
COMPUTAÇÃO DE ALTO DESEMPENHO …‡ÃO DE ALTO DESEMPENHO ENVO… · requisito parcial para a...
70
CENTRO UNIVERSITÁRIO VILA VELHA CURSO DE CIÊNCIA DA COMPUTAÇÃO WESLEY DOS SANTOS MENENGUCI COMPUTAÇÃO DE ALTO DESEMPENHO ENVOLVENDO CLUSTERS E MÉTODOS NUMÉRICOS VILA VELHA 2008
Transcript of COMPUTAÇÃO DE ALTO DESEMPENHO …‡ÃO DE ALTO DESEMPENHO ENVO… · requisito parcial para a...

CENTRO UNIVERSITÁRIO VILA VELHA
CURSO DE CIÊNCIA DA COMPUTAÇÃO
WESLEY DOS SANTOS MENENGUCI
COMPUTAÇÃO DE ALTO DESEMPENHO
ENVOLVENDO CLUSTERS E MÉTODOS
NUMÉRICOS
VILA VELHA
2008


WESLEY DOS SANTOS MENENGUCI
COMPUTAÇÃO DE ALTO DESEMPENHO
ENVOLVENDO CLUSTERS E MÉTODOS
NUMÉRICOS
Trabalho de Conclusão de Curso apresen-tado ao Centro Univertário Vila Velha comorequisito parcial para a obtenção do graude Bacharel em Ciência da Computação.Orientador: Leonardo Muniz de Lima
VILA VELHA
2008

WESLEY DOS SANTOS MENENGUCI
COMPUTAÇÃO DE ALTO DESEMPENHO
ENVOLVENDO CLUSTERS E MÉTODOS
NUMÉRICOS
BANCA EXAMINADORA
Prof. Msc. Leonardo Muniz de LimaCentro Universitário Vila VelhaOrientador
Prof. Msc. Cristiano BiancardiCentro Universitário Vila Velha
Prof. Msc. Vinícius RosalémCentro Universitário Vila Velha
Trabalho de Conclusão de Curso
aprovado em 26/11/2008.

Aos meus pais João e Deni

AGRADECIMENTOS
Agradeço primeiramente a Deus por até aqui ter sempre me agraciado.
Agradeço ao meu Orientador Leonardo Lima pela oportunidade e pela ajuda na
realização deste trabalho.
Agradeço à minha família por sempre terem me apoiado.

“Eu não falhei, encontrei 10 mil soluções que não davam certo”
Thomas A. Edison

LISTA DE FIGURAS
1 Pipeline: (a) estágios do pipeline e (b) execução dos estágios em um
pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2 Taxonomia de Flynn para computadores paralelos . . . . . . . . . . . . 14
3 Arquitetura SISD, onde: MM é o Módulo de Memória e o EP é o Ele-
mento de Processamento . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Arquitetura MISD, onde: MM são os módulos de Memória e EP os Ele-
mentos de Processamento . . . . . . . . . . . . . . . . . . . . . . . . . 15
5 Arquitetura SIMD, onde: MM são os Módulos de Memória e EP os Ele-
mentos de Processamento . . . . . . . . . . . . . . . . . . . . . . . . . 16
6 : Arquitetura MIMD, onde EP são os Elementos de Processamento . . . 16
7 Multiprocessador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
8 Multicomputador . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
9 Visão geral da classificação de máquinas paralelas quanto ao compar-
tilhamento de memória . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
10 Estrutura de um sistema DSM . . . . . . . . . . . . . . . . . . . . . . . 20
11 Estrutura de um NOW . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
12 Estrutura de um COW. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
13 Estrutura de um PVP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
14 Estrutura de um SMP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
15 Estrutura de um MPP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
16 Principais diferenças entre agregados e MPP . . . . . . . . . . . . . . . 26
17 Visão geral do CLuster Enterprise . . . . . . . . . . . . . . . . . . . . . 31
18 Malha exemplo. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35

19 Espalhamento da temperatura em uma placa com lados à mesma tem-
peratura. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
20 Espalhamento da temperatura em uma placa com lados a temperaturas
distintas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
21 Estratégia de paralelização . . . . . . . . . . . . . . . . . . . . . . . . . 38
22 Estratégia de paralelização . . . . . . . . . . . . . . . . . . . . . . . . . 39
23 Resultado utilizando algoritmo seqüêncial. . . . . . . . . . . . . . . . . . 41
24 Resultado utilizando algoritmo paralelo em 3 processadores. . . . . . . 42
25 Coeficientes de relaxação . . . . . . . . . . . . . . . . . . . . . . . . . . 42
26 Speedup para a malha 1024x1024 . . . . . . . . . . . . . . . . . . . . . 43
27 Eficiência para a malha 1024x1024 . . . . . . . . . . . . . . . . . . . . . 44
28 Tempo de execução para a malha 1024x1024 . . . . . . . . . . . . . . . 44
29 Speedup para a malha 5120x5120 . . . . . . . . . . . . . . . . . . . . . 45
30 Eficiência para a malha 5120x5120 . . . . . . . . . . . . . . . . . . . . . 46
31 Tempo de Execução para a malha 5120x5120 . . . . . . . . . . . . . . . 46

SUMÁRIO
RESUMO
1 INTRODUÇÃO 9
2 FUNDAMENTOS DA COMPUTAÇÃO PARALELA 12
2.1 CLASSIFICAÇÃO DAS ARQUITETURAS PARALELAS . . . . . . . . . 12
2.1.1 CLASSIFICAÇÃO SEGUNDO NÍVEIS DE PARALELISMO . . . 12
2.1.2 CLASSIFICAÇÃO DE FLYNN . . . . . . . . . . . . . . . . . . . . 13
2.1.3 CLASSIFICAÇÃO SEGUNDO COMPARTILHAMENTO DE ME-
MÓRIA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.4 REDES DE ESTAÇÕES DE TRABALHO (NOW) . . . . . . . . . 20
2.1.5 MÁQUINAS AGREGADAS (COW) . . . . . . . . . . . . . . . . . 21
2.1.6 CLASSIFICAÇÃO DAS REDES DE INTERCONEXÃO . . . . . . 22
2.2 TENDÊNCIAS PARA A CONSTRUÇÃO DAS PRÓXIMAS MÁQUINAS . 23
2.3 PARADIGMAS DE PROGRAMAÇÃO . . . . . . . . . . . . . . . . . . . . 25
2.4 MESSAGE PASSING INTERFACE - MPI . . . . . . . . . . . . . . . . . 27
2.5 CLUSTER ENTERPRISE . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3 MÉTODOS NUMÉRICOS 32
3.1 Método das Diferenças Finitas . . . . . . . . . . . . . . . . . . . . . . . 32
3.2 Malha e Métodos Iterativos . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.3 Exemplo Prático . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4 SOLUÇÃO APRESENTADA 37

4.1 ESTRATÉGIA DE PARALELIZAÇÃO . . . . . . . . . . . . . . . . . . . . 37
4.2 RESULTADOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
5 CONCLUSÃO 47
REFERÊNCIAS 48
CÓDIGO FONTE PARALELO PROPOSTO 51

RESUMO
No presente trabalho é realizado um estudo sobre os conceitos fundamentais dacomputação paralela, onde são apresentadas arquiteturas e paradigmas de progra-mação.Para demonstrar o alto desempenho de clusters de estações de trabalho éapresentada uma solução paralela de uma equação diferencial de segunda ordem dis-cretizada pelo método das diferenças finitas. As trocas de mensagem são realizadaspor meio da biblioteca MPI (Message Passing Interface). Por fim são apresentadostestes de desempenho medindo speedup e eficiência do problema proposto.
Palavras-chave: Computação Paralela, Clusters, Métodos Numéricos, MPI.

11
1 INTRODUÇÃO
A capacidade do homem em fazer cálculos foi um dos fatores que ajudaram no
desenvolvimento da computação. No decorrer da história da humanidade vários mé-
todos foram sendo utilizados para se conseguir fazer tais cálculos. Desde ferramentas
de construção simples e de operação manual como o ábaco; as máquinas com en-
grenagens como a calculadora de Blaise pascal; o "calculador analítico"de Charles
Babbage - projeto que introduzia uma memória em sua máquina mecânica; as publi-
cações do matemático George Boole sobre a "lógica booleana"; a máquina de perfurar
cartões do Dr. Herman Hollerit que revolucionou a forma de processarem dados dos
censos da época; o projeto lógico do computador de Von Neumann; os primeiros com-
putadores eletromecânicos [1, 2]. Enfim, toda essa evolução relata a necessidade do
homem em aumentar o poder de fazer cálculos, ou seja, o poder de computar dados.
Essa necessidade existe ainda hoje. A saída para esse gargalo computacional,
que é o poder de processamento, ainda se encontra distante. Mesmo os milhões
de operações por segundo proporcionadas pelas máquinas atuais ainda não são o
bastante para se resolverem problemas cada vez mais complexos.
Astrônomos tentam entender o sentido do universo, biólogos tentam entender as
implicações do genoma humano. Não importa o poder computacional, ele nunca será
suficiente.
Limitações físicas e financeiras têm impedido o aumento da velocidade dos com-
putadores seqüenciais - computadores que tratam instruções em série, uma após a
outra, por meio de uma CPU. Dentre essas limitações pode-se analisar que apenas
aumentar o clock das máquinas, nos levaria a um gargalo baseado na teoria da relati-
vidade de Einstein, o que implica em dizer que um sinal elétrico não pode ser mais rá-
pido que a luz, ou ainda, analisando a miniaturização dos componentes, a qual diminui
as distâncias das trocas de dados proporcionando assim um aumento computacional,
trás o problema quanto à dissipação do calor gerado.

12
Entretanto sabe-se que os problemas computacionais podem ser divididos em pe-
daços e serem solucionados ao mesmo tempo, ou seja, solucionados de forma pa-
ralela. Pode-se então utilizar do uso de simultâneos recursos computacionais, como
processadores, para tentar suprir a demanda computacional. Essa abordagem é de-
nominada computação paralela.
O conhecimento sobre a arquitetura paralela auxilia em todo o ciclo de desen-
volvimento de aplicações paralelas, uma vez que o conhecimento de características
específicas da máquina implica na obtenção de desempenho. As opções de arquitetu-
ras paralelas são variadas, envolvendo desde supercomputadores a máquinas como
os clusters. As primeiras são equipamentos desenvolvidos especificamente para a ob-
tenção de alto desempenho, porém seu problema esbarra no alto custo desta solução.
A outra opção mencionada é composta por aglomerados de computadores comerci-
ais interligadas por uma rede de comunicação e possui uma eficiência menor, mesmo
assim apresenta um bom poder computacional e um custo bem menor.
O cluster é formado por diversas máquinas, conforme mencionado anteriormente,
cada uma com seu próprio processador e sua própria memória. Para que um pro-
cessador conheça dados não pertencentes a sua memória são realizadas operações
de envio e recebimento de mensagens. Existem diferentes aplicativos que criam uma
interface entre esses diversos computadores, assim realizando de maneira simples a
comunicação entre os mesmos. Um dos modelos de programação paralela que utiliza
troca de mensagens para essa comunicação é o MPI (Message Passing Interface) [3].
Em tal padrão as operações de envio e recebimento de mensagens são representa-
das por primitivas send e receive. Neste trabalho é utilizada a biblioteca lam-mpi7.1.2,
sendo esta uma distribuição livre do modelo MPI.
Um cluster pode ser construído para atender certa finalidade, esta finalidade varia
de acordo com o foco a ser atendido, seja em um cluster de alta disponibilidade ou em
cluster de alto desempenho. O primeiro se propõe a manter um sistema ou recurso
sempre ativo, como um servidor. O outro mencionado foi criado para suprir a neces-
sidade de um equipamento com grande poder computacional, não necesariamente
atendendo imediatamente uma requisição como o primeiro.
Problemas como a discretização de uma equação diferencial podem demandar
grande tempo de processamento. Atualmente a computação paralela tem se mostrado
bastante eficaz na busca de um melhor desempenho para realizar essa tarefa. Para
solucionar inúmeros problemas de diversas áreas do conhecimento humano, como a

13
discretização mencionada anteriormente, existem ferramentas fortemente embasadas
na matemática como os métodos numéricos computacionais. Tais métodos retornam
uma solução aproximada que pode ser muito bem aceita em um contexto real.
Diversos trabalhos encontrados na literatura apresentam a obtenção de alto de-
sempenho utilizando-se clusters de estações de trabalho onde vários problemas com-
plexos foram solucionados por meio de métodos numéricos computacionais. Dentre
eles pode ser destacado o estudo de Angeli [4], em 2003. Neste trabalho é apresen-
tado um algoritmo paralelo eficiente para o método dos elementos finitos utilizando o
padrão MPI, cujos resultados apontam que tal código pode melhorar significativamente
a capacidade de previsão e a eficiência para simulações em larga escala.
Outro trabalho relacionado é o desenvolvido por Abboud [5], em 2003, que apre-
senta um modelo paralelo para o método dos volumes finitos de um problema com
grande esforço computacional. Os resultados obtidos deste mostram um considerável
ganho de desempenho com a utilização do processamento paralelo.
Ainda pode ser mencionado o estudo realizado por Lima [6], em 2004, que apre-
senta o desempenho da paralelização do método dos elementos finitos, utilizando
clusters de estações de trabalho e a biblioteca MPI para a troca de mensagens.
Baseado nos trabalhos mencionados acima este trabalho se propõe a mostrar
um alto desempenho utilizando-se a computação paralela. Para prover o paralelismo
será utilizado um cluster. O problema proposto é dado por uma equação diferencial
parcial que será discretizada por pelo método das diferenças finitas, necessitando para
isso um alto poder computacional. Tal equação pode ser empregada para modelar
comportamentos em diversos campos da ciência como astronomia, eletromagnetismo,
mecânica dos fluidos, entre outras. Sendo então empregada em problemas como a
condução de calor em uma placa plana, a determinação deo potencial elétrico para
uma região dentro de uma calha de seção retangular, entre outros.
Este trabalho conta de mais 4 seções além desta introdução. Na próxima seção
são apresentados os fundamentos da computação paralela, tais como as arquiteturas
paralelas e suas classificações e os paradigmas de programação paralela. Na seção 3
é relatado o Método das Diferenças Finitas bem como a discretização de uma equação
diferencial de segunda ordem utilizando tal método. Na seção 4 é relatada a solução
paralela apresentada e seus respectivos testes de desempenho. Na ultima seção são
apresentadas as principais conclusões obtidas.

14
2 FUNDAMENTOS DACOMPUTAÇÃO PARALELA
Este capítulo procura abranger os fundamentos da computação paralela de forma
prática e objetiva, fornecendo o embasamento teórico básico para a realização deste
trabalho. Descreve, os principais e mais representativos modelos arquitetônicos dos
computadores paralelos e apresenta as características principais das linguagens de
programação paralela disponíveis, por fim foca na arquitetura e no paradigma de pro-
gramação utilizado no desenvolvimento deste trabalho.
2.1 CLASSIFICAÇÃO DAS ARQUITETURAS PARALELAS
A classificação ou taxonomia de arquiteturas paralelas para a computação paralela
tem sido objeto de esforço de inúmeros pesquisadores [7, 8, 9], mas nenhuma delas
chega a ser tratada como a derradeira taxonomia, a classificação sem contestação,
mesmo porque existem diferentes âmbitos para serem classificados. Serão apresen-
tadas algumas classificações para uma melhor compreensão da arquitetura paralela.
2.1.1 CLASSIFICAÇÃO SEGUNDO NÍVEIS DE PARALELISMO
A classificação segundo níveis de paralelismo, também chamada de granulosi-
dade, diz respeito ao tamanho das sub-tarefas que podem ser executadas pelos pro-
cessadores ou ainda a quantidade de trabalho realizado entre as iterações dos pro-
cessadores. Dentro dessa classificação há uma separação consagrada na literatura
que a divide em: fina, média e grossa [10, 8].
A granulosidade fina compreende o nível de instrução, nível este caracterizado
pelo paralelismo de baixo nível, onde existem inúmeros processos pequenos e simples
cuja unidade de paralelismo está relacionada às instruções e operações. Esse para-

15
lelismo em nível de instrução pode então ser atingido utilizando técnicas tais como: o
pipeline [11, 12] - instruções divididas em conjuntos de estágios que equivalem à ta-
refa total e que são executadas com concorrência de tempo, como demonstra a Figura
1. - as técnicas superescalares [13] - extensão da técnica pipeline para instrução de
instruções com paralelismo simultâneo, ou seja, emprego de mais de um pipeline - ou
ainda por meio da arquitetura VLIW (Very Long Instruction Word) [14] - tenta alcan-
çar paralelismo de instrução reunindo várias operações em uma única instrução muito
longa.
Figura 1: Pipeline: (a) estágios do pipeline e (b) execução dos estágios em um pipeline
A granulosidade média, ou nível de thread, se constitui de vários processos médios
onde as unidades de paralelismo são blocos e sub-rotinas. Essa granulosidade pode
se basear em técnicas como threads [15] - execução simultânea de diversos fluxos
de execução sobre os recursos de uma mesma arquitetura - ou SMT (Simultaneous
Multithreaded) [16]. Por último a granulosidade grossa, ou em nível de processo, se
constitui por um paralelismo de alto nível, ou seja, por poucos, grandes e comple-
xos processos. Sua unidade de paralelismo se encontra justamente nos processos
e programas. Este nível de paralelismo é encontrado em Multiprocessadores e em
Multicomputadores (ver subseção 2.1.3).
2.1.2 CLASSIFICAÇÃO DE FLYNN
A classificação de Flynn é muito utilizada e mesmo tendo se originado em meados
da década de 1970 ainda é válida e muito difundida. Dois conceitos são a base para a

16
classificação de Flynn [7], sendo eles o fluxo de instrução e o fluxo de dados. Segundo
A. S. Tanenbaum [17]:
Um Fluxo de instruções corresponde a um contador de programa. Um
sistema com n CPUs possui n contadores de programa, e então n fluxo de
instruções... Um fluxo de dados corresponde a um conjunto de operandos.
Um programa que calcula a média de uma lista de temperaturas possui 1
fluxo de dados; um programa que calcula a média das temperaturas de 100
termômetros espalhados por todo o mundo possui 100 fluxos de dados.
Um computador executa seqüências de instruções sobre uma seqüência de dados.
De acordo com a classificação de Flynn podemos diferenciar o fluxo de instruções (ins-
truction stream) do fluxo de dados (data stream) e ainda se estes fluxos são múltiplos
ou simples. Baseando-se na independência dos fluxos Flynn propôs a criação de 4
classes, mostradas na Figura 2.
Figura 2: Taxonomia de Flynn para computadores paralelos
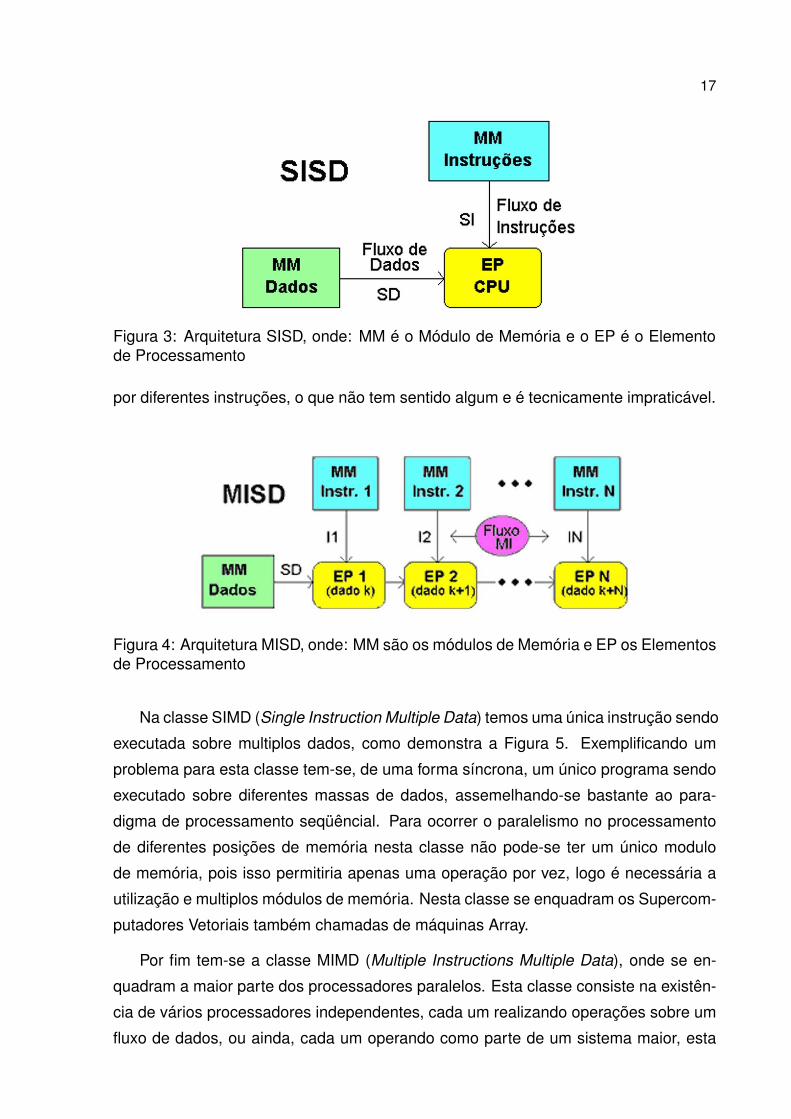
O conceito das máquinas SISD (Single Instruction Single Data) é o mesmo do
computador clássico de Von Neuman. Um único fluxo de instruções atua sobre um
único fluxo de dados, sendo executada uma operação de cada vez, como demonstrado
na Figura 3.
Máquinas MISD (Multiple Instruction Single Data) se enquandram em uma classe
um tanto quanto intrigante. Nesse caso tería-se multiplas instruções sendo executa-
das sobre uma única porção de dados, Figura 4. Não se sabe ao certo se tal classe
realmente existe. Algum autores encaram máquinas Pipeline como MISD [18], outros
consideram esta classe como sendo vazia, pois vários fluxos de instrução agindo so-
bre um mesmo fluxo de dados implica na utilização da mesma posição de memória
17
Figura 3: Arquitetura SISD, onde: MM é o Módulo de Memória e o EP é o Elementode Processamento
por diferentes instruções, o que não tem sentido algum e é tecnicamente impraticável.
Figura 4: Arquitetura MISD, onde: MM são os módulos de Memória e EP os Elementosde Processamento
Na classe SIMD (Single Instruction Multiple Data) temos uma única instrução sendo
executada sobre multiplos dados, como demonstra a Figura 5. Exemplificando um
problema para esta classe tem-se, de uma forma síncrona, um único programa sendo
executado sobre diferentes massas de dados, assemelhando-se bastante ao para-
digma de processamento seqüêncial. Para ocorrer o paralelismo no processamento
de diferentes posições de memória nesta classe não pode-se ter um único modulo
de memória, pois isso permitiria apenas uma operação por vez, logo é necessária a
utilização e multiplos módulos de memória. Nesta classe se enquadram os Supercom-
putadores Vetoriais também chamadas de máquinas Array.
Por fim tem-se a classe MIMD (Multiple Instructions Multiple Data), onde se en-
quadram a maior parte dos processadores paralelos. Esta classe consiste na existên-
cia de vários processadores independentes, cada um realizando operações sobre um
fluxo de dados, ou ainda, cada um operando como parte de um sistema maior, esta

18
Figura 5: Arquitetura SIMD, onde: MM são os Módulos de Memória e EP os Elementosde Processamento
classe pode ser exemplificada na Figura 6. De uma forma genérica, qualquer grupo de
máquinas sendo utilizadas como uma unidade se enquadra nesta classe, basta exe-
cutarem um sistema distribuído. A mesma analogia ao processamento de posições
de memória da classe SIMD é utilizável na classe MIMD. Como representantes desta
classe pode-se citar servidores com multiplos processadores (dual; quad), redes de
estações.
Figura 6: : Arquitetura MIMD, onde EP são os Elementos de Processamento

19
Nestas duas classes, SIMD e MIMD, se enquadram as máquinas paralelas.
2.1.3 CLASSIFICAÇÃO SEGUNDO COMPARTILHAMENTO DE ME-MÓRIA
Expandindo um pouco o esboço da classificação proposta por Flynn pode-se ainda
subdividir a classe MIMD no que tange ao tipo de acesso à memória. Sendo assim
encontram-se basicamente dois tipos de máquinas, as com memória compartilhada,
os multiprocessadores [18] e as com memória não-compartilhada ou distribuída, os
multicomputadores [18].
Os Multiprocessadores (MPs) são baseados na replicação de um único elemento
computacional, neste caso a CPU. Sendo assim todas as CPUs irão utilizar a mesma
memória como na Figura 7, daí o termo memória compartilhada. É claro que essa
concorrência causará condições de corrida em torno da utilização da memória, mas
esse não será o foco deste trabalho. A forma de acesso à memória compartilhada,
por sua vez, pode ser realizada de duas formas, assim formando dois grupos de MPs:
UMA (Uniform Acess Memory ) e NUMA (Non-Uniform Acess Memory ).
O acesso uniforme do MP UMA ocorre pelo fato de ter a mesma velocidade de lei-
tura para qualquer palavra na memória. Nos MP NUMA essa uniformidade no acesso
à memória não ocorre tendo em vista que o tempo de acesso varia dependendo do
módulo de memória. Os MP NUMA também utilizam de memória cache. Como todas
as CPUs possuem sua própria cache surge o problema de sincronizar as cópias nos
caches com as informações em memória remota, essa sincronia chama-se coerên-
cia de cache. Quanto ao tratamento da coerência do cache podem-se subdividir os
MPs NUMA em 4 subgrupos: primeiramente os NCC-NUMA (Non-Cache-Coherent
Non-Uniform Memory Acess) onde não há coerência do cachê, em seguida os CC-
NUMA (Cache-Coherent Non-Uniform Memory Acess) que possui coerência de cache
garantida por hardware, encontra-se também os SC-NUMA (Software-Coherent Non-
Uniform memory acess) onde a coerência da cache é garantida por software e por fim
os COMA (Cachê Only Memory Acess) onde todas as memórias locais são estrutura-
das como memória cache.
O acesso à memória, seja UMA ou NUMA, é realizado através de operações do
tipo load e store, tendo em vista que há uma única área de memória, desta forma a
comunicação entre os processos é bastante eficiente.

20
Figura 7: Multiprocessador
Nos multicomputadores (MCs) a replicação não ocorre em apenas um elemento
computacional. Nestas máquinas encontramos ao menos a replicação de CPU e de
memória, desta forma todas as CPUs têm sua própria área de memória cujo acesso
é exclusivamente seu, como na Figura 8. Essa exclusividade no acesso à memória
indica que não existe acesso a variáveis remotas, o que classifica tais máquinas como
NORMA (Non-Remote Acess Memory ). A comunicação entre os processos é então
realizada através de troca de mensagens, desta forma há então a necessidade de uma
rede de comunicação entre os módulos de CPU/memória, a interface de comunicação
desta rede é análoga ao compartilhamento de memória, a diferença está na latência, o
envio das mensagens é da ordem de microssegundos, enquanto o acesso à memória
compartilhada é de ordem de nanossegundos.
Figura 8: Multicomputador
Quanto ao paralelismo, tanto os MPs quanto os MCs se enquadram na classifi-
cação de sistemas fortemente acoplados (rightly-couple) devido a suas latências, ou
seja, os tempos de acesso à memória serem considerados baixos [18]. Na classifi-
cação de sistemas fracamente acoplados (loosely-couple) enquadram-se os Sistemas

21
Distribuídos (SDs), devido sua latência ser da ordem de milissegundos [18]. Tais sis-
temas são definidos por A. S. Tanenbaum como:
"coleção de computadores independentes que se apresenta ao usuário
como um sistema único e consistente".
Ou seja, são computadores completos interligados por uma rede de comunicação
de longa distância, como a internet, ou seja, os SDs são independentes da locali-
zação geográfica das máquinas [18]. Esses computadores podem ser as estações
de trabalho de algum laboratório de informática ou diversos computadores pessoais
espalhados pelo mundo, porém quando estas máquinas estão ociosas trabalham em
conjunto se comunicando pela rede.
Tanto os sistemas fortemente acoplados quanto os sistemas fracamente acopla-
dos atendem às necessidades para as quais foram desenvolvidos, porém em uma
análise relacionando as três ordens de latência mencionadas constata-se, para uma
mesma computação, que essa diferença do tempo de execução pode ser a mesma
diferença de um dia para três anos.
A Figura 9 mostra uma visão geral da classificação de máquinas paralelas quanto
ao compartilhamento de memória com exemplos de máquinas comerciais.
Figura 9: Visão geral da classificação de máquinas paralelas quanto ao compartilha-mento de memória
Ainda quanto ao compartilhamento de memória também se pode encontrar Memó-
ria Compartilhada Distribuída (DSM - Distributed Shared Memory ) [11]. Nesta classifi-
cação tem-se a ilusão de que temos uma memória compartilhada, quando na verdade
temos módulos de memória distribuídos, como ilustrado na Figura 10. Apesar dessa

22
distribuição física dos módulos de memória, qualquer processo pode endereçar to-
das as memórias. Isso implica na possibilidade de acesso a informações de outros
módulos de memória, ou seja, acesso remoto.
Figura 10: Estrutura de um sistema DSM
2.1.4 REDES DE ESTAÇÕES DE TRABALHO (NOW)
Um tipo de sistemas distribuídos são as Redes de Estações de Trabalho (NOW -
Network Of Workstations) [11] onde várias máquinas convencionais - estações de tra-
balho - são interligadas por uma rede de comunicação convencional, como a Ethernet
[19] e a ATM [20], formando assim uma máquina NORMA com baixo custo de implan-
tação e alto nível de escalabilidade como na Figura 11, onde P/C é o processador,
ML é a memória local, A é o adaptador de barramento, DL é o disco local e AR é o
adaptador de rede.
Os adaptadores de rede utilizados que dão suporte à utilização de vários perifé-
ricos e as tecnologias de rede de comunicação que não possuem otimização para
comunicação paralela, evidenciam que tais tecnologias não foram concebidas para
fins de comunicação distribuída, sendo assim as NOWs acabam se enquadrando em
sistemas fracamente acoplados (loosely acouple) [11], o que acarreta uma perda de
desempenho.
Devido a sua relação custo/benefício as NOWs acabam sendo utilizadas em am-
bientes de ensino de processamento paralelo ou em aplicações onde a comunicação
entre processos não seja muito intensa. Como exemplo de NOW pode-se citar o

23
Figura 11: Estrutura de um NOW
SETI@HOME1, da Universidade da Califórnia, Berkeley.
2.1.5 MÁQUINAS AGREGADAS (COW)
A essência das Máquinas Agregadas (COW - Cluster Of Workstations) é análoga
ao conceito das NOWs, porém ao contrário destas as COWs foram desenvolvidas
com o objetivo de executar operações paralelas. Para isso as estações de trabalho
são interligadas por uma tecnologia de rede dedicada ao processamento paralelo.
Uma outra característica das COWs são as estações sem cabeça (headless works-
tation) - estações não possuem monitor, teclado e mouse - o que também explica o
fato dessas máquinas serem chamadas de pilhas de computadores pessoais (Pile of
PC´s).
Conclui-se que as COWs integram todas as vantagens das NOWs, escalabilidade
e baixo custo, e tenta suprir sua principal desvantagem, grande perda de desempenho
causado pelo grande tempo de latência destes. A Figura 12. trás a estrutura de um
COW, onde: P/C representa os processadores, ML a memória local, A o adaptador de
barramento, DL o disco local e AR oadaptador de rede.
Atualmente uma forma bastante utilizada para se obter alto desempenho é através
de clusters [21].
Como cada máquina possui sua própria memória e CPU (podendo ser também
utilizadas máquinas multiprocessadas) existe uma grande necessidade de comunica-
ção entre os nós, essa comunicação é realizada através de mecanismos de troca de
mensagens (message passing).
1http://setiathome.berkeley.edu/

24
Figura 12: Estrutura de um COW.
A utilização de cluster para processamento paralelo é feito dividindo o problema
entre os vários membros do cluster. Para um melhor aproveitamento do ambiente
em cluster a aplicação deve ser desenvolvida segundo um modelo de programação
paralela (ver subseção 2.3).
São inúmeras as vantagens de utilização de clusters [22], dentre elas pode se
destacar: Alto Desempenho, Escalabilidade, Tolerância a Falhas, entre outras. Os
clusters ainda podem ser configurados de acordo com sua finalidade, tais como: Clus-
ter de Alta Disponibilidade [22, 23], que mantém um determinado serviço de forma
segura o maior tempo possível; Cluster de Alto Desempenho [22, 23], que provê alto
poder computacional; entre outras. Como exemplo de Máquinas Agregadas pode-se
citar o Cluster Enterprise do LCAD (Laboratório de Computação de Alto Desempenho)
da UFES2.
2.1.6 CLASSIFICAÇÃO DAS REDES DE INTERCONEXÃO
Para classificar as redes de comunicação primeiramente deve-se tomar como base
qual dentre as várias tecnologias de comunicação será abordada. Este trabalho abor-
dará um pouco do padrão Ethernet [24], por esta ser a tecnologia de LAN (Local Área
Network ) mais amplamente utilizada. Segundo o padrão OSI [25] este protocolo se
2www.lcad.inf.ufes.br

25
enquadra na camada de enlace, camada esta responsável pela transmissão e recep-
ção de quadros - como são denominadas as mensagens para esta camada - através
do controle de fluxo. O Ethernet também estabelece um protocolo de comunicação
entre sistemas diretamente conectados.
O padrão Ethernet, desde sua criação, vem sendo aprimorado e assim originando
várias versões. A maioria das diferenças das variedades de Ethernet se encontra nas
variações de velocidade e de cabeamento. Por muitos anos o padrão dominante foi o
Ethernet 10 Mbits/s (10BASE-T), mas com o tempo tornou-se insuficiente para suprir
o aumento do trafego e grandes transferências de arquivos.
Para suprir essa demanda uma nova versão foi desenvolvida, a Fast-Ethernet 100
Mbits/s (100BASE-T), esta versão utiliza o mesmo tipo de cabeamento da versão an-
terior, o que facilita a transição entre estas versões uma vez que é necessária apenas
a troca para uma placa de rede compatível.
Uma versão mais avançada é a Gigabit Ethernet 1000 Mbits/s (1000BASE-T) que
é a mais utilizada atualmente. Esta ainda mantém as características do padrão Ether-
net para, assim como o Fast-Ethernet, facilitar a migração de versão.
Um outro padrão é o 10 Gigabit Ethernet. Esta Ethernet é muito nova, possui
apenas uma especificação suplementar dentro dos padrões IEEE (Instituto Institute
of Electrical and Electronics Engineers) sendo assim continua em vista sobre qual
padrão vai ganhar a aceitação comercial. Mesmo com essa evolução das versões,
nota-se uma diferença entre os valores reais e os valores teóricos para o tempo de
transmissão devido aos custos de mensagens e também pelas várias camadas do
TCP/IP [26] que geram grandes cabeçalhos nas mensagens. Essa sensibilidade ao
aumento do trafego é devida à utilização, pelo protocolo Ethernet, de detecção de
colisão, o que afeta principalmente no tempo de latência e na vazão da rede.
2.2 TENDÊNCIAS PARA A CONSTRUÇÃO DAS PRÓXI-MAS MÁQUINAS
São vários os âmbitos que tangem a paralelização, quanto ao paralelismo físico
podem-se destacar três modelos que encabeçam as tendências para as próximas
máquinas paralelas: os Processadores Vetoriais Paralelos, os Multiprocessadores Si-
métricos e as Máquinas Maciçamente Paralelas.
26
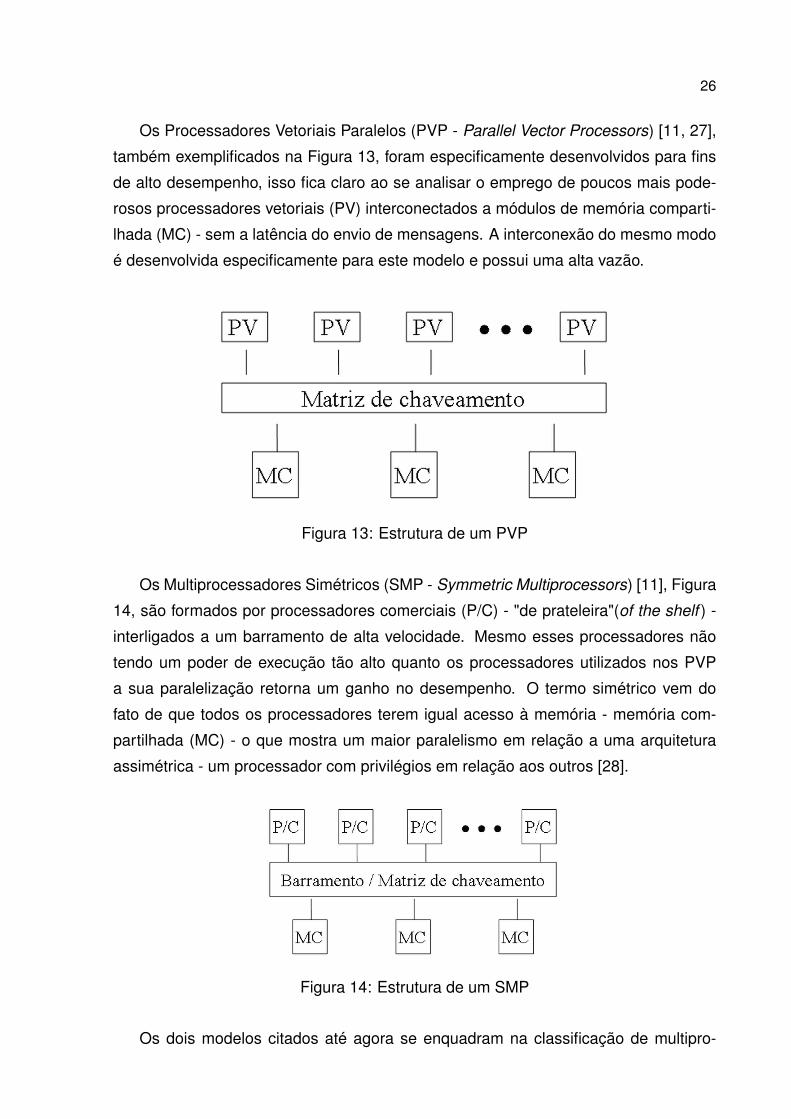
Os Processadores Vetoriais Paralelos (PVP - Parallel Vector Processors) [11, 27],
também exemplificados na Figura 13, foram especificamente desenvolvidos para fins
de alto desempenho, isso fica claro ao se analisar o emprego de poucos mais pode-
rosos processadores vetoriais (PV) interconectados a módulos de memória comparti-
lhada (MC) - sem a latência do envio de mensagens. A interconexão do mesmo modo
é desenvolvida especificamente para este modelo e possui uma alta vazão.
Figura 13: Estrutura de um PVP
Os Multiprocessadores Simétricos (SMP - Symmetric Multiprocessors) [11], Figura
14, são formados por processadores comerciais (P/C) - "de prateleira"(of the shelf ) -
interligados a um barramento de alta velocidade. Mesmo esses processadores não
tendo um poder de execução tão alto quanto os processadores utilizados nos PVP
a sua paralelização retorna um ganho no desempenho. O termo simétrico vem do
fato de que todos os processadores terem igual acesso à memória - memória com-
partilhada (MC) - o que mostra um maior paralelismo em relação a uma arquitetura
assimétrica - um processador com privilégios em relação aos outros [28].
Figura 14: Estrutura de um SMP
Os dois modelos citados até agora se enquadram na classificação de multipro-

27
cessadores UMA, pois ambas possuem o paradigma de memória compartilhada. A
escalabilidade desses modelos é afetada devido à interconexão - normalmente uma
matriz de chaveamento nos PVP e um barramento nos SMP [28] - devido a isso a mai-
oria dos SMP encontrados no mercado possuem uma média de 50 processadores.
As Máquinas Maciçamente Paralelas (MPP - Massively Parallel Processors) [11],
Figura 15, se baseiam na utilização de multicomputadores com inúmeros processa-
dores comerciais (P/C) interligados por uma rede proprietária de alta velocidade. Ao
contrário dos PVP, os processadores utilizados nas MPP possuem um poder com-
putacional médio ou pequeno, porém a paralelização de milhares destes elementos
computacionais também implica em um aumento no desempenho. Este modelo im-
plementa o paradigma de memória distribuída (M) - cada nó de processamento possui
sua própria memória local, o que o caracteriza como uma máquina NORMA, assim
sendo altamente escaláveis.
Figura 15: Estrutura de um MPP
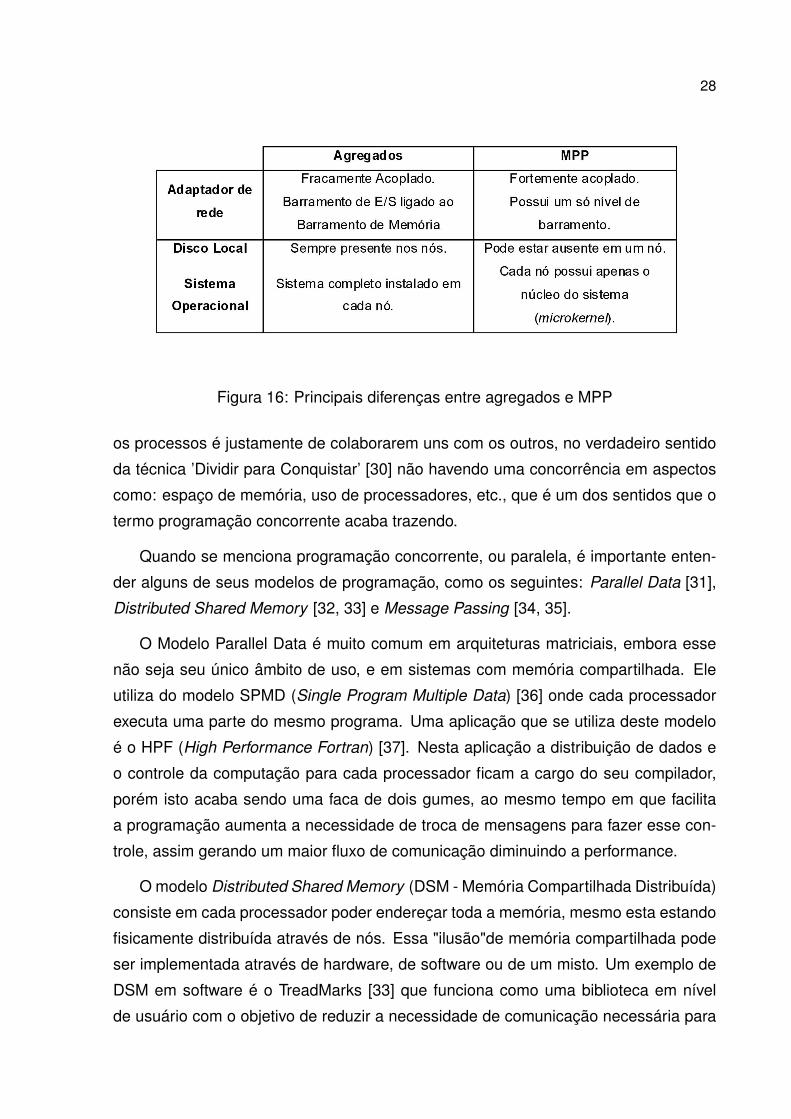
As principais diferenças entre MPP e agregados podem ser vistos na Figura 16.
2.3 PARADIGMAS DE PROGRAMAÇÃO
Uma vez tratados dos modelos físicos para a paralelização devem-se considerar
os paradigmas de programação para as arquiteturas mencionadas nas seções anteri-
ores.
A programação seqüencial é uma alternativa. Nessa programação existe apenas
um fluxo de controle durante a execução, este é o modo mais comum de se escrever
um programa. Outra alternativa é a programação concorrente [29], onde há a exe-
cução de diversos processos que cooperam ou mesmo concorrem entre si. Ainda
existe também a programação paralela, nesta programação o foco da iteração entre
28
Figura 16: Principais diferenças entre agregados e MPP
os processos é justamente de colaborarem uns com os outros, no verdadeiro sentido
da técnica ’Dividir para Conquistar’ [30] não havendo uma concorrência em aspectos
como: espaço de memória, uso de processadores, etc., que é um dos sentidos que o
termo programação concorrente acaba trazendo.
Quando se menciona programação concorrente, ou paralela, é importante enten-
der alguns de seus modelos de programação, como os seguintes: Parallel Data [31],
Distributed Shared Memory [32, 33] e Message Passing [34, 35].
O Modelo Parallel Data é muito comum em arquiteturas matriciais, embora esse
não seja seu único âmbito de uso, e em sistemas com memória compartilhada. Ele
utiliza do modelo SPMD (Single Program Multiple Data) [36] onde cada processador
executa uma parte do mesmo programa. Uma aplicação que se utiliza deste modelo
é o HPF (High Performance Fortran) [37]. Nesta aplicação a distribuição de dados e
o controle da computação para cada processador ficam a cargo do seu compilador,
porém isto acaba sendo uma faca de dois gumes, ao mesmo tempo em que facilita
a programação aumenta a necessidade de troca de mensagens para fazer esse con-
trole, assim gerando um maior fluxo de comunicação diminuindo a performance.
O modelo Distributed Shared Memory (DSM - Memória Compartilhada Distribuída)
consiste em cada processador poder endereçar toda a memória, mesmo esta estando
fisicamente distribuída através de nós. Essa "ilusão"de memória compartilhada pode
ser implementada através de hardware, de software ou de um misto. Um exemplo de
DSM em software é o TreadMarks [33] que funciona como uma biblioteca em nível
de usuário com o objetivo de reduzir a necessidade de comunicação necessária para

29
manter a consistência de memória.
O modelo Message Passing (Troca de Mensagens) é voltado para sistemas que
usam memória distribuída. Existem aplicações que implementam esse modelo, tais
como o PMV (Parallel Virtual Machine) [38] e o MPI (Message Passing Interface) [3],
que funcionam como bibliotecas em nível de Sistema Operacional.
O PMV emula um sistema com memória distribuída em uma rede heterogênea -
com máquinas diferentes - para o envio (send) e recebimento (receive) de mensagens,
assim se mostrando como um sistema único para o usuário. Sua máquina virtual se
divide em duas partes: uma biblioteca e um daemon. Em sua biblioteca encontram-se
as funções para a comunicação/troca de mensagens. O Daemon é um processo que
executa em segundo plano em todas as máquinas e que é gerencia toda a paraleliza-
ção.
O MPI é uma biblioteca que fornece todas as funcionalidades básicas para a co-
municação dos processos, ou seja, os processos se comunicam chamando rotinas
de sua biblioteca para enviar e receber mensagens. O MPI é formado por conjuntos
de processos onde cada processo é criado para um processador; possui paralelismo
explicito - o programador é responsável pela maior parte do esforço de paralelização,
ao contrário do paralelismo implícito onde a aplicação é paralelizada sem a interven-
ção do programador. Sua funcionalidade consiste na subdivisão dos problemas em
pequenas partes que são enviadas aos processadores, depois esses pequenos re-
sultados são agrupados constituindo assim o resultado final. Existem duas principais
distribuições livres dessa biblioteca, sendo elas LAM-MPI3 e MPICH4.
2.4 MESSAGE PASSING INTERFACE - MPI
O padrão MPI apresenta algumas vantagens sobre os demais padrões mencio-
nados na seção anterior, possui um maior desempenho em relação ao TreadMarks e
HPF e uma maior versatilidade em relação ao PVM.
A biblioteca MPI foi desenvolvida para ser padrão em ambientes de memória dis-
tribuída, em Message Passing e em Computação Paralela. Dentre as plataformas alvo
da biblioteca MPI estão os Clusters de Estações de Trabalho. É portável para qualquer
arquitetura e possui aproximadamente 125 funções para programação e ferramentas
3Disponível em: www.lam-mpi.org4Disponível em: www-unix.mcs.anl.gov/mpi/mpich/

30
de análise e performanse. Todo seu paralelismo é explícito.
Neste trabalho é usado o padrão MPI com a distribuição livre da biblioteca lam-mpi,
mais expecificamente a versão lam-mpi7.1.2. Lam-mpi, ou lam, é uma implementação
baseada em daemons. Inicialmente esses deamons são criados baseados em uma
lista de máquinas remotas gerenciadas pelo usuário. Eles permanecem parados até
que eles recebam uma mensagem para carregar um arquivo executável MPI para co-
meçar a execução. Os três passos básicos para executar programas paralelos através
do lam-mpi são: 1 - Inicializa o lam-mpi, o que cria os deamons nas máquinas; 2 -
Executa programas MPI enquanto as deamons lam-mpi existirem em background e 3
- conclui o lam-mpi enviando comandos de finalização.
Alguns conceitos do MPI serão abordados, tais como: Processo, Rank, Grupos,
Comunicador, Application Buffer e System Buffer.
Um Processo é uma parte do programa e pode ser executado em uma ou mais
máquinas.
O Rank é uma identificação única que é atribuída pelo sistema a um processo
quando este é inicializado. Essa identificação é contínua e representada por um nú-
mero inteiro começando de zero até N -1, onde N é o número de processos, cada
processo possui um Rank próprio que é utilizado para receber e enviar mensagens.
Grupo é um conjunto ordenado de processos e é associado a um Comunicador.
Comunicador é um objeto local que representa o domínio de uma comunicação, ou
seja, representa o conjunto de processos que podem ser contactados. Existe um co-
municador pré-definido que inclui todos os processos definidos pelo usuário, chamado
MPI_COMM_WORLD.
Application Buffer é o endereço de memória que armazena um dado que o pro-
cesso necessita enviar ou receber e é gerenciado pela aplicação.
System Buffer é o endereço de memória reservado pelo sistema para armazenar
mensagens.
Algumas funções do MPI se mostram sendo indispensáveis, outras se apresentam
com certa freqüência em inúmeras implementações, por isso é importante comentar
sobre algumas delas.
MPI_Init, é a função que inicializa um processo MPI, sendo a primeira rotina a ser
chamada por um processo. Também sincroniza todos os processos na inicialização

31
de uma aplicação MPI.
MPI_Finalize, é a função chamada para encerrar o MPI, ou seja, é a ultima função
a ser chamada. É usada para liberar memória e não possui argumentos.
MPI_Comm_size, função que identifica, para um determinado comunicador, um
número inteiro de processos.
MPI_Comm_rank, função que identifica, para um determinado grupo, o rank do
processo.
MPI_Send, é a rotina básica de envio de mensagens do MPI, utiliza o modo de
comunicação "blocking send"(envio bloqueante), o que traz maior segurança na trans-
mição da mensagem. Após o retorno libera o "system buffer "e permite acesso ao
"application buffer ".
MPI_Recv, é a rotina básica de recebimento de mensagens do MPI.
MPI_Allreduce, é uma rotina que aplica uma operação de redução sobre um con-
junto de processos definidos pelo comunicador e dispõe o resultado para todos os
processos.5.
2.5 CLUSTER ENTERPRISE
Os testes do presente trabalho foram realizados no Cluster Enterprise do Labo-
ratório de Computação de Alto Desempenho do Centro Tecnológico da Universidade
Federal do Espírito Santo (LCAD - CT - UFES). Este aglomerado é totalmente ope-
racional desde 2003 e é composto por 64 nós de processamento e um nó servidor
(master ). Todos os seus nós utilizam o sistema operacional Linux Red Hat, a instala-
ção local visa diminuir ao máximo o tráfego na rede. Dentre as ferramentas disponíveis
no Enterprise foram utilizados o compilador gcc da linguagem C para GNU/Linux, e a
biblioteca do Padrão MPI lam-mpi 7.1.2.
O código seqüencial foi compilado utilizando "gcc -o <arq> <arq.c>"e o código
paralelo "mpicc -o <arq> <arq.c>".
Cada nó possui 256 MB de memória SDRAM, 20 GB de memória de armaze-
namento e um processador AMD ATHLON XP 1800 com 2 unidades de processa-
mento para operações de ponto flutuante operando a uma freqüência de 1,53 GHz,5http://www.inf.puc-rio.br/ alvim/MPI/lam.html

32
totalizando 16 GB de memória RAM, 1,2 TB de capacidade de armazenamento, um
desempenho teórica de pico igual a 3,05 GFLOP/s por nó de processamento e uma
performance teórica de pico do sistema de 195,8 GFLOP/s. Testes rodando o High-
Performance Linpack Benchmark (programa para teste de desempenho de supercom-
putadores paralelos - basicamente uma fatoração LU de uma matriz densa) mostraram
uma performance real de 1,79 Gflop/s por nó e um desempenho real do sistema de 47
GFLOP/s.
A rede de interconexão é composta por dois switches com 48 portas cada, onde a
cada porta possui capacidade teórica de 100Mb/s para comunicação entre os nós de
processamento e se comunicam entre si por um módulo Gigabit Ethernet (1000 Mb/s).
A quantidade de nós é dividida igualmente entre os dois switches e um deles possui
uma porta Gigabit a mais para conexão com o servidor.
O nó servidor possui basicamente a mesma configuração dos nós de processa-
mento, as únicas resalvas é que conta com 512 MB de RAM, 80 GB de disco e duas
placas de rede, sendo uma Gigabit Ethernet que se conecta com um dos switches
do cluster e outra Fast-Ethernet para conexão externa. Esta máquina também é res-
ponsável pela distribuição dos processos nos nós de processamento, pelo armazena-
mento das contas de usuários e por atividades de configuração, atualização e monito-
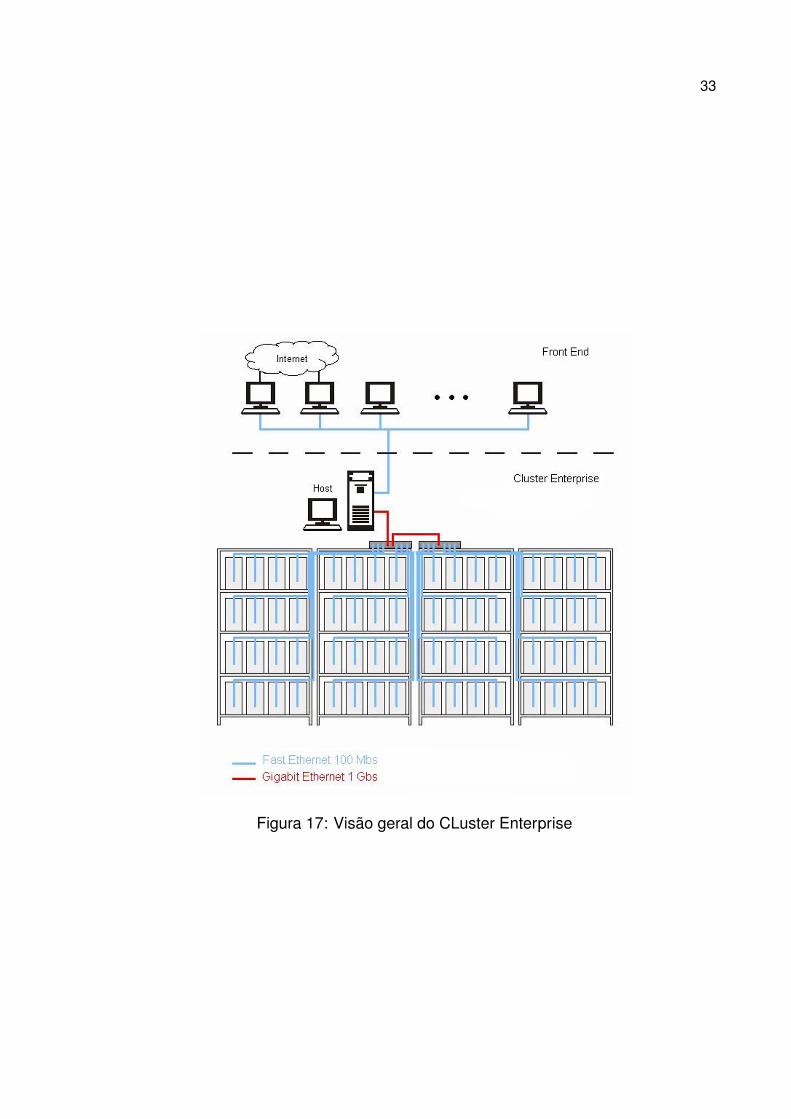
ramento dos nós de processamento. A Figura 17 ilustra as conexões de rede entre as
máquinas externas, o servidor e os nós de processamento.
O acesso aos recursos computacionais do cluster pode ser feito de duas formas
principais: acessando diretamente as máquinas do LCAD ou através de acesso re-
moto. O acesso remoto é feito, ao se logar à máquina do LCAD utilizando nome
e senha cadastrados, através de SSH (Secure Shell) [36]. Os arquivos podem ser
transferidos para o LCAD através de SPC (Secure Copy ) [36] para as máquinas.
33
Figura 17: Visão geral do CLuster Enterprise

34
3 MÉTODOS NUMÉRICOS
Métodos numéricos [39] podem ser empregados juntamente com o contexto de
arquiteturas paralelas e programação paralela para a obtenção de ganho de per-
formance. Grande parte de problemas de diversas áreas podem ser solucionados
utilizando-se tais métodos. Para um processo de modelagem computacional de al-
gum problema consideram-se duas etapas. A primeira consta da identificação dos
fatores que influenciam de maneira relevante no problema para a obtenção de um mo-
delo matemático. A segunda etapa é a obtenção de resultados através desse modelo
matemático, esta é a tarefa atribuída aos métodos numéricos.
A essência dos métodos numéricos está na discretização do contínuo, e é isto
que torna um problema "finito"e capaz de ser solucionado através de computadores.
Um exemplo de utilização de métodos numéricos é na discretização de equações
diferenciais [40].
3.1 Método das Diferenças Finitas
Equações diferenciais parciais aparecem com freqüência na solução de problemas
em diversas áreas do conhecimento. O presente trabalho apresenta o processo de
discretização pelo método das diferenças finitas da equação 3.1:
−(
∂ 2u∂x2 +
∂ 2
∂y2
)+a
∂u∂x
+b∂u∂y
+ cu = f (x,y) (3.1)
Onde a, b, c e f (x,y) são conhecidas e u(x,y) é conhecida em sua região de con-
torno.
A equação de Laplace, equação que modela comportamentos de diversos campos
da ciência como astronomia, eletromagnetismo, mecânica dos fluidos, entre outras, é
um caso particular da equação descrita acima. Sendo assim, tal equação pode ser

35
empregada em problemas como a condução de calor em uma placa plana, a deter-
minação de potencial elétrico para a região dentro de uma calha de seção retangular,
entre outros.
Tais métodos foram implementados originalmente para a programação seqüen-
cial, porém observa-se um aumento de desempenho quando são implementados em
programação paralela.
O método das Diferenças Finitas consiste na aproximação de derivadas por meio
de um número finito de diferenças.
A incógnita de uma equação diferencial é uma função u(x) definida em todos os
pontos do intervalo no qual a equação está sendo resolvida. O primeiro passo para
solução numérica de equações diferenciais é discretizar a região onde se procura
a solução, ou seja, defini-se uma malha, que é o conjunto finito de pontos também
chamados de nós da malha. Calculam-se aproximações de u(x) nesses nós.
O segundo passo consiste na discretização das diferenciais que estão na equação.
Essas derivadas são aproximadas por meio de diferenças entre valores da solução
discretizada.
A ferramenta básica na definição das aproximações de derivadas é a série de
Taylor. Essa série traz informações sobre a função em um ponto x através de uma
avaliação da vizinhança de x, isto é, no ponto x + h. Sendo assim uma expansão em
série de Taylor da função u(x) é apresentada na equação 3.2:
u(x+h) = u(x)+hu′(x)+h2
2!u′′(x)+ . . .+
h5
n!un(x)+
h(n+1)
(n+1)!u5(x) (3.2)
O último termo representa o erro da aproximação, esse erro se torna irrelevante
para valores muito pequenos de h. Usando-se essa expansão da série de Taylor e to-
mando n = 2 pode-se chegar a fórmula avançada 3.3 para a discretização da derivada:
u(x+h) = u(x)+hu′(x)+h2
2u′′(x)+
h3
3!u′′′(x) (3.3)
Analogamente, tomando −h chega-se a formula atrasada 3.4:
u(x−h) = u(x)−hu′(x)+h2
2u′′(x)− h3
3!u′′′(x) (3.4)
Subtraindo a última expressão da penúltima chega-se a fórmula centrada 3.5 para

36
a discretização da derivada e o seu erro:
u′(x) =u(x+h)−u(x−h)
2h+
h2
3!u′′ (3.5)
Seguindo as mesmas idéias pode-se estabelecer a expressão 3.6 para o cálculo
de aproximações para a derivada segunda:
u′′(x) =u(x+h)−2u(x)+u(x−h)
2h+
h2
12uiv (3.6)
No método das Diferenças Finitas as derivadas presentes na equação diferencial
3.1 são substituídas pelas aproximações 3.5 e 3.6.
Para facilitar a impementação computacional pode-se adotar a notação ui para a
aproximação de u(xi). Sendo assim as equações 3.5 e 3.6 podem ser substituídas
pelas equações 3.7 e 3.8 seguintes:
u′(x)∼= ui+1−ui−1
2h(3.7)
u′′(x)∼= ui+1−2ui +ui−1
h2 (3.8)
Com isso pode-se discretizar a função 3.1 com a utilização do método das Dife-
renças Finitas, obtendo a discretização mostrada na fórmula 3.9:
−(
ui, j+1−2ui, j +ui, j−1
h2x
+ui+1, j−ui, j +ui−1, j
h2y
)+a
ui, j+1−ui, j−1
2hx+b
ui+1, j−ui−1, j
2hy+cui, j = f (x,y)
(3.9)
3.2 Malha e Métodos Iterativos
Como já mencionado na seção 3.1, o método das diferenças finitas traz informa-
ções sobre a função x através de uma avaliação da vizinhança de x, isto é, no ponto
x + h. Com isso percebe-se que um ponto é aferido com a contribuição de seus vizi-
nhos, ou seja de seu contorno. Com isso torna-se necessário uma estrutura matricial
para para ser calculado a equação diferencial utilizando tal método. Essa estrutura
matricial também é chamada de malha, e seus elementos são chamados de nós. A
Figura 18 representa uma malha onde o nó 8 é calculado com a contribuição dos nós
3, 7, 9 e 13.

37
Figura 18: Malha exemplo.
Como a equação 3.9 pode ser escrita em todos os pontos da malha tem-se um
sistema com tantas equações e incógnitas quanto os elementos da malha. Para resol-
ver esse sistema pode-se utilizar de métodos para solução de sistemas lineares, tais
como o método iterativo Gauss-Seidel [39], onde as iterações são calculadas aprovei-
tando os cálculos já atualizados de outras componentes para atualizar a componente
que está sendo computada.
Para a equação 3.9, as iterações são calculadas usando a equação 3.10:
ui, j =fi, j−
(a
2hx− 1
h2x
)ui, j+1 +
(a
2hx+ 1
h2xui, j−1
)−
(b
2hy− 1
h2y
)ui+1, j +
(b
2hy+ 1
h2y
)ui−1, j
(2h2
x+ 2
h2y+ c
)
(3.10)
Comparado com o método iterativo Jacobi [39], o método Gauss-Seidel possui
uma convergência mais rápida pois se utiliza de atualizações imediatas em suas ite-
rações, porém há uma técnica de aceleração da convergência dos métodos iterativos
Conhecida com o nome de Successive Over Relaxation (SOR) [39]. Esse método de-
fine a próxima iteração como uma média entre a iteração e a próxima iteração obtida
pelo método Gauss-Seidell.
As iterações, associadas ao parâmetro w do método SOR, são definidas pela
equação 3.11:
xk+1SOR = (1−w)xk
SOR +wxk+1Gauss−Seidell (3.11)
No método SOR, w é chamado de parâmetro de relaxação. Observa-se que
quando w = 1 tem-se o método Gauss-Seidel. A escolha de 1 < w < 2 caracteriza
os métodos de sobre-relaxação e valores 0 < w < 1 os métodos de sub-relaxação.
Com isso destaca-se que o o método SOR só converge se 0 < w < 2.

38
3.3 Exemplo Prático
Um exemplo prático da utilização dos métodos numéricos até aqui apresentados
é na condução de calor em uma placa plana. A equação de Laplace 3.12, que é um
caso particular da equação 3.1, em condições ideais de condutividade e variação de
temperatura, rege a condução de calor em uma placa plana.
−(
∂ 2T∂x2 +
∂ 2T∂y2
)= 0 (3.12)
Em uma placa retangular cada ponto da mesma pode ser considerado como um
nó de uma malha. Se cada lado da placa for submetido a uma temperatura pode-
se calcular o espalhamento do calor em toda a placa retangular plana. Se essas
temperaturas de contorno forem iguais, os valores do interior da malha devem ser
aproximadamente iguais para todos os pontos da discretização. As figuras ?? e 20
mostram o espalhamento do calor em uma placa retangular plana com valores de
contorno iguais e distintos, respectivamente. Quanto mais pontos a malha tiver, mais
próximos serão os nó vizinhos e mais precisa a solução.
Figura 19: Espalhamento da temperatura em uma placa com lados à mesma tempe-ratura.
Figura 20: Espalhamento da temperatura em uma placa com lados a temperaturasdistintas.

39
4 SOLUÇÃO APRESENTADA
Este capitulo apresenta a solução paralela para a discretização da equação 3.1,
mostrada anteriormente na seção 3, e envolve os métodos numéricos também relacio-
nados àquela seção, bem como a utilização do padrão MPI, especificamente a versão
lam7.1.2, para as trocas de mensagens.
4.1 ESTRATÉGIA DE PARALELIZAÇÃO
O problema consiste em, tendo uma malha bidimensional com valores de con-
torno conhecido conseguir a solução para qualquer nó interno à malha, ou seja, obter
os elementos internos de uma matriz bidimencional onde apenas as primeiras e ul-
timas linhas e colunas possuem valores conhecidos. Essa malha é obtida conforme
mencionado na seção 3.2. Este problema análogo ao apresentado na seção 3.3.
A estratégia paralela para se solucionar tal problema é basicamente subdividir
essa malha entre os nós de processamento de um cluster.
Tal divisão pode ser feita de diversas maneiras. Uma forma simples e prática é,
se tendo um determinado domínio em x e em y, ou seja, uma matriz com y linhas e x
colunas, criar n matrizes colunas, onde n é o número de nós de processamento que
serão utilizados. Tal estratégia pode ser ilustrada pela Figura 21.
Pode haver casos em que a divisão da malha entre os processos não seja exata.
Para garantir a generalização da solução, se necessário, o ultimo processo recebe
uma fração da malha de tamanho diferenciado das frações dos demais processos. De
certa forma isso pode prejudicar o balanceamento de carga da solução, porém esse
balanceamento pode ser garantido se trabalhando com malhas que sejam divisíveis
pelo número de nós de processamento utilizados.
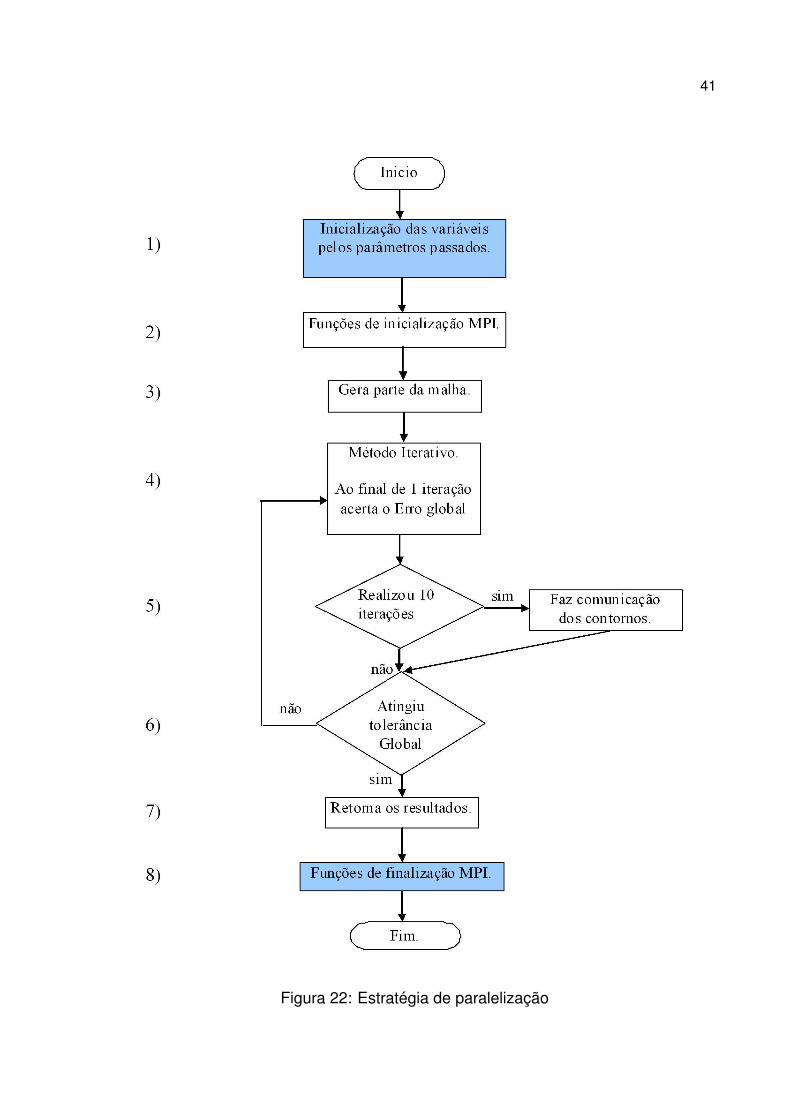
A figura 22 contém os principais passos do algoritmo paralelo proposto. O passo

40
1 representa onde é feito a inicialização das variáveis do programa que são passados
como parâmetro pela linha de comando. O passo 2 representa a utilização das subro-
tinas de inicialização MPI, tais como MPI_Init, MPI_Comm_size e MPI_Comm_rank.
No passo 3 são construídos as partes da malha referentes a cada nó de processa-
mento. No passo 4 tem-se início o processo iterativo e ao final de cada iteração é feito
o acerto do erro global, variável que coordena o mesmo erro para todos os processos.
Tal correção é feita através da função MPI_Allreduce, onde esta retornará o valor má-
ximo dentre todos os erros locais. No passo 5 há um teste onde, a cada 10 iterações, é
realizada uma troca de mensagens entre os valores de contornos dos processos para
correção dos valores interiores aos mesmos. O passo 6 representa a condição para
término das iterações. No passo 7 há o retorno dos resultados do processo, onde os
valores obtidos são armqzenados em arquivos. Para finalizar o algoritmo paralelo é
chamada a subrotina MPI_Finalize, fechando assim o passo 8.
Figura 21: Estratégia de paralelização
41
Figura 22: Estratégia de paralelização

42
Segue em seqüência o pseudocódigo do algoritmo proposto:
InicioInicia variáveis com valores passados por parâmetro
Inicia funções MPI
Aloca o subdomínio referente ao processo
Enquanto não atingir a tolerânciaFaça:
Realiza uma iteração através do método SORAcerta o erro global através da função MPI_Allreduce
Se realizou 10 iteraçõesinicio:
Faz a comunicação dos contornos dos subdomínios através das funçõesMPI_Send e MPI_recv
fimFim
Guarda os resultados obtidos em arquivo
Desaloca o subdomínio
Finaliza as funções MPIFim
4.2 RESULTADOS
O tempo de execução de um algoritmo é o tempo necessário para a sua execução,
seja ele seqüencial ou paralelo. Essa aferição é base para a obtenção de outras
métricas de desempenho. O tempo de execução do código proposto foi medido com
o auxílio de algumas funções padrão da Linguagem C que utilizam a biblioteca time.h.
Para medir o desempenho dos algoritmos seqüencial e paralelo foram utilizadas

43
duas medidas de quantização: Speedup [10, 41] e Eficiência [42, 43].
Speedup (Sp) é a relação entre o tempo de execução de um algoritmo em um pro-
cessador (T1) e o tempo de executá-lo em p processadores (Tp), ou seja, é o aumento
da velocidade de um algoritmo paralelo em relação ao seqüencial. Essa medida pode
ser definida por 4.1.
Sp =T1
Tp(4.1)
Eficiência (E) é a relação entre o speedup e o número de processadores (p), isto
é, verifica a utilização do processador ou o quanto o processador está sendo utilizado.
Essa relação varia entre 0 e 1, ou seja, entre 0% e 100% pode ser determinada por 4.2
E =Spp
(4.2)
Foram executados testes que utilizaram 1, 2, 4, 6 e 8 processadores e em cada
caso foi avaliado seu desempenho.
Para o teste seqüencial utilizou-se um algoritmo estritamente seqüencial, ou seja,
um programa sem nenhuma paralelização e sem sub-rotinas MPI. Dessa forma considerou-
se o desempenho da solução paralela em relação a um algoritmo seqüencial.
Um comparativo entre os resultados obtidos entre o processamento sequêncial e
o paralelo pode ser verificado nas Figuras 23 e 24, que apresentam, respectivamente,
um gráfico do resultado seqüêncial e outro com o resultado utilizando 3 processadores,
ambos com os mesmos valores de contorno.
Figura 23: Resultado utilizando algoritmo seqüêncial.
44
Figura 24: Resultado utilizando algoritmo paralelo em 3 processadores.
Os testes de desempenho foram executados utilizando-se dois tamanhos distintos
de malhas, onde foram considerados os respectivos tamanhos de memória alocados
para cada malha de forma que os mesmos não necessitassem fazer uso de swaping
nos nós de processamento. O tamanho da malha está diretamente ligado ao poder de
processamento necessário para sua resolução, ou seja, quanto maior a malha mais
computação ela necessitará para ser resolvida.
Para a primeira malha, cujo tamanho é 1024x1024, verificou-se a contribuição do
método SOR, seção 3.2 no número de iterações realizada pela solução, o que pode
ser verificado na tabela 25.
Figura 25: Coeficientes de relaxação
Para os valores do coeficiente de relaxação w 3 entre 1.5 e 0.5 não se percebe uma
redução muito significativa quanto ao número de iterações; para o valor de w = 1.9
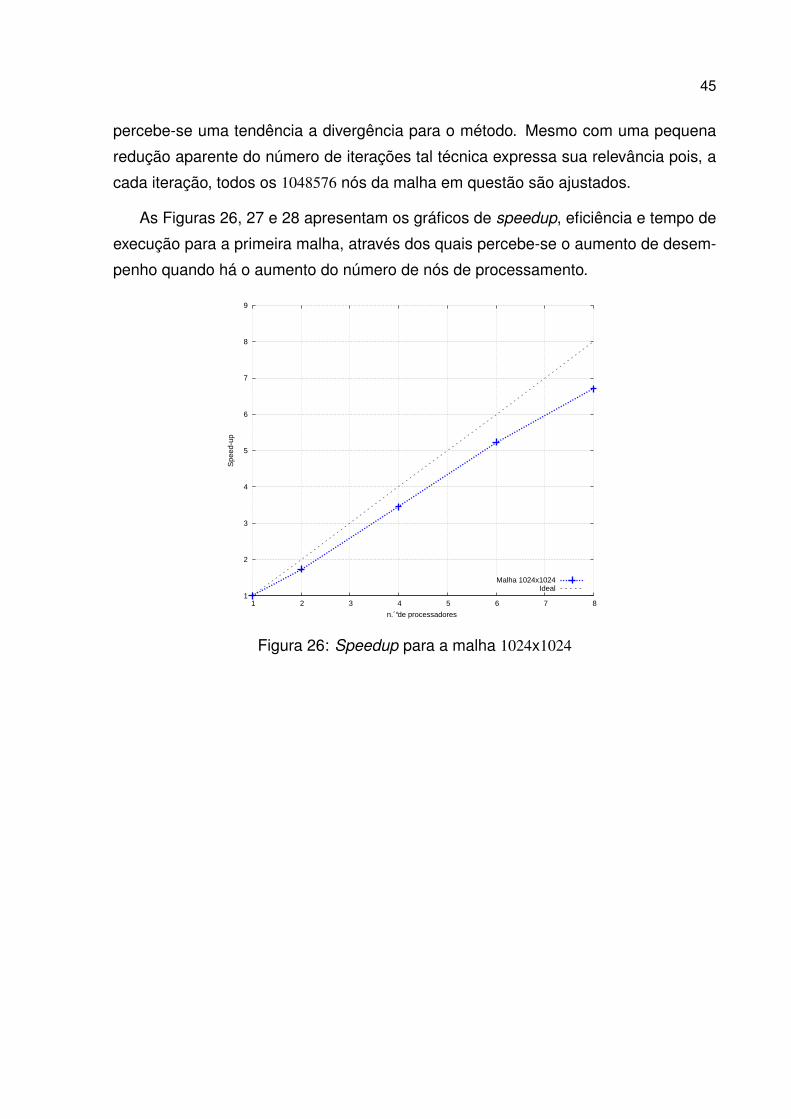
45
percebe-se uma tendência a divergência para o método. Mesmo com uma pequena
redução aparente do número de iterações tal técnica expressa sua relevância pois, a
cada iteração, todos os 1048576 nós da malha em questão são ajustados.
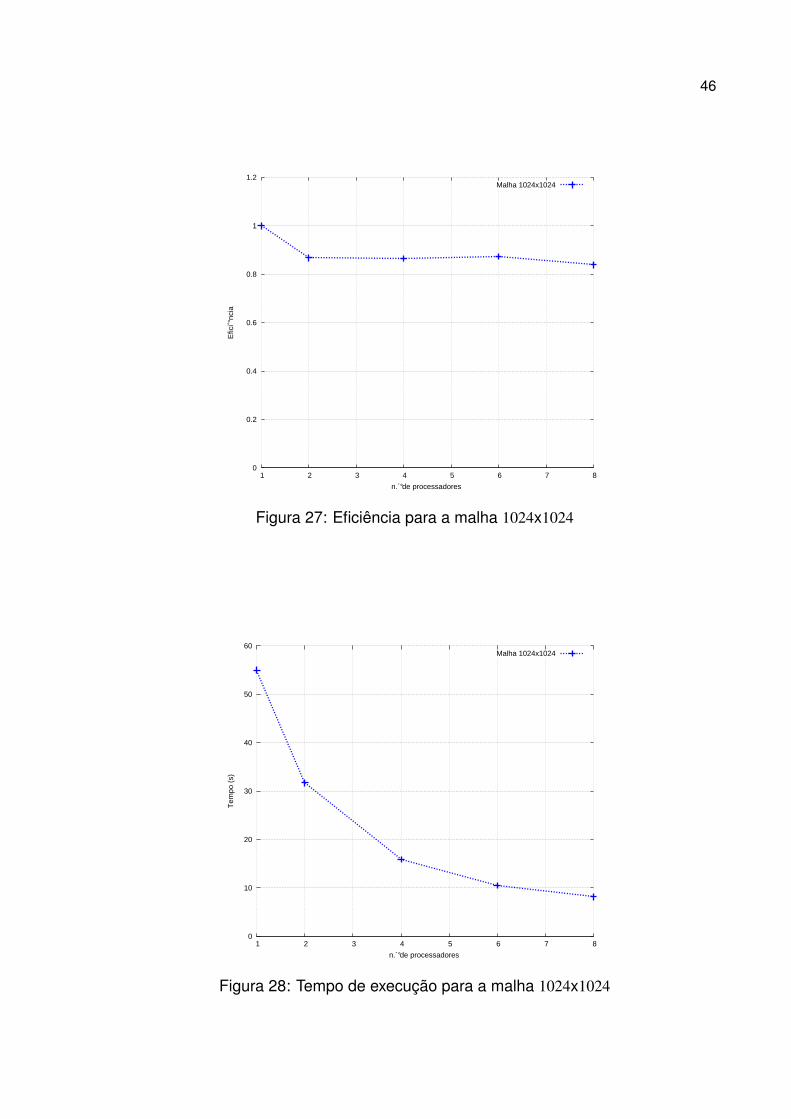
As Figuras 26, 27 e 28 apresentam os gráficos de speedup, eficiência e tempo de
execução para a primeira malha, através dos quais percebe-se o aumento de desem-
penho quando há o aumento do número de nós de processamento.
1
2
3
4
5
6
7
8
9
1 2 3 4 5 6 7 8
Spe
ed-u
p
n.´° de processadores
Malha 1024x1024Ideal
Figura 26: Speedup para a malha 1024x1024
46
0
0.2
0.4
0.6
0.8
1
1.2
1 2 3 4 5 6 7 8
Efic
iˆ“nc
ia
n.´° de processadores
Malha 1024x1024
Figura 27: Eficiência para a malha 1024x1024
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8
Tem
po (
s)
n.´° de processadores
Malha 1024x1024
Figura 28: Tempo de execução para a malha 1024x1024
47
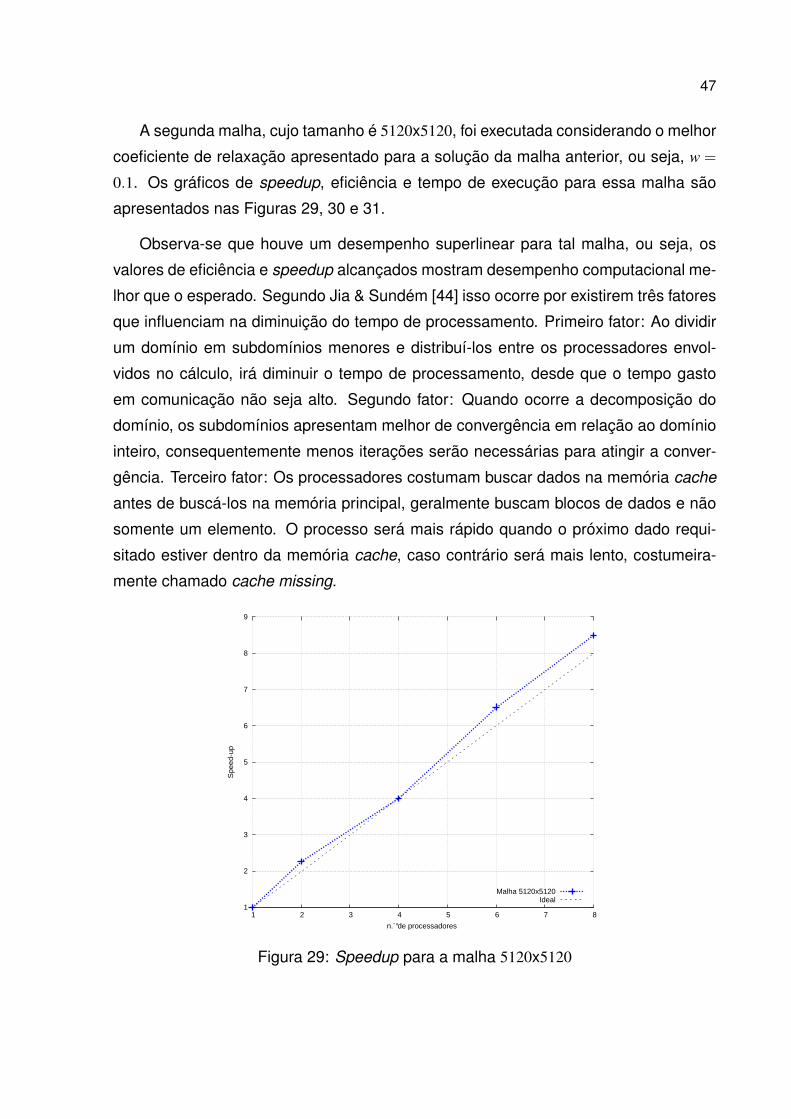
A segunda malha, cujo tamanho é 5120x5120, foi executada considerando o melhor
coeficiente de relaxação apresentado para a solução da malha anterior, ou seja, w =
0.1. Os gráficos de speedup, eficiência e tempo de execução para essa malha são
apresentados nas Figuras 29, 30 e 31.
Observa-se que houve um desempenho superlinear para tal malha, ou seja, os
valores de eficiência e speedup alcançados mostram desempenho computacional me-
lhor que o esperado. Segundo Jia & Sundém [44] isso ocorre por existirem três fatores
que influenciam na diminuição do tempo de processamento. Primeiro fator: Ao dividir
um domínio em subdomínios menores e distribuí-los entre os processadores envol-
vidos no cálculo, irá diminuir o tempo de processamento, desde que o tempo gasto
em comunicação não seja alto. Segundo fator: Quando ocorre a decomposição do
domínio, os subdomínios apresentam melhor de convergência em relação ao domínio
inteiro, consequentemente menos iterações serão necessárias para atingir a conver-
gência. Terceiro fator: Os processadores costumam buscar dados na memória cache
antes de buscá-los na memória principal, geralmente buscam blocos de dados e não
somente um elemento. O processo será mais rápido quando o próximo dado requi-
sitado estiver dentro da memória cache, caso contrário será mais lento, costumeira-
mente chamado cache missing.
1
2
3
4
5
6
7
8
9
1 2 3 4 5 6 7 8
Spe
ed-u
p
n.´° de processadores
Malha 5120x5120Ideal
Figura 29: Speedup para a malha 5120x5120

48
0
0.2
0.4
0.6
0.8
1
1.2
1 2 3 4 5 6 7 8
Efic
ienc
ia
n.´° de processadores
Malha 5120x5120
Figura 30: Eficiência para a malha 5120x5120
0
200
400
600
800
1000
1200
1 2 3 4 5 6 7 8
Tem
po (
s)
n.´° de processadores
Malha 5120x5120
Figura 31: Tempo de Execução para a malha 5120x5120

49
5 CONCLUSÃO
Neste trabalho foi realizado um estudo dos elementos para obtenção de alto de-
sempenho como arquiteturas paralelas bem como os paradigmas de programação
paralela. Focou-se uma solução baseada no paradigma Message Passing, adotando
como padrão o MPI, aplicado ao processamento paralelo em clusters de estações de
trabalho. A solução trata da resolução de um sistema linear presente em uma malha,
onde cada nó era expresso como uma equação diferencial de segunda ordem.
Para medir o desempenho da solução foram analisados (speedup) e eficiência
para duas malhas distintas, sendo uma menor, 1024x1024 nós, e outra maior, 5120x5120
nós.
Nos dois casos foi obtido um aumento de desempenho à medida que também
se aumentava o número de nós de processamento. A segunda malha apresentou
desempenho superlinear, ultrapassando assim as expectativas esperadas. Através
dos resultados expostos concluiu-se que a proposta de se obter alto desempenho
utilizando-se clusters de estações de trabalho é válida.
Como trabalhos futuros são sugeridos implementações de algoritmos para equa-
ções mais complexas, que estendam os conceitos apresentados para casos tridimen-
sionais e que demandem maior consumo computacional, como exemplo as equações
de Navier-Stokes que são equações diferenciais que descrevem o escoamento de flui-
dos. Realizar testes em máquinas com memória compartilhada.

50
REFERÊNCIAS
[1] CONSTABLE, R.L. Computer Science: Achievements and Challenges circa 2000.march 2000.
[2] FEDELI R. D.; POLLONI, E. G. F. P. F. E. Introdução à Ciência da Computação.São Paulo: Thomson, 2003.
[3] MPI Message Passing Interface Forum. MPI: A Message Passing Interface. In Pro-ceedings of Supercomputing ’93. IEEE Computer Society Press, p. p. 878–883,1993.
[4] ANGELI J. P. DE; VALLI, A. M. P. D. S. A. F. R. N. C. Numerical simulations of thenavier-stokes equations using clusters of workstations. Vitória, ES, 2003.
[5] ABBOUD H. J.; REIS, N. C. S. A. B. S. J. M. Reconstrução do campo de vento tri-dimensional em regiões de topografia complexa usando clusters de computadores.Vitória, ES, 2003.
[6] LIMA L. M. DE; MELOTTI, B. Z. C. L. V. A. M. P. Uma implementação paralela,eficiente do método dos elementos finitos para equação de advecção e difusão.Vitória, ES, Brasil, 2004.
[7] FLYNN, M. J. Some computer organizations end their effectiveness. IEEE Transec-tion on Computers 21, v. 21, p. p. 948–960, 1972.
[8] NAVAUX, P. O. A. Introdução ao processamento paralelo. RBC - Revista Brasileirade Computação, v. 5, p. p. 31–43, Outubro 1972.
[9] DUNCAN, R. A survey of parallel computer architectures. IEEE Computer, p. p.5–16, Fevereiro 2000.
[10] KIRNER, C. Arquiteturas de sistemas avançados de computação. Anais da Jor-nada IPUSP/IEEE em sistemas de computação de Alto Desempenho, p. p. 307–353,1991.
[11] ROSE C. A. F. DE, N. Arquiteturas Paralelas. [S.l.]: Sagra Luzzatto, 2003.
[12] HENNESSY J.; PATTERSON, D. A. Computer Architecture: A Quantitative Appro-ach. [S.l.]: San Mateo, 1994. (Morgan Kaufmann).
[13] GONÇALVES R. A. L.; NAVAUX, P. O. A. A utilização de buffer de remessa uni-ficado em arquiteturas superescalares com fluxos balanceados de instruções. Con-ferência Latino Americana de Informática, v. 24, 1998.

51
[14] ITO, S. A. Arquiteturas VLIW: Uma Alternativa para Ex-ploração de Paralelismo a Nível de Instrução. URL:http://www.inf.ufrgs.br/procpar/disc/cmp134/trabs/T1/981/VLIW/vliw10.htm. Acessoem 27/04/2008.
[15] COSTA C. M. DA; STRINGHINI, D. ERAD 2002 - Escola Regional de Alto Desem-penho. São Leopoldo - RS: Sagra-Luzzatto, 2002.
[16] TULLSEN D. M.; EGGERS, S. J. L. H. M. Simultaneous multithreading: Maximi-zing on-chip parallelism. Proceedings of the ISCA, Itália, 1995.
[17] TANENBAUM, A. S. Organização estruturada de computadores. 3. ed. Rio deJaneiro: Prentice Hall, 1999.
[18] TANENBAUM, A. S. Sistemas Operacionais Modernos. 2. ed. São Paulo: Pearson- Prentice Hall, 2006.
[19] SOARES L. F. G.; LEMOS, G. S. C. Redes de computadores: das LANS, MANSe WANS às redes ATM. rev. e ampl. Rio de Janeiro: Campus, 1995.
[20] HAENDEL M.; HUBER, M. S. S. ATM Networks: Comcepts Protocols Aplications.[S.l.]: Addison-Wesley, 1998.
[21] MARTINS E; FERREIRA, G. M. H. M. Cluster. 2005.
[22] JÚNIOR E. P. F., F. R. B. Construindo Supercomputadores com Linux: ClusterBeowulf. Goiânia, Goiás: [s.n.], 2005. p. 104 p. Departamento de Telecomunicações,Cefet-Go. Departamento de Telecomunicações, Cefet-Go.
[23] PITANGA, M. Construindo Supercomputadores com Linux. Rio de janeiro: Bras-port Livros e Multimídia Ltda, 2004.
[24] B., R. M. D. R. Ethernet: Distributed Packet Switching for Local ComputerNetworks. 1996. Cópia em HTML do artigo de 1996, parte dos textos lássicos daACM.
[25] PETERSON L. L., D. B. S. Computer Networks: A system approach. [S.l.]: MorganKaufman Publishers, 2000.
[26] H., C. TCP/IP Network Administration. [S.l.]: O’Reilly, 1998.
[27] DONGARRA, J. The linpack benchmark: na explanation. Internacional Confe-rence on Supercomputing, Springer-Verlag, Berlin, v. 1, p. p. 456–474, 1988.
[28] HWANG, K. Advanced Comtuter Archtecture: Parallelism, Scalability, Program-mability. [S.l.]: McGraw-Hill, 1993.
[29] OLIVEIRA R. S. DE; CARISSIMI, A. d. S. T. S. S. Sistemas Operacionais. 2. ed.[S.l.]: Sagra Luzzatto, 2002. (Série Livros Didáticos, v. 11).
[30] VERRISSIMO, F. Paralelização de Algoritmos de Busca. Rio de Janeiro: [s.n.],2001. UFRJ/COPPE/PESC.

52
[31] FUDOLI, C. A. Notícias do Centro Nacional de Processamento de Alto Desempe-nho em São Paulo. 1998.
[32] TANENBAUM, A. S. Distributed Operating Systems. [S.l.]: Prentice Hall, 1995.
[33] AMZA, C. Treadmarks: Shared memory computing on networks of workstations.Computer, Innovative Technology for Computer Professionals, Nova York, v. 29, n. 2,p. p. 18–28, Fevereiro 1996.
[34] LU, Honghui. [S.l.]: SuperComputing´95, Message Passing versus distributedShared Memory on Networks of Workstations. 95.
[35] LU, H. Quantifying the performance differences between pvm and treadmarks.Journal of Parallel and Distributed Computation, v. 43, n. 2, p. p. 65–78, 1997.
[36] DAREMA, F. Spmd model: past, present and future, recent advances in paral-lel virtual machine and message passing interface. 8th European PVM/MPI Users’Group Meeting, p. p. 1, Setembro 2001. Lecture Notes in Computer Science 2131.
[37] C., M. A. HPF Programming Course Notes. Setembor 1997. University of Liver-pool.
[38] CAMBRIDGE. PVM Parallel Virtual Machine, A User’s Guide and Tutorial forNetworked Parallel Computing. Mit press. [S.l.], 1994.
[39] CUNHA, M. C. C. Métodos Numéricos. 2. ed. [S.l.]: Unicamp, 2000.
[40] CUMINATO, J. M. J. Discretização de Equações Diferenciais Parciais, Técnicasde Diferenças Finitas. [S.l.]: SBMAC, 1996.
[41] FOSTER, I. Designing and Buildind Parallel Program. [S.l.]: Addison-Wesley Pu-blishing Company, 1995. (1).
[42] QUINN, M. J. Designing Efficient Algorithms for Parallel Computers. [S.l.]: Mc-Graw Hill, 1987.
[43] ALMASI G. S.; GOTTLIEB, A. Highly Parallel Computing. 2. ed. [S.l.]: The Benja-min Cummings, 1994.
[44] JIA R.; SUNDéN, B. Parallelization of a multi-blocked cfd code via three strategiesfor fluid flow and heat transfer analysis, computers and fluids. v. 33, p. p. 57–80,2004.

53
CÓDIGO FONTE PARALELO
PROPOSTO
# include <stdlib.h># include <stdio.h># include <time.h># include <math.h># include "mpi.h"
/* DECLARACAO DAS FUNCOES ***************************************/void corrige_val_contorno (double ** matriz, double nx, double ny,int rank, int ultProcesso, MPI_Status status);void destroi_matriz (double ** matriz, double nx, double ny);double func ( double ** matriz, double x, double y, double c);double ** gera_matriz (double ** matriz, double nx, double ny);void imprime_matriz (double ** matriz, double nx, double ny);void inicia_val_contorno (double ** matriz, double nx, double ny,double Un, double Us, double Uw, double Ue);int sor (double ** matriz, double nx, double ny, double hx, double hy,double a, double b, double c, double tol, double w, int rank,int ultProcesso, MPI_Status status);
/* FUNCAO MAIN **************************************************/int main (int argc, char ** argv){
/* Variaveis para o MPI */int rank; // ranking dos processosint noProcessos; // numero de processos

54
int ultProcesso; // guarda o valor do rank do ultimo processo;
/* Variýveis do problema */// DomÃnios
double Dx = atof (argv [1]); //atof (argv [1]);double Dy = atof (argv [2]);
// Intervalos internos a matriz (n - 1)double nx = atof (argv [3]);double ny = atof (argv [4]);
// Valores conhecidos da funcao discretizadadouble a = atof (argv [5]);double b = atof (argv [6]);double c = atof (argv [7]);
// Passos da malhadouble hx = Dx/nx;double hy = Dy/ny;
// Valores de contorno global;double Un = atof (argv [8]);double Us = atof (argv [9]);double Uw = atof (argv [10]);double Ue = atof (argv [11]);
// Toleranciadouble tol = atof (argv [12]); // Tolerancia para cada submatrize
// Indice de relaxacao - metodo SORdouble w = atof (argv [13]);
// Total de iteracoes do problemaint iter_G;
/* Inicializa o sistema de troca de mensagens */MPI_Init (&argc,&argv);
MPI_Comm_rank (MPI_COMM_WORLD, &rank); // Obtem o rank do processoMPI_Comm_size (MPI_COMM_WORLD, &noProcessos); // Obtem numero de processosMPI_Status status;

55
ultProcesso = noProcessos - 1; // Acerta o ranking do ultimo processo
/* Testa de à c© um nÃnico processo */if (noProcessos == 1){
double ** u = gera_matriz (u, nx, ny);inicia_val_contorno (u, nx, ny, Un, Us, Uw, 0);
iter_G = sor (u, nx, ny, hx, hy, a, b, c, tol, w, rank, ultProcesso,status);
imprime_matriz (u, nx, ny);destroi_matriz (u, nx, ny);
}/* Rotina para mais de um processo */
else{
/* Testes de primeira matriz e ultima matriz*/if (rank == 0) // Primeira matriz{
double ** u = gera_matriz (u, (nx/noProcessos), ny);inicia_val_contorno (u, (nx/noProcessos), ny, Un, Us, Uw, 0);
iter_G = sor (u, (nx/noProcessos), ny, hx, hy, a, b, c, tol, w, rank,ultProcesso, status);
imprime_matriz (u, (nx/noProcessos), ny);destroi_matriz (u, (nx/noProcessos), ny);
}else if (rank == ultProcesso) // Ultima Matriz{
int excesso = (int)nx%noProcessos;double ** u = gera_matriz (u, ((nx/noProcessos) + excesso), ny);inicia_val_contorno (u, ((nx/noProcessos) + excesso), ny, Un, Us,
0, Ue);
iter_G = sor (u, ((nx/noProcessos) + excesso), ny, hx, hy, a, b, c,

56
tol, w, rank, ultProcesso, status);imprime_matriz (u, ((nx/noProcessos) + excesso), ny);destroi_matriz (u, ((nx/noProcessos) + excesso), ny);
}else // Demais matrizas{
double ** u = gera_matriz (u, (nx/noProcessos), ny);inicia_val_contorno (u, (nx/noProcessos), ny, Un, Us, 0, 0);
iter_G = sor (u, (nx/noProcessos), ny, hx, hy, a, b, c, tol, w,rank, ultProcesso, status);
imprime_matriz (u, (nx/noProcessos), ny);destroi_matriz (u, (nx/noProcessos), ny);
}}
/* Finaliza o sistema de troca de mensagens */MPI_Finalize ();
if (rank == 0) // Apenas para o primeiro processo{
printf ("\n\nTempo de Execu�ÿo (ms):\n");printf ("\t\t%.0lf\n", ((double) clock ())/(CLOCKS_PER_SEC/1000));printf ("\nTotal de iteracoes:\n");printf ("\t\t%d\n\n", iter_G);
}
//printf ("Tempo: %.0lf\n", (double) clock ());system ("pause");return 0;
}
/* FUNCOES ******************************************************//************************************************************************

57
NOME: corrige_val_contorno ()
DESCRICAO:Funcao que faz a comunica�ÿo (send, receive) dos valores de
contorno
PARAMETROS:double **matriz : O ponteiro para ponteiro contera a matriz
(apontarapara ela)
double nx : Numero de intervalos internos da matriz em x (colinas)double ny : Numero de intervalos internos da matriz em y (linhas)int rank : Valor do ranking do processoint ultProcesso : Valor do ranking do ultimo processo
RETORNO:-
*************************************************************************/void corrige_val_contorno (double ** matriz, double nx, double ny,int rank, int ultProcesso, MPI_Status status){
double * contorno_W = (double *) malloc ((ny + 1)*sizeof (double));double * contorno_E = (double *) malloc ((ny + 1)*sizeof (double));int i;int j;
//---------------------------------------- ENVIA// Verifica qual processo irý enviar.
if (rank == 0) // Primeiro Processo{
for (i = 0; i <= (int)ny; i++){
contorno_E [i] = matriz [i][((int)nx-1)];}

58
MPI_Send (contorno_E, ((int)ny + 1), MPI_DOUBLE, (rank + 1), 1,MPI_COMM_WORLD);
}else if (rank == ultProcesso) // Ultimo Processo{
for (i = 0; i <= (int)ny; i++){
contorno_W [i] = matriz [i][1];}MPI_Send (contorno_W, ((int)ny + 1), MPI_DOUBLE, (rank - 1), 1,
MPI_COMM_WORLD);}else // Demais Processo{
for (i = 0; i <= (int)ny; i++){
contorno_E [i] = matriz [i][((int)nx-1)];}MPI_Send (contorno_E, ((int)ny + 1), MPI_DOUBLE, (rank + 1), 1,
MPI_COMM_WORLD);
for (j = 0; j <= (int)ny; j++){
contorno_W [j] = matriz [j][1];}MPI_Send (contorno_W, ((int)ny + 1), MPI_DOUBLE, (rank - 1), 1,
MPI_COMM_WORLD);}
//MPI_Send (void * buf, int count, MPI_Datatype datatype, int dest,int tag, comm MPI_Comm);
//------------------------------------------ RECEBEif (rank == 0) // Primeiro Processo{

59
MPI_Recv (contorno_W, ((int)ny + 1), MPI_DOUBLE, (rank + 1), 1,MPI_COMM_WORLD, &status);
for (i = 0; i <= (int)ny; i++){
matriz [i][(int)nx] = contorno_W [i];}
}else if (rank == ultProcesso) // Ultimo Processo{
MPI_Recv (contorno_E, ((int)ny + 1), MPI_DOUBLE, (rank - 1), 1,MPI_COMM_WORLD, &status);
for (i = 0; i <= (int)ny; i++){
matriz [i][0] = contorno_E [i];}}
else // Demais Processos{
MPI_Recv (contorno_W, ((int)ny + 1), MPI_DOUBLE, (rank + 1), 1,MPI_COMM_WORLD, &status);
for (i = 0; i <= (int)ny; i++){
matriz [i][(int)nx] = contorno_W [i];}
MPI_Recv (contorno_E, ((int)ny + 1), MPI_DOUBLE, (rank - 1), 1,MPI_COMM_WORLD, &status);
for (j = 0; j <= (int)ny; j++){
matriz [j][0] = contorno_E [j];}
}
free (contorno_W);free (contorno_E);

60
//MPI_Recv (&dir, 1, MPI_DOUBLE, (rank - 1), 1, MPI_COMM_WORLD, &status);
}
/************************************************************************NOME: destroi_matriz ()
DESCRICAO:Funcao que desaloca dinamicamente a matriz com a equacaodiscretizada
PARAMETROS:double **matriz : O ponteiro para ponteiro contera a matriz
(apontara para ela)double nx : Numero de intervalos internos da matriz em x (colinas)double ny : Numero de intervalos internos da matriz em y (linhas)
RETORNO:-
*************************************************************************/void destroi_matriz (double ** matriz, double nx, double ny){
int i;
for (i = 0; i <= nx; i++) // desaloca o interior da matriz(vetores que foram apontados)
{free (matriz [i]);
}
free (matriz); // desaloca os ponteiros para ponteiros}

61
/************************************************************************NOME: func ()
DESCRICAO:Funcao que retorna o valor, de acordo com as variaveis,para uma funcao conhecida. Esta funÃ�ÿo à c© um vator de acerto equacaode discretizada
PARAMETROS:double ** matriz : O ponteiro para ponteiro que contera a matrizdouble x : Valor de x para a funcaodouble y : Valor de y para a funcaodouble c : Valor conhecido da equacao discretizada
RETORNO:double resultado
*************************************************************************/double func ( double ** matriz, double x, double y, double c){
double resultado;
resultado = c*matriz[(int)x][(int)y];
return resultado;}
/************************************************************************NOME: gera_matriz ()
DESCRICAO:Funcao que aloca dinamicamente uma matriz que sera a matrizcom a equacao discretizada

62
PARAMETROS:double ** matriz : O ponteiro para ponteiro contera a matriz
(apontara para ela)double nx : Numero de intervalos internos da matriz em x (colinas)double ny : Numero de intervalos internos da matriz em y (linhas)
RETORNO:double ** matriz
*************************************************************************/double ** gera_matriz (double ** matriz, double nx, double ny){
/*Exemplificacao:Alocando 11 posicoes, de 0 a 10,tem-se os contornos e 9 posicoes internas
Depois de iniciada com os valores de contorno:p/ n = 6
0 1 2 3 4 5 61 i i i i i 62 i i i i i 63 i i i i i 64 i i i i i 65 i i i i i 66 6 6 6 6 6 6
onde tem-se os contornos com seus respectivosvalores e o interior da matriz i = 0
*/
// Inicio da alocacao dinamica para uma matrizmatriz = (double **) calloc ((ny + 1), sizeof (double));

63
if (!matriz){
printf ("\n\tErro na alocacao de memoria!!!\n\n");exit (1);
}
int i;
for (i = 0; i <= ny; i++){
matriz [i] = (double *) calloc ((nx + 1), sizeof (double));if (!matriz [i]){
printf ("\n\tErro na alocacao de memoria!!!\n\n");exit (1);
}}
// Fim da alocacao dinamica de uma matriz
return matriz;}
/************************************************************************NOME: imprime_matriz ()
DESCRICAO:Funcao que imprime a matriz com a equacao discretizada
PARAMETROS:double **matriz : O ponteiro para ponteiro contera a matriz
(apontara para ela)double nx : Numero de intervalos internos da matriz em x (colinas)double ny : Numero de intervalos internos da matriz em y (linhas)

64
RETORNO:-
*************************************************************************/void imprime_matriz (double ** matriz, double nx, double ny){
int i, j;/*
Para mostra matriz inteira (com osvalores de contorno)- Intervalo = 0 : n
Para mostrar apenas a matriz interna(sem os valores de contorno)
- Intervalo = 1 : n-1*/
for (i = ny; i >= 0; i--) // Varre toda a matriz{
for (j = 0; j <= nx ; j++){
printf ("%.2lf\t", matriz [i][j]);}printf ("\n");
}
printf ("\n");}
/************************************************************************NOME: inicia_val_contorno ()
DESCRICAO:Funcao que inicia a matriz com os respectivos valores de contorno
PARAMETROS:double **matriz : O ponteiro para ponteiro contera a matriz
(apontara para ela)

65
double nx : Numero de intervalos internos da matriz em x (colinas)double ny : Numero de intervalos internos da matriz em y (linhas)double Un : Contorno Norte da solucaodouble Us : Contorno Sul da solucaodouble Uw : Contorno Oeste da solucaodouble Ue : Contorno Leste da solucao
RETORNO:double ** matriz
*************************************************************************/void inicia_val_contorno (double ** matriz, double nx, double ny,double Un, double Us, double Uw, double Ue){
int i, j;for (i = 0; i <= nx; i++){
matriz[0][i] = Us;matriz[(int)ny][i] = Un;
}for (i = 0; i <= ny; i++){
matriz[i][0] = Uw;matriz[i][(int)nx] = Ue;
}/*
Gera uma media para os encontros dos contornos('cantos' da matriz)
*/matriz[0][0] = (Us + Uw)/2;matriz[0][(int)nx] = (Us + Ue)/2;matriz[(int)ny][(int)nx] = (Un + Ue)/2;matriz[(int)ny][0] = (Un + Uw)/2;
}

66
/************************************************************************NOME: sor ()
DESCRICAO:Funcao que realiza o metodo iterativo SOR para preencher ointerior da matriz
PARAMETROS:double **matriz : O ponteiro para ponteiro contera a matriz
(apontara para ela)
RETORNO:int iter : Quantidade de iteracoes necessarias para atender
a tolerancia*************************************************************************/int sor (double ** matriz, double nx, double ny, double hx, double hy,double a, double b, double c, double tol, double w, int rank,int ultProcesso, MPI_Status status){
double erro_G; // Erro maximo globaldouble erro_M; // Erro maximo da iteracao de um processo localdouble erro; // Erro da iteracao vigente
erro_M = tol + 1; // Estrapola o erro para entrar no while
// Variaveis da funcao discretizadadouble T1;double T2;double T3;double T4;double T5;
// Inicializacao da variaveis da funcao discretizadaT1 = a/(2*hx) - 1/(hx*hx);T2 = a/(2*hx) + 1/(hx*hx);

67
T3 = b/(2*hy) - 1/(hy*hy);T4 = b/(2*hy) + 1/(hy*hy);T5 = 2/(hx*hx) + 2/(hy*hy) + c;
int iter; // Contador de iteracoesint i, j;double matriz_old; // Valor antigo da posicao para a
iteracao vigentedouble matriz_seidel; // Valor novo (calculado) da posicao
para a iteracao vigente
iter = 0; // Inicialisando o contador
/*int MPI_Allreduce(void* sendbuf,void* recvbuf,int count, MPI_Datatype
datatype,MPI_Op op,MPI_Comm comm);
*/
while (erro_G >= tol){
erro_M = 0; // Ajusta o erro PARA nao SE ter um while infinito
for (i = 1; i < (int)ny; i++){for (j = 1; j < (int)nx; j++){
matriz_old = matriz[i][j]; // Recebe posicao atual// Seidel recebe o valor da funcao discretizadamatriz_seidel = (func(matriz, i, j, c) - T1*matriz[i][j+1]
+ T2*matriz[i][j-1] - T3*matriz[i+1][j] + T4*matriz[i-1][j])/T5;/*
Implementacao do metodo SOR.*/
matriz[i][j] = (1 - w)*matriz_old + w*matriz_seidel;

68
erro = abs (matriz[i][j] - matriz_old); // Calcula oerro para a iteracao vigente
if (erro > erro_M){
erro_M = erro;}
}}iter++;
/* Verifica a quantidade de itera�oes para se uma troca demensagens */
if (((iter%10) == 0) && (ultProcesso != 0)){
corrige_val_contorno (matriz, nx, ny, rank, ultProcesso, status);}
/* Gera o erro global - erro_G Ã c© o maior entre os erros erro_M - eenvia para todos os processos */
MPI_Allreduce(&erro_M, &erro_G, 1, MPI_DOUBLE, MPI_MAX,MPI_COMM_WORLD);
}
return iter;}


















