
Fit Metrocamp 2016
50
Paralelização com OpenMP - CUDA FIT - Metrocamp 2016
-
Upload
leandro-zanotto -
Category
Technology
-
view
83 -
download
0
Transcript of Fit Metrocamp 2016

Paralelização comOpenMP - CUDA
FIT - Metrocamp 2016

FIT- Metrocamp 2016 2
Agenda
● Apresentação● Introdução● Motivação● OpenMP● CUDA● Otimização● Perguntas

FIT- Metrocamp 2016 3
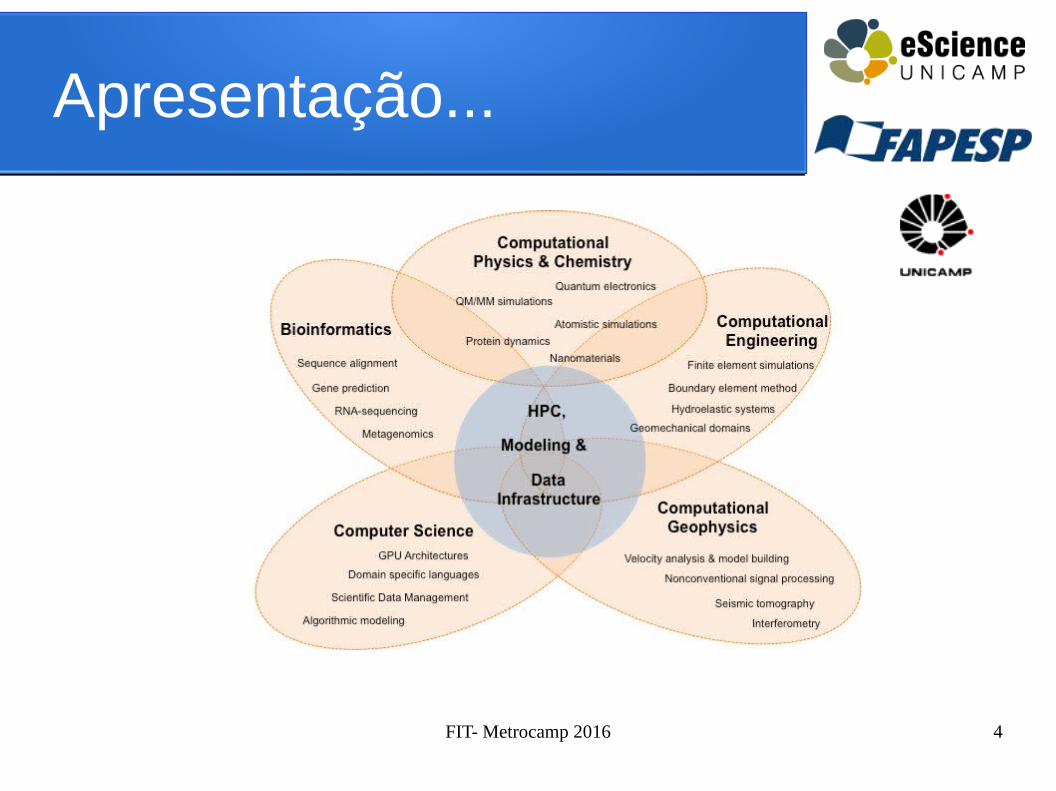
Apresentação
● Desenvolvimento de Software no Centro de Engenharia e Ciências Computacionais Unicamp
● Software com foco em HPC● Resolver problemas que exigem alto poder
computacional
FIT- Metrocamp 2016 4
Apresentação...

FIT- Metrocamp 2016 5
Apresentação...
Cluster Composition with Xeon Processor
1 Head node with 40 cores Intel Xeon E5-2660 v2 of 2.20GHz, 128G memory.
1 Login node with 40 cores HT Intel Xeon E5-2660 v2 of 2.20GHz, 128G memory and 1 Nvidia Quadro 4000 card.
32 Graphic nodes with 40 cores HT Intel Xeon E5-2670 v2 of 2.50GHz, 64G memory and 2 Nvidia Tesla K20M card.
1 UV20 node with 64 cores HT Intel Xeon E5-4650L of 2.60GHz, 1TB memory and 1 Intel Xeon-Phi card with 57 cores.
1 Storage node with 32 cores HT Intel Xeon E5-2660 of 2.20GHz, 128G memory and 56 disks of 4TB in RAID6 array.
Interconnection with Gigabit Ethernet switch and Infiniband 40 Gb/sec (4X QDR) switch
The cluster is connected to two UPSs in parallel to 20kV and IQ of the diesel generator.
Total Cluster Memory - 3,3 TB
Theoretical Performance Total Cluster - 96 Tflops

FIT- Metrocamp 2016 6
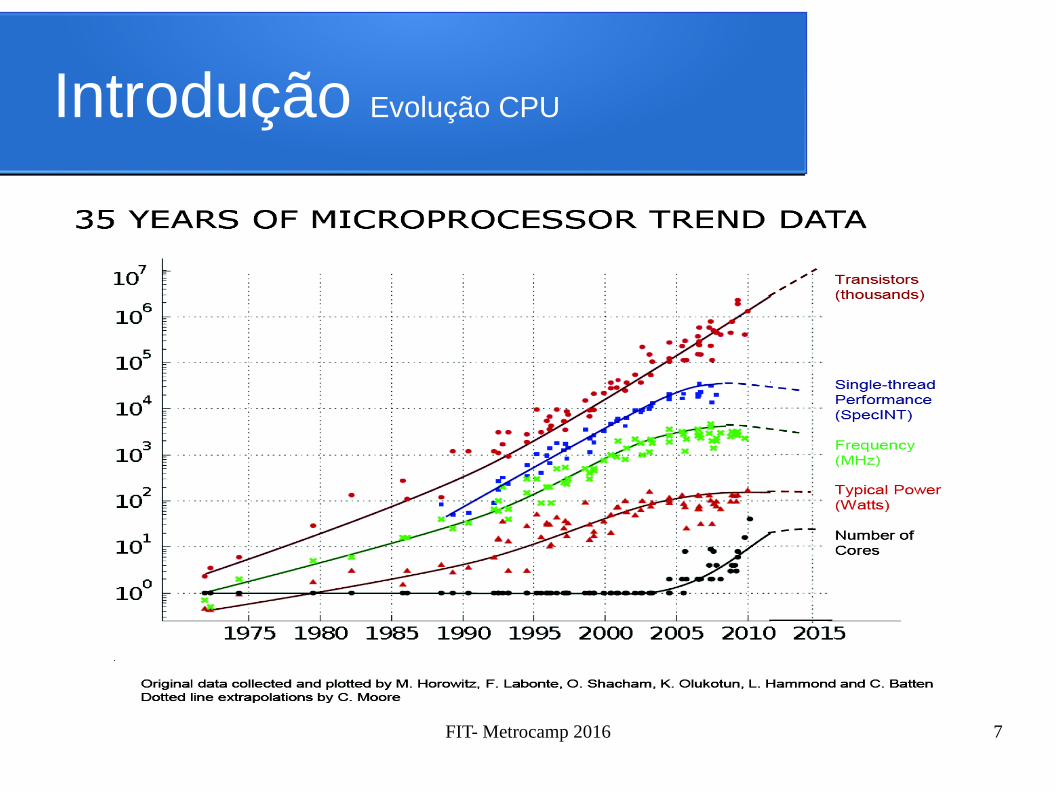
Introdução
● Processadores eram Seriais (até ± 2006)● A cada nova geração Aumentava a sua
frequência (+ transistors, litografia menor)
● Algumas novas tecnologias foram sendo adicionadas (Ex. Cache – SSE – AVX – VT – TM)
FIT- Metrocamp 2016 7
Introdução Evolução CPU

FIT- Metrocamp 2016 8
Introdução
Lei de Moore
O número de transistores dos chips teria um aumento de
100%, pelo mesmo custo, a cada período de 18 meses

FIT- Metrocamp 2016 9
Introdução
Memory WallO aumento da lacuna entre a velocidade da CPU e Memória
ILP WallO aumento da dificuldade em encontrar paralelismo suficiente em um único fluxo de instrução para manter alta performance em um processador com um só núcleo
The power wall Ao aumentar a frequencia do processador temos um aumento do consumo de energia tornando inviável com os sistemas de resfriamento mais baratos.

FIT- Metrocamp 2016 10
Introdução
Solução● Diminuir a frequência● Multicore

FIT- Metrocamp 2016 11
Motivação
● Aumento do número de cores disponíveis● Novas tecnologias para aumentar o
desempenho dos códigos● Surgimento de GPUs e Coprocesadores● Qualquer smartphone produzido hoje tem
no mínimo 2 cores

FIT- Metrocamp 2016 12
OpenMP
● API para programação Multi-core● Utiliza Memória Compartilhada● Multiplas Plataformas● Suporta C / C++ e Fortran

FIT- Metrocamp 2016 13
OpenMP – Conceitos básicos
● Core● Thread● Condições de Corridas● Speedup● Eficiência

FIT- Metrocamp 2016 14
OpenMP – Conceitos básicos
Fork - Join
Master Thread 1
2
4
threads
região paralela
threads
região paralela
3
1
2
3

FIT- Metrocamp 2016 15
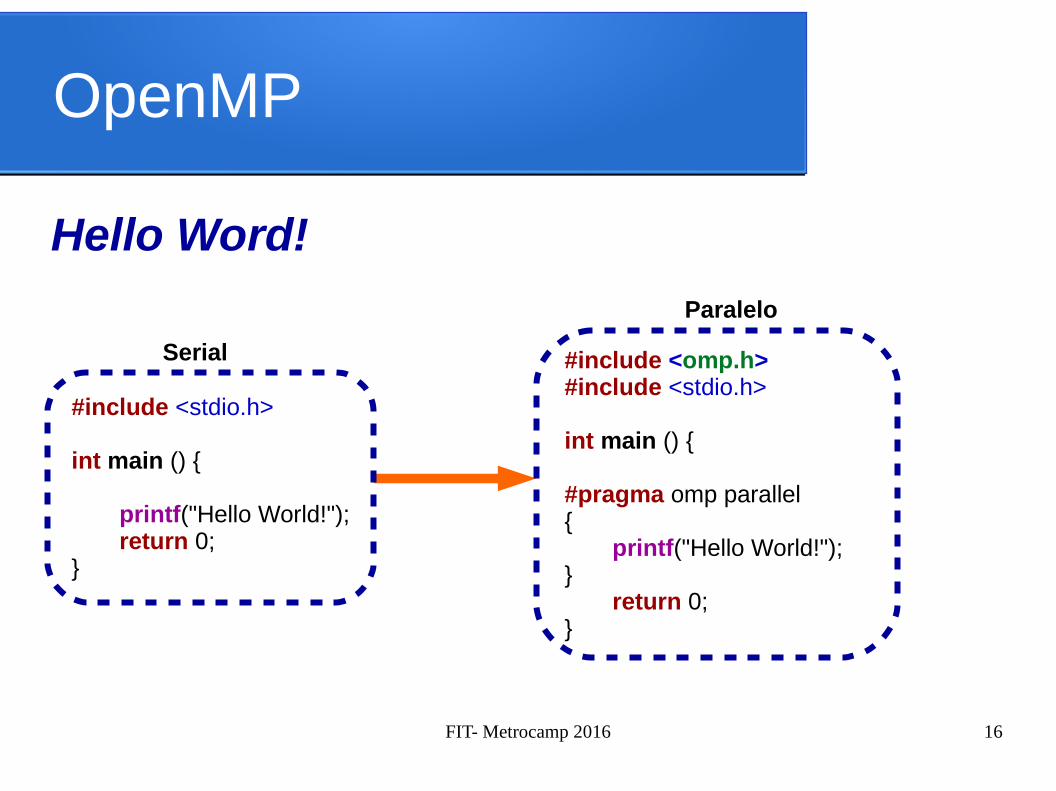
OpenMP
Hello Word!
#include <stdio.h>
int main () {
printf("Hello World!");return 0;
}
Serial
FIT- Metrocamp 2016 16
OpenMP
Hello Word!
#include <stdio.h>
int main () {
printf("Hello World!");return 0;
}
Serial
Paralelo
#include <omp.h>#include <stdio.h>
int main () {
#pragma omp parallel{
printf("Hello World!");}
return 0;}

FIT- Metrocamp 2016 17
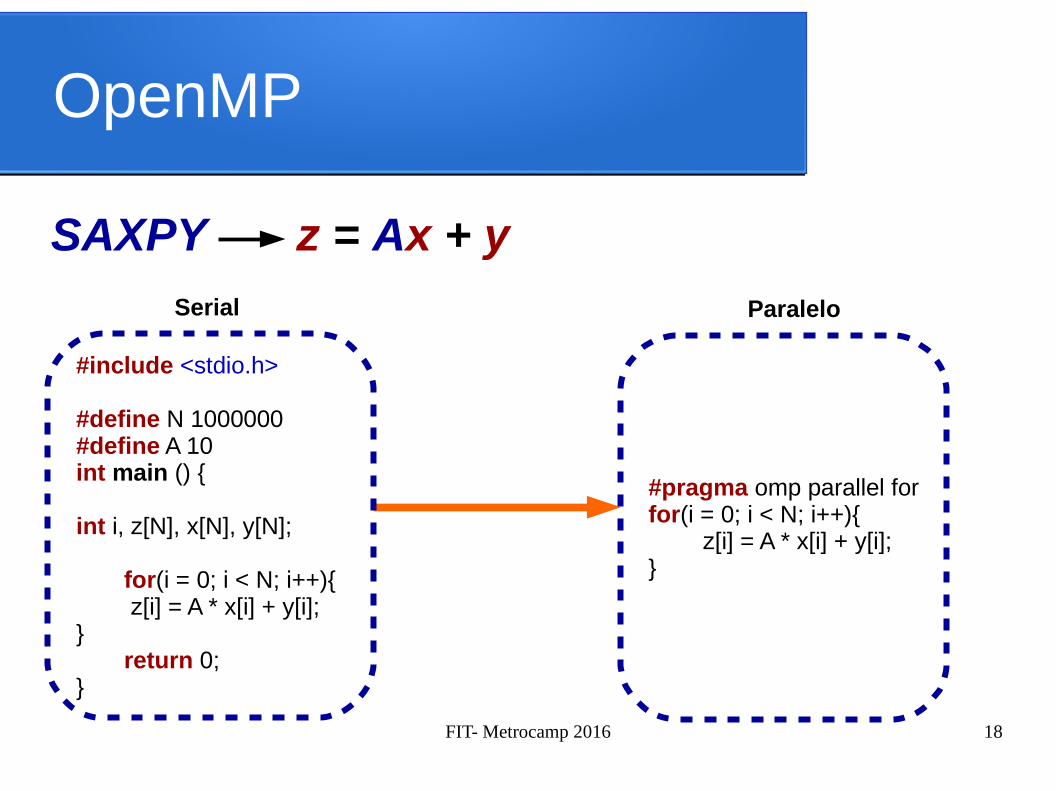
OpenMP
SAXPY z = Ax + y
#include <stdio.h>
#define N 1000000#define A 10int main () {
int i, z[N], x[N], y[N];
for(i = 0; i < N; i++){ z[i] = A * x[i] + y[i];
}return 0;
}
Serial
FIT- Metrocamp 2016 18
OpenMP
SAXPY z = Ax + y
#include <stdio.h>
#define N 1000000#define A 10int main () {
int i, z[N], x[N], y[N];
for(i = 0; i < N; i++){ z[i] = A * x[i] + y[i];
}return 0;
}
Serial
#pragma omp parallel forfor(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];}
Paralelo

FIT- Metrocamp 2016 19
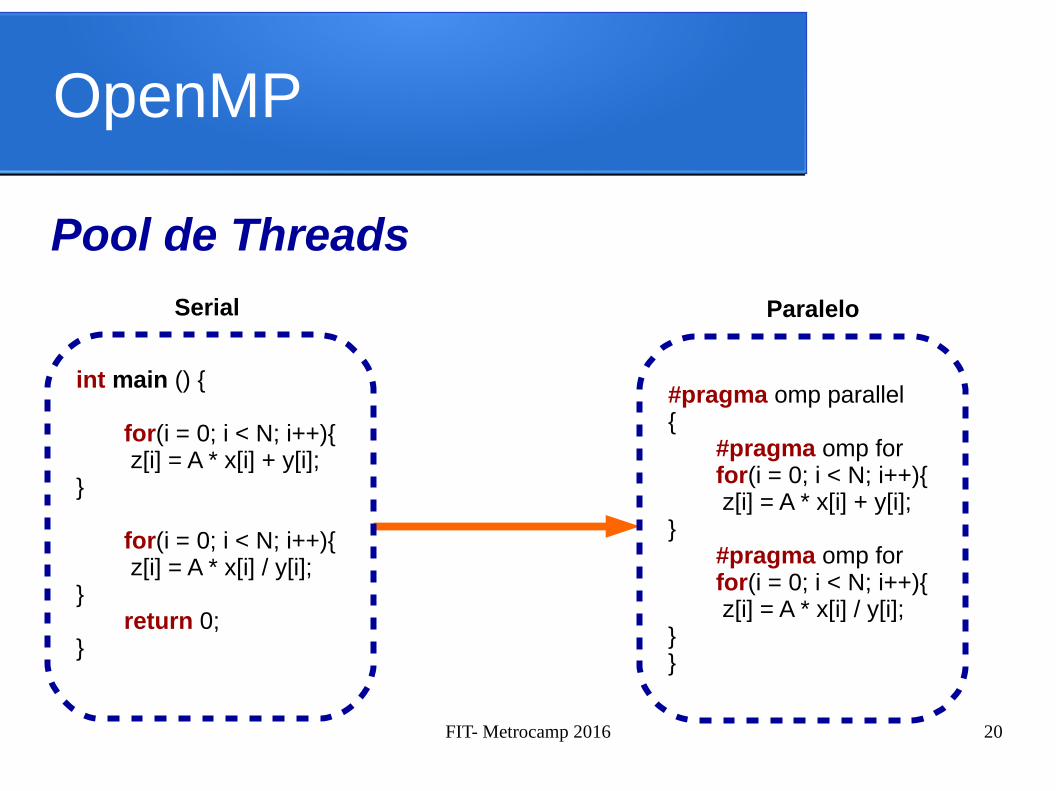
OpenMP
Pool de Threads
int main () {
for(i = 0; i < N; i++){ z[i] = A * x[i] + y[i];
}
for(i = 0; i < N; i++){ z[i] = A * x[i] / y[i];
}return 0;
}
Serial
FIT- Metrocamp 2016 20
OpenMP
Pool de Threads
int main () {
for(i = 0; i < N; i++){ z[i] = A * x[i] + y[i];
}
for(i = 0; i < N; i++){ z[i] = A * x[i] / y[i];
}return 0;
}
Serial
#pragma omp parallel{
#pragma omp forfor(i = 0; i < N; i++){ z[i] = A * x[i] + y[i];
}#pragma omp forfor(i = 0; i < N; i++){ z[i] = A * x[i] / y[i];
}}
Paralelo

FIT- Metrocamp 2016 21
OpenMP
Scheduling● A cargas de trabalho nem sempre são do mesmo tamanho● Veremos 3 maneiras de dividir a carga de trabalho
✔ Static✔ Dynamic✔ Guided

FIT- Metrocamp 2016 22
OpenMP
Scheduling - Static
Divide o loop em pedaços de tamanhos iguais ou quanto possivel no caso do numero de iterações não serem divisíveis pelo número de threads multiplicados pelo tamanho do
pedaço.
#pragma omp parallel for schedule(static)for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];}
T0 T1 T2 T3
T0 T1 T2 T3 T0 T1 T2 T3 T0 T1 T2 T3
static,1
static,3

FIT- Metrocamp 2016 23
OpenMP
Scheduling - Dynamic
Usa a fila de trabalho interna para dar o tamanho do pedaço do bloco das iterações de cada thread. Quando uma thread termina, ele pega o próximo bloco de iterações do loop
do topo da fila.
#pragma omp parallel for schedule(dynamic)for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];}
T0 T1T2 T3 T0T1T2 T3 T0T1 T2 T3
dynamic,3
FIT- Metrocamp 2016 24
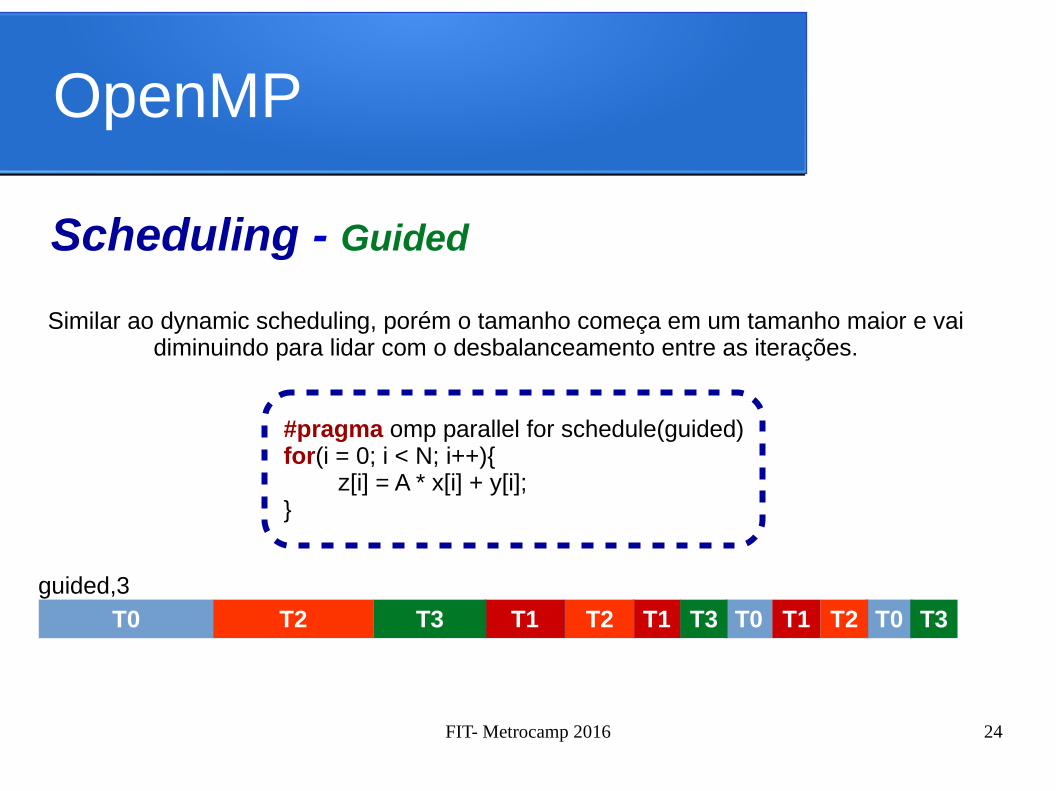
OpenMP
Scheduling - Guided
Similar ao dynamic scheduling, porém o tamanho começa em um tamanho maior e vai diminuindo para lidar com o desbalanceamento entre as iterações.
#pragma omp parallel for schedule(guided)for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];}
T0 T1T2 T3 T0T1T2 T3 T0T1 T2 T3
guided,3
FIT- Metrocamp 2016 25
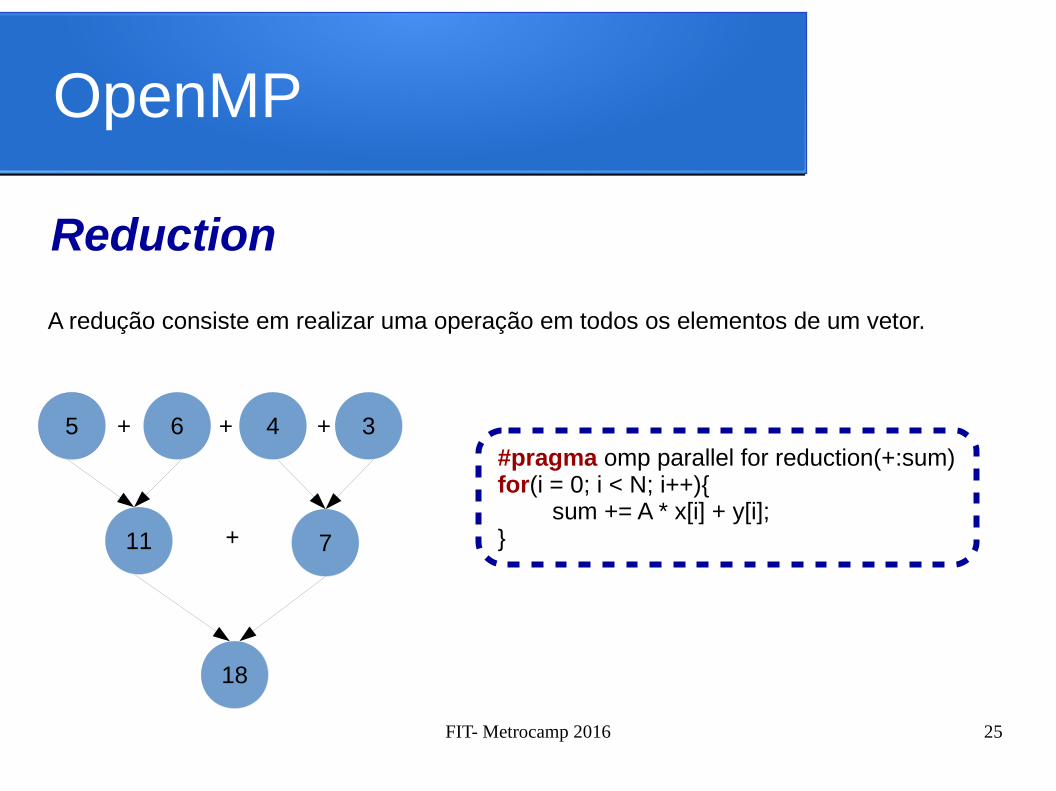
OpenMP
Reduction
A redução consiste em realizar uma operação em todos os elementos de um vetor.
#pragma omp parallel for reduction(+:sum)for(i = 0; i < N; i++){
sum += A * x[i] + y[i];}
5 4 36
11 7
18
+ + +
+
FIT- Metrocamp 2016 26
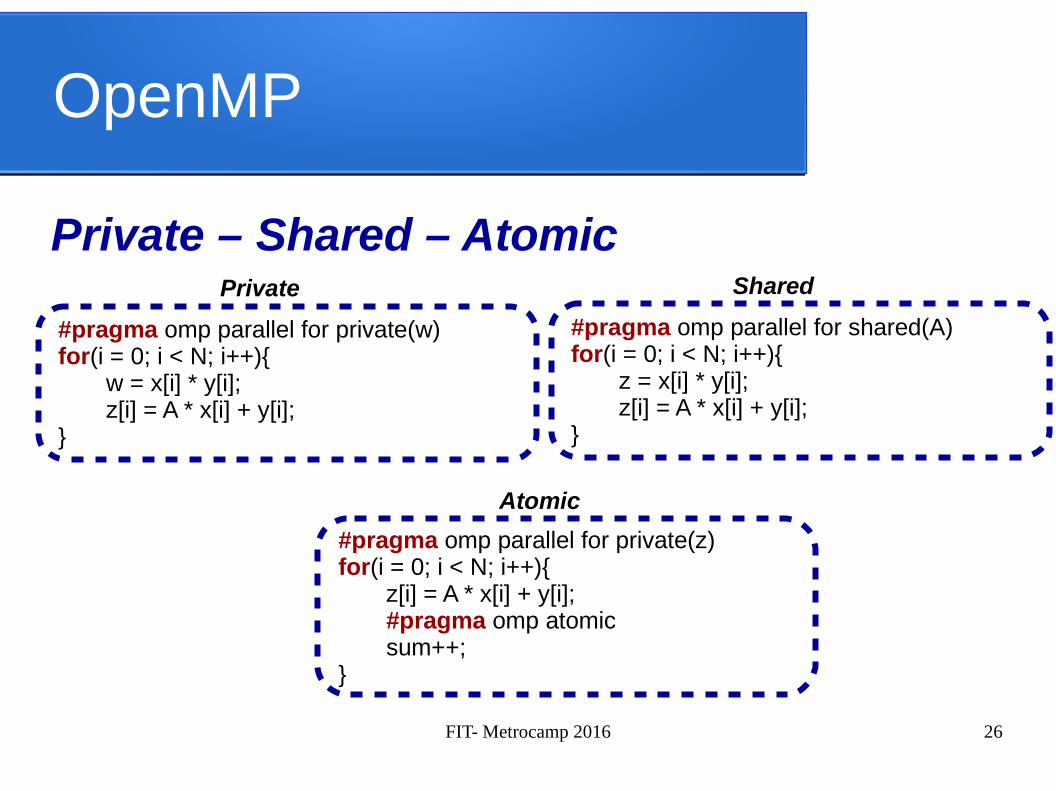
OpenMP
Private – Shared – Atomic
#pragma omp parallel for private(w)for(i = 0; i < N; i++){
w = x[i] * y[i];z[i] = A * x[i] + y[i];
}
Private
#pragma omp parallel for private(z)for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];#pragma omp atomicsum++;
}
Atomic
#pragma omp parallel for shared(A)for(i = 0; i < N; i++){
z = x[i] * y[i];z[i] = A * x[i] + y[i];
}
Shared
FIT- Metrocamp 2016 27
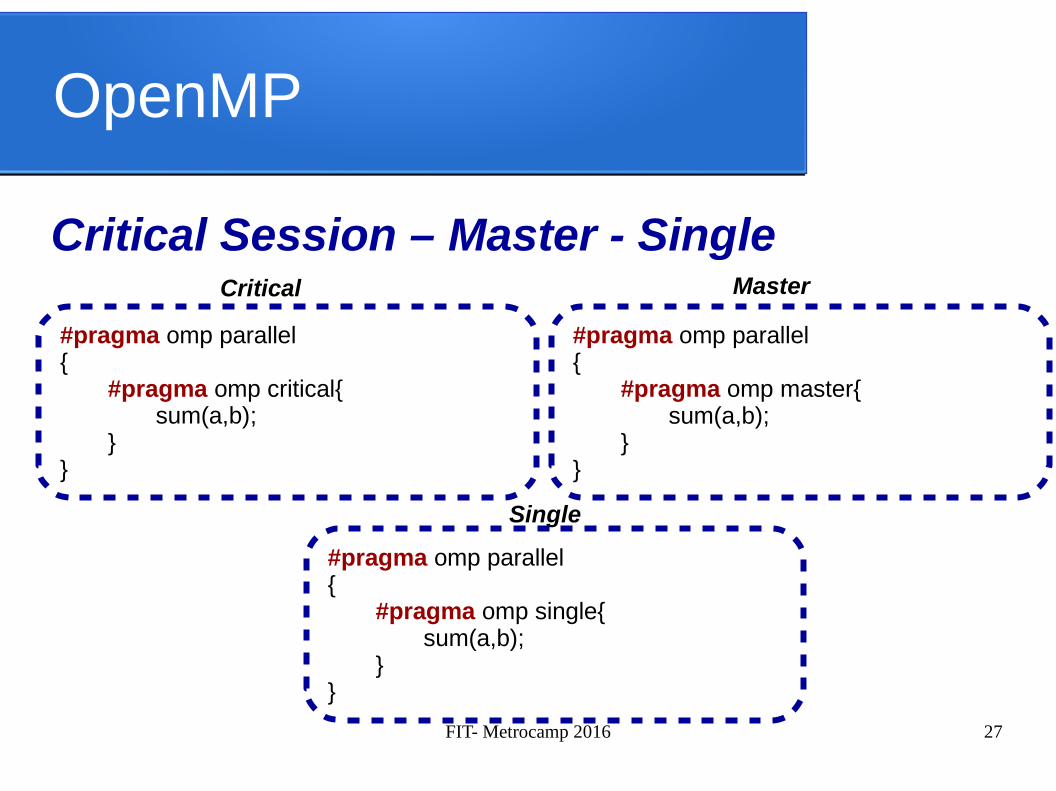
OpenMP
Critical Session – Master - Single
#pragma omp parallel {
#pragma omp critical{sum(a,b);
}}
Critical
Single
Master
#pragma omp parallel {
#pragma omp master{sum(a,b);
}}
#pragma omp parallel {
#pragma omp single{sum(a,b);
}}

FIT- Metrocamp 2016 28
Profile
Não advinhe, meça!

FIT- Metrocamp 2016 29
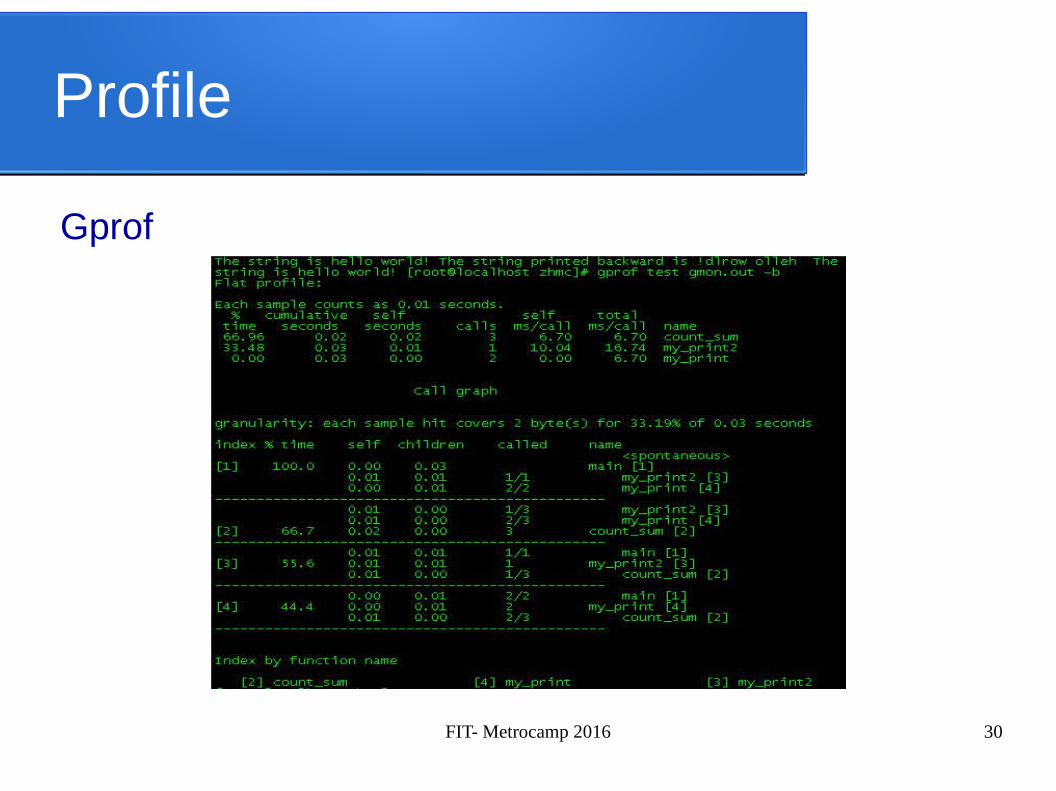
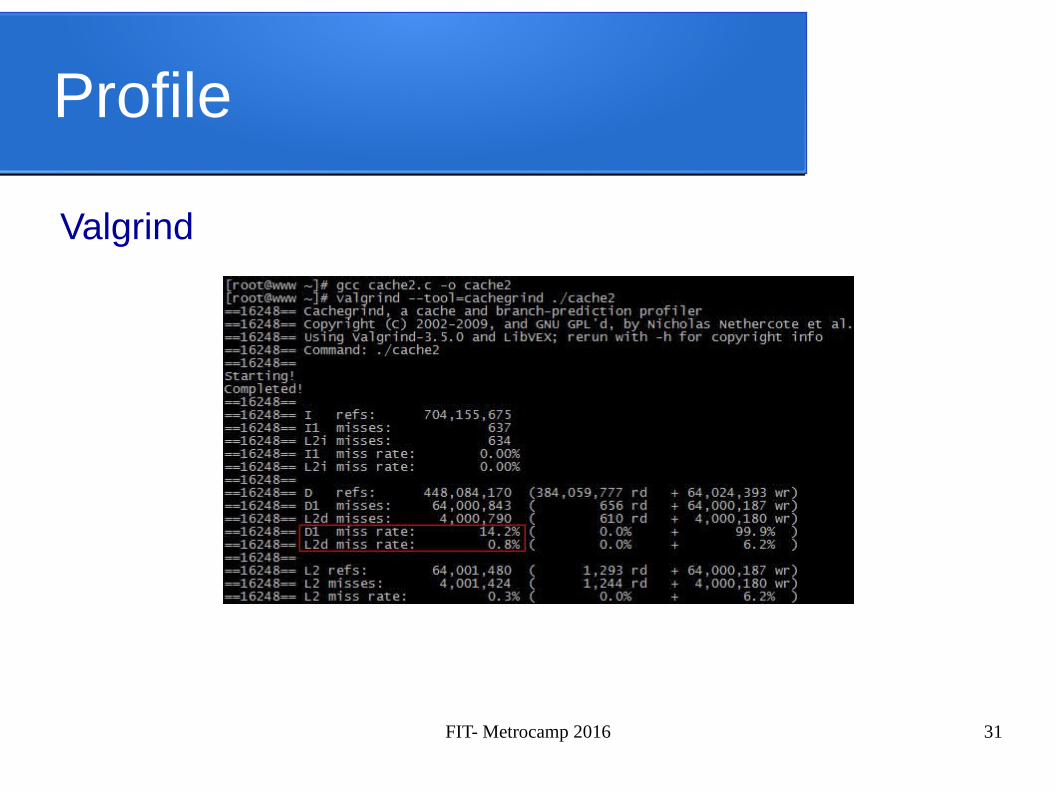
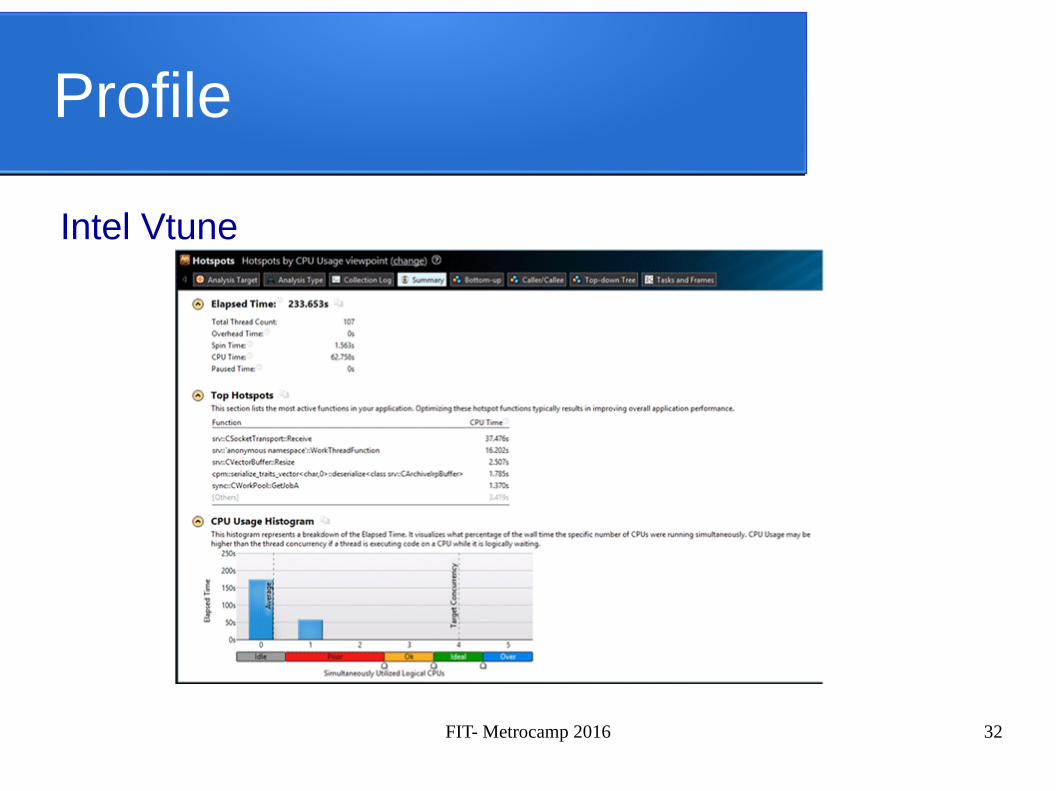
Profile
Existem ferramentas que auxiliam a identificar trechos em potencial, afim de aumentar o desempenho
✔ Gprof✔ Valgrind✔ Intel Vtune
FIT- Metrocamp 2016 30
Profile
Gprof
FIT- Metrocamp 2016 31
Profile
Valgrind
FIT- Metrocamp 2016 32
Profile
Intel Vtune
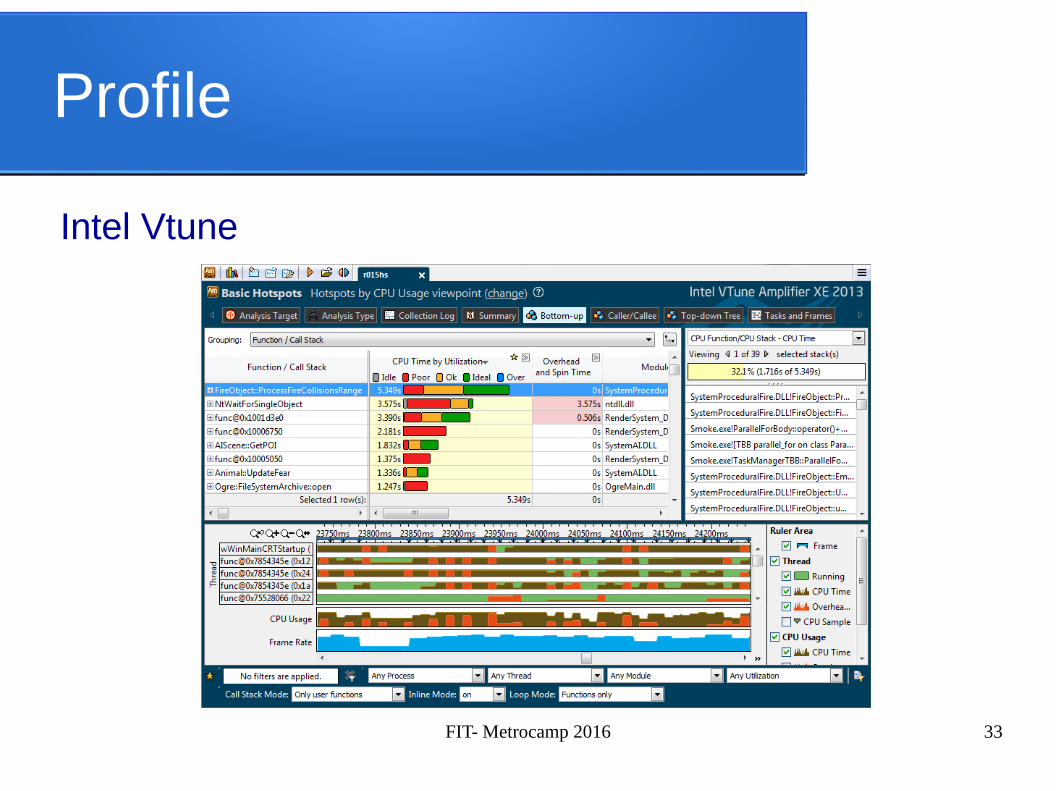
FIT- Metrocamp 2016 33
Profile
Intel Vtune

FIT- Metrocamp 2016 34
CUDA
Compute Unified Device Architecture
● Desenvolvido pela Nvidia – 2006● Arquitetura● Programação com CUDA
FIT- Metrocamp 2016 35
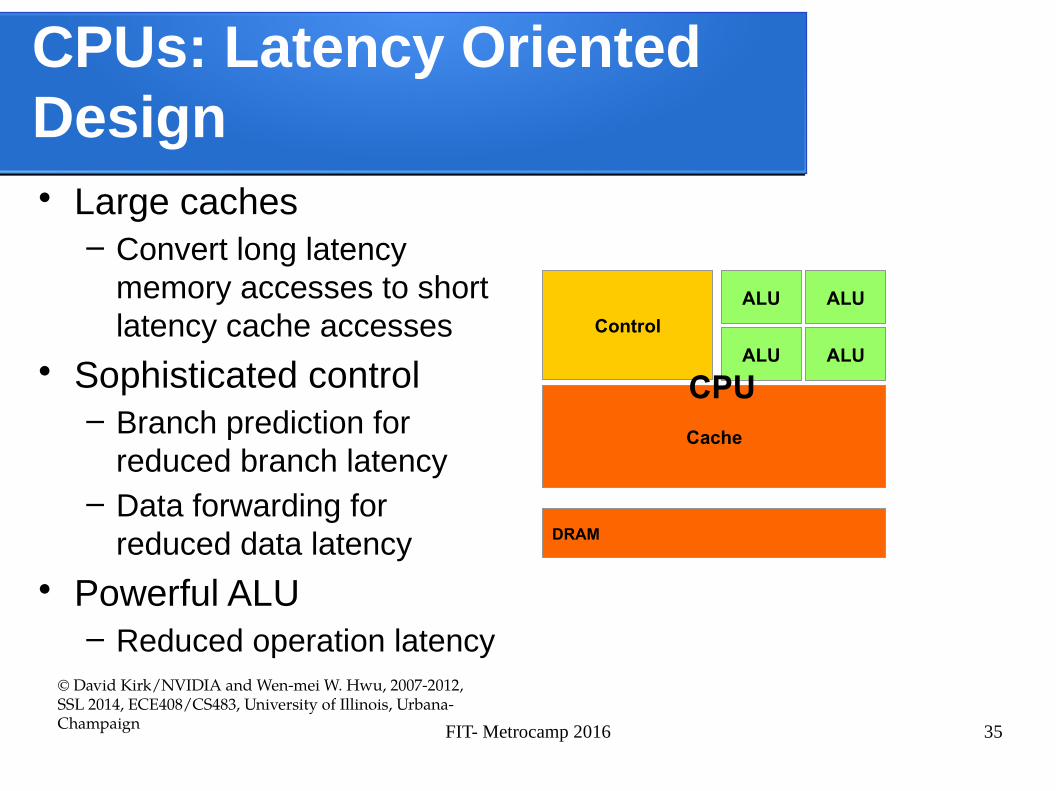
CPUs: Latency Oriented Design • Large caches
– Convert long latency memory accesses to short latency cache accesses
• Sophisticated control– Branch prediction for
reduced branch latency– Data forwarding for
reduced data latency
• Powerful ALU– Reduced operation latency
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2012, SSL 2014, ECE408/CS483, University of Illinois, Urbana-Champaign
Cache
ALU
Control
ALU
ALU
ALU
DRAM
CPU

FIT- Metrocamp 2016 36
GPUs: Throughput Oriented Design• Small caches
– To boost memory throughput
• Simple control– No branch prediction– No data forwarding
• Energy efficient ALUs– Many, long latency but heavily
pipelined for high throughput
• Require massive number of threads to tolerate latencies
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2012, SSL 2014, ECE408/CS483, University of Illinois, Urbana-Champaign
DRAM
GPU
FIT- Metrocamp 2016 37
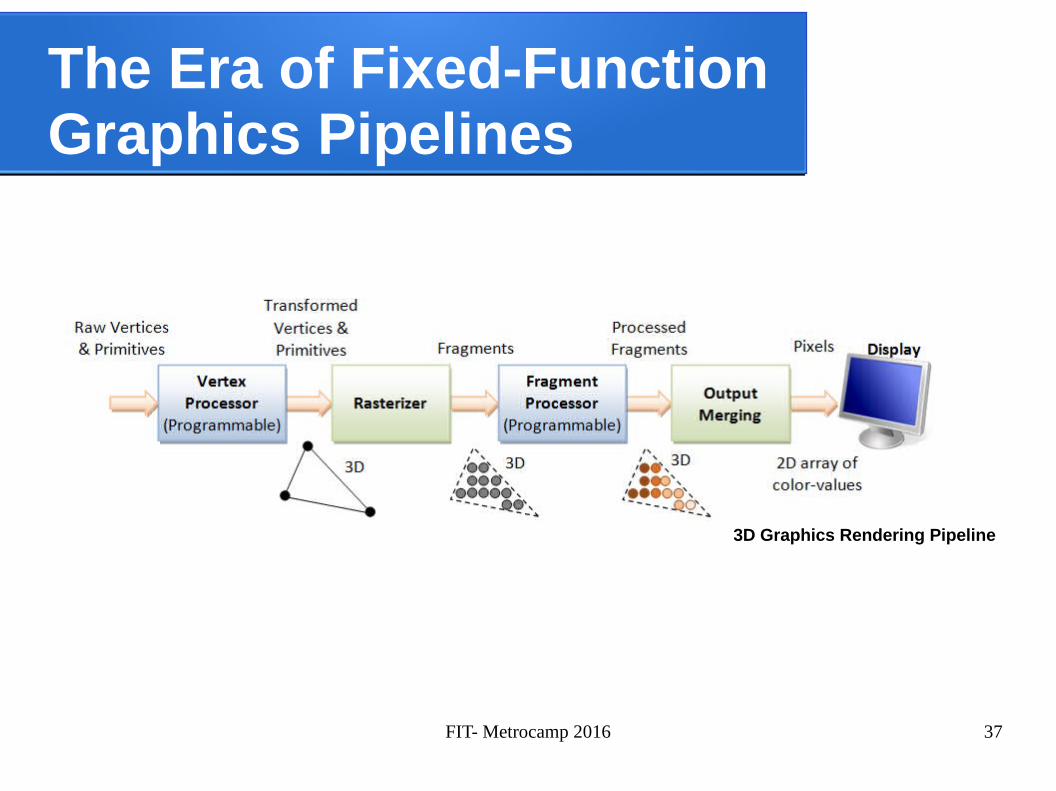
The Era of Fixed-FunctionGraphics Pipelines
3D Graphics Rendering Pipeline
FIT- Metrocamp 2016 38
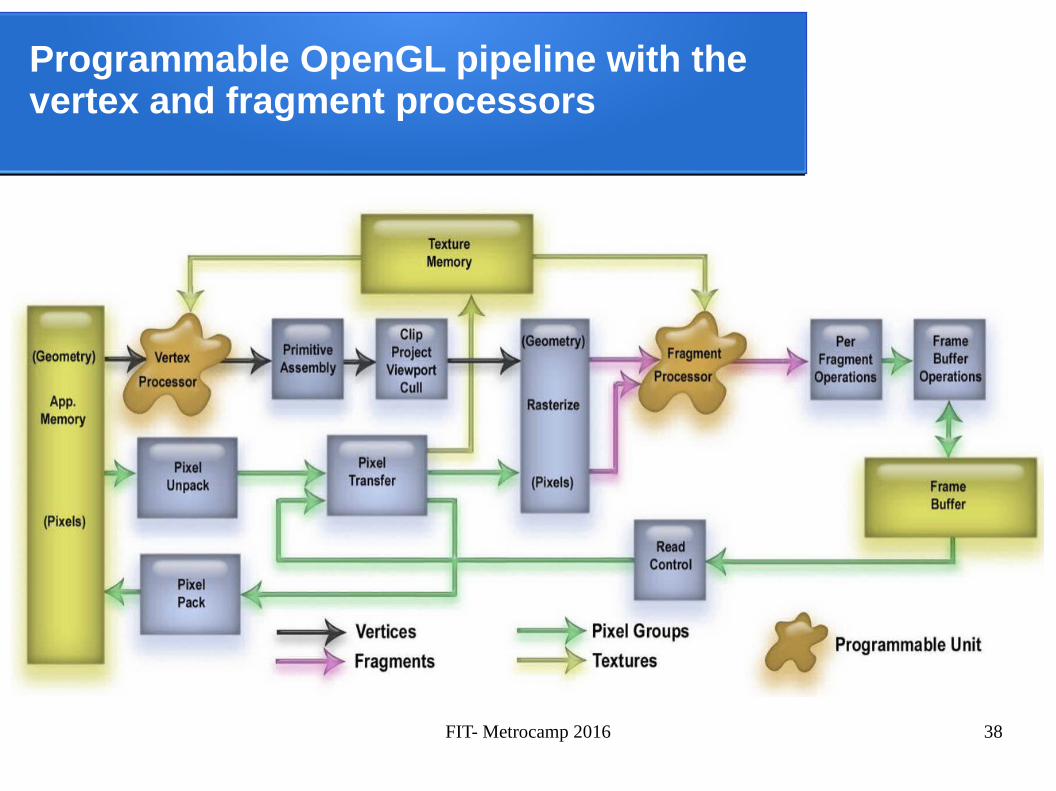
Programmable OpenGL pipeline with the vertex and fragment processors
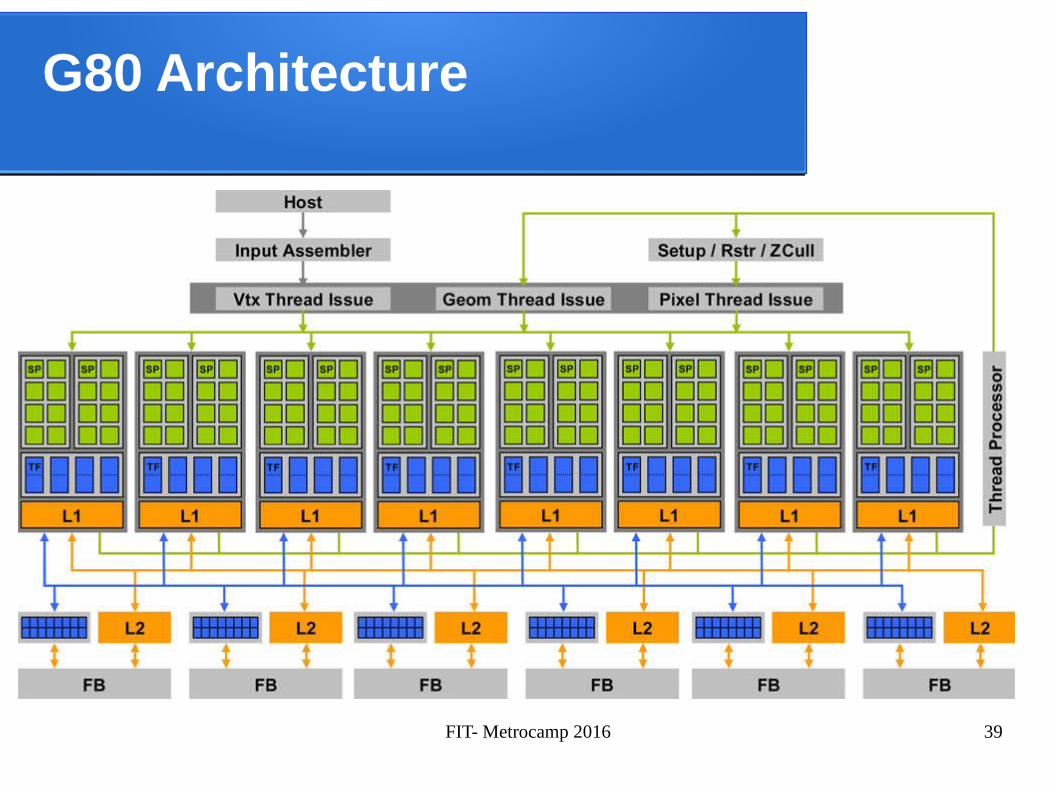
FIT- Metrocamp 2016 39
G80 Architecture

FIT- Metrocamp 2016 40
Pascal Architecture

FIT- Metrocamp 2016 41
Programação com CUDA
PCIe Bus
Host Device

FIT- Metrocamp 2016 42
Programação com CUDA
void saxpy(int n, float a, float *x, float *y, float *z){
for(int i = 0; i < n; i++){ z[i] = a * x[i] + y[i];
}
Serial
SAXPY z = Ax + y

FIT- Metrocamp 2016 43
Programação com CUDA
__global__ void saxpy(int n, float a, float *x, float *y, float *z){
tid = threadIdx.x + blockDim.x * blockIdx.x ; if (tid < n) {
z[tid] = a * x[tid] + y[tid];}
}
CUDA
SAXPY z = Ax + y

FIT- Metrocamp 2016 44
Programação com CUDA
CUDA – Chamada do Host
SAXPY z = Ax + y
//Configuração do Bloco e da Griddim3 dimBlock(256,1,1);dim3 dimGrid(ceil(n/256.0),1,1);
int *h_a, *h_b, *h_c;int *d_a, *d_b, *d_c;unsigned int n, size;
n = 1000000;
//Alocando as variveis no hosth_a = (int*)malloc(n * sizeof(int));h_b = (int*)malloc(n * sizeof(int));h_c = (int*)malloc(n * sizeof(int));
//Alocando as variaveis no devicesize = n * sizeof(int);cudaMalloc((void**)&d_a,size);cudaMalloc((void**)&d_b,size);cudaMalloc((void**)&d_c,size);
//Gerar os valores para os vetores a e b
//Copiar os dados do Host para o DevicecudaMemcpy(d_a,h_a,size,cudaMemcpyHostToDevice);cudaMemcpy(d_b,h_b,size,cudaMemcpyHostToDevice);
vecAddKernel<<<ceil(n/256.0),256>>>(d_a,d_b,d_c,n);
//Copiar o resultado do Device para o HostcudaMemcpy(h_c,d_c,size,cudaMemcpyDeviceToHost);
//Liberar Memória do Hostfree(h_a); free(h_b); free(h_c);
//Liberar Memória do DevicecudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
FIT- Metrocamp 2016 45
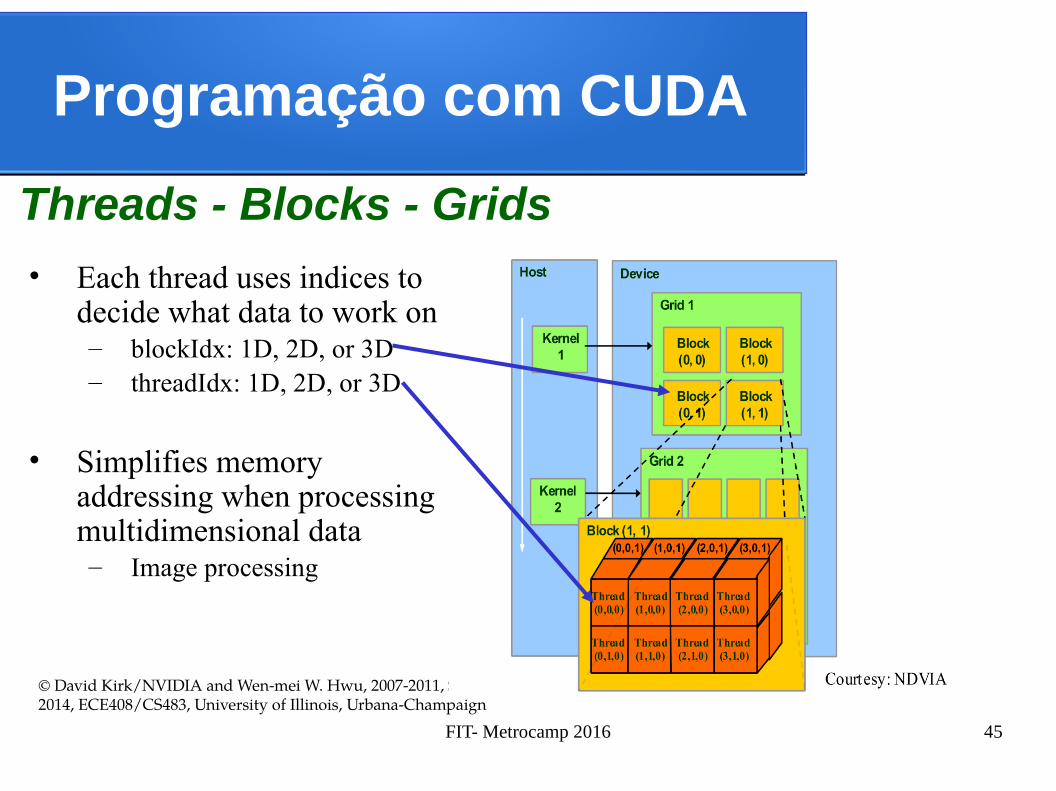
Programação com CUDA
Threads - Blocks - Grids
© David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2011, SSL 2014, ECE408/CS483, University of Illinois, Urbana-Champaign
• Each thread uses indices to decide what data to work on– blockIdx: 1D, 2D, or 3D – threadIdx: 1D, 2D, or 3D
• Simplifies memoryaddressing when processingmultidimensional data– Image processing

FIT- Metrocamp 2016 46
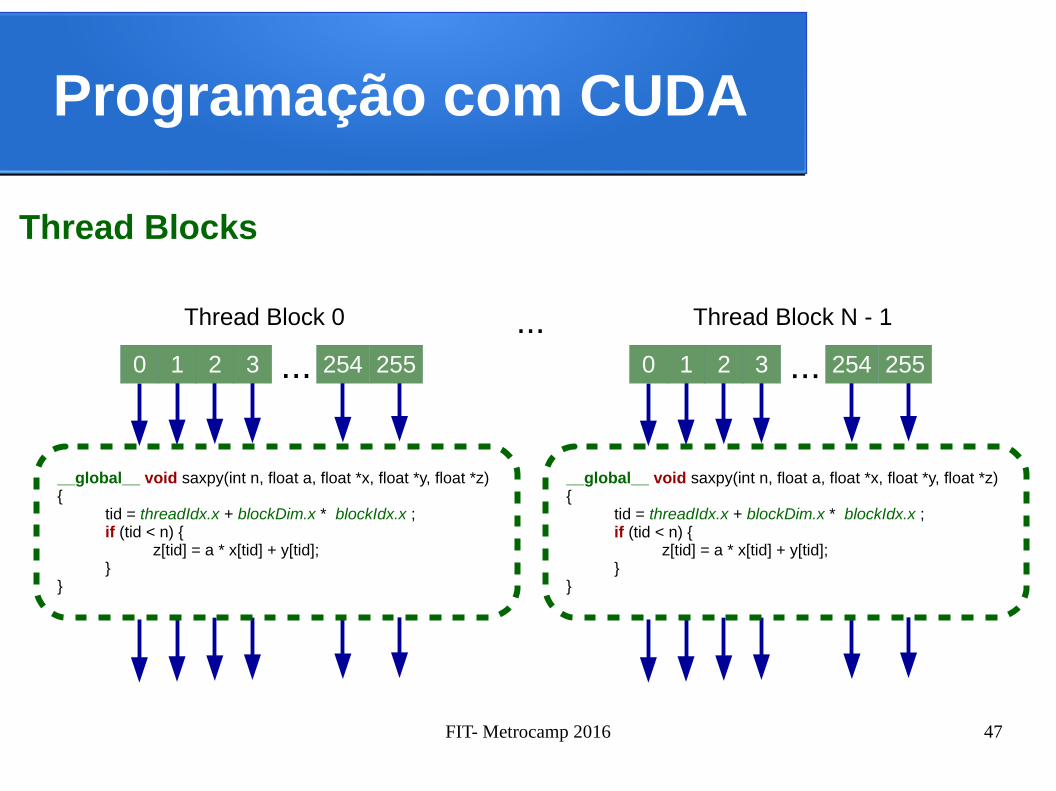
Programação com CUDA
Um CUDA Kernel em um Grid que possui um conjunto de threads
__global__ void saxpy(int n, float a, float *x, float *y, float *z){
tid = threadIdx.x + blockDim.x * blockIdx.x ; if (tid < n) {
z[tid] = a * x[tid] + y[tid];}
}
...0 1 2 3 254 255
FIT- Metrocamp 2016 47
Programação com CUDA
Thread Blocks
...0 1 2 3 254 255
__global__ void saxpy(int n, float a, float *x, float *y, float *z){
tid = threadIdx.x + blockDim.x * blockIdx.x ; if (tid < n) {
z[tid] = a * x[tid] + y[tid];}
}
Thread Block 0
...0 1 2 3 254 255
__global__ void saxpy(int n, float a, float *x, float *y, float *z){
tid = threadIdx.x + blockDim.x * blockIdx.x ; if (tid < n) {
z[tid] = a * x[tid] + y[tid];}
}
Thread Block N - 1...
FIT- Metrocamp 2016 48
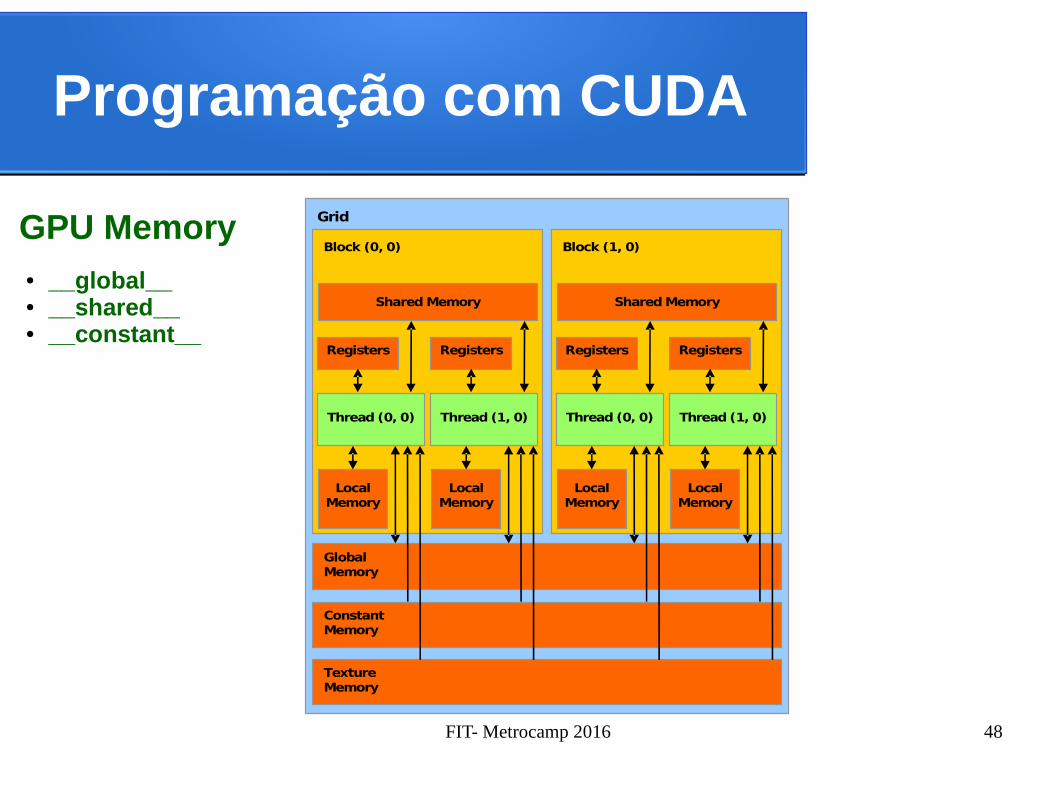
Programação com CUDA
GPU Memory Grid
Constant Memory
Texture Memory
Global Memory
Block (0, 0)
Shared Memory
Local Memory
Thread (0, 0)
Registers
Local Memory
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Local Memory
Thread (0, 0)
Registers
Local Memory
Thread (1, 0)
Registers
● __global__● __shared__● __constant__
FIT- Metrocamp 2016 49
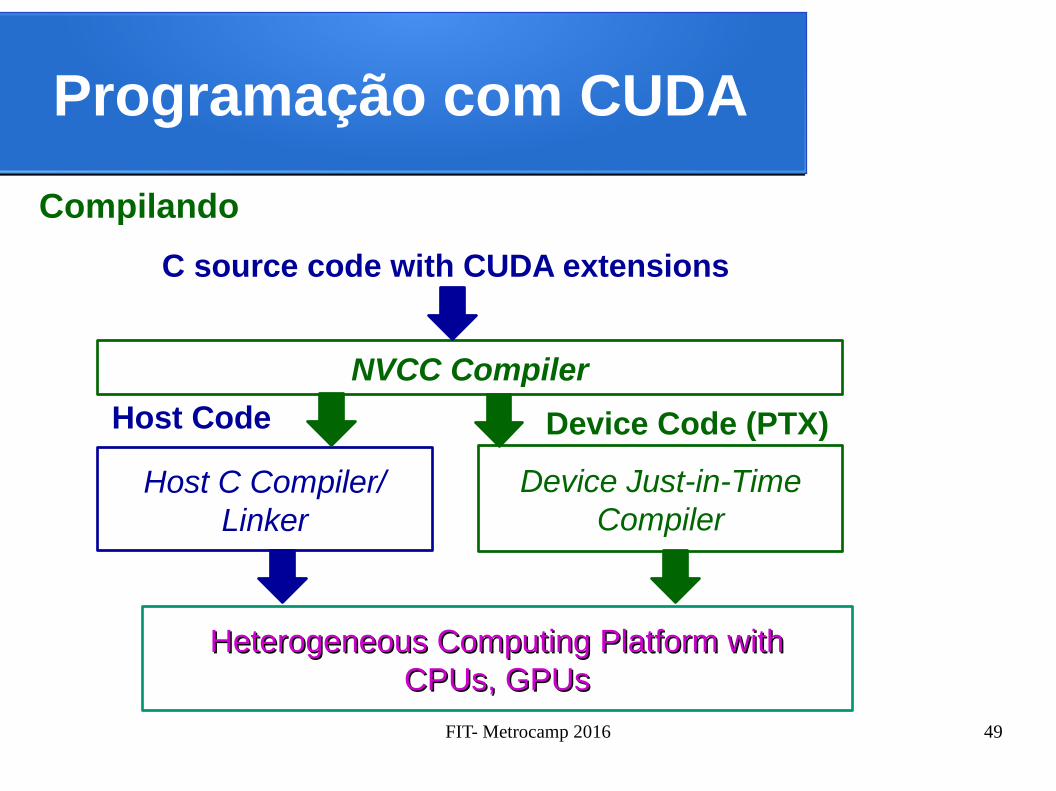
Programação com CUDA
Compilando
C source code with CUDA extensions
NVCC Compiler
Host C Compiler/ Linker
Host Code Device Code (PTX)
Device Just-in-Time Compiler
Heterogeneous Computing Platform withHeterogeneous Computing Platform withCPUs, GPUsCPUs, GPUs

FIT- Metrocamp 2016 50
Perguntas


















