset(offvar),family=poisson(link=identity),
maxit=maxit,start=pm)
} else {
stop(paste("\nEsta funcao so aceita as ligacoes:
canonica (log), raiz quadrada e identidade!!!\nLigacao
",link," desconhecida!!!\n"))
}}}
w <- fit$weights
W <- diag(w)
H <- solve(t(X)%*%W%*%X)
H <- sqrt(W)%*%X%*%H%*%t(X)%*%sqrt(W)
h <- diag(H)
h[round(h,15)==1]<-0.999999999999999

4.0 Apêndice A - Função para construção do envelope simulado Poisson 52
m <- predict(fit,type="response")
y <- fit$y
e[,i] <-
sort( if(res=="Q") {
qnorm( runif(n=n,min=ppois(y-1,m),max=ppois(y,m)) )
} else {
if(res=="D") {
resid(fit,type="deviance")/sqrt(1-h)
} else {
if(res=="P") {
resid(fit,type="pearson")/sqrt(1-h)
} else {
if(res=="A") {
1.5*( y^(2/3) - m^(2/3) )/(m^(1/6))
} else {
if(res=="W") {
sign(y-m)*sqrt((1-h)*(( resid(fit,type="deviance")/
sqrt(1-h) )^2)+(h*( resid(fit,type="pearson")/sqrt(1-h) )^2))
} else {
if(res=="C") {
(h/((1-h)*p))*((resid(fit,type="pearson")/sqrt(1-h))^2)
} else {
stop(paste("\nVoce nao escolheu corretamente um dos residuos
disponiveis!!!\n"))
}}}}}
})
}
for(i in 1:n) {
eo <- sort(e[i,])
e1[i] <- quantile(eo,alfa)
e2[i] <- quantile(eo,1-alfa)
}
med <- apply(e,1,median)
if(quad==T) {

4.0 Apêndice A - Função para construção do envelope simulado Poisson 53
par(pty="s")
}
if(res=="C") {
#Segundo McCullagh e Nelder (1989, pág.407) e
Paula (2003, pág.57) deve-se usar qnorm((n+1:n+.5)/(2*n+1.125))
#Segundo Neter et alli (1996, pág.597) deve-se usar
qnorm((n+1:n-.125)/(2*n+0.5))
qq<-qnorm((n+1:n+.5)/(2*n+1.125))
plot(qq,sort(r),xlab="Quantil Meio-Normal",ylab=tipo,
ylim=range(r,e1,e2), pch=16)
} else {
qq<-qnorm((1:n-.375)/(n+.25))
plot(qq,sort(r),xlab="Quantil da Normal Padrão",ylab=tipo,
ylim=range(r,e1,e2), pch=16)
}
lines(qq,e1,lty=1)
lines(qq,e2,lty=1)
lines(qq,med,lty=2)
nome<-nome[order(r)]
r<-sort(r)
while ( (!is.numeric(iden)) || (round(iden,0) != iden)
|| (iden < 0) ) {
cat("Digite o num.de pontos a ser identificado (0=nenhum)
e <enter> para continuar\n")
out <- readline()
iden<-as.numeric(out)
}
if(iden>0) {identify(qq,r,n=iden,labels=nome)}
if(quad==T) {
par(pty="m")
}
cat("Banda de ",conf*100,"% de confianca,
obtida por ",sim," simulacoes.\n")
}

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 54
Apêndice B - Resíduos de Pearson e Componentes do DesvioEstudentizados
Modelo ZIP
### Ajustando um ZIP ###
ajuste_zip = vglm(abelhas1 ~ hora1, zipoisson, trace=TRUE)
#############################################################
################### Resíduos Padronizados ###################
#############################################################
y=(ajuste_zip)@y
mi=fitted(ajuste_zip)
r=y-mi;round(r,4)
fi=exp(predict(ajuste_zip)[,1])/(1+exp(predict(ajuste_zip)[,1]))
a=1-fi
X=ajuste_zip@x
A=diag(a)
w=weights(ajuste_zip,matrix.arg = T,type="working")
w=w[,2]
W=diag(w)
H=sqrt(W)%*%X%*%solve(t(X)%*%W%*%X)%*%t(X)%*%sqrt(W)
h=diag(H)
V=vcov(ajuste_zip)
### Função de variância:
## Poisson Inflacionada de zeros
Vp=mi+(fi/(1-fi))*mi^2

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 55
## Resíduos de Pearson Estudentizados:
r_pearson = r/sqrt(Vp)
r_pearson_est = r/sqrt(Vp*(1-h));r_pearson_est
[,1]
1 0.0000000000
2 0.0000000000
3 0.0000000000
4 0.0000000000
5 -0.0005565164
6 -0.0005565164
7 -0.0005565164
8 -0.0005565164
9 -1.5137491275
10 -1.5137491275
11 -0.6344058757
12 -0.4594508929
13 -0.8093608585
14 -0.6344058757
15 1.5870752740
16 2.4240407976
17 2.0055580358
18 2.0055580358
19 -0.2750555987
20 -1.8573012942
21 -0.8024708306
22 -0.8024708306
23 -1.7746724864
24 -1.4378305014
25 -1.7746724864
26 -1.1009885165
27 -1.5978672649
28 -0.7366453945
29 -0.7366453945

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 56
30 -0.7366453945
31 4.6567451357
32 1.9114858814
33 4.1076932848
34 2.4605377323
35 -0.8154992556
36 -0.8154992556
## Resíduos Componentes do Desvio:
## Modelo Corrente ##
fi_cor=exp(predict(ajuste_zip)[,1])/(1+exp(predict(ajuste_zip)[,1]))
lambda_cor=exp(predict(ajuste_zip)[,2])
mu=y[9:36] ### mu=média da Poisson p/ não zeros ###
fr=c(10,10,3,1,1,3,1,3,2,2,1,2,3,3,5,1,5,1,1,5,5,5,3,
1,1,2,2,2)
## Log-verossimilhança ##
log_nzero_y = fr*log((1-fi_cor[9:36])*
(exp(-mu)*(mu^y[9:36])/factorial(y[9:36])))
log_nzero_yhat = fr*log((1-fi_cor[9:36])*
(exp(-mi[9:36])*(mi[9:36]^y[9:36])/factorial(y[9:36])))
## Resíduos ##
r_cdp=sign(y[9:36]-mi[9:36])*sqrt(2*(log_nzero_y-log_nzero_yhat))
cbind(y[9:36], mi[9:36],log_nzero_y, log_nzero_yhat, r_cdp)
log_nzero_y log_nzero_yhat r_cdp
9 0 2.167919 0.000000 -21.679189 -6.5847080
10 0 2.167919 0.000000 -21.679189 -6.5847080

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 57
11 36 39.626109 -8.139039 -8.652684 -1.0135529
12 37 39.626109 -2.726650 -2.815658 -0.4219186
13 35 39.626109 -2.698994 -2.980197 -0.7499380
14 36 39.626109 -8.139039 -8.652684 -1.0135529
15 32 24.415098 -2.654411 -3.726603 1.4643715
16 36 24.415098 -8.139038 -15.322592 3.7903968
17 34 24.415098 -5.369139 -8.718134 2.5880475
18 34 24.415098 -5.369139 -8.718134 2.5880475
19 14 15.043032 -2.244419 -2.281445 -0.2721254
20 8 15.043032 -3.938141 -7.920632 -2.8222299
21 12 15.043032 -6.505004 -7.497804 -1.4091128
22 12 15.043032 -6.505004 -7.497804 -1.4091128
23 4 9.268561 -8.164382 -17.700511 -4.3671796
24 5 9.268561 -1.740302 -2.922912 -1.5379270
25 4 9.268561 -8.164382 -17.700511 -4.3671796
26 6 9.268561 -1.828694 -2.488043 -1.1483457
27 2 5.710698 -1.306853 -2.919163 -1.7957227
28 4 5.710698 -8.164382 -9.596934 -1.6926621
29 4 5.710698 -8.164382 -9.596934 -1.6926621
30 4 5.710698 -8.164382 -9.596934 -1.6926621
31 12 3.518569 -6.505004 -25.227390 6.1192133
32 7 3.518569 -1.903790 -3.237349 1.6331313
33 11 3.518569 -2.125460 -7.182278 3.1801943
34 8 3.518569 -3.938141 -8.117473 2.8911353
35 1 2.167919 -2.000000 -2.788303 -1.2556293
36 1 2.167919 -2.000000 -2.788303 -1.2556293
## Resíduos Componentes do Desvio Estudentizados ##
r_cdpe=r_cdp/(1-h[9:36]);r_cdpe
9 10 11 12 13 14
-6.9598726 -6.9598726 -1.2293792 -0.5117621 -0.9096300 -1.2293792
15 16 17 18 19 20
1.5653264 4.0517096 2.7664694 2.7664694 -0.2846754 -2.9523859

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 58
21 22 23 24 25 26
-1.4740985 -1.4740985 -4.5926759 -1.6173368 -4.5926759 -1.2076397
27 28 29 30 31 32
-1.9015100 -1.7923780 -1.7923780 -1.7923780 6.4906537 1.7322635
33 34 35 36
3.3732343 3.0666291 -1.3271690 -1.3271690
Modelo ZINB
### Ajustando um ZINB ###
ajuste_zinb = vglm(abelhas1 ~ hora1, zinegbinomial(zero=NULL))
#############################################################
################### Resíduos Padronizados ###################
#############################################################
y=(ajuste_zinb)@y
mi=fitted(ajuste_zinb)
r=y-mi;round(r,4)
fi=exp(predict(ajuste_zinb)[,1])/(1+exp(predict(ajuste_zinb)[,1]))
k=exp(predict(ajuste_zinb)[,3])
a=1-fi
X=ajuste_zinb@x
A=diag(a)
w=weights(ajuste_zinb,matrix.arg = T,type="working")
w=w[,2]
W=diag(w)
H=sqrt(W)%*%X%*%solve(t(X)%*%W%*%X)%*%t(X)%*%sqrt(W)
h=diag(H)
### Função de variância:

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 59
## Binomial Negativa Inflacionada de zeros:
Vbn=(1-fi)*(1+mi/k+fi*mi)*mi
## Resíduos de Pearson Estudentizados:
r_pearson_est = r[9:36]/sqrt(Vbn[9:36]*(1-h[9:36]))
zeros=rep(0,8)
r_pearson_est=c(zeros,r_pearson_est)
[,1]
[1,] 0.0000000
[2,] 0.0000000
[3,] 0.0000000
[4,] 0.0000000
[5,] 0.0000000
[6,] 0.0000000
[7,] 0.0000000
[8,] 0.0000000
[9,] -0.6280321
[10,] -0.6285356
[11,] -0.5813602
[12,] -0.4331373
[13,] -0.7159681
[14,] -0.5838946
[15,] 1.2072865
[16,] 1.8598204
[17,] 1.5374252
[18,] 1.5306795
[19,] -0.1741103
[20,] -1.2985084
[21,] -0.5522340
[22,] -0.5497627
[23,] -1.1157681

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 60
[24,] -0.9026261
[25,] -1.1134456
[26,] -0.6834691
[27,] -0.8801578
[28,] -0.3902429
[29,] -0.3872780
[30,] -0.3877649
[31,] 2.3750620
[32,] 0.9925991
[33,] 2.0810790
[34,] 1.2572340
[35,] -0.3255062
[36,] -0.3254858
## Resíduos Componentes do Desvio:
## Modelo Corrente ##
fi_cor=exp(predict(ajuste_zinb)[,1])/(1+exp(predict(ajuste_zinb)[,1]))
k_cor=exp(predict(ajuste_zinb)[,3])
mu=exp(predict(ajuste_zinb)[,2]) # parâmetro mi da BN inflacionada #
ynz=y[9:36] # corresponde as observações não zeros pela
estrutura do modelo ZINB #
## Log-verossimilhança ##
log_nzero_y=fr*log((1-fi_cor[9:36])*
(choose(y[9:36]+k_cor[9:36]-1,y[9:36])*
(k_cor[9:36]/(k_cor[9:36]+ynz))^k_cor[9:36])*
(ynz/(k_cor[9:36]+ynz))^y[9:36])
log_nzero_yhat=fr*log((1-fi_cor[9:36])*
(choose(y[9:36]+k_cor[9:36]-1, y[9:36])*
(k_cor[9:36]/(k_cor[9:36]+mi[9:36]))^k_cor[9:36])*
(mi[9:36]/(k_cor[9:36]+mi[9:36]))^y[9:36])

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 61
## Resíduos ##
r_cdbn=sign(y[9:36]-mi[9:36])*sqrt(2*(log_nzero_y-log_nzero_yhat))
cbind(y[9:36], mi[9:36],log_nzero_y, log_nzero_yhat, r_cdbn)
log_nzero_y log_nzero_yhat r_cdbn
9 0 2.079219 0.000000 -7.967290 -3.9918141
10 0 2.079219 0.000000 -7.967290 -3.9918141
11 36 39.998458 -8.683420 -9.106001 -0.9193274
12 37 39.998458 -2.912320 -2.990611 -0.3957043
13 35 39.998458 -2.876209 -3.098977 -0.6674859
14 36 39.998458 -8.683420 -9.106001 -0.9193274
15 32 24.435398 -2.981075 -3.583868 1.0979917
16 36 24.435398 -9.206379 -13.179373 2.8188629
17 34 24.435398 -6.052008 -7.919500 1.9326111
18 34 24.435398 -6.052008 -7.919500 1.9326111
19 14 14.927792 -2.580820 -2.595614 -0.1720124
20 8 14.927792 -4.375369 -6.490458 -2.0567396
21 12 14.927792 -7.405415 -7.881138 -0.9754209
22 12 14.927792 -7.405415 -7.881138 -0.9754209
23 4 9.119515 -9.428643 -13.704576 -2.9243573
24 5 9.119515 -2.040464 -2.545354 -1.0048776
25 4 9.119515 -9.428643 -13.704576 -2.9243573
26 6 9.119515 -2.172075 -2.438941 -0.7305694
27 2 5.571189 -1.602329 -2.201810 -1.0949713
28 4 5.571189 -10.564755 -10.989656 -0.9218470
29 4 5.571189 -10.564755 -10.989656 -0.9218470
30 4 5.571189 -10.564755 -10.989656 -0.9218470
31 12 3.403487 -10.400119 -13.842833 2.6240098
32 7 3.403487 -2.958270 -3.254749 0.7700384
33 11 3.403487 -3.383657 -4.340211 1.3831519
34 8 3.403487 -6.165534 -7.048028 1.3285284
35 1 2.079219 -3.347824 -3.502977 -0.5570521

4.0 Apêndice B - Resíduos de Pearson e Componentes do Desvio Estudentizados 62
36 1 2.079219 -3.347824 -3.502977 -0.5570521
## Resíduos Componentes do Desvio Estudentizados ##
r_cdbne=r_cdbn/(1-h[9:36])
9 10 11 12 13 14
-4.0905423 -4.0971038 -1.1544767 -0.4904960 -0.8135174 -1.1645643
15 16 17 18 19 20
1.1621941 3.0296027 2.0750557 2.0568862 -0.1819288 -2.1700692
21 22 23 24 25 26
-1.0422030 -1.0328958 -3.1179169 -1.0828809 -3.1049509 -0.7871707
27 28 29 30 31 32
-1.1525872 -0.9854794 -0.9705615 -0.9730038 2.7595138 0.8080881
33 34 35 36
1.4301458 1.3693295 -0.5691707 -0.5690992


















