
Monitorização de SLA IP - paginas.fe.up.ptpaginas.fe.up.pt/~ee02187/tese/ficheiros/pdi.pdf ·...
51
Faculdade de Engenharia da Universidade do Porto Monitorização de SLA IP Paulo Jorge Lopes Soares Vaz Relatório de Projecto realizado no âmbito do Mestrado Integrado em Engenharia Electrotécnica e de Computadores Major Telecomunicações Orientador: Prof. João Manuel Couto das Neves Julho de 2010
-
Upload
dangnguyet -
Category
Documents
-
view
234 -
download
1
Transcript of Monitorização de SLA IP - paginas.fe.up.ptpaginas.fe.up.pt/~ee02187/tese/ficheiros/pdi.pdf ·...

Faculdade de Engenharia da Universidade do Porto
Monitorização de SLA IP
Paulo Jorge Lopes Soares Vaz
Relatório de Projecto realizado no âmbito do Mestrado Integrado em Engenharia Electrotécnica e de Computadores
Major Telecomunicações
Orientador: Prof. João Manuel Couto das Neves
Julho de 2010

ii
© Paulo Vaz, 2010

iii
Resumo
Com o crescimento exponencial da Internet e a sua contínua evolução, assiste-se a um
aumento da importância e dependência nos serviços de rede por parte das empresas, o que as
leva a procurar junto das operadoras e fornecedoras de serviços maiores garantias de
desempenho e qualidade de serviço, uma vez que uma eventual falha pode ser muito
prejudicial, quer ao nível financeiro, quer ao nível da competitividade da empresa.
Para tal existe o chamado Service Level Agreement, um contrato entre um Service
Provider e um cliente (empresa) que define quais as expectativas que ambos devem ter em
termos de definição de serviços, disponibilidade, desempenho e operacionalidade do sistema.
Para essa contratualização quer o administrador da rede quer os SP têm de saber quais as
métricas a monitorizar, quem as vai monitorar e como elas irão ser monitorizadas. Se isto não
estiver bem definido pode levar a confusões sobre as responsabilidades atribuídas a cada
entidade e à insatisfação com o SLA acordado.
Este projecto procura desenvolver uma ferramenta que utilizando um interface Web
permita a monitorização, geração de alertas e gestão dos vários SLA contratados para
circuitos ou serviços e sistemas de uma rede empresarial.

iv

v
Abstract
With the exponential growth of Internet and its continuing evolution, we are witnessing
an increasing importance and reliance on network services for businesses, which leads them
to look at operators and service providers for greater assurance in terms of quality and
performance service, since a failure can be very damaging, both financial and in terms of
competitiveness.
To this end, there is the Service Level Agreement, a contract between a Service Provider
and a client that defines the expectations that both should have in terms of services,
availability, performance and operability of the system. For such contracts, either the
network administrator or the SP has to know what metrics to monitor, how they will be
monitored and those who will monitor. If this is not well defined, it can lead to confusion
about the responsibilities assigned to each entity and to dissatisfaction with the agreed SLA.
This project seeks to develop a tool using a web interface that allows monitoring, alarm
generation and management of various SLA contracted for circuits or services and systems in
a corporate network.

vi

vii
ÍNDICE
INTRODUÇÃO ............................................................................................ 1
1.1 TEMA E CONTEXTO .............................................................................. 1
1.2 OBJECTIVO ...................................................................................... 3
1.3 ESTRUTURA DA DISSERTAÇÃO .................................................................... 3
SLA ........................................................................................................ 5
2.1 OBJECTIVOS E PROCESSO DE DESENVOLVIMENTO .................................................. 5
2.2 DESCRIÇÃO ...................................................................................... 6
2.3 PROBLEMAS ..................................................................................... 7
2.4 SLA EM REDES IP ............................................................................... 7
ESTADO DA ARTE ....................................................................................... 9
3.1 NAGIOS ......................................................................................... 9
3.2 CACTI .......................................................................................... 14
3.3 OPSVIEW ....................................................................................... 18
3.4 OPENNMS ..................................................................................... 22
3.5 ZABBIX ......................................................................................... 24
3.6 ZENOSS ........................................................................................ 26
3.7 CISCO IOS IP SERVICE LEVEL AGREEMENTS ..................................................... 28
3.8 CONCLUSÕES ................................................................................... 31
PLANO DE TRABALHO ................................................................................ 33
4.1 PLANO DE TAREFAS ............................................................................. 33
4.2 CALENDARIZAÇÃO .............................................................................. 34
REFERÊNCIAS ........................................................................................... 35

viii

ix
Lista de figuras
Figura 1.1 - Tripla redundância de rede ............................................................. 2
Figura 3.1 – Nagios: Interface Gráfica .............................................................. 10
Figura 3.2 – Nagios: Sumário ......................................................................... 10
Figura 3.3 – Nagios: Estado dos serviços ............................................................ 11
Figura 3.4 – Nagios: Alertas ........................................................................... 11
Figura 3.5 – Nagios: Notificações .................................................................... 14
Figura 3.6 – Cacti: Princípios de Funcionamento ................................................. 15
Figura 3.7 – Cacti: Equipamentos .................................................................... 16
Figura 3.8 – Cacti: Árvore de gráficos .............................................................. 17
Figura 3.9 – Cacti: Gestão Utilizadores ............................................................. 17
Figura 3.10 – Opsview: Interface Gráfica ........................................................... 18
Figura 3.11 - Opsview: Estado de host e serviços ................................................. 20
Figura 3.12 – Opsview: Mapa da rede ............................................................... 20
Figura 3.13 – OpenNMS: Interface Gráfica ......................................................... 22
Figura 3.14 - OpenNMS: Alertas e Notificações ................................................... 23
Figura 3.15 – Zabbix: Organização .................................................................. 24
Figura 3.16 – Zabbix: Interface Gráfica ............................................................. 25
Figura 3.17 – Zenoss: Interface Gráfica ............................................................ 27
Figura 3.18 – Zenoss: Visão Geral ................................................................... 28
Figura 3.19 – Cisco IOS IP SLA funções, métricas e operações ................................. 30

x

xi
Lista de tabelas
Tabela 1.1 - Disponibilidade: Tempo de downtime em minutos ................................ 2
Tabela 4.1 – Calendarização do Projecto .......................................................... 34

xii
xiii
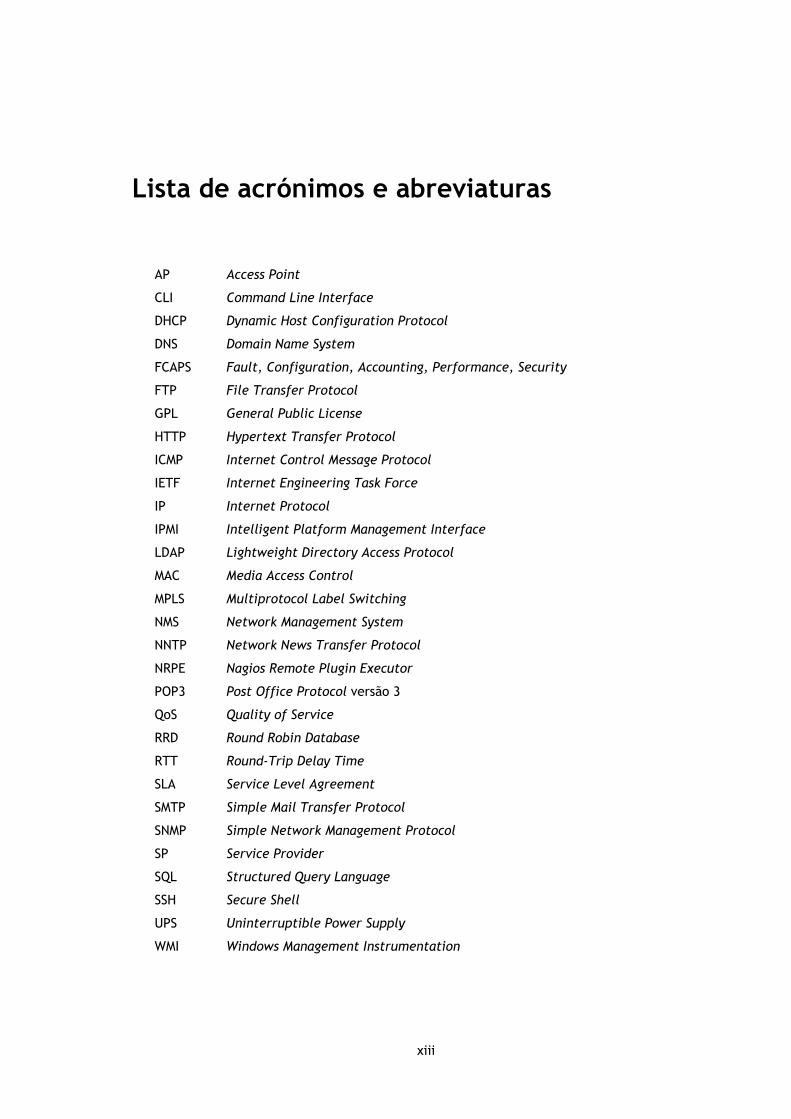
Lista de acrónimos e abreviaturas
AP Access Point
CLI Command Line Interface
DHCP Dynamic Host Configuration Protocol
DNS Domain Name System
FCAPS Fault, Configuration, Accounting, Performance, Security
FTP File Transfer Protocol
GPL General Public License
HTTP Hypertext Transfer Protocol
ICMP Internet Control Message Protocol
IETF Internet Engineering Task Force
IP Internet Protocol
IPMI Intelligent Platform Management Interface
LDAP Lightweight Directory Access Protocol
MAC Media Access Control
MPLS Multiprotocol Label Switching
NMS Network Management System
NNTP Network News Transfer Protocol
NRPE Nagios Remote Plugin Executor
POP3 Post Office Protocol versão 3
QoS Quality of Service
RRD Round Robin Database
RTT Round-Trip Delay Time
SLA Service Level Agreement
SMTP Simple Mail Transfer Protocol
SNMP Simple Network Management Protocol
SP Service Provider
SQL Structured Query Language
SSH Secure Shell
UPS Uninterruptible Power Supply
WMI Windows Management Instrumentation

xiv

1
Capítulo 1
Introdução
Este capítulo pretende apresentar uma visão geral do trabalho a desenvolver para a
presente dissertação, através da exposição do tema abordado, descrição dos seus objectivos e
finalmente a apresentação da estrutura do relatório.
1.1 Tema e Contexto
Com o crescimento exponencial da Internet e a sua contínua evolução, que permitiu o
acesso a novos tipos de serviço, verifica-se actualmente um aumento da importância e da
dependência nos serviços de rede por parte das empresas, o que as leva a procurar maiores
garantias de desempenho e qualidade de serviço por parte das operadoras e fornecedoras de
serviços, uma vez que uma eventual falha pode ser muito prejudicial, quer ao nível
financeiro, quer ao nível da competitividade da empresa.
Um administrador de rede tem de controlar um sistema mais complexo, com um número
cada vez maior de equipamentos e serviços, o que aliado à necessidade de obtenção de
informação rápida sobre problemas que tenham ocorrido ou que estejam prestes a acontecer
devido aos prejuízos que uma eventual falha na rede ou um tempo de downtime, por mínimo
que seja podem provocar, tornam incomportável a monitorização manual do sistema.
Assim as empresas necessitam de ter uma forma de previsão e monitorização de serviços
IP independentemente do custo. Aí entra o SLA (Service Level Agreement), que por definição,
é um contrato entre um SP (Service Provider) e um cliente que define as expectativas que
ambos devem ter em termos de definição de serviços e consequente disponibilidade,
desempenho e operacionalidade do sistema. Para a gestão apropriada dos serviços deve haver
um consenso sobre os serviços entre o SP e o cliente.
Com um SLA o administrador da rede tem a capacidade de definir quais os níveis de
serviço adequados para aplicações e serviços críticos e essenciais para o normal
funcionamento da empresa, tendo em atenção a eficiência da rede e a experiência de
utilização por parte do utilizador comum, podendo proceder a alterações na configuração da
rede com base em métricas de desempenho optimizadas. Ao isolar de forma proactiva os

2 Introdução
problemas da rede podem também reduzir o tempo de detecção e reparação de problemas.
Na óptica do cliente, os SLA servem também para verificar se o SP está a cumprir com os
níveis acordados e contratados e em caso de falha procurar ser ressarcido pelos eventuais
prejuízos causados.
Como tal as empresas procuram junto dos SP garantir níveis de disponibilidade de serviço
altos para que os tempos de downtime sejam os mais reduzidos possíveis. Essa
disponibilidade, tal como descrito em [1], pode ser expressa como uma percentagem de
uptime por ano, mês, semana, dia ou hora comparada com o tempo total desse período.
Algumas empresas poderão mesmo necessitar de 99,999%, os chamados “cinco noves”, de
disponibilidade, que tal como se encontra indicado na Tabela 1.1, indica 5 minutos de
downtime por ano.
Tabela 1.1 - Disponibilidade: Tempo de downtime em minutos
Disponibilidade Hora Diária Semanal Anual Anual (Horas)
99,999% 0,0006 0,01 0,1 5
99,98% 0,012 0,29 2 105 1h 45min
99,95% 0,03 0,72 5 263 4h 23min
99,90% 0,06 1,44 10 526 8h 46min
99,70% 0,18 4,32 30 1577 26h 17min
99,50% 0,3 7,2 50,4 2628 43h 48min
Algo que para se conseguir obter implica tripla redundância, isto, é 3 ISP diferentes a
fornecer o serviço a uma mesma empresa, tal como é apresentado na Figura 1.1.
Figura 1.1 - Tripla redundância de rede, em [1]

Introdução 3
Esta, ou outras soluções que garantam qualidade de serviço com níveis inferiores, pode
apresentar custos muito elevados, o que aliado à necessidade que a empresa tem de verificar
se o acordo com os SP está a ser cumprido, implementando soluções de monitorização e
gestão de serviços, pode levar a que a empresa seja incapaz de suportar os custos associados
a este conjunto de soluções.
Para os SP a definição dos SLA também tem vantagens. Obtêm maiores margens de lucro,
aumentam a satisfação do cliente e melhoram a posição competitiva.
1.2 Objectivo
O objectivo desta dissertação passa por desenvolver uma ferramenta que permita
monitorar e gerir os SLA contratados para circuitos ou sistemas de uma rede empresarial.
Esta ferramenta resultará da integração e configuração de ferramentas open source,
utilizando um interface Web que permitirá a monitorização, geração de alertas e gestão dos
vários SLA definidos para serviços e sistemas na rede.
1.3 Estrutura da dissertação
Este relatório encontra-se organizado em quatro capítulos.
No primeiro capítulo é descrita a motivação para o desenvolvimento desta dissertação e
os objectivos da mesma.
No segundo capítulo é descrito o que são SLAs e IP SLAs fazendo referência a métricas
típicas, operações suportadas e a sua evolução.
No terceiro capítulo são apresentadas soluções actuais, disponíveis no mercado, para a
monitorização de SLAs IP.
No quarto capítulo é apresentado o plano de trabalho a desenvolver, bem como a
calendarização das diferentes fases de trabalho.

4 Introdução

5
Capítulo 2
SLA
Neste capítulo é descrito o que são SLAs e IP SLAs fazendo uma breve apresentação sobre
os objectivos, desenvolvimento e problemas.
2.1 Objectivos e processo de desenvolvimento
Os objectivos de um SLA passam por ser um meio de prevenção e resolução de conflitos,
melhor gestão dos recursos financeiros, definição da qualidade de serviço entre outras. Deve
ser definido e usado de acordo com as características dos serviços pretendidos pelo cliente e
especificam as obrigações que clientes e SPs devem respeitar em termos de desempenho,
disponibilidade e segurança de serviços bem como os procedimentos a realizar em caso de
falha desse serviço. Um SLA pode ser especificado quer para serviços já utilizados pelo
cliente, quer para sistemas que ainda nem sequer foram projectados.
O processo de desenvolvimento de um SLA passa por:
Identificação das necessidades do cliente;
Determinação dos níveis de serviço;
Acordo entre cliente e SP em termos de:
o Níveis de serviço;
o Prevenção de conflitos;
o Gestão de expectativas;
Definição das regras de colaboração entre cliente e SP.

6 SLA
2.2 Descrição
Um SLA é a formalização de QoS (Quality of Service) num contrato entre um cliente e um
SP, tal como descrito em [1].
Geralmente um SLA, tal como é descrito em [2] é composto por:
Descrição do serviço a ser disponibilizado;
Descrição do nível de desempenho do serviço, definindo parâmetros como fiabilidade,
disponibilidade e segurança;
Descrição de procedimentos para comunicação de problemas, desde entidade a
contactar até à forma de apresentação formal do problema;
Definição do tempo máximo de resposta (tempo desde que o problema é comunicado
pelo cliente até que alguém do SP o comece a resolver) a um problema;
Definição de tempo máximo de resolução do problema;
Descrição da forma como se processa a monitorização e gestão dos serviços, quem
está a monitorizar o sistema, que tipos de dados podem ser monitorizados, período de
amostragem, onde e como esses dados devem ser guardados e permissões de acesso a
esses dados;
Descrição das consequências a que o SP está sujeito em caso de falha no cumprimento
das obrigações acordadas, que passam por condições para rescisão de contrato até
indemnizações a atribuir em caso de perda de receitas por falha de serviço;
Definição das condições que permitem ao SP não respeitar, num determinado
momento, os níveis de serviço acordados.
Um SLA deverá assim apresentar uma visão geral dos diferentes parâmetros que compõem
os serviços contratados, as situações em que podem ocorrer falhas e como resolvê-las,
procurando encontrar um equilíbrio entre as necessidades e expectativas do cliente e aquilo
que o SP pode ou quer fornecer.
Um SLA deve ser especificado em termos de eficiência e características de negócio:
o Conhecimento das necessidades do cliente leva à correcta identificação das
prioridades em relação aos elementos que compõem um SLA;
o O peso relativo dos elementos de um SLA deve ter em conta as características
do negócio da empresa;
O desenvolvimento de um SLA deve ser efectuado de forma organizada e estruturada
o que permite evitar tomadas de decisões precipitadas que possam levar à obtenção
de um SLA incompleto;
Um SLA é mais efectivo se tanto o SP como o cliente compreendam o seu conteúdo;
Um SLA deve ser baseado em elementos como disponibilidade, segurança,
desempenho, apoio ao utilizador e prevenção de desastres de preferência utilizando
termos que possam ser mensuráveis de forma a aumentar o nível de compreensão e
limitar os problemas e conflitos que especificações subjectivas podem provocar;
Diferentes grupos de utilizadores têm diferentes necessidades, o que deve levar a
uma diferenciação de serviços e a uma mais eficiente utilização destes.

SLA 7
2.3 Problemas
Tal como descrito em [3] os SLA apresentam alguns problemas que passam por:
Especificação do esforço vs especificação de resultados: Geralmente os SLAs referem
apenas o esforço que um SP tem de despender em caso da ocorrência de falhas na
rede, não existe referências para os objectivos que um dado serviço deve cumprir;
Especificação de métricas pouco clara: Alguns dos termos utilizados na especificação
dos elementos dos SLAs podem ser de difícil compreensão. Por exemplo, será que um
cliente sabe o que quer dizer uma disponibilidade de serviço de 98%? Saberá qual a
diferença entre disponibilidade de 98% ou 99%?
Especificação de serviços incompleta: Existe dificuldade em especificar com
exactidão parâmetros como controlo de segurança e previsão de catástrofes, uma vez
que geralmente só após estes problemas ocorrerem é que se consegue descrever com
exactidão tudo o que pode ocorrer;
Gestão de custos incorrecta: Apesar de indicar qual o custo que um determinado
serviço possuí, geralmente este não se encontra diferenciado e relacionado com as
necessidades do cliente. Ou seja a relação preço/desempenho para o cliente não é
optimizada.
Como consequência, um SLA pode torna-se um documento de difícil compreensão, restrita
apenas a um pequeno conjunto de pessoas com elevada formação técnica, o que pode levar a
confusões sobre as responsabilidades atribuídas a cada entidade, à dificuldade de interpretar
correctamente os serviços acordados e à insatisfação do cliente com o SLA acordado.
2.4 SLA em Redes IP
Tal como descrito em [2] no contexto das redes IP um SLA pode ser fornecido para três
tipos de ambientes, serviços de conectividade de rede, serviços de alojamento e serviços de
integração entre os serviços de conectividade e alojamento, sendo os recursos dentro da rede
fornecidos para cumprir os objectivos de desempenho e disponibilidade desejados, reduzindo
dessa forma o custo operacional sem provocar um impacto negativo na satisfação do cliente.
Nos serviços de conectividade de rede, as redes dos clientes encontram-se ligadas
directamente à rede do ISP através de routers que se encontram nos APs (Acess Points). Para
este tipo de redes os limites de disponibilidade e desempenho passam por exemplo por:
Latência através da rede do ISP entre 2 routers de acesso do cliente na mesma área;
Latência através da rede do ISP entre 2 routers de acesso do cliente no mesmo país;
Latência através da rede do ISP entre 2 routers de acesso do cliente em continentes
diferentes;
Tempo de quebra de ligação (perda de 100% de pacotes medidos através de um ping).

8 SLA
Serviços de alojamento são oferecidos por operadores que suportam e alojam os
diferentes tipos de servidores dos seus clientes. Estes serviços vão desde alojamento de sítios
Web (Web Hosting), locais para guardar servidores, manutenção de servidores ou dos
conteúdos e aplicações alojadas no sítio.
Os SLA oferecidos para este tipo de serviços passam pelos tempos de uptime e o nível de
desempenho dos servidores que estão a ser alojados. Estes operadores controlam apenas as
comunicações do lado do servidor, não têm nenhum controlo sobre as comunicações do lado
do cliente, nem sobre o desempenho da rede. Pode também alojar múltiplos clientes num
mesmo sítio e dessa forma é responsável por assegurar que a performance de um servidor de
um cliente não é afectada pelos pedidos direccionados a outros clientes.
Elementos típicos de performance e disponibilidade são os seguintes:
Tempo de indisponibilidade de um servidor alojado;
Número de pedidos que um servidor pode suportar;
Número mínimo de servidores disponíveis em todo o momento;
Throughput (taxa de transferência) suportado por um determinado servidor.
Um terceiro tipo de serviço fornece um serviço consolidado em que o SP controla a rede
bem como a infra-estrutura de alojamento. Alguns exemplos de elementos presentes num SLA
são os seguintes
Tempo máximo de pesquisa;
Downtime, não programado, do servidor de correio electrónico.
Em todos estes ambientes operacionais, a natureza dos serviços fornecidos, os objectivos
de desempenho e disponibilidade e os mecanismos usados para monitorizar o desempenho dos
serviços é diferentes, mas os componentes dos SLA são relativamente semelhantes.

9
Capítulo 3
Estado da Arte
Neste capítulo são apresentadas soluções actuais, disponíveis no mercado, para a
monitorização de SLAs IP.
3.1 Nagios
O Nagios é uma ferramenta open source para monitorização de sistemas de rede,
desenhada para correr em ambientes Unix e licenciada nos termos da licença GNU GPL
(General Public License) versão 2, sendo por isso um software livre.
Faz a monitorização de serviços de rede como o SMTP (Simple Mail Transfer Protocol),
POP3 (Post Office Protocol versão 3), HTTP (Hypertext Transfer Protocol), NNTP (Network
News Transfer Protocol), ICMP (Internet Control Message Protocol), SNMP (Simple Network
Management Protocol), FTP (File Transfer Protocol), SSH (Secure Shell) e DNS (Domain Name
System) bem como a monitorização de recursos (como carga do processador ou utilização de
disco) de diversos tipos de equipamentos como servidores (Windows ou Unix), routers,
switches ou impressoras.
O Nagios, tal como indicado em [4] e [5], apresenta informação ou através de um pagina
Web, apresentada na Figura 3.1, ou através de e-mail ou mesmo por SMS de acordo com os
parâmetros definidos pelo administrador da rede que está a ser monitorizada.

10 Estado da Arte
Figura 3.1 – Nagios: Interface Gráfica, em [6]
A interface Web apresenta informação diversificada, desde um sumário da situação geral,
Figura 3.2, à apresentação de serviços problemáticos, estado de serviços, Figura 3.3,
procurando apresentar a informação de forma estruturada e individualizada, apresentando
por exemplo quem foi informado e que tipo situação ocorreu, Figura 3.4.
Geralmente as condições de serviço encontram-se divididas em três categorias:
Funcionamento normal (apresentação gráfica a verde na página Web);
Aviso (apresentação gráfica a amarelo na página Web);
Situações críticas (apresentação gráfica a vermelho na página Web).
Figura 3.2 – Nagios: Sumário, em [6]

Estado da Arte 11
Figura 3.3 – Nagios: Estado dos serviços, em [6]
Figura 3.4 – Nagios: Alertas, em [6]

12 Estado da Arte
O Nagios utiliza o conceito de objectos. Como objectos entende todos os elementos que
estão envolvidos na lógica de monitorização e notificação. Esses objectos são
Hosts – equipamentos físicos da rede (servidores, workstations, routers, switches e
impressoras identificados por um endereço (IP (Internet Protocol) ou MAC (Media
Acess Control)), podendo ter um ou mais serviços associados e ter uma relação
pai/filho com outros hosts. Podem ser associados nos chamados Host Groups de forma
a permitir uma visualização mais simplificada do seu estado ou configurações na
interface Web;
Serviços – Associados a hosts representam recursos destes como carga do processador,
utilização de disco, ou serviços oferecidos como HTTP, FTP, SSH, DNS podendo
também eles ser agrupados em Service Groups com o mesmo efeito dos Host Groups;
Contactos – Pessoas que estão envolvidos no processo de notificação, onde está
englobado métodos de notificação, tipos de notificação a receber. Também podem
ser agrupados em Contact Groups de forma a facilitar a definição de utilizadores a
notificar;
Períodos de Tempo – Engloba períodos de monitorização de hosts e serviços e de
notificação a contactos;
Comandos – Utilizados para indicar ao Nagios que programas ou scripts deve executar.
Aqui encontram-se os hosts, service checks e as notificações.
Ao contrário de outras ferramentas de monitorização o Nagios apresenta uma estrutura
modular, utilizando programas externos, criados geralmente por elementos da comunidade,
que adicionam novas funcionalidades de monitorização, informação e notificação,
melhorando o desempenho do Nagios e tornando-o uma ferramenta mais poderosa. Esses
programas são denominados de plugins, e podem ser obtidos em [7] e [8]. Estes plugins são
executados quando é necessário verificar o estado de um host ou serviço retornando os
resultados para o Nagios, que por sua vez processa esses resultados e toma as medidas
necessárias, como por exemplo notificar contactos. Desde que o plugin tenha sido criado, o
Nagios pode testar tudo aquilo que possa ser medido electronicamente, desde temperatura e
humidade de salas de servidores, a muitos outros tipos de informação desde que essa
informação possa ser avaliada a partir de um computador.
O Nagios realiza vários testes distinguindo esses testes entre host check e service check.
Um host check, realiza testes simples como um ping para verificar e testar a atingibilidade de
máquinas específicas, sendo realizado em intervalos de tempo regulares (definindo para isso
as opções ceck_interval e retry_interval nas definições de host) ou então apenas quando lhe
é solicitado. Por exemplo, se um dos serviços monitorizados estiver acessível, é assumido que
a máquina onde está a correr também está disponível e este tipo de testes é descartado. Os
hosts verificados podem encontrar-se em um de três estados possíveis:
UP;
DOWN;
UREACHABLE.
Estes estados traduzem as informações (OK, WARNING, UNKNOWN e CRITICAL) que são
retornadas pelos plugins que são quem realiza este tipo de testes.

Estado da Arte 13
Já um service check testa individualmente serviços como o HTTP, o SMTP e o DNS, mas
também a carga do processador e os processos a correr nas máquinas. Tal como um host
check pode ser feito em intervalos de tempo regulares ou apenas quando é solicitado. Um
teste possível consiste em verificar, para um dado serviço, se a porta que ele utiliza se
encontra aberta e se ele se encontra à escuta nela. Para verificar se um serviço está
realmente a funcionar o Nagios testa serviços de forma mais aprofundada. Os serviços podem
encontrar-se em um de quatro estados possíveis:
UP;
WARNING;
UNKNOWN;
CRITICAL.
O Nagios pode monitorizar os hosts e os serviços de forma activa ou passiva. Os chamados
active checks são o método mais comum para fazer a monitorização, podendo ser iniciados
por um processo do Nagios ou então executados regularmente. Quando o Nagios necessita de
verificar o estado de um host ou serviço executa um plugin indicando a informação que é
preciso verificar. Esse plugin verifica o estado operacional do host ou serviço e retorna os
resultados para o Nagios, que os processa realizando depois as acções necessárias.
Os passive checks pelo contrário não são executados pelo Nagios mas sim por
aplicações/processos externos que submetem os resultados obtidos ao Nagios para serem
processados. Este tipo de verificação é útil para a monitorização de serviços de natureza
assíncrona ou que se encontram localizados atrás de uma firewall não podendo dessa forma
serem verificados activamente. Exemplos de serviços deste tipo incluem os SNMP traps e
alertas de segurança.
Possui um sistema de notificação, apresentado na Figura 3.5, podendo-se configurar grupo
de contacto (que contém um ou mais contactos individuais) que deve ser informado para um
determinado host ou serviço, horas a que essas notificações podem e devem ser feitas ou se
simplesmente as notificações podem ser descartadas. Tem em atenção que um contacto pode
ser membro de mais do que um grupo de contacto pelo que antes de enviar notificações
remove todas as notificações duplicadas para um contacto.
Para além de permitir controlar quando é que os host e service checks podem ser
realizados, ou quando as notificações podem ser enviadas, o Nagios também permite
programar quando um host ou serviço pode ser desligado para, por exemplo, realizar
operações de manutenção.

14 Estado da Arte
Figura 3.5 – Nagios: Notificações, em [6]
3.2 Cacti
O Cacti é uma ferramenta open source para monitorização de redes. Para poder ser
utilizado necessita que o sistema tenha instalado RRDTool, MySQL, PHP e um servidor Web
como, por exemplo, o Apache, e pode ser instalada quer em ambientes Unix quer em
ambientes Windows.
Os seus pontos fortes passam pela facilidade de configuração, ter uma interface Web
flexível, ter um fórum público com uma comunidade bastante activa, o que permite a
introdução de novas funcionalidades e melhoramentos, partilha de templates entre
utilizadores e a integração com outras ferramentas como o NTOP.
Tal como indicado em [9] e [10] o seu funcionamento passa por três princípios:
Obtenção de dados;
Armazenamento de dados;
Apresentação de dados.

Estado da Arte 15
Figura 3.6 – Cacti: Princípios de Funcionamento
A obtenção de dados é feita utilizando uma ferramenta denominada Poller que é
executada a partir do programa responsável pelo agendamento de operações num sistema
operativo. Em Unix o crontab. Devido à complexidade dos sistemas actuais, elas possuem
diversos tipos de equipamentos como routers, switchs, servidores, UPS (Uninterruptible
Power Supply), entre outros. Para obter dados deste conjunto de equipamentos o Cacti usa o
SNMP, podendo monitorizar todos os equipamentos que são capazes de utilizar SNMP. A
configuração desta ferramenta pode ser feita a partir da interface.
Para o armazenamento dos dados o Cacti utiliza o RRDTool. O RRD (Round Robin
Database) é um sistema que permite armazenar e apresentar dados como largura de banda da
rede, temperatura de máquinas e carga do servidor de forma rápida e fácil uma vez que
armazena esses dados de uma forma compacta utilizando para o efeito funções de
consolidação como o AVERAGE; MAXIMUM, MINIMUM e LAST.
A partir da interface gráfica do Cacti é possível fazer toda a gestão da monitorização da
rede. Tal como se apresenta na Figura 3.7 pode-se adicionar equipamentos para monitorizar,
tendo a possibilidade de indicar informações como descrição, hostname (endereço IP ou
hostname que será resolvido por DNS), template para gráficos (listas de gráficos para serem
usados neste host) e opções de disponibilidade e conectividade, como definição de Ping
(método, porta e tempo de timeout), opções de SNMP (versão, porta e tempo de timeout) ou
opções relacionadas com segurança.

16 Estado da Arte
Figura 3.7 – Cacti: Equipamentos, em [11]
A apresentação de dados também é baseada no RRDTool e na sua função de criação de
gráficos que combinada com o servidor Web permite que os gráficos criados sejam acedidos a
partir de um qualquer browser ou plataforma. Quase tudo no Cacti está relacionado com
gráficos e no menu da interface gráfica encontra-se o item Graph Management para fazer a
gestão e listagem de todos os gráficos disponíveis. Criam-se, modificam-se ou apagam-se
gráficos para os equipamentos introduzidos. Possuí diversas opções desde a escolha de tipos
de gráfico, variáveis, sendo que a maior parte das opções já se encontram configuradas no
template do gráfico. Pode-se, por exemplo, apresentar os gráficos hierarquicamente, usando
para o efeito árvores de gráficos, tal como apresentado na Figura 3.8.

Estado da Arte 17
Figura 3.8 – Cacti: Árvore de gráficos, em [11]
Permite gestão de utilizadores, tal como apresentado na Figura 3.9, indicando, nome,
nome de utilizador, palavra passe e outros parâmetros como as permissões de visualização de
equipamentos e gráficos a que um utilizador pode aceder.
Figura 3.9 – Cacti: Gestão Utilizadores, em [11]
Uma grande vantagem do Cacti, que o distingue dos demais é a utilização de templates.
Estes templates permitem facilitar a configuração de recolha de dados, sem que para isso
interesse o equipamento que os irá disponibilizar. O Cacti usa três tipos de template, para
dados, gráficos e para hosts.

18 Estado da Arte
Os templates de dados são usados para definir os parâmetros para a obtenção dos dados,
desde tipo, métodos e intervalos de actualização. Os templates de gráficos definem um
esqueleto de um gráfico, ou seja, como é que os dados recolhidos irão ser visualizados com
parâmetros que vão desde tipo de dados a visualizar, formato de imagem, resolução, escala
entre outros. Um template para host associa os templates de dados e gráficos mais
convenientes para um determinado tipo de equipamento, seja ele router, switch ou servidor.
Pode-se utilizar templates já presentes no Cacti, ou então criar-se templates próprios
com os parâmetros que se acharem mais convenientes ou então exportar templates criados
por outros utilizadores. Isso é possível devido ao facto do Cacti permitir importar e/ou
exportar templates a partir da interface gráfica.
Outra funcionalidade existente é o PHP Script Server, ferramenta que permite a recolha
de dados a partir de scripts PHP, que pela sua natureza torna o processo de pesquisa e
recolha de dados bem mais rápido e eficiente. Tal como acontece com os templates, também
aqui existe a possibilidade de utilizar scripts que já vêm instalados (o Cacti já possuí dois
scripts para recolha de dados sobre espaço em disco e utilização de processadores) ou então
scripts próprios que um utilizador cria para recolher a informação que pretende em um
determinado equipamento.
3.3 Opsview
O Opsview Community, [12] é uma ferramenta open source para monitorização de redes,
servidores e aplicações, distribuída sob a licença GPL versão 2. Fornece uma interface Web
para administração, configuração e visualização de sistemas, Figura 3.10.
Figura 3.10 – Opsview: Interface Gráfica, em [13]

Estado da Arte 19
A particularidade desta ferramenta é ela ser baseada e construída a partir de tecnologia e
ferramentas open source já existentes, entre as quais encontram-se:
Perl – Linguagem de programação principal do Opsview;
Catalyst – Framework para desenvolvimento de aplicações Web, baseado no padrão
de arquitectura de software MVC (Model-view-controller);
MySQL – Base de dados;
Apache – Servidor Web;
Nagios: Que providencia a base das capacidades de monitorização do Opsview;
Net-SNMP: Para suporte SNMP;
RRDTool – Para grafismo.
O Opsview corre em Linux, tendo suporte para as distribuições CentOS, Debien, Red Hat e
Ubuntu, bem como para o sistema operativo Solaris. Para além disso suporta tecnologias de
virtualização como o VMware Player, Server e ESX, Parallels, Xen Hypervisor e KVM
Hypervisor.
Suporta o uso de agentes de monitorização para a recolha de dados de equipamentos
localizados remotamente. Os mais comuns são o SNMP, o NRPE (Nagios Remote Plugin
Executor) e o NSClient++, usado para plataformas Microsoft Windows, sendo que um qualquer
agente que seja compatível com o Nagios deve funcionar com o Opsview.
Uma vez que o Nagios encontra-se integrado nesta solução, o Opsview utiliza a quase
totalidade dos conceitos do Nagios em termos de hosts, services, host checks, service checks,
active checks e passive checks. Os estados de serviço (OK, CRITICAL, WARNING E UNKOWN) e
de host (UP, DOWN E UNREACHABLE) também são os mesmos. A diferença encontra-se no
conceito de service group. No Nagios um service group é uma lista de serviços associados a
um host, já no Opsview um service group é um conjunto de service checks sem qualquer
associação a um host, pelo que o Opsview não tem nenhum tipo de configuração para um
service group do Nagios.
Tal como o Nagios utiliza plugins para a realização de active checks, sendo estes os
responsáveis por verificar se um equipamento ou sistema se encontra a funcionar ou não,
podendo ser utilizados múltiplas vezes em serviços diferentes. Entre os plugins que o Opsview
destaca encontram-se o check_disk para verificação de espaço livre em disco e o check_http
que verifica as respostas de um URL.
A partir da interface Web, tal como é mostrado na Figura 3.11 e descrito em [13], é
possível um conjunto de acções que passam pela visualização de hosts e serviços, de forma
organizada e hierárquica, resultados de service checks, gráficos de desempenho de serviços,
visualização de alertas, configuração de hosts, service checks, associação de service checks
com hosts, adição de host templates, adição de utilizadores e mapa da estrutura da rede, tal
como mostrado na Figura 3.12.

20 Estado da Arte
Figura 3.11 - Opsview: Estado de host e serviços, em [13]
Figura 3.12 – Opsview: Mapa da rede, em [14]

Estado da Arte 21
O Opsview já vem com service checks pré-definidos e agrupados em templates. A partir
destes pode fazer monitorização de aplicações, bases de dados, rede, serviços de rede,
sistemas operativos e SNMP. Alguns dos templates encontram-se em [15] destacando-se a
monitorização de:
Aplicações
o Alfresco;
o Servidor Web Apache;
o Atlassian;
o Servidor aplicações Jboss;
o Serviços OpenSimulator.
Negócio
o Monitores SLA que fornecem estatísticas sobre disponibilidade.
Servidores de Bases de dados
o MySQL;
o Oracle;
o PostgreSQL.
Rede
o Conectividade de rede
o Equipamentos de rede Cisco
Serviços de rede
o Servidores DNS;
o Protocolos Email;
o Servidores LDAP.
Sistemas Operativos
o Sistemas Unix e Linux;
o Servidores VMware ESX;
o Servidores Microsoft Windows.
SNMP
o Processamento de SNMP traps;
o Routers, firewalls e switches Cisco;
o MIB-II.

22 Estado da Arte
3.4 OpenNMS
O OpenNMS (Network Management System), [16], é uma plataforma open source de
gestão e monitorização de redes empresariais. Desenvolvida sob o modelo de gestão de redes
FCAPS (Fault, Configuration, Accounting, Performance, Security) é distribuída sobre a licença
GPL.
O OpenNMS é escrito em Java, para além de utilizar para base de dados o PostgreSQL e o
RRDTool, mais concretamente o JRobin (porta Java para o RRDTool), para ferramenta gráfica
e suporta os sistemas operativos Red Hat, Debian, Fedora, Mandriva, SuSE, Solaris, Mac OS X e
Microsoft Windows.
As suas funcionalidades passam pela determinação de disponibilidade e latência de
serviços, recolha, armazenamento e apresentação de dados recolhidos, gestão de eventos
(como por exemplo SNMP traps), alarmes e notificações.
Figura 3.13 – OpenNMS: Interface Gráfica, em [17]
Tal como indicado em [18], o OpenNMS está focalizado nos recursos dos serviços da rede
como, acessos a páginas Web e bases de dados, DNS e DHCP (Dynamic Host Configuration
Protocol), apesar de providenciar informação mais tradicional noutras ferramentas de gestão
e monitorização de redes, como informação sobre switches, routers entre outros.
Utiliza dois meios para recolha de dados. O primeiro é através dos chamados monitors que
se conectam a um recurso da rede e realizam um teste para verificar se ele responde
correctamente. Se tal não acontecer um evento é gerado. O segundo meio é através da
utilização dos denominados collectors, que recolhem dados SNMP. Os dados podem ser
recolhidos por SNMP, JMX (Java Management Extensions) e HTTP.

Estado da Arte 23
Para recolher dados o OpenNMS, tal como descrito em [19] primeiro tem de descobrir os
elementos que tem de monitorizar. A esses elementos dá-lhe o nome de interface, sendo que
uma interface é identificada por um endereço IP e os serviços são mapeados em interfaces.
Se mais do que uma interface estiver num mesmo equipamento então elas são agrupados em
um nó. A descoberta faz-se primeiro detectando o endereço IP a monitorizar e depois
descobrindo quais os serviços que são suportados por esse endereço IP.
Os eventos gerados são de dois tipos, os gerados internamente pelo OpenNMS e os gerados
externamente por SNMP traps. São caracterizados por parâmetros como descrição e
gravidade. Os diferentes níveis de gravidade, tal como apresentado em [20] que um evento
pode tomar são:
Critical: Numerosos equipamentos da rede são afectados pelo evento;
Major: Um equipamento encontra-se em baixo;
Minor: Parte de um equipamento, seja serviço ou interface parou de funcionar;
Warning: Evento que pode requerer atenção;
Normal: Apenas informativo, não necessitando de realização de acções;
Cleared: Indicação que um erro anterior foi corrigido e um serviço ou interface foi
restaurado;
Indeterminate: Impossibilidade de associação de evento com um nível de gravidade.
O OpenNMS também possui a funcionalidade de notificação. Caso ocorra um determinado
evento, uma notificação é enviada para um utilizador ou grupos de utilizadores ou para a
interface gráfica ou por email. A informação contida pela notificação passa por endereço IP,
serviço, mensagem de erro entre outras.
Figura 3.14 - OpenNMS: Alertas e Notificações, em [17]
Tal como nas outras ferramentas apresentadas, pode-se configurar utilizadores ou grupos
de utilizadores com diferentes permissões de acesso a elementos da rede, dados e
notificações, sendo que uma das particularidades é a possibilidade de configurar o OpenNMS
para suportar autenticação LDAP (Lightweight Directory Access Protocol), [21].

24 Estado da Arte
3.5 Zabbix
O Zabbix é uma ferramenta open source, distribuída sob os termos da licença GNU GPL
versão 2, para gestão de rede, com o objectivo de monitorizar o estado de vários serviços de
rede, bem como servidores ou outro tipo de hardware. Tal como descrito em [22] é
caracterizado como sendo um sistema de monitorização semi-distribuído com gestão
centralizada. A sua organização encontra-se dividida em 3 módulos principais
Base de dados, para armazenamento de dados, podendo ser utilizado MySQL,
PostgreSQL, SQLite ou Oracle;
Servidor, para proceder a monitorização directa de equipamentos e serviços;
Interface Gráfica, para interacção com os restantes módulos baseada em PHP e
JavaScript.
Figura 3.15 – Zabbix: Organização
As suas funcionalidades são:
Suporte para sistemas operativos Linux, AIX, FreeBSD, OpenBSD e Solaris;
Agentes nativos para a maioria das versões de sistema operativo Unix e Microsoft
Windows para monitorização de estatísticas como carga do processador, utilização da
rede, espaço em disco;
Monitorização de SNMP (todas as versões), SMTP ou HTTP e equipamentos IPMI
(Intelligent Platform Management Interface);
Capacidade de visualização gráfica dos testes efectuados;
Notificações;
Utilização de templates.
A interface gráfica permite várias opções de visualização que vão desde um simples
gráfico até mapas de rede para além de apresentar um conjunto de informações que vão
desde estado do Zabbix, estado do sistema, problemas ocorridos e mais um conjunto extenso

Estado da Arte 25
de informações sobre sistemas operativos, serviços, estado de servidores, routers e páginas
Web. A partir dela, tal como nas diversas ferramentas já apresentadas, pode-se gerir
utilizadores, métodos de autenticação, permissões e configurar as notificações a enviar em
caso de ocorrência de problemas. No caso do Zabbix o método mais comum de notificação é o
email.
Figura 3.16 – Zabbix: Interface Gráfica, em [23]
O Zabbix utiliza o conceito de item, entidade que guarda os dados monitorizados. Sem
items a informação não pode ser obtida. Existem dois tipos de, os chamados passive items,
em que o servidor conecta-se ao agente de cada vez que pretende testar um item, e os active
items, em que pelo contrário é o agente que se conecta ao servidor fazendo download da
lista de items a testar e informando periodicamente o servidor com os novos dados obtidos.
Possuí diversos tipos de categorias que vão desde Zabbix agent (entidade a que o servidor se
conecta para recolher dados), simple check, SNMP agent (para recolha de dados SNMP), entre
outros. Host é uma entidade que agrupa items, pode ser um switch, servidor, máquina virtual
ou um sítio Web, identificado por nome, grupo (importante uma vez que no Zabbix as
permissões só podem ser dadas a grupos de hosts e não a hosts individuais) e endereço IP.
Para testar hosts utiliza o conceito de triggers, definindo os parâmetros de teste para
verificar a ocorrência de problemas. Para o envio de notificações, tem-se de configurar no
Zabbix aquilo que ele define como actions, que basicamente são o conjunto de acções que o
servidor Zabbix deve tomar em caso de problemas. Define-se a mensagem a enviar, a quem se
envia a mensagem, o tipo de problema ocorrido e tipo de operações devem ser efectuadas.

26 Estado da Arte
3.6 Zenoss
O Zenoss Core é uma aplicação open source de gestão de redes e servidores lançado sobre
a licença GNU GPL versão 2 que fornece uma interface Web para administração de sistema,
monitorização de disponibilidade, desempenho e eventos. Possuem uma versão empresarial,
paga, baseada na versão Core, no entanto existe uma comunidade bastante activa do Zenoss
que desenvolve novas funcionalidades, documentação, manuais e fóruns de discussão para a
versão gratuita o que permite que o Zenoss esteja sempre a evoluir com novas soluções e
serviços.
O Zenoss é baseado, não só em programação própria, mas também através da integração
de tecnologias open source, tais como:
Python: Languagem de programação;
Zope: Servidor de aplicações escrito em Python;
Twisted: Framework de rede open source escrita em Python para a criação de
servidores SSH, proxy, HTTP e SMTP;
Net-SNMP: Suporte SNMP para monitorização de informações de sistema;
RRDTool: Ferramenta para suporte gráfico dos dados;
MySQL: Base de dados.
O Zenoss possui suporte para os sistemas operativos Red Hat, Fedora, Ubuntu, Debian,
SUSE, OpenSUSE, Mac OS X, VMWare, FreeBSD, Solaris e Gentoo.
Tal como indicado em [24] encontra-se dividido em 4 camadas:
User layer: Interface gráfica para acesso e gestão do sistema;
Data layer: Dados recolhidos guardados em bases de dados separadas, de acordo com
a sua utilização
o Dados de desempenho para serem processados e apresentados graficamente;
o Dados de configurações de equipamentos, grupos e localização;
o Dados de ocorrência de eventos;
Process layer: Gestão das comunicações entre a camada de obtenção e a camada de
dados;
Colecction layer: Obtenção de dados, através de SNMP, SSH e WMI (Windows
Management Instrumentation), de máquinas remotamente localizadas e transmissão
para a camada de dados;
Algumas das suas funcionalidades e capacidades são:
Monitorização da disponibilidade de equipamentos de rede utilizando SNMP, SSH e
WMI;
Monitorização de serviços de rede como HTTP, POP3, FTP, NNTP, entre outros;
Monitorização de recursos e desempenho de equipamentos (carga do processador,
utilização de disco);
Gestão de utilizadores, eventos e falhas;

Estado da Arte 27
Descoberta automática de recursos e topologia da rede, bem como a alterações na
configuração da rede;
Sistema de notificação;
Suporte do formato de plugins do Nagios, a que dão o nome de Zen Packs.
Tal como em outras ferramentas, a partir da interface gráfica, Figura 3.17 e Figura 3.18
são apresentadas informações de sistema (recursos, lista de equipamentos, serviços),
utilizando um sistema semelhante ao do Nagios, por exemplo, utilizando código de cores para
diferenciar os estados de equipamentos e serviços (verde se estiver a funcionar
correctamente, amarelo em caso de possibilidade de ocorrência de erros, vermelho em caso
de falha), apresentação gráfica de dados, eventos (detecção de erros com informação sobre
identificação de equipamento, endereço IP, gravidade, tipo de erro ocorrido), topologia da
rede, vista geográfica (utilizando Google Maps) da rede, informação de utilizadores, bem
como permite a gestão de equipamentos, serviços, notificações (situações, método, tipo de
mensagem a enviar) e utilizadores (informação de autenticação, permissões, associação a
grupos).
Figura 3.17 – Zenoss: Interface Gráfica, em [25]

28 Estado da Arte
Figura 3.18 – Zenoss: Visão Geral, em [26]
Para a adição de novas funcionalidades, utiliza os chamados ZenPacks que providenciam
uma arquitectura de plugins, tal como a utilizada pelo Nagios, para permitir aos membros da
comunidade aumentar e melhorar as funcionalidades e capacidades do Zenoss, através da
introdução de novas classes de eventos ou serviços, comandos, gráficos, entre outros. Podem
ser criados a partir da interface gráfica, ou através do desenvolvimento de scripts ou daemons
para integração com o Zenoss. A empresa que desenvolve o Zenoss pode criar ZenPacks
exclusivos para incentivar a compra da versão paga, os chamados Commercial ZenPacks, no
entanto os utilizadores podem criar os seus próprios ZenPacks, os chamados Core ZenPacks, e
disponibiliza-los para todos os utilizadores, o que permite a evolução também da versão Core.
3.7 Cisco IOS IP Service Level Agreements
Tal como indicado em [27] a Cisco também apresenta uma solução para monitorização e
gestão de SLA, a Cisco IOS IP Service Level Agreement, uma funcionalidade para
monitorização de desempenho de rede em equipamentos Cisco. Apesar de muitos dos
protocolos utilizados pela Cisco serem standards IETF (Internet Engineering Task Force), a
solução não é um standard IETF. Permite aos utilizadores verificar garantias de serviços,
aumentar a fiabilidade da rede ao validar o desempenho da rede e identificar de forma pro-
activa os problemas da rede. Para tal utiliza monitorização activa para gerar tráfego de forma
contínua, de forma a poder permitir a determinação da performance e saúde da rede,

Estado da Arte 29
calculando métricas de desempenho como jitter, latência, tempos de resposta de rede e
servidores e perdas de pacotes.
Tal como indicado em [28] e [29] procura portanto permitir aos utilizadores
Implementar novas aplicações e serviços de forma mais rápida e eficiente;
Observação de desempenho e identificação de problemas para permitir um aumento
da fiabilidade da rede;
Verificação e monitorização de QoS e níveis de serviço diferenciados.
Aproveitando as características oferecidas pela Cisco IOS IP SLAs, tais como:
Estar embebido no software Cisco IOS, não necessitando de aplicações externas nem
de custos adicionais;
Monitorização em tempo real de estado e desempenho da rede;
Capacidade de verificação e medida de parâmetros necessários para SLAs;
Notificações com SNMP trap em caso de detecção de problemas como perda de
pacotes, perda de conectividade e erro de verificação de dados (dados nos pacote de
origem e resposta serem diferentes);
Controlo e obtenção de dados usando SNMP ou Cisco IOS Software CLI (Command Line
Interface);
Simulação de codecs e medição de qualidade VoIP;
Monitorização de rede MPLS;
Integrado em ferramentas de gestão de outras entidades, como a Agilent, Concord
Communication ou HP Openview;
Possibilidade de configuração do protocolo de controlo com autenticação MD5.
Todos os equipamentos Cisco que correm Cisco IOS Software suportam a Cisco IOS IP SLAs
com a excepção da Cisco Catalyst 4500 Series Switch.
Resumindo, a utilização desta solução está orientada para:
Visualização do desempenho de serviços de VoIP, vídeo, MPLS (Multiprotocol Label
Switching) e redes VPN;
Monitorização de SLAs;
Monitorização de desempenho e disponibilidade da rede;
Avaliação do estado dos serviços da rede;
Monitorização do desempenho de aplicações;
Resolução de problemas operacionais da rede.
As principais métricas a testar passam pelo atraso, jitter, perda de pacotes sequenciação
de pacotes, conectividade, caminho (por salto), tempo de download de servidor e sítio Web e
qualidade de voz, de forma a garantir monitorização de desempenho VoIP, de disponibilidade
e desempenho de aplicações e equipamentos, de tempo de resposta de servidores, de
desempenho de servidor DNS, de desempenho de servidor DHCP, FTP e desempenho de sítios
Web

30 Estado da Arte
Algumas das principais operações realizadas são:
VoIP: Medição de RTT (Round-trip delay time), atraso, jitter e perda de pacotes,
simulação de codecs G.711 e G729;
DNS: Medição de tempo de DNS Lookup;
DHCP: Medição de RTT para obtenção de um endereço IP;
FTP: Medição de RTT para transferência de um ficheiro;
HTTP: Medição de RTT para abrir uma página Web.
Figura 3.19 – Cisco IOS IP SLA funções, métricas e operações [29]

Estado da Arte 31
3.8 Conclusões
Analisando as ferramentas apresentadas pode-se afirmar que todas elas não divergem
muito na forma como gerem e monitorizam serviços e equipamentos. As principais diferenças
residem no tipo de base de dados a utilizar, se utilizam elementos externos ao programa para
proceder à monitorização (como os plugins do Nagios), se utilizam ferramentas já existentes
(como no caso do Opsview que utiliza Nagios) ou uma estrutura criada de raiz. Outro ponto de
divergência é a forma de apresentar e o próprio conteúdo das interfaces gráficas de gestão. A
partir disto já se pode neste momento apresentar uma possível solução, sem grandes
especificações, para o trabalho de Dissertação a realizar no próximo semestre, tendo em
atenção que ao longo do desenvolvimento do trabalho alterações podem e devem ocorrer. Tal
como indicado nos objectivos do trabalho a solução passa pela integração de ferramentas
open source utilizando um interface Web para a monitorização de serviços e gestão de
sistemas.
Principal tecnologia open source integrada:
Apache – Servidor Web;
MySQL – Base de Dados;
Net-SNMP – Suporte SNMP;
PHP – Linguagem de programação em que se baseará a interface Web;
Python – Linguagem de programação principal;
RRDTool – Suporte gráfico dos dados;
Ubuntu 10.04 – Sistema Operativo.
A estrutura da solução passa por:
Interface Web
Função de acesso e gestão de sistema
o Configuração de equipamentos e serviços;
o Visualização organizada de equipamentos e serviços:
Simples gráfico de desempenho;
Árvore de gráficos de desempenho;
Mapa da rede.
o Visualização gráfica de dados de estado e desempenho de equipamentos e
serviços;
o Configuração e gestão de utilizadores:
Criação;
Autenticação;
Grupos;
Permissões.
o Configuração e visualização de alertas;
o Configuração de notificações:
Email.

32 Estado da Arte
Base de Dados
Estruturação da base de dados tendo em atenção as diferentes situações e utilizações
dos dados:
o Dados de sistema e serviços recolhidos para apresentação;
o Dados de configurações de sistema (equipamentos, utilizadores, serviços);
o Dados de eventos, alertas e notificações.
Servidor:
o A partir dele proceder-se à monitorização de equipamentos e serviços.
As métricas e serviços a monitorizar serão:
VoIP:
o Medição de RTT;
o Atraso;
o Jitter;
o Perda de Pacotes;
o Qualidade de voz.
Serviço DNS:
o Tempo de DNS lookup.
Serviço DHCP:
o Medição de RTT para obtenção de endereço IP.
Serviço Email;
Serviço FTP:
o Medição de RTT para transferência de um ficheiro.
Serviço HTTP:
o Medição de RTT para abertura de uma página Web.
Disponibilidade de equipamentos:
o Teste de conectividade (ping).
Tráfego de dados:
o Jitter;
o Perda de pacotes;
o Latência;
o QoS.

33
Capítulo 4
Plano de Trabalho
Neste capítulo é apresentado o plano de trabalho a desenvolver, bem como a
calendarização das diferentes fases do trabalho, tendo em atenção que ao longo do projecto
poderão ocorrer alterações.
4.1 Plano de tarefas
O plano de tarefas ficou definido da seguinte forma
Estudo, análise e compreensão do problema;
Estudo do estado da arte relativamente a monitorização de SLAs IP;
Identificação do conjunto de métricas a monitorizar;
Especificação de uma solução para a monitorização de SLAs IP;
Especificação de cenários de teste;
Desenvolvimento da solução;
Teste e validação da solução desenvolvida;
Escrita da Dissertação.

34 Plano de Trabalho
4.2 Calendarização
Ao longo do trabalho desenvolvido para a Preparação da Dissertação prevê-se que os 3
primeiros pontos do plano de tarefas fiquem concluídos até que à entrega do Relatório Final,
a 5 de Julho de 2010. A calendarização do restante trabalho é apresentada na Tabela 4.1
Tabela 4.1 – Calendarização do Projecto
Tarefas Setembro Outubro Novembro Dezembro Janeiro
Especificação da solução
Especificação de cenários de teste
Desenvolvimento da solução
Teste e validação da solução desenvolvida
Escrita da dissertação

35
Referências
1. Neves, João. Planeamento: Análise de Requisitos. [Online] [Citação: 21 de Abril de
2010.] http://www.inescporto.pt/~jneves/feup/2009-2010/pgre/requirements.pdf.
2. Service Level Agreements on IP Networks. Verma, Dinesh C. 9, s.l. : Proceedings of the
IEEE, 2004, Vol. 92, pp. 1382-1388. ISSN: 0018-9219.
3. Bouman, Jacques, Trienekens, Jos e van der Zwan, Mark. Specification Of Service
Level Agreements, Clarifying On The Basis Of Practical Research. Washington DC : IEEE
Computer Society, 1999. ISBN: 0-7695-0328-4.
4. Barth, Wolfgang. Nagios: System and Network Monitoring. 1st. 2006. pp. 16-18. ISBN 1-
59327-070-4.
5. Contributors, Nagios Core Development Team and Community. Nagios Core Version
3.x Documentation. [Online] [Citação: 26 de Junho de 2010.]
http://nagios.sourceforge.net/docs/nagios-3.pdf.
6. Nagios Screenshots. [Online] [Citação: 26 de Junho de 2010.]
http://www.nagios.org/about/screenshots.
7. [Online] [Citação: 23 de Abril de 2010.] http://exchange.nagios.org/.
8. [Online] [Citação: 23 de Abril de 2010.] http://www.nagios.org/download/plugins.
9. Berry, Ian, et al. The Cacti Manual. [Online] [Citação: 26 de Junho de 2010.]
http://www.cacti.net/downloads/docs/html/.
10. Kundu, Dinangkur e Lavlu, S. M. Ibrahim. Cacti 0.8 Network Monitoring. s.l. : Packt
Publishing, 2009. ISBN 978-1-847195-96-8.

36 Referências
11. Cacti Screenshots. [Online] [Citação: 26 de Junho de 2010.]
http://www.cacti.net/screenshots.php.
12. Opsview Community Edition 3.7. [Online] [Citação: 27 de Junho de 2010.]
http://docs.opsview.com/doku.php?id=opsview-community.
13. The Opsview Quick Start Guide. [Online] [Citação: 27 de Junho de 2010.]
http://docs.opsview.com/doku.php?id=opsview-community:quickstart.
14. Opsview Monitoring Web User Interface. [Online] [Citação: 27 de Junho de 2010.]
http://docs.opsview.com/doku.php?id=opsview-community:monitoringui.
15. Host Template. [Online] [Citação: 27 de Junho de 2010.]
http://docs.opsview.com/doku.php?id=opsview-community:initialconfiguration:templates.
16. Main Page. [Online] [Citação: 27 de Junho de 2010.]
http://www.opennms.org/wiki/Main_Page.
17. OpenNMS Screenshots. [Online] [Citação: 27 de Junho de 2010.]
http://sourceforge.net/project/screenshots.php?group_id=4141.
18. Polling Configuration How-To. [Online] [Citação: 27 de Junho de 2010.]
http://www.opennms.org/wiki/Polling_Configuration_How-To.
19. Discovery. [Online] [Citação: 27 de Junho de 2010.]
http://www.opennms.org/wiki/Discovery_Configuration_How-To.
20. Severity. [Online] [Citação: 27 de Junho de 2010.]
http://www.opennms.org/wiki/Severity.
21. Spring Security and LDAP. [Online] [Citação: 27 de Junho de 2010.]
http://www.opennms.org/wiki/Spring_Security_and_LDAP.
22. Olups, Rihards. Zabbix 1.8 Network Monitoring. s.l. : Packt Publishing, 2010. ISBN
978-1-847197-68-9.
23. Zabbix Screenshots. [Online] [Citação: 29 de Junho de 2010.]
http://www.zabbix.com/screenshots.php.
24. Zenoss Administration 2.5.2. [Online] [Citação: 30 de Junho de 2010.]
http://community.zenoss.org/community/documentation/official_documentation/zenoss-
guide/2.5.2.

Referências 37
25. Zenoss Screenshots. [Online] [Citação: 30 de Junho de 2010.]
http://ostatic.com/zenoss-core/screenshot/1.
26. Zenoss Core Screenshots. [Online] [Citação: 30 de Junho de 2010.]
http://ostatic.com/zenoss-core/screenshot/1.
27. Cisco IOS IP Service Level Agreements Q&A. [Online] [Citação: 28 de Junho de 2010.]
http://www.cisco.com/en/US/technologies/tk648/tk362/tk920/technologies_qas0900aecd80
17bd5a.html.
28. Cisco IOS IP Service Level Agreement Data Sheet. [Online] [Citação: 28 de Junho de
2010.]
http://www.cisco.com/en/US/technologies/tk648/tk362/tk920/technologies_white_paper09
00aecd8017531d.html.
29. Cisco IOS IP Service Level Agreements User Guide. [Online] [Citação: 28 de Junho de
2010.]
http://www.cisco.com/en/US/technologies/tk648/tk362/tk920/technologies_white_paper09
186a00802d5efe.html.


















