
Arquitetura NUMA1 - each.usp.br · 2Apple iOS < vers~ao 4 n~ao e t~ao moderno assim ,. 8/36....
41
Arquitetura NUMA Arquitetura NUMA 1 Daniel de Angelis Cordeiro INRIA MOAIS project Laboratoire d’Informatique de Grenoble Universit´ e de Grenoble, Fran¸ca 6 de Outubro de 2010 1 Baseado em slides feitos por Christiane Pousa Ribeiro 1 / 36
Transcript of Arquitetura NUMA1 - each.usp.br · 2Apple iOS < vers~ao 4 n~ao e t~ao moderno assim ,. 8/36....
Arquitetura NUMA
Arquitetura NUMA1
Daniel de Angelis Cordeiro
INRIA MOAIS projectLaboratoire d’Informatique de Grenoble
Universite de Grenoble, Franca
6 de Outubro de 2010
1Baseado em slides feitos por Christiane Pousa Ribeiro1 / 36

Arquitetura NUMA
Outline
1 IntroducaoClassificacao de Flynn
2 Arquiteturas Monoprocessadas
3 Arquiteturas MultiprocessadasMemoria DistribuıdaMemoria Compartilhada
Uniform memory access
4 Non-uniform memory accessProtocolos de Coerencia de CacheProgramando em Maquinas NUMA
2 / 36

Arquitetura NUMA
Introducao
Outline
1 IntroducaoClassificacao de Flynn
2 Arquiteturas Monoprocessadas
3 Arquiteturas MultiprocessadasMemoria DistribuıdaMemoria Compartilhada
Uniform memory access
4 Non-uniform memory accessProtocolos de Coerencia de CacheProgramando em Maquinas NUMA
3 / 36

Arquitetura NUMA
Introducao
Classificacao de Flynn
Classificacao de Flynn
Proposta na decada de 60, classifica as arquiteturas decomputadores baseando-se no numero de instrucoes paralelas e nofluxo de dados:
Single Instruction, Single Data stream (SISD): umcomputador sequencial, que trata um unico fluxo deinstrucoes gerado pelo programa (ex: PCs monoprocessadostradicionais);
Single Instruction, Multiple Data streams (SIMD): cadainstrucao e executada em um conjunto diferente de dados,possivelmente por diferentes processadores (ex: processadoresvetoriais ou GPUs);
4 / 36

Arquitetura NUMA
Introducao
Classificacao de Flynn
Classificacao de Flynn
Multiple Instruction, Single Data stream (MISD): cadaprocessador executa um conjunto diferente de instrucoes(arquitetura incomum);
Multiple Instruction, Multiple Data streams (MIMD): cadaprocessador executa um conjunto diferente de instrucoes,aplicadas em um conjunto distinto de dados (ex: sistemasdistribuıdos).
5 / 36
Arquitetura NUMA
Introducao
Classificacao de Flynn
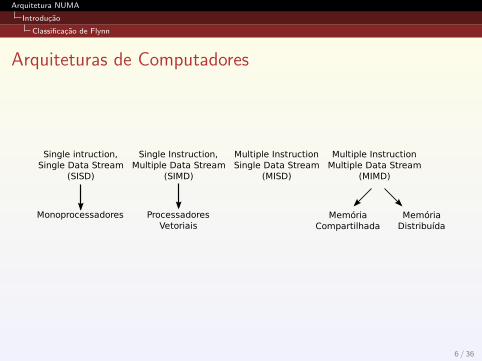
Arquiteturas de Computadores
Single intruction,Single Data Stream
(SISD)
Single Instruction,Multiple Data Stream
(SIMD)
Multiple InstructionSingle Data Stream
(MISD)
Multiple InstructionMultiple Data Stream
(MIMD)
Monoprocessadores ProcessadoresVetoriais
MemóriaCompartilhada
MemóriaDistribuída
6 / 36

Arquitetura NUMA
Arquiteturas Monoprocessadas
Outline
1 IntroducaoClassificacao de Flynn
2 Arquiteturas Monoprocessadas
3 Arquiteturas MultiprocessadasMemoria DistribuıdaMemoria Compartilhada
Uniform memory access
4 Non-uniform memory accessProtocolos de Coerencia de CacheProgramando em Maquinas NUMA
7 / 36

Arquitetura NUMA
Arquiteturas Monoprocessadas
Arquiteturas Monoprocessadas
Caracterısticas
Apenas um elemento de processamento.
Programacao sequencial (com uso de interrupcoes).
Sistemas operacionais “modernos”2 multiplexam multiplastarefas em um unico processador (sistemas demultiprogramacao).
2Apple iOS < versao 4 nao e tao moderno assim ,.8 / 36

Arquitetura NUMA
Arquiteturas Monoprocessadas
Arquiteturas Monoprocessadas
Exemplos
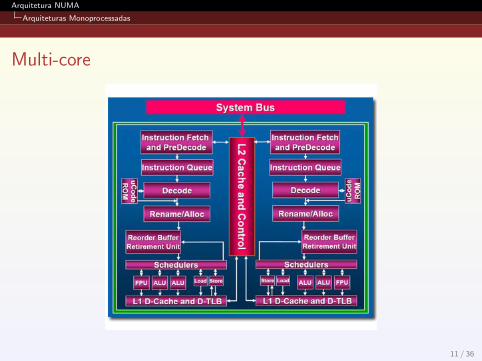
Hyperthreading;
Processadores multi-core;
Processadores AMD dual-core, quad-core, etc.
9 / 36

Arquitetura NUMA
Arquiteturas Monoprocessadas
Hyperthreading
10 / 36
Arquitetura NUMA
Arquiteturas Monoprocessadas
Multi-core
11 / 36

Arquitetura NUMA
Arquiteturas Monoprocessadas
Dual-core
12 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Outline
1 IntroducaoClassificacao de Flynn
2 Arquiteturas Monoprocessadas
3 Arquiteturas MultiprocessadasMemoria DistribuıdaMemoria Compartilhada
Uniform memory access
4 Non-uniform memory accessProtocolos de Coerencia de CacheProgramando em Maquinas NUMA
13 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Arquiteturas Multiprocessadas
Formadas por multiplos elementos de processamento;
Podem ser classificadas em:
Memoria distribuıda;Memoria compartilhada.
14 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Distribuıda
Memoria Distribuıda
Grupo de computadores autonomos (nos) que trabalhamjuntos como um recurso unico;
Cada processador possui seus proprios bancos de memoriaprivados;
Os nos sao interligados por redes de alto desempenho.
15 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Distribuıda
Exemplos
16 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Distribuıda
Exemplos
16 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Distribuıda
Vantagens de Memoria Distribuıda
Escalabilidade Vertical: e possıvel aumentar o podercomputacional do sistema com a adicao de novoscomponentes a cada um dos nos, individualmente (maisCPUs, mais memoria, etc.);
Escalabilidade Horizontal: e possıvel aumentar o podercomputacional do sistema com a adicao de novos nos nosistema;
Alta disponibilidade: a falha de um no nao necessariamentecausa a indisponibilidade de todo sistema;
Otimo custo/benefıcio.
17 / 36
Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Distribuıda
Exemplos
Exemplos classicos:
Aglomerados de computadores (clusters). Exemplo: Beowulf
Grades computacionais (grid computing). Exemplos:InteGrade, OurGrid (brasileiros), BOINC, Globus, Grid’5000,etc.
18 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Compartilhada
Memoria Compartilhada
P PPP
P PPP
P
P
P
P
P
P
P
PMemóriaCompartilhada
19 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Compartilhada
Memoria Compartilhada
Elementos de processamento compartilham a mesma memoria.
Programacao realizada atraves de variaveis compartilhadas(mais facil para programar) e/ou troca de mensagens pararealizar comunicacao entre processos.
Mais difıcil obter escalabilidade. Inclusao de novos elementosde processamento e limitada.
Aparicao de problemas de Coerencia de Cache.
20 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Compartilhada
Tipos de Memoria Compartilhada
Os sistemas de memoria compartilhada podem ser de dois tipos:
UMA – Uniform memory access
NUMA – Non-uniform memory access
Single intruction,Single Data Stream
(SISD)
Single Instruction,Multiple Data Stream
(SIMD)
Multiple InstructionSingle Data Stream
(MISD)
Multiple InstructionMultiple Data Stream
(MIMD)
Monoprocessadores ProcessadoresVetoriais
MemóriaCompartilhada
MemóriaDistribuída
UMA (SMP) NUMA
21 / 36

Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Compartilhada
Uniform memory access
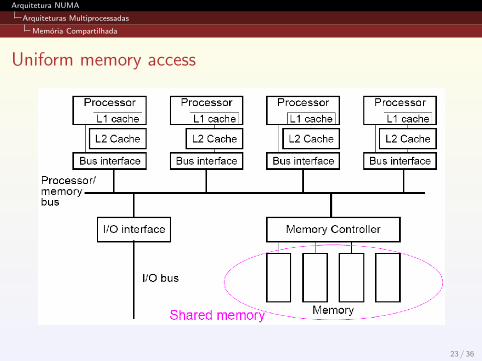
O tempo de acesso a memoria principal e igual para todos osprocessadores;
Sistemas multiprocessados UMA sao chamadas de SistemasSMP (symmetric multiprocessing);
Tipicamente, todos os acessos a memoria sao realizadosatraves do mesmo barramento:
problemas de contencao: competicao entre as CPUs peloacesso ao barramento provoca queda de desempenho;escalabilidade reduzida: em geral, limitada a 32 processadores.
22 / 36
Arquitetura NUMA
Arquiteturas Multiprocessadas
Memoria Compartilhada
Uniform memory access
23 / 36

Arquitetura NUMA
Non-uniform memory access
Outline
1 IntroducaoClassificacao de Flynn
2 Arquiteturas Monoprocessadas
3 Arquiteturas MultiprocessadasMemoria DistribuıdaMemoria Compartilhada
Uniform memory access
4 Non-uniform memory accessProtocolos de Coerencia de CacheProgramando em Maquinas NUMA
24 / 36

Arquitetura NUMA
Non-uniform memory access
Motivacao
Memory gap: processadores modernos operam em umavelocidade consideravelmente maior do que a memoriaprincipal:
uma instrucao pode fazer o processador esperar varios ciclos deprocessamento ate que a memoria principal seja acessada;
Aumento do tamanho e complexidade dos sistemas paralelosfazem com que aumentar a quantidade de memoria cache naoseja suficiente para resolver o problema;
Em sistemas multiprocessados, apenas um processador temacesso a memoria principal por vez.
25 / 36

Arquitetura NUMA
Non-uniform memory access
Solucao: NUMA
26 / 36
Arquitetura NUMA
Non-uniform memory access
Solucao: NUMA
26 / 36

Arquitetura NUMA
Non-uniform memory access
NUMA
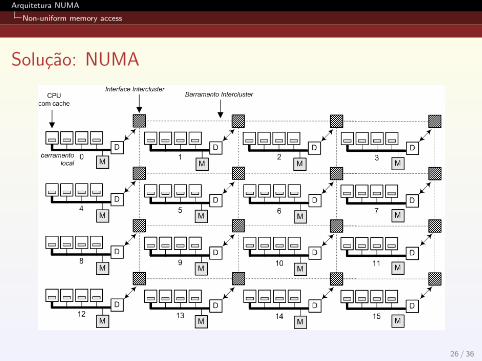
Ao contrario de sistemas SMP, os processadores estao adistancias diferentes da memoria (existencia de memoria locale remota);
Fator NUMA: razao entre o tempo de acesso a uma memorialocal e tempo de acesso a memoria local;
Calculos locais de um processador podem usar a memoria maisproxima, reduzindo o problema de contencao de memoria.
27 / 36

Arquitetura NUMA
Non-uniform memory access
Cache
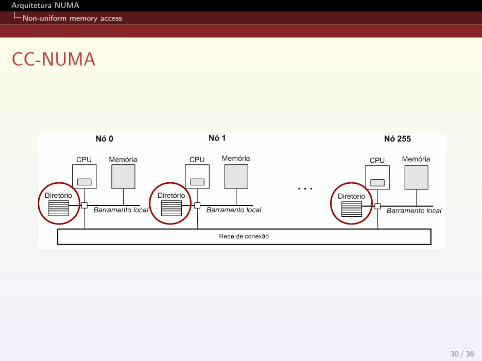
Em relacao ao cache, existem dois tipos de arquiteturas NUMA:
No Cache NUMA (NC-NUMA);
Cache coherent NUMA (CC-NUMA).
28 / 36

Arquitetura NUMA
Non-uniform memory access
NC-NUMA
C.m* foi o primeiro (1974) sistema NUMA a ser desenvolvido(Universidade Carnegie Mellon).
29 / 36
Arquitetura NUMA
Non-uniform memory access
CC-NUMA
30 / 36

Arquitetura NUMA
Non-uniform memory access
Protocolos de Coerencia de Cache
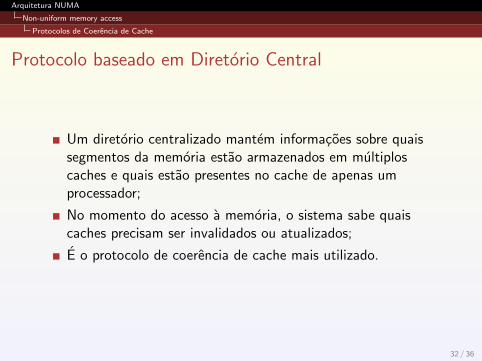
Snooping protocol
Controladores de cache monitoram a atividade do barramentoe atualizam ou invalidam as entradas do cache conformenecessario.
Sao de dois tipos:
Write-invalidate: o processador que ira escrever na memoriaenvia um aviso pelo barramento. Todos os processadoreschecam se possuem uma copia em cache e a invalidam.Write-update: um processador envia via broadcast o novovalor de um dado e todas as copias em cache sao atualizadas.
Write-invalidate e mais eficiente na utilizacao da largura debanda do barramento, enquanto Write-update tem avantagem de fazer os novos valores apareceram mais cedo noscaches.
31 / 36
Arquitetura NUMA
Non-uniform memory access
Protocolos de Coerencia de Cache
Protocolo baseado em Diretorio Central
Um diretorio centralizado mantem informacoes sobre quaissegmentos da memoria estao armazenados em multiploscaches e quais estao presentes no cache de apenas umprocessador;
No momento do acesso a memoria, o sistema sabe quaiscaches precisam ser invalidados ou atualizados;
E o protocolo de coerencia de cache mais utilizado.
32 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
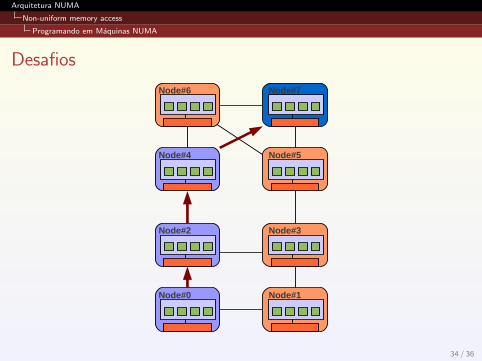
Desafios
Ao escrever programas de alto desempenho para maquinas NUMA,o programador deve ter em mente os seguintes problemas:
Latencia;
Largura de banda;
Desbalanceamento de carga;
Memory affinity.
33 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Desafios
Node#0 Node#1
Node#2 Node#3
Node#4 Node#5
Node#6 Node#7
34 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Desafios
Node#0 Node#1
Node#2 Node#3
Node#4 Node#5
Node#6 Node#7
34 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Desafios
Node#0 Node#1
Node#2 Node#3
Node#4 Node#5
Node#6 Node#7
34 / 36
Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Desafios
Node#0 Node#1
Node#2 Node#3
Node#4 Node#5
Node#6 Node#7
34 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Polıticas de Alocacao de Memoria
Trabalho realizado por Christiane Pousa Ribeiro eJean-Francois Mehaut no LIG, em Grenoble.
Propoem uma interface de programacao NUMA-aware ondecabe ao proprio programador definir como e onde alocar aspaginas de memoria.
Prove diferentes polıticas de alocacao de memoria, divididasem tres grupos:
bind : segmenta blocos de memoria e aloca na memoria doprocessador mais proximo;
cyclic : blocos de memoria sao alocados entre os processadoresusando alguma heurıstica tipo round-robin;
random: blocos de memoria sao espalhados aleatoriamenteentre os nodos.
35 / 36

Arquitetura NUMA
Non-uniform memory access
Programando em Maquinas NUMA
Minas
Memory affInity maNAgement Framework
gerencia memory affinity em multiprocessadores de memoriacompartilhada hierarquicos (ccNUMA);duas abordagens distintas: gerenciamento explıcito (MAi) ougeracao automatica de codigo otimizado (MApp);Otimizacao de uso de largura de banda e latencia emaplicacoes com padroes de acesso a memoria regulares ouirregulares;Interfaces em C, C++ e Fortran 90.
36 / 36


















