
ANÁLISE ESTÁTICA PARA A ORIENTAÇÃO E … · vii ABSTRACT In the scientific community, the use...
71
ANÁLISE ESTÁTICA PARA A ORIENTAÇÃO E APERFEIÇOAMENTO DE CÓDIGOS EM PYTHON Fábio Antunes Gomes Projeto de Graduação apresentado ao Curso de Engenharia da Computação e Informação da Escola Politécnica, Universidade Federal do Rio de Janeiro, como parte dos requisitos necessários à obtenção do título de Engenheiro. Orientador: Flávio Luis de Mello Rio de Janeiro Setembro de 2017
Transcript of ANÁLISE ESTÁTICA PARA A ORIENTAÇÃO E … · vii ABSTRACT In the scientific community, the use...

ANÁLISE ESTÁTICA PARA A ORIENTAÇÃO E
APERFEIÇOAMENTO DE CÓDIGOS EM PYTHON
Fábio Antunes Gomes
Projeto de Graduação apresentado ao Curso de
Engenharia da Computação e Informação da
Escola Politécnica, Universidade Federal do Rio
de Janeiro, como parte dos requisitos necessários à
obtenção do título de Engenheiro.
Orientador: Flávio Luis de Mello
Rio de Janeiro
Setembro de 2017



iv
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO
Escola Politécnica – Departamento de Eletrônica e de Computação
Centro de Tecnologia, bloco H, sala H-217, Cidade Universitária
Rio de Janeiro – RJ CEP 21949-900
Este exemplar é de propriedade da Universidade Federal do Rio de Janeiro, que
poderá incluí-lo em base de dados, armazenar em computador, microfilmar ou adotar
qualquer forma de arquivamento.
É permitida a menção, reprodução parcial ou integral e a transmissão entre
bibliotecas deste trabalho, sem modificação de seu texto, em qualquer meio que esteja
ou venha a ser fixado, para pesquisa acadêmica, comentários e citações, desde que sem
finalidade comercial e que seja feita a referência bibliográfica completa.
Os conceitos expressos neste trabalho são de responsabilidade do(s) autor(es).

v
AGRADECIMENTO
Agradeço ao professor Flávio Luis de Mello, por toda a sua paciência e
dedicação durante a realização deste projeto.
A minha mãe e toda a minha família por todo o suporte emocional e financeiro e
minha formação.
A todos os amigos que me acompanharam nesta jornada.
E a todos os professores com quem tive a honra de estudar.

vi
RESUMO
A disponibilização de servidores de uso compartilhado para o tratamento de
dados é uma prática muito comum na comunidade científica, pois permite que seja feito
um melhor uso dos servidores através da minimização de seu tempo ocioso. Mas os
benefícios dessa prática podem ser parcialmente anulados se o código submetido ao
servidor contiver algum tipo de defeito crítico que afete a disponibilidade do servidor,
anulando os ganhos antes mencionados. Esta monografia identifica más práticas de
programação que podem levar a erros em tempo de execução ou a falhas de segurança, e
propõe uma abordagem para encontrá-las a fim de evitar a sua execução, utilizando de
análise estática de código para Python. Esta proposta dá origem a uma aplicação que
servirá como um ensaio de viabilidade. Seus objetivos são identificar padrões que
indiquem a existências das más práticas antes mencionadas e notificar o seu usuário do
local no código aonde eles foram produzidos, de maneira a orientá-lo para que aprimore
suas capacidades de desenvolvedor e seja capaz de escrever códigos de maior qualidade.
Dentre os nove fatos observados relacionados com alarmes de criticidade, um deles foi
implementado para demonstrar a viabilidade do mecanismo de análise ora apresentado.
Palavras-Chave: análise estática, más práticas, detecção de padrões, Python

vii
ABSTRACT
In the scientific community, the use of shared servers for the treatment of a large
scale of data, is a very common practice. It allows for a better use of computational
resources by minimizing the server’s idle time. But the benefits of this practice may be
reduced if the code submitted by its users contains some kind of critical defect that
compromises the server’s availability, because its execution would result in a loss of
computational resources, partially canceling the benefits before mentioned. This work
identifies bad programming practices that may result in runtime errors or security
vulnerabilities and proposes an approach to find them and avoid their execution, using
static analysis of Python code. This proposal results in an application that will serve as a
feasibility test. Its objectives are to identify patterns that suggest the use of bad
practices, described in this document, and notify the user of their localization in the
code, in order to help him or her to improve his or hers coding abilities and write better
quality code. Among the nine observed facts that represent critical indicators, one of
them was implemented to demonstrate the viability of the before mentioned analysis
mechanism.
Keywords: static code analysis, bad practices, pattern detection, Python

viii
SIGLAS
AST – Abstract Syntax Tree
DoS – Denial of Service
IDE – Integrated Development Environment
OCL – Object Constraint Language
PEP8 – Python Enhancement Proposals 8
UFRJ – Universidade Federal do Rio de Janeiro
XSS – Cross-site Scripting

ix
Sumário
LISTA DE FIGURAS ............................................................................................... XI
LISTA DE TABELAS............................................................................................. XII
CAPÍTULO 1 INTRODUÇÃO .................................................................................. 1
1.1 – TEMA ................................................................................................................ 1
1.2 – DELIMITAÇÃO ................................................................................................... 1
1.3 – JUSTIFICATIVA ................................................................................................... 1
1.4 – OBJETIVOS ........................................................................................................ 2
1.5 – METODOLOGIA .................................................................................................. 2
1.6 – DESCRIÇÃO ....................................................................................................... 3
CAPÍTULO 2 FUNDAMENTAÇÕES ....................................................................... 4
2.1 – ANÁLISE ESTÁTICA ............................................................................................ 4
2.2 – SCRIPTS BACK-END ........................................................................................... 4
2.3 – ANALISADORES SINTÁTICOS .............................................................................. 6
2.4 – LINGUAGEM PYTHON ....................................................................................... 10
2.5 – PARSERS UTILITÁRIOS PARA PYTHON ............................................................... 11
2.5.1 - Pycodestyle .............................................................................................. 11
2.5.2 - Módulo Tokenize ...................................................................................... 13
2.5.3 - Módulo Parser ......................................................................................... 15
2.5.4 – Módulo AST (Abstract Syntax Tree) ......................................................... 17
2.6 – TRABALHOS RELACIONADOS ........................................................................... 18
CAPÍTULO 3 SOLUÇÃO PROPOSTA .................................................................. 20
3.1 – DESCRIÇÃO DO PROBLEMA .............................................................................. 20
3.2 – DESCRIÇÃO DA SOLUÇÃO ................................................................................. 20
3.3 – FATOS OBSERVADOS ....................................................................................... 23
3.3.1 – Loops While ............................................................................................. 23
3.3.2 – Loops For ................................................................................................ 23
3.3.3 – Geração de Threads ................................................................................ 24
3.3.4 – Acesso a Recursos Externos ..................................................................... 26

x
3.3.5 – Saltos incondicionais ............................................................................... 27
3.3.6 – Comunicação entre processos .................................................................. 27
3.3.7 – Acesso a Portas ....................................................................................... 29
3.3.8 – Acesso a Recursos Lentos ........................................................................ 29
3.3.9 – Reflexão ................................................................................................... 30
3.4 – O LOOP FOR .................................................................................................... 31
3.4.1 – Conjuntos de objetos ................................................................................ 33
3.5 – DESAFIOS DA ANÁLISE ESTÁTICA ..................................................................... 34
CAPÍTULO 4 IMPLEMENTAÇÃO ........................................................................ 37
4.1 – DETERMINANDO O TIPO DE UMA VARIÁVEL ..................................................... 38
4.2 – OS TIPOS ......................................................................................................... 38
4.3 – VARIÁVEIS E CONTAINERS ............................................................................... 39
4.4 – GESTORES DE CONTEXTO ................................................................................. 40
4.4.1 – Atribuição (Assign) .................................................................................. 41
4.4.2 – Controle de Fluxo .................................................................................... 41
4.4.3 – Definição de Função ................................................................................ 42
4.4.4 – Chamada de Função ................................................................................ 42
4.4.5 - Definição de Classe .................................................................................. 42
4.5 – REFERÊNCIAS .................................................................................................. 44
4.6 – IMPLEMENTANDO A REGRA DO LOOP FOR ........................................................ 44
4.7 –TESTES DE SANIDADE ....................................................................................... 47
CAPÍTULO 5 CONCLUSÃO ................................................................................... 49
5.1 – CONCLUSÕES ................................................................................................... 49
5.2 – TRABALHOS FUTUROS ..................................................................................... 49
BIBLIOGRAFIA ...................................................................................................... 51
ANEXO A BASE DE TESTES ................................................................................. 54

xi
Lista de Figuras
2.1 – Diagrama de porcentagem de uso de linguagens em back-end . . . . . . . . . . . 11
3.1 – Diagrama de funcionamento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1 – Diagrama de Classes Simplificado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2 – Diagrama de Classes Detalhado . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43

xii
Lista de Tabelas
2.1 – Exemplo de sequência de análise top-down . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 – Exemplo de sequência de análise bottom-up . . . . . . . . . . . . . . . . . . . . . . . . . 9

1
Capítulo 1
Introdução
1.1 – Tema
O tema deste trabalho é a identificação de um conjunto de práticas de
programação em Python que frequentemente resultam em erros em tempo de execução
ou potenciais vulnerabilidades. O problema a ser resolvido é propor uma abordagem
para localização de más práticas de programação utilizando análise estática de código,
de modo a alertar um programador de possíveis melhorias a serem feitas no programa
analisado, para gerar um código de maior qualidade.
1.2 – Delimitação
Este trabalho foi feito tendo em mente o contexto de servidores cujo uso é
compartilhado por vários colaboradores. Nele pressupõe-se que os usuários não têm fim
malicioso, uma vez que já estariam autorizados a utilizar o servidor por meio de algum
sistema de autenticação.
Este trabalho será uma prova de conceito que poderá servir como base para a
criação de uma aplicação capaz de encontrar estaticamente más práticas em programas
Python. Para tal será apresentada a implementação de uma aplicação capaz de encontrar
as más práticas relativas a loops for, identificadas neste documento.
1.3 – Justificativa
A disponibilização de servidores para o tratamento de dados é uma prática muito
comum na comunidade científica. Isso permite que diferentes pessoas dentro de uma
mesma organização tenham acesso simultâneo a máquinas capazes de processar grandes

2
volumes de dados, sem que seja necessário adquirir uma máquina individual para cada
uma dessas pessoas. Adicionalmente, essa prática faz com que haja uma melhor
utilização dos recursos disponíveis, já que com múltiplos usuários, as máquinas terão
menos tempo ocioso. Porém, o fato desta prática criar um regime de concorrência, traz o
potencial risco de indisponibilidade por falha do servidor, causado pela submissão de
tarefas contendo erros.
Neste contexto, uma aplicação capaz de detectar tais erros de maneira
preventiva, economizaria uma expressiva quantidade de recursos. Ela traria ainda o
benefício adicional de agilizar o processo de depuração de erros, uma vez que, sendo
capaz de detectá-los, a aplicação indicaria para o programador tal problema. Além
disso, como efeito colateral, há a possibilidade de reduzir a indisponibilidade dos
servidores, um impedimento relacionado com o mau uso de seus recursos.
Atualmente o Pylint é o analisador de código mais utilizado para Python. Seus
principais objetivos são verificar se o código por ele analisado segue o guia de estilo de
Python (PEP8) e determinar se o programa apresenta erros simples, como tentar utilizar
uma variável antes dela ser inicializada. A aplicação proposta neste trabalho também
terá como objetivo ajudar no aprimoramento do código analisado, porém isso será feito
com uma abordagem diferente do Pylint, tentando tratar questões de maior
complexidade.
1.4 – Objetivo
Este trabalho tem como objetivo a elaboração de uma prova de conceito que
poderá servir como base para a criação de uma aplicação capaz de encontrar
estaticamente más práticas em programas Python.
1.5 – Metodologia
Para a realização deste trabalho, inicialmente foi definido um conjunto de
práticas na programação Python que frequentemente levam a erros em tempo de

3
execução ou a potenciais falhas de segurança. Boa parte do conhecimento necessário
para determinar quais são as possíveis más práticas foi adquirido durante meu duplo
diploma na França, onde tive a oportunidade de trabalhar em uma empresa da área de
segurança que fazia testes de intrusão em aplicações web.
Em seguida foi criada uma aplicação capaz de prever a ocorrência de um desses
tipos de evento em programas Python, antes do início de sua execução em um servidor.
Sua finalidade é evitar o incremento da probabilidade de falha do servidor, através da
prevenção de execução de códigos defeituosos. No final, para testar o funcionamento da
aplicação, foram criados programas contendo as vulnerabilidades previstas e verificado
se a aplicação era capaz de encontrá-las.
1.6 – Descrição
No Capítulo 2 é apresentado o contexto para o qual a aplicação está sendo
projetada. Ele começa com uma breve descrição de análise estática, seguida de uma
explicação resumida de analisadores sintáticos. Depois é apresentada a linguagem
Python e quais tecnologias foram utilizadas para a concepção da aplicação, e no final é
feita uma menção a trabalhos relacionados.
A solução proposta é abordada no Capítulo 3, iniciando-se com a descrição do
problema, seguida da apresentação da proposta de solução em si. Após são descritas as
más práticas identificadas no trabalho e explicadas as escolhas de regras de inferência.
Este capítulo termina com a descrição do funcionamento do loop for e dos desafios
apresentados pela análise estática.
No Capítulo 4 é detalhada a implementação da aplicação e é apresentada a
maneira como foram conduzidos os seus testes de sanidade.
O Capítulo 5 finaliza o documento, avaliando se os objetivos descritos na Seção
1.4 foram obtidos e propõe aprimoramentos para a aplicação.

4
Capítulo 2
Fundamentações
2.1 – Análise Estática
A análise estática consiste em analisar um código fonte, em uma tentativa de
encontrar erros ou vulnerabilidades, sem que o código seja executado [13]. No ciclo de
produção de um software, este tipo de análise geralmente é realizado antes da análise
dinâmica, como testes unitários e testes de integração.
Entre suas vantagens em relação ao testes dinâmicos, pode-se citar a
escalabilidade [13], o fator dela permitir que erros sejam encontrados mais cedo no ciclo
de desenvolvimento de um software e a sua capacidade de indicar a localização exata do
código aonde o erro foi produzido [5]. Em contrapartida a análise estática tem a
desvantagem de produzir falsos positivos e falsos negativos, e ser incapaz de analisar
eventos produzidos em tempo de execução, como dados de entrada do usuário.
2.2 – Scripts Back-end
Scripts são programas escritos para ambientes computacionais, contendo
sequências de comandos que automatizam a execução de tarefas que poderiam ser
realizadas individualmente por um operador. Um exemplo muito conhecido de
linguagem de scripting é a linguagem bash, utilizada nos terminais Linux.
O termo back-end refere-se a tudo que não é interface com o usuário. No
contexto do modelo cliente-servidor, seria tudo que se encontra no lado do servidor,
como por exemplo, bancos de dados e o sistema que comanda a lógica de um website.
A utilização de scripts back-end em um ambiente web, refere-se à utilização de
software no lado do servidor para executar algum tipo de código, ao invés de utilizar

5
recursos do lado cliente, como por exemplo, um navegador. No contexto web isso pode
ser utilizado para gerar páginas dinamicamente, sem criar uma carga extra para o
navegador do cliente e sem necessitar que o mesmo possua algum software específico
instalado.
Essa técnica pode ainda permitir que um cliente envie instruções para serem
executadas no servidor. Com isso usuários podem ter acesso remoto a máquinas com
capacidade de processamento e acesso a dados diferenciados daqueles disponíveis
localmente. Contudo, esse tipo de uso traz também consigo uma série de desafios.
Um deles é lidar com a concorrência entre múltiplos usuários tentando acessar
os mesmos recursos do servidor simultaneamente. Isso normalmente é gerido pelo
próprio sistema operacional do servidor mas pode ainda assim ser um problema, pois se
não houver um mecanismo eficiente que regule o quanto um usuário pode demandar por
vez, pode ocorrer uma sobrecarga do servidor por um ou mais jobs, o que
consequentemente levaria a uma negação de serviço.
Outro desafio é se certificar que os recursos do servidor não estão sendo
desperdiçados, intencionalmente ou não, pelos usuários. Erros simples em um script,
como a falta de uma condição de parada de um loop, pode fazer com que um programa
não termine de rodar antes que seu tempo limite de execução seja esgotado. Esse tipo de
erro, além de consumir uma elevada quantidade de tempo de processamento, fará com
que um script não gere resultados conclusivos, o que configura um completo
desperdício dos recursos de servidor.
Um terceiro desafio é garantir que o código enviado por um cliente é seguro.
Pela própria natureza deste tipo de aplicação que roda em um servidor, há uma
probabilidade elevada de que ela seja usada para fins maliciosos. Um hacker poderia
por exemplo, ganhar acesso aos servidores através da exploração de alguma
vulnerabilidade, ou usar o servidor de uma maneira não prevista para atacar outras
máquinas na rede.
2.3 – Analisadores Sintáticos

6
A análise sintática é o processo de analisar uma sequência de símbolos,
conforme as regras de uma gramática formal. No contexto de linguagens de
programação, um analisador sintático é um componente de software responsável por
verificar que um código de entrada, previamente dividido em tokens por um analisador
léxico, esteja de acordo com as regras estabelecidas pela sua gramática. Ele é
responsável também por construir uma estrutura de dados, como por exemplo uma
árvore de análise, que representa os dados de entrada de forma estruturada.
Geralmente os analisadores sintáticos são utilizados como uma etapa
intermediária no processo de compilação, cujos dados de saída serão posteriormente
usados por um analisador semântico. Alguns outros usos são o emprego em IDEs, para
identificar erros de sintaxe durante o processo de desenvolvimento, e como componente
de verificação ortográfica para corretores de texto automatizados.
Existem dois tipos de abordagens para um analisador sintático, top-down e
bottom-up. A primeira abordagem começa a partir da raiz da árvore de derivação e vai
expandindo os nós da árvore até encontrar um token (folha) que corresponda a um
símbolo da sequência que está sendo analisada. A segunda tem um comportamento
oposto à primeira, começando a partir das folhas, ele converte a sequência de entrada
em tokens e faz o caminho inverso, reduzindo combinações de tokens e termos em
outros termos até chegar ao nó raiz.
Para melhor compreender estas abordagens, será usada a seguinte gramática
como exemplo:
1 <goal> ::= <expr>
2 <expr> ::= <term> <expr'>
3 <expr'> ::= + <expr>
4 | - <expr>
5 | Є
6 <term> ::= <factor> <term'>
7 <term'> ::= * <term>
8 | / <term>

7
9 | Є
10 <factor> ::= number
11 | id
Ambos os exemplos terão a seguinte string de entrada: x - 2 * y
Tanto a gramática deste exemplo, quanto a sua resolução no caso top-down
foram retiradas das aulas do curso Compiler Design [23], conduzidas pelo professor
Lawrence Rauchweger na Texas A&M University. A resolução do caso bottom-up foi
feita pelo autor baseada nas aulas do mesmo curso.
2.3.1 – Análise top-down
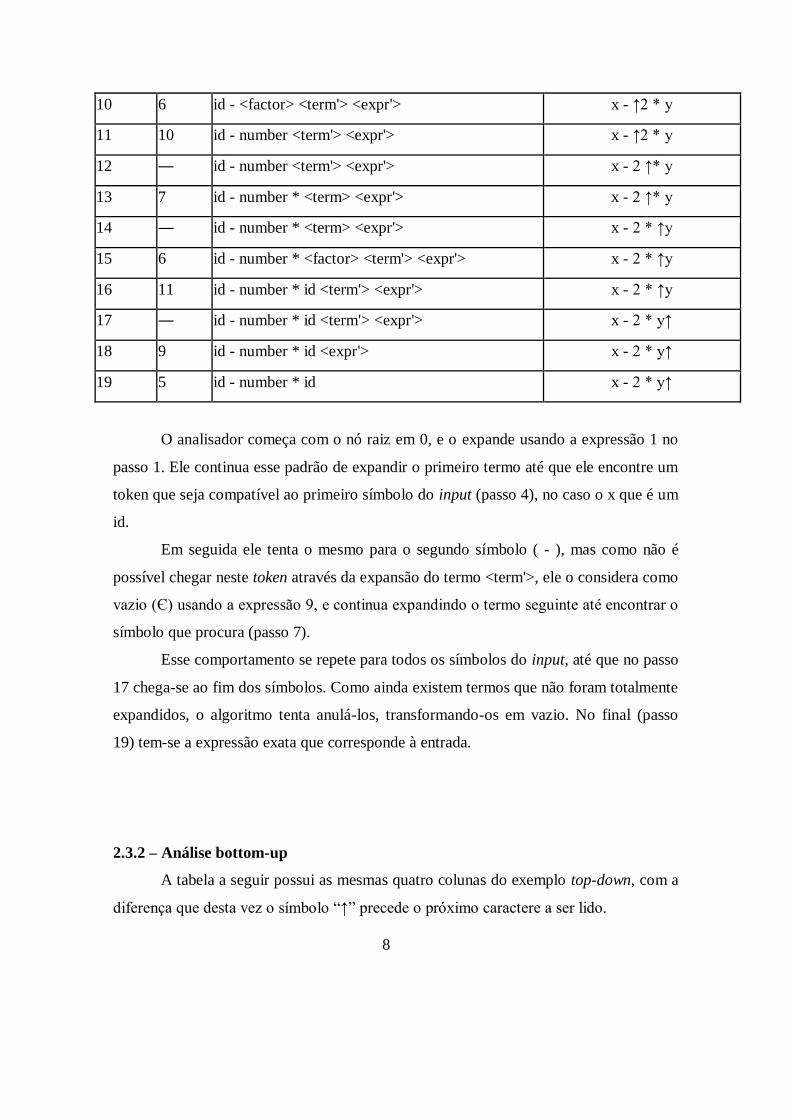
A tabela a seguir possui quatro colunas. A primeira coluna denota o passo atual
do algoritmo, a segunda a expressão utilizada na iteração, a terceira a forma sequencial
das folhas da árvore de derivação encontrada ao final do passo em questão e a quarta
mostra qual símbolo de entrada está sendo analisado no momento (precedido pelo
caractere ↑).
Tabela 2.1- Exemplo de sequência de análise top-down
Passo Expr Forma Sequencial Símbolo de Entrada
0 ― <goal> ↑x - 2 * y
1 1 <expr> ↑x - 2 * y
2 2 <term> <expr'> ↑x - 2 * y
3 6 <factor> <term'> <expr'> ↑x - 2 * y
4 11 id <term'> <expr'> ↑x - 2 * y
5 ― id <term'> <expr'> x ↑- 2 * y
6 9 id <expr'> x ↑- 2 * y
7 4 id - <expr> x ↑- 2 * y
8 ― id - <expr> x - ↑2 * y
9 2 id - <term> <expr'> x - ↑2 * y
8
10 6 id - <factor> <term'> <expr'> x - ↑2 * y
11 10 id - number <term'> <expr'> x - ↑2 * y
12 ― id - number <term'> <expr'> x - 2 ↑* y
13 7 id - number * <term> <expr'> x - 2 ↑* y
14 ― id - number * <term> <expr'> x - 2 * ↑y
15 6 id - number * <factor> <term'> <expr'> x - 2 * ↑y
16 11 id - number * id <term'> <expr'> x - 2 * ↑y
17 ― id - number * id <term'> <expr'> x - 2 * y↑
18 9 id - number * id <expr'> x - 2 * y↑
19 5 id - number * id x - 2 * y↑
O analisador começa com o nó raiz em 0, e o expande usando a expressão 1 no
passo 1. Ele continua esse padrão de expandir o primeiro termo até que ele encontre um
token que seja compatível ao primeiro símbolo do input (passo 4), no caso o x que é um
id.
Em seguida ele tenta o mesmo para o segundo símbolo ( - ), mas como não é
possível chegar neste token através da expansão do termo <term'>, ele o considera como
vazio (Є) usando a expressão 9, e continua expandindo o termo seguinte até encontrar o
símbolo que procura (passo 7).
Esse comportamento se repete para todos os símbolos do input, até que no passo
17 chega-se ao fim dos símbolos. Como ainda existem termos que não foram totalmente
expandidos, o algoritmo tenta anulá-los, transformando-os em vazio. No final (passo
19) tem-se a expressão exata que corresponde à entrada.
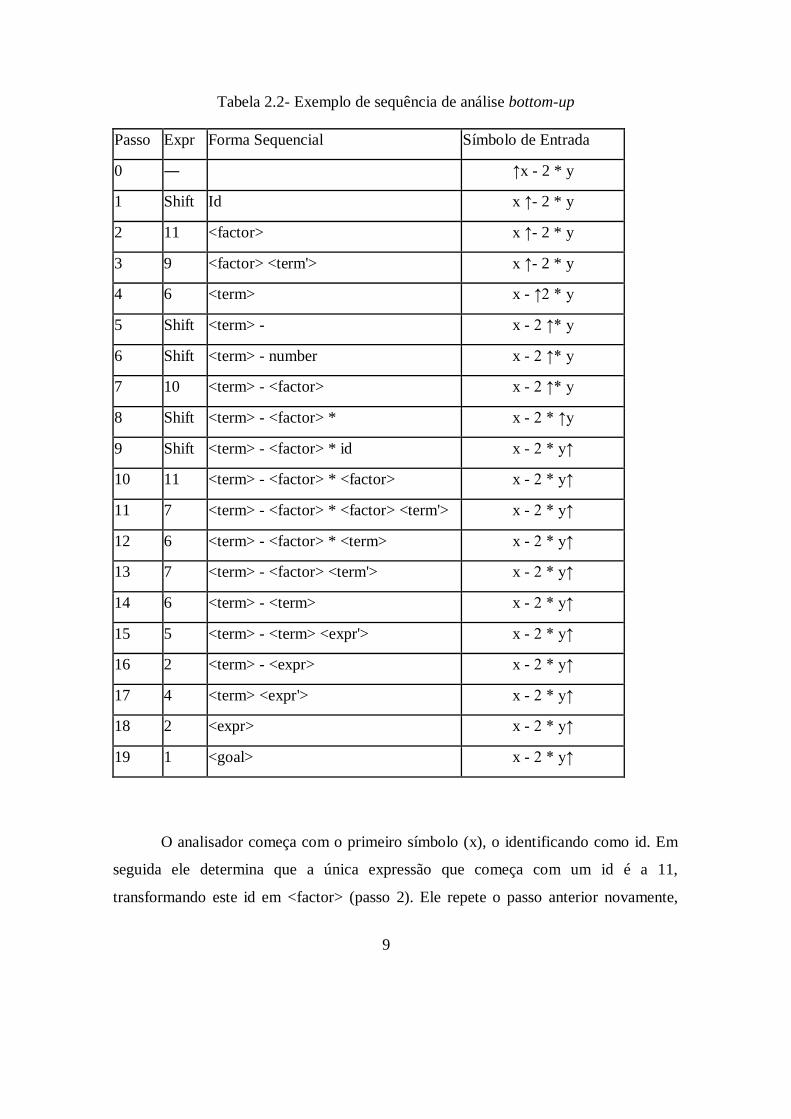
2.3.2 – Análise bottom-up
A tabela a seguir possui as mesmas quatro colunas do exemplo top-down, com a
diferença que desta vez o símbolo “↑” precede o próximo caractere a ser lido.
9
Tabela 2.2- Exemplo de sequência de análise bottom-up
Passo Expr Forma Sequencial Símbolo de Entrada
0 ― ↑x - 2 * y
1 Shift Id x ↑- 2 * y
2 11 <factor> x ↑- 2 * y
3 9 <factor> <term'> x ↑- 2 * y
4 6 <term> x - ↑2 * y
5 Shift <term> - x - 2 ↑* y
6 Shift <term> - number x - 2 ↑* y
7 10 <term> - <factor> x - 2 ↑* y
8 Shift <term> - <factor> * x - 2 * ↑y
9 Shift <term> - <factor> * id x - 2 * y↑
10 11 <term> - <factor> * <factor> x - 2 * y↑
11 7 <term> - <factor> * <factor> <term'> x - 2 * y↑
12 6 <term> - <factor> * <term> x - 2 * y↑
13 7 <term> - <factor> <term'> x - 2 * y↑
14 6 <term> - <term> x - 2 * y↑
15 5 <term> - <term> <expr'> x - 2 * y↑
16 2 <term> - <expr> x - 2 * y↑
17 4 <term> <expr'> x - 2 * y↑
18 2 <expr> x - 2 * y↑
19 1 <goal> x - 2 * y↑
O analisador começa com o primeiro símbolo (x), o identificando como id. Em
seguida ele determina que a única expressão que começa com um id é a 11,
transformando este id em <factor> (passo 2). Ele repete o passo anterior novamente,

10
determinando que a única expressão que teria como primeiro termo um <factor> seria a
6, logo o termo que segue a atual forma sequencial deve ser um <term’>, como o
próximo símbolo de entrada (“-”) não corresponde a nenhuma das expressões de
<term’> ele assume que existe um símbolo vazio e usa a expressão 9 seguida da
expressão 6 (passos 3 e 4).
Repetindo o processo do passo 2, o analisador verifica que a única expressão
que possui um <term> como seu primeiro elemento é a expressão 2, logo a atual forma
sequencial deve ser sucedida de um termo do tipo <expr’>. Mas desta vez existe uma
expressão para <expr’> iniciada por um símbolo “-”, então o analisador adiciona este
símbolo a sua forma sequencial (passo 5) e determina que ele será sucedido por <expr>.
E desta forma, o analisador continua combinando as expressões da gramática, para que
elas correspondam aos símbolos de entrada, até o momento que ele finalmente consegue
chegar na forma <term><expr’> (passo 17), a qual ele visava desde o passo 5. E depois
ele continua com o mesmo comportamento até chegar na raiz da árvore.
2.4 – Linguagem Python
Python é uma linguagem de criada em 1991 por Guido van Rossum. Seu design
foi voltada para uma filosofia que enfatiza a legibilidade [1], reforçando isso através
obrigatoriedade de indentação para delimitar blocos de código e pela sintaxe simples
que torna a linguagem parecida com pseudo-código executável [2]. Sua tipagem é
dinâmica, fazendo com que objetos não possuam um tipo rígido e evita a necessidade de
inicializa-los previamente a sua utilização.
Python é uma linguagem interpretada, isso significa que, ao contrário de
linguagens compiladas, um programa em Python não precisa passar por uma etapa de
compilação, na qual o código fonte é convertido para linguagem de máquina. Ao invés
disso, ele é lido e executado diretamente por um programa chamado de interpretador. A
ausência da necessidade de compilação faz com que o ciclo de desenvolvimento, teste e
implantação de um programa seja mais rápido, tornando a linguagem bastante atrativa
no meio científico e para prototipagem. Porém, esta característica traz consigo a

11
desvantagem de ter um maior tempo de execução esperado, em relação às linguagens
compiladas [3].
Apesar das vantagens mencionadas, Python não é uma linguagem muito
utilizada em servidores, entre outros motivos, devido ao seu maior tempo de execução
esperado, que implica em maiores custos. Em seguida, encontra-se um diagrama com o
uso de linguagens de programação no back-end de websites.
Figura 2.1- Diagrama de porcentagem de uso de linguagens em back-end (adaptado)
Fonte: w3techs [4]
2.5 – Parsers Utilitários para Python
2.5.1 - Pycodestyle
Pacote de Python utilizado para verificar se um código fonte de entrada está
seguindo as convenções do guia de estilo do Python, conhecido como PEP8 [20]. Em
um primeiro momento um analisador de estilo precisa também fazer o parsing do
código. Logo, analisar o método utilizado pelo pycodestyle para fazer esse parsing foi
uma fonte importante de informação, que posteriormente levou à descoberta do módulo
mais adequado chamado tokenize.

12
Exemplo:
pycodestyle_test_script.py
1 #Lack of space after the comment symbol
2 import math
3
4 def test_function():
5 print "Should have missing white space error after this line"
6
7 for i in range(10):
8 print i
Para o código acima, o pycodestyle encontrou os seguintes erros:
pycodestyle_test_script.py:1:1: E265 block comment should start with '# '
pycodestyle_test_script.py:4:1: E302 expected 2 blank lines, found 1
pycodestyle_test_script.py:7:1: E305 expected 2 blank lines after class or
function definition, found 1
O primeiro aponta a falta de um espaço após o símbolo de comentário. Essa
verificação pode ser feita facilmente verificando os dois primeiros caracteres das tokens
de COMMENT. No caso o python reconhece a seguinte token para a primeira linha:
COMMENT '#Lack of space after the comment symbol'. Como o segundo caracter não
é um espaço em branco, o pycodestyle reconhece um erro de estilo na primeira linha.
O segundo aponta a falta de duas quebras de linha após o bloco de início do
programa, geralmente contendo comentários e importações de outros módulos. Para isso
o pycodestyle utiliza uma expressão regular que verifica o fim deste bloco e conta o
número de tokens NL que o seguem para verificar se existem exatamente 2.
O terceiro aponta a falta de duas quebras de linha após a definição da função
test_function(). Sua verificação é feita de maneira similar à do erro anterior. Após
encontrar o fim de um bloco de declaração de função ou classe, ele verifica que os dois
últimos tokens são do tipo NL e envia um erro caso não sejam.

13
2.5.2 - Módulo Tokenize
Módulo da biblioteca padrão do Python que fornece um scanner léxico para
código fonte Python. Sua principal função, que possui o mesmo nome do módulo,
consegue ler um código fonte de Python e o decompor nas tokens básicas
compreendidas pelo interpretador. [21]
Do output da função tokenize, podem ser extraídas informações essenciais para a
realização deste projeto, como por exemplo o início e fim de um bloco (if, while, for e
etc), através das tokens INDENT e DEDENT e o fim de cada uma das linhas de código
através do token NEWLINE. Essa token é ainda diferenciada de um statement que
utiliza várias linhas (como a inicialização de tuplas e listas), pois caso isso aconteça ele
usa a token NL, ao invés da token NEWLINE.
Exemplo:
#Código
i = 0
while i < 5:
i += 1
print(i)
print("Hello")
#Output do Tokenize
0,0-0,0: ENCODING 'utf-8'
1,0-1,1: NAME 'i'
1,2-1,3: OP '='
1,4-1,5: NUMBER '0'
1,5-1,6: NEWLINE '\n'
2,0-2,5: NAME 'while'
2,6-2,7: NAME 'i'
2,8-2,9: OP '<'
2,10-2,11: NUMBER '5'

14
2,11-2,12: OP ':'
2,12-2,13: NEWLINE '\n'
3,0-3,4: INDENT ' '
3,4-3,5: NAME 'i'
3,6-3,8: OP '+='
3,9-3,10: NUMBER '1'
3,10-3,11: NEWLINE '\n'
4,4-4,9: NAME 'print'
4,9-4,10: OP '('
4,10-4,11: NAME 'i'
4,11-4,12: OP ')'
4,12-4,13: NEWLINE '\n'
5,0-5,0: DEDENT ''
5,0-5,5: NAME 'print'
5,5-5,6: OP '('
5,6-5,13: STRING '"Hello"'
5,13-5,14: OP ')'
5,14-5,15: NEWLINE '\n'
6,0-6,0: ENDMARKER ''
Neste exemplo temos todos os tokens encontrados pelo módulo tokenize. Os dados de
saída estão divididos em três colunas, onde a coluna da esquerda representa a posição de
início (linha e coluna) do token e sua posição de fim, separados por hífen. A coluna
central representa a classificação daquele token e a coluna da direita mostra o token em
si.
Como pode ser visto no exemplo, o primeiro token representa sempre o
encoding que está sendo usado no código fonte fornecido. Nas quatro tokens seguintes
encontra-se a decomposição da primeira linha do código (i = 0), que é uma simples
atribuição de valor, contendo uma token do tipo NAME, que representa a variável i,
seguida por uma token do tipo OP, para o operador “=”, uma token NUMBER para o

15
número 0 e finalmente uma token NEWLINE para representar o fim da linha de código.
Para a segunda linha temos a linha onde se inicia o loop while, que é
representada por uma token NAME(while), seguida da condição do loop representada
por 3 tokens: NAME(i), OP(<) e NUMBER(5). Essa condição é seguida de uma token
OP para o operador “:” e uma token de NEWLINE para fazer a quebra de linha.
Após a linha que define a condição de parada do loop, temos o bloco de código
iniciado na linha três pela token INDENT e se estendendo até o final da linha quatro, e
finalizado no início da linha cinco pela token DEDENT. Este bloco segue os mesmo
padrões anteriormente utilizados. Os nomes de variáveis e funções são descritos por
tokens do tipo NAME, todos os tipos de operadores, incluindo parênteses, são descritos
por tokens do tipo OP, números são descritos por tokens NUMBER e ao final de cada
linha existe uma token NEWLINE.
Na linha cinco encontra-se um exemplo de uma chamada da função print,
passando como parâmetro uma string. Nela encontra-se uma token NAME para o nome
da função, uma token STRING que representa a string “Hello” rodeada pelos dois
tokens de operadores parênteses (OP) e terminada com uma quebra de linha
(NEWLINE). E para marcar o fim do programa, é utilizada uma token
ENDMARKER.
Apesar da delimitação precisa que este módulo dá de cada bloco de código, os
dados de retorno deste módulos são muito simples. Sua utilização como ponto inicial da
aplicação demandaria uma grande quantidade de trabalho para transformar as sequência
de tokens, por ele fornecida, em estruturas de dados que facilitassem a implementação
das regras de inferência que serão explicadas posteriormente.
2.5.3 - Módulo Parser
Módulo da biblioteca padrão Python que fornece uma interface ao analisador
sintático interno do Python e seu compilador de byte-code. Seu principal propósito é
permitir que um código Python seja capaz de modificar a árvore sintática de uma
expressão e gerar código executável a partir dela. [19]
Para um código fonte extremamente simples, por exemplo um programa

16
composto apenas da linha print("Hello World"), pode-se gerar uma árvore sintática
(st), através da função parser.suite(). Essa árvore por sua vez pode ser convertida em
um formato de listas ou tuplas, através das funções parser.st2list() e parser.st2tuple(),
gerando a seguinte lista:
[257, [267, [268, [269, [272, [1, 'print', 1], [304, [305, [306, [307, [308, [310, [311,
[312, [313, [314, [315, [316, [317, [318, [7, '(', 1], [320, [304, [305, [306, [307, [308,
[310, [311, [312, [313, [314, [315, [316, [317, [318, [3, '"Hello World"',
1]]]]]]]]]]]]]]]], [8, ')', 1]]]]]]]]]]]]]]]]], [4, '', 1]]], [4, '', 1], [0, '', 1]]
Ou com os números inteiros traduzidos para os símbolos e tokens que eles representam
tem-se a seguinte árvore:
['file_input', ['stmt', ['simple_stmt', ['small_stmt', ['print_stmt', ['NAME', 'print',
'NAME'], ['test', ['or_test', ['and_test', ['not_test', ['comparison', ['expr',
['xor_expr', ['and_expr', ['shift_expr', ['arith_expr', ['term', ['factor', ['power',
['atom', ['LPAR', '(', 'NAME'], ['testlist_comp', ['test', ['or_test', ['and_test',
['not_test', ['comparison', ['expr', ['xor_expr', ['and_expr', ['shift_expr',
['arith_expr', ['term', ['factor', ['power', ['atom', ['STRING', '"Hello World"',
'NAME']]]]]]]]]]]]]]]], ['RPAR', ')', 'NAME']]]]]]]]]]]]]]]]], ['NEWLINE', '',
'NAME']]], ['NEWLINE', '', 'NAME'], ['ENDMARKER', '', 'NAME']]
Se necessário seria possível modificar a sub-lista que contém a string "Hello
World", transformá-la novamente em um objeto st, com a função parser.sequence2st(),
e a compilar novamente em um objeto de código que pode ser avaliado pela função
eval().
Esse módulo é interessante para esse projeto, por causa de sua capacidade de
fornecer a árvore sintática completa de uma string de código Python, através das
funções st2tuple e st2list. Mas ao mesmo tempo, o excesso de detalhe das árvores
geradas e a dificuldade de acessar um elemento em específico podem vir a tornar o
processo de analisar um código fonte muito complexo e difícil para o escopo deste

17
trabalho.
2.5.4 – Módulo AST (Abstract Syntax Tree)
Pacote de Python que semelhantemente ao módulo Parser gera a árvore
sintática de um programa em Python. A sua principal diferença é que a árvore gerada
por este módulo está encapsulada em estruturas de dados que tornam mais simples a sua
leitura e interpretação [22], o que foi o principal motivo para a escolha deste módulo
para servir de base para a aplicação que será apresentada no curso deste trabalho. Em
seguida está representada a estrutura gerada por AST para um for simples.
# Código:
for i in a:
print i
# Estrutura gerada pelo módulo ast:
For(target = Name(id='i', ctx=Store()),
iter = Name(id='a', ctx=Load()),
body = [Print(dest=None, values=[Name(id='i', ctx=Load())], nl=True)],
orelse = []
)
No exemplo acima pode-se observar que o for foi encapsulado em um objeto
For que possui quatro atributos. O primeiro, target, referencia as variáveis às quais o
loop atribuirá um valor, no caso a variável i. O segundo, iter, representa o item sobre o
qual será iterado, no exemplo a variável a. O terceiro, o atributo body, referencia uma
lista das instruções que serão executadas durante o loop, neste caso contendo apenas
uma instrução do tipo Print. E o último atributo (orelse) consiste de uma lista de todas
as instruções que seriam executadas ao final do loop, no caso nenhuma pois este for não
possui um Else no final.
2.6 – Trabalhos Relacionados

18
Seifert e Samlaus [6] apresentam um método para fazer a análise estática de um
código fonte de uma linguagem genérica. Ele utiliza como entrada a definição de
sintaxe da linguagem na qual o código fonte a ser analisado foi escrito, e desta forma
gerar sua árvore sintática. Em seguida ele procura na árvore sintática padrões
indesejáveis definidos em uma linguagem OCL (Object Constraint Language), como
por exemplo a declaração de uma variável cujo nome tem tamanho inferior a um valor
especificado. O interesse deste artigo é que ele mostra um método de procurar padrões
em código fonte estaticamente, através da árvore sintática abstrata.
Kuo et al. [7] propõem uma abordagem para tentar identificar estaticamente
falhas de segurança em códigos fontes. A linguagem nele estudada é PHP, que possui
algumas semelhanças com Python, no aspecto de ser uma linguagem de script,
interpretada e com tipagem dinâmica. No artigo são propostos alguns conceitos como a
análise do fluxo no código, para determinar quais variáveis podem estar “infectadas”,
em outras palavras, variáveis cujo conteúdo foi submetido pelos usuários em tempo de
execução e portanto podendo conter código malicioso. A partir dessa classificação é
definido se essas variáveis podem ou não ser usadas em funções mais críticas, como por
exemplo a função eval, que faz o uso de reflexão (interpretação de código gerado em
tempo de execução). As ideias nele propostas, apesar de terem um viés para a área de
segurança, podem ser adaptadas para a busca de más práticas de programação, ainda
que não tenham um intuito malicioso.
Gomes [8], em sua dissertação, apresenta a Plataforma Tile-in-One e propõe o
uso de algoritmos de aprendizado de máquina para a identificação preventiva de falhas
em códigos fonte. Este trabalho é importante no sentido de que ele é o precursor do que
será apresentado nos capítulos a seguir, que tentam dar uma nova visão ao que já foi
criado previamente para a plataforma Tile-in-One, apesar de utilizar uma abordagem
distinta.
Dahse [17] introduz uma ferramenta cujo objetivo é reduzir o tempo necessário
para fazer um teste de intrusão de uma aplicação PHP. Essa ferramenta faz uma análise
estática do código fonte da aplicação, utilizando o conceito de análise de variáveis
“infectadas” (“taint analysis”) anteriormente mecionada. Ela utiliza principalmente os

19
tokens gerados pela função token_get_all para encontrar as funções e variáveis
“infectadas”. Apesar da análise token a token não ser a mais indicada para o que será
feito neste trabalho, Dahse utiliza-se de um pré-processamento, removendo alguns tipos
de tokens e substituindo alguns caracteres especiais. Esta ideia pode vir a ser útil para
facilitar o tratamento do código neste projeto.
Jovanovic et al.[18] implementam um protótipo de aplicação focada na detecção
de cross-site scripting (XSS) em códigos PHP, batizada de Pixy. Ela utiliza
principalmente conceitos de “taint analysis” e análise do fluxo de dados, já
mencionados anteriormente. No artigo é mencionado também o conceito de “alias
analysis”, que consiste em verificar todas as variáveis que apontam para um
determinado objeto. Este conceito será importante para a verificação da regra do loop
for, que será apresentada posteriormente neste trabalho.

20
Capítulo 3
Solução Proposta
3.1 – Descrição do Problema
Em um ambiente de um servidor compartilhado, no qual múltiplos
colaboradores podem submeter programas para execução, garantir que os códigos a
serem executados não possuam erros é especialmente importante, pois se trata de um
regime de concorrência. Porém, muitas vezes os usuários destes ambientes não tem
como principal preocupação a qualidade do código que estão produzindo, uma vez que
os problemas que eles têm a resolver são, naturalmente, de maior importância.
Contudo, esta falta de preocupação com a qualidade do código, muitas vezes
levam a más práticas de programação, que por sua vez podem resultar na submissão de
programas contendo erros ou vulnerabilidades. Esta situação se torna ainda pior quando
é feita a reutilização de código por parte dos colaboradores, que pode resultar na
propagação dos erros antes mencionados. Desta forma, deseja-se fazer a detecção destas
más práticas, antes de sua execução, evitando as possíveis consequências de sua
submissão e orientando os usuários para que possam aprimorar suas habilidades ao
programar.
3.2 – Descrição da Solução
Para resolver este problema, foram selecionados uma série de erros e más
práticas, que acontecem com frequência durante o processo de desenvolvimento de um
programa, especificamente para Python. Os erros e más práticas identificados neste
trabalho são:
O uso de loops while para iterar sobre um conjunto fixo de elementos.
Alterar a quantidade de elementos de um conjunto sobre o qual se está iterando

21
com um loop for.
Uso indevido de threads.
Acesso a recursos externos não confiáveis.
Mal uso de saltos incondicionais.
Comunicação perniciosa entre processos
Uso de funções que façam ou liberem o acesso a portas.
Acesso desnecessário a recursos lentos.
Uso indevido de reflexão.
Uma vez listados estes erros, foi construída uma aplicação em Python capaz de
ler o código fonte bruto e identificar as diferentes estruturas do código. A partir destas
estruturas ela é capaz de encontrar padrões que indicam a existência desses erros e más
práticas que, a partir deste momento serão chamados de fatos observados, são descritos
na seção seguinte.
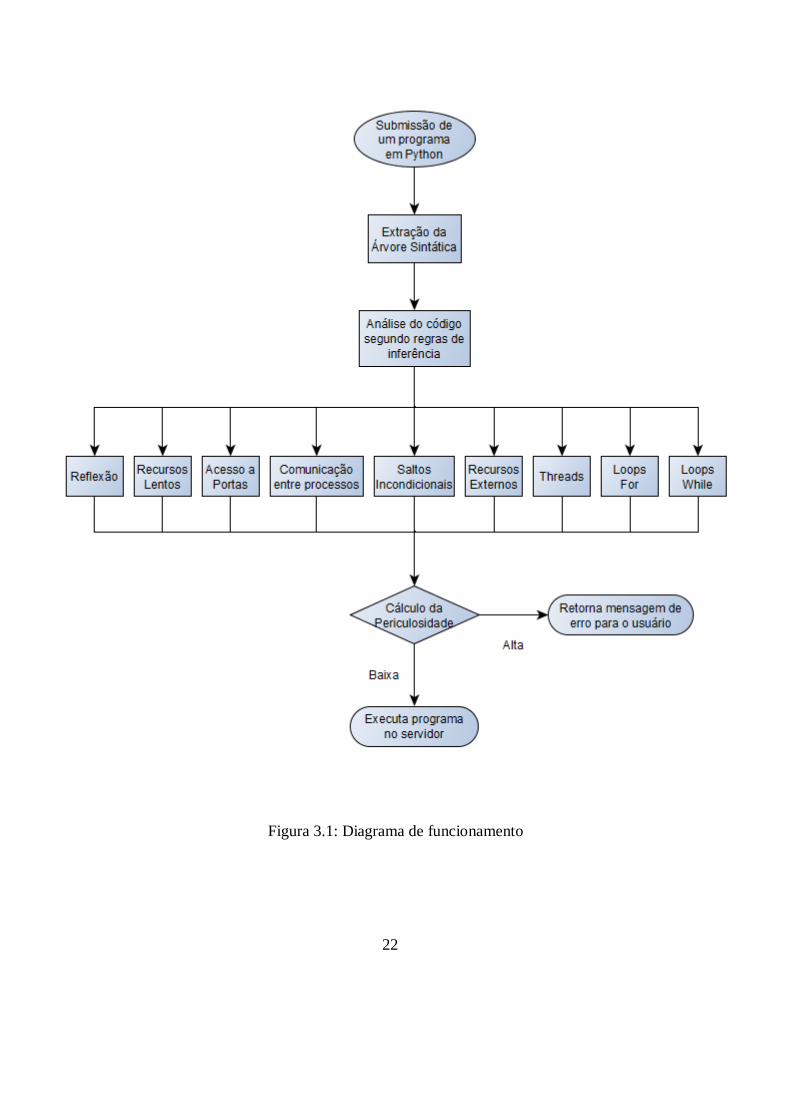
O funcionamento da aplicação encontra-se ilustrado na Figura 3.1. Ela começa
com a submissão de um programa em Python, por parte do usuário. O código é lido e
transformado em uma árvore sintática, pelo módulo AST da biblioteca padrão de
Python. Em seguida esta árvore é enviada para o analisador de código, que vai procurar
padrões que indiquem a ocorrência de cada um dos fatos antes mencionados.
Finalmente, com base na quantidade de ocorrências de cada fato, é calculada a
periculosidade do programa, que determina se ele poderá ou não ser executado no
servidor.
22
Figura 3.1: Diagrama de funcionamento

23
3.3 – Fatos Observados
3.3.1 – Loops While
Loops do tipo while geralmente são evitados no contexto de Python. O seu
principal motivo é que na maioria das vezes em que se deseja utilizar um loop, o
objetivo é iterar sobre um conjunto fixo de elementos, tipicamente uma lista cujo
tamanho não será alterado durante o loop. Neste caso, deve-se dar preferência ao loop
for, porque a própria maneira na qual ele é construído evita a ocorrência de loops
infinitos resultantes de erros. Além disso, quando comparados um loop for e um loop
while com um contador de loop explícito, executando a mesma função sobre um mesmo
conjunto iterável, o while sempre será mais lento [9].
Devido à grande versatilidade do loop for em Python, o loop while é geralmente
limitado a casos em que não se conhece o número de iterações a serem executadas,
como por exemplo quando se precisa de algum tipo de dado de entrada do usuário [15].
Por isso o mais comum é propositalmente definir loops while como loops infinitos
(while True), aliado ao uso da instrução break como condição de parada.
Proposta de índice de inferência: contagem de loops while cuja condição de teste é
diferente de True.
3.3.2 – Loops For
Como descrito anteriormente, deve-se dar preferência ao uso do loop for sobre o
loop while ao se iterar sobre um conjunto de elementos, devido à sua sintaxe mais limpa
e menos susceptível a erros por parte do programador, e devido à sua maior eficiência
em geral. Em certos casos, o programador pode desejar modificar o conjunto sobre o
qual se está iterando durante o loop, adicionando ou removendo elementos. Esse tipo de
manipulação costuma gerar um comportamento do for pouco intuitivo para o
programador, podendo resultar até mesmo em um loop infinito. Logo, neste caso em
específico, é preferível iterar sobre uma cópia deste conjunto.
Está ilustrado a seguir um exemplo de como esta prática pode vir a ser

24
maliciosa:
#Código
example_list = [1]
for i in example_list:
example_list.append(0)
Neste exemplo, a cada iteração do loop um novo elemento é adicionado ao fim
da lista, o que faz com que o interpretador rode uma iteração adicional deste loop para o
novo elemento (0), repetindo esse processo por tempo indefinido. O mesmo aconteceria
se o elemento fosse adicionado ao início da lista, sendo a única diferença que a variável
i tomaria sempre o valor do mesmo elemento (1).
Proposta de índice de inferência: contagem de loops for que modificam o conjunto
sobre o qual se está iterando.
3.3.3 – Geração de Threads
Multithreading é a capacidade de um processo de criar várias linhas de execução
(threads) concorrentes. Estes threads geralmente são utilizados para executar tarefas em
paralelo, com o objetivo de otimizar o uso da CPU, seja através do uso de seus
múltiplos núcleos, ou do aproveitamento de seu tempo ocioso devido a tarefas que
requerem um tempo de espera, como o acesso a disco. Em relação ao uso de múltiplos
processos, multithreading tem a vantagem de que todos os threads compartilham os
dados do processo, e portanto eles ocupam no total menos espaço na memória do
computador.
Em Python, multithreading pode ser obtido através da derivação da classe
Thread, pertencente ao módulo threading, reescrevendo na subclasse as funções de
inicialização(__init__) e execução (run). Essa classe possui as estruturas clássicas de
gestão de concorrência, como semáforos e locks. Além disso Python possui também o
módulo Queue que implementa três tipos diferentes de fila (FIFO, LIFO e Heap de
prioridade), projetadas para o uso em um contexto de produtores e consumidores,

25
especialmente úteis em programação com threads.
Apesar deste foco no paralelismo, dependendo do interpretador, múltiplos
threads não conseguirão atuar simultaneamente devido à “global interpreter lock”
(GIL) [10]. Se trata de um semáforo interno do interpretador que sincroniza a execução
dos threads, de modo a permitir que apenas um deles execute em um determinado
momento. E a cada determinado número de instruções executadas ou quando o thread
ativo é bloqueado, a GIL é liberada para que um outro thread possa executar.
Isso faz com que o uso de threads represente um ganho de desempenho apenas
quando se deseja paralelizar processos que utilizem operações de I/O, como acesso à
disco ou a transferência de informações da rede. Porque, por serem lentas, estas
operações bloqueariam a execução do thread ativo até que os dados fiquem prontos para
ser processados, e liberaria a GIL para que um thread que estivesse em espera pudesse
executar. Desta maneira a invocação de uma operação de I/O não implicaria no bloqueio
do processo como um todo. Caso o intuito da utilização de múltiplos threads seja fazer
o aproveitamento dos múltiplos núcleos do processador, aconselha-se a utilização do
módulo multiprocessing [11].
Em relação à geração dos threads, não existe um modo simples de determinar a
quantidade de threads que devem ser gerados em um programa. Isso depende de
diversos fatores, como a quantidade de memória disponível para o processo e o tempo
médio que o thread passará bloqueado. Mas independentemente da quantidade de
threads que serão gerados, uma boa prática é utilizar um loop for para a sua geração,
pois como já descrito nas seções anteriores, este tipo de loop realiza uma quantidade
fixa e bem definida de iterações, evitando a geração infinita de threads.
Proposta de índice de inferência: Contar a quantidade de operações de I/O dentro de
classes que estendam threads.

26
3.3.4 – Acesso a Recursos Externos
Define-se aqui como recursos externos, tudo aquilo o que não faz parte do
enviado pelo usuário para o servidor e que possa ser consumido como recurso
computacional. Isto inclui desde dados armazenados no próprio servidor, seja em uma
base de dados ou no próprio sistema de arquivos em disco, até serviços online.
Este tipo de recurso pode ser especialmente perigoso quando sua fonte é
desconhecida ou não confiável. Isso se mostra claro quando é analisado o principal
mecanismo de infecção de vírus atualmente, os droppers. Tratam-se de programas
simples, que conseguem passar desapercebidos em uma varredura de um programa
antivírus, e cuja única função é instalar o vírus propriamente dito, que pode já estar
contido no dropper ou que será baixado durante a sua execução.
Logo o mau uso deste tipo de recurso pode ser uma potencial fonte de infecção
ao servidor, com efeitos indesejáveis, tais como: dar o controle do servidor para um
atacante, permitir a sua utilização para atacar outras máquinas da rede, ou derrubar
serviços do servidor, entre outros. Desta forma, recomenda-se nunca utilizar um recurso
de fonte não confiável, o que no caso em questão, pode ser algo externo ao domínio
cern.ch. Deve-se também ter cautela ao se utilizar recursos cujas fontes sejam
confiáveis, pois nem sempre se pode garantir que estes recursos se encontram livres de
infecção. Em outras palavras, a utilização deste tipo de recurso deve ser feita apenas
quando extremamente necessário.
Proposta de índice de inferência:
- Contagem de importação de módulos que não sejam parte da biblioteca padrão ou
não estejam no mesmo pacote do módulo que está sendo rodado. Uma abordagem pode
ser a realização de um scan recursivo em todos os módulos que estiverem sendo
importados.
- Contagem de uso de funções que façam pedidos à recursos externos, como requests
http e acesso à sockets.

27
3.3.5 – Saltos incondicionais
Em Python não existe um comando goto ou jump, que represente um salto
incondicional para uma determinada linha do código. Isso pode ser considerado um
benefício da linguagem, já que na maioria das vezes esse tipo de salto torna o código
mais confuso e portanto, aumenta a chance de inserção de erros durante a sua escrita ou
durante revisões.
Na verdade, em Python, como em outras linguagens usam-se majoritariamente
saltos condicionais, como o if, para se fazer o controle do fluxo de execução do
programa. E existem instruções que causam saltos incondicionais como o continue e o
break, que são formas mais restritas do goto, usadas quando for necessário parar uma
ou todas as iterações de um loop de maneira abrupta. Ambos estes comandos, apesar de
substituíveis, podem as vezes tornar o código mais legível, porém devem ser utilizados
com cautela. Como indicação geral para a sua boa utilização, eles devem ser
empregados junto a saltos condicionais, como condição de parada de um loop.
Proposta de índice de inferência: quantidade de saltos incondicionais dividido pelo
número de linhas de cada loop.
3.3.6 – Comunicação entre processos
A comunicação entre processos é feita quando se deseja transmitir dados entre
diferentes processos. Ela pode ser realizada, entre processos em uma mesma máquina,
ou entre máquinas diferentes através da rede. Esta seção vai abordar principalmente o
caso de processos em uma mesma máquina, e vai focar na utilização do módulo
multiprocessing, por motivos já explicados na seção de Geração de Threads.
A necessidade de usar múltiplos processos em um único programa surge quando
se tem acesso a diversos núcleos de processamento e deseja-se distribuir tarefas entre
eles para otimizar o uso de recursos da máquina. Uma das maneiras mais comuns de se
fazer a distribuição destes recursos é o modelo Produtor-Consumidor, no qual um ou
mais processos produtores geram dados que serão consumidos pelos processos
consumidores. Um exemplo de uso deste modelo poderia ser um caso aonde existem

28
processos (produtores) que buscam informação em diferentes bancos de dados e a
disponibilizam para os consumidores tratarem.
Para a implementação deste modelo, alguns detalhes referentes à concorrência
devem ser considerados. O primeiro deles é a necessidade de haver exclusão mútua ao
se acessar o buffer dos “produtos”. O segundo detalhe é garantir que não ocorrerão erros
ou deadlocks quando um produtor tenta adicionar um item a um buffer cheio, ou quando
um consumidor tenta retirar um item de um buffer vazio.
Ambos esses problemas podem ser resolvidos através do uso de semáforos e
monitores, porém a implementação é complicada e pode levar programadores
inexperientes a cometer erros. Para evitar tal tipo de problema, recomenda-se usar a
classe queue do módulo multiprocessing, pois ela já possui essas manipulações de
semáforo encapsuladas em suas funções put e get, tornando seu uso transparente ao
programador.
Mas nem sempre se busca um comportamento do tipo Produtor-Consumidor
entre os processos. Pode ser que para uma determinada aplicação seja necessário o uso
de pipes, ou de algum módulo que faça a chamada de um método remoto como o
xmlrpc. Se esse for o caso, deve-se sempre utilizar algum limite de tempo para o
recebimento da resposta (timeout). Isso evita que problemas de sincronização, como a
perda de uma mensagem ou a terminação de um dos processos, resultem em um
processo eternamente bloqueado, esperando uma resposta.
Por último, vale ressaltar que chamadas a processos remotos se enquadram no
caso de acesso a recurso externo, logo devem ser feitas respeitando as recomendações
da Seção 3.3.4. Um bom exemplo desta necessidade é o próprio módulo xmlrpc antes
mencionado, que na própria documentação do Python [14] possui um aviso para
possíveis vulnerabilidades que podem ser exploradas por dados construídos de maneira
maliciosa.
Proposta de índice de inferência:
- Contagem do uso explícito de semáforos e monitores.
- Verificar se está sendo utilizado um tempo de timeout em funções que façam a troca

29
de mensagens.
3.3.7 – Acesso a Portas
Uma porta é um ponto virtual utilizado para transmitir e receber dados entre
diferentes processos em um mesmo computador, ou entre diferentes máquinas na rede.
O principal modo de utilização de portas é o modelo cliente/servidor, no qual uma
aplicação é dividida em dois programas, um consumidor de serviços e outro produtor
dos mesmos. O primeiro tem como papel fazer a requisição de um ou mais serviços e o
segundo se mantém em espera, e uma vez que essa requisição seja feita ele a executa.
Este tipo de acesso é considerado um acesso a recurso externo e portanto possui
as mesmas vulnerabilidades apresentadas na seção de Acesso a Recursos Externos,
porém possui uma característica adicional. Além dele permitir a utilização de dados
potencialmente não seguros, quando utilizado como servidor, o programa também
possibilita que fontes exteriores, potencialmente desconhecidas, façam chamadas aos
serviços disponibilizados no servidor. Tal cenário pode dar a um hacker, a possibilidade
de utilizar essas chamadas para fazer uma grande variedade de ataques, indo desde a
injeção de código no servidor, até a utilização do servidor para fazer um ataque de
negação de serviços (DoS) em outras máquinas.
Proposta de índice de inferência: Quantidade de funções que fazem/disponibilizam o
acesso às portas.
3.3.8 – Acesso a Recursos Lentos
Pela própria natureza do uso de scripts, é muito provável que durante sua
execução será feito algum acesso a um recurso tido como lento, em outras palavras, um
recurso cuja velocidade de resposta é consideravelmente menor do que a do
processador. Uma das ocorrências mais comuns deste tipo de acesso é a requisição de
dados, de uma base de dados em disco ou em um servidor remoto, que serão
posteriormente utilizados no programa.
Mas apesar de frequentemente utilizado, o acesso à esse tipo de recurso deve ser

30
feito com cautela, pois ao ser requisitado, o sistema operacional bloqueia esse processo
até que ele esteja pronto para prosseguir. Sabendo disso, é importante que no seu uso
seja definido um tempo máximo de espera (timeout). Porque caso ocorra uma falha em
algum componente, que impeça o envio de resposta a solicitação de um recurso lento, o
processo que o solicitou poderá ficar eternamente bloqueado na memória do
computador, esperando a resposta.
Além disso, outros cuidados devem ser tomados, como evitar ativamente que um
mesmo recurso seja solicitado múltiplas vezes durante a execução de um script, através
do seu armazenamento em memória. Outro cuidado seria utilizar múltiplas threads
quando necessário fazer múltiplas requisições a recursos independentes, para otimizar o
uso do tempo livre do processador, como descrito na Seção 3.3.3.
Proposta de índice de inferência:
- Contar a quantidade de acessos redundantes a recursos lentos que poderiam ter sido
armazenados na memória.
- Verificar qual/se o tempo de timeout está sendo usado a cada acesso a recurso de
rede.
3.3.9 – Reflexão
Reflexão é a habilidade que um programa tem de manipular como dados algo
que represente seu estado durante a sua própria execução [12]. Este tipo de habilidade
possui diversas utilidades, como a de adaptar um programa a diferentes situações de
maneira dinâmica ou a de inspecionar variáveis, classes e etc, em tempo de execução.
Contudo, uma funcionalidade como esta de elevado grau de liberdade para o
programa, representa também um risco em potencial quando utilizada para gerar código
em tempo de execução. Isso fica evidente quando se analisa a vulnerabilidade mais
comum em aplicações web, a injeção de código, que é frequentemente causada pelo uso
de dados de entrada de usuário para escrever código que será avaliado em tempo de
execução.
Apesar de ataques maliciosos estarem fora do escopo deste trabalho, ainda assim

31
se aconselha evitar o uso de funções como eval e exec. Tais descuidos ao tratar dados
utilizados na geração dinâmica de código podem implicar um comportamento errático e
imprevisível do programa.
Proposta de índice de inferência: Contagem de chamada a funções que avaliam e
executam código dinamicamente.
3.4 – O Loop For
O caso do loop for foi escolhido para ser abordado neste trabalho, pois ele
apresenta diversas particularidades interessantes, que demandam uma análise completa
e serão apresentadas na Seção 3.5. Além disso, uma vez bem definidas as abordagens
para este caso, tem-se como resultado uma aplicação cuja expansão para tratar os outros
casos pode ser feita de maneira simples. Esta seção visa explicar as particularidades do
funcionamento de um loop for em Python, para determinar quais características a
aplicação deve possuir.
O for, por definição, aceita um conjunto de variáveis sobre as quais serão
atribuídos valores a cada iteração e um objeto iterável, de onde, em geral, são retirados
estes valores. No Python qualquer objeto pode ser aceito como iterável desde que ele
possua definida uma função com o nome __iter__, que será invocada no início da
execução do for, e deve retornar um objeto que será utilizado como iterador.
Este objeto é responsável por determinar qual valor o for utilizará em cada
iteração do loop. A condição para que um objeto funcione como iterador, é que ele
tenha definida a função next (ou __next__ no caso de Python 3). Esta função é
invocada a cada iteração do loop e deve retornar o próximo valor a ser utilizado, ou
levantar uma exceção “StopIteration” caso o loop tenha chegado ao fim.
Exemplo:
class CustomListIterator:
def __init__(self, elements):
self.elements = elements
self.iteration_index = -1

32
def next(self):
self.iteration_index += 1
if self.iteration_index >= len(self.elements):
raise StopIteration
else:
return self.elements[self.iteration_index]
class CustomList:
def __init__(self, elements=[]):
self.elements = elements
def __iter__(self):
return CustomListIterator(self.elements)
def append(self, value):
self.elements.append(value)
a = CustomList([1, 2, 3])
for i in a:
print i
else:
a.append(i + 1)
A classe “CustomList” deste exemplo foi construída para imitar o
funcionamento de uma lista ao ser iterada. Quando executado este programa teria o
seguinte funcionamento ao atingir o loop for:
1- Inicialmente o for invoca a função __iter__ do objeto a e armazena uma
referência para o valor retornado, no caso um objeto do tipo
“CustomListIterator”.
2- É invocada a função next do objeto armazenado em 1.
3- Se esta função levantar uma exceção do tipo “StopIteration”, o loop
termina, pulando para o passo 6. Caso contrário ele atribui a i o valor
retornado no passo 2.

33
4- São executadas as instruções do corpo do loop, imprimindo o valor de i.
5- Retorna-se para o passo 2, começando uma nova iteração.
6- Executam-se as instruções do else, adicionando ao final da lista de elementos
de a o último valor atribuído a i, incrementado de 1.
Neste exemplo o for poderia se manter eternamente em loop, se em seu corpo
houvesse alguma instrução que a cada iteração adicionasse um novo elemento a lista de
elementos de a, como por exemplo a.append(0). Se isso tivesse ocorrido, a função
next, invocada no passo 2, jamais levantaria uma exceção, pois a cada nova iteração a
lista de elementos de a seria maior em um elemento.
3.4.1 – Conjuntos de objetos
Na biblioteca padrão de Python existem diversas estruturas de dados que podem
ser iteradas por um loop for. Dentre elas as mais comumente utilizados são as listas,
tuplas e strings, que são sequencias ordenadas de objetos. Para este projeto foram
observadas as maneiras de se alterar a quantidade de elementos das listas, pois das três
estruturas antes mencionadas esta é a única dinâmica.
Isso quer dizer que quando se tenta adicionar um novo elemento a uma tupla ou
a uma string, o interpretador cria um novo objeto que contém a concatenação dos
valores antigos e novos. Já no caso das listas, o interpretador consegue adicionar novos
elementos sem precisar gerar um novo objeto. Devido a esse comportamento, não
ocorrem erros de loop infinito ao se iterar sobre tuplas e strings, pois o objeto iterado
referido pelo for (obtido no passo 1 do exemplo da Seção 3.4) não é o mesmo que o
referido pela variável após sua modificação.
Quanto as formas de se adicionar objetos a uma lista, existem duas maneiras que
podem gerar um loop infinito quando feitas dentro de um for. A primeira é através da
utilização do operador composto de soma e atribuição, representado pelos caracteres
mais e igual (+=). Este operador, no caso das listas, acrescenta todos os elementos de
uma lista presente à sua direita, à lista que está sendo operada, localizada à sua
esquerda. Como por exemplo:
Sendo a = [1, 2, 3] e b = [4, 5].

34
Ao se executar a instrução a += b, teríamos:
a = [1, 2, 3, 4, 5]
A segunda maneira é através das funções insert, append e extend, específicas
da classe lista. Estas funções quando invocadas como atributo de um objeto l do tipo
lista (por exemplo l.append(atr)), inserem em l o atributo (atr) que lhe foi passado
como argumento. Como por exemplo:
Sendo a = [1, 2, 3] e b = [4, 5].
Ao se executar a instrução a.append(b), teríamos:
a = [1, 2, 3, [4, 5]]
Já a instrução a.extend(b), aplicada sobre o mesmo caso inicial resultaria em:
a = [1, 2, 3, 4, 5]
E por fim a instrução a.insert(i, b) inseriria o valor de b na posição i, então para:
i = 1 teríamos a = [1, [4, 5], 2, 3]
Nota-se que o resultado da operação “a += b” é igual ao da chamada de função
“a.extend(b)”. Isso ocorre pois o que o operador “+=” faz no caso das listas, é
essencialmente, chamar a função extend, como pode ser observado no código fonte do
interpretador cpython[16].
3.5 – Desafios da Análise Estática
Segundo descritos na Seção 3.4.1, a aplicação produzida neste trabalho tem
como função encontrar instruções que fazem o uso do operador “+=” ou das funções
insert, append e extend sobre um objeto que está sendo iterado em um for. Vale
ressaltar aqui que no caso das listas, uma instrução do tipo “a += b” não equivale a “a =
a + b”. Pois, apesar de ambas gerarem em a uma lista que concatena a lista a e a lista b,
a primeira adiciona ao objeto que estava referenciado em a todos os elementos da lista
b, atuando essencialmente como a função extend. Já a segunda gera um novo objeto
que possui todos os elementos de a e todos os elementos de b, e o atribui a a, de modo
que o objeto referenciado em a se torna diferente do que havia sido armazenado por um
loop for, não configurando assim um loop infinito.
Estas instruções em um primeiro momento podem parecer bem simples de serem

35
encontradas em uma análise estática, consistindo apenas de uma verificação rápida por
declarações do tipo “iter += lista” ou “iter.append(atr)”. Porém o problema é mais
complexo do que aparenta, pois estas declarações podem ser feitas através de uma outra
variável que referencia o objeto iterado ou dentro de uma chamada de função que
possua referência a esse objeto, seja esta através do uso de uma variável global ou tendo
sido passada como argumento.
Exemplo:
def foo(l):
l.append(0)
a = [1, 2, 3]
for i in a:
foo(a)
No exemplo acima, a busca de uma instrução da forma “a.append(atr)” não
resultaria em nada. Porém a instrução “l.append(0)” é executada durante chamada da
função foo, localizada dentro do for. Como nessa chamada de função a é passado como
argumento, ao qual é atribuído o nome l, qualquer modificação imposta a l é também
imposta a a, pois ambos referenciam o mesmo objeto. Logo, neste exemplo existe uma
infração a uma das regras, apesar de append nunca ter sido chamado diretamente para a.
A linguagem Python oferece ainda um desafio adicional por causa de sua
tipagem dinâmica, que em alguns casos, torna impossível determinar estaticamente o
tipo da variável que está sendo operada em determinadas instruções do código. Esta
incerteza faz com que a análise estática seja especialmente difícil quando se faz a
chamada de uma função, pois uma instrução do tipo “obj.foo()” pode executar funções
diferentes dependendo do tipo de objeto “obj”.
A seguir, este exemplo de polimorfismo fica mais claro. Nele o objeto “obj”
pode ser uma instancia de “obj_1” ou “obj_2” dependendo do valor da variável
“condition”, e portanto ao se fazer a chamada de função “obj.foo()” o valor impresso
na tela poderá ser 1 ou 2.
Exemplo:

36
class obj_1:
def foo(self):
print 1
class obj_2:
def foo(self):
print 2
if condition:
obj = obj_1()
else:
obj = obj_2()
obj.foo()Capítulo 4
Implementação
Ao se considerar os desafios apresentados na Seção 3.5, fica claro que técnicas
simples de leitura do código não seriam suficientes para encontrar as formas mais
complexas do fato observado que deve ser tratado. Por causa disso, foi estabelecido que
a aplicação aqui implementada funcionaria de maneira similar a um interpretador,
mantendo em memória representações dos objetos que seriam gerados ao se executar o
código que está sendo analisado, e um dicionário contendo as referências de cada
variável.
Esta aplicação possui uma classe principal responsável pela gestão do contexto
das variáveis (GlobalContext), que recebe como entrada a AST do programa a ser
analisado. Esta classe é capaz de ler cada um dos tipos de nós de instrução presentes na
AST e fazer as devidas manipulações no dicionário de variáveis. A aplicação possui
ainda classes especializadas para a leitura de instruções em contextos locais como o de
chamada de funções e declaração de classes.
Uma visão geral das classes da aplicação está presente na Figura 4.1, e estas
serão exploradas um pouco mais a fundo nas seções deste capítulo.

37
Figura 4.1: Diagrama de Classes Simplificado
4.1 – Determinando o Tipo de Uma Variável
O primeiro dos desafios, mencionados na Seção 3.5, que a aplicação deve tratar
é o da tipagem dinâmica. Ao se analisar a árvore sintática, o único momento em que se
é possível determinar o tipo de uma variável é quando se encontra um nó de atribuição
(Assign). Este nó possui um atributo value que contém o valor da atribuição e um
atributo target, que consiste de uma lista de todos os alvos aos quais o valor será
atribuído.
Quando surge um nó Assign, o interpretador inicializa a variável caso ela ainda
não tenha sido inicializada e aponta a sua referência para o objeto que lhe foi atribuído.
Logo, se for possível determinar o tipo de value, podendo ele ser um tipo nativo, ou
uma referência a uma variável cujo tipo já é conhecido, o gestor de contexto é capaz de
determinar e atualizar o tipo das variáveis alvo da atribuição, deixando de lado os tipos
que ela possuía anteriormente.
O único problema desta abordagem é que no caso de atribuições feitas dentro do
corpo de estruturas de controle de fluxo, como if/else, não é possível determinar
estaticamente se elas serão executadas ou não. Quando estas bifurcações no fluxo do
programa ocorrem, é criada uma cópia do contexto atual para cada uma das possíveis
alternativas. Estas cópias seguem lendo as instruções de seu respectivo caminho e ao
final elas são fundidas, resultando na possibilidade de uma variável ter múltiplos tipos.
4.2 – Os Tipos
Na árvore sintática gerada pelo módulo ast, existem 6 tipos nativos para Python
2.x:
- Num, que pode representar um inteiro, float ou número complexo e tem o seu
valor armazenado em seu atributo n. Ex: O float 1.5 geraria o nó Num(n=1.5)
- Str, que representa uma sequência de caracteres e tem o seu valor armazenado
no atributo s. Ex: A string “texto” geraria o nó Str(s='texto').
- List e Tuple, representam respectivamente listas e tuplas, que são grupos de
objetos ordenados, podendo eles serem dinâmicos no caso das listas, ou estáticos no

38
caso da tupla. Ambos os tipos de nós possuem o atributo elts, que é uma lista
responsável por armazenar os nós dos elementos que estão contidos na lista, e o atributo
ctx, que assume o valor de um nó Store se a lista ou tupla for o alvo de uma atribuição,
ou o valor de um nó Load caso contrário. Ex: A lista [1, “texto”] geraria um nó
List(elts=[Num(n=1), Str(s='texto')], ctx=Load()).
- Set, representa estruturas que armazenam coleções desordenados de objetos
únicos. Similar as listas e tuplas, o nó de um set possui um atributo elts para armazenar
seus elementos, mas não possui o atributo ctx, pois nunca é utilizado como alvo de uma
atribuição. Ex: O set {1, “texto”} geraria um nó Set(elts=[Num(n=1), Str(s='texto')]).
- Dict, representa os dicionários da biblioteca padrão de Python. Assim como as
listas, tuplas e sets, os dicionários funcionam como containers, mas em vez de
possuírem uma lista de elementos, eles possuem os atributos keys e values, que
representam respectivamente uma lista de chaves e uma lista de seus valores
correspondentes. Ex: O dicionário {1: “texto_1”, 2: “texto_2”} geraria um nó
Dict(keys=[Num(n=1), Num(n=2)], values=[Str(s='texto_1'), Str(s='texto_2')]).
Para representar os tipos nativos, foram criadas as classes TypeObject e
Container. Elas possuem o atributo object_type, que consiste de uma string com o
nome do tipo nativo escrito em letras minúsculas e precedido pelo caractere jogo da
velha. Este atributo é utilizado como uma “etiqueta” que informa o tipo de objeto que as
instancias dessas classes representam.
Além dos tipos nativos, foram considerados ainda 3 outros tipos, as funções, as
classes e os objetos, e para representa-los foram criadas respectivamente as classes
Function, CustomClass e CustomObject. Estas classes, além do atributo object_type,
possuem atributos e funções específicos, como uma lista de argumentos de uma função,
ou uma função que busca um atributo de um objeto, considerando fatores como a sua
herança.
4.3 – Variáveis e Containers
Para se armazenar os objetos que contém os possíveis tipos de cada variável,
apresentados na Seção 4.2, foi criada a classe “Variable”. Seu atributo content consiste
de uma lista de todos os tipos que podem ter sido atribuídos à variável que ela

39
representa. Os objetos que implementam a classe “Variable” são os objetos utilizados
no dicionário de variáveis do gestor de contexto.
Existe ainda a classe “Container”, mencionada na Seção 4.2. É uma
especialização da classe “Variable”, para os tipos nativos de Python que comportam
múltiplos elementos, como as listas e tuplas. Um objeto que instancia esta classe, tem
um funcionamento dual de “Variable” e “TypeObject”, possuindo portanto um
atributo object_type que indica o seu tipo, e um atributo content que consiste de uma
lista de objetos “Variable” e “Container” que ele referencia.
4.4 – Gestores de Contexto
A classe GlobalContext e suas classes filhas foram inspiradas no mecanismo de
controle dos registros de ativação presente nas linguagens de programação. Elas
funcionam de forma similar a um interpretador, sendo capaz de ler sequencialmente as
instruções de um programa, codificadas em uma árvore de sintaxe pelo módulo ast do
Python, e tratar cada tipo de instrução (atribuição, loop for, loop while e etc) segundo
o que será descrito posteriormente nesta seção.
Ao ler uma instrução, estas classes tem como principal objetivo reconhecer
atribuições e os tipos que estão sendo amarrados. Em seguida, elas atualizam o seu
dicionário de variáveis, com os resultados da atribuição. Este último, consiste de um
dicionário da biblioteca padrão de Python, no qual as chaves são strings com o nome
das variáveis e o valor correspondente a cada chave é um objeto do tipo “Variable”.
A principal classe gestora de contexto, o “GlobalContext”, é responsável por
gerir o contexto global do programa. Ela é a conhecedora de todas as variáveis globais e
possui funções para o tratamento dos diferentes tipos de nós da árvore sintática. A
leitura de qualquer instrução do corpo do programa é feita utilizando este contexto, e
cabe a ele gerar outros contextos se necessário.
As classes derivadas da “LocalContext”, são responsáveis por gerir o contexto
dentro das chamadas de função e declaração de classes. Como elas derivam
indiretamente da classe “GlobalContext”, elas possuem todas as funções de tratamento
de instruções, sendo algumas sobrescritas para ter comportamento específico de

40
contextos locais. Elas possuem ainda referências para o contexto global e para o
contexto que as gerou, podendo ele ser local ou global. Estas referências são necessárias
caso alguma das instruções utilize um nome que não está definido no contexto corrente,
como por exemplo, uma chamada de uma função definida no contexto global, e é feita
dentro de uma outra chamada de função.
O modo como os gestores de contexto tratam os principais tipos de instrução
será explicado nas subseções a seguir.
4.4.1 – Atribuição (Assign)
Tipo de nó responsável pela definição dos tipos das variáveis. Ao ser encontrado
são avaliados as suas propriedades value e targets, correspondentes respectivamente ao
valor a ser atribuído e a uma lista das variáveis às quais este valor será atribuído. Após
avaliadas ambas as propriedades, as variáveis, determinadas pelo atributo targets, têm
sua lista de tipos atualizada no dicionário de variáveis, com os tipos encontrados ao se
avaliar o atributo value.
4.4.2 – Controle de Fluxo
Foram consideradas instruções de controle de fluxo, todas as instruções que
podem implicar em mais de um fluxo de execução no programa, como por exemplo as
instruções de if e for. Para tratar tais instruções o gestor de contexto cria uma cópia de
si, para cada um dos possíveis caminhos que o programa pode tomar ao executar tal
instrução. Em seguida cada cópia executa as instruções pertencentes ao fluxo para o
qual ela foi criada. E no final cada uma das cópias é fundida ao contexto inicial, sendo
as listas contendo os tipos de cada uma das variáveis concatenadas.
Exemplo:
if condition: a = 5 else: a = "string"
Para tratar a instrução do exemplo acima, o gestor de contexto bifurcaria a sua
execução em duas frentes, criando uma cópia de si mesmo para tratar o fluxo do
programa que passaria pelas instruções contidas na parte do if (a = 5), e outra para tratar

41
as instruções contidas no else. Após o término de ambos os fluxos a primeira cópia do
gestor de contexto consideraria a como sendo um tipo numérico, e para a segunda cópia,
a seria do tipo string. Ao chegar neste ponto o gestor de contexto faria a fusão dos dois
resultados, atualizando o seu dicionário de variáveis para considerar que a pode ser
tanto do tipo numérico, quanto do tipo string.
4.4.3 – Definição de Função
Ao analisar uma definição de função, o gestor de contexto cria um objeto do tipo
“Function” para conter o código e os argumentos da função, e o armazena em seu
dicionário de variáveis. A rotina para tratar as definições de função, por si só não realiza
grandes alterações no estado do programa, porém ela é um passo essencial para o
tratamento das chamadas de função.
4.4.4 – Chamada de Função
A análise de uma chamada de função começa com a determinação de qual
função está sendo chamada. Uma vez determinada qual função deverá ser analisada, é
criado um objeto instanciando a classe “FunctionContext”, que será responsável por
tratar todas as particularidades de uma chamada de função, como a gestão dos
argumentos e das variáveis globais, bem como pela execução do código presente no
corpo da função.
Uma vez terminada a execução do contexto da função, são atualizadas no
contexto global todas as alterações que foram feitas às variáveis globais e é retornada
uma lista com todos os possíveis tipos de retorno da função. Caso haja mais de uma
possibilidade de função a ser executada no primeiro passo, o programa trata todas as
opções como se estivesse tratando um caso de múltiplos fluxos. Neste caso ele criaria
um “FunctionContext” para cada uma das possíveis funções a serem executadas, e
fundiria os resultados no final.
4.4.5 - Definição de Classe
A análise de uma definição de classe se assemelha em muito à de uma chamada
de função. Ele começa com a criação de um gestor de contexto do tipo “ClassContext”,
especializado no tratamento de definições de classe. Então são extraídas todas as
variáveis locais deste gestor de contexto, para criar um objeto do tipo “CustomClass”
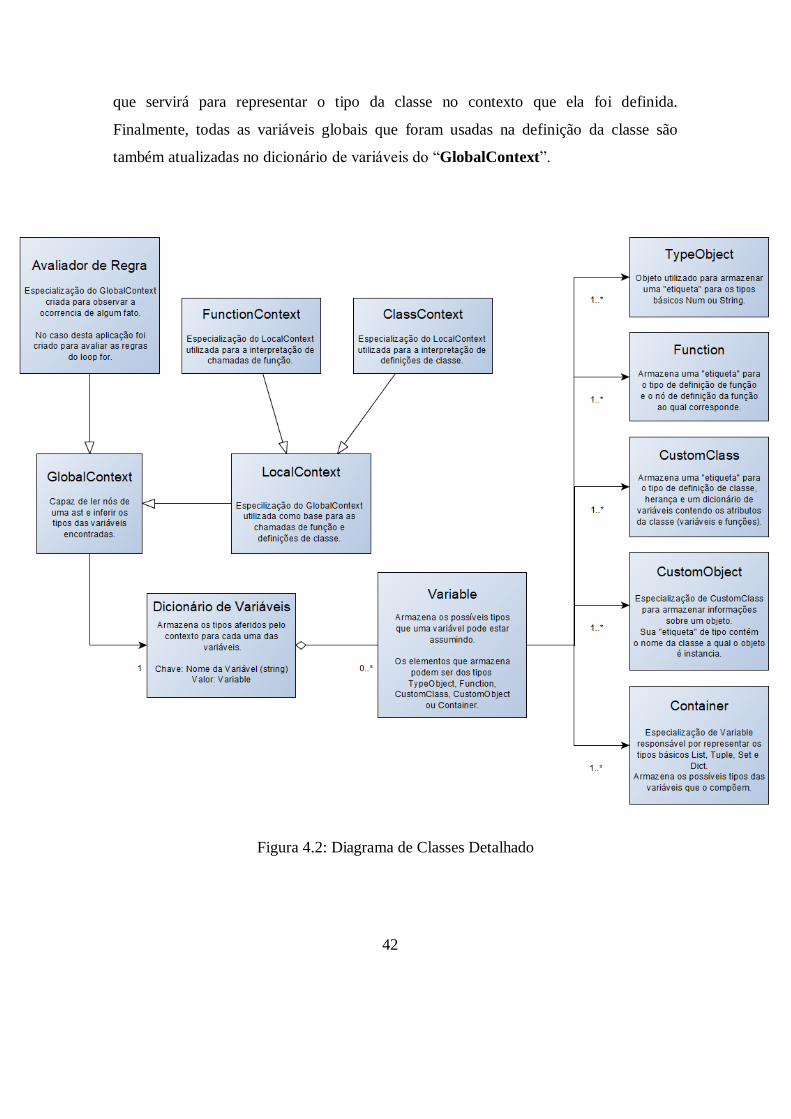
42
que servirá para representar o tipo da classe no contexto que ela foi definida.
Finalmente, todas as variáveis globais que foram usadas na definição da classe são
também atualizadas no dicionário de variáveis do “GlobalContext”.
Figura 4.2: Diagrama de Classes Detalhado

43
4.5 – Referências
Um dos possíveis casos mencionados anteriormente, no qual se torna difícil
determinar estaticamente se há ou não modificação de uma variável var, é quando esta
modificação é feita indiretamente, usando o nome de uma outra variável que referencia
o mesmo objeto que var. Por exemplo, se duas variáveis a e b estiverem referenciando
uma mesma lista e a for escolhida como objeto iterável de um loop, qualquer
modificação feita em b no corpo deste loop será feita também em a, configurando um
possível caso de erro.
Exemplo:
a = [1, 2, 3]
b = a
for i in a:
b += [0]
A solução para este possível problema veio naturalmente com o design da
aplicação. Como os tipos são determinados quando há atribuições, e são representados
como objetos, ao se identificar uma atribuição “a = b”, as referências a todos os
“TypeObjects” de a são copiadas para a lista de tipos de b. Deste modo, uma procura
no conteúdo de duas variáveis a e b por objetos comuns permite determinar se duas
variáveis referenciam um mesmo objeto.
4.6 – Implementando a Regra do Loop For
Com a implementação do gestor de contexto terminada, torna-se mais simples
implementar classes capazes de inferir se alguma regra está sendo quebrada. Basta
estender a classe “GlobalContext” e reescrever as funções que leem os tipos de nós
específicos a nova regra.
Desta forma, as seguintes regras devem ser aplicadas quando analisando o corpo
de um loop for:
1. Não devem existir operações do tipo “+=” que têm como alvo o objeto iterado
pelo for.

44
2. Não devem ser feitas invocações das funções insert, append e extend do objeto
iterado pelo loop for.
Em ambos os casos, as regra só podem ser avaliadas ao se ler uma instrução que
está dentro de um loop for, portanto em chamadas aninhadas dentro da função que
avalia um nó do tipo for (read_for). Este fato faz com que seja necessário disponibilizar
para todas as funções de leitura de nós, quais são os objetos iterados no momento de sua
execução, sem que o cabeçalho das funções seja modificado.
Para que este comportamento fosse obtido, foi adicionada a classe uma lista de
objetos iterados, desta forma qualquer função pode acessá-la. Além disso, a função
read_for foi modificada para que no início de sua execução tais objetos fossem
adicionados ao final da lista antes mencionada, e uma vez finalizada a leitura de seu
corpo, eles fossem removidos. Desta forma, além de garantir que as regras sejam
avaliadas somente dentro do corpo do for, é garantido também que as regras serão
propriamente avaliadas no caso de múltiplos for aninhados.
Uma vez modificado o read_for, as funções que leem os nós que podem
quebrar as regras já possuem os meios necessários para aferir tais ocorrências. Para a
primeira regra, a função em questão é a read_aug_assign. Ela foi modificada para que
toda vez que encontrar um nó cujo operador for “+=”, seja feita uma verificação se o
seu alvo faz referência a algum dos elementos da lista de objetos iterados. Se isso
acontecer o contador de infrações é incrementado.
Exemplo:
# Código
a = [1, 2, 3]
for i in a:
a += [0]
# AST
For(target=Name(id='i',ctx=Store()),
iter=Name(id='a',ctx=Load()),
body=[AugAssign(target=Name(id='a',ctx=Store()),

45
op=Add(),
value=List(elts=[Num(n=0)], ctx=Load()))],
orelse=[]
)
Ao se avaliar o for do código acima, a função read_for inicialmente avaliaria o
atributo iter do nó, extraindo todos os objetos aos quais ele pode corresponder, no caso
apenas um objeto lista, e os adiciona à lista de objetos iterados. Em seguida ele
começaria a avaliar o corpo do for, cuja única instrução é “a += [0]”. Como o nó desta
instrução é do tipo “AugAssign”, a função read_aug_assign é invocada.
Esta função por sua vez, avaliza o operador da instrução e determina que ele é
do tipo “+=”, então ela avalia se algum dos possíveis objetos, aos quais seu alvo pode
corresponder, encontra-se na lista de objetos iterados. Quando descobre que isso é
verdade, ela incrementa o contador de infrações de regra e continua sua execução.
Finalmente, ao final da execução da função read_for o único objeto que estava na lista
de objetos iterados é removido, de modo a impedir que posteriores instruções similares
a “a += lista” sejam avaliadas como infrações.
Para a segunda regra, a função capaz de avalia-la é a read_call, que faz a leitura
das chamadas de função. Esta é modificada de maneira semelhante ao que foi feito na
função read_aug_assign. Sempre que a função invocada for uma das três mencionadas
na regra (append, insert e extend), verifica-se se o objeto ao qual pertence essa
chamada encontra-se na lista de objetos iterados. Caso isso ocorra, configura-se também
uma quebra de regra, e o contador de infrações é novamente incrementado.
Esta abordagem, apesar de prática possui um empecilho. Ao se estender a classe
“GlobalContext”, as modificações feitas em suas funções não são automaticamente
aplicadas às instâncias da classe “LocalContext” que forem geradas por ela. Por isso,
foi necessário que a base da classe “LocalContext” fosse determinada dinamicamente.
Para que esse funcionamento fosse alcançado, utilizou-se como artifício o padrão de
projeto “Factory”, no qual a classe é definida localmente, dentro de uma função e as
suas bases são passadas como argumento, e no final a função retorna a classe construída
dentro de sua execução.

46
Exemplo:
def makeLocalContext(bases):
class LocalContext(bases):
# ---- funções da classe ----
# ...
return LocalContext
4.7 –Testes de Sanidade
Como para esse projeto não estava disponível uma base de testes, foram gerados
um total de 12 scripts que contém combinações dos seguintes casos de erro previstos:
1- Uso do operador “+=”, tendo como alvo o objeto iterado por um loop for.
2- Uso das funções insert, append e extend de um objeto iterado por um loop for.
3- Casos 1 e 2 utilizando uma variável que referência um objeto iterado por um
loop for. Por exemplo:
a = [1, 2, 3]
b = a
for i in a:
b += [0]
4- Casos 1 e 2, sendo a variável uma variável global de uma chamada função feita
dentro de um loop for. Por exemplo:
def f():
global a
a += [0]
a = [1, 2, 3]
for i in a:
f()
5- Casos 1 e 2, tendo a variável sido passada por um argumento de uma função. Por
exemplo:

47
def f(v):
v += [0]
a = [1, 2, 3]
for i in a:
f(a)
6- Casos 1 e 2 contendo múltiplos for aninhados. Por exemplo:
a = [1, 2, 3]
b = [0, 0, 0]
for i in a:
for j in b:
a += [0]
7- Casos 4 e 5 com múltiplas chamadas de função aninhadas. Por exemplo:
def f1():
global a
f2(a)
def f2(v):
v += [0]
a = [1, 2, 3]
for i in a:
f1()
No Anexo A são apresentados estes 12 scripts utilizados na base de testes, e
ainda, estes scripts contém 62 eventos de erro a serem identificados. A aplicação de
análise dos scripts, uma vez executada, foi capaz de identificar os erros com 100% de
aproveitamento.

48
Capítulo 5
Conclusão
5.1 – Conclusões
Apesar de o experimento ter sido feito com um conjunto de testes limitado e de
apenas ter sido implementado o analisador de um dos fatos, pode-se concluir que a
extração dos parâmetros descritos na Seção 3.3 é possível, mesmo com todos os
desafios impostos pelo tipo de análise que deve ser conduzido e pela linguagem. Além
disso, a abordagem utilizada neste trabalho se mostrou capaz de extrair grandes
quantidades de informações implícitas no código devido a seu funcionamento similar ao
de um interpretador. Porém, por ser tratar de uma análise estática, esta aplicação ainda é
incapaz de ler todo tipo de construção dinâmica de código ou importação dinâmica de
módulos.
Com isso, as técnicas aqui descritas poderiam ser utilizadas para a criação de
uma aplicação capaz de orientar desenvolvedores para a criação de códigos de maior
qualidade. Poderiam ainda ser integradas aos analisadores de códigos já existentes,
permitindo que eles sejam capazes de fazer análises mais robustas e de implementar
regras mais complexas.
5.2 – Trabalhos Futuros
A princípio, seria importante para esta aplicação que fosse implementada a
leitura das instruções dos tipos try e import, que foram deixadas de lado, e os outros
índices de inferência, para que uma análise mais completa de sua viabilidade pudesse
ser feita. Ficam delegados também a trabalhos futuros o cálculo do índice de
periculosidade de um programa a partir dos índices de inferência obtidos da avaliação

49
das diferentes regras, e a elaboração de um conjunto de testes mais rigoroso, que possa
botar a aplicação realmente a prova.
Existindo uma versão mais completa da aplicação descrita neste trabalho, ela
pode vir a ser útil em qualquer projeto que necessite fazer o uso da análise estática de
um programa em Python, como por exemplo projetos nas áreas de Segurança e
Qualidade de Software. Por isso seria interessante ter uma maneira mais simples de
escrever uma regra de inferência, possivelmente em uma linguagem especial, similar ao
que foi feito por Seifert e Samlaus utilizando OCL [6]. Isso permitiria a adoção desta
aplicação de maneira mais rápida, sem necessitar conhecer a fundo o seu
funcionamento.
Existem ainda dois experimentos que poderiam aumentar a precisão das análises
da aplicação. O primeiro seria a criação de um analisador análogo ao aqui descrito para
a biblioteca padrão de Python, escrita em C, para que ela pudesse integrar o
funcionamento desta aos seus testes. E o segundo seria tentar inserir este tipo de análise
em um interpretador Python, de modo a analisar cada instrução, logo antes de executá-
la. Isso tornaria a aplicação capaz de ler as construções dinâmicas mencionadas
anteriormente, sendo ainda capaz de evitar a execução de código defeituoso ou
malicioso.
Finalmente, seria importante criar uma extensa base de testes, contendo tanto
programas defeituosos quanto programas livres de falhas. Esta seria utilizada para fazer
a análise da eficiência das ferramentas que virão a ser desenvolvidas.

50
Bibliografia
[1] Python Software Foundation, “What is Python? Executive Summary,” 2017.
[Online]. Available: https://www.python.org/doc/essays/blurb/. [Acesso em 31
Maio 2017].
[2] PyScience-Brasil, "Python: O que é? Por que usar?," [Online]. Available:
http://pyscience-brasil.wikidot.com/python:python-oq-e-pq. [Accessed 14 9 2017].
[3] Python Software Foundation, “Comparing Python to Other Languages,” 1997.
[Online]. Available: https://www.python.org/doc/essays/comparisons/. [Acesso em
31 Maio 2017].
[4] W3Techs, “Usage Statistics and Market Share of Server-side Programming
Languages for Websites, May 2017,” 2017. [Online]. Available:
https://w3techs.com/technologies/overview/programming_language/all. [Acesso em
10 Maio 2017].
[5] GCN, “Static vs dynamic code analysis,” [Online]. Available:
https://gcn.com/articles/2009/02/09/static-vs-dynamic-code-analysis.aspx. [Acesso
em 14 Setembro 2017].
[6] Mirko Seifert and Roland Samlaus. "Static Source Code Analysis using OCL",
Proceedings of the 8th International Workshop on OCL Concepts and Tools (OCL
2008) at MoDELS 2008, Electronic Communications of the EASST, 2008. doi:
10.14279/tuj.eceasst.15.174
[7] Yao-Wen Huang; Fang Yu; Christian Hang; Chung-Hung Tsai; D. T. Lee; Sy-Yen
Kuo. "Securing Web Application Code by Static Analysis and Runtime Protection",
In: WWW Proceedings of the 13th international conference on World Wide Web ,
New York, p.17-22, 2004. doi: 10.1145/988672.988679

51
[8] A. A. S. Gomes, "Inteligência Computacional na Avaliação de Códigos em um
Sistema Complexo de Detecção com Desenvolvimento Colaborativo," Dissertação
de Mestrado em Engenharia Elétrica, Universidade Federal do Rio de Janeiro, Rio
de Janeiro, 2016.
[9] Python.org, “Python Patterns - An Optimization Anecdote,” Python Software
Foundation, [Online]. Available: https://www.python.org/doc/essays/list2str/.
[Acesso em 20 Junho 2017].
[10] D. Beazley, “Understanding the Python GIL,” em PyCon 2010, Atlanta, Georgia,
2010.
[11] Python Software Foundation, “16.6 multiprocesing - Process-based "threading"
interface - Python 2.7.13 documentation,” 2017. [Online]. Available:
https://docs.python.org/2/library/multiprocessing.html. [Acesso em 23 Junho 2017].
[12] J. M. e. al, "A Tutorial on Behavioral Reflection and its Implementation," Montréal,
Quebec, Canada, 1996.
[13] OWASP, “Static Code Analysis,” [Online]. Available:
https://www.owasp.org/index.php/Static_Code_Analysis. [Acesso em 05 Agosto
2017].
[14] Python Software Foundation, “20.23. xmlrpclib — XML-RPC client access,”
[Online]. Available: https://docs.python.org/2/library/xmlrpclib.html#module-
xmlrpclib. [Acesso em 11 Agosto 2017].
[15] Steve Holden (Chairman da PyCon, 2003 a 2005), “While Loop,” [Online].
Available: https://wiki.python.org/moin/WhileLoop. [Acesso em 08 Agosto 2017].
[16] Python Software Foundation, “cpython,” [Online]. Available:
https://hg.python.org/cpython/file/db842f730432/Objects/listobject.c#l914. [Acesso
em 11 Agosto 2017].
[17] J. Dahse, “RIPS - A static source code analyser for vulnerabilities in PHP scripts,”
the Month of PHP Security, 24 Maio 2010.

52
[18] N. Jovanovic, C. Kruegel, and E. Kirda, “Pixy: a static analysis tool for detecting
Web application vulnerabilities,” 2006 IEEE Symposium on Security and Privacy
(S&P’06), 2006. doi: 10.1109/sp.2006.29
[19] Python Software Foundation, “32.1. parser — Access Python parse trees,” [Online].
Available: https://docs.python.org/2/library/parser.html. [Acesso em 14 Maio
2017].
[20] Johann C. Rocholl, Florent Xicluan and Ian Lee, “Introduction — pycodestyle
2.3.1 documentation,” [Online]. Available:
http://pycodestyle.pycqa.org/en/latest/intro.html. [Acesso em 14 Setembro 2017].
[21] Python Software Foundation, “32.7. tokenize — Tokenizer for Python source,”
[Online]. Available: https://docs.python.org/2/library/tokenize.html. [Acesso em 14
Maio 2017].
[22] T. Kluyver, "Green Tree Snakes - the missing Python AST docs," [Online].
Available: https://greentreesnakes.readthedocs.io/en/latest/. [Accessed 14 Setembro
2017].
[23] L. Rauchwerger, “CSCE 434-500: Compiler Design,” 2017. [Online]. Available:
https://parasol.tamu.edu/~rwerger/Courses/434/lec6.pdf.

53
Anexo A
Base de Testes
Teste 1
a = [1, 2, 3]
for i in a:
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
Teste dos casos base de loop infinito do for.
Teste 2
a = [1, 2, 3]
b = a
for i in a:
b += [4] #Erro
b.append(4) #Erro
b.insert(4,1) #Erro
b.extend([4]) #Erro
Teste dos casos base de loop infinito do for, usando uma variável b que
referencia o mesmo objeto que a variável a que foi passada para o for.
Teste 3
def f():
global a
global b

54
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
b += [4] #Erro
b.append(4) #Erro
b.insert(4,1) #Erro
b.extend([4]) #Erro
a = [1, 2, 3]
b = a
for i in a:
f()
Teste dos casos base de loop infinito do for, usando variáveis globais de uma
função invocada dentro do for. Nota-se aqui que foram testados os casos tanto da
variável a que foi passada para o for, quanto o da variável b, que referencia o mesmo
objeto que a.
Teste 4
def f(v):
v += [4] #Erro para f(a) e f(b)
v.append(4) #Erro para f(a) e f(b)
v.insert(4,1) #Erro para f(a) e f(b)
v.extend([4]) #Erro para f(a) e f(b)
a = [1, 2, 3]
b = a
for i in a:
f(a)
f(b)
Teste dos casos base de loop infinito do for, no qual o objeto iterado é passado
como argumento para uma função invocada dentro do for.

55
Teste 5
def f(a):
a += [4] #Erro para f(a)
a.append(4) #Erro para f(a)
a.insert(4,1) #Erro para f(a)
a.extend([4]) #Erro para f(a)
a = [1, 2, 3]
b = [1, 2, 3]
for i in a:
f(a)
f(b)
Este teste apesar de parecer redundante em relação ao teste 4, tem como objetivo
verificar que a aplicação não está interpretando a variável a dentro da função f, como
uma variável global.
Teste 6
def f1():
f2()
def f2():
global a, b
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
b += [4]
b.append(4)
b.insert(4,1)
b.extend([4])
a = [1, 2, 3]
b = [1, 2, 3]

56
for i in a:
f1()
Teste para garantir que a regra é verificada mesmo com chamadas de função
aninhadas.
Teste 7
def f1(v):
f2(v)
def f2(v):
v += [4] #Erro para f1(a)
v.append(4) #Erro para f1(a)
v.insert(4,1) #Erro para f1(a)
v.extend([4]) #Erro para f1(a)
a = [1, 2, 3]
b = [1, 2, 3]
for i in a:
f1(a)
f1(b)
Mistura do teste 4 com o teste 6, garante que a regra é verificada em chamadas
de função aninhadas, nas quais o objeto iterado é passado como argumento para f1 e
sucessivamente para f2.
Teste 8
def f1():
global a, b
f2(a)
f2(b)
def f2(v):
v += [4] #Erro para f2(a)
v.append(4) #Erro para f2(a)

57
v.insert(4,1) #Erro para f2(a)
v.extend([4]) #Erro para f2(a)
a = [1, 2, 3]
b = [1, 2, 3]
for i in a:
f1()
Mistura do teste 3 com o teste 6, garante que a regra é verificada em chamadas
de função aninhadas, nas quais o objeto iterado é obtido em f1 como uma variável
global e é passado como argumento para f2.
Teste 9
a = [1, 2, 3]
b = [1, 2, 3]
for i in a:
b += [4]
for j in b:
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
b += [4] #Erro
Teste para garantir que na ocorrência de múltiplos loops for aninhados, a regra é
verificada para o for exterior.
Teste 10
a = [1, 2, 3]
b = [1, 2, 3]
c = a
d = b
for i in a:
d += [4]

58
for j in b:
c += [4] #Erro
c.append(4) #Erro
c.insert(4,1) #Erro
c.extend([4]) #Erro
d += [4] #Erro
Mistura do teste 9, com o teste 2. Garante que a regra é verificada em loops
aninhados, mesmo quando se utilizam variáveis que referenciam o objeto iterado pelo
loop.
Teste 11
def f2():
global a, b
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
b += [4]
b.append(4)
b.insert(4,1)
b.extend([4])
def f1(v):
for i in v:
f2()
a = [1, 2, 3]
b = [1, 2, 3]
f1(a)
Teste que garante a execução da verificação, mesmo quando o for encontra-se
em contexto local.

59
Teste 12
def f1(v):
for i in v:
f2()
def f2():
global a, b
a += [4] #Erro
a.append(4) #Erro
a.insert(4,1) #Erro
a.extend([4]) #Erro
b += [4] #Erro
b.append(4) #Erro
b.insert(4,1) #Erro
b.extend([4]) #Erro
a = [1, 2, 3]
b = [1, 2, 3]
for i in b:
f1(a)
Mistura de diversos testes com loops e funções aninhadas alternadamente.


















