
Banco de Dados I MóduloI: Introdução a Sistemas de ...clodis/BDI/BDI_2007_Modulo1_2.pdf · Banco...
57
Módulo I: Introdução a Sistemas de Banco de Dados (Aula 2) Clodis Boscarioli Banco de Dados I 2007
Transcript of Banco de Dados I MóduloI: Introdução a Sistemas de ...clodis/BDI/BDI_2007_Modulo1_2.pdf · Banco...

Módulo I: Introdução a
Sistemas de Banco de Dados
(Aula 2)
Clodis Boscarioli
Banco de Dados I
2007

Agenda:
� Abstração e seus níveis;
� Modelos de Dados:� Hierárquico;
� Redes;
� Relacional;
� Orientado a Objetos.
� Arquiteturas de Banco de Dados.

Banco de dados e Abstração de Dados� Um dos maiores benefícios dos sistemas de banco de dados é proporcionar aos
usuários uma visão abstrata dos dados. O sistema é capaz de ocultar alguns detalhes sobre a forma de armazenamento e a manutenção dos dados.
� A eficiência da recuperação de informações está relacionada à forma como as estruturas de representação são projetadas e, dado a complexidade e importância destas representações, elas devem ser protegidas em níveis de abstrações.
� Estes níveis facilitam a manutenção do sistema e a interação dos usuários com os sistemas. São eles:
Nível de visão: O mais alto nível de abstração. Proporciona uma visão parcial do banco de dados. Diferentes visões são usadas por diferentes usuários.
Nível lógico: Implica em definir quais dados serão armazenados e quais são os inter-relacionamentos existentes entre eles. Usado pelos administradores de banco de dados e programadores.
Nível físico: Mais baixo nível de abstração. Implica em como os dados estão, de fato, armazenados (descrição em detalhes das estruturas de dados). Administradores de banco de dados devem ter noções da organização deste nível.
Visão 1 Visão 2 Visão n......
Nível de visão
Nível lógico quais
Nível físico0 1 1 como

Níveis de Abstração
� Nível de visão: Sub-conjunto de dados que podem existir apenas durante a execução de uma operação (Por exemplo, uma consulta ao banco de dados).
� Nível lógico: Um registro de dado é descrito por um tipo definido (como um tipo em linguagem de programação) e as inter-relações entre dados são definidas.
� Nível físico: Um registro de dado pode ser descrito como um bloco consecutivo de memória (por exemplo, palavras ou bytes).

BD: Instâncias e Esquemas
� Esquema: Projeto geral do banco de dados. Os esquemas são alterados com pouca freqüência.
� Cliente (nome_cliente: string; seguro_social: string; rua_cliente: string; cidade_cliente: string).
� Instância: O conjunto de informações contidas em um determinado banco de dados, em um dado momento.
� Cliente_1: Cliente;(João da Silva, 5.929.555.99, R. Vicente Machado, São Paulo)
� Cliente_2: Cliente;(Marcos Pereira, 8.223.938.51, R. Carvalho Bueno, São Paulo)
Esquemas também são vistos em diferentes níveis de abstração: físico, lógico e sub-esquemas.

Modelos de Dados
� O Modelo de Dados é a principal ferramenta que fornece a abstração a um BD. É um conjunto de conceitos que podem ser usados para descrever a estrutura de uma base de dados. Por estrutura de uma base de dados entende-se os tipos de dados, relacionamentos e restrições pertinentes aos dados. Muitos modelos de dados também definem um conjunto de operações para especificar como recuperar e modificar a base de dados.

Um banco de dados hierárquico é uma coleção de
registros conectados uns aos outros por meio de links (uma
associação entre exatamente dois registros). Cada registro é
uma coleção de campos (atributos), cada qual contendo
somente um valor.
Um BD Hierárquico é um tipo coleção de árvores com raiz
(floresta) e pode ser feita uma referência a cada uma dessas
árvores.
Modelo de Dados Hierárquico

Exemplo:
Conta
possui 2 campos
Cliente
possui 3 campos
Modelos de Dados Hierárquico
número_conta saldo
nome rua_cliente cidade_cliente
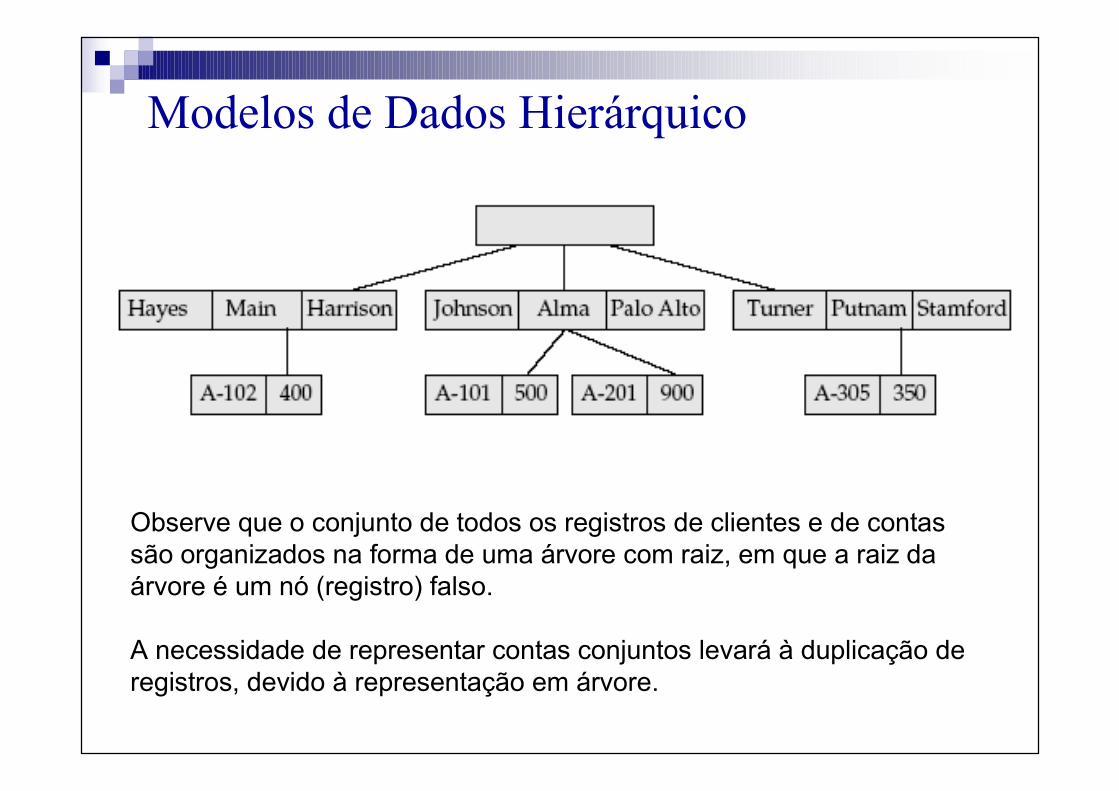
Modelos de Dados Hierárquico
Observe que o conjunto de todos os registros de clientes e de contas são organizados na forma de uma árvore com raiz, em que a raiz da árvore é um nó (registro) falso.
A necessidade de representar contas conjuntos levará à duplicação de registros, devido à representação em árvore.

O Sistema de Banco de Dados IMS
� O modelo hierárquico é significativo principalmente devido à importância do sistema de banco de dados IMS da IBM.
� O IMS (Information Management System) é um dos mais antigos e mais amplamente utilizados sistema de bancos de dados.
� Os desenvolvedores deste sistema estão entre os primeiros a tratarem características como concorrência, recuperação, integridade e processamento eficiente de consultas.
� Recursos de manipulação: get e where.

Modelo Hierárquico - Problemas
� Complexidade dos diagramas de estrutura de
árvore;
� Não pode haver ciclos no gráfico básico de um
diagrama de estrutura de árvore;
� Restrições à cardinalidade dos links (de muitos
para muitos (N:M) e de muitos para um (N:1));
� Ausência de facilidades de consultas
declarativas;
� Necessidade de navegação por ponteiros para
acesso à informações;
� Consultas complexas.

Modelo de Dados de Rede
Um banco de dados de rede é uma coleção de registros
conectados uns aos outros por meio de links (associação entre exatamente dois registros, onde ele pode ser entendido
como uma forma restrita (binária) de relacionamento entre os
dados a serem armazenados).
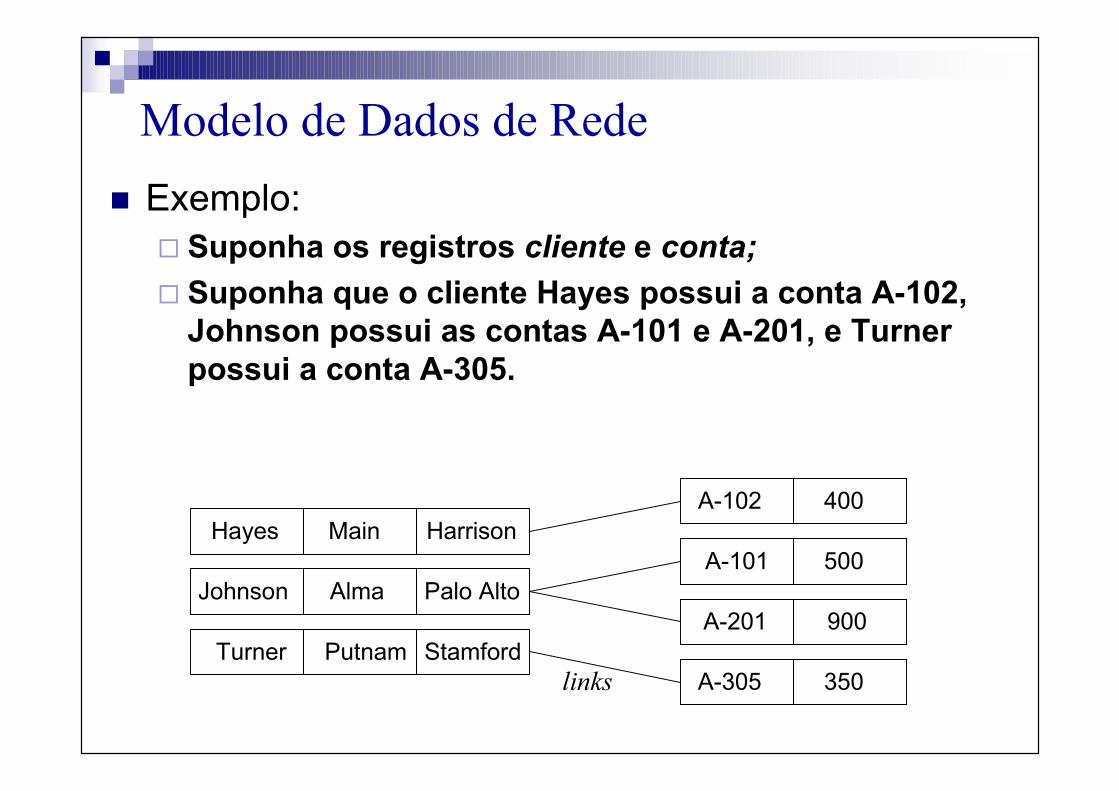
Modelo de Dados de Rede
� Exemplo:� Suponha os registros cliente e conta;
� Suponha que o cliente Hayes possui a conta A-102,
Johnson possui as contas A-101 e A-201, e Turner
possui a conta A-305.
Hayes Main Harrison
Johnson Alma Palo Alto
Turner Putnam Stamford
A-102
A-101
A-201
A-305
400
500
900
350links

Modelo de Dados de Rede
Na representação geral apresentada com o link
depositante, que é binário e de muitos para muitos, está
especificado que um cliente pode possuir diversas contas e
que uma conta pode pertencer a vários clientes diferentes.
Se o link depositante fosse de um para muitos, de cliente
para conta, ele teria uma seta apontando para o registro
cliente.
número_conta saldonome rua_cliente cidade_clientedepositante
número_conta saldonome rua_cliente cidade_clientedepositante
Se o link fosse de um para um, então duas setas seriam
colocadas na representação geral.

número_conta saldonome rua_cliente cidade_cliente
gerente
nome_agencia fundos
Modelo de Dados de Rede
Considere a necessidade de controle das contas, agências
e clientes de um determinado banco financeiro. Um link
(gerente), entre estes registros, permite este
acompanhamento de dados relacionados as contas
bancárias existentes.
Com isso, um cliente pode possuir diversas contas, cada qual
localizada em uma determinada agência do banco e que uma
conta pode pertencer a vários clientes diferentes.
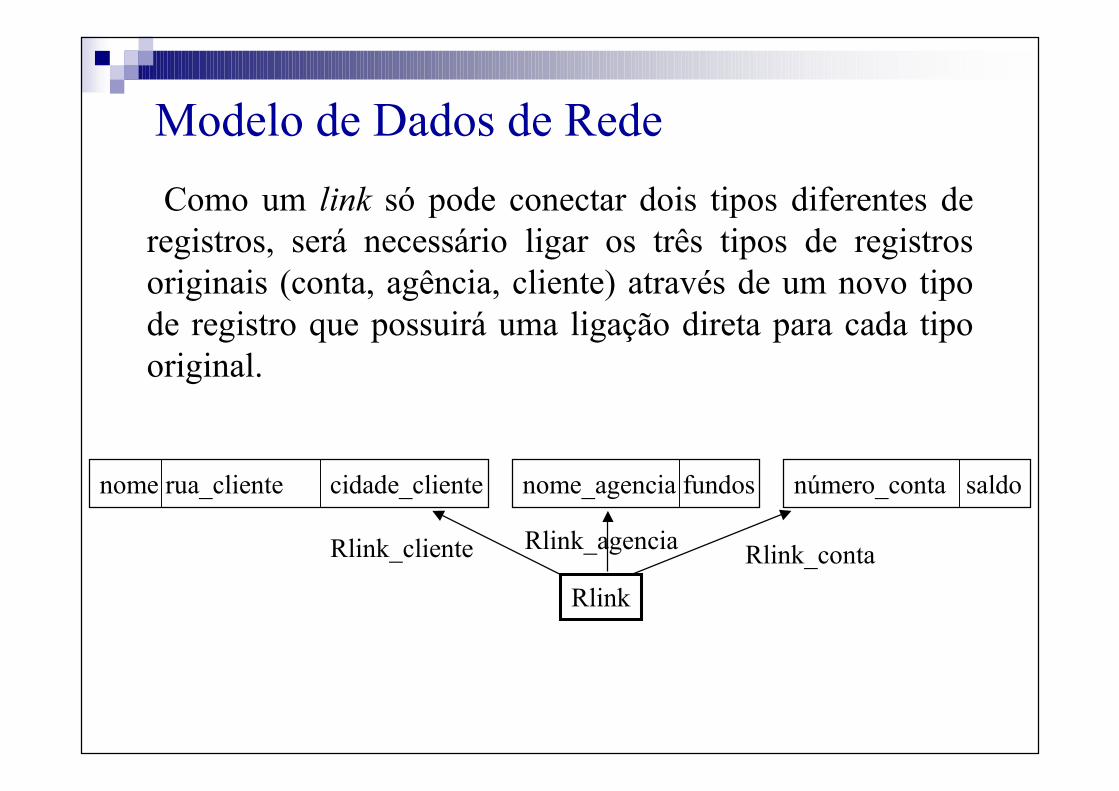
Como um link só pode conectar dois tipos diferentes de
registros, será necessário ligar os três tipos de registros
originais (conta, agência, cliente) através de um novo tipo
de registro que possuirá uma ligação direta para cada tipo
original.
Modelo de Dados de Rede
número_conta saldonome rua_cliente cidade_cliente
Rlink
nome_agencia fundos
Rlink_cliente Rlink_agenciaRlink_conta

Modelo de Dados de Rede
Este novo tipo de registro pode não ter campos ou terá
apenas um campo contendo um identificador único gerado
pelo sistema e não utilizado diretamente pela aplicação.
Também serão criados três ligações de muitos para um
(Rlink_cliente, Rlink_agência, Rlink_conta) para realizar o
relacionamento entre os registros.
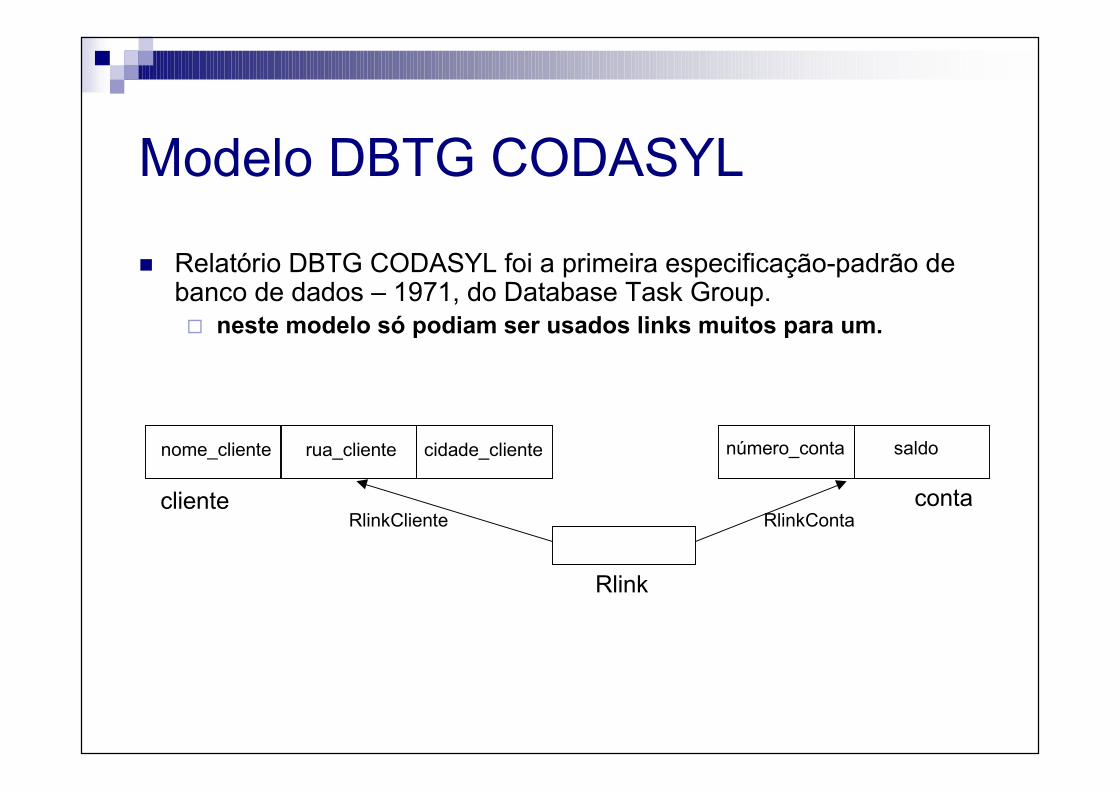
Modelo DBTG CODASYL
� Relatório DBTG CODASYL foi a primeira especificação-padrão de banco de dados – 1971, do Database Task Group.� neste modelo só podiam ser usados links muitos para um.
nome_cliente rua_cliente cidade_cliente número_conta saldo
cliente conta
Rlink
RlinkCliente RlinkConta

Modelo DBTG CODASYL� A linguagem de manipulação de dados do DBTG
consiste em comandos que são embutidos em uma linguagem hospedeira.
� Os comandos habilitam o programador a selecionar registros do banco de dados baseados no valor de um determinado campo, e fazer iterações sobre os registros selecionados por meio da repetição de comandos para obter o próximo registro.
� O programador também tem à sua disposição, comandos para encontrar o proprietário de um conjunto do qual um registro participe, e para fazer iterações sobre os membros do conjunto.
� Existem comandos para atualizar o banco de dados.

Exemplos
� Encontre a rua do cliente Hayes:
� Encontre os clientes que morem na cidade de nome Harrison:
DB-Status = 0 significa que o comando find duplicate obteve sucesso!

Modelo de Redes - Problemas
� O modelo de rede é fortemente dependente da implementação.
� Registros artificiais precisam ser criados para implementar relacionamentos muitos para muitos.
� As consultas são complicadas: o programador é forçado a pensar em termos de links e, em como percorrê-los para obter as informações de que necessita. Essa manipulação de dados é chamada navegacional.
� Manteve-se, durante anos, à frente do modelo relacional porque, inicialmente, as implementações do modelo relacional eram ineficientes.

Modelo de Dados Relacional
� O Modelo Relacional (MR) é considerado o primeiro modelo de dados efetivamente usado em aplicações comerciais.
� Foi introduzido por Codd em 1970.
� É o modelo que possui a base mais formal entre os modelos de dados, entretanto é o mais simples e com estrutura de dados mais uniforme.

MR - Estrutura Básica
� Um banco de dados relacional consiste de uma coleção de tabelasde nomes únicos.
� Cada tabela possui um conjunto de linhas que representa um relacionamento entre um conjunto de valores.
� O conceito de tabelas está intimamente ligado ao conceito de umarelação matemática – de onde se origina o nome deste modelo.
� Uma tabela é formada por um conjunto de colunas denominadas de atributos e por um conjunto de linhas denominadas de tuplas.
� Para cada atributo existe um conjunto de valores permitidos, chamado de domínio.

MR - Formalmente...
� Suponha que D1 denote o domínio do atributo A1, D2 denote o domínio do atributo A2 e ... Dn denote o domínio do atributo Na da tabela T1. Qualquer linha da tabela que possui estes atributos édenotada pela tupla (d1,d2,...,dn) em que d1, d2 e dn estão, respectivamente em D1, D2 e Dn. Em geral, uma instância de T1 é um subconjunto de
D1 X D2 X ... X Dn.
� Matematicamente, define-se uma relação como um subconjunto de um produto cartesiano de uma lista de domínios.

Modelo Relacional
� No modelo relacional, exige-se que para todas as relações r, os domínios de todos os atributos de r sejam atômicos (os elementos desse domínio devem ser unidades indivisíveis).� Exemplo: Os inteiros é um domínio atômico, mas o conjunto
de todos os conjuntos de inteiros não é um domínio atômico.
� Nota: o importante não é propriamente o domínio, mas como usamos os elementos desse domínio no banco de dados.
� É possível que diferentes atributos possuam o mesmo domínio.
� Diferenças e similaridades entre domínios nos diferentes níveis de abstração:� Suponha os atributos: nome_agência e nome_cliente
� Possuem o mesmo domínio no nível físico;� Possuem domínios diferentes no nível conceitual.

MR - Conceitos� Considere a relação conta:
� A relação conta possui sete tuplas.
� Uma variável tupla se refere a uma linha da tabela.
� t[nome_agência] denota o valor da tupla t no atributo nome_agência;
750A-217Brighton
700A-222Redwood
900A-201Brighton
350A-305Round Hill
400A-102Perryridge
700A-215Mianus
500A-101Downtown
saldonúmero_contanome_agência
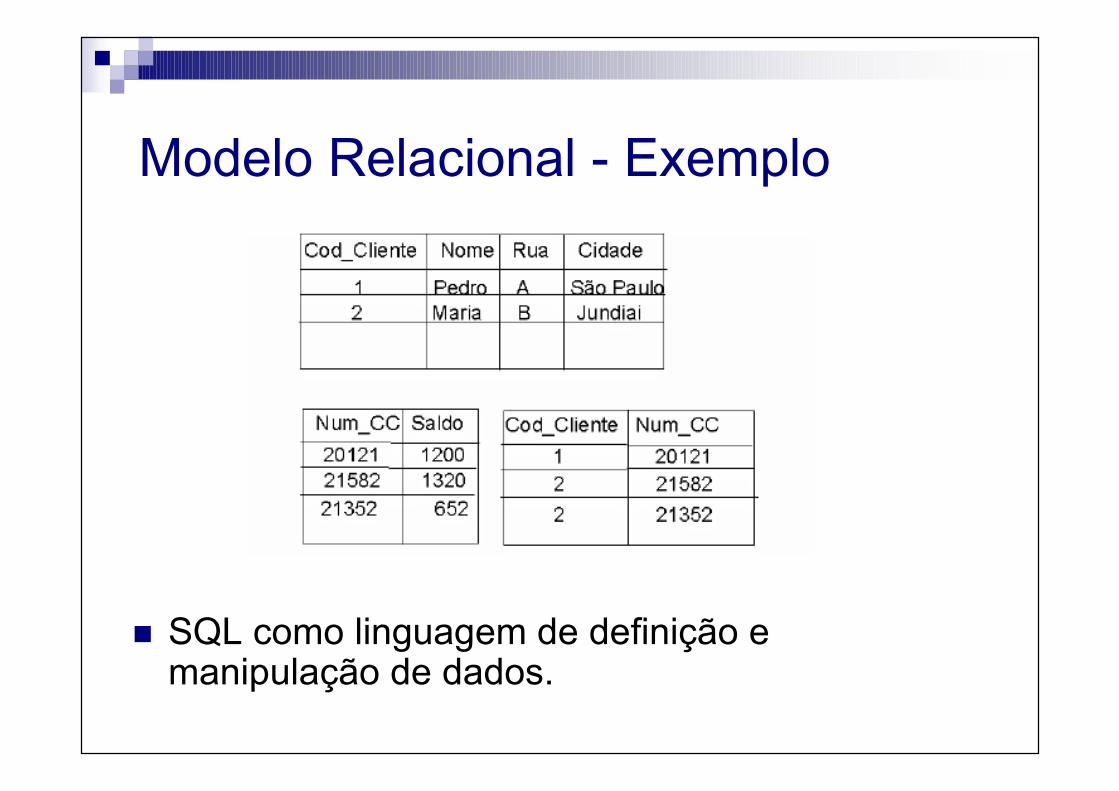
Modelo Relacional - Exemplo
� SQL como linguagem de definição e manipulação de dados.

As 12 Regras de Codd
� Edgard F. Codd, em 1985, estabeleceu as 12 regras de Codd que determinam o quanto um banco de dados é relacional.
� Algumas vezes as regras se tornam uma barreira e nem todos os SGBDs relacionais fornecem suporte a elas.

As 12 Regras de Codd
1. Regra das informações em tabelas:As informações a serem armazenadas no banco de
dados devem ser apresentadas como relações (tabelas formadas por linhas e colunas) e o vínculo de dados entre as tabelas deve ser estabelecido por meio de valores de campos comuns. Isso se aplica tanto aos dados quanto aos metadados (que são descrições dos objetos do banco de dados).

As 12 Regras de Codd
2. Regra de acesso garantido:
Para que o usuário possa acessar as informações contidas no banco de dados, o método de referência deve ser o nome da tabela, o valor da chave primária e o nome do campo/coluna.

As 12 Regras de Codd
3. Regra de tratamento sistemático de valores nulos:
O SGBD deve ser capaz de tratar valores que não são fornecidos pelos usuários, de maneira que permita a distinção de dados reais. Valores nulos devem ter um tratamento diferente de “valores em branco”.

As 12 Regras de Codd
4. Regra do catálogo relacional ativo:Toda a estrutura do banco de dados (domínios, campos, tabelas, regras de integridade, índices, etc) deve estar disponível em tabelas (também referenciadas como catálogo).
Sua manipulação é possível por meio de linguagens específicas. Essas tabelas são, geralmente, manipuladas pelo próprio sistema no momento em que o usuário efetua alterações na estrutura do banco de dados.

As 12 Regras de Codd
5. Regras de atualização de alto-nível:
Essa regra diz que o usuário deve ter capacidade de manipular as informações do banco de dados em grupos de registros, ou seja, ser capaz de inserir, alterar e excluir vários registros ao mesmo tempo.

As 12 Regras de Codd
6. Regra de sub-linguagem de dados abrangente:
Pelo menos uma linguagem deve ser suportada, para que o usuário possa manipular a estrutura do banco de dados (como criação e alteração de tabelas), assim como extrair, inserir, atualizar ou excluir dados, definir restrições de acesso e controle de transações (commit e rollback, por exemplo). Deve ser possível ainda a manipulação dos dados por meio de programas aplicativos.

As 12 Regras de Codd
7. Regra de independência física:
Quando for necessária alguma modificação na forma como os dados estão armazenados fisicamente, nenhuma alteração deve ser necessárias nas aplicações que fazem uso do banco de dados, assim como devem permanecer inalterados os mecanismos de consulta e manipulação de dados utilizados pelos usuários finais.

As 12 Regras de Codd
8. Regra de independência lógica:
Qualquer alteração efetuada na estrutura do banco de dados como inclusão ou exclusão de campos de uma tabela ou alteração no relacionamento entre tabelas não deve afetar o aplicativo que o usa.
Da mesma forma, o aplicativo somente deve manipular visões dessas tabelas.

As 12 Regras de Codd
9. Regra de atualização de visões:
Uma vez que as visões dos dados de uma ou mais tabelas são, teoricamente suscetíveis atualizações, então um aplicativo que faz uso desses dados deve ser capaz de efetuar alterações, exclusões e inclusões neles. Essas atualizações, no entanto, devem ser repassadas automaticamente às tabelas originais.

As 12 Regras de Codd
10. Regra de independência de integridade:
As várias formas de integridade de banco de dados (integridade de entidade, integridade referencial, restrições, obrigatoriedade de valores, etc) precisam ser estabelecidas dentro do catálogo do sistema ou dicionário de dados, e ser totalmente independentes da lógica dos aplicativos.

As 12 Regras de Codd
11. Regra de independência de distribuição:
Alguns SGBDs, notadamente os que seguem o padrão SQL, podem ser distribuídos em diversas plataformas/equipamentos que se encontrem interligados em rede. Essa capacidade de distribuição não pode afetar a funcionalidade do sistema e dos aplicativos que fazem uso do banco de dados.

As 12 Regras de Codd
12. Regra não-subversiva:
O sistema deve ser capaz de impedir qualquer usuário ou programador de transgredir os mecanismos de segurança, regras de integridade do banco de dados e restrições, utilizando algum recurso de linguagem de baixo nível que eventualmente possam ser oferecidos pelo próprio sistema.
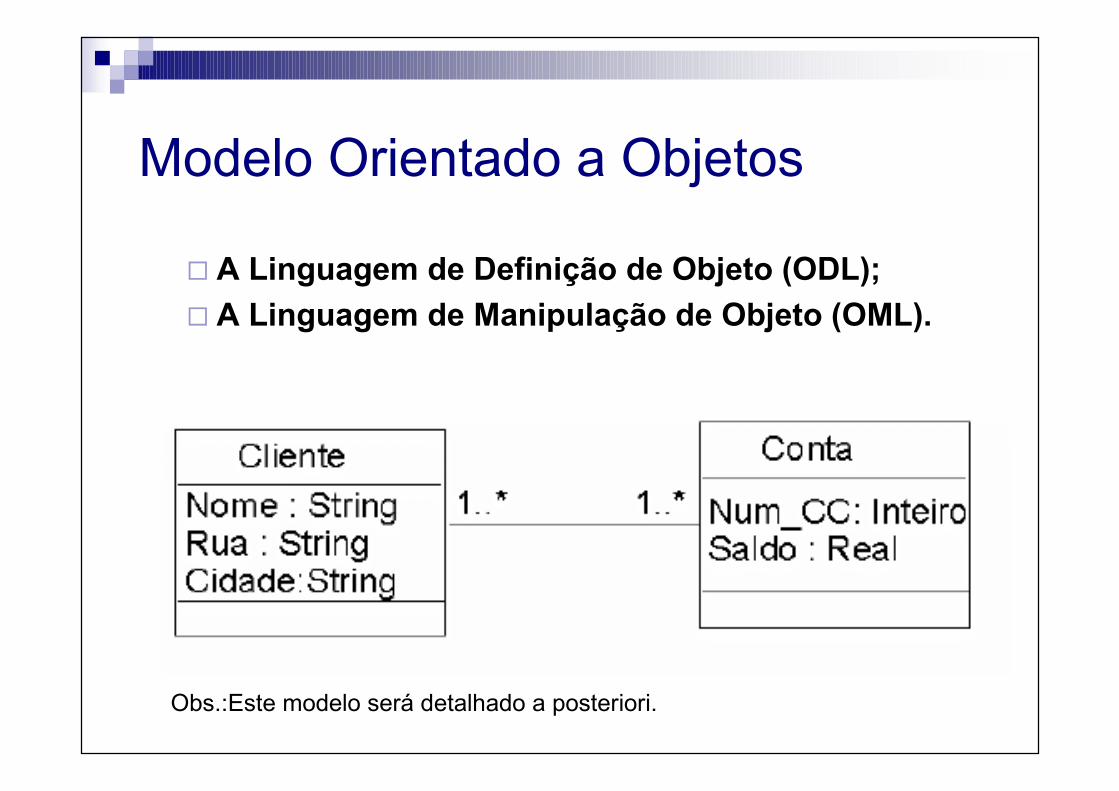
Modelo Orientado a Objetos
� A Linguagem de Definição de Objeto (ODL);
� A Linguagem de Manipulação de Objeto (OML).
Obs.:Este modelo será detalhado a posteriori.

Arquiteturas de BD – Visão Geral
A arquitetura de um sistema de banco de dados está relacionada à arquitetura do sistema básico computacional sobre qual o sistema de banco de dados é executado:
� Redes de computadores: existência de servidores e clientes e também permite distribuição;
� Processamento paralelo: otimização do trabalho do sistema de banco de dados;
� Distribuição de dados: otimização do trabalho e da segurança de um sistema de banco de dados

As funcionalidade de um sistema de banco de dados podem ser divididas em duas categorias:
� Front-end: consiste em ferramentas como formulários, gerador de relatórios e recursos de interface gráfica.
� Back-end: gerencia as estruturas de acesso, desenvolvimento e otimização de consultas, controle de concorrência e recuperação.
A interface entre o front-end e o back-end é feita por meio da SQL ou de um programa de aplicação. O link é feito por meio de drivers(interfaces Open DataBase Connectivity), nativos ou não.
� Para avaliar a arquitetura ideal, deve-se saber qual o desempenho que se espera do sistema de banco de dados:
� Throughput: é o número de tarefas que podem ser realizadas em uma dado intervalo de tempo;
� Tempo de resposta: é o tempo total que o sistema leva para completar uma única tarefa.
Arquiteturas de Banco de Dados

Sistemas Centralizados
� São aqueles executados sobre um sistema computacional que não interage com outros sistemas;
� Podem ser executados em computadores pessoais ou em computadores de grande porte;
� Possibilidade de haver recursos multitarefas, nos quais vários processos podem ser executados em um processador, de modo compartilhado;
� Mesmo havendo multiprocessamento (concorrência), a granularidadedo paralelismo é grossa, ou seja, uma transação não tem sua execução particionada entre diferentes processadores. Apresentam alto throughput mas baixo tempo de resposta.
� Front-end e back-end executados em um único sistema.
� O uso de “terminais” como clientes de um servidor iniciou os desenvolvimentos da arquitetura cliente-servidor.

Sistema Cliente-servidor
� Os terminais são substituídos por computadores pessoais.
� Existe a figura de sistemas servidores que atende a solicitações de sistemas clientes, conectados por meio de um sistema de rede.
� Sistemas servidores pode ser caracterizados, de modo geral, como:
� Servidores de transações (ou de consultas): Recebe a requisição do cliente, executa a ação e manda os dados de resposta para o cliente.
� Servidores de dados: Possibilitam que os clientes atuem diretamente nos dados. Implementam meios de indexação de dados e gerenciamento de transações, tal que os dados nunca se tornem inconsistentes.

Servidores de Transações
� Segue a divisão funcional entre front-end (suportado pelo cliente) e back-end (suportado pelo servidor, sendo possível estendê-lo para o cliente se o processamento é estendido a ele).
� Geralmente, clientes enviam solicitações ao sistema servidor, noqual essas transações são executadas, e os resultados são enviados de volta ao cliente que tem a responsabilidade de exibição destes dados.
� Padrões de conexão de banco de dados (ODBC – open database connectivity – por exemplo) permitem a comunicação entre clientes e servidores (back-ends e front-ends podem ser de diferentes fabricantes).
� Qualquer cliente que use a interface ODBC pode se conectar a qualquer servidor que forneça essa interface.
� Front-ends especializados para tarefas específicas: planilhas eletrônicas que acessam base de dados.

Sistemas Distribuídos (SD)
� O banco de dados é armazenado em diversos computadores (nós ou sites), que se comunicam por intermédio de uma rede.
� Não existe compartilhamento de memória ou discos.
� Existe variação entre tipos e tamanhos dos computadores envolvidos.
� Os sites estão distribuídos geograficamente e possuem administrações independentes.
� São permitidas transações locais (acessa um único site –onde é iniciada) ou globais (acessa diferentes sites, inclusive aquele onde é iniciada).

Exemplo:
� Considere o sistema de uma empresa bancária que consiste em quatro agências em quatro cidades diferentes (cada uma é um site).
� Cada agência possui seu próprio computador, com um banco de dados abrangendo todas as contas referentes àquela agência.� Esquema_conta = (nome_agência, número_conta, saldo)
� Há também um único site que mantém informações sobre todas as agências do banco.� Esquema_agência = (nome_agência, cidade_agência,
fundos)

Transações
Transação 1
� Adicionar 50 reais à conta A-177 localizada na agência de Cascavel.
� Se a transação foi iniciada na agência de Cascavel, ela é considerada local;
� Se a transação não foi iniciada na agência de Cascavel, ela é considerada global.
Transação 2
� Transferir 50 reais da conta A-177 para a conta A-305, a qual está localizada na agência de Ponta Grossa.
� É uma transação global, uma vez que contas em sites diferentes sofrem acessos como resultado de sua execução.

Razões para utilizar Distribuição
� Compartilhamento de dados: proporcionar o acesso a dados residentes em sites diversos.
� Autonomia: cada site possui um “nível” de controle sobre os seus dados.
� Disponibilidade: se um site “sai do ar”, os demais sites podem continuar em operação (existência de replicação de dados).

SD - Desvantagem
� Acréscimo de complexidade necessário para assegurar a coordenação entre os sites.
� Custo de desenvolvimento de softwares de aplicação e
gerenciamento;
� Maior dificuldade em assegurar a precisão dos algoritmos;
� As trocas de mensagens e processamento adicional para
coordenar os sites significa uma quantidade maior de
trabalho no sistema

Sistemas Paralelos� Neste sistema, muitas operações são realizadas simultaneamente.
Isto aumentam a velocidade de processamento, útil para aplicações que geram consultas em bancos de dados muito grandes (da ordem de terabytes) ou que tenham que processar um volume muito grande de transações por segundo (da ordem de milhares de transações por segundo).
� A questão da granularidade:� Equipamento de granularidade-grossa: consiste em poucos e
poderosos processadores
� Equipamento de granularidade-fina ou de paralelismo intensivo: consiste de milhares de pequenos processadores
� A questão da aceleração:� Refere-se à redução do tempo de execução de uma tarefa por meio
do aumento do grau de paralelismo
� A questão da escalabilidade:� Diz respeito ao manuseio de um número maior de tarefas por meio
do aumento do grau de paralelismo.
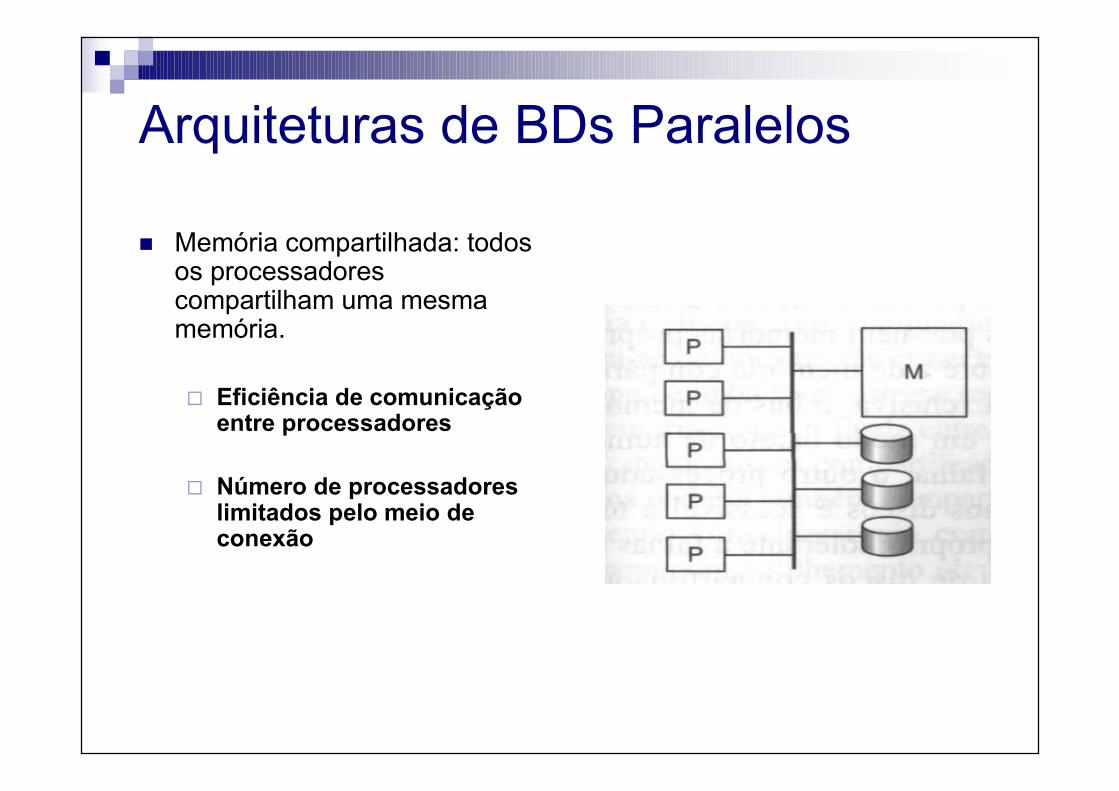
Arquiteturas de BDs Paralelos
� Memória compartilhada: todos os processadores compartilham uma mesma memória.
� Eficiência de comunicação entre processadores
� Número de processadores limitados pelo meio de conexão
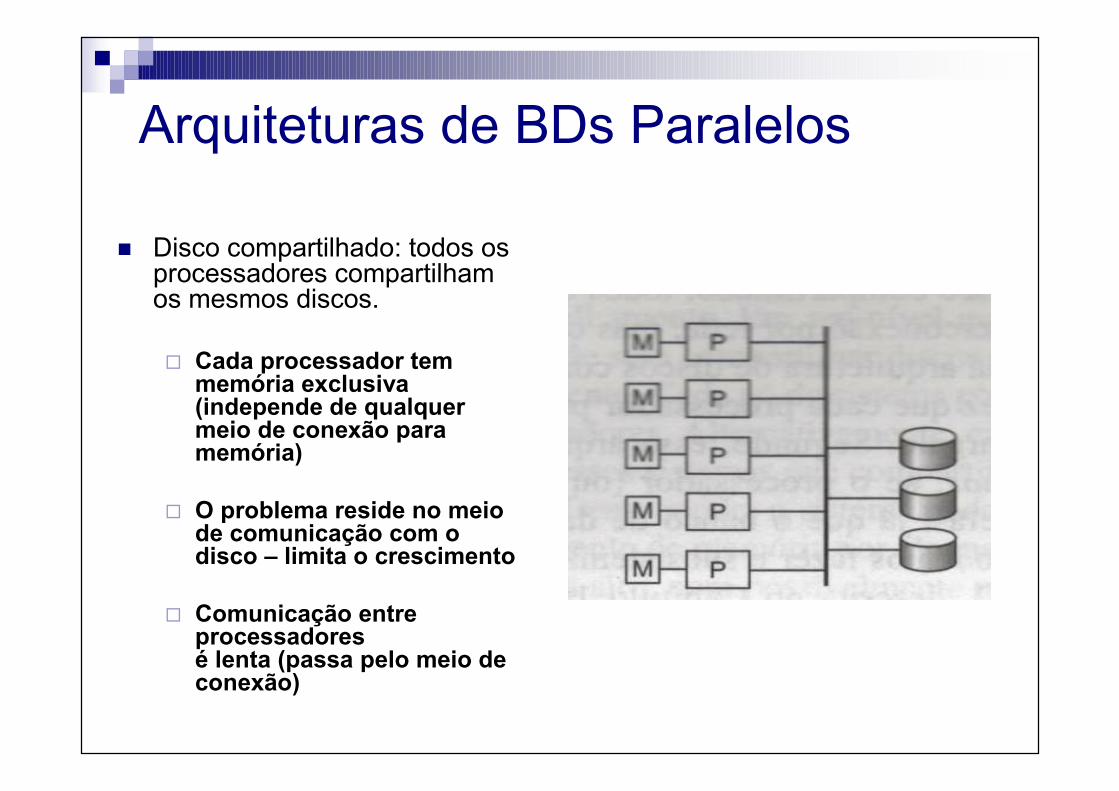
Arquiteturas de BDs Paralelos
� Disco compartilhado: todos os processadores compartilham os mesmos discos.
� Cada processador tem memória exclusiva (independe de qualquer meio de conexão para memória)
� O problema reside no meio de comunicação com o disco – limita o crescimento
� Comunicação entre processadores é lenta (passa pelo meio de conexão)
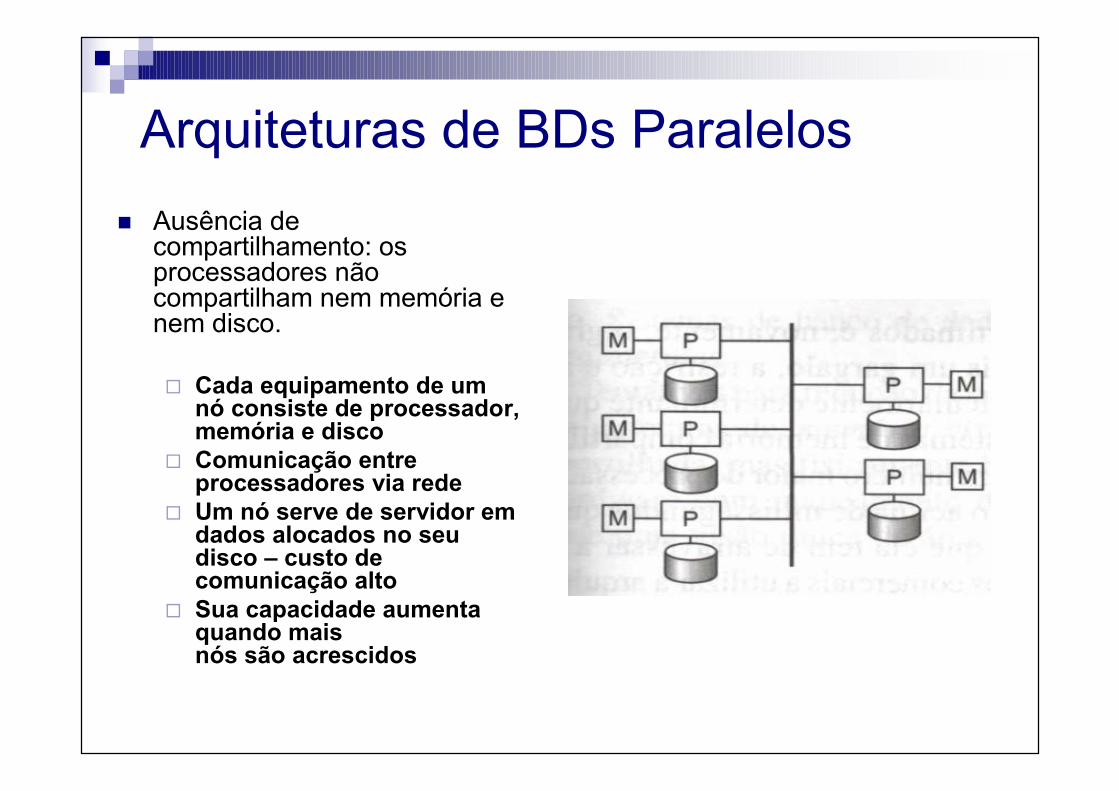
Arquiteturas de BDs Paralelos
� Ausência de compartilhamento: os processadores não compartilham nem memória e nem disco.
� Cada equipamento de um nó consiste de processador, memória e disco
� Comunicação entre processadores via rede
� Um nó serve de servidor em dados alocados no seu disco – custo de comunicação alto
� Sua capacidade aumenta quando mais nós são acrescidos

Arquiteturas de BDs Paralelos
� Hierárquico: Híbrido das arquiteturas anteriores.� No nível mais alto os nós são conectados por uma rede, sem
compartilhar recursos
� No nível mais baixo, percebe-se que cada nó é constituído de
sistemas de compartilhamento.

Bibliografia Utilizada:
� Sistemas de Banco de Dados. (Cap. 1, 16, Apêndices A e B). Abraham Silberchatz, Henry F. Korth e S. Sudarshan. 3ª Edição. Makron Books, 1999.
� Introdução a Sistemas de Banco de Dados. (Cap. 1-2). C. J. Date. 7ª Edição, Editora Campus, 2000.
� Introdução a Banco de Dados (Apostila). (Cap. 1-3). Osvaldo Kotaro Takai, Isabel Cristina Italiano, João Eduardo Ferreira. DCC-IME-USP, 2005.
� Sistemas de Banco de Dados, Fundamentos e Aplicações. (Cap. 1-2). R Elsmari, S. B. Navathe. Rio de Janeiro: Editora LTC, 2002.
� Fundamentos de Banco de Dados. W. P. Alvez. Editora Érica, 2004.


















