
Análise de Casos de Teste Estatisticamente Relevantes ... · Apoiado em técnicas tradicionais de...
88
Pontifícia Universidade Católica do Rio Grande do Sul Faculdade de Informática Pós-Graduação em Ciência da Computação Análise de Casos de Teste Estatisticamente Relevantes Através da Descrição Formal de Programas Cristiano Bertolini Dissertação apresentada como requisito parcial à obtenção do grau de mestre em Ciência da Computação Orientador: Prof. Dr. Paulo Hen- rique Lemelle Fernandes Porto Alegre, janeiro de 2006
-
Upload
trinhxuyen -
Category
Documents
-
view
223 -
download
0
Transcript of Análise de Casos de Teste Estatisticamente Relevantes ... · Apoiado em técnicas tradicionais de...

Pontifícia Universidade Católica do Rio Grande do SulFaculdade de Informática
Pós-Graduação em Ciência da Computação
Análise de Casos de Teste
Estatisticamente Relevantes Através
da Descrição Formal de Programas
Cristiano Bertolini
Dissertação apresentada como
requisito parcial à obtenção do
grau de mestre em Ciência da
Computação
Orientador: Prof. Dr. Paulo Hen-
rique Lemelle Fernandes
Porto Alegre, janeiro de 2006

"Not Everything that counts can be
counted, and not everything that
can be counted counts."
Albert Einstein

iii
Resumo
Este trabalho aborda a qualidade da geração estatística de casos de teste noteste estatístico através da descrição formal de programas. A principal contribuiçãoconsiste na proposta de uma métrica para o cálculo de índice de cobertura baseadoem trajetórias; ou seja, é formalizada uma métrica que verifica a relevância deconjuntos de casos de teste. São utilizadas Cadeias de Markov (MC) e Redes deAutômatos Estocásticos (SAN) como métodos formais de descrição de modelosde uso, no sentido de verificar vantagens e desvantagens no processo de teste es-tatístico utilizado. No decorrer do trabalho, discute-se uma análise quantitativada geração de casos de teste, bem como sua eficiência para os formalismos MCe SAN. Como resultado, são apresentadas uma análise quantitativa da geraçãode casos de teste e a evolução de resultados numéricos para a métrica proposta.Verificou-se com a análise quantitativa que a implementação em SAN apresentouuma pequena vantagem na geração de casos de teste. Com a métrica propostapode-se avaliar tanto para SAN quanto para MC o índice de cobertura de umadeterminada amostra de casos de teste.

iv
Abstract
This work focus on the quality of test case generation through the formalprogram description. The main contribution of this dissertation is a new metric tocompute coverage test case index based on model trajectories. The proposed metricverifies the statistical relevance of a given set of test cases. Markov Chains (MC)and Stochastic Automata Network (SAN) are used as formal methods to describeusage models in order to investigate the benefits in the applied statistical testingprocess. It is discussed a quantitative analysis of the test cases generation andits efficiency to MC and SAN formalisms. As results of this work, it is presenteda quantitative analysis of test case generation and a numerical evaluation to themetric coverage test case index.

Sumário
RESUMO iii
ABSTRACT iv
LISTA DE TABELAS viii
LISTA DE FIGURAS ix
LISTA DE SÍMBOLOS E ABREVIATURAS x
Capítulo 1: Introdução 1
Capítulo 2: Teste Estatístico 42.1 Teste de Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Técnicas e Processos de Testes . . . . . . . . . . . . . . . . . . . . . 52.3 Modelos de Uso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3.1 Benefícios e Limitações dos Modelos de Uso no Teste Es-tatístico de Software . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Especificação Baseada em Modelos Formais . . . . . . . . . . . . . . 82.4.1 Cadeias de Markov - MC . . . . . . . . . . . . . . . . . . . . 9
2.4.1.1 Definição Formal . . . . . . . . . . . . . . . . . . . 102.4.1.2 Definição Informal . . . . . . . . . . . . . . . . . . 10
2.4.2 Redes de Autômatos Estocásticos - SAN . . . . . . . . . . . 112.4.2.1 Definição Formal . . . . . . . . . . . . . . . . . . . 112.4.2.2 Definição Informal . . . . . . . . . . . . . . . . . . 13
Capítulo 3: Estudos de Caso 173.1 Exemplo: Sistema de Login . . . . . . . . . . . . . . . . . . . . . . . 173.2 Estudo de Caso 1: Simple Counter Navigation . . . . . . . . . . . . 20
v

SUMÁRIO vi
3.2.1 Descrição da Aplicação . . . . . . . . . . . . . . . . . . . . . 203.2.2 Modelo de Cadeia de Markov . . . . . . . . . . . . . . . . . 213.2.3 Modelo SAN . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 Estudo de Caso 2: Calendar Manager . . . . . . . . . . . . . . . . . 243.3.1 Descrição da Aplicação . . . . . . . . . . . . . . . . . . . . . 243.3.2 Modelo de Cadeia de Markov . . . . . . . . . . . . . . . . . 253.3.3 Modelo SAN . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.4 Estudo de Caso 3: Docs Editor . . . . . . . . . . . . . . . . . . . . 30
Capítulo 4: Geração Estatística de Casos de Teste 324.1 Ferramentas de Geração Estatística . . . . . . . . . . . . . . . . . . 34
4.1.1 STAGE-Model . . . . . . . . . . . . . . . . . . . . . . . . . 354.1.2 STAGE-Test . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Capítulo 5: Análise Quantitativa 395.1 Diversidade de Geração . . . . . . . . . . . . . . . . . . . . . . . . . 395.2 Tempo de Geração . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Capítulo 6: Métricas de Qualidade 446.1 Qualidade de Test Suites . . . . . . . . . . . . . . . . . . . . . . . . 44
6.1.1 Comparação Baseada em Transições . . . . . . . . . . . . . . 456.1.2 Comparação Baseada em Eventos . . . . . . . . . . . . . . . 46
6.2 Índice de Cobertura Baseado em Trajetórias . . . . . . . . . . . . . 466.2.1 Probabilidade dos Casos de Teste . . . . . . . . . . . . . . . 46
6.3 Exemplo: Sistema de Login . . . . . . . . . . . . . . . . . . . . . . . 496.4 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Capítulo 7: Conclusões 577.1 Construção dos Modelos de Uso . . . . . . . . . . . . . . . . . . . . 577.2 Geração dos Casos de Teste . . . . . . . . . . . . . . . . . . . . . . 587.3 Métricas de Qualidade . . . . . . . . . . . . . . . . . . . . . . . . . 587.4 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
REFERÊNCIAS BIBLIOGRÁFICAS 62
Apêndice A: Probabilidades 67A.1 Probabilidades Condicionais . . . . . . . . . . . . . . . . . . . . . . 67

SUMÁRIO vii
Apêndice B: Sistema de Login 69B.1 Modelo PEPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
Apêndice C: Simple Counter Navigation 70C.1 Modelo PEPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
Apêndice D: Calendar Manager 72D.1 Modelo PEPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
Apêndice E: Docs Editor 75E.1 Modelo PEPS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
ÍNDICE REMISSIVO 78

Lista de Tabelas
3.1 Correspondência dos estados da MC: Sistema de Login. . . . . . . . 203.2 Correspondência dos estados da MC: Simple Counter Navigation. . 243.3 Correspondência dos estados da MC: Calendar Manager. . . . . . . 29
6.1 Probabilidade dos estados atingíveis: Sistema de Login. . . . . . . . 506.2 Probabilidade dos casos de teste: Sistema de Login. . . . . . . . . . 526.3 Valores - Simple Counter Navigation. . . . . . . . . . . . . . . . . . 546.4 Valores - Calendar Manager. . . . . . . . . . . . . . . . . . . . . . . 556.5 Valores - Docs Editor. . . . . . . . . . . . . . . . . . . . . . . . . . 56
viii

Lista de Figuras
2.1 Exemplo de MC. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112.2 Exemplo SAN com dois autômatos independentes. . . . . . . . . . . 132.3 Exemplo SAN de um evento sincronizante. . . . . . . . . . . . . . . 142.4 Exemplo SAN utilizando taxa funcional. . . . . . . . . . . . . . . . 16
3.1 Sistema de Login. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2 Modelo MC: Sistema de Login. . . . . . . . . . . . . . . . . . . . . . 183.3 Modelo SAN: Sistema de Login. . . . . . . . . . . . . . . . . . . . . 193.4 Modelo MC: Simple Counter Navigation. . . . . . . . . . . . . . . . 213.5 Modelo SAN: Simple Counter Navigation. . . . . . . . . . . . . . . 233.6 Modelo MC: Calendar Manager. . . . . . . . . . . . . . . . . . . . . 263.7 Modelo SAN: Calendar Manager. . . . . . . . . . . . . . . . . . . . 283.8 Modelo SAN: Docs Editor. . . . . . . . . . . . . . . . . . . . . . . . 31
4.1 STAGE Framework. . . . . . . . . . . . . . . . . . . . . . . . . . . . 344.2 STAGE-Model. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 354.3 STAGE-Test. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.1 Análise de diversidade: Calendar Manager. . . . . . . . . . . . . . . 405.2 Análise de diversidade: Docs Editor. . . . . . . . . . . . . . . . . . 415.3 Análise de eficiência: Simple Counter Navigation. . . . . . . . . . . 425.4 Análise de eficiência: Calendar Manager. . . . . . . . . . . . . . . . 425.5 Análise de eficiência: Docs Editor. . . . . . . . . . . . . . . . . . . . 43
6.1 Índice de cobertura: Sistema de Login. . . . . . . . . . . . . . . . . 536.2 Índice de cobertura: Simple Counter Navigation. . . . . . . . . . . . 546.3 Índice de cobertura: Calendar Manager. . . . . . . . . . . . . . . . 556.4 Índice de cobertura: Docs Editor. . . . . . . . . . . . . . . . . . . . 56
ix

Lista de Símbolos e Abreviaturas
MC Markov Chains 2
SAN Stochastic Automata Networks 2
UML Unified Modeling language. 9
FSM Finite State Machine 9
CTMC Continuous Time Markov Chain 10
HTML HyperText Markup Language. 20
JSP Java Server Pages 24
CPTS Centro de Pesquisa em Teste de Software. 32
STAGE State Based Test Generator 33
XML Extensible Markup Language 33
EMC Embedded Markov Chains 60
DTMC Discrete Time Markov Chains 60
x

Capítulo 1
Introdução
Com a crescente demanda por sistemas de computação mais robustos, estes tornam-se cada vez mais complexos e requerem um maior grau de precisão, por exemplo,sistemas web onde performance e confiabilidade são requisitos necessários para osucesso desses sistemas e satisfação dos usuários [29]. Há uma crescente neces-sidade de software com alta confiabilidade e qualidade, como aplicações críticas,Web, médicas e outros sistemas de controle. Neste sentido, muitas formas demelhoria dos processos de desenvolvimento de software são utilizadas e diversosartefatos e ferramentas buscam melhorar o desenvolvimento, como a utilização demétodos formais para descrever requerimentos, especificações, designs e testes [1].
As inovações e melhorias dos processos de desenvolvimento de software aju-dam a ter software com alta qualidade e de alta confiabilidade, mas continua anecessidade deles serem testados, o que significa que os métodos utilizados paratestes devem ser eficientes para que problemas possam ser detectados e corrigidosantes de chegaram ao usuário final. Assim, métodos formais tornam-se uma boaabordagem a ser utilizada, podendo ser utilizados desde a fase de requisitos até afase de teste [1, 11].
Muitos sistemas atuais são expostos a uma quantidade exaustiva de testes natentativa de minimizar possíveis falhas e, mesmo assim, a confiabilidade não égarantida na maioria dos casos. No entanto, nem sempre é possível realizar testesde forma exaustiva devido ao alto custo e tempo gasto; assim, necessitamos detécnicas que tornem a prática de testar viável e com bons resultados [48].
Muitas técnicas, conceitos e estilos de teste são descritos na literatura devidoà popularização da orientação a objetos e modelos em engenharia de software.Assim, tem sido grande a utilização de teste de software baseado em modelos(model-based testing) [13], que possui como base um modelo formal da aplicaçãoonde torna-se possível a geração de casos de teste.
Considerando sistemas complexos, sistemas que necessitam de confiabilidade,ou sistemas que necessitam de uma quantidade de testes mais apurados, então
1

CAPÍTULO 1. INTRODUÇÃO 2
existe a necessidade de uma geração de casos de teste automática. Entre os bene-fícios da geração automática de testes pode-se citar a economia de tempo e recursos(pessoas). Adicionalmente, através da geração estatística de casos de teste, pode-seestimar a confiabilidade de um determinado sistema.
Apoiado em técnicas tradicionais de teste de software, como o teste funcionale o teste estrutural, o teste estatístico compreende a aplicação da ciência estatís-tica para a solução de problemas de teste de software [42]. A utilização de testeestatístico usualmente requer a utilização de procedimentos randômicos como pro-cedimentos de amostragem, algoritmos randômicos ou construções randômicas [10].Neste contexto, a utilização do teste estatístico deve-se apoiar em ferramentas quesuportem todo este processo de teste.
Outro fator importante na automatização do processo de teste estatístico é aforma como a aplicação é representada. Desta forma, são construídos modelos quebuscam expressar a realidade de um sistema. Estes modelos além de representaremcaracterísticas do sistema podem ser utilizados na geração de casos de teste. Osformalismos para a construção de modelos adotados neste trabalho são as Cadeiasde Markov (MC) [43], pela grande utilização na construção de modelos de uso, eas Redes de Autômatos Estocásticos (SAN) [36] que representam um formalismomais sofisticado, onde os modelos são representados de forma modular e com issotorna-se mais fácil e viável a construção de modelos maiores. Tais formalismosutilizam a noção de "estado do sistema"e as transições levam a um novo estado dosistema. Em [14] é apresentada a primeira utilização das SAN no teste estatístico,assim, essa dissertação busca dar continuação a este trabalho focando em questõescomo métricas de qualidade no teste estatístico, visto que o trabalho, anteriormenterealizado, apenas introduzia a utilização de SAN no contexto de teste estatístico.
Para a consolidação do referencial teórico sobre os modelos de uso utilizandométodos formais (MC e SAN), três estudos de caso foram realizados. Nos estudosde caso buscou-se explorar a sua equivalência com as Cadeias de Markov atravésda construção da Cadeia de Markov correspondente a SAN, e a sua verificaçãoatravés da ferramenta PEPS [6].
O intuito foi avaliar quantitativamente os casos de teste e verificar através deexperimentos a eficiência da geração automática. A avaliação mostrou a eficiênciana geração através da análise de tempo dos algoritmos de geração e a qualidadena geração através da diversidade de casos de teste gerados, ou seja, a cada novoconjunto de casos de teste gerados, casos de teste únicos eram gerados.
Um dos pontos de investigação deste trabalho compreende a análise de métri-cas para o teste estatístico. Algumas métricas são propostas na literatura comotécnicas de comparação de vetores para MC. No entanto, como essas técnicas cor-respondem a comparação das freqüências das transições dos modelos em MC, paraSAN elas não se aplicam da mesma forma devido à semântica dada às transições

CAPÍTULO 1. INTRODUÇÃO 3
através dos eventos. Desta forma, também é proposta uma métrica de cálculo doíndice de cobertura baseado em trajetórias, que é aplicada tanto para MC quantopara SAN.
Os objetivos gerais desse trabalho são de consolidar a utilização de SAN paraa construção de modelos de uso e propor uma métrica de análise de cobertura dageração de casos de teste baseada nas probabilidades dos estados do modelo. Osobjetivos específicos correspondem a análise dos casos de teste gerados, traçandoum comparativo entre MC e SAN; descrição do processo de teste utilizado nageração de casos de teste; e cálculo do índice de cobertura de cada caso de teste.Cabe ressaltar que o comparativo realizado teve como base uma ferramenta degeração estatística chamada STAGE que será apresentada no decorrer do trabalho.
Este trabalho está estruturado da seguinte forma. O Capítulo 2 apresenta oreferencial teórico sobre teste estatístico de software utilizando modelos de uso,bem como alguns formalismos existentes e utilizados no decorrer do trabalho. OCapítulo 3 apresenta os estudos de caso realizados. No Capítulo 4 é apresentado oprocesso de teste estatístico utilizado e as ferramentas de automação. No Capítulo5 são apresentados os resultados numéricos para a análise quantitativa da geraçãode casos de teste. O Capítulo 6 apresenta a métrica de cálculo do índice decobertura dos casos de teste. Por fim, são apresentados as conclusões e o referencialbibliográfico utilizado.

Capítulo 2
Teste Estatístico
Este capítulo apresenta um embasamento teórico e um panorama histórico do usode teste de software, enfocando no teste estatístico de software com a utilização demodelos de uso. Para tanto, divide-se em uma abordagem sobre teste de softwareem geral partindo para a definição de teste estatístico apoiado em modelos deuso. Logo após, são descritos alguns formalismos utilizados no teste estatístico desoftware para a geração de casos de teste.
2.1 Teste de Software
Em um processo de desenvolvimento de sistemas, o ciclo de testes é responsávelpor garantir que o produto tenha sido construído com qualidade e para que sejamcorrigidos erros de execução e especificação. A alta qualidade gerada é uma dasprincipais motivações para se ter processos de teste de software bem definidos eeficientes.
Alguns importantes conceitos que estão presentes nesta seção são confiabilidadee falhas. Confiabilidade em software pode ser definida como a probabilidade queo software não irá falhar durante o uso operacional [48]. Em [24] são apresentadosdefinições diferentes para erro, falha e defeito:
• Falha (Fault): Corresponde a uma condição anômala, causada por erros deprojeto, problemas de fabricação ou distúrbios externos. Uma falha em umsistema ocorre quando o comportamento deste sistema foge de sua normali-dade, a qual é especificada na fase de projeto.
• Erro (Error): Corresponde à manifestação de uma falha no sistema, cau-sando disparidade nas respostas apresentadas, que diferem do valor previsto.
• Defeito (Defect): Corresponde à incapacidade de algum componente emrealizar a função para o qual foi projetado.
4

CAPÍTULO 2. TESTE ESTATÍSTICO 5
No entanto para fins de entendimento deste trabalho e por conveniência, assume-se que erro, falha e defeito são sinônimos e ocorrem quando o software não é execu-tado de acordo com sua especificação. Assim, segundo Myers [33] teste é o processode executar um programa com a intenção de encontrar erros, isto é, aplicar proces-sos de validação e verificação através da análise do software, buscando encontrarfalhas de execução e funcionalidade.
As atividades de testes podem compreender um esforço grande no desenvolvi-mento de um software, e muitas vezes não contemplam todas as funcionalidadese rotinas de execução. Várias estratégias podem ser empregadas para assegurar acorreta execução do software. Em [40] são apresentadas três fases de teste:
• Teste de unidade (Unit testing): Nesta fase cada unidade que compõe osistema é testada separadamente, desde que as unidades sejam pequenas (epossam ser testadas separadamente), buscando encontrar erros de especifi-cação e implementação em cada unidade [25].
• Teste de integração (Integration testing): Nesta fase as unidades são agru-padas formando subsistemas, por exemplo, interfaces. Os módulos são tes-tados adicionando as unidades de forma incremental ao subsistema. Assima unidade responsável por uma falha é mais facilmente identificada [25].
• Teste de sistema (System testing): Nesta fase o objetivo é identificar errosde funções e características de desempenho que não estejam de acordo coma especificação [38].
Além dessas fases, em [30] duas outras fases são apresentadas, o teste deaceitação e o teste de regressão. O teste de aceitação tem por objetivo avaliara confiabilidade e performance do sistema em um comportamento operacional, re-quer então uma coleção de informações sobre como o usuário gostaria de usar osistema, o que é chamado de alfa teste, e muitas vezes seguido pelo beta teste queenvolve a utilização do software pelos usuários. O teste de regressão é feito emuma nova versão para assegurar que não houve perda de confiabilidade, quandoimportantes adições ou modificações são feitas para uma versão existente.
2.2 Técnicas e Processos de Testes
As técnicas de teste são classificadas de acordo com a origem da informação que éutilizada para estabelecer os requisitos de testes [40], e têm por objetivo encontrarfalhas no software. As principais técnicas de teste são o teste funcional, o testeestrutural e o teste estatístico.

CAPÍTULO 2. TESTE ESTATÍSTICO 6
O teste funcional, conhecido também como caixa-preta (black-box), enxerga osistema como uma caixa fechada onde não se tem conhecimento sobre sua imple-mentação ou seu comportamento interno. No teste funcional os testes são geradossomente considerando os valores de entrada e saída do sistema utilizando comobase a sua especificação [30].
O teste estrutural, também conhecido como caixa branca (white-box), esta-belece os requisitos do software baseados na sua implementação. Sendo assim,a geração dos testes leva em conta as estruturas lógicas e funcionais implemen-tadas, verificando se as funcionalidades e resultados gerados estão de acordo coma especificação [33].
Estas duas primeiras técnicas de teste são usualmente as mais utilizadas. Ostestes funcionais são aplicados geralmente em testes de unidades, enquanto ostestes estruturais são aplicados geralmente em testes de integração e testes desistema [2].
O teste estatístico é visto como um excelente complemento para as técnicas deteste existentes podendo ser utilizado não como uma diferente técnica de testes,mas como uma técnica que visa somar confiabilidade às demais técnicas [20]. Por-tanto, o teste estatístico pode ser definido como a aplicação da ciência estatísticapara a solução de problemas de teste de software [42] e é desenvolvido para carac-terizar a população que utiliza o software.
2.3 Modelos de Uso
Os modelos de uso caracterizam-se pelo uso operacional do software e são baseadosem especificações funcionais e no uso das especificações para o desenvolvimento dosoftware. Assim todas as informações necessárias para desenvolver o modelo devemser disponíveis antes do começo da implementação, o que torna os modelos de usoartefatos importantes para o desenvolvimento, por exemplo, de funções em termosde probabilidade de uso [48]. Também é apresentada uma metodologia para acriação de modelos de uso dividida em oito etapas [48], como segue:
1. Revisar a especificação do software: Nesta etapa a especificação do softwareé revisada e compreendida, para que o modelo de uso possa refletir o uso dosoftware partindo de uma especificação funcional completa.
2. Identificar o uso do software, usuário e ambiente de uso: Nesta etapa édefinido o ambiente operacional o qual o software vai ser aplicado [48]:
• Usuário: Compreende a entidade que interage com o software, e podeser uma pessoa, um periférico ou outro sistema.

CAPÍTULO 2. TESTE ESTATÍSTICO 7
• Uso: Compreende a maneira como o software é processado, e pode seruma seção de trabalho, transações ou qualquer outra unidade de serviço.
• Ambiente: Compreende os fatores externos ao software que podem in-terferir no seu funcionamento, e pode ser interações com outros sistemas(banco de dados, dispositivos de E / S), plataforma, integridade de da-dos, necessidade de acessos simultâneos, etc.
3. Definir parâmetros de ambiente: Existe uma grande quantidade de combi-nações de valores para os parâmetros utilizados por um software, incluindomúltiplos estímulos aplicados simultaneamente. Nesta etapa são definidosos parâmetros que serão suficientes e que satisfaçam o sistema e contribuempara o desenvolvimento de modelos de uso de forma que estes se tornemsimples e eficazes.
4. Determinar o nível de granularidade: A granularidade dos modelos de usotendem a aumentar com seu custo de desenvolvimento e manutenção. Nestaetapa, para determinar os níveis de granularidade deve-se periodicamenteanalisar o custo de desenvolvimento e manutenção do modelo e os benefíciosde se ter um teste de melhor qualidade.
5. Desenvolver a estrutura do modelo de uso: Os modelos de uso são compostospor eventos e transições entre os eventos, sendo que os eventos partem deum estado para outro. Nesta etapa o modelo de uso pode ser representadopor um grafo, gramática formal, MC ou SAN.
6. Verificar se a estrutura do modelo de uso está de acordo com a especificação:Nesta etapa todos os parâmetros que afetam a estrutura dos modelos devemser verificados, como classes de usuários e funções críticas do sistema, entreoutros.
7. Desenvolver a distribuição da probabilidade para o modelo: Nesta etapa,para cada transição é definida uma probabilidade, e um conjunto de tran-sições que definem a distribuição da probabilidade. Essa distribuição é abase para que o teste estatístico de software possa ser executado.
8. Verificar a distribuição da probabilidade: Nesta etapa é feita uma verificaçãoda distribuição da probabilidade na tentativa de minimizar erros.
Estas etapas incluem todos os passos necessários para a construção de ummodelo de uso. No entanto, cabe ressaltar que um modelo de uso define apenasaspectos funcionais de um software, não considerando aspectos não funcionais ouestruturais do software modelado.

CAPÍTULO 2. TESTE ESTATÍSTICO 8
2.3.1 Benefícios e Limitações dos Modelos de Uso no Teste
Estatístico de Software
É notório que o teste estatístico baseado nos modelos de uso possui muitos benefí-cios, mas por outro lado, também possui algumas limitações. Como a modelagemé feita baseada em estados surge o problema da explosão dos estados, ou seja,modelos muito complexos que necessitam de uma modelagem com muitos estadospode tornar a sua construção impraticável. Este problema pode ser contornadoadicionando uma maior abstração ao modelo, no entanto outro problema é gerado:A perda de informações [26]. Uma alternativa é a utilização de redes de autômatosestocásticos (SAN) que será discutida adiante.
Há muitos benefícios no teste estatístico de software com modelos de uso; algunspodem ser vistos em [37], como:
• Fonte para estimativas de planejamento: Os resultados obtidos podem serutilizados para estimar custo e tempo no desenvolvimento de novos software.
• Geração de testes automática: A utilização de modelos de uso torna-se idealpara a geração automática de testes, por exemplo, utilizando cadeias deMarkov para a execução de testes estatísticos de software.
• Testes eficientes: Os testes tornam-se bem estruturados e contribuem para aobtenção de resultados mais eficientes.
• Gerenciamento quantitativo dos testes: Os resultados quantitativos dos testesacabam ajudando no gerenciamento e tomadas de decisão.
• Verificação de confiabilidade: Com a utilização dos modelos de uso as métri-cas de confiabilidade têm melhorado e, portanto, tornado as aplicações maisconfiáveis.
Cabe ressaltar que a utilização dos modelos de uso não garante todos os bene-fícios; algumas vezes alguns são mais enfatizados ou priorizados. Neste sentido,nesta dissertação os benefícios dos modelos de uso que buscou-se explorar forama geração de testes automática, gerenciamento quantitativo dos casos de teste everificação de confiabilidade.
2.4 Especificação Baseada em Modelos Formais
Modelos são usados para compreender, especificar e desenvolver sistemas em muitasáreas [4]. No desenvolvimento de casos de teste e análise de confiabilidade estesmodelos tornam-se muito interessantes, principalmente em sistemas complexos e

CAPÍTULO 2. TESTE ESTATÍSTICO 9
difíceis de serem testados exaustivamente [5]. O teste baseado em modelos significarepresentar as informações de um determinado sistema em um modelo. Há umagrande quantidade de modelos atualmente e cada um descreve diferentes aspectosdo comportamento do software, como: Controle de fluxo, fluxo de dados, grafos,máquinas de estado, entre outros [13].
Atualmente os formalismos mais populares para a geração de casos de teste sãobaseados em estados, ou seja, os modelos utilizam-se de um conjunto de estadospara a representação de um comportamento do sistema.
Dentre os formalismos utilizados, é crescente a utilização dos modelos da UML,que substituem a simples representação de estilo gráfico por uma poderosa estru-tura de linguagem. Portanto, UML é uma linguagem para construção de modelosde software dos mais simples até os mais complexos e vem sendo utilizada commuitos fins. Além da UML ser utilizada em diversas fases do desenvolvimento desistemas, também podemos encontrar diversos trabalhos sobre teste baseado emUML, como, por exemplo, em [39] onde é proposto uma geração estatística decasos de teste baseada na utilização do diagrama de estados da UML.
Como este trabalho representa uma continuação ao trabalho desenvolvido em[14], os modelos formais utilizados são as Cadeias de Markov (MC) e Redes deAutômatos Estocásticos (SAN). As MC são muito utilizadas na construção demodelos de uso para o teste estatístico, e as SAN possuem o mesmo poder derepresentação das MC, no entanto, de forma modular. Com isso, este trabalhonão visa discutir outras formas de representação formal dos modelos de uso, masbusca explorar as MC e SAN no sentido de avaliar métricas e resultados na geraçãode casos de teste.
A seguir, é apresentada uma descrição formal e informal dos modelos utiliza-dos nesta dissertação, ou seja, as Cadeias de Markov e as Redes de AutômatosEstocásticos.
2.4.1 Cadeias de Markov - MC
Uma máquina de estados finita (FSM) é representada por arcos que correspondema transições que interligam estados. Cada transição contém o estado origem, umevento de entrada, saída ou uma ação e o próximo estado [5, 19]. Máquina deestados finitos também são conhecidas como autômatos finitos e são aplicadaspara qualquer modelo que possa ser descrito com precisão por um número finitode estados e geralmente pequeno [13]. As FSM também são empregadas no testede software como visto em [28].
Grafos são equivalentes a máquinas de estados finitos e modelam sistemas com-plexos e de tempo-real. Grafos fornecem um framework para especificar máquinasde estados em uma hierarquia, ou seja, um simples estado pode ser expandido em

CAPÍTULO 2. TESTE ESTATÍSTICO 10
outra máquina de estados e eles também agregam características especiais paramáquinas de estados concorrentes [13].
As Cadeias de Markov (MC) são por sua vez uma extensão das máquinas deestados e grafos onde as transições possuem taxas ou probabilidades.
2.4.1.1 Definição Formal
Considera-se a formalização de um modelo em Cadeias de Markov a Escala deTempo Contínuo1 (CTMC - Continuous Time Markov Chain) compreendendo umconjunto finito de estados e transições.
Dado um conjunto finito E de estados, uma MC é definida como:
(E, Tx,y)
Onde:
• E = E1, E2, . . . , En representa um conjunto de estados, onde n é um númerointeiro, positivo e finito.
• Tx,y representa uma taxa (não nula) de ocorrência de uma transição do estadoEx para o estado Ey.
Outra definição formal das MC pode ser encontrada em [49].
2.4.1.2 Definição Informal
Um processo estocástico é definido como um conjunto de variáveis randômicasdefinidas em um espaço de probabilidade e indexadas por um parâmetro t, ondet representa um intervalo de tempo que pode variar de (− ∝, + ∝). Os valoresassumidos pelo conjunto de variáveis randômicas são chamados de estados. Oprocesso estocástico é discreto quando o intervalo de tempo é discreto e, portantochamado de processo estocástico discreto, (ex. T = (0, 1, 2, . . .)). O processoestocástico é contínuo quando o intervalo de tempo é contínuo, e chamado deprocesso estocástico contínuo (ex. T = (0 ≤ t ≤ +∝)) [43].
O processo estocástico é definido como estacionário quando independe de mu-danças do tempo inicial. Portanto, processo Markoviano é um processo estocásticoquando é caracterizado por não possuir memória em relação ao passado do sistema,isto é, somente o estado atual do sistema pode influenciar no próximo estado [34].
Os estados em um processo Markoviano representam o estado do software. Asações executadas pelos usuários do sistema são definidas como transições entre
1Nos modelos em CTMC as transições entre os estados podem ocorrer em qualquer instantede tempo [43].

CAPÍTULO 2. TESTE ESTATÍSTICO 11
os estados (representadas por arcos). Assim, as MC são definidas como modelosmatemáticos para a resolução de fenômenos randômicos em um tempo. Esse tempoé considerado discreto e possui um número de estados finitos e enumeráveis.
As MC no contexto de modelos de uso podem ser descritas em duas fases deconstrução: A fase estrutural onde os estados e arcos da cadeia são definidos, e afase estatística onde são atribuídas as probabilidades de transições. Como vistona Figura 2.1, o modelo pode ser descrito em um alto nível de abstração. Porexemplo, em uma aplicação o modelo possui um estado inicial (Invocation) e umestado final (Termination). O estado de uso (Usage) representa um conjunto deestados que determina as ações executadas no software em questão [50].
Invocation Usage Termination
Figura 2.1: Exemplo de MC.
A utilização das MC como um modelo para a geração de casos de teste ébastante difundida na literatura, podendo ser encontrados diversos trabalhos [3,45–47,51].
2.4.2 Redes de Autômatos Estocásticos - SAN
As SAN foram propostas por Plateau [36] e consistem em um conjunto de subsis-temas representados por autômatos estocásticos e a interação entre os subsistemasé feita através de regras estabelecidas entre os estados internos de cada autô-mato. As SAN são muito apropriadas para a modelagem de sistemas paralelos edistribuídos que podem, muitas vezes, ser vistos como coleções de componentesque atuam de forma independente, requerendo somente eventuais interações comoações sincronizadas [36].
2.4.2.1 Definição Formal
A descrição formal aqui apresentada é dada de forma diferente da descrição formalapresentada nos trabalhos de Fernandes e Plateau [16,17,35,36].
Dados n conjuntos Si de estados (estados locais), uma SAN é definido a partirde A = A1, A2, . . . An sendo um conjunto de autômatos, onde cada autômato Ai
é composto por estados de Si. Uma SAN é uma estrutura:
(G,E,R, P, I)

CAPÍTULO 2. TESTE ESTATÍSTICO 12
Onde:
• G = G1, G2, . . . Gm é um conjunto de estados globais, tal que cada Gi éum elemento de A1 ×A2× · · ·×An. Em outras palavras, cada estado globalé uma combinação de estados locais de um autômato.
• E = E1, E2, . . . Ek é um conjunto de eventos. Cada evento é uma funçãoEi : G → P (G). Ou seja, cada evento mapeia estados locais em conjuntosde estados globais. Quando um evento é disparado, a SAN pode ir paraqualquer elemento do conjunto especificado por uma função, dependendodas probabilidades associadas ao evento. Assumindo que um estado globalé uma lista de estados locais, a função descreve para cada autômato Ai emuma rede, o que acontece no autômato quando o evento é disparado. Eventospodem ser classificados como locais e sincronizantes. Um evento local mudao estado de somente um autômato e um evento sincronizante muda o estadode dois ou mais autômatos.
• R = R1, R2, . . . Rk é um conjunto de taxas funcionais, uma para cadaevento. Cada função Ri : G → R
+ descreve a taxa de ocorrência do eventode cada estado global.
• P = P1, P2, . . . Pk é um conjunto de funções de probabilidade de transição(possivelmente vazio), um para cada tupla (evento, estado global). Comodefinido acima, para um evento i, quando a SAN está em um estado globalGi e o evento é disparado, a SAN vai para o estado Gj o qual deve serum elemento de Ei(Gi). A função de probabilidade de transição descreve aprobabilidade de diferentes elementos de Ei(Gi) estarem selecionados. Usual-mente, Ei(Gi) tem somente um estado, então a definição dessa probabilidadeé opcional.
• I ⊆ G é um conjunto (possivelmente vazio) de estados iniciais. Na definiçãooriginal SAN não possui um estado inicial, mas um conjunto de estadosatingíveis. A definição de estados iniciais é útil em modelos de uso, e nãomuda o formalismo SAN.
Qualquer SAN pode ser convertida em uma MC correspondente [16]. Os esta-dos da MC correspondem aos estados globais da SAN.
As SAN têm demonstrado um grande número de vantagens para a modelagemde sistemas complexos em comparação com as MC [18,41]. Para o teste estatísticobaseado em modelos de uso as vantagens também são evidentes e os modelos SANsão construídos sem perda de informações. Modelos de uso descritos com SANtêm algumas características interessantes [15]:

CAPÍTULO 2. TESTE ESTATÍSTICO 13
• requisitos do ambiente podem ser explicitamente modelados, por exemplo,servidores, comunicação entre ambientes diferentes, etc;
• a representação é modular, melhorando a manutenção e leitura do modelo;
• um uso individual é uma seqüência de estados globais em uma SAN, assim,sua descrição é mais detalhada, o que torna simples o mapeamento de usoem casos de teste.
2.4.2.2 Definição Informal
Como mencionado, no formalismo SAN os estados globais são definidos como acombinação de estados de cada autômato, chamados estados locais. Na Figura 2.2pode ser visto um exemplo de um modelo SAN com dois autômatos completamenteindependentes.
x(1)
A(2)A(1)
y(1)z(1)
u(2)
w(2)
e1
e2
e3
e4e5
Tipo Evento Taxa Tipo Evento TaxaLoc e1 τ1 Loc e4 τ4
Loc e2 τ2 Loc e5 τ5
Loc e3 τ3
Figura 2.2: Exemplo SAN com dois autômatos independentes.
O autômato A(1) possui três estados locais (x(1), y(1), z(1)). O autômato A(2)
possui dois estados locais (u(2), w(2)). Os eventos nesse exemplo são consideradoslocais, pois cada evento altera apenas o estado de um autômato. Por exemplo,caso o autômato A(1) encontre-se no estado x(1) e o autômato A(2) encontre-seno estado u(2), o autômato A(1) pode passar do estado x(1) para y(1), conforme oevento e1, independente em que estado o autômato A(2) se encontre.
O estado local de um autômato em um tempo t é justamente o estado em queele ocupa no tempo t, e o estado global em um tempo t é dado pelo estado local emcada um dos autômatos da SAN ocupa neste mesmo tempo t. Seguindo o exemplo

CAPÍTULO 2. TESTE ESTATÍSTICO 14
da Figura 2.2 alguns estados globais são x(1)u(2), y(1)u(2), y(1)w(2), z(1)w(2), y(1)u(2).Há basicamente duas formas que as SAN interagem [44]:
• A taxa em que uma transição pode ocorrer em um autômato pode ser umafunção de um estado de outro autômato. Assim transições são chamadasde taxas funcionais. Transições que não são funcionais são chamadas deconstantes.
• Uma transição em um autômato pode forçar a ocorrência de uma transiçãoem um ou mais autômatos. Este tipo de transição é dita como transiçõessincronizantes. Uma transição sincronizante também pode ser representadapor uma taxa funcional ou constante.
Em uma rede de autômatos estocásticos os estados dos autômatos podem sofrermudanças. Quando um evento local muda de estado sem interferir no estado dosdemais autômatos, o evento é chamado de evento local. Quando um evento mudanão somente o seu estado, mas também o estado de outros autômatos simultane-amente, então é chamado de evento sincronizante.
Na Figura 2.3 observamos o evento sincronizante s que representa transiçõesdisparadas simultaneamente nos autômatos A(1) e A(2), onde uma alteração noestado global do modelo ocorre através de uma alteração nos estados locais deambos os autômatos. Também podemos observar no exemplo os eventos locais e1,e2, e3 do autômato A(1), e e4 do autômato A(2) que representam as transições queocorrem no seu autômato através da alteração no estado local do autômato.
x(1)
A(2)A(1)
y(1)z(1)
u(2)
w(2)
e1
e2
e4
s
sπ1
sπ2
e3
Tipo Evento Taxa Tipo Evento TaxaLoc e1 τ1 Loc e4 τ4
Loc e2 τ2 Syn s τ5
Loc e3 τ3
Figura 2.3: Exemplo SAN de um evento sincronizante.
Um evento sincronizante é associado a um conjunto de no mínimo duas tran-sições. As transições sincronizantes possuem estruturas chamadas tripla de sin-

CAPÍTULO 2. TESTE ESTATÍSTICO 15
cronização que é definida por um identificador do evento sincronizante, uma taxade disparo e uma probabilidade de ocorrência [17]:
• Nome do evento sincronizante: É o identificador do evento, onde cada eventosincronizante possui um nome único identificando que a transição ocorresimultaneamente.
• Taxa de disparo: É a taxa em que o evento ocorre. A taxa é apresentadaapenas em um autômato, sendo omitida dos demais (π1 e π2 na Figura 2.3).
• Probabilidade de ocorrência: Cada transição que sai de um mesmo estadolocal recebe uma probabilidade de ocorrência, sendo que essas transições nãoocorrem simultaneamente e a soma das probabilidades é igual a um.
Considerando os tipos de eventos, locais e sincronizantes, podemos ter taxasconstantes apresentadas como números reais não negativos, e taxas funcionaisrepresentadas por uma função para um único número real não negativo. As taxasfuncionais e os eventos sincronizantes representam as duas formas de interaçãoentre autômatos em uma SAN [44].
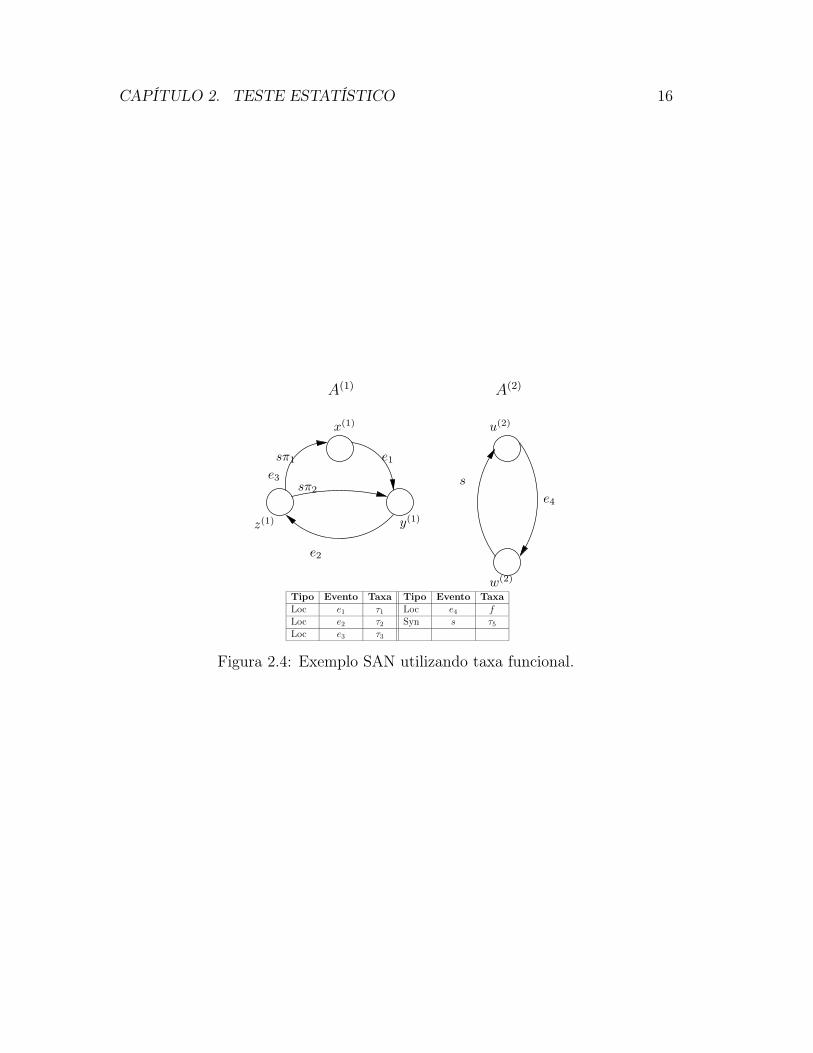
Os estados da SAN indicam qual é a taxa utilizada no momento da transição.No exemplo da Figura 2.4, o autômato A(2) apresenta, além do evento local l4, ataxa funcional f , definida como:
f =
λ1 se A(1) estiver no estado x(1)
0 se A(1) estiver no estado y(1)
λ2 se A(1) estiver no estado z(1)
(2.1)
Assim, a transição do estado u(2) para o estado w(2) irá ocorrer com a taxade λ1 se o autômato A(1) estiver no estado x(1). Se o se o autômato A(1) estiverem z(1) a taxa de transição será de λ2. Caso o autômato A(1) esteja no estadoy(1), a transição u(2) para w(2) não irá ocorrer, portanto com taxa igual a zero.Neste exemplo, a taxa funcional está sendo utilizada com um evento local, porémela não está limitada a apenas eventos locais, podendo ser utilizada com eventossincronizantes.
As SAN representam uma importante ferramenta de modelagem que se tornamuito útil principalmente para sistemas paralelos e distribuídos. Estes sistemas po-dem dispor de muitos estados e, portanto, a sua representação utilizando MC poderesultar no problema de explosão de estados. Além disso, tais sistemas freqüen-temente podem ser vistos como módulos ou coleções de componentes e, portanto,o aspecto modular que as SAN agregam acaba sendo uma importante vantagemfrente às MC [44].
CAPÍTULO 2. TESTE ESTATÍSTICO 16
x(1)
A(2)A(1)
y(1)z(1)
u(2)
w(2)
e1
e2
s
sπ1
sπ2
e3
e4
Tipo Evento Taxa Tipo Evento TaxaLoc e1 τ1 Loc e4 f
Loc e2 τ2 Syn s τ5
Loc e3 τ3
Figura 2.4: Exemplo SAN utilizando taxa funcional.

Capítulo 3
Estudos de Caso
Este capítulo descreve os estudos de caso realizados com a finalidade de evoluiralguns resultados numéricos na geração estatística de casos de teste. Um pequenoexemplo de um sistema de login é apresentado por completo, demonstrando todoo processo de construção de um modelo de uso. O primeiro estudo de caso refere-se à aplicação Simple Counter Navigation, que corresponde a uma aplicação denavegação entre páginas Web. Para o segundo estudo de caso utilizou-se a apli-cação Calendar Manager, que se caracteriza por um sistema de gerenciamento docalendário acadêmico, com funcionalidades de edição de calendários e seus respec-tivos eventos. No terceiro estudo de caso, modelou-se a aplicação Docs Editor queconsiste em um editor de planos de teste.
3.1 Exemplo: Sistema de Login
Considere um simples sistema de login com dois diálogos: O primeiro é o diálogode login (Figura 3.1a), onde o usuário entra com seu nome e senha; se o nome esenha estiverem incorretos, a aplicação apresenta uma mensagem de erro (Figura3.1b); o segundo diálogo apresenta um menu onde o usuário pode simplesmentesair da aplicação (Figura 3.1c).
Na Figura 3.2, a Cadeia de Markov (MC) equivalente descreve a aplicação com4 estados e 7 transições. Cada estado corresponde a:
• Estado Start : Representa o estado inicial da aplicação. Quando a transiçãocom taxa τ1 é executada a aplicação é iniciada.
• Estado Password : Representa a tela de validação do nome e senha (Figura3.1a). Estando neste estado a aplicação pode passar para o estado PNotOKcom uma taxa de transição τ5 ou para o estado menu executando a taxa de
17

CAPÍTULO 3. ESTUDOS DE CASO 18
Username/PasswordInvalid
(a)
(b)
(c)
Username/PasswordValid
Figura 3.1: Sistema de Login.
τ3. Se a transição com taxa τ2 é executada a aplicação é finalizada voltandopara o estado inicial.
• Estado PNotOK : Representa a mensagem de erro (Figura 3.1b). Executandoa transição com taxa τ4 a aplicação volta para o estado Password. Se atransição com taxa τ2 é executada a aplicação é finalizada voltando para oestado inicial.
• Estado Menu: Representa o menu da aplicação (Figura 3.1c). Quando atransição com taxa τ2 é executada a aplicação é finalizada voltando para oestado inicial.
Start
PNotOK
Menu
Password
τ2
τ1
τ5
τ4
τ3
τ2
τ2
Figura 3.2: Modelo MC: Sistema de Login.
Na Figura 3.3 esta mesma aplicação é descrita por uma SAN com dois autô-matos representando em que tela estamos e qual o status da tela. Neste modelotemos cinco eventos possíveis:
• Evento ST: Representa o início da execução, ou seja, a alteração do estadoinicial [Start, Waiting] para o estado global [Password, Waiting].

CAPÍTULO 3. ESTUDOS DE CASO 19
• Evento QT: Representa o fim da execução por interrupção ou término nor-mal, ou seja, a alteração do estado [Password, Waiting] para [Start, Waiting]ou estado [Menu, Waiting] para [Start, Waiting] ou estado [Menu, POK] para[Start, Waiting].
• Evento S: Representa a entrada de um usuário no sistema, ou seja, a alteraçãodo estado [Password, Waiting] para [POK, Menu].
• Evento l1: Representa um usuário inválido, ou seja, a alteração do estado[Password, Waiting] para [Password, PNotOk].
• Evento l2: Representa a saída da mensagem de erro e retorno para a telade login, ou seja, a alteração do estado [Password, PNotOk] para [Password,Waiting].
Menu
QT
SPassword
QT
S
QT
Start
Waiting
POK
PNotOKST
ST QT
Windows Status
l1
l2
Tipo Evento Taxa Tipo Evento TaxaSync ST 2.0 Sync S 1.5Sync QT 0.1 Loc l2 1.0Loc l1 f
f = [st Windows == Password] ∗ 0.5
Figura 3.3: Modelo SAN: Sistema de Login.
ST , QT e S são eventos sincronizantes, enquanto l1 e l2 são locais. O eventolocal l1 tem uma taxa funcional f . Segundo a definição de f , este evento só poderáocorrer quando o autômato Windows estiver no estado Password. Observa-se que omodelo SAN possui nove estados globais onde apenas quatro são atingíveis (Tabela3.1). Neste sentido, o modelo SAN acaba não se tornando mais compacto que seumodelo equivalente MC. Mesmo assim, o objetivo em apresentar esse modelo é oentendimento de como as aplicações são modeladas.
As taxas reais para os modelos de uso são obtidas por logs de usuários, ou seja,a aplicação é monitorada por um determinado período de tempo e os logs geradossão convertidos em taxas. Desta forma, a aplicação é utilizada por um tempoarbitrário e então logs contendo informações de uso (links visitados, formuláriospreenchidos, etc) são gerados. O percentual de ocorrência de transições (MC) oueventos (SAN) é interpretado como taxa de ocorrência. Por exemplo, se o evento

CAPÍTULO 3. ESTUDOS DE CASO 20
Tabela 3.1: Correspondência dos estados da MC: Sistema de Login.
SAN - Estado global MC - Estado(Start, Waiting) Start(Start, PNokOK) ———(Start, POK) ———(Password, Wainting) Password(Password, PNokOK) PNotOK(Password, POK) ———(Menu, Waiting) ———(Menu, PNokOK) ———(Menu, POK) Menu
S ocorre dez vezes em um total de vinte vezes, logo, sua taxa é igual à 0.5. Umexemplo desse processo pode ser visto em [29].
3.2 Estudo de Caso 1: Simple Counter Navigation
Para o primeiro estudo de caso utilizou-se uma aplicação chamada Simple CounterNavigation a qual foi desenvolvida pelo CPTS. Primeiramente é apresentada umadescrição da aplicação, e logo após seu modelo MC seguido pelo modelo SANequivalente.
3.2.1 Descrição da Aplicação
A aplicação consiste em páginas HTML e JavaScript. A aplicação é apresentadada seguinte forma:
• Tela Inicial (estado Start): Apresenta o início da aplicação e possui doislinks: link NEXT1 que vai para a próxima janela e link CLOSE que fechaa aplicação.
• Janela 1 (estado main): Apresenta uma única opção disponível e o linkNEXT2 para a janela 2.
• Janela 2 (estado win01): Apresenta dois links para caminhos diferentes. Nolink CAMINHO1 a aplicação retorna a tela inicial, e no link CAMINHO2a aplicação passa para a janela 3.

CAPÍTULO 3. ESTUDOS DE CASO 21
• Janela 3 (estados win0301, win0101, win0302, win0402, win0303): Apresentaum contador com valor inicial igual a 0 e cada vez que o link NEXT5 éacionado, a aplicação passa para a janela 4, onde o contador é incrementado.Quando o contador tiver o valor 2 a próxima vez em que o link NEXT5 foracionado a aplicação retorna a tela inicial.
• Janela 4 (estado win02): Apresenta a última tela da aplicação onde é possívelvoltar para a tela inicial através do link NEXT7 ou retornar a tela anterioratravés do link BACK.
3.2.2 Modelo de Cadeia de Markov
O modelo MC para a aplicação Simple Counter Navigation possui nove estadosconforme apresentado na Figura 3.4.
ST
QT
LV
L2
S
L1start
main
win01
win02
win03_01
win04_01
T
V
L3
L4
win03_02
win04_02
win03_03
V
T
T
L5
L6
Figura 3.4: Modelo MC: Simple Counter Navigation.
3.2.3 Modelo SAN
O modelo de uso da aplicação considera os seguintes elementos:
• A aplicação ativa e não ativa.
• A navegabilidade da aplicação, ou seja, as telas e as opções (links) de nave-gação disponíveis ao usuário.
• O contador existente na janela 3.

CAPÍTULO 3. ESTUDOS DE CASO 22
Sendo assim, foram definidos três autômatos para a aplicação:
• Autômato Application: Representa o início da aplicação (estado run) e ofechamento da aplicação, fazendo a aplicação voltar a um estado inicial start.
• Autômato Navigation: Representa as possibilidades de navegação entre astelas da aplicação.
• Autômato Count: Representa o contador da aplicação.
O modelo SAN apresentado na Figura 3.5 possui cinco eventos sincronizantese sete eventos locais, possuindo um total de 60 estados, sendo que apenas 9 sãoatingíveis. Na situação inicial da aplicação (tela inicial), ela encontra-se no estadorun do autômato Aplication, estado main do autômato Navigation e no estadostart do autômato Cont.
Os eventos sincronizantes são:
• Evento ST : Ocorre quando a aplicação é iniciada passando do estado start,
start, start para o estado run,main, start.
• Evento QT : Ocorre quando a aplicação é encerrada, ou seja quando o usuárioacionar o link CLOSE na tela inicial.
• Evento S: Ocorre quando a aplicação passa para a tela onde possui o conta-dor (Janela 3).
• Evento V e T : Ocorrem quando o usuário volta para a tela inicial.
Os eventos locais são:
• Evento L1: Ocorre quando a aplicação passa do estado main para o estadowin01 do autômato Navigation.
• Evento L2: Ocorre quando a aplicação passa do estado win01 para o estadowin02 do autômato Navigation.
• Evento L3: Ocorre quando a aplicação passa do estado win03_01 para oestado win04_01 do autômato Cont.
• Evento L4: Ocorre quando a aplicação passa do estado win04_01 para oestado win03_02 do autômato Cont.
• Evento L5: Ocorre quando a aplicação passa do estado win03_02 para oestado win04_02 do autômato Cont.

CAPÍTULO 3. ESTUDOS DE CASO 23
Aut Aplication (AA)
ST
QTstart run
ST
QT
LV
L2
S
L1
V T
start
main
win01
win02
win03
Aut Navigation (AN)
V
T
ST S f
start
win04_01
L4 L5 L6L3
win03_01
win03_02
win04_02
win03_03
Aut Cont (AC)
TT
V
Figura 3.5: Modelo SAN: Simple Counter Navigation.
• Evento L6: Ocorre quando a aplicação passa do estado win04_02 para oestado win03_03 do autômato Cont.
• Evento LV : Ocorre quando a aplicação passa do estado win02 para o estadomain do autômato Navigation.
Logo após, foi gerada a descrição textual do modelo SAN conforme apresentadano Apêndice C. Tal descrição é utilizada para a obtenção das probabilidades dosestados que serão utilizadas para o cálculo da métrica.
O modelo SAN corresponde a MC apresentada na Tabela 3.2, onde observa-sea equivalência dos estados da MC para o formalismo SAN.

CAPÍTULO 3. ESTUDOS DE CASO 24
Tabela 3.2: Correspondência dos estados da MC: Simple Counter Navigation.
Estados da Cadeia Autômatos da SANde Markov Application Navigation Cont
start start start start
main run main start
win01 run win01 start
win02 run win02 start
win03_01 run win03 win03_01win04_01 run win03 win04_01win03_02 run win03 win03_02win04_02 run win03 win04_02win03_03 run win03 win03_03
Note que mesmo o modelo SAN possuindo uma complexidade maior e o modeloMarkov ser relativamente simples, ambos são equivalentes e representam exata-mente as mesmas funcionalidades do modelo.
3.3 Estudo de Caso 2: Calendar Manager
Para o segundo estudo de caso utilizou-se uma aplicação Web que cria calendáriosacadêmicos e organiza as datas de eventos, feriados, inicio e fim de semestre, etc.Baseado nas funcionalidades da aplicação procurou-se construir o modelo SAN.Assim, foi modelada a MC correspondente identificando os estados da cadeia comseu estado global correspondente do modelo SAN. Fazendo uso da ferramentaPEPS, descreveu-se o modelo SAN em uma linguagem textual conforme pode servisto no Apêndice D.
3.3.1 Descrição da Aplicação
A aplicação é acessada através de um browser e é composta por páginas JSP. Asua principal funcionalidade é a manutenção de calendários através da inclusão eedição de eventos. A aplicação é apresentada da seguinte forma:
• Tela Inicial: Corresponde à tela de entrada da aplicação, onde possui doislinks. O primeiro link "ADM"refere-se a uma área restrita a usuários cadastra-dos onde são acessadas as funções administrativas da aplicação. O segundolink "CONSULTAR"refere-se a uma área publica onde qualquer usuáriopode consultar o calendário.

CAPÍTULO 3. ESTUDOS DE CASO 25
• Tela Login: Nesta tela é acessada através do link "ADM"e possui um for-mulário para a identificação de usuários devendo ser informados o nome e asenha. O usuário pode também cancelar e voltar para a tela inicial.
• Tela Menu Inicial: Nesta tela o usuário autorizado encontra as opções devisualizar calendário, criar eventos, pesquisar eventos e criar novo calendáriosão apresentadas em um menu esquerdo.
• Tela Criar Eventos: Representa a tela onde os eventos são criados. Quandoo botão (link) OK é acionado e os campos do formulário são validados.Também possui a possibilidade de cancelar essa ação.
• Tela Pesquisar: Representa a tela de pesquisa que possibilita a localizaçãodos eventos do calendário. Caso seja requisitado uma consulta com o campode texto em branco todas as ocorrências serão listadas.
• Tela Lista Pesquisa: Representa o resultado de uma pesquisa dos eventos.Observa-se que cada evento possui dois links. O link "APAGAR"que apagao evento e o link "ALTERAR"direciona a outra página para a realização deuma possível alteração.
• Tela Altera: Representa a tela de alteração da descrição de um evento. Pos-suindo o botão (link) de "GRAV AR"o qual confirma a alteração, e o botão(link) de "CANCELAR"que cancela a alteração.
• Tela Cria novo Calendário: Representa a inserção de um novo calendário,por exemplo, a inserção do calendário acadêmico para o próximo ano. Casoo botão (link) "GRAV AR"é acionado, efetua-se a validação do formulárioe um novo calendário é criado. Possui também a opção de cancelar a açãoatravés do botão (link) "CANCELAR".
3.3.2 Modelo de Cadeia de Markov
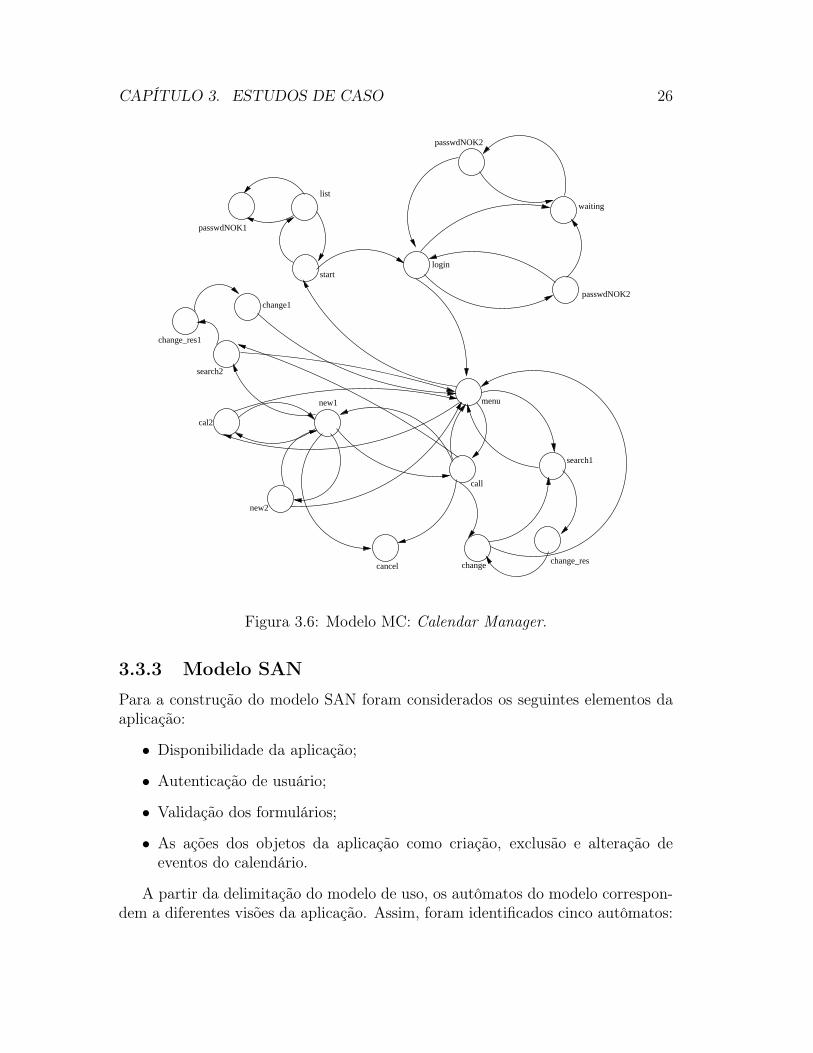
O modelo equivalente, que constitui na combinação de todos os autômatos, possui336 estados globais (2×3×4×2×7) onde apenas 16 desses estados são atingíveisconforme apresentado na Figura 3.6. Este modelo não mostra os eventos por umaquestão de visualização.
CAPÍTULO 3. ESTUDOS DE CASO 26
passwdNOK1
list
passwdNOK2
login
menu
changecancel
call
cal2
passwdNOK2
search1
change_res
new2
search2
new1
start
waiting
change1
change_res1
Figura 3.6: Modelo MC: Calendar Manager.
3.3.3 Modelo SAN
Para a construção do modelo SAN foram considerados os seguintes elementos daaplicação:
• Disponibilidade da aplicação;
• Autenticação de usuário;
• Validação dos formulários;
• As ações dos objetos da aplicação como criação, exclusão e alteração deeventos do calendário.
A partir da delimitação do modelo de uso, os autômatos do modelo correspon-dem a diferentes visões da aplicação. Assim, foram identificados cinco autômatos:

CAPÍTULO 3. ESTUDOS DE CASO 27
• O autômato Application: Representa o estado inicial (start) e estado final(run) da aplicação.
• O autômato Navigation: Representa as possibilidades de navegação na apli-cação, ou seja, o usuário pode apenas consultar o calendário ou entrar emuma área restrita onde poderá realizar alterações nos calendários.
• O autômato Password: Representa a validação de usuários. Partindo de umestado inicial (waiting). Se algum erro de autenticação ocorrer o autômatopassará para o estado (passwdNOK). Se o usuário for validado com sucessoo autômato passará para o estado (passwdOK).
• O autômato Validation: Representa as validações de formulários (exceto deusuário) realizadas pela aplicação. Por default definiu-se que a aplicaçãoencontra-se no estado (testOK), e se ocorrer algum erro de validação, entãoo autômato passa para o estado (testNOK).
• O autômato Menu: Representa todas as possibilidades de manutenção doscalendários, e também a criação de novos calendários.
Na Figura 3.7 temos a representação do modelo SAN da aplicação. O modeloé composto de três eventos locais e 13 eventos sincronizantes. O estado inicial(tela inicial) do modelo é representado pelos estados start do autômato AA, start
do autômato AN , testOK do autômato AV , waiting do autômato AP e start doautômato AM .
Os eventos locais são representados por:
• Evento LA: Ocorre quando o usuário encontra-se na tela de pesquisa e efetuaa pesquisa de um ou mais eventos.
• Evento LB: Ocorre quando o usuário encontra-se na tela com os resultadosda pesquisa e aciona o link ALTERAR.
• Evento LD: Ocorre quando um evento é excluído do calendário acadêmico.
Os eventos sincronizantes são representados por:
• Evento ST : Representa o início da aplicação, ou seja, quando o usuário iniciao acesso às funcionalidades da aplicação.
• Evento QT : Este evento leva os estados dos autômatos para o estado inicial.
• Evento C: Este evento leva os estados do autômato para o estado inicialquando a senha do usuário não é válida, ou quando ao entrar na tela de logino usuário aciona o botão (link) "CANCELAR".

CAPÍTULO 3. ESTUDOS DE CASO 28
Aut Menu (AM) Aut Password (AP)
Aut Validation (AV)
run
startQT
Aut Aplication (AA)ST
Vπ1
search
change
change_res
cal
Vπ3
Vπ2 newNEπ8
NEπ9
SEπ6
NCπ4
NCπ5 LB
OK
CA
LD
CA
CA
CA
NI
CI
LA
start
view
S
QT
QT
SEπ7
Aut Navigation (AN)
V
passwdOK
waiting
QT
S
f
f
C QT
R passwdNOK
QT
f
testNOK
testOK
NE
SE NC
QT
CAOK
CA
CASE
VNC
NI
CI
CI
NEQTOK
NI
S
login
C
QT
R
loginNOK
STπ2
list
STπ1
QT
QT
start
QT
Figura 3.7: Modelo SAN: Calendar Manager.
• Evento S: Representa a transação onde os usuários já validados entram emuma área restrita. Possui uma taxa funcional f .
• Evento V : Ocorre quando o usuário após efetuado o login aciona em uma dasopções do menu (Criar Eventos, Pesquisar Eventos, Cria Novo Calendário).Possui uma taxa funcional f .
• Evento NE: Ocorre quando o usuário encontra-se em Criar Evento e acionauma das funcionalidades: Pesquisar Eventos ou Cria Novo Calendário. Pos-sui uma taxa funcional f .
• Evento OK: Ocorre quando uma alteração em um evento do calendário éefetuada. Possui uma taxa funcional f .
• Evento SE: Ocorre quando o usuário encontra-se em Pesquisar Eventos eaciona a funcionalidade de Criar Evento ou Cria Novo Calendário. Possuiuma taxa funcional f .
• Evento CA: Ocorre sempre quando alguma ação é cancelada. Possui umataxa funcional f .
• Evento CI: Ocorre quando um novo calendário é inserido. Possui uma taxafuncional f .
• Evento NI: Ocorre quando um novo evento do calendário é incluído. Possuiuma taxa funcional f .

CAPÍTULO 3. ESTUDOS DE CASO 29
• Evento NC: Ocorre quando o usuário encontra-se em Cria Novo Calendárioe aciona a funcionalidade de Pesquisar Eventos ou Criar Evento. Possui umataxa funcional f .
• Evento R: Este evento ocorre quando o login não é validado pela ocorrênciade alguma inconsistência informada pelo usuário.
Para compilação na ferramenta PEPS, gera-se uma descrição textual do modeloda Figura 3.7, apresentada no Apêndice D. Utilizando a ferramenta PEPS é pos-sível resolver o modelo, ou seja, encontrar a distribuição estacionária dos estadosglobais.
Cada um dos estados da MC corresponde a um estado global da SAN. Omapeamento dos estados globais visto na Tabela 3.3 apresenta para cada estadoda MC a combinação dos estados locais correspondente a um estado global daSAN.
Tabela 3.3: Correspondência dos estados da MC: Calendar Manager.
Estados da Autômatos da SANCadeia de Markov Application Navigation Password Validation Menu
start start start waiting testOK start
list run list waiting testOK start
login run login passwdOK testOK start
menu run login passwdOK testOK view
new run login passwdOK testOK new
cal run login passwdOK testOK cal
search run login passwdOK testOK search
change_res run login passwdOK testOK change_res
change run login passwdOK testOK change
cancel run login passwdOK testNOK view
new2 run login passwdOK testNOK new
cal2 run login passwdOK testNOK cal
search2 run login passwdOK testNOK search
change_res2 run login passwdOK testNOK change_res
change2 run login passwdOK testNOK change
loginNOK run loginNOK passwdNOK testOK start
Observe que este modelo não apresenta muitos estados atingíveis, no entanto aquantidade de transições é significativa o que torna o modelo em SAN muito maisclaro.

CAPÍTULO 3. ESTUDOS DE CASO 30
3.4 Estudo de Caso 3: Docs Editor
Docs Editor é um editor de documentos baseado em formulários genéricos paraser usado na criação e manutenção de informações sobre teste. O modelo MC doDocs Editor é composto por 417 estados e 2593 transições. Cabe ressaltar queo modelo MC não é apresentado graficamente pelo fato de possuir uma grandequantidade de estados. Desta forma a visualização do modelo MC torna-se difícil,e a manutenção do modelo requer cautela e atenção.
O modelo SAN (Figura 3.8) é composto por seis autômatos com 720 (2×2×2×3× 3× 10×) estados, tendo 417 estados atingíveis. Os 6 autômatos que compõemo modelo SAN são:
• Autômato Server (AS): Representa a ativação ou não do servidor.
• Autômato Application (AA): Representa o início e o fim da aplicação.
• Autômato Browser (AB): Representa a visualização ativa ou não do browser.
• Autômato Tree (AT): Representa a árvore de navegação utilizada para qual-quer mudança efetuada em um documento.
• Autômato Document (ADoc): Representa um documento aberto, salvo ounão aberto.
• Autômato Dialogs (AD): Representa todos os diálogos da aplicação.
Algumas considerações sobre os estudos de caso são interessantes de seremobservadas. Primeiramente observa-se que dos estudos de caso realizados apenaso último (Docs Editor) apresenta uma quantidade de estados grande tornando-seinviável a sua representação em MC. Desta forma para todos os demais estudos decaso são apresentados o modelo SAN e MC correspondente.
Observa-se também que com as SAN aplicações maiores tornam-se mais fá-ceis de serem usadas, no entanto uma serie de estados inatingíveis são inseridosno modelo. Além de conceitos mais elaborados como estados globais e locais etaxas funcionais, mesmo assim, o formalismo é mais poderoso pois aplicações maiscomplexas podem ser modeladas de forma mais fácil.

CAPÍTULO 3. ESTUDOS DE CASO 31
l2 run
ST R
browser no browserQT R
RR
start
QT l3
l4
QT l6
l5
unit
title
QT
QT
RR
C O S
TS
D
l20
ndoc
QT
start
d7
S
d1
O
CC
C
T
Tnd
d6
d8
l9
l18
l19
l8
D
Automato Dialogs (AD)
Automato Document (ADoc)
Automato Server (AS) Automato Application (AP) Automato Browser (AB)
Automato Tree (AT)
no serverserver
l1
root
other
leaf
QT
l17
l16l13 l11
d5
d3
d4
l12l10
d2ST
QT
l15 l14
Type Event Rate Type Event Rate Type Event RateSync ST τ1 Sync C τ10 Loc l6 τ19
Sync QT τ2 Sync T τ11 Loc l7 τ20
Sync R τ3 Sync D τ12 Loc l8 τ21
Sync S τ4 loc l3 τ13 ∗ f Loc l9 τ22
Loc l1 τ5 Sync l4 τ14 Loc l10 τ23
Loc l2 τ6 Sync l5 τ15 Loc l11 τ24 ∗ f
Loc l12 τ7 Sync l13 τ16 Loc l14 τ25 ∗ f2Loc l15 τ8 Sync l16 τ17 Loc l17 τ26
Loc l18 τ9 Sync l19 τ18
f = [st Documents == Unititled];f2 = [st Tree == Root&&Documents == NoDoc];
Figura 3.8: Modelo SAN: Docs Editor.

Capítulo 4
Geração Estatística de Casos deTeste
Este capítulo apresenta um processo de desenvolvimento de teste estatístico desoftware utilizado no Centro de Pesquisa em Teste de Software (CPTS) e asferramentas utilizadas na automatização de todo o processo.
O processo de teste estatístico utilizado no CPTS pode ser dividido em seisetapas:
1. Identificação de funcionalidades: Corresponde em identificar funcionalidadesda aplicação e aspectos que se pretende agregar confiabilidade e minimizarao máximo eventuais falhas.
2. Construção do modelo: Corresponde em descrever formalmente o modelo daaplicação, ou as funcionalidades que se pretende testar, em MC ou SAN.Cabe ressaltar que aspectos com ambiente também podem ser consideradosna modelagem da aplicação (como por exemplo sistema operacional, browser,etc.). Assim, é importante que a modelagem descreva exatamente tudo quese pretende testar.
3. Atribuição de probabilidades: Corresponde em definir os aspectos estatísticosdo modelo, ou seja, as probabilidades de ocorrência das transições (MC)ou eventos (SAN). Estas probabilidades são extraídas de logs de usuários,versões beta ou mesmo versões anteriores.
4. Geração dos casos de teste: Corresponde em utilizar o modelo formal (MC ouSAN) da aplicação para a execução de algoritmos estatísticos, ou seja, geraros casos de teste que correspondem a um conjunto de execuções a seremrealizadas na aplicação.
32

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 33
5. Descrição dos objetos da aplicação: Corresponde em mapear no modelo for-mal os objetos da aplicação, ou seja, os componentes visuais como botões,menus, janelas.
6. Geração de scripts de teste: Corresponde em utilizar os casos de teste geradose traduzi-los para um script que possa ser utilizado por uma ferramenta queleia e automatize uma seqüência de execuções (por exemplo, um robô).
Basicamente, o processo de automatização na área de Teste de Software requera geração de casos de teste e scripts que executem estes casos de teste em umaaplicação para a sua validação. Foi desenvolvido pelo CPTS um framework de au-tomatização do processo de teste estatístico chamado State Based Test Generator- STAGE.
A Figura 4.1 apresenta uma visão geral das ferramentas que compõem o STAGEpara a automatização do processo de teste estatístico [12]. Assim, para que sejapossível gerar os scripts de teste é necessário que uma aplicação seja modeladautilizando-se algum método formal através da ferramenta STAGE-Model que seráapresentada na próxima seção. Para fazer esta modelagem não é necessário ter-sea aplicação concluída, ou seja, é possível fazer esta modelagem através da especi-ficação da aplicação, pois é nela onde devemos encontrar todas as informaçõesrelevantes para o conhecimento da aplicação. No entanto a extração das taxasou probabilidades de ocorrências poderão não corresponder a realidade, caso essainformação não esteja descrita na especificação, ou não se possa extrair as taxasatravés de logs.
Observa-se na Figura 4.1 que o STAGE está integrado com a ferramenta PEPSpossibilitando a exportação e importação da matriz esparsa1 e modelo SAN. Alémdisso, ele possui um módulo responsável por mapear os estados do modelo nos ob-jetos da aplicação. Esse mapeamento é feito através de arquivos XML e possibilitaa geração automática dos scripts.
Como está sendo proposto nesta dissertação a utilização de uma métrica queterá como objetivo verificar a relevância dos casos de teste gerados, pode-se incor-porar no processo de teste estatístico mais duas etapas:
• Resolução do modelo: Corresponde em descrever o modelo MC ou SAN emformato textual que servirá de entrada para o PEPS e compilá-lo e executá-lo. O intuito dessa etapa é obter um arquivo com os estados atingíveis esuas respectivas probabilidades e um arquivo com a matrix de taxas (outransições) do modelo.
• Execução da métrica: Corresponde em executar o cálculo da métrica de
1Uma matriz esparsa é uma matriz onde a maioria de seus elementos são nulos [31].

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 34
índice de cobertura baseado em trajetórias e, assim, saber o percentual derelevância de um determinado conjunto de casos de teste.
Script engine(Rational)
Test CasesMCVFSMFSM
SAN
.san
.hbf
.xml
PEPS STAGE−Model STAGE−Test STAGE−Script
Figura 4.1: STAGE Framework.
Os arquivos de saída da ferramenta PEPS podem ser utilizados como entradapara as ferramentas do framework. A saída compreende em dois arquivos:
• Arquivo HBF: Corresponde ao arquivo que possui a matriz correspondentea MC. Este arquivo é gerado a partir do modelo SAN através da ferramentaPEPS.
• Arquivo REA: Corresponde ao arquivo que possui o vetor de probabilidadesdos estados atingíveis. A Tabela 6.1 apresenta os estados globais atingíveise a probabilidade de cada estado. Observa-se que a soma das probabilidadesdo modelo é igual a 1 e foi calculada a partir do software PEPS.
4.1 Ferramentas de Geração Estatística
A seguir são apresentadas as duas principais ferramentas de geração estatísticautilizadas. No contexto deste trabalho, não é avaliado a geração e execução dosscripts. Assim, as ferramentas utilizadas compreendem a ferramenta de modelagemdos casos de uso (STAGE-Model) e a ferramenta de geração de casos de teste(STAGE-Test) [12].

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 35
4.1.1 STAGE-Model
O STAGE-Model é uma ferramenta que permite modelar aplicações em conjun-tos de estados e transições que correspondem à um modelo da aplicação, ou seja,é possível modelar utilizando qualquer um dos seguintes formalismos: Máquinasde Estado Finitas, Máquinas de Estado Finitas com Variáveis, SAN ou MC. Nosmodelos de casos de uso, por exemplo, temos estados que representam as telas daaplicação e transições que representam as ações do usuário sobre o sistema. Con-forme visto na Figura 4.2, o STAGE-Model apresenta-se como um editor gráficopara representar formalmente uma aplicação.
Figura 4.2: STAGE-Model.
Para a correta geração dos casos de teste, deve-se observar que para modelagemna ferramenta STAGE-Model alguns aspectos são importantes:
• O modelo de estados deve estar completamente especificado.
• Todos os estados devem possuir um conjunto de entradas (inputs) que osidentifiquem.
• Todos os estados devem possuir uma saída associada, ou seja, uma tela queos identifiquem.
• Não pode-se ter estados isolados, ou seja, sem transições que cheguem ousaiam dele.

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 36
• Devemos ter um estado inicial (Start), a partir do qual se inicia a modelagem.
• Precisa-se definir eventos do tipo mestre (master) e escravos (quit) para cadaum dos eventos do modelo. Os eventos do tipo master correspondem aoinicio do modelo eu os do tipo quit representam os estados finais do modelo.
4.1.2 STAGE-Test
Com o objetivo de prover maior confiabilidade e agilidade na criação de casosde teste e scripts, a ferramenta denominada STAGE-Test é responsável por geraros casos de teste e scripts. Esta ferramenta tem como entrada de dados paraa geração de casos de teste a modelagem da aplicação utilizando a ferramentaSTAGE-Model.
A saída da aplicação STAGE-Test, vista na Figura 4.3, corresponde a umatest suite que pode ser salva em uma base de dados ou em arquivo. As testsuites geradas são arquivos base para a geração dos scripts usados na execuçãoautomática dos casos de teste.
Figura 4.3: STAGE-Test.
Além da geração baseada em SAN também é possível gerar casos de teste uti-lizando outros formalismos como: Máquina de estados finitos, máquina de estados

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 37
finito com variável, MC. Cabe ressaltar que a ferramenta STAGE-Test apenasgera os casos de teste e os scripts, sendo que a execução dos scripts é realizada naferramenta RoboJ da Rational para execução automática de testes.
A ferramenta STAGE-Test é capaz de criar os seguintes tipos de scripts deteste para o aplicativo RobotJ da Rational:
• Script de Performance: Este tipo de script é utilizado para testar o tempode resposta de um servidor, simulando múltiplos usuários realizando múlti-plas requisições.
• Script de Duração: Este script é utilizado para executar casos de testesobre uma aplicação durante um longo período de tempo.
• Script de Navegação: Este script é utilizado para navegar sobre a aplicaçãoverificando a ligação entre as janelas da aplicação.
Então, logo após termos modelado na ferramenta STAGE-Model, faz-se o usoda ferramenta STAGE-test, que irá ler o modelo de estados e gerar os casos deteste. Porém é importante observar que esta ferramenta possui alguns métodos degeração de casos de teste. Assim, os métodos utilizados pela ferramenta de acordocom o formalismo são:
• FSM - Máquina de estados finitos:
– Wp Method: Este método gera casos de teste concisos e abrangentespara interfaces de software.
– Graph Tracker: Este método gera o conjunto dos menores caminhosdo grafo em questão, ou seja, caminhos que passam por todos os estadosdo autômato o mínimo possível de vezes.
• VFCM - Máquina de estados finitos com variável:
– Automaton Converter. método utilizado para converter uma VFSMpara FSM. Este método de transformação funciona parcialmente.
• MC - Cadeias de Markov:
– Random Test: Este método utiliza a geração de números aleatóriospara a criação dos casos de teste. Assim, de acordo com a probabilidadegerada os casos de teste são criado.
• SAN - Rede de Autômatos Estocásticos:

CAPÍTULO 4. GERAÇÃO ESTATÍSTICA DE CASOS DE TESTE 38
– San Test: Este método gera casos de teste sobre SAN, baseado emuma geração aleatória de casos de teste supondo distribuição uniforme(equiprovável) de todos os eventos.
Portanto, com os casos de teste modelados e gerados é possível criar qualquerum dos scripts que a ferramenta suporta. Logo após, este script deverá ser inseridono RobotJ como um novo projeto a fim de testar a aplicação.

Capítulo 5
Análise Quantitativa
No sentido de avaliar a geração automática de test suites esta seção demonstraas técnicas utilizadas como medidas de qualidade e uma análise quantitativa dosresultados, para ambos os formalismos: Cadeias de Markov (MC) e Redes deAutômatos Estocásticos (SAN). A análise apresentada nesta seção também podeser encontrada em [9].
Dois pontos são considerados importantes na geração estatística de casos deteste:
• Eficiência na geração: Pelo fato de se trabalhar com amostras estatísticas euma grande quantidade de casos de teste, os algoritmos de geração de casosde teste devem ser rápidos e eficientes;
• Diversidade de Casos de teste: Como um dos objetivos do teste estatístico éprover confiabilidade nas aplicações, quanto maior a quantidade de casos deteste novos, maior serão as situações testadas, e como conseqüência, maiora confiabilidade.
Nas primeiras análises realizadas verificamos: A diversidade de geração dosmodelos computada pelos casos de teste únicos gerados em test suites ; tempo degeração dos algoritmos.
Entretanto, medidas de qualidade mais precisas são necessárias para compararo modelo com as test suites geradas. Desta forma, são apresentadas medidas decomparação de test suites geradas e uma descrição formal do cálculo do índice decobertura de uma test suite.
5.1 Diversidade de Geração
A diversidade de geração dos casos de teste é estimada pela geração de um con-junto satisfatório de casos de teste, ou seja, uma test suite que forneça um bom
39

CAPÍTULO 5. ANÁLISE QUANTITATIVA 40
conjunto de casos de teste distintos sobre o total de casos de teste gerados. Assim,verificamos quantos casos de testes únicos são adicionados a cada test suite geradopara um modelo. Desta forma foram geradas 10 test suite com 500 casos de teste,totalizando 5000 casos de teste. As test suite gerada são limitadas a casos de testede tamanho 10, 20, 30 e 40 passos. Cada passo corresponde a mudança de umestado possuindo a seguinte estrutura estado-transição-estado. Por exemplo, seuma test suite está limitada a 10 passos significa que somente casos de teste comaté 10 passos serão gerados.
As Figuras 5.1 e 5.2 apresentam o número absoluto de novos casos de testegerados para os modelos em SAN e MC das aplicações Calendar Manager e DocsEditor. A partir dessas curvas pode-se observar uma melhor qualidade na geraçãopara os modelos em SAN. Nesse sentido, entende-se que quanto mais casos deteste novos forem gerados, melhor será a qualidade da test suite. Para a aplicaçãoCalendar Manager, a complexidade do modelo SAN é provavelmente a causa paraa irregularidade das curvas. Para a aplicação Docs Editor, o tamanho do modelo(417 estados) deve ser responsável pelos melhores resultados obtidos para o modelodescrito em SAN. Observa-se que os resultados obtidos correspondem a geração decasos de teste utilizando uma ferramenta específica, STAGE-Test, com algoritmosde geração específicos descritos no capítulo anterior.
10 Passos
0
100
200
300
400
500
600
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
30 Passos
0
100
200
300
400
500
600
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
20 Passos
0
100
200
300
400
500
600
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
40 Passos
0
100
200
300
400
500
600
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e te
ste
Dis
tinto
s
Total de Caos de Teste
SANMARKOV
Figura 5.1: Análise de diversidade: Calendar Manager.
Nos gráficos, observa-se uma considerável flutuação dos valores devido a na-tureza randômica do processo de geração. Uma simples comparação mostra o alto

CAPÍTULO 5. ANÁLISE QUANTITATIVA 41
10 Passos
0
500
1000
1500
2000
2500
3000
3500
4000
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
30 Passos
0
500
1000
1500
2000
2500
3000
3500
4000
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
20 Passos
0
500
1000
1500
2000
2500
3000
3500
4000
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de Teste
SANMARKOV
40 Passos
0
500
1000
1500
2000
2500
3000
3500
4000
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Qtd
de
Cas
os d
e T
este
Dis
tinto
s
Total de Casos de teste
SANMARKOV
Figura 5.2: Análise de diversidade: Docs Editor.
número de casos de teste distintos, apontando para uma melhor qualidade dastest suites geradas pelos modelos SAN. É importante ressaltar que os modelosnão são equivalentes em termos de estrutura, mas são equivalentes no sentido derepresentarem a mesma realidade.
Para estimar a diversidade dos casos de teste gerados, assume-se que quantomais alto o percentual de novos casos de teste melhor é a sua cobertura, ou seja, seum número maior de casos de teste é gerado, um número maior de funcionalidadesda aplicação são testadas ou pode-se dizer que a aplicação é testada de forma maisexaustiva.
5.2 Tempo de Geração
Foram geradas sete test suites a partir dos modelos SAN e MC para as aplicaçõesSimple Counter Navigation, Calendar Manager e Docs Editor. Cada test suitecorresponde a um conjunto de casos de teste e foram geradas com 100, 500, 1000,2000, 3000, 4000 e 5000 casos de teste, também limitadas com tamanho de 10, 20,30 e 40 passos.
As Figuras 5.3, 5.4 e 5.5 mostram o tempo de processamento (em segundos)para as test suites geradas. O experimento foi gerado em um Pentium III 550MHzcom 256 MB de RAM acessando uma base de dados SQL Server.
A partir desses resultados observa-se o pequeno tempo necessário para a geração

CAPÍTULO 5. ANÁLISE QUANTITATIVA 42
10 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
30 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
20 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV 40 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
Figura 5.3: Análise de eficiência: Simple Counter Navigation.
10 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
30 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
20 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
40 Passos
0
1
2
3
4
5
6
7
8
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
Figura 5.4: Análise de eficiência: Calendar Manager.
de casos de teste para modelos pequenos (Simple Counter Navigation e CalendarManager). Para a geração de 5000 casos de teste limitados em 40 passos o tempo
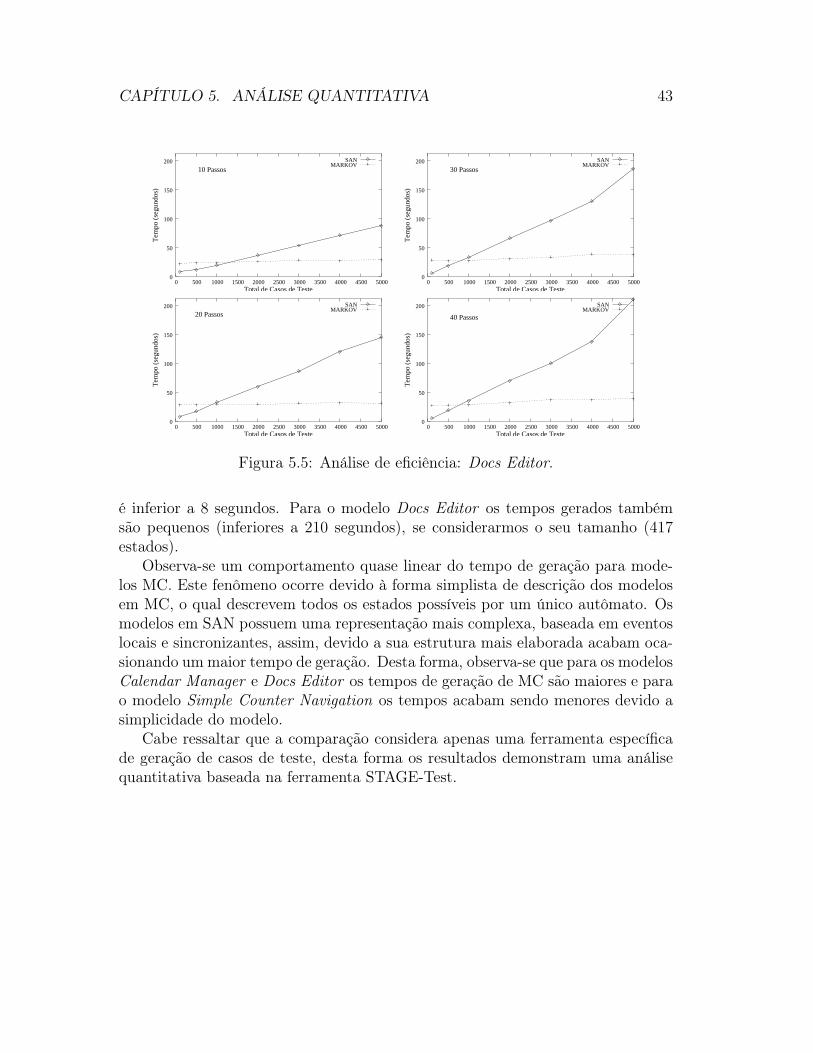
CAPÍTULO 5. ANÁLISE QUANTITATIVA 43
10 Passos
0
50
100
150
200
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
30 Passos
0
50
100
150
200
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
20 Passos
0
50
100
150
200
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
40 Passos
0
50
100
150
200
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Tem
po (
segu
ndos
)
Total de Casos de Teste
SANMARKOV
Figura 5.5: Análise de eficiência: Docs Editor.
é inferior a 8 segundos. Para o modelo Docs Editor os tempos gerados tambémsão pequenos (inferiores a 210 segundos), se considerarmos o seu tamanho (417estados).
Observa-se um comportamento quase linear do tempo de geração para mode-los MC. Este fenômeno ocorre devido à forma simplista de descrição dos modelosem MC, o qual descrevem todos os estados possíveis por um único autômato. Osmodelos em SAN possuem uma representação mais complexa, baseada em eventoslocais e sincronizantes, assim, devido a sua estrutura mais elaborada acabam oca-sionando um maior tempo de geração. Desta forma, observa-se que para os modelosCalendar Manager e Docs Editor os tempos de geração de MC são maiores e parao modelo Simple Counter Navigation os tempos acabam sendo menores devido asimplicidade do modelo.
Cabe ressaltar que a comparação considera apenas uma ferramenta específicade geração de casos de teste, desta forma os resultados demonstram uma análisequantitativa baseada na ferramenta STAGE-Test.

Capítulo 6
Métricas de Qualidade
Este capítulo descreve as métricas de qualidade no teste estatístico utilizadas emMC e a métrica proposta para estimar a cobertura de uma determinada test suite,desta forma poderemos saber o quanto significativa é a test suite gerada. Assim,no decorrer deste capítulo a métrica será apresentada, bem como um exemplode como a métrica é calculada. Também são apresentados os resultados para osestudos de caso propostos.
Os casos de teste correspondem a uma execução de um software e, por semprerepresentarem o início e fim de um software, assumimos que a execução de umcaso de teste não herda erros e nem os propaga. Considerando isso, pode-se dizerque os casos de teste não possuem memória, e estamos considerando apenas ascaracterísticas modeladas. Desta forma, o índice de cobertura diz respeito somenteaos aspectos modelados, e apenas corresponderá à aplicação como um todo se amesma estiver toda descrita formalmente através de um modelo em MC ou SAN.
6.1 Qualidade de Test Suites
A geração de uma test suite para um software pode não ser suficiente para umteste eficiente. Portanto, pode-se comparar a distribuição de probabilidades domodelo, também chamado de cadeia de uso (usage chain), com a distribuição deprobabilidades de uma test suite gerada, também conhecida como cadeia de teste(testing chain).
A comparação entre as distribuições de uso e teste nos mostra a diferençaentre o uso esperado e o atual. Desta forma, quanto menor a diferença entreas distribuições mais representativa é a test suite gerada, ou seja, uma melhorqualidade de geração. A qualidade de geração de uma test suite corresponde àmenor diferença entre a descrição formal de um programa (modelo MC ou SAN)e o conjunto de casos de teste gerados.
44

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 45
Essas métricas baseadas em comparações de vetores são utilizadas principal-mente como critério de parada no processo de teste. Baseado na geração de casosde teste a comparação de vetores objetiva determinar o número de casos de testesuficientes para uma determinada aplicação. Assim, os dois vetores correspondemàs taxas do modelo e às taxas apuradas em cada test suite.
Em Farina [14] pode-se encontrar uma análise mais detalhada do discriminantede Kullback bem como alguns resultados numéricos. Em Sayre [41] além do dis-criminante de Kullback também é utilizada a distância Euclidiana. No contextodesse trabalho as métricas também serão descritas e discutidas.
A distância Euclidiana corresponde a verificar a similaridade de dois vetores.Desta forma, quando o vetor de freqüências da cadeia de uso aproxima-se do vetorda cadeia de teste, maior é a convergência com relação às transições do modelo.A distância Euclidiana pode ser computada como:
K(U, T ) =
√
∑
i,j
(u i,j − ti,j), (6.1)
onde ui,j e ti,j correspondem à probabilidade de ir do estado i para o estado j
da cadeia de uso e da cadeia de teste, respectivamente.O discriminante de Kullback corresponde ao valor esperado da razão de proba-
bilidade logarítmica para dois processos estocásticos e é calculado pela fórmula [27]:
K(U, T ) =u
∑
i=1
π(i)u
∑
j=1
ui,j log(ui,j
ti,j
) (6.2)
6.1.1 Comparação Baseada em Transições
Em MC tradicionalmente dois métodos são utilizados para verificar a similaridadeentre uma distribuição de uso e de teste: a distância Euclidiana e o discriminantede Kullback [27, 41]. A verificação é realizada com base em comparações que sãofeitas a partir das freqüências das transições descritas no modelo e a freqüência daocorrência das transições na test suite gerada.
Quando um ou mais arcos da cadeia de uso não acontecem na cadeia de teste(test suite gerada), então existem transições possíveis na cadeia de uso e impossíveisna cadeia de teste. Logo, quanto maior for a quantidade de transições que nãoapareçam na cadeia de teste, maior será a diferença entre as cadeias, ou seja, aqualidade da test suite será inferior se comparado com uma cadeia de teste ondeapareçam mais transições.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 46
6.1.2 Comparação Baseada em Eventos
Diferente de uma MC, a mudança do estado global de uma SAN pode ocorreratravés de eventos. Desta forma, em uma MC cada transição está associada a umvalor, ou seja a um único evento. Em SAN as transições estão associadas a eventos,ou seja, cada transição pode possuir vários eventos. Considerando que cada eventoem uma SAN corresponde a pelo menos uma transição em MC, pode-se utilizar asmétricas empregadas em MC (distância Euclidiana e discriminante de Kullback),realizando uma comparação baseada em eventos.
6.2 Índice de Cobertura Baseado em Trajetórias
Nesta seção a métrica de cálculo do índice de cobertura baseado em trajetórias éformalizada. Ela compreende a resolução do modelo SAN ou MC e, com base novetor de probabilidades dos estados do modelo, são calculadas as probabilidadesde cada caso de teste. Um caso de teste compreende um conjunto de passos, osquais para cada um dos passos é calculada a sua probabilidade. Desta forma, comà probabilidades de todos os casos de teste de uma test suite, obtemos um índiceque indica o percentual de cobertura.
Cabe ressaltar que a resolução do modelo SAN ou MC nos dá um vetor deprobabilidades estacionário para o cálculo da métrica, ou seja, onde o tempo tendeao infinito. Uma das alternativas estudadas no decorrer desse trabalho foi a uti-lização da análise transiente, no entanto verificou-se que tal abordagem não seriaadequada para o teste estatístico [7]. Mesmo assim, a análise transiente mostrou-seútil como índice de desempenho de sistemas tolerantes a falhas, onde o tempo éum fator extremamente relevante [8].
6.2.1 Probabilidade dos Casos de Teste
A métrica proposta tem como base as probabilidades dos estados atingíveis domodelo, ou seja, quando se está em um estado e calcula-se a probabilidade de sechegar a outro estado, tem-se a probabilidade de um passo, ou trajeto, com relaçãoao funcionamento do sistema, já que consideramos as probabilidades dos estados.
Considere U = T1, T2, . . . , TM como um test suite composto de M casos deteste, onde Ti é o caso de teste de índice i. Um caso de teste é uma seqüênciacomposta de N transições de estados do modelo, ou seja, é uma seqüência de uso dosoftware modelado. Casos de teste (ou trajetórias) são basicamente representadospor uma seqüência de estado-transição-estado (passo). A partir do estado inicial deum passo é possível encontrar seus estados finais através da execução dos eventos.
Formalmente um caso de teste é uma estrutura (S, E), onde:

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 47
• S = S1,S2, . . . ,SN+1 corresponde a um conjunto ordenado de estadosglobais (SAN) ou estados (MC);
• E = E1, E2, . . . , EN corresponde a um conjunto de eventos (SAN) ou tran-sições (MC).
Considera-se que uma trajetória é composta por uma quantidade de passosfinita e conhecida, onde assume-se os seguintes axiomas:
• Cada passo é composto por um estado inicial i e um estado final k;
• Estando no estado i é possível ir para qualquer um dos seus estados suces-sores;
• Para a probabilidade do passo considera-se que estando no estado i entãoum evento (ou transição) é executado para o estado k;
Assim, como mencionado, uma trajetória é composta por passos e cada passotem uma probabilidade σ. Tal probabilidade é a ocorrência de uma transição doiesimo para iesimo + 1 estado e é dada por:
σi =πi+1∑
∀k<<i
πk
, (6.3)
onde πi é a probabilidade do iesimo estado da solução estacionária (ou transiente)de um modelo, e ∀k << i significa a possibilidade de ir para todos kesimo estadossucessores1 do iesimo estado.
A probabilidade de um caso de teste é o produtório de todas as probabilidadesdos passos σi (i = 1..N) do caso de teste, o qual compreende uma trajetória T .Assim, a probabilidade de um caso de teste PT é dada por:
PT =N∏
i=1
σi (6.4)
Uma test suite pode conter muitos casos de teste replicados. Entretanto énecessário considerar apenas casos de teste distintos para avaliar a cobertura deuma test suite. O número de casos de teste distintos D pode ser menor ou igualao número total de casos de teste M . Desta forma, o percentual de coberturaC de uma test suite U é calculada pela soma da probabilidade de todos os casosdistintos, ou seja, é dada por:
1Os estados sucessores do iesimo estado correspondem a todo estado com uma taxa não nulade ir do iesimo para qualquer kesimo estado.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 48
C =D
∑
T =1
PT (6.5)
Observa-se que a partir de um modelo pode-se gerar infinitos casos de teste,logo o cálculo da cobertura C de um test suite é assintótico, ou seja, o índice decobertura pode ser perto mas nunca igual a 1.
Para verificar a qualidade da geração de casos de teste, utiliza-se a distânciaEuclidiana e o discriminante de Kullback, ou seja, dois vetores são comparados:Vetor de probabilidades Φ e o vetor de freqüências dos casos de teste σ.
O vetor de probabilidades Φ é obtido a partir de uma test suite e contém apenasas probabilidades dos casos de teste distintos, ou seja, o vetor de probabilidades Φé composto por D probabilidades, onde a cardinalidade do vetor de probabilidadesé dada por |Φ| = D e D ≤ M .
O vetor de freqüências σ é também composto por D probabilidades. Estasprobabilidades são computadas a partir da freqüência dos casos de teste replicadosdo test suite. Após a normalização, que é dada pela contagem de casos de testereplicados sobre o total de casos de teste gerados, obtém-se o vetor de freqüênciaΘ (
∑D
i=1Θi = 1).O vetor de freqüência pode ser utilizado para a verificação dos casos de teste
replicados. No entanto, justifica-se gerar casos de teste replicados somente seaspectos do ambiente (sistema operacional, browser, etc.) são considerados. Aanálise dos casos de teste replicados não será considerada nesta dissertação, ouseja, o trabalho realizado procura avaliar e calcular a probabilidade de um conjuntode casos de teste.
O cálculo do índice de cobertura pode ser visto no Algoritmo 1. Basicamenteo algoritmo percorre todos os casos de teste; para cada um são calculados todos ospassos resultando na probabilidade de um caso de teste. A soma da probabilidadede todos os casos de teste corresponde ao índice do percentual de cobertura baseadoem trajetórias.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 49
Algoritmo 1 Cálculo do índice de cobertura
1 Entrada:
2 arquivo HBF /*armazena a matriz*/3 arquivo REA /*armazena as probabilidades*/4 t e s t s u i t e5 Variáveis:
6 s t a t e I=nu l l /*armazena o primeiro estado*/7 s t a t eJ=nu l l /*armazena o próximo estado*/8 probI=0 /*armazena a probabilidade do primeiro estado*/9 probJ=0 /*armazena a probabilidade do próximo estado*/
10 probab i l i tyPath =1.0 /*armazena a probabilidade de um caso de teste*/11 coverageTes tSu i t e =1.0 /*armazena o índice de cobertura*/12 /*para cada um dos casos de teste*/13 Passos:
14 Enquanto e x i s t i r ca sos de t e s t e 15 t r a j e t o r i a /* armazena o primeiro caso de teste*/16 Para toda a t r a j e t o r i a 17 se f o r a pr ime i ra vez 18 s t a t e I = pr ime i ro estado g l oba l19 s t a t eJ = segundo estado g l oba l20 senao21 s t a t eJ recebe o próximo estado global22 23 /*para todo o vetor rea composto por estado global e probabilidade*/24 Para todo o arquivo REA25 probI = probab i l i dade s t a t e I26 probJ = probab i l i dade s t a t eJ27
28 pPath = stateJ∑
∀stateI<<stateJ
stateI;
29 probab i l i tyPath = probab i l i tyPath ∗ pPath ;30 s t a t e I = s ta t eJ ;31 32 coverageTes tSu i t e = coverageTes tSu i t e + probab i l i tyPath ;33
6.3 Exemplo: Sistema de Login
Seguindo o exemplo do Sistema de Login (seção 3.1), esta seção demonstra o cálculoda métrica a fim de exemplificar como a mesma é calculada. Cabe ressaltar queas taxas para esse modelo foram atribuídas de maneira arbitrária por se tratarde apenas um exemplo utilizado para demonstrar o processo de construção de ummodelo de uso e a aplicação da métrica de cálculo do índice de cobertura.
O exemplo do cálculo da métrica será apresentado com base no modelo SANda aplicação login. No entanto, pode-se aplicar a métrica da mesma forma para o

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 50
modelo MC sem qualquer perda de informação ou alteração no resultado final.Baseado nas taxas da aplicação (Figura 3.3 Capítulo 3), o modelo é descrito
em formato textual o qual será a entrada para o software PEPS.
Tabela 6.1: Probabilidade dos estados atingíveis: Sistema de Login.
Estado Global Probabilidade(Start, Waiting) 0.04624277456047144(Password, Waiting) 0.05780346825957454(Password, PNotOK) 0.02890173418839295(Menu, POK) 0.867052022991561
Cada um dos estados globais da SAN apresentada na Tabela 6.1 equivale a umestado da MC correspondente, ou seja, tendo a descrição formal da aplicação emSAN ou MC pode-se calcular a métrica. Observa-se também que as probabilidadessomam 1 e elas dependem das transições e taxas associadas aos eventos.
As probabilidades de cada estado e a matriz HBF são utilizadas para automati-zar e calcular o índice de cobertura. Além destes arquivos são necessários os casosde teste gerados, os quais possuem a estrutura mínima (estado global - evento -estado global).
O primeiro passo a ser realizado é calcular a probabilidade de cada caso deteste, e para isso calculamos a probabilidade de todos os passos do caso de teste,ou seja, o conjunto de estados globais (SAN) ou estados (MC). Seguindo o exemplodo sistema de Login, vamos assumir o caso de teste seguindo a estrutura estadoglobal-evento-estado global:
(Start,Waiting)st(Password,Waiting)s(Menu, POK)qt(Start,Waiting)
Tendo o caso de teste o qual se deseja saber a probabilidade, a proxima etapacorresponde a determinar a probabilidade de cada um dos passos do caso de teste,ou seja, precisamos saber a probabilidade de estando no estado (Start, Waiting) irpara o estado (Password, Waiting), do estado (Password, Waiting) para o estado(Menu, POK), e do estado (Menu, POK) para o estado (Start, Waiting). Assim,com a utilização da fórmula 6.3 temos:
• Estado global (Start, Waiting) executando o evento st para o estado global(Password, Waiting):
σi =0.05780346825957454
0.05780346825957454,
σi = 1.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 51
• Estado global (Password, Waiting) executando o evento s para o estadoglobal (Menu, POK):
σi =0.867052022991561
0.867052022991561 + 0.04624277456047144 + 0.02890173418839295,
σi =0.867052022991561
0.94219653174042539,
σi = 0, 9202.
• Estado global (Menu, POK) executando o evento qt para o estado global(Start, Waiting):
σi =0.04624277456047144
0.04624277456047144,
σi = 1.
Após o cálculo de cada passo que compõe o caso de teste, a probabilidade docaso de teste é dada pelo produto de cada passo, ou seja:
PT = 1 ∗ 0.9202 ∗ 1,
PT = 0.9202.
Assim, são calculada todas as probabilidades dos casos de teste que compõemuma test suite. A Tabela 6.2 apresenta a test suite com dez casos de teste e suasrespectivas probabilidades. Portanto o índice de cobertura baseado nas trajetóriasé dado pelo somatório de todas as probabilidades dos casos de teste, que neste casocorresponde a 0.9970, ou seja, pode-se dizer o conjunto de casos de teste geradoscobrem 99, 70% da aplicação modelada.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 52
Tabela 6.2: Probabilidade dos casos de teste: Sistema de Login.
Caso de Teste Probabilidade (PT )(Start, Waiting) st (Password, Waiting) qt (Start, Waiting) 0, 049079754597538(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) qt 0, 024539877348530(Start, Waiting)(Start, Waiting) st (Password, Waiting) s (Menu, POK) qt 0, 920245398685497(Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 001505513949186(Password, Waiting) qt (Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000752756976119(Password, Waiting) l1 (Password, PNotOK) qt (Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000023090704858(Password, Waiting) l1 (Password, PNotOK) l2 (Password, Waiting) qt(Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000046181409622(Password, Waiting) l1 (Password, PNotOK) l2 (Password, Waiting) s(Menu, POK) qt(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000865901430386(Password, Waiting) l1 (Password, PNotOK) l2 (Password, Waiting) l1(Password, PNotOK) qt (Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000026561393649(Password, Waiting) l1 (Password, PNotOK) l2 (Password, Waiting) l1(Password, PNotOK) l2 (Password, Waiting) s (Menu, POK) qt(Start, Waiting)(Start, Waiting) st (Password, Waiting) l1 (Password, PNotOK) l2 0, 000000814766679(Password, Waiting) l1 (Password, PNotOK) l2 (Password, Waiting) l1(Password, PNotOK) l2 (Password, Waiting) l1 (Password, PNotOK) l2(Password, Waiting) s (Menu, POK) qt (Start, Waiting)
Na Figura 6.1 observa-se o índice de cobertura convertido em percentual paraa test suite gerada. Nota-se que os casos de teste onde o usuário da aplicação loginerra muitas vezes ao logar, acabam tendo uma probabilidade muito pequena.

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 53
0
20
40
60
80
100
0 2 4 6 8 10
Cob
ertu
ra e
m %
Casos de Teste
Figura 6.1: Índice de cobertura: Sistema de Login.
6.4 Resultados
Com o objetivo de validar a métrica foram gerados test suites para os estudos decaso realizados. Desta forma, procurou-se verificar o índice de cobertura dos casosde teste gerados. O índice é expresso em percentual e para a aplicação SimpleCounter Navigation gerou-se test suites de 100, 500 e 1000 casos de teste. Para asoutras duas aplicações, Calendar Manager e Docs Editor, foram gerados test suitesde 100, 500, 1000 e 5000 casos de teste. Cada caso de teste possui no máximo 40passos, ou seja 40 conjuntos de estados globais e eventos.
É importante ressaltar que são computados a probabilidade apenas dos casos deteste únicos, ou seja em um conjunto de 100 casos de teste apenas as probabilidadesdos casos de teste únicos são calculadas considerando que muitos dos casos deteste gerados são replicados. Foram utilizados para o cálculo da métrica vetorescom probabilidades estacionárias dos estados atingíveis do modelo, ou seja, asprobabilidades dos estados são dadas em um tempo não determinado.
Para a aplicação Simple Counter Navigation, o Gráfico 6.2 apresenta o resultadopara as test suites geradas. Observa-se que foram gerados apenas três conjuntos decasos de teste, pelo fato de ser uma aplicação simples e desta forma os conjuntosgerados mostraram-se com uma cobertura superior a 99%. Na Tabela 6.3 sãoapresentados os valores do gráfico.
Observa-se que a diferença entre a geração de 100 e 500 casos de teste para aaplicação Simple Counter Navigation é pequena, menor que 1%. Assim, podemos

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 54
observar que mais casos de teste com probabilidades muito pequenas são gerados.Para esta aplicação uma amostra com 100 casos de teste já corresponde a umíndice superior a 84%, o que pode ser considerado uma amostra relevante para umconjunto pequeno de casos de teste.
Tabela 6.3: Valores - Simple Counter Navigation.
Casos de Teste Índice de Cobertura (%)100 84.0452137451500 99.2125434861000 99.895545215
0
20
40
60
80
100
0 200 400 600 800 1000
Cob
ertu
ra e
m %
Casos de Teste
Figura 6.2: Índice de cobertura: Simple Counter Navigation.
Para a aplicação Calendar Manager, o Gráfico 6.3 apresenta o resultado paraas test suites geradas, e na Tabela 6.4 são apresentados os valores do gráfico.Diferentemente da aplicação Simple Counter Navigation, a aplicação CalendarManager possui um modelo um pouco maior e uma quantidade elevada de eventosem seu modelo. Desta forma precisa-se gerar uma quantidade maior de casos deteste para se obter um índice de cobertura satisfatório. Entende-se por índicesatisfatório um valor acima de 99%, que indica que todos os casos de teste comprobabilidades maiores foram gerados.
Observa-se também, que a grande quantidade de eventos do modelo acabacriando a necessidade de se gerar mais casos de teste para se obter um índice de

CAPÍTULO 6. MÉTRICAS DE QUALIDADE 55
cobertura elevado. Desta forma, pode-se concluir que não somente o acréscimo deestados no modelo como também o acréscimo de eventos, exigem a geração de ummaior número de casos de teste.
Tabela 6.4: Valores - Calendar Manager.
Casos de Teste Índice de Cobertura (%)100 64.56241545462500 69.545151561231000 96.544512140055000 99.45216581480
0
20
40
60
80
100
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Cob
ertu
ra e
m %
Casos de Teste
Figura 6.3: Índice de cobertura: Calendar Manager.
Para a aplicação Docs editor, o Gráfico 6.4 apresenta o resultado para as testsuites geradas. Na Tabela 6.5 são apresentados os valores do gráfico. Para estaaplicação, como se tem um modelo consideravelmente maior que os demais apre-sentados, gerou-se um conjunto de 5000 casos de teste para se conseguir um índicede cobertura superior a 99%. Cabe ressaltar que a geração é feita de forma au-tomática e, conforme apresentado no capítulo anterior, a geração é eficiente e adiferença de tempo de geração é mínimo para um conjunto de 100 e 5000 casos deteste.
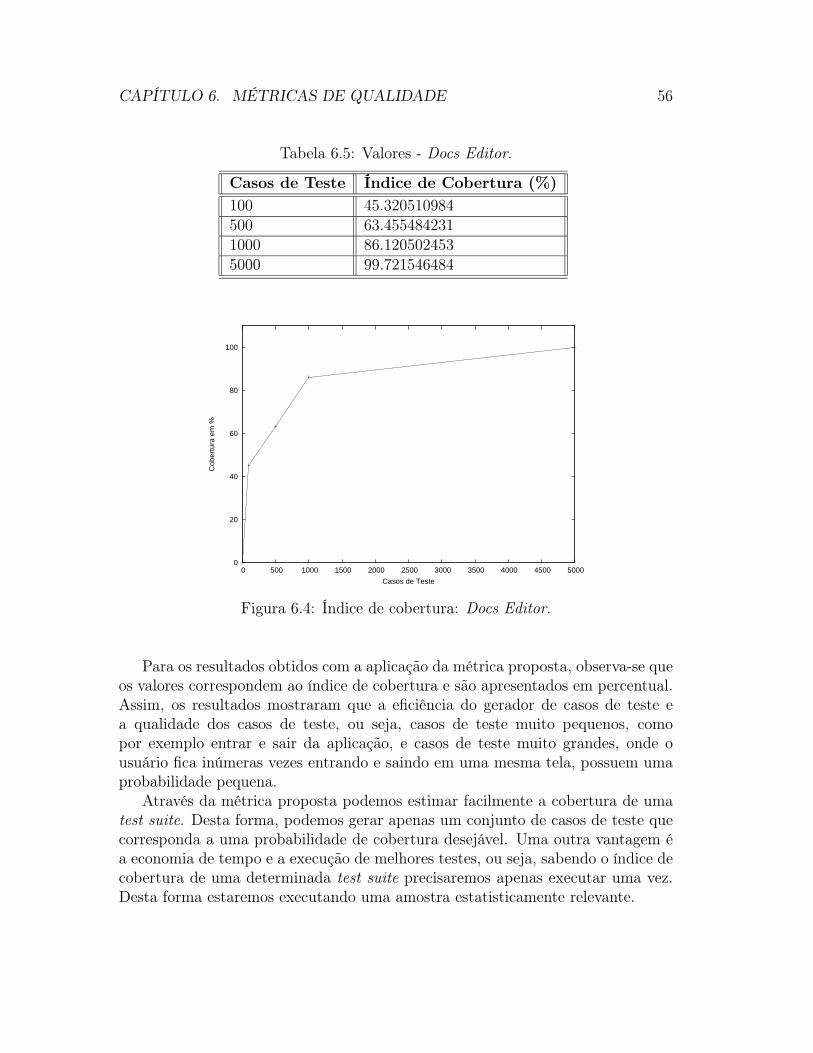
CAPÍTULO 6. MÉTRICAS DE QUALIDADE 56
Tabela 6.5: Valores - Docs Editor.
Casos de Teste Índice de Cobertura (%)100 45.320510984500 63.4554842311000 86.1205024535000 99.721546484
0
20
40
60
80
100
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Cob
ertu
ra e
m %
Casos de Teste
Figura 6.4: Índice de cobertura: Docs Editor.
Para os resultados obtidos com a aplicação da métrica proposta, observa-se queos valores correspondem ao índice de cobertura e são apresentados em percentual.Assim, os resultados mostraram que a eficiência do gerador de casos de teste ea qualidade dos casos de teste, ou seja, casos de teste muito pequenos, comopor exemplo entrar e sair da aplicação, e casos de teste muito grandes, onde ousuário fica inúmeras vezes entrando e saindo em uma mesma tela, possuem umaprobabilidade pequena.
Através da métrica proposta podemos estimar facilmente a cobertura de umatest suite. Desta forma, podemos gerar apenas um conjunto de casos de teste quecorresponda a uma probabilidade de cobertura desejável. Uma outra vantagem éa economia de tempo e a execução de melhores testes, ou seja, sabendo o índice decobertura de uma determinada test suite precisaremos apenas executar uma vez.Desta forma estaremos executando uma amostra estatisticamente relevante.

Capítulo 7
Conclusões
O presente trabalho apresentou uma análise quantitativa da geração de casos deteste baseado nos estudos de caso realizados, assim, pode-se evidenciar vantagense desvantagens de ambos os formalismos (Cadeias de Markov (MC) e Redes deAutômatos Estocásticos (SAN)) tanto na construção dos modelos de uso quantona geração dos casos de teste para a ferramenta STAGE-Test. Desta forma, surgiua necessidade de estimar com maior precisão a qualidade da geração de casos deteste. Como principal contribuição desse trabalho é proposta uma métrica que visaverificar a relevância de um determinado conjunto de casos de teste, determinandoassim, a probabilidade de cobertura de uma test suite.
Neste capítulo são apresentadas as conclusões referentes ao trabalho desen-volvido, abordando o desenvolvimento dos modelos de uso com MC e SAN, ageração dos casos de teste e a métrica de cálculo do índice de cobertura. Por fim,são apresentados alguns possíveis trabalhos futuros.
7.1 Construção dos Modelos de Uso
A construção dos modelos de uso utilizando MC é bastante difundida na literatura,no entanto, apresenta algumas limitações por descrever uma aplicação como umúnico conjunto de estados e transições. Desta forma, a medida que estados e tran-sições são inseridas, além de aumentar a complexidade do modelo, a visualizaçãoe manutenção dos estados e transições torna-se cada vez mais oneroso.
Como as SAN são equivalentes às MC e tudo que se pode definir formalmentecom MC pode-se definir com SAN, as SAN representam uma excelente alternativapara a construção de modelos de uso com uma grande quantidade de estados. Umdos pontos a serem observados, é visto nos estudos de caso, onde para a aplicaçãoDocs Editor a utilização de SAN possibilita uma melhor manutenção e visualizaçãodo modelo, considerando que a MC correspondente possui 417 estados. No segundo
57

CAPÍTULO 7. CONCLUSÕES 58
estudo de caso, a aplicação Calendar Manager, apesar de possuir uma quantidadepequena de estados, possui uma grande quantidade de transições, o que torna omodelo SAN mais legível e de fácil manutenção. No entanto quando os modelospossuem uma quantidade de estados e transições pequena, ambos os formalismospodem ser utilizados sem um apresentar vantagens consideráveis em relação aooutro.
Portanto, podemos perceber com os estudos de caso realizados que, a medidaque a complexidade e tamanho das aplicações aumentam, a utilização das SANacrescenta qualidade aos modelos, e torna-se uma melhor opção com relação àsMC.
7.2 Geração dos Casos de Teste
O processo automatizado de teste estatístico descrito neste trabalho consiste naconstrução de casos de uso e geração de casos de teste e scripts. Assim, um dostrabalhos realizados nessa dissertação consistiu em realizar uma avaliação quan-titativa dos casos de teste gerados com a finalidade de verificar a qualidade dogerador de casos de teste e a qualidade da geração.
Observou-se que o gerador de casos de teste (STAGE-Test) é eficiente, gerandocasos de teste de forma rápida conforme visto nos gráficos de tempo de geração.Eficiência na geração de casos de teste é uma característica desejável no testeestatístico, considerando que às vezes torna-se necessário gerar uma grande quan-tidade de casos de teste. Podemos concluir que o gerador de casos de teste atendeperfeitamente às expectativas do teste estatístico quanto à eficiência. Nesse sen-tido, observou-se também que o tempo de geração em MC tende a ser mais rápidodevido ao fato das MC possuírem uma estrutura mais simples do que as SAN.
Outra característica importante a ser observada na geração dos casos de testeconsiste na diversidade de geração, ou seja, quanto mais casos de teste diferentesforem gerados, maior será a possibilidade de encontrar falhas. A diversidade degeração influencia diretamente na qualidade do teste e por conseqüência do pro-duto final. Portanto, constatou-se que os dois algoritmos de geração de casos deteste, baseado em MC e em SAN, possuem qualidade na geração, sendo que aimplementação em SAN consegue-se gerar mais casos de teste distintos do que apartir da MC.
7.3 Métricas de Qualidade
As métricas de qualidade utilizadas em MC, como as métricas de comparação devetores, acabam não se aplicando da mesma forma em SAN, mesmo os formalismos

CAPÍTULO 7. CONCLUSÕES 59
sendo equivalentes. Isto ocorre pelo fato que essas técnicas são baseadas na fre-qüência de transições das MC, e em SAN as transições não são associadas a taxas,mas a eventos que por sua vez agregam uma semântica diferente às transições.
A métrica proposta baseou-se na probabilidade dos estados do modelo, ou seja,considera-se que o modelo tenha sido resolvido e por sua vez os passos em umaMC ou SAN podem ser calculados com base na probabilidade do estado que sedeseja chegar e todos as suas alternativas (estados alcançáveis). Desta forma, foiformalizada uma métrica chamada de Índice de Cobertura Baseada em Trajetórias.Assim, assumindo uma determinada test suite, a métrica fornece a probabilidadede cobertura dos casos de teste.
Observou-se nos resultados para os estudos de caso realizados, que as test suitesgeram um índice de cobertura satisfatório, ou seja, com uma probabilidade maiorque 99%. O que observou-se é que casos de teste muito grandes, ou muito pequenos,possuem uma probabilidade muito pequena, o que corresponde à realidade. As-sim, podemos concluir que a geração de casos de teste pode ter uma coberturasatisfatória se levarmos em conta a probabilidade calculada pela métrica de índicede cobertura baseada em trajetórias.
Um dos pontos a serem observados é tendo uma métrica que nos possibilitasaber o índice de cobertura de uma determinada test suite, podemos facilmentedefinir um critério de parada, ou seja, definir um número de casos de teste par umadeterminada aplicação que seja suficiente para garantir qualidade e confiabilidade.Por exemplo, podemos admitir que nosso critério de parada é de 90%, desta forma,quando uma test suite possuir um índice de cobertura igual ou superior a 0.9, issonos indica que podemos parar de gerar casos de teste.
A métrica de índice de cobertura baseada em trajetórias foi utilizada primeira-mente para a avaliação de test suites, no entanto, os algoritmos estatísticos degeração de casos de teste poderiam incorporá-la no sentido de melhorarem suaqualidade de geração.
Os resultados da métrica de qualidade foram obtidos utilizando um vetor deprobabilidades estacionário, ou seja, considera-se as probabilidades dos estadoscomo se o sistema estivesse em funcionamento por um período indeterminado detempo. No entanto, pode-se facilmente obter os resultados da métrica utilizandoum vetor de probabilidades transientes [7], ou seja, considerando as probabilidadesdos estados do sistema como se ele estivesse em funcionamento por um períodode tempo determinado. Desta forma, para sistemas críticos ou tolerantes a falhasque necessitem estar em funcionamento sem falhas por um determinado períodode tempo, poderia-se gerar conjuntos de casos de teste com índices de coberturamais reais ao funcionamento do sistema.
Outro fator importante a se destacar são as métricas e critérios de parada uti-lizadas na literatura [21–23], que no geral avaliam apenas a execução dos scripts e

CAPÍTULO 7. CONCLUSÕES 60
não a geração dos casos de teste, como o que está sendo proposto. Assim, podemosconcluir que a métrica proposta poderia ser utilizada também como indicativo deeficiência na execução dos scripts e confiabilidade.
7.4 Trabalhos Futuros
Através desta dissertação surgem vários trabalhos futuros no sentido de comple-mentar e dar continuidade ao trabalho realizado. Primeiramente, surge a necessi-dade de execução dos scripts no sentido de verificar a relação entre a eficiência doíndice de cobertura e as falhas encontradas.
A aplicação de novas métricas para o cálculo do índice de cobertura, por exem-plo, a utilização de Cadeias de Markov Embutidas [43] (EMC). As EMC consis-tem em transformar uma CTMC para uma Cadeia de Markov de Tempo Discreto1
(DTMC - Discrete Time Markov Chains). Desta forma, poderiam ser utilizadasapenas as taxas do modelo para o cálculo de uma nova métrica. Neste sentido,teoricamente a métrica apresentada nesta dissertação tende a ser melhor por con-siderar as trajetórias de um estado até outro baseado no funcionamento de todo osistema (probabilidades do modelo).
As ferramentas de suporte ao teste estatístico utilizadas poderiam fazer usoda métrica. O gerador de casos de teste STAGE-Test poderia utilizar a métricacomo uma opção para estimar se a test suite gerada é suficiente. Como sabemosestimar a cobertura de uma determinada test suite, então, poderia-se utilizar amétrica como base para a construção de uma nova ferramenta, ou seja, novosalgoritmos de geração de casos de teste estatísticos. Desta forma, a geração nãoseria mais randômica, mas os algoritmos poderiam incorporar a métrica tanto nageração quanto como um critério de parada. Por fim, poderia-se formalizar todo oprocesso de teste estatístico desde a construção dos modelos de uso até a execuçãodos scripts em sistemas de missão crítica.
Com relação aos modelos MC e SAN, poderíamos considerar futuramente ainclusão de pontos de dados. Ou seja, estados que poderiam assumir diferentesvalores. Por exemplo, se considerarmos uma tela com um campo text-box ondeo usuário pode entrar com qualquer tipo de caracter (string, números, caracteresespeciais, etc). Cada tipo de caracter também poderia estar sendo validado seconsiderarmos este estado como um ponto de dados.
Outras formas de verificação também podem ser utilizadas no teste de software.Um importante trabalho futuro que também pode se tornar útil na verificação deerros em aplicações seria utilizar verificação formal através de técnicas de model
1Nos modelos em DTMC as transições entre os estados ocorrem em um determinado instantede tempo [43].

CAPÍTULO 7. CONCLUSÕES 61
checking [28]. Assim, como trabalho futuro pode-se pesquisar técnicas de modelchecking em SAN.

Referências Bibliográficas
[1] A. ABDURAZIK, P. AMMANN, W. DING, and J. OFFUTT. Evaluation ofThree Specification-Based Testing Criteria. In 6th IEEE International Con-ference on Complex Computer Systems (ICECCS’00), pages 179–187, Tokyo,Japan, Setembro 2000.
[2] A. ABDURAZIK and J. OFFUTT. Generating Test Cases from UML Spec-ifications. In 2th International Conference on the Unified Modeling Language(UML99), Fort Collins, CO, Outubro 1999.
[3] M. Al-GHAFEES and J. A. WHITTAKER. Markov Chain-based Test DataAdequacy Criteria: a Complete Family. Informing Science InSITE - WhereParallels Intersect, pages 13–37, Junho 2002.
[4] L. APFELBAUM and J. DOYLE. Model Based Testing. In 10th InternationalSoftware Quality Week (QW97), San Francisco, CA, 1997.
[5] L. APFELBAUM and J. DOYLE. Model Based Testing. San Francisco, CA,1997.
[6] A. BENOIT, L. BRENNER, P. FERNANDES, B. PLATEAU, and W. J.STEWART. The PEPS Software Tool. In 13 International Conferenceon Modelling Techniques and Tools for Computer Performance Evalution(TOOLS 2003), Urbana-Champaign, Illinois, USA, 2003.
[7] C. BERTOLINI. Análise Transiente em Redes de Autômatos EstocásticosUtilizando o Método da Uniformização. Trabalho individual II, Novembro2003.
[8] C. BERTOLINI, L. BRENNER, A. SALES, P. FERNANDES, andA. ZORZO. Structured Stochastic Modeling of Fault-Tolerant Systems. In12th Annual Meeting of the IEEE / ACM International Symposium on Mod-eling, Analysis, and Simulation of Computer and Telecommunication Systems(MASCOTS), Volendam, Netherlands, Outubro 2004.
62

REFERÊNCIAS BIBLIOGRÁFICAS 63
[9] C. BERTOLINI, A. G. FARINA, P. FERNANDES, and F. M. OLIVEIRA.Test Case Generation Using Stochastic Automata Networks: QuantitativeAnalysis. In Proceedings of the 2nd International Conference on SoftwareEngineering and Formal Methods, pages 251–260, Beijing, China, Setembro2004.
[10] M. BLUM and O. GOLDREICH. Towards a Computational Theory of Statis-tical Tests. In 33rd Annual Symposium on Foundations of Computer Science,pages 406–416, Pittsburgh, USA, 1992.
[11] J. BOWEN, K. BOGDANOV, J. CLARK, M. HARMAN, and P. KRAUSE.FORTEST: Formal Methods and Testing. In 26th Annual International Com-puter Software and Applications Conference, pages 91–104, Oxford, England,Agosto 2002.
[12] B COPSTEIN and F. M. OLIVEIRA. Effective Statistical Test Script Gen-eration. In The 15th IEEE International Symposium on Software ReliabilityEngineering, Saint-Malo, France, Novembro 2004.
[13] I. K. El-FAR and J. A. WHITTAKER. Encyclopedia of Software Engineer-ing, chapter Model-based Software Testing. J.J. Marciniak (ed.), Wiley, 2ndedition, 2001.
[14] A. G. FARINA. Aplicação de redes de Autômatos Estocásticos no Testeestatístico de Software. Master’s thesis, Pontifícia Universidade Católica doRio Grande do Sul, Porto alegre, Brasil, 2002.
[15] A. G. FARINA, P. FERNANDES, and F. M. OLIVEIRA. Representing Soft-ware Models with Stochastic Automata Networks. In 14Th InternationalConference on Software Engineering and Knowledge Engineering, pages 401– 407. ACM Press, 2002.
[16] P. FERNANDES. Méthodes Numériques Pour la Solution de SystèmesMarkoviens à Grand Espace d’états. PhD thesis, INPG, Grenoble, France,1998.
[17] P. FERNANDES, B. PLATEAU, and W. J. STEWART. Efficient Descriptor- Vector Multiplication in Stochastic Automata Networks. Journal of theACM, 45(3):381–414, 1998.
[18] J. M. FOURNEAU and B. PLATEAU. PEPS: a Package for Solving ComplexMarkov Models of Parallel Systems. In Proceedings of the Fourth InternationalConference on Modelling Techniques and Tools for Computer PerformanceEvaluation, Palma, Spain, 1988.

REFERÊNCIAS BIBLIOGRÁFICAS 64
[19] W. GRIESKAMP, Y. GUREVICH, W. SCHULTE, and M. VEANES. Gener-ating Finite State Machines from Abstract State Machines. In Proceedings ofthe international symposium on Software testing and analysis, pages 112–122,Roma, Italy, 2002. ACM Press.
[20] R. HANA. Tailoring Cleanroom for Industrial Use. IEEE Software, 15(6):46–55, 1998.
[21] M. J. HARROLD, R. GUPTA, and M. L. SOFFA. A methodology for Con-trolling the Size of a Test Suite. ACM Transactions on Software Engineeringand Methodology (TOSEM), 2(3):270–285, 1993.
[22] J. R. HORGAN, S. LONDON, and M. R. LYU. A Coverage Analysis Toolfor the Effectiveness of Software Testing. In Fourth International Symposiumon Software Reliability Engineering, pages 25–34, Denver, USA, 1993.
[23] J. R. HORGAN, S. LONDON, and M. R. LYU. Achieving Software QualityWith Testing Coverage Measures. IEEE Computer, 27(9):60–69, 1994.
[24] P. JALOTE. Fault Tolerance in Distributed Systems. Englewood Cliffs: Pren-tice Hall, 1994.
[25] P. C. JORGENSEN. Software Testing A Craftsman’s Approach. CRC Press,Boca Raton, Florida, 1995.
[26] D. P. KELLY and R. OSHANA. Improving Software Quality using StatisticalTesting Techniques. Information and Software Technology, 24(12):801–807,2000.
[27] S. KULLBACK. Information Theory and Statistics. Dover Publications, Inc,1978.
[28] M. LEUCKER. Model-based Testing of Reactive Systems. In Tutorial of the2nd International Conference on Software Engineering and Formal Methods,Beijing, China, Setembro 2004.
[29] Z. LI and J. TIAN. Testing the Suitability of Markov Chains as Web UsageModels. In 27th Annual International Computer Software and ApplicationsConference, Dallas, Texas, Novembro 2003.
[30] Y. K. MALAIYA. Automated Test Software. Wiley Encyclopedia of Electricaland Electronics Engineering, pages 135–141, 1999.

REFERÊNCIAS BIBLIOGRÁFICAS 65
[31] C. D. MEYER. Matrix Analysis and Applied Linear Algebra. Society forIndustrial and Applied Mathematics: Prentice Hall, Philadelphia, PA, USA,2000.
[32] I. MITRANI. Probabilistic Modelling. Cambridge University Press, 1998.
[33] G. J. MYERS. The Art of Software Testing. John Wiley and Sons, Ontario,Canada, 1979.
[34] J. R. NORRIS. Markov Chains. Cambridge University Press, New York,USA, 1998.
[35] B. PLATEAU. De l’Evaluation du Parallélisme et de la Synchronisation. PhDthesis, Paris-Sud, Orsay, France, 1984.
[36] B. PLATEAU and K. ATIF. Stochastic Automata Networks for ModellingParallel Systems. IEEE Transactions on Software Engineering, 17(10):1093–1108, 1991.
[37] J. POORE and C. J. TRAMMELL. Application of Estatistical Science toTesting and Evaluting Software Intensive Systems. Statistics, Testing, andDefense Acquisition: Background Papers. The National Academy Press, 2000.
[38] R. S. PRESSMAN. Software Engineering - A Practitioner’s Approach.McGraw-Hill, Nova York, NY, 5th edition, 2000.
[39] M. RIEBISCH, I. PHILIPPOW, and M. GÖTZE. UML-Based Statistical TestCase Generation. In AKSIT M., MEZINI M., and UNLAND R., editors, Ob-jects, Components, Architectures, Services, and Applications for a NetworkedWorld. Proceedings of the International Conference NetObjectDays, volume2591 of Lecture Notes in Computer Science, pages 394–411. Springer-Verlag,Erfurt, Germany, Outubro 2002.
[40] A. R. C. ROCHA, J. C. MALDONADO, and K. C. WEBER. Qualidade deSoftware: Teoria e Prática. Prentice Hall, São Paulo, 2001.
[41] K. SAYRE. Improved Techniques for Software Testing Based on MarkovChain Usage Models. PhD thesis, University of Tennessee, Knoxville, USA,1999.
[42] K. SAYRE and J. POORE. Partition Testing With Usage Models. Informa-tion and Software Technology, v. 42(12):845–850, 2000.
[43] W. J. STEWART. Introduction to the Numerical Solution of Markov Chains.Princeton University Press, 1994.

REFERÊNCIAS BIBLIOGRÁFICAS 66
[44] W. J. STEWART, K. ATIF, and B. PLATEAU. The Numerical Solutionof Stochastic Automata Network. European Journal of Operations Research,86:503–525, 1995.
[45] J. TIAN and E. LIN. Unified Markov Models for Software Testing, Perfor-mance Evaluation, and Reliability Analysis. In 4th International Conferenceon Reliability and Quality in Design, Seattle, USA, Agosto 1998.
[46] C. TRAMMELL. Quantifying the Reliability of Software: Statistical Test-ing Based on a Usage Model. In 2th International Symposium on SoftwareEngineering Standards, Montreal, Canada, Agosto 1995.
[47] G. H. WALTON and J. H. POORE. Generating Transition Probabilities toSupport Model-Based Software Testing. Software Practice and Experience,30(10):1095–1106, 2000.
[48] G. H. WALTON, J. H. POORE, and C. J. TRAMMELL. Statistical Testingof Software Based on a Usage Model. Software - Practice and Experience,25(1):97–108, 1995.
[49] T. WEBBER. Alternativas para o Tratamento Numérico Otimizado da Mul-tiplicação Vetor-Descritor. Master’s thesis, Pontifícia Universidade Católicado Rio Grande do Sul, Porto Alegre, Brasil, 2003.
[50] J. A. WHITTAKER and J. H. POORE. Markov Analysis of Software Spec-ifications. ACM Transactions on Software Engineering and Methodology,2(1):93–106, Janeiro 1993.
[51] J. A. WHITTAKER and M. G. THOMASON. A Markov Chain Model forStatistical Software Testing. IEEE Transactions on Software Engineering,20(10):812–824, Julho 1994.

Apêndice A
Probabilidades
Um conjunto finito de estados é dado por Ω onde usualmente um conjunto de even-tos E é associado a ele. Cada evento E corresponde a um número denominadoprobabilidade e denotado por P (E). Por convenção, as probabilidades são normal-izadas, sendo que todos os eventos estão em um intervalo fechado [0, 1]. Assim, aprobabilidade P definida sobre o conjunto de todos os eventos deve satisfazer trêsaxiomas1 [32]:
• P1 : 0 ≤ P (e) ≤ 1 para todo e ∈ E
• P2 : P (Ω) = 1
• P3 : se E1, E2, ...En é um conjunto de eventos então∑
∞
i=1 P (Ei) = 1.
Sendo assim, para os axiomas P2 e P3, assumindo que E1, E2, ...En é umconjunto de eventos de Ω, então:
∑
∀i=1
∞
pi = 1. (A.1)
Desta forma, para cada evento E temos que P (E) = 1 − P (E), sendo que aprobabilidade do evento ser zero é P (0) = 1 − P (Ω) = 0.
A.1 Probabilidades Condicionais
Se A e B são dois eventos com probabilidades positivas, então a probabilidadecondicional de A, dado B, é denotada por P (A|B) e definida como [32]:
1Axiomas são premissas evidentes que se admitem como verdadeiras sem exigência de demon-stração.
67

APÊNDICE A. PROBABILIDADES 68
P (A|B) =P (AB)
P (B). (A.2)
Se A e B são independentes, ou seja, a ocorrência de um evento não dependeda ocorrência do outro, então P (A|B) = P (A), assim, a ocorrência de B nãoinfluência a probabilidade de A.
Portanto, assumindo a equação A.2 podemos interpretar a probabilidade de umevento como a freqüência com que esse evento ocorre. Então, P (AB)
P (B)corresponde
a freqüência de ocorrência de AB quando B ocorre. Assim, a probabilidade de A
e B ocorrer pode ser definida por:
P (A|B) = P (A|B)P (B) = P (B|A)P (A). (A.3)
Generalizando para n eventos, sendo n o número de eventos e n > 2 temos:
P (A1, A2, ...An) = [i=1∏
n−1
P (Ai|Ai+1 . . . An)]P (An). (A.4)

Apêndice B
Sistema de Login
B.1 Modelo PEPSfunc = (st Automato_Navegacao==Password);f1 = 1.0;g1 = 0.5*func;QT1 = 0.1;ST1 = 2;S1 = 1.5;
eventsloc f f1loc g g1syn QT QT1syn S S1syn ST ST1
partial reachability = ((st Automato_Navegacao==Start) && (st Automato_Senha==Waiting));
network login (continuous)
aut Automato_Navegacaostt Start to (Password) STstt Password to (Menu) Sto (Start) QTstt Menu to (Start) QT
aut Automato_Senhastt Waiting to (PNotOk) gto (POK) Sto (Waiting) QT STstt PNotOk to (Waiting) fstt POK to (Waiting) QT
resultsvar = st Automato_Senha == Waiting;
69

Apêndice C
Simple Counter Navigation
C.1 Modelo PEPSidentifierst0 = 1.0;t1 = 1.0;t2 = 1.0;t3 = 1.0;t4 = 1.0;t5 = 1.0;t6 = 1.0;QTTax = 1.0;STax = 1.0;STTax = 1.0;TTax = 1.0;VTax = 1.0;slvTax = 1.00;
eventsloc L1 t0loc L2 t1loc L3 t2loc L4 t3loc L5 t4loc L6 t5loc LV t6syn QT QTTaxsyn S STaxsyn ST STTaxsyn T TTaxsyn V VTax
partial reachability = ((st nav==start) && (st cont==start) && (st Application==Start));
network Workshop (continuous)
aut navstt startto (main)ST(slvTax)stt mainto (start)
70

APÊNDICE C. SIMPLE COUNTER NAVIGATION 71
QT(slvTax)to (win01)L1stt win01to (win02)L2to (win03)Sstt win02to (main)LVstt win03to (main)TV
aut contstt startto (start)QT(slvTax)to (win03_01)S(slvTax)stt win03_01to (start)T(slvTax)to (win04_01)L3stt win04_01to (start)V(slvTax)to (win03_02)L4stt win03_02to (win04_02)L5stt win04_02to (start)V(slvTax)to (win03_03)L6stt win03_03to (start)T(slvTax)
aut Applicationstt Startto (Run)STstt Runto (Start)QT
resultsvar = st Application == Run;

Apêndice D
Calendar Manager
D.1 Modelo PEPSidentifiersf = (st AA == run);t1 = 1;t2 = 2;t3 = 3;t4 = 4 * f;t5 = 5 * f;t6 = 6 * f;t7 = 7 * f;t8 = 8 * f;t9 = 9;t10 = 10 * f;t11 = 11 * f;t12 = 12 * f;t13 = 13 * f;t14 = 14 * f;t15 = 15;t16 = 16;t17 = 17;pi1 = 0.1;pi2 = 0.3;pi3 = 0.6;pi4 = 0.6;pi5 = 0.4;pi6 = 0.3;pi7 = 0.7;pi8 = 0.2;pi9 = 0.8;
eventssyn ST (t1)syn QT (t2)syn C (t3)syn S (t4)syn V (t5)syn NC (t6)syn NE (t7)syn SE (t8)
72

APÊNDICE D. CALENDAR MANAGER 73
syn X (t9)syn CA (t10)syn NI (t11)syn CI (t12)syn OK (t13)loc L0 (t14)loc LA (t15)loc LB (t16)loc LD (t17)
partial reachability = ((st AA == start) && (st AN == start) && (st AP == waiting) && (st AV == testOK)&& (st AM == start));
network ec(continuous)
aut AA //aut Aplicationstt start to(run) STstt run to(start) QT
aut AN //aut Navegationstt start to(list) ST(pi6)to(login) ST(pi7)stt list to(start) QTstt login to(start) QT Cto(login) S
aut AP //aut Passwordstt waiting to(passwdOK) Sto(passwdNOK) L0to(waiting) QT Cstt passwdOK to(waiting) QTstt passwdNOK to(waiting) C
aut AV //aut Validationstt testOK to(testOK) QT NE OK SE CA CI NI NC X Vto(testNOK) NE OK SE CA V NI NC CIstt testNOK to(testOK) QT CA X
aut AM //aut Menustt start to(view) Sstt view to(start) QTto(new) V(pi1)to(cal) V(pi2)to(search) V(pi3)stt new to(view) CA Xto(cal) NE(pi8)to(search) NE(pi9)to(new) NI Xstt cal to(new) NC(pi4)to(change) NC(pi5)to(view) CA Xto(cal) CI Xstt search to(new) SE(pi6)to(cal) SE(pi7)to(view) CA Xto(change_res) LAstt change_res to(change_res) LDto(change) LBstt change to(search) OKto(view) CA
results

APÊNDICE D. CALENDAR MANAGER 74
result1 = (st AA == run);

Apêndice E
Docs Editor
E.1 Modelo PEPSidentifiersf= (st Documents==Unititled);f2= (st Tree==Root && Documents==NoDoc);t0 = 0.02;t1 = 6.1;t2 = 0.01*f;t3 = 0.05;t4 = 0.33;t5 = 0.03;t6 = 0.56*f2;t7 = 0.15;t8 = 0.3;t9 = 0.22;t10 = 0.02;t11 = 1.19;t12 = 0.99;t13 = 0.07;t14 = 0.07;t15 = 0.39;t16 = 0.02;t17 = 0.82;t18 = 1.0;t19 = 1.0;QTTax = 1.0;RTax = 1.0;STax = 0.57;STTax = 1.0;TTax = 0.04;UTax = 0.31;VTax = 0.05;WTax = 0.36;slvTax = 1.00;
eventsloc a22 t0loc l1 t1loc l10 t2loc l11 t3loc l12 t4
75

APÊNDICE E. DOCS EDITOR 76
loc l13 t5loc l14 t6loc l15 t7loc l16 t8loc l17 t9loc l18 t10loc l19 t11loc l2 t12loc l20 t13loc l21 t14loc l22 t15loc l23 t16loc l24 t17loc l25 t18loc l26 t19loc l27 t20loc l28 t21loc l29 t22loc l3 t23loc l30 t24loc l31 t25loc l32 t26loc l4 t27loc l5 t28loc l6 t29loc l7 t30loc l8 t31loc l9 t32syn QT QTTaxsyn R RTaxsyn S STaxsyn ST STTaxsyn T TTaxsyn C UTaxsyn O VTaxsyn D WTax
partial reachability = ((st Documents==NoDoc) && (st Dialogs==Start) && (st Tree==Root) && (st Server==Server)&& (st Browser==Browser) && (st ApplicationControl==Start));
network DocsEditor (continuous)
aut Documents stt NoDocto (Unititled) Sto (Titled) Dto (NoDoc) QT(slvTax)stt Unititledto (NoDoc) R C O QT(slvTax)to (Titled) Tstt Titledto (Unititled) Sto (NoDoc) R QT(slvTax)to (Titled) l20
aut Dialogsstt Startto (Dialog8) ST(slvTax)stt NoStatusto (Start) QT(slvTax)to (Dialog1) Sto (Dialog3) l10to (Dialog4) D l11

APÊNDICE E. DOCS EDITOR 77
to (Dialog5) l13to (Dialog6) l17to (Dialog7) l19to (Dialog8) ST(slvTax)stt Dialog1to (NoStatus) O Cto (Dialog2) l8stt Dialog2to (NoStatus) C Tstt Dialog3to (NoStatus) C Tstt Dialog4to (NoStatus) l12to (Dialog2) l9stt Dialog5to (NoStatus) l13to (Dialog8) l15stt Dialog6to (NoStatus) l16stt Dialog7to (NoStatus) l18stt Dialog8to (NoStatus) QT(slvTax)to (Dialog5) l14
aut Treestt Rootto (Leaf) l6to (Other) l3stt Leafto (Root) QT(slvTax)to (Other) l5stt Otherto (Leaf) l4to (Root) QT(slvTax)
aut Serverstt Serverto (NoServer) l1stt NoServerto (Server) l2
aut Browserstt Browserto (Browser) R(slvTax)to (NoBrowser) R(slvTax)stt NoBrowserto (NoBrowser) R(slvTax)to (Browser) R(slvTax)
aut ApplicationControlstt Startto (Running) STstt Runningto (Start) QTresultsvar = st ApplicationControl == Running;

Índice Remissivo
Análise estacionária, 53, 59Análise transiente, 46, 47, 59
Cadeia de Markov, 9, 15, 17, 21, 25, 34, 37Cadeia de Markov Embutida, 60Casos de teste, 4, 8, 9, 13, 17, 32, 39, 41, 46, 56, 57Confiabilidade, 4, 5, 8, 32, 36, 59, 60CTMC, 10, 60
Discriminante de Kullback, 45, 48Distância Euclidiana, 45DTMC, 60
Grafos, 9
Máquina de estados finita, 9, 37Máquina de estados finita com variáveis, 37Matriz esparsa, 33Model-based testing, 1Model checking, 61Modelos de uso, 4, 6, 8, 11, 19, 57
PEPS, 24, 29, 33, 50
Redes de Autômatos Estocásticos, 8, 9, 11, 35, 37,39, 57
Teste estatístico, 4, 5, 12, 32, 33, 39, 44, 46, 58, 60Teste estrutural, 5, 6Teste funcional, 5, 6Teste de integração, 5Teste de regressão, 5Teste de sistema, 5Teste de unidade, 5
UML, 9
78


















