
DaC-Join: Um algoritmo de junção para memórias...
35
DaC - Join: Um algoritmo de junção para memórias assimétricas Aluno : Namom Alves Alencar Orientador : José Maria Monteiro Co - Orientador : Angelo Brayner
Transcript of DaC-Join: Um algoritmo de junção para memórias...

DaC-Join: Um algoritmo de junção
para memórias assimétricas
Aluno: Namom Alves Alencar
Orientador: José Maria Monteiro
Co-Orientador: Angelo Brayner

Introdução
Performance
Processadores
Número de operações por segundo Crescido exponencialmente
HD
Número de operações de leitura/escrita Crescido marginalmente
Surgimento dos SSDs
04/10/2016Namom Alves Alencar2

Problema
Será que os bancos de dados existentes são adequados as características dos SSDs?
Os algoritmos de junção consideram o custo de uma leitura igual ao de uma escrita Porém, em SSDs, a escrita é mais cara que a leitura.
Também devemos levar em consideração os novos modelos de computadores com múltiplos processadores.
04/10/2016Namom Alves Alencar3

Objetivo
Construir um algoritmo de junção para esse novo cenário.
Levar em consideração características de SSDsvelocidade de escrita é mais lenta que a velocidade de
leitura
paralelismo de chips dentro do SSD
velocidade leitura randômica constante
Tirar proveito dos diversos chips/cores disponibilizados nos computadores de hoje.
04/10/2016Namom Alves Alencar4
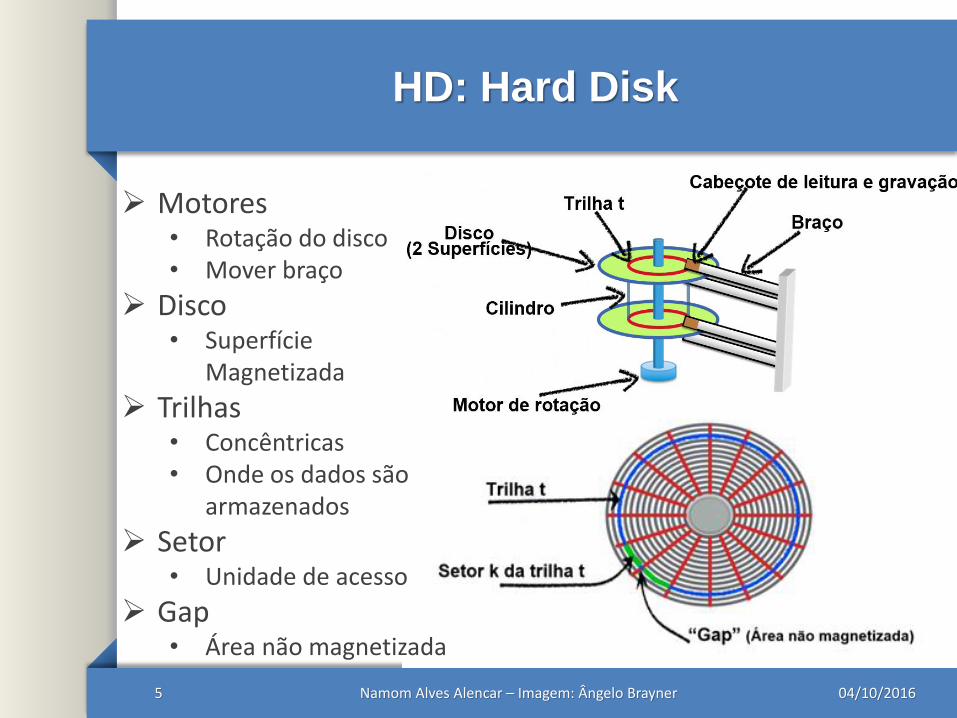
HD: Hard Disk
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner5
Motores• Rotação do disco• Mover braço
Disco• Superfície
Magnetizada
Trilhas• Concêntricas• Onde os dados são
armazenados
Setor• Unidade de acesso
Gap• Área não magnetizada
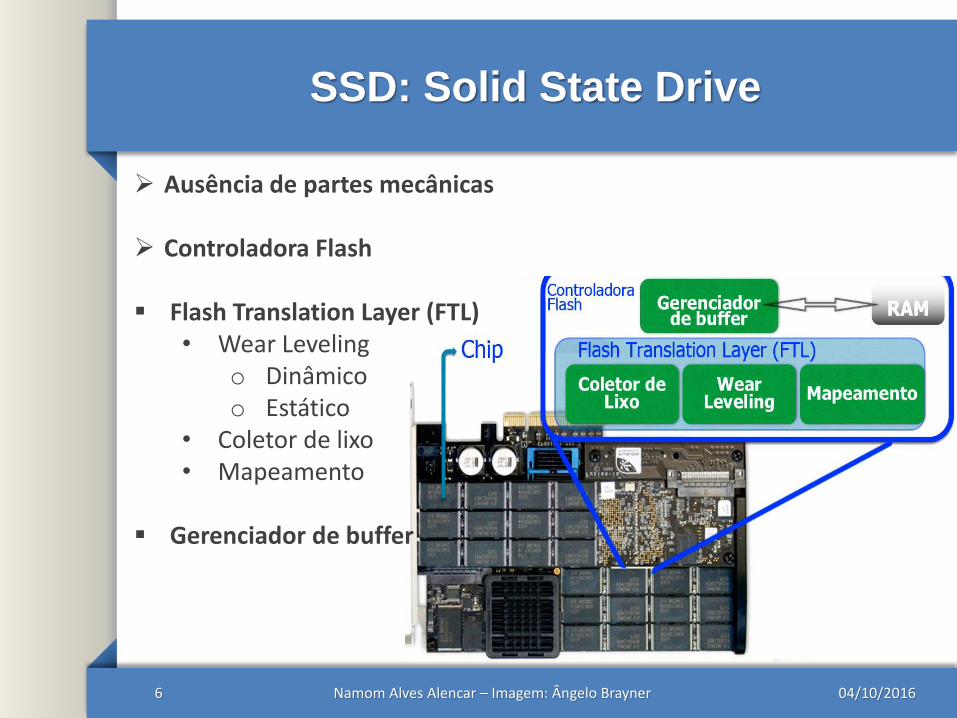
SSD: Solid State Drive
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner6
Ausência de partes mecânicas
Controladora Flash
Flash Translation Layer (FTL)• Wear Leveling
o Dinâmicoo Estático
• Coletor de lixo• Mapeamento
Gerenciador de buffer
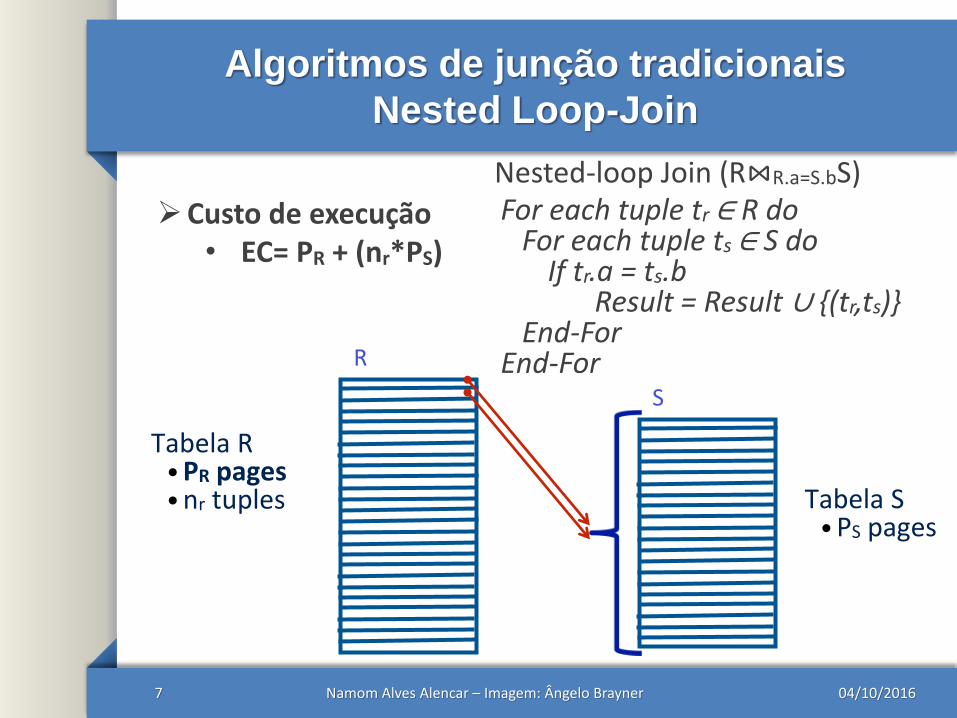
Algoritmos de junção tradicionais
Nested Loop-Join
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner7
R
S
Tabela R• PR pages• nr tuples Tabela S
• PS pages
Custo de execução• EC= PR + (nr*PS)
For each tuple tr ∈ R doFor each tuple ts ∈ S do
If tr.a = ts.bResult = Result ∪ {(tr,ts)}
End-ForEnd-For
Nested-loop Join (R⋈R.a=S.bS)
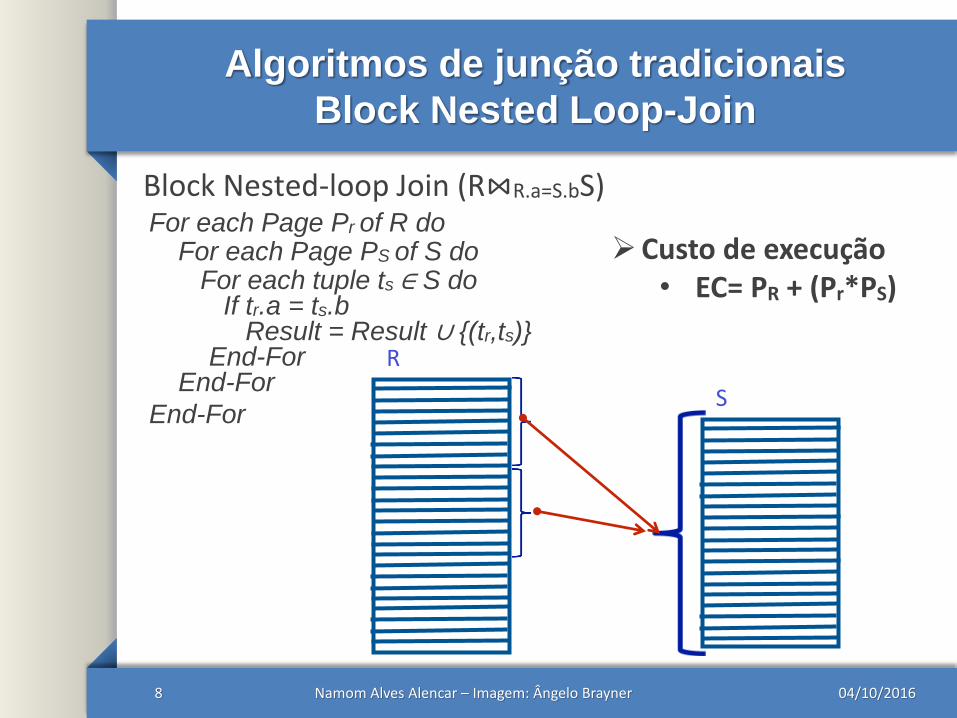
Algoritmos de junção tradicionais
Block Nested Loop-Join
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner8
R
S
Custo de execução• EC= PR + (Pr*PS)
For each Page Pr of R doFor each Page PS of S do
For each tuple ts ∈ S doIf tr.a = ts.b
Result = Result ∪ {(tr,ts)}End-For
End-For
End-For
Block Nested-loop Join (R⋈R.a=S.bS)

Algoritmos de junção tradicionais
Merge-Join
04/10/2016Namom Alves Alencar9
Tabelas ordenadasCusto de execução
• EC= PR + PS
Tabelas NÃO ordenadas 1 - Ordenação das tabelas
• COR = 2pr(𝐥𝐨𝐠𝑩−𝟏 Τ(𝒑𝒓 𝑩)+1) • COS = 2ps(𝐥𝐨𝐠𝑩−𝟏 Τ(𝒑𝒔 𝑩)+1)
• B = Número de páginas no buffer 2 - Realizar o Join
• CJ = PR + PS
• Custo de execução• EC= PR + PS + COR +COS
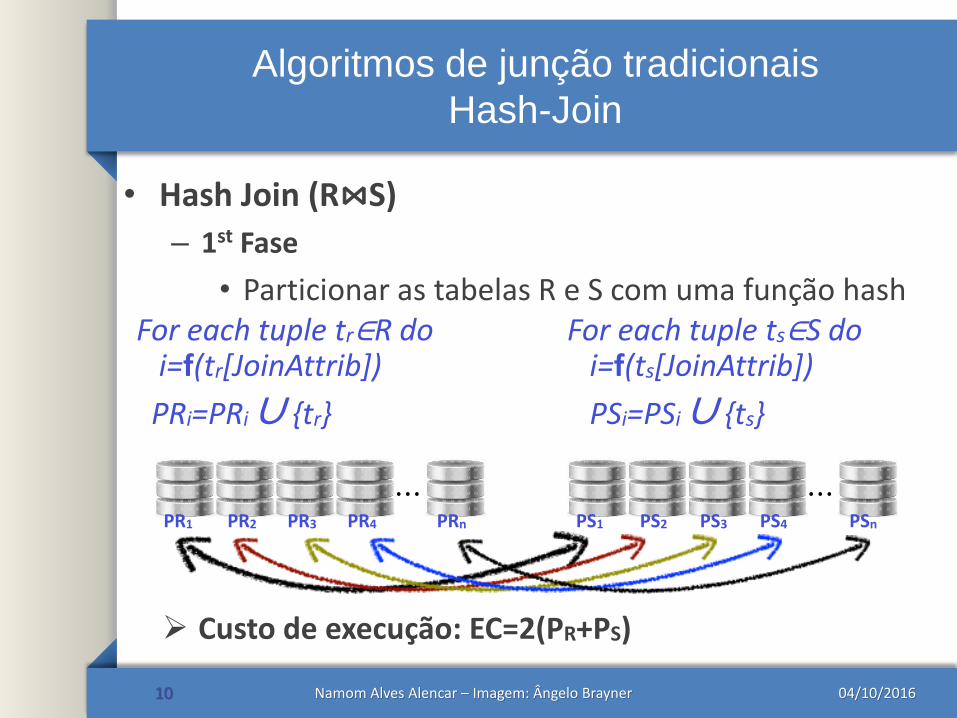
Algoritmos de junção tradicionais
Hash-Join
• Hash Join (R⋈S)
– 1st Fase
• Particionar as tabelas R e S com uma função hash
10
For each tuple tr∈R doi=f(tr[JoinAttrib])
PRi=PRi∪ {tr}
For each tuple ts∈S doi=f(ts[JoinAttrib])
PSi=PSi∪ {ts}
⋯PR1 PR2 PR3 PR4 PRn
⋯PS1 PS2 PS3 PS4 PSn
Custo de execução: EC=2(PR+PS)
Namom Alves Alencar – Imagem: Ângelo Brayner 04/10/2016
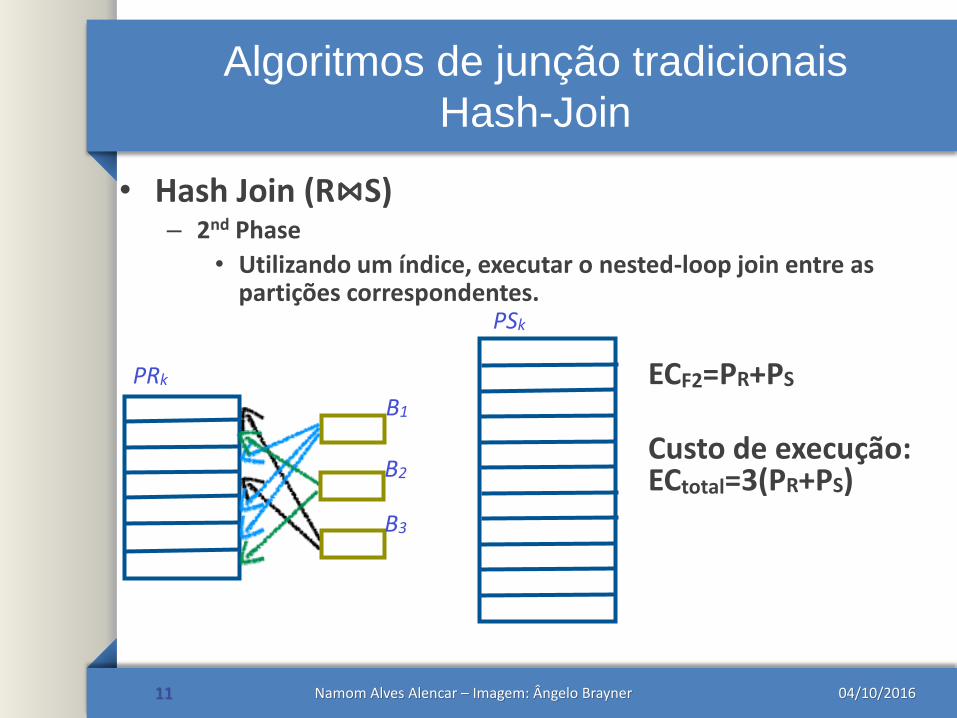
Algoritmos de junção tradicionais
Hash-Join
• Hash Join (R⋈S)– 2nd Phase
• Utilizando um índice, executar o nested-loop join entre as partições correspondentes.
11
PRk
B1
B2
B3
PSk
ECF2=PR+PS
Custo de execução: ECtotal=3(PR+PS)
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner
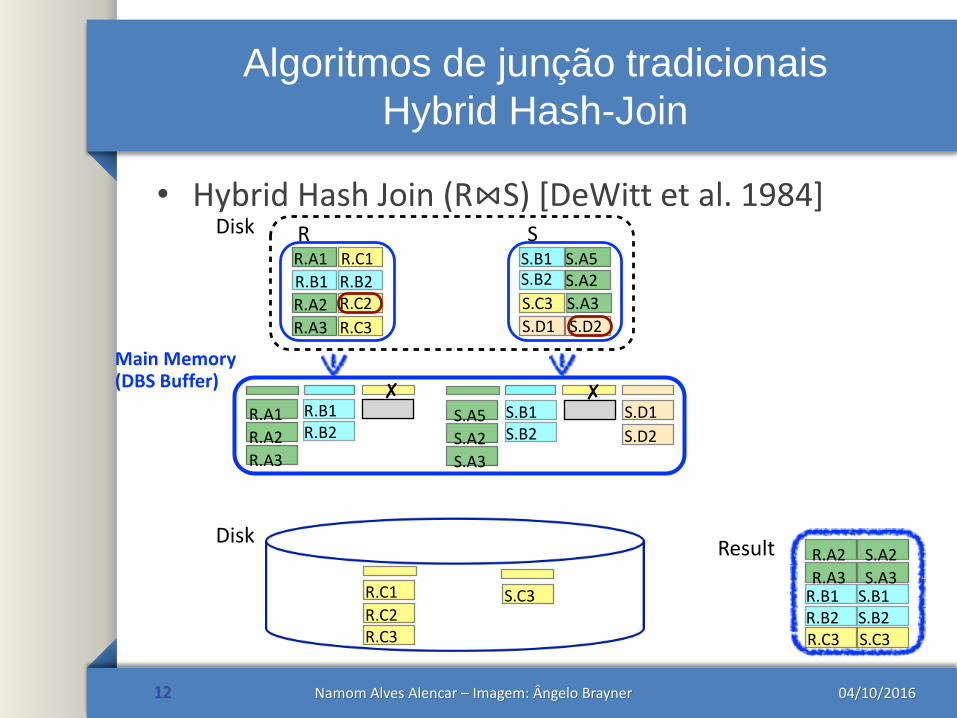
Algoritmos de junção tradicionais
Hybrid Hash-Join
• Hybrid Hash Join (R⋈S) [DeWitt et al. 1984]
12
R.A1
R.A2
R.A3
R.B1 R.B2
R.C1
R.C2
R.C3
R
R.A1
S.B1 S.A5S.B2
S.C3
S.D2S.D1
S.A2
S.A3
S
R.B1
R.A2
R.A3
R.C1R.B2
R.C2
R.C1
R.C3
S.D2S.A5 S.B1
S.A2
S.A3
S.C3S.B2
S.D1
R.C3 S.C3
S.C3
Disk
Main Memory(DBS Buffer)
Disk
✘ ✘
R.A2
R.A3
S.A2
S.A3R.B1R.B2
S.B1S.B2
Result
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner
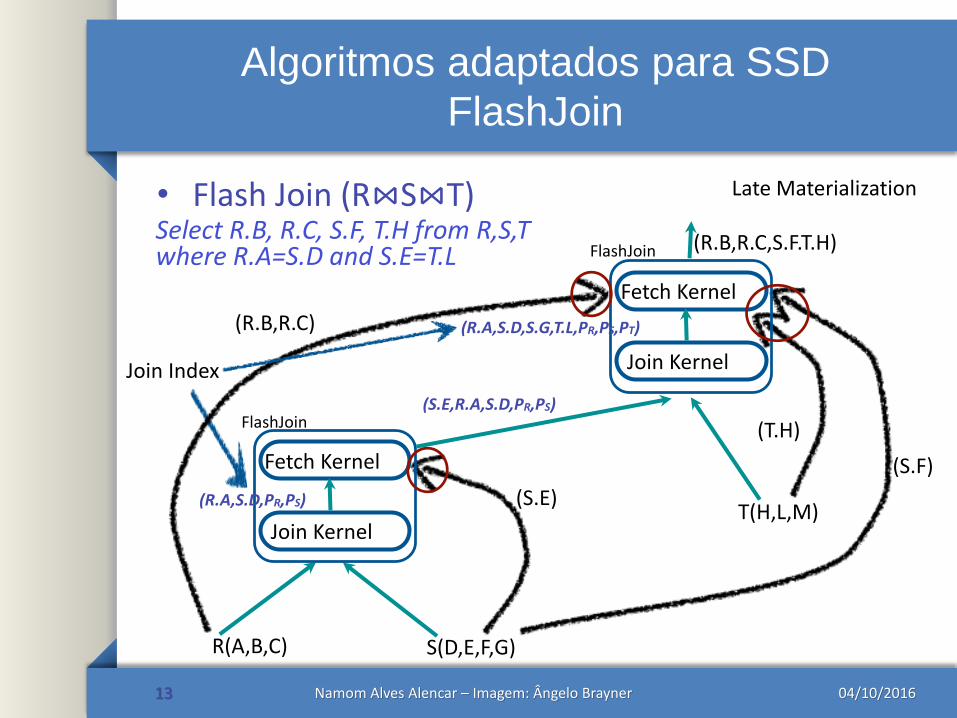
Algoritmos adaptados para SSD
FlashJoin
• Flash Join (R⋈S⋈T)
13
Select R.B, R.C, S.F, T.H from R,S,Twhere R.A=S.D and S.E=T.L
(S.E)
Join Index
(R.B,R.C,S.F.T.H)
(S.F)
(T.H)
(R.B,R.C)
S(D,E,F,G)R(A,B,C)
Fetch Kernel
Join Kernel
(R.A,S.D,PR,PS)
FlashJoin
Fetch Kernel
Join Kernel
T(H,L,M)
(S.E,R.A,S.D,PR,PS)
(R.A,S.D,S.G,T.L,PR,PS,PT)
FlashJoin
Late Materialization
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner

Materialização Mista e Tardia
04/10/2016Namom Alves Alencar14
• FlashJoin• Late Materialization
• Sempre causa releituras
• Hybrid Hash Join• Early Materialization
• Não causa releituras
• DaC-Join• Mix Materialization
• Releitura apenas para projeção
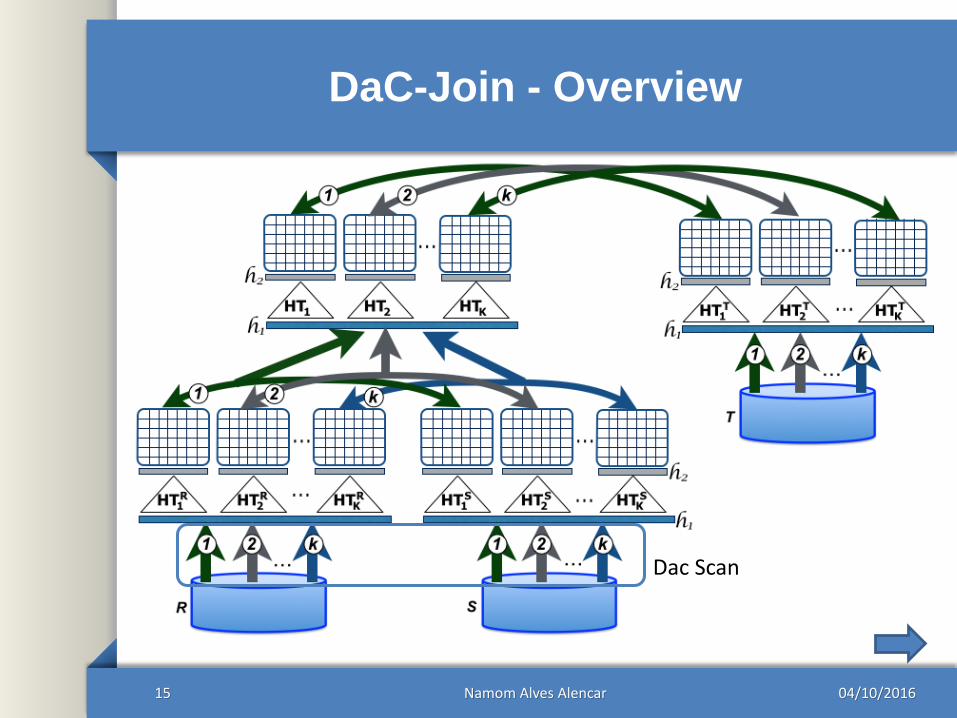
DaC-Join - Overview
04/10/2016Namom Alves Alencar15
Dac Scan

DaC-Join – Multi Scan Phase
04/10/2016Namom Alves Alencar16
• Multi Scan Phase
• Iniciamos k processos(threads)
• Cada processo é responsável por ler uma bloco da tabela
• A segunda leitura do processo p será no bloco p+k• Exemplo: Iniciamos 4 threads
• Thread 1 vai ler os blocos: 1, 5, 9…• Thread 2 vai ler os blocos: 2, 6, 10…• Thread 3 vai ler os blocos: 3, 7, 11…• Thread 4 vai ler os blocos: 4, 8, 12…

DaC-Join – Join Phase
04/10/2016Namom Alves Alencar17
• Join Phase
• Utilizada para separar as tuplas em sua respectivasuper-partição(super-hash-table).
• Utilizada para separar as tuplas em sua respectivasub-partição(sub-hash-table).

DaC-Join – Join Phase
04/10/2016Namom Alves Alencar18
• Join Phase
• Temos k processos(threads)
• Temos k super-partições(super-hash-table)
• Então, cada processo(thread) fica responsável porfazer a junção das tuplas de uma super-partição.

Experimentos Junções
19
QA: 1.147.084Select * from orders, lineitemwhere o_orderdate >= 1993-10-01 and o_orderdate < 1994-01-01 and l_returnflag = ’R’ and l_orderkey = o_orderkey
Q5n: 1.147.084Select * from customer, orders, lineitem, supplier, nation, region where l_orderkey = o_orderkey and c_custkey = o_custkeyand l_suppkey = s_suppkey and c_nationkey = n_nationkeyand n_regionkey = r_regionkey and r_name = ’ASIA’ and o_orderdate >= 1994-01-01 and o_orderdate < 1995-01-01
04/10/2016Namom Alves Alencar
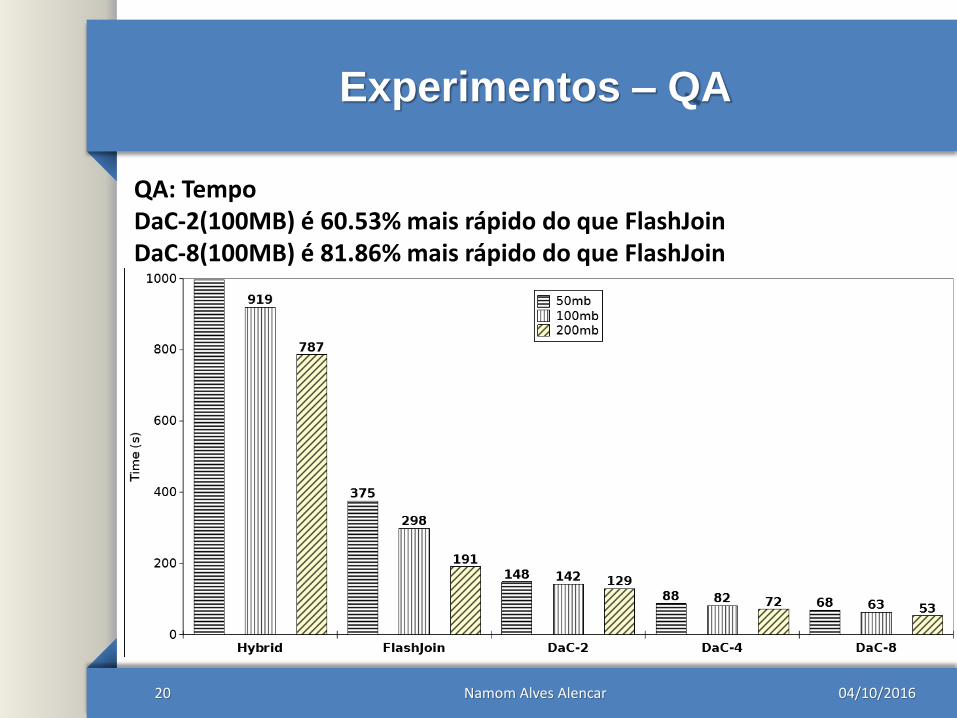
Experimentos – QA
20
QA: TempoDaC-2(100MB) é 60.53% mais rápido do que FlashJoinDaC-8(100MB) é 81.86% mais rápido do que FlashJoin
04/10/2016Namom Alves Alencar
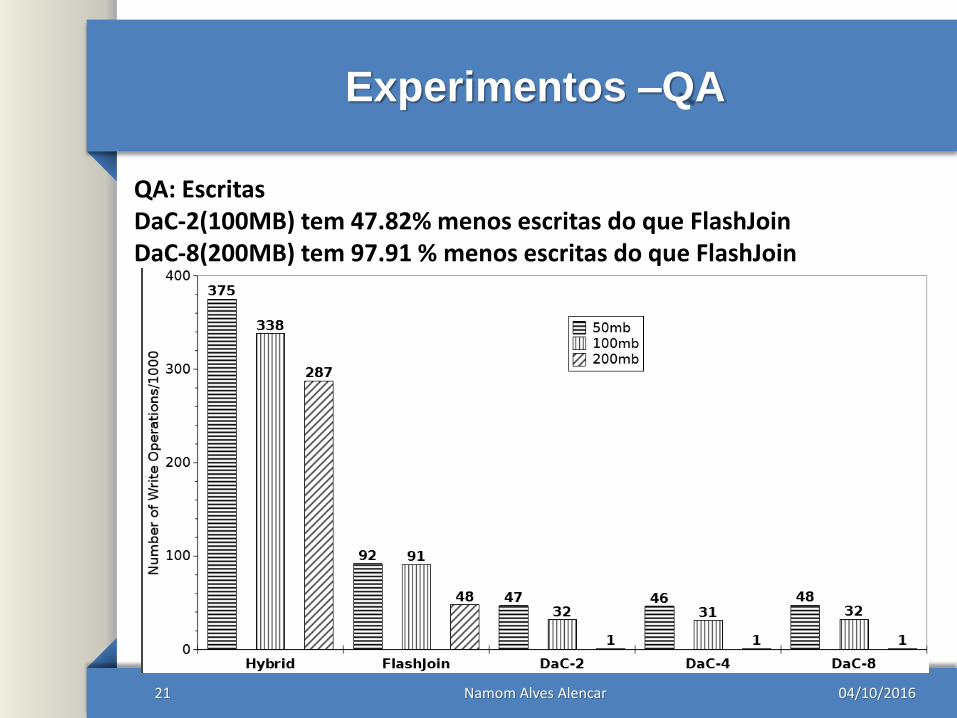
Experimentos –QA
21
QA: EscritasDaC-2(100MB) tem 47.82% menos escritas do que FlashJoin DaC-8(200MB) tem 97.91 % menos escritas do que FlashJoin
04/10/2016Namom Alves Alencar
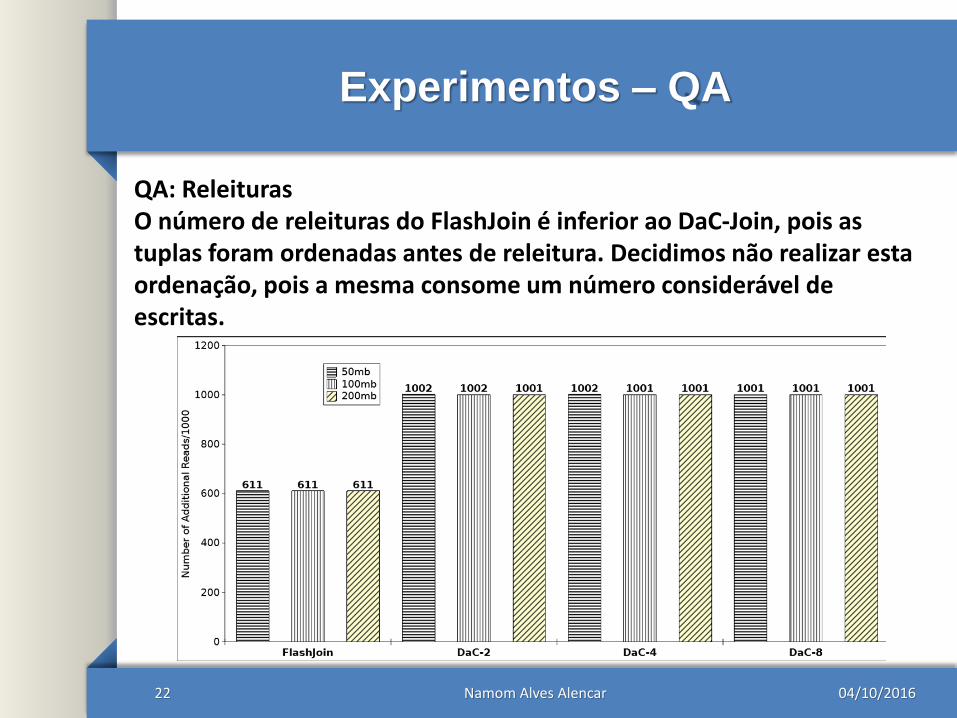
Experimentos – QA
22
QA: ReleiturasO número de releituras do FlashJoin é inferior ao DaC-Join, pois as tuplas foram ordenadas antes de releitura. Decidimos não realizar estaordenação, pois a mesma consome um número considerável de escritas.
04/10/2016Namom Alves Alencar
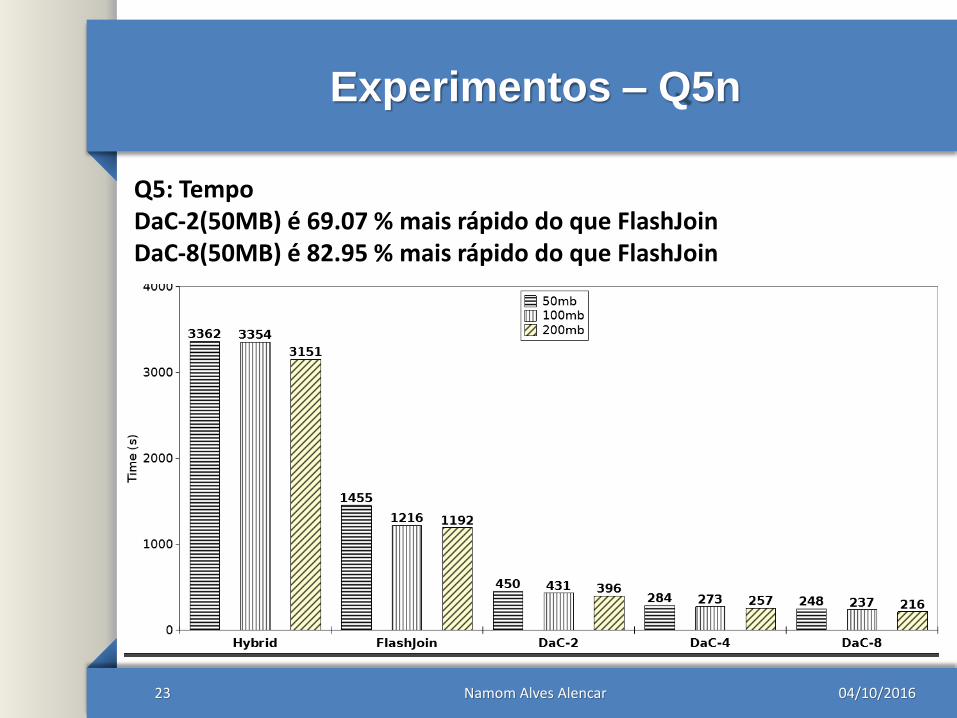
Experimentos – Q5n
23
Q5: TempoDaC-2(50MB) é 69.07 % mais rápido do que FlashJoinDaC-8(50MB) é 82.95 % mais rápido do que FlashJoin
04/10/2016Namom Alves Alencar
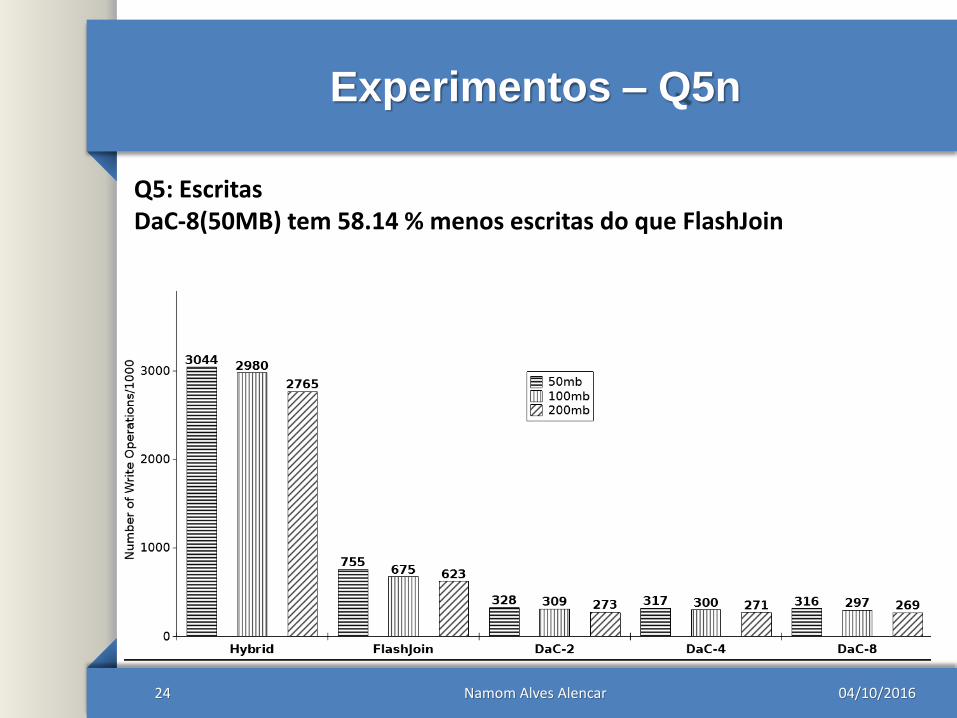
Experimentos – Q5n
04/10/2016Namom Alves Alencar24
Q5: EscritasDaC-8(50MB) tem 58.14 % menos escritas do que FlashJoin
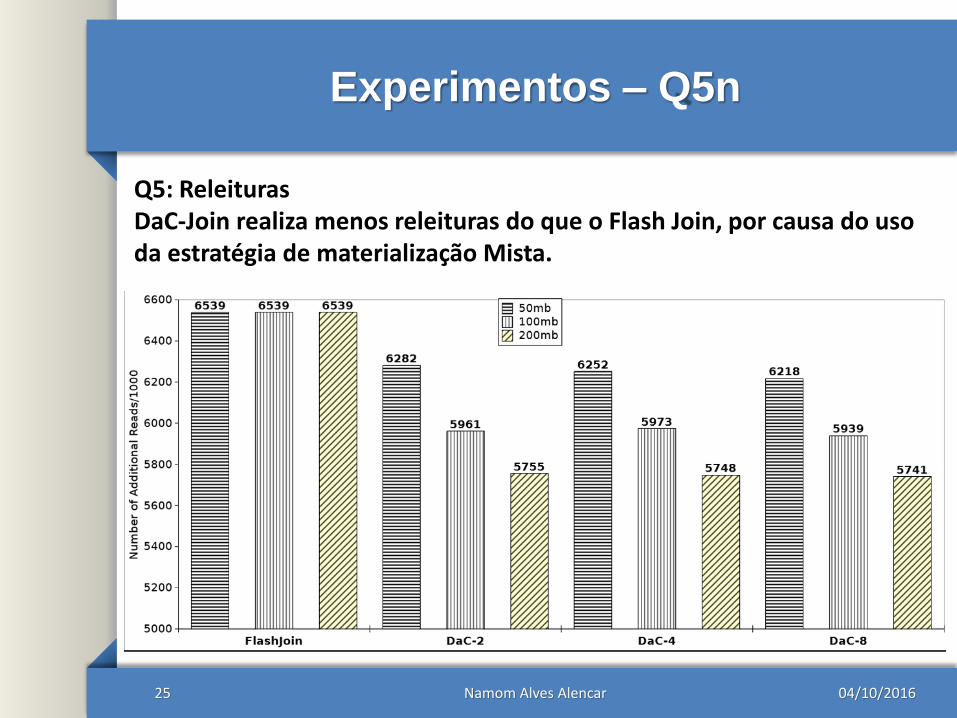
Experimentos – Q5n
04/10/2016Namom Alves Alencar25
Q5: ReleiturasDaC-Join realiza menos releituras do que o Flash Join, por causa do usoda estratégia de materialização Mista.

Conclusão
04/10/2016Namom Alves Alencar26
• Ter o conhecimento das caracteristicas da mídia, pode nos fornecer diversos meios para melhorar os algoritmos dos SGBDs.
• Uma vez que conseguimos reduzir o número de escritas, também reduzimos o tempo execução.
• Tomamos vantagem também tempo de acesso randômico constante. Operações de releitura.
• A estratégia de Dividir para Conquistar torna o processo muito mais rapido uma vez que utilizamos multiplos processadores.

Obrigado
Aluno: Namom Alves Alencar
Orientador: José Maria Monteiro
Co-Orientador: Ângelo Brayner
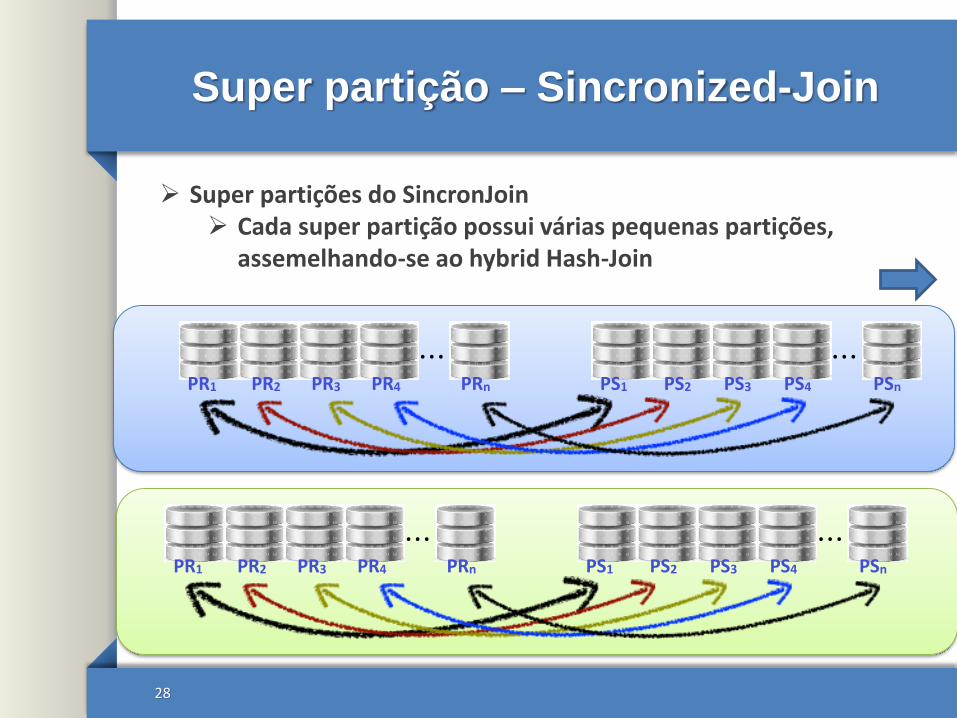
Super partição – Sincronized-Join
28
⋯PR1 PR2 PR3 PR4 PRn
⋯PS1 PS2 PS3 PS4 PSn
⋯PR1 PR2 PR3 PR4 PRn
⋯PS1 PS2 PS3 PS4 PSn
Super partições do SincronJoin Cada super partição possui várias pequenas partições,
assemelhando-se ao hybrid Hash-Join

Program Operation- Physical Write -
29
PA PC
PD PE PF
S1: Block B with clean pages (all bits set to 1)
PA
PF
S2: New data should be inserted into pages PA and PF
★ Program operation
PB
Block B

PAPA
Logical Write
30
PB PC
PD PE PF
PA' PB' PC'
PD' PE' PF’
Block B'
Block B
PC'
PF'PE'
PF
S3: New data should be inserted into pages PE of B★ Program operation can not be execute any more★ Pages of B are rewritten in a new clean block B’★ Pages PA and PF become stale pages

Write Amplification
• Tanto o coletor de lixo, quanto o wear leveling causam escritas extras nos SSDs.
• Tornando o número real de escritas superior ao número de escritas requisitadas pelos aplicativos.
• Esta característica é chamada de write amplification.
31
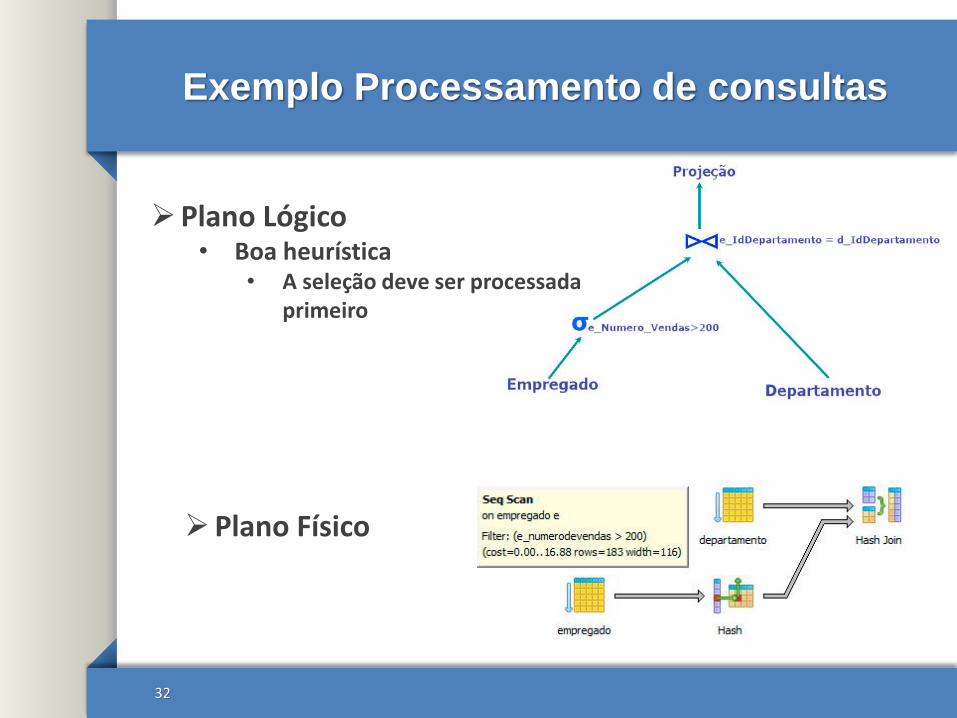
Exemplo Processamento de consultas
32
Plano Lógico• Boa heurística
• A seleção deve ser processada primeiro
Plano Físico
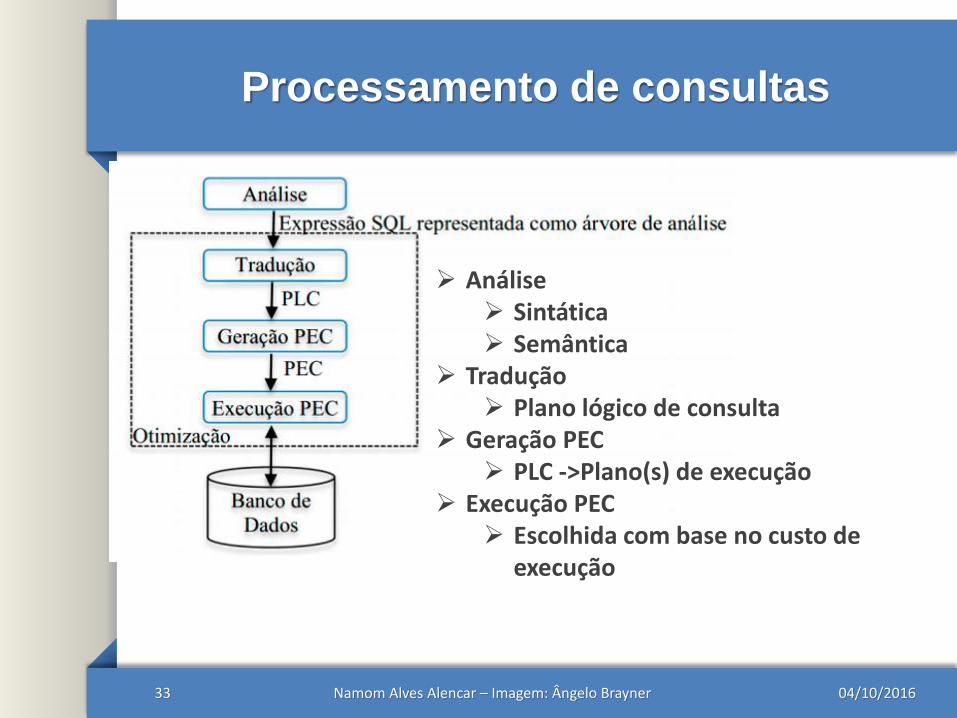
Processamento de consultas
04/10/2016Namom Alves Alencar – Imagem: Ângelo Brayner33
Análise Sintática Semântica
Tradução Plano lógico de consulta
Geração PEC PLC ->Plano(s) de execução
Execução PEC Escolhida com base no custo de
execução

Características dos SSDs
• O tempo de procura de um dado é muito baixo, pelo fato de não possuir componentes mecânicos;
• O tempo de acesso a dados aleatórios é praticamente constante. Normalmente este tempo é 0,1 milissegundo ou menos;
• Nos SSDs temos altas taxas de transferência de dados. Abaixo mostraremos a leitura e a escrita sequencial, medidas em mb/s. Logo após mostraremos a leitura e a escrita randômica, medidas em IOPS;– A taxa de transferência da leitura sequencial pode chegar até 540 mb/s.– A taxa de transferência escrita sequencial pode chegar até 330 mb/s.– A leitura randômica realiza até 98.000 IOPS.– A escrita randômica realiza até 60.000 IOPS.
• Os SSDs apresentam um baixo consumo de energia, onde a média de consumo de energia por operação é de 0,127W;
• O SSD não perde desempenho, mesmo quando cheio;• Os SSDs são altamente confiáveis, uma vez que a média de falha é de 1
em cada 1,5 milhões de horas de uso.
34
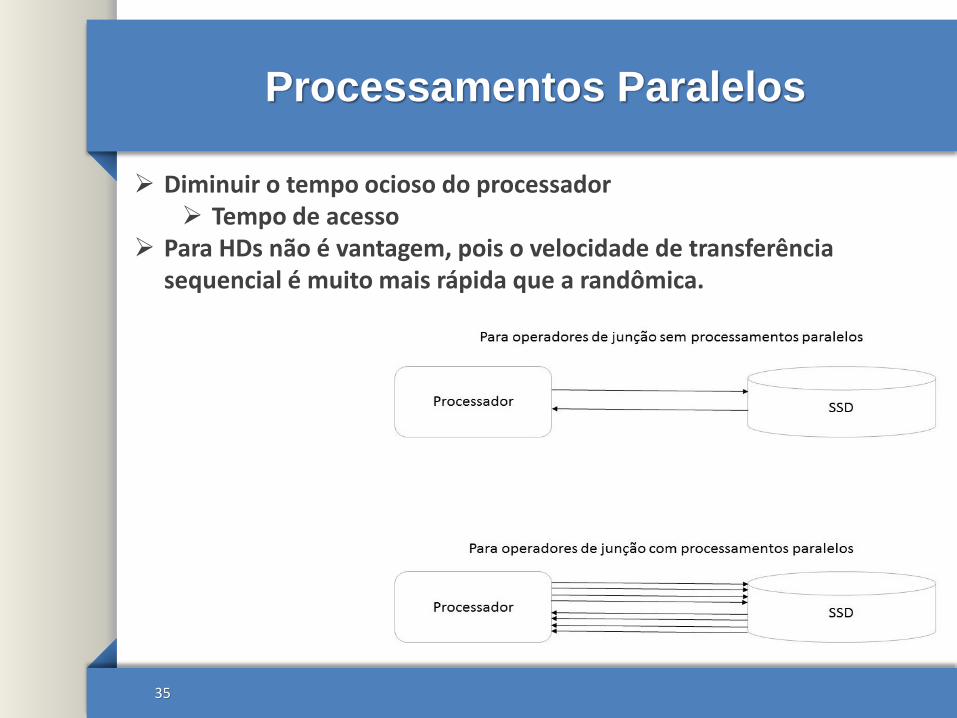
Processamentos Paralelos
35
Diminuir o tempo ocioso do processador Tempo de acesso
Para HDs não é vantagem, pois o velocidade de transferência sequencial é muito mais rápida que a randômica.

















![[Tutorial] Recuperar arquivos de HDs ou partições danificada](https://static.fdocumentos.tips/doc/165x107/55cf9b23550346d033a4e023/tutorial-recuperar-arquivos-de-hds-ou-particoes-danificada.jpg)
