
Histórico da Internet - marilia.unesp.br§ão de Informação na Web Histórico da ... Humanas”,...
47
1 Recuperação de Informação na Web Histórico da Internet 1957 – Sputnik (primeiro satélite artificial) – URSS ◦ URSS na frente da corrida especial 1958 – ARPA (Advanced Research Projects Agency) ◦ Mobilização de pesquisas (universitárias) para alcançar a superioridade tecnológica militar em relação à União Soviética 1962 – Rand Paul Baran foi contratado para fazer desenvolver uma rede de comunicação que sobrevivesse à um ataque nuclear. A rede deveria funcionar mesmo que um de seus pontos fosse destruído.
Transcript of Histórico da Internet - marilia.unesp.br§ão de Informação na Web Histórico da ... Humanas”,...

1
Recuperação de Informação na Web
Histórico da Internet
� 1957 – Sputnik (primeiro satélite artificial) – URSS◦ URSS na frente da corrida especial
� 1958 – ARPA (Advanced Research Projects Agency)◦ Mobilização de pesquisas (universitárias) para alcançar a
superioridade tecnológica militar em relação à União Soviética
� 1962 – Rand Paul Baran foi contratado para fazer desenvolver uma rede de comunicação que sobrevivesse à um ataque nuclear. A rede deveria funcionar mesmo que um de seus pontos fosse destruído.

2
Histórico da Internet
� 1969 – Entrou em funcionamento a ARPANET com a Ligação de quatro nós da rede◦ UCLA (Universidade da Califórnia – Los Angeles),
◦ SRI (Stanford Research Institute),
◦ UCSB (Universidade da Califórnia – Santa Bárbara),
◦ Universidade de Utah
� 1971 – Criado um programa de e-mail
� 1972 – ARPA foi renomeada DARPA
Histórico da Internet
� 1973 - Internacionalização◦ University College of London (Inglaterra)
◦ Royal Radas Establishment (Noruega)
� 1973◦ Definição do protocolo TCP/IP
◦ Esboço do padrão ETHERNET
� 1974◦ Primeira vez que se utiliza o termo INTERNET, por Vint
Cerf e Bob Kahn em artigo sobre TCP

3
Histórico da Internet
� 1975 – 15 nós◦ Centros universitários
� 1976◦ Desenvolvimento do padrão ETHERNET
◦ Utilização do TCP/IP na ARPANET
� 1979 – Criação da USENET que permitia discusão em grupo de problemas científicos
� 1981◦ Surge a rede cooperativa BITNET
� e-mail, List Server, transferência de arquivos
Histórico da Internet
� 1983◦ A Universidade de Wisconsin criou o Domain Name
System (DNS)
◦ Separação� MilNET, (Instituições militares)� ARPANET (trabalhos de pesquisas avançadas)
◦ Criação da USENET com o objetivo de se criarem grupos de discussão sobre diversos assuntos;
◦ Surgimento das estações de trabalho
� Década de 1980◦ ARPANET � ARPA-INTERNET � INTERNET
4
Histórico da Internet
� Década de 90 – privatização da Internet
� 1990◦ Surgimento do ARCHIE, sistema de pesquisa na Internet
� 1991◦ Surgimento do GOPHER
Histórico da Internet
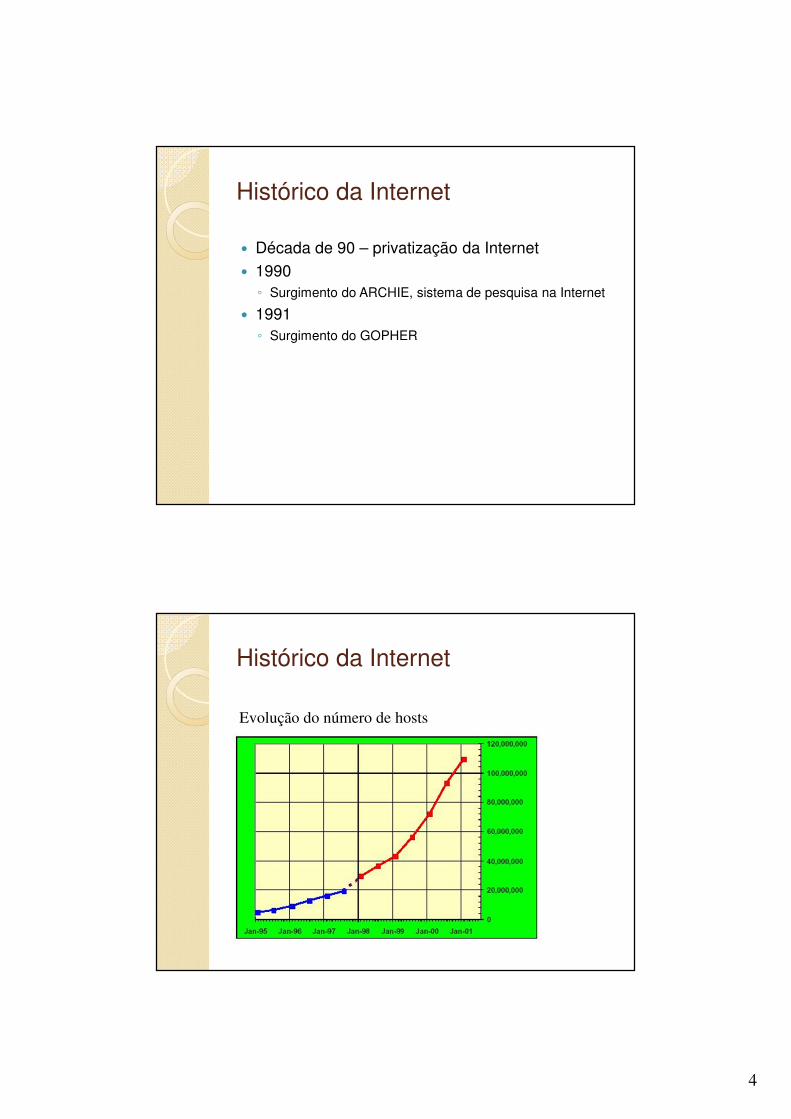
Evolução do número de hosts

5
Histórico da Internet
� A Internet é uma rede de redes de computadores que trocam informações entre si;
� Esses computadores (micro ou de grande porte) podem ser de qualquer tipo, arquitetura, marca ou modelo;
� Podem utilizar qualquer tipo de sistema operacional;
� Esses computadores estão interligados por linha comum de telefone, linhas privadas de comunicação, canais de satélite, cabos submarinos e outros meios de comunicação;
WEB

6
WEB
� 1990 – Criação da World Wide Web (www)◦ Motivação: Dificuldade no uso da Internet;
◦ Capacidade de transmissão de gráficos limitada;
◦ Oferecia um sistema de fácil utilização;
◦ Baseado parcialmente no trabalho de Ted Nelson �Hipertexto
WEB
� Navegadores (browsers)◦ Mosaic (1993) – Marc Andreessen
◦ Netscape (1994)
◦ Internet Explorer (1995)
� 1995 – Java (Sun Microsystems)◦ Applets
� 1999 – JINI (Sun Microsystems)◦ Permitir que qualquer tipo de rede composta de serviços e
dos clientes destes serviços seja facilmente montada, desmontada e mantida.

7
WEB
� O conjunto de serviços e recursos mudam constantemente, de acordo com o surgimento de novas tecnologias;◦ Correio eletrônico;
◦ Notícias, informação jornalística;
◦ Transferência de arquivos;
◦ Grupos ou comunidades virtuais;
◦ etc.
WEB
� Grupos de discussão◦ variedade de temas
� Bases de dados temáticas◦ principalmente instituições acadêmicas e de pesquisa;
� Informação comunitária◦ bibliotecas públicas
◦ galerias de arte
◦ informações turísticas
◦ informações meteorológicas
◦ etc...

8
WEB
� Recursos de governo
� Catálogos de bibliotecas
� Recursos comerciais◦ Bases de dados comerciais (pagas)
� DIALOG: mais de 400 bases de dados sobre qualquer assunto� Dow Jones News/Retrieval: acesso a mais de 1300
publicações e 70 bases de dados
◦ Compras� Livrarias, lojas, supermercados, etc.
WEB:recuperação de informação
� Sites de Busca
� Softwares de busca
� Bases de dados

9
Características da WEB
Características da WEB
� Características da Web◦ Unidades (fontes) de informação
� Páginas
◦ Padrão para especificação de páginas� HTML (Hypertext Markup Language)
◦ Esquema de endereçamento� URL (Universal Resource Locator)
◦ Protocolo comum� HTTP (Hypertext Transfer Protocol)

10
Características da WEB
� arquivo acessado utilizando o protocolo HTTP
� armazenado no computador chamado www.eca.usp.br,
� “br” indica que este computador está localizado no Brasil.
� No diretório (pasta) /graduaca/infogera/ deste computador está localizado o arquivo com o nome index.htm.
� A extensão “.htm” (ou .html) indica que se trata de um arquivo no formato HTML.
URL
Características da WEB
� HTML = Hypertext Markup Language◦ Conjunto fixo de marcações (tags);
◦ Permite utilizar janelas (frames), imagens e tabelas e ligações entre páginas Web.

11
Características da WEB
<html><head>
<title>Página HTML</title></head><body>
Página HTML simples</body>
</html>
HTML
Visualizar
Características da WEB
<html>
<head>
<title>Receita de pão de queijo</title></head>
<body>
<h1>Pão de Queijo</h1><p>Aprenda esta receita nada mineira, mas que dá ótimos resultados: é
rápida, fácil e tem um bom rendimento.</p><h2>Ingredientes</h2><ul>
<li>uma e meia xícara de chá de polvilho azedo<li>uma xícara de chá de maizena<li>uma colher de chá de fermento em pó<li>meia xícara de chá de leite<li>meia xícara de chá de água<li>meia xícara de chá de óleo<li>uma e meia colher de chá de sal<li>um ovo<li>uma xícara de chá de queijo tipo Minas ralado
</ul>
<h2>Modo de preparo</h2><ol>
<li>Misture e peneire os ingredientes secos (menos o queijo).<li>Após peneirar, junte o queijo e misture bem, acrescente os
demais ingredientes e amasse até obter uma massa lisa e uniforme;<li>Faça bolinhas e coloque numa assadeira untada e enfarinhada.<li>Leve ao fogo quente (200º C) por 25 minutos.
</ol>
</body>
</html>
HTML
Visualizar

12
Características da WEB
Usuário (Cliente)
Endereço ( URL )
Página ( HTML)
Browser
Servidor
Protocolo de transferência de páginas Web. Permite ao browser“conversar” com o servidor, fazendo pedidos e recebendo respostas em forma de página Web, geralmente escritas em HTML.
HTTP
Recuperação de Informação na WEB

13
Recuperação de informação na WEB
� Sites de Busca (search engines/buscadores)◦ Permitem ao usuário submeter sua expressão de busca e
recuperar uma lista (geralmente ordenada) de endereços de páginas (URLs) que presumivelmente são relevantes para a sua necessidade de informação
◦ Maioria de uso geral
◦ Em um acervo extremamente grande como é a Web é essencial uma indexação antecipada de seus documentos (páginas).� A maioria dos mecanismos de busca da Web gera índices.� Pelo caráter dinâmico da Web esses índices devem
permanecer em constante processo de atualização
Recuperação de informação na WEB
� Sites de busca◦ Índexação
� Não Automática� O autor fornece dados sobre sua página e associa a ela uma ou
mais categorias que descrevem o assunto tratado na página
� Automática� Spiders (robôs, crawlers ou worms)� Partindo de uma lista inicial de URLs, rastreiam a estrutura
hipertextual da WEB, colhendo informações sobre as páginas que encontram;
� Idexam cada página utilizando métodos de indexação automática

14
Recuperação de informação na WEB
� Indexação não-automática (manual)◦ Indexadores profissionais especificam uma hierarquia de
assuntos e indexam as páginas Web utilizando tais categorias.
◦ Uma URL submetida pode ser associada a uma categoria de qualquer nível. Por exemplo, ela pode ser ligada a uma categoria principal, “Ciência”, ou à subcategoria, “Ciências Humanas”, ou à sub-subcategoria, “Biblioteconomia e Ciência da Informação”.
◦ A URL cadastrada é avaliada por profissionais, que podendo alterar os dados fornecidos pelo usuário.
◦ Caso um usuário não consiga encontrar uma categoria apropriada para descrever sua página, ele pode sugerir uma nova categoria.
Recuperação de informação na WEB

15
Recuperação de informação na WEB
� Indexação automática◦ A indexação automática é realizada através de duas
etapas:� Seleção de endereços (URLs) de páginas;� Indexação das páginas, gerando para cada uma um conjunto
de termos de indexação.
◦ Existem programas que “viajam” através da Web a fim de selecionar URLs de páginas de potencial interesse para que sejam indexadas. Utilizando a metáfora da Web, esses programas são chamados de spiders (aranhas) ou ainda robôs, crawlers ou worms.
◦ Partindo de uma lista inicial de URLs, esses robôs rastreiam a estrutura hipertextual da Web colhendo informação sobre as páginas que encontram.
Recuperação de informação na WEB
� Indexação automática: Estratégias◦ breadth-first - visa maximizar a amplitude da pesquisa
descendo apenas poucos níveis de cada site
◦ depth-first - visa maximizar a profundidade buscando um maior detalhamento do assunto tratado pelo site.
� Quando uma nova página é recuperada, o spider
extrai todas as URLs dessa página e os adiciona na sua base de dados.

16
Recuperação de informação na WEB
� Indexação automática◦ Para aumentar a velocidade de cobertura da Web podem
ser usados vários spiders trabalhando em paralelo, cada um cobrindo uma região ou um domínio diferente da Web e enviando suas URLs para a base de dados
◦ Depois de formado o banco de dados de URLs o robô poderá acessar cada página e indexá-la usando métodos de indexação automática.
Recuperação de Informação na WEB
� Buscas◦ Geralmente dois níveis de busca: básico e avançado
◦ Básico:� Buscas booleanas utilizando os operadores AND, OR, NOT ou
alguma outra forma;
◦ Avançado:� Buscas por proximidade: NEAR, ADJ� Buscas por tipo de mídia ou tipo de arquivo: “.JPG”, “.MPEG”,
“.GIF”, etc.

17
Recuperação de Informação na WEB
Recuperação de Informação na WEB
� Meta-buscadores◦ Realizam buscas utilizando diversos mecanismos de
busca;� A expressão de busca é traduzida e enviada para cada um dos
mecanismos que o meta-buscador utiliza.� Cada buscador retornará uma lista de URLs� O meta-buscador agrega as listas em uma única lista,
eliminando possíveis duplicações.

18
Recuperação de Informação na WEB
Recuperação de Informação na WEB

19
Recuperação de Informação na WEB
� Desafios: dados◦ Distribuídos
� Dados espalham-se através de uma grande quantidade de computadores e plataformas, conectados sem nenhuma topologia pré-definida;
◦ Voláteis� Novos computadores e dados podem ser adicionados e removidos
facilmente;
◦ Grande volume� Rápido crescimento
◦ Dados não estruturados e redundantes� Não segue um modelo conceitual que poderia garantir consistência;� Muito dados duplicados: de maneira livre ou via espelhos ou cópias;
◦ Qualidade� Não há um processo editorial;� Dados serem imprecisos, errados, obsoletos, inválidos;
◦ Heterogêneos� Dados de variados formatos (texto, imagem, video), diferentes idiomas,
variados alfabetos;
Recuperação de Informação na WEB
� Desafios: usuário◦ Expressão de busca (consulta)
� Necessidades de informação difíceis de serem expressas em uma busca/consulta;
� São sempre imperfeitas;
◦ Interpretação dos resultados� Mesmo se bem definida a busca, os resultados constar de
milhares e até milhões de páginas. Ou mesmo não se obter nenhuma resposta;

20
Vídeo
A Pesquisa
A linguagem HTML

21
A linguagem HTML
� HyperText Markup Language◦ Linguagem de marcação◦ Divide o texto em várias partes, identificadas por tags
(etiquetas).� nome do autor da página� cabeçalho da página� uma imagem� uma tabela� um link
� Os browsers (navegadores) são softwares que interpretam e exibem as páginas HTML,◦ Mosaic◦ Netscape◦ Internet Explorer
A linguagem HTML:tags
<html>
<head>
<title>meu primeiro HTML</title></head>
<body>
<h1>Esta é minha primeira página em HTML</h1></body>
</html>
São indicações apresentadas entre os caracteres de menor e maior( < > ) que representam os elementos de uma página

22
A linguagem HTML:tags
� <HTML> </HTML>◦ Informa o inicio e o final de uma página escrita em HTML;
� <HEAD> </HEAD> ◦ identificam o inicio e o término de uma área de descrições
gerais da página tais como título, autor, etc.
� <TITLE> </TITLE>◦ Responsável por exibir o titulo da página. Alguns
navegadores (browsers) exibem o título da página no título da janela onde está o browser.
� <BODY> </BODY>◦ É o corpo da página, onde estão as informações que se
deseja apresentar;
<html>
<head>
<title>Exemplo de cabeçalhos</title></head>
<body>
<h1>Cabeçalho de nível 1</h1><h2>Cabeçalho de nível 2</h2><h3>Cabeçalho de nível 3</h3><h4>Cabeçalho de nível 4</h4><h5>Cabeçalho de nível 5</h5><h6>Cabeçalho de nível 6</h6>
</body>
</html>
A linguagem HTML:tags
� <H1> </H1>◦ tag de cabeçalho de nivel 1
� Os números indicam o nível do cabeçalho (de H1 a H6).
� Quando apresentados, apresentam letras maiores e em negrito, dependendo do nível
Visualizar

23
A linguagem HTML:tags
Estilo Sintaxe
Negrito <B> Texto </B>
Itálico <I> Texto <I>
Sublinhado <U> Texto </U>
Letreiro <MARQUEE > Texto </MARQUEE>
<html>
<head>
<title>Teste de Tags</title></head>
<body>
<h1>Teste de alguns tags em páginas HTML</h1><B> Negrito </B> <p>
<I> Itálico <I> <p>
<U> Sublinhado </U> <p>
<MARQUEE> Letreiro </MARQUEE> <p>
</body>
</html>
Visualizar
A linguagem HTML
HTML<html>
<head><title>O Mundo é Grande</title>
</head><body><b><font size="5" face="Arial">O Mundo é Grande</font></b></p>O mundo é grande e cabe<br>nesta janela sobre o mar.</p>O mar é grande e cabe<br>na cama e no colchão de amar.</p>O amor é grande e cabe<br>no breve espaço de beijar.</p><img border="0" src="drummond.jpg" width="129" height="173"><p style="margin-top: 0"><a href="http://pt.wikipedia.org/wiki/Carlos_Drummond_de_Andrade">Carlos Drummond de
Andrade</a></body>
</html>
Visualizar

24
A linguagem XML
A linguagem XML
� A linguagem XML (Extensible Markup Language)◦ Permite a criação de um número ilimitado de marcações
(tags);
◦ Não possui recursos para descrever o aspecto visual das páginas Web;
◦ Permite estruturar e descrever informação.
<html>
<body>
<font size="4">Micromputador</font><ul>
<li>Modelo: Pentium 4<li>velocidade 1.5 GHz<li>256MB de RAM<li>Monitor de 17 polegadas<li>Impressora HP Deskjet 930c
</ul>
</body>
</html>
<microcomputador>
<modelo>Pentium 4</modelo><velocidade>1.5 GHz</velocidade><ram>256Mb de memória</ram><monitor>17 polegadas</monitor><teclado>Sim</teclaco><mouse>Sim</mouse><estabilizador>Sim</estabilizador><impressora>Não</impressora>
</microcomputador>
HTML
XML
Visualizar Visualizar

25
A linguagem XML
<?xml version='1.0' encoding='ISO-8859-1'?><microcomputador>
<modelo>Pentium 4</modelo><velocidade>3.4</velocidade><ram>256</ram><monitor><marca>Samsung</marca><modelo>SyncMaster 551v</modelo>
</monitor><impressora>
<marca>HP</marca><modelo>Deskejet 930c</modelo>
</impressora></microcomputador>
Visualizar
A linguagem XML:esquemas
<!ELEMENT livro (titulo,genero?,autor+,editora,ano)><!ELEMENT titulo (#PCDATA)><!ELEMENT genero (#PCDATA)><!ELEMENT autor (nome, dtnasc)><!ELEMENT nome (#PCDATA)><!ELEMENT dtnasc (#PCDATA)><!ELEMENT editora (#PCDATA)>
<!ELEMENT ano (#PCDATA)>
DTD (arquivo: “livro.dtd”)
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE livro SYSTEM "livro.dtd"><livro>
<titulo>A Rosa do Povo</titulo><genero>poesia</genero><autor>
<nome>Carlos Drummond de Andrade</nome><dtnasc>1902-10-31</dtnasc>
</autor>
<editora>José Olympio</editora><ano>1993</ano>
</livro>
XML (arquivo: “livro.xml”)

26
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name=“microcomputador">
<xs:complexType>
<xs:sequence>
<xs:element name=“modelo" type="xs:string"/>
<xs:element name=“velocidade" type="xs:numeric"/>
<xs:element name=“ram" type="xs:integer"/>
<xs:element name=“monitor" type="TMonitor"/>
<xs:element name=“impressora" type="TImpressora"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:complexType name="TMonitor">
<xs:sequence>
<xs:element name=“marca" type="xs:string"/>
<xs:element name=“modelo" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
<?xml version='1.0' encoding='ISO-8859-1'?><microcomputador xmlns:xsi="http://www.usp.br/micro.xsd">
<modelo>Pentium 4</modelo><velocidade>3.4</velocidade><ram>256</ram><monitor>
<marca>Samsung</marca><modelo>SyncMaster 551v</modelo>
</monitor>
<impressora>
<marca>HP</marca><modelo>Deskejet 930c</modelo>
</impressora>
</microcomputador>
XML Schema ( micro.xsd )
XML
A linguagem XML:esquemas
A linguagem XML:xsl
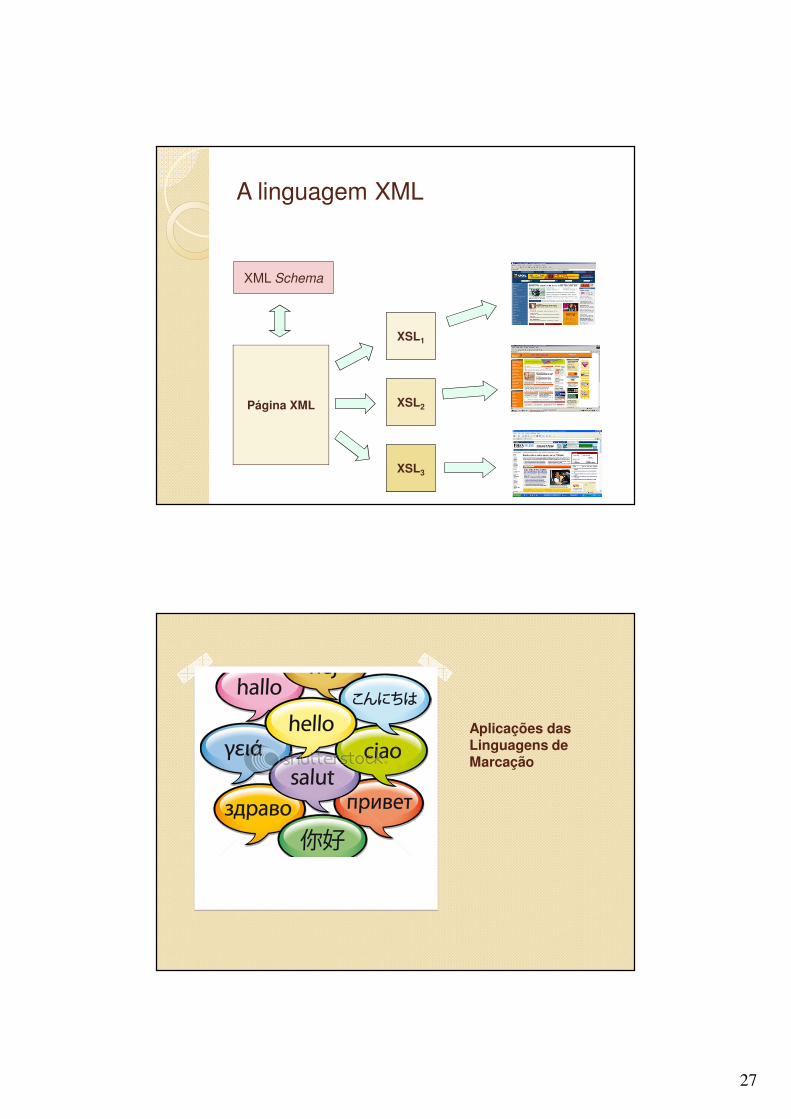
� XSL (Extensible Stylesheet Language)◦ Fornece uma “folha de estilo” poderosa e com uma sintaxe
fácil para expressar como os documentos XML serão apresentados
◦ Podem ser desenvolvidas várias folhas de estilo de maneira que o mesmo documento XML pode ser apresentado de muitas formas diferentes.
27
A linguagem XML
Página XML
XML Schema
XSL1
XSL2
XSL3
Aplicações das Linguagens de Marcação

28
MusicXML<?xml version="1.1" encoding="UTF-8" standalone="no"?><!DOCTYPE score-partwise PUBLIC
"-//Recordare//DTD MusicXML 1.1 Partwise//EN""http://www.musicxml.org/dtds/partwise.dtd">
<score-partwise><part-list><score-part id="P1">
<part-name>Music</part-name></score-part>
</part-list><part id="P1"><measure number="1">
<attributes><divisions>1</divisions><key>
<fifths>0</fifths></key><time>
<beats>4</beats><beat-type>4</beat-type>
</time><clef>
<sign>G</sign><line>2</line>
</clef></attributes>
<note><pitch>
<step>C</step><octave>4</octave>
</pitch><duration>4</duration><type>whole</type>
</note></measure>
</part></score-partwise>
VRMLVirtual Reality Modeling Language
#VRML V2.0 utf8# The VRML 2.0 Sourcebook# Copyright (c) 1997# Andrea L. Ames, David R. Nadeau, and John L. Moreland
Group {children [# Ground
Shape {appearance DEF White Appearance {
material Material { }}geometry Box {
size 25.0 0.1 25.0 }},# Left Column
Transform {translation -2.0 3.0 0.0children Shape {
appearance USE Whitegeometry Cylinder {
radius 0.3height 6.0 }}},
# Right ColumnTransform {
translation 2.0 3.0 0.0children Shape {
appearance USE Whitegeometry Cylinder {
radius 0.3height 6.0 }}},
# Archway spanTransform {
translation 0.0 6.05 0.0children Shape {
appearance USE Whitegeometry Box {
size 4.6 0.4 0.6}}}]}

29
CMLChemical Markup Language
Adrenalina
<molecule><atomArray><atom id="a1" elementType="C" x3="-0.296900" y3="0.897900" z3="0.000000"/><atom id="a2" elementType="C" x3="-0.296900" y3="-0.612100" z3="0.000000"/><atom id="a3" elementType="C" x3="-1.627300" y3="1.656600" z3="0.000000"/><atom id="a4" elementType="C" x3="0.989600" y3="1.865500" z3="0.000000"/><atom id="a5" elementType="C" x3="-1.641900" y3="-1.378000" z3="0.000000"/><atom id="a6" elementType="C" x3="-2.957700" y3="0.886900" z3="0.000000"/><atom id="a7" elementType="C" x3="2.265000" y3="1.055500" z3="0.000000"/><atom id="a8" elementType="O" x3="0.007300" y3="3.067600" z3="0.000000"/><atom id="a9" elementType="C" x3="-2.965000" y3="-0.604700" z3="0.000000"/><atom id="a10" elementType="O" x3="-1.656600" y3="-2.932000" z3="0.000000"/><atom id="a11" elementType="N" x3="3.701700" y3="1.979100" z3="0.000000"/><atom id="a12" elementType="O" x3="-4.302700" y3="-1.363400" z3="0.000000"/><atom id="a13" elementType="C" x3="5.068700" y3="1.037200" z3="0.000000"/><atom id="a14" elementType="H" x3="2.144000" y3="2.884400" z3="0.000000"/></atomArray><bondArray><bond atomRefs2="a1 a2" order="1"/><bond atomRefs2="a1 a3" order="2"/><bond atomRefs2="a1 a4" order="1"/><bond atomRefs2="a2 a5" order="2"/><bond atomRefs2="a3 a6" order="1"/><bond atomRefs2="a4 a7" order="1"/><bond atomRefs2="a4 a8" order="1"/><bond atomRefs2="a5 a9" order="1"/><bond atomRefs2="a5 a10" order="1"/><bond atomRefs2="a7 a11" order="1"/><bond atomRefs2="a9 a12" order="1"/><bond atomRefs2="a11 a13" order="1"/><bond atomRefs2="a6 a9" order="2"/><bond atomRefs2="a4 a14" order="1"/></bondArray>
</molecule>
MathMLMathematical Markup Language
<math><mrow><mi>x</mi><mo>=</mo><mfrac><mrow>
<mrow><mo>-</mo><mi>b</mi>
</mrow>
<mo>±</mo>...
... <msqrt>
<mrow><msup>
<mi>b</mi><mn>2</mn>
</msup><mo>-</mo><mrow>
<mn>4</mn><mo>⁢</mo><mi>a</mi><mo>⁢</mo><mi>c</mi>
</mrow></mrow>
</msqrt></mrow><mrow>
<mn>2</mn><mo>⁢</mo><mi>a</mi>
</mrow></mfrac></mrow>
</math>

30
MarcXML
Web Semântica

31
A Web semântica é uma visão para o futuro da Web
em que informação recebe significado explícito,
tornando possível processar de forma mais eficiente a
informação disponível na Web.
WEB Semântica
Web SemânticaWeb Atual X Web Semântica

32
Web SemânticaCamadas
WEB Semânticacenário
Lucy precisa marcar uma consulta médica com um ortopedista e uma série de sessões de fisioterapia para sua mãe. Como ela vai ter de levar sua mãe às consultas, é necessário que estas sejam marcadas em um horário em que Lucy esteja livre, e de preferência em um local perto da casa da sua mãe. Tanto o médico quanto os fisioterapeutas devem ser qualificados e fazer parte do plano de saúde da família.
Lucy requisita a marcação da consulta ao seu agente:
1. O agente recupera o tratamento prescrito à mãe de Lucy do agente do médico que está cuidando dela;
2. O agente procura em várias listas de provedores de serviços de saúde e verifica aqueles que fazem parte do plano de saúde da mãe de Lucy, que ficam dentro de um raio de dois quilómetros de sua casa e estão classificados como bons profissionais em um serviço de classificação de profissionais de saúde;
3. O agente então tenta achar casamentos entre os horários disponíveis da agenda de Lucy e os horários vagos dos profissionais (disponibilizados através de seus agentes ou site na web)

33
Web SemânticaCamadas
Padrão adotado mundialmente que possibilita que todos os caracteres de todas as linguagens escritas utilizadas no planeta possam ser representados em computadores
Web SemânticaCamadas
Identificador Uniforme de Recurso (URI) é uma cadeia de carateres compacta usada para identificar ou denominar um recurso na Internet.
URL, URI, URN

34
Web SemânticaCamadas
XML (eXtensible Markup Language): linguagem de marcação cuja principal característica é a possibilidade de se definir um número ilimitado de tags.
Web SemânticaCamada XML
42<idade> </idade>
<funcionário>
</funcionário>
<nome> </nome>José da Silva

35
WEB Semântica:XML e XML Schema
Esquema XML (XML
Schema)XML Schema (http://sites.uol.com.br/ferneda/livro.xsd)
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="livro">
<xs:complexType>
<xs:sequence>
<xs:element name="titulo" type="xs:string"/>
<xs:element name="genero" type="xs:string"/>
<xs:element name="autor" type="TAutor" minOccurs="1"/>
<xs:element name="editora" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:complexType name="TAutor">
<xs:sequence>
<xs:element name="nome" type="xs:string"/>
<xs:element name="dtnasc" type="xs:date"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
XML
<livro xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://sites.uol.com.br/ferneda/livro.xsd">
<titulo>A Rosa do Povo</titulo>
<genero>poesia</genero>
<autor>
<nome>Carlos Drummond de Andrade</nome>
<dtnasc>1902-10-31</dtnasc>
</autor>
<editora>Jose Olympio</editora>
</livro>
Web SemânticaCamadas
A Resource Description Framework (RDF) fornece um meio de agregar semântica a um documento sem se referir à sua estrutura.

36
Web SemânticaRDF
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Descriptionrdf:about="https://www.facebook.com/iAngelinaJolieofficial/"><nome>Angelina Jolie Pitt</nome><nacionalidade>norte-americana</nacionalidade><data_nascimento>1975-06-04</data_nascimento><altura>1.70</altura><peso>65</peso><olhos>verdes</olhos>
</rdf:Description></rdf:RDF>
<conjuge>https://www.facebook.com/Bred-Pitt-412696162128064</conjuge>
WEB Semântica:RDF
� RDF (Resource Description Framework)◦ Permite fazer "declarações" a respeito de recursos da
Web;
◦ Está baseada em três tipos de objetos: � recurso (“resource”),
� ualquer objeto da Web que possui um endereço, como, por exemplo, uma página HTML ou XML identificada por uma URL;
� propriedade (“property”);� Uma propriedade é uma característica, um atributo ou uma relação
usada para descrever um recurso;
� declaração (“statement”);� recurso + propriedade.

37
WEB Semântica:RDF
� RDF (Resource Description Framework)� Permite fazer "declarações" a respeito de recursos da Web;
� Uma declaração pode ser dividida em três partes:� sujeito� predicado� objeto
Declaração Propriedade Domínio
Sujeito Recurso
Predicado Nome da propriedade
Objeto Valor da propriedade Recurso ou literal
WEB Semântica:RDF
Sujeito (recurso) http://www.familia.org/joao
Predicado (propriedade) NumFone
Objeto (valor) 3432-2677
<rdf:RDF
<rdf:Description about=”http://www.familia.org/joao”>
<p:NumFone>
3432-2677
</p:NumFone>
</rdf:Description>
</rdf:RDF>
www.familia.org/joaoNumFone "3432-2677"

38
WEB Semântica:RDF
Sujeito (recurso) http://www.familia.org/joao
Predicado (propriedade) Cadado_com
Objeto (valor) http://www.familia.org/maria
<rdf:RDF
<rdf:Description about=”http://www.familia.org/joao”>
<f:Casado_com>
www.familia.org/maria</f:Casado_com>
</rdf:Description>
</rdf:RDF>
www.familia.org/joaoCasado com www.familia.org/maria
WEB Semântica:RDF
<rdf:RDF
<rdf:Description about=”http://www.familia.org/joao”>
<p:NumFone>
3432-2677
</p:NumFone>
<f:Casado_com>
www.familia.org/maria
</f:Casado_com>
</rdf:Description>
</rdf:RDF>
www.familia.org/joaoCasado_com
www.familia.org/maria
3432-2677

39
WEB Semântica:RDF - exemplo
Sujeito (recurso) Pedro Álvares Cabral (http://www.vidaslusofonas.pt/pedro_a_cabral.htm)Predicado (propriedade) DescobriuObjeto (valor ou recurso) Brasil (http://pt.wikipedia.org/wiki/Brasil)
“Pedro Álvares Cabral (http://www.vidaslusofonas.pt/pedro_a_cabral.htm)descobriu o Brasil (http://pt.wikipedia.org/wiki/Brasil)”
Brasil(http://pt.wikipedia.org/wiki/Brasil)
Pedro Álvares Cabral(http://www.vidaslusofonas.pt/pedro_a_cabral.htm)
Descobriu
<rdf:RDF><rdf:Description about=“(http://www.vidaslusofonas.pt/pedro_a_cabral.htm”><Descobriu>
<rdf:Description about=“http://pt.wikipedia.org/wiki/Brasil”></rdf:Description>
</Descobriu></rdf:Description>
</rdf:RDF>
WEB Semântica:RDF - exemplo
data_descobrimento
1500-04-22
Pedro Álvares Cabral nome
nome
Brasil
<rdf:RDF>
<rdf:Description about=“http://www.vidaslusofonas.pt/pedro_a_cabral.htm”><nome>Pedro Álvares Cabral</nome><Descobriu>
<rdf:Description about=“http://pt.wikipedia.org/wiki/Brasil”><nome>Brasil</nome><data_descobrimento>1500-04-22</data_descobrimento>
</rdf:Description>
</Descobriu></rdf:Description>
</rdf:RDF>
http://pt.wikipedia.org/wiki/Brasil
http://www.vidaslusofonas.pt/pedro_a_cabral.htm Descobriu

40
WEB Semântica:RDF Schema
<rdfs:Class rdf:ID="Publicacao"><rdfs:subClassOf resource="http://www.w3.org/2000/01/rdf-schema#"/>
</rdfs:Class>
<rdf:Property rdf:ID="titulo"><rdfs:domain rdf:resource="#Publicacao"/><rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#string"/>
</rdf:Property>
<rdf:Property rdf:ID="genero"><rdfs:domain rdf:resource="#Publicacao"/><rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#string"/>
</rdf:Property>
<rdfs:Class rdf:ID="Livro"><rdfs:subClassOf rdf:resource="#Publicacao"/>
</rdfs:Class>
<rdf:Property rdf:ID="ISBN"><rdfs:domain rdf:resource="#Livro"/><rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#integer"/>
</rdf:Property>
<rdf:Property rdf:ID="editora"><rdfs:domain rdf:resource="#Livro"/><rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#string"/>
</rdf:Property>
<rdf:Property rdf:ID="escreve"><rdfs:domain rdf:resource="#Autor"/><rdfs:domain rdf:resource="#Livro"/>
</rdf:Property>
RDF Schema
WEB Semântica:RDF Schema
<Autor rdf:about="http://www.carlosdrummond.com.br"><nome>Carlos Drummond de Andrade</nome><dtnasc>1902-10-31</dtnasc><escreve><Livro><titulo>A Rosa do Povo</titulo><genero>Poesia</genero><editora>Jose Olympio</editora><ISBN>8501061360</ISBN>
</Livro></escreve>
</Autor>
RDF

41
WEB Semântica:RDF Schema - exemplo
Descobridor
String
nome
País
String
nome
Date
data_descobrimento
descobriu
<rdfs:Class rdf:ID="Descobridor"><dfs:subClassOf rdf:resource="http://www.w3.org/2000/01/rdf-schema#"/>
</rdfs:Class>
<rdf:Property rdf:ID="nome"><rdfs:domain rdf:resource="#Descobridor"/><rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#string"/>
</rdf:Property><rdfs:Class rdf:ID="Paisrdfs:subClassOf rdf:resource="http://www.w3.org/2000/01/rdf-schema#"/>
</rdfs:Class>
<rdf:Property rdf:ID="nome"><rdfs:domain rdf:resource="#Pais<rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#string"/>
</rdf:Property>
<rdf:Property rdf:ID="data_descobrimento”><rdfs:domain rdf:resource="#Pais<rdfs:range rdf:resource="http://www.w3.org/TR/xmlschema-2/#date"/>
</rdf:Property>
<rdf:Property rdf:ID="descobriu"><rdfs:domain rdf:resource="#Descobridor"/><rdfs:domain rdf:resource="#Pais"/>
</rdf:Property>
WEB Semântica:RDF Schema - exemplo
Definida a estrutura de classes, podem-se associar a ela recursos (resources) na forma de instâncias de uma ou mais classes, como exemplificado abaixo, onde é definida uma instância da classe Descobridor.
Descobridor(http://www.vidaslusofonas.pt/pedro_a_cabral.htm)
Paíshttp://pt.wikipedia.org/wiki/Brasil
Descobriu
data_descobrimento
1500-04-22
Pedro Álvares Cabralnome
nome
Brasil
<Descobridor rdf:about="http://www.vidaslusofonas.pt/pedro_a_cabral.htm"><nome>Pedro Alvares Cabral</nome><descobriu><Pais rdf:about="http://pt.wikipedia.org/wiki/Brasil"><nome>Brasil</nome><data_descobrimento>1500-04-22</data_descobrimento>
</Pais></decobriu>
</Descobridor>
42
Web SemânticaCamadas
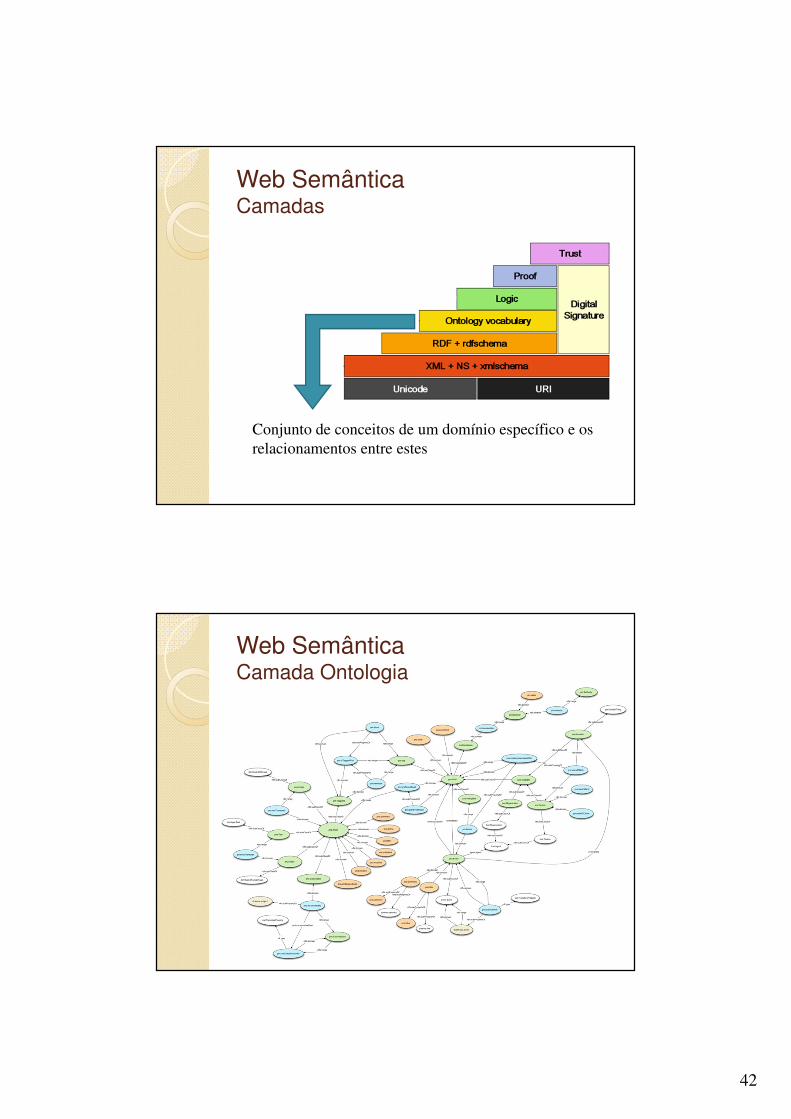
Conjunto de conceitos de um domínio específico e os relacionamentos entre estes
Web SemânticaCamada Ontologia

43
WEB Semântica:Ontologia
◦ Termo originário da filosofia� Disciplina que trata do assunto da existência� “Parte da filosofia que trata do ser enquanto ser, isto é, do ser
como tendo uma natureza comum que é inerente a todos e a cada um dos seres”;
◦ No contexto da Web Semântica...� “Descrição formal dos conceitos e relacionamentos que
existem dentro de um domínio”.
WEB Semântica:Ontologia
slot-def comeinverse é-comido-por
slot-def tem-parteinverse é-parte-deproperties transitive
class-def animal
class-def plantasubclass-of NOT animal
class-def árvoresubclass-of planta
class-def galhoslot-constraint é-parte-de
has-value árvore
class-def folhaslot-constraint é-parte-de
has-value galho...
.
.
.
class-def defined carnívorosubclass-of animalslot-constraint come value-type animal
class-def defined herbívorosubclass-of animalslot-constraint come
value-type planta OR
(slot-constraint é-parte-de has-value planta)
class-def herbívorosubclass-of NOT carnívoro
class-def girafasubclass-of animalslot-constraint come value-type folha
class-def leão
subclass-of animal
slot-constraint come value-type herbívoro

44
Web SemânticaCamadas
Vídeo
O Poder das Pessoas

45
Discussão
Discussão
� A predominância da linguagem HTML como estrutura informacional da Web;
� HTML x XML
� buscadores e algoritmos de rankeamento
� Na história da Web observa-se inicialmente uma ênfase no caráter comunicativo/divulgador de seu conteúdo.
� Progressivamente o foco da atenção recai sobre a significação. Essa mudança é notada claramente pelo surgimento sucessivo das linguagens de marcação.
� Da HTML à Web Semântica, novos recursos estão sendo implementados, sempre visando um maior nível semântico para os documentos da Web.

46
Discussão
� A Web Semântica ainda está dando os seus primeiros passos, sendo difícil prever seu futuro.
� A sua complexidade é ainda um grande empecilho, mas isso poderá ser contornado com a sua consolidação e a criação de ferramentas que facilitem sua utilização.
� A Web é um enorme campo de prova para diversas teorias relacionadas ao tratamento e recuperação da informação.
� Desde o seu nascimento poucas mudanças ocorreram em sua estrutura básica. Talvez a Web Semântica seja a mudança necessária para que a Web se torne realmente uma fonte de informação confiável.
Referências bibliográficas

47
Referências bibliográficas
� KAPPE, F. Aspects of a modern multi-media information
system. PhD Thesis, Graz University of Technology, Austria, 1991.
� ANDREWS, K.; KAPPE, F.; MAURER, H. Serving information to the Web with Hyper-G. Computer Network
and ISDN Systems, v. 27, n. 6, 1995, p.919-926.
� BUSBY. M. Learn Google. Plano, Texas: Wordware, 2003.
� CROFT, W.B.; METZLER, D.; STROHMAN, T. Search
Engines: information retrieval in practice. Addison Wesley, 2009.
� DAUM, B; MERTEN U. Arquitetura de sistemas com XML. Rio de Janeiro: Campus, 2002.















![Subcategoria A2 - repositorio.ul.ptrepositorio.ul.pt/bitstream/10451/846/4/20169_ulsd_dep.17810_tm... · sincero com o aluno [pior enfermeira orientadora] “(…) não falou nisso](https://static.fdocumentos.tips/doc/165x107/5bf2e8e609d3f2dc7c8cba5d/subcategoria-a2-sincero-com-o-aluno-pior-enfermeira-orientadora-nao.jpg)


