
Modelagem de dados com medidas repetidas via …...Dados Internacionais de Catalogação na...
93
UNIVERSIDADE FEDERAL DO CEARÁ CENTRO DE CIÊNCIAS DEPARTAMENTO DE ESTATÍSTICA E MATEMÁTICA APLICADA CURSO DE GRADUAÇÃO EM ESTATÍSTICA JOÃO VICTOR BASTOS DE FREITAS MODELAGEM DE DADOS COM MEDIDAS REPETIDAS VIA EQUAÇÕES DE ESTIMAÇÃO GENERALIZADAS FORTALEZA 2018
Transcript of Modelagem de dados com medidas repetidas via …...Dados Internacionais de Catalogação na...

UNIVERSIDADE FEDERAL DO CEARÁ
CENTRO DE CIÊNCIAS
DEPARTAMENTO DE ESTATÍSTICA E MATEMÁTICA APLICADA
CURSO DE GRADUAÇÃO EM ESTATÍSTICA
JOÃO VICTOR BASTOS DE FREITAS
MODELAGEM DE DADOS COM MEDIDAS REPETIDAS VIA EQUAÇÕES DE
ESTIMAÇÃO GENERALIZADAS
FORTALEZA
2018

JOÃO VICTOR BASTOS DE FREITAS
MODELAGEM DE DADOS COM MEDIDAS REPETIDAS VIA EQUAÇÕES DE
ESTIMAÇÃO GENERALIZADAS
Trabalho de Conclusão de Curso apresentado aoCurso de Graduação em Estatística do Centrode Ciências da Universidade Federal do Ceará,como requisito parcial à obtenção do grau debacharel em Estatística.
Orientador: Prof. Dr. Juvêncio SantosNobre
FORTALEZA
2018

Dados Internacionais de Catalogação na Publicação Universidade Federal do Ceará
Biblioteca UniversitáriaGerada automaticamente pelo módulo Catalog, mediante os dados fornecidos pelo(a) autor(a)
F936m Freitas, João Victor Bastos de. Modelagem de dados com medidas repetidas via Equações de Estimação Generalizadas / João VictorBastos de Freitas. – 2018. 92 f. : il. color.
Trabalho de Conclusão de Curso (graduação) – Universidade Federal do Ceará, Centro de Ciências,Curso de Estatística, Fortaleza, 2018. Orientação: Prof. Dr. Juvêncio Santos Nobre.
1. Modelagem. 2. Medidas repetidas. 3. Equações de Estimação Generalizadas. 4. Modelos LinearesGeneralizados. I. Título. CDD 519.5

JOÃO VICTOR BASTOS DE FREITAS
MODELAGEM DE DADOS COM MEDIDAS REPETIDAS VIA EQUAÇÕES DE
ESTIMAÇÃO GENERALIZADAS
Trabalho de Conclusão de Curso apresentado aoCurso de Graduação em Estatística do Centrode Ciências da Universidade Federal do Ceará,como requisito parcial à obtenção do grau debacharel em Estatística.
Aprovada em:
BANCA EXAMINADORA
Prof. Dr. Juvêncio Santos Nobre (Orientador)Universidade Federal do Ceará (UFC)
Prof. Dr. João Mauricio Araújo MotaUniversidade Federal do Ceará (UFC)
Profa. Dra. Sílvia Maria de FreitasUniversidade Federal do Ceará (UFC)

Aos meus pais Eliane e Luciano pelo amor e
carinho, e por sempre colocarem a educação dos
filhos como prioridade
Ao meu mestre Prof. Juvêncio por sempre acre-
ditar em mim, obrigado por tudo.

AGRADECIMENTOS
Aos meus pais a quem devo tudo e que sempre foram minha principal inspiração
como pessoas. Obrigado pelos conselhos, pela educação a que me foi dada, pelos ensinamentos,
amor, carinho e por sempre me incentivarem e acreditarem em mim. Esse momento é uma
conquista nossa.
À minha tia Wana, minha avó Isabel e minha irmã por sempre estarem presentes,
acreditarem e cuidarem de mim.
Ao meu orientador, professor Juvêncio Santos Nobre. Obrigado por ter aceitado ser
meu co-orientador do PET, a partir daquele dia comecei a ter entusiasmo para estudar e fazer
pós-graduação, e o levo como inspiração para isso. Agradeço por sempre estar disponível para
conversar, aconselhar e orientar, e por sempre fazê-los com sinceridade e respeito, o que me
levou a ser uma pessoa melhor. Foi uma honra ter sido seu orientando, e levarei isso para minha
vida toda.
Ao professor João Maurício pelos conselhos, amizade e o incentivo em fazer o
mestrado. Agradeço também por sempre acreditar em mim e os "carões" dados durante todo
esse tempo de graduação que me fizeram ser um aluno melhor.
Ao professor André Jalles, meu primeiro orientador. Obrigado por todo o apoio e
conselhos dados no começo do curso, e por me ensinar a relação do mito da caverna de Platão
com a Estatística.
Ao professor Júlio Barros por ter enxergado algum potencial em mim e me dado a
oportunidade de participar do grupo PET-Estatística. Obrigado pelos valiosos conselhos e pelo
carinho, esses que foram de grande ajuda na minha trajetória da graduação.
A todos que fazem parte do Departamento de Estatística e Matemática Aplicada da
UFC. Agradeço pelos ensinamentos aos professores: Ana Maria, André Jalles, Carlos Diego,
Gualberto Agamez, João Maurício, José Aílton, José Roberto, Júlio Barros, Juvêncio Nobre,
Luis Gustavo, Leandro Chaves, Maria Jacqueline, Rafael Farias, Ronald Targino e Silvia Maria.
Agradeço também aos funcionários pela simpatia e atenção: Claryssa, Luisa, Erione, Edson,
Lourdes e Tatiana.
À minha namorada e melhor amiga Áurea, por sempre estar ao meu lado quando
precisei, pela paciência e amor dados nos meus momentos de ansiedade durante a graduação.
Você foi a melhor companhia que eu poderia desejar.
Aos meus amigos de graduação, principalmente aos que tenho um carinho especial:

Allyson ("montagens do Maraca"), Danrley ("Hambúrguer frio?"), Diego ("o homem nasce
bom..."), Eduardo ("não confio em uma disciplina que não tem densidade"), John ("se uma
sanfona custa 20000, imagina um cavalo"), Lucas, leia-se Maraca ("ei man"), Ramon ("Adobe"),
Roberto ("cara, eu não sei de nada"), Victor ("big data").
Aos membros da minha banca professor João Maurício e professora Silvia Maria
pela disponibilidade e pelos comentários de refinamento do presente trabalho.
Ao Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) pelo
apoio parcial financeiro através de uma bolsa de iniciação científica.
E a todos os familiares, colegas e amigos que não mencionei que contribuiram nessa
trajetória, direta ou indiretamente.

“Our world, our life, our destiny, are dominated
by uncertainty; this is perhaps the only statement
we may assert without uncertainty.”
(De Finneti, 1906-1985)
“Statistics are like bikinis. What they reveal is
suggestive, but what they conceal is vital.”
(Aaron Levenstein, 1911-1986)
“A statistician’s wife had twins. He was deligh-
ted. He rang the minister who was also delighted.
"Bring them to church on Sunday and we’ll bap-
tize them,"said the minister. "No,"replied the
statistician. "Baptize one. We’ll keep the other
as a control.”
(STATS: The Magazine For Students of
Statistics, Winter 1996, Number 15)

RESUMO
Em muitas situações de interesse é comum se ter mais de uma observação por unidade experimen-
tal, gerando assim os experimentos com medidas repetidas. Na modelagem de tais experimentos
se faz necessário considerar e modelar a estrutura de dependência intra-unidades experimentais.
As primeiras propostas de modelagem foram baseadas sob suposição de normalidade, todavia
nem sempre apresentam uma boa alternativa. Dito isso, uma alternativa de flexibilização, é fazer
uso das Equações de Estimação Generalizadas (EEG’s). Esses modelos utilizam de propriedades
de funções de estimação para construir equações de estimação que incorporam uma estrutura de
correlação. Tais equações, inicialmente, foram obtidas para os Modelos Lineares Generalizados,
do qual trataremos aqui. Neste trabalho será apresentada a teoria de funções de estimação e a
construção das EEG’s, bem como técnicas para seleção de modelo e da matriz de correlação
de trabalho, estatísticas para testar hipóteses lineares de interesse com relação aos parâmetros
de regressão, além de técnicas de diagnóstico de influência global e local. Será apresentada e
discutida através de exemplos práticos a importância e necessidade da modelagem utilizando
EEG’s.
Palavras-chave: Modelagem. Medidas repetidas. Equações de Estimação Generalizadas.
Modelos Lineares Generalizados.

ABSTRACT
In many situations of intereset it is commom to have more than one observation for experimental
unit, thus generating the experiments with repeated measures. In the modeling of such experi-
ments is necessary consider and model the intra-unit dependency structure. The first modeling
proposals were based on normality assumption, but do not always present a good alternative.
That being said, an flexibilization alternative, is to make use of Generalized Estimating Equations
(GEE’s). These models use properties of estimating functions to build estimating equations which
incorporate an correlation structure. Such equations, initially, were obtained for Generalized
Linear Models, whose we will deal with here. In this work the theory of estimating functions
and the constructions of GEE’s will be presented, as well as techniques for model selections and
working correlation matrix selection, statistics to test linear hypothesis of interest with respect
to regression parameters, as well as diagnostic techniques of global and local influence. The
importance and necessity of modeling using GEE’s will be presented and discussed through
practical examples.
Keywords: Modeling. Repeated measures. Generalized Estimating Equations. Generalized
Linear Models.

LISTA DE FIGURAS
Figura 1 – Gráfico de dispersão da habilidade de leitura versus idade. . . . . . . . . . . 19
Figura 2 – Gráfico de dispersão da habilidade de leitura versus idade com duas observa-
ções por indivíduo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Figura 3 – Perfis individuais e diagrama de dispersão da habilidade de leitura versus idade. 20
Figura 4 – Perfis médios da média da conversão alimentar ± 1,96(erros-padrão). . . . . 21
Figura 5 – Curvatura normal para uma superfície αααω e direção unitária h. . . . . . . . 51
Figura 6 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes
de hipóteses de correlação nula, entre os tempos de coleta. . . . . . . . . . . 63
Figura 7 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes
de hipóteses de correlação nula, entre as dietas. . . . . . . . . . . . . . . . 63
Figura 8 – Variograma amostral para a conversão alimentar média. . . . . . . . . . . . 64
Figura 9 – Gráfico de probabilidade meio-normal com envelope simulado para o modelo
Normal com ligação canônica e matriz de correlação uniforme. . . . . . . . 64
Figura 10 – Distância de Cook Normalizada para o modelo Gama com ligação canônica
e matriz de correlação uniforme. . . . . . . . . . . . . . . . . . . . . . . . 66
Figura 11 – Resíduos padronizados para o modelo Gama com ligação canônica e matriz
de correlação uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Figura 12 – Gráfico de probabilidade meio−normal com envelope simulado para o mo-
delo Gama com ligação canônica e matriz de correlação uniforme. . . . . . 67
Figura 13 – Resíduos de Pearson versus |dmax| para o esquema de perturbação ponderação
de casos para o modelo Gama com ligação canônica e matriz de correlação
uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Figura 14 – Resíduos de Pearson versus |dmax| para o esquema de perturbação da variável
resposta para o modelo Gama com ligação canônica e matriz de correlação
uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Figura 15 – Resíduos de Pearson versus |dmax| para o esquema de perturbação da matriz
de correlação RRR para o modelo Gama com ligação canônica e matriz de
correlação uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
Figura 16 – Gráficos de diagnóstico sem as observações (11,1) e (12,1) para o modelo
Gama com ligação canônica e matriz de correlação uniforme. . . . . . . . . 69

Figura 17 – Gráficos dos Resíduos de Pearson versus |dmax| para os esquemas de pertur-
bação ponderação de casos, variável resposta e matriz de correlaço RRR para o
modelo Gama com ligação canônica e matriz de correlação uniforme. . . . . 70
Figura 18 – Perfis médios do número de células cancerígenas ± 1,96 (erros-padrão). . . 71
Figura 19 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes
de hipóteses de correlação nula, entre os tempos de coleta. . . . . . . . . . . 72
Figura 20 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes
de hipóteses de correlação nula entre as drogas. . . . . . . . . . . . . . . . 72
Figura 21 – Variograma amostral para o número de células cancerígenas. . . . . . . . . 73
Figura 22 – Medida hi j para o modelo Poisson com ligação canônica e matriz de correla-
ção AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
Figura 23 – Medida HHH i para o modelo Poisson com ligação canônica e matriz de correla-
ção AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
Figura 24 – Distância de Cook normalizada para o modelo Poisson com ligação canônica
e matriz de correlação AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . 75
Figura 25 – Resíduos padronizados para o modelo Poisson com ligação canônica e matriz
de correlação AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Figura 26 – Gráfico de probabilidade meio-normal com envelope simulado para o modelo
Poisson com ligação canônica e matriz de correlação AR-1. . . . . . . . . . 76
Figura 27 – Resíduos de Pearson versus Gráficos |dmax| para os esquemas de perturbação
ponderação de casos, variável resposta, matriz de correlação RRR e covariáveis
NGB e NGV para o modelo Poisson com ligação canônica e matriz de
correlação AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
Figura 28 – Gráficos de diagnóstico sem as unidades experimentais 16 e 24 para o modelo
Poisson com ligação canônica e matriz de correlação AR-1. . . . . . . . . . 78
Figura 29 – Resíduos de Pearson versus |dmax| para os esquemas de perturbação pondera-
ção de casos, variável resposta, matriz de correlação RRR e covariáveis NGB
e NGV sem as unidades experimentais 16 e 24 para o modelo Poisson com
ligação canônica e matriz de correlação AR-1. . . . . . . . . . . . . . . . . 79

LISTA DE TABELAS
Tabela 1 – Conversão alimentar: ração (em kg)/ganho de peso (em kg). . . . . . . . . . 21
Tabela 2 – Médias (em kg) e erros padrão da conversão alimentar por tratamento do dia 28. 22
Tabela 3 – Valores de Quase-verossimilhança, QIC e RJC referentes as matrizes de
correlação de trabalho propostas do modelo Gama com ligação canônica. . . 65
Tabela 4 – Estimativas e erros-padrão do modelo Gama com ligação canônica e estrutura
de correlação uniforme. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Tabela 5 – Valores de Quase-verossimilhança, QIC e RJC referentes as matrizes de
correlação de trabalho propostas do modelo Poisson com ligação canônica. . 73
Tabela 6 – Estimativas e erros-padrão do modelo Poisson com ligação canônica e estru-
tura de correlação AR-1. . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
Tabela 7 – Algumas das distribuições mais importantes da família exponencial e suas
respectivas propriedades. . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Tabela 8 – Algumas das funções de ligação mais importantes e suas respectivas proprie-
dades. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Tabela 9 – Conjunto de dados referente à aplicação da seção 4.3. . . . . . . . . . . . . 92

LISTA DE SÍMBOLOS
yyy Vetor aleatório associado a todas as observações
yyyi Vetor aleatório associado a i-ésima unidade experimental
yi j Observação j relacionada ao i-ésimo indivíduo
ΨΨΨ Função de estimação de um vetor aleatório
ΨΨΨn Função de estimação de uma amostra
ΨΨΨi Função de estimação de um vetor aleatório associado a i-ésima unidade
experimental
ΨΨΨI∗n Equação de Estimação Independente
ΨΨΨGn Equação de Estimação Generalizada
θθθ Parâmetros de interesse
Θ Espaço paramétrico
Ω Espaço amostral
A Álgebra
P Espaço de probabilidade
p Número de parâmetros de regressão
µ Parâmetro representando a média
µµµ i Média da i-ésima unidade experimental
µi j Média da i-ésima unidade experimental no j-ésimo instante
φ Parâmetro representando a dispersão
ηi j Preditor linear da i-ésima unidade experimental no j-ésimo instante
βββ Vetor de coeficientes de regressão
σ2 Parâmetro que representa a variância
RRRvi Verdadeira matriz de correlação associada a yyyi
RRRi Matriz de correlação de trabalho associada a yyyi
ααα Vetor de parâmetros de correlação
VVV (.) Matriz de variabilidade
SSS(.) Matriz de sensibilidade

JJJ(.) Matriz de informação de Godambe
XXX Matriz de especificação
XXX i Matriz de especificação associada a i-ésima unidade experimental
xxxi j Vetor de variáveis explicativas para a unidade experimental i no j-ésimo
instante
HHH Matriz de projeção
HHH i Matriz de projeção da i-ésima unidade experimental
hi j valor da diagonal principal de HHH da i-ésima unidade experimental no j-ésimo
instante
g(.) Função de ligação
ri j Resíduo de Pearson da i-ésima unidade experimental no j-ésimo instante
(rp)i j Resíduo padronizado da i-ésima unidade experimental no j-ésimo instante
tr(.) Traço de uma matriz
ωωω vetor de perturbação
ωωω0 vetor de não perturbação

SUMÁRIO
1 INTRODUÇÃO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.1 Experimentos de medidas repetidas . . . . . . . . . . . . . . . . . . . . . 17
1.2 Modelos para dados longitudinais . . . . . . . . . . . . . . . . . . . . . . 22
2 EQUAÇÕES DE ESTIMAÇÃO GENERALIZADAS . . . . . . . . . . . 26
2.1 Funções de estimação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.2 Modelagem da média . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.3 Equações de Estimação . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.3.1 Equações de Estimação Independentes . . . . . . . . . . . . . . . . . . . 31
2.3.2 Equações de Estimação Generalizadas . . . . . . . . . . . . . . . . . . . . 33
2.3.3 Estimação dos parâmetros . . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.3.3.1 Etapas para estimação dos parâmetros . . . . . . . . . . . . . . . . . . . . 38
2.4 Teste de hipóteses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4.1 Teste de Wald . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.4.2 Teste Escore . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.5 Seleção de modelos e de matriz de correlação . . . . . . . . . . . . . . . 40
2.5.1 QIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
2.5.2 CIC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
2.5.3 Critério de Rotnitzky-Jewell . . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.5.4 Variograma amostral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3 MÉTODOS DE DIAGNÓSTICO . . . . . . . . . . . . . . . . . . . . . . 44
3.1 Alavancagem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.2 Análise de resíduos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.2.1 Envelope simulado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
3.2.1.1 Construção do gráfico de probabilidade meio-normal com envelope simulado 48
3.3 Análise de eliminação de casos . . . . . . . . . . . . . . . . . . . . . . . . 49
3.4 Influência local . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.4.1 Influência local generalizada . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.5 Influência local para equações de estimação . . . . . . . . . . . . . . . . 53
3.6 Esquemas de perturbação sob homogeneidade da dispersão . . . . . . . 56
3.6.1 Ponderação de casos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57

3.6.2 Perturbação da variável resposta . . . . . . . . . . . . . . . . . . . . . . . 57
3.6.3 Perturbação individual das covariáveis . . . . . . . . . . . . . . . . . . . . 58
3.6.4 Perturbação do parâmetro de precisão . . . . . . . . . . . . . . . . . . . . 59
3.6.5 Perturbação na matriz de correlação de trabalho . . . . . . . . . . . . . . 60
4 APLICAÇÕES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.1 Recursos computacionais . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.2 Aplicação 1: Estudo de dietas do frango de corte . . . . . . . . . . . . . 62
4.3 Aplicação 2: Estudo sobre drogas para quimioterapia . . . . . . . . . . 71
5 CONSIDERAÇÕES FINAIS . . . . . . . . . . . . . . . . . . . . . . . . 80
5.1 Conclusões . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.2 Trabalhos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
APÊNDICES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
APÊNDICE A – Detalhes para obtenção das medidas de influência local . 89
A.1 Perturbação da variável resposta . . . . . . . . . . . . . . . . . . . . . . 89
A.2 Perturbação individual das covariáveis . . . . . . . . . . . . . . . . . . . 90
APÊNDICE B – Tabelas . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
APÊNDICE C – Banco de dados utilizado nas aplicação 2 . . . . . . . . . 92

17
1 INTRODUÇÃO
Neste capítulo será introduzido o conceito de experimentos de dados com medidas
repetidas, bem como a importância de uma boa modelagem para esses tipos de dados e os
principais modelos encontrados na literatura.
1.1 Experimentos de medidas repetidas
Em muitos campos científicos é comum realizar pesquisas em que se deseja estudar
uma variável resposta medida em unidades de uma ou mais populações, denominadas unidades
experimentais. Dito isso, podemos destacar duas principais estratégias de coleta de dados: a
primeira, denominada de estudo transversal, que envolve uma única observação (realizada em
um instante específico) da variável resposta para cada unidade experimental de uma amostra de
cada população de interesse. Na segunda estratégia de coleta, várias observações da variável
resposta são feitas sobre a mesma unidade experimental ao longo de alguma condição de
avaliação, esses tipos de dados são chamados de medidas repetidas.
Um exemplo simples de coleta de dados com medidas repetidas é quando estudamos
o efeito que algum medicamento tem em uma pessoa ao longo de um tratamento, então realizamos
exames em cada indivíduo em períodos de horas ou dias, por exemplo. Experimentos de medidas
repetidas em que as condições de avaliação não podem ser aleatorizadas, como por exemplo,
o tempo, são denominados experimentos longitudinais, que geram os dados longitudinais.
Em Bioestatística essa forma de coleta de dados também é conhecida como estudos de coorte,
e em outros campos do conhecimento, como Sociologia, Economia ou Administração, ela é
costumeiramente denominada de dados em painel.
Os estudos com dados longitudinais, do qual trataremos ao longo desse trabalho,
constituem então uma poderosa estratégia na pesquisa, pois é possível caracterizar e avaliar
alterações globais, e intraunidades experimentais ao longo do tempo, e relacioná-las com um
conjunto de fatores que não o tempo de observação. Experimentos longitudinais permitem
estudar a variável resposta sob níveis constantes, em que foram coletadas, de outras variáveis que
possam influenciá-la. Segundo Singer et al. (2017), esta característica é importante nos casos em
que a variabilidade interunidades experimentais é maior do que a variabilidade intraunidades
experimentais. Em um estudo transversal, por exemplo, nos limitaríamos a avaliar apenas
alterações globais.

18
Quando o esquema de coleta de dados proposto determina que todas as unidades
experimentais sejam avaliadas em instantes de tempo iguais (igualmente espaçados ou não),
dizemos que o planejamento é balanceado com relação ao tempo. Por outro lado, se o esquema
de coleta de dados determina que conjuntos de unidades experimentais sejam observados em
conjuntos de instantes diferentes (como no caso dos planejamentos transversais mistos segundo
a nomenclatura apresentada por Rao e Rao (1966)) ou que as observações sejam coletadas
irregularmente ao longo do tempo, ele é denominado desbalanceado com relação ao tempo.
Nos casos em que a coleta foi planejada de forma balanceada mas existem observações omissas,
os dados são ditos desbalanceados com relação ao tempo também.
A principal desvantagem de se optar por um estudo longitudinal está relacionada
com o custo, pois muitas vezes exige uma maior atenção para que as observações das unidades
experimentais sejam coletada nos instantes pré-determinados, além disso, o período de estudo
pode ser longo. A análise de dados obtidos desse tipo de estudo pode ser considerada também
uma desvantagem, pois é, em geral, mais difícil que a análise obtida de dados de estudos
transversais
Singer et al. (2017) destacam que no processo de modelagem de dados longitudinais
espera-se observar dependência entre as medidas feitas nas mesmas unidades experimentais,
o que pode acarretar um fenômeno conhecido como trilhamento (tracking), segundo o qual,
unidades experimentais com níveis de resposta mais altos (ou baixos) no inicio da coleta das
observações tendem a manter suas posições relativas ao longo de todo o estudo. Não modelar a
estrutura de dependência ou modelar erroneamente pode ocasionar uma sub ou superestimação
dos erros-padrão de alguns dos parâmetros de interesse ou todos.
Exemplo 1: Para ilustrar melhor a vantagem de se optar por uma análise com medidas repetidas,
consideremos um estudo hipotético, semelhante ao apresentado em Diggle et al. (1994), em que
queremos estudar a relação da idade de uma criança com uma certa habilidade de leitura, expressa
em termos de um índice na escala de [0,10]. Para isso, suponha que coletamos inicialmente
uma amostra com 6 crianças de diferentes idades e realizamos um estudo transversal (uma única
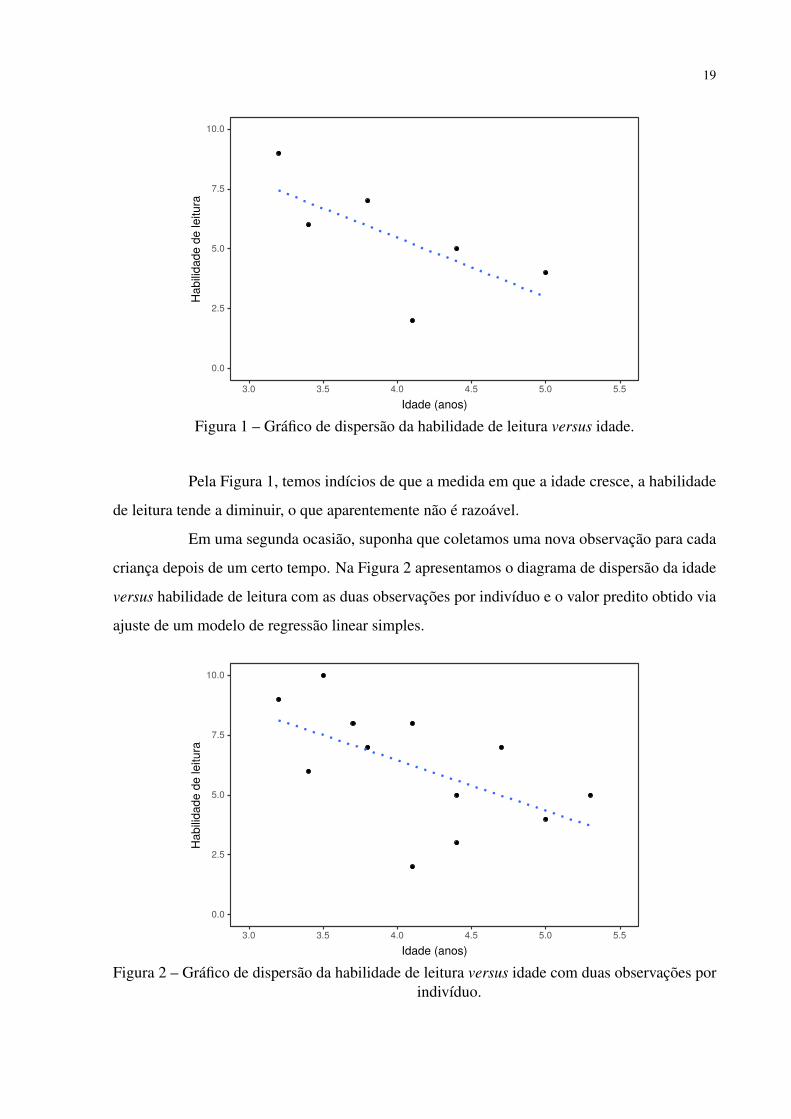
observação realizada num instante especificado). Na Figura 1 apresentamos um diagrama de
dispersão da idade versus a habilidade de leitura, com a respectiva linha associada ao valor
predito obtido via ajuste de um modelo de regressão linear simples.
19
0.0
2.5
5.0
7.5
10.0
3.0 3.5 4.0 4.5 5.0 5.5Idade (anos)
Hab
ilidad
e de
leitu
ra
Figura 1 – Gráfico de dispersão da habilidade de leitura versus idade.
Pela Figura 1, temos indícios de que a medida em que a idade cresce, a habilidade
de leitura tende a diminuir, o que aparentemente não é razoável.
Em uma segunda ocasião, suponha que coletamos uma nova observação para cada
criança depois de um certo tempo. Na Figura 2 apresentamos o diagrama de dispersão da idade
versus habilidade de leitura com as duas observações por indivíduo e o valor predito obtido via
ajuste de um modelo de regressão linear simples.
0.0
2.5
5.0
7.5
10.0
3.0 3.5 4.0 4.5 5.0 5.5Idade (anos)
Hab
ilidad
e de
leitu
ra
Figura 2 – Gráfico de dispersão da habilidade de leitura versus idade com duas observações porindivíduo.
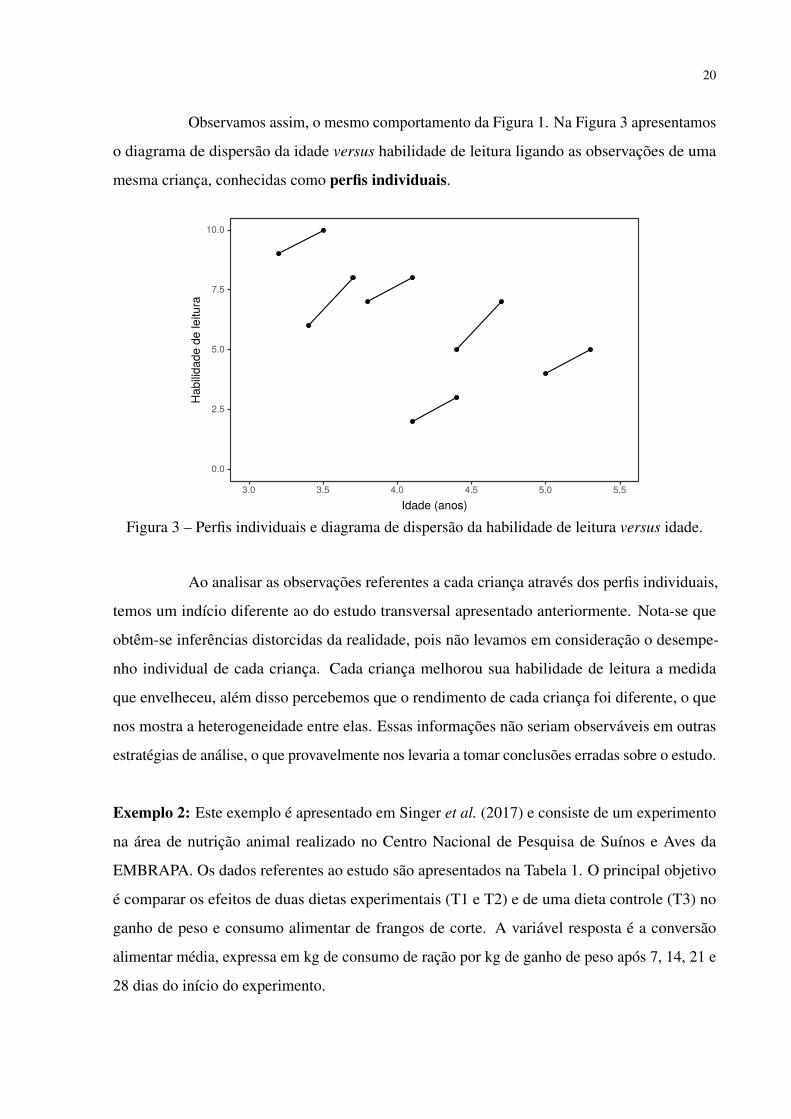
20
Observamos assim, o mesmo comportamento da Figura 1. Na Figura 3 apresentamos
o diagrama de dispersão da idade versus habilidade de leitura ligando as observações de uma
mesma criança, conhecidas como perfis individuais.
0.0
2.5
5.0
7.5
10.0
3.0 3.5 4.0 4.5 5.0 5.5Idade (anos)
Hab
ilidad
e de
leitu
ra
Figura 3 – Perfis individuais e diagrama de dispersão da habilidade de leitura versus idade.
Ao analisar as observações referentes a cada criança através dos perfis individuais,
temos um indício diferente ao do estudo transversal apresentado anteriormente. Nota-se que
obtêm-se inferências distorcidas da realidade, pois não levamos em consideração o desempe-
nho individual de cada criança. Cada criança melhorou sua habilidade de leitura a medida
que envelheceu, além disso percebemos que o rendimento de cada criança foi diferente, o que
nos mostra a heterogeneidade entre elas. Essas informações não seriam observáveis em outras
estratégias de análise, o que provavelmente nos levaria a tomar conclusões erradas sobre o estudo.
Exemplo 2: Este exemplo é apresentado em Singer et al. (2017) e consiste de um experimento
na área de nutrição animal realizado no Centro Nacional de Pesquisa de Suínos e Aves da
EMBRAPA. Os dados referentes ao estudo são apresentados na Tabela 1. O principal objetivo
é comparar os efeitos de duas dietas experimentais (T1 e T2) e de uma dieta controle (T3) no
ganho de peso e consumo alimentar de frangos de corte. A variável resposta é a conversão
alimentar média, expressa em kg de consumo de ração por kg de ganho de peso após 7, 14, 21 e
28 dias do início do experimento.
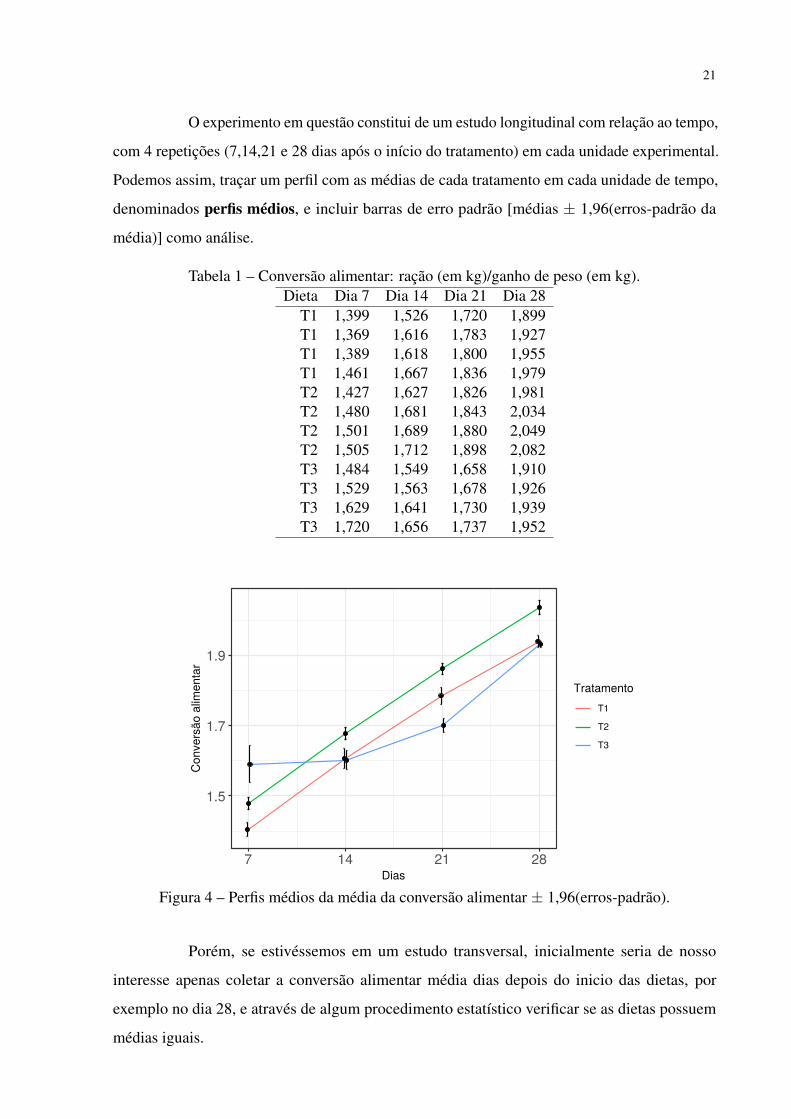
21
O experimento em questão constitui de um estudo longitudinal com relação ao tempo,
com 4 repetições (7,14,21 e 28 dias após o início do tratamento) em cada unidade experimental.
Podemos assim, traçar um perfil com as médias de cada tratamento em cada unidade de tempo,
denominados perfis médios, e incluir barras de erro padrão [médias ± 1,96(erros-padrão da
média)] como análise.
Tabela 1 – Conversão alimentar: ração (em kg)/ganho de peso (em kg).Dieta Dia 7 Dia 14 Dia 21 Dia 28
T1 1,399 1,526 1,720 1,899T1 1,369 1,616 1,783 1,927T1 1,389 1,618 1,800 1,955T1 1,461 1,667 1,836 1,979T2 1,427 1,627 1,826 1,981T2 1,480 1,681 1,843 2,034T2 1,501 1,689 1,880 2,049T2 1,505 1,712 1,898 2,082T3 1,484 1,549 1,658 1,910T3 1,529 1,563 1,678 1,926T3 1,629 1,641 1,730 1,939T3 1,720 1,656 1,737 1,952
1.5
1.7
1.9
7 14 21 28Dias
Con
vers
ão a
limen
tar
TratamentoT1
T2
T3
Figura 4 – Perfis médios da média da conversão alimentar ± 1,96(erros-padrão).
Porém, se estivéssemos em um estudo transversal, inicialmente seria de nosso
interesse apenas coletar a conversão alimentar média dias depois do inicio das dietas, por
exemplo no dia 28, e através de algum procedimento estatístico verificar se as dietas possuem
médias iguais.

22
Tabela 2 – Médias (em kg) e erros padrão da conversão alimentar por tratamento do dia 28.Dieta Média Erro Padrão
T1 1,9 <0,1T2 2,0 <0,1T3 1,9 <0,01
Através da Figura 4 e da Tabela 2 temos indícios que no dia 28 as médias dos
tratamentos T1 e T3 são semelhantes levando em consideração o erro padrão, porém ao tomar
essas evidências não estaríamos levando em consideração o processo ou efeito que essas dietas
tiveram ao longo desses 28 dias. Há indícios de um comportamento diferente ao longo do
tratamento principalmente entre os dias 7 e 14, em que se observa que o tratamento T1 tinha
média inferior ao T3 mas obteve um grande crescimento ao longo desses 7 dias. É importante
saber tratar descritivamente ou modelar futuramente exemplos como esse para que possamos
avaliar a relação entre as unidades de tempo, o efeito da dieta ao longo do tratamento e se o
animal pode ser um fator que influencia no estudo, resultados esses que não teríamos em um
estudo transversal.
Para mais detalhes sobre estudos longitudinais, há uma vasta literatura sobre o
assunto, entre eles, veja por exemplo, Ware (1985), Diggle et al. (1994), Vonesh e Chinchilli
(1996), Singer e Andrade (2000), Demidenko (2013) e Singer et al. (2017).
1.2 Modelos para dados longitudinais
Tendo em vista esses exemplos apresentados, existe uma variedade de desafios
na análise de dados longitudinais, pois suas medidas são multivariadas e podem possuir uma
estrutura de correlação complexa em que sua modelagem desempenha um papel fundamental
na análise desses tipos de dados. Para tal, existe uma grande variedade de técnicas para a
modelagem de experimentos com dados longitudinais, entre elas destacamos:
• Modelos Lineares Mistos com distribuição normal (Henderson (1953) e Henderson et al.
(1959)): Aqui, os parâmetros de regressão variam para cada indivíduo explicando as fontes
de heterogeneidade da população. Há um subconjunto dos parâmetros de regressão que
são tomados como efeitos fixos, esses são compartilhados por todos os indivíduos, outro
subconjunto contém os parâmetros que são de efeitos aleatórios,i.e., esses são específicos
para cada indivíduo, ou seja, cada unidade experimental tem a sua própria trajetória média.
A grande vantagem desse modelo está na flexibilidade que oferece para estudar a correlação
entre e intraunidades amostrais. Porém, esse modelo necessita que algumas suposições,

23
como normalidade, sejam válidas;
• Modelos Não Lineares Mistos (LINDSTROM; BATES, 1990): É utilizado quando a
suposição de linearidade dos parâmetros na função de regressão não é satisfeita. Esse
modelo considera que a esperança condicional da variável resposta dado as covariáveis
de um modelo misto é uma função não linear dos parâmetros. Uma das vantagens desse
modelo é que ele permite modificar a estrutura da matriz de variâncias e covariâncias dos
erros, adaptando-se a cada caso. No entanto, a estimação dos parâmetros do modelo não
linear misto, em geral, faz necessário a utilização de métodos iterativos e maior esforço
computacional, além de exigir valores iniciais para as estimativas dos parâmetros, o que
requer o conhecimento de técnicas adicionais e do fenômeno em estudo.
• Modelos Lineares Generalizados Mistos (BRESLOW; CLAYTON, 1993): É uma extensão
dos Modelos Lineares Generalizados (NELDER; WEDDERBURN, 1972), no qual permite
a adição de componentes de variabilidade devida a efeitos aleatórios, ou seja, são Modelos
Lineares Generalizados (MLG’s) que incluem efeitos aleatórios no preditor linear, além
dos efeitos fixos, permitindo modelar a estrutura de correlação intraunidades experimentais.
Uma de suas vantagens, é que assim como os MLG’s, é permitida uma flexibilidade na
distribuição da variável resposta. Sua principal desvantagem está no fato de necessitar
de métodos iterativos e de aproximação de integrais ou do integrando para estimar seus
parâmetros.
• Modelos Lineares Mistos Semiparamétricos (ZEGER; DIGGLE, 1994): Constitui tam-
bém uma extensão dos Modelos Lineares Mistos Normais, mas adiciona uma função não
paramétrica para explicar os efeitos fixos e uma para os efeitos aleatórios. Essas funções
não paramétricas fornecem uma flexibilidade com relação a forma funcional da função de
regressão, o que pode nos dar estimativas mais robustas em relação as observações discre-
pantes. As desvantagens desse método são a complexidade em estimar e fazer inferências,
fazendo uso constante de métodos de aproximação numérica e não-paramétricos.
• Modelos Lineares Mistos Assimétricos(Arellano-Valle et al. (2005) e Pinheiro et al.
(2001)): Flexibiliza a suposição de normalidade, permitindo que tanto o efeito aleatório
como o erro condicional possuam distribuições Normais ou t-assimétricas. Sua principal
vantagem está no fato de modelar bem a assimetria dos dados, gerando estimadores mais
robustos. Suas desvantagens são exigir conhecimento a priori sobre a distribuição dos
dados e a utilização constante de algoritmos de otimização, além da complexidade dos

24
modelos e eventuais instabilidades numéricas.
• Modelos Lineares Mistos Elípticos (SAVALLI et al., 2006): Flexibiliza a suposição
de normalidade, permitindo que a distribuição da fonte de variação tenha uma curtose
diferente da normal, ou seja, uma distribuição de cauda mais pesada ou mais leve. Como
consequência, os estimadores de máxima verossimilhança dos parâmetros envolvidos
são mais robustos, no sentido da distância de Mahalanobis. Sua desvantagem está na
complexidade do modelo e uso constante de métodos de iteração.
O fato de existir uma versão multivariada da distribuição normal com boas proprie-
dades facilita o estudo de alguns desses modelos citados do ponto de vista inferencial. Porém,
abandonando a suposição de normalidade, surge uma série de dificuldades devido a falta de
distribuições multivariadas alternativas que garantam também essas boas propriedades.
Uma das várias alternativas de tratamentos para dados longitudinais são as baseadas
nas funções de estimação (GODAMBE, 1991) para a obtenção das estimativas dos parâmetros
de um modelo de interesse que não é, necessariamente, completamente conhecido.
Uma função de estimação é uma função da amostra e dos parâmetros de interesse.
No estudo dessas funções buscamos condições que nos garantam que os estimadores dos pa-
râmetros associados possuam boas propriedades. Dito isso, estamos interessados nas funções
de estimação cujas raízes são estimadores dos parâmetros de interesse, e esses tem boas pro-
priedades como consistência e distribuição assintótica conhecida sob algumas condições de
regularidade.
Liang e Zeger (1986) a partir disso, propõem analisar dados com medidas repetidas
utilizando MLG’s, introduzindo o método das Equações de Estimação Generalizadas (EEG’s)
para a estimação da média e tratando os parâmetros de correlação como parâmetros de perturba-
ção. Através de propriedades de funções de estimação e sob algumas condições de regularidade,
esses autores obtêm estimadores consistentes para os parâmetros de regressão, desde que esse
modelo esteja corretamente especificado.
Posteriormente, Prentice e Zhao (1991) e Lipsitz et al. (1991) utilizam equações
de estimação para obter estimadores consistentes da média e da correlação e, neste caso, é
necessário que tanto o modelo de regressão como a estrutura de correlação estejam corretamente
especificados.
O uso de Equações de Estimação Generalizadas torna-se um procedimento esta-
tístico extremamente versátil, pois tais equações incorporam uma estrutura de correlação de

25
"trabalho", que fornecem estimadores consistentes e assintoticamente normais para os parâmetros
dos modelos de regressão, além de permitir uma flexibilidade na distribuição da variável resposta.
Neste presente trabalho serão apresentadas as propriedades de uma função de esti-
mação, bem como suas vantagens ao ser utilizada e a construção do modelo das EEG’s a partir
dela, além de explorarmos técnicas para seleção do melhor modelo, da matriz de correlação de
trabalho e testes de hipóteses para os parâmetros de interesse. Serão apresentadas também as
técnicas de análise de diagnóstico mais comuns: Análise de resíduos e Análise de influência
(global e local).

26
2 EQUAÇÕES DE ESTIMAÇÃO GENERALIZADAS
Neste capítulo serão apresentadas as definições e principais resultados que concernem
a teoria de funções de estimação. O leitor interessado em obter mais detalhes, podem vê-los em
Godambe(1960, 1991), Godambe e Kale (1991), Sen e Singer (1993), Jørgensen e Labouriau
(1994), Artes (1997), Godambe (1997), Venezuela (2003), Artes e Botter (2005) e Sen et al.
(2009), por exemplo.
2.1 Funções de estimação
Dizemos que uma função ψψψ é uma função de estimação do vetor aleatório yyy e dos
parâmetros de interesse θθθ se para cada θθθ ∈Θ, ψψψ(((θθθ ;;;yyy))) = (ψ1, ...,ψp)> é uma variável aleatória,
em que Θ⊆ Rp representa o espaço paramétrico. Consideraremos aqui casos regulares, ou seja,
situações em que Θ é compacto e tem dimensão finita p, sendo os parâmetros verdadeiros θθθ 000,
pontos do interior de Θ.
Considerando agora uma amostra de n vetores aleatórios independentes yyyi =(yi1, ...,yiti)>,
i = 1, ...,n e que cada vetor da amostra esteja relacionado com uma função de estimação ψψψ i,
então uma função de estimação da amostra ΨΨΨn(θθθ) é definida como:
ΨΨΨn(yyy;θθθ) =n
∑i=1
ψψψ i(yyyi;θθθ),
em que yyy = (yyy>1 , ...,yyy>n )>. Neste trabalho nos restringiremos às funções de estimação cujas raízes
são estimadores dos parâmetros de interesse, isto é
ΨΨΨn(yyy; θθθ) = 000, (2.1)
que é denominada função de estimação.
Definição 1 Seja y1, ...,yn uma amostra aleatória com E(yi) = µi(θθθ), µi duplamente diferenciá-
vel com relação a θθθ e Var(yi) = σ2, então
ΨΨΨn(yyy;θθθ) =n
∑i=1
∂ µi(θθθ)
∂θθθ[yi−µi(θθθ)]. (2.2)
Em que a função de estimação associada a (2.2) é chamada de Equação de estima-
ção e suas raízes são os estimadores de mínimos quadrados de θθθ .

27
Definição 2 Dizemos que Ψ(θθθ) e Φ(θθθ) são funções de estimação equivalentes se
Ψ(θθθ) =C(θθθ)ΦΦΦ(θθθ),
sendo CCC(θθθ) uma matriz quadrada de posto completo.
Pelo fato de CCC(θθθ) ser de posto completo, pode-se afirmar que se θθθ n é a raiz de uma
função de estimação, ela será raiz de todas as funções de estimação equivalentes. Além disso, é
possível concluir que há infinitas funções de estimação equivalentes a uma particular função.
Definição 3 A função Ψn(θθθ) é dita ser não viciada se
Eθθθ [ΨΨΨn(θθθ)] = 000, ∀θθθ ∈Θ.
Se todas as funções de estimação ψψψ i forem não viciadas, então ΨΨΨn também será não viciada.
Em geral, como citado anteriormente, estamos buscando funções de estimação
cujas raízes possuem boas propriedades assintóticas, para isso devemos estudar as propriedades
assintóticas dos estimadores através das propriedades da função de estimação. Uma delas é o
conceito de regularidade de uma função de estimação e da matriz de informação de Godambe,
esses resultados podem ser vistos em Godambe (1960), por exemplo.
Definição 4 Seja ΨΨΨn uma função de estimação não viciada, sua matriz de variabilidade e de
sensibilidade (ambas matrizes quadradas de ordem p× p), são dadas, respectivamente, por:
VΨ(θθθ) = Eθθθ [ΨΨΨn(θθθ)ΨΨΨ>n (θθθ)], (2.3)
SΨ(θθθ) = Eθθθ
[∂
∂θθθ>ΨΨΨn(θθθ)
]. (2.4)
Definição 5 Seja (Ω,A ,P) um espaço de probabilidades, Ω ⊂ R um espaço amostral sobre
o qual define-se P = Pθθθ : θθθ ∈Θ⊆ Rp, para algum p ∈ N. Uma função de estimação
ΨΨΨn(θθθ) : Ω×Θ→ Rp é dita ser regular se ∀θθθ ∈Θ e i, j = 1, ..., p,
1. ΨΨΨn(θθθ) é uma função de estimação não viciada;
2. A derivada ∂ΨΨΨn(θθθ)/∂θi existe e é contínua quase certamente ∀yyy ∈Ω;
3. É possível permutar o sinal de integração e derivação da seguinte forma:
∂
∂θi
∫Ω
ΨΨΨn(θθθ ,yyy)dPθθθ =∫
Ω
∂
∂θi[ΨΨΨn(θθθ ,yyy)]dPθθθ .
O fato de ψψψ(θθθ) ser integrável como função de yyy para cada θi, pela propriedade 2,
e supondo que ∂ψψψ(θθθ ,yyy)/∂θi é dominada por uma função integrável, garantem essa
inversão de operações;

28
4. Eθθθ [ΨΨΨi(θ)ΨΨΨ j(θ)] ∈ R e VΨ(θθθ) é positiva definida;
5. Eθθθ
[∂
θlΨΨΨi(θθθ)
∂
θkΨΨΨ j(θθθ)
]∈ R, em que l,k = 1, ..., p e SΨ(θθθ) é não singular.
Definição 6 Definimos a matriz de informação de Godambe de θθθ associada a uma função de
estimação regular ΨΨΨn por:
JJJΨ(θθθ) = SSS>Ψ(θθθ)VVV−1Ψ (θθθ)SSSΨ(θθθ).
A matriz de informação de Godambe tem o mesmo papel da informação de Fisher,
i.e., ela "carrega" informação sobre a variabilidade dos estimadores. Note que se SSSΨ(θθθ) =
−VVV Ψ(θθθ), então a matriz de informação de Godambe coincide com a matriz de informação de
Fisher.
Outro conceito importante, que será dado a seguir, é o de otimalidade das funções de
estimação, pois esse garante a normalidade assintótica dos estimadores.
Definição 7 Seja Qi(θθθ), i = 1, ...,n matrizes não estocásticas e ui = ui(yi;θθθ) vetores com média
zero mutuamente independentes, uma classe de funções de estimação é dita ser aditiva ou linear
(CROWDER, 1987) se:
`(u) =
ΨΨΨnnn ∈ℜ : ΨΨΨnnn(((θθθ))) =
n
∑i=1
Qi(θθθ)ui(yi;θθθ)
. (2.5)
Definição 8 Uma função de estimação regular é dita ser ótima se suas raízes possuem variância
assintótica mínima. A função de estimação ótima da classe de funções de estimação lineares
segundo Crowder (1987) é dada por:
ΨΨΨ∗n(θθθ) =n
∑i=1
Q∗i (θθθ)ui(yi;θθθ), (2.6)
em que
Q∗i (θθθ) = E(
∂ui
∂θθθ>
)>Cov(ui)
−1,
com
Cov(ui) = diagVar(ui)1/2RRRv(ui)diagVar(ui)
1/2, (2.7)
sendo RRRv(ui) a verdadeira matriz de correlação de ui, para i = 1, . . . ,n.
É importante ressaltar que a Definição 2 também vale para a otimalidade de uma
função de estimação. Os teoremas a seguir estabelecem condições que garantem a normalidade
assintótica dos estimadores obtidos a partir das funções de estimação regulares.

29
Teorema 1 (JøRGENSEN; LABOURIAU, 1994) Seja Ψ : Ω×Θ→Rp uma função de estimação
regular e θnn≥1 uma sequência de estimadores satisfazendo (2.1), e suponha que existe θ ∈Θ
de tal modo que
θnP−→ θ ,
em que θn é assintoticamente normal, logo
√n(θ −θ)
D−→N (0, J−1Ψ (θθθ)),
em que
JΨ(θθθ) = limn→∞
1nS>Ψ(θθθ)V−1
Ψ (θθθ)SΨ(θθθ),
que desempenha o papel de uma matriz de informação de Godambe assintótica.
Aqui o símbolo " D−→" é usado para denotar a convergência em distribuição (relacio-
nada a Pθ ) e " P−→" a convergência em probabilidade.
Teorema 2 Considerando que
1. yi, i = 1, ...,n são vetores aleatórios ti-dimensionais independentes;
2. ψψψ i(θθθ) = (ψi1, ...,ψip)>, i = 1, ...,n, são funções de estimação regulares;
3. ΨΨΨn(θθθ) = ∑ni=1 ψψψ i(θθθ);
4. para δ > 0:
Eθθθ
sup
hhh:||hhh||≤δ
∣∣∣∣∣∣∣∣ ∂
∂θθθ>>>ψψψ i(θθθ +hhh)− ∂
∂θθθ>>>ψψψ iii(θθθ)
∣∣∣∣∣∣∣∣
P−→ φδ ,
conforme n→ ∞, φδ → ∞ quando δ → ∞ e φδ → 0 quando δ → 0;
5. quando n→ ∞:1n
∂ΨΨΨn
∂θθθ> (θθθ)
P−→ SSSΨ(θθθ);
6.1n
n
∑i=1
Cov(ψi)→V (θθθ) positiva definida;
7. quando n→ ∞:ΨΨΨn(θθθ)√
nD−→Np(0,VVV Ψ(θθθ));
8. θθθ n é a solução para ΨΨΨn(www) = 000, www ∈Θ;

30
e sob condições que garantam a existência de uma sequência de raízes de ΨΨΨn(www) que sejam
limitadas em probabilidade, ou restrita a um conjunto compacto quase certamente quando
n→ ∞, vem que
θθθ nP−→ θθθ e
√n(θθθ −θθθ)
D−→N (0, JJJ−1Ψ (θθθ)).
Uma prova para o Teorema 2 pode ser vista em Jørgensen e Labouriau (1994,
p. 144), por exemplo. Vale notar que aqui são generalizações das condições de regularidade de
Frechet-Cramer-Rao (SEN et al., 2009). Como sugestão, o leitor pode ver o caso uniparamétrico
em Godambe (1960).
2.2 Modelagem da média
Antes de falarmos sobre Equações de Estimação precisamos definir um conceito que
será utilizado durante o texto.
Suponha que foi coletada uma amostra aleatória de tamanho n e que a i-ésima unidade
experimental, i = 1,2, . . . ,n, foi observada ti vezes ao longo de uma condição de avaliação, como
por exemplo o tempo, e cada observação está associada a um valor da variável resposta yi j. Além
disso admita que cada observação é influenciada por um conjunto de p covariáveis, ou seja, que
complementam ou substituem o controle local.
Dito isso seja xxxi j = (xi j1,xi j2, . . . ,xi jp)> o vetor que contém os valores das p co-
variáveis para o indivíduo i no j-ésimo instante, yyyi = (yi1, . . . ,yiti)> um vetor (ti× 1) com as
respostas observadas para o i-ésimo indivíduo e associado a ele XXX i = (xxxi1, . . . ,xxxiti)> uma matriz
de especificação (ti× p). Vamos assumir que a distribuição marginal de yi j pertence a família
exponencial linear unidimensional, i.e., sua densidade marginal pode ser escrita como:
f (yi j|θi j,φ) = exp
φ [yi jθi j−b(θi j)]+ c(yi j,φ)1X (yi j),
com
E(yi j) = µi j = b(1)(θi j) e Var(yi j) = φ−1b(2)(θi j), (2.8)
em que b(.) e c(.) são funções conhecidas, φ−1 um parâmetro de dispersão conhecido e os índices
1 e 2 sobrescritos representam a primeira e segunda derivadas com relação a θi j, respectivamente.
Primeiramente estabeleceremos um modelo para a média:
g(µi j) = ηi j = xxx>i jβββ , (2.9)

31
em que βββ = (β1, . . . ,βp)> é um vetor de parâmetros e g(.) é denominada função de ligação,
que é assumida ser monótona e ao menos duplamente diferenciável.
Na próxima seção será abordado o passo a passo para a construção das equações de
estimação como feito por Liang e Zeger (1986), assim como o processo para a estimação dos
parâmetros do modelo e os testes de hipóteses adequados.
2.3 Equações de Estimação
Nesta seção, apresentamos as equações de estimação generalizadas propostas por
Liang e Zeger (1986) sob a ótica dos modelos lineares generalizados com medidas repetidas.
2.3.1 Equações de Estimação Independentes
Liang e Zeger (1986) utilizaram inicialmente uma função de estimação mais simples
para βββ . Suponha que as distribuições marginais de yi j podem ser modeladas segundo um
modelo linear generalizado e que as observações repetidas na mesma unidade experimental são
independentes. Vale ressaltar que aqui estamos trabalhando com o caso em que o número de
repetições em cada unidade experimental podem ser diferentes, isto é, podemos ter um estudo
desbalanceado. Resultados para esse caso como apresentados aqui podem ser vistos também em
Oesselmann (2016) e Galdino (2015), por exemplo.
Para a construção das equações de estimação, considere a definição de função de
estimação ótima descrita em (2.5). Considere também uuui = uuui(yyyi;βββ ) = yyyi− µµµ i vetores com
média zero mutuamente independentes e satisfazendo as propriedades das funções de estimação
regulares, em que µµµ iii = (µi1, . . . ,µiti)>. Assumindo independência entre as observações de uma
mesma unidade experimental, as componentes da função de estimação ótima são dadas por:
Eβββ
(∂uuui
∂βββ>
)>= Eβββ
[∂ (yyyi−µµµ i)
∂βββ>
]>=−Eβββ
(∂ µµµ i
∂βββ>
)>=−Eβββ
(∂ηηη i
∂βββ
∂ µµµ i∂ηηη i
)>=
=−XXX>i ΛΛΛi =−DDD>i ,
Covβββ (uuui) = Cov(yyyi) = diagVar(yi j)= φ−1diagb(2)(θi j)= φ
−1AAAi,

32
em que,
XXX i =∂ηηη i
∂βββ= (xxxi1, . . . ,xxxiti)
>,com dimensão (ti× p),
ΛΛΛi = diag
∂ µi j
∂ηi j
,com dimensão (ti× ti) e
AAAi = diag
∂ µi j
∂θi j
= diagb(2)(θi j),com dimensão (ti× ti),
em que ηηη i = (ηi1, . . . ,ηiti)> e j = 1, . . . , ti. Dessa forma a função de estimação ótima definida
segundo os termos apresentados é equivalente a:
ΨΨΨ∗n(βββ∗I ) = φ
n
∑i=1
DDD>i AAA−1i (yyyi−µµµ i),
que é a função escore de um MLG. Então de forma análoga a (2.2) se igualarmos a função de
estimação a zero obtemos a equação de estimação independente de βββ , que é dada por:
ΨΨΨI∗n (βββ
∗I ) = φ
n
∑i=1
DDD>i AAA−1i (yyyi− µµµ i) = 000. (2.10)
Sob condições gerais de regularidade (Ver Teorema 2, seção 2.1), pode-se demonstrar
que βββ∗I é um estimador consistente para βββ , além disso,
√n(βββ I−βββ )
D→Np(000,(JJJ∗I )
−1) ,em que
JJJ∗I (βββ I) =J∗In
= limn→∞
1n
n
∑i=1
SSSIi
n
∑i=1
VVV Ii
−1 n
∑i=1
SSSIi
,
com
SSSi = Eβββ
[∂
∂βββ>DDD>i AAA−1
i (yyyi−µµµ i)
]= DDD>i AAA−1
i Eβββ
[∂
∂βββ> (yyyi−µµµ i)
]=−DDD>i AAA−1
i DDDi,
e
VVV i = Eβββ
[DDD>i AAA−1
i (yyyi−µµµ i)(yyyi−µµµ i)>AAA−1
i DDDi
]= DDD>i AAA−1
i Eβββ
[(yyyi−µµµ i)(yyyi−µµµ i)
>]
AAA−1i DDDi = DDD>i AAA−1
i Cov(yyyi)AAA−1i DDDi
= DDD>i AAA−1i φ
−1AAAiAAA−1i DDDi =−φ
−1SSSi.
Logo, temos que a matriz de informação de Godambe associada a equação de
estimação independente de βββ é dada por
JJJ∗I (βββ I) = φ
n
∑i=1
DDD>i AAA−1i DDDi.

33
Note que aqui continuamos tendo resultados idênticos aos obtidos via modelos
lineares generalizados. Um estimador consistente para a matriz de variâncias e covariâncias de
βββ I é dado por
(JJJ∗I )−1 =
φ
n
∑i=1
DDD>i AAA−1i DDDi
−1
.
Sendo todas as quantidades avaliadas em βββ I . Notemos que ΨΨΨI∗n (βββ ∗I ) é uma função
escore, logo a matriz de informação de Godambe de βββ I coincide com a informação de Fisher.
2.3.2 Equações de Estimação Generalizadas
Agora vamos apresentar o desenvolvimento e o conceito de equações de estimação
generalizadas propostos por Liang e Zeger (1986), que é o caso em que as observações de uma
mesma unidade experimental podem ser dependentes.
Para obtermos as Equações de Estimação Generalizadas, Liang e Zeger (1986)
apresentam algumas modificações em ΨΨΨI∗n (βββ
∗I ) dada em (2.10), de modo que a nova função
incorpore alguma informação sobre a estrutura de dependência dos dados. Os termos da função
de estimação ótima, ficam então dados por:
Eβββ
(∂uuui
∂βββ>
)>= Eβββ
[∂ (yyyi−µµµ i)
∂βββ>
]>=−Eβββ
(∂ µµµ i
∂βββ>
)>=−XXX>i ΛΛΛi =−DDD>i ,
e
Covβββ (uuui) = Cov(yyyi) = diagVar(yi j)1/2 RRRv
i diagVar(yi j)1/2
= φ−1AAA1/2
i RRRvi AAA1/2
i = ΣΣΣi,
sendo RRRvi a verdadeira matriz de correlação das componentes de yyyi, com i = 1, . . . ,n e todas as
matrizes como definidas para as Equações de Estimação Independentes. Logo, a equação de
estimação de βββ quando consideramos a verdadeira matriz de correlação é dada por:
ΨΨΨG∗n (βββ
∗G) =
n
∑i=1
DDD>i ΣΣΣ−1
i (yyyi− µµµ i) = 000. (2.11)
Sob condições gerais de regularidade (Ver Teorema 2, seção 2.1), Liang e Zeger
(1986) demonstraram, utilizando propriedade de funções de estimação, que βββ∗G, raiz de (2.11), é
um estimador consistente de βββ e ainda que,
√n(βββ
∗G−βββ )
D→Np(000,(JJJ∗G)
−1) ,

34
em que
JJJ∗G(βββ G) =JJJ∗Gn
= limn→∞
1n
n
∑i=1
SSSGi
n
∑i=1
VVV Gi
−1 n
∑i=1
SSSGi
,
com
SSSGi = Eβββ
[∂
∂βββ>DDD>i ΣΣΣ−1
i (yyyi−µµµ i)
]= DDD>i ΣΣΣ−1
i Eβββ
[∂
∂βββ> (yyyi−µµµ i)
]=−DDD>i ΣΣΣ−1
i DDDi,
e
VVV Gi = Eβββ
[DDD>i ΣΣΣ−1
i (yyyi−µµµ i)(yyyi−µµµ i)>ΣΣΣ−1
i DDDi
]= DDD>i ΣΣΣ−1
i Eβββ
[(yyyi−µµµ i)(yyyi−µµµ i)
>]
ΣΣΣ−1i DDDi = DDD>i ΣΣΣ−1
i Cov(yyyi)ΣΣΣ−1i DDDi
= DDD>i ΣΣΣ−1i DDDi =−SSSi.
Logo temos que a matriz de informação de Godambe associada a equação de estima-
ção generalizada de βββ é dada por
JJJ∗G(βββ G) =n
∑i=1
DDD>i ΣΣΣ−1i DDDi.
Neste caso, um estimador consistente para a matriz de variâncias e covariâncias de
βββ G é dado por
(JJJ∗G)−1 =
n
∑i=1
DDD>i ΣΣΣ−1
i DDDi
−1
, (2.12)
sendo todas as quantidades avaliadas em βββ G. Na literatura esse estimador recebe os nomes de
estimador "naive" ou "model-based".
Na prática a função ΨΨΨG∗n (βββ
∗G) é pouco utilizada, pois em geral, a matriz de correlação
verdadeira RRRvi é desconhecida. Para contornar esse problema, Liang e Zeger (1986) definiram
RRRi(ααα) como sendo uma matriz simétrica (ti× ti) satisfazendo as condições para ser uma matriz
de correlação, denominada matriz de correlação de trabalho ou matriz de trabalho em que
ααα , é um vetor (s× 1) que caracteriza completamente RRRi(ααα). A ideia é que a matriz trabalho
não precisa ser necessariamente a verdadeira matriz de correlação das componentes dos yyyiii’s, e
como ela representa a correlação entre as observações de um mesmo grupo, logo os valores de
RRRi(ααα) estão contidos no intervalo [−1,1]. Com isso as Equações de Estimação Generalizadas
(EEG’s) de βββ são dadas por:
ΨΨΨGn (βββ G) = ΨΨΨG
n
[βββ G, α(βββ G, φφφ)
]=
n
∑i=1
DDD>i ΩΩΩ−1
i (yyyi− µµµ i) = 000, (2.13)

35
em que
ΩΩΩi = ΩΩΩi(ααα,φ) = φ−1AAA1/2
i RRRi(ααα)AAA1/2i ,
e α sendo um estimador consistente de α .
As equações de estimação dadas em (2.13) deixam de ser ótimas, e por isso, podem
ser viesadas. É necessário então que ααα seja determinado de modo que βββ G continue sendo um
estimador consistente de βββ e assintoticamente normal. Na prática, φ quase sempre também é
desconhecido, logo, também é necessário propor um estimador para esse parâmetro. Para que o
estimador de βββ preserve as propriedades de estimação ótima, os estimadores de ααα e φ devem
satisfazer algumas condições descritas no teorema a seguir.
Teorema 3 Seja βββ G a raiz de (2.13). Sob condições gerais de regularidade e assumindo que
1. ααα(βββ ,φ) é um estimador√
n-consistente de ααα;
2. φ(βββ ) é um estimador√
n-consistente de φ e
3.∣∣∣∣∂ ααα(βββ ,φ)/∂φ
∣∣∣∣≤ HHH(yyy,βββ ), sendo HHH(yyy,βββ ) uma função Op(1), i.e., limitada em probabili-
dade;
Então, temos que βββ G é um estimador consistente de βββ e
√n(βββ G−βββ )
D→Np(000,(JJJG)
−1) ,em que
JJJG(βββ G) =JJJG
n= lim
n→∞
1n
n
∑i=1
SSSi
n
∑i=1
VVV i
−1 n
∑i=1
SSSi
,
com
SSSi = Eβββ
[∂
∂βββ>DDD>i ΩΩΩ−1
i (yyyi−µµµ i)
]= DDD>i ΩΩΩ−1
i Eβββ
[∂
∂βββ> (yyyi−µµµ i)
]=−DDD>i ΩΩΩ−1
i DDDi,
e
VVV Gi = Eβββ
[DDD>i ΩΩΩ−1
i (yyyi−µµµ i)(yyyi−µµµ i)>ΩΩΩ−1
i DDDi
]= DDD>i ΩΩΩ−1
i Eβββ
[(yyyi−µµµ i)(yyyi−µµµ i)
>]
ΩΩΩ−1i DDDi
= DDD>i ΩΩΩ−1i Cov(yyyi)ΩΩΩ
−1i DDDi.

36
A prova desse resultado encontra-se em Liang e Zeger (1986). Vale enfatizar que os
resultados do Teorema 3 são válidos mesmo quando RRRi(ααα) não corresponde a verdadeira matriz
de correlações de yyyi.
A matriz de covariâncias de βββ GGG pode ser consistentemente estimada (LIANG;
ZEGER, 1986) por:
JJJ−1G =
n
∑i=1
SSSi
−1 n
∑i=1
DDD>i ΩΩΩ−1
i uuuiuuu>i ΩΩΩ−1i DDDi
n
∑i=1
SSSi
−1
. (2.14)
A estimativa da expressão (2.14) é obtida substituindo ααα,βββ e φ pelo seus respectivos
estimadores consistentes. Na literatura esse estimador recebe o nome de estimador robusto,
empírico ou sanduíche. Quando RRRi(ααα) for a verdadeira matriz de correlação das componentes
de yyyi, então ΩΩΩi =Cov(yyyi) e o estimador robusto coincidirá com o estimador "naive" definido em
(2.12).
Considerando que o modelo de regressão está corretamente especificado, o estimador
"naive" é consistente se a matriz de trabalho também está corretamente especificada. Já o estima-
dor robusto é, em todos os casos, consistente. Além disso o estimador robusto é assintoticamente
não viesado, mas pode ser viesado quando temos um número pequeno de unidades experimentais.
Segundo Prentice (1988), quando o tamanho da amostra é menor do que 20, o estimador "naive"
pode ter melhores propriedades mesmo se RRRi(ααα) não estiver corretamente especificado.
2.3.3 Estimação dos parâmetros
Para a obtenção das estimativas βββ G, utilizaremos um método iterativo que combina
o método modificado de Newton (ver, JøRGENSEN et al.,1996, por exemplo) para estimar βββ
com o método dos momentos para estimar ααα e φφφ . Logo, expandindo as EEG’s dadas em (2.13)
em torno de um valor incial β(0)G , o processo iterativo para estimar βββ é dado por:
βββ(k+1)G = βββ
(k)G −SSS−1
(βββ(k)G
)ΨΨΨG
n
(βββ(k)G
)=
= βββ(k)G −
Eβββ
[∂
∂βββ>ΨΨΨG
n
(βββ(k)G
)]−1
ΨΨΨGn
(βββ(k)G
)=
= βββ(k)G +
[
n
∑i=1
DDD>i ΩΩΩ−1
i DDDi
]−1[ n
∑i=1
DDD>i ΩΩΩ−1
i (yyyi− µµµ i)
](k)
, (2.15)
sendo k = 0,1,2, . . . o número de iterações. O índice k sobrescrito nas equações indica que as
matrizes e os vetores são atualizados pelas estimativas de βββ , ααα e φ na k-ésima iteração.

37
Lembrando que a matriz DDDi é dada pela multiplicação ΛΛΛiXXX i, de forma que podemos
reescrever, então, a expressão (2.15), chegando a um processo iterativo de mínimos quadrados
reponderados dado da seguinte forma:
βββ(k+1)G ≈
[
n
∑i=1
XXX>i WWW iXXX i
]−1[ n
∑i=1
XXX>i WWW izzzi
](k)
, (2.16)
com WWW i = ΛΛΛ>i ΩΩΩ−1i ΛΛΛi e zzzi = ηηη i + ΛΛΛ−1
i (yyyi− µµµ i). Perceba que zzz desempenha o papel de uma
variável resposta modificada e WWW é uma matriz de pesos. Ambos podem mudar a cada passo do
processo iterativo.
Liang e Zeger (1986) utilizam o métodos dos momentos para estimar os parâmetros
de correlação ααα e o parâmetro de escala φ , e os escrevem em função do resíduo de Pearson. Dito
isso, o resíduo de Pearson para a observação yi j na k-ésima iteração é dado por:
r(k)i j =yi j− µ
(k)i j√
a(k)i j
, (2.17)
com ai j sendo o j-ésimo elemento da diagonal principal de AAAi. Se o quarto momento de yi j é
finito, a estimativa de φ obtida na k-ésima iteração é dada por:
φ(k) =
∑n
i=1
(r(k)i j
)2
(N− p)
−1
, (2.18)
em que N = ∑ni=1 ti. O procedimento das EEG’s para estimar βββ permite que a estrutura de
correlação entre as observações da mesma unidade experimental seja especificada de diferentes
formas. A seguir, apresentamos algumas estruturas comumente utilizadas para RRRi(α). Notemos,
entretanto, que para qualquer RRRi(ααα) dada, βββ G e JJJ−1G serão consistentes e a eficiência cresce
quanto mais próxima da verdadeira matriz de correlação estiver a escolha da matriz de trabalho.
1. A matriz de correlação padrão uniforme é obtida admitindo-se Corr(yi j,yil)= α , ∀ j 6= l
e 1≤ j, l ≤ ti, ou seja, assume-se que a correlação entre quaisquer duas observações de
um mesmo indivíduo é sempre a mesma. A partir do estimador consistente para α dado φ
(LAIRD; WARE, 1982), a estimativa de α na k-ésima iteração é dada por:
α(k) =
φ (k)
n
n
∑i=1
1ti(ti−1)
ti
∑j=1
ti
∑l=1l 6= j
r(k)i j r(k)il . (2.19)
2. A matriz de correlação autorregressiva de primeira ordem AR(1), assume que Corr(yi j,yil)=
α | j−1|, 1 ≤ j, l ≤ ti, ou seja, admitimos que a correlação entre dois instantes de tempo

38
decai exponencialmente de acordo com a distância das observações. A estimativa de α na
k-ésima iteração é dada por:
α(k) =
φ (k)
n
n
∑i=1
1(ti−1)
(ti−1)
∑j=1
r(k)i j r(k)i,( j+1). (2.20)
3. Quando a matriz de correlação é a não estruturada, ou seja, α jl é dada pela correlação
linear de Pearson entre ui j e uil , com i = 1, . . . ,n e j, l = 1, . . . , ti. O ( j, j′)-ésimo elemento
de RRRi pode ser estimado por
R j j′ =φ (k)
n
n
∑i=1
r(k)i j r(k)i,( j′)
.
Outras estruturas de matrizes de correlação de trabalho podem ser vistas em Hardin
e Hilbe (2012), por exemplo. Agora que temos as formas para estimar todos os parâmetros,
Venezuela (2003) apresenta as etapas que nos mostram como na prática podemos estimar os
parâmetros βββ , ααα e φ .
2.3.3.1 Etapas para estimação dos parâmetros
1. Supondo independência entre as observações da mesma unidade experimental, utilizamos a
equação (2.16) para estimar βββ . O processo µ(0)i j = yi j. É possível notar que a suposição de
independência elimina os parâmetros ααα e φ do processo de estimação de βββ neste primeiro
passo.
2. Definimos uma matriz de correlação de trabalho para ser utilizada na modelagem dos
dados. Se a estrutura de correlação escolhida for a independente, a estimativa de βββ é o
vetor de valores obtidos na convergência do processo iterativo da etapa 1. Caso contrário,
passamos para o próximo passo.
3. Utilizamos novamente a equação (2.16), considerando como βββ(0)G a estimativa de βββ
encontrada no passo 1.
4. Calculamos o resíduo de Pearson r(0)i j , estimamos o parâmetro de escala φ (0) e os parâme-
tros de correlação ααα(0).
5. Estimamos os parâmetros de regressão βββ(k)G através da expressão (2.16).
6. Em seguida o resíduo de Pearson r(k)i j é calculado através de (2.17), o parâmetro de escala
φ (k) é estimado através de (2.18) e os parâmetros de correlação ααα(k) através de alguma
das formas apresentadas anteriormente. E esse passo do processo é repetido até satisfazer
algum critério de convergência.

39
2.4 Teste de hipóteses
Duas abordagens comuns para a construção de estatísticas de teste para testes de
hipóteses são o teste de Wald e o teste de escore. Geralmente esses testes são abordados para
modelos baseados em verossimilhança, aqui mostraremos suas respectivas versões em Equações
de Estimação Generalizadas. O leitor interessado em obter mais detalhes, podem ver mais sobre
o assunto em Venezuela (2003) e Hardin e Hilbe (2012), por exemplo.
Primeiramente, assuma que βββ é o vetor (p×1) de coeficientes de regressão, e pode
ser escrito como o vetor aumentado (γγγ>,δδδ>)>, em que γ contém os parâmetros de interesse, e δ
os demais componentes. Boa parte dos testes de hipóteses de interesse, podem ser expressos da
seguinte forma: H0 : γγγ = γγγ0 versus Ha : γγγ 6= γγγ0.
Serão apresentadas a seguir adaptações das estatísticas do tipo Wald (WALD, 1943)
e escore de Rao (RAO, 1948) para equações de estimação generalizadas como mostradas em
Venezuela (2003) e Hardin e Hilbe (2012).
2.4.1 Teste de Wald
Utilizando o estimador sanduíche, a estatística do tipo Wald para EEG’s é dada
por:
Qw = (γγγG− γγγ0)>JJJ−1γG(γγγG− γγγ0),
em que γγγG o vetor (q× 1) dos q primeiros componentes de θθθ G e JJJ−1γG
a submatriz (q× q) do
estimador robusto JJJ−1G expresso em (2.14). Considerando que:
√n(βββ G−βββ G)
D→Np(000,JJJ−1G ),
quando n→∞, temos, sob a hipótese nula, que Qw têm distribuição assintótica χ2q (Qui-quadrado
com q graus de liberdade).
2.4.2 Teste Escore
A estatística do tipo escore para EEG’s é dada por:
Qs = ΨΨΨG(γγγ0)>VVV−1γγγ0
ΨΨΨG(γγγ0),
em que ΨΨΨG(γγγ0) é o subvetor (q×1) de ΨΨΨG e VVV γ0 a submatriz (q×q) da matriz de variabilidade
expressa no estimador robusto dado em (2.14), avaliados no vetor γγγ0. De forma semelhante a
estatística de Wald generalizada, sob H0, Qs tem distribuição assintótica χ2q .

40
Porém, ao se utilizar a estimativa sanduíche, poderá surgir em alguns casos problemas
de singularidade devido ao número de unidades experimentais ser pequeno. Rotnitzky e Jewell
(1990) apresentam uma alternativa ao teste de Wald e ao teste de escore generalizado denominada
testes de trabalho, nesta abordagem utiliza-se o estimador Naive apresentado em (2.12).
Podemos ter interesse em algumas situações práticas, em testarmos hipóteses na
forma de igualdades ou desigualdades lineares, isto é, H0 : CCCβββ === 000 contra Ha : CCCβββ 6 6 6=== 000 em
que CCC é uma matriz de posto completo, por exemplo. Cardoso (2000) apresenta testes de
hipóteses convenientes para trabalhar com modelos em que supomos algum tipo de restrição aos
parâmetros.
2.5 Seleção de modelos e de matriz de correlação
A escolha do modelo apropriado é um passo extremamente importante na modelagem,
pois, busca-se o modelo mais parcimonioso, ou seja, o modelo que envolva o mínimo de
parâmetros possíveis e que explique bem o comportamento da variável resposta.
O critério de informação de Akaike ou AIC (AKAIKE, 1998), é uma medida uti-
lizada para a seleção do melhor modelo, sua construção foi motivada por ser um estimador
assintoticamente não viesado para a divergência de Kullback-Leibler (KULLBACK; LEIBLER,
1951), que está relacionada à informação perdida por se usar um modelo aproximado e não o
verdadeiro. Dessa forma, o modelo selecionado dentre aqueles pertencentes ao conjunto de
modelos candidatos será o com valor da medida AIC mais próximo de 0, dada por:
AIC =−2 `(βββ )+2p,
em que `(.) é o logaritmo da função de verossimilhança atribuída aos dados, βββ é o estimador de
máxima verossimilhança com base no modelo candidato e p é o número de parâmetros.
2.5.1 QIC
Como a construção das equações de estimação generalizadas não são baseadas em
funções de verossimilhanças, Pan (2001) propõe uma modificação na medida AIC notando que,
quando assumimos independência entre todas as observações, as equações de estimação definidas
por Liang e Zeger (1986) são equivalentes a função quase-escore (MCGULLAGH; NELDER,
2013). Essa medida é denominada QIC (Quasi-Information Criterium), e é útil tanto para a
seleção de modelos como para a escolha da matriz de correlação de trabalho.

41
Quando supomos independência entre todas as observações e supomos homogenei-
dade em relação à dispersão, as equações de estimação dadas anteriormente são equivalentes as
suas funções escores. Assim, a medida QIC proposta para selecionar uma matriz de correlação
de trabalho RRR pode ser escrita, com base no logaritmo da função de verossimilhança, da seguinte
forma:
QIC(RRR)≡−2 `(βββ (RRR))+2tr(
SSSI JJJ−1R
), (2.21)
em que `(.) é o logaritmo da função de verossimilhança que gera a função escore equivalente à
equação de estimação quando assumimos independência entre todas as observações, SSSI é a matriz
de sensibilidade sob a estrutura de independência, JJJ−1R é o estimador robusto sob a estrutura RRR,
os quais são avaliados em βββ (RRR) que é a estimativa de βββ com a matriz de correlação RRR e tr denota
o traço da matriz.
Quando todas as especificações da modelagem via equações de estimação generali-
zadas estão corretas, SSSI e JJJ−1R são assintoticamente equivalentes e o tr
(SSSI JJJ−1R
)≈ 2 (PAN, 2001).
Nesse caso, a medida QIC pode ser reduzida a:
QICs(RRR)≡−2 `(
βββ (RRR))+2p,
a qual é proposta para ser utilizada na seleção de covariáveis.
Venezuela (2003) alerta que tais medidas só são válidas quando o parâmetro de dis-
persão φ−1 é conhecido e único, quando for desconhecido, calculamos a medida QIC utilizando
o maior valor estimado para o parâmetro de dispersão dentre os modelos candidatos e QICs
utilizando o valor estimado para o parâmetro de dispersão ajustando com todas as covariáveis
inclusas.
2.5.2 CIC
Hin e Wang (2009) propuseram uma modificação para o QIC denominada CIC(Correlation
information criterion), dada por:
CIC(RRR) = tr(
SSSI JJJ−1R
).
Essa medida foi construída baseada no segundo termo de (2.21) que representa
a penalidade do QIC. O primeiro termo da QIC representa a quase-verossimilhança quando
assumimos independência entre as observações, logo, os autores propuseram retirá-lo pois ele
não depende de um RRR especificado.

42
2.5.3 Critério de Rotnitzky-Jewell
Como citado anteriormente, Rotnitzky e Jewell (1990) propuseram um teste de
hipóteses para os coeficientes de regressão, as estatísticas do teste, QQQ000, QQQ111 e QQQ são dadas
respectivamente por
QQQ0 =1n
n
∑i=1
DDD>i ΩΩΩ−1i uuuiuuu>i ΩΩΩ−1
i DDDi,
QQQ1 =1n
n
∑i=1
DDD>i ΩΩΩ−1i DDDi,
QQQ = QQQ−10 QQQ1.
Quando a matriz de correlação de trabalho está corretamente especificada, QQQ é
aproximadamente uma matriz identidade. Portanto, Hin et al. (2007) descrevem o critério de
Rotnitsky-Jewell (RJC) para a matriz de correlação de trabalho como:
RJC(RRR) =[(1− tr(QQQ)/p)2 +(1− tr(QQQ2)/p)2
]1/2.
Se a matriz de correlação de trabalho está corretamente especificada, RJC é igual a 0.
2.5.4 Variograma amostral
Uma técnica gráfica descritiva para o auxilio na escolha da matriz de correlação de
trabalho é fazer uso do variograma amostral. Para o seu cálculo considera-se as observações
padronizadas ∆i j = (yi j− yi)/si, em que yi e si é a média e o desvio padrão das observações da i-
ésima unidade experimental, respectivamente. Os pontos do variograma amostral são calculados
a partir de duas observações da mesma unidade experimental:
vi jk =12(∆i j−∆ik)
2.
Comumente plota-se vi jk em função das distâncias entre as condições de avaliação
ui jk = |ti j− tik| e comparamos seus valores com σ2 que é estimado por:
σ2 =
12Nk ∑
i 6=l∑j,k
vi jkl,
em que k é a quantidade de termos de ∑ j,k, vi jkl = (∆i j−∆lk)2/2 e N é o número de pares de
observações obtidas em unidades experimentais diferentes. Valores do variograma amostral
próximos de σ2 indicam correlação nula.

43
Vale notar que a construção do variograma não requer que o estudo seja balanceado,
por exemplo. Essa ferramenta é amplamente utilizada na área de Geoestatística para avaliar
correlação espacial e foi originalmente utilizada como ferramenta descritiva em Jowett (1952).

44
3 MÉTODOS DE DIAGNÓSTICO
Uma das etapas mais importantes em qualquer processo de modelagem é a análise
de diagnóstico, através dela podemos verificar possíveis afastamentos das suposições feitas
pelo modelo, além de nos permitir encontrar possíveis observações extremas que interferem
desproporcionalmente ou inferencialmente nos resultados do ajuste.
A análise de diagnóstico tem longa data, e iniciou-se com a análise de resíduos para
verificar possíveis observações que apresentam um grande afastamento dos demais (outliers),
pontos que exercem um peso desproporcional nas estimativas dos parâmetros do modelo
(observações influentes) ou de avaliar a adequação da distribuição proposta para a variável
resposta. Em modelos lineares normais, os resíduos são utilizados também para avaliar as suposi-
ções de linearidade dos efeitos, de independência e de homoscedasticidade da fonte de variação.
Existe uma diversidade de técnicas para a análise de resíduos em modelos lineares normais, Cox
e Snell (1968) apresentam uma forma bastante geral de definir resíduos. Belsley et al. (1980) e
Cook e Weisberg (1982) apresentam uma série de técnicas baseados nos resíduos, bem como
outras quantidades uteis para análise de diagnóstico. Atkinson (1981) propõe a construção por
simulação de Monte Carlo de uma banda de confiança para os resíduos, denominada envelope,
e que permite uma melhor comparação entre os resíduos e os percentis da distribuição normal
padrão.
Outro conjunto de técnicas importantes no processo de diagnóstico é a análise de
sensibilidade, que consiste em avaliar alterações no modelo ajustado quando perturbações são
introduzidas nos dados ou nas suposições. Estas técnicas se dividem em influência global e local.
A análise de influência global usualmente é dividida em análise de pontos de alavanca (leverage
analysis), que consiste em estudar a influência de uma observação no seu respectivo valor predito
(HOAGLIN; WELSCH, 1978) e análise de omissão de casos (case deletion analysis), que pode
avaliar, por exemplo, o impacto da retirada de uma observação particular nas estimativas dos
parâmetros de posição de um modelo de regressão, nesse caso a distância de Cook (COOK,
1977) é comumente utilizada para este fim. Já a análise de influência local (COOK, 1986)
avalia o efeito de uma perturbação infinitesimal dos dados ou algum componente do modelo.
O leitor interessado em saber mais sobre essas técnicas de diagnóstico para modelos lineares
normais e conhecer outras pode consultar também: Belsley et al. (1980), Cook e Weisberg
(1982), Chatterjee e Hadi (1988), Atkinson e Riani (2000) e Paula (2013), por exemplo.
Para o modelo linear generalizado as técnicas de diagnóstico estão bem definidas e

45
como sugestão, o leitor pode consultar Pregibon (1981), Williams (1984), McCullagh (2018),
Williams (1987), Gilberto e Clovis (1988), Davison e Gigli (1989), Paula (1995, 1999, 2013) e
Wei et al. (1998), por exemplo. Venezuela et al. (2007) apresenta as extensões dessas técnicas
para os modelos de EEG’s com medidas repetidas com base nas propostas de Preisser e Qaqish
(1996) e Tan et al. (1997).
Entre outros trabalhos citados na literatura que tratam de técnicas de diagnóstico
para EEG’s temos Preisser e Qaqish (1996) que apresentam formas de detectar observações e/ou
unidades experimentais influentes em MLG’s com medidas repetidas, Chang (2000) apresenta
um teste não-paramétrico para a avaliar a aleatoriedade dos resíduos, Pan (2001) apresenta
medidas para escolher a melhor matriz de correlação de trabalho e para selecionar covariáveis
baseados no AIC (critério de informação de Akaike).
Aqui iremos apresentar as técnicas como mostradas e desenvolvidas em Venezuela
et al. (2007) e Venezuela et al. (2011).
3.1 Alavancagem
Em modelos lineares normais a ideia principal que está por trás do conceito de
pontos de alavanca é estudar a influência da i-ésima observação yi sobre o próprio valor ajustado
yi através de hii, os elementos da diagonal principal de HHH, uma vez que hii = ∂ yi/∂yi, ou seja,
hii corresponde à variação de yi quando yi é acrescido de um infinitésimo. Para mais detalhes
sobre alavancagem em modelos de regressão linear, veja por exemplo, Hoaglin e Welsch (1978),
Cook e Weisberg (1982), Emerson et al. (1984), Laurent e Cook (1992) e Wei et al. (1998).
Uma definição de alavancagem para MLG’s foi proposta por Pregibon (1981), que
propõe uma medida construída fazendo analogia entre a solução para βββ num MLG utilizando
o método da máxima verossimilhança e a solução de mínimos quadrados de uma regressão
linear ponderada. Essa proposta foi estendida para EEG por Venezuela et al. (2007) como será
mostrado adiante. Da equação (2.16), tem-se que na convergência:
βββ G ≈
[n
∑i=1
XXX>i WWW iXXX i
]−1[ n
∑i=1
XXX>i WWW izzzi
], (3.1)
sendo WWW = diag(WWW 111, . . . ,WWW nnn) com dimensão (N ×N), e N = ∑ni=1 ti. Neste caso, podemos
reescrever βββ G da seguinte forma:
βββ G ≈(
XXX>WWWXXX)−1(
XXX>WWWzzz),

46
em que XXX = (XXX>1 , . . . ,XXX>n )> e zzz = (zzz>1 , . . . ,zzz
>n )>, com dimensões (N× p) e (N× 1) respecti-
vamente. Neste caso, βββ G pode ser interpretado como uma solução de mínimos quadrados da
regressão linear, com fonte de variação normal, de WWW1/2
zzz tendo como matriz de especificação
WWW1/2
XXX . A matriz de projeção da solução de mínimos quadrados da regressão linear de zzziii contra
XXX i e pesos WWW i é dada por:
HHH iii = WWW iii1/2
XXX iii(((XXX>>>WWWXXX)))−1XXX>>>iii WWW
1/2iii , (3.2)
em que HHH = diag(HHH1, . . . ,HHHn), i.e., HHH i desempenha o papel de matriz de projeção ortogonal
local de vetores no Rn no subespaço gerado pelas colunas da matriz WWW1/2i XXX i. Para grandes
amostras, essa matriz coincide com uma generalização proposta por Wei et al. (1998) da matriz
de projeção HHH em uma classe bem geral de modelos de regressão.
Venezuela et al. (2007) sugerem utilizarmos os elementos da diagonal principal da
matriz HHH para detectar possíveis pontos de alavanca assim como proposto por Hoaglin e Welsch
(1978) para modelos normais lineares. Um ponto de alavanca ocorre quando este for ponto
remoto no subespaço gerado pelas colunas da matriz de especificação. Assim, um valor alto de
hi j indica a influência do valor observado no correspondente valor ajustado.
Supondo que todos os pontos exercem a mesma influência sobre os valores ajustados,
podemos esperar que cada valor da diagonal principal de HHH esteja próximo de tr(HHH)/N = p/N.
Assim, os pontos para os quais hi j for maior que algum valor arbitrário, como por exemplo 2p/n,
podem ser considerados como possíveis pontos de alavanca, embora seja mais comum apenas
avaliar visualmente em um gráfico pontos que estejam mais distantes dos demais.
Analogamente, a i-ésima unidade experimental pode ser caracterizada como unidade
experimental alavanca se
hhhi =1ti
ti
∑j=1
hi j =tr(HHH i)
ti≥ 2p
N.
Notemos que os valores de HHH i dependem da matriz de pesos WWW i, o que nos mostra
a contribuição de RRRi nessa medida de diagnóstico. Podemos detectar os possíveis pontos de
alavanca através de um gráfico com os valores da diagonal principal da matriz HHH, hi j, i = 1, . . . ,n
e h= 1, . . . , ti, versus i que indica a ordem em que cada unidade experimental aparece no conjunto
de dados (índice). Se o interesse é verificar se a unidade experimental é um ponto de alavanca,
então fazemos hhhi versus os índices das unidades amostrais.

47
3.2 Análise de resíduos
De modo análogo à matriz HHH, podemos considerar aqui o vetor de resíduos ordinários
da solução de mínimos quadrados da regressão linear de zzz contra XXX e pesos WWW :
rrr∗ = WWW1/2
(zzz− ηηη) =WWW 1/2ΛΛΛ−1i (yyy− µµµ),
em que AAA = diag(AAA1, . . . , AAAn) e GGG = diag(GGG1, . . . , GGGn), ambas com dimensão (N ×N), yyy =
(yyy>1 , . . . ,yyy>n )> e µµµ = (µµµ>1 , . . . , µµµ
>n )>, ambas com dimensão (N × 1). Se assumirmos que
Cov(z)∼=WWW−1, temos que
Cov(rrr∗) = Cov(
WWW1/2
zzz−−−WWW1/2
XXX βββ
)= Cov
(WWW
1/2zzz−−−WWW
1/2XXX(
XXX>>>WWWXXX)−1
XXX>>>WWWzzz)
= (IIIN−HHH)WWW1/2Cov(zzz)WWW 1/2
(IIIN−HHH)∼= (IIIN−HHH) ,
sendo IIIN a matriz identidade de dimensão (N×N) e HHH a matriz de projeção dada em (3.2).
Como os elementos de rrr∗ podem possuir variâncias diferentes, o que dificulta compará-los entre
si, utilizamos o resíduo padronizado associado à observação yi j, que é dado por
(rp)i j =mmm>i jrrr
∗i√
1−hi j, (3.3)
sendo mmmi j um vetor de tamanho ti com a posição referente à observação yi j contendo o valor 1 e
as demais posições contendo o valor zero e hi j o j-ésimo elemento da diagonal principal de HHH i,
i = 1, . . . ,n e j = 1, ..., ti.
O gráfico de índices versus (rp)i j pode indicar possíveis observações influentes e
valores ajustados versus (rp)i j pode ser utilizado para checar a linearidade dos efeitos.
3.2.1 Envelope simulado
Uma outra técnica gráfica para avaliar o ajuste do modelo é o gráfico de probabili-
dade meio-normal com envelope simulado proposto por Atkinson (1985). Em um gráfico de
probabilidade meio-normal, dispomos o i-ésimo valor absoluto ordenado dos resíduos padroni-
zados rp∗i , i = 1, . . . ,N, versus o valor esperado da estatística de ordem, em valor absoluto, da
normal padrão, N (0,1), dado por:
E(|Z(i)|)∼= Φ−1(
i+N−1/82N +1/2
), (3.4)

48
em que Φ(.) é a distribuição acumulada da normal padrão.
Esse gráfico pode ser utilizado mesmo que os resíduos não sigam uma distribuição
normal (NETER et al., 1996). Quando isso ocorre não esperamos que os resíduos padronizados
tenham comportamento em torno de uma reta que faz um angulo de 45o com o eixo das abcissas.
A seguir, apresentamos um algoritmo para a construção do gráfico de probabilidade
meio-normal com envelope simulado:
3.2.1.1 Construção do gráfico de probabilidade meio-normal com envelope simulado
1. Para cada unidade experimental i, i = 1, . . . , ti, simule um vetor de respostas de tamanho ti,
levando em consideração o vetor de médias e a matriz de covariâncias ajustados aos dados
originais.
2. Ajuste, às respostas simuladas no passo 1, o mesmo modelo que foi ajustado aos dados
originais.
3. Calcule os resíduos padronizados utilizando (3.3) e ordene os seus valores absolutos.
4. Repita os três primeiros passos mais 24 vezes (número de réplicas sugerido por Tan et
al. (1997)). Aqui, definiremos (rp)lm como sendo o l-ésimo valor absoluto ordenado do
resíduo padronizado pertencente a m-ésima simulação, l = 1, . . . ,N e m = 1, . . . ,M, com
M = 25.
5. Determine o mínimo, a mediana e o máximo dos menores valores absolutos dos resíduos
padronizados de todas as simulações, isto é, (rp)1m,m = 1, . . . ,25.
6. Repita o passo anterior para os segundos menores valores absolutos dos resíduos padroni-
zados das simulações, (rp)2m, e assim sucessivamente, até os maiores valores absolutos
dos resíduos padronizados das simulações, (rp)Nm. Ao final deste passo teremos 3 vetores
contendo os mínimos, as medianas e os máximos dos valores absolutos dos resíduos
padronizados.
7. Disponha em um gráfico os valores mínimos, medianos e máximos obtidos nos passos
anteriores versus os correspondentes valores esperados em (3.4). Una os pontos referentes
aos valores mínimos, medianos e máximos.
Grandes desvios dos pontos em relação a mediana dos valores simulados ou a
ocorrência de pontos próximos ou fora dos limites da banda de simulação são indícios de que o
modelo pode não ser apropriado. E se existirem, os pontos aberrantes devem aparecer no topo
direito do gráfico separado dos demais pontos.

49
Atkinson (1985) sugere um número de simulações M = 19, assim, há uma chance
de 5%, de que o maior valor absoluto dos resíduos dos dados originais fique fora dos limites
da banda de simulação quando o modelo ajustado estiver correto. Um Algoritmo para gerar
variáveis aleatórias correlacionadas da distribuição Binomial pode ser visto em (PARK et al.,
1996), para as distribuições Poisson e Gama pode ser visto em (PARK; SHIN, 1998). Para
gerar valores da distribuição normal multivariada, utilizamos o comando rmvnorm do pacote
dae existente no software R (R Core Team, 2018).
3.3 Análise de eliminação de casos
Um ponto é dito ser influente se ele tem grande peso na estimação dos parâmetros
do modelo, por exemplo, e para detectá-lo, a medida mais conhecida é a distância de Cook
(COOK, 1977). Essa distância mede o impacto no valor predito avaliando o afastamento entre βββ ,
utilizando todas as observações, e sem a observação yi j,(
βββ (i j)
).
Como, em alguns modelos, não é possível obter uma forma analítica para βββ (i j),
Pregibon (1981) propõe utilizar uma aproximação de um passo, que consiste em tomar a primeira
iteração do processo iterativo pelo método modificado de Newton ou scoring de Fisher (dado em
2.15) quando o mesmo é iniciado em βββ G. Esta aproximação foi introduzida por Pregibon (1981)
para MLG’s com medidas repetidas e é dada por:
βββ(1)G(i j) = βββ G−
[XXX>WWWXXX
]−1[XXX>WWW
1/2eeei j
][eee>i jWWW
1/2ΛΛΛ−1(yyy− µµµ)
]1−hi j
.
Logo, a distância de Cook, quando se elimina a j-ésima observação da i-ésima
unidade experimental, é dada por
(DC)i j =1p(βββ G− βββ G(i j))
>XXX>WWWXXX(βββ G− βββ G(i j)) = r2i j
hi j
p(1−hi j),
que possui expressão similar a distância de Cook em modelos lineares. Para detectarmos um
ponto influente podemos fazer um gráfico da distância de Cook padronizada (DC)i j/∑i, j DCi j
versus o índice i a fim de obtermos uma medida na escala [0,1] e destacarmos as observações
com valores altos na distância de Cook em relação aos demais.
As medidas de diagnóstico apresentadas podem não ter acurácia se a estimativa da
matriz de correlação de trabalho, RRR(α), não for próxima a verdadeira. A partir daqui, assuma
sem perda de generalidade que ti = t, i = 1, . . . ,n, e para facilitação de notação que ΨΨΨGn = ΨΨΨ e
βββ G = βββ .

50
3.4 Influência local
A análise de influência global nos dá resultados muito gerais sobre a influência de
certas observações sobre o modelo e suas suposições, e não nos permite identificar em quais
componentes essas observações são influentes.
O método da influência local proposto por Cook (1986) consiste em verificar, através
de uma medida apropriada de influência, a robustez das estimativas fornecidas pelo modelo me-
diante o efeito de pequenas perturbações no próprio modelo ou nos dados. Se essas perturbações
causarem efeitos desproporcionais em determinados componentes do modelo, então, teremos
indícios de que ele está mal ajustado ou que existem afastamentos nas suposições do modelo
proposto. Através da influência local, podemos identificar quais observações são responsáveis
por essas discrepâncias, ajudando assim, na escolha de um modelo mais adequado aos dados.
Através dessas medidas podemos avaliar se precisamos de um modelo mais robusto
ou um que adote a suposição de heterogeneidade do parâmetro de dispersão, por exemplo.
Podemos também tomar conclusões sobre uma covariável do modelo, como por exemplo, avaliar
se ela é sensível a valores altos, podendo não ser uma boa preditora.
A medida de influência mais utilizada para avaliar o efeito das perturbações em
algum componente do modelo é o afastamento da verossimilhança (likelihood displacement)
proposto por Cook (1986), que é definido por:
LD(ωωω) = 2`(βββ )− `(βββ |ωωω)
,
em que ωωω = (ω1, . . . ,ωN)>, ωωω ∈Ω⊂ RN é o vetor de perturbações (N×1) com N = nt, `(βββ )
e `(βββ |ωωω) o logaritmo da função de verossimilhança para o modelo postulado e o logaritmo da
função de verossimilhança para o modelo perturbado, respectivamente. Admite-se a existência
de um vetor de não perturbação ωωω0, i.e., ∃ ωωω0 : `(βββ |ωωω0) = `(βββ )⇔ LD(ωωω0) = 0.
A ideia da influência local é avaliar o comportamento da função LD(ω) em uma
vizinhança de ωωω000. Para isso, considera-se uma superfície geométrica (N + 1)-dimensional
denominada Gráfico de influência formada pelos valores do vetor:
αααω =[ωωω>>>,LD>ω
],
quando ωωω varia em Ω. Dito isso, o método de influência local consiste em avaliar como a
superfície αααω desvia-se do seu plano tangente em ωωω0(T0), essa análise pode ser feita estudando-
se as curvaturas das seções normais da superfície αααω em ωωω0 que são intersecções de αααω com

51
planos contendo o vetor normal com seu plano tangente em ωωω0, essas curvaturas são denominadas
curvaturas normais. Verbeke e Molenberghs (2000) ilustraram essa ideia como vista na Figura
5.
Figura 5 – Curvatura normal para uma superfície αααω e direção unitária h.Fonte: Verbeke e Molenberghs (2000).
A intersecção entre a seção normal e o plano tangente T0 é denominada linha
projetada. Cadigan e Farrell (2002) descreveram a medida LDw para um caso mais geral,
avaliando o afastamento de uma função de ajuste F (βββ ) duplamente diferenciável em βββ e que
tem como estimador para βββ , denotado por βββ , a solução de:
ΨΨΨ(βββ ) =
[∂F (βββ )
∂βββ
]∣∣∣∣βββ=βββ
= 000. (3.5)
Dessa forma temos que a medida de afastamento dessa função de ajuste é dada por:
FD(ωωω) = 2
F (βββ )−F (βββ |ωωω),
em que βββ |ωωω é a estimativa que maximiza a função de ajuste perturbada F (βββ |ωωω). Note que F
pode ser alguma outra escolha como, por exemplo, a função de quase-verossimilhança, deixando
a proposta de Cadigan e Farrell mais geral do que a proposta de Cook.
A seguir apresentaremos uma extensão da proposta de Cook (1986) escrita na
forma mais geral de Cadigan e Farrell (2002), denominada influência local generalizada.

52
Posteriormente, apresentaremos uma medida de influência local para equações de estimação
desenvolvidas por Venezuela et al. (2011), e pode ser vista também em Venezuela (2008).
3.4.1 Influência local generalizada
Nesse contexto, a medida FD(ωωω) pode ser utilizada para comparar βββ e βββ ω com
respeito aos contornos de uma função de ajuste qualquer quando variamos ωωω em Ω. Porém,
ao se avaliar FD(ωωω) para todo ωωω ∈Ω pode ser inviável devido a infinidade de valores que este
pode assumir. Dessa forma, Cook (1986) propõe estudar o comportamento local de FD(ωωω) para
qualquer valor de ωωω em uma vizinhança de ωωω0, que é o vetor de não perturbação apresentado
anteriormente, de forma análoga aqui temos também que F (βββ |ωωω0) = F (βββ )⇒ FDω0 = 0.
A sugestão de Cook (1986) é estudar a curvatura normal (BATES; WATTS, 1980) da
linha projetada no gráfico FD(ωωω0+addd)×a, em que a ∈R e ddd é uma direção arbitrária de norma
igual a um (||ddd||= 1). Cook (1986) mostra que a curvatura normal na direção ddd é dada por:
Cd(βββ ) = 2|ddd>∆∆∆>F−1∆∆∆ddd|,
em que −F é a matriz observada de Fisher:
F =∂ 2F (βββ )
∂βββ∂βββ> =
∂ΨΨΨ(βββ )
∂βββ> , (3.6)
em que ΨΨΨ(.|.) é o vetor gradiente da função de ajuste F (.|.). E ∆∆∆ é a matriz:
∆∆∆ =∂ 2F (βββ |ωωω)
∂βββ∂ωωω>=
∂ΨΨΨ(βββ |ωωω)
∂ωωω>, (3.7)
com todas as quantidades avaliadas em βββ = βββ e ωωω = ωωω0. Para identificar as observações que,
sob pequenas perturbações, exercem notável influência local em FD(ωωω000), devemos analisar a
direção do autovetor dmax correspondente à linha projetada de maior curvatura Cmax que é obtida
pelo maior autovalor da matriz:
−∆∆∆>F−1∆∆∆. (3.8)
O leitor interessado no assunto pode consultar Lobato (2005) e Silva (2014), por
exemplo, para entender com mais detalhes a ideia de Cook (1986).
Os gráficos mais usuais de diagnóstico de influência local são:
• Gráfico de índices versus dmaxi;

53
• Gráfico de índice versus curvatura normal padronizada Ci, em que:
Ci =Chi
∑nj=1Ch j
,
em que hhhiii é um vetor unitário na direção da i-ésima observação que é formado por zeros
com o valor 1 na i-ésima posição. Outras formas de padronização de Ch são propostas por
Poon e Poon (2002).
Além disso, também é possível avaliar a influência local apenas para um subvetor
βββ 1 de βββ , assumindo que esse vetor pode ser particionado da forma βββ = (βββ>1 ,βββ>2 )>. Nesse caso,
a curvatura normal na direção ddd é dada por:
Cd(βββ 1) = 2∣∣∣∣ddd>∆∆∆>
(F−1− F
β2β2)
∆∆∆ddd∣∣∣∣,
em que
Fβ2β2 =
000 000
000 F−1β2β2
,com F β2β2 avaliada em βββ . O gráfico de índices versus dmaxi da matriz −∆∆∆>
(F−1− F
β2β2)
∆∆∆
pode revelar quais observações são influentes em βββ 1. De modo análogo, a curvatura normal para
o subvetor βββ 2 na direção ddd é dada por:
Cd(βββ 2) = 2∣∣∣∣ddd>∆∆∆>
(F−1− F
β1β1)
∆∆∆ddd∣∣∣∣,
em que
Fβ2β2 =
F−1β1β1
000
000 000
,com F β1β1 avaliada em βββ . Aqui também o gráfico de índices versus dmaxi da matriz−∆∆∆>
(F−1− F
β1β1)
∆∆∆
pode revelar quais observações são influentes em βββ 2.
3.5 Influência local para equações de estimação
Na seção anterior vimos que a medida de influência local proposta por Cadigan e
Farrell (2002) pode ser construída a partir de qualquer função F (βββ ) desde que esta exista e
satisfaça (3.5). A partir de (3.5) vemos que podemos construir a medida de influência local a
partir do vetor gradiente ΨΨΨ(βββ ) sem necessariamente conhecer F (βββ ) que o gera.

54
No contexto das equações de estimação generalizadas, não conhecemos a função de
verossimilhança ou a função de ajuste que gera essas equações. Entretanto vamos garantir sua
existência assumindo que qualquer equação de estimação generalizada, que utiliza a verdadeira
matriz de correlação quando construída a partir de (2.6) ou que utiliza uma matriz de correlação
de trabalho RRR(ααα) conhecida, satisfaz as propriedades de quase-verossimilhança citadas por
McGullagh e Nelder (2013, Seção 9.3.2).
Esses autores descrevem que uma função de quase-escore com observações depen-
dentes é um vetor gradiente de uma quase-verossimilhança, desde que a derivada dessa função
quase-escore com relação a βββ seja uma matriz simétrica ou, de forma similar, desde que as
derivadas dos componentes de Cov(yyyi)−1 com respeito a µµµ i sejam iguais sob permutação dos
três índices, ou seja
∂Cov(yi j,yil)−1
∂ µik=
∂Cov(yi j,yik)−1
∂ µil=
∂Cov(yil,yik)−1
∂ µi j,
com i = 1, . . . ,n e j, l,k = 1, . . . , t. No nosso caso, as derivadas dos componentes da matriz
Cov(ui)−1 descrita em (2.7) com respeito a µµµ i são iguais sob a permutação dos três índices j, l
e k, com i = 1, . . . ,n e j, l,k = 1, . . . , t. Isso acontece quando utilizamos a verdadeira matriz de
correlação RRRv(uuui) ou quando utilizamos uma matriz de correlação de trabalho RRR(ααα) conhecida,
já que ambas não dependem de µµµ . Logo, garantimos que qualquer equação de estimação ΨΨΨ(βββ )
com as propriedades citadas acima é um vetor gradiente de uma função de ajuste F (βββ ). Isto é,
podemos assumir que existe F (βββ ) tal que
∂F (βββ )
∂βββ= ΨΨΨ(βββ ) e ΨΨΨ(βββ ) = 000,
em que βββ é o ponto máximo de F (βββ ). Dessa forma podemos utilizar a matriz ∆∆∆ definida em
(3.7) para obter o autovetor dmax a partir de (3.8).
Devido a matriz F definida em (3.6) não ser facilmente obtida, Cadigan (1995)
propõe simplificá-la utilizando seu respectivo valor esperado. No nosso caso, o valor esperado
de F é dado pela matriz de sensibilidade definida em (2.3).
Assim, considerando que ΨΨΨ(βββ ) é um vetor gradiente de uma função de ajuste F ,
ainda que desconhecida, e satisfaz (3.5), Venezuela et al. (2011) utilizam a ideia de Cook (1986)
para construir uma medida de influência local para equação de estimação dada pelo autovetor
dmax correspondente ao maior autovalor da matriz

55
−∆∆∆>SSS−1∆∆∆, (3.9)
em que
∆∆∆ =∂ΨΨΨ(βββ |ωωω))
∂ωωω>e SSS = F = E
(∂ΨΨΨ(βββ )
∂βββ>
),
com todas as quantidades avaliadas em βββ = βββ e ωωω = ωωω0. Assim, o gráfico de índice versus dmax
pode revelar quais observações são influentes no componente do modelo a ser estudado.
Aqui, podemos usar também o conceito de partição apresentado na seção (3.4.1),
i.e., o vetor βββ pode ser particionado em βββ = (βββ>1 ,βββ>2 )>.
Logo, para identificar as observações que são influentes somente na estimação de
βββ 1, a curvatura normal na direção ddd é dada por Cd(βββ ) = 2|ddd>∆∆∆>(SSS−1−SSSβ2β2)∆∆∆ddd|, em que
SSSβ2β2 =
000 000
000 SSS−1β2β2
,com SSSβ2β2 avaliada em βββ . O gráfico de índices contra o maior autovetor de ∆∆∆>(SSS−1−SSSβ2β2)∆∆∆
pode revelar quais observações são influentes, segundo o esquema de perturbação considerado,
na estimação de βββ 1.
De forma análoga, a curvatura normal para o vetor de parâmetros βββ 2 na direção ddd é
dada por Cd(γγγ) = 2|ddd>∆∆∆>(SSS−1−SSSβ1β1)∆∆∆ddd|, em que
SSSβ1β1 =
SSS−1β1β1
000
000 000
,com SSSβ1β1 avaliada em θθθ . O gráfico de índices contra o maior autovetor de ∆∆∆>(SSS−1−SSSβ1β1)∆∆∆
pode revelar quais observações são influentes, segundo o esquema de perturbação considerado,
na estimação de βββ 2.
A seguir, apresentaremos as medidas de influência local para alguns esquemas de
perturbação no contexto das equações de estimação generalizadas como propostas por Venezuela
et al. (2011). Essas medidas são desenvolvidas para os esquemas de perturbação de ponderação
de casos, da variável resposta, de uma covariável contínua da matriz de especificação, no
parâmetro de precisão e na matriz de correlação de trabalho. Todos esses esquemas são tratados
sob homogeneidade do parâmetro de dispersão. Para os esquemas de perturbação em que

56
supomos heterogeneidade do parâmetro de dispersão o leitor interessado pode ver Venezuela
(2008), por exemplo.
Em geral, observações destacadas na ponderação de casos podem ser interpretadas
como uma perturbação na variância de cada unidade experimental, em especial para modelos
lineares normais (THOMAS; COOK, 1989). Perturbação na variável resposta pode ser vista
como uma forma alternativa de identificar outliers (SCHWARZMANN, 1991). O esquema de
perturbação individual das covariáveis ajuda a avaliar a influência de cada uma no processo de
estimação, além de verificar sua sensibilidade a valores altos. No entanto, esse esquema faz
sentido apenas se a covariável é de natureza contínua. Perturbação no parâmetro de precisão
indica o quão sensível o modelo é em relação a suposição de homoscedasticidade. Finalmente, a
perturbação da matriz de correlação de trabalho pode indicar, por exemplo, se precisamos utilizar
uma outra estrutura de matriz de correlação.
3.6 Esquemas de perturbação sob homogeneidade da dispersão
Para avaliar a influência das observações na estimação dos parâmetros de regressão
ou em qualquer outro componente do modelo, ou para auxiliar na indicação de um modelo mais
adequado aos dados, podemos analisar graficamente o comportamento das medidas de influência
local de diversas formas.
As equações de estimação generalizadas para modelagem da média sob suposição de
homogeneidade do parâmetro de dispersão são definidas em (2.13), e podem ser reescritas como:
ΨΨΨ(βββ ) = DDD>ΩΩΩ−1uuu = XXX>WWWΛΛΛ−1uuu. (3.10)
Sua matriz de sensibilidade fica então dada por:
SSS =−XXX>WWWXXX , (3.11)
em que XXX =(XXX>1 , . . . ,XXX
>n)>
, ΛΛΛ = (ΛΛΛ1, . . . ,ΛΛΛn)>, ΩΩΩ = (ΩΩΩ1, . . . ,ΩΩΩn)
>, WWW = (WWW 1, . . . ,WWW n)>
e uuu =(uuu>1 , . . . ,uuu
>n)>. Assim, as medidas de influência local descritas a seguir para alguns
esquemas de perturbação sob homogeneidade da dispersão serão definidas a partir das equações
(3.10) e (3.11), avaliadas sob as estimativas do modelo postulado(
βββ>,γγγ>
)>e em ωωω0.

57
3.6.1 Ponderação de casos
Considere o esquema de perturbação (VENEZUELA et al., 2011):
ΨΨΨ(βββ |ωωω) = XXX>WWWΛΛΛ−1diag(ωωω)uuu, (3.12)
em que ωωω =(ωωω>1 , . . . ,ωωω
>n)>, com ωωω i = (ωi1, . . . ,ωit)
>, i = 1, . . . ,n. Aqui, o vetor de não
perturbação ωωω0, assume ωi j = 1, com i = 1, . . . ,n e j = 1, . . . , t.
Para o esquema de perturbação definido em (3.12), temos que ∆∆∆ = XXX>WWWΛΛΛ−1diag(uuu).
Neste caso a matriz definida em (3.9) é dada por:
diag(uuu)ΛΛΛ−1WWW>XXX(XXX>WWWXXX)−1XXX>WWWΛΛΛ−1diag(uuu), (3.13)
avaliada em ωωω0 e em(
βββ>, φ)>
.
3.6.2 Perturbação da variável resposta
Considere um esquema aditivo de perturbação na variável resposta yi j (VENEZUELA
et al., 2011) , i = 1, . . . ,n e j = 1, . . . , t dado por
yωi j = yi j +ωi j
√Var(yi j), (3.14)
em que o vetor de não perturbação assume ωi j = 0, ou seja, ωωω0 = 000.
Analisando a equação de estimação definida em (3.10), o único componente que
depende da variável resposta é o vetor uuu. Assim, considerando uuuω o vetor uuu com perturbação na
variável resposta, a equação de estimação perturbada é dada por
ΨΨΨ(βββ |ωωω) = XXX>WWWΛΛΛ−1uuuω ,
em que uuuω =(uuu>
ω1, . . . ,uuu>ωn)>, com uuuωi = (uωi1, . . . ,uωit)
>, i = 1, . . . ,n. Nesse caso, a matriz
definida em (3.7) fica expressa por ∆∆∆ = XXX>WWWΛΛΛ−1B, em que
B =∂uuuωωω
∂ωωω>.
Logo, com base em (3.9), a medida de influência local com perturbação na variável
resposta é obtida da matriz
BΛΛΛ−1WWW>XXX(XXX>WWWXXX)−1XXX>WWWΛΛΛ−1B,

58
avaliada em ωωω0 e em(
βββ>, φ)>
. Seguindo a equação de estimação definida em (2.13), temos
que
uωi j = yωi j−µi j,
com i = 1, . . . ,n e j = 1, . . . , t. Considerando a definição de yωi j em (3.14), temos que
∂uωi j
∂ωi j=√
Var(yi j) = si j,
sendo si j a raiz quadrada da variância definida em (2.8), com i = 1, . . . ,n e j = 1, . . . , t. Assim,
temos
B = SSS,
em que SSS = diag(SSS1, . . . ,SSSn), e Si = diag(si1, . . . ,sit), com i = 1, . . . ,n.
3.6.3 Perturbação individual das covariáveis
Thomas e Cook (1989) propõem um esquema aditivo de perturbação na k-ésima
coluna da matriz de covariáveis XXX , xxxk = (x11k,x12k, . . . ,xntk)>, em que o vetor perturbado xxxωk
tem cada componente dado por
xωi jk = xi jk +ωi jsxk , (3.15)
em que sxk é um fator de escala dado pelo desvio padrão de xxxk, com i = 1, . . . ,n e j = 1, . . . , t.
Aqui, o vetor de não pertubação ωωω0 = 000.
Assim, usando como exemplo um modelo linear com intercepto, se k 6= 2 e k 6= p, o
modelo perturbado segundo o esquema definido em (3.15) fica dado por:
g(µωi j) = ηωi j = β1 + xi j2β2 + · · ·+ xωi jkβk + · · ·+ xi jpβp
Na equação de estimação definida em (3.10), todos os seus componentes dependem
de qualquer covariável. Logo, a equação de estimação perturbada para esse esquema é dada por
ΨΨΨ(βββ |ωωω) = XXX>ω ΛΛΛωΩΩΩ−1ω uuuω ,
em que o índice ω indica que as matrizes XXX ,ΛΛΛ e ΩΩΩ e o vetor uuu dependem, de alguma forma, da
perturbação definida em (3.15).

59
Por consequência, a derivada de ΨΨΨ(βββ |ωωω) com relação ao vetor ωωω> pode ser expressa,
segundo Harville (1997), por
∆∆∆ = XXX>ω ΛΛΛω
[ΩΩΩ−1
ω
∂uuuω
∂ωωω>+
∂ΩΩΩ−1ω
∂ωωω>diag(uuuω)
]+
[XXX>ω
∂ΛΛΛω
∂ωωω>+
∂XXX>ω∂ωωω>
ΛΛΛω
]ΩΩΩ−1
ω diag(uuuω),
em que a derivada de XXX>ω com relação à ωωω> é uma matriz p×N de zeros exceto na k-ésima linha
que é composta pela constante sxk , com N = nt, e
∂ΩΩΩ−1ω
∂ωωω>=−ΩΩΩ−1
ω
∂ΩΩΩω
∂ωωω>ΩΩΩ−1
ω . (3.16)
No nosso caso, temos que
ΛΛΛωi = diag(
∂ µωi1
∂ηωi1, . . . ,
∂ µωit
∂ηωit
), ΩΩΩωi = φ
−1AAA1/2ωi RRR(ααα)AAA1/2
ωi e uuuωi = yyyi−µµµωi, (3.17)
em que AAAωi = (aωi1, . . . ,aωit), µµµωi = (µωi1, . . . ,µωit)>, e aωi j = v(µωi j), com i = 1, . . . ,n e
j = 1, . . . , t. Assim obtemos
∂ΛΛΛωi
∂ωωω>i= βksxkΛΛΛωi
∂ΩΩΩωi
∂ωωω>i=
12
φ−1
βksxk
[AAA1/2
ωi RRR(ααα)Aωi +AωiRRR(ααα)AAA1/2ωi
], e
∂uuuωi
∂ωωω>i=−βksxkGGGωi,
em que ΛΛΛωi = diag(∂ 2µωi1)/∂η2ωi1, . . . ,∂
2µωit)/∂η2ωit) e A ωi = AAA1/2
ωi ϒϒϒωiΛΛΛωi, em que ϒϒϒωi =
diag(∂v(µωi1)/∂ µωi1, . . . ,µωit)/∂ µωit), com i = 1,2, . . . ,n e j = 1, . . . , t.
3.6.4 Perturbação do parâmetro de precisão
Como proposta de Venezuela et al. (2011), considere um esquema de perturbação do
parâmetro de precisão, de forma que esse não seja constante ao longo das observações e entre os
indivíduos, ou seja,
φωi j =φ
ωi j, (3.18)
com i = 1, . . . ,n e j = 1, . . . , t. Nesse esquema de perturbação, ωωω0 = 1. Da equação (3.10),
obtemos a seguinte equação de estimação perturbada
ΨΨΨ(βββ |ωωω) = XXX>ΛΛΛωΩΩΩ−1ω uuuω , (3.19)

60
em que o índice ω indica que as matrizes ΛΛΛ e ΩΩΩ e o vetor uuu dependem, de alguma forma, da
pertubação definida em (3.18). Assim, segundo Harville (1997), a matriz definida em (3.7) pode
ser expressa por
∆∆∆ = XXX>ΛΛΛωΩΩΩ−1ω
∂uuuω
∂ωωω>+XXX>ΛΛΛω
∂ΩΩΩ−1ω
∂ωωω>diag(uuuω)+XXX>
∂ΛΛΛω
∂ωωω>ΩΩΩ−1
ω diag(uuuω). (3.20)
No caso em que estamos trabalhando, temos que
ΩΩΩωi = ΦΦΦ−1ωi AAA1/2
i RRR(ααα)AAA1/2i ,
em que ΦΦΦ−1ωi = diag(φ−1
ωi1, . . . ,φ−1ωit ), com i = 1, . . . ,n e j = 1, . . . , t. Notemos que da equação
(3.20) apenas a segundo parcela depende de φ , logo temos que
∂ΩΩΩωi
∂ωωω>=
∂ΦΦΦ−1ωi
∂ωωω>iAAA1/2
i RRR(ααα)AAA1/2i = φ
−1AAA1/2i RRR(ααα)AAA1/2
i = ΩΩΩ,
com i = 1, . . . ,n e j = 12, . . . , t. Logo, com base em (3.9), a medida de influência local com
perturbação no parâmetro de precisão é obtida da matriz:
diag(uuu)ΩΩΩ−1ΛΛΛ>XXX(XXX>WWWXXX)−1XXX>ΛΛΛΩΩΩ−1diag(uuu), (3.21)
avaliada em ωωω0. A matriz definida em (3.21) é a mesma descrita em (3.13), do qual obtemos
a medida de influência para ponderação de casos. Isso indica que a perturbação no parâmetro
de precisão, além de ser interpretada como uma perturbação na variância de cada observação,
também pode ser vista como uma perturbação na homoscedasticidade.
3.6.5 Perturbação na matriz de correlação de trabalho
Considere RRR(ααα) uma matriz de correlação de trabalho definida numa forma geral
dada pelo vetor de correlações ααα = (α11,α12, . . . ,α(t−1)t ,αtt)>, em que α j j = 1 e α j j′ = α j′ j,
com j 6= j′ e j, j′ = 1, . . . , t. As matrizes de correlação de trabalho apresentadas nesse trabalho
na forma geral estão descritas em (2.19) e (2.20).
Venezuela et al. (2011) propõem um possível esquema de perturbação no vetor de
correlações ααα de forma que esse não seja o mesmo entre as unidades experimentais e ao longo
das observações, que é dado por
αωi( j j′) =α j j′
ωi( j j′). (3.22)

61
Nesse tipo de perturbação, ωωω0 = 1. A equação de estimação perturbada segundo o
esquema (3.22) é dada por
ΨΨΨ(βββ |ωωω) = XXX>ΛΛΛΩΩΩ−1ω uuu,
em que apenas a matriz ΩΩΩ é alterada com essa perturbação. Assim, a matriz definida em (3.7)
pode ser expressa por
∆∆∆ = XXX>ΛΛΛ∂ΩΩΩ−1
ω
∂ωωω>diag(uuu),
sendo a derivada de ΩΩΩ−1ω com relação a ωωω> dada em (3.16) e
∂ΩΩΩωi
∂ωωω>i( j j′)
= Var(uuui)1/2 ∂RRR(αααωi))
∂ωωω>i( j j′)
Var(uuui)1/2,
em que ∂RRR(αααωi)/∂ωωω i( j j′) é uma matriz (t× t) nula exceto pelos termos ( j j′) e ( j′ j), que são
iguais a −α j j′ ,com i = 1, . . . ,n, j < j′ e j, j′ = 1, . . . , t, qualquer que seja a estrutura da matriz
de correlação de trabalho.

62
4 APLICAÇÕES
4.1 Recursos computacionais
As aplicações foram feitas com o auxílio do software R (R Core Team, 2018) e
dos seguintes pacotes:
• aod (LESNOFF; LANCELOT, 2012);
• gee (CAREY et al., 2015);
• tidyverse (WICKHAM, 2017);
• MuMIn (BARTOn, 2018);
• GGally (SCHLOERKE et al., 2018);
• joineR (PHILIPSON et al.(2018) e WILLIAMSON et al.(2008));
• Matrix (BATES; MAECHLER, 2018).
Uma sub-rotina em linguagem R para calcular as medidas de análise de resíduos e
influência global está disponível em <https://www.ime.usp.br/~giapaula/cursosgrad.htm>, aqui
foram feitas apenas algumas modificações para adaptar os gráficos para o ggplot. As rotinas
utilizadas nesse trabalho podem ser solicitados via e-mail: <[email protected]>.
Se o leitor busca outra maneira de ajustar modelos de EEG’s pode-se utilizar o
PROC GENMOD do software SAS, onde em sua página oficial encontra-se diversos tutoriais e
exemplos feitos.
4.2 Aplicação 1: Estudo de dietas do frango de corte
Essa aplicação se refere ao estudo apresentado no Exemplo 2 do Capítulo 1, agora,
desejamos modelar a variável Conversão alimentar média (ração em kg/Ganho de peso em kg)
de frangos de corte em relação as dietas T1,T2 e T3. Primeiramente, podemos estudar a relação
entre os tempos de coleta através da Figura 6, em que verificamos uma possível relação linear
entre os dias 14 e 21, 14 e 28 e 21 e 28. Através da Figura 7 podemos verificar também correlação
entre as dietas.
Através de um variograma com relação aos tempos da conversão alimentar média
padronizada podemos ter uma noção da estrutura de covariância que podemos adotar na modela-
gem. Observando a Figura 8 temos indícios de que a estrutura de correlação possa ser uniforme
devido a uma certa tendência horizontal da curva, mas também pode ser AR-1, devido ao leve
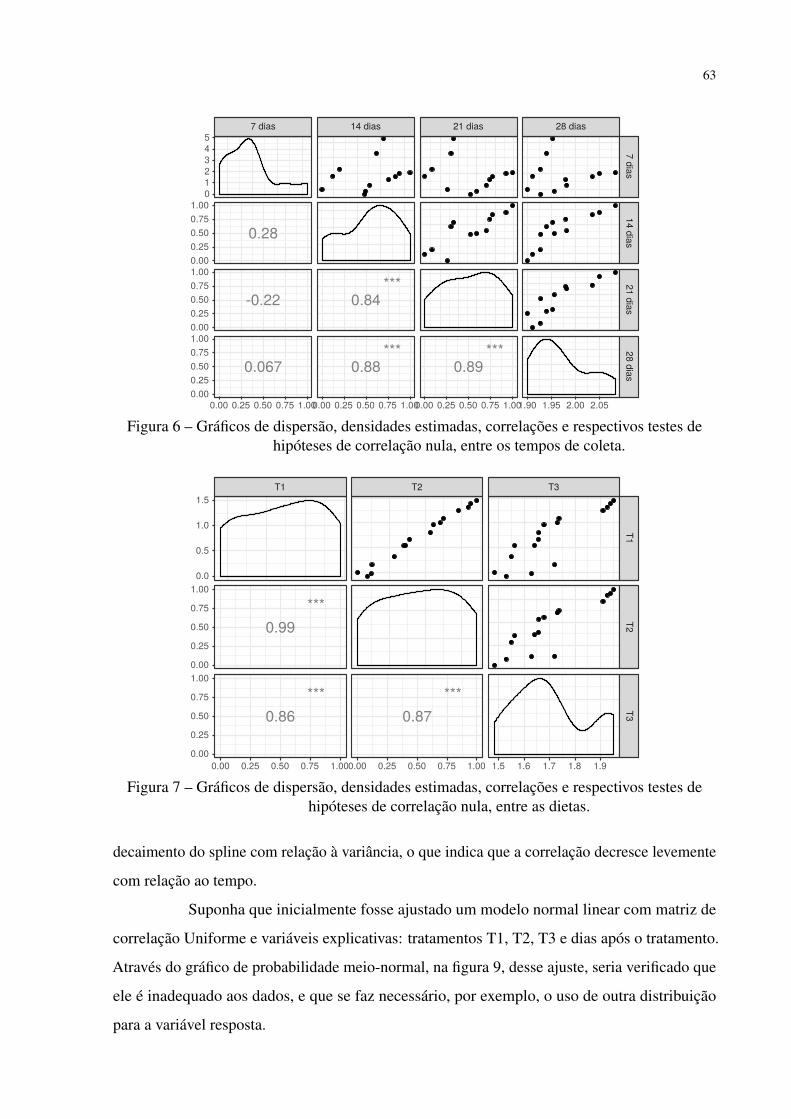
63
0.28
-0.22
0.067
0.84***
0.88***
0.89***
7 dias 14 dias 21 dias 28 dias
7 dias14 dias
21 dias28 dias
0.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.001.90 1.95 2.00 2.05
012345
0.000.250.500.751.00
0.000.250.500.751.00
0.000.250.500.751.00
Figura 6 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes dehipóteses de correlação nula, entre os tempos de coleta.
0.99***
0.86***
0.87***
T1 T2 T3
T1T2
T3
0.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.00 1.5 1.6 1.7 1.8 1.9
0.0
0.5
1.0
1.5
0.00
0.25
0.50
0.75
1.00
0.00
0.25
0.50
0.75
1.00
Figura 7 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes dehipóteses de correlação nula, entre as dietas.
decaimento do spline com relação à variância, o que indica que a correlação decresce levemente
com relação ao tempo.
Suponha que inicialmente fosse ajustado um modelo normal linear com matriz de
correlação Uniforme e variáveis explicativas: tratamentos T1, T2, T3 e dias após o tratamento.
Através do gráfico de probabilidade meio-normal, na figura 9, desse ajuste, seria verificado que
ele é inadequado aos dados, e que se faz necessário, por exemplo, o uso de outra distribuição
para a variável resposta.
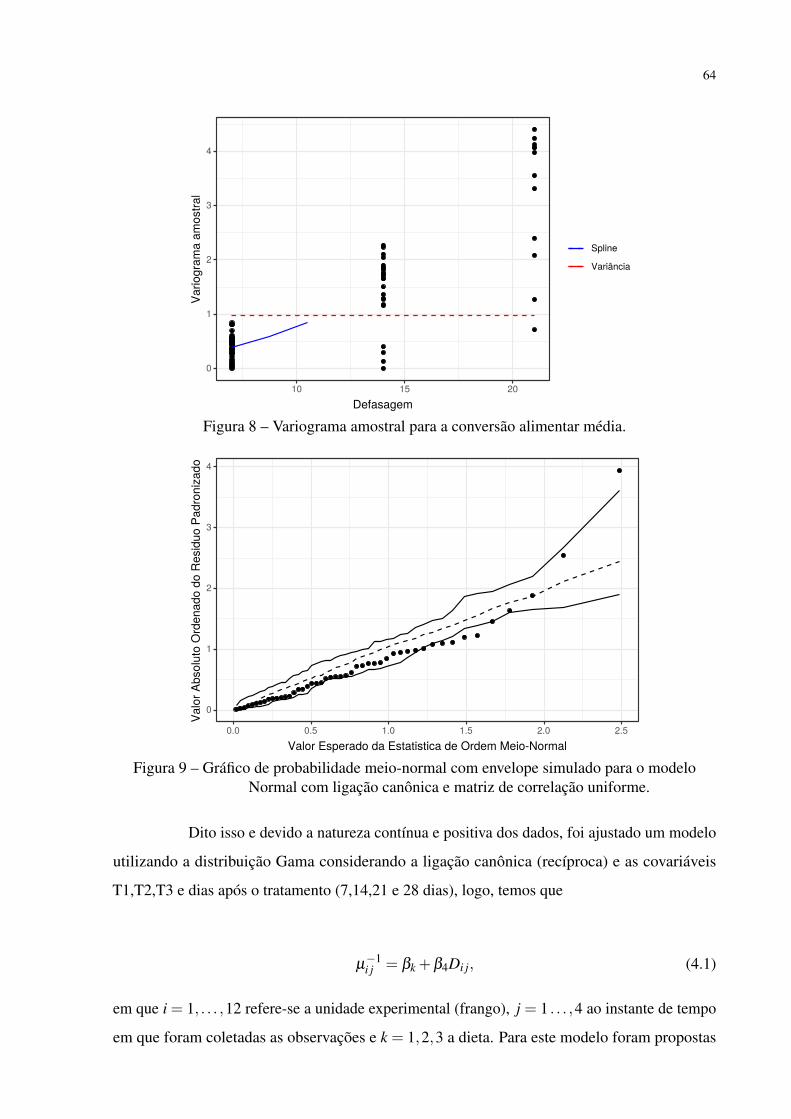
64
0
1
2
3
4
10 15 20Defasagem
Vario
gram
a am
ostra
l
Spline
Variância
Figura 8 – Variograma amostral para a conversão alimentar média.
0
1
2
3
4
0.0 0.5 1.0 1.5 2.0 2.5Valor Esperado da Estatistica de Ordem Meio-Normal
Valo
r Abs
olut
o O
rden
ado
do R
esid
uo P
adro
niza
do
Figura 9 – Gráfico de probabilidade meio-normal com envelope simulado para o modeloNormal com ligação canônica e matriz de correlação uniforme.
Dito isso e devido a natureza contínua e positiva dos dados, foi ajustado um modelo
utilizando a distribuição Gama considerando a ligação canônica (recíproca) e as covariáveis
T1,T2,T3 e dias após o tratamento (7,14,21 e 28 dias), logo, temos que
µ−1i j = βk +β4Di j, (4.1)
em que i = 1, . . . ,12 refere-se a unidade experimental (frango), j = 1 . . . ,4 ao instante de tempo
em que foram coletadas as observações e k = 1,2,3 a dieta. Para este modelo foram propostas

65
3 tipos de matrizes de correlação de trabalho: Uniforme, AR-1 e não estruturada. Através da
Tabela 3 observamos que a matriz de estrutura uniforme obteve menor QIC e RJC, logo, ela foi
escolhida para explicar a correlação entre as observações da mesma unidade experimental.
Tabela 3 – Valores de Quase-verossimilhança, QIC e RJC referentes as matrizes de correlaçãode trabalho propostas do modelo Gama com ligação canônica.
Matriz de correlação Quase-verossimilhança QIC RJCUniforme -73,70 156,64 1,37
AR-1 -73,71 156,67 1,38Não estruturada -73,71 159,77 1,41
A Tabela 4 apresenta os resultados do ajuste para o modelo proposto. Através do
teste de Wald, notamos que todos os parâmetros são altamente significativos, ou seja, os testes
apresentaram valor-p muito abaixo de 0,01 para cada parâmetro e conjuntamente com todos os
parâmetros (valor-p< 0,0001)
Tabela 4 – Estimativas e erros-padrão do modelo Gama com ligação canônica e estrutura decorrelação uniforme.
Erro padrãoParâmetro Estimativa Naive Robusto Valor-p (Wald)β1(dieta1) 0,7345 0,0110 0,0124 <0,0001β2(dieta2) 0,7082 0,0108 0,0117 <0,0001β3(dieta3) 0,7282 0,0110 0,0155 <0,0001β4(Dias) -0,0077 0,0004 0,0005 <0,0001
α(Correlação) 0,1161
Aplicando as técnicas de diagnóstico descritas, iremos verificar se há pontos influen-
tes ou aberrantes calculando a distância de Cook normalizada e os resíduos padronizados para
avaliar a unidade experimental e a repetição (i, j), com i = 1, . . . ,12 e j = 1,2,3,4. Analisando
as Figuras 10 e 11 destacamos 2 possíveis pontos influentes globalmente referentes a dieta
T2, (11,1) e (12,1). No gráfico de probabilidade meio-normal com envelope simulado 12, não
observamos pontos distantes dos demais e fora da banda de confiança, o que indica que nosso
modelo foi bem ajustado aos dados.
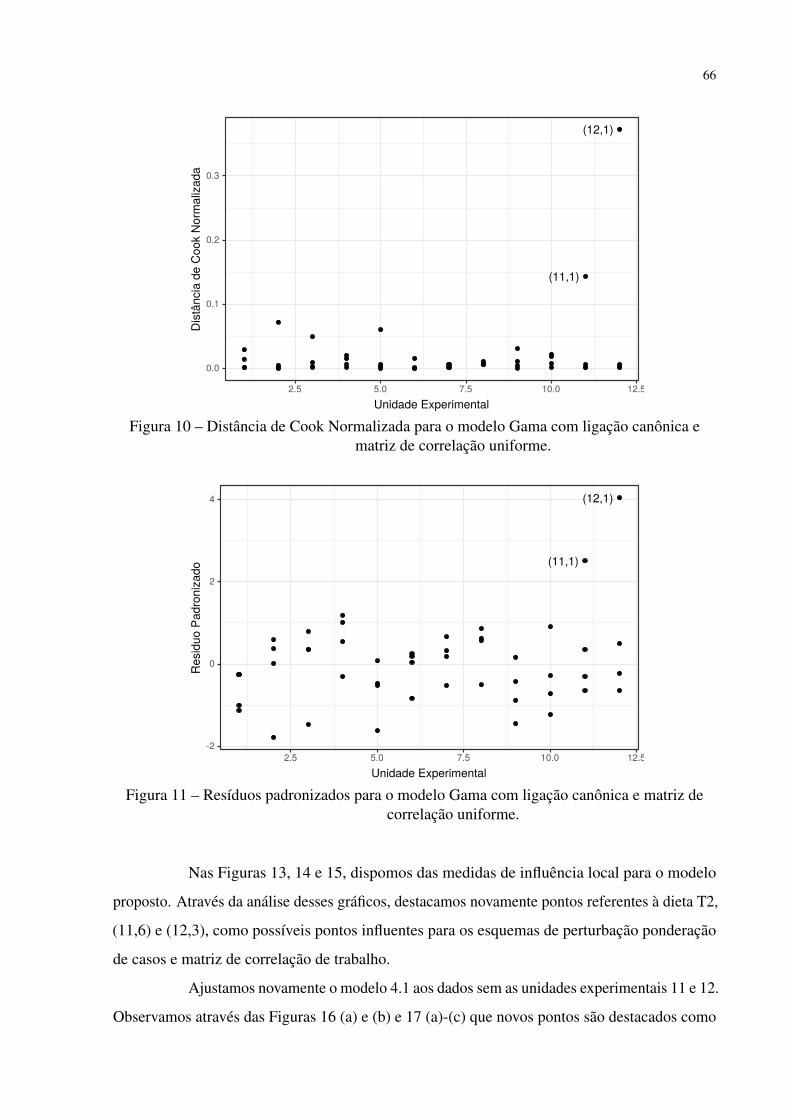
66
(11,1)
(12,1)
0.0
0.1
0.2
0.3
2.5 5.0 7.5 10.0 12.5Unidade Experimental
Dis
tânc
ia d
e C
ook
Nor
mal
izad
a
Figura 10 – Distância de Cook Normalizada para o modelo Gama com ligação canônica ematriz de correlação uniforme.
(11,1)
(12,1)
-2
0
2
4
2.5 5.0 7.5 10.0 12.5Unidade Experimental
Res
iduo
Pad
roni
zado
Figura 11 – Resíduos padronizados para o modelo Gama com ligação canônica e matriz decorrelação uniforme.
Nas Figuras 13, 14 e 15, dispomos das medidas de influência local para o modelo
proposto. Através da análise desses gráficos, destacamos novamente pontos referentes à dieta T2,
(11,6) e (12,3), como possíveis pontos influentes para os esquemas de perturbação ponderação
de casos e matriz de correlação de trabalho.
Ajustamos novamente o modelo 4.1 aos dados sem as unidades experimentais 11 e 12.
Observamos através das Figuras 16 (a) e (b) e 17 (a)-(c) que novos pontos são destacados como
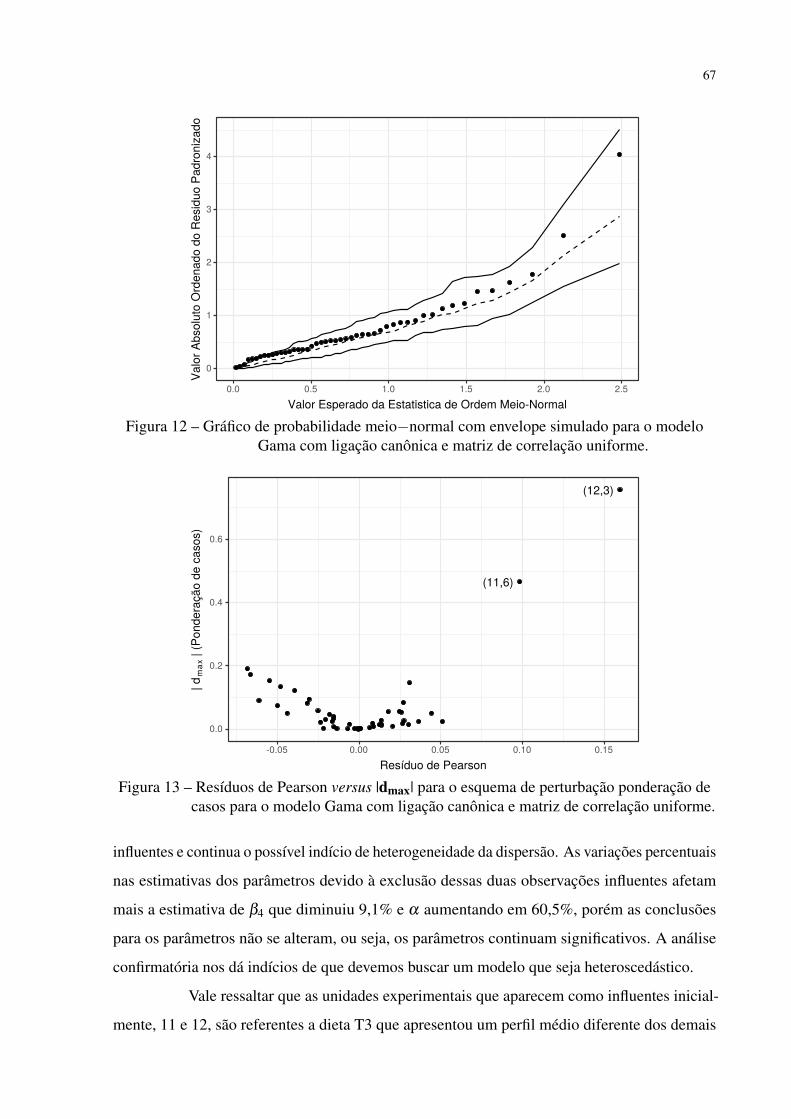
67
0
1
2
3
4
0.0 0.5 1.0 1.5 2.0 2.5Valor Esperado da Estatistica de Ordem Meio-Normal
Valo
r Abs
olut
o O
rden
ado
do R
esid
uo P
adro
niza
do
Figura 12 – Gráfico de probabilidade meio−normal com envelope simulado para o modeloGama com ligação canônica e matriz de correlação uniforme.
(11,6)
(12,3)
0.0
0.2
0.4
0.6
-0.05 0.00 0.05 0.10 0.15Resíduo de Pearson
| dm
ax |
(Pon
dera
ção
de c
asos
)
Figura 13 – Resíduos de Pearson versus |dmax| para o esquema de perturbação ponderação decasos para o modelo Gama com ligação canônica e matriz de correlação uniforme.
influentes e continua o possível indício de heterogeneidade da dispersão. As variações percentuais
nas estimativas dos parâmetros devido à exclusão dessas duas observações influentes afetam
mais a estimativa de β4 que diminuiu 9,1% e α aumentando em 60,5%, porém as conclusões
para os parâmetros não se alteram, ou seja, os parâmetros continuam significativos. A análise
confirmatória nos dá indícios de que devemos buscar um modelo que seja heteroscedástico.
Vale ressaltar que as unidades experimentais que aparecem como influentes inicial-
mente, 11 e 12, são referentes a dieta T3 que apresentou um perfil médio diferente dos demais
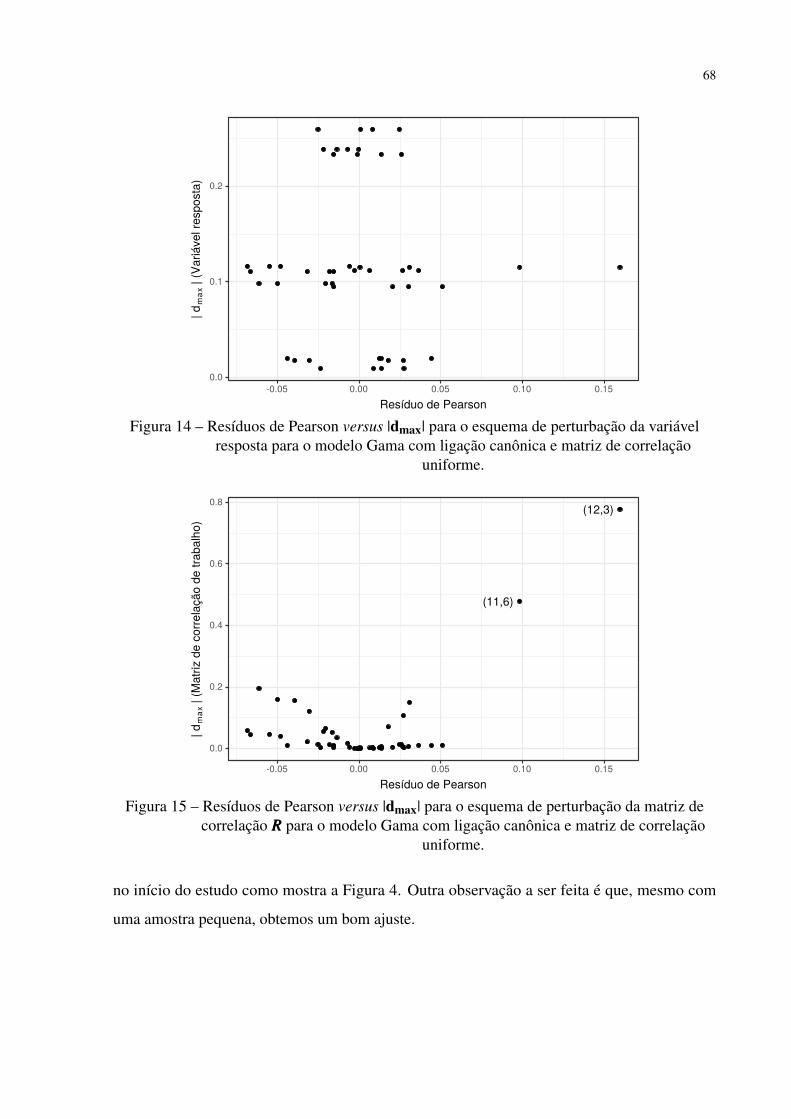
68
0.0
0.1
0.2
-0.05 0.00 0.05 0.10 0.15Resíduo de Pearson
| dm
ax |
(Var
iáve
l res
post
a)
Figura 14 – Resíduos de Pearson versus |dmax| para o esquema de perturbação da variávelresposta para o modelo Gama com ligação canônica e matriz de correlação
uniforme.
(11,6)
(12,3)
0.0
0.2
0.4
0.6
0.8
-0.05 0.00 0.05 0.10 0.15Resíduo de Pearson
| dm
ax |
(Mat
riz d
e co
rrela
ção
de tr
abal
ho)
Figura 15 – Resíduos de Pearson versus |dmax| para o esquema de perturbação da matriz decorrelação RRR para o modelo Gama com ligação canônica e matriz de correlação
uniforme.
no início do estudo como mostra a Figura 4. Outra observação a ser feita é que, mesmo com
uma amostra pequena, obtemos um bom ajuste.
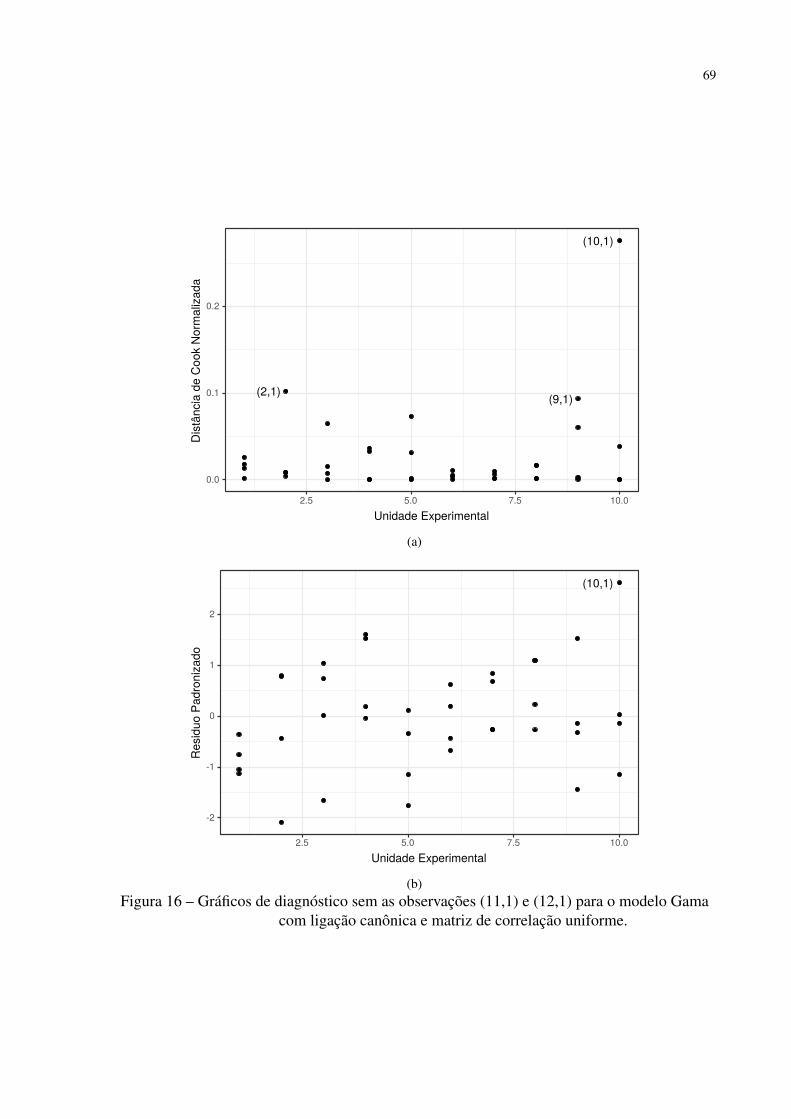
69
(2,1) (9,1)
(10,1)
0.0
0.1
0.2
2.5 5.0 7.5 10.0Unidade Experimental
Dis
tânc
ia d
e C
ook
Nor
mal
izad
a
(a)
(10,1)
-2
-1
0
1
2
2.5 5.0 7.5 10.0Unidade Experimental
Res
iduo
Pad
roni
zado
(b)Figura 16 – Gráficos de diagnóstico sem as observações (11,1) e (12,1) para o modelo Gama
com ligação canônica e matriz de correlação uniforme.
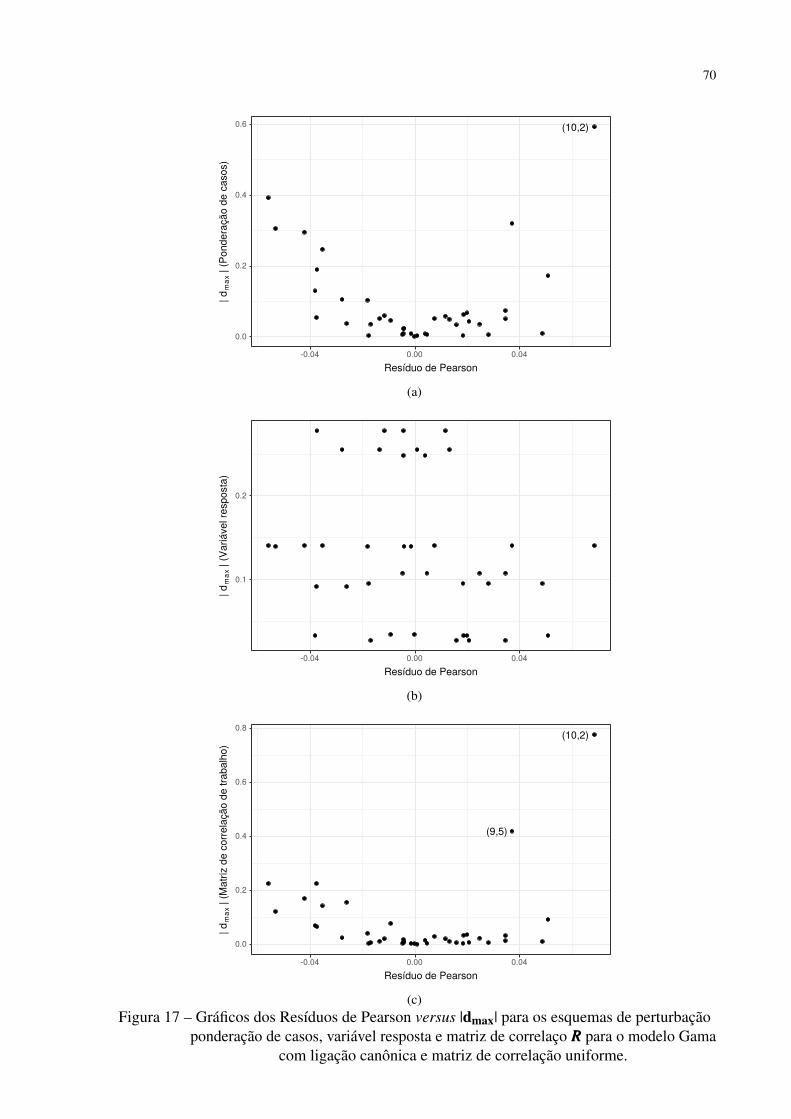
70
(10,2)
0.0
0.2
0.4
0.6
-0.04 0.00 0.04Resíduo de Pearson
| dm
ax |
(Pon
dera
ção
de c
asos
)
(a)
0.1
0.2
-0.04 0.00 0.04Resíduo de Pearson
| dm
ax |
(Var
iáve
l res
post
a)
(b)
(9,5)
(10,2)
0.0
0.2
0.4
0.6
0.8
-0.04 0.00 0.04Resíduo de Pearson
| dm
ax |
(Mat
riz d
e co
rrela
ção
de tr
abal
ho)
(c)Figura 17 – Gráficos dos Resíduos de Pearson versus |dmax| para os esquemas de perturbação
ponderação de casos, variável resposta e matriz de correlaço RRR para o modelo Gamacom ligação canônica e matriz de correlação uniforme.
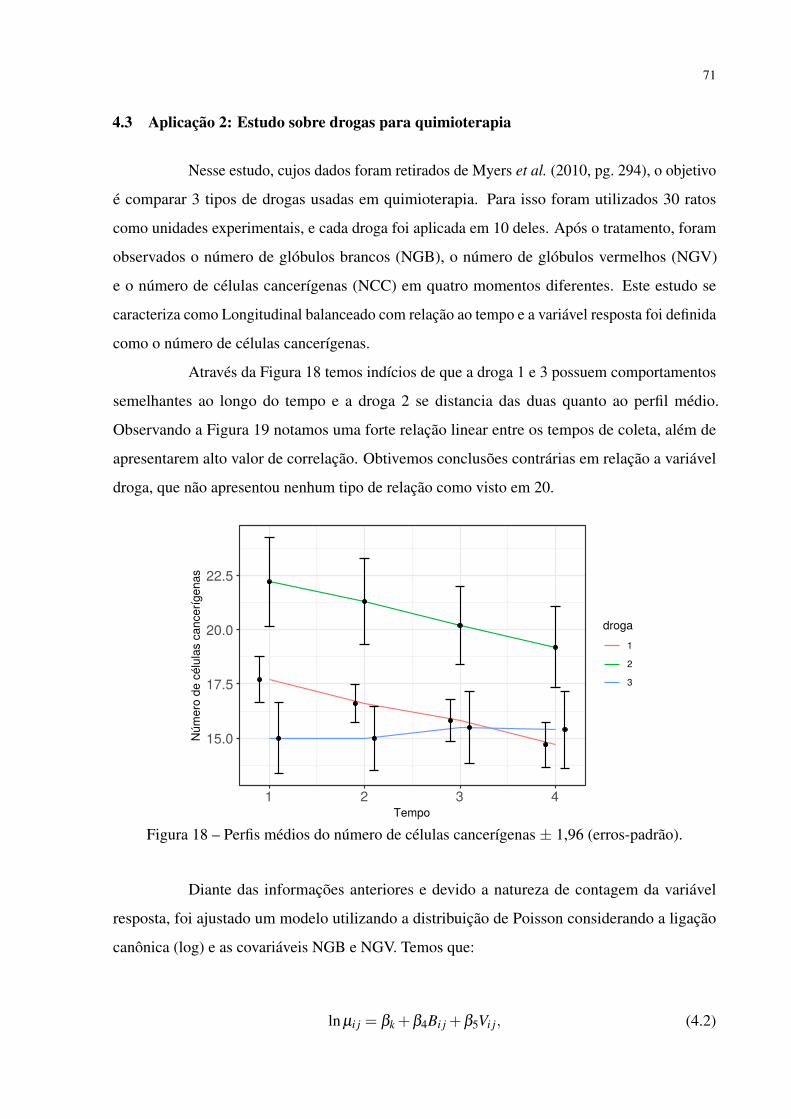
71
4.3 Aplicação 2: Estudo sobre drogas para quimioterapia
Nesse estudo, cujos dados foram retirados de Myers et al. (2010, pg. 294), o objetivo
é comparar 3 tipos de drogas usadas em quimioterapia. Para isso foram utilizados 30 ratos
como unidades experimentais, e cada droga foi aplicada em 10 deles. Após o tratamento, foram
observados o número de glóbulos brancos (NGB), o número de glóbulos vermelhos (NGV)
e o número de células cancerígenas (NCC) em quatro momentos diferentes. Este estudo se
caracteriza como Longitudinal balanceado com relação ao tempo e a variável resposta foi definida
como o número de células cancerígenas.
Através da Figura 18 temos indícios de que a droga 1 e 3 possuem comportamentos
semelhantes ao longo do tempo e a droga 2 se distancia das duas quanto ao perfil médio.
Observando a Figura 19 notamos uma forte relação linear entre os tempos de coleta, além de
apresentarem alto valor de correlação. Obtivemos conclusões contrárias em relação a variável
droga, que não apresentou nenhum tipo de relação como visto em 20.
15.0
17.5
20.0
22.5
1 2 3 4Tempo
Núm
ero
de c
élul
as c
ance
rígen
as
droga1
2
3
Figura 18 – Perfis médios do número de células cancerígenas ± 1,96 (erros-padrão).
Diante das informações anteriores e devido a natureza de contagem da variável
resposta, foi ajustado um modelo utilizando a distribuição de Poisson considerando a ligação
canônica (log) e as covariáveis NGB e NGV. Temos que:
ln µi j = βk +β4Bi j +β5Vi j, (4.2)
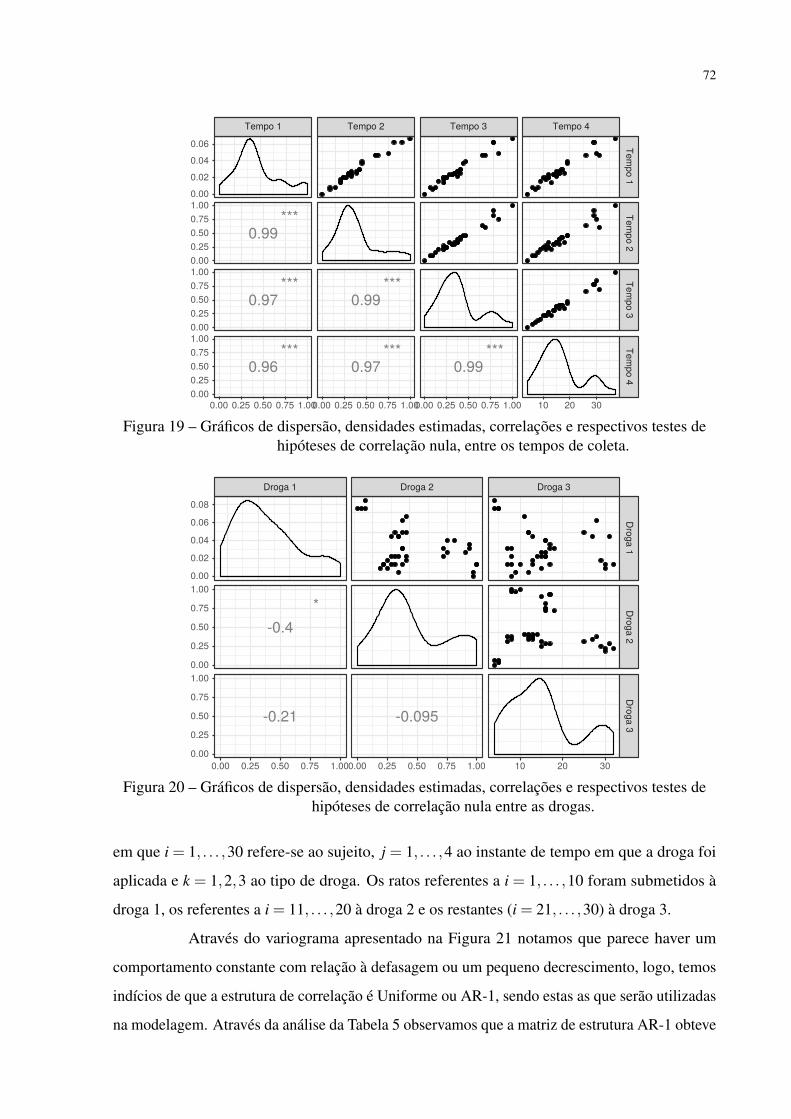
72
0.99***
0.97***
0.96***
0.99***
0.97***
0.99***
Tempo 1 Tempo 2 Tempo 3 Tempo 4
Tempo 1
Tempo 2
Tempo 3
Tempo 4
0.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.00 10 20 30
0.000.020.040.06
0.000.250.500.751.00
0.000.250.500.751.00
0.000.250.500.751.00
Figura 19 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes dehipóteses de correlação nula, entre os tempos de coleta.
-0.4*
-0.21
-0.095
Droga 1 Droga 2 Droga 3
Droga 1
Droga 2
Droga 3
0.00 0.25 0.50 0.75 1.000.00 0.25 0.50 0.75 1.00 10 20 30
0.00
0.02
0.04
0.06
0.08
0.00
0.25
0.50
0.75
1.00
0.00
0.25
0.50
0.75
1.00
Figura 20 – Gráficos de dispersão, densidades estimadas, correlações e respectivos testes dehipóteses de correlação nula entre as drogas.
em que i = 1, . . . ,30 refere-se ao sujeito, j = 1, . . . ,4 ao instante de tempo em que a droga foi
aplicada e k = 1,2,3 ao tipo de droga. Os ratos referentes a i = 1, . . . ,10 foram submetidos à
droga 1, os referentes a i = 11, . . . ,20 à droga 2 e os restantes (i = 21, . . . ,30) à droga 3.
Através do variograma apresentado na Figura 21 notamos que parece haver um
comportamento constante com relação à defasagem ou um pequeno decrescimento, logo, temos
indícios de que a estrutura de correlação é Uniforme ou AR-1, sendo estas as que serão utilizadas
na modelagem. Através da análise da Tabela 5 observamos que a matriz de estrutura AR-1 obteve
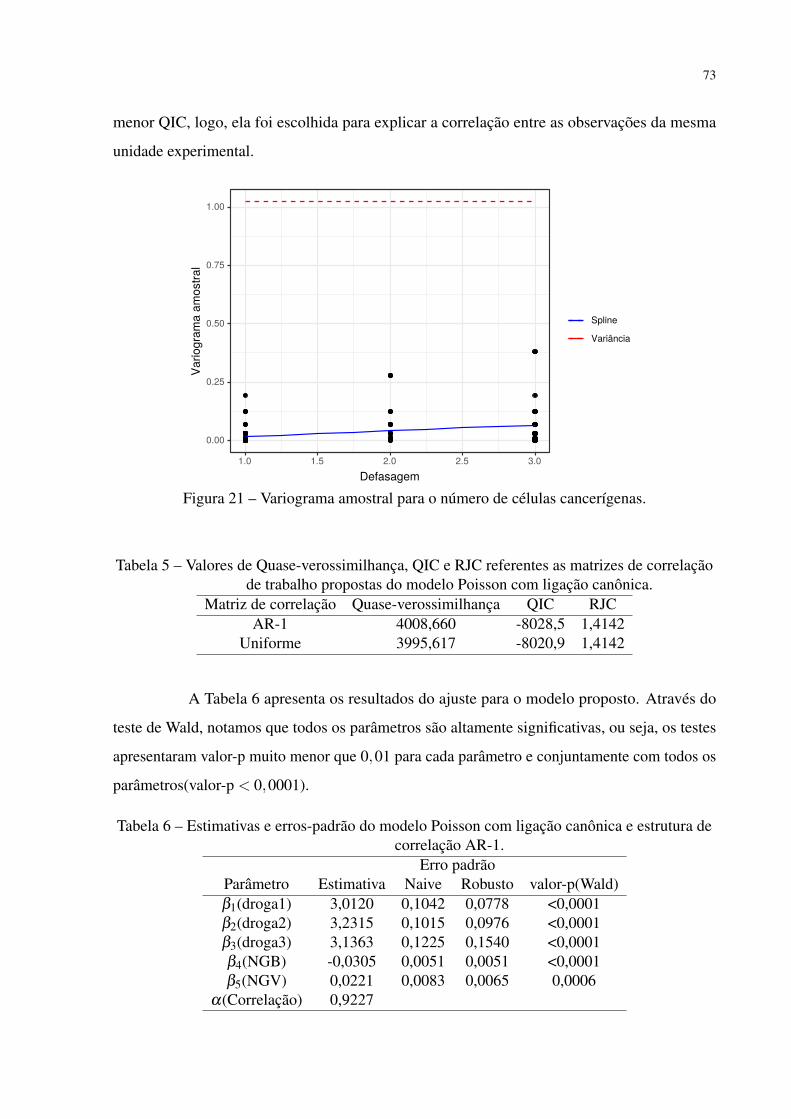
73
menor QIC, logo, ela foi escolhida para explicar a correlação entre as observações da mesma
unidade experimental.
0.00
0.25
0.50
0.75
1.00
1.0 1.5 2.0 2.5 3.0Defasagem
Vario
gram
a am
ostra
l
Spline
Variância
Figura 21 – Variograma amostral para o número de células cancerígenas.
Tabela 5 – Valores de Quase-verossimilhança, QIC e RJC referentes as matrizes de correlaçãode trabalho propostas do modelo Poisson com ligação canônica.
Matriz de correlação Quase-verossimilhança QIC RJCAR-1 4008,660 -8028,5 1,4142
Uniforme 3995,617 -8020,9 1,4142
A Tabela 6 apresenta os resultados do ajuste para o modelo proposto. Através do
teste de Wald, notamos que todos os parâmetros são altamente significativas, ou seja, os testes
apresentaram valor-p muito menor que 0,01 para cada parâmetro e conjuntamente com todos os
parâmetros(valor-p < 0,0001).
Tabela 6 – Estimativas e erros-padrão do modelo Poisson com ligação canônica e estrutura decorrelação AR-1.
Erro padrãoParâmetro Estimativa Naive Robusto valor-p(Wald)β1(droga1) 3,0120 0,1042 0,0778 <0,0001β2(droga2) 3,2315 0,1015 0,0976 <0,0001β3(droga3) 3,1363 0,1225 0,1540 <0,0001β4(NGB) -0,0305 0,0051 0,0051 <0,0001β5(NGV) 0,0221 0,0083 0,0065 0,0006
α(Correlação) 0,9227
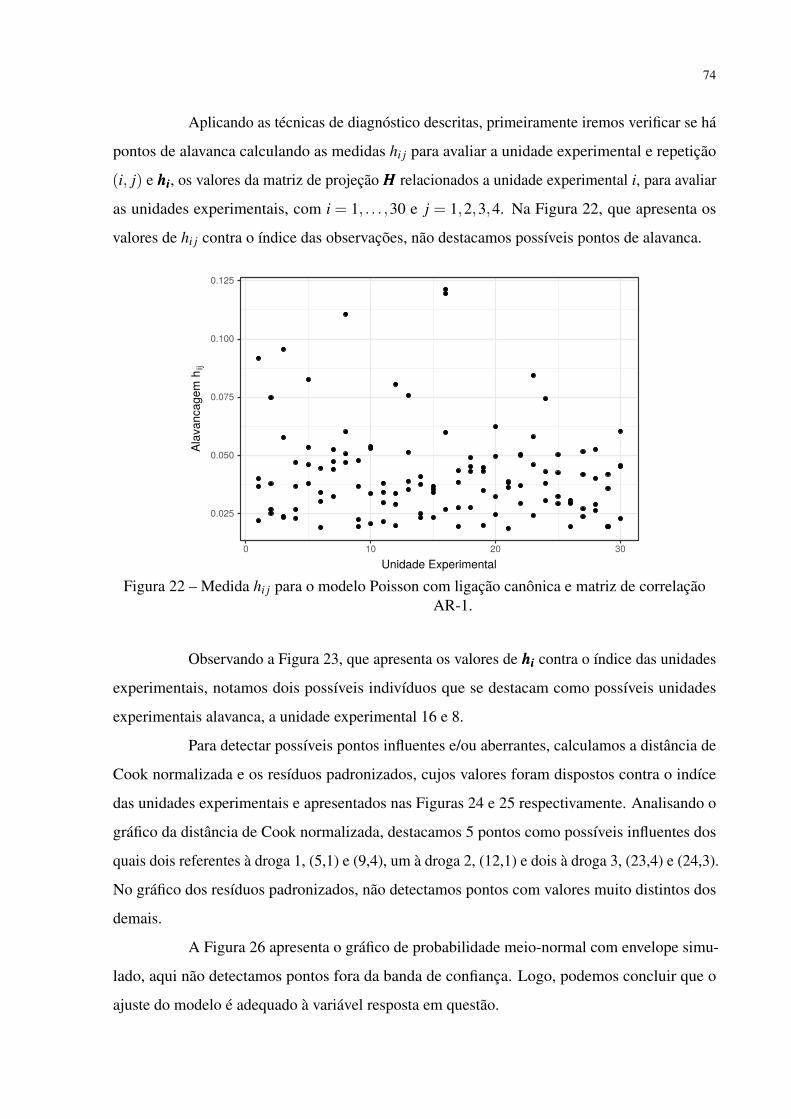
74
Aplicando as técnicas de diagnóstico descritas, primeiramente iremos verificar se há
pontos de alavanca calculando as medidas hi j para avaliar a unidade experimental e repetição
(i, j) e hhhiii, os valores da matriz de projeção HHH relacionados a unidade experimental i, para avaliar
as unidades experimentais, com i = 1, . . . ,30 e j = 1,2,3,4. Na Figura 22, que apresenta os
valores de hi j contra o índice das observações, não destacamos possíveis pontos de alavanca.
0.025
0.050
0.075
0.100
0.125
0 10 20 30Unidade Experimental
Alav
anca
gem
hij
Figura 22 – Medida hi j para o modelo Poisson com ligação canônica e matriz de correlaçãoAR-1.
Observando a Figura 23, que apresenta os valores de hhhiii contra o índice das unidades
experimentais, notamos dois possíveis indivíduos que se destacam como possíveis unidades
experimentais alavanca, a unidade experimental 16 e 8.
Para detectar possíveis pontos influentes e/ou aberrantes, calculamos a distância de
Cook normalizada e os resíduos padronizados, cujos valores foram dispostos contra o indíce
das unidades experimentais e apresentados nas Figuras 24 e 25 respectivamente. Analisando o
gráfico da distância de Cook normalizada, destacamos 5 pontos como possíveis influentes dos
quais dois referentes à droga 1, (5,1) e (9,4), um à droga 2, (12,1) e dois à droga 3, (23,4) e (24,3).
No gráfico dos resíduos padronizados, não detectamos pontos com valores muito distintos dos
demais.
A Figura 26 apresenta o gráfico de probabilidade meio-normal com envelope simu-
lado, aqui não detectamos pontos fora da banda de confiança. Logo, podemos concluir que o
ajuste do modelo é adequado à variável resposta em questão.
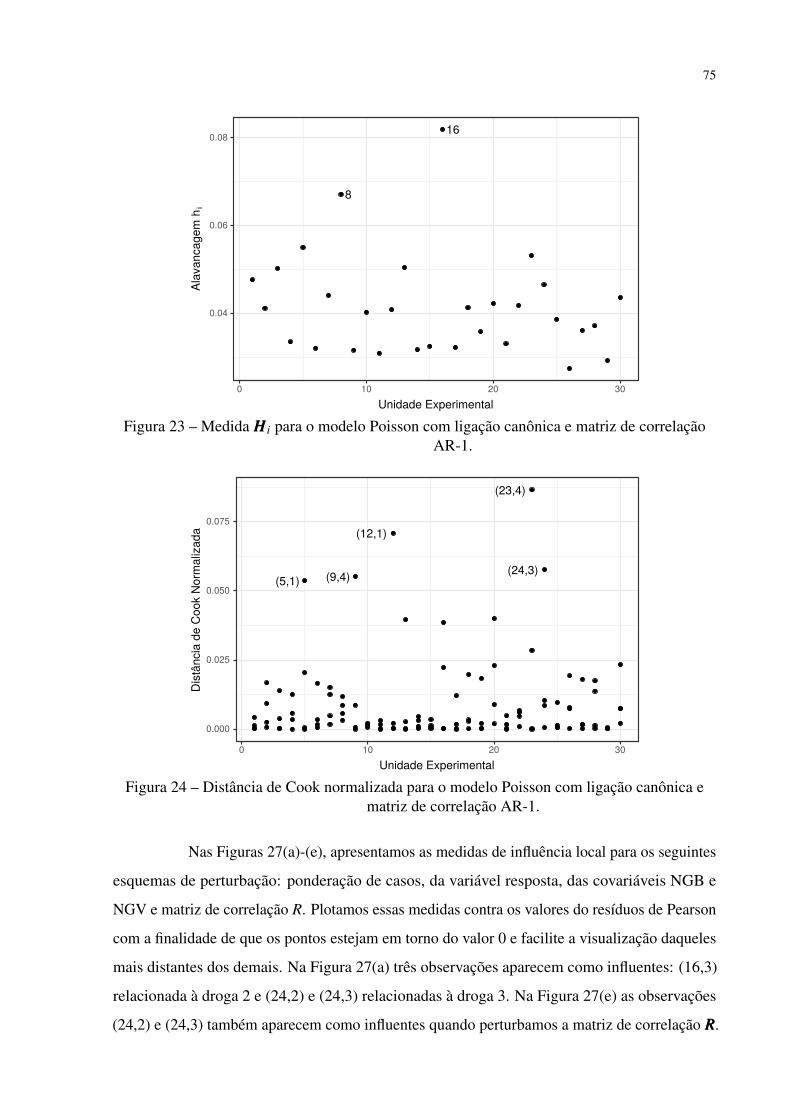
75
8
16
0.04
0.06
0.08
0 10 20 30Unidade Experimental
Alav
anca
gem
hi
Figura 23 – Medida HHH i para o modelo Poisson com ligação canônica e matriz de correlaçãoAR-1.
(5,1) (9,4)
(12,1)
(23,4)
(24,3)
0.000
0.025
0.050
0.075
0 10 20 30Unidade Experimental
Dis
tânc
ia d
e C
ook
Nor
mal
izad
a
Figura 24 – Distância de Cook normalizada para o modelo Poisson com ligação canônica ematriz de correlação AR-1.
Nas Figuras 27(a)-(e), apresentamos as medidas de influência local para os seguintes
esquemas de perturbação: ponderação de casos, da variável resposta, das covariáveis NGB e
NGV e matriz de correlação R. Plotamos essas medidas contra os valores do resíduos de Pearson
com a finalidade de que os pontos estejam em torno do valor 0 e facilite a visualização daqueles
mais distantes dos demais. Na Figura 27(a) três observações aparecem como influentes: (16,3)
relacionada à droga 2 e (24,2) e (24,3) relacionadas à droga 3. Na Figura 27(e) as observações
(24,2) e (24,3) também aparecem como influentes quando perturbamos a matriz de correlação RRR.
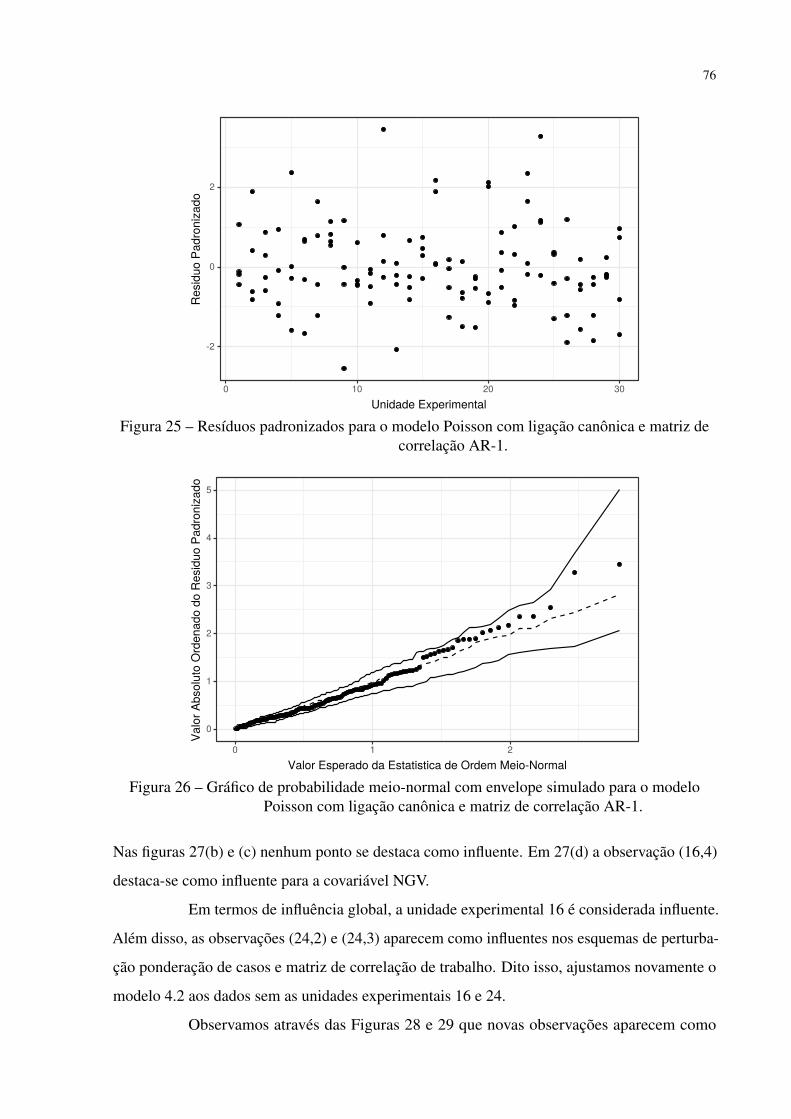
76
-2
0
2
0 10 20 30Unidade Experimental
Res
iduo
Pad
roni
zado
Figura 25 – Resíduos padronizados para o modelo Poisson com ligação canônica e matriz decorrelação AR-1.
0
1
2
3
4
5
0 1 2Valor Esperado da Estatistica de Ordem Meio-Normal
Valo
r Abs
olut
o O
rden
ado
do R
esid
uo P
adro
niza
do
Figura 26 – Gráfico de probabilidade meio-normal com envelope simulado para o modeloPoisson com ligação canônica e matriz de correlação AR-1.
Nas figuras 27(b) e (c) nenhum ponto se destaca como influente. Em 27(d) a observação (16,4)
destaca-se como influente para a covariável NGV.
Em termos de influência global, a unidade experimental 16 é considerada influente.
Além disso, as observações (24,2) e (24,3) aparecem como influentes nos esquemas de perturba-
ção ponderação de casos e matriz de correlação de trabalho. Dito isso, ajustamos novamente o
modelo 4.2 aos dados sem as unidades experimentais 16 e 24.
Observamos através das Figuras 28 e 29 que novas observações aparecem como
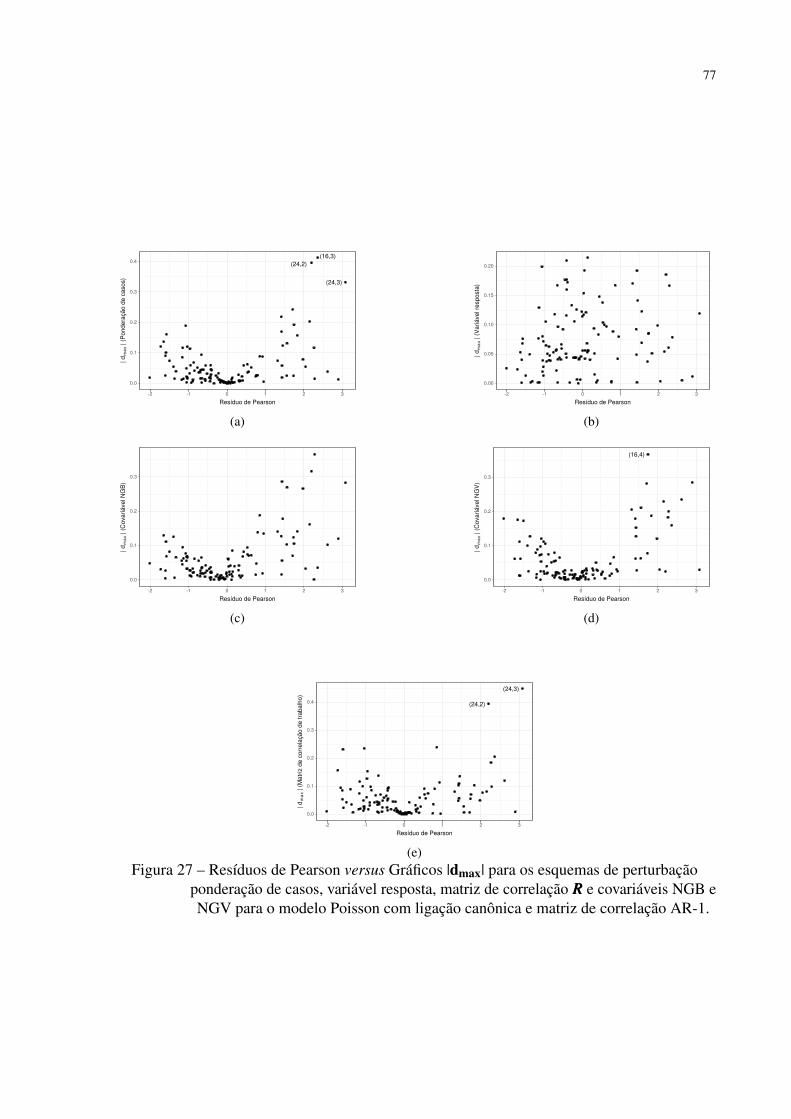
77
(16,3)(24,2)
(24,3)
0.0
0.1
0.2
0.3
0.4
-2 -1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Pon
dera
ção
de c
asos
)
(a)
0.00
0.05
0.10
0.15
0.20
-2 -1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Var
iáve
l res
post
a)
(b)
0.0
0.1
0.2
0.3
-2 -1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Cov
ariá
vel N
GB)
(c)
(16,4)
0.0
0.1
0.2
0.3
-2 -1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Cov
ariá
vel N
GV)
(d)
(24,2)
(24,3)
0.0
0.1
0.2
0.3
0.4
-2 -1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Mat
riz d
e co
rrela
ção
de tr
abal
ho)
(e)Figura 27 – Resíduos de Pearson versus Gráficos |dmax| para os esquemas de perturbação
ponderação de casos, variável resposta, matriz de correlação RRR e covariáveis NGB eNGV para o modelo Poisson com ligação canônica e matriz de correlação AR-1.
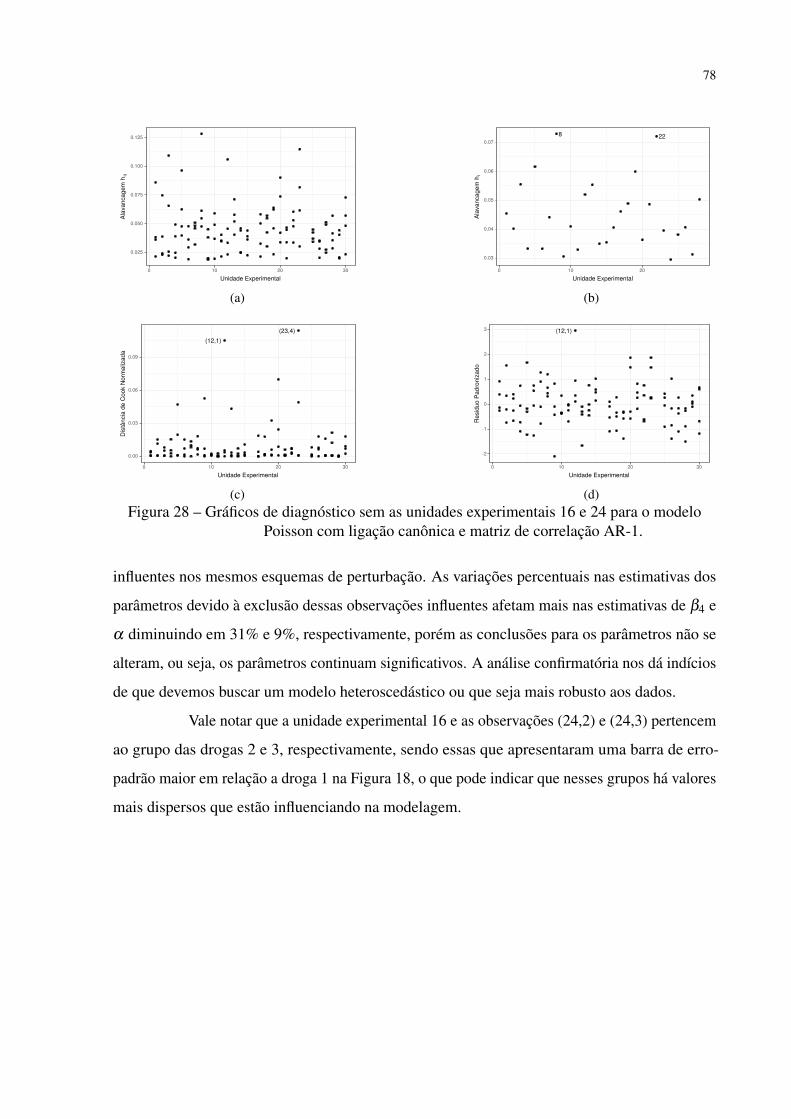
78
0.025
0.050
0.075
0.100
0.125
0 10 20 30Unidade Experimental
Alav
anca
gem
hij
(a)
8 22
0.03
0.04
0.05
0.06
0.07
0 10 20Unidade Experimental
Alav
anca
gem
hi
(b)
(12,1)(23,4)
0.00
0.03
0.06
0.09
0 10 20 30Unidade Experimental
Dis
tânc
ia d
e C
ook
Nor
mal
izad
a
(c)
(12,1)
-2
-1
0
1
2
3
0 10 20 30Unidade Experimental
Res
iduo
Pad
roni
zado
(d)Figura 28 – Gráficos de diagnóstico sem as unidades experimentais 16 e 24 para o modelo
Poisson com ligação canônica e matriz de correlação AR-1.
influentes nos mesmos esquemas de perturbação. As variações percentuais nas estimativas dos
parâmetros devido à exclusão dessas observações influentes afetam mais nas estimativas de β4 e
α diminuindo em 31% e 9%, respectivamente, porém as conclusões para os parâmetros não se
alteram, ou seja, os parâmetros continuam significativos. A análise confirmatória nos dá indícios
de que devemos buscar um modelo heteroscedástico ou que seja mais robusto aos dados.
Vale notar que a unidade experimental 16 e as observações (24,2) e (24,3) pertencem
ao grupo das drogas 2 e 3, respectivamente, sendo essas que apresentaram uma barra de erro-
padrão maior em relação a droga 1 na Figura 18, o que pode indicar que nesses grupos há valores
mais dispersos que estão influenciando na modelagem.
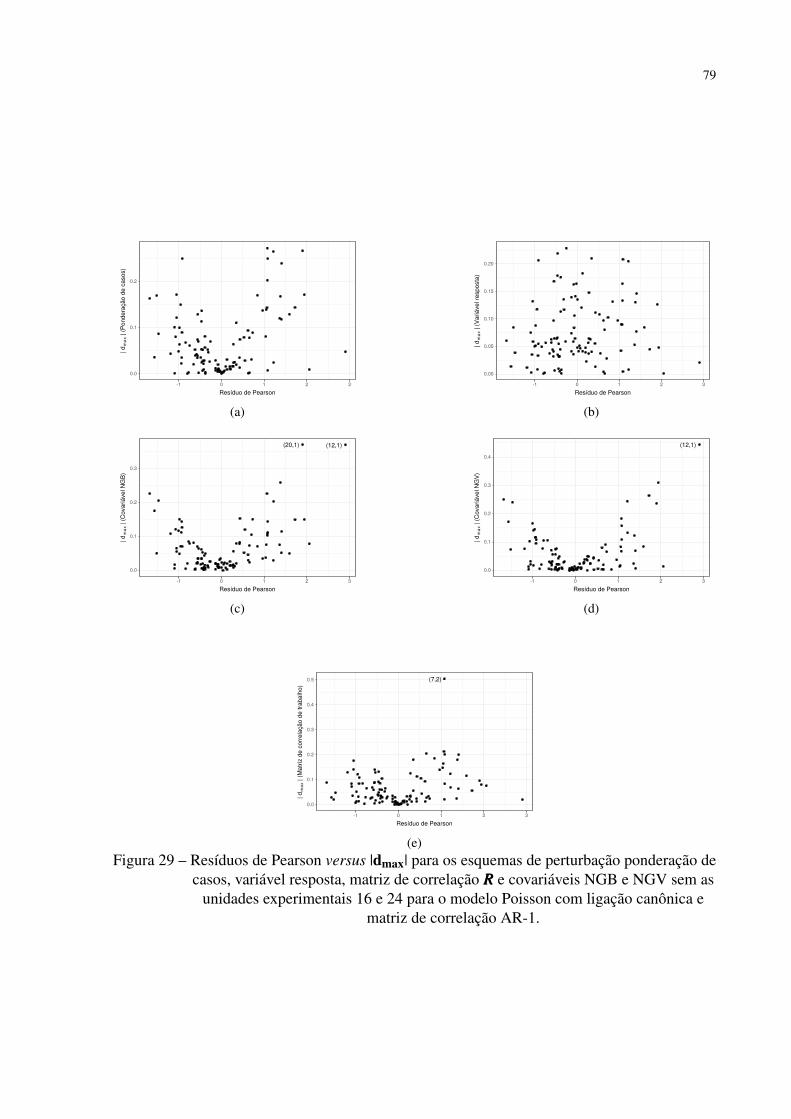
79
0.0
0.1
0.2
-1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Pon
dera
ção
de c
asos
)
(a)
0.00
0.05
0.10
0.15
0.20
-1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Var
iáve
l res
post
a)
(b)
(12,1)(20,1)
0.0
0.1
0.2
0.3
-1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Cov
ariá
vel N
GB)
(c)
(12,1)
0.0
0.1
0.2
0.3
0.4
-1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Cov
ariá
vel N
GV)
(d)
(7,2)
0.0
0.1
0.2
0.3
0.4
0.5
-1 0 1 2 3Resíduo de Pearson
| dm
ax |
(Mat
riz d
e co
rrela
ção
de tr
abal
ho)
(e)Figura 29 – Resíduos de Pearson versus |dmax| para os esquemas de perturbação ponderação de
casos, variável resposta, matriz de correlação RRR e covariáveis NGB e NGV sem asunidades experimentais 16 e 24 para o modelo Poisson com ligação canônica e
matriz de correlação AR-1.

80
5 CONSIDERAÇÕES FINAIS
Neste trabalho foi apresentada a modelagem de dados com medidas repetidas uti-
lizando Equações de Estimação Generalizadas. Foi apresentada a construção das EEG’s, mos-
trando a teoria que concerne as funções de estimação e os MLG’s. Posteriormente, foi apresentado
o método de estimação dos parâmetros via método modificado de Newton combinado com o
método dos momentos, bem como etapas para a construção desse algoritmo de estimação.
Apresentamos as estatísticas do tipo Wald e escore de Rao em suas versões para
EEG’s para testar hipóteses lineares de interesse com relação aos parâmetros. Também apresenta-
mos uma modificação do AIC, denominada QIC, para verificar a qualidade do ajuste do modelo
e da matriz de correlação de trabalho, e os critérios CIC e RJC para a matriz de correlação de
trabalho.
Apresentamos, como análise de diagnóstico global, a matriz de alavancagem gene-
ralizada, distância de Cook, resíduo padronizado e gráfico de probabilidade meio-normal com
envelope simulado para o modelo de EEG utilizado. Apresentamos também a proposta de análise
de influência local e uma ideia escrita em uma forma mais geral denominada de influência local
generalizada. Esquemas de perturbação foram apresentados para ponderação de casos, para a
variável resposta, para uma covariável contínua da matriz de especificação, para o parâmetro de
precisão e para a matriz de correlação de trabalho.
5.1 Conclusões
O uso de EEG’s apresenta diversas vantagens frente aos modelos usuais, entre elas,
destacamos: a garantia da consistência dos estimadores sob certas condições de regularidade,
a flexibilidade da variável resposta e a inclusão da matriz de correlação de trabalho. Por
consequência das vantagens citadas, frequentemente produzimos estimativas com erros-padrão
menores.
5.2 Trabalhos futuros
Muito ainda há a ser desenvolvido sobre os modelos baseados em EEG’s. Primeira-
mente, esse modelo pode ser estendido utilizando distribuições mais flexíveis, como por exemplo,
já estamos em fase de finalização de um artigo sobre uma extensão de EEG’s utilizando a distri-
buição Beta Prime reparametrizada (BOURGUIGNON et al., 2018) como uma nova proposta

81
para analisar dados positivos de medidas repetidas. Outra extensão poderia ser feita utilizando a
distribuição BerG (BOURGUIGNON; WEISS, 2017) do qual teríamos um modelo para dados
de contagem com medidas repetidas que pode suportar sub, equi e superdispersão. Citamos
também algumas outras ideias de estudos futuros:
• Apresentar algoritmos de simulação de variáveis correlacionadas para qualquer distribuição
desde que conheçamos sua função de distribuição inversa, permitindo assim construirmos
gráficos de envelope simulados para os resíduos baseados nas mesmas, por exemplo. Uma
sugestão seria trabalhar com cópulas gaussianas (JOE, 1997) ou o algoritmo NORTA
(CHEN, 2001). Tal ferramenta já está sendo utilizada no artigo que está sendo finalizado
de modelos beta prime para dados positivos de medidas repetidas.
• Estender as EEG’s para casos em que temos erros de medição nas covariáveis.
• Estender as EEG’s para a abordagem multivariada como um caso especial dos Modelos
Multivariados de Covariância Lineares Generalizados propostos por Bonat e Jørgensen
(2016), e posteriormente desenvolver métodos de análise de diagnóstico.

82
REFERÊNCIAS
AKAIKE, H. Information theory and an extension of the maximum likelihood principle. In:Selected papers of hirotugu akaike. New York: Springer, 1998. p. 199–213.
ARELLANO-VALLE, R.; BOLFARINE, H.; LACHOS, V. Skew-normal linear mixed models.Journal of Data Science, v. 3, n. 4, p. 415–438, 2005.
ARTES, R. Extensões da teoria das equações de estimação generalizadas a dadoscirculares e modelos de dispersão. São Paulo: IME - USP. Tese de Doutorado, 1997.
ARTES, R.; BOTTER, D. A. Funções de Estimação em Modelos de Regressão. São Paulo:Insper Instituto de Ensino e Pesquisa - IME - USP, 2005.
ATKINSON, A. Plots, Transformations, and Regression: An Introduction to GraphicalMethods of Diagnostic Regression Analysis. Oxford: Clarendon Press, 1985. (OxfordStatistical Science Series).
ATKINSON, A.; RIANI, M. Robust Diagnostic Regression Analysis. New York: SpringerScience & Business Media, 2000.
ATKINSON, A. C. Two graphical displays for outlying and influential observations in regression.Biometrika, [Oxford University Press, Biometrika Trust], v. 68, n. 1, p. 13–20, 1981.
BARTOn, K. MuMIn: Multi-Model Inference. [S.l.], 2018. R package version 1.42.1.Disponível em: <https://CRAN.R-project.org/package=MuMIn>.
BATES, D.; MAECHLER, M. Matrix: Sparse and Dense Matrix Classes and Methods.[S.l.], 2018. R package version 1.2-14. Disponível em: <https://CRAN.R-project.org/package=Matrix>.
BATES, D. M.; WATTS, D. G. Relative curvature measures of nonlinearity. Journal of theRoyal Statistical Society. Series B (Methodological), [Royal Statistical Society, Wiley], v. 42,n. 1, p. 1–25, 1980.
BELSLEY, D. A.; KUH, E.; WELSCH, R. E. Regression Diagnostics: Identifying InfluentialData and Sources of Collinearity. New York: John Wiley & Sons, 1980. (Wiley Series inProbability and Statistics).
BONAT, W. H.; JØRGENSEN, B. Multivariate covariance generalized linear models. Journalof the Royal Statistical Society: Series C (Applied Statistics), Wiley Online Library, v. 65,n. 5, p. 649–675, 2016.
BOURGUIGNON, M.; SANTOS-NETO, M.; CASTRO, M. de. A new regression model forpositive data. 2018. ArXiv:1804.07734.
BOURGUIGNON, M.; WEISS, C. H. An inar(1) process for modeling count time series withequidispersion, underdispersion and overdispersion. TEST, v. 26, n. 4, p. 847–868, 2017.
BRESLOW, N. E.; CLAYTON, D. G. Approximate inference in generalized linear mixedmodels. Journal of the American Statistical Association, [American Statistical Association,Taylor & Francis, Ltd.], v. 88, n. 421, p. 9–25, 1993.

83
CADIGAN, N. Local influence in structural equation models. Structural Equation Modeling:A Multidisciplinary Journal, Routledge, v. 2, n. 1, p. 13–30, 1995.
CADIGAN, N. G.; FARRELL, P. J. Generalized local influence with applications to fish stockcohort analysis. Journal of the Royal Statistical Society Series C, v. 51, p. 469–483, 2002.
CARDOSO, N. J. Testes para hipóteses restritas em desigualdades lineares usandoequações de estimação generalizadas. São Paulo: IME - USP. Tese de Doutorado, 2000.
CAREY, V. J.; LUMLEY, T.; RIPLEY., B. gee: Generalized Estimation Equation Solver.[S.l.], 2015. R package version 4.13-19. Disponível em: <https://CRAN.R-project.org/package=gee>.
CHANG, Y.-C. Residuals analysis of the generalized linear models for longitudinal data.Statistics in Medicine, v. 19, n. 10, p. 1277–1293, 2000.
CHATTERJEE, S.; HADI, A. S. Sensitivity Analysis in Linear Regression. New York: JohnWiley & Sons, 1988. (Wiley Series in Probability and Statistics).
CHEN, H. Initialization for norta: Generation of random vectors with specified marginals andcorrelations. INFORMS Journal on Computing, v. 13, n. 4, p. 312–331, 2001.
COOK, R. D. Detection of influential observation in linear regression. Technometrics, Taylor &Francis, v. 19, n. 1, p. 15–18, 1977.
COOK, R. D. Assessment of local influence. Journal of the Royal Statistical Society. SeriesB (Methodological), [Royal Statistical Society, Wiley], v. 48, n. 2, p. 133–169, 1986.
COOK, R. D.; WEISBERG, S. Residuals and Influence in Regression. New York:Chapman and Hall, 1982. (Retrieved from the University of Minnesota Digital Conservancy,http://hdl.handle.net/11299/37076).
COX, D. R.; SNELL, E. J. A general definition of residuals. Wiley for the Royal StatisticalSociety, v. 30, n. 2, p. 248–275, 1968.
CROWDER, M. On linear and quadratic estimating functions. Biometrika, [Oxford UniversityPress, Biometrika Trust], v. 74, n. 3, p. 591–597, 1987.
DAVISON, A. C.; GIGLI, A. Deviance residuals and normal scores plots. Biometrika, [OxfordUniversity Press, Biometrika Trust], v. 76, n. 2, p. 211–221, 1989.
DEMIDENKO, E. Mixed Models: Theory and Applications with R, 2nd Edition. New York:John Wiley & Sons, 2013. (Wiley Series in Probability and Statistics).
DIGGLE, P.; HEAGERTY, P.; LIANG, K.-Y.; ZEGER, L. S. Analysis of Longitudinal Data.Oxford: [s.n.], 1994. v. 25.
EMERSON, J. D.; HOAGLIN, D. C.; KEMPTHORNE, P. J. Leverage in least squaresadditive-plus-multiplicative fits for two-way tables. Journal of the American StatisticalAssociation, [American Statistical Association, Taylor & Francis, Ltd.], v. 79, n. 386, p.329–335, 1984.

84
GALDINO, M. V. Modelos lineares generalizados mistos e equações de estimaçãogeneralizadas para dados binário aplicados em anestesiologia veterinária. São Paulo:Universidade Estadual Paulista Júlio de Mesquita Filho, Instituto de Biociências de Botucatu.Dissertação de Mestrado, 2015.
GILBERTO, A.; CLOVIS, A. P. Diagnostics for glms with linear inequality parameterconstraints. Communications in Statistics - Theory and Methods, Taylor & Francis, v. 17,n. 12, p. 4205–4219, 1988.
GODAMBE, V.; KALE, B. (Ed.). Estimating functions: an overview. Oxford: EstimatingFunctions. (Ed. V.P. Godambe), Oxford University Press, 1991. 1–20 p.
GODAMBE, V. P. An optimum property of regular maximum likelihood estimation. The Annalsof Mathematical Statistics, Institute of Mathematical Statistics, v. 31, n. 4, p. 1208–1211,1960.
GODAMBE, V. P. (Ed.). Estimating Functions. Oxford: Oxford University Press, 1991.
GODAMBE, V. P. Estimating functions: A synthesis of least squares and maximum likelihoodmethods. Lecture Notes-Monograph Series, Institute of Mathematical Statistics, v. 32, p.5–15, 1997.
HARDIN, J.; HILBE, J. Generalized Estimating Equations (GEE). [S.l.]: Chapman andHall/CRC, 2012. v. 99.
HARVILLE, D. A. Matrix Algebra Form a Statistician’s Perspective. New York: Taylor &Francis Group, 1997.
HENDERSON, C. R. Estimation of variance and covariance components. Biometrics, [Wiley,International Biometric Society], v. 9, n. 2, p. 226–252, 1953.
HENDERSON, C. R.; KEMPTHORNE, O.; SEARLE, S. R.; KROSIGK, C. M. von. Theestimation of environmental and genetic trends from records subject to culling. Biometrics,[Wiley, International Biometric Society], v. 15, n. 2, p. 192–218, 1959.
HIN, L.-Y.; CAREY, V. J.; WANG, Y.-G. Criteria for working–correlation–structure selection ingee. The American Statistician, Taylor & Francis, v. 61, n. 4, p. 360–364, 2007.
HIN, L.-Y.; WANG, Y.-G. Working-correlation-structure identification in generalized estimatingequations. Statistics in Medicine, v. 28, n. 4, p. 642–658, 2009.
HOAGLIN, D. C.; WELSCH, R. E. The hat matrix in regression and anova. The AmericanStatistician, Taylor & Francis, v. 32, n. 1, p. 17–22, 1978.
JOE, H. Multivariate Models and Multivariate Dependence Concepts. [S.l.]: Chapman andHall/CRC, 1997. (Chapman & Hall/CRC Monographs on Statistics and Applied Probability).
JOWETT, G. H. The accuracy of systematic sampling from conveyor belts. Journal of theRoyal Statistical Society. Series C (Applied Statistics), [Wiley, Royal Statistical Society],v. 1, n. 1, p. 50–59, 1952.
JøRGENSEN, B.; LABOURIAU, R. Exponential Families and Theoretical Inference.Vancouver: Leture notes, University of British Columbia, 1994.

85
JøRGENSEN, B.; LUNDBYE-CHRISTENSEN, S.; SONG, P. X.-K.; SUN, L. State-spacemodels for multivariate longitudinal data of mixed types. The Canadian Journal of Statistics /La Revue Canadienne de Statistique, [Statistical Society of Canada, Wiley], v. 24, n. 3, p.385–402, 1996.
KULLBACK, S.; LEIBLER, R. A. On information and sufficiency. The Annals ofMathematical Statistics, Institute of Mathematical Statistics, v. 22, n. 1, p. 79–86, 1951.
LAIRD, N. M.; WARE, J. H. Random-effects models for longitudinal data. Biometrics, [Wiley,International Biometric Society], v. 38, n. 4, p. 963–974, 1982.
LAURENT, R. T. S.; COOK, R. D. Leverage and superleverage in nonlinear regression. Journalof the American Statistical Association, [American Statistical Association, Taylor & Francis,Ltd.], v. 87, n. 420, p. 985–990, 1992.
LESNOFF, M.; LANCELOT, R. aod: Analysis of Overdispersed Data. [S.l.], 2012. R packageversion 1.3. Disponível em: <http://cran.r-project.org/package=aod>.
LIANG, K.-Y.; ZEGER, S. L. Longitudinal data analysis using generalized linear models.Biometrika, [Oxford University Press, Biometrika Trust], v. 73, n. 1, p. 13–22, 1986.
LINDSTROM, M. J.; BATES, D. M. Nonlinear mixed effects models for repeated measures data.Biometrics, [Wiley, International Biometric Society], v. 46, n. 3, p. 673–687, 1990.
LIPSITZ, S. R.; LAIRD, N. M.; HARRINGTON, D. P. Generalized estimating equations forcorrelated binary data: Using the odds ratio as a measure of association. Biometrika, [OxfordUniversity Press, Biometrika Trust], v. 78, n. 1, p. 153–160, 1991.
LOBATO, D. Influência Local em Modelos de Regressão. Campina Grande: UFCG.Dissertação de Mestrado, 2005.
MCCULLAGH, P. Tensor methods in statistics. [S.l.]: Courier Dover Publications, 2018.
MCGULLAGH, P.; NELDER, J. A. Generalized Linear Models. London: 2nd edn, Chapmanand Hall, 2013.
MYERS, R. H.; MONTGOMERY, D. C.; VINING, G. G.; ROBINSON, T. J. GeneralizedLinear Models with Applications in Engineering and the Sciences. New York: 2 ed. , JohnWiley & Sons, inc., Hoboken, New Jersey, 2010.
NELDER, J. A.; WEDDERBURN, R. W. M. Generalized linear models. Journal of the RoyalStatistical Society A, n. 135, p. 370–84, 1972.
NETER, J.; KUTNER, M. H.; NASCHSTHEIM, C. J.; WASSERMAN, W. Applied LinearStatistical Models. Chicago: [s.n.], 1996.
OESSELMANN, C. C. Equações de estimação generalizadas com resposta binomialnegativa : modelando dados correlacionados de contagem com sobredispersão [online].[S.l.]: Instituto de Matemática e Estatística, Universidade de São Paulo. Dissertação de Mestrado,2016.
PAN, W. Akaike’s information criterion in generalized estimating equations. Biometrics, v. 57,n. 1, p. 120–125, 2001.

86
PARK, C. G.; PARK, T.; SHIN, D. W. A simple method for generating correlated binary variates.The American Statistician, [American Statistical Association, Taylor & Francis, Ltd.], v. 50,n. 4, p. 306–310, 1996.
PARK, C. G.; SHIN, D. W. An algorithm for generating correlated random variables in a class ofinfinitely divisible distributions. Journal of Statistical Computation and Simulation, Taylor& Francis, v. 61, n. 1-2, p. 127–139, 1998.
PAULA, A. G. Influence and residuals in restricte generalized linear models. Journal ofStatistical Computation and Simulation, Taylor & Francis, v. 51, n. 2-4, p. 315–331, 1995.
PAULA, G. A. Leverage in inequality-constrained regression models. Journal of the RoyalStatistical Society: Series D (The Statistician), v. 48, n. 4, p. 529–538, 1999.
PAULA, G. A. Modelos de regressão com apoio computacional. São Paulo: Departamento deEstatística. Universidade de São Paulo, 2013.
PHILIPSON, P.; SOUSA, I.; DIGGLE, P. J.; WILLIAMSON, P.; KOLAMUNNAGE-DONA, R.; HENDERSON, R.; HICKEY, G. L. joineR: Joint Modelling of RepeatedMeasurements and Time-to-Event Data. [S.l.], 2018. R package version 1.2.4. Disponívelem: <https://github.com/graemeleehickey/joineR/>.
PINHEIRO, J. C.; LIU, C.; WU, Y. N. Efficient algorithms for robust estimation in linearmixed-effects models using the multivariate t distribution. Journal of Computational andGraphical Statistics, Taylor & Francis, v. 10, n. 2, p. 249–276, 2001.
POON, W.-Y.; POON, Y. S. Conformal normal curvature and assessment of local influence.Journal of the Royal Statistical Society: Series B (Statistical Methodology), v. 61, n. 1, p.51–61, 2002.
PREGIBON, D. Logistic regression diagnostics. The Annals of Statistics, Institute ofMathematical Statistics, v. 9, n. 4, p. 705–724, 1981.
PREISSER, J. S.; QAQISH, B. F. Deletion diagnostics for generalised estimating equations.Biometrika, [Oxford University Press, Biometrika Trust], v. 83, n. 3, p. 551–562, 1996.
PRENTICE, R. L. Correlated binary regression with covariates specific to each binaryobservation. Biometrics, [Wiley, International Biometric Society], v. 44, n. 4, p. 1033–1048,1988.
PRENTICE, R. L.; ZHAO, L. P. Estimating equations for parameters in means and covariancesof multivariate discrete and continuous responses. Biometrics, [Wiley, International BiometricSociety], v. 47, n. 3, p. 825–839, 1991.
R Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria,2018. Disponível em: <https://www.R-project.org/>.
RAO, M. N.; RAO, C. R. Linked cross-sectional study for determining norms and growthrates: A pilot survey on indian school-going boys. Sankhya: The Indian Journal of Statistics,Series B (1960-2002), Springer, v. 28, n. 3/4, p. 237–258, 1966.
RAO, R. C. Large sample tests of statistical hypotheses concerning several parameterswith applications to problems of estimation. Mathematical Proceedings of the CambridgePhilosophical Society, Cambridge University Press, v. 44, n. 1, p. 50–57, 1948.

87
ROTNITZKY, A.; JEWELL, N. P. Hypothesis testing of regression parameters in semiparametricgeneralized linear models for cluster correlated data. Biometrika, [Oxford University Press,Biometrika Trust], v. 77, n. 3, p. 485–497, 1990.
SAVALLI, C.; PAULA, G. A.; CYSNEIROS, F. J. Assessment of variance components inelliptical linear mixed models. Statistical Modelling, v. 6, n. 1, p. 59–76, 2006.
SCHLOERKE, B.; CROWLEY, J.; COOK, D.; BRIATTE, F.; MARBACH, M.; THOEN, E.;ELBERG, A.; LARMARANGE, J. GGally: Extension to ’ggplot2’. [S.l.], 2018. R packageversion 1.4.0. Disponível em: <https://CRAN.R-project.org/package=GGally>.
SCHWARZMANN, B. A connection between local-influence analysis and residual diagnostics.Technometrics, Taylor & Francis, v. 33, n. 1, p. 103–104, 1991.
SEN, P. K.; SINGER, J. M. Large Sample Methods in Statistics: an introdution withapplications. Boca Raton: [s.n.], 1993.
SEN, P. K.; SINGER, J. M.; LIMA, A. C. Pedroso de. From Finite Sample to AsymptoticMethods in Statistics. Cambridge: Cambridge University Press, 2009. (Cambridge Series inStatistical and Probabilistic Mathematics).
SILVA, A. A. T. Influência local em modelos lineares generalizados mistos com variávelresposta discreta. São Paulo: IME - USP. Tese de Doutorado, 2014.
SINGER, J.; NOBRE, J.; ROCHA, F. Análise de Dados Longitudinais (versão parcialpreliminar). [S.l.: s.n.], 2017.
SINGER, J. M.; ANDRADE, D. F. 5 analysis of longitudinal data. In: Bioenvironmental andPublic Health Statistics. [S.l.]: Elsevier, 2000, (Handbook of Statistics, v. 18). p. 115 – 160.
TAN, M.; QU, Y.; H.KUTNER, M. Model diagnostics for marginal regression analysis ofcorrelated binary data. Communications in Statistics - Simulation and Computation, Taylor& Francis, v. 26, n. 2, p. 539–558, 1997.
THOMAS, W.; COOK, R. D. Assessing influence on regression coefficients in generalized linearmodels. Biometrika, [Oxford University Press, Biometrika Trust], v. 76, n. 4, p. 741–749, 1989.
VENEZUELA, M. K. Modelos Lineares Generalizados para Análise de Dados comMedidas Repetidas. São Paulo: IME - USP. Dissertação de Mestrado, 2003.
VENEZUELA, M. K. Equação de estimação generalizada e influência local para modelosde regressão beta com medidas repetidas. São Paulo: IME - USP. Tese de Doutorado, 2008.
VENEZUELA, M. K.; BOTTER, D. A.; SANDOVAL, M. C. Diagnostic techniques ingeneralized estimating equations. Journal of Statistical Computation and Simulation, Taylor& Francis, v. 77, n. 10, p. 879–888, 2007.
VENEZUELA, M. K.; SANDOVAL, M. C.; BOTTER, D. A. Local influence in estimatingequations. Computational Statistics & Data Analysis, v. 55, n. 4, p. 1867 – 1883, 2011.
VERBEKE, G.; MOLENBERGHS, G. Linear Mixed Models for Longitudinal Data. NewYork: [s.n.], 2000.

88
VONESH, E.; CHINCHILLI, V. M. Linear and nonlinear models for the analysis ofrepeated measurements. Boca Raton: CRC press, 1996.
WALD, A. Tests of statistical hypotheses concerning several parameters when the numberof observations is large. Transactions of the American Mathematical Society, AmericanMathematical Society, v. 54, n. 3, p. 426–482, 1943.
WARE, J. H. Linear models for the analysis of longitudinal studies. The American Statistician,[American Statistical Association, Taylor & Francis, Ltd.], v. 39, n. 2, p. 95–101, 1985.
WEI, B.-C.; HU, Y.-Q.; FUNG, W.-K. Generalized leverage and its applications. ScandinavianJournal of Statistics, v. 25, n. 1, p. 25–37, 1998.
WICKHAM, H. tidyverse: Easily Install and Load the ’Tidyverse’. [S.l.], 2017. R packageversion 1.2.1. Disponível em: <https://CRAN.R-project.org/package=tidyverse>.
WILLIAMS, D. A. Residuals in generalized linear models. In: Proceedings of the 12th.International Biometrics Conference, Tokyo, p. 59–68, 1984.
WILLIAMS, D. A. Generalized linear model diagnostics using the deviance and single casedeletions. Journal of the Royal Statistical Society. Series C (Applied Statistics), [Wiley,Royal Statistical Society], v. 36, n. 2, p. 181–191, 1987.
WILLIAMSON, P.; KOLAMUNNAGE-DONA, R.; PHILIPSON, P.; MARSON, A. G. Jointmodelling of longitudinal and competing risks data. Statistics in Medicine, v. 27, p. 6426–6438,2008.
ZEGER, S. L.; DIGGLE, P. J. Semiparametric models for longitudinal data with application tocd4 cell numbers in hiv seroconverters. Biometrics, [Wiley, International Biometric Society],v. 50, n. 3, p. 689–699, 1994.

89
APÊNDICE A – DETALHES PARA OBTENÇÃO DAS MEDIDAS DE INFLUÊNCIA
LOCAL
Neste apêndice apresentamos de forma detalhada os cálculos desenvolvidos em
Venezuela et al. (2011) para obtenção das medidas de influência local sob a ótica dos MLGs
apresentadas na seção 3.5.
No caso em que estamos trabalhando temos que θθθ = βββ = (βββ 111, . . . ,βββ ppp), e ∆∆∆ é uma
matriz p×N, em que N = nt, dada por:
∆∆∆ =∂ΨΨΨ(((βββ |||ωωω)))
∂ωωω>>>=
(∂ΨΨΨ(((βββ |||ωωω)))
∂ω11
∂ΨΨΨ(((βββ |||ωωω)))
∂ω12. . .
∂ΨΨΨ(((βββ |||ωωω)))
∂ωnt
), (A.1)
avaliada em βββ , φ e ωωω000, em que ωωω = (ωωω>>>111 , . . . ,ωωω>>>nnn )>, com ωωω iii = (ωi1, . . . ,ωit)
>, i = 1, . . . ,n.
A.1 Perturbação da variável resposta
Considerando o esquema de perturbação dado em (3.14), temos que
uωi j = yωi j−µi j, (A.2)
em que
yωi j = yi j +ωi j
√Var(yi j).
Logo, a matriz (A.1) pode ser expressa por ∆∆∆ = XXX>>>WWWΛΛΛ−1B, sendo
B =∂uuuω
∂ωωω>>>=
(∂uuuω
∂ω11
∂uuuω
∂ω12. . .
∂uuuω
∂ωnt
),
avaliada em βββ , φ e ωωω000. Assim, a derivada de (A.2) com relação à perturbação ωi j é dada por
∂uωi j
ωi j=
∂ (yi j +ωi j√
Var(yi j)−µi j)
∂ωi j=√
Var(yi j) = si j,
com i = 1, . . . ,n e j = 1, . . . , t.

90
A.2 Perturbação individual das covariáveis
De (3.17), as derivadas de ΛΛΛωi,,,ΩΩΩωi e uuuωi todas com relação a ωωω>>>iii são dadas por
∂ΩΩΩωi
∂ωωω>>>iii=
∂
[φ−1AAA1/2
ωi RRR(((ααα)))AAA1/2ωi
]∂ωωω>>>iii
= φ−1
[AAA1/2
ωi RRR(((ααα)))∂AAA1/2
ωi
∂ωωω>>>i+
∂AAA1/2ωi
∂ωωω>>>iAAA1/2
ωi RRR(((ααα)))
]e
∂uuuωi
∂ωωω>>>iii=
∂ (((yyyiii−−−µµµωi)
∂ωωω>>>iii=−∂ µµµωi
∂ωωω>>>iii,
em que
∂AAAωi
∂ωωω>>>iii= diag
(∂aωi1
∂ωi1, . . . ,
∂aωit
∂ωit
),
∂ΛΛΛωi
∂ωωω>>>iii= diag
(∂
∂ωi1
[∂ µωi1
∂ηωi1
], . . . ,
∂
∂ωit
[∂ µωit
∂ηωit
])e
∂ µµµωi
∂ωωω>>>iii= diag
(∂ µωi1
∂ωi1, . . . ,
∂ µωit
∂ωit
),
sendo
∂aωi j
∂ωi j=
∂v(µωi j)
∂ µωi j
∂ µωi j
∂ωi j,
∂
∂ωi1
[∂ µωi j
∂ηωi j
]=
∂ 2µωi j
∂η2ωi j
βksxk,
∂a1/2ωi j
∂ωi j=
12
a−1/2ωi j
∂aωi j
∂ωi je
∂ µωi j
∂ωi j=
∂ µωi j
∂ηωi jβksxk,
com i = 1, . . . ,n, j = 1, . . . , t e k representa a coluna de XXX com perturbação, k = 2, . . . , p.
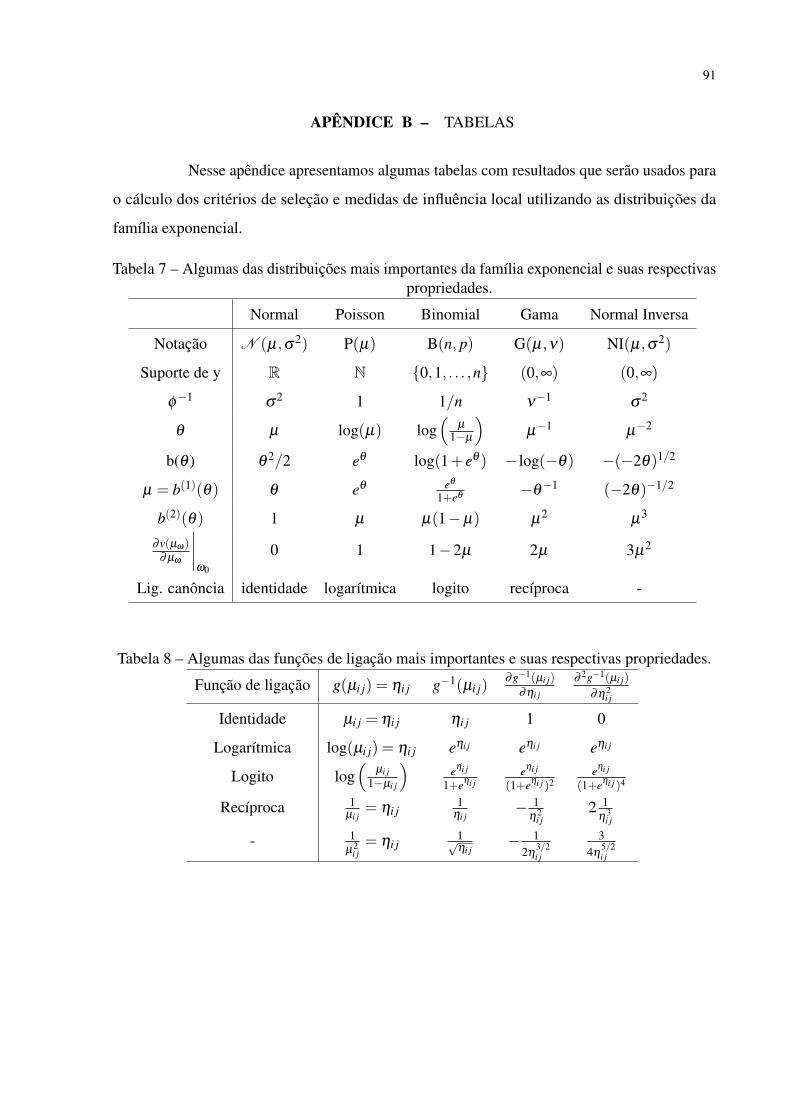
91
APÊNDICE B – TABELAS
Nesse apêndice apresentamos algumas tabelas com resultados que serão usados para
o cálculo dos critérios de seleção e medidas de influência local utilizando as distribuições da
família exponencial.
Tabela 7 – Algumas das distribuições mais importantes da família exponencial e suas respectivaspropriedades.
Normal Poisson Binomial Gama Normal Inversa
Notação N (µ,σ2) P(µ) B(n, p) G(µ,ν) NI(µ,σ2)
Suporte de y R N 0,1, . . . ,n (0,∞) (0,∞)
φ−1 σ2 1 1/n ν−1 σ2
θ µ log(µ) log(
µ
1−µ
)µ−1 µ−2
b(θ ) θ 2/2 eθ log(1+ eθ ) − log(−θ) −(−2θ)1/2
µ = b(1)(θ) θ eθ eθ
1+eθ −θ−1 (−2θ)−1/2
b(2)(θ) 1 µ µ(1−µ) µ2 µ3
∂v(µω )∂ µω
∣∣∣∣ω0
0 1 1−2µ 2µ 3µ2
Lig. canôncia identidade logarítmica logito recíproca -
Tabela 8 – Algumas das funções de ligação mais importantes e suas respectivas propriedades.
Função de ligação g(µi j) = ηi j g−1(µi j)∂g−1(µi j)
∂ηi j
∂ 2g−1(µi j)
∂η2i j
Identidade µi j = ηi j ηi j 1 0
Logarítmica log(µi j) = ηi j eηi j eηi j eηi j
Logito log(
µi j1−µi j
)eηi j
1+eηi jeηi j
(1+eηi j )2eηi j
(1+eηi j )4
Recíproca 1µi j
= ηi j1
ηi j− 1
η2i j
2 1η3
i j
- 1µ2
i j= ηi j
1√ηi j
− 12η
3/2i j
34η
5/2i j
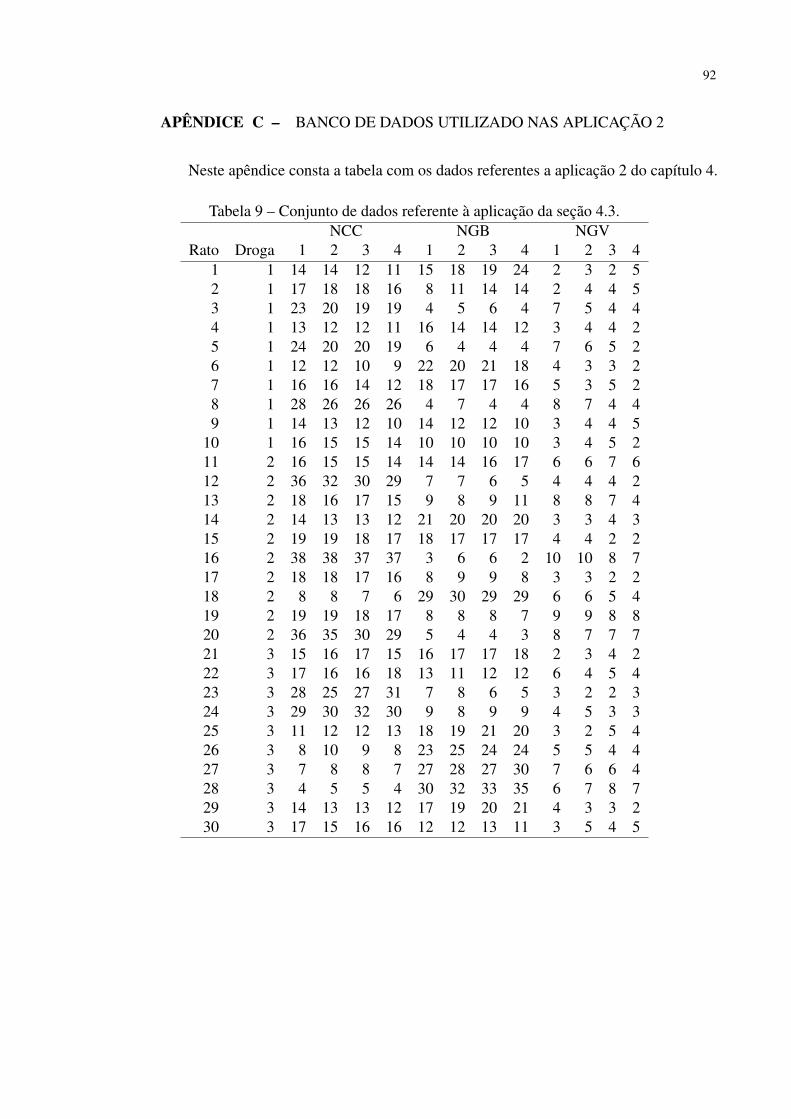
92
APÊNDICE C – BANCO DE DADOS UTILIZADO NAS APLICAÇÃO 2
Neste apêndice consta a tabela com os dados referentes a aplicação 2 do capítulo 4.
Tabela 9 – Conjunto de dados referente à aplicação da seção 4.3.NCC NGB NGV
Rato Droga 1 2 3 4 1 2 3 4 1 2 3 41 1 14 14 12 11 15 18 19 24 2 3 2 52 1 17 18 18 16 8 11 14 14 2 4 4 53 1 23 20 19 19 4 5 6 4 7 5 4 44 1 13 12 12 11 16 14 14 12 3 4 4 25 1 24 20 20 19 6 4 4 4 7 6 5 26 1 12 12 10 9 22 20 21 18 4 3 3 27 1 16 16 14 12 18 17 17 16 5 3 5 28 1 28 26 26 26 4 7 4 4 8 7 4 49 1 14 13 12 10 14 12 12 10 3 4 4 5
10 1 16 15 15 14 10 10 10 10 3 4 5 211 2 16 15 15 14 14 14 16 17 6 6 7 612 2 36 32 30 29 7 7 6 5 4 4 4 213 2 18 16 17 15 9 8 9 11 8 8 7 414 2 14 13 13 12 21 20 20 20 3 3 4 315 2 19 19 18 17 18 17 17 17 4 4 2 216 2 38 38 37 37 3 6 6 2 10 10 8 717 2 18 18 17 16 8 9 9 8 3 3 2 218 2 8 8 7 6 29 30 29 29 6 6 5 419 2 19 19 18 17 8 8 8 7 9 9 8 820 2 36 35 30 29 5 4 4 3 8 7 7 721 3 15 16 17 15 16 17 17 18 2 3 4 222 3 17 16 16 18 13 11 12 12 6 4 5 423 3 28 25 27 31 7 8 6 5 3 2 2 324 3 29 30 32 30 9 8 9 9 4 5 3 325 3 11 12 12 13 18 19 21 20 3 2 5 426 3 8 10 9 8 23 25 24 24 5 5 4 427 3 7 8 8 7 27 28 27 30 7 6 6 428 3 4 5 5 4 30 32 33 35 6 7 8 729 3 14 13 13 12 17 19 20 21 4 3 3 230 3 17 15 16 16 12 12 13 11 3 5 4 5


















