
DISSERTAÇÃO DE MESTRADO ... - repositorio.ufrn.br · DISSERTAÇÃO DE MESTRADO ... (1955)...
71
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE CENTRO DE CIÊNCIAS EXTAS E DA TERRA-CCET PROGRAMA DE PÓS-GRADUAÇÃO EM MATEMÁTICA APLICADA E ESTATÍSTICA - PPGMAE DISSERTAÇÃO DE MESTRADO CARACTERIZAÇÃO ESTATÍSTICA DE EXTREMOS DE PROCESSOS SÍSMICOS VIA DISTRIBUIÇÃO GENERALIZADA DE PARETO. ESTUDO DE CASO: JOÃO CÂMARA – RN. Autor: Raimundo Nonato Castro da Silva Orientador: Prof. Dr. Paulo Sérgio Lucio Co-orientador: Prof. Dr. Aderson Farias do Nascimento Natal – RN, Dezembro de 2008
Transcript of DISSERTAÇÃO DE MESTRADO ... - repositorio.ufrn.br · DISSERTAÇÃO DE MESTRADO ... (1955)...

UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXTAS E DA TERRA-CCET
PROGRAMA DE PÓS-GRADUAÇÃO EM MATEMÁTICA APLICADA E
ESTATÍSTICA - PPGMAE
DISSERTAÇÃO DE MESTRADO
CARACTERIZAÇÃO ESTATÍSTICA DE EXTREMOS DE
PROCESSOS SÍSMICOS VIA DISTRIBUIÇÃO GENERALIZADA
DE PARETO. ESTUDO DE CASO: JOÃO CÂMARA – RN.
Autor: Raimundo Nonato Castro da Silva
Orientador: Prof. Dr. Paulo Sérgio Lucio
Co-orientador: Prof. Dr. Aderson Farias do Nascimento
Natal – RN, Dezembro de 2008

1
UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
CENTRO DE CIÊNCIAS EXTAS E DA TERRA-CCET
PROGRAMA DE PÓS-GRADUAÇÃO EM MATEMÁTICA APLICADA E
ESTATÍSTICA - PPGMAE
DISSERTAÇÃO DE MESTRADO
CARACTERIZAÇÃO ESTATÍSTICA DE EXTREMOS DE
PROCESSOS SÍSMICOS VIA DISTRIBUIÇÃO GENERALIZADA
DE PARETO. ESTUDO DE CASO: JOÃO CÂMARA – RN.
Autor: Raimundo Nonato Castro da Silva
Dissertação de mestrado apresentada
em 5 de dezembro de 2008, para a
obtenção do título de Mestre em
Matemática Aplicada e Estatística
pelo Programa de Pós-Graduação em
Matemática Aplicada e Estatística
(PPGMAE) da Universidade Federal
do Rio Grande do Norte (UFRN).
Comissão Examinadora:
Prof. Dr. Paulo Sérgio Lucio (Orientador)
Prof. Dr. Aderson Farias do Nascimento (Co-orientador)
Prof. Dr. Walter Eugênio de Medeiros
Profa. Dra. Sílvia Maria de Freitas
Natal – RN, Dezembro de 2008

2
AGRADECIMENTOS
Agradeço a todos que contribuíram, direta ou indiretamente, para a realização deste
trabalho.
Ao meu orientador, Prof. Paulo Sérgio Lucio, pela sua paciência e atenção.
À minha família, especialmente, meus pais.
A todos os meus amigos, especialmente, Francisco Marcio Barboza e Daniel Matos de
Carvalho pelas discussões matemáticas e estatísticas e pelas dicas no R.
Ao PPGMAE pela oportunidade de cursar o mestrado.

3
SUMÁRIO
1– Introdução.................................................................................................... 6
2 – A Filosofia da Teoria de Valores Extremos............................................. 9
2.1 – A Distribuição Generalizada de Valores Extremos (GEV)................................9
2.2 – Inferência sobre os Parâmetros da GEV...........................................................13
2.2.1 – Estimação dos quantis extremos da GEV...........................................19
2.3 – A Distribuição Generalizada de Pareto (GPD)..................................................19
2.3.1 - Seleção de um Limiar...........................................................................24
2.4 – Inferência sobre os Parâmetros da GPD...........................................................25
2.5 - Relação entre a Distribuição q-Exponencial e a GPD.......................................26
3 – Alguns Métodos de Estimação dos Parâmetros da GPD.......................29
3.1 - Máxima Verossimilhança (MLE)..........................................................................29
3.2 - Máxima Verossimilhança Penalizada (MPLE)....................................................30
3.3 - Momentos (MOM).................................................................................................30
3.4 - Pickands (PICKANDS)…………..................................………..............................31
3.5 - Momentos Ponderado por Probabilidades: (PWMB e PWMU).........................31
3.6- Divergência Média da Densidade (MDPD)…...............................................…...32
3.7 - Mediana (MED).....................................................................................................32
3.8 - Melhor Qualidade do Ajuste (MGF)……….…….................................................33
3.9 – Máxima Entropia (POME)...................................................................................33
3.9.1 - Especificação das Restrições.............................................................35
3.9.2 - Construção da Função de Entropia....................................................35
3.9.3 - Relação entre os Parâmetros da GPD e as Restrições.....................36
4 – Diagnóstico de Adequação do Modelo....................................................40
4.1 – Teste de Adequação do Modelo...........................................................41
5 – Estudo de Caso: João Câmara – RN........................................................43
5.1 – Caracterização do Município e o Sismo Histórico...........................................43
5.2 – Análise dos Dados..............................................................................................46 5.3 - Reconstrução de Extremos via Simulação de Monte Carlo.............................51
6 – Considerações Finais................................................................................55
Referencias Bibliográficas……….....……....................……………………..…57
Apêndices.........................................................................................................60

4
RESUMO
O objetivo desse trabalho é fazer uma breve discussão dos métodos de estimação dos
parâmetros da distribuição generalizada de Pareto (GPD). Sendo abordadas as
seguintes técnicas: máxima verossimilhança (MLE), máxima verossimilhança
penalizada (MPLE), métodos dos momentos (moments), Pickands (Pickands),
momentos ponderados pela probabilidade: viesado e não-viesado (PWMB, PWMU),
divergência média da densidade (MDPD), melhor qualidade do ajuste (MGF), mediana
(MED) e o método da máxima entropia (POME), técnica que neste trabalho receberá
uma maior atenção. A título de ilustração foram feitos ajustes para a distribuição
generalizada de Pareto, para uma seqüência de sismos intraplacas, ocorridos no
município de João Câmara, NE Brasil que foi monitorado continuamente durante dois
anos (1987 e 1988). Verificou-se que o MLE e o POME foram os métodos mais
eficientes, dando basicamente os mesmos erros médios quadráticos. Com base no
limiar de 1,5º foi estimado o risco sísmico para o município, sendo estimado o nível de
retorno para os sismos de intensidade 1,5º, 2,0º, 2,5º, 3,0º e para o sismo mais intenso
já registrado no município, ocorrido em novembro de 1986 que teve a magnitude de
5,2º.
Palavras-Chave: Eventos Extremos, Simulação Estocástica, Máxima Entropia, Risco
Sísmico.

5
ABSTRACT
The work is to make a brief discussion of methods to estimate the parameters of the
Generalized Pareto distribution (GPD). Being addressed the following techniques:
Moments (moments), Maximum Likelihood (MLE), Biased Probability Weighted
Moments (PWMB), Unbiased Probability Weighted Moments (PWMU), Mean Power
Density Divergence (MDPD), Median (MED), Pickands (PICKANDS), Maximum
Penalized Likelihood (MPLE), Maximum Goodness-of-fit (MGF) and the Maximum
Entropy (POME) technique, the focus of this manuscript. By way of illustration
adjustments were made for the Generalized Pareto distribution, for a sequence of
earthquakes intraplacas which occurred in the city of João Câmara in the northeastern
region of Brazil, which was monitored continuously for two years (1987 and 1988). It
was found that the MLE and POME were the most efficient methods, giving them
basically mean squared errors. Based on the threshold of 1.5 degrees was estimated
the seismic risk for the city, and estimated the level of return to earthquakes of intensity
1.5°, 2.0°, 2.5°, 3.0° and the most intense earthquake never registered in the city,
which occurred in November 1986 with magnitude of about 5.2º.
Key-words: Extreme Events, Stochastic Simulation, Maximum Entropy, Seismic
Hazard.

6
CAPÍTULO 1: INTRODUÇÃO
De forma geral, a previsão probabilística da ocorrência de eventos extremos é
de vital importância para o planejamento das atividades sujeitas a seus efeitos
adversos, e uma das formas de modelar esses eventos, é utilizar a teoria de valores
extremos (TEV) proposta por Fisher e Tippett (1928). Onde segundo essa teoria,
existem três tipos de distribuições assintóticas de valores extremos, a do tipo I
conhecida como Gumbel, a do tipo II conhecida com Fréchet e a do tipo III conhecida
com Weibull. Outra forma para esse tipo de modelagem é utilizar um importante
teorema limite conhecido como distribuições acima de um limiar (Peaks-over-
Threshold - POT), conhecido como teorema de Gnedenko-Pickands-Balkema-Haan
(1941). De uma forma geral, o POT, refere-se à distribuição dos eventos
condicionados por valores acima de um limiar pré-fixado. Esse teorema garante que
sob certas condições (domínio de atração do máximo), que o limite dessa distribuição
é a distribuição generalizada de Pareto (GPD), observa-se então que a idéia é estimar
a cauda da distribuição, tanto na TEV como no POT.
Os sismos1 podem ser considerados como um exemplo de eventos extremos,
uma vez que não é um fenômeno que ocorre normalmente, sua presença quando
ocorre, aparece nas caudas da distribuição, dessa forma, tanto a TEV como o POT,
podem ser utilizados para modelar esses tipos de evento.
Se a modelagem do sismo for através dos máximos observados em períodos
de tempo, a abordagem deve ser feita através da TEV, mas Coles (2001) diz que na
prática surge um problema em particular ao se escolher essa teoria. Escolhida a
distribuição o grau de incerteza não poderá ser medido, uma vez, que se aceita o
modelo, dessa forma não podendo ser medido o grau de incerteza, mesmo que esse
possa ser significativo. Portanto, Jenkinson (1955) unificou os três tipos de
distribuições assintóticas, numa única família conhecida como a distribuição de valores
extremos Generalizadas (GEV), onde a mesma se baseia nos máximos de um bloco.
Outra alternativa seria selecionar um limiar e a analisar os sismos acima dele,
nesse caso seria utilizada a distribuição generalizada de Pareto (GPD), esse método
tem a vantagem de não deixar extremos fora das análises, por que Patutikof et. al
(1999) quando fez uma revisão dos métodos de análise de extremos, utilizando a
teoria clássica, observou que a mesma só considera o máximo dentro de cada época,
isso faz com que outros extremos que tenham sido observados naquela época, sejam
ignorados.

7
Os abalos sísmicos1 quando ocorrem, podem causar grandes impactos na
sociedade. No município de João Câmara, situado no estado do Rio Grande do Norte,
por exemplo, em novembro de 1986 ocorreu um sismo que atingiu a magnitude de 5,22
graus na escala de Ricther3, sendo um dos maiores já registrado no Brasil.
Sismos de intensidades moderadas, como o ocorrido em João Câmara, podem
causar danos nas estruturas de casas e prédios, queda nas redes de transmissão de
energia elétrica e a vibração de estruturas e equipamentos. A importância dos efeitos
deste fenômeno geofísico está, portanto, intimamente ligado ao desenvolvimento da
tecnologia dos materiais e da engenharia estrutural. Segundo Pisarenko et al. (2008),
os sismos passaram a ser um grande problema á medida que as construções
tornaram-se mais altas e os tsunamis começaram a ocorrer.
Este manuscrito foi desenvolvido com o objetivo principal de apresentar a
metodologia para se ajustar a distribuição generalizada de Pareto aos dados sísmicos
do município de João Câmara, sendo feita também uma reconstrução das séries de
sismos via simulações de monte Carlo, para obter a probabilidade de ocorrência diária
de sismos acima de 1,5º na escala Ricther e estimar o período de retorno para os
sismos de intensidade 1,5º, 2,5º, 3,0º e o sismo histórico de 5,2º na escala Ricther.
O texto encontra-se estruturado em seis capítulos. No presente capítulo é feita
a justificativa do trabalho e delineado o seu objetivo, segue-se no capítulo 2 - A
filosofia da teoria de valores extremos, onde foi feita uma revisão de literatura sobre a
distribuição de extremos generalizadas (GEV), a distribuição generalizada de Pareto
(GPD) bem como a seleção de um limiar e por fim a relação entre a distribuição q-
exponencial e a GPD.
No capítulo 3 – Métodos de estimação dos parâmetros da distribuição
generalizada de Pareto, mostramos vários métodos de estimação dos parâmetro da
GPD dando um maior destaque ao método da máxima entropia (POME).
1 Um sismo, também chamado de terremoto, é um fenômeno de vibração brusca e passageira da superfície da Terra, resultante de
movimentos subterrâneos de placas rochosas, de atividade vulcânica, ou por deslocamentos (migração) de gases no interior da Terra,
principalmente metano. O movimento é causado pela liberação rápida de grandes quantidades de energia sob a forma de ondas
sísmicas. 2
Na faixa de 5,0-5,9 um sismo é considerado moderado, podendo causar danos maiores em edifícios mal concebidos em zonas
restritas. Provocam danos ligeiros nos edifícios bem construídos, sua freqüência é da ordem de 800 por ano3 É uma escala logarítmica utilizada para medir a magnitude dos abalos sísmicos. Foi criada pelos sismógrafos Beno Gutenberg e
Charles Francis Richter que estudavam os sismos da Califórnia e colocada em prática em 1935. A escala Richter varia de 0 a 9 graus
de acordo com a extensão do movimento do solo medindo ondas do tipo P e S. Ondas do tipo P são ondas primárias que se espalham
por movimentos de compressão e dilatação do local que pode ser em terra firme ou em oceanos e mares. São as ondas sísmicas mais
rápidas, cuja velocidade adquirida no solo varia entre a adquirida em água. Ondas do tipo S são ondas secundárias que se espalham
por movimentos ondulatórios para cima e para baixo alterando a forma dos elementos. As ondas S se desenvolvem somente no solo
com velocidade inferior às ondas P.

8
No capítulo 4 – Diagnóstico de adequação do modelo, são mostradas técnicas
para verificar e testar o ajuste do modelo.
No capítulo 5 – Estudo de caso: João Câmara-RN, apresentamos os principais
resultados obtidos pelo ajuste da GPD aos sismos observados de forma continua no
município durante o período de 23/05/1987 a 07/07/1988.
No capítulo 6 – Considerações finais, apresentam-se os aspectos que se
mostraram mais significativos no decorrer do estudo no que se refere aos resultados
obtidos, bem como se incluem algumas sugestões sobre o que poderá ser a
continuação iniciada com esse trabalho.
Nos apêndices constam rotinas no R para ilustrar as distribuições GEV e GPD
e para fazer a analise dos dados, bem como os ajustes para os outros métodos que se
mostraram menos eficiente para estimar os da distribuição generalizada de Pareto,
cuja a inclusão no texto parece desaconselhável por tornar a leitura menos agradável
ou pelas informações nelas apresentadas não se considerar essencial para a
compreensão do texto.

9
CAPÍTULO 2: A FILOSOFIA DA TEORIA DE VALORES EXTREMOS
A teoria de valores extremos tem como objetivo o estudo estatístico de
fenômenos de risco elevado com impactos catastróficos, que surgem em diversos
ramos das Ciências tais como a Meteorologia e a Climatologia. Valores extremos
podem ser considerados aqueles eventos raros que ocorrem nas caudas das
distribuições (fenômenos caudais), isto é, distantes do aglomerado ou da aglomeração
(média e mediana) do amontoado da distribuição. Não há, todavia, uma definição que
possa ser considerada universal de eventos extremos! Em muitas instâncias, eventos
extremos podem ser definidos como aqueles eventos que excedem em magnitude a
algum limiar ou patamar ou podem ser definidos como o máximo (ou mínimo) de uma
variável aleatória em determinado período.
2.1 A distribuição Generalizada de Valores Extremos (GEV)
Seja X uma variável aleatória, assumindo valores nos reais. A freqüência
relativa com que estes valores ocorrem define a distribuição de freqüência ou
distribuição de probabilidade de X e é especificada pela função de distribuição
acumulada dada por:
( )xXPxFx ≤=)( , )(xFx é uma função não-decrescente de x, e 1)(0 ≤≤ xFx para todo o x.
Em geral, estamos interessados em variáveis aleatórias continuas, para o qual
( ) 0== xXP para todo x, isto é, as probabilidades pontuais são nulas. Neste caso, (.)xF
é uma função continua e tem uma função inversa (.)x , a função quantil de X. Dado
qualquer valor zp, 10 << pz , x(zp) é o único valor que satisfaz:
ppx zzxF =))((
Para uma probabilidade p, x(p) é o quantil da probabilidade não excedente p,
isto é, o valor tal que a probabilidade de X não exceder x(p) é p. O objetivo da análise
de freqüência é estimar corretamente os quantis da distribuição de uma variável
aleatória.
A abordagem clássica da teoria de valores extremos consiste em caracterizar
as caudas (superior ou inferior) da distribuição de xF a partir da distribuição do
máximo. Assim, definimos ( )nn XXM ,.....,max 1= como o máximo de um conjunto de n
variáveis aleatórias independentes e identicamente distribuídas. Para obter-se a
distribuição do mínimo usa-se a relação:
( ) ( )nn XXXX ,.....,max,.....,min 11 −=

10
Na teoria a função de distribuição exata do máximo pode ser obtida para todos
os valores de n, da seguinte forma:
( ) ( ) ( ) ( )[ ]nxi
n
innM XFxXPxXxXPxMPF
n=≤∏=≤≤=≤=
=11 ,......., ,
para ℜ∈x e Nn ∈ . Todavia, este resultado não é útil na prática, visto que não
conhecemos a função de distribuição de xF . Segundo Coles (2001), uma
possibilidade é utilizar técnicas estatísticas para estimar xF para dados observados, e
substituir esta estimativa na equação acima. Infelizmente, pequenas discrepâncias na
estimativa de xF podem conduzir a substancias discrepâncias em ( )[ ]nx XF .
Uma alternativa é aceitar que xF seja desconhecida, e olhar para as famílias
aproximadas dos modelos de ( )[ ]nx XF , que pode ser estimado com base somente em
dados extremos. Isto é similar a prática usual de aproximar a distribuição da média
amostral pela distribuição normal, como justificado pelo teorema central do limite
(TCL). Além disso, podemos pensar que o comportamento assintótico de nM pode
estar relacionado com a cauda de xF próximo do limite superior do suporte da
distribuição de X, pois os valores do máximo são aqueles que se localizam perto
desse limite. Dessa maneira, denotamos por:
( ){ }1:sup <ℜ∈= xFxx xFX, o limite superior do suporte da distribuição de xF .
Observamos que, para todo xFxx < ,
( ) ( )[ ] 0,→=≤n
xn XFPxMP , ∞→n ,
e, no caso de ∞<xFx , temos para
xFxx > que:
( ) ( )[ ] 1==≤n
xn XFPxMP ,
logo, à medida que n cresce a distribuição de nM é degenerada4 sendo, portanto, um
resultado que não fornece muita informação.
Esta dificuldade pode ser sanada considerando-se uma seqüência de
constantes 0>nσ e nμ tais que:
n
nnn
MM
σ
μ−=*
convirja para uma função não-degenerada, para ∞→n . O teorema seguinte fornece o
resultado de convergência em distribuição para o máximo centrado e normalizado.
4 Em matemática, uma distribuição degenerada é a distribuição de probabilidade de uma variável aleatória discreta cujo suporte consiste de somente um valor.

11
Teorema (Fisher – Tippett, 1928): seja ( )nX uma seqüência de variáveis
aleatórias independentes e identicamente distribuídas. Se existirem seqüência de
constantes normalizadoras 0>nσ e nμ e uma distribuição não-degenerada H tal que:
HM d
n
nn ⎯→⎯−
σ
μ,
onde ⎯→⎯d representa convergência em distribuição, então H é do tipo de uma das
três funções de distribuição:
i -Tipo I de Gumbel:
( )ℜ∈
⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −−−= x
xxH I ,expexp)(
σ
μ;
ii -Tipo II de Fréchet:
,0)( =xH II se 0≤x
( )
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−=−ξ
σ
μxxH Ii exp)( , se 0>x ;
iii -Tipo III de Weibull:
( )
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎦⎤
⎢⎣⎡ −−−=
ξ
σ
μxxH III exp)( , se 0≤x
,1)( =xH III se 0>x .
A prova do teorema de Fisher-Tippett não será apresentada aqui, no entanto, uma
demonstração rigorosa desse resultado é apresentada por Gnedenko (1943).
Ainda sob o ponto de vista da modelagem as três distribuições de valores
extremos ),(xH I )(xH II e )(xH III sejam bem diferentes, do ponto de vista
matemático estão bastante relacionadas. Pode-se mostrar que se X>0, então:
)(~)(~)ln()(~ 1 xHXxHXxHX IIIIII−−⇔⇔ ξ .
Coles (2001), afirma que existem dois problemas na prática a serem resolvidos,
primeiramente uma técnica para escolher qual das três famílias é a mais apropriada,
em seguida, tomada tal decisão e feito a conclusão, presumem que a escolha esteja
correta e não é medido o grau de incerteza, embora essa possa ser significativa.
Dessa forma Jenkinson (1951), mostrou que as três famílias poderiam ser unificadas
em uma única família, a família de valores extremos generalizadas, dada da seguinte
forma:

12
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−=
−ξ
σ
μξ
1
1exp)(x
xH .
Definida no conjunto ( )⎭⎬⎫
⎩⎨⎧
>−
+ 01:σ
μξ
xx , sendo que os parâmetros satisfazem,
0, >∞<<∞− σμ e ∞<<∞− ξ , o modelo é tri-paramérico, sendo um parâmetro de
localização, um de escala e um de forma, onde o parâmetro ξ é quem determina a
forma da distribuição, quando: 0>ξ tem-se a distribuição de Fréchet, 0<ξ obtem-se
a de Weibull. Sendo que o limite de F(x) quando 0→ξ , a distribuição assume a
seguinte forma:
⎥⎦
⎤⎢⎣
⎡
⎭⎬⎫
⎩⎨⎧
⎟⎠⎞
⎜⎝⎛ −
−−=σ
μxxH expexp)( , ∞<<∞− x ,
que representa a função de distribuição da Gumbell, com parâmetros de localização e
escala μ e σ, respectivamente, sendo σ>0.
Dessa forma, em vez de se ter que escolher uma família inicialmente, para
depois estimar os parâmetros, a inferência se faz diretamente sobre o parâmetro de
forma ξ . A Figura 1, onde no apêndice B mostramos a rotina no R para gerar a
mesma, apresenta os gráficos da função de distribuição para 5,1−=ξ (Weibull), ξ
tendendo a zero (Gumbel) e 5,1=ξ (Fréchet), com 0=μ e 4761,0=σ .
Para se encontrar a função densidade de probabilidade (f.d.p.) da função
generalizada de valores extremos (GEV), deriva-se a função de distribuição da GEV
em relação à x, obtendo-se:
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−⎥⎦
⎤⎢⎣
⎡
⎭⎬⎫
⎩⎨⎧
⎟⎠⎞
⎜⎝⎛ −
−+=
−⎟⎟⎠
⎞⎜⎜⎝
⎛ +−
ξξ
ξ
σ
μξ
σ
μξ
σ
11
1exp11
)(xx
xh ,
onde ξ
σμ −<<∞− x , para 0<ξ , que corresponde a densidade da Weibull e
∞<<−
xξ
σμ, para 0>ξ , gerando-se a densidade da Fréchet, por fim quando o
limite para ξ tendendo a zero, tem-se:
⎭⎬⎫
⎩⎨⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −−−⎟
⎠⎞
⎜⎝⎛ −−=
σ
μ
σ
μ
σ
xxxh expexpexp
1)( , definida em ∞<<∞− x
gerando a função densidade da Gumbel.

13
Figura 1: Ilustração das três funções de distribuições acumuladas da família de
valores extremos generalizados (GEV).
A Figura 2 apresenta os gráficos da função densidade de probabilidade da
GEV para 4,0−=ξ (Weibull), ξ tendendo a zero (Gumbel) e 4,0=ξ (Fréchet), com
12=μ e 2=σ , onde observa-se que o parâmetro ξ é quem determina a natureza
das caudas da distribuição.
Fazendo-se uso de uma linguagem mais informal, o caso 0>ξ é o caso das
“caudas pesada” no qual ξ
1
~)(1−
− xxH , 0<ξ é o caso das “caudas leves”, em que
a distribuição tem um ponto final finito (o menor valor de x para o qual H(x) =1) em que
μ
σμ −=x . Se 0=ξ , as caudas da distribuição estão entre leves e pesadas, na qual
)(1 xH− decresce exponencialmente para grandes valores de x. Isto mostra que em
aplicações as três famílias são bastante diferentes nos extremos.
Quanto às aplicações, a distribuição GEV tem sido utilizada em vários estudos,
por exemplo, Hosking e Wallis (1997) utilizou a GEV para análise de freqüências de
vazões, por outro lado, Bautista (2002) utilizou a GEV para analisar as velocidades
máximas do vento.
2.2 Inferência sobre os Parâmetros da GEV
Para se fazer inferências sobre os parâmetros da GEV, Coles (2001) afirma
que foram propostas várias técnicas, entre elas, incluem-se métodos gráficos,
estimação pelo método dos momentos, máxima verossimilhança. Cada uma destas
técnicas apresenta pontos fortes e fracos. Coles (2001) afirma que o método da
máxima verossimilhança é o mais atraente devido as suas características, contanto

14
que as condições de regularidades sejam satisfeitas, ou seja, a função de
verossimilhança seja monótona crescente.
Figura 2: Ilustração das funções densidade de probabilidades das três formas da
família de valores extremos generalizados (GEV).
Smith (1985) observou que dependendo da estimativa do parâmetro de forma
pelo método da máxima verossimilhança, essas condições nem sempre são
observadas, uma vez que:
• Se 5,0−>ξ , os estimadores de máxima verossimilhança são regulares, tendo
suas propriedades assintóticas habituais;
• Se, 5,01 −<<− ξ o estimador de máxima verossimilhança é geralmente
encontrado, porém as condições de regularidades não são observadas;
• Se, 1−<ξ não é possível obter os estimadores de máxima verossimilhança.
Hosking et al (1985b), ao utilizar simulações computacionais para estimar os
parâmetros da GEV pelo método da máxima verossimilhança através do processo
interativo de Newton-Raphson, observaram que poderia existir problemas de
convergência, pelo fato das condições de regularidades não serem atendidas. Sendo
que esse caso é muito raro, pois só ocorre quando 5,0−<ξ , que de acordo com
Coles (2001), corresponde ao caso onde a cauda superior é muito curta. Hosking et.
al. (1985b) também mostraram que ao se trabalhar com dados reais o valor de
)5,0;5,0(−∈ξ , esses resultados foram confirmados através de simulações

15
computacionais por Brabson e Patutikof (2000), onde concluíram que o valor de
)5,0;5,0(−∈ξ , portanto a eficiência das estimativas de máxima verossimilhança dos
parâmetros na prática, não apresenta maiores problemas.
Todavia, além do estimador de máxima verossimilhança, outros métodos têm sido
utilizados para estimar os parâmetros da GEV, podemos citar de acordo Hosking et. al.
(1985b), por exemplo: método dos momentos, probabilidades ponderadas, método dos
momentos L, onde os mesmos mostraram-se mais eficientes que o método da máxima
verossimilhança, no que tange ao viés e as variâncias amostrais, em amostras cujos
tamanhos variam entre 15 e 100. Porém, conforme Smith (2001), nenhum dos
métodos citados permite a generalização como faz o método da máxima
verossimilhança, portanto desenvolveremos agora esse método.
Considerando que nXX ,...,1 são uma série de realizações aleatórias
independentes, identicamente distribuídas e ordenadas, com função densidade de
probabilidade da GEV, a função de verossimilhança ( ) ( ) ( )∏=
==n
iixhLL
1
;,, θξσμθ é
dada por:
( ) ( ) ∏ ∑= =
−⎟⎟⎠
⎞⎜⎜⎝
⎛ +−
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+==n
i
n
i
iξ
iξξ
n σμxξ
σμxξ
σξσμLθL
1 1
11
1exp11
,, ,
que para 0<ξ , assume valores diferentes de zero, se todos os valores de xi
( )ni ,...,2,1= forem menores do que ξ
σμ − , ou seja, se nx>−
ξ
σμ , sendo xn o maior
valor da série de observações, e para 0>ξ , se todos os valores de xi ( )ni ,...,2,1=
forem maiores que ξ
σμ − , ou seja, 1x<−
ξ
σμ o menor valor da série de
observações. Caso contrário ( ) 0=θL .
É mais conveniente (de forma matemática, dada a monotonicidade da função)
tomar o logaritmo e trabalhar com o logaritmo da função verossimilhança, que é dado
por:
( ) ( )[ ] ∑ ∑= =
−
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+⎟⎠
⎞⎜⎝
⎛ +−−==
n
i
n
i
iξ
i
σμxξ
σμxξ
ξξσnξσμLξσμl
1 1
1
11ln1
ln,,ln,,

16
∑=
−
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+⎟⎠
⎞⎜⎝
⎛ +−−=
n
i
iξ
i
σμxξσ
μxξξξσ
1
1
11ln1
ln ,
para nx>−ξ
σμ e 0<ξ ou 1x<−
ξ
σμ se 0>ξ . Caso contrário o ( )ξσμl ,, não
existe! Os estimadores de máxima verossimilhança de μ , σ e ξ são obtidos
maximizando o logaritmo da função verossimilhança ( )ξσμl ,, em relação a cada
parâmetro e a raiz obtida, a sua solução. Assim:
( ) 0,,0=
∂
∂=ξσμl
μ μμ ; ( ) 0,,0=
∂
∂=ξσμl
σ σσ ; ( ) 0,,0=
∂
∂=ξσμl
ξ ξξ
ou, seja:
011
1^
1^
^
^
=⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−+
∑=
−n
i
ξi
σ
wξ
σ
0
11
1
1^^
^ 2^
^
=
⎪⎪⎭
⎪⎪⎬
⎫
⎪⎪⎩
⎪⎪⎨
⎧⎥⎦
⎤⎢⎣
⎡−⎟⎠⎞
⎜⎝⎛
+⎟⎠⎞
⎜⎝⎛
−
+− ∑=
−
n
i i
ξii
w
wξμx
σσ
n
( ) 0ln1
11
^
^
^^
^
^ 2
1^ =
⎪⎪⎭
⎪⎪⎬
⎫
⎪⎪⎩
⎪⎪⎨
⎧⎟⎠⎞
⎜⎝⎛
−
−
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡⎟⎠⎞
⎜⎝⎛
−
−⎟⎠⎞⎜
⎝⎛ −∑
=
−n
ii
i
i
i
iξi
wσ
μx
wσξ
μxw
ξw , sendo
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
+=^
^
1σ
μxξwi
i .
Como este sistema de equações não possui solução analítica, utilizaram-se
procedimentos iterativos para obter as estimativas dos parâmetros de máxima
verossimilhança usando a matriz de informação de Fisher, M . A fórmula interativa é,
para 0≥j , ( ) ( ) ( )θlgradθMθθ jjj ⎟⎠⎞⎜
⎝⎛+=
−+
^ 11 onde ( )ξσμθ ,,= com:
( ) ⎟⎟⎠
⎞⎜⎜⎝
⎛∂
∂−
∂
∂−
∂
∂−=−
ξl
σl
μlθlgrad ,, e
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛
∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−
⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛
∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−
⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛
∂
∂−
=⎟⎠⎞
⎜⎝⎛
ξl
Eμξ
lE
σξl
E
μξl
Eμl
Eσμl
E
σξl
Eσμl
Eσ
lE
θM
2
222
2
2
22
22
2
2
^
,
onde os elementos de M podem ser expressos em termos da função gama:
( ) dxxer rx 1Γ −−∫= e ( ) ( ) drrdrψ Γlog=

17
como:
( )[ ]pξξσ
n
σl
E +−−=⎟⎟⎠
⎞⎜⎜⎝
⎛∂
∂− 2Γ21
222
2
( )[ ]ξpξσ
n
μσl
E −−=⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂− 2Γ
2
2
( ){ }⎥⎦⎤
⎢⎣⎡
−−−−
−−=⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂−
ξp
qξ
ξγξσn
ξσl
E2Γ1
12
2
pσn
μl
E22
2
=⎟⎟⎠
⎞⎜⎜⎝
⎛
∂
∂−
⎥⎦
⎤⎢⎣
⎡+=⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−
ξp
qσξn
ξμl
E2
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡++⎟
⎠
⎞⎜⎝
⎛−−+=⎟⎟
⎠
⎞⎜⎜⎝
⎛∂
∂−
ξp
ξq
ξγπ
ξn
ξl
E2
2
22
2 211
2
6,
sendo ( ) ( )ξξp 21Γ12
−−= , ( ) ( ) ( )⎭⎬⎫
⎩⎨⎧ −
−−−=ξξξψξq
112Γ e 5772157.0=γ a
constante de Eüler.
No procedimento iterativo, fixa-se um valor inicial arbitrário ξ 0 para ξ , e
sugerem-se como valores iniciais μ0 e σ0 para μ e σ , valores tais que ( ) XXE = e
( ) sXVar 2= , sendo X a média e s2 a variância da série de observações (amostrais).
Considerando-se a função densidade de probabilidade, obtém-se:
( ) ( )[ ]11Γ −−+= ξξσμXE , se 1<ξ ,
e
( ) ( ) ( )[ ]ξξξσXVar −−−= 1Γ21Γ 2
2
2
, se 2
1<ξ ,
sendo as seguintes expressões para os valores iniciais:
( ) ( )ξξξ
sσ0
20
20
01Γ21Γ −−−
=
( ) ( )[ ]( ) ( )ξξ
ξξξs
xσξξ
xμ0
20
20
00
0
0
00 1Γ21Γ
11Γ11Γ−−−
−−−=−−
−= .

18
Jenkinson (1955) sugeriu que se devia usar a matriz informação de Fisher para
amostras completas, entretanto para amostras censuradas estas esperanças não
existem no sentido usual, e foi observado num número de estudos simulados, que a
convergência para θ é consideravelmente mais rápida, usando a matriz ⎟⎠⎞
⎜⎝⎛ ^
θV ao
invés da matriz ⎟⎠⎞
⎜⎝⎛ ^
θM . Assim é usual aproximar a matriz ⎟⎠⎞
⎜⎝⎛ ^
θM por esta nova
matriz ⎟⎠⎞
⎜⎝⎛ ^
θV , descrita por:
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
⎟⎟⎠
⎞⎜⎜⎝
⎛
∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−
⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛
∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−
⎟⎟⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛∂∂
∂−⎟⎟
⎠
⎞⎜⎜⎝
⎛
∂
∂−
=⎟⎠⎞
⎜⎝⎛
ξl
μξl
σξl
μξl
μl
σμl
σξl
σμl
σl
θV
2
222
2
2
22
22
2
2
^
.
Com esta nova matriz, o cálculo iterativo de θ , envolve rapidez computacional e
converge para 10 3−<lgrad em menos de 5 iterações.
Para o caso particular da distribuição generalizada de valores extremos com
0→ξ , temos a distribuição Gumbel, o logaritmo da função verossimilhança é dado
por: ( ) ∑= ⎭
⎬⎫
⎩⎨⎧
⎟⎠⎞
⎜⎝⎛ −
−−⎟⎠⎞
⎜⎝⎛ −
−−=n
i
ii
σμx
σμxσσμl
1
expln, , e os estimadores de máxima
verossimilhança de μ e σ são obtidos pela solução de:
( ) 0,0=
∂
∂=σμl
μ μμ ; ( ) 0,0
=∂
∂=σμl
σ σσ ,
ou seja
0exp1
1^
^
^=
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
−− ∑=
nσ
μx
σ
n
i
i ,
0exp1
1^
^
^
^
^
^
^=
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧−
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
−⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
−⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
− ∑=
nσ
μx
σ
μx
σ
μx
σ
n
i
iii .
Mais uma vez, este sistema não possui solução analítica e deve-se usar o
mesmo método iterativo descrito a cima para a obtenção da solução numérica,
tomando como valores iniciais μ0 e σ0 para μ e σ a soluções obtidas através do
cálculo dos momentos. Para este caso tem-se:

19
( ) σγμXE += , ( )6
22σπXVar = ,
com 5772157.0=γ a constante de Eüler, logo
sxsπ
γxμ 45005.06
0 −≅−= , ssπσ 77970.06
0 ≅= ,
que correspondem aos limites quando 00 →ξ .
2.2.1 Estimação dos Quantis Extremos da GEV
Após terem sido estimados os parâmetros da GEV, será possível obter a
estimação de quantis ( pz ) as probabilidades (p), pois os mesmos dependem desses
parâmetros, para isso basta inverter a função de distribuição de valores extremos,
onde os quantis são dados da seguinte forma:
( ){ }[ ]ξ
ξ
σμ −
−−−−= pz p 1log1 , se 0≠ξ
( ){ }pz p −−−= 1loglogσμ , se 0=ξ ,
onde: ( ) pzF p −= 1 . Sendo que pz , corresponde ao nível de retorno associado ao
período de retorno p
1.
Coles (2001), define ( )py p −−= 1log , e na expressão dos quantis, tem-se:
[ ]ξ
ξ
σμ −
−−= pp yz 1 , se 0≠ξ
pp yz logσμ −= , se 0=ξ .
Isso permite gerar um gráfico em escala logarítmica, onde no eixo das abscissas
representa-se py e no das ordenadas pz ou equivalentemente, o gráfico pode ser
gerado com log py contra pz , onde o mesmo relaciona a freqüência de eventos
extremos, conforme o sinal do parâmetro de forma.
2.3 A Distribuição Generalizada de Pareto (GPD)
Suponha nXX ,....,1 variáveis aleatórias independentes e identicamente
distribuídas, tendo função de distribuição XF . Seja xFx o limite superior da distribuição
de XF . Chamamos de um limiar alto um valor no suporte de X perto de xFx .

20
Denominamos “excedentes” aqueles valores iX tais que uX i > . Denotamos por uN
o número de excedentes do limiar u. Isto é,
∑=
>=n
iuXu i
N1
)(1 , onde: => )(1 uX i1 se uX i > ,
=> )(1 uX i 0 caso contrário.
Os excessos (pontos excedentes) além do limiar u, denotados por nuYY ,....,1 são
os valores 0≥− uX i . A Figura 3 mostra as observações 121,...., XX e os excessos
além do limiar u=4.
Esta abordagem se diferencia da abordagem clássica, pois a teoria clássica se
baseia na análise do valor do máximo (ou mínimo) em uma época. Como será visto na
definição que se segue, essa abordagem permite a análise de todos os dados
disponíveis que excedem um limiar, porém esse limiar deverá garantir a distribuição
assintótica de valores extremos, sem as quais não será possível fazer as inferências.
Definição: Dado um limiar u, a distribuição dos valores de x acima de u é dada
por:
{ } ( )( )
0 ,1
1| >
−
+−=>+> y
uF
yuFuXyuXP , (1)
que representa a probabilidade do valor de x ultrapassa u por no máximo um montante
y, onde y=x-u.
Figura 3: Ilustração do gráfico de barras das observações de uma seqüência de
variáveis aleatórias 121,...., XX , onde se destacam os excessos acima do limiar u=4.

21
Seja F uma distribuição generalizada de valor extremo, tal que:
( )⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−=
−
σμxξxF
ξ1exp
1
para qualquer 0, >σμ e ℜ∈ξ . Então a
probabilidade condicional, quando uX > , sabendo-se que
( ) ⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+−≈
−
σμxξxFn
ξ1ln
1
, e que para valores elevados de x se deve fazer uma
expansão à Taylor de forma que ( ) ( ){ }xFxF −−≈ 1ln , substituindo e re-arranjando
para u , tem-se ( ) ⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+≈−
−
σμuξ
nuF
ξ1
11
1
e de uma forma similar para 0>y ,
( ) ⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+
+≈+−
−
σμyuξ
nyuF
ξ1
11
1
.
Desta forma, tem-se:
{ } ( )( ) ⎟
⎠⎞⎜
⎝⎛ +=
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −+
+
=−
+−=>+>
−
−
−
~
1
1
1
1
11
11
1
1|
σ
yξ
σμuξ
n
σμyuξ
n
uF
yuFuXyuXP
ξ
ξ
ξ
,
com ( )μuξσσ −+=~
.
Assim, a função distribuição de ( )μX − , condicionada a uX > , é
aproximadamente:
( ) ⎟⎠⎞⎜
⎝⎛ +−=
−
~
1
11σ
yξyH
ξ
,
definida em ⎭⎬⎫
⎩⎨⎧
>⎟⎠⎞
⎜⎝⎛
+> 010:~
σyξeyy , onde ( )μuξσσ −+=~
.
Coles (2001) afirma que a família de distribuições definida acima é chamada
família generalizada de Pareto. A função distribuição condicional é aproximadamente a
distribuição generalizada de Pareto (GPD), que representa as três distribuições em
uma só forma, sob a γ-parametrização: ( ) γxγγxW1
11);( −+−= . Assim como as
distribuições GEV são as distribuições limite para o máximo, as do tipo GPD são as
formas paramétricas para distribuições limite de excessos (Teorema de Balkema-de

22
Haan). As distribuições generalizadas de Pareto são da forma Exponencial ( 0=γ ),
Pareto tipo II ( 0>γ ) e Pareto comum ou Beta ( 0<γ ).
Os parâmetros da distribuição generalizada de Pareto para excessos que
ultrapassam limiares (Peaks-over-Threshold - POT) são determinados por aqueles
associados às distribuições generalizadas de valores extremos (GEV). No limite de
( )xF quando 0→ξ tem-se a distribuição acumulada de Gumbel:
( ) ⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−−=σμx
xF expexp , e a função distribuição de ( )μX − , condicional com
uX > , é aproximadamente: ( ) ⎟⎠⎞
⎜⎝⎛
−−=σy
yH exp1 , com 0>y .
A Figura 4, onde a rotina para mostrar a ilustração encontra-se no apêndice B,,
apresenta os gráficos da função de distribuição da GPD para 4,0−=ξ (Pareto comum
ou Beta), ξ tendendo a zero (exponencial) e 4,0=ξ (Pareto tipo II), todas com
2=σ , observa-se que assim como na GEV o parâmetro ξ é quem determina as
caudas da distribuição.
Por fim, as distribuições GPD e GEV estão relacionadas da seguinte maneira:
( ))(ln1)( xHxG += , ( ) 1)(ln −>xH .
Esta relação explica por que as densidades da GPD possuem cauda extrema
assintoticamente equivalente às de uma GEV. A Figura 5, onde também a rotina
implementado no R esta no apêndice B, ilustra este fato e mostra a proximidade das
caudas de algumas distribuições GPD com algumas GEV.

23
Figura 4: Ilustração da função densidade de probabilidade das três formas da
distribuição generalizada de Pareto (GPD).
Figura 5: Densidades da GPD e GEV. (a) Pareto comum (Beta) e Weibull, ambas com
0,2ξ −= ; (b) Pareto tipo II e Fréchet, ambas com 2,0=ξ . As densidades da GEV
todas possuem 0=μ e todas as densidades possuem 1=σ .

24
2.3.1 Seleção do Limiar
Na escolha do limiar u nos deparamos com alguns problemas, pois um valor
para u muito “alto” implicará em um número pequeno de observações na cauda,
podendo resultar numa maior variabilidade dos estimadores. Porém, um limiar que não
seja suficientemente alto não satisfaz as suposições teóricas e pode resultar em
estimativas distorcidas, portanto uma idéia é monitorar os valores extremos como será
descrito.
Para a determinação do limiar recorre-se à análise gráfica da linearidade de nuobservações que excedem os vários limiares u determinados na própria amostra.
Assim, o gráfico de vida média residual, usado para a determinação visual de u é
construído da seguinte forma: ( )⎭⎬⎫
⎩⎨⎧
<⎟⎟⎠
⎞⎜⎜⎝
⎛−∑
=
xuuxn
un
ii
u
u
max1
:1
, , em que xxx nu,...,, 21
consistem nas observações que excedem u e xmax é o valor mais elevado das
observações.
Na prática dois métodos são avaliados para esse propósito: uma técnica
exploratória e a outra é avaliar a estabilidade dos parâmetros estimados, baseado no
ajuste de uma gama de limiares de acordo com o gráfico descrito acima.
Conforme Coles (2001), o primeiro método é baseado na média da distribuição
da GPD. Se Y seguir uma distribuição generalizada de Pareto com parâmetros de
escala e forma, σ , ξ , respectivamente, então:
ξ
σ
−=
1)( yE , desde que 1<ξ , uma vez que se 1≥ξ a esperança será infinita; e
( )ξ
σYVar21
2
−= , com
2
1<ξ .
Seja u0 o limiar mais baixo de uma série XXX n,...,, 21 arbitrária, então
( ) ( )ξ
σuXuXEYE u
−=>−=
1| 0
00 com 1<ξ , em que σu0 é o parâmetro de escala
correspondente aos excessos do limiar u0 . Mas se a distribuição de Pareto é válida
para os excessos de u0 , também é igualmente válido para os excessos de limiares
uu 0> , sujeitos a apropriada variação no parâmetro escala para σ u . Então, para:
uu 0> , ( )ξ
uξσξ
σuXuXE uu
−
+=
−=>−
11| 0 .
Segundo Coles (2001), a GPD é um modelo razoável para os excessos acima
do limiar u0 , assim como para um limiar mais elevado u. Os parâmetros de forma das
duas distribuições são idênticos. No entanto, o valor do parâmetro de escala para o

25
limiar uu 0> é ( )uuξσσ uu 00−+= , que varia com u a menos que 0=ξ . Esta
dificuldade pode ser remediada pela re-parametrização do parâmetro de escala como:
uξσσ u −=* e ( )ξxσu −= 1 , com x a média dos excessos para de cada limiar u , e ξ
determinado da média e do desvio padrão dos excessos de cada limiar u , e
conseqüentemente as estimativas de ambos σ* e ξ serão constantes acima de u0 ,
se u0 é um limiar valido para os excessos que seguem uma GPD. Assim, são
representados os gráficos de σ* e ξ versus u , juntamente com os intervalos de
confiança que são obtidos pela matriz variância e covariância V para ξ e para σ*
pelo método Delta, usando:
( ) σVσσVar T *** ∇∇≈ , com [ ]uξσ
σσ
σu
T −=⎥⎦
⎤⎢⎣
⎡∂
∂
∂
∂=∇ ,1,
*** .
2.4 Inferência sobre os Parâmetros da GPD
A estimação dos parâmetros da GPD pode ser feitos por vários métodos, entre
eles, tem-se o da máxima verossimilhança, Davison (1984), Hosking e Wallis (1987),
método dos momentos, método da máxima entropia (POME) e o método dos
momentos ponderados, Singh e Guo (1995), onde a eficiência de cada método
depende da situação estudada, estes métodos serão detalhados no capítulo 3, sendo
dada nesse capítulo somente uma abordagem baseada numa importante propriedade
da GPD.
Lin (2001) mostra que uma importante propriedade da distribuição generalizada
de Pareto, ocorre quando 1−>ξ , onde a média de excessos, ao longo de um limiar,
u, é uma função linear de u:
( )ξ
ξσ
+
−=>−
1/
uuXuXE , portanto o gráfico da linearidade da média de
excessos, poderá ser utilizado como um indicador da adequação do modelo da GPD.
Essa propriedade permite estimar os parâmetros de forma e escala da
distribuição generalizada de Pareto, da seguinte forma:
Define-se a média de excessos de uma amostra (MEA), como uma função
dada abaixo:

26
( )( )
{ }∑
∑
=>
=
+−
=n
iux
n
ii
n
í
uXue
1
1
1, no que diz respeito ao limiar u, onde o + garante que apenas
os valores positivos de ( )uX i − serão contados. Ou seja, a MEA é a soma dos
excessos durante o limiar u, dividido pelo numero de pontos dos dados que excede ao
limiar u. Dessa forma a média de excessos da amostra é o estimador empírico da
média de excessos de um limiar (MEL), portanto, ξ e σ da GPD, podem ser
determinado pela inclinação e o intercepto da MEA utilizando as seguintes equações:
Inclinação=ξ
ξ
+−
1
e
Intercepto= ξ
σ
+1.
2.5 Relação entre a Distribuição q-Exponencial e a GPD
Shalizi (2007), ao estudar o estimador de máxima verossimilhança da distribuição
q-Exponencial, também conhecida como distribuição de T-salis, essa distribuição é
definida através do complementar da função de distribuição, sendo mais conhecida
como a função de sobrevivência, onde a mesma possui a seguinte forma:
( ) q
qk k
xqxXP
−
⎟⎠⎞
⎜⎝⎛ −
−=≥1
1
,
11)( .
Essa reparametrização ajuda a simplificar a estimação dos parâmetros e fazer
uma ligação com a distribuição de Pareto, para encontrar o estimador de máxima
verossimilhança para a distribuição q-exponencial, portanto é mais fácil utilizar a
reparametrização e no final retornar ao sistema inicial, caso seja desejado.
Shalizi (2007), define a nova reparametrização, da seguinte forma q−
−=1
1θ e
k*θσ = , para recuperar os parâmetros iniciais basta fazer: θ
11+=q e
θ
σ=k , logo
a função de sobrevivência, em relação aos novos parâmetros, é:
θ
σθσ
−
⎟⎠⎞
⎜⎝⎛
+=≥x
xXP 1)(, , para se encontrar a função densidade de probabilidade,
basta derivar a função acima em relação à x, obtendo-se:

27
1
, 1)(−−
⎟⎠⎞
⎜⎝⎛
+=θ
σθσσ
θ xxP , onde a mesma possui uma distribuição de Pareto com
parâmetro de forma α e ponto de corte 0y .
se P(y)=0, quando 0yy < ,
1
0
)(−−
⎟⎟⎠
⎞⎜⎜⎝
⎛∝
α
y
yyP .
Assim X tem uma distribuição q-exponencial e σ
x+1 , tem uma distribuição de
Pareto com ponto de corte igual a 1 e parâmetro de forma θ , resultando em uma
distribuição de Pareto do tipo II, sendo sua forma padrão:
( ) α
σθσ
μ−
⎟⎠⎞
⎜⎝⎛ −
+=x
xP 1)(,
que é uma distribuição q-Exponencial quando 0=μ e θσ = .
Neste capítulo foi vista a filosofia da teoria de valores extremos, através de
uma revisão de literatura da GEV, bem como sobre as inferências a respeito dos seus
parâmetros, dando maior ênfase ao estimador de máxima verossimilhança, uma vez,
que de acordo com a revisão de literatura feita é o que tem mostrado melhor
desempenho para estimar os parâmetros da GEV, em seguida foi feita uma revisão de
literatura também para a GPD e mostrando a importante relação entre GEV e GPD,
bem como a seleção do seu limiar e para encerrar foi vista uma relação importante
entre a distribuição q-exponencial e a GPD, sendo gerada a partir de uma
reparametrização na Pareto tipo II, esse artifício facilita bastante para encontrar o
estimador de máxima veossimilhança da GPD quando o parâmetro de forma for
positivo.
Dessa forma, têm-se duas maneiras de se modelar o máximo de uma
seqüência de variáveis aleatórias independentes e identicamente distribuídas:
1. Máximo em Bloco, onde se seleciona o máximo de cada período, porém nessa
abordagem corre-se o risco de deixarmos alguns máximos de fora, dessa
forma comprometendo as estimativas bem como previsões/predições;
2. Observações acima de um limiar u, nesse tipo de modelagem busca-se
modelar a seqüências de variáveis aleatórias acima dele, onde a distribuição
limite é a distribuição generalizada de Pareto, sendo que nesse modelo o
problema consiste na escolha desse limiar, que pode ser feita por duas
maneiras: uma através de técnicas exploratórias e a outra através de técnicas
gráficas, olhando sempre a estabilização dos parâmetros e tomando o cuidado

28
na escolha do mesmo, para não violar a convergência assintótica e nem ficar
com poucas observações acima do limiar selecionado.
Assim, uma vez escolhido o modelo, no presente estudo a modelagem será via
GPD, por essa razão na secção que trata das inferências dos parâmetros da GPD só
foi abordado o método de estimação baseado na propriedade da linearidade da
distribuição generalizada de Pareto, pois no capítulo 3 será visto os métodos de
estimação dos parâmetros da GPD que foram utilizados no estudo de caso, sendo que
o método estudado com mais detalhes foi o da máxima entropia (POM), uma vez que
esse método tem sido bastante estudado nos últimos anos, e sempre mostrando estar
entre os métodos mais eficientes de estimação dos parâmetros da GPD.

29
CAPÍTULO 3: ALGUNS MÉTODOS DE ESTIMAÇÃO DOS PARÂMETROS
DA DISTRIBUIÇÃO GENERALIZADA DE PARETO (GPD)
Vários métodos de estimação dos parâmetros da GPD já foram propostos,
sendo que nos últimos anos o método da máxima entropia (POME) tem sido bastante
utilizado por vários autores, em geral Sing e Guo (1995), Oztekin (2004), onde o
POME sempre que comparado com outros métodos, obteve menor erro quadrático
médio. Por essa razão nas próximas secções, serão mostrados todos os métodos
utilizados no presente estudo, sendo que o da máxima entropia será desenvolvido de
forma integral.
3.1 Método da Máxima Verossimilhança (MLE)
Para se encontrar o estimador de máxima verossimilhança, precisamos
encontrar o log da função de verossimilhança, que de acordo com Oztekim (2004) é:
( )∑=
⎥⎦⎤
⎢⎣⎡
−−⎟⎟⎠
⎞⎜⎜⎝
⎛ −+−=
n
iii xnxL
1
11
ln),,,( μσ
ξ
ξ
ξσμσξ , onde os ix são valores observados na
amostra e n o tamanho da amostra, o método se baseia na maximização dos
parâmetros da equação acima.
Para a maximização, Rheinboldt (1998), utilizou o método direto ou de Newton-
Rapson, para isso ele resolveu as equação parciais em relação a cada parâmetro
desconhecido, onde as derivadas parciais em relação ao parâmetro de forma são
dadas a seguir:
( )( )
( )
( ) ( )( )
.01
1
,01
11ln
1 2
1
21
=
⎟⎠⎞
⎜⎝⎛ −
−
−−
−=∂
∂
=
⎟⎠⎞
⎜⎝⎛ −
−
−−
+
⎟⎠⎞
⎜⎝⎛ −
−
=∂
∂
∑
∑∑
=
=
=
ξ
σ
μξσ
μξξ
σξ
ξ
σ
μξσ
μξ
ξ
σ
μξ
ξ
n
i i
i
n
i i
in
i
i
xx
nL
xx
xL
Sendo que Singh e Guo (1995) mostraram que o log da função de
verossimilhança é viesado em relação ao parâmetro de localização μ, dessa forma não
é possível encontrar o estimador de máxima verossimilhança para o parâmetro de
localização. Para tanto será escolhido o menor valor da amostra para estimar o
parâmetro de localização.

30
3.2 Método da Máxima Verossimilhança Penalizada (MPLE)
Apesar do método da máxima verossimilhança ser um dos mais eficientes, ele
apresenta sérios problemas em relação às especificidades dos modelos de sismos,
uma vez que a severidade apresenta eventos extremos. Assim, existe um maior
interesse na cauda da distribuição subjacente, sendo que o método da máxima
verossimilhança pondera cada valor da distribuição igualmente, por outro lado esse
efeito da ponderação igualitária é resolvido por intermédio do método da máxima
verossimilhança penalizada.
Coles e Dixon (1999), sugerem para o estimador de máxima verossimilhança
penalizada usar a seguinte a função:
1)( =xf se 0≤ix
=⎟⎟
⎠
⎞
⎜⎜
⎝
⎛⎥⎦
⎤⎢⎣
⎡−
−−
λ
α 11
1exp
ix, se 10 ≤≤ ix
= 0 se 1≥ix ,
onde α e λ , são as constantes penalizadas. Coles e Dixon (1999) sugerem ainda
que 1== λα .
3.3 Método dos Momentos (MOM)
As características das distribuições de probabilidades podem ser sumarizadas
pelos momentos populacionais. O momento de primeira ordem, em relação à origem
dos X, representa a média populacional ( )μ , e o momento central de ordem r=2 é, por
definição, a variância ( )2σ de X. As quantidades que podem ser deduzidas do
momento central de ordem 2 são o desvio-padrão ( )σ e o coeficiente de variação
(CV). Para r>2, é usual descrever as características da função de distribuição através
das razões adimensionais rμ e 2
2
r−
μ , das quais se destacam os coeficientes de
assimetria ( sC ) e de curtose (k), dados por:
2
3
23
−
= μμsC e 224−= μμk .
Os momentos amostrais são estimados por quantidades similares, calculadas a
partir dos dados de uma amostra de tamanho n. Por exemplo, o estimador natural de
μ é a média aritmética ou o momento amostral de primeira ordem em relação à

31
origem, n
xn
ii∑
= =1-
x , os momentos amostrais (m) de ordem (r) superior são estimadores
viesados dos momentos populacionais de mesma ordem, entretanto podem ser
corrigidos para produzir estimadores sem viés, por exemplo, para variância e
assimetria, respectivamente:
( )( ) 3
32
22
21 ,
1
s
m
nn
nCm
n
nS s
−−=
−=
Portanto, de acordo com Hosking e Wallis (1987) os estimadores da
distribuição generalizada de Pareto pelo método dos momentos (MOM), são:
( ) ( )( )[ ]( )( )
( )ξ
ξξ
ξ
σ
ξ
σμ
31
112 ,
2121 ,
1 2
22
+
−−=
++=
++=
−
sCSx
onde 2, Sx−
e sC , são a media a variância e a assimetria, respectivamente
3.4 Método de Pickands (Pickands)
Os métodos de estimação do parâmetro de forma da distribuição generalizada
de Pareto têm encontrados alguns problemas no que tange ao viés e a variância, com
o intuito de amenizar esses problemas, Pickands (1975) propôs um estimador
baseado em estatísticas robustas para o parâmetro de forma da GPD como pode ser
visto a seguir:
Seja nnn XX ,,1 ,......, , estatísticas de ordem para uma amostra independente de
tamanho n e função de distribuição da GPD. O estimador de Pickands é:
⎟⎟⎠
⎞⎜⎜⎝
⎛
−
−=
+−+−
+−+−
nknnkn
nknnkn
XX
XX
,14,12
,12,1log2log
1ξ , para
4,......,1
nk =
onde Dekkers e Haan (1989), verificaram a consistência e a normalidade assintótica
do estimador.
3.5 Método do Momento Ponderado pelas Probabilidades: viesado e
não-viesado (PWMB, PWMU)
Conforme Hosking e Wallis (1987), o estimador (PWMB), possui parâmetros
especiais de forma e escala, esses parâmetros são chamados de “Diagrama de
Posição”. Os mesmos recomendam que o parâmetro de forma inicialmente seja de
0,35, enquanto o de posição assuma o valor zero. Posteriormente, pode ser testado
diferentes valores.

32
Para o PWMB, PWMU aproximados, Dupuis e Tsao (1998), propõem a
utilização de estimadores híbridos, uma vez que o mesmo evita o fato de não possuir
pontos viáveis.
3.6 Divergência Média da Densidade (MDPD)
A estimação do parâmetro da distribuição generalizada de Pareto pelo MDPD
foi proposta por Júarez e Schucany (2004), onde os mesmos recomendam para o
parâmetro de forma da distribuição generalizada de Pareto (GPD) o valor de 0,1,
nesse mesmo trabalho são recomendados valores pequenos para o parâmetro de
forma. Para um α>0 o estimador para a GPD é o valor ⎟⎠⎞
⎜⎝⎛ ^^
, αα σξ , que minimizam a
equação abaixo:
( )
αξ
αααα
ξσαξαασ
σξ)1(
1
1
1111
11
1),(
−
=
−
⎟⎠⎞
⎜⎝⎛
−⎟⎠⎞
⎜⎝⎛
+−−+
= ∑ in
i
X
nH ,
sobre
( ) { }⎭⎬⎫
⎩⎨⎧ +
<<<<−∞<>Θ∈≤≤ α
αξξσξσσξ
10,,0,max,0:,
1eX i
ni
A restrição { } σξ <≤≤
ini
X1max , deve-se à dependência do suporte dos parâmetros. A
restrição α
αξ
+<
1 é necessária para as condições de regularidades da integral da
GPD.
3.7 Método da Mediana (MED)
Welsh e Peng (2001), no artigo “Robust Estimation of the Generalized Pareto
Distribution”, utiliza o mesmo princípio que He e Fung (1999), quando eles propuseram
o método da mediana para a distribuição de Weibull com dois parâmetros, sendo os
mesmos da seguinte forma:
)(12 iXMediana
−=
ξ
ξσ ,
onde iX , são os valores observados da variável aleatória.
( )( )ξ
ξσξ
ξ
ξ
σ
ξ
ZX
X
X
Medianai
i
i
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
+
+−
⎟⎠
⎞⎜⎝
⎛+
22
11log

33
( ) ( ) 2
11
1log,10
2
=∫⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
>−+
−−<< ξξ
ξ
ξξ zy
yy
dy .
3.8 Método da Melhor Qualidade do Ajuste (MGF)
Para o estimador MGF, Luceño (2005), propõem o seguinte algoritmo para
estimar os parâmetros de forma e escala, ξ e σ da distribuição generalizada de
Pareto. São os seguintes passos no delineamento do pseudo-algoritmo:
(1) Calcule
∑ ⎥⎦
⎤⎢⎣
⎡−
−−=
),......,max(1ln
1
1
1
~
n
i
xx
x
nξ
e
2
1
2
2
1−
=∑
−=
x
n
x
z
n
ii
;
(2) se 75,0~
<ξ e Z<0,2, calcule os MLEs padronizados para ξ e σ ;
(3) caso contrário estime ξ usando a equação do ~
ξ e ),,.........max( 21
~~
xxξσ = .
Segundo Luceño (2005), a justificativa para esse procedimento é que quando
ξ é grande, a amplitude da GPD é ξ
σ≤≤ x0 e o método da máxima verossimilhança
falha. Portanto para ξ uma alternativa é utilizar ),......,max( 1~
~
nxx=
ξ
σ.
3.9 Método da Máxima Entropia (POME)
Shannon (1948) definiu entropia como uma medida numérica de incerteza, ou
reciprocamente o conteúdo de informação associou com uma distribuição de
probabilidade, );( θxf , sendo θ o vetor de parâmetros, utilizado para descrever uma

34
variável aleatória X. A função de entropia de Shanoon ( )H f para X continua, é dada
da seguinte forma:
∫∞
∞−
−= dxxfxffH );(ln);()( θθ com 1);( =∫∞
∞−
dxxf θ , (3)
onde ( )H f é a entropia para );( θxf que pode ser vista como o valor médio de
);(ln θxf− .
De acordo com Jaynes (1961), o viés mínimo da distribuição de X é o que
maximiza a entropia sujeita a determinada informação ou que satisfaça o princípio da
máxima entropia (POME). Portanto os parâmetros da distribuição podem ser obtidos
alcançado o máximo de ( )H f . O uso deste princípio pode gerar as distribuições de
probabilidade menos viesadas em base de dados limitadas e incompletas discutidas
por vários autores e pode ser aplicada a problemas diversos, por exemplo, Singh e
Fiorentino (1992). Jaynes (1968) argumentou que o POME é o critério lógico e racional
para escolher uma função especifica );( θxf , que maximiza ( )H f e satisfazendo a
determinada informação que expressa como restrição. Em outras palavras, para
determinar a informação, por exemplo, média, variância, assimetria, limite superior,
limite inferior, entre outras, a distribuição derivada pelo princípio da máxima entropia é
a que representa melhor a variável aleatória X; implicitamente, esta distribuição
representa melhor a amostra da qual a informação foi retirada.
Inversamente, se era desejado ajustar uma distribuição de probabilidade
especifica a uma amostra de dados, então o POME pode especificar as restrições
exclusivamente (ou a informação) precisando derivar daquela informação. Os
parâmetros da distribuição são relacionados com essas restrições. Uma discussão
excelente da razão matemática é determinada por Levine e Tribus (1979).
Determinando m restrições linearmente independentes , 1, 2........,iC i m= da
seguinte forma:
∫= dxxfxwC ii );()( θ , mi ,.......,2,1= , (4)
onde iw são algumas funções cuja média é calculada em cima de );( θxf são
especificadas, então o máximo de ( )H f sujeito a equação (4) é determinada pela
distribuição:
⎥⎦
⎤⎢⎣
⎡−−= ∑
=
m
iii xwaaxf
10 )();( θ , (5)

35
sendo , 0,1, 2,....,ia i m= os multiplicadores de lagrange, que são determinados pela
equação (4) e (5). Inserindo a equação (5) na equação (3) gera-se a entropia de
);( θxf , em termos das restrições e multiplicadores de Lagrange.
∑=
+=m
iiiCaafH
10)( , (6)
A maximização de ( )H f estabelece o relacionamento entre as restrições e os
multiplicadores de Lagrange. Dessa forma para estimar os parâmetros da GPD, pelo
princípio da máxima entropia (POME), devem-se:
I. Especificar as constantes apropriadas;
II. Derivar a função de distribuição da entropia;
III. Derivar em relação entre os multiplicadores de Lagrange e as
restrições.
Para uma formalização maior deste método veja Tribus (1969), Jaynes (1968), Levine
e Tribus (1979) e Sing e Rajagopol (1986)
3.9.1 Especificação das Restrições
A entropia para a distribuição generalizada de Pareto pode ser obtida inserindo
a equação (6) na equação (13), obtendo:
( )dxxf
xdxxffH );(11
1);(ln)( θ
σ
μξ
ξθ
μμ∫∫∞∞
⎥⎦⎤
⎢⎣⎡ −
−⎥⎦
⎤⎢⎣
⎡−+= . (7)
Comparando a equação (7) com a equação (6), as restrições adequadas para a
equação 1, podem ser escritas conforme Singh & Rajagopal, (1986), como:
∫∞
=μ
θ 1);( dxxf , (8) e ( ) ( )
∫∞
⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−=⎥⎦⎤
⎢⎣⎡ −
−μ σ
μξσ
σ
μξ xExf
x1ln);(1ln . (9)
Essas restrições são únicas e especificam as informações suficientes para a
distribuição generalizada de Pareto (GPD). A primeira restrição especifica a
probabilidade total. A segunda restrição especifica a média do logaritmo da razão
inversa do parâmetro de escala para a de taxa de fracasso. Conceitualmente, isto
define o valor esperado negativo da taxa de fracasso do parâmetro de escala. Os
parâmetros da distribuição são relacionados com estas restrições.
3.9.2 Construção da Função de Entropia
A função de distribuição de probabilidade da GPD correspondente ao princípio
da máxima entropia (POME) e consistente com as equações (8) e (9), possui a
seguinte forma:

36
( )⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−−−=σ
μξθ
xaaxf 1lnexp);( 10 , (10)
onde: 0a e 1a são os multiplicadores de Lagrange. A justificativa matemática para a
equação (10) foi apresentada por Tribus (1969). Aplicando a equação da Distribuição
de Valores Extremos com a restrição da probabilidade total, obtemos:
( )dx
xaa ∫
∞
⎟⎟⎠
⎞⎜⎜⎝
⎛⎥⎦⎤
⎢⎣⎡ −
−−=μ σ
μξ1lnexp)exp( 10 , (11)
que retorna a função de partição:
10 1
1)exp(
aa
−=
ξ
σ. (12)
O zero do multiplicador de Lagrange é dado por:
⎟⎟⎠
⎞⎜⎜⎝
⎛−
=1
0 1
1ln
aa
ξ
σ (13)
inserindo a equação (12) na equação (10), obtemos:
( ) ( ) 1
1);(a
xxxf
−
⎟⎠⎞
⎜⎝⎛ −
−−
=σ
μξ
σ
μξθ . (14)
Comparando a equação (14) com a equação (6), obtem-se:
ξ
11 1 =− a . (15)
Tomando o logaritmo da equação (14), tem-se:
( ) ( )⎥⎦⎤
⎢⎣⎡ −
−−−−+=σ
μξσξθ
xaaxf 1lnln1lnln);(ln 11 (16)
Dessa forma, a entropia ( )H f da GPD é:
( ) ( ) ( )⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−++−−−=σ
μξσξ
xEaafH 1lnln1lnln 11 (17)
3.9.3 Relação Entre os Parâmetros da GPD e as Restrições
De acordo com Singh e Rajagopol (1986), a relação entre os parâmetros da
GPD e as restrições é obtida através das derivadas parciais da entropia ( )H f em
relação aos multiplicadores de Lagrange, bem como a distribuição dos parâmetros e,
em seguida, igualar a as derivadas a zero, e utilizar as restrições. Por fim utilizar as

37
derivadas parciais da equação (17), em relação à 1a , ξ , σ e μ separadamente e
igualando as derivadas de cada equação em relação à zero, temos:
( )01
1
1
11
=⎥⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−+−
=∂
∂
σ
μξ xE
aa
H (18)
( )
( )0
1
11 =
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
−
−−=∂
∂
σ
μξσ
μξ
ξξ x
x
EaH
(19)
( )
( ) 01
11 =
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
−
−+=∂
∂
σ
μξσ
μξ
σσ x
x
EaH (20)
( )0
1
111 =
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
−+=∂
∂
σ
μξσμ xEa
H. (21)
Simplificando as equações (18) em relação a (21), temos, respectivamente:
( )
11
11
a
xE
−−=⎥
⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−σ
μξ (22)
( )
( )1
1
1 ax
x
Eξ
σ
μξσ
μξ
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
−
(23)
( )
( )1
1
1 ax
x
Eξ
σ
μξσ
μξ
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
−
(24)
( )0
1
1=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜
⎝
⎛
−−
σ
μξ xE (25)
Observa-se que a equação (25) não tem solução viável. As equações (23) e
(24) são as mesmas. Para se obter uma solução única, será preciso adicionar
equações, que serão obtidas através da diferenciação dos multiplicadores de lagrange
e igualando a zero. Para finalizar em termos da equação (11), será escrita como:

38
( )dx
xaa
⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−−= ∫∞
σ
μξ
μ
1lnexpln 10 , (26)
Diferenciando-se a equação (26), em relação à 1a , tem-se:
( ) ( )
( )dx
xa
dxxx
a
a
a
⎥⎦
⎤⎢⎣
⎡
⎭⎬⎫
⎩⎨⎧ −
−−
⎥⎦⎤
⎢⎣⎡ −
−⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−−
−=∂
∂
∫
∫∞
∞
σ
μξ
σ
μξ
σ
μξ
μ
μ
1lnexp
1ln1lnexp
0
1
1
0
( ) ( )dx
xxaa
a
a⎥⎦⎤
⎢⎣⎡ −
−⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−−−−=∂
∂∫∞
σ
μξ
σ
μξ
μ
1ln1lnexp 101
0
( )⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−−=∂
∂
σ
μξ xE
a
a1
1
0 . (27)
De acordo com Tribus (1969):
( )⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−=∂
∂
σ
μξ x
a
a1lnvar
21
02
(28)
onde var [.] representa a variância da quantidade entre chaves. Da equação (12),
temos:
( )10 1lnln aa −−⎟⎟⎠
⎞⎜⎜⎝
⎛=
ξ
σ (29)
diferenciando a equação (39) em relação à 1a , tem-se:
11
0
1
1
aa
a
−=
∂
∂ (30)
( )211
20
2
1
1
aa
a
−=
∂
∂ (31)
comparando a equação (40), com a equação, com a equação (37), obtem-se:
( )( )2
11
11ln
a
xE
−−=
⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−σ
μξ (32)
Que por sua vez é igual à equação (32). Comparando a equação (41) com a
equação (37), tem-se:
( )( )2
11
11lnvar
a
x
−−=
⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−σ
μξ (33)
Portanto, a equação de estimação dos parâmetros da distribuição generalizada
de Pareto pelo princípio da máxima entropia consiste das equações (22), (23) e (33).

39
Da equação (15), nota-se que ξ
111 −=a , substituindo esse valor nas equações (22),
(23) e (33), tem-se:
( )ξ
σ
μξ−=
⎭⎬⎫
⎩⎨⎧
⎥⎦⎤
⎢⎣⎡ −
−x
E 1ln
( ) ξσ
μξ −−=
⎪⎪⎭
⎪⎪⎬
⎫
⎪⎪⎩
⎪⎪⎨
⎧
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−
1
1
1
1ln
xE
( ) 21lnvar ξσ
μξ=⎥
⎦
⎤⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
−x
.
Nesse capítulo foi estudada a forma analítica dos métodos de estimação dos
parâmetros da GPD, em relação ao estimador de máxima verossimilhança verificamos
que o mesmo não possui solução analítica, devendo ser utilizados soluções
numéricas para encontrá-los.
O estimador de máxima entropia foi desenvolvido de forma integral, partindo
desde a construção da função de entropia da GPD até encontrar a forma analítica dos
mesmos, uma vez que esse método tem-se mostrado bastante eficiente para estimar
os parâmetros da GPD.
O capítulo 4 vem da necessidade de como em qualquer análise estatística
verificar a qualidade do ajuste dos dados, por essa razão no capítulo seguinte serão
abordados dois métodos para diagnosticar o ajuste do modelo aos dados. Um será
através de métodos gráficos e o outro para testar realmente o ajuste, o qual será feito
através do teste Anderson-Darling.

40
CAPÍTULO 4: DIAGNÓSTICO DE ADEQUAÇÃO DO MODELO
Na prática, em geral, dispõe-se de dados de uma variável aleatória cuja
distribuição da população é desconhecida. Assim, é necessário, identificar a
distribuição de probabilidade com melhor aderência aos resultados experimentais. Em
algumas situações, é possível utilizar informações de outras variáveis que descrevem
fenômenos aleatórios similares. Dessa maneira, seria estimada uma possível
distribuição de probabilidade, então o problema seria estabelecer um critério de
aceitação ou rejeição do modelo. Por outro lado, em muitos casos não se tem idéia da
distribuição da variável. Quando isso acontece os métodos gráficos, podem ser
utilizados para ver se a distribuição de probabilidade se adere aos dados, conforme
descrito a seguir.
Coles (2001), os excessos do limiar u, )()1( .... kxx ≤≤ e um modelo estimado
^
H , o gráfico de probabilidades consiste dos pontos:
⎭⎬⎫
⎩⎨⎧
=⎟⎠⎞
⎜⎝⎛
+kixG
k
ii ,....,1,)(,
1 )(
^
Onde )(^
xG é dado de acordo com a equação (2).
O gráfico dos quantis, de acordo com Coles (2001), quando 0^
≠ξ é constituído
do conjunto de pontos:
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
=⎟⎟⎠
⎞⎜⎜⎝
⎛⎟⎠⎞
⎜⎝⎛
+
−
kixk
iG i ,....,1,,
1 )(
1^
, onde
⎟⎠⎞
⎜⎝⎛ −−+= −
−
1)(^
^
^1^
ξ
ξ
σuxuG
Coles (2001) afirma, ainda, que se o modelo estimado for razoável para os
excessos de u, tanto o gráfico de probabilidades normal como os de quantis devem
ser aproximadamente lineares.
O nível de retorno, conforme Coles (2001) consiste do conjunto de pontos
⎭⎬⎫
⎩⎨⎧
⎟⎠⎞
⎜⎝⎛
mzm^
, para valores grande de m, onde mx^
são estimativas de m-observaçoes do
nível de retorno:

41
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡−⎟
⎠⎞
⎜⎝⎛
+= 1
^
^
^
^^ ξ
ςξ
σum muz
A escala utilizada é logarítmica, por tanto é de fundamental importância testar o
ajuste do modelo, uma vez que a estimação errada do parâmetro de forma pode levar
a previsão bastante distorcida da realidade.
4.1 Teste de Adequação do Modelo
Os métodos gráficos descrito acima dão apenas um diagnóstico do ajuste
do modelo, para confirmar a aderência dos dados é necessário testar realmente o
ajuste, onde alguns testes de hipóteses não paramétricos podem ser utilizados
para esse fim, uma vez que. Estes consideram a forma da distribuição da
população em lugar dos parâmetros por esse motivo são chamados de testes não
paramétricos, sendo que no caso de extremos, a idéia e pegar um teste que não
seja sensível as caudas, como é o caso do teste de Anderson-Darling.
O teste de Anderson-Darling é um dos testes estatísticos mais poderosos
para detectar a aderência dos dados às distribuições caudais. É uma generalização do
teste de Klmogorov-Smirnov (KS), porém dando mais peso às caudas. Ele é também
uma alternativa ao teste Qui-Quadrado. Pode ser usado com tamanhos de amostra
pequenos 25≤n .
O teste avalia, em geral, se a amostra vem de uma distribuição qualquer
especificada. A fórmula para o teste estatístico A para avaliar se os dados ( )nYY ,....,1 ,
ordenados vêm de uma distribuição com função de distribuição F, é dado por:
SnA −−=2 , onde
( )( )[ ]∑ −+−+−
= knk YFYFn
kS 11ln)(ln
12
O teste estatístico pode então ser comparado contra os valores críticos da
distribuição teórica (dependendo de qual função de distribuição Fx é usada) para
determinar o valor-p.
Por fim, depois de escolhido o método de estimação do máximo, onde
presente estudo será através da escolha de um limiar u, portanto a modelagem
será via GPD. Feito isso a idéia seguinte é escolher o limiar de acordo com os
métodos sugeridos no capítulo 2 e em seguida estimar os parâmetros da
distribuição generalizada de Pareto, pelos métodos vistos no capítulo 3, feito isso o

42
passo final será verificar a aderência dos dados a GPD, onde será feito um
diagnóstico gráfico como descrito nesse capítulo e por último testado à aderência
através do teste de Anderson Darling, que com foi descrito é o mais adequado
para testar as caudas.
No capítulo 5 será feito o estudo de caso no município de João Câmara, NE
do Brasil, onde em 1986 foi registrado o maior sismo já catalogado no país. Os
dados utilizados para esse estudo foram os sismos registrados de maneira
continua por um sismógrafo eletrônico no período de 1987 a 1988. Pelo
comportamento dos sismos, o modelo que aparece como candidato natural é o da
GPD, por que a idéia e escolher um sismo e em seguida analisar todos aqueles
acima dele. Dessa forma a idéia e escolher o limiar utilizando a técnica gráfica
vista no capítulo 2, na secção relacionada à escolha do limiar e em seguida serão
estimados os parâmetros da GPD, de acordo com os métodos estudados no
capítulo 3 e comparados através do erro padrão, com o objetivo de identificar os
métodos mais eficientes e por ultimo iremos verificar a aderência dos dados, sendo
feito um diagnóstico de ajuste através de métodos gráficos e em seguida testada a
aderência através do teste de Anderson Darling, pois como foi descrito nesse
capítulo é o teste mais adequado para medir o ajuste das caudas.

43
CAPÍTULO 5: ESTUDO DE CASO: JOÃO CÂMARA – RN
O município de João Câmara localizado no estado do Rio Grande do Norte,
nordeste do Brasil, possui uma área 714,95 km2 e uma população de 30.423
habitantes segundo o IBGE (2007), sendo um dos municípios com maior atividade
sísmica no país. A Figura 6 mostra as coordenadas geográficas do município, a
legenda usada para a localidade pelo Instituto Brasileiro de Geográfica e Estatística é
JoCra.
Figura 6: Localização do município de João Câmara – RN, Brasil.
5.1 Caracterização do Município e o Sismo Histórico
O município de João Câmara esta situado na mesorregião Agreste Potiguar e
na microrregião Baixa Verde, limitando-se com os municípios de Parazinho, Touros,
Pureza, Poço Branco, Bento Fernandes, Jardim de Angicos, Jandaíra e Pedra Preta,
abrangendo uma área de 714,95 km2, inseridos nas folhas Pureza (SB.25-V-C-I) e
João Câmara (SB.25-V-C-IV), na escala de 1:100.000, editadas pela SUDENE. A sede
do Município tem uma altitude de 160m e apresenta coordenadas de 05º32’16,8’’ de
latitude sul e 35º49’12,6’’ de longitude oeste, distando da capital cerca de 86 km,
sendo seu acesso a partir de Natal, efetuado através da rodovia pavimentada BR-406.
“O Nordeste brasileiro é a região onde ocorrem atividades sísmicas com maior
freqüência. O registro desse tipo de fenômeno é conhecido, com segurança, desde
1724 (Salvador - BA). Há 200 anos, no dia 8 de agosto de 1808 ocorreu o tremor de

44
Açu, de magnitude estimada em 4.8, sentido no Rio Grande do Norte, Ceará, Piauí e
Pernambuco. Desde então vários tremores ocorreram na região, geralmente na forma
de enxames em que a atividade se prolonga por até 10 anos, causando muitas vezes
danos em edificações, além de pânico e fuga da população como aconteceu em João
Câmara (RN - 1950, 1986 e 1991), Caruaru (PE - 1967) e em Doutor Severiano/Pereiro
(RN - 1968). Até o presente ocorreram três eventos de magnitude maior ou igual a 5.0
no Nordeste, todos causando grandes danos em edificações na área epicentral, com
colapso de paredes: em Cascavel (CE), com magnitude 5.2 em 1980; e João Câmara
(RN) por duas vezes, em 1986 (5.1) e em 1991 (5.0). Segundo Joaquim Mendes
Ferreira, coordenador do Laboratório Sismológico da UFRN, que faz parte do recém-
criado Departamento de Geofísica, o estudo da atividade sísmica se faz necessário para
o planejamento do desenvolvimento da região, pois, através dele é possível avaliar com
precisão o risco sísmico. Em julho de 1986 tem início a mais espetacular atividade
sísmica ocorrida no Brasil, em João Câmara (RN), onde foram registrados entre 1986 e
1993 mais de 50 mil tremores, em sua maioria microtremores. Neste período, foram
registrados dois tremores de magnitude igual ou superior a 5.0 e mais de 20 tremores
de magnitude igual ou superior a 4.0, que causaram danos extensos a muitas
edificações e pânico na população. Pesquisadores do país e do exterior acorreram ao
local e, após o maior tremor, ocorrido em 30 de novembro de 1986, de magnitude 5.1,
até o presidente da República na época, José Sarney, esteve lá.”
Fonte: http://www.sbgf.org.br/publicacoes/boletins/boletim5_2008.pdf
Danos significativos ocorreram tanto na área urbana como na rural fazendo
com que grande parte da população abandonasse a cidade, bem como a presença do
presidente da Republica na época. A Figura 7 ilustra a ação dos bombeiros no
município depois da ocorrência do sismo histórico.
Figura 7: Atuação dos bombeiros na área urbana de João Câmara, ocasionado pelo
tremor de 30/11/86.

45
O sismo causou danos em muitas construções na área urbana da cidade, pois
na época as construções de uma maneira geral não estavam preparadas para esse
tipo de fenômeno, como pode ser visto na Figura 8.
Figura 8: Danos na área urbana de João Câmara, ocasionado pelo tremor de
30/11/86.
Na área rural os efeitos foram ainda mais fortes, como pode ser visto na Figura
9, pois as casas da área rural eram construídas de forma muito precária.
Figura 9: Efeitos na zona rural do maior sismo ocorrido em João Câmara.
O efeito do sismo causa grande repercussão nacional, tanto que na época até
o presidente da república José Sarney e alguns de seus ministros visitaram a
localidade, como pode ser visto na Figura 10.
Ações da Secretaria de Defesa Civil, além de entidades estaduais e federais,
ajudaram a minimizar os problemas dos habitantes locais. Os sismos destruíram ou
danificaram 4.000 casas e 500 delas foram reconstruídas adotando certas normas
anti-sísmicas, desenvolvidas pelo Batalhão de Engenharia do Exército. Os grupos de
sismologia da UnB, USP e da UFRN desdobraram esforços para documentar, estudar
e mesmo orientar as autoridades diante da constância dos abalos sísmicos.

46
Figura 10: Chefe da defesa civil presta esclarecimentos ao Presidente da República
sobre a atividade sísmica de João Câmara.
5.2 Análise dos Dados
A análise dos dados foi feita no programa R, versão 2.6, através do pacote
POT, com exceção do método da máxima entropia, todos os outros estão
implementados nesse pacote e para implementar o POME foi utilizada a função optim,
para poder encontrar as estimativas desse método.
Foram catalogados 2733 sismos forma continua no período de 23/05/1987 a
07/07/1988, o modelo utilizado foi o POT, pois a idéia era observar os sismos acima
de um limiar, portanto a modelagem do sismo máximo foi feito através da distribuição
generalizada de Pareto. Inicialmente selecionou-se o limiar, para essa seleção foi
utilizada a técnica gráfica baseada na linearidade da função média dos excessos
empíricos descrita no Capítulo 2 (sessão 2.3.1). Esse método auxilia na determinação
do limiar u alto o suficiente para a aproximação da distribuição dos excessos por uma
GPD seja justificada. Dessa forma, iremos escolher u tal que a partir dele os excessos
é aproximadamente linear para ux ≥ . Além disso, foi feito também o gráfico de
dispersão para que fosse verificada a dispersão dos dados em relação ao limiar
escolhido. As Figuras 11 e 12 ilustram os procedimentos clássicos adotados para a
seleção do limiar e a inspeção visual do processo pontual.
Analisando a Figura 11 percebemos que fazer a escolha adequada do limiar
por esse procedimento não é tarefa fácil. No entanto, pela Figura 11 podemos verificar
que a linearidade começa um pouco antes de 1,5º. Por isso, para os dados dessa
tomada, escolhemos u=1,4º. Na Figura 12 vemos que a escolha do limiar segue as
recomendações de Coles (2001), uma vez que o limiar não é muito baixo, de forma
que venha a afetar o comportamento assintótico, e nem muito alto de forma que
fiquem poucos máximo para a análise.

47
Figura 11: Representação gráfica da vida média residual da variável aleatória sismos
no município de Câmara – uma ferramenta para a seleção do limiar de valores
extremos.
Figura 12: Representação gráfica da dispersão temporal dos sismos no município de
Câmara. A linha vermelha representao limiar selecionado.
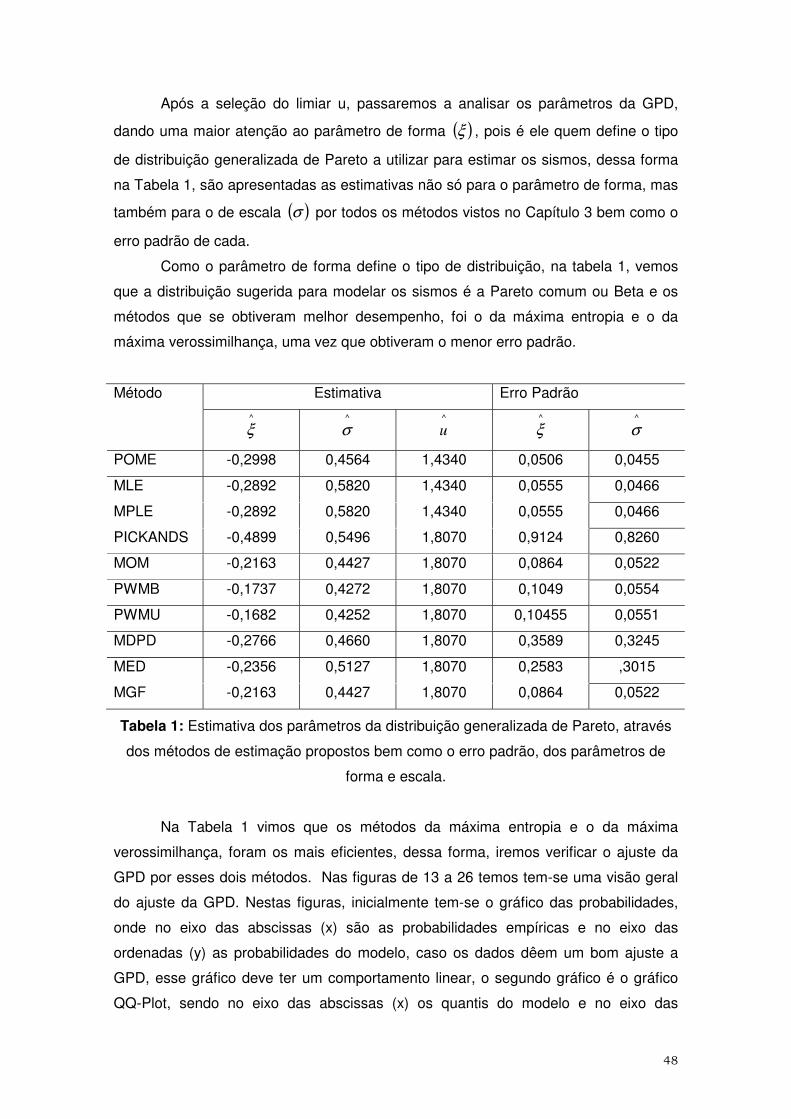
48
Após a seleção do limiar u, passaremos a analisar os parâmetros da GPD,
dando uma maior atenção ao parâmetro de forma ( )ξ , pois é ele quem define o tipo
de distribuição generalizada de Pareto a utilizar para estimar os sismos, dessa forma
na Tabela 1, são apresentadas as estimativas não só para o parâmetro de forma, mas
também para o de escala ( )σ por todos os métodos vistos no Capítulo 3 bem como o
erro padrão de cada.
Como o parâmetro de forma define o tipo de distribuição, na tabela 1, vemos
que a distribuição sugerida para modelar os sismos é a Pareto comum ou Beta e os
métodos que se obtiveram melhor desempenho, foi o da máxima entropia e o da
máxima verossimilhança, uma vez que obtiveram o menor erro padrão.
Estimativa Erro Padrão Método
^
ξ^
σ^
u^
ξ^
σ
POME -0,2998 0,4564 1,4340 0,0506 0,0455
MLE -0,2892 0,5820 1,4340 0,0555 0,0466
MPLE -0,2892 0,5820 1,4340 0,0555 0,0466
PICKANDS -0,4899 0,5496 1,8070 0,9124 0,8260
MOM -0,2163 0,4427 1,8070 0,0864 0,0522
PWMB -0,1737 0,4272 1,8070 0,1049 0,0554
PWMU -0,1682 0,4252 1,8070 0,10455 0,0551
MDPD -0,2766 0,4660 1,8070 0,3589 0,3245
MED -0,2356 0,5127 1,8070 0,2583 ,3015
MGF -0,2163 0,4427 1,8070 0,0864 0,0522
Tabela 1: Estimativa dos parâmetros da distribuição generalizada de Pareto, através
dos métodos de estimação propostos bem como o erro padrão, dos parâmetros de
forma e escala.
Na Tabela 1 vimos que os métodos da máxima entropia e o da máxima
verossimilhança, foram os mais eficientes, dessa forma, iremos verificar o ajuste da
GPD por esses dois métodos. Nas figuras de 13 a 26 temos tem-se uma visão geral
do ajuste da GPD. Nestas figuras, inicialmente tem-se o gráfico das probabilidades,
onde no eixo das abscissas (x) são as probabilidades empíricas e no eixo das
ordenadas (y) as probabilidades do modelo, caso os dados dêem um bom ajuste a
GPD, esse gráfico deve ter um comportamento linear, o segundo gráfico é o gráfico
QQ-Plot, sendo no eixo das abscissas (x) os quantis do modelo e no eixo das

49
ordenadas (y) os quantis empíricos, a análise é similar a do gráfico de probabilidades,
se os dados tiverem um bom a juste a GPD, espera-se que esse gráfico tambem seja
linear. O terceiro gráfico é o que mede o ajuste entre a distribuição teórica e a
empírica, se os dados tiverem um bom ajuste espera-se que as duas curvas fiquem
bem próximas e por fim temos o gráfico que estima os vários níveis de retorno
associado aos períodos de retorno, esse gráfico ira permitir analisar o período de
retorno dos sismos associado ao nível de retorno dos mesmos. Portanto as Figuras 13
e 14 mostram essas análises para os métodos da máxima entropia e da máxima
verossimilhança respectivamente, sendo que esses diagnóstocos foram obtidos
também para todos os outros métodos estudados como pode ser visto no Apêndice C.
Figura 13: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método da Máxima Entropia( POME).
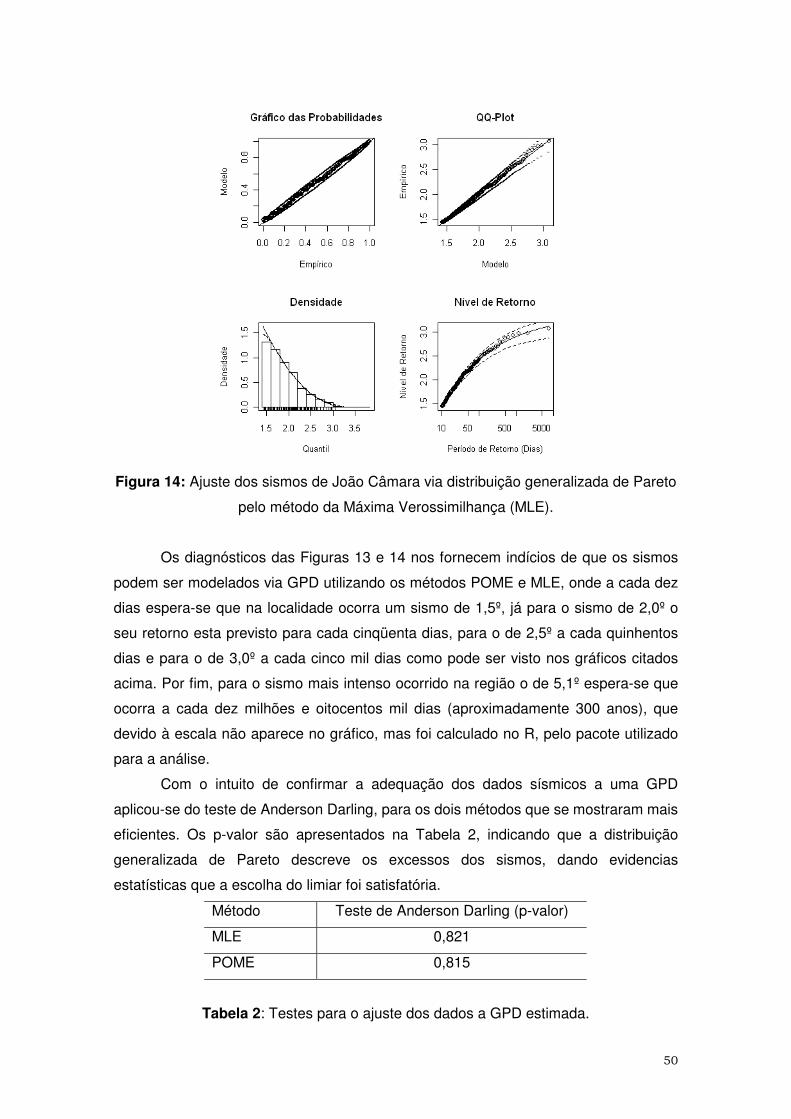
50
Figura 14: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método da Máxima Verossimilhança (MLE).
Os diagnósticos das Figuras 13 e 14 nos fornecem indícios de que os sismos
podem ser modelados via GPD utilizando os métodos POME e MLE, onde a cada dez
dias espera-se que na localidade ocorra um sismo de 1,5º, já para o sismo de 2,0º o
seu retorno esta previsto para cada cinqüenta dias, para o de 2,5º a cada quinhentos
dias e para o de 3,0º a cada cinco mil dias como pode ser visto nos gráficos citados
acima. Por fim, para o sismo mais intenso ocorrido na região o de 5,1º espera-se que
ocorra a cada dez milhões e oitocentos mil dias (aproximadamente 300 anos), que
devido à escala não aparece no gráfico, mas foi calculado no R, pelo pacote utilizado
para a análise.
Com o intuito de confirmar a adequação dos dados sísmicos a uma GPD
aplicou-se do teste de Anderson Darling, para os dois métodos que se mostraram mais
eficientes. Os p-valor são apresentados na Tabela 2, indicando que a distribuição
generalizada de Pareto descreve os excessos dos sismos, dando evidencias
estatísticas que a escolha do limiar foi satisfatória.
Método Teste de Anderson Darling (p-valor)
MLE 0,821
POME 0,815
Tabela 2: Testes para o ajuste dos dados a GPD estimada.

51
5.3 - Reconstrução de Extremos via Simulação Monte Carlo
Para estudar o desempenho dos métodos de estimação para períodos mais
longos (10,15 e 20 anos), foi feita uma reconstrução do sinal do sismo, utilizando
simulações de Monte Carlo, tato pelo MLE como pelo POME para os períodos citados,
como pode ser visto nos gráficos de 15 a 20, onde os mesmos dão indícios de um
bom ajuste para períodos futuros. Sendo que essa reconstrução deve seguir o
teorema de Nyquist-Shannon, onde o mesmo diz que para a reconstrução de um sinal
a freqüência deve ser o dobro do espectro. Como o sismo é um sinal, tomou-se
cuidado para verificar se o mesmo seguia esse procedimento, uma vez que o principio
de reamostragem em sinal consiste da conversão de um sinal em uma seqüência
numérica.
Figura 15: Reconstrução dos sismos no Município de João Câmara, pelo método da
Máxima Verossimilhança para um período de 10 anos.
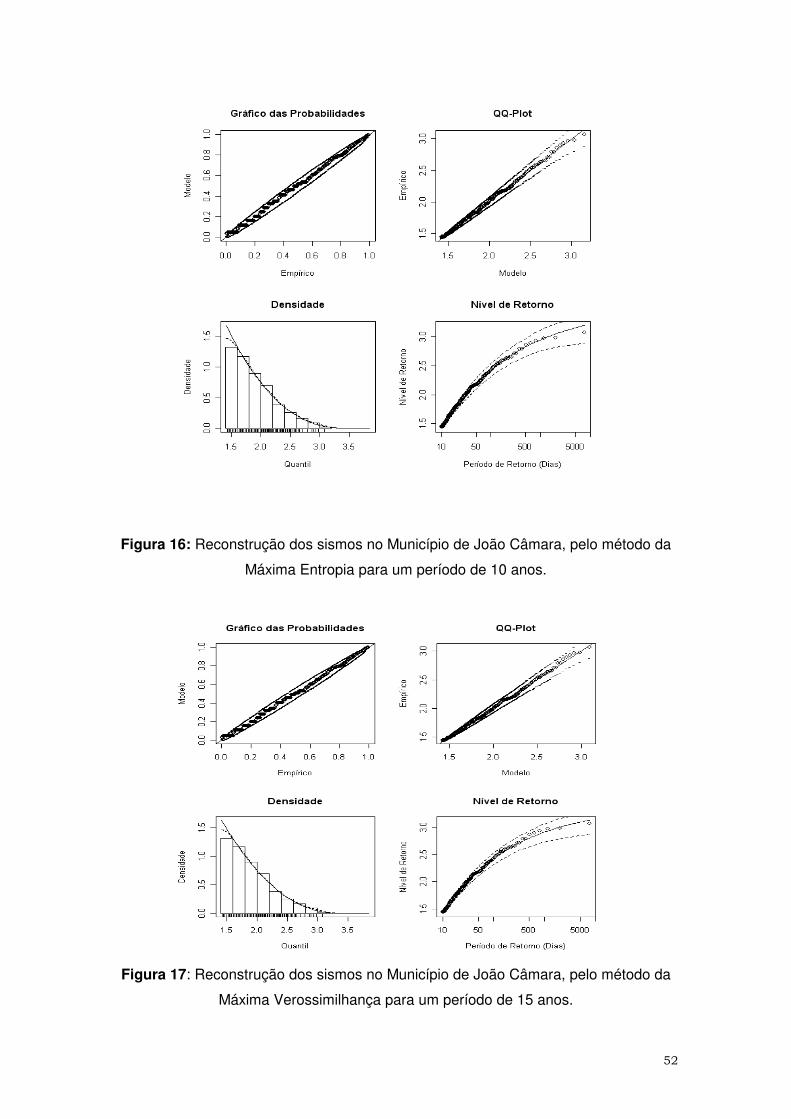
52
Figura 16: Reconstrução dos sismos no Município de João Câmara, pelo método da
Máxima Entropia para um período de 10 anos.
Figura 17: Reconstrução dos sismos no Município de João Câmara, pelo método da
Máxima Verossimilhança para um período de 15 anos.

53
Figura 18: Reconstrução dos sismos no Município de João Câmara, pelo método da
Máxima Entropia para um período de 15 anos.
Figura 19: Reconstrução dos sismo no Município de João Câmara, pelo método da
Máxima Verossimilhança para um período de 20 anos.
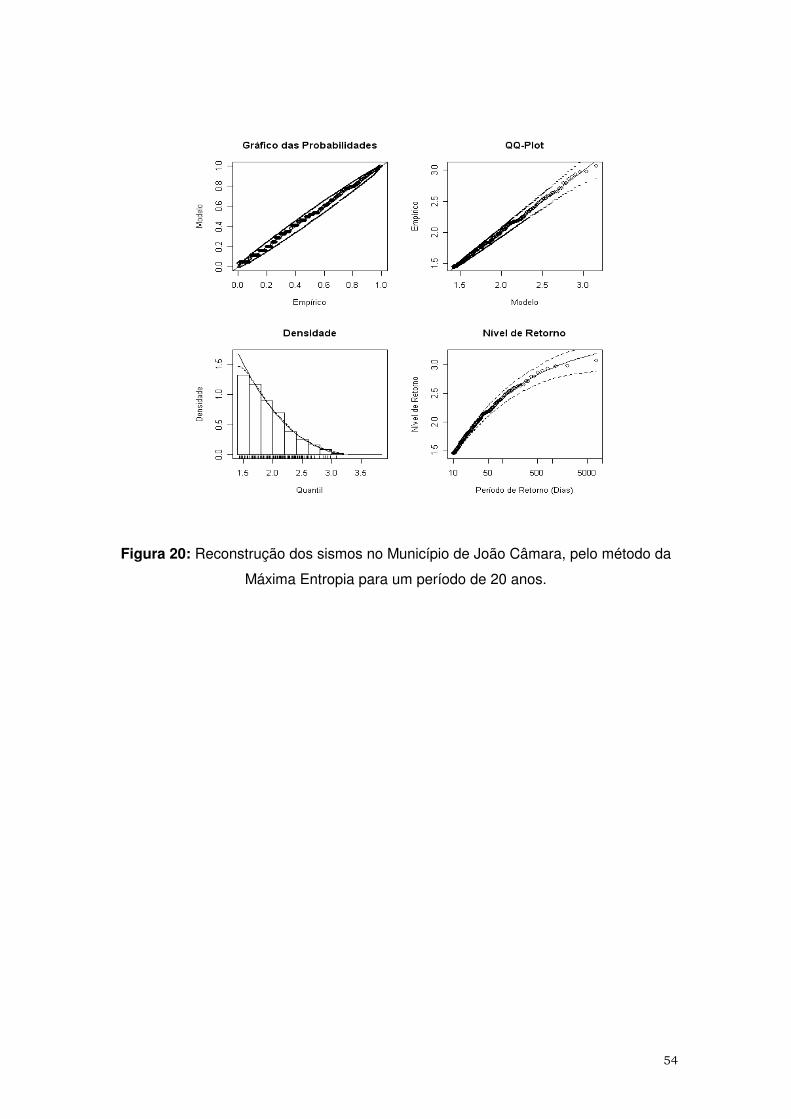
54
Figura 20: Reconstrução dos sismos no Município de João Câmara, pelo método da
Máxima Entropia para um período de 20 anos.

55
CAPÍTULO 6: CONSIDERAÇÕES FINAIS
A análise dos valores dos sismos medidos de forma continua no sismógrafo
digital no período de 23/05/1987 a 07/07/1988 no município de João Câmara - RN
através da distribuição generalizada de Pareto permitiu verificar que para a estimação
dos parâmetros, os métodos da máxima entropia e o da máxima verossimilhança são
os mais eficientes. Pelo fato do parâmetro de forma ser negativo, não só pelos
métodos mais eficientes, mas sim por todos os métodos em que os dados foram
analisados, a distribuição mais adequada para fazer previsões/predições é a
distribuição de Pareto comum ou Beta com um limiar estimado de 1,4º.
Com esse ajuste, verificou-se que o período de retorno estimado de
aproximadamente dez dias, prevê sismos de 1,5º, que não são sentidos pela
população, por outro lado um sismo de 2,5º que já é percebido pela população estima-
se que ocorra a cada 500 dias, já o sismo histórico aquele que esta no imaginário
popular ocorrido em novembro de 1986, é pouco provável, pois o seu nível de retorno
é para 300 anos.
Por tanto um dos pontos importantes concernentes aos eventos severos é
caracterizá-los e entender com profundidade a sua natureza, origem e conseqüências.
Este ponto é crucial para melhor previsibilidade e divulgação para usuários, seja em
termos de alertas ou informações diversas para os órgãos competentes de apoio bem
como para a população em geral.
A utilização da teoria de valores extremos e do procedimento
apresentado, especificamente para análise da ocorrência de sismos, apresenta
a vantagem adicional de se obter uma distribuição que melhor se ajusta aos
períodos de retorno, ou seja, previsões poderão ser feitas com mais segurança.
Os dados sísmicos são raros e de difícil obtenção, necessitando de um grande
esforço técnico para a sua realização e são fundamentais para a verificação das
metodologias de previsão, por essa razão um dos limitadores do trabalho são
justamente os dados, portanto ser faz necessária uma monitoração mais continua para
que a qualidade das previsões/predições sejam mais confiáveis
Desta forma, considerando a análise estatística realizada, as conclusões
obtidas e as limitações existentes, fica como sugestão para trabalhos futuros verificar
como a partir da distribuição generalizada de Pareto, como e com qual precisão, é
possível estimar as durações de sismos máximos, além disso, se possível, verificar o
ajuste da GPD num espaçamento uniforme (se possível), modelar o risco sísmico para

56
as regiões de maior intensidade sísmica no Rio Grande do Norte e no caso para todo
o Nordeste brasileiro.
Este trabalho representa uma primeira tentativa a nível local de se modelar sismos
na região, haja vista que não se tem nenhum trabalho documentado nesse sentido.
Espera-se que os resultados obtidos possam contribuir para o conhecimento do
processo sísmico, a fim de orientar os impactos tanto desse tipo de evento tanto a
nível técnico quanto econômico.

57
REFERÊNCIAS BIBLIOGRÁFICAS
[1] Balkema, A.A. e Haan, L. de (1974). Residual life time at great age. Ann. Probab. 2,
792-804.
[2] Bautista, E. A. L. A. (2002). Distribuição Generalizada de Valores Extremos no
Estudo da Velocidade Máxima do Vento em Piracicaba, SP. Piracicaba -SP: ESALQ,
Tese (Doutorado em Agronomia) - Escola Superior de Agricultura Luiz de Queiroz,
p.47.
[3] Brabson, B.B. e Palutikof, J.P. (2000). “Tests of the Generalized Pareto Distribution
for predicting extreme wind speeds.” Journal of Applied Meteorology, p.39 .
[4] Coles S. (2001). Introduction to Statistical Modelling of Extreme Values, Springer.
[5] Coles, S. e Dixon. M. (1999). Likelihood-based inference for extreme value models,
Extremes ,p. 23.
[6] Davison, A. (1984). Modelling excesses over high thresholds, with an application, in
J. de Oliveira, ed., 'Statistical Extremes e Applications', D. Reidel, p. 461-482.
[7] Dekkers, A. L. ,M, de HaanL. (1989). On the estimation of the extreme value index
and large quantile estimation, Ann, Statist, p.17.
[8] Dupuis, D.J. e Tsao, M. (1998). A hydrid estimator for the Generalized Pareto and
Extreme-Value distributions. Communications in Statistics: Theory and Methods, p.27.
[9] Fisher, R.A., Tippett, L.H.C. (1928). Limiting forms of the frequency distribution of
the largest or smallest member of a sample. Proceedings of the Cambridge
Philosophical Society, p.180-190.
[10] Gnedenko, B.V. (1943). Sur la distribution limite du terme maximum d’une serie
aléatorie. Annales des Mathemátiques, p.423-453.
[11] Haan, L. e Lin, T. (2001). On convergence toward an extreme value distribution in
C [0,1]. Annalys of Prob. , p. 467-483.
[12] He, X, e Fung, W,K. (1999), “Method of Medians for life time data with Weibull
models”,Statistics in Medicine ,p. 1993-2009.
[13] Hosking, J. R. M., Wallis, J. R., e Wood, E. F. (1985b),Estimation of the
generalized extreme-value distribution by the method of probability-weighted moments.
Technometrics, , p.251-261.
[14] Hosking, J. and Wallis, J. (1987). 'Parameter and quantile estimation for the
generalized Pareto distribution', Technometrics , p. 339-349.

58
[15] Jaynes, E. T. (1961), Probability Theory in Science and Engineering. McGraw-Hill,
New York, USA.
[16] Jaynes, E. T. (1968). Prior probabilities. IEEE Trans. Syst. Man. Cybern. (SSC-4),
p. 227-241.
[17] Jenkinson, A. F. (1955). The frequency distribution of the annual maximum (or
minimum) of meteorological elements, Quarterly Journal of the Royal Meteorological
Society, London, p.158-171.
[18] Júarez S. F., William S. R. (2004), Robust and Efficient Estimation for the
Generalized Pareto Distribution.
[19] Luceño A. (2006), Fitting the generalized Pareto distribution to data using
maximum goodness-of-,t estimators, Computational Statistics & Data Analysis, p.904-
917.
[20] Levine, R. D. e Tribus, M. (1979). The Maximum Entropy Formalism. MIT Press,
Cambridge, Massachusetts, USA.
[21] Oztekin, T. (2004). Comparison of Parameter Estimation Methods for the Three-
Parameter Generalized Pareto Distribution, University of Gaziosmanpaßa, Faculty of
Agriculture, Agriculture Technology, Tokat – TURKEY.
[22] Patutikof, J.P., Brabson, B.B., Lister, D.H. e Adcock, S.T. (1999). “A review of
methods to calculate extreme wind speeds.” Meteorol. Appl. 6, p.119-132.
[23] Pisarenko ,V.F., A. Sornette, D. Sornette e M.V. Rodkin (2008). Characterization of
the Tail of the Distribution of Earthquake Magnitudes by combining the GEV and GPD
descriptions of Extreme Value Theory.
[24] Pickands III, J. (1975). Statistical inference using extreme order statistics. Ann.
Statist. 3, p.119-131.
[25] Rheinboldt, W.C. (1998). Methods for Solving Systems of Nonlinear Equations,
SIAM, PA, USA. P.148.
[26] Shalizi, C. R. (2007). Maximum Likelihood Estimation for q-Exponential (Tsallis)
Distributions, Statistics Department, Carnegie Mellon University.
[27] Shannon C. E. (1998). "Communication in the presence of noise", Proc. Institute of
Radio Engineers, vol. 37, no.1, pp. 10-21, Jan. 1949. Reprint as classic paper in: Proc.
IEEE, Vol. 86, No. 2.
[28] Singh, V. P. e Rajagopal, A. K. (1986). A new method of parameter estimation for
hydrologie frequency analysis. Hydrol. Sci. Technol. , p. 33-40.

59
[29] Singh, V. P. e H. Guo (1995). Parameter estimation for 3-parameter generalized
pareto distribution by the principle of maximum entropy (POME), Department of Civil
Engineering, Louisiana State University, Baton Rouge, Louisiana, USA.
[30] Smith, R.L. (1985). Maximum likelihood estimation in a class of nonregular cases.
Biometrika , p. 67-90.
[31] Smith, R.L. (2001), Extreme Values. Chapter 8 in Environmental Statistics Lecture
Notes v. 5, Univ. of North Carolina.
[32] Singh, V. P. e Fiorentino, M. (1992). A historical perspective of entropy
applications in water resources. In: Entropy and Energy Dissipation in Water
Resources, ed. V. P. Singh & M. Fiorentino, Kluwer. Dordrecht, The Netherlands, p.21-
61.
[33] Welsh, A.H. e Peng, L. (2001), Robust Estimate of the Generalized Pareto
Distribution, Australia.

60
APÊNDICES

61
Apêndice A: Rotina no R para analise dos dados
O programa abaixo foi utilizado para encontrar as estimativas, usando o pacote
POT, sendo que para encontrar as estimativas pelo POME, utilizou-se a função optim.
# ==========================================================#
# A N Á L I S E D E E V E N T O S E X T R E M O S #
# (SISMOS) #
# ==========================================================#
# LEITURA DOS DADOS
observações= read.table("F:/dados RN2.txt",header=T)
# GRÁFICO DE DISPERSÃO
plot(observações, ylab = "Sismos Observados em João Câmara", xlab = "Período",
main = "João Câmara", type = "p")
# THRESHOLD
t = quantile(observações[,"obs"], prob=0.45, na.rm=T, names = F)
abline(h=t, lty=2, col = 2)
legend("topright", "Threshold", col = "red", lty = 2.5, box.lty = 0, cex=0.8)
# CARREGANDO O PACOTE POT
library(POT)
# AJUSTANDO A GPD
fitted = fitgpd(observações[,"obs"], thres = t, est = 'moments', corr = TRUE)
# MÉDIA DE EVENTOS EXTREMOS
mu <- fitted$nat / diff(range(observações[,"time"]))
# ANÁLISE GRÁFICA
p22 = par(mfrow=c(2,2))
plot(fitted, mu, main="Gráfico das Probabilidades", xlab = "Empírico", ylab="Modelo",
which = 1)
plot(fitted, mu, main="QQ-Plot", xlab = "Modelo", ylab="Empírico", which = 2)
plot(fitted, mu, main="Densidade", xlab = "Quantil", ylab="Densidade", which = 3)
plot(fitted, mu, main="Nível de Retorno", xlab = "Período de Retorno (Anos)",
ylab="Nível de Retorno", which = 4)
# plot(fitted, mu)
# pp(fitted)
# qq(fitted)
# dens(fitted)
# retlev(fitted)
par(p22)

62
Apêndice B:
Rotina no R para gerar as três formas das funções de
distribuição da GEV
#================================================================#
# Ilustração das três funções de distribuições acumuladas da família de valores#
#extremos generalizados (GEV) #
#===============================================================#
Wei = function(x,alfa,a,b){exp(-(-(x-b)/a)^alfa)}
mal = function(x) x - x + 1
curve(Wei(x,-0.4,2,12),-10,10,ylab="Familia Generalizada de Valores Extremos", col =
"blue")
curve(mal(x),0,10, col = "blue", add = TRUE)
#Gumbell
Gum = function(x,a,b){exp(-exp(-(x-b)/a))}
curve(Gum(x,2,12),-2,10,lty = 1,col = "green",ylab="GEV",add = TRUE)
# Freechet
Frec = function(x,alfa,a,b){exp(-((x-b)/a)^(-alfa))}
curve(Frec(x,0.4,2,12),0,10, add=TRUE, col="black",lty = 1)
legend(-7,.6,legend = c("Gumbel","Frechet","Weibul"), c("green","black","blue"))
Rotina no R para as três formas das densidades da GEV
#================================================================#
# Ilustração das três densidades de probabilidade da família de valores #
#extremos generalizados (GEV) #
#===============================================================#
curve((1/2.6)*(1+.3*((x-10)/2.6))^(-4.333333)*exp(-(1+.3*((x-10)/2.6))^(-
1/0.3)),1.3333,30,ylab="Frechet", col = "green",add=TRUE)
curve((1/2.6)*(1-.3*((x-10)/2.6))^(2.333333)*exp(-(1-.3*((x-
10)/2.6))^(1/0.3)),2,30,ylab="Weibul", col = "red", add=TRUE)
curve((1/2.6)*(exp(-((x-10)/2.6))*exp(-exp(-(x-10)/2.6))),2,30,ylab="Gumbel", col =
"blue", add=TRUE)

63
Rotina no R para as ilustrar as observações acima de um
excesso
#=======================================#
# Grafico de barras para ilustrar a formação da GPD #
#=======================================#
z<-rpois(100,5)
plot(table(z), type = "h", col = "blue", lwd=12, main="rpois(100,lambda=5)")
#=======================================#
# Limiar #
#=======================================#
t = quantile(z[,"Xi"], prob=0.90, na.rm=T, names = F)
abline(h=t, lty=2, col = 2)
legend("topright", col = "blue", lty = 2, box.lty = 0, cex=0.8)
Rotina no R para Ilustração da função densidade de
probabilidade das três formas da distribuição generalizada de
Pareto (GPD).
#================================================================#
# Ilustração das três densidades de probabilidade da distirbuição generalizada #
#dePareto (GPD) #
#================================================================#
curve(-0.2*10*x^(1.2),1.3333,30,ylab="Pareto comum ou Beta", col =
"green",add=TRUE)
curve(0.2*10*x^(-0.8),1.3333,30,ylab="Pareto tipo II", col = "green",add=TRUE)
curve(-10*exp^(-10),1.3333,30,ylab="Pareto comum ou Beta", col =
"green",add=TRUE)

64
Rotina no R para Ilustração da convergência da GEV e GPD.
#================================================================#
# Ilustração da convergência da GEV (Frechet) e GPD (Pareto tipo II) #
#dePareto (GPD) #
#================================================================#
curve(0.2*10*x^(-0.8),1.3333,30,ylab="Pareto tipo II", col = "blue",add=TRUE)
curve((1/2.6)*(1+.3*((x-10)/2.6))^(-4.333333)*exp(-(1+.3*((x-10)/2.6))^(-
1/0.3)),1.3333,30,ylab="Frechet", col = "green",add=TRUE)
#================================================================#
# Ilustração da convergência da GEV (Weibul) e GPD (Beta) #
#dePareto (GPD) #
#================================================================#
curve(-10*exp^(-10),1.3333,30,ylab="Pareto comum ou Beta", col = "blue",add=TRUE)
curve((1/2.6)*(1-.3*((x-10)/2.6))^(2.333333)*exp(-(1-.3*((x-
10)/2.6))^(1/0.3)),2,30,ylab="Weibul", col = "red", add=TRUE)

65
Apêndice C:
Ajuste dos dados pelo método de PICKANDS
Mesmo possuindo a menor eficiência entre todos os métodos analisados, nota-
se pelo o diagnóstico gráfico que os dados dão um bom ajuste a GPD por esse
método, a vantagem teórica do método e o fato dele ser robusto.
Figura 21: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método de Pickands.

66
Ajuste dos dados pelo método dos MOMENTOS
O método dos momentos da um bom ajuste também para a GPD, e tem a
vantagem de ser o terceiro método mais eficiente, como pode ser visto na Tabela 1.
Figura 22: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método de momentos.

67
Ajuste dos dados pelo método da PWMB
Esse método tabalha com uma ponderação no viés dos estimadores, a idéia
dele e diminuir esse viés, sendo que no presente estudo ele não ficou entre os
métodos mais eficientes, sendo que ser podemos notar na figura 23, que os dados dão
um bom ajuste por esse modelo.
Figura 23: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método das probabilidades ponderadas viesadas.
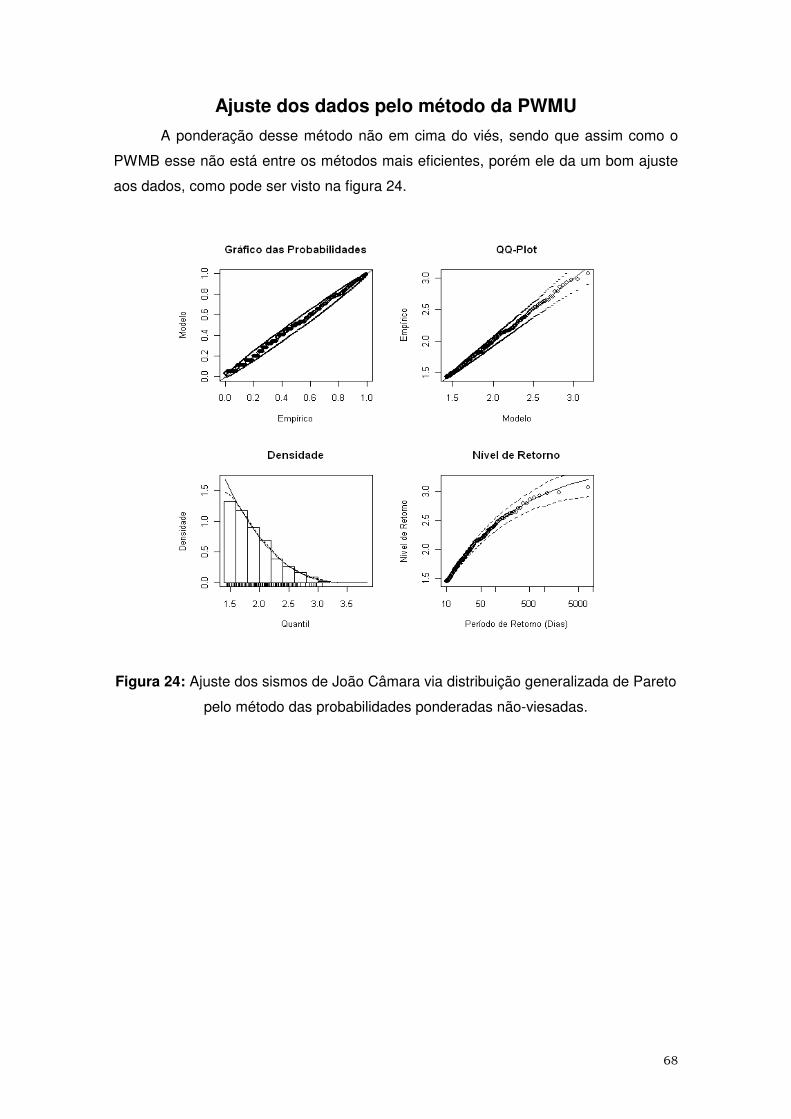
68
Ajuste dos dados pelo método da PWMU
A ponderação desse método não em cima do viés, sendo que assim como o
PWMB esse não está entre os métodos mais eficientes, porém ele da um bom ajuste
aos dados, como pode ser visto na figura 24.
Figura 24: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método das probabilidades ponderadas não-viesadas.
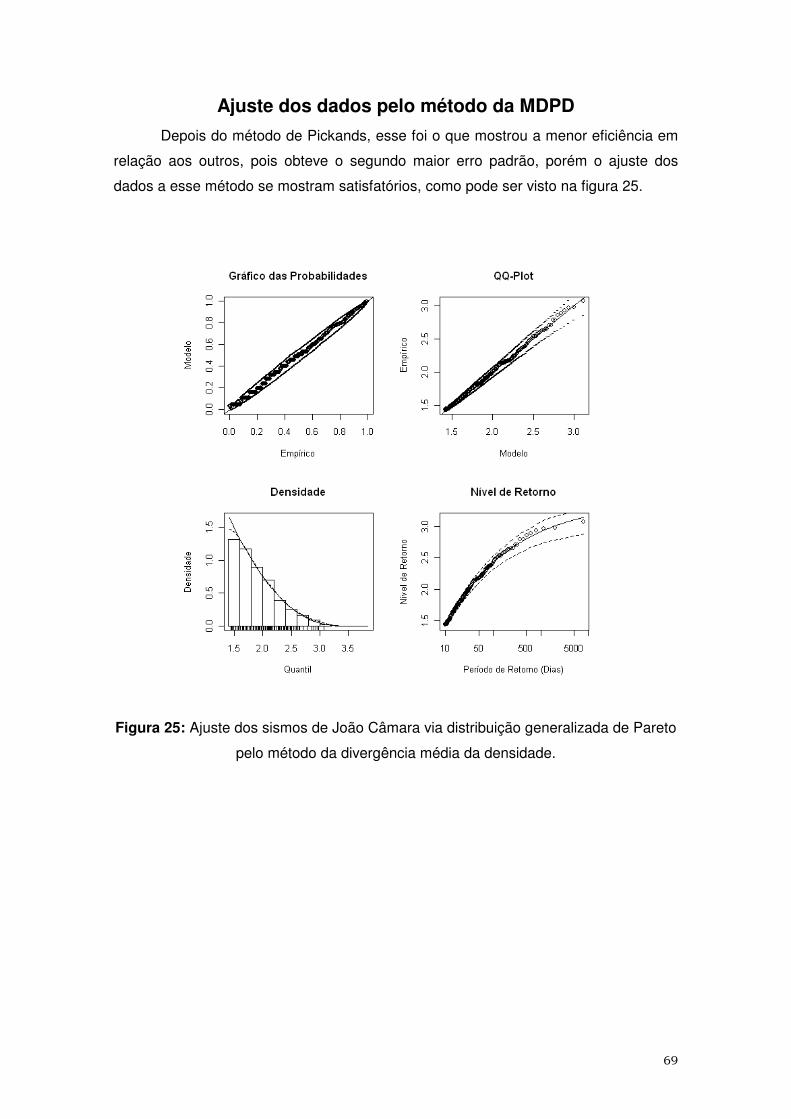
69
Ajuste dos dados pelo método da MDPD
Depois do método de Pickands, esse foi o que mostrou a menor eficiência em
relação aos outros, pois obteve o segundo maior erro padrão, porém o ajuste dos
dados a esse método se mostram satisfatórios, como pode ser visto na figura 25.
Figura 25: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método da divergência média da densidade.

70
Ajuste dos dados pelo método da MED
Mesmo não estando entre os métodos mais eficientes de estimação na
verdade foi o que obteve a terceira pior eficiência, o método da mediana que é um
método robusto, mostra que os dados dão um bom ajuste como pode ser visto na
figura 26.
Figura 26: Ajuste dos sismos de João Câmara via distribuição generalizada de Pareto
pelo método da mediana.








![dissertação [28]](https://static.fdocumentos.tips/doc/165x107/5866939d1a28abe1408b857d/dissertacao-28.jpg)









