

Correlação Probabilística em Bancos de Dados...
21
Correlação Probabilística em Bancos de Dados Governamentais Clícia Pinto, RobespierrePita, Pedro Melo, Samila Sena, Marcos Barreto
-
Upload
truongcong -
Category
Documents
-
view
215 -
download
0
Transcript of Correlação Probabilística em Bancos de Dados...

Correlação Probabilística em Bancos de Dados Governamentais
Clícia Pinto, RobespierrePita, Pedro Melo, Samila Sena, Marcos Barreto

Conteúdo
1. Introdução
2. Dados Governamentais e Programas Sociais
3. Metodologia de Correlação Probabilística
4. Estudos de Caso
5. Conclusão

Introdução
● Integração de dados em sistemas de saúde:
○ Suporte para análise de políticas públicas
○ Monitoramento de Intervenções
○ Acompanhamento do tratamento de pacientes
● Ausência de atributos identificadores únicos exige correlação
probabilística
● Grande volume de dados a serem integrados: Big Data

Questões Relevantes para a Aplicação:
● Qualidade dos dados
● Segurança de armazenamento
● Preservação da privacidade
● Padronização dos dados
● Desempenho
● Acurácia
Introdução
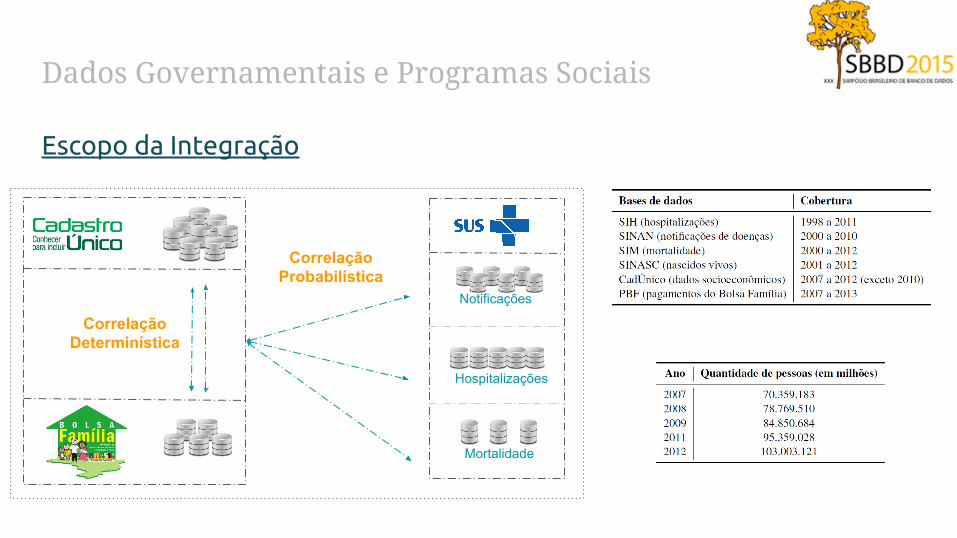
Dados Governamentais e Programas Sociais
Escopo da Integração
Notificações
Hospitalizações
Mortalidade
CorrelaçãoDeterminística
CorrelaçãoProbabilística
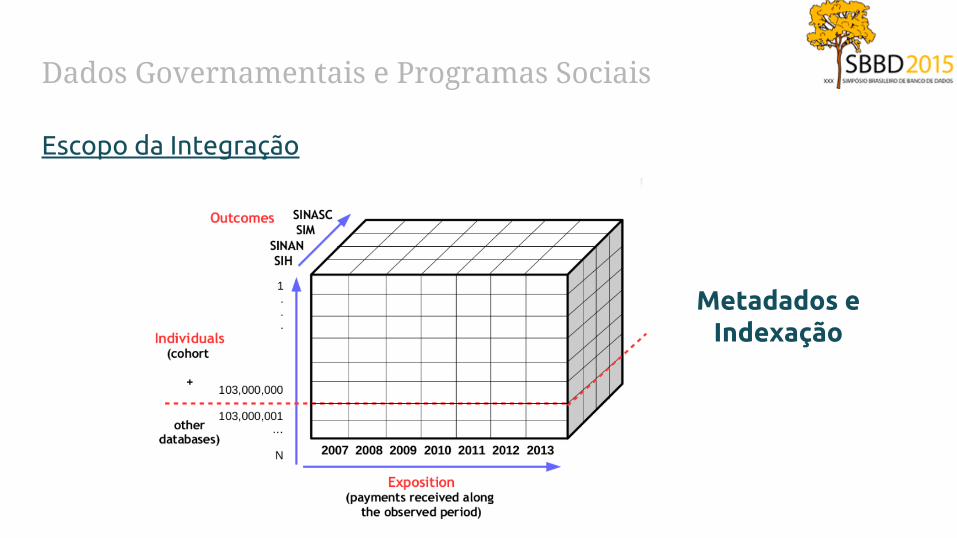
Dados Governamentais e Programas Sociais
Escopo da Integração
Metadados e Indexação
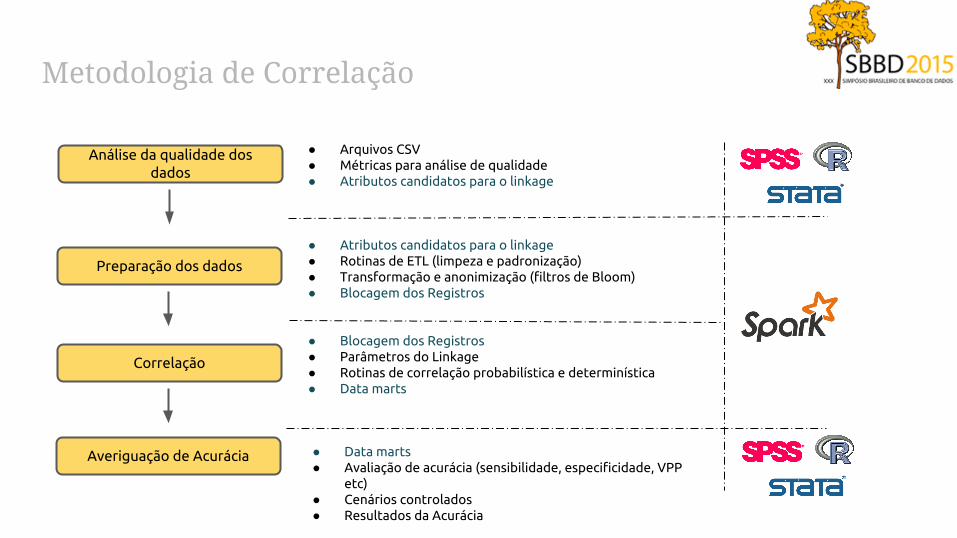
Metodologia de Correlação
Análise da qualidade dos dados
Preparação dos dados
Correlação
Averiguação de Acurácia
● Arquivos CSV● Métricas para análise de qualidade● Atributos candidatos para o linkage
● Atributos candidatos para o linkage● Rotinas de ETL (limpeza e padronização)● Transformação e anonimização (filtros de Bloom)● Blocagem dos Registros
● Blocagem dos Registros● Parâmetros do Linkage● Rotinas de correlação probabilística e determinística● Data marts
● Data marts● Avaliação de acurácia (sensibilidade, especificidade, VPP
etc)● Cenários controlados● Resultados da Acurácia

Análise da Qualidade dos Dados
Questões Relevantes para a aplicação:
● Equivalência de variáveis
● Análise de valores ausentes
● Eleição das variáveis da correlação
○ Quantidade x Desempenho
NomeNome da mãeData de nascimentoMunicípio de ResidênciaSexo
Variáveis de interesse para a correlação probabilística:

Preparação dos Dados
1. Padronização
● Extração de colunas
● Substituição de valores ausentes
● Tratamento de caracteres especiais
● Padronização em datas e códigos

Preparação dos Dados
● Agrupar registros com mesma chave○ A chave é extraída dos próprios registros
2. Blocagem
Blocagem padrão
Blocagem por predicados
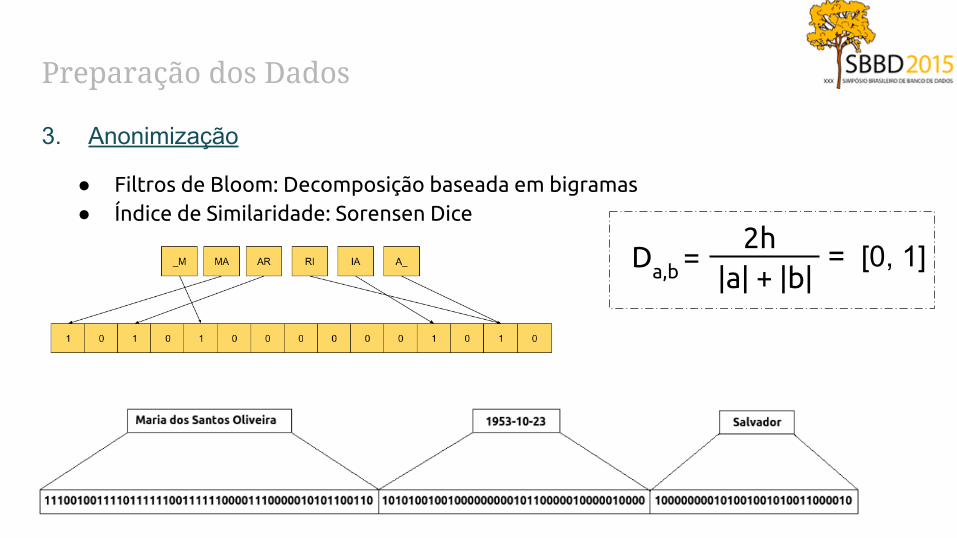
Preparação dos Dados
3. Anonimização
● Filtros de Bloom: Decomposição baseada em bigramas● Índice de Similaridade: Sorensen Dice
2h|a| + |b|
Da,b = = [0, 1]

Correlação
● Determinística
○ Códigos de identificação (NIS)
○ Sexo
○ Códigos de município
● Probabilística
○ Nomes em geral
Maria S. Oliveira rua Caetano Moura Salvador
Maria dos Santos Oliveira rua Caetano Moura Salvador
Maria S. Oliveira rua Caetano Moura 2927408
Maria dos Santos Oliveira rua Caetano Moura 2927408
F
F
Correlação probabilística simples
Correlação probabilística híbrida
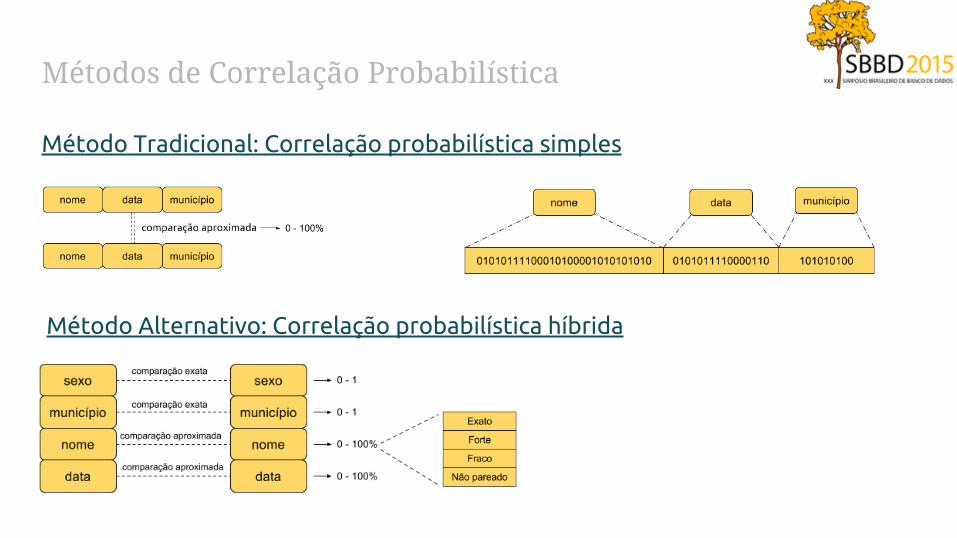
Métodos de Correlação Probabilística
Método Tradicional: Correlação probabilística simples
Método Alternativo: Correlação probabilística híbrida
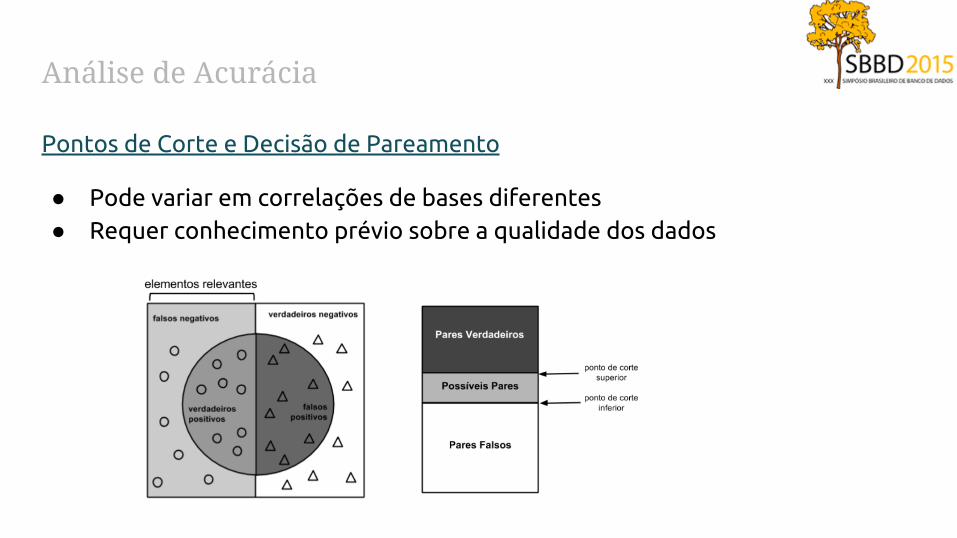
Análise de Acurácia
Pontos de Corte e Decisão de Pareamento
● Pode variar em correlações de bases diferentes● Requer conhecimento prévio sobre a qualidade dos dados

Análise de Acurácia
Pontos de Corte e Decisão de Pareamento
● Pode variar em correlações de bases diferentes● Requer conhecimento prévio sobre a qualidade dos dados
- Geração de data mart- Análises específicas

Análise de Acurácia
● Problemas:
○ Ausência de um padrão ouro
○ Inviabilidade da verificação manual
● Estratégia:
○ Bases de dados controladas
■ Bases pré-fabricadas
■ Bases reais com resultados conhecidos
■ Amostras das bases a serem relacionadas
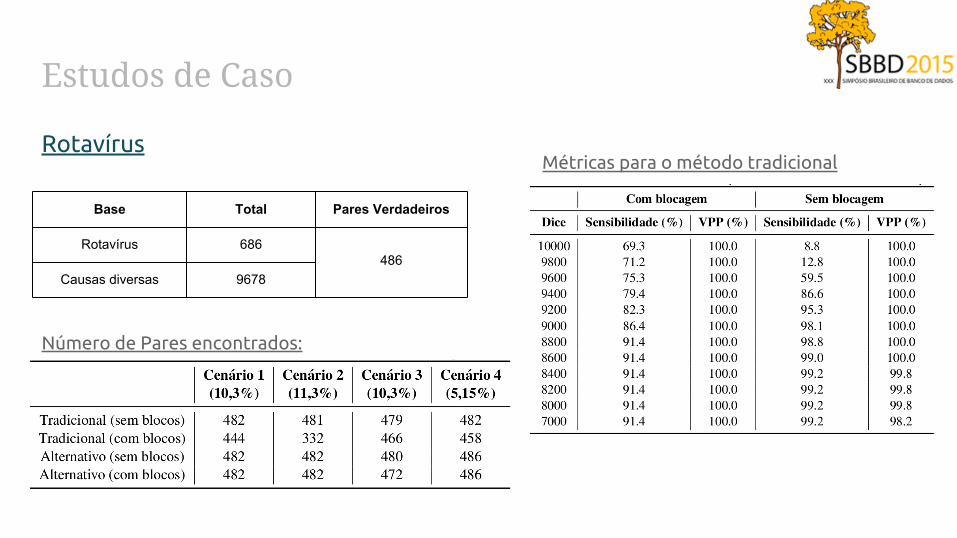
Estudos de Caso
Rotavírus
Número de Pares encontrados:
Base Total Pares Verdadeiros
Rotavírus 686486
Causas diversas 9678
Métricas para o método tradicional
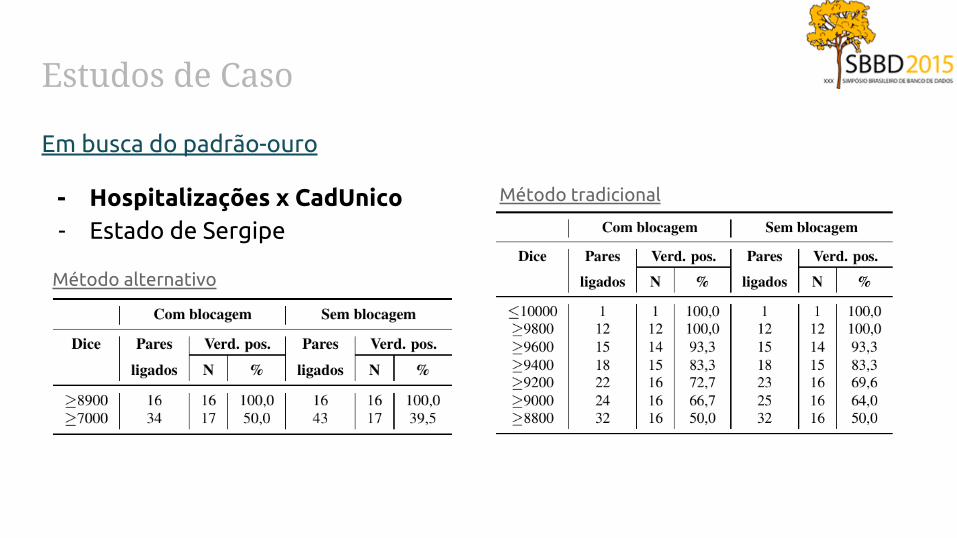
Estudos de Caso
Em busca do padrão-ouro
- Hospitalizações x CadUnico- Estado de Sergipe
Método alternativo
Método tradicional
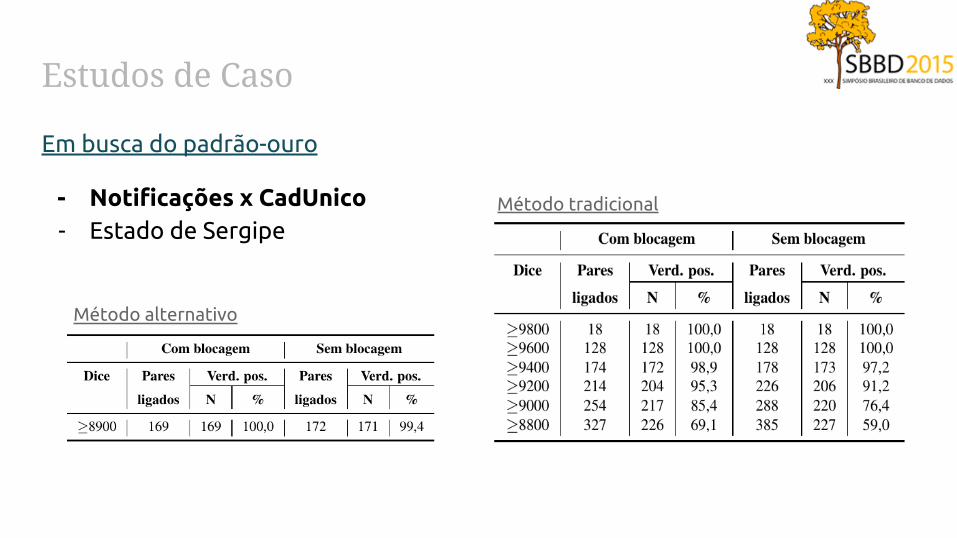
Estudos de Caso
Em busca do padrão-ouro
- Notificações x CadUnico- Estado de Sergipe
Método alternativo
Método tradicional

Conclusões
● Solução em pipeline
● Atenção às principais questões da correlação
● Solução genérica e adaptável
● Garantia de desempenho, segurança acurácia:
○ Ambiente distribuído do Apache-Spark
○ Comparação com filtros de Bloom
○ Blocagem x acurácia
○ Pontos de corte baseado em amostragem das bases













![PORTFÓLIO DE SOLUÇÕES - s-printingmarketingportal.ext ...s-printingmarketingportal.ext.hp.com/pdf/[Brochure] Business Core 2... · (PDF, RTF, CSV, HTML, TXT, PPTX, XLSX, DOCX pesquisáveis)](https://static.fdocumentos.tips/doc/165x107/5cb3935288c99357178b4fc9/portfolio-de-solucoes-s-pri-s-pri-brochure-business-core-2-pdf.jpg)




