
COMPILAÇÃO DE ALGORITMOS EM JAVAÔ PARA SISTEMAS …w3.ualg.pt/~jmcardo/MyThesis/PhD.pdf · João...
312
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO COMPILAÇÃO DE ALGORITMOS EM JAVA PARA SISTEMAS COMPUTACIONAIS RECONFIGURÁVEIS COM EXPLORAÇÃO DO PARALELISMO AO NÍVEL DAS OPERAÇÕES João Manuel Paiva Cardoso (Mestre) Dissertação para a obtenção do grau de Doutor em Engenharia Electrotécnica e de Computadores Orientador: Doutor Horácio Cláudio de Campos Neto Presidente: Reitor da Universidade Técnica de Lisboa Vogais: Doutor António Manuel de Brito Ferrari Almeida Doutor Guilherme Diniz Moreno da Silva Arroz Doutor Carlos Francisco Beltran Tavares de Almeida Doutor Henrique Manuel Dinis dos Santos Doutor Horácio Cláudio de Campos Neto Doutor Leonel Augusto Pires Seabra de Sousa Outubro de 2000
Transcript of COMPILAÇÃO DE ALGORITMOS EM JAVAÔ PARA SISTEMAS …w3.ualg.pt/~jmcardo/MyThesis/PhD.pdf · João...

UNIVERSIDADE TÉCNICA DE LISBOA
INSTITUTO SUPERIOR TÉCNICO
COMPILAÇÃO DE ALGORITMOS EM JAVA PARA SISTEMAS
COMPUTACIONAIS RECONFIGURÁVEIS COM EXPLORAÇÃO DO PARALELISMO
AO NÍVEL DAS OPERAÇÕES
João Manuel Paiva Cardoso
(Mestre)
Dissertação para a obtenção do grau de Doutor em
Engenharia Electrotécnica e de Computadores
Orientador: Doutor Horácio Cláudio de Campos Neto
Presidente: Reitor da Universidade Técnica de Lisboa
Vogais: Doutor António Manuel de Brito Ferrari Almeida
Doutor Guilherme Diniz Moreno da Silva Arroz
Doutor Carlos Francisco Beltran Tavares de Almeida
Doutor Henrique Manuel Dinis dos Santos
Doutor Horácio Cláudio de Campos Neto
Doutor Leonel Augusto Pires Seabra de Sousa
Outubro de 2000


Copyright, João Manuel Paiva Cardoso, 2000
Título: “COMPILAÇÃO DE ALGORITMOS EM JAVA PARA SISTEMAS
COMPUTACIONAIS RECONFIGURÁVEIS COM EXPLORAÇÃO DO
PARALELISMO AO NÍVEL DAS OPERAÇÕES”
Autor: João Manuel Paiva Cardoso
Mestre em Eng.ª Electrotécnica e de Computadores, IST/UTL, 1997
Licenciado em Eng.ª Electrónica e Telecomunicações, Universidade de Aveiro, 1993
Email: [email protected]
Tese realizada sob a supervisão do
Doutor Eng.º Horácio Cláudio de Campos Neto
Professor Associado do Departamento de Engenharia
Electrotécnica e de Computadores
Instituto Superior Técnico


v
Dedico esta tese a meus pais,

vi

vii
“Não se pode pensar,
fora das possibilidades da língua em que se pensa.”
Vergílio Ferreira, Pensar, Maio 1991

viii

ix
Agradecimentos
Esta tese e o trabalho nela descrito não teriam sido possíveis de realizar sem a ajuda e
compreensão de muitas pessoas. Por isso, sinto a necessidade de agradecer a todos
aqueles cujos contributos foram em meu entender mais notórios. Fico-lhes
imensamente agradecido e peço que eventuais omissões sejam perdoadas.
Agradeço ao meu orientador, Prof. Horácio Neto, pelo incentivo, discussão de ideias,
orientação, conselhos e total disponibilidade demonstrada ao longo da realização da
tese. Os meus agradecimentos por me ter facultado trabalhar no grupo ESDA do
INESC, pela forma como lidou comigo durante todos estes anos, pelos momentos de
descontracção proporcionados, principalmente nos almoços, fundamentais para que o
trabalho ao longo do dia não se tornasse monótono e fatigante, por ter acreditado nas
minhas capacidades, por algumas das vezes me ter feito acordar para caminhos
factíveis, e pela forma como me deixou percorrer o meu próprio caminho. Agradeço-
lhe também as inúmeras revisões realizadas em versões preliminares desta tese e em
artigos publicados.
Aos meus colegas de sala no INESC, Ana e Marcelino, pelos momentos que passámos
juntos, pela amizade, e por nos termos compreendido sempre tão bem. Pelas tentativas
de todos por alegrar o ambiente e por tornar a realização dos nossos doutoramentos
menos morosa.
Ao Mário Véstias, pelas discussões quase diárias que tivemos sobre todos os aspectos
de investigação. Muitas delas, embora tivessem parecido a ambos pouco profícuas,
reconheço agora que foram muito importantes.
Ao Anton Chichkov pelas discussões que tivemos nas fases iniciais deste trabalho, por
me ter despertado para a computação reconfigurável e por me ter feito aperceber de
algumas das lacunas existentes nesta área. O trabalho desenvolvido para a sua tese de
doutoramento viria a servir de suporte e de inspiração para algumas ideias de
importância inolvidável no cômputo geral.
Ao José Sousa por todo o ânimo acrescentado que veio incutir ao grupo, pela força
inicial de alguém que acaba de chegar, pelo apoio que me deu e pelas trocas de ideias

x
que tivemos sobre computação reconfigurável.
À Claudia Calidonna por me ter despertado para as propriedades do HTG de Girkar &
Polychronopoulos depois de algumas discussões que tivemos durante o curso:
“Architecture and Programming of Parallel High Performance Systems”, no Centro
para Computação de Alto-Desempenho em Groningen.
A todos os elementos do grupo ESDA do INESC, Ana Teresa, Mário Véstias, José
Sousa, e Paulo Flores por todo o apoio e pela verdadeira equipa que formámos sempre
que foi preciso resolver um problema. Agradeço também ao José Pedro Abreu pelo
apoio dado sempre que por mim solicitado quando ainda era membro do grupo.
Agradeço ao Prof. Arlindo Oliveira por me ter um dia proposto uma visita ao
laboratório PARADES em Roma para apresentar o meu trabalho inicial,
proporcionando-me o contacto com um laboratório de investigação autónomo. Esta
visita acabou por também marcar a evolução desta tese.
Agradeço todo o apoio demonstrado pelos meus pais – Maria Cristina de Paiva e Luís
Cardoso Adrega –, irmãos – Isabel e Zé – e cunhados – Cristina e Albertino. Durante
o tempo de realização do trabalho que culminou com a escrita desta tese vi-me muitas
vezes privado da companhia de toda a minha família e, por isso, agradeço-lhes toda a
compreensão e encorajamento demonstrados. Aos meus sobrinhos – Tininha, João,
Pedro e Tiago – pelos momentos de companhia proporcionados, poucos mas sempre
revitalizantes.
Agradeço à Prof. Otília e ao Prof. Armando, por terem despertado em mim o gosto
pela aprendizagem, pela leitura, e por desde sempre me manterem em permanente
motivação.
Agradeço à Teresa, pela compreensão que demonstrou ao longo de todo este tempo.
Por nunca ter transformado os maus momentos dela em maus momentos meus e por
ter sempre compreendido as minhas fases menos boas.
Aos meus amigos por me terem sempre compreendido e dado imensa força para que
os meus objectivos fossem realizados e pelos sempre surpreendentes convívios em
que pude desfrutar da companhia deles em Faro, Lisboa ou Aveiro.

xi
Esta tese não teria sido possível de realizar sem a autorização de dispensa de serviço
docente dada pela Universidade do Algarve. Neste particular, estou também
agradecido à Área Departamental de Eng.ª Electrónica e Computação da Unidade de
Ciências Exactas e Humanas por não se ter oposto ao facto de eu ter vindo fazer
doutoramento ao IST.
Agradeço o suporte do programa de doutoramento da acção 5.2 do Prodep, que
possibilitou a minha ausência da Universidade do Algarve nos 3 anos completamente
devotados à realização desta tese.
Agradeço o apoio financeiro proporcionado pelos Projectos do programa Praxis XXI,
da Fundação para a Ciência e Tecnologia, PRAXIS/2/2.1/TIT/1643/95 e
PRAXIS/P/EEI/12154/1998. Estes apoios revelaram-se fundamentais para a
apresentação de publicações relacionadas com esta tese em conferências
internacionais.
Por último, agradeço o apoio dado sob a forma de bolsas de viagens, de alojamento e
de despesas da NATO, da JNICT e da União Europeia que me permitiram frequentar
os cursos “A NATO Advanced Study Institute on System Level Synthesis” e
“International School on Advanced Algorithmic Techniques for Parallel Computation
with Applications”, e a escola de Verão “Architecture and Programming of Parallel
High Performance Systems”.
Lisboa, Outubro de 2000

xii

xiii
Resumo
Neste trabalho é proposta uma estratégia inovadora para compilar algoritmos descritos
em linguagem Java em hardware reconfigurável. A estratégia é suportada por várias
etapas de análise e optimização que permitem gerar eficientemente hardware
especializado. Estas etapas foram implementadas, originando dois compiladores, e
foram estudadas e validadas com exemplos reais.
Os dois compiladores desenvolvidos actuam em série e possibilitam a compilação de
um algoritmo representado por bytecodes de Java em hardware reconfigurável
constituído por um FPGA (Field-Programmable Gate Array) acoplado a uma ou mais
memórias. É apresentado um fluxo completo de compilação, desde a representação
dos bytecodes fonte num formato intermédio propício para explorar os graus elevados
de paralelismo possíveis com os FPGAs da nova geração e a existência de fluxos de
controlo múltiplos, até à geração da estrutura das unidades de dados e da descrição
das unidades de controlo. De permeio são dissecadas as técnicas necessárias para a
geração de uma arquitectura específica e especializada, que implemente
eficientemente o algoritmo fonte em hardware reconfigurável, e permitindo, caso
necessário, a partilha temporal do FPGA.
Os resultados obtidos com a geração do hardware para um número significativo de
exemplos mostram que as técnicas implementadas concretizam a compilação em
tempos de computação razoáveis com resultados eficientes. Estes resultados
confirmam a validade da metodologia proposta e mostram a eficiência, exequibilidade
e efectividade do fluxo de compilação desenvolvido.

xiv

xv
Abstract
This thesis proposes a novel strategy for the compilation of algorithms described in
the Java language to reconfigurable hardware. The strategy is supported by a number
of analysis and optimizations steps that permit to generate efficiently specialized
hardware. These steps were implemented, originating two compilers, and they were
studied and validated with real examples.
The two compilers work in serial and make possible the compilation of an algorithm
represented in Java bytecodes to reconfigurable hardware consisting of one FPGA
(Field-Programmable Gate Array) coupled to one or more memories. A complete
compilation flow is presented, from the representation of the bytecodes on a format
suitable to expose explicitly the larger degrees of parallelism that can be satisfied with
the FPGAs of the new generation and the existence of multiple control flows, to the
generation of the structure of the datapath unit and the description of the control unit.
Meanwhile, the techniques necessary to the generation of a specific and specialized
architecture that implements efficiently the source algorithm in reconfigurable
hardware, and enabling, when necessary, the time-sharing of the FPGA, are also
described.
The results obtained with the hardware generation for a significant set of examples
show that the implemented techniques achieve the compilation in reasonable amounts
of CPU time with efficient results. These results support and validate the proposed
methodology and show the effectiveness of the developed compilation flow.

xvi

xvii
Palavras Chave Java
Compilação
Optimização de Código
Paralelismo ao Nível de Instruções
Computação Reconfigurável/Adaptativa
Síntese de Arquitecturas
Keywords Java
Compilation
Code Optimization
Instruction-Level Parallelism (ILP)
Reconfigurable/Adaptative Computing
Architectural Synthesis

xviii

xix
Índice
CAPÍTULO 1. INTRODUÇÃO 1
1.1 FUNDAMENTOS DE COMPUTAÇÃO RECONFIGURÁVEL 3
1.1.1 ORGANIZAÇÃO DOS SISTEMAS PARA SUPORTE DE COMPUTAÇÃO
RECONFIGURÁVEL 5
1.2 INCENTIVO PARA A INVESTIGAÇÃO EM COMPILADORES PARA SISTEMAS
COMPUTACIONAIS RECONFIGURÁVEIS 7
1.2.1 POR QUÊ COMPILAR DE JAVA, E EM PARTICULAR DOS BYTECODES? 12
1.2.2 POR QUÊ EXPLORAR O PARALELISMO PARA ALÉM DOS BLOCOS BÁSICOS? 13
1.3 CONTRIBUIÇÕES DA TESE 14
1.4 ESTRUTURA DA TESE 17
CAPÍTULO 2. COMPILADORES PARA RECONFIGWARE (HARDWARE
RECONFIGURÀVEL) 21
2.1 COMPILADORES PARA FCCMS 22
2.2 COMPILADOR APRESENTADO POR CHICHKOV 27
2.3 COMPILADOR PRISM-I E II 28
2.4 TRANSMOGRIFIER-C 29
2.5 COMPILADOR NAPA C 30
2.6 SÍNTESE DE PIPELINES EM FPGAS 31
2.7 UTILIZAÇÃO DE AMBIENTES DE SÍNTESE ARQUITECTURAL ADAPTADOS
PARA FPGAS 33
2.8 COMPILADORES PARA ARQUITECTURAS NÃO COMERCIAIS 35
2.9 CONCLUSÕES 40
CAPÍTULO 3. MODELOS DE REPRESENTAÇÃO INTERMÉDIA E SUA
CONSTRUÇÃO 45
3.1 MODELOS DE REPRESENTAÇÃO 46
3.2 ETAPAS ÍNICIAS DO COMPILADOR 49
3.2.1 CONSTRUÇÃO DO GRAFO DE FLUXO DE CONTROLO 50
3.2.2 IDENTIFICAÇÃO DOS CICLOS 52

xx
3.3 CONSTRUÇÃO DO GRAFO DE DEPENDÊNCIAS DE CONTROLO 53
3.4 EXPOSIÇÃO AUTOMÀTICA DE DEPENDÊNCIAS DE DADOS 54
3.4.1 DEPENDÊNCIAS DE DADOS RELATIVAS A VARIÁVEIS LOCAIS 55
3.4.2 DEPENDÊNCIAS DE DADOS ORIGINADAS PELO USO DA PILHA DE
OPERANDOS 59
3.4.3 DEPENDÊNCIAS DE DADOS RELATIVAS AO USO DE ARRAYS 61
3.4.4 DEPENDÊNCIAS DE DADOS RELATIVAS AO USO DE ATRIBUTOS (CAMPOS) 63
3.5 O GRAFO DE DEPENDÊNCIAS DE DADOS 63
3.6 COMPUTAÇÃO DOS PONTOS DE SELECÇÃO E DA LÓGICA DECISÓRIA DO
PROGRAMA 66
3.6.1 PONTOS DE SELECÇÃO 67
3.6.2 TIPOS DE LÓGICA DECISÓRIA DO PROGRAMA UTILIZADOS 69
3.7 COMPUTAÇÃO DO GRAFO HIERÁRQUICO DE DEPENDÊNCIAS DO
PROGRAMA 72
3.8 CRIAÇÃO DO DFG GLOBAL 73
3.9 CONCLUSÕES 76
CAPÍTULO 4. SUPORTE À GERAÇÃO DE RECONFIGWARE 79
4.1 PRÉ-ETAPAS DO NENYA 79
4.2 ESTRUTURA DO RECONFIGWARE GERADO PELO NENYA 81
4.3 BIBLIOTECA TECNOLÓGICA 82
4.4 MAPEAMENTO DE OPERAÇÕES EM UNIDADES FUNCIONAIS E
ESCALONAMENTOS INICIAIS 86
4.5 ACESSOS A MEMÓRIAS EXTERNAS 92
4.5.1 ESPECIALIZAÇÃO PARA O CÁLCULO DE ENDEREÇOS 92
4.5.2 PARTILHA DE ACESSOS A MEMÓRIAS 94
4.6 ATRIBUIÇÃO DE REGISTOS 95
4.7 PARTILHA DE UNIDADES FUNCIONAIS 97
4.8 GERAÇÃO DO RECONFIGWARE PARA A UNIDADE DE DADOS 100
4.9 SUPORTE DE RETAGUARDA DA GERAÇÃO DE RECONFIGWARE 103
4.10 CONCLUSÕES 104
CAPÍTULO 5. OPTIMIZAÇÕES DO GRAFO DE FLUXO DE DADOS 107
5.1 OPTIMIZAÇÕES DE FLUXO DE DADOS 107
5.1.1 REASSOCIAÇÃO DE OPERAÇÕES 109

xxi
5.1.2 REDUÇÃO DO CUSTO DE OPERAÇÕES 111
5.2 TRABALHOS PRÉVIOS EM AFERIÇÃO DO NÚMERO DE BITS DE
REPRESENTAÇÃO 114
5.3 AFERIÇÃO DE SUBTIPOS PRIMITIVOS NOS BYTECODES 117
5.4 AFERIÇÃO DO NÚMERO DE BITS DE REPRESENTAÇÃO NO NENYA 119
5.5 PROPAGAÇÃO DE PADRÕES DE CONSTANTES AO NÍVEL DO BIT 121
5.6 AFERIÇÃO DO NÚMERO DE BITS EM REGIÕES CÍCLICAS 124
5.7 RESULTADOS 129
5.8 CONCLUSÕES 135
CAPÍTULO 6. PARTIÇÃO TEMPORAL 137
6.1 INCENTIVO PARA A PARTIÇÃO TEMPORAL 138
6.2 PANORÂMICA RELATIVAMENTE À PARTIÇÃO TEMPORAL 140
6.3 FORMULAÇÃO DO PROBLEMA 142
6.4 ESQUEMAS DE SUPORTE À EXECUÇÃO DE FRACÇÕES TEMPORAIS 144
6.5 MÉTODOS BASEADOS NOS ESQUEMAS ASAP/ALAP 146
6.6 O ALGORITMO DE PARTIÇÃO TEMPORAL BASEADO NUM ESCALONADOR
ESTÁTICO EM LISTA 150
6.7 ABORDAGEM BASEADA NO SIMULATED ANNEALING 152
6.8 RESULTADOS EXPERIMENTAIS 156
6.9 CONCLUSÕES 161
CAPÍTULO 7. ESCALONAMENTO BASEADO EM REGIÕES 163
7.1 ESCALONAMENTO E GRAFOS GERADOS 164
7.2 ESCALONAMENTO DE REGIÕES ACÍCLICAS 168
7.3 ESCALONAMENTO DE REGIÕES CÍCLICAS/ACÍCLICAS 170
7.4 ESCALONAMENTO DE REGIÕES CÍCLICAS CONCORRENTES 177
7.5 MELHORIAS DE DESEMPENHO DO HPDG SOBRE O CDFG 180
7.6 CONCLUSÕES 183
CAPÍTULO 8. PROTÓTIPOS E RESULTADOS EXPERIMENTAIS 185
8.1 COMPILADORES GALADRIEL & NENYA 186
8.2 ESTUDOS EXPERIMENTAIS 187
8.3 PROTOTIPAGEM NA FAMÍLIA DE FPGAS XC6200 192

xxii
8.3.1 DESCODIFICADOR DE HAMMING 192
8.3.2 PROBLEMAS COM A INTEGRAÇÃO DAS FASES DE RETAGUARDA 196
8.4 PROTOTIPAGEM NA FAMÍLIA DE FPGAS VIRTEX 197
8.5 CONCLUSÕES 200
CAPÍTULO 9. CONCLUSÕES 203
9.1 TRABALHO REALIZADO 203
9.2 PERSPECTIVAS DE TRABALHO FUTURO 205
APÊNDICE A TECNOLOGIA JAVA 211
APÊNDICE B FLUXO DE COMPILAÇÃO ALVEJANDO ASICS 215
APÊNDICE C IMPLEMENTAÇÃO SIMPLIFICADA DE ALGUMAS
CONSTRUÇÕES ORIENTADAS POR OBJECTOS EM HARDWARE
ESPECÍFICO 219
APÊNDICE D EXEMPLOS UTILIZADOS 223
D.1 GRUPO DE NÚCLEOS DE ALGORITMOS 223
D.2 ALGORITMOS MAIS COMPLEXOS 228
APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE 233
APÊNDICE F GLOSSÁRIO 239
APÊNDICE G LISTA DE SÍMBOLOS 247
REFERÊNCIAS 251

xxiii
Lista de Figuras
Figura 1.1. Célula representativa da maioria dos FPGAs de granulosidade fina. 4
Figura 1.2. Exemplo de uma matriz de células e de interligações comum na
maioria dos FPGAs comerciais. 4
Figura 1.3. Organização de um sistema de computação com integração de
hardware reconfigurável. 5
Figura 1.4. Número de transístores integrados num único dispositivo. 8
Figura 1.5. Fluxo de compilação. 15
Figura 1.6. Arquitectura alvejada pelo compilador de reconfigware desenvolvido. 15
Figura 1.7. Etapas realizadas pelos compiladores. 20
Figura 2.1. Exemplo de compilação de uma descrição alto-nível para VHDL
comportamental ao nível de transferências entre registos. 26
Figura 2.2. Organização do compilador NAPA C. 30
Figura 2.3. Exemplo de um ciclo do tipo FOR: a) código em Modula-2; b) grafo
de fluxo de dados do corpo do ciclo. 33
Figura 2.4. Grafo de fluxo de dados com os valores calculados e os registos de
pipeline. 33
Figura 2.5. Arquitectura do rDPA. 36
Figura 2.6. Arquitectura do RaPiD. 38
Figura 2.7. Exemplo de agrupamento de operações pelo compilador de C para o
Chimaera. 38
Figura 3.1. Fluxo para obtenção do HPDG e do DFG global no GALADRIEL a
partir dos bytecodes Java. 49
Figura 3.2. a) Instruções da JVM para o método “mult” extraídas dos bytecodes;
b) CFG de blocos básicos obtido. 51
Figura 3.3. Árvore de dominâncias para o exemplo “mult”. 53
Figura 3.4. Exemplo “mult”: a) Árvore de pós-dominâncias; b) CDG. 54
Figura 3.5. Identificação de definições e de usos no exemplo “mult”. 56
Figura 3.6. Conjuntos obtidos pela análise das definições incidentes. 57

xxiv
Figura 3.7. Cadeias de uso-definição (UD). 57
Figura 3.8. Cadeias de definição-uso (DU) e os blocos básicos onde ocorrem as
respectivas definições e usos. 57
Figura 3.9. Algoritmo para computar as cadeias uso-definição. 58
Figura 3.10. Algoritmo para computar as cadeias definição-uso a partir das cadeias
uso-definição. 58
Figura 3.11. Computação das dependências de dados oriundas do uso da pilha de
operandos. 60
Figura 3.12. Algoritmo que analisa as dependências entre blocos básicos ao nível
da pilha de operandos. 60
Figura 3.13. Exemplo que ilustra a sobreposição de elementos em memória: a)
fragmento de código em Java; b) endereços de cada array em
memória para os dois caminhos mutuamente exclusivos. 62
Figura 3.14. Transformação do programa para resolução estática da sobreposição
condicional de dois arrays. 63
Figura 3.15. DDG do exemplo “mult”: os círculos nos laços indicam dependências
entre iterações do ciclo. 64
Figura 3.16. Identificação de conjuntos de blocos básicos mutuamente exclusivos
no CDG: a) exclusividade ao mesmo nível; b) exclusividade em níveis
diferentes. 65
Figura 3.17. Exemplo que identifica as dependências de dados na mesma iteração
de um ciclo. a) CFG do exemplo com dois blocos básicos mutuamente
exclusivos; b) CDG do exemplo. 66
Figura 3.18. a) Exemplo em Java com os blocos básicos identificados; b)
respectivo CFG. 68
Figura 3.19. CDG, DDG e MDG obtidos para o exemplo. 68
Figura 3.20. DDG em que estão representados os pontos de selecção. 69
Figura 3.21. Exemplo que ilustra os caminhos de selecção que permitem
seleccionar, de um conjunto de definições que alcançam um
determinado uso, a definição correcta para o valor específico das
condições. a) CFG do exemplo; b) correspondente CDG. 71
Figura 3.22. Transformações realizadas na vanguarda das fases de compilação: a)

xxv
fragmento de código Java; b) instruções JVM correspondentes; c)
CFG com um DFG por cada bloco básico; d) DDG; e) CDG; f)
HPDG. 73
Figura 3.23. Exemplo da construção do DFG para um bloco básico: a) instruções
JVM do bloco básico; b) correspondente DFG. 74
Figura 3.24. DFG global para o exemplo da Figura 3.22. 78
Figura 4.1. Etapas realizadas pelo NENYA. 80
Figura 4.2. Identificação de um segmento de código com restrição temporal. 81
Figura 4.3. Estrutura do hardware no FPGA. 82
Figura 4.4. Colocação relativa de células no FPGA: a) atributos no VHDL; b)
colocação no FPGA que é sempre relativa ao posicionamento do nível
imediatamente a seguir na hierarquia de componentes. 83
Figura 4.5. Melhoria relativa em termos de área e de atraso para circuitos de
adição do tipo “ripple-carry” gerados pela macrocélula versus
somadores sintetizados pela ferramenta de síntese lógica. 84
Figura 4.6. Descrição de uma macrocélula na biblioteca tecnológica. 85
Figura 4.7. Área dos circuitos de multiplicação sintetizados tendo em conta
diferentes tamanhos (em número de bits) dos operandos e do
resultado. 86
Figura 4.8. Algoritmo do escalonador ASAP sem restrições de recursos baseado
em pilha. 87
Figura 4.9. Algoritmo iterativo do escalonador ASAP sem restrições de recursos. 88
Figura 4.10. Algoritmo do escalonador ASAP sem restrições de recursos quando os
nós do DFG são acedidos por ordem topológica. 88
Figura 4.11. Melhorias dos algoritmos ASAP, com os nós topologicamente
ordenados e com o método iterativo, relativamente ao algoritmo
baseado em pilha. 89
Figura 4.12. Impacto na execução: a) com registos; b) sem registos entre
operações. 90
Figura 4.13. Algoritmo para mapear as operações nas unidades funcionais. 91
Figura 4.14. Algoritmo que, para cada memória, atribui os endereços BASE dos
arrays mapeados na memória considerada. 94

xxvi
Figura 4.15. Acessos à macrocélula de interface com uma memória externa
acoplada ao FPGA. 95
Figura 4.16. Grafo da unidade de dados representativo do DFG global da Figura
3.24 quando os dois arrays são mapeados numa memória de porto
único. 97
Figura 4.17. a) segmento de código Java; b) DFG correspondente; c) DFG com
partilha de um multiplicador entre caminhos mutuamente exclusivos;
d) DFG com partilha do multiplicador e do somador. 99
Figura 4.18. Transformações realizadas no DFG global para aceder à memória
externa quando os arrays não são colocados em posições de memória
que possibilitem a simplificação do circuito de endereçamento. 101
Figura 4.19. Transformação entre a) DFG global e b) correspondente grafo de
hardware; c) parte da estrutura descrita em VHDL. 102
Figura 4.20. Etapas de retaguarda a partir da descrição em VHDL para a família
XC6000 de FPGAs da Xilinx. 104
Figura 5.1. Impacto da utilização de THR na computação do número de bits: a)
cadeia de somadores com três níveis; b) redução do número de níveis
para dois com consequente redução do número de bits. 110
Figura 5.2. Resultados da aplicação de THR e da aferição do número de bits
suficiente no escalonamento de exemplos que somam elementos de
um array. 111
Figura 5.3. Árvore de decomposições da expressão 350 × a. 113
Figura 5.4. Número de operações (adições e multiplicações) obtidas pela
decomposição binária para redução do custo de multiplicações de uma
variável por constantes de 0 a 65.535 com a utilização de adições,
subtracções e deslocamentos. 114
Figura 5.5. Exemplo de aferição de tipos primitivos do DFG. 118
Figura 5.6. Algoritmo de propagação em sentido inverso. 120
Figura 5.7. Algoritmo de propagação em sentido directo. 121
Figura 5.8. Exemplo que reverte os dois primeiros bits de uma palavra: a)
propagação para trás; b) propagação para a frente; c) propagação de
padrões de constantes ao nível do bit. 124

xxvii
Figura 5.9. Número de bits da variável A suficiente para cada iteração. 126
Figura 5.10. Melhorias, em termos de área, do NENYA com optimizações e da
síntese lógica (SL) em relação ao NENYA sem optimizações. 133
Figura 5.11. Melhorias, em termos de atraso, do NENYA com optimizações e da
síntese lógica (SL) em relação ao NENYA sem optimizações. 134
Figura 5.12. Percentagem para o exemplo I da área do circuito dedicada aos
multiplexadores para compilações com e sem as optimizações. 134
Figura 6.1. DFG para o corpo do ciclo do exemplo HAL e o custo de cada
operador. 145
Figura 6.2. Execução do corpo do ciclo do exemplo HAL com partilha temporal
do FPGA. 146
Figura 6.3. Aplicação de dois esquemas de partição temporal: a) pelos níveis de
ASAP; b) pelos níveis de ALAP. 147
Figura 6.4. Algoritmo para partição temporal orientado pela mobilidade de cada
nó e com procura no mesmo nível de ASAP ou ALAP. 149
Figura 6.5. Algoritmo de partição temporal baseado no algoritmo estático de
escalonamento em lista. 151
Figura 6.6. Versão do algoritmo Simulated Annealing para partição temporal. 154
Figura 6.7. Exemplo de um movimento entre fracções temporais considerado
válido pela abordagem SA (Simulated Annealing) apresentada. 155
Figura 6.8. Gráfico comparativo das diversas abordagens. 160
Figura 7.1. a) Exemplo; b) atraso para cada operação do exemplo; c) Os dois
blocos básicos e os DFGs correspondentes; d) Escalonamento ao nível
do bloco básico; e) Agrupamento dos dois blocos básicos e DFG
global; f) Escalonamento com agrupamento de blocos básicos. 166
Figura 7.2. Melhorias relativas do escalonamento interblocos básicos baseado na
granulosidade do operador versus a granulosidade do bloco básico. 167
Figura 7.3. Escalonamento com diferentes ordenações das operações: a) DFG
inicial; b) possível escalonamento com prioridade unicamente baseada
no valor da mobilidade de cada operação; c) escalonamento com
prioridades atribuídas às operações com base na mobilidade e nos
sucessores comuns. 169

xxviii
Figura 7.4. Algoritmo de escalonamento por regiões. 171
Figura 7.5. Algoritmo de escalonamento de regiões cíclicas. 172
Figura 7.6. Algoritmo de criação do STG (State Transition Graph). 173
Figura 7.7. Algoritmo de criação do STG (2ª parte). 174
Figura 7.8. Algoritmo de criação do STG (3ª parte). 174
Figura 7.9. Grafo da unidade de dados gerada pelo NENYA para o exemplo da
soma de dois vectores. 175
Figura 7.10. Escalonamento de operações. 176
Figura 7.11. a) Nível de topo do HPDG para o exemplo Kalman; Diagramas de
blocos que representam as FSMs responsáveis pela execução da
unidade de dados do exemplo: b) quando não há partilha de recursos
entre os ciclos “loop.1” e “loop.4”; c) quando há partilha de recursos
entre os ciclos “loop.1” e “loop.4”. 179
Figura 7.12. Densidade de operações por ciclo de relógio para dois modelos de
representação. 180
Figura 7.13. Número máximo de operações por estado do STG para dois modelos
de representação. 181
Figura 7.14. Desempenhos dos escalonamentos feitos sobre o HPDG e sobre o
CDFG – valores normalizados ao CDFG. 181
Figura 7.15. Densidade de operações por estado do STG para dois modelos de
representação, utilizando uma memória de porto único. 182
Figura 7.16. Número máximo de operações por estado do STG para dois modelos
de representação, utilizando uma memória de porto único. 182
Figura 7.17. Desempenhos dos escalonamentos feitos sobre o HPDG e sobre o
CDFG, utilizando uma memória de porto único. 183
Figura 8.1. Resultados de escalonamentos para várias versões do exemplo
KALMAN considerando várias memórias externas. 188
Figura 8.2. Número de operações em execução num estado do STG para o
exemplo KALMAN considerando vários números de memórias
acopladas ao FPGA. 189
Figura 8.3. Rácios dos melhores e dos piores escalonamentos para as várias
versões sobre o escalonamento considerando uma memória de portos

xxix
múltiplos. 190
Figura 8.4. Efeitos da utilização de THR com uma de um porto ou de portos
múltiplos ou várias memórias para o exemplo KALMAN. 190
Figura 8.5. Degradação do desempenho com uma memória de porto único versus
uma memória multiporto. 191
Figura 8.6. DFG do exemplo HAMMING gerado pelo NENYA. 193
Figura 8.7. Exemplo HAMMING: a) Grafo de fluxo de controlo (CFG); b)
implantação física no FPGA XC6216. 194
Figura 8.8. Efectividade das optimizações do fluxo de dados no desempenho do
reconfigware. 199
Figura 8.9. Efectividade das optimizações do fluxo de dados na área de
reconfigware. 199
Figura 8.10. Acelerações do reconfigware versus software. 200
Figura A.1. Fluxo de compilação/execução da tecnologia Java. 211
Figura B.1. O ambiente de compilação de fragmentos de código Java em hardware
específico com a utilização de uma ferramenta de síntese arquitectural. 215
Figura B.2. Tradução de Java com a utilização de operações de leitura e escrita. 217
Figura C.1. Desdobramento de objectos. 221
Figura C.2. Aplanação da estrutura hierárquica de classes. 221
Figura C.3. Implementação de despacho dinâmico. 222
Figura D.1. Exemplo REVERSE. 224
Figura D.2. Exemplo COUNT8. 224
Figura D.3. Exemplo HAMMDIST. 224
Figura D.4. Exemplo EVENONES. 225
Figura D.5. Exemplo SQRT. 225
Figura D.6. Exemplo USQRT. 226
Figura D.7. Exemplo CRC-32. 226
Figura D.8. Exemplo HAMMING. 227
Figura D.9. Exemplo MULT. 227

xxx
Figura D.10. Exemplo KALMAN. 230
Figura E.1. Biblioteca para comunicação software/hardware: a) Declaração da
classe Java que contém os métodos nativos; b) Cabeçalhos da
declaração dos métodos em linguagem C; c) chamada da classe em
Java. 234
Figura E.2. Exemplo de comunicação entre o software e o reconfigware que
implementa o exemplo apresentado na Figura 3.23. 235
Figura E.3. a) Segmento de software inicial; b) Solução reconfigware/software. 236
Figura E.4. Implantação física (Layout) do exemplo EUCDIST no FPGA
XC6216. 237

xxxi
Lista de Tabelas
Tabela 1.1. Alguns sistemas computacionais reconfiguráveis. 6
Tabela 1.2. O subconjunto da linguagem Java cujas instruções correspondentes da
JVM (Java Virtual Machine) são suportadas correntemente pelo
NENYA é mostrado dentro de rectângulos. 17
Tabela 2.1. Exemplos de arquitecturas. 36
Tabela 2.2. Intervalos de acelerações apresentadas na literatura para dispositivos
que incorporam um microprocessador e lógica reconfigurável. 40
Tabela 2.3. Resumo das características dos compiladores considerados. 41
Tabela 2.4. Resumo das características dos compiladores considerados no que
respeita à possibilidade de partição reconfigware/software. 44
Tabela 5.1. Regras de propagação em sentidos directo e inverso para alguns
operadores. 119
Tabela 5.2. Algumas operações e respectivas simplificações quando em presença
de um operando constante. 122
Tabela 5.3. Codificação e o respectivo valor lógico para cada bit. 123
Tabela 5.4. Regras para a propagação de padrões de constantes ao nível do bit em
alguns operadores. 123
Tabela 5.5. Resultados que ilustram a utilização das optimizações descritas com o
exemplo A. 130
Tabela 5.6. Resultados obtidos com os exemplos B, C e D para optimizações
diferentes. 131
Tabela 5.7. Resultados que ilustram a utilização das optimizações descritas com
os exemplos E, F, G, H e I. 132
Tabela 5.8. Tempos de computação da síntese lógica e do GALADRIEL +
NENYA. 135
Tabela 6.1. Resultados para o corpo do exemplo HAL. 150
Tabela 6.2. Resultados para o exemplo HAL. 158
Tabela 6.3. Resultados para o filtro SEWHA, considerando dois dispositivos com
áreas máximas de 4.096 células e de 16.384 células. 158

xxxii
Tabela 6.4. Resultados para 100 grafos gerados pseudo-aleatoriamente. 159
Tabela 8.1. Macrocélulas utilizadas pelo NENYA para implementar o
descodificador de Hamming. 194
Tabela 8.2. Resultados do reconfigware para o descodificador de Hamming. 194
Tabela 8.3. Resultados da compilação do exemplo HAMMING utilizando várias
optimizações. 196
Tabela 8.4. Resultados da compilação para reconfigware. 198
Tabela D.1. Características do primeiro grupo de exemplos. 228
Tabela D.2. Características dos exemplos considerados: codificação de imagem e
vídeo. 232
Tabela D.3. Características dos exemplos considerados: Filtros de processamento
de imagens. 232
Tabela D.4. Características do exemplo Kalman. 232
Tabela D.5. Características dos outros exemplos considerados. 232

xxxiii
Lista de Exemplos
Exemplo 3.1. Sobreposição de elementos em memória. 62
Exemplo 3.2. Dependências de dados na mesma iteração de um ciclo. 65
Exemplo 3.3. Grafos de representação para um exemplo. 67
Exemplo 3.4. Obtenção da lógica decisória do programa. 70
Exemplo 3.5. DFG para um bloco básico. 74
Exemplo 3.6. DFG global. 75
Exemplo 4.1. Partilha de recursos em caminhos mutuamente exclusivos. 98
Exemplo 4.2. Geração da unidade de dados para o exemplo da Figura 3.22. 102
Exemplo 5.1. Redução do custo de multiplicação por constantes. 112
Exemplo 5.2. Aferição de subtipos primitivos nos bytecodes. 118
Exemplo 5.3. Identificação do número de bits na presença de ciclos. 125
Exemplo 6.1. Corpo do ciclo do exemplo HAL. 145
Exemplo 6.2. Partição temporal orientada pelos níveis de ASAP ou de ALAP. 147
Exemplo 6.3. Corpo do ciclo do exemplo HAL. 148
Exemplo 6.4. Movimentos válidos entre fracções temporais. 155
Exemplo 7.1. Agrupamento de blocos básicos. 165
Exemplo 7.2 Escalonamento de um ciclo. 174
Exemplo 7.3. Execução concorrente de regiões cíclicas. 178
Exemplo B.1. Exemplo da tradução de bytecodes Java para VHDL comportamental. 216
Exemplo C.1. Desdobramento de objectos. 220
Exemplo C.2. Aplanação da estrutura hierárquica de classes. 221
Exemplo C.3. Implementação de despacho dinâmico. 222

xxxiv

1
1. Introdução
"It is a very good thing if you keep your eye on the donut and not on the
hole. In other words follow the story and not to get lost in technology."
David Lynch
Os sistemas computacionais reconfiguráveis têm como característica principal a presença de
hardware que pode ser modificado durante o ciclo de vida do dispositivo. Estes sistemas
combinam a especialização de hardware dedicado e graus de flexibilidade ainda mais
poderosos do que os disponíveis pelos componentes de software. Enquanto que os
componentes software estão limitados à arquitectura do microprocessador utilizado, a
utilização de hardware reconfigurável (reconfigware) permite ter arquitecturas adaptadas às
aplicações.
Embora o conceito de adaptabilidade de uma arquitectura à aplicação tivesse sido introduzido
por Estrin no início da década de 60 [Estrin60], só com o desenvolvimento dos primeiros
dispositivos de lógica programável [Brown96] comercializados em meados dos anos 80 pela
Xilinx [XilinxURL] e pela Altera [AlteraURL], é que alguns investigadores começaram
a visionar a efectividade deste novo paradigma de computação [Gray89] designado por
computação reconfigurável1.
1 Alguns autores designam a computação reconfigurável por computação adaptativa e as máquinas de computação baseadas neste conceito por “máquinas de computação personalizadas no campo” (FCCMs, do inglês: Field-Custom Computing Machines) ou simplesmente por “máquinas de computação personalizadas” (CCMs).

2 CAP. 1 INTRODUÇÃO
A área de computação reconfigurável, enquanto área emergente, tem atraído diversas
comunidades de investigadores. Algumas revistas científicas de âmbito genérico têm dado
ênfase a esta área promissora [Villasenor97][Economist99] que se prevê vir a desempenhar
um papel fundamental na forma como é realizada a computação. Diversas áreas podem
beneficiar deste modelo: os sistemas de comunicação, os sistemas de vídeo, os sistemas
embebidos de 3ª geração [Master99], etc. A par com as conferências internacionais
específicas [FCCMURL][FPLURL][FPGA93-00][RAWURL][MAPURL][EvolvURL] têm
aparecido workshops e sessões especiais em muitas das mais prestigiadas conferências
[DACURL][PACT][SPIE][PDTA][HPCA][HICSS98] (só para citar algumas) que de alguma
forma traduzem o interesse generalizado por esta área.
Contudo, ao nível comercial, o mercado de computação reconfigurável só nos finais dos anos
90 parece ter atraído os fabricantes de dispositivos lógicos programáveis após fabricação
(FPGAs). Uma das experiências mais interessantes foi a fabricação pela Xilinx da série de
FPGAs XC6200 [Xilinx97], que acabou por ser descontinuada. Esta série de FPGAs
representa um dos poucos dispositivos comerciais realmente idealizado para suporte à
computação reconfigurável. Os novos FPGAs integram algumas facilidades vocacionadas
para este paradigma, como sejam os bancos de memória distribuídos pelo agregado,
capacidade de reconfiguração parcial, e tempos de reconfiguração mais reduzidos (família
Virtex [VirtexURL] de FPGAs da Xilinx, por exemplo). Contudo, continua a não haver, por
parte dos principais fabricantes de FPGAs, uma aposta clara e específica para computação
reconfigurável. Entretanto, a comunidade espera que a investigação bem sucedida de
arquitecturas, de ferramentas e de compiladores, e o desenvolvimento de aplicações chave
possam vir a tornar a computação reconfigurável como um modelo dominante em muitas
áreas aplicacionais e possam também sensibilizar os fabricantes de FPGAs.
Com a explosão do consumo de potência em processadores de sinais digitais (DSPs) e
microprocessadores maioritariamente devida às unidades de controlo, busca e descodificação
de instruções e distribuição do relógio pelo integrado (60-90% do consumo de potência total,
dependendo do microprocessador [Brooks99]), ao utilizarem arquitecturas específicas sem
serem baseadas no modelo de software, os FPGAs podem ter um papel fundamental nos
sistemas computacionais do futuro.
Na maioria dos sistemas computacionais reconfiguráveis os dispositivos de reconfigware são
adicionados aos sistemas de software tradicionais com o objectivo de retirar as melhores

CAP. 1 INTRODUÇÃO 3
potencialidades dos dois tipos de computação. Por isso, faz sentido aproveitar algumas ideias
de projecto de sistemas com componentes hardware e software que foram identificadas pela
comunidade de co-projecto hardware/software2 [Micheli97]. Embora se possam utilizar e
adaptar algumas dessas ideias a nova dimensão de reconfiguração adicionada ao projecto dos
componentes hardware abre novas perspectivas e requer abordagens adequadas.
Nos últimos anos foram desenvolvidas inúmeras aplicações computacionais em sistemas
reconfiguráveis muitas das quais foram apresentadas em sessões de aplicações das
conferências específicas a este tema enumeradas previamente. Existem áreas de aplicação em
que a utilização destes sistemas fornece implementações com desempenhos inalcançáveis
com sistemas computacionais tradicionais e até com sistemas de topo de gama. Contudo, a
programação destes sistemas assenta tipicamente na experiência dos projectistas de hardware
e, por este motivo, um dos maiores desafios da comunidade que investiga na área de
computação reconfigurável aponta para a investigação e desenvolvimento de ferramentas de
suporte3. Para atrair a comunidade de software (a qual se acredita ter o predomínio no
desenvolvimento de sistemas electrónicos digitais) é necessário que sejam investigadas
formas eficientes de compilar automaticamente para reconfigware aplicações descritas a um
nível de abstracção elevado. Foi com este incentivo que o trabalho desta tese foi efectuado.
1.1 Fundamentos de Computação Reconfigurável
Os FPGAs são os dispositivos com maior utilização pela comunidade de computação
reconfigurável [Hauck98]. Sem perda de generalidade, pode assumir-se que os FPGAs se
baseiam na célula básica representada na Figura 1.1. As saídas da célula podem ser
programadas para serem oriundas de um registo ou do bloco de lógica reconfigurável. Este
bloco pode ser constituído por uma LUT4 ou por um esquema de multiplexadores e é
programado por bits armazenados em memória (SRAM em FPGAs do tipo SRAM). Um
FPGA é constituído por uma matriz (agregado) de células (ver Figura 1.2) com canais de fios
2 Projecto em que se estabelecem compromissos entre componentes hardware e componentes software, com vista à integração conjunta, respeitando os objectivos de desempenho e a tecnologia de implementação. 3 Aconselha-se a consulta de [Compton00], onde é apresentada uma panorâmica do estado-da-arte em sistemas e software para computação reconfigurável. 4 Do inglês: Look-Up Table.

4 CAP. 1 INTRODUÇÃO
cujas ligações podem ser programadas e normalmente de posicionamento simétrico que
permite a posição relativa de blocos e o movimento destes sem nova colocação e
encaminhamento. Em algumas famílias de FPGAs existem também blocos de memória do
tipo RAM distribuídos pelo agregado. Em [Brown96] pode ser encontrada uma panorâmica
sobre dispositivos de lógica programável.
Lógica Reconfigurável
FF
Figura 1 .1 . Célula representat iva da maior ia dos FPGAs de
granulosidade f ina.
célula célula célula
célula célula célula
Figura 1 .2 . Exemplo de um a matr iz de células e de inter l igações comum
na maior ia dos FPGAs comerc ia is .
Alguns FPGAs permitem a reconfiguração parcial do agregado, permitindo a execução de
regiões de reconfigware concorrentemente com a reconfiguração de outras regiões do
dispositivo. A família de FPGAs XC6200 permite a reconfiguração parcial, e permite que um
sistema de hospedagem tenha acesso a todos os registos internos sem necessidade de
encaminhamentos especiais para os pinos do dispositivo [Churcher95]. Em placas que

CAP. 1 INTRODUÇÃO 5
utilizam esta família de FPGAs o acesso aos registos internos é feito por endereçamento e o
software vê os recursos do FPGA mapeados na memória do sistema [Nisbet97].
1.1.1 Organização dos Sistemas para Suporte de Computação
Reconfigurável
A colocação de reconfigware nos sistemas de computação tradicionais pode ser considerada
nas proximidades de quase todos os componentes dos sistemas computacionais, ou mesmo
nos próprios componentes. Este facto deve-se às vantagens de colocação de elementos de
processamento o mais próximo possível do local de armazenamento dos dados durante a
execução. A Figura 1.3 ilustra uma organização computacional tradicional e a existência
possível de reconfigware. Uma das abordagens deste visionamento é a colocação de
pequenas unidades de lógica reconfigurável em memórias [Oskin98], que permite que
pequenas partes da execução de um programa possam ser computadas neste dispositivo sem
intervenção do microprocessador (não necessita de transferências dos dados entre memória e
microprocessador e vice-versa).
L1 Cache
L2
Cache
RW
RW
Barramento de memória
Barramento de E/S
Memória RW RW RW
RW
CPU RW
RW DISCO
Figura 1 .3 . Organização de um s is tema de computação com integração
de hardware reconf igurável (RW).

6 CAP. 1 INTRODUÇÃO
Os sistemas de suporte à computação reconfigurável actualmente existentes podem ser
agrupados em quatro tipos distintos5, baseados na localização do reconfigware:
• Unidades funcionais reconfiguráveis: são sistemas em que um agregado (matriz) de
células lógicas reconfiguráveis integra o microprocessador com acoplamento via
barramento interno com acesso ao ficheiro de registos. Normalmente, a unidade
funcional implementa sequências de instruções e não tem acesso directo ao exterior
do microprocessador nem a memórias internas;
• Co-processadores: do mesmo tipo do sistema anterior mas no qual o agregado pode
ter execução autónoma e tem acesso a memórias internas ou externas;
• Placas conectadas ao sistema de hospedagem: estes sistemas integram as vulgares
placas comerciais de FPGAs que são conectadas normalmente a barramentos de
periféricos do sistema de hospedagem (ligação ao barramento PCI6, por exemplo).
Uma lista bastante exaustiva de placas pode ser consultada em [FCMURL];
• Processadores principais: este tipo de sistemas são uma solução isolada em que o
reconfigware desempenha a computação principal (são sistemas maioritariamente
utilizados para resolver problemas específicos).
Na Tabela 1.1 são apresentados alguns exemplos para cada um dos tipos supraenumerados.
Tabela 1 .1 . Alguns sistemas computacionais reconf iguráveis.
Acoplamento Exemplo de sistemas
Unidade Funcional Reconfigurável
Chimaera [Hauck97][Ye00b] PRISC7 [Razdan94a][Razdan94c][Razdan94a] OneChip [Witting96] ConCISe [Kastrup99][Kastrup00] Active Pages [Oskin98]
Co-Processador NAPA [Gokhale98]
5 Em [Radunovic98] pode ser encontrado um agrupamento diferente para as arquitecturas de sistemas
computacionais reconfiguráveis.
6 Do ingles: Peripheral Controller Interface. 7 Do inglês: Programmable Reduced Instruction Set Computers.

CAP. 1 INTRODUÇÃO 7
DISC8 [Wirthlin95] REMARC9 [Miyamori98] Garp [Hauser97] Piperench [Goldstein99][Goldstein00] RaPiD [Ebeling95] Spyder [Iseli93] MorphoSys [Singh98][Lee00] Lista de Guccione [FCMURL]
Placas para conexão ao sistema de hospedagem
HOT-I,II [Nisbet97] Xputer [Hartenst90][Hartenst95] PRISM I,II [Athanas93][Wazlows93] SPLASH 1,2 [Gokhale90][Arnold92] ArMem [Raimbault93] Teramac [Amerson95] DECPerLe-1 [Moll95] Transmogrifier 1,2 [Lewis98]
Processador Principal RAW [Waingold97] HAL [StarBridURL] DeCypher [TimeLoURL]
1.2 Incentivo para a Investigação em Compiladores para
Sistemas Computacionais Reconfiguráveis
A utilização de reconfigware torna possível acoplar o computador de hospedagem com
recursos hardware mais flexíveis, melhor adaptados à aplicação em execução corrente, e com
a possibilidade de adaptação a novas versões de uma aplicação. Mais ainda, a capacidade de
reconfigurações dinâmicas torna possível a partilha temporal do dispositivo de reconfigware
por tarefas diferentes, que pode reduzir significativamente a área de silício necessária para
implementar o sistema. A diminuição dos tempos de reconfiguração começa de facto a tornar
viável o conceito de “hardware virtual” (baseado na assumpção de que existem recursos
hardware teoricamente ilimitados).
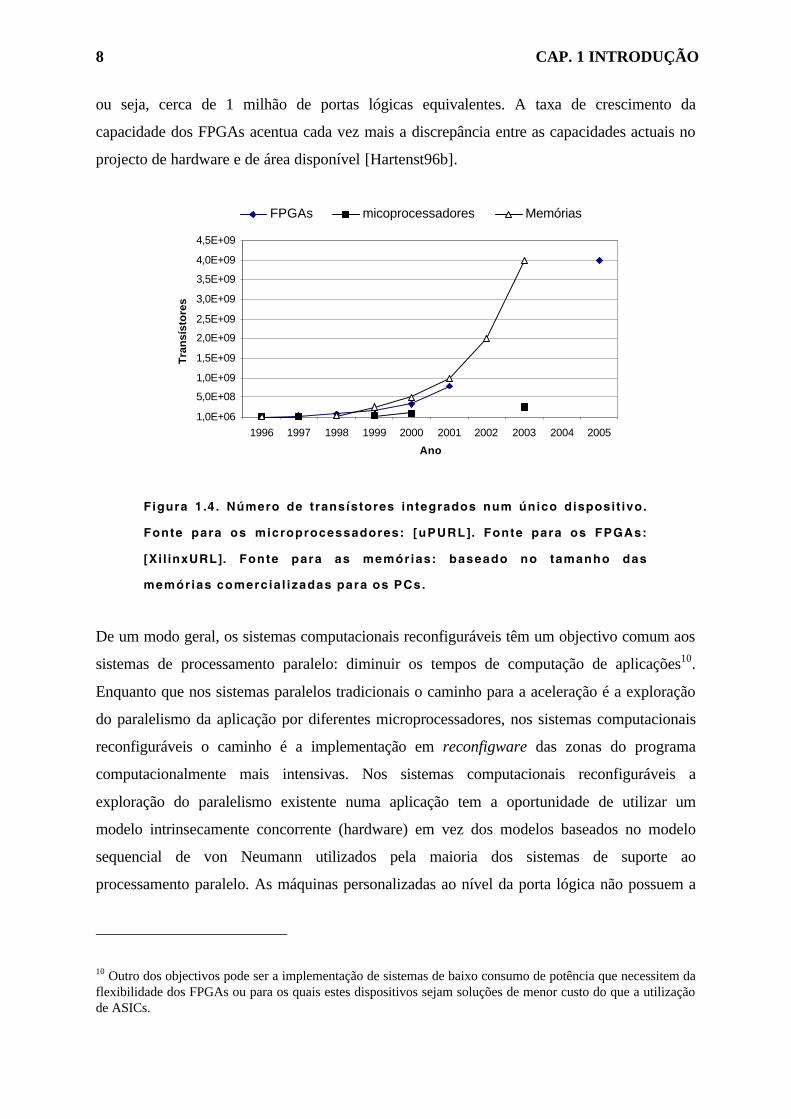
Os dispositivos de reconfigware, como sejam os FPGAs, têm tido aumentos da capacidade
(número de transístores) no mesmo circuito integrado mais acentuados do que o dos
congéneres microprocessadores (ver Figura 1.4). Este crescimento (apenas comparável ao das
memórias RAM) deve-se à regularidade da estrutura dos FPGAs e ao facto destes
dispositivos não terem custos de teste tão elevados como os microprocessadores. Os novos
FPGAs anunciam a existência de 4 milhões de portas de sistema (system gates) [VirtexURL],
8 Do inglês: Dynamic Instruction Set Computer. 9 Do inglês: REconfigurable Multimedia Array Coprocessor.
8 CAP. 1 INTRODUÇÃO
ou seja, cerca de 1 milhão de portas lógicas equivalentes. A taxa de crescimento da
capacidade dos FPGAs acentua cada vez mais a discrepância entre as capacidades actuais no
projecto de hardware e de área disponível [Hartenst96b].
1,0E+06
5,0E+08
1,0E+09
1,5E+09
2,0E+09
2,5E+09
3,0E+09
3,5E+09
4,0E+09
4,5E+09
1996 1997 1998 1999 2000 2001 2002 2003 2004 2005
Ano
Tra
nsí
sto
res
FPGAs micoprocessadores Memórias
Figura 1 .4 . Número de transístores integrados num único disposit ivo.
Fonte para os microprocessadores: [uPURL]. Fonte para os FPGAs:
[Xi l inxURL]. Fonte para as memórias: baseado no tamanho das
memór ias comerc ia l izadas para os PCs.
De um modo geral, os sistemas computacionais reconfiguráveis têm um objectivo comum aos
sistemas de processamento paralelo: diminuir os tempos de computação de aplicações10.
Enquanto que nos sistemas paralelos tradicionais o caminho para a aceleração é a exploração
do paralelismo da aplicação por diferentes microprocessadores, nos sistemas computacionais
reconfiguráveis o caminho é a implementação em reconfigware das zonas do programa
computacionalmente mais intensivas. Nos sistemas computacionais reconfiguráveis a
exploração do paralelismo existente numa aplicação tem a oportunidade de utilizar um
modelo intrinsecamente concorrente (hardware) em vez dos modelos baseados no modelo
sequencial de von Neumann utilizados pela maioria dos sistemas de suporte ao
processamento paralelo. As máquinas personalizadas ao nível da porta lógica não possuem a
10 Outro dos objectivos pode ser a implementação de sistemas de baixo consumo de potência que necessitem da flexibilidade dos FPGAs ou para os quais estes dispositivos sejam soluções de menor custo do que a utilização de ASICs.

CAP. 1 INTRODUÇÃO 9
limitação de largura de banda no carregamento de instruções, facto que limita o desempenho
das arquitecturas paralelas baseadas em vários microprocessadores.
Contudo, apesar de novas arquitecturas terem sido propostas e novos conceitos apresentados
[Radunovic98], a utilização dos sistemas computacionais reconfiguráveis requer etapas
morosas e complexas que requerem conhecimentos específicos de projecto de hardware.
Como foi mencionado em [Smith97], a computação reconfigurável utilizada com o objectivo
de melhorar o desempenho de aplicações necessita de uma metodologia suportada por
compiladores que possam explorar automaticamente as sinergias existentes nestes sistemas.
Enquanto não existir um suporte efectivo a estes sistemas, os programadores de software não
se sentirão atraídos pelo desenvolvimento de aplicações neste modelo, pois a implementação
dos mesmos requer muito tempo de projecto e necessita de especialistas de hardware.
O desenvolvimento de aplicações em sistemas computacionais reconfiguráveis aponta para as
seguintes metodologias:
• Utilização de objectos hardware (cores) fornecidos por vendedores específicos e
desenvolvidos por projectistas de hardware, com interface específico à linguagem de
software utilizada. Este método pode ser apropriado para desenvolvimento de
aplicações que necessitem de funcionalidades standard como sejam: FFTs,
codificadores/descodificadores JPEG, MPEG, etc.
• Utilização de ferramentas que forneçam, a partir de uma descrição da aplicação numa
linguagem com níveis de abstracção elevados, o código objecto para ser executado no
microprocessador e os ficheiros de configuração para programar a parte de
reconfigware.
Esta tese pretende resolver alguns dos problemas existentes ao nível da compilação de
reconfigware incluída no segundo tópico anterior. A possibilidade, contudo, de inclusão de
bibliotecas de componentes reconfigware durante o desenvolvimento de um sistema deve ser
considerada em trabalhos futuros. Esta integração pode não ser uma tarefa simples por
envolver a compilação de interfaces que dependem dos modelos de comunicação utilizados
pelos componentes.
Para se produzirem compiladores eficientes devem ser combinadas técnicas das áreas de
compiladores e de automação do projecto de circuitos integrados de aplicação específica

10 CAP. 1 INTRODUÇÃO
(ASICs). Da última, destacam-se algumas das ideias utilizadas pela comunidade de síntese
arquitectural [Gajski92]. As técnicas de síntese arquitectural permitem a geração do hardware
a partir de descrições a um nível de abstracção próximo dos níveis utilizados em linguagens
de programação de software (linguagem C, por exemplo) com base em componentes pré-
definidos que implementam os operadores da linguagem.
Contudo, muitas das etapas das ferramentas de síntese arquitectural produzem resultados
ineficientes quando o circuito gerado é mapeado num FPGA pelas razões seguintes:
• a arquitectura baseada num ficheiro de registos é centralizada e necessita da análise de
vida das variáveis de forma a utilizar o menor número possível de registos, enquanto
que num FPGA os registos são distribuídos e em número elevado;
• a partilha de unidades funcionais, por exemplo somadores, produz resultados práticos
ineficientes, pois na maioria dos FPGAs, a área de um somador do tipo ripple-carry é
similar à área de cada um dos componentes necessários para a implementação da
partilha de qualquer unidade funcional11: circuitos de selecção de entradas
(multiplexador, por exemplo) e registos;
• a partilha de recursos pode complicar a colocação e encaminhamento e produzir
resultados inesperados.
A maioria dos sistemas de síntese arquitectural utiliza um conjunto discreto de componentes
sem parametrização durante o escalonamento (o que conduz em muitos casos a um
desnecessário sobredimensionamento face ao número de bits requerido pelas operações) de
forma a facilitar o mapeamento e o escalonamento, que mesmo assim continuam a ser
problemas computacionalmente árduos (difíceis) [Micheli94][Gajski92]. A maioria das
ferramentas afere um componente mesmo quando a funcionalidade não requer lógica
(deslocadores por constantes, por exemplo).
O tempo de computação necessário por estas ferramentas (síntese arquitectural, síntese
lógica, colocação e encaminhamento) é inaceitável para a comunidade de sistemas
computacionais reconfiguráveis, que prognostica ferramentas com tempos de computação
11 Partilhas baseadas em colocação dos operandos em série não necessitam de circuitos de selecção mas de registos com deslocamento.

CAP. 1 INTRODUÇÃO 11
competitivos com os tempos gastos pelos compiladores de software. Em [Postula98] a síntese
arquitectural de um algoritmo computacionalmente intensivo descrito em VHDL
comportamental que foi traduzido directamente (preservando as construções iniciais) de uma
versão em Fortran requereu 22 horas para produzir um circuito com 429 CLBs12 (duas vezes
mais lento e 30% maior do que uma versão especificada manualmente em VHDL-RTL e
posteriormente sintetizada).
Muitas das ferramentas só consideram o paralelismo existente dentro de blocos básicos, facto
que limita o desempenho. Utilizam a técnica de armazenar as variáveis, com cadeias
definição-uso entre blocos básicos, em registos que facilita a selecção das definições de entre
caminhos mutuamente exclusivos, por ser garantida pela máquina de estados que controla o
fluxo de execução, mas pode prejudicar o escalonamento. Este fluxo controlado pela máquina
de estados respeita, na maioria das vezes, o fluxo de controlo originalmente descrito pelo
programador que não é necessariamente o melhor e que foi idealizado tendo em mente o
modelo sequencial de computação.
Pelos motivos supracitados, as técnicas tradicionais utilizadas em síntese arquitectural para
alvejarem ASICs têm de ser redefinidas. Trabalhos iniciais realizados pelo autor desta tese
(ver apêndice B) serviram para identificar estas limitações. A maioria destas limitações deve-
se ao facto do alvo reconfigware permitir reconfiguração e ter uma estrutura pré-definida
(fixa) e por isso sem a liberdade de implantação física (layout) dos ASICs. Devem ser
adicionadas etapas que permitam lidar com a possibilidade de partilha temporal do FPGA,
que pode permitir o uso de áreas de silício menores. A exploração da partilha de operadores,
com viabilidade, pode reduzir o número de configurações necessárias e, por isso, deve
também ser considerada. As capacidades de reconfiguração dinâmica e parcial são outros
factores que podem ser explorados pelas etapas de compilação de modo a que a
implementação final sirva os propósitos do programador de modo mais eficaz.
Em conclusão, para que a computação reconfigurável possa ser adoptada como um
paradigma de computação têm de ser desenvolvidas ferramentas eficientes, rápidas, de fácil
manuseamento e que explorem o conceito de “hardware virtual”. É notório que estas
ferramentas devem resolver as inadequações da síntese arquitectural supraidentificadas.
12 Configurable Logic Blocks de um FPGA XC4010 da Xilinx.

12 CAP. 1 INTRODUÇÃO
1.2.1 Porquê compilar de Java, e em particular dos bytecodes?
A linguagem de programação utilizada não deve estar dependente da informação temporal e
deve permitir ao programador uma abstracção elevada em relação aos recursos de hardware
(arquitectura, componentes, implantação física, etc.). Uma das linguagens de programação
que tem vindo a captar enorme entusiasmo e adeptos em diversas áreas é a linguagem Java
[Gosling97] acompanhada da sua tecnologia de suporte [Gosling96]. Esta linguagem tem sido
considerada para especificação de sistemas hardware/software [Passerone98][Helaihel97]
[Cardoso98a] e hardware [Weaver98] [Bellows98].
A adopção da linguagem Java como linguagem de programação de sistemas computacionais
reconfiguráveis assenta nos seguintes factos:
• Simplicidade da linguagem, sem perda de potencialidades julgadas críticas na
especificação de sistemas complexos;
• Utilização de referências e ausência de ponteiros. Não permite aritmética sobre
referências e a memória de armazenamento é tratada com a atomicidade de objectos
ou de arrays e não por endereços físicos;
• Nível de abstracção elevado e orientação por objectos de raiz;
• Suporte à programação concorrente, pela utilização de threads. Permite que ao nível
de granulosidades mais grossas (por exemplo tarefas, processos) a concorrência seja
especificada explicitamente pelo programador (a este nível é facilmente identificada),
utilizando as capacidades inatas da linguagem de expressar concorrência;
• Tecnologia neutral: independente do sistema operativo e da arquitectura utilizados,
permitindo o desenvolvimento de aplicações portáveis;
• Sintaxe parecida com o C/C++, que facilita a migração dos inúmeros utilizadores
destas linguagens e a tradução do código existente;
• Contém um modelo de tratamento de excepções;
• Existência de ferramentas de compilação e de depuração grátis.

CAP. 1 INTRODUÇÃO 13
Em particular, a utilização do modelo de bytecodes do Java [Gosling95] que utiliza a
máquina abstracta da tecnologia Java (JVM13) [Lindholm96] tem as seguintes vantagens:
• Independente da plataforma de execução;
• Executável;
• Orientado por objectos;
• Mantém quase toda a informação do programa fonte;
• Utilização de referências com atomicidade do objecto ou do array;
• Um modelo de execução na Internet;
• Suporta várias linguagens de programação de software.
A par das vantagens supracitadas, o facto da representação em bytecodes de uma aplicação
ser fruto de algumas etapas iniciais e neutrais de compilação foi outro dos pontos chave que
originou a adopção deste modelo como formato de entrada para o compilador de anteguarda
implementado no âmbito desta tese.
1.2.2 Porquê explorar o paralelismo para além dos blocos básicos?
O grau de paralelismo em cada bloco básico em programas de fluxo de controlo intensivo é
muito baixo, ao contrário dos programas de fluxo de dados intensivo, nos quais os blocos
básicos aparentam muito mais operações e por isso graus de paralelismo muito maiores.
Estudos mostram que o grau de paralelismo ao nível de instruções (ILP14) em cada bloco
básico é tipicamente de 2 a 3,5 [Fisher95]. Por este motivo, nos casos em que o engenho
computacional suporta graus de paralelismo mais elevados é necessário que o compilador
procure paralelismo entre blocos básicos e gere implementações com fluxos de controlo
múltiplos.
13 Do ingles: Java Virtual Machine. 14 Do inglês: Instruction-Level Parallelism.

14 CAP. 1 INTRODUÇÃO
Na compilação para processadores VLIW15 e superescalares alguns autores revelam que a
utilização das optimizações de código e dos escalonadores convencionais não permitiam ter
maior aceleração do que 2 sobre os processadores escalares em aplicações
predominantemente de fluxo de controlo intensivo [Hwu93].
Como em FPGAs existe a liberdade de implementação de arquitecturas adaptadas à aplicação
e suporte efectivo de graus elevados de ILP, a exposição do paralelismo a vários níveis de
granulosidade e escalonadores que lidem eficientemente com o paralelismo exibido devem
ser tarefas de investigação prementes.
1.3 Contribuições da Tese
Esta tese propõe o fluxo de compilação para sistemas computacionais reconfiguráveis
ilustrado na Figura 1.5. O fluxo referido é uma proposta original e os compiladores
implementados de suporte ao mesmo são contribuições originais e bem sucedidas como o
leitor pode constatar pela análise ao estado-da-arte em compiladores para sistemas
computacionais reconfiguráveis baseados em FPGAs. Os dois compiladores novos que
actuam em sequência são:
• Um compilador de anteguarda, designado por GALADRIEL, que recebe um
algoritmo em bytecodes do Java e efectua várias etapas que conduzem a
representações intermédias vocacionadas para as características do hardware.
• Um compilador para reconfigware, designado por NENYA, que tem como alvo a
arquitectura ilustrada na Figura 1.6, constituída por um FPGA acoplado a várias
memórias.
No que se refere ao compilador de anteguarda, são propostas e implementadas várias análises
que permitem extrair dos bytecodes o paralelismo existente num dado método. Este trabalho
fornece representações intermédias que possibilitam implementações com fluxos de controlo
múltiplos e graus de paralelismo teoricamente sem limites. Segundo julgamos saber foi o
15 Do inglês: Very Long Instruction Width.

CAP. 1 INTRODUÇÃO 15
primeiro trabalho a partir dos bytecodes do Java de uma dada aplicação e a computar os
grafos de representação para um modelo intrinsecamente concorrente.
Reconfigware
CPU
I/O
Memória Principal
Memória
Retaguarda
Descrição RTL-VHDL
Bitstreams
Biblioteca de
Macrocélulas
DFG (DataFlow Graph)
COMPILADOR DE
ANTEGUARDA
Java Classfiles
COMPILAÇÂO PARA
RECONFIGWARE
Java Classfiles com
comunicação com RPUs
GALADRIEL
NENYA Descrição da Arquitectura
Alvo Compilação do
Software
HPDG (Hierarchical Program
Dependence Graph)
Figura 1 .5 . F luxo de compi lação.
RAM
FPGA
RAM
RAM RAM
...
...
SISTEMA DE HOSPEDAGEM
Figura 1 .6 . Arquitectura alvejada pelo compilador de reconfigware
desenvolv ido.

16 CAP. 1 INTRODUÇÃO
No que se refere ao compilador NENYA foram integrados os seguintes algoritmos, que por si
só são contribuições originais:
• Um novo algoritmo de partição temporal baseado no escalonador de lista. Nas fases
de investigação e desenvolvimento do algoritmo o mesmo foi confrontado com outros
algoritmos previamente propostos na literatura e com uma versão do simulated
annealing realizada também no âmbito desta dissertação. Os resultados comprovam a
eficiência, efectividade e robustez do algoritmo desenvolvido. Pelo que é do nosso
conhecimento, foi também a primeira vez que o simulated annealing foi utilizado para
resolver o problema da partição temporal;
• Algoritmos que permitem determinar estaticamente, para cada operando, o número de
bits suficiente para satisfazer a funcionalidade inicial e que desempenham um papel
crucial na compilação para hardware específico como é demonstrado pelos resultados
apresentados;
• Um algoritmo que realiza a propagação de constantes ao nível do bit com resultados
de grande impacto em aplicações que manipulem bits. A eficiência deste algoritmo é
testemunhada pelos resultados obtidos de núcleos de aplicações;
• Um escalonador baseado em regiões que permite efectuar o escalonamento de
estruturas de representação hierárquicas, a implementação de ciclos em hardware
específico e o controlo das sequências de acesso à mesma memória RAM.
Outros dos algoritmos desenvolvidos são implementações adaptadas de análises sólidas
existentes e que servem de etapas para a optimização global e automatização da geração do
hardware. Neste contexto, é possível reivindicar abordagens diferentes de resolução dos
problemas que surgiram, alguns dos quais pelo facto do ponto de partida da compilação
serem programas em linguagem Java.
A versão actual do compilador NENYA aceita os bytecodes correspondentes a enunciados em
linguagem Java de controlo, ciclos, variáveis do tipo array, dados do tipo inteiro (byte,
int), booleano, etc (ver Tabela 1.2). O subconjunto da linguagem aceite presentemente
garante, sem alterações, a compilação de muitos algoritmos realistas, ao contrário da maioria
dos compiladores previamente desenvolvidos (ver capítulo 2).

CAP. 1 INTRODUÇÃO 17
Tabela 1 .2 . O subconjunto da l inguagem Java cujas instruções
correspondentes da JVM são suportadas correntemente pe lo NENYA é
mostrado dentro de rectângulos (♣♣ apenas arrays unidimensionais) .
Tipos de dados Operações Controlo e outros mecanismos
Boolean Byte Short Int char Long Float, double, Referências a arrays♣ Referências a objectos
/, %, *, ++, --, +, -, <<, >>, >>>, ||, &&, &, |, ^, ~, <, >, <=, >=, ==, !=
Tratamento de excepções Invocação de métodos Criação de objectos Criação de arrays♣ While, for, do while Break, continue If, ? :, switch Conversões (cast)
O objectivo de compilar para reconfigware, algoritmos descritos em linguagens de
programação de software com exploração do paralelismo implícito, foi amplamente atingido.
A dissertação e os compiladores nela propostos provam a exequibilidade do fluxo de
compilação apresentado. A efectividade dos compiladores é demonstrada por exemplos
realistas e complexos, que provam o conceito e as análises de optimização propostas.
As ferramentas realizadas permitem o suporte a investigações futuras de novas soluções para
alguns problemas específicos (partição espacial, mapeamento e escalonamento com partilha
de operadores, partição hardware/software, etc.). Sem ferramentas de arquitectura aberta,
onde possam ser integradas, estas tarefas são difíceis de validar e torna-se intrincado avaliar o
seu potencial.
1.4 Estrutura da Tese
A tese é constituída por nove capítulos (incluindo o actual). Na Figura 1.7 estão apresentadas
as etapas que constituem os compiladores GALADRIEL e NENYA e, para cada etapa, é
indicado o capítulo onde o leitor pode encontrar informações. Em alguns capítulos são
apresentados resultados que demonstram a escolha de um método particular. De seguida é
resumido cada um dos capítulos subsequentes.
CAP. 2: COMPILADORES PARA RECONFIGWARE: são descritos os compiladores
para reconfigware encontrados na literatura que de alguma forma estão relacionados com o
trabalho apresentado. Na parte final do capítulo é situado o trabalho realizado no âmbito
desta tese em relação ao estado da arte.

18 CAP. 1 INTRODUÇÃO
CAP. 3: MODELOS DE REPRESENTAÇÃO INTERMÉDIA E SUA CONSTRUÇÃO:
são apresentadas as representações intermédias utilizadas pelos compiladores desenvolvidos e
explicadas as etapas realizadas pelo compilador de anteguarda (GALADRIEL).
CAP. 4: SUPORTE À GERAÇÃO DE RECONFIGWARE: são descritas as etapas de
suporte adoptadas no compilador NENYA com vista à geração de reconfigware especializado
a partir dos modelos de representação intermédios propostos no capítulo 3.
CAP. 5: OPTIMIZAÇÕES DO GRAFO DE FLUXO DE DADOS: são apresentadas as
técnicas de optimização do grafo de fluxo de dados, as técnicas para a determinação do
número de bits suficiente para preservar a funcionalidade original para cada operação, e as
técnicas que exploram a possibilidade de propagação dos bits constantes e permitem eliminar
lógica desnecessária.
CAP. 6: PARTIÇÃO TEMPORAL: é apresentada a abordagem utilizada na partição
temporal para que a implementação final possa ser executada por multiplexagem do FPGA.
Para tal, é apresentado um novo algoritmo baseado em heurísticas e uma forma de partição
temporal baseada no algoritmo de optimização simulated annealing.
CAP. 7: ESCALONAMENTO BASEADO EM REGIÕES: é apresentado o método de
escalonamento que origina a descrição da máquina de estados responsável pela orquestração
da execução.
CAP. 8: PROTÓTIPOS E RESULTADOS EXPERIMENTAIS: são apresentados
resultados obtidos com os compiladores apresentados considerando exemplos complexos e
são avaliados os impactos das optimizações sobre esses exemplos.
CAP. 9: CONCLUSÕES: são apresentadas as conclusões acerca do trabalho efectuado e
enumeradas algumas ideias e direcções passíveis de investigação e desenvolvimento futuros.

CAP. 1 INTRODUÇÃO 19
Netlists (EDIF)
NENYA
Descrição da Arquitectura
Alvo
Atribuição e Mapeamento de UFs
Partição Temporal & Escalonamento
STG (State Transition Graphs)
RTG (Reconfiguration Transition Graph)
Síntese de FSMs
Atribuição de Registos
Optimizações do DFG
Inferência de Bits
Propagação de Bits Constantes
Reassociação de Operações
Redução do custo de Operações
Caracterização das Macrocélulas
STG para VHDL-RTL
comportamental
DFG para VHDL-RTL estrutural
Tradução de VHDL-RTL Estrutural
para EDIF
GALADRIEL
CAPÍTULO 3
CAPÍTULO 5
CAPÍTULOS 6 e 7
CAPÍTULO 4
CAPÍTULO 4
DFG HPDG
DDG CDG
Bytecodes Java
CFG
MDG
Figura 1 .7 . Etapas real izadas pelos compi ladores.
São partes constituintes desta tese sete apêndices que adicionam algumas explicações e
funcionam como complemento:
APÊNDICE A: é apresentada uma descrição breve sobre a tecnologia Java.
APÊNDICE B: é apresentado um fluxo de compilação que alveja ASICs através da
utilização de uma ferramenta de síntese arquitectural. Este fluxo foi considerado no início dos
trabalhos que conduziram a esta tese.

20 CAP. 1 INTRODUÇÃO
APÊNDICE C: são apresentados alguns conceitos que permitem a implementação
simplificada de algumas construções orientadas por objectos em hardware específico.
APÊNDICE D: é apresentado o modo como é efectuada a interface e a comunicação
reconfigware/software para alguns dos exemplos que foram prototipados.
APÊNDICE E: são apresentados os exemplos considerados durante a tese.
APÊNDICE F: é apresentado o glossário dos termos e acrónimos mais utilizados.
APÊNDICE G: é apresentada uma lista dos símbolos utilizados.

21
2. Compiladores para Reconfigware1
"Did not Gandalf tell you that the rings give power according to the measure of each possessor? Before you could use that power you would need to become far stronger, and to train your will to the domination of others."
J. R. R. Tolkien, The Fellowship of the Ring
Neste capítulo são descritos trabalhos em compilação de programas em linguagens com nível
de abstracção elevado para máquinas de computação reconfigurável. Pretendeu-se descrever
com algum pormenor as abordagens consideradas mais importantes, desde os primeiros
protótipos até aos trabalhos actualmente em investigação e desenvolvimento.
Foi dado maior destaque a compiladores que têm como alvo FPGAs comerciais por estarem
mais relacionados com o trabalho desta tese. Contudo, incluem-se alguns compiladores para
arquitecturas em investigação, desde arquitecturas de granulosidade mais grossa do que a dos
vulgares FPGAs comerciais, a dispositivos que incluem microprocessador e lógica
reconfigurável.
São assim apresentados os compiladores PRISM-I [Athanas93], II [Wazlows93],
Transmogrifier C [Galloway95] e NAPA C [Gokhale98], e ainda os compiladores para o
Garp [Callahan00], para o RaPiD [Cronquist98], para o PipeRench [Budiu99], e para o
Chimaera [Ye00a]. Para finalizar o capítulo são apresentados alguns dos trabalhos em síntese
1 Abreviatura para hardware reconfigurável.

22 CAP. 2 COMPILADORES PARA RECONFIGWARE
de pipelines. Não são considerados trabalhos em síntese lógica dedicados a FPGAs
[Vincent93] por, na maioria dos casos, partirem de um nível de abstracção mais baixo e
utilizarem níveis de representação intermédia ao nível da porta/função lógica.
2.1 Compiladores para FCCMs
O processo de transformação de uma descrição numa linguagem alto-nível numa descrição
capaz de ser directamente interpretada pela máquina alvo considerada, seja esta real ou
virtual, designa-se por compilação. Nos casos em que a máquina alvo tem uma arquitectura
pré-definida (microprocessadores, por exemplo) a descrição obtida programa de algum modo
a execução dos recursos pré-existentes e daí o nome de compilação. Quando a máquina alvo
não tem inerentemente nenhuma arquitectura pré-associada (como é o caso de um ASIC) o
processo designa-se por síntese de hardware, embora no início fosse chamado de
“compilação de silício”. Os FCCMs situam-se entre estes dois tipos de engenhos
computacionais. Embora tenham inerentemente uma arquitectura pré-definida (matriz de
CLBs2 nos FPGAs, por exemplo), têm a flexibilidade de poderem teoricamente implementar
qualquer circuito digital tal como nos ASICs. Este facto origina muitas vezes a utilização dos
dois termos, compilação e síntese, para referenciar o processo anteriormente identificado.
Esta dicotomia entre os dois termos deve-se também ao facto de a comunidade de síntese
arquitectural tratar, ao nível de ferramentas, os FPGAs como ASICs. Contudo, a
especificidade dos primeiros aliada à flexibilidade até então apenas disponível em
componentes software, tem originado interesses na área emergente designada por
computação reconfigurável, e consequente investigação e desenvolvimento de ferramentas de
compilação apropriadas.
Os chamados “compiladores de silício” tiveram origem em finais da década de 80
[Johnson83], [Ullman84], [Girczyc85] e [Trickey85]. A compilação de linguagens alto-nível
em hardware específico foi inicialmente considerada pelos sistemas HARP (Fortran)
[Tanaka89], Flamel (Pascal) [Trickey87], Cyber (C e BDL) [Wakabay91] e [Girczyc85]
(Ada). Depois destas abordagens iniciais a investigação foi centrada para a compilação de
silício a partir de modelos descritivos adequados à representação de hardware específico,
2 Do inglês: Configurable Logic Block.

CAP. 2 COMPILADORES PARA RECONFIGWARE 23
como são os casos das linguagens de descrição de hardware (Verilog e VHDL).
Recentemente, contudo, a compilação a partir de linguagens de programação (C, por
exemplo) tem angariado cada vez mais adeptos e mais esforços de investigação
nomeadamente na área emergente de computação reconfigurável. Esta tendência deve-se a
vários factores:
• Necessidade de níveis de abstracção mais elevados, que possam facilitar a
especificação de sistemas cada vez mais complexos;
• Necessidade de proliferar o conceito por comunidades reticentes aos modelos de
hardware, devido à disparidade entre as semânticas dos modelos de computação;
• Reutilização de inúmeros algoritmos já implementados em linguagens com grande
utilização;
• Constante aumento do número de elementos lógicos em FPGAs, que requer cada vez
mais esforços na inovação com menor ênfase na redução da área.
Compiladores para hardware de descrições efectuadas em alto-nível, sobretudo de C, são
comercializados por algumas empresas. Destes, destacam-se os compiladores de: C-RTL para
Verilog [CLevelURL], ANSI-C para Verilog-RTL [CompiURL], Java para Verilog-RTL
[LavaURL], C para Verilog ou VHDL [FrontierURL], C/C++ para Verilog-RTL
[CynAppsURL], etc. Uma das abordagens engloba na linguagem Verilog semânticas e
sintaxes parecidas com o C [SuperURL]. A iniciativa SystemC [SystemCURL] parece
pretender definir um standard para descrição de sistemas baseado na linguagem C++. Estes
esforços acrescentam às linguagens de software a possibilidade de descrever ao nível RTL3.
Contudo, todos os compiladores descritos foram desenvolvidos para alvejarem hardware não
reconfigurável, e por isso não incluem técnicas específicas para alvejar reconfigware.
Existem duas abordagens para o desenvolvimento de sistemas baseados em FCCMs
utilizando uma linguagem de alto-nível (normalmente de software):
• Implementação do algoritmo com base em componentes a implementar no FPGA que
constituem uma arquitectura de processamento pré-definida (neste caso é vulgar a
3 Do inglês: Register Transfer Level.

24 CAP. 2 COMPILADORES PARA RECONFIGWARE
utilização de mecanismos que possam especificar ao nível RTL). Nesta abordagem é
especificado um sistema digital que implemente o algoritmo;
• especificação do algoritmo como se se tratasse de software puro, com a utilização das
construções permitidas pela linguagem utilizada, e sem qualquer referência implícita
aos componentes alvo utilizados e, por isso, também sem referência à arquitectura que
implementará o algoritmo.
A primeira abordagem tem sido bastante utilizada por permitir a utilização de linguagens
amplamente disseminadas e, através de algumas extensões ou utilização de bibliotecas
apropriadas, capacidades não suportadas por linguagens de descrição de hardware. Alguns
exemplos desta abordagem utilizam C++ [Iseli95], [Mencer98] ou Java [Weaver98],
[Bellows98]. Este tipo de compiladores serão nesta tese identificados por “geradores de
circuitos”, por não incluírem as etapas de um verdadeiro compilador, e por partirem de
descrições muito próximas do hardware a implementar (sendo por isso análogas a linguagens
assembly). Para desenvolver reconfigware com estas abordagens é necessário que o
programador domine o desenvolvimento de circuitos digitais, pois a descrição é ao nível de
portas lógicas ou de transferência entre registos (RTL). Um dos casos de maior sucesso é o
ambiente de desenvolvimento de circuitos digitais em FPGAs designado por JHDL (Java
Hardware Description Language) [Bellows98][JHDLURL], que, com base em APIs4
específicos e na tecnologia Java, inclui simulador, síntese de máquinas de estado,
mapeamento no FPGA alvo, colocação relativa, etc. Existem também interfaces amigáveis
com FPGAs como são os casoss dos APIs JERC [Lechner97] e JBits [Guccione00] para
Java, que permitem que em linguagem Java se programe respectivamente os bitstreams de
FPGAs das famílias Xilinx XC6200, e XC4000 e Virtex.
A segunda abordagem considerada, por estar a um nível de programação distante do nível de
portas lógicas e da arquitectura do hardware (do sistema digital que implementará um
determinado algoritmo), não necessita que o programador seja um perito em projecto de
sistemas digitais. Existem pelo menos duas vertentes nesta abordagem: a transformação do
algoritmo inicial numa descrição VHDL-RTL sintetizável por ferramentas de síntese lógica
para FCCMs (Synplify [Synplicity99] para FPGAs, por exemplo), ou a utilização de
4 Do inglês: Application Program Interface.

CAP. 2 COMPILADORES PARA RECONFIGWARE 25
técnicas de síntese arquitectural para geração das unidades de dados e de controlo, embora
sendo possível utilizar também síntese lógica para optimização, o resultado pode ser
directamente submetido às ferramentas de colocação e encaminhamento (P&R 5) comerciais
com utilização de geradores de circuitos ou de implementações prévias para cada operador
utilizado. É nesta última vertente que se enquadra o trabalho apresentado nesta tese.
Alguns compiladores compilam apenas blocos básicos [Gokhale98][Gokhale95], outros
aceitam também construções condicionais do tipo if-then-else [Ye00a][Chichkov98] e outros
permitem segmentos de código que contêm ciclos [Callahan00][Wazlows93] nos quais se
incluem os compiladores desenvolvidos no âmbito desta tese. Algumas destas limitações são
explicadas por os compiladores terem sempre como alvo uma arquitectura que contém um
microprocessador encarregue de executar as partes da aplicação não suportadas pelo
compilador para reconfigware.
Existem poucos compiladores que integram partição temporal, como o compilador NENYA
desenvolvido neste trabalho, e o ambiente SPARCS (Synthesis and Partitioning for Adaptive
and Reconfigurable Computer Systems) [Ouaiss98a]. Alguns autores investigam o
escalonamento e a partição temporal partindo de grafos de representação inseridos
manualmente [Vasilko96]. Embora estes possam ser obtidos automaticamente por um
compilador de anteguarda, a sua não integração num fluxo de compilação torna morosa a
exploração de exemplos de grandes dimensões.
Existem trabalhos que compilam programas em occam [Page91], Handel-C [Page96], Oberon
[Wirth98], MATLAB (projecto MATCH) [Banerjee00], SA-C (projecto CAMERON)
[Hammes99][Rinker00], Khoros (projecto Champion) [Natarajan99], C (projecto
DEFACTO) [Diniz00][Bondala99a], entre outros, em reconfigware do tipo FPGA. Alguns
deles transformam a descrição fonte em VHDL comportamental ao nível RTL para que
depois uma ferramenta de síntese lógica produza o circuito final. Um dos exemplos anteriores
é o projecto MATCH. Na Figura 2.1 pode ser vista a tradução de um segmento de código
MATLAB para VHDL-RTL comportamental.
Algumas das abordagens não exploram o potencial implícito de paralelização existente em
muitos algoritmos. Alguns destes compiladores, mais simplificados por muitas das etapas
5 Do inglês: Place and Route. Em português: colocação e encaminhamento.

26 CAP. 2 COMPILADORES PARA RECONFIGWARE
intermédias não serem efectuadas, são orientados pela sintaxe da descrição inicial [Page96]
[Wirth98].
Em [Page96] são apresentadas técnicas para compilar para hardware programas em Handel-C
(subconjunto de Occam2 [Page91]). Esta linguagem permite enunciados de paralelização de
operações que permitem ao programador especificar concorrência a níveis de abstracção
baixos. Sendo um compilador orientado pela sintaxe, apenas o paralelismo explicitamente
especificado é considerado em hardware. A abordagem considera que entre atribuições a
variáveis todas as operações são executadas num ciclo. Este facto permite que o hardware
gerado pelo compilador seja independente do FPGA considerado (sem ser considerado uma
biblioteca tecnológica) mas tem a enorme desvantagem de não considerar o facto de haver
grandes desfasamentos entre atrasos para operações diferentes. Esta desvantagem é ainda
mais notória quando são considerados diferentes tamanhos de palavra.
Figura 2 .1 . Exemplo de compi lação de uma descr ição a l to -nível para
VHDL comportamental ao nível de transferências entre registos (RTL) .
Figura extraída de [Baner jee00].
Em [Wirth98] é apresentado um compilador protótipo para compilar programas em Oberon
para reconfigware. Este compilador utiliza um esquema parecido ao anterior.

CAP. 2 COMPILADORES PARA RECONFIGWARE 27
Em [Wo94] é apresentado um compilador de C em agregados de células, que compila
programas num subconjunto da linguagem C em estruturas de portas lógicas. O compilador
fornece a estrutura num formato aceite pela ferramenta de P&R utilizada. O compilador
utiliza a abordagem de compilação para uma máquina de estados algorítmica, na qual o fluxo
de controlo é misturado com as operações. Embora o compilador explore o paralelismo ao
nível do bloco básico é incapaz de o explorar a outros níveis. O compilador não utiliza uma
biblioteca de descrição das características dos operadores. Estes são assumidos como tendo
atraso de um ciclo de relógio e a sua execução é embebida num dos estados da máquina de
estados.
2.2 Compilador Apresentado por Chichkov
Chichkov [Chichkov98][Chichkov97] apresentou outro compilador de um subconjunto de C
que utiliza o formato RTL*6 do GCC [gccURL] para gerar VHDL-RTL comportamental da
parte do código original que é implementado em hardware específico. O compilador não
aceita enunciados com ciclos, arrays, estruturas, ponteiros, chamadas a funções,
recursividade, etc.
O compilador integra um tradutor dirigido pela sintaxe que gera a partir da descrição RTL*
de cada bloco básico uma descrição VHDL-RTL comportamental equivalente. Em
[Chichkov98] são apresentadas implementações combinatórias e sequenciais de cada bloco
básico.
Na abordagem sequencial são utilizados sinais de concluído_entrada e concluído_saída para
sincronizar o funcionamento de um bloco básico. O compilador insere registos nos arcos de
dependências de dados entre blocos básicos e os laços de dependências de controlo são
implementados por sinais que determinam o estado dos registos de saída e de entrada de cada
bloco básico. O compilador assume que a implementação hardware de cada bloco básico
executa num ciclo de relógio, facto que degrada a execução global, pois o ciclo de relógio do
reconfigware para uma região tem de ter período igual ao maior dos atrasos dos blocos
básicos pertencentes a essa região.
6 Representação intermédia utilizada pelo GCC (não confundir com o RTL de especificações para descrever o nível de abstracção em linguagens de descrição de hardware) que é baseada em código de três endereços.

28 CAP. 2 COMPILADORES PARA RECONFIGWARE
Para implementar o reconfigware no FPGA são utilizadas ferramentas comerciais de síntese
lógica e de colocação e encaminhamento.
Embora com grandes limitações no suporte a construções da linguagem C, o compilador
produz, sendo grande parte do processo controlado manualmente, estimativas do software e
do reconfigware (para a família de FPGAs XC4000 da Xilinx) e realiza a partição entre estes
dois componentes baseada na extracção de paralelismo entre blocos básicos.
2.3 Compilador PRISM-I e II
Em [Athanas93] é apresentado um compilador de linguagem C para um sistema constituído
por um processador de propósito geral e FPGAs. Os segmentos de código, sob a forma de
funções, computacionalmente intensivos são compilados em reconfigware de forma a que ao
código software sejam adicionadas operações especiais implementadas em FPGAs.
O compilador foi designado por PRISM [Athanas92] (Processor Reconfiguration Instruction
Set Metamorphosis) e o protótipo inicial por PRISM-I [Athanas93]. Mais tarde foram
apresentados melhoramentos no PRISM-II [Wazlows93], relacionados principalmente com o
suporte de construções da linguagem C. O programador escolhe as funções que deseja que
sejam implementadas como operações especiais e que, por isso, necessitam de ser compiladas
para hardware.
Este compilador foi um dos primeiros trabalhos a integrar totalmente no processo de
compilação a síntese de algumas operações (transparente ao programador). O compilador
aceita um programa como entrada e produz uma imagem mista (reconfigware/software)
como saída. A imagem reconfigware consiste na especificação física utilizada para programar
o agregado reconfigurável, a imagem software consiste em código de máquina vulgar com a
adição de código que realiza a comunicação com os novos elementos computacionais.
O compilador explora o paralelismo existente dentro dos blocos básicos, mas não altera o
fluxo de controlo imposto pelo modelo sequencial utilizado pela linguagem C. O grau de
paralelismo obtido é por isso bastante limitado.
O subconjunto da linguagem C suportado inclui dados do tipo inteiro, instruções condicionais
e ciclos. Não inclui operações de vírgula flutuante, variáveis do tipo array, estruturas de

CAP. 2 COMPILADORES PARA RECONFIGWARE 29
dados mais complexas (registos), ponteiros, etc. O compilador de C da GNU (GCC) é
utilizado como anteguarda (é utilizada a representação intermédia, RTL*, fornecida pelo
GCC).
O compilador pode converter a representação RTL* em VHDL, criar os grafos de fluxo de
controlo e de fluxo de dados e usá-los para gerar a representação do circuito. São utilizadas
ferramentas comerciais para gerar a imagem hardware da representação do circuito.
Os tempos de compilação sem terem em conta a colocação e o encaminhamento são na
ordem dos minutos mesmo para exemplos pequenos [Athanas93]. O compilador é orientado
pelo CFG obtido da descrição fonte e por isso não considera a ordem das instrução de acordo
com as dependências expostas.
Em [Agarwal94] são apresentados melhoramentos relativos à geração da unidade de controlo.
São apresentadas técnicas que permitem o agrupamento de estados relativos a blocos básicos
distintos.
2.4 Transmogrifier-C
Outros dos compiladores que parte de um algoritmo descrito num subconjunto da linguagem
C, com algumas extensões, é o compilador Transmogrifier C [Galloway95]. Este
compilador tem como alvo a família de FGPAs XC4000 da Xilinx. O compilador não permite
a existência no código de entrada de variáveis do tipo array, estruturas de dados do tipo
registo, ponteiros, etc. O programador deve especificar no programa, através de directivas, o
número de bits de cada tipo de representação de inteiros suportada.
O subconjunto da linguagem C é bastante reduzido no compilador apresentado em
[Galloway95]. Não são suportadas multiplicações, divisões, ponteiros, arrays, estruturas,
recursividade, ciclos for e do-while, etc.
O compilador produz uma solução do tipo máquina de estados com operações que apenas
mudam de estado no início de um ciclo ou de uma chamada a uma função. A única forma de
partilha de recursos é realizada pelo programador ao definir funções nas quais integra as
zonas de código cujas implementações deseja serem partilhadas no reconfigware.

30 CAP. 2 COMPILADORES PARA RECONFIGWARE
O compilador realiza algumas optimizações lógicas, embora com bons resultados apenas para
funções lógicas de (até) 4 variáveis.
2.5 Compilador NAPA C
O compilador NAPA C [Gokhale98] (cujo fluxo se encontra ilustrado na Figura 2.2) tem
como objectivo a geração de reconfigware optimizado para implementação de partes de um
programa na linguagem NAPA C. Esta linguagem é um subconjunto da linguagem C
adicionado de algumas características (construções de especificação de paralelismo, tipos de
dados com especificação do número de bits, etc.). Nesta abordagem, o programador declara o
fragmento do código a ser compilado para reconfigware. A linguagem aceita como modelos
de comunicação: chamada de procedimentos (passagem dos parâmetros - executa e retorna o
resultado num número de ciclos de relógio), memória partilhada (o processador de
hospedagem passa os endereços de dados e o reconfigware opera autonomamente) e cadeias-
de-dados7 (interface FIFO8 fornece dados sincronamente com o reconfigware).
MARGE Module Generator
HDL
Software Blocos FPGA
Plataforma Alvo ou
Co-Simulador Hardware/Software FPGA
bitstreams
C ou C paralelo SUIF: pré-processamento e co-síntese Suporte de
Execução Software
Gerador de Módulos
P&R
HDL
Suporte de Execução Hardware
Executável Síntese
Figura 2 .2 . Organização do compi lador NAPA C.
A ferramenta responsável pela geração do reconfigware é o MARGE (Malleable
Architecture Generator) [Gokhale98]. O compilador utiliza uma biblioteca de funções
7 No inglês: streams. 8 Do inglês: First In First Out.

CAP. 2 COMPILADORES PARA RECONFIGWARE 31
(ALUs, contadores, codificadores, filtros, SRAMs, bancos de registos, etc.) parametrizáveis
de acordo com o número de bits dos operandos. Alguns destes elementos são pré-colocados e
pré-encaminhados reduzindo o tempo de compilação total de horas para minutos
[Gokhale97]. As macros podem ser especificadas pelo programador utilizando a ferramenta
Modgen [Gokhale98]. Esta ferramenta utiliza uma linguagem parecida com C, e integra um
ambiente de simulação que permite testar rapidamente cada módulo. São aceites
especificações do número de bits, forma geométrica, etc. O resultado da compilação para
reconfigware é uma descrição RTL com componentes do Modgen.
A ferramenta só compila para reconfigware o conteúdo de blocos básicos. O controlo é
efectuado pelo componente software. O compilador tenta reutilizar componentes sempre que
a unidade funcional seja do tamanho e funcionalidade apropriadas e não esteja a ser utilizada
por uma operação no ciclo escalonado. O escalonamento das operações é feito pela rotulagem
de cada instância do Modgen na descrição RTL do número da instrução e do número do
ciclo. O compilador utiliza um registo por cada variável declarada no programa e o conjunto
de registos necessário para armazenar dados temporariamente (os registos são implementados
pelo banco de registos do Modgen).
Em [Gokhale97] o compilador tem como alvo o FPGA, National Semiconductor CLAy
FPGA9, de granulosidade fina, e em [Gokhale98] o dispositivo NAPA (RISC+FPGA)
[Rupp98].
Em [Gokhale99] é apresentado um algoritmo integrado no compilador NAPA C para mapear
variáveis do tipo array em memórias conectadas ao FPGA. Para reduzir o espaço de
exploração, de cariz exponencial, é utilizada uma técnica de busca, conhecida por
enumeração implícita.
2.6 Síntese de Pipelines em FPGAs
Alguns autores têm-se preocupado com a síntese de circuitos baseados em pipelines na
implementação de ciclos (de último nível10, quando existem encadeamentos) para que a
9 Neste FPGA cada célula tem 3 entradas e duas saídas. O FPGA é reconfigurável parcialmente por cada célula. O CLAy31 pode ser totalmente reconfigurado em cerca de 0,6 ms (8 milhões de portas lógicas por segundo).

32 CAP. 2 COMPILADORES PARA RECONFIGWARE
próxima iteração de um ciclo possa ser executada antes do término da iteração actual. Esta
técnica é conhecida no meio dos compiladores por software pipelining [Muchnick97] e na
área de síntese arquitectural por loop folding [Gajski92].
As técnicas apresentadas para síntese de circuitos com funcionamento em pipelines são
utilizadas em ciclos bem comportados (limites constantes) e com indexação de elementos de
arrays utilizando funções de acesso do tipo affine11. O objectivo destes compiladores, dos
quais se destacam [Weinhardt00] e [Diniz00], é a inserção de registos de forma a que o
circuito possa funcionar à frequência de trabalho da largura de banda das entradas/saídas.
Weinhardt [Weinhardt97][Weinhardt99][Weinhardt00] tem investigado e desenvolvido
técnicas para síntese dos pipelines de modo a obter um circuito eficiente para ser
implementado em FPGAs. As técnicas apresentadas permitem executar todos as operações
dos ciclos de último nível em paralelo. O compilador permite executar o corpo do ciclo
interno em apenas um ciclo desde que não seja necessário seriar os acessos à mesma memória
quando o corpo do ciclo inclui acessos. Em [Weinhardt99][Weinhardt00] são apresentadas
algumas transformações (desenrolamento de ciclos, por exemplo) que potenciam o aumento
do paralelismo. As técnicas descritas são úteis para programas vectorizáveis, como são
muitos dos algoritmos de processamento de sinais e imagens. As técnicas são viáveis apenas
quando existem padrões de acesso a arrays do tipo X[i+c] ou X[-i+c] (i identifica uma
variável de indução, c identifica uma constante) e o ciclo tem um contador que começa por
zero e é sempre incrementado de uma unidade (do tipo: FOR I:=0 TO N DO...). Em muitos
dos casos é possível, com transformações do programa fonte, obter ciclos deste tipo
[Muchnick97].
A unidade de controlo do pipeline sintetizado utiliza contadores que implementam a estrutura
de controlo do ciclo.
A Figura 2.3b ilustra o grafo de fluxo de dados gerado pelo compilador a partir do código do
exemplo ilustrado na Figura 2.3a. A Figura 2.4 apresenta o grafo de fluxo de dados da Figura
2.3b com os registos inseridos para que seja permitida a execução em pipelines.
10 Em inglês: inner loops. 11 Do tipo: C1×X+C2, com C1 e C2 constantes do tipo inteiro;

CAP. 2 COMPILADORES PARA RECONFIGWARE 33
Em [Moisset99][Diniz00] é apresentado outro compilador para sintetizar pipelines. Uma
unidade centralizada controla a execução em pipeline e implementa a interface com a
memória externa. A compilação proposta é baseada na tradução directa da árvore abstracta de
sintaxe (AST12) para VHDL-RTL comportamental. Análise de dependências de dados
determinam o número e o local de buffers e como controlar a execução utilizando pipelines.
O compilador considera a adição de registos de forma a reduzir o número de acessos a
memórias externas.
a) b)
Figura 2 .3 . Exemplo de um cic lo do t ipo FOR: a) código em Modula -2; b)
grafo de f luxo de dados do corpo do ciclo. ( f igura extraída de
[Weinhardt97])
Figura 2 .4 . Grafo de f luxo de dados com os valores calculados e os
registos de pipel ine. ( f igura extraída de [Weinhardt97])
12 Do inglês: Abstract Syntax Tree.

34 CAP. 2 COMPILADORES PARA RECONFIGWARE
2.7 Utilização de Ambientes de Síntese Arquitectural Adaptados
para FPGAs
Algumas ferramentas iniciais tiveram como alvo FPGAs unicamente para efeitos de teste de
circuitos mais tarde implementados em ASICs. Alguns autores pegaram em ferramentas e
conceitos de síntese arquitectural e criaram ambientes para computação reconfigurável. Essas
abordagens são cada vez mais inapropriadas para alvejarem os FPGAs da nova geração
devido ao facto destes não serem meros agregados de células lógicas. O sistema COBRA-
ABS [Duncan98] é um exemplo de uma destas abordagens. Outro exemplo, embora os
autores tenham integrado ferramentas dedicadas a sistemas computacionais reconfiguráveis é
o projecto SPARCS [Ouaiss98a].
A ferramenta COBRA-ABS [Duncan98] sintetiza arquitecturas personalizadas para
algoritmos com grande intensidade de fluxo de dados descritos num subconjunto de C (os
autores não especificam quais as restrições). A ferramenta integra os problemas de partição
espacial, escalonamento, mapeamento e alocação num problema de optimização global
resolvido por um algoritmo baseado no simulated annealing. O sistema alvo do COBRA-
ABS é uma plataforma constituída por vários FPGAs, ASICs de aritmética, e memórias
RAM. O sistema utiliza uma arquitectura alvo tipo VLIW13, com ficheiros de registos (de
dados, de constantes e de endereços) e uma unidade de controlo centrais. Os FPGAs são a
única parte do sistema alvo possível de reconfigurar. As especificações ao nível de
transferência de registos podem depois ser implementadas em FPGAs por ferramentas
comerciais de síntese, de colocação e encaminhamento. A ferramenta utiliza a abordagem da
síntese arquitectural tendo como alvo ASICs e, por isso, incorre nos principais defeitos
daquela abordagem. Embora a utilização do simulated annealing para resolver os problemas
da síntese arquitectural globalmente possa permitir melhorias significativas, os tempos de
computação apresentados tornam proibitiva esta abordagem (11 a 12 horas numa estação de
trabalho Sun Ultra 1/140 para sintetizar um exemplo com 13 operações e 12 acessos à
memória para cada arquitectura de placa considerada) [Duncan98] no contexto de compilação
13 Do inglês: Very Long Instruction Width.

CAP. 2 COMPILADORES PARA RECONFIGWARE 35
para FCCMs. O sistema considera várias memórias acopladas aos FPGAs mas o mapeamento
de arrays em cada uma delas é realizado manualmente.
O sistema SPARCS [Ouaiss98a] aceita descrições comportamentais de grafos de tarefas em
que cada tarefa é especificada em VHDL. O sistema tem como alvo um número de FPGAs e
memórias. As ligações entre FPGAs e as memórias podem ser estáticas ou configuráveis. É
utilizada partição temporal e espacial antes das fases de síntese arquitectural. Em cada uma
destas fases são utilizadas estimativas que entram em linha de conta com as fases seguintes.
São utilizadas ferramentas de síntese lógica e de P&R comerciais como ferramentas de
retaguarda.
2.8 Compiladores para Arquitecturas não Comerciais
Têm sido investigadas e desenvolvidas inúmeras arquitecturas para suporte da computação
reconfigurável. Todas elas têm por base uma matriz de células em que as interligações e a
funcionalidade de cada célula podem ser reconfiguráveis. Ao nível da complexidade
funcional destas células podem-se considerar três subconjuntos de arquitecturas, com
exemplos ilustrados na Tabela 2.1:
• Granulosidade fina: as células podem implementar funções lógicas simples, e para
se implementar, por exemplo, um somador tem de se utilizar várias destas células.
Este subconjunto engloba os FPGAs comerciais;
• Granulosidade média: as células podem implementar operações mais complexas do
que no subconjunto anterior. Algumas das arquitecturas utilizam células que podem
implementar operações lógico-aritméticas;
• Granulosidade grossa: as células são constituídas por verdadeiros núcleos de
processamento que muitas das vezes incorporam um microprocessador e memória
acoplados a uma matriz de lógica reconfigurável com arquitectura que pode ser de um
dos tipos anteriores.
Também é possível utilizar uma camada intermédia que define um modelo de arquitectura
cujas unidades funcionais são reconfiguradas conforme a aplicação. Esta máquina é depois

36 CAP. 2 COMPILADORES PARA RECONFIGWARE
implementada num dispositivo de granulosidade mais fina (um dos exemplos é o
microprocessador DISC [Wirthlin95]). Este tipo de abordagem pode permitir a utilização de
compiladores existentes para, por exemplo, processadores superescalares embora mantenha,
na generalidade, as deficiências dos microprocessadores.
Os elementos de processamento reconfiguráveis que integram agregados de ALUs são
habitualmente designados por Field-Programmable ALU Arrays (FPAAs).
Tabela 2 .1 . Exemplos de arqui tecturas.
Granulosidade de cada célula
Exemplo de dispositivos Tipo de célula Número de bits
FPGAs, CPLDs LUT, multiplexador, registo 2-5 Fina (fio) DPGA [DeHon96] LUT 4 Xputer (rDPA) [Hartenst95][Hartenst90]
ALU + registo 32
MATRIX [Mirsky96] ALU com multiplicador + memória 8 RaPiD [Ebeling95] ALU, multiplicadores, registos, RAM 16
Média (operando)
PipeRench [Goldstein99][Goldstein00]
ALU + Ficheiro de registos de passagem
2-3214
Grossa (dados) RAW [Waingold97] RISC+FPGA+memória 32
No paradigma Xputer [Hartenst90] um rDPA (re-configurable Data-Path Architecture)
[Hartenst95][Hartenst96a] - matriz de ALUs com 32 bits (Figura 2.5) – é utilizado para
realizar o processamento mais intensivo. Estas ALUs de 32 bits podem ser reconfiguradas
para executarem alguns dos operadores da linguagem C. Em [Becker98] é apresentado o
CoDe-X, uma ferramenta para compilar para o Xputer. O objectivo desta ferramenta é o
mapeamento automático das porções mais apropriadas de um programa em C em rPDAs.
Alguns resultados obtidos com esta abordagem foram apresentados em [Hartenst96a], sendo
reportadas acelerações (comparados com a execução dos programas sem suporte de rDPAs)
de 13 para o algoritmo de compressão, e de 70 para um filtro FIR15 bidimensional.
No PipeRench [Goldstein99] é utilizada uma matriz de elementos de processamento. Cada
elemento é constituído por uma ALU e um ficheiro de registos de passagem. A arquitectura
foi realizada para permitir facilidades de computação em pipeline em aplicações baseadas em
14 Têm sido considerados estudos de desempenho considerando granulosidades de 2 a 32 bits. 15 Do inglês: Finite Impulse Response.

CAP. 2 COMPILADORES PARA RECONFIGWARE 37
cadeias-de-dados. A ideia centra-se na virtualização da máquina e encadeamento em
pipelines da execução-reconfiguração. O sistema é programado em DIL16 [Budiu99], que é
uma linguagem de atribuição-única e com operadores do tipo dos de C. A linguagem permite
a especificação discreta do número de bits para cada variável declarada. O programador pode
utilizar essa propriedade ou delegar para os analisadores apresentados em [Budiu00] a
extracção do número de bits. O compilador de DIL para o PipeRench foi apresentado em
[Budiu99]. O compilador expande todas as chamadas a funções, desenrola todos os ciclos
(para implementação no PipeRench são apenas permitidos ciclos com número de iterações
conhecido estaticamente), para produzir um programa planar em código de atribuição-única
sobre o qual são realizadas as análises de extracção de bits, a decomposição de operadores, e
a colocação e encaminhamento. Para esta última etapa são utilizados algoritmos “gulosos”
desenvolvidos pelos autores [Budiu99] que tornam esta fase 2 a 3 ordens de magnitude mais
rápida do que quando realizada por ferramentas comerciais.
Figura 2 .5 . Arquitectura do rDPA (f igura extraída de [Hartenst90]).
No RaPiD [Ebeling95] é utilizada uma matriz linear de unidades funcionais, cujo tipo de
função é determinado pela aplicação, interligadas, como desejado, por barramentos
segmentados (ver Figura 2.6) programáveis após fabricação. O modelo de computação
utilizado é baseado em cadeias-de-dados, os dados entram no pipeline via cadeias-de-dados
de entrada e saem via cadeias-de-dados de saída. O compilador aceita RaPiD C, que é uma
nova linguagem de programação paralela baseada no C, com algumas extensões. A
16 Do inglês: Dataflow Intermediate Language, que é uma linguagem intermédia para compilação de linguagens alto-nível.

38 CAP. 2 COMPILADORES PARA RECONFIGWARE
linguagem permite a especificação de paralelismo, movimento de dados e partição
[Cronquist98].
O compilador extrai os ciclos internos de último nível, desenrola-os e gera a unidade de
dados responsável pela implementação destes.
Outros compiladores têm como arquitectura alvo um microprocessador com conexão a uma
matriz de lógica reconfigurável. Um dos compiladores para uma arquitectura deste tipo é o
compilador de C para o Chimaera [Ye00a]. Neste último, sequências de instruções em C são
agrupadas em uma única operação implementada no reconfigware (Dst = f(src1, scr2, …,
src9);). A Figura 2.7 ilustra um exemplo de agrupamento de instruções.
Memória
A L U
A L U
Memória
Cadeias de
dados de
saída
C adeias de
dados de
entrada
A L U
Multiplicador
A L U
Função Personalizada Multiplicador
Figura 2 .6 . Arquitectura do RaPiD.
r4 = RFUOP #1;
... r2 = r3<<2; r4 = r2+r5; r6 = lw 0(r4); ...
Figura 2 .7 . Exemplo de agrupamento de operações pelo compi lador de
C para o Chimaera [Ye00a].

CAP. 2 COMPILADORES PARA RECONFIGWARE 39
Os objectivos do compilador para o Garp [Hauser97] (constituído por um processador RISC
e uma matriz de lógica reconfigurável integrados no mesmo dispositivo) são permitir a co-
compilação, e reduzir o tempo de mapeamento e colocação tornando-o comparável à
compilação de software.
Este compilador designado por garpcc [Callahan98a] compila programas em linguagem C na
arquitectura Garp. O compilador procura no código por núcleos intensivos (ciclos ou partes
de ciclos) para serem implementados na matriz de lógica reconfigurável, que funciona como
co-processador. O resto do programa é executado no microprocessador. O compilador utiliza
o hiperbloco [Mahlke92], representação utilizada por alguns compiladores para processadores
do tipo VLIW, para identificar a parte de cada ciclo que vai ser implementada em hardware
específico. A formação do hiperbloco é, por enquanto, feita de modo a que instruções que não
podem ser implementadas em hardware (chamadas ao sistema, por exemplo) fiquem fora do
hiperbloco, e pontos de saída deste são utilizados para manter o fluxo de controlo original. As
implementações funcionam com interactividade entre o núcleo de processamento do Garp e
a lógica reconfigurável.
Os blocos básicos contidos num hiperbloco dão origem a um grafo de fluxo de dados (DFG)
transformando o fluxo de controlo em execução predicativa. Em seguida, a ferramenta Gama
[Callahan98b] pega no DFG e gera a configuração para a matriz. O Gama realiza o
mapeamento dos módulos, a colocação e o encaminhamento. Um controlador é sintetizado
pelo Gama para coordenar a execução dos módulos.
O processador e o co-processador reconfigurável têm acesso ao mesmo sistema de memória
(incluindo todas as memórias cache). Por isso, a transferência de dados incorre num custo
adicional pequeno em virtude do reconfigware aceder directamente às memórias do sistema.
Na Tabela 2.2 são apresentados algumas acelerações reportadas na literatura para
arquitecturas de suporte à computação reconfigurável que adicionam a um microprocessador
do tipo RISC um agregado de lógica reconfigurável.
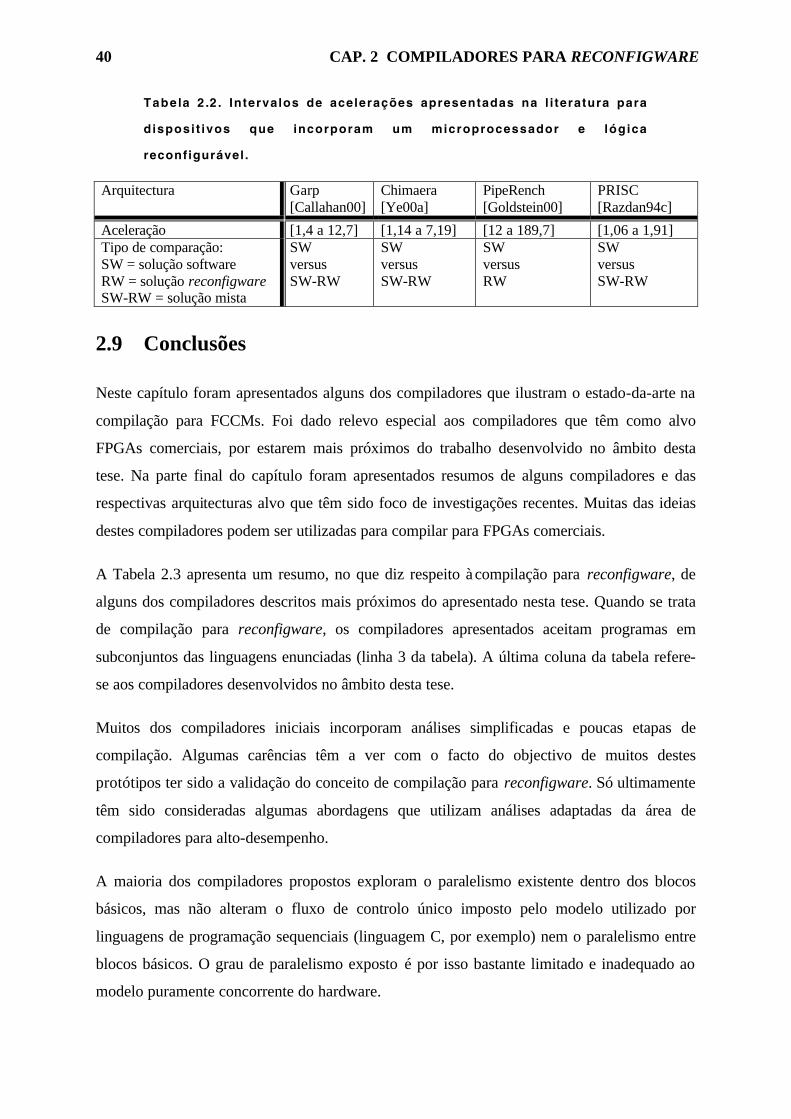
40 CAP. 2 COMPILADORES PARA RECONFIGWARE
Tabela 2 .2 . Intervalos de acelerações apresentadas na l i teratura para
disposi t ivos que incorporam um microprocessador e lógica
reconfigurável .
Arquitectura Garp [Callahan00]
Chimaera [Ye00a]
PipeRench [Goldstein00]
PRISC [Razdan94c]
Aceleração [1,4 a 12,7] [1,14 a 7,19] [12 a 189,7] [1,06 a 1,91] Tipo de comparação: SW = solução software RW = solução reconfigware SW-RW = solução mista
SW versus SW-RW
SW versus SW-RW
SW versus RW
SW versus SW-RW
2.9 Conclusões
Neste capítulo foram apresentados alguns dos compiladores que ilustram o estado-da-arte na
compilação para FCCMs. Foi dado relevo especial aos compiladores que têm como alvo
FPGAs comerciais, por estarem mais próximos do trabalho desenvolvido no âmbito desta
tese. Na parte final do capítulo foram apresentados resumos de alguns compiladores e das
respectivas arquitecturas alvo que têm sido foco de investigações recentes. Muitas das ideias
destes compiladores podem ser utilizadas para compilar para FPGAs comerciais.
A Tabela 2.3 apresenta um resumo, no que diz respeito à compilação para reconfigware, de
alguns dos compiladores descritos mais próximos do apresentado nesta tese. Quando se trata
de compilação para reconfigware, os compiladores apresentados aceitam programas em
subconjuntos das linguagens enunciadas (linha 3 da tabela). A última coluna da tabela refere-
se aos compiladores desenvolvidos no âmbito desta tese.
Muitos dos compiladores iniciais incorporam análises simplificadas e poucas etapas de
compilação. Algumas carências têm a ver com o facto do objectivo de muitos destes
protótipos ter sido a validação do conceito de compilação para reconfigware. Só ultimamente
têm sido consideradas algumas abordagens que utilizam análises adaptadas da área de
compiladores para alto-desempenho.
A maioria dos compiladores propostos exploram o paralelismo existente dentro dos blocos
básicos, mas não alteram o fluxo de controlo único imposto pelo modelo utilizado por
linguagens de programação sequenciais (linguagem C, por exemplo) nem o paralelismo entre
blocos básicos. O grau de paralelismo exposto é por isso bastante limitado e inadequado ao
modelo puramente concorrente do hardware.

CAP. 2 COMPILADORES PARA RECONFIGWARE 41
Alguns compiladores integram etapas de retaguarda que abordam as fases de colocação e
encaminhamento de modo diferente das ferramentas comerciais. Nestas abordagens são
utilizadas heurísticas, para a colocação e encaminhamento do circuito constituído por
componentes, que tornam rápida a compilação da linguagem até às cadeias de bits para
reconfiguração do FPGA. Estas heurísticas, ao contrário da utilização do simulated annealing
por parte da maioria, senão todas, das ferramentas comerciais de colocação e
encaminhamento, não são vocacionadas para a procura de soluções óptimas. É por isso
possível realizar as tarefas de colocação e encaminhamento com tempos de computação na
ordem dos segundos, em vez de minutos ou horas necessários com ferramentas comerciais.
Tabela 2 .3 . Resumo das caracter íst icas dos compi ladores considerados
(as característ icas referem -se à compi lação para reconfigware ). ♠♠
suportada pela ferramenta de síntese lógica. ♣♣real izadas por uma
ferramenta de síntese lógica comercial .
Compilador PRISM-I, II
Transmogrifier-C
Chichkov NAPA C (MARGE
)
Compilador para o Garp
GALADRIEL +
NENYA
Ano da 1ª publicação
1993 [Athanas92][Athana
s93]
1995 [Gallowa
y95]
1997 [Chichkov98][Chichk
ov97]
1997 [Gokhale98][Gokh
ale97]
1998 [Callaha
n98a] [Callaha
n98b]
1998:1999 [Cardoso98a]
Linguagem C C com extensões
C C com extensões (paralelo,...)
C Qualquer linguagem compilável para a JVM
Representações intermédias utilizadas
DFG + CFG
AST CDG + DDG + AST
AST Hiperbloco + DFG
HPDG + DFG
Construções condicionais If-then-else
3 3 3 - 3 3
Ciclos 3 Do tipo while
corpo corpo 3 3
Arrays 3 - - 3 3 3 Mapeamento de arrays em memórias
- - - Automático ou manual
- Manual ou exaustivo
Considera várias unidades funcionais para a mesma operação?
- - - - - 3
Escalonamento - Muda de estado no
- Partilha de
- Estático e baseado em
42 CAP. 2 COMPILADORES PARA RECONFIGWARE
início de ciclos e de chamadas a funções
operações (não é indicado algoritmo)
lista por regiões
Partição temporal - - - - - 3 Dispositivo alvo, resultados apresentados
FPGA, XC4000
FPGA, XC4000
XC4000, FPGA♠
FPGA ♠, NAPA
Garp (uP+FPGA)
FPGA♠ + memória acoplada
Optimização booleana
3 Limitada (bons resultados para funções de até 4 variáveis)
Realizada por uma ferramenta de síntese lógica
Utiliza-ção de macro-células parame-trizáveis
? Utilização de macrocélulas parametrizá-veis
Extracção da largura de bits
Optimiza-ções booleanas
Optimiza-ções booleanas
♣ Especifi-cação pelo progra-mador
- 3 ou ♣
Grau de Paralelismo
Operações ao nível do bloco básico
Operações ao nível do bloco básico
Operações ao nível do bloco básico
Opera-ções ao nível do bloco básico
Opera-ções ao nível do hiper-bloco
Operações ao nível da função
Modelo utilizado para representar o reconfigware (se algum)
Directa-mente bitstreams
Directa-mente bitstreams (XNF)
VHDL comporta-mental
Formato proprie-tário de bit-streams
VHDL estrutural da unidade de dados, VHDL-RTL do STG
Unidade de controlo
FSM FSM com codifica-ção OHE
Mecanis-mo de semáforospor cada bloco básico ou implemen-tação puramente combina-tória
Sequen-ciadores embebi-dos
Sequen-ciadores embebi-dos
FSM
Retaguarda P&R comercial
P&R comercial
P&R comercial
P&R comercial
Gama (ferra-menta dos autores)
P&R comercial
Em conclusão, o trabalho apresentado nesta tese difere das abordagens que têm sido mais
disseminadas pelo facto de compilar algoritmos especificados em software a um nível de
abstracção elevado, e ter como alvo um FPGA com uma ou mais memórias externas

CAP. 2 COMPILADORES PARA RECONFIGWARE 43
acopladas. O algoritmo pode ser textualmente descrito em qualquer linguagem de
programação que possa ser compilada para a JVM. Neste momento, os compiladores
suportam um subconjunto de bytecodes do Java suficientemente lato para permitir a
compilação de exemplos reais. O compilador utiliza janelas temporais de granulosidade
inferior ao período do ciclo de relógio para escalonar operações, considera diferentes
alternativas para a mesma operação, e entra em linha de conta com o número de bits dos
operandos para estimar o atraso e a área de cada operação. Vários graus de paralelismo são
expostos pelo compilador de anteguarda para que se obtenham implementações em
reconfigware eficientes. Análises de inferência do número de bits suficientes para cada
operando de forma a preservar a funcionalidade original são parte integrante dos
compiladores desenvolvidos. Dos compiladores apresentados na Tabela 2.3 é o único que
integra partição temporal. No que se refere à capacidade de explorar paralelismo em
espectros vastos apenas o compilador para o Garp se assemelha ao compilador aqui
apresentado.
Embora não tenha sido dada ênfase à partição reconfigware/software, necessária na maioria
dos compiladores para computação reconfigurável pois a maioria dos sistemas de suporte à
computação reconfigurável incluem componentes software (microprocessadores, por
exemplo) são apresentadas na Tabela 2.4 as propriedades dos compiladores da Tabela 2.3
referentes a este tipo de partição. A maioria das abordagens, quando em presença de
arquitecturas com um microprocessador, opta pela realização manual da partição
reconfigware/software (o utilizador tem de distinguir o segmento de código ou a função que
acha com capacidade para que a implementação em reconfigware possa acelerar o
desempenho global). Uma forma para lidar com instruções com implementações em
reconfigware ineficientes ou impossíveis que possam aparecer no segmento de código a
implementar em reconfigware é a abordagem do compilador para o Garp. Alguns autores,
dos quais destacamos o trabalho de Chichkov, têm desenvolvido métodos quasi-automáticos
para a partição reconfigware/software. Nos últimos anos têm sido investigados pela
comunidade de co-projecto hardware/software métodos para resolver o problema
[Micheli97]. Contudo, no âmbito de sistemas computacionais reconfiguráveis o problema da
partição hardware/software reveste-se de diferenças significativas, que têm a ver com a
capacidade destes sistemas terem teoricamente recursos de reconfigware ilimitados.
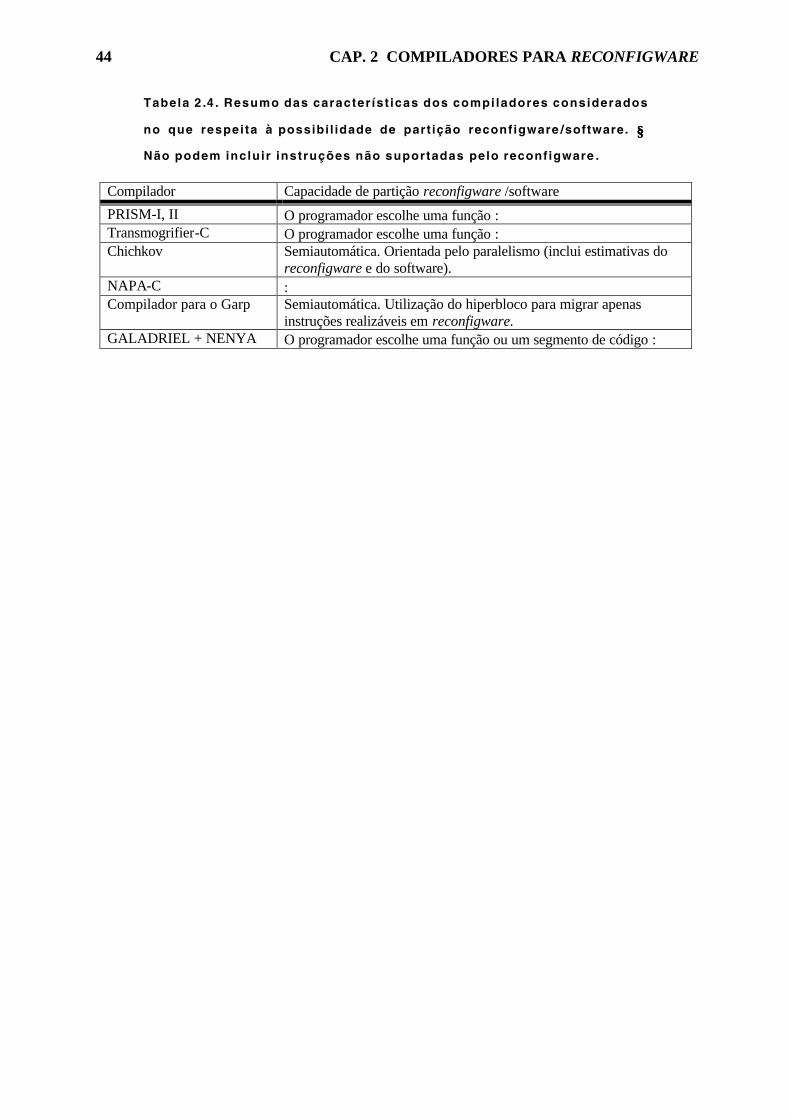
44 CAP. 2 COMPILADORES PARA RECONFIGWARE
Tabela 2 .4 . Resumo das caracter íst icas dos compi ladores considerados
no que respei ta à possibi l idade de part ição reconfigware /software. ♣♣
Não podem incluir instruções não suportadas pelo reconfigware .
Compilador Capacidade de partição reconfigware /software
PRISM-I, II O programador escolhe uma função ♣ Transmogrifier-C O programador escolhe uma função ♣ Chichkov Semiautomática. Orientada pelo paralelismo (inclui estimativas do
reconfigware e do software). NAPA-C ♣ Compilador para o Garp Semiautomática. Utilização do hiperbloco para migrar apenas
instruções realizáveis em reconfigware. GALADRIEL + NENYA O programador escolhe uma função ou um segmento de código ♣

45
3. Modelos de Representação Intermédia e sua Construção
“But Galadriel sat upon a white palfrey and was robed all in glimmering white, like clouds about the moon; for she herself seemed to shine with a soft light.”
J. R. R. Tolkien, The Return of the King
Neste capítulo são apresentadas as representações intermédias propostas e utilizadas pelos
compiladores desenvolvidos. Estas representações, ao exibirem explicitamente o paralelismo
ao nível da operação, entre blocos básicos e entre ciclos considerando sempre a granulosidade
da operação, permitem a exploração eficiente de implementações em hardware específico.
Para tal, são utilizados dois modelos de representação que permitem lidar com a hierarquia
definida pelos ciclos no programa fonte e com o paralelismo ao nível da operação nos
agrupamentos de blocos básicos.
Ao longo do capítulo são explicadas as etapas realizadas pelo compilador de anteguarda
implementado no âmbito da tese que permitem a exposição do paralelismo e a construção das
representações intermédias a partir dos bytecodes do Java. Remetemos o leitor não
familiarizado com a tecnologia Java para um resumo situado no apêndice A, no qual pode
encontrar algumas fontes.

46 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
3.1 Modelos de Representação
O grau de paralelismo em cada bloco básico em programas com fluxo de controlo intensivo
(CFI1) é muito baixo (2 a 3,5 [Fisher95]), ao contrário dos programas com fluxo de dados
intensivo (DFI2), nos quais os blocos básicos contêm muito mais operações e por isso
potenciais graus de paralelismo, ao nível da operação/instrução, mais elevados. Em relação à
compilação para reconfigware é necessário que o compilador procure também o paralelismo
entre blocos básicos e permita a execução especulativa de operações e de fluxos de controlo
múltiplos.
A comunidade de síntese arquitectural centrou inicialmente os esforços na automatização do
conceito de gerar a partir de uma descrição alto-nível uma arquitectura específica que
implementa essa descrição. Para isso, serviu-se das análises robustas, e utilizadas
previamente pelos compiladores de software tendo predominantemente como alvo modelos
de computação do tipo von Neumman. Este facto, originou o uso de representações que não
possibilitam elevados graus de paralelismo em aplicações CFI, como por exemplo o uso do
CDFG3 que é a utilização do grafo de fluxo de controlo (CFG4) [Aho86] com cada bloco
básico representado por um grafo de fluxo de dados (DFG5) [Gajski92]. Este modelo tem,
quando se considera um número elevado de unidades funcionais que podem executar em
paralelo, as seguintes desvantagens:
• Um único fluxo de controlo, baseado em descrições feitas propositadamente para o
modelo de computação de von Neumman. Embora na maioria das HDLs6 possam co-
1 Do inglês: Control-Flow Intensive. 2 Do inglês: Data-Flow Intensive. 3 Do inglês Control/Data Flow Graph. Têm existido definições não consensuais do CDFG. Nesta tese referimo-nos à definição em [Gajski92]. Muitos autores chamam ao DFG com nós de branch (SELECT), de merge (END_SELECT), de entry e de exit de CDFG [Ouaiss98b] (embora na maioria dos casos esta representação assuma também apenas um fluxo de controlo). Uma forma especializada desta representação, denominada de CDFG disjunto, permite representar o comportamento do sistema, apresentando dois modelos de grafos separados. Um, responsável pela modelação do fluxo de dados, o outro, responsável pela modelação do fluxo de controlo. Esta representação é referida pois é propícia para a modelação de sistemas baseados em duas unidades, Controlo + Dados. As construções de controlo são mapeadas em nós de fluxo de controlo e atribuições dentro dos blocos básicos são mapeadas em fluxos de dados. Esta representação captura sequência, saltos condicionais, ciclos e actividades operacionais descritas pelas instruções de atribuição em VHDL. 4 Do inglês: Control Flow Graph. 5 Do ingles: Data Flow Graph. 6 Do inglês: Hardware Description Languages. Em português: Linguagens de Descrição de Hardware.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 47
existir processos concorrentes, este tipo de concorrência só parece fazer sentido a
níveis altos e nunca ao nível de operadores, por se tornar fastidioso e erróneo
descrever paralelismo ao nível de operações;
• Impossibilidade de explorar o paralelismo existente entre blocos básicos;
• Disposição dos blocos básicos apenas pela ordem de um único fluxo de controlo e não
das dependências de dados e de controlo.
Uma representação ao nível da operação é o DFG estendido com nós que permitem a
representação de estruturas de controlo e de ciclos [Eijndhov92][Gajski92]. Embora esta
representação permita o acesso ao nível da operação, o tratamento a este nível é complicado
sem a presença de hierarquias que representem eficientemente os ciclos do programa fonte, e
por isso muitos dos compiladores utilizem como representação de topo o CFG. Pelo que
julgamos saber, as ferramentas de síntese arquitectural embora usem o DFG estendido
mantêm um único fluxo de controlo para representação do código sequencial da descrição
fonte7.
Duas formas conhecidas na literatura de exibir explicitamente os dois tipos de dependências
(de dados e de controlo) são o grafo de dependências de dados (DDG8) e o grafo de
dependências de controlo (CDG9) [Cytron91]. Com estas duas formas pode ser construído
um CFG com um único fluxo de controlo que exibe alguma concorrência entre blocos
básicos. Esta construção, utilizada em [Chichkov98] na partição reconfigware/software,
embora exponha o paralelismo existente entre blocos básicos continua a ser, na perspectiva
do hardware, uma representação de um único fluxo de controlo10.
Os modelos de representação utilizados nesta tese tentam suprimir as lacunas dos modelos
anteriormente revistos no contexto de compilação para engenhos computacionais
personalizados com suporte amplo de paralelismo. É utilizado um grafo que representa a
hierarquia da descrição fonte e no qual cada nó contempla uma região de nós e laços no DFG
7 Normalmente um por cada processo existente na descrição fonte (por exemplo, VHDL). 8 Do inglês: Data-Dependence Graph. 9 Do inglês: Control-Dependence Graph. 10 Chichkov considera fluxos de controlo com execução concorrente entre o componente software e o componente hardware.

48 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
global (representa toda a região de código a ser compilado). A representação hierárquica foi
denominada de grafo hierárquico de dependências do programa (HPDG11), cuja construção
será explicada neste capítulo. Este grafo exibe explicitamente as dependências de dados,
fluxos de controlo múltiplos e os ciclos existentes no programa fonte (nesta representação são
encapsulados em hierarquias). As primeiras etapas do compilador constroem o CFG de
blocos básicos. Como o CFG representa a estrutura sequencial (um único fluxo de controlo)
da função original é necessário expor as dependências de controlo e de dados para que a
função original possa ser representada mais eficientemente e sejam expostos, sempre que
possível, vários fluxos de controlo. Por estes motivos são construídos o CDG, o grafo de
dependências de fusão (MDG12) e o DDG que servirão de suporte à criação do HPDG e do
DFG global.
O DFG global incorpora explicitamente os predicados (condições segundo as quais
determinada instrução é executada) para operações cuja execução dependa de construções
condicionais acíclicas. Um predicado de uma operação define se essa operação será
executada com base na avaliação de uma função lógica cujas variáveis são resultados de
comparações. O uso de predicados foi abordado para conversão de programas com saltos em
código puramente sequencial na formação do hiperbloco13 [Mahlke92]. Esta conversão é
utilizada na compilação de programas para arquitecturas que suportam a execução predicativa
(EPIC [Schlansk00], por exemplo) e transforma dependências sobre uma sequência de saltos
condicionais em dependências sobre uma sequência de comparações que formam funções
lógicas de conjunções e/ou de disjunções designadas por funções lógicas decisórias do
programa14. A transformação completa é designada por predicados completamente resolvidos
e para cada instrução existente num caminho condicional do CFG é lhe associado um
predicado (activado ou desactivado pela lógica decisória do programa).
O processo de compilação foi dividido em diversas etapas. O compilador designado por
GALADRIEL é o responsável pelas etapas que terminam na criação do HPDG e do DFG
11 Do inglês: Hierarchical Program Dependence Graph. 12 Do inglês: Merge-Dependence Graph. 13 Conjunto de blocos básicos que formam um bloco com apenas uma entrada e com várias possibilidades de saída. 14 A criação da lógica decisória do programa é um problema bem compreendido [August99] na compilação para arquitecturas que suportam a execução predicativa, representa a condição para a qual determinada instrução do programa é executada e tem de ser tal que permita o correcto funcionamento da execução em modo predicativo.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 49
global e que são consideradas etapas de anteguarda (ver fluxo de compilação representado na
Figura 3.1). O GALADRIEL recebe como descrição fonte a classfile [Lindholm96] que
contém o método seleccionado pelo utilizador. No caso da classe que contém o método a
compilar estar representada numa linguagem textual, o passo prévio à execução do
GALADRIEL deverá ser a geração dos bytecodes que a representam por compilação para a
JVM [Lindholm96] (no caso do código ser em Java pode ser, por exemplo, utilizado o javac
[J2SDKURL]).
DFG HPDG
DDG CDG
Bytecodes Java
CFG
MDG
Figura 3 .1 . F luxo para obtenção do HPDG e do DFG global no
GALADRIEL a par t i r dos bytecodes Java .
Nas secções seguintes é descrito em pormenor como são obtidas pelo compilador, dos
bytecodes Java de uma aplicação, as representações intermédias.
3.2 Etapas Inicias do Compilador
O compilador de anteguarda GALADRIEL começa por extrair, da classfile fonte, a
informação necessária (métodos, tabela de excepções, etc.) e armazena-a num modelo
interno.
As análises consideradas pelo GALADRIEL são intraprocedimentais, ou seja apenas são
realizadas ao longo da estrutura interna dos métodos e não incluem análises
interprocedimentais (entre métodos/funções).

50 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
3.2.1 Construção do Grafo de Fluxo de Controlo
O GALADRIEL extrai as instruções da JVM dos bytecodes da classfile para o método
seleccionado (ver o exemplo da Figura 3.2a) e constrói o grafo que representa o fluxo de
controlo, CFG15, em que cada nó (vértice) representa uma instrução JVM, e que como o
próprio nome indica representa o fluxo de controlo do método especificado.
Para analisar as dependências de controlo e de dados o CFG inicial é transformado de tal
modo que cada novo vértice é um bloco básico [Aho86] (ver o exemplo da Figura 3.2b). A
definição de bloco básico é a mesma que a utilizada em [Bik97] e cada bloco básico
representa uma sequência de instruções JVM consecutivas nos bytecodes no qual o fluxo de
controlo entra no início e o único ponto de saída é a última instrução sem a possibilidade de
saltos ou de geração de uma excepção excepto no fim e sem a possibilidade de ser iniciado
excepto na primeira instrução. O interior de um bloco básico pode ser representado por um
grafo acíclico direccionado (DAG16).
Definição 3 -1 17
O CFG, G = (V, E, START, END), consiste num grafo direccionado/orientado
com um conjunto de vértices V que representam instruções e um conjunto de
laços E que representam a dependência de execução entre instruções. O grafo
inclui o vértice START, início do CFG, e o vértice END, término do CFG. O
vértice START não tem predecessores e o vértice END não tem sucessores. Cada
vértice está contido no caminho entre o vértice START e o vértice END. Existe
um laço entre dois nós (ν1, ν2), ambos pertencentes a V, sse a instrução do
vértice ν2 pode ser executada imediatamente a seguir à execução da instrução em
ν1.
15 O CFG referido suporta vértices do tipo switch, como são os casos dos vértices formados pelas instruções da JVM: tableswitch e lookupswitch. 16 Do inglês: Directed Acyclic Graph. 17 A definição é válida para o CFG de blocos básicos em que neste caso onde se lê instrução deve ler-se bloco básico.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 51
Method mult(II)I 0: iconst_0 1: istore_2 2: iconst_0 3: istore_3 4: goto 14 5: iload_2 6: iload_0 7: iadd 8: istore_2 9: iinc 3 1 10: iload_3 11: iload_1 12: if_icmplt 5 13: iload_2 14: ireturn
0: iconst_0 1: istore_2 2: iconst_0 3: istore_3 4: goto 14
5: iload_2 6: iload_0 7: iadd 8: istore_2 9: iinc 3 1
10: iload_3 11: iload_1 12: if_icmplt 5
13: iload_2 14: ireturn
start
end
BB0
BB2 BB1
BB3
a ) b)
Figura 3 .2 . a) Instruções da JVM para o método “mul t” extra ídas dos
bytecodes; b) CFG de blocos básicos obt ido, no qual os rectângulos
representam os blocos básicos ident i f icados por BB#.
As instruções de invocação de métodos e de criação de objectos formam só por si um bloco
básico. Para a formação de blocos básicos são inicialmente identificados os líderes, tal como
em [Bik97]. Contudo, o GALADRIEL, por omissão, não considera as instruções que podem
gerar excepções como delimitadores de blocos básicos. As regras na formação dos líderes são
as seguintes:
• A primeira instrução no CFG é um líder;
• Todas as invocações de métodos são líderes;
• Qualquer instrução que seja o alvo de saltos condicionais ou incondicionais (if_<>,
goto, tableswitch, lookupswitch, etc.) é um líder;
• Qualquer instrução a seguir a uma invocação de um método ou a um salto é um líder.

52 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
Cada bloco básico consiste em um líder e em todas as instruções que, em sentido directo (do
fluxo), se lhe seguem no CFG até ao líder imediatamente a seguir (exclusive) ou até ao
vértice END.
Neste CFG existe um laço (ν1, ν2) sse o bloco básico ν2 representa instruções JVM a seguir
ao bloco básico ν1 nos bytecodes e ν1 não termina num salto incondicional, ou se a última
instrução de ν1 é um salto (condicional ou incondicional) para a primeira instrução de ν2.
Existe também um laço entre o bloco básico de cada tableswitch ou lookupswitch e
o bloco básico de cada instrução que é definida como alvo destes selectores. Para cada
chamada a sub-rotinas existe um laço da instrução que chama a sub-rotina (jsr ou jsr_w)
até ao primeiro bloco básico da sub-rotina e do bloco básico que contém a instrução ret
(retorno de uma sub-rotina) até ao bloco básico que contém a instrução imediatamente a
seguir ao jsr ou ao jsr_w. Existe também um laço de cada bloco básico que contém uma
instrução que pode originar uma excepção até ao bloco básico de tratamento de excepções e
até ao correspondente bloco básico de término anormal.
3.2.2 Identificação dos Ciclos
De seguida, a partir do CFG formado por blocos básicos de um dado método é determinado o
respectivo conjunto de dominadores [Aho86]. Considerando os vértices ν1, ν2 ∈ V (conjunto
dos nós do CFG), diz-se que ν1 domina ν2 se todos os caminhos do nó START a ν2 contêm o
vértice ν1. Por definição um nó domina-se a si próprio. A árvore de dominâncias, na qual
Dom(νi) ⊂ V, para todos os vértices ν i ∈ V, é criada com o algoritmo iterativo indicado em
[Aho86]. Na Figura 3.3 é apresentado um exemplo de uma árvore de dominâncias.
Um laço (ν2, ν1) ∈ E (conjunto dos laços do CFG) em que ν2 ∈ Dom(ν1) chama-se um laço
refluente [Aho86] e define um ciclo natural L: L ⊂ V, consistindo de todos os vértices que
podem chegar a ν2 sem passarem por ν1. Na presença de ciclos encadeados o conjunto L2
para um ciclo interno está contido no conjunto L1 do ciclo externo. Nesta abordagem
considera-se que o grafo de cada método é redutível, isto é, a única forma de entrar num ciclo
é pelo cabeçalho. Este tipo de grafos permite a partição em dois grafos disjuntos, um obtido
pelos lados afluentes (grafo acíclico), e outro pelos lados refluentes. Como a linguagem Java

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 53
não possui a instrução goto18, os grafos obtidos são sempre redutíveis, e a identificação de
ciclos naturais pelo modo apresentado não tem limitações [Aho86].
start
BB0
BB1
BB2
BB3
Figura 3 .3 . Árvore de dominâncias para o exemplo “mult”: os blocos
básicos BB1 e BB2 per tencem ao c ic lo .
3.3 Construção do Grafo de Dependências de Controlo
Para geração do CDG é primeiramente construída a árvore de pós-dominâncias (ver o
exemplo da Figura 3.4a). Esta é construída de modo similar à árvore de dominâncias, só que
neste caso o CFG é percorrido do fim (nó END) para o princípio (nó START) usando o
sentido inverso do indicado em cada laço. Considerando os vértices ν1 e ν2 ∈ V, diz-se que ν2
pós-domina ν1 se todos os caminhos inversos do nó END a ν1 incluem o vértice ν2. Por
definição um nó pós-domina-se a si próprio.
Com a árvore de pós-dominâncias e o CFG é criado o CDG com base no facto de um nó ν1
ser dependente em termos de controlo do nó ν2 sse:
1. Existir um caminho não nulo de ν2 a ν1, de modo a que ν1 pós-domina todos os
nós após ν2 no caminho, e
2. ν1 não pós-domina estritamente o nó ν2.
18 A instrução existe e é utilizada na JVM. Por isso não é garantido que os bytecodes Java tenham sempre grafos redutíveis (por exemplo quando são obtidos por compilação de um programa numa linguagem que aceite instruções do tipo goto).

54 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
end
BB3
BB1
BB2
BB0
start
BB2 BB3
BB1
BB0 end
T: 2 →→ 1
a ) b)
Figura 3 .4 . Exemplo “mult”: a) Árvore de pós-dominâncias; b) CDG, em
que o laço em torno de um vért ice indica que o b loco básico é o
cabeçalho do c ic lo.
O CDG contém nos laços entre blocos básicos rótulos que indicam em que condição
(verdadeira ou falsa) é executado o bloco básico destino. O CDG obtido para o exemplo
considerado, com o algoritmo implementado, está ilustrado na Figura 3.4b. O rótulo T: 2 → 1
indica que em caso da condição no bloco básico BB2 ser avaliada como verdadeira (T=true)
deve ser realizado o salto de BB2 para BB1.
3.4 Exposição Automática das Dependências de Dados
As dependências de dados podem ser classificadas em quatro subtipos:
§ Dependências verdadeiras (ou de fluxo): ocorrem quando uma instrução I1 escreve
num local que a instrução I2 mais tarde lê. Ex. a = …; …; … = a. Um bloco básico BBi é
fluxo-dependente do bloco básico BBj se usar uma variável definida pela última vez em
BBj e se existir um caminho no CFG entre BBj e BBi;
§ Antidependências: ocorrem quando uma instrução I1 lê um local no qual a instrução I2
mais tarde escreverá. Ex. … = a; …; a = …;
§ Dependências de saída: ocorrem quando uma instrução I1 escreve num local mais tarde
também escrito pela instrução I2. Ex. a = …; …; a = …;

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 55
§ Dependências de entrada: ocorrem quando uma instrução I1 lê um local que a instrução
I2 mais tarde também lerá. Ex. … = a; …; … = a;.
As dependências de entrada não restringem a ordem das instruções, não sendo por isso
consideradas pelo compilador.
Ao nível do código constituído por instruções da JVM foram identificadas várias origens de
dependências de dados: pelo uso das variáveis locais, pelo uso da pilha de operandos, pelo
uso de variáveis do tipo array e pelo uso dos campos (atributos) de um objecto.
Outras dependências identificadas são dependências semânticas tais como a criação de um
objecto e a invocação do seu construtor19.
3.4.1 Dependências de Dados Relativas a Variáveis Locais
São definidas variáveis locais quando aparece no código qualquer instrução que atribui um
valor a uma variável local. No contexto da JVM acontece com as instruções: istore_<l>,
istore, iinc, fstore_<l>, fstore, astore_<a>, astore, dstore_<d>,
dstore, lstore_<l>, ou lstore. Exemplos de definições podem ser visualizados na
Figura 3.5 (d1, d2, etc).
Se N palavras são passadas como parâmetros de um método do tipo static, então a
invocação do método forma a definição inicial das primeiras N variáveis locais do método
invocado (ver definições d1 e d2 na Figura 3.5). No caso do método invocado não ser do tipo
static, a primeira definição contém o apontador this e são inicialmente definidas N+1
variáveis locais.
Quando existe nos bytecodes uma instrução que usa o valor de uma variável local:
iload_<l>, iload, iinc, fload_<l>, fload, aload_<a>, aload, dload_<d>,
dload, lload_<l>, ou lload, diz-se que a variável local é usada. O estudo da utilização
de variáveis é feito pela análise de cada bloco básico. Para cada bloco básico são
identificadas as variáveis locais cujos valores sejam utilizados internamente ao bloco. No
19 Embora o compilador tenha capacidade para as identificar, para efeitos de geração do hardware estas não serão abordadas nesta tese, por não ser permitida a criação de objectos nos segmentos de código a compilar.

56 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
mesmo bloco é considerada sempre a última referência à mesma variável. Exemplo de usos
podem ser visualizados na Figura 3.5.
Method mult(II)I //d1, d2 0: iconst_0 1: istore_2 //d3 2: iconst_0 BB0 3: istore_3 //d4 4: goto 14 5: iload_2 //u1 6: iload_0 //u2 7: iadd BB1 8: istore_2 //d5 9: iinc 3 1 //d6,u3 10: iload_3 //u4 11: iload_1 //u5 BB2 12: if_icmplt 7 13: iload_2 //u6 BB3 14: ireturn
Figura 3 .5 . Ident i f icação de def inições e de usos no exemplo “mult” .
Para se obterem as dependências de dados de fluxo entre blocos do CFG, são determinadas as
cadeias uso-definição e definição-uso [Aho86]. Cada uso ui de uma variável local tem um
conjunto associado UD(ui), constituído por todas as definições que atingem ou alcançam esse
uso20. Por outro lado, cada definição de uma variável local dj tem um conjunto associado
DU(dj), constituído por todos os usos que são atingidos por esta definição.
O compilador GALADRIEL executa um algoritmo que define para cada bloco básico o
conjunto das definições que o alcançam (incidentes). O algoritmo utilizado é o algoritmo
iterativo “worklist” indicado em [Aho86] que se baseia nas equações (3.1) e (3.2).
U)(
)()(iBBpredx
i xOutBBIn∈
= (3 .1 )
))()(()()( xKillxInxGenxOut −∪= (3 .2 )
O algoritmo computa quatro conjuntos para cada bloco básico: as definições geradas (Gen);
as definições mortas (Kill); as definições de entrada (In); e as definições de saída (Out). O
20 Uma definição de uma variável x diz-se que alcança um uso de x se existe um caminho de fluxo de controlo da definição até ao uso que não passe por outra definição de x.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 57
resultado do algoritmo para o exemplo “mult” é apresentado na Figura 3.6 considerando as
definições e usos identificados na Figura 3.5.
Bloco básico (vi) Gen[vi] Kill[vi] In[vi] Out[vi] BB0 d3, d4 d5, d6 d1, d2 d1, d2, d3, d4 BB1 d5, d6 d3, d4 d1-6 d1, d2, d5, d6 BB2 ∅ ∅ d1-6 d1-6 BB3 d1-6 ∅ ∅ d1-6
Figura 3 .6 . Conjuntos obt idos pela anál ise das def inições incidentes
(d1-6 = d1, d2, d3, d4, d5, d6) .
A Figura 3.7 mostra as cadeias UD para cada uso de uma variável local para o método “mult”
que tem vindo a ser considerado.
u1 u2 u3 u4 u5 u6 UD(u) d5, d3 d1 d4, d6 d4, d6 d2 d3, d5
Figura 3 .7 . Cadeias de uso-definição (UD).
Depois de determinadas as cadeias UD para cada uso de uma variável local, são determinadas
as cadeias DU, pela relação u ∈∈ DU(d) ⇔⇔ d ∈∈ UD(u) [Bik97], e para o exemplo que temos
vindo a considerar obtêm-se as cadeias representadas na Figura 3.8.
d1 d2 d3 d4 d5 d6 BBdef 0 0 0 0 1 1 DU(di) u2 u5 u1, u6 u3, u4 u1, u6 u3, u4 BBuso 1 2 1, 3 1, 2 1, 3 1, 2
Figura 3 .8 . Cadeias de def inição-uso (DU) e os b locos básicos onde
ocorrem as respect ivas def in ições e usos.
Estas cadeias contêm informações para a análise das dependências de dados. Se DU(di) = φ
então a definição não alcança nenhum uso e a correspondente instrução pode ser eliminada
(código morto). Se UD(ui) = φ, então a variável usada não foi iniciada (erro de programa)21.
21 Nunca ocorre na linguagem Java, pois todas as variáveis têm de ser iniciadas.

58 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
Compute Use-Definition (UD) Chains Inputs: Defs Vector, Usages Vector Output: Array of UD Chains CompUD Foreach Usagesi LocalUse = Usagesi.getLocal(); BBNum = Usagesi.getBBNum(); InstNum = Usagesi.getInstNum(); Rd_in = DefsBBNum.getIn(); Rd_gen = DefsBBNum.getGen(); Foreach rd_genj Find y : (Defsy.getDefNum() == rd_genj.value) && (Defsy.getBBNum == BBNum) && (Defsy.getInstNum() < InstNum); If y found If(Defsy.getLocal() == LocalUse) NumDef = Defsy.getDefNum(); UDi.add(rd_inj); Foreach rd_inj Find k : Defsk.getDefNum() == rd_inj.value; If k find If((Defsk.getLocal() == LocalUse) && !((y find) && (NumDef == Defsy.getDefNum()) && (y != Defsk.getdefNum()))) UDi.add(rd_inj);
Figura 3 .9 . Algor i tmo para computar as cadeias uso-definição.
Compute Definition-Use (DU) Chains Inputs: Defs Vector, Usages Vector, Array of UD Chains Output: Array of DU Chains CompUD Foreach Usagesi Defs1 = UDi; Foreach Defs1j Index = Def1j.value; DUindex-1 = DUindex-1.add(i+1)
Figura 3 .10 . Algor i tmo para computar as cadeias def inição-uso a part ir
das cadeias uso-definição.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 59
Se uma determinada definição da variável local l1 gerada num bloco básico BBj alcança o
uso de l1 no bloco básico BBi, então o bloco i depende, em termos de fluxo de dados
relacionados com as variáveis locais, do bloco j (BBj → BBi).
Como veremos mais à frente não há necessidade de determinar as dependências de dados do
tipo anti e de saída no âmbito das variáveis locais.
3.4.2 Dependências de Dados Originadas pelo Uso da Pilha de Operandos
O compilador GALADRIEL percorre cada instrução no CFG e guarda o estado da pilha de
operandos após a execução de cada instrução. O uso da pilha de operandos pela JVM obedece
a determinadas regras [Lindholm96]. A pilha de operandos contém sempre o mesmo número
de elementos (palavras) antes da execução de uma determinada instrução do CFG, mesmo
que a execução do programa passe por esta instrução repetidamente ou possa entrar vinda de
mais do que um caminho do CFG. É esta propriedade que torna realizável a determinação
estática dos estados da pilha.
Na Figura 3.11 encontram-se entre colchetes os números das instruções, pela ordem dos
bytecodes na correspondente classfile, que mantêm, ou formam, um uso de uma palavra da
pilha para um exemplo. Por exemplo, após a execução da primeira instrução (iconst_0) o
topo da pilha contém o valor 0 (informação representada no primeiro estado da pilha).
Depois do estado da pilha ser determinado para cada instrução é executado o algoritmo
apresentado na Figura 3.12 (para simplificar é apresentada uma versão que não considera as
dependências formadas pelas instruções dup, swap, etc.), que retorna a árvore de
dependências entre blocos ao nível da utilização da pilha. No algoritmo, st_in[ν] representa o
estado da pilha imediatamente anterior ao bloco básico ν e st_out[ν] representa o estado da
pilha imediatamente a seguir ao bloco básico ν. O algoritmo tem por base o seguinte facto:
quando todos os estados que entram num bloco básico saírem do bloco e não forem usados
por mais nenhuma instrução, o correcto funcionamento do bloco não depende de elementos
da pilha de operandos de mais nenhum bloco básico. Na prática a maioria das instruções que
usa operandos da pilha retira-os e coloca um novo operando (os estados da pilha na saída do
bloco são diferentes dos estados da pilha na entrada do bloco). As instruções que utilizam
elementos da pilha sem os retirarem, como é o caso da instrução dup, necessitam que o

60 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
algoritmo teste a existência deste tipo de instruções em cada bloco básico e determine os
blocos básicos fornecedores dos operandos utilizados.
0: iconst _0 [0 CONST 0] 1: istore _2 [ ] 2: iconst _0 [2 CONST 0] 3: istore _3 [ ] 4: goto 14 [ ]
5: iload _2 [5 VAR 2] 6: iload _0 [5 VAR 2 6 VAR 0] 7: iadd [7 EXP] 8: istore _2 [ ] 9: iinc 3 1 [ ]
10: iload _3 [10 VAR 3] 11: iload _1 [10 VAR 3 11 VAR 1] 12: if_ icmplt 5 [ ]
13: iload _2 [13 VAR 2] 14: ireturn [14 VAR]
BB0
BB1
BB2
BB3
Instruções JVM Estados da Pilha
Figura 3 .11 . Computação das dependências de dados or iundas da
ut i l ização da pi lha de operandos.
Input: CFGBB= (V, E), where each vertex of the CFG has information about the stack contents. Output: Dependence graph between BBs of the method. st_in[v1] = stack_state(Last_Inst(v0)); for each vi ∈ V – v0 st_out[vi] = stack_state(Last_Inst(vi)); for each elementj ∈ st_in[vi] if(elementj ≠ st_out[vi]j) vi dependes of CFGBBk : CFGBBk ⊃ Inst[elementj]); for each Instj ∈ vI if(Instj ∈ dup, …) vi dependes of CFGBBk : CFGBBk ⊃ Last_element(stack_state(Instj)); st_In[vI+1] = st_out[vi];
Figura 3 .12 . Algor i tmo que anal isa as dependências entre blocos
básicos ao nível da pi lha de operandos.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 61
Uma análise ao conteúdo da pilha de modo a que a utilização de constantes guardadas na
pilha de operandos não possa introduzir dependências de dados desnecessárias deve ser
realizada em versões subsequentes do compilador.
3.4.3 Dependências de Dados Relativas ao Uso de Arrays
As dependências de dados oriundas do uso de variáveis do tipo array são computadas da
mesma forma que as das variáveis locais, com a diferença que as definições e os usos são
determinados por inspecção no código do método pelas instruções da JVM de acesso a
elementos do array. Nesta versão do GALADRIEL estas dependências entram em linha de
conta com acessos a arrays diferentes mas não distinguem acessos a elementos diferentes do
mesmo array. Embora as análises à indexação de elementos de arrays possam potenciar a
exposição de graus de paralelismo maiores, foram deixadas para melhoramentos futuros, por
serem de maior complexidade.
As análises de dependências de dados ao nível de arrays necessitam, ao contrário das análises
no contexto das variáveis locais, de considerar também as antidependências e as
dependências de saída. As antidependências são computadas considerando o problema das
definições incidentes em modo inverso (retrocessivo). Com base no atravessamento do CFG
em sentido inverso são computadas as cadeias de definição-uso, considerando os usos como
definições e as definições como usos. As dependências de saída são computadas por simples
atravessamento do CFG sem iterações.
A sobreposição de elementos em memória22, exemplificada na Figura 3.13, é um problema
com análise similar ao problema das “expressões disponíveis” [Muchnick97]. Designamos
este problema por “atribuição de objectos/arrays disponíveis”. Uma atribuição objecto/array
A está disponível num ponto p do programa, se para todos os caminhos no CFG do nó
START até p existe uma atribuição A e nenhuma definição da variável23 atribuída em A entre
a atribuição e p. Para cada atribuição de objectos/arrays disponíveis as duas variáveis usadas
na expressão de atribuição têm de ser tratadas como uma variável única. Por enquanto, este
22 Deve responder à questão: “Podem duas referências aceder sempre/nunca/talvez à mesma posição de memória?” 23 O problema é definido com variáveis locais, pois nos bytecodes as referências a todos os objectos/arrays são guardadas em variáveis locais.

62 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
problema não se encontra resolvido em casos em que condicionalmente possa ser realizada
atribuição da mesma referência, e terá que ser o programador a alterar o código fonte de
modo a que as atribuições a elementos sobrepostos em memória estejam estaticamente
resolvidas (ver Exemplo 3-1).
Exemplo 3 -1 . Sobreposição de e lementos em memór ia .
O exemplo da Figura 3.13a ilustra o caso em que sempre que seja executada
a atribuição (B=A) na linha 6 a atribuição ao elemento 2 do array B na
linha 12 (B[2]=...) seja de facto ao array A, pois ambas as variáveis B e A
identificam, nesse caso, o mesmo array. Uma análise conservadora de
extracção do paralelismo considera que nos pontos de acesso a A ou a B
alcançados no programa pela atribuição (B=A) ambas as variáveis A e B
identificam o mesmo array. Uma possibilidade mais eficiente seria a
resolução estática da sobreposição com base na transformação do tipo da
identificada na Figura 3.14. Nesta transformação quando um ponto P do
programa com um acesso a um array é alcançado por mais do que um
identificador de arrays é transformado no código condicional que permite
seleccionar o identificador correcto (ver linhas 7 a 10 da Figura 3.14).
1. … 2. int[] A = new int[10]; 3. int[] B = null; 4. ... 5. If(t) 6. B = A; 7. else 8. B = new int[10]; 9. ... 10. A[3] = …; 11. ... 12. B[2] = …; 13. ...
A
B A
B A
A[3]= …; B[2] = …;
A[3]= …; B[2] = …;
a ) b)
Figura 3 .13 . Exemplo que i lustra a sobreposição de e lementos em
memória: a ) f ragmento de código em Java; b) endereços de cada array
em memór ia para os dois caminhos mutuamente exc lus ivos.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 63
1. … 2. int[] A = new int[10]; 3. int[] B = new int[10]; 4. ... 5. A[3] = …; 6. ... 7. If(t) 8. A[2] = …; 9. else 10. B[2] = …; 11. ...
Figura 3 .14 . Transformação do programa para resolução estát ica da
sobreposição condicional de dois arrays.
3.4.4 Dependências de Dados Relativas ao Uso de Atributos (Campos)
Parte das análises das dependências de dados no âmbito de definições/usos de campos de
objectos podem ser realizadas com a determinação das definições incidentes. Contudo, a este
nível as análises devem ter em conta a criação de objectos o que implica análises
interprocedimentais. Uma análise conservativa que não distinga campos do mesmo objecto
(uso da atomicidade do objecto) pode simplificar a análise, embora restrinja a possibilidade
de paralelização. A extracção do paralelismo relativa a campos de objectos reserva-se para
desenvolvimentos futuros.
3.5 O Grafo de Dependências de Dados
A reunião das dependências de dados (dependências ao nível das variáveis locais,
dependências ao nível da utilização da pilha de operandos, etc.) forma o grafo de
dependências de dados (DDG) do método especificado que permite representar
explicitamente o paralelismo ao nível dos dados passível de ser exposto pelas análises
utilizadas. A Figura 3.15 ilustra o DDG para o exemplo “mult” na qual se pode ver uma
dependência entre iterações do ciclo identificada por um laço com um círculo.
Definição 3 -2
O DDG é um grafo direccionado que engloba o conjunto de vértices do CFG de
onde foi obtido, mas em que os laços entre blocos básicos representam
dependências de dados que restringem a ordem pela qual estes blocos devem ser

64 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
executados de forma a preservar a funcionalidade do programa ao nível de
dependências de dados. Cada laço é anotado com a seguinte informação:
• Origem da dependência: variável local, pilha de operandos, ou arrays;
• Identificador da origem: número da variável local, nível da pilha, ou
identificador do array;
• Tipo da dependência: de fluxo, anti, de saída;
• Tipo de ciclo-dependência: na mesma iteração ou entre iterações.
start
BB0
BB2 BB1 BB3
Figura 3 .15 . DDG do exemplo “mult”: os c í rculos nos laços indicam
dependências entre i terações do cic lo.
As dependências de dados na presença de ciclos são agrupadas no DDG em dois conjuntos
distintos:
• O conjunto das dependências originadas por fluxos na mesma iteração (identificadas
na Figura 3.15 por laços sem círculos);
• O conjunto das dependências originadas por fluxos entre iterações diferentes
(originados pelos laços refluentes das regiões cíclicas e identificadas na Figura 3.15
por laços com círculos).
O conjunto de dependências de laços originados pela mesma iteração de um ciclo é um
subconjunto das cadeias de definição-uso tal que24:
24 Considerando o CFG ordenado topologicamente no que respeita aos laços não refluentes.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 65
1. O identificador do bloco básico do uso é menor que o identificador do bloco básico da
definição, e
2. Não exista um caminho entre o bloco básico do uso e o bloco básico da definição no
CDG, e
3. A dependência não seja entre dois blocos básicos pertencentes a conjuntos
mutuamente exclusivos.
Ao nível do CDG, dois blocos básicos são mutuamente exclusivos se ambos tiverem o
mesmo nó (diferente do nó START e do nó cabeçalho de um ciclo) de raiz na subárvore do
CDG a que ambos pertencem e os laços desse nó a cada um deles tiverem rótulos diferentes.
Na Figura 3.16 são apresentados alguns exemplos.
start
BB1
BB0
F
BB2
T
start
BB0
F
BB2
BB1
BB3
BB4
F
T
T
a ) b)
Figura 3 .16 . Ident i f icação de conjuntos de blocos básicos mutuamente
exclusivos no CDG: a) exclusiv idade ao mesmo nível , BB1
BB2; b)
exclusividade em níveis di ferentes, BB1, BB2, BB3
BB4 e BB2
BB3 .
Def inição 3 -3
Dois conjuntos de blocos básicos são mutuamente exclusivos se por cada
passagem (iteração) da execução do programa apenas um deles puder ser
executado.
Exemplo 3 -2 . Dependências de dados na mesma i teração de um c ic lo .
Na Figura 3.17 são apresentadas duas dependências possíveis de dados
(cujos laços são ilustrados a tracejado por d1 e d2 no CDG) obtidas pela

66 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
análise de definições de alcance. Embora o identificador do bloco básico do
uso seja menor que o identificador do bloco básico da definição, não são
dependências na mesma iteração do ciclo. A dependência d1 é uma
dependência criada pelo nó refluente que forma o ciclo e a dependência d2
é uma dependência entre regiões mutuamente exclusivas e por isso refere-se
também a dependências entre iterações diferentes do ciclo.
start
BB4
BB1
BB0
BB2
BB3
d 1
d 2
start
BB4 T
BB0
BB1 BB2
BB3
end
F
T F
T T
T F
a ) b)
Figura 3 .17 . Exemplo que ident i f ica as dependências de dados na
mesma i teração de um c ic lo . a ) CFG do exemplo com dois b locos
básicos mutuamente exclusivos (BB1
BB2) ; b) CDG do exemplo (os
laços a t racejado representam possíveis cadeias de def in ição-uso).
3.6 Computação dos Pontos de Selecção e da Lógica Decisória
do Programa
No âmbito da compilação, para hardware específico, abordada nesta tese é necessário
determinar os pontos de selecção (pontos do programa ou da representação intermédia onde é
necessário colocar unidades de selecção de entre vários dados oriundos de caminhos
mutuamente exclusivos), os nós condicionais que controlam esses pontos de selecção (que
definem a condição para que um dado oriundo de um determinado caminho alcance o ponto
de selecção) e os nós condicionais que controlam as operações com efeitos colaterais em
caminhos mutuamente exclusivos.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 67
3.6.1 Pontos de Selecção
Para a representação do programa no DFG global são primeiramente determinados os pontos
de selecção onde são colocadas estruturas de selecção como por exemplo multiplexadores.
Estes pontos de selecção são devidos a definições da mesma variável em pontos do programa
(caminhos mutuamente exclusivos) que permitem que essas definições alcancem um
determinado ponto do DFG.
Por inspecção do DDG o compilador, para cada nó com mais do que um laço incidente e que
represente uma dependência de dados de fluxo rotulada com a mesma variável local, insere
um ponto de selecção que é dependente dos nós exibidos no grafo de dependências de fusão
(MDG). Os pontos de selecção são controlados por lógica decisória do programa que é
constituída por uma função lógica que representa a condição para a qual determinada
definição possa atingir um ponto de selecção. A lógica que controla a selecção é determinada
por inspecção do CDG.
Definição 3 -4
Um ponto de selecção é um ponto no qual deve ser colocado um mecanismo de
selecção que permita escolher entre duas ou mais definições da mesma variável
que alcançam esse ponto.
Definição 3 -5
O MDG é um grafo direccionado em que os laços entre nós (blocos básicos do
CFG) representam dependências de controlo de selecção ou de execução. Os
nós fonte indicam nós controladores e os nós destino indicam os nós que
necessitam de ser controlados.
Exemplo 3 -3 . Grafos de representação para um exemplo.
Considere-se o código Java e o CFG correspondente apresentados
respectivamente nas alíneas a) e b) da Figura 3.18. As variáveis locais da
JVM l0, l1 e l2 correspondem respectivamente às variáveis no código Java
f, h e e. A Figura 3.19 ilustra os grafos DDG, CDG e MDG obtidos para
o exemplo. O laço a tracejado entre BB0 e BB1 indica uma dependência de
saída, que como foi previamente explicado não é considerada. No DDG
representado pode ver-se que cada uma das variáveis l1 e l2 tem mais do

68 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
que uma definição a atingir o BB3. A definição de l1 em BB2 ou o valor de
l1 passado como argumento da função atinge BB3 caso o teste da condição
na linha 3 da Figura 3.18a seja respectivamente falso ou verdadeiro. Por
este motivo é colocado um ponto de selecção para seleccionar de entre as
duas ligações de l1 que atingem BB3 com base no valor da comparação
referida. Pode ver-se também que para l2 também existem duas ligações a
atingirem o BB3 e por isso é necessário mais um ponto de selecção. O
MDG do exemplo representado por um laço entre BB0 e BB3 indica que os
pontos de selecção em BB3 dependem da comparação em BB0. A inserção
de pontos de selecção, sob a forma de multiplexadores, pode ser vista na
Figura 3.20. A transformação permite que os blocos básicos BB1 e BB2
sejam executados especulativamente (executados em paralelo ou antes da
execução de BB0).
1. static int ex(int f, int h) 2. int e = 0; BB0 3. if(f<4) BB0 4. e = f + h; BB1 5. else 6. h = 3 * h; BB2 7. e = 3 * h + e; BB3 8. return e; BB3 9.
2
3
start
0
1
end
T F
a ) b)
Figura 3 .18 . a ) Exemplo em Java com os blocos básicos identi f icados;
b) respect ivo CFG.
2
3
start
0
1
end
2
start
0
1
l0, l1
l0, l1
l2
DDG CDG
l2 l1
l1
0
0
start
0
3
MDG
T F
Figura 3 .19 . CDG, DDG e MDG obt idos para o exemplo .

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 69
2
3
start
0 1
end
l0, l1
l1_1
l1
l2_1 l2
l2_2 l1_2
Mux(l1, l1_1) Mux(l2, l2_1)
Figura 3 .20 . DDG em que estão representados os pontos de se lecção.
3.6.2 Tipos de Lógica Decisória do Programa Utilizados
Um modelo com computação especulativa de todas as operações excepto a escrita em
memória, apenas requer lógica decisória nos pontos de selecção e nos pontos de escrita em
memória25 que pertençam no CFG a caminhos mutuamente exclusivos. No âmbito desta tese
são, por isso, considerados dois tipos de lógica decisória do programa:
• Lógica decisória de selecção26: responsável pela selecção da definição correcta de
uma variável;
• Lógica decisória de execução: responsável pela execução de uma operação (atribuição
a um elemento de um array, por exemplo).
Como os registos são só usados para preservar a funcionalidade dos ciclos, e são colocados à
frente dos pontos de selecção que possam existir no corpo de um ciclo, a decisão de escrita é
feita inteiramente pela unidade de controlo cuja geração é descrita no capítulo 7.
Surgem duas questões na construção da lógica decisória do programa:
• Como obter expressões com o mínimo de condições na lógica decisória do programa?
• Como obter o mínimo de lógica decisória do programa?
25 Nestes casos, e devido aos acessos a memórias terem execução síncrona, a lógica decisória é utilizada pela unidade de controlo para decidir a execução ou não da operação em causa. 26 A condição sob a qual uma definição atinge um nó confluente no CFG foi também considerada como extensão do formato Single Static Assignment (SSA) [Cytron91] e foi denominada de Gated Single-Assignment (GSA) [Balance90].

70 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
O primeiro problema é resolvido pela determinação da função lógica decisória do programa
tomando como base o caminho de selecção no CDG de cada definição ao uso. Esta é obtida
pela inspecção do DDG e do CDG, no qual dois nós condicionantes em série implicam
conjunções e dois nós condicionantes que sejam fontes para um determinado bloco básico
implicam disjunções. O GALADRIEL representa a função lógica decisória do programa
explicitamente no DFG.
No segundo problema, estudado em [August99] no âmbito de compilação para máquinas de
execução predicativa, a lógica decisória de programa é representada em diagramas de decisão
binários ordenados (OBDDs27) [Micheli94] para posterior aplicação de optimizações
booleanas. No caso de compilação para hardware específico as conjunções e disjunções da
lógica decisória de programa são implementadas por simples portas lógicas AND e OR, de
muito menores custos do que no caso das máquinas de execução predicativa em que são
utilizadas instruções lógicas para computar a lógica decisória. É, por isso, necessário avaliar o
impacto do uso das optimizações booleanas nas funções lógicas decisórias de forma a que se
consiga responder à pergunta: vale a pena optimizar as funções de lógica decisória no
contexto de compilação para hardware específico?
Definição 3 -6
Caminho de selecção de duas ou mais definições da mesma variável que
alcançam um determinado uso é o caminho mais longo no CDG constituído pelos
nós condicionais entre as definições e os usos.
Definição 3 -7
Função lógica decisória do programa é uma função lógica cujos literais são nós
condicionais do CDG que activam um caminho de selecção ou a execução de
uma determinada operação.
Exemplo 3 -4 . Obtenção da lógica decisór ia do programa.
A Figura 3.21 ilustra a obtenção da lógica decisória num ponto de selecção.
No fragmento existem duas definições da variável A que podem alcançar o
uso de A em BB3. Por este motivo é inserido um ponto de selecção em
27 Do inglês: Ordered Binary Decision Diagrams.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 71
BB3. Os caminhos de execução possíveis do fragmento do programa
apresentado são:
a) BB0 → BB1 → BB3: este caminho é percorrido caso a avaliação da
expressão lógica p0 && !p1 tenha valor verdadeiro.
b) BB0 → BB1 → BB2 → BB3: este caminho é percorrido caso a avaliação
da expressão lógica p0 && p1 tenha valor verdadeiro.
c) BB0 → BB2 → BB3: este caminho é percorrido caso a avaliação da
expressão lógica !p0 tenha valor verdadeiro.
Se analisarmos o CFG, verificamos que para que a definição Def1 (BB0)
atinja o uso1 (BB3) tem que ser percorrido o caminho a) e que isso
acontece quando p0 && !p1 tiver valor lógico verdadeiro. A outra definição
que também alcança o uso em BB3 é a definição Def2 (BB2) e tal é
possível para os caminhos b) ou c). Por isso a lógica decisória destes dois
caminhos é a conjunção das lógicas decisórias para cada caminho !p0 || (p0
&& p1).
start
BB3
BB2
T
p0
end
F
T
BB0
p1
BB1
F
A = … Def1
… = A … uso1
A = … Def2
start
BB0
BB1
BB2
BB3
OR
AND
a) b)
!p0 || (p0 && p1)
p0 && !p1
F T
T
Figura 3 .21 . Exemplo que i lustra os caminhos de selecção que
permitem seleccionar , de um conjunto de def in ições que a lcançam um
determinado uso, a def inição correcta para o valor específ ico das
condições. a ) CFG do exemplo; b) correspondente CDG.

72 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
3.7 Computação do Grafo Hierárquico de Dependências do
Programa
Uma representação intermédia eficiente para lidar com o paralelismo funcional é o grafo
hierárquico de tarefas (HTG28) [Girkar92]. O HTG, como o próprio nome indica, é uma
representação hierárquica e permite que:
• todos os nós na hierarquia sejam representados por grafos direccionados acíclicos
(DAGs);
• os ciclos e as estruturas de controlo estejam explicitamente representados por
hierarquias (sub-HTGs);
• como é uma representação intermédia construída com base nas dependências de dados
e de controlo possibilita a exposição explícita de vários fluxos de controlo.
O HTG é constituído por nós de três tipos: compostos (que representam blocos if-then-else),
ciclos, e simples (que representam instruções ou blocos básicos). Os nós do tipo ciclo e os
nós compostos servem como ponte para sub-HTGs que representam o corpo destas estruturas.
O grafo hierárquico de dependências do programa (HPDG) proposto nesta tese é baseado no
HTG com as seguintes ressalvas:
• Só incorpora níveis de hierarquia na presença de ciclos. A representação usa a
conversão de saltos condicionais em pontos de selecção, a execução especulativa de
todas as operações excepto da escrita em memória, que usam as funções de lógica
decisória, e, por estes motivos, não necessita de utilizar directamente o CDG;
• O HPDG representa em cada nível hierárquico um subconjunto do DDG (não inclui as
dependências de dados entre iterações diferentes de um ciclo, e por isso fornece um
grafo acíclico) reunido com o MDG;
• Cada nó sem hierarquia no HPDG tem uma região associada no DFG global que
representa as operações e as interligações entre elas do programa original.
28 Do inglês: Hierarchical Task Graphs.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 73
A Figura 3.22 ilustra as representações utilizadas durante as fases de anteguarda do
compilador. Na Figura 3.22f pode ver-se o HPDG para o exemplo apresentado.
1 iconst_0 2 istore_2 3 iconst_0 4 istore_3 5 goto 22 6 aload_0 7 iload_3 8 saload 9 aload_1 10 iload_3 11 saload 12 isub 13 i2s 14 istore 4 15 iload_2 16 iload 4 17 iload 4 18 imul 19 iadd 20 istore_2 21 iinc 3 1 22 iload_3 23 iconst_4 24 if_icmplt 6 25 iload_2 25 ireturn
… int L2NORM = 0; for(int i=0; i<4;i++) short Aux = X[i] - Y[i]; L2NORM += Aux*Aux; …
a)
b)
0 0
l3 l2
4 l3
l2
l3 l0
l3 l1
l4
l2
l2
l3
l3
BB0
BB4
BB5
BB1
BB2
BB3
load
load
c)
BB0
BB1
BB2
BB3
BB4
BB5
start
end
d)
e)
Região cíclica
1 2 3
4
start
end
start
3
0
1
2
5
4
0
5
ciclo.1
1 2
3
4
start
end
start
end
f)
Figura 3 .22 . Transformações real izadas na vanguarda das fases de
compi lação: a) f ragmento de código Java; b) instruções JVM
correspondentes; c ) CFG com um DFG por cada b loco básico; d) DDG;
e ) CDG; f ) HPDG.
3.8 Criação do DFG Global
Para gerar o DFG global é inicialmente criado um DFG para cada bloco básico. Cada DFG é
constituído por um conjunto de nós que representam operações (aritméticas, lógicas e
comparações), variáveis, constantes, escrita e leitura em memória, e por um conjunto de laços
que representam o fluxo de dados entre os nós ou simplesmente precedências. Os nós de
variáveis servem também para interligar um nó fonte a diferentes receptores. Os nós do tipo

74 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
variável no DFG podem ser mapeados em fios, registos, ou locais de memória durante as
fases de escalonamento.
Exemplo 3 -5 . DFG para um bloco básico.
Considere-se as instruções JVM de um bloco básico de um exemplo
hipotético apresentadas na Figura 3.23a. A sequência de instruções descreve
a expressão: TOPO pilha = (l10 + l13) × l2 + l11 + l14.
Na Figura 3.23b está ilustrado o DFG correspondente no qual os círculos
representam operações e os rectângulos representam usos/atribuições de/a
variáveis. Como se pode ver pela figura, esta representação exibe
explicitamente o paralelismo ao nível de operações.
Iload 10 Iload 13 Iadd Iload_2 Imul Iload 11 Iload 14 Iadd Iadd
l10 l13
l2 l11 l14
TOPO pilha
start
end a ) b)
Figura 3 .23 . Exemplo da construção do DFG para um bloco básico: a )
instruções JVM do bloco básico; b) correspondente DFG.
A criação de cada DFG é realizada usando a simulação do funcionamento da pilha de
operandos. O algoritmo é incremental, começa com a primeira instrução JVM do bloco
básico e vai construindo o DFG à medida que vai percorrendo as instruções que se seguem
até ao fim do bloco básico em consideração. Os operandos de uma dada operação são
procurados pela ordem LIFO29 no DFG construído até então. Se um operando não existir é
criado um nó do tipo variável que identifica o nível da pilha e a partir daqui o operando em
causa.
29 Do inglês: Last In First Out.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 75
Os acessos a elementos de arrays dentro de um bloco básico são seriados com laços próprios
por simples atravessamento em sentido directo do DFG que representa o bloco básico em
consideração. Esta análise distingue acessos a diferentes arrays, mas não a elementos do
mesmo array. A análise de dependência de dados ao nível de arrays fornece as dependências
de fluxo, anti e de saída.
Exemplo 3 -6 . DFG global .
Na Figura 3.24 é apresentado o DFG global que representa o exemplo da
Figura 3.22. Pela figura pode ver-se que o DFG global é planar. Podem
distinguir-se facilmente no DFG os nós que representam operações. Os nós
trapezoidais da figura representam acessos a elementos de arrays (neste
caso leituras). Os rectângulos na figura representam nós de variáveis às
quais foram atribuídos registos. O processo de identificação dos mesmos só
será explicado no capítulo seguinte.
REG i
0
REG i
4
lt_N
Endereço X
Endereço Y
LOAD X LOAD Y
REG RESULT
0
L2NORM
REG RESULT
Figura 3 .24 . DFG global para o exemplo da Figura 3 .22 . Dois nós em
formato de rectângulo com rótulos iguais representam atr ibuições ao
mesmo regis to .
O DFG global é criado com base no HPDG, nos DFGs construídos para cada bloco básico e
na lógica decisória de programa. O DFG global é um DAG que contém, de forma a
possibilitar a correcta representação do programa original, mecanismos que implementam os

76 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...
fluxos de controlo sempre que haja necessidade da preservação dos mesmos. Nos pontos de
selecção são colocadas estruturas de selecção sob a forma de multiplexadores e a lógica
decisória e de selecção é também representada no DFG global. Sempre que seja necessário,
existe um laço no DFG global entre a lógica decisória e a escrita de um elemento de um
array.
Cada nó do DFG global é rotulado com um majorante do número de vezes que a execução do
programa passa pelo nó, por 1 se o nó não pertencer a um ciclo e por +∞ quando o número de
iterações não for conhecido estaticamente.
3.9 Conclusões
Neste capítulo foi inicialmente explicado como é criado o CFG de um método em Java
bytecodes. Foi também explicado como extrair o paralelismo existente no CFG do programa
original para ser representado num DDG. Com base nos resultados conhecidos da área de
compilação de software em microprocessadores foram implementadas as análises que
possibilitam a extracção dos ciclos e a criação do CDG.
Foram descritos os tipos de dependências e identificados aqueles que realmente é necessário
preservar na compilação para um modelo personalizado com elevados graus de paralelismo e
de fluxos de controlo teoricamente ilimitados.
É proposta uma representação que permite manusear ciclos eficientemente, mantendo a
hierarquia existente no programa original. Esta representação, denominada de HPDG, é
obtida da reunião de um subconjunto do DDG com o MDG e é por isso uma representação
poderosa para lidar com o paralelismo ao nível de dados existente entre blocos básicos ou
ciclos. Esta representação tem associado um DFG global que representa as operações do
programa original e a forma como estão interligadas e com algumas transformações permite
fornecer a imagem da unidade de dados específica.
Embora as análises desenvolvidas sejam intraprocedimentais, extensões das mesmas podem
ser facilmente integradas no compilador. A extracção do paralelismo existente em acessos à
memória (arrays, por exemplo) fica reservada para futuras melhorias do compilador
GALADRIEL.

CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA... 77
Existem alguns problemas na extracção de paralelismo de descrições baseadas no modelo de
computação de von Neumann (linguagens puramente sequenciais). Um deles é a
possibilidade de quebra de especificações baseadas propositadamente no modelo sequencial.
Este facto pode ocorrer, por exemplo, em ciclos de espera ou de gasto de tempo. Quando não
há dependências na descrição fonte, estes ciclos podem ser escalonados em posições que
alteram a funcionalidade prevista. Só a utilização de directivas explícitas pelo programador
poderão resolver este problema.
Segundo julgamos saber, o trabalho apresentado neste capítulo foi um dos primeiros a:
• considerar a compilação dos bytecodes do Java tendo como alvo FCCMs30 baseadas
em FPGAs;
• considerar a extracção e exploração do paralelismo ao nível de operações a partir dos
bytecodes;
• fornecer representações intermédias com fluxos de controlo múltiplos vocacionadas
para a compilação para FCCMs.
As representações apresentadas, algumas delas obtidas por extensões de trabalhos publicados
pelas comunidades de síntese arquitectural e de compiladores de software em
microprocessadores, são também contribuições originais no âmbito da área científica na qual
esta tese se insere. Realça-se que, segundo o que nos é julgado saber, o uso de uma estrutura
hierárquica com base no grafo de dependências de dados e no grafo de dependências de fusão
nunca tinha sido considerado anteriormente.
Como suporte à depuração e compreensão, todos os grafos podem ser visualizados
graficamente com o uso do programa DOTTY [DottyURL]. Para tal o compilador de
anteguarda, GALADRIEL, fornece os ficheiros de texto necessários.
30 Do inglês: Field-Custom Computing Machines.

78 CAP. 3 MODELOS DE REPRESENTAÇÃO INTERMÉDIA...

79
4. Suporte à Geração de Reconfigware
“[…] On her finger was Nenya, the ring wrought of mithril, that bore a single white stone flickering like frosty air.”
J. R. R. Tolkien, The Return of the King
Este capítulo descreve as etapas de suporte adoptadas no compilador NENYA com vista à
geração de hardware reconfigurável especializado a partir dos modelos de representação
apresentados no capítulo anterior. Estas etapas, em conjunto com outras descritas nos
capítulos subsequentes, permitem ao NENYA suportar a compilação para uma arquitectura
constituída por um FPGA acoplado a uma ou mais memórias RAM via barramentos
independentes. São apresentados os conceitos que permitem o suporte a este tipo de
compilação e as estruturas que são geradas para a automatização de todo o processo. As
etapas incluem o mapeamento de operações, do DFG global descrito no capítulo 3, em
unidades funcionais e a atribuição de registos de modo a que a funcionalidade de programas
com ciclos seja preservada.
4.1 Pré-Etapas do NENYA
O compilador apresentado pode ser usado para compilar um programa completo para
reconfigware, desde que o programa respeite o subconjunto de Java presentemente aceite
pelo NENYA, ou segmentos de código de um programa cuja implementação final usa uma
arquitectura constituída por componentes software (microprocessador e memória RAM) e

80 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
reconfigware. A comunicação software/reconfigware é realizada com bibliotecas de interface
pré-definidas entre os dois componentes (ver Apêndice E).
Antes da execução, o compilador necessita das especificações do ciclo de relógio do
reconfigware, das memórias externas, da área máxima do FPGA, e da caracterização dos
componentes responsáveis pelos operadores existentes no programa fonte em linguagem
Java.
O compilador NENYA recebe os grafos gerados pelo GALADRIEL para um dado método
em Java e a identificação do segmento de código desse método que o programador deseja
compilar para reconfigware. As etapas realizadas pelo NENYA encontram-se ilustradas na
Figura 4.1.
Netlists (EDIF)
DFG
NENYA Descrição da Arquitectura
Alvo
Atribuição e Mapeamento de UFs
Partição Temporal & Escalonamento
STG (State Transition Graphs)
RTG (Reconfiguration Transition Graph)
Síntese de FSMs
Atribuição de Registos
Optimizações do DFG
HPDG
Inferência de Bits
Propagação de Bits Constantes
Reassociação de Operações
Redução do Custo de Operações
Caracterização das Macrocélulas
STG para VHDL-RTL
Comportamental
DFG para VHDL-RTL Estrutural
Tradução de VHDL-RTL Estrutural
para EDIF
Figura 4 .1 . Etapas real izadas pelo NENYA.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 81
Por omissão, o GALADRIEL considera o corpo do método especificado pelo programador
para ser compilado para reconfigware. O utilizador pode servir-se de rótulos especiais para
identificar a região do código Java que deseja compilar para reconfigware. A rotulagem é
feita com a utilização de chamadas a métodos definidos em classes específicas (ver Figura
4.2) que são identificadas posteriormente pelo GALADRIEL. Com este modo de rotulagem
não é necessário estender a linguagem Java, o que permite o uso, sem restrições, da
tecnologia Java existente. A invocação dos métodos start() (linha 5) e end() (linha 7) de uma
instância da classe MAXTIME (linha 3) identifica um segmento de código e permite que o
utilizador obtenha uma estimativa do tempo de computação do segmento, quando
implementado em software, por execução do programa.
1. import Timing.MAXTIME; 2. ... 3. MAXTIME Code1 = new MAXTIME(10e-6); // 10uS 4. ... 5. Code1.start(); 6. ... // segmento de código com restrição temporal 7. Code1.end(); 8. ...
Figura 4 .2 . Ident i f icação de um segmento de código com restr ição temporal .
4.2 Estrutura do Reconfigware gerado pelo NENYA
A estrutura utilizada pelo NENYA para implementar o reconfigware relativo a uma dada
descrição em Java no FPGA é ilustrada na Figura 4.3. A arquitectura assenta no modelo
constituído por duas unidades diferenciadas que interagem entre si: a unidade de controlo e a
unidade de dados.
A unidade de dados pode incorporar, em aplicações que os necessitem, componentes que
acedem a dispositivos externos ao FPGA (quadrados a preto na Figura 4.3). Um destes tipos
de componentes é a macrocélula de acesso a uma memória externa. O endereçamento de
dados armazenados numa memória é realizado por circuitos especializados (constituídos por
macrocélulas) presentes na unidade de dados.
O compilador baseia-se numa biblioteca de macrocélulas parametrizáveis, definidas sob a
forma de geradores de circuitos, para produzir a unidade de dados. Cada uma das
macrocélulas gera a estrutura de um circuito especializado que representa uma determinada

82 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
operação. Para que o NENYA possa gerar o reconfigware, a cada nó do DFG global que
representa um operador é associado o componente, da biblioteca de macrocélulas, de
funcionalidade correspondente com menor atraso. O compilador permite o refinamento
automático do supracitado mapeamento inicial. Baseando-se no tempo livre de cada
operador, procura por macrocélulas que tenham funcionalidade equivalente mas um menor
custo em termos de área de circuito e que não alterem o atraso do caminho crítico.
A unidade de controlo é responsável pelo controlo dos acessos a memórias externas, pelo
controlo de escritas em registos e pela execução correcta dos ciclos.
Unidade de Controlo
Unidade de
Dados
sinais de controlo
sinais de estado
done
clock
reset
start
Figura 4 .3 . Estrutura do hardw are no FPGA.
Não foram consideradas outras formas de execução, como o uso de controlo distribuído,
constituído por sequenciadores com comunicação entre si, embebido na unidade de dados. A
utilização de controlo distribuído, no contexto de FPGAs, pode apresentar algumas
vantagens, tais como, permitir sintonizar mais facilmente os atrasos devidos ao
encaminhamento. No entanto, são necessários estudos comparativos detalhados para se
obterem conclusões definitivas.
4.3 Biblioteca Tecnológica
Como foi anteriormente referido, o compilador NENYA baseia-se numa biblioteca de
macrocélulas sob a forma de geradores de circuitos para produzir a unidade de dados. A
biblioteca [Cardoso99d] considerada tem como alvo a família XC6000 de FPGAs da Xilinx
[Xilinx97]. Alguns componentes foram adaptados das implementações em
[Velab98][Hartenst98].
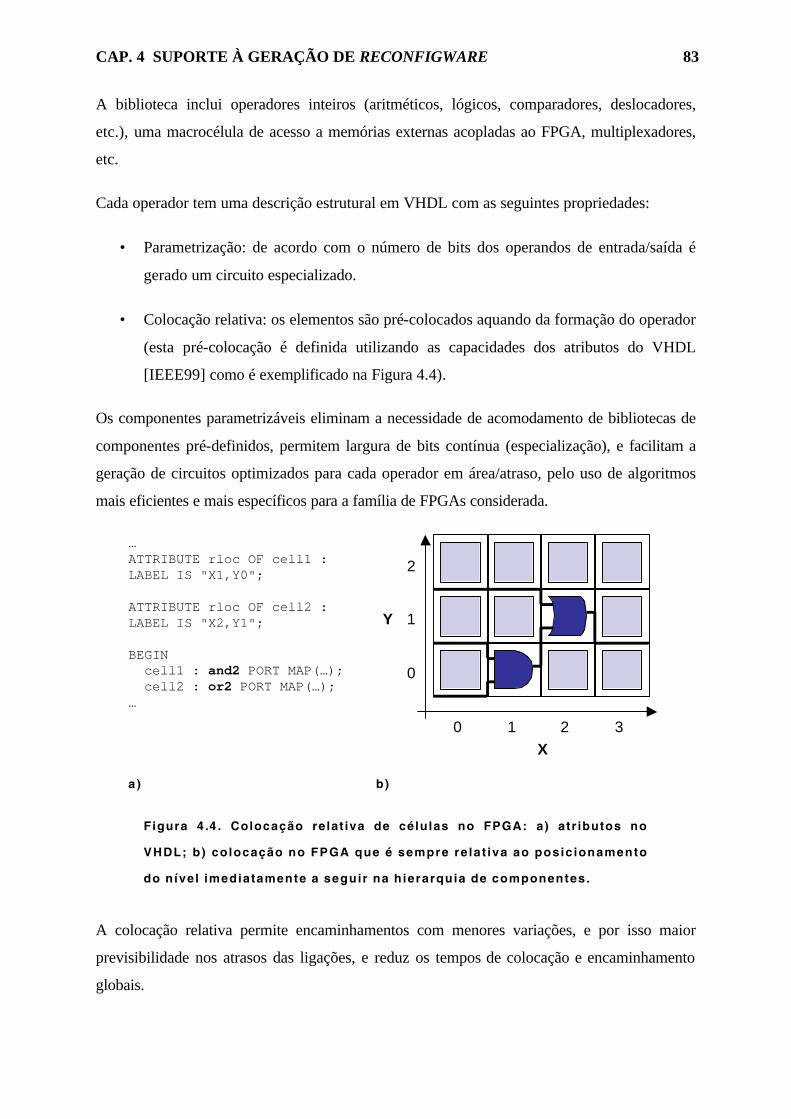
CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 83
A biblioteca inclui operadores inteiros (aritméticos, lógicos, comparadores, deslocadores,
etc.), uma macrocélula de acesso a memórias externas acopladas ao FPGA, multiplexadores,
etc.
Cada operador tem uma descrição estrutural em VHDL com as seguintes propriedades:
• Parametrização: de acordo com o número de bits dos operandos de entrada/saída é
gerado um circuito especializado.
• Colocação relativa: os elementos são pré-colocados aquando da formação do operador
(esta pré-colocação é definida utilizando as capacidades dos atributos do VHDL
[IEEE99] como é exemplificado na Figura 4.4).
Os componentes parametrizáveis eliminam a necessidade de acomodamento de bibliotecas de
componentes pré-definidos, permitem largura de bits contínua (especialização), e facilitam a
geração de circuitos optimizados para cada operador em área/atraso, pelo uso de algoritmos
mais eficientes e mais específicos para a família de FPGAs considerada.
… ATTRIBUTE rloc OF cell1 : LABEL IS "X1,Y0"; ATTRIBUTE rloc OF cell2 : LABEL IS "X2,Y1"; BEGIN cell1 : and2 PORT MAP(…); cell2 : or2 PORT MAP(…); …
X 0 1 2 3
0
1
2
Y
a ) b)
Figura 4 .4 . Colocação relat iva de células no FPGA: a) atr ibutos no
VHDL; b) colocação no FPGA que é sempre re la t iva ao posic ionamento
do nível imediatamente a seguir na hierarquia de componentes.
A colocação relativa permite encaminhamentos com menores variações, e por isso maior
previsibilidade nos atrasos das ligações, e reduz os tempos de colocação e encaminhamento
globais.

84 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
No caso da família de FPGAs XC6000, a descrição estrutural em VHDL assenta na utilização
das portas lógicas elementares que podem ser implementadas por cada célula da FPGA.
A Figura 4.5 apresenta os resultados obtidos em termos de melhoria relativa da
implementação de somadores com o uso de uma macrocélula em comparação com o uso de
síntese lógica [Synopsys95]. Verifica-se que o uso da macrocélula permite a utilização de
somadores com menores atrasos e áreas menores. Outros ganhos, relativamente à utilização
de geradores de circuitos em vez de síntese lógica, poderiam ser reportados:
• no tempo total de computação para a criação da estrutura lógica, que é muito menor
no caso das macrocélulas, pois é apenas necessário criar a estrutura, sem ser
necessário realizar qualquer tipo de optimizações da lógica;
• no tempo de computação para a colocação e encaminhamento, que é menor no caso
das macrocélulas devido a estas serem pré-colocadas.
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
4 8 16 24 32
melhoria_área
melhoria_atraso
Figura 4 .5 . Melhor ia re lat iva em termos de área e de atraso para
circuitos de adição do t ipo “ripple -carry ” (área mínima) gerados pela
macrocélula versus somadores s intet izados pela ferramenta de s íntese
lógica (com direct iva de área mínima).
Em vez de VHDL podem ser utilizadas outras linguagens para a geração dos circuitos para as
macrocélulas. Alguns autores desenvolveram ambientes que permitem gerar circuitos com
base na descrição em C++ [Mencer98] ou em Java [Weaver98][Bellows98] da estrutura ao
nível de porta lógica. Outra forma poderia ser a utilização de geradores de circuitos

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 85
disponibilizados pelos fabricantes de FPGAs, como é o caso do X-BLOX [X-Blox92] da
Xilinx existente para algumas das famílias de FPGAs deste fabricante. Qualquer destas
abordagens permitiria a prototipagem para mais do que uma família de FPGAs. Contudo, a
escolha recaiu no VHDL por ser aceite pela maioria das ferramentas de retaguarda e por isso
possibilitar o suporte de FPGAs de famílias e marcas diferentes. O facto das abordagens mais
interessantes a geradores de circuitos (as supracitadas baseadas em C++ ou Java) serem
proprietárias e encontrarem-se em fases de investigação e desenvolvimento foi outro dos
motivos pelo qual a escolha recaiu em VHDL.
Nas fases de alocação e escalonamento o compilador utiliza uma descrição de cada operador
para a família de FPGAs utilizada. Um ficheiro que contém a caracterização da biblioteca de
componentes é interpretado pelo compilador. Um exemplo da caracterização de um
multiplicador de inteiros é ilustrado na Figura 4.6. O compilador suporta o parsing do
ficheiro e o carregamento dos componentes num formato intermédio apropriado para o
processamento durante a fase de mapeamento de operadores a componentes. Este esquema
permite que o NENYA possa compilar para várias famílias de FPGAs, bastando para isso que
o utilizador forneça a descrição de cada macrocélula com base na caracterização da área e
atraso em função do número de bits dos operandos. Esta descrição de cada componente
permite que o NENYA utilize estimativas de atraso e de área para cada componente, de
forma a poder realizar o escalonamento e estimar a área total necessária para implementar o
circuito.
1. … 2. Component mult_op 3. Area=(a+b)**2; //a e b representam o número 4. //de bits de cada operando. 5. Delay=14*a-20ns; //atraso da macrocélula 6. //em função de a. 7. Operation=imul; //tipo de função 8. … //imul=multiplicador de inteiros 9. 10. …
Figura 4 .6 . Descr ição de uma macrocélula na bibl ioteca tecnológica.
De futuro pode ser considerada a utilização de Java para caracterizar cada macrocélula em
vez da descrição utilizada (ver Figura 4.6). O uso de Java possibilitaria caracterizações mais
exactas, pelo uso de construções condicionais e expressões mais complexas aceites pela
linguagem, para modelar a área e o atraso de cada operador. A Figura 4.7 representa o gráfico

86 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
que caracteriza os multiplicadores obtidos, por síntese lógica mantendo as mesmas directivas
(área mínima), quando se consideram vários tamanhos de operandos e do resultado, e ilustra a
complexidade que poderia ter uma caracterização menos pessimista.
4 6 8 1216
2432
4864
3224
168
4
0
1000
2000
3000
4000
5000
6000
7000
8000
células
bits do resultadobits dos
operandos
7000-8000
6000-7000
5000-6000
4000-5000
3000-4000
2000-3000
1000-2000
0-1000
Figura 4 .7 . Área dos circuitos de mult ipl icação sintet izados tendo em
conta d i ferentes tamanhos (em número de bi ts) dos operandos e do
resultado.
4.4 Mapeamento de Operações em Unidades Funcionais e
Escalonamentos Iniciais
Cada nó do DFG global, que representa um operador, é mapeado num componente da
biblioteca de macrocélulas para que o reconfigware possa ser gerado. À partida, o compilador
atribui, a cada operador, o componente de funcionalidade correspondente com menor atraso
existente na biblioteca especificada pelo utilizador. Com base nesta atribuição são realizados
os escalonamentos ASAP1 e ALAP2 sem restrições de recursos. Estes escalonamentos são
1 Do inglês: As Soon As Possible (ASAP). Esquema de escalonamento em que as operações são colocadas o mais próximo possível do início do escalonamento. 2 Do inglês: As Late As Possible (ALAP). Esquema de escalonamento em que as operações são colocadas o mais próximo possível do fim do escalonamento.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 87
obtidos pelo atravessamento do DFG global do início para o fim e vice-versa,
respectivamente. Foram consideradas várias possibilidades para implementar os esquemas
ASAP e ALAP. Uma implementação, baseada em pilha, do esquema ASAP é apresentada na
Figura 4.8. No algoritmo, succ()e pred() representam respectivamente no DFG os nós
sucessores e os nós predecessores do nó considerado e push() representa a colocação de
um nó no topo da pilha se o topo ainda não contiver o nó considerado. A função MAX calcula
o máximo de dois números inteiros. Esta versão tem o pior tempo de execução proporcional a
|V|+|E| (O(|V|+|E|)), sendo |V| o número de nós e |E| o número de laços do grafo. Na prática,
contudo, o carregamento de nós na pilha necessita de tamanho suplementar de memória, no
pior dos casos proporcional a |E|, facto que agrava o tempo de execução do algoritmo no caso
de grafos com elevado número de laços. Uma forma de melhorar o tempo de computação do
algoritmo consiste em implementar uma versão iterativa deste (ver Figura 4.9) que não
necessita do uso da pilha. O grafo é sucessivamente atravessado, e para cada nó são
determinados os tempos do escalonamento, até que não haja modificações no escalonamento.
Esta versão tem o pior tempo de execução proporcional a |V|2+|V||E| (O(|V|2+|V||E|)), mas na
prática comporta-se melhor do que o algoritmo baseado em pilha, devido ao facto da maioria
dos nós do DFG poderem ser acedidos por ordem topológica (em alguns casos obteve-se
metade do tempo de execução do algoritmo baseado em pilha) e de não requerer memória
adicional.
1. ASAP(DAG DFG) 2. Stack Nodes = new Stack(); 3. Forall Succ(DFG.START) 4. Nodes.push(succ(DFG.START)); 5. 6. 7. while(!Nodes.empty()) 8. DAGNode A = Nodes.pop(); 9. 10. Foreach DAGNode Bi ∈ A.pred() 11. ASAPstart(A) = MAX(ASAPend(Bi), ASAPstart(A)); 12. 13. 14. ASAPend(A) = ASAPstart(A) + delay(A); 15. 16. Forall DAGNodes ∈ A.succ() 17. Nodes.push(A.succ()); 18. 19. 20.
Figura 4 .8 . Algor i tmo do escalonador ASAP sem restr ições de recursos
baseado em pi lha .

88 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
1. ASAP(DAG DFG) 2. Boolean modified; 3. do 4. modified = false; 5. 6. foreach(DAGNode Aj ∈ DFG) 7. int oldASAPstart = ASAPstart(Aj) 8. int newASAPstart = oldASAPstart; 9. Foreach DAGNode Bi ∈ Aj.pred() 10. newASAPstart = MAX(ASAPend(Bi), newASAPstart); 11. 12. if(newASAPstart ≠ oldASAPstart) 13. ASAPend(Aj) = newASAPstart + delay(A); 14. modified = true; 15. 16. while(modified) 17.
Figura 4 .9 . Algori tmo i terat ivo do escalonador ASAP sem restr ições de
recursos.
Para facilitar todas as análises baseadas no atravessamento do DFG global, a criação deste é
realizada de forma a que a ordem de armazenamento dos nós no DFG seja a ordem
topológica no mesmo. Deste modo, os algoritmos de ASAP/ALAP utilizados requerem
apenas uma simples passagem pelo DFG. Na Figura 4.10 é apresentado o algoritmo de ASAP
usado, que é semelhante ao algoritmo da Figura 4.9 com excepção dos enunciados
encarregues da parte iterativa. Com o algoritmo da Figura 4.10 o pior tempo de execução é
proporcional a |V|+|E| (O(|V|+|E|)).
1. ASAP(DAG DFG) 2. foreach(DAGNode Aj ∈ DFG in topological order) 3. int oldASAPstart = ASAPstart(Aj) 4. int newASAPstart = oldASAPstart; 5. Foreach DAGNode Bi ∈ Aj.pred() 6. newASAPstart = MAX(ASAPend(Bi), newASAPstart); 7. 8. if(newASAPstart ≠ oldASAPstart) 9. ASAPend(Aj) = newASAPstart + delay(A); 10. 11. 12.
Figura 4 .10 . Algor i tmo do escalonador ASAP sem restr ições de
recursos quando os nós do DFG são acedidos por ordem topológica .
O algoritmo para efectuar o escalonamento ALAP é similar aos anteriores com as
modificações baseadas no facto de que este necessita de atravessamento do DFG por ordem

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 89
inversa do fluxo (começa com o atraso máximo obtido pelo ASAP) e é baseado na equação
ALAPend(A) = MIN(ALAPstart(Succ(A)), ALAPend(A)), em que MIN
representa o cálculo do valor mínimo de dois números inteiros. Tal como foi descrito para o
algoritmo de ASAP, quando o DFG é representado por ordem topológica, o algoritmo de
ALAP só necessita de uma passagem pelo DFG global.
Todos os algoritmos apresentados são genéricos e simplificados para melhor compreensão
(não incluem o tratamento de operações especiais, por exemplo). A Figura 4.11 apresenta
alguns resultados comparativos dos três algoritmos propostos para o ASAP com exemplos
apresentados no apêndice D. A utilização do algoritmo de uma passagem origina, como seria
de esperar, melhorias significativas que, por isso, justificam a sua escolha. O algoritmo
iterativo também produziu melhores resultados, exceptuando um caso (Mult53), do que o
algoritmo baseado em pilha.
-40,0%
-20,0%
0,0%
20,0%
40,0%
60,0%
80,0%
100,0%
Mult53 Mult89 Mult161 Mult305 Mult573 sqrt217 usqrt603
Melhoria(Top. Ord.) Melhoria(Iterativo)
Figura 4 .11 . Melhor ias dos a lgor i tmos ASAP, com os nós
topologicamente ordenados e com o método i terat ivo, re lat ivamente ao
a lgor i tmo baseado em pi lha (os números a segui r ao nome do exemplo
ident i f icam o número de nós de cada DFG global ) .
Os escalonamentos realizados são ditos de granulosidade fina, por serem feitos em fracções
do período do ciclo de relógio3 previamente escolhido pelo utilizador, ao invés dos
3 É usado um décimo do período como passo de escalonamento. Pode também ser utilizado o máximo divisor comum de todos os atrasos das macrocélulas utilizadas como passo.

90 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
escalonamentos feitos com o período do ciclo de relógio como escala mínima [Micheli94]
(ditos de granulosidade grossa). A utilização destes últimos é por vezes devida ao facto de os
operandos/resultados das unidades funcionais estarem/serem armazenados em registos, em
alguns casos apenas nas fronteiras de blocos básicos, que são carregados em transições
positivas ou negativas do ciclo de relógio (embora também seja possível realizar
encadeamentos de operações num mesmo ciclo de relógio [Micheli94]).
No NENYA os operandos e os resultados das unidades funcionais são, sempre que possível,
promovidos a fios. Este facto permite que as unidades que necessitam de operandos
fornecidos por outras unidades comecem, para efeitos de escalonamento, virtualmente a
execução no final do tempo de atraso do caminho crítico das fornecedoras. Pode-se ver pela
Figura 4.12a que quando existem registos entre unidades funcionais4, o começo da execução
de cada unidade tem de ser escalonado para o início de um novo ciclo de relógio. No caso em
que não existem registos entre operações as unidades podem começar a execução de seguida
(ver Figura 4.12b). É óbvio que para operações que não sejam mutuamente exclusivas e que
partilhem fisicamente a mesma unidade funcional, a necessidade de armazenar os dados
correspondentes a cada operação introduz registos e induz o escalonamento das operações
para o início do ciclo de relógio.
REG
REG
OP2
REG
OP1
OP1
OP2
a ) b )
Figura 4 .12 . Impacto na execução: a) com registos; b) sem re gistos
entre operações.
4 Para unidades funcionais puramente combinatórias.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 91
Quando aparece um nó do DFG que refere uma unidade funcional cuja actividade só pode ser
iniciada no início de um ciclo de relógio (acessos à memória, escrita em registos e unidades
partilhadas) é lhe atribuído um valor de ASAP correspondente ao início do ciclo de relógio
mais próximo, que não viole os tempos de finalização das unidades que fornecem dados à
unidade em consideração.
O mapeamento inicial realizado atribui a cada operador do DFG o componente da biblioteca
de macrocélulas mais rápido (linhas 3 a 5 da Figura 4.13). De seguida o algoritmo de
mapeamento utilizado, ilustrado na Figura 4.13, tenta refinar o mapeamento inicial com base
no tempo livre de cada operação. Após a obtenção das medidas ASAPstart, ASAPend, ALAPstart
e ALAPend para cada nó do DFG (linhas 5 e 6 da Figura 4.13), determinando os
escalonamentos ASAP e ALAP sem restrições de recursos e sem tratamento especial dos nós
pertencentes a regiões cíclicas e/ou ramos condicionais (linhas 6 e 7 da Figura 4.13).
1. Mapping 2. Library LD = LoadLibrary(); 3. Map each Operation Nodei of DFG to a 4. Functional equivalent Macrocell ∈ LD with 5. Minimum delay; 6. DelayMAX = Compute fine-grain ASAP(ASAPstart, ASAPend); 7. Compute fine-grain ALAP(ASAPstart,ASAPend, DelayMAX); 8. Compute TI(ASAP, ALAP); 9. Refine Mapping(TI, DFG); 10. 11. 12. Refine Mapping(TI, DFG) 13. Foreach Operation Nodei of DFG with TI > Delayi 14. S1 = Search in LD for the set of functional 15. Equivalent Macrocells of the operation 16. in Nodei; 17. If((S1 ≠ ∅) && (Search Macroj ∈ S1 with 18. lower area and delayj ≤ TI(Nodei))) 19. Nodei.SetMacro(Macroj); 20. Compute the new fine-grain ASAP for the 21. path which contains Nodei; 22. Compute the new fine-grain ALAP for the 23. path which contains Nodei; 24. Compute the new TIs for the path which 25. Contains Nodei; 26. 27. 28.
Figura 4 .13 . Algor i tmo para mapear as operações nas unidades
funcionais (macrocélulas) . O algori tmo engloba o ref inamento do
mapeamento, ao permit i r a t roca entre macrocélu las de menor área
desde que a mesma não v io le o caminho cr í t ico .

92 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
Após o cálculo dos escalonamentos ASAP e ALAP, é determinado o tempo que uma
operação pode usar sem afectar o atraso do caminho crítico (linha 7 da Figura 4.13). Este
intervalo de tempo é calculado pela equação (4.1), e representa a soma da mobilidade (tempo
livre que uma operação individualmente ainda pode usar sem que isso altere o atraso do
caminho crítico e que é calculado pela subtracção dos tempos de ALAP e de ASAP relativos
a essa operação) com o atraso da operação.
startiendii ASAPALAPTI −= (4 .1 )
Baseado no TI de cada operação do DFG, o algoritmo selecciona de entre as macrocélulas
com funcionalidade equivalente a de menor área que não perturbe o atraso do caminho crítico
(linhas 13 a 16 da Figura 4.13). Para cada troca de macrocélula o algoritmo repete o processo
até não serem possíveis mais refinamentos.
4.5 Acessos a Memórias Externas
Nesta versão do compilador, o mapeamento de variáveis do tipo array utilizadas na descrição
fonte é feito em dispositivos de memória externos ao FPGA, por ser a forma de garantir
espaço para armazenamento, principalmente em FPGAs sem memórias internas como é o
caso da família XC6200. Em trabalhos futuros espera poder-se promover o armazenamento
de arrays, sempre que tal for possível, em memórias internas do FPGA5. De forma a reduzir
o impacto dos acessos a elementos de arrays armazenados externamente, é considerado o uso
de várias memórias acopladas ao FPGA e formas de mapeamento destas de forma a que o
cálculo de endereços, por impor custos elevados de área e de atraso, seja feito por um circuito
de dimensão e atraso reduzidos.
4.5.1 Especialização para o Cálculo de Endereços
A localização em memória (endereço físico) do elemento indexado por I de um array uni-
dimensional A, A[I], é calculada pela equação (4.2) em modelos sem offset (linguagens
5 Os novos FPGAs, como é o caso da família Virtex de FPGAs da Xilinx [VirtexURL], integram bancos de memória distribuídos e possibilitam que cada CLB (Configurable Logic Block) possa também ser usado como memória de tamanho reduzido.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 93
Java e C, por exemplo). O termo BASE representa o endereço físico a partir do qual se
situam todos os elementos do array (normalmente por ordem crescente) e o factor de
multiplicação W representa a transformação necessária que normalmente é função da unidade
de endereçamento (múltipo do byte) e do tipo de dados do array (arrays do tipo int em
memórias endereçáveis byte-a-byte requerem W=4, por exemplo).
I x W + BASE (4 .2 )
Como os dados são representados em múltiplos do byte, o factor multiplicativo na equação
pode ser implementado por um simples deslocador por uma constante que, no caso de
hardware especializado, é implementado simplificadamente por interligações sem
necessidade de lógica.
A complexidade do conversor de índices de arrays em endereços físicos da memória onde
estão armazenados os elementos do array depende da posição destes na memória. Quando os
arrays são mapeados em posições de memória múltiplas de 2n o factor de soma do índice
alinhado ao endereço base do respectivo array pode ser substituído por uma simples
concatenação de bits identificadores do endereço base com o índice. Por exemplo, se o array
A tiver dimensão de 8 bytes e endereço base (endereço do primeiro elemento) 64, a instrução
A[i] pode ser especificada em VHDL por A(“0..01000” & i(2 downto 0)) e,
como se pode constatar, a implementação reduz a geração do endereçamento a simples
interligações. Este tipo de alocação usa os recursos da memória de uma forma pouco
económica6, mas permite optimização no acesso (não havendo necessidade do somador, facto
que poderia degradar o desempenho e aumentaria a área do circuito). Embora a compilação
de implementações reconfigware assumindo a colocação de arrays na memória
contiguamente não traga qualquer problema adicional, nesta versão, o compilador usa sempre
a alocação dos arrays anteriormente explicada para que os acessos às memórias não afecte
tanto o desempenho.
Na Figura 4.14 é apresentado o algoritmo de atribuição de endereços base a cada array na
memória definida pelo mapeamento. O algoritmo pressupõe que previamente foi feito o
mapeamento dos arrays nas memórias disponíveis e assegurado que a atribuição de
6 Na maioria de aplicações parece ser tolerável devido aos recursos de memória existentes na maioria das placas para computação reconfigurável e na maioria dos próprios FPGAs serem grandes.

94 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
endereços base não implica a violação do tamanho máximo de cada memória. O algoritmo
assume que o tamanho dos arrays foi determinado previamente e, por isso, quando o
compilador não consegue obter esta informação requer a inserção da mesma pelo utilizador.
1. MapBase(ℑℑ(℘)) 2. Foreach Memoryi ∈∈ ℑℑ 3. Boolean lastshift = false; 4. int ArrayRef = 0, ArrayBef = 0, thisNumArrays = 0; 5. ℘ = arrays mapped to Memoryi sorted by increasing size; 6. foreach Arrayj ∈∈ ℘ // por ordem crescente 7. int bytes = getScale(Arrayj.type); 8. if(thisNumArrays == 0) 9. ArrayRefs[Arrayj] = 0; 10. else 11. ArrayRef = 2^log2(Arrayj.size*bytes); 12. if(ArrayRef == ArrayBef) 13. ArrayRef[Arrayj] = ArrayRef[Arrayj-1] + 14. 2^log2((Arrayj.size-1)*bytes); 15. lastshift = !lastshift; 16. else 17. ArrayRefs[Arrayj] = ArrayRef; 18. lastshift = false, 19. 20. 21. thisNumArrays++; 22. ArrayBef = ArrayRef; 23. 24. return ArrayRefs; 25.
Figura 4 .14 . Algor i tmo que, para cada memória, atr ibui os endereços
BASE dos arrays mapeados na memór ia considerada .
Para cada memória externa (ℑ representa o conjunto de memórias), o algoritmo determina o
endereço do primeiro elemento de cada um dos arrays mapeados nessa memória. De seguida
o algoritmo visita cada um dos arrays pela ordem crescente do tamanho em bytes (linhas 5 e
6 da Figura 4.14). Ao primeiro array da lista ordenada é atribuído o endereço zero (linha 9 da
Figura 4.14). Aos restantes são atribuídos endereços com apenas um bit com valor lógico um
que garantam espaço suficiente entre endereços para armazenar cada um dos arrays (linhas
10 a 20).
4.5.2 Partilha de Acessos a Memórias
Por cada memória externa de porto único acoplada ao FPGA por um barramento próprio é
instanciada uma macrocélula que corresponde a um circuito de acesso especializado. O

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 95
diagrama de blocos da macrocélula é exemplificado na Figura 4.15. Todos os acessos a esta
macrocélula são multiplexados no tempo e por isso são colocados blocos de selecção nas
linhas de endereçamento e de dados com mais do que uma linha incidente. A unidade de
controlo é responsável por assegurar a ordem de acessos correcta.
LEITURA/ ESCRITA
…
Índice1 αα1
Índice2
Índicek
…
αα1
ααk
Memória
…
…
Dados de entrada
Endereços Dados de saída
FPGA
Selecciona
selecciona
WE
Figura 4 .15 . Acessos à macrocélu la de in ter face com uma memória
externa acoplada ao FPGA. Os índices de 1 a k ident i f icam elementos de
u m array e os parâmetros αα representam a t ransformação do índice no
endereço real na memória . Caixas axadrezadas representam registos.
Os dados de entrada da macrocélula que acede à RAM usam registos a seguir aos blocos de
selecção para armazenar os valores dos dados e dos endereços, pois deste modo o
escalonamento obtido é mais eficiente quando há acessos consecutivos à macro. Os registos
isolam o valor do bloco de selecção permitindo que enquanto a macrocélula está em execução
os valores para o próximo acesso possam já estar a ser seleccionados.
Para memórias com mais do que um porto é instanciada uma macrocélula de interface para
cada porto.
4.6 Atribuição de Registos
O compilador usa sempre que possível a promoção de variáveis em fios, mesmo nos casos em
que a variável tem um registo da JVM associado. A promoção em fios em descrições
acíclicas implica a não necessidade de registos para garantir o correcto funcionamento. Com
este tipo de promoção não é necessário respeitar dependências de dados de saída e anti, e de

96 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
restauro de execução especulativa em descrições com apenas variáveis locais. A eliminação
das dependências de saída e anti pode potenciar maiores graus de paralelismo sempre que tais
existam.
A compilação relativa à maioria dos dispositivos de lógica reconfig uráveis não necessita de
utilizar técnicas de partilha de registos baseadas no tempo de vida das variáveis, pois estes
possuem inerentemente registos em número elevado sem gastos adicionais. Na maioria dos
FPGAs o tamanho de um registo é equivalente ao tamanho de um multiplexador, tornando
inglória a partilha baseada na poupança de área. Além do mais, as unidades de dados
baseadas em arquitecturas com ficheiros de registos, sendo vocacionadas para a reutilização
destes (registos), tornam o encaminhamento mais complicado, são muito mais apropriadas
para a liberdade de implantação física de um ASIC do que para as arquitecturas pré-definidas
de FPGAs, e restringem a implementação de graus elevados de paralelismo. Por estes
motivos não se considera a reutilização de registos, nem arquitecturas alvo baseadas na
partilha de uma ou mais unidades de ficheiros de registos.
Contudo, os registos são necessários para implementar ciclos e para permitir a partilha de
unidades funcionais por operadores. Como a versão corrente do compilador não permite a
partilha de unidades funcionais da forma usual, apenas as unidades de acesso às memórias
externas necessitam de registos para armazenar os valores lidos. Apenas operações do mesmo
tipo em caminhos mutuamente exclusivos podem utilizar a mesma unidade funcional sem a
necessidade de armazenamento de dados, pois a unidade é apenas utilizada uma única vez por
cada passagem do programa, como se explicará na secção seguinte.
No caso dos ciclos os registos são necessários para armazenar dados cujo valor é necessário
entre iterações. O compilador determina o número de registos mínimo e os nós de variáveis
no DFG global onde estes devem ser colocados para preservar a computação de ciclos. O
algoritmo procura no DFG por cadeias uso-definição dentro de um ciclo. Para uma dada
variável que refere um registo, a última definição anterior à execução do ciclo e a última
definição dentro do ciclo são, respectivamente, a primeira e a última atribuições ao registo.
No caso de existirem pontos de selecção alcançados por atribuições a uma variável que
necessita de um registo, este é colocado a seguir ao ponto de selecção.
O DFG ilustrado na Figura 3.24 apresenta a atribuição de registos a variáveis realizada pelo
NENYA. Cada registo atribuído apresenta o desdobramento no DFG dado pela inicialização

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 97
da variável e pela última definição desta no corpo do ciclo. É por isso que aparecem na
Figura 3.24 dois nós para o registo “REG i” e dois para o registo “REG Result”. As duas
atribuições a qualquer destes registos são implementadas na unidade de dados por
multiplexamento dos laços incidentes aos nós identificadores da mesma variável à qual foi
atribuído um registo (ver Figura 4.16).
REG i
0
4
lt_N
Address X
REG Xi REG Yi
REG RESULT
0
L2NORM
LOAD
Sel1
Sel2
Address YSel3
g)
Figura 4 .16 . Grafo da unidade de dados representat ivo do DFG global da
Figura 3.24 quando os dois arrays são mapeados numa memór ia de
porto único. As atr ibuições ao mesmo registo foram mult ip lexadas.
4.7 Partilha de Unidades Funcionais
A partilha viável de unidades funcionais por operações aritméticas de grandes dimensões
(multiplicadores, por exemplo) deve ser considerada em trabalhos futuros. Esta não foi
considerada nesta dissertação por a mesma requerer também abordagens diferentes dos
métodos usualmente propostos pela comunidade de síntese arquitectural vocacionada para
ASICs [Gajski92][Micheli94] e necessitar de investigações morosas que são naturalmente
complementares a esta tese. Algoritmos que entrem em linha de conta com a possibilidade da
partilha de unidades funcionais e de partição temporal necessitam de ser investigados. Alguns
trabalhos têm proposto formas de lidar com estes dois problemas baseadas em programação
linear inteira (ILP7) em conjunção com heurísticas [Ouaiss98a], o que limita fortemente a sua
aplicação por implicar elevados tempos de computação. Contudo, o problema é ainda mais
complexo pois a partilha de unidades funcionais por operadores distantes no DFG pode
7 Do inglês: Integer Linear Programming.

98 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
complicar a colocação e encaminhamento, podendo não reduzir a área do circuito final como
era esperado durante o escalonamento.
No compilador é usada uma forma de partilha de unidades funcionais sem necessidade da
intervenção da unidade de controlo. Este tipo de partilha de recursos é exemplificada no
Exemplo 4-1 e pode ser utilizado em caminhos mutuamente exclusivos que façam uso de
operadores com a mesma funcionalidade e só permite a partilha de uma unidade por apenas
um operador de cada caminho mutuamente exclusivo. O mecanismo baseia-se na utilização
da selecção do caminho, pela lógica decisória do programa, para também seleccionar os
operandos da unidade partilhada entre operações de caminhos mutuamente exclusivos. É por
isso um mecanismo de partilha espacial e não permite a partilha temporal de uma unidade
funcional por duas operações executadas incondicionalmente.
A partilha pode reduzir a área do circuito mas pode também introduzir atrasos no caminho
crítico pois a selecção de operandos do operador partilhado precisa de conhecer o resultado
da lógica decisória. Por este motivo o mecanismo pode ser avaliado previamente pelo
utilizador. Por omissão, o compilador não considera a partilha anterior.
Exemplo 4 -1 . Part i lha de recursos em caminhos mutuamente exc lus ivos.
Considere-se o segmento de código Java apresentado na Figura 4.17a. O
código é constituído por dois caminhos mutuamente exclusivos. Um dos
caminhos é constituído pelo bloco básico BB1 que contém duas
multiplicações e uma adição (linha 3). O outro caminho é constituído pelo
bloco básico BB2 que contém uma multiplicação e uma adição (linha 5). A
Figura 4.17b apresenta o DFG correspondente ao segmento de código
apresentado. Neste exemplo todas as operações de multiplicação podem
partilhar entre elas a mesma unidade de multiplicação. Contudo para
preservar a funcionalidade a partilha da mesma unidade por operações
pertencentes ao mesmo caminho necessita do uso de registos e da
interacção com a unidade de controlo.
Para que a partilha seja apenas assegurada por fluxo de dados a partilha de
um multiplicador tem de ser feita entre Op1 e Op3 ou Op2 e Op3. Com a
partilha de um multiplicador entre Op1 e Op3 obtém-se o DFG

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 99
representado na Figura 4.17c. Da mesma forma as operações de adição Op4
e Op5 podem também partilhar a mesma unidade de adição. O DFG
representado na Figura 4.17d ilustra a partilha de um multiplicador e de um
somador.
Este tipo de partilha não requer interacção com a unidade de controlo como
se pode constatar. Contudo, deve-se ter em conta que neste exemplo a
selecção de operandos do operador partilhado Figura 4.17b precisa de
conhecer o resultado da comparação, e por isso o atraso do caminho crítico
é maior.
1. … 2. if(f<10) 3. a = b * c + d * e; BB1 4. else 5. a = d * c + e; BB2 6. … a_1
c
a_3 Mux(a_1, a_2)
a_2
d
e
e d c b 10 f
BB1 BB2
1 2 3
4 5
6
a ) b)
a_1
a_3
Mux(a_1, a_2)
a_2
e
e
d
c
b 10 f
d
Mux(b, d)
a_3
e
e
d
c
b 10 f
d
Mux(b, d)
c ) d)
Figura 4 .17 . a) segmento de código Java; b) DFG correspondente; c)
DFG com part i lha de um mult ip l icador entre caminhos mutuamente
exclusivos; d) DFG com part i lha do mult ip l icador e do somador.

100 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
4.8 Geração do Reconfigware para a Unidade de Dados
A unidade de dados é obtida do DFG global após algumas transformações:
• A partilha de uma macrocélula nos acessos à mesma memória externa, requer a
colocação de circuitos que seleccionem de entre as linhas de dados e de
endereçamento incidentes a essa macrocélula, e de registos para cada leitura existente
no DFG;
• Os acessos necessitam da resolução estática do endereço base de cada array e do
circuito gerador do endereçamento. É necessário colocar um somador no circuito de
endereçamento sempre que os arrays não sejam colocados em posições de memória
que permitam formas simplificadas de endereçamento. A Figura 4.18 mostra o DFG
obtido dos bytecodes, no qual o endereço do array acedido se encontra armazenado
numa variável local, e um DFG representativo das transformações realizadas;
• Os nós do DFG representando a mesma variável, à qual foi atribuído um registo, são
transformados num único registo. A saída do registo é ligada a todos os laços de saída
dos nós dessa variável e são colocados multiplexadores ligados ao registo para
seleccionar de entre os laços incidentes aos nós da variável;
• Por cada ponto de selecção necessita de ser colocada no DFG global uma unidade de
selecção.
As unidades de selecção podem ser implementadas por um ou mais multiplexadores ou por
um conjunto de drivers tri-state. Por exemplo, a família XC6200 não suporta drivers tri-state
e por isso as unidades de selecção são sempre implementadas à custa dos multiplexadores de
duas entradas e de uma saída suportados por cada célula do FPGA. Em FPGAs com suporte a
tri-state, as unidades de selecção podem ser implementadas por uma linha acedida por estes
drivers. Este mecanismo de selecção tem vantagens óbvias, pois permite reduzir a área total
do circuito e o atraso do bloco de selecção face ao mecanismo implementado por
multiplexadores quando o número de linhas a seleccionar é acima de um certo valor8.
8 Depende da granulosidade e da arquitectura do FPGA.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 101
… aload_1 bipush 7 iaload …
REG
0
GALADRIEL
SRAM MACRO
… … = A[7]; …
7
2 Nó de leitura da memória
Nó de variável
0x00000f00 7
Endereço real do array A na
memória.
NENYA
start
end
end
start
Figura 4 .18 . Transformações real izadas no DFG global para aceder à
memór ia externa quando os arrays não são co locados em posições de
memória que possibi l i tem a simpl i f icação do circui to de
endereçamento.
Durante o escalonamento o compilador estima a área e o atraso do multiplexador baseando-
se, sempre que necessário, na criação de uma árvore balanceada de multiplexadores. O
número de multiplexadores básicos (2 entradas:1 saída) é obtido subtraindo uma unidade ao
número de entradas (N), e o número de níveis da árvore é dado pela expressão log2(N). Os
multiplexadores considerados pressupõem que a selecção das linhas é realizada por linhas
descodificadas. Cada multiplexador recebe um conjunto de operandos v1, v2, … vn, e um
conjunto de sinais de selecção s1, s2, ..sm, e retorna um operando. Cada sinal de selecção tem
origem directa de um comparador ou da unidade de controlo. Além do conjunto de
multiplexadores (2:1) é necessária lógica para controlar a passagem de dados pela árvore de
modo a respeitar a funcionalidade pretendida. O número de portas lógicas equivalentes é
estimado como sendo igual ao número necessário de multiplexadores básicos, quando este
número é maior do que um (um multiplexador de duas entradas não precisa de lógica para
resolver a selecção na árvore balanceada de multiplexadores).
O NENYA gera o VHDL-RTL estrutural respectivo a partir do DFG global tendo em conta
as transformações necessárias e por isso não necessita da criação explícita do grafo
representativo da unidade de dados. A Figura 4.19a apresenta uma parte de um DFG global

102 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
típico ao qual foi atribuído um registo. A representação em grafo do hardware da unidade de
dados que implementa este DFG é apresentado na Figura 4.19b. Do DFG global da Figura
4.19a, o VHDL-RTL estrutural representativo do grafo da Figura 4.19b pode ser gerado
automaticamente sem ser necessária a criação deste último (ver Figura 4.19c).
A geração do VHDL-RTL estrutural para unidades de dados em que haja partilha da
macrocélula de acesso a uma memória é realizada de modo semelhante (sem criação explícita
de um grafo com a partilha).
REG 1
0
REG 1
1
0
2
3
4
REG 1
0
a ) b)
1. ... 2. lv_0 <= (others => “0”); 3. Mux_1: mux generic map(32) port map(sel_1_2, lv_0, lv_2, lv_aux_1); 4. REG1: reg generic map(32) port map(clock, load_1, lv_aux_1, lv_1); 5. lv_3 <= lv_1; 6. ... c )
Figura 4 .19 . Transformação entre a) DFG global (do lado direi to
encontram -se os ident i f icadores dos nós) e b) correspondente grafo da
unidade de dados; c) parte da estrutura descr i ta em VHDL.
Exemplo 4 -2 . Geração da unidade de dados para o exemplo da Figura
3.22.
A Figura 4.16 apresenta o grafo representativo da unidade de dados após a
aplicação das transformações ao DFG global da Figura 3.25 gerado pelo
NENYA a partir do exemplo da Figura 3.22. Este grafo é facilmente

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 103
representado em VHDL estrutural, pois apenas é necessário instanciar as
operações envolvidas (utilizando elementos da biblioteca tecnológica) e os
sinais que interligam esses componentes.
Como se pode ver na Figura 4.16 foram atribuídos dois registos
relacionados com o ciclo. O registo “REG i” é usado pela unidade de
controlo para supervisionar a execução das iterações do ciclo e o registo
“REG RESULT” armazena o valor do resultado rotulado de "L2NORM".
Os registos “REG Xi” e “REG Yi” são usados para armazenar os dados
lidos na memória externa pela macrocélula de acesso (os registos de
armazenamento do endereço, de cada dado de entrada na macrocélula de
acesso à memória não estão representados).
4.9 Suporte de Retaguarda da Geração de Reconfigware
De forma a implementar o hardware num FPGA é necessário gerar a descrição da unidade de
dados e da unidade de controlo num formato que possa ser suportado pelas ferramentas de
colocação e encaminhamento para o FPGA específico. Optou-se pelo formato EDIF
[Stanford90] por ser aceite pela maioria das ferramentas e suportar os atributos de colocação
relativa.
A geração do EDIF que representa a unidade de dados é uma simples tradução entre uma
estrutura definida em VHDL para EDIF, e por isso, caso também exista descrição estrutural
das macrocélulas, não necessita de passagem por ferramentas de síntese lógica. No caso da
compilação para a família de FPGAs XC6000 da Xilinx [Xilinx97] é usado o programa
VELAB [VelabURL] para fornecer as descrições em EDIF.
A descrição da unidade de controlo é gerada pelo compilador em VHDL-RTL
comportamental e por isso é necessário utilizar uma ferramenta de síntese lógica para se obter
o circuito final.
As etapas de retaguarda referentes ao uso de FPGAs da família XC6000 encontram-se
ilustradas na Figura 4.20. Para esta família de FPGAs foi usada a ferramenta de síntese lógica

104 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE
“Design Compiler” da Synopsys [Synopsys95]. Contudo as etapas de síntese lógica
requeridas pelo NENYA podem ser realizadas por qualquer ferramenta de síntese lógica9
(Synplify [Synplicity99] da Synplicity, por exemplo), desde que o FPGA utilizado seja
suportado pela ferramenta.
No caso de não existirem descrições estruturais das macrocélulas para uma dada família de
FPGAs pode ser usada uma ferramenta de síntese lógica para obtenção do circuito da unidade
de dados. Neste caso, é utilizada a descrição comportamental das macrocélulas da biblioteca
tecnológica, podendo a síntese ser realizada por qualquer ferramenta de síntese lógica que
aceite descrições em VHDL e suporte o FPGA considerado.
Síntese Lógica
FPGA: Colocação e
Encaminhamento
Descrições RTL-VHDL
estrutura (EDIF)
bitstreams
Biblioteca de Macrocélulas para o FPGA
1. Synopsys Design Compiler 2. velab
XACTstep 6000 series
VHDL para EDIF
1 2
Unidade de Dados
Unidade de Controlo
Figura 4 .20 . Etapas de retaguarda a part i r da descr ição em VHDL para a
famí l ia XC6000 de FPGAs da Xi l inx .
4.10 Conclusões
Neste capítulo foram descritas as etapas realizadas pelo compilador NENYA para gerar a
unidade de dados.
9 Terá, logicamente, de suportar descrições fonte em VHDL-RTL.

CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE 105
Foram explicados os processos de atribuição de registos de modo a garantir o funcionamento
correcto dos ciclos, e de mapeamento de operações do DFG global em unidades funcionais
implementadas por macrocélulas. Foi apresentado o algoritmo que realiza o refinamento do
mapeamento quando existem várias unidades funcionais para implementar o mesmo
operador.
Foram descritas as vantagens do uso de macrocélulas para auxiliar as etapas de compilação e
as etapas de retaguarda necessárias para compilar para FPGAs. Foram também explicados os
acessos a memórias externas ao FPGA e a geração do VHDL estrutural que representa a
unidade de dados com base na instanciação de macrocélulas.
A partilha de componentes apresentada tem a limitação de só poder ser realizada entre
caminhos mutuamente exclusivos mas não necessita de interacção com a unidade de controlo.
O uso de controlo distribuído implementado por sequenciadores (simples contadores) com
comunicação entre si em vez da unidade de controlo central necessita de ser estudado. Esta
forma de controlo permitiria ter uma arquitectura alvo localmente síncrona e globalmente
assíncrona e não necessitaria de escalonamento global, pois a comunicação entre
sequenciadores garantiria a ordem correcta de execução das operações.

106 CAP. 4 SUPORTE À GERAÇÃO DE RECONFIGWARE

107
5. Optimizações do Grafo de Fluxo de Dados
“She lifted up her hand and from the ring that she wore there issued a great light that illuminated her alone and left all else dark.”
J. R. R. Tolkien, The Fellowship of the Ring
Neste capítulo são apresentadas as técnicas para optimização do grafo de fluxo de dados
(DFG) implementadas no compilador NENYA: reassociação de operações de uma expressão
e a redução da força (ou do custo) de operações. Ambas as técnicas ao potenciarem a redução
do caminho crítico e da área do circuito produzem soluções mais eficientes.
São ainda apresentadas técnicas para a determinação do número de bits “seguro” – suficiente
para preservar a funcionalidade - para cada operação do DFG global, tendo em vista a
redução do atraso e da área total do circuito final. São também apresentadas técnicas que,
baseadas no conhecimento de constantes ao nível do bit, exploram a possibilidade de
propagação dos bits constantes e permitem eliminar lógica desnecessária. Estas técnicas são
utilizadas ao nível da estrutura que interliga as operações (DFG), não necessitam da
representação de cada operador ao nível da porta lógica e foram implementadas e integradas
no compilador NENYA. São efectivas e eficientes em algoritmos com ciclos e permitem
melhoramentos significativos na geração de hardware específico.
Para finalizar o capítulo, são apresentados resultados obtidos pela execução do NENYA, com
e sem as etapas de optimização, que permitem aquilatar a potencialidade das técnicas
apresentadas (em alguns casos produzem resultados próximos de soluções quasi-óptimas).

108 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
5.1 Optimizações de Fluxo de Dados
Algumas das técnicas utilizadas na optimização de representações obtidas de linguagens
imperativas [Aho86], por produzirem bons resultados independentemente da máquina alvo
(tipo de processador ou hardware específico), encaixam bem nas fases iniciais de qualquer
compilador e por isso podem ser realizadas antes da compilação para o modelo intermédio
sobre o qual se efectuará a compilação para a arquitectura alvo utilizada. Em casos em que
não se tem acesso ao código original da aplicação, mas apenas a um modelo intermédio
(representação bytecodes, por exemplo), estas optimizações devem ser consideradas nesse
nível para colmatar eventuais deficiências.
As optimizações sobre o fluxo de dados englobam [Muchnick97]: propagação de constantes,
substituição de operações entre constantes pelo resultado estaticamente conhecido,
eliminação de operações redundantes (subexpressões comuns), eliminação de código morto
(inatingível), detecção de operações invariantes a iterações de ciclos e movimento destas para
fora do corpo do ciclo. As simplificações algébricas (por exemplo: I2, por I×I; -1×A, por -A; -
(-J), por J; 0+I, por I) são também independentes da arquitectura escolhida (a sua utilização
não necessita de conhecimento da arquitectura e produz sempre resultados iguais ou
melhores).
No fluxo de compilação proposto nesta tese, todas as técnicas anteriores pertenceriam a fases
de pré-compilação (optimização de bytecodes), não sendo neste momento concretizadas pelo
compilador GALADRIEL. Nesta fase é admitido que algumas destas técnicas foram
realizadas anteriormente (compilação para os bytecodes, por exemplo).
Outras optimizações transformam algumas estruturas de controlo em fluxos de dados como
são os casos do desenrolamento de ciclos e da expansão de funções. Estas técnicas podem
proporcionar, combinadas ou não com as optimizações de fluxo de dados, graus de
paralelismo mais elevados, mas não foram incluídas nesta versão do compilador por não
serem o objectivo principal do trabalho.
Algumas optimizações sobre o fluxo de dados são específicas a uma determinada
implementação. Neste conjunto encontram-se: redução da força de operações1 (ex. 2×I, por
1 Em inglês: operator strength reduction.

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 109
I<<1; 3×I, por I+(I<<1)), reunião de operações sucessivas em uma única operação existente
na biblioteca com funcionalidade equivalente, e reassociação de operações2 (THR)
[Gajski92][Micheli94]. O uso de THR foi primeiramente estudado por [Baer68][Muraoka71]
e estendido posteriormente em [Brent74].
A redução da força de operações é uma técnica maioritariamente aplicada às operações de
multiplicação e divisão sobre dados do tipo inteiro, quando um dos operandos é uma
constante [Magenhei88]. A técnica resume-se à substituição destes operadores por operações
de menor custo (adição, subtracção e deslocamento). A operação de subtracção pode ser
utilizada quando não é feito tratamento de overflows da operação original no modelo
utilizado (ex. 7×I, por (I<<3)-I) 3.
A reassociação de operações de forma a permitir a diminuição da altura de um DFG é
bastante poderosa quando a máquina computacional alvo tem capacidade para executar várias
instruções em paralelo. Esta transformação possibilita, através de algumas propriedades
matemáticas (comutatividade, associatividade e distributividade), em muitos casos, a redução
do número de operações em cascata e, como será explicado posteriormente, a diminuição do
próprio tamanho dos operadores.
Em seguida são apresentadas as técnicas – reassociação e redução da força de operações - que
foram implementadas no NENYA.
5.1.1 Reassociação de Operações
Como foi referido anteriormente a reassociação de operações é uma transformação realizada
sobre o fluxo de dados que permite reordenar um DFG de modo a que a distância do início ao
fim seja reduzida (expondo maior grau de paralelismo). A transformação baseia-se nos casos
mais simples (quando todos os nós do conjunto considerado desempenham a mesma
operação) no balanceamento de uma árvore, ou na utilização das propriedades associativa,
comutativa e distributiva em casos mais complexos. A redução conduz a melhores resultados
na maioria dos casos, principalmente quando em presença de recursos suficientes para fazer
face ao paralelismo acrescentado. A reassociação na presença de operações com atrasos
2 Conhecida na literatura por Tree-Height Reduction (THR). 3 Transformações deste tipo podem ser utilizadas em linguagens que ignorem o overflow.

110 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
diferentes tem como objectivo a diminuição do atraso do DFG que pode não ter a mesma
solução do que a diminuição da altura do grafo.
A redução permite também que a computação do número de bits obtenha, em alguns casos,
melhores resultados. Na Figura 5.1 é apresentado um exemplo que ilustra o uso de THR para
reduzir o atraso do circuito. A optimização permitiu a redução do número de bits de dois dos
somadores com consequências na diminuição da área e do próprio atraso.
start
end
+
a2
a)
+
+
b
c
d
2
3
4
5
2
2
start
end
+
a2
+
+
b d2
3 3
4
2c2
b)
Figura 5 .1 . Impacto do uso de THR na computação do número de b i ts :
a ) cadeia de somadores com três n íveis; b) redução do número de
n íve is para dois com consequente redução do número de b i ts . Os
rótulos nos laços indicam o número de bi ts suf ic iente.
Por questões de prioridade, a versão actual do compilador NENYA realiza apenas THR de
cadeias de adições, multiplicações, ANDs e ORs, por se julgarem os casos mais comuns. Este
suporte a THR permitiu a avaliação do impacto nos exemplos considerados nesta tese. Após a
extracção destas cadeias no DFG, o compilador gera, para cada uma, uma árvore balanceada
e refaz o DFG com base nas árvores geradas. A colocação das entradas em cada árvore
balanceada deve ser de modo a permitir que os resultados disponíveis mais cedo possam ligar
ao último nível da árvore (primeiro nível de lógica). Existem casos em que o uso de THR
pode desfavorecer o escalonamento [Cardoso99e] e por isso a sua aplicação pode ser inibida
por uma opção do compilador. Esta deterioração pode ocorrer quando a unidade a partilhar
tem atraso maior do que a cadeia de operadores potencial para o THR.

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 111
A Figura 5.2 apresenta os resultados do escalonamento (número máximo de ciclos de relógio
para executar o reconfigware) da soma de todos os elementos de um array, considerando
arrays com 10, 20, 30 e 40 elementos, e do tipo byte, short e int, com e sem utilização
de THR. O escalonamento é o resultado da aplicação do escalonador estático baseado em
lista (descrito no capítulo 7) considerando que os elementos do array se encontram todos na
mesma memória acoplada ao FPGA. Considera-se também que a memória é de porto único.
Os resultados mostram ganhos que atingem valores próximos de 60% (soma de 40
elementos) quando se utiliza THR, mesmo em exemplos em que o paralelismo não é
completamente explorado devido à restrição de apenas se efectuar um acesso à memória ao
mesmo tempo.
0
10
20
30
40
50
60
10 20 30 40
Número de elementos somados
Mel
ho
ria
rela
tiva
no
es
calo
nam
ento
(%
)
byte[] short[] int[]
Figura 5 .2 . Resul tados da apl icação de THR e da afer ição do número de
b i ts suf ic iente no escalonamento de exemplos que somam elementos
d e u m array. Os resul tados apresentam a melhor ia re lat iva sobre o
esca lonamento sem THR.
5.1.2 Redução do Custo de Operações
Esta técnica de optimização, como foi anteriormente referido, permite a substituição de
operações com custos elevados (área, atraso, etc.) por operações de custos menores que
implementem a funcionalidade inicial. Os casos mais simples de redução do custo de uma
operação ocorrem quando em presença de divisões ou multiplicações por constantes do tipo 2
elevado a N, em que N representa um número inteiro positivo. Nestes casos, cada operação é
substituída por um deslocamento por uma constante (implementado por interligações), de

112 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
valor N, para a esquerda ou para a direita caso se trate, respectivamente, de uma
multiplicação ou de uma divisão.
Quando a constante não é do tipo 2N a redução do custo da operação (multiplicação ou
divisão) tem de ser feita com base em adições, subtracções e deslocamentos. Nestes casos o
compilador NENYA apenas realiza a redução do custo de operações em multiplicações por
constantes com os métodos explicados de seguida. Trabalhos futuros devem considerar a
redução do custo de divisões por constantes deste tipo.
Uma forma natural de realizar a redução do custo de multiplicações por constantes é a
geração de sequências de deslocamentos e adições. Esta transformação pode ser obtida por
inspecção na representação binária da constante pelos bits de valor lógico igual a um, sendo
por isso de implementação fácil. Este método utiliza, considerando que a constante tem N bits
de valor lógico um, N-1 adições. O aumento linear de operações com o número de bits da
constante indicia que esta técnica pode não fornecer soluções eficientes.
De forma a proporcionar soluções mais eficientes, o algoritmo realizado para redução do
custo de multiplicações por constantes cria uma árvore exaustiva da decomposição da
operação em sequências de multiplicações por constantes do tipo 2N (implementadas por
simples deslocadores por constantes) considerando sequências de adições e subtracções.
Supondo que o menor ramo da árvore criada é constituído por K níveis, então a expressão
final necessita de K-1 operações de soma ou subtracção. A criação da árvore pode ser
melhorada por memorização de expressões (linha a tracejado da Figura 5.3) e supressões
(pruning) no espaço de procura de modo a evitar construções e procuras redundantes.
Exemplo 5 -1 . Redução do custo de mult ip l icação por constantes.
Considere-se a multiplicação de uma variável do tipo inteiro, a, pela
constante 350 (350×a). A árvore da decomposição da expressão em somas e
subtracções de multiplicações por constantes do tipo 2N está ilustrada na
Figura 5.3. As setas a tracejado na figura representam memorização de
expressões cuja decomposição já havia sido representada na árvore. Por
inspecção da árvore o algoritmo escolhe a primeira expressão encontrada
com o menor número de operações: 512×a-(128×a+32×a+2×a). A
expressão 256×a+128×a-(32×a+2×a) é outra das soluções com número
mínimo de operações. A solução com apenas deslocamentos e adições pode

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 113
ser obtida directamente da representação binária da constante (350 =
b’101011110): 256×a+64×a+16×a+8×a+4×a+2×a. Esta última solução
precisa de 5 somas ao invés de 2 somas e de 1 subtracção requeridos pela
primeira solução. Este exemplo ilustra a redução permitida pelo uso de
somas e subtracções em vez de apenas somas.
512×a
350×a
256×a 94×a
256×a 94×a 128×a
162×a
34×a
128×a 34×a 64×a 30×a
64×a 30×a 32×a 2×a
32×a 2×a 16×a 14×a
16×a 2×a 8×a 6×a
128×a 34×a 64×a 30×a
64×a 30×a 32×a 2×a
32×a 2×a 16×a 14×a
8×a 2×a 4×a 2×a
Figura 5 .3 . Árvore de decomposições da expressão 350 × a .
A Figura 5.4 ilustra a distribuição da expressão a×C, variando a constante C de 0 a 65.535,
pelo número de operações obtido utilizando o método apresentado de redução do custo da
multiplicação em somas, subtracções e deslocamentos. O número máximo de operações
(adições e/ou subtracções) obtido é de 9. Com a redução do custo obtida directamente da
representação binária o número máximo de somas é de 16. Como se pode ver, o uso de somas
e subtracções em vez do uso de apenas somas pode reduzir significativamente o número de
operações necessárias com redução da área e do atraso do circuito para implementar a
funcionalidade original (multiplicação por uma constante).
A utilização de redução do custo de operações é deixada ao critério do utilizador (através da
invocação de uma opção quando da execução do NENYA), de forma a que este possa avaliar
o impacto desta no reconfigware final.

114 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
1 2 3 4 5 6 7 8 9 10
#Operações (adições/subtracções)
#Co
nst
ante
s
Figura 5 .4 . Número de operações (adições e mult ip l icações) obtidas
pela decomposição binár ia para redução do custo de mult ip l icações de
uma var iável por constantes de 0 a 65.535 (16 bi ts) com o uso de
adições, subtracções e deslocamentos (não considerados no número
de operações) . O eixo vert ical representa o número de constantes.
Como trabalho futuro podem ser considerados algoritmos que, para obtenção de soluções
mais eficientes, para além de decompor possam também factorizar. Este último método é
baseado na factorização da constante e posterior substituição de cada uma das constantes por
somas/subtracções e deslocamentos [Bernstein86][Briggs94].
Ao novo DFG obtido por aplicação destas técnicas deve ser aplicado THR para produzir
implementações melhores em hardware reconfigurável. Neste momento a aplicação desta
técnica é apenas considerada para cadeias com a mesma operação desde que esta goze da
propriedade associativa.
5.2 Trabalhos Prévios em Aferição do Número de Bits de
Representação
Em muitos programas os tipos de dados utilizados apresentam um sobredimensionamento no
que respeita ao número de bits necessário para preservar a funcionalidade pretendida. Este
facto pode não afectar o desempenho e área quando são utilizados elementos de
processamento com unidades de dados fixas (microprocessadores, por exemplo), mas pode
ser incomportável em elementos de processamento com capacidades específicas e

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 115
especializadas. As linguagens mais disseminadas para programar software apenas permitem
declarações de tipos de dados inteiros em alguns múltiplos do byte, para ajudar o
programador e principalmente devido às implementações em microprocessadores RISC4 não
favorecerem na maioria dos casos a especificidade. Alguns autores adoptaram, para projecto
de sistemas embebidos baseados em núcleos de processamento com unidade de dados
parametrizável no que respeita ao tamanho de palavra, linguagens baseadas no C como é o
caso da linguagem Valen-C em que o programador tem de especificar o número de bits para
cada tipo de dados aquando da declaração [Inoue98]. Contudo o uso de declarações com
especificação do número de bits tornam a programação mais complexa e dão muitas vezes
azo a especificações erróneas, pelo facto do programador não se ter apercebido, por exemplo,
da possível saturação de uma determinada variável.
Por estes motivos é necessário integrar em compiladores para hardware reconfigurável
técnicas que permitam reduzir o número de bits de cada operação e operando do algoritmo
fonte, preservando a funcionalidade original. A redução do número de bits tem implicações
directas na área e no atraso dos circuitos gerados, como é o caso da compilação com suporte
de macrocélulas com propriedades de especialização.
A aferição estática do número de bits das operações foi previamente utilizada por
[Razdan94a][Razdan94b][Razdan94c] no âmbito da utilização de unidades de lógica
reconfigurável acopladas à unidade de dados de um microprocessador. Estes autores
apresentam análises que exploraram a integração de sequências de operações talhadas para
serem implementadas por instruções especiais, com preponderância de sequências de
instruções que manuseiam bits.
Com base em algumas das técnicas previamente apresentadas, realizaram-se estudos que
permitiram o desenvolvimento de análises estáticas de aferição do número de bits.
Praticamente em paralelo [Budiu00] propôs também técnicas com objectivos similares. A
utilização da linguagem DIL5 - que só permite que o programador especifique os subtipos no
interface da função com o exterior – pelos autores torna proibitivo o uso de análises de
aferição do número de bits.
4 Do inglês: Reduced Instruction Set Computers. 5 Do inglês: Dataflow Intermediate Language, que é uma linguagem intermédia para compilação de linguagens alto-nível.

116 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
Em [Stephen00] são propostas análises baseadas na determinação dos intervalos de valores
para cada variável. A análise é completamente estática e para casos com sequências não
lineares os algoritmos iteram até encontrarem o ponto fixo. Embora estas análises possam
determinar intervalos mais próximos dos efectivamente necessários, pois incluem também
informações paralelas (o tamanho de arrays e o facto dos índices a estes arrays não
indexarem elementos fora destes tamanhos, por exemplo), não têm a capacidade de lidar ao
nível de bits sem ser nas extremidades de cada palavra.
Alguns autores que utilizam análises dinâmicas com métodos baseados na extracção de
informação através da execução do programa reclamam, justamente, que a análise estática é
frequentemente demasiado pessimista. Contudo, as análises dinâmicas incorrem do elevado
tempo de execução, em presença de estruturas cíclicas encadeadas, e podem retornar
informação dependente do conjunto de prova utilizado, podendo por isso incorrer em
imprecisões quando entradas não abrangidas no conjunto de prova desencadeiam padrões de
execução não considerados na fase de análise. Contudo, em [Ogawa99] foi proposta uma
nova forma de análise dinâmica que não necessita de conjuntos de prova, embora mantenha a
desvantagem de requerer longos tempos de compilação.
Implementações capazes de tirar dinamicamente partido da presença de dados com número
de bits de representação não standard têm também sido abordadas no contexto de
arquitecturas de processadores genéricos [Brooks99].
Há autores [Bondala99b] que, em computação reconfigurável, apresentaram formas de
especialização do hardware para cada iteração de um ciclo, com base na extracção do número
de bits suficiente, através de análise dinâmica baseada em conjuntos de prova.
Das técnicas estáticas utilizadas, a abordagem apresentada neste capítulo é mais eficiente do
que as análises com base no desenrolamento do ciclo, ou com simulação das iterações deste.
Algumas das técnicas aqui descritas, principalmente as análises para aferição do número de
bits suficiente e a propagação de constantes ao nível de bit, apresentam conceitos, tanto
quanto sabemos, nunca até aqui considerados num compilador.
As técnicas de [Budiu00] e de [Stephen00], tal como as técnicas propostas nesta tese,
melhoram os pressupostos de [Razdan94a][Razdan94b][Razdan94c] ao considerarem
também ciclos. Contudo, a forma de lidar com ciclos é diferente da técnica proposta nesta
tese, na qual são consideradas expressões que captam o comportamento de operações com as

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 117
iterações do ciclo em vez de iterar um ciclo até ao ponto estável ser encontrado. Outras
diferenças residem no uso do DFG em vez do uso de cadeias definição-uso.
5.3 Aferição de Subtipos Primitivos nos Bytecodes
A JVM utiliza operadores com comprimento de palavra de 32 ou 64 bits. Quando, por
exemplo, é necessário proceder a uma operação de 32 bits cujo resultado é representado em 8
bits (tipo primitivo byte) é utilizada, a seguir à operação, uma instrução que converte o
resultado de 32 em 8 bits (int2byte).
A análise começa com a atribuição a cada nó do número conservador de bits (32 ou 64 bits).
Nos pontos de conversão é atribuído o número de bits do tipo para o qual um determinado
valor é convertido, e nos nós que representam constantes é fixado o número necessário para
representar o valor, número este que não volta a ser mudado durante as propagações
efectuadas pelas análises.
Para se extraírem os tipos de dados primitivos de uma representação de tamanho menor que
32 bits, utilizados pela JVM (byte, char e short), é necessário propagar no sentido oposto ao
fluxo de dados e no sentido do fluxo de dados (a partir daqui utilizar-se-ão os termos
propagação inversa e propagação directa) a informação dada pelas conversões de tipos. As
variáveis que constituem argumentos ou que são retornadas duma função têm representações
nos bytecodes explicitamente tipificadas e, por esse motivo, revelam-se importantes na
inferência de tipos primitivos.
Este esquema com propagações inversas e directas deve ser repetido até que haja
convergência, ou seja, até que deixe de haver alterações durante as propagações. As
propagações referidas são feitas no DFG global (percorrendo em sentido directo ou em
sentido inverso as cadeias de operações que o constituem). Esta análise é parecida com a
análise identificada em [Aho86] para inferir tipos na análise de linguagens com referências-
fracas6 (apontadores que podem referenciar qualquer tipo de dados - apontadores para tipo
void na linguagem C, por exemplo) e foi, tanto quanto sabemos, pela primeira vez utilizada
no âmbito de inferência de tipos primitivos na JVM pelo autor desta tese em [Cardoso99a].
6 Do inglês: weak-references, que é o oposto de strong-references (referências fortes: quando o tipo de dados para o qual um ponteiro aponta é conhecido estaticamente).

118 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
O facto de nos bytecodes o tipo boolean ser representado como byte pode implicar
implementações sobredimensionadas quando não é feita a aferição do número de bits de cada
operando/operação existente no DFG.
Exemplo 5 -2 . Aferiç ão de subt ipos pr imit ivos nos bytecodes.
Na Figura 5.5 é apresentado o código de um exemplo que ilustra uma
conversão de tipos e o respectivo DFG. O exemplo consiste de uma
multiplicação de dois inteiros (32 bits) em que só são utilizados os 8 bits
menos significativos do resultado. Como a operação de multiplicação
precisa de fornecer apenas esses 8 bits, é intuitivo que são apenas
necessários os 8 bits menos significativos de cada um dos operandos e
consequentemente a operação pode ser realizada por um multiplicador com
operandos e resultado representados cada um por 8 bits (8 × 8 = 8)7.
start
end
l1
iload_1iload_3imuli2bistore_2
l2
l3
int a, b;…byte c = (byte) (a * b);
8i2b: converte uma representação deinteirocom sinal de tamanho 32para 8 bits.
Figura 5 .5 . Exemplo de afer ição de t ipos pr imit ivos do DFG.
A técnica anterior permite a inferência dos subtipos de dados primitivos da linguagem Java
nos bytecodes da aplicação. Contudo, os tipos de dados utilizados pelo programador não são
necessariamente as escolhas acertadas e o facto de ter de considerar tipos de dados de um
subconjunto dos múltiplos do byte origina, muitas vezes, o sobredimensionamento na escolha
do tamanho das variáveis para armazenar os valores. De forma a que o hardware gerado seja
o menos dependente possível das declarações de dados impostas pelo programador, são
necessárias análises mais poderosas/sofisticadas que permitem determinar o número
7 Operandos e resultado de 8 bits.

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 119
suficiente de bits para cada operador e para cada operando preservando a funcionalidade
original. Neste sentido, são apresentadas na próxima secção técnicas de aferição do número
de bits que se servem da inferência dos tipos de dados primitivos para fornecer os majorantes
do número de bits para cada operando e operador.
5.4 Aferição do Número de Bits de Representação no NENYA
A análise baseia-se no atravessamento em sentidos inverso e directo do DFG e no uso de
regras para cada operação que permitem a propagação do número de bits. A Tabela 5.1
apresenta as regras utilizadas com alguns operadores. Por exemplo, a cada operação lógica do
tipo AND, em que um dos operandos é uma constante positiva, é atribuído ao resultado o
número de bits até ao último bit de valor lógico um presente na representação binária da
constante. As atribuições apresentadas só são feitas se o número de bits que daí resulta for
inferior ao número de bits actual.
Tabela 5 .1 . Regras de propagação em sent idos directo e inverso para
a lguns operadores. Bi ts(A) representa o número de bi ts para o
operando A.
Operação A = B op C
Sentido directo Sentido inverso
× Bits(A) = Bits(B) + Bits(C) Bits(B) = Bits(Asucc) Bits(C) = Bits(Asucc)
+, - Bits(A) = MAX(Bits(B), Bits(C))+1 MAX: valor máximo
Bits(B) = Bits(Asucc) Bits(C) = Bits(Asucc)
>>, >>>, C == const Bits(A) = Bits(B) - Bits(const) Bits(B) = Bits(A)+Bits(const) <<, C == const Bits(A) = Bits(B) + Bits(const) Bits(B) = Bits(A)-Bits(const) &, |, ^, ~ Bits(A) = MAX(Bits(B), Bits(C))
MAX: valor máximo Bits(B) = Bits(Asucc) Bits(C) = Bits(Asucc)
&, C== const Bits(A) = NumBits2LastOne(const) NumBits2LastOne: Número de bits do bit menos significativo até ao bit mais significativo de valor lógico um.
Bits(B) = Bits(Asucc)
A= MUX(A1, A2, …An) MUX: multiplexador
Bits(A) = Máximo de bits de todos os predecessores
Bits(Ai) = Bits(Asucc)
Com o uso do DFG o compilador extrai para cada operador o número de bits suficiente de
modo a preservar a funcionalidade original. Para cada laço do DFG é atribuído o número de
bits. Este número de bits é sempre menor ou igual ao número de bits inferido pela análise
efectuada de aferição de subtipos.

120 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
Algumas operações permitem identificar operandos sempre positivos, permitindo assim
eventuais simplificações. O facto de nos bytecodes e na própria linguagem Java não existirem
tipos para declarações de variáveis que armazenem apenas números inteiros positivos (ao
contrário do tipo unsigned int da linguagem C, por exemplo) pode tornar a aferição do
número de bits menos agressiva, ao não poder, ou não ser possível identificar, em algumas
situações, operandos sempre positivos.
Na propagação inversa, quando na presença de um nó em que a saída fornece valores a mais
do que um operador, o número de bits a atribuir é o número de bits máximo de todos os laços
de saída que o nó tem, sempre que este número seja menor que o número de bits considerado
inicialmente (antes das propagações).
No caso de operadores de deslocamento em que ambos os operandos não são constantes, é
preservada a informação ou utilizado o valor máximo (desde que este valor seja inferior ao
valor inicial) quando o operador é respectivamente um deslocador para a direita ou para a
esquerda.
A Figura 5.6 e a Figura 5.7 ilustram simplificadamente os algoritmos de propagação inversa e
directa. As funções CompWidthRev e CompWidthFor são baseadas nas regras representadas
na Tabela 5.1. Os algoritmos apresentados são iterativos devido ao facto de necessitarem de
menos memória, do que algoritmos recursivos ou algoritmos baseados na utilização de uma
lista ou pilha com os sucessores ou predecessores do nó em análise.
1. Boolean change =false; 2. Do 3. Change = false; 4. Foreach Node A ∈ DFG 5. Foreach Bi ∈ (A.getPred() ≠ STARTnode) 6. Bi.setWidth(CompWidthRev(A, Bi)); 7. Forall Cj ∈ (Bi.getSucc() ≠ ENDnode) 8. MaxOut = max(Cj.getWidth()); 9. 10. Bi.setWidth(MaxOut, MaxWidth(Bi)); 11. If(width of Bi was modified) change = true; 12. 13. 14. while(change);
Figura 5 .6 . Algor i tmo de propagação em sent ido inverso.

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 121
1. Boolean change = false; 2. Do 3. Change = false; 4. Foreach Node A ∈ DFG 5. Foreach Bi ∈ (A.getPred() ≠ STARTnode) 6. If(A ≠ ConstNode) 7. A.setWidth(CompWidthFor(A, Bi)); 8. 9. 10. If(width of A was modified) change = true; 11. 12. while(change);
Figura 5 .7 . Algor i tmo de propagação em sent ido directo.
Este método serve para determinar o número de bits suficiente para cada operando/operador
que, quando permite a redução, tem implicações directas na área e no desempenho da unidade
de dados.
5.5 Propagação de Padrões de Constantes ao Nível do Bit
Além da redução do número de bits suficiente para cada operador, para se obterem melhores
resultados no circuito final, deve ser considerada a propagação de constantes ao nível do bit,
pois esta permite em algumas operações reduzir a área e o atraso do circuito gerado, devido à
simplificação obtida quando se sabe à partida que um determinado bit tem valor lógico um ou
zero. Estas simplificações podem produzir melhores resultados quando em presença de
operações lógicas e são de uso limitado em operações aritméticas, como se pode ver pela
Tabela 5.2. Ao nível dos operadores lógicos é fácil aos geradores de circuitos instanciarem as
portas necessárias com base no conhecimento de bits constantes.
Outra simplificação pode ocorrer quando os padrões de entrada de uma dada operação têm
valores lógicos iguais numa determinada posição. Quando em presença de multiplexadores e
comparadores, esses bits constantes e com o mesmo valor podem ser excluídos da
computação realizada por estas operações (por exemplo: a comparação, 00uuu0 == u0uuuu,
pode ser realizada com um comparador de 5 bits em vez de 6, pois o bit 5 de ambos os
operandos tem o mesmo valor), reduzindo deste modo a área total necessária.

122 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
Tabela 5 .2 . A lgumas operações e respect ivas s impl i f icações quando em
presença de um operando constante .
Operação bit tem o valor lógico zero bit tem o valor lógico um AND Bit de saída igual a zero Bit de saída ligado ao bit de entrada OR Bit de saída ligado ao bit de entrada Bit de saída igual a um XOR Bit de saída ligado ao bit de entrada Bit de saída igual ao bit de entrada invertido EQ8 Bit de saída ligado ao bit de entrada
invertido Bit de saída igual ao bit de entrada
+9 Bit de saída ligado ao bit do carry-out do último FA
-
A representação utilizada dos padrões de constantes ao nível do bit é baseada em três estados
para cada bit 0, 1, u, representando respectivamente os valores lógico zero, um e
indefinido10 (representa um sinal cujo valor não é possível conhecer estaticamente). Esta
representação, de modo a facilitar a propagação, foi codificada em duas representações de
padrões: a representação do valor lógico zero (PZ) e do valor lógico um (PU). Cada padrão é
representado num inteiro em que a posição de cada bit representa o estado do respectivo bit
do operador considerado. O padrão que representa o valor lógico zero utiliza o zero para
representar o zero e o valor lógico um para representar outro valor qualquer. O padrão que
representa o valor lógico um utiliza o um para representar o um e o zero para representar
outro valor qualquer. Na Tabela 5.3 é ilustrada a representação utilizada para cada bit e o
respectivo valor lógico.
Esta representação permite, durante a propagação, que para cada operador lógico no DFG
seja simplesmente realizada uma operação lógica sobre os padrões de entrada. A Tabela 5.4
apresenta as regras utilizadas pelo algoritmo de propagação directa, idêntico ao apresentado
na Figura 5.7. Esta análise pode ser estendida para multiplicações e adições/subtracções
embora regras para lidarem com este tipo de operações sejam dependentes da estrutura das
unidades utilizadas. Por exemplo, a área do multiplicador pode ser reduzida quando os
operandos de entrada têm os primeiros bits iguais ao valor lógico zero (estes podem ser
8 Esta simplificação é exemplificada, mas apenas se deve ao facto do primeiro nível do operador EQ (retorna o valor um quando os dois operandos de entrada são ambos iguais) ser constituído por XORs. Esta simplificação é de utilização limitada, por ser dependente da estrutura da unidade funcional. 9 Esta simplificação apenas se deve ao facto de se assumir a utilização de um somador do tipo ripple-carry constituído por FAs (do inglês: Full-Adders - somadores completos). 10 Não confundir com o 'u' normalmente utilizado na lógica de 9 estados, na qual indefinido indica que ainda não foi inicializado.
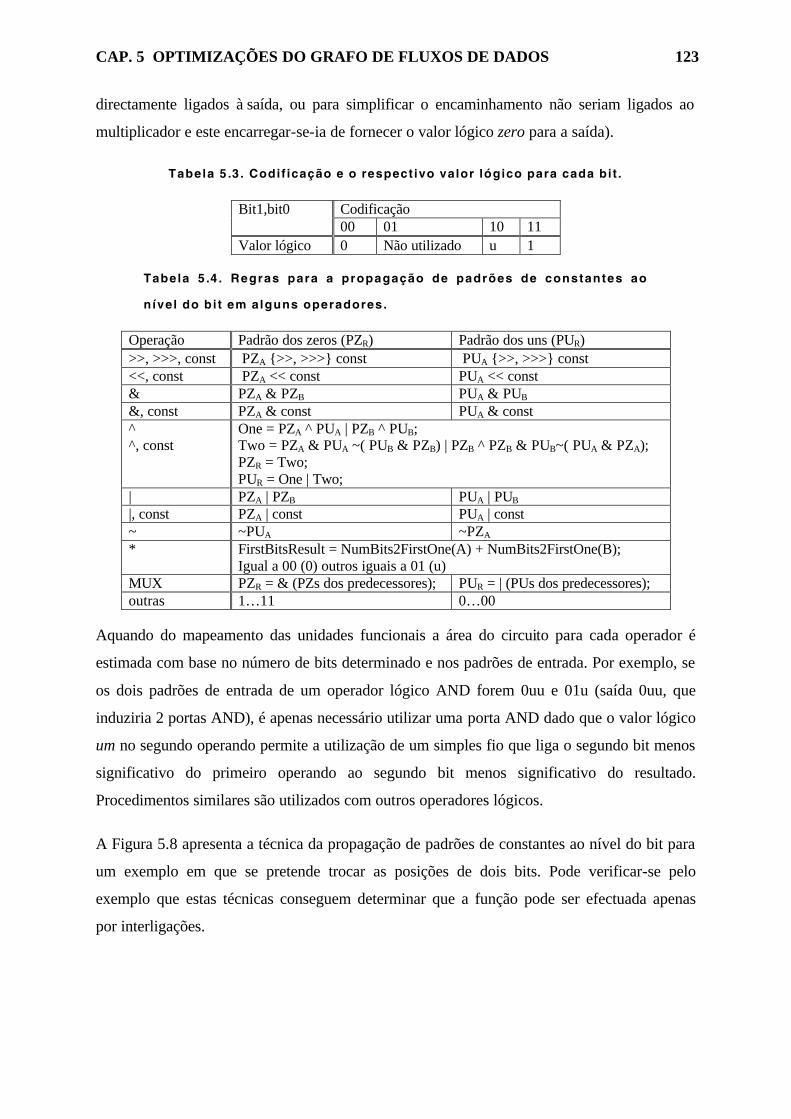
CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 123
directamente ligados à saída, ou para simplificar o encaminhamento não seriam ligados ao
multiplicador e este encarregar-se-ia de fornecer o valor lógico zero para a saída).
Tabela 5 .3 . Codif icação e o respect ivo valor lógico para cada bit .
Codificação Bit1,bit0 00 01 10 11
Valor lógico 0 Não utilizado u 1
Tabela 5 .4 . Regras para a propagação de padrões de constantes ao
nível do bi t em alguns operadores.
Operação Padrão dos zeros (PZR) Padrão dos uns (PUR) >>, >>>, const PZA >>, >>> const PUA >>, >>> const <<, const PZA << const PUA << const & PZA & PZB PUA & PUB &, const PZA & const PUA & const ^ ^, const
One = PZA ^ PUA | PZB ^ PUB; Two = PZA & PUA ~( PUB & PZB) | PZB ^ PZB & PUB~( PUA & PZA); PZR = Two; PUR = One | Two;
| PZA | PZB PUA | PUB |, const PZA | const PUA | const ~ ~PUA ~PZA * FirstBitsResult = NumBits2FirstOne(A) + NumBits2FirstOne(B);
Igual a 00 (0) outros iguais a 01 (u) MUX PZR = & (PZs dos predecessores); PUR = | (PUs dos predecessores); outras 1…11 0…00
Aquando do mapeamento das unidades funcionais a área do circuito para cada operador é
estimada com base no número de bits determinado e nos padrões de entrada. Por exemplo, se
os dois padrões de entrada de um operador lógico AND forem 0uu e 01u (saída 0uu, que
induziria 2 portas AND), é apenas necessário utilizar uma porta AND dado que o valor lógico
um no segundo operando permite a utilização de um simples fio que liga o segundo bit menos
significativo do primeiro operando ao segundo bit menos significativo do resultado.
Procedimentos similares são utilizados com outros operadores lógicos.
A Figura 5.8 apresenta a técnica da propagação de padrões de constantes ao nível do bit para
um exemplo em que se pretende trocar as posições de dois bits. Pode verificar-se pelo
exemplo que estas técnicas conseguem determinar que a função pode ser efectuada apenas
por interligações.

124 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
start
end
>> &
<<&
|
1
1
1
131
22
1
32 32
32
start
end
>> &
<<&
|
1
1
1
11
22
1
1 2
2
start
end
>> &
<<&
|
1
1
1
10u0
u1u0u1u0
0u1
0u1 u00
u0u1
a) b) c)
Figura 5 .8 . Exemplo que reverte os dois pr imeiros bi ts de uma palavra:
a) propagação para trás; b) propagação para a f rente; c) propagação de
padrões de constantes ao nível do bi t . Os rótulos nos laços em a) e b)
indicam o número de bi ts suf ic iente e os rótulos em c) indicam a
representação dos padrões (os índices nos u’s indicam o número do
bit).
Estas técnicas também permitem ao compilador NENYA identificar que instruções de alto
nível, tais como (detecção do valor de um bit):
if((ans & 0x8000) == 0x8000)
podem ser implementadas sem utilização de portas lógicas.
Em [Budiu00] é utilizada a propagação de don’t cares. Esta análise pode ter impacto na
propagação inversa de máscaras AND de bits internos (1010, por exemplo). Este tipo de
propagação, apenas suportado neste momento nos bits mais significativos (0111, por
exemplo), poderia ser integrado sem dificuldade nas análises propostas nesta tese.
5.6 Aferição do Número de Bits em Regiões Cíclicas
As regiões cíclicas de um programa desempenham um papel fundamental pois normalmente
representam as partes mais intensivas de computação, e por isso são as melhores candidatas a
optimizações. É nestas regiões que pequenas reduções no tamanho de bits de uma operação
podem implicar ganhos elevados ao nível do atraso total do ciclo, devido ao facto do
operador ser por norma executado várias vezes.

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 125
A cada nó do DFG pertencente a uma região cíclica é atribuído o número de vezes que será
executado em cada chamada da função que o contém. Nos casos em que não é possível
determinar estaticamente este número11 é atribuído +∞ ao nó.
Exemplo 5 -3 . Ident i f icação do número de bi ts na presença de cic los.
Do exemplo a seguir pode ver-se que a variável Sum entra no ciclo com
valor zero atribuído (1 bit necessário):
Short[] A;
Int Sum = 0;
For(int I=0; I< 10; I++)
Sum += A[I];
O ciclo executará 10 iterações. Assim, a variável Sum necessitará de 16 +
log2(11) = 20 bits (< 32 bits da representação do int). A variável de
controlo de iterações do ciclo, I, toma valores entre [0, 10], e requer 1 +
log2(11) = 5 bits.
Para uma determinada soma com uso-definição de operandos do tipo A = A+B, em que não
existem definições da variável B dentro da região cíclica e, supondo que a instrução é
executada N vezes, pode ser obtido um limite superior do número máximo de bits suficiente
para armazenar o valor da variável A por:
++≤ )1(log))(),(max()( 2 NBBitsABitsABits inicial (5 .1 )
em que Bits(Ainicial) indica o número de bits da variável A imediatamente antes da execução
do ciclo. Quando existem definições da variável B dentro da região cíclica obtemos:
NBBitsABitsABits inicialinicial +≤ ))(),(max()( (5 .2 )
11 Por dois motivos: porque a análise implementada não é suficientemente poderosa para extrair a informação, ou por que de facto o número de vezes que o nó é repetido depende dos valores dos dados com que o programa é estimulado.

126 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
A Figura 5.9 apresenta o número de bits suficiente para armazenar o valor da variável A,
considerando a expressão A = A + 3 (com o valor 0 atribuído inicialmente a A), em cada
iteração para um total de 20, obtido pela simulação da execução repetitiva da expressão e pela
aplicação directa da equação (5.1).
01234567
1 3 5 7 9 11 13 15 17 19
Iteração (N)
Nú
mer
o d
e b
its
Óptimo Limite Superior
Figura 5 .9 . Número de bi ts da var iável A suf ic iente para cada i teração
(exemplo A = A + 3 , com 0 como valor in ic ia l de A) .
No caso de se estar perante uma operação de multiplicação em que há iterativamente uso-
definição de um dos operandos, como seja a instrução A = A ×× B, supondo como
anteriormente que esta instrução é executada N vezes, e que não existe qualquer definição de
B dentro da região cíclica:
)()()( BBitsNABitsABits inicial ×+≤ (5 .3 )
Quando existem definições da variável B dentro da região cíclica obtemos:
[ ])()(2)( 1inicialinicial
N BBitsABitsABits +×≤ − (5 .4 )
Quando na presença de expressões do tipo A = A << k, em que k é um valor constante,
teremos:
kNABitsABits inicial +≤ )()( (5 .5 )

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 127
Quando na presença de expressões do tipo A = A >> k, em que k é um valor constante,
teremos:
kABitsABits inicial −≤ )()( (5 .6 )
A inequação (5.6) é utilizada para salvaguardar o valor das expressões intermédias. Contudo,
no final da execução do ciclo com N iterações, a variável A poderia ser representada pelo
número de bits inicial menos N vezes k se a expressão for de facto executada N vezes.
Devido ao facto da análise ser insensível ao fluxo de programa, para salvaguardar a correcta
funcionalidade é utilizada simplesmente a equação (5.6).
As equações anteriores têm como valor máximo o número de bits do tipo de dados em que
cada variável foi declarada. Dos exemplos apresentados torna-se intuitiva a forma como é
calculado o número de bits para os restantes operadores.
O algoritmo implementado executa sobre o DFG global12 e integra os algoritmos
apresentados na Figura 5.6 e Figura 5.7 com ligeiras modificações. As etapas do algoritmo
são as seguintes:
1. Propagação em sentido inverso sem distinção de operações em regiões cíclicas;
2. Propagação em sentido directo sem distinção de operações em regiões cíclicas;
3. Propagação em sentido directo a partir dos nós de variáveis aos quais foi atribuído um
registo que representam no DFG a primeira atribuição. A propagação inclui
informação relativa ao ciclo e as equações apresentadas anteriormente;
4. Propagação em sentido directo das modificações em cada ciclo para o exterior e para
os ciclos dependentes. Para cada ciclo dependente é exigido o regresso ao ponto 3.
A sequência de etapas 1 e 2 é realizada sucessivamente até que haja convergência. Como se
pode ver nas etapas 3 e 4 não é realizada propagação em sentido inverso para fora nem para
dentro de ciclos. Realçamos mais uma vez que, para todos os algoritmos, os valores
12 O DFG global utilizado é sempre acíclico (regiões cíclicas são representadas pela hierarquia no HPDG), como foi explicado no capítulo 3.

128 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
determinados para cada variável (nó identificador de uma variável no DFG) só são
considerados se forem menores que o número de bits inferido pela análise de aferição de
subtipos.
Todas as análises apresentadas são conservadoras, no sentido em que para preservarem a
funcionalidade optam, por defeito ou sempre que haja lacunas de informação, pelos limites
máximos (declarados pelo programador). A própria análise não é sensível ao comportamento
do corpo do ciclo, obtendo-se por isso sobredimensionamentos quando em presença de
instruções de um ciclo que não são executadas em todas as iterações como é o caso da
instrução 5 do seguinte pedaço de código:
1. Int a = 0; 2. For(int I = 0; I < 10; i++) 3. a++; 4. If(I == 2) 5. a = a << 2; 6.
A análise proposta anteriormente obtém, para a variável A, 25 bits - próximo do valor exacto
21, considerando que a instrução 5 é executada em todas as iterações do ciclo. Contudo, o
número de bits necessário para armazenar o valor da variável A é 12 (devido ao facto da
instrução 5 ser executada apenas na terceira iteração do ciclo).
A análise descrita produz também resultados válidos para exemplos do tipo seguinte:
1. Int a = 0; 2. For(int I = 0; I < 10; i++) 5. If(I == 2) 6. a = a << 2; 7. else 8. a++; 9.
Neste caso o número de bits final para armazenar a variável é obtido pelo deslocamento de
dois bits.
O desenrolamento de um ciclo pode provocar o uso de um número de bits maior do que seria
suficiente devido ao cariz pessimista da determinação do número de bits em algumas
operações. Se considerarmos, por exemplo, uma expressão A = A+1 dentro de um ciclo que
itera 10 vezes e supondo que A chega ao ciclo com comprimento de 16 bits obtém-se, pela
aplicação da equação (5.1), 20 bits para armazenar o valor da variável. Se, por outro lado, o
ciclo for desenrolado e mantida a cadeia de somas com a aplicação da regra para os

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 129
somadores apresentada anteriormente obtêm-se 26 bits para armazenar a variável. O número
exacto de bits necessário para a variável A é 17. Como se pode ver, utilizando as análises
propostas, o desenrolamento do ciclo, sem optimizações, traduziu-se num número de bits
para A mais pessimista do que o determinado sem desenrolamento.
Análises baseadas nos intervalos de valores que cada variável pode ter, nas quais se considera
a abordagem recente em [Stephen00], forneceriam os 17 bits. Como trabalho futuro, as
análises propostas nesta tese deverão ser combinadas com análises baseadas nos intervalos de
valores para que o hardware específico obtido seja ainda mais eficiente.
5.7 Resultados
Foram utilizados vários exemplos para avaliar o impacto das técnicas descritas neste capítulo.
A descrição de cada um dos exemplos encontra-se no apêndice D. Para cada exemplo, são
apresentados os resultados obtidos pela utilização de síntese lógica (SL) a partir da descrição
em VHDL com o uso da ferramenta “Design Compiler” [Synopsys95] da Synopsys, em
modo “medium effort” e com directiva para obtenção de área mínima. Na maioria dos casos
foi feito o desagrupamento da estrutura após a primeira optimização e realizada uma nova
optimização sobre a estrutura planar. Os resultados são baseados em estimativas obtidas pelo
NENYA ou pela ferramenta de síntese lógica e reportam-se unicamente à estrutura dos
circuitos em portas lógicas (sem custos de encaminhamentos). O uso de síntese lógica,
possível neste subconjunto de exemplos, serve para ilustrar a distância das análises propostas
a resultados próximos do óptimo.
O primeiro subconjunto de exemplos representa algoritmos simples com manuseamento de
bits intenso mas sem estruturas de controlo do tipo if-then-else. O exemplo A (REVERSE) é
utilizado para ilustrar as capacidades da propagação de constantes ao nível do bit. Ao
desenrolar-se o ciclo obtém-se um DFG com um número significativo de operações, algumas
das quais podem ser directamente implementadas por interligações (deslocamentos por
valores constantes). Com a propagação referida, o circuito final obtido tem área zero e atraso
originado unicamente pelas interligações. Este resultado é obtido sem que haja optimizações
“booleanas” complexas com a criação da representação do circuito ao nível lógico. Na Tabela
5.5 são apresentados os resultados obtidos utilizando o compilador NENYA aquando da
aplicação das optimizações descritas ao exemplo A. Os resultados apresentados na 4ª coluna
da tabela mostram a capacidade dos optimizadores integrados no compilador (aferição do

130 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
número de bits e da propagação dos padrões de constantes ao nível do bit) na geração de um
circuito unicamente constituído por interligações. Este resultado foi também alcançado pela
ferramenta de síntese lógica supracitada. A ferramenta de síntese arquitectural CADDY
[CaddyII] originou uma complicada estrutura de multiplexadores e unidades lógicas.
Todos os tempos de compilação apresentados na Tabela 5.5 referem-se aos tempos de
execução das ferramentas desde o código fonte até à geração dos ficheiros que descrevem em
VHDL a estrutura do circuito.
Os resultados ao nível de área ocupada e atraso global são ainda mais desfasados quando
também se consideram os atrasos das interligações, após se ter feito a colocação e o
encaminhamento no FPGA utilizado [Xilinx97].
Tabela 5 .5 . Resultados que i lustram o uso das opt imizações descr i tas
com o exemplo A .
NENYA Optimização s/ Optimizações ANB13 ANB+PBC14
SL CADDY
Área (células) 2.016 527 0 0 - Atraso (ns) 165 160 0 0 - Tempo de compilação 4,9s 5,2s 5,4s 39s >10m
Como se pode ver pelo exemplo apresentado, as técnicas anteriormente descritas revelam-se
fundamentais para a compilação de descrições software que utilizam intensivamente
manipulações de bits, como são os casos das aplicações de codificação/descodificação e
criptografia.
A Tabela 5.6 mostra os resultados obtidos com o uso das optimizações para os restantes
exemplos. A utilização de THR permitiu reduzir o número de somadores em cadeia nos
exemplos B (COUNT) e C (HAMMDIST), diminuindo por isso o atraso do circuito. No
entanto, o uso desta técnica não potenciou optimizações na aferição do número de bits e
consequente redução da área necessária, devido ao facto dos operandos não terem
declarações no programa com menor número de bits do que o resultado. Os resultados
apresentados na Tabela 5.6 para os exemplos B e C ilustram melhorias significativas do
NENYA em comparação com a síntese lógica. Parte destas melhorias são devidas ao uso de
13 ANB - Aferição do número de bits suficiente. 14 PBC - propagação de padrões de constantes ao nível do bit.
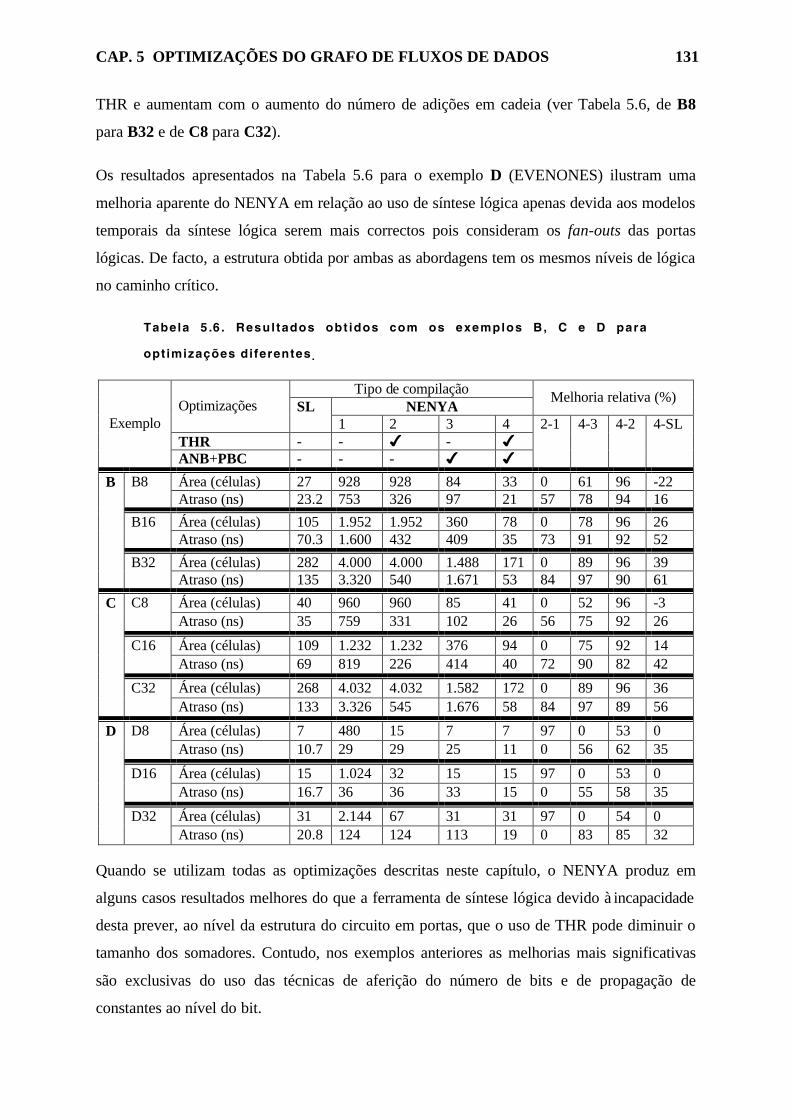
CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 131
THR e aumentam com o aumento do número de adições em cadeia (ver Tabela 5.6, de B8
para B32 e de C8 para C32).
Os resultados apresentados na Tabela 5.6 para o exemplo D (EVENONES) ilustram uma
melhoria aparente do NENYA em relação ao uso de síntese lógica apenas devida aos modelos
temporais da síntese lógica serem mais correctos pois consideram os fan-outs das portas
lógicas. De facto, a estrutura obtida por ambas as abordagens tem os mesmos níveis de lógica
no caminho crítico.
Tabela 5 .6 . Resul tados obt idos com os exemplos B, C e D para
opt imizações di ferentes .
Tipo de compilação SL NENYA
Melhoria relativa (%) Optimizações
1 2 3 4 THR - - 4 - 4
Exemplo
ANB+PBC - - - 4 4
2-1 4-3 4-2 4-SL
B B8 Área (células) 27 928 928 84 33 0 61 96 -22 Atraso (ns) 23.2 753 326 97 21 57 78 94 16
B16 Área (células) 105 1.952 1.952 360 78 0 78 96 26 Atraso (ns) 70.3 1.600 432 409 35 73 91 92 52
B32 Área (células) 282 4.000 4.000 1.488 171 0 89 96 39 Atraso (ns) 135 3.320 540 1.671 53 84 97 90 61
C C8 Área (células) 40 960 960 85 41 0 52 96 -3 Atraso (ns) 35 759 331 102 26 56 75 92 26
C16 Área (células) 109 1.232 1.232 376 94 0 75 92 14 Atraso (ns) 69 819 226 414 40 72 90 82 42
C32 Área (células) 268 4.032 4.032 1.582 172 0 89 96 36 Atraso (ns) 133 3.326 545 1.676 58 84 97 89 56
D D8 Área (células) 7 480 15 7 7 97 0 53 0 Atraso (ns) 10.7 29 29 25 11 0 56 62 35
D16 Área (células) 15 1.024 32 15 15 97 0 53 0 Atraso (ns) 16.7 36 36 33 15 0 55 58 35
D32 Área (células) 31 2.144 67 31 31 97 0 54 0 Atraso (ns) 20.8 124 124 113 19 0 83 85 32
Quando se utilizam todas as optimizações descritas neste capítulo, o NENYA produz em
alguns casos resultados melhores do que a ferramenta de síntese lógica devido à incapacidade
desta prever, ao nível da estrutura do circuito em portas, que o uso de THR pode diminuir o
tamanho dos somadores. Contudo, nos exemplos anteriores as melhorias mais significativas
são exclusivas do uso das técnicas de aferição do número de bits e de propagação de
constantes ao nível do bit.

132 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
As optimizações foram também testadas em alguns exemplos com uma componente de
controlo importante. Na Tabela 5.7 são apresentados os resultados obtidos utilizando as
técnicas abordadas e a comparação com os resultados obtidos com a ferramenta de síntese
lógica. Para estes exemplos o NENYA ficou mais distante de resultados quasi-óptimos. Este
facto deve-se sobretudo à capacidade das optimizações sobre estruturas ao nível da porta
lógica poderem realizar transformações “booleanas” que optimizam as construções de
controlo. Na presença de estruturas de controlo do tipo if-then-else o NENYA insere pontos
de selecção sob a forma de multiplexadores que acabam por necessitar de bastante área. Os
resultados menos eficientes do NENYA devem-se também ao facto deste não permitir
optimizações em profundidade. Para estes exemplos não existe potencial para a aplicação de
THR.
Tabela 5 .7 . Resultados que i lustram o uso das opt imizações descr i tas
com os exemplos E, F , G, H e I .
Tipo de compilação NENYA
Melhoria relativa (%) Optimizações SL
1 2 3 ANB - - 4 4
Exemplo
PBC - - 4
2-1 3-1 3-2 3-SL
E: USQRT Área (células) 1.358 6.944 3.922 3.712 44 47 5 -173 Atraso (ns) 977 3.313 2.493 2.493 25 25 0 -155
F: CRC-32 Área (células) 41 1.760 761 415 57 76 45 -912 Atraso (ns) 13,13 574 77 56 87 90 27 -327
G: HAMMING Área (células) 41 860 106 63 88 93 41 -54 Atraso (ns) 19,6 109 51 30 53 72 41 -53
H: SQRT Área (células) 154 1.760 409 253 77 86 38 -64 Atraso (ns) 186,6 1.239 361 307 71 75 15 -65
I: MULT Área (células) 3.259 23.471 20.495 20.401 13 13 0 -526 Atraso (ns) 540 3.843 3.781 3.776 2 2 0 -599
I1: MULT Área (células) 3.259 - - 4.002 - - - -23 (Uso de SSA) Atraso (ns) 540 - - 3.432 - - - -536
A Figura 5.10 e a Figura 5.11 ilustram respectivamente as melhorias de área e de atraso
obtidas pelo NENYA com todas as optimizações (NENYAOpt) e pela síntese lógica (SL)
relativamente aos resultados obtidos pelo NENYA sem aferição do número de bits suficiente
e propagação de constantes ao nível do bit. Nos exemplos com manipulação de bits
dominante as optimizações obtiveram melhorias na ordem dos 90%. Para o exemplo I as
técnicas enunciadas neste capítulo permitiram melhorias de apenas 13,1% e 1,7%
relativamente à área e ao atraso. Contudo, para este exemplo o potencial de melhoramento é

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 133
da ordem de 90% como se pode constatar pelos resultados obtidos pela utilização de síntese
lógica.
Nos exemplos F e I a maior parte da área do circuito obtido pelo NENYA é devida aos
multiplexadores utilizados nos pontos de selecção. A Figura 5.12 mostra a percentagem de
área ocupada pelos multiplexadores no exemplo I. Este facto mostra a deficiência da
determinação dos pontos de selecção a partir das cadeias de definição-uso quando existem
muitas definições a alcançarem um determinado uso oriundas de sequências de enunciados de
controlo. Ao último uso de uma variável chegam todas as definições possíveis dessa variável,
o que para o exemplo I se traduz na colocação de pontos de selecção com vários operandos
de entrada que requerem grandes unidades de selecção. A colocação de multiplexadores nos
pontos de selecção φ da representação SSA15 [Cytron91] permitiu reduzir o número de
multiplexadores e obter um circuito com área muito mais próxima da área do circuito obtido
por síntese lógica (ver I1 na Tabela 5.7).
0%
20%
40%
60%
80%
100%
A B8 B16 B32 C8 C16 C32 D8 D16 D32 E F G H I
Exemplo
NENYAOPt SL
Figura 5 .10 . Melhor ias , em termos de área, do NENYA com opt imizações
(NENYAOpt) e da s íntese lógica (SL) em re lação ao NENYA sem
opt imizações.
15 Do inglês: Single Static Assignment.

134 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
0%
20%
40%
60%
80%
100%
A B8 B16 B32 C8 C16 C32 D8 D16 D32 E F G H I
Exemplo
NENYAOpt SL
Figura 5 .11 . Melhor ias , em termos de at raso, do NENYA com
opt imizações (NENYAOpt) e da s íntese lógica (SL) em relação ao
NENYA sem opt imizações .
68%70%72%74%76%78%80%82%84%86%88%
s/Optimizações ANB ANB+PBC
Opções do NENYA
Per
cen
tag
em d
e Á
rea
de
MU
XE
S
Figura 5 .12 . Percentagem para o exemplo I da área do c i rcui to dedicada
aos mul t ip lexadores para compi lações com e sem as opt imizações.
Análises de fluxos de dados utilizando a representação SSA serão incorporadas
proximamente para se poder avaliar quantitativamente a determinação de pontos de selecção
por cada uma das análises.
Na Tabela 5.8 estão representados os tempos de compilação da descrição de alto-nível até à
obtenção da descrição em VHDL da estrutura de cada circuito. Como se pode constatar, os
tempos de computação do NENYA em relação aos do Design Compiler são bastante
inferiores. Os rácios dos tempos de computação entre as duas abordagens vão de 1,9 a 3.024.
Os tempos de computação obtidos pela execução do NENYA são dominados pelo

CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS 135
processamento do JIT16 e daí aparecerem na tabela muitos casos com tempos na ordem dos
9s.
Tabela 5 .8 . Tempos de computação da s íntese lógica e do GALADRIEL +
N E N Y A .
Tempo de Computação Exemplo LS GALADRIEL
+ NENYA
Aceleração
A: REVERSE 39s < 9s 4,3 B8: COUNT8 68s < 9s 7,6 B16: COUNT16 4m < 9s 26,7 B32: COUNT32 13m < 10s 78 C8: HAMMDIST8 3,2m < 9s 21,3 C16: HAMMDIST16 36m < 9s 240 C32: HAMMDIST32 2,37h < 9s 1.348 D8: EVENONES8 17s < 9s 1,9 D16: EVENONES16 31s < 9s 3,4 D32: EVENONES32 57s < 9s 6,3 E: SQRT 1,7m < 9s 11,3 F: USQRT 8,4h <10s 3.024 G: CRC-32 28,3s < 9s 3,1 H: HAMMING 39,7s < 9s 4,4 I: MULTUNROLLED 31,2m < 13s 144,1
5.8 Conclusões
Neste capítulo foram apresentadas as optimizações do grafo de fluxo de dados integradas no
compilador NENYA. Estas optimizações incluem: reassociação de operações, redução do
custo de multiplicações/divisões por constantes, inferências dos subtipos de dados primitivos,
aferição do número de bits e propagação de constantes ao nível do bit. Estas optimizações,
feitas nas primeiras fases da compilação para reconfigware, são potencializadas pela
utilização de macrocélulas parametrizáveis para cada operador existente na descrição alto-
nível
Os resultados da aplicação das optimizações revelaram grande potencial e melhorias
significativas sobre a compilação para hardware específico sem a utilização das mesmas. Os
resultados obtidos pelo NENYA, em exemplos possíveis de aplicabilidade de síntese lógica e
em que não existem (ou não são dominantes) fluxos de controlo na descrição, revelaram-se
16 Do inglês: Just In Time.

136 CAP. 5 OPTIMIZAÇÕES DO GRAFO DE FLUXOS DE DADOS
próximos e em alguns casos melhores (quando existe potencial para realizar THR) do que os
obtidos com uma ferramenta comercial de síntese lógica17 à correspondente descrição em
VHDL. Embora o intuito desta comparação nunca ter tido o objectivo de mostrar
melhoramentos, mas sim atestar das distâncias entre os resultados obtidos pelos métodos
apresentados e os resultados próximos do óptimo fornecidos pela síntese lógica, os resultados
revelaram que a utilização das optimizações sugeridas sobre um DFG podem em alguns casos
se sobrepor aos utilizados por algumas ferramentas comerciais de síntese lógica.
As optimizações de reassociação de operações (THR) e de redução do custo de operações
foram consideradas simplistamente para possibilitar a integração no NENYA e com o
objectivo principal de obtenção do efeito destas em alguns exemplos. Contudo, trabalhos
futuros devem debruçar-se na procura de formas mais poderosas de resolução dos dois
problemas sem hipotecarem a razoabilidade dos tempos de compilação. Ao nível das
optimizações algébricas, alguns autores têm investigado formas de optimização, sendo uma
delas baseada em algoritmos genéticos [Landwehr97] e por isso demasiado complexa. É por
isso necessário investigar heurísticas que permitam tempos de computação reduzidos.
As análises propostas e implementadas de aferição do número de bits suficiente para
representação dos operandos são puramente estáticas e utilizam equações que permitem
determinar os bits suficientes em operações internas a ciclos. As análises iteram de modo a
haver convergência e não utilizam o processo de iteração até ao ponto fixo na presença de
ciclos. As análises propostas podem ser combinadas com algumas das propostas
recentemente em [Stephen00] para se obterem melhores resultados. A aferição dos padrões
de constantes ao nível do bit permite em muitos exemplos com manuseamento de bits
optimizações favoráveis e, pelo que nos foi possível averiguar, nunca tinha sido proposta.
Todas as técnicas apresentadas podem ser incluídas em qualquer compilador para hardware
específico e não somente para hardware reconfigurável.
17 O tipo de compilação sugerido tem vantagens intrínsecas em relação à utilização de síntese lógica, como sejam a capacidade de compilar descrições com comportamentos cíclicos sem resolução estática, compilar para arquitecturas com dispositivos RAM acoplados ao FPGA, permitir a compilação de exemplos de grandes dimensões sem os enormes esforços computacionais (tempo de execução e memória de sistema) da síntese lógica, entre outras.

137
6. Partição Temporal
“The biggest difference between time and space is that you can’t reuse
time.”
Merrick Furst
Neste capítulo é descrita a abordagem utilizada na partição temporal de descrições de alto-
nível para que a implementação final possa ser executada por multiplexagem do FPGA. É
apresentado um novo algoritmo baseado em heurísticas, que assenta na reformulação do
algoritmo estático de escalonamento baseado em lista [Gajski92], especialmente adaptado
para lidar com a partição temporal. O algoritmo selecciona os nós da representação
intermédia de grafos para serem mapeados numa fracção temporal com base em modelos de
custo calculados estaticamente. De forma a aliviar o tempo de computação não é considerada
a reavaliação dos custos durante a execução do algoritmo. O custo para cada modelo integra
os efeitos de comunicação, o caminho crítico e a possibilidade do caminho crítico esconder
os atrasos dos nós paralelos.
Os resultados experimentais atestam as virtudes do algoritmo face a diversas abordagens e
mostram que o algoritmo é capaz de encontrar bons resultados, quando comparado com
outros métodos, em tempos de computação razoáveis. Os resultados também mostram que o
algoritmo é robusto, efectivo e eficiente.
Para se ter noção da distância dos resultados obtidos por métodos construtivos a resultados
próximos de valores óptimos foi implementada uma versão da partição temporal com base no
algoritmo simulated annealing. Pelo que julgamos saber esta implementação foi uma das
primeiras a usar o simulated annealing para partição temporal.

138 CAP. 6 PARTIÇÃO TEMPORAL
No capítulo começam por ser explicadas as razões para a partição temporal e descritas
algumas das abordagens mais interessantes. É apresentada a formulação do problema que se
pretende solucionar, e são apresentadas algumas das formas de execução de fracções
temporais pela partilha de uma unidade de processamento reconfigurável. São descritos os
esquemas de partição temporal baseados nos escalonadores ASAP e ALAP. De seguida, são
dissecados o algoritmo desenvolvido e uma versão do simulated annealing para lidar com a
partição temporal. Finalmente são apresentados resultados e conclusões.
6.1 Incentivo para a Partição Temporal
A disponibilidade de arquitecturas de unidades de processamento reconfiguráveis, como é o
caso dos novos FPGAs, com menores tempos de reconfiguração, tornou possível a
concretização do conceito de “hardware virtual” [Long93]: os recursos de hardware são
considerados ilimitados e a partição temporal é usada para resolver a implementação de
circuitos cujo tamanho excede a área disponível. As fracções obtidas são executadas pela
partilha temporal do dispositivo de um modo que cada fracção cabe na área disponível e a
funcionalidade global é preservada. Contudo, a investigação e o desenvolvimento de
algoritmos de partição temporal, capazes de explorar este conceito encontram-se ainda numa
fase embrionária. O problema da partição temporal requer compromissos entre paralelismo,
custos de comunicação, atraso e tempo de reconfiguração. Os nós do grafo que representa o
circuito ou um programa têm de ser escalonados em fracções temporais que são executadas
no dispositivo uma de cada vez. A partição temporal tem de preservar as dependências entre
nós (que são inerentemente dependências temporais) de forma a que um nó A dependente de
um nó B não possa ser mapeado numa fracção executada antes da fracção que contém o nó B.
Como foi descrito em [GajjalaPu98b], o problema tem similaridades com o problema de
escalonamento da síntese de alto-nível [Micheli94]. As similitudes dos dois problemas
permitem o uso dos esquemas de escalonamento para partição temporal. Um factor
importante, contudo, que deve ser considerado é o custo de intercomunicação (comunicação
entre fracções originada pelo corte de ligações no grafo original que requer o transporte de
dados) que pode ser muito dispendioso e é dependente do fraccionamento considerado.
O conceito de partilha temporal de um dispositivo lógico programável pode vir a ser uma
solução eficiente ao permitir a substituição de placas inteiras de circuitos integrados ou a
poupança de área de silício. Uma das aplicações do conceito é a mutação entre

CAP. 6 PARTIÇÃO TEMPORAL 139
funcionalidades que têm exclusividade mútua no domínio do tempo, tal como a comutação
entre esquemas de codificação/descodificação nos sistemas de comunicação, vídeo ou áudio.
Este tipo de aplicação tem o nome de mutação de contexto em que cada contexto pode
representar uma funcionalidade atómica e independente. Para cada funcionalidade podem,
contudo, existir várias configurações obtidas por partição temporal.
Foi já demonstrado que FPGAs de granulosidade fina, como é o caso da família de FPGAs
Xilinx [Xilinx97], podem ser aceleradores eficientes de desempenho quando comparado com
implementações puramente software. Em particular, o FPGA XC6200 tem características
específicas, como são os casos de tempos de reconfiguração menores do que os FPGAs
tradicionais, que o tornaram predilecto para reconfiguração dinâmica e parcial [Hudson98].
Contudo, este FPGA não incorpora mecanismos para implementação eficiente do
fraccionamento temporal e o tempo de reconfiguração de todo o dispositivo é na ordem das
centenas de microsegundos (XC6216). Esforços de investigação pela indústria têm sido
considerados para melhorar as capacidades dos FPGAs em lidarem com o conceito de
“hardware virtual”. Alguns apresentam unidades de processamento reconfiguráveis que
armazenam várias configurações no dispositivo permitindo a mutação de contextos em
poucos nanosegundos [Scalera98][Trimberger97][Fujii99]. O armazenamento das várias
configurações pode ser realizado durante o arranque do sistema, ou em paralelo com a
execução da configuração activa1. Um dos novos dispositivos é o DRLE2 [Fujii99] da NEC,
que apenas necessita de 5 nanosegundos para comutar de configurações e suporta até 8
configurações no dispositivo. Os autores afirmam ter planos para realizarem dispositivos
deste tipo com capacidade de armazenamento de 100 configurações. A tendência para se
terem configurações passivas no dispositivo em detrimento de mais células de lógica é
explicada pelo facto de que a área da SRAM para armazenar os bits de configuração para
cada célula é mais pequena do que a própria célula.
Mecanismos de comunicação eficientes entre fracções temporais têm sido activamente
pesquisados. A maioria dos esforços considera registos especiais do FPGA que mantêm o
estado entre contextos sempre que necessário (um exemplo são os micro-registos
[Trimberger97]).
1 A configuração que define o circuito actualmente em execução ou disponível para execução. 2 Do inglês: Dynamically Reconfigurable Logic Engine.

140 CAP. 6 PARTIÇÃO TEMPORAL
A partição temporal considerada no âmbito desta tese refere-se à partição no domínio do
tempo, de um algoritmo fonte, durante as fases da geração de uma arquitectura específica que
implemente o referido algoritmo. Os algoritmos têm, contudo, versatilidade suficiente para
também serem aplicados à prototipagem rápida. O trabalho desenvolvido permitiu a
realização de algoritmos que automatizam o processo de partição temporal, mantendo tempos
de computação competitivos. Foi dado particular ênfase à consideração dos custos de
comunicação entre fracções temporais.
6.2 Panorâmica Relativamente à Partição Temporal
A investigação de algoritmos para automatizar o processo de partição temporal de um grafo,
representativo de uma descrição comportamental, cuja implementação será executada pela
partilha temporal de uma unidade de processamento reconfigurável foi, quanto sabemos,
primeiramente formulada em [Vasilko96][Long93].
Em [Chang97] os autores usam um escalonador em lista para minimizarem o número de fios
entre fracções temporais (e consequentemente o número de buffers necessários). O algoritmo
computa ao nível da estrutura (4-LUTs3) de circuitos combinatórios, usa o caminho crítico
como função de prioridade, e o fanout de cada nó para desempate. A abordagem é apropriada
para unidades de processamento reconfiguráveis com registos que mantêm o estado entre
fracções temporais. Estes tipos de arquitecturas têm custos de comunicação pequenos, e a
optimização global pode ser resolvida usando apenas o caminho crítico como primeira chave
de prioridades. Os autores desenvolveram uma extensão do algoritmo de escalonamento
directo baseado em forças que também considera circuitos sequenciais [Chang98].
Em [Trimberger98] é usada uma variante do escalonador estático baseado em lista seguida de
um optimizador para partição temporal de circuitos. O algoritmo usa três regras para
seleccionar de entre os nós prontos para mapeamento e é vocacionado para o FPGA “Time-
Multiplexed” [Trimberger97].
Em [Liu98][Liu99] é apresentado um método baseado no fluxo na rede para multi-partição.
Em [Liu98] o algoritmo tem como alvo o FPGA “Time-Multiplexed” e os resultados superam
3 LUTs de 4 entradas.

CAP. 6 PARTIÇÃO TEMPORAL 141
o algoritmo baseado em lista usado em [Trimberger98], em termos de custos de comunicação
(número de fios entre fracções temporais). O algoritmo usa o cômputo do máximo-fluxo
mínimo-corte iterativamente para encontrar k fracções. Os resultados em [Liu99] mostram
melhorias sobre a extensão do algoritmo FDS4 [Chang98] no que respeita aos custos de
comunicação. Resultados comparativos do atraso global não são apresentados nem
examinados e, por isso, é por enquanto desconhecida a eficiência desta abordagem em
optimizar globalmente.
As abordagens apresentadas anteriormente são todas baseadas na estrutura do circuito final
mapeado no FPGA alvo. São, por isso, apropriadas para a prototipagem com o intuito de
depuração/emulação, mas não podem explorar o fraccionamento ao nível comportamental.
Este facto é fundamental quando se considera a integração da partição temporal na
compilação de descrições alto-nível. Mais ainda, estas abordagens sofrem do número pesado
de laços e nós (fios e de portas lógicas) que têm de ser manipulados. Em níveis de
representação mais elevados, os nós representam operações que encapsulam estruturas
complicadas e apenas os grupos de fios que transportam operandos são visíveis a esse nível.
Contudo, o uso de um nível de representação mais elevado usa a atomicidade do nó e, por
isso, não permite granulosidades mais finas.
Alguns autores, tais como [Vasilko96][Ouaiss98a], consideraram a partição temporal a níveis
altos de abstracção tendo em mente a integração da síntese. Em [Vasilko96] é apresentada
uma heurística baseada no escalonador estático baseado em lista, estendido para considerar
restrições dinâmicas de área. A abordagem não considera os custos de comunicação.
Em [Ouaiss98a][Kaul98] a partição temporal é formalizada por um modelo de programação
não linear 0-1. Contudo, mesmo para grafos pequenos, a formulação não é sempre resolvida
em tempos de execução razoáveis. Estes problemas são NP completos e métodos baseados
em heurísticas têm de ser desenvolvidos para permitir a partição temporal automática de
exemplos complexos.
Em [GajjalaPu98b] [GajjalaPu99] é apresentado um algoritmo baseado nos níveis atribuídos
pelo escalonamento ASAP sem restrições de recursos. É também apresentado um algoritmo
4 Do inglês: Force Direct Scheduling. Ver, por exemplo, [Micheli94].

142 CAP. 6 PARTIÇÃO TEMPORAL
com capacidade de agrupamento de nós. Estes algoritmos são de baixa complexidade e
tornam factível a partição temporal automática.
Para que a partição temporal seja realizada de modo a minimizar uma determinada função de
custo, que pode incluir o caminho crítico global e os custos de comunicação de dados entre
fracções temporais, foi por nós estudado e reformulado o algoritmo de escalonamento
estático baseado em lista que é apresentado neste capítulo.
6.3 Formulação do Problema
Considere-se um programa fonte descrito por um grafo, G = (V, E), ordenado, direccionado e
acíclico com |V| nós, ν1, ν2,…, ν|V| e |E| laços, e em que cada nó νi representa um
comportamento. Cada laço ei,j ∈ E representa uma dependência temporal5 entre os nós νi e νj.
Uma dependência pode ser apenas de precedência ou de transporte (de dados entre dois nós).
O nível hierárquico de topo do HPDG, descrito no capítulo 3, é um grafo deste tipo. O HPDG
é uma representação hierárquica em que os níveis da hierarquia traduzem a presença de ciclos
no programa fonte. O nível mais baixo da representação é ilustrado sob a forma de um DFG,
no qual os nós representam operações. Para simplificar o problema só se consideram nós do
HPDG com atrasos conhecidos estaticamente. Cada nó do HPDG sem hierarquia representa
uma região do DFG.
Assume-se que os valores do atraso e da área (CLBs, células, etc.) para cada nó foram
determinados previamente. O tempo de comunicação associado a cada laço ei,j representativo
de uma dependência de transporte é calculado por:
≡
≠
×
=
)Part()Part( if 0
)Part()Part( if bw
d
)(e
ij
ijji,
ji,
νν
ννξω (6 .1 )
Em que bw representa a largura de banda máxima para cada leitura/escrita atómica, e di,j é o
número de bytes da comunicação do laço ei,j. A multiplicação por ξ modela a comunicação
5 De tal forma que νi → νj.

CAP. 6 PARTIÇÃO TEMPORAL 143
necessária para guardar um operando e torná-lo disponível na fracção seguinte. Por exemplo,
para operandos guardados numa memória ξ deve ser igual a dois pois, para cada inter-
comunicação, o operando tem de ser guardado pela fracção onde foi definido e lido pela
fracção que o usa (assumindo tempos de escrita e de leitura iguais). Uma dependência de
precedência (sem transporte) tem custo zero (valor de di,j igual a zero).
O objectivo da partição temporal é a criação de um conjunto de fracções temporais de modo a
que um determinado custo6 seja minimizado e cada fracção caiba na área de reconfigware
disponível. Cada fracção, Πi, é um subconjunto não vazio de V. Poderemos dizer que um
grafo G partido temporalmente em k subconjuntos é correcto se e só se:
• O conjunto de fracções temporais ℘ = Π1 ∪ Π2 ∪ … ∪ Πk ≡ V;
• ∀ Πi ∈ ℘, Area(Πi) ≤ MaxArea; Cada fracção temporal cabe nos recursos
disponibilizados do FPGA.
• ∀ ei,j ∈ Ε, (℘(νi) → ℘(νj)) ∨ (℘(νi) ≡℘(νj)); → indica a ordem de execução. Todas
as dependências de dados são obedecidas (condição necessária para obter a mesma
funcionalidade).
Um conjunto correcto de fracções temporais garante que a descrição mantém a
funcionalidade original. Na partição temporal podem-se ter em conta diversos objectivos,
como sejam a minimização do atraso global ou do número de laços entre fracções. O custo
que reflecte o atraso global da execução de um grafo numa unidade de processamento
reconfigurável por multiplexagem no tempo pode ser calculado pela equação:
( ) ( ) ( )[ ] ( )[ ]∑=
Π+Π+Π×=ΩNumPart
iiAtrasoiiciclosA MaxOutInRWModelG
1
, τ (6 .2 )
Em que τciclos representa o número de ciclos de relógio para ler/escrever um operando de
tamanho menor ou igual à largura de banda da interface de comunicação. A função
6 Neste trabalho o custo a minimizar é o tempo de computação total do reconfigware sem contar com os custos de reconfiguração.

144 CAP. 6 PARTIÇÃO TEMPORAL
MaxAtraso(Πi) calcula o atraso do caminho crítico7 da fracção Πi e as funções In(Πi), Out(Πi)
correspondem à soma dos pesos dos laços de entrada/saída (ω(ei,j)) de um nó sem considerar
as entradas e as saídas primárias.
6.4 Esquemas de Suporte à Execução de Fracções Temporais
É importante, sob o ponto de vista de compilação para computação reconfigurável, considerar
organizações diferentes dos dispositivos que constituem o sistema. Cada organização pode
impor custos diferentes de comunicação entre fracções temporais devido a esquemas
diferentes de comunicação.
Pelo menos três mecanismos de comunicação entre fracções temporais podem ser
considerados:
• O uso de registos e de uma tarefa em execução no microprocessador para controlar a
escrita/leitura de dados entre fracções. Este esquema é apropriado para placas de
unidades de processamento reconfiguráveis com um microprocessador ou
microcontrolador que pode gerir as reconfigurações e comunicações, ou para placas
sem qualquer esquema de armazenamento (buffer) que lhes permitam manter dados
entre fracções. Com o advento de dispositivos que integram um microprocessador e
uma unidade de processamento reconfigurável no mesmo circuito integrado este pode
ser um esquema eficiente devido aos custos reduzidos de comunicação entre os dois
engenhos;
• O uso de um conjunto de registos na unidade de processamento reconfigurável quando
o dispositivo pode ser reconfigurado parcialmente. A área de registos pode ser
configurada inicialmente e partilhada temporalmente pelas fracções. Este esquema é
apropriado para FPGAs com recursos especiais (por exemplo, micro-registos) para
partilha temporal;
• O uso de memórias acopladas ao FPGA para guardar os dados interfracções. O
hardware usa circuitos de interface a estas memórias. Este esquema é apropriado para
7 Para simplificar assumem-se tempos de execução deterministas.

CAP. 6 PARTIÇÃO TEMPORAL 145
unidades de processamento reconfiguráveis sem microprocessadores de hospedagem
ou quando as comunicações entre as dois engenhos são demasiado elevadas. É também
útil quando é necessário transferir grandes quantidades de dados (por exemplo, arrays).
Exemplo 6 -1 . Corpo do c ic lo do exemplo HAL.
A Figura 6.1 apresenta o DFG do corpo do ciclo do exemplo HAL
[Paulin86]. No canto direito são apresentados os custos de implementação
dos operadores considerados pelo exemplo. A Figura 6.2 mostra o grafo
repartido por duas fracções temporais. Este fraccionamento temporal
necessita que apenas um operando seja transferido entre fracções. No início
o FPGA é reconfigurado com o reconfigware da primeira fracção e os
operandos de entrada (x, dx, u e y) são disponibilizados. No fim da
execução desta fracção, são guardados o operando intermédio (aux) e os
primeiros resultados (y_1 e x_1). De seguida o FPGA é reconfigurado com
o reconfigware da segunda fracção e disponibilizados os operandos (aux,
dx, y e u). No fim da execução desta fracção, é guardado o outro resultado
(u_1). O buffer para armazenar o operando intermédio pode ser uma
posição em memória, um registo local, ou registos do próprio
microprocessador.g
Operador (16 bits)
Área (células)
Atraso (ciclos de relógio)
× 1024 20
+, - 48 6
<< 1 << 1
+
×
u
×
dx
-
u
-
×
dx
+
u_1
x y
+
dx x
x_1
×
dx u
y_1
+
y
Gexec = 58 ciclos Área(G) = 4.384 células
Figura 6 .1 . DFG para o corpo do c ic lo do exemplo HAL e o custo de
cada operador .

146 CAP. 6 PARTIÇÃO TEMPORAL
<< 1
<< 1
+
×
u
×
dx
-
u
-
×
dx +
u_1
x
y
dx x
x_1
×
dx u
y_1
+
y
x
dx
y
u
x_1
y_1 aux
aux
dx
u
x_1
y_1
aux
dx
u_1
tempo
+
x
dx
y
u
aux
aux
x_1
y_1
u_1
reconfiguração
execução
reconfiguração
execução
Figura 6 .2 . Execução do corpo do c ic lo do exemplo HAL com part i lha
tempora l do FPGA.
6.5 Métodos Baseados nos Esquemas ASAP/ALAP
Os métodos de partição temporal mais simples baseiam-se nos níveis de ASAP8
[GajjalaPu99]. Nestes métodos é atribuído a cada nó do DFG o número máximo de nós que é
necessário percorrer do início do grafo até ao nó inclusive. O algoritmo começa pelos nós do
primeiro nível obtido pelo ASAP e vai mapeando um-a-um na fracção temporal enquanto a
área não for excedida. Quando aparece um nó cuja área excede a área disponível é criada uma
nova fracção temporal. Depois de todos os nós de um dado nível ASAP serem mapeados, o
algoritmo considera os nós do nível imediatamente a seguir. O algoritmo continua até que
todos os nós do DFG tenham sido mapeados. A selecção dos nós de um dado nível de ASAP
é arbitrária.
8 O nível de ASAP de um determinado nó do grafo indica o número de nós anteriores ao nó considerado que se encontram no caminho do início do grafo até esse nó.

CAP. 6 PARTIÇÃO TEMPORAL 147
Um algoritmo semelhante orientado pelos níveis de ALAP pode também ser considerado. No
Exemplo 6-2 o algoritmo de partição temporal baseado nos níveis ALAP produz melhores
resultados do que o baseado nos níveis ASAP. Este facto deve-se à proximidade local de
dependências nos níveis ALAP.
Exemplo 6 -2 . Part ição temporal or ientada pelos níveis de ASAP ou de
A L A P .
Suponha-se que todos os laços têm os mesmos custos de comunicação, cada
nó tem uma unidade de área e a área máxima do FPGA é de 4 unidades. O
fraccionamento temporal resultante da aplicação de uma versão do
algoritmo apresentado em [GajjalaPu99] com orientação ASAP ou ALAP é
apresentado nas Figura 6.3.a e Figura 6.3.b respectivamente. Para este
exemplo a orientação pelos níveis ALAP produz menos laços de
comunicação entre as duas fracções temporais.g
2
3
4
5 6 7 1
L1 L2 L3 L4
2 3
4
5 6 7 1
L1 L2 L3 L4
a ) b)
Figura 6 .3 . Apl icação de dois esquemas de part ição temporal : a) pelos
níveis de ASAP; b) pelos níveis de ALAP.
Foram implementados dois esquemas. O algoritmo 1 estende o algoritmo apresentado em
[GajjalaPu99]. O algoritmo permite seleccionar um nó da lista de nós com o mesmo nível de
ASAP ou ALAP por uma função local de prioridades. Esta função é aplicada a todos os nós
do mesmo nível e permite orientar a selecção pela ordem crescente de mobilidades. Assim, o
caminho crítico do DFG tem maior prioridade no mapeamento dos nós na fracção temporal
em preenchimento (corrente).

148 CAP. 6 PARTIÇÃO TEMPORAL
Este algoritmo considera uma nova fracção quando aparece um nó que não cabe na área
disponível sem, contudo, considerar os outros nós do nível em consideração.
O algoritmo 2 (ver Figura 6.4) tenta resolver este problema, ao considerar a procura recursiva
na lista de nós prontos para mapeamento na fracção temporal corrente, de nós que possam ser
alojados. O algoritmo considera que cada nó do grafo foi previamente rotulado com o nível
ASAP ou ALAP. No início o algoritmo, por cada nível, forma uma pilha com todos os nós
desse nível ordenados pelo valor da mobilidade9 (linhas 4 a 10 da Figura 6.4). De seguida vai
atribuindo os nós da pilha à fracção temporal em consideração até que esta atinja a área
máxima (linhas 11 a 19). Sempre que o mapeamento de um determinado nó ultrapasse a área
máxima disponível o algoritmo tenta mapear outro nó. Quando, para o nível em consideração,
não houver mais nós possíveis de serem mapeados na fracção temporal corrente é criada uma
nova fracção temporal (linha 21) e o algoritmo prossegue com o mapeamento. Quando
durante o mapeamento de nós a uma dada fracção, a pilha for esvaziada é criada uma nova
pilha considerando os nós do nível seguinte (linhas 23 e 24). O algoritmo termina quando
todos os nós tiverem sido mapeados em fracções temporais.
Este algoritmo pode também ser baseado nos níveis de ASAP ou ALAP e pode incluir a
função de custo do algoritmo 1.
Exemplo 6 -3 . Corpo do c ic lo do exemplo HAL.
Considere-se novamente o corpo do ciclo do exemplo HAL com operandos
de 16 bits. O circuito correspondente ao DFG inicial sem partilha de
operadores cabe apenas no FPGA XC6264. Quando se usa o FPGA
XC6216 o DFG tem que ser partido em dois. A Tabela 6.1 apresenta as
características do hardware implementado considerando cada um dos
FPGAs mencionados. A implementação de partilha temporal do FPGA usa
software para escalonar as reconfigurações e a escrita/leitura dos operandos.
A área máxima disponibilizada foi especificada como sendo de 60% (2.458
células no FPGA XC6216) da área total do FPGA (para garantir que a
colocação e encaminhamento seja realizável). Os resultados obtidos com o
9 Segmento temporal no qual um determinado nó pode ser escalonado sem alterar o atraso do caminho crítico. É obtido, para cada nó do DFG, pela diferença entre o valor de ALAP e o valor de ASAP do nó.

CAP. 6 PARTIÇÃO TEMPORAL 149
uso do algoritmo da Figura 6.4 orientado pelos níveis de ASAP são
apresentados nas linhas terceira e quarta da Tabela 6.1. O uso do algoritmo
mencionado permitiu que o fraccionamento resultante mantivesse (sem
considerar os custos da comunicação) o caminho crítico da implementação
sem partição (3ª coluna da tabela). Melhores desempenhos globais podem
ser obtidos com o uso de uma memória local para armazenar os operandos,
pois os custos de comunicação seriam inferiores. Os tempos de
reconfiguração apresentados (REC) não consideram as capacidades de
reconfiguração parcial do FPGA, facto que poderia diminuir o número de
pares de endereço/dados e consequentemente o tempo de reconfiguração. O
fraccionamento realizado adiciona 4 escritas e 2 leituras às leituras/escritas
da implementação sem fracções (última coluna da tabela).
1.TempPart(Schedul, SL, ScheduleNum, CurrentLevel, 2. IsALAP, NodesLevel, SameLevel) 3. If(CurrentLevel <= getMaxLevels()) 4. SameLevel = SortMobility(SL, CurrentLevel, 5. IsALAP); 6. If(NodesLevel == null) 7. NodesLevel = new Stack(); 8. Colocação dos nós do nível corrente 9. (SameLevel) em NodesLevel; 10. 11. Foreach Unscheduled Node of CurrentLevel 12. Sorted by mobility 13. NodesLevel.peek(Nodei); 14. If(Area(Nodei) + Schedul(ScheduleNum).getArea() < AMAX) 15. Schedul(ScheduleNum).Put(Nodei); 16. Sched(ScheduleNum).upDateArea(Area(Nodei)); 17. NodesLevel.Pop(Nodei) 18. 19. 20. If(NodesLevel.notEmpty()) 21. ScheduleNum++; 22. else 23. NodesLevel = null; 24. CurrentLevel++; 25. 26. TempPart(Schedul,SL,ScheduleNum,CurrentLevel, 27. IsALAP,NodesLevel,SameLevel); 28. 29.
Figura 6 .4 . Algori tmo para part ição temporal or ientado pela mobi l idade
de cada nó e com procura no mesmo n íve l de ASAP ou ALAP.

150 CAP. 6 PARTIÇÃO TEMPORAL
Tabela 6 .1 . Resultados para o corpo do exemplo HAL (♠♠ valores
est imados sem os tempos de comunicação) .
FPGA Área (células)
atraso (ns) ♠
Pares de endereço-
dados
X × Y células
REC (µs)
# escritas/ leituras
XC6264 4.420 564 7.263 108×72 220,1 4/3 2.328 255 3.873 64×64 117,4 4/4 XC6216 Fracção #1
Fracção #2 2.156 309 3.346 52×64 101,4 4/1
6.6 O Algoritmo de Partição Temporal Baseado num Escalonador
Estático em Lista
Nesta secção apresenta-se um algoritmo que ao tentar minimizar uma função global, que
integra os custos de comunicação e o atraso do caminho crítico, permite a obtenção de
fraccionamentos mais eficazes. O algoritmo de partição temporal é baseado num escalonador
estático em lista (ELS) [Cardoso99c] e está representado sumariamente na Figura 6.5. O
algoritmo começa por considerar os valores de ASAP e de ALAP de cada nó (linhas 2 e 3).
Um custo calculado pela equação (6.3) é adicionado a cada nó do grafo na fase inicial (linhas
7 a 9). Cada termo da equação tem um factor multiplicativo para dar mais peso aos custos de
comunicação (α), caminho crítico (β), ou ao compromisso entre os dois (η). O termo (6.4) dá
ênfase aos custos de comunicação. O termo (6.5) tenta preconizar o paralelismo existente,
dando mais peso aos nós com menor ASAP (criando a oportunidade de colocação de nós
disponíveis em paralelo com os nós do caminho crítico já mapeados). Este factor aumenta
quando se diminui o peso dos custos de comunicação. O terceiro termo (6.6) representa o
valor do ASAP de granularidade fina do nó.
Ao factor de escala (scale) foi atribuído o valor da divisão do número máximo de níveis do
ASAP pelo atraso do caminho crítico. Experimentalmente foi determinado que o peso η
expresso por β/(α+1) conduzia a bons resultados. Contudo, outro peso independente pode ser
usado para não limitar a exploração de soluções.
De seguida, o algoritmo insere na lista de nós disponíveis para mapeamento (List) na
primeira fracção temporal todos os nós do grafo cujo nó fonte seja unicamente o nó START
(linha 11). Esta lista é ordenada pela ordem descendente dos custos de cada nó (linha 12).

CAP. 6 PARTIÇÃO TEMPORAL 151
1. ELS(MaxArea, G(V, E),α, β, η) 2. Compute ASAP(G); 3. Compute ALAP(G); 4. 5. Int CurrentArea=0, SchedNum=0, NumNode=0, NumSchedNodes=0; 6. 7. For each vi ∈ V 8. Costsvi=ComputeCost(vi, α, β, η); 9. 10. 11. List = Create List of ready nodes to be scheduled; 12. Sort(list, Costs); 13. 14. BitSet SchedNodes = new BitSet(|V|); 15. 16. While(NumSchedNodes < |V|) 17. Node A = List.ElementAt(NumNode); 18. Boolean Fit = ((CurrentArea + Area(A)) <= MaxArea); 19. If(Fit) 20. List.removeElement(A(Area, Delay)); 21. ScheduleElement(A, CurrentArea, SchedNum, SchedNodes); 22. NumSchedNodes++; 23. If(List.Update(G, A, SchedNodes)) 24. Sort(List, Costs); 25. NumNode = 0; 26. else if(NumNode ≥ List.size()) && (List.size() != 0) 27. SchedNum++; NumNode = 0; CurrentArea = 0; 28. 29. else if(NumNode ≤≤ List.size()-2) 30. NumNode++; 31. else 32. SchedNum++; NumNode = 0; CurrentArea = 0; 33. 34. 35.
Figura 6 .5 . Algori tmo de part ição temporal baseado no algor i tmo
estát ico de escalonamento em l ista .
[ ] ( ) ( ) ( )idelayidelaycommicommi vvvvW ψβψηψα ×+×+×= / (6 .3 )
( ) ( ) ( )[ ]iiicomm vLevelALAPMaxLevelsvOutvIn +−−=ψ (6 .4 )
( )istartdelaycomm vASAPscale ×−=/ψ (6 .5 )

152 CAP. 6 PARTIÇÃO TEMPORAL
( )istartdelay vALAPscale×−=ψ (6 .6 )
Na linha 14 é criado um vector de bits com tamanho igual ao número de nós do grafo, que
indicará os nós que já tiverem sido mapeados, e que na criação terá todos os bits a zero
indicando que nenhum foi ainda mapeado.
As linhas 16 a 34 representam o núcleo do algoritmo que é executado até que todos os nós
tenham sido mapeados numa fracção temporal (linha 16). Da lista é indexado um nó (linha
17), de seguida é determinado se esse mesmo nó cabe na fracção temporal corrente (linha
18), e se couber é executado o ramo condicional correspondente (linhas 20 à 28).
Sempre que um nó é mapeado numa fracção (linhas 20 a 22) o algoritmo determina se o
mapeamento desse nó disponibiliza, do conjunto dos seus sucessores, outros nós (linha 23).
Se tal acontecer, os nós da lista de nós disponíveis para serem mapeados são ordenados pela
ordem descendente dos custos (linha 24) e o próximo nó da lista a ser considerado para a
fracção corrente é o primeiro da lista (linha 25)10. No caso de nenhum nó ter sido
acrescentado à lista após mapeamento do nó em último lugar da lista e esta ainda contiver nós
é criada uma nova fracção temporal (linha 27). Por cada nó da lista considerado que não
caiba na fracção corrente (linha 29) é indexado o nó seguinte da lista (linha 30). Quando o
indexamento realizado pela variável NumNode tiver considerado o último nó na procura de
um nó que caiba no fraccionamento corrente é criada uma nova fracção temporal (linha 32).
Os algoritmos de ASAP e de ALAP têm complexidades computacionais de Ο(|V|+|E|) e o
algoritmo ELS apresentado de Ο(|V|2+|E|).
6.7 Abordagem Baseada no Simulated Annealing
Sem o conhecimento de resultados óptimos ou quasi-óptimos é impossível sabermos se
merece a pena investir no refinamento e na investigação de algoritmos que possam produzir
resultados melhores. Contudo, a exploração exaustiva do espaço de exploração não é
10 Uma melhoria seria considerar o primeiro dos nós na lista ordenada dos que foram inseridos ou do nó que se encontrava em consideração imediatamente antes da actualização da lista.

CAP. 6 PARTIÇÃO TEMPORAL 153
praticável devido ao número elevado de alternativas. A modelação ILP11 do problema da
partição temporal também parece não ser praticável em exemplos de dimensões elevadas,
como o comprovam os elevados tempos de computação apresentados em [Kaul98].
Pelos motivos acima expostos, considerou-se nesta tese um algoritmo iterativo com
características que permitissem escapar a mínimos locais e que permitisse avaliar a distância
dos métodos construtivos baseados em heurísticas a soluções próximas do óptimo. A escolha
recaiu no simulated annealing12 (SA) [Kirkpatrick83] pela facilidade de implementação e por
ter custos computacionais toleráveis. Os algoritmos baseados no simulated annealing
caracterizam-se por a temperaturas altas a probabilidade de aceitação de movimentos que têm
custos piores ser maior, e à medida que a temperatura decresce a probabilidade de aceitação
de movimentos com custos piores vai também decrescendo. Esta característica de que
movimentos que produzem custos piores terem sempre possibilidades de serem aceites
permite que o algoritmo fuja a mínimos locais.
A versão implementada é sintonizada para a resolução da partição temporal (ver Figura 6.6).
O algoritmo parte de um fraccionamento temporal inicial (obtido pelos métodos construtivos
previamente considerados, por exemplo) e tenta refiná-lo movendo nós (escolhidos
aleatoriamente de entre os nós que podem ser movidos validamente) entre fracções adjacentes
(linhas 11 e 12). A opção de partir de um fraccionamento inicial realizável permite que o
algoritmo retorne sempre um fraccionamento temporal factível, pois como é sabido o SA não
garante que em tempo limitado seja encontrada uma solução realizável.
Defin ição 6 -1 . Movimento vál ido de um nó entre f racções temporais .
É um movimento de um nó entre fracções adjacentes que não viola nenhuma
precedência temporal, mas que pode originar a excedência da área máxima
disponível na fracção temporal receptora.
O algoritmo vai iterativamente construindo novos fraccionamentos temporais tentando
conseguir fraccionamentos que melhorem o valor da função de custo (6.2). No algoritmo, k1
11 Do inglês: Integer Linear Programming. 12 A intenção desta investigação não foi avançar o estado da arte nos procedimentos do simulated annealing em geral. Por isso, as opções realizadas não serão, nesta tese, discutidas nem justificadas em pormenor.

154 CAP. 6 PARTIÇÃO TEMPORAL
representa o peso do atraso do caminho crítico e k2 o peso dos custos de comunicação entre
fracções.
Por cada decréscimo da temperatura são realizadas várias iterações (linhas 10 a 28). Por cada
iteração é realizado um movimento válido de um nó. A probabilidade de aceitação de um
novo movimento é dada pelo valor da exponencial e-∆/temp e o critério de aceitação é baseado
na escolha de um número aleatório pertencente ao intervalo [0, 1] (linha 16). Na equação
temp representa a temperatura corrente e ∆ a diferença entre o custo da última solução e o
custo da solução actual (linha 13).
1. doSimAnnealTempPart(graph G, TempPart TP, int k1, int k2) 2. TempPart newTP = TP.clone(); 3. int iter = Anneal.computeIter(G); 4. float temp = Anneal.FindTemp(TP, iter, k1, k2);
5. float ε = 0.9f; 6. float γ = 1.02f 7. long costOld = TP.getCost(k1, k2); 8. long costMin = CostOld; 9. do 10. for(int I=0; I<iter;I++) 11. <NumNodeA, NumPartA, NumPartB> = TP.getValidMove(); 12. boolean unfeas = TP.move(NumNodeA, NumPartA, NumPartB); 13. long costNew = unfeas ? (costMin+1) : TP.getCost(k1, k2); 14. long delta = costNew – costOld; 15. if(delta > 0)
16. if(random.nextFloat() < temp
delta
e−
) 17. TP.undoMove(NumNodeA, NumPartA, NumPartB); 18. else 19. costOld = costNew; 20. else 21. if(!unfeas) 22. if(costNew < costMin) 23. costMin = costNew; 24. newTP = TP.clone(); 25. 26. costOld = costNew; 27. 28.
29. temp = ε * temp; 30. iter = γ * iter; 31. while (temp > Anneal.finalTemp); 32. return newTP; 33.
F igura 6 .6 . Versão do a lgori tmo Simulated Annealing para part ição
temporal .

CAP. 6 PARTIÇÃO TEMPORAL 155
Exemplo 6 -4 . Movimentos vál idos entre f racções temporais .
A Figura 6.7 mostra um exemplo de um movimento válido realizado pelo
SA apresentado. Supondo um fraccionamento temporal inicial como o
apresentado na Figura 6.7, o algoritmo escolhe aleatoriamente duas fracções
adjacentes e um nó que possa ser movido entre as duas. Na Figura 6.7 um
nó seleccionado do conjunto 1, 8, 6, 7 produz um movimento válido da
fracção #1 para a #2. Um nó seleccionado do conjunto 9, 11 produz um
movimento válido da fracção #2 para a #1. Se, por exemplo, considerarmos
o movimento do nó 7 da fracção #1 para a #2 o próximo movimento válido
deverá ser escolhido dos subconjuntos 1, 8, 6, 4 ou 9, 11, 7 para cada
uma das direcções referidas.
Quando um movimento de um nó causa a criação de uma fracção temporal irrealizável (a
área da fracção excede a área total disponibilizada) é atribuído ao custo desse fraccionamento
um valor maior do que o valor mínimo encontrado até então (linha 13). A solução final
resultante corresponde ao fraccionamento com menor custo encontrado até então (linhas 22 a
25).
<< 1 << 1
+
××
u
××
dx
-
u
-
××
dx
+
u_1
x y
++
dx x
x_1
××
dx u
y_1
y
+
1 2 3 4
5 6 7
8
9
10 11
12
Fracção #1
Fracção #2
Figura 6 .7 . Exemplo de um movimento entre f racções temporais
considerado vál ido pela abordagem SA apresentada.

156 CAP. 6 PARTIÇÃO TEMPORAL
Outras possibilidades poderiam ser consideradas, como sejam o movimento de nós entre
fracções não adjacentes e o movimento de agrupamentos de nós. Este tipo de movimentos
poderá ajudar o algoritmo a encontrar soluções óptimas mais rapidamente mas não foram
realizados estudos que o confirmem.
A temperatura inicial é calculada com base na média do número de movimentos numa pré-
avaliação do SA (linha 4). O número de iterações é função do número mínimo de fracções e
do número de nós no grafo (linha 4). O SA implementado usa uma relação de arrefecimento ε
fixa para calcular a próxima temperatura Tk = ε × Tk-1 (linha 29). Os resultados experimentais
indicaram que um valor de ε de 0,95 produz resultados satisfatórios. O número de iterações
para cada valor de temperatura é calculado por Iterk = γ × Iterk-1 (linha 30) em que γ foi fixado
em 1,02. O algoritmo finaliza (linha 31) quando a temperatura atinge o valor fixado como
mínimo (para a maioria dos casos foi aceitável 0,1).
O uso do algoritmo baseado no simulated annealing permite explorar a utilização de um
número maior de fracções temporais do que o usado pela solução inicial. Para tal, o utilizador
necessita de especificar o número de fracções temporais vazias que deve ser adicionado à
solução inicial que será fornecida ao algoritmo.
6.8 Resultados Experimentais
Todos os algoritmos supracitados foram implementados em linguagem Java. Nesta secção
são apresentados resultados experimentais de forma a se poderem avaliar os algoritmos.
Os símbolos Ω, Γexec e ∆com referem o resultado total e resultados parcelares da equação (6.2).
Na expressão (6.7) é indicada cada parcela correspondente ao símbolo indicado. Ω representa
o atraso do caminho crítico do grafo (sem a escrita/leitura das entradas/saídas primárias) em
ciclos de relógio. Os resultados não consideram a escrita/leitura das entradas/saídas primárias
nem a possibilidade de intercalar a execução com comunicações entre fracções temporais. O
factor δ serve para, sempre que necessário, inibir a soma dos tempos de execução do caminho
crítico de cada fracção (δ =0).

CAP. 6 PARTIÇÃO TEMPORAL 157
( ) ( )[ ][ ] ( )[ ]444 3444 2144444 344444 21
exec
Max
com
OutInNumPart
iiAtraso
NumPart
iiiciclos
Γ
Π+
∆
Π+Π×=Ω ∑∑== 11
δτ (6.7)
S1 refere o algoritmo em [GajjalaPu98b] que foi explicado previamente. S2 refere o mesmo
algoritmo orientado pelos níveis de ALAP. S3 e S4 referem o algoritmo da Figura 6.4 que
pode ser orientado pelos níveis ASAP (S3) ou ALAP (S4). S5 é uma versão de S2 com os nós
ordenados pela ordem ascendente dos níveis de ALAP e os nós com o mesmo nível de ALAP
ordenados pelos níveis de ASAP (por ordem ascendente). S6 é uma versão de S1 no qual os
nós de cada nível ASAP são ordenados pela ordem ascendente dos níveis de ALAP. S7 é uma
versão do algoritmo estático baseado em lista em que os nós da lista de nós prontos para
mapeamento são ordenados pela ordem ascendente do valor ALAPstart. Finalmente, os
algoritmos ELS e SA referem respectivamente a extensão ao escalonador estático baseado em
lista (ver Figura 6.5) e à abordagem simulated annealing (ver Figura 6.6).
Nas tabelas, E é a melhoria do custo da solução SA relativamente à solução ELS e é
calculada pela expressão ( ) ELSSAELSE ΩΩ−Ω= .
Os tempos de computação apresentados referem os tempos de execução dos Java bytecodes,
obtidos pela compilação pelo javac do JDK1.2, com o JIT da Symantec num PC (@133MHz,
64 MB RAM, Windows95). Os métodos construtivos obtiveram cada solução em menos de 1
ms.
Os resultados do SA nas Tabela 6.2 e Tabela 6.3 são resultados muito próximos do óptimo. O
algoritmo foi executado diversas vezes, muitas das vezes partindo de soluções iniciais
resultado da aplicação prévia do SA, e os resultados foram sempre os mesmos.
O primeiro exemplo a considerar é o corpo do ciclo do exemplo HAL [Paulin86] cujo DFG
foi previamente apresentado na Figura 6.1. O exemplo tem área total de 4.384 células e atraso
do caminho crítico de 58 ciclos de relógio.
Os resultados apresentados na Tabela 6.2 mostram melhorias pequenas do SA em relação ao
ELS. O SA tem a capacidade de criar agrupamentos de nós com ligações fortes entre eles
reduzindo os custos de comunicação. Estes resultados também mostram que o ELS produz
resultados pelo menos tão bons como os obtidos pelas outras heurísticas.

158 CAP. 6 PARTIÇÃO TEMPORAL
Tabela 6 .2 . Resul tados para o exemplo HAL ( ττciclos=2).
CASO #Part. Max Área
Medidas S1 S2 S3 S4 S5 S6 S7 ELS α=2
SA
E (%)
A 5 2.457
Ω ∆com
Γexec
tempo
70 6 58 -
86 4 78 -
86 4 78 -
80 4 72 -
80 4 72 -
70 6 58 -
80 4 72 -
66, β=20 4 58 < 1 ms
62 2 58 7,8 s
6,1
B 2 4.096
Ω ∆com
Γexec
tempo
66 4 58 -
86 4 78 -
66 4 58 -
84 6 72 -
84 6 72 -
66 4 58 -
84 6 72 -
66, β=1 4 58 < 1 ms
60 2 58 5,7 s
9,1
O segundo exemplo é o filtro SEWHA [Jain88]. O exemplo é constituído por 16
multiplicadores e 12 somadores (28 nós no DFG) contribuindo para uma área total de 16.960
células e um caminho crítico de 90 ciclos de relógio (consideraram-se operandos de 16 bits).
Os resultados revelaram que os piores resultados obtidos pelo ELS normalmente aparecem
quando poucas fracções temporais necessitam de ser consideradas. O ELS sofre da
incapacidade de balancear as fracções (por ser um algoritmo “guloso”, tenta preencher as
fracções temporais sequencialmente). Como foi referido esta deficiência tem mais impacto
quando o número de fracções temporais é pequeno, como se pode constatar pelos resultados
apresentados na Tabela 6.2 e na Tabela 6.3.
Tabela 6 .3 . Resultados para o f i l t ro SEWHA, considerando dois
d isposi t ivos com áreas máximas de 4 .096 célu las (casos A) e de 16.384
células (casos B) respect ivamente.
CASO/#Part τciclos Medidas S1 S2 ELS (α,β) SA tempo E (%) A1/5 2 Ω 222 202 202 (2,20) 194 26,4 s 3,9 B1/2 2 Ω 134 142 134 (2, 1) 98 90 s 26,8 A2/5 1 Ω 186 166 166 (1, 1) 162 25,4 s 2,4 B2/2 1 Ω 122 126 122 (1, 1) 94 85 s 22,95 A3/5 0 Γexec 150 130 118 (0, 1) 118 26 s 0 B3/2 0 Γexec 110 110 110 (0, 1) 90 68 s 18,18 A4/5 1 ∆com 36 36 26 (13 laços) (1, 0) 22 19,2 s 15,38 B4/2 1 ∆com 12 16 6 (3 laços) (1, 0) 2 66,7 s 66,7
Na maioria das vezes os resultados não melhoram se se permitir que o SA explore mais
fracções do que o número obtido pelo S1 (o SA converge para o número mínimo de fracções
temporais).

CAP. 6 PARTIÇÃO TEMPORAL 159
Para permitir um estudo estatístico do comportamento dos vários algoritmos foi
implementado um sintetizador de grafos pseudo-aleatórios. O sintetizador permite seleccionar
o número de nós e para cada nó, o número máximo de laços de saída, os valores mínimo e
máximo da área e atraso, e o grau de paralelismo que permite sintetizar grafos preconizando
seriação ou paralelismo.
Na Tabela 6.4 estão apresentados resultados, que podem ser visualizados graficamente na
Figura 6.8, obtidos com grafos sintetizados. Cada grafo tem 50 nós e os laços de saída de
cada nó variam entre 0 e 4, ou entre 0 e 10. Para cada algoritmo é apresentada a melhoria
relativamente ao método S1. São também apresentados resultados para custos de
comunicação diferentes.
As linhas 2 e 3 da Tabela 6.4 apresentam os resultados considerando que cada leitura/escrita
para comunicação entre fracções temporais custa 2 ciclos de relógio. As linhas 4 e 5,
apresentam resultados combinando custos de comunicação e de atraso do caminho crítico. Os
resultados das linhas 6 e 7 foram obtidos, quando apenas foi considerada o atraso do caminho
crítico e as linhas 8 e 9 apresentam resultados, quando apenas são considerados os custos de
comunicação. A última coluna apresenta a média das melhorias relativas do SA sobre o ELS
e a última linha as médias das melhorias relativas para os diversos custos de
intercomunicação considerados.
Tabela 6 .4 . Resul tados para 100 grafos gerados pseudo-aleator iamente.
Laços de saída
τciclos / δ
S2 S3 S4 S5 S6 S7 ELS (α,β) SA E
(%)
1: [0 10] 2/1 -0,9 9,1 1,1 -2,2 -1,4 9,2 12,2 (2,1) 29,7 19,9 2: [0 4] 2/1 -1,0 12,4 1,7 -3,1 -0,8 14,5 18,5 (2,1) 38,1 24 3: [0 10] 1/1 -0,3 5,8 0,2 -0,7 0,7 8,7 6,8 (1,1) 22,9 17,3 4: [0 4] 1/1 -0,3 7,4 0,7 -1,1 3,3 13,7 10,6 (1,1) 28 19,5 5: [0 10] 0/1 2,8 -8,6 -3,5 5,4 8,6 6,0 9,5 (0,1) 13 3,9 6: [0 4] 0/1 2,2 -11,1 -2,9 5,8 16,2 10,8 10,9 (0,1) 16 5,7 7: [0 10] 1/0 -2,2 15,3 2,7 -5,1 -5,3 10,3 29,8 (1,0) 45 21,7
E/N (%)
8: [0 4] 1/0 -2,5 22,9 -3,7 -7,1 -9,8 16,0 48 (1,0) 57,8 18,8
Total 9: - - 0,28 6,65 -0,46 -1,0 1,4 11,2 18,3 20,6 16,4
Os resultados apresentados para o SA foram obtidos pela execução deste tendo como solução
inicial o fraccionamento temporal fornecido pelo ELS. Em muitos casos voltou-se a executar
repetidamente o SA com a solução obtida anteriormente pelo próprio até não se verificarem
melhorias significativas.

160 CAP. 6 PARTIÇÃO TEMPORAL
A Tabela 6.4 mostra que o S3 foi o melhor algoritmo das abordagens baseadas nos níveis
ASAP/ALAP no que respeita a custos de comunicação13. Os resultados mostram melhores
soluções dos escalonadores baseados em lista sobre as abordagens ASAP/ALAP no que
respeita ao atraso do caminho crítico como seria de esperar devido à oportunidade de
executar nós disponíveis em paralelo com nós do caminho crítico.
-20
-10
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 Ganhototal
S2S3S4S5S6S7ELSSAE
Figura 6 .8 . Gráfico comparat ivo das diversas abordagens. O e ixo
hor izontal representa os números indicados na segunda coluna da
Tabela 6 .4 . O eixo vert ical representa a melhoria relat iva (%) a S1.
S6 revelou-se o melhor algoritmo dos métodos construtivos exceptuando o ELS quando o
objectivo é a minimização do atraso do caminho crítico sem entrar em linha de conta com os
custos de comunicação entre fracções temporais. Este facto deve-se ao algoritmo considerar
primeiramente o mapeamento de todos os nós de um determinado nível antes de considerar os
nós do nível imediatamente a seguir. Quando se utiliza um algoritmo de escalonamento
baseado em lista, para cada nó escalonado, o algoritmo procura por nós que possam ser
adicionados à lista de nós prontos, devido ao facto de terem todos os nós fonte mapeados.
Quando os custos de comunicação entre fracções não são negligenciáveis, mas sem pesos
13 Na função do custo total (6.7) a atribuição dos valores: a) (τciclos =0, δ≠0): implica apenas consideração dos custos de execução (atraso do caminho crítico); b) (τciclos ≠0, δ=0): implica apenas consideração dos custos de comunicação.

CAP. 6 PARTIÇÃO TEMPORAL 161
demasiado elevados, o S7 foi o melhor dos métodos construtivos considerados, e os
resultados até ultrapassam os obtidos com o ELS, sem exploração dos custos de cada termo
na função de custo. Devido ao facto do ELS se poder reduzir ao S7 (fazendo α=0, β=1, η=0
na equação (6.3)) estes resultados são por isso também encontrados pelo ELS para os valores
indicados dos parâmetros.
Os resultados mostram uma melhoria global do ELS em relação às outras heurísticas
consideradas. O ELS encontrou uma solução comparável em média em cerca de 16% do
resultado obtido pelo SA (de 4 a 24%). É previsível que, utilizando o ELS, melhores
resultados possam ser conseguidos explorando os parâmetros α, β na equação (6.3) como
foram os casos apresentados na Tabela 6.2 (caso A) e na Tabela 6.3 (caso A1) nos quais foi
utilizado 20 para o valor de β. A exploração do parâmetro η na mesma equação pode também
permitir a obtenção de resultados melhores.
Os resultados obtidos de experiências com grafos gerados pseudo-aleatoriamente confirmam
o pressuposto de que o número de fracções obtido pelas heurísticas (ASAP, ELS, etc.) é
próximo do óptimo, e poucos casos necessitaram de mais fracções (uma) para minimizar a
função de custo. Esta observação pode ser explicada pelo facto de que mais fracções têm
tendência a aumentar o atraso do caminho crítico, e apenas em poucos casos podem reduzir o
custo total das comunicações entre fracções.
6.9 Conclusões
Foram apresentadas neste capítulo técnicas de partição temporal que exploram o conceito de
“hardware virtual”.
Os resultados mostram que algoritmos simples podem ser usados para resolver a partição
temporal ao nível comportamental. O algoritmo apresentado (ELS), baseado num escalonador
estático em lista, reduz a complexidade da implementação e o tempo de computação. Sendo
um algoritmo inicialmente usado para escalonamento de operações pode ser facilmente
capacitado para a partilha de recursos (embora a metodologia mais fácil seja a execução do
algoritmo para diferentes restrições do número de recursos, o espaço de exploração
exponencial torna esta solução proibitiva e por isso, formas de redução do espaço, sem
realização de escalonamento, devem ser consideradas). A baixa complexidade do ELS torna-

162 CAP. 6 PARTIÇÃO TEMPORAL
o apropriado para lidar com grafos de grande dimensão. Os resultados mostraram a eficiência
do algoritmo e as melhorias obtidas relativamente a algoritmos de partição temporal mais
simples. Os resultados mostram melhorias sobre a abordagem ASAP apresentada em
[GajjalaPu98a] e [GajjalaPu98b] sem acrescentar demasiada complexidade computacional.
Neste capítulo foi também apresentada uma versão do simulated annealing para resolução da
partição temporal. Contudo, esquemas mais eficientes de “arrefecimento” necessitam de ser
estudados para englobar o algoritmo no compilador. Com base nos tempos de computação e
nos resultados obtidos, a solução SA não parece, pelo menos só por si, uma escolha razoável
para compiladores quando um dos objectivos principais é a celeridade da compilação. No
entanto, a abordagem SA pode ser usada depois do ELS como um procedimento de
refinamento, sempre que a rapidez de compilação não for prioritária.
Os resultados obtidos mostraram que na maioria das vezes o número óptimo de fracções
temporais é o mínimo. Esta conclusão, baseada em resultados obtidos pelo SA, vem ao
encontro de [DeHon96].
Esquemas de partição temporal capazes de lidar com a partição temporal de ciclos deverão
ser investigados. A técnica de distribuição de ciclos usada pela comunidade de compiladores
de software é um bom ponto de partida.
A possibilidade de partilha de recursos hardware de dimensões elevadas (como é o caso dos
multiplicadores) deverá também ser considerada. Pode aliviar os efeitos de comunicação e
permite a reutilização de operadores cuja configuração está activa.
O algoritmo ELS apresentado neste capítulo foi englobado no compilador NENYA
apresentado nesta tese e a sua integração será dissecada no capítulo 7.

163
7. Escalonamento Baseado em Regiões
“Lost time is never found again.”
John H. Aughey
Nos capítulos anteriores foram apresentados os modelos intermédios, optimizações do fluxo
de dados, o suporte à geração do reconfigware e a partição temporal. Neste capítulo é
detalhado o modo como é obtido o controlo responsável por orquestrar a execução do
algoritmo em reconfigware. Para tal, é descrito o escalonador que aqui se refere à ordenação
estática de operações, existentes em modelos intermédios que representam fluxos intensivos
de controlo e/ou de dados, pelos ciclos de relógio. O método de escalonamento é baseado em
regiões constituídas pelo conjunto de operações resultante da união de vários blocos básicos.
Embora nos tenhamos baseado num dos algoritmos de escalonamento mais simples - o
algoritmo de escalonamento estático baseado em lista [Gajski92] - os conceitos podem ser
aplicados a outros algoritmos de escalonamento mais complexos. O principal objectivo foi o
de garantir tempos de compilação competitivos com a compilação de software, sem descurar
critérios que asseguram resultados minimamente eficientes. Concretamente, uma das
finalidades deste escalonador é a de resolver os conflitos nos acessos às memórias acopladas

164 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
ao FPGA, ao sequenciar esses mesmos acessos durante a execução do hardware1. Outra das
finalidades é a de controlar a execução de regiões cíclicas2.
O capítulo começa por descrever os tipos de escalonamento possíveis com base na
representação em grafos utilizada. É definido o grafo, que representa as transições de estados,
gerado pelo escalonador e é apresentado o algoritmo de escalonamento baseado em regiões.
Embora não tenham sido ainda implementadas no compilador são apresentadas formas de
lidar com regiões cíclicas concorrentes. Por último, são apresentados alguns resultados
comparativos entre um escalonamento baseado no bloco básico com o escalonamento
baseado em regiões.
7.1 Escalonamento e Grafos Gerados
Os tipos de escalonamento podem ser agrupados pelo tipo de grafos representantes da
descrição inicial e pela forma como lidam com esses mesmos grafos:
• CDFG3: Os escalonamentos baseados neste tipo de representação escalonam, bloco
básico a bloco básico (ou instrução a instrução), as operações, pela ordem de
aparecimento no CFG construído a partir da descrição alto-nível. Este tipo de
representação restringe o escalonamento ao não tirar completamente partido do
paralelismo interbloco existente e da possibilidade de existência de fluxos de controlo
múltiplos. Contudo, a representação permite lidar facilmente com estruturas de
controlo. Alguns autores estudaram esquemas que permitem movimentações de
operações (cujos movimentos não violem dependências) entre blocos básicos de
forma a melhorar os resultados finais quando existem restrições de recursos.
• DFG4 estendido5: Esta representação torna mais difícil a manipulação de ramos
condicionais, mas permite a representação do paralelismo existente ao nível da
1 O escalonador pode ser facilmente expandido para suportar partilha de unidades funcionais (por exemplo multiplicadores). 2 Consideramos região cíclica como sendo a região de um programa que compreende um ciclo podendo ou não conter sub-regiões cíclicas (ciclos). No caso geral, a existência de recursividade no programa também forma regiões cíclicas, mas este tipo de regiões cíclicas não serão abordadas nesta tese. 3 Do inglês: Control/Data Flow Graph. 4 Do inglês: Data Flow Graph.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 165
operação. No PRISM-II [Agarwal94] é utilizado o CFG de blocos básicos para
escalonar as operações apresentadas no DFG global. São utilizadas técnicas de
agrupamento de estados. Contudo, o escalonamento interblocos tem a granulosidade
do bloco básico.
• HPDG6: Esta representação assume tantos fluxos de controlo quantos os que forem
necessários. O escalonamento tomando como base este tipo de modelo pode ser
baseado em regiões, o que permite a obtenção de melhores resultados. Neste
escalonamento, os blocos básicos no HPDG são agrupados para formarem uma região
do DFG global, que é posteriormente escalonada em conjunto. Este tipo de
escalonamento permite que as operações apareçam no escalonamento pelas
dependências determinadas, possibilitando que operações em diferentes blocos
básicos possam ser consideradas no mesmo passo de escalonamento devido à
ausência de dependências de dados e/ou ao facto de poderem ter execução
especulativa.
Em [Cardoso99a] foi considerado um escalonamento baseado nos CDG e DDG sem
agrupamentos por regiões. Este tipo de escalonamento, embora útil para lidar com a
reestruturação baseada nas dependências de dados lidava com um DFG por cada bloco
básico. Não permitia formar agregações de blocos básicos nem manter, por cada agregação,
ligação aos nós correspondentes no DFG global. Essa forma de escalonamento, embora capaz
de considerar dependências interblocos, pode produzir escalonamentos ineficientes devido à
granulosidade utilizada. A Figura 7.2 apresenta as melhorias obtidas para um conjunto de
exemplos cujas características se encontram descritas no apêndice D. Dos exemplos
considerados obteve-se uma melhoria relativa de quase 35% para o exemplo USQRT. Para os
exemplos CRC-32 e HAMMING não foram obtidas melhorias.
Exemplo 7 -1 . Agrupamento de b locos básicos.
Considere-se o exemplo com dois blocos básicos apresentado na Figura
7.1a e os atrasos para cada operação definidos na Figura 7.1b. Ao se
considerarem os blocos básicos individualmente (ver Figura 7.1c) é obtido
5 Adicionado de nós de if, case, loop e select. 6 Do inglês: Hierarchical Program Dependence Graph.

166 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
o escalonamento apresentado na Figura 7.1d. No caso dos blocos básicos
serem agrupados (ver Figura 7.1e) o escalonamento obtido (ver Figura 7.1f)
elimina um ciclo de relógio (6 ciclos) ao escalonamento de blocos básicos
sem agrupamento (7 ciclos) da Figura 7.1d.
... A = B*C; BB0 D = A*(E+C); BB0 If(A > 10) BB0 C = A+F; BB1 …
B C E
F
A
C
BB0
BB1
10
a) c)
B C E
F
A
C
BB0 – BB1
10
e)
10
d)
f) b)
Figura 7 .1 . a) Exemplo; b) atraso para cada operação do exemplo (cada
quadrado representa um cic lo de re lógio) ; c) Os dois blocos básicos e
os DFGs correspondentes; d) Escalonamento ao nível do bloco básico;
e) Agrupamento dos dois blocos básicos e DFG global ; f )
Esca lonamento com agrupamento de b locos básicos.
O processo de escalonamento utiliza como entrada os grafos previamente apresentados no
capítulo 3. Assim, é assumida a existência do grafo que representa a hierarquia (HPDG) e do
DFG global. Cada nó do grafo hierárquico identifica os nós do DFG que lhe pertencem.
Nesta fase, os nós correspondentes a operações do DFG global devem ter associada uma
macrocélula existente na biblioteca tecnológica [Cardoso99d], como foi descrito no capítulo
4 (e por isso devem estar caracterizados em termos de atraso e de área). Nesta fase os
escalonamentos ASAP e ALAP foram também determinados (capítulo 4).
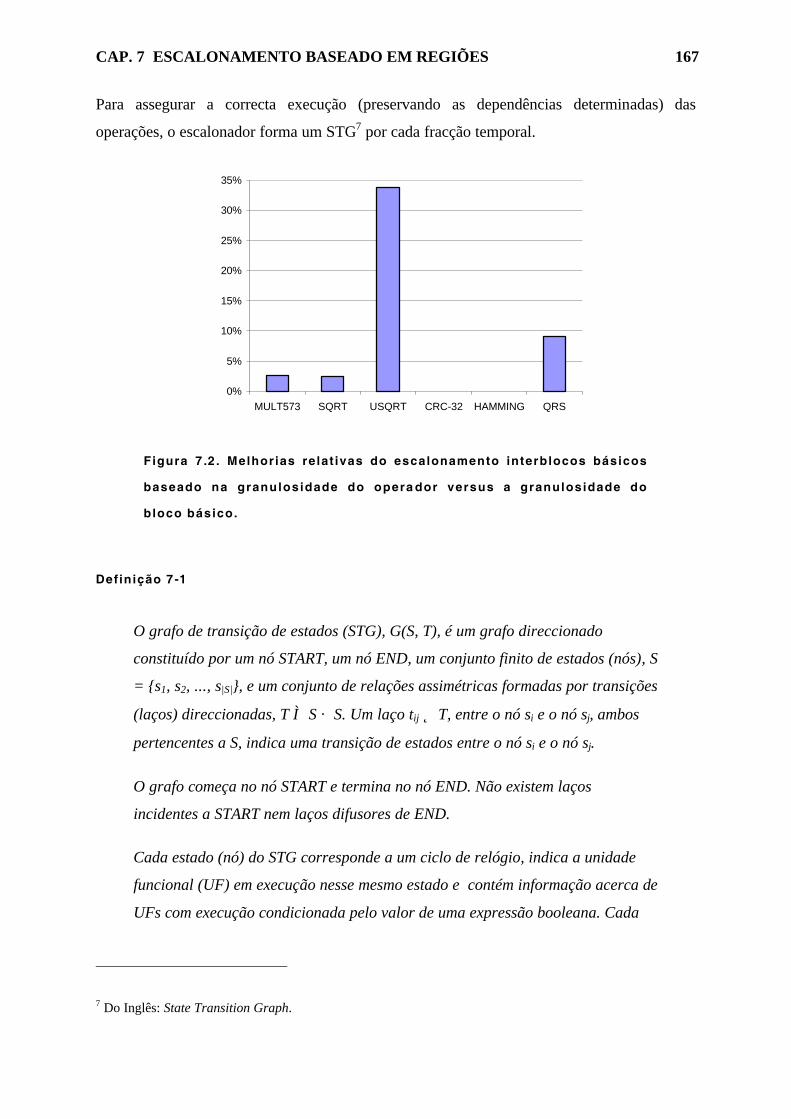
CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 167
Para assegurar a correcta execução (preservando as dependências determinadas) das
operações, o escalonador forma um STG7 por cada fracção temporal.
0%
5%
10%
15%
20%
25%
30%
35%
MULT573 SQRT USQRT CRC-32 HAMMING QRS
Figura 7 .2 . Melhorias relat ivas do escalonamento interblocos básicos
baseado na granulosidade do opera dor versus a granulosidade do
bloco básico.
Def inição 7 -1
O grafo de transição de estados (STG), G(S, T), é um grafo direccionado
constituído por um nó START, um nó END, um conjunto finito de estados (nós), S
= s1, s2, ..., s|S|, e um conjunto de relações assimétricas formadas por transições
(laços) direccionadas, T ⊂ S × S. Um laço tij ∈ T, entre o nó si e o nó sj, ambos
pertencentes a S, indica uma transição de estados entre o nó si e o nó sj.
O grafo começa no nó START e termina no nó END. Não existem laços
incidentes a START nem laços difusores de END.
Cada estado (nó) do STG corresponde a um ciclo de relógio, indica a unidade
funcional (UF) em execução nesse mesmo estado e contém informação acerca de
UFs com execução condicionada pelo valor de uma expressão booleana. Cada
7 Do Inglês: State Transition Graph.

168 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
estado atribui o valor dos respectivos sinais possivelmente condicionados por
sinais externos.
O STG representa também quais as condições para haver a transição para um
estado específico sempre que exista mais do que uma opção.
Cada STG gerado pode depois ser implementado por hardware específico, sob a forma de
uma máquina de estados finita (FSM8). O compilador gera uma descrição VHDL
comportamental ao nível de transferência de registos para cada STG que pode posteriormente
ser sintetizada em hardware específico por uma ferramenta de síntese lógica.
Existem diversas possibilidades para garantir o funcionamento de descrições alto-nível cuja
execução pode percorrer caminhos diferentes (ramos de construções if-else, por exemplo):
• Explicitamente pelo STG, ao incluir os caminhos do CFG. Esta representação permite
lidar facilmente com operações load/store mutuamente exclusivas, pois o próprio
caminho percorrido no STG garante a resolução de conflitos.
• Por ligações directas entre as operações que seleccionam o caminho a ser percorrido,
a selecção de definições que alcançam um determinado ponto e a atribuição de
predicados em operações com efeitos colaterais (escritas em memória).
Como um dos objectivos deste trabalho é permitir a execução especulativa de operações em
casos em que tal execução não necessita de ser restaurada optou-se pela segunda opção.
7.2 Escalonamento de Regiões Acíclicas
O escalonamento de regiões acíclicas resume-se ao simples escalonador estático em lista que
vai resolvendo a competição por unidades funcionais operador a operador, com base na
atribuição de prioridades. Na literatura podem-se encontrar diversos esquemas de atribuição
de prioridades a operadores [Gajski92][Micheli94]. No algoritmo utilizado as prioridades são
baseadas no valor de ALAP de cada operação, mas como veremos de seguida é
implicitamente utilizada uma segunda chave.
8 Do Inglês: Finite-State Machine.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 169
Na Figura 7.3 são apresentados resultados obtidos por um escalonador estático baseado em
lista com diferentes ordenações das operações a escalonar. O exemplo (ver Figura 7.3a)
ilustra o facto de que ordenações baseadas em mobilidades, tempo que falta para o fim, etc,
podem produzir escalonamentos ineficientes. No exemplo, as operações de leitura de
elementos dos arrays A e B, assim como as duas primeiras operações de adição têm os
mesmos escalonamentos ASAP e ALAP. Se considerarmos que só é possível um acesso à
memória em cada ciclo de relógio e que existe apenas um somador, o escalonamento
resultante, baseado nas mobilidades dos operadores, pode ser o representado na Figura 7.3b.
Este tipo de ordenação dos operadores não toma em consideração o facto de duas ou mais
operações poderem produzir dados para a mesma operação. Uma forma de lidar com este
problema é utilizar uma segunda chave, ou seja operações com o mesmo valor de primeira
chave (mobilidades, por exemplo) são ordenadas pelo valor da segunda (em ordem crescente
ou decrescente). O ordenamento com base numa segunda chave que agrupa as operações com
sucessores comuns e que tenham a mesma mobilidade produz o escalonamento apresentado
na Figura 7.3c. Embora este exemplo também utilize partilha de somadores, mesmo quando
apenas os acessos a memória são seriados esta segunda chave pode produzir resultados
melhores.
B[2] A[1] B[4] A[3]
C[1]
B[2]
A[1]
B[4]
A[3]
C[1]
B[2]
A[1]
B[4]
A[3]
C[1]
a) b) c)
Figura 7 .3 . Escalonamento com di ferentes ordenações das operações
(os rectângulos representam acessos a e lementos de arrays): a ) DFG
inic ia l ; b) possível escalonamento com pr ior idade unicamente baseada
no valor da mobi l idade de cada operação; c ) escalonamento com
prioridades atr ibuídas às operações com base na mobi l idade e nos
sucessores comuns.

170 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
O algoritmo considerado não tem necessidade de produzir a segunda chave devido ao facto
das operações nos bytecodes aparecerem pela ordem de consumo.
Na secção seguinte é apresentado o algoritmo de escalonamento geral que aceita regiões
cíclicas e acíclicas.
7.3 Escalonamento de Regiões Cíclicas/Acíclicas
Na Figura 7.4 é apresentado o algoritmo de escalonamento por regiões com a partição
temporal incorporada. Recordamos que o algoritmo de partição temporal foi introduzido
previamente no capítulo 6. A partição temporal é realizada no nível de topo do HPDG e por
isso apenas o algoritmo de escalonamento do nível hierárquico de topo considera a partição
temporal. Para níveis da hierarquia abaixo deste é utilizado o algoritmo apresentado na Figura
7.5 que é fundamentalmente uma versão do algoritmo da Figura 7.4 sem a inclusão dos
aspectos relacionados com a partição temporal.
O algoritmo da Figura 7.4 vai agrupando os blocos básicos até que apareça um nó
identificador de um ciclo ou até que não existam nós para agrupar. Sempre que aparece um
nó identificador de um ciclo (linha 12) o algoritmo realiza o escalonamento do agrupamento
criado até então (desde o último grupo escalonado), linha 13, e um novo segmento de estados
é adicionado ao STG. Em seguida, é chamado o algoritmo de escalonamento de regiões
cíclicas (linha 14).
O algoritmo de escalonamento de regiões cíclicas apresentado na Figura 7.5 começa por
encontrar o nó no DFG global da região considerada que controla o ciclo (linha 2). De
seguida o algoritmo comporta-se similarmente ao algoritmo anterior, isto é, vai agrupando
blocos básicos até aparecerem novas regiões cíclicas, e nessa situação é chamado
recursivamente (linha 13), ou até todos os blocos básicos terem sido agrupados (linha 7). No
final, o algoritmo coloca o laço cíclico no STG (linha 23) e retorna informação que permite
que os novos segmentos de estados a adicionar ao STG partam do estado que representa o
início de um ciclo.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 171
1. DoSchedRec(MaxArea, DFG(V, E), Costs) 2. int CurrentArea=0, SchedNum=0, NumNode=0, NumSchedNodes=0; 3. SortedList = Create a sorted List of ready nodes; 4. BitSet SchedNodes = new BitSet(|V|); 5. STG = doInitSTG(); 6. while(NumSchedNodes < |V|) 7. Node A = SortedList.ElementAt(NumNode); 8. Boolean Fit = ((CurrentArea + Area(A)) <= MaxArea); 9. if(Fit) 10. SortedList.removeElement(A); 11. NumSchedNodes++; 12. if(A instanceof Loop) 13. doSTG(A, STG); Figura 7.6 14. doSchedRecLoop(A, STG); Figura 7.5 15. else 16. ScheduleElement(A, CurrentArea, SchedNum, SchedNodes); 17. 18. if(SortedList.Update(DFG, A, SchedNodes)) 19. NumNode = 0; 20. else if(NumNode ≥ List.size()) && (List.size() != 0) 21. SchedNum++; NumNode = 0; CurrentArea = 0; 22. STG = InitSTG(); 23. 24. else 25. if(NumNode ≤≤ SortedList.size()-2) 26. NumNode++; 27. else 28. SchedNum++; NumNode = 0; CurrentArea = 0; 29. doFinalEdge(STG); 30. STG = InitSTG(); 31. 32. 33. doSTG(A, STG); Figura 7.6 34. doFinalEdge(STG); 35.
Figura 7 .4 . Algor i tmo de escalonamento por regiões.
O algoritmo que escalona as operações de uma região do DFG global é apresentado nas
Figura 7.6, Figura 7.7 e Figura 7.8. Este algoritmo, como foi previamente referido, é baseado
no algoritmo de escalonamento estático baseado em lista. Os nós disponíveis para
escalonamento são ordenados pelo valor das respectivas mobilidades em ordem crescente
(linha 7 e linha 27 da Figura 7.6). O algoritmo apresentado utiliza três vectores: o vector
List que armazena as operações disponíveis para serem escalonadas, o vector Link que
armazena as operações que já foram escalonadas mas que ainda não completaram a execução,
o vector ListComp que armazena as operações que terminaram a execução (são movidos de
Link para ListComp aquando do término da execução). Quando é acrescentada uma
operação ao vector ListComp o algoritmo procura na região se há operações que possam
ficar disponíveis para serem escalonadas e adiciona-as ao vector List.

172 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
1. DoSchedRecLoop(LoopNode B, StateTransGraph STG) 2. IfNode If1 = getIF(B); 3. GraphNew Ginner = B.getContent(); 4. Vector List = Ginner.getFirstNodes(); 5. Vector ListReady = new Vector(); 6. int NumNodesSched = 0, NumNode = 0; 7. while(NumNodesSched < Ginner.size()) 8. Node A = List.element(NumNode); 9. List.remove(NumNode); 10. NumNodesSched++; 11. if(A instanceof LoopNode) 12. doSTG(STG, getRegion(ListReady)); Figura 7.6 13. doSchedRecLoop(A); 14. else 15. ListReady.add(A); 16. ListSched.set(A.getID()); 17. 18. if(UpDate(A, ListSched, List) 19. NumNode = 0; 20. 21. 22. doSTG(STG); Figura 7.6 23. doBackEdge(STG); 24.
Figura 7 .5 . Algor i tmo de escalonamento de regiões cíc l icas.
Por cada novo estado (linha 12 da Figura 7.6) o algoritmo avança passo a passo (linha 17) até
ao fim do estado (linha 13). No final, um novo ciclo de relógio é considerado (linha 33).
O algoritmo vai produzindo o escalonamento utilizando o passo de granulosidade fina, que é
uma fracção do período do ciclo de relógio escolhido previamente (capítulo 4). Por cada
incrementação do passo é subtraído a todas as operações existentes no vector Link o valor
do incremento (linha 18).
Para a partilha de recursos o algoritmo utiliza uma janela temporal para cada operador a
partilhar (neste momento unicamente acessos à memória) e só atribui à janela temporal o
atraso de um operador do mesmo tipo quando a janela temporal está vazia (tem o valor menor
ou igual a zero, linha 4 da Figura 7.7). A atribuição do atraso de um operador a uma janela
temporal corresponde ao escalonamento do operador. Por cada incrementação do passo é
também subtraído a cada janela temporal o valor do incremento (linha 18 da Figura 7.6).

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 173
1. DoSTG(Node A, StateTransGraph STG, DAG Region(DFG), ControlNode) 2. StateSTG LastState = STG.getLasState(); 3. StateSTG State = LastState; 4. int StateID = LastStateID; 5. StateSTG ControlStateInit, ControlStateEnd; 6. Vector List = getFirstNodes(Region); 7. List.doSort(); 8. Vector Link = new Vector(), Comp = new Vector(); 9. int[] MemSlot = new int[Board.NumOffMemories]; 10. int step = 0; clockCycle = 0; 11. while(!(List.isEmpty() && Link.isEmpty())) 12. State = new StateSTG(StateID++); 13. while(getNumCLKs(step) <= clockCycle) 14. for each Node Ai ∈List 15. Schedul(Ai, List, ListComp, Link, ControlNode); 16. 17. step += stepInc; 18. boolean hasCtrEnded = Decrement(MemSlot, ListComp); 19. if(hasCtrEnded) ControlStateEnd = State; 20. Boolean update = false; 21. for each Node Bj ListComp 22. if(update(Bj)) 23. ListComp.remove(Bj); 24. update = true; 25. 26. 27. if(update) List.doSort(); 27. 28. if(LastState has only registers) 29. STG.add(State); 30. STG.addEdge(LastState, State); 31. LastState = State; 32. else StateID--; 33. clockCyle++; 34. 35. ControlStateEnd.addFlag(ControlNode); 36. Return Loop Information(ControlStateEnd, ControlStateInit); 37.
Figura 7 .6 . Algor i tmo de cr iação do STG.
A parte do algoritmo representada na Figura 7.8 retira o nó da lista de nós disponíveis para
serem escalonados (linha 2) e se o nó tiver atraso não nulo (linha 3) adiciona-o à lista de nós
que foram escalonados mas ainda não completaram a execução (Link, linha 4). No caso do
atraso ser nulo (linha 5) é feita a busca de nós que possam ficar disponíveis para serem
escalonados e se essa busca der resultados os nós encontrados são adicionados
ordenadamente à lista de nós disponíveis para escalonamento (linhas 6 a 8).
Como foi referido, o algoritmo utiliza uma janela temporal para cada memória e assume que
os arrays foram previamente mapeados em cada uma das memórias existentes. Os nós no

174 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
DFG de acesso à memória são rotulados com o identificador da respectiva memória. No caso
de partilha de outros recursos o mapeamento pode ser feito durante a execução do algoritmo
de escalonamento. O algoritmo necessita, nesse caso, de procurar uma janela temporal livre
com o mesmo tipo do operador a escalonar.
1. Schedul(DAGNode A, Vector List, Vector ListComp, Vector Link, DAGNode ControlNode) 2. if(Ai instanceof LdNode or StNode) 3. int MemID = Ai.getMemID(); 4. if((MemSlot[MemID] <= 0) && isInitCycle(step)) 5. MemSlot[MemID] = Ai.delay(); 6. LastState.add(Sel, St1, Ai); 7. Schedule(Ai,Link, List); Figura 7.8 8. 9. else if((Ai is Register) && isInitCycle(step)) 10. Schedule(Ai,Link, List); Figura 7.8 11. if(Ai.isFirstAssign()) 12. LastState.add(Sel, St1, Ai); 13. else 14. EndLoopState.add(Sel, St1, Ai); 15. 16. else if(Ai is ControlNode) 17. ControlStateInit = State; 18. ControlStateEnd = State; 19. Schedule(Ai,Link, List); Figura 7.8 20. else 21. Schedule(Ai,Link, List); Figura 7.8 22. 23.
Figura 7 .7 . Algor i tmo de cr iação do STG (2ª parte).
1. Schedule(DAGNode A, Vector Link, Vector List) 2. List.remove(A); 3. if(Ai.delay() > 0) 4. Link.add(A); 5. else 6. if(update(A, List)) 7. List.doSort(); 8. 9. 10.
Figura 7 .8 . Algor i tmo de cr iação do STG (3ª parte).
Exemplo 7 -2 Escalonamento de um c ic lo .
Considere-se o exemplo seguinte, e que os arrays A, B e C foram
mapeados numa memória de um porto:

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 175
for(int i=0;i<10;i++)
c[I]=a[I]+b[I];
O compilador produz um STG com 9 estados com execução em 73 ciclos (7
× 10 + 1 + 2). A Figura 7.9 apresenta o grafo correspondente à unidade de
dados gerada pelo NENYA e a Figura 7.10 ilustra o escalonamento das
operações em cada estado do STG. No último estado de cada iteração de
um ciclo (estado 9 para o exemplo da Figura 7.10) são gerados os sinais
necessários para o estado seguinte (primeiro estado de cada iteração do
ciclo). Não é, por isso, necessário utilizar um estado unicamente
responsável pela actualização de uma nova iteração da região cíclica. Deve-
se ter em atenção que, no exemplo considerado, o primeiro acesso à
memória (leitura) é feito de forma especulativa, e por isso o endereço
determinado pelo índice vem directamente do multiplexador em vez do
registo que armazena o valor referente à variável i. No fim de cada iteração
do ciclo a variável i é actualizada no início do estado imediatamente a
seguir à iteração.
REG i
0
10
lt_N
Endereço A
REG Ai REG Bi
LOAD/STORE Sel1 Endereço B
Sel2
Endereço C
Ci
Figura 7 .9 . Grafo da unidade de dados gerada pe lo NENYA para o
exemplo da soma de dois vectores .

176 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
++ < 10
+
2
3
4
5
6
7
8
9
B[I]
A[I]
C[I]
start
end
+ = 3,54 ciclos load/store = 1 ciclo ++ = 0,4 ciclos < 10 = 0,37 ciclos
Estado
1
Figura 7 .10 . Escalonamento de operações (exemplo: soma de vectores,
C = A + B, com 10 e lementos cada) .
O algoritmo descrito até aqui escalona em série regiões cíclicas que apareçam lado a lado no
HPDG. A possibilidade de execução concorrente destas regiões pode ser uma fonte de
melhoria de desempenho, pois permite a sobreposição de regiões por natureza
computacionalmente intensivas. Na secção seguinte é apresentada uma forma de lidar com a
execução de regiões cíclicas concorrentes.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 177
7.4 Escalonamento de Regiões Cíclicas Concorrentes
A principal característica do modelo de representação utilizado é o de explicitamente
representar regiões com possibilidade de serem executadas concorrentemente. O
escalonamento deste tipo de concorrência pode ser realizado região-a-região e o controlador
gerado pode ser constituído por FSMs também concorrentes, sincronizadas nos pontos de
junção (término das regiões concorrentes). As regiões cíclicas concorrentes apresentam,
contudo, dificuldades suplementares sempre que seja necessário partilhar recursos entre elas.
Em [Lakshmin99] é apresentado um escalonador que permite a execução de regiões cíclicas
em paralelo por meio de uma única FSM. Quando existem várias regiões cíclicas prontas a
escalonar, o escalonador resolve estaticamente a partilha de unidades ao considerar todos os
casos possíveis de execução dessas regiões. Por isso, sofre do problema da explosão devido à
necessidade de cobertura de todos os casos possíveis (término de cada ciclo e execução dos
restantes).
Nesta tese é apresentada uma abordagem diferente. Cada região cíclica pode ser representada
por uma sub-STG, havendo execução concorrente entre sub-STGs que representem regiões
cíclicas com funcionamento concorrente. No caso de existirem regiões cíclicas concorrentes é
construído um STG que incorpora dois tipos de nós especiais, o nó fork e o nó join. O nó fork
inicia sub-STGs e o nó join sincroniza sub-STGs. Cada sub-STG pode ser implementado por
uma FSM activada por um sinal de start e que após finalizar a execução produz um sinal de
done. Os nós de join que aparecem no STG podem ser implementados por estados da FSM
que ficam à espera que sejam activados todos os sinais done de cada FSM correspondente a
cada sub-STG.
Quando não existem competições interciclos o escalonamento é facilitado e resolve-se pela
simples geração de escalonadores concorrentes com pontos de sincronização no fim.
Os possíveis conflitos nas utilizações dos mesmos operadores por parte de, por exemplo duas
regiões concorrentes, são salvaguardados por um mecanismo de arbitragem que resolve
acessos ao mesmo recurso. Para simplificar o processo de arbitragem são dadas prioridades

178 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
estáticas a cada região cíclica concorrente9. O árbitro baseado neste esquema é bastante
simples (formado, para cada sinal de aceitação, pela conjunção do próprio com os sinais de
requerimento com maior prioridade invertidos). As prioridades podem ser baseadas na ordem
decrescente dos pesos calculados com o número de iterações multiplicado pelo atraso do
caminho crítico do ciclo (operações em ciclos com maior tempo de execução devem ter maior
prioridade). Neste mecanismo, existe um árbitro por cada porto de cada memória acedido por
mais do que uma região cíclica concorrente.
Exemplo 7 -3 . Execução concorrente de regiões cícl icas.
Considere-se o filtro Kalman, cujas características se encontram ilustradas
no apêndice D. O GALADRIEL fornece para o nível de topo do HPDG o
grafo representado na Figura 7.11a. Pelo HPDG pode ver-se que os nós
“loop.1” e “loop.4” representativos respectivamente dos dois primeiros
ciclos do exemplo podem ter execução concorrente. Quando os arrays X e
Y são mapeados em memórias distintas (MEM0 e MEM1 da Figura 7.11b)
o funcionamento concorrente pode ser realizado pela execução concorrente
de duas FSMs como indicado no diagrama de blocos da Figura 7.11b. Para
tal é apenas necessário que a ambas seja comunicado o início de execução
pela FSM anterior e que a execução da FSM posterior entre em execução
quando as duas FSMs concorrentes terminarem. Quando os arrays X e Y
são mapeados na mesma memória (MEM0 da Figura 7.11c) o
funcionamento concorrente pode ser realizado pela execução concorrente
de duas FSMs em que os acessos de cada sub-STG são arbitrados como
indicado no diagrama de blocos da Figura 7.11c. Neste caso cada sub-STG
tem um estado de espera até que lhe seja dada permissão para aceder ao
recurso partilhado.
9 Em [Ouaiss00] é apresentado um esquema de arbitragem baseado no round-robin que parece ser mais propício para acessos a recursos partilhados no contexto de aplicações multitarefas.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 179
0
start
end
loop.1
3 6
loop.4
loop.7
loop.13
18
12
STG0
STG1 STG2
STG3
a) b )
MEM1 MEM0
STG0
STG1 STG2
STG3
c)
ÁRBITRO
MEM0
Figura 7 .11 . a ) Níve l de topo do HPDG para o exemplo Kalman (os nós
“ loop.#” encapsulam o resto da hierarquia e as regiões def inidas por
c ic los estão representadas por t raços) ; Diagramas de blocos que
representam as FSMs responsáveis pe la execução da unidade de dados
do exemplo: b) quando não há part i lha de recursos entre os c ic los
“ loop.1” e “ loop.4”; c) quando há part i lha de recursos entre os ciclos
“loop.1” e “ loop.4”.

180 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
7.5 Melhorias de Desempenho do HPDG sobre o CDFG
No início do capítulo foram descritas as vantagens do HPDG que justificaram a opção pela
utilização deste modelo hierárquico em vez de um modelo hierárquico obtido directamente do
CFG original. Nesta secção comparam-se escalonamentos partindo de cada um destes dois
modelos. Para tal são apresentados resultados para vários exemplos.
Para medir o grau de paralelismo foram utilizadas as medidas do número máximo de
operações em execução num ciclo de relógio (estado do STG) e a soma do número de
operações em execução por cada ciclo de relógio a dividir pelo número total de ciclos de
relógio.
As Figura 7.12 e Figura 7.13 apresentam os resultados destas duas medidas para os dois tipos
de grafos (CDFG e HPDG) para exemplos com grande densidade de construções
condicionais (if-then-else). Na Figura 7.13 pode ver-se que em alguns casos o número
máximo de operações em execução num estado é muito maior no HPDG do que no CDFG.
Intuitivamente, se o número de operações em paralelo aumenta, diminui o número de estados
e consequentemente aumenta a densidade de operações em execução por ciclo de relógio
como se pode verificar pela Figura 7.12. No que respeita ao número máximo de operações
em execução num estado, no exemplo USQRT são conseguidos, com a utilização do HPDG
versus a do CDFG, aumentos de 12 para 54 e no INTERSECT de 5 para 65. Para os outros
exemplos os aumentos foram menos significativos mas não deixam de ser importantes.
0
5
10
15
20
25
SQRT
USQRT
CRC-32
QRS
HAMM
ING
MASKBIT
SCCW
INTERSECT
CDFG
HPDG
Figura 7 .12 . Densidade de operações por c ic lo de re lógio para dois
modelos de representação (exemplos com grande densidade de
construções condicionais: if-then-else).

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 181
0
10
20
30
40
50
60
70
SQRT
USQRT
CRC-32
QRS
HAMM
ING
MASKBIT
SCCW
INTERSECT
CDFG
HPDG
Figura 7 .13 . Número máximo de operações por estado do STG para dois
modelos de representação (exemplos com grande densidade de
construções condic ionais: if-then-else).
A Figura 7.14 apresenta a efectividade do escalonamento no desempenho a partir do HPDG
face ao CDFG. Pode ver-se que para 3 dos exemplos (CRC-32, QRS e INTERSECT) o
número de ciclos de relógio obtido com a utilização do HPDG é cerca de 10% do obtido com
a utilização do CDFG. Para todos os exemplos o número de ciclos de relógio obtido com a
utilização do HPDG é inferior a 70% do obtido com a utilização do CDFG.
0%10%20%30%40%50%60%70%80%90%
100%
SQRT
USQRT
CRC-32
QRS
HAMM
ING
MASKBIT
SCCW
INTERSECT
CDFG
HPDG
Figura 7 .14 . Desempenhos dos escalonamentos fe i tos sobre o HPDG e
sobre o CDFG – va lores normal izados ao CDFG (exemplos com grande
densidade de construções condicionais: if-then-else).
As Figura 7.15 e Figura 7.16 mostram os resultados das duas medidas para os dois tipos de
grafos (CDFG e HPDG) para exemplos com utilização elevada de arrays, considerando uma
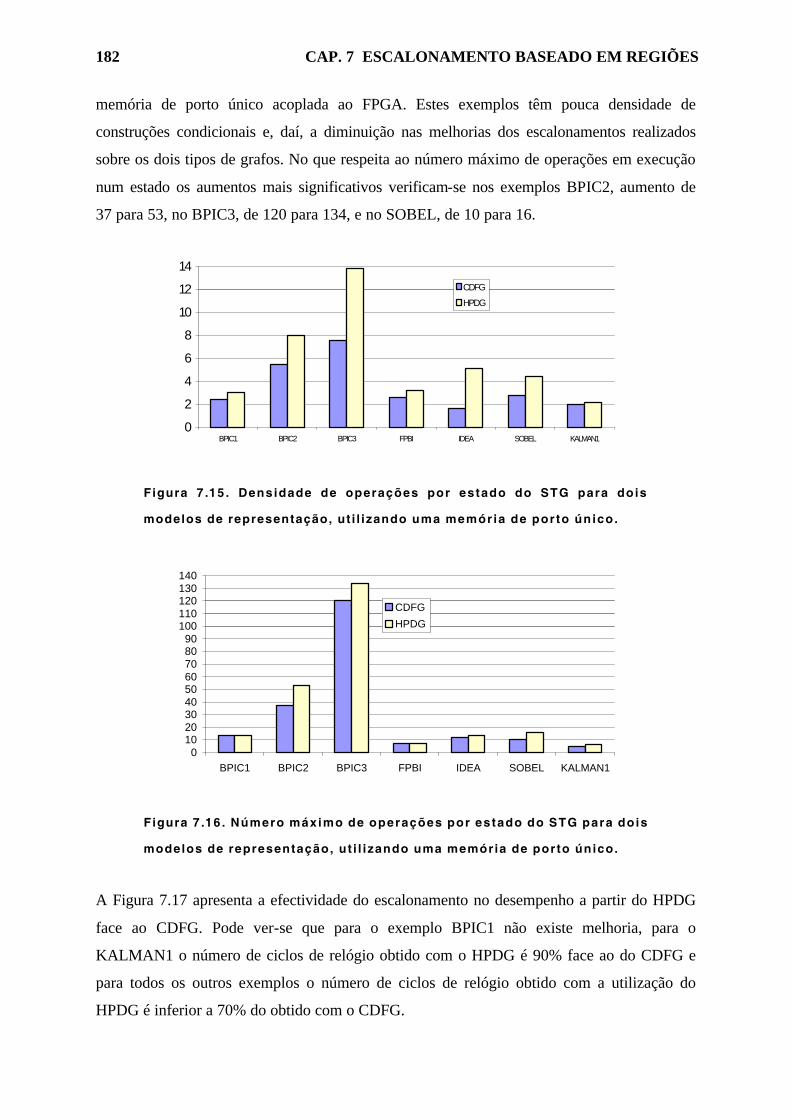
182 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
memória de porto único acoplada ao FPGA. Estes exemplos têm pouca densidade de
construções condicionais e, daí, a diminuição nas melhorias dos escalonamentos realizados
sobre os dois tipos de grafos. No que respeita ao número máximo de operações em execução
num estado os aumentos mais significativos verificam-se nos exemplos BPIC2, aumento de
37 para 53, no BPIC3, de 120 para 134, e no SOBEL, de 10 para 16.
0
2
4
6
8
10
12
14
BPIC1 BPIC2 BPIC3 FPBI IDEA SOBEL KALMAN1
CDFG
HPDG
Figura 7 .15 . Densidade de operações por estado do STG para dois
modelos de representação, ut i l izando uma memór ia de por to único.
0102030405060708090
100110120130140
BPIC1 BPIC2 BPIC3 FPBI IDEA SOBEL KALMAN1
CDFG
HPDG
Figura 7 .16 . Número máximo de operações por estado do STG para dois
modelos de representação, ut i l izando uma memória de porto único.
A Figura 7.17 apresenta a efectividade do escalonamento no desempenho a partir do HPDG
face ao CDFG. Pode ver-se que para o exemplo BPIC1 não existe melhoria, para o
KALMAN1 o número de ciclos de relógio obtido com o HPDG é 90% face ao do CDFG e
para todos os outros exemplos o número de ciclos de relógio obtido com a utilização do
HPDG é inferior a 70% do obtido com o CDFG.

CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES 183
0%
20%
40%
60%
80%
100%
BPIC1 BPIC2 BPIC3 FPBI IDEA SOBEL KALMAN1
CDFG
HPDG
Figura 7 .17 . Desempenhos dos escalonamentos fe i tos sobre o HPDG e
sobre o CDFG, ut i l izando uma memória de porto único (valores
normal izados ao CDFG).
Os resultados apresentados nesta secção mostram em geral melhorias significativas do
escalonamento com o HPDG face ao escalonamento com o CDFG. As melhorias aumentam
quando o algoritmo fonte tem um número elevado de construções condicionais e blocos
básicos sem dependências de dados (possibilita a execução paralela destes).
7.6 Conclusões
Neste capítulo foi demonstrada a exequibilidade da utilização do HPDG em conjunto com o
DFG global propostos no capítulo 3 como representações intermédias para compilação de
linguagens de alto-nível em hardware específico.
A forma como é feito o escalonamento por regiões foi ilustrada e comparada com
escalonamentos baseados no bloco básico. Foram apresentadas as vantagens de executar o
escalonamento sobre o HPDG face ao CDFG. O CDFG aqui considerado mantém a ordem de
blocos básicos do CFG e o escalonamento é realizado bloco básico a bloco básico com a
utilização do DFG global. Os resultados mostram as melhorias que se obtiveram com o
escalonamento sobre o HPDG em vez do CDFG. Estas melhorias são mais significativas
quando os exemplos são do tipo de fluxo de controlo intensivo. O escalonamento por regiões
permite fornecer arquitecturas sintonizadas com o paralelismo previamente exposto, permite
a execução especulativa de operações, a execução concorrente de regiões cíclicas e a
utilização real de fluxos de controlo múltiplos.

184 CAP. 7 ESCALONAMENTO BASEADO EM REGIÕES
O escalonamento é de resolução fina, possibilitando por isso, e sempre que possível, o
encadeamento de operações no mesmo ciclo.
O trabalho futuro deve ter em conta a técnica de folding de ciclos10 [Gajski92] e de
exploração do factor de desenrolamento de modo a permitir melhores desempenhos das
implementações finais.
O esquema de arbitragem de acessos a recursos partilhados por regiões cíclicas concorrentes
que sejam expostas pelas análises de dependências deverá ser avaliado em implementações
futuras. Deverá ser estudado se a adição de arbitragem permite obter melhores desempenhos
do que a simples execução destas regiões sequencialmente.
O escalonador implementado não distingue ramos mutuamente exclusivos. Os
melhoramentos devem ter em conta caminhos de saída de ramos mutuamente exclusivos
considerando a execução especulativa de operações sem efeitos colaterais.
Sob o ponto de vista de melhoramento de desempenho, uma optimização possível é a criação
de caminhos de saída de unidades funcionais com base na pré-detecção de zeros nos
operandos de entrada. Por exemplo, a detecção de zeros nos 16 bits mais significativos dos
dois operandos de entrada de um multiplicador de 32 bits permitiria que o resultado estivesse,
sob o ponto de vista do escalonamento, disponível mais cedo quando os operandos de entrada
obedecessem a esse critério (utilizaria o atraso máximo para realizar uma multiplicação de 16
bits em vez do referente a uma multiplicação de 32 bits).
10 Nome atribuído pela comunidade de síntese arquitectural. Normalmente designada pela comunidade de compiladores de software por software pipelining ou mais correctamente por loop pipelining [Muchnick97].

185
8. Protótipos e Resultados Experimentais
“Few things are harder to put up with than a good example.”
Mark Twain
Conforme referido, foram implementados dois compiladores protótipo (GALADRIEL e
NENYA) que permitiram validar a metodologia e as análises propostas. Neste capítulo,
começa-se por descrever os aspectos de suporte no desenvolvimento dos dois compiladores e
ainda as limitações dos mesmos. De seguida, e de modo a consubstanciar a validação da
metodologia, são apresentados resultados da compilação de exemplos mais complexos. Os
exemplos permitiram a compilação directa do código original sem ser necessário alterar os
algoritmos de maneira a que estes fossem suportados pelos compiladores. Pretendeu-se, para
além de mostrar as características dos elementos compilados para uma arquitectura específica
face à execução dos mesmos em software, apresentar resultados da aplicação de diversas
optimizações e da utilização de várias memórias acopladas ao FPGA usufruindo de
barramentos distintos. Nos exemplos apresentados todas as variáveis do tipo array são
consideradas indivisíveis, havendo mapeamento em várias memórias de forma a melhorar o
desempenho sempre que existam recursos. Alguns resultados consideram o caso teórico
extremo de utilização de memórias com número de portos suficientemente elevado de forma
a que não haja competição pelos recursos de acesso à memória para cada aplicação (permite
avaliar a degradação do desempenho resultante da seriação dos acessos à mesma memória).
Estes resultados permitiram avaliar as optimizações sem inibição do paralelismo exposto.

186 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
As características dos exemplos considerados neste capítulo encontram-se detalhadas no
apêndice D. Os exemplos foram escolhidos de modo a serem abrangidas várias áreas
computacionais. São considerados, entre outros, exemplos de processamento de imagem
(Sobel e FPBI), de criptografia (IDEA) e codificação (DCT). As dimensões dos exemplos
vão desde 10 até 400 linhas de código Java. O conjunto inclui exemplos com 7 ciclos e 6
variáveis do tipo array. O maior dos DFG globais gerados pelo GALADRIEL para os
exemplos considerados tem 1.558 nós.
Os tempos de execução do software apresentados foram medidos numa Sun SPARC 10,
com 196MB de RAM, sob o sistema operativo Solaris 2.5.
8.1 Compiladores GALADRIEL & NENYA
As duas ferramentas foram desenvolvidas inteiramente com a linguagem Java, utilizando
alguns dos APIs1 fornecidos pela tecnologia Java [Gosling96] e alguns pacotes em Java
disponíveis publicamente. Foram utilizados durante o desenvolvimento os seguintes pacotes:
o gerador de analisadores léxicos e sintácticos JavaCC [JavaCCURL], o gerador de bytecodes
Jas [JasURL] e o carregador de ficheiros de classes Java [Mcma96URL].
Foram desenvolvidas aproximadamente 30.000 linhas de código em Java (incluindo os
comentários) distribuídas por 131 classes. A utilização da tecnologia Java no
desenvolvimento dos compiladores revelou-se bastante eficaz corroborando o aumento de
produtividade na programação utilizando esta tecnologia defendido por muitos utilizadores.
A ferramenta DOTTY [DottyURL] desempenhou um papel fundamental na visualização dos
grafos apresentados e na depuração da geração dos mesmos. Por opção, o compilador pode
gerar ficheiros com a representação dos grafos no formato aceite pelo DOTTY.
O pacote em Java de visualização gráfica GOOGU [GooguURL] ajudou na depuração dos
escalonamentos gerados pelo NENYA por inspecção dos gráficos de Gantt. Do mesmo modo
o compilador pode gerar os ficheiros que representam o escalonamento para serem lidos pelo
GOOGU.
1 Do inglês: Application Programmer´s Interface.

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 187
Para prototipagem de exemplos foram utilizadas as classes em Java para comunicação com a
placa de desenvolvimento HOT da VCC fornecidas pelo fabricante [VCCURL].
Embora o compilador de anteguarda, GALADRIEL, não inclua a exposição de paralelismo a
todos os níveis (utiliza análises conservativas) não apresenta restrições à linguagem Java. O
compilador NENYA aceita presentemente os tipos de dados, as operações sobre esses dados e
as construções de controlo apresentados na Tabela 1.2. Algumas das restrições serão
certamente consideradas em trabalhos futuros e outras, por incluírem construções demasiado
complexas para serem implementadas em FPGA, necessitam de investigações prévias. Para
as operações de divisão (“/”) e do resto da divisão (“%”) não existe ainda suporte de
macrocélulas na biblioteca desenvolvida.
Quando o utilizador não tem macrocélulas para um dado FPGA pode ser utilizada uma
ferramenta de síntese lógica (que suporte o dispositivo e aceite descrições em VHDL) no
processo de geração do circuito da unidade de dados. Neste caso, são utilizadas as descrições
em VHDL comportamental de cada uma das macrocélulas. Contudo, para exemplos que
necessitem de unidade de controlo o utilizador tem de caracterizar, em termos de área e de
atraso, as macrocélulas com base nos resultados obtidos pela ferramenta de síntese lógica.
8.2 Estudos Experimentais
A utilização da reassociação de operações (THR) levanta algumas questões: Qual o impacto
desta optimização em exemplos reais? Será que a utilização de THR quando o paralelismo
exposto não é correspondido/satisfeito produz sempre melhores resultados? Outras dúvidas
estão relacionadas com a utilização do desenrolamento de ciclos e de várias memórias.
Pretende-se, por isso, nesta secção, avaliar quantitativamente o impacto das optimizações e a
degradação do desempenho resultante dos acessos a uma memória terem de ser seriados em
exemplos reais.
Os resultados apresentados nesta secção reportam valores obtidos pelo escalonamento sem
serem considerados os efeitos da colocação e do encaminhamento (P&R) no FPGA alvo
(família XC6200).
A Figura 8.1 apresenta os resultados obtidos para o exemplo KALMAN original
(KALMAN1) explorando o número de memórias acopladas ao FPGA. O exemplo utiliza 6

188 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
variáveis do tipo array. Na figura é apresentado o melhor escalonamento para cada número
de memórias externas considerado. Os resultados foram obtidos pela exploração exaustiva do
mapeamento das variáveis do tipo array nas memórias acopladas ao FPGA realizando para
cada mapeamento o escalonamento. Devido ao espaço de exploração ser exponencial (MN,
em que M é o número de memórias e N o número de arrays, quando todas as memórias são
consideradas diferentes) esta solução é de aplicação restrita pelos elevados recursos
computacionais necessários. Como curiosidade, refira-se que a exploração exaustiva do
espaço de mapeamentos possíveis durou 31 minutos para o exemplo KALMAN1 e 12 horas
para o exemplo KALMAN2. Tempos de computação maiores são necessários para as outras
versões do exemplo KALMAN. O NENYA permite também o mapeamento manual que,
embora ajude em alguns casos, não é viável em exemplos complexos, por ser difícil ao
programador encontrar o melhor mapeamento. As formas de mapeamento sem necessidade
de escalonamento serão estudadas futuramente. Estas formas devem permitir encontrar
mapeamentos quasi-óptimos (no sentido de fornecerem os melhores desempenhos) sem a
necessidade de realizar o escalonamento e da procura exaustiva do espaço constituído pelos
mapeamentos possíveis.
0
20
40
60
80
100
120
140
1 2 3 4 5 6
#Memórias
Atr
aso
(u
s) KALMAN1
KALMAN2
KALMAN3
KALMAN4
Figura 8 .1 . Resul tados de escalonamentos para vár ias versões do
exemplo KALMAN (ut i l iza 6 var iáveis do t ipo array) considerando vár ias
memórias externas. Para cada conjunto de memórias externas
acopladas é representado o mapeamento que produz o melhor
desempenho.

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 189
Pela Figura 8.1 pode verificar-se que para o algoritmo original o melhor escalonamento é
obtido com apenas 2 memórias, com 4 memórias para a versão KALMAN2, com 3 memórias
para a versão KALMAN3 e 5 memórias para KALMAN4. A figura indica que com
desenrolamento parcial e a utilização de várias memórias foi possível obter uma aceleração
de quase 7 sobre o escalonamento da versão original considerando apenas uma memória.
O desenrolamento de alguns ciclos realizado nas versões KALMAN2, KALMAN3 e
KALMAN4 aumentou o grau de paralelismo existente como se pode verificar pela Figura
8.2. A versão KALMAN3 permitiu reduzir o número de acessos a arrays o que se traduziu no
facto desta versão necessitar de menos uma memória do que o KALMAN2 para produzir o
mesmo escalonamento.
A Figura 8.3 mostra os rácios obtidos para os melhores e para os piores escalonamentos da
Figura 8.1 sobre o escalonamento considerando uma memória multiporto. A figura ilustra que
com o mapeamento óptimo dos arrays em várias memórias o paralelismo existente no
algoritmo sem utilização de THR é praticamente satisfeito como se pode ver pelas melhorias
pequenas obtidas sobre os melhores escalonamentos (segundo grupo de colunas na Figura
8.3). Com a utilização de THR pode ver-se que os melhores escalonamentos obtidos pela
utilização de várias memórias são mais modestos (último grupo de colunas na Figura 8.3),
pois os graus de paralelismo não são satisfeitos. Formas de conseguir satisfazer esse
paralelismo passam pela utilização de memórias com mais do que um porto e/ou pela partição
de cada array por mais do que uma memória.
05
101520253035404550
1 2 3 4
#Memórias
#Op
eraç
ões
KALMAN1
KALMAN2
KALMAN3
KALMAN4
Figura 8 .2 . Número de operações em execução num estado do STG para
o exemplo KALMAN considerando vár ios números de memór ias
acopladas ao FPGA.

190 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
0,51,01,52,02,53,03,54,04,55,0
pior
/m
ultip
orto
s/T
HR
mel
hor/
mul
tipor
tos/
TH
R
pior
/m
ultip
orto
c/T
HR
mel
hor/
mul
tipor
toc/
TH
R
Ace
lera
ção
KALMAN1KALMAN2KALMAN3KALMAN4
Figura 8 .3 . Rácios dos melhores e dos p iores escalonamentos para as
vár ias versões sobre o escalonamento considerando uma memór ia de
portos múlt iplos.
Na Figura 8.4 pode ver-se que a utilização de THR nas versões com potencial (KALMAN2,
3 e 4) pode fornecer escalonamentos melhores ou piores. Com a utilização de apenas uma
memória o resultado do escalonamento para as versões KALMAN2 e 3 utilizando THR foi
melhorado. Para várias memórias os resultados da aplicação de THR foram todos piores.
Contudo, no caso hipotético de utilização de uma memória de portos múltiplos (sem inibição
do paralelismo potenciado pela utilização de THR) a aplicação de THR produz melhorias
significativas.
0
20
40
60
80
100
120
140
KALMAN1 KALMAN2 KALMAN3 KALMAN4
atra
so (
us)
s/ THR (1 Mem)
THR (1 Mem)
s/ THR (6 Mem)
THR (6 Mem)
s/ THR (multiporto)
c/ THR (multiporto)
Figura 8 .4 . Efe i tos da ut i l ização de THR com uma de um porto ou de
por tos múl t ip los ou vár ias memórias para o exemplo KALMAN.

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 191
A Figura 8.5 ilustra a degradação do desempenho resultante da seriação dos acessos a uma
memória de apenas um único porto face à utilização de uma memória multiporto hipotética.
A utilização de uma memória hipotética de portos múltiplos serve para indicar o desempenho
máximo que se poderia obter com a utilização de várias memórias acopladas ao FPGA ou
com a utilização de uma memória com mais do que um porto. A figura ilustra um aumento da
degradação do desempenho quando se utiliza a técnica de desenrolamento de ciclos
(exemplos BPIC, FPBI e DCT).
80%
100%
120%
140%
160%
180%
200%
BPIC1 BPIC2 BPIC3 FPBI FPBI1 FPBI2 FPBI3 IDEA SOBEL DCT DCT1
Figura 8 .5 . Degradação do desempenho (va lores maiores do que 100%)
com uma memór ia de por to único versus uma memór ia mul t ipor to
(va lores normal izados aos desempenhos obt idos com memória
multiporto). Foi ut i l izado THR nos exemplos em que este permite
melhorar os resul tados do escalonamento.
As análises experimentais apresentadas servem para se ter uma ideia dos graus de paralelismo
expostos pela utilização do desenrolamento de ciclos. Embora na maioria dos casos o
paralelismo aumente, a seriação de acessos a memórias pode limitar as melhorias de
desempenho obtidas. Em alguns casos estas seriações restringem as próprias optimizações
sobre o fluxo de dados como é o caso de THR (em alguns casos a sua utilização piora o
desempenho final). São necessárias várias memórias acopladas ao FPGA com barramentos
distintos de forma a não defraudar as expectativas em exemplos com elevado número de
acessos à memória. Este facto torna -se ainda mais evidente quando a aplicação do
desenrolamento não permite reduzir o número total de acessos à memória.

192 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
A utilização teórica de uma memória multiporto serve para mostrar o paralelismo realmente
exposto e indicia perdas que justificam esforços na investigação de técnicas de partição de
arrays por várias memórias. Como era intuitivo, em exemplos com grande número de acessos
ao mesmo array, e sem ser considerada a partição destes, a existência de uma memória com
mais do que um porto é em alguns casos mais benéfica do que a utilização de várias
memórias.
8.3 Prototipagem na Família de FPGAs XC6200
Foram efectuados protótipos de alguns exemplos, para validar os compiladores apresentados,
na placa de desenvolvimento [Nisbet97] ligada ao barramento PCI2 de um computador
pessoal (PC) com sistema operativo Windows98. O FPGA utilizado foi o XC6216
[Xilinx97]. Foram implementados vários exemplos para validação dos compiladores. A título
de exemplo são apresentados os resultados obtidos da compilação do exemplo HAMMING
descrito no apêndice D.
8.3.1 Descodificador de Hamming
O exemplo HAMMING depois de compilado para os bytecodes Java tem 121 instruções JVM
agrupadas pelo GALADRIEL em 6 blocos básicos. A Figura 8.6 ilustra o DFG global do
exemplo gerado pelo GALADRIEL. Na figura, os laços estão rotulados com o número de bits
suficiente obtido pela análise de aferição do número de bits apresentada neste trabalho. A
Tabela 8.1 ilustra as macrocélulas utilizadas pelo NENYA na estrutura final do circuito. A
utilização da macrocélula CONST_op é apenas devida ao facto do programa Velab
[VelabURL] não suportar descrições em VHDL com atribuições de constantes a variáveis. O
circuito gerado pelo NENYA com estas constantes requer 321 células (ver linha NENYA da
Tabela 8.2). A Figura 8.7a apresenta o CFG do exemplo HAMMING e a Figura 8.7b
apresenta a implantação física (layout) do circuito num FPGA XC6216 com identificação da
área do circuito ocupada por cada bloco básico do CFG.
2 Do inglês: Peripheral Controller Interface.
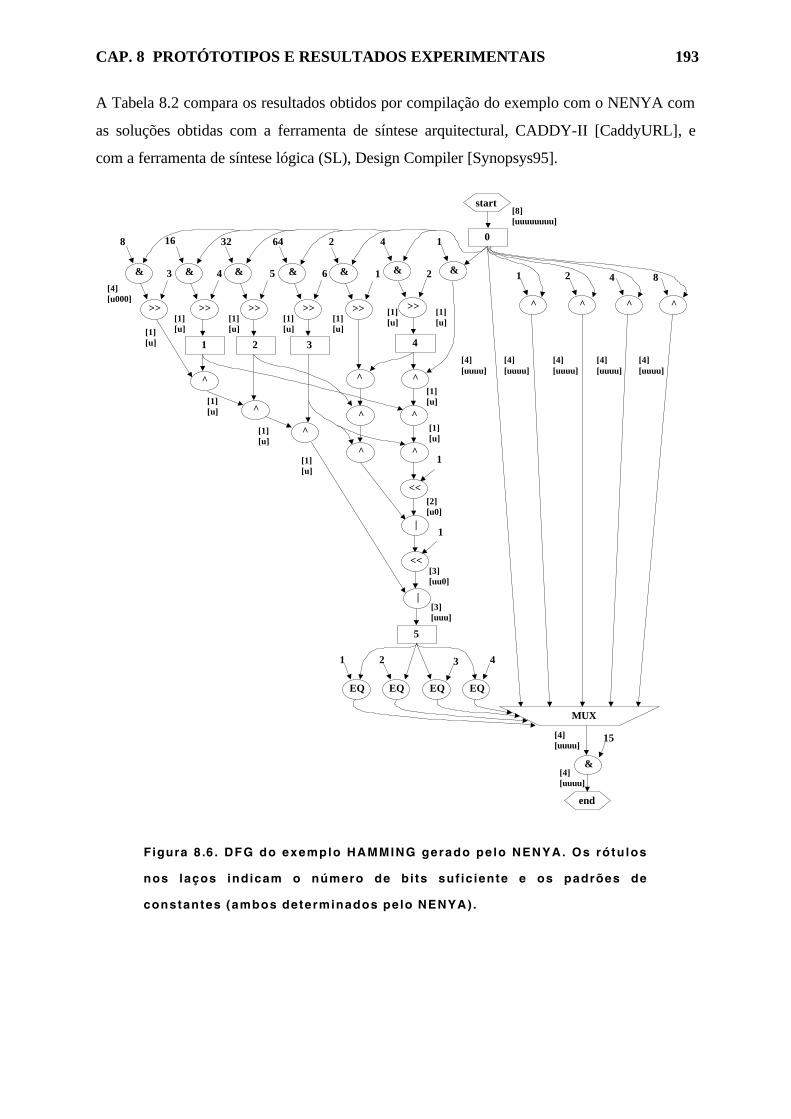
CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 193
A Tabela 8.2 compara os resultados obtidos por compilação do exemplo com o NENYA com
as soluções obtidas com a ferramenta de síntese arquitectural, CADDY-II [CaddyURL], e
com a ferramenta de síntese lógica (SL), Design Compiler [Synopsys95].
end
start
&
0
>>
&
>>
&
>>
&
>>
&
>>
&
>>
1
^
2
^
3
^
^
4
^
8 16
3 4
32
5
64
6
2
1
4
2 &
1
^ ^
^ ^
<<
1
|
<<
1
|
5
EQ
1
EQ
2
EQ EQ
4 3
MUX
&
15
^
1
^
2
^
4
^
8 [4] [u000]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[1] [u]
[8] [uuuuuuuu]
[1] [u]
[1] [u]
[2] [u0]
[3] [uu0]
[3] [uuu]
[4] [uuuu]
[4] [uuuu]
[4] [uuuu]
[4] [uuuu]
[4] [uuuu]
[4] [uuuu]
[4] [uuuu]
Figura 8 .6 . DFG do exemplo HAMMING gerado pe lo NENYA. Os rótu los
nos laços indicam o número de bi ts suf ic iente e os padrões de
constantes (ambos determinados pelo NENYA).

194 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
Tabela 8 .1 . Macrocélulas ut i l izadas pelo NENYA para implementar o
descodi f icador de Hamming.
Macrocélula Descrição Quantidade AND_op AND lógico 8 CONST_op Constante 16 OR_op OR lógico 2 XOR_op XOR lógico 13 SHR_c_op Deslocamento lógico para a direita 6 SHL_c_op Deslocamento lógico para a esquerda 2 MUX_5_1 Multiplexador de 5 entradas 1 EQ_op Comparador de igualdade 4
Tabela 8 .2 . Resultados do reconfigware para o descodif icador de
HAMMING. (♠♠ sem os at rasos provocados pelo encaminhamento; ♣♣
est imat iva fe i ta pela ferramenta XACTstep; REC: tempo de
conf iguração, com base no PCI de 32bi ts @33MHz) .
atraso (ns) Ferramenta Área (células) ♠ ♣
Pares endereço/dados
X × Y células REC (µs)
NENYA 75 32 76 181 11×7 5,48 SL 41 19,6 52 127 7×8 3,85
CADDY 1.080 - - - - -
2
5
start
0
3
end
CFG
41
BB0
BB5
BB4
BB3
BB2 BB1 REG IN
REG OUT
a) b)
Figura 8 .7 . Exemplo HAMMING: a) Grafo de f luxo de controlo (CFG); b)
implantação f ís ica no FPGA XC6216 .
O circuito obtido pela ferramenta de síntese arquitectural não foi prototipado no FPGA
devido à impossibilidade de o fazer em tempo útil. O circuito tem uma estrutura irregular e as

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 195
fases de colocação têm de ser feitas manualmente. O circuito requer 1.080 células de lógica
(ver linha CADDY na Tabela 8.2), facto que ilustra as deficiências da síntese arquitectural.
Este circuito utiliza vários multiplexadores e registos. O resultado não considera a aplanação
da estrutura RTL e subsequente síntese lógica. A área obtida pelo NENYA é inferior à obtida
pela ferramenta de síntese arquitectural devido à habilidade do NENYA de tirar partido da
especialização das macrocélulas parametrizáveis em vez da utilização de componentes
genéricos e das análises de extracção do número de bits e de propagação de constantes ao
nível do bit. A ferramenta de síntese arquitectural produz sempre uma unidade de controlo
mesmo que esta não seja necessária (nos casos em que o software garante o controlo, por
exemplo).
O circuito gerado por aplicação de síntese lógica tem 41 células de área e 52 ns de atraso (ver
linha SL na Tabela 8.2). Embora a síntese lógica possa ser aplicada a este exemplo, não o
pode ser em exemplos de grande complexidade por ser demasiadamente ineficiente gerar a
estrutura do circuito ao nível booleano (portas lógicas ou diagramas de decisão binários).
Ainda mais, quando o algoritmo fonte inclui acessos a memória e ciclos, a síntese lógica pura
não é apropriada e nem mesmo factível. Os resultados obtidos pela utilização de síntese
lógica são apresentados apenas como referências quasi-óptimas.
Na Tabela 8.2 estão ilustrados os atrasos fornecidos por cada uma das ferramentas e os
atrasos fornecidos pela ferramenta de colocação e encaminhamento [Xact97] após colocação
e encaminhamento do circuito no FPGA. As diferenças nos atrasos devem-se ao peso do
encaminhamento no atraso do caminho crítico que, nestes exemplos, chega a atingir
aproximadamente 70% do atraso global.
Todos os tempos de computação foram medidos da descrição fonte até à geração da estrutura
do circuito no formato EDIF [Stanford90]. O tempo de compilação do exemplo pelo
GALADRIEL+NENYA foi menor do que 4s (dos bytecodes do exemplo até à geração dos
ficheiros VHDL que descrevem a estrutura do circuito) e o tempo total de compilação
(GALADRIEL+NENYA seguido do VELAB) de cerca de 10s (execuções feitas numa Sun
SPARC 10 com o GALADRIEL+NENYA executado por um compilador do tipo JIT). Este
exemplo mostra uma redução substancial no tempo de compilação do
GALADRIEL+NENYA (10s) em relação à síntese arquitectural (> 8m) e à síntese lógica
(54s).

196 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
Sem optimizações o NENYA gerou um circuito com 321 células (ver 1 na Tabela 8.3). Com
utilização da expansão de constantes e de deslocamentos obteve-se, por compilação com o
NENYA, 201 células (ver 2 na Tabela 8.3). Na compilação concretizada pelo NENYA as
operações de deslocamento por uma constante são promovidas a fios. Quando operações
AND, OR, XOR e EQ lidam com um operando de entrada constante podem também ser
implementadas por fios. Com esta transformação a área do circuito gerado pelo NENYA
passa de 201 para 178 células (ver 2 e 3 na Tabela 8.3). A aplicação da propagação de
constantes ao nível do bit forneceu área de 75 células (ver 4 e 5 na Tabela 8.3), muito mais
próxima da área resultante da aplicação de síntese lógica (41 células).
Tabela 8 .3 . Resul tados da compi lação do exemplo HAMMING ut i l i zando
vár ias opt imizações.
Abordagem SL GALADRIEL+NENYA 1 2 3 4 5
Tempo de compilação 54s 10s 10s 10s 10s 10s Área (células) 41 321 201 178 75 75 Rectângulo no FPGA (X×Y) 7×8 24×32 19×19 - 11×8 - Pares de endereçamento/dados 127 946 514 - 181 - Atraso estimado antes do P&R (ns) 19,6 50 50 46 32 26 Atraso estimado após o P&R (ns) 52 160 150 - 76 -
Propagação de constants ao nível do bit - 4 4 THR (reassociação de operações) - 4 4 Macrocélulas - 4 4 4 4 4 Macrocélulas especializadas - 4 4 4 4 Aferição do número de bits suficiente - 4 4 4 4
8.3.2 Problemas com a Integração das Fases de Retaguarda
A inexistência de estimativas dos atrasos do encaminhamento, durante as fases de
escalonamento, requer que no circuito prototipado a frequência de relógio seja diminuída até
que seja garantido o funcionamento do mesmo. Em alguns casos é necessário refinar a
unidade de controlo para se obterem soluções melhores.
A unidade de controlo centralizada requer muitas vezes a utilização de interligações longas
com maiores atrasos, facto que limita a frequência de relógio máxima. Problemas devidos aos
escassos recursos de encaminhamento da família de FPGAs XC6000 e ao estado embrionário
do software de colocação e encaminhamento, XACTstep [Xact97], tornam as etapas de
colocação e encaminhamento morosas e semimanuais.

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 197
Nos circuitos de controlo e em ligações irregulares entre as macrocélulas da unidade de
dados, as etapas de colocação e encaminhamento são dificílimas e requerem intervenção do
utilizador.
A frequência de relógio dos exemplos é também limitada pela impossibilidade da ferramenta
XACTstep realizar colocação e encaminhamento com directivas de atraso.
8.4 Prototipagem na Família de FPGAs Virtex
Devido às limitações da família de FPGAs XC6000 e da respectiva ferramenta de colocação e
encaminhamento os exemplos mais complexos foram prototipados na família de FPGAs
Virtex [VirtexURL]. Por não se terem ainda macrocélulas para esta família de FPGAs é
utilizada síntese lógica (ferramenta Synplify [Synplicity99]) para implementar a unidade de
dados gerada pelo NENYA, em que para cada operador em vez da utilização dos geradores
de circuitos é utilizada a descrição VHDL-comportamental respectiva [Cardoso99d].
Antes da compilação é necessário descrever as macrocélulas para o FPGA alvo. A descrição
utilizada para a família Virtex de FPGAs baseou-se na síntese de cada componente variando
o número de bits dos operandos de entrada e após a colocação e o encaminhamento. São por
isso estimativas bastante próximas do circuito prototipado. Na descrição da biblioteca foram
apenas consideradas implementações das macrocélulas com área mínima.
A síntese lógica, elaborada pelo Synplify, e a colocação e encaminhamento, executada pela
ferramenta Alliance da Xilinx [Alliance98], foram realizadas sem restrições de desempenho e
com directiva de área mínima.
As experiências foram conduzidas sem intervenção do utilizador desde a compilação do
GALADRIEL+NENYA até à geração dos bitstreams. Foi seleccionada uma frequência de
relógio de 33MHz durante a compilação com o NENYA. Em todos os exemplos, os circuitos
finais foram testados com a frequência anterior. Os resultados foram validados por simulação
do VHDL representativo do reconfigware com a informação fornecida após colocação e
encaminhamento.
A Tabela 8.4 mostra os resultados da compilação: número de linhas de VHDL geradas pelo
NENYA, número máximo de operações em execução num estado, percentagem de recursos

198 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
utilizados no FPGA, número de slices3 do FPGA, número de flip-flops (FFs) do circuito final,
tempo de CPU gasto pelo GALADRIEL + NENYA, e o tempo de execução da solução
reconfigware. Os circuitos obtidos têm tamanhos de 3.148 a 86.006 portas equivalentes
(eqG). O número máximo de operações em execução num estado vai desde 8 a 54. Os
resultados para o exemplo FPBI1 consideram imagens de 16×16 pixéis.
Por omissão, os resultados apresentados consideram apenas uma memória de porto único
acoplada ao FPGA.
Para os exemplos, o tempo de CPU gasto na SL foi entre 1 a 23 minutos4, e na colocação e
encaminhamento entre 5 a 100 minutos. A fase de SL pode ser parcialmente eliminada e a
geração da unidade de dados pode ser realizada em segundos com a utilização de geradores
de circuitos. Esperamos também que o tempo de CPU gasto na colocação e encaminhamento
possa ser substancialmente reduzido com a utilização de macrocélulas com pré-colocação
relativa.
Tabela 8 .4 . Resul tados da compi lação para reconfigware. Todos os
exemplos foram protót ipados num FPGA Vir tex XCV300-4, excepto o
exemplo DCT2 que fo i protót ipado num XCV400-4 .
Exemplo
# Linhas VHDL (caminho de dados)
# Linhas de VHDL (unidade de controlo)
Número Máximo Ops./ Estado
% FPGA #Slices #eqG
# FFs
GALADRIEL+ NENYA tempo de CPU (s)
Tempo de execução do Reconfigware
DCT 1.877 742 8 22 681 13.586 267 14,1 264,7µs DCT1 2.452 1.029 27 86 2.650 58.532 644 16,6 165,8µs DCT2 4.710 417 44 79 3.798 86.006 340 16,3 16,1µs IDEA 1.963 410 19 43 1.323 30.277 372 10,1 6,3µs FPBI1 492 203 10 12 374 7.608 216 9,7 113,4µs USQRT 1.430 91 54 5 166 3.148 24 9,6 696,9ns
As Figura 8.8 e Figura 8.9 mostram, respectivamente, o efeito de cada optimização do fluxo
de dados realizada pelo NENYA no escalonamento e na área do circuito, considerando
3 Cada Slice na família Virtex é constituído por dois LUTs e cada CLB por dois Slices. 4 O tempo de computação da colocação e encaminhamento refere o tempo de CPU até à geração dos bitstreams.

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 199
apenas uma memória de porto único acoplada ao FPGA. As optimizações consideradas são:
reassociação de operações (THR), redução do custo de operações (OSR), inferência do
número de bits e propagação de bits constantes (ANB+PBC). Os valores apresentados são
normalizados aos resultados obtidos sem utilização das optimizações. Os resultados mostram
que as optimizações OSR e ANB+PBC têm um maior impacto na redução da área do que no
desempenho. A utilização de THR no FPBI1 e no DCT2 prejudica o desempenho devido à
seriação dos acessos à memória que restringe o grau de ILP exposto.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
USQRT FPBI1 IDEA DCT DCT1 DCT2
s/ opt
c/ THR
c/ OSR
c/ ANB+PBC
melhor
Figura 8 .8 . Efect iv idade das opt imizações do f luxo de dados no
desempenho do reconfigware.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
USQRT FPBI1 IDEA DCT DCT1 DCT2
s/ opt
c/ THR
c/ OSR
c/ ANB+PBC
melhor
Figura 8 .9 . Efect iv idade das opt imizações do f luxo de dados na área de
reconfigware.

200 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
A Figura 8.10 mostra as acelerações obtidas pela execução do reconfigware versus a
execução do software, utilizando o compilador JIT integrado no pacote Java2 SDK
[J2SDKURL]. Na figura, (1) representa o caso em que são utilizadas várias memórias de
porto único, e (2) o caso de uma memória de acessos múltiplos ao mesmo tempo (máximo de
14 leituras para o DCT1 e 7 leituras para o DCT2). Os resultados para o DCT1(2) e DCT2(2)
mostram a efectividade da utilização de THR quando os acessos a memórias não necessitam
de partilhar o interface. A utilização apenas teórica de uma memória de portos múltiplos é
considerado apenas para mostrar o quanto a partilha do interface com a memória pode limitar
o grau de ILP previamente exposto. Neste caso o DCT2(2) com a utilização de THR tem um
máximo de 256 operações em execução no mesmo estado, em vez das 42 da implementação
apresentada na Tabela 8.4.
1435
10
3651
1930
310
25 3994 132
598 676
1
10
100
1000
10000
USQRT
FPBI1
IDEA
DCTDCT1
DCT2
DCT(1)
DCT1(1)
DCT1(2)
DCT1(2)
THR
DCT2(2)
DCT2(2)
THRA
cele
raçã
o (
JIT
/Rec
on
fig
war
e)
Figura 8 .10 . Acelerações do reconfigware versus software.
Estes resultados podem ainda ser melhorados de várias formas: direccionando a SL e a
colocação e encaminhamento, sintonizando a frequência de relógio de acordo com o
escalonamento realizado pelo NENYA, procurando experimentalmente a frequência de
relógio máxima de funcionamento do circuito, ou utilizando macrocélulas com atrasos
menores.
8.5 Conclusões
Embora os tempos de execução do GALADRIEL+NENYA sejam reduzidos, importa realçar
que o desenvolvimento do software dos compiladores foi sempre orientado para a robustez,

CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS 201
facilidade de adicionar funcionalidades, facilidade de leitura, teste, e nunca
predominantemente de desempenho. São por isso previsíveis melhorias de desempenho por
simples reescrita de partes do código. Um dos exemplos que corrobora esta afirmação é a
utilização de várias passagens de análises independentes que poderiam ser englobadas em
uma única passagem.
Foram apresentados resultados para um conjunto de exemplos que ilustram as capacidades
dos compiladores desenvolvidos. Vários estudos foram apresentados, variando o número de
memórias, com desenrolamento de ciclos, que permitiram ilustrar os níveis de paralelismo
extraídos.
O desenrolamento de ciclos, por enquanto realizado manualmente, permitiu estudar melhor o
efeito de algumas das optimizações, pois na maioria das vezes aumenta o potencial de
paralelismo e do efeito das optimizações de código. Contudo, a utilização de desenrolamento
nos casos em que este potencia o aumento do paralelismo não produz só por si melhorias
significativas. Este facto é mais notório quando se utiliza apenas uma memória com um único
porto que inibe o paralelismo existente ao necessitar que os acessos sejam seriados
independentemente de serem acessos a arrays distintos. A análise conservadora de
dependências relacionadas com os acessos a arrays também inibe muitas das vezes o
potencial real que pode existir ao desenrolar-se um ciclo quando em presença de memórias
com mais do que um porto. É por isso necessário integrar análises que resolvam a extracção
do paralelismo ao nível dos acessos a elementos de cada array. Estas análises são de
importância fundamental quando se consideram memórias com mais do que um porto ou
quando cada array pode ser partido em fracções e estas mapeadas em memórias distintas.
De futuro será integrado o desenrolamento automático de ciclos, parcial e global. O folding
de ciclos será também integrado e espera-se poder avaliar as optimizações em conjunto com
esta técnica.
A aplicação de transformações (desenrolamento de ciclos, redução de acessos à memória)
potencia aumentos da aceleração com favorecimento da versão reconfigware sobre o
software devido à natureza mais especializada e concorrente do reconfigware.
A utilização de THR deve ser sempre considerada quando o potencial de paralelismo é
satisfeito completamente. Caso contrário, a utilização desta optimização deve ser avaliada
pelo utilizador pois o DFG obtido pode originar escalonamentos com pior desempenho.

202 CAP. 8 PROTÓTOTIPOS E RESULTADOS EXPERIMENTAIS
Para os exemplos considerados, a utilização de redução do custo de operações produziu
sempre resultados satisfatórios, mesmo considerando o facto de que as adições e subtracções
utilizam circuitos com área mínima.
Como se pode constatar pelos resultados apresentados a utilização das análises de aferição do
número de bits e de propagação de constantes ao nível do bit produz quase sempre melhorias
significativas.
O reconfigware para a família Virtex de FPGAs foi obtido automaticamente. Este facto
indica claramente que foi plenamente atingido um dos principais objectivos deste trabalho: o
de propiciar a utilização de reconfigware por utilizadores sem conhecimentos de projecto de
hardware.

203
9. Conclusões
«”It is good to be back in the world of light and warmth,”
said Galadriel, and Isildur thought that never before had her
many years shown so clearly on her face.»
Cirdan, The Gray Havens - Songs & Tales
Neste capítulo são sumariados os objectivos cumpridos pelo trabalho realizado, apresentadas
algumas conclusões, e sugeridos trabalhos futuros que podem contribuir para melhorar os
compiladores descritos e para desenvolver o estado da arte em compilação para hardware
reconfigurável.
9.1 Trabalho Realizado
Esta tese apresenta um caminho dos bytecodes do Java até hardware reconfigurável suportado
eficientemente por ferramentas computacionais (compiladores). Os compiladores permitem a
criação de arquitecturas específicas e eficientes para serem implementadas em FPGAs. As
arquitecturas geradas permitem explorar o paralelismo massivo possível de exposição a partir
de uma descrição sequencial de um algoritmo.
É uma abordagem genérica que permite que qualquer algoritmo (desde que obedeça ao
subconjunto da linguagem actualmente aceite) possa ser compilado e executado num FPGA
sem que o utilizador tenha conhecimentos de projecto de hardware.

204 CAP. 9 CONCLUSÕES
Devido à complexidade computacional1 da maioria dos problemas existentes na compilação
de descrições alto-nível em hardware específico (vulgo síntese arquitectural), torna-se
necessário dividir as fases de compilação em etapas permitindo que cada uma delas seja
resolvida com algoritmos baseados em heurísticas. O fluxo de compilação foi, por isso,
dividido em fases procurando sempre atingir resultados globais eficientes.
Globalmente, as contribuições desta tese são:
• Fornecer um caminho automático de algoritmos descritos em Java até à sua
implementação num FPGA;
• Permitir a compilação rápida e específica para FPGAs com uma ou mais memórias do
tipo SRAM acopladas;
• Exposição automática de graus de paralelismo elevados e representação explícita
desse mesmo paralelismo;
• Exposição automática dos vários fluxos de controlo que possam existir e
representação explícita dos mesmos;
• Escalonamento das operações e dos ciclos sempre ao nível das operações quer seja
quando se trata de um bloco básico ou de múltiplos blocos básicos com ou sem
dependências entre eles;
• Possibilidade de execução especulativa de todas as operações exceptuando operações
de escrita em memória;
• Partição temporal baseada numa nova reformulação do algoritmo de escalonamento
baseado em lista;
• Apresentação de alguns estudos que permitem aquilatar de possíveis melhoramentos e
da efectividade das análises propostas;
Por todos os pontos supraenunciados consideramos que os objectivos propostos foram
amplamente atingidos. A dissertação e os compiladores nela apresentados provam a
1 Acredita-se que o conjunto das tarefas (algumas delas já provadas serem NP-completas, como são os casos do escalonamento e da alocação) forme um problema global NP-difícil.

CAP. 9 CONCLUSÕES 205
exequibilidade, efectividade e eficiência do fluxo de compilação proposto. A compilação é
realizada em tempos de computação aceitáveis (dezenas de segundos em exemplos bastante
complexos). Os resultados obtidos da compilação de exemplos reais complexos
consubstanciam a metodologia e as análises de optimização apresentadas. Os resultados
confrontados com resultados quasi-óptimos comprovam a eficiência das técnicas de
compilação propostas.
As técnicas desenvolvidas representam um passo importante para que qualquer programador
(e não apenas os projectistas de hardware) possa utilizar eficientemente os recursos de
hardware reconfigurável que eventualmente estejam disponíveis no sistema computacional
utilizado.
No entanto, muito trabalho poderá ser adicionado de forma a potenciar ainda mais os
compiladores desenvolvidos. Por isso, de seguida são apresentadas ideias e descritos alguns
pontos de investigação que poderão ser considerados num futuro próximo.
9.2 Perspectivas de Trabalho Futuro
Existem possibilidades variadas de trabalho futuro nesta área. São descritas aqui as que se
julgam mais relevantes e com maiores possibilidades de serem consideradas proximamente.
Estruturas de Representação Intermédia
A utilização do formato de atribuição única (SSA2) está em consideração. As análises de
construção deste formato permitirão diminuir o tamanho dos pontos de selecção em alguns
exemplos.
Inferências do Número de Bits nos Operandos
A comparação das análises propostas nesta tese para aferição do número de bits de cada
operando com as propostas recentemente em [Stephen00] e a possibilidade de combinação de
ambas deve ser considerada.
Optimizações de Ciclos
2 Do ingles: Static Single Assignment.

206 CAP. 9 CONCLUSÕES
Duas das técnicas com possibilidade de fornecerem resultados melhores ao nível do tempo de
execução da implementação em hardware reconfigurável lidam com a existência de ciclos
nos algoritmos fonte. Estas técnicas referem-se à utilização de software pipelining (folding de
ciclos) e de desenrolamento de ciclos.
A primeira permitirá a obtenção de implementações mais rápidas sem adicionar muito mais
área ao circuito final.
A integração de desenrolamento parcial ou total de ciclos permitirá, na maioria dos casos, o
aumento do grau de paralelismo, embora com aumento da área do circuito final que necessita
de, por isso, ser considerado. Esta técnica deve ser integrada com a partição temporal de
forma a que a exploração do factor de desenrolamento possa ser automaticamente utilizada
para fornecer implementações de ciclos que possam caber na área confinada a cada fracção
temporal.
A integração de técnicas que lidem com as optimizações anteriores foram propostas no
projecto AXEL [AxelURL] financiado pelo programa PRAXIS XXI e encontram-se em fase
de investigação.
A utilização de desenrolamento de ciclos parcial de modo a potenciar a aplicação de SWAR3
em acessos a memórias deve ser também considerada, pois permitirá, em alguns casos,
diminuir o número de acessos a memórias.
Partição Temporal
Algoritmos de partição temporal que permitam considerar os tempos de reconfiguração, a
partilha de algumas unidades e o intercalamento entre execução e reconfiguração devem
constituir um foco de novas investigações e desenvolvimentos. O intercalamento entre a
execução de uma fracção temporal e a reconfiguração da próxima fracção temporal a
executar pode permitir a obtenção de fraccionamentos temporais mais eficientes. Contudo
esta característica torna a tarefa de partição temporal mais complicada, pois para além desta
ser capaz de fornecer um fraccionamento eficiente também tem de considerar que cada
fracção deve ocupar um determinado espaço variável de forma a minimizar o tempo de
execução global. Um algoritmo baseado em heurísticas foi recentemente apresentado em
3 Do inglês: SIMD (Single Instruction, Multiple Data) Within A Register.

CAP. 9 CONCLUSÕES 207
[Ganesan00] que realiza a partição temporal considerando a divisão do FPGA em duas partes
de igual área (uma para reconfiguração, a outra para execução). Embora a divisão utilizada
possa produzir intercalamentos de reconfiguração e execução ineficientes o trabalho
supracitado é um bom ponto de partida.
Partilha de Unidades Funcionais
Deveriam ser consideradas técnicas que permitam explorar rapidamente a partilha de algumas
unidades funcionais (multiplicadores, por exemplo). É conveniente que uma nova abordagem
não assente na maioria das abordagens da síntese arquitectural para ASICs. Nestas últimas, o
utilizador escolhe o número de unidades funcionais para cada operador, ou a ferramenta
explora o espaço de projecto exaustivamente, ou com técnicas de supressão (prunning) de
buscas. Estas abordagens são demasiado complexas, só se justificando para implementações
em ASICs e não para compilação normal, em que o programador espera resultados o mais
rapidamente possível.
Escalonamento
A possibilidade do escalonamento utilizar unidades funcionais com mais do que um atraso
para término de computação deve ser considerada. Algumas unidades funcionais podem
terminar a computação antes do atraso máximo, com base na identificação de bits mais
significativos de nível lógico zero nos operandos de entrada. Este tipo de término foi
utilizado no âmbito de microprocessadores [Brooks99].
O escalonamento deve também ser estendido de modo a permitir a execução concorrente de
ciclos presentes lado-a-lado (mesmo nível) no HPDG. O principal problema reside no facto
dos ciclos concorrentes poderem aceder à mesma memória no mesmo instante. Uma das
formas de resolver o problema é a utilização do mecanismo de arbitragem baseado em
prioridades estáticas que foi apresentado no capítulo 7.
É também importante que sejam considerados acessos a memórias do tipo DRAM. O trabalho
apresentado em [Panda97] é um bom ponto de partida.
Integração de Colocação

208 CAP. 9 CONCLUSÕES
Espera-se que se possa num futuro próximo incluir na compilação fases de colocação com
base na geometria de cada macrocélula. Algum do trabalho apresentado em
[Callahan98b][Budiu99] pode servir como ponto de partida, embora nestes casos os autores
usem uma granulosidade abaixo do nível da operação.
Algoritmos baseados em heurísticas necessitam de ser estudados e os resultados avaliados na
prototipagem para FPGAs comerciais. Espera-se que com a colocação a este nível se possa
reduzir substancialmente o tempo de CPU gasto nas fases de colocação e encaminhamento.
Partição de Arrays
As arquitecturas com memórias distribuídas necessitam, para que o compilador possa
fornecer reconfigware eficiente, que a partição de um array por mais de uma memória seja
realizada automaticamente. Uma panorâmica da partição de arrays por bancos de memória
utilizada pela comunidade de computação de alto-desempenho pode ser consultada em
[Gokhale92].
Mapeamento de Arrays em Memórias
A hierarquia de memórias disponível nos sistemas reconfiguráveis que utilizam os novos
FPGAs (Virtex, por exemplo) necessita que, ao nível da compilação, os arrays possam ser
mapeados automaticamente nos níveis de memória existentes.
No âmbito da síntese arquitectural, algumas formas de distribuição de variáveis do tipo array
pelas memórias disponíveis foram consideradas em [Schmit97][Ramachan94]. Em especial,
são apresentadas em [Schmit98] técnicas de agrupamento e de colocação de arrays em
memória de forma a minimizar as unidades de endereçamento. Estas técnicas permitem
economizar mais memória do que a colocação dos arrays em bancos de tamanho 2N.
Recentemente, algumas formas de resolver o problema começaram a ser exploradas no
âmbito de compiladores para computação reconfigurável. Em [Gokhale99] é utilizada uma
técnica baseada na estimativa do custo de um determinado mapeamento para selecção de
entre as várias possibilidades. Esta técnica não necessita que para cada mapeamento seja feito
o escalonamento. Contudo, é necessário quantificar as distâncias dos resultados a
mapeamentos óptimos ou pelo menos quasi-óptimos. Uma técnica conhecida por enumeração
implícita é utilizada para reduzir o espaço de exploração, reconhecidamente exponencial.

CAP. 9 CONCLUSÕES 209
Os trabalhos supracitados parecem ser bons pontos de partida para a investigação destes
problemas.
Melhorias na Exposição de Paralelismo
Devem ser consideradas análises que possam expor o paralelismo ao nível de acessos a
elementos do mesmo array. Este paralelismo pode ter bastante impacto quando as memórias
têm mais do que um porto.
Compilação para Reconfigware de Descrições Orientadas por Objectos
Algumas construções orientadas por objectos podem ser implementadas eficientemente por
aplicação de transformações como o desdobramento de objectos, aplanação da estrutura
hierárquica, alocação estática e implementação de despacho dinâmico de métodos. O trabalho
desenvolvido nas fases iniciais desta tese é um bom começo para a síntese arquitectural de
descrições de alto-nível orientadas por objectos (ver apêndice C).
Necessitam de ser realizados estudos que quantifiquem a viabilidade da resolução estática de
invocações de métodos e das referências em exemplos reais. É também necessário avaliar a
utilização de implementações em hardware específico que durante a execução resolvam as
propriedades dinâmicas. Estas últimas implementações podem ter praticabilidade devido à
dimensão dos novos FPGAs. A conjugação destas duas formas (resoluções estática e
dinâmica) é definitivamente a mais apropriada para implementações específicas de uma
aplicação e, por isso, devem ser estudadas técnicas de resolução estática de algumas
construções com propriedades dinâmicas sempre que tal for possível, e implementações de
unidades em hardware específico que resolvam dinamicamente essas construções.
A utilização de algumas técnicas de gestão de memória para lidar com alocação de dados em
especificações que utilizam estruturas de dados (listas ligadas, por exemplo), deveria ser
considerada [Jong95].
A síntese de hardware a partir de especificações orientadas por objectos tem tido atenções
recentes. Em [Radetzki00] pode ser encontrada uma descrição da panorâmica sobre algumas
das abordagens existentes e é apresentada uma metodologia que sintetiza cada objecto numa
unidade de dados e de controlo que implementa todos os serviços disponibilizados pelo
objecto em causa. A metodologia tem algumas restrições mas parece ser um bom ponto de
partida.

210 CAP. 9 CONCLUSÕES
Considerações sobre Bytecodes Actualmente não Suportados
Será evidentemente importante permitir o suporte de programas em Java que usem métodos.
A possibilidade da partilha da implementação em reconfigware de cada método em relação à
expansão do seu corpo deve também constar no processo de compilação para que o utilizador
possa avaliar várias implementações.
Geradores de Operadores Lógico-Aritméticos Universais
O estudo e desenvolvimento de geradores de circuitos para cada operador suportado na
compilação para reconfigware que permitam prototipar várias FPGAs deve ser realizado.
Estes geradores podem ser baseados em descrições estruturais de cada operador (em Java ou
VHDL) com base num conjunto primitivo de portas lógicas de, por exemplo, duas entradas.
Na anteguarda, uma tarefa de mapeamento no FPGA alvejado permitirá a geração da
estrutura com um formato, por exemplo EDIF, possível de ser lido pelas ferramentas de
colocação e encaminhamento proprietárias.
Geração dos Circuitos de Controlo
O desenvolvimento de métodos que possam sintetizar a unidade de controlo a partir do grafo
de transições de estados (STG) deve ser considerado para que os compiladores não
necessitem da intervenção de uma ferramenta de síntese lógica. Neste contexto deve ser
comparada a utilização de contadores/sequenciadores com a utilização de máquinas de estado
finitas com codificação do tipo One-Hot.
Desenvolvimento de Código
O autor espera que a avaliação e depuração dos compiladores continue para que estes possam
vir a ser utilizados pela comunidade científica interessada.
Por último, a realização de uma interface Web para que o compilador possa estar disponível
numa página Web para avaliação [CardosoURL] por parte de possíveis interessados é sob o
ponto de vista de desenvolvimento bastante aliciante.
Por último, espera-se que a infra-estrutura desenvolvida no âmbito desta tese possa ser
utilizada para investigação e ensino.

251
Referências
[Agarwal94] Lalit Agarwal, Mike Wazlowski, and Sumit Ghosh, “An Asynchronous
Approach to Efficient Execution of Programs on Adaptive Architectures Utilizing
FPGAs”, In Proc. of the 2nd IEEE Workshop on FPGAs for Custom Computing
Machines (FCCM’94), Napa Valley, CA, USA, April 10-13, 1994, Published by the
IEEE Computer Society Press, Duncan A. Buell and Kenneth L. Pocek, editors, Los
Alamitos, CA, USA, 1994, pp. 101-110.
[Ahmed74] N. Ahmed, T. Natarajan, and K.R. Rao, “Discrete cosine transform,” IEEE
Trans. On Computers, vol. C-23, pp. 90-93, Jan 1974.
[Aho86] A. V. Aho, R. Sethi, J. D. Ullman, Compilers: Principles, Techniques and
Tools, Addison-Wesley, Reading, Massachusetts, 1986.
[Alliance98] Xilinx, Inc., “Alliance M1.5.19,” 1998, San Jose, CA, USA.
[AlteraURL] Altera Inc., URL: http://www.altera.com.
[Amerson95] R. Amerson, R. J. Carter, W. B. Culbertson, P. Kuekes, G. Snider, “Teramac
- Configurable Custom Computing,” In Proc. of the IEEE Symposium on FPGAs for
Custom Computing Machines (FCCM’95), Napa Valley, CA, USA, April 19-21, 1995,
Published by the IEEE Computer Society Press, Peter Athanas and Kenneth L. Pocek,
editors, Los Alamitos, CA, USA, 1995, pp. 32-38.
[Arnold92] J. M. Arnold, et al., “The Splash 2,” In Proc. of the 4th Annual ACM
Symposium on Parallel Algorithms and Architectures, June 1992, pp. 316-324.
[Athanas92] Peter Mark Athanas, An Adaptive Machine Architecture and Compiler for
Dynamic Processor Reconfiguration, PhD Thesis, Brown University, 1992.

252 REFERÊNCIAS
[Athanas93] P. Athanas, and H. Silverman, “Processor Reconfiguration through
Instruction-Set Metamorphosis: Architecture and Compiler,” IEEE Computer, vol. 26,
n. 3, March 1993, pp. 11-18.
[August99] David I. August, et al., “The Program Decision Logic Approach to Predicated
Execution,” In Proc. of the (ISCA99), 1999.
[AxelURL] Projecto AXEL, “AXEL: Acceleration of Computationally Intensive
Algorithms Using Systems Based on Dynamic Reconfiguration,” INESC: ESDA Group,
URL: http://esda.inesc.pt/esda/Projects/axel/main.html. Projecto
PRAXIS/P/EEI/12154/1998.
[Baer68] J. L. Baer, and D. P. Bovet, “Compilation of Arithmetic Expressions for
Parallel Computations,” In Proc. of the IFIP Congress, 1968, pp. 34-46.
[Balance90] R. Balance, A. Maccabe, and K. Ottenstein, “The program dependence web: a
representation supporting control-, data-, and demand-driven interpretation of
imperative languages,” In Proc. of the SIGPLAN’90 Conference on Programming
Language Design and Implementation, June 1990, pp. 257-271.
[Banerjee00] P. Banerjee, et al., “A MATLAB Compiler For Distributed, Heterogeneous,
Reconfigurable Computing Systems,” In Proc. of the IEEE Symposium on Field-
Programmable Custom Computing Machines (FCCM’00), Napa Valley, CA, USA,
April 16-19, 2000, Published by the IEEE Computer Society Press, Kenneth L. Pocek
and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 2000.
[Becker98] J. Becker, R. Hartenstein, M. Herz, U. Nageldinger, “Parallelization in Co-
Compilation for Configurable Accelerators,” In Proc. of the Asia South Pacific Design
Automation Conference (ASP-DAC'98), Yokohama, Japan, February 10-13, 1998.
[Bellows98] P. Bellows, and B. Hutchings, “JHDL-An HDL for Reconfigurable Systems,”
In Proc. of the IEEE 6th Symposium on Field-Programmable Custom Computing
Machines (FCCM'98), Napa Valley, CA, USA, April 15-17, 1998, Published by the
IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds, editors, Los
Alamitos, CA, USA, 1998, pp. 175-184.

REFERÊNCIAS 253
[Ben92URL] ______, Benchmarks repository, Workshop on High-Level Synthesis, 1992,
1995, ftp://ftp.ics.uci.edu/pub/hlsynth/HLSynth92.
[Ben95URL] ______, Benchmarks repository, Workshop on High-Level Synthesis, 1995,
ftp://ftp.ics.uci.edu/pub/hlsynth/HLSynth95.
[Bernstein86] Robert Bernstein, “Multiplication by Integer Constants,” In Software Practice
and Experience, Vol. 16, No. 7, July, 1986, pp. 641-652.
[Bik97] Aart J.C. Bik, and Dennis B. Gannon, “javab - a prototype bytecode
parallelization tool”, Computer Science Department Technical Report, Indiana
University, USA, URL: http://www.extreme.indiana.edu/hpjava/, 1997, pp. 46.
[Bondala99a] Kiran Bondalapati, et al., “DEFACTO: A Design Environment for Adaptive
Computing Technology”, In Proc. of the 6th Reconfigurable Architectures Workshop
(RAW'99), San Juan, Puerto Rico, April 12, 1999, Published in Springer-Verlag,
Berlin,Germany, 1999.
[Bondala99b] Kiran Bondalapati, and Viktor K. Prasanna, “Dynamic Precision Management
for Loop Computations on Reconfigurable Architectures,” In Proc. of the IEEE 7th
Symposium on Field-Programmable Custom Computing Machines (FCCM'99), Napa
Valley, CA, USA, April 21-23, 1999, Published by the IEEE Computer Society Press,
Kenneth L. Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1999, pp. 249-
258.
[Brent74] R. P. Brent, “The Parallel Evaluation of Generic Arithmetic Expressions,” In
Journal of the ACM, 21(2), 1974.
[Briggs94] Preston Briggs, Tim Harvey, “Multiplication by Integer Constants,” July 13,
1994. URL: http://softlib.rice.edu/MSCP
[Brooks99] David Brooks, and Margaret Martonosi. “Dynamically Exploiting Narrow
Width Operands to Improve Processor Power and Performance,” In Proc. of the Fifth
Intl. Symposium on High-Performance Computer Architecture, Orlando, Jan. 1999.

254 REFERÊNCIAS
[Brown96] Stephen Brown, and Jonathan Rose, “FPGA and CPLD Architectures: A
Tutorial,” IEEE Design & Test of Computers, Summer 1996, Vol. 13, No. 2, pp. 42-
57.
[Budimlic97] Zoran Budimlic and Ken Kennedy. “Optimizing Java - theory and practice”.
In Concurrency, Practice and Experience, 9(6):445-463, 1997.
[Budiu00] Mihai Budiu, Seth Copen Goldstein, Majd Sakr and Kip Walker, “BitValue
Inference: Detecting and Exploiting Narrow Bitwidth Computations,” In Proc. of the
European Conference on Parallel Computing (EuroPar’00), Munich, Germany, Aug.
2000.
[Budiu99] Mihai Budiu, and Seth Copen Goldstein, “Fast Compilation for Pipelined
Reconfigurable Fabrics,” In Proc. of the ACM/SIGDA 6th International Symposium on
Field Programmable Gate Arrays, Monterey, CA, USA, January, 1999.
[CaddyURL] CADDY-II, FZI, Karlsruhe, version 5.10. URL:
http://www.fzi.de/sim/people/ bringmann/caddy/caddy.html.
[Callahan00] Timothy J. Callahan, John Hauser, and John Wawrzynek, “The Garp
Architecture and C Compiler,” IEEE Computer, Vol.33, No. 4, April 2000, pp. 62-69.
[Callahan98a] Timothy J. Callahan and John Wawrzynek, “Instruction Level Parallelism for
Reconfigurable Computing,” In Proc. Of the 8th International Workshop on Field-
Programmable Logic and Applications (FPL'98), Tallinn, Estonia, August 31-
September 3, 1998. Published in Springer-Verlag LNCS 1482, Hartenstein and
Keevallik eds, Berlin, Germany, 1998, pp. 248-257.
[Callahan98b] Timothy J. Callahan, Philip Chong, Andri DeHon, and John Wawrzynek,
“Fast Module Mapping and Placement for Datapaths in FPGAs,” In Proc. of the 1998
ACM/SIGDA Sixth International Symposium on Field Programmable Gate Arrays
(FPGA'98), February 22-24, 1998, ACM Press, New York, USA, pp. 123-132.
[Cardoso98a] João M. P. Cardoso, and Horácio C. Neto, “An Approach to Hardware
Synthesis from a System Java(tm) Specification “, In Proc. of the 1st International
Workshop on Design, Test and Applications (WDTA’98), Sponsored by IEEE region 8

REFERÊNCIAS 255
and IEEE TTTC, ISBN 953-184-009-1, Dubrovnik, Croatia, June 8-10, 1998, pp. 149-
152.
[Cardoso98b] João M. P. Cardoso, and Horácio C. Neto, “Towards an Automatic Path from
Java(tm) Bytecodes to Hardware Through High-Level Synthesis”, In Proc. of the 5th
IEEE International Conference on Electronics, Circuits and Systems (ICECS-98),
Lisbon, Portugal, September 7-10, 1998, Vol. 1, pp. 85-88.
[Cardoso99a] João M. P. Cardoso, and Horácio C. Neto, “Macro-Based Hardware
Compilation of Java Bytecodes into a Dynamic Reconfigurable Computing System,”
In Proc. of the IEEE 7th Symposium on Field-Programmable Custom Computing
Machines (FCCM'99), Napa Valley, CA, USA, April 21-23, 1999, Published by the
IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds, editors, Los
Alamitos, CA, USA, 1999, pp. 2-11.
[Cardoso99b] João M. P. Cardoso, and Horácio C. Neto, “Fast Hardware Compilation of
Behaviors into an FPGA-Based Dynamic Reconfigurable Computing System,” In Proc.
of the XII Symposium on Integrated Circuits and Systems Design (SBCCI’99), (Co-
)Sponsored by the Brazilian Computer Society and the IFIP WG 10.5, Natal-RN, Brazil,
Sept. 29-Oct. 2, 1999, In Vladimir C. Alves, Marcelo Lubaszewski, and Ivan S. Silva
(Editors), IEEE Computer Society Press, Los Alamitos, CA, USA, pp. 150-153.
[Cardoso99c] João M. P. Cardoso, and Horácio C. Neto, “An Enhanced Static-List
Scheduling Algorithm for Temporal Partitioning onto RPUs,” In Proc. of the IFIP TC10
WG10.5 X International Conference on Very Large Scale Integration (VLSI'99),
Lisbon, December 1-3, 1999. VLSI: Systems on a Chip, Luis M. Silveira, Srinivas
Devadas and Ricardo Reis (Editors), Kluwer Academic Publishers, pp. 485-496.
[Cardoso99d] J. M. P. Cardoso, H. C. Neto, “The Library of macro-cells used by NENYA:
Circuit generators for the Xilinx XC6000 FPGA series,” INESC Technical Report,
December 1998, revised April 1999.
[Cardoso99e] João M. P. Cardoso, and Mário P. Véstias, “Architectures and Compilation
Techniques to Support the Reconfigurable Computing Concept”, In Crossroads, the
Association for Computing Machinery (ACM) Student Magazine, topic: Computer

256 REFERÊNCIAS
Architectures, Spring 1999, Issue 5.3, pp. 15-22. Version online at:
http://turing.acm.org/crossroads/xrds5-3/rcconcept.html.
[CardosoURL] João M. P. Cardoso, “The Galadriel & Nenya Home Page: A Compilation
Path from Java Programs to Reconfigurable Computing,” INESC, ESDA group, Lisbon,
Portugal. URL: http://esda.inesc.pt/~jmpc/GALNEN/GALNEN.html.
[Chang97] Douglas Chang, Malgorzata Marek-Sadowska, “Buffer Minimization and
Time-multiplexed I/O on Dynamically Reconfigurable FPGAs,” In Proc. 5th
ACM/SIGDA International Symposium on Field Programmable Gate Arrays
(FPGA'97), Monterey, CA, USA, 1997, pp. 142-148.
[Chang98] Douglas Chang, Malgorzata Marek-Sadowska, “Partitioning Sequential
Circuits on Dynamically Reconfigurable FPGAs,” In Proc. 6th ACM/SIGDA
International Symposium on Field Programmable Gate Arrays (FPGA'98), Monterey,
CA, USA, February 22-24, 1998.
[Chichkov97] A. V. Chichkov, C. B. Almeida, “An Hardware/Software Partitioning
Algorithm for Custom Computing Machines”, Published in Springer-Verlag Lecture
Notes in Computer Science 1304, W. Luk, P. Y. K. Cheung, and M. Glesner, Eds.
Berlin, Germany, 1997, pp.274-283.
[Chichkov98] A. V. Chichkov, Metodologia de Co-Projecto Hardware/Software Para
Arquitecturas Computacionais Reconfiguráveis Utilizando uma Partição Baseada no
Paralelismo Implícito, Dissertação para a obtenção do grau de doutor em Engenharia
Electrotécnica e de Computadores, Instituto Superior Técnico (IST) da Universidade
Técnica de Lisboa (UTL), Lisboa, Janeiro de 1998.
[Churcher95] Steven Churcher, Tom Kean, and Bill Wilkie, “XC6200 FastMap Processor
Interface,” In Proc. of the Int. Conference on Field-Programmable Logic and
Applications (FPL’95), Oxford, United Kingdom, Aug.-Sept., 1995. Published in
Springer-Verlag LNCS 975, Will Moore and Wayne Luk, eds., Berlin, Germany, 1995,
pp. 36-43.
[Cierniak97] Michal Cierniak and Wei Li. “Optimizing Java bytecodes,” In Concurrency,
Practice and Experience, 9(6):427-444, 1997.

REFERÊNCIAS 257
[CLevelURL] C Level Design, Inc., URL: http://www.cleveldesign.com.
[CompiURL] Compilogic Corporation, D. Soderman, Y. Panchul, “Implementating C
Designs in Hardware: ANSI C to RTL Verilog Design & Test-Bench Compiler,” March
1998. URL: http://www.compilogic.com/pubs.htm.
[Compton00] K. Compton, S. Hauck, “Configurable Computing: A Survey of Systems and
Software,” submitted to ACM Computing Surveys, 2000.
[Connor97] J. Michael O'Connor and Marc Tremblay, “picoJava-I: The Java Virtual
Machine in Hardware”, IEEE Micro, Vol. 17, No. 2, March-April 1997, pp.
[Cramer97] Timothy Cramer, et al., “Compiling Java Just in Time”, IEEE Micro,
May/June 1997, pp. 36-43.
[Cronquist98] D. C. Cronquist, P. Franklin, S. Berg, M. Ebeling, “Specifying and Compiling
Applications for RaPiD,” In Proc. of the IEEE Symposium on FPGAs for Custom
Computing Machines (FCCM’98), Napa Valley, CA, USA, April 15-17, 1998,
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1998, pp. 116-125.
[CynAppsURL] CynApps, Inc., URL: http://www.cynapps.com.
[Cytron91] Ron Cytron, et al., “Efficiently Computing static single assignment form and
the control dependence graph,” In ACM Transactions on Programming Languages and
Systems, 13(4), October 1991, pp. 451-490.
[DACURL] _____, Proc. of the IEEE/ACM Design Automation Conference. URL:
http://www.dac.com.
[DeHon96] A. DeHon, Reconfigurable Architectures for General Purpose Computing,
PhD Thesis, AI Technical Report 1586, Massachusetts Institute of Technology, 545
Technology Sq., Cambridge, MA02139, Sept. 1996, URL:
http://www.ai.mit.edu/people/andre/phd.html.
[Diniz00] Pedro Diniz, and Joonseok Park, “Automatic Synthesis of Data Storage and
Control Structures for FPGA-based Computing Engines,” In Proc. Of the IEEE

258 REFERÊNCIAS
Symposium on Field-Programmable Custom Computing Machines (FCCM’00), Napa
Valley, CA, USA, April 16-19, 2000, Published by the IEEE Computer Society Press,
Kenneth L. Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 2000.
[DottyURL] AT&T Inc., dotty: Graphviz, version 1.3, 1998. URL: http://
www.research.att.com/sw/tools/graphviz.
[Duncan98] A. A. Duncan, D. C. Hendry, and P. Gray, “An overview of the COBRA-
ABS high level synthesis system for multi-FPGA Systems,” In Proc. of the IEEE
Symposium on FPGAs for Custom Computing Machines (FCCM’98), Napa Valley, CA,
USA, April 15-17, 1998, Published by the IEEE Computer Society Press, Kenneth L.
Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1998, pp. 106-115.
[Ebeling95] M. Ebeling, D. C. Cronquist, and P. Franklin, “RaPiD - Reconfigurable
Pipelined Datapath,” In Proc. of the International Workshop on Field Programmable
Logic and Applications (FPL'95), Oxford, United Kingdom, Aug.-Sept., 1995.
Published in Springer-Verlag LNCS 975, Will Moore and Wayne Luk, eds., Berlin,
Germany, 1995, pp. 126-135.
[Economist99] The Economist Scince and Technology: “Hardware goes soft,”
http://www.economist.com/editorial/freeforall/22-5-99/st9188.html, 22 May 1999.
[Eijndhov92] Jos T. J. van Eijndhoven and Leon Stok, “A Data Flow Graph Exchange
Standard,” In Proc. of the European Conference on Design Automation (EDAC’92),
Brussels, Belgium, March 1992, pp. 193-199.
[Ernst93] Rolf Ernst, J. Henkel, T. Benner, “HW-SW Cosynthesis for
Microcontrollers,” In IEEE Design & Test of Computers, Vol. 10, No. 4, December
1993, pp. 64-75.
[Estrin60] Gerald Estrin, “Organization of computer systems - the fixed plus variable
structure computer,” In Proceedings of the Western Joint Computer Conference, May
1960, pp. 33-40.
[EvolvURL] _____, Proc. of the SA/DoD Workshop on Evolvable Hardware, 13-15 July,
Silicon Valley, CA, USA . URL: http://ic-www.arc.nasa.gov/ic/eh2000/.

REFERÊNCIAS 259
[FCCMURL] _____, Proc. of the IEEE Symposium on Field-Programmable Custom
Computing Machines. 1993-2000. URL: http://www.fccm.org. Printed by IEEE
Computer Society Press, Los Alamitos, Calif., USA.
[FCMURL] Steve Guccione, “List of FPGA-based Computing Machines,” URL:
http://www.io.com/~guccione/HW_list.html.
[Fisher95] J. A. Fisher, and B. R. Rau, “Instruction-Level Parallel Processing,” In H. C.
Torng and S.Vassiliadis, editors, Instruction-Level Parallel Processors, IEEE Computer
Society Press, 1995, pp. 41-49.
[FPGA93-00] _____, Proc. of the ACM/SIGDA International Symposium on Field-
Programmable Gate Arrays (FPGA), 1993-2000.
[FPLURL] _____, Proc. of the International Workshop on Field-Programmable Logic
and Applications. 1991-2000. URL: http://xputers.informatik.uni-kl.de/FPL/index_fpl
.html. Printed by Springer-Verlag.
[FrontierURL] Frontier Design, Inc., URL: http://www.frontierd.com.
[Fujii99] T. Fujii, K.-i. Furuta, M. Motomura, M. Nomura, M. Mizuno, K.-i. Anjo, K.
Wakabayashi, Y. Hirota, Y.-e. Nakazawa, H. Ito, M. Yamashina, “A Dynamically
Reconfigurable Logic Engine with a Multi-Context/Multi-Mode Unified-Cell
Architecture,” In Proc. IEEE International Solid State Circuits Conference (ISSCC'99),
San Francisco, CA, Feb. 15-17, 1999. See NEC Corp., Kanagawa, Japan, URL:
http://www.nec.co.jp/english/today/newsrel/9902/1502.html.
[GajjalaPu98a] Karthikeya M. GajjalaPurna, and Dinesh Bhatia, “Emulating Large Designs on
Small Reconfigurable Hardware”, In Proc. 9th IEEE International Workshop on Rapid
System Prototyping (RSP '98), Leuven, Belgium, June 3 –5, 1998.
[GajjalaPu98b] Karthikeya M. GajjalaPurna, and Dinesh Bhatia, “Partitioning in Time: A
Paradigm for Reconfigurable Computing”, In Proc. IEEE Int. Conference on Computer
Design (ICCD'98), Austin, Texas, October 5-7, 1998, pp. 340-345.

260 REFERÊNCIAS
[GajjalaPu99] Karthikeya M. GajjalaPurna, and Dinesh Bhatia, “Temporal Partitioning and
Scheduling Data Flow Graphs for Reconfigurable Computers”, In IEEE Transactions on
Computers, vol. 48, no. 6, June 1999, pp. 579-591.
[Gajski92] D. Gajski, et al., High-Level Synthesis, Introduction to Chip and System
Design, Kluwer Academic Publishers, 1992.
[Galloway95] D. Galloway, “The Transmogrifier C Hardware Description Language and
Compiler for FPGAs”, In Proc. of the 3rd IEEE Workshop on FPGAs for Custom
Computing Machines (FCCM’95), Napa Valley, CA, USA, April 19-21, 1995,
Published by the IEEE Computer Society Press, Peter Athanas and Kenneth L. Pocek,
editors, Los Alamitos, CA, USA, 1995, pp. 136-144.
[Ganesan00] Satish Ganesan, and Ranga Vemuri, “An Integrated Temporal Partitioning
and Partial Reconfiguration Technique for Design Latency Improvement,” In Proc.
Design, Automation & Test in Europe (DATE'00), Paris, France, March 27-30, 2000,
pp. 320-325.
[gccURL] ______, GNU C Compiler, URL: http://www.gnu.org.
[Girczyc85] E. F. Girczyc, et al.: “Applicability of a Subset of Ada as an Algorithmic
Hardware Description Language for Graph-Based Hardware Compilation”, IEEE
Transactions on CAD, April 1985, pp. 134-142.
[Girkar92] M. Girkar, and C. D. Polychronopoulos, “Automatic Extraction of Functional
Parallelism from ordinary Programs,” In IEEE Transactions on Parallel and Distributed
Systems, Vol. 3,No. 2, March 1992, pp. 166-178.
[Gokhale90] Maya Gokhale, et al., “SPLASH: A Reconfigurable Linear Logic Array,” In
Proc. of the International Conference on Parallel Processing, Aug. 1990, pp. 526-532.
[Gokhale92] Maya Gokhale, and W. Carlson, “An Introduction to compilation issues for
parallel machines,” In The Journal of Supercomputing, December 1992, pp. 283-314.
[Gokhale95] Maya Gokhale and A. Marks, “Automatic Synthesis of Parallel Programs
Targeted to Dynamically Reconfigurable Logic Arrays,” In Proc. of the International

REFERÊNCIAS 261
Workshop on Field Programmable Logic and Applications (FPL'95), Oxford, United
Kingdom, Aug.-Sept., 1995. Published in Springer-Verlag LNCS 975, Will Moore and
Wayne Luk, eds., Berlin, Germany, 1995, pp. 399-408.
[Gokhale97] Maya Gokhale, and Edson Gomersall, “High-Level Compilation for Fine
Grained FPGAs,” In Proc. of the IEEE 5th Symposium on Field-Programmable Custom
Computing Machines (FCCM'97), Napa Valley, CA, USA, April 16-18, 1997,
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1997, pp. 165-173.
[Gokhale98] Maya Gokhale, and Janice M. Stone, “Napa C: Compiling for a Hybrid/FPGA
Architecture,” In Proc. of the IEEE 6th Symposium on Field-Programmable Custom
Computing Machines (FCCM'98), Napa Valley, CA, USA, April 15-17, 1998,
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1998, pp. 126-135.
[Gokhale99] Maya Gokhale and Janice M. Stone, “Automatic Allocation of Arrays to
Memories in FPGA Processors with Multiple Memory Banks,” In Proc. of the IEEE 7th
Symposium on Field-Programmable Custom Computing Machines (FCCM'99), Napa
Valley, CA, USA, April 21-23, 1999, Published by the IEEE Computer Society Press,
Kenneth L. Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1999, pp. 63-
69.
[Goldstein00] Seth Copen Goldstein, Herman Schmit, Mihai Budiu, Srihari Cadambi, Matt
Moe, and Reed Taylor, “PipeRench: A Reconfigurable Architecture and Compiler,” In
IEEE Computer, Vol.33, No. 4, April 2000, pp. 70-77.
[Goldstein99] Seth Copen Goldstein, Herman Schmit, Matthew Moe, Mihai Budiu, Srihari
Cadambi, R. Reed Taylor, Ronald Laufer, “PipeRench: a Coprocessor for Streaming
Multimedia Acceleration,” In Proc. of the 26th Annual International Symposium on
Computer Architecture (ISCA'99), June 1999.
[GooguURL] Genetic Adaptive System Lab, GOOGU (Generic Object-Oriented Graphing
Utility), version 1.3.4, University of Nevada, Reno, USA, 1998. URL:
http://gaslab.cs.unr.edu/googu-demo/.

262 REFERÊNCIAS
[Gordon98] Rob Gordon, Essential JNI: Java Native Interface, Prentice Hall, Upper
Saddle River, NJ 07458, 1998.
[Gosling95] James Gosling, “Java Intermediate Bytecodes,” In Proc of the ACM
SIGPLAN Workshop on Intermediate Representations (IR'95), ACM SIGPLAN Notices
(March 1995).
[Gosling96] James Gosling, Bill Joy, and Guy Steele, The Java Language Specification,
Addison-Wesley, Reading, Massachusetts, 1996.
[Gosling97] Ken Arnold, James Gosling. Java Programming Language. Addison-Wesley,
Reading, Massachusetts, 1997.
[Gray89] J. Gray, and T. Kean, “Configurable hardware: A new paradigm for
computation,” Advanced Research in VLSI, In Proc. of the Decennial Caltech
Conference on VLSI, Pasadena, CA, 1989.
[Guccione00] Steve Guccione, Delon Levi and Prasanna Sundararajan, “Jbits: Java based
interface for reconfigurable computing,” In Proc. of the Military and Aerospace
Applications of Programmable Devices and Technologies Conference (MAPLD'00),
The Johns Hopkins Univerisity- Applied Physics Laboratory, Laurel, Maryland, USA,
September 26-28, 2000.
[Hammes99] J. Hammes, R. Rinker, W. Böhm, W. Najjar, B. Draper, R. Beveridge,
“Cameron: High Level Language Compilation for Reconfigurable Systems,” In Proc. of
the Int. Conference on Parallel Architectures and Compilation Techniques (PACT'99),
Newport Beach, CA, USA, Oct. 12-16, 1999.
[Hartenst90] R. W. Hartenstein, A. G. Hirschbiel, and M. Weber, “The Machine Paradigm
Of Xputers and its Application to Digital Signal Processing Acceleration,” In Proc. of
the International Conference on Parallel Processing, 1990.
[Hartenst95] R. W. Hartenstein and R. Kress, “A Datapath Synthesis System for the Re-
configurable Datapath Architecture,” In Proc. of the Asia and South Pacific Design
Automation Conference (ASP-DAC’95), 1995, pp. 479-484

REFERÊNCIAS 263
[Hartenst96a] R. W. Hartenstein, et al., “High-Performance Computing Using a
Reconfigurable Accelerator,” In CPE Journal, Special Issue of Concurrency: Practice
and Experience, John Wiley & Sons Ltd., 1996.
[Hartenst96b] Reiner W. Hartenstein, Jurgen Becker, Michael Herz, et al., “Co-Design and
High Performance Computing: Scenes and Crisis”, In Proc. of the Reconfigurable
Technology for Rapid Product Development & Computing, Part of SPIE's International
Symposium '96, Boston, USA, Nov. 1996.
[Hartenst98] R. W. Hartenstein, M. Herz, and F. Gilbert, “Designing for Xilinx XC6200
FPGAs,” In Proc. of 8th International Workshop on Field Programmable Logic and
Applications (FPL'98), Tallinn, Estonia, August 31-September 3, 1998. Published in
Springer-Verlag LNCS 1482, Hartenstein and Keevallik eds, Berlin, Germany, 1998, pp.
29-38.
[Hauck97] S. Hauck, T. W. Fry, M. M. Hosler, J. P. Kao, “The Chimaera Reconfigurable
Functional Unit”, In Proc. of the 5th IEEE Symposium on Field Programmable Custom
Computing Machines (FCCM'97), Napa Valley, CA, USA, April 16-18, 1997,
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1997, pp. 87-96.
[Hauck98] S. Hauck, “The Roles of FPGAs in Reprogrammable Systems,” In
Proceedings of the IEEE, Vol. 86, No. 4, pp. 615-638, April, 1998.
[Hauser97] J. R. Hauser, J. Wawrzynek, “Garp: A MIPS Processor with a Reconfigurable
Coprocessor”, In Proc. of the IEEE Symposium on FPGAs for Custom Computing
Machines (FCCM’97), Napa Valley, CA, USA, April 16-18, 1997, Published by the
IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds, editors, Los
Alamitos, CA, USA, 1997, pp. 12-21.
[Helaihel97] R. Helaihel, and K. Olukotun, “Java as a specification Language for
Hardware-Software Systems,” In Proc. of the ICCAD’97, San Jose, CA, USA,
November 9-13, 1997, pp. 690-697.

264 REFERÊNCIAS
[HICSS98] _____, Configware Minitrack in the Software Technology Track of the
Thirty-First Hawaii International Conference on System Sciences (HICSS-31), Hawaii,
Jan 1998.
[HPCA] _____, International Symposium on High-Performance Computer
Architecture, (HPCA'98) Las Vegas, Nevada USA, 31January - 4 February, 1998, IEEE
Computer Society.
[Hsieh97] C.-H. A. Hsieh et al., “Optimizing NET Compilers for Improved Java
Performance,” In IEEE computer, June 1997, pp. 67-76.
[Hudson98] R. D. Hudson, D. I. Lehn, and P. M. Athanas, “A Run-Time Reconfigurable
Engine for Image Interpolation”, In Proc. of the 6th IEEE Symposium on Field
Programmable Custom Computing Machines (FCCM'98), Napa Valley, CA, USA,
April 15-17, 1998, Published by the IEEE Computer Society Press, Kenneth L. Pocek
and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1998, pp. 88-95.
[Hwu93] Wen-mei W. Hwu, et al.. “The SuperBlock: An Effective Technique for
VLIW and Superscalar Compilation,” In Journal of Supercomputing, Kluwer Academic
Publishers, 1993, pp. 229-248.
[IEEE99] The Institute of Electrical and Electronics Engineers, Inc., IEEE Standard
1076.1-1999 VHDL Language Reference Manual, IEEE, 1999.
[IMS93] IMS, 1.2 µm CMOS Gate Forest Static Cells, 15-Dec-93.
[Inoue98] Akihiko Inoue, et al., “Language and Compiler for Optimizing Datapath
Widths of Embedded Systems,” In IEICE Transactions Fundamentals, vol. E81-A, no.
12, December, 1998, pp. 2595-2604.
[Iseli93] Christian Iseli, and Eduardo Sanchez, “Spyder: A Reconfigurable VLIW
Processor using FPGAs,” In Proc. of the IEEE Workshop on FPGAs for Custom
Computing Machines (FCCM’93), Napa Valley, CA, USA, April 5-7, 1993, Published
by the IEEE Computer Society Press, Duncan A. Buell and Kenneth L. Pocek, editors,
Los Alamitos, CA, USA, 1993, pp. 17-24.

REFERÊNCIAS 265
[Iseli95] Christian Iseli, and Eduardo Sanchez, “A C++ compiler for FPGA custom
execution units synthesis,” In Proc. of the IEEE Symposium on FPGAs for Custom
Computing Machines (FCCM’95), Napa Valley, CA, USA, April 19-21, 1995,
Published by the IEEE Computer Society Press, Peter Athanas and Kenneth L. Pocek,
editors, Los Alamitos, CA, USA, 1995, pp. 173-179.
[J2SDKURL] Sun Microsystems, Inc., The Java Developer’s Kit, URL:
http://java.sun.com/j2se.
[Jain88] R. Jain, A. Parker, N. Park, “Module Selection for Pipelined Synthesis, “ In
Proc. 25th Design Automation Conference, 1988, pp. 542-547.
[JasURL] K. B. Sriram, Jas: Java bytecode assembler, version 0.4, 1997. URL:
http://www.sbktech.org/jas.html.
[JavaCCURL] Sun, Inc., JavaCC: Java Compiler Compiler, version 0.7.1, 1998, URL:
http://www.suntest.com/JavaCC/.
[JHDLURL] URL: http://www.jhdl.org
[Johnson83] S. C. Johnson, “Code Generation for Silicon,” In Proc. of the 10th Annual
ACM Symposium on Principles of Programming Languages, 1983, pp. 14-19.
[Jong95] G. de Jong, et al., “Background memory management for dynamic data
structure intensive processing systems”, In Proc. of the IEEE ICCAD’95, San Jose, CA,
USA, Nov. 1995, pp. 515-520.
[JVMLanURL] Robert Tolksdorf, Programming Languages for the Java Virtual Machine.
Since November 2, 1996. URL: http://grunge.cs.tu-berlin.de/~tolk/vmlanguages.html
[Kastrup00] Bernardo Kastrup, Jeroen Trum, Orlando Moreira, Jan Hoogerbrugge, and
Jef van Meerbergen, “Compiling Applications for ConCISe: An Example of Automatic
HW/SW Partitioning and Synthesis,” In Proc. of the 10th Int. Conference on Field-
Programmable Logic and Applications (FPL’00), Villach, Austria, August 27-30, 2000.
Published in Springer-Verlag Lecture Notes in Computer Science 1896, Reiner W.
Hartenstein and Herbert Grünbacher (Editors), Berlin, pp. 695-706.

266 REFERÊNCIAS
[Kastrup99] Bernardo Kastrup, Arjan Bink, and Jan Hoogerbrugge, “ConCISe: A
Compiler-Driven CPLD-Based Instruction Set Accelerator,” In Proc. of the IEEE 7th
Symposium on Field-Programmable Custom Computing Machines (FCCM'99), Napa
Valley, CA, USA, April 21-23, 1999, Published by the IEEE Computer Society Press,
Kenneth L. Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1999, pp. 92-
101.
[Kaul98] M. Kaul, R. Vemuri, “Optimal Temporal Partitioning and Synthesis for
Reconfigurable Architectures,” In Proc. Design, Automation & Test in Europe
(DATE'98), Paris, France, Feb. 23-26, 1998, pp. 389-396.
[Kirkpatrick83] S. Kirkpatrick, C. Gelatt, Jr., and M. Vecchi, “Optimization by Simulated
Annealing,” In Science, Vol. 220, No. 4598, May 1983, pp. 671-680.
[Lakshmin99] G. Lakshminarayana, K. S. Khouri, and N. K. Jha, “Wavesched: A Novel
Scheduling Technique for Control-Flow Intensive Designs,” In IEEE Transactions on
Computer-Aided Design of Integrated Circuits and Systems, vol. 18, no. 5, May 1999,
pp. 505-523.
[Landwehr97] Birger Landwehr, and Peter Marwedel, “A New Optimization Technique for
Improving Resource Exploitation and Critical Path Minization,” In Proc. of the 10th
International Symposium on System Synthesis, 1997, pp. 65 – 72.
[LavaURL] LavaLogic, TSI TelSys, Inc., URL: http://www.lavalogic.com.
[Lechner97] Eric Lechner, and Steve Guccione, “The Java Environment for
Reconfigurable Computing,” In Proc. of the 7th International Workshop on Field-
Programmable Logic and Applications (FPL'97), London, United Kingdom, September
1997. Published in Springer-Verlag LNCS 1304, Wayne Luk and Peter Y. K. Cheung,
eds., Berlin, Germany, 1997, pp. 284-293.
[Lee00] Ming-Hau Lee, “Design and Implementation of the MorphoSys
Reconfigurable Computing Processor,” In Journal of VLSI and Signal Processing-
Systems for Signal, Image and Video Technology, March 2000.

REFERÊNCIAS 267
[Lewis98] D. Lewis, D. Galloway, M. van Ierssel, J. Rose, P. Chow, “The
Transmogrifier-2: A 1 Million Gate Rapid Prototyping System,” in IEEE Transactions
on VLSI, Vol. 6, No. 2, June 1998, pp 188-198.
[Lindholm96] Tim Lindholm and Frank Yellin. The Java Virtual Machine Specification.
Addison-Wesley, Reading, Massachusetts, 1996.
[Liu98] Huiqun Liu, and D. F. Wong, “Network flow based circuit partitioning for
time-multiplexed FPGAs,” In Proc. ACM/IEEE International Conference on Computer
Aided Design (ICCAD'98), San Jose, CA, November, 1998.
[Liu99] Huiqun Liu, and D. F. Wong, “Circuit partitioning for dynamically
reconfigurable FPGAs,” In Proc. International Symposium on Field Programmable
Gate Arrays (FPGA'99), Monterey, CA, Feb 21-23, 1999.
[Lobo91] Donald A. Lobo, and Barry M. Pangrle, “Redundant operator creation: a
scheduling optimization technique,” In Proc. of the 28th Conference on ACM/IEEE
Design Automation Conference (DAC'91), 1991, pp. 775 - 778.
[Long93] X.-P. Long, H. Amano, “WASMII: a Data Driven Computer on a Virtual
Hardware,” In Proc. 1st IEEE Workshop on FPGAs for Custom Computing Machines
(FCCM’93), Napa Valley, CA, USA, April 5-7, 1993, Published by the IEEE Computer
Society Press, Duncan A. Buell and Kenneth L. Pocek, editors, Los Alamitos, CA,
USA, 1993, pp. 33-42.
[Magenhei88] Daniel J. Magenheimer, Liz Peters, Karl W. Pettis, and Dan Zuras, “Integer
Multiplication and Division on the HP Precision Architecture,” In IEEE Transactions on
Computers, vol. 37, no. 8, August 1988, pp. 980-990.
[Mahlke92] Scott A. Mahlke, David C. Lin, William Y. Chen, Richard E. Hank, Roger A.
Bringmann, “Effective Compiler Support for Predicated Execution Using the
Hyperblock,” In Proc. of the 25th International Symposium on Microarchitecture, Dec.
1992, pp. 45-54.

268 REFERÊNCIAS
[MAPURL] _____, Proc. of the Military and Aerospace Applications of Programmable
Devices and Technologies Conference (MAPLD), 1998-2000. URL:
http://rk.gsfc.nasa.gov
[Master99] Paul Master, and Peter M. Athanas, “Reconfigurable Computing Offers
Options for 3G,” In Wireless Systems Design, January 1999, pp. 20-23.
[Mcma96URL] Chuck McManis, Class Loader Package, version 1.6, August 1995. See “The
basics of Java class loaders”, In JavaWorld, October 1996, URL:
http://www.javaworld.com/javaworld/jw-10-1996/jw-10-indepth.html.
[Mencer98] O. Mencer, M. Morf, and M. J. Flynn, “PAM-Blox: High Performance FPGA
Design for Adaptive Computing,” In Proc. of the IEEE 6th Symposium on Field-
Programmable Custom Computing Machines (FCCM'98), Napa Valley, CA, USA,
April 15-17, 1998, Published by the IEEE Computer Society Press, Kenneth L. Pocek
and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1998, pp. 167-174.
[Micheli94] G. De Micheli, Synthesis and Optimization of Digital Circuits, McGraw Hill,
1994.
[Micheli97] G. De Micheli, R. K. Gupta, “Hardware/Software Co-Design,” In
Proceedings of the IEEE, vol. 85, no. 3, March 1997, pp. 349-365.
[Mirsky96] E. Mirsky, and A. DeHon, “MATRIX: A Reconfigurable Computing Device
with Configurable Instruction Deployable Resources,” In Proc. of the IEEE Symposium
on FPGAs for Custom Computing Machines (FCCM’96), Napa Valley, CA, USA, April
17-19, 1996, Published by the IEEE Computer Society Press, Kenneth L. Pocek and
Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1996, pp. 157-166.
[Miyamori98] T. Miyamori, and K. Olukotun, “A Quantitative Analysis of Reconfigurable
Coprocessors for Multimedia Applications,” In Proc. of the 6th IEEE Symposium on
Field Programmable Custom Computing Machines (FCCM'98), Napa Valley, CA,
USA, April 15-17, 1998, Published by the IEEE Computer Society Press, Kenneth L.
Pocek and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1998, pp. 2-11.

REFERÊNCIAS 269
[Moisset99] Pablo Moisset, Joonseok Park and Pedro Diniz, “Very High-Level Synthesis
of Control and Datapath Structure for Reconfigurable Logic Devices,” In Proc. of the
Second Workshop on Compiler and Architecture Support for Embedded Systems
(CASES'99), Washington, DC, USA, Oct. 1999.
[Moll95] L. Moll, J. Vuillemin, P. Boucard, “High-Energy Physics on DECPeRLe-1
Programmable Active Memory,” In Proc. of the ACM/SIGDA International Symposium
on Field-Programmable Gate Arrays (FPGA’95), 1995, pp. 47-52.
[Morse94] Morse Rodriguez, “Evaluating Video Codecs,” In IEEE Multimedia, Fall
1994, pp. 25-33.
[Muchnick97] S. S. Muchnick. Advanced Compiler Design and Implementation. Morgan
Kaufmann Publishers, Inc., San Francisco, CA, USA, 1997.
[Muraoka71] Y. Muraoka, Parallelism Exposure and Exploitation in Programs, PhD
Thesis, University of Illinois, Urbana-Champagne, 1971.
[Natarajan99] S. Natarajan, B. Levine, C.Tan, D. Newport, D. Bouldin, “Automatic
Mapping of Khoros-based applications to adaptive computing systems,” In Proc. of the
Military and Aerospace Applications of Programmable Devices and Technologies
Conference (MAPLD'99), Laurel, MD, USA, Sept. 28-30, 1999, pp. 101-107.
[Nicolau91] Alexandru Nicolau, and Roni Potasmann, “Incremental tree height reduction
for high level synthesis,” In Proc. of the 28th Conference on ACM/IEEE Design
Automation Conference (DAC'91), 1991, pp. 770 - 774.
[Nisbet97] S. Nisbet, and S. A. Guccione, “The XC6200DS Development System,” In
Proc. of the 7th Int. Workshop on Field-Programmable Logic and Applications
(FPL'97), London, United Kingdom, September 1997. Published in Springer-Verlag
LNCS 1304, Wayne Luk and Peter Y. K. Cheung, eds., Berlin, Germany, 1997, pp. 61-
68.
[Ogawa99] Osamu Ogawa, et al., “Hardware Synthesis from C Programs with Estimation
of Bit Length of Variables,” In IEICE Transactions Fundamentals, vol. E82-A, no. 11,
November, 1999, pp. 2338-2346.

270 REFERÊNCIAS
[Oskin98] Mark Oskin, Frederic T. Chong, and Timothy Sherwood, “Active Pages: A
Model of Computation for Intelligent Memory,” In Proc. of the 25th Annual
International Symposium on Computer Architecture (ISCA98), Barcelona, Spain, pp.
192-203.
[Ouaiss00] Iyad Ouaiss, and Ranga Vemuri, “Efficient Resource Arbitration in
Reconfigurable Computing Environments,” In Proc. Design, Automation & Test in
Europe (DATE'00), Paris, France, March 27-30, 2000, pp. 560-566.
[Ouaiss98a] I. Ouaiss, et al., “An Integrated Partioning and Synthesis System for
Dynamically Reconfigurable Multi-FPGA Architectures,” In Proc. 5th Reconfigurable
Architectures Workshop (RAW'98), Orlando, Florida, USA, March 30, 1998, Published
in Springer-Verlag LNCS 1388, José Rolim, editor, Berlin,Germany, 1998, pp. 31-36.
[Ouaiss98b] Iyad Ouaiss, et al., “A Unified Specification Model of Concurrency and
Coordination for Synthesis from VHDL,” In Proc. of the International Conference on
Information Systems Analysis and Synthesis (ISAS’98), Orlando, Florida, July 12-16,
1998.
[PACT] _____, Proc. of the PACT'99 Workshop on Reconfigurable Computing
(WoRC'99), held in conjunction with PACT'99.
[Page91] Ian Page and Wayne Luk “Compiling occam into FPGAs,” In FPGAs, Will
Moore and Wayne Luk, editors, Abingdon EE&CS Books, Abingdon, England, UK,
1991, pp. 271-283.
[Page96] Ian Page, “Constructing Hardware-Software Systems from a Single
Description,” In Journal of VLSI Signal Processing, Dec. 1996, pp. 87-107.
[Panda97] Preeti Ranjan Panda, Nikil D. Dutt, Alexandru Nicolau, “Exploiting Off-Chip
Memory Access Modes in High-Level Synthesis,” In Proc. of the IEEE/ACM
International Conference on Computer Aided Design (ICCAD’97), Austin, October
1997.

REFERÊNCIAS 271
[Passerone98] C. Passerone, et al., “Modeling Reactive Systems in Java,” In Proc. of the 6th
IEEE/ACM Int. Workshop on HW/SW Co-Design, Seattle, Washington, USA, March
15-18, 1998.
[Paulin86] P. G. Paulin, J. P. Knight, and E. F. Girczyc, “HAL: A Multi-Paradigm
Approach to Automatic Data Path Synthesis, “ in Proc. 23rd Design Automation
Conference, June 29-July 2, 1986, 263-270.
[PCI95URL] PCI Special Interest Group, PCI Local Bus Specification – Revision 2.1, June
1995. URL: http://www.pcisig.com.
[PDTA] _____, The International Workshop: “Engineering of Reconfigurable
Hardware/Software Objects (ENREGLE),” http://www.cs.rdg.ac.uk/~tpp/enr.html,
International Conference on Parallel and Distributed Processing Techniques and
Applications (PDPTA), http://www.cps.udayton.edu/~pan/pdpta/.
[Postula98] Adam Postula, et al., “A Comparision of High Level Synthesis and Register
Transfer Level Design Techniques for Custom Computing Machines,” In Proc. of the 31
Hawaii Int. Conference on System Sciences (HICSS-31), January 1998, vol. VII, pp.
207-214.
[Radetzki00] von Martin Radetski, Synthesis of Digital Circuits from Object-Oriented
Specifications, IX, 252 S., Oldenburg, University, Ph.D. Thesis, 2000.
http://www.bis.uni-oldenburg.de/dissertation/2000/radsyn00/radsyn00.html
[Radunovic98] B. Radunovic, V. Milutinovic, “A Survey of Reconfigurable Computing
Architectures,” Tutorial in 8th Int. Workshop on Field Programmable Logic and
Applications (FPL'98), Tallinn, Estonia, August 31-September 3, 1998. Published in
Springer-Verlag LNCS 1482, Hartenstein and Keevallik eds, Berlin, Germany, 1998, pp.
376-385.
[Raimbault93] F. Raimbault, D. Lavenier, S. Rubini, and B. Pottier. “Fine grain parallelism
on an MIMD machine using FPGAs,” In D. Buell and K. Pocek, editors, Proceeding of
IEEE Workshop FPGAs for custom computing machines, volume 3890-02, Napa,
California, April 1993. IEEE Computer Society Press.

272 REFERÊNCIAS
[Ramachan94] L. Ramachandran, D. D. Gajski, and V. Chaiyakul, “An Algorithm for array
variable clustering,” in Proc. of the European Design Test Conference (EDAC’94),
1994.
[RAWURL] _____, Proceedings of the Reconfigurable Architectures Workshop (RAW).
Part of the International Parallel and Distributed Processing Symposium (IPDPS), 1994-
1999 (RAA 94-96). URL: http://xputers.informatik.uni-kl.de/RAW/index_raw.html.
[Razdan94a] Rahul Razdan, PRISC: Programmable Reduced Instruction Set Computers.
Ph.D. Thesis, Harvard University, Division of Applied Sciences, May 1994. (Harvard
University Technical Report 14-94, Center for Research in Computing Technology,
1994).
[Razdan94b] Rahul Razdan, K. Brace, and M. D. Smith, “PRISC Software Acceleration
Techniques”, In Proc. of the IEEE International Conference on Computer Design, Oct.
1994, pp. 145-149.
[Razdan94c] Rahul Razdan, and Michael D. Smith, “A High-Performance
Microarchitecture with Hardware-Programmable Functional Units,” In Proc. of the 27th
Annual IEEE/ACM Intl. Symposium on Microarchitecture (MICRO-27), IEEE
Computer Society Press, Los Alamitos, CA, USA, November 1994, pp. 172-180.
[Rinker00] R. Rinker, et al., “Compiling Image Processing Applications to
Reconfigurable Hardware,” In Proc. of the IEEE International Conference on
Application-Specific Systems, Architectures and Processors (ASAP’00), Boston,
Massachusetts, USA, July 10-12, 2000.
[Rupp98] C. Rupp, et al., “The NAPA Adaptive Processing Architecture,” In Proc. of
the IEEE 6th Symposium on Field-Programmable Custom Computing Machines
(FCCM'98), Napa Valley, CA, USA, April 15-17, 1998, Published by the IEEE
Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds, editors, Los Alamitos,
CA, USA, 1998, pp. 28-37.
[Scalera98] S. M. Scalera, J. R. Vázquez, “The Design and Implementation of a Context
Switching FPGA,” In Proceeding 6th IEEE Symposium on Field-Programmable Custom
Computing Machines (FCCM’98), Napa Valley, CA, USA, April 15-17, 1998,

REFERÊNCIAS 273
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1998, pp. 78-85.
[Schlansk00] M. S. Schlansker and B. Ramakrishna Rau, “EPIC: Explicity Parallel
Instruction Computing,” In IEEE Computer, Vol. 33, No. 2, February 2000, pp. 37-45.
[Schmit97] Herman Schmit, and Donald E. Thomas, “Synthesis of Applications-Specific
Memory Designs,” In IEEE Transactions on VLSI Systems, Vol. 5, No. 1, pp. 101-111
March, 1997.
[Schmit98] Herman Schmit, and Donald E. Thomas, “Address Generation for Memories
Containing Multiple Arrays,” In IEEE Transactions on CAD, vol.17, no.5, pp. 377-385,
May, 1998.
[Schneier96] Bruce Schneier, Applied Cryptography, John Wiley, New York, USA, 1996.
[Sedgewick92] Robert Sedgewick, Algorithms in C++, Addison-Wesley, Publishing
Company, Inc., 1992.
[Singh98] Hartej Singh, et al., “MorphoSys: An Integrated Re-configurable
Architecture,” In Proc. of the NATO RTO Symposium of System Concepts and
Integration, Monterey, CA, USA, April 1998.
[Smith97] W. H. Mangione-Smith, et al., “Seeking Solutions in Configurable
Computing,” In IEEE Computer, 30, 12 December 1997, pp. 38-43.
[SPIE] _____, International Society for Optical Engineering (SPIE) Photonics East
Conference, In John Schewel, editor, 1995-2000.
[Stanford90] P. Stanford, and P. Mancuso, eds., EDIF Electronic Design Interchange
Format Version 2 0 0. Electronic Industries Association, 2nd ed., 1990.
[StarBridURL] Star Bridge Systems, Inc., URL: http//www.starbridgesystems.com, Draper,
Utah, USA.
[Stephen00] Mark Stephenson, Jonathan Babb, and Saman Amarasinghe, “Bitwidth
Analysis with Application to Silicon Compilation,” In Proc. of the SIGPLAN Conference

274 REFERÊNCIAS
on Programming Language Design and Implementation (PLDI2000), Vancouver,
British Columbia, Canada, June 2000. See BitWise Project: URL:
http://www.cag.lcs.mit.edu/bitwise.
[SuperURL] Co-Design, Inc., URL: http://www.co-design.com/superlog.
[Synopsys95] Synopsys Inc., Design Compiler v3.3a, April 8, 1995.
[Synplicity99] Synplicity Inc., Synplify v5.2.2a, 1999.
[SystemCURL] The Open SystemC Initiative, URL: http://www.systemc.org.
[Tanaka89] Toshiaki Tanaka, Tsutomu Kobayashi, and Osamu Karatsu, “HARP: Fortran
to Silicon,” In IEEE Tansactions on Computer-Aided Design, vol. 8, no. 6, June 1989,
pp. 649-660.
[TimeLoURL] TimeLogic, Corp., URL: http//www.timelogic.com, Incline Village, Nevada,
USA.
[Trickey85] Howard Trickey, Compiling Pascal Programs into Silicon, Ph.D. Thesis,
Stanford University, USA, 1985.
[Trickey87] Howard Trickey, “Flamel: A High-Level Hardware Compiler,” In IEEE
Transactions on Computer-Aided Design, Vol 6, No 2, March 1987.
[Trimberger97] S. Trimberger, D. Carberry, A. Johnson, J. Wong, “A Time-Multiplexed
FPGA,” In Proceeding of the 5th IEEE Symposium on Field-Programmable Custom
Computing Machines (FCCM’97), Napa Valley, CA, USA, April 16-18, 1997,
Published by the IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds,
editors, Los Alamitos, CA, USA, 1997, pp. 22-28.
[Trimberger98] Steve Trimberger, “Scheduling Designs into a Time-Multiplexed FPGA,” In
Proc. 6th ACM/SIGDA International Symposium on Field Programmable Gate Arrays
(FPGA'98), Monterey, CA, USA, February 22-24, 1998.
[Ullman84] J. D. Ullman, Computational Aspects of VLSI, Computer Science Press,
Rockville, Md, 1984.

REFERÊNCIAS 275
[uPURL] ____, “General Processor Information”, URL:
http://bwrc.eecs.berkeley.edu/CIC/summary.
[Vasilko96] M. Vasilko, D. Ait-Boudaoud, “Architectural Synthesis Techniques for
Dynamically Reconfigurable Logic,” In Proc. 6th Int. Workshop on Field-
Programmable Logic and Applications (FPL'96), Darmstadt, Germany, Sept. 23-25,
1996, Published in Springer-Verlag LNCS 1142, Reiner R. Hartenstein and Menfred
Glesner, edts., 1996, pp. 290-296.
[VCCURL] VCC, Corp., The HOT-I and HOTF-I boards of RPUs. With the Xilinx(tm)
XC6162 and XC6264 respectively. URL: http://www.vcc.com/Hotworks.html.
[Velab98] ____, Paramaterised Library for XC6200, Velab – VHDL Elaborator,
January 1998.
[VelabURL] Douglas M. Grant, Velab: VHDL Elaborator for XC6200, v0.52, October
1997. See: Velab Release Notes, Xilinx Inc., URL:
http://www.xilinx.com/apps/velabrel.html, 1998.
[Villasenor97] John Villasenor, William H. Mangione-Smith, “Configurable Computing”, In
Scientific American, June 1997, pp. 66-71. URL:
http://www.sciam.com/0697issue/0697villasenor.html.
[Vincent93] Alberto Sangiovanni-Vincentelli, Abbas El Gamal, and Jonathan Rose,
“Synthesis methods for field programmable gate arrays,” In Proceedings of the IEEE,
81(7), July 1993, pp. 1057-1083.
[VirtexURL] Xilinx, Inc., “The Virtex Series of FPGAs,” URL:
http://www.xilinx.com/products/virtex.
[VIUFURL] _____, 3rd Annual VIUF Design Contest, 1997. URL:
http://rassp.scra.org/Fall97_VIUF/Design_Contest/.
[Waingold97] Elliot Waingold, et al., “Baring It All to Software: Raw Machines,” In IEEE
Computer, September 1997, pp. 86-93.

276 REFERÊNCIAS
[Wakabay91] K. Wakabayashi, “Cyber: High-Level Synthesis System from Software into
ASIC,” In High-Level VLSI Synthesis, Kluwer Academic Publishers, 1991, pp. 79-104.
[Wazlows93] M. Wazlowski, et al, “PRISM-II Compiler and Architecture”, In Proc. of the
IEEE Workshop on FPGAs for Custom Computing Machines, Napa, CA, April 5-7,
1993, pp. 9-16.
[Weaver98] M. Chu, N. Weaver, K. Sulimma, A. DeHon, and J. Wawrzynek, “Object
Oriented Circuit-Generators in Java,” In Proc. of the IEEE 6th Symposium on Field-
Programmable Custom Computing Machines (FCCM'98), Napa Valley, CA, USA,
April 15-17, 1998, Published by the IEEE Computer Society Press, Kenneth L. Pocek
and Jeffrey Arnolds, editors, Los Alamitos, CA, USA, 1998, pp. 158-166.
[Weinhardt00] M. Weinhardt and W. Luk, “Pipeline Vectorization,” submitted to: IEEE
Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2000.
[Weinhardt97] M. Weinhardt, “Pipeline Synthesis and Optimization for Reconfigurable
Custom Computing Machines,” Interner Bericht 1/97, Fakultdt fur Informatik,
Universitdt Karlsruhe; also presented at poster session of 5th ACM/SIGDA Int.
Symposium on FPGAs (FPGA’97), Monterey, CA, Feb. 1997.
[Weinhardt99] M. Weinhardt and W. Luk, “Pipeline Vectorization for Reconfigurable
Systems,” In Proc. of the IEEE Symposium on Field-Programmable Custom Computing
Machines (FCCM'99), Napa Valley, CA, USA, April 21-23, 1999, Published by the
IEEE Computer Society Press, Kenneth L. Pocek and Jeffrey Arnolds, editors, Los
Alamitos, CA, USA, 1999, pp. 52-62.
[Wirth98] Niklaus Wirth, “Hardware Compilation: Translating Programs into Circuits,”
In IEEE Computer, June 1998, pp. 25-31.
[Wirthlin95] M. J. Wirthlin, and B. L. Hutchings, “A Dynamic Instruction Set Computer”,
In Proc. of the 4th IEEE Symposium on FPGAs for Custom Computing Machines
(FCCM'95), Napa Valley, CA, USA, April 19-21, 1995, Published by the IEEE
Computer Society Press, Peter Athanas and Kenneth L. Pocek, editors, Los Alamitos,
CA, USA, 1995, pp. 99-107.

REFERÊNCIAS 277
[Witting96] R. D. Witting, and P. Chow, “OneChip: An FPGA Processor with
Reconfigurable Logic”, In Proc. of the IEEE Symposium on FPGAs for Custom
Computing Machines, Napa Valley, CA, USA, April 17-19, 1996, pp. 126-135.
[Wo94] David Wo, and Kevin Forward, “Compiling to the Gate Level for
Reconfigurable Co-Processor”, In Proc. of the IEEE Symposium on FPGAs for Custom
Computing Machines (FCCM’94), Napa Valley, CA, USA, April 10-13, 1994,
Published by the IEEE Computer Society Press, Duncan A. Buell and Kenneth L.
Pocek, editors, Los Alamitos, CA, USA, 1994, pp. 147-154.
[Xact97] Xilinx, Inc., XACTstep 6000 Series tool, Xilinx, San Jose, CA, USA, 1997.
[X-Blox92] Xilinx Inc., San Jose, CA, USA, X-BLOX Design Tool User Guide, 1992.
[Xilinx97] Xilinx Inc., San Jose, CA, USA, XC6000 Field Programmable Gate Arrays,
version 1.10, April 24, 1997.
[XilinxURL] Xilinx Inc., URL: http://www.xilinx.com.
[Ye00a] Z. Ye, N. Shenoy, and P. Banerjee, “A C Compiler for a Processor with a
Reconfigurable Functional Unit,” In Proc. of the ACM/SIGDA Symposium on Field
Programmable Gate Arrays (FPGA’2000), Monterey, CA, Feb. 2000.
[Ye00b] Z. Ye, P. Banerjee, S. Hauck, and A. Moshovos “CHIMAERA: A High-
Performance Architecture with a Tightly-Coupled Reconfigurable Unit,” In Proc. of the
International Symposium on Computer Architecture (ISCA’2000), Toronto, CANADA,
June 2000.

278 REFERÊNCIAS

211
Apêndice A Tecnologia Java O fluxo de compilação/execução da tecnologia Java pode ser visto na Figura A.1. Cada classe
descrita em linguagem Java é compilada (javac [J2SDKURL], por exemplo) para um ficheiro
designado por classfile, que contém toda a informação necessária do programa origem num
formato conhecido como bytecodes [Gosling95], de modo a poder ser executado por uma
máquina abstracta. Os bytecodes de cada classe são constituídos por uma constant pool (com
as referências simbólicas, cadeias de caracteres constantes, entre outras informações). Estes
bytecodes contêm ainda instruções para cada método, definidas por uma máquina virtual
designada por JVM [Lindholm96].
CAFEBABE0003002D00 2008...
Processador Java
Programa em Java
Compilador de Java
Compilador JIT Interpretador
Bytecodes para Código nativo
Bibliotecas Nativas (.so, .dll)
Classfiles Java
(.class)
Compilador de Java para Código Nativo
Class Mult static int mult(int a, int b) int r=0; for(int i=0; i<b; i++) r+=a; return r;
Figura A .1 . F luxo de compi lação/execução da tecnologia Java.

212 APÊNDICE A TECNOLOGIA JAVA
Este modelo de representação executável preserva quase toda a informação original como por
exemplo a divisão em classes, os campos e métodos de cada classe, os arrays existentes no
programa original1, etc.
A JVM tem uma arquitectura baseada numa pilha de operandos - escolhida por ser eficiente
na interpretação e portabilidade para diferentes arquitecturas alvo (RISC e CISC), e por
garantir ficheiros objecto de dimensão reduzida - e registos.
Os tipos de dados da JVM são: byte, short, int, long, float, double, char, returnAddress.
Todas as mnemónicas (200 atribuídas, 24 variações rápidas, e 2 reservadas) têm 8 bits
seguidas de 0 a 4 operandos.
As instruções aritméticas e lógicas retiram os operandos das posições cimeiras da pilha e
colocam o resultado no topo (exemplo: iadd corresponde ao RISC a: add tos, tos-1,
tos, sendo tos o conteúdo do topo da pilha).
A pilha de operandos é também utilizada para a passagem dos argumentos e retorno de
valores dos métodos. Existem instruções para movimentar valores das variáveis locais para o
topo da pilha e vice-versa, instruções para a criação e manipulação de objectos, de arrays,
instruções de fluxo de controlo (if, goto, switch, etc.), saltos para sub-rotinas para
tratamento de excepções, invocação de métodos, etc.
Os bytecodes podem ser executados por 4 modos diferentes:
• por um interpretador (por exemplo: java [J2SDKURL]);
• por um compilador JIT2 [Cramer97] (normalmente chamada de compilação
dinâmica);
• por tradução dos bytecodes em código nativo [Hsieh97];
• por implementações da JVM ou de parte da JVM em hardware, como é o caso do
processador picoJava-I [Connor97].
1 Não havendo, quando não existe sobreposição em memória, a ambiguidade nos acessos a arrays como acontece em códigos de três endereços em que os arrays do programa são embebidos numa memória global. 2 Do inglês: Just-In-Time.

APÊNDICE A TECNOLOGIA JAVA 213
Têm sido desenvolvidos tradutores directos de Java para C, que depois utilizam um
compilador de C. Esta solução, contudo, abdica, entre outras coisas, da principal
característica desta tecnologia, que é a proliferação de aplicações em classfiles e não de
ficheiros de texto com o programa original.
Têm também sido desenvolvidos compiladores de diversas linguagens3 (Ada, Eiffel, Cobol,
Scheme, etc.) tendo como alvo a JVM. Estes compiladores geram bytecodes a partir do
programa fonte (descrito numa linguagem de programação diferente da linguagem Java). As
propriedades do modelo bytecodes tornam a utilização de várias linguagens para uma
aplicação uma realidade, e reforçam a ideia do modelo JVM como um possível modelo de
distribuição de aplicações independente da plataforma.
Têm sido feitos inúmeros esforços com a finalidade de acelerar a execução dos bytecodes.
Alguns destes esforços foram direccionados para a optimização dos bytecodes estaticamente,
com técnicas avançadas de compilação [Cierniak97][Budimlic97] (conhecidos por
optimizadores bytecodes-to-bytecodes). Outros baseiam-se na utilização de técnicas ao nível
dos compiladores do tipo JIT [Cramer97]. E ainda outros optam pela paralelização dos
bytecodes. Em [Bik97] é descrita uma ferramenta para detecção automática de paralelismo
implícito em código cíclico ao nível da JVM. Esta paralelização tem como objectivo tirar
partido de arquitecturas que tenham suporte efectivo de multi-threads.
3 Uma lista de alguns compiladores pode ser consultada em [JVMLang].

214 APÊNDICE A TECNOLOGIA JAVA

215
Apêndice B Fluxo de Compilação Alvejando ASICs Este apêndice descreve um fluxo de compilação, a partir de um algoritmo em linguagem
Java, que integra uma ferramenta de síntese arquitectural tradicional. É explicado um
caminho de um subconjunto de bytecodes do Java de uma dada aplicação à geração de VHDL
comportamental que pode depois ser utilizado por uma ferramenta de síntese arquitectural
para a criação do circuito final. Este fluxo de compilação foi considerado no início dos
trabalhos que conduziram a esta tese e publicado em [Cardoso98b].
A Figura B.1 ilustra o referido fluxo de compilação. O fluxo utiliza como retaguarda uma
ferramenta de síntese arquitectural (é utilizado o CADDY-II [CaddyURL]).
Programa em
Java
Compilador para
bytecodes
Bytecodes Java GALADRIEL
VHDL comportamental
Síntese Arquitectural
VHDL RTL
Síntese Lógica
EDIF Colocação &
Encaminhamento Netlist do circuito
Figura B .1 . O ambiente de compi lação de f ragmentos de código Java
em hardware especí f ico com a ut i l ização de uma ferramenta de s íntese
arquitectural.

216 APÊNDICE B FLUXO DE COMPILAÇÃO ALVEJANDO ASICS
A compilação de bytecodes para VHDL comportamental é directamente realizada sobre os
bytecodes. Cada tradução fornece uma entidade VHDL constituída por um único processo. A
tradução é facilitada pela prévia identificação dos ciclos, e da informação relativa às
dependências de controlo, e pelo facto do VHDL gerado incluir a pilha de operandos.
Cada tipo primitivo da linguagem Java (byte, short, int, boolean, long, e char) é traduzido
para o tipo correspondente em VHDL4.
De momento, o VHDL comportamental gerado utiliza 32 bits como comprimento de palavra.
As instruções da JVM para conversão de tipos são traduzidas para funções VHDL
equivalentes. Por exemplo, a instrução i2s (int para short) é traduzida para p# :=
int2short(p#), em que int2short é a função VHDL que converte um inteiro de 32
bits para 16 bits (esta função reside na biblioteca de conversões) ambos representados em
complemento para dois.
As operações com operandos de 64 bits (tipo long) utilizam dois níveis da pilha de
operandos ou duas variáveis locais para armazenar cada operando. Por exemplo, a instrução
da JVM, ladd é convertida em (p#+1, p#) := (p# & p#+1) + (p#+2 &
p#+3), em que & é o operador de concatenação.
As instruções de leitura/escrita de elementos de arrays são traduzidas para funções em
VHDL de funcionalidade semelhante.
Exemplo B -1 . Exemplo da t radução de bytecodes Java para VHDL
comportamental .
Considere-se o fragmento Java apresentado na Figura B.2 que especifica a
expressão: (b + c) × d + e + f; em que todos os operandos são do tipo int
(32 bits). O compilador identifica as variáveis e os operandos da pilha que
têm de ser transferidos entre o software e o hardware e vice-versa. Neste
caso identifica 5 variáveis locais de entrada e o operando do topo da pilha
como resultado. O corpo da arquitectura da entidade em VHDL lê 5
operandos de 32 bit e retorna o resultado em 32 bits (ver Figura B.2, na
qual Din e Dout são portos da entidade).
4 Funções de suporte a operações de vírgula flutuante seriam, contudo, necessárias.

APÊNDICE B FLUXO DE COMPILAÇÃO ALVEJANDO ASICS 217
(…) index = (b + c) * d + e + f; (…)
VHDL
bytecodes
(…) iload 10 iload 13 iadd iload_2 imul iload 11 iload 14 iadd iadd (…)
(…) l10 := Din; -- read() l13 := Din; -- read() l2 := Din; -- read() l11 := Din; -- read() l14 := Din; -- read() p1 := l10; p2 := l13; p1 := p2 + p1; p2 := l2; p1 := p2 * p1; p2 := l11; p3 := l14; p2 := p3 + p2; p1 := p2 + p1; Dout <= p1; -- write() (…)
código Java
Com a construção de um DFG para cada bloco básico
p1 := (l10 + l13) * l2 + l11 + l14;
Figura B .2 . Tradução de Java com a ut i l ização de o perações de le i tura e
escrita.
A tradução dos bytecodes para VHDL com utilização do funcionamento da pilha de
operandos assume que a ferramenta de síntese arquitectural é suficientemente poderosa para
optimizar a descrição.
Cada ramo da construção switch do Java, quando não termina num break é copiado para
cada uma das opções em VHDL (todas as opções da instrução when, do VHDL, terminam a
instrução no fim do ramo). Quando várias opções da instrução Java switch seleccionam o
mesmo corpo de instruções é utilizada a construção when do VHDL com o OR das opções.
Todos os ciclos do código Java são implementados por construções do tipo while do
VHDL. Contudo, os ciclos do programa fonte não podem ter internamente instruções break.
Embora este fluxo de compilação possa parecer propício para realizar hardware específico a
partir de descrições de algoritmos em linguagem Java, tal facto não é inteiramente aplicável
tratando-se de reconfigware. As propriedades inerentes ao reconfigware fazem com que
técnicas especializadas tenham de ser utilizadas para se obterem soluções eficientes. O alvo

218 APÊNDICE B FLUXO DE COMPILAÇÃO ALVEJANDO ASICS
reconfigware permite reconfiguração e tem uma estrutura pré-definida (fixa) e por isso sem a
liberdade de implantação física (layout) dos ASICs.

219
Apêndice C Implementação Simplificada de Algumas Construções Orientadas por Objectos em Hardware Específico É fundamental que as ferramentas de compilação para hardware específico possam
estabelecer um caminho automático de especificações orientadas por objectos até uma
arquitectura sintonizada com a própria aplicação. Em muitos casos, estas especificações
podem ser implementadas simplificadamente em hardware específico. Para tal, são
necessárias algumas transformações (previamente apresentadas em [Cardoso98a]):
• Desdobramento de objectos: nesta transformação o objecto é expandido nos campos
e nos métodos que o constituem (ver Exemplo C-1);
• Aplanação da estrutura hierárquica: nesta transformação são englobadas em
instâncias de classes que sejam derivadas todas as características das classes na
hierarquia (ver Exemplo C-2);
• Implementação de despacho dinâmico: quando não é conhecida estaticamente a
classe de um determinado objecto referenciado, a invocação de um método nessa
referência é resolvida pela determinação do objecto de entre o conjunto
dinamicamente possível (ver Exemplo C-3);
• Alocação estática de objectos: uma das formas de lidar com a criação de objectos é
fazer a pré-alocação destes em memória durante a compilação. Devido à natureza
parcialmente dinâmica da linguagem Java, o compilador tem de determinar que

220 APÊNDICE C IMPLEMENTAÇÃO SIMPLIFICADA DE ALGUMAS...
classes na hierarquia de classes poderão ser instanciadas pela aplicação. Muitas das
características dinâmicas podem ser resolvidas estaticamente. Uma das
transformações é realizada pela análise pessimista da alocação de objectos em
memória. Na pré-alocação é determinado o conjunto de classes que possam definir
uma determinada referência a um objecto e alocada memória capaz de armazenar o
objecto de maior dimensão. A criação de objectos e arrays dentro de ciclos pode ser
estaticamente resolvida quando é possível de determinar estaticamente o número das
iterações do ciclo ou um seu majorante. A incapacidade de resolução estática de
objectos ou de arrays dentro de ciclos mal-comportados (quando o número de
iterações não pode ser conhecido estaticamente) é um exemplo da necessidade de
construções dinâmicas em hardware específico. Sem alocação dinâmica, quando uma
variável pode armazenar a referência para instâncias de classes diferentes, tem de ser
reservada memória que possa albergar o maior dos objectos. Este problema pode ter
custos incomportáveis quando existem arrays de objectos ou criações de objectos
inseridas em estruturas cíclicas.
Todas as transformações anteriores requerem a existência da hierarquia de classes em tempo
de compilação e são orientadas para implementações simplificadas em hardware específico.
Parece ser opinião unânime de que a implementação em hardware específico de mecanismos
que assegurem o funcionamento das propriedades dinâmicas requer custos e complexidades
demasiadamente elevados. Contudo, formas de implementação necessitam de ser
investigadas.
Foram apresentadas formas simples e eficientes de implementação de descrições orientadas
por objectos em hardware específico que se baseiam na resolução estática dessas construções.
Para consolidar as técnicas propostas necessitam de ser elaborados estudos de avaliação e
aplicabilidade das mesmas em exemplos complexos.
Exemplo C -1 . Desdobramento de objectos.
Na Figura C.1 é apresentada a classe “Rect”, constituída por dois atributos
do tipo inteiro, um construtor e um método que calcula a área de um
rectângulo. O programa cria um novo objecto do tipo “Rect” (com
parâmetros l1 e l2) e invoca o método area(). O construtor pode ser
realizado por simples atribuição às duas variáveis correspondentes aos

APÊNDICE C IMPLEMENTAÇÃO SIMPLIFICADA DE ALGUMAS... 221
atributos dos valores iniciais (l1 e l2) e a invocação do método por um
procedimento que recebe como parâmetros as variáveis correspondentes aos
atributos e a variável que armazena a área calculada.
Rect
Int l1; Int l2; Rect(int a, int b) This.l1 = a; This.l2 = b; public int area() return (this.l1 * this.l2);
Java … rect S = new Rect(l1, l2); … int area = S.area(); …
VHDL … Rect_l1 := l1; Rect_l2 := l2; … Rect_area(Rect_l1, Rect_l2, area); …
Figura C .1 . Desdobramento de objectos.
Exemplo C -2 . Aplanação da estrutura hierárquica de c lasses.
Na Figura C.2 são apresentadas duas classes: a classe “Circle” e a classe
derivada “Rect”. O encapsulamento dos atributos da classe mãe
(“Circle”) na classe derivada (“Rect”) produz uma nova classe “Rect”.
A partir desta pode ser utilizado o supracitado desdobramento de objectos
para implementar o objecto em hardware.
Circle
Int l1; Circle(radius a) This.l1 = a; public int area() return 3*l1*l1;
Rect extends Circle
Int l2; Rect(int a, int b) Super(a); This.l2 = b; public int area() return l1*l2;
Int l1; Int l2; Rect(int a, int b) This.l1 = a; This.l2 = b; public int area() return l1*l2;
Rect
Figura C .2 . Aplanação da estrutura hierárquica de c lasses.

222 APÊNDICE C IMPLEMENTAÇÃO SIMPLIFICADA DE ALGUMAS...
Exemplo C -3 . Implementação de despacho d inâmico.
Na Figura C.3 é apresentado um exemplo em que num determinado ponto
do programa não é possível conhecer estaticamente a classe do objecto que
a variável S referencia. Por este motivo, o método invocado na linha 9
(caixa Java) pode ser o método area() da classe “Rect” ou o da classe
“Circle”. Com a codificação de cada classe é possível implementar a
especificação em VHDL no qual é determinada a classe que foi instanciada
e por isso chamado o respectivo método (linhas 13 a 17 da caixa VHDL).
…
Neste ponto S pode ser uma referência a um objecto do tipo Rect ou Circle
Java 1. … 2. Shape S; 3. … 4. if(option == 2) 5. S = new Rect(l1, l2); 6. Else 7. S = new Circle(l1); 8. … 9. int Area = S.area(); 10. …
VHDL 1. … 2. Type CLASSES is (Circle, Rect); 3. Variable Class_1: CLASSES; 4. … 5. if(option = 2) then 6. newRect(l1, l2, Rect_l1_1, Rect_l2_1); 7. Class_1 := Rect; 8. else 9. newCircle(l1, Circle_radius_1); 10. Class_1 := Circle; 11. end if; 12. … 13. if(Class_1 = CLASSES’(Rect)) then 14. Rect_area(Rect_l1_1, Rect_l2_1, area); 15. Else 16. Circle_area(Circle_radius_1, area); 17. End if; 18. …
Figura C .3 . Implementação de despacho d inâmico.

223
Apêndice D Exemplos Utilizados
“Example is not the main thing in influencing others. It is the only thing.”
Albert Schweitzer
Neste apêndice são apresentados os exemplos considerados na dissertação. É apresentado o
código Java para cada um dos exemplos mais simples. São também apresentadas, para cada
exemplo, as características principais (linhas de código Java, número de blocos básicos,
número de instruções da JVM, número de nós do DFG global gerado pelo GALADRIEL,
número de ciclos, número de variáveis do tipo array e número de acessos à memória).
O primeiro grupo de exemplos refere-se a núcleos de processamento simples, que na maioria
das vezes integram exemplos reais. Todos os exemplos deste grupo podem ser
implementados por aplicação de síntese lógica ao código, numa linguagem de descrição de
hardware, traduzido directamente das versões em Java. O segundo grupo de exemplos integra
algoritmos completos e mais complexos.
Alguns exemplos considerados referem-se aos exemplos apresentados com os ciclos
desenrolados totalmente ou de um factor K. Um ciclo desenrolado de um factor K significa
que o novo ciclo tem como corpo K iterações do ciclo original.
D.1 Grupo de Núcleos de Algoritmos
A: REVERSE
Função que reverte os bits de uma palavra de 32 bits (ver Figura D.1). Esta função é utilizada
por algumas implementações da transformada de Fourier (FFT).

224 APÊNDICE D EXEMPLOS UTILIZADOS
int Reverse(int Word) int WordRev = 0; For(int I=0; I<32; I++) WordRev |= (Word & 1); WordRev << 1; Word >> 1; Return WordRev;
Figura D .1 . Exemplo REVERSE.
B: COUNT
Função que conta o número de bits de valor lógico um de uma palavra (ver Figura D.2). B8
identifica o exemplo desenrolado e que utiliza como entrada um palavra de 8 bits, B16, o
exemplo desenrolado com palavra de 16 bits e B32, o exemplo desenrolado com palavra de
32 bits.
Int count(int word) int NumOnes = 0; For(int I=0; I<8; I++) NumOnes += (Word >> I) & 1; Return NumOnes;
Figura D .2 . Exemplo COUNT8.
C: HAMMDIST
Função que retorna a distância de Hamming entre duas palavras (ver Figura D.3). C8
identifica o exemplo desenrolado com palavras de 8 bits, C16, o exemplo desenrolado com
palavras de 16 bits e C32, o exemplo desenrolado com palavras de 32 bits.
Int hammingDist(int I1, int I2) Int result = 0; Int xor1 = I1 ^ I2; For(int I=0; I<32; I++) Result = (xor1 & 1) + result; Xor1 = xor1 >> 1; return result;
Figura D .3 . Exemplo HAMMDIST.

APÊNDICE D EXEMPLOS UTILIZADOS 225
D: EVENONES
Função que retorna um se o número de bits de uma palavra iguais a um for ímpar (ver Figura
D.4). D8 identifica o exemplo desenrolado com palavra de 8 bits, D16, o exemplo
desenrolado com palavra de 16 bits e D32, o exemplo desenrolado com palavra de 32 bits.
Int evenOnes(int temp, int Num) Int cnt = 0; For(int I=0; I<Num; I++) Cnt ^= (temp & 1); temp >>= 1; return cnt;
Figura D .4 . Exemplo E V E N O N E S .
E: SQRT
Função que calcula a raiz quadrada, de um número inteiro de 12 bits, implementada em Java
(ver Figura D.5). O resultado é representado em 6 bits. E1 identifica o exemplo desenrolado.
public static short sqrt(short vsqn) short vsq = vsqn, asq = 0, a = 0, tvsq = 0; for (int i = 0; i < 6; i++) short nasq = (short) (((asq+a) << 2) | 1); short sa = (short) (a << 1); tvsq = (short) ((tvsq << 2) | ((vsq >> 10) & 3)); vsq = (short) (vsq << 2); if (nasq <= tvsq) a = (short) (sa | 1); asq = nasq; else a = sa; asq = (short) (asq << 2); return a;
Figura D .5 . Exemplo SQRT.
F: USQRT
Função que calcula a raiz quadrada de um número inteiro representado em 32 bits (ver Figura
D.6). O resultado é representado por apenas 16 bits. F1 identifica o exemplo desenrolado.

226 APÊNDICE D EXEMPLOS UTILIZADOS
public static int usqrt(int x) int a = 0; // accumulator int r = 0; // remainder int e = 0; // trial product for (int i = 0; i < 16; i++) r = (r << 2) + (((x & (3 << 14)) >> 14)); x <<= 2; a <<= 1; e = (a << 1) + 1; if (r >= e) r -= e; a++; return (e>>9);
Figura D .6 . Exemplo USQRT.
G: CRC-32
Função que calcula o CRC (Cyclic Redundancy Check) de 32 bits, um byte de cada vez
utilizando a convenção Big-Endian (ver Figura D.7). O polinomial gerado é o utilizado no
protocolo Ethernet: 1245101112162632 ++++++++++ xxxxxxxxxx .
int crc_32(int data) data = data & 0xff; int ans = data << 24; for(int i=0;i<8;i++) if((ans & 0x80000000) == 0x80000000) ans = (ans << 1) ^ 0x04c11db7; else ans <<= 1; return ans;
Figura D .7 . Exemplo CRC-32 .
H: HAMMING
Função que implementa um descodificador de Hamming de uma palavra de 7 bits (ver Figura
D.8). O resultado é representado em 4 bits.

APÊNDICE D EXEMPLOS UTILIZADOS 227
static byte Hamming(byte word) byte syndrome, bit1, bit2, bit3; byte bit4, bit5, bit6, bit7; bit1 = (byte) (word & 0x1); bit2 = (byte) ((word & 0x2) >> 1); bit3 = (byte) ((word & 0x4) >> 2); bit4 = (byte) ((word & 0x8) >> 3); bit5 = (byte) ((word & 0x10) >> 4); bit6 = (byte) ((word & 0x20) >> 5); bit7 = (byte) ((word & 0x40) >> 6); syndrome=(byte)(bit1^bit3^bit5^bit7); syndrome <<= 1; syndrome|=(byte)(bit2^bit3^bit6^bit7); syndrome <<= 1; syndrome|=(byte)(bit4^bit5^bit6^bit7); switch(syndrome) case 1: word ^= 0x1; break; case 2: word ^= 0x2; break; case 3: word ^= 0x4; break; case 4: word ^= 0x8; break; return (byte) (word & 0xf);
Figura D .8 . Exemplo HAMMING.
I: MULT
Função que implementa um multiplicador de dois inteiros positivos de 32 bits com resultado
representado em 32 bits (ver Figura D.9). I1 identifica o exemplo completamente
desenrolado, I2 desenrolado de um factor de 2, I4 de um factor de 4, I8 de um factor de 8 e
I16 de um factor de 16.
public int mult(int x, int y) int t1 = x; int t2 = y; int t3 = 0; // mult result for(int i=0; i < 32; i++) // 32 bits if((t2 & 0x1) == 0x1) t0 += t1; t1 <<= 1; t2 >>= 1; return t0;
Figura D .9 . Exemplo MULT.

228 APÊNDICE D EXEMPLOS UTILIZADOS
Na Tabela D.1 são apresentas algumas das características dos exemplos previamente
apresentados.
Tabela D .1 . Caracter íst icas do pr imeiro grupo de exemplos.
Exemplo # linhas de Java
# Inst. JVM
# BBs # nós do DFG
A: REVERSE 10 25 4 26 A1: REVERSE+ 129 440 1 251 B: COUNT 7 19 4 21 B8: COUNT8+ 11 62 1 39 B16: COUNT16+ 21 126 1 79 B32: COUNT32+ 39 254 1 159 C: HAMMDIST 9 28 4 27 C8: HAMMDIST8+ 19 80 1 48 C16: HAMMDIST16+ 36 194 1 98 C32: HAMMDIST32+ 71 320 1 192 D: EVENONES 8 21 4 23 D8: EVENONES8+ 18 76 1 45 D16: EVENONES16+ 37 164 1 99 D32: EVENONES32+ 71 336 1 201 E: SQRT 21 65 7 57 E1: SQRT+ 75 256 19 217 F: USQRT 17 49 6 51 F1: USQRT+ 130 477 31 485 G: CRC-32 10 34 7 34 G1: CRC-32+ 46 153 25 157 H: HAMMING 25 121 6 75 I: MULT 11 32 6 36 I2: MULT2 19 49 8 55 I4: MULT4 23 83 12 96 I8: MULT8 39 151 20 190 I16: MULT16 71 287 36 426 I1: MULT+ 228 542 65 573
D.2 Algoritmos mais Complexos
DCT (Discrete Cosine Transform)
O DCT [Ahmed74] é uma transformada utilizada pelos standards de codificação de imagem
(JPEG – Joint Photographic Expert Group) e de vídeo (MPEG5 - Motion Picture Expert
Group) e transforma uma representação (sinal) no domínio do espaço para o domínio da
frequência.
5 Os standards de codificação/descodificação MPEG utilizam respectivamente o DCT e o IDCT.

APÊNDICE D EXEMPLOS UTILIZADOS 229
O DCT considerado é o DCT bidimensional que recebe blocos de pixeis de dimensão 8 × 8
(dimensão utilizada pela maioria dos standards de compressão de dados). A implementação
em Java não é uma implementação optimizada mas a simples divisão do DCT 2-D em dois
DCT 1-D (cada um dos quais é realizado por simples multiplicação de matrizes) e uma
transposição de matrizes. A equação (D.1) ilustra as operações realizadas, na qual a matriz W
representa a matriz de coeficientes, X a matriz de entrada e Y a matriz de saída (todas as
matrizes são de dimensão 8 × 8). A implementação considerada utiliza os coeficientes
representados por 12 bits (vírgula fixa).
( )TWXWY ××= (D .1 )
Um DCT é realizado sobre uma imagem bidimensional (M × N) decompondo esta em blocos
de 8 × 8, sendo cada um deles computados pela equação anterior.
O exemplo DCT identifica o exemplo completo e DCT1 o exemplo completo com os ciclos
internos dos algoritmos de multiplicação de matrizes completamente desenrolados. O
exemplo DCT2 utiliza apenas dois ciclos.
Filtro Kalman
O filtro Kalman foi traduzido da versão em VHDL utilizada como exemplo-teste
(benchmark) para síntese arquitectural [Ben92URL]. O exemplo KALMAN1 é a descrição
traduzida directamente do original (ver Figura D.10), KALMAN2 uma versão com os dois
ciclos internos desenrolados, KALMAN3 uma versão com os dois primeiros ciclos e os dois
ciclos internos desenrolados e KALMAN4 com os dois primeiros ciclos, o ciclo interno da
segunda região cíclica e os últimos dois desenrolados.
1. static final short[] kalman1(short[] A, short[] X, 2. short[] K, short[] Y, short[] G) 2. 3. 4. short[] V = new short[4]; 5. 6. //Initializing state Vector X 7. for(int i=0; i<16; i++) 8. X[i] = 0; 9. 10. 11. for(int i=13; i<16; i++) 12. Y[i] = 0; 13. 14. 15. // Computing state Vector X

230 APÊNDICE D EXEMPLOS UTILIZADOS
16. for(int i=0; i<16; i++) 17. short temp = 0; 18. for(int j=0; j<16; j++) 19. int index = i * 16 + j; 20. temp += (short) (A[index] * X[j] + K[index] * Y[j]); 21. 22. X[i] = temp; 23. 24. 25. // Computing output Vector V 26. for(int i=0; i<4; i++) 27. short temp = 0; 28. for(int j=0; j<16; j++) 29. int index = i * 16 + j; 30. temp += (short) (G[index] * X[j]); 31. 32. V[i] = (short) (temp * Y[i+1]); 33. 34. 35. // Output Vector V 36. return V; 37.
Figura D .10 . Exemplo KALMAN.
Filtro Passa-Baixo para Imagens (FPBI)
Implementação em Java de um algoritmo que implementa um filtro passa-baixo para imagens
2-D. O algoritmo percorre a imagem inicial com uma janela de dimensão 3 por 3 pixeis. Cada
pixel da imagem filtrada é determinado pela soma pesada do pixel e dos seus vizinhos na
imagem original. A primeira implementação do algoritmo (FPBI) tem 4 ciclos encadeados e
utiliza um array onde são colocados os 9 coeficientes do filtro. Os dois ciclos mais externos
iteram sobre as linhas e colunas da imagem. A segunda implementação (FPBI1) foi obtida
desenrolando os dois ciclos internos. A terceira implementação (FPBI2) é uma versão da
anterior com os coeficientes fixos. A quarta implementação (FPBI3) é baseada na versão
anterior com o segundo ciclo desenrolado de um factor de 2. A quinta implementação
(FPBI4) é baseada na versão anterior com o segundo ciclo desenrolado de um factor de 2.
Detecção de Contornos (SOBEL)
Versão em Java do algoritmo de detecção de contornos, Sobel, proposto em [VIUFURL]. O
algoritmo utiliza dois níveis de convolução (horizontal seguida de vertical).

APÊNDICE D EXEMPLOS UTILIZADOS 231
IDEA
Parte do algoritmo de encriptação IDEA (International Data Encryption Algorithm)
[Schneier96]. O exemplo IDEA refere-se à encriptação de 8 elementos do tipo byte baseada
numa subchave de 52 elementos e retorna 8 bytes.
QRS
Algoritmo de monitorização do batimento cardíaco em ECG [Ben95URL]. A implementação
em Java corresponde ao código interno do ciclo infinito.
BPIC (Binary Pattern Image Coding)
Algoritmo que decompõe uma imagem em blocos de 4×4 pixeis e codifica cada bloco numa
única palavra de 32 bits [Morse94]. Como exemplo é considerada a parte do algoritmo que
calcula a codificação baseado na luminância e na média das luminâncias dos pixeis de um
determinado bloco.
EUCDIST
Algoritmo que calcula a distância euclideana entre dois vectores. A implementação utiliza
arrays com elementos do tipo short (16 bits) para armazenar os vectores. Este algoritmo é
amplamente utilizado em técnicas de agrupamento (clustering), processamento de imagem,
reconhecimento de voz, etc.
CCW e INTERSEC
São duas funções de geometria [Sedgewick92]. CCW implementa uma função que determina
se, dados três pontos num plano bidimensional, o trajecto que começa no primeiro, passa pelo
segundo e termina no terceiro é um trajecto no sentido directo dos ponteiros de um relógio ou
em sentido inverso. Intersec é uma função que indica se dois segmentos de recta num plano
bidimensional, cada um representada por dois pontos, se intersectam. O algoritmo utiliza o
algoritmo CCW.
Nas Tabela D.2, Tabela D.3, Tabela D.4 e Tabela D.5 estão representadas algumas das
características dos exemplos deste grupo.

232 APÊNDICE D EXEMPLOS UTILIZADOS
Tabela D .2 . Caracter íst icas dos exemplos considerados: codif icação de
imagem e v ídeo.
Exemplo # linhas de Java
# Inst. JVM
# BBs # Nós do DFG
# ciclos
# arrays
# acessos à memória
DCT1 33 406 25 407 8 5 4.352 DCT2 46 586 19 495 6 5 2.304 DCT3 188 930 7 1.257 2 3 256 BPIC1 56 203 30 199 7 5 24.832 BPIC2 116 537 42 468 3 5 24.832 BPIC3 178 1.082 39 831 2 5 24.832
Tabela D .3 . Caracter íst icas dos exemplos considerados: Fi l t ros de
processamento de imagens.
Exemplo
# linhas de Java
# Inst. JVM
# BBs
# Nós do DFG
# ciclos
# arrays
# acessos à memória Imagem: (m×n) pixeis
FPBI 28 110 13 116 4 3 9+19× ((m-3) × (n-3)) FPBI1 28 230 7 156 2 3 9+19× ((m-3) × (n-3)) FPBI2 42 276 7 185 2 3 9+15× (n-3) × (m-3) FPBI3 23 160 7 108 2 2 10× (n-3) × (m-3) FPBI4 40 183 7 121 2 2 7× (n-3) × (m-3) SOBEL 71 267 29 310 7 4 11×m×n-9×m+2×n-4
Tabela D .4 . Caracter íst icas do exemplo Kalman.
Exemplo # linhas de Java
# Inst. JVM
# BBs
# Nós do DFG
# ciclos
# arrays
# acessos à memória
KALMAN1 30 118 19 108 6 6 1.191 KALMAN2 96 694 13 438 4 6 1.191 KALMAN3 135 770 7 443 2 6 853 KALMAN4 239 1.417 4 656 1 6 853
Tabela D .5 . Caracter íst icas dos outros exemplos considerados.
Exemplo # linhas de Java
# Inst. JVM
# BBs
# Nós do DFG
# ciclos
# arrays
# acessos à memória
QRS 95 327 49 351 - - - IDEA 128 544 64 544 1 3 68 EUCDIST 8 26 4 23 1 2 2×n CCW 14 65 10 61 - - - INTERSEC 74 312 40 260 - - -

233
Apêndice E Interface Software/Reconfigware Para comunicação entre o software (sob a forma de bytecodes) e o hardware são utilizadas
chamadas a métodos nativos [Gordon98] (C ou C++) inseridas nos bytecodes da aplicação
sempre que seja necessária comunicação entre os dois domínios. A Figura E.1 mostra uma
interface simples (utilizando o conceito de memória partilhada, em que portos de
entrada/saída do FPGA se encontram mapeados em posições de memória). A classe Java que
contém os métodos nativos é ilustrada na Figura E.1a. Estes métodos nativos são descritos em
C (cujos cabeçalhos se encontram na Figura E.1b). A Figura E.1c ilustra a utilização da classe
de interface num programa em Java. A Figura E.2 ilustra os bytecodes (assumindo a
configuração do FPGA com o circuito em fases anteriores) que implementam a comunicação
com o reconfigware responsável pela implementação do exemplo da Figura 3.23. No código
da figura aparecem as colocações dos 5 operandos em registos do FPGA e no final da
execução do reconfigware, a transferência do resultado para o topo da pilha da JVM.
Os exemplos realizados utilizam a placa de desenvolvimento descrita em [Nisbet97]
conectada ao barramento PCI [PCI95URL] de um PC. Para a comunicação
software/reconfigware foi utilizada a classe em Java fornecida pelo fabricante [VCCURL],
que permite aceder do código Java aos recursos da placa (FPGA, RAMs, etc.). As variáveis
do tipo array que têm de ser transferidas para o reconfigware são copiadas para as memórias
SRAM da placa. Os elementos de variáveis do tipo array são transferidos de ou para as
memórias da placa e o reconfigware gerado pelo NENYA assume a pré-colocação destes
elementos. A comunicação de escalares (variáveis de tipo primitivo) entre os dois

234 APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE
componentes é feita pela utilização da interface FastMap6 [Churcher95]. Para cada variável
que necessita de comunicação é colocado numa coluna do FPGA um registo acessível pelo
sistema de computacional de hospedagem (PC).
a)
1. package HwInterface; 2. public class InOut 3. final static public void setup() 4. System.loadLibrary("InOutNat"); 5. 6. final static public native void write(int Address, int Data); 7. final static public native int read(int Address); 8. … 9. b)
10. #include <jni.h> 11. #include "HwInterface_InOut.h" 12. JNIEXPORT void JNICALL Java_HwInterface_InOut_write 13. (JNIEnv *Env, jobject c, jint a, jint b) … 14. JNIEXPORT jint JNICALL Java_HwInterface_InOut_read 15. (JNIEnv *Env, jobject c, jint a) … c )
16. … 17. HwInterface.InOut.setup(); … 18. HwInterface.InOut.write(Address1, Data1); 19. … 20. Data2 = HwInterface.InOut.read(Address2); 21. …
Figura E .1 . Bibl ioteca para comunicação software/hardware: a)
Declaração da c lasse Java que contém os métodos nat ivos; b)
Cabeçalhos da declaração dos métodos em l in guagem C; c ) chamada
da c lasse em Java .
O mecanismo utilizado para sincronizar a execução do reconfigware com o software é o
seguinte: durante a execução do reconfigware, o software pode esperar até que seja atribuído
o valor lógico um à flag de concluído, ou por um número pré-definido de milisegundos.
Durante a espera podem ser executadas instruções que não dependam de resultados do
reconfigware.
6 Os dispositivos da família XC6200 de FPGAs são acedidos via um interface SRAM: todos os FFs (Flip-Flops) do FPGA são mapeados na memória do sistema de hospedagem possibilitando que o conteúdo dos mesmos possa ser escrito ou lido pelo software por simples acesso à memória.

APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE 235
1. … 2. new #2 class InOut 3. dup 4. invokenonvirtual #5 <Method InOut.init()V> 5. astore 1 6. // transfere para o reconfigware os 5 operandos 7. // l10, l13, l2, l11, l14 8. aload 1 9. iconst 0 // posição 0 10. iload 10 // operando 10 11. invokevirtual #4 <Method InOut.write(II)V> 12. aload 1 13. iconst 1 // posição 1 14. iload 13 // operando 13 15. invokevirtual #4 <Method InOut.write(II)V> 16. aload 1 17. iconst 2 // posição 2 18. iload 2 // operando 2 19. invokevirtual #4 <Method InOut.write(II)V> 20. aload 1 21. iconst 3 // posição 3 22. iload_11 // operando 11 23. invokevirtual #4 <Method InOut.write(II)V> 24. aload 1 25. iconst 4 // posição 4 26. iload 13 // operando 13 27. invokevirtual #4 <Method InOut.write(II)V> 28. 29. // Espera que o reconfigware calcule 30. 31. aload 1 32. iconst 5 33. invokevirtual #4 <Method InOut.read(I)I> 34. // resultado no topo da pilha da JVM 35. ...
Figura E .2 . Exemplo de comunicação entre o sof tware e o reconfigware
que implementa o exemplo apresentado na Figura 3.23.
De seguida apresenta-se um exemplo que foi realizado e que é constituído por um
componente software e um componente reconfigware [Cardoso99b].
O algoritmo de determinação da distância euclideana é um algoritmo simples (ver EUCDIST
no apêndice D). A Figura E.3b mostra a versão reconfigware/software do exemplo puramente
software da Figura E.3a. A versão reconfigware/software utiliza, por parte do software, o
mecanismo de espera pela activação do sinal concluído fornecido pelo reconfigware (Figura
E.3b).
Para a dimensão dos vectores X e Y de 4 a implementação tem uma área de 1.481 células e
atraso de 1,9 µs. O atraso foi medido com a frequência máxima de 20MHz determinada

236 APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE
experimentalmente. O tempo de execução não tem em conta os custos de transferência para
armazenar os dois vectores nas memórias da placa e para ir buscar o resultado com a
utilização da interface FastMap. A implantação física (layout) do exemplo no FPGA
XC6216 está ilustrado na Figura E.4.
… // Number of array elements N int N=4; // create a reconfigware object Reconfigware RW1 = new Reconfigware(“vect_dist.cal”); // set the FPGA clock frequency to 20MHz RW1.setClock(20); // Give control of the memory of the board to the Host RW1.setBankControl(0); //send the arrays to the memory of the board RW1.writeRAM(X, AddrX, N); RW1.writeRAM(Y, AddrY, N); //give control of the memory of the board to the FPGA RW1.setBankControl(3); RW1.setMapLow32(0xfffffffe); // reset the FSM RW1.setColumn(RESET, 0); // start the FSM RW1.setColumn(START, 1); // pool the DONE bit till the completion of the // hardware execution do while(board.getColumn(DONE) != 1); // get the result from the register on the FPGA RW1.setMapLow32(0); Int L2NORM = RW1.getColumn(RESULT); // return the control of the memory of the board //to the host RW1.setBankControl(0); …
… // Number of array elements N int N=4; MAXTIME c1 = new MAXTIME(); c1.start(); int L2NORM = 0; for(int i=0; i<N;i++) short Aux = X[i] - Y[i]; L2NORM += Aux*Aux; c1.end(); …
a) b)
Figura E .3 . a) Segmento de software inicial ; b) Solução
reconfigware/software.
O exemplo apresentado permite ilustrar a interface reconfigware/software utilizada. Esta
interface baseia-se na utilização de uma placa ligada ao PCI de um computador pessoal e
forma por isso um sistema computacional reconfigurável com custos elevados de
comunicação entre os componentes reconfigware e software. Outros sistemas, como por
exemplo aqueles em que o componente reconfigware é ligado ao barramento de sistema ou os
novos dispositivos com o componente reconfigware integrado no mesmo dispositivo do que o
microprocessador têm custos de comunicação muito mais baixos e, por isso, permitem
soluções mistas mais eficazes.

APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE 237
Figura E .4 . Implantação f ís ica (Layout) do exemplo EUCDIST n o F P G A
XC6216 .

238 APÊNDICE E INTERFACE SOFTWARE/RECONFIGWARE

239
Apêndice F Glossário
ALAP – Acrónimo para: As Late As Possible. Esquema de escalonamento em que as
operações são executadas o mais próximo possível do fim.
ALU – Acrónimo para: Arithmetic-Logic Unit. Unidade lógico-aritmética. Esta unidade é
responsável pela realização de operações aritméticas (adição, multiplicação, etc.) e lógicas
(AND, OR, XOR, etc.).
ANB – Acrónimo para: aferição do número de bits suficiente.
Anteguarda – Termo utilizado para designar as fases iniciais do fluxo de compilação
proposto.
API – Acrónimo para: Application Programmer´s Interface. Interface software que permite a
aplicações comunicarem entre si.
ASAP – Acrónimo para: As Soon As Possible. Esquema de escalonamento em que as
operações são executadas o mais próximo possível do início.
ASIC – Acrónimo para: Application Specific Integrated Circuit. Circuito integrado de
aplicação específica.
Bytecodes – Representação binária de uma classe previamente compilada para a JVM.
Cadeias-de-dados – Utilizado na tese para designar séries não interrompidas de dados. Em
inglês é utilizado o termo streams.
Caminho Crítico – caminho de um grafo, constituído pela sequência de nós, com maior
atraso.

240 APÊNDICE F GLOSSÁRIO
CCM – Acrónimo para: Custom Computing Machine. Máquina computacional
personalizada.
CDFG – Acrónimo para: Control/Data Flow Graph. Grafo de Fluxo de Dados e de Controlo.
CDG – Acrónimo para: Control Dependence Graph. Grafo de Dependências de Controlo.
CFG – Acrónimo para: Control Flow Graph. Grafo de Fluxo de Controlo.
CFI – Acrónimo para: Control-Flow Intensive. Denominação dada a programas com fluxo
de controlo intensivo.
Classfile – Nome dado ao ficheiro que armazena os bytecodes de uma classe.
CLB – Acrónimo para: Configurable Logic Block. Bloco de lógica reconfigurável de um
FPGA.
Computação Adaptativa – o mesmo que Computação Reconfigurável.
Computação Reconfigurável – Tipo de computação baseado em máquinas computacionais
personalizadas, que combinam as sinergias de FPGAs com capacidades elevadas com
sistemas computacionais baseados em microprocessadores. Definição por Danish Bathia: ''An
ability for software to reach through the hardware layers and change the data-path for
optimising the performance''.
Configuração – programação da lógica e do encaminhamento de um agregado de lógica
configurável ou reconfigurável.
Co-Projecto Hardware/Software – Projecto concorrente do hardware e do software.
CPLD – Acrónimo para: Complex Programmable Logic Devices. Dispositivos de Lógica
Programável Complexos.
CPU – Acrónimo para: Central Processing Unit. Unidade de processamento central.
DAG – Acrónimo para: Directed Acyclic Graph. Grafo acíclico direccionado/orientado.
DDG – Acrónimo para: Data Dependence Graph. Grafo de Dependências de Dados.
DFG – Acrónimo para: Data Flow Graph. Grafo de Fluxo de Dados.

APÊNDICE F GLOSSÁRIO 241
DFI – Acrónimo para: Data-Flow Intensive. Nome dado a programas com fluxo de dados
intensivo.
DISC – Acrónimo para: Dynamic Instruction Set Computer. Computador com conjunto de
instruções dinâmico.
Dispositivos Reconfiguráveis – dispositivos de lógica que podem ser configurados uma ou
mais vezes.
DRLE – Acrónimo para: Dynamically Reconfigurable Logic Engine. Engenho de lógica
reconfigurável dinamicamente.
DSP – Acrónimo para: Digital Signal Processor. Processador de sinais digitais.
Equivalent Gates – (portas lógicas equivalentes) Número de transístores do circuito
considerado dividido pelo número de transístores de uma porta lógica NAND de duas
entradas (normalmente 4 transístores em tecnologia CMOS).
Escalonamento – Distribuição das operações de um grafo por passos temporais de modo a
que a relação temporal entre as operações no grafo seja mantida e existam nesse passo
temporal os recursos necessários para executar as operações consideradas.
Escalonamento Baseado em Lista – Escalonamento em que as operações são
incrementalmente alocadas a recursos vagos e em que é mantida uma lista de operações
disponíveis para serem escalonadas que vai sendo actualizada por cada operação escalonada.
Uma operação da lista é escolhida para escalonamento (desde que haja recursos livres) com
base em mecanismos de prioridades. As prioridades podem ser: estáticas (prioridades
determinadas em fases prévias ao escalonamento) ou dinâmicas (as prioridades são
reanalisadas durante o escalonamento com base nas operações previamente escalonadas).
FCCM – Acrónimo para: Field-Custom Computing Machine. Máquina computacional
personalizada no “campo”.
FIFO – Acrónimo para: First In First Out. Tipo de armazenamento em que o primeiro dado
a ser guardado é o primeiro a poder saír (ao contrário de uma pilha de dados).
Fluxo de Controlo Único – Tipo de execução em que os blocos básicos são executados
sequencialmente e não havendo, por isso, execução concorrente de blocos básicos.

242 APÊNDICE F GLOSSÁRIO
Fluxos de Controlo Múltiplos – Tipo de execução em que os blocos básicos podem ser
executados concorrentemente independentemente de serem blocos básicos com vários
destinos de fluxo de controlo.
FPAA – Acrónimo para: Field-Programmable ALU Arrays. Agregados de ALUs
programáveis pós-fabricação.
FPGA – Acrónimo para: Field Programmable Gate Arrays. Agregados de lógica
programáveis no “campo”.
FSM – Acrónimo para: Finite-State Machine. Máquina de estados finitos.
GALADRIEL – Nome atribuído ao compilador de anteguarda desenvolvido. O nome foi
retirado de textos de J. R. R. Tolkien: Rainha Elven de Lothlórien. Personagem do mundo
fantástico inventado por J. R. R. Tolkien. Galadriel em Sindarin (linguagem inventada por
J. R. R. Tolkien) significa: “A senhora da luz”.
Gráfico de Gantt – Nome dado a gráficos de barras horizontais que representam relações
temporais.
Grafo Direccionado ou Orientado – Tipo de grafo em que os laços têm atribuído um
sentido.
GSA – Acrónimo para: Gated Single-Assignment.
HAL – Nome dado ao exemplo da equação diferencial [Paulin86].
HDL – Acrónimo para: Hardware Description Language. Linguagem de descrição de
hardware.
HPDG – Acrónimo para: Hierarchical Program Dependence Graph. Grafo hierárquico de
dependências de programa.
HTG – Acrónimo para: Hierarchical Task Graphs. Grafo hierárquico de tarefas.
IEEE – Acrónimo para: Institute of Electrical and Electronic Engineers. Organização
internacional que agrega engenheiros de electrotecnia, electrónica, computadores e áreas
afins de todo o mundo.

APÊNDICE F GLOSSÁRIO 243
ILP – Acrónimo para: Instruction Level Parallelism. Paralelismo ao nível da
instrução/operação. No contexto de investigação operacional é o acrónimo para: Integer
Linear Programming. Programação Linear Inteira.
Inlining – (por exemplo de funções). Utilizado o termo português: expansão.
JIT – Acrónimo para: Just In Time. Compiladores do tipo JIT são caracterizados por
compilarem no imediato (compilam no momento de executar).
JVM – Acrónimo para: Java Virtual Machine. Máquina virtual da tecnologia Java.
Loop – Utilizado o termo português: ciclo. Embora no contexto de grafos o termo ciclo possa
representar não apenas loops mas também recursividade.
LUT – Acrónimo para: Look-Up Table. Tipo de implementação da unidade de funções
lógicas utilizado pela maioria dos FPGAs que é uma memória do tipo RAM, pequena e
rápida. (por exemplo: 4-LUTs indica que se trata de um FPGA com LUTs de 4 entradas)
Mapeamento – Estabelecer uma relação entre duas coisas.
NENYA – Nome atribuído ao compilador desenvolvido responsável pelas fases de síntese
arquitectural. Textos de J. R. R. Tolkien: um dos três aneis Elven feitos por Celebrimbor.
Chamado de Ring of Water, Ring of Adamant ou White Ring. O anel foi dado a Galadriel.
Operator Stength Reduction – Redução do custo de operações (redução da capacidade).
Utilizado em multiplicações e divisões por constantes (estas operações são transformadas em
sequências de deslocamentos e de somas/subtracções que implementam a operação original).
Ordenação Topológica de um DAG – É uma ordenação linear de todos os nós (vértices) do
DAG de modo a que se existir um laço entre o nó u e o nó v (u, v), então u aparece antes de v
na ordem.
OSR – Acrónimo para: Operator Strength Reduction. Redução do custo de operações.
P&R – Acrónimo para: Place and Route. Colocação e encaminhamento.
Partição Espacial – Habilidade de partir (dividir) uma função/circuito por um conjunto de
dispositivos de lógica reconfigurável.

244 APÊNDICE F GLOSSÁRIO
Partição Temporal – Habilidade de partir (dividir) uma função/circuito de modo a que cada
parte (fracção) possa ser executada por partilha temporal de um ou mais dispositivos de
lógica reconfigurável.
PCB – Acrónimo para: propagação de padrões de constantes ao nível do bit.
PCI – Acrónimo para: Peripheral Controller Interface.
RAM – Acrónimo para: Random-Access Memory. Memória de acesso aleatório.
rDPA – Acrónimo para: re-configurable Data-Path Architecture. Arquitectura de unidades
de dados reconfiguráveis.
Reconfiguração Dinâmica – Personalização de um agregado de lógica reconfigurável
durante a execução.
Reconfigware – Utilizado como abreviatura para hardware reconfigurável (reconfigurable
hardware).
Retaguarda – Termo utilizado para designar as fases finais do fluxo de compilação proposto.
RISC – Acrónimo para: Reduced Instruction-Set Computer. Microprocessador com conjunto
de instruções reduzido.
RPU – Acrónimo para: Reconfigurable Processing Unit. Unidade reconfigurável de
processamento.
RTL – Acrónimo para: Register Transfer Level. Nível de transferência entre registos.
SA – Acrónimo utilizado na tese para indicar o algoritmo realizado de partição temporal
baseado no algoritmo de optimização Simulated Annealing.
Shifter – deslocador de uma palavra.
Síntese arquitectural (em inglês: Architectural Synthesis) – geração a partir de uma descrição
em alto-nível da estrutura baseada em componentes e suas interligações ao nível de
transferência entre registos. É designada muitas vezes por “síntese de alto nível” (em inglês:
high-level synthesis) ou por “síntese comportamental” (em inglês: behavioral synthesis).

APÊNDICE F GLOSSÁRIO 245
Definição em [Gajski92]: ''A transformation of a behavioural description into a set of
connected storage and functional units''.
SRAM – Acrónimo para: Static Random-Access Memory. Memória estática de acesso
aleatório.
SRAM FPGA – Tipo de FPGA baseado em tecnologia de memórias estáticas que é
reprogramável no campo e requer dispositivos de arranque externos.
SSA – Acrónimo para: Single Static Assignment. Formato estático de atribuição única.
STG – Acrónimo para: State Transition Graph. Grafo de transição de estados.
THR – Acrónimo para: Tree-Height Reduction. Redução/diminuição da altura de uma árvore
por distribuição paralela dos seus nós (também designado por reassociação de operações).
Unrolling – (por exemplo de ciclos). Utilizado o termo português: desenrolamento.
VHDL – Acrónimo para: VHSIC (Very High Speed Integrated Circuit) Hardware
Description Language. Linguagem de descrição de hardware com ampla aceitação e
normalizada pelo IEEE.
VLIW – Acrónimo para: Very-Long Instruction Width. Tipo de arquitectura em que uma
instrução é utilizada para fornecer dados a várias unidades funcionais com execução
concorrente.

246 APÊNDICE F GLOSSÁRIO

247
Apêndice G Lista de Símbolos ! NOT lógico;
& operação AND;
&& AND lógico;
µ
ν indica que os nós µ e ν são mutuamente exclusivos;
µ → ν indica que o nó µ é executado depois de ν;
≡ coincidente;
∅ conjunto ou lista vazia;
≠ diferente;
⊂ está contido no conjunto ou na lista;
∨ ou lógico;
∈ pertence ao conjunto;
∪ reunião de conjuntos;
℘(ν) identificador da fracção temporal que contém o nó ν;
(µ, v) indica a existência de um laço entre os nós µ e ν;
x retorna o número inteiro mais próximo menor ou igual a x: ceiling(x);

248 APÊNDICE G LISTA DE SÍMBOLOS
| operação OR;
|| OR lógico;
|V| indica o número de elementos do conjunto V;
~ operação de negação;
Area(...) estimativa da área do circuito correspondente a um nó ou a um conjunto de
nós;
ASAPstart(ν) tempo imediatamente antes da execução do nó ν quando o escalonamento é
feito pela ordem ASAP;
Bits(A) número de bits para representar a variável A;
Dom(ν) conjunto de nós do CFG dominados pelo nó ν;
E conjunto de laços de um grafo;
forall para todos os elementos de um conjunto ou lista;
foreach para cada elemento de um conjunto ou lista;
G grafo;
Gen(ν) conjunto de definição geradas no bloco básico ν;
In(ν) conjunto de definição que entram no bloco básico ν;
In(Πi) número de entradas de dados na fracção temporal Πi;
Kill(ν) conjunto de definição mortas no bloco básico ν;
LevelALAP(ν) valor do nível do nó ν quando os níveis são atribuídos pela ordem ALAP;
MAX(A, B) valor máximo entre A e B;
MIN(A, B) valor mínimo entre A e B;
MUX() multiplexagem das entradas especificadas como parâmetros;

APÊNDICE G LISTA DE SÍMBOLOS 249
Op operação aritmética ou lógica;
Out(ν) conjunto de definição que saem do bloco básico ν;
Out(Πi) número de saídas de dados na fracção temporal Πi;
PosDom(ν) conjunto de nós do CFG pós-dominados pelo nó ν;
Pred(ν) conjunto de nós de um grafo predecessores ao nó ν;
sse se e só se;
Succ(ν) conjunto de nós de um grafo sucessores ao nó ν;
thread sequência de instruções que formam blocos computacionais que podem ser
executados concorrentemente ou em paralelo (vulgarmente designadas por
“processos leves”, em virtude de permitirem exprimir concorrência com
granulosidades mais finas do que as utilizadas nos processos);
V conjunto de nós (vértices) de um grafo;

250 APÊNDICE G LISTA DE SÍMBOLOS


















