Capítulo 8 O Modelo de Regressão Múltipla: Testes de ... · 8.1 O Teste F • O teste F para um...
39
Capítulo 8 O Modelo de Regressão Múltipla: Testes de Hipóteses e a Utilização de Informações Não Amostrais
Transcript of Capítulo 8 O Modelo de Regressão Múltipla: Testes de ... · 8.1 O Teste F • O teste F para um...

Capítulo 8
O Modelo de Regressão Múltipla: Testes de
Hipóteses e a Utilização de Informações Não Amostrais

• Um importante ponto que nós encontramos nesse capítulo é a utilização da distribuição F para testar simultaneamente uma hipótese nula com duas ou mais hipóteses a respeito dos parâmetros no modelo de regressão múltipla.
• As teorias que os economistas desenvolvem também fornecem, em alguns casos, informação não amostral que pode ser utilizada junto com a informação contida na amostra de dados para estimar os parâmetros de um modelo de regressão.
• O procedimento que combina esses dois tipos de informação é chamado de mínimos quadrados restritos.
• Ele pode ser uma técnica útil quando os dados não são ricos em informação (uma condição chamada colinearidade) e a informação teórica é boa. O procedimento de mínimos quadrados restritos também desempenha uma regra prática útil quando testamos hipóteses.
• Nesse capítulo nós adotamos as hipóteses RM1-RM6, incluindo a de normalidade.
• Se os erros não forem normais, então os resultados apresentados nesse capítulo poderão ser relativamente mantidos se a amostra for grande.
• O que nós descobrimos nesse capítulo é que uma única hipótese nula que pode envolver dois ou mais parâmetros é passível de ser testada via um teste t ou um teste F. Ambos são equivalentes. Uma hipótese nula conjunta que envolva um conjunto de hipóteses é testada via um teste F .

8.1 O Teste F
• O teste F para um conjunto de hipóteses é baseado na comparação da soma de quadrados dos erros do modelo de regressão múltipla original, não restrito, com a soma de quadrados dos erros do modelo de regressão no qual a hipótese nula é admitida como verdadeira. • Considere o exemplo da rede de lanchonetes onde a receita total semanal da rede (RT) é uma função de um índice de preço de todos os produtos vendidos (p) e dos gastos semanais com propaganda (a).
1 2 3t t t tRT p a e (8.1.1)
• Suponha que nós desejamos testar a hipótese de que a variação no preço não tem efeito sobre a receita total contra a hipótese alternativa de que o preço tem efeito.
• As hipóteses nula e alternativa são: e . 0 2: 0H 1 2: 0H
• O modelo restrito que assume que a hipótese nula é verdadeira é
1 3t t tRT a e (8.1.2)
• A soma de quadrados dos erros da equação (8.1.2) será maior do que a da equação (8.1.1).
•A idéia do teste F é que se essas somas de quadrados dos erros forem substancialmente diferentes, então a suposição de que a hipótese nula é verdadeira reduz significativamente a habilidade do modelo em ajustar os dados e, assim, os dados não dão base para a hipótese nula. •Se a hipótese nula for verdadeira, nós esperamos que os dados sejam compatíveis com as condições colocadas nos parâmetros. Assim, nós esperamos uma pequena mudança na soma de quadrados dos erros quando a hipótese nula é verdadeira.

• Nós chamamos a soma de quadrados dos erros no modelo que assume ser verdadeira a hipótese nula de soma de quadrados dos erros restrita, ou RSQE
• A soma de quadrados dos erros do modelo original é a soma de quadrados dos erros não restrita, ou SQEU. É sempre verdadeiro que 0R USQE SQE
• Seja J o número de hipóteses. • A estatística geral F é dada por
R U
U
SQE SQE JF
SQE T K
(8.1.3)
•Se a hipótese nula for verdadeira, então a estatística F tem uma distribuição F com J graus de liberdade no numerador e graus de liberdade no denominador. T K
• Nós rejeitamos a hipótese nula se o valor da estatística do teste F se tornar muito grande. Nós comparamos o valor de F com um valor crítico o qual deixa uma probabilidade na cauda superior da distribuição F com J e graus de liberdade.
,cFT K
• Para os modelos restrito e não restrito nas equações (8.1.1) e (8.1.2), respectivamente, nós encontramos
USQE = 1805,168 RSQE = 1964,758

• A estatística do teste F é:
1964,758 1805,168 1
1805,168 52 3
4,332
R U
U
SQE SQE JF
SQE T K
• Para a distribuição , o valor crítico para = 0,05 é 1,49F
= 4,038. Como F = 4,332 , nós rejeitamos a hipótese nula e concluímos que o preço tem um efeito significativo sobre a receita total.
cFcF
•O valor-p para esse teste é p = P[ 4,332] = 0,0427, o qual é menor do que = 0,05, e assim nós rejeitamos a hipótese nula sobre esta base também.
(1,49)F
• O valor-p pode também ser obtido usando um software moderno.
Tabela 8.1 Saída do EViews para o Teste do Coeficiente Preço
Hipótese Nula: C(2)=0
Estatíst.-F 4,331940 Probabilidade 0,042651
• Quando é testado uma hipótese nula de “igualdade” contra uma alternativa de “desigualdade”, tanto um teste t como um teste F podem ser usados e os resultados obtidos serão idênticos. • A razão para isso é que existe uma relação exata entre as distribuições t e F. O quadrado de uma variável aleatória t com gl graus de liberdade é uma variável aleatória F com distribuição .
1,glF
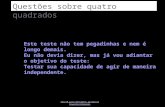
8.1.1 A Distribuição F : Teoria
Uma variável aleatória F é formada pela divisão de duas variáveis aleatórias independentes qui-quadradas, que são divididas por seus graus de liberdade.
Se e e se e são independentes, então 1
2
1 ~m
V 2
2
2 ~m
V 1V 2V
1 2
1
1.
2
2
~m m
Vm
F FV
m
(8.1.4)
• Diz-se que a distribuição F tem m1 graus de liberdade no numerador e m2 graus de liberdade no denominador. Os valores de m1 e m2 determinam a forma da distribuição, o qual em geral parece com a da Figura 8.1. O intervalo da variável aleatória é (0, ) e ela tem uma longa cauda à direita.

•Podemos provar que:
2
1 2~R U
J
SQE SQEV
2
2 2~U
T K
SQEV
(8.1.5)
(8.1.6)
onde V1 e V2 são independentes.
• O resultado para V1 exige que a hipótese nula relevante seja verdadeira; o que para V2 não é exigido. • Note que é cancelado quando dividimos V1 por V2, produzindo
2
1
2
R U
U
SQE SQE JV JF
V T K SQE T K
(8.1.7)

8.2 Teste de Significância de um Modelo
• Uma importante aplicação do teste F é para o que chamamos de “teste da significância global do modelo”. Considere novamente o modelo geral de regressão múltipla com (K 1) variáveis explanatórias e K coeficientes desconhecidos.
1 2 2 3 3t t t tK K ty x x x e (8.2.1)
• Para examinar se temos um modelo explanatório viável, nós elaboramos as seguintes hipóteses nula e alternativa
0 2 3
1
: 0, 0, , 0
: um dos não é zero
K
k
H
H pelo menos
(8.2.2)
• A hipótese nula tem K1 partes e é chamada de hipótese conjunta.
• Se essa hipótese nula for verdadeira, nenhuma das variáveis explanatórias influenciam o y e assim nosso modelo é de pouco ou nenhum valor.
• Se a hipótese alternativa H1 for verdadeira, então pelo menos um dos parâmetros não é zero. A hipótese alternativa não indica, contudo, qual dessas variáveis pode ser. • Como nós estamos testando se nós temos ou não um modelo explanatório viável, o teste para (8.4.2) é algumas vezes chamado de teste de significância global do modelo de regressão.
• Para testar a hipótese conjunta , o qual na verdade são K1 hipóteses, nós utilizamos um teste baseado na distribuição F.
0 2 3: 0KH

• Se a hipótese nula for verdadeira, então o modelo restrito é
0 2 3: 0, 0, , 0KH
1t ty e (8.2.3)
• O estimador de mínimos quadrados de 1 nesse modelo restrito é , o qual é a média amostral das
*
1
tyb y
T
observações em relação à variável dependente.
• A soma de quadrados dos erros restrita da hipótese (8.2.2) é
* 2 2
1( ) ( )R t tSQE y b y y SQT
• Nesse caso particular, no qual estamos testando a hipótese nula que todos os parâmetros do modelo são zero, exceto o intercepto, a soma de quadrados dos erros restrita é a soma de quadrados total (SQT) do modelo completo sem restrição.
• A soma de quadrados dos erros não restrita é a soma de quadrados dos erros extraída do modelo sem restrição, ou SQEU = SQE. • O número de hipóteses é J = K1. • Assim, para testar a significância global de um modelo, a estatística de teste F pode ser modificada como
( ) /( 1)
/( )
SQT SQE KF
SQE T K
(8.2.4)
• O valor calculado dessa estatística é comparada com o valor crítico da distribuição F(K-1,T-K).

• Para ilustrar, nós testamos a significância global da regressão utilizada para explicar a receita total da rede de lanchonetes. Nós queremos testar se os coeficientes do preço e do gasto com propaganda são iguais a zero, contra a hipótese alternativa de que pelo menos um dos coeficiente é diferente de zero. Assim, no modelo
1 2 3t t t tRT p a e nós queremos testar
0 2 3: 0, 0H contra a alternativa
1 2 3: 0, ou 0, ou ambos não são zeroH
• Os “ingredientes” para esse teste e o próprio valor da estatística do teste são apresentados na Tabela de Análise de Variância pela maioria dos softwares de regressão.
• A saída do programa para os dados da rede de lanchonetes aparecem na Tabela 8.2. Dessa tabela, nós vemos que e . 13581RSQE SQT 1805,2USQE SQE
Tabela 8.2 Tabela ANOVA obtida pelo SHAZAM
ANÁLISE DA VARIÂNCIA
SQ GL QM F
REGRESSÃO 11776 2. 5888,1 159,828
ERRO 1805,2 49. 36,840 P-VALUE
TOTAL 13581 51. 266,30 0,000

• Por sua vez, a divisão dos Quadrados Médios é o valor F para o teste da significância global do modelo. Para os dados da rede de lanchonetes, esse cálculo é
( ) /( 1) (13581,35 1805,168) / 2 5888,09159,83
/( ) 1805,168/(52 3) 36,84
SQT SQE KF
SQE T K
• O valor crítico de 5% para a estatística F com (2, 49) graus de liberdade é Fc = 3,187. • Como 159,83 > 3,187, nós rejeitamos H0 e concluímos que a relação estimada é significativa. • Ao invés de considerarmos o valor crítico, nós poderíamos ter feito nossas conclusões baseadas no valor-p

8.3 Um Modelo Estendido
Nós temos assumido 1 2 3t t t tRT p a e (8.3.1)
• À medida que o nível de gastos com propaganda aumenta, nós esperaríamos que um retorno decrescente se apresentasse. • Um modo de permitir retornos decrescentes para a propaganda é incluir o valor ao quadrado da propaganda, a2, no modelo como outra variável explanatória. Assim,
2
1 2 3 4t t t t tRT p a a e
• A resposta de E(RT) para a é
3 4
( mantido constante)
( ) ( )2t t
t
t tp
E RT E RTa
a a
(8.3.2)
(8.3.3)
• Nós esperamos que 3 > 0. Também, para atingir retornos decrescentes, a resposta deve diminuir à medida que at aumenta; isto é, nós esperamos 4 < 0. • As estimativas de mínimos quadrados, utilizando os dados na Tabela 7.1, são
2ˆ 104,81 6,582 2,948 0,0017
(6,58) (3,459) (0,786) (0,0361) (e.p.)
t t t tRT p a a (R8.4)
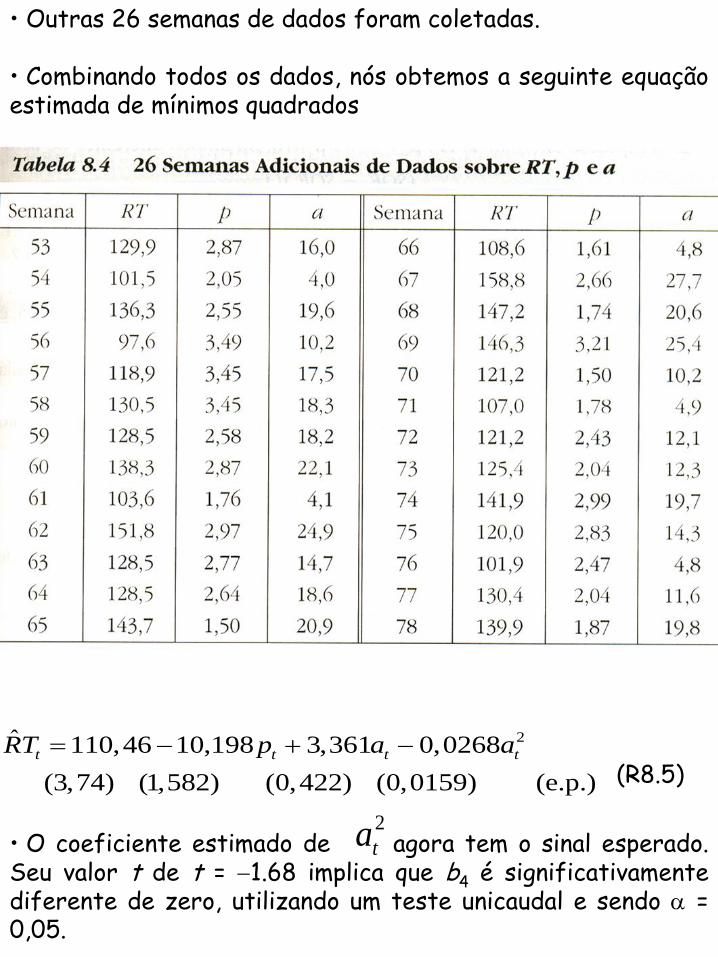
• Outras 26 semanas de dados foram coletadas. • Combinando todos os dados, nós obtemos a seguinte equação estimada de mínimos quadrados
2ˆ 110,46 10,198 3,361 0,0268
(3,74) (1,582) (0,422) (0,0159) (e.p.)
t t t tRT p a a
(R8.5)
• O coeficiente estimado de agora tem o sinal esperado. Seu valor t de t = 1.68 implica que b4 é significativamente diferente de zero, utilizando um teste unicaudal e sendo = 0,05.
2
ta

8.4 Teste de Algumas Hipótese Econômicas
8.4.1 A Significância da Propaganda
• Nosso modelo expandido é
2
1 2 3 4t t t t tRT p a a e (8.4.1)
• Como nós testaríamos se a propaganda tem uma efeito sobre a receita total? Se 3 ou 4 não forem iguais a zero então a propaganda tem um efeito sobre a receita. • Com base em um teste t unicaudal nós podemos concluir que, individualmente, 3 e 4 não são zero e que apresentam o correto sinal.
• O teste conjunto usará a estatística F em (8.1.3) para testar
0 3 4: 0, 0H

• Compare o modelo não restrito na equação 8.4.1 com o modelo restrito, o qual assume que a hipótese nula é verdadeira. • O modelo restrito é
1 2t t tRT p e (8.4.2)
Os elementos do teste são:
1. A hipótese nula conjunta 0 3 4: 0, 0H
2. A hipótese alternativa
1 3 4: 0, ou 0, ou ambos não são zeroH
3. A estatística do teste é
( ) /
/( )
R U
U
SQE SQE JF
SQE T K
com J=2,
T=78 e K= 4. SQEU = 2592,301 é a soma de quadrados dos erros de (8.4.1). SQER = 20907,331 é a soma de quadrados dos erros de (8.4.2).
4. Se a hipótese nula conjunta for verdadeira, então . O valor crítico Fc vem da distribuição F(2,74), e,
para um nível de significância de = 0,05, ele é 3,120. ( , )~ J T KF F
5. O valor da estatística F é F = 261,41 > Fc e nós rejeitamos a hipótese nula, concluindo que pelo menos um deles não é zero. Assim, a propaganda tem um efeito significativo sobre a receita total.

8.4.2 O Nível Ótimo de Propaganda
• De (8.3.3), o benefício marginal de uma unidade adicional de propaganda é o aumento na receita total de:
3 4
( mantido constante)
( )2t
t
t p
E RTa
a
• Gastos com propaganda deveriam aumentar até o ponto onde o benefício marginal de $1 de propaganda se igualasse a (ou fosse para) $1, ou onde
3 42 1ta
• Utilizando as estimativas de mínimos quadrados para 3 e 4 em (R8.5), nós podemos estimar o nível ótimo de propaganda de
ˆ3,361 2( 0,0268) 1ta
• Resolvendo, nós obtemos , o qual implica que o nível ótimo de propaganda semanal é $44.048,50.
ˆ 44,0485ta
• Suponha que o gerente de uma lanchonete, com base na sua experiência em outras cidades, pensa que $44.048,50 é muito alto e que o nível ótimo de propaganda é, na verdade, aproximadamente $40.000.

• A hipótese nula que nós desejamos testar é 0 3 4: 2 (40) 1H
contra a alternativa de que . A estatística do teste é
1 3 4: 2 (40) 1H
3 4
3 4
( 80 ) 1
ep( 80 )
b bt
b b
2
3 4 3 4 3 4ˆ ˆ ˆ ˆvar( 80 ) var( ) 80 var( ) 2(80)cov( , ) 0,76366b b b b b b
• Então, o valor calculado da estatística t é 1,221 1
0,2520,76366
t
• O valor crítico para esse teste bicaudal vem da distribuição t(74). Ao nível de significância de =0,05, tc = 1,993 e assim nós não podemos rejeitar a hipótese nula de que o nível ótimo de propaganda é $40.000 por semana.
• Alternativamente, utilizando um teste F, a estatística do teste é
( ) /
/( )
R U
U
SQE SQE JF
SQE T K
onde J=1, T=78 e K= 4.
SQEU = 2592,301 é a soma de quadrados dos erros do modelo completo não restrito em (8.4.1).
•SQER é a soma de quadrados dos erros do modelo restrito, no qual é admitido que a hipótese nula é verdadeira. O modelo restrito é
2
1 2 4 4( ) (1 80 )t t t t t tRT a p a a e

• Rearranjando, nós temos
2
1 2 4( ) ( 80 )t t t t t tRT a p a a e
• A estimação desse modelo pelo procedimento de mínimos quadrados produz a soma de quadrados dos erros restrita SQER = 2594,533. O valor calculado da estatística F é
(2594,533 2592,301) /1
2592,302 / 74
0,0637
F
• O valor crítico Fc vem da distribuição F(1,74). Para = 0,05, o valor crítico é Fc = 3,970.
8.4.3 O Nível Ótimo de Propaganda e Preço
• Espera-se uma receita total semanal de $175.000 se a propaganda for $40.000 e o preço for de p=$2. • No contexto de nosso modelo,
2
1 2 3 4
2
1 2 3 4
( )
(2) (40) (40)
175
t t t tE RT p a a
• Nós agora formulamos as duas hipótese conjuntas
0 3 4 1 2 3 4: 2 (40) 1, 2 40 1600 175H
• Porque existem J=2 hipóteses para testar conjuntamente, nós usaremos um teste F.

• A estatística do teste é , ( ) /
/( )
R U
U
SQE SQE JF
SQE T K
onde J=2.
O valor calculado da estatística F é F=1,75.
• O valor crítico para o teste vem da distribuição F(2,74) e é Fc = 3,120. • Como F < Fc , nós não rejeitamos a hipótese nula.
8.5 A Utilização de Informações Não Amostrais
• Da teoria da escolha do consumidor na microeconomia, nós sabemos que a demanda por um bem dependerá do preço daquele bem, do preço de outros bens, particularmente de bens substitutos e complementares, e da renda.
• No caso da cerveja, é razoável relacionar quantidade demandada (q) com o preço da cerveja (pC), o preço de outras bebidas (pB), o preço de todos os outros bens e serviços restantes (pR), e a renda (m).
• Nós escrevemos esta relação como
, , ,C B Rq f p p p m (8.5.1)

• Nós admitimos que a forma funcional log-log é apropriada para esta relação
1 2 3 4 5ln ln ln ln lnC B Rq p p p m (8.5.2)
•Uma parte relevante da informação não amostral é que os agentes econômicos não sofrem de “ilusão monetária”. •Ter todos os preços e renda variando na mesma proporção é equivalente a multiplicar cada preço e a renda por uma constante
1 2 3 4 5
1 2 3 4 5 2 3 4 5
ln ln ln ln ln
ln ln ln ln ln
C B R
C B R
q p p p m
p p p m
(8.5.3)
• Para não existir qualquer mudança em ln(q), quando todos preços e a renda sobem na mesma proporção, dever ser verdade que
2 3 4 5 0 (8.5.4)
• Para introduzir a informação amostral, resolvemos a equação da restrição em relação a um dos k’s.
2 3 4 5 0
4 2 3 5 (8.5.6)
• Substituindo essa expressão no modelo original:
1 2 3 2 3 5 5
1 2 3 5
1 2 3 5
ln ln ln ln ln
ln ln ln ln ln ln
ln ln ln
t Ct Bt Rt t t
Ct Rt Bt Rt t Rt t
Ct Bt tt
Rt Rt Rt
q p p p m e
p p p p m p e
p p me
p p p
(8.5.7)

• Para conseguir “as estimativas restritas de mínimos quadrados”, nós utilizamos a estimação por mínimos quadrados para o modelo restrito.
ˆln 4,798 1,2994ln 0,1868ln 0,9458ln
(3,714) (0,166) (0,284) (0,427)
Ct Bt tt
Rt Rt Rt
p p mq
p p p
(R8.8)
• Vamos denotar as estimativas restritas de mínimos quadrados na equação R8.8 como . *
kb
* * * *
4 2 3 5
( 1,2994) 0,1868 0,9458 0,1668
b b b b
• O estimador restrito de mínimos quadrados é tendencioso, e , *
k kE b a menos que as restrições impostas sejam
exatamente verdadeiras.
• A segunda propriedade do estimador restrito de mínimos quadrados é que sua variância é menor do que a variância do estimador de mínimos quadrados, sendo as restrições impostas verdadeiras ou não.
• Incorporando a informação adicional aos dados, nós geralmente abrimos mão da não tendenciosidade em favor de variâncias reduzidas.

8.6 Especificação do Modelo
• Quais considerações são importantes quando é escolhido um modelo? • Quais são as conseqüências de escolher o modelo errado? • Existem modos de avaliar se um modelo é adequado?
8.6.1 Variáveis Omitidas e Irrelevantes
• Suponha que, em uma indústria, a taxa de salários dos empregados Wt depende da experiência Et e da motivação deles Mt
1 2 3t t t tW E M e (8.6.1)
• Os dados da motivação não estão disponíveis. Assim, ao invés de 8.6.1, nós estimamos o modelo
1 2t t tW E v (8.6.2)
• Pela estimação de (8.6.2) nós estamos impondo a restrição = 0 quando ela não é verdadeira.
3
• O estimador de mínimos quadrados para e será geralmente viesado, embora ele tenha pequena variância.
1 2

• A conseqüência de omitir variáveis relevantes pode levar a você pensar que uma boa estratégia é incluir tantas variáveis quanto possíveis em seu modelo. Contudo, isso pode aumentar as variâncias de suas estimativas pela presença de variáveis irrelevantes.
• Suponha que a correta especificação seja
1 2 3t t t tW E M e (8.6.3)
• Mas nós estimamos o modelo
1 2 3 4t t t t tW E M C e
onde Ct é o número de crianças do t empregado, e onde, na realidade, = 0.
4
Então, Ct é uma variável irrelevante. Incluí-la não faz com que o estimador de mínimos quadrados seja viesado, mas significa que as variâncias de b1, b2 e b3 serão maiores do que aquelas obtidas pela estimação do modelo correto em (8.6.3).

8.6.1a Viés de Variáveis Omitidas: Uma Prova
• Suponha que o modelo verdadeiro seja mas nós estimamos o modelo omitindo h do modelo.
1 2 3 ,y x h e
1 2 ,y x e
• Então nós utilizamos o estimador
*
2 2 2
( )( ) ( )
( ) ( )
t t t t
t t
x x y y x x yb
x x x x
2 3 t t t tw h we onde
2( )
tt
t
x xw
x x

• Assim,
*
2 2 3 2( ) t tE b w h • Analisando mais de perto, nós encontramos que
2 2
( ) ( )( )
( ) ( )
t t t t
t t
t t
x x h x x h hw h
x x x x
2
( )( ) ( 1) ˆcov( , )
ˆ( ) ( 1) var( )
t t t t
t t
x x h h T x h
x x T x
• Conseqüentemente,
*
2 2 3 2
ˆcov( , )( )
ˆvar( )
t t
t
x hE b
x
• Conhecendo o sinal de e o sinal da covariância entre 2
tx th e , saberemos a direção do viés.
• Mesmo sabendo que a omissão de uma variável da regressão geralmente viesa o estimador de mínimos quadrados, se a covariância amostral, ou a correlação amostral, entre e a variável omitida for zero, então o estimador de mínimos quadrados no modelo mal especificado ainda será não viesado.
tx
th

8.6.2 Teste para Modelo Especificado Incorretamente: o Teste RESET
• O teste RESET (Regression Specification Error Test – Teste de Erro de Especificação da Regressão) é designado para detectar variáveis omitidas e forma funcional incorreta. Ele é conduzido como se segue. • Suponha que nós especificamos e testamos o modelo de regressão
1 2 2 3 3t t t ty x x e (8.6.4)
• Sejam os valores preditos de ty
1 2 2 3 3ˆ
t t ty b b x b x
• Considere os dois seguintes modelos artificiais
(8.6.5)
2
1 2 2 3 3 1ˆ
t t t t ty x x y e
2 3
1 2 2 3 3 1 2ˆ ˆ
t t t t t ty x x y y e
(8.6.6)
(8.6.7)

• Em (8.6.6), um teste para a especificação incorreta é um teste de contra a alternativa .
0 1: 0H 1 1: 0H
• Em (8.6.7), testar contra ou é um teste para a especificação incorreta.
0 1 2: 0H 1 1: 0H 2 0
• A rejeição de implica que o modelo original é inadequado e pode ser melhorado. Uma falha na rejeição de diz que o teste não foi capaz de detectar qualquer má especificação.
0H0H
• De uma forma geral, a filosofia do teste é: Se nós podemos melhorar significativamente o modelo pela inclusão artificial de poder de predição, então o modelo original deve ter sido inadequado. • Como um exemplo do teste, considere o exemplo da demanda de cerveja usado na Seção 8.5 para ilustrar a inclusão de informação não amostral.
1 2 3 4 5ln( ) ln( ) ln( ) ln( ) ln( )t Ct Bt Rt t tq p p p m e
(8.6.8)
• Estimando esse modelo e, então, aumentando-o com quadrados das predições, e, depois, aumentando-o novamente com os quadrados e cubos das predições, obtemos os resultados do teste RESET na metade superior da Tabela 8.5. • Os valores F são bem pequenos e seus correspondentes valores-p de 0,93 e 0,70 estão bem acima do nível de significância usual de 0,05. Pelo teste RESET, não existe evidência que sugira que o modelo log-log é inadequado.

Tabela 8.5 Resultados do Teste RESET para o Exemplo da Demanda de Cerveja
Teste RESET: Modelo LOG-LOG
Estatíst.-F (1 termo) 0,0075 Probabilidade 0,9319
Estatíst.-F (2 termos) 0,3581 Probabilidade 0,7028
Teste RESET: Modelo LINEAR
Estatíst.-F (1 termo) 8,8377 Probabilidade 0,0066
Estatíst.-F (2 termos) 4,7618 Probabilidade 0,0186
• Agora, suponha que nós especificamos um modelo linear ao invés do modelo log-log.
1 2 3 4 5t Ct Bt Rt t tq p p p m e (8.6.9)
• Aumentado esse modelo com os quadrados e, depois, com os quadrados e cubos das predições , temos os resultados do teste RESET na metade inferior da Tabela 8.5. Os valores-p de 0,0066 e 0,0186 estão abaixo de 0,05, o que sugere que o modelo linear é inadequado.
ˆtq

8.7 Variáveis Econômicas Colineares
• Quando os dados são o resultado de um experimento não controlado, muitas das variáveis econômicas podem se mover juntas de uma maneira sistemática.
• Tais variáveis são ditas colineares e o problema é denominado colinearidade ou multicolinearidade, quando diversas variáveis estão envolvidas.
• Considere o problema enfrentado pela rede de lanchonetes. Suponha que seja prática comum coordenar dois tipos de propaganda, de tal forma que ao mesmo tempo apareçam propagandas nos jornais e haja distribuição de planfetos contendo promoções de preços para os lanches.
• Será difícil para esses dados revelarem os efeitos separados desses dois tipos de propaganda. Pelo fato de que esses dois tipos de propaganda se movem juntos, será difícil identificar seus efeitos separadamente sobre a receita total.
• Considere a relação de produção. Existem certamente fatores de produção (insumos), tal como trabalho e capital, que são usados em proporções relativamente fixas. • Relações de proporções entre variáveis constituem o próprio tipo de relações sistemáticas que resumem a “colinearidade”.
• Uma problema relacionado existe quando os valores de uma variável explanatória não variam muito dentro da amostra de dados. Quando uma variável explanatória apresenta pequena variação, então é difícil isolar seu impacto.

8.7.1 As Conseqüências Estatísticas da Colinearidade
1. Sempre que existir uma ou mais relações lineares exatas entre as variáveis explanatórias, então existe a condição de colinearidade exata, ou multicolinearidade exata. Nesse caso, o estimador de mínimos quadrados não é definido.
2. Quando existem dependências lineares quase exatas entre as variáveis explanatórias, algumas variâncias, erros padrão e covariâncias dos estimadores de mínimos quadrados podem ser grandes.
3. Quando os erros padrão do estimador forem grandes, é provável que os testes t usuais levem a conclusão de que as estimativas dos parâmetros não são significativamente diferentes de zero. Esse resultado ocorre apesar da possibilidade de termos um alto R2 ou “valores F” indicando “significativo” poder explanatório do modelo como um todo.
4. Os estimadores podem ser muito sensíveis a adições ou subtrações de poucas observações, ou a subtração de uma variável aparentemente insignificante.
5. Apesar da dificuldade em isolar o efeitos individuais das variáveis de tal amostra, previsões precisas podem ser possíveis de obter.

8.7.2 Identificando e Suavizando a Colinearidade
• Um modo simples de detectar relações colineares é utilizar os coeficientes de correlação amostral entre pares de variáveis explanatórias. Uma regra prática é que se o coeficiente de correlação entre duas variáveis explanatórias for maior do que 0,8 ou 0,9, existirão evidências de uma associação linear forte e uma potencial relação de colinearidade prejudicial.
• Um segundo procedimento simples e eficiente para identificar a presença de colinearidade é estimar a chamada “regressão auxiliar”. Nessa regressão de mínimos quadrados, a variável à esquerda da equação é uma das variáveis explanatórias e as variáveis do lado direito são todas as outras variáveis explanatórias restantes.
•Por exemplo, a regressão auxiliar para xt2 é
2 1 1 3 3t t t K tKx a x a x a x erro
• Se o R2 desse modelo artificial é alto, ou superior a 0,80, a implicação é que uma grande parte da variação em xt2 é explicada pela variação nas outras variáveis explanatórias.
• Uma solução é obter mais informação e incluí-la na análise.
• Uma forma de obter mais informação é conseguindo uma melhor e mais completa base de dados.
• Nós podemos melhorar a estrutura do problema introduzindo informação não amostral na forma de restrições sobre os parâmetros.

8.8 Previsão
• Considere 1 2 2 3 3t t t ty x x e (8.8.1)
onde os et são variáveis aleatórias não correlacionadas com média 0 e variância .
2
• Dado um conjunto de valores para as variáveis explicativas , o problema da previsão é prever os valores da variável dependente y0, o qual é dado por
02 031 x x
0 1 02 2 03 3 0y x x e (8.8.2)
• Admitimos que o erro aleatório e0 não é correlacionado com os erros amostrais et e possui a mesma média 0 e variância 2
• Tomando essas hipóteses, o melhor previsor linear não viesado de y0 é dado por
0 1 02 2 03 3y b x b x b
(8.8.3)

• Esse previsor é não viesado no sentido de que o valor médio do erro de previsão é zero; isto é, se é o erro de previsão, então . 0 0
ˆ( )f y y ( ) 0E f
• O previsor é o melhor dentre qualquer previsor não tendencioso e linear de y0, pois, para qualquer outro, a variância do erro de previsão é maior do que .
0 0ˆvar( ) varf y y
1 2 02 3 03 0 1 2 02 3 03
0 1 2 02 3 03
2 2
0 1 02 2 03 3
02 1 2 03 1 3
02 03 2 3
var( ) var[( ) ( )]
var( )
var( ) var( ) var( ) var( )
2 cov( , ) 2 cov( , )
2 cov( , )
f x x e b b x b x
e b b x b x
e b x b x b
x b b x b b
x x b b
(8.8.4)

• Cada um desses termos envolvem , o qual pode ser substituído por seu estimador para a obtenção da variância estimada do erro de previsão . A raiz quadrada dessa quantidade é o erro padrão do erro de previsão:
22ˆvar( )f
ˆep( ) var( )f f
•Se os erros aleatórios et e e0 são normalmente distribuídos, ou se a amostra for grande, então
0 0
0 0
ˆ~
ep( ) ˆ ˆvarT K
y yft
f y y
(8.8.5)
•Um intervalo de previsão de 100(1)% para y0 é: , onde tc é um valor crítico da distribuição t(T-K).
0ˆ ep( )cy t f