
ESTUDOOMPARATIVO C ENTRE SVM E RNA NO … · defeito de pista externa em rolamentos, como...
8
ESTUDO COMPARATIVO ENTRE SVM E RNA NO RECONHECIMENTO DE DEFEITO EM ROLAMENTOS DE MOTORES DE INDUÇÃO TRIFÁSICOS RODRIGO HENRIQUE CUNHA PALÁCIOS, IVAN NUNES DA SILVA, WAGNER FONTES GODOY Departamento de Engenharia Elétrica, Escola de Engenharia de São Carlos, Laboratório de Automação Inteli- gente de Processos e Sistemas, Universidade de São Paulo, São Carlos, São Paulo Email: [email protected], [email protected], [email protected] ALESSANDRO GOEDTEL, WYLLIAM SALVIANO GONGORA, TIAGO DRUMMOND LOPES Departamento de Engenharia Elétrica, Centro Integrado de Pesquisa em Controle e Automação, Universidade Tecnológica Federal do Paraná, Cornélio Procópio, Paraná Email: [email protected], [email protected], [email protected] Abstract – One of the most important elements of electromechanical power conversion in industrial processes, the three phase induction motor is constantly subject of research aiming to reduce maintenance rates and also unscheduled downtime in the pro- cess. Great part of the defects in these motors occurs in the bearing. Hence, the use of intelligent systems capable of predicting faults in electric motors has been widely addressed. Thus, the purpose of this work is to present a comparative implementation study of SVM (Support Vector Machine) and ANN (Artificial Neural Network) as pattern classifiers, to identify bearing outside lane fault, by using current and voltage signals in the time domain to determine the accuracy rate and processing time. Experi- mental results are presented to validate the proposal. Keywords – Three-Phase Induction Motors, Pattern Recognition, Intelligent Systems, SVM, ANN Resumo – Um dos mais importantes elementos de conversão eletromecânica de energia nos processos industriais, o motor de in- dução trifásico é constantemente alvo de pesquisas para diminuir as taxas de manutenções e paradas não programadas no proces- so. Grande parte dos defeitos em motores ocorre em rolamentos. A utilização de sistemas inteligentes capazes de predizer os de- feitos nos motores elétricos tem sido amplamente abordada nesse sentido. Assim, a proposta desse trabalho consiste em apresen- tar um estudo comparativo de aplicação entre SVM (Support Vector Machine) e RNA (Rede Neural Artificial) para identificar defeito de pista externa em rolamentos, como classificadores de padrões, utilizando dados de corrente e tensão de motores de in- dução trifásicos, no domínio do tempo, para determinar a taxa de acurácia e tempos de processamento. Resultados experimentais são apresentados para validar a proposta. Palavras-chave – Motores de Indução Trifásicos, Reconhecimento de Padrões, Sistemas Inteligentes, SVM, RNA. 1 Introdução O motor de indução trifásico (MIT) é amplamen- te empregado em ambientes industriais e cada vez mais as empresas estão preocupadas em obter o maior proveito dos seus motores. Assim, buscam-se soluções que possam maximizar a eficiência energé- tica e reduzir os custos com manutenções, bem com as paradas não programadas em suas linhas de pro- dução. Muitas técnicas podem ser empregadas para de- tecção de defeitos, como por exemplo, a manuten- ção preditiva. Esta metodologia permite avaliar as condições reais de operação da máquina utilizando dados coletados diretamente do equipamento. Alguns indícios podem ser percebidos quando um motor começa a apresentar defeitos como: mu- danças nos sinais associados às vibrações mecâni- cas, variação na temperatura de operação, ruídos audíveis e alterações no campo eletromagnético, dentre outros. Assim, a análise dos referidos indícios auxiliam na detecção de defeitos quando estão ainda em fase de evolução. Desta forma, o engenheiro de manutenção pode planejar uma ação corretiva e minimizar os impactos no processo produtivo (A- raújo et al., 2010). Os sistemas inteligentes baseados em Redes Neurais Artificiais (RNA), Lógica Fuzzy (LF) e Sistemas Híbridos (SH) estão sendo empregados na identificação e resolução de diversos problemas relacionados ao controle e acionamento de máquinas elétricas. Estas estratégias são capazes de classificar e determinar a origem de defeitos ainda em evolu- ção (Santos et al., 2011; Sayouti et al., 2011; Ghate and Dudul, 2009; Seera, 2012). Um exemplo do uso de sistemas inteligentes é o ambiente WEKA (Waikato Environment for Kno- wledge Analysis) (Hall et al., 2009), criado pela Universidade de Waikato, Nova Zelândia, que pos- sui vários algoritmos implementados que ajudam na resolução de problemas envolvendo classificação, mineração de dados e sistemas de aprendizagem. Neste trabalho, o WEKA é usado como uma fer- ramenta para reconhecer defeitos em rolamentos de motores de indução trifásicos baseados nos métodos de classificação SVM (Support Vector Machine) e RNA (Rede Neural Artificial), com análise dos sinais de corrente (I) e tensão (V) no domínio do tempo. Os dados de entrada para os algoritmos de a- prendizagem são constituídos de medições do sinal de tensão e corrente em meio ciclo de onda. Estes sinais são discretizados e normalizados, em ensaios Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014 3013
Transcript of ESTUDOOMPARATIVO C ENTRE SVM E RNA NO … · defeito de pista externa em rolamentos, como...

ESTUDO COMPARATIVO ENTRE SVM E RNA NO RECONHECIMENTO DE DEFEITO EM ROLAMENTOS DE MOTORES DE INDUÇÃO TRIFÁSICOS
RODRIGO HENRIQUE CUNHA PALÁCIOS, IVAN NUNES DA SILVA, WAGNER FONTES GODOY
Departamento de Engenharia Elétrica, Escola de Engenharia de São Carlos, Laboratório de Automação Inteli-
gente de Processos e Sistemas, Universidade de São Paulo, São Carlos, São Paulo
Email: [email protected], [email protected], [email protected]
ALESSANDRO GOEDTEL, WYLLIAM SALVIANO GONGORA, TIAGO DRUMMOND LOPES
Departamento de Engenharia Elétrica, Centro Integrado de Pesquisa em Controle e Automação, Universidade
Tecnológica Federal do Paraná, Cornélio Procópio, Paraná
Email: [email protected], [email protected], [email protected]
Abstract – One of the most important elements of electromechanical power conversion in industrial processes, the three phase
induction motor is constantly subject of research aiming to reduce maintenance rates and also unscheduled downtime in the pro-
cess. Great part of the defects in these motors occurs in the bearing. Hence, the use of intelligent systems capable of predicting
faults in electric motors has been widely addressed. Thus, the purpose of this work is to present a comparative implementation
study of SVM (Support Vector Machine) and ANN (Artificial Neural Network) as pattern classifiers, to identify bearing outside
lane fault, by using current and voltage signals in the time domain to determine the accuracy rate and processing time. Experi-mental results are presented to validate the proposal.
Keywords – Three-Phase Induction Motors, Pattern Recognition, Intelligent Systems, SVM, ANN
Resumo – Um dos mais importantes elementos de conversão eletromecânica de energia nos processos industriais, o motor de in-
dução trifásico é constantemente alvo de pesquisas para diminuir as taxas de manutenções e paradas não programadas no proces-
so. Grande parte dos defeitos em motores ocorre em rolamentos. A utilização de sistemas inteligentes capazes de predizer os de-
feitos nos motores elétricos tem sido amplamente abordada nesse sentido. Assim, a proposta desse trabalho consiste em apresen-
tar um estudo comparativo de aplicação entre SVM (Support Vector Machine) e RNA (Rede Neural Artificial) para identificar
defeito de pista externa em rolamentos, como classificadores de padrões, utilizando dados de corrente e tensão de motores de in-
dução trifásicos, no domínio do tempo, para determinar a taxa de acurácia e tempos de processamento. Resultados experimentais
são apresentados para validar a proposta.
Palavras-chave – Motores de Indução Trifásicos, Reconhecimento de Padrões, Sistemas Inteligentes, SVM, RNA.
1 Introdução
O motor de indução trifásico (MIT) é amplamen-
te empregado em ambientes industriais e cada vez
mais as empresas estão preocupadas em obter o
maior proveito dos seus motores. Assim, buscam-se
soluções que possam maximizar a eficiência energé-
tica e reduzir os custos com manutenções, bem com
as paradas não programadas em suas linhas de pro-
dução.
Muitas técnicas podem ser empregadas para de-
tecção de defeitos, como por exemplo, a manuten-
ção preditiva. Esta metodologia permite avaliar as condições reais de operação da máquina utilizando
dados coletados diretamente do equipamento.
Alguns indícios podem ser percebidos quando
um motor começa a apresentar defeitos como: mu-
danças nos sinais associados às vibrações mecâni-
cas, variação na temperatura de operação, ruídos
audíveis e alterações no campo eletromagnético,
dentre outros. Assim, a análise dos referidos indícios
auxiliam na detecção de defeitos quando estão ainda
em fase de evolução. Desta forma, o engenheiro de
manutenção pode planejar uma ação corretiva e
minimizar os impactos no processo produtivo (A-raújo et al., 2010).
Os sistemas inteligentes baseados em Redes Neurais Artificiais (RNA), Lógica Fuzzy (LF) e
Sistemas Híbridos (SH) estão sendo empregados na
identificação e resolução de diversos problemas
relacionados ao controle e acionamento de máquinas
elétricas. Estas estratégias são capazes de classificar
e determinar a origem de defeitos ainda em evolu-
ção (Santos et al., 2011; Sayouti et al., 2011; Ghate
and Dudul, 2009; Seera, 2012).
Um exemplo do uso de sistemas inteligentes é o
ambiente WEKA (Waikato Environment for Kno-
wledge Analysis) (Hall et al., 2009), criado pela Universidade de Waikato, Nova Zelândia, que pos-
sui vários algoritmos implementados que ajudam na
resolução de problemas envolvendo classificação,
mineração de dados e sistemas de aprendizagem.
Neste trabalho, o WEKA é usado como uma fer-
ramenta para reconhecer defeitos em rolamentos de
motores de indução trifásicos baseados nos métodos
de classificação SVM (Support Vector Machine) e
RNA (Rede Neural Artificial), com análise dos
sinais de corrente (I) e tensão (V) no domínio do
tempo.
Os dados de entrada para os algoritmos de a-prendizagem são constituídos de medições do sinal
de tensão e corrente em meio ciclo de onda. Estes
sinais são discretizados e normalizados, em ensaios
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3013

de 50 pontos para cada valor das tensões Va, Vb, Vc
e 50 pontos para os valores das correntes Ia, Ib, Ic. A
saída consiste num valor binário para indicar os
defeitos no rolamento ou condição normal de fun-
cionamento do MIT. Assim, é possível analisar a
taxa de acurácia dos algoritmos de aprendizagem e
reconhecer um padrão para prever a condição de possíveis defeitos dos rolamentos dos motores.
Este trabalho está dividido da seguinte forma: na
Seção 2, são discutidos alguns aspectos relacionados
às Falhas em MITs. Na Seção 3, as principais carac-
terísticas de SVM e RNA são apresentadas. Na
Seção 4, a metodologia da preparação dos dados e
uso de laboratório são demonstrados. Na Seção 5,
são apresentados os resultados experimentais. En-
fim, na Seção 6, são realizadas as conclusões do
trabalho.
2 Falhas no MIT
O monitoramento das condições de operação de
um MIT em uma indústria é uma tarefa muito im-
portante e possibilita o diagnóstico de defeitos e
previsão das suas condições de operação. Esse tema
tem atraído a atenção de vários pesquisadores duran-
te os últimos anos. Tal fato se deve à considerável
influência dos motores sobre a continuidade opera-
cional dos processos industriais (Bellini et al., 2008). A detecção e o correto diagnóstico precoce
dos defeitos incipientes permitem minimizar a ocor-
rência de danos ao processo, aumento da disponibi-
lidade dos equipamentos e consequente manutenção
dos resultados financeiros.
Os motores elétricos estão sujeitos a vários tipos
de defeitos, que podem ser divididos em dois grupos
distintos: defeitos elétricos e defeitos mecânicos
(Bellini et al., 2008). A Tabela 1 apresenta a classi-
ficação dos principais tipos de defeitos em MIT.
Tabela 1. Principais tipos de defeitos em MIT
Defeitos Elétricos Defeitos Mecânicos
Enrolamento de estator Desgaste de acoplamento
Enrolamento de rotor Desalinhamento
Barras quebradas Excentricidade
Anéis quebrados Rolamento
Conexões
Dos defeitos citados na literatura, estima-se que os rolamentos são responsáveis por aproximadamen-
te 40% das paradas indesejadas dos MIT (Kowalski
and Kowalska., 2003).
O escopo deste trabalho aborda somente os de-
feitos relativos à pista externa de rolamentos. De
acordo com Araújo et. al. (2010), a deterioração de
rolamentos também pode ocorrer em função das
correntes de modo comum que circulam pelos mes-
mos devido à carga eletrostática induzida no eixo do
motor. Outro fator refere-se às pulsações de conju-
gado causadas pela existência de harmônicos de
baixa ordem na alimentação ou relativas a possíveis
barras quebradas. Na Figura 1 é apresentado um
gráfico comparativo entre os diversos tipos de fa-
lhas, conforme os estudos encomendados pelas
agências IEEE (Institute of Electrical and Electro-nics Engineers) e EPRI (Electric Power Research
Institute).
Figura 1. Percentual de ocorrência de falhas em MIT
Métodos tradicionais consideram o monitora-
mento da temperatura e vibração dos rolamentos,
visando estimar suas condições de operação. No
entanto, o custo de sensores para monitoramento de
vibrações, associados aos dispositivos de processa-
mento de sinais, restringem sua utilização em má-
quinas de pequeno porte. Contudo, métodos alterna-
tivos, baseados em inteligência computacional, estão cada vez mais sendo pesquisados para a identifica-
ção de defeitos em MIT.
3 Aspectos sobre SVM e RNA
Os agentes classificadores são métodos compu-
tacionais supervisionados que têm por objetivo criar
um modelo que prevê a classe de um determinado
conjunto de dados baseando-se em conjunto de
dados pré-estabelecidos (Serasiya and Chaudhary, 2012).
Neste trabalho, são utilizados RNA com a ar-
quitetura PMC (Perceptron de Múltiplas Camadas)
e SVM, a fim de verificar a acurácia dos modelos e
os respectivos tempos de construção e validação do
modelo.
3.1 SVM
SVM são sistemas de aprendizagem de máquina
treinados com um algoritmo de otimização matemá-
tica e que implementam um limite derivado da teo-
ria de aprendizagem estatística. Essa estratégia de
aprendizagem foi desenvolvida por Vladmir Vapnik
(Vapnik, 1999).
O treinamento de SVM envolve a otimização de
uma função quadrática convexa, que é um problema
1900ral1900ral1900ral1900ral1900ral1900ral1900ral1900ral1900ral1900ral IEEE
EPRI
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3014

de otimização matemática e envolve poucos parâ-
metros livres que precisam ser ajustados pelo usuá-
rio e não há uma dependência, pelos menos de uma
forma explícita, na dimensão do espaço de entrada
do problema, isso sugere que o SVM pode ser útil
em problemas com um grande número de entradas,
conforme se pode observar no trabalho proposto. Essa técnica pode ser aplicada ao reconheci-
mento de padrões (estimar funções indicadores),
regressão (estimar funções de valores reais) e extra-
ção de características. O processo decisório em
problemas de reconhecimento de padrões pode ser
realizado através de funções que dividem o espaço
de características em regiões. Uma das formas de
fazer esta separação é por meio de hiperplanos.
A ideia inicial básica do SVM é mapear os da-
dos de entrada em um espaço de características por
meio de um mapa não linear. No espaço de caracte-rísticas, a função de decisão linear é construída.
Assumindo um conjunto de dados S onde
�� ∈ ��(� = 1, … , �). (1)
Cada ponto �� pertence a duas classes e é dado um
rótulo �� ∈ {1, −1}. Dado uma função não linear
∅(∙) para mapear os dados de amostra, a partir do
espaço ��, as características espaço F. Então o
hiperplano (� ∙ ∅(�)) + � separa os dados, de acor-
do com a Equação (2),
�(�) = ����[� ∙ ∅(�) + �], (2)
onde � é o vetor ortogonal ao hiperplano e � é o
deslocamento do hiperplano a partir da origem.
O hiperplano tenderá a uma separação, com o
menor erro de generalização. Para maximizar a
margem da tarefa tem-se a Equação (3),
����(�) = ! (� ∙ �), (3)
sujeito a Equação (2). Na Figura 2 são ilustrados os
hiperplanos de suporte e o hiperplano ótimo repre-
sentando a separação de amostras em duas classes
distintas.
Usando o método dos multiplicadores de La-
grange, este problema de otimização pode ser con-
vertido conforme apresentado na Equação (4),
" = ! (� ∙ �) − ∑ $�%�& (��(� ∙ '(��) + �) − 1), (4)
onde $�são os multiplicadores Lagrangeanos. As
derivadas de � e � são dadas pelas seguintes Equa-
ções (5) e (6),
()(* = ∑ ��$�%�& = 0 (5)
()(, = � − ∑ ��$�'(��)%�& = 0. (6)
Substituindo as Equações (5) e (6) na Equação (4),
tem-se,
" = ∑ $�%�& − 12∑ $�$.���/%�,.& 0'(��) ∙ '1�.23. (7)
Este deve ser maximizado com respeito ao $� sujeito à restrição seguinte,
4 $� ≥ 0∑ ��$� = 0%�&
6 . (8)
Figura 2. Hiperplano de separação ótimo na linha amarela centra-
lizada com seus hiperplanos de suporte em linha tracejada.
Quando a máxima margem do hiperplano é en-
contrada, apenas os pontos que se encontram mais
próximo do hiperplano tem $� ≥ 0 e estes pontos são chamados de vetores de suporte e todos os ou-
tros pontos têm $� = 0. Isto significa que a repre-
sentação do hiperplano é dada apenas pelos pontos
mais próximos a ele e que são os padrões mais sig-
nificativos dos dados. A função de decisão resultan-
te é dada pela Equação (9),
� = ����7∑ ���∈89 $�:1'(��) ∙ '(�)2 + �:;, (9)
onde $�: é a solução da restrição do problema de
maximização, �: é o deslocamento do hiperplano a
partir da origem após a solução da restrição do pro-
blema e SV representa os índices dos vetores de
suporte. A Equação (9) também pode ser escrita conforme a Equação (10),
� = ����7∑ $�:��<(�� , �) + �%�& ;. (10)
No caso, em que os dados de treinamento não
podem ser linearmente separados, variáveis de folga
não negativos ℵ� são introduzidos em condições de
desigualdade e a soma das variáveis de folga multi-
plicado pelo parâmetro ? é adicionada na função
objetivo. Isto corresponde a adição da fronteira
superior ? com o elemento $. A otimização do
problema é realizada conforme demonstrada na
Equação (11),
min"C = ! ‖�‖! + ? ∑ ℵ�%�& . (11)
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3015

A Equação (11) pode ser transformada de acordo
com a Equação (12),
maxG(α) =∑ α� − !
%�& ∑ α�α.y�y.<(x� , x.)%�,.&
�. J. 4∑ α��� = 0α� ≥ 0%�& 0 ≤ α� ≤ ? 6 . (12)
3.1 RNA
Os sistemas baseados em RNA possuem eleva-
das taxas de computação por utilizarem um número
elevado de elementos processadores simples massi-
vamente conectados. Em resumo, as RNA's podem
ser caracterizadas como modelos computacionais,
com propriedades particulares, cujas principais
características são definidas como segue: (i) capaci-
dade intrínseca de operação em paralelo; (ii) não há a necessidade de conhecimento a priori de eventuais
modelos matemáticos que descrevem o comporta-
mento de determinada aplicação; (iii) sistemas inspi-
rados no cérebro humano; (iv) habilidade de apren-
der a partir da experiência.
As redes PMC possuem os mesmos princípios
proposto por Rosenblatt (1958), com a diferenciação
que apresentam uma ou mais camadas intermediá-
rias, conhecidas como camadas escondidas. A estru-
tura apresentada na Figura 3 é proposta em uma
grande diversidade de aplicações e pode ser utiliza-
da como aproximador universal de função, classifi-cação de padrões, identificação de sistemas, otimi-
zação, controle de processos entre outros (Haykin,
2001). Também se define que seu treinamento é
realizado de forma supervisionada, fazendo com que
a rede ajuste seus pesos para melhor atender os
objetivos da aplicação.
Figura 3. Arquitetura da rede neural artificial PMC (Silva, Spatti
e Flauzino, 2010)
Para um melhor entendimento do principio de
funcionamento envolvido com o algoritmo backpro-
pagation, faz-se necessário definir diversas variá-
veis e parâmetros auxiliares que norteiam a deriva-
ção do algoritmo, como segue:
- WMN(O)
são matrizes de pesos cujos elementos
denotam o valor do peso sináptico conectando ao j-
ésimo neurônio da camada (L) ao i-ésimo neurônio
da camada (L-1).
- IMN(O)são vetores cujo os elementos denotam a
entrada ponderada em relação ao j-ésimo neurônio
da camada L, os quais são definidos pela Equações
(11), (12) e (13),
IM( ) =∑ WMN( )QN&R . xN ↔ IM( ) (11)
=WM,T( ). xR +WM,
( ). x +⋯+WM,Q( ). xQ
IM(!) = ∑ WMN(!)QN&R . YN( ) ↔ IM(!) (12)
=WM,T(!). YR( ) +WM,
(!). Y ( ) +⋯+WM,Q (!) . YQ ( )
IM(W) = ∑ WMN(W)QN&R . YN(!) ↔ IM(W) (13)
=WM,T(W). YR(!) +WM,
(W). Y (!) +⋯+WM,Q!(W) . YQ!(!)
-YM(O)são vetores cujo os elementos denotam a
saída do j-ésimo neurônio em relação a camada L,
os quais são definidos pelas Equações (14), (15) e (16) que seguem,
YM( ) = g(IM( )) (14)
YM(!) = g(IM(!)) (15)
YM(W) = g1IM(W)2, (16)
onde g representa uma função de ativação que deve
ser contínua e diferenciável em todo o seu domínio.
A partir da Figura 3, observa-se que os nós da camada de entrada da rede fornecem as informações
(vetores de entrada), as quais constituem os sinais de
entrada, que são aplicados aos neurônios da segunda
camada (1ª camada neural). Os sinais de saída da
segunda camada são utilizados como entradas para a
terceira camada (2ª camada neural). Finalmente, o
conjunto de sinais de saída apresentados pelos neu-
rônios da camada de saída reflete a resposta final da
rede em relação ao vetor de entrada fornecido pelos
nós fontes da primeira camada. O treinamento ou
processo de aprendizagem de uma rede neural artifi-cial consiste em ajustar os pesos sinápticos (matriz
de pesos W) de forma que a aplicação de um con-
junto de entradas produza um conjunto de saídas
desejadas. O treinamento supervisionado das RNA
que formam a rede Perceptron utilizadas neste traba-
lho é baseado no algoritmo de aprendizagem back-
propagation (Haykin, S., 2009). As funções Erro
Quadrático (E(k)) e Erro Quadrático Médio (EM)
são utilizadas como critérios de desempenho e de
parada do processo de treinamento.
4 Aquisição e Tratamento dos Dados
Para o caso em estudo neste trabalho, as tensões
e correntes foram medidas em um MIT de 1 CV do
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3016

fabricante WEG. Este motor foi utilizado em labora-
tório, em perfeitas condições de operação. Para
determinação de defeito, foram criadas defeitos na
pista externa do rolamento para a aquisição dos
dados de tensão e corrente. A Figura 4 ilustra o
defeito criado em laboratório. As falhas de ranhuras
presentes na pista externa ou interna do rolamento são ocasionadas pelo escorregamento da esfera na
pista, por choque mecânico no eixo do motor ou
rolamento ou mesmo montagem incorreta da peça
no mancal do eixo. Este tipo de falha ocasiona um
ponto específico de defeito na pista do rolamento.
Para isso, foi realizada em laboratório a desmonta-
gem do rolamento e a inserção da ranhura por meio
da mini retífica de alta rotação.
Figura 4. Falha localizada de ranhuras na pista externa
A Figura 5 ilustra o método de aquisição e tra-
tamento dos dados utilizados neste trabalho. Os
dados para treinamento e validação do MIT de 1
CV, em condições normais de funcionamento e com
o rolamento defeituoso, foram adquiridos através de
ensaios na bancada experimental apresentada na
Figura 6. Esta bancada tem como característica
monitorar as grandezas de tensão, corrente, vibra-
ção, torque e velocidade de um MIT. As placas de condicionamento de sinais dos sensores Hall ampli-
ficam as tensões de fase e correntes de linha que são
repassadas às entradas analógicas da placa de aqui-
sição de dados.
Conforme observada na Figura 6, esta bancada
dispõe de um MIT acoplado a um gerador de corren-
te contínua que faz a imposição de torque no eixo da
máquina. Nos detalhes da Figura 6, são mostrados
os variadores de tensão independentes por fase para
desbalanço de tensões (Goedtel, 2007). O motor
empregado nos experimentos realizados em labora-tório é da marca WEG modelo Dahlander 12 pontas
com potência de 1 CV, tendo como rotação 1700
rpm para uma alimentação em 220V senoidal em
60Hz. O rolamento em análise foi o NSK 6204 com
8 esferas e a coleta do sinal da corrente de estator
utilizou uma taxa de 25000 amostras por segundo.
Figura 5. Método de aquisição dos dados
Por meio da interface de comunicação com um computador, provida pela DAQ, as informações de
sinais são recebidas e armazenadas por meio do
software Matlab®. A DAQ utilizada neste processo
é da National Instruments™ modelo USB 6221, a
qual dispõe de 16 entradas analógicas e permite a
comunicação simplificada com o computador por
meio de cabo USB.
Figura 6. Bancada experimental do laboratório
A bancada conta ainda com um torquímetro de
dupla faixa de atuação com sensor de velocidade
integrado. O dispositivo da marca Kistler, modelo
4503A50W, permite a leitura de sinais analógicos
ou digitais até 50 Nm e 7000 rpm .
A rotina de comunicação da placa com o compu-
tador utiliza a interface da plataforma Matlab®.
Assim, todos os dados das grandezas são lidos e
armazenados em forma de planilhas eletrônicas.
Para obter a classificação quanto ao funciona-
mento adequado do rolamento, foram amostrados os
sinais das correntes e tensões trifásicas dos MITs em análise. Para tanto, foram separados os dados para
as construções dos modelos inteligentes, conforme
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3017

observado na Tabela 2. Salienta-se que as amostras
são sinais dos MITs em regime permanente, adqui-
ridas em ensaios na bancada experimental, com
conjugado de carga variando de 0,5 a 6 Nm e com
16 combinações de desequilíbrio de tensão entre as
fases, considerando o limite máximo de ±10%. Do
total de 224 amostras utilizadas neste trabalho, 112 amostras estavam em condições de defeitos no ro-
lamento do motor e 112 amostras são relativos aos
sinais do motor em condições normais de funciona-
mento.
Os dados de entrada utilizados para este traba-
lho são os sinais no domínio do tempo de correntes
(Ia,b,c) e tensões (Va,b,c) de uma máquina trifásica.
Assim, faz-se necessário a montagem de um vetor
coluna com os pontos de tensões e correntes de cada
fase do sistema coletado, subsequentes um do outro.
A Tabela 3 apresenta a estrutura de uma amostra, para a composição de cada amostra, considera-se 50
pontos para cada valor Va, Vb, Vc e 50 pontos para
cada valor de corrente Ia, Ib, Ic, correspondentes a
um semiciclo de onda no domínio do tempo, con-
forme ilustrado na Figura 7. A última coluna da
matriz representa a classe do problema (0 para mo-
tor sem defeito no rolamento e 1 para motor com
defeito).
Tabela 2. Divisão das amostras dos motores para tratamento,
treinamento e validação
Motores 1 CV
Amostras Treinamento 157
Validação 67
Total 224
Foi gerado um script em Matlab® para separa-
ção dos dados de treinamento do algoritmo classifi-
cador e da sua validação. O conjunto de dados de
treinamento compreende de 70% do conjunto de
casos disponíveis sendo que os restantes 30% são
utilizados para validação.
Tabela 3. Estrutura dos dados utilizados por amostra tratada
Va Vb Vc Ia Ib Ic Saída 1x50 1x50 1x50 1x50 1x50 1x50 0/1
O script separa no conjunto de treinamento os
casos em que ocorre os máximos e mínimos de
tensões e correntes a fim de garantir que todo o
domínio de operação seja abrangido pelos métodos
classificadores. Os demais casos são sorteados alea-toriamente para compor o arquivo de treinamento. A
separação dos dados é necessária para obter um
arquivo de treinamento e um arquivo de validação,
conforme observado na Tabela 2, que são utilizados
pela plataforma WEKA.
Após os dados serem tratados pelo Matlab® o
script desenvolvido gera um arquivo “.arff”, no qual
é especificamente formatado como entrada de dados
para a execução dos algoritmos no WEKA, confor-
me quantidade de amostras demonstradas na Tabela
2. Para as duas ferramentas de classificação de pa-
drões utilizadas neste trabalho, aplicou-se o mesmo
conjunto de dados para treinamento e validação.
Figura 7. Sinal Discretizado
5 Resultados Experimentais
O WEKA (Waikato Environment for Knowled-
ge Analysis) é um sistema de mineração de dados
desenvolvido na Universidade de Waikato. É um
ambiente de aprendizagem com muitos algoritmos
de aprendizado. Os classificadores de padrões apre-
sentados na Seção 3 são utilizados neste trabalho por meio do WEKA. Este trabalho visa investigar,
baseado na problemática do assunto, qual dos méto-
dos inteligentes se comportará melhor para a neces-
sidade de resolução do problema em termos acurácia
e tempo computacional.
Para a execução das estratégias propostas neste
trabalho, foram efetuadas algumas configurações
específicas para o treinamento e validação, de acor-
do com as Tabelas 5 e 6. Na Tabela 4, o parâmetro
Epsilon é relativo à taxa de erro de arrendondamen-
to, a função kernel está relacionada à função núcleo do SVM, neste trabalho é utilizada a função Poly-
nomial Kernel (Shashua, 2009). O parâmetro tole-
rância está relacionado ao limite de erro aceitável.
Tabela 4. Parâmetros de configuração do SVM
Parâmetros Valores
Epsilon 1.0E-12
Função kernel Polynomial Kernel
Parâmetro de Tolerância 0,001
Os parâmetros de configuração da RNA (PMC)
estão dispostos na Tabela 5. A arquitetura e as con-figurações, para este trabalho, foram determinadas
de forma empírica.
Na Tabela 6 e na Figura 8 é mostrado o tempo
de execução dos algoritmos, tanto na construção dos
modelos quanto na execução da validação, o tempo
apurado é mostrado em segundos. Pode-se observar
que nos casos estudados, o algoritmo que obteve
uma execução mais rápida foi o SVM, com 0,03
segundos, na validação dos dados amostrados e 7,89
segundos na construção do modelo. A RNA de-
monstrou demasiado tempo computacional na cons-trução do modelo, com 211,61 segundos e obteve
uma taxa de validação inferior ao SVM com 0,41
segundos.
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3018
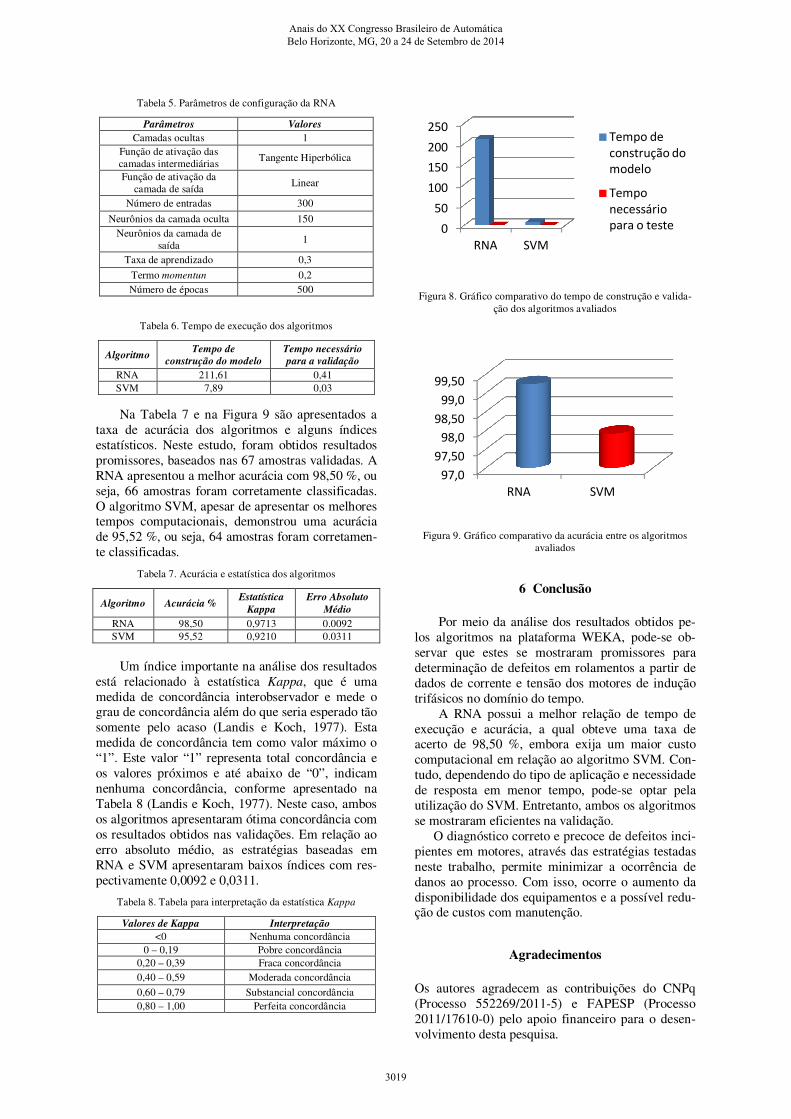
Tabela 5. Parâmetros de configuração da RNA
Parâmetros Valores
Camadas ocultas 1
Função de ativação das
camadas intermediárias Tangente Hiperbólica
Função de ativação da
camada de saída Linear
Número de entradas 300
Neurônios da camada oculta 150
Neurônios da camada de
saída 1
Taxa de aprendizado 0,3
Termo momentun 0,2
Número de épocas 500
Tabela 6. Tempo de execução dos algoritmos
Algoritmo Tempo de
construção do modelo
Tempo necessário
para a validação
RNA 211,61 0,41
SVM 7,89 0,03
Na Tabela 7 e na Figura 9 são apresentados a
taxa de acurácia dos algoritmos e alguns índices
estatísticos. Neste estudo, foram obtidos resultados
promissores, baseados nas 67 amostras validadas. A
RNA apresentou a melhor acurácia com 98,50 %, ou
seja, 66 amostras foram corretamente classificadas.
O algoritmo SVM, apesar de apresentar os melhores tempos computacionais, demonstrou uma acurácia
de 95,52 %, ou seja, 64 amostras foram corretamen-
te classificadas.
Tabela 7. Acurácia e estatística dos algoritmos
Algoritmo Acurácia % Estatística
Kappa
Erro Absoluto
Médio
RNA 98,50 0,9713 0.0092
SVM 95,52 0,9210 0.0311
Um índice importante na análise dos resultados
está relacionado à estatística Kappa, que é uma
medida de concordância interobservador e mede o grau de concordância além do que seria esperado tão
somente pelo acaso (Landis e Koch, 1977). Esta
medida de concordância tem como valor máximo o
“1”. Este valor “1” representa total concordância e
os valores próximos e até abaixo de “0”, indicam
nenhuma concordância, conforme apresentado na
Tabela 8 (Landis e Koch, 1977). Neste caso, ambos
os algoritmos apresentaram ótima concordância com
os resultados obtidos nas validações. Em relação ao
erro absoluto médio, as estratégias baseadas em
RNA e SVM apresentaram baixos índices com res-
pectivamente 0,0092 e 0,0311.
Tabela 8. Tabela para interpretação da estatística Kappa
Valores de Kappa Interpretação
<0 Nenhuma concordância
0 – 0,19 Pobre concordância
0,20 – 0,39 Fraca concordância
0,40 – 0,59 Moderada concordância
0,60 – 0,79 Substancial concordância
0,80 – 1,00 Perfeita concordância
Figura 8. Gráfico comparativo do tempo de construção e valida-
ção dos algoritmos avaliados
Figura 9. Gráfico comparativo da acurácia entre os algoritmos
avaliados
6 Conclusão
Por meio da análise dos resultados obtidos pe-
los algoritmos na plataforma WEKA, pode-se ob-
servar que estes se mostraram promissores para
determinação de defeitos em rolamentos a partir de
dados de corrente e tensão dos motores de indução
trifásicos no domínio do tempo.
A RNA possui a melhor relação de tempo de
execução e acurácia, a qual obteve uma taxa de acerto de 98,50 %, embora exija um maior custo
computacional em relação ao algoritmo SVM. Con-
tudo, dependendo do tipo de aplicação e necessidade
de resposta em menor tempo, pode-se optar pela
utilização do SVM. Entretanto, ambos os algoritmos
se mostraram eficientes na validação.
O diagnóstico correto e precoce de defeitos inci-
pientes em motores, através das estratégias testadas
neste trabalho, permite minimizar a ocorrência de
danos ao processo. Com isso, ocorre o aumento da
disponibilidade dos equipamentos e a possível redu-ção de custos com manutenção.
Agradecimentos
Os autores agradecem as contribuições do CNPq
(Processo 552269/2011-5) e FAPESP (Processo
2011/17610-0) pelo apoio financeiro para o desen-
volvimento desta pesquisa.
0
50
100
150
200
250
RNA SVM
Tempo de
construção do
modelo
Tempo
necessário
para o teste
97,0
97,50
98,0
98,50
99,0
99,50
RNA SVM
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3019

Referências Bibliográficas
Araújo, R. S., Rodrigues, R., Paula, H. e Baccarini,
L. (2010). Desgaste prematuro e falhas recorrentes
dos rolamentos de um MIT: Estudo de caso, Indus-
tryApplications (INDUSCON), 9th IEEE/IAS Inter-
nationalConferenceon, pp. 1-6.
Bellini, A., Filippetti, F., Tassoni, C., Capolino, G.
A. (2008). Advances in diagnostic techniques for
induction machines. IEEE Transactions on Industri-
al Eletronics, vol. 55, nº 12, pp. 4109-4126.
Ghate, V., Dudul, S. (2009). Fault diagnosis of three
phase induction motor using neural network tech-
niques, Emerging Trends in Engineering and Tech-
nology (ICETET), 2nd International Conference on,
pp. 922-928.
Goedtel, A. (2007). Estimador Neural de Velocidade
para Motores de Indução Trifásico. 159 p. Tese
(Doutorado) — Escola de Engenharia de São Carlos
- Universidade de São Paulo, São Carlos-SP.
Haykin, S. (2009). Neural Networks and Learnig
Machines. Prentice Hall.
Hall, Mark; Frank, Eibe; Holmes, Geoffrey;
Pfahringer, Bernhard; Reutemann, Peter; Witten, Ian
H. (2009). The WEKA Data Mining Software: An
Update; SIGKDD Explorations, Volume 11, Issue 1.
Kowalski, C. T. e Orlowska-Kowalska, T. (2003).
Neural networks application for induction motor faults diagnosis, Mathematics and Computers in
Simulation 63(3-5): pp. 435-448.
Landis, J. Richard e Koch, Gary G. (1977). The
Measurement of Observer Agreement for Categori-
cal Data, International Biometric Society,
Vol. 33, N. 1, pp. 159-174.
Rosenblatt, F. (1958). The perceptron: A probabilis-
tic model for information storage and organization
in the brain, Phisicological Review 65(3): 386-408.
Santos, T. H., Goedtel, A., Silva, S. e Suetake, M.
(2011). A neural speed estimator in threephase in-
duction motors powered by a driver with scalar
control, Power Electronics Conference (COBEP),
Brazilian, pp. 44-49.
Sayouti, Y., Abbou, A., Akherraz, M. e Mahmoudi,
H. (2011). Sensor less low speed control with
annmras for direct torque controlled induction motor
drive, Power Engineering, Energy and Electrical
Drives (POWERENG), International Conference on, pp. 1-5.
Seera, M., Lim, C. P., Ishak, D. e Singh, H. (2012).
Fault detection and diagnosis of induction motors
using motor current signature analysis and a hybrid
fmm - cart model, Neural Networks and Learning
Systems, IEEE Transactions on 23(1): pp. 97-108.
Serasiya, S. D., Chaudhary, N. (2012). Simulation
of Various Classifications Results using WEKA.
International Journal of Recent Technology and Engineering (IJRTE), vol. 1, nº13, pp. 1-4.
Shashua, Amnon (2009). Introduction to Machine
Learning: Class Notes 67577, Corr, vol.
abs/0904.3664.
Silva, I. N., Spatti, D. H. e Flauzino, R. A. (2010).
Redes Neurais Artificiais para engenharia e ciências
aplicadas, 1ª edição, São Paulo: Artliber.
Vapnik VN (1995) The Nature of Statistical Learn-ing Theory. Springer-Verlag New York, Inc., New
York, NY, USA
Anais do XX Congresso Brasileiro de Automática Belo Horizonte, MG, 20 a 24 de Setembro de 2014
3020


















