
índices en bases de datos
130
1 Índices http://es.wikipedia.org/wiki/Indexar BASES DE DATOS JOSÉ CUARTAS José Andrés Cuartas Muñoz
-
Upload
josecuartas -
Category
Education
-
view
6.079 -
download
1
Transcript of índices en bases de datos

1
Índiceshttp://es.wikipedia.org/wiki/Indexar
BASES DE DATOSJOSÉ CUARTAS
José Andrés Cuartas Muñoz
2
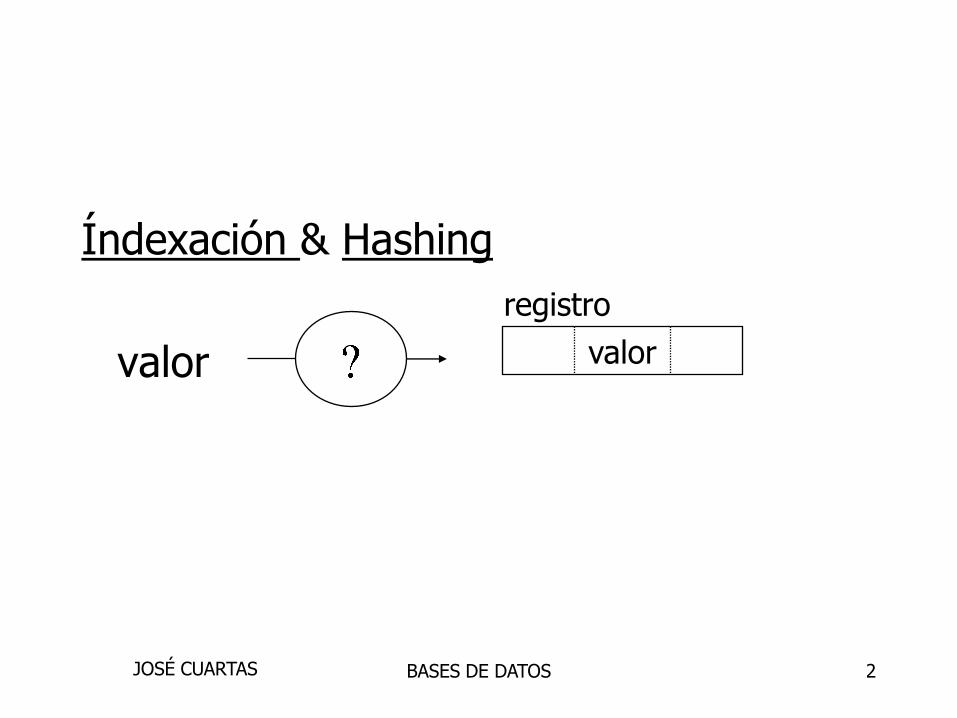
Índexación & Hashing
valor valor
registro
BASES DE DATOSJOSÉ CUARTAS

3
Tópicos
• Indices convencionales
• B-trees
• Esquema Hashing
BASES DE DATOSJOSÉ CUARTAS

4
Archivo secuencial
2010
4030
6050
8070
10090
• Se organizan por un campo de ordenacióngeneralmente claves primarias o únicas
BASES DE DATOSJOSÉ CUARTAS

5
Archivo de datos secuencial
2010
4030
6050
8070
10090
Índice denso
10203040
50607080
90100110120
bloque
• Se tiene una entradaen un registro en uno de los bloquesdel archivo de índices por cadaentrada en al archivo de datos
• En este tipo de índicese tiene un valor clave y un puntero al registro.
• por se tan pequeño se mantiene en el buffer
BASES DE DATOSJOSÉ CUARTAS
Puntero a registro

6
2010
4030
6050
8070
10090
Índice no denso
10305070
90110130150
170190210230
Archivo de datos secuencial
• Se tiene una entradaen un registro en uno de los bloquesdel archivo de índices por cadabloque en al archivo de datos
BASES DE DATOSJOSÉ CUARTAS
Puntero a bloque
7
2010
4030
6050
8070
10090
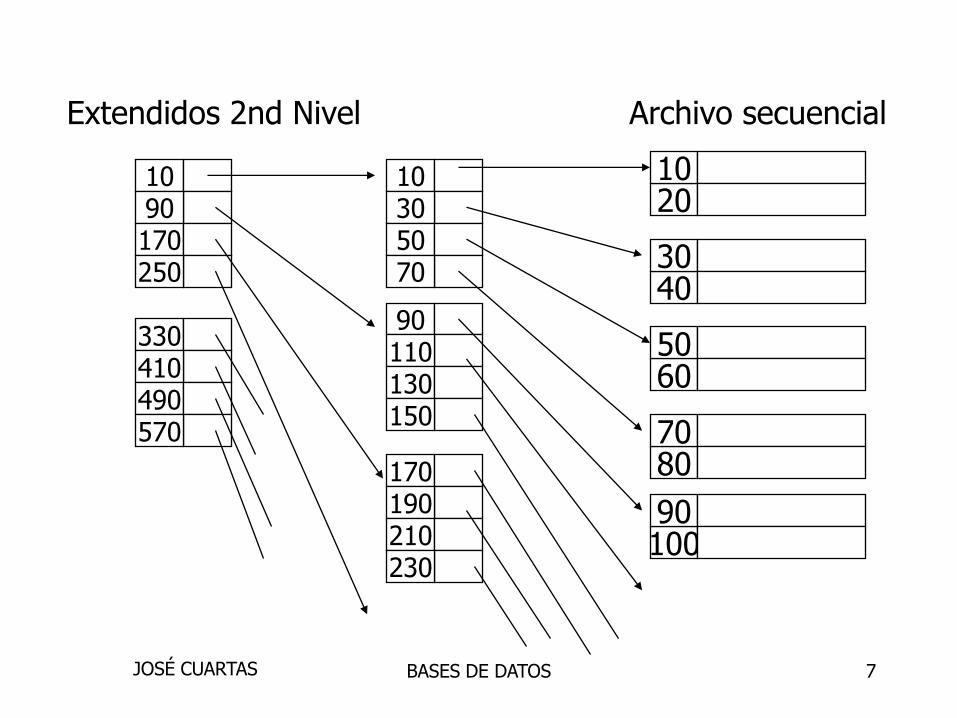
Extendidos 2nd Nivel
10305070
90110130150
170190210230
1090170250
330410490570
Archivo secuencial
BASES DE DATOSJOSÉ CUARTAS

8
• Comentarios:
{ARCHIVO,INDICES} pueden ser contiguos
o no (Bloques encadenados)
BASES DE DATOSJOSÉ CUARTAS

9
Notas sobre punteros:
(1) Punteros a bloque (índice no denso) pueden ser mas pequeños que un puntero a registro
BP
RP
BASES DE DATOSJOSÉ CUARTAS

10
(2)Si el archivo es contiguo , entonces se puede omitir los punteros (e.j, computación)
Notas sobre punteros:
BASES DE DATOSJOSÉ CUARTAS
11
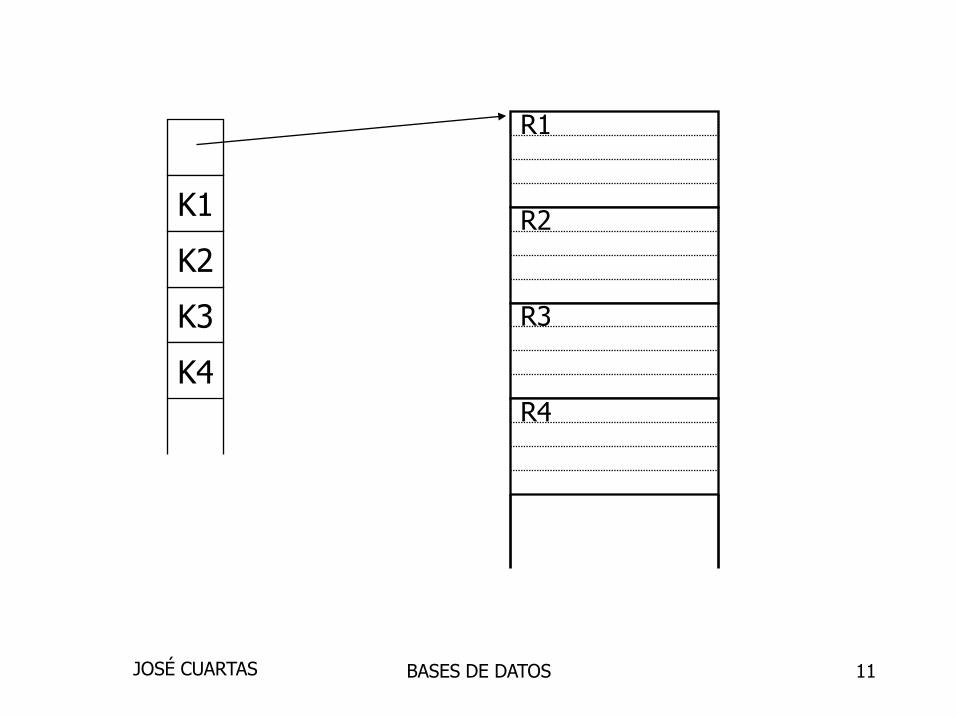
K1
K3
K4
K2
R1
R2
R3
R4
BASES DE DATOSJOSÉ CUARTAS

12
K1
K3
K4
K2
R1
R2
R3
R4
dice:1024 BPor bloque
• Si se desea el bloque K3:consigue el desplazamiento(3-1)1024= 2048 bytes
BASES DE DATOSJOSÉ CUARTAS

13
No densos vs. Densos
• No denso o agrupados: Menos espacio porregistro del índice, esto permite mas almacenamiento de indices en la memoria
• Denso: Se puede saber si existe algún registro sin acceso al archivo
(Mas tarde:
– No denso mejor para inserciones– Denso necesarios para índice secundario)
BASES DE DATOSJOSÉ CUARTAS

14
Términos
• Archivo de indice secuencial
• Clave de búsqueda ( Clave primaria)
• Índice primario (en archivo secuencial)
• Índice secundario
• Índice denso (Para cada dato una clave de búsqueda)
• Índice no denso o índice de agrupamiento
• Índice multiple-nivel
BASES DE DATOSJOSÉ CUARTAS

15
Siguiente:
• Claves de búsqueda duplicadas
• Eliminación/Inserción
• Índice secundario
BASES DE DATOSJOSÉ CUARTAS

16
Claves duplicadas
1010
2010
3020
3030
4540
BASES DE DATOSJOSÉ CUARTAS

17
1010
2010
3020
3030
4540
10101020
20303030
1010
2010
3020
3030
4540
10101020
20303030
Índice denso, una posible implementación?
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS

18
1010
2010
3020
3030
4540
10203040
Índice denso, un mejor posibilidad?
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS

19
1010
2010
3020
3030
4540
10102030
Índice no denso, una posibilidad?
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS
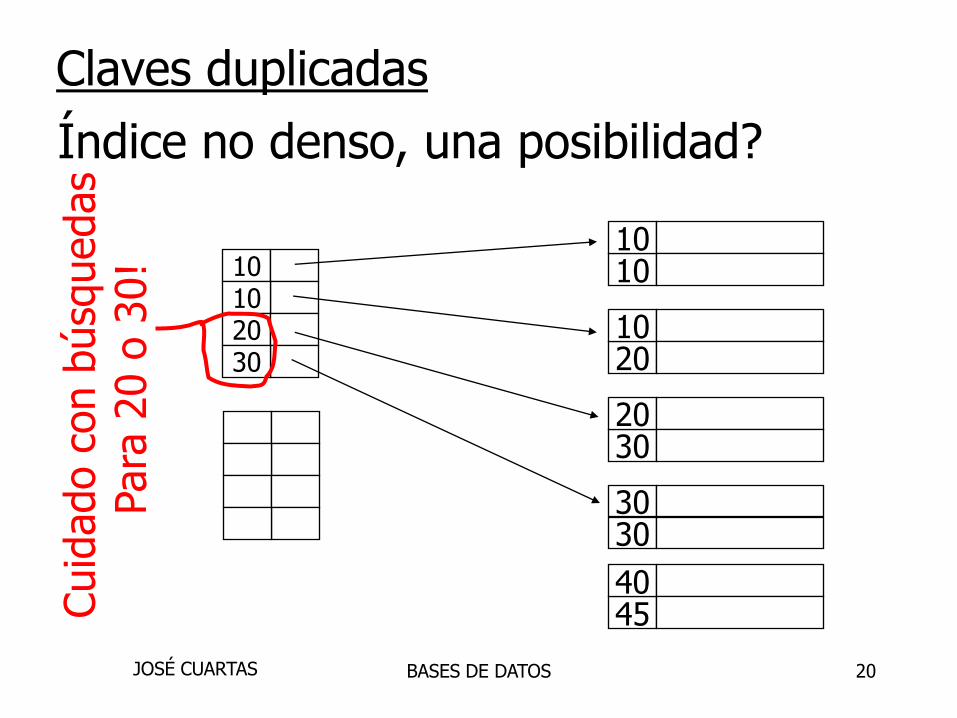
20
1010
2010
3020
3030
4540
10102030
Índice no denso, una posibilidad?
Cuid
ado
con b
úsq
uedas
Para
20 o
30!
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS

21
1010
2010
3020
3030
4540
10203030
Índice no denso, otra posibilidad?– Primer lugar de la nueva clave de bloque
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS
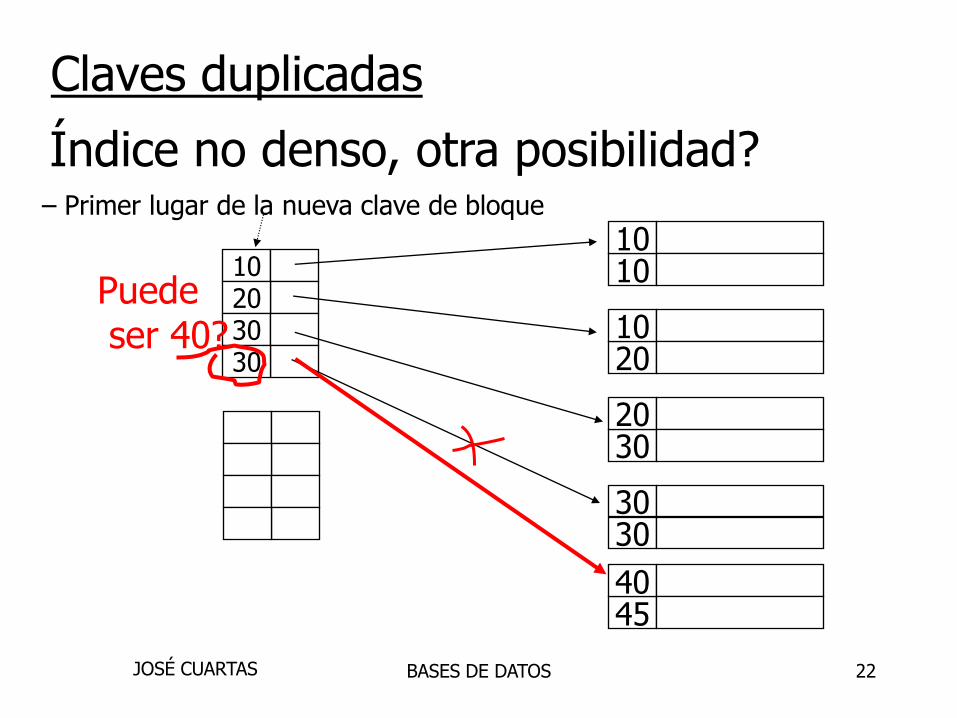
22
1010
2010
3020
3030
4540
10203030
Índice no denso, otra posibilidad?
Puedeser 40?
Claves duplicadas
BASES DE DATOSJOSÉ CUARTAS
– Primer lugar de la nueva clave de bloque
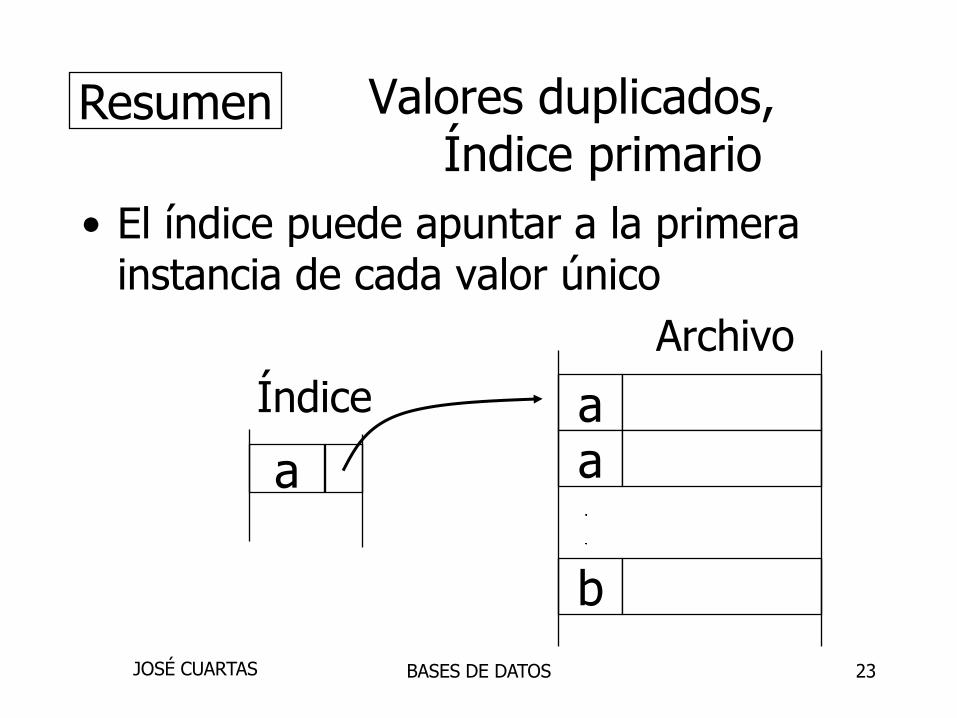
23
Valores duplicados, Índice primario
• El índice puede apuntar a la primerainstancia de cada valor único
Archivo
Índice
Resumen
a
aa
b
BASES DE DATOSJOSÉ CUARTAS

24
Eliminación de índice no densos
2010
4030
6050
8070
10305070
90110130150
BASES DE DATOSJOSÉ CUARTAS
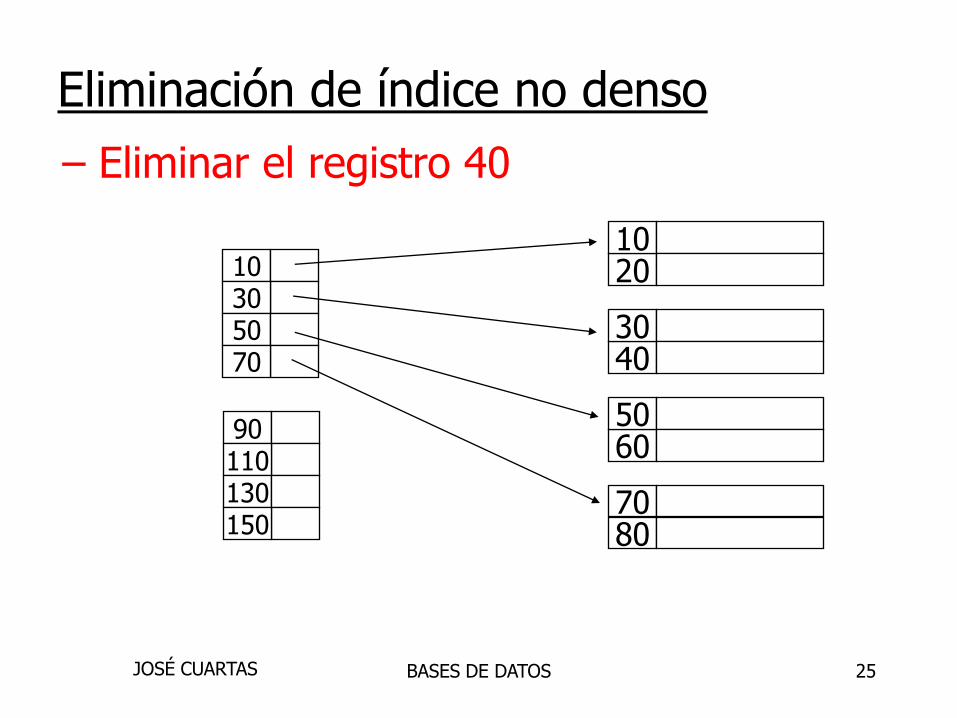
25
2010
4030
6050
8070
10305070
90110130150
– Eliminar el registro 40
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice no denso

26
2010
4030
6050
8070
10305070
90110130150
– Eliminar el registro 40
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice no denso

27
2010
4030
6050
8070
10305070
90110130150
– Eliminar el registro 30
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice no denso

28
2010
4030
6050
8070
10305070
90110130150
– Elimina el registro 30
4040
Eliminación de índice no denso
BASES DE DATOSJOSÉ CUARTAS

29
2010
4030
6050
8070
10305070
90110130150
– Elimina los registros 30 y 40
Eliminación de índices no densos
BASES DE DATOSJOSÉ CUARTAS
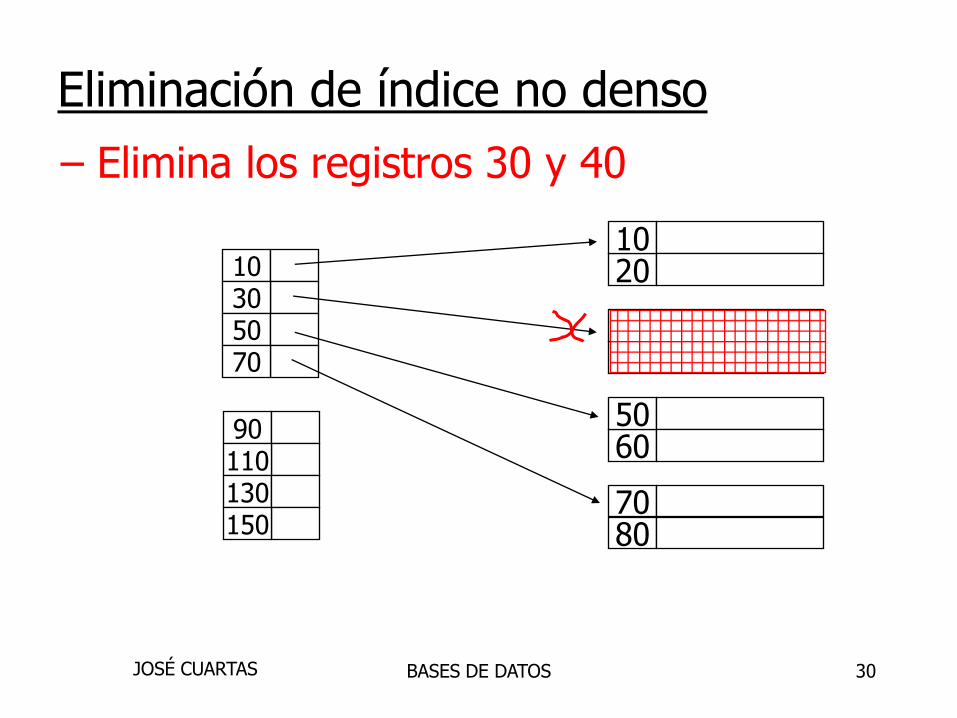
30
2010
4030
6050
8070
10305070
90110130150
– Elimina los registros 30 y 40
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice no denso

31
2010
4030
6050
8070
10305070
90110130150
50
70
– Elimina los registros 30 y 40
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice no denso

32
2010
4030
6050
8070
10203040
50607080
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice denso

33
2010
4030
6050
8070
10203040
50607080
– Eliminar registro 30
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice denso

34
2010
4030
6050
8070
10203040
50607080
40
– Eliminar registro 30
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice denso

35
2010
4030
6050
8070
10203040
50607080
4040
– Eliminar registro 30
BASES DE DATOSJOSÉ CUARTAS
Eliminación de índice denso

36
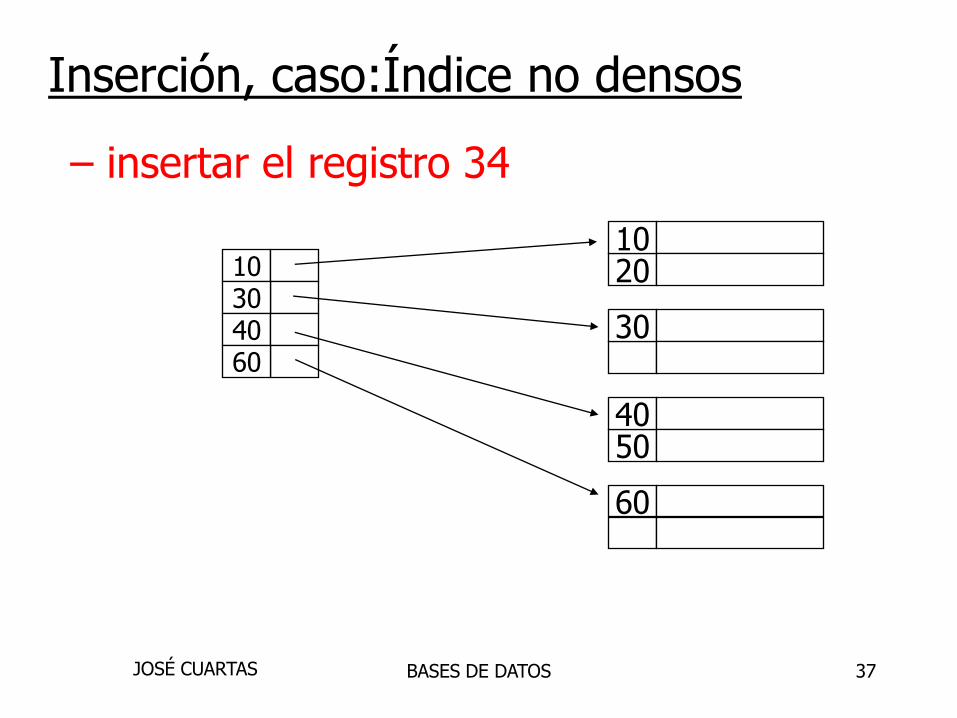
2010
30
5040
60
10304060
Inserción, caso:Índice no densos
BASES DE DATOSJOSÉ CUARTAS
37
2010
30
5040
60
10304060
– insertar el registro 34
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

38
2010
30
5040
60
10304060 34
• que buena suerte!se tiene espacio libre
donde se nesecita
– insertar el registro 34
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

39
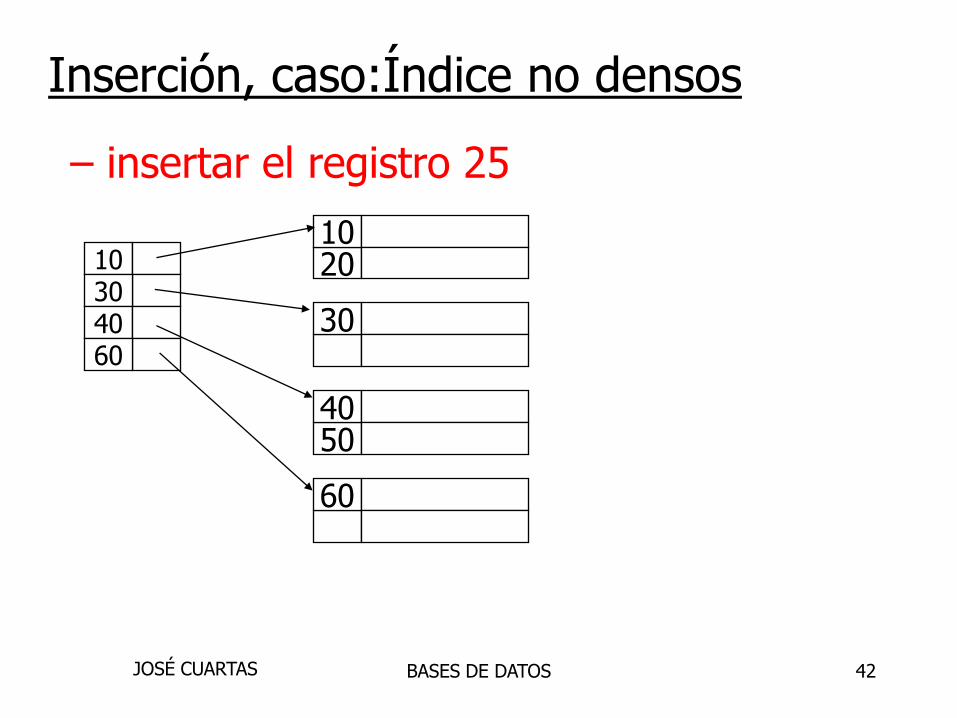
2010
30
5040
60
10304060
– insertar el registro 15
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

40
2010
30
5040
60
10304060
15
2030
20
– insertar el registro 15
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

41
2010
30
5040
60
10304060
15
2030
20
• Inmediata reoganización• Variación:
– inserta un nuevo bloque (archivo encadenado)– actualiza el índice
– insertar el registro 15
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos
42
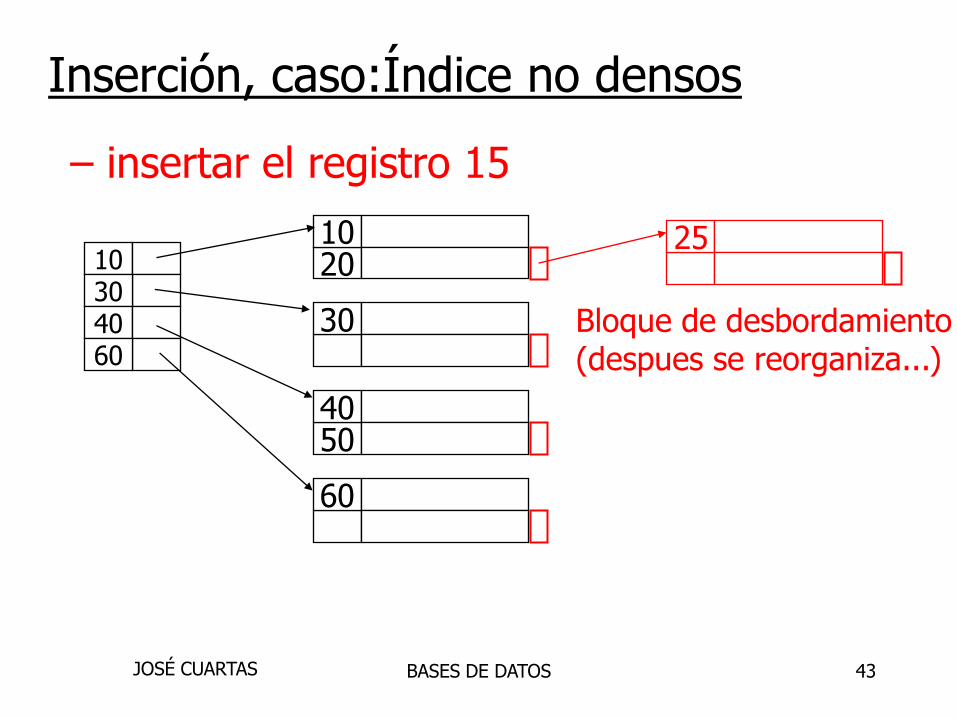
2010
30
5040
60
10304060
– insertar el registro 25
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos
43
2010
30
5040
60
10304060
25
Bloque de desbordamiento(despues se reorganiza...)
– insertar el registro 15
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

44
• Similar
• es mas costoso . . .
BASES DE DATOSJOSÉ CUARTAS
Inserción, caso:Índice no densos

45
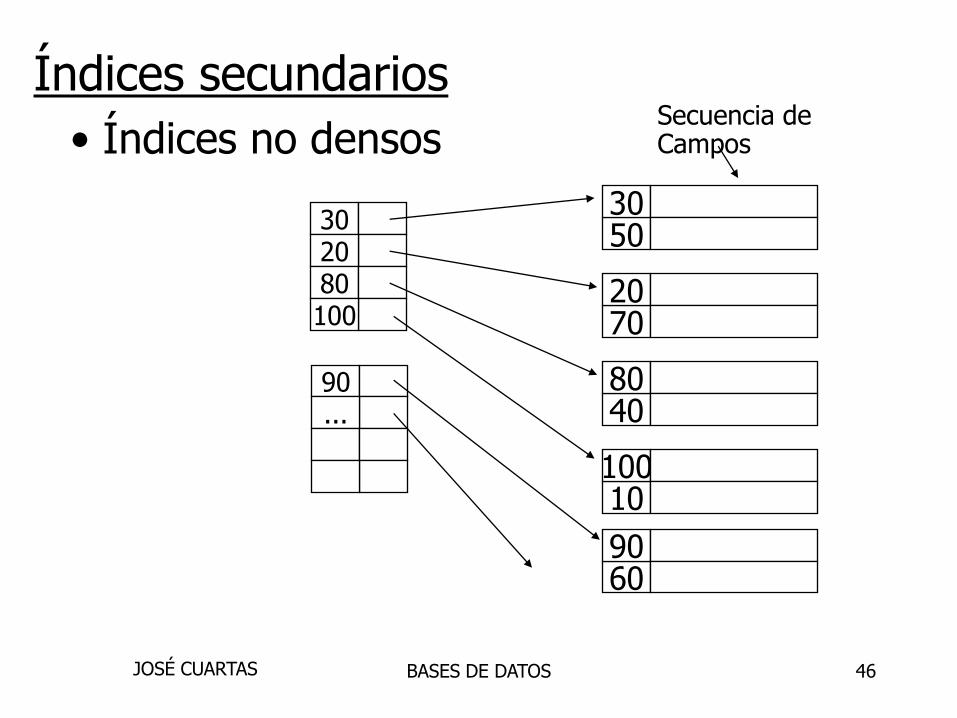
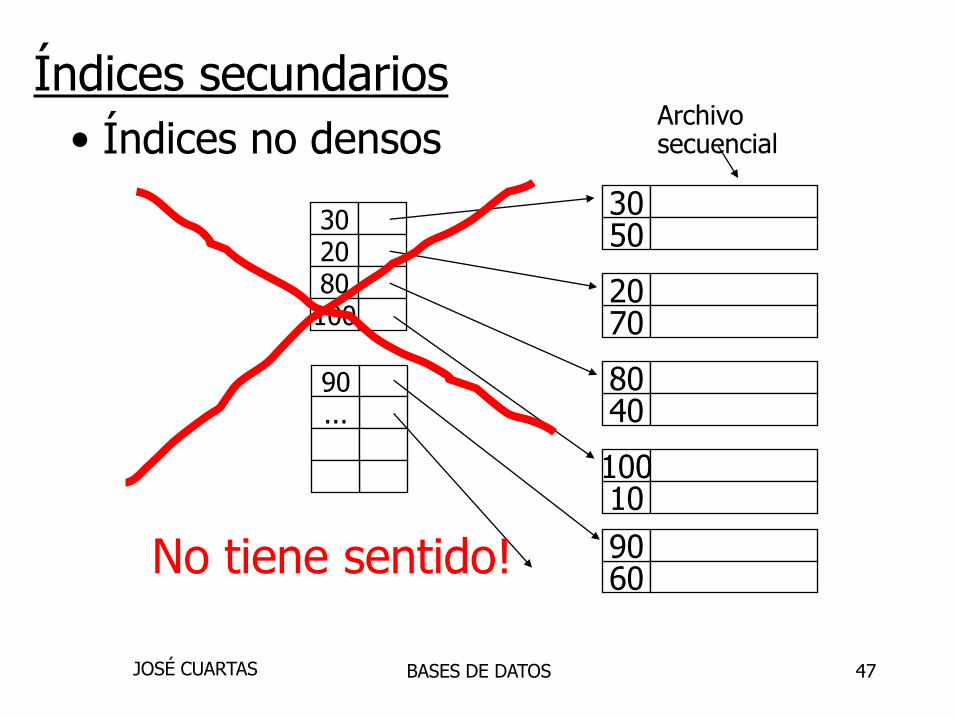
Índices secundarios
5030
7020
4080
10100
6090
Secuencia deCampos
BASES DE DATOSJOSÉ CUARTAS
• Este índice no determina el lugar
del regitro en el archivo de datos.
• Siempre son densos en el ultimo nivel
• Se pueden crear varios índices secundarios
• Demasiado costo en las operaciones….
• Cuando se usa un índice secundario se cambia
la vista de los registros, su localidad física
no cambia.
46
Secuencia deCampos
5030
7020
4080
10100
6090
302080100
90...
Índices secundarios
• Índices no densos
BASES DE DATOSJOSÉ CUARTAS
47
5030
7020
4080
10100
6090
• Índices no densos
302080100
90...
No tiene sentido!
Índices secundariosArchivosecuencial
BASES DE DATOSJOSÉ CUARTAS

48
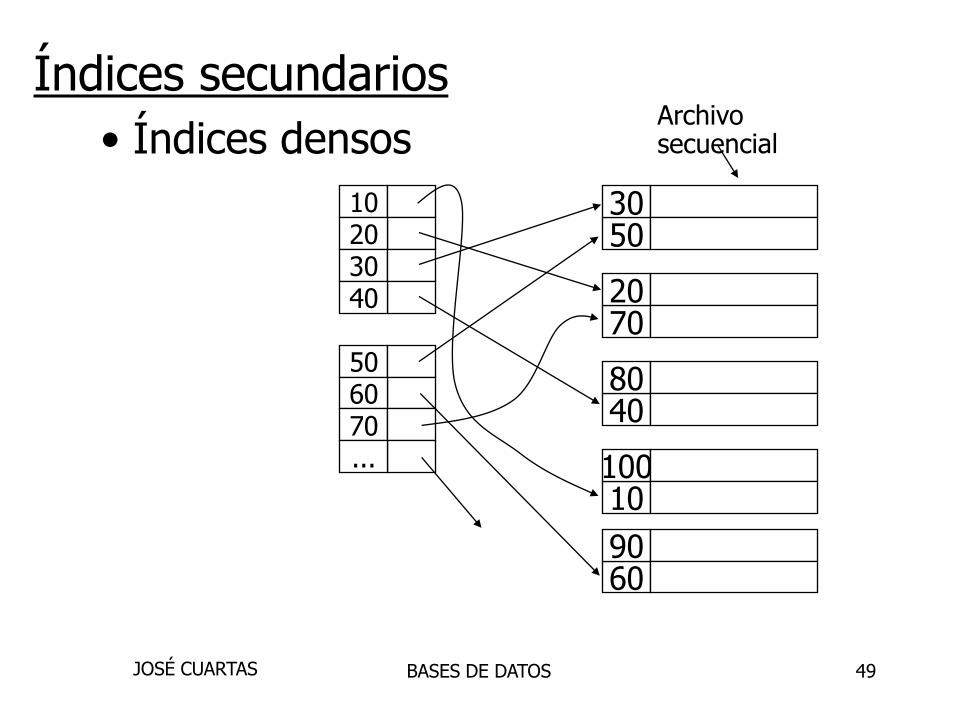
Archivosecuencial
5030
7020
4080
10100
6090
• Índices densos
Índices secundarios
BASES DE DATOSJOSÉ CUARTAS
49
5030
7020
4080
10100
6090
10203040
506070...
Archivosecuencial
Índices secundarios
• Índices densos
BASES DE DATOSJOSÉ CUARTAS
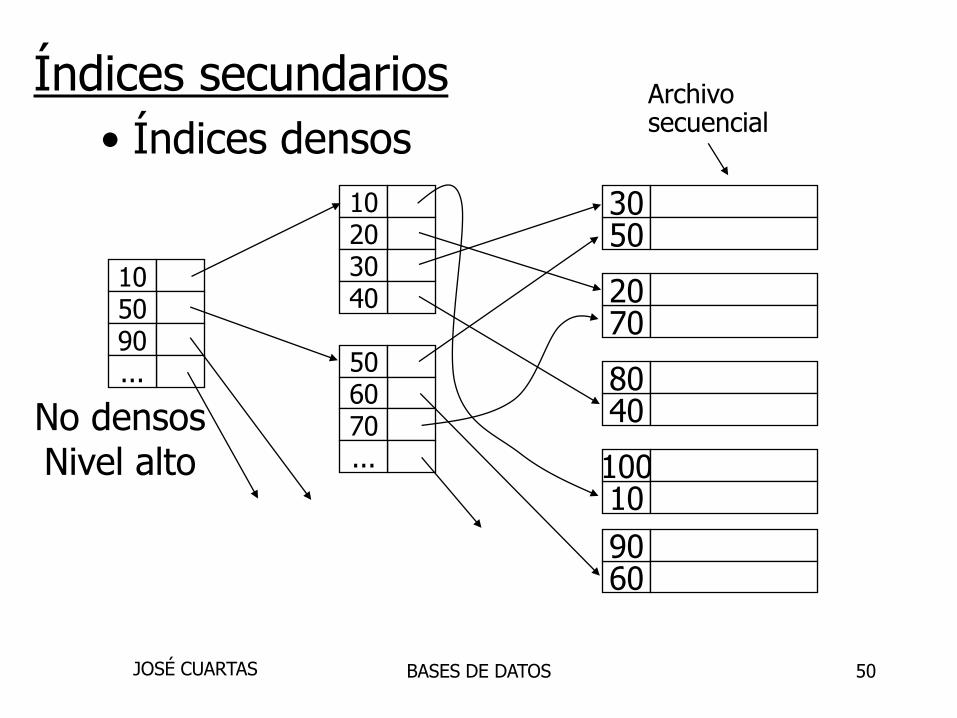
50
5030
7020
4080
10100
6090
10203040
506070...
105090...
No densosNivel alto
Archivosecuencial
Índices secundarios
• Índices densos
BASES DE DATOSJOSÉ CUARTAS

51
Con los índices secundarios:
• El nivel bajo es denso
• Los otros niveles son no densos
También: Punteros son punteros a registro(no punteros a bloques; no se computan)
BASES DE DATOSJOSÉ CUARTAS

52
Valores duplicados & Índices secundarios
1020
4020
4010
4010
4030
BASES DE DATOSJOSÉ CUARTAS

53
1020
4020
4010
4010
4030
10101020
20304040
4040...
Valores duplicados & Índices secundarios
Una opción...
BASES DE DATOSJOSÉ CUARTAS

54
1020
4020
4010
4010
4030
10101020
20304040
4040...
Una opción...
Problema:Exceso sobrencabezado!
• espacio en disco• tiempo de búsqueda
Valores duplicados & Índices secundarios
BASES DE DATOSJOSÉ CUARTAS

55
1020
4020
4010
4010
4030
10
Otra opción...
40
30
20
Valores duplicados & Índices secundarios
BASES DE DATOSJOSÉ CUARTAS

56
1020
4020
4010
4010
4030
10
Otra opción...
40
30
20
Problema:Registro de tamañovariable en losíndices!
Valores duplicados & Indices secundarios
BASES DE DATOSJOSÉ CUARTAS
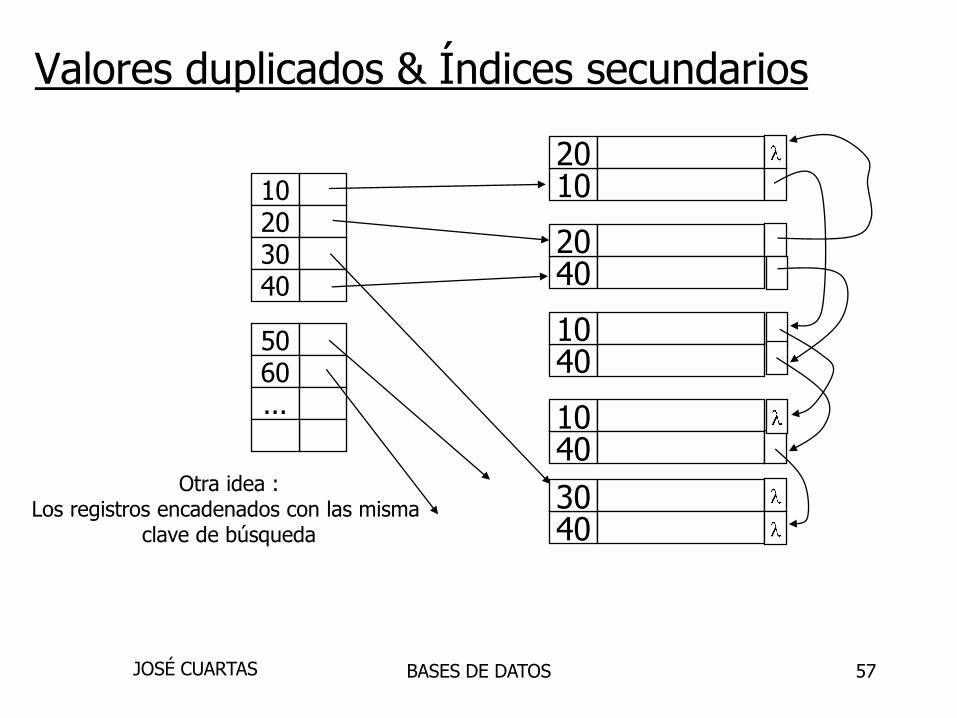
57
1020
4020
4010
4010
4030
10203040
5060...
Otra idea :Los registros encadenados con las misma
clave de búsqueda
Valores duplicados & Índices secundarios
BASES DE DATOSJOSÉ CUARTAS

58
1020
4020
4010
4010
4030
10203040
5060...
Problemas:• Nesecita adicionar campos al registro• Nesecita llevar el seguimento de los campos
Valores duplicados & Índices secundarios
BASES DE DATOSJOSÉ CUARTAS
Otra idea :Los registros encadenados con las misma
clave de búsqueda

59
1020
4020
4010
4010
4030
10203040
5060...
Nivel intermedio de indirección
Valores duplicados & Índices secundarios
BASES DE DATOSJOSÉ CUARTAS

60
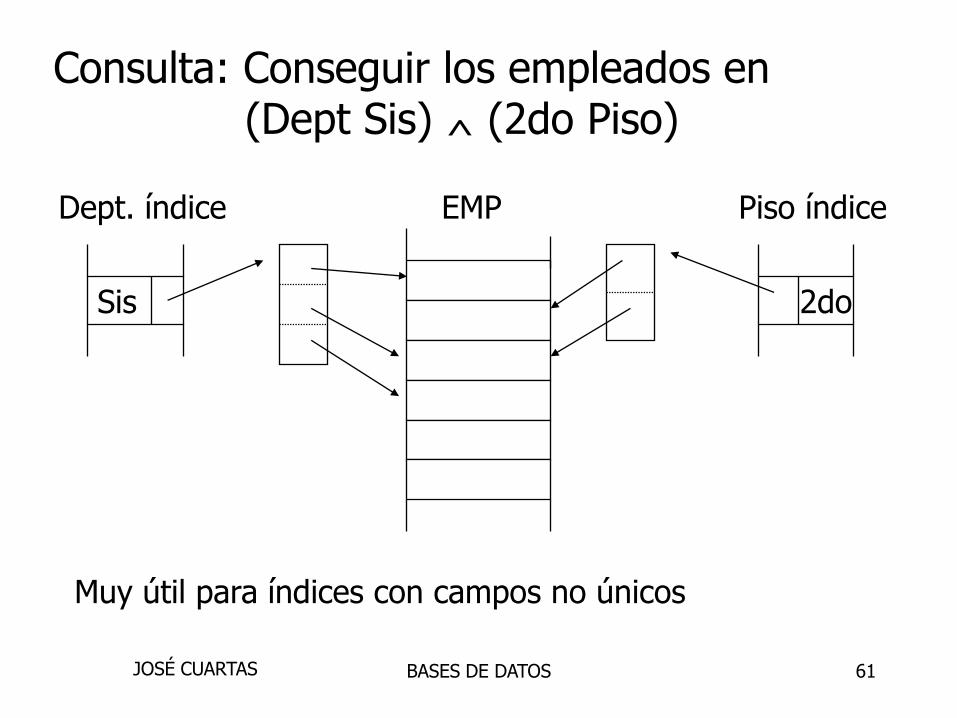
Porque los “niveles intermedios” son las ideales
Indices Registros
Nombre: primario EMP (nombre,dept,piso,...)
Dept: secundario
Piso: secundario
BASES DE DATOSJOSÉ CUARTAS
61
Consulta: Conseguir los empleados en(Dept Sis) ^ (2do Piso)
Dept. índice EMP Piso índice
Sis 2do
BASES DE DATOSJOSÉ CUARTAS
Muy útil para índices con campos no únicos

62
Sis 2do
Se cruza el nivel intermedio de Dept con la
cubeta de 2do Piso consiguiendo los empleados
Consulta: Conseguir los empleados en(Dept Sis) ^ (2do Piso)
Dept. índice EMP Piso índice
BASES DE DATOSJOSÉ CUARTAS

63
Resumiendo
• Indices convencionales
– Ideas basicas: densos, no desos, multiple-nivel…
– Claves duplicadas
– Eliminación/Inserción
– Indices secundarios– Nivel intermedio de indirección
BASES DE DATOSJOSÉ CUARTAS

64
Índice convencional
Ventajas:
- Simples- Los Índeces se almacenan un archivo secuencial fácil
de escanear
Desventajas:- Costoso en inserción, - Perdidad secuencia y balance
BASES DE DATOSJOSÉ CUARTAS
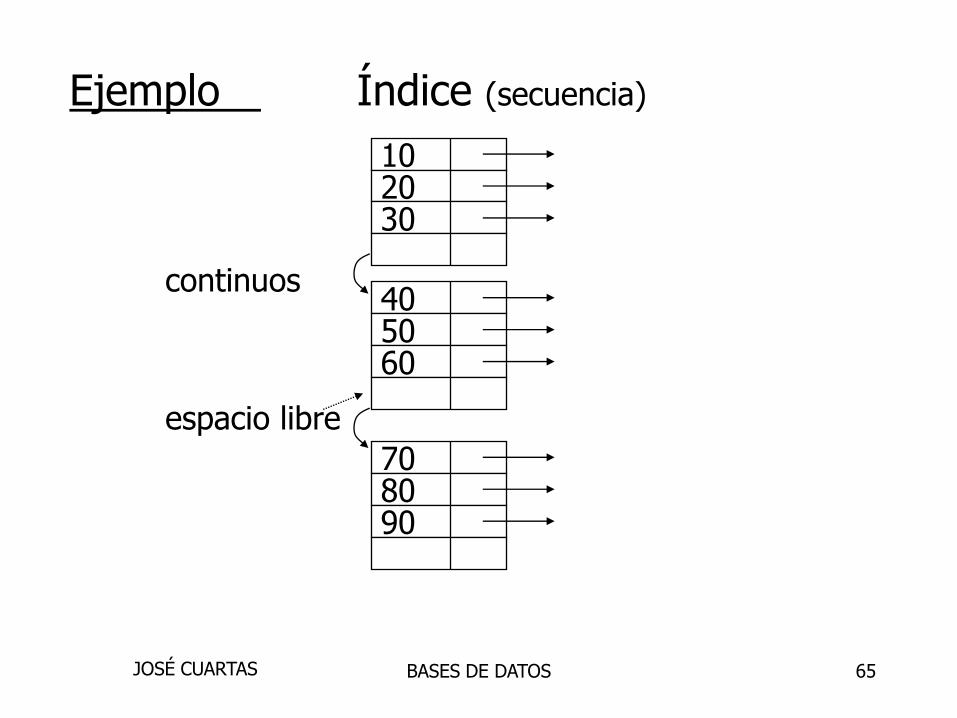
65
Ejemplo Índice (secuencia)
continuos
espacio libre
102030
405060
708090
BASES DE DATOSJOSÉ CUARTAS
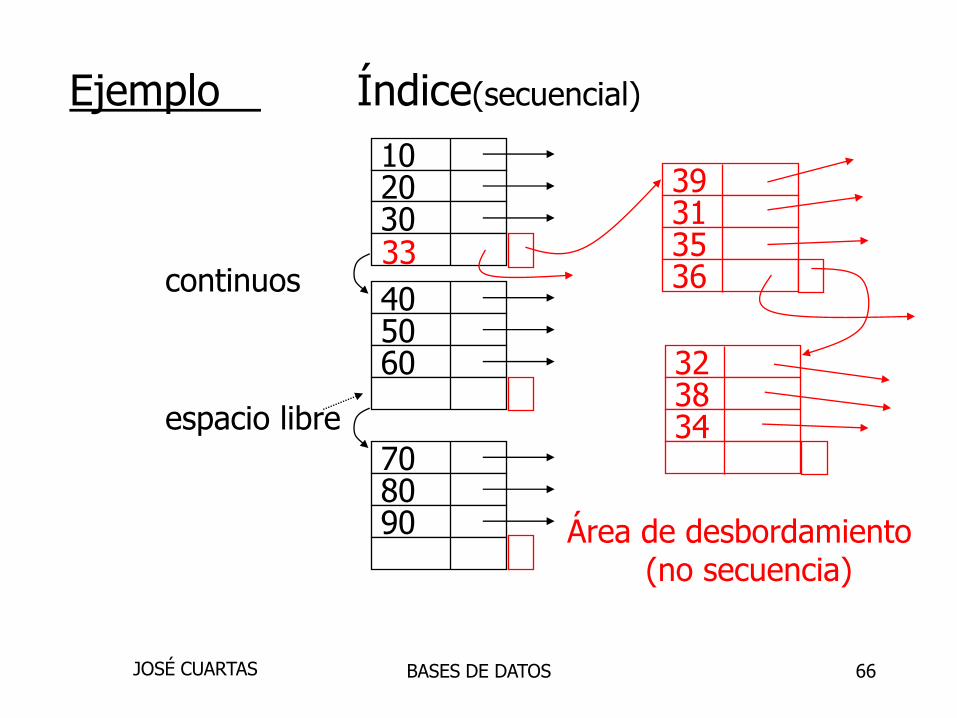
66
Ejemplo Índice(secuencial)
continuos
espacio libre
102030
405060
708090
39313536
323834
33
Área de desbordamiento(no secuencia)
BASES DE DATOSJOSÉ CUARTAS

67
Esquema:
• Indice convencional
• B-Trees Siguiente
BASES DE DATOSJOSÉ CUARTAS

68
• Suguiente: Otro tipo de índice
– Cuando nose desea secuencialidad
– Trata de obtener “balance”
BASES DE DATOSJOSÉ CUARTAS
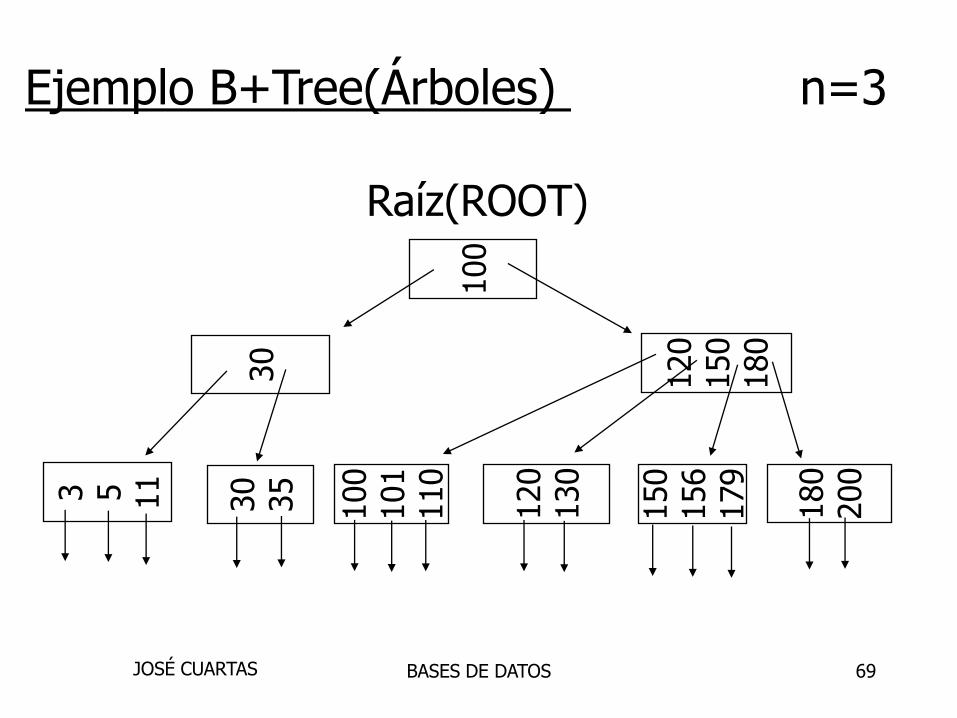
69
Raíz(ROOT)
Ejemplo B+Tree(Árboles) n=3
100
120
150
180
30
3 5 11
30
35
100
101
110
120
130
150
156
179
180
200
BASES DE DATOSJOSÉ CUARTAS

70
Ejemplo de un nodo interno
Claves Claves Claves Claves
< 57 57 k<81 81 k<95 95
57
81
95
BASES DE DATOSJOSÉ CUARTAS
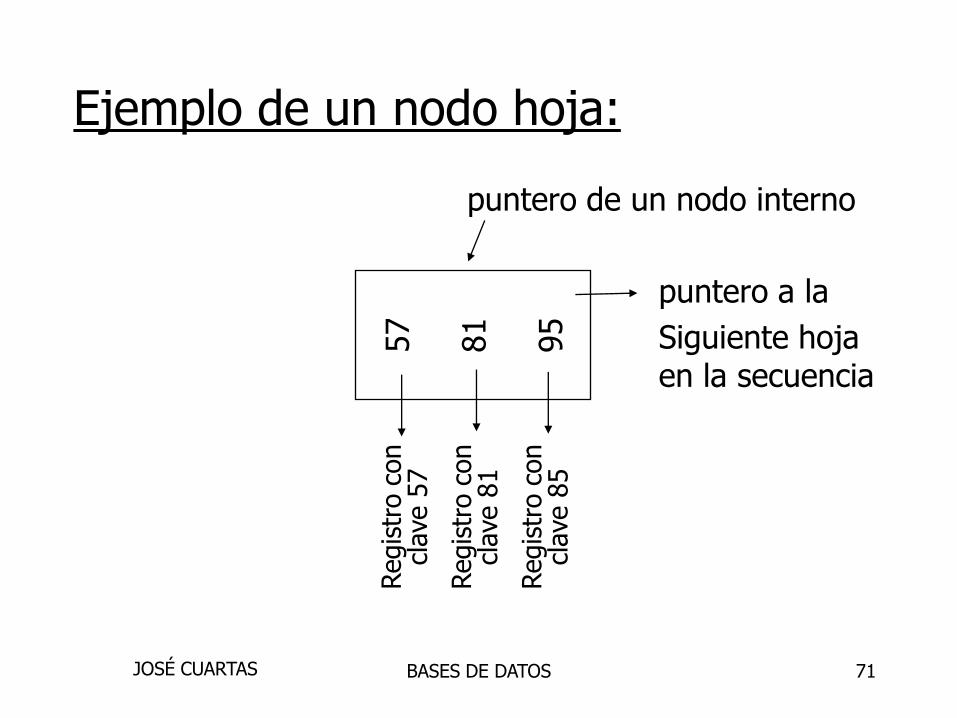
71
Ejemplo de un nodo hoja:
puntero de un nodo interno
puntero a la
Siguiente hojaen la secuencia
57
81
95
Regis
tro
con
clave 5
7
Regis
tro
con
clave 8
1
Regis
tro
con
clave 8
5
BASES DE DATOSJOSÉ CUARTAS
72
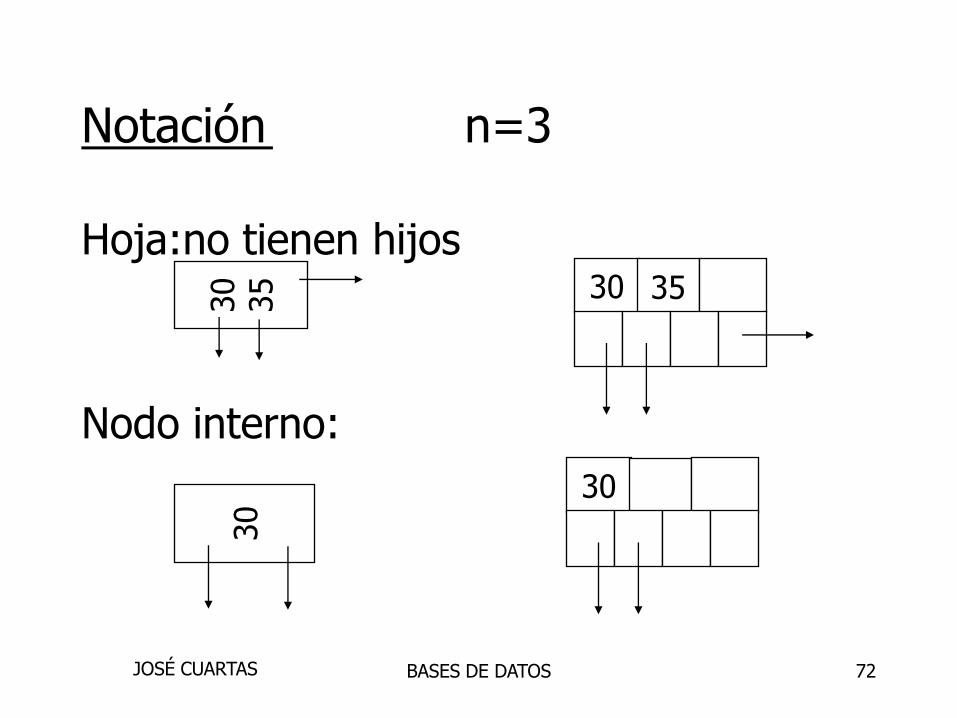
Notación n=3
Hoja:no tienen hijos
Nodo interno:
30
35
30
30 35
30
BASES DE DATOSJOSÉ CUARTAS

73
Tamaño del nodo: n+1 punteros
n Claves de búsqueda(fijos)
BASES DE DATOSJOSÉ CUARTAS

74
No se desea un nodo vacío
• Utilize por lo menos
Nodo interno: (n+1)/2 punteros
Hoja: (n+1)/2 punteros a datos
BASES DE DATOSJOSÉ CUARTAS

75
Full node min. node
Nodo interno
Hoja
n=3
120
150
180
30
3 5 11
30
35
Cuenta
seim
pre
sies
vací
o
BASES DE DATOSJOSÉ CUARTAS

76
Reglas B+tree árbol de orden n
(1) Todas las hojas están al mismo nivel(balanceado)
(2) Punteros en las hojas son a los registros excepto para“punteros de secuencia”
BASES DE DATOSJOSÉ CUARTAS

77
(3) Número de punteros/claves para B+tree
No-hojas(no-raíz) n+1 n (n+1)/2 (n+1)/2 - 1
hojas(no-raíz) n+1 n
Raíz n+1 n 1 1
Max Max Min Minptrs Clavesptrs data Claves
(n+1)/2 (n+1)/2
BASES DE DATOSJOSÉ CUARTAS

78
Inserción en el B+tree
(a) Simple caso– Espacio disponible en la hoja
(b) Desborde de hoja
(c) Desborde de Nodo interno
(d) Nueva raíz
BASES DE DATOSJOSÉ CUARTAS

79
(a) Inserción clave = 32 n=3
3 5 11
30
31
30
100
BASES DE DATOSJOSÉ CUARTAS

80
n=3
3 5 11
30
31
30
100
32
(a) Inserción clave = 32
BASES DE DATOSJOSÉ CUARTAS
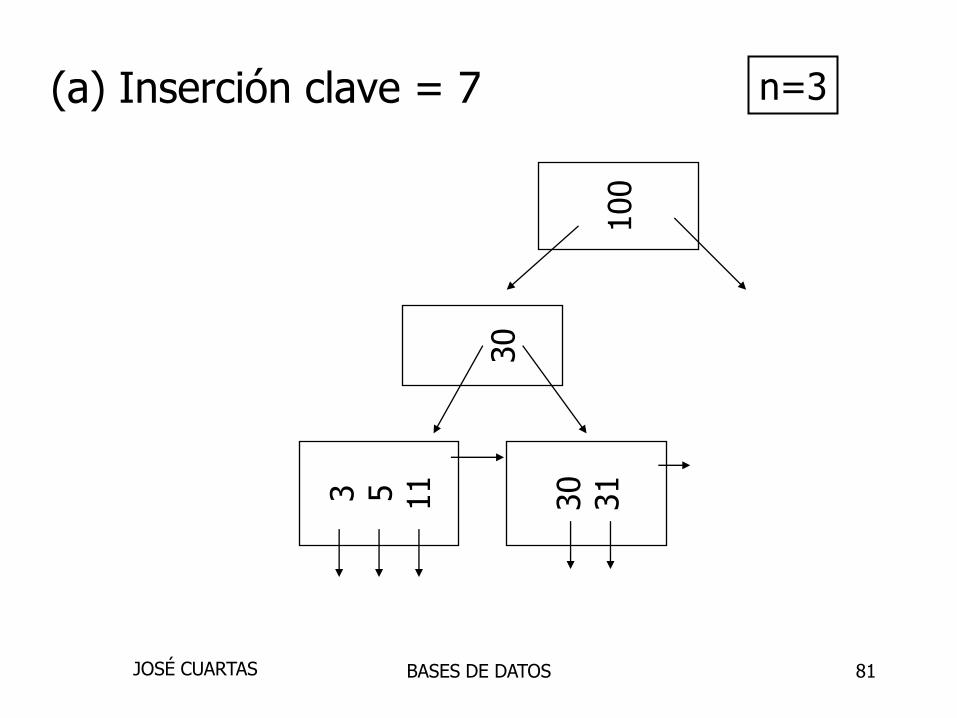
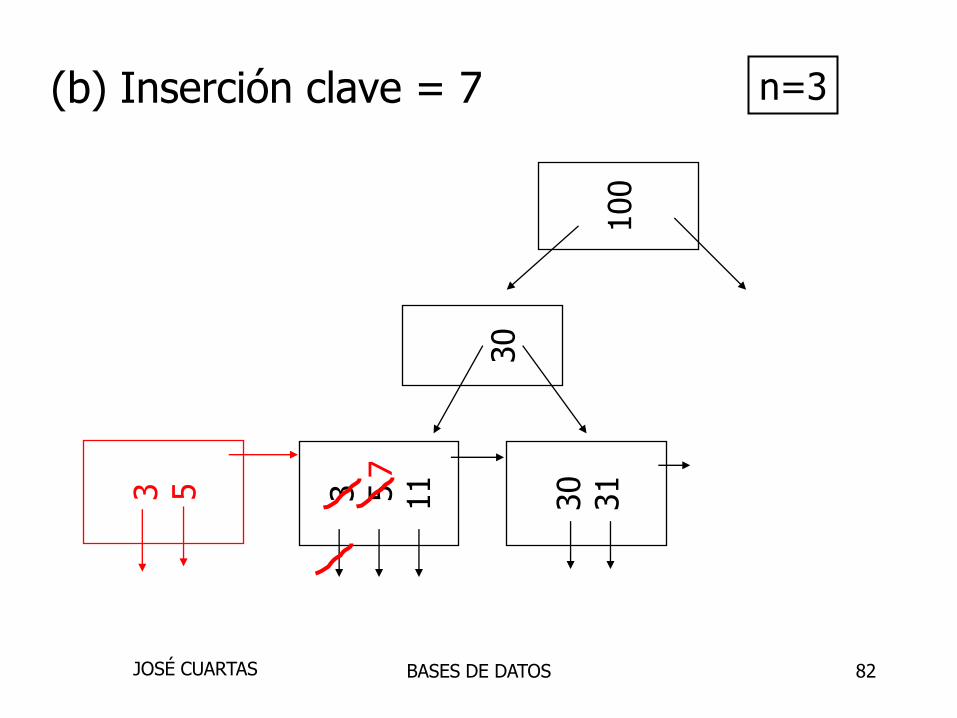
81
(a) Inserción clave = 7 n=3
3 5 11
30
31
30
100
BASES DE DATOSJOSÉ CUARTAS
82
n=3
3 5 11
30
31
30
100
3 5
7
(b) Inserción clave = 7
BASES DE DATOSJOSÉ CUARTAS

83
n=3
3 5 11
30
31
30
100
3 5
7
7
(b) Inserción clave = 7
BASES DE DATOSJOSÉ CUARTAS
84
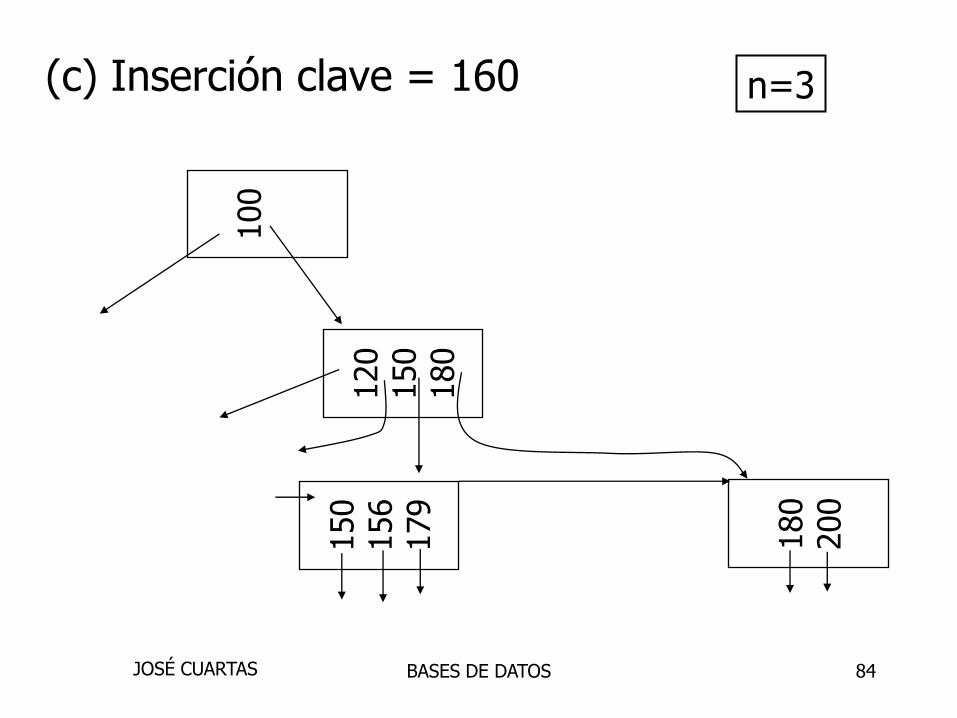
(c) Inserción clave = 160 n=3
100
120
150
180
150
156
179
180
200
BASES DE DATOSJOSÉ CUARTAS
85
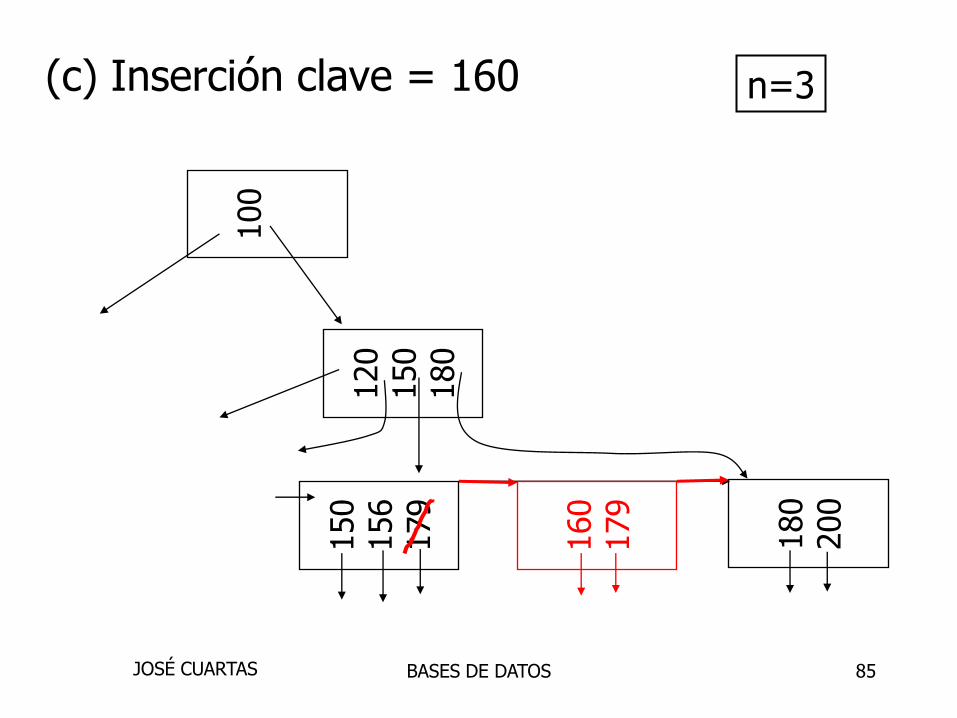
(c) Inserción clave = 160 n=3
100
120
150
180
150
156
179
180
200
160
179
BASES DE DATOSJOSÉ CUARTAS

86
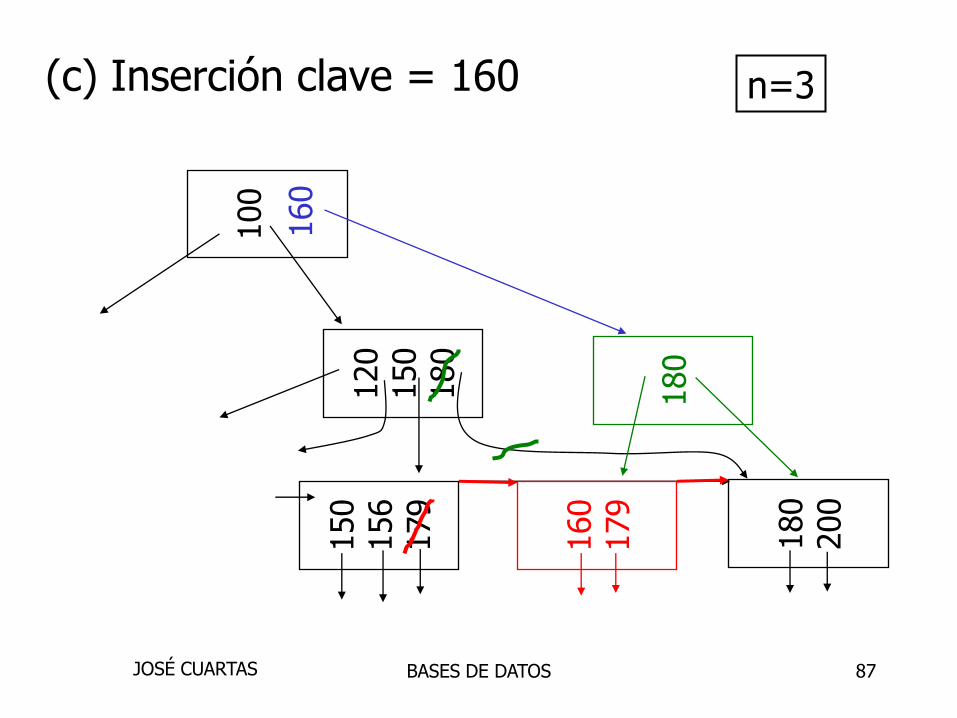
(c) Inserción clave = 160 n=3
100
120
150
180
150
156
179
180
200
180
160
179
BASES DE DATOSJOSÉ CUARTAS
87
(c) Inserción clave = 160 n=3
100
120
150
180
150
156
179
180
200
160
180
160
179
BASES DE DATOSJOSÉ CUARTAS
88
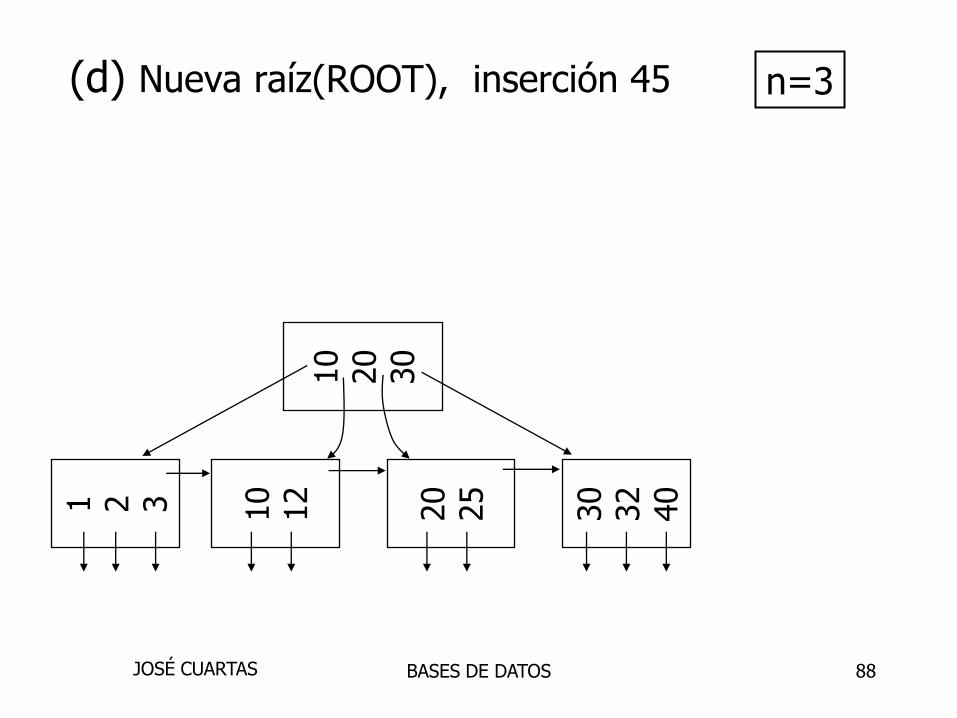
(d) Nueva raíz(ROOT), inserción 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
BASES DE DATOSJOSÉ CUARTAS
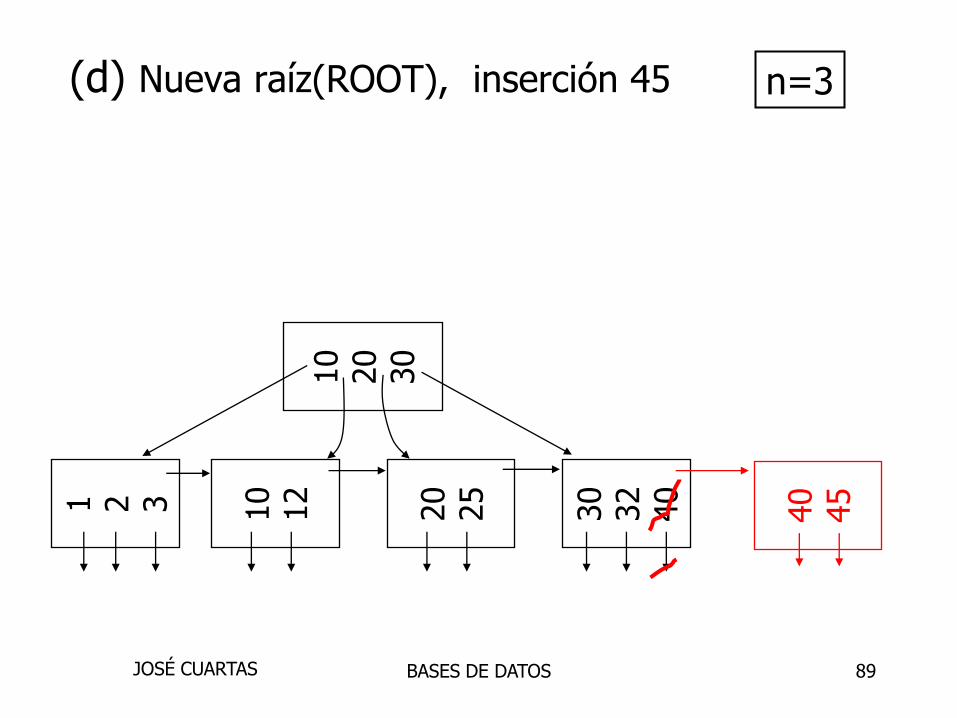
89
(d) Nueva raíz(ROOT), inserción 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
40
45
BASES DE DATOSJOSÉ CUARTAS

90
(d) Nueva raíz(ROOT), inserción 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
40
45
40
BASES DE DATOSJOSÉ CUARTAS

91
(d) Nueva raíz(ROOT), inserción 45 n=3
10
20
30
1 2 3 10
12
20
25
30
32
40
40
45
40
30Nueva raíz
BASES DE DATOSJOSÉ CUARTAS

92
(a) Caso simple - no hay ejemplo
(b) Combinación con el vecino (sibling)
(c) Redistribución de claves de búsqueda
(d) Caso (b) o (c) en nodo interno
Eliminación de B+tree
BASES DE DATOSJOSÉ CUARTAS
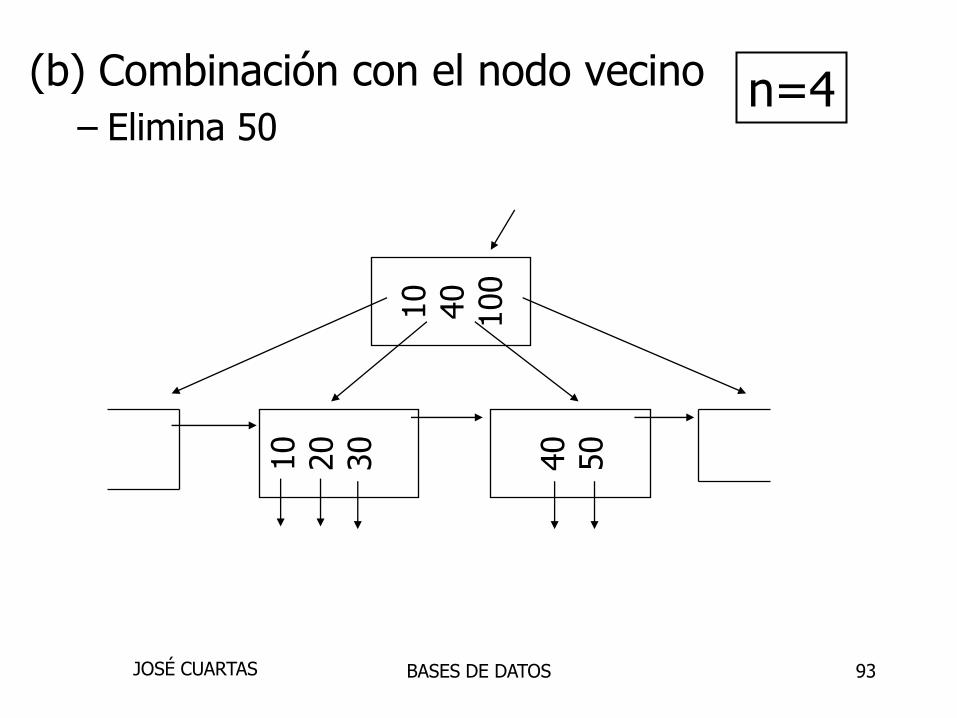
93
(b) Combinación con el nodo vecino
– Elimina 50
10
40
100
10
20
30
40
50
n=4
BASES DE DATOSJOSÉ CUARTAS
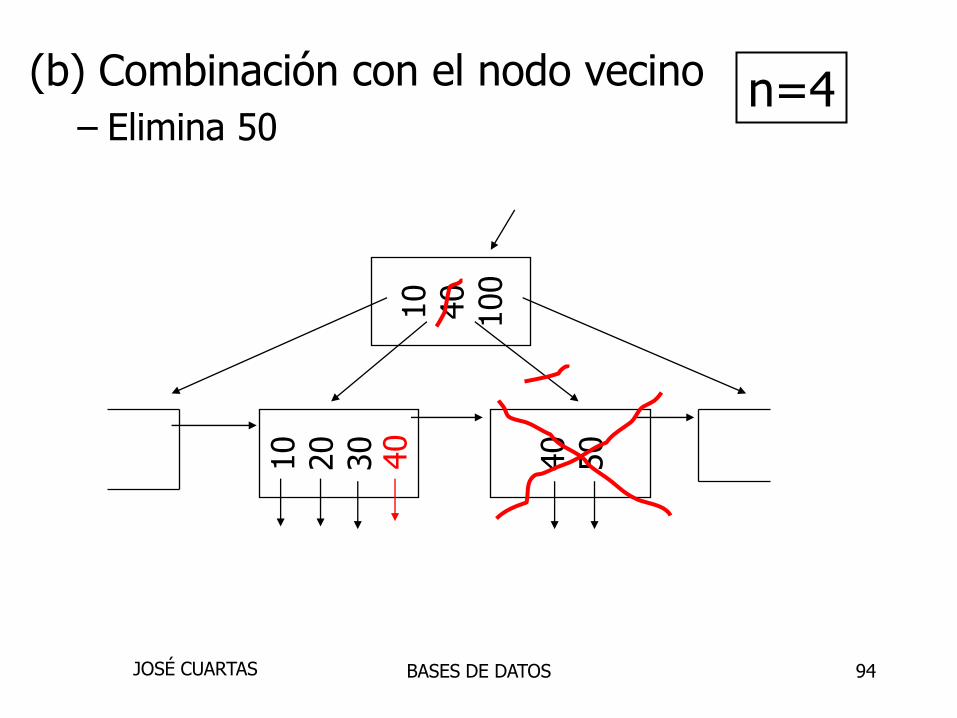
94
10
40
100
10
20
30
40
50
n=4
40
(b) Combinación con el nodo vecino
– Elimina 50
BASES DE DATOSJOSÉ CUARTAS

95
(c) Redistribución de Claves
– Eliminación 50
10
40
100
10
20
30
35
40
50
n=4
BASES DE DATOSJOSÉ CUARTAS
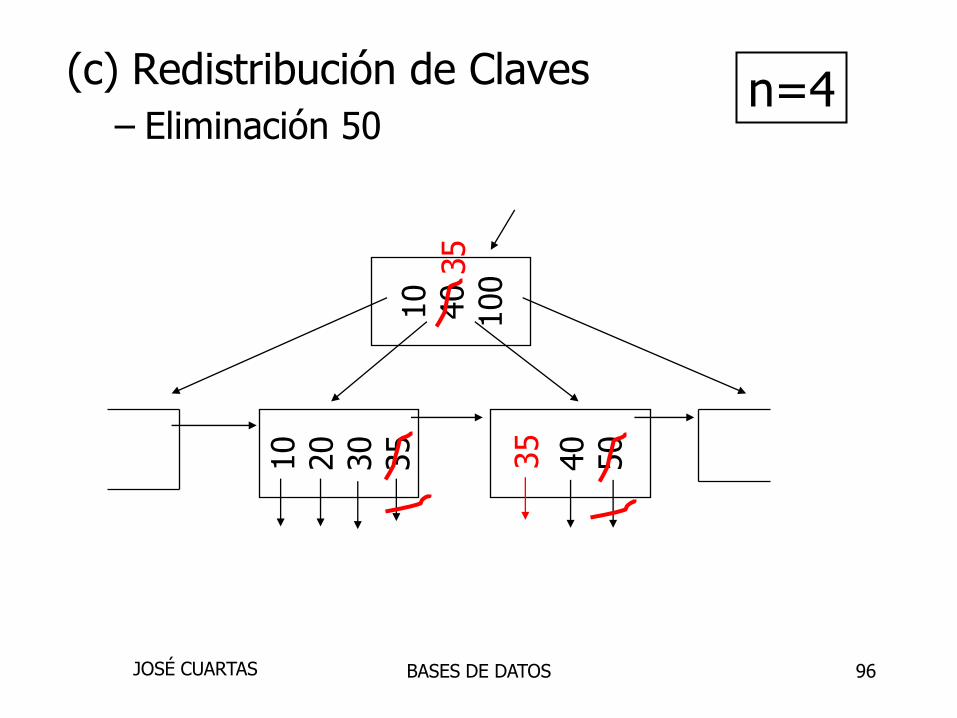
96
(c) Redistribución de Claves
– Eliminación 50
10
40
100
10
20
30
35
40
50
n=4
35
35
BASES DE DATOSJOSÉ CUARTAS
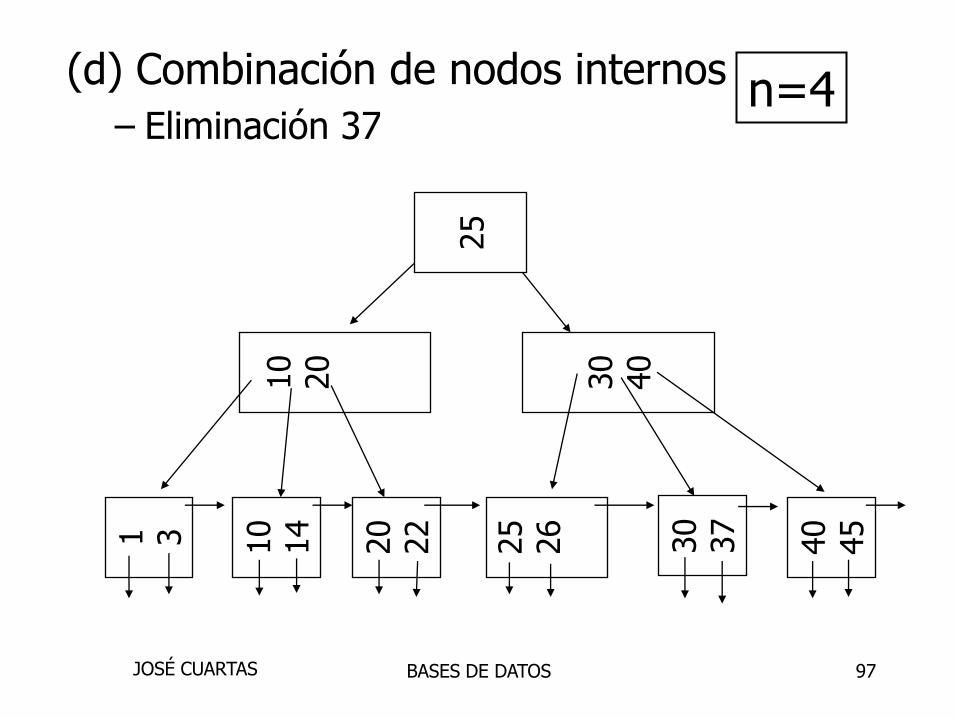
97
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
n=4
25
(d) Combinación de nodos internos
– Eliminación 37
BASES DE DATOSJOSÉ CUARTAS

98
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
(d) Combinación de nodos internos
– Eliminación 37n=4
30
25
BASES DE DATOSJOSÉ CUARTAS
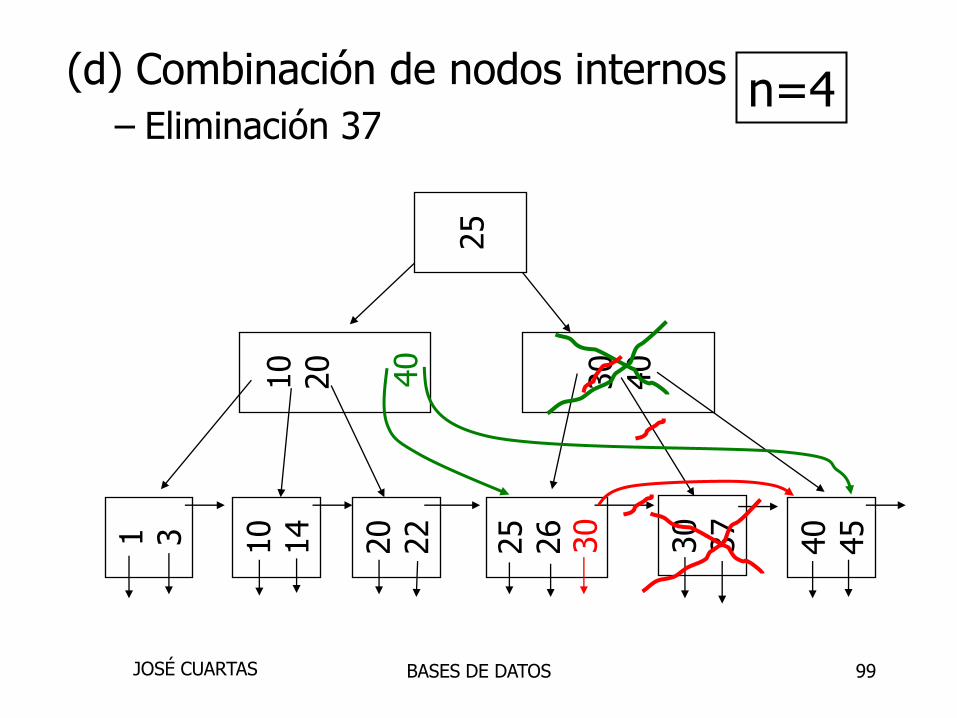
99
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
n=4
40
30
25
(d) Combinación de nodos internos
– Eliminación 37
BASES DE DATOSJOSÉ CUARTAS

100
40
45
30
37
25
26
20
22
10
141 3
10
20
30
40
n=4
40
30
25
25
Nueva raíz
(d) Combinación de nodos internos
– Eliminación 37
BASES DE DATOSJOSÉ CUARTAS

101
Comparasión: B-trees vs. estaticosíndice de archivo secuencial
Ref #1: Held & Stonebraker
“B-Trees Re-examined”
CACM, Feb. 1978
BASES DE DATOSJOSÉ CUARTAS

102
Ref # 1 claims:
- Controld e concurrenciaes muy duro en B-Trees
- B-tree consumen más espacio
Para la comparación:
Bloque= 512 bytesclave = puntero= 4 bytes4 datos de registro por bloque
BASES DE DATOSJOSÉ CUARTAS

103
Ejemplo: 1 Bloque de índice estatico
k1
k2
k3
k1
k2
k3
1 datablock
127 claves
(127+1)4 = 512 Bytes
-> punteros a un índice explicito! Por encima de 127bloques
BASES DE DATOSJOSÉ CUARTAS

104
Ejemplo: 1 Bloque B-tree
k1
k2
...
k63
k1
k2
k3
1 datablock
siguiente
-
63 Claves
63x(4+4)+8 = 512 Bytes
-> punteros necesarios en B-tree por encima de 63porque índice no contiguo
BASES DE DATOSJOSÉ CUARTAS

105
Ref. #1 análisis
• Para un bloque de archivodespués de 32,000 inserciones
después de 16,000 búsquedas
El índice ahorra suficiente espaciopara la reorganización
BASES DE DATOSJOSÉ CUARTAS

106
• Para un bloque de archivodespués de 32,000 inserciones
después de 16,000 búsquedas
El índice ahorra suficiente espaciopara la reorganización
Ref. #1 conclusión Mejor índice estático!!
Ref. #1 análisis
BASES DE DATOSJOSÉ CUARTAS

107
Ref #2: M. Stonebraker,
“Retrospective on a databasesystem,” TODS, June 1980
Ref. #2 conclusión Mejor B-trees!!
BASES DE DATOSJOSÉ CUARTAS

108
• DBA no nesecitan saber cuandoreorganizar
• DBA no nesecitan conocer como estande cargados las páginas del nuevoíndice
Ref. #2 conclusión B-trees mejor!!
BASES DE DATOSJOSÉ CUARTAS

109
• Buffering
– B-tree: tiene requerimiento de buffer fijo
– Estatico: debe leer varios bloques de desbordamiento por eficiencia (buffer largos y de tamaño variable)
Ref. #2 conclusión Mejor B-trees!!
BASES DE DATOSJOSÉ CUARTAS

110
Problema interesante:
Para B+tree, que tan largo debe ser n?
…
n número de claves / nodo
BASES DE DATOSJOSÉ CUARTAS

111
(1) Tiempo de lectura de un nodo de disco es (S+Tn) msec.
Supuestos:
BASES DE DATOSJOSÉ CUARTAS

112
Supuestos:
(2) Un bloque en memoria, usa búsquedabinaria por clave de búsqueda:
(a + b LOG2 n) msec.
Para algunas costantes a,b; se asume a << S
(1) Tiempo de lectura de un nodo de disco es (S+Tn) msec.
BASES DE DATOSJOSÉ CUARTAS

113
(1) Tiempo de lectura de un nodo de disco es (S+Tn) msec.
(2) Un bloque en memoria, usa unabusqueda binaria para localizar la clave:
(a + b LOG2 n) msec.
Para algunas costantes a,b; se asume a << S
(3) Asumen B+tree esta lleno, i.e., # nodos examinados es LOGn N
donde N = # registros
Supuestos:
BASES DE DATOSJOSÉ CUARTAS

114
Se consigue:
f(n) = Tiempo para encontrar un registro
f(n)
nopt n
BASES DE DATOSJOSÉ CUARTAS

115
Variación B+tree: B-tree (no +)
• Idea:
– Evitar claves duplicadas
– Tener punteros a registro en nodosinternos
BASES DE DATOSJOSÉ CUARTAS

116
registro registro registrocon K1 con K2 con K3
a las claves a las claves a las claves a lasclaves < K1 K1<x<K2 K2<x<k3>k3
K1 P1 K2 P2 K3 P3
BASES DE DATOSJOSÉ CUARTAS

117
Ejemplo B-tree n=2
65
125
145
165
85
105
25
45
10
20
30
40
110
120
90
100
70
80
170
180
50
60
130
140
150
160
BASES DE DATOSJOSÉ CUARTAS
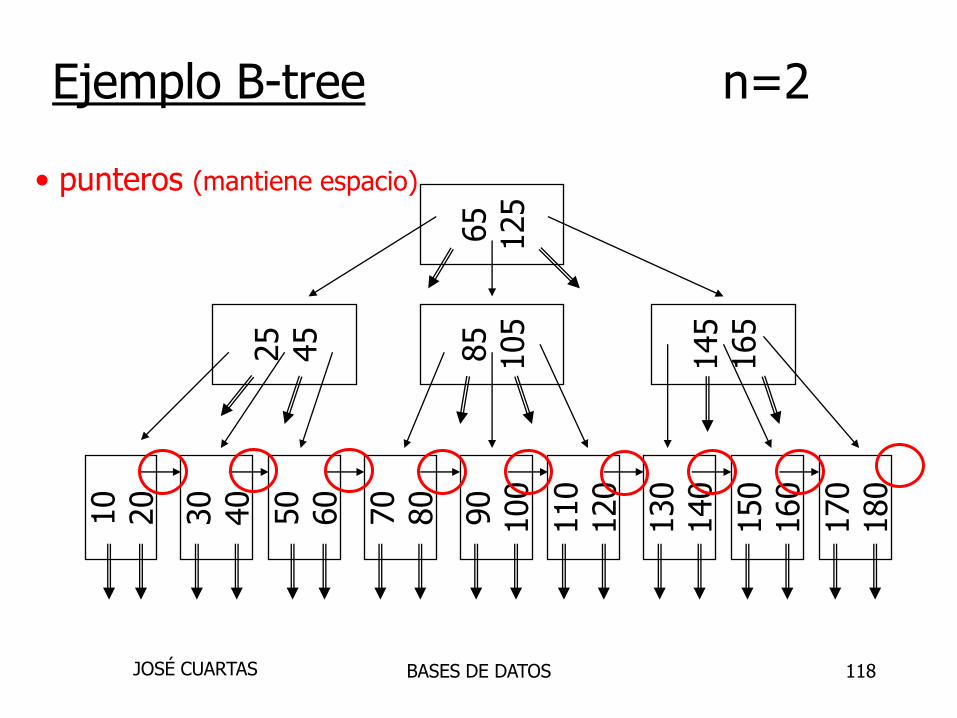
118
Ejemplo B-tree n=2
65
125
145
165
85
105
25
45
10
20
30
40
110
120
90
100
70
80
170
180
50
60
130
140
150
160
• punteros (mantiene espacio)
BASES DE DATOSJOSÉ CUARTAS
119
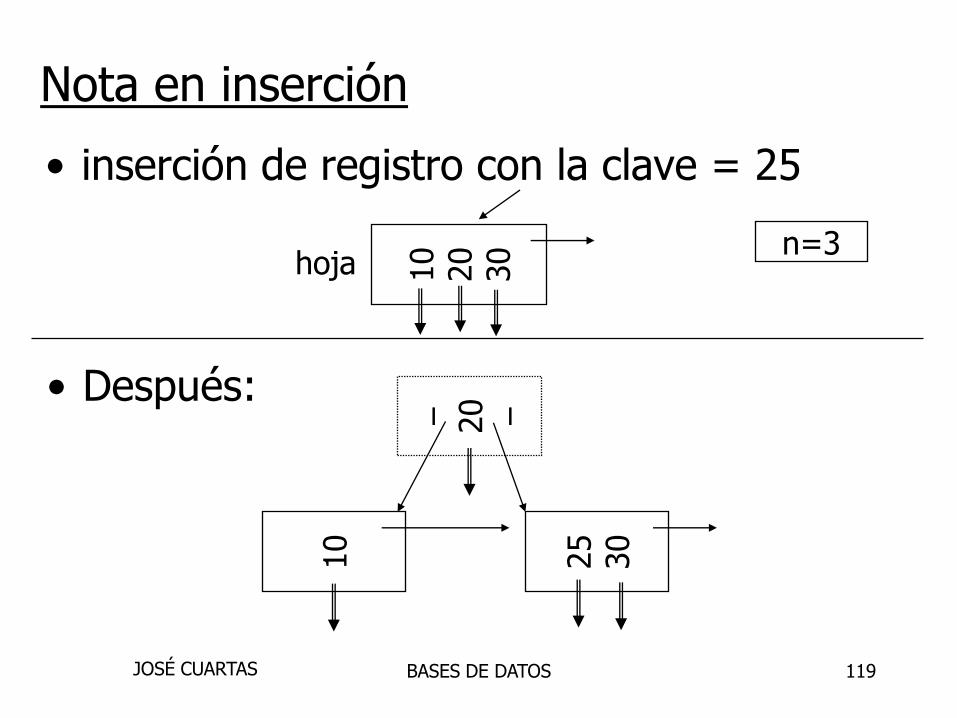
Nota en inserción
• inserción de registro con la clave = 25
10
20
30 n=3
hoja
10
– 20 –
25
30
• Después:
BASES DE DATOSJOSÉ CUARTAS

120
Ventajas y desventajas:
B-trees tiene mas rapida búsqueda que
B+trees
en B-tree, nodos internos & hoja diferente
tamaño
en B-tree, la eliminación es complicada
Preferido el B+trees!
BASES DE DATOSJOSÉ CUARTAS

121
Pero note:
• Si el bloque es de tamaño fijo
(Debido a restricciones de disco y buffer)
Entonces la búsqueda por B+tree esmucho mejor!!
BASES DE DATOSJOSÉ CUARTAS

122
Ejemplo:
- Punteros 4 bytes
- Claves 4 bytes
- Bloques 100 bytes (just example)
- Búsqueda para un btree de nivel 2
BASES DE DATOSJOSÉ CUARTAS

123
Raíz tiene 8 claves + 8 punteros a registro+ 9 punteros hijo
= 8x4 + 8x4 + 9x4 = 100 bytes
B-tree:
BASES DE DATOSJOSÉ CUARTAS

124
B-tree:
De cada 9 hijos: 12 rec. puntero(+12 keys)
= 12x(4+4) + 4 = 100 bytes
Raíz tiene 8 claves + 8 punteros a registro+ 9 punteros hijo
= 8x4 + 8x4 + 9x4 = 100 bytes
BASES DE DATOSJOSÉ CUARTAS

125
B-tree:
2-nivel B-tree, Max # registros=
12x9 + 8 = 116
De cada 9 hijos: 12 rec. puntero(+12 keys)
= 12x(4+4) + 4 = 100 bytes
BASES DE DATOSJOSÉ CUARTAS
Raíz tiene 8 claves + 8 punteros a registro+ 9 punteros hijo
= 8x4 + 8x4 + 9x4 = 100 bytes

126
B+tree:
BASES DE DATOSJOSÉ CUARTAS
Raíz tiene 12 claves + 13 punteros hijo
= 12x4 + 13x4 = 100 bytes

127
Raíz tiene 12 claves + 13 punteros hijo
= 12x4 + 13x4 = 100 bytes
B+tree:
Por cada 13 hijos: 12 rec. ptrs (+12 keys)
= 12x(4 +4) + 4 = 100 bytes
BASES DE DATOSJOSÉ CUARTAS

128
B+tree:
2-nivel B+tree, Max # registros
= 13x12 = 156
BASES DE DATOSJOSÉ CUARTAS
Raíz tiene 12 claves + 13 punteros hijo
= 12x4 + 13x4 = 100 bytes
Por cada 13 hijos: 12 rec. ptrs (+12 keys)
= 12x(4 +4) + 4 = 100 bytes
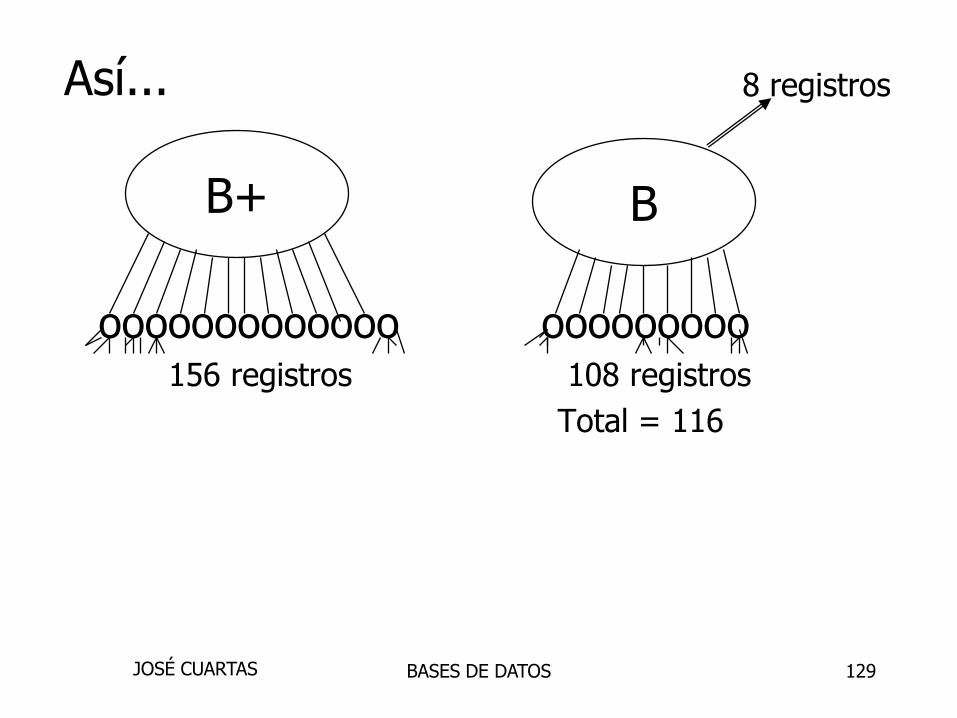
129
Así...
ooooooooooooo ooooooooo156 registros 108 registros
Total = 116
B+ B
8 registros
BASES DE DATOSJOSÉ CUARTAS
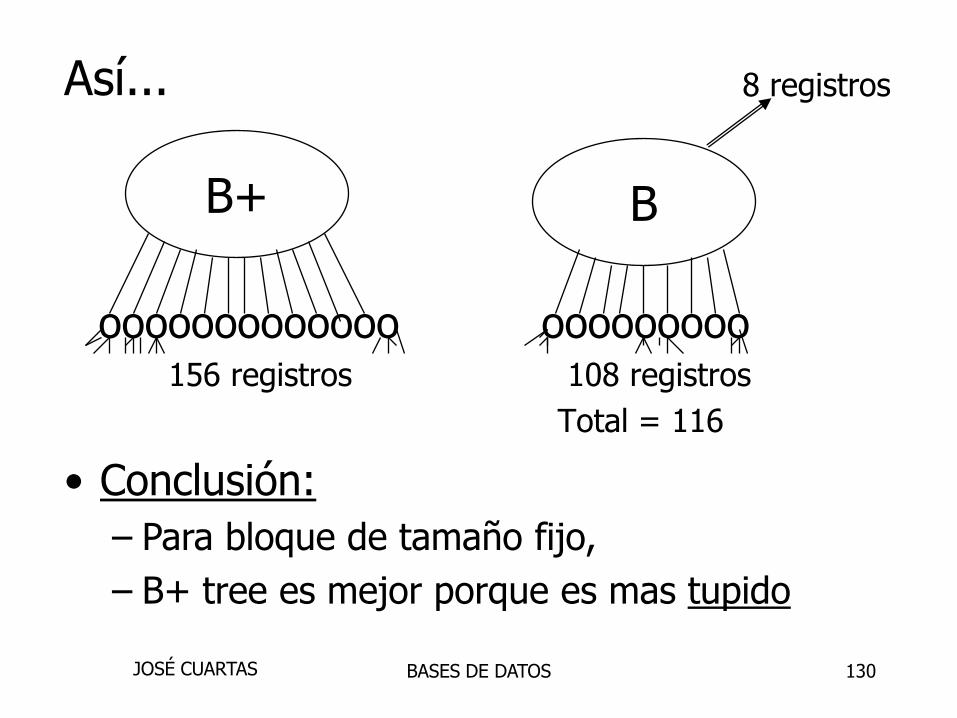
130
Así...
ooooooooooooo ooooooooo156 registros 108 registros
Total = 116
B+ B
8 registros
• Conclusión:
– Para bloque de tamaño fijo,
– B+ tree es mejor porque es mas tupido
BASES DE DATOSJOSÉ CUARTAS


















