
APLICATIVO MÓVEL PARA GESTÃO DE …monografias.poli.ufrj.br/monografias/monopoli10016608.pdf ·...
57
APLICATIVO MÓVEL PARA GESTÃO DE BIBLIOTECAS PESSOAIS Evana Cristina Carvalho dos Santos Projeto de Graduação apresentado ao Curso de Engenharia de Computação e Informação da Escola Politécnica, Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Engenheira. Orientador: Jano Moreira de Souza Rio de Janeiro Abril de 2016
Transcript of APLICATIVO MÓVEL PARA GESTÃO DE …monografias.poli.ufrj.br/monografias/monopoli10016608.pdf ·...

APLICATIVO MÓVEL PARA GESTÃO DE BIBLIOTECAS PESSOAIS
Evana Cristina Carvalho dos Santos
Projeto de Graduação apresentado ao Curso de
Engenharia de Computação e Informação da
Escola Politécnica, Universidade Federal do
Rio de Janeiro, como parte dos requisitos
necessários à obtenção do título de Engenheira.
Orientador: Jano Moreira de Souza
Rio de Janeiro
Abril de 2016

ii
APLICATIVO MÓVEL PARA GESTÃO DE BIBLIOTECAS
PESSOAIS
Evana Cristina Carvalho dos Santos
PROJETO DE GRADUAÇÃO SUBMETIDO AO CORPO DOCENTE DO CURSO
DE ENGENHARIA DE COMPUTAÇÃO E INFORMAÇÃO DA ESCOLA
POLITÉCNICA DA UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO
PARTE DOS REQUISITOS NECESSÁRIOS PARA A OBTENÇÃO DO GRAU
DE ENGENHEIRA DE COMPUTAÇÃO E INFORMAÇÃO.
Examinada por:
Prof. Jano Moreira de Souza, Ph.D.
Prof. Claudio Esperança, Ph.D.
Prof. Sergio Palma da Justa Medeiros, D.Sc.
.
RIO DE JANEIRO, RJ - BRASIL
ABRIL de 2016

iii
Santos, Evana Cristina Carvalho dos
Aplicativo Móvel para Gestão de Bibliotecas Pessoais /
Evana Cristina Carvalho dos Santos. – Rio de Janeiro:
UFRJ/ Escola Politécnica, 2016.
VII, 50 p.: il.; 29,7 cm.
Orientador: Jano Moreira de Souza
Projeto de Graduação – UFRJ/ Escola Politécnica/ Curso
de Engenharia de Computação e Informação, 2016.
Referencias Bibliográficas: p. 49-50.
1. Reconhecimento Ótico de Caracteres 2. Processamento
de Imagens 3. Aplicativo 4. Gestão de Bibliotecas Pessoais
I. Souza, Jano Moreira de. II. Universidade Federal do Rio de
Janeiro, Escola Politécnica, Curso de Engenharia de
Computação e Informação. III. Título

iv
DEDICATÓRIA
À minha mãe.

v
AGRADECIMENTOS
Primeiramente, agradeco à minha mãe, meu exemplo de vida e superação, pelo seu
amor, apoio e compreensão nos momentos mais desafiadores ao longo de toda a minha
vida, mas principalmente por acreditar em mim. À minha família, pelo seu carinho,
paciência e incentivo. Aos meus amigos, por não me abandonarem, mesmo com as
minhas ausências. Em especial, aos amigos de ECI, pelas melhores memórias desses
seis anos, tendo enfrentado juntos as dificuldades e por terem me ensinado muito.
Agradeço a todos os meus professores por contribuirem para a minha formação,
transmitindo os seus conhecimentos, e, especialmente, ao professor Jano Moreira de
Souza, por aceitar orientar este projeto, ao professor Ricardo Marroquim, por sua
disposição em contribuir com este trabalho e aos professores Claudio Esperança e
Sergio Palma, por participarem da banca.
Por fim, gostaria de agradecer a todos que participaram e contribuíram, mesmo que
indiretamente, para me tornar a pessoa que sou hoje.

vi
Resumo do Projeto de Graduação apresentado à Escola Politécnica/ UFRJ como
parte dos requisitos necessários para a obtenção do grau de Engenheira de
Computação e Informação.
Aplicativo Móvel para Gestão de Bibliotecas Pessoais
Evana Cristina Carvalho dos Santos
Abril/2016
Orientador: Jano Moreira de Souza
Curso: Engenharia de Computação e Informação
Devido ao crescimento no número de visitantes e vendas em feiras de livros como a
Bienal do Livro no Rio é cada vez mais difícil para os indivíduos controlarem quais
livros possuem, o que algumas vezes causa livros duplicados. Fica ainda mais difícil,
quando se tem várias camadas de livros na mesma prateleira porque as obras que estão
por trás são raramente manuseadas. Além disso, não é fácil encontrar o livro buscado
numa situação como a descrita acima devido ao fato de não se saber previamente em
qual prateleira está e, consequentemente, ser necessário buscar em todas até localizá-lo,
gerando um grande desperdício de tempo e esforço na reorganização. No entanto, com a
difusão dos celulares e do acesso a internet, surgem novas possibilidades como o
desenvolvimento de uma aplicação com o objetivo de auxiliar o gerenciamento de
coleções de livros com foco em facilitar a carga inicial de dados através de
Reconhecimento Ótico de Caracteres.
Palavras-chave: Software Web, Reconhecimento Ótico de Caracteres, Processamento
de Imagens, Gestão de Bibliotecas Pessoais.

vii
Abstract of Undergraduate Project presented to POLI/UFRJ as a partial fulfillment
of the requirements for the degree of Engineer.
Mobile Application for Personal Libraries Management
Evana Cristina Carvalho dos Santos
April/2016
Advisor: Jano Moreira de Souza
Course: Computing and Information Engineering
Due to the increasing number of visitors and sales in fairs like the Bienal do Livro in
Rio it is getting harder for individuals keep track of which books they own, what
causes doubled books sometimes. It gets even harder, when there are multiple layers
of books on the same shelf because the ones behind are rarely handled. Futhermore, it
is not easy to find certain book in a situation like the described above due to the fact
that it is not previously known in which shelf it is and, consequently, it is necessary to
search them all until finding it, generating a big waste of time and effort in the
reorganization. However, with the spread of smartphones and Internet access, new
possibilities arise like the development of an application with the aim of supporting
the management of book collections focused in facilitating the initial data-load
process through Optical Character Recognition.
Keywords: Software Web, Optical Character Recognition, Image Processing, Personal
Library Management.

1
Sumário
1. Introdução ............................................................................................................................................ 2
2. Trabalhos Relacionados ....................................................................................................................... 4
1. ShelvAR .......................................................................................................................................... 4
2. Book Crawler .................................................................................................................................. 4
3. My Book List .................................................................................................................................. 4
4. Bibliophilia ...................................................................................................................................... 5
5. BookBuddy ..................................................................................................................................... 5
3. Conceitos ............................................................................................................................................. 6
1. ISBN ................................................................................................................................................ 6
2. API .................................................................................................................................................. 6
3. REST ............................................................................................................................................... 6
4. SOAP............................................................................................................................................... 7
5. XML ................................................................................................................................................ 7
6. JSON ............................................................................................................................................... 7
7. Product Advertising API ................................................................................................................. 7
8. Biblioteca do Congresso Americano ............................................................................................. 10
9. Google Books ................................................................................................................................ 11
4. Arquitetura ......................................................................................................................................... 13
1. Plataforma Android ....................................................................................................................... 13
2. Estrutura de Dados ........................................................................................................................ 14
3. Casos de Uso ................................................................................................................................. 16
5. Reconhecimento Ótico de Caracteres ................................................................................................ 22
1. Processamento da Imagem ............................................................................................................ 23
2. Resultados ..................................................................................................................................... 30
6. Repositórios ....................................................................................................................................... 33
1. Amazon ......................................................................................................................................... 34
2. Biblioteca do Congresso Americano ............................................................................................. 39
3. Google books................................................................................................................................. 43
7. Conclusão .......................................................................................................................................... 47

2
1. Introdução
A manutenção do catálogo de livros de um indivíduo pode ser uma tarefa complexa
para ele. Além disso, com a internet e a facilidade de ler livros online em qualquer
dispositivo, é comum para pessoas que gostam de ler se depararem com a dúvida se já
possuem determinada obra, principalmente em feiras como a Bienal. Fica ainda mais
dificil, quando se tem várias camadas de livros na mesma prateleira porque os que estão
por trás acabam sendo manuseados raramente.
Numa situação como a descrita, não é fácil encontrar certo livro devido ao fato de não
se saber a priori em qual prateleira ele está e, por conseguinte, ser necessário buscar em
todas até localizá-lo, gerando um grande desperdício de tempo e esforço por ter que
recolocar tudo no lugar após a busca.
Bancos de dados aparentam ser uma boa solução para este problema, porém são de
difícil utilização para leigos e não são portáteis. Além disso, digitar título e autor, pelo
menos, de uma grande quantidade de livros é uma tarefa extremamente cansativa e,
devido a isso, desencorajadora.
O uso de planilhas, como as do Microsoft Excel, é uma alternativa de maior facilidade
para pessoas em geral e portátil, visto que a maioria dos celulares atuais possui diversas
opções de aplicativos para criar e editar planilhas que, normalmente, fazem backup
automático para algum serviço de nuvem. No entanto, o problema da carga inicial de
dados persiste. Ademais, planilhas não são escaláveis, ou seja, a medida que a
quantidade de dados aumenta, o desempenho é prejudicado e softwares, como o
Microsoft Excel, possuem limites fixos para o tamanho de planilhas.
A proposta deste projeto é resolver os problemas citados acima usando um aplicativo
móvel para apoio à gestão de coleções pessoais. A solução utiliza um banco de dados
construído de forma incremental para armazenar os dados de livros e prateleiras da

3
coleção do usuário. Embora, bancos de dados não pareçam ser a melhor dentre as
opções citadas, eles podem ser mais facilmente integrados a aplicativos, abstraindo as
questões computacionais, agilizando pesquisas e resolvendo assim os problemas de falta
de conhecimento técnico e portabilidade. E, para resolver a questão da carga inicial de
dados, é proposto o uso da câmera do celular para fotografar as prateleiras, fazer o
reconhecimento dos títulos nas lombadas dos livros através de Reconhecimento Ótico
de Caracteres (Optical Character Recognition ou OCR) e buscar os dados relevantes
dos livros a partir de repositórios como a Biblioteca do Congresso Americano, Google
Books e Amazon.
O objetivo deste trabalho é mostrar como foi desenvolvido tal projeto. Esta monografia
está dividida em 6 capítulos, além desta introdução. O capítulo 2 descreve algumas
soluções existentes para alguns dos problemas apresentados. Os conceitos fundamentais
para o total entendimento do trabalho são apresentados no capítulo 3. A arquitetura
utilizada no projeto é explicada no capítulo 4. O capítulo 5 aborda o Reconhecimento
Ótico de Caracteres e seus resultados. Os repositórios usados para obtenção das
informações dos livros são mostrados no capítulo 6. E, por último, o capítulo 7 conclui
o trabalho.

4
2. Trabalhos Relacionados
As aplicações descritas neste capítulo referem-se a outras soluções que apoiam a
gerência de coleções de objetos reais, especificamente livros, e que visam facilitar a sua
localização. Embora algumas das abordagens sejam diferentes da seguida neste
trabalho, as soluções mencionadas neste capítulo e a proposta neste trabalho tem alguns
objetivos em comum.
1. ShelvAR
É um aplicativo desenvolvido por um grupo de pesquisa em realidade aumentada da
Universidade de Miami focado no auxílio da reposição de livros em estantes em
bibliotecas, segundo [1]. Ele utiliza a camera do aparelho para indicar os livros fora de
lugar através de realidade aumentada e etiquetas com códigos previamente colocadas
nas lombadas dos livros.
2. Book Crawler
Como explicado em [2], este aplicativo facilita o cadastro utilizando a camera do
dispositivo para reconhecer o ISBN através do código de barras da obra, buscando as
informações relevantes e permitindo ao usuário editá-las. Ele também permite marcar
livros como lidos ou emprestados, funcionalidades que também fazem parte da solução
proposta neste trabalho. Além disso, ele mostra a disponibilidade de determinada obra
em bibliotecas locais e avaliações de livros.
3. My Book List
É outro aplicativo que permite escanear o código de barras do livro com a camera e
retorna os dados encontrados através do ISBN escaneado de repositórios como a
Amazon, de acordo com [3]. Além disso, ele permite a captura da capa do livro para

5
visualização numa estante virtual dentro da aplicação, compra de livros e
compartilhamento dos dados.
4. Bibliophilia
Em [4], é descrito que esta aplicação facilita o cadastro dos livros através do
escaneamento do código de barras e a busca das principais informações através do
ISBN de repositórios como o Google Books. Ele permite também a importação de
múltiplos livros de um arquivo .csv e backup e restauração direto da nuvem através da
sincronização com Dropbox e Google Drive.
5. BookBuddy
Este aplicativo permite o escaneamento do ISBN e a importação livros do Google
Books, GoodReads e LibraryThing, dentre outros, para facilitar a catalogação. Ademais,
ele suporta o compartilhamento de livros em redes sociais, marcação de livros como
emprestados e sincronização com o Dropbox.
Dentre as aplicações citadas, o Shelvar é a única que não permite o escaneamento do
ISBN por utilizar suas próprias etiquetas, sendo essa uma de suas fraquezas por obrigar
o usuário a etiquetar e associar códigos a todos os livros e a largura de certos livros
dificultar a marcação. Apesar disso, elas o permitem identificar rapidamente livros fora
do lugar. Os outros aplicativos, focam na facilitação da carga inicial de dados através do
escaneamento do código de barras para obtenção dos dados através do ISBN. No
entanto, isso não resolve completamente o problema porque o usuário ainda precisa
retirar o livro da prateleira para escaneá-lo, enquanto a solução proposta neste trabalho
só necessita que os livros sejam removidos caso existam mais livros atrás.

6
3. Conceitos
Neste capítulo serão explicados conceitos relacionados ao domínio e às tecnologias
utilizadas que serão cruciais para o entendimento do trabalho.
1. ISBN
Segundo [5], ISBN é o acrônimo para International Standard Book Number, um padrão
internacional de código identificador único para cada livro criado em 1967. Como pode
ser visto na Figura 1, ele é composto por partes referentes ao país, a editora e o título,
dentre outros, e passou a ter 13 dígitos em 2007.
Figura 1: Formação do ISBN. Fonte: [5].
2. API
Interface de Programação de Aplicação (Application Programming Interface) ou API
são padrões de comunicação criados por um software para que outros softwares
consigam acessá-lo de forma automatizada e usar os seus serviços. Elas podem ser
REST e SOAP.
3. REST
Em [6], é explicado que REST é o acrônimo para Representational State Transfer e é
um tipo de arquitetura que utiliza URLs com os parâmetros no formato de pares chave-
valor para a requisição ao servidor (ou request como será referido daqui em diante) e o
protocolo HTTP para comunicação. Devido ao fato de usar uma URL, ele não pode

7
conter espaços que precisam ser codificados como ‘%20’ já que ao ser encontrado um
espaço o request é considerado terminado.
4. SOAP
Simple Object Access Protocol ou SOAP que é um outro tipo de arquitetura que utiliza
uma estrutura XML chamada envelope SOAP, onde os parâmetros são inseridos,
também é descrito em [6]. Embora REST seja mais simples, SOAP suporta outros tipos
de comunicação como, por exemplo, SSH, que é uma das razões pelas quais é mais
robusto.
5. XML
XML é a sigla para eXtensible Markup Language que é uma linguagem de marcação
recomendada pela World Wide Web Consortium (ou W3C) uma das organizações
responsáveis pela padronização da Web.
6. JSON
JSON ou JavaScript Object Notation é um formato de troca de dados baseado em pares
chave-valor para estruturas de dados arbitrarias.
7. Product Advertising API
A Amazon possui a Product Advertising API que disponibiliza a maioria das
funcionalidades de seu site, como buscar características de produtos que será usada
neste trabalho. Esta API é completamente explicada em [7] e aqui só serão introduzidos
os termos que serão usados neste trabalho. Serão utilizados REST requests, mas essa
API também suporta SOAP e retorna respostas estruturadas de acordo com o
responseGroup escolhido no formato XML. A seguir, são explicados os conceitos dessa
API que serão utilizados.

8
Operation
Como o próprio nome sugere, é o tipo de operação ou request que se deseja realizar.
Existem três tipos de operações Search, Lookup e Cart. Neste projeto serão utilizados
apenas o Search e o Lookup. O primeiro possui apenas um subtipo que é o ItemSearch,
enquanto o segundo possui três, são eles: BrowseNodeLookup, ItemLookup e
SimilarityLookup. Destes, apenas o ItemLookup será usado.
ItemSearch
Esta operação busca itens na Amazon em uma determinada categoria de produtos
(SearchIndex) e um valor a ser buscado e retorna até 10 itens por página. Um exemplo
típico de request deste tipo de operação com livros é ilustrado na Figura 2.
http://webservices.amazon.com/onca/xml?
Service=AWSECommerceService&
AWSAccessKeyId=[AWS Access Key ID]&
AssociateTag=[Associate ID]&
Operation=ItemSearch&
Keywords=[keywords%20separated%20by%20encoded%20spaces]&
SearchIndex=Books
&Timestamp=[YYYY-MM-DDThh:mm:ssZ]
&Signature=[Request Signature]
Figura 2: Formato de request com operação ItemSearch. Adaptado de: [7].
ItemLookup
Esta operação busca itens na Amazon através de um identificador e fornece, por padrão,
os atributos ASIN, Manufacturer, ProductGroup, e Title. Porém, como esse conjunto de
atributos não inclui todos os que eu necessito, especifiquei o ResponseGroup como
ItemAttributes para retornar todos os atributos de cada item encontrado. Na Figura 3, é
mostrado um exemplo típico de request deste tipo de operação com livros.

9
http://webservices.amazon.com/onca/xml?
Service=AWSECommerceService&
AWSAccessKeyId=[AWS Access Key ID]&
AssociateTag=[Associate ID]&
Operation=ItemLookup&
ItemId=[id]&
SearchIndex=Books&
IdType=ISBN&
ResponseGroup=ItemAttributes
&Timestamp=[YYYY-MM-DDThh:mm:ssZ]
&Signature=[Request Signature]
Figura 3: Formato de request com operação ItemLookup. Adaptado de: [7].
Service
É o serviço a ser usado e seu valor é sempre AWSECommerceService independente do
tipo de operação ou local.
AWSAccessKeyId
É o identificador de acesso a API do desenvolvedor cadastrado.
AssociateTag
A Product Advertising API é parte do Amazon Associates que permite que indivíduos
vendam produtos da Amazon em seus próprios sites e recebam por isso. Essa tag é o
que permite a Amazon identificar a origem do request e pagar ao desenvolvedor pelas
compras efetuadas através do seu site.
ResponseGroup
Definem os atributos do item buscado a serem retornados, chamados ItemAttributes.
Para livros, os principais atributos são título(Title), autor(Author) e ISBN, mas existem
muitos outros que não mencionarei porque não são o foco do presente trabalho.
Keywords
São uma ou mais palavras que se deseja buscar. Em termos de livros, pode ser título ou
autor, por exemplo.

10
IdType
Quando se busca um item específico com o ItemLookup, é bom especificar o tipo de
identificador usado para acelerar a pesquisa. O IdType é exatamente para isso e neste
trabalho vai sempre ter o valor de ISBN.
ItemId
O código identificador do item a ser procurado.
Timestamp
Contém a data e hora completa do request de acordo com o Greenwich Mean Time ou
GMT e é utilizado para autenticação.
Signature
É a assinatura usada para autenticação. Ela é criada a partir do tipo do request, da URI e
de um conjunto ordenado dos parâmetros utilizados com uma chave secreta fornecida
pela Amazon para cada desenvolvedor junto com o AWSAccessKeyId.
8. Biblioteca do Congresso Americano
A Biblioteca do Congresso Americano utiliza o protocolo Search/Retrieve via URL ou
SRU que é um padrão baseado em Web Services para buscas que retorna respostas no
formato XML com uma estrutura determinado pelo recordSchema que seria o
equivalente ao responseGroup da Product Advertising API. Em [8], encontra-se uma
descrição mais completa de seus termos.
Operation
Como na Product Advertising API da Amazon, os requests a API da Biblioteca do
Congresso Americano também possuem um parâmetro para designar a operação a ser
realizada. O valor que será usado nesse projeto será o searchRetrieve que serve tanto
para a busca geral por título, como pela busca individual por ISBN.

11
Version
A versão do protocolo que será usada.
MaximumRecords
É o número limite de registros a serem enviado na resposta.
RecordSchema
O SRU suporta diversos formatos para transferência dos dados, dentre eles o dc (Dublin
Core Record Schema) e o mods (Metadata Object Description Schema) que serão
utilizados neste projeto. Na Figura 4, encontra-se um exemplo típico do uso de cada um.
http://lx2.loc.gov:210/lcdb?
version=1.1&
operation=searchRetrieve&
query=title%20separated%20by%20encoded%20spaces&
maximumRecords=10&
recordSchema=dc
http://lx2.loc.gov:210/lcdb?
version=1.1&
operation=searchRetrieve&
query=bath.isbn=ISBN&
maximumRecords=1&
recordSchema=mods
Figura 4: Exemplos de requests usando recordSchemas dc e mods. Adpatado de: [8].
9. Google Books
Como as APIs apresentadas previamente, a Google Books API permite a utilização de
algumas das funcionalidades disponíveis no site Google Books de forma automatizada.
No entanto, diferentemente das anteriores, ela retorna respostas em formato JSON e
permite a utilização de REST através de JavaScript. Esta API suporta cinco tipos de
operações: list, insert, update, delete e get, dos quais apenas o útlimo será utilizado.
Volume
Representa um livro ou revista e é o recurso principal da API, sendo todos os outros
conectados a ele.

12
Figura 5: Exemplos de requests com titulo e ISBN. Adptado de: [9]
Como pode ser constatado nos exemplos de requests na Figura 5, esta API não possui
diferentes conjuntos de informações para resposta e os espaços são codificados com o
síbolo “+” em vez de “%20”. Além disso, a letra “q” é utilizada para indicar os
parâmetros da busca. Ela pode ser utilizada diretamente com uma palavra chave como
em “q=cooking” ou com filtros como intitle para título e isbn para o ISBN, como é
demonstrado em [9].
GET
https://www.googleapis.com/books/v1/volumes?
q=intitle:title+separated+by+encoded+spaces
GET
https://www.googleapis.com/books/v1/volumes?
q=isbn:ISBN

13
4. Arquitetura
Neste capítulo será explicada a arquitetura da solução proposta e as tecnologias
utilizadas, bem como as suas funcionalidades.
1. Plataforma Android
Como o Android é o sistema operacional móvel mais vendido no mundo e continuou
aumentando sua porcentagem do mercado em 2014, como visto na Tabela 1, ele foi
escolhido como plataforma de desenvolvimento. Além disso, diferentemente do iOS, ele
permite o desenvolvimento de aplicativos de forma gratuita.
Tabela 1: Vendas Mundiais de Celulares para Usuários Finais por Sistema Operacional
em 2014 (Milhares de Unidades). Adaptado de: [10].
Sistema Operacional
2014
Unidades
2014 Quota de
Mercado(%)
2013
Unidades
2013 Quota de
Mercado(%)
Android 1.004,675 80.7 761,288 78.5
iOS 191,426 15.4 150,786 15.5
Windows 35,133 2.8 30,714 3.2
BlackBerry 7,911 0.6 18,606 1.9
Other OS 5,745 0.5 8,327 0.9
Total 1,244,890 100.0 969,721 100.0
Embora o Android ofereça uma opção de Banco de Dados no próprio aparelho, o
SQLite, foi dado preferência a utilização do Postgres através de um web-service
utilizando SOAP para a comunicação cliente-servidor. Pode-se argumentar que essa
estrutura tem um custo alto por depender da internet para a transmissão dos dados, no
entanto, dado que a maior demanda de conexão será durante a carga inicial e o usuário

14
estará em casa, ele pode utilizar a rede wi-fi de sua residência sem sobrecarregar seus
dados móveis.
2. Estrutura de Dados
O aplicativo utiliza três entidades: usuário, prateleira e livro que podem ser vistas na
Figura 6 e o dicionário de dados é apresentado na Tabela 2. O usuário se cadastra no
sistema fornecendo um nome, pelo qual ele será identificado enquanto logado, um email
e uma senha, sendo os dois últimos os dados necessários para fazer login. Só é possível
começar a cadastrar livros após a criação de pelo menos uma prateleira, pois os livros
são associados a elas, como pode ser observado na Figura 7.
Figura 6: Modelo Conceitual utilizado.
Figura 7: Modelo Lógico utilizado.
Tabela 2: Dicionário de dados utilizado.
User
idUser Código identificador do usuário
username Nome do usuário
password Senha do usuário usada para o acesso ao aplicativo
email Email do usuário usado para o acesso ao aplicativo
Bookshelf
idBookshelf Código identificador da prateleira
shelf Nome da prateleira
Prateleira possui
armazena
Usuário Livro

15
column Coluna da prateleira
line Linha da prateleira
layer Camada da prateleira
amount Quantidade de livros na prateleira
idUser Código identificador do usuário. Representa a qual usuário
pertence a prateleira
Book
idBook Código identificador do livro
title Título do livro
author Autor do livro
isbn Código ISBN do livro
publisher Editora do livro
edition Edição do livro
dateRead Data da leitura do livro
dateLoaned Data do empréstimo do livro
personLoaned Pessoa para qual o livro foi emprestado
position Posição do livro na prateleira
idBookshelf Código identificador da prateleira. Representa em qual
prateleira está o livro
Após logar, o usuário pode então cadastrar prateleiras especificando estante, coluna,
linha e camada. Para entender melhor o que cada um desses atributos representa, basta
ver a Figura 8.
Figura 8: Organização de uma prateleira usada pelo sistema.

16
3. Casos de Uso
Nesta seção serão abordadas todas as funcionalidades do aplicativo através da descrição
textual dos seus casos de uso e serão incluídas as descrições detalhadas em tabela dos
dois casos de uso mais importantes e complexos.
Como visto na Figura 7, para cadastrar um livro é preciso ter alguma prateleira
cadastrada que por sua vez precisa de um usuário cadastrado e logado. Para cadastrar
um usuário novo, é só abrir o aplicativo pela primeira vez, onde será exibida a tela de
login, preencher o email e clicar em Entrar ou Cadastrar-se. O aplicativo exibirá a tela
de Cadastro já com o email preenchido, o usuário informará um nome de usuário e
senha e ao clicar em Salvar será exibida a mensagem “Usuário cadastrado com sucesso”
e ele será redirecionado a tela de login.
Depois de cadastrado o usuário, ao fornecer email e senha e clicar em Entrar ou
Cadastrar-se, o sistema exibe a tela principal com a aba Prateleiras selecionada, como é
ilustrado na Figura 9. Para sair ou ver as informações do usuário logado, é só clicar nos
três pontinhos na barra de título e escolher Sair ou Minha conta, respectivamente.
Quanto às prateleiras, o usuário pode adicionar uma nova, listar as cadastradas e editar
ou remover uma prateleira do sistema sempre com a aba Prateleiras selecionada na tela
principal. Para adicionar, ele deve clicar em Adicionar, preencher os dados e clicar em
Salvar. Enquanto que para modificar ou excluir é preciso listá-las através do botão
Listar e clicar no botão Editar ou Apagar, respectivamente.

17
Figura 9: Tela principal do aplicativo.
Por serem os casos de uso mais complexos do sistemas, Reconhecer títulos e Escanear
ISBN estão explicados detalhadamente nas Tabelas 3 e 4, nesta ordem.
Tabela 3: Descrição do caso de uso Reconhecer títulos.
Reconhecer títulos
Inicio Usuário clica em “Fotografar” na aba
“Prateleiras”
Funcionalidades Envolvidas Reconhecer títulos nas lombadas dos
livros
Condições
Invariante
Pré-condições Usuário deve estar logado no sistema
Pós-condições
Interações
Fluxo Principal
Usuário Sistema

18
1. Usuário clica em “Fotografar” na aba
“Prateleiras”
2. Sistema exibe tela “Fotografar”
3. Usuário seleciona a prateleira desejada e a
língua dos livros a serem fotografados
4. Usuário clica em “Fotografar”
5. Sistema exibe a câmera padrão do
Android
6. Usuário tira a foto
7.Sistema exibe a foto capturada
8. Usuário confirma o uso da foto exibida [A1]
9.Sistema processa a imagem e
reconhece os títulos
10. Sistema exibe a tela “Buscar”
com os títulos reconhecidos
11. Usuário escolhe a base
12. Usuário clica na lupa ao lado de um título
[A2]
13. Sistema exibe modal com
primeiro registro [A3]
14. Usuário clica em “Salvar [A4] [A5]
15. Sistema exibe a tela Manter
Livro com as informações do modal
16. Usuário clica em “Salvar” [A6]
17. Sistema exibe a mensagem
“Livro salvo com sucesso”
18. Sistema volta para a tela
“Buscar”
19. Caso de uso é encerrado [A7]
Fluxo Alternativo
[A1] Usuário tira outra foto
Volta para o passo 8

19
[A2] Usuário adiciona um título
Volta para o passo 12
[A3] Sistema exibe mensagem
“Nenhum resultado encontrado.
Tente selecionar outra base para
pesquisa.”
Volta para o passo 11
[A4] Usuário navega entre os registros no
modal
Volta para o passo 14
[A5] Usuário fecha o modal por não ter o livro
procurado
Volta para o passo 11
[A6] Usuário edita alguma informação do
livro
Volta para o passo 16
[A7] Volta para o passo 12
Com relação aos livros, também é possível cadastrá-los manualmente e através do
escaneamento do ISBN com a câmera, além do reconhecimento dos títulos explicado
acima. Para cadastrar manualmente, basta clicar em Adicionar com a aba Livros
selecionada, preencher os campos marcados com o símbolo asterístico (*), escolher a
prateleira e clicar em Salvar. Enquanto que para escanear, o procedimento está descrito
na Tabela 4, como dito anteriormente.
Tabela 4: Descrição do caso de uso Reconhecer títulos.
Escanear ISBN
Inicio Usuário clica em “Escanear” na aba
“Livros”
Funcionalidades Envolvidas Adicionar livro a partir do ISBN
Condições
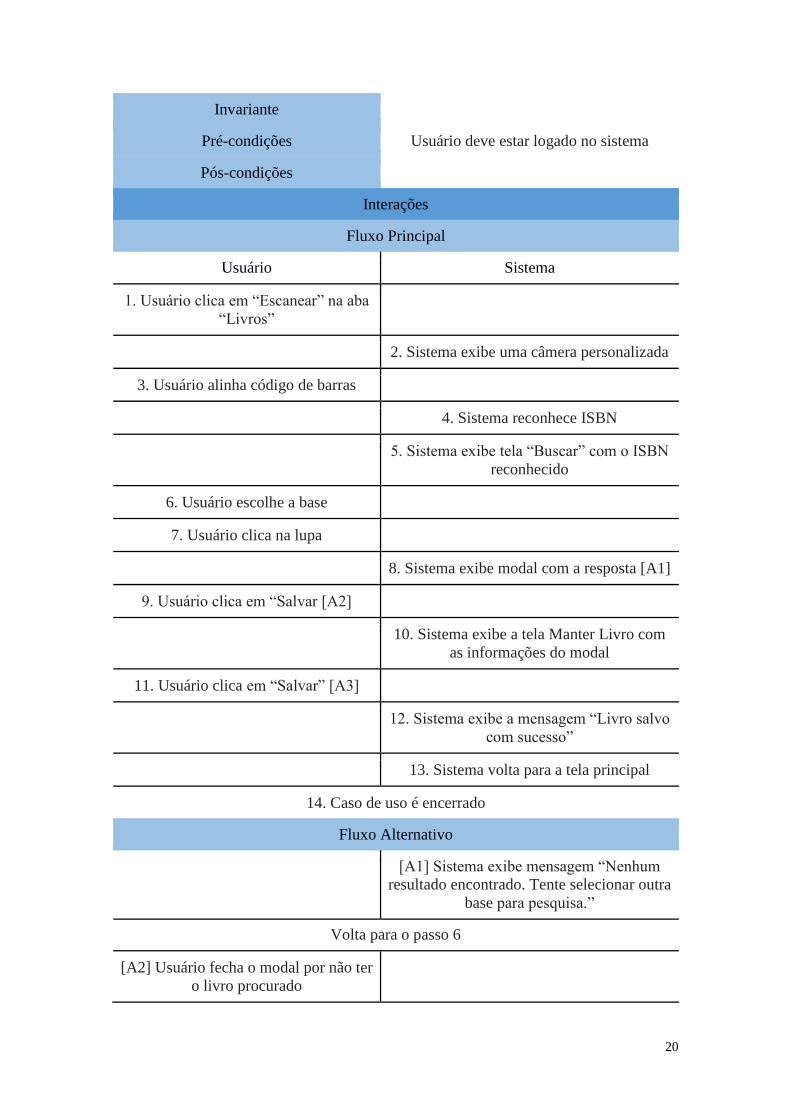
20
Invariante
Pré-condições Usuário deve estar logado no sistema
Pós-condições
Interações
Fluxo Principal
Usuário Sistema
1. Usuário clica em “Escanear” na aba
“Livros”
2. Sistema exibe uma câmera personalizada
3. Usuário alinha código de barras
4. Sistema reconhece ISBN
5. Sistema exibe tela “Buscar” com o ISBN
reconhecido
6. Usuário escolhe a base
7. Usuário clica na lupa
8. Sistema exibe modal com a resposta [A1]
9. Usuário clica em “Salvar [A2]
10. Sistema exibe a tela Manter Livro com
as informações do modal
11. Usuário clica em “Salvar” [A3]
12. Sistema exibe a mensagem “Livro salvo
com sucesso”
13. Sistema volta para a tela principal
14. Caso de uso é encerrado
Fluxo Alternativo
[A1] Sistema exibe mensagem “Nenhum
resultado encontrado. Tente selecionar outra
base para pesquisa.”
Volta para o passo 6
[A2] Usuário fecha o modal por não ter
o livro procurado

21
Volta para o passo 6
[A3] Usuário edita alguma informação
do livro
Volta para o passo 11
Por fim, com a aba Livros selecionada, também é possível listar todos os livros
cadastrados no sistema e editar ou remover algum. Além disso, existe a opção de buscar
livros específicos através do título, autor ou ISBN. Para modificar ou excluir é preciso
listar os livros através do botão Listar e clicar no botão Editar ou Apagar,
respectivamente. Enquanto que, para buscar, o usuário deve clicar na lupa no topo da
tela principal, digitar o termo a ser pesquisado e pressionar Enter.

22
5. Reconhecimento Ótico de Caracteres
Reconhecimento Ótico de Caracteres é uma tecnologia que transforma texto impresso
ou manuscrito em imagens e arquivos de texto escaneados em um conjunto de
caracteres editável em alguma codificação interpretável pelo computador de forma
similar ao que uma pessoa faz ao ler.
Segundo [11], o desenvolvimento do OCR começou por volta de 1950, mas era muito
lento e só conseguia escanear uma linha de cada vez. Com a invenção do scanner de
mesa e outros avanços de hardware, tornou-se possível digitalizar uma página inteira
por vez e vários tipos de documentos. Além disso, a velocidade do reconhecimento
aumentou, diminuindo o custo da tecnologia.
Embora os algoritmos de reconhecimento e os computadores não tivessem uma
performance muito boa, durante os anos de 1960, os desenvolvimentos de pesquisas em
softwares de OCR também avançaram bastante. No entanto, ele ainda era muito
suscetível a erros de acordo com a qualidade da digitalização e, devido a isso, empresas
fabricantes de software OCR forçaram a padronização de fontes, tintas e outros aspectos
que podiam influenciar a qualidade do reconhecimento. Com a padronização, a
eficiência do OCR melhorou bastante, bem como a sua velocidade, o que diminuiu mais
ainda o seu custo.
Existem diversas opções de softwares que fazem reconhecimento ótico de caracteres,
sendo a maioria deles proprietários, como ABBYY Cloud OCR SDK, OmniPage e
Nicomsoft OCR SDK, por exemplo. Dentre as gratuitas, uma das mais famosas é a
Tesseract que, de acordo com [12], foi inicialmente desenvolvido pela HP com o intuito
de ser acoplada aos seus scanners quando o OCR estava apenas começando e era
extremamente dependente da qualidade da imagem. Ela foi testada no UNLV Annual
Test of OCR Accuracy em 1995 e obteve ótimos resultados como pode ser visto em

23
[13], porém não virou parte de nenhum produto e seu código foi aberto em 2005.
Devido a isso, ela foi escolhida para ser usada no presente projeto.
Esta biblioteca possui como requisitos imagens com 300 dpi e que o texto a ser
reconhecido seja horizontal, como a maioria delas. Em decorrência disso, foi necessário
rotacionar a imagem durante o pré-processamento.
Conforme explicado em [12], a Tesseract funciona da seguinte forma: primeiro, ela
encontra e armazena o contorno das componentes conexas que são organizados em
linhas do texto. Estas linhas serão analizadas de acordo com o espacamento que será
usado em seguida para dividí-las em palavras. Em seguida, o reconhecimento
propriamente dito é feito em duas etapas, na primeira tenta-se reconhecer cada palavra e
as que atigem determinado nível de aceitação são utilizadas no treinamento de um
classificador adaptativo para melhorar o reconhecimento gradativamente. Devido a isso,
tem-se a segunda etapa que consiste numa segunda tentativa de reconhecimento porque
o classificador pode ter aprendido algo no final.
1. Processamento da Imagem
Em busca de tentar melhorar a qualidade do reconhecimento que será visto na próxima
seção e levando em consideração que, do ponto de vista de um livro, o restante da
imagem é ruído, é feito um pré-processamento da imagem visando segmentá-la livro a
livro para submetê-los individualmente ao OCR. Para isso, foi utilizada a biblioteca
OpenCV.
OpenCV é uma biblioteca de visão computacional de código aberto gratuita para uso
acadêmico e comercial focada em eficiência e inicialmente desenvolvida pelo
laboratório de pesquisa da Intel. Ela é multi-plataforma e possui interfaces em várias
linguagens, incluindo Java. Dentre suas diversas aplicações encontram-se remoção de

24
olhos vermelhos de fotos, rastreamento de objetos em movimento e reconhecimento de
faces. Além disso, é utilizada por mais de 40 milhões de usuários, incluindo grandes
empresas como Google, Microsoft e Sony.
Figura 10: Exemplo de foto de prateleira.
Primeiramente, obtém-se um valor para o limite (threshold) usando um método
adaptativo de Otsu. Em segundo lugar, o método Canny(Mat image, Mat edges, double
threshold1, double threshold2) é usado para gerar uma imagem binária (edges) do
mesmo tamanho da entrada (Figura 10) de fundo preto, onde os pixels brancos são as
bordas detectadas como na Figura 11.

25
Figura 11: Retorno no método Canny.
O método Canny, explicado em [14] se baseia no operador de Laplace que usa segundas
derivadas para detectar discontinuidades dado que quando uma função está variando
muito rápido a sua primeira derivada é maior até atingir um máximo local, que se traduz
em uma segunda derivada igual a 0, e depois vai diminuindo. Os pontos onde a segunda
derivada é zero são analisados de acordo com os limites máximo (threshold2) e mínimo
(threshold1) de forma que um pixel só é considerado borda se ele tiver um gradiente
maior que o threshold2 ou se ele está entre threshold1 e threshold2, mas esta ao lado de
um pixel maior que threshold2.
Na sequência, obtenho as linhas verticais (lines) que serão usadas como candidatas para
o corte da imagem posteriormente e são mostradas em azul na Figura 12, usando a
imagem binária gerada acima (edges) com o método HoughLines(Mat edges, Mat lines,
double rho, double theta, int threshold), que se baseia no algoritmo de Hough. O
HoughLines considera que todo ponto pode fazer parte de um conjunto de linhas e as

26
parametriza como um ponto usando coordenadas polares (rho, theta), sendo que rho é a
distancia da origem até a linha e theta, o ângulo que o segmento de reta de tamanho rho
forma com o eixo X. Este método retorna apenas as linhas parametrizadas pelo rho e
theta fornecidos que são maiores que threshold. Como a equação de uma linha usando
coordenadas polares é dada por rho = x*cos(theta) + y*sen(theta), uso theta igual a
pi/180 para obter apenas as linhas verticais.
Figura 12: Linhas candidatas a cortar a imagem encontradas com HoughLines.
Em seguida, uso o método findContours(Mat edges, List<MatOfPoint> contours, Mat
hierarchy, int mode, int method) que retorna uma lista com todos os contornos
(contours) da entrada (edges), que podem ser vistos na Figura 13, e testo se as linhas
candidatas a segmentar a foto cruzam com menos de um certo número de contornos. Se
positivo, elas são usadas para cortar a imagem, caso contrário elas são descartadas. As
linhas verdes da Figura 14 são as que passaram no teste e serão usadas para o corte da
foto.

27
Figura 13: Contornos retornados pelo findContours.
Figura 14: Linhas selecionadas para o corte da imagem.

28
Os argumentos mode e method são, respectivamente, o que vai ser retornado e como,
enquanto o argumento hierarchy é a hierarquia dos contornos retornados. A hierarquia é
uma matriz que armazena para cada contorno o indice do contorno anterior, do
posterior, do pai e do filho.
Segundo x, mode pode ter quatro valores diferentes: CV_RETR_EXTERNAL que
retorna somente os contornos mais externos, CV_RETR_LIST que retorna todos os
contornos sem inferir nada sobre sua hierarquia, CV_ RETR_CCOMP que retorna todos
os contornos e os classifica em apenas dois níveis ou CV_RETR_TREE que retorna
todos os contornos e uma hierarquia completa entre eles.
Ainda de acordo com x, method pode assumir cinco valores distintos, sendo
CV_CHAIN_APPROX_NONE, que retorna todos os pontos de um contorno, e
CV_CHAIN_APPROX_SIMPLE, que retorna apenas os pontos extremos de segmentos
horizontais, verticais ou diagonais, os mais importantes.
Finalmente, corto a imagem e rotaciono os pedaços em 90º no sentido anti-horário para
serem usadas como entrada do Tesseract porque uma de suas condições é que o texto a
ser reconhecido seja horizontal, como visto anteriormente. As imagens cortadas e
rotacionadas se encontram nas Figuras 15a-g.

29
Figura 15a-g: Imagens finais a serem usadas no reconhecimento.

30
2. Resultados
A seguir, são mostrados alguns dos resultados obtidos em diferentes situações. É
importante salientar que os resultados que serão apresentados nesta e nas próximas
seções foram obtidos num tablet Dell Venue7-3740-A10 com Android 4.4.4, 16GB e
câmera de 5 megapixels.
O OCR foi testado com várias fotos, porém, para não alongar demais o trabalho, serão
apresentados os resultados de apenas uma foto escolhida de forma randômica, que neste
caso significa que ela não foi escolhida por nenhum motivo específico como apresentar
o melhor ou o pior reconhecimento.
Na primeira tentativa com a Tesseract, a imagem mostrada na Figura 10 foi apenas
rotacionada por 90º no sentido anti-horário e foi obtido o texto mostrado na primeira
coluna da Tabela 4. Em seguida, foi utlizada uma expressão REGEX para remover os
caracteres que não fossem números e letras e o resultado ficou bem mais legível, como
ilustrado na segunda coluna da Tabela 5.
Tabela 5: Resultados obtidos com Tesseract sem pré-processamento.
Sem filtro REGEX Com filtro REGEX
*' THE DAMNCI CODEX %=
‘I } Q" , , . *5 V :1
jab? LEONA-«x. ‘4“ ,_(1AM[1._3;;
; jg MARTIN v IHRONES §L‘
! . ,/ .
m .M
, 31”,? , . ‘ ./ , p
dela cruz skmnyvdjppmg
3 ‘ j 33
de Ia cruz 6:2: 53:41:“H4e3390
. die *8 cruz crazy hot
Fifty Shades of Grey H E, 1;, James; :33 3
Fifty Shades Darker : E L 3,3: fl
1:: ’1‘ M
4 9' :5 '54 "j i
THE DAMNCI CODEX
I Q 5 V 1
jab LEONA x 4 1AM 1 3
jg MARTIN v IHRONES L
m M
31 p
dela cruz skmnyvdjppmg
3 j 33
de Ia cruz 6 2 53 41 H4e3390
die 8 cruz crazy hot
Fifty Shades of Grey H E 1 James 33 3
Fifty Shades Darker E L 3 3
1 1 M
4 9 5 54 j i

31
Finalmente, o resultado obtido após o pré-processamento da imagem usada é mostrado
na Figura 16.
a DAN BROWN i
THE DAMNCI CODE g
2 13 w 1 i
aftGEORCJE RR gi A GAME 1
J A RTIN 7f 7 THRONES 4
1 1 1 i u 4 WWW
dela cruz Ski Hy dippmgI
aIdela cruz sun kissed
J l I Fifty Shades of Grey H E L James
Fifty Shades Darker E E L James a 1
5
Z3 3 93
5r if 12 3 7 E
a 9 a a if 2 2
a 2 g M 2 I 5
J 3 2 t 3 a 9 75 A
n 1 V w
C
Figura 16: Resultado obtido com Tesseract após pré-processamento.
Como pode ser visto, o pré-processamento melhorou o reconhecimento de alguns
títulos, porém piorou o de outros e, obviamente, essa melhora ou piora e o seu grau
variam de imagem para imagem. Devido a performance da Tesseract não ter sido tão
boa quanto o esperado, decidiu-se testar uma alternativa proprietária para avaliar a
diferença de desempenho.
Dentre as diversas opções, foi escolhida a ABBYY Cloud OCR SDK, cuja
documentação é descrita em [15], devido a estar entre as mais conhecidas. Utilizando a
mesma Figura 10 como entrada, foi obtido o resultado ilustrado na Figura 17. Para isso,
foi executado o mesmo procedimento adotado na primeira tentativa com a Tesseract de
simplesmente rotacionar a imagem da figura 10 por 90º no sentido anti-horário.

32
DAN BROWN
THE DA^lNCI OODE
■
■I GEORGE R.R. a GAME of-|
MARTIN THRONES
DE LA CRUZ 1 u c Bloods
u e r a d e HYPERION DBG
de la cruz @ skinny-dipping
de la cruz @ sun-kissed
de la cruz ® crazy hot
Fifty Shades of Grey E L James ©
Fifty Shades Darker E L James ©
A p s i ** €0 W
4 * % t
Figura 17: Texto reconhecido usando ABBYY.
Como observado, o reconhecimento da ABBYY foi melhor que o da Tesseract, o que já
era esperado devido a primeira ser uma biblioteca paga. Porém, ela também teve alguma
dificuldade em reconhecer alguns títulos, especificamente, os que estão reescritos sobre
eles mesmos em uma cor similar e com letra cursiva.

33
6. Repositórios
Como explicado anteriormente, os dados dos livros são obtidos através do
reconhecimento de seus títulos nas lombadas dos livros nas fotos das prateleiras. Para
facilitar a catalogação, faz-se necessário o acesso a um repositório online de livros onde
esses dados possam ser encontrados.
Na expectativa de encontrar uma base atualizada e de fácil acesso com os dados dos
livros em português, foi pesquisada a Fundação Biblioteca Nacional por ser a agência
brasileira responsável por conceder ISBNs para todos os livros editados em território
nacional. No entanto, só é possível consultar a sua base com um registro por vez através
do site http://www.isbn.bn.br/website/consulta/cadastro e com a utilização de um
captcha.
Depois de pesquisar em outros sites da Biblioteca Nacional, foram encontradas duas
outras alternativas de sites de consulta http://acervo.bn.br/sophia_web/index.html e
http://bndigital.bn.br/acervodigital/, sendo o primeiro referente ao acervo completo da
Biblioteca Nacional e o segundo referente ao seu acervo disponível para consulta digital
e, portanto, bem menor que o anterior. O problema é que nenhuma destas opções
oferece uma API para acesso automatizado.
Em busca de uma resposta concreta em relação a API, foi consultada a Biblioteca
Nacional e a Agência Nacional do ISBN que confirmaram que o referido recurso não
existe. Devido a isso, foram incorporados o Google Books e a Amazon como
repositórios por serem sites bem difundidos no Brasil, na esperança de que devido a isso
possuíssem um vasto catálogo de livros em português.

34
A mesma dificuldade não se repetiu com os livros em Inglês, os quais podem ser
consultados a partir de diversos repositórios como os dois citados acima e a Biblioteca
do Congresso Americano que é a maior biblioteca do mundo.
Utilizando alguns dos títulos reconhecidos na Figura 16 e ISBNs, foram testados os três
repositórios e os resultados obtidos são apresentados a seguir, mostrando apenas os dois
primeiros resultados de cada busca quando houverem dois ou mais e removendo os
demais e o conteúdo de algumas tags que não serão utilizadas no presente trabalho.
1. Amazon
Busca por título
Sem sucesso
<ItemSearchResponse
xmlns="http://webservices.amazon.com/AWSECommerceService/2011-08-01">
<OperationRequest>
<HTTPHeaders>...</HTTPHeaders>
<RequestId>0dc19d0d-ad0f-4384-9126-914ee0480edb</RequestId>
<Arguments>...</Arguments>
<RequestProcessingTime>0.0533120000000000</RequestProcessingTime>
</OperationRequest>
<Items>
<Request>
<IsValid>True</IsValid>
<ItemSearchRequest>
<Keywords>THE DAMNCI CODE g</Keywords>
<ResponseGroup>Small</ResponseGroup>
<SearchIndex>Books</SearchIndex>
</ItemSearchRequest>
<Errors>
<Error>
<Code>AWS.ECommerceService.NoExactMatches</Code>
<Message>We did not find any matches for your request.</Message>
</Error>
</Errors>
</Request>
<TotalResults>0</TotalResults>
<TotalPages>0</TotalPages>
<MoreSearchResultsUrl>...</MoreSearchResultsUrl>
</Items>
</ItemSearchResponse>

35
Com sucesso
<ItemSearchResponse
xmlns="http://webservices.amazon.com/AWSECommerceService/2011-08-01">
<OperationRequest>
<HTTPHeaders>...</HTTPHeaders>
<RequestId>5a6ef911-aaac-48bb-b09c-061d295f53b2</RequestId>
<Arguments>...</Arguments>
<RequestProcessingTime>0.3604570000000000</RequestProcessingTime>
</OperationRequest>
<Items>
<Request>
<IsValid>True</IsValid>
<ItemSearchRequest>
<Keywords>Fifty Shades Darker E E L James a 1</Keywords>
<ResponseGroup>ItemAttributes</ResponseGroup>
<SearchIndex>Books</SearchIndex>
</ItemSearchRequest>
</Request>
<TotalResults>14</TotalResults>
<TotalPages>2</TotalPages>
<MoreSearchResultsUrl>...</MoreSearchResultsUrl>
<Item>
<ASIN>0345803493</ASIN>
<DetailPageURL>...</DetailPageURL>
<ItemLinks>...</ItemLinks>
<ItemAttributes>
<Author>E. L. James</Author>
<Binding>Paperback</Binding>
<Brand>Random House</Brand>
<CatalogNumberList>...</CatalogNumberList>
<EAN>9780345803498</EAN>
<EANList>...</EANList>
<Edition>Reprint</Edition>
<Feature>Adults Only</Feature>
<Feature>Fifty Shades Of Grey</Feature>
<Feature>Fifty Shades Darker</Feature>
<IsAdultProduct>0</IsAdultProduct>
<ISBN>0345803493</ISBN>
<ItemDimensions>...</ItemDimensions>
<Label>Vintage</Label>
<Languages>...</Languages>
<ListPrice>...</ListPrice>
<Manufacturer>Vintage</Manufacturer>
<ManufacturerMinimumAge
Units="months">252</ManufacturerMinimumAge>
<Model>RH-FSD2</Model>
<MPN>RH3498</MPN>
<NumberOfItems>1</NumberOfItems>

36
<NumberOfPages>544</NumberOfPages>
<PackageDimensions>...</PackageDimensions>
<PackageQuantity>1</PackageQuantity>
<PartNumber>RH3498</PartNumber>
<ProductGroup>Book</ProductGroup>
<ProductTypeName>ABIS_BOOK</ProductTypeName>
<PublicationDate>2012-04-17</PublicationDate>
<Publisher>Vintage</Publisher>
<ReleaseDate>2012-04-17</ReleaseDate>
<Studio>Vintage</Studio>
<Title>Fifty Shades Darker</Title>
</ItemAttributes>
</Item>
<Item>
<ASIN>1101946342</ASIN>
<DetailPageURL>...</DetailPageURL>
<ItemLinks>...</ItemLinks>
<ItemAttributes>
<Author>E L James</Author>
<Binding>Paperback</Binding>
<Brand>Random House</Brand>
<CatalogNumberList>...</CatalogNumberList>
<EAN>9781101946343</EAN>
<EANList>...</EANList>
<Feature>...</Feature>
<Feature>...</Feature>
<Feature>...</Feature>
<Feature>...</Feature>
<Feature>...</Feature>
<IsAdultProduct>0</IsAdultProduct>
<ISBN>1101946342</ISBN>
<ItemDimensions>...</ItemDimensions>
<Label>Vintage</Label>
<Languages>...</Languages>
<ListPrice>...</ListPrice>
<Manufacturer>Vintage</Manufacturer>
<Model>RH-GREY</Model>
<MPN>CNVELD-RH6350</MPN>
<NumberOfItems>1</NumberOfItems>
<NumberOfPages>576</NumberOfPages>
<PackageDimensions>...</PackageDimensions>
<PackageQuantity>1</PackageQuantity>
<PartNumber>CNVELD-RH6350</PartNumber>
<ProductGroup>Book</ProductGroup>
<ProductTypeName>ABIS_BOOK</ProductTypeName>
<PublicationDate>2015-06-18</PublicationDate>
<Publisher>Vintage</Publisher>
<ReleaseDate>2015-06-18</ReleaseDate>
<Studio>Vintage</Studio>

37
<Title>
Grey: Fifty Shades of Grey as Told by Christian (Fifty Shades of Grey
Series)
</Title>
</ItemAttributes>
</Item>
<Item>...</Item>
</Items>
</ItemSearchResponse>
Busca por ISBN
<ItemLookupResponse
xmlns="http://webservices.amazon.com/AWSECommerceService/2011-08-
01">
<OperationRequest>
<HTTPHeaders>...</HTTPHeaders>
<RequestId>25ce8470-c255-4106-ad04-bce2c34087f2</RequestId>
<Arguments>...</Arguments>
<RequestProcessingTime>0.1586340000000000</RequestProcessingTime
>
</OperationRequest>
<Items>
<Request>
<IsValid>True</IsValid>
<ItemLookupRequest>
<IdType>ISBN</IdType>
<ItemId>9780553573404</ItemId>
<ResponseGroup>ItemAttributes</ResponseGroup>
<SearchIndex>All</SearchIndex>
<VariationPage>All</VariationPage>
</ItemLookupRequest>
</Request>
<Item>
<ASIN>0553573403</ASIN>
<DetailPageURL>...</DetailPageURL>
<ItemLinks>...</ItemLinks>
<ItemAttributes>
<Author>George R.R. Martin</Author>
<Binding>Mass Market Paperback</Binding>
<Brand>Martin, George R. R.</Brand>
<CatalogNumberList>...</CatalogNumberList>
<Color>White</Color>
<EAN>9780553573404</EAN>
<EANList>...</EANList>
<Feature>ISBN13: 9780553573404</Feature>
<Feature>Condition: New</Feature>

38
<Feature>...</Feature>
<ISBN>0553573403</ISBN>
<ItemDimensions>...</ItemDimensions>
<Label>Bantam</Label>
<Languages>...</Languages>
<ListPrice>...</ListPrice>
<Manufacturer>Bantam</Manufacturer>
<MPN>9780553573404</MPN>
<NumberOfItems>1</NumberOfItems>
<NumberOfPages>831</NumberOfPages>
<PackageDimensions>...</PackageDimensions>
<PartNumber>9780553573404</PartNumber>
<ProductGroup>Book</ProductGroup>
<ProductTypeName>ABIS_BOOK</ProductTypeName>
<PublicationDate>1997-08-04</PublicationDate>
<Publisher>Bantam</Publisher>
<ReleaseDate>1997-08-04</ReleaseDate>
<Studio>Bantam</Studio>
<Title>A Game of Thrones (A Song of Ice and Fire, Book 1)</Title>
</ItemAttributes>
</Item>
<Item>
<ASIN>B000QCS8TW</ASIN>
<DetailPageURL>...</DetailPageURL>
<ItemLinks>...</ItemLinks>
<ItemAttributes>
<Author>George R. R. Martin</Author>
<Binding>Kindle Edition</Binding>
<EISBN>9780553897845</EISBN>
<Format>Kindle eBook</Format>
<Label>Bantam</Label>
<Languages>...</Languages>
<Manufacturer>Bantam</Manufacturer>
<NumberOfPages>819</NumberOfPages>
<ProductGroup>eBooks</ProductGroup>
<ProductTypeName>ABIS_EBOOKS</ProductTypeName>
<PublicationDate>2003-01-01</PublicationDate>
<Publisher>Bantam</Publisher>
<ReleaseDate>2003-01-01</ReleaseDate>
<Studio>Bantam</Studio>
<Title>A Game of Thrones (A Song of Ice and Fire, Book 1)</Title>
</ItemAttributes>
</Item>
</Items>
</ItemLookupResponse>

39
2. Biblioteca do Congresso Americano
Busca por título
Sem sucesso
<zs:searchRetrieveResponse
xmlns:zs="http://www.loc.gov/zing/srw/">
<zs:version>1.1</zs:version>
<zs:numberOfRecords>0</zs:numberOfRecords>
<zs:echoedSearchRetrieveRequest>
<zs:version>1.1</zs:version>
<zs:query>THE DAMNCI CODE g</zs:query>
<zs:maximumRecords>10</zs:maximumRecords>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordSchema>dc</zs:recordSchema>
</zs:echoedSearchRetrieveRequest>
</zs:searchRetrieveResponse>
Com sucesso
<zs:searchRetrieveResponse xmlns:zs="http://www.loc.gov/zing/srw/">
<zs:version>1.1</zs:version>
<zs:numberOfRecords>131</zs:numberOfRecords>
<zs:records>
<zs:record>
<zs:recordSchema>dc</zs:recordSchema>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordData>
<srw_dc:dc xmlns:srw_dc="info:srw/schema/1/dc-schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="info:srw/schema/1/dc-schema
http://www.loc.gov/standards/sru/resources/dc-schema.xsd">
<title xmlns="http://purl.org/dc/elements/1.1/">100 essential American
poems /</title>
<creator xmlns="http://purl.org/dc/elements/1.1/">Pockell,
Leslie.</creator>
<type xmlns="http://purl.org/dc/elements/1.1/">text</type>
<publisher xmlns="http://purl.org/dc/elements/1.1/">New York : Thomas
Dunne Books,</publisher>
<date xmlns="http://purl.org/dc/elements/1.1/">2009.</date>
<language xmlns="http://purl.org/dc/elements/1.1/">eng</language>
<description xmlns="http://purl.org/dc/elements/1.1/">...</description>
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<description xmlns="http://purl.org/dc/elements/1.1/"/>

40
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<subject xmlns="http://purl.org/dc/elements/1.1/">American
poetry.</subject>
<identifier xmlns="http://purl.org/dc/elements/1.1/">...</identifier>
<identifier
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:9780312369804
(alk. paper)</identifier>
<identifier
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:0312369808 (alk.
paper)</identifier>
</srw_dc:dc>
</zs:recordData>
<zs:recordPosition>1</zs:recordPosition>
</zs:record>
<zs:record>
<zs:recordSchema>dc</zs:recordSchema>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordData>
<srw_dc:dc xmlns:srw_dc="info:srw/schema/1/dc-schema"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="info:srw/schema/1/dc-schema
http://www.loc.gov/standards/sru/resources/dc-schema.xsd">
<title xmlns="http://purl.org/dc/elements/1.1/">9-11 : artists
respond.</title>
<creator xmlns="http://purl.org/dc/elements/1.1/">Chaos!
Comics.</creator>
<creator xmlns="http://purl.org/dc/elements/1.1/">Dark Horse
Comics.</creator>
<creator xmlns="http://purl.org/dc/elements/1.1/">Image
Comics.</creator>
<creator xmlns="http://purl.org/dc/elements/1.1/">DC Comics,
Inc.</creator>
<type xmlns="http://purl.org/dc/elements/1.1/">text</type>
<type xmlns="http://purl.org/dc/elements/1.1/">Graphic novels.</type>
<type xmlns="http://purl.org/dc/elements/1.1/">Graphic novels United
States.</type>
<publisher xmlns="http://purl.org/dc/elements/1.1/">Milwaukie, Or. :
Dark Horse Comics,</publisher>
<date xmlns="http://purl.org/dc/elements/1.1/">c2002.</date>
<language xmlns="http://purl.org/dc/elements/1.1/">eng</language>
<description xmlns="http://purl.org/dc/elements/1.1/">Subtitle from vol.
1.</description>
<description xmlns="http://purl.org/dc/elements/1.1/">...</description>
<description xmlns="http://purl.org/dc/elements/1.1/">...</description>
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<description xmlns="http://purl.org/dc/elements/1.1/"/>
<subject xmlns="http://purl.org/dc/elements/1.1/">...</subject>
<subject xmlns="http://purl.org/dc/elements/1.1/">...</subject>
<identifier

41
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:1563898810 (pbk. :
v. 1)</identifier>
<identifier
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:9781563898815
(pbk. : v. 1)</identifier>
<identifier
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:1563898780 (pbk. :
v. 2)</identifier>
<identifier
xmlns="http://purl.org/dc/elements/1.1/">URN:ISBN:9781563898785
(pbk. : v. 2)</identifier>
</srw_dc:dc>
</zs:recordData>
<zs:recordPosition>2</zs:recordPosition>
</zs:record>
<zs:record>...</zs:record>
</zs:records>
<zs:nextRecordPosition>11</zs:nextRecordPosition>
<zs:echoedSearchRetrieveRequest>
<zs:version>1.1</zs:version>
<zs:query>a DAN BROWN i</zs:query>
<zs:maximumRecords>10</zs:maximumRecords>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordSchema>dc</zs:recordSchema>
</zs:echoedSearchRetrieveRequest>
</zs:searchRetrieveResponse>
Busca por ISBN
<zs:searchRetrieveResponse xmlns:zs="http://www.loc.gov/zing/srw/">
<zs:version>1.1</zs:version>
<zs:numberOfRecords>1</zs:numberOfRecords>
<zs:records>
<zs:record>
<zs:recordSchema>mods</zs:recordSchema>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordData>
<mods xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.loc.gov/mods/v3" version="3.5"
xsi:schemaLocation="http://www.loc.gov/mods/v3
http://www.loc.gov/standards/mods/v3/mods-3-5.xsd">
<titleInfo>
<title>Once upon a time</title>
<subTitle>a collection of classic fairy tales</subTitle>
</titleInfo>
<titleInfo type="uniform">...</titleInfo>
<name type="personal">

42
<namePart>Grimm, Jacob</namePart>
<namePart type="date">1785-1863</namePart>
</name>
<name type="personal">
<namePart>Grimm, Wilhelm</namePart>
<namePart type="date">1786-1859</namePart>
</name>
<name type="personal">
<namePart>Tong, Kevin</namePart>
</name>
<typeOfResource>text</typeOfResource>
<originInfo>
<place>...</place>
<place>...</place>
<publisher>Hyperion</publisher>
<dateIssued>c2011</dateIssued>
<dateIssued encoding="marc">2011</dateIssued>
<issuance>monographic</issuance>
</originInfo>
<language>...</language>
<language objectPart="translation">...</language>
<physicalDescription>...</physicalDescription>
<abstract type="Summary">...</abstract>
<tableOfContents>...</tableOfContents>
<note type="statement of responsibility" altRepGroup="00">illustrated by
Kevin Tong.</note>
<subject>...</subject>
<subject authority="lcsh">...</subject>
<classification authority="lcc">GR166 .K5313 2011</classification>
<classification authority="ddc" edition="23">398.2/0943</classification>
<relatedItem>...</relatedItem>
<identifier type="isbn">9781401324636</identifier>
<identifier type="isbn">1401324630</identifier>
<identifier type="lccn">2011036526</identifier>
<identifier type="oclc">ocn749869054</identifier>
<relatedItem>...</relatedItem>
<relatedItem>...</relatedItem>
<recordInfo>...</recordInfo>
</mods>
</zs:recordData>
<zs:recordPosition>1</zs:recordPosition>
</zs:record>
</zs:records>
<zs:echoedSearchRetrieveRequest>
<zs:version>1.1</zs:version>
<zs:query>bath.isbn=9781401324636</zs:query>
<zs:maximumRecords>1</zs:maximumRecords>
<zs:recordPacking>xml</zs:recordPacking>
<zs:recordSchema>mods</zs:recordSchema>

43
</zs:echoedSearchRetrieveRequest>
</zs:searchRetrieveResponse>
3. Google books
Busca por título
Sem sucesso (THE DAMNCI CODE g)
{
"kind": "books#volumes",
"totalItems": 0
}
Com sucesso (a DAN BROWN i)
{
"kind": "books#volumes",
"totalItems": 574,
"items": [
{
"kind": "books#volume",
"volumeInfo": {
"title": "Suia para A CHAVE DE SALOMAO de DAN BROWN",
"authors": [
"GREG TAYLOR"
],
"publisher": "Editora Record",
"description": ...,
"industryIdentifiers": [
{
"type": "ISBN_10",
"identifier": "8501073903"
},
{
"type": "ISBN_13",
"identifier": "9788501073907"
}
],
"readingModes": {...},

44
"pageCount": 206,
"printType": "BOOK"
},
{...}
]
}
Busca por ISBN
{
"kind": "books#volumes",
"totalItems": 1,
"items": [
{
"kind": "books#volume",
"id": "bIZiAAAAMAAJ",
"etag": "QEvQOUNH560",
"selfLink": "https://www.googleapis.com/books/v1/volumes/bIZiAAAAMAAJ",
"volumeInfo": {
"title": "A Game of Thrones",
"authors": [
"George R. R. Martin"
],
"publisher": "Spectra",
"publishedDate": "1997",
"description": ...,
"industryIdentifiers": [
{
"type": "OTHER",
"identifier": "UOM:39015050507618"
}
],
"readingModes": {...},
"pageCount": 835,
"printType": "BOOK",
"categories": [...],
"averageRating": 4.0,
"ratingsCount": 1437,
"maturityRating": "NOT_MATURE",
"allowAnonLogging": false,
"contentVersion": "1.0.1.0.preview.0",
"imageLinks": {...},

45
"language": "en",
"previewLink": ...,
"infoLink": ...,
"canonicalVolumeLink": ...
},
"saleInfo": {
"country": "BR",
"saleability": "NOT_FOR_SALE",
"isEbook": false
},
"accessInfo": {
"country": "BR",
"viewability": "NO_PAGES",
"embeddable": false,
"publicDomain": false,
"textToSpeechPermission": "ALLOWED",
"epub": {
"isAvailable": false
},
"pdf": {
"isAvailable": false
},
"webReaderLink": ...,
"accessViewStatus": "NONE",
"quoteSharingAllowed": false
},
"searchInfo": {...}
}
]
}
Devido à inexistência de um repositório brasileiro, os três repositórios mencionados
foram testados com alguns livros em português através do título e do ISBN,
principalmente, para ter uma ideia de sua abrangência dos livros na língua portuguesa
por não serem iniciativas brasileiras. Nestes testes foram utilizados livros de autores
diferentes e de categorias diversas, incluindo livros de ficção, livros universitários de
matemática, livros de linguística e um livro didático de francês, dentre outros.

46
Dos três repositórios, o que apresentou os melhores resultados foi o da Amazon que não
encontrou apenas o livro “Alter Ego +3”. A Google Books ficou logo atrás e a
Biblioteca do Congresso Americano foi a que se mostrou a menos abrangente.

47
7. Conclusão
Conforme foi visto nos capítulos anteriores, o desenvolvimento de uma aplicação com o
objetivo de auxiliar o gerenciamento de coleções de livros com foco em facilitar a carga
inicial de dados é um tema bastante explorado conforme indicado pelo grande número
de aplicativos encontrados. As aplicações já desenvolvidas, resolvem alguns dos
problemas mencionados no trabalho utilizando diversas abordagens como realidade
aumentada e escaneamento de ISBNs, por exemplo, enquanto a proposta principal deste
trabalho é utilizar o reconhecimento ótico de caracteres.
Resumindo, foi desenvolvido neste projeto um aplicativo orientado a objeto com
reconhecimento de título através de OCR e processamento de imagens que consulta
APIs de outros sistemas para facilitar a carga inicial de dados.
Com relação aos repositórios, eles foram essenciais para o êxito na realização deste
trabalho porque sem eles o principal objetivo não teria sido atingido. Além disso, a
despeito da dificuldade inicial de encontrar um repositório brasileiro, a alternativa
utilizada se mostrou uma boa opção para livros em português conforme comprovado
pelos testes realizados.
Ademais, foi mostrado como a qualidade do OCR ainda pode evoluir bastante,
conforme observado nos resultados obtidos, principalmente, com a Tesseract dado que o
reconhecimento ainda é bastante variável, dependendo muito da qualidade, iluminação,
distância e ângulo da foto. Embora a alternativa proprietária testada tenha retornado um
resultado melhor, ela também tem suas fraquezas, como textos sobrepostos.
Apesar disso, o principal objetivo do trabalho que era evitar que o usuário tivesse que
digitar todas as informações livro a livro ainda é atendido mesmo que o reconhecimento
esteja aquém do desejado porque a pessoa pode só editar o título reconhecido, sem nem

48
precisar remover o livro da estante e o restante das informações vem dos repositórios
utilizados.

49
Referências Bibliográficas
[1] THE AUGMENTED REALITY CENTER, “ShelvAR”, 2016, Disponível em:
http://augmentedreality.miamioh.edu/portfolio-items/shelvar/, (Acesso em: 17 jan.
2016).
[2] CHIISAI APP SOLUTIONS, LLC., “BOOK CRAWLER OVERVIEW”,
Disponível em: http://www.chiisai.com/j25/, (Acesso em: 9 ago. 2015).
[3] BALLI, G., “My Book List – Keep a collection of all your books on iPhone &
iPad”, Disponível em: http://giacomoballi.com/entrepreneur/my-book-list/, (Acesso em:
11 fev. 2016).
[4] PANURGE WEB STUDIO, “The main functions of Bibliophilia”, Disponível em:
http://www.panurge.it/bibliophilia/index_en.php, (Acesso em: 17 mar. 2016).
[5] AGÊNCIA BRASILEIRA DO ISBN, “Tudo sobre o ISBN”. Disponível em:
http://www.isbn.bn.br/website/tudo-sobre-o-isbn. Acesso em: 16 jan. 2016.
[6] MORGAN, E. L., “An Introduction to the Search/Retrieve URL Service (SRU)”.
Ariadne, n. 40, jul. 2004. Disponível em: http://www.ariadne.ac.uk/issue40/morgan/.
(Acesso em: 23 mar. 2016).
[7] AMAZON, “Product Advertising API Developer Guide”,
http://aws.amazon.com/archives/Product-Advertising-API/8967000559514506, 2013,
(Acesso em fevereiro 2016).
[8] LIBRARY OF CONGRESS, “SRU 1.1 Specification”, Disponível em:
http://www.loc.gov/standards/sru/, (Acesso em: 20 nov. 2015).
[9] GOOGLE, “Google Books API”, Disponível em:
https://developers.google.com/books/, (Acesso em: 20 nov. 2015).

50
[10] GARTNER, INC., “Gartner Says Worldwide Smartphone Sales Grew 9.7 Percent
in Fourth Quarter of 2015”, 2016, Disponível em:
http://www.gartner.com/newsroom/id/2996817, (Acesso em: 15 mar. 2016).
[11] CHERIET, M., KHARMA, N., LIU, C. L., et al, Character recognition systems:
a guide for students and practitioners. John Wiley & Sons, 2007.
[12] SMITH, R. 2007. “An Overview of the Tesseract OCR Engine”. In: Proceedings of
the IEEE Ninth International Conference on Document analysis and Recognition, pp.
629-633, Curitiba, Set 2007.
[13] RICE, S. V., JENKINS, F. R., NARTKER, T. A., The Fourth Annual Test of OCR
Accuracy, Las Vegas, 1995.
[14] BRADSKI, G., KAEHLER, A., Learning OpenCV. 1ed. Sebastopol, O’Reilly
Media, Inc., 2008.
[15] ABBYY, “Cloud OCR SDK Documentation“, Disponível em:
http://ocrsdk.com/documentation/, (Acesso em: 14 mar. 2016).


















