
Pós-Graduação em Ciência da Computação · descoberta automática de conhecimento que visa...
86
Pós-Graduação em Ciência da Computação “Classificação Supervisionada Usando Dados Simbólicos de Semântica Modal” por Fábio César Donato Silva Fábio César Donato Silva Fábio César Donato Silva Fábio César Donato Silva Dissertação de Mestrado Universidade Federal de Pernambuco [email protected] www.cin.ufpe.br/~posgraduacao RECIFE, Agosto de 2007
Transcript of Pós-Graduação em Ciência da Computação · descoberta automática de conhecimento que visa...

Pós-Graduação em Ciência da Computação
“Classificação Supervisionada Usando Dados
Simbólicos de Semântica Modal”
por
Fábio César Donato SilvaFábio César Donato SilvaFábio César Donato SilvaFábio César Donato Silva
Dissertação de Mestrado
Universidade Federal de Pernambuco [email protected]
www.cin.ufpe.br/~posgraduacao
RECIFE, Agosto de 2007

UNIVERSIDADE FEDERAL DE PERNAMBUCO
CENTRO DE INFORMÁTICA
PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO
FÁBIO CÉSAR DONATO SILVA
“Classificador Supervisionado Usando Dados Simbólicos de Semântica Modal”
ESTE TRABALHO FOI APRESENTADO À PÓS-GRADUAÇÃO EM
CIÊNCIA DA COMPUTAÇÃO DO CENTRO DE INFORMÁTICA DA
UNIVERSIDADE FEDERAL DE PERNAMBUCO COMO REQUISITO
PARCIAL PARA OBTENÇÃO DO GRAU DE MESTRE EM CIÊNCIA
DA COMPUTAÇÃO.
ORIENTADOR: PROF. DR. FRANCISCO DE ASSIS TENÓRIO DE CARVALHO CO-ORIENTADORA: PROFª. DRª. RENATA MARIA CARDOSO RODRIGUES DE SOUZA
RECIFE, AGOSTO/2007

- iii -
Dedico este trabalho a minha esposa e
a meus filhos que me incentivaram e
apoiaram.

- iv -
AGRADECIMENTOS
Agradeço primeiramente a Deus que pelo milagre da vida estamos aqui hoje.
Ao orientador, Prof. Francisco de Assis Tenório de Carvalho pela paciência e
confiança em mim depositadas.
A co-orientadora, Profª. Renata Maria Cardoso Rodrigues Souza quem com tanto
empenho e dedicação me impulsionou a esse desfecho.
Aos amigos que nos momento difíceis estavam ao lado para dar um devido apoio.
Ao CNPq pelo apoio financeiro.

- v -
ABSTRACT
The Symbolic Data Analysis (SDA) is a domain in the area of automatic discovery of
knowledge that it aims at to develop methods for described data for variables that can assume
as value lists of categories, intervals or distributions of probability. These variables allow to
take in account the variability and/or uncertainty present in the data.
This work presents a symbolic classifier of modal semantics for symbolic data of type
interval. The considered classifier presents two basic stages, the learning and the allocation,
where both need one step precedent of pre-processing that transforms the symbolic data of the
type interval into symbolic data modal. Each example of the set of learning is described for a
vector of intervals. After the pre-processing, each example starts to be described for a vector
of distributions of weights. After the stage of learning, each group is also described for a
vector of distributions of weights that summarize the information of the examples of the
group. Each new example to be attributed to the one class (stage of allocation), represented
for a vector of intervals, after the step of pre-processing starts to be described for a vector of
distributions of weights. The allocation of an example to a class is carried through
dissimilarity functions that compare pairs of vectors of distributions of weights. Some
functions of dissimilarity of this type are considered in this work.
The evaluation of the performance of this classifier is carried through the real
application of the same the synthetic data sets in an experience Carlo Monte and reals data
sets having used the technique of crossed validation leave-one-out. The performance is
measured by the tax (average) of error of classification and by the time of execution of the
stages of learning and classification. Moreover, the performance of this classifier was
compared with the performance of a type classifier k nearest neighbors also to modal
semantics. Through these examples, this work shows some of the interests of this classifier of
modal semantics.
Keywords: Symbolic Data Analysis, Modal Symbolic Classifier, Unsupervised
Classification, Modal Symbolic Data, Dissimilarity Functions.

- vi -
RESUMO
A Análise de Dados Simbólicos (Symbolic Data Analysis) é um domínio na área de
descoberta automática de conhecimento que visa desenvolver métodos para dados descritos
por variáveis que podem assumir como valor conjuntos ou listas de categorias, intervalos ou
distribuições de probabilidade. Essas variáveis permitem levar em conta a variabilidade e/ou a
incerteza presente nos dados.
Este trabalho apresenta um classificador simbólico de semântica modal para dados
simbólicos de tipo intervalo. O classificador proposto apresenta duas etapas básicas, a
aprendizagem e a alocação, onde ambas necessitam de uma etapa precedente de pré-
processamento que transforma os dados simbólicos do tipo intervalo em dados simbólicos
modal. Cada exemplo do conjunto de aprendizagem é descrito por um vetor de intervalos.
Após o pré-processamento, cada exemplo passa a ser descrito por um vetor de distribuições de
pesos. Após a etapa de aprendizagem, cada classe é também descrita por um vetor de
distribuições de pesos que sintetiza as informações dos exemplos da classe. Cada novo
exemplo a ser atribuído a uma classe (etapa de alocação), representado por um vetor de
intervalos, após a fase de pré-processamento passa a ser descrito por um vetor de distribuições
de pesos. A alocação de um exemplo a uma classe é realizada através de funções de
dissimilaridade que comparam pares de vetores de distribuições de pesos. Algumas funções
de dissimilaridade desse tipo são consideradas nesse trabalho.
A avaliação do desempenho desse classificador é realizada através da aplicação do
mesmo a conjuntos de dados sintéticos em uma experiência Monte Carlo e a conjuntos de
dados reais usando a técnica de validação cruzada leave-one-out. O desempenho é medido
pela taxa (média) de erro de classificação e pelo tempo de execução das etapas de
aprendizagem e classificação. Além disso, o desempenho desse classificador foi comparado
com o desempenho de um classificador de tipo k-vizinhos mais próximos também de
semântica modal. Através desses exemplos, esse trabalho mostra alguns dos interesses desse
classificador de semântica modal.
Palavras-chave: Analise de Dados Simbólicos, Classificador Simbólico Modal, Classificação
Supervisionada, Dados Simbólicos Modas, Funções de Dissimilaridade.

- vii -
CONTEÚDO
1 Introdução ................................................................................................................ 11
1.1 Motivação ................................................................................................ 11
1.2 Objetivos .................................................................................................. 12
1.3 Organização da dissertação.................................................................... 13
2 Classificadores Simbólicos .................................................................................... 16
2.1 Introdução ............................................................................................... 16
2.2 Dados Usuais........................................................................................... 17
2.3 Dados Simbólicos .................................................................................... 18
2.3.1 Dados Simbólicos descrevendo indivíduos ................................. 18
2.3.2 Dados Simbólicos descrevendo classes de indivíduos................ 19
2.3.3 Variáveis Simbólicas ...................................................................... 19
2.3.3.1 Variáveis Multivaloradas........................................................ 19
2.3.3.2 Variável do tipo modal ........................................................... 20
2.3.4 Operadores simbólicos................................................................... 20
2.4 Análise Discriminante Fatorial para dados simbólicos ....................... 21
2.5 Redes Multi-Layer Perceptron para dados simbólicos ........................ 24
2.5.1 Método dos valores extremos........................................................ 25
2.5.2 Método probabilísticos................................................................... 26
2.6 Discriminante de Kernel para dados simbólicos.................................. 26
2.7 Árvore de classificação para dados simbólicos .................................... 28
2.8 Classificador baseado em região do tipo casca convexa...................... 30
2.8.1 Regiões e Grafos ............................................................................. 30
2.8.2 Casca Convexa................................................................................ 31
2.9 K-vizinhos mais próximos para dados simbólicos............................... 32
2.10 Conclusão ................................................................................................ 34
3 Classificador Modal ................................................................................................ 35
3.1 Módulo de Aprendizagem..................................................................... 36
3.1.1 Etapa de Pré-processamento ......................................................... 36
3.1.2 Etapa de Generalização.................................................................. 39

Conteúdo
- viii -
3.2 Módulo de Alocação............................................................................... 40
3.2.1 Etapa de Pré-processamento ......................................................... 41
3.2.2 Etapa de Afetação........................................................................... 42
3.2.3 Funções híbridas de dissimilaridade para dados modais........... 44
3.2.3.1 Função híbrida de dissimilaridade baseada em um
coeficiente de afinidade ................................................................ 45
3.2.3.1 Função híbrida de dissimilaridade baseada em uma
distância de Minkowski Lr ........................................................... 47
3.2.3.1 Função híbrida de dissimilaridade baseada em um
índice de acordo e desacordo ....................................................... 48
3.3 Algoritmo................................................................................................. 51
3.4 Conclusão ................................................................................................ 52
4 Classificador K-vizinhos mais próximos para dados intervalares .................. 53
4.1 Módulo de Aprendizagem..................................................................... 54
4.2 Módulo de Alocação............................................................................... 55
4.3 Conclusão ................................................................................................ 57
5 Avaliação Experimental.......................................................................................... 58
5.1 Dados Sintéticos do tipo Intervalo ........................................................ 58
5.2 Experiências Monte Carlo ...................................................................... 62
5.2.1 Resultados da taxa de erro ............................................................ 62
5.2.2 Resultados do tempo (em segundos)............................................ 65
5.3 Aplicação com um conjunto de dados intervalares reais .................... 67
5.5 Software do classificado modal e do ID-KNN ..................................... 69
5.5 Conclusão ................................................................................................ 73
6 Conclusão e Trabalhos Futuros ............................................................................. 74
6.1 Trabalhos Futuros ................................................................................... 75
Apêndice A.................................................................................................................. 76
Referências .................................................................................................................. 81

- ix -
LISTA DE FIGURAS
Figura 2.1 Operadores Junção e Conjunção......................................................................... 21
Figura 3.1 Distribuição de pesos das classes 1 (a) e 2 (b) .................................................... 40
Figura 5.1 Conjunto de dados quantitativos 1...................................................................... 59
Figura 5.2 Conjunto de dados quantitativos 2...................................................................... 60
Figura 5.3 Conjunto de dados simbólicos 1 ......................................................................... 61
Figura 5.4 Conjunto de dados simbólicos 2 ......................................................................... 70
Figura 5.5 Janela de execução do classificador modal ......................................................... 70
Figura 5.6 Janela de execução do classificador ID-KNN ..................................................... 70

- x -
LISTA DE TABELAS
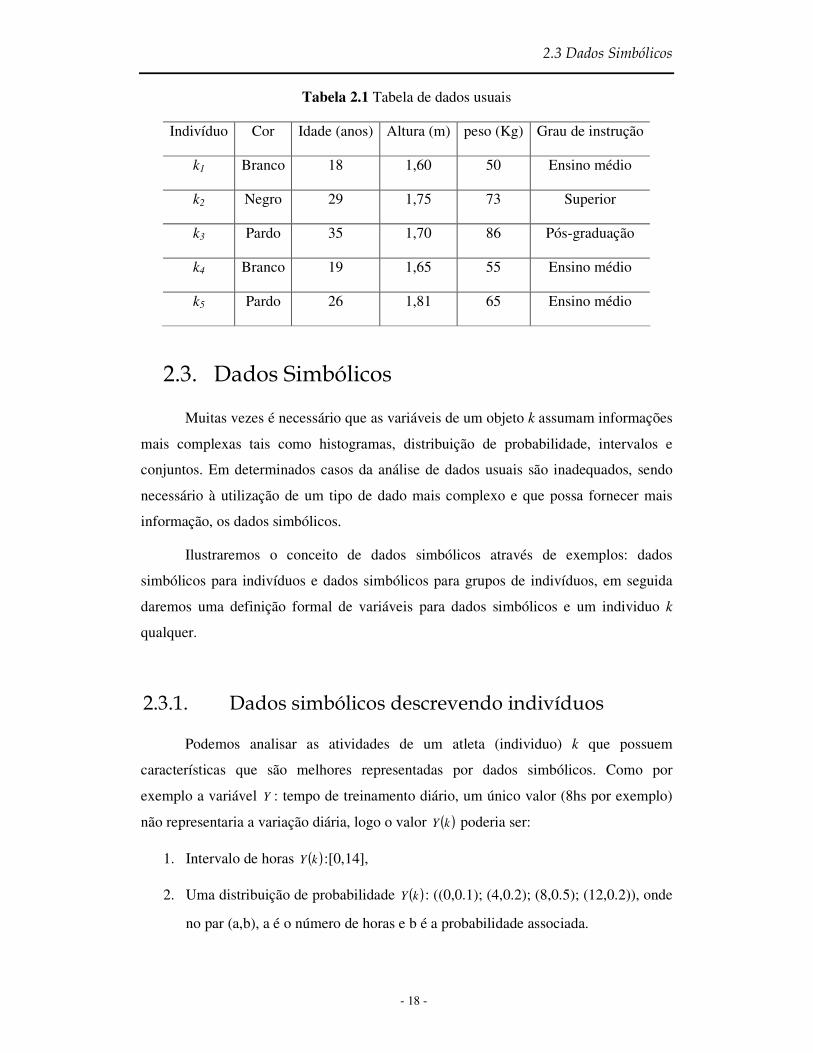
Tabela 2.1 Tabela de dados usuais....................................................................................... 18
Tabela 3.1 Uma tabela de dados simbólicos do tipo intervalo .............................................. 37
Tabela 3.2 Descrições modais dos indivíduos da Tabela 3.1 ................................................ 38
Tabela 3.3 Descrições modais para as classes de indivíduos da Tabela 3.2 .......................... 39
Tabela 3.4 Novos objetos descritos por uma variável simbólica do tipo intervalo ................ 42
Tabela 3.5 Descrições modais para os objetos da Tabela 3.4 ............................................... 42
Tabela 3.6 Descrições modais das classes de acordo com o objeto ...................................... 43
Tabela 3.7 Índices de desacordo e acordo para dados modais .............................................. 48
Tabela 5.1 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d1 ................................ 62
Tabela 5.2 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d2 ............................... 63
Tabela 5.3 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d3 ................................ 63
Tabela 5.4 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d1 ................................ 64
Tabela 5.5 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d2 ................................ 64
Tabela 5.6 A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d3 ................................ 64
Tabela 5.7 Testes de Hipóteses t-Student usando a função de agregação d1 ......................... 65
Tabela 5.8 A média (%) e o desvio padrão (em parênteses) do tempo (em segundos) para o conjunto de dados intervalar 1 conforme função de agregação dz (z=1,2,3) ......... 66
Tabela 5.9 A média (%) e o desvio padrão (em parênteses) do tempo (em segundos) para o conjunto de dados intervalar 2 conforme função de agregação dz (z=1,2,3) ......... 66
Tabela 5.10 Valores máximo e mínimo de temperaturas em graus centígrados de 37 cidades........................................................................................................................ 68
Tabela 5.11 Média (%) da taxa de erro para a temperatura das cidades do conjunto de dados simbólicos do tipo intervalo de acordo com a função de agregação dz (z=1,2,3)68
Tabela 5.12 Resultado da classificação das cidades do conjunto de dados intervalares temperatura...................................................................................................... 71
Tabela 5.13 Informações do sistema e entradas para o classificador modal .......................... 71
Tabela 5.14 Informações do sistema e entradas para o classificador ID-KNN ...................... 71

Capítulo 1
- 11 -
1. Introdução
1.1. Motivação
A disseminação do uso dos computadores nas organizações tem alterado
radicalmente a maneira como as aplicações são conduzidas. A cada dia, mais operações
corriqueiras são automatizadas e a cada nova transação, como compras com cartão de
crédito, operações bancárias, novos registros correspondentes são armazenados.
Sistemas de gerenciadores de banco de dados estão presentes na maioria das
organizações públicas e empresas de médio e grande porte, contendo os mais diferentes
dados sobre produtos, fornecedores, clientes, empregados, etc. Além disso, avanços em
aquisição de dados, desde um simples leitor de código de barras até sistemas de
sensoriamento remoto geram grandes volumes de dados.
Entretanto num ambiente mutável torna-se necessário novas técnicas e
ferramentas de extração e análise de conhecimentos que agilizem o processo decisório
de uma empresa. A realização de Data Warehousing [Garden, 1998] é considerado um
dos primeiros passos para tornar factível a análise de grande quantidade de dados no
apoio ao processo decisório. O objetivo é criar um repositório, conhecido como Data
Warehouse (DW), que contem dados limpos, agregados e consolidados. No entanto, a
análise de dados através de um DW geralmente não extrapolam a realização de simples
consultas e diante disto, diversos estudos têm sido direcionado ao desenvolvimento de
tecnologias de extração automática de conhecimentos.
A descoberta de conhecimentos de dados (Knowledge Discovery in Database
KDD) [Fayyad et al, 1996] é uma área de pesquisa em bastante evidência no momento
que visa desenvolver meios automáticos de prospecção de conhecimento em grandes
bases de dados.
As ferramentas para execução do processo de mineração são genéricas e
derivadas de diferentes áreas de conhecimento tais como da estatística, inteligência
artificial e banco de dados. As técnicas estatísticas multivariadas englobam algoritmos
que podem ser aplicados para descobrir estruturas em um conjunto de dados. Embora as
técnicas multivariadas tradicionais sejam bem aplicadas para sumarizar e analisar
conjuntos de dados clássicos, com o explosivo crescimento das tecnologias da

1.2 Objetivos
- 12 -
informação estas técnicas têm sido inapropriadas para tratar conjuntos de dados
representados por informações mais complexas como, por exemplo, intervalos. Além
disso, os métodos estatísticos não possuem estruturas adequadas que possibilitem
sintetizar grandes conjuntos de dados perdendo o mínimo possível de informação dos
dados originais. Como uma alternativa para generalizar as atuais técnicas estatísticas
para estas informações mais complexas, surge a análise de dados simbólicos (Symbolic
Data Analysis (SDA)).
A análise de dados simbólicos [Billard & Diday, 2000] é uma abordagem na
área da descoberta automática de conhecimentos (KDD) e gerenciamento de dados,
relacionada com análise de dados multivariados, reconhecimento de padrões,
inteligência artificial e banco de dados. O principal objetivo de SDA é desenvolver
métodos para tratamento de dados mais complexos como intervalos, conjuntos e
distribuição de probabilidades ou de pesos. SDA inicia com a agregação/redução de
bases de dados clássicos em uma estrutura mais complexa chamada de dados
simbólicos, pois eles contêm variação interna e são estruturados. A etapa seguinte
consiste na extensão dos métodos e algoritmos de extração de conhecimentos (técnicas
estatísticas) a partir de dados usuais, para os dados simbólicos.
A motivação deste trabalho é construir um classificador para dados descritos por
vetores de valores quantitativos, onde a representação das classes é dado por uma
descrição simbólica do tipo modal (uma distribuição de pesos) para cada uma das
classes de indivíduos e usar essas descrições modais para classificar novos exemplos
usando funções de proximidades para dados modais.
1.2. Objetivos
O objetivo principal deste trabalho é implementar uma abordagem para o
classificador baseado em uma descrição simbólica do tipo modal para dados do tipo
intervalo e utilizando várias distâncias baseadas em funções hibridas de comparação que
medem a dissimilaridade entre vetores da distribuição dos pesos.
No contexto das aplicações os seguintes pontos serão abordados:
• Implementar o classificador Modal para Dados Intervalaras de Semântica
Modal utilizando a linguagem de programação C/C++.

1.3 Organização da dissertação
- 13 -
• A avaliação experimental do classificador de semântica modal para
dados do tipo intervalo que será discutido no capítulo 3 verificando o
desempenho do classificador modal com dados sintéticos e reais do tipo
intervalo.
• Implementar o classificador k-vizinhos mais próximos para dados
intervalares ID-KNN ( Interval Data K-Nearest Neighbor ) que é uma
adaptação do SO-NN (Symbolic Objects Nearest Neighbor) proposto por
[Appice et al, 2006].
• Fazer um estudo comparativo do desempenho do classificador de
semântica modal para dados do tipo intervalo com o desempenho do
classificador ID-KNN.
1.3. Organização da dissertação
Além deste capítulo, no qual foi apresentado tanto a motivação quanto o
objetivo principal do trabalho, esta dissertação será apresentada em mais cinco capítulos
que são:
Capítulo 2 Classificadores Simbólicos
A finalidade deste capítulo é fornecer uma breve explanação sobre as extensões
para dados simbólicos dos algoritmos de classificação supervisionada clássicos.
Iniciaremos apresentando os dois tipos de dados que os classificadores aceitam com
entrada: os dados usuais (seção 2.2) e os dados simbólicos (seção 2.3). Nas seções
subseqüentes entraremos em detalhe na abordagem simbólica de alguns algoritmos de
classificação supervisionada clássicos. Análise Discriminante Fatorial para dados
simbólicos na seção 2.4; Redes multilayer perceptron para dados simbólicos na seção
2.5; Discriminante kernel para dados simbólicos na seção 2.6; Árvore de classificação
para dados simbólicos na seção 2.7. Classificador Simbólico baseado em Região tipo
Casca Convexa na seção 2.8; O classificador SO-NN na seção 2.9; Por fim a conclusão
na seção 2.10.

1.3 Organização da dissertação
- 14 -
Capítulo 3 Classificador Modal
Esse capítulo apresenta um classificador de semântica modal para dados do tipo
intervalo. A entrada do classificador modal é uma tabela de dados cujas linhas são
objetos (indivíduos) e cujas colunas são valores assumidos por variáveis simbólicas do
tipo intervalo.
Nas seções (3.1) e (3.2) são propostas com maiores detalhes os módulos de
aprendizagem e de alocação do classificador modal para dados do tipo intervalo,
respectivamente. Na seção (3.3) é descrito o algoritmo de construção do classificador
modal. Para finalizar, a seção (3.4) apresenta a conclusão e considerações finais desse
capítulo.
Capítulo 4 Classificador k-vizinhos mais próximos para dados intervalares (ID-
KNN)
Neste capítulo é apresentado o algoritmo de construção do classificador ID-
KNN que foi implementado nesse trabalho com o intuito de viabilizar a comparação
entre esse e o classificador modal.
Nas seções (4.1) e (4.2) são propostas com maiores detalhes os módulos de
aprendizagem e de alocação do classificador ID-KNN, respectivamente. Por fim neste
capitulo temos uma conclusão na seção (4.3).
Capítulo 5 Avaliação Experimental
Esse capítulo apresenta uma avaliação experimental do classificador de
semântica modal para dados do tipo intervalo discutido no capítulo 3 Que será dividido
em quatro seções. Na seção (5.1) são apresentados os dados sintéticos que foram
utilizados nas experiências. Na seção (5.2) veremos as experiências de Monte Carlo e os
resultados da taxa de erro e do tempo para dados sintéticos. Na seção (5.3) teremos uma
aplicação com um conjunto de dados intervalares reais. Na seção (5.4) explanamos
sobre o software desenvolvido e na última seção (5.5) é exposta uma conclusão dessa
avaliação experimental.

1.3 Organização da dissertação
- 15 -
Capítulo 6 Conclusão e Trabalhos Futuros
Neste capítulo serão mostradas a conclusão e as considerações finais deste
trabalho bem como os trabalhos futuros que poderão ser realizados a partir da idéia aqui
apresentada.

Capítulo 2
- 16 -
2. Classificadores Simbólicos
2.1. Introdução
A Analise de Dados Simbólicos é um domínio novo na área de descoberta do
conhecimento e de gerenciamento de dados, relacionado à análise multivalorada,
reconhecimento de padrões e a inteligência artificial. Com o aumento do interesse da
comunidade científica pela a análise de dados simbólicos, alguns dos algoritmos de
classificação supervisionada clássicos atualmente já possuem uma extensão para dados
simbólicos. Em [Palumbo et al, 2000] foi proposto uma generalização da Análise
Discriminante Fatorial para dados simbólicos. Em [Rossi & Conan-Guez, 2002] foi
elaborado dois métodos que permitem o uso de dados simbólicos do tipo intervalo como
entrada para redes multi-layer perceptrons, já em [Rasson & Lissoir, 2000] foi
apresentado uma abordagem da Análise do Discriminante Kernel para dados
simbólicos. Em [Ciampi et al, 2000] foi proposto estender o algoritmo de crescimento
de árvore de classificação para dados imprecisos. Em [D’Oliveira et al, 2004] foi
introduzido um classificador para dados descritos por vetores de valores quantitativos
baseado em regiões de tipo casca convexa. Em [Appice et al, 2006] foi introduzido um
processo aprendizagem dita “preguiçosa” SO-NN (Symbolic Objects Nearest Neighbor)
que é um classificador baseado em exemplos que estende o k-vizinho mais próximo (k-
NN) a objetos simbólicos.
Em sua grande maioria os classificadores para dados simbólicos também
aceitam como entrada dados usuais. Portanto para um melhor entendimento deste
capitulo apresentaremos brevemente os dados usuais (seção 2.2) e os dados simbólicos
(seção 2.3). Nas seções subseqüentes serão discutidos detalhes sobre cada algoritmo de
classificação mencionado anteriormente. Análise Discriminante Fatorial para dados
simbólicos na seção 2.4; Redes Multi-Layer Perceptron para dados simbólicos na seção
2.5; Discriminante Kernel para dados simbólicos na seção 2.6; Árvore de classificação
para dados simbólicos na seção 2.7; Classificador Simbólico baseado em Região tipo
Casca Convexa na seção 2.8; O classificador SO-NN na seção 2.9; Por fim a conclusão
na seção 2.10.

2.2 Dados Usuais
- 17 -
2.2. Dados usuais
Os dados usuais descrevem situações relativamente simples, tais como mostrado
na Tabela 2.1. Estes dados são obtidos principalmente pelas características de
indivíduos (pessoas, objetos, produto), e sua principal propriedade é que tais
características são definidas por um único valor cada. A seguir uma definição mais
formal.
Para um dado número n de objetos n,...,2,1=Ω , p variáveis pYY ,,1 K descrevem
suas características. A variável clássica iY é definida como o mapeamento de um único
valor de Ω para iγ , sendo iγ o domínio de iY , tal que ( )kYx iki = é o valor observado
para o indivíduo k [Bock, 2000].
As variáveis usuais podem ser classificadas como quantitativas ou qualitativas
conforme as definições abaixo:
iY é quantitativa se iγ é idêntico ou está contido em ℜ : ℜ⊆iγ . As variáveis
quantitativas podem ser subdivididas em:
I. Quantitativa contínua se iγ é um intervalo de ℜ .
II. Quantitativa discreta se iγ é um conjunto finito ou infinito contável de
valores de ℜ .
iY é qualitativa (categórica) se iγ é finito e seus elementos são categorias sem
significado numérico. As variáveis qualitativas também podem ser subdivididas
conforme o seguinte:
I. Qualitativa nominal se iγ não possui estrutura interna.
II. Qualitativa ordinal se existe uma ordem linear total entre as categorias de
iγ .
A Tabela 2.1 é uma tabela de dados usuais para 5 indivíduos com 3 variáveis
quantitativas peso, altura e idade, sendo peso e altura quantitativas contínuas e idade
quantitativas discreta; e 2 variáveis qualitativas cor e grau de instrução, sendo cor
qualitativa nominal e grau de instrução qualitativa ordinal.
2.3 Dados Simbólicos
- 18 -
Tabela 2.1 Tabela de dados usuais
Indivíduo Cor Idade (anos) Altura (m) peso (Kg) Grau de instrução
k1 Branco 18 1,60 50 Ensino médio
k2 Negro 29 1,75 73 Superior
k3 Pardo 35 1,70 86 Pós-graduação
k4 Branco 19 1,65 55 Ensino médio
k5 Pardo 26 1,81 65 Ensino médio
2.3. Dados Simbólicos
Muitas vezes é necessário que as variáveis de um objeto k assumam informações
mais complexas tais como histogramas, distribuição de probabilidade, intervalos e
conjuntos. Em determinados casos da análise de dados usuais são inadequados, sendo
necessário à utilização de um tipo de dado mais complexo e que possa fornecer mais
informação, os dados simbólicos.
Ilustraremos o conceito de dados simbólicos através de exemplos: dados
simbólicos para indivíduos e dados simbólicos para grupos de indivíduos, em seguida
daremos uma definição formal de variáveis para dados simbólicos e um individuo k
qualquer.
2.3.1. Dados simbólicos descrevendo indivíduos
Podemos analisar as atividades de um atleta (individuo) k que possuem
características que são melhores representadas por dados simbólicos. Como por
exemplo a variável Y : tempo de treinamento diário, um único valor (8hs por exemplo)
não representaria a variação diária, logo o valor ( )kY poderia ser:
1. Intervalo de horas ( )kY :[0,14],
2. Uma distribuição de probabilidade ( )kY : ((0,0.1); (4,0.2); (8,0.5); (12,0.2)), onde
no par (a,b), a é o número de horas e b é a probabilidade associada.

2.3 Dados Simbólicos
- 19 -
2.3.2. Dados simbólicos descrevendo classes de
indivíduos
Os dados simbólicos são especialmente adequados para representar classes de
indivíduos (objetos agregados). Vamos considerar que estamos analisando os
municípios da Região Metropolitana do Recife (conjuntos de indivíduos) e k é um
desses municípios; uma características a ser considerada seria Y : grau de instrução dos
habitantes. O valor ( )kY poderia ser:
1. O conjunto de graus de instrução ( )kY : analfabeto, fundamental, médio, superior,
pós-graduação.
2. Mais adequadamente uma distribuição de probabilidade ( )kY : ((analfabeto,0.2);
(fundamental,0.3); (médio,0.3); (superior,0.1); (pós-graduação,0.1)).
2.3.3. Variáveis Simbólicas
2.3.3.1. Variáveis Multivaloradas
A variável simbólica Y definida para cada indivíduo k de um conjunto de n
indivíduos é dita como multivalorada com domínio γ se ( )kY é subconjunto de γ .
1 Uma variável Y é dita multivalorada categórica se γ é um conjunto finito de
categorias onde estas variáveis categóricas podem ser subdivididas em nominais e
ordinais.
• Variáveis Multivaloradas Nominais: não dispõem de uma ordem entre seus
elementos: Instituições bancárias ( )kY : Banco do Brasil, Itaú, Bradesco, Caixa,
Banco Real.
• Variáveis Multivaloradas Ordinais: onde seus elementos descrevem uma ordem
pré-definida: Faixa Etária ( )kY : Criança, Jovem, Adulto, Idoso.
2 Uma variável Y é dita multivalorada quantitativa se ( )kY é um conjunto finito de
números reais. Números de filhos ( )kY : 0, 1, 2, 3, 4, 5, 6.

2.3 Dados Simbólicos
- 20 -
3 Uma variável Y é dita multivalorada do tipo intervalo se ( )kY é um intervalo dos
números reais ou um intervalo com respeito a uma determinada ordem em γ . Salário
em Recife ( )kY : [200,8000].
2.3.3.2. Variável do tipo modal
A variável modal Y definida sobre um conjunto K,, kaE = de objetos com
domínio γ é uma função ( ) ( ) ( )( )kqkSkY ,= onde:
• ( )kq é uma medida ou uma distribuição(freqüência, pesos, probabilidade) definida
no domínio γ .
• ( ) γ⊆kS é o suporte de q no domínio γ .
As variáveis modais associam para cada categoria ( )kYy ∈ , distribuição de
freqüências, pesos ou probabilidades que indica quão freqüente, típico ou relevante a
categoria y é considerada para o objeto k.
2.3.4. Operadores Simbólicos
Supomos dois indivíduos Eba ∈, descritos por p variáveis simbólicas como
segue:
( ) ( ) ( )( ) ( )pjpj AAAaYaYaYa ,,,,,,,, 11 KKKK ==
( ) ( ) ( )( ) ( )pjpj BBBbYbYbYb ,,,,,,,, 11 KKKK ==
Onde cada variável simbólica Yj possui valores no domínio Dj, e Aj e Bj são
subconjuntos de Dj.
Seja junção representada por ⊕ e conjunção por ⊗ :
• Junção: A junção possui uma formulação diferente a depender do tipo da
variável que faz a operação como argumentos. Se a variável for uma variável do
tipo intervalo ou do tipo ordinal, nós temos ],[ jujlj AAA = e ],[ jujlj BBB = ,
mas se a variável forem do tipo quantitativa a junção se transforma em união jA
e jB (veja a equação 2.1).

2.4 Análise Discriminante Fatorial para dado Simbólicos
- 21 -
j
Bj
A ⊕
j
Bj
A ⊗
vaquantitati variável
intervalar e ordinal variável)(),(
,max,min
=⊕
jB
jA
juB
juA
jlB
jlA
jB
jA
U
(2.1)
• Conjunção: A conjunção de dois subconjuntos jjj DBA ⊆, é definida como
segue:
jj BAj
Bj
A I=⊗ (2.2)
Para uma melhor entendimento de como se comportam esses operadores temos a
seguir uma visualização gráfica para ilustrar como mostra a figura 2.1.
Figura 2.1: Operadores junção e conjunção
2.4. Análise Discriminante Fatorial para dados
Simbólicos
A análise estatística multivariada utilizando funções discriminantes foi
inicialmente aplicada para decidir à qual de dois grupos pertenceriam indivíduos sobre
os quais tinham sido feitas diversas e idênticas mensurações. Análise Discriminante
refere-se a um conjunto de técnicas cujo objetivo é descrever as relações entre um
conjunto de p variáveis quantitativas (descritores) e uma variável categórica com m
rótulos, a variável classificatória que define a partição da população de interesse em m
classes.
São considerados dois aspectos principais na Análise Discriminante:

2.4 Análise Discriminante Fatorial para dado Simbólicos
- 22 -
• Uma seleção do melhor subconjunto dos descritores originais (aspecto de
seleção).
• A construção da regra de decisão (regra de classificação) com objetivo de
classificar elementos em uma das m classes (aspecto classificatório).
O aspecto de seleção na Análise Discriminante Fatorial (Factorial Data Analysis
- FDA) [Johnson & Wichern, 2001] é constituído em termos de combinação linear das p
variáveis descritoras originais que são escolhidas de forma que se obtenha a melhor
visualização das classes no espaço fatorial. O aspecto classificatório da FDA é realizado
pela definição da regra de classificação geométrica que se baseia na proximidade entre o
individuo e a classe.
A Análise Discriminante Fatorial para Dados Simbólicos é um método
simbólico-numérico, baseado em uma analise numérica dos dados simbólicos
transformados e em uma interpretação simbólica dos resultados. Este método é
constituído dos seguintes passos.
I. Quantificação dos descritores.
II. FDA nos descritores quantificados.
III. Interpretação simbólica dos resultados.
A primeira etapa da Análise Discriminante Fatorial para Dados Simbólicos que é
a quantificação dos descritores é realizada pela transformação numérica do dado
simbólico que consiste em uma determinada codificação adequada de acordo com o tipo
de variável (seção 2.3). Ao final deste processo obtemos N descritores numéricos.
A segunda etapa assume jθ , Nj ,,1K=∀ como os novos descritores.
O número de coordenadas a serem mantidas na análise discriminante fatorial é
escolhida de forma usual para N o número de descritores e m o número de classes a
porcentagem de variância dos descritores aplicada das ( )1,min −≤ Nmq primeiras
coordenadas.
Na ultima fase a representação é feita pela definição da regra de classificação
geométrica. Considerando que ambos a instância a ser classificada e as classes são
representados no espaço fatorial por retângulos. A classificação da instância em uma
classe iC é definida de acordo com dois eventos:

2.4 Análise Discriminante Fatorial para dado Simbólicos
- 23 -
i. Se o exemplo (retângulo) estiver incluído na classe iC , este é rotulado a
esta classe.
ii. Se o exemplo está parcialmente ou completamente fora de todas as
classes ou dentro de uma área de sobreposição entre duas ou mais
classes, considera-se uma medida de similaridade para determinar a qual
classe iC o elemento pertence.
Na literatura existem algumas regras de classificação geométrica [Bock &
Diday, 2000], podemos destacar àquelas baseadas no potencial descritor ( ).π , definido
por De Carvalho [De Carvalho, 1992] como o volume do produto cartesiano dos
domínios das variáveis. Abaixo apresentamos uma regra de classificação baseada no
potencial descritor.
Regra de classificação baseada em uma extensão da medida de
dissimilaridade de Minkowsky
Esta medida de dissimilaridade baseada em uma medida de dissimilaridade
proposta por Ichino e Yaguchi [Ichino & Yaguchi, 1994] e generalizada para dado
simbólico por De Carvalho e Diday [De Carvalho & Diday, 1998]:
( ) ( )[ ]mm
sjsj pd ∑=α
αα ωωψωω ,,
Onde jω e sω são a representação fatorial de dois elementos j e s na
coordenada α e m é o número de coordenadas fatoriais,
( ) ( ) ( ) ( ) ( ) ( )( )( )js
jsjsjsjs
sjSS
SSSSSSSS
αα
αααααααα
µ
µµµγµµωω
⊕
−−+−⊕=Ψ
II 2,
Com [ ]1,0∈γ , ( )sSαµ é o tamanho do intervalo do elemento na coordenada α ,
( )js SS ααµ ⊕ é o tamanho da junção dos intervalos dos elementos j e s na coordenada
α , ( )js SS ααµ I é o tamanho da conjunção de dos intervalos dos elementos na
coordenada α .
(2.1)
(2.2)

2.5 Redes Multi-Layer Perceptron para dados Simbólicos
- 24 -
Dado um exemplo u de um conjunto de teste, ele será alocado a uma
determinada classe iC se a média das distâncias entre u e todos os elementos da classe
iC for menor em relação a todas as médias das outras classes.
2.5. Redes Multi-Layer Perceptron para dados
simbólicos
As Redes Neurais Artificiais, RNAs, são sistemas paralelos e distribuídos
compostos por unidades de processamentos simples (nodos) que computam
determinadas funções matemáticas (usualmente não lineares), normalmente adaptativas,
cuja organização e funcionamento destas redes é inspirado em uma estrutura física
concebida pela natureza do cérebro humano [Braga et al, 2000]. Tais unidades são
dispostas em uma ou mais camadas e interligadas por um grande número de conexões,
geralmente, unidirecionais. Na maioria dos modelos estas conexões estão associadas a
pesos, os quais armazenam o conhecimento representado no modelo e servem para
ponderar a entrada recebida por cada neurônio da rede. O funcionamento destas redes é
inspirado em uma estrutura física concebida pela natureza do cérebro humano.
Dentre os vários modelos de redes neurais artificiais, a rede Perceptron Multi-
Camadas (multi-layer perceptron - MLP) é a mais difundida. Tipicamente, a rede
consiste de um conjunto de unidades sensoriais que constituem a camada de entrada,
uma ou mais camadas escondidas e uma camada de saída de nós computacionais. Seu
poder computacional excede a capacidade das redes simples sem camada intermediária
como Perceptron e Adaline, podendo tratar dados que não são linearmente separáveis
[Braga et al, 2000].
As principais características de uma rede MLP são:
• Número mínimo de três camadas (entrada, escondida, saída);
• Apresenta um alto grau de conectividade entre as camadas;
• Fluxo de informação unilateral;
• O modelo de cada unidade de processamento inclui um função de ativação não-
linear, normalmente a logística (sigmóide) ou a tangente hiperbólica;

2.5 Redes Multi-Layer Perceptron para dados Simbólicos
- 25 -
• A fim de ajustar as conexões entre as unidades de processamento é utilizado um
algoritmo de treinamento;
O backpropagation [Rumelhart & McClelland, 1986] é o algoritmo de
treinamento supervisionado mais conhecido para as redes MLP. Para tanto, utiliza pares
de entrada associados com a saída desejada para ajustar os pesos da rede por um
mecanismo de adaptação por correção de erros em duas fases (forward e backward). O
backpropagation baseia-se na regra delta generalizada, recorrendo ao método do
gradiente para ajustar os pesos das conexões entre os nodos.
Em [Rossi & Conan-Guez, 2002] foi estudado dois tipos de métodos que
permitem o uso de dados simbólicos do tipo intervalo como entrada para redes MLP´s:
a abordagem dos valores extremos e dois procedimentos probabilísticos. Estes métodos
possuem as seguintes características:
• Podem ser implementados facilmente em software de redes neurais existentes.
Um outro método baseado na idéia da aritmética do intervalo [Simoff, 1996]
necessita que todas as etapas da rede neural (inicialização, treinamento,
visualização, etc.) sejam modificadas e adaptadas ao método.
• A MLP treinada com intervalos através de um destes métodos suporta tanto
intervalos como dados usuais quantitativos como entrada. Esta característica é
importante já que um dado usual pode ser considerado um intervalo cujos
limites sejam iguais.
2.5.1. Método dos valores extremos
A forma mais simples de se tratar intervalo com entrada para uma MLP é
transformar cada intervalo em um par de dados usuais, por exemplo os limites inferiores
e superiores do intervalo, ou o centro e amplitude do intervalo. Com este artifício é
possível utilizar a MLP clássica, porém dobra a quantidade de dados de entrada.
A fim de usar dados usuais em uma MLP treinada com o método dos valores
extremos, deve-se replicar estes dados, isto é, uma entrada ( )nxx ,,1 K torna-se
( )nn xxxx ,,,, 11 K .

2.6 Discriminante de Kernel para dados Simbólicos
- 26 -
2.5.2. Método probabilísticos
Uma forma de tratar dados do tipo intervalo é considera-los como simples dados
probabilísticos. Se uma amostra para a MLP é descrita pelo intervalo [a,b], uma
possível interpretação é presumir que de fato a amostra pode assumir qualquer valor
entre a e b, com probabilidade uniforme.
Baseado nesta premissa, o método da média substitui cada intervalo pela sua
média e treina a rede com os valores obtidos. Dados usuais são tratados diretamente.
Uma outra maneira de proceder é substituir cada amostra por um conjunto de
valores reais. Estes valores são obtidos a partir de simulação, supondo que o intervalo
[a,b] corresponde a uma distribuição uniforme em [a,b]. Esta abordagem é chamada de
método de simulação. Para entradas novas de dados usuais, é usada a MLP treinada
diretamente. Para entradas novas do tipo intervalo são gerados valores reais simulados e
computada a saída correspondente normalmente.
2.6. Discriminante de Kernel para dados
Simbólicos
Nesta seção apresentaremos o método estatístico de classificação supervisionado
conhecido como função kernel. Inicialmente apresentaremos o caso clássico e por fim a
abordagem simbólica.
Consideremos que o conjunto de treinamento é formado pelas classes gΠΠ ,,1 K
e estas, por sua vez, são descritas por g densidades de probabilidades,
( ) ( )xfxf g,,1 K .Quando as densidades são conhecidas, o problema da classificação é
resolvido facilmente pelos métodos de máxima verossimilhança ou pela regra de Bayes
(caso também seja fornecida a probabilidade a priori).
Na maioria dos casos reais, porém, não é possível supor um modelo paramétrico
sobre as densidades de probabilidade das classes. Nestas circunstâncias, métodos não
paramétricos devem ser usados para obter as estimativas das densidades. O
discriminante kernel é um destes métodos.

2.6 Discriminante de Kernel para dados Simbólicos
- 27 -
O estimador de densidade kernel para a densidade de probabilidade kf ,
gk ≤≤1 , e dado quantitativo d-dimensional é fornecido pela seguinte expressão:
( )( ) ∑=
−=
kn
i k
ki
d
kk
kh
xxK
hnxf
12
1ˆ , dx ℜ∈ ,
onde
• 0>kh é a largura da janela pré definida para a k-ésima população
• ∑ =
−kn
ik
ki
h
xxK
1 informa o número de elementos do conjunto de treinamento cuja
distância seja menor que kh de x.
Como já vimos, o estimador de densidade de kernel é uma ferramenta que
permite o estatístico construir densidade em qualquer conjunto de dados [Rasson &
Lissoir, 2000]. Afim de adaptar o método para dados simbólicos, algumas novas
medidas de densidades faz-se necessária.
Vamos supor que cada indivíduo seja descrito por p variáveis simbólicas
( )pYYX ,,1 K= . Com objetivo de resolver o problema de discriminação para dados
simbólicos, teremos que encontrar analogia com o estimador de densidade clássico
apresentado anteriormente, que mede a concentração de dados na vizinhança de xX = .
Desta forma, a estimação de densidade é realizada contando os pontos do conjunto de
treinamento de cada população dentro do “hipercubo”, usando uma medida de
dissimilaridade d1 [Esposito et al, 2000] entre os objetos simbólicos x,y:
( ) ( )∑=
=kn
i
kihx
k
k xKn
xI1
,
1ˆ
onde
( )( )( )
≥
<=
hyxdse
hyxdseyK hx ,0
,1
1
1,
(2.3)
(2.4)
(2.5)

2.7 Árvore de classificação para dados simbólicos
- 28 -
2.7. Árvore de classificação para dados simbólicos
As arvores de classificação ([Breiman el al, 1984] e [Ciampi, 1992]) tem como
objetivo predizer o número de objetos em k classes representados pela variável
categórica c através da medição de uma ou mais variáveis preditoras. Em outras
palavras, consiste em encontrar as probabilidades P[ c |y], kc ,,1 K∈ , onde y denota a
descrição de um objeto pelas variáveis preditoras.
O algoritmo de árvore de classificação compõe-se de quatro etapas básicas
[Lewis, 2000]. Na primeira temos a construção da árvore, utilizando algoritmo de
partição recursiva dos nós. Cada nó resultante é atribuído a uma classe, baseando na
probabilidade a priori de cada classe, da matriz de custo e na fração de elementos de
cada classe no nó resultante. A segunda etapa consiste parar o processo de construção
da árvore. Neste ponto foi produzida uma árvore “máxima” que provavelmente sobre
ajustou a informação contida na base de treinamento. Já a terceira etapa consta da poda
da árvore que resulta na criação de uma seqüência de árvores cada vez mais simples.
Por fim a quarta etapa é a seleção da árvore ótima, aquela que ajusta melhor a
informação da base de aprendizagem sem sobre ajustá-la.
Em algoritmos de construção de arvores de classificação clássicos (por exemplo
nos métodos CART ou RECPAM, respectivamente, propostos por ]Breiman et al, 1984]
e [Ciampi, 1992]), os dados usuais estudados são considerados por uma amostra de
aprendizagem denotada por ( ) NiycL ii ,,1;, K== . No contexto de objetos simbólicos,
nós agora representaremos e generalizaremos esta série de dados de como uma lista β
(para dados) das asserções: Niba ii ,,1; K=∧=β onde ai e bi são asserções,
respectivamente, definidas nas variáveis C e Y.
O método apresentado em [Ciampi et al, 2000] propõe estender o algoritmo de
construção de árvore para dados imprecisos ou probabilísticos. O objetivo do método
proposto é construir interativamente a partir de uma lista de dados simbólicos β (base de
treinamento), com ajuda de um procedimento de partição interativa, outra lista ω
(menor) de dados simbólicos que constitui a melhor representação da lista β.
Tttt ,,1; K=∧= γαω

2.7 Árvore de classificação para dados simbólicos
- 29 -
onde tt γα ∧ ,é a descrição de uma folha t da árvore (isto é, de uma região t do espaço da
descrição). Pelo sumário ω, nós consultamos assim às descrições das sub-populações
associadas aos nós terminais da árvore binária. Quanto para a série de dados de β , um
objeto do sumário ω é expresso também nos termos das asserções tα e
tγ ,
respectivamente, definida no critério e nas variáveis preditoras.
Em outras palavras, o objetivo do método é aumentar interativamente o conjunto
ω, que a cada passo, produz a melhor informação significativa sobre o conjunto β. Este
processo é escrito em forma do seguinte problema de maximização:
Max GInf(ω,β)
Onde GInf é uma medida geral de informação que expressa um conceito de
adequação entre dois conjuntos de asserções. A idéia geral da partição simbólica
recursiva é resumida no algoritmo abaixo:
1. Entrada: CONJUNTO DOS DADOS SIMBÓLICOS A SEREM
ESTUDADOS (β)
2. PARTICIONAMENTO SIMBÓLICO RECURSIVO
Aumenta interativamente o conjunto ω a partir dos dados β tal que, em
cada passo, GInf(ω,β) é máxima.
3. Saída: SUMÁRIO DOS DADOS SIMBÓLICOS (ω)
(descrição da árvore binária)
O fato que os dados estão representados como uma tabela, pôde induzir a sentir
que poderia conseguir tudo que foi conseguido pelo tratamento dado por um método
completamente clássico. A matriz da tabela , entretanto, é ajustada a uma representação
conveniente e o ponto da vista adotado aqui é completamente diferente do clássico.
Então, os valores dos preditores (as probabilidades associadas a cada marcador) seriam
tratados no intervalo [0,1] e aqui poderíamos encontrar partições do tipo: [Yj ≥ p] com
p∈[0,1]: um indivíduo dado seria atribuído a ramo da direita ou esquerda de um nó, se é
um indivíduo do conjunto atual, ou de um indivíduo observado em alguma ocasião
futura.
(2.6)

2.8 Classificador Simbólico baseado em região do tipo casca convexa
- 30 -
Este é um ponto completamente diferente do trabalho que foi desenvolvido. Do
ponto da vista deste trabalho, um indivíduo tem o valor do definido para cada preditor,
embora nosso conhecimento deste valor possa ser alterado pela incerteza. O algoritmo,
para a escolha atual dos conjunto dos objetos simbólicos βY e βC, permite-nos chegar,
dos dados que são tidos como imprecisos, a uma descrição de um relacionamento entre
os valores reais das variáveis. Finalmente, note isso além da possibilidade para produzir
atribuições mais flexíveis de objetos novos às classes de uma partição prévia, permiti
esta aproximação, sobretudo, para construir a árvore sem perder nenhuma informação
que relaciona-se a imprecisão que afete os dados.
2.8. Classificador Simbólico baseado em região do
tipo casca convexa
O trabalho introduz um classificador para dados descritos por vetores de valores
quantitativos baseado em regiões tipo casca convexa [D’Oliveira et al, 2004]. A idéia
central desta abordagem é construir regiões que descrevem e discriminem classes de
exemplos observados.
Basicamente esse classificador é dividido nas etapas de aprendizagem e de
alocação. A etapa de aprendizagem fornece a descrição de uma classe por uma região
(ou conjunto de regiões) definida pelo hiper-cubo formado pelos objetos pertencentes a
esta classe. Esta descrição é obtida através de um operador simbólico (junção) e um
Grafo de Vizinhos Mútuos. Na etapa de alocação, cada nova observação é afetada a uma
classe ou grupo de acordo com uma função de dissimilaridade que compara a descrição
de uma classe (uma região ou um conjunto de regiões) com um ponto em pℜ .
Para um melhor entendimento dos processos envolvidos nesse classificador
vamos fazer um breve comentário sobre conceitos de regiões, Grafos e Casca Convexa.
2.8.1. Regiões e Grafos
A proposta apresentada é fundamentada no método orientado a região para dados
simbólicos que são representados por vetores de variáveis quantitativas. O valor

2.8 Classificador Simbólico baseado em região do tipo casca convexa
- 31 -
assumido pela característica quantitativa de interesse pode ser tanto um valor contínuo
como um intervalo.
Seja kNkkk wwC ,,1 K= , mk ,,1K= , uma classe de indivíduos com
∅=′kk CC I se kk ′≠ e Ω==
m
k 1U . O indivíduo klw , kNl ,,1K= é representado pelo
vetor de dados contínuo ( )klpklkl xxx ,,1 K= .
A junção entre os vetores de dados contínuos klx ( )kNl ,,1K= é um vetor de
intervalos que é definido como
( )pkNpkjkNjkkNkkNklkl kkkk
xxxxxxXXy ⊕⊕⊕⊕⊕⊕=⊕= KKKKKK 111111 ,,,, , onde
[ ]jkNjkjkNjkjkNjk kkk
xxxxxx ,,max,,,min 111 KKK =⊕⊕ ( )pj ,,1K= .
A J-região associada à classe kC é a região em pℜ que é obtida pela junção dos
objetos pertencentes à classe kC e é definido como RJ ( kC ) = x ∈ pℜ :
jkNjk k
xx ,,min 1 K ≤ jx ≤ jkNjk k
xx ,,max 1 K , ( )pj ,,1K= . O volume associado ao
hipercubo definido pela região RJ ( kC ) é π(RJ ( kC )).
Dois indivíduos 1kω e 2kω são vizinhos mútuos se: ∀ lk′ω ∈ kC ′ (k’ ∈ 1,..,m, k’
≠ k), lkx ′ ∉Rj 1kω , 1kω ( )kNl ,,1 K= , ou seja, 1kω e 2kω são vizinhos mútuos se a
região formada por eles não contiver nenhum elemento de outra classe.
Uma clique H é um subgrafo completo máximo de G, isto é, para todos os pares
de possíveis vértices de H existe uma aresta, ao adicionar à H um outro vértice de G,
não existirá uma aresta para cada possível par de vértices de H.
Um grafo de vizinhos mútuos de iC em relação à iC′ , denominado
MNG( iC / iC′ )), é um grafo cujos vértices são os objetos da classe iC e cujas arestas são
formadas pelos pares distintos de objetos de iC que satisfazem à relação de vizinhos
mútuos, isto é, MNG( iC / iC ))=(V,A), onde V= iC e A=(sip , siq) ∈ iC x iC = sip ≠ siq e
sip é vizinho mútuo de siq.
2.8.2. Casca Convexa
A casca convexa é uma das mais importantes estruturas na geometria
computacional, principalmente usada como ferramenta para construção de outras

2.9 K-vizinhos mais próximos para dados simbólicos
- 32 -
estruturas em uma variedade de circunstâncias além de exercer um papel fundamental
na matemática pura.
Existe uma variedade de definições de casca convexa, porém a definição abaixo é,
talvez, a mais clara:
Definição: A casca convexa de um conjunto de pontos S é a interseção de todos os
semi-espaços que contém S.
É importante ressaltar que a casca convexa de um conjunto de pontos, apesar do
nome, é uma região "sólida" fechada incluindo todos os pontos internos, porém são seus
limites que computamos.
Concluindo, foi desenvolvido um classificador para dados descritos por vetores
de valores quantitativos, onde a representação das classes, a aproximação do Grafos de
Vizinhos Mútuos e a função de dissimilaridade são baseados em regiões de tipo casca
convexa. Também foi introduzido uma função de dissimilaridade que combina a
diferença de volume e a diferença de posição entre a descrição do objeto a ser alocado e
a descrição de uma classe para formar uma função de dissimilaridade baseada em
diferenças de volume.
2.9. K-vizinhos mais próximos para dados
simbólicos
SO-NN (Symbolic Objects Nearest Neighbor) [Appice et al, 2006] é um
classificador baseado em exemplos que estende o k-vizinho mais próximo (k-NN) a
objetos simbólicos (OS). O método empregado difere do k-NN clássico em quatro
aspectos. Primeiramente a saída da classificação está na forma de uma variável
simbólica modal que descreve mais informações que uma simples etiqueta única para
rotular a classe. Uma medida de dissimilaridade é usada em segundo para estimar a
distância entre os objetos simbólicos. Terceiro que a contribuição de cada vizinho é
tornada mais relevante com respeito a sua proximidade ao objeto simbólico a ser
classificado (objeto simbólico do teste). Quarto o k é extraído automaticamente na base
de uma validação cruzada dos dados do treinamento.

2.9 K-vizinhos mais próximos para dados simbólicos
- 33 -
Certamente, SO-NN, diferentemente do k-NN tradicional e de outros
classificadores simbólicos, não prediz simplesmente o valor desconhecido da classe
para variável Y , mas o valor de uma nova variável modal Y ′ˆ que descreve exatamente o
vetor da probabilidade da classe cuja dimensão corresponde ao cardinalidade de Y .
O classificador k-NN é uma técnica simples, bem conhecida da classificação que
requer uma métrica, um inteiro positivo k, e um conjuntos dos exemplos para o
treinamento rotulados. Um exemplo novo é atribuído um rótulo que o representa mais
freqüentemente entre seus k vizinhos mais próximos; isto é, o conjunto dos protótipos
de k que são os mais próximos a ele com respeito a métrica. Esta técnica atraiu o
interesse considerável devido a sua simplicidade. É também notável que não requer
exemplos a ser representado em um espaço apropriado do vetor, desde que somente a
medida de dissimilaridade ou a função de distância são requeridas para comparar
qualquer par de exemplos. Entretanto, o classificador tradicional do k-NN supõe que
todos os exemplos do treinamento correspondem aos pontos no espaço m-dimensional
mℜ e os vizinhos mais próximos de um novo exemplo estão definidos tipicamente nos
termos da distância euclidiana padrão. Conseqüentemente, uma extensão do k-NN aos
objetos simbólicos requerer o uso de uma medida adequada d da distância para os
objetos simbólicos, que não pode simplesmente ser representado como pontos em mℜ .
O desempenho de um classificador do k-NN pode significativamente depender
do tamanho da vizinhança (valor de k) escolhida e um tamanho diferente é apropriado
para diferentes problemas. Entretanto, nós podemos observar que tornando mais
relevante as distâncias em SO-NN, não há nenhum dano em permitir que a todo o
treinamento os objetos simbólicos tenham uma influência na classificação de um objeto
simbólico, desde que os objetos mais distantes tenham menos efeito na estimação da
probabilidade da classe. No caso em que todos os objetos simbólicos do treinamento
contribuem para classificar um exemplo novo do teste, o algoritmo trabalha como um
método global, quanto ao caso em que o k (k < n) os mais próximos dos objetos
simbólicos do treinamento são considerados, o algoritmo trabalha como um método
local, desde que somente os dados locais à área em torno que o contribuem para definir
as probabilidades da classe. Em todo o caso, os métodos locais têm vantagens
significativas quando a medida da probabilidade definida no espaço de objetos
simbólicos para cada classe quando é muito complexa, mas podem ainda ser descritos
por uma coleção de aproximações locais menos complexas. Conseqüentemente, a

2.10 Conclusão
- 34 -
escolha de k é crítica, desde que representa um limite entre aproximações locais e
globais das medidas da probabilidade. O valor apropriado de k a ser feito exame para a
classificação pode automaticamente ser induzido durante o processo da aprendizagem.
A observação empírica é crucial, pois é aquela que faz um exame de uma
vizinhança que seja menor do que os número de objetos presentes no conjunto de
treinamento ou mesmo possa melhorar a exatidão. Permite induzir a vizinhança
otimizada durante a fase de aprendizagem e de classificar eficazmente os objetos. Além
disso, como mostrado em [Gora et al, 2002], a busca para o melhor k pode ser reduzida
da escala [1, #O] à escala [1, O# ], sem diminuir em demasiada exatidão na
aproximação.
2.10. Conclusão
Neste capítulo nos apresentamos alguns classificadores supervisionados
clássicos que foram adaptados para trabalhar com dados simbólicos, dentre os quais
podemos citar Análise Discriminante Fatorial para dados simbólicos; Redes Multi-
Layer Perceptron para dados simbólicos; Discriminante Kernel para dados simbólicos;
Árvore de classificação para dados simbólicos; Classificador Simbólico baseado em
Região tipo Casca Convexa e o classificador SO-NN.
No próximo capitulo será explanado o classificador simbólico para dados
simbólico de semântica modal. A idéia é construir uma descrição simbólica do tipo
modal (uma distribuição de pesos) para cada uma das classes de indivíduos e usar as
descrições modais das classes para classificar novos exemplos usando funções de
proximidades.

Capítulo 3
- 35 -
3. Classificador Modal
Esse capítulo apresenta um classificador de semântica modal para dados do tipo
intervalo. A entrada do classificador modal é uma tabela de dados cujas linhas são
objetos (indivíduos) e cujas colunas são valores assumidos por variáveis simbólicas do
tipo intervalo. O objetivo é construir uma descrição simbólica do tipo modal (uma
distribuição de pesos) para cada uma das classes de indivíduos e usar essas descrições
modais para classificar novos exemplos usando funções de proximidades para dados
modais. Nesse classificador, as distribuições de pesos são construídas para descrever e
discriminar classes de indivíduos representados por vetores de dados que permitem
levar em conta variação ou incerteza. O classificador modal tem dois módulos:
aprendizagem e alocação.
O módulo de aprendizagem do classificador modal é dividido em duas etapas.
Na etapa de pré-processamento, cada intervalo do conjunto de aprendizagem é
transformado em uma distribuição de pesos da seguinte forma: um intervalo é
decomposto em intervalos menores e um peso é associado a cada um desses intervalos
para formar uma distribuição de pesos. Portanto, a saída dessa etapa é uma tabela de
dados cujas linhas são vetores de distribuições de peso representando os indivíduos.
Em seguida inicia-se a fase de generalização que visa obter também vetores de
distribuições de pesos para representar as classes de indivíduos. Os pesos das
distribuições de uma classe são computados pela média dos pesos das distribuições dos
indivíduos pertencentes a essa classe.
O módulo de alocação é também dividido em duas etapas. A primeira realiza um
pré-processamento no vetor de intervalos que descreve um novo indivíduo a ser
classificado. Cada intervalo desse vetor é transformado em uma distribuição de pesos. A
segunda é responsável pela afetação desse indivíduo a uma das classes pré-existentes.
Nessa última etapa, serão usadas funções de proximidade entre duas descrições modais
(dois vetores de pesos).
Nas seções 3.1 e 3.2 são descritas em maiores detalhes os módulos de
aprendizagem e de alocação do classificador modal para dados de tipo intervalo,
respectivamente. Na seção 3.3 é descrito o algoritmo de construção do classificador

3.1 Módulo de Aprendizagem
- 36 -
modal. Para finalizar, a seção 3.4 apresenta a conclusão e considerações finais desse
capítulo.
3.1 Módulo de Aprendizagem
Esse módulo consiste na construção de um descritor simbólico modal para cada
uma das classes sintetizando a informação entre os indivíduos pertencentes as suas
respectivas classes. A entrada do classificador é uma tabela de dados simbólicos que é
composta por n linhas e p colunas cujas linhas são os objetos (indivíduos) e as colunas
são variáveis simbólicas do tipo intervalo.
Duas etapas constituem o processo de aprendizagem: pré-processamento e
generalização.
3.1.1 Etapa de Pré-processamento
O objetivo da etapa de pré-processamento é transformar vetores de dados do tipo
intervalo (descrições dos indivíduos do conjunto de treinamento) em vetores de dados
do tipo modal para formar a entrada do classificador simbólico proposto nesse trabalho.
Uma solução possível para este problema é definir um método para transformar
uma variável do tipo intervalo a uma variável do tipo modal [De Carvalho et al, 1999].
Após ter aplicado este método, as variáveis transformadas terão uma distribuição do
peso que possa ser analisada pelas funções de dissimilaridade modal definidas
especialmente para o cálculo da dissimilaridade entre duas descrições simbólicas
modais usando suas distribuições do peso e seus suportes a elas associadas.
Seja kC , Kk ,...,1= , uma classe de kn objetos indexados por ki ( )kni ,...,1= com
∅=′kk CC I se kk ′≠ e Ω== k
K
k C1U um conjunto de treinamento de tamanho
∑ ==
K
k knn1
. Cada objeto ki ( )kni ,...,1= é descrito por p variáveis simbólicas do tipo
intervalo pXX ,...,1 e uma variável nominal 1+pX que representa a classe do objeto.
Uma variável simbólica jX ( )pj ,...,1= é do tipo intervalo se, dado um objeto
ki de kC ),...,1( Kk = , ( ) [ ]j
j
ki
j
ki
j
kij AbaxkiX ⊆== , sendo [ ]baAj ,= um intervalo. Uma

3.1 Módulo de Aprendizagem
- 37 -
variável simbólica jX~
( pj ,...,1= ) é do tipo modal se, dado um objeto ki de kC
),...,1( Kk = , ))(),((~)(~
kikiSxkiX j
kij q== sendo )(kiS um suporte (uma lista ordenada
ou não ordenada ou um vetor de intervalos) e )(kiq um vetor de pesos definido em
)(kiS tal que um peso )(mω é associado para cada categoria ou intervalo )(kiSm ∈ .
A Tabela 3.1 mostra um conjunto de dados simbólicos do tipo intervalo. Nessa
tabela, existem seis objetos pertencentes a duas classes. Nessa tabela, cada objeto é
descrito por uma variável simbólica do tipo intervalo e uma variável nominal que é a
classe do objeto.
Tabela 3.1. Uma tabela de dados simbólicos de tipo intervalo.
Elemento Dado intervalar Classe
e1 [10,30] 1
e2 [15,30] 1
e3 [25,35] 1
e4 [90,130] 2
e5 [110,120] 2
e6 [125,140] 2
Seja ( )j
H
j
j jII ,...,
~1=A um vetor de intervalos da variável j ( )pj ,...,1= cujos
limites ( )j
j
h HhI ,...,1= são obtidos a partir dos limites ordenados dos intervalos n+1
intervalos [ ] baxxxxxx j
Kn
j
K
j
kn
j
k
j
n
j
Kk,,,...,,...,,...,,...,,..., 11111 1
considerando as seguintes
propriedades:
1. [ ]baI j
h
H
hj ,1 ==U
2. ∅=′j
h
j
h II I se hh ′≠
3. Ω∈∃∀ kih tal que ∅≠j
ki
j
h xI I
Seja ( ))(),...,()(~
1 kiIkiIki j
H
j
j jki
=A um vetor de intervalos do indivíduo ki para
variável j ( pj ,...,1= ) obtido considerando as seguintes propriedades:

3.1 Módulo de Aprendizagem
- 38 -
1. j
j
h kiI A~
)( ∈
2. ( ) [ ] j
ki
j
ki
j
ki
j
h
H
h xbakiIj
ki === ,1U .
A descrição modal do indivíduo ki para variável j ( pj ,...,1= ) é
))(),(~
(~)(~
kikixkiX j
j
j
kij qA== com ( ))(),...,()( 1 kiqkiqkiq j
H
jjj
ki
= e ( )j
ki
j
h Hhkiq ,...1)( =
( )( )j
ki
j
ki
j
hj
hxl
xIlkiq
I=)(
sendo ( )Il o comprimento de um intervalo fechado I .
Note que para cada variável j ( pj ,...,1= ) é permitido ter um vetor de
intervalos ( )kijA~
diferente associado a um dado modal j
kix~ . Portanto, pode existir um
suporte diferente para cada dado modal j
kix~ .
Considerando as descrições do tipo intervalo dos indivíduos da Tabela 3.1, tem-
se o seguinte vetor de intervalos: ( )110
19
18
17
16
15
14
13
12
111 ,,,,,,,,,
~IIIIIIIIII=A
com [ [15,1011 =I , [ [25,151
2 =I , [ [30,2513 =I , [ [35,301
4 =I , [ [90,3515 =I , [ [110,901
6 =I ,
[ [120,11017 =I , [ [125,1201
8 =I , [ [130,12519 =I e [ [140,1301
10 =I .
A Tabela 3.2 apresenta as descrições modais para os indivíduos (objetos) da
Tabela 3.1 obtidas a partir de ( )110
19
18
17
16
15
14
13
12
111 ,,,,,,,,,
~IIIIIIIIII=A .
Tabela 3.2: Descrições modais dos indivíduos da Tabela 3.1.
Objeto Dado Modal ( )1
~X Classe
e1 (0.25[10,15[); (0.50[15,25[); (0.25[25,30[) 1
e2 (0.667[15,25[); (0.333[25,30[) 1
e3 (0.50[25,30[); (0.50[30,35[) 1
e4 (0.50[90,110[); (0.25[110,120[); (0.125[120,125[); (0.125[125,130[) 2
e5 (1.0[110,120[) 2
e6 (0.33[125,130[); (0.67[130,140[) 2
(3.1)

3.1 Módulo de Aprendizagem
- 39 -
3.1.2 Etapa de Generalização
Nessa etapa, cada classe é representada por um vetor de variáveis simbólicas
modais. A descrição simbólica de cada classe é uma generalização das descrições
simbólicas dos seus indivíduos que foram construídas na etapa de pré-processamento.
Seja kC ),...,1( Kk = uma classe de kn objetos. Cada elemento de kC é
representado por um vetor de dados simbólico modal. Esta classe também é
representada por um vetor de dados simbólicos do tipo modal ( )p
kkk ggg ~,...,~~ 1= ,
( ) ( )( )kkg j
j
j
k vA ,~~ = ( )pj ,...,1= , em que ( ) ( ) ( )( )
j
j
H
j
j kIkIk jk
AA~
,...,~
1 ⊂= é um vetor de
intervalos e ( ) ( ) ( )( )kvkvk j
H
jjj
k
,...,1=v é um vetor de pesos.
Os limites destes intervalos ( )( )j
k
j
h Hh kI ,...,1= são obtidos pela ordenação dos
limites dos intervalos )(kiI j
h dos indivíduos que pertencem à classe kC
( ) ( ) ( ) ( )
k
j
Hk
jj
H
jknIknIkIkI j
kkn
jk
,...,,...,1,...,1 111
. Os pesos ( )kv j
h são calculados por:
( ) ( )∑∈
=kCi
j
h
k
j
h kiqn
kv1
Note que ao nível de cada variável j ( pj ,...,1= ) existe um vetor de intervalos
( ) ( ) ( )( )kIkIk j
H
j
j jk
,...,~
1=A diferente para cada dado modal j
kg~ . A Tabela 3.3 apresenta a
descrição modal de cada classe de indivíduos da Tabela 3.2.
Tabela 3.3: Descrições modais para as classes de indivíduos da Tabela 3.2.
Classe Dado modal
1 ((0.0833 [10,15[); (0.3889 [15,25[); (0.3611 [25,30[); (0.1667[30,35[);
2 ((0.1667[90,110[); (0.4167[110,120[); (0.0417[120,125[); (0.1527[125,130[);
(0.2222[130,140[))
(3.2)
3.2 Módulo de Alocação
- 40 -
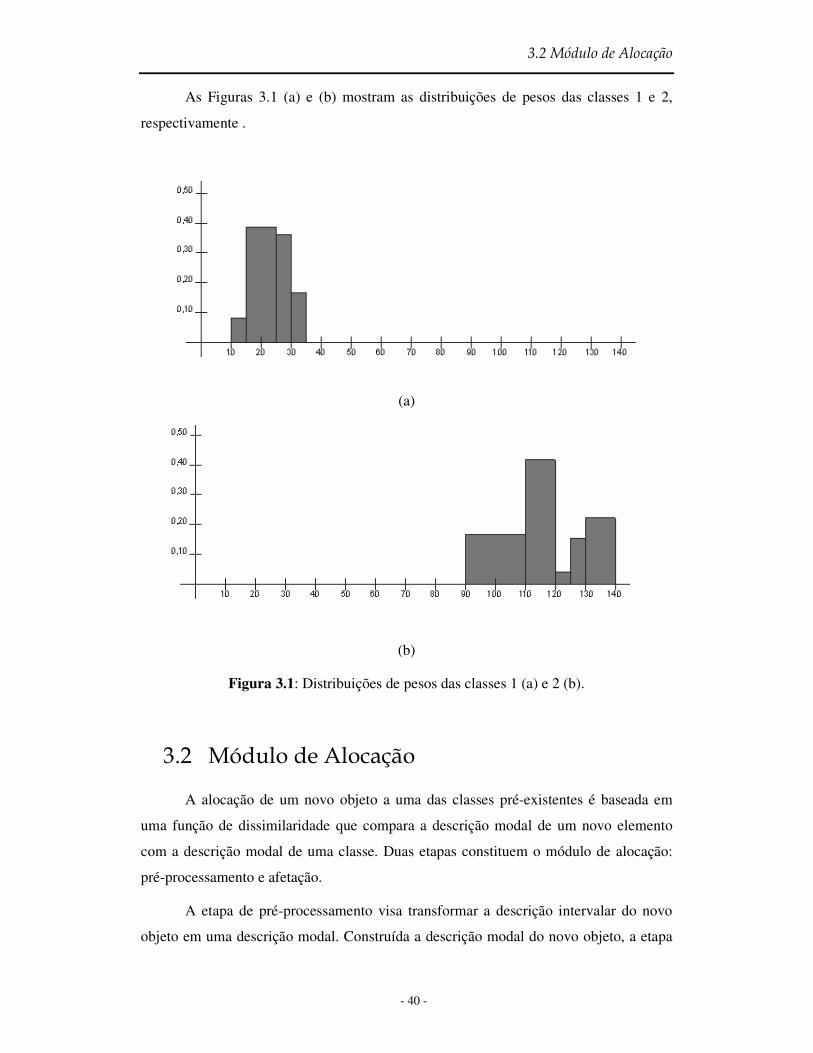
As Figuras 3.1 (a) e (b) mostram as distribuições de pesos das classes 1 e 2,
respectivamente .
(a)
(b)
Figura 3.1: Distribuições de pesos das classes 1 (a) e 2 (b).
3.2 Módulo de Alocação
A alocação de um novo objeto a uma das classes pré-existentes é baseada em
uma função de dissimilaridade que compara a descrição modal de um novo elemento
com a descrição modal de uma classe. Duas etapas constituem o módulo de alocação:
pré-processamento e afetação.
A etapa de pré-processamento visa transformar a descrição intervalar do novo
objeto em uma descrição modal. Construída a descrição modal do novo objeto, a etapa

3.2 Módulo de Alocação
- 41 -
de afetação consiste em medir as diferenças entre a descrição modal do novo objeto e a
descrição modal de uma classe usando uma função de dissimilaridade entre duas
distribuições de pesos. O novo objeto é associado à classe cuja dissimilaridade é
mínima.
3.2.1 Etapa de Pré-processamento
Seja [ ] [ ]( )ppp baxbaxx ωωωωωωω ,,...,, 111 === a descrição de tipo intervalo de um
objetoω a ser classificado. A idéia dessa etapa é obter a descrição de tipo modal
( ) ))(,~
(~)(~
ωωω ωj
j
j
j xX qA*== ao nível da variável j ( pj ,...,1= ) para o novo objeto
ω . Nessa direção, o vetor de intervalos ( )j
H
j
j jII ,...,
~1=A ( pj ,...,1= ) obtido na etapa
de pré-processamento do módulo de aprendizagem é atualizado.
Seja ( )j
H
jj jII **
1*
*,...,~
ω=A uma versão atualizada do conjunto de intervalos
( )j
H
j
j jIIω
,...,~
1=A tal que *
jA~
é obtido a partir da ordenação dos limites dos intervalos
[ ] jjj
H
j baII j ωω ,,,...,1 .
A descrição modal do objeto ω é ( ) ))(,~~)(
~ * ωωω ωj
j
j
j xX qA(== com
( ) ( ) ( )( )ωωωω
j
H
j
j jII **1 *,...,
~=A sendo um conjunto de intervalos satisfazendo as seguintes
propriedades:
1. ( ) ( )ωω ** ~j
j
hI A∈ ( )jHh *,...,1 ω=
2. ( ) ( ) jj
h
H
h xIj
ω
ωω ==
*1
*
U .
O peso )(ωj
tq é definido por:
( )( )j
jj
tj
txl
xIlq
ω
ωωI
=)(
(3.3)

3.2 Módulo de Alocação
- 42 -
Com o objetivo de ilustrar essa etapa de pré-processamento a Tabela 3.4 mostra
a descrição de tipo intervalo de dois novos objetos que serão afetados a uma das classes
pré-existentes da Tabela 3.3.
Tabela 3.4: Novos objetos descritos por uma variável simbólica do tipo intervalo
Objeto Dado Intervalar
a [20,30]
b [120,135]
Considerando 112
111
110
19
18
17
16
15
14
13
12
11
*1 ,,,,,,,,,,,
~IIIIIIIIIIII=A com [ [15,101
1 =I ,
[ [20,1512 =I , [ [25,201
3 =I ,, [ [30,2514 =I , [ [35,301
5 =I , [ [90,3516 =I , [ [110,901
7 =I ,
[ [120,11018 =I , [ [125,1201
9 =I , [ [130,125110 =I , [ [135,1301
11 =I e [ [140,135112 =I , a
Tabela 3.5 apresenta as descrições modais dos objetos da Tabela 3.4.
Tabela 3.5: Descrições modais para os objetos da Tabela 3.4
Elemento Dado Modal ( )1
~X
a (0.5[20,25[); (0.5[25,30[)
b (0.333[120,125[); (0.333[125,130[); (0.334[130,135[)
3.2.2 Etapa de Afetação
Seja ω um novo objeto a ser classificado com descrição modal
))(,~
(~ * ωωj
j
j qx A= obtida na etapa de pré-processamento.
Se ∅≠∩ )(A~
)(A~ * kjj ω , é necessário atualizar a descrição modal
( ) ( )( )kkg j
j
j
k vA ,~~ = ( )pj ,...,1= de kC : ( ) ( )( )kkg jj
k vA*
j ,~~ = sendo

3.2 Módulo de Alocação
- 43 -
( ) ( ) ( )( )kIkIk j
H
jj j
k
**1
**,...,
~=A obtido pela ordenação dos limites dos intervalos
( ) ( ) ( ) ( ) ωωω
j
H
jj
H
jjj
k
IIkIkI **11 ,...,,,..., e o vetor de pesos definido por
( )( ) ( )( )
( )( )kIl
kIkIlkvkv
j
h
j
t
j
hj
h
j
t
*
)(I
∗=
para j
kHt *,...,1∈ e ( ) ( ) ∅≠∈ kIkIHh j
t
j
h
j
k
*,...,1 I , caso contrário 0)( =kv j
t.
Além disso, a descrição ( ) ))(,~
(~ * ωωωj
j
jx qA= do novo indivíduo ω é também
ajustada de acordo com a classe kC : ( ) ( )kAA jj
** ~~=ω e
( )
( )j
jj
tj
txl
xIlq
ω
ωωI
=)(
para j
kHt *,...,1∈ .
A Tabela 3.6 ilustra as descrições modais das classes atualizadas de acordo com
o objeto a ser afetado. Comparando essas descrições com as suas descrições prévias
mostradas na Tabela 3.3, observe que a descrição modal da classe 1C permanece a
mesma quando o elemento a ser classificado é o objeto b e descrição modal da classe
2C permanece a mesma quando o elemento a ser classificado é o objeto a . Isso ocorreu
porque não existe interseção entre os suportes das descrições modais do objeto corrente
e da classe.
Tabela 3.6: Descrições modais das classes de acordo com o objeto.
Objeto Classe Dado modal
1 ((0.0833 [10,15[); (0.19445 [15,20[); (0.19445 [20,25[);
(0.3611 [25,30[); (0.1667[30,35[)) a
2 ((0.1667[90,110[); (0.4167[110,120[); (0.0417[120,125[);
(0.1527[125,130[); (0.2222[130,140[))
1 ((0.0833 [10,15[); (0.3889 [15,25[); (0.3611 [25,30[);
(0.1667[30,35[)); b
2 ((0.1667[90,110[); (0.4167[110,120[); (0.0417[120,125[);
(0.1527[125,130[); (0.1111[130,135[); (0.1111[135,140[))
(3.4)
(3.5)

3.2 Módulo de Alocação
- 44 -
A regra de classificação é definida como segue:
R: ω é afetado à classe kC se
( ) ( ) KmCdCd mk ,...,1,,, ∈∀≤ ωω
sendo ( )kCd ,ω uma função que mede dissimilaridade entre a descrição modal da
classe kC e a descrição modal de um objeto ω .
Na próxima seção, serão apresentadas as funções de dissimilaridades para dados
modais introduzidas nesse trabalho.
3.2.3 Funções híbridas de dissimilaridade para dados
modais
A dissimilaridade entre dois objetos mede o grau de diferenças.
Definição
Seja Ω um conjunto de indivíduos e ω ∈ Ω um indivíduo. Um índice de
dissimilaridade d é uma aplicação d: Ω×Ω → R+, que satisfaz às seguintes propriedades:
1. ∀ ω ∈ Ω, d (ω,ω) = 0.
2. ),(),( :),( ''' ωωωωωω dd =Ω×Ω∈∀ (simetria)
As funções de dissimilaridades discutidas nesta subseção são definidas através
de duas funções: uma medida de comparação em nível de cada variável (quantitativa ou
qualitativa) e uma medida de agregação, para agregar as comparações e obter uma
função de dissimilaridade global.
As funções de dissimilaridade clássicas para distribuições de pesos são casos
ou transformação de φ -divergente ou Ι -divergente introduzido por Csiszàr [Csiszàr,
1967] que usa razão de verossimilhança. Estas funções consideram que os suportes da
distribuição de pesos sejam idênticos.
Nesse trabalho, o suporte da distribuição de pesos definido para cada variável
j ( )pj ,...,1= pode não ser o mesmo para todas as classes e indivíduos e assim se faz
(3.6)

3.2 Módulo de Alocação
- 45 -
necessário usar uma função de comparação que permita levar em conta as diferenças em
posição (suporte) e em conteúdo (pesos).
Portanto, as diferenças entre duas descrições modais ao nível da variável
j ( )pj ,...,1= são calculadas por uma função híbrida com dois componentes: conteúdo
e separação.
( )( ) ( )( ) ( ) ( )( )
2
,,,1
kvqkvqC
jjj
p
jjj
C
k
jωφωφ
ωφ+
=
A componente j
Cφ mede às diferenças em conteúdo satisfazendo as seguintes
propriedades:
• ( ) ( )( ) 0, =kvq jjj
C ωφ se ( ) )(kvq jj =ω para )(~
)(~ ** ωjj AkA = .
• ( ) ( )( ) 1, =kvq jjj
C ωφ se =∩ )(~
)(~ ** ωjj AkA ∅.
• ( ) ( )( ) 1,0 <≤ kvq jjj
C ωφ para ≠∩ )(~
)(~ ** ωjj AkA ∅.
A componente j
pφ mede as diferenças em posição satisfazendo as seguintes
propriedades:
• ( ) ( )( ) 0, =kvq jjj
p ωφ para ≠∩ )(~
)(~ * ωjj AkA ∅.
• ( ) ( )( )kvq jjj
p ,0 ωφ< <1 para =∩ )(~
)(~ * ωjj AkA ∅ .
Nesse contexto, três famílias de funções híbridas de dissimilaridade baseadas em
dois componentes são introduzidas a seguir.
3.2.3.1 Função hibrida de dissimilaridade baseada em um coeficiente de
afinidade
Nesta família de função hibrida de dissimilaridade, j
Cφ mede às diferenças em
conteúdo baseada no coeficiente de afinidade proposto por Bacelar-Nicolau [Bacelar-
Nicolau,1985] e j
pφ mede às diferenças em posição (suporte) para variável j
( )pj ,...,1=
(3.7)

3.2 Módulo de Alocação
- 46 -
( ) ( )( ) ( ) ( )∑=
∗−=
*
1
1,jH
t
j
t
j
t
jjj
C qkvkvq ωωφ
( ) ( )( ) ( ) ( )( ) ( )( ) ( )( )( ) ( )( )ω
ωωωφ
jj
jjjjjjj
pAkAl
AlkAlAkAlkvq
*
**
~~
~~~~,
⊕
−−⊕=
com ( )( ) ( )] maxmax, minmin[)( *k
j
kik
j
ki
jj CibCialAkAl ∈∈=⊕ ω ,
( ) ( )],[)(~
k
j
kik
j
ki
j Ci bmaxCi aminlkAl ∈∈= e
( ) ( )],[)(~* jjj balAl ωωω = , sendo ( )*l o comprimento do intervalo * .
A dissimilaridade global entre a descrição modal da classe kC e a descrição
modal de um objeto ω é definida agregando as comparações hibridas baseadas em um
coeficiente de afinidade para formar de uma função de agregação tal como a
generalização da métrica de Minkowski
( ) ( )[ ]q
j
q
k
jj
k CwCd ∑=
=1
11 ,, ωφω
Considerando 1=q e 1=w , e utilizando as descrições modais dos objetos a e b
da Tabelas 3.5 e as descrições modais das classes 1 e 2 da Tabela 3.6 obtêm-se os
seguintes resultados para os componentes de dissimilaridade 1Cφ e 1
pφ e a função de
dissimilaridade global d1:
a) para o objeto a e a classe C1
( ) ( )( ) 4729,0277775,011, 111 =−=vaqCφ ( ) ( )( ) 0,01, 111 =veq apφ
A dissimilaridade entre o objeto a e a classe C1 é: ( ) 2364,0, 11 =Cad
b) para o objeto a e a classe C2
( ) ( )( ) 0,10,012, 111 =−=vaqCφ ( ) ( )( ) 50,020140
30902, 111 =
−
−=vaqpφ
A dissimilaridade entre o objeto a e a classe C2 é: ( ) 7500,0, 21 =Cad
c) para o objeto b e a classe C1
A dissimilaridade entre o objeto b e a classe C1 é: ( ) 8400,0, 11 =Cbd
(3.8)
(3.9)
(3.10)

3.2 Módulo de Alocação
- 47 -
d) para o objeto b e a classe C2
A dissimilaridade entre o objeto b e a classe C2 é: ( ) 3404,0, 21 =Cbd
De acordo com os resultados ( a) – d) ) acima, o objeto a é associado a classe 1C
e o objeto b é afetado a classe 2C .
3.2.3.2 Função hibrida de dissimilaridade baseada em uma distância
de Minkowski Lr
Nesta família a função hibrida de dissimilaridade, o componente ( ) ( )( )kvq jjj
C ,ωφ representa as diferenças em conteúdo para a variável j ( )pj ,...,1=
usando a distância Lr de Minkowski [De Carvalho et al., 2004] com ( ),...2,1=r para o nosso trabalho utilizaremos 2=r .
( ) ( )( )( ) ( )
( )( ) ( )( )[ ]∑∑=
=+
−=
*
*
11
,j
j
H
tH
t
rj
t
rj
t
rj
t
j
tjjj
C
wqkv
wqkvkvq ωφ
Note que esta distância esta normalizada com o termo no denominador da
equação 3.11 ( ( )( ) ( )( )[ ]∑ =+
*
1
jH
t
rj
t
rj
t wqkv ) e a componente em posição ( ) ( )( )kvq jjj
P ,ωφ é:
( ) ( )( ) ( ) ( )( ) ( )( ) ( )( )( ) ( )( )ω
ωωωφ
jj
jjjjjjj
pAkAl
AlkAlAkAlkvq
*
**
~~
~~~~,
⊕
−−⊕=
A dissimilaridade global entre a descrição modal da classe kC e a descrição
modal do objeto ω é definida agregando a comparação hibrida baseada na distância Lr
de Minkowski para obter uma função de agregação tal como a métrica Minkowski.
( ) ( )[ ]q
p
j
q
k
jj
k CwCd ∑=
=1
22 ,, ωφω
Novamente, usando as descrições modais das Tabelas 3.5 e 3.6 têm-se os
seguintes resultados para os componentes de dissimilaridade 1Cφ (com r = 1) e 1
pφ e a
função de dissimilaridade global d2:
(3.11)
(3.12)
(3.13)

3.2 Módulo de Alocação
- 48 -
a) para o objeto a e a classe C1
( )( ) ( )( )[ ] 0.21)(
1
11*1 =+∑ =
kH
t att eqv ( ) ( )( ) 4444,01, 111 =veq aCφ ( ) ( )( ) 0,01, 111 =veq apφ
A dissimilaridade entre o objeto a e a classe C1 é: ( ) 2222,0, 12 =Cad
b) para o objeto a e a classe C2
( )( ) ( )( )[ ] 0,22)(
1
11*1
=+∑ =
kH
t tt aqv ( ) ( )( ) 0,12, 111 =vaqCφ ( ) ( )( ) 5000,02, 111 =vaqpφ
A dissimilaridade entre o objeto a e a classe C2 é: ( ) 7500,0, 22 =Cad
c) para o objeto b e a classe C1
A dissimilaridade entre o objeto b e a classe C1 é: ( ) 8400,0, 12 =Cbd
d) para o objeto b e a classe C2
A dissimilaridade entre o objeto b e a classe C2 é: ( ) 3750,0, 22 =Cbd
De acordo com os resultados ( a) – d) ) acima, o objeto a é associado a classe 1C
e o objeto b é afetado a classe 2C .
3.2.3.3 Função hibrida de dissimilaridade baseada em um índice de
acordo e desacordo
A função medindo as diferenças em conteúdo ( ) ( )( )kvq jjj
C ,ωφ ( )pj ,...,1= é
definida usando índices de acordo e desacordo [Bezerra & De Carvalho, 2004]. Desta
forma, considere a seguinte tabela de índices.
Tabela 3.7: Índices de desacordo e acordo para dados modais
Acordo Desacordo
Acordo
( )( ) ( )( )∑ ∩∈
=kAAm
j
mjj q** ωω ωα
( )( ) ( )( )∑ ∩∈
=kAAm
j
mk jj kv** ωα
( )( ) ( )∑
∩∈
=kAAm
j
mjj q** ωω ωβ
Desacordo ( )( ) ( )∑
∩∈
=kAAm
j
mk jj kv** ωγ

3.2 Módulo de Alocação
- 49 -
O índice ωα procura computar a soma dos pesos relativos a distribuição de
pesos ( )ωj
mq no caso de interseção dos suportes ( )ωjA* e ( )kA j* . O índice kα registra
a soma equivalente pesos da distribuição de pesos ( )kq j
m na mesma condição anterior.
O índice ωβ computa a soma dos pesos que pertence somente à distribuição de pesos
( )ωj
mq e o índice kγ computa a soma dos pesos que pertence somente à distribuição
( )kq j
m.
Usando os índices da tabela acima, a função ( ) ( )( )kvq jjj
C ,ωφ é dada por:
( ) ( )( )( )( ) ( )( )
++−+
++−=
γαβα
α
γαβα
αωφ
ωω
ω
kk
kjjj
C kvq 112
1,
com ( ) ( )( ) [ ]1,0, ∈kvq jjj
C ωφ .
A componente posição ( ) ( )( )kvq jjj
P ,ωφ é:
( ) ( )( ) ( ) ( )( ) ( )( ) ( )( )( ) ( )( )ω
ωωωφ
jj
jjjjjjj
pAkAl
AlkAlAkAlkvq
*
**
~~
~~~~,
⊕
−−⊕=
A dissimilaridade global entre a descrição modal da classe kC e a descrição
modal do objeto ω é definida agregando a comparação hibrida baseada em índices de
acordo e desacordo para obter uma função de agregação tal como a métrica Minkowski.
( ) ( )[ ]q
p
j
q
k
jj
k CwCd ∑=
=1
33 ,, ωφω
Usando as descrições modais das Tabelas 3.5 e 3.6 são obtidos os seguintes
resultados para os componentes de dissimilaridade 1Cφ e 1
pφ e a função de
dissimilaridade global d3:
(3.14)
(3.15)
(3.16)

3.2 Módulo de Alocação
- 50 -
a) para o objeto a e a classe C1
Os valores para os índices de acordo e desacordo são:
( )( ) ( )( ) 0.15,05,0
1
11*1* =+==∑ ∩∈ AaAm me aq
aα ( )
( ) ( )( ) 5555,011
11 1*1* ==∑ ∩∈ AaAm mvα
( )( ) ( )
0.01
11*1* ==∑
∩∈ AaAm me aq
aβ ( )
( ) ( )0.01
1
11 1*1* ==∑
∩∈ AaAm mvγ
Os valores para os componentes conteúdo e posição são:
( ) ( )( )( )( ) ( )( )
++−+
++−=
05555,005555,0
5555,01
00,100,1
0,11
2
11, 111 vaqCφ
( ) ( )( ) 0,01, 111 =vaqCφ
( ) ( )( ) 0,01, 111 =vaqpφ
A dissimilaridade entre o objeto a e a classe C1 é: ( ) 0,0, 13 =Cad .
b) para o objeto a e a classe C2
Os valores para os índices de acordo e desacordo são:
( )( ) ( )( ) 0,0
2
11*1* ==∑ ∩∈ AaAm me aq
aα ( )
( ) ( )( ) 0,022
11 1*1* ==∑ ∩∈ AaAm mvα
( )( ) ( )
0,12
11*1* ==∑
∩∈ AaAm me aq
aβ ( )
( ) ( )0,12
2
11 1*1* ==∑
∩∈ AaAm mvγ
Os valores para os componentes conteúdo e posição são:
( ) ( )( ) 0,12, 111 =vaqCφ ( ) ( )( ) 50,02, 111 =vaqpφ
A dissimilaridade entre o objeto a e a classe C2 é: ( ) 7500,0, 23 =Cad .
c) para o objeto b e a classe C1
A dissimilaridade entre o objeto b e a classe C1 é: ( ) 8400,0, 13 =Cbd .
d) para o objeto b e a classe C2
A dissimilaridade entre o objeto b e a classe C2 é: ( ) 1763,0, 23 =Cbd .
De acordo com os resultados ( a) – d) ) acima, o objeto a é associado a classe 1C
e o objeto b é afetado a classe 2C .

3.3 Algoritmo
- 51 -
3.3 Algoritmo
A seguir é apresentado o algoritmo de construção do classificador modal. Dois
módulos são considerados nesse algoritmo: aprendizagem e alocação. A entrada do
classificador modal é um conjunto de dados do tipo intervalo. Esse conjunto é dividido
em dois conjuntos: treinamento e teste. O módulo de aprendizagem usa o conjunto de
treinamento e o módulo de alocação usa o conjunto de teste.
________________________________________________________________ 1. Módulo de aprendizagem
1.1 Etapa de Pré-processamento: para cada variável j ( )pj ,...,1=
obtenha o conjunto de intervalos j
H
j
j jIIA ,...,
~1= de acordo com as
propriedades mostradas em seção 3.1.1. para cada indivíduo ki ( )mk ,...,1= e ( )kni ,...,1=
para cada variável j ( )pj ,...,1=
obtenha ))(),(~
(~)(~
kiqkiAxkiX j
j
j
kij == usando a equação (3.1).
1.2 Etapa de Generalização: para cada variável j ( )pj ,...,1=
para cada classe kC ( )Kk ,...,1=
obtenha ( ) ( )( )kvkAg j
j
j
k ,~~ = usando a equação (3.2).
2. Módulo de alocação para cada novo indivíduo ω faça
2.1 Etapa de Pré-processamento: para cada variável j ( )pj ,...,1=
adicione ],[ jj ba ωω a jA~
e obtenha o novo conjunto de intervalos jA*~.
obtenha ))(),(~
(~ * ωωωj
jj
i qAx = usando a equação (3.3).
2.2. Etapa de Afetação: para cada classe kC ( )Kk ,...,1=
para cada variável j ( )pj ,...,1=
se ≠∩ )(~
)(~ * ωjj AkA ∅ ,
obtenha ( ) ( )( )kvkAg jj
j
k ,~~ *= usando a equação (3.4)
atualize jxω
~ usando a equação (3.5)
compute a dissimilaridade ),( kq Cd ω usando uma das seguintes
equações: (3.10) para 1=q , (3.13) para 2=q e (3.16)
para 3=q .
afete o novo indivíduo à classe kC tal que
( ) ( ) KmCdCd mkq ,...,1,,, ∈∀≤ ωω
____________________________________________________________________________

3.4 Conclusão
- 52 -
3.4 Conclusão
Nesse capítulo foi apresentado um classificador de semântica modal para dados
do tipo intervalo. O classificador modal tem dois módulos: aprendizagem e alocação. O
módulo de aprendizagem é organizado em duas etapas. A primeira etapa, chamada de
pré-processamento, visa transformar as descrições intervalares dos indivíduos do
conjunto de treinamento em descrições modais (distribuições de pesos). A segunda
etapa, chamada de generalização, consiste em obter um vetor de distribuições de pesos
para cada classe de indivíduos cujos elementos são médias dos pesos das distribuições
dos indivíduos pertencentes a essa classe. O módulo de alocação também é dividido em
duas etapas. A primeira etapa, chamada de pré-processamento, consiste em obter um
vetor de distribuição de pesos para cada novo indivíduo a ser classificado. A segunda
etapa, chamada de afetação, compara o novo indivíduo com cada uma das classes pré-
existentes usando uma função híbrida de dissimilaridade. Três famílias de funções
híbridas de dissimilaridade para distribuições de pesos foram consideradas nesse
trabalho. Essas funções combinam as diferenças em conteúdo e em posição (suporte)
para medir a dissimilaridade entre duas distribuições de pesos. O novo indivíduo é
afetado à classe cuja dissimilaridade é mínima.

Capítulo 4
- 53 -
4. Classificador k-vizinhos mais
próximos para dados intervalares
(ID-KNN)
Esta seção apresenta um classificador baseado em exemplos (lazy learning) para
dados simbólicos de tipo intervalo, aqui chamado ID-KNN (Interval Data K-Nearest
Neighbor). Esse classificador necessita de uma etapa de pré-processamento para
transformar dados intervalares em dados modais (distribuições de pesos).
Os classificadores vizinhos mais próximos (1-NN e k-NN [Cover & Hart, 1967])
são procedimentos não paramétricos populares usados executar o classificação. Esta
regra da decisão fornece a atribuição de um rótulo da classe a um exemplo
desconhecido baseado nos rótulos da classe da freqüência representada pelos vizinhos
os mais próximos ao exemplo desconhecido.
Os algoritmos de buscas mais rápidas de vizinhos mais próximos foram uma das
alternativas para aliviar o custo computacional ([Grother et al., 1997], [Djouadi &
Bouktache, 1997]). Por outro lado, comprimindo os exemplos do conjunto de
treinamento, o espaço de armazenamento e o custo computacional podem ser reduzidos.
Neste sentido, as aproximações tradicionais do classificador de NN [Hart, 1968],
[Gates, 1972], [Ferri et al., 1999] foram propostos protótipos dessa seleção do conjunto
de exemplos do treinamento para reduzindo o custo e preservar o desempenho do
classificador. Os classificadores que utilizam protótipos obtêm um conjunto de
protótipos que agem como representantes das classes. A regra de classificação é baseada
na distância mínima entre um exemplo desconhecido e o protótipo de uma classe. A
vantagem estes classificador é que têm alguns protótipos que sumarizam
economicamente todos os pontos chave dos dados. A quantização de aprendizagem do
vetor (LVQ) [Kohonen, 1989] é provavelmente o classificador o mais bem conhecido
que utiliza protótipo. Um outro classificador de protótipo é o modelo de mistura
Gaussiana que é baseado em modelar as densidades das classe condicionais como uma
mistura de gaussiana [Duda et al., 2001].

4.1 Módulo de aprendizagem
- 54 -
O ID-KNN difere do k-NN clássico principalmente que os indivíduos ou objetos
são descritos por vetores de dados que não somente podem assumir um único valor, mas
um conjunto de valores, um intervalo ou uma distribuição de pesos. A regra de
classificação é baseada na freqüência de determinada classe dos que estiverem mais
próximos do objeto de teste e considerando também o tamanho da vizinhança do
elemento a ser classificado, a quantidade de elementos de cada classe que estão nessa
vizinhança e um vetor de pesos em que cada coluna diz respeito a uma classe.
Seja mC , Mm ,...1= , uma classe de mn objetos indexados por mi ( )mni ,...,1=
com ∅='mm CC I se 'mm ≠ e Ω== m
M
m C1U um conjunto de treinamento de tamanho
∑ ==
M
m mnn1
. Cada objeto mi ( )mni ,...,1= é descrito por p variáveis simbólicas do
tipo intervalo pXX ,...,1 e uma variável nominal 1+pX que representa a classe do objeto.
Uma variável simbólica jX ( pj ,...,1= ) é do tipo intervalo se, dado um objeto
mi de mC ),...,1( Mm = , ( ) [ ]j
j
ki
j
ki
j
kij AbaxkiX ⊆== , sendo [ ]baAj ,= é um intervalo.
Uma variável simbólica jX~
( pj ,...,1= ) é do tipo modal se, dado um objeto mi de mC
),...,1( Mm = , ))(),(()(~
miqmiSmiX j = sendo )(miS um suporte e )(miq um vetor de
pesos definido em )(miS tal que um peso )(gω é associado para cada categoria
)(miSg ∈ .
Dois módulos constituem o classificador ID-KNN: aprendizagem que visa
converter dos dados intervalares do conjunto de treinamento em dados do tipo modal e a
alocação que tem como propósito classificar os indivíduos do conjunto de teste.
4.1. Modulo de aprendizagem
O módulo de aprendizagem transforma as descrições intervalares de um
conjunto de treinamento em descrições modais utilizando as mesmas técnicas da etapa
de pré-processamento empregada no classificador modal, para a conversando dos dados
simbólicos do tipo intervalo em dados simbólicos do tipo modal. A saída desse módulo
é uma tabela cujas linhas são indivíduos ou objetos e as colunas são variáveis
simbólicas modais.

4.2 Módulo de alocação
- 55 -
4.2. Modulo de alocação
O módulo de alocação objetiva classificar os indivíduos do conjunto de teste a
uma das classes pré-existentes usando uma das funções de dissimilaridades híbridas
apresentadas no capítulo 3 para comparar a descrição modal do indivíduo do conjunto
de teste com a descrição modal de cada elemento da sua vizinhança.
Sejam ω um indivíduo ou objeto a ser classificado a uma classe mC
),...,1( Mm = ; ,...,)( 1 kk ooO =ω a vizinhança de ω determinada pelo conjunto de
treinamento e número de vizinhos k . Sendo ))(),...,((F 1 MCfCf ∈∈= ωω um vetor
de freqüências em que )( mCf ∈ω é a freqüência de ω pertencer à classe mC .
Seja ),( lowd a medida de dissimilaridade entre ω e um elemento de sua
vizinhança lo através de uma das três famílias de funções de dissimilaridade propostas
na seção 3.2.3 do capítulo 3, o novo elemento ω vai ser classificado de acordo com a
maior freqüência )( mCf ∈ω& ),...,1( Mm = existente de determinada classe em relação
a vizinhança pré-estabelecida dentre os mais próximos segundo a medida de
dissimilaridade utilizada.
O intuito da construção desse classificador ID-KNN é viabilizar um comparação
entre o classificador modal proposto nesse trabalho com um outro classificador de
semântica modal para dados intervalares e verificarmos como ambos os classificadores
se comporta com algumas configurações de dados simulados e também com dados do
tipo real.
A seguir é descrito o algoritmo de construção do classificador ID-KNN para
dados modais. Esse algoritmo difere do classificador modal em dois pontos. Primeiro o
classificador não tem a etapa de generalização do módulo de aprendizagem. Segundo a
regra de classificação do módulo de alocação é baseada na máxima freqüência de
determinada classe entre a vizinhança em estudo.

4.2 Módulo de alocação
- 56 -
Algoritmo ____________________________________________________________________________
1. Módulo de aprendizagem
para cada variável j ( )pj ,...,1=
obtenha o conjunto de intervalos j
H
j
j jIIA ,...,
~1= de acordo com as
propriedades mostradas em seção 3.1.1. para cada indivíduo mi ( )Mm ,...,1= e ( )mni ,...,1=
para cada variável j ( )pj ,...,1=
obtenha a descrição modal ))(),(~
(~)(~
miqmiAxmiX j
j
j
kij ==
usando a equação (3.1). 2. Módulo de alocação
para cada novo indivíduo ω faça 2.1 Etapa de Pré-processamento:
para cada variável j ( )pj ,...,1=
adicione o intervalo ],[ ωω ba a jA~
e obtenha o novo conjunto jA*~.
obtenha a descrição modal ))(),(~
(~ ωωωj
j
j
i qAx = do
indivíduo ω usando a equação (3.3). 2.2. Etapa de Afetação:
para cada mC ( )Mm ,...,1=
para cada indivíduo mi ( )mni ,...,1=
para cada variável j ( )pj ,...,1=
se ≠∩ )(~
)(~ * ωjj AmiA ∅ ,
obtenha ( ) ( )( )mivmiAg jj
j
k ,~~ *= usando a equação
(3.4) atualize jxω
~ usando a equação (3.5)
compute a dissimilaridade ),( kq Cd ω usando uma
das seguintes equações: (3.10) para 1=q , (3.13) para 2=q e (3.16) para 3=q .
determine os k-vizinhos mais próximos de ω de acordo com os resultados ),( mid q ω .
para cada classe m obtenha a freqüência )( mCf ∈ω
afete o novo indivíduo à classe mC tal que
MhCfCf hm ,...,1),()( ∈∀∈≥∈ ωω

4.3 Conclusão
- 57 -
4.3. Conclusão
Nesse capítulo foi apresentado um classificador K-vizinhos mais próximos para
dados intervalares (ID-KNN). O classificador ID-KNN tem dois módulos:
aprendizagem e alocação. O módulo de aprendizagem visa transformar as descrições
intervalares dos indivíduos do conjunto de treinamento em descrições modais
(distribuições de pesos). O módulo de alocação possui uma regra de classificação
baseada em estimativas de probabilidade e o novo indivíduo é afetado à classe cuja
probabilidade é máxima. Três famílias de funções híbridas de dissimilaridade para
distribuições de pesos foram consideradas nesse trabalho. Essas funções combinam as
diferenças em conteúdo e em posição (suporte) para medir a dissimilaridade entre duas
distribuições de pesos. O novo indivíduo é afetado à classe cuja dissimilaridade é
mínima.
No próximo capítulo, será apresentada uma avaliação experimental do
classificador modal com diferentes conjuntos de dados simulados e um conjunto de
dados reais do tipo intervalo.

Capítulo 5
- 58 -
5. Avaliação Experimental
Esse capítulo apresenta uma avaliação experimental do classificador de
semântica modal para dados do tipo intervalo discutido no capítulo 3. O objetivo é
avaliar o desempenho do classificador modal com dados sintéticos e reais do tipo
intervalo. A avaliação é baseada na taxa de erro de classificação obtida através de um
conjunto de teste e pelo tempo (em segundos) total de execução das etapas de
aprendizagem e alocação desse classificador. Com o intuito de obter um resultado
representativo dessas medidas, as etapas de aprendizagem e alocação do classificador
foram organizadas no quadro de uma experiência Monte Carlo. Para dados sintéticos,
foram tomadas 100 réplicas de cada conjunto com idênticas propriedades estatísticas.
Para dados reais, foi usada uma técnica de validação cruzada leave-one-out. Além disso,
o desempenho do classificador modal foi comparado com o desempenho de um
classificador k-vizinhos mais próximos de semântica modal para dados intervalares que
foi estudado e implementado durante esse trabalho. Esse classificador foi inspirado no
classificador SO-NN (Symbolic Object Nearest Neighbor) proposto por [Appice et al,
2006] para dados modais e booleanos.
O restante desse capítulo é dividido em quatro seções. Na primeira seção (5.1)
são apresentados os dados sintéticos que foram utilizados nas experiências. Em seguida
na seção (5.2) veremos as experiências de Monte Carlo e os resultados da taxa de erro e
do tempo para dados sintéticos. Na seção (5.3) teremos uma aplicação com um conjunto
de dados intervalares reais e na última seção (5.4) é exposta uma conclusão dessa
avaliação experimental.
5.1. Dados Sintéticos do tipo Intervalo
Em cada experimento, nós consideramos dois conjuntos de dados em ℜ2. Cada
conjunto de dados tem 250 pontos agrupados em três classes de diferentes formas e
tamanhos: duas classes com formas elípticas de tamanhos 70 e 80 e uma classe com a
forma esférica de tamanho 100. Cada classe deste conjunto de dados quantitativos é
gerada segundo uma distribuição normal bi-variada com vetor de médias µ e matriz de
covariâncias ∑ representada por:

5.1 Dados Sintéticos do tipo Intervalo
- 59 -
=
2
1
µ
µµ e
=Σ
2221
2121
σσρσ
σρσσ
Nós consideramos duas diferentes configurações de conjunto de dados
quantitativos: 1) dados gerados segundo com uma distribuição normal bi-variada com
classes bem separadas e 2) dados gerados segundo com uma distribuição normal bi-
variada com sobreposição de classes.
As classes do conjunto de dados 1 foram geradas de acordo com os parâmetros a
seguir (configuração 1):
a) Classe 1: 1µ = 17, 2µ =34, 21σ =36, 2
2σ =64 e 12ρ = 0.85
b) Classe 2: 1µ = 37, 2µ =59, 21σ =25, 2
2σ =25 e 12ρ = 0.0
c) Classe 3: 1µ = 61, 2µ =31, 21σ =49, 2
2σ =100 e 12ρ = – 0.85
Figura 5.1 ilustra o conjunto de dados 1 mostrando classes bem separadas ao
longo de uma variável e sobrepostas a nível da outra variável.
Configuração 1
0,0
10,0
20,0
30,0
40,0
50,0
60,0
70,0
80,0
0,0 20,0 40,0 60,0 80,0 100,0
Classe 1
Classe 2
Classe 3
Figura 5.1: Conjunto de dados quantitativos 1
As classes do conjunto de dados 2 foram geradas de acordo com os parâmetros
a seguir (configuração 2):
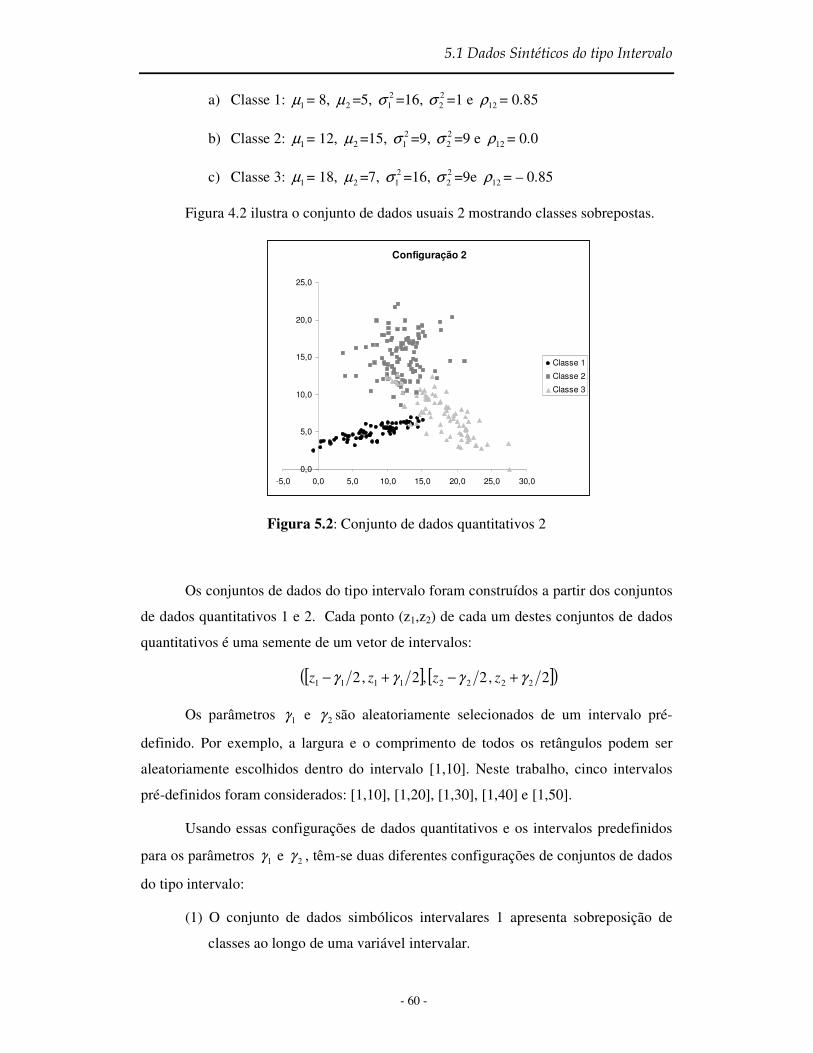
5.1 Dados Sintéticos do tipo Intervalo
- 60 -
a) Classe 1: 1µ = 8, 2µ =5, 21σ =16, 2
2σ =1 e 12ρ = 0.85
b) Classe 2: 1µ = 12, 2µ =15, 21σ =9, 2
2σ =9 e 12ρ = 0.0
c) Classe 3: 1µ = 18, 2µ =7, 21σ =16, 2
2σ =9e 12ρ = – 0.85
Figura 4.2 ilustra o conjunto de dados usuais 2 mostrando classes sobrepostas.
Configuração 2
0,0
5,0
10,0
15,0
20,0
25,0
-5,0 0,0 5,0 10,0 15,0 20,0 25,0 30,0
Classe 1
Classe 2
Classe 3
Figura 5.2: Conjunto de dados quantitativos 2
Os conjuntos de dados do tipo intervalo foram construídos a partir dos conjuntos
de dados quantitativos 1 e 2. Cada ponto (z1,z2) de cada um destes conjuntos de dados
quantitativos é uma semente de um vetor de intervalos:
[ ] [ ]( )2,2,2,2 22221111 γγγγ +−+− zzzz
Os parâmetros 1γ e 2γ são aleatoriamente selecionados de um intervalo pré-
definido. Por exemplo, a largura e o comprimento de todos os retângulos podem ser
aleatoriamente escolhidos dentro do intervalo [1,10]. Neste trabalho, cinco intervalos
pré-definidos foram considerados: [1,10], [1,20], [1,30], [1,40] e [1,50].
Usando essas configurações de dados quantitativos e os intervalos predefinidos
para os parâmetros 1γ e 2γ , têm-se duas diferentes configurações de conjuntos de dados
do tipo intervalo:
(1) O conjunto de dados simbólicos intervalares 1 apresenta sobreposição de
classes ao longo de uma variável intervalar.

5.1 Dados Sintéticos do tipo Intervalo
- 61 -
(2) O conjunto de dados simbólicos intervalares 2 mostra sobreposição de
classes ao longo de duas variáveis intervalar.
Figura 5.3 ilustra o conjunto de dados intervalar 1 mostrando classes separadas
com parâmetros 1γ e 2γ randomicamente selecionados no intervalo [1,10].
Figura 5.3: Conjunto de dados simbólicos 1
Figura 5.4 ilustra o conjunto de dados intervalar 2 mostrando classes sobrepostas
com parâmetros 1γ e 2γ randomicamente selecionados no intervalo [1,10].
Figura 5.4: Conjunto de dados simbólicos 2

5.2 Experiências Monte Carlo
- 62 -
5.2. Experiências Monte Carlo
A avaliação do desempenho dos classificadores modal e ID-KNN é baseada na
estimativa da taxa de erro de classificação e do tempo de execução usando o método
Monte Carlo com 100 replicações. A finalidade da aplicação do método Monte Carlo é
propiciar uma melhor avaliação quantitativa do desempenho dos métodos. Neste
estudo, são usados os conjuntos de dados sintéticos 1 e 2 de tipo intervalo mostrando
diferentes graus de dificuldade de classificação.
5.2.1. Resultados da taxa de erro
As Tabelas 5.1, 5.2 e 5.3 mostram os valores das médias e os respectivos desvios
padrões da taxa de erro para os classificadores modal e ID-KNN usando o conjunto de
dados intervalares 1 com 1γ e 2γ selecionados de [1,10], [1,20], [1,30], [1,40] e [1,50] e
as funções de agregação d1, d2 e d3 respectivamente, com parâmetros q = 1 e jw = 1/2
( )2,.1=j . Para o classificador ID-KNN, o melhor resultado para a taxa de erro é obtido
com o número da vizinhança k=5 para todas as distâncias analisadas.
Note que, para o classificador modal a distância d1 mostrou o melhor resultado
da taxa de erro, com média 2.43% enquanto que o classificador ID-KNN obteve
melhore resultado na distância d3 com média de 1.86%. Essa configuração trata-se de
um caso moderado de classificação e o classificador ID-KNN foi superior ao
classificador modal em todas as situações com o número da vizinhança k=5.
Tabela 5.1: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d1
Classificador ID-KNN Valor dos
Intervalos Classificador
Modal k = 1 k = 5 k = 10 k = 15
[1,10] 2.10
(0.0095) 2.38
(0.0106) 1.81
(0.0083) 2.04
(0.0089) 2.10
(0.0096)
[1,20] 2.18
(0.0100) 2.28
(0.0114) 1.64
(0.0084) 1.66
(0.0088) 1.76
(0.0093)
[1,30] 2.42
(0.0109) 2.54
(0.0109) 1.80
(0.0087) 1.98
(0.0093) 1.98
(0.0096)
[1,40] 2.75
(0.0116) 2.77
(0.0112) 2.04
(0.0088) 2.12
(0.0104) 2.26
(0.0111)
[1,50] 2.72
(0.0104) 2.74
(0.0107) 2.07
(0.0100) 2.14
(0.0095) 2.25
(0.0090)
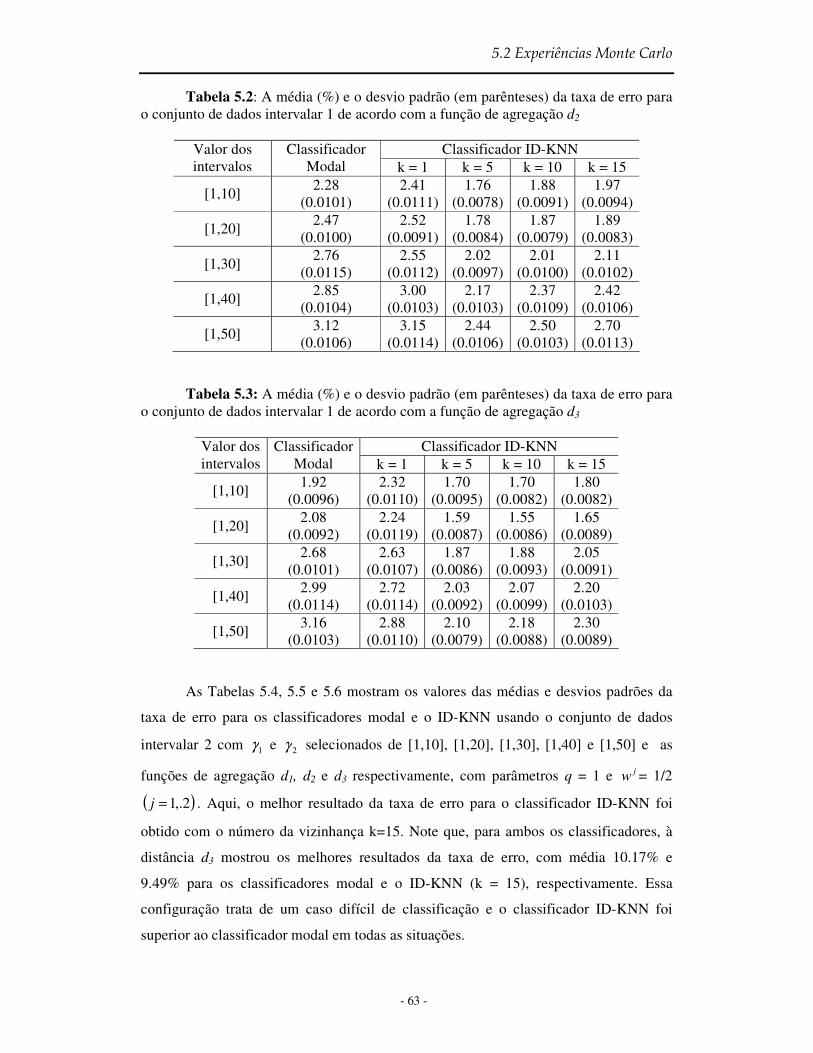
5.2 Experiências Monte Carlo
- 63 -
Tabela 5.2: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d2
Classificador ID-KNN Valor dos
intervalos Classificador
Modal k = 1 k = 5 k = 10 k = 15
[1,10] 2.28
(0.0101) 2.41
(0.0111) 1.76
(0.0078) 1.88
(0.0091) 1.97
(0.0094)
[1,20] 2.47
(0.0100) 2.52
(0.0091) 1.78
(0.0084) 1.87
(0.0079) 1.89
(0.0083)
[1,30] 2.76
(0.0115) 2.55
(0.0112) 2.02
(0.0097) 2.01
(0.0100) 2.11
(0.0102)
[1,40] 2.85
(0.0104) 3.00
(0.0103) 2.17
(0.0103) 2.37
(0.0109) 2.42
(0.0106)
[1,50] 3.12
(0.0106) 3.15
(0.0114) 2.44
(0.0106) 2.50
(0.0103) 2.70
(0.0113)
Tabela 5.3: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 1 de acordo com a função de agregação d3
Classificador ID-KNN Valor dos
intervalos Classificador
Modal k = 1 k = 5 k = 10 k = 15
[1,10] 1.92
(0.0096) 2.32
(0.0110) 1.70
(0.0095) 1.70
(0.0082) 1.80
(0.0082)
[1,20] 2.08
(0.0092) 2.24
(0.0119) 1.59
(0.0087) 1.55
(0.0086) 1.65
(0.0089)
[1,30] 2.68
(0.0101) 2.63
(0.0107) 1.87
(0.0086) 1.88
(0.0093) 2.05
(0.0091)
[1,40] 2.99
(0.0114) 2.72
(0.0114) 2.03
(0.0092) 2.07
(0.0099) 2.20
(0.0103)
[1,50] 3.16
(0.0103) 2.88
(0.0110) 2.10
(0.0079) 2.18
(0.0088) 2.30
(0.0089)
As Tabelas 5.4, 5.5 e 5.6 mostram os valores das médias e desvios padrões da
taxa de erro para os classificadores modal e o ID-KNN usando o conjunto de dados
intervalar 2 com 1γ e 2γ selecionados de [1,10], [1,20], [1,30], [1,40] e [1,50] e as
funções de agregação d1, d2 e d3 respectivamente, com parâmetros q = 1 e jw = 1/2
( )2,.1=j . Aqui, o melhor resultado da taxa de erro para o classificador ID-KNN foi
obtido com o número da vizinhança k=15. Note que, para ambos os classificadores, à
distância d3 mostrou os melhores resultados da taxa de erro, com média 10.17% e
9.49% para os classificadores modal e o ID-KNN (k = 15), respectivamente. Essa
configuração trata de um caso difícil de classificação e o classificador ID-KNN foi
superior ao classificador modal em todas as situações.
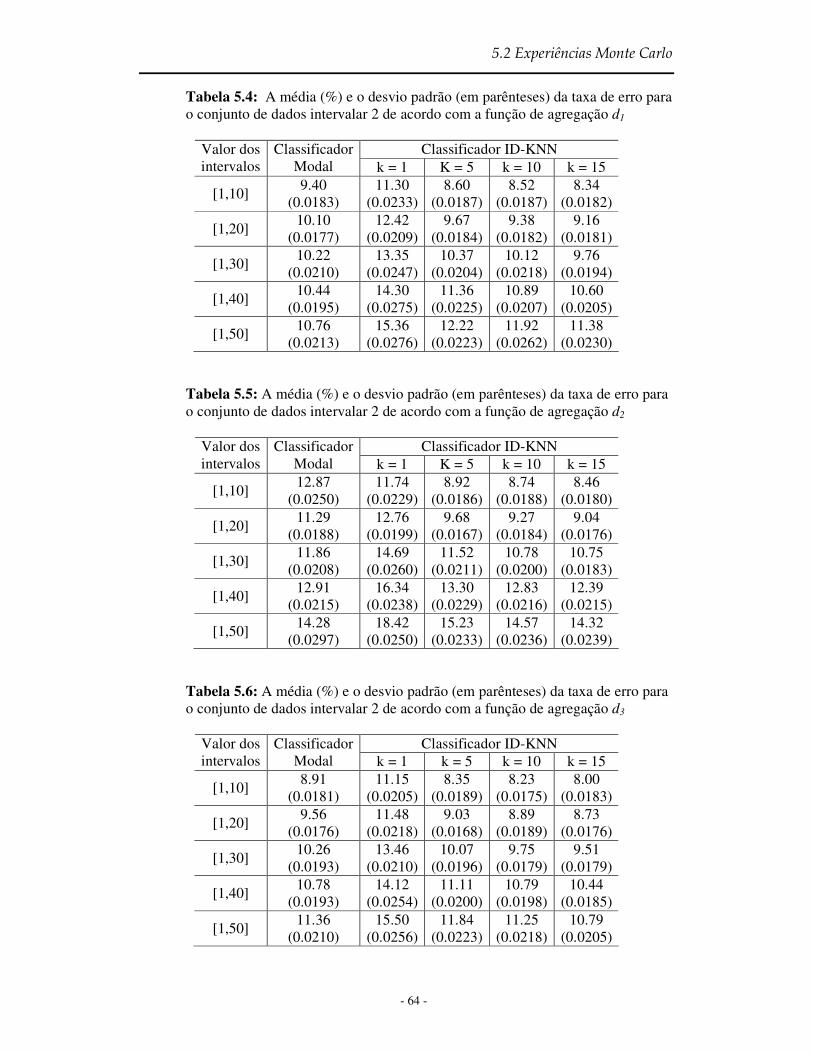
5.2 Experiências Monte Carlo
- 64 -
Tabela 5.4: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d1
Classificador ID-KNN Valor dos
intervalos Classificador
Modal k = 1 K = 5 k = 10 k = 15
[1,10] 9.40
(0.0183) 11.30
(0.0233) 8.60
(0.0187) 8.52
(0.0187) 8.34
(0.0182)
[1,20] 10.10
(0.0177) 12.42
(0.0209) 9.67
(0.0184) 9.38
(0.0182) 9.16
(0.0181)
[1,30] 10.22
(0.0210) 13.35
(0.0247) 10.37
(0.0204) 10.12
(0.0218) 9.76
(0.0194)
[1,40] 10.44
(0.0195) 14.30
(0.0275) 11.36
(0.0225) 10.89
(0.0207) 10.60
(0.0205)
[1,50] 10.76
(0.0213) 15.36
(0.0276) 12.22
(0.0223) 11.92
(0.0262) 11.38
(0.0230)
Tabela 5.5: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d2
Classificador ID-KNN Valor dos
intervalos Classificador
Modal k = 1 K = 5 k = 10 k = 15
[1,10] 12.87
(0.0250) 11.74
(0.0229) 8.92
(0.0186) 8.74
(0.0188) 8.46
(0.0180)
[1,20] 11.29
(0.0188) 12.76
(0.0199) 9.68
(0.0167) 9.27
(0.0184) 9.04
(0.0176)
[1,30] 11.86
(0.0208) 14.69
(0.0260) 11.52
(0.0211) 10.78
(0.0200) 10.75
(0.0183)
[1,40] 12.91
(0.0215) 16.34
(0.0238) 13.30
(0.0229) 12.83
(0.0216) 12.39
(0.0215)
[1,50] 14.28
(0.0297) 18.42
(0.0250) 15.23
(0.0233) 14.57
(0.0236) 14.32
(0.0239)
Tabela 5.6: A média (%) e o desvio padrão (em parênteses) da taxa de erro para o conjunto de dados intervalar 2 de acordo com a função de agregação d3
Classificador ID-KNN Valor dos
intervalos Classificador
Modal k = 1 k = 5 k = 10 k = 15
[1,10] 8.91
(0.0181) 11.15
(0.0205) 8.35
(0.0189) 8.23
(0.0175) 8.00
(0.0183)
[1,20] 9.56
(0.0176) 11.48
(0.0218) 9.03
(0.0168) 8.89
(0.0189) 8.73
(0.0176)
[1,30] 10.26
(0.0193) 13.46
(0.0210) 10.07
(0.0196) 9.75
(0.0179) 9.51
(0.0179)
[1,40] 10.78
(0.0193) 14.12
(0.0254) 11.11
(0.0200) 10.79
(0.0198) 10.44
(0.0185)
[1,50] 11.36
(0.0210) 15.50
(0.0256) 11.84
(0.0223) 11.25
(0.0218) 10.79
(0.0205)

5.2 Experiências Monte Carlo
- 65 -
Para concluir a avaliação experimental usando a taxa de erro como medida de
desempenho, a Tabela 5.7 mostra as hipóteses de testes t-Student para amostras
independentes com nível de significância 5% onde 1µ e 2µ são, respectivamente, as
médias da taxa de erro para o classificador ID-KNN (k = 5 para o conjunto de dados
intervalares 1 e k = 15 para o conjunto de dados intervalares 2) e o classificador modal
com distância d3. Nessa tabela, os valores das estatísticas dos testes de hipóteses
revelam que o desempenho médio (medido pela taxa de erro) do classificador ID-KNN
é superior ao do classificador modal.
Tabela 5.7: Testes de Hipóteses t-Student usando a função de agregação d3
Conjunto de dados intervalares 1 Conjunto de dados intervalares 2 Valor dos intervalos
H0: 1µ = 2µ
H1: 1µ < 2µ Decisão
H0: 1µ = 2µ
H1: 1µ < 2µ Decisão
[1,10] -1.63 Não Rejeita H0 -3.53 Rejeita H0 [1,20] -3.87 Rejeita H0 -3.33 Rejeita H0 [1,30] -6.08 Rejeita H0 -2.85 Rejeita H0 [1,40] -6.55 Rejeita H0 -1.27 Não Rejeita H0 [1,50] -8.16 Rejeita H0 -1.94 Rejeita H0
5.2.2. Resultado do tempo (em segundos)
O tempo de execução dos classificadores é computado considerando as etapas de
aprendizagem e alocação nas 100 replicações. As Tabelas 5.8 e 5.9 mostram os valores
das medias e desvios padrões do tempo para os classificadores modal e ID-KNN com
k=1 e configurações dos conjuntos de dados intervalares 1 e 2, respectivamente,
utilizando as funções de agregação dz (z = 1, 2, 3) com parâmetros q = 1 e jw = 0,5
( )2,.1=j . Realmente, em média, o tempo de execução gasto pelo classificador ID-KNN
é muito superior ao tempo gasto pelo classificador modal em ambas as configurações e
para todas as distâncias. Note que, para ambas configurações e classificadores, a
distância d2 apresentou o pior resultado e a distância d3 obteve o melhor resultado em
termos de tempo de execução.
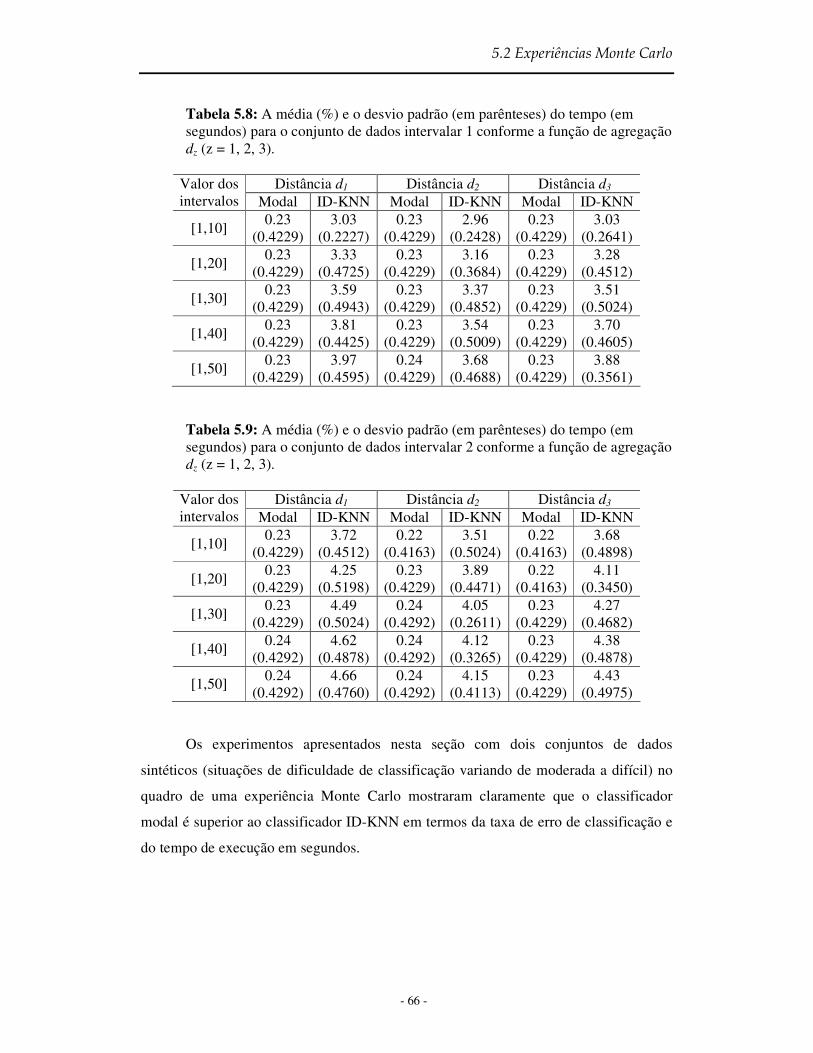
5.2 Experiências Monte Carlo
- 66 -
Tabela 5.8: A média (%) e o desvio padrão (em parênteses) do tempo (em segundos) para o conjunto de dados intervalar 1 conforme a função de agregação dz (z = 1, 2, 3).
Distância d1 Distância d2 Distância d3 Valor dos intervalos Modal ID-KNN Modal ID-KNN Modal ID-KNN
[1,10] 0.23
(0.4229) 3.03
(0.2227) 0.23
(0.4229) 2.96
(0.2428) 0.23
(0.4229) 3.03
(0.2641)
[1,20] 0.23
(0.4229) 3.33
(0.4725) 0.23
(0.4229) 3.16
(0.3684) 0.23
(0.4229) 3.28
(0.4512)
[1,30] 0.23
(0.4229) 3.59
(0.4943) 0.23
(0.4229) 3.37
(0.4852) 0.23
(0.4229) 3.51
(0.5024)
[1,40] 0.23
(0.4229) 3.81
(0.4425) 0.23
(0.4229) 3.54
(0.5009) 0.23
(0.4229) 3.70
(0.4605)
[1,50] 0.23
(0.4229) 3.97
(0.4595) 0.24
(0.4229) 3.68
(0.4688) 0.23
(0.4229) 3.88
(0.3561) Tabela 5.9: A média (%) e o desvio padrão (em parênteses) do tempo (em segundos) para o conjunto de dados intervalar 2 conforme a função de agregação dz (z = 1, 2, 3).
Distância d1 Distância d2 Distância d3 Valor dos intervalos Modal ID-KNN Modal ID-KNN Modal ID-KNN
[1,10] 0.23
(0.4229) 3.72
(0.4512) 0.22
(0.4163) 3.51
(0.5024) 0.22
(0.4163) 3.68
(0.4898)
[1,20] 0.23
(0.4229) 4.25
(0.5198) 0.23
(0.4229) 3.89
(0.4471) 0.22
(0.4163) 4.11
(0.3450)
[1,30] 0.23
(0.4229) 4.49
(0.5024) 0.24
(0.4292) 4.05
(0.2611) 0.23
(0.4229) 4.27
(0.4682)
[1,40] 0.24
(0.4292) 4.62
(0.4878) 0.24
(0.4292) 4.12
(0.3265) 0.23
(0.4229) 4.38
(0.4878)
[1,50] 0.24
(0.4292) 4.66
(0.4760) 0.24
(0.4292) 4.15
(0.4113) 0.23
(0.4229) 4.43
(0.4975)
Os experimentos apresentados nesta seção com dois conjuntos de dados
sintéticos (situações de dificuldade de classificação variando de moderada a difícil) no
quadro de uma experiência Monte Carlo mostraram claramente que o classificador
modal é superior ao classificador ID-KNN em termos da taxa de erro de classificação e
do tempo de execução em segundos.

5.3 Aplicação com um conjunto de dados intervalares reais
- 67 -
5.3. Aplicação com um conjunto de dados
intervalares reais
Os classificadores ID-KNN e modal foram também avaliados com um conjunto
de dados intervalares reais. O desempenho desses classificadores foi medido pela
estimativa da taxa de erro usando o método de validação cruzada leave-one-out.
O conjunto de dados de temperatura tem sido aplicado em diferentes trabalhos
na literatura da análise de dados simbólicos ([Guru et al, 2004], [De Carvalho, 2006]).
Esse conjunto contém 37 cidades, cada cidade é descrita por 12 variáveis do tipo
intervalo que são mínimas e máximas de temperaturas em graus centígrados de 12
meses. A Tabela 5.10 mostra uma parte desse conjunto de dados.
Segundo observadores humanos, a classificação a priori para este conjunto de
dados intervalares é [Guru et al, 2004]:
a) Classe 1: Bahraim, Bombay, Cairo, Calcutta, Colombo, Dubai, Hong
Kong, Kula Lampu,r Madra,s Manila, Mexixo, Nairobi, New Delhi e Sydney
b) Classe 2: Amsterdam, Athens, Copenhagen, Frankfurt, Geneva, Lisbon,
London, Madri, Moscow, Munich, New York, Paris, Rome, San
Francisco, Seoul, Stockholm, Tokyo, Toronto, Vienna e Zurich
c) Classe 3: Mauritius
d) Classe 4: Theran.
Nessa classificação a priori, as cidades da classe 1 estão localizadas entre 0 e 40
graus de latitudes e as cidades da classe 2 estão, em sua maioria, localizadas entre 40 e
60 graus de latitudes. Algumas cidades, que estão próximas da costa e estão localizadas
entre 0 e 40 graus, estão classificadas como da classe 2. A ilha Mauritius e a cidade
Tehran são classes unitárias, que são classes 3 e 4, respectivamente. As classes obtidas
usando a abordagem de agrupamento proposto em Guru et al. (2004) estão de acordo
com essa classificação a priori obtida por observadores humanos.
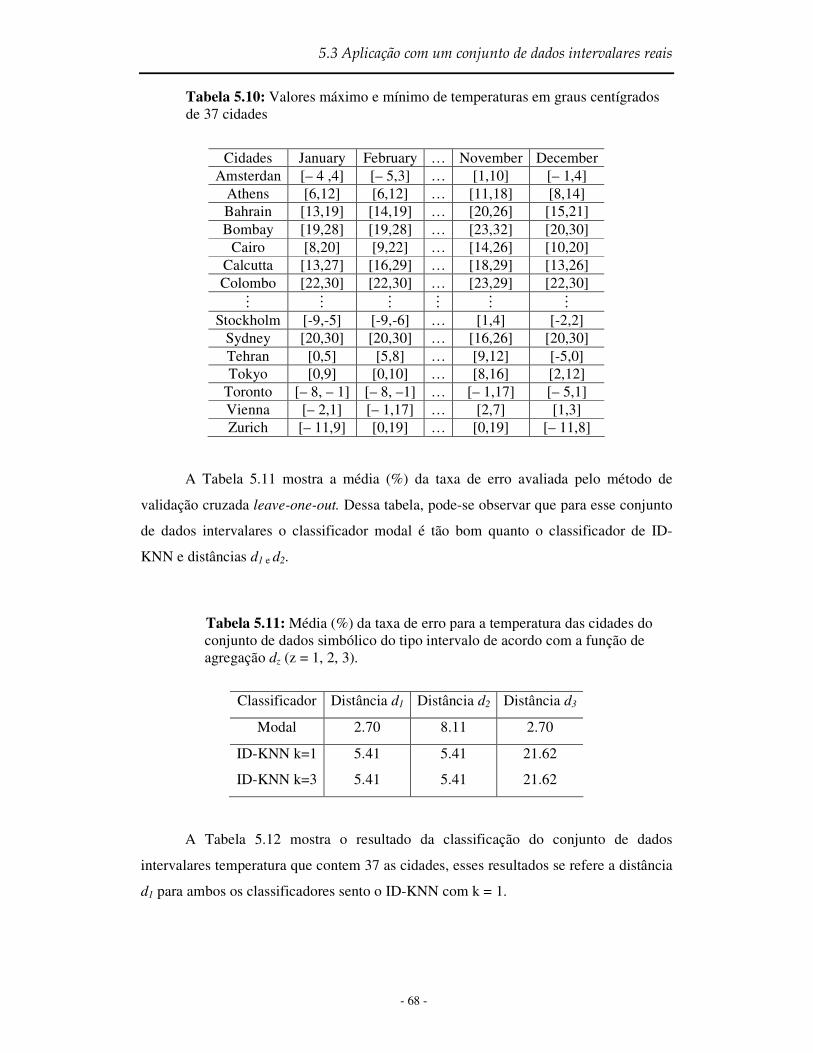
5.3 Aplicação com um conjunto de dados intervalares reais
- 68 -
Tabela 5.10: Valores máximo e mínimo de temperaturas em graus centígrados de 37 cidades
Cidades January February … November December Amsterdan [– 4 ,4] [– 5,3] … [1,10] [– 1,4]
Athens [6,12] [6,12] … [11,18] [8,14] Bahrain [13,19] [14,19] … [20,26] [15,21] Bombay [19,28] [19,28] … [23,32] [20,30]
Cairo [8,20] [9,22] … [14,26] [10,20] Calcutta [13,27] [16,29] … [18,29] [13,26] Colombo [22,30] [22,30] … [23,29] [22,30]
M M M M M M Stockholm [-9,-5] [-9,-6] … [1,4] [-2,2]
Sydney [20,30] [20,30] … [16,26] [20,30] Tehran [0,5] [5,8] … [9,12] [-5,0] Tokyo [0,9] [0,10] … [8,16] [2,12]
Toronto [– 8, – 1] [– 8, –1] … [– 1,17] [– 5,1] Vienna [– 2,1] [– 1,17] … [2,7] [1,3] Zurich [– 11,9] [0,19] … [0,19] [– 11,8]
A Tabela 5.11 mostra a média (%) da taxa de erro avaliada pelo método de
validação cruzada leave-one-out. Dessa tabela, pode-se observar que para esse conjunto
de dados intervalares o classificador modal é tão bom quanto o classificador de ID-
KNN e distâncias d1 e d2.
Tabela 5.11: Média (%) da taxa de erro para a temperatura das cidades do conjunto de dados simbólico do tipo intervalo de acordo com a função de agregação dz (z = 1, 2, 3).
Classificador Distância d1 Distância d2 Distância d3
Modal 2.70 8.11 2.70
ID-KNN k=1
ID-KNN k=3
5.41
5.41
5.41
5.41
21.62
21.62
A Tabela 5.12 mostra o resultado da classificação do conjunto de dados
intervalares temperatura que contem 37 as cidades, esses resultados se refere a distância
d1 para ambos os classificadores sento o ID-KNN com k = 1.

5.4 Software do classificador modal e do ID-KNN
- 69 -
Tabela 5.12: Resultado da classificação das cidades do conjunto de dados
intervalares temperatura.
Cidade Classe
a priori ID-KN Modal Cidade
Classe
a priori ID-KN Modal
Amssterdam 2 2 2 MexicoCity 1 1 3
Athens 2 2 2 Moscow 2 2 2
Bahrain 1 1 1 Munich 2 2 2
Bombay 1 1 1 Nairobi 1 1 1
Cairo 1 1 1 NewDelhi 1 1 1
Calcutta 1 1 1 NewYork 2 2 2
Colombo 1 1 1 Paris 2 2 2
Copenhagen 2 2 2 Rome 2 2 2
Dubal 1 1 1 SanFrancisco 2 2 2
Frankfurt 2 2 2 Seoul 2 2 2
Geneva 2 2 2 Singapore 1 1 1
HongKong 1 1 1 Stockholm 2 2 2
KulaLumpur 1 1 1 Sydney 1 1 1
Lisbon 2 2 2 Tehran 4 2 4
London 2 2 2 Tokyo 2 2 2
Madras 1 1 1 Toronto 2 2 2
Madrid 2 2 2 Vienna 2 2 2
Manila 1 1 1 Zurich 2 2 2
Mauritius 3 1 3
5.4. Software do classificador modal e do ID-KNN
O classificador modal para dados do tipo intervalo e o k-vizinhos mais próximos
para dado intervalares (ID-KNN) foram implementados na linguagem de programação
C/C++ com o uso do software Microsoft Visual C++ 6.0. O resultado dessa
implementação é um programa que pode ser utilizado para a classificação
supervisionada de dados do tipo intervalo.
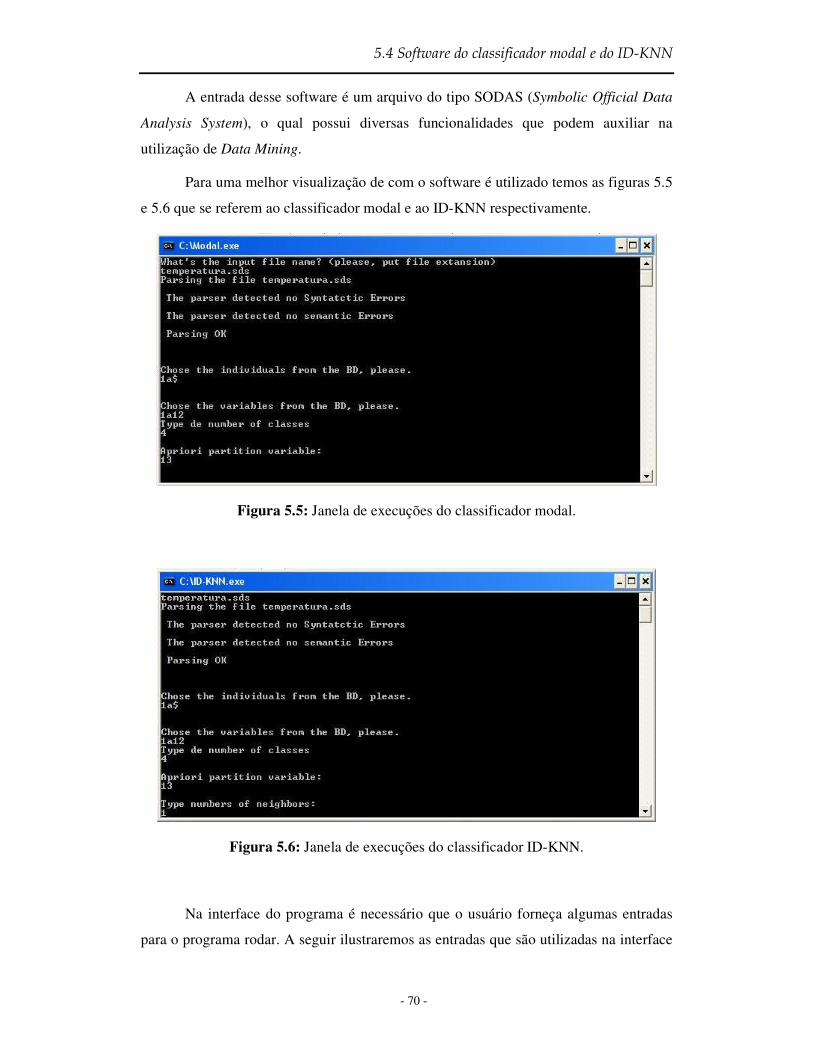
5.4 Software do classificador modal e do ID-KNN
- 70 -
A entrada desse software é um arquivo do tipo SODAS (Symbolic Official Data
Analysis System), o qual possui diversas funcionalidades que podem auxiliar na
utilização de Data Mining.
Para uma melhor visualização de com o software é utilizado temos as figuras 5.5
e 5.6 que se referem ao classificador modal e ao ID-KNN respectivamente.
Figura 5.5: Janela de execuções do classificador modal.
Figura 5.6: Janela de execuções do classificador ID-KNN.
Na interface do programa é necessário que o usuário forneça algumas entradas
para o programa rodar. A seguir ilustraremos as entradas que são utilizadas na interface

5.4 Software do classificador modal e do ID-KNN
- 71 -
do software para o classificador modal na tabela 5.12 e para o classificador ID-KNN na
tabela 5.13 com exemplo que foi utilizado para o arquivo de dados reais
temperatura.sds:
Tabela 5.13: Informações do sistema e entradas para o classificador modal.
Informações do sistema Entrada do usuário
What’s the input file name? (please, put file
extansion) temperatura.sds
Chose the individuals for the BD, please. 1a$ (representa todos os indivíduos)
Chose the variables from the BD, please. 1a12 (são todas as variáveis, 12
meses)
Type number of classes: 4 (número de classes)
Apriori partition variable: 13 (variável a priori)
Tabela 5.14: Informações do sistema e entradas para o classificador modal.
Informações do sistema Entrada do usuário
What’s the input file name? (please, put file
extansion) temperatura.sds
Chose the individuals for the BD, please. 1a$ (representa todos os indivíduos)
Chose the variables from the BD, please. 1a12 (são todas as variáveis, 12
meses)
Type number of classes: 4 (número de classes)
Apriori partition variable: 13 (variável a priori)
Type numbers of neighbors: 1 (número de vizinhos)
Como saída do software temos um arquivo .txt com os resultados das taxas
médias dos erros e os respectivos desvios padrões associados as funções de

5.4 Software do classificador modal e do ID-KNN
- 72 -
dissimilaridades em estudo que ilustraremos a seguir para o classificador modal e para o
ID-KNN que se apresentam da mesma forma.
Impressão do arquivo Taxa_de_Erro_Global.txt
“temperatura.sds
d1
Erro da Classe 1: 0.066667
Erro da Classe 2: 0.000000
Erro da Classe 3: 0.000000
Erro da Classe 4: 0.000000
Media = 0.027027
Desvio = 0.164399
************************
d2
Erro da Classe 1: 0.200000
Erro da Classe 2: 0.000000
Erro da Classe 3: 0.000000
Erro da Classe 4: 0.000000
Media = 0.081081
Desvio = 0.276725
*************************
d3
Erro da Classe 1: 0.000000
Erro da Classe 2: 0.000000
Erro da Classe 3: 1.000000
Erro da Classe 4: 0.000000
Media = 0.027027
Desvio = 0.164399
*************************
”

5.5 Conclusão
- 73 -
5.5. Conclusão
Esse capítulo apresentou uma avaliação experimental para o classificador modal
proposto nesse trabalho considerando dois conjuntos de dados intervalares sintéticos
mostrando diferentes casos de dificuldade de classificação e um conjunto de dados reais
de temperatura. O desempenho desse classificador foi medido pela taxa de erro de
classificação calculada usando um conjunto de teste e pelo tempo de execução em
segundos gastos nas etapas de aprendizagem e alocação. Para dados sintéticos, essas
medidas foram estimadas no quadro de uma experiência Monte Carlo para cada
conjunto. Para dados reais as a taxa de erro foi computada usando o método de
validação cruzada leave-one-out.
O classificador modal foi comparado com um classificador, aqui chamado ID-
KNN, para dados modais estudado nesse trabalho. Esse classificador é uma adaptação
do classificador k-NN clássico sendo este adaptado para tratar dados modais cujo
suporte das variáveis é um vetor de intervalos. Os resultados de taxa de erro e tempo
mostraram que, em média, o classificador ID-KNN é superior ao classificador modal
considerando diferentes conjuntos de dados intervalares sintéticos, diferentes funções de
dissimilaridade e diferentes tamanhos de vizinhança para o classificador ID-KNN. A
aplicação com o conjunto de dados de temperatura considerando também diferentes
funções de dissimilaridade e diferentes tamanhos de vizinhança para o classificador ID-
KNN, revelou que os classificadores apresentaram desempenhos similares em termos da
taxa de erro porém, o classificador modal mostrou melhores resultados.
Em se falando de custo computacional o classificador modal é bem superior ao
classificador ID-KNN pos, ele sumariza a informação na etapa de generalização
representando as classes por seus respectivos protótipos minimizando, assim, as
comparações feitas entre o conjunto de teste e os representantes das classes e perdendo
menos tempo em termos de classificação dos elementos do conjunto de teste. Em contra
partida o ID-KNN tem que fazer as comparações entre todos os elementos do conjunto
de treinamento identificar os mais próximos e afetar de acordo com a maior freqüência
entre os k mais próximos, demandando um tempo computacional bem superior ao
classificador modal.
O próximo capítulo apresenta as conclusões finais dessa dissertação assim como
as suas contribuições e trabalhos futuros.

Capítulo 6
- 74 -
6. Conclusão e Trabalhos futuros
Este capítulo fornece as considerações finais relacionadas com esta dissertação
bem como as extensões que possam surgir originadas do trabalho aqui exposto.
O contexto deste trabalho esta inserido na abordagem simbólica em análise de
dados (SDA – Symbolic Data Analysis) relacionada com métodos para a extração de
conhecimentos em grandes bases de dados. O principal objetivo da SDA é desenvolver
métodos para o tratamento de dados mais complexos como intervalos, conjuntos e
distribuição de probabilidades (ou de pesos). Esses métodos em geral (mas não sempre)
são extensões dos métodos e algoritmos de extração de conhecimentos (técnicas
estatísticas e de aprendizagem de máquina) para dados usuais.
Neste trabalho foi desenvolvido um classificador simbólico de semântica modal
para dados do tipo intervalo. Esse classificador pressupõe uma etapa inicial onde os
exemplos descritos por vetores de intervalos passam a ser descritos por vetores de
distribuições de pesos que passam então a ser a entrada do classificador. Ele possui duas
etapas, a aprendizagem propriamente dita e a alocação. Após a etapa de aprendizagem,
cada classe é também descrita por um vetor de distribuições de pesos via operações de
generalização que sintetiza as informações dos exemplos da referida classe. A regra de
alocação de um exemplo a uma classe é realizada através de funções de dissimilaridade
que comparam vetores de distribuições de pesos. Dessa forma, o exemplo a ser
classificado, descrito por um vetor de intervalos, deve passar também por uma etapa de
pre-processamento para então ser descrito também por um vetor de distribuições
(uniformes) de pesos. Três famílias de funções de dissimilaridade para distribuições de
pesos foram estudadas nesse trabalho.
A avaliação do desempenho desse classificador foi baseada na taxa (média) de
erro de classificação obtida através da aplicação do mesmo à conjuntos de teste e pelo
tempo médio (em segundos) total de execução das etapas de aprendizagem e alocação
desse classificador. Com o intuito de obter um resultado representativo dessas medidas,
as etapas de aprendizagem e alocação do classificador foram organizadas no quadro de
uma experiência Monte Carlo no caso de dados sintéticos. Nessa experiência, foram
consideradas 100 réplicas de cada conjunto (aprendizagem e teste) com idênticas
propriedades estatísticas. Para dados reais, foi usada uma técnica de validação cruzada

6.1 Trabalhos Futuros
- 75 -
leave-one-out. Além disso, o desempenho do classificador modal foi comparado com o
desempenho de um classificador para dados modais (aqui chamado ID-KNN) que foi
estudado nesse trabalho.
Os resultados obtidos para a taxa de erro e o tempo de execução mostraram que,
em média, o classificador ID-KNN é superior ao classificador modal considerando
diferentes conjuntos de dados intervalares sintéticos, diferentes funções de
dissimilaridade e diferentes tamanhos de vizinhança para o classificador ID-KNN. O
estudo do conjunto de dados de temperatura considerando também diferentes funções de
dissimilaridade e diferentes tamanhos de vizinhança para o classificador ID-KNN,
revelou que esses classificadores apresentaram desempenhos similares sendo o
classificador modal superior, em termos da taxa de erro.
É importante salientar que no período de estudo e implementação do
classificador modal um artigo foi publicado [Silva et al., 2006] no ICONIP-2006 (13th
International Conference on Neural Information Processing) que é uma importante
conferência internacional anual para explorar e trocar idéias em redes neural e em
disciplinas relacionadas.
A contribuição principal do trabalho é a comparação de várias medidas de
dissimilaridades e de seus componentes internos (pesos) e seus suportes e selecionar a
melhor medida para um problema na análise de dados. Escolhendo e aplicando funções
diferentes de dissimilaridade à mesma base de dados, é possível descobrir a função a
mais indicada de dissimilaridade a ser aplicada a um problema específico.
6.1. Trabalhos Futuros
Com relação a continuidade deste trabalho, pode-se mencionar as seguintes
extensões:
I. Fazer um estudo comparativo do classificador simbólico modal para
dados do tipo intervalo com outras técnicas de classificação
supervisionada existentes com por exemplo Redes Neurais Artificiais.
II. Adaptar e testar outras distâncias para os dados simbólicos modais bem
como utilizar outras bases de dados reais para um melhor validação do
método.

- 76 -
Apêndice A
Arquivo “temperatura.sds “
A seguir um exemplo de um arquivo no formato padrão de SODA’s que é o
arquivo “temperatura.sds” que foi utilizado nos testes das aplicações com dados reais
que é um conjunto contém 37 cidades, cada cidade é descrita por 12 variáveis do tipo
intervalo que são mínimas e máximas de temperaturas em graus centígrados de 12
meses.
SODAS = (
CONTAINS = (
FILES, HEADER, INDIVIDUALS, VARIABLES, RECTANGLE_MATRIX
),
FILE = (
procedure_name = "db2so" ,
version = "sans" ,
create_date = ""
),
HEADER = (
title = "temperaturas" ,
sub_title = "h" ,
indiv_nb = 37 ,
var_nb = 13 ,
rules_nb = 0 ,
nb_var_set = 0 ,
nb_indiv_set = 0 ,
nb_var_nom = 0 ,
nb_var_cont = 0 ,
nb_var_text = 0 ,
nb_var_cont_symb = 12 ,
nb_var_nom_symb = 1 ,
nb_var_nom_mod = 0 ,
nb_na = 0 ,

Apêndice A
- 77 -
nb_null = 0 ,
nb_nu = 0 ,
nb_hierarchies = 0
),
INDIVIDUALS = (
(0,"AA00", "Amssterdam" ),
(1,"AA01", "Athens" ),
(2,"AA02", "Bahrain" ),
(3,"AA03", "Bombay" ),
(4,"AA04", "Cairo" ),
(5,"AA05", "Calcutta" ),
(6,"AA06", "Colombo" ),
(7,"AA07", "Copenhagen" ),
(8,"AA08", "Dubal" ),
(9,"AA09", "Frankfurt" ),
(10,"AA10", "Geneva" ),
(11,"AA11", "HongKong" ),
(12,"AA12", "KulaLumpur" ),
(13,"AA13", "Lisbon" ),
(14,"AA14", "London" ),
(15,"AA15", "Madras" ),
(16,"AA16", "Madrid" ),
(17,"AA17", "Manila" ),
(18,"AA18", "Mauritius" ),
(19,"AA19", "MexicoCity" ),
(20,"AA20", "Moscow" ),
(21,"AA21", "Munich" ),
(22,"AA22", "Nairobi" ),
(23,"AA23", "NewDelhi" ),
(24,"AA24", "NewYork" ),
(25,"AA25", "Paris" ),
(26,"AA26", "Rome" ),
(27,"AA27", "SanFrancisco" ),

Apêndice A
- 78 -
(28,"AA28", "Seoul" ),
(29,"AA29", "Singapore" ),
(30,"AA30", "Stockholm" ),
(31,"AA31", "Sydney" ),
(32,"AA32", "Tehran" ),
(33,"AA33", "Tokyo" ),
(34,"AA34", "Toronto" ),
(35,"AA35", "Vienna" ),
(36,"AA36", "Zurich" )
),
VARIABLES = (
(1 ,inter_cont ,"" ,"AB00" ,"JAN" ,0, 0, -13, 31),
(2 ,inter_cont ,"" ,"AC00" ,"FEB" ,0, 0, -12, 32),
(3 ,inter_cont ,"" ,"AD00" ,"MAR" ,0, 0, -8, 34),
(4 ,inter_cont ,"" ,"AE00" ,"APR" ,0, 0, -2, 36),
(5 ,inter_cont ,"" ,"AF00" ,"MAY" ,0, 0, -8, 40),
(6 ,inter_cont ,"" ,"AG00" ,"JUN" ,0, 0, 5, 39),
(7 ,inter_cont ,"" ,"AH00" ,"JUL" ,0, 0, 8, 39),
(8 ,inter_cont ,"" ,"AI00" ,"AUG" ,0, 0, 8, 40),
(9 ,inter_cont ,"" ,"AJ00" ,"SEPT" ,0, 0, 5, 37),
(10 ,inter_cont ,"" ,"AK00" ,"OCT" ,0, 0, 0, 34),
(11 ,inter_cont ,"" ,"AL00" ,"NOV" ,0, 0, -3, 32),
(12 ,inter_cont ,"" ,"AM00" ,"DEC" ,0, 0, -11, 31),
(13 ,nominal ,"" ,"AE00" ,"Edibility" ,0, 0 ,4, (
(1 ,"AE01" ,"U" ,0),
(2 ,"AE02" ,"U" ,0),
(3 ,"AE02" ,"U" ,0),
(4 ,"AE03" ,"T" ,0 ) )
)
),

Apêndice A
- 79 -
RECTANGLE_MATRIX = (
(( -4 : 4 ), ( -5 : 3 ), ( 2 : 12 ), ( 5 : 15 ), ( 7 : 17 ), ( 10 : 20 ), ( 10 : 20 ), ( 12 : 23 ), ( 10 : 20 ), ( 5 : 15 ), ( 1 : 10 ), ( -1 : 4 ), 2),
(( 6 : 12 ), ( 6 : 12 ), ( 8 : 16 ), ( 11 : 19 ), ( 16 : 25 ), ( 19 : 29 ), ( 22 : 32 ), ( 22 : 32 ), ( 19 : 28 ), ( 16 : 23 ), ( 11 : 18 ), ( 8 : 14 ), 2),
(( 13 : 19 ), ( 14 : 19 ), ( 17 : 23 ), ( 21 : 27 ), ( 25 : 32 ), ( 28 : 34 ), ( 29 : 36 ), ( 30 : 36 ), ( 28 : 34 ), ( 24 : 31 ), ( 20 : 26 ), ( 15 : 21 ), 1),
(( 19 : 28 ), ( 19 : 28 ), ( 22 : 30 ), ( 24 : 32 ), ( 27 : 33 ), ( 26 : 32 ), ( 25 : 30 ), ( 25 : 30 ), ( 24 : 30 ), ( 24 : 32 ), ( 23 : 32 ), ( 20 : 30 ), 1),
(( 8 : 20 ), ( 9 : 22 ), ( 11 : 25 ), ( 14 : 29 ), ( 17 : 33 ), ( 20 : 35 ), ( 22 : 36 ), ( 22 : 35 ), ( 20 : 33 ), ( 18 : 31 ), ( 14 : 26 ), ( 10 : 20 ), 1),
(( 13 : 27 ), ( 16 : 29 ), ( 21 : 34 ), ( 24 : 36 ), ( 26 : 36 ), ( 26 : 33 ), ( 26 : 32 ), ( 26 : 32 ), ( 26 : 32 ), ( 24 : 32 ), ( 18 : 29 ), ( 13 : 26 ), 1),
(( 22 : 30 ), ( 22 : 30 ), ( 23 : 31 ), ( 24 : 31 ), ( 25 : 31 ), ( 25 : 30 ), ( 25 : 29 ), ( 25 : 29 ), ( 25 : 30 ), ( 24 : 29 ), ( 23 : 29 ), ( 22 : 30 ), 1),
(( -2 : 2 ), ( -3 : 2 ), ( -1 : 5 ), ( 3 : 10 ), ( 8 : 16 ), ( 11 : 20 ), ( 14 : 22 ), ( 14 : 21 ), ( 11 : 18 ), ( 7 : 12 ), ( 3 : 7 ), ( 1 : 4 ), 2),
(( 13 : 23 ), ( 14 : 24 ), ( 17 : 28 ), ( 19 : 31 ), ( 22 : 34 ), ( 25 : 36 ), ( 28 : 39 ), ( 28 : 39 ), ( 25 : 37 ), ( 21 : 34 ), ( 17 : 30 ), ( 14 : 26 ), 1),
(( -10 : 9 ), ( -8 : 10 ), ( -4 : 17 ), ( 0 : 24 ), ( 3 : 27 ), ( 7 : 30 ), ( 8 : 32 ), ( 8 : 31 ), ( 5 : 27 ), ( 0 : 22 ), ( -3 : 14 ), ( -8 : 10 ), 2),
(( -3 : 5 ), ( -6 : 6 ), ( 3 : 9 ), ( 7 : 13 ), ( 10 : 17 ), ( 15 : 17 ), ( 16 : 24 ), ( 16 : 23 ), ( 11 : 19 ), ( 6 : 13 ), ( 3 : 8 ), ( -2 : 6 ), 2),
(( 13 : 17 ), ( 12 : 16 ), ( 15 : 19 ), ( 19 : 23 ), ( 22 : 27 ), ( 25 : 29 ), ( 25 : 30 ), ( 25 : 30 ), ( 25 : 29 ), ( 22 : 27 ), ( 18 : 23 ), ( 14 : 19 ), 1),
(( 22 : 31 ), ( 23 : 32 ), ( 23 : 33 ), ( 23 : 33 ), ( 23 : 32 ), ( 23 : 32 ), ( 23 : 31 ), ( 23 : 32 ), ( 23 : 32 ), ( 23 : 31 ), ( 23 : 31 ), ( 23 : 31 ), 1),
(( 8 : 13 ), ( 8 : 14 ), ( 9 : 16 ), ( 11 : 18 ), ( 13 : 21 ), ( 16 : 24 ), ( 17 : 26 ), ( 18 : 27 ), ( 17 : 24 ), ( 14 : 21 ), ( 11 : 17 ), ( 8 : 14 ), 2),
(( 2 : 6 ), ( 2 : 7 ), ( 3 : 10 ), ( 5 : 13 ), ( 8 : 17 ), ( 11 : 20 ), ( 13 : 22 ), ( 13 : 21 ), ( 11 : 19 ), ( 8 : 14 ), ( 5 : 10 ), ( 3 : 7 ), 2),
(( 20 : 30 ), ( 20 : 31 ), ( 22 : 33 ), ( 26 : 35 ), ( 28 : 39 ), ( 27 : 38 ), ( 26 : 36 ), ( 26 : 35 ), ( 25 : 34 ), ( 24 : 32 ), ( 22 : 30 ), ( 21 : 29 ), 1),
(( 1 : 9 ), ( 1 : 12 ), ( 3 : 16 ), ( 6 : 19 ), ( 9 : 24 ), ( 13 : 29 ), ( 16 : 34 ), ( 16 : 33 ), ( 13 : 28 ), ( 8 : 20 ), ( 4 : 14 ), ( 1 : 9 ), 2),
(( 21 : 27 ), ( 22 : 27 ), ( 24 : 29 ), ( 24 : 31 ), ( 25 : 31 ), ( 25 : 31 ), ( 23 : 29 ), ( 24 : 28 ), ( 25 : 28 ), ( 24 : 29 ), ( 22 : 28 ), ( 22 : 27 ), 1),
(( 22 : 28 ), ( 22 : 29 ), ( 22 : 29 ), ( 21 : 28 ), ( 19 : 25 ), ( 18 : 24 ), ( 17 : 23 ), ( 17 : 23 ), ( 17 : 24 ), ( 18 : 25 ), ( 19 : 27 ), ( 21 : 28 ), 3),

Apêndice A
- 80 -
(( 6 : 22 ), ( 15 : 23 ), ( 17 : 25 ), ( 18 : 27 ), ( 18 : 27 ), ( 18 : 27 ), ( 18 : 27 ), ( 18 : 26 ), ( 18 : 26 ), ( 16 : 25 ), ( 14 : 25 ), ( 8 : 23 ), 1),
(( -13 : -6 ), ( -12 : -15 ), ( -8 : 0 ), ( 0 : 8 ), ( 7 : 18 ), ( 11 : 23 ), ( 13 : 24 ), ( 11 : 22 ), ( 6 : 16 ), ( 1 : 8 ), ( -5 : 0 ), ( -11 : -5 ), 2),
(( -6 : 1 ), ( -5 : 3 ), ( -2 : 9 ), ( 3 : 14 ), ( 7 : 18 ), ( 10 : 21 ), ( 12 : 23 ), ( 11 : 23 ), ( 8 : 20 ), ( 4 : 13 ), ( 0 : 7 ), ( -4 : 2 ), 2),
(( 12 : 25 ), ( 13 : 26 ), ( 14 : 25 ), ( 14 : 24 ), ( 13 : 22 ), ( 12 : 21 ), ( 11 : 21 ), (11 : 21 ), ( 11 : 24 ), ( 13 : 24 ), ( 13 : 23 ), ( 13 : 23 ), 1),
(( 6 : 21 ), ( 10 : 24 ), ( 14 : 29 ), ( 20 : 36 ), ( 26 : 40 ), ( 28 : 39 ), ( 27 : 35 ), ( 26 : 34 ), ( 24 : 34 ), ( 18 : 34 ), ( 11 : 28 ), ( 7 : 23 ), 1),
(( -2 : 4 ), ( -3 : 4 ), ( 1 : 9 ), ( 6 : 15 ), ( 12 : 22 ), ( 17 : 27 ), ( 21 : 29 ), ( 20 : 28 ), ( 16 : 24 ), ( 11 : 19 ), ( 5 : 12 ), ( -2 : 6 ), 2),
(( 1 : 7 ), ( 1 : 7 ), ( 2 : 12 ), ( 5 : 16 ), ( 8 : 19 ), ( 12 : 22 ), ( 14 : 24 ), ( 13 : 24 ), ( 11 : 21 ), ( 7 : 16 ), ( 4 : 10 ), ( 1 : 6 ), 2),
(( 4 : 11 ), ( 5 : 13 ), ( 7 : 16 ), ( 10 : 19 ), ( 13 : 23 ), ( 17 : 28 ), ( 20 : 31 ), ( 20 : 31 ), ( 17 : 27 ), ( 13 : 21 ), ( 9 : 16 ), ( 5 : 12 ), 2),
(( 6 : 13 ), ( 6 : 14 ), ( 7 : 17 ), ( 8 : 18 ), ( 10 : 19 ), ( 11 : 21 ), ( 12 : 22 ), ( 12 : 22 ), ( 12 : 23 ), ( 11 : 22 ), ( 8 : 18 ), ( 6 : 14 ), 2),
(( 0 : 7 ), ( 1 : 6 ), ( 1 : 8 ), ( 6 : 16 ), ( 12 : 22 ), ( 16 : 25 ), ( 18 : 31 ), ( 16 : 30 ), ( 9 : 28 ), ( 3 : 24 ), ( 7 : 19 ), ( 1 : 8 ), 2),
(( 23 : 30 ), ( 23 : 30 ), ( 24 : 31 ), ( 24 : 31 ), ( 24 : 30 ), ( 25 : 30 ), ( 25 : 30 ), ( 25 : 30 ), ( 24 : 30 ), ( 24 : 30 ), ( 24 : 30 ), ( 23 : 30 ), 1),
(( -9 : -5 ), ( -9 : -6 ), ( -4 : -2 ), ( 1 : 8 ), ( 6 : 15 ), ( 11 : 19 ), ( 14 : 22 ), ( 13 : 20 ), ( 9 : 15 ), ( 5 : 9 ), ( 1 : 4 ), ( -2 : 2 ), 2),
(( 20 : 30 ), ( 20 : 30 ), ( 18 : 26 ), ( 16 : 23 ), ( 12 : 20 ), ( 5 : 17 ), ( 8 : 16 ), ( 9 : 17 ), ( 11 : 20 ), ( 13 : 22 ), ( 16 : 26 ), ( 20 : 30 ), 1),
(( 0 : 5 ), ( 5 : 8 ), ( 10 : 15 ), ( 15 : 18 ), ( 20 : 25 ), ( 28 : 30 ), ( 36 : 38 ), ( 38 : 40 ), ( 29 : 30 ), ( 18 : 20), ( 9 : 12 ), ( -5 : 0 ), 4),
(( 0 : 9 ), ( 0 : 10 ), ( 3 : 13 ), ( 9 : 18 ), ( 14 : 23 ), ( 18 : 25 ), ( 22 : 29 ), ( 23 : 31 ), ( 20 : 27 ), ( 13 : 21 ), ( 8 : 16 ), ( 2 : 12 ), 2),
(( -8 : -1 ), ( -8 : -1 ), ( -4 : 4 ), ( -2 : 11 ), ( -8 : 18 ), ( 13 : 24 ), ( 16 : 27 ), ( 16 : 26 ), ( 12 : 22 ), ( 6 : 14 ), ( -1 : 17 ), ( -5 : 1 ), 2),
(( -2 : 1 ), ( -1 : 3 ), ( 1 : 8 ), ( 5 : 14 ), ( 10 : 19 ), ( 13 : 22 ), ( 15 : 24 ), ( 14 : 23 ), ( 11 : 19 ), ( 7 : 13 ), ( 2 : 7 ), ( 1 : 3 ), 2),
(( -11 : 9 ), ( -8 : 15 ), ( -7 : 18 ), ( -1 : 21 ), ( 2 : 27 ), ( 6 : 30 ), ( 10 : 31 ), ( 8 : 25 ), ( 5 : 23 ), ( 3 : 22 ), ( 0 : 19 ), ( -11 : 8 ), 2)
))
END

- 81 -
Referências
[Appice et al., 2006] Appice, A., D'Amato, C., Esposito, F. and Malerba, D.: Classification of symbolic objects: A lazy learning approach. Journal of Intelligent Data Analysis vol.10 (2006) pp.301-324 IOS Press.
[Bacelar-Nicolau,1985] Bacelar-Nicolau, H. The Affinity Coefficient in Cluster
Analysis, Methods of Operation Research, v. 53, p. 507-512, Martin J. Bekman et al. (ed), Verlag Anton Hain, Munchen, 1985.
[Bezerra & De Carvalho, 2004]
Bezerra, B. L. D., De Carvalho, F. A. T. A symbolic
approach for content-based information filtering. Information Processing Letters, Amsterdam (Holland), v. 92, n.1, p.45-52, 2004.
[Billard & Diday, 2000]
L. Billard and E. Diday. Regression analysis for interval-
valued data. In H. A. L. Kiers et al, editor, Data Analysis, Classification and Related Methods, pages 369-374, Berlin, 2000.
[Breiman el al., 1984] Leo Breiman, Jerome H. Friedman, Richard A. Olshen, and Charles J. Stone. Classification and Regression Trees. Wadsworth, 1984.
[Bock, 2000] Hans Hermann Bock. The classical data situation. In Hans-Herman Bock and Edwin Diday, editors, Analysis of
Symbolic Data: Exloratory Methods for Extracting
Statistical Information from Complex Data, pages 24-38, Germany, 2000. Springer.
[Bock & Diday, 2000] Bock, H.H., Diday, E. Analysis of Symbolic Data.
Exploratory Methods for Extracting Statistical Information
from Complex Data, series: Studies in Classification, Data Analysis, and Knowledge Organization, v. 15, Springer-Verlag, Berlin, 2000.
[Braga et al., 2000] A. P. Braga, T. B. Ludermir, and A. de Carvalho. Redes
Neurais Artificiais - Teoria e Aplicações. LTC, Rio de Janeiro, 2000.
[Ciampi, 1992] A. Ciampi. Constructing prediction trees from data: the recpam approach. Proceedings from the Prague University Summer School on Computacional Aspect of Model Choice, pages 105-152. Verlag, 1992.

Referências Bibliográficas
- 82 -
[Ciampi et al., 2000] A. Ciampi, E. Diday, J. Lebbe, E. Périnel, and R. Vignes. Growing a tree classifier with imprecise data. Pattern Recognition Letters, 21(9):787-803, 2000.
[Cover & Hart, 1967] Cover, T. M. and Hart, P. E.: Nearest neighbor patter
lassification, IEEE Trans Inform Theory, 13, 1967, 21-27
[Csiszàr, 1967] Csiszàr, I: Information-type measures of difference of probability distributions and indirect observations. Studia Scient. MAth. Hung, 2, (1967), 299-318.
[D’Oliveira et al., 2004]
D'Oliveira, S., De Carvalho, F.A.T. and Souza, R.M.C.R.: Classifcation of sar images through a convex hull region
oriented approach. In: N. R. Palet al. (Eds.). 11th International Conference on Neural Information Processing (ICONIP-2004), Lectures Notes in Computer Science - LNCS 3316, Springer, (2004), 769-774
[De Carvalho, 1992] De Carvalho, F.A.T.: Méthodes Descriptives en Analyse des
Données Symboliques. PhD thesis, Université Paris IX-Dauphine, 1992.
[De Carvalho, 2006] De Carvalho, F.A.T.: Fuzzy c-means clustering methods for
symbolic interval data. Pattern recognition Letters, 28, 423-437, 2006.
[De Carvalho et al., 1999]
De Carvalho, F. A. T., Verde, R., Lechevallier, Y. A dynamic
clustering of symbolic objcts based on a context dependent
proximity measure. In: IX International Symposium on Applied Stochastic Models and Data analysis. Lisboa: University of Lisboa, p. 237 – 242, 1999.
[De Carvalho et al., 2004]
De Carvalho, F. A. T., Lechevallier, Y. , Souza, R. M. C. R. . A dynamic cluster algorithm based on adaptive Lr distances
for quantitative data. 9th Conference of the International Federation of Classification Societies (IFCS2004). New York (USA): Springer-Verlag, 2004. p. 33-42.
[De Carvalho & Diday, 1998]
De Carvalho, F.A.T. and Diday, E.: Indices de proximité
entre objects symboliques qui tient compte des contraintes
dans l´espace de description. Induction symbolic et numerique à partir de données, Toulouse, 1998. CEPADUES.
[Djouadi & Bouktache, 1997]
Djouadi, A. and Bouktache, E.: Afast algorithm for the
nearest-neighbor classier, IEEE Trans. Pattern Anal. Mach. Intell. 19, (3), 1997, 277-282

Referências Bibliográficas
- 83 -
[Duda et al., 2001]. Duda, R. O., Hart, P. E. and Stork, D. G.: Pattern
Classificarion, Second Ed., Wiley, New York, 2001
[Esposito et al., 2000] Esposito, F., Malerba, D., Tamma, V. Dissimilarity
Measures for Symbolic Objects. In: Bock, H.H., Diday, E. (eds.): Analysis of Symbolic Data. Exploratory Methods for extracting Statistical Information from Complex Data, Series: Studies in Classification, Data Analysis, and Knowledge Organization, Springer-Verlag, Berlin, v. 15, p. 165-185, 2000.
[Fayyad et al., 1996] U. Fayyad, G. Platetsky-Shapiro, and P. Smyth. From data
minig to knowledge discovery: an overview. In Advances in
Knowledge Discovery and Data Mining, pages 1-34, 1996.
[Ferri et al., 1999] Ferri, F. J., Albert, J. V. and Vidal, E.: Considerations about
sample-size sensitivity of a family of edited nearest-neighbor
rules, IEEE Trans. Systems Man Cybernet. Part B: Cybernet. 29 (4), 1999, 667-672
[Garden, 1998] S. R. Garden. Building the data warehouse. Communications of the ACM, 41(9):52-60, 1998.
[Gates, 1972] Gates, G. W.: The reduced nearest neighbor rule, IEEE Trans. Inform. Theory, 18, 1972, 431-433
[Gora et al., 2002] Gora, G., Wojna, A.: RIONA: A Classifier Combining Rule
Induction and k-NN Method with Automated Selection of
Optimal Neighbourhood. Proceedings of the Thirteenth European Conference on Machine Learning, Springer-Verlag, 2430, (2002), 111-123.
[Grother et al., 1997] Grother, P. J., Candela, G. T. and Blue, J. L.: Fast
implementarions od nearest neighbor classiers, Pattern Recognition 30, (3), 1997, 459-465
[Guru et al., 2004] Guru, D.S., Kiaranagi, B.B. and Nagabhushan, P.: Multivalued type proximity measure and concept of mutual
similarity value useful for clustering symbolic patterns. Pattern recognition Letters, 25, 1203-1213, 2004.
[Hart, 1968] Hart, P. E.: The condensed nearest neighbor rule, IEEE Trans. Inform. Theory, 14, 1968, 515-516
[Ichino & Yaguchi, 1994]
Ichino, M., Yaguchi, H. Generalized minkowski metrics for
mixed feature-type data analysis. IEEE Transactions on Systems, Man, and Cybernetics, v. 24, n. 4, p. 698-708, 1994.

Referências Bibliográficas
- 84 -
[Johnson & Wichern, 2001]
Richard Arnold Johnson and Dean W. Wichern. Applied
Multivariate Statistical Analysis. Prentice Hall, fifth edition, 2001.
[Kohonen, 1989] Kohonen, T.: Self-organizarion and Associative Memory, Third Ed., Springer, Heidelberg, Germany, 1989
[Lewis, 2000] Roger J. Lewis. An introduction to classification and
regression tree (cart) analysis. Annual Meeting of the Society for Academic Emergency Medicine, San Francisco, California, 2000.
[Palumbo et al., 2000] F. Palumbo N. Carlo Lauro, R. Verde. Factorial
discriminant analysis on symbolic objects. In Hans-Herman Bock and Edwin Diday, editors, Analysis of Symbolic Data: Exploratory Methods for Extracting Statistical Information from Complex Data, pages 212-233, Germany, 2000. Springer.
[Rasson & Lissoir, 2000]
Jean-Paul Rasson and Sandrine Lissoir. Classical methods of
discrimination. In Hans-Herman Bock and Edwin Diday, editors, Analysis of Symbolic Data: Exloratory Methods for Extracting Statistical Information from Complex Data, pages 234-240, Germany, 2000. Springer.
[Rossi & Conan-Guez, 2002]
Fabrice Rossi and Brieuc Conan-Guez. Multi-layer
perceptron on interval data. Classification, Clustering, and Data Analysis (IFCS 2002), pages 427-434, Cracow, Poland, 2002.
[Rumelhart & McClelland, 1986]
J.L. Rumelhart, D.E.; McClelland. Parallel Distributed
Processing: Explorations in the Microstruture of Cognition, volume 1. Cambridge, Mass, 1986.
[Silva et al., 2006] SILVA, Fabio C.d. ; DE CARVALHO, F. T. ; SOUZA, R. M. C. R. ; SILVA, J. Q. . A Modal Symbolic Classifier for
Interval Data. In: 13th International Conference on Neural Information Processing - ICONIP2006. Heidelberg (Germany) : Springer, 2006. v. 4233. p. 50-59.
[Simoff, 1996] S. J. Simoff. Handling uncertainty in neural networks: An
interval approach. Int. Conf. on Neural Networks, pages 606-610, Washington, 1996. IEEE.


Silva, Fábio César Donato Classificação supervisionada usando dados
simbólicos de semântica modal / Fábio César Donato Silva. – Recife: O Autor, 2007. x, 84 folhas : il., fig., tab.
Dissertação (mestrado) – Universidade Federal de Pernambuco. CIn. Ciência da Computação, 2007.
Inclui bibliografia e apêndice.
1. Inteligência artificial. 2. Inteligência computacional. Título.
006.3 CDD (22.ed.) MEI2008-078


















